
title: Document redaction
emoji: 📝
colorFrom: blue
colorTo: yellow
sdk: docker
app_file: app.py
pinned: false
license: agpl-3.0
Document redaction
version: 0.6.2
Redact personally identifiable information (PII) from documents (pdf, images), open text, or tabular data (xlsx/csv/parquet). Please see the User Guide for a walkthrough on how to use the app. Below is a very brief overview.
To identify text in documents, the 'local' text/OCR image analysis uses spacy/tesseract, and works ok for documents with typed text. If available, choose 'AWS Textract service' to redact more complex elements e.g. signatures or handwriting. Then, choose a method for PII identification. 'Local' is quick and gives good results if you are primarily looking for a custom list of terms to redact (see Redaction settings). If available, AWS Comprehend gives better results at a small cost.
After redaction, review suggested redactions on the 'Review redactions' tab. The original pdf can be uploaded here alongside a '...redaction_file.csv' to continue a previous redaction/review task. See the 'Redaction settings' tab to choose which pages to redact, the type of information to redact (e.g. people, places), or custom terms to always include/ exclude from redaction.
NOTE: The app is not 100% accurate, and it will miss some personal information. It is essential that all outputs are reviewed by a human before using the final outputs.
USER GUIDE
Experiment with the test (public) version of the app
You can test out many of the features described in this user guide at the public test version of the app, which is free. AWS functions (e.g. Textract, Comprehend) are not enabled (unless you have valid API keys).
Chat over this user guide
You can now speak with a chat bot about this user guide (beta!)
Table of contents
- Example data files
- Basic redaction
- Customising redaction options
- Reviewing and modifying suggested redactions
- Redacting tabular data files (CSV/XLSX) or copy and pasted text
See the advanced user guide here:
- Merging redaction review files
- Identifying and redacting duplicate pages
- Fuzzy search and redaction
- Export redactions to and import from Adobe Acrobat
- Using the AWS Textract document API
- Using AWS Textract and Comprehend when not running in an AWS environment
- Modifying existing redaction review files
Example data files
Please try these example files to follow along with this guide:
- Example of files sent to a professor before applying
- Example complaint letter (jpg)
- Partnership Agreement Toolkit (for signatures and more advanced usage)
- Dummy case note data
{kind=link}
Basic redaction
The document redaction app can detect personally-identifiable information (PII) in documents. Documents can be redacted directly, or suggested redactions can be reviewed and modified using a grapical user interface. Basic document redaction can be performed quickly using the default options.
Download the example PDFs above to your computer. Open up the redaction app with the link provided by email.
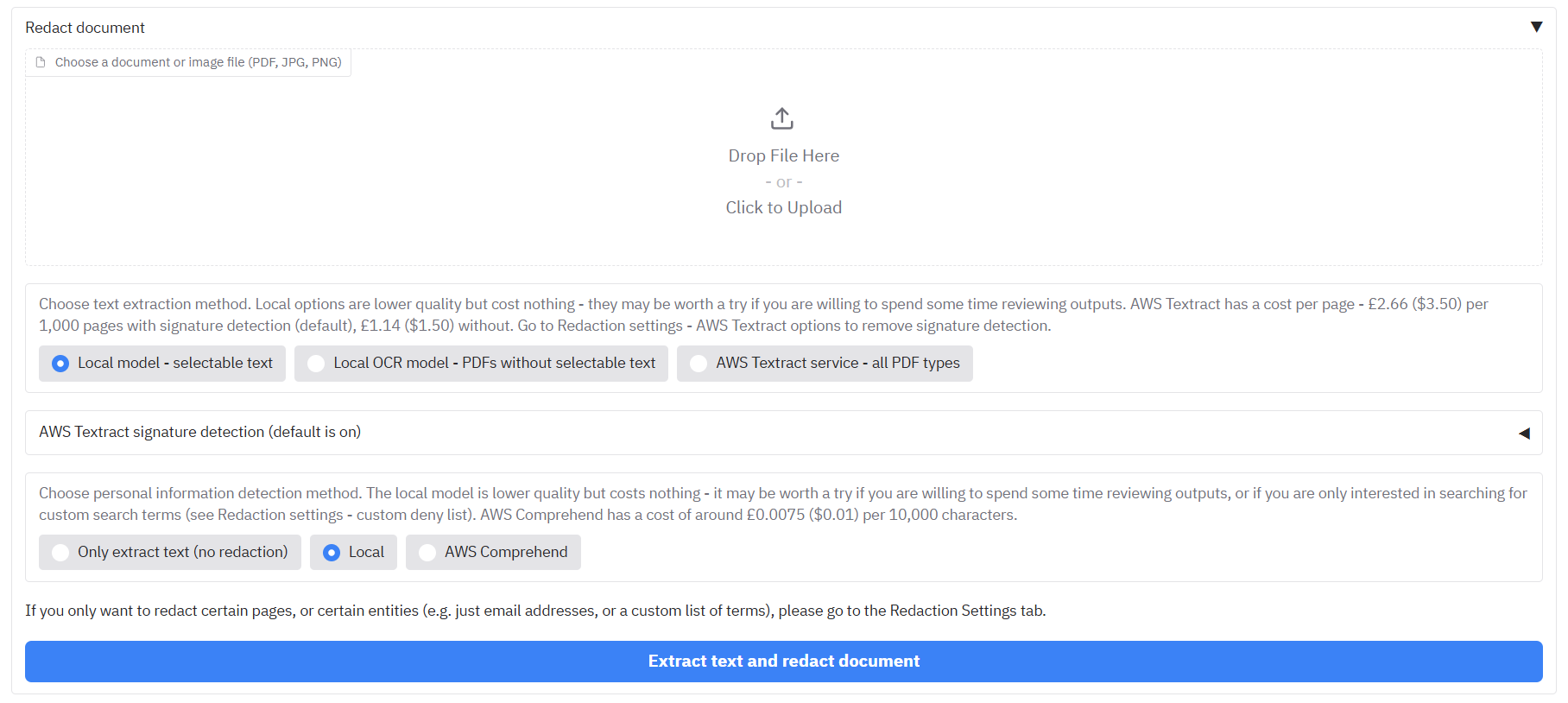
Upload files to the app
The 'Redact PDFs/images tab' currently accepts PDFs and image files (JPG, PNG) for redaction. Click on the 'Drop files here or Click to Upload' area of the screen, and select one of the three different example files (they should all be stored in the same folder if you want them to be redacted at the same time).
Text extraction
First, select one of the three text extraction options:
- 'Local model - selectable text' - This will read text directly from PDFs that have selectable text to redact (using PikePDF). This is fine for most PDFs, but will find nothing if the PDF does not have selectable text, and it is not good for handwriting or signatures. If it encounters an image file, it will send it onto the second option below.
- 'Local OCR model - PDFs without selectable text' - This option will use a simple Optical Character Recognition (OCR) model (Tesseract) to pull out text from a PDF/image that it 'sees'. This can handle most typed text in PDFs/images without selectable text, but struggles with handwriting/signatures. If you are interested in the latter, then you should use the third option if available.
- 'AWS Textract service - all PDF types' - Only available for instances of the app running on AWS. AWS Textract is a service that performs OCR on documents within their secure service. This is a more advanced version of OCR compared to the local option, and carries a (relatively small) cost. Textract excels in complex documents based on images, or documents that contain a lot of handwriting and signatures.
Optional - select signature extraction
If you chose the AWS Textract service above, you can choose if you want handwriting and/or signatures redacted by default. Choosing signatures here will have a cost implication, as identifying signatures will cost ~£2.66 ($3.50) per 1,000 pages vs ~£1.14 ($1.50) per 1,000 pages without signature detection.
PII redaction method
If you are running with the AWS service enabled, here you will also have a choice for PII redaction method:
- 'Only extract text - (no redaction)' - If you are only interested in getting the text out of the document for further processing (e.g. to find duplicate pages, or to review text on the Review redactions page)
- 'Local' - This uses the spacy package to rapidly detect PII in extracted text. This method is often sufficient if you are just interested in redacting specific terms defined in a custom list.
- 'AWS Comprehend' - This method calls an AWS service to provide more accurate identification of PII in extracted text.
Optional - costs and time estimation
If the option is enabled (by your system admin, in the config file), you will see a cost and time estimate for the redaction process. 'Existing Textract output file found' will be checked automatically if previous Textract text extraction files exist in the output folder, or have been previously uploaded by the user (saving time and money for redaction).

Optional - cost code selection
If the option is enabled (by your system admin, in the config file), you may be prompted to select a cost code before continuing with the redaction task.

