

license: mit
task_categories:
- question-answering
- mathematical-reasoning
language:
- en
size_categories:
- 500<n<1K
PHYBench: Holistic Evaluation of Physical Perception and Reasoning in Large Language Models
[🌐 Project] [📄 Paper] [💻 Code] [🌟 Overview] [🔧 Data Details] [🚩 Citation]
![]()
New Updates
- 2025.4.25: We release our code of EED Score. View and star on our github page!
- Recently: The leaderboard is still under progress, we'll release it as soon as possible.
🚀 Acknowledgement and Progress
We're excited to announce the initial release of our PHYBench dataset!
- 100 fully-detailed examples including handwritten solutions, questions, tags, and reference answers.
- 400 additional examples containing questions and tags.
📂 Dataset Access
You can access the datasets directly via Hugging Face:
- PHYBench-fullques.json: 100 examples with complete solutions.
- PHYBench-onlyques.json: 400 examples (questions and tags only).
- PHYBench-questions.json: Comprehensive set of all 500 questions.
📊 Full-Dataset Evaluation & Leaderboard
We are actively finalizing the full-dataset evaluation pipeline and the real-time leaderboard. Stay tuned for their upcoming release!
Thank you for your patience and ongoing support! 🙏
For further details or collaboration inquiries, please contact us at [email protected].
🌟 Overview
PHYBench is the first large-scale benchmark specifically designed to evaluate physical perception and robust reasoning capabilities in Large Language Models (LLMs). With 500 meticulously curated physics problems spanning mechanics, electromagnetism, thermodynamics, optics, modern physics, and advanced physics, it challenges models to demonstrate:
- Real-world grounding: Problems based on tangible physical scenarios (e.g., ball inside a bowl, pendulum dynamics)
