diff --git a/.idea/.gitignore b/.idea/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..359bb5307e8535ab7d59faf27a7377033291821e
--- /dev/null
+++ b/.idea/.gitignore
@@ -0,0 +1,3 @@
+# 默认忽略的文件
+/shelf/
+/workspace.xml
diff --git a/.idea/SpecDETR.iml b/.idea/SpecDETR.iml
new file mode 100644
index 0000000000000000000000000000000000000000..19db66aa4b03cf4a21a31ca6eff8ea1e78468d60
--- /dev/null
+++ b/.idea/SpecDETR.iml
@@ -0,0 +1,18 @@
+
+
+
+
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/.idea/inspectionProfiles/Project_Default.xml b/.idea/inspectionProfiles/Project_Default.xml
new file mode 100644
index 0000000000000000000000000000000000000000..4236084796cdad78697a268b040c7fa48dcb746d
--- /dev/null
+++ b/.idea/inspectionProfiles/Project_Default.xml
@@ -0,0 +1,42 @@
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/.idea/inspectionProfiles/profiles_settings.xml b/.idea/inspectionProfiles/profiles_settings.xml
new file mode 100644
index 0000000000000000000000000000000000000000..105ce2da2d6447d11dfe32bfb846c3d5b199fc99
--- /dev/null
+++ b/.idea/inspectionProfiles/profiles_settings.xml
@@ -0,0 +1,6 @@
+
+
+
+
\ No newline at end of file
diff --git a/.idea/misc.xml b/.idea/misc.xml
new file mode 100644
index 0000000000000000000000000000000000000000..48b5d73e6d0f8a63615540de4ad07c9d1fea19db
--- /dev/null
+++ b/.idea/misc.xml
@@ -0,0 +1,4 @@
+
+
+
\ No newline at end of file
diff --git a/.idea/modules.xml b/.idea/modules.xml
new file mode 100644
index 0000000000000000000000000000000000000000..05d31953795a1314f7ffd3eef4cf534d70d6a5e9
--- /dev/null
+++ b/.idea/modules.xml
@@ -0,0 +1,8 @@
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/MANIFEST.in b/MANIFEST.in
new file mode 100644
index 0000000000000000000000000000000000000000..6300b224c7a4886f659b6e632e8118df8daf22ca
--- /dev/null
+++ b/MANIFEST.in
@@ -0,0 +1,6 @@
+include requirements/*.txt
+include mmdet/VERSION
+include mmdet/.mim/model-index.yml
+include mmdet/.mim/demo/*/*
+recursive-include mmdet/.mim/configs *.py *.yml
+recursive-include mmdet/.mim/tools *.sh *.py
diff --git a/benchmark.py b/benchmark.py
new file mode 100644
index 0000000000000000000000000000000000000000..b1764f79a77099640ca9baf9f83e682207f04858
--- /dev/null
+++ b/benchmark.py
@@ -0,0 +1,133 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os
+os.environ["CUDA_VISIBLE_DEVICES"] = "0"
+from mmengine import MMLogger
+from mmengine.config import Config, DictAction
+from mmengine.dist import init_dist
+from mmengine.registry import init_default_scope
+from mmengine.utils import mkdir_or_exist
+
+from mmdet.utils.benchmark import (DataLoaderBenchmark, DatasetBenchmark,
+ InferenceBenchmark)
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='MMDet benchmark')
+ parser.add_argument('--config',default='./configs/specdetr_sb-2s-100e_hsi.py',help='test config file path')
+ parser.add_argument('--checkpoint',default='./work_dirs/SpecDETR/SpecDETR_100e.pth', help='checkpoint file')
+ parser.add_argument(
+ '--task',
+ choices=['inference', 'dataloader', 'dataset'],
+ default='inference',
+ help='Which task do you want to go to benchmark')
+ parser.add_argument(
+ '--repeat-num',
+ type=int,
+ default=1,
+ help='number of repeat times of measurement for averaging the results')
+ parser.add_argument(
+ '--max-iter', type=int, default=2000, help='num of max iter')
+ parser.add_argument(
+ '--log-interval', type=int, default=50, help='interval of logging')
+ parser.add_argument(
+ '--num-warmup', type=int, default=5, help='Number of warmup')
+ parser.add_argument(
+ '--fuse-conv-bn',
+ action='store_true',
+ help='Whether to fuse conv and bn, this will slightly increase'
+ 'the inference speed')
+ parser.add_argument(
+ '--dataset-type',
+ choices=['train', 'val', 'test'],
+ default='test',
+ help='Benchmark dataset type. only supports train, val and test')
+ parser.add_argument(
+ '--work-dir',
+ help='the directory to save the file containing '
+ 'benchmark metrics')
+ parser.add_argument(
+ '--cfg-options',
+ nargs='+',
+ action=DictAction,
+ help='override some settings in the used config, the key-value pair '
+ 'in xxx=yyy format will be merged into config file. If the value to '
+ 'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
+ 'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
+ 'Note that the quotation marks are necessary and that no white space '
+ 'is allowed.')
+ parser.add_argument(
+ '--launcher',
+ choices=['none', 'pytorch', 'slurm', 'mpi'],
+ default='none',
+ help='job launcher')
+ parser.add_argument('--local_rank', type=int, default=0)
+ args = parser.parse_args()
+ if 'LOCAL_RANK' not in os.environ:
+ os.environ['LOCAL_RANK'] = str(args.local_rank)
+ return args
+
+
+def inference_benchmark(args, cfg, distributed, logger):
+ benchmark = InferenceBenchmark(
+ cfg,
+ args.checkpoint,
+ distributed,
+ args.fuse_conv_bn,
+ args.max_iter,
+ args.log_interval,
+ args.num_warmup,
+ logger=logger)
+ return benchmark
+
+
+def dataloader_benchmark(args, cfg, distributed, logger):
+ benchmark = DataLoaderBenchmark(
+ cfg,
+ distributed,
+ args.dataset_type,
+ args.max_iter,
+ args.log_interval,
+ args.num_warmup,
+ logger=logger)
+ return benchmark
+
+
+def dataset_benchmark(args, cfg, distributed, logger):
+ benchmark = DatasetBenchmark(
+ cfg,
+ args.dataset_type,
+ args.max_iter,
+ args.log_interval,
+ args.num_warmup,
+ logger=logger)
+ return benchmark
+
+
+def main():
+ args = parse_args()
+ cfg = Config.fromfile(args.config)
+ if args.cfg_options is not None:
+ cfg.merge_from_dict(args.cfg_options)
+
+ init_default_scope(cfg.get('default_scope', 'mmdet'))
+
+ distributed = False
+ if args.launcher != 'none':
+ init_dist(args.launcher, **cfg.get('env_cfg', {}).get('dist_cfg', {}))
+ distributed = True
+
+ log_file = None
+ if args.work_dir:
+ log_file = os.path.join(args.work_dir, 'benchmark.log')
+ mkdir_or_exist(args.work_dir)
+
+ logger = MMLogger.get_instance(
+ 'mmdet', log_file=log_file, log_level='INFO')
+
+ benchmark = eval(f'{args.task}_benchmark')(args, cfg, distributed, logger)
+ benchmark.run(args.repeat_num)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/configs/_base_/datasets/cityscapes_detection.py b/configs/_base_/datasets/cityscapes_detection.py
new file mode 100644
index 0000000000000000000000000000000000000000..caeba6bfcd26d8954fc9d499446e93323e372959
--- /dev/null
+++ b/configs/_base_/datasets/cityscapes_detection.py
@@ -0,0 +1,84 @@
+# dataset settings
+dataset_type = 'CityscapesDataset'
+data_root = 'data/cityscapes/'
+
+# Example to use different file client
+# Method 1: simply set the data root and let the file I/O module
+# automatically infer from prefix (not support LMDB and Memcache yet)
+
+# data_root = 's3://openmmlab/datasets/segmentation/cityscapes/'
+
+# Method 2: Use `backend_args`, `file_client_args` in versions before 3.0.0rc6
+# backend_args = dict(
+# backend='petrel',
+# path_mapping=dict({
+# './data/': 's3://openmmlab/datasets/segmentation/',
+# 'data/': 's3://openmmlab/datasets/segmentation/'
+# }))
+backend_args = None
+
+train_pipeline = [
+ dict(type='LoadImageFromFile', backend_args=backend_args),
+ dict(type='LoadAnnotations', with_bbox=True),
+ dict(
+ type='RandomResize',
+ scale=[(2048, 800), (2048, 1024)],
+ keep_ratio=True),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='PackDetInputs')
+]
+
+test_pipeline = [
+ dict(type='LoadImageFromFile', backend_args=backend_args),
+ dict(type='Resize', scale=(2048, 1024), keep_ratio=True),
+ # If you don't have a gt annotation, delete the pipeline
+ dict(type='LoadAnnotations', with_bbox=True),
+ dict(
+ type='PackDetInputs',
+ meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'scale_factor'))
+]
+
+train_dataloader = dict(
+ batch_size=1,
+ num_workers=2,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ batch_sampler=dict(type='AspectRatioBatchSampler'),
+ dataset=dict(
+ type='RepeatDataset',
+ times=8,
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ ann_file='annotations/instancesonly_filtered_gtFine_train.json',
+ data_prefix=dict(img='leftImg8bit/train/'),
+ filter_cfg=dict(filter_empty_gt=True, min_size=32),
+ pipeline=train_pipeline,
+ backend_args=backend_args)))
+
+val_dataloader = dict(
+ batch_size=1,
+ num_workers=2,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ ann_file='annotations/instancesonly_filtered_gtFine_val.json',
+ data_prefix=dict(img='leftImg8bit/val/'),
+ test_mode=True,
+ filter_cfg=dict(filter_empty_gt=True, min_size=32),
+ pipeline=test_pipeline,
+ backend_args=backend_args))
+
+test_dataloader = val_dataloader
+
+val_evaluator = dict(
+ type='CocoMetric',
+ ann_file=data_root + 'annotations/instancesonly_filtered_gtFine_val.json',
+ metric='bbox',
+ backend_args=backend_args)
+
+test_evaluator = val_evaluator
diff --git a/configs/_base_/datasets/cityscapes_instance.py b/configs/_base_/datasets/cityscapes_instance.py
new file mode 100644
index 0000000000000000000000000000000000000000..136403136c67a6726662832b66f56701ff5aba8a
--- /dev/null
+++ b/configs/_base_/datasets/cityscapes_instance.py
@@ -0,0 +1,113 @@
+# dataset settings
+dataset_type = 'CityscapesDataset'
+data_root = 'data/cityscapes/'
+
+# Example to use different file client
+# Method 1: simply set the data root and let the file I/O module
+# automatically infer from prefix (not support LMDB and Memcache yet)
+
+# data_root = 's3://openmmlab/datasets/segmentation/cityscapes/'
+
+# Method 2: Use backend_args, file_client_args in versions before 3.0.0rc6
+# backend_args = dict(
+# backend='petrel',
+# path_mapping=dict({
+# './data/': 's3://openmmlab/datasets/segmentation/',
+# 'data/': 's3://openmmlab/datasets/segmentation/'
+# }))
+backend_args = None
+
+train_pipeline = [
+ dict(type='LoadImageFromFile', backend_args=backend_args),
+ dict(type='LoadAnnotations', with_bbox=True, with_mask=True),
+ dict(
+ type='RandomResize',
+ scale=[(2048, 800), (2048, 1024)],
+ keep_ratio=True),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='PackDetInputs')
+]
+
+test_pipeline = [
+ dict(type='LoadImageFromFile', backend_args=backend_args),
+ dict(type='Resize', scale=(2048, 1024), keep_ratio=True),
+ # If you don't have a gt annotation, delete the pipeline
+ dict(type='LoadAnnotations', with_bbox=True, with_mask=True),
+ dict(
+ type='PackDetInputs',
+ meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'scale_factor'))
+]
+
+train_dataloader = dict(
+ batch_size=1,
+ num_workers=2,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ batch_sampler=dict(type='AspectRatioBatchSampler'),
+ dataset=dict(
+ type='RepeatDataset',
+ times=8,
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ ann_file='annotations/instancesonly_filtered_gtFine_train.json',
+ data_prefix=dict(img='leftImg8bit/train/'),
+ filter_cfg=dict(filter_empty_gt=True, min_size=32),
+ pipeline=train_pipeline,
+ backend_args=backend_args)))
+
+val_dataloader = dict(
+ batch_size=1,
+ num_workers=2,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ ann_file='annotations/instancesonly_filtered_gtFine_val.json',
+ data_prefix=dict(img='leftImg8bit/val/'),
+ test_mode=True,
+ filter_cfg=dict(filter_empty_gt=True, min_size=32),
+ pipeline=test_pipeline,
+ backend_args=backend_args))
+
+test_dataloader = val_dataloader
+
+val_evaluator = [
+ dict(
+ type='CocoMetric',
+ ann_file=data_root +
+ 'annotations/instancesonly_filtered_gtFine_val.json',
+ metric=['bbox', 'segm'],
+ backend_args=backend_args),
+ dict(
+ type='CityScapesMetric',
+ seg_prefix=data_root + 'gtFine/val',
+ outfile_prefix='./work_dirs/cityscapes_metric/instance',
+ backend_args=backend_args)
+]
+
+test_evaluator = val_evaluator
+
+# inference on test dataset and
+# format the output results for submission.
+# test_dataloader = dict(
+# batch_size=1,
+# num_workers=2,
+# persistent_workers=True,
+# drop_last=False,
+# sampler=dict(type='DefaultSampler', shuffle=False),
+# dataset=dict(
+# type=dataset_type,
+# data_root=data_root,
+# ann_file='annotations/instancesonly_filtered_gtFine_test.json',
+# data_prefix=dict(img='leftImg8bit/test/'),
+# test_mode=True,
+# filter_cfg=dict(filter_empty_gt=True, min_size=32),
+# pipeline=test_pipeline))
+# test_evaluator = dict(
+# type='CityScapesMetric',
+# format_only=True,
+# outfile_prefix='./work_dirs/cityscapes_metric/test')
diff --git a/configs/_base_/datasets/coco_detection.py b/configs/_base_/datasets/coco_detection.py
new file mode 100644
index 0000000000000000000000000000000000000000..fdf8dfad9476b1d7b7a4e8c3e2832f115a1ea7f2
--- /dev/null
+++ b/configs/_base_/datasets/coco_detection.py
@@ -0,0 +1,95 @@
+# dataset settings
+dataset_type = 'CocoDataset'
+data_root = 'data/coco/'
+
+# Example to use different file client
+# Method 1: simply set the data root and let the file I/O module
+# automatically infer from prefix (not support LMDB and Memcache yet)
+
+# data_root = 's3://openmmlab/datasets/detection/coco/'
+
+# Method 2: Use `backend_args`, `file_client_args` in versions before 3.0.0rc6
+# backend_args = dict(
+# backend='petrel',
+# path_mapping=dict({
+# './data/': 's3://openmmlab/datasets/detection/',
+# 'data/': 's3://openmmlab/datasets/detection/'
+# }))
+backend_args = None
+
+train_pipeline = [
+ dict(type='LoadImageFromFile', backend_args=backend_args),
+ dict(type='LoadAnnotations', with_bbox=True),
+ dict(type='Resize', scale=(1333, 800), keep_ratio=True),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='PackDetInputs')
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile', backend_args=backend_args),
+ dict(type='Resize', scale=(1333, 800), keep_ratio=True),
+ # If you don't have a gt annotation, delete the pipeline
+ dict(type='LoadAnnotations', with_bbox=True),
+ dict(
+ type='PackDetInputs',
+ meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'scale_factor'))
+]
+train_dataloader = dict(
+ batch_size=2,
+ num_workers=2,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ batch_sampler=dict(type='AspectRatioBatchSampler'),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ ann_file='annotations/instances_train2017.json',
+ data_prefix=dict(img='train2017/'),
+ filter_cfg=dict(filter_empty_gt=True, min_size=32),
+ pipeline=train_pipeline,
+ backend_args=backend_args))
+val_dataloader = dict(
+ batch_size=1,
+ num_workers=2,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ ann_file='annotations/instances_val2017.json',
+ data_prefix=dict(img='val2017/'),
+ test_mode=True,
+ pipeline=test_pipeline,
+ backend_args=backend_args))
+test_dataloader = val_dataloader
+
+val_evaluator = dict(
+ type='CocoMetric',
+ ann_file=data_root + 'annotations/instances_val2017.json',
+ metric='bbox',
+ format_only=False,
+ backend_args=backend_args)
+test_evaluator = val_evaluator
+
+# inference on test dataset and
+# format the output results for submission.
+# test_dataloader = dict(
+# batch_size=1,
+# num_workers=2,
+# persistent_workers=True,
+# drop_last=False,
+# sampler=dict(type='DefaultSampler', shuffle=False),
+# dataset=dict(
+# type=dataset_type,
+# data_root=data_root,
+# ann_file=data_root + 'annotations/image_info_test-dev2017.json',
+# data_prefix=dict(img='test2017/'),
+# test_mode=True,
+# pipeline=test_pipeline))
+# test_evaluator = dict(
+# type='CocoMetric',
+# metric='bbox',
+# format_only=True,
+# ann_file=data_root + 'annotations/image_info_test-dev2017.json',
+# outfile_prefix='./work_dirs/coco_detection/test')
diff --git a/configs/_base_/datasets/coco_instance.py b/configs/_base_/datasets/coco_instance.py
new file mode 100644
index 0000000000000000000000000000000000000000..e91cb354038db4df3b990b307a5da9d77f341a88
--- /dev/null
+++ b/configs/_base_/datasets/coco_instance.py
@@ -0,0 +1,95 @@
+# dataset settings
+dataset_type = 'CocoDataset'
+data_root = 'data/coco/'
+
+# Example to use different file client
+# Method 1: simply set the data root and let the file I/O module
+# automatically infer from prefix (not support LMDB and Memcache yet)
+
+# data_root = 's3://openmmlab/datasets/detection/coco/'
+
+# Method 2: Use `backend_args`, `file_client_args` in versions before 3.0.0rc6
+# backend_args = dict(
+# backend='petrel',
+# path_mapping=dict({
+# './data/': 's3://openmmlab/datasets/detection/',
+# 'data/': 's3://openmmlab/datasets/detection/'
+# }))
+backend_args = None
+
+train_pipeline = [
+ dict(type='LoadImageFromFile', backend_args=backend_args),
+ dict(type='LoadAnnotations', with_bbox=True, with_mask=True),
+ dict(type='Resize', scale=(1333, 800), keep_ratio=True),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='PackDetInputs')
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile', backend_args=backend_args),
+ dict(type='Resize', scale=(1333, 800), keep_ratio=True),
+ # If you don't have a gt annotation, delete the pipeline
+ dict(type='LoadAnnotations', with_bbox=True, with_mask=True),
+ dict(
+ type='PackDetInputs',
+ meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'scale_factor'))
+]
+train_dataloader = dict(
+ batch_size=2,
+ num_workers=2,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ batch_sampler=dict(type='AspectRatioBatchSampler'),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ ann_file='annotations/instances_train2017.json',
+ data_prefix=dict(img='train2017/'),
+ filter_cfg=dict(filter_empty_gt=True, min_size=32),
+ pipeline=train_pipeline,
+ backend_args=backend_args))
+val_dataloader = dict(
+ batch_size=1,
+ num_workers=2,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ ann_file='annotations/instances_val2017.json',
+ data_prefix=dict(img='val2017/'),
+ test_mode=True,
+ pipeline=test_pipeline,
+ backend_args=backend_args))
+test_dataloader = val_dataloader
+
+val_evaluator = dict(
+ type='CocoMetric',
+ ann_file=data_root + 'annotations/instances_val2017.json',
+ metric=['bbox', 'segm'],
+ format_only=False,
+ backend_args=backend_args)
+test_evaluator = val_evaluator
+
+# inference on test dataset and
+# format the output results for submission.
+# test_dataloader = dict(
+# batch_size=1,
+# num_workers=2,
+# persistent_workers=True,
+# drop_last=False,
+# sampler=dict(type='DefaultSampler', shuffle=False),
+# dataset=dict(
+# type=dataset_type,
+# data_root=data_root,
+# ann_file=data_root + 'annotations/image_info_test-dev2017.json',
+# data_prefix=dict(img='test2017/'),
+# test_mode=True,
+# pipeline=test_pipeline))
+# test_evaluator = dict(
+# type='CocoMetric',
+# metric=['bbox', 'segm'],
+# format_only=True,
+# ann_file=data_root + 'annotations/image_info_test-dev2017.json',
+# outfile_prefix='./work_dirs/coco_instance/test')
diff --git a/configs/_base_/datasets/coco_instance_semantic.py b/configs/_base_/datasets/coco_instance_semantic.py
new file mode 100644
index 0000000000000000000000000000000000000000..cc961863306690c056e564b542d518c0ebfbb7e2
--- /dev/null
+++ b/configs/_base_/datasets/coco_instance_semantic.py
@@ -0,0 +1,78 @@
+# dataset settings
+dataset_type = 'CocoDataset'
+data_root = 'data/coco/'
+
+# Example to use different file client
+# Method 1: simply set the data root and let the file I/O module
+# automatically infer from prefix (not support LMDB and Memcache yet)
+
+# data_root = 's3://openmmlab/datasets/detection/coco/'
+
+# Method 2: Use `backend_args`, `file_client_args` in versions before 3.0.0rc6
+# backend_args = dict(
+# backend='petrel',
+# path_mapping=dict({
+# './data/': 's3://openmmlab/datasets/detection/',
+# 'data/': 's3://openmmlab/datasets/detection/'
+# }))
+backend_args = None
+
+train_pipeline = [
+ dict(type='LoadImageFromFile', backend_args=backend_args),
+ dict(
+ type='LoadAnnotations', with_bbox=True, with_mask=True, with_seg=True),
+ dict(type='Resize', scale=(1333, 800), keep_ratio=True),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='PackDetInputs')
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile', backend_args=backend_args),
+ dict(type='Resize', scale=(1333, 800), keep_ratio=True),
+ # If you don't have a gt annotation, delete the pipeline
+ dict(
+ type='LoadAnnotations', with_bbox=True, with_mask=True, with_seg=True),
+ dict(
+ type='PackDetInputs',
+ meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'scale_factor'))
+]
+
+train_dataloader = dict(
+ batch_size=2,
+ num_workers=2,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ batch_sampler=dict(type='AspectRatioBatchSampler'),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ ann_file='annotations/instances_train2017.json',
+ data_prefix=dict(img='train2017/', seg='stuffthingmaps/train2017/'),
+ filter_cfg=dict(filter_empty_gt=True, min_size=32),
+ pipeline=train_pipeline,
+ backend_args=backend_args))
+
+val_dataloader = dict(
+ batch_size=1,
+ num_workers=2,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ ann_file='annotations/instances_val2017.json',
+ data_prefix=dict(img='val2017/'),
+ test_mode=True,
+ pipeline=test_pipeline,
+ backend_args=backend_args))
+
+test_dataloader = val_dataloader
+
+val_evaluator = dict(
+ type='CocoMetric',
+ ann_file=data_root + 'annotations/instances_val2017.json',
+ metric=['bbox', 'segm'],
+ format_only=False,
+ backend_args=backend_args)
+test_evaluator = val_evaluator
diff --git a/configs/_base_/datasets/coco_panoptic.py b/configs/_base_/datasets/coco_panoptic.py
new file mode 100644
index 0000000000000000000000000000000000000000..2d75660f4b4073052e46aef2816018cfdd0eaaec
--- /dev/null
+++ b/configs/_base_/datasets/coco_panoptic.py
@@ -0,0 +1,94 @@
+# dataset settings
+dataset_type = 'CocoPanopticDataset'
+# data_root = 'data/coco/'
+
+# Example to use different file client
+# Method 1: simply set the data root and let the file I/O module
+# automatically infer from prefix (not support LMDB and Memcache yet)
+
+data_root = 's3://openmmlab/datasets/detection/coco/'
+
+# Method 2: Use `backend_args`, `file_client_args` in versions before 3.0.0rc6
+# backend_args = dict(
+# backend='petrel',
+# path_mapping=dict({
+# './data/': 's3://openmmlab/datasets/detection/',
+# 'data/': 's3://openmmlab/datasets/detection/'
+# }))
+backend_args = None
+
+train_pipeline = [
+ dict(type='LoadImageFromFile', backend_args=backend_args),
+ dict(type='LoadPanopticAnnotations', backend_args=backend_args),
+ dict(type='Resize', scale=(1333, 800), keep_ratio=True),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='PackDetInputs')
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile', backend_args=backend_args),
+ dict(type='Resize', scale=(1333, 800), keep_ratio=True),
+ dict(type='LoadPanopticAnnotations', backend_args=backend_args),
+ dict(
+ type='PackDetInputs',
+ meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'scale_factor'))
+]
+
+train_dataloader = dict(
+ batch_size=2,
+ num_workers=2,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ batch_sampler=dict(type='AspectRatioBatchSampler'),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ ann_file='annotations/panoptic_train2017.json',
+ data_prefix=dict(
+ img='train2017/', seg='annotations/panoptic_train2017/'),
+ filter_cfg=dict(filter_empty_gt=True, min_size=32),
+ pipeline=train_pipeline,
+ backend_args=backend_args))
+val_dataloader = dict(
+ batch_size=1,
+ num_workers=2,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ ann_file='annotations/panoptic_val2017.json',
+ data_prefix=dict(img='val2017/', seg='annotations/panoptic_val2017/'),
+ test_mode=True,
+ pipeline=test_pipeline,
+ backend_args=backend_args))
+test_dataloader = val_dataloader
+
+val_evaluator = dict(
+ type='CocoPanopticMetric',
+ ann_file=data_root + 'annotations/panoptic_val2017.json',
+ seg_prefix=data_root + 'annotations/panoptic_val2017/',
+ backend_args=backend_args)
+test_evaluator = val_evaluator
+
+# inference on test dataset and
+# format the output results for submission.
+# test_dataloader = dict(
+# batch_size=1,
+# num_workers=1,
+# persistent_workers=True,
+# drop_last=False,
+# sampler=dict(type='DefaultSampler', shuffle=False),
+# dataset=dict(
+# type=dataset_type,
+# data_root=data_root,
+# ann_file='annotations/panoptic_image_info_test-dev2017.json',
+# data_prefix=dict(img='test2017/'),
+# test_mode=True,
+# pipeline=test_pipeline))
+# test_evaluator = dict(
+# type='CocoPanopticMetric',
+# format_only=True,
+# ann_file=data_root + 'annotations/panoptic_image_info_test-dev2017.json',
+# outfile_prefix='./work_dirs/coco_panoptic/test')
diff --git a/configs/_base_/datasets/deepfashion.py b/configs/_base_/datasets/deepfashion.py
new file mode 100644
index 0000000000000000000000000000000000000000..a93dc7152f7a2e28ab726c79f9398a1034b7b4a1
--- /dev/null
+++ b/configs/_base_/datasets/deepfashion.py
@@ -0,0 +1,95 @@
+# dataset settings
+dataset_type = 'DeepFashionDataset'
+data_root = 'data/DeepFashion/In-shop/'
+
+# Example to use different file client
+# Method 1: simply set the data root and let the file I/O module
+# automatically infer from prefix (not support LMDB and Memcache yet)
+
+# data_root = 's3://openmmlab/datasets/detection/coco/'
+
+# Method 2: Use `backend_args`, `file_client_args` in versions before 3.0.0rc6
+# backend_args = dict(
+# backend='petrel',
+# path_mapping=dict({
+# './data/': 's3://openmmlab/datasets/detection/',
+# 'data/': 's3://openmmlab/datasets/detection/'
+# }))
+backend_args = None
+
+train_pipeline = [
+ dict(type='LoadImageFromFile', backend_args=backend_args),
+ dict(type='LoadAnnotations', with_bbox=True, with_mask=True),
+ dict(type='Resize', scale=(750, 1101), keep_ratio=True),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='PackDetInputs')
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile', backend_args=backend_args),
+ dict(type='Resize', scale=(750, 1101), keep_ratio=True),
+ dict(type='LoadAnnotations', with_bbox=True, with_mask=True),
+ dict(
+ type='PackDetInputs',
+ meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'scale_factor'))
+]
+train_dataloader = dict(
+ batch_size=2,
+ num_workers=2,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ batch_sampler=dict(type='AspectRatioBatchSampler'),
+ dataset=dict(
+ type='RepeatDataset',
+ times=2,
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ ann_file='Anno/segmentation/DeepFashion_segmentation_train.json',
+ data_prefix=dict(img='Img/'),
+ filter_cfg=dict(filter_empty_gt=True, min_size=32),
+ pipeline=train_pipeline,
+ backend_args=backend_args)))
+val_dataloader = dict(
+ batch_size=1,
+ num_workers=2,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ ann_file='Anno/segmentation/DeepFashion_segmentation_query.json',
+ data_prefix=dict(img='Img/'),
+ test_mode=True,
+ pipeline=test_pipeline,
+ backend_args=backend_args))
+test_dataloader = dict(
+ batch_size=1,
+ num_workers=2,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ ann_file='Anno/segmentation/DeepFashion_segmentation_gallery.json',
+ data_prefix=dict(img='Img/'),
+ test_mode=True,
+ pipeline=test_pipeline,
+ backend_args=backend_args))
+
+val_evaluator = dict(
+ type='CocoMetric',
+ ann_file=data_root +
+ 'Anno/segmentation/DeepFashion_segmentation_query.json',
+ metric=['bbox', 'segm'],
+ format_only=False,
+ backend_args=backend_args)
+test_evaluator = dict(
+ type='CocoMetric',
+ ann_file=data_root +
+ 'Anno/segmentation/DeepFashion_segmentation_gallery.json',
+ metric=['bbox', 'segm'],
+ format_only=False,
+ backend_args=backend_args)
diff --git a/configs/_base_/datasets/hsi_detection.py b/configs/_base_/datasets/hsi_detection.py
new file mode 100644
index 0000000000000000000000000000000000000000..58b0e33e46e9bd7c66f74ee865b3c41ed4ed2c57
--- /dev/null
+++ b/configs/_base_/datasets/hsi_detection.py
@@ -0,0 +1,96 @@
+# dataset settings
+dataset_type = 'HSIDataset'
+data_root = '/media/ubuntu/data/HTD_dataset/SPOD_30b_8c/'
+# Example to use different file client
+# Method 1: simply set the data root and let the file I/O module
+# automatically infer from prefix (not support LMDB and Memcache yet)
+
+
+# Method 2: Use `backend_args`, `file_client_args` in versions before 3.0.0rc6
+# backend_args = dict(
+# backend='petrel',
+# path_mapping=dict({
+# './data/': 's3://openmmlab/datasets/detection/',
+# 'data/': 's3://openmmlab/datasets/detection/'
+# }))
+
+normalized_basis =3000
+backend_args = None
+train_pipeline = [
+ dict(type='LoadHyperspectralImageFromFiles', to_float32 =True, normalized_basis=normalized_basis),
+ dict(type='LoadAnnotations', with_bbox=True),
+ # dict(type='Resize', scale=(512, 512), keep_ratio=True),
+ dict(type='HSIResize', scale_factor=1, keep_ratio=True),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='PackDetInputs',meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', 'flip', 'flip_direction','scale_factor'))
+]
+test_pipeline = [
+ dict(type='LoadHyperspectralImageFromFiles', to_float32 =True, normalized_basis=normalized_basis),
+ # dict(type='Resize', scale=(512, 512), keep_ratio=True),
+ dict(type='HSIResize', scale_factor=1, keep_ratio=True),
+ # If you don't have a gt annotation, delete the pipeline
+ dict(type='LoadAnnotations', with_bbox=True),
+ dict(
+ type='PackDetInputs',
+ meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', 'scale_factor'))
+]
+train_dataloader = dict(
+ batch_size=4,
+ num_workers=2,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ batch_sampler=dict(type='AspectRatioBatchSampler'),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ ann_file='annotations/train.json',
+ data_prefix=dict(img='train/'),
+ filter_cfg=dict(filter_empty_gt=True, min_size=32),
+ pipeline=train_pipeline,
+ backend_args=backend_args))
+val_dataloader = dict(
+ batch_size=1,
+ num_workers=2,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ ann_file='annotations/test.json',
+ data_prefix=dict(img='test/'),
+ test_mode=True,
+ pipeline=test_pipeline,
+ backend_args=backend_args))
+test_dataloader = val_dataloader
+
+val_evaluator = dict(
+ type='CocoMetric',
+ ann_file=data_root + 'annotations/test.json',
+ metric=['bbox','proposal_fast'],
+ classwise = True,
+ format_only=False,
+ backend_args=backend_args)
+test_evaluator = val_evaluator
+
+# inference on test dataset and
+# format the output results for submission.
+# test_dataloader = dict(
+# batch_size=1,
+# num_workers=2,
+# persistent_workers=True,
+# drop_last=False,
+# sampler=dict(type='DefaultSampler', shuffle=False),
+# dataset=dict(
+# type=dataset_type,
+# data_root=data_root,
+# ann_file=data_root + 'annotations/image_info_test-dev2017.json',
+# data_prefix=dict(img='test2017/'),
+# test_mode=True,
+# pipeline=test_pipeline))
+# test_evaluator = dict(
+# type='CocoMetric',
+# metric='bbox',
+# format_only=True,
+# ann_file=data_root + 'annotations/image_info_test-dev2017.json',
+# outfile_prefix='./work_dirs/coco_detection/test')
diff --git a/configs/_base_/datasets/objects365v1_detection.py b/configs/_base_/datasets/objects365v1_detection.py
new file mode 100644
index 0000000000000000000000000000000000000000..ee398698608543e13188452a816283e9a2563390
--- /dev/null
+++ b/configs/_base_/datasets/objects365v1_detection.py
@@ -0,0 +1,74 @@
+# dataset settings
+dataset_type = 'Objects365V1Dataset'
+data_root = 'data/Objects365/Obj365_v1/'
+
+# Example to use different file client
+# Method 1: simply set the data root and let the file I/O module
+# automatically infer from prefix (not support LMDB and Memcache yet)
+
+# data_root = 's3://openmmlab/datasets/detection/coco/'
+
+# Method 2: Use `backend_args`, `file_client_args` in versions before 3.0.0rc6
+# backend_args = dict(
+# backend='petrel',
+# path_mapping=dict({
+# './data/': 's3://openmmlab/datasets/detection/',
+# 'data/': 's3://openmmlab/datasets/detection/'
+# }))
+backend_args = None
+
+train_pipeline = [
+ dict(type='LoadImageFromFile', backend_args=backend_args),
+ dict(type='LoadAnnotations', with_bbox=True),
+ dict(type='Resize', scale=(1333, 800), keep_ratio=True),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='PackDetInputs')
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile', backend_args=backend_args),
+ dict(type='Resize', scale=(1333, 800), keep_ratio=True),
+ # If you don't have a gt annotation, delete the pipeline
+ dict(type='LoadAnnotations', with_bbox=True),
+ dict(
+ type='PackDetInputs',
+ meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'scale_factor'))
+]
+train_dataloader = dict(
+ batch_size=2,
+ num_workers=2,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ batch_sampler=dict(type='AspectRatioBatchSampler'),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ ann_file='annotations/objects365_train.json',
+ data_prefix=dict(img='train/'),
+ filter_cfg=dict(filter_empty_gt=True, min_size=32),
+ pipeline=train_pipeline,
+ backend_args=backend_args))
+val_dataloader = dict(
+ batch_size=1,
+ num_workers=2,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ ann_file='annotations/objects365_val.json',
+ data_prefix=dict(img='val/'),
+ test_mode=True,
+ pipeline=test_pipeline,
+ backend_args=backend_args))
+test_dataloader = val_dataloader
+
+val_evaluator = dict(
+ type='CocoMetric',
+ ann_file=data_root + 'annotations/objects365_val.json',
+ metric='bbox',
+ sort_categories=True,
+ format_only=False,
+ backend_args=backend_args)
+test_evaluator = val_evaluator
diff --git a/configs/_base_/datasets/objects365v2_detection.py b/configs/_base_/datasets/objects365v2_detection.py
new file mode 100644
index 0000000000000000000000000000000000000000..b25a7ba901befa8d61e3cdae8a7c68fb8a9c5aef
--- /dev/null
+++ b/configs/_base_/datasets/objects365v2_detection.py
@@ -0,0 +1,73 @@
+# dataset settings
+dataset_type = 'Objects365V2Dataset'
+data_root = 'data/Objects365/Obj365_v2/'
+
+# Example to use different file client
+# Method 1: simply set the data root and let the file I/O module
+# automatically infer from prefix (not support LMDB and Memcache yet)
+
+# data_root = 's3://openmmlab/datasets/detection/coco/'
+
+# Method 2: Use `backend_args`, `file_client_args` in versions before 3.0.0rc6
+# backend_args = dict(
+# backend='petrel',
+# path_mapping=dict({
+# './data/': 's3://openmmlab/datasets/detection/',
+# 'data/': 's3://openmmlab/datasets/detection/'
+# }))
+backend_args = None
+
+train_pipeline = [
+ dict(type='LoadImageFromFile', backend_args=backend_args),
+ dict(type='LoadAnnotations', with_bbox=True),
+ dict(type='Resize', scale=(1333, 800), keep_ratio=True),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='PackDetInputs')
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile', backend_args=backend_args),
+ dict(type='Resize', scale=(1333, 800), keep_ratio=True),
+ # If you don't have a gt annotation, delete the pipeline
+ dict(type='LoadAnnotations', with_bbox=True),
+ dict(
+ type='PackDetInputs',
+ meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'scale_factor'))
+]
+train_dataloader = dict(
+ batch_size=2,
+ num_workers=2,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ batch_sampler=dict(type='AspectRatioBatchSampler'),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ ann_file='annotations/zhiyuan_objv2_train.json',
+ data_prefix=dict(img='train/'),
+ filter_cfg=dict(filter_empty_gt=True, min_size=32),
+ pipeline=train_pipeline,
+ backend_args=backend_args))
+val_dataloader = dict(
+ batch_size=1,
+ num_workers=2,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ ann_file='annotations/zhiyuan_objv2_val.json',
+ data_prefix=dict(img='val/'),
+ test_mode=True,
+ pipeline=test_pipeline,
+ backend_args=backend_args))
+test_dataloader = val_dataloader
+
+val_evaluator = dict(
+ type='CocoMetric',
+ ann_file=data_root + 'annotations/zhiyuan_objv2_val.json',
+ metric='bbox',
+ format_only=False,
+ backend_args=backend_args)
+test_evaluator = val_evaluator
diff --git a/configs/_base_/datasets/openimages_detection.py b/configs/_base_/datasets/openimages_detection.py
new file mode 100644
index 0000000000000000000000000000000000000000..129661b405c70d3e2d0d2c4741e3a59333dd960c
--- /dev/null
+++ b/configs/_base_/datasets/openimages_detection.py
@@ -0,0 +1,81 @@
+# dataset settings
+dataset_type = 'OpenImagesDataset'
+data_root = 'data/OpenImages/'
+
+# Example to use different file client
+# Method 1: simply set the data root and let the file I/O module
+# automatically infer from prefix (not support LMDB and Memcache yet)
+
+# data_root = 's3://openmmlab/datasets/detection/coco/'
+
+# Method 2: Use `backend_args`, `file_client_args` in versions before 3.0.0rc6
+# backend_args = dict(
+# backend='petrel',
+# path_mapping=dict({
+# './data/': 's3://openmmlab/datasets/detection/',
+# 'data/': 's3://openmmlab/datasets/detection/'
+# }))
+backend_args = None
+
+train_pipeline = [
+ dict(type='LoadImageFromFile', backend_args=backend_args),
+ dict(type='LoadAnnotations', with_bbox=True),
+ dict(type='Resize', scale=(1024, 800), keep_ratio=True),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='PackDetInputs')
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile', backend_args=backend_args),
+ dict(type='Resize', scale=(1024, 800), keep_ratio=True),
+ # avoid bboxes being resized
+ dict(type='LoadAnnotations', with_bbox=True),
+ # TODO: find a better way to collect image_level_labels
+ dict(
+ type='PackDetInputs',
+ meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'scale_factor', 'instances', 'image_level_labels'))
+]
+
+train_dataloader = dict(
+ batch_size=2,
+ num_workers=0, # workers_per_gpu > 0 may occur out of memory
+ persistent_workers=False,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ batch_sampler=dict(type='AspectRatioBatchSampler'),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ ann_file='annotations/oidv6-train-annotations-bbox.csv',
+ data_prefix=dict(img='OpenImages/train/'),
+ label_file='annotations/class-descriptions-boxable.csv',
+ hierarchy_file='annotations/bbox_labels_600_hierarchy.json',
+ meta_file='annotations/train-image-metas.pkl',
+ pipeline=train_pipeline,
+ backend_args=backend_args))
+val_dataloader = dict(
+ batch_size=1,
+ num_workers=0,
+ persistent_workers=False,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ ann_file='annotations/validation-annotations-bbox.csv',
+ data_prefix=dict(img='OpenImages/validation/'),
+ label_file='annotations/class-descriptions-boxable.csv',
+ hierarchy_file='annotations/bbox_labels_600_hierarchy.json',
+ meta_file='annotations/validation-image-metas.pkl',
+ image_level_ann_file='annotations/validation-'
+ 'annotations-human-imagelabels-boxable.csv',
+ pipeline=test_pipeline,
+ backend_args=backend_args))
+test_dataloader = val_dataloader
+
+val_evaluator = dict(
+ type='OpenImagesMetric',
+ iou_thrs=0.5,
+ ioa_thrs=0.5,
+ use_group_of=True,
+ get_supercategory=True)
+test_evaluator = val_evaluator
diff --git a/configs/_base_/datasets/semi_coco_detection.py b/configs/_base_/datasets/semi_coco_detection.py
new file mode 100644
index 0000000000000000000000000000000000000000..694f25f841e06dbb59a699dfe13c18e34dbdce9f
--- /dev/null
+++ b/configs/_base_/datasets/semi_coco_detection.py
@@ -0,0 +1,178 @@
+# dataset settings
+dataset_type = 'CocoDataset'
+data_root = 'data/coco/'
+
+# Example to use different file client
+# Method 1: simply set the data root and let the file I/O module
+# automatically infer from prefix (not support LMDB and Memcache yet)
+
+# data_root = 's3://openmmlab/datasets/detection/coco/'
+
+# Method 2: Use `backend_args`, `file_client_args` in versions before 3.0.0rc6
+# backend_args = dict(
+# backend='petrel',
+# path_mapping=dict({
+# './data/': 's3://openmmlab/datasets/detection/',
+# 'data/': 's3://openmmlab/datasets/detection/'
+# }))
+backend_args = None
+
+color_space = [
+ [dict(type='ColorTransform')],
+ [dict(type='AutoContrast')],
+ [dict(type='Equalize')],
+ [dict(type='Sharpness')],
+ [dict(type='Posterize')],
+ [dict(type='Solarize')],
+ [dict(type='Color')],
+ [dict(type='Contrast')],
+ [dict(type='Brightness')],
+]
+
+geometric = [
+ [dict(type='Rotate')],
+ [dict(type='ShearX')],
+ [dict(type='ShearY')],
+ [dict(type='TranslateX')],
+ [dict(type='TranslateY')],
+]
+
+scale = [(1333, 400), (1333, 1200)]
+
+branch_field = ['sup', 'unsup_teacher', 'unsup_student']
+# pipeline used to augment labeled data,
+# which will be sent to student model for supervised training.
+sup_pipeline = [
+ dict(type='LoadImageFromFile', backend_args=backend_args),
+ dict(type='LoadAnnotations', with_bbox=True),
+ dict(type='RandomResize', scale=scale, keep_ratio=True),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='RandAugment', aug_space=color_space, aug_num=1),
+ dict(type='FilterAnnotations', min_gt_bbox_wh=(1e-2, 1e-2)),
+ dict(
+ type='MultiBranch',
+ branch_field=branch_field,
+ sup=dict(type='PackDetInputs'))
+]
+
+# pipeline used to augment unlabeled data weakly,
+# which will be sent to teacher model for predicting pseudo instances.
+weak_pipeline = [
+ dict(type='RandomResize', scale=scale, keep_ratio=True),
+ dict(type='RandomFlip', prob=0.5),
+ dict(
+ type='PackDetInputs',
+ meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'scale_factor', 'flip', 'flip_direction',
+ 'homography_matrix')),
+]
+
+# pipeline used to augment unlabeled data strongly,
+# which will be sent to student model for unsupervised training.
+strong_pipeline = [
+ dict(type='RandomResize', scale=scale, keep_ratio=True),
+ dict(type='RandomFlip', prob=0.5),
+ dict(
+ type='RandomOrder',
+ transforms=[
+ dict(type='RandAugment', aug_space=color_space, aug_num=1),
+ dict(type='RandAugment', aug_space=geometric, aug_num=1),
+ ]),
+ dict(type='RandomErasing', n_patches=(1, 5), ratio=(0, 0.2)),
+ dict(type='FilterAnnotations', min_gt_bbox_wh=(1e-2, 1e-2)),
+ dict(
+ type='PackDetInputs',
+ meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'scale_factor', 'flip', 'flip_direction',
+ 'homography_matrix')),
+]
+
+# pipeline used to augment unlabeled data into different views
+unsup_pipeline = [
+ dict(type='LoadImageFromFile', backend_args=backend_args),
+ dict(type='LoadEmptyAnnotations'),
+ dict(
+ type='MultiBranch',
+ branch_field=branch_field,
+ unsup_teacher=weak_pipeline,
+ unsup_student=strong_pipeline,
+ )
+]
+
+test_pipeline = [
+ dict(type='LoadImageFromFile', backend_args=backend_args),
+ dict(type='Resize', scale=(1333, 800), keep_ratio=True),
+ dict(
+ type='PackDetInputs',
+ meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'scale_factor'))
+]
+
+batch_size = 5
+num_workers = 5
+# There are two common semi-supervised learning settings on the coco dataset:
+# (1) Divide the train2017 into labeled and unlabeled datasets
+# by a fixed percentage, such as 1%, 2%, 5% and 10%.
+# The format of labeled_ann_file and unlabeled_ann_file are
+# instances_train2017.{fold}@{percent}.json, and
+# instances_train2017.{fold}@{percent}-unlabeled.json
+# `fold` is used for cross-validation, and `percent` represents
+# the proportion of labeled data in the train2017.
+# (2) Choose the train2017 as the labeled dataset
+# and unlabeled2017 as the unlabeled dataset.
+# The labeled_ann_file and unlabeled_ann_file are
+# instances_train2017.json and image_info_unlabeled2017.json
+# We use this configuration by default.
+labeled_dataset = dict(
+ type=dataset_type,
+ data_root=data_root,
+ ann_file='annotations/instances_train2017.json',
+ data_prefix=dict(img='train2017/'),
+ filter_cfg=dict(filter_empty_gt=True, min_size=32),
+ pipeline=sup_pipeline,
+ backend_args=backend_args)
+
+unlabeled_dataset = dict(
+ type=dataset_type,
+ data_root=data_root,
+ ann_file='annotations/instances_unlabeled2017.json',
+ data_prefix=dict(img='unlabeled2017/'),
+ filter_cfg=dict(filter_empty_gt=False),
+ pipeline=unsup_pipeline,
+ backend_args=backend_args)
+
+train_dataloader = dict(
+ batch_size=batch_size,
+ num_workers=num_workers,
+ persistent_workers=True,
+ sampler=dict(
+ type='GroupMultiSourceSampler',
+ batch_size=batch_size,
+ source_ratio=[1, 4]),
+ dataset=dict(
+ type='ConcatDataset', datasets=[labeled_dataset, unlabeled_dataset]))
+
+val_dataloader = dict(
+ batch_size=1,
+ num_workers=2,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ ann_file='annotations/instances_val2017.json',
+ data_prefix=dict(img='val2017/'),
+ test_mode=True,
+ pipeline=test_pipeline,
+ backend_args=backend_args))
+
+test_dataloader = val_dataloader
+
+val_evaluator = dict(
+ type='CocoMetric',
+ ann_file=data_root + 'annotations/instances_val2017.json',
+ metric='bbox',
+ format_only=False,
+ backend_args=backend_args)
+test_evaluator = val_evaluator
diff --git a/configs/_base_/datasets/voc0712.py b/configs/_base_/datasets/voc0712.py
new file mode 100644
index 0000000000000000000000000000000000000000..47f5e6563b7f47dd6cfec02248d4c8decd32afe4
--- /dev/null
+++ b/configs/_base_/datasets/voc0712.py
@@ -0,0 +1,92 @@
+# dataset settings
+dataset_type = 'VOCDataset'
+data_root = 'data/VOCdevkit/'
+
+# Example to use different file client
+# Method 1: simply set the data root and let the file I/O module
+# automatically Infer from prefix (not support LMDB and Memcache yet)
+
+# data_root = 's3://openmmlab/datasets/detection/segmentation/VOCdevkit/'
+
+# Method 2: Use `backend_args`, `file_client_args` in versions before 3.0.0rc6
+# backend_args = dict(
+# backend='petrel',
+# path_mapping=dict({
+# './data/': 's3://openmmlab/datasets/segmentation/',
+# 'data/': 's3://openmmlab/datasets/segmentation/'
+# }))
+backend_args = None
+
+train_pipeline = [
+ dict(type='LoadImageFromFile', backend_args=backend_args),
+ dict(type='LoadAnnotations', with_bbox=True),
+ dict(type='Resize', scale=(1000, 600), keep_ratio=True),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='PackDetInputs')
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile', backend_args=backend_args),
+ dict(type='Resize', scale=(1000, 600), keep_ratio=True),
+ # avoid bboxes being resized
+ dict(type='LoadAnnotations', with_bbox=True),
+ dict(
+ type='PackDetInputs',
+ meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'scale_factor'))
+]
+train_dataloader = dict(
+ batch_size=2,
+ num_workers=2,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ batch_sampler=dict(type='AspectRatioBatchSampler'),
+ dataset=dict(
+ type='RepeatDataset',
+ times=3,
+ dataset=dict(
+ type='ConcatDataset',
+ # VOCDataset will add different `dataset_type` in dataset.metainfo,
+ # which will get error if using ConcatDataset. Adding
+ # `ignore_keys` can avoid this error.
+ ignore_keys=['dataset_type'],
+ datasets=[
+ dict(
+ type=dataset_type,
+ data_root=data_root,
+ ann_file='VOC2007/ImageSets/Main/trainval.txt',
+ data_prefix=dict(sub_data_root='VOC2007/'),
+ filter_cfg=dict(
+ filter_empty_gt=True, min_size=32, bbox_min_size=32),
+ pipeline=train_pipeline,
+ backend_args=backend_args),
+ dict(
+ type=dataset_type,
+ data_root=data_root,
+ ann_file='VOC2012/ImageSets/Main/trainval.txt',
+ data_prefix=dict(sub_data_root='VOC2012/'),
+ filter_cfg=dict(
+ filter_empty_gt=True, min_size=32, bbox_min_size=32),
+ pipeline=train_pipeline,
+ backend_args=backend_args)
+ ])))
+
+val_dataloader = dict(
+ batch_size=1,
+ num_workers=2,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ ann_file='VOC2007/ImageSets/Main/test.txt',
+ data_prefix=dict(sub_data_root='VOC2007/'),
+ test_mode=True,
+ pipeline=test_pipeline,
+ backend_args=backend_args))
+test_dataloader = val_dataloader
+
+# Pascal VOC2007 uses `11points` as default evaluate mode, while PASCAL
+# VOC2012 defaults to use 'area'.