The relevant cost code can be found either by: 1. Using the search bar above the data table to find relevant cost codes, then clicking on the relevant row, or 2. typing it directly into the dropdown to the right, where it should filter as you type.
Optional - Submit whole documents to Textract API
If this option is enabled (by your system admin, in the config file), you will have the option to submit whole documents in quick succession to the AWS Textract service to get extracted text outputs quickly (faster than using the 'Redact document' process described here). This feature is described in more detail in the advanced user guide.
Redact the document
Click 'Redact document'. After loading in the document, the app should be able to process about 30 pages per minute (depending on redaction methods chose above). When ready, you should see a message saying that processing is complete, with output files appearing in the bottom right.
Redaction outputs

- '...redacted.pdf' files contain the original pdf with suggested redacted text deleted and replaced by a black box on top of the document.
- '...ocr_results.csv' files contain the line-by-line text outputs from the entire document. This file can be useful for later searching through for any terms of interest in the document (e.g. using Excel or a similar program).
- '...review_file.csv' files are the review files that contain details and locations of all of the suggested redactions in the document. This file is key to the review process, and should be downloaded to use later for this.
Additional AWS Textract / local OCR outputs
If you have used the AWS Textract option for extracting text, you may also see a '..._textract.json' file. This file contains all the relevant extracted text information that comes from the AWS Textract service. You can keep this file and upload it at a later date alongside your input document, which will enable you to skip calling AWS Textract every single time you want to do a redaction task, as follows:

Similarly, if you have used the 'Local OCR method' to extract text, you may see a '..._ocr_results_with_words.json' file. This file works in the same way as the AWS Textract .json results described above, and can be uploaded alongside an input document to save time on text extraction in future in the same way.
Downloading output files from previous redaction tasks
If you are logged in via AWS Cognito and you lose your app page for some reason (e.g. from a crash, reloading), it is possible recover your previous output files, provided the server has not been shut down since you redacted the document. Go to 'Redaction settings', then scroll to the bottom to see 'View all output files from this session'.

Basic redaction summary
We have covered redacting documents with the default redaction options. The '...redacted.pdf' file output may be enough for your purposes. But it is very likely that you will need to customise your redaction options, which we will cover below.
Customising redaction options
On the 'Redaction settings' page, there are a number of options that you can tweak to better match your use case and needs.
Custom allow, deny, and page redaction lists
The app allows you to specify terms that should never be redacted (an allow list), terms that should always be redacted (a deny list), and also to provide a list of page numbers for pages that should be fully redacted.
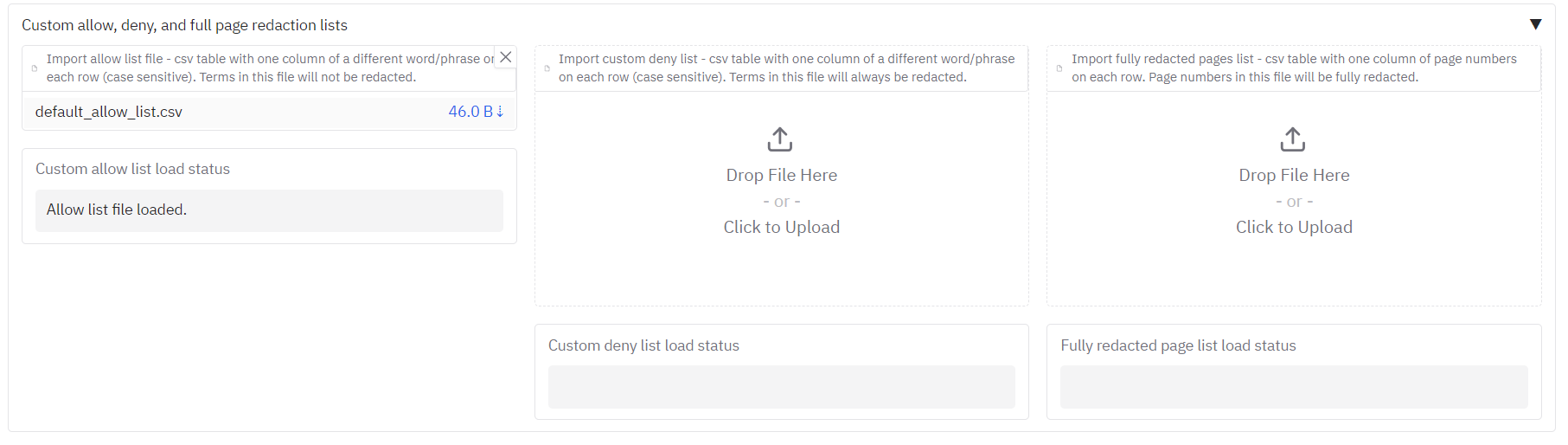
Allow list example
It may be the case that specific terms that are frequently redacted are not interesting to
In the redacted outputs of the 'Example of files sent to a professor before applying' PDF, you can see that it is frequently redacting references to Dr Hyde's lab in the main body of the text. Let's say that references to Dr Hyde were not considered personal information in this context. You can exclude this term from redaction (and others) by providing an 'allow list' file. This is simply a csv that contains the case sensitive terms to exclude in the first column, in our example, 'Hyde' and 'Muller glia'. The example file is provided here.
To import this to use with your redaction tasks, go to the 'Redaction settings' tab, click on the 'Import allow list file' button halfway down, and select the csv file you have created. It should be loaded for next time you hit the redact button. Go back to the first tab and do this.
Deny list example
Say you wanted to remove specific terms from a document. In this app you can do this by providing a custom deny list as a csv. Like for the allow list described above, this should be a one-column csv without a column header. The app will suggest each individual term in the list with exact spelling as whole words. So it won't select text from within words. To enable this feature, the 'CUSTOM' tag needs to be chosen as a redaction entity (the process for adding/removing entity types to redact is described below).
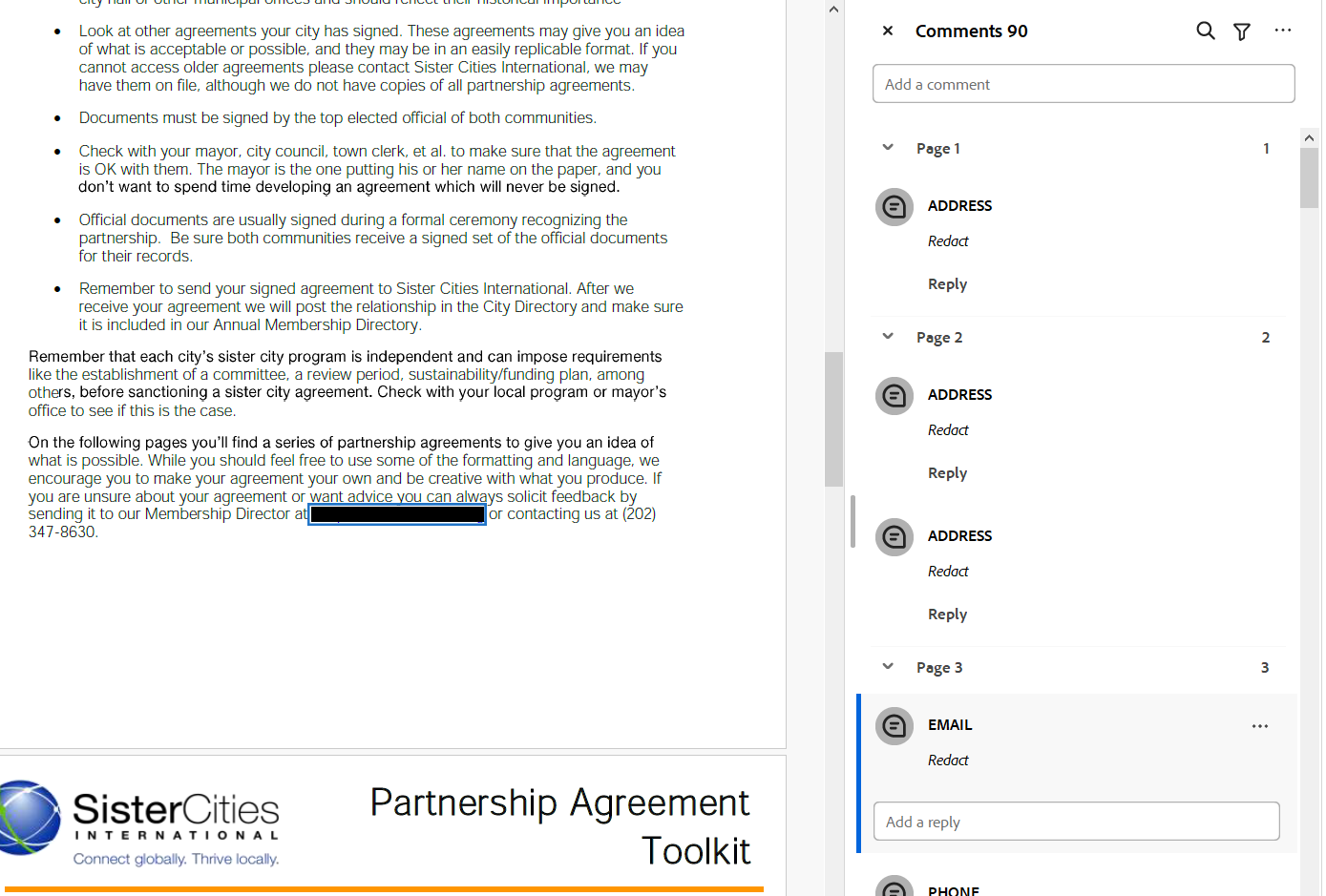
Here is an example using the Partnership Agreement Toolkit file. This is an example of a custom deny list file. 'Sister', 'Sister City' 'Sister Cities', 'Friendship City' have been listed as specific terms to redact. You can see the outputs of this redaction process on the review page:
 .
.
You can see that the app has highlighted all instances of these terms on the page shown. You can then consider each of these terms for modification or removal on the review page explained here.
Full page redaction list example
There may be full pages in a document that you want to redact. The app also provides the capability of redacting pages completely based on a list of input page numbers in a csv. The format of the input file is the same as that for the allow and deny lists described above - a one-column csv without a column header. An example of this is here. You can see an example of the redacted page on the review page:
 .
.
Using the above approaches to allow, deny, and full page redaction lists will give you an output like this.
Adding to the loaded allow, deny, and whole page lists in-app
If you open the accordion below the allow list options called 'Manually modify custom allow...', you should be able to see a few tables with options to add new rows:

If the table is empty, you can add a new entry, you can add a new row by clicking on the '+' item below each table header. If there is existing data, you may need to click on the three dots to the right and select 'Add row below'. Type the item you wish to keep/remove in the cell, and then (important) press enter to add this new item to the allow/deny/whole page list. Your output tables should look something like below.

Redacting additional types of personal information
You may want to redact additional types of information beyond the defaults, or you may not be interested in default suggested entity types. There are dates in the example complaint letter. Say we wanted to redact those dates also?
Under the 'Redaction settings' tab, go to 'Entities to redact (click close to down arrow for full list)'. Different dropdowns are provided according to whether you are using the Local service to redact PII, or the AWS Comprehend service. Click within the empty box close to the dropdown arrow and you should see a list of possible 'entities' to redact. Select 'DATE_TIME' and it should appear in the main list. To remove items, click on the 'x' next to their name.
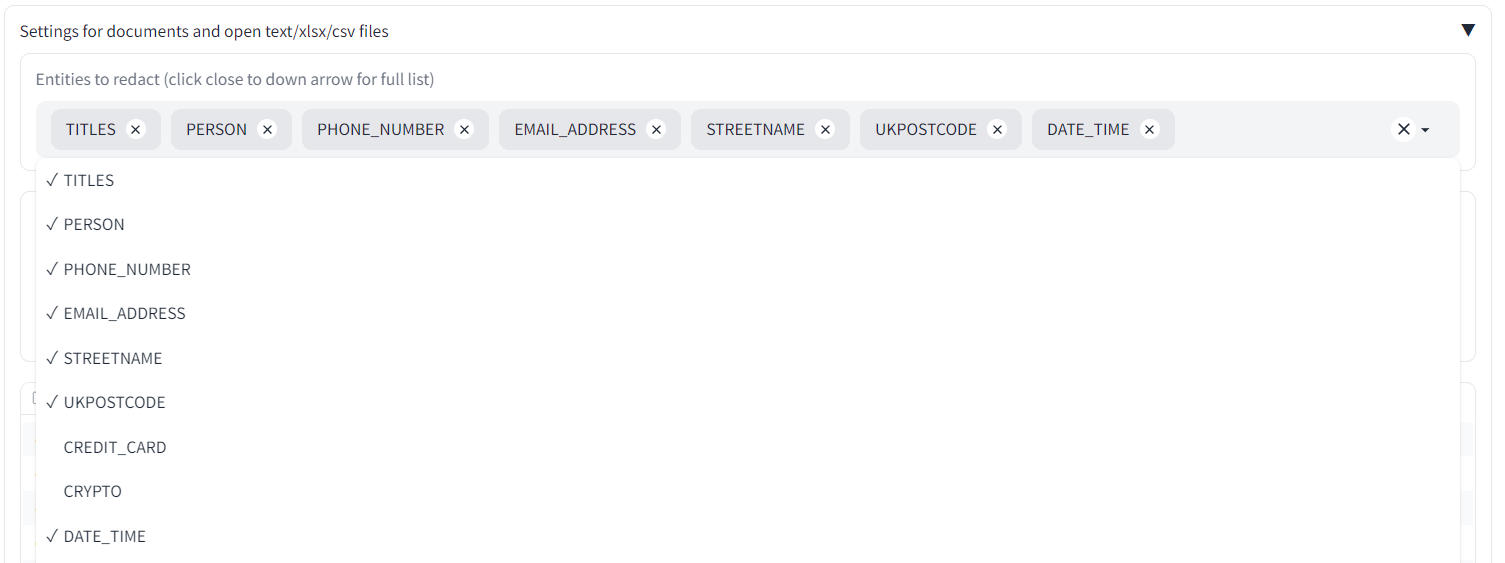
Now, go back to the main screen and click 'Redact Document' again. You should now get a redacted version of 'Example complaint letter' that has the dates and times removed.
If you want to redact different files, I suggest you refresh your browser page to start a new session and unload all previous data.
Redacting only specific pages
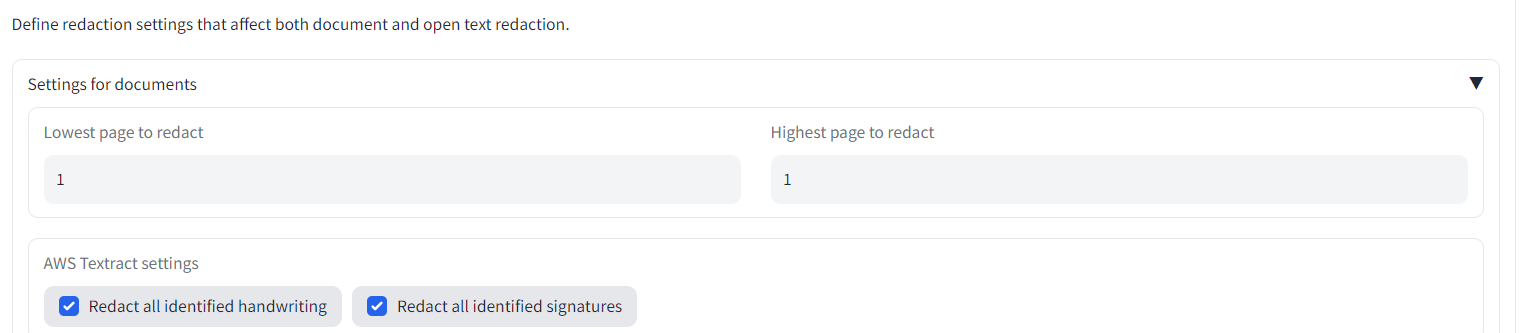
Say also we are only interested in redacting page 1 of the loaded documents. On the Redaction settings tab, select 'Lowest page to redact' as 1, and 'Highest page to redact' also as 1. When you next redact your documents, only the first page will be modified.
Handwriting and signature redaction
The file Partnership Agreement Toolkit (for signatures and more advanced usage) is provided as an example document to test AWS Textract + redaction with a document that has signatures in. If you have access to AWS Textract in the app, try removing all entity types from redaction on the Redaction settings and clicking the big X to the right of 'Entities to redact'.
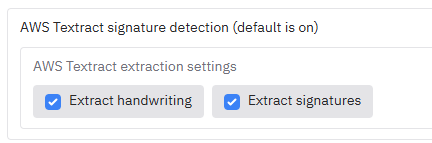
To ensure that handwriting and signatures are enabled (enabled by default), on the front screen go the 'AWS Textract signature detection' to enable/disable the following options :
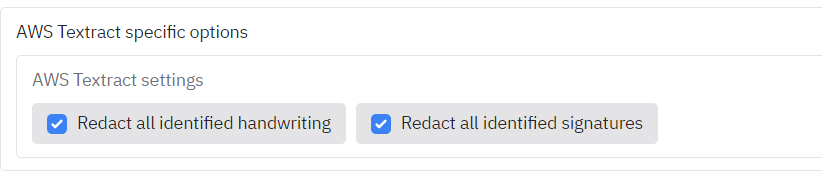
The outputs should show handwriting/signatures redacted (see pages 5 - 7), which you can inspect and modify on the 'Review redactions' tab.