- Multi-step reasoning: Average solution length of 3,000 characters requiring 10+ intermediate steps
- Symbolic precision: Strict evaluation of LaTeX-formulated expressions through novel Expression Edit Distance (EED) Score
Key innovations:
- 🎯 EED Metric: Smoother measurement based on the edit-distance on expression tree
- 🏋️ Difficulty Spectrum: High school, undergraduate, Olympiad-level physics problems
- 🔍 Error Taxonomy: Explicit evaluation of Physical Perception (PP) vs Robust Reasoning (RR) failures
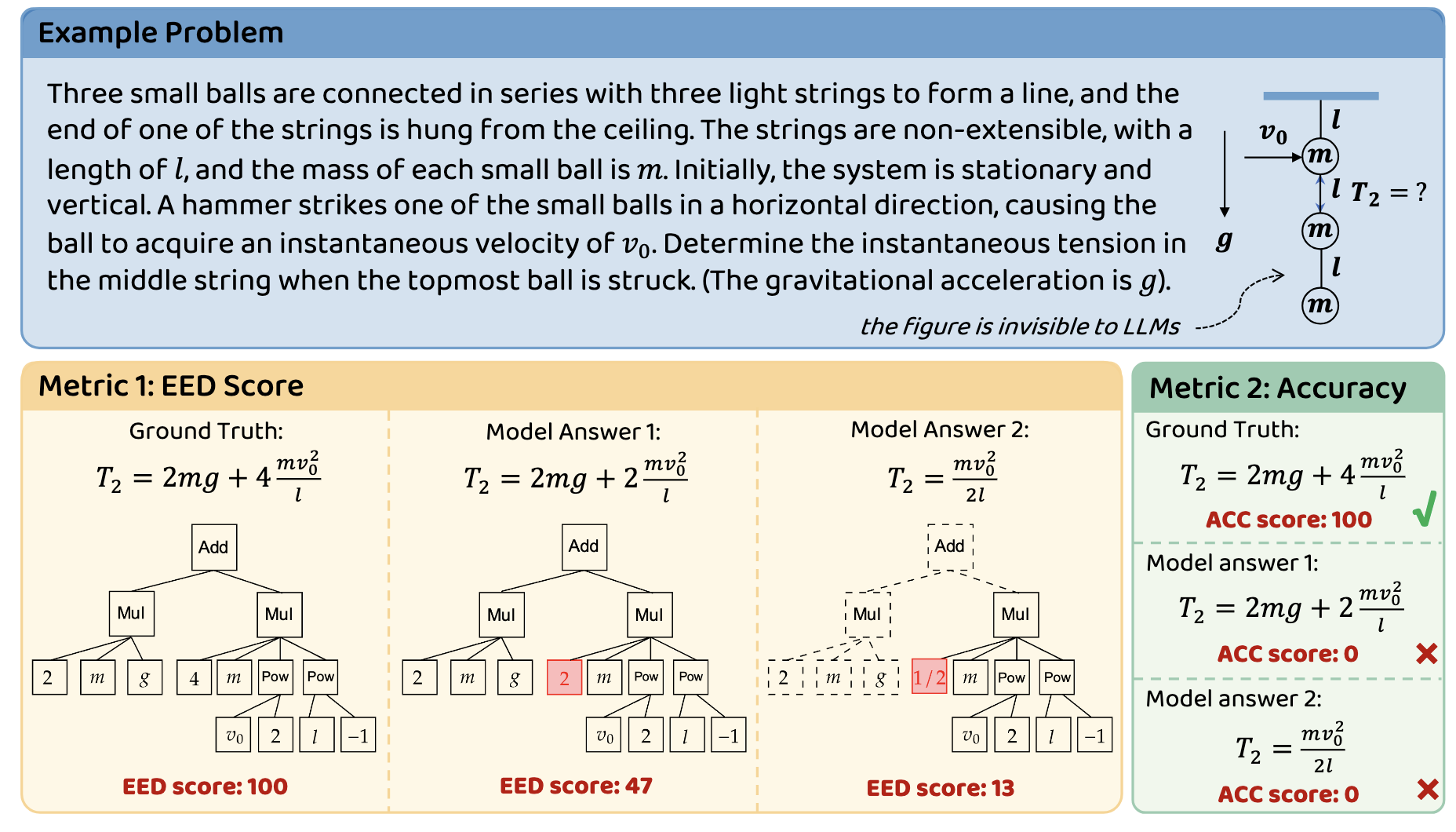
🔧 Example Problems
Put some problem cards here
Answer Types:
🔹 Strict symbolic expressions (e.g., \sqrt{\frac{2g}{3R}})
🔹 Multiple equivalent forms accepted
🔹 No numerical approximations or equation chains
🛠️ Data Curation
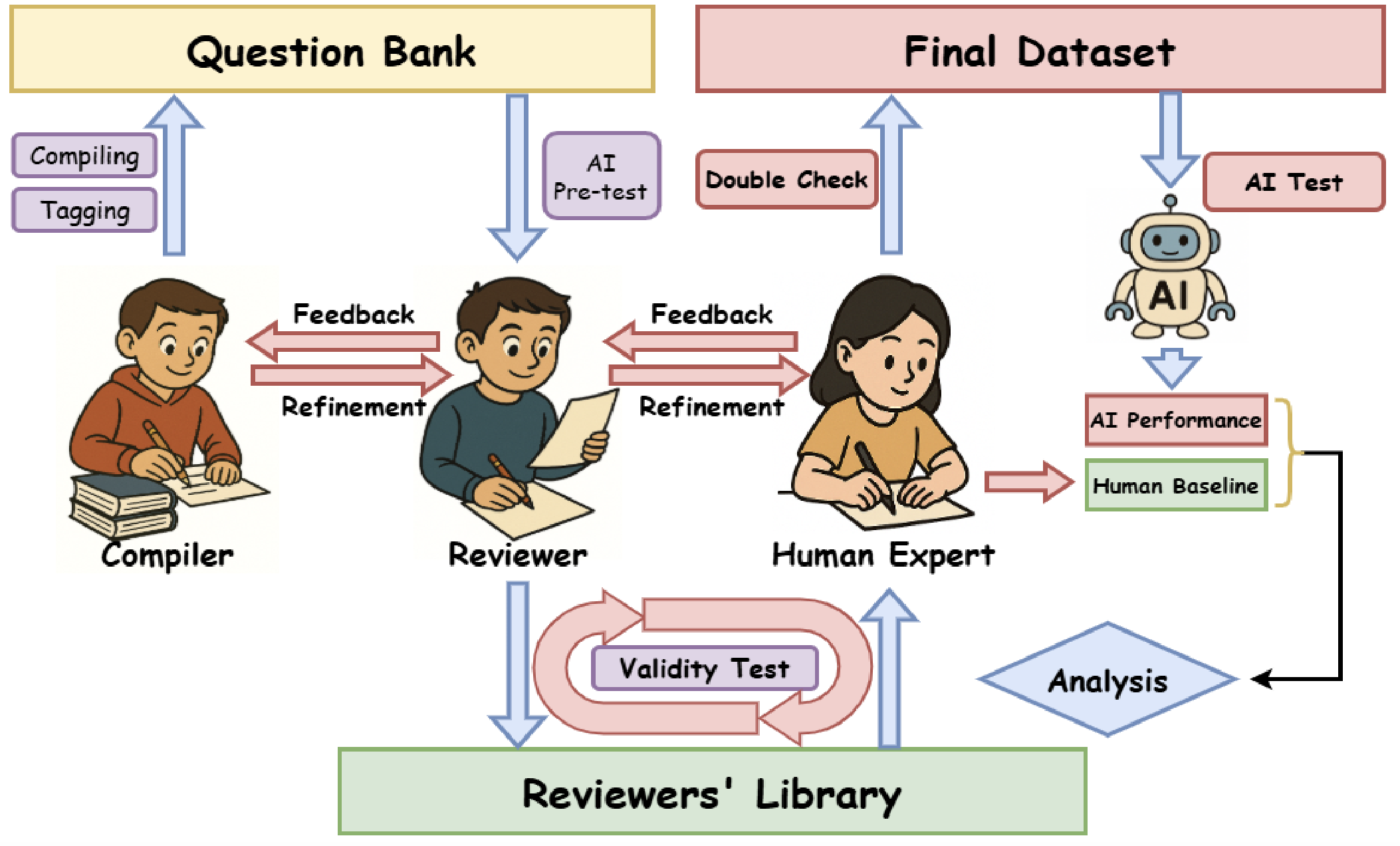
3-Stage Rigorous Validation Pipeline
Expert Creation & Strict Screening
- 178 PKU physics students contributed problems that are:
- Almost entirely original/custom-created
- None easily found through direct internet searches or standard reference materials
- Strict requirements:
- Single unambiguous symbolic answer (e.g.,
T=2mg+4mv₀²/l) - Text-only solvability (no diagrams/multimodal inputs)
- Rigorously precise statements to avoid ambiguity
- Solvable using only basic physics principles (no complex specialized knowledge required)
- Single unambiguous symbolic answer (e.g.,
- No requirements on AI test to avoid filtering for AI weaknesses
- 178 PKU physics students contributed problems that are:
Multi-Round Academic Review
- 3-tier verification process:
- Initial filtering: Reviewers assessed format validity and appropriateness (not filtering for AI weaknesses)