+val_evaluator = dict(type='VOCMetric', metric='mAP', eval_mode='11points')
+test_evaluator = val_evaluator
diff --git a/configs/_base_/datasets/wider_face.py b/configs/_base_/datasets/wider_face.py
new file mode 100644
index 0000000000000000000000000000000000000000..7042bc46e877ed899969730325143307e15adf64
--- /dev/null
+++ b/configs/_base_/datasets/wider_face.py
@@ -0,0 +1,73 @@
+# dataset settings
+dataset_type = 'WIDERFaceDataset'
+data_root = 'data/WIDERFace/'
+# Example to use different file client
+# Method 1: simply set the data root and let the file I/O module
+# automatically infer from prefix (not support LMDB and Memcache yet)
+
+# data_root = 's3://openmmlab/datasets/detection/cityscapes/'
+
+# Method 2: Use `backend_args`, `file_client_args` in versions before 3.0.0rc6
+# backend_args = dict(
+# backend='petrel',
+# path_mapping=dict({
+# './data/': 's3://openmmlab/datasets/detection/',
+# 'data/': 's3://openmmlab/datasets/detection/'
+# }))
+backend_args = None
+
+img_scale = (640, 640) # VGA resolution
+
+train_pipeline = [
+ dict(type='LoadImageFromFile', backend_args=backend_args),
+ dict(type='LoadAnnotations', with_bbox=True),
+ dict(type='Resize', scale=img_scale, keep_ratio=True),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='PackDetInputs')
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile', backend_args=backend_args),
+ dict(type='Resize', scale=img_scale, keep_ratio=True),
+ dict(type='LoadAnnotations', with_bbox=True),
+ dict(
+ type='PackDetInputs',
+ meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'scale_factor'))
+]
+
+train_dataloader = dict(
+ batch_size=2,
+ num_workers=2,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ batch_sampler=dict(type='AspectRatioBatchSampler'),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ ann_file='train.txt',
+ data_prefix=dict(img='WIDER_train'),
+ filter_cfg=dict(filter_empty_gt=True, bbox_min_size=17, min_size=32),
+ pipeline=train_pipeline))
+
+val_dataloader = dict(
+ batch_size=1,
+ num_workers=2,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ ann_file='val.txt',
+ data_prefix=dict(img='WIDER_val'),
+ test_mode=True,
+ pipeline=test_pipeline))
+test_dataloader = val_dataloader
+
+val_evaluator = dict(
+ # TODO: support WiderFace-Evaluation for easy, medium, hard cases
+ type='VOCMetric',
+ metric='mAP',
+ eval_mode='11points')
+test_evaluator = val_evaluator
diff --git a/configs/_base_/default_runtime.py b/configs/_base_/default_runtime.py
new file mode 100644
index 0000000000000000000000000000000000000000..daaf03a81ec264d0b13a48439a8b834b34b9178a
--- /dev/null
+++ b/configs/_base_/default_runtime.py
@@ -0,0 +1,25 @@
+default_scope = 'mmdet'
+
+default_hooks = dict(
+ timer=dict(type='IterTimerHook'),
+ logger=dict(type='LoggerHook', interval=50),
+ param_scheduler=dict(type='ParamSchedulerHook'),
+ # checkpoint=dict(type='CheckpointHook',interval=-1, by_epoch=True, save_best='auto'),
+ checkpoint=dict(type='CheckpointHook', interval=999999, by_epoch=True),
+ sampler_seed=dict(type='DistSamplerSeedHook'),
+ visualization=dict(type='DetVisualizationHook'))
+
+env_cfg = dict(
+ cudnn_benchmark=False,
+ mp_cfg=dict(mp_start_method='fork', opencv_num_threads=0),
+ dist_cfg=dict(backend='nccl'),
+)
+
+vis_backends = [dict(type='LocalVisBackend')]
+visualizer = dict(
+ type='DetLocalVisualizer', vis_backends=vis_backends, name='visualizer')
+log_processor = dict(type='LogProcessor', window_size=50, by_epoch=True)
+
+log_level = 'INFO'
+load_from = None
+resume = False
diff --git a/configs/_base_/models/cascade-mask-rcnn_r50_fpn.py b/configs/_base_/models/cascade-mask-rcnn_r50_fpn.py
new file mode 100644
index 0000000000000000000000000000000000000000..c5167f7a02e66c80bd8ec8cc7572acb22eaadba5
--- /dev/null
+++ b/configs/_base_/models/cascade-mask-rcnn_r50_fpn.py
@@ -0,0 +1,203 @@
+# model settings
+model = dict(
+ type='CascadeRCNN',
+ data_preprocessor=dict(
+ type='DetDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True,
+ pad_mask=True,
+ pad_size_divisor=32),
+ backbone=dict(
+ type='ResNet',
+ depth=50,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ frozen_stages=1,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ norm_eval=True,
+ style='pytorch',
+ init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50')),
+ neck=dict(
+ type='FPN',
+ in_channels=[256, 512, 1024, 2048],
+ out_channels=256,
+ num_outs=5),
+ rpn_head=dict(
+ type='RPNHead',
+ in_channels=256,
+ feat_channels=256,
+ anchor_generator=dict(
+ type='AnchorGenerator',
+ scales=[8],
+ ratios=[0.5, 1.0, 2.0],
+ strides=[4, 8, 16, 32, 64]),
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[.0, .0, .0, .0],
+ target_stds=[1.0, 1.0, 1.0, 1.0]),
+ loss_cls=dict(
+ type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
+ loss_bbox=dict(type='SmoothL1Loss', beta=1.0 / 9.0, loss_weight=1.0)),
+ roi_head=dict(
+ type='CascadeRoIHead',
+ num_stages=3,
+ stage_loss_weights=[1, 0.5, 0.25],
+ bbox_roi_extractor=dict(
+ type='SingleRoIExtractor',
+ roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=0),
+ out_channels=256,
+ featmap_strides=[4, 8, 16, 32]),
+ bbox_head=[
+ dict(
+ type='Shared2FCBBoxHead',
+ in_channels=256,
+ fc_out_channels=1024,
+ roi_feat_size=7,
+ num_classes=80,
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[0., 0., 0., 0.],
+ target_stds=[0.1, 0.1, 0.2, 0.2]),
+ reg_class_agnostic=True,
+ loss_cls=dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=False,
+ loss_weight=1.0),
+ loss_bbox=dict(type='SmoothL1Loss', beta=1.0,
+ loss_weight=1.0)),
+ dict(
+ type='Shared2FCBBoxHead',
+ in_channels=256,
+ fc_out_channels=1024,
+ roi_feat_size=7,
+ num_classes=80,
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[0., 0., 0., 0.],
+ target_stds=[0.05, 0.05, 0.1, 0.1]),
+ reg_class_agnostic=True,
+ loss_cls=dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=False,
+ loss_weight=1.0),
+ loss_bbox=dict(type='SmoothL1Loss', beta=1.0,
+ loss_weight=1.0)),
+ dict(
+ type='Shared2FCBBoxHead',
+ in_channels=256,
+ fc_out_channels=1024,
+ roi_feat_size=7,
+ num_classes=80,
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[0., 0., 0., 0.],
+ target_stds=[0.033, 0.033, 0.067, 0.067]),
+ reg_class_agnostic=True,
+ loss_cls=dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=False,
+ loss_weight=1.0),
+ loss_bbox=dict(type='SmoothL1Loss', beta=1.0, loss_weight=1.0))
+ ],
+ mask_roi_extractor=dict(
+ type='SingleRoIExtractor',
+ roi_layer=dict(type='RoIAlign', output_size=14, sampling_ratio=0),
+ out_channels=256,
+ featmap_strides=[4, 8, 16, 32]),
+ mask_head=dict(
+ type='FCNMaskHead',
+ num_convs=4,
+ in_channels=256,
+ conv_out_channels=256,
+ num_classes=80,
+ loss_mask=dict(
+ type='CrossEntropyLoss', use_mask=True, loss_weight=1.0))),
+ # model training and testing settings
+ train_cfg=dict(
+ rpn=dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.7,
+ neg_iou_thr=0.3,
+ min_pos_iou=0.3,
+ match_low_quality=True,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=256,
+ pos_fraction=0.5,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=False),
+ allowed_border=0,
+ pos_weight=-1,
+ debug=False),
+ rpn_proposal=dict(
+ nms_pre=2000,
+ max_per_img=2000,
+ nms=dict(type='nms', iou_threshold=0.7),
+ min_bbox_size=0),
+ rcnn=[
+ dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.5,
+ neg_iou_thr=0.5,
+ min_pos_iou=0.5,
+ match_low_quality=False,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=512,
+ pos_fraction=0.25,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=True),
+ mask_size=28,
+ pos_weight=-1,
+ debug=False),
+ dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.6,
+ neg_iou_thr=0.6,
+ min_pos_iou=0.6,
+ match_low_quality=False,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=512,
+ pos_fraction=0.25,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=True),
+ mask_size=28,
+ pos_weight=-1,
+ debug=False),
+ dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.7,
+ neg_iou_thr=0.7,
+ min_pos_iou=0.7,
+ match_low_quality=False,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=512,
+ pos_fraction=0.25,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=True),
+ mask_size=28,
+ pos_weight=-1,
+ debug=False)
+ ]),
+ test_cfg=dict(
+ rpn=dict(
+ nms_pre=1000,
+ max_per_img=1000,
+ nms=dict(type='nms', iou_threshold=0.7),
+ min_bbox_size=0),
+ rcnn=dict(
+ score_thr=0.05,
+ nms=dict(type='nms', iou_threshold=0.5),
+ max_per_img=100,
+ mask_thr_binary=0.5)))
diff --git a/configs/_base_/models/cascade-rcnn_r50_fpn.py b/configs/_base_/models/cascade-rcnn_r50_fpn.py
new file mode 100644
index 0000000000000000000000000000000000000000..50c57f01ca3a6ea827f71801b0c233af268914f9
--- /dev/null
+++ b/configs/_base_/models/cascade-rcnn_r50_fpn.py
@@ -0,0 +1,185 @@
+# model settings
+model = dict(
+ type='CascadeRCNN',
+ data_preprocessor=dict(
+ type='DetDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True,
+ pad_size_divisor=32),
+ backbone=dict(
+ type='ResNet',
+ depth=50,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ frozen_stages=1,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ norm_eval=True,
+ style='pytorch',
+ init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50')),
+ neck=dict(
+ type='FPN',
+ in_channels=[256, 512, 1024, 2048],
+ out_channels=256,
+ num_outs=5),
+ rpn_head=dict(
+ type='RPNHead',
+ in_channels=256,
+ feat_channels=256,
+ anchor_generator=dict(
+ type='AnchorGenerator',
+ scales=[8],
+ ratios=[0.5, 1.0, 2.0],
+ strides=[4, 8, 16, 32, 64]),
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[.0, .0, .0, .0],
+ target_stds=[1.0, 1.0, 1.0, 1.0]),
+ loss_cls=dict(
+ type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
+ loss_bbox=dict(type='SmoothL1Loss', beta=1.0 / 9.0, loss_weight=1.0)),
+ roi_head=dict(
+ type='CascadeRoIHead',
+ num_stages=3,
+ stage_loss_weights=[1, 0.5, 0.25],
+ bbox_roi_extractor=dict(
+ type='SingleRoIExtractor',
+ roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=0),
+ out_channels=256,
+ featmap_strides=[4, 8, 16, 32]),
+ bbox_head=[
+ dict(
+ type='Shared2FCBBoxHead',
+ in_channels=256,
+ fc_out_channels=1024,
+ roi_feat_size=7,
+ num_classes=80,
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[0., 0., 0., 0.],
+ target_stds=[0.1, 0.1, 0.2, 0.2]),
+ reg_class_agnostic=True,
+ loss_cls=dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=False,
+ loss_weight=1.0),
+ loss_bbox=dict(type='SmoothL1Loss', beta=1.0,
+ loss_weight=1.0)),
+ dict(
+ type='Shared2FCBBoxHead',
+ in_channels=256,
+ fc_out_channels=1024,
+ roi_feat_size=7,
+ num_classes=80,
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[0., 0., 0., 0.],
+ target_stds=[0.05, 0.05, 0.1, 0.1]),
+ reg_class_agnostic=True,
+ loss_cls=dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=False,
+ loss_weight=1.0),
+ loss_bbox=dict(type='SmoothL1Loss', beta=1.0,
+ loss_weight=1.0)),
+ dict(
+ type='Shared2FCBBoxHead',
+ in_channels=256,
+ fc_out_channels=1024,
+ roi_feat_size=7,
+ num_classes=80,
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[0., 0., 0., 0.],
+ target_stds=[0.033, 0.033, 0.067, 0.067]),
+ reg_class_agnostic=True,
+ loss_cls=dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=False,
+ loss_weight=1.0),
+ loss_bbox=dict(type='SmoothL1Loss', beta=1.0, loss_weight=1.0))
+ ]),
+ # model training and testing settings
+ train_cfg=dict(
+ rpn=dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.7,
+ neg_iou_thr=0.3,
+ min_pos_iou=0.3,
+ match_low_quality=True,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=256,
+ pos_fraction=0.5,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=False),
+ allowed_border=0,
+ pos_weight=-1,
+ debug=False),
+ rpn_proposal=dict(
+ nms_pre=2000,
+ max_per_img=2000,
+ nms=dict(type='nms', iou_threshold=0.7),
+ min_bbox_size=0),
+ rcnn=[
+ dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.5,
+ neg_iou_thr=0.5,
+ min_pos_iou=0.5,
+ match_low_quality=False,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=512,
+ pos_fraction=0.25,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=True),
+ pos_weight=-1,
+ debug=False),
+ dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.6,
+ neg_iou_thr=0.6,
+ min_pos_iou=0.6,
+ match_low_quality=False,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=512,
+ pos_fraction=0.25,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=True),
+ pos_weight=-1,
+ debug=False),
+ dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.7,
+ neg_iou_thr=0.7,
+ min_pos_iou=0.7,
+ match_low_quality=False,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=512,
+ pos_fraction=0.25,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=True),
+ pos_weight=-1,
+ debug=False)
+ ]),
+ test_cfg=dict(
+ rpn=dict(
+ nms_pre=1000,
+ max_per_img=1000,
+ nms=dict(type='nms', iou_threshold=0.7),
+ min_bbox_size=0),
+ rcnn=dict(
+ score_thr=0.05,
+ nms=dict(type='nms', iou_threshold=0.5),
+ max_per_img=100)))
diff --git a/configs/_base_/models/fast-rcnn_r50_fpn.py b/configs/_base_/models/fast-rcnn_r50_fpn.py
new file mode 100644
index 0000000000000000000000000000000000000000..2bd45e9266b01df302b78e50258fa1572144cb21
--- /dev/null
+++ b/configs/_base_/models/fast-rcnn_r50_fpn.py
@@ -0,0 +1,68 @@
+# model settings
+model = dict(
+ type='FastRCNN',
+ data_preprocessor=dict(
+ type='DetDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True,
+ pad_size_divisor=32),
+ backbone=dict(
+ type='ResNet',
+ depth=50,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ frozen_stages=1,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ norm_eval=True,
+ style='pytorch',
+ init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50')),
+ neck=dict(
+ type='FPN',
+ in_channels=[256, 512, 1024, 2048],
+ out_channels=256,
+ num_outs=5),
+ roi_head=dict(
+ type='StandardRoIHead',
+ bbox_roi_extractor=dict(
+ type='SingleRoIExtractor',
+ roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=0),
+ out_channels=256,
+ featmap_strides=[4, 8, 16, 32]),
+ bbox_head=dict(
+ type='Shared2FCBBoxHead',
+ in_channels=256,
+ fc_out_channels=1024,
+ roi_feat_size=7,
+ num_classes=80,
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[0., 0., 0., 0.],
+ target_stds=[0.1, 0.1, 0.2, 0.2]),
+ reg_class_agnostic=False,
+ loss_cls=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),
+ loss_bbox=dict(type='L1Loss', loss_weight=1.0))),
+ # model training and testing settings
+ train_cfg=dict(
+ rcnn=dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.5,
+ neg_iou_thr=0.5,
+ min_pos_iou=0.5,
+ match_low_quality=False,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=512,
+ pos_fraction=0.25,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=True),
+ pos_weight=-1,
+ debug=False)),
+ test_cfg=dict(
+ rcnn=dict(
+ score_thr=0.05,
+ nms=dict(type='nms', iou_threshold=0.5),
+ max_per_img=100)))
diff --git a/configs/_base_/models/faster-rcnn_r50-caffe-c4.py b/configs/_base_/models/faster-rcnn_r50-caffe-c4.py
new file mode 100644
index 0000000000000000000000000000000000000000..15d2db72e48790505c2a1e4e7d184c1803f7ab31
--- /dev/null
+++ b/configs/_base_/models/faster-rcnn_r50-caffe-c4.py
@@ -0,0 +1,123 @@
+# model settings
+norm_cfg = dict(type='BN', requires_grad=False)
+model = dict(
+ type='FasterRCNN',
+ data_preprocessor=dict(
+ type='DetDataPreprocessor',
+ mean=[103.530, 116.280, 123.675],
+ std=[1.0, 1.0, 1.0],
+ bgr_to_rgb=False,
+ pad_size_divisor=32),
+ backbone=dict(
+ type='ResNet',
+ depth=50,
+ num_stages=3,
+ strides=(1, 2, 2),
+ dilations=(1, 1, 1),
+ out_indices=(2, ),
+ frozen_stages=1,
+ norm_cfg=norm_cfg,
+ norm_eval=True,
+ style='caffe',
+ init_cfg=dict(
+ type='Pretrained',
+ checkpoint='open-mmlab://detectron2/resnet50_caffe')),
+ rpn_head=dict(
+ type='RPNHead',
+ in_channels=1024,
+ feat_channels=1024,
+ anchor_generator=dict(
+ type='AnchorGenerator',
+ scales=[2, 4, 8, 16, 32],
+ ratios=[0.5, 1.0, 2.0],
+ strides=[16]),
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[.0, .0, .0, .0],
+ target_stds=[1.0, 1.0, 1.0, 1.0]),
+ loss_cls=dict(
+ type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
+ loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
+ roi_head=dict(
+ type='StandardRoIHead',
+ shared_head=dict(
+ type='ResLayer',
+ depth=50,
+ stage=3,
+ stride=2,
+ dilation=1,
+ style='caffe',
+ norm_cfg=norm_cfg,
+ norm_eval=True,
+ init_cfg=dict(
+ type='Pretrained',
+ checkpoint='open-mmlab://detectron2/resnet50_caffe')),
+ bbox_roi_extractor=dict(
+ type='SingleRoIExtractor',
+ roi_layer=dict(type='RoIAlign', output_size=14, sampling_ratio=0),
+ out_channels=1024,
+ featmap_strides=[16]),
+ bbox_head=dict(
+ type='BBoxHead',
+ with_avg_pool=True,
+ roi_feat_size=7,
+ in_channels=2048,
+ num_classes=80,
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[0., 0., 0., 0.],
+ target_stds=[0.1, 0.1, 0.2, 0.2]),
+ reg_class_agnostic=False,
+ loss_cls=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),
+ loss_bbox=dict(type='L1Loss', loss_weight=1.0))),
+ # model training and testing settings
+ train_cfg=dict(
+ rpn=dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.7,
+ neg_iou_thr=0.3,
+ min_pos_iou=0.3,
+ match_low_quality=True,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=256,
+ pos_fraction=0.5,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=False),
+ allowed_border=-1,
+ pos_weight=-1,
+ debug=False),
+ rpn_proposal=dict(
+ nms_pre=12000,
+ max_per_img=2000,
+ nms=dict(type='nms', iou_threshold=0.7),
+ min_bbox_size=0),
+ rcnn=dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.5,
+ neg_iou_thr=0.5,
+ min_pos_iou=0.5,
+ match_low_quality=False,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=512,
+ pos_fraction=0.25,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=True),
+ pos_weight=-1,
+ debug=False)),
+ test_cfg=dict(
+ rpn=dict(
+ nms_pre=6000,
+ max_per_img=1000,
+ nms=dict(type='nms', iou_threshold=0.7),
+ min_bbox_size=0),
+ rcnn=dict(
+ score_thr=0.05,
+ nms=dict(type='nms', iou_threshold=0.5),
+ max_per_img=100)))
diff --git a/configs/_base_/models/faster-rcnn_r50-caffe-dc5.py b/configs/_base_/models/faster-rcnn_r50-caffe-dc5.py
new file mode 100644
index 0000000000000000000000000000000000000000..189915e3d9ce7239493da6465931f91e2d9d664f
--- /dev/null
+++ b/configs/_base_/models/faster-rcnn_r50-caffe-dc5.py
@@ -0,0 +1,111 @@
+# model settings
+norm_cfg = dict(type='BN', requires_grad=False)
+model = dict(
+ type='FasterRCNN',
+ data_preprocessor=dict(
+ type='DetDataPreprocessor',
+ mean=[103.530, 116.280, 123.675],
+ std=[1.0, 1.0, 1.0],
+ bgr_to_rgb=False,
+ pad_size_divisor=32),
+ backbone=dict(
+ type='ResNet',
+ depth=50,
+ num_stages=4,
+ strides=(1, 2, 2, 1),
+ dilations=(1, 1, 1, 2),
+ out_indices=(3, ),
+ frozen_stages=1,
+ norm_cfg=norm_cfg,
+ norm_eval=True,
+ style='caffe',
+ init_cfg=dict(
+ type='Pretrained',
+ checkpoint='open-mmlab://detectron2/resnet50_caffe')),
+ rpn_head=dict(
+ type='RPNHead',
+ in_channels=2048,
+ feat_channels=2048,
+ anchor_generator=dict(
+ type='AnchorGenerator',
+ scales=[2, 4, 8, 16, 32],
+ ratios=[0.5, 1.0, 2.0],
+ strides=[16]),
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[.0, .0, .0, .0],
+ target_stds=[1.0, 1.0, 1.0, 1.0]),
+ loss_cls=dict(
+ type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
+ loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
+ roi_head=dict(
+ type='StandardRoIHead',
+ bbox_roi_extractor=dict(
+ type='SingleRoIExtractor',
+ roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=0),
+ out_channels=2048,
+ featmap_strides=[16]),
+ bbox_head=dict(
+ type='Shared2FCBBoxHead',
+ in_channels=2048,
+ fc_out_channels=1024,
+ roi_feat_size=7,
+ num_classes=80,
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[0., 0., 0., 0.],
+ target_stds=[0.1, 0.1, 0.2, 0.2]),
+ reg_class_agnostic=False,
+ loss_cls=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),
+ loss_bbox=dict(type='L1Loss', loss_weight=1.0))),
+ # model training and testing settings
+ train_cfg=dict(
+ rpn=dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.7,
+ neg_iou_thr=0.3,
+ min_pos_iou=0.3,
+ match_low_quality=True,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=256,
+ pos_fraction=0.5,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=False),
+ allowed_border=0,
+ pos_weight=-1,
+ debug=False),
+ rpn_proposal=dict(
+ nms_pre=12000,
+ max_per_img=2000,
+ nms=dict(type='nms', iou_threshold=0.7),
+ min_bbox_size=0),
+ rcnn=dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.5,
+ neg_iou_thr=0.5,
+ min_pos_iou=0.5,
+ match_low_quality=False,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=512,
+ pos_fraction=0.25,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=True),
+ pos_weight=-1,
+ debug=False)),
+ test_cfg=dict(
+ rpn=dict(
+ nms=dict(type='nms', iou_threshold=0.7),
+ nms_pre=6000,
+ max_per_img=1000,
+ min_bbox_size=0),
+ rcnn=dict(
+ score_thr=0.05,
+ nms=dict(type='nms', iou_threshold=0.5),
+ max_per_img=100)))
diff --git a/configs/_base_/models/faster-rcnn_r50_fpn.py b/configs/_base_/models/faster-rcnn_r50_fpn.py
new file mode 100644
index 0000000000000000000000000000000000000000..31aa1461799a988a11adb901306a063fd3f0b951
--- /dev/null
+++ b/configs/_base_/models/faster-rcnn_r50_fpn.py
@@ -0,0 +1,114 @@
+# model settings
+model = dict(
+ type='FasterRCNN',
+ data_preprocessor=dict(
+ type='DetDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True,
+ pad_size_divisor=32),
+ backbone=dict(
+ type='ResNet',
+ depth=50,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ frozen_stages=1,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ norm_eval=True,
+ style='pytorch',
+ init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50')),
+ neck=dict(
+ type='FPN',
+ in_channels=[256, 512, 1024, 2048],
+ out_channels=256,
+ num_outs=5),
+ rpn_head=dict(
+ type='RPNHead',
+ in_channels=256,
+ feat_channels=256,
+ anchor_generator=dict(
+ type='AnchorGenerator',
+ scales=[8],
+ ratios=[0.5, 1.0, 2.0],
+ strides=[4, 8, 16, 32, 64]),
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[.0, .0, .0, .0],
+ target_stds=[1.0, 1.0, 1.0, 1.0]),
+ loss_cls=dict(
+ type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
+ loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
+ roi_head=dict(
+ type='StandardRoIHead',
+ bbox_roi_extractor=dict(
+ type='SingleRoIExtractor',
+ roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=0),
+ out_channels=256,
+ featmap_strides=[4, 8, 16, 32]),
+ bbox_head=dict(
+ type='Shared2FCBBoxHead',
+ in_channels=256,
+ fc_out_channels=1024,
+ roi_feat_size=7,
+ num_classes=80,
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[0., 0., 0., 0.],
+ target_stds=[0.1, 0.1, 0.2, 0.2]),
+ reg_class_agnostic=False,
+ loss_cls=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),
+ loss_bbox=dict(type='L1Loss', loss_weight=1.0))),
+ # model training and testing settings
+ train_cfg=dict(
+ rpn=dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.7,
+ neg_iou_thr=0.3,
+ min_pos_iou=0.3,
+ match_low_quality=True,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=256,
+ pos_fraction=0.5,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=False),
+ allowed_border=-1,
+ pos_weight=-1,
+ debug=False),
+ rpn_proposal=dict(
+ nms_pre=2000,
+ max_per_img=1000,
+ nms=dict(type='nms', iou_threshold=0.7),
+ min_bbox_size=0),
+ rcnn=dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.5,
+ neg_iou_thr=0.5,
+ min_pos_iou=0.5,
+ match_low_quality=False,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=512,
+ pos_fraction=0.25,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=True),
+ pos_weight=-1,
+ debug=False)),
+ test_cfg=dict(
+ rpn=dict(
+ nms_pre=1000,
+ max_per_img=1000,
+ nms=dict(type='nms', iou_threshold=0.7),
+ min_bbox_size=0),
+ rcnn=dict(
+ score_thr=0.05,
+ nms=dict(type='nms', iou_threshold=0.5),
+ max_per_img=100)
+ # soft-nms is also supported for rcnn testing
+ # e.g., nms=dict(type='soft_nms', iou_threshold=0.5, min_score=0.05)
+ ))
diff --git a/configs/_base_/models/mask-rcnn_r50-caffe-c4.py b/configs/_base_/models/mask-rcnn_r50-caffe-c4.py
new file mode 100644
index 0000000000000000000000000000000000000000..de1131b24893ae24bd99923895fd844837c9b46d
--- /dev/null
+++ b/configs/_base_/models/mask-rcnn_r50-caffe-c4.py
@@ -0,0 +1,132 @@
+# model settings
+norm_cfg = dict(type='BN', requires_grad=False)
+model = dict(
+ type='MaskRCNN',
+ data_preprocessor=dict(
+ type='DetDataPreprocessor',
+ mean=[103.530, 116.280, 123.675],
+ std=[1.0, 1.0, 1.0],
+ bgr_to_rgb=False,
+ pad_mask=True,
+ pad_size_divisor=32),
+ backbone=dict(
+ type='ResNet',
+ depth=50,
+ num_stages=3,
+ strides=(1, 2, 2),
+ dilations=(1, 1, 1),
+ out_indices=(2, ),
+ frozen_stages=1,
+ norm_cfg=norm_cfg,
+ norm_eval=True,
+ style='caffe',
+ init_cfg=dict(
+ type='Pretrained',
+ checkpoint='open-mmlab://detectron2/resnet50_caffe')),
+ rpn_head=dict(
+ type='RPNHead',
+ in_channels=1024,
+ feat_channels=1024,
+ anchor_generator=dict(
+ type='AnchorGenerator',
+ scales=[2, 4, 8, 16, 32],
+ ratios=[0.5, 1.0, 2.0],
+ strides=[16]),
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[.0, .0, .0, .0],
+ target_stds=[1.0, 1.0, 1.0, 1.0]),
+ loss_cls=dict(
+ type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
+ loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
+ roi_head=dict(
+ type='StandardRoIHead',
+ shared_head=dict(
+ type='ResLayer',
+ depth=50,
+ stage=3,
+ stride=2,
+ dilation=1,
+ style='caffe',
+ norm_cfg=norm_cfg,
+ norm_eval=True),
+ bbox_roi_extractor=dict(
+ type='SingleRoIExtractor',
+ roi_layer=dict(type='RoIAlign', output_size=14, sampling_ratio=0),
+ out_channels=1024,
+ featmap_strides=[16]),
+ bbox_head=dict(
+ type='BBoxHead',
+ with_avg_pool=True,
+ roi_feat_size=7,
+ in_channels=2048,
+ num_classes=80,
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[0., 0., 0., 0.],
+ target_stds=[0.1, 0.1, 0.2, 0.2]),
+ reg_class_agnostic=False,
+ loss_cls=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),
+ loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
+ mask_roi_extractor=None,
+ mask_head=dict(
+ type='FCNMaskHead',
+ num_convs=0,
+ in_channels=2048,
+ conv_out_channels=256,
+ num_classes=80,
+ loss_mask=dict(
+ type='CrossEntropyLoss', use_mask=True, loss_weight=1.0))),
+ # model training and testing settings
+ train_cfg=dict(
+ rpn=dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.7,
+ neg_iou_thr=0.3,
+ min_pos_iou=0.3,
+ match_low_quality=True,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=256,
+ pos_fraction=0.5,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=False),
+ allowed_border=0,
+ pos_weight=-1,
+ debug=False),
+ rpn_proposal=dict(
+ nms_pre=12000,
+ max_per_img=2000,
+ nms=dict(type='nms', iou_threshold=0.7),
+ min_bbox_size=0),
+ rcnn=dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.5,
+ neg_iou_thr=0.5,
+ min_pos_iou=0.5,
+ match_low_quality=False,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=512,
+ pos_fraction=0.25,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=True),
+ mask_size=14,
+ pos_weight=-1,
+ debug=False)),
+ test_cfg=dict(
+ rpn=dict(
+ nms_pre=6000,
+ nms=dict(type='nms', iou_threshold=0.7),
+ max_per_img=1000,
+ min_bbox_size=0),
+ rcnn=dict(
+ score_thr=0.05,
+ nms=dict(type='nms', iou_threshold=0.5),
+ max_per_img=100,
+ mask_thr_binary=0.5)))
diff --git a/configs/_base_/models/mask-rcnn_r50_fpn.py b/configs/_base_/models/mask-rcnn_r50_fpn.py
new file mode 100644
index 0000000000000000000000000000000000000000..b4ff7a49d0a2f0abd4823ef89ad957d9708085e7
--- /dev/null
+++ b/configs/_base_/models/mask-rcnn_r50_fpn.py
@@ -0,0 +1,127 @@
+# model settings
+model = dict(
+ type='MaskRCNN',
+ data_preprocessor=dict(
+ type='DetDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True,
+ pad_mask=True,
+ pad_size_divisor=32),
+ backbone=dict(
+ type='ResNet',
+ depth=50,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ frozen_stages=1,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ norm_eval=True,
+ style='pytorch',
+ init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50')),
+ neck=dict(
+ type='FPN',
+ in_channels=[256, 512, 1024, 2048],
+ out_channels=256,
+ num_outs=5),
+ rpn_head=dict(
+ type='RPNHead',
+ in_channels=256,
+ feat_channels=256,
+ anchor_generator=dict(
+ type='AnchorGenerator',
+ scales=[8],
+ ratios=[0.5, 1.0, 2.0],
+ strides=[4, 8, 16, 32, 64]),
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[.0, .0, .0, .0],
+ target_stds=[1.0, 1.0, 1.0, 1.0]),
+ loss_cls=dict(
+ type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
+ loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
+ roi_head=dict(
+ type='StandardRoIHead',
+ bbox_roi_extractor=dict(
+ type='SingleRoIExtractor',
+ roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=0),
+ out_channels=256,
+ featmap_strides=[4, 8, 16, 32]),
+ bbox_head=dict(
+ type='Shared2FCBBoxHead',
+ in_channels=256,
+ fc_out_channels=1024,
+ roi_feat_size=7,
+ num_classes=80,
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[0., 0., 0., 0.],
+ target_stds=[0.1, 0.1, 0.2, 0.2]),
+ reg_class_agnostic=False,
+ loss_cls=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),
+ loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
+ mask_roi_extractor=dict(
+ type='SingleRoIExtractor',
+ roi_layer=dict(type='RoIAlign', output_size=14, sampling_ratio=0),
+ out_channels=256,
+ featmap_strides=[4, 8, 16, 32]),
+ mask_head=dict(
+ type='FCNMaskHead',
+ num_convs=4,
+ in_channels=256,
+ conv_out_channels=256,
+ num_classes=80,
+ loss_mask=dict(
+ type='CrossEntropyLoss', use_mask=True, loss_weight=1.0))),
+ # model training and testing settings
+ train_cfg=dict(
+ rpn=dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.7,
+ neg_iou_thr=0.3,
+ min_pos_iou=0.3,
+ match_low_quality=True,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=256,
+ pos_fraction=0.5,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=False),
+ allowed_border=-1,
+ pos_weight=-1,
+ debug=False),
+ rpn_proposal=dict(
+ nms_pre=2000,
+ max_per_img=1000,
+ nms=dict(type='nms', iou_threshold=0.7),
+ min_bbox_size=0),
+ rcnn=dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.5,
+ neg_iou_thr=0.5,
+ min_pos_iou=0.5,
+ match_low_quality=True,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=512,
+ pos_fraction=0.25,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=True),
+ mask_size=28,
+ pos_weight=-1,
+ debug=False)),
+ test_cfg=dict(
+ rpn=dict(
+ nms_pre=1000,
+ max_per_img=1000,
+ nms=dict(type='nms', iou_threshold=0.7),
+ min_bbox_size=0),
+ rcnn=dict(
+ score_thr=0.05,
+ nms=dict(type='nms', iou_threshold=0.5),
+ max_per_img=100,
+ mask_thr_binary=0.5)))
diff --git a/configs/_base_/models/retinanet_r50_fpn.py b/configs/_base_/models/retinanet_r50_fpn.py
new file mode 100644
index 0000000000000000000000000000000000000000..53662c9f1390af22b15c5591e122b0aa0b2d6c92
--- /dev/null
+++ b/configs/_base_/models/retinanet_r50_fpn.py
@@ -0,0 +1,68 @@
+# model settings
+model = dict(
+ type='RetinaNet',
+ data_preprocessor=dict(
+ type='DetDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True,
+ pad_size_divisor=32),
+ backbone=dict(
+ type='ResNet',
+ depth=50,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ frozen_stages=1,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ norm_eval=True,
+ style='pytorch',
+ init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50')),
+ neck=dict(
+ type='FPN',
+ in_channels=[256, 512, 1024, 2048],
+ out_channels=256,
+ start_level=1,
+ add_extra_convs='on_input',
+ num_outs=5),
+ bbox_head=dict(
+ type='RetinaHead',
+ num_classes=80,
+ in_channels=256,
+ stacked_convs=4,
+ feat_channels=256,
+ anchor_generator=dict(
+ type='AnchorGenerator',
+ octave_base_scale=4,
+ scales_per_octave=3,
+ ratios=[0.5, 1.0, 2.0],
+ strides=[8, 16, 32, 64, 128]),
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[.0, .0, .0, .0],
+ target_stds=[1.0, 1.0, 1.0, 1.0]),
+ loss_cls=dict(
+ type='FocalLoss',
+ use_sigmoid=True,
+ gamma=2.0,
+ alpha=0.25,
+ loss_weight=1.0),
+ loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
+ # model training and testing settings
+ train_cfg=dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.5,
+ neg_iou_thr=0.4,
+ min_pos_iou=0,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='PseudoSampler'), # Focal loss should use PseudoSampler
+ allowed_border=-1,
+ pos_weight=-1,
+ debug=False),
+ test_cfg=dict(
+ nms_pre=1000,
+ min_bbox_size=0,
+ score_thr=0.05,
+ nms=dict(type='nms', iou_threshold=0.5),
+ max_per_img=100))
diff --git a/configs/_base_/models/rpn_r50-caffe-c4.py b/configs/_base_/models/rpn_r50-caffe-c4.py
new file mode 100644
index 0000000000000000000000000000000000000000..ed1dbe746d432d96d70e7dc9048c9e1b1727c938
--- /dev/null
+++ b/configs/_base_/models/rpn_r50-caffe-c4.py
@@ -0,0 +1,64 @@
+# model settings
+model = dict(
+ type='RPN',
+ data_preprocessor=dict(
+ type='DetDataPreprocessor',
+ mean=[103.530, 116.280, 123.675],
+ std=[1.0, 1.0, 1.0],
+ bgr_to_rgb=False,
+ pad_size_divisor=32),
+ backbone=dict(
+ type='ResNet',
+ depth=50,
+ num_stages=3,
+ strides=(1, 2, 2),
+ dilations=(1, 1, 1),
+ out_indices=(2, ),
+ frozen_stages=1,
+ norm_cfg=dict(type='BN', requires_grad=False),
+ norm_eval=True,
+ style='caffe',
+ init_cfg=dict(
+ type='Pretrained',
+ checkpoint='open-mmlab://detectron2/resnet50_caffe')),
+ neck=None,
+ rpn_head=dict(
+ type='RPNHead',
+ in_channels=1024,
+ feat_channels=1024,
+ anchor_generator=dict(
+ type='AnchorGenerator',
+ scales=[2, 4, 8, 16, 32],
+ ratios=[0.5, 1.0, 2.0],
+ strides=[16]),
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[.0, .0, .0, .0],
+ target_stds=[1.0, 1.0, 1.0, 1.0]),
+ loss_cls=dict(
+ type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
+ loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
+ # model training and testing settings
+ train_cfg=dict(
+ rpn=dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.7,
+ neg_iou_thr=0.3,
+ min_pos_iou=0.3,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=256,
+ pos_fraction=0.5,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=False),
+ allowed_border=-1,
+ pos_weight=-1,
+ debug=False)),
+ test_cfg=dict(
+ rpn=dict(
+ nms_pre=12000,
+ max_per_img=2000,
+ nms=dict(type='nms', iou_threshold=0.7),
+ min_bbox_size=0)))
diff --git a/configs/_base_/models/rpn_r50_fpn.py b/configs/_base_/models/rpn_r50_fpn.py
new file mode 100644
index 0000000000000000000000000000000000000000..6bc4790434a368d0728d74dcd7ba79e665aae276
--- /dev/null
+++ b/configs/_base_/models/rpn_r50_fpn.py
@@ -0,0 +1,64 @@
+# model settings
+model = dict(
+ type='RPN',
+ data_preprocessor=dict(
+ type='DetDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True,
+ pad_size_divisor=32),
+ backbone=dict(
+ type='ResNet',
+ depth=50,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ frozen_stages=1,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ norm_eval=True,
+ style='pytorch',
+ init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50')),
+ neck=dict(
+ type='FPN',
+ in_channels=[256, 512, 1024, 2048],
+ out_channels=256,
+ num_outs=5),
+ rpn_head=dict(
+ type='RPNHead',
+ in_channels=256,
+ feat_channels=256,
+ anchor_generator=dict(
+ type='AnchorGenerator',
+ scales=[8],
+ ratios=[0.5, 1.0, 2.0],
+ strides=[4, 8, 16, 32, 64]),
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[.0, .0, .0, .0],
+ target_stds=[1.0, 1.0, 1.0, 1.0]),
+ loss_cls=dict(
+ type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
+ loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
+ # model training and testing settings
+ train_cfg=dict(
+ rpn=dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.7,
+ neg_iou_thr=0.3,
+ min_pos_iou=0.3,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=256,
+ pos_fraction=0.5,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=False),
+ allowed_border=-1,
+ pos_weight=-1,
+ debug=False)),
+ test_cfg=dict(
+ rpn=dict(
+ nms_pre=2000,
+ max_per_img=1000,
+ nms=dict(type='nms', iou_threshold=0.7),
+ min_bbox_size=0)))
diff --git a/configs/_base_/models/ssd300.py b/configs/_base_/models/ssd300.py
new file mode 100644
index 0000000000000000000000000000000000000000..fd113c7cbc41494eabb6a56061f8a90343ac9efd
--- /dev/null
+++ b/configs/_base_/models/ssd300.py
@@ -0,0 +1,63 @@
+# model settings
+input_size = 300
+model = dict(
+ type='SingleStageDetector',
+ data_preprocessor=dict(
+ type='DetDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[1, 1, 1],
+ bgr_to_rgb=True,
+ pad_size_divisor=1),
+ backbone=dict(
+ type='SSDVGG',
+ depth=16,
+ with_last_pool=False,
+ ceil_mode=True,
+ out_indices=(3, 4),
+ out_feature_indices=(22, 34),
+ init_cfg=dict(
+ type='Pretrained', checkpoint='open-mmlab://vgg16_caffe')),
+ neck=dict(
+ type='SSDNeck',
+ in_channels=(512, 1024),
+ out_channels=(512, 1024, 512, 256, 256, 256),
+ level_strides=(2, 2, 1, 1),
+ level_paddings=(1, 1, 0, 0),
+ l2_norm_scale=20),
+ bbox_head=dict(
+ type='SSDHead',
+ in_channels=(512, 1024, 512, 256, 256, 256),
+ num_classes=80,
+ anchor_generator=dict(
+ type='SSDAnchorGenerator',
+ scale_major=False,
+ input_size=input_size,
+ basesize_ratio_range=(0.15, 0.9),
+ strides=[8, 16, 32, 64, 100, 300],
+ ratios=[[2], [2, 3], [2, 3], [2, 3], [2], [2]]),
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[.0, .0, .0, .0],
+ target_stds=[0.1, 0.1, 0.2, 0.2])),
+ # model training and testing settings
+ train_cfg=dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.5,
+ neg_iou_thr=0.5,
+ min_pos_iou=0.,
+ ignore_iof_thr=-1,
+ gt_max_assign_all=False),
+ sampler=dict(type='PseudoSampler'),
+ smoothl1_beta=1.,
+ allowed_border=-1,
+ pos_weight=-1,
+ neg_pos_ratio=3,
+ debug=False),
+ test_cfg=dict(
+ nms_pre=1000,
+ nms=dict(type='nms', iou_threshold=0.45),
+ min_bbox_size=0,
+ score_thr=0.02,
+ max_per_img=200))
+cudnn_benchmark = True
diff --git a/configs/_base_/schedules/schedule_1x.py b/configs/_base_/schedules/schedule_1x.py
new file mode 100644
index 0000000000000000000000000000000000000000..8900d58d6084c92cf5ae8a3444f188bfc4404959
--- /dev/null
+++ b/configs/_base_/schedules/schedule_1x.py
@@ -0,0 +1,28 @@
+# training schedule for 1x
+train_cfg = dict(type='EpochBasedTrainLoop', max_epochs=12, val_interval=1)
+val_cfg = dict(type='ValLoop')
+test_cfg = dict(type='TestLoop')
+
+# learning rate
+param_scheduler = [
+ dict(
+ type='LinearLR', start_factor=0.001, by_epoch=False, begin=0, end=500),
+ dict(
+ type='MultiStepLR',
+ begin=0,
+ end=12,
+ by_epoch=True,
+ milestones=[8, 11],
+ gamma=0.1)
+]
+
+# optimizer
+optim_wrapper = dict(
+ type='OptimWrapper',
+ optimizer=dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001))
+
+# Default setting for scaling LR automatically
+# - `enable` means enable scaling LR automatically
+# or not by default.
+# - `base_batch_size` = (8 GPUs) x (2 samples per GPU).
+auto_scale_lr = dict(enable=False, base_batch_size=4)
diff --git a/configs/_base_/schedules/schedule_20e.py b/configs/_base_/schedules/schedule_20e.py
new file mode 100644
index 0000000000000000000000000000000000000000..75f958b0ed11d77ae3aebff6b7a5d8cb80797d9f
--- /dev/null
+++ b/configs/_base_/schedules/schedule_20e.py
@@ -0,0 +1,28 @@
+# training schedule for 20e
+train_cfg = dict(type='EpochBasedTrainLoop', max_epochs=20, val_interval=1)
+val_cfg = dict(type='ValLoop')
+test_cfg = dict(type='TestLoop')
+
+# learning rate
+param_scheduler = [
+ dict(
+ type='LinearLR', start_factor=0.001, by_epoch=False, begin=0, end=500),
+ dict(
+ type='MultiStepLR',
+ begin=0,
+ end=20,
+ by_epoch=True,
+ milestones=[16, 19],
+ gamma=0.1)
+]
+
+# optimizer
+optim_wrapper = dict(
+ type='OptimWrapper',
+ optimizer=dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001))
+
+# Default setting for scaling LR automatically
+# - `enable` means enable scaling LR automatically
+# or not by default.
+# - `base_batch_size` = (8 GPUs) x (2 samples per GPU).
+auto_scale_lr = dict(enable=False, base_batch_size=16)
diff --git a/configs/_base_/schedules/schedule_2x.py b/configs/_base_/schedules/schedule_2x.py
new file mode 100644
index 0000000000000000000000000000000000000000..5b7b241de6f3285e0f127f3c0581c8c84de463e4
--- /dev/null
+++ b/configs/_base_/schedules/schedule_2x.py
@@ -0,0 +1,28 @@
+# training schedule for 2x
+train_cfg = dict(type='EpochBasedTrainLoop', max_epochs=24, val_interval=1)
+val_cfg = dict(type='ValLoop')
+test_cfg = dict(type='TestLoop')
+
+# learning rate
+param_scheduler = [
+ dict(
+ type='LinearLR', start_factor=0.001, by_epoch=False, begin=0, end=500),
+ dict(
+ type='MultiStepLR',
+ begin=0,
+ end=24,
+ by_epoch=True,
+ milestones=[16, 22],
+ gamma=0.1)
+]
+
+# optimizer
+optim_wrapper = dict(
+ type='OptimWrapper',
+ optimizer=dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001))
+
+# Default setting for scaling LR automatically
+# - `enable` means enable scaling LR automatically
+# or not by default.
+# - `base_batch_size` = (8 GPUs) x (2 samples per GPU).
+auto_scale_lr = dict(enable=False, base_batch_size=16)
diff --git a/configs/backup/albu_example/README.md b/configs/backup/albu_example/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..169a8c73a5459b36db7f040dcf4831eeeb287a19
--- /dev/null
+++ b/configs/backup/albu_example/README.md
@@ -0,0 +1,31 @@
+# Albu Example
+
+> [Albumentations: fast and flexible image augmentations](https://arxiv.org/abs/1809.06839)
+
+
+
+## Abstract
+
+Data augmentation is a commonly used technique for increasing both the size and the diversity of labeled training sets by leveraging input transformations that preserve output labels. In computer vision domain, image augmentations have become a common implicit regularization technique to combat overfitting in deep convolutional neural networks and are ubiquitously used to improve performance. While most deep learning frameworks implement basic image transformations, the list is typically limited to some variations and combinations of flipping, rotating, scaling, and cropping. Moreover, the image processing speed varies in existing tools for image augmentation. We present Albumentations, a fast and flexible library for image augmentations with many various image transform operations available, that is also an easy-to-use wrapper around other augmentation libraries. We provide examples of image augmentations for different computer vision tasks and show that Albumentations is faster than other commonly used image augmentation tools on the most of commonly used image transformations.
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+#include
+#include "mmdeploy/detector.hpp"
+
+int main() {
+ const char* device_name = "cuda";
+ int device_id = 0;
+ std::string model_path = "work_dirs/rtmdet-sdk";
+ std::string image_path = "demo/resources/det.jpg";
+
+ // 1. load model
+ mmdeploy::Model model(model_path);
+ // 2. create predictor
+ mmdeploy::Detector detector(model, mmdeploy::Device{device_name, device_id});
+ // 3. read image
+ cv::Mat img = cv::imread(image_path);
+ // 4. inference
+ auto dets = detector.Apply(img);
+ // 5. deal with the result. Here we choose to visualize it
+ for (int i = 0; i < dets.size(); ++i) {
+ const auto& box = dets[i].bbox;
+ fprintf(stdout, "box %d, left=%.2f, top=%.2f, right=%.2f, bottom=%.2f, label=%d, score=%.4f\n",
+ i, box.left, box.top, box.right, box.bottom, dets[i].label_id, dets[i].score);
+ if (bboxes[i].score < 0.3) {
+ continue;
+ }
+ cv::rectangle(img, cv::Point{(int)box.left, (int)box.top},
+ cv::Point{(int)box.right, (int)box.bottom}, cv::Scalar{0, 255, 0});
+ }
+ cv::imwrite("output_detection.png", img);
+ return 0;
+}
+```
+
+To build C++ example, please add MMDeploy package in your CMake project as following:
+
+```cmake
+find_package(MMDeploy REQUIRED)
+target_link_libraries(${name} PRIVATE mmdeploy ${OpenCV_LIBS})
+```
+
+#### Other languages
+
+- [C# API Examples](https://github.com/open-mmlab/mmdeploy/tree/1.x/demo/csharp)
+- [JAVA API Examples](https://github.com/open-mmlab/mmdeploy/tree/1.x/demo/java)
+
+### Deploy RTMDet Instance Segmentation Model
+
+We support RTMDet-Ins ONNXRuntime and TensorRT deployment after [MMDeploy v1.0.0rc2](https://github.com/open-mmlab/mmdeploy/tree/v1.0.0rc2). And its deployment process is almost consistent with the detection model.
+
+#### Step1. Install MMDeploy >= v1.0.0rc2
+
+Please refer to the [MMDeploy-1.x installation guide](https://mmdeploy.readthedocs.io/en/1.x/get_started.html#installation) to install the latest version.
+Please remember to replace the pre-built package with the latest version.
+The v1.0.0rc2 package can be downloaded from [v1.0.0rc2 release page](https://github.com/open-mmlab/mmdeploy/releases/tag/v1.0.0rc2).
+
+Step2. Convert Model
+
+This step has no difference with the previous tutorial. The only thing you need to change is switching to the RTMDet-Ins deploy config:
+
+- If you want to use ONNXRuntime, please use [`configs/mmdet/instance-seg/instance-seg_rtmdet-ins_onnxruntime_static-640x640.py`](https://github.com/open-mmlab/mmdeploy/blob/dev-1.x/configs/mmdet/instance-seg/instance-seg_rtmdet-ins_onnxruntime_static-640x640.py) as the deployment config.
+- If you want to use TensorRT, please use [`configs/mmdet/instance-seg/instance-seg_rtmdet-ins_tensorrt_static-640x640.py`](https://github.com/open-mmlab/mmdeploy/blob/dev-1.x/configs/mmdet/instance-seg/instance-seg_rtmdet-ins_tensorrt_static-640x640.py).
+
+Here we take converting RTMDet-Ins-s to TensorRT as an example:
+
+```shell
+# go to the mmdeploy folder
+cd ${PATH_TO_MMDEPLOY}
+
+# download RTMDet-s checkpoint
+wget -P checkpoint https://download.openmmlab.com/mmdetection/v3.0/rtmdet/rtmdet-ins_s_8xb32-300e_coco/rtmdet-ins_s_8xb32-300e_coco_20221121_212604-fdc5d7ec.pth
+
+# run the command to start model conversion
+python tools/deploy.py \
+ configs/mmdet/instance-seg/instance-seg_rtmdet-ins_tensorrt_static-640x640.py \
+ ${PATH_TO_MMDET}/configs/rtmdet/rtmdet-ins_s_8xb32-300e_coco.py \
+ checkpoint/rtmdet-ins_s_8xb32-300e_coco/rtmdet-ins_s_8xb32-300e_coco_20221121_212604-fdc5d7ec.pth \
+ demo/resources/det.jpg \
+ --work-dir ./work_dirs/rtmdet-ins \
+ --device cuda:0 \
+ --show
+```
+
+If the script runs successfully, you will see the following files:
+
+```
+|----work_dirs
+ |----rtmdet-ins
+ |----end2end.onnx # ONNX model
+ |----end2end.engine # TensorRT engine file
+```
+
+After this, you can check the inference results with MMDeploy Model Converter API:
+
+```python
+from mmdeploy.apis import inference_model
+
+result = inference_model(
+ model_cfg='${PATH_TO_MMDET}/configs/rtmdet/rtmdet-ins_s_8xb32-300e_coco.py',
+ deploy_cfg='${PATH_TO_MMDEPLOY}/configs/mmdet/instance-seg/instance-seg_rtmdet-ins_tensorrt_static-640x640.py',
+ backend_files=['work_dirs/rtmdet-ins/end2end.engine'],
+ img='demo/resources/det.jpg',
+ device='cuda:0')
+```
+
+### Model Config
+
+In MMDetection's config, we use `model` to set up detection algorithm components. In addition to neural network components such as `backbone`, `neck`, etc, it also requires `data_preprocessor`, `train_cfg`, and `test_cfg`. `data_preprocessor` is responsible for processing a batch of data output by dataloader. `train_cfg`, and `test_cfg` in the model config are for training and testing hyperparameters of the components.Taking RTMDet as an example, we will introduce each field in the config according to different function modules:
+
+```python
+model = dict(
+ type='RTMDet', # The name of detector
+ data_preprocessor=dict( # The config of data preprocessor, usually includes image normalization and padding
+ type='DetDataPreprocessor', # The type of the data preprocessor. Refer to https://mmdetection.readthedocs.io/en/latest/api.html#mmdet.models.data_preprocessors.DetDataPreprocessor
+ mean=[103.53, 116.28, 123.675], # Mean values used to pre-training the pre-trained backbone models, ordered in R, G, B
+ std=[57.375, 57.12, 58.395], # Standard variance used to pre-training the pre-trained backbone models, ordered in R, G, B
+ bgr_to_rgb=False, # whether to convert image from BGR to RGB
+ batch_augments=None), # Batch-level augmentations
+ backbone=dict( # The config of backbone
+ type='CSPNeXt', # The type of backbone network. Refer to https://mmdetection.readthedocs.io/en/latest/api.html#mmdet.models.backbones.CSPNeXt
+ arch='P5', # Architecture of CSPNeXt, from {P5, P6}. Defaults to P5
+ expand_ratio=0.5, # Ratio to adjust the number of channels of the hidden layer. Defaults to 0.5
+ deepen_factor=1, # Depth multiplier, multiply number of blocks in CSP layer by this amount. Defaults to 1.0
+ widen_factor=1, # Width multiplier, multiply number of channels in each layer by this amount. Defaults to 1.0
+ channel_attention=True, # Whether to add channel attention in each stage. Defaults to True
+ norm_cfg=dict(type='SyncBN'), # Dictionary to construct and config norm layer. Defaults to dict(type=’BN’, requires_grad=True)
+ act_cfg=dict(type='SiLU', inplace=True)), # Config dict for activation layer. Defaults to dict(type=’SiLU’)
+ neck=dict(
+ type='CSPNeXtPAFPN', # The type of neck is CSPNeXtPAFPN. Refer to https://mmdetection.readthedocs.io/en/latest/api.html#mmdet.models.necks.CSPNeXtPAFPN
+ in_channels=[256, 512, 1024], # Number of input channels per scale
+ out_channels=256, # Number of output channels (used at each scale)
+ num_csp_blocks=3, # Number of bottlenecks in CSPLayer. Defaults to 3
+ expand_ratio=0.5, # Ratio to adjust the number of channels of the hidden layer. Default: 0.5
+ norm_cfg=dict(type='SyncBN'), # Config dict for normalization layer. Default: dict(type=’BN’)
+ act_cfg=dict(type='SiLU', inplace=True)), # Config dict for activation layer. Default: dict(type=’Swish’)
+ bbox_head=dict(
+ type='RTMDetSepBNHead', # The type of bbox_head is RTMDetSepBNHead. RTMDetHead with separated BN layers and shared conv layers. Refer to https://mmdetection.readthedocs.io/en/latest/api.html#mmdet.models.dense_heads.RTMDetSepBNHead
+ num_classes=80, # Number of categories excluding the background category
+ in_channels=256, # Number of channels in the input feature map
+ stacked_convs=2, # Whether to share conv layers between stages. Defaults to True
+ feat_channels=256, # Feature channels of convolutional layers in the head
+ anchor_generator=dict( # The config of anchor generator
+ type='MlvlPointGenerator', # The methods use MlvlPointGenerator. Refer to https://github.com/open-mmlab/mmdetection/blob/main/mmdet/models/task_modules/prior_generators/point_generator.py#L92
+ offset=0, # The offset of points, the value is normalized with corresponding stride. Defaults to 0.5
+ strides=[8, 16, 32]), # Strides of anchors in multiple feature levels in order (w, h)
+ bbox_coder=dict(type='DistancePointBBoxCoder'), # Distance Point BBox coder.This coder encodes gt bboxes (x1, y1, x2, y2) into (top, bottom, left,right) and decode it back to the original. Refer to https://github.com/open-mmlab/mmdetection/blob/main/mmdet/models/task_modules/coders/distance_point_bbox_coder.py#L9
+ loss_cls=dict( # Config of loss function for the classification branch
+ type='QualityFocalLoss', # Type of loss for classification branch. Refer to https://mmdetection.readthedocs.io/en/latest/api.html#mmdet.models.losses.QualityFocalLoss
+ use_sigmoid=True, # Whether sigmoid operation is conducted in QFL. Defaults to True
+ beta=2.0, # The beta parameter for calculating the modulating factor. Defaults to 2.0
+ loss_weight=1.0), # Loss weight of current loss
+ loss_bbox=dict( # Config of loss function for the regression branch
+ type='GIoULoss', # Type of loss. Refer to https://mmdetection.readthedocs.io/en/latest/api.html#mmdet.models.losses.GIoULoss
+ loss_weight=2.0), # Loss weight of the regression branch
+ with_objectness=False, # Whether to add an objectness branch. Defaults to True
+ exp_on_reg=True, # Whether to use .exp() in regression
+ share_conv=True, # Whether to share conv layers between stages. Defaults to True
+ pred_kernel_size=1, # Kernel size of prediction layer. Defaults to 1
+ norm_cfg=dict(type='SyncBN'), # Config dict for normalization layer. Defaults to dict(type='BN', momentum=0.03, eps=0.001)
+ act_cfg=dict(type='SiLU', inplace=True)), # Config dict for activation layer. Defaults to dict(type='SiLU')
+ train_cfg=dict( # Config of training hyperparameters for ATSS
+ assigner=dict( # Config of assigner
+ type='DynamicSoftLabelAssigner', # Type of assigner. DynamicSoftLabelAssigner computes matching between predictions and ground truth with dynamic soft label assignment. Refer to https://github.com/open-mmlab/mmdetection/blob/main/mmdet/models/task_modules/assigners/dynamic_soft_label_assigner.py#L40
+ topk=13), # Select top-k predictions to calculate dynamic k best matches for each gt. Defaults to 13
+ allowed_border=-1, # The border allowed after padding for valid anchors
+ pos_weight=-1, # The weight of positive samples during training
+ debug=False), # Whether to set the debug mode
+ test_cfg=dict( # Config for testing hyperparameters for ATSS
+ nms_pre=30000, # The number of boxes before NMS
+ min_bbox_size=0, # The allowed minimal box size
+ score_thr=0.001, # Threshold to filter out boxes
+ nms=dict( # Config of NMS in the second stage
+ type='nms', # Type of NMS
+ iou_threshold=0.65), # NMS threshold
+ max_per_img=300), # Max number of detections of each image
+)
+```
diff --git a/configs/backup/rtmdet/classification/README.md b/configs/backup/rtmdet/classification/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..6aee2c61794ae943f340985884db36b71ce2f4a0
--- /dev/null
+++ b/configs/backup/rtmdet/classification/README.md
@@ -0,0 +1,56 @@
+# CSPNeXt ImageNet Pre-training
+
+In this folder, we provide the imagenet pre-training config of RTMDet's backbone CSPNeXt.
+
+## Requirements
+
+To train with these configs, please install [MMClassification 1.x](https://github.com/open-mmlab/mmclassification/tree/1.x) first.
+
+Install by MIM:
+
+```shell
+mim install mmcls>=1.0.0rc0
+```
+
+or install by pip:
+
+```shell
+pip install mmcls>=1.0.0rc0
+```
+
+## Prepare Dataset
+
+To pre-train on ImageNet, you need to prepare the dataset first. Please refer to the [guide](https://mmclassification.readthedocs.io/en/1.x/user_guides/dataset_prepare.html#imagenet).
+
+## How to Train
+
+You can use the classification config in the same way as the detection config.
+
+For single-GPU training, run:
+
+```shell
+python tools/train.py \
+ ${CONFIG_FILE} \
+ [optional arguments]
+```
+
+For multi-GPU training, run:
+
+```shell
+bash ./tools/dist_train.sh \
+ ${CONFIG_FILE} \
+ ${GPU_NUM} \
+ [optional arguments]
+```
+
+More details can be found in [user guides](https://mmdetection.readthedocs.io/en/latest/user_guides/train.html).