Reviewing and modifying suggested redactions
Sometimes the app will suggest redactions that are incorrect, or will miss personal information entirely. The app allows you to review and modify suggested redactions to compensate for this. You can do this on the 'Review redactions' tab.
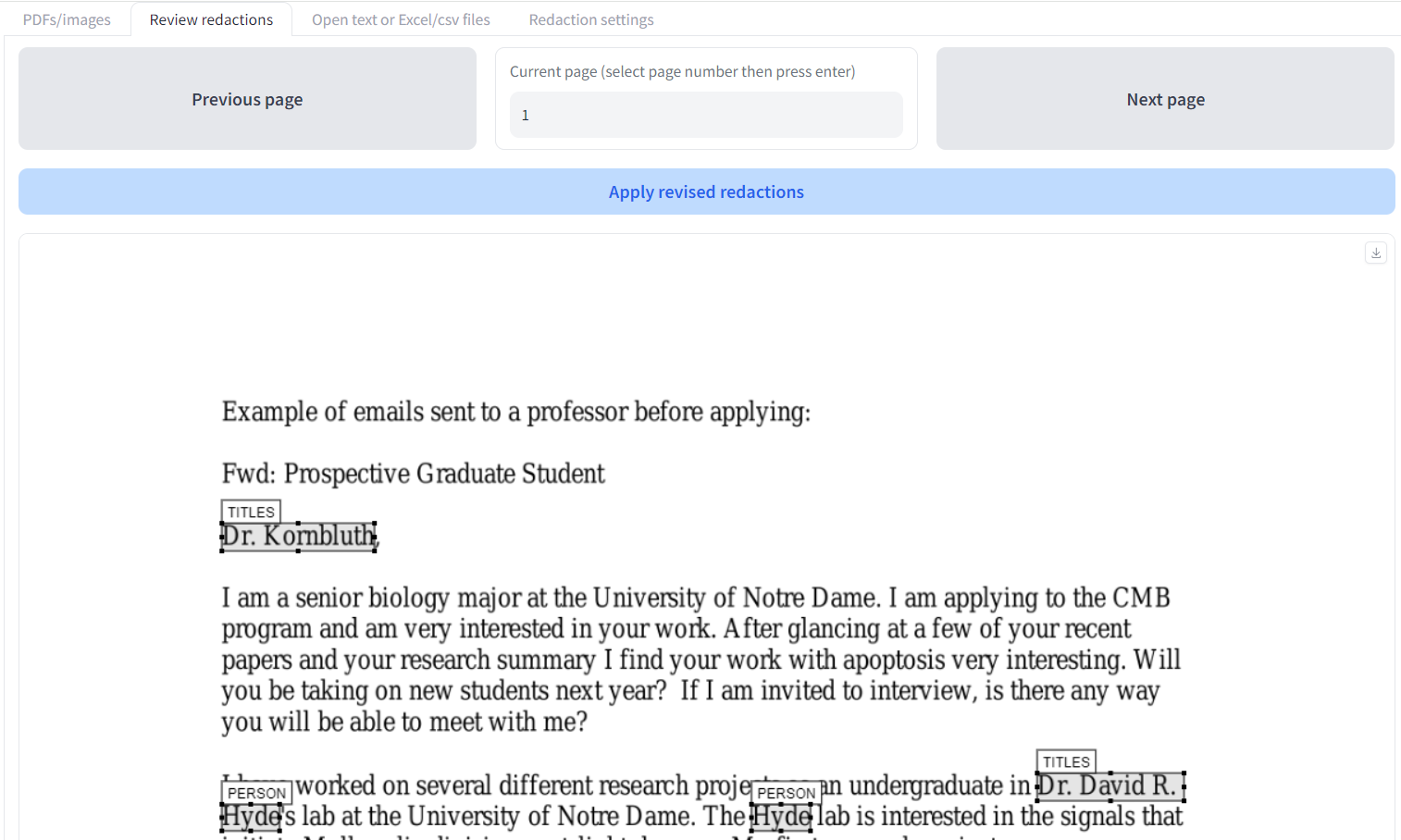
We will go through ways to review suggested redactions with an example.On the first tab 'PDFs/images' upload the 'Example of files sent to a professor before applying.pdf' file. Let's stick with the 'Local model - selectable text' option, and click 'Redact document'. Once the outputs are created, go to the 'Review redactions' tab.
On the 'Review redactions' tab you have a visual interface that allows you to inspect and modify redactions suggested by the app. There are quite a few options to look at, so we'll go from top to bottom.
Uploading documents for review
The top area has a file upload area where you can upload original, unredacted PDFs, alongside the '..._review_file.csv' that is produced by the redaction process. Once you have uploaded these two files, click the 'Review PDF...' button to load in the files for review. This will allow you to visualise and modify the suggested redactions using the interface below.
Optionally, you can also upload one of the '..._ocr_output.csv' files here that comes out of a redaction task, so that you can navigate the extracted text from the document.

You can upload the three review files in the box (unredacted document, '..._review_file.csv' and '..._ocr_output.csv' file) before clicking 'Review PDF...', as in the image below:

NOTE: ensure you upload the unredacted document here and not the redacted version, otherwise you will be checking over a document that already has redaction boxes applied!
Page navigation
You can change the page viewed either by clicking 'Previous page' or 'Next page', or by typing a specific page number in the 'Current page' box and pressing Enter on your keyboard. Each time you switch page, it will save redactions you have made on the page you are moving from, so you will not lose changes you have made.
You can also navigate to different pages by clicking on rows in the tables under 'Search suggested redactions' to the right, or 'search all extracted text' (if enabled) beneath that.
The document viewer pane
On the selected page, each redaction is highlighted with a box next to its suggested redaction label (e.g. person, email).
There are a number of different options to add and modify redaction boxes and page on the document viewer pane. To zoom in and out of the page, use your mouse wheel. To move around the page while zoomed, you need to be in modify mode. Scroll to the bottom of the document viewer to see the relevant controls. You should see a box icon, a hand icon, and two arrows pointing counter-clockwise and clockwise.
Click on the hand icon to go into modify mode. When you click and hold on the document viewer, This will allow you to move around the page when zoomed in. To rotate the page, you can click on either of the round arrow buttons to turn in that direction.
NOTE: When you switch page, the viewer will stay in your selected orientation, so if it looks strange, just rotate the page again and hopefully it will look correct!
Modify existing redactions (hand icon)
After clicking on the hand icon, the interface allows you to modify existing redaction boxes. When in this mode, you can click and hold on an existing box to move it.

Click on one of the small boxes at the edges to change the size of the box. To delete a box, click on it to highlight it, then press delete on your keyboard. Alternatively, double click on a box and click 'Remove' on the box that appears.
Add new redaction boxes (box icon)
To change to 'add redaction boxes' mode, scroll to the bottom of the page. Click on the box icon, and your cursor will change into a crosshair. Now you can add new redaction boxes where you wish. A popup will appear when you create a new box so you can select a label and colour for the new box.
'Locking in' new redaction box format
It is possible to lock in a chosen format for new redaction boxes so that you don't have the popup appearing each time. When you make a new box, select the options for your 'locked' format, and then click on the lock icon on the left side of the popup, which should turn blue.

You can now add new redaction boxes without a popup appearing. If you want to change or 'unlock' the your chosen box format, you can click on the new icon that has appeared at the bottom of the document viewer pane that looks a little like a gift tag. You can then change the defaults, or click on the lock icon again to 'unlock' the new box format - then popups will appear again each time you create a new box.
Apply redactions to PDF and Save changes on current page
Once you have reviewed all the redactions in your document and you are happy with the outputs, you can click 'Apply revised redactions to PDF' to create a new '_redacted.pdf' output alongside a new '_review_file.csv' output.
If you are working on a page and haven't saved for a while, you can click 'Save changes on current page to file' to ensure that they are saved to an updated 'review_file.csv' output.