- Ambiguity detection and revision: Reviewers analyzed LLM-generated solutions to identify potential ambiguities in problem statements
- Iterative improvement cycle: Questions refined repeatedly until all LLMs can understand the question and follow the instructions to produce the expressions it believes to be right.
- 3-tier verification process:
Human Expert Finalization
- 81 PKU students participated:
- Each student independently solved 8 problems from the dataset
- Evaluate question clarity, statement rigor, and answer correctness
- Establish of human baseline performance meanwhile
📊 Evaluation Protocol
Machine Evaluation
Dual Metrics:
- Accuracy: Binary correctness (expression equivalence via SymPy simplification)
- EED Score: Continuous assessment of expression tree similarity
The EED Score evaluates the similarity between the model-generated answer and the ground truth by leveraging the concept of expression tree edit distance. The process involves the following steps:
Simplification of Expressions:Both the ground truth (
gt) and the model-generated answer (gen) are first converted into simplified symbolic expressions using thesympy.simplify()function. This step ensures that equivalent forms of the same expression are recognized as identical.Equivalence Check:If the simplified expressions of
gtandgenare identical, the EED Score is assigned a perfect score of 100, indicating complete correctness.Tree Conversion and Edit Distance Calculation:If the expressions are not identical, they are converted into tree structures. The edit distance between these trees is then calculated using an extended version of the Zhang-Shasha algorithm. This distance represents the minimum number of node-level operations (insertions, deletions, and updates) required to transform one tree into the other.