+
+## Results and Models
+
+| Model | resolution | Params(M) | Flops(G) | Top-1 (%) | Top-5 (%) | Download |
+| :----------: | :--------: | :-------: | :------: | :-------: | :-------: | :---------------------------------------------------------------------------------------------------------------------------------: |
+| CSPNeXt-tiny | 224x224 | 2.73 | 0.34 | 69.44 | 89.45 | [model](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-tiny_imagenet_600e-3a2dd350.pth) |
+| CSPNeXt-s | 224x224 | 4.89 | 0.66 | 74.41 | 92.23 | [model](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-s_imagenet_600e-ea671761.pth) |
+| CSPNeXt-m | 224x224 | 13.05 | 1.93 | 79.27 | 94.79 | [model](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-m_8xb256-rsb-a1-600e_in1k-ecb3bbd9.pth) |
+| CSPNeXt-l | 224x224 | 27.16 | 4.19 | 81.30 | 95.62 | [model](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-l_8xb256-rsb-a1-600e_in1k-6a760974.pth) |
+| CSPNeXt-x | 224x224 | 48.85 | 7.76 | 82.10 | 95.69 | [model](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-x_8xb256-rsb-a1-600e_in1k-b3f78edd.pth) |
diff --git a/configs/backup/rtmdet/classification/cspnext-l_8xb256-rsb-a1-600e_in1k.py b/configs/backup/rtmdet/classification/cspnext-l_8xb256-rsb-a1-600e_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..d2e70539f05da69cca53f273d11e3296c87c4eda
--- /dev/null
+++ b/configs/backup/rtmdet/classification/cspnext-l_8xb256-rsb-a1-600e_in1k.py
@@ -0,0 +1,5 @@
+_base_ = './cspnext-s_8xb256-rsb-a1-600e_in1k.py'
+
+model = dict(
+ backbone=dict(deepen_factor=1, widen_factor=1),
+ head=dict(in_channels=1024))
diff --git a/configs/backup/rtmdet/classification/cspnext-m_8xb256-rsb-a1-600e_in1k.py b/configs/backup/rtmdet/classification/cspnext-m_8xb256-rsb-a1-600e_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..e1b1352dd91a803eeafe80f587203f96a247c27f
--- /dev/null
+++ b/configs/backup/rtmdet/classification/cspnext-m_8xb256-rsb-a1-600e_in1k.py
@@ -0,0 +1,5 @@
+_base_ = './cspnext-s_8xb256-rsb-a1-600e_in1k.py'
+
+model = dict(
+ backbone=dict(deepen_factor=0.67, widen_factor=0.75),
+ head=dict(in_channels=768))
diff --git a/configs/backup/rtmdet/classification/cspnext-s_8xb256-rsb-a1-600e_in1k.py b/configs/backup/rtmdet/classification/cspnext-s_8xb256-rsb-a1-600e_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..5708a45e63287daf41aabc5cbf06224508111321
--- /dev/null
+++ b/configs/backup/rtmdet/classification/cspnext-s_8xb256-rsb-a1-600e_in1k.py
@@ -0,0 +1,64 @@
+_base_ = [
+ 'mmcls::_base_/datasets/imagenet_bs256_rsb_a12.py',
+ 'mmcls::_base_/schedules/imagenet_bs2048_rsb.py',
+ 'mmcls::_base_/default_runtime.py'
+]
+
+model = dict(
+ type='ImageClassifier',
+ backbone=dict(
+ type='mmdet.CSPNeXt',
+ arch='P5',
+ out_indices=(4, ),
+ expand_ratio=0.5,
+ deepen_factor=0.33,
+ widen_factor=0.5,
+ channel_attention=True,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='mmdet.SiLU')),
+ neck=dict(type='GlobalAveragePooling'),
+ head=dict(
+ type='LinearClsHead',
+ num_classes=1000,
+ in_channels=512,
+ loss=dict(
+ type='LabelSmoothLoss',
+ label_smooth_val=0.1,
+ mode='original',
+ loss_weight=1.0),
+ topk=(1, 5)),
+ train_cfg=dict(augments=[
+ dict(type='Mixup', alpha=0.2),
+ dict(type='CutMix', alpha=1.0)
+ ]))
+
+# dataset settings
+train_dataloader = dict(sampler=dict(type='RepeatAugSampler', shuffle=True))
+
+# schedule settings
+optim_wrapper = dict(
+ optimizer=dict(weight_decay=0.01),
+ paramwise_cfg=dict(bias_decay_mult=0., norm_decay_mult=0.),
+)
+
+param_scheduler = [
+ # warm up learning rate scheduler
+ dict(
+ type='LinearLR',
+ start_factor=0.0001,
+ by_epoch=True,
+ begin=0,
+ end=5,
+ # update by iter
+ convert_to_iter_based=True),
+ # main learning rate scheduler
+ dict(
+ type='CosineAnnealingLR',
+ T_max=595,
+ eta_min=1.0e-6,
+ by_epoch=True,
+ begin=5,
+ end=600)
+]
+
+train_cfg = dict(by_epoch=True, max_epochs=600)
diff --git a/configs/backup/rtmdet/classification/cspnext-tiny_8xb256-rsb-a1-600e_in1k.py b/configs/backup/rtmdet/classification/cspnext-tiny_8xb256-rsb-a1-600e_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..af3170bdc51778c4601d4426aa88cc27c608f100
--- /dev/null
+++ b/configs/backup/rtmdet/classification/cspnext-tiny_8xb256-rsb-a1-600e_in1k.py
@@ -0,0 +1,5 @@
+_base_ = './cspnext-s_8xb256-rsb-a1-600e_in1k.py'
+
+model = dict(
+ backbone=dict(deepen_factor=0.167, widen_factor=0.375),
+ head=dict(in_channels=384))
diff --git a/configs/backup/rtmdet/classification/cspnext-x_8xb256-rsb-a1-600e_in1k.py b/configs/backup/rtmdet/classification/cspnext-x_8xb256-rsb-a1-600e_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..edec48d78dbefdb7783c5dd50e97873e29ea6497
--- /dev/null
+++ b/configs/backup/rtmdet/classification/cspnext-x_8xb256-rsb-a1-600e_in1k.py
@@ -0,0 +1,5 @@
+_base_ = './cspnext-s_8xb256-rsb-a1-600e_in1k.py'
+
+model = dict(
+ backbone=dict(deepen_factor=1.33, widen_factor=1.25),
+ head=dict(in_channels=1280))
diff --git a/configs/backup/rtmdet/metafile.yml b/configs/backup/rtmdet/metafile.yml
new file mode 100644
index 0000000000000000000000000000000000000000..c4e8c9b796c9f3a3e6f1366862e1f6f2e6f3e502
--- /dev/null
+++ b/configs/backup/rtmdet/metafile.yml
@@ -0,0 +1,186 @@
+Collections:
+ - Name: RTMDet
+ Metadata:
+ Training Data: COCO
+ Training Techniques:
+ - AdamW
+ - Flat Cosine Annealing
+ Training Resources: 8x A100 GPUs
+ Architecture:
+ - CSPNeXt
+ - CSPNeXtPAFPN
+ README: configs/rtmdet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v3.0.0rc1/mmdet/models/detectors/rtmdet.py#L6
+ Version: v3.0.0rc1
+
+Models:
+ - Name: rtmdet_tiny_8xb32-300e_coco
+ Alias:
+ - rtmdet-t
+ In Collection: RTMDet
+ Config: configs/rtmdet/rtmdet_tiny_8xb32-300e_coco.py
+ Metadata:
+ Training Memory (GB): 11.7
+ Epochs: 300
+ Results:
+ - Task: Object Detection
+ Dataset: COCO
+ Metrics:
+ box AP: 40.9
+ Weights: https://download.openmmlab.com/mmdetection/v3.0/rtmdet/rtmdet_tiny_8xb32-300e_coco/rtmdet_tiny_8xb32-300e_coco_20220902_112414-78e30dcc.pth
+
+ - Name: rtmdet_s_8xb32-300e_coco
+ Alias:
+ - rtmdet-s
+ In Collection: RTMDet
+ Config: configs/rtmdet/rtmdet_s_8xb32-300e_coco.py
+ Metadata:
+ Training Memory (GB): 15.9
+ Epochs: 300
+ Results:
+ - Task: Object Detection
+ Dataset: COCO
+ Metrics:
+ box AP: 44.5
+ Weights: https://download.openmmlab.com/mmdetection/v3.0/rtmdet/rtmdet_s_8xb32-300e_coco/rtmdet_s_8xb32-300e_coco_20220905_161602-387a891e.pth
+
+ - Name: rtmdet_m_8xb32-300e_coco
+ Alias:
+ - rtmdet-m
+ In Collection: RTMDet
+ Config: configs/rtmdet/rtmdet_m_8xb32-300e_coco.py
+ Metadata:
+ Training Memory (GB): 27.8
+ Epochs: 300
+ Results:
+ - Task: Object Detection
+ Dataset: COCO
+ Metrics:
+ box AP: 49.1
+ Weights: https://download.openmmlab.com/mmdetection/v3.0/rtmdet/rtmdet_m_8xb32-300e_coco/rtmdet_m_8xb32-300e_coco_20220719_112220-229f527c.pth
+
+ - Name: rtmdet_l_8xb32-300e_coco
+ Alias:
+ - rtmdet-l
+ In Collection: RTMDet
+ Config: configs/rtmdet/rtmdet_l_8xb32-300e_coco.py
+ Metadata:
+ Training Memory (GB): 43.2
+ Epochs: 300
+ Results:
+ - Task: Object Detection
+ Dataset: COCO
+ Metrics:
+ box AP: 51.3
+ Weights: https://download.openmmlab.com/mmdetection/v3.0/rtmdet/rtmdet_l_8xb32-300e_coco/rtmdet_l_8xb32-300e_coco_20220719_112030-5a0be7c4.pth
+
+ - Name: rtmdet_x_8xb32-300e_coco
+ Alias:
+ - rtmdet-x
+ In Collection: RTMDet
+ Config: configs/rtmdet/rtmdet_x_8xb32-300e_coco.py
+ Metadata:
+ Training Memory (GB): 61.1
+ Epochs: 300
+ Results:
+ - Task: Object Detection
+ Dataset: COCO
+ Metrics:
+ box AP: 52.6
+ Weights: https://download.openmmlab.com/mmdetection/v3.0/rtmdet/rtmdet_x_8xb32-300e_coco/rtmdet_x_8xb32-300e_coco_20220715_230555-cc79b9ae.pth
+
+ - Name: rtmdet-ins_tiny_8xb32-300e_coco
+ Alias:
+ - rtmdet-ins-t
+ In Collection: RTMDet
+ Config: configs/rtmdet/rtmdet-ins_tiny_8xb32-300e_coco.py
+ Metadata:
+ Training Memory (GB): 18.4
+ Epochs: 300
+ Results:
+ - Task: Object Detection
+ Dataset: COCO
+ Metrics:
+ box AP: 40.5
+ - Task: Instance Segmentation
+ Dataset: COCO
+ Metrics:
+ mask AP: 35.4
+ Weights: https://download.openmmlab.com/mmdetection/v3.0/rtmdet/rtmdet-ins_tiny_8xb32-300e_coco/rtmdet-ins_tiny_8xb32-300e_coco_20221130_151727-ec670f7e.pth
+
+ - Name: rtmdet-ins_s_8xb32-300e_coco
+ Alias:
+ - rtmdet-ins-s
+ In Collection: RTMDet
+ Config: configs/rtmdet/rtmdet-ins_s_8xb32-300e_coco.py
+ Metadata:
+ Training Memory (GB): 27.6
+ Epochs: 300
+ Results:
+ - Task: Object Detection
+ Dataset: COCO
+ Metrics:
+ box AP: 44.0
+ - Task: Instance Segmentation
+ Dataset: COCO
+ Metrics:
+ mask AP: 38.7
+ Weights: https://download.openmmlab.com/mmdetection/v3.0/rtmdet/rtmdet-ins_s_8xb32-300e_coco/rtmdet-ins_s_8xb32-300e_coco_20221121_212604-fdc5d7ec.pth
+
+ - Name: rtmdet-ins_m_8xb32-300e_coco
+ Alias:
+ - rtmdet-ins-m
+ In Collection: RTMDet
+ Config: configs/rtmdet/rtmdet-ins_m_8xb32-300e_coco.py
+ Metadata:
+ Training Memory (GB): 42.5
+ Epochs: 300
+ Results:
+ - Task: Object Detection
+ Dataset: COCO
+ Metrics:
+ box AP: 48.8
+ - Task: Instance Segmentation
+ Dataset: COCO
+ Metrics:
+ mask AP: 42.1
+ Weights: https://download.openmmlab.com/mmdetection/v3.0/rtmdet/rtmdet-ins_m_8xb32-300e_coco/rtmdet-ins_m_8xb32-300e_coco_20221123_001039-6eba602e.pth
+
+ - Name: rtmdet-ins_l_8xb32-300e_coco
+ Alias:
+ - rtmdet-ins-l
+ In Collection: RTMDet
+ Config: configs/rtmdet/rtmdet-ins_l_8xb32-300e_coco.py
+ Metadata:
+ Training Memory (GB): 59.8
+ Epochs: 300
+ Results:
+ - Task: Object Detection
+ Dataset: COCO
+ Metrics:
+ box AP: 51.2
+ - Task: Instance Segmentation
+ Dataset: COCO
+ Metrics:
+ mask AP: 43.7
+ Weights: https://download.openmmlab.com/mmdetection/v3.0/rtmdet/rtmdet-ins_l_8xb32-300e_coco/rtmdet-ins_l_8xb32-300e_coco_20221124_103237-78d1d652.pth
+
+ - Name: rtmdet-ins_x_8xb16-300e_coco
+ Alias:
+ - rtmdet-ins-x
+ In Collection: RTMDet
+ Config: configs/rtmdet/rtmdet-ins_x_8xb16-300e_coco.py
+ Metadata:
+ Training Memory (GB): 33.7
+ Epochs: 300
+ Results:
+ - Task: Object Detection
+ Dataset: COCO
+ Metrics:
+ box AP: 52.4
+ - Task: Instance Segmentation
+ Dataset: COCO
+ Metrics:
+ mask AP: 44.6
+ Weights: https://download.openmmlab.com/mmdetection/v3.0/rtmdet/rtmdet-ins_x_8xb16-300e_coco/rtmdet-ins_x_8xb16-300e_coco_20221124_111313-33d4595b.pth
diff --git a/configs/backup/rtmdet/rtmdet-ins_l_8xb32-300e_coco.py b/configs/backup/rtmdet/rtmdet-ins_l_8xb32-300e_coco.py
new file mode 100644
index 0000000000000000000000000000000000000000..6b4b9240a64d39d8a16352ef87de53af9e81ac96
--- /dev/null
+++ b/configs/backup/rtmdet/rtmdet-ins_l_8xb32-300e_coco.py
@@ -0,0 +1,104 @@
+_base_ = './rtmdet_l_8xb32-300e_coco.py'
+model = dict(
+ bbox_head=dict(
+ _delete_=True,
+ type='RTMDetInsSepBNHead',
+ num_classes=80,
+ in_channels=256,
+ stacked_convs=2,
+ share_conv=True,
+ pred_kernel_size=1,
+ feat_channels=256,
+ act_cfg=dict(type='SiLU', inplace=True),
+ norm_cfg=dict(type='SyncBN', requires_grad=True),
+ anchor_generator=dict(
+ type='MlvlPointGenerator', offset=0, strides=[8, 16, 32]),
+ bbox_coder=dict(type='DistancePointBBoxCoder'),
+ loss_cls=dict(
+ type='QualityFocalLoss',
+ use_sigmoid=True,
+ beta=2.0,
+ loss_weight=1.0),
+ loss_bbox=dict(type='GIoULoss', loss_weight=2.0),
+ loss_mask=dict(
+ type='DiceLoss', loss_weight=2.0, eps=5e-6, reduction='mean')),
+ test_cfg=dict(
+ nms_pre=1000,
+ min_bbox_size=0,
+ score_thr=0.05,
+ nms=dict(type='nms', iou_threshold=0.6),
+ max_per_img=100,
+ mask_thr_binary=0.5),
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile', backend_args={{_base_.backend_args}}),
+ dict(
+ type='LoadAnnotations',
+ with_bbox=True,
+ with_mask=True,
+ poly2mask=False),
+ dict(type='CachedMosaic', img_scale=(640, 640), pad_val=114.0),
+ dict(
+ type='RandomResize',
+ scale=(1280, 1280),
+ ratio_range=(0.1, 2.0),
+ keep_ratio=True),
+ dict(
+ type='RandomCrop',
+ crop_size=(640, 640),
+ recompute_bbox=True,
+ allow_negative_crop=True),
+ dict(type='YOLOXHSVRandomAug'),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='Pad', size=(640, 640), pad_val=dict(img=(114, 114, 114))),
+ dict(
+ type='CachedMixUp',
+ img_scale=(640, 640),
+ ratio_range=(1.0, 1.0),
+ max_cached_images=20,
+ pad_val=(114, 114, 114)),
+ dict(type='FilterAnnotations', min_gt_bbox_wh=(1, 1)),
+ dict(type='PackDetInputs')
+]
+
+train_dataloader = dict(pin_memory=True, dataset=dict(pipeline=train_pipeline))
+
+train_pipeline_stage2 = [
+ dict(type='LoadImageFromFile', backend_args={{_base_.backend_args}}),
+ dict(
+ type='LoadAnnotations',
+ with_bbox=True,
+ with_mask=True,
+ poly2mask=False),
+ dict(
+ type='RandomResize',
+ scale=(640, 640),
+ ratio_range=(0.1, 2.0),
+ keep_ratio=True),
+ dict(
+ type='RandomCrop',
+ crop_size=(640, 640),
+ recompute_bbox=True,
+ allow_negative_crop=True),
+ dict(type='FilterAnnotations', min_gt_bbox_wh=(1, 1)),
+ dict(type='YOLOXHSVRandomAug'),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='Pad', size=(640, 640), pad_val=dict(img=(114, 114, 114))),
+ dict(type='PackDetInputs')
+]
+custom_hooks = [
+ dict(
+ type='EMAHook',
+ ema_type='ExpMomentumEMA',
+ momentum=0.0002,
+ update_buffers=True,
+ priority=49),
+ dict(
+ type='PipelineSwitchHook',
+ switch_epoch=280,
+ switch_pipeline=train_pipeline_stage2)
+]
+
+val_evaluator = dict(metric=['bbox', 'segm'])
+test_evaluator = val_evaluator
diff --git a/configs/backup/rtmdet/rtmdet-ins_m_8xb32-300e_coco.py b/configs/backup/rtmdet/rtmdet-ins_m_8xb32-300e_coco.py
new file mode 100644
index 0000000000000000000000000000000000000000..66da9148775b425c6b0052beb04f9c8ca17257d9
--- /dev/null
+++ b/configs/backup/rtmdet/rtmdet-ins_m_8xb32-300e_coco.py
@@ -0,0 +1,6 @@
+_base_ = './rtmdet-ins_l_8xb32-300e_coco.py'
+
+model = dict(
+ backbone=dict(deepen_factor=0.67, widen_factor=0.75),
+ neck=dict(in_channels=[192, 384, 768], out_channels=192, num_csp_blocks=2),
+ bbox_head=dict(in_channels=192, feat_channels=192))
diff --git a/configs/backup/rtmdet/rtmdet-ins_s_8xb32-300e_coco.py b/configs/backup/rtmdet/rtmdet-ins_s_8xb32-300e_coco.py
new file mode 100644
index 0000000000000000000000000000000000000000..28bc21cc93bb36d2d2fc8601b06bb0f0c58d6d49
--- /dev/null
+++ b/configs/backup/rtmdet/rtmdet-ins_s_8xb32-300e_coco.py
@@ -0,0 +1,80 @@
+_base_ = './rtmdet-ins_l_8xb32-300e_coco.py'
+checkpoint = 'https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-s_imagenet_600e.pth' # noqa
+model = dict(
+ backbone=dict(
+ deepen_factor=0.33,
+ widen_factor=0.5,
+ init_cfg=dict(
+ type='Pretrained', prefix='backbone.', checkpoint=checkpoint)),
+ neck=dict(in_channels=[128, 256, 512], out_channels=128, num_csp_blocks=1),
+ bbox_head=dict(in_channels=128, feat_channels=128))
+
+train_pipeline = [
+ dict(type='LoadImageFromFile', backend_args={{_base_.backend_args}}),
+ dict(
+ type='LoadAnnotations',
+ with_bbox=True,
+ with_mask=True,
+ poly2mask=False),
+ dict(type='CachedMosaic', img_scale=(640, 640), pad_val=114.0),
+ dict(
+ type='RandomResize',
+ scale=(1280, 1280),
+ ratio_range=(0.5, 2.0),
+ keep_ratio=True),
+ dict(
+ type='RandomCrop',
+ crop_size=(640, 640),
+ recompute_bbox=True,
+ allow_negative_crop=True),
+ dict(type='YOLOXHSVRandomAug'),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='Pad', size=(640, 640), pad_val=dict(img=(114, 114, 114))),
+ dict(
+ type='CachedMixUp',
+ img_scale=(640, 640),
+ ratio_range=(1.0, 1.0),
+ max_cached_images=20,
+ pad_val=(114, 114, 114)),
+ dict(type='FilterAnnotations', min_gt_bbox_wh=(1, 1)),
+ dict(type='PackDetInputs')
+]
+
+train_pipeline_stage2 = [
+ dict(type='LoadImageFromFile', backend_args={{_base_.backend_args}}),
+ dict(
+ type='LoadAnnotations',
+ with_bbox=True,
+ with_mask=True,
+ poly2mask=False),
+ dict(
+ type='RandomResize',
+ scale=(640, 640),
+ ratio_range=(0.5, 2.0),
+ keep_ratio=True),
+ dict(
+ type='RandomCrop',
+ crop_size=(640, 640),
+ recompute_bbox=True,
+ allow_negative_crop=True),
+ dict(type='FilterAnnotations', min_gt_bbox_wh=(1, 1)),
+ dict(type='YOLOXHSVRandomAug'),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='Pad', size=(640, 640), pad_val=dict(img=(114, 114, 114))),
+ dict(type='PackDetInputs')
+]
+
+train_dataloader = dict(dataset=dict(pipeline=train_pipeline))
+
+custom_hooks = [
+ dict(
+ type='EMAHook',
+ ema_type='ExpMomentumEMA',
+ momentum=0.0002,
+ update_buffers=True,
+ priority=49),
+ dict(
+ type='PipelineSwitchHook',
+ switch_epoch=280,
+ switch_pipeline=train_pipeline_stage2)
+]
diff --git a/configs/backup/rtmdet/rtmdet-ins_tiny_8xb32-300e_coco.py b/configs/backup/rtmdet/rtmdet-ins_tiny_8xb32-300e_coco.py
new file mode 100644
index 0000000000000000000000000000000000000000..954f911614e75eb9910effbf1bbc1d7b01120276
--- /dev/null
+++ b/configs/backup/rtmdet/rtmdet-ins_tiny_8xb32-300e_coco.py
@@ -0,0 +1,48 @@
+_base_ = './rtmdet-ins_s_8xb32-300e_coco.py'
+
+checkpoint = 'https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-tiny_imagenet_600e.pth' # noqa
+
+model = dict(
+ backbone=dict(
+ deepen_factor=0.167,
+ widen_factor=0.375,
+ init_cfg=dict(
+ type='Pretrained', prefix='backbone.', checkpoint=checkpoint)),
+ neck=dict(in_channels=[96, 192, 384], out_channels=96, num_csp_blocks=1),
+ bbox_head=dict(in_channels=96, feat_channels=96))
+
+train_pipeline = [
+ dict(type='LoadImageFromFile', backend_args={{_base_.backend_args}}),
+ dict(
+ type='LoadAnnotations',
+ with_bbox=True,
+ with_mask=True,
+ poly2mask=False),
+ dict(
+ type='CachedMosaic',
+ img_scale=(640, 640),
+ pad_val=114.0,
+ max_cached_images=20,
+ random_pop=False),
+ dict(
+ type='RandomResize',
+ scale=(1280, 1280),
+ ratio_range=(0.5, 2.0),
+ keep_ratio=True),
+ dict(type='RandomCrop', crop_size=(640, 640)),
+ dict(type='YOLOXHSVRandomAug'),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='Pad', size=(640, 640), pad_val=dict(img=(114, 114, 114))),
+ dict(
+ type='CachedMixUp',
+ img_scale=(640, 640),
+ ratio_range=(1.0, 1.0),
+ max_cached_images=10,
+ random_pop=False,
+ pad_val=(114, 114, 114),
+ prob=0.5),
+ dict(type='FilterAnnotations', min_gt_bbox_wh=(1, 1)),
+ dict(type='PackDetInputs')
+]
+
+train_dataloader = dict(dataset=dict(pipeline=train_pipeline))
diff --git a/configs/backup/rtmdet/rtmdet-ins_x_8xb16-300e_coco.py b/configs/backup/rtmdet/rtmdet-ins_x_8xb16-300e_coco.py
new file mode 100644
index 0000000000000000000000000000000000000000..daaa640edac6b2114caf13b650d99d7c7632629a
--- /dev/null
+++ b/configs/backup/rtmdet/rtmdet-ins_x_8xb16-300e_coco.py
@@ -0,0 +1,31 @@
+_base_ = './rtmdet-ins_l_8xb32-300e_coco.py'
+
+model = dict(
+ backbone=dict(deepen_factor=1.33, widen_factor=1.25),
+ neck=dict(
+ in_channels=[320, 640, 1280], out_channels=320, num_csp_blocks=4),
+ bbox_head=dict(in_channels=320, feat_channels=320))
+
+base_lr = 0.002
+
+# optimizer
+optim_wrapper = dict(optimizer=dict(lr=base_lr))
+
+# learning rate
+param_scheduler = [
+ dict(
+ type='LinearLR',
+ start_factor=1.0e-5,
+ by_epoch=False,
+ begin=0,
+ end=1000),
+ dict(
+ # use cosine lr from 150 to 300 epoch
+ type='CosineAnnealingLR',
+ eta_min=base_lr * 0.05,
+ begin=_base_.max_epochs // 2,
+ end=_base_.max_epochs,
+ T_max=_base_.max_epochs // 2,
+ by_epoch=True,
+ convert_to_iter_based=True),
+]
diff --git a/configs/backup/rtmdet/rtmdet_l_8xb32-300e_coco.py b/configs/backup/rtmdet/rtmdet_l_8xb32-300e_coco.py
new file mode 100644
index 0000000000000000000000000000000000000000..e4c46aadbda12fa9eb42360e8d8aa116c24c2696
--- /dev/null
+++ b/configs/backup/rtmdet/rtmdet_l_8xb32-300e_coco.py
@@ -0,0 +1,178 @@
+_base_ = [
+ '../_base_/default_runtime.py', '../_base_/schedules/schedule_1x.py',
+ '../_base_/datasets/coco_detection.py', './rtmdet_tta.py'
+]
+model = dict(
+ type='RTMDet',
+ data_preprocessor=dict(
+ type='DetDataPreprocessor',
+ mean=[103.53, 116.28, 123.675],
+ std=[57.375, 57.12, 58.395],
+ bgr_to_rgb=False,
+ batch_augments=None),
+ backbone=dict(
+ type='CSPNeXt',
+ arch='P5',
+ expand_ratio=0.5,
+ deepen_factor=1,
+ widen_factor=1,
+ channel_attention=True,
+ norm_cfg=dict(type='SyncBN'),
+ act_cfg=dict(type='SiLU', inplace=True)),
+ neck=dict(
+ type='CSPNeXtPAFPN',
+ in_channels=[256, 512, 1024],
+ out_channels=256,
+ num_csp_blocks=3,
+ expand_ratio=0.5,
+ norm_cfg=dict(type='SyncBN'),
+ act_cfg=dict(type='SiLU', inplace=True)),
+ bbox_head=dict(
+ type='RTMDetSepBNHead',
+ num_classes=80,
+ in_channels=256,
+ stacked_convs=2,
+ feat_channels=256,
+ anchor_generator=dict(
+ type='MlvlPointGenerator', offset=0, strides=[8, 16, 32]),
+ bbox_coder=dict(type='DistancePointBBoxCoder'),
+ loss_cls=dict(
+ type='QualityFocalLoss',
+ use_sigmoid=True,
+ beta=2.0,
+ loss_weight=1.0),
+ loss_bbox=dict(type='GIoULoss', loss_weight=2.0),
+ with_objectness=False,
+ exp_on_reg=True,
+ share_conv=True,
+ pred_kernel_size=1,
+ norm_cfg=dict(type='SyncBN'),
+ act_cfg=dict(type='SiLU', inplace=True)),
+ train_cfg=dict(
+ assigner=dict(type='DynamicSoftLabelAssigner', topk=13),
+ allowed_border=-1,
+ pos_weight=-1,
+ debug=False),
+ test_cfg=dict(
+ nms_pre=30000,
+ min_bbox_size=0,
+ score_thr=0.001,
+ nms=dict(type='nms', iou_threshold=0.65),
+ max_per_img=300),
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile', backend_args={{_base_.backend_args}}),
+ dict(type='LoadAnnotations', with_bbox=True),
+ dict(type='CachedMosaic', img_scale=(640, 640), pad_val=114.0),
+ dict(
+ type='RandomResize',
+ scale=(1280, 1280),
+ ratio_range=(0.1, 2.0),
+ keep_ratio=True),
+ dict(type='RandomCrop', crop_size=(640, 640)),
+ dict(type='YOLOXHSVRandomAug'),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='Pad', size=(640, 640), pad_val=dict(img=(114, 114, 114))),
+ dict(
+ type='CachedMixUp',
+ img_scale=(640, 640),
+ ratio_range=(1.0, 1.0),
+ max_cached_images=20,
+ pad_val=(114, 114, 114)),
+ dict(type='PackDetInputs')
+]
+
+train_pipeline_stage2 = [
+ dict(type='LoadImageFromFile', backend_args={{_base_.backend_args}}),
+ dict(type='LoadAnnotations', with_bbox=True),
+ dict(
+ type='RandomResize',
+ scale=(640, 640),
+ ratio_range=(0.1, 2.0),
+ keep_ratio=True),
+ dict(type='RandomCrop', crop_size=(640, 640)),
+ dict(type='YOLOXHSVRandomAug'),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='Pad', size=(640, 640), pad_val=dict(img=(114, 114, 114))),
+ dict(type='PackDetInputs')
+]
+
+test_pipeline = [
+ dict(type='LoadImageFromFile', backend_args={{_base_.backend_args}}),
+ dict(type='Resize', scale=(640, 640), keep_ratio=True),
+ dict(type='Pad', size=(640, 640), pad_val=dict(img=(114, 114, 114))),
+ dict(
+ type='PackDetInputs',
+ meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'scale_factor'))
+]
+
+train_dataloader = dict(
+ batch_size=32,
+ num_workers=10,
+ batch_sampler=None,
+ pin_memory=True,
+ dataset=dict(pipeline=train_pipeline))
+val_dataloader = dict(
+ batch_size=5, num_workers=10, dataset=dict(pipeline=test_pipeline))
+test_dataloader = val_dataloader
+
+max_epochs = 300
+stage2_num_epochs = 20
+base_lr = 0.004
+interval = 10
+
+train_cfg = dict(
+ max_epochs=max_epochs,
+ val_interval=interval,
+ dynamic_intervals=[(max_epochs - stage2_num_epochs, 1)])
+
+val_evaluator = dict(proposal_nums=(100, 1, 10))
+test_evaluator = val_evaluator
+
+# optimizer
+optim_wrapper = dict(
+ _delete_=True,
+ type='OptimWrapper',
+ optimizer=dict(type='AdamW', lr=base_lr, weight_decay=0.05),
+ paramwise_cfg=dict(
+ norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True))
+
+# learning rate
+param_scheduler = [
+ dict(
+ type='LinearLR',
+ start_factor=1.0e-5,
+ by_epoch=False,
+ begin=0,
+ end=1000),
+ dict(
+ # use cosine lr from 150 to 300 epoch
+ type='CosineAnnealingLR',
+ eta_min=base_lr * 0.05,
+ begin=max_epochs // 2,
+ end=max_epochs,
+ T_max=max_epochs // 2,
+ by_epoch=True,
+ convert_to_iter_based=True),
+]
+
+# hooks
+default_hooks = dict(
+ checkpoint=dict(
+ interval=interval,
+ max_keep_ckpts=3 # only keep latest 3 checkpoints
+ ))
+custom_hooks = [
+ dict(
+ type='EMAHook',
+ ema_type='ExpMomentumEMA',
+ momentum=0.0002,
+ update_buffers=True,
+ priority=49),
+ dict(
+ type='PipelineSwitchHook',
+ switch_epoch=max_epochs - stage2_num_epochs,
+ switch_pipeline=train_pipeline_stage2)
+]
diff --git a/configs/backup/rtmdet/rtmdet_m_8xb32-300e_coco.py b/configs/backup/rtmdet/rtmdet_m_8xb32-300e_coco.py
new file mode 100644
index 0000000000000000000000000000000000000000..c83f5a60bd7d9f85f46574ee4cd19027391b5e1e
--- /dev/null
+++ b/configs/backup/rtmdet/rtmdet_m_8xb32-300e_coco.py
@@ -0,0 +1,6 @@
+_base_ = './rtmdet_l_8xb32-300e_coco.py'
+
+model = dict(
+ backbone=dict(deepen_factor=0.67, widen_factor=0.75),
+ neck=dict(in_channels=[192, 384, 768], out_channels=192, num_csp_blocks=2),
+ bbox_head=dict(in_channels=192, feat_channels=192))
diff --git a/configs/backup/rtmdet/rtmdet_s_8xb32-300e_coco.py b/configs/backup/rtmdet/rtmdet_s_8xb32-300e_coco.py
new file mode 100644
index 0000000000000000000000000000000000000000..cbf76247b74e94735eea0dd70ce6ac9e57f4dadf
--- /dev/null
+++ b/configs/backup/rtmdet/rtmdet_s_8xb32-300e_coco.py
@@ -0,0 +1,62 @@
+_base_ = './rtmdet_l_8xb32-300e_coco.py'
+checkpoint = 'https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-s_imagenet_600e.pth' # noqa
+model = dict(
+ backbone=dict(
+ deepen_factor=0.33,
+ widen_factor=0.5,
+ init_cfg=dict(
+ type='Pretrained', prefix='backbone.', checkpoint=checkpoint)),
+ neck=dict(in_channels=[128, 256, 512], out_channels=128, num_csp_blocks=1),
+ bbox_head=dict(in_channels=128, feat_channels=128, exp_on_reg=False))
+
+train_pipeline = [
+ dict(type='LoadImageFromFile', backend_args={{_base_.backend_args}}),
+ dict(type='LoadAnnotations', with_bbox=True),
+ dict(type='CachedMosaic', img_scale=(640, 640), pad_val=114.0),
+ dict(
+ type='RandomResize',
+ scale=(1280, 1280),
+ ratio_range=(0.5, 2.0),
+ keep_ratio=True),
+ dict(type='RandomCrop', crop_size=(640, 640)),
+ dict(type='YOLOXHSVRandomAug'),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='Pad', size=(640, 640), pad_val=dict(img=(114, 114, 114))),
+ dict(
+ type='CachedMixUp',
+ img_scale=(640, 640),
+ ratio_range=(1.0, 1.0),
+ max_cached_images=20,
+ pad_val=(114, 114, 114)),
+ dict(type='PackDetInputs')
+]
+
+train_pipeline_stage2 = [
+ dict(type='LoadImageFromFile', backend_args={{_base_.backend_args}}),
+ dict(type='LoadAnnotations', with_bbox=True),
+ dict(
+ type='RandomResize',
+ scale=(640, 640),
+ ratio_range=(0.5, 2.0),
+ keep_ratio=True),
+ dict(type='RandomCrop', crop_size=(640, 640)),
+ dict(type='YOLOXHSVRandomAug'),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='Pad', size=(640, 640), pad_val=dict(img=(114, 114, 114))),
+ dict(type='PackDetInputs')
+]
+
+train_dataloader = dict(dataset=dict(pipeline=train_pipeline))
+
+custom_hooks = [
+ dict(
+ type='EMAHook',
+ ema_type='ExpMomentumEMA',
+ momentum=0.0002,
+ update_buffers=True,
+ priority=49),
+ dict(
+ type='PipelineSwitchHook',
+ switch_epoch=280,
+ switch_pipeline=train_pipeline_stage2)
+]
diff --git a/configs/backup/rtmdet/rtmdet_tiny_8xb32-300e_coco.py b/configs/backup/rtmdet/rtmdet_tiny_8xb32-300e_coco.py
new file mode 100644
index 0000000000000000000000000000000000000000..a686f4a7f0c4c3bed956c2a3fa504ea8863c669d
--- /dev/null
+++ b/configs/backup/rtmdet/rtmdet_tiny_8xb32-300e_coco.py
@@ -0,0 +1,43 @@
+_base_ = './rtmdet_s_8xb32-300e_coco.py'
+
+checkpoint = 'https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-tiny_imagenet_600e.pth' # noqa
+
+model = dict(
+ backbone=dict(
+ deepen_factor=0.167,
+ widen_factor=0.375,
+ init_cfg=dict(
+ type='Pretrained', prefix='backbone.', checkpoint=checkpoint)),
+ neck=dict(in_channels=[96, 192, 384], out_channels=96, num_csp_blocks=1),
+ bbox_head=dict(in_channels=96, feat_channels=96, exp_on_reg=False))
+
+train_pipeline = [
+ dict(type='LoadImageFromFile', backend_args={{_base_.backend_args}}),
+ dict(type='LoadAnnotations', with_bbox=True),
+ dict(
+ type='CachedMosaic',
+ img_scale=(640, 640),
+ pad_val=114.0,
+ max_cached_images=20,
+ random_pop=False),
+ dict(
+ type='RandomResize',
+ scale=(1280, 1280),
+ ratio_range=(0.5, 2.0),
+ keep_ratio=True),
+ dict(type='RandomCrop', crop_size=(640, 640)),
+ dict(type='YOLOXHSVRandomAug'),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='Pad', size=(640, 640), pad_val=dict(img=(114, 114, 114))),
+ dict(
+ type='CachedMixUp',
+ img_scale=(640, 640),
+ ratio_range=(1.0, 1.0),
+ max_cached_images=10,
+ random_pop=False,
+ pad_val=(114, 114, 114),
+ prob=0.5),
+ dict(type='PackDetInputs')
+]
+
+train_dataloader = dict(dataset=dict(pipeline=train_pipeline))
diff --git a/configs/backup/rtmdet/rtmdet_tta.py b/configs/backup/rtmdet/rtmdet_tta.py
new file mode 100644
index 0000000000000000000000000000000000000000..f7adcbc712af32eee4e53c3f7d239a15cfe528b5
--- /dev/null
+++ b/configs/backup/rtmdet/rtmdet_tta.py
@@ -0,0 +1,35 @@
+tta_model = dict(
+ type='DetTTAModel',
+ tta_cfg=dict(nms=dict(type='nms', iou_threshold=0.6), max_per_img=100))
+
+img_scales = [(640, 640), (320, 320), (960, 960)]
+tta_pipeline = [
+ dict(type='LoadImageFromFile', backend_args=None),
+ dict(
+ type='TestTimeAug',
+ transforms=[
+ [
+ dict(type='Resize', scale=s, keep_ratio=True)
+ for s in img_scales
+ ],
+ [
+ # ``RandomFlip`` must be placed before ``Pad``, otherwise
+ # bounding box coordinates after flipping cannot be
+ # recovered correctly.
+ dict(type='RandomFlip', prob=1.),
+ dict(type='RandomFlip', prob=0.)
+ ],
+ [
+ dict(
+ type='Pad',
+ size=(960, 960),
+ pad_val=dict(img=(114, 114, 114))),
+ ],
+ [
+ dict(
+ type='PackDetInputs',
+ meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'scale_factor', 'flip', 'flip_direction'))
+ ]
+ ])
+]
diff --git a/configs/backup/rtmdet/rtmdet_x_8xb32-300e_coco.py b/configs/backup/rtmdet/rtmdet_x_8xb32-300e_coco.py
new file mode 100644
index 0000000000000000000000000000000000000000..16a33632c00b19b270b237f5dcd8f603350ac0c9
--- /dev/null
+++ b/configs/backup/rtmdet/rtmdet_x_8xb32-300e_coco.py
@@ -0,0 +1,7 @@
+_base_ = './rtmdet_l_8xb32-300e_coco.py'
+
+model = dict(
+ backbone=dict(deepen_factor=1.33, widen_factor=1.25),
+ neck=dict(
+ in_channels=[320, 640, 1280], out_channels=320, num_csp_blocks=4),
+ bbox_head=dict(in_channels=320, feat_channels=320))
diff --git a/configs/backup/sabl/README.md b/configs/backup/sabl/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..c730729cfc72a7e3efe885f814ce18c16d2f4a6d
--- /dev/null
+++ b/configs/backup/sabl/README.md
@@ -0,0 +1,47 @@
+# SABL
+
+> [Side-Aware Boundary Localization for More Precise Object Detection](https://arxiv.org/abs/1912.04260)
+
+
+
+## Abstract
+
+Current object detection frameworks mainly rely on bounding box regression to localize objects. Despite the remarkable progress in recent years, the precision of bounding box regression remains unsatisfactory, hence limiting performance in object detection. We observe that precise localization requires careful placement of each side of the bounding box. However, the mainstream approach, which focuses on predicting centers and sizes, is not the most effective way to accomplish this task, especially when there exists displacements with large variance between the anchors and the targets. In this paper, we propose an alternative approach, named as Side-Aware Boundary Localization (SABL), where each side of the bounding box is respectively localized with a dedicated network branch. To tackle the difficulty of precise localization in the presence of displacements with large variance, we further propose a two-step localization scheme, which first predicts a range of movement through bucket prediction and then pinpoints the precise position within the predicted bucket. We test the proposed method on both two-stage and single-stage detection frameworks. Replacing the standard bounding box regression branch with the proposed design leads to significant improvements on Faster R-CNN, RetinaNet, and Cascade R-CNN, by 3.0%, 1.7%, and 0.9%, respectively.
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
`_
+
+ The implementation logic is referred to
+ https://github.com/Sense-X/TSD/blob/master/mmdet/datasets/samplers/distributed_classaware_sampler.py
+
+ Args:
+ dataset: Dataset used for sampling.
+ seed (int, optional): random seed used to shuffle the sampler.
+ This number should be identical across all
+ processes in the distributed group. Defaults to None.
+ num_sample_class (int): The number of samples taken from each
+ per-label list. Defaults to 1.
+ """
+
+ def __init__(self,
+ dataset: BaseDataset,
+ seed: Optional[int] = None,
+ num_sample_class: int = 1) -> None:
+ rank, world_size = get_dist_info()
+ self.rank = rank
+ self.world_size = world_size
+
+ self.dataset = dataset
+ self.epoch = 0
+ # Must be the same across all workers. If None, will use a
+ # random seed shared among workers
+ # (require synchronization among all workers)
+ if seed is None:
+ seed = sync_random_seed()
+ self.seed = seed
+
+ # The number of samples taken from each per-label list
+ assert num_sample_class > 0 and isinstance(num_sample_class, int)
+ self.num_sample_class = num_sample_class
+ # Get per-label image list from dataset
+ self.cat_dict = self.get_cat2imgs()
+
+ self.num_samples = int(math.ceil(len(self.dataset) * 1.0 / world_size))
+ self.total_size = self.num_samples * self.world_size
+
+ # get number of images containing each category
+ self.num_cat_imgs = [len(x) for x in self.cat_dict.values()]
+ # filter labels without images
+ self.valid_cat_inds = [
+ i for i, length in enumerate(self.num_cat_imgs) if length != 0
+ ]
+ self.num_classes = len(self.valid_cat_inds)
+
+ def get_cat2imgs(self) -> Dict[int, list]:
+ """Get a dict with class as key and img_ids as values.
+
+ Returns:
+ dict[int, list]: A dict of per-label image list,
+ the item of the dict indicates a label index,
+ corresponds to the image index that contains the label.
+ """
+ classes = self.dataset.metainfo.get('classes', None)
+ if classes is None:
+ raise ValueError('dataset metainfo must contain `classes`')
+ # sort the label index
+ cat2imgs = {i: [] for i in range(len(classes))}
+ for i in range(len(self.dataset)):
+ cat_ids = set(self.dataset.get_cat_ids(i))
+ for cat in cat_ids:
+ cat2imgs[cat].append(i)
+ return cat2imgs
+
+ def __iter__(self) -> Iterator[int]:
+ # deterministically shuffle based on epoch
+ g = torch.Generator()
+ g.manual_seed(self.epoch + self.seed)
+
+ # initialize label list
+ label_iter_list = RandomCycleIter(self.valid_cat_inds, generator=g)
+ # initialize each per-label image list
+ data_iter_dict = dict()
+ for i in self.valid_cat_inds:
+ data_iter_dict[i] = RandomCycleIter(self.cat_dict[i], generator=g)
+
+ def gen_cat_img_inds(cls_list, data_dict, num_sample_cls):
+ """Traverse the categories and extract `num_sample_cls` image
+ indexes of the corresponding categories one by one."""
+ id_indices = []
+ for _ in range(len(cls_list)):
+ cls_idx = next(cls_list)
+ for _ in range(num_sample_cls):
+ id = next(data_dict[cls_idx])
+ id_indices.append(id)
+ return id_indices
+
+ # deterministically shuffle based on epoch
+ num_bins = int(
+ math.ceil(self.total_size * 1.0 / self.num_classes /
+ self.num_sample_class))
+ indices = []
+ for i in range(num_bins):
+ indices += gen_cat_img_inds(label_iter_list, data_iter_dict,
+ self.num_sample_class)
+
+ # fix extra samples to make it evenly divisible
+ if len(indices) >= self.total_size:
+ indices = indices[:self.total_size]
+ else:
+ indices += indices[:(self.total_size - len(indices))]
+ assert len(indices) == self.total_size
+
+ # subsample
+ offset = self.num_samples * self.rank
+ indices = indices[offset:offset + self.num_samples]
+ assert len(indices) == self.num_samples
+
+ return iter(indices)
+
+ def __len__(self) -> int:
+ """The number of samples in this rank."""
+ return self.num_samples
+
+ def set_epoch(self, epoch: int) -> None:
+ """Sets the epoch for this sampler.
+
+ When :attr:`shuffle=True`, this ensures all replicas use a different
+ random ordering for each epoch. Otherwise, the next iteration of this
+ sampler will yield the same ordering.
+
+ Args:
+ epoch (int): Epoch number.
+ """
+ self.epoch = epoch
+
+
+class RandomCycleIter:
+ """Shuffle the list and do it again after the list have traversed.
+
+ The implementation logic is referred to
+ https://github.com/wutong16/DistributionBalancedLoss/blob/master/mllt/datasets/loader/sampler.py
+
+ Example:
+ >>> label_list = [0, 1, 2, 4, 5]
+ >>> g = torch.Generator()
+ >>> g.manual_seed(0)
+ >>> label_iter_list = RandomCycleIter(label_list, generator=g)
+ >>> index = next(label_iter_list)
+ Args:
+ data (list or ndarray): The data that needs to be shuffled.
+ generator: An torch.Generator object, which is used in setting the seed
+ for generating random numbers.
+ """ # noqa: W605
+
+ def __init__(self,
+ data: Union[list, np.ndarray],
+ generator: torch.Generator = None) -> None:
+ self.data = data
+ self.length = len(data)
+ self.index = torch.randperm(self.length, generator=generator).numpy()
+ self.i = 0
+ self.generator = generator
+
+ def __iter__(self) -> Iterator:
+ return self
+
+ def __len__(self) -> int:
+ return len(self.data)
+
+ def __next__(self):
+ if self.i == self.length:
+ self.index = torch.randperm(
+ self.length, generator=self.generator).numpy()
+ self.i = 0
+ idx = self.data[self.index[self.i]]
+ self.i += 1
+ return idx
diff --git a/mmdet/datasets/samplers/multi_source_sampler.py b/mmdet/datasets/samplers/multi_source_sampler.py
new file mode 100644
index 0000000000000000000000000000000000000000..6efcde35e1375547239825a8f78a9e74f7825290
--- /dev/null
+++ b/mmdet/datasets/samplers/multi_source_sampler.py
@@ -0,0 +1,214 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import itertools
+from typing import Iterator, List, Optional, Sized, Union
+
+import numpy as np
+import torch
+from mmengine.dataset import BaseDataset
+from mmengine.dist import get_dist_info, sync_random_seed
+from torch.utils.data import Sampler
+
+from mmdet.registry import DATA_SAMPLERS
+
+
+@DATA_SAMPLERS.register_module()
+class MultiSourceSampler(Sampler):
+ r"""Multi-Source Infinite Sampler.
+
+ According to the sampling ratio, sample data from different
+ datasets to form batches.
+
+ Args:
+ dataset (Sized): The dataset.
+ batch_size (int): Size of mini-batch.
+ source_ratio (list[int | float]): The sampling ratio of different
+ source datasets in a mini-batch.
+ shuffle (bool): Whether shuffle the dataset or not. Defaults to True.
+ seed (int, optional): Random seed. If None, set a random seed.
+ Defaults to None.
+
+ Examples:
+ >>> dataset_type = 'ConcatDataset'
+ >>> sub_dataset_type = 'CocoDataset'
+ >>> data_root = 'data/coco/'
+ >>> sup_ann = '../coco_semi_annos/instances_train2017.1@10.json'
+ >>> unsup_ann = '../coco_semi_annos/' \
+ >>> 'instances_train2017.1@10-unlabeled.json'
+ >>> dataset = dict(type=dataset_type,
+ >>> datasets=[
+ >>> dict(
+ >>> type=sub_dataset_type,
+ >>> data_root=data_root,
+ >>> ann_file=sup_ann,
+ >>> data_prefix=dict(img='train2017/'),
+ >>> filter_cfg=dict(filter_empty_gt=True, min_size=32),
+ >>> pipeline=sup_pipeline),
+ >>> dict(
+ >>> type=sub_dataset_type,
+ >>> data_root=data_root,
+ >>> ann_file=unsup_ann,
+ >>> data_prefix=dict(img='train2017/'),
+ >>> filter_cfg=dict(filter_empty_gt=True, min_size=32),
+ >>> pipeline=unsup_pipeline),
+ >>> ])
+ >>> train_dataloader = dict(
+ >>> batch_size=5,
+ >>> num_workers=5,
+ >>> persistent_workers=True,
+ >>> sampler=dict(type='MultiSourceSampler',
+ >>> batch_size=5, source_ratio=[1, 4]),
+ >>> batch_sampler=None,
+ >>> dataset=dataset)
+ """
+
+ def __init__(self,
+ dataset: Sized,
+ batch_size: int,
+ source_ratio: List[Union[int, float]],
+ shuffle: bool = True,
+ seed: Optional[int] = None) -> None:
+
+ assert hasattr(dataset, 'cumulative_sizes'),\
+ f'The dataset must be ConcatDataset, but get {dataset}'
+ assert isinstance(batch_size, int) and batch_size > 0, \
+ 'batch_size must be a positive integer value, ' \
+ f'but got batch_size={batch_size}'
+ assert isinstance(source_ratio, list), \
+ f'source_ratio must be a list, but got source_ratio={source_ratio}'
+ assert len(source_ratio) == len(dataset.cumulative_sizes), \
+ 'The length of source_ratio must be equal to ' \
+ f'the number of datasets, but got source_ratio={source_ratio}'
+
+ rank, world_size = get_dist_info()
+ self.rank = rank
+ self.world_size = world_size
+
+ self.dataset = dataset
+ self.cumulative_sizes = [0] + dataset.cumulative_sizes
+ self.batch_size = batch_size
+ self.source_ratio = source_ratio
+
+ self.num_per_source = [
+ int(batch_size * sr / sum(source_ratio)) for sr in source_ratio
+ ]
+ self.num_per_source[0] = batch_size - sum(self.num_per_source[1:])
+
+ assert sum(self.num_per_source) == batch_size, \
+ 'The sum of num_per_source must be equal to ' \
+ f'batch_size, but get {self.num_per_source}'
+
+ self.seed = sync_random_seed() if seed is None else seed
+ self.shuffle = shuffle
+ self.source2inds = {
+ source: self._indices_of_rank(len(ds))
+ for source, ds in enumerate(dataset.datasets)
+ }
+
+ def _infinite_indices(self, sample_size: int) -> Iterator[int]:
+ """Infinitely yield a sequence of indices."""
+ g = torch.Generator()
+ g.manual_seed(self.seed)
+ while True:
+ if self.shuffle:
+ yield from torch.randperm(sample_size, generator=g).tolist()
+ else:
+ yield from torch.arange(sample_size).tolist()
+
+ def _indices_of_rank(self, sample_size: int) -> Iterator[int]:
+ """Slice the infinite indices by rank."""
+ yield from itertools.islice(
+ self._infinite_indices(sample_size), self.rank, None,
+ self.world_size)
+
+ def __iter__(self) -> Iterator[int]:
+ batch_buffer = []
+ while True:
+ for source, num in enumerate(self.num_per_source):
+ batch_buffer_per_source = []
+ for idx in self.source2inds[source]:
+ idx += self.cumulative_sizes[source]
+ batch_buffer_per_source.append(idx)
+ if len(batch_buffer_per_source) == num:
+ batch_buffer += batch_buffer_per_source
+ break
+ yield from batch_buffer
+ batch_buffer = []
+
+ def __len__(self) -> int:
+ return len(self.dataset)
+
+ def set_epoch(self, epoch: int) -> None:
+ """Not supported in `epoch-based runner."""
+ pass
+
+
+@DATA_SAMPLERS.register_module()
+class GroupMultiSourceSampler(MultiSourceSampler):
+ r"""Group Multi-Source Infinite Sampler.
+
+ According to the sampling ratio, sample data from different
+ datasets but the same group to form batches.
+
+ Args:
+ dataset (Sized): The dataset.
+ batch_size (int): Size of mini-batch.
+ source_ratio (list[int | float]): The sampling ratio of different
+ source datasets in a mini-batch.
+ shuffle (bool): Whether shuffle the dataset or not. Defaults to True.
+ seed (int, optional): Random seed. If None, set a random seed.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ dataset: BaseDataset,
+ batch_size: int,
+ source_ratio: List[Union[int, float]],
+ shuffle: bool = True,
+ seed: Optional[int] = None) -> None:
+ super().__init__(
+ dataset=dataset,
+ batch_size=batch_size,
+ source_ratio=source_ratio,
+ shuffle=shuffle,
+ seed=seed)
+
+ self._get_source_group_info()
+ self.group_source2inds = [{
+ source:
+ self._indices_of_rank(self.group2size_per_source[source][group])
+ for source in range(len(dataset.datasets))
+ } for group in range(len(self.group_ratio))]
+
+ def _get_source_group_info(self) -> None:
+ self.group2size_per_source = [{0: 0, 1: 0}, {0: 0, 1: 0}]
+ self.group2inds_per_source = [{0: [], 1: []}, {0: [], 1: []}]
+ for source, dataset in enumerate(self.dataset.datasets):
+ for idx in range(len(dataset)):
+ data_info = dataset.get_data_info(idx)
+ width, height = data_info['width'], data_info['height']
+ group = 0 if width < height else 1
+ self.group2size_per_source[source][group] += 1
+ self.group2inds_per_source[source][group].append(idx)
+
+ self.group_sizes = np.zeros(2, dtype=np.int64)
+ for group2size in self.group2size_per_source:
+ for group, size in group2size.items():
+ self.group_sizes[group] += size
+ self.group_ratio = self.group_sizes / sum(self.group_sizes)
+
+ def __iter__(self) -> Iterator[int]:
+ batch_buffer = []
+ while True:
+ group = np.random.choice(
+ list(range(len(self.group_ratio))), p=self.group_ratio)
+ for source, num in enumerate(self.num_per_source):
+ batch_buffer_per_source = []
+ for idx in self.group_source2inds[group][source]:
+ idx = self.group2inds_per_source[source][group][
+ idx] + self.cumulative_sizes[source]
+ batch_buffer_per_source.append(idx)
+ if len(batch_buffer_per_source) == num:
+ batch_buffer += batch_buffer_per_source
+ break
+ yield from batch_buffer
+ batch_buffer = []
diff --git a/mmdet/datasets/transforms/__init__.py b/mmdet/datasets/transforms/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..ca6c87f659e3d1fde21f47e78507986ce8598e39
--- /dev/null
+++ b/mmdet/datasets/transforms/__init__.py
@@ -0,0 +1,45 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .augment_wrappers import AutoAugment, RandAugment
+from .colorspace import (AutoContrast, Brightness, Color, ColorTransform,
+ Contrast, Equalize, Invert, Posterize, Sharpness,
+ Solarize, SolarizeAdd)
+from .formatting import ImageToTensor, PackDetInputs, ToTensor, Transpose
+from .geometric import (GeomTransform, Rotate, ShearX, ShearY, TranslateX,
+ TranslateY)
+from .instaboost import InstaBoost
+from .loading import (FilterAnnotations, InferencerLoader, LoadAnnotations,
+ LoadEmptyAnnotations, LoadImageFromNDArray,
+ LoadMultiChannelImageFromFiles, LoadPanopticAnnotations,
+ LoadProposals)
+from .transforms import (Albu, CachedMixUp, CachedMosaic, CopyPaste, CutOut,
+ Expand, FixShapeResize, MinIoURandomCrop, MixUp,
+ Mosaic, Pad, PhotoMetricDistortion, RandomAffine,
+ RandomCenterCropPad, RandomCrop, RandomErasing,
+ RandomFlip, RandomShift, Resize, SegRescale,
+ YOLOXHSVRandomAug)
+from .hsi.hsi_load import LoadHyperspectralImageFromFiles, LoadHyperspectralMaskImageFromFiles, LoadAnnotationsPiexlTarget
+from .hsi.sirst_load import LoadSIRSTImageFromFiles
+from .hsi.hsi_resize import HSIResize, ResizePiexlTarget
+from .hsi.hsi_flip import RandomFlipPiexlTarget
+from .hsi.irfly_load import LoadIRFlyImageFromFiles
+from .hsi.hsi_formatting import PackDetInputsPiexlTarget
+from .wrappers import MultiBranch, ProposalBroadcaster, RandomOrder
+
+__all__ = [
+ 'PackDetInputs', 'ToTensor', 'ImageToTensor', 'Transpose',
+ 'LoadImageFromNDArray', 'LoadAnnotations', 'LoadPanopticAnnotations',
+ 'LoadMultiChannelImageFromFiles', 'LoadProposals', 'Resize', 'RandomFlip',
+ 'RandomCrop', 'SegRescale', 'MinIoURandomCrop', 'Expand',
+ 'PhotoMetricDistortion', 'Albu', 'InstaBoost', 'RandomCenterCropPad',
+ 'AutoAugment', 'CutOut', 'ShearX', 'ShearY', 'Rotate', 'Color', 'Equalize',
+ 'Brightness', 'Contrast', 'TranslateX', 'TranslateY', 'RandomShift',
+ 'Mosaic', 'MixUp', 'RandomAffine', 'YOLOXHSVRandomAug', 'CopyPaste',
+ 'FilterAnnotations', 'Pad', 'GeomTransform', 'ColorTransform',
+ 'RandAugment', 'Sharpness', 'Solarize', 'SolarizeAdd', 'Posterize',
+ 'AutoContrast', 'Invert', 'MultiBranch', 'RandomErasing',
+ 'LoadEmptyAnnotations', 'RandomOrder', 'CachedMosaic', 'CachedMixUp',
+ 'FixShapeResize', 'ProposalBroadcaster', 'InferencerLoader',
+ 'LoadHyperspectralImageFromFiles', 'HSIResize', 'LoadHyperspectralMaskImageFromFiles', 'LoadSIRSTImageFromFiles',
+ 'LoadIRFlyImageFromFiles', 'LoadAnnotationsPiexlTarget', 'ResizePiexlTarget', 'RandomFlipPiexlTarget',
+ 'PackDetInputsPiexlTarget'
+]
diff --git a/mmdet/datasets/transforms/__pycache__/__init__.cpython-37.pyc b/mmdet/datasets/transforms/__pycache__/__init__.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..c1be8d04ac369a1e7b234ce44e8cf41ef0f67543
Binary files /dev/null and b/mmdet/datasets/transforms/__pycache__/__init__.cpython-37.pyc differ
diff --git a/mmdet/datasets/transforms/__pycache__/augment_wrappers.cpython-37.pyc b/mmdet/datasets/transforms/__pycache__/augment_wrappers.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..09015b0d7060989a6bc75ac5ec181221b305d256
Binary files /dev/null and b/mmdet/datasets/transforms/__pycache__/augment_wrappers.cpython-37.pyc differ
diff --git a/mmdet/datasets/transforms/__pycache__/colorspace.cpython-37.pyc b/mmdet/datasets/transforms/__pycache__/colorspace.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..8e20b2156ecad31fdeb72b8e664ed01809a6c56d
Binary files /dev/null and b/mmdet/datasets/transforms/__pycache__/colorspace.cpython-37.pyc differ
diff --git a/mmdet/datasets/transforms/__pycache__/formatting.cpython-37.pyc b/mmdet/datasets/transforms/__pycache__/formatting.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..f7f31d843ce700892ab572adf8d141e3382fc9a0
Binary files /dev/null and b/mmdet/datasets/transforms/__pycache__/formatting.cpython-37.pyc differ
diff --git a/mmdet/datasets/transforms/__pycache__/geometric.cpython-37.pyc b/mmdet/datasets/transforms/__pycache__/geometric.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..84879efed40687dc314172446eff1c52cd524de0
Binary files /dev/null and b/mmdet/datasets/transforms/__pycache__/geometric.cpython-37.pyc differ
diff --git a/mmdet/datasets/transforms/__pycache__/instaboost.cpython-37.pyc b/mmdet/datasets/transforms/__pycache__/instaboost.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..f7312728710ea15401ff5703e25682e10346a786
Binary files /dev/null and b/mmdet/datasets/transforms/__pycache__/instaboost.cpython-37.pyc differ
diff --git a/mmdet/datasets/transforms/__pycache__/loading.cpython-37.pyc b/mmdet/datasets/transforms/__pycache__/loading.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..d90771d8343c4bc95040d7fceeff291e1389204a
Binary files /dev/null and b/mmdet/datasets/transforms/__pycache__/loading.cpython-37.pyc differ
diff --git a/mmdet/datasets/transforms/__pycache__/wrappers.cpython-37.pyc b/mmdet/datasets/transforms/__pycache__/wrappers.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..828a517a08d886d45c21d4f08646844be8e518c2
Binary files /dev/null and b/mmdet/datasets/transforms/__pycache__/wrappers.cpython-37.pyc differ
diff --git a/mmdet/datasets/transforms/augment_wrappers.py b/mmdet/datasets/transforms/augment_wrappers.py
new file mode 100644
index 0000000000000000000000000000000000000000..19fae6efdf66aa4c26bb85a2f2c96a1e079320b8
--- /dev/null
+++ b/mmdet/datasets/transforms/augment_wrappers.py
@@ -0,0 +1,264 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Optional, Union
+
+import numpy as np
+from mmcv.transforms import RandomChoice
+from mmcv.transforms.utils import cache_randomness
+from mmengine.config import ConfigDict
+
+from mmdet.registry import TRANSFORMS
+
+# AutoAugment uses reinforcement learning to search for
+# some widely useful data augmentation strategies,
+# here we provide AUTOAUG_POLICIES_V0.
+# For AUTOAUG_POLICIES_V0, each tuple is an augmentation
+# operation of the form (operation, probability, magnitude).
+# Each element in policies is a policy that will be applied
+# sequentially on the image.
+
+# RandAugment defines a data augmentation search space, RANDAUG_SPACE,
+# sampling 1~3 data augmentations each time, and
+# setting the magnitude of each data augmentation randomly,
+# which will be applied sequentially on the image.
+
+_MAX_LEVEL = 10
+
+AUTOAUG_POLICIES_V0 = [
+ [('Equalize', 0.8, 1), ('ShearY', 0.8, 4)],
+ [('Color', 0.4, 9), ('Equalize', 0.6, 3)],
+ [('Color', 0.4, 1), ('Rotate', 0.6, 8)],
+ [('Solarize', 0.8, 3), ('Equalize', 0.4, 7)],
+ [('Solarize', 0.4, 2), ('Solarize', 0.6, 2)],
+ [('Color', 0.2, 0), ('Equalize', 0.8, 8)],
+ [('Equalize', 0.4, 8), ('SolarizeAdd', 0.8, 3)],
+ [('ShearX', 0.2, 9), ('Rotate', 0.6, 8)],
+ [('Color', 0.6, 1), ('Equalize', 1.0, 2)],
+ [('Invert', 0.4, 9), ('Rotate', 0.6, 0)],
+ [('Equalize', 1.0, 9), ('ShearY', 0.6, 3)],
+ [('Color', 0.4, 7), ('Equalize', 0.6, 0)],
+ [('Posterize', 0.4, 6), ('AutoContrast', 0.4, 7)],
+ [('Solarize', 0.6, 8), ('Color', 0.6, 9)],
+ [('Solarize', 0.2, 4), ('Rotate', 0.8, 9)],
+ [('Rotate', 1.0, 7), ('TranslateY', 0.8, 9)],
+ [('ShearX', 0.0, 0), ('Solarize', 0.8, 4)],
+ [('ShearY', 0.8, 0), ('Color', 0.6, 4)],
+ [('Color', 1.0, 0), ('Rotate', 0.6, 2)],
+ [('Equalize', 0.8, 4), ('Equalize', 0.0, 8)],
+ [('Equalize', 1.0, 4), ('AutoContrast', 0.6, 2)],
+ [('ShearY', 0.4, 7), ('SolarizeAdd', 0.6, 7)],
+ [('Posterize', 0.8, 2), ('Solarize', 0.6, 10)],
+ [('Solarize', 0.6, 8), ('Equalize', 0.6, 1)],
+ [('Color', 0.8, 6), ('Rotate', 0.4, 5)],
+]
+
+
+def policies_v0():
+ """Autoaugment policies that was used in AutoAugment Paper."""
+ policies = list()
+ for policy_args in AUTOAUG_POLICIES_V0:
+ policy = list()
+ for args in policy_args:
+ policy.append(dict(type=args[0], prob=args[1], level=args[2]))
+ policies.append(policy)
+ return policies
+
+
+RANDAUG_SPACE = [[dict(type='AutoContrast')], [dict(type='Equalize')],
+ [dict(type='Invert')], [dict(type='Rotate')],
+ [dict(type='Posterize')], [dict(type='Solarize')],
+ [dict(type='SolarizeAdd')], [dict(type='Color')],
+ [dict(type='Contrast')], [dict(type='Brightness')],
+ [dict(type='Sharpness')], [dict(type='ShearX')],
+ [dict(type='ShearY')], [dict(type='TranslateX')],
+ [dict(type='TranslateY')]]
+
+
+def level_to_mag(level: Optional[int], min_mag: float,
+ max_mag: float) -> float:
+ """Map from level to magnitude."""
+ if level is None:
+ return round(np.random.rand() * (max_mag - min_mag) + min_mag, 1)
+ else:
+ return round(level / _MAX_LEVEL * (max_mag - min_mag) + min_mag, 1)
+
+
+@TRANSFORMS.register_module()
+class AutoAugment(RandomChoice):
+ """Auto augmentation.
+
+ This data augmentation is proposed in `AutoAugment: Learning
+ Augmentation Policies from Data `_
+ and in `Learning Data Augmentation Strategies for Object Detection
+ `_.
+
+ Required Keys:
+
+ - img
+ - gt_bboxes (BaseBoxes[torch.float32]) (optional)
+ - gt_bboxes_labels (np.int64) (optional)
+ - gt_masks (BitmapMasks | PolygonMasks) (optional)
+ - gt_ignore_flags (bool) (optional)
+ - gt_seg_map (np.uint8) (optional)
+
+ Modified Keys:
+
+ - img
+ - img_shape
+ - gt_bboxes
+ - gt_bboxes_labels
+ - gt_masks
+ - gt_ignore_flags
+ - gt_seg_map
+
+ Added Keys:
+
+ - homography_matrix
+
+ Args:
+ policies (List[List[Union[dict, ConfigDict]]]):
+ The policies of auto augmentation.Each policy in ``policies``
+ is a specific augmentation policy, and is composed by several
+ augmentations. When AutoAugment is called, a random policy in
+ ``policies`` will be selected to augment images.
+ Defaults to policy_v0().
+ prob (list[float], optional): The probabilities associated
+ with each policy. The length should be equal to the policy
+ number and the sum should be 1. If not given, a uniform
+ distribution will be assumed. Defaults to None.
+
+ Examples:
+ >>> policies = [
+ >>> [
+ >>> dict(type='Sharpness', prob=0.0, level=8),
+ >>> dict(type='ShearX', prob=0.4, level=0,)
+ >>> ],
+ >>> [
+ >>> dict(type='Rotate', prob=0.6, level=10),
+ >>> dict(type='Color', prob=1.0, level=6)
+ >>> ]
+ >>> ]
+ >>> augmentation = AutoAugment(policies)
+ >>> img = np.ones(100, 100, 3)
+ >>> gt_bboxes = np.ones(10, 4)
+ >>> results = dict(img=img, gt_bboxes=gt_bboxes)
+ >>> results = augmentation(results)
+ """
+
+ def __init__(self,
+ policies: List[List[Union[dict, ConfigDict]]] = policies_v0(),
+ prob: Optional[List[float]] = None) -> None:
+ assert isinstance(policies, list) and len(policies) > 0, \
+ 'Policies must be a non-empty list.'
+ for policy in policies:
+ assert isinstance(policy, list) and len(policy) > 0, \
+ 'Each policy in policies must be a non-empty list.'
+ for augment in policy:
+ assert isinstance(augment, dict) and 'type' in augment, \
+ 'Each specific augmentation must be a dict with key' \
+ ' "type".'
+ super().__init__(transforms=policies, prob=prob)
+ self.policies = policies
+
+ def __repr__(self) -> str:
+ return f'{self.__class__.__name__}(policies={self.policies}, ' \
+ f'prob={self.prob})'
+
+
+@TRANSFORMS.register_module()
+class RandAugment(RandomChoice):
+ """Rand augmentation.
+
+ This data augmentation is proposed in `RandAugment:
+ Practical automated data augmentation with a reduced
+ search space `_.
+
+ Required Keys:
+
+ - img
+ - gt_bboxes (BaseBoxes[torch.float32]) (optional)
+ - gt_bboxes_labels (np.int64) (optional)
+ - gt_masks (BitmapMasks | PolygonMasks) (optional)
+ - gt_ignore_flags (bool) (optional)
+ - gt_seg_map (np.uint8) (optional)
+
+ Modified Keys:
+
+ - img
+ - img_shape
+ - gt_bboxes
+ - gt_bboxes_labels
+ - gt_masks
+ - gt_ignore_flags
+ - gt_seg_map
+
+ Added Keys:
+
+ - homography_matrix
+
+ Args:
+ aug_space (List[List[Union[dict, ConfigDict]]]): The augmentation space
+ of rand augmentation. Each augmentation transform in ``aug_space``
+ is a specific transform, and is composed by several augmentations.
+ When RandAugment is called, a random transform in ``aug_space``
+ will be selected to augment images. Defaults to aug_space.
+ aug_num (int): Number of augmentation to apply equentially.
+ Defaults to 2.
+ prob (list[float], optional): The probabilities associated with
+ each augmentation. The length should be equal to the
+ augmentation space and the sum should be 1. If not given,
+ a uniform distribution will be assumed. Defaults to None.
+
+ Examples:
+ >>> aug_space = [
+ >>> dict(type='Sharpness'),
+ >>> dict(type='ShearX'),
+ >>> dict(type='Color'),
+ >>> ],
+ >>> augmentation = RandAugment(aug_space)
+ >>> img = np.ones(100, 100, 3)
+ >>> gt_bboxes = np.ones(10, 4)
+ >>> results = dict(img=img, gt_bboxes=gt_bboxes)
+ >>> results = augmentation(results)
+ """
+
+ def __init__(self,
+ aug_space: List[Union[dict, ConfigDict]] = RANDAUG_SPACE,
+ aug_num: int = 2,
+ prob: Optional[List[float]] = None) -> None:
+ assert isinstance(aug_space, list) and len(aug_space) > 0, \
+ 'Augmentation space must be a non-empty list.'
+ for aug in aug_space:
+ assert isinstance(aug, list) and len(aug) == 1, \
+ 'Each augmentation in aug_space must be a list.'
+ for transform in aug:
+ assert isinstance(transform, dict) and 'type' in transform, \
+ 'Each specific transform must be a dict with key' \
+ ' "type".'
+ super().__init__(transforms=aug_space, prob=prob)
+ self.aug_space = aug_space
+ self.aug_num = aug_num
+
+ @cache_randomness
+ def random_pipeline_index(self):
+ indices = np.arange(len(self.transforms))
+ return np.random.choice(
+ indices, self.aug_num, p=self.prob, replace=False)
+
+ def transform(self, results: dict) -> dict:
+ """Transform function to use RandAugment.
+
+ Args:
+ results (dict): Result dict from loading pipeline.
+
+ Returns:
+ dict: Result dict with RandAugment.
+ """
+ for idx in self.random_pipeline_index():
+ results = self.transforms[idx](results)
+ return results
+
+ def __repr__(self) -> str:
+ return f'{self.__class__.__name__}(' \
+ f'aug_space={self.aug_space}, '\
+ f'aug_num={self.aug_num}, ' \
+ f'prob={self.prob})'
diff --git a/mmdet/datasets/transforms/colorspace.py b/mmdet/datasets/transforms/colorspace.py
new file mode 100644
index 0000000000000000000000000000000000000000..e0ba2e97c7eedf65df5ab8942ee461f48a785f39
--- /dev/null
+++ b/mmdet/datasets/transforms/colorspace.py
@@ -0,0 +1,493 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+from typing import Optional
+
+import mmcv
+import numpy as np
+from mmcv.transforms import BaseTransform
+from mmcv.transforms.utils import cache_randomness
+
+from mmdet.registry import TRANSFORMS
+from .augment_wrappers import _MAX_LEVEL, level_to_mag
+
+
+@TRANSFORMS.register_module()
+class ColorTransform(BaseTransform):
+ """Base class for color transformations. All color transformations need to
+ inherit from this base class. ``ColorTransform`` unifies the class
+ attributes and class functions of color transformations (Color, Brightness,
+ Contrast, Sharpness, Solarize, SolarizeAdd, Equalize, AutoContrast, Invert,
+ and Posterize), and only distort color channels, without impacting the
+ locations of the instances.
+
+ Required Keys:
+
+ - img
+
+ Modified Keys:
+
+ - img
+
+ Args:
+ prob (float): The probability for performing the geometric
+ transformation and should be in range [0, 1]. Defaults to 1.0.
+ level (int, optional): The level should be in range [0, _MAX_LEVEL].
+ If level is None, it will generate from [0, _MAX_LEVEL] randomly.
+ Defaults to None.
+ min_mag (float): The minimum magnitude for color transformation.
+ Defaults to 0.1.
+ max_mag (float): The maximum magnitude for color transformation.
+ Defaults to 1.9.
+ """
+
+ def __init__(self,
+ prob: float = 1.0,
+ level: Optional[int] = None,
+ min_mag: float = 0.1,
+ max_mag: float = 1.9) -> None:
+ assert 0 <= prob <= 1.0, f'The probability of the transformation ' \
+ f'should be in range [0,1], got {prob}.'
+ assert level is None or isinstance(level, int), \
+ f'The level should be None or type int, got {type(level)}.'
+ assert level is None or 0 <= level <= _MAX_LEVEL, \
+ f'The level should be in range [0,{_MAX_LEVEL}], got {level}.'
+ assert isinstance(min_mag, float), \
+ f'min_mag should be type float, got {type(min_mag)}.'
+ assert isinstance(max_mag, float), \
+ f'max_mag should be type float, got {type(max_mag)}.'
+ assert min_mag <= max_mag, \
+ f'min_mag should smaller than max_mag, ' \
+ f'got min_mag={min_mag} and max_mag={max_mag}'
+ self.prob = prob
+ self.level = level
+ self.min_mag = min_mag
+ self.max_mag = max_mag
+
+ def _transform_img(self, results: dict, mag: float) -> None:
+ """Transform the image."""
+ pass
+
+ @cache_randomness
+ def _random_disable(self):
+ """Randomly disable the transform."""
+ return np.random.rand() > self.prob
+
+ @cache_randomness
+ def _get_mag(self):
+ """Get the magnitude of the transform."""
+ return level_to_mag(self.level, self.min_mag, self.max_mag)
+
+ def transform(self, results: dict) -> dict:
+ """Transform function for images.
+
+ Args:
+ results (dict): Result dict from loading pipeline.
+
+ Returns:
+ dict: Transformed results.
+ """
+
+ if self._random_disable():
+ return results
+ mag = self._get_mag()
+ self._transform_img(results, mag)
+ return results
+
+ def __repr__(self) -> str:
+ repr_str = self.__class__.__name__
+ repr_str += f'(prob={self.prob}, '
+ repr_str += f'level={self.level}, '
+ repr_str += f'min_mag={self.min_mag}, '
+ repr_str += f'max_mag={self.max_mag})'
+ return repr_str
+
+
+@TRANSFORMS.register_module()
+class Color(ColorTransform):
+ """Adjust the color balance of the image, in a manner similar to the
+ controls on a colour TV set. A magnitude=0 gives a black & white image,
+ whereas magnitude=1 gives the original image. The bboxes, masks and
+ segmentations are not modified.
+
+ Required Keys:
+
+ - img
+
+ Modified Keys:
+
+ - img
+
+ Args:
+ prob (float): The probability for performing Color transformation.
+ Defaults to 1.0.
+ level (int, optional): Should be in range [0,_MAX_LEVEL].
+ If level is None, it will generate from [0, _MAX_LEVEL] randomly.
+ Defaults to None.
+ min_mag (float): The minimum magnitude for Color transformation.
+ Defaults to 0.1.
+ max_mag (float): The maximum magnitude for Color transformation.
+ Defaults to 1.9.
+ """
+
+ def __init__(self,
+ prob: float = 1.0,
+ level: Optional[int] = None,
+ min_mag: float = 0.1,
+ max_mag: float = 1.9) -> None:
+ assert 0. <= min_mag <= 2.0, \
+ f'min_mag for Color should be in range [0,2], got {min_mag}.'
+ assert 0. <= max_mag <= 2.0, \
+ f'max_mag for Color should be in range [0,2], got {max_mag}.'
+ super().__init__(
+ prob=prob, level=level, min_mag=min_mag, max_mag=max_mag)
+
+ def _transform_img(self, results: dict, mag: float) -> None:
+ """Apply Color transformation to image."""
+ # NOTE defaultly the image should be BGR format
+ img = results['img']
+ results['img'] = mmcv.adjust_color(img, mag).astype(img.dtype)
+
+
+@TRANSFORMS.register_module()
+class Brightness(ColorTransform):
+ """Adjust the brightness of the image. A magnitude=0 gives a black image,
+ whereas magnitude=1 gives the original image. The bboxes, masks and
+ segmentations are not modified.
+
+ Required Keys:
+
+ - img
+
+ Modified Keys:
+
+ - img
+
+ Args:
+ prob (float): The probability for performing Brightness transformation.
+ Defaults to 1.0.
+ level (int, optional): Should be in range [0,_MAX_LEVEL].
+ If level is None, it will generate from [0, _MAX_LEVEL] randomly.
+ Defaults to None.
+ min_mag (float): The minimum magnitude for Brightness transformation.
+ Defaults to 0.1.
+ max_mag (float): The maximum magnitude for Brightness transformation.
+ Defaults to 1.9.
+ """
+
+ def __init__(self,
+ prob: float = 1.0,
+ level: Optional[int] = None,
+ min_mag: float = 0.1,
+ max_mag: float = 1.9) -> None:
+ assert 0. <= min_mag <= 2.0, \
+ f'min_mag for Brightness should be in range [0,2], got {min_mag}.'
+ assert 0. <= max_mag <= 2.0, \
+ f'max_mag for Brightness should be in range [0,2], got {max_mag}.'
+ super().__init__(
+ prob=prob, level=level, min_mag=min_mag, max_mag=max_mag)
+
+ def _transform_img(self, results: dict, mag: float) -> None:
+ """Adjust the brightness of image."""
+ img = results['img']
+ results['img'] = mmcv.adjust_brightness(img, mag).astype(img.dtype)
+
+
+@TRANSFORMS.register_module()
+class Contrast(ColorTransform):
+ """Control the contrast of the image. A magnitude=0 gives a gray image,
+ whereas magnitude=1 gives the original imageThe bboxes, masks and
+ segmentations are not modified.
+
+ Required Keys:
+
+ - img
+
+ Modified Keys:
+
+ - img
+
+ Args:
+ prob (float): The probability for performing Contrast transformation.
+ Defaults to 1.0.
+ level (int, optional): Should be in range [0,_MAX_LEVEL].
+ If level is None, it will generate from [0, _MAX_LEVEL] randomly.
+ Defaults to None.
+ min_mag (float): The minimum magnitude for Contrast transformation.
+ Defaults to 0.1.
+ max_mag (float): The maximum magnitude for Contrast transformation.
+ Defaults to 1.9.
+ """
+
+ def __init__(self,
+ prob: float = 1.0,
+ level: Optional[int] = None,
+ min_mag: float = 0.1,
+ max_mag: float = 1.9) -> None:
+ assert 0. <= min_mag <= 2.0, \
+ f'min_mag for Contrast should be in range [0,2], got {min_mag}.'
+ assert 0. <= max_mag <= 2.0, \
+ f'max_mag for Contrast should be in range [0,2], got {max_mag}.'
+ super().__init__(
+ prob=prob, level=level, min_mag=min_mag, max_mag=max_mag)
+
+ def _transform_img(self, results: dict, mag: float) -> None:
+ """Adjust the image contrast."""
+ img = results['img']
+ results['img'] = mmcv.adjust_contrast(img, mag).astype(img.dtype)
+
+
+@TRANSFORMS.register_module()
+class Sharpness(ColorTransform):
+ """Adjust images sharpness. A positive magnitude would enhance the
+ sharpness and a negative magnitude would make the image blurry. A
+ magnitude=0 gives the origin img.
+
+ Required Keys:
+
+ - img
+
+ Modified Keys:
+
+ - img
+
+ Args:
+ prob (float): The probability for performing Sharpness transformation.
+ Defaults to 1.0.
+ level (int, optional): Should be in range [0,_MAX_LEVEL].