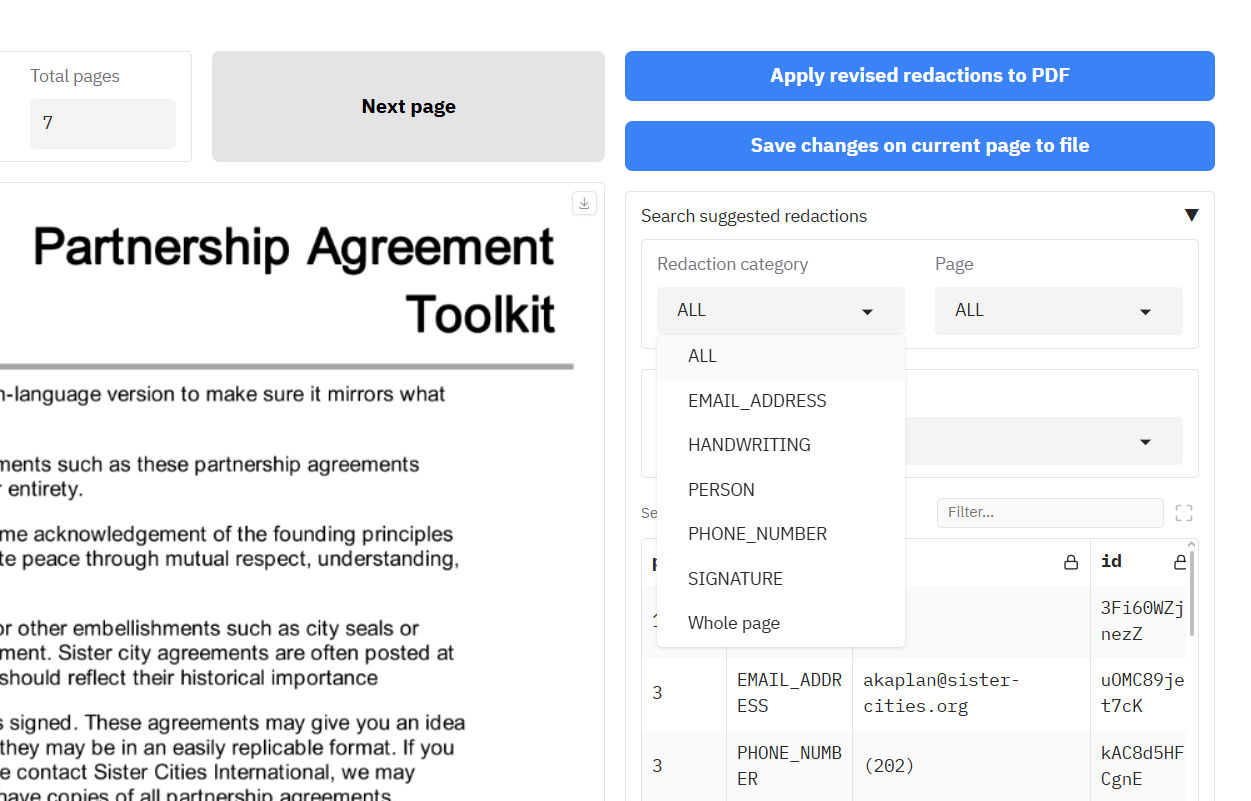
Selecting and removing redaction boxes using the 'Search suggested redactions' table
The table shows a list of all the suggested redactions in the document alongside the page, label, and text (if available).
If you click on one of the rows in this table, you will be taken to the page of the redaction. Clicking on a redaction row on the same page should change the colour of redaction box to blue to help you locate it in the document viewer (just in app, not in redaction output PDFs).