Relative Edit Distance and Scoring:The relative edit distance ( r ) is computed as the ratio of the edit distance to the size of the ground truth tree. The EED Score is then determined based on this relative distance:
- If ( r = 0 ) (i.e., the expressions are identical), the score is 100.
- If ( 0 < r < 0.6 ), the score is calculated as ( 60 - 100r ).
- If ( r \geq 0.6 ), the score is 0, indicating a significant discrepancy between the model-generated answer and the ground truth.
This scoring mechanism provides a continuous measure of similarity, allowing for a nuanced evaluation of the model's reasoning capabilities beyond binary correctness.
Key Advantages:
- 204% higher sample efficiency vs binary metrics
- Distinguishes coefficient errors (30<EED score<60) vs structural errors (EED score<30)
Human Baseline
- Participants: 81 PKU physics students
- Protocol:
- 8 problems per student: Each student solved a set of 8 problems from PHYBench dataset
- Time-constrained solving: 3 hours
- Performance metrics:
- 61.9±2.1% average accuracy
- 70.4±1.8 average EED Score
- Top quartile reached 71.4% accuracy and 80.4 EED Score
- Significant outperformance vs LLMs: Human experts outperformed all evaluated LLMs at 99% confidence level
- Human experts significantly outperformed all evaluated LLMs (99.99% confidence level)
📝 Main Results
The results of the evaluation are shown in the following figure:
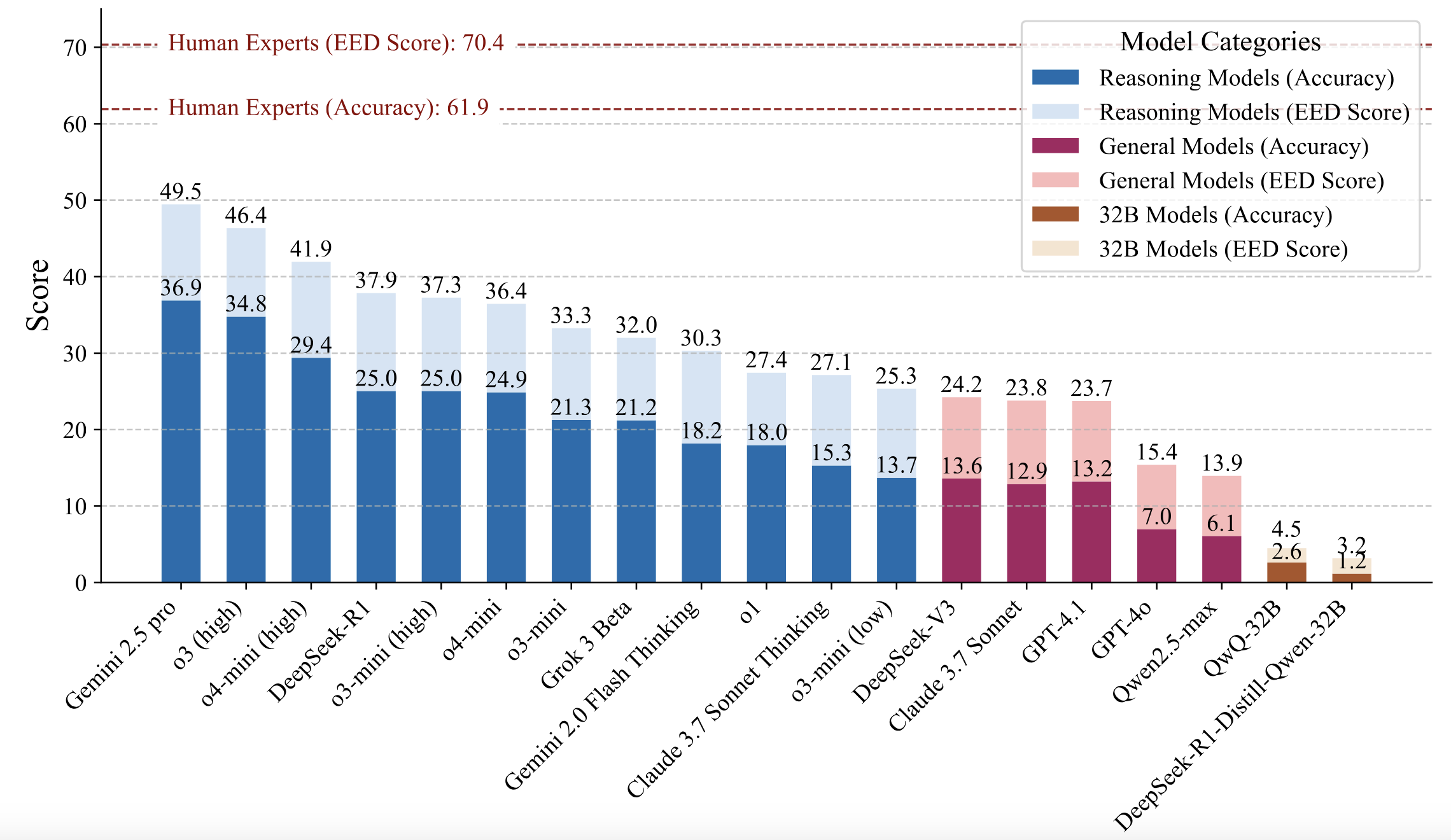
Significant Performance Gap: Even state-of-the-art LLMs significantly lag behind human experts in physical reasoning. The highest-performing model, Gemini 2.5 Pro, achieved only a 36.9% accuracy, compared to the human baseline of 61.9%.
EED Score Advantages: The EED Score provides a more nuanced evaluation of model performance compared to traditional binary scoring methods.