+ If level is None, it will generate from [0, _MAX_LEVEL] randomly.
+ Defaults to None.
+ min_mag (float): The minimum magnitude for Sharpness transformation.
+ Defaults to 0.1.
+ max_mag (float): The maximum magnitude for Sharpness transformation.
+ Defaults to 1.9.
+ """
+
+ def __init__(self,
+ prob: float = 1.0,
+ level: Optional[int] = None,
+ min_mag: float = 0.1,
+ max_mag: float = 1.9) -> None:
+ assert 0. <= min_mag <= 2.0, \
+ f'min_mag for Sharpness should be in range [0,2], got {min_mag}.'
+ assert 0. <= max_mag <= 2.0, \
+ f'max_mag for Sharpness should be in range [0,2], got {max_mag}.'
+ super().__init__(
+ prob=prob, level=level, min_mag=min_mag, max_mag=max_mag)
+
+ def _transform_img(self, results: dict, mag: float) -> None:
+ """Adjust the image sharpness."""
+ img = results['img']
+ results['img'] = mmcv.adjust_sharpness(img, mag).astype(img.dtype)
+
+
+@TRANSFORMS.register_module()
+class Solarize(ColorTransform):
+ """Solarize images (Invert all pixels above a threshold value of
+ magnitude.).
+
+ Required Keys:
+
+ - img
+
+ Modified Keys:
+
+ - img
+
+ Args:
+ prob (float): The probability for performing Solarize transformation.
+ Defaults to 1.0.
+ level (int, optional): Should be in range [0,_MAX_LEVEL].
+ If level is None, it will generate from [0, _MAX_LEVEL] randomly.
+ Defaults to None.
+ min_mag (float): The minimum magnitude for Solarize transformation.
+ Defaults to 0.0.
+ max_mag (float): The maximum magnitude for Solarize transformation.
+ Defaults to 256.0.
+ """
+
+ def __init__(self,
+ prob: float = 1.0,
+ level: Optional[int] = None,
+ min_mag: float = 0.0,
+ max_mag: float = 256.0) -> None:
+ assert 0. <= min_mag <= 256.0, f'min_mag for Solarize should be ' \
+ f'in range [0, 256], got {min_mag}.'
+ assert 0. <= max_mag <= 256.0, f'max_mag for Solarize should be ' \
+ f'in range [0, 256], got {max_mag}.'
+ super().__init__(
+ prob=prob, level=level, min_mag=min_mag, max_mag=max_mag)
+
+ def _transform_img(self, results: dict, mag: float) -> None:
+ """Invert all pixel values above magnitude."""
+ img = results['img']
+ results['img'] = mmcv.solarize(img, mag).astype(img.dtype)
+
+
+@TRANSFORMS.register_module()
+class SolarizeAdd(ColorTransform):
+ """SolarizeAdd images. For each pixel in the image that is less than 128,
+ add an additional amount to it decided by the magnitude.
+
+ Required Keys:
+
+ - img
+
+ Modified Keys:
+
+ - img
+
+ Args:
+ prob (float): The probability for performing SolarizeAdd
+ transformation. Defaults to 1.0.
+ level (int, optional): Should be in range [0,_MAX_LEVEL].
+ If level is None, it will generate from [0, _MAX_LEVEL] randomly.
+ Defaults to None.
+ min_mag (float): The minimum magnitude for SolarizeAdd transformation.
+ Defaults to 0.0.
+ max_mag (float): The maximum magnitude for SolarizeAdd transformation.
+ Defaults to 110.0.
+ """
+
+ def __init__(self,
+ prob: float = 1.0,
+ level: Optional[int] = None,
+ min_mag: float = 0.0,
+ max_mag: float = 110.0) -> None:
+ assert 0. <= min_mag <= 110.0, f'min_mag for SolarizeAdd should be ' \
+ f'in range [0, 110], got {min_mag}.'
+ assert 0. <= max_mag <= 110.0, f'max_mag for SolarizeAdd should be ' \
+ f'in range [0, 110], got {max_mag}.'
+ super().__init__(
+ prob=prob, level=level, min_mag=min_mag, max_mag=max_mag)
+
+ def _transform_img(self, results: dict, mag: float) -> None:
+ """SolarizeAdd the image."""
+ img = results['img']
+ img_solarized = np.where(img < 128, np.minimum(img + mag, 255), img)
+ results['img'] = img_solarized.astype(img.dtype)
+
+
+@TRANSFORMS.register_module()
+class Posterize(ColorTransform):
+ """Posterize images (reduce the number of bits for each color channel).
+
+ Required Keys:
+
+ - img
+
+ Modified Keys:
+
+ - img
+
+ Args:
+ prob (float): The probability for performing Posterize
+ transformation. Defaults to 1.0.
+ level (int, optional): Should be in range [0,_MAX_LEVEL].
+ If level is None, it will generate from [0, _MAX_LEVEL] randomly.
+ Defaults to None.
+ min_mag (float): The minimum magnitude for Posterize transformation.
+ Defaults to 0.0.
+ max_mag (float): The maximum magnitude for Posterize transformation.
+ Defaults to 4.0.
+ """
+
+ def __init__(self,
+ prob: float = 1.0,
+ level: Optional[int] = None,
+ min_mag: float = 0.0,
+ max_mag: float = 4.0) -> None:
+ assert 0. <= min_mag <= 8.0, f'min_mag for Posterize should be ' \
+ f'in range [0, 8], got {min_mag}.'
+ assert 0. <= max_mag <= 8.0, f'max_mag for Posterize should be ' \
+ f'in range [0, 8], got {max_mag}.'
+ super().__init__(
+ prob=prob, level=level, min_mag=min_mag, max_mag=max_mag)
+
+ def _transform_img(self, results: dict, mag: float) -> None:
+ """Posterize the image."""
+ img = results['img']
+ results['img'] = mmcv.posterize(img, math.ceil(mag)).astype(img.dtype)
+
+
+@TRANSFORMS.register_module()
+class Equalize(ColorTransform):
+ """Equalize the image histogram. The bboxes, masks and segmentations are
+ not modified.
+
+ Required Keys:
+
+ - img
+
+ Modified Keys:
+
+ - img
+
+ Args:
+ prob (float): The probability for performing Equalize transformation.
+ Defaults to 1.0.
+ level (int, optional): No use for Equalize transformation.
+ Defaults to None.
+ min_mag (float): No use for Equalize transformation. Defaults to 0.1.
+ max_mag (float): No use for Equalize transformation. Defaults to 1.9.
+ """
+
+ def _transform_img(self, results: dict, mag: float) -> None:
+ """Equalizes the histogram of one image."""
+ img = results['img']
+ results['img'] = mmcv.imequalize(img).astype(img.dtype)
+
+
+@TRANSFORMS.register_module()
+class AutoContrast(ColorTransform):
+ """Auto adjust image contrast.
+
+ Required Keys:
+
+ - img
+
+ Modified Keys:
+
+ - img
+
+ Args:
+ prob (float): The probability for performing AutoContrast should
+ be in range [0, 1]. Defaults to 1.0.
+ level (int, optional): No use for AutoContrast transformation.
+ Defaults to None.
+ min_mag (float): No use for AutoContrast transformation.
+ Defaults to 0.1.
+ max_mag (float): No use for AutoContrast transformation.
+ Defaults to 1.9.
+ """
+
+ def _transform_img(self, results: dict, mag: float) -> None:
+ """Auto adjust image contrast."""
+ img = results['img']
+ results['img'] = mmcv.auto_contrast(img).astype(img.dtype)
+
+
+@TRANSFORMS.register_module()
+class Invert(ColorTransform):
+ """Invert images.
+
+ Required Keys:
+
+ - img
+
+ Modified Keys:
+
+ - img
+
+ Args:
+ prob (float): The probability for performing invert therefore should
+ be in range [0, 1]. Defaults to 1.0.
+ level (int, optional): No use for Invert transformation.
+ Defaults to None.
+ min_mag (float): No use for Invert transformation. Defaults to 0.1.
+ max_mag (float): No use for Invert transformation. Defaults to 1.9.
+ """
+
+ def _transform_img(self, results: dict, mag: float) -> None:
+ """Invert the image."""
+ img = results['img']
+ results['img'] = mmcv.iminvert(img).astype(img.dtype)
diff --git a/mmdet/datasets/transforms/formatting.py b/mmdet/datasets/transforms/formatting.py
new file mode 100644
index 0000000000000000000000000000000000000000..143f5184d1b4c77f5a461e8f700b25f6b09cc70e
--- /dev/null
+++ b/mmdet/datasets/transforms/formatting.py
@@ -0,0 +1,283 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import numpy as np
+from mmcv.transforms import to_tensor
+from mmcv.transforms.base import BaseTransform
+from mmengine.structures import InstanceData, PixelData
+
+from mmdet.registry import TRANSFORMS
+from mmdet.structures import DetDataSample
+from mmdet.structures.bbox import BaseBoxes
+
+
+@TRANSFORMS.register_module()
+class PackDetInputs(BaseTransform):
+ """Pack the inputs data for the detection / semantic segmentation /
+ panoptic segmentation.
+
+ The ``img_meta`` item is always populated. The contents of the
+ ``img_meta`` dictionary depends on ``meta_keys``. By default this includes:
+
+ - ``img_id``: id of the image
+
+ - ``img_path``: path to the image file
+
+ - ``ori_shape``: original shape of the image as a tuple (h, w)
+
+ - ``img_shape``: shape of the image input to the network as a tuple \
+ (h, w). Note that images may be zero padded on the \
+ bottom/right if the batch tensor is larger than this shape.
+
+ - ``scale_factor``: a float indicating the preprocessing scale
+
+ - ``flip``: a boolean indicating if image flip transform was used
+
+ - ``flip_direction``: the flipping direction
+
+ Args:
+ meta_keys (Sequence[str], optional): Meta keys to be converted to
+ ``mmcv.DataContainer`` and collected in ``data[img_metas]``.
+ Default: ``('img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'scale_factor', 'flip', 'flip_direction')``
+ """
+ mapping_table = {
+ 'gt_bboxes': 'bboxes',
+ 'gt_bboxes_labels': 'labels',
+ 'gt_masks': 'masks'
+
+ }
+
+ def __init__(self,
+ meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'scale_factor', 'flip', 'flip_direction')):
+ self.meta_keys = meta_keys
+
+ def transform(self, results: dict) -> dict:
+ """Method to pack the input data.
+
+ Args:
+ results (dict): Result dict from the data pipeline.
+
+ Returns:
+ dict:
+
+ - 'inputs' (obj:`torch.Tensor`): The forward data of models.
+ - 'data_sample' (obj:`DetDataSample`): The annotation info of the
+ sample.
+ """
+ packed_results = dict()
+ if 'img' in results:
+ img = results['img']
+ if len(img.shape) < 3:
+ img = np.expand_dims(img, -1)
+ # To improve the computational speed by by 3-5 times, apply:
+ # If image is not contiguous, use
+ # `numpy.transpose()` followed by `numpy.ascontiguousarray()`
+ # If image is already contiguous, use
+ # `torch.permute()` followed by `torch.contiguous()`
+ # Refer to https://github.com/open-mmlab/mmdetection/pull/9533
+ # for more details
+ if not img.flags.c_contiguous:
+ img = np.ascontiguousarray(img.transpose(2, 0, 1))
+ img = to_tensor(img)
+ else:
+ img = to_tensor(img).permute(2, 0, 1).contiguous()
+
+ packed_results['inputs'] = img
+
+ if 'gt_ignore_flags' in results:
+ valid_idx = np.where(results['gt_ignore_flags'] == 0)[0]
+ ignore_idx = np.where(results['gt_ignore_flags'] == 1)[0]
+
+ data_sample = DetDataSample()
+ instance_data = InstanceData()
+ ignore_instance_data = InstanceData()
+
+ for key in self.mapping_table.keys():
+ if key not in results:
+ continue
+ if key == 'gt_masks' or isinstance(results[key], BaseBoxes):
+ if 'gt_ignore_flags' in results:
+ instance_data[
+ self.mapping_table[key]] = results[key][valid_idx]
+ ignore_instance_data[
+ self.mapping_table[key]] = results[key][ignore_idx]
+ else:
+ instance_data[self.mapping_table[key]] = results[key]
+ else:
+ if 'gt_ignore_flags' in results:
+ instance_data[self.mapping_table[key]] = to_tensor(
+ results[key][valid_idx])
+ ignore_instance_data[self.mapping_table[key]] = to_tensor(
+ results[key][ignore_idx])
+ else:
+ instance_data[self.mapping_table[key]] = to_tensor(
+ results[key])
+ data_sample.gt_instances = instance_data
+ data_sample.ignored_instances = ignore_instance_data
+
+ if 'proposals' in results:
+ proposals = InstanceData(
+ bboxes=to_tensor(results['proposals']),
+ scores=to_tensor(results['proposals_scores']))
+ data_sample.proposals = proposals
+
+ if 'gt_seg_map' in results:
+ gt_sem_seg_data = dict(
+ sem_seg=to_tensor(results['gt_seg_map'][None, ...].copy()))
+ data_sample.gt_sem_seg = PixelData(**gt_sem_seg_data)
+
+ img_meta = {}
+ for key in self.meta_keys:
+ assert key in results, f'`{key}` is not found in `results`, ' \
+ f'the valid keys are {list(results)}.'
+ img_meta[key] = results[key]
+
+ data_sample.set_metainfo(img_meta)
+ packed_results['data_samples'] = data_sample
+
+ return packed_results
+
+ def __repr__(self) -> str:
+ repr_str = self.__class__.__name__
+ repr_str += f'(meta_keys={self.meta_keys})'
+ return repr_str
+
+
+@TRANSFORMS.register_module()
+class ToTensor:
+ """Convert some results to :obj:`torch.Tensor` by given keys.
+
+ Args:
+ keys (Sequence[str]): Keys that need to be converted to Tensor.
+ """
+
+ def __init__(self, keys):
+ self.keys = keys
+
+ def __call__(self, results):
+ """Call function to convert data in results to :obj:`torch.Tensor`.
+
+ Args:
+ results (dict): Result dict contains the data to convert.
+
+ Returns:
+ dict: The result dict contains the data converted
+ to :obj:`torch.Tensor`.
+ """
+ for key in self.keys:
+ results[key] = to_tensor(results[key])
+ return results
+
+ def __repr__(self):
+ return self.__class__.__name__ + f'(keys={self.keys})'
+
+
+@TRANSFORMS.register_module()
+class ImageToTensor:
+ """Convert image to :obj:`torch.Tensor` by given keys.
+
+ The dimension order of input image is (H, W, C). The pipeline will convert
+ it to (C, H, W). If only 2 dimension (H, W) is given, the output would be
+ (1, H, W).
+
+ Args:
+ keys (Sequence[str]): Key of images to be converted to Tensor.
+ """
+
+ def __init__(self, keys):
+ self.keys = keys
+
+ def __call__(self, results):
+ """Call function to convert image in results to :obj:`torch.Tensor` and
+ transpose the channel order.
+
+ Args:
+ results (dict): Result dict contains the image data to convert.
+
+ Returns:
+ dict: The result dict contains the image converted
+ to :obj:`torch.Tensor` and permuted to (C, H, W) order.
+ """
+ for key in self.keys:
+ img = results[key]
+ if len(img.shape) < 3:
+ img = np.expand_dims(img, -1)
+ results[key] = to_tensor(img).permute(2, 0, 1).contiguous()
+
+ return results
+
+ def __repr__(self):
+ return self.__class__.__name__ + f'(keys={self.keys})'
+
+
+@TRANSFORMS.register_module()
+class Transpose:
+ """Transpose some results by given keys.
+
+ Args:
+ keys (Sequence[str]): Keys of results to be transposed.
+ order (Sequence[int]): Order of transpose.
+ """
+
+ def __init__(self, keys, order):
+ self.keys = keys
+ self.order = order
+
+ def __call__(self, results):
+ """Call function to transpose the channel order of data in results.
+
+ Args:
+ results (dict): Result dict contains the data to transpose.
+
+ Returns:
+ dict: The result dict contains the data transposed to \
+ ``self.order``.
+ """
+ for key in self.keys:
+ results[key] = results[key].transpose(self.order)
+ return results
+
+ def __repr__(self):
+ return self.__class__.__name__ + \
+ f'(keys={self.keys}, order={self.order})'
+
+
+@TRANSFORMS.register_module()
+class WrapFieldsToLists:
+ """Wrap fields of the data dictionary into lists for evaluation.
+
+ This class can be used as a last step of a test or validation
+ pipeline for single image evaluation or inference.
+
+ Example:
+ >>> test_pipeline = [
+ >>> dict(type='LoadImageFromFile'),
+ >>> dict(type='Normalize',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ to_rgb=True),
+ >>> dict(type='Pad', size_divisor=32),
+ >>> dict(type='ImageToTensor', keys=['img']),
+ >>> dict(type='Collect', keys=['img']),
+ >>> dict(type='WrapFieldsToLists')
+ >>> ]
+ """
+
+ def __call__(self, results):
+ """Call function to wrap fields into lists.
+
+ Args:
+ results (dict): Result dict contains the data to wrap.
+
+ Returns:
+ dict: The result dict where value of ``self.keys`` are wrapped \
+ into list.
+ """
+
+ # Wrap dict fields into lists
+ for key, val in results.items():
+ results[key] = [val]
+ return results
+
+ def __repr__(self):
+ return f'{self.__class__.__name__}()'
diff --git a/mmdet/datasets/transforms/geometric.py b/mmdet/datasets/transforms/geometric.py
new file mode 100644
index 0000000000000000000000000000000000000000..d2cd6be258f73a69aa2c2b36fef64c6c4e46a2a4
--- /dev/null
+++ b/mmdet/datasets/transforms/geometric.py
@@ -0,0 +1,754 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+
+from typing import Optional, Union
+
+import cv2
+import mmcv
+import numpy as np
+from mmcv.transforms import BaseTransform
+from mmcv.transforms.utils import cache_randomness
+
+from mmdet.registry import TRANSFORMS
+from mmdet.structures.bbox import autocast_box_type
+from .augment_wrappers import _MAX_LEVEL, level_to_mag
+
+
+@TRANSFORMS.register_module()
+class GeomTransform(BaseTransform):
+ """Base class for geometric transformations. All geometric transformations
+ need to inherit from this base class. ``GeomTransform`` unifies the class
+ attributes and class functions of geometric transformations (ShearX,
+ ShearY, Rotate, TranslateX, and TranslateY), and records the homography
+ matrix.
+
+ Required Keys:
+
+ - img
+ - gt_bboxes (BaseBoxes[torch.float32]) (optional)
+ - gt_masks (BitmapMasks | PolygonMasks) (optional)
+ - gt_seg_map (np.uint8) (optional)
+
+ Modified Keys:
+
+ - img
+ - gt_bboxes
+ - gt_masks
+ - gt_seg_map
+
+ Added Keys:
+
+ - homography_matrix
+
+ Args:
+ prob (float): The probability for performing the geometric
+ transformation and should be in range [0, 1]. Defaults to 1.0.
+ level (int, optional): The level should be in range [0, _MAX_LEVEL].
+ If level is None, it will generate from [0, _MAX_LEVEL] randomly.
+ Defaults to None.
+ min_mag (float): The minimum magnitude for geometric transformation.
+ Defaults to 0.0.
+ max_mag (float): The maximum magnitude for geometric transformation.
+ Defaults to 1.0.
+ reversal_prob (float): The probability that reverses the geometric
+ transformation magnitude. Should be in range [0,1].
+ Defaults to 0.5.
+ img_border_value (int | float | tuple): The filled values for
+ image border. If float, the same fill value will be used for
+ all the three channels of image. If tuple, it should be 3 elements.
+ Defaults to 128.
+ mask_border_value (int): The fill value used for masks. Defaults to 0.
+ seg_ignore_label (int): The fill value used for segmentation map.
+ Note this value must equals ``ignore_label`` in ``semantic_head``
+ of the corresponding config. Defaults to 255.
+ interpolation (str): Interpolation method, accepted values are
+ "nearest", "bilinear", "bicubic", "area", "lanczos" for 'cv2'
+ backend, "nearest", "bilinear" for 'pillow' backend. Defaults
+ to 'bilinear'.
+ """
+
+ def __init__(self,
+ prob: float = 1.0,
+ level: Optional[int] = None,
+ min_mag: float = 0.0,
+ max_mag: float = 1.0,
+ reversal_prob: float = 0.5,
+ img_border_value: Union[int, float, tuple] = 128,
+ mask_border_value: int = 0,
+ seg_ignore_label: int = 255,
+ interpolation: str = 'bilinear') -> None:
+ assert 0 <= prob <= 1.0, f'The probability of the transformation ' \
+ f'should be in range [0,1], got {prob}.'
+ assert level is None or isinstance(level, int), \
+ f'The level should be None or type int, got {type(level)}.'
+ assert level is None or 0 <= level <= _MAX_LEVEL, \
+ f'The level should be in range [0,{_MAX_LEVEL}], got {level}.'
+ assert isinstance(min_mag, float), \
+ f'min_mag should be type float, got {type(min_mag)}.'
+ assert isinstance(max_mag, float), \
+ f'max_mag should be type float, got {type(max_mag)}.'
+ assert min_mag <= max_mag, \
+ f'min_mag should smaller than max_mag, ' \
+ f'got min_mag={min_mag} and max_mag={max_mag}'
+ assert isinstance(reversal_prob, float), \
+ f'reversal_prob should be type float, got {type(max_mag)}.'
+ assert 0 <= reversal_prob <= 1.0, \
+ f'The reversal probability of the transformation magnitude ' \
+ f'should be type float, got {type(reversal_prob)}.'
+ if isinstance(img_border_value, (float, int)):
+ img_border_value = tuple([float(img_border_value)] * 3)
+ elif isinstance(img_border_value, tuple):
+ assert len(img_border_value) == 3, \
+ f'img_border_value as tuple must have 3 elements, ' \
+ f'got {len(img_border_value)}.'
+ img_border_value = tuple([float(val) for val in img_border_value])
+ else:
+ raise ValueError(
+ 'img_border_value must be float or tuple with 3 elements.')
+ assert np.all([0 <= val <= 255 for val in img_border_value]), 'all ' \
+ 'elements of img_border_value should between range [0,255].' \
+ f'got {img_border_value}.'
+ self.prob = prob
+ self.level = level
+ self.min_mag = min_mag
+ self.max_mag = max_mag
+ self.reversal_prob = reversal_prob
+ self.img_border_value = img_border_value
+ self.mask_border_value = mask_border_value
+ self.seg_ignore_label = seg_ignore_label
+ self.interpolation = interpolation
+
+ def _transform_img(self, results: dict, mag: float) -> None:
+ """Transform the image."""
+ pass
+
+ def _transform_masks(self, results: dict, mag: float) -> None:
+ """Transform the masks."""
+ pass
+
+ def _transform_seg(self, results: dict, mag: float) -> None:
+ """Transform the segmentation map."""
+ pass
+
+ def _get_homography_matrix(self, results: dict, mag: float) -> np.ndarray:
+ """Get the homography matrix for the geometric transformation."""
+ return np.eye(3, dtype=np.float32)
+
+ def _transform_bboxes(self, results: dict, mag: float) -> None:
+ """Transform the bboxes."""
+ results['gt_bboxes'].project_(self.homography_matrix)
+ results['gt_bboxes'].clip_(results['img_shape'])
+
+ def _record_homography_matrix(self, results: dict) -> None:
+ """Record the homography matrix for the geometric transformation."""
+ if results.get('homography_matrix', None) is None:
+ results['homography_matrix'] = self.homography_matrix
+ else:
+ results['homography_matrix'] = self.homography_matrix @ results[
+ 'homography_matrix']
+
+ @cache_randomness
+ def _random_disable(self):
+ """Randomly disable the transform."""
+ return np.random.rand() > self.prob
+
+ @cache_randomness
+ def _get_mag(self):
+ """Get the magnitude of the transform."""
+ mag = level_to_mag(self.level, self.min_mag, self.max_mag)
+ return -mag if np.random.rand() > self.reversal_prob else mag
+
+ @autocast_box_type()
+ def transform(self, results: dict) -> dict:
+ """Transform function for images, bounding boxes, masks and semantic
+ segmentation map.
+
+ Args:
+ results (dict): Result dict from loading pipeline.
+
+ Returns:
+ dict: Transformed results.
+ """
+
+ if self._random_disable():
+ return results
+ mag = self._get_mag()
+ self.homography_matrix = self._get_homography_matrix(results, mag)
+ self._record_homography_matrix(results)
+ self._transform_img(results, mag)
+ if results.get('gt_bboxes', None) is not None:
+ self._transform_bboxes(results, mag)
+ if results.get('gt_masks', None) is not None:
+ self._transform_masks(results, mag)
+ if results.get('gt_seg_map', None) is not None:
+ self._transform_seg(results, mag)
+ return results
+
+ def __repr__(self) -> str:
+ repr_str = self.__class__.__name__
+ repr_str += f'(prob={self.prob}, '
+ repr_str += f'level={self.level}, '
+ repr_str += f'min_mag={self.min_mag}, '
+ repr_str += f'max_mag={self.max_mag}, '
+ repr_str += f'reversal_prob={self.reversal_prob}, '
+ repr_str += f'img_border_value={self.img_border_value}, '
+ repr_str += f'mask_border_value={self.mask_border_value}, '
+ repr_str += f'seg_ignore_label={self.seg_ignore_label}, '
+ repr_str += f'interpolation={self.interpolation})'
+ return repr_str
+
+
+@TRANSFORMS.register_module()
+class ShearX(GeomTransform):
+ """Shear the images, bboxes, masks and segmentation map horizontally.
+
+ Required Keys:
+
+ - img
+ - gt_bboxes (BaseBoxes[torch.float32]) (optional)
+ - gt_masks (BitmapMasks | PolygonMasks) (optional)
+ - gt_seg_map (np.uint8) (optional)
+
+ Modified Keys:
+
+ - img
+ - gt_bboxes
+ - gt_masks
+ - gt_seg_map
+
+ Added Keys:
+
+ - homography_matrix
+
+ Args:
+ prob (float): The probability for performing Shear and should be in
+ range [0, 1]. Defaults to 1.0.
+ level (int, optional): The level should be in range [0, _MAX_LEVEL].
+ If level is None, it will generate from [0, _MAX_LEVEL] randomly.
+ Defaults to None.
+ min_mag (float): The minimum angle for the horizontal shear.
+ Defaults to 0.0.
+ max_mag (float): The maximum angle for the horizontal shear.
+ Defaults to 30.0.
+ reversal_prob (float): The probability that reverses the horizontal
+ shear magnitude. Should be in range [0,1]. Defaults to 0.5.
+ img_border_value (int | float | tuple): The filled values for
+ image border. If float, the same fill value will be used for
+ all the three channels of image. If tuple, it should be 3 elements.
+ Defaults to 128.
+ mask_border_value (int): The fill value used for masks. Defaults to 0.
+ seg_ignore_label (int): The fill value used for segmentation map.
+ Note this value must equals ``ignore_label`` in ``semantic_head``
+ of the corresponding config. Defaults to 255.
+ interpolation (str): Interpolation method, accepted values are
+ "nearest", "bilinear", "bicubic", "area", "lanczos" for 'cv2'
+ backend, "nearest", "bilinear" for 'pillow' backend. Defaults
+ to 'bilinear'.
+ """
+
+ def __init__(self,
+ prob: float = 1.0,
+ level: Optional[int] = None,
+ min_mag: float = 0.0,
+ max_mag: float = 30.0,
+ reversal_prob: float = 0.5,
+ img_border_value: Union[int, float, tuple] = 128,
+ mask_border_value: int = 0,
+ seg_ignore_label: int = 255,
+ interpolation: str = 'bilinear') -> None:
+ assert 0. <= min_mag <= 90., \
+ f'min_mag angle for ShearX should be ' \
+ f'in range [0, 90], got {min_mag}.'
+ assert 0. <= max_mag <= 90., \
+ f'max_mag angle for ShearX should be ' \
+ f'in range [0, 90], got {max_mag}.'
+ super().__init__(
+ prob=prob,
+ level=level,
+ min_mag=min_mag,
+ max_mag=max_mag,
+ reversal_prob=reversal_prob,
+ img_border_value=img_border_value,
+ mask_border_value=mask_border_value,
+ seg_ignore_label=seg_ignore_label,
+ interpolation=interpolation)
+
+ @cache_randomness
+ def _get_mag(self):
+ """Get the magnitude of the transform."""
+ mag = level_to_mag(self.level, self.min_mag, self.max_mag)
+ mag = np.tan(mag * np.pi / 180)
+ return -mag if np.random.rand() > self.reversal_prob else mag
+
+ def _get_homography_matrix(self, results: dict, mag: float) -> np.ndarray:
+ """Get the homography matrix for ShearX."""
+ return np.array([[1, mag, 0], [0, 1, 0], [0, 0, 1]], dtype=np.float32)
+
+ def _transform_img(self, results: dict, mag: float) -> None:
+ """Shear the image horizontally."""
+ results['img'] = mmcv.imshear(
+ results['img'],
+ mag,
+ direction='horizontal',
+ border_value=self.img_border_value,
+ interpolation=self.interpolation)
+
+ def _transform_masks(self, results: dict, mag: float) -> None:
+ """Shear the masks horizontally."""
+ results['gt_masks'] = results['gt_masks'].shear(
+ results['img_shape'],
+ mag,
+ direction='horizontal',
+ border_value=self.mask_border_value,
+ interpolation=self.interpolation)
+
+ def _transform_seg(self, results: dict, mag: float) -> None:
+ """Shear the segmentation map horizontally."""
+ results['gt_seg_map'] = mmcv.imshear(
+ results['gt_seg_map'],
+ mag,
+ direction='horizontal',
+ border_value=self.seg_ignore_label,
+ interpolation='nearest')
+
+
+@TRANSFORMS.register_module()
+class ShearY(GeomTransform):
+ """Shear the images, bboxes, masks and segmentation map vertically.
+
+ Required Keys:
+
+ - img
+ - gt_bboxes (BaseBoxes[torch.float32]) (optional)
+ - gt_masks (BitmapMasks | PolygonMasks) (optional)
+ - gt_seg_map (np.uint8) (optional)
+
+ Modified Keys:
+
+ - img
+ - gt_bboxes
+ - gt_masks
+ - gt_seg_map
+
+ Added Keys:
+
+ - homography_matrix
+
+ Args:
+ prob (float): The probability for performing ShearY and should be in
+ range [0, 1]. Defaults to 1.0.
+ level (int, optional): The level should be in range [0,_MAX_LEVEL].
+ If level is None, it will generate from [0, _MAX_LEVEL] randomly.
+ Defaults to None.
+ min_mag (float): The minimum angle for the vertical shear.
+ Defaults to 0.0.
+ max_mag (float): The maximum angle for the vertical shear.
+ Defaults to 30.0.
+ reversal_prob (float): The probability that reverses the vertical
+ shear magnitude. Should be in range [0,1]. Defaults to 0.5.
+ img_border_value (int | float | tuple): The filled values for
+ image border. If float, the same fill value will be used for
+ all the three channels of image. If tuple, it should be 3 elements.
+ Defaults to 128.
+ mask_border_value (int): The fill value used for masks. Defaults to 0.
+ seg_ignore_label (int): The fill value used for segmentation map.
+ Note this value must equals ``ignore_label`` in ``semantic_head``
+ of the corresponding config. Defaults to 255.
+ interpolation (str): Interpolation method, accepted values are
+ "nearest", "bilinear", "bicubic", "area", "lanczos" for 'cv2'
+ backend, "nearest", "bilinear" for 'pillow' backend. Defaults
+ to 'bilinear'.
+ """
+
+ def __init__(self,
+ prob: float = 1.0,
+ level: Optional[int] = None,
+ min_mag: float = 0.0,
+ max_mag: float = 30.,
+ reversal_prob: float = 0.5,
+ img_border_value: Union[int, float, tuple] = 128,
+ mask_border_value: int = 0,
+ seg_ignore_label: int = 255,
+ interpolation: str = 'bilinear') -> None:
+ assert 0. <= min_mag <= 90., \
+ f'min_mag angle for ShearY should be ' \
+ f'in range [0, 90], got {min_mag}.'
+ assert 0. <= max_mag <= 90., \
+ f'max_mag angle for ShearY should be ' \
+ f'in range [0, 90], got {max_mag}.'
+ super().__init__(
+ prob=prob,
+ level=level,
+ min_mag=min_mag,
+ max_mag=max_mag,
+ reversal_prob=reversal_prob,
+ img_border_value=img_border_value,
+ mask_border_value=mask_border_value,
+ seg_ignore_label=seg_ignore_label,
+ interpolation=interpolation)
+
+ @cache_randomness
+ def _get_mag(self):
+ """Get the magnitude of the transform."""
+ mag = level_to_mag(self.level, self.min_mag, self.max_mag)
+ mag = np.tan(mag * np.pi / 180)
+ return -mag if np.random.rand() > self.reversal_prob else mag
+
+ def _get_homography_matrix(self, results: dict, mag: float) -> np.ndarray:
+ """Get the homography matrix for ShearY."""
+ return np.array([[1, 0, 0], [mag, 1, 0], [0, 0, 1]], dtype=np.float32)
+
+ def _transform_img(self, results: dict, mag: float) -> None:
+ """Shear the image vertically."""
+ results['img'] = mmcv.imshear(
+ results['img'],
+ mag,
+ direction='vertical',
+ border_value=self.img_border_value,
+ interpolation=self.interpolation)
+
+ def _transform_masks(self, results: dict, mag: float) -> None:
+ """Shear the masks vertically."""
+ results['gt_masks'] = results['gt_masks'].shear(
+ results['img_shape'],
+ mag,
+ direction='vertical',
+ border_value=self.mask_border_value,
+ interpolation=self.interpolation)
+
+ def _transform_seg(self, results: dict, mag: float) -> None:
+ """Shear the segmentation map vertically."""
+ results['gt_seg_map'] = mmcv.imshear(
+ results['gt_seg_map'],
+ mag,
+ direction='vertical',
+ border_value=self.seg_ignore_label,
+ interpolation='nearest')
+
+
+@TRANSFORMS.register_module()
+class Rotate(GeomTransform):
+ """Rotate the images, bboxes, masks and segmentation map.
+
+ Required Keys:
+
+ - img
+ - gt_bboxes (BaseBoxes[torch.float32]) (optional)
+ - gt_masks (BitmapMasks | PolygonMasks) (optional)
+ - gt_seg_map (np.uint8) (optional)
+
+ Modified Keys:
+
+ - img
+ - gt_bboxes
+ - gt_masks
+ - gt_seg_map
+
+ Added Keys:
+
+ - homography_matrix
+
+ Args:
+ prob (float): The probability for perform transformation and
+ should be in range 0 to 1. Defaults to 1.0.
+ level (int, optional): The level should be in range [0, _MAX_LEVEL].
+ If level is None, it will generate from [0, _MAX_LEVEL] randomly.
+ Defaults to None.
+ min_mag (float): The maximum angle for rotation.
+ Defaults to 0.0.
+ max_mag (float): The maximum angle for rotation.
+ Defaults to 30.0.
+ reversal_prob (float): The probability that reverses the rotation
+ magnitude. Should be in range [0,1]. Defaults to 0.5.
+ img_border_value (int | float | tuple): The filled values for
+ image border. If float, the same fill value will be used for
+ all the three channels of image. If tuple, it should be 3 elements.
+ Defaults to 128.
+ mask_border_value (int): The fill value used for masks. Defaults to 0.
+ seg_ignore_label (int): The fill value used for segmentation map.
+ Note this value must equals ``ignore_label`` in ``semantic_head``
+ of the corresponding config. Defaults to 255.
+ interpolation (str): Interpolation method, accepted values are
+ "nearest", "bilinear", "bicubic", "area", "lanczos" for 'cv2'
+ backend, "nearest", "bilinear" for 'pillow' backend. Defaults
+ to 'bilinear'.
+ """
+
+ def __init__(self,
+ prob: float = 1.0,
+ level: Optional[int] = None,
+ min_mag: float = 0.0,
+ max_mag: float = 30.0,
+ reversal_prob: float = 0.5,
+ img_border_value: Union[int, float, tuple] = 128,
+ mask_border_value: int = 0,
+ seg_ignore_label: int = 255,
+ interpolation: str = 'bilinear') -> None:
+ assert 0. <= min_mag <= 180., \
+ f'min_mag for Rotate should be in range [0,180], got {min_mag}.'
+ assert 0. <= max_mag <= 180., \
+ f'max_mag for Rotate should be in range [0,180], got {max_mag}.'
+ super().__init__(
+ prob=prob,
+ level=level,
+ min_mag=min_mag,
+ max_mag=max_mag,
+ reversal_prob=reversal_prob,
+ img_border_value=img_border_value,
+ mask_border_value=mask_border_value,
+ seg_ignore_label=seg_ignore_label,
+ interpolation=interpolation)
+
+ def _get_homography_matrix(self, results: dict, mag: float) -> np.ndarray:
+ """Get the homography matrix for Rotate."""
+ img_shape = results['img_shape']
+ center = ((img_shape[1] - 1) * 0.5, (img_shape[0] - 1) * 0.5)
+ cv2_rotation_matrix = cv2.getRotationMatrix2D(center, -mag, 1.0)
+ return np.concatenate(
+ [cv2_rotation_matrix,
+ np.array([0, 0, 1]).reshape((1, 3))]).astype(np.float32)
+
+ def _transform_img(self, results: dict, mag: float) -> None:
+ """Rotate the image."""
+ results['img'] = mmcv.imrotate(
+ results['img'],
+ mag,
+ border_value=self.img_border_value,
+ interpolation=self.interpolation)
+
+ def _transform_masks(self, results: dict, mag: float) -> None:
+ """Rotate the masks."""
+ results['gt_masks'] = results['gt_masks'].rotate(
+ results['img_shape'],
+ mag,
+ border_value=self.mask_border_value,
+ interpolation=self.interpolation)
+
+ def _transform_seg(self, results: dict, mag: float) -> None:
+ """Rotate the segmentation map."""
+ results['gt_seg_map'] = mmcv.imrotate(
+ results['gt_seg_map'],
+ mag,
+ border_value=self.seg_ignore_label,
+ interpolation='nearest')
+
+
+@TRANSFORMS.register_module()
+class TranslateX(GeomTransform):
+ """Translate the images, bboxes, masks and segmentation map horizontally.
+
+ Required Keys:
+
+ - img
+ - gt_bboxes (BaseBoxes[torch.float32]) (optional)
+ - gt_masks (BitmapMasks | PolygonMasks) (optional)
+ - gt_seg_map (np.uint8) (optional)
+
+ Modified Keys:
+
+ - img
+ - gt_bboxes
+ - gt_masks
+ - gt_seg_map
+
+ Added Keys:
+
+ - homography_matrix
+
+ Args:
+ prob (float): The probability for perform transformation and
+ should be in range 0 to 1. Defaults to 1.0.
+ level (int, optional): The level should be in range [0, _MAX_LEVEL].
+ If level is None, it will generate from [0, _MAX_LEVEL] randomly.
+ Defaults to None.
+ min_mag (float): The minimum pixel's offset ratio for horizontal
+ translation. Defaults to 0.0.
+ max_mag (float): The maximum pixel's offset ratio for horizontal
+ translation. Defaults to 0.1.
+ reversal_prob (float): The probability that reverses the horizontal
+ translation magnitude. Should be in range [0,1]. Defaults to 0.5.
+ img_border_value (int | float | tuple): The filled values for
+ image border. If float, the same fill value will be used for
+ all the three channels of image. If tuple, it should be 3 elements.
+ Defaults to 128.
+ mask_border_value (int): The fill value used for masks. Defaults to 0.
+ seg_ignore_label (int): The fill value used for segmentation map.
+ Note this value must equals ``ignore_label`` in ``semantic_head``
+ of the corresponding config. Defaults to 255.
+ interpolation (str): Interpolation method, accepted values are
+ "nearest", "bilinear", "bicubic", "area", "lanczos" for 'cv2'
+ backend, "nearest", "bilinear" for 'pillow' backend. Defaults
+ to 'bilinear'.
+ """
+
+ def __init__(self,
+ prob: float = 1.0,
+ level: Optional[int] = None,
+ min_mag: float = 0.0,
+ max_mag: float = 0.1,
+ reversal_prob: float = 0.5,
+ img_border_value: Union[int, float, tuple] = 128,
+ mask_border_value: int = 0,
+ seg_ignore_label: int = 255,
+ interpolation: str = 'bilinear') -> None:
+ assert 0. <= min_mag <= 1., \
+ f'min_mag ratio for TranslateX should be ' \
+ f'in range [0, 1], got {min_mag}.'
+ assert 0. <= max_mag <= 1., \
+ f'max_mag ratio for TranslateX should be ' \
+ f'in range [0, 1], got {max_mag}.'
+ super().__init__(
+ prob=prob,
+ level=level,
+ min_mag=min_mag,
+ max_mag=max_mag,
+ reversal_prob=reversal_prob,
+ img_border_value=img_border_value,
+ mask_border_value=mask_border_value,
+ seg_ignore_label=seg_ignore_label,
+ interpolation=interpolation)
+
+ def _get_homography_matrix(self, results: dict, mag: float) -> np.ndarray:
+ """Get the homography matrix for TranslateX."""
+ mag = int(results['img_shape'][1] * mag)
+ return np.array([[1, 0, mag], [0, 1, 0], [0, 0, 1]], dtype=np.float32)
+
+ def _transform_img(self, results: dict, mag: float) -> None:
+ """Translate the image horizontally."""
+ mag = int(results['img_shape'][1] * mag)
+ results['img'] = mmcv.imtranslate(
+ results['img'],
+ mag,
+ direction='horizontal',
+ border_value=self.img_border_value,
+ interpolation=self.interpolation)
+
+ def _transform_masks(self, results: dict, mag: float) -> None:
+ """Translate the masks horizontally."""
+ mag = int(results['img_shape'][1] * mag)
+ results['gt_masks'] = results['gt_masks'].translate(
+ results['img_shape'],
+ mag,
+ direction='horizontal',
+ border_value=self.mask_border_value,
+ interpolation=self.interpolation)
+
+ def _transform_seg(self, results: dict, mag: float) -> None:
+ """Translate the segmentation map horizontally."""
+ mag = int(results['img_shape'][1] * mag)
+ results['gt_seg_map'] = mmcv.imtranslate(
+ results['gt_seg_map'],
+ mag,
+ direction='horizontal',
+ border_value=self.seg_ignore_label,
+ interpolation='nearest')
+
+
+@TRANSFORMS.register_module()
+class TranslateY(GeomTransform):
+ """Translate the images, bboxes, masks and segmentation map vertically.
+
+ Required Keys:
+
+ - img
+ - gt_bboxes (BaseBoxes[torch.float32]) (optional)
+ - gt_masks (BitmapMasks | PolygonMasks) (optional)
+ - gt_seg_map (np.uint8) (optional)
+
+ Modified Keys:
+
+ - img
+ - gt_bboxes
+ - gt_masks
+ - gt_seg_map
+
+ Added Keys:
+
+ - homography_matrix
+
+ Args:
+ prob (float): The probability for perform transformation and
+ should be in range 0 to 1. Defaults to 1.0.
+ level (int, optional): The level should be in range [0, _MAX_LEVEL].
+ If level is None, it will generate from [0, _MAX_LEVEL] randomly.
+ Defaults to None.
+ min_mag (float): The minimum pixel's offset ratio for vertical
+ translation. Defaults to 0.0.
+ max_mag (float): The maximum pixel's offset ratio for vertical
+ translation. Defaults to 0.1.
+ reversal_prob (float): The probability that reverses the vertical
+ translation magnitude. Should be in range [0,1]. Defaults to 0.5.
+ img_border_value (int | float | tuple): The filled values for
+ image border. If float, the same fill value will be used for
+ all the three channels of image. If tuple, it should be 3 elements.
+ Defaults to 128.
+ mask_border_value (int): The fill value used for masks. Defaults to 0.
+ seg_ignore_label (int): The fill value used for segmentation map.
+ Note this value must equals ``ignore_label`` in ``semantic_head``
+ of the corresponding config. Defaults to 255.
+ interpolation (str): Interpolation method, accepted values are
+ "nearest", "bilinear", "bicubic", "area", "lanczos" for 'cv2'
+ backend, "nearest", "bilinear" for 'pillow' backend. Defaults
+ to 'bilinear'.
+ """
+
+ def __init__(self,
+ prob: float = 1.0,
+ level: Optional[int] = None,
+ min_mag: float = 0.0,
+ max_mag: float = 0.1,
+ reversal_prob: float = 0.5,
+ img_border_value: Union[int, float, tuple] = 128,
+ mask_border_value: int = 0,
+ seg_ignore_label: int = 255,
+ interpolation: str = 'bilinear') -> None:
+ assert 0. <= min_mag <= 1., \
+ f'min_mag ratio for TranslateY should be ' \
+ f'in range [0,1], got {min_mag}.'
+ assert 0. <= max_mag <= 1., \
+ f'max_mag ratio for TranslateY should be ' \
+ f'in range [0,1], got {max_mag}.'
+ super().__init__(
+ prob=prob,
+ level=level,
+ min_mag=min_mag,
+ max_mag=max_mag,
+ reversal_prob=reversal_prob,
+ img_border_value=img_border_value,
+ mask_border_value=mask_border_value,
+ seg_ignore_label=seg_ignore_label,
+ interpolation=interpolation)
+
+ def _get_homography_matrix(self, results: dict, mag: float) -> np.ndarray:
+ """Get the homography matrix for TranslateY."""
+ mag = int(results['img_shape'][0] * mag)
+ return np.array([[1, 0, 0], [0, 1, mag], [0, 0, 1]], dtype=np.float32)
+
+ def _transform_img(self, results: dict, mag: float) -> None:
+ """Translate the image vertically."""
+ mag = int(results['img_shape'][0] * mag)
+ results['img'] = mmcv.imtranslate(
+ results['img'],
+ mag,
+ direction='vertical',
+ border_value=self.img_border_value,
+ interpolation=self.interpolation)
+
+ def _transform_masks(self, results: dict, mag: float) -> None:
+ """Translate masks vertically."""
+ mag = int(results['img_shape'][0] * mag)
+ results['gt_masks'] = results['gt_masks'].translate(
+ results['img_shape'],
+ mag,
+ direction='vertical',
+ border_value=self.mask_border_value,
+ interpolation=self.interpolation)
+
+ def _transform_seg(self, results: dict, mag: float) -> None:
+ """Translate segmentation map vertically."""
+ mag = int(results['img_shape'][0] * mag)
+ results['gt_seg_map'] = mmcv.imtranslate(
+ results['gt_seg_map'],
+ mag,
+ direction='vertical',
+ border_value=self.seg_ignore_label,
+ interpolation='nearest')
diff --git a/mmdet/datasets/transforms/hsi/__init__.py b/mmdet/datasets/transforms/hsi/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/mmdet/datasets/transforms/hsi/__pycache__/__init__.cpython-37.pyc b/mmdet/datasets/transforms/hsi/__pycache__/__init__.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..caefa6d182375fb833bbd39402c047d819473fa1
Binary files /dev/null and b/mmdet/datasets/transforms/hsi/__pycache__/__init__.cpython-37.pyc differ
diff --git a/mmdet/datasets/transforms/hsi/__pycache__/hsi_flip.cpython-37.pyc b/mmdet/datasets/transforms/hsi/__pycache__/hsi_flip.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..10ec8cafaf5d8b871cdab081a1a13a41a56e0bd8
Binary files /dev/null and b/mmdet/datasets/transforms/hsi/__pycache__/hsi_flip.cpython-37.pyc differ
diff --git a/mmdet/datasets/transforms/hsi/__pycache__/hsi_formatting.cpython-37.pyc b/mmdet/datasets/transforms/hsi/__pycache__/hsi_formatting.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..9d4bd581ec467bd79f159cc2817059664ba0f5d0
Binary files /dev/null and b/mmdet/datasets/transforms/hsi/__pycache__/hsi_formatting.cpython-37.pyc differ
diff --git a/mmdet/datasets/transforms/hsi/__pycache__/hsi_load.cpython-37.pyc b/mmdet/datasets/transforms/hsi/__pycache__/hsi_load.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..4f3a89fc76b0fcea6e5a26ad3124fb6c8c8b4f53
Binary files /dev/null and b/mmdet/datasets/transforms/hsi/__pycache__/hsi_load.cpython-37.pyc differ
diff --git a/mmdet/datasets/transforms/hsi/__pycache__/hsi_resize.cpython-37.pyc b/mmdet/datasets/transforms/hsi/__pycache__/hsi_resize.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..ba17794a6c3996e49f2257d9c6e755e36233f08d
Binary files /dev/null and b/mmdet/datasets/transforms/hsi/__pycache__/hsi_resize.cpython-37.pyc differ
diff --git a/mmdet/datasets/transforms/hsi/__pycache__/irfly_load.cpython-37.pyc b/mmdet/datasets/transforms/hsi/__pycache__/irfly_load.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..a4c2cfd59a8355f746b93956bea9ddc90e118a46
Binary files /dev/null and b/mmdet/datasets/transforms/hsi/__pycache__/irfly_load.cpython-37.pyc differ
diff --git a/mmdet/datasets/transforms/hsi/__pycache__/sirst_load.cpython-37.pyc b/mmdet/datasets/transforms/hsi/__pycache__/sirst_load.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..647d1f5cec1e3edc867695b67feb11cf822cecaf
Binary files /dev/null and b/mmdet/datasets/transforms/hsi/__pycache__/sirst_load.cpython-37.pyc differ
diff --git a/mmdet/datasets/transforms/hsi/hsi_flip.py b/mmdet/datasets/transforms/hsi/hsi_flip.py
new file mode 100644
index 0000000000000000000000000000000000000000..db75b3c46eb5c10fa6b2ee2e269b208683dd2715
--- /dev/null
+++ b/mmdet/datasets/transforms/hsi/hsi_flip.py
@@ -0,0 +1,114 @@
+import mmcv
+import numpy as np
+
+from mmcv.transforms import RandomFlip as MMCV_RandomFlip
+
+
+from mmdet.registry import TRANSFORMS
+from mmdet.structures.bbox import HorizontalBoxes, autocast_box_type
+
+
+@TRANSFORMS.register_module()
+class RandomFlipPiexlTarget(MMCV_RandomFlip):
+ """Flip the image & bbox & mask & segmentation map. Added or Updated keys:
+ flip, flip_direction, img, gt_bboxes, and gt_seg_map. There are 3 flip
+ modes:
+
+ - ``prob`` is float, ``direction`` is string: the image will be
+ ``direction``ly flipped with probability of ``prob`` .
+ E.g., ``prob=0.5``, ``direction='horizontal'``,
+ then image will be horizontally flipped with probability of 0.5.
+ - ``prob`` is float, ``direction`` is list of string: the image will
+ be ``direction[i]``ly flipped with probability of
+ ``prob/len(direction)``.
+ E.g., ``prob=0.5``, ``direction=['horizontal', 'vertical']``,
+ then image will be horizontally flipped with probability of 0.25,
+ vertically with probability of 0.25.
+ - ``prob`` is list of float, ``direction`` is list of string:
+ given ``len(prob) == len(direction)``, the image will
+ be ``direction[i]``ly flipped with probability of ``prob[i]``.
+ E.g., ``prob=[0.3, 0.5]``, ``direction=['horizontal',
+ 'vertical']``, then image will be horizontally flipped with
+ probability of 0.3, vertically with probability of 0.5.
+
+
+ Required Keys:
+
+ - img
+ - gt_bboxes (BaseBoxes[torch.float32]) (optional)
+ - gt_masks (BitmapMasks | PolygonMasks) (optional)
+ - gt_seg_map (np.uint8) (optional)
+
+ Modified Keys:
+
+ - img
+ - gt_bboxes
+ - gt_masks
+ - gt_seg_map
+
+ Added Keys:
+
+ - flip
+ - flip_direction
+ - homography_matrix
+
+
+ Args:
+ prob (float | list[float], optional): The flipping probability.
+ Defaults to None.
+ direction(str | list[str]): The flipping direction. Options
+ If input is a list, the length must equal ``prob``. Each
+ element in ``prob`` indicates the flip probability of
+ corresponding direction. Defaults to 'horizontal'.
+ """
+
+ def _record_homography_matrix(self, results: dict) -> None:
+ """Record the homography matrix for the RandomFlip."""
+ cur_dir = results['flip_direction']
+ h, w = results['img'].shape[:2]
+
+ if cur_dir == 'horizontal':
+ homography_matrix = np.array([[-1, 0, w], [0, 1, 0], [0, 0, 1]],
+ dtype=np.float32)
+ elif cur_dir == 'vertical':
+ homography_matrix = np.array([[1, 0, 0], [0, -1, h], [0, 0, 1]],
+ dtype=np.float32)
+ elif cur_dir == 'diagonal':
+ homography_matrix = np.array([[-1, 0, w], [0, -1, h], [0, 0, 1]],
+ dtype=np.float32)
+ else:
+ homography_matrix = np.eye(3, dtype=np.float32)
+
+ if results.get('homography_matrix', None) is None:
+ results['homography_matrix'] = homography_matrix
+ else:
+ results['homography_matrix'] = homography_matrix @ results[
+ 'homography_matrix']
+
+ @autocast_box_type()
+ def _flip(self, results: dict) -> None:
+ """Flip images, bounding boxes, and semantic segmentation map."""
+ # flip image
+ results['img'] = mmcv.imflip(
+ results['img'], direction=results['flip_direction'])
+
+ img_shape = results['img'].shape[:2]
+
+ # flip bboxes
+ if results.get('gt_bboxes', None) is not None:
+ results['gt_bboxes'].flip_(img_shape, results['flip_direction'])
+
+ # flip masks
+ if results.get('gt_masks', None) is not None:
+ results['gt_masks'] = results['gt_masks'].flip(
+ results['flip_direction'])
+
+
+ if results.get('gt_seg', None) is not None:
+ results['gt_seg'] = mmcv.imflip(
+ results['gt_seg'], direction=results['flip_direction'])
+ if results.get('gt_abu', None) is not None:
+ results['gt_abu'] = mmcv.imflip(
+ results['gt_abu'], direction=results['flip_direction'])
+ # record homography matrix for flip
+ self._record_homography_matrix(results)
\ No newline at end of file
diff --git a/mmdet/datasets/transforms/hsi/hsi_formatting.py b/mmdet/datasets/transforms/hsi/hsi_formatting.py
new file mode 100644
index 0000000000000000000000000000000000000000..be449c212d910f47acb1cf509565629de7ba934d
--- /dev/null
+++ b/mmdet/datasets/transforms/hsi/hsi_formatting.py
@@ -0,0 +1,138 @@
+from ..formatting import ImageToTensor, PackDetInputs, ToTensor, Transpose
+
+import numpy as np
+from mmcv.transforms import to_tensor
+from mmcv.transforms.base import BaseTransform
+from mmengine.structures import InstanceData, PixelData
+
+from mmdet.registry import TRANSFORMS
+from mmdet.structures import DetDataSample
+from mmdet.structures.bbox import BaseBoxes
+
+
+@TRANSFORMS.register_module()
+class PackDetInputsPiexlTarget(PackDetInputs):
+ """Pack the inputs data for the detection / semantic segmentation /
+ panoptic segmentation.
+
+ The ``img_meta`` item is always populated. The contents of the
+ ``img_meta`` dictionary depends on ``meta_keys``. By default this includes:
+
+ - ``img_id``: id of the image
+
+ - ``img_path``: path to the image file
+
+ - ``ori_shape``: original shape of the image as a tuple (h, w)
+
+ - ``img_shape``: shape of the image input to the network as a tuple \
+ (h, w). Note that images may be zero padded on the \
+ bottom/right if the batch tensor is larger than this shape.
+
+ - ``scale_factor``: a float indicating the preprocessing scale
+
+ - ``flip``: a boolean indicating if image flip transform was used
+
+ - ``flip_direction``: the flipping direction
+
+ Args:
+ meta_keys (Sequence[str], optional): Meta keys to be converted to
+ ``mmcv.DataContainer`` and collected in ``data[img_metas]``.
+ Default: ``('img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'scale_factor', 'flip', 'flip_direction')``
+ """
+ def transform(self, results: dict) -> dict:
+ """Method to pack the input data.
+
+ Args:
+ results (dict): Result dict from the data pipeline.
+
+ Returns:
+ dict:
+
+ - 'inputs' (obj:`torch.Tensor`): The forward data of models.
+ - 'data_sample' (obj:`DetDataSample`): The annotation info of the
+ sample.
+ """
+ packed_results = dict()
+ if 'img' in results:
+ img = results['img']
+ if len(img.shape) < 3:
+ img = np.expand_dims(img, -1)
+ # To improve the computational speed by by 3-5 times, apply:
+ # If image is not contiguous, use
+ # `numpy.transpose()` followed by `numpy.ascontiguousarray()`
+ # If image is already contiguous, use
+ # `torch.permute()` followed by `torch.contiguous()`
+ # Refer to https://github.com/open-mmlab/mmdetection/pull/9533
+ # for more details
+ if not img.flags.c_contiguous:
+ img = np.ascontiguousarray(img.transpose(2, 0, 1))
+ img = to_tensor(img)
+ else:
+ img = to_tensor(img).permute(2, 0, 1).contiguous()
+
+ packed_results['inputs'] = img
+
+ if 'gt_ignore_flags' in results:
+ valid_idx = np.where(results['gt_ignore_flags'] == 0)[0]
+ ignore_idx = np.where(results['gt_ignore_flags'] == 1)[0]
+
+ data_sample = DetDataSample()
+ instance_data = InstanceData()
+ ignore_instance_data = InstanceData()
+
+ for key in self.mapping_table.keys():
+ if key not in results:
+ continue
+ if key == 'gt_masks' or isinstance(results[key], BaseBoxes):
+ if 'gt_ignore_flags' in results:
+ instance_data[
+ self.mapping_table[key]] = results[key][valid_idx]
+ ignore_instance_data[
+ self.mapping_table[key]] = results[key][ignore_idx]
+ else:
+ instance_data[self.mapping_table[key]] = results[key]
+ else:
+ if 'gt_ignore_flags' in results:
+ instance_data[self.mapping_table[key]] = to_tensor(
+ results[key][valid_idx])
+ ignore_instance_data[self.mapping_table[key]] = to_tensor(
+ results[key][ignore_idx])
+ else:
+ instance_data[self.mapping_table[key]] = to_tensor(
+ results[key])
+ data_sample.gt_instances = instance_data
+ data_sample.ignored_instances = ignore_instance_data
+
+ if 'proposals' in results:
+ proposals = InstanceData(
+ bboxes=to_tensor(results['proposals']),
+ scores=to_tensor(results['proposals_scores']))
+ data_sample.proposals = proposals
+
+ if 'gt_seg_map' in results:
+ gt_sem_seg_data = dict(
+ sem_seg=to_tensor(results['gt_seg_map'][None, ...].copy()))
+ data_sample.gt_sem_seg = PixelData(**gt_sem_seg_data)
+ if 'gt_seg' in results:
+ if 'gt_abu' in results:
+ gt_pixel_data = dict(
+ seg=to_tensor(results['gt_seg'][None, ...].copy()),
+ abu=to_tensor(results['gt_abu'][None, ...].copy()),
+ )
+ else:
+ gt_pixel_data = dict(
+ seg=to_tensor(results['gt_seg'][None, ...].copy()),
+ )
+ data_sample.gt_pixel = PixelData(**gt_pixel_data)
+
+ img_meta = {}
+ for key in self.meta_keys:
+ assert key in results, f'`{key}` is not found in `results`, ' \
+ f'the valid keys are {list(results)}.'
+ img_meta[key] = results[key]
+
+ data_sample.set_metainfo(img_meta)
+ packed_results['data_samples'] = data_sample
+
+ return packed_results
\ No newline at end of file
diff --git a/mmdet/datasets/transforms/hsi/hsi_load.py b/mmdet/datasets/transforms/hsi/hsi_load.py
new file mode 100644
index 0000000000000000000000000000000000000000..23dc6a33f1c43eb0c85824c104a2095917f29286
--- /dev/null
+++ b/mmdet/datasets/transforms/hsi/hsi_load.py
@@ -0,0 +1,648 @@
+from mmcv.transforms import to_tensor
+from mmengine.structures import InstanceData, PixelData
+from mmdet.structures import DetDataSample
+from mmdet.structures.bbox import BaseBoxes
+import mmengine.fileio as fileio
+from typing import Optional, Tuple, Union
+import mmcv
+import numpy as np
+import pycocotools.mask as maskUtils
+import torch
+from mmcv.transforms import BaseTransform
+from mmcv.transforms import LoadAnnotations as MMCV_LoadAnnotations
+from mmdet.registry import TRANSFORMS
+from mmdet.structures.bbox import get_box_type
+from mmdet.structures.mask import BitmapMasks, PolygonMasks
+import scipy.io as sio
+
+def hsifromfile(img_path, backend='npy' ) -> np.ndarray:
+ """Read an image from bytes.
+
+ Args:
+ backend (str | None): The image decoding backend type.
+ Returns:
+ ndarray: Loaded image array.
+
+ Examples:
+ """
+ if backend =='npy':
+ img = np.load(img_path)
+ return img
+
+@TRANSFORMS.register_module()
+class LoadHyperspectralImageFromFiles(BaseTransform):
+ """Load multi-channel images from a list of separate channel files.
+
+ Required Keys:
+
+ - img_path
+
+ Modified Keys:
+
+ - img
+ - img_shape
+ - ori_shape
+
+ Args:
+ to_float32 (bool): Whether to convert the loaded image to a float32
+ numpy array. If set to False, the loaded image is an uint8 array.
+ Defaults to False.
+ """
+
+ def __init__(
+ self,
+ to_float32: bool = False,
+ normalized_basis = None,
+ ) -> None:
+ self.to_float32 = to_float32
+ self.normalized_basis = normalized_basis
+
+ def transform(self, results: dict) -> dict:
+ """Transform functions to load multiple images and get images meta
+ information.
+
+ Args:
+ results (dict): Result dict from :obj:`mmdet.CustomDataset`.
+
+ Returns:
+ dict: The dict contains loaded images and meta information.
+ """
+
+ img = hsifromfile(results['img_path'])
+ # up_limit = 3500
+ # low_limit = 600
+ # new_img = (img - low_limit) / up_limit
+ # new_img[new_img > 1] = 1
+ # new_img[new_img < 0] = 0
+ # img = new_img * 255
+ if self.normalized_basis == None:
+ img = img/500
+ else:
+ img = img/np.array(self.normalized_basis)
+ if self.to_float32:
+ img = img.astype(np.float32)
+
+ results['img'] = img
+ results['img_shape'] = img.shape[:2]
+ results['ori_shape'] = img.shape[:2]
+ return results
+
+ def __repr__(self):
+ repr_str = (f'{self.__class__.__name__}('
+ f'to_float32={self.to_float32}, ')
+ return repr_str
+
+
+@TRANSFORMS.register_module()
+class LoadAnnotationsPiexlTarget(MMCV_LoadAnnotations):
+ """Load and process the ``instances`` and ``seg_map`` annotation provided
+ by dataset.
+
+ The annotation format is as the following:
+
+ .. code-block:: python
+
+ {
+ 'instances':
+ [
+ {
+ # List of 4 numbers representing the bounding box of the
+ # instance, in (x1, y1, x2, y2) order.
+ 'bbox': [x1, y1, x2, y2],
+
+ # Label of image classification.
+ 'bbox_label': 1,
+
+ # Used in instance/panoptic segmentation. The segmentation mask
+ # of the instance or the information of segments.
+ # 1. If list[list[float]], it represents a list of polygons,
+ # one for each connected component of the object. Each
+ # list[float] is one simple polygon in the format of
+ # [x1, y1, ..., xn, yn] (n≥3). The Xs and Ys are absolute
+ # coordinates in unit of pixels.
+ # 2. If dict, it represents the per-pixel segmentation mask in
+ # COCO’s compressed RLE format. The dict should have keys
+ # “size” and “counts”. Can be loaded by pycocotools
+ 'mask': list[list[float]] or dict,
+
+ }
+ ]
+ # Filename of semantic or panoptic segmentation ground truth file.
+ 'seg_map_path': 'a/b/c'
+ }
+
+ After this module, the annotation has been changed to the format below:
+
+ .. code-block:: python
+
+ {
+ # In (x1, y1, x2, y2) order, float type. N is the number of bboxes
+ # in an image
+ 'gt_bboxes': BaseBoxes(N, 4)
+ # In int type.
+ 'gt_bboxes_labels': np.ndarray(N, )
+ # In built-in class
+ 'gt_masks': PolygonMasks (H, W) or BitmapMasks (H, W)
+ # In uint8 type.
+ 'gt_seg_map': np.ndarray (H, W)
+ # in (x, y, v) order, float type.
+ }
+
+ Required Keys:
+
+ - height
+ - width
+ - instances
+
+ - bbox (optional)
+ - bbox_label
+ - mask (optional)
+ - ignore_flag
+
+ - seg_map_path (optional)
+
+ Added Keys:
+
+ - gt_bboxes (BaseBoxes[torch.float32])
+ - gt_bboxes_labels (np.int64)
+ - gt_masks (BitmapMasks | PolygonMasks)
+ - gt_seg_map (np.uint8)
+ - gt_ignore_flags (bool)
+
+ Args:
+ with_bbox (bool): Whether to parse and load the bbox annotation.