You can choose a specific entity type to see which pages the entity is present on. If you want to go to the page specified in the table, you can click on a cell in the table and the review page will be changed to that page.
To filter the 'Search suggested redactions' table you can:
- Click on one of the dropdowns (Redaction category, Page, Text), and select an option, or
- Write text in the 'Filter' box just above the table. Click the blue box to apply the filter to the table.
Once you have filtered the table, you have a few options underneath on what you can do with the filtered rows:
- Click the 'Exclude specific row from redactions' button to remove only the redaction from the last row you clicked on from the document.
- Click the 'Exclude all items in table from redactions' button to remove all redactions visible in the table from the document. Important: ensure that you have clicked the blue tick icon next to the search box before doing this, or you will remove all redactions from the document. If you do end up doing this, click the 'Undo last element removal' button below to restore the redactions.
NOTE: After excluding redactions using either of the above options, click the 'Reset filters' button below to ensure that the dropdowns and table return to seeing all remaining redactions in the document.
If you made a mistake, click the 'Undo last element removal' button to restore the Search suggested redactions table to its previous state (can only undo the last action).
Navigating through the document using the 'Search all extracted text'
The 'search all extracted text' table will contain text if you have just redacted a document, or if you have uploaded a '..._ocr_output.csv' file alongside a document file and review file on the Review redactions tab as described above.
You can navigate through the document using this table. When you click on a row, the Document viewer pane to the left will change to the selected page.
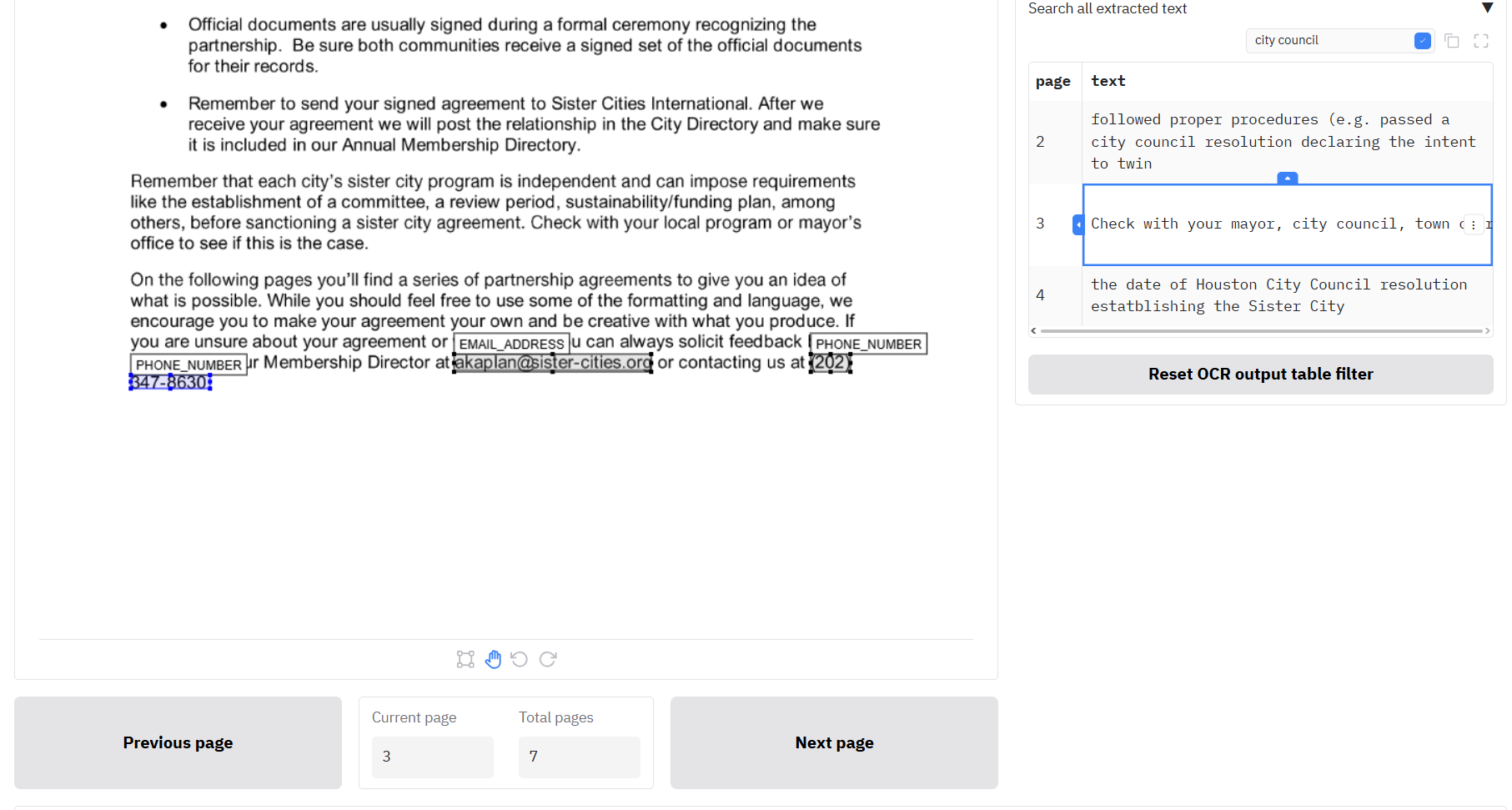
You can search through the extracted text by using the search bar just above the table, which should filter as you type. To apply the filter and 'cut' the table, click on the blue tick inside the box next to your search term. To return the table to its original content, click the button below the table 'Reset OCR output table filter'.
Redacting tabular data files (XLSX/CSV) or copy and pasted text
Tabular data files (XLSX/CSV)
The app can be used to redact tabular data files such as xlsx or csv files. For this to work properly, your data file needs to be in a simple table format, with a single table starting from the first cell (A1), and no other information in the sheet. Similarly for .xlsx files, each sheet in the file that you want to redact should be in this simple format.
To demonstrate this, we can use the example csv file 'combined_case_notes.csv', which is a small dataset of dummy social care case notes. Go to the 'Open text or Excel/csv files' tab. Drop the file into the upload area. After the file is loaded, you should see the suggested columns for redaction in the box underneath. You can select and deselect columns to redact as you wish from this list.
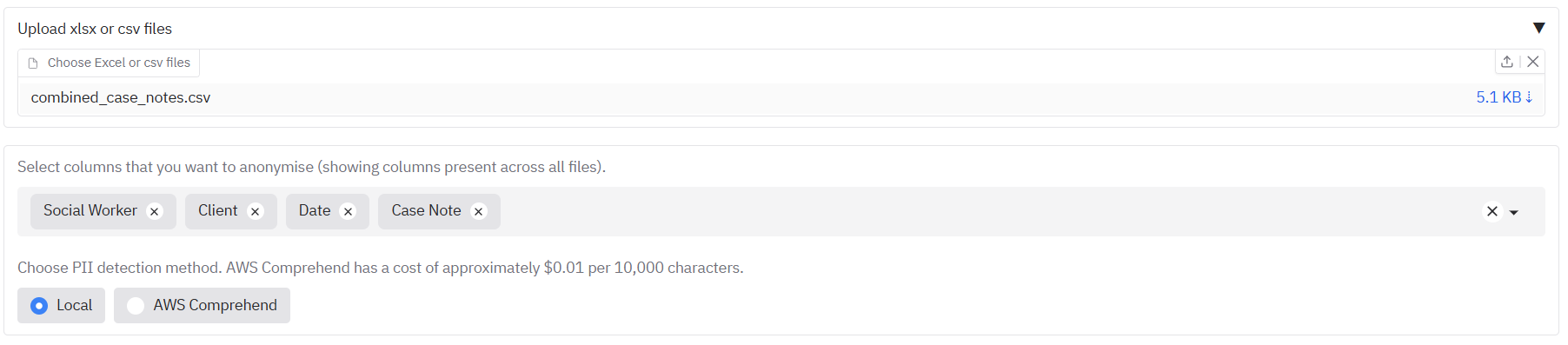
If you were instead to upload an xlsx file, you would see also a list of all the sheets in the xlsx file that can be redacted. The 'Select columns' area underneath will suggest a list of all columns in the file across all sheets.
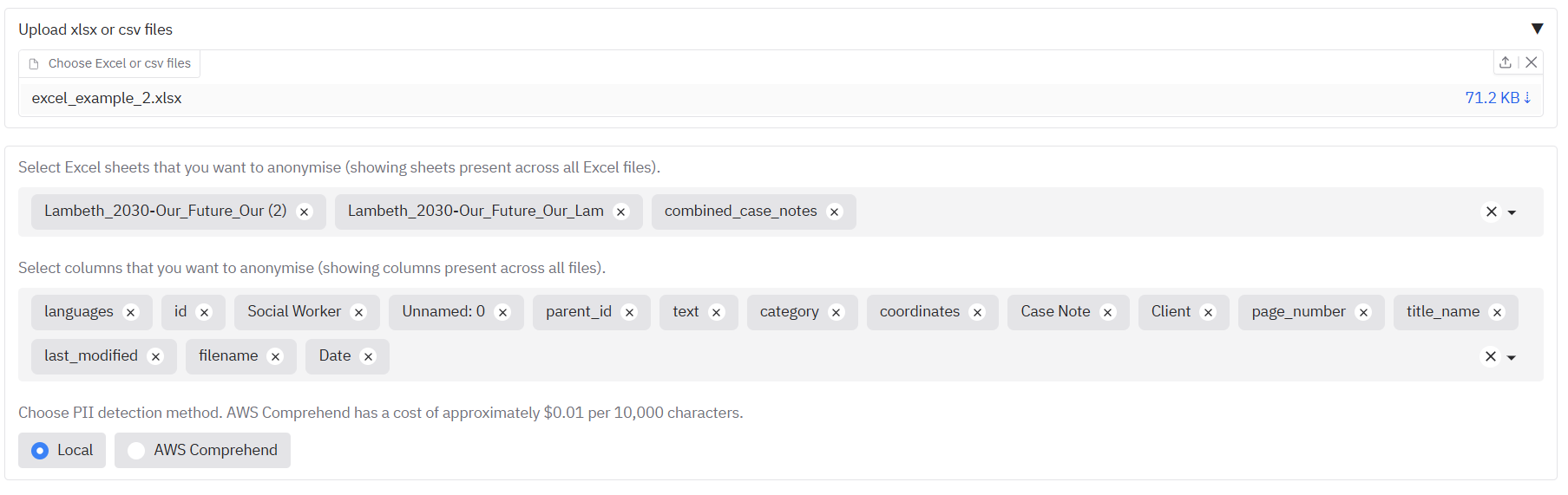
Once you have chosen your input file and sheets/columns to redact, you can choose the redaction method. 'Local' will use the same local model as used for documents on the first tab. 'AWS Comprehend' will give better results, at a slight cost.
When you click Redact text/data files, you will see the progress of the redaction task by file and sheet, and you will receive a csv output with the redacted data.
Choosing output anonymisation format
You can also choose the anonymisation format of your output results. Open the tab 'Anonymisation output format' to see the options. By default, any detected PII will be replaced with the word 'REDACTED' in the cell. You can choose one of the following options as the form of replacement for the redacted text:
- replace with 'REDACTED': Replaced by the word 'REDACTED' (default)
- replace with : Replaced by e.g. 'PERSON' for people, 'EMAIL_ADDRESS' for emails etc.
- redact completely: Text is removed completely and replaced by nothing.
- hash: Replaced by a unique long ID code that is consistent with entity text. I.e. a particular name will always have the same ID code.
- mask: Replace with stars '*'.
Redacting copy and pasted text
You can also write open text into an input box and redact that using the same methods as described above. To do this, write or paste text into the 'Enter open text' box that appears when you open the 'Redact open text' tab. Then select a redaction method, and an anonymisation output format as described above. The redacted text will be printed in the output textbox, and will also be saved to a simple csv file in the output file box.
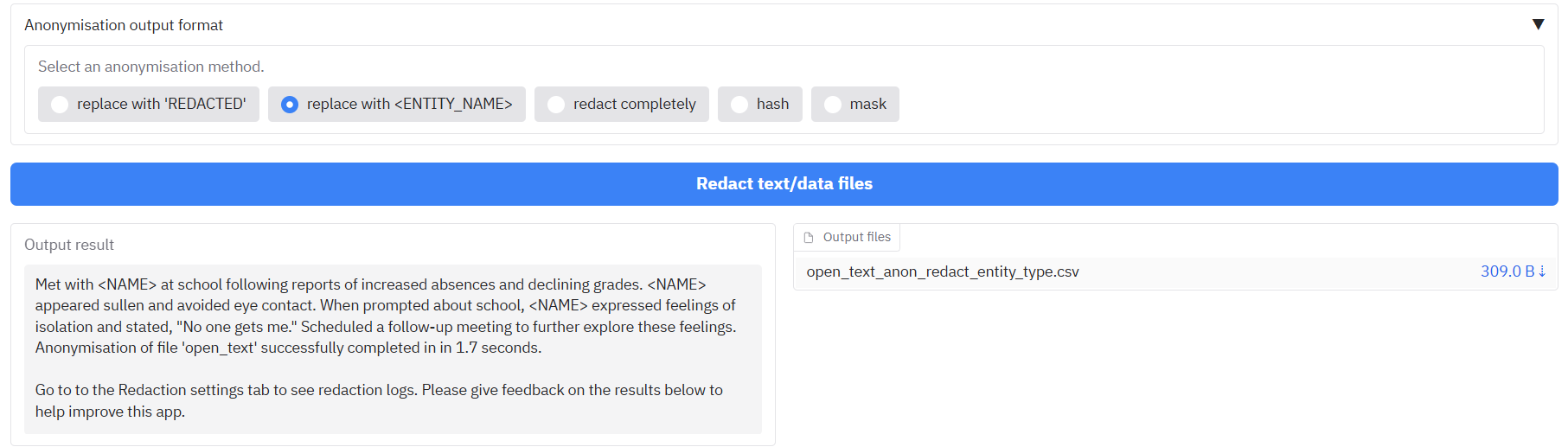
Redaction log outputs
A list of the suggested redaction outputs from the tabular data / open text data redaction is available on the Redaction settings page under 'Log file outputs'.
ADVANCED USER GUIDE
This advanced user guide will go over some of the features recently added to the app, including: modifying and merging redaction review files, identifying and redacting duplicate pages across multiple PDFs, 'fuzzy' search and redact, and exporting redactions to Adobe Acrobat.
Table of contents
- Merging redaction review files
- Identifying and redacting duplicate pages
- Fuzzy search and redaction
- Export redactions to and import from Adobe Acrobat
- Using the AWS Textract document API
- Using AWS Textract and Comprehend when not running in an AWS environment
- Modifying existing redaction review files
Merging redaction review files
Say you have run multiple redaction tasks on the same document, and you want to merge all of these redactions together. You could do this in your spreadsheet editor, but this could be fiddly especially if dealing with multiple review files or large numbers of redactions. The app has a feature to combine multiple review files together to create a 'merged' review file.