Domain-Specific Strengths: Different models exhibit varying strengths in different domains of physics:
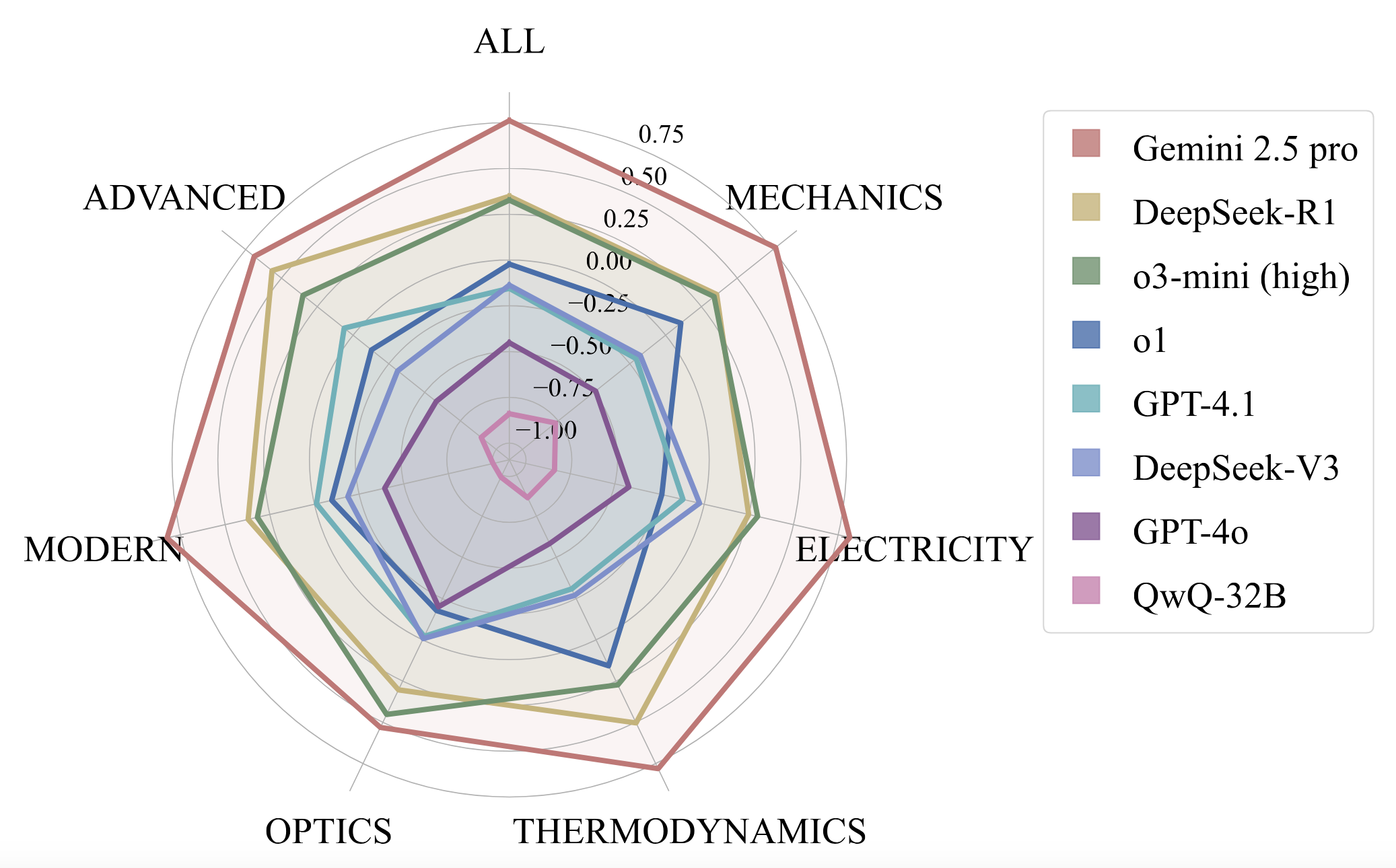
- Gemini 2.5 Pro shows strong performance across most domains
- DeepSeek-R1 and o3-mini (high) shows comparable performance in mechanics and electricity
- Most models struggle with advanced physics and modern physics
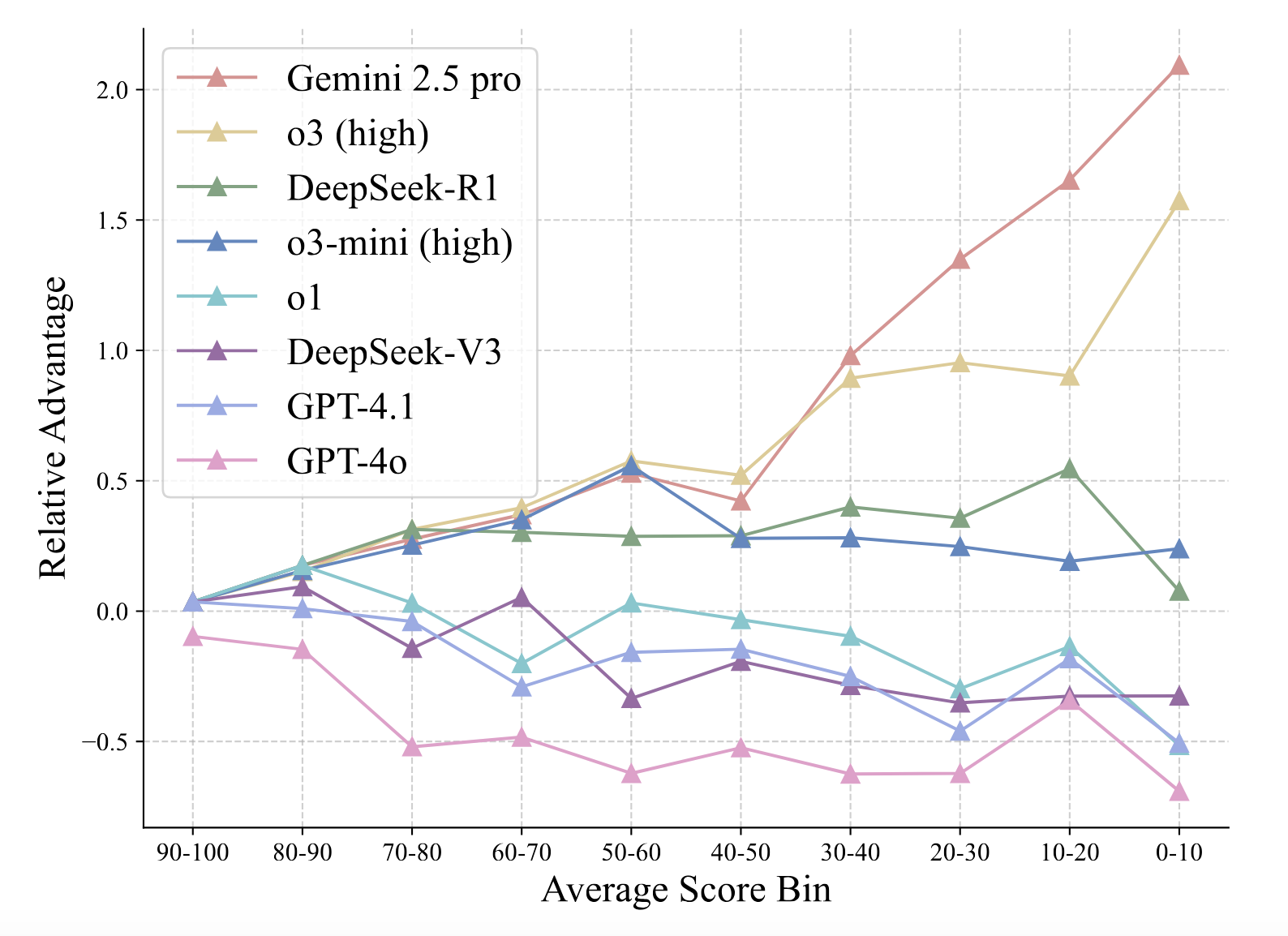
Difficulty Handling: Comparing the advantage across problem difficulties, Gemini 2.5 Pro gains a pronounced edge on harder problems, followed by o3 (high).
😵💫 Error Analysis
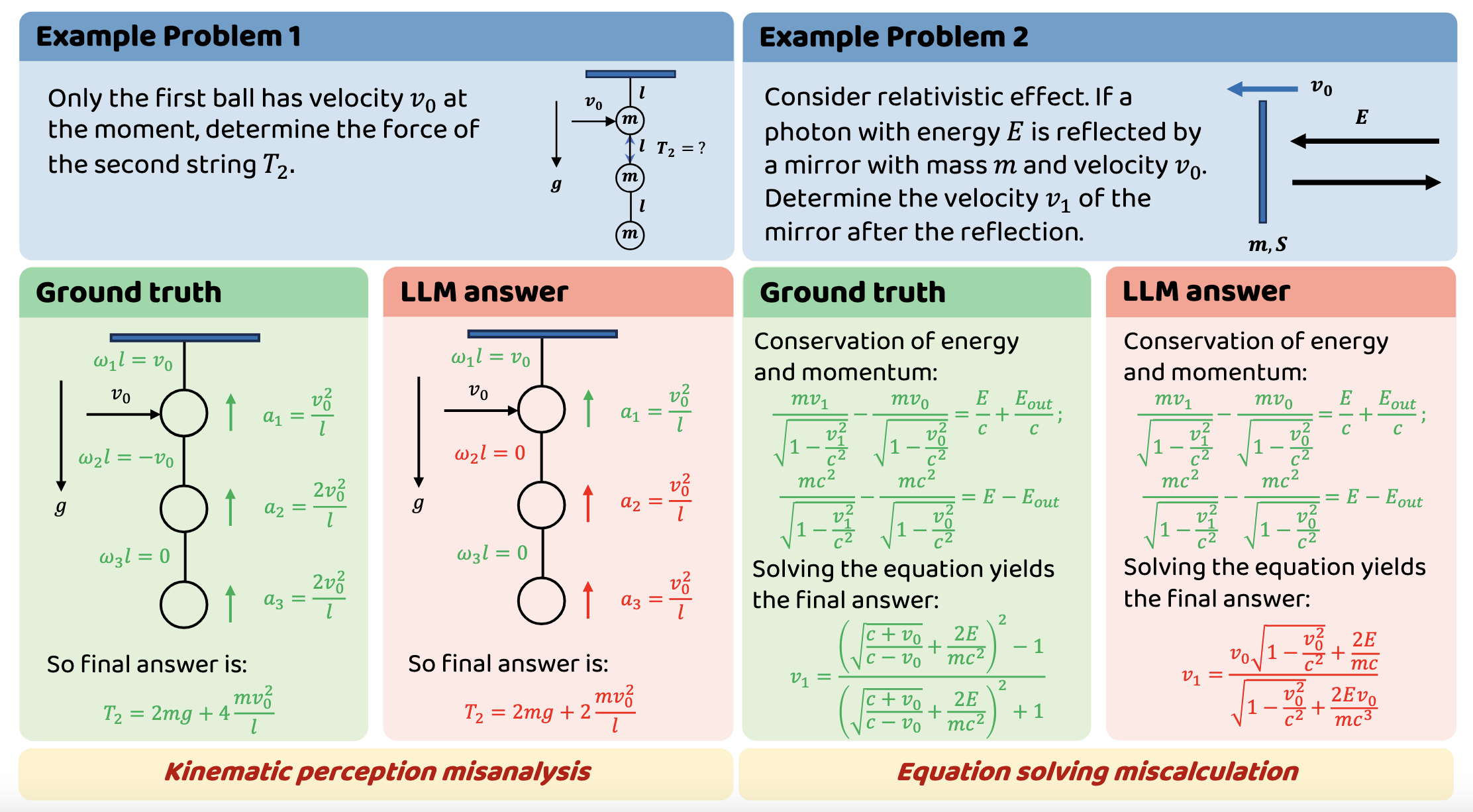
We categorize the capabilities assessed by the PHYBench benchmark into two key dimensions: Physical Perception (PP) and Robust Reasoning (RR):