+ Defaults to True.
+ with_label (bool): Whether to parse and load the label annotation.
+ Defaults to True.
+ with_mask (bool): Whether to parse and load the mask annotation.
+ Default: False.
+ with_seg (bool): Whether to parse and load the semantic segmentation
+ annotation. Defaults to False.
+ poly2mask (bool): Whether to convert mask to bitmap. Default: True.
+ box_type (str): The box type used to wrap the bboxes. If ``box_type``
+ is None, gt_bboxes will keep being np.ndarray. Defaults to 'hbox'.
+ imdecode_backend (str): The image decoding backend type. The backend
+ argument for :func:``mmcv.imfrombytes``.
+ See :fun:``mmcv.imfrombytes`` for details.
+ Defaults to 'cv2'.
+ backend_args (dict, optional): Arguments to instantiate the
+ corresponding backend. Defaults to None.
+ """
+
+ def __init__(self,
+ with_mask: bool = False,
+ with_seg: bool = False,
+ with_abu: bool = False,
+ poly2mask: bool = True,
+ box_type: str = 'hbox',
+ **kwargs) -> None:
+ super(LoadAnnotationsPiexlTarget, self).__init__(**kwargs)
+ self.with_mask = with_mask
+ self.poly2mask = poly2mask
+ self.box_type = box_type
+ self.with_seg = with_seg
+ self.with_abu = with_abu
+
+ def _load_bboxes(self, results: dict) -> None:
+ """Private function to load bounding box annotations.
+
+ Args:
+ results (dict): Result dict from :obj:``mmengine.BaseDataset``.
+ Returns:
+ dict: The dict contains loaded bounding box annotations.
+ """
+ gt_bboxes = []
+ gt_ignore_flags = []
+ for instance in results.get('instances', []):
+ gt_bboxes.append(instance['bbox'])
+ gt_ignore_flags.append(instance['ignore_flag'])
+ if self.box_type is None:
+ results['gt_bboxes'] = np.array(
+ gt_bboxes, dtype=np.float32).reshape((-1, 4))
+ else:
+ _, box_type_cls = get_box_type(self.box_type)
+ results['gt_bboxes'] = box_type_cls(gt_bboxes, dtype=torch.float32)
+ results['gt_ignore_flags'] = np.array(gt_ignore_flags, dtype=bool)
+
+ def _load_labels(self, results: dict) -> None:
+ """Private function to load label annotations.
+
+ Args:
+ results (dict): Result dict from :obj:``mmengine.BaseDataset``.
+
+ Returns:
+ dict: The dict contains loaded label annotations.
+ """
+ gt_bboxes_labels = []
+ for instance in results.get('instances', []):
+ gt_bboxes_labels.append(instance['bbox_label'])
+ # TODO: Inconsistent with mmcv, consider how to deal with it later.
+ results['gt_bboxes_labels'] = np.array(
+ gt_bboxes_labels, dtype=np.int64)
+
+ def _poly2mask(self, mask_ann: Union[list, dict], img_h: int,
+ img_w: int) -> np.ndarray:
+ """Private function to convert masks represented with polygon to
+ bitmaps.
+
+ Args:
+ mask_ann (list | dict): Polygon mask annotation input.
+ img_h (int): The height of output mask.
+ img_w (int): The width of output mask.
+
+ Returns:
+ np.ndarray: The decode bitmap mask of shape (img_h, img_w).
+ """
+
+ if isinstance(mask_ann, list):
+ # polygon -- a single object might consist of multiple parts
+ # we merge all parts into one mask rle code
+ rles = maskUtils.frPyObjects(mask_ann, img_h, img_w)
+ rle = maskUtils.merge(rles)
+ elif isinstance(mask_ann['counts'], list):
+ # uncompressed RLE
+ rle = maskUtils.frPyObjects(mask_ann, img_h, img_w)
+ else:
+ # rle
+ rle = mask_ann
+ mask = maskUtils.decode(rle)
+ return mask
+
+ def _process_masks(self, results: dict) -> list:
+ """Process gt_masks and filter invalid polygons.
+
+ Args:
+ results (dict): Result dict from :obj:``mmengine.BaseDataset``.
+
+ Returns:
+ list: Processed gt_masks.
+ """
+ gt_masks = []
+ gt_ignore_flags = []
+ for instance in results.get('instances', []):
+ gt_mask = instance['mask']
+ # If the annotation of segmentation mask is invalid,
+ # ignore the whole instance.
+ if isinstance(gt_mask, list):
+ gt_mask = [
+ np.array(polygon) for polygon in gt_mask
+ if len(polygon) % 2 == 0 and len(polygon) >= 6
+ ]
+ if len(gt_mask) == 0:
+ # ignore this instance and set gt_mask to a fake mask
+ instance['ignore_flag'] = 1
+ gt_mask = [np.zeros(6)]
+ elif not self.poly2mask:
+ # `PolygonMasks` requires a ploygon of format List[np.array],
+ # other formats are invalid.
+ instance['ignore_flag'] = 1
+ gt_mask = [np.zeros(6)]
+ elif isinstance(gt_mask, dict) and \
+ not (gt_mask.get('counts') is not None and
+ gt_mask.get('size') is not None and
+ isinstance(gt_mask['counts'], (list, str))):
+ # if gt_mask is a dict, it should include `counts` and `size`,
+ # so that `BitmapMasks` can uncompressed RLE
+ instance['ignore_flag'] = 1
+ gt_mask = [np.zeros(6)]
+ gt_masks.append(gt_mask)
+ # re-process gt_ignore_flags
+ gt_ignore_flags.append(instance['ignore_flag'])
+ results['gt_ignore_flags'] = np.array(gt_ignore_flags, dtype=bool)
+ return gt_masks
+
+ def _load_masks(self, results: dict) -> None:
+ """Private function to load mask annotations.
+
+ Args:
+ results (dict): Result dict from :obj:``mmengine.BaseDataset``.
+ """
+ h, w = results['ori_shape']
+ gt_masks = self._process_masks(results)
+ if self.poly2mask:
+ gt_masks = BitmapMasks(
+ [self._poly2mask(mask, h, w) for mask in gt_masks], h, w)
+ else:
+ # fake polygon masks will be ignored in `PackDetInputs`
+ gt_masks = PolygonMasks([mask for mask in gt_masks], h, w)
+ results['gt_masks'] = gt_masks
+
+ def _load_seg_map(self, results: dict) -> None:
+ """Private function to load semantic segmentation annotations.
+
+ Args:
+ results (dict): Result dict from
+ :class:`mmengine.dataset.BaseDataset`.
+
+ Returns:
+ dict: The dict contains loaded semantic segmentation annotations.
+ """
+ assert results['seg_path'] is not None
+ img_bytes = fileio.get(results['seg_path'])
+ img = mmcv.imfrombytes(
+ img_bytes, flag='grayscale', backend='pillow')
+ results['gt_seg'] = img.astype('float32')
+
+ def _load_abu_map(self, results: dict) -> None:
+ """Private function to load semantic segmentation annotations.
+
+ Args:
+ results (dict): Result dict from
+ :class:`mmengine.dataset.BaseDataset`.
+
+ Returns:
+ dict: The dict contains loaded semantic segmentation annotations.
+ """
+ assert results['abu_path'] is not None
+ img = sio.loadmat(results['abu_path'])['data']
+ results['gt_abu'] = img.astype('float32')
+ # img_bytes = fileio.get(results['seg_path'])
+ # img = mmcv.imfrombytes(
+ # img_bytes, flag='grayscale', backend='pillow')
+ # results['gt_seg'] = img
+
+
+
+ def transform(self, results: dict) -> dict:
+ """Function to load multiple types annotations.
+
+ Args:
+ results (dict): Result dict from :obj:``mmengine.BaseDataset``.
+
+ Returns:
+ dict: The dict contains loaded bounding box, label and
+ semantic segmentation.
+ """
+
+ if self.with_bbox:
+ self._load_bboxes(results)
+ if self.with_label:
+ self._load_labels(results)
+ if self.with_mask:
+ self._load_masks(results)
+ if self.with_seg:
+ self._load_seg_map(results)
+ if self.with_abu:
+ self._load_abu_map(results)
+
+ return results
+
+ def __repr__(self) -> str:
+ repr_str = self.__class__.__name__
+ repr_str += f'(with_bbox={self.with_bbox}, '
+ repr_str += f'with_label={self.with_label}, '
+ repr_str += f'with_mask={self.with_mask}, '
+ repr_str += f'with_seg={self.with_seg}, '
+ repr_str += f'with_abu={self.with_abu}, '
+ repr_str += f'poly2mask={self.poly2mask}, '
+ repr_str += f"imdecode_backend='{self.imdecode_backend}', "
+ repr_str += f'backend_args={self.backend_args})'
+ return repr_str
+
+
+
+
+
+@TRANSFORMS.register_module()
+class LoadHyperspectralMaskImageFromFiles(BaseTransform):
+ """Load multi-channel images from a list of separate channel files.
+
+ Required Keys:
+
+ - img_path
+
+ Modified Keys:
+
+ - img
+ - img_shape
+ - ori_shape
+
+ Args:
+ to_float32 (bool): Whether to convert the loaded image to a float32
+ numpy array. If set to False, the loaded image is an uint8 array.
+ Defaults to False.
+ """
+
+ def __init__(
+ self,
+ to_float32: bool = False,
+ normalized_basis = None,
+ color_type: str = 'color',
+ imdecode_backend: str = 'cv2',
+ backend_args: Optional[dict] = None
+ ) -> None:
+ self.to_float32 = to_float32
+ self.normalized_basis = normalized_basis
+ self.color_type = color_type
+ self.imdecode_backend = imdecode_backend
+ self.backend_args: Optional[dict] = None
+ if backend_args is not None:
+ self.backend_args = backend_args.copy()
+
+ def transform(self, results: dict) -> dict:
+ """Transform functions to load multiple images and get images meta
+ information.
+
+ Args:
+ results (dict): Result dict from :obj:`mmdet.CustomDataset`.
+
+ Returns:
+ dict: The dict contains loaded images and meta information.
+ """
+
+ img = hsifromfile(results['img_path']+'_rd.npy')
+ # up_limit = 3500
+ # low_limit = 600
+ # new_img = (img - low_limit) / up_limit
+ # new_img[new_img > 1] = 1
+ # new_img[new_img < 0] = 0
+ # img = new_img * 255
+ if self.normalized_basis == None:
+ img = img/1000
+ else:
+ img = img/np.array(self.normalized_basis)
+ if self.to_float32:
+ img = img.astype(np.float32)
+
+ maskname = results['mask_path']+'_mask.png'
+ mask_bytes = fileio.get(
+ maskname, backend_args=self.backend_args)
+ mask = mmcv.imfrombytes(
+ mask_bytes, flag=self.color_type, backend=self.imdecode_backend)
+ if self.to_float32:
+ mask = mask.astype(np.float32)
+
+ mask[mask == 255] = 1
+ mask = np.repeat(mask, 17, axis = 2)
+ img = img * mask
+
+ results['img'] = img
+ results['img_shape'] = img.shape[:2]
+ results['ori_shape'] = img.shape[:2]
+ return results
+
+ def __repr__(self):
+ repr_str = (f'{self.__class__.__name__}('
+ f'to_float32={self.to_float32}, ')
+ return repr_str
+
+
+def to_tensor_HSI(
+ data: Union[torch.Tensor, np.ndarray]) -> torch.Tensor:
+ """Convert objects of various python types to :obj:`torch.Tensor`.
+
+ Supported types are: :class:`numpy.ndarray`, :class:`torch.Tensor`,
+ :class:`Sequence`, :class:`int` and :class:`float`.
+
+ Args:
+ data (torch.Tensor | numpy.ndarray | Sequence | int | float): Data to
+ be converted.
+
+ Returns:
+ torch.Tensor: the converted data.
+ """
+
+ if isinstance(data, torch.Tensor):
+ return data
+ elif isinstance(data, np.ndarray):
+ # rw by lzx
+ if data.dtype == '>i2':
+ return torch.from_numpy(data.astype(np.float32))
+ else:
+ return torch.from_numpy(data)
+ else:
+ raise TypeError(f'type {type(data)} cannot be converted to tensor.')
+
+@TRANSFORMS.register_module()
+class PackDetInputs_HSI(BaseTransform):
+ """Pack the inputs data for the detection / semantic segmentation /
+ panoptic segmentation.
+
+ The ``img_meta`` item is always populated. The contents of the
+ ``img_meta`` dictionary depends on ``meta_keys``. By default this includes:
+
+ - ``img_id``: id of the image
+
+ - ``img_path``: path to the image file
+
+ - ``ori_shape``: original shape of the image as a tuple (h, w)
+
+ - ``img_shape``: shape of the image input to the network as a tuple \
+ (h, w). Note that images may be zero padded on the \
+ bottom/right if the batch tensor is larger than this shape.
+
+ - ``scale_factor``: a float indicating the preprocessing scale
+
+ - ``flip``: a boolean indicating if image flip transform was used
+
+ - ``flip_direction``: the flipping direction
+
+ Args:
+ meta_keys (Sequence[str], optional): Meta keys to be converted to
+ ``mmcv.DataContainer`` and collected in ``data[img_metas]``.
+ Default: ``('img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'scale_factor', 'flip', 'flip_direction')``
+ """
+ mapping_table = {
+ 'gt_bboxes': 'bboxes',
+ 'gt_bboxes_labels': 'labels',
+ 'gt_masks': 'masks'
+ }
+
+ def __init__(self,
+ meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'scale_factor', 'flip', 'flip_direction')):
+ self.meta_keys = meta_keys
+
+ def transform(self, results: dict) -> dict:
+ """Method to pack the input data.
+
+ Args:
+ results (dict): Result dict from the data pipeline.
+
+ Returns:
+ dict:
+
+ - 'inputs' (obj:`torch.Tensor`): The forward data of models.
+ - 'data_sample' (obj:`DetDataSample`): The annotation info of the
+ sample.
+ """
+ packed_results = dict()
+ if 'img' in results:
+ img = results['img']
+ if len(img.shape) < 3:
+ img = np.expand_dims(img, -1)
+ # To improve the computational speed by by 3-5 times, apply:
+ # If image is not contiguous, use
+ # `numpy.transpose()` followed by `numpy.ascontiguousarray()`
+ # If image is already contiguous, use
+ # `torch.permute()` followed by `torch.contiguous()`
+ # Refer to https://github.com/open-mmlab/mmdetection/pull/9533
+ # for more details
+ if not img.flags.c_contiguous:
+ img = np.ascontiguousarray(img.transpose(2, 0, 1))
+ img = to_tensor(img)
+ else:
+ img = to_tensor(img).permute(2, 0, 1).contiguous()
+
+ packed_results['inputs'] = img
+
+ if 'gt_ignore_flags' in results:
+ valid_idx = np.where(results['gt_ignore_flags'] == 0)[0]
+ ignore_idx = np.where(results['gt_ignore_flags'] == 1)[0]
+
+ data_sample = DetDataSample()
+ instance_data = InstanceData()
+ ignore_instance_data = InstanceData()
+
+ for key in self.mapping_table.keys():
+ if key not in results:
+ continue
+ if key == 'gt_masks' or isinstance(results[key], BaseBoxes):
+ if 'gt_ignore_flags' in results:
+ instance_data[
+ self.mapping_table[key]] = results[key][valid_idx]
+ ignore_instance_data[
+ self.mapping_table[key]] = results[key][ignore_idx]
+ else:
+ instance_data[self.mapping_table[key]] = results[key]
+ else:
+ if 'gt_ignore_flags' in results:
+ instance_data[self.mapping_table[key]] = to_tensor(
+ results[key][valid_idx])
+ ignore_instance_data[self.mapping_table[key]] = to_tensor(
+ results[key][ignore_idx])
+ else:
+ instance_data[self.mapping_table[key]] = to_tensor(
+ results[key])
+ data_sample.gt_instances = instance_data
+ data_sample.ignored_instances = ignore_instance_data
+
+ if 'proposals' in results:
+ proposals = InstanceData(
+ bboxes=to_tensor(results['proposals']),
+ scores=to_tensor(results['proposals_scores']))
+ data_sample.proposals = proposals
+
+ if 'gt_seg_map' in results:
+ gt_sem_seg_data = dict(
+ sem_seg=to_tensor(results['gt_seg_map'][None, ...].copy()))
+ data_sample.gt_sem_seg = PixelData(**gt_sem_seg_data)
+
+ img_meta = {}
+ for key in self.meta_keys:
+ assert key in results, f'`{key}` is not found in `results`, ' \
+ f'the valid keys are {list(results)}.'
+ img_meta[key] = results[key]
+
+ data_sample.set_metainfo(img_meta)
+ packed_results['data_samples'] = data_sample
+
+ return packed_results
+
+ def __repr__(self) -> str:
+ repr_str = self.__class__.__name__
+ repr_str += f'(meta_keys={self.meta_keys})'
+ return repr_str
+
+
diff --git a/mmdet/datasets/transforms/hsi/hsi_loading.py b/mmdet/datasets/transforms/hsi/hsi_loading.py
new file mode 100644
index 0000000000000000000000000000000000000000..4b24a7a6fe316bfec40deb2d7b7e15443350ba53
--- /dev/null
+++ b/mmdet/datasets/transforms/hsi/hsi_loading.py
@@ -0,0 +1,282 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Tuple, Union
+
+import mmcv
+import numpy as np
+import pycocotools.mask as maskUtils
+import torch
+from mmcv.transforms import BaseTransform
+from mmcv.transforms import LoadAnnotations as MMCV_LoadAnnotations
+from mmcv.transforms import LoadImageFromFile
+from mmengine.fileio import get
+from mmengine.structures import BaseDataElement
+
+from mmdet.registry import TRANSFORMS
+from mmdet.structures.bbox import get_box_type
+from mmdet.structures.bbox.box_type import autocast_box_type
+from mmdet.structures.mask import BitmapMasks, PolygonMasks
+
+
+@TRANSFORMS.register_module()
+class LoadAnnotations(MMCV_LoadAnnotations):
+ """Load and process the ``instances`` and ``seg_map`` annotation provided
+ by dataset.
+
+ The annotation format is as the following:
+
+ .. code-block:: python
+
+ {
+ 'instances':
+ [
+ {
+ # List of 4 numbers representing the bounding box of the
+ # instance, in (x1, y1, x2, y2) order.
+ 'bbox': [x1, y1, x2, y2],
+
+ # Label of image classification.
+ 'bbox_label': 1,
+
+ # Used in instance/panoptic segmentation. The segmentation mask
+ # of the instance or the information of segments.
+ # 1. If list[list[float]], it represents a list of polygons,
+ # one for each connected component of the object. Each
+ # list[float] is one simple polygon in the format of
+ # [x1, y1, ..., xn, yn] (n≥3). The Xs and Ys are absolute
+ # coordinates in unit of pixels.
+ # 2. If dict, it represents the per-pixel segmentation mask in
+ # COCO’s compressed RLE format. The dict should have keys
+ # “size” and “counts”. Can be loaded by pycocotools
+ 'mask': list[list[float]] or dict,
+
+ }
+ ]
+ # Filename of semantic or panoptic segmentation ground truth file.
+ 'seg_map_path': 'a/b/c'
+ }
+
+ After this module, the annotation has been changed to the format below:
+
+ .. code-block:: python
+
+ {
+ # In (x1, y1, x2, y2) order, float type. N is the number of bboxes
+ # in an image
+ 'gt_bboxes': BaseBoxes(N, 4)
+ # In int type.
+ 'gt_bboxes_labels': np.ndarray(N, )
+ # In built-in class
+ 'gt_masks': PolygonMasks (H, W) or BitmapMasks (H, W)
+ # In uint8 type.
+ 'gt_seg_map': np.ndarray (H, W)
+ # in (x, y, v) order, float type.
+ }
+
+ Required Keys:
+
+ - height
+ - width
+ - instances
+
+ - bbox (optional)
+ - bbox_label
+ - mask (optional)
+ - ignore_flag
+
+ - seg_map_path (optional)
+
+ Added Keys:
+
+ - gt_bboxes (BaseBoxes[torch.float32])
+ - gt_bboxes_labels (np.int64)
+ - gt_masks (BitmapMasks | PolygonMasks)
+ - gt_seg_map (np.uint8)
+ - gt_ignore_flags (bool)
+
+ Args:
+ with_bbox (bool): Whether to parse and load the bbox annotation.
+ Defaults to True.
+ with_label (bool): Whether to parse and load the label annotation.
+ Defaults to True.
+ with_mask (bool): Whether to parse and load the mask annotation.
+ Default: False.
+ with_seg (bool): Whether to parse and load the semantic segmentation
+ annotation. Defaults to False.
+ poly2mask (bool): Whether to convert mask to bitmap. Default: True.
+ box_type (str): The box type used to wrap the bboxes. If ``box_type``
+ is None, gt_bboxes will keep being np.ndarray. Defaults to 'hbox'.
+ imdecode_backend (str): The image decoding backend type. The backend
+ argument for :func:``mmcv.imfrombytes``.
+ See :fun:``mmcv.imfrombytes`` for details.
+ Defaults to 'cv2'.
+ backend_args (dict, optional): Arguments to instantiate the
+ corresponding backend. Defaults to None.
+ """
+
+ def __init__(self,
+ with_mask: bool = False,
+ poly2mask: bool = True,
+ box_type: str = 'hbox',
+ **kwargs) -> None:
+ super(LoadAnnotations, self).__init__(**kwargs)
+ self.with_mask = with_mask
+ self.poly2mask = poly2mask
+ self.box_type = box_type
+
+ def _load_bboxes(self, results: dict) -> None:
+ """Private function to load bounding box annotations.
+
+ Args:
+ results (dict): Result dict from :obj:``mmengine.BaseDataset``.
+ Returns:
+ dict: The dict contains loaded bounding box annotations.
+ """
+ gt_bboxes = []
+ gt_ignore_flags = []
+ for instance in results.get('instances', []):
+ gt_bboxes.append(instance['bbox'])
+ gt_ignore_flags.append(instance['ignore_flag'])
+ if self.box_type is None:
+ results['gt_bboxes'] = np.array(
+ gt_bboxes, dtype=np.float32).reshape((-1, 4))
+ else:
+ _, box_type_cls = get_box_type(self.box_type)
+ results['gt_bboxes'] = box_type_cls(gt_bboxes, dtype=torch.float32)
+ results['gt_ignore_flags'] = np.array(gt_ignore_flags, dtype=bool)
+
+ def _load_labels(self, results: dict) -> None:
+ """Private function to load label annotations.
+
+ Args:
+ results (dict): Result dict from :obj:``mmengine.BaseDataset``.
+
+ Returns:
+ dict: The dict contains loaded label annotations.
+ """
+ gt_bboxes_labels = []
+ for instance in results.get('instances', []):
+ gt_bboxes_labels.append(instance['bbox_label'])
+ # TODO: Inconsistent with mmcv, consider how to deal with it later.
+ results['gt_bboxes_labels'] = np.array(
+ gt_bboxes_labels, dtype=np.int64)
+
+ def _poly2mask(self, mask_ann: Union[list, dict], img_h: int,
+ img_w: int) -> np.ndarray:
+ """Private function to convert masks represented with polygon to
+ bitmaps.
+
+ Args:
+ mask_ann (list | dict): Polygon mask annotation input.
+ img_h (int): The height of output mask.
+ img_w (int): The width of output mask.
+
+ Returns:
+ np.ndarray: The decode bitmap mask of shape (img_h, img_w).
+ """
+
+ if isinstance(mask_ann, list):
+ # polygon -- a single object might consist of multiple parts
+ # we merge all parts into one mask rle code
+ rles = maskUtils.frPyObjects(mask_ann, img_h, img_w)
+ rle = maskUtils.merge(rles)
+ elif isinstance(mask_ann['counts'], list):
+ # uncompressed RLE
+ rle = maskUtils.frPyObjects(mask_ann, img_h, img_w)
+ else:
+ # rle
+ rle = mask_ann
+ mask = maskUtils.decode(rle)
+ return mask
+
+ def _process_masks(self, results: dict) -> list:
+ """Process gt_masks and filter invalid polygons.
+
+ Args:
+ results (dict): Result dict from :obj:``mmengine.BaseDataset``.
+
+ Returns:
+ list: Processed gt_masks.
+ """
+ gt_masks = []
+ gt_ignore_flags = []
+ for instance in results.get('instances', []):
+ gt_mask = instance['mask']
+ # If the annotation of segmentation mask is invalid,
+ # ignore the whole instance.
+ if isinstance(gt_mask, list):
+ gt_mask = [
+ np.array(polygon) for polygon in gt_mask
+ if len(polygon) % 2 == 0 and len(polygon) >= 6
+ ]
+ if len(gt_mask) == 0:
+ # ignore this instance and set gt_mask to a fake mask
+ instance['ignore_flag'] = 1
+ gt_mask = [np.zeros(6)]
+ elif not self.poly2mask:
+ # `PolygonMasks` requires a ploygon of format List[np.array],
+ # other formats are invalid.
+ instance['ignore_flag'] = 1
+ gt_mask = [np.zeros(6)]
+ elif isinstance(gt_mask, dict) and \
+ not (gt_mask.get('counts') is not None and
+ gt_mask.get('size') is not None and
+ isinstance(gt_mask['counts'], (list, str))):
+ # if gt_mask is a dict, it should include `counts` and `size`,
+ # so that `BitmapMasks` can uncompressed RLE
+ instance['ignore_flag'] = 1
+ gt_mask = [np.zeros(6)]
+ gt_masks.append(gt_mask)
+ # re-process gt_ignore_flags
+ gt_ignore_flags.append(instance['ignore_flag'])
+ results['gt_ignore_flags'] = np.array(gt_ignore_flags, dtype=bool)
+ return gt_masks
+
+ def _load_masks(self, results: dict) -> None:
+ """Private function to load mask annotations.
+
+ Args:
+ results (dict): Result dict from :obj:``mmengine.BaseDataset``.
+ """
+ h, w = results['ori_shape']
+ gt_masks = self._process_masks(results)
+ if self.poly2mask:
+ gt_masks = BitmapMasks(
+ [self._poly2mask(mask, h, w) for mask in gt_masks], h, w)
+ else:
+ # fake polygon masks will be ignored in `PackDetInputs`
+ gt_masks = PolygonMasks([mask for mask in gt_masks], h, w)
+ results['gt_masks'] = gt_masks
+
+ def transform(self, results: dict) -> dict:
+ """Function to load multiple types annotations.
+
+ Args:
+ results (dict): Result dict from :obj:``mmengine.BaseDataset``.
+
+ Returns:
+ dict: The dict contains loaded bounding box, label and
+ semantic segmentation.
+ """
+
+ if self.with_bbox:
+ self._load_bboxes(results)
+ if self.with_label:
+ self._load_labels(results)
+ if self.with_mask:
+ self._load_masks(results)
+ if self.with_seg:
+ self._load_seg_map(results)
+ return results
+
+ def __repr__(self) -> str:
+ repr_str = self.__class__.__name__
+ repr_str += f'(with_bbox={self.with_bbox}, '
+ repr_str += f'with_label={self.with_label}, '
+ repr_str += f'with_mask={self.with_mask}, '
+ repr_str += f'with_seg={self.with_seg}, '
+ repr_str += f'poly2mask={self.poly2mask}, '
+ repr_str += f"imdecode_backend='{self.imdecode_backend}', "
+ repr_str += f'backend_args={self.backend_args})'
+ return repr_str
+
+
diff --git a/mmdet/datasets/transforms/hsi/hsi_resize.py b/mmdet/datasets/transforms/hsi/hsi_resize.py
new file mode 100644
index 0000000000000000000000000000000000000000..2c5981ad2bbdf61c0beaf17f4bd5a507c5c7dd27
--- /dev/null
+++ b/mmdet/datasets/transforms/hsi/hsi_resize.py
@@ -0,0 +1,423 @@
+from mmdet.registry import TRANSFORMS
+import mmcv
+import numpy as np
+from mmdet.structures.bbox.box_type import autocast_box_type
+from mmcv.image.geometric import _scale_size
+from typing import Dict, Iterable, List, Optional, Sequence, Tuple, Union
+from mmcv.transforms.base import BaseTransform
+
+
+
+def rescale_size(old_size: tuple,
+ scale: Union[float, int, tuple],
+ return_scale: bool = False) -> tuple:
+ """Calculate the new size to be rescaled to.
+
+ Args:
+ old_size (tuple[int]): The old size (w, h) of image.
+ scale (float | tuple[int]): The scaling factor or maximum size.
+ If it is a float number, then the image will be rescaled by this
+ factor, else if it is a tuple of 2 integers, then the image will
+ be rescaled as large as possible within the scale.
+ return_scale (bool): Whether to return the scaling factor besides the
+ rescaled image size.
+
+ Returns:
+ tuple[int]: The new rescaled image size.
+ """
+ w, h = old_size
+ if isinstance(scale, (float, int)):
+ if scale <= 0:
+ raise ValueError(f'Invalid scale {scale}, must be positive.')
+ scale_factor = scale
+ elif isinstance(scale, tuple):
+ max_long_edge = max(scale)
+ max_short_edge = min(scale)
+ scale_factor = min(max_long_edge / max(h, w),
+ max_short_edge / min(h, w))
+ else:
+ raise TypeError(
+ f'Scale must be a number or tuple of int, but got {type(scale)}')
+
+ new_size = _scale_size((w, h), scale_factor)
+
+ if return_scale:
+ return new_size, scale_factor
+ else:
+ return new_size
+
+
+def hsiresize(
+ img: np.ndarray,
+ size: Tuple[int, int],
+ return_scale: bool = False,
+) -> Union[Tuple[np.ndarray, float, float], np.ndarray]:
+ """Resize image to a given size.
+
+ Args:
+ img (ndarray): The input image.
+ size (tuple[int]): Target size (w, h).
+ return_scale (bool): Whether to return `w_scale` and `h_scale`.
+ interpolation (str): Interpolation method, accepted values are
+ "nearest", "bilinear", "bicubic", "area", "lanczos" for 'cv2'
+ backend, "nearest", "bilinear" for 'pillow' backend.
+ out (ndarray): The output destination.
+ backend (str | None): The image resize backend type. Options are `cv2`,
+ `pillow`, `None`. If backend is None, the global imread_backend
+ specified by ``mmcv.use_backend()`` will be used. Default: None.
+
+ Returns:
+ tuple | ndarray: (`resized_img`, `w_scale`, `h_scale`) or
+ `resized_img`.
+ """
+ h, w = img.shape[:2]
+ # assert (size[1]%h == 0) and (size[0]%w == 0), 'size error'
+ w_scale = int(size[0] / w)
+ h_scale = int(size[1] / h)
+ resized_img = np.repeat(np.repeat(img, w_scale, axis=0), h_scale, axis=1)
+ if not return_scale:
+ return resized_img
+ else:
+ return resized_img, w_scale, h_scale
+
+
+@TRANSFORMS.register_module()
+class HSIResize(BaseTransform):
+ """Resize images & bbox & seg & keypoints.
+
+ This transform resizes the input image according to ``scale`` or
+ ``scale_factor``. Bboxes, seg map and keypoints are then resized with the
+ same scale factor.
+ if ``scale`` and ``scale_factor`` are both set, it will use ``scale`` to
+ resize.
+
+ Required Keys:
+
+ - img
+ - gt_bboxes (optional)
+ - gt_seg_map (optional)
+ - gt_keypoints (optional)
+
+ Modified Keys:
+
+ - img
+ - gt_bboxes
+ - gt_seg_map
+ - gt_keypoints
+ - img_shape
+
+ Added Keys:
+
+ - scale
+ - scale_factor
+ - keep_ratio
+
+ Args:
+ scale (int or tuple): Images scales for resizing. Defaults to None
+ scale_factor (float or tuple[float]): Scale factors for resizing.
+ Defaults to None.
+ keep_ratio (bool): Whether to keep the aspect ratio when resizing the
+ image. Defaults to False.
+ clip_object_border (bool): Whether to clip the objects
+ outside the border of the image. In some dataset like MOT17, the gt
+ bboxes are allowed to cross the border of images. Therefore, we
+ don't need to clip the gt bboxes in these cases. Defaults to True.
+ backend (str): Image resize backend, choices are 'cv2' and 'pillow'.
+ These two backends generates slightly different results. Defaults
+ to 'cv2'.
+ interpolation (str): Interpolation method, accepted values are
+ "nearest", "bilinear", "bicubic", "area", "lanczos" for 'cv2'
+ backend, "nearest", "bilinear" for 'pillow' backend. Defaults
+ to 'bilinear'.
+ """
+
+ def __init__(self,
+ scale: Optional[Union[int, Tuple[int, int]]] = None,
+ scale_factor: Optional[Union[int, Tuple[int,
+ int]]] = None,
+ keep_ratio: bool = False,
+ clip_object_border: bool = True,
+ backend: str = 'cv2',
+ interpolation='bilinear') -> None:
+ assert scale is not None or scale_factor is not None, (
+ '`scale` and'
+ '`scale_factor` can not both be `None`')
+ assert scale is None, ('please input scale_factor instead of scale' )
+
+ if scale is None:
+ self.scale = None
+ else:
+ if isinstance(scale, int):
+ self.scale = (scale, scale)
+ else:
+ self.scale = scale
+ self.backend = backend
+ self.interpolation = interpolation
+ self.keep_ratio = keep_ratio
+ self.clip_object_border = clip_object_border
+ if scale_factor is None:
+ self.scale_factor = None
+ elif isinstance(scale_factor, int):
+ self.scale_factor = (scale_factor, scale_factor)
+ elif isinstance(scale_factor, tuple):
+ assert (len(scale_factor)) == 2
+ self.scale_factor = scale_factor
+ else:
+ raise TypeError(
+ f'expect scale_factor is float or Tuple(float), but'
+ f'get {type(scale_factor)}')
+ # assert (isinstance(scale_factor[0], int) and isinstance(scale_factor[1], int)),\
+ # 'scale_factor should be an integer'
+
+ def _resize_img(self, results: dict) -> None:
+ """Resize images with ``results['scale']``."""
+
+ if results.get('img', None) is not None:
+ if self.keep_ratio:
+ h, w = results['img'].shape[:2]
+
+ new_size, scale_factor = rescale_size((w, h), results['scale'], return_scale=True)
+ img, w_scale, h_scale = hsiresize(results['img'], new_size, return_scale=True,)
+ else:
+ img, w_scale, h_scale = hsiresize(results['img'], results['scale'],return_scale=True,)
+ results['img'] = img
+ results['img_shape'] = img.shape[:2]
+ results['scale_factor'] = (w_scale, h_scale)
+ results['keep_ratio'] = self.keep_ratio
+
+ def _resize_masks(self, results: dict) -> None:
+ """Resize masks with ``results['scale']``"""
+ if results.get('gt_masks', None) is not None:
+ if self.keep_ratio:
+ results['gt_masks'] = results['gt_masks'].rescale(
+ results['scale'])
+ else:
+ results['gt_masks'] = results['gt_masks'].resize(
+ results['img_shape'])
+
+ def _resize_bboxes(self, results: dict) -> None:
+ """Resize bounding boxes with ``results['scale_factor']``."""
+ if results.get('gt_bboxes', None) is not None:
+ results['gt_bboxes'].rescale_(results['scale_factor'])
+ if self.clip_object_border:
+ results['gt_bboxes'].clip_(results['img_shape'])
+
+ def _resize_seg(self, results: dict) -> None:
+ """Resize semantic segmentation map with ``results['scale']``."""
+ if results.get('gt_seg_map', None) is not None:
+ if self.keep_ratio:
+ gt_seg = mmcv.imrescale(
+ results['gt_seg_map'],
+ results['scale'],
+ interpolation='nearest',
+ backend=self.backend)
+ else:
+ gt_seg = mmcv.imresize(
+ results['gt_seg_map'],
+ results['scale'],
+ interpolation='nearest',
+ backend=self.backend)
+ results['gt_seg_map'] = gt_seg
+
+ def _resize_keypoints(self, results: dict) -> None:
+ """Resize keypoints with ``results['scale_factor']``."""
+ if results.get('gt_keypoints', None) is not None:
+ keypoints = results['gt_keypoints']
+
+ keypoints[:, :, :2] = keypoints[:, :, :2] * np.array(
+ results['scale_factor'])
+ if self.clip_object_border:
+ keypoints[:, :, 0] = np.clip(keypoints[:, :, 0], 0,
+ results['img_shape'][1])
+ keypoints[:, :, 1] = np.clip(keypoints[:, :, 1], 0,
+ results['img_shape'][0])
+ results['gt_keypoints'] = keypoints
+
+ def _record_homography_matrix(self, results: dict) -> None:
+ """Record the homography matrix for the Resize."""
+ w_scale, h_scale = results['scale_factor']
+ homography_matrix = np.array(
+ [[w_scale, 0, 0], [0, h_scale, 0], [0, 0, 1]], dtype=np.float32)
+ if results.get('homography_matrix', None) is None:
+ results['homography_matrix'] = homography_matrix
+ else:
+ results['homography_matrix'] = homography_matrix @ results[
+ 'homography_matrix']
+
+ @autocast_box_type()
+ def transform(self, results: dict) -> dict:
+ """Transform function to resize images, bounding boxes and semantic
+ segmentation map.
+
+ Args:
+ results (dict): Result dict from loading pipeline.
+ Returns:
+ dict: Resized results, 'img', 'gt_bboxes', 'gt_seg_map',
+ 'scale', 'scale_factor', 'height', 'width', and 'keep_ratio' keys
+ are updated in result dict.
+ """
+ if self.scale:
+ results['scale'] = self.scale
+ else:
+ img_shape = results['img'].shape[:2]
+ results['scale'] = _scale_size(img_shape[::-1], self.scale_factor)
+ self._resize_img(results)
+ self._resize_bboxes(results)
+ self._resize_masks(results)
+ self._resize_seg(results)
+ self._record_homography_matrix(results)
+ return results
+
+ def __repr__(self) -> str:
+ repr_str = self.__class__.__name__
+ repr_str += f'(scale={self.scale}, '
+ repr_str += f'scale_factor={self.scale_factor}, '
+ repr_str += f'keep_ratio={self.keep_ratio}, '
+ repr_str += f'clip_object_border={self.clip_object_border}), '
+ repr_str += f'backend={self.backend}), '
+ repr_str += f'interpolation={self.interpolation})'
+ return repr_str
+
+
+@TRANSFORMS.register_module()
+class ResizePiexlTarget(BaseTransform):
+ """Resize images & bbox & seg & keypoints.
+
+ This transform resizes the input image according to ``scale`` or
+ ``scale_factor``. Bboxes, seg map and keypoints are then resized with the
+ same scale factor.
+ if ``scale`` and ``scale_factor`` are both set, it will use ``scale`` to
+ resize.
+
+ Required Keys:
+
+ - img
+ - gt_bboxes (optional)
+ - gt_seg_map (optional)
+ - gt_keypoints (optional)
+
+ Modified Keys:
+
+ - img
+ - gt_bboxes
+ - gt_seg_map
+ - gt_keypoints
+ - img_shape
+
+ Added Keys:
+
+ - scale
+ - scale_factor
+ - keep_ratio
+
+ Args:
+ scale (int or tuple): Images scales for resizing. Defaults to None
+ scale_factor (float or tuple[float]): Scale factors for resizing.
+ Defaults to None.
+ keep_ratio (bool): Whether to keep the aspect ratio when resizing the
+ image. Defaults to False.
+ clip_object_border (bool): Whether to clip the objects
+ outside the border of the image. In some dataset like MOT17, the gt
+ bboxes are allowed to cross the border of images. Therefore, we
+ don't need to clip the gt bboxes in these cases. Defaults to True.
+ backend (str): Image resize backend, choices are 'cv2' and 'pillow'.
+ These two backends generates slightly different results. Defaults
+ to 'cv2'.
+ interpolation (str): Interpolation method, accepted values are
+ "nearest", "bilinear", "bicubic", "area", "lanczos" for 'cv2'
+ backend, "nearest", "bilinear" for 'pillow' backend. Defaults
+ to 'bilinear'.
+ """
+
+ def __init__(self,
+ scale_factor: float = 1.0,
+ clip_object_border: bool = True,) -> None:
+ self.clip_object_border = clip_object_border
+ self.scale_factor = scale_factor
+ self.keep_ratio = True
+
+ def _resize_img(self, results: dict) -> None:
+ """Resize images with ``results['scale']``."""
+ h, w = results['img'].shape[:2]
+ new_size = _scale_size((w, h), self.scale_factor)
+ img, w_scale, h_scale = hsiresize(results['img'], new_size, return_scale=True,)
+ results['img'] = img
+ results['img_shape'] = img.shape[:2]
+ results['scale_factor'] = (w_scale, h_scale)
+ results['keep_ratio'] = self.keep_ratio
+
+ def _resize_bboxes(self, results: dict) -> None:
+ """Resize bounding boxes with ``results['scale_factor']``."""
+ if results.get('gt_bboxes', None) is not None:
+ results['gt_bboxes'].rescale_(results['scale_factor'])
+ if self.clip_object_border:
+ results['gt_bboxes'].clip_(results['img_shape'])
+
+ def _resize_masks(self, results: dict) -> None:
+ """Resize masks with ``results['scale']``"""
+ if results.get('gt_masks', None) is not None:
+ if self.keep_ratio:
+ results['gt_masks'] = results['gt_masks'].rescale(
+ results['scale'])
+ else:
+ results['gt_masks'] = results['gt_masks'].resize(
+ results['img_shape'])
+
+ def _resize_seg(self, results: dict) -> None:
+ """Resize semantic segmentation map with ``results['scale']``."""
+ if results.get('gt_seg', None) is not None:
+ h, w = results['gt_seg'].shape[:2]
+ new_size = _scale_size((w, h), self.scale_factor)
+ gt_seg = hsiresize(results['gt_seg'], new_size, return_scale=False,)
+ results['gt_seg'] = gt_seg
+
+ def _resize_abu(self, results: dict) -> None:
+ """Resize semantic segmentation map with ``results['scale']``."""
+ if results.get('gt_abu', None) is not None:
+ h, w = results['gt_abu'].shape[:2]
+ new_size = _scale_size((w, h), self.scale_factor)
+ gt_abu = hsiresize(results['gt_abu'], new_size, return_scale=False,)
+ results['gt_abu'] = gt_abu
+
+ def _record_homography_matrix(self, results: dict) -> None:
+ """Record the homography matrix for the Resize."""
+ w_scale, h_scale = results['scale_factor']
+ homography_matrix = np.array(
+ [[w_scale, 0, 0], [0, h_scale, 0], [0, 0, 1]], dtype=np.float32)
+ if results.get('homography_matrix', None) is None:
+ results['homography_matrix'] = homography_matrix
+ else:
+ results['homography_matrix'] = homography_matrix @ results[
+ 'homography_matrix']
+
+ def transform(self, results: dict) -> dict:
+ """Transform function to resize images, bounding boxes, semantic
+ segmentation map and keypoints.
+
+ Args:
+ results (dict): Result dict from loading pipeline.
+ Returns:
+ dict: Resized results, 'img', 'gt_bboxes', 'gt_seg_map',
+ 'gt_keypoints', 'scale', 'scale_factor', 'img_shape',
+ and 'keep_ratio' keys are updated in result dict.
+ """
+
+ # if self.scale:
+ # results['scale'] = self.scale
+ # else:
+ img_shape = results['img'].shape[:2]
+ results['scale'] = _scale_size(img_shape[::-1],
+ self.scale_factor) # type: ignore
+ self._resize_img(results)
+ self._resize_bboxes(results)
+ self._resize_masks(results)
+ self._resize_seg(results)
+ self._resize_abu(results)
+ self._record_homography_matrix(results)
+ return results
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ repr_str += f'scale_factor={self.scale_factor}, '
+ return repr_str
+
diff --git a/mmdet/datasets/transforms/hsi/irfly_load.py b/mmdet/datasets/transforms/hsi/irfly_load.py
new file mode 100644
index 0000000000000000000000000000000000000000..4bf3ed6e506b221c692ebcc4cc674a4a19195829
--- /dev/null
+++ b/mmdet/datasets/transforms/hsi/irfly_load.py
@@ -0,0 +1,118 @@
+from typing import Optional, Tuple, Union
+
+import matplotlib.pyplot as plt
+import tifffile
+import torch
+import numpy as np
+import mmcv
+from mmcv.transforms import to_tensor
+from mmcv.transforms.base import BaseTransform
+from mmengine.structures import InstanceData, PixelData
+from mmdet.registry import TRANSFORMS
+from mmdet.structures import DetDataSample
+from mmdet.structures.bbox import BaseBoxes
+import mmengine.fileio as fileio
+
+
+def irflyfromfile(img_path, img_num=1,repeat =1) -> np.ndarray:
+ """Read an image from bytes.
+
+ Args:
+ backend (str | None): The image decoding backend type.
+ Returns:
+ ndarray: Loaded image array.
+
+ Examples:
+ """
+
+ with tifffile.TiffFile(img_path) as tif:
+ img = tif.asarray()
+ img = np.expand_dims(img, axis=-1)
+ img_name = img_path.split('/')[-1]
+ try:
+ img_id = int(img_name.split('.')[0])
+ except:
+ img_id = 1
+ for i in range(1, img_num):
+ img_id_i = img_id - 1
+ img_name_i = str(img_id_i).zfill(6)+'.tiff'
+ img_path_i = img_path.replace(img_name, img_name_i)
+ with tifffile.TiffFile(img_path_i) as tif:
+ img_i = tif.asarray()
+ img_i = np.expand_dims(img_i, axis=-1)
+ img = np.concatenate((img_i, img), axis=-1)
+ img = np.repeat(img,repeat,axis=-1)
+ return img
+
+@TRANSFORMS.register_module()
+class LoadIRFlyImageFromFiles(BaseTransform):
+ """Load multi-channel images from a list of separate channel files.
+
+ Required Keys:
+
+ - img_path
+
+ Modified Keys:
+
+ - img
+ - img_shape
+ - ori_shape
+
+ Args:
+ to_float32 (bool): Whether to convert the loaded image to a float32
+ numpy array. If set to False, the loaded image is an uint8 array.
+ Defaults to False.
+ """
+
+ def __init__(
+ self,
+ to_float32: bool = False,
+ image_num: int = 1,
+ repeat: int =1,
+ normalized_basis = None,
+ ) -> None:
+ self.to_float32 = to_float32
+ self.image_num = image_num
+ self.repeat = repeat
+ self.normalized_basis = normalized_basis
+
+ def transform(self, results: dict) -> dict:
+ """Transform functions to load multiple images and get images meta
+ information.
+
+ Args:
+ results (dict): Result dict from :obj:`mmdet.CustomDataset`.
+
+ Returns:
+ dict: The dict contains loaded images and meta information.
+ """
+
+ img = irflyfromfile(results['img_path'],img_num = self.image_num, repeat=self.repeat)
+ # up_limit = 3500
+ # low_limit = 600
+ # new_img = (img - low_limit) / up_limit
+ # new_img[new_img > 1] = 1
+ # new_img[new_img < 0] = 0
+ # img = new_img * 255
+ if self.normalized_basis == None:
+ img = img/1500
+ else:
+ img = img/np.array(self.normalized_basis)
+ if self.to_float32:
+ img = img.astype(np.float32)
+
+ results['img'] = img
+ results['img_shape'] = img.shape[:2]
+ results['ori_shape'] = img.shape[:2]
+ return results
+
+ def __repr__(self):
+ repr_str = (f'{self.__class__.__name__}('
+ f'to_float32={self.to_float32}, ')
+ return repr_str
+
+
+
+
+
+
diff --git a/mmdet/datasets/transforms/hsi/sirst_load.py b/mmdet/datasets/transforms/hsi/sirst_load.py
new file mode 100644
index 0000000000000000000000000000000000000000..e1c224115f9f052225fde4ecf4873396eee0955d
--- /dev/null
+++ b/mmdet/datasets/transforms/hsi/sirst_load.py
@@ -0,0 +1,108 @@
+import random
+from typing import Optional, Tuple, Union
+
+import torch
+import numpy as np
+import mmcv
+from mmcv.transforms import to_tensor
+from mmcv.transforms.base import BaseTransform
+from mmengine.structures import InstanceData, PixelData
+from mmdet.registry import TRANSFORMS
+from mmdet.structures import DetDataSample
+from mmdet.structures.bbox import BaseBoxes
+import mmengine.fileio as fileio
+import cv2
+import matplotlib.pyplot as plt
+
+# def hsifromfile(img_path, backend='npy' ) -> np.ndarray:
+# """Read an image from bytes.
+#
+# Args:
+# backend (str | None): The image decoding backend type.
+# Returns:
+# ndarray: Loaded image array.
+#
+# Examples:
+# """
+# if backend =='npy':
+# img = np.load(img_path)
+# return img
+
+@TRANSFORMS.register_module()
+class LoadSIRSTImageFromFiles(BaseTransform):
+ """Load multi-channel images from a list of separate channel files.
+
+ Required Keys:
+
+ - img_path
+
+ Modified Keys:
+
+ - img
+ - img_shape
+ - ori_shape
+
+ Args:
+ to_float32 (bool): Whether to convert the loaded image to a float32
+ numpy array. If set to False, the loaded image is an uint8 array.
+ Defaults to False.
+ """
+
+ def __init__(
+ self,
+ to_float32: bool = False,
+ normalized_basis = None,
+ range_change = False,
+ ) -> None:
+ self.to_float32 = to_float32
+ self.normalized_basis = normalized_basis
+ self.range_change = range_change
+ def transform(self, results: dict) -> dict:
+ """Transform functions to load multiple images and get images meta
+ information.
+
+ Args:
+ results (dict): Result dict from :obj:`mmdet.CustomDataset`.
+
+ Returns:
+ dict: The dict contains loaded images and meta information.
+ """
+
+ # img = hsifromfile(results['img_path'])
+ img = plt.imread(results['img_path'])
+ # up_limit = 3500
+ # low_limit = 600
+ # new_img = (img - low_limit) / up_limit
+ # new_img[new_img > 1] = 1
+ # new_img[new_img < 0] = 0
+ # img = new_img * 255
+ # if self.normalized_basis == None:
+ # img = img/500
+ # else:
+ # img = img/255
+ # img = img[:,:,0]
+ if len(img.shape) == 2:
+ img = np.repeat(np.expand_dims(img, axis=-1), 3, axis=-1)
+ # print(img.shape)
+ if img.shape[-1] !=3:
+ img = img[:,:,:3]
+ if self.to_float32:
+ img = img.astype(np.float32)
+ img = (img-np.min(img))/(np.max(img)-np.min(img)+1e-8)
+ if self.range_change ==True:
+ img = (0.7+random.random()*0.3)*img
+ # img = img + random.random()*0.2
+ results['img'] = img
+ results['img_shape'] = img.shape[:2]
+ results['ori_shape'] = img.shape[:2]
+ return results
+
+ def __repr__(self):
+ repr_str = (f'{self.__class__.__name__}('
+ f'to_float32={self.to_float32}, ')
+ return repr_str
+
+
+
+
+
diff --git a/mmdet/datasets/transforms/instaboost.py b/mmdet/datasets/transforms/instaboost.py
new file mode 100644
index 0000000000000000000000000000000000000000..30dc1603643ec8d398bfade95f5ec1c9b8f89c8d
--- /dev/null
+++ b/mmdet/datasets/transforms/instaboost.py
@@ -0,0 +1,150 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Tuple
+
+import numpy as np
+from mmcv.transforms import BaseTransform
+
+from mmdet.registry import TRANSFORMS
+
+
+@TRANSFORMS.register_module()
+class InstaBoost(BaseTransform):
+ r"""Data augmentation method in `InstaBoost: Boosting Instance
+ Segmentation Via Probability Map Guided Copy-Pasting
+ `_.
+
+ Refer to https://github.com/GothicAi/Instaboost for implementation details.
+
+
+ Required Keys:
+
+ - img (np.uint8)
+ - instances
+
+ Modified Keys:
+
+ - img (np.uint8)
+ - instances
+
+ Args:
+ action_candidate (tuple): Action candidates. "normal", "horizontal", \
+ "vertical", "skip" are supported. Defaults to ('normal', \
+ 'horizontal', 'skip').
+ action_prob (tuple): Corresponding action probabilities. Should be \
+ the same length as action_candidate. Defaults to (1, 0, 0).
+ scale (tuple): (min scale, max scale). Defaults to (0.8, 1.2).
+ dx (int): The maximum x-axis shift will be (instance width) / dx.
+ Defaults to 15.
+ dy (int): The maximum y-axis shift will be (instance height) / dy.
+ Defaults to 15.
+ theta (tuple): (min rotation degree, max rotation degree). \
+ Defaults to (-1, 1).
+ color_prob (float): Probability of images for color augmentation.
+ Defaults to 0.5.
+ hflag (bool): Whether to use heatmap guided. Defaults to False.
+ aug_ratio (float): Probability of applying this transformation. \
+ Defaults to 0.5.
+ """
+
+ def __init__(self,
+ action_candidate: tuple = ('normal', 'horizontal', 'skip'),
+ action_prob: tuple = (1, 0, 0),
+ scale: tuple = (0.8, 1.2),
+ dx: int = 15,
+ dy: int = 15,
+ theta: tuple = (-1, 1),
+ color_prob: float = 0.5,
+ hflag: bool = False,
+ aug_ratio: float = 0.5) -> None:
+
+ import matplotlib
+ import matplotlib.pyplot as plt
+ default_backend = plt.get_backend()
+
+ try:
+ import instaboostfast as instaboost
+ except ImportError:
+ raise ImportError(
+ 'Please run "pip install instaboostfast" '
+ 'to install instaboostfast first for instaboost augmentation.')
+
+ # instaboost will modify the default backend
+ # and cause visualization to fail.
+ matplotlib.use(default_backend)
+
+ self.cfg = instaboost.InstaBoostConfig(action_candidate, action_prob,
+ scale, dx, dy, theta,
+ color_prob, hflag)
+ self.aug_ratio = aug_ratio
+
+ def _load_anns(self, results: dict) -> Tuple[list, list]:
+ """Convert raw anns to instaboost expected input format."""
+ anns = []
+ ignore_anns = []
+ for instance in results['instances']:
+ label = instance['bbox_label']
+ bbox = instance['bbox']
+ mask = instance['mask']
+ x1, y1, x2, y2 = bbox
+ # assert (x2 - x1) >= 1 and (y2 - y1) >= 1
+ bbox = [x1, y1, x2 - x1, y2 - y1]
+
+ if instance['ignore_flag'] == 0:
+ anns.append({
+ 'category_id': label,
+ 'segmentation': mask,
+ 'bbox': bbox
+ })
+ else:
+ # Ignore instances without data augmentation
+ ignore_anns.append(instance)
+ return anns, ignore_anns
+
+ def _parse_anns(self, results: dict, anns: list, ignore_anns: list,
+ img: np.ndarray) -> dict:
+ """Restore the result of instaboost processing to the original anns
+ format."""
+ instances = []
+ for ann in anns:
+ x1, y1, w, h = ann['bbox']
+ # TODO: more essential bug need to be fixed in instaboost
+ if w <= 0 or h <= 0:
+ continue
+ bbox = [x1, y1, x1 + w, y1 + h]
+ instances.append(
+ dict(
+ bbox=bbox,
+ bbox_label=ann['category_id'],
+ mask=ann['segmentation'],
+ ignore_flag=0))
+
+ instances.extend(ignore_anns)
+ results['img'] = img
+ results['instances'] = instances
+ return results
+
+ def transform(self, results) -> dict:
+ """The transform function."""
+ img = results['img']
+ ori_type = img.dtype
+ if 'instances' not in results or len(results['instances']) == 0:
+ return results
+
+ anns, ignore_anns = self._load_anns(results)
+ if np.random.choice([0, 1], p=[1 - self.aug_ratio, self.aug_ratio]):
+ try:
+ import instaboostfast as instaboost
+ except ImportError:
+ raise ImportError('Please run "pip install instaboostfast" '
+ 'to install instaboostfast first.')
+ anns, img = instaboost.get_new_data(
+ anns, img.astype(np.uint8), self.cfg, background=None)
+
+ results = self._parse_anns(results, anns, ignore_anns,
+ img.astype(ori_type))
+ return results
+
+ def __repr__(self) -> str:
+ repr_str = self.__class__.__name__
+ repr_str += f'(aug_ratio={self.aug_ratio})'
+ return repr_str
diff --git a/mmdet/datasets/transforms/loading.py b/mmdet/datasets/transforms/loading.py
new file mode 100644
index 0000000000000000000000000000000000000000..1a408e4d4ec3eab5b3b667e98b56f264b63d68ff
--- /dev/null
+++ b/mmdet/datasets/transforms/loading.py
@@ -0,0 +1,879 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Tuple, Union
+
+import mmcv
+import numpy as np
+import pycocotools.mask as maskUtils
+import torch
+from mmcv.transforms import BaseTransform
+from mmcv.transforms import LoadAnnotations as MMCV_LoadAnnotations
+from mmcv.transforms import LoadImageFromFile
+from mmengine.fileio import get
+from mmengine.structures import BaseDataElement
+
+from mmdet.registry import TRANSFORMS
+from mmdet.structures.bbox import get_box_type
+from mmdet.structures.bbox.box_type import autocast_box_type
+from mmdet.structures.mask import BitmapMasks, PolygonMasks
+
+
+@TRANSFORMS.register_module()
+class LoadImageFromNDArray(LoadImageFromFile):
+ """Load an image from ``results['img']``.
+
+ Similar with :obj:`LoadImageFromFile`, but the image has been loaded as
+ :obj:`np.ndarray` in ``results['img']``. Can be used when loading image
+ from webcam.
+
+ Required Keys:
+
+ - img
+
+ Modified Keys:
+
+ - img
+ - img_path
+ - img_shape
+ - ori_shape
+
+ Args:
+ to_float32 (bool): Whether to convert the loaded image to a float32
+ numpy array. If set to False, the loaded image is an uint8 array.
+ Defaults to False.
+ """
+
+ def transform(self, results: dict) -> dict:
+ """Transform function to add image meta information.
+
+ Args:
+ results (dict): Result dict with Webcam read image in
+ ``results['img']``.
+
+ Returns:
+ dict: The dict contains loaded image and meta information.
+ """
+
+ img = results['img']
+ if self.to_float32:
+ img = img.astype(np.float32)
+
+ results['img_path'] = None
+ results['img'] = img
+ results['img_shape'] = img.shape[:2]
+ results['ori_shape'] = img.shape[:2]
+ return results
+
+
+@TRANSFORMS.register_module()
+class LoadMultiChannelImageFromFiles(BaseTransform):
+ """Load multi-channel images from a list of separate channel files.
+
+ Required Keys:
+
+ - img_path
+
+ Modified Keys:
+
+ - img
+ - img_shape
+ - ori_shape
+
+ Args:
+ to_float32 (bool): Whether to convert the loaded image to a float32
+ numpy array. If set to False, the loaded image is an uint8 array.
+ Defaults to False.
+ color_type (str): The flag argument for :func:``mmcv.imfrombytes``.
+ Defaults to 'unchanged'.
+ imdecode_backend (str): The image decoding backend type. The backend
+ argument for :func:``mmcv.imfrombytes``.
+ See :func:``mmcv.imfrombytes`` for details.
+ Defaults to 'cv2'.
+ file_client_args (dict): Arguments to instantiate the
+ corresponding backend in mmdet <= 3.0.0rc6. Defaults to None.
+ backend_args (dict, optional): Arguments to instantiate the
+ corresponding backend in mmdet >= 3.0.0rc7. Defaults to None.
+ """
+
+ def __init__(
+ self,
+ to_float32: bool = False,
+ color_type: str = 'unchanged',
+ imdecode_backend: str = 'cv2',
+ file_client_args: dict = None,
+ backend_args: dict = None,
+ ) -> None:
+ self.to_float32 = to_float32
+ self.color_type = color_type
+ self.imdecode_backend = imdecode_backend
+ self.backend_args = backend_args
+ if file_client_args is not None:
+ raise RuntimeError(
+ 'The `file_client_args` is deprecated, '
+ 'please use `backend_args` instead, please refer to'
+ 'https://github.com/open-mmlab/mmdetection/blob/main/configs/_base_/datasets/coco_detection.py' # noqa: E501
+ )
+
+ def transform(self, results: dict) -> dict:
+ """Transform functions to load multiple images and get images meta
+ information.
+
+ Args:
+ results (dict): Result dict from :obj:`mmdet.CustomDataset`.
+
+ Returns:
+ dict: The dict contains loaded images and meta information.
+ """
+
+ assert isinstance(results['img_path'], list)
+ img = []
+ for name in results['img_path']:
+ img_bytes = get(name, backend_args=self.backend_args)
+ img.append(
+ mmcv.imfrombytes(
+ img_bytes,
+ flag=self.color_type,
+ backend=self.imdecode_backend))
+ img = np.stack(img, axis=-1)
+ if self.to_float32:
+ img = img.astype(np.float32)
+
+ results['img'] = img
+ results['img_shape'] = img.shape[:2]
+ results['ori_shape'] = img.shape[:2]
+ return results
+
+ def __repr__(self):
+ repr_str = (f'{self.__class__.__name__}('
+ f'to_float32={self.to_float32}, '
+ f"color_type='{self.color_type}', "
+ f"imdecode_backend='{self.imdecode_backend}', "
+ f'backend_args={self.backend_args})')
+ return repr_str
+
+
+@TRANSFORMS.register_module()
+class LoadAnnotations(MMCV_LoadAnnotations):
+ """Load and process the ``instances`` and ``seg_map`` annotation provided
+ by dataset.
+
+ The annotation format is as the following:
+
+ .. code-block:: python
+
+ {
+ 'instances':
+ [
+ {
+ # List of 4 numbers representing the bounding box of the
+ # instance, in (x1, y1, x2, y2) order.
+ 'bbox': [x1, y1, x2, y2],
+
+ # Label of image classification.
+ 'bbox_label': 1,
+
+ # Used in instance/panoptic segmentation. The segmentation mask
+ # of the instance or the information of segments.
+ # 1. If list[list[float]], it represents a list of polygons,
+ # one for each connected component of the object. Each
+ # list[float] is one simple polygon in the format of
+ # [x1, y1, ..., xn, yn] (n≥3). The Xs and Ys are absolute
+ # coordinates in unit of pixels.
+ # 2. If dict, it represents the per-pixel segmentation mask in
+ # COCO’s compressed RLE format. The dict should have keys
+ # “size” and “counts”. Can be loaded by pycocotools
+ 'mask': list[list[float]] or dict,
+
+ }
+ ]
+ # Filename of semantic or panoptic segmentation ground truth file.
+ 'seg_map_path': 'a/b/c'
+ }
+
+ After this module, the annotation has been changed to the format below:
+
+ .. code-block:: python
+
+ {
+ # In (x1, y1, x2, y2) order, float type. N is the number of bboxes
+ # in an image
+ 'gt_bboxes': BaseBoxes(N, 4)
+ # In int type.
+ 'gt_bboxes_labels': np.ndarray(N, )
+ # In built-in class
+ 'gt_masks': PolygonMasks (H, W) or BitmapMasks (H, W)
+ # In uint8 type.
+ 'gt_seg_map': np.ndarray (H, W)
+ # in (x, y, v) order, float type.
+ }
+
+ Required Keys:
+
+ - height
+ - width
+ - instances
+
+ - bbox (optional)
+ - bbox_label
+ - mask (optional)
+ - ignore_flag
+
+ - seg_map_path (optional)
+
+ Added Keys:
+
+ - gt_bboxes (BaseBoxes[torch.float32])
+ - gt_bboxes_labels (np.int64)
+ - gt_masks (BitmapMasks | PolygonMasks)
+ - gt_seg_map (np.uint8)
+ - gt_ignore_flags (bool)
+
+ Args:
+ with_bbox (bool): Whether to parse and load the bbox annotation.
+ Defaults to True.
+ with_label (bool): Whether to parse and load the label annotation.
+ Defaults to True.
+ with_mask (bool): Whether to parse and load the mask annotation.
+ Default: False.
+ with_seg (bool): Whether to parse and load the semantic segmentation
+ annotation. Defaults to False.
+ poly2mask (bool): Whether to convert mask to bitmap. Default: True.
+ box_type (str): The box type used to wrap the bboxes. If ``box_type``
+ is None, gt_bboxes will keep being np.ndarray. Defaults to 'hbox'.
+ imdecode_backend (str): The image decoding backend type. The backend
+ argument for :func:``mmcv.imfrombytes``.
+ See :fun:``mmcv.imfrombytes`` for details.
+ Defaults to 'cv2'.
+ backend_args (dict, optional): Arguments to instantiate the
+ corresponding backend. Defaults to None.
+ """
+
+ def __init__(self,
+ with_mask: bool = False,
+ poly2mask: bool = True,
+ box_type: str = 'hbox',
+ **kwargs) -> None:
+ super(LoadAnnotations, self).__init__(**kwargs)
+ self.with_mask = with_mask
+ self.poly2mask = poly2mask
+ self.box_type = box_type
+
+ def _load_bboxes(self, results: dict) -> None:
+ """Private function to load bounding box annotations.