You can find this option at the bottom of the 'Redaction Settings' tab. Upload multiple review files here to get a single output 'merged' review_file. In the examples file, merging the 'review_file_custom.csv' and 'review_file_local.csv' files give you an output containing redaction boxes from both. This combined review file can then be uploaded into the review tab following the usual procedure.
Identifying and redacting duplicate pages
The files for this section are stored here.
Some redaction tasks involve removing duplicate pages of text that may exist across multiple documents. This feature calculates the similarity of text in all pages of input PDFs, calculates a similarity score, and then flags pages above a certain similarity score (90%) for removal by creating a 'whole page' redaction list file for each input PDF.

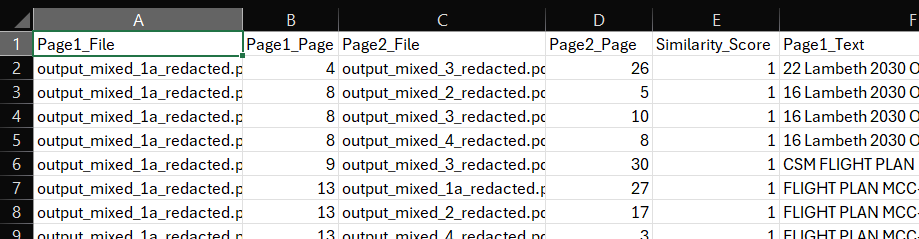
The similarity calculation is based on using the 'ocr_outputs.csv' file that is output every time that you perform a redaction task. From the file folder, upload the four 'ocr_output.csv' files provided in the example folder into the file area. Click 'Identify duplicate pages' and you will see a number of files returned. In case you want to see the original PDFs, they are available here.

First, there is a 'combined_ocr_result...' file that just merges together all the text from the input files. 'page_similarity_results.csv' shows a breakdown of the pages from each file that are most similar to each other above the threshold (90% similarity). You can compare the text in the two columns 'Page_1_Text' and 'Page_2_Text'.
The remaining output files are suffixed with '_whole_page.csv'. These are the same files that can be used to redact whole pages as described in the 'Full page redaction list example' section. For each PDF involved in the duplicate detection process, you can upload the relevant '_whole_page.csv' file into the relevant area, then do a new redaction task for the PDF file without any entity types selected. This way, only the suggested whole pages will be suggested for redaction and nothing else.

If you want to combine the results from this redaction process with previous redaction tasks for the same PDF, you could merge review file outputs following the steps described in Merging existing redaction review files above.
Fuzzy search and redaction
The files for this section are stored here.
Sometimes you may be searching for terns that are slightly mispelled throughout a document, for example names. The document redaction app gives the option for searching for long phrases that may contain spelling mistakes, a method called 'fuzzy matching'.
To do this, go to the Redaction Settings, and the 'Select entity types to redact' area. In the box below relevant to your chosen redaction method (local or AWS Comprehend), select 'CUSTOM_FUZZY' from the list. Next, we can select the maximum number of spelling mistakes allowed in the search (up to nine). Here, you can either type in a number or use the small arrows to the right of the box. Change this option to 3. This will allow for a maximum of three 'changes' in text needed to match to the desired search terms.
The other option we can leave as is (should fuzzy search match on entire phrases in deny list) - this option would allow you to fuzzy search on each individual word in the search phrase (apart from stop words).
Next, we can upload a deny list on the same page to do the fuzzy search. A relevant deny list file can be found here - you can upload it following these steps. You will notice that the suggested deny list has spelling mistakes compared to phrases found in the example document.

Upload the Partnership-Agreement-Toolkit file into the 'Redact document' area on the first tab. Now, press the 'Redact document' button.
Using these deny list with spelling mistakes, the app fuzzy match these terms to the correct text in the document. After redaction is complete, go to the Review Redactions tab to check the first tabs. You should see that the phrases in the deny list have been successfully matched.

Export to and import from Adobe
Files for this section are stored here.
Exporting to Adobe Acrobat
The Document Redaction app has a feature to export suggested redactions to Adobe, and likewise to import Adobe comment files into the app. The file format used is the .xfdf Adobe comment file format - you can find more information about how to use these files here.
To convert suggested redactions to Adobe format, you need to have the original PDF and a review file csv in the input box at the top of the Review redactions page.

Then, you can find the export to Adobe option at the bottom of the Review redactions tab. Adobe comment files will be output here.

Once the input files are ready, you can click on the 'Convert review file to Adobe comment format'. You should see a file appear in the output box with a '.xfdf' file type. To use this in Adobe, after download to your computer, you should be able to double click on it, and a pop-up box will appear asking you to find the PDF file associated with it. Find the original PDF file used for your redaction task. The file should be opened up in Adobe Acrobat with the suggested redactions.
Importing from Adobe Acrobat
The app also allows you to import .xfdf files from Adobe Acrobat. To do this, go to the same Adobe import/export area as described above at the bottom of the Review Redactions tab. In this box, you need to upload a .xfdf Adobe comment file, along with the relevant original PDF for redaction.

When you click the 'convert .xfdf comment file to review_file.csv' button, the app should take you up to the top of the screen where the new review file has been created and can be downloaded.

Using the AWS Textract document API
This option can be enabled by your system admin, in the config file ('SHOW_WHOLE_DOCUMENT_TEXTRACT_CALL_OPTIONS' environment variable, and subsequent variables). Using this, you will have the option to submit whole documents in quick succession to the AWS Textract service to get extracted text outputs quickly (faster than using the 'Redact document' process described here).
Starting a new Textract API job
To use this feature, first upload a document file in the file input box in the usual way on the first tab of the app. Under AWS Textract signature detection you can select whether or not you would like to analyse signatures or not (with a cost implication).
Then, open the section under the heading 'Submit whole document to AWS Textract API...'.
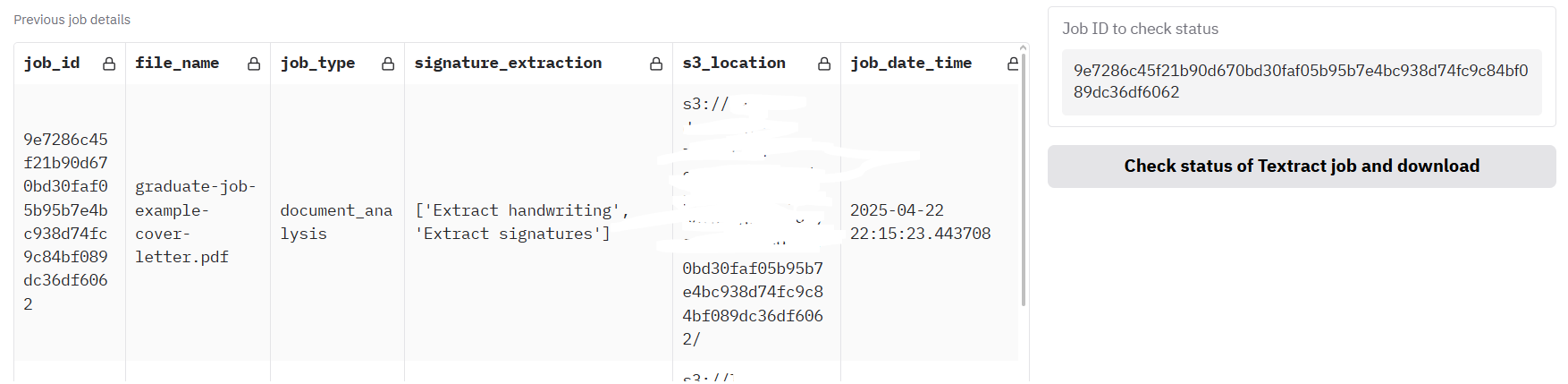
Click 'Analyse document with AWS Textract API call'. After a few seconds, the job should be submitted to the AWS Textract service. The box 'Job ID to check status' should now have an ID filled in. If it is not already filled with previous jobs (up to seven days old), the table should have a row added with details of the new API job.
Click the button underneath, 'Check status of Textract job and download', to see progress on the job. Processing will continue in the background until the job is ready, so it is worth periodically clicking this button to see if the outputs are ready. In testing, and as a rough estimate, it seems like this process takes about five seconds per page. However, this has not been tested with very large documents. Once ready, the '_textract.json' output should appear below.
Textract API job outputs
The '_textract.json' output can be used to speed up further redaction tasks as described previously, the 'Existing Textract output file found' flag should now be ticked.