- Physical Perception (PP) Errors: During this phase, models engage in intensive semantic reasoning, expending significant cognitive effort to identify relevant physical objects, variables, and dynamics. Models make qualitative judgments about which physical effects are significant and which can be safely ignored. PP manifests as critical decision nodes in the reasoning chain. An example of a PP error is shown in Example Problem 1.
- Robust Reasoning (RR) Errors: In this phase, models produce numerous lines of equations and perform symbolic reasoning. This process forms the connecting chains between perception nodes. RR involves consistent mathematical derivation, equation solving, and proper application of established conditions. An example of a RR error is shown in Example Problem 2.

🚩 Citation
@misc{qiu2025phybenchholisticevaluationphysical,
title={PHYBench: Holistic Evaluation of Physical Perception and Reasoning in Large Language Models},
author={Shi Qiu and Shaoyang Guo and Zhuo-Yang Song and Yunbo Sun and Zeyu Cai and Jiashen Wei and Tianyu Luo and Yixuan Yin and Haoxu Zhang and Yi Hu and Chenyang Wang and Chencheng Tang and Haoling Chang and Qi Liu and Ziheng Zhou and Tianyu Zhang and Jingtian Zhang and Zhangyi Liu and Minghao Li and Yuku Zhang and Boxuan Jing and Xianqi Yin and Yutong Ren and Zizhuo Fu and Weike Wang and Xudong Tian and Anqi Lv and Laifu Man and Jianxiang Li and Feiyu Tao and Qihua Sun and Zhou Liang and Yushu Mu and Zhongxuan Li and Jing-Jun Zhang and Shutao Zhang and Xiaotian Li and Xingqi Xia and Jiawei Lin and Zheyu Shen and Jiahang Chen and Qiuhao Xiong and Binran Wang and Fengyuan Wang and Ziyang Ni and Bohan Zhang and Fan Cui and Changkun Shao and Qing-Hong Cao and Ming-xing Luo and Muhan Zhang and Hua Xing Zhu},
year={2025},
eprint={2504.16074},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2504.16074},
}