+
+ Args:
+ results (dict): Result dict from :obj:``mmengine.BaseDataset``.
+ Returns:
+ dict: The dict contains loaded bounding box annotations.
+ """
+ gt_bboxes = []
+ gt_ignore_flags = []
+ for instance in results.get('instances', []):
+ gt_bboxes.append(instance['bbox'])
+ gt_ignore_flags.append(instance['ignore_flag'])
+ if self.box_type is None:
+ results['gt_bboxes'] = np.array(
+ gt_bboxes, dtype=np.float32).reshape((-1, 4))
+ else:
+ _, box_type_cls = get_box_type(self.box_type)
+ results['gt_bboxes'] = box_type_cls(gt_bboxes, dtype=torch.float32)
+ results['gt_ignore_flags'] = np.array(gt_ignore_flags, dtype=bool)
+
+ def _load_labels(self, results: dict) -> None:
+ """Private function to load label annotations.
+
+ Args:
+ results (dict): Result dict from :obj:``mmengine.BaseDataset``.
+
+ Returns:
+ dict: The dict contains loaded label annotations.
+ """
+ gt_bboxes_labels = []
+ for instance in results.get('instances', []):
+ gt_bboxes_labels.append(instance['bbox_label'])
+ # TODO: Inconsistent with mmcv, consider how to deal with it later.
+ results['gt_bboxes_labels'] = np.array(
+ gt_bboxes_labels, dtype=np.int64)
+
+ def _poly2mask(self, mask_ann: Union[list, dict], img_h: int,
+ img_w: int) -> np.ndarray:
+ """Private function to convert masks represented with polygon to
+ bitmaps.
+
+ Args:
+ mask_ann (list | dict): Polygon mask annotation input.
+ img_h (int): The height of output mask.
+ img_w (int): The width of output mask.
+
+ Returns:
+ np.ndarray: The decode bitmap mask of shape (img_h, img_w).
+ """
+
+ if isinstance(mask_ann, list):
+ # polygon -- a single object might consist of multiple parts
+ # we merge all parts into one mask rle code
+ rles = maskUtils.frPyObjects(mask_ann, img_h, img_w)
+ rle = maskUtils.merge(rles)
+ elif isinstance(mask_ann['counts'], list):
+ # uncompressed RLE
+ rle = maskUtils.frPyObjects(mask_ann, img_h, img_w)
+ else:
+ # rle
+ rle = mask_ann
+ mask = maskUtils.decode(rle)
+ return mask
+
+ def _process_masks(self, results: dict) -> list:
+ """Process gt_masks and filter invalid polygons.
+
+ Args:
+ results (dict): Result dict from :obj:``mmengine.BaseDataset``.
+
+ Returns:
+ list: Processed gt_masks.
+ """
+ gt_masks = []
+ gt_ignore_flags = []
+ for instance in results.get('instances', []):
+ gt_mask = instance['mask']
+ # If the annotation of segmentation mask is invalid,
+ # ignore the whole instance.
+ if isinstance(gt_mask, list):
+ gt_mask = [
+ np.array(polygon) for polygon in gt_mask
+ if len(polygon) % 2 == 0 and len(polygon) >= 6
+ ]
+ if len(gt_mask) == 0:
+ # ignore this instance and set gt_mask to a fake mask
+ instance['ignore_flag'] = 1
+ gt_mask = [np.zeros(6)]
+ elif not self.poly2mask:
+ # `PolygonMasks` requires a ploygon of format List[np.array],
+ # other formats are invalid.
+ instance['ignore_flag'] = 1
+ gt_mask = [np.zeros(6)]
+ elif isinstance(gt_mask, dict) and \
+ not (gt_mask.get('counts') is not None and
+ gt_mask.get('size') is not None and
+ isinstance(gt_mask['counts'], (list, str))):
+ # if gt_mask is a dict, it should include `counts` and `size`,
+ # so that `BitmapMasks` can uncompressed RLE
+ instance['ignore_flag'] = 1
+ gt_mask = [np.zeros(6)]
+ gt_masks.append(gt_mask)
+ # re-process gt_ignore_flags
+ gt_ignore_flags.append(instance['ignore_flag'])
+ results['gt_ignore_flags'] = np.array(gt_ignore_flags, dtype=bool)
+ return gt_masks
+
+ def _load_masks(self, results: dict) -> None:
+ """Private function to load mask annotations.
+
+ Args:
+ results (dict): Result dict from :obj:``mmengine.BaseDataset``.
+ """
+ h, w = results['ori_shape']
+ gt_masks = self._process_masks(results)
+ if self.poly2mask:
+ gt_masks = BitmapMasks(
+ [self._poly2mask(mask, h, w) for mask in gt_masks], h, w)
+ else:
+ # fake polygon masks will be ignored in `PackDetInputs`
+ gt_masks = PolygonMasks([mask for mask in gt_masks], h, w)
+ results['gt_masks'] = gt_masks
+
+ def transform(self, results: dict) -> dict:
+ """Function to load multiple types annotations.
+
+ Args:
+ results (dict): Result dict from :obj:``mmengine.BaseDataset``.
+
+ Returns:
+ dict: The dict contains loaded bounding box, label and
+ semantic segmentation.
+ """
+
+ if self.with_bbox:
+ self._load_bboxes(results)
+ if self.with_label:
+ self._load_labels(results)
+ if self.with_mask:
+ self._load_masks(results)
+ if self.with_seg:
+ self._load_seg_map(results)
+ return results
+
+ def __repr__(self) -> str:
+ repr_str = self.__class__.__name__
+ repr_str += f'(with_bbox={self.with_bbox}, '
+ repr_str += f'with_label={self.with_label}, '
+ repr_str += f'with_mask={self.with_mask}, '
+ repr_str += f'with_seg={self.with_seg}, '
+ repr_str += f'poly2mask={self.poly2mask}, '
+ repr_str += f"imdecode_backend='{self.imdecode_backend}', "
+ repr_str += f'backend_args={self.backend_args})'
+ return repr_str
+
+
+@TRANSFORMS.register_module()
+class LoadPanopticAnnotations(LoadAnnotations):
+ """Load multiple types of panoptic annotations.
+
+ The annotation format is as the following:
+
+ .. code-block:: python
+
+ {
+ 'instances':
+ [
+ {
+ # List of 4 numbers representing the bounding box of the
+ # instance, in (x1, y1, x2, y2) order.
+ 'bbox': [x1, y1, x2, y2],
+
+ # Label of image classification.
+ 'bbox_label': 1,
+ },
+ ...
+ ]
+ 'segments_info':
+ [
+ {
+ # id = cls_id + instance_id * INSTANCE_OFFSET
+ 'id': int,
+
+ # Contiguous category id defined in dataset.
+ 'category': int
+
+ # Thing flag.
+ 'is_thing': bool
+ },
+ ...
+ ]
+
+ # Filename of semantic or panoptic segmentation ground truth file.
+ 'seg_map_path': 'a/b/c'
+ }
+
+ After this module, the annotation has been changed to the format below:
+
+ .. code-block:: python
+
+ {
+ # In (x1, y1, x2, y2) order, float type. N is the number of bboxes
+ # in an image
+ 'gt_bboxes': BaseBoxes(N, 4)
+ # In int type.
+ 'gt_bboxes_labels': np.ndarray(N, )
+ # In built-in class
+ 'gt_masks': PolygonMasks (H, W) or BitmapMasks (H, W)
+ # In uint8 type.
+ 'gt_seg_map': np.ndarray (H, W)
+ # in (x, y, v) order, float type.
+ }
+
+ Required Keys:
+
+ - height
+ - width
+ - instances
+ - bbox
+ - bbox_label
+ - ignore_flag
+ - segments_info
+ - id
+ - category
+ - is_thing
+ - seg_map_path
+
+ Added Keys:
+
+ - gt_bboxes (BaseBoxes[torch.float32])
+ - gt_bboxes_labels (np.int64)
+ - gt_masks (BitmapMasks | PolygonMasks)
+ - gt_seg_map (np.uint8)
+ - gt_ignore_flags (bool)
+
+ Args:
+ with_bbox (bool): Whether to parse and load the bbox annotation.
+ Defaults to True.
+ with_label (bool): Whether to parse and load the label annotation.
+ Defaults to True.
+ with_mask (bool): Whether to parse and load the mask annotation.
+ Defaults to True.
+ with_seg (bool): Whether to parse and load the semantic segmentation
+ annotation. Defaults to False.
+ box_type (str): The box mode used to wrap the bboxes.
+ imdecode_backend (str): The image decoding backend type. The backend
+ argument for :func:``mmcv.imfrombytes``.
+ See :fun:``mmcv.imfrombytes`` for details.
+ Defaults to 'cv2'.
+ backend_args (dict, optional): Arguments to instantiate the
+ corresponding backend in mmdet >= 3.0.0rc7. Defaults to None.
+ """
+
+ def __init__(self,
+ with_bbox: bool = True,
+ with_label: bool = True,
+ with_mask: bool = True,
+ with_seg: bool = True,
+ box_type: str = 'hbox',
+ imdecode_backend: str = 'cv2',
+ backend_args: dict = None) -> None:
+ try:
+ from panopticapi import utils
+ except ImportError:
+ raise ImportError(
+ 'panopticapi is not installed, please install it by: '
+ 'pip install git+https://github.com/cocodataset/'
+ 'panopticapi.git.')
+ self.rgb2id = utils.rgb2id
+
+ super(LoadPanopticAnnotations, self).__init__(
+ with_bbox=with_bbox,
+ with_label=with_label,
+ with_mask=with_mask,
+ with_seg=with_seg,
+ with_keypoints=False,
+ box_type=box_type,
+ imdecode_backend=imdecode_backend,
+ backend_args=backend_args)
+
+ def _load_masks_and_semantic_segs(self, results: dict) -> None:
+ """Private function to load mask and semantic segmentation annotations.
+
+ In gt_semantic_seg, the foreground label is from ``0`` to
+ ``num_things - 1``, the background label is from ``num_things`` to
+ ``num_things + num_stuff - 1``, 255 means the ignored label (``VOID``).
+
+ Args:
+ results (dict): Result dict from :obj:``mmdet.CustomDataset``.
+ """
+ # seg_map_path is None, when inference on the dataset without gts.
+ if results.get('seg_map_path', None) is None:
+ return
+
+ img_bytes = get(
+ results['seg_map_path'], backend_args=self.backend_args)
+ pan_png = mmcv.imfrombytes(
+ img_bytes, flag='color', channel_order='rgb').squeeze()
+ pan_png = self.rgb2id(pan_png)
+
+ gt_masks = []
+ gt_seg = np.zeros_like(pan_png) + 255 # 255 as ignore
+
+ for segment_info in results['segments_info']:
+ mask = (pan_png == segment_info['id'])
+ gt_seg = np.where(mask, segment_info['category'], gt_seg)
+
+ # The legal thing masks
+ if segment_info.get('is_thing'):
+ gt_masks.append(mask.astype(np.uint8))
+
+ if self.with_mask:
+ h, w = results['ori_shape']
+ gt_masks = BitmapMasks(gt_masks, h, w)
+ results['gt_masks'] = gt_masks
+
+ if self.with_seg:
+ results['gt_seg_map'] = gt_seg
+
+ def transform(self, results: dict) -> dict:
+ """Function to load multiple types panoptic annotations.
+
+ Args:
+ results (dict): Result dict from :obj:``mmdet.CustomDataset``.
+
+ Returns:
+ dict: The dict contains loaded bounding box, label, mask and
+ semantic segmentation annotations.
+ """
+
+ if self.with_bbox:
+ self._load_bboxes(results)
+ if self.with_label:
+ self._load_labels(results)
+ if self.with_mask or self.with_seg:
+ # The tasks completed by '_load_masks' and '_load_semantic_segs'
+ # in LoadAnnotations are merged to one function.
+ self._load_masks_and_semantic_segs(results)
+
+ return results
+
+
+@TRANSFORMS.register_module()
+class LoadProposals(BaseTransform):
+ """Load proposal pipeline.
+
+ Required Keys:
+
+ - proposals
+
+ Modified Keys:
+
+ - proposals
+
+ Args:
+ num_max_proposals (int, optional): Maximum number of proposals to load.
+ If not specified, all proposals will be loaded.
+ """
+
+ def __init__(self, num_max_proposals: Optional[int] = None) -> None:
+ self.num_max_proposals = num_max_proposals
+
+ def transform(self, results: dict) -> dict:
+ """Transform function to load proposals from file.
+
+ Args:
+ results (dict): Result dict from :obj:`mmdet.CustomDataset`.
+
+ Returns:
+ dict: The dict contains loaded proposal annotations.
+ """
+
+ proposals = results['proposals']
+ # the type of proposals should be `dict` or `InstanceData`
+ assert isinstance(proposals, dict) \
+ or isinstance(proposals, BaseDataElement)
+ bboxes = proposals['bboxes'].astype(np.float32)
+ assert bboxes.shape[1] == 4, \
+ f'Proposals should have shapes (n, 4), but found {bboxes.shape}'
+
+ if 'scores' in proposals:
+ scores = proposals['scores'].astype(np.float32)
+ assert bboxes.shape[0] == scores.shape[0]
+ else:
+ scores = np.zeros(bboxes.shape[0], dtype=np.float32)
+
+ if self.num_max_proposals is not None:
+ # proposals should sort by scores during dumping the proposals
+ bboxes = bboxes[:self.num_max_proposals]
+ scores = scores[:self.num_max_proposals]
+
+ if len(bboxes) == 0:
+ bboxes = np.zeros((0, 4), dtype=np.float32)
+ scores = np.zeros(0, dtype=np.float32)
+
+ results['proposals'] = bboxes
+ results['proposals_scores'] = scores
+ return results
+
+ def __repr__(self):
+ return self.__class__.__name__ + \
+ f'(num_max_proposals={self.num_max_proposals})'
+
+
+@TRANSFORMS.register_module()
+class FilterAnnotations(BaseTransform):
+ """Filter invalid annotations.
+
+ Required Keys:
+
+ - gt_bboxes (BaseBoxes[torch.float32]) (optional)
+ - gt_bboxes_labels (np.int64) (optional)
+ - gt_masks (BitmapMasks | PolygonMasks) (optional)
+ - gt_ignore_flags (bool) (optional)
+
+ Modified Keys:
+
+ - gt_bboxes (optional)
+ - gt_bboxes_labels (optional)
+ - gt_masks (optional)
+ - gt_ignore_flags (optional)
+
+ Args:
+ min_gt_bbox_wh (tuple[float]): Minimum width and height of ground truth
+ boxes. Default: (1., 1.)
+ min_gt_mask_area (int): Minimum foreground area of ground truth masks.
+ Default: 1
+ by_box (bool): Filter instances with bounding boxes not meeting the
+ min_gt_bbox_wh threshold. Default: True
+ by_mask (bool): Filter instances with masks not meeting
+ min_gt_mask_area threshold. Default: False
+ keep_empty (bool): Whether to return None when it
+ becomes an empty bbox after filtering. Defaults to True.
+ """
+
+ def __init__(self,
+ min_gt_bbox_wh: Tuple[int, int] = (1, 1),
+ min_gt_mask_area: int = 1,
+ by_box: bool = True,
+ by_mask: bool = False,
+ keep_empty: bool = True) -> None:
+ # TODO: add more filter options
+ assert by_box or by_mask
+ self.min_gt_bbox_wh = min_gt_bbox_wh
+ self.min_gt_mask_area = min_gt_mask_area
+ self.by_box = by_box
+ self.by_mask = by_mask
+ self.keep_empty = keep_empty
+
+ @autocast_box_type()
+ def transform(self, results: dict) -> Union[dict, None]:
+ """Transform function to filter annotations.
+
+ Args:
+ results (dict): Result dict.
+
+ Returns:
+ dict: Updated result dict.
+ """
+ assert 'gt_bboxes' in results
+ gt_bboxes = results['gt_bboxes']
+ if gt_bboxes.shape[0] == 0:
+ return results
+
+ tests = []
+ if self.by_box:
+ tests.append(
+ ((gt_bboxes.widths > self.min_gt_bbox_wh[0]) &
+ (gt_bboxes.heights > self.min_gt_bbox_wh[1])).numpy())
+ if self.by_mask:
+ assert 'gt_masks' in results
+ gt_masks = results['gt_masks']
+ tests.append(gt_masks.areas >= self.min_gt_mask_area)
+
+ keep = tests[0]
+ for t in tests[1:]:
+ keep = keep & t
+
+ if not keep.any():
+ if self.keep_empty:
+ return None
+
+ keys = ('gt_bboxes', 'gt_bboxes_labels', 'gt_masks', 'gt_ignore_flags')
+ for key in keys:
+ if key in results:
+ results[key] = results[key][keep]
+
+ return results
+
+ def __repr__(self):
+ return self.__class__.__name__ + \
+ f'(min_gt_bbox_wh={self.min_gt_bbox_wh}, ' \
+ f'keep_empty={self.keep_empty})'
+
+
+@TRANSFORMS.register_module()
+class LoadEmptyAnnotations(BaseTransform):
+ """Load Empty Annotations for unlabeled images.
+
+ Added Keys:
+ - gt_bboxes (np.float32)
+ - gt_bboxes_labels (np.int64)
+ - gt_masks (BitmapMasks | PolygonMasks)
+ - gt_seg_map (np.uint8)
+ - gt_ignore_flags (bool)
+
+ Args:
+ with_bbox (bool): Whether to load the pseudo bbox annotation.
+ Defaults to True.
+ with_label (bool): Whether to load the pseudo label annotation.
+ Defaults to True.
+ with_mask (bool): Whether to load the pseudo mask annotation.
+ Default: False.
+ with_seg (bool): Whether to load the pseudo semantic segmentation
+ annotation. Defaults to False.
+ seg_ignore_label (int): The fill value used for segmentation map.
+ Note this value must equals ``ignore_label`` in ``semantic_head``
+ of the corresponding config. Defaults to 255.
+ """
+
+ def __init__(self,
+ with_bbox: bool = True,
+ with_label: bool = True,
+ with_mask: bool = False,
+ with_seg: bool = False,
+ seg_ignore_label: int = 255) -> None:
+ self.with_bbox = with_bbox
+ self.with_label = with_label
+ self.with_mask = with_mask
+ self.with_seg = with_seg
+ self.seg_ignore_label = seg_ignore_label
+
+ def transform(self, results: dict) -> dict:
+ """Transform function to load empty annotations.
+
+ Args:
+ results (dict): Result dict.
+ Returns:
+ dict: Updated result dict.
+ """
+ if self.with_bbox:
+ results['gt_bboxes'] = np.zeros((0, 4), dtype=np.float32)
+ results['gt_ignore_flags'] = np.zeros((0, ), dtype=bool)
+ if self.with_label:
+ results['gt_bboxes_labels'] = np.zeros((0, ), dtype=np.int64)
+ if self.with_mask:
+ # TODO: support PolygonMasks
+ h, w = results['img_shape']
+ gt_masks = np.zeros((0, h, w), dtype=np.uint8)
+ results['gt_masks'] = BitmapMasks(gt_masks, h, w)
+ if self.with_seg:
+ h, w = results['img_shape']
+ results['gt_seg_map'] = self.seg_ignore_label * np.ones(
+ (h, w), dtype=np.uint8)
+ return results
+
+ def __repr__(self) -> str:
+ repr_str = self.__class__.__name__
+ repr_str += f'(with_bbox={self.with_bbox}, '
+ repr_str += f'with_label={self.with_label}, '
+ repr_str += f'with_mask={self.with_mask}, '
+ repr_str += f'with_seg={self.with_seg}, '
+ repr_str += f'seg_ignore_label={self.seg_ignore_label})'
+ return repr_str
+
+
+@TRANSFORMS.register_module()
+class InferencerLoader(BaseTransform):
+ """Load an image from ``results['img']``.
+
+ Similar with :obj:`LoadImageFromFile`, but the image has been loaded as
+ :obj:`np.ndarray` in ``results['img']``. Can be used when loading image
+ from webcam.
+
+ Required Keys:
+
+ - img
+
+ Modified Keys:
+
+ - img
+ - img_path
+ - img_shape
+ - ori_shape
+
+ Args:
+ to_float32 (bool): Whether to convert the loaded image to a float32
+ numpy array. If set to False, the loaded image is an uint8 array.
+ Defaults to False.
+ """
+
+ def __init__(self, **kwargs) -> None:
+ super().__init__()
+ self.from_file = TRANSFORMS.build(
+ dict(type='LoadImageFromFile', **kwargs))
+ self.from_ndarray = TRANSFORMS.build(
+ dict(type='mmdet.LoadImageFromNDArray', **kwargs))
+
+ def transform(self, results: Union[str, np.ndarray, dict]) -> dict:
+ """Transform function to add image meta information.
+
+ Args:
+ results (str, np.ndarray or dict): The result.
+
+ Returns:
+ dict: The dict contains loaded image and meta information.
+ """
+ if isinstance(results, str):
+ inputs = dict(img_path=results)
+ elif isinstance(results, np.ndarray):
+ inputs = dict(img=results)
+ elif isinstance(results, dict):
+ inputs = results
+ else:
+ raise NotImplementedError
+
+ if 'img' in inputs:
+ return self.from_ndarray(inputs)
+ return self.from_file(inputs)
diff --git a/mmdet/datasets/transforms/transforms.py b/mmdet/datasets/transforms/transforms.py
new file mode 100644
index 0000000000000000000000000000000000000000..b844d0a3fe7d14c6a4192b26dfcdb8008d6c0288
--- /dev/null
+++ b/mmdet/datasets/transforms/transforms.py
@@ -0,0 +1,3636 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+import inspect
+import math
+from typing import List, Optional, Sequence, Tuple, Union
+
+import cv2
+import mmcv
+import numpy as np
+from mmcv.image.geometric import _scale_size
+from mmcv.transforms import BaseTransform
+from mmcv.transforms import Pad as MMCV_Pad
+from mmcv.transforms import RandomFlip as MMCV_RandomFlip
+from mmcv.transforms import Resize as MMCV_Resize
+from mmcv.transforms.utils import avoid_cache_randomness, cache_randomness
+from mmengine.dataset import BaseDataset
+from mmengine.utils import is_str
+from numpy import random
+
+from mmdet.registry import TRANSFORMS
+from mmdet.structures.bbox import HorizontalBoxes, autocast_box_type
+from mmdet.structures.mask import BitmapMasks, PolygonMasks
+from mmdet.utils import log_img_scale
+
+try:
+ from imagecorruptions import corrupt
+except ImportError:
+ corrupt = None
+
+try:
+ import albumentations
+ from albumentations import Compose
+except ImportError:
+ albumentations = None
+ Compose = None
+
+Number = Union[int, float]
+
+
+@TRANSFORMS.register_module()
+class Resize(MMCV_Resize):
+ """Resize images & bbox & seg.
+
+ This transform resizes the input image according to ``scale`` or
+ ``scale_factor``. Bboxes, masks, and seg map are then resized
+ with the same scale factor.
+ if ``scale`` and ``scale_factor`` are both set, it will use ``scale`` to
+ resize.
+
+ Required Keys:
+
+ - img
+ - gt_bboxes (BaseBoxes[torch.float32]) (optional)
+ - gt_masks (BitmapMasks | PolygonMasks) (optional)
+ - gt_seg_map (np.uint8) (optional)
+
+ Modified Keys:
+
+ - img
+ - img_shape
+ - gt_bboxes
+ - gt_masks
+ - gt_seg_map
+
+
+ Added Keys:
+
+ - scale
+ - scale_factor
+ - keep_ratio
+ - homography_matrix
+
+ Args:
+ scale (int or tuple): Images scales for resizing. Defaults to None
+ scale_factor (float or tuple[float]): Scale factors for resizing.
+ Defaults to None.
+ keep_ratio (bool): Whether to keep the aspect ratio when resizing the
+ image. Defaults to False.
+ clip_object_border (bool): Whether to clip the objects
+ outside the border of the image. In some dataset like MOT17, the gt
+ bboxes are allowed to cross the border of images. Therefore, we
+ don't need to clip the gt bboxes in these cases. Defaults to True.
+ backend (str): Image resize backend, choices are 'cv2' and 'pillow'.
+ These two backends generates slightly different results. Defaults
+ to 'cv2'.
+ interpolation (str): Interpolation method, accepted values are
+ "nearest", "bilinear", "bicubic", "area", "lanczos" for 'cv2'
+ backend, "nearest", "bilinear" for 'pillow' backend. Defaults
+ to 'bilinear'.
+ """
+
+ def _resize_masks(self, results: dict) -> None:
+ """Resize masks with ``results['scale']``"""
+ if results.get('gt_masks', None) is not None:
+ if self.keep_ratio:
+ results['gt_masks'] = results['gt_masks'].rescale(
+ results['scale'])
+ else:
+ results['gt_masks'] = results['gt_masks'].resize(
+ results['img_shape'])
+
+ def _resize_bboxes(self, results: dict) -> None:
+ """Resize bounding boxes with ``results['scale_factor']``."""
+ if results.get('gt_bboxes', None) is not None:
+ results['gt_bboxes'].rescale_(results['scale_factor'])
+ if self.clip_object_border:
+ results['gt_bboxes'].clip_(results['img_shape'])
+
+ def _resize_seg(self, results: dict) -> None:
+ """Resize semantic segmentation map with ``results['scale']``."""
+ if results.get('gt_seg_map', None) is not None:
+ if self.keep_ratio:
+ gt_seg = mmcv.imrescale(
+ results['gt_seg_map'],
+ results['scale'],
+ interpolation='nearest',
+ backend=self.backend)
+ else:
+ gt_seg = mmcv.imresize(
+ results['gt_seg_map'],
+ results['scale'],
+ interpolation='nearest',
+ backend=self.backend)
+ results['gt_seg_map'] = gt_seg
+
+ def _record_homography_matrix(self, results: dict) -> None:
+ """Record the homography matrix for the Resize."""
+ w_scale, h_scale = results['scale_factor']
+ homography_matrix = np.array(
+ [[w_scale, 0, 0], [0, h_scale, 0], [0, 0, 1]], dtype=np.float32)
+ if results.get('homography_matrix', None) is None:
+ results['homography_matrix'] = homography_matrix
+ else:
+ results['homography_matrix'] = homography_matrix @ results[
+ 'homography_matrix']
+
+ @autocast_box_type()
+ def transform(self, results: dict) -> dict:
+ """Transform function to resize images, bounding boxes and semantic
+ segmentation map.
+
+ Args:
+ results (dict): Result dict from loading pipeline.
+ Returns:
+ dict: Resized results, 'img', 'gt_bboxes', 'gt_seg_map',
+ 'scale', 'scale_factor', 'height', 'width', and 'keep_ratio' keys
+ are updated in result dict.
+ """
+ if self.scale:
+ results['scale'] = self.scale
+ else:
+ img_shape = results['img'].shape[:2]
+ results['scale'] = _scale_size(img_shape[::-1], self.scale_factor)
+ self._resize_img(results)
+ self._resize_bboxes(results)
+ self._resize_masks(results)
+ self._resize_seg(results)
+ self._record_homography_matrix(results)
+ return results
+
+ def __repr__(self) -> str:
+ repr_str = self.__class__.__name__
+ repr_str += f'(scale={self.scale}, '
+ repr_str += f'scale_factor={self.scale_factor}, '
+ repr_str += f'keep_ratio={self.keep_ratio}, '
+ repr_str += f'clip_object_border={self.clip_object_border}), '
+ repr_str += f'backend={self.backend}), '
+ repr_str += f'interpolation={self.interpolation})'
+ return repr_str
+
+
+@TRANSFORMS.register_module()
+class FixShapeResize(Resize):
+ """Resize images & bbox & seg to the specified size.
+
+ This transform resizes the input image according to ``width`` and
+ ``height``. Bboxes, masks, and seg map are then resized
+ with the same parameters.
+
+ Required Keys:
+
+ - img
+ - gt_bboxes (BaseBoxes[torch.float32]) (optional)
+ - gt_masks (BitmapMasks | PolygonMasks) (optional)
+ - gt_seg_map (np.uint8) (optional)
+
+ Modified Keys:
+
+ - img
+ - img_shape
+ - gt_bboxes
+ - gt_masks
+ - gt_seg_map
+
+
+ Added Keys:
+
+ - scale
+ - scale_factor
+ - keep_ratio
+ - homography_matrix
+
+ Args:
+ width (int): width for resizing.
+ height (int): height for resizing.
+ Defaults to None.
+ pad_val (Number | dict[str, Number], optional): Padding value for if
+ the pad_mode is "constant". If it is a single number, the value
+ to pad the image is the number and to pad the semantic
+ segmentation map is 255. If it is a dict, it should have the
+ following keys:
+
+ - img: The value to pad the image.
+ - seg: The value to pad the semantic segmentation map.
+ Defaults to dict(img=0, seg=255).
+ keep_ratio (bool): Whether to keep the aspect ratio when resizing the
+ image. Defaults to False.
+ clip_object_border (bool): Whether to clip the objects
+ outside the border of the image. In some dataset like MOT17, the gt
+ bboxes are allowed to cross the border of images. Therefore, we
+ don't need to clip the gt bboxes in these cases. Defaults to True.
+ backend (str): Image resize backend, choices are 'cv2' and 'pillow'.
+ These two backends generates slightly different results. Defaults
+ to 'cv2'.
+ interpolation (str): Interpolation method, accepted values are
+ "nearest", "bilinear", "bicubic", "area", "lanczos" for 'cv2'
+ backend, "nearest", "bilinear" for 'pillow' backend. Defaults
+ to 'bilinear'.
+ """
+
+ def __init__(self,
+ width: int,
+ height: int,
+ pad_val: Union[Number, dict] = dict(img=0, seg=255),
+ keep_ratio: bool = False,
+ clip_object_border: bool = True,
+ backend: str = 'cv2',
+ interpolation: str = 'bilinear') -> None:
+ assert width is not None and height is not None, (
+ '`width` and'
+ '`height` can not be `None`')
+
+ self.width = width
+ self.height = height
+ self.scale = (width, height)
+
+ self.backend = backend
+ self.interpolation = interpolation
+ self.keep_ratio = keep_ratio
+ self.clip_object_border = clip_object_border
+
+ if keep_ratio is True:
+ # padding to the fixed size when keep_ratio=True
+ self.pad_transform = Pad(size=self.scale, pad_val=pad_val)
+
+ @autocast_box_type()
+ def transform(self, results: dict) -> dict:
+ """Transform function to resize images, bounding boxes and semantic
+ segmentation map.
+
+ Args:
+ results (dict): Result dict from loading pipeline.
+ Returns:
+ dict: Resized results, 'img', 'gt_bboxes', 'gt_seg_map',
+ 'scale', 'scale_factor', 'height', 'width', and 'keep_ratio' keys
+ are updated in result dict.
+ """
+ img = results['img']
+ h, w = img.shape[:2]
+ if self.keep_ratio:
+ scale_factor = min(self.width / w, self.height / h)
+ results['scale_factor'] = (scale_factor, scale_factor)
+ real_w, real_h = int(w * float(scale_factor) +
+ 0.5), int(h * float(scale_factor) + 0.5)
+ img, scale_factor = mmcv.imrescale(
+ results['img'], (real_w, real_h),
+ interpolation=self.interpolation,
+ return_scale=True,
+ backend=self.backend)
+ # the w_scale and h_scale has minor difference
+ # a real fix should be done in the mmcv.imrescale in the future
+ results['img'] = img
+ results['img_shape'] = img.shape[:2]
+ results['keep_ratio'] = self.keep_ratio
+ results['scale'] = (real_w, real_h)
+ else:
+ results['scale'] = (self.width, self.height)
+ results['scale_factor'] = (self.width / w, self.height / h)
+ super()._resize_img(results)
+
+ self._resize_bboxes(results)
+ self._resize_masks(results)
+ self._resize_seg(results)
+ self._record_homography_matrix(results)
+ if self.keep_ratio:
+ self.pad_transform(results)
+ return results
+
+ def __repr__(self) -> str:
+ repr_str = self.__class__.__name__
+ repr_str += f'(width={self.width}, height={self.height}, '
+ repr_str += f'keep_ratio={self.keep_ratio}, '
+ repr_str += f'clip_object_border={self.clip_object_border}), '
+ repr_str += f'backend={self.backend}), '
+ repr_str += f'interpolation={self.interpolation})'
+ return repr_str
+
+
+@TRANSFORMS.register_module()
+class RandomFlip(MMCV_RandomFlip):
+ """Flip the image & bbox & mask & segmentation map. Added or Updated keys:
+ flip, flip_direction, img, gt_bboxes, and gt_seg_map. There are 3 flip
+ modes:
+
+ - ``prob`` is float, ``direction`` is string: the image will be
+ ``direction``ly flipped with probability of ``prob`` .
+ E.g., ``prob=0.5``, ``direction='horizontal'``,
+ then image will be horizontally flipped with probability of 0.5.
+ - ``prob`` is float, ``direction`` is list of string: the image will
+ be ``direction[i]``ly flipped with probability of
+ ``prob/len(direction)``.
+ E.g., ``prob=0.5``, ``direction=['horizontal', 'vertical']``,
+ then image will be horizontally flipped with probability of 0.25,
+ vertically with probability of 0.25.
+ - ``prob`` is list of float, ``direction`` is list of string:
+ given ``len(prob) == len(direction)``, the image will
+ be ``direction[i]``ly flipped with probability of ``prob[i]``.
+ E.g., ``prob=[0.3, 0.5]``, ``direction=['horizontal',
+ 'vertical']``, then image will be horizontally flipped with
+ probability of 0.3, vertically with probability of 0.5.
+
+
+ Required Keys:
+
+ - img
+ - gt_bboxes (BaseBoxes[torch.float32]) (optional)
+ - gt_masks (BitmapMasks | PolygonMasks) (optional)
+ - gt_seg_map (np.uint8) (optional)
+
+ Modified Keys:
+
+ - img
+ - gt_bboxes
+ - gt_masks
+ - gt_seg_map
+
+ Added Keys:
+
+ - flip
+ - flip_direction
+ - homography_matrix
+
+
+ Args:
+ prob (float | list[float], optional): The flipping probability.
+ Defaults to None.
+ direction(str | list[str]): The flipping direction. Options
+ If input is a list, the length must equal ``prob``. Each
+ element in ``prob`` indicates the flip probability of
+ corresponding direction. Defaults to 'horizontal'.
+ """
+
+ def _record_homography_matrix(self, results: dict) -> None:
+ """Record the homography matrix for the RandomFlip."""
+ cur_dir = results['flip_direction']
+ h, w = results['img'].shape[:2]
+
+ if cur_dir == 'horizontal':
+ homography_matrix = np.array([[-1, 0, w], [0, 1, 0], [0, 0, 1]],
+ dtype=np.float32)
+ elif cur_dir == 'vertical':
+ homography_matrix = np.array([[1, 0, 0], [0, -1, h], [0, 0, 1]],
+ dtype=np.float32)
+ elif cur_dir == 'diagonal':
+ homography_matrix = np.array([[-1, 0, w], [0, -1, h], [0, 0, 1]],
+ dtype=np.float32)
+ else:
+ homography_matrix = np.eye(3, dtype=np.float32)
+
+ if results.get('homography_matrix', None) is None:
+ results['homography_matrix'] = homography_matrix
+ else:
+ results['homography_matrix'] = homography_matrix @ results[
+ 'homography_matrix']
+
+ @autocast_box_type()
+ def _flip(self, results: dict) -> None:
+ """Flip images, bounding boxes, and semantic segmentation map."""
+ # flip image
+ results['img'] = mmcv.imflip(
+ results['img'], direction=results['flip_direction'])
+
+ img_shape = results['img'].shape[:2]
+
+ # flip bboxes
+ if results.get('gt_bboxes', None) is not None:
+ results['gt_bboxes'].flip_(img_shape, results['flip_direction'])
+
+ # flip masks
+ if results.get('gt_masks', None) is not None:
+ results['gt_masks'] = results['gt_masks'].flip(
+ results['flip_direction'])
+
+ # flip segs
+ if results.get('gt_seg_map', None) is not None:
+ results['gt_seg_map'] = mmcv.imflip(
+ results['gt_seg_map'], direction=results['flip_direction'])
+
+ # record homography matrix for flip
+ self._record_homography_matrix(results)
+
+
+@TRANSFORMS.register_module()
+class RandomShift(BaseTransform):
+ """Shift the image and box given shift pixels and probability.
+
+ Required Keys:
+
+ - img
+ - gt_bboxes (BaseBoxes[torch.float32])
+ - gt_bboxes_labels (np.int64)
+ - gt_ignore_flags (bool) (optional)
+
+ Modified Keys:
+
+ - img
+ - gt_bboxes
+ - gt_bboxes_labels
+ - gt_ignore_flags (bool) (optional)
+
+ Args:
+ prob (float): Probability of shifts. Defaults to 0.5.
+ max_shift_px (int): The max pixels for shifting. Defaults to 32.
+ filter_thr_px (int): The width and height threshold for filtering.
+ The bbox and the rest of the targets below the width and
+ height threshold will be filtered. Defaults to 1.
+ """
+
+ def __init__(self,
+ prob: float = 0.5,
+ max_shift_px: int = 32,
+ filter_thr_px: int = 1) -> None:
+ assert 0 <= prob <= 1
+ assert max_shift_px >= 0
+ self.prob = prob
+ self.max_shift_px = max_shift_px
+ self.filter_thr_px = int(filter_thr_px)
+
+ @cache_randomness
+ def _random_prob(self) -> float:
+ return random.uniform(0, 1)
+
+ @autocast_box_type()
+ def transform(self, results: dict) -> dict:
+ """Transform function to random shift images, bounding boxes.
+
+ Args:
+ results (dict): Result dict from loading pipeline.
+
+ Returns:
+ dict: Shift results.
+ """
+ if self._random_prob() < self.prob:
+ img_shape = results['img'].shape[:2]
+
+ random_shift_x = random.randint(-self.max_shift_px,
+ self.max_shift_px)
+ random_shift_y = random.randint(-self.max_shift_px,
+ self.max_shift_px)
+ new_x = max(0, random_shift_x)
+ ori_x = max(0, -random_shift_x)
+ new_y = max(0, random_shift_y)
+ ori_y = max(0, -random_shift_y)
+
+ # TODO: support mask and semantic segmentation maps.
+ bboxes = results['gt_bboxes'].clone()
+ bboxes.translate_([random_shift_x, random_shift_y])
+
+ # clip border
+ bboxes.clip_(img_shape)
+
+ # remove invalid bboxes
+ valid_inds = (bboxes.widths > self.filter_thr_px).numpy() & (
+ bboxes.heights > self.filter_thr_px).numpy()
+ # If the shift does not contain any gt-bbox area, skip this
+ # image.
+ if not valid_inds.any():
+ return results
+ bboxes = bboxes[valid_inds]
+ results['gt_bboxes'] = bboxes
+ results['gt_bboxes_labels'] = results['gt_bboxes_labels'][
+ valid_inds]
+
+ if results.get('gt_ignore_flags', None) is not None:
+ results['gt_ignore_flags'] = \
+ results['gt_ignore_flags'][valid_inds]
+
+ # shift img
+ img = results['img']
+ new_img = np.zeros_like(img)
+ img_h, img_w = img.shape[:2]
+ new_h = img_h - np.abs(random_shift_y)
+ new_w = img_w - np.abs(random_shift_x)
+ new_img[new_y:new_y + new_h, new_x:new_x + new_w] \
+ = img[ori_y:ori_y + new_h, ori_x:ori_x + new_w]
+ results['img'] = new_img
+
+ return results
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ repr_str += f'(prob={self.prob}, '
+ repr_str += f'max_shift_px={self.max_shift_px}, '
+ repr_str += f'filter_thr_px={self.filter_thr_px})'
+ return repr_str
+
+
+@TRANSFORMS.register_module()
+class Pad(MMCV_Pad):
+ """Pad the image & segmentation map.
+
+ There are three padding modes: (1) pad to a fixed size and (2) pad to the
+ minimum size that is divisible by some number. and (3)pad to square. Also,
+ pad to square and pad to the minimum size can be used as the same time.
+
+ Required Keys:
+
+ - img
+ - gt_bboxes (BaseBoxes[torch.float32]) (optional)
+ - gt_masks (BitmapMasks | PolygonMasks) (optional)
+ - gt_seg_map (np.uint8) (optional)
+
+ Modified Keys:
+
+ - img
+ - img_shape
+ - gt_masks
+ - gt_seg_map
+
+ Added Keys:
+
+ - pad_shape
+ - pad_fixed_size
+ - pad_size_divisor
+
+ Args:
+ size (tuple, optional): Fixed padding size.
+ Expected padding shape (width, height). Defaults to None.
+ size_divisor (int, optional): The divisor of padded size. Defaults to
+ None.
+ pad_to_square (bool): Whether to pad the image into a square.
+ Currently only used for YOLOX. Defaults to False.
+ pad_val (Number | dict[str, Number], optional) - Padding value for if
+ the pad_mode is "constant". If it is a single number, the value
+ to pad the image is the number and to pad the semantic
+ segmentation map is 255. If it is a dict, it should have the
+ following keys:
+
+ - img: The value to pad the image.
+ - seg: The value to pad the semantic segmentation map.
+ Defaults to dict(img=0, seg=255).
+ padding_mode (str): Type of padding. Should be: constant, edge,
+ reflect or symmetric. Defaults to 'constant'.
+
+ - constant: pads with a constant value, this value is specified
+ with pad_val.
+ - edge: pads with the last value at the edge of the image.
+ - reflect: pads with reflection of image without repeating the last
+ value on the edge. For example, padding [1, 2, 3, 4] with 2
+ elements on both sides in reflect mode will result in
+ [3, 2, 1, 2, 3, 4, 3, 2].
+ - symmetric: pads with reflection of image repeating the last value
+ on the edge. For example, padding [1, 2, 3, 4] with 2 elements on
+ both sides in symmetric mode will result in
+ [2, 1, 1, 2, 3, 4, 4, 3]
+ """
+
+ def _pad_masks(self, results: dict) -> None:
+ """Pad masks according to ``results['pad_shape']``."""
+ if results.get('gt_masks', None) is not None:
+ pad_val = self.pad_val.get('masks', 0)
+ pad_shape = results['pad_shape'][:2]
+ results['gt_masks'] = results['gt_masks'].pad(
+ pad_shape, pad_val=pad_val)
+
+ def transform(self, results: dict) -> dict:
+ """Call function to pad images, masks, semantic segmentation maps.
+
+ Args:
+ results (dict): Result dict from loading pipeline.
+
+ Returns:
+ dict: Updated result dict.
+ """
+ self._pad_img(results)
+ self._pad_seg(results)
+ self._pad_masks(results)
+ return results
+
+
+@TRANSFORMS.register_module()
+class RandomCrop(BaseTransform):
+ """Random crop the image & bboxes & masks.
+
+ The absolute ``crop_size`` is sampled based on ``crop_type`` and
+ ``image_size``, then the cropped results are generated.
+
+ Required Keys:
+
+ - img
+ - gt_bboxes (BaseBoxes[torch.float32]) (optional)
+ - gt_bboxes_labels (np.int64) (optional)
+ - gt_masks (BitmapMasks | PolygonMasks) (optional)
+ - gt_ignore_flags (bool) (optional)
+ - gt_seg_map (np.uint8) (optional)
+
+ Modified Keys:
+
+ - img
+ - img_shape
+ - gt_bboxes (optional)
+ - gt_bboxes_labels (optional)
+ - gt_masks (optional)
+ - gt_ignore_flags (optional)
+ - gt_seg_map (optional)
+
+ Added Keys:
+
+ - homography_matrix
+
+ Args:
+ crop_size (tuple): The relative ratio or absolute pixels of
+ (width, height).
+ crop_type (str, optional): One of "relative_range", "relative",
+ "absolute", "absolute_range". "relative" randomly crops
+ (h * crop_size[0], w * crop_size[1]) part from an input of size
+ (h, w). "relative_range" uniformly samples relative crop size from
+ range [crop_size[0], 1] and [crop_size[1], 1] for height and width
+ respectively. "absolute" crops from an input with absolute size
+ (crop_size[0], crop_size[1]). "absolute_range" uniformly samples
+ crop_h in range [crop_size[0], min(h, crop_size[1])] and crop_w
+ in range [crop_size[0], min(w, crop_size[1])].
+ Defaults to "absolute".
+ allow_negative_crop (bool, optional): Whether to allow a crop that does
+ not contain any bbox area. Defaults to False.
+ recompute_bbox (bool, optional): Whether to re-compute the boxes based
+ on cropped instance masks. Defaults to False.
+ bbox_clip_border (bool, optional): Whether clip the objects outside
+ the border of the image. Defaults to True.
+
+ Note:
+ - If the image is smaller than the absolute crop size, return the
+ original image.
+ - The keys for bboxes, labels and masks must be aligned. That is,
+ ``gt_bboxes`` corresponds to ``gt_labels`` and ``gt_masks``, and
+ ``gt_bboxes_ignore`` corresponds to ``gt_labels_ignore`` and
+ ``gt_masks_ignore``.
+ - If the crop does not contain any gt-bbox region and
+ ``allow_negative_crop`` is set to False, skip this image.
+ """
+
+ def __init__(self,
+ crop_size: tuple,
+ crop_type: str = 'absolute',
+ allow_negative_crop: bool = False,
+ recompute_bbox: bool = False,
+ bbox_clip_border: bool = True) -> None:
+ if crop_type not in [
+ 'relative_range', 'relative', 'absolute', 'absolute_range'
+ ]:
+ raise ValueError(f'Invalid crop_type {crop_type}.')
+ if crop_type in ['absolute', 'absolute_range']:
+ assert crop_size[0] > 0 and crop_size[1] > 0
+ assert isinstance(crop_size[0], int) and isinstance(
+ crop_size[1], int)
+ if crop_type == 'absolute_range':
+ assert crop_size[0] <= crop_size[1]
+ else:
+ assert 0 < crop_size[0] <= 1 and 0 < crop_size[1] <= 1
+ self.crop_size = crop_size
+ self.crop_type = crop_type
+ self.allow_negative_crop = allow_negative_crop
+ self.bbox_clip_border = bbox_clip_border
+ self.recompute_bbox = recompute_bbox
+
+ def _crop_data(self, results: dict, crop_size: Tuple[int, int],
+ allow_negative_crop: bool) -> Union[dict, None]:
+ """Function to randomly crop images, bounding boxes, masks, semantic
+ segmentation maps.
+
+ Args:
+ results (dict): Result dict from loading pipeline.
+ crop_size (Tuple[int, int]): Expected absolute size after
+ cropping, (h, w).
+ allow_negative_crop (bool): Whether to allow a crop that does not
+ contain any bbox area.
+
+ Returns:
+ results (Union[dict, None]): Randomly cropped results, 'img_shape'
+ key in result dict is updated according to crop size. None will
+ be returned when there is no valid bbox after cropping.
+ """
+ assert crop_size[0] > 0 and crop_size[1] > 0
+ img = results['img']
+ margin_h = max(img.shape[0] - crop_size[0], 0)
+ margin_w = max(img.shape[1] - crop_size[1], 0)
+ offset_h, offset_w = self._rand_offset((margin_h, margin_w))
+ crop_y1, crop_y2 = offset_h, offset_h + crop_size[0]
+ crop_x1, crop_x2 = offset_w, offset_w + crop_size[1]
+
+ # Record the homography matrix for the RandomCrop
+ homography_matrix = np.array(
+ [[1, 0, -offset_w], [0, 1, -offset_h], [0, 0, 1]],
+ dtype=np.float32)
+ if results.get('homography_matrix', None) is None:
+ results['homography_matrix'] = homography_matrix
+ else:
+ results['homography_matrix'] = homography_matrix @ results[
+ 'homography_matrix']
+
+ # crop the image
+ img = img[crop_y1:crop_y2, crop_x1:crop_x2, ...]
+ img_shape = img.shape
+ results['img'] = img
+ results['img_shape'] = img_shape[:2]
+
+ # crop bboxes accordingly and clip to the image boundary
+ if results.get('gt_bboxes', None) is not None:
+ bboxes = results['gt_bboxes']
+ bboxes.translate_([-offset_w, -offset_h])
+ if self.bbox_clip_border:
+ bboxes.clip_(img_shape[:2])
+ valid_inds = bboxes.is_inside(img_shape[:2]).numpy()
+ # If the crop does not contain any gt-bbox area and
+ # allow_negative_crop is False, skip this image.
+ if (not valid_inds.any() and not allow_negative_crop):
+ return None
+
+ results['gt_bboxes'] = bboxes[valid_inds]
+
+ if results.get('gt_ignore_flags', None) is not None:
+ results['gt_ignore_flags'] = \
+ results['gt_ignore_flags'][valid_inds]
+
+ if results.get('gt_bboxes_labels', None) is not None:
+ results['gt_bboxes_labels'] = \
+ results['gt_bboxes_labels'][valid_inds]
+
+ if results.get('gt_masks', None) is not None:
+ results['gt_masks'] = results['gt_masks'][
+ valid_inds.nonzero()[0]].crop(
+ np.asarray([crop_x1, crop_y1, crop_x2, crop_y2]))
+ if self.recompute_bbox:
+ results['gt_bboxes'] = results['gt_masks'].get_bboxes(
+ type(results['gt_bboxes']))
+
+ # crop semantic seg
+ if results.get('gt_seg_map', None) is not None:
+ results['gt_seg_map'] = results['gt_seg_map'][crop_y1:crop_y2,
+ crop_x1:crop_x2]
+
+ return results
+
+ @cache_randomness
+ def _rand_offset(self, margin: Tuple[int, int]) -> Tuple[int, int]:
+ """Randomly generate crop offset.
+
+ Args:
+ margin (Tuple[int, int]): The upper bound for the offset generated
+ randomly.
+
+ Returns:
+ Tuple[int, int]: The random offset for the crop.
+ """
+ margin_h, margin_w = margin
+ offset_h = np.random.randint(0, margin_h + 1)
+ offset_w = np.random.randint(0, margin_w + 1)
+
+ return offset_h, offset_w
+
+ @cache_randomness
+ def _get_crop_size(self, image_size: Tuple[int, int]) -> Tuple[int, int]:
+ """Randomly generates the absolute crop size based on `crop_type` and
+ `image_size`.
+
+ Args:
+ image_size (Tuple[int, int]): (h, w).
+
+ Returns:
+ crop_size (Tuple[int, int]): (crop_h, crop_w) in absolute pixels.
+ """
+ h, w = image_size
+ if self.crop_type == 'absolute':
+ return min(self.crop_size[1], h), min(self.crop_size[0], w)
+ elif self.crop_type == 'absolute_range':
+ crop_h = np.random.randint(
+ min(h, self.crop_size[0]),
+ min(h, self.crop_size[1]) + 1)
+ crop_w = np.random.randint(
+ min(w, self.crop_size[0]),
+ min(w, self.crop_size[1]) + 1)
+ return crop_h, crop_w
+ elif self.crop_type == 'relative':
+ crop_w, crop_h = self.crop_size
+ return int(h * crop_h + 0.5), int(w * crop_w + 0.5)
+ else:
+ # 'relative_range'
+ crop_size = np.asarray(self.crop_size, dtype=np.float32)
+ crop_h, crop_w = crop_size + np.random.rand(2) * (1 - crop_size)
+ return int(h * crop_h + 0.5), int(w * crop_w + 0.5)
+
+ @autocast_box_type()
+ def transform(self, results: dict) -> Union[dict, None]:
+ """Transform function to randomly crop images, bounding boxes, masks,
+ semantic segmentation maps.
+
+ Args:
+ results (dict): Result dict from loading pipeline.
+
+ Returns:
+ results (Union[dict, None]): Randomly cropped results, 'img_shape'
+ key in result dict is updated according to crop size. None will
+ be returned when there is no valid bbox after cropping.
+ """
+ image_size = results['img'].shape[:2]
+ crop_size = self._get_crop_size(image_size)
+ results = self._crop_data(results, crop_size, self.allow_negative_crop)
+ return results
+
+ def __repr__(self) -> str:
+ repr_str = self.__class__.__name__
+ repr_str += f'(crop_size={self.crop_size}, '
+ repr_str += f'crop_type={self.crop_type}, '
+ repr_str += f'allow_negative_crop={self.allow_negative_crop}, '
+ repr_str += f'recompute_bbox={self.recompute_bbox}, '
+ repr_str += f'bbox_clip_border={self.bbox_clip_border})'
+ return repr_str
+
+
+@TRANSFORMS.register_module()
+class SegRescale(BaseTransform):
+ """Rescale semantic segmentation maps.
+
+ This transform rescale the ``gt_seg_map`` according to ``scale_factor``.
+
+ Required Keys:
+
+ - gt_seg_map
+
+ Modified Keys:
+
+ - gt_seg_map
+
+ Args:
+ scale_factor (float): The scale factor of the final output. Defaults
+ to 1.
+ backend (str): Image rescale backend, choices are 'cv2' and 'pillow'.
+ These two backends generates slightly different results. Defaults
+ to 'cv2'.
+ """
+
+ def __init__(self, scale_factor: float = 1, backend: str = 'cv2') -> None:
+ self.scale_factor = scale_factor
+ self.backend = backend
+
+ def transform(self, results: dict) -> dict:
+ """Transform function to scale the semantic segmentation map.
+
+ Args:
+ results (dict): Result dict from loading pipeline.
+
+ Returns:
+ dict: Result dict with semantic segmentation map scaled.
+ """
+ if self.scale_factor != 1:
+ results['gt_seg_map'] = mmcv.imrescale(
+ results['gt_seg_map'],
+ self.scale_factor,
+ interpolation='nearest',
+ backend=self.backend)
+
+ return results
+
+ def __repr__(self) -> str:
+ repr_str = self.__class__.__name__
+ repr_str += f'(scale_factor={self.scale_factor}, '
+ repr_str += f'backend={self.backend})'
+ return repr_str
+
+
+@TRANSFORMS.register_module()
+class PhotoMetricDistortion(BaseTransform):
+ """Apply photometric distortion to image sequentially, every transformation
+ is applied with a probability of 0.5. The position of random contrast is in
+ second or second to last.
+
+ 1. random brightness
+ 2. random contrast (mode 0)
+ 3. convert color from BGR to HSV
+ 4. random saturation
+ 5. random hue
+ 6. convert color from HSV to BGR
+ 7. random contrast (mode 1)
+ 8. randomly swap channels
+
+ Required Keys:
+
+ - img (np.uint8)
+
+ Modified Keys:
+
+ - img (np.float32)
+
+ Args:
+ brightness_delta (int): delta of brightness.
+ contrast_range (sequence): range of contrast.
+ saturation_range (sequence): range of saturation.
+ hue_delta (int): delta of hue.
+ """
+
+ def __init__(self,
+ brightness_delta: int = 32,
+ contrast_range: Sequence[Number] = (0.5, 1.5),
+ saturation_range: Sequence[Number] = (0.5, 1.5),
+ hue_delta: int = 18) -> None:
+ self.brightness_delta = brightness_delta
+ self.contrast_lower, self.contrast_upper = contrast_range
+ self.saturation_lower, self.saturation_upper = saturation_range
+ self.hue_delta = hue_delta
+
+ @cache_randomness
+ def _random_flags(self) -> Sequence[Number]:
+ mode = random.randint(2)
+ brightness_flag = random.randint(2)
+ contrast_flag = random.randint(2)
+ saturation_flag = random.randint(2)
+ hue_flag = random.randint(2)
+ swap_flag = random.randint(2)
+ delta_value = random.uniform(-self.brightness_delta,
+ self.brightness_delta)
+ alpha_value = random.uniform(self.contrast_lower, self.contrast_upper)
+ saturation_value = random.uniform(self.saturation_lower,
+ self.saturation_upper)
+ hue_value = random.uniform(-self.hue_delta, self.hue_delta)
+ swap_value = random.permutation(3)
+
+ return (mode, brightness_flag, contrast_flag, saturation_flag,
+ hue_flag, swap_flag, delta_value, alpha_value,
+ saturation_value, hue_value, swap_value)
+
+ def transform(self, results: dict) -> dict:
+ """Transform function to perform photometric distortion on images.
+
+ Args:
+ results (dict): Result dict from loading pipeline.
+
+ Returns:
+ dict: Result dict with images distorted.
+ """
+ assert 'img' in results, '`img` is not found in results'
+ img = results['img']
+ img = img.astype(np.float32)
+
+ (mode, brightness_flag, contrast_flag, saturation_flag, hue_flag,
+ swap_flag, delta_value, alpha_value, saturation_value, hue_value,
+ swap_value) = self._random_flags()
+
+ # random brightness
+ if brightness_flag:
+ img += delta_value
+
+ # mode == 0 --> do random contrast first
+ # mode == 1 --> do random contrast last
+ if mode == 1:
+ if contrast_flag:
+ img *= alpha_value
+
+ # convert color from BGR to HSV
+ img = mmcv.bgr2hsv(img)
+
+ # random saturation
+ if saturation_flag:
+ img[..., 1] *= saturation_value
+ # For image(type=float32), after convert bgr to hsv by opencv,
+ # valid saturation value range is [0, 1]
+ if saturation_value > 1:
+ img[..., 1] = img[..., 1].clip(0, 1)
+
+ # random hue
+ if hue_flag:
+ img[..., 0] += hue_value
+ img[..., 0][img[..., 0] > 360] -= 360
+ img[..., 0][img[..., 0] < 0] += 360
+
+ # convert color from HSV to BGR
+ img = mmcv.hsv2bgr(img)
+
+ # random contrast
+ if mode == 0:
+ if contrast_flag:
+ img *= alpha_value
+
+ # randomly swap channels
+ if swap_flag:
+ img = img[..., swap_value]
+
+ results['img'] = img
+ return results
+
+ def __repr__(self) -> str:
+ repr_str = self.__class__.__name__
+ repr_str += f'(brightness_delta={self.brightness_delta}, '
+ repr_str += 'contrast_range='
+ repr_str += f'{(self.contrast_lower, self.contrast_upper)}, '
+ repr_str += 'saturation_range='
+ repr_str += f'{(self.saturation_lower, self.saturation_upper)}, '
+ repr_str += f'hue_delta={self.hue_delta})'
+ return repr_str
+
+
+@TRANSFORMS.register_module()
+class Expand(BaseTransform):
+ """Random expand the image & bboxes & masks & segmentation map.
+
+ Randomly place the original image on a canvas of ``ratio`` x original image
+ size filled with mean values. The ratio is in the range of ratio_range.
+
+ Required Keys:
+
+ - img
+ - img_shape
+ - gt_bboxes (BaseBoxes[torch.float32]) (optional)
+ - gt_masks (BitmapMasks | PolygonMasks) (optional)
+ - gt_seg_map (np.uint8) (optional)
+
+ Modified Keys:
+
+ - img
+ - img_shape
+ - gt_bboxes
+ - gt_masks
+ - gt_seg_map
+
+
+ Args:
+ mean (sequence): mean value of dataset.
+ to_rgb (bool): if need to convert the order of mean to align with RGB.
+ ratio_range (sequence)): range of expand ratio.
+ seg_ignore_label (int): label of ignore segmentation map.
+ prob (float): probability of applying this transformation
+ """
+
+ def __init__(self,
+ mean: Sequence[Number] = (0, 0, 0),
+ to_rgb: bool = True,
+ ratio_range: Sequence[Number] = (1, 4),
+ seg_ignore_label: int = None,
+ prob: float = 0.5) -> None:
+ self.to_rgb = to_rgb
+ self.ratio_range = ratio_range
+ if to_rgb:
+ self.mean = mean[::-1]
+ else:
+ self.mean = mean
+ self.min_ratio, self.max_ratio = ratio_range
+ self.seg_ignore_label = seg_ignore_label
+ self.prob = prob
+
+ @cache_randomness
+ def _random_prob(self) -> float:
+ return random.uniform(0, 1)
+
+ @cache_randomness
+ def _random_ratio(self) -> float:
+ return random.uniform(self.min_ratio, self.max_ratio)
+
+ @cache_randomness
+ def _random_left_top(self, ratio: float, h: int,
+ w: int) -> Tuple[int, int]:
+ left = int(random.uniform(0, w * ratio - w))
+ top = int(random.uniform(0, h * ratio - h))
+ return left, top
+
+ @autocast_box_type()
+ def transform(self, results: dict) -> dict:
+ """Transform function to expand images, bounding boxes, masks,
+ segmentation map.
+
+ Args:
+ results (dict): Result dict from loading pipeline.
+
+ Returns:
+ dict: Result dict with images, bounding boxes, masks, segmentation
+ map expanded.
+ """
+ if self._random_prob() > self.prob:
+ return results
+ assert 'img' in results, '`img` is not found in results'
+ img = results['img']
+ h, w, c = img.shape
+ ratio = self._random_ratio()
+ # speedup expand when meets large image
+ if np.all(self.mean == self.mean[0]):
+ expand_img = np.empty((int(h * ratio), int(w * ratio), c),
+ img.dtype)
+ expand_img.fill(self.mean[0])
+ else:
+ expand_img = np.full((int(h * ratio), int(w * ratio), c),
+ self.mean,
+ dtype=img.dtype)
+ left, top = self._random_left_top(ratio, h, w)
+ expand_img[top:top + h, left:left + w] = img
+ results['img'] = expand_img
+ results['img_shape'] = expand_img.shape[:2]
+
+ # expand bboxes
+ if results.get('gt_bboxes', None) is not None:
+ results['gt_bboxes'].translate_([left, top])
+
+ # expand masks
+ if results.get('gt_masks', None) is not None:
+ results['gt_masks'] = results['gt_masks'].expand(
+ int(h * ratio), int(w * ratio), top, left)
+
+ # expand segmentation map
+ if results.get('gt_seg_map', None) is not None:
+ gt_seg = results['gt_seg_map']
+ expand_gt_seg = np.full((int(h * ratio), int(w * ratio)),
+ self.seg_ignore_label,
+ dtype=gt_seg.dtype)
+ expand_gt_seg[top:top + h, left:left + w] = gt_seg
+ results['gt_seg_map'] = expand_gt_seg
+
+ return results
+
+ def __repr__(self) -> str:
+ repr_str = self.__class__.__name__
+ repr_str += f'(mean={self.mean}, to_rgb={self.to_rgb}, '
+ repr_str += f'ratio_range={self.ratio_range}, '
+ repr_str += f'seg_ignore_label={self.seg_ignore_label}, '
+ repr_str += f'prob={self.prob})'
+ return repr_str
+
+
+@TRANSFORMS.register_module()
+class MinIoURandomCrop(BaseTransform):
+ """Random crop the image & bboxes & masks & segmentation map, the cropped
+ patches have minimum IoU requirement with original image & bboxes & masks.
+
+ & segmentation map, the IoU threshold is randomly selected from min_ious.
+
+
+ Required Keys:
+
+ - img
+ - img_shape
+ - gt_bboxes (BaseBoxes[torch.float32]) (optional)
+ - gt_bboxes_labels (np.int64) (optional)
+ - gt_masks (BitmapMasks | PolygonMasks) (optional)
+ - gt_ignore_flags (bool) (optional)
+ - gt_seg_map (np.uint8) (optional)
+
+ Modified Keys:
+
+ - img
+ - img_shape
+ - gt_bboxes
+ - gt_bboxes_labels
+ - gt_masks
+ - gt_ignore_flags
+ - gt_seg_map
+
+
+ Args:
+ min_ious (Sequence[float]): minimum IoU threshold for all intersections
+ with bounding boxes.
+ min_crop_size (float): minimum crop's size (i.e. h,w := a*h, a*w,
+ where a >= min_crop_size).
+ bbox_clip_border (bool, optional): Whether clip the objects outside
+ the border of the image. Defaults to True.
+ """
+
+ def __init__(self,
+ min_ious: Sequence[float] = (0.1, 0.3, 0.5, 0.7, 0.9),
+ min_crop_size: float = 0.3,
+ bbox_clip_border: bool = True) -> None:
+
+ self.min_ious = min_ious
+ self.sample_mode = (1, *min_ious, 0)
+ self.min_crop_size = min_crop_size
+ self.bbox_clip_border = bbox_clip_border
+
+ @cache_randomness
+ def _random_mode(self) -> Number:
+ return random.choice(self.sample_mode)
+
+ @autocast_box_type()
+ def transform(self, results: dict) -> dict:
+ """Transform function to crop images and bounding boxes with minimum
+ IoU constraint.
+
+ Args:
+ results (dict): Result dict from loading pipeline.
+
+ Returns:
+ dict: Result dict with images and bounding boxes cropped, \
+ 'img_shape' key is updated.