You can now easily get the '..._ocr_output.csv' redaction output based on this '_textract.json' (described in Redaction outputs) by clicking on the button 'Convert Textract job outputs to OCR results'. You can now use this file e.g. for identifying duplicate pages, or for redaction review.
Using AWS Textract and Comprehend when not running in an AWS environment
AWS Textract and Comprehend give much better results for text extraction and document redaction than the local model options in the app. The most secure way to access them in the Redaction app is to run the app in a secure AWS environment with relevant permissions. Alternatively, you could run the app on your own system while logged in to AWS SSO with relevant permissions.
However, it is possible to access these services directly via API from outside an AWS environment by creating IAM users and access keys with relevant permissions to access AWS Textract and Comprehend services. Please check with your IT and data security teams that this approach is acceptable for your data before trying the following approaches.
To do the following, in your AWS environment you will need to create a new user with permissions for "textract:AnalyzeDocument", "textract:DetectDocumentText", and "comprehend:DetectPiiEntities". Under security credentials, create new access keys - note down the access key and secret key.
Direct access by passing AWS access keys through app
The Redaction Settings tab now has boxes for entering the AWS access key and secret key. If you paste the relevant keys into these boxes before performing redaction, you should be able to use these services in the app.
Picking up AWS access keys through an .env file
The app also has the capability of picking up AWS access key details through a .env file located in a '/config/aws_config.env' file (default), or alternative .env file location specified by the environment variable AWS_CONFIG_PATH. The env file should look like the following with just two lines:
AWS_ACCESS_KEY= your-access-key AWS_SECRET_KEY= your-secret-key
The app should then pick up these keys when trying to access the AWS Textract and Comprehend services during redaction.
Again, a lot can potentially go wrong with AWS solutions that are insecure, so before trying the above please consult with your AWS and data security teams.
Modifying existing redaction review files
You can find the folder containing the files discussed in this section here.
As well as serving as inputs to the document redaction app's review function, the 'review_file.csv' output can be modified outside of the app, and also merged with others from multiple redaction attempts on the same file. This gives you the flexibility to change redaction details outside of the app.
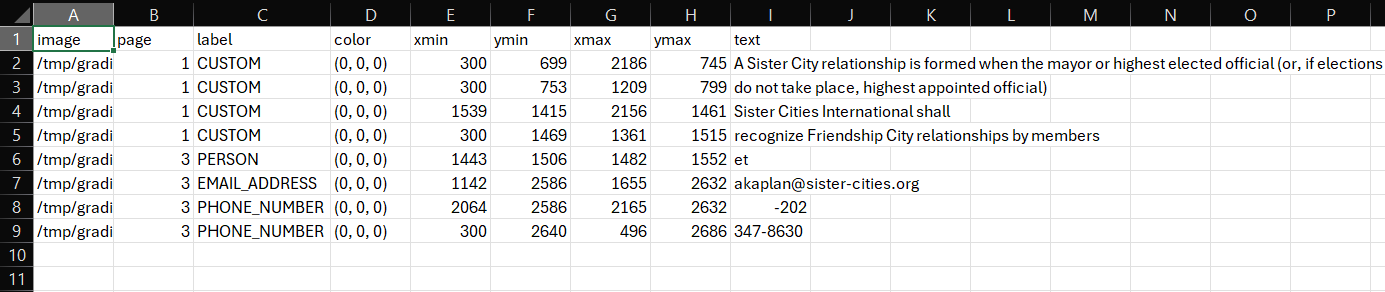
If you open up a 'review_file' csv output using a spreadsheet software program such as Microsoft Excel you can easily modify redaction properties. Open the file 'Partnership-Agreement-Toolkit_0_0_redacted.pdf_review_file_local.csv', and you should see a spreadshet with just four suggested redactions (see below). The following instructions are for using Excel.
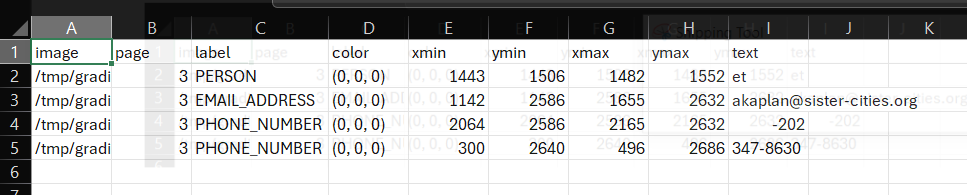
The first thing we can do is remove the first row - 'et' is suggested as a person, but is obviously not a genuine instance of personal information. Right click on the row number and select delete on this menu. Next, let's imagine that what the app identified as a 'phone number' was in fact another type of number and so we wanted to change the label. Simply click on the relevant label cells, let's change it to 'SECURITY_NUMBER'. You could also use 'Finad & Select' -> 'Replace' from the top ribbon menu if you wanted to change a number of labels simultaneously.
How about we wanted to change the colour of the 'email address' entry on the redaction review tab of the redaction app? The colours in a review file are based on an RGB scale with three numbers ranging from 0-255. You can find suitable colours here. Using this scale, if I wanted my review box to be pure blue, I can change the cell value to (0,0,255).
Imagine that a redaction box was slightly too small, and I didn't want to use the in-app options to change the size. In the review file csv, we can modify e.g. the ymin and ymax values for any box to increase the extent of the redaction box. For the 'email address' entry, let's decrease ymin by 5, and increase ymax by 5.
I have saved an output file following the above steps as 'Partnership-Agreement-Toolkit_0_0_redacted.pdf_review_file_local_mod.csv' in the same folder that the original was found. Let's upload this file to the app along with the original pdf to see how the redactions look now.
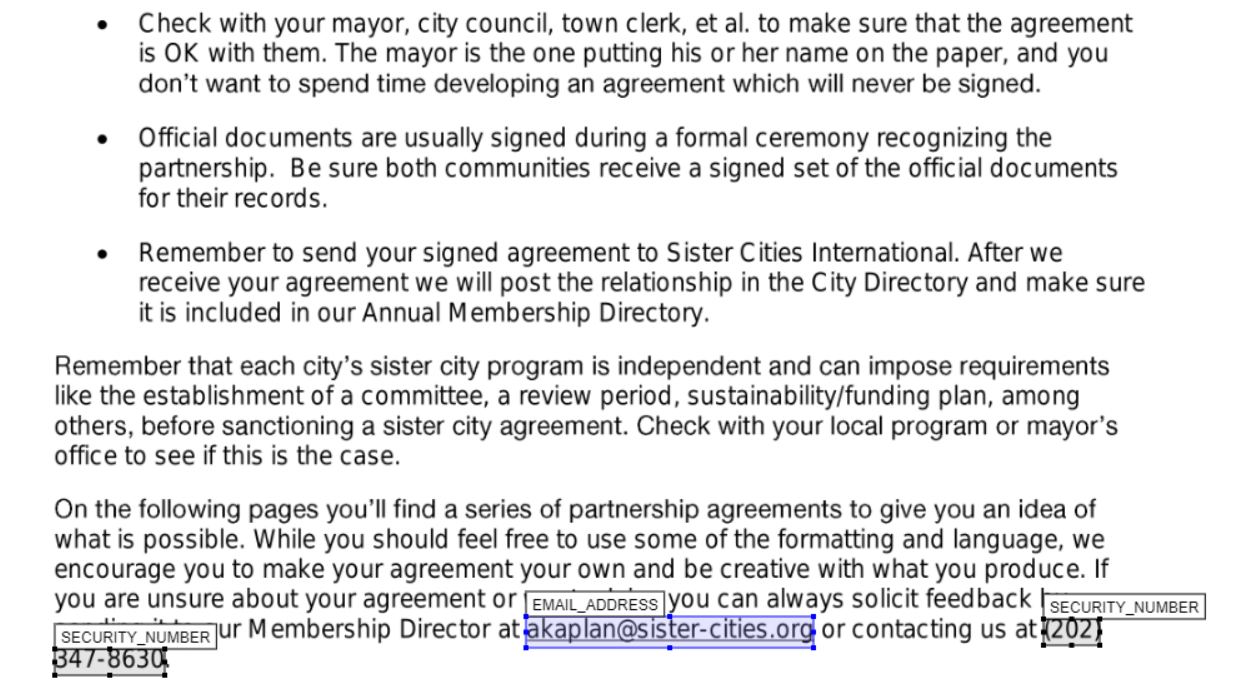
We can see from the above that we have successfully removed a redaction box, changed labels, colours, and redaction box sizes.