+ """
+ assert 'img' in results, '`img` is not found in results'
+ assert 'gt_bboxes' in results, '`gt_bboxes` is not found in results'
+ img = results['img']
+ boxes = results['gt_bboxes']
+ h, w, c = img.shape
+ while True:
+ mode = self._random_mode()
+ self.mode = mode
+ if mode == 1:
+ return results
+
+ min_iou = self.mode
+ for i in range(50):
+ new_w = random.uniform(self.min_crop_size * w, w)
+ new_h = random.uniform(self.min_crop_size * h, h)
+
+ # h / w in [0.5, 2]
+ if new_h / new_w < 0.5 or new_h / new_w > 2:
+ continue
+
+ left = random.uniform(w - new_w)
+ top = random.uniform(h - new_h)
+
+ patch = np.array(
+ (int(left), int(top), int(left + new_w), int(top + new_h)))
+ # Line or point crop is not allowed
+ if patch[2] == patch[0] or patch[3] == patch[1]:
+ continue
+ overlaps = boxes.overlaps(
+ HorizontalBoxes(patch.reshape(-1, 4).astype(np.float32)),
+ boxes).numpy().reshape(-1)
+ if len(overlaps) > 0 and overlaps.min() < min_iou:
+ continue
+
+ # center of boxes should inside the crop img
+ # only adjust boxes and instance masks when the gt is not empty
+ if len(overlaps) > 0:
+ # adjust boxes
+ def is_center_of_bboxes_in_patch(boxes, patch):
+ centers = boxes.centers.numpy()
+ mask = ((centers[:, 0] > patch[0]) *
+ (centers[:, 1] > patch[1]) *
+ (centers[:, 0] < patch[2]) *
+ (centers[:, 1] < patch[3]))
+ return mask
+
+ mask = is_center_of_bboxes_in_patch(boxes, patch)
+ if not mask.any():
+ continue
+ if results.get('gt_bboxes', None) is not None:
+ boxes = results['gt_bboxes']
+ mask = is_center_of_bboxes_in_patch(boxes, patch)
+ boxes = boxes[mask]
+ boxes.translate_([-patch[0], -patch[1]])
+ if self.bbox_clip_border:
+ boxes.clip_(
+ [patch[3] - patch[1], patch[2] - patch[0]])
+ results['gt_bboxes'] = boxes
+
+ # ignore_flags
+ if results.get('gt_ignore_flags', None) is not None:
+ results['gt_ignore_flags'] = \
+ results['gt_ignore_flags'][mask]
+
+ # labels
+ if results.get('gt_bboxes_labels', None) is not None:
+ results['gt_bboxes_labels'] = results[
+ 'gt_bboxes_labels'][mask]
+
+ # mask fields
+ if results.get('gt_masks', None) is not None:
+ results['gt_masks'] = results['gt_masks'][
+ mask.nonzero()[0]].crop(patch)
+ # adjust the img no matter whether the gt is empty before crop
+ img = img[patch[1]:patch[3], patch[0]:patch[2]]
+ results['img'] = img
+ results['img_shape'] = img.shape[:2]
+
+ # seg fields
+ if results.get('gt_seg_map', None) is not None:
+ results['gt_seg_map'] = results['gt_seg_map'][
+ patch[1]:patch[3], patch[0]:patch[2]]
+ return results
+
+ def __repr__(self) -> str:
+ repr_str = self.__class__.__name__
+ repr_str += f'(min_ious={self.min_ious}, '
+ repr_str += f'min_crop_size={self.min_crop_size}, '
+ repr_str += f'bbox_clip_border={self.bbox_clip_border})'
+ return repr_str
+
+
+@TRANSFORMS.register_module()
+class Corrupt(BaseTransform):
+ """Corruption augmentation.
+
+ Corruption transforms implemented based on
+ `imagecorruptions `_.
+
+ Required Keys:
+
+ - img (np.uint8)
+
+
+ Modified Keys:
+
+ - img (np.uint8)
+
+
+ Args:
+ corruption (str): Corruption name.
+ severity (int): The severity of corruption. Defaults to 1.
+ """
+
+ def __init__(self, corruption: str, severity: int = 1) -> None:
+ self.corruption = corruption
+ self.severity = severity
+
+ def transform(self, results: dict) -> dict:
+ """Call function to corrupt image.
+
+ Args:
+ results (dict): Result dict from loading pipeline.
+
+ Returns:
+ dict: Result dict with images corrupted.
+ """
+
+ if corrupt is None:
+ raise RuntimeError('imagecorruptions is not installed')
+ results['img'] = corrupt(
+ results['img'].astype(np.uint8),
+ corruption_name=self.corruption,
+ severity=self.severity)
+ return results
+
+ def __repr__(self) -> str:
+ repr_str = self.__class__.__name__
+ repr_str += f'(corruption={self.corruption}, '
+ repr_str += f'severity={self.severity})'
+ return repr_str
+
+
+@TRANSFORMS.register_module()
+@avoid_cache_randomness
+class Albu(BaseTransform):
+ """Albumentation augmentation.
+
+ Adds custom transformations from Albumentations library.
+ Please, visit `https://albumentations.readthedocs.io`
+ to get more information.
+
+ Required Keys:
+
+ - img (np.uint8)
+ - gt_bboxes (HorizontalBoxes[torch.float32]) (optional)
+ - gt_masks (BitmapMasks | PolygonMasks) (optional)
+
+ Modified Keys:
+
+ - img (np.uint8)
+ - gt_bboxes (HorizontalBoxes[torch.float32]) (optional)
+ - gt_masks (BitmapMasks | PolygonMasks) (optional)
+ - img_shape (tuple)
+
+ An example of ``transforms`` is as followed:
+
+ .. code-block::
+
+ [
+ dict(
+ type='ShiftScaleRotate',
+ shift_limit=0.0625,
+ scale_limit=0.0,
+ rotate_limit=0,
+ interpolation=1,
+ p=0.5),
+ dict(
+ type='RandomBrightnessContrast',
+ brightness_limit=[0.1, 0.3],
+ contrast_limit=[0.1, 0.3],
+ p=0.2),
+ dict(type='ChannelShuffle', p=0.1),
+ dict(
+ type='OneOf',
+ transforms=[
+ dict(type='Blur', blur_limit=3, p=1.0),
+ dict(type='MedianBlur', blur_limit=3, p=1.0)
+ ],
+ p=0.1),
+ ]
+
+ Args:
+ transforms (list[dict]): A list of albu transformations
+ bbox_params (dict, optional): Bbox_params for albumentation `Compose`
+ keymap (dict, optional): Contains
+ {'input key':'albumentation-style key'}
+ skip_img_without_anno (bool): Whether to skip the image if no ann left
+ after aug. Defaults to False.
+ """
+
+ def __init__(self,
+ transforms: List[dict],
+ bbox_params: Optional[dict] = None,
+ keymap: Optional[dict] = None,
+ skip_img_without_anno: bool = False) -> None:
+ if Compose is None:
+ raise RuntimeError('albumentations is not installed')
+
+ # Args will be modified later, copying it will be safer
+ transforms = copy.deepcopy(transforms)
+ if bbox_params is not None:
+ bbox_params = copy.deepcopy(bbox_params)
+ if keymap is not None:
+ keymap = copy.deepcopy(keymap)
+ self.transforms = transforms
+ self.filter_lost_elements = False
+ self.skip_img_without_anno = skip_img_without_anno
+
+ # A simple workaround to remove masks without boxes
+ if (isinstance(bbox_params, dict) and 'label_fields' in bbox_params
+ and 'filter_lost_elements' in bbox_params):
+ self.filter_lost_elements = True
+ self.origin_label_fields = bbox_params['label_fields']
+ bbox_params['label_fields'] = ['idx_mapper']
+ del bbox_params['filter_lost_elements']
+
+ self.bbox_params = (
+ self.albu_builder(bbox_params) if bbox_params else None)
+ self.aug = Compose([self.albu_builder(t) for t in self.transforms],
+ bbox_params=self.bbox_params)
+
+ if not keymap:
+ self.keymap_to_albu = {
+ 'img': 'image',
+ 'gt_masks': 'masks',
+ 'gt_bboxes': 'bboxes'
+ }
+ else:
+ self.keymap_to_albu = keymap
+ self.keymap_back = {v: k for k, v in self.keymap_to_albu.items()}
+
+ def albu_builder(self, cfg: dict) -> albumentations:
+ """Import a module from albumentations.
+
+ It inherits some of :func:`build_from_cfg` logic.
+
+ Args:
+ cfg (dict): Config dict. It should at least contain the key "type".
+
+ Returns:
+ obj: The constructed object.
+ """
+
+ assert isinstance(cfg, dict) and 'type' in cfg
+ args = cfg.copy()
+ obj_type = args.pop('type')
+ if is_str(obj_type):
+ if albumentations is None:
+ raise RuntimeError('albumentations is not installed')
+ obj_cls = getattr(albumentations, obj_type)
+ elif inspect.isclass(obj_type):
+ obj_cls = obj_type
+ else:
+ raise TypeError(
+ f'type must be a str or valid type, but got {type(obj_type)}')
+
+ if 'transforms' in args:
+ args['transforms'] = [
+ self.albu_builder(transform)
+ for transform in args['transforms']
+ ]
+
+ return obj_cls(**args)
+
+ @staticmethod
+ def mapper(d: dict, keymap: dict) -> dict:
+ """Dictionary mapper. Renames keys according to keymap provided.
+
+ Args:
+ d (dict): old dict
+ keymap (dict): {'old_key':'new_key'}
+ Returns:
+ dict: new dict.
+ """
+ updated_dict = {}
+ for k, v in zip(d.keys(), d.values()):
+ new_k = keymap.get(k, k)
+ updated_dict[new_k] = d[k]
+ return updated_dict
+
+ @autocast_box_type()
+ def transform(self, results: dict) -> Union[dict, None]:
+ """Transform function of Albu."""
+ # TODO: gt_seg_map is not currently supported
+ # dict to albumentations format
+ results = self.mapper(results, self.keymap_to_albu)
+ results, ori_masks = self._preprocess_results(results)
+ results = self.aug(**results)
+ results = self._postprocess_results(results, ori_masks)
+ if results is None:
+ return None
+ # back to the original format
+ results = self.mapper(results, self.keymap_back)
+ results['img_shape'] = results['img'].shape[:2]
+ return results
+
+ def _preprocess_results(self, results: dict) -> tuple:
+ """Pre-processing results to facilitate the use of Albu."""
+ if 'bboxes' in results:
+ # to list of boxes
+ if not isinstance(results['bboxes'], HorizontalBoxes):
+ raise NotImplementedError(
+ 'Albu only supports horizontal boxes now')
+ bboxes = results['bboxes'].numpy()
+ results['bboxes'] = [x for x in bboxes]
+ # add pseudo-field for filtration
+ if self.filter_lost_elements:
+ results['idx_mapper'] = np.arange(len(results['bboxes']))
+
+ # TODO: Support mask structure in albu
+ ori_masks = None
+ if 'masks' in results:
+ if isinstance(results['masks'], PolygonMasks):
+ raise NotImplementedError(
+ 'Albu only supports BitMap masks now')
+ ori_masks = results['masks']
+ if albumentations.__version__ < '0.5':
+ results['masks'] = results['masks'].masks
+ else:
+ results['masks'] = [mask for mask in results['masks'].masks]
+
+ return results, ori_masks
+
+ def _postprocess_results(
+ self,
+ results: dict,
+ ori_masks: Optional[Union[BitmapMasks,
+ PolygonMasks]] = None) -> dict:
+ """Post-processing Albu output."""
+ # albumentations may return np.array or list on different versions
+ if 'gt_bboxes_labels' in results and isinstance(
+ results['gt_bboxes_labels'], list):
+ results['gt_bboxes_labels'] = np.array(
+ results['gt_bboxes_labels'], dtype=np.int64)
+ if 'gt_ignore_flags' in results and isinstance(
+ results['gt_ignore_flags'], list):
+ results['gt_ignore_flags'] = np.array(
+ results['gt_ignore_flags'], dtype=bool)
+
+ if 'bboxes' in results:
+ if isinstance(results['bboxes'], list):
+ results['bboxes'] = np.array(
+ results['bboxes'], dtype=np.float32)
+ results['bboxes'] = results['bboxes'].reshape(-1, 4)
+ results['bboxes'] = HorizontalBoxes(results['bboxes'])
+
+ # filter label_fields
+ if self.filter_lost_elements:
+
+ for label in self.origin_label_fields:
+ results[label] = np.array(
+ [results[label][i] for i in results['idx_mapper']])
+ if 'masks' in results:
+ assert ori_masks is not None
+ results['masks'] = np.array(
+ [results['masks'][i] for i in results['idx_mapper']])
+ results['masks'] = ori_masks.__class__(
+ results['masks'], ori_masks.height, ori_masks.width)
+
+ if (not len(results['idx_mapper'])
+ and self.skip_img_without_anno):
+ return None
+ elif 'masks' in results:
+ results['masks'] = ori_masks.__class__(results['masks'],
+ ori_masks.height,
+ ori_masks.width)
+
+ return results
+
+ def __repr__(self) -> str:
+ repr_str = self.__class__.__name__ + f'(transforms={self.transforms})'
+ return repr_str
+
+
+@TRANSFORMS.register_module()
+@avoid_cache_randomness
+class RandomCenterCropPad(BaseTransform):
+ """Random center crop and random around padding for CornerNet.
+
+ This operation generates randomly cropped image from the original image and
+ pads it simultaneously. Different from :class:`RandomCrop`, the output
+ shape may not equal to ``crop_size`` strictly. We choose a random value
+ from ``ratios`` and the output shape could be larger or smaller than
+ ``crop_size``. The padding operation is also different from :class:`Pad`,
+ here we use around padding instead of right-bottom padding.
+
+ The relation between output image (padding image) and original image:
+
+ .. code:: text
+
+ output image
+
+ +----------------------------+
+ | padded area |
+ +------|----------------------------|----------+
+ | | cropped area | |
+ | | +---------------+ | |
+ | | | . center | | | original image
+ | | | range | | |
+ | | +---------------+ | |
+ +------|----------------------------|----------+
+ | padded area |
+ +----------------------------+
+
+ There are 5 main areas in the figure:
+
+ - output image: output image of this operation, also called padding
+ image in following instruction.
+ - original image: input image of this operation.
+ - padded area: non-intersect area of output image and original image.
+ - cropped area: the overlap of output image and original image.
+ - center range: a smaller area where random center chosen from.
+ center range is computed by ``border`` and original image's shape
+ to avoid our random center is too close to original image's border.
+
+ Also this operation act differently in train and test mode, the summary
+ pipeline is listed below.
+
+ Train pipeline:
+
+ 1. Choose a ``random_ratio`` from ``ratios``, the shape of padding image
+ will be ``random_ratio * crop_size``.
+ 2. Choose a ``random_center`` in center range.
+ 3. Generate padding image with center matches the ``random_center``.
+ 4. Initialize the padding image with pixel value equals to ``mean``.
+ 5. Copy the cropped area to padding image.
+ 6. Refine annotations.
+
+ Test pipeline:
+
+ 1. Compute output shape according to ``test_pad_mode``.
+ 2. Generate padding image with center matches the original image
+ center.
+ 3. Initialize the padding image with pixel value equals to ``mean``.
+ 4. Copy the ``cropped area`` to padding image.
+
+ Required Keys:
+
+ - img (np.float32)
+ - img_shape (tuple)
+ - gt_bboxes (BaseBoxes[torch.float32]) (optional)
+ - gt_bboxes_labels (np.int64) (optional)
+ - gt_ignore_flags (bool) (optional)
+
+ Modified Keys:
+
+ - img (np.float32)
+ - img_shape (tuple)
+ - gt_bboxes (BaseBoxes[torch.float32]) (optional)
+ - gt_bboxes_labels (np.int64) (optional)
+ - gt_ignore_flags (bool) (optional)
+
+ Args:
+ crop_size (tuple, optional): expected size after crop, final size will
+ computed according to ratio. Requires (width, height)
+ in train mode, and None in test mode.
+ ratios (tuple, optional): random select a ratio from tuple and crop
+ image to (crop_size[0] * ratio) * (crop_size[1] * ratio).
+ Only available in train mode. Defaults to (0.9, 1.0, 1.1).
+ border (int, optional): max distance from center select area to image
+ border. Only available in train mode. Defaults to 128.
+ mean (sequence, optional): Mean values of 3 channels.
+ std (sequence, optional): Std values of 3 channels.
+ to_rgb (bool, optional): Whether to convert the image from BGR to RGB.
+ test_mode (bool): whether involve random variables in transform.
+ In train mode, crop_size is fixed, center coords and ratio is
+ random selected from predefined lists. In test mode, crop_size
+ is image's original shape, center coords and ratio is fixed.
+ Defaults to False.
+ test_pad_mode (tuple, optional): padding method and padding shape
+ value, only available in test mode. Default is using
+ 'logical_or' with 127 as padding shape value.
+
+ - 'logical_or': final_shape = input_shape | padding_shape_value
+ - 'size_divisor': final_shape = int(
+ ceil(input_shape / padding_shape_value) * padding_shape_value)
+
+ Defaults to ('logical_or', 127).
+ test_pad_add_pix (int): Extra padding pixel in test mode.
+ Defaults to 0.
+ bbox_clip_border (bool): Whether clip the objects outside
+ the border of the image. Defaults to True.
+ """
+
+ def __init__(self,
+ crop_size: Optional[tuple] = None,
+ ratios: Optional[tuple] = (0.9, 1.0, 1.1),
+ border: Optional[int] = 128,
+ mean: Optional[Sequence] = None,
+ std: Optional[Sequence] = None,
+ to_rgb: Optional[bool] = None,
+ test_mode: bool = False,
+ test_pad_mode: Optional[tuple] = ('logical_or', 127),
+ test_pad_add_pix: int = 0,
+ bbox_clip_border: bool = True) -> None:
+ if test_mode:
+ assert crop_size is None, 'crop_size must be None in test mode'
+ assert ratios is None, 'ratios must be None in test mode'
+ assert border is None, 'border must be None in test mode'
+ assert isinstance(test_pad_mode, (list, tuple))
+ assert test_pad_mode[0] in ['logical_or', 'size_divisor']
+ else:
+ assert isinstance(crop_size, (list, tuple))
+ assert crop_size[0] > 0 and crop_size[1] > 0, (
+ 'crop_size must > 0 in train mode')
+ assert isinstance(ratios, (list, tuple))
+ assert test_pad_mode is None, (
+ 'test_pad_mode must be None in train mode')
+
+ self.crop_size = crop_size
+ self.ratios = ratios
+ self.border = border
+ # We do not set default value to mean, std and to_rgb because these
+ # hyper-parameters are easy to forget but could affect the performance.
+ # Please use the same setting as Normalize for performance assurance.
+ assert mean is not None and std is not None and to_rgb is not None
+ self.to_rgb = to_rgb
+ self.input_mean = mean
+ self.input_std = std
+ if to_rgb:
+ self.mean = mean[::-1]
+ self.std = std[::-1]
+ else:
+ self.mean = mean
+ self.std = std
+ self.test_mode = test_mode
+ self.test_pad_mode = test_pad_mode
+ self.test_pad_add_pix = test_pad_add_pix
+ self.bbox_clip_border = bbox_clip_border
+
+ def _get_border(self, border, size):
+ """Get final border for the target size.
+
+ This function generates a ``final_border`` according to image's shape.
+ The area between ``final_border`` and ``size - final_border`` is the
+ ``center range``. We randomly choose center from the ``center range``
+ to avoid our random center is too close to original image's border.
+ Also ``center range`` should be larger than 0.
+
+ Args:
+ border (int): The initial border, default is 128.
+ size (int): The width or height of original image.
+ Returns:
+ int: The final border.
+ """
+ k = 2 * border / size
+ i = pow(2, np.ceil(np.log2(np.ceil(k))) + (k == int(k)))
+ return border // i
+
+ def _filter_boxes(self, patch, boxes):
+ """Check whether the center of each box is in the patch.
+
+ Args:
+ patch (list[int]): The cropped area, [left, top, right, bottom].
+ boxes (numpy array, (N x 4)): Ground truth boxes.
+
+ Returns:
+ mask (numpy array, (N,)): Each box is inside or outside the patch.
+ """
+ center = boxes.centers.numpy()
+ mask = (center[:, 0] > patch[0]) * (center[:, 1] > patch[1]) * (
+ center[:, 0] < patch[2]) * (
+ center[:, 1] < patch[3])
+ return mask
+
+ def _crop_image_and_paste(self, image, center, size):
+ """Crop image with a given center and size, then paste the cropped
+ image to a blank image with two centers align.
+
+ This function is equivalent to generating a blank image with ``size``
+ as its shape. Then cover it on the original image with two centers (
+ the center of blank image and the random center of original image)
+ aligned. The overlap area is paste from the original image and the
+ outside area is filled with ``mean pixel``.
+
+ Args:
+ image (np array, H x W x C): Original image.
+ center (list[int]): Target crop center coord.
+ size (list[int]): Target crop size. [target_h, target_w]
+
+ Returns:
+ cropped_img (np array, target_h x target_w x C): Cropped image.
+ border (np array, 4): The distance of four border of
+ ``cropped_img`` to the original image area, [top, bottom,
+ left, right]
+ patch (list[int]): The cropped area, [left, top, right, bottom].
+ """
+ center_y, center_x = center
+ target_h, target_w = size
+ img_h, img_w, img_c = image.shape
+
+ x0 = max(0, center_x - target_w // 2)
+ x1 = min(center_x + target_w // 2, img_w)
+ y0 = max(0, center_y - target_h // 2)
+ y1 = min(center_y + target_h // 2, img_h)
+ patch = np.array((int(x0), int(y0), int(x1), int(y1)))
+
+ left, right = center_x - x0, x1 - center_x
+ top, bottom = center_y - y0, y1 - center_y
+
+ cropped_center_y, cropped_center_x = target_h // 2, target_w // 2
+ cropped_img = np.zeros((target_h, target_w, img_c), dtype=image.dtype)
+ for i in range(img_c):
+ cropped_img[:, :, i] += self.mean[i]
+ y_slice = slice(cropped_center_y - top, cropped_center_y + bottom)
+ x_slice = slice(cropped_center_x - left, cropped_center_x + right)
+ cropped_img[y_slice, x_slice, :] = image[y0:y1, x0:x1, :]
+
+ border = np.array([
+ cropped_center_y - top, cropped_center_y + bottom,
+ cropped_center_x - left, cropped_center_x + right
+ ],
+ dtype=np.float32)
+
+ return cropped_img, border, patch
+
+ def _train_aug(self, results):
+ """Random crop and around padding the original image.
+
+ Args:
+ results (dict): Image infomations in the augment pipeline.
+
+ Returns:
+ results (dict): The updated dict.
+ """
+ img = results['img']
+ h, w, c = img.shape
+ gt_bboxes = results['gt_bboxes']
+ while True:
+ scale = random.choice(self.ratios)
+ new_h = int(self.crop_size[1] * scale)
+ new_w = int(self.crop_size[0] * scale)
+ h_border = self._get_border(self.border, h)
+ w_border = self._get_border(self.border, w)
+
+ for i in range(50):
+ center_x = random.randint(low=w_border, high=w - w_border)
+ center_y = random.randint(low=h_border, high=h - h_border)
+
+ cropped_img, border, patch = self._crop_image_and_paste(
+ img, [center_y, center_x], [new_h, new_w])
+
+ if len(gt_bboxes) == 0:
+ results['img'] = cropped_img
+ results['img_shape'] = cropped_img.shape[:2]
+ return results
+
+ # if image do not have valid bbox, any crop patch is valid.
+ mask = self._filter_boxes(patch, gt_bboxes)
+ if not mask.any():
+ continue
+
+ results['img'] = cropped_img
+ results['img_shape'] = cropped_img.shape[:2]
+
+ x0, y0, x1, y1 = patch
+
+ left_w, top_h = center_x - x0, center_y - y0
+ cropped_center_x, cropped_center_y = new_w // 2, new_h // 2
+
+ # crop bboxes accordingly and clip to the image boundary
+ gt_bboxes = gt_bboxes[mask]
+ gt_bboxes.translate_([
+ cropped_center_x - left_w - x0,
+ cropped_center_y - top_h - y0
+ ])
+ if self.bbox_clip_border:
+ gt_bboxes.clip_([new_h, new_w])
+ keep = gt_bboxes.is_inside([new_h, new_w]).numpy()
+ gt_bboxes = gt_bboxes[keep]
+
+ results['gt_bboxes'] = gt_bboxes
+
+ # ignore_flags
+ if results.get('gt_ignore_flags', None) is not None:
+ gt_ignore_flags = results['gt_ignore_flags'][mask]
+ results['gt_ignore_flags'] = \
+ gt_ignore_flags[keep]
+
+ # labels
+ if results.get('gt_bboxes_labels', None) is not None:
+ gt_labels = results['gt_bboxes_labels'][mask]
+ results['gt_bboxes_labels'] = gt_labels[keep]
+
+ if 'gt_masks' in results or 'gt_seg_map' in results:
+ raise NotImplementedError(
+ 'RandomCenterCropPad only supports bbox.')
+
+ return results
+
+ def _test_aug(self, results):
+ """Around padding the original image without cropping.
+
+ The padding mode and value are from ``test_pad_mode``.
+
+ Args:
+ results (dict): Image infomations in the augment pipeline.
+
+ Returns:
+ results (dict): The updated dict.
+ """
+ img = results['img']
+ h, w, c = img.shape
+ if self.test_pad_mode[0] in ['logical_or']:
+ # self.test_pad_add_pix is only used for centernet
+ target_h = (h | self.test_pad_mode[1]) + self.test_pad_add_pix
+ target_w = (w | self.test_pad_mode[1]) + self.test_pad_add_pix
+ elif self.test_pad_mode[0] in ['size_divisor']:
+ divisor = self.test_pad_mode[1]
+ target_h = int(np.ceil(h / divisor)) * divisor
+ target_w = int(np.ceil(w / divisor)) * divisor
+ else:
+ raise NotImplementedError(
+ 'RandomCenterCropPad only support two testing pad mode:'
+ 'logical-or and size_divisor.')
+
+ cropped_img, border, _ = self._crop_image_and_paste(
+ img, [h // 2, w // 2], [target_h, target_w])
+ results['img'] = cropped_img
+ results['img_shape'] = cropped_img.shape[:2]
+ results['border'] = border
+ return results
+
+ @autocast_box_type()
+ def transform(self, results: dict) -> dict:
+ img = results['img']
+ assert img.dtype == np.float32, (
+ 'RandomCenterCropPad needs the input image of dtype np.float32,'
+ ' please set "to_float32=True" in "LoadImageFromFile" pipeline')
+ h, w, c = img.shape
+ assert c == len(self.mean)
+ if self.test_mode:
+ return self._test_aug(results)
+ else:
+ return self._train_aug(results)
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ repr_str += f'(crop_size={self.crop_size}, '
+ repr_str += f'ratios={self.ratios}, '
+ repr_str += f'border={self.border}, '
+ repr_str += f'mean={self.input_mean}, '
+ repr_str += f'std={self.input_std}, '
+ repr_str += f'to_rgb={self.to_rgb}, '
+ repr_str += f'test_mode={self.test_mode}, '
+ repr_str += f'test_pad_mode={self.test_pad_mode}, '
+ repr_str += f'bbox_clip_border={self.bbox_clip_border})'
+ return repr_str
+
+
+@TRANSFORMS.register_module()
+class CutOut(BaseTransform):
+ """CutOut operation.
+
+ Randomly drop some regions of image used in
+ `Cutout `_.
+
+ Required Keys:
+
+ - img
+
+ Modified Keys:
+
+ - img
+
+ Args:
+ n_holes (int or tuple[int, int]): Number of regions to be dropped.
+ If it is given as a list, number of holes will be randomly
+ selected from the closed interval [``n_holes[0]``, ``n_holes[1]``].
+ cutout_shape (tuple[int, int] or list[tuple[int, int]], optional):
+ The candidate shape of dropped regions. It can be
+ ``tuple[int, int]`` to use a fixed cutout shape, or
+ ``list[tuple[int, int]]`` to randomly choose shape
+ from the list. Defaults to None.
+ cutout_ratio (tuple[float, float] or list[tuple[float, float]],
+ optional): The candidate ratio of dropped regions. It can be
+ ``tuple[float, float]`` to use a fixed ratio or
+ ``list[tuple[float, float]]`` to randomly choose ratio
+ from the list. Please note that ``cutout_shape`` and
+ ``cutout_ratio`` cannot be both given at the same time.
+ Defaults to None.
+ fill_in (tuple[float, float, float] or tuple[int, int, int]): The value
+ of pixel to fill in the dropped regions. Defaults to (0, 0, 0).
+ """
+
+ def __init__(
+ self,
+ n_holes: Union[int, Tuple[int, int]],
+ cutout_shape: Optional[Union[Tuple[int, int],
+ List[Tuple[int, int]]]] = None,
+ cutout_ratio: Optional[Union[Tuple[float, float],
+ List[Tuple[float, float]]]] = None,
+ fill_in: Union[Tuple[float, float, float], Tuple[int, int,
+ int]] = (0, 0, 0)
+ ) -> None:
+
+ assert (cutout_shape is None) ^ (cutout_ratio is None), \
+ 'Either cutout_shape or cutout_ratio should be specified.'
+ assert (isinstance(cutout_shape, (list, tuple))
+ or isinstance(cutout_ratio, (list, tuple)))
+ if isinstance(n_holes, tuple):
+ assert len(n_holes) == 2 and 0 <= n_holes[0] < n_holes[1]
+ else:
+ n_holes = (n_holes, n_holes)
+ self.n_holes = n_holes
+ self.fill_in = fill_in
+ self.with_ratio = cutout_ratio is not None
+ self.candidates = cutout_ratio if self.with_ratio else cutout_shape
+ if not isinstance(self.candidates, list):
+ self.candidates = [self.candidates]
+
+ @autocast_box_type()
+ def transform(self, results: dict) -> dict:
+ """Call function to drop some regions of image."""
+ h, w, c = results['img'].shape
+ n_holes = np.random.randint(self.n_holes[0], self.n_holes[1] + 1)
+ for _ in range(n_holes):
+ x1 = np.random.randint(0, w)
+ y1 = np.random.randint(0, h)
+ index = np.random.randint(0, len(self.candidates))
+ if not self.with_ratio:
+ cutout_w, cutout_h = self.candidates[index]
+ else:
+ cutout_w = int(self.candidates[index][0] * w)
+ cutout_h = int(self.candidates[index][1] * h)
+
+ x2 = np.clip(x1 + cutout_w, 0, w)
+ y2 = np.clip(y1 + cutout_h, 0, h)
+ results['img'][y1:y2, x1:x2, :] = self.fill_in
+
+ return results
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ repr_str += f'(n_holes={self.n_holes}, '
+ repr_str += (f'cutout_ratio={self.candidates}, ' if self.with_ratio
+ else f'cutout_shape={self.candidates}, ')
+ repr_str += f'fill_in={self.fill_in})'
+ return repr_str
+
+
+@TRANSFORMS.register_module()
+class Mosaic(BaseTransform):
+ """Mosaic augmentation.
+
+ Given 4 images, mosaic transform combines them into
+ one output image. The output image is composed of the parts from each sub-
+ image.
+
+ .. code:: text
+
+ mosaic transform
+ center_x
+ +------------------------------+
+ | pad | pad |
+ | +-----------+ |
+ | | | |
+ | | image1 |--------+ |
+ | | | | |
+ | | | image2 | |
+ center_y |----+-------------+-----------|
+ | | cropped | |
+ |pad | image3 | image4 |
+ | | | |
+ +----|-------------+-----------+
+ | |
+ +-------------+
+
+ The mosaic transform steps are as follows:
+
+ 1. Choose the mosaic center as the intersections of 4 images
+ 2. Get the left top image according to the index, and randomly
+ sample another 3 images from the custom dataset.
+ 3. Sub image will be cropped if image is larger than mosaic patch
+
+ Required Keys:
+
+ - img
+ - gt_bboxes (BaseBoxes[torch.float32]) (optional)
+ - gt_bboxes_labels (np.int64) (optional)
+ - gt_ignore_flags (bool) (optional)
+ - mix_results (List[dict])
+
+ Modified Keys:
+
+ - img
+ - img_shape
+ - gt_bboxes (optional)
+ - gt_bboxes_labels (optional)
+ - gt_ignore_flags (optional)
+
+ Args:
+ img_scale (Sequence[int]): Image size after mosaic pipeline of single
+ image. The shape order should be (width, height).
+ Defaults to (640, 640).
+ center_ratio_range (Sequence[float]): Center ratio range of mosaic
+ output. Defaults to (0.5, 1.5).
+ bbox_clip_border (bool, optional): Whether to clip the objects outside
+ the border of the image. In some dataset like MOT17, the gt bboxes
+ are allowed to cross the border of images. Therefore, we don't
+ need to clip the gt bboxes in these cases. Defaults to True.
+ pad_val (int): Pad value. Defaults to 114.
+ prob (float): Probability of applying this transformation.
+ Defaults to 1.0.
+ """
+
+ def __init__(self,
+ img_scale: Tuple[int, int] = (640, 640),
+ center_ratio_range: Tuple[float, float] = (0.5, 1.5),
+ bbox_clip_border: bool = True,
+ pad_val: float = 114.0,
+ prob: float = 1.0) -> None:
+ assert isinstance(img_scale, tuple)
+ assert 0 <= prob <= 1.0, 'The probability should be in range [0,1]. ' \
+ f'got {prob}.'
+
+ log_img_scale(img_scale, skip_square=True, shape_order='wh')
+ self.img_scale = img_scale
+ self.center_ratio_range = center_ratio_range
+ self.bbox_clip_border = bbox_clip_border
+ self.pad_val = pad_val
+ self.prob = prob
+
+ @cache_randomness
+ def get_indexes(self, dataset: BaseDataset) -> int:
+ """Call function to collect indexes.
+
+ Args:
+ dataset (:obj:`MultiImageMixDataset`): The dataset.
+
+ Returns:
+ list: indexes.
+ """
+
+ indexes = [random.randint(0, len(dataset)) for _ in range(3)]
+ return indexes
+
+ @autocast_box_type()
+ def transform(self, results: dict) -> dict:
+ """Mosaic transform function.
+
+ Args:
+ results (dict): Result dict.
+
+ Returns:
+ dict: Updated result dict.
+ """
+ if random.uniform(0, 1) > self.prob:
+ return results
+
+ assert 'mix_results' in results
+ mosaic_bboxes = []
+ mosaic_bboxes_labels = []
+ mosaic_ignore_flags = []
+ if len(results['img'].shape) == 3:
+ mosaic_img = np.full(
+ (int(self.img_scale[1] * 2), int(self.img_scale[0] * 2), 3),
+ self.pad_val,
+ dtype=results['img'].dtype)
+ else:
+ mosaic_img = np.full(
+ (int(self.img_scale[1] * 2), int(self.img_scale[0] * 2)),
+ self.pad_val,
+ dtype=results['img'].dtype)
+
+ # mosaic center x, y
+ center_x = int(
+ random.uniform(*self.center_ratio_range) * self.img_scale[0])
+ center_y = int(
+ random.uniform(*self.center_ratio_range) * self.img_scale[1])
+ center_position = (center_x, center_y)
+
+ loc_strs = ('top_left', 'top_right', 'bottom_left', 'bottom_right')
+ for i, loc in enumerate(loc_strs):
+ if loc == 'top_left':
+ results_patch = copy.deepcopy(results)
+ else:
+ results_patch = copy.deepcopy(results['mix_results'][i - 1])
+
+ img_i = results_patch['img']
+ h_i, w_i = img_i.shape[:2]
+ # keep_ratio resize
+ scale_ratio_i = min(self.img_scale[1] / h_i,
+ self.img_scale[0] / w_i)
+ img_i = mmcv.imresize(
+ img_i, (int(w_i * scale_ratio_i), int(h_i * scale_ratio_i)))
+
+ # compute the combine parameters
+ paste_coord, crop_coord = self._mosaic_combine(
+ loc, center_position, img_i.shape[:2][::-1])
+ x1_p, y1_p, x2_p, y2_p = paste_coord
+ x1_c, y1_c, x2_c, y2_c = crop_coord
+
+ # crop and paste image
+ mosaic_img[y1_p:y2_p, x1_p:x2_p] = img_i[y1_c:y2_c, x1_c:x2_c]
+
+ # adjust coordinate
+ gt_bboxes_i = results_patch['gt_bboxes']
+ gt_bboxes_labels_i = results_patch['gt_bboxes_labels']
+ gt_ignore_flags_i = results_patch['gt_ignore_flags']
+
+ padw = x1_p - x1_c
+ padh = y1_p - y1_c
+ gt_bboxes_i.rescale_([scale_ratio_i, scale_ratio_i])
+ gt_bboxes_i.translate_([padw, padh])
+ mosaic_bboxes.append(gt_bboxes_i)
+ mosaic_bboxes_labels.append(gt_bboxes_labels_i)
+ mosaic_ignore_flags.append(gt_ignore_flags_i)
+
+ mosaic_bboxes = mosaic_bboxes[0].cat(mosaic_bboxes, 0)
+ mosaic_bboxes_labels = np.concatenate(mosaic_bboxes_labels, 0)
+ mosaic_ignore_flags = np.concatenate(mosaic_ignore_flags, 0)
+
+ if self.bbox_clip_border:
+ mosaic_bboxes.clip_([2 * self.img_scale[1], 2 * self.img_scale[0]])
+ # remove outside bboxes
+ inside_inds = mosaic_bboxes.is_inside(
+ [2 * self.img_scale[1], 2 * self.img_scale[0]]).numpy()
+ mosaic_bboxes = mosaic_bboxes[inside_inds]
+ mosaic_bboxes_labels = mosaic_bboxes_labels[inside_inds]
+ mosaic_ignore_flags = mosaic_ignore_flags[inside_inds]
+
+ results['img'] = mosaic_img
+ results['img_shape'] = mosaic_img.shape[:2]
+ results['gt_bboxes'] = mosaic_bboxes
+ results['gt_bboxes_labels'] = mosaic_bboxes_labels
+ results['gt_ignore_flags'] = mosaic_ignore_flags
+ return results
+
+ def _mosaic_combine(
+ self, loc: str, center_position_xy: Sequence[float],
+ img_shape_wh: Sequence[int]) -> Tuple[Tuple[int], Tuple[int]]:
+ """Calculate global coordinate of mosaic image and local coordinate of
+ cropped sub-image.
+
+ Args:
+ loc (str): Index for the sub-image, loc in ('top_left',
+ 'top_right', 'bottom_left', 'bottom_right').
+ center_position_xy (Sequence[float]): Mixing center for 4 images,
+ (x, y).
+ img_shape_wh (Sequence[int]): Width and height of sub-image
+
+ Returns:
+ tuple[tuple[float]]: Corresponding coordinate of pasting and
+ cropping
+ - paste_coord (tuple): paste corner coordinate in mosaic image.
+ - crop_coord (tuple): crop corner coordinate in mosaic image.
+ """
+ assert loc in ('top_left', 'top_right', 'bottom_left', 'bottom_right')
+ if loc == 'top_left':
+ # index0 to top left part of image
+ x1, y1, x2, y2 = max(center_position_xy[0] - img_shape_wh[0], 0), \
+ max(center_position_xy[1] - img_shape_wh[1], 0), \
+ center_position_xy[0], \
+ center_position_xy[1]
+ crop_coord = img_shape_wh[0] - (x2 - x1), img_shape_wh[1] - (
+ y2 - y1), img_shape_wh[0], img_shape_wh[1]
+
+ elif loc == 'top_right':
+ # index1 to top right part of image
+ x1, y1, x2, y2 = center_position_xy[0], \
+ max(center_position_xy[1] - img_shape_wh[1], 0), \
+ min(center_position_xy[0] + img_shape_wh[0],
+ self.img_scale[0] * 2), \
+ center_position_xy[1]
+ crop_coord = 0, img_shape_wh[1] - (y2 - y1), min(
+ img_shape_wh[0], x2 - x1), img_shape_wh[1]
+
+ elif loc == 'bottom_left':
+ # index2 to bottom left part of image
+ x1, y1, x2, y2 = max(center_position_xy[0] - img_shape_wh[0], 0), \
+ center_position_xy[1], \
+ center_position_xy[0], \
+ min(self.img_scale[1] * 2, center_position_xy[1] +
+ img_shape_wh[1])
+ crop_coord = img_shape_wh[0] - (x2 - x1), 0, img_shape_wh[0], min(
+ y2 - y1, img_shape_wh[1])
+
+ else:
+ # index3 to bottom right part of image
+ x1, y1, x2, y2 = center_position_xy[0], \
+ center_position_xy[1], \
+ min(center_position_xy[0] + img_shape_wh[0],
+ self.img_scale[0] * 2), \
+ min(self.img_scale[1] * 2, center_position_xy[1] +
+ img_shape_wh[1])
+ crop_coord = 0, 0, min(img_shape_wh[0],
+ x2 - x1), min(y2 - y1, img_shape_wh[1])
+
+ paste_coord = x1, y1, x2, y2
+ return paste_coord, crop_coord
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ repr_str += f'(img_scale={self.img_scale}, '
+ repr_str += f'center_ratio_range={self.center_ratio_range}, '
+ repr_str += f'pad_val={self.pad_val}, '
+ repr_str += f'prob={self.prob})'
+ return repr_str
+
+
+@TRANSFORMS.register_module()
+class MixUp(BaseTransform):
+ """MixUp data augmentation.
+
+ .. code:: text
+
+ mixup transform
+ +------------------------------+
+ | mixup image | |
+ | +--------|--------+ |
+ | | | | |
+ |---------------+ | |
+ | | | |
+ | | image | |
+ | | | |
+ | | | |
+ | |-----------------+ |
+ | pad |
+ +------------------------------+
+
+ The mixup transform steps are as follows:
+
+ 1. Another random image is picked by dataset and embedded in
+ the top left patch(after padding and resizing)
+ 2. The target of mixup transform is the weighted average of mixup
+ image and origin image.
+
+ Required Keys:
+
+ - img
+ - gt_bboxes (BaseBoxes[torch.float32]) (optional)
+ - gt_bboxes_labels (np.int64) (optional)
+ - gt_ignore_flags (bool) (optional)
+ - mix_results (List[dict])
+
+
+ Modified Keys:
+
+ - img
+ - img_shape
+ - gt_bboxes (optional)
+ - gt_bboxes_labels (optional)
+ - gt_ignore_flags (optional)
+
+
+ Args:
+ img_scale (Sequence[int]): Image output size after mixup pipeline.
+ The shape order should be (width, height). Defaults to (640, 640).
+ ratio_range (Sequence[float]): Scale ratio of mixup image.
+ Defaults to (0.5, 1.5).
+ flip_ratio (float): Horizontal flip ratio of mixup image.
+ Defaults to 0.5.
+ pad_val (int): Pad value. Defaults to 114.
+ max_iters (int): The maximum number of iterations. If the number of
+ iterations is greater than `max_iters`, but gt_bbox is still
+ empty, then the iteration is terminated. Defaults to 15.
+ bbox_clip_border (bool, optional): Whether to clip the objects outside
+ the border of the image. In some dataset like MOT17, the gt bboxes
+ are allowed to cross the border of images. Therefore, we don't
+ need to clip the gt bboxes in these cases. Defaults to True.
+ """
+
+ def __init__(self,
+ img_scale: Tuple[int, int] = (640, 640),
+ ratio_range: Tuple[float, float] = (0.5, 1.5),
+ flip_ratio: float = 0.5,
+ pad_val: float = 114.0,
+ max_iters: int = 15,
+ bbox_clip_border: bool = True) -> None:
+ assert isinstance(img_scale, tuple)
+ log_img_scale(img_scale, skip_square=True, shape_order='wh')
+ self.dynamic_scale = img_scale
+ self.ratio_range = ratio_range
+ self.flip_ratio = flip_ratio
+ self.pad_val = pad_val
+ self.max_iters = max_iters
+ self.bbox_clip_border = bbox_clip_border
+
+ @cache_randomness
+ def get_indexes(self, dataset: BaseDataset) -> int:
+ """Call function to collect indexes.
+
+ Args:
+ dataset (:obj:`MultiImageMixDataset`): The dataset.
+
+ Returns:
+ list: indexes.
+ """
+
+ for i in range(self.max_iters):
+ index = random.randint(0, len(dataset))
+ gt_bboxes_i = dataset[index]['gt_bboxes']
+ if len(gt_bboxes_i) != 0:
+ break
+
+ return index
+
+ @autocast_box_type()
+ def transform(self, results: dict) -> dict:
+ """MixUp transform function.
+
+ Args:
+ results (dict): Result dict.
+
+ Returns:
+ dict: Updated result dict.
+ """
+
+ assert 'mix_results' in results
+ assert len(
+ results['mix_results']) == 1, 'MixUp only support 2 images now !'
+
+ if results['mix_results'][0]['gt_bboxes'].shape[0] == 0:
+ # empty bbox
+ return results
+
+ retrieve_results = results['mix_results'][0]
+ retrieve_img = retrieve_results['img']
+
+ jit_factor = random.uniform(*self.ratio_range)
+ is_filp = random.uniform(0, 1) > self.flip_ratio
+
+ if len(retrieve_img.shape) == 3:
+ out_img = np.ones(
+ (self.dynamic_scale[1], self.dynamic_scale[0], 3),
+ dtype=retrieve_img.dtype) * self.pad_val
+ else:
+ out_img = np.ones(
+ self.dynamic_scale[::-1],
+ dtype=retrieve_img.dtype) * self.pad_val
+
+ # 1. keep_ratio resize
+ scale_ratio = min(self.dynamic_scale[1] / retrieve_img.shape[0],
+ self.dynamic_scale[0] / retrieve_img.shape[1])
+ retrieve_img = mmcv.imresize(
+ retrieve_img, (int(retrieve_img.shape[1] * scale_ratio),
+ int(retrieve_img.shape[0] * scale_ratio)))
+
+ # 2. paste
+ out_img[:retrieve_img.shape[0], :retrieve_img.shape[1]] = retrieve_img
+
+ # 3. scale jit
+ scale_ratio *= jit_factor
+ out_img = mmcv.imresize(out_img, (int(out_img.shape[1] * jit_factor),
+ int(out_img.shape[0] * jit_factor)))
+
+ # 4. flip
+ if is_filp:
+ out_img = out_img[:, ::-1, :]
+
+ # 5. random crop
+ ori_img = results['img']
+ origin_h, origin_w = out_img.shape[:2]
+ target_h, target_w = ori_img.shape[:2]
+ padded_img = np.ones((max(origin_h, target_h), max(
+ origin_w, target_w), 3)) * self.pad_val
+ padded_img = padded_img.astype(np.uint8)
+ padded_img[:origin_h, :origin_w] = out_img
+
+ x_offset, y_offset = 0, 0
+ if padded_img.shape[0] > target_h:
+ y_offset = random.randint(0, padded_img.shape[0] - target_h)
+ if padded_img.shape[1] > target_w:
+ x_offset = random.randint(0, padded_img.shape[1] - target_w)
+ padded_cropped_img = padded_img[y_offset:y_offset + target_h,
+ x_offset:x_offset + target_w]
+
+ # 6. adjust bbox
+ retrieve_gt_bboxes = retrieve_results['gt_bboxes']
+ retrieve_gt_bboxes.rescale_([scale_ratio, scale_ratio])
+ if self.bbox_clip_border:
+ retrieve_gt_bboxes.clip_([origin_h, origin_w])
+
+ if is_filp:
+ retrieve_gt_bboxes.flip_([origin_h, origin_w],
+ direction='horizontal')
+
+ # 7. filter
+ cp_retrieve_gt_bboxes = retrieve_gt_bboxes.clone()
+ cp_retrieve_gt_bboxes.translate_([-x_offset, -y_offset])
+ if self.bbox_clip_border:
+ cp_retrieve_gt_bboxes.clip_([target_h, target_w])
+
+ # 8. mix up
+ ori_img = ori_img.astype(np.float32)
+ mixup_img = 0.5 * ori_img + 0.5 * padded_cropped_img.astype(np.float32)
+
+ retrieve_gt_bboxes_labels = retrieve_results['gt_bboxes_labels']
+ retrieve_gt_ignore_flags = retrieve_results['gt_ignore_flags']
+
+ mixup_gt_bboxes = cp_retrieve_gt_bboxes.cat(
+ (results['gt_bboxes'], cp_retrieve_gt_bboxes), dim=0)
+ mixup_gt_bboxes_labels = np.concatenate(
+ (results['gt_bboxes_labels'], retrieve_gt_bboxes_labels), axis=0)
+ mixup_gt_ignore_flags = np.concatenate(
+ (results['gt_ignore_flags'], retrieve_gt_ignore_flags), axis=0)
+
+ # remove outside bbox
+ inside_inds = mixup_gt_bboxes.is_inside([target_h, target_w]).numpy()
+ mixup_gt_bboxes = mixup_gt_bboxes[inside_inds]
+ mixup_gt_bboxes_labels = mixup_gt_bboxes_labels[inside_inds]
+ mixup_gt_ignore_flags = mixup_gt_ignore_flags[inside_inds]
+
+ results['img'] = mixup_img.astype(np.uint8)
+ results['img_shape'] = mixup_img.shape[:2]
+ results['gt_bboxes'] = mixup_gt_bboxes
+ results['gt_bboxes_labels'] = mixup_gt_bboxes_labels
+ results['gt_ignore_flags'] = mixup_gt_ignore_flags
+
+ return results
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ repr_str += f'(dynamic_scale={self.dynamic_scale}, '
+ repr_str += f'ratio_range={self.ratio_range}, '
+ repr_str += f'flip_ratio={self.flip_ratio}, '
+ repr_str += f'pad_val={self.pad_val}, '
+ repr_str += f'max_iters={self.max_iters}, '
+ repr_str += f'bbox_clip_border={self.bbox_clip_border})'
+ return repr_str
+
+
+@TRANSFORMS.register_module()
+class RandomAffine(BaseTransform):
+ """Random affine transform data augmentation.
+
+ This operation randomly generates affine transform matrix which including
+ rotation, translation, shear and scaling transforms.
+
+ Required Keys:
+
+ - img
+ - gt_bboxes (BaseBoxes[torch.float32]) (optional)
+ - gt_bboxes_labels (np.int64) (optional)
+ - gt_ignore_flags (bool) (optional)
+
+ Modified Keys:
+
+ - img
+ - img_shape
+ - gt_bboxes (optional)
+ - gt_bboxes_labels (optional)
+ - gt_ignore_flags (optional)
+
+ Args:
+ max_rotate_degree (float): Maximum degrees of rotation transform.
+ Defaults to 10.
+ max_translate_ratio (float): Maximum ratio of translation.
+ Defaults to 0.1.
+ scaling_ratio_range (tuple[float]): Min and max ratio of
+ scaling transform. Defaults to (0.5, 1.5).
+ max_shear_degree (float): Maximum degrees of shear
+ transform. Defaults to 2.
+ border (tuple[int]): Distance from width and height sides of input
+ image to adjust output shape. Only used in mosaic dataset.
+ Defaults to (0, 0).
+ border_val (tuple[int]): Border padding values of 3 channels.
+ Defaults to (114, 114, 114).
+ bbox_clip_border (bool, optional): Whether to clip the objects outside
+ the border of the image. In some dataset like MOT17, the gt bboxes
+ are allowed to cross the border of images. Therefore, we don't
+ need to clip the gt bboxes in these cases. Defaults to True.
+ """
+
+ def __init__(self,
+ max_rotate_degree: float = 10.0,
+ max_translate_ratio: float = 0.1,
+ scaling_ratio_range: Tuple[float, float] = (0.5, 1.5),
+ max_shear_degree: float = 2.0,
+ border: Tuple[int, int] = (0, 0),
+ border_val: Tuple[int, int, int] = (114, 114, 114),
+ bbox_clip_border: bool = True) -> None:
+ assert 0 <= max_translate_ratio <= 1
+ assert scaling_ratio_range[0] <= scaling_ratio_range[1]
+ assert scaling_ratio_range[0] > 0
+ self.max_rotate_degree = max_rotate_degree
+ self.max_translate_ratio = max_translate_ratio
+ self.scaling_ratio_range = scaling_ratio_range
+ self.max_shear_degree = max_shear_degree
+ self.border = border
+ self.border_val = border_val
+ self.bbox_clip_border = bbox_clip_border
+
+ @cache_randomness
+ def _get_random_homography_matrix(self, height, width):
+ # Rotation
+ rotation_degree = random.uniform(-self.max_rotate_degree,
+ self.max_rotate_degree)
+ rotation_matrix = self._get_rotation_matrix(rotation_degree)
+
+ # Scaling
+ scaling_ratio = random.uniform(self.scaling_ratio_range[0],
+ self.scaling_ratio_range[1])
+ scaling_matrix = self._get_scaling_matrix(scaling_ratio)
+
+ # Shear
+ x_degree = random.uniform(-self.max_shear_degree,
+ self.max_shear_degree)
+ y_degree = random.uniform(-self.max_shear_degree,
+ self.max_shear_degree)
+ shear_matrix = self._get_shear_matrix(x_degree, y_degree)
+
+ # Translation
+ trans_x = random.uniform(-self.max_translate_ratio,
+ self.max_translate_ratio) * width
+ trans_y = random.uniform(-self.max_translate_ratio,
+ self.max_translate_ratio) * height
+ translate_matrix = self._get_translation_matrix(trans_x, trans_y)
+
+ warp_matrix = (
+ translate_matrix @ shear_matrix @ rotation_matrix @ scaling_matrix)
+ return warp_matrix
+
+ @autocast_box_type()
+ def transform(self, results: dict) -> dict:
+ img = results['img']
+ height = img.shape[0] + self.border[1] * 2
+ width = img.shape[1] + self.border[0] * 2
+
+ warp_matrix = self._get_random_homography_matrix(height, width)
+
+ img = cv2.warpPerspective(
+ img,
+ warp_matrix,
+ dsize=(width, height),
+ borderValue=self.border_val)
+ results['img'] = img
+ results['img_shape'] = img.shape[:2]
+
+ bboxes = results['gt_bboxes']
+ num_bboxes = len(bboxes)
+ if num_bboxes:
+ bboxes.project_(warp_matrix)
+ if self.bbox_clip_border:
+ bboxes.clip_([height, width])
+ # remove outside bbox
+ valid_index = bboxes.is_inside([height, width]).numpy()
+ results['gt_bboxes'] = bboxes[valid_index]
+ results['gt_bboxes_labels'] = results['gt_bboxes_labels'][
+ valid_index]
+ results['gt_ignore_flags'] = results['gt_ignore_flags'][
+ valid_index]
+
+ if 'gt_masks' in results:
+ raise NotImplementedError('RandomAffine only supports bbox.')
+ return results
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ repr_str += f'(max_rotate_degree={self.max_rotate_degree}, '
+ repr_str += f'max_translate_ratio={self.max_translate_ratio}, '
+ repr_str += f'scaling_ratio_range={self.scaling_ratio_range}, '
+ repr_str += f'max_shear_degree={self.max_shear_degree}, '
+ repr_str += f'border={self.border}, '
+ repr_str += f'border_val={self.border_val}, '
+ repr_str += f'bbox_clip_border={self.bbox_clip_border})'
+ return repr_str
+
+ @staticmethod
+ def _get_rotation_matrix(rotate_degrees: float) -> np.ndarray:
+ radian = math.radians(rotate_degrees)
+ rotation_matrix = np.array(
+ [[np.cos(radian), -np.sin(radian), 0.],
+ [np.sin(radian), np.cos(radian), 0.], [0., 0., 1.]],
+ dtype=np.float32)
+ return rotation_matrix
+
+ @staticmethod
+ def _get_scaling_matrix(scale_ratio: float) -> np.ndarray:
+ scaling_matrix = np.array(
+ [[scale_ratio, 0., 0.], [0., scale_ratio, 0.], [0., 0., 1.]],
+ dtype=np.float32)
+ return scaling_matrix
+
+ @staticmethod
+ def _get_shear_matrix(x_shear_degrees: float,
+ y_shear_degrees: float) -> np.ndarray:
+ x_radian = math.radians(x_shear_degrees)
+ y_radian = math.radians(y_shear_degrees)
+ shear_matrix = np.array([[1, np.tan(x_radian), 0.],
+ [np.tan(y_radian), 1, 0.], [0., 0., 1.]],
+ dtype=np.float32)
+ return shear_matrix
+
+ @staticmethod
+ def _get_translation_matrix(x: float, y: float) -> np.ndarray:
+ translation_matrix = np.array([[1, 0., x], [0., 1, y], [0., 0., 1.]],
+ dtype=np.float32)
+ return translation_matrix
+
+
+@TRANSFORMS.register_module()
+class YOLOXHSVRandomAug(BaseTransform):
+ """Apply HSV augmentation to image sequentially. It is referenced from
+ https://github.com/Megvii-
+ BaseDetection/YOLOX/blob/main/yolox/data/data_augment.py#L21.
+
+ Required Keys:
+
+ - img
+
+ Modified Keys:
+
+ - img
+
+ Args:
+ hue_delta (int): delta of hue. Defaults to 5.
+ saturation_delta (int): delta of saturation. Defaults to 30.
+ value_delta (int): delat of value. Defaults to 30.
+ """
+
+ def __init__(self,
+ hue_delta: int = 5,
+ saturation_delta: int = 30,
+ value_delta: int = 30) -> None:
+ self.hue_delta = hue_delta
+ self.saturation_delta = saturation_delta
+ self.value_delta = value_delta
+
+ @cache_randomness
+ def _get_hsv_gains(self):
+ hsv_gains = np.random.uniform(-1, 1, 3) * [
+ self.hue_delta, self.saturation_delta, self.value_delta
+ ]
+ # random selection of h, s, v
+ hsv_gains *= np.random.randint(0, 2, 3)
+ # prevent overflow
+ hsv_gains = hsv_gains.astype(np.int16)
+ return hsv_gains
+
+ def transform(self, results: dict) -> dict:
+ img = results['img']
+ hsv_gains = self._get_hsv_gains()
+ img_hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV).astype(np.int16)
+
+ img_hsv[..., 0] = (img_hsv[..., 0] + hsv_gains[0]) % 180
+ img_hsv[..., 1] = np.clip(img_hsv[..., 1] + hsv_gains[1], 0, 255)
+ img_hsv[..., 2] = np.clip(img_hsv[..., 2] + hsv_gains[2], 0, 255)
+ cv2.cvtColor(img_hsv.astype(img.dtype), cv2.COLOR_HSV2BGR, dst=img)
+
+ results['img'] = img
+ return results
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ repr_str += f'(hue_delta={self.hue_delta}, '
+ repr_str += f'saturation_delta={self.saturation_delta}, '
+ repr_str += f'value_delta={self.value_delta})'
+ return repr_str
+
+
+@TRANSFORMS.register_module()
+class CopyPaste(BaseTransform):
+ """Simple Copy-Paste is a Strong Data Augmentation Method for Instance
+ Segmentation The simple copy-paste transform steps are as follows:
+
+ 1. The destination image is already resized with aspect ratio kept,
+ cropped and padded.
+ 2. Randomly select a source image, which is also already resized
+ with aspect ratio kept, cropped and padded in a similar way
+ as the destination image.
+ 3. Randomly select some objects from the source image.
+ 4. Paste these source objects to the destination image directly,
+ due to the source and destination image have the same size.
+ 5. Update object masks of the destination image, for some origin objects
+ may be occluded.
+ 6. Generate bboxes from the updated destination masks and
+ filter some objects which are totally occluded, and adjust bboxes
+ which are partly occluded.
+ 7. Append selected source bboxes, masks, and labels.
+
+ Required Keys:
+
+ - img
+ - gt_bboxes (BaseBoxes[torch.float32]) (optional)
+ - gt_bboxes_labels (np.int64) (optional)
+ - gt_ignore_flags (bool) (optional)
+ - gt_masks (BitmapMasks) (optional)
+
+ Modified Keys:
+
+ - img
+ - gt_bboxes (optional)
+ - gt_bboxes_labels (optional)
+ - gt_ignore_flags (optional)
+ - gt_masks (optional)
+
+ Args:
+ max_num_pasted (int): The maximum number of pasted objects.
+ Defaults to 100.
+ bbox_occluded_thr (int): The threshold of occluded bbox.
+ Defaults to 10.
+ mask_occluded_thr (int): The threshold of occluded mask.
+ Defaults to 300.
+ selected (bool): Whether select objects or not. If select is False,
+ all objects of the source image will be pasted to the
+ destination image.
+ Defaults to True.
+ """
+
+ def __init__(
+ self,
+ max_num_pasted: int = 100,
+ bbox_occluded_thr: int = 10,
+ mask_occluded_thr: int = 300,
+ selected: bool = True,
+ ) -> None:
+ self.max_num_pasted = max_num_pasted
+ self.bbox_occluded_thr = bbox_occluded_thr
+ self.mask_occluded_thr = mask_occluded_thr
+ self.selected = selected
+
+ @cache_randomness
+ def get_indexes(self, dataset: BaseDataset) -> int:
+ """Call function to collect indexes.s.
+
+ Args:
+ dataset (:obj:`MultiImageMixDataset`): The dataset.
+ Returns:
+ list: Indexes.
+ """
+ return random.randint(0, len(dataset))
+
+ @autocast_box_type()
+ def transform(self, results: dict) -> dict:
+ """Transform function to make a copy-paste of image.
+
+ Args:
+ results (dict): Result dict.
+ Returns:
+ dict: Result dict with copy-paste transformed.
+ """
+
+ assert 'mix_results' in results
+ num_images = len(results['mix_results'])
+ assert num_images == 1, \
+ f'CopyPaste only supports processing 2 images, got {num_images}'
+ if self.selected:
+ selected_results = self._select_object(results['mix_results'][0])
+ else:
+ selected_results = results['mix_results'][0]
+ return self._copy_paste(results, selected_results)
+
+ @cache_randomness
+ def _get_selected_inds(self, num_bboxes: int) -> np.ndarray:
+ max_num_pasted = min(num_bboxes + 1, self.max_num_pasted)
+ num_pasted = np.random.randint(0, max_num_pasted)
+ return np.random.choice(num_bboxes, size=num_pasted, replace=False)
+
+ def _select_object(self, results: dict) -> dict:
+ """Select some objects from the source results."""
+ bboxes = results['gt_bboxes']
+ labels = results['gt_bboxes_labels']
+ masks = results['gt_masks']
+ ignore_flags = results['gt_ignore_flags']
+
+ selected_inds = self._get_selected_inds(bboxes.shape[0])
+
+ selected_bboxes = bboxes[selected_inds]
+ selected_labels = labels[selected_inds]
+ selected_masks = masks[selected_inds]
+ selected_ignore_flags = ignore_flags[selected_inds]
+
+ results['gt_bboxes'] = selected_bboxes
+ results['gt_bboxes_labels'] = selected_labels
+ results['gt_masks'] = selected_masks
+ results['gt_ignore_flags'] = selected_ignore_flags
+ return results
+
+ def _copy_paste(self, dst_results: dict, src_results: dict) -> dict:
+ """CopyPaste transform function.
+
+ Args:
+ dst_results (dict): Result dict of the destination image.
+ src_results (dict): Result dict of the source image.
+ Returns:
+ dict: Updated result dict.
+ """
+ dst_img = dst_results['img']
+ dst_bboxes = dst_results['gt_bboxes']
+ dst_labels = dst_results['gt_bboxes_labels']
+ dst_masks = dst_results['gt_masks']
+ dst_ignore_flags = dst_results['gt_ignore_flags']
+
+ src_img = src_results['img']
+ src_bboxes = src_results['gt_bboxes']
+ src_labels = src_results['gt_bboxes_labels']
+ src_masks = src_results['gt_masks']
+ src_ignore_flags = src_results['gt_ignore_flags']
+
+ if len(src_bboxes) == 0:
+ return dst_results
+
+ # update masks and generate bboxes from updated masks
+ composed_mask = np.where(np.any(src_masks.masks, axis=0), 1, 0)
+ updated_dst_masks = self._get_updated_masks(dst_masks, composed_mask)
+ updated_dst_bboxes = updated_dst_masks.get_bboxes(type(dst_bboxes))
+ assert len(updated_dst_bboxes) == len(updated_dst_masks)
+
+ # filter totally occluded objects
+ l1_distance = (updated_dst_bboxes.tensor - dst_bboxes.tensor).abs()
+ bboxes_inds = (l1_distance <= self.bbox_occluded_thr).all(
+ dim=-1).numpy()
+ masks_inds = updated_dst_masks.masks.sum(
+ axis=(1, 2)) > self.mask_occluded_thr
+ valid_inds = bboxes_inds | masks_inds
+
+ # Paste source objects to destination image directly
+ img = dst_img * (1 - composed_mask[..., np.newaxis]
+ ) + src_img * composed_mask[..., np.newaxis]
+ bboxes = src_bboxes.cat([updated_dst_bboxes[valid_inds], src_bboxes])
+ labels = np.concatenate([dst_labels[valid_inds], src_labels])
+ masks = np.concatenate(
+ [updated_dst_masks.masks[valid_inds], src_masks.masks])
+ ignore_flags = np.concatenate(
+ [dst_ignore_flags[valid_inds], src_ignore_flags])
+
+ dst_results['img'] = img
+ dst_results['gt_bboxes'] = bboxes
+ dst_results['gt_bboxes_labels'] = labels
+ dst_results['gt_masks'] = BitmapMasks(masks, masks.shape[1],
+ masks.shape[2])
+ dst_results['gt_ignore_flags'] = ignore_flags
+
+ return dst_results
+
+ def _get_updated_masks(self, masks: BitmapMasks,
+ composed_mask: np.ndarray) -> BitmapMasks:
+ """Update masks with composed mask."""
+ assert masks.masks.shape[-2:] == composed_mask.shape[-2:], \
+ 'Cannot compare two arrays of different size'
+ masks.masks = np.where(composed_mask, 0, masks.masks)
+ return masks
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ repr_str += f'(max_num_pasted={self.max_num_pasted}, '
+ repr_str += f'bbox_occluded_thr={self.bbox_occluded_thr}, '
+ repr_str += f'mask_occluded_thr={self.mask_occluded_thr}, '
+ repr_str += f'selected={self.selected})'
+ return repr_str
+
+
+@TRANSFORMS.register_module()
+class RandomErasing(BaseTransform):
+ """RandomErasing operation.
+
+ Random Erasing randomly selects a rectangle region
+ in an image and erases its pixels with random values.
+ `RandomErasing `_.
+
+ Required Keys:
+
+ - img
+ - gt_bboxes (HorizontalBoxes[torch.float32]) (optional)
+ - gt_bboxes_labels (np.int64) (optional)
+ - gt_ignore_flags (bool) (optional)
+ - gt_masks (BitmapMasks) (optional)
+
+ Modified Keys:
+ - img
+ - gt_bboxes (optional)
+ - gt_bboxes_labels (optional)
+ - gt_ignore_flags (optional)
+ - gt_masks (optional)
+
+ Args:
+ n_patches (int or tuple[int, int]): Number of regions to be dropped.
+ If it is given as a tuple, number of patches will be randomly
+ selected from the closed interval [``n_patches[0]``,
+ ``n_patches[1]``].
+ ratio (float or tuple[float, float]): The ratio of erased regions.
+ It can be ``float`` to use a fixed ratio or ``tuple[float, float]``
+ to randomly choose ratio from the interval.
+ squared (bool): Whether to erase square region. Defaults to True.
+ bbox_erased_thr (float): The threshold for the maximum area proportion
+ of the bbox to be erased. When the proportion of the area where the
+ bbox is erased is greater than the threshold, the bbox will be
+ removed. Defaults to 0.9.
+ img_border_value (int or float or tuple): The filled values for
+ image border. If float, the same fill value will be used for
+ all the three channels of image. If tuple, it should be 3 elements.
+ Defaults to 128.
+ mask_border_value (int): The fill value used for masks. Defaults to 0.
+ seg_ignore_label (int): The fill value used for segmentation map.
+ Note this value must equals ``ignore_label`` in ``semantic_head``
+ of the corresponding config. Defaults to 255.
+ """
+
+ def __init__(
+ self,
+ n_patches: Union[int, Tuple[int, int]],
+ ratio: Union[float, Tuple[float, float]],
+ squared: bool = True,
+ bbox_erased_thr: float = 0.9,
+ img_border_value: Union[int, float, tuple] = 128,
+ mask_border_value: int = 0,
+ seg_ignore_label: int = 255,
+ ) -> None:
+ if isinstance(n_patches, tuple):
+ assert len(n_patches) == 2 and 0 <= n_patches[0] < n_patches[1]
+ else:
+ n_patches = (n_patches, n_patches)
+ if isinstance(ratio, tuple):
+ assert len(ratio) == 2 and 0 <= ratio[0] < ratio[1] <= 1
+ else:
+ ratio = (ratio, ratio)
+
+ self.n_patches = n_patches
+ self.ratio = ratio
+ self.squared = squared
+ self.bbox_erased_thr = bbox_erased_thr
+ self.img_border_value = img_border_value
+ self.mask_border_value = mask_border_value
+ self.seg_ignore_label = seg_ignore_label
+
+ @cache_randomness
+ def _get_patches(self, img_shape: Tuple[int, int]) -> List[list]:
+ """Get patches for random erasing."""
+ patches = []
+ n_patches = np.random.randint(self.n_patches[0], self.n_patches[1] + 1)
+ for _ in range(n_patches):
+ if self.squared:
+ ratio = np.random.random() * (self.ratio[1] -
+ self.ratio[0]) + self.ratio[0]
+ ratio = (ratio, ratio)
+ else:
+ ratio = (np.random.random() * (self.ratio[1] - self.ratio[0]) +
+ self.ratio[0], np.random.random() *
+ (self.ratio[1] - self.ratio[0]) + self.ratio[0])
+ ph, pw = int(img_shape[0] * ratio[0]), int(img_shape[1] * ratio[1])
+ px1, py1 = np.random.randint(0,
+ img_shape[1] - pw), np.random.randint(
+ 0, img_shape[0] - ph)
+ px2, py2 = px1 + pw, py1 + ph
+ patches.append([px1, py1, px2, py2])
+ return np.array(patches)
+
+ def _transform_img(self, results: dict, patches: List[list]) -> None:
+ """Random erasing the image."""
+ for patch in patches:
+ px1, py1, px2, py2 = patch
+ results['img'][py1:py2, px1:px2, :] = self.img_border_value
+
+ def _transform_bboxes(self, results: dict, patches: List[list]) -> None:
+ """Random erasing the bboxes."""
+ bboxes = results['gt_bboxes']
+ # TODO: unify the logic by using operators in BaseBoxes.
+ assert isinstance(bboxes, HorizontalBoxes)
+ bboxes = bboxes.numpy()
+ left_top = np.maximum(bboxes[:, None, :2], patches[:, :2])
+ right_bottom = np.minimum(bboxes[:, None, 2:], patches[:, 2:])
+ wh = np.maximum(right_bottom - left_top, 0)
+ inter_areas = wh[:, :, 0] * wh[:, :, 1]
+ bbox_areas = (bboxes[:, 2] - bboxes[:, 0]) * (
+ bboxes[:, 3] - bboxes[:, 1])
+ bboxes_erased_ratio = inter_areas.sum(-1) / (bbox_areas + 1e-7)
+ valid_inds = bboxes_erased_ratio < self.bbox_erased_thr
+ results['gt_bboxes'] = HorizontalBoxes(bboxes[valid_inds])
+ results['gt_bboxes_labels'] = results['gt_bboxes_labels'][valid_inds]
+ results['gt_ignore_flags'] = results['gt_ignore_flags'][valid_inds]
+ if results.get('gt_masks', None) is not None:
+ results['gt_masks'] = results['gt_masks'][valid_inds]
+
+ def _transform_masks(self, results: dict, patches: List[list]) -> None:
+ """Random erasing the masks."""
+ for patch in patches:
+ px1, py1, px2, py2 = patch
+ results['gt_masks'].masks[:, py1:py2,
+ px1:px2] = self.mask_border_value
+
+ def _transform_seg(self, results: dict, patches: List[list]) -> None:
+ """Random erasing the segmentation map."""
+ for patch in patches:
+ px1, py1, px2, py2 = patch
+ results['gt_seg_map'][py1:py2, px1:px2] = self.seg_ignore_label
+
+ @autocast_box_type()
+ def transform(self, results: dict) -> dict:
+ """Transform function to erase some regions of image."""
+ patches = self._get_patches(results['img_shape'])
+ self._transform_img(results, patches)
+ if results.get('gt_bboxes', None) is not None:
+ self._transform_bboxes(results, patches)
+ if results.get('gt_masks', None) is not None:
+ self._transform_masks(results, patches)
+ if results.get('gt_seg_map', None) is not None:
+ self._transform_seg(results, patches)
+ return results
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ repr_str += f'(n_patches={self.n_patches}, '
+ repr_str += f'ratio={self.ratio}, '
+ repr_str += f'squared={self.squared}, '
+ repr_str += f'bbox_erased_thr={self.bbox_erased_thr}, '
+ repr_str += f'img_border_value={self.img_border_value}, '
+ repr_str += f'mask_border_value={self.mask_border_value}, '
+ repr_str += f'seg_ignore_label={self.seg_ignore_label})'
+ return repr_str
+
+
+@TRANSFORMS.register_module()
+class CachedMosaic(Mosaic):
+ """Cached mosaic augmentation.
+
+ Cached mosaic transform will random select images from the cache
+ and combine them into one output image.
+
+ .. code:: text
+
+ mosaic transform
+ center_x
+ +------------------------------+
+ | pad | pad |
+ | +-----------+ |
+ | | | |
+ | | image1 |--------+ |
+ | | | | |
+ | | | image2 | |
+ center_y |----+-------------+-----------|
+ | | cropped | |
+ |pad | image3 | image4 |
+ | | | |
+ +----|-------------+-----------+
+ | |
+ +-------------+
+
+ The cached mosaic transform steps are as follows:
+
+ 1. Append the results from the last transform into the cache.
+ 2. Choose the mosaic center as the intersections of 4 images
+ 3. Get the left top image according to the index, and randomly
+ sample another 3 images from the result cache.
+ 4. Sub image will be cropped if image is larger than mosaic patch
+
+ Required Keys:
+
+ - img
+ - gt_bboxes (np.float32) (optional)
+ - gt_bboxes_labels (np.int64) (optional)
+ - gt_ignore_flags (bool) (optional)
+
+ Modified Keys:
+
+ - img
+ - img_shape
+ - gt_bboxes (optional)
+ - gt_bboxes_labels (optional)
+ - gt_ignore_flags (optional)
+
+ Args:
+ img_scale (Sequence[int]): Image size after mosaic pipeline of single
+ image. The shape order should be (width, height).
+ Defaults to (640, 640).
+ center_ratio_range (Sequence[float]): Center ratio range of mosaic
+ output. Defaults to (0.5, 1.5).
+ bbox_clip_border (bool, optional): Whether to clip the objects outside
+ the border of the image. In some dataset like MOT17, the gt bboxes
+ are allowed to cross the border of images. Therefore, we don't
+ need to clip the gt bboxes in these cases. Defaults to True.
+ pad_val (int): Pad value. Defaults to 114.
+ prob (float): Probability of applying this transformation.
+ Defaults to 1.0.
+ max_cached_images (int): The maximum length of the cache. The larger
+ the cache, the stronger the randomness of this transform. As a
+ rule of thumb, providing 10 caches for each image suffices for
+ randomness. Defaults to 40.
+ random_pop (bool): Whether to randomly pop a result from the cache
+ when the cache is full. If set to False, use FIFO popping method.
+ Defaults to True.
+ """
+
+ def __init__(self,
+ *args,
+ max_cached_images: int = 40,
+ random_pop: bool = True,
+ **kwargs) -> None:
+ super().__init__(*args, **kwargs)
+ self.results_cache = []
+ self.random_pop = random_pop
+ assert max_cached_images >= 4, 'The length of cache must >= 4, ' \
+ f'but got {max_cached_images}.'
+ self.max_cached_images = max_cached_images
+
+ @cache_randomness
+ def get_indexes(self, cache: list) -> list:
+ """Call function to collect indexes.
+
+ Args:
+ cache (list): The results cache.
+
+ Returns:
+ list: indexes.
+ """
+
+ indexes = [random.randint(0, len(cache) - 1) for _ in range(3)]
+ return indexes
+
+ @autocast_box_type()
+ def transform(self, results: dict) -> dict:
+ """Mosaic transform function.
+
+ Args:
+ results (dict): Result dict.
+
+ Returns:
+ dict: Updated result dict.
+ """
+ # cache and pop images
+ self.results_cache.append(copy.deepcopy(results))
+ if len(self.results_cache) > self.max_cached_images:
+ if self.random_pop:
+ index = random.randint(0, len(self.results_cache) - 1)
+ else:
+ index = 0
+ self.results_cache.pop(index)
+
+ if len(self.results_cache) <= 4:
+ return results
+
+ if random.uniform(0, 1) > self.prob:
+ return results
+ indices = self.get_indexes(self.results_cache)
+ mix_results = [copy.deepcopy(self.results_cache[i]) for i in indices]
+
+ # TODO: refactor mosaic to reuse these code.
+ mosaic_bboxes = []
+ mosaic_bboxes_labels = []
+ mosaic_ignore_flags = []
+ mosaic_masks = []
+ with_mask = True if 'gt_masks' in results else False
+
+ if len(results['img'].shape) == 3:
+ mosaic_img = np.full(
+ (int(self.img_scale[1] * 2), int(self.img_scale[0] * 2), 3),
+ self.pad_val,
+ dtype=results['img'].dtype)
+ else:
+ mosaic_img = np.full(
+ (int(self.img_scale[1] * 2), int(self.img_scale[0] * 2)),
+ self.pad_val,
+ dtype=results['img'].dtype)
+
+ # mosaic center x, y
+ center_x = int(
+ random.uniform(*self.center_ratio_range) * self.img_scale[0])
+ center_y = int(
+ random.uniform(*self.center_ratio_range) * self.img_scale[1])
+ center_position = (center_x, center_y)
+
+ loc_strs = ('top_left', 'top_right', 'bottom_left', 'bottom_right')
+ for i, loc in enumerate(loc_strs):
+ if loc == 'top_left':
+ results_patch = copy.deepcopy(results)
+ else:
+ results_patch = copy.deepcopy(mix_results[i - 1])
+
+ img_i = results_patch['img']
+ h_i, w_i = img_i.shape[:2]
+ # keep_ratio resize
+ scale_ratio_i = min(self.img_scale[1] / h_i,
+ self.img_scale[0] / w_i)
+ img_i = mmcv.imresize(
+ img_i, (int(w_i * scale_ratio_i), int(h_i * scale_ratio_i)))
+
+ # compute the combine parameters
+ paste_coord, crop_coord = self._mosaic_combine(
+ loc, center_position, img_i.shape[:2][::-1])
+ x1_p, y1_p, x2_p, y2_p = paste_coord
+ x1_c, y1_c, x2_c, y2_c = crop_coord
+
+ # crop and paste image
+ mosaic_img[y1_p:y2_p, x1_p:x2_p] = img_i[y1_c:y2_c, x1_c:x2_c]
+
+ # adjust coordinate
+ gt_bboxes_i = results_patch['gt_bboxes']
+ gt_bboxes_labels_i = results_patch['gt_bboxes_labels']
+ gt_ignore_flags_i = results_patch['gt_ignore_flags']
+
+ padw = x1_p - x1_c
+ padh = y1_p - y1_c
+ gt_bboxes_i.rescale_([scale_ratio_i, scale_ratio_i])
+ gt_bboxes_i.translate_([padw, padh])
+ mosaic_bboxes.append(gt_bboxes_i)
+ mosaic_bboxes_labels.append(gt_bboxes_labels_i)
+ mosaic_ignore_flags.append(gt_ignore_flags_i)
+ if with_mask and results_patch.get('gt_masks', None) is not None:
+ gt_masks_i = results_patch['gt_masks']
+ gt_masks_i = gt_masks_i.rescale(float(scale_ratio_i))
+ gt_masks_i = gt_masks_i.translate(
+ out_shape=(int(self.img_scale[0] * 2),
+ int(self.img_scale[1] * 2)),
+ offset=padw,
+ direction='horizontal')
+ gt_masks_i = gt_masks_i.translate(
+ out_shape=(int(self.img_scale[0] * 2),
+ int(self.img_scale[1] * 2)),
+ offset=padh,
+ direction='vertical')
+ mosaic_masks.append(gt_masks_i)
+
+ mosaic_bboxes = mosaic_bboxes[0].cat(mosaic_bboxes, 0)
+ mosaic_bboxes_labels = np.concatenate(mosaic_bboxes_labels, 0)
+ mosaic_ignore_flags = np.concatenate(mosaic_ignore_flags, 0)
+
+ if self.bbox_clip_border:
+ mosaic_bboxes.clip_([2 * self.img_scale[1], 2 * self.img_scale[0]])
+ # remove outside bboxes
+ inside_inds = mosaic_bboxes.is_inside(
+ [2 * self.img_scale[1], 2 * self.img_scale[0]]).numpy()
+ mosaic_bboxes = mosaic_bboxes[inside_inds]
+ mosaic_bboxes_labels = mosaic_bboxes_labels[inside_inds]
+ mosaic_ignore_flags = mosaic_ignore_flags[inside_inds]
+
+ results['img'] = mosaic_img
+ results['img_shape'] = mosaic_img.shape[:2]
+ results['gt_bboxes'] = mosaic_bboxes
+ results['gt_bboxes_labels'] = mosaic_bboxes_labels
+ results['gt_ignore_flags'] = mosaic_ignore_flags
+
+ if with_mask:
+ mosaic_masks = mosaic_masks[0].cat(mosaic_masks)
+ results['gt_masks'] = mosaic_masks[inside_inds]
+ return results
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ repr_str += f'(img_scale={self.img_scale}, '
+ repr_str += f'center_ratio_range={self.center_ratio_range}, '
+ repr_str += f'pad_val={self.pad_val}, '
+ repr_str += f'prob={self.prob}, '
+ repr_str += f'max_cached_images={self.max_cached_images}, '
+ repr_str += f'random_pop={self.random_pop})'
+ return repr_str
+
+
+@TRANSFORMS.register_module()
+class CachedMixUp(BaseTransform):
+ """Cached mixup data augmentation.
+
+ .. code:: text
+
+ mixup transform
+ +------------------------------+
+ | mixup image | |
+ | +--------|--------+ |
+ | | | | |
+ |---------------+ | |
+ | | | |
+ | | image | |
+ | | | |
+ | | | |
+ | |-----------------+ |
+ | pad |
+ +------------------------------+
+
+ The cached mixup transform steps are as follows:
+
+ 1. Append the results from the last transform into the cache.
+ 2. Another random image is picked from the cache and embedded in
+ the top left patch(after padding and resizing)
+ 3. The target of mixup transform is the weighted average of mixup
+ image and origin image.
+
+ Required Keys:
+
+ - img
+ - gt_bboxes (np.float32) (optional)
+ - gt_bboxes_labels (np.int64) (optional)
+ - gt_ignore_flags (bool) (optional)
+ - mix_results (List[dict])
+
+
+ Modified Keys:
+
+ - img
+ - img_shape
+ - gt_bboxes (optional)
+ - gt_bboxes_labels (optional)
+ - gt_ignore_flags (optional)
+
+
+ Args:
+ img_scale (Sequence[int]): Image output size after mixup pipeline.
+ The shape order should be (width, height). Defaults to (640, 640).
+ ratio_range (Sequence[float]): Scale ratio of mixup image.
+ Defaults to (0.5, 1.5).
+ flip_ratio (float): Horizontal flip ratio of mixup image.
+ Defaults to 0.5.
+ pad_val (int): Pad value. Defaults to 114.
+ max_iters (int): The maximum number of iterations. If the number of
+ iterations is greater than `max_iters`, but gt_bbox is still
+ empty, then the iteration is terminated. Defaults to 15.
+ bbox_clip_border (bool, optional): Whether to clip the objects outside
+ the border of the image. In some dataset like MOT17, the gt bboxes
+ are allowed to cross the border of images. Therefore, we don't
+ need to clip the gt bboxes in these cases. Defaults to True.
+ max_cached_images (int): The maximum length of the cache. The larger
+ the cache, the stronger the randomness of this transform. As a
+ rule of thumb, providing 10 caches for each image suffices for
+ randomness. Defaults to 20.
+ random_pop (bool): Whether to randomly pop a result from the cache
+ when the cache is full. If set to False, use FIFO popping method.
+ Defaults to True.
+ prob (float): Probability of applying this transformation.
+ Defaults to 1.0.
+ """
+
+ def __init__(self,
+ img_scale: Tuple[int, int] = (640, 640),
+ ratio_range: Tuple[float, float] = (0.5, 1.5),
+ flip_ratio: float = 0.5,
+ pad_val: float = 114.0,
+ max_iters: int = 15,
+ bbox_clip_border: bool = True,
+ max_cached_images: int = 20,
+ random_pop: bool = True,
+ prob: float = 1.0) -> None:
+ assert isinstance(img_scale, tuple)
+ assert max_cached_images >= 2, 'The length of cache must >= 2, ' \
+ f'but got {max_cached_images}.'
+ assert 0 <= prob <= 1.0, 'The probability should be in range [0,1]. ' \
+ f'got {prob}.'
+ self.dynamic_scale = img_scale
+ self.ratio_range = ratio_range
+ self.flip_ratio = flip_ratio
+ self.pad_val = pad_val
+ self.max_iters = max_iters
+ self.bbox_clip_border = bbox_clip_border
+ self.results_cache = []
+
+ self.max_cached_images = max_cached_images
+ self.random_pop = random_pop
+ self.prob = prob
+
+ @cache_randomness
+ def get_indexes(self, cache: list) -> int:
+ """Call function to collect indexes.
+
+ Args:
+ cache (list): The result cache.
+
+ Returns:
+ int: index.
+ """
+
+ for i in range(self.max_iters):
+ index = random.randint(0, len(cache) - 1)
+ gt_bboxes_i = cache[index]['gt_bboxes']
+ if len(gt_bboxes_i) != 0:
+ break
+ return index
+
+ @autocast_box_type()
+ def transform(self, results: dict) -> dict:
+ """MixUp transform function.
+
+ Args:
+ results (dict): Result dict.
+
+ Returns:
+ dict: Updated result dict.
+ """
+ # cache and pop images
+ self.results_cache.append(copy.deepcopy(results))
+ if len(self.results_cache) > self.max_cached_images:
+ if self.random_pop:
+ index = random.randint(0, len(self.results_cache) - 1)
+ else:
+ index = 0
+ self.results_cache.pop(index)
+
+ if len(self.results_cache) <= 1:
+ return results
+
+ if random.uniform(0, 1) > self.prob:
+ return results
+
+ index = self.get_indexes(self.results_cache)
+ retrieve_results = copy.deepcopy(self.results_cache[index])
+
+ # TODO: refactor mixup to reuse these code.
+ if retrieve_results['gt_bboxes'].shape[0] == 0:
+ # empty bbox
+ return results
+
+ retrieve_img = retrieve_results['img']
+ with_mask = True if 'gt_masks' in results else False
+
+ jit_factor = random.uniform(*self.ratio_range)
+ is_filp = random.uniform(0, 1) > self.flip_ratio
+
+ if len(retrieve_img.shape) == 3:
+ out_img = np.ones(
+ (self.dynamic_scale[1], self.dynamic_scale[0], 3),
+ dtype=retrieve_img.dtype) * self.pad_val
+ else:
+ out_img = np.ones(
+ self.dynamic_scale[::-1],
+ dtype=retrieve_img.dtype) * self.pad_val
+
+ # 1. keep_ratio resize
+ scale_ratio = min(self.dynamic_scale[1] / retrieve_img.shape[0],
+ self.dynamic_scale[0] / retrieve_img.shape[1])
+ retrieve_img = mmcv.imresize(
+ retrieve_img, (int(retrieve_img.shape[1] * scale_ratio),
+ int(retrieve_img.shape[0] * scale_ratio)))
+
+ # 2. paste
+ out_img[:retrieve_img.shape[0], :retrieve_img.shape[1]] = retrieve_img
+
+ # 3. scale jit
+ scale_ratio *= jit_factor
+ out_img = mmcv.imresize(out_img, (int(out_img.shape[1] * jit_factor),
+ int(out_img.shape[0] * jit_factor)))
+
+ # 4. flip
+ if is_filp:
+ out_img = out_img[:, ::-1, :]
+
+ # 5. random crop
+ ori_img = results['img']
+ origin_h, origin_w = out_img.shape[:2]
+ target_h, target_w = ori_img.shape[:2]
+ padded_img = np.ones((max(origin_h, target_h), max(
+ origin_w, target_w), 3)) * self.pad_val
+ padded_img = padded_img.astype(np.uint8)
+ padded_img[:origin_h, :origin_w] = out_img
+
+ x_offset, y_offset = 0, 0
+ if padded_img.shape[0] > target_h:
+ y_offset = random.randint(0, padded_img.shape[0] - target_h)
+ if padded_img.shape[1] > target_w:
+ x_offset = random.randint(0, padded_img.shape[1] - target_w)
+ padded_cropped_img = padded_img[y_offset:y_offset + target_h,
+ x_offset:x_offset + target_w]
+
+ # 6. adjust bbox
+ retrieve_gt_bboxes = retrieve_results['gt_bboxes']
+ retrieve_gt_bboxes.rescale_([scale_ratio, scale_ratio])
+ if with_mask:
+ retrieve_gt_masks = retrieve_results['gt_masks'].rescale(
+ scale_ratio)
+
+ if self.bbox_clip_border:
+ retrieve_gt_bboxes.clip_([origin_h, origin_w])
+
+ if is_filp:
+ retrieve_gt_bboxes.flip_([origin_h, origin_w],
+ direction='horizontal')
+ if with_mask:
+ retrieve_gt_masks = retrieve_gt_masks.flip()
+
+ # 7. filter
+ cp_retrieve_gt_bboxes = retrieve_gt_bboxes.clone()
+ cp_retrieve_gt_bboxes.translate_([-x_offset, -y_offset])
+ if with_mask:
+ retrieve_gt_masks = retrieve_gt_masks.translate(
+ out_shape=(target_h, target_w),
+ offset=-x_offset,
+ direction='horizontal')
+ retrieve_gt_masks = retrieve_gt_masks.translate(
+ out_shape=(target_h, target_w),
+ offset=-y_offset,
+ direction='vertical')
+
+ if self.bbox_clip_border:
+ cp_retrieve_gt_bboxes.clip_([target_h, target_w])
+
+ # 8. mix up
+ ori_img = ori_img.astype(np.float32)
+ mixup_img = 0.5 * ori_img + 0.5 * padded_cropped_img.astype(np.float32)
+
+ retrieve_gt_bboxes_labels = retrieve_results['gt_bboxes_labels']
+ retrieve_gt_ignore_flags = retrieve_results['gt_ignore_flags']
+
+ mixup_gt_bboxes = cp_retrieve_gt_bboxes.cat(
+ (results['gt_bboxes'], cp_retrieve_gt_bboxes), dim=0)
+ mixup_gt_bboxes_labels = np.concatenate(
+ (results['gt_bboxes_labels'], retrieve_gt_bboxes_labels), axis=0)
+ mixup_gt_ignore_flags = np.concatenate(
+ (results['gt_ignore_flags'], retrieve_gt_ignore_flags), axis=0)
+ if with_mask:
+ mixup_gt_masks = retrieve_gt_masks.cat(
+ [results['gt_masks'], retrieve_gt_masks])
+
+ # remove outside bbox
+ inside_inds = mixup_gt_bboxes.is_inside([target_h, target_w]).numpy()
+ mixup_gt_bboxes = mixup_gt_bboxes[inside_inds]
+ mixup_gt_bboxes_labels = mixup_gt_bboxes_labels[inside_inds]
+ mixup_gt_ignore_flags = mixup_gt_ignore_flags[inside_inds]
+ if with_mask:
+ mixup_gt_masks = mixup_gt_masks[inside_inds]
+
+ results['img'] = mixup_img.astype(np.uint8)
+ results['img_shape'] = mixup_img.shape[:2]
+ results['gt_bboxes'] = mixup_gt_bboxes
+ results['gt_bboxes_labels'] = mixup_gt_bboxes_labels
+ results['gt_ignore_flags'] = mixup_gt_ignore_flags
+ if with_mask:
+ results['gt_masks'] = mixup_gt_masks
+ return results
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ repr_str += f'(dynamic_scale={self.dynamic_scale}, '
+ repr_str += f'ratio_range={self.ratio_range}, '
+ repr_str += f'flip_ratio={self.flip_ratio}, '
+ repr_str += f'pad_val={self.pad_val}, '
+ repr_str += f'max_iters={self.max_iters}, '
+ repr_str += f'bbox_clip_border={self.bbox_clip_border}, '
+ repr_str += f'max_cached_images={self.max_cached_images}, '
+ repr_str += f'random_pop={self.random_pop}, '
+ repr_str += f'prob={self.prob})'
+ return repr_str
diff --git a/mmdet/datasets/transforms/wrappers.py b/mmdet/datasets/transforms/wrappers.py
new file mode 100644
index 0000000000000000000000000000000000000000..3a17711c06bfbd4dc0038dce9ea7796d1476c37e
--- /dev/null
+++ b/mmdet/datasets/transforms/wrappers.py
@@ -0,0 +1,277 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+from typing import Callable, Dict, List, Optional, Union
+
+import numpy as np
+from mmcv.transforms import BaseTransform, Compose
+from mmcv.transforms.utils import cache_random_params, cache_randomness
+
+from mmdet.registry import TRANSFORMS
+
+
+@TRANSFORMS.register_module()
+class MultiBranch(BaseTransform):
+ r"""Multiple branch pipeline wrapper.
+
+ Generate multiple data-augmented versions of the same image.
+ `MultiBranch` needs to specify the branch names of all
+ pipelines of the dataset, perform corresponding data augmentation
+ for the current branch, and return None for other branches,
+ which ensures the consistency of return format across
+ different samples.
+
+ Args:
+ branch_field (list): List of branch names.
+ branch_pipelines (dict): Dict of different pipeline configs
+ to be composed.
+
+ Examples:
+ >>> branch_field = ['sup', 'unsup_teacher', 'unsup_student']
+ >>> sup_pipeline = [
+ >>> dict(type='LoadImageFromFile'),
+ >>> dict(type='LoadAnnotations', with_bbox=True),
+ >>> dict(type='Resize', scale=(1333, 800), keep_ratio=True),
+ >>> dict(type='RandomFlip', prob=0.5),
+ >>> dict(
+ >>> type='MultiBranch',
+ >>> branch_field=branch_field,
+ >>> sup=dict(type='PackDetInputs'))
+ >>> ]
+ >>> weak_pipeline = [
+ >>> dict(type='LoadImageFromFile'),
+ >>> dict(type='LoadAnnotations', with_bbox=True),
+ >>> dict(type='Resize', scale=(1333, 800), keep_ratio=True),
+ >>> dict(type='RandomFlip', prob=0.0),
+ >>> dict(
+ >>> type='MultiBranch',
+ >>> branch_field=branch_field,
+ >>> sup=dict(type='PackDetInputs'))
+ >>> ]
+ >>> strong_pipeline = [
+ >>> dict(type='LoadImageFromFile'),
+ >>> dict(type='LoadAnnotations', with_bbox=True),
+ >>> dict(type='Resize', scale=(1333, 800), keep_ratio=True),
+ >>> dict(type='RandomFlip', prob=1.0),
+ >>> dict(
+ >>> type='MultiBranch',
+ >>> branch_field=branch_field,
+ >>> sup=dict(type='PackDetInputs'))
+ >>> ]
+ >>> unsup_pipeline = [
+ >>> dict(type='LoadImageFromFile'),
+ >>> dict(type='LoadEmptyAnnotations'),
+ >>> dict(
+ >>> type='MultiBranch',
+ >>> branch_field=branch_field,
+ >>> unsup_teacher=weak_pipeline,
+ >>> unsup_student=strong_pipeline)
+ >>> ]
+ >>> from mmcv.transforms import Compose
+ >>> sup_branch = Compose(sup_pipeline)
+ >>> unsup_branch = Compose(unsup_pipeline)
+ >>> print(sup_branch)
+ >>> Compose(
+ >>> LoadImageFromFile(ignore_empty=False, to_float32=False, color_type='color', imdecode_backend='cv2') # noqa
+ >>> LoadAnnotations(with_bbox=True, with_label=True, with_mask=False, with_seg=False, poly2mask=True, imdecode_backend='cv2') # noqa
+ >>> Resize(scale=(1333, 800), scale_factor=None, keep_ratio=True, clip_object_border=True), backend=cv2), interpolation=bilinear) # noqa
+ >>> RandomFlip(prob=0.5, direction=horizontal)
+ >>> MultiBranch(branch_pipelines=['sup'])
+ >>> )
+ >>> print(unsup_branch)
+ >>> Compose(
+ >>> LoadImageFromFile(ignore_empty=False, to_float32=False, color_type='color', imdecode_backend='cv2') # noqa
+ >>> LoadEmptyAnnotations(with_bbox=True, with_label=True, with_mask=False, with_seg=False, seg_ignore_label=255) # noqa
+ >>> MultiBranch(branch_pipelines=['unsup_teacher', 'unsup_student'])
+ >>> )
+ """
+
+ def __init__(self, branch_field: List[str],
+ **branch_pipelines: dict) -> None:
+ self.branch_field = branch_field
+ self.branch_pipelines = {
+ branch: Compose(pipeline)
+ for branch, pipeline in branch_pipelines.items()
+ }
+
+ def transform(self, results: dict) -> dict:
+ """Transform function to apply transforms sequentially.
+
+ Args:
+ results (dict): Result dict from loading pipeline.
+
+ Returns:
+ dict:
+
+ - 'inputs' (Dict[str, obj:`torch.Tensor`]): The forward data of
+ models from different branches.
+ - 'data_sample' (Dict[str,obj:`DetDataSample`]): The annotation
+ info of the sample from different branches.
+ """
+
+ multi_results = {}
+ for branch in self.branch_field:
+ multi_results[branch] = {'inputs': None, 'data_samples': None}
+ for branch, pipeline in self.branch_pipelines.items():
+ branch_results = pipeline(copy.deepcopy(results))
+ # If one branch pipeline returns None,
+ # it will sample another data from dataset.
+ if branch_results is None:
+ return None
+ multi_results[branch] = branch_results
+
+ format_results = {}
+ for branch, results in multi_results.items():
+ for key in results.keys():
+ if format_results.get(key, None) is None:
+ format_results[key] = {branch: results[key]}
+ else:
+ format_results[key][branch] = results[key]
+ return format_results
+
+ def __repr__(self) -> str:
+ repr_str = self.__class__.__name__
+ repr_str += f'(branch_pipelines={list(self.branch_pipelines.keys())})'
+ return repr_str
+
+
+@TRANSFORMS.register_module()
+class RandomOrder(Compose):
+ """Shuffle the transform Sequence."""
+
+ @cache_randomness
+ def _random_permutation(self):
+ return np.random.permutation(len(self.transforms))
+
+ def transform(self, results: Dict) -> Optional[Dict]:
+ """Transform function to apply transforms in random order.
+
+ Args:
+ results (dict): A result dict contains the results to transform.
+
+ Returns:
+ dict or None: Transformed results.
+ """
+ inds = self._random_permutation()
+ for idx in inds:
+ t = self.transforms[idx]
+ results = t(results)
+ if results is None:
+ return None
+ return results
+
+ def __repr__(self):
+ """Compute the string representation."""
+ format_string = self.__class__.__name__ + '('
+ for t in self.transforms:
+ format_string += f'{t.__class__.__name__}, '
+ format_string += ')'
+ return format_string
+
+
+@TRANSFORMS.register_module()
+class ProposalBroadcaster(BaseTransform):
+ """A transform wrapper to apply the wrapped transforms to process both
+ `gt_bboxes` and `proposals` without adding any codes. It will do the
+ following steps:
+
+ 1. Scatter the broadcasting targets to a list of inputs of the wrapped
+ transforms. The type of the list should be list[dict, dict], which
+ the first is the original inputs, the second is the processing
+ results that `gt_bboxes` being rewritten by the `proposals`.
+ 2. Apply ``self.transforms``, with same random parameters, which is
+ sharing with a context manager. The type of the outputs is a
+ list[dict, dict].
+ 3. Gather the outputs, update the `proposals` in the first item of
+ the outputs with the `gt_bboxes` in the second .
+
+ Args:
+ transforms (list, optional): Sequence of transform
+ object or config dict to be wrapped. Defaults to [].
+
+ Note: The `TransformBroadcaster` in MMCV can achieve the same operation as
+ `ProposalBroadcaster`, but need to set more complex parameters.
+
+ Examples:
+ >>> pipeline = [
+ >>> dict(type='LoadImageFromFile'),
+ >>> dict(type='LoadProposals', num_max_proposals=2000),
+ >>> dict(type='LoadAnnotations', with_bbox=True),
+ >>> dict(
+ >>> type='ProposalBroadcaster',
+ >>> transforms=[
+ >>> dict(type='Resize', scale=(1333, 800),
+ >>> keep_ratio=True),
+ >>> dict(type='RandomFlip', prob=0.5),
+ >>> ]),
+ >>> dict(type='PackDetInputs')]
+ """
+
+ def __init__(self, transforms: List[Union[dict, Callable]] = []) -> None:
+ self.transforms = Compose(transforms)
+
+ def transform(self, results: dict) -> dict:
+ """Apply wrapped transform functions to process both `gt_bboxes` and
+ `proposals`.
+
+ Args:
+ results (dict): Result dict from loading pipeline.
+
+ Returns:
+ dict: Updated result dict.
+ """
+ assert results.get('proposals', None) is not None, \
+ '`proposals` should be in the results, please delete ' \
+ '`ProposalBroadcaster` in your configs, or check whether ' \
+ 'you have load proposals successfully.'
+
+ inputs = self._process_input(results)
+ outputs = self._apply_transforms(inputs)
+ outputs = self._process_output(outputs)
+ return outputs
+
+ def _process_input(self, data: dict) -> list:
+ """Scatter the broadcasting targets to a list of inputs of the wrapped
+ transforms.
+
+ Args:
+ data (dict): The original input data.
+
+ Returns:
+ list[dict]: A list of input data.
+ """
+ cp_data = copy.deepcopy(data)
+ cp_data['gt_bboxes'] = cp_data['proposals']
+ scatters = [data, cp_data]
+ return scatters
+
+ def _apply_transforms(self, inputs: list) -> list:
+ """Apply ``self.transforms``.
+
+ Args:
+ inputs (list[dict, dict]): list of input data.
+
+ Returns:
+ list[dict]: The output of the wrapped pipeline.
+ """
+ assert len(inputs) == 2
+ ctx = cache_random_params
+ with ctx(self.transforms):
+ output_scatters = [self.transforms(_input) for _input in inputs]
+ return output_scatters
+
+ def _process_output(self, output_scatters: list) -> dict:
+ """Gathering and renaming data items.
+
+ Args:
+ output_scatters (list[dict, dict]): The output of the wrapped
+ pipeline.
+
+ Returns:
+ dict: Updated result dict.
+ """
+ assert isinstance(output_scatters, list) and \
+ isinstance(output_scatters[0], dict) and \
+ len(output_scatters) == 2
+ outputs = output_scatters[0]
+ outputs['proposals'] = output_scatters[1]['gt_bboxes']
+ return outputs
diff --git a/mmdet/datasets/utils.py b/mmdet/datasets/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..a281fb0b99e111fd5c4e12c6639efc38f33c3224
--- /dev/null
+++ b/mmdet/datasets/utils.py
@@ -0,0 +1,48 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+
+from mmcv.transforms import LoadImageFromFile
+
+from mmdet.datasets.transforms import LoadAnnotations, LoadPanopticAnnotations
+from mmdet.registry import TRANSFORMS
+
+
+def get_loading_pipeline(pipeline):
+ """Only keep loading image and annotations related configuration.
+
+ Args:
+ pipeline (list[dict]): Data pipeline configs.
+
+ Returns:
+ list[dict]: The new pipeline list with only keep
+ loading image and annotations related configuration.
+
+ Examples:
+ >>> pipelines = [
+ ... dict(type='LoadImageFromFile'),
+ ... dict(type='LoadAnnotations', with_bbox=True),
+ ... dict(type='Resize', img_scale=(1333, 800), keep_ratio=True),
+ ... dict(type='RandomFlip', flip_ratio=0.5),
+ ... dict(type='Normalize', **img_norm_cfg),
+ ... dict(type='Pad', size_divisor=32),
+ ... dict(type='DefaultFormatBundle'),
+ ... dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels'])
+ ... ]
+ >>> expected_pipelines = [
+ ... dict(type='LoadImageFromFile'),
+ ... dict(type='LoadAnnotations', with_bbox=True)
+ ... ]
+ >>> assert expected_pipelines ==\
+ ... get_loading_pipeline(pipelines)
+ """
+ loading_pipeline_cfg = []
+ for cfg in pipeline:
+ obj_cls = TRANSFORMS.get(cfg['type'])
+ # TODO:use more elegant way to distinguish loading modules
+ if obj_cls is not None and obj_cls in (LoadImageFromFile,
+ LoadAnnotations,
+ LoadPanopticAnnotations):
+ loading_pipeline_cfg.append(cfg)
+ assert len(loading_pipeline_cfg) == 2, \
+ 'The data pipeline in your config file must include ' \
+ 'loading image and annotations related pipeline.'
+ return loading_pipeline_cfg
diff --git a/mmdet/datasets/voc.py b/mmdet/datasets/voc.py
new file mode 100644
index 0000000000000000000000000000000000000000..65e73f2f0bd4f2b16d5237cd3b5f342e44cf0438
--- /dev/null
+++ b/mmdet/datasets/voc.py
@@ -0,0 +1,31 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmdet.registry import DATASETS
+from .xml_style import XMLDataset
+
+
+@DATASETS.register_module()
+class VOCDataset(XMLDataset):
+ """Dataset for PASCAL VOC."""
+
+ METAINFO = {
+ 'classes':
+ ('aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat',
+ 'chair', 'cow', 'diningtable', 'dog', 'horse', 'motorbike', 'person',
+ 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor'),
+ # palette is a list of color tuples, which is used for visualization.
+ 'palette': [(106, 0, 228), (119, 11, 32), (165, 42, 42), (0, 0, 192),
+ (197, 226, 255), (0, 60, 100), (0, 0, 142), (255, 77, 255),
+ (153, 69, 1), (120, 166, 157), (0, 182, 199),
+ (0, 226, 252), (182, 182, 255), (0, 0, 230), (220, 20, 60),
+ (163, 255, 0), (0, 82, 0), (3, 95, 161), (0, 80, 100),
+ (183, 130, 88)]
+ }
+
+ def __init__(self, **kwargs):
+ super().__init__(**kwargs)
+ if 'VOC2007' in self.sub_data_root:
+ self._metainfo['dataset_type'] = 'VOC2007'
+ elif 'VOC2012' in self.sub_data_root:
+ self._metainfo['dataset_type'] = 'VOC2012'
+ else:
+ self._metainfo['dataset_type'] = None
diff --git a/mmdet/datasets/wider_face.py b/mmdet/datasets/wider_face.py
new file mode 100644
index 0000000000000000000000000000000000000000..62c7fff869ab970b6f96908a998ba6feb25ea205
--- /dev/null
+++ b/mmdet/datasets/wider_face.py
@@ -0,0 +1,90 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+import xml.etree.ElementTree as ET
+
+from mmengine.dist import is_main_process
+from mmengine.fileio import get_local_path, list_from_file
+from mmengine.utils import ProgressBar
+
+from mmdet.registry import DATASETS
+from mmdet.utils.typing_utils import List, Union
+from .xml_style import XMLDataset
+
+
+@DATASETS.register_module()
+class WIDERFaceDataset(XMLDataset):
+ """Reader for the WIDER Face dataset in PASCAL VOC format.
+
+ Conversion scripts can be found in
+ https://github.com/sovrasov/wider-face-pascal-voc-annotations
+ """
+ METAINFO = {'classes': ('face', ), 'palette': [(0, 255, 0)]}
+
+ def load_data_list(self) -> List[dict]:
+ """Load annotation from XML style ann_file.
+
+ Returns:
+ list[dict]: Annotation info from XML file.
+ """
+ assert self._metainfo.get('classes', None) is not None, \
+ 'classes in `XMLDataset` can not be None.'
+ self.cat2label = {
+ cat: i
+ for i, cat in enumerate(self._metainfo['classes'])
+ }
+
+ data_list = []
+ img_ids = list_from_file(self.ann_file, backend_args=self.backend_args)
+
+ # loading process takes around 10 mins
+ if is_main_process():
+ prog_bar = ProgressBar(len(img_ids))
+
+ for img_id in img_ids:
+ raw_img_info = {}
+ raw_img_info['img_id'] = img_id
+ raw_img_info['file_name'] = f'{img_id}.jpg'
+ parsed_data_info = self.parse_data_info(raw_img_info)
+ data_list.append(parsed_data_info)
+
+ if is_main_process():
+ prog_bar.update()
+ return data_list
+
+ def parse_data_info(self, img_info: dict) -> Union[dict, List[dict]]:
+ """Parse raw annotation to target format.
+
+ Args:
+ img_info (dict): Raw image information, usually it includes
+ `img_id`, `file_name`, and `xml_path`.
+
+ Returns:
+ Union[dict, List[dict]]: Parsed annotation.
+ """
+ data_info = {}
+ img_id = img_info['img_id']
+ xml_path = osp.join(self.data_prefix['img'], 'Annotations',
+ f'{img_id}.xml')
+ data_info['img_id'] = img_id
+ data_info['xml_path'] = xml_path
+
+ # deal with xml file
+ with get_local_path(
+ xml_path, backend_args=self.backend_args) as local_path:
+ raw_ann_info = ET.parse(local_path)
+ root = raw_ann_info.getroot()
+ size = root.find('size')
+ width = int(size.find('width').text)
+ height = int(size.find('height').text)
+ folder = root.find('folder').text
+ img_path = osp.join(self.data_prefix['img'], folder,
+ img_info['file_name'])
+ data_info['img_path'] = img_path
+
+ data_info['height'] = height
+ data_info['width'] = width
+
+ # Coordinates are in range [0, width - 1 or height - 1]
+ data_info['instances'] = self._parse_instance_info(
+ raw_ann_info, minus_one=False)
+ return data_info
diff --git a/mmdet/datasets/xml_style.py b/mmdet/datasets/xml_style.py
new file mode 100644
index 0000000000000000000000000000000000000000..f5a6d8ca9b933d45af71c8b020aab5b6459cd3c4
--- /dev/null
+++ b/mmdet/datasets/xml_style.py
@@ -0,0 +1,186 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+import xml.etree.ElementTree as ET
+from typing import List, Optional, Union
+
+import mmcv
+from mmengine.fileio import get, get_local_path, list_from_file
+
+from mmdet.registry import DATASETS
+from .base_det_dataset import BaseDetDataset
+
+
+@DATASETS.register_module()
+class XMLDataset(BaseDetDataset):
+ """XML dataset for detection.
+
+ Args:
+ img_subdir (str): Subdir where images are stored. Default: JPEGImages.
+ ann_subdir (str): Subdir where annotations are. Default: Annotations.
+ backend_args (dict, optional): Arguments to instantiate the
+ corresponding backend. Defaults to None.
+ """
+
+ def __init__(self,
+ img_subdir: str = 'JPEGImages',
+ ann_subdir: str = 'Annotations',
+ **kwargs) -> None:
+ self.img_subdir = img_subdir
+ self.ann_subdir = ann_subdir
+ super().__init__(**kwargs)
+
+ @property
+ def sub_data_root(self) -> str:
+ """Return the sub data root."""
+ return self.data_prefix.get('sub_data_root', '')
+
+ def load_data_list(self) -> List[dict]:
+ """Load annotation from XML style ann_file.
+
+ Returns:
+ list[dict]: Annotation info from XML file.
+ """
+ assert self._metainfo.get('classes', None) is not None, \
+ '`classes` in `XMLDataset` can not be None.'
+ self.cat2label = {
+ cat: i
+ for i, cat in enumerate(self._metainfo['classes'])
+ }
+
+ data_list = []
+ img_ids = list_from_file(self.ann_file, backend_args=self.backend_args)
+ for img_id in img_ids:
+ file_name = osp.join(self.img_subdir, f'{img_id}.jpg')
+ xml_path = osp.join(self.sub_data_root, self.ann_subdir,
+ f'{img_id}.xml')
+
+ raw_img_info = {}
+ raw_img_info['img_id'] = img_id
+ raw_img_info['file_name'] = file_name
+ raw_img_info['xml_path'] = xml_path
+
+ parsed_data_info = self.parse_data_info(raw_img_info)
+ data_list.append(parsed_data_info)
+ return data_list
+
+ @property
+ def bbox_min_size(self) -> Optional[str]:
+ """Return the minimum size of bounding boxes in the images."""
+ if self.filter_cfg is not None:
+ return self.filter_cfg.get('bbox_min_size', None)
+ else:
+ return None
+
+ def parse_data_info(self, img_info: dict) -> Union[dict, List[dict]]:
+ """Parse raw annotation to target format.
+
+ Args:
+ img_info (dict): Raw image information, usually it includes
+ `img_id`, `file_name`, and `xml_path`.
+
+ Returns:
+ Union[dict, List[dict]]: Parsed annotation.
+ """
+ data_info = {}
+ img_path = osp.join(self.sub_data_root, img_info['file_name'])
+ data_info['img_path'] = img_path
+ data_info['img_id'] = img_info['img_id']
+ data_info['xml_path'] = img_info['xml_path']
+
+ # deal with xml file
+ with get_local_path(
+ img_info['xml_path'],
+ backend_args=self.backend_args) as local_path:
+ raw_ann_info = ET.parse(local_path)
+ root = raw_ann_info.getroot()
+ size = root.find('size')
+ if size is not None:
+ width = int(size.find('width').text)
+ height = int(size.find('height').text)
+ else:
+ img_bytes = get(img_path, backend_args=self.backend_args)
+ img = mmcv.imfrombytes(img_bytes, backend='cv2')
+ height, width = img.shape[:2]
+ del img, img_bytes
+
+ data_info['height'] = height
+ data_info['width'] = width
+
+ data_info['instances'] = self._parse_instance_info(
+ raw_ann_info, minus_one=True)
+
+ return data_info
+
+ def _parse_instance_info(self,
+ raw_ann_info: ET,
+ minus_one: bool = True) -> List[dict]:
+ """parse instance information.
+
+ Args:
+ raw_ann_info (ElementTree): ElementTree object.
+ minus_one (bool): Whether to subtract 1 from the coordinates.
+ Defaults to True.
+
+ Returns:
+ List[dict]: List of instances.
+ """
+ instances = []
+ for obj in raw_ann_info.findall('object'):
+ instance = {}
+ name = obj.find('name').text
+ if name not in self._metainfo['classes']:
+ continue
+ difficult = obj.find('difficult')
+ difficult = 0 if difficult is None else int(difficult.text)
+ bnd_box = obj.find('bndbox')
+ bbox = [
+ int(float(bnd_box.find('xmin').text)),
+ int(float(bnd_box.find('ymin').text)),
+ int(float(bnd_box.find('xmax').text)),
+ int(float(bnd_box.find('ymax').text))
+ ]
+
+ # VOC needs to subtract 1 from the coordinates
+ if minus_one:
+ bbox = [x - 1 for x in bbox]
+
+ ignore = False
+ if self.bbox_min_size is not None:
+ assert not self.test_mode
+ w = bbox[2] - bbox[0]
+ h = bbox[3] - bbox[1]
+ if w < self.bbox_min_size or h < self.bbox_min_size:
+ ignore = True
+ if difficult or ignore:
+ instance['ignore_flag'] = 1
+ else:
+ instance['ignore_flag'] = 0
+ instance['bbox'] = bbox
+ instance['bbox_label'] = self.cat2label[name]
+ instances.append(instance)
+ return instances
+
+ def filter_data(self) -> List[dict]:
+ """Filter annotations according to filter_cfg.
+
+ Returns:
+ List[dict]: Filtered results.
+ """
+ if self.test_mode:
+ return self.data_list
+
+ filter_empty_gt = self.filter_cfg.get('filter_empty_gt', False) \
+ if self.filter_cfg is not None else False
+ min_size = self.filter_cfg.get('min_size', 0) \
+ if self.filter_cfg is not None else 0
+
+ valid_data_infos = []
+ for i, data_info in enumerate(self.data_list):
+ width = data_info['width']
+ height = data_info['height']
+ if filter_empty_gt and len(data_info['instances']) == 0:
+ continue
+ if min(width, height) >= min_size:
+ valid_data_infos.append(data_info)
+
+ return valid_data_infos
diff --git a/mmdet/engine/__init__.py b/mmdet/engine/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..c91ace6ffa20948af572d3a0fd594e8a0b091775
--- /dev/null
+++ b/mmdet/engine/__init__.py
@@ -0,0 +1,5 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .hooks import * # noqa: F401, F403
+from .optimizers import * # noqa: F401, F403
+from .runner import * # noqa: F401, F403
+from .schedulers import * # noqa: F401, F403
diff --git a/mmdet/engine/__pycache__/__init__.cpython-37.pyc b/mmdet/engine/__pycache__/__init__.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..63aa438b93610c5499d375084c70187429107afe
Binary files /dev/null and b/mmdet/engine/__pycache__/__init__.cpython-37.pyc differ
diff --git a/mmdet/engine/hooks/__init__.py b/mmdet/engine/hooks/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..c0e3fb0df8b7f3908f894002a435f9ada342652f
--- /dev/null
+++ b/mmdet/engine/hooks/__init__.py
@@ -0,0 +1,18 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .checkloss_hook import CheckInvalidLossHook
+from .mean_teacher_hook import MeanTeacherHook
+from .memory_profiler_hook import MemoryProfilerHook
+from .num_class_check_hook import NumClassCheckHook
+from .pipeline_switch_hook import PipelineSwitchHook
+from .set_epoch_info_hook import SetEpochInfoHook
+from .sync_norm_hook import SyncNormHook
+from .utils import trigger_visualization_hook
+from .visualization_hook import DetVisualizationHook
+from .yolox_mode_switch_hook import YOLOXModeSwitchHook
+
+__all__ = [
+ 'YOLOXModeSwitchHook', 'SyncNormHook', 'CheckInvalidLossHook',
+ 'SetEpochInfoHook', 'MemoryProfilerHook', 'DetVisualizationHook',
+ 'NumClassCheckHook', 'MeanTeacherHook', 'trigger_visualization_hook',
+ 'PipelineSwitchHook'
+]
diff --git a/mmdet/engine/hooks/__pycache__/__init__.cpython-37.pyc b/mmdet/engine/hooks/__pycache__/__init__.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..c0b4d6e7a6dbf3b328045789e7a3184c27ad5df8
Binary files /dev/null and b/mmdet/engine/hooks/__pycache__/__init__.cpython-37.pyc differ
diff --git a/mmdet/engine/hooks/__pycache__/checkloss_hook.cpython-37.pyc b/mmdet/engine/hooks/__pycache__/checkloss_hook.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..b0792f729724c4e67516b9471d54c87db9062e8f
Binary files /dev/null and b/mmdet/engine/hooks/__pycache__/checkloss_hook.cpython-37.pyc differ
diff --git a/mmdet/engine/hooks/__pycache__/mean_teacher_hook.cpython-37.pyc b/mmdet/engine/hooks/__pycache__/mean_teacher_hook.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..82e6005fe2fa3d9e8ad338e3b9d2833ebdfde5de
Binary files /dev/null and b/mmdet/engine/hooks/__pycache__/mean_teacher_hook.cpython-37.pyc differ
diff --git a/mmdet/engine/hooks/__pycache__/memory_profiler_hook.cpython-37.pyc b/mmdet/engine/hooks/__pycache__/memory_profiler_hook.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..370f8518a3e1ff003756b5691c0ae07c537c6564
Binary files /dev/null and b/mmdet/engine/hooks/__pycache__/memory_profiler_hook.cpython-37.pyc differ
diff --git a/mmdet/engine/hooks/__pycache__/num_class_check_hook.cpython-37.pyc b/mmdet/engine/hooks/__pycache__/num_class_check_hook.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..8f049de68c6459dc77ddf63bd89045d4e64cfe11
Binary files /dev/null and b/mmdet/engine/hooks/__pycache__/num_class_check_hook.cpython-37.pyc differ
diff --git a/mmdet/engine/hooks/__pycache__/pipeline_switch_hook.cpython-37.pyc b/mmdet/engine/hooks/__pycache__/pipeline_switch_hook.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..4cb424f306f617f78d5002ed20fb14c3a7fbaab3
Binary files /dev/null and b/mmdet/engine/hooks/__pycache__/pipeline_switch_hook.cpython-37.pyc differ
diff --git a/mmdet/engine/hooks/__pycache__/set_epoch_info_hook.cpython-37.pyc b/mmdet/engine/hooks/__pycache__/set_epoch_info_hook.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..fade6a8923811173660be024866b4ee562a52e60
Binary files /dev/null and b/mmdet/engine/hooks/__pycache__/set_epoch_info_hook.cpython-37.pyc differ
diff --git a/mmdet/engine/hooks/__pycache__/sync_norm_hook.cpython-37.pyc b/mmdet/engine/hooks/__pycache__/sync_norm_hook.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..b7cff006afb48dc0016315ff061836eb418d08a0
Binary files /dev/null and b/mmdet/engine/hooks/__pycache__/sync_norm_hook.cpython-37.pyc differ
diff --git a/mmdet/engine/hooks/__pycache__/utils.cpython-37.pyc b/mmdet/engine/hooks/__pycache__/utils.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..f8e22caab57c9c5565df1489e618c412d3adb0ee
Binary files /dev/null and b/mmdet/engine/hooks/__pycache__/utils.cpython-37.pyc differ
diff --git a/mmdet/engine/hooks/__pycache__/visualization_hook.cpython-37.pyc b/mmdet/engine/hooks/__pycache__/visualization_hook.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..38254a11a09ea3b1960a0994b3bf18ea3c5d5a0f
Binary files /dev/null and b/mmdet/engine/hooks/__pycache__/visualization_hook.cpython-37.pyc differ
diff --git a/mmdet/engine/hooks/__pycache__/yolox_mode_switch_hook.cpython-37.pyc b/mmdet/engine/hooks/__pycache__/yolox_mode_switch_hook.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..f25068090785991baadbaa80c26727ce829baa0e
Binary files /dev/null and b/mmdet/engine/hooks/__pycache__/yolox_mode_switch_hook.cpython-37.pyc differ
diff --git a/mmdet/engine/hooks/checkloss_hook.py b/mmdet/engine/hooks/checkloss_hook.py
new file mode 100644
index 0000000000000000000000000000000000000000..3ebfcd5dfcd7ae329399723d3a9c0fc0a0d722ef
--- /dev/null
+++ b/mmdet/engine/hooks/checkloss_hook.py
@@ -0,0 +1,42 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional
+
+import torch
+from mmengine.hooks import Hook
+from mmengine.runner import Runner
+
+from mmdet.registry import HOOKS
+
+
+@HOOKS.register_module()
+class CheckInvalidLossHook(Hook):
+ """Check invalid loss hook.
+
+ This hook will regularly check whether the loss is valid
+ during training.
+
+ Args:
+ interval (int): Checking interval (every k iterations).
+ Default: 50.
+ """
+
+ def __init__(self, interval: int = 50) -> None:
+ self.interval = interval
+
+ def after_train_iter(self,
+ runner: Runner,
+ batch_idx: int,
+ data_batch: Optional[dict] = None,
+ outputs: Optional[dict] = None) -> None:
+ """Regularly check whether the loss is valid every n iterations.
+
+ Args:
+ runner (:obj:`Runner`): The runner of the training process.
+ batch_idx (int): The index of the current batch in the train loop.
+ data_batch (dict, Optional): Data from dataloader.
+ Defaults to None.
+ outputs (dict, Optional): Outputs from model. Defaults to None.
+ """
+ if self.every_n_train_iters(runner, self.interval):
+ assert torch.isfinite(outputs['loss']), \
+ runner.logger.info('loss become infinite or NaN!')
diff --git a/mmdet/engine/hooks/mean_teacher_hook.py b/mmdet/engine/hooks/mean_teacher_hook.py
new file mode 100644
index 0000000000000000000000000000000000000000..b924c0a5934248d05e7ce1add50e7574b739b9c7
--- /dev/null
+++ b/mmdet/engine/hooks/mean_teacher_hook.py
@@ -0,0 +1,87 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional
+
+import torch.nn as nn
+from mmengine.hooks import Hook
+from mmengine.model import is_model_wrapper
+from mmengine.runner import Runner
+
+from mmdet.registry import HOOKS
+
+
+@HOOKS.register_module()
+class MeanTeacherHook(Hook):
+ """Mean Teacher Hook.
+
+ Mean Teacher is an efficient semi-supervised learning method in
+ `Mean Teacher `_.
+ This method requires two models with exactly the same structure,
+ as the student model and the teacher model, respectively.
+ The student model updates the parameters through gradient descent,
+ and the teacher model updates the parameters through
+ exponential moving average of the student model.
+ Compared with the student model, the teacher model
+ is smoother and accumulates more knowledge.
+
+ Args:
+ momentum (float): The momentum used for updating teacher's parameter.
+ Teacher's parameter are updated with the formula:
+ `teacher = (1-momentum) * teacher + momentum * student`.
+ Defaults to 0.001.
+ interval (int): Update teacher's parameter every interval iteration.
+ Defaults to 1.
+ skip_buffers (bool): Whether to skip the model buffers, such as
+ batchnorm running stats (running_mean, running_var), it does not
+ perform the ema operation. Default to True.
+ """
+
+ def __init__(self,
+ momentum: float = 0.001,
+ interval: int = 1,
+ skip_buffer=True) -> None:
+ assert 0 < momentum < 1
+ self.momentum = momentum
+ self.interval = interval
+ self.skip_buffers = skip_buffer
+
+ def before_train(self, runner: Runner) -> None:
+ """To check that teacher model and student model exist."""
+ model = runner.model
+ if is_model_wrapper(model):
+ model = model.module
+ assert hasattr(model, 'teacher')
+ assert hasattr(model, 'student')
+ # only do it at initial stage
+ if runner.iter == 0:
+ self.momentum_update(model, 1)
+
+ def after_train_iter(self,
+ runner: Runner,
+ batch_idx: int,
+ data_batch: Optional[dict] = None,
+ outputs: Optional[dict] = None) -> None:
+ """Update teacher's parameter every self.interval iterations."""
+ if (runner.iter + 1) % self.interval != 0:
+ return
+ model = runner.model
+ if is_model_wrapper(model):
+ model = model.module
+ self.momentum_update(model, self.momentum)
+
+ def momentum_update(self, model: nn.Module, momentum: float) -> None:
+ """Compute the moving average of the parameters using exponential
+ moving average."""
+ if self.skip_buffers:
+ for (src_name, src_parm), (dst_name, dst_parm) in zip(
+ model.student.named_parameters(),
+ model.teacher.named_parameters()):
+ dst_parm.data.mul_(1 - momentum).add_(
+ src_parm.data, alpha=momentum)
+ else:
+ for (src_parm,
+ dst_parm) in zip(model.student.state_dict().values(),
+ model.teacher.state_dict().values()):
+ # exclude num_tracking
+ if dst_parm.dtype.is_floating_point:
+ dst_parm.data.mul_(1 - momentum).add_(
+ src_parm.data, alpha=momentum)
diff --git a/mmdet/engine/hooks/memory_profiler_hook.py b/mmdet/engine/hooks/memory_profiler_hook.py
new file mode 100644
index 0000000000000000000000000000000000000000..3dcdcae0b669ade46026d28c46b35f35d90b504b
--- /dev/null
+++ b/mmdet/engine/hooks/memory_profiler_hook.py
@@ -0,0 +1,121 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Sequence
+
+from mmengine.hooks import Hook
+from mmengine.runner import Runner
+
+from mmdet.registry import HOOKS
+from mmdet.structures import DetDataSample
+
+
+@HOOKS.register_module()
+class MemoryProfilerHook(Hook):
+ """Memory profiler hook recording memory information including virtual
+ memory, swap memory, and the memory of the current process.
+
+ Args:
+ interval (int): Checking interval (every k iterations).
+ Default: 50.
+ """
+
+ def __init__(self, interval: int = 50) -> None:
+ try:
+ from psutil import swap_memory, virtual_memory
+ self._swap_memory = swap_memory
+ self._virtual_memory = virtual_memory
+ except ImportError:
+ raise ImportError('psutil is not installed, please install it by: '
+ 'pip install psutil')
+
+ try:
+ from memory_profiler import memory_usage
+ self._memory_usage = memory_usage
+ except ImportError:
+ raise ImportError(
+ 'memory_profiler is not installed, please install it by: '
+ 'pip install memory_profiler')
+
+ self.interval = interval
+
+ def _record_memory_information(self, runner: Runner) -> None:
+ """Regularly record memory information.
+
+ Args:
+ runner (:obj:`Runner`): The runner of the training or evaluation
+ process.
+ """
+ # in Byte
+ virtual_memory = self._virtual_memory()
+ swap_memory = self._swap_memory()
+ # in MB
+ process_memory = self._memory_usage()[0]
+ factor = 1024 * 1024
+ runner.logger.info(
+ 'Memory information '
+ 'available_memory: '
+ f'{round(virtual_memory.available / factor)} MB, '
+ 'used_memory: '
+ f'{round(virtual_memory.used / factor)} MB, '
+ f'memory_utilization: {virtual_memory.percent} %, '
+ 'available_swap_memory: '
+ f'{round((swap_memory.total - swap_memory.used) / factor)}'
+ ' MB, '
+ f'used_swap_memory: {round(swap_memory.used / factor)} MB, '
+ f'swap_memory_utilization: {swap_memory.percent} %, '
+ 'current_process_memory: '
+ f'{round(process_memory)} MB')
+
+ def after_train_iter(self,
+ runner: Runner,
+ batch_idx: int,
+ data_batch: Optional[dict] = None,
+ outputs: Optional[dict] = None) -> None:
+ """Regularly record memory information.
+
+ Args:
+ runner (:obj:`Runner`): The runner of the training process.
+ batch_idx (int): The index of the current batch in the train loop.
+ data_batch (dict, optional): Data from dataloader.
+ Defaults to None.
+ outputs (dict, optional): Outputs from model. Defaults to None.
+ """
+ if self.every_n_inner_iters(batch_idx, self.interval):
+ self._record_memory_information(runner)
+
+ def after_val_iter(
+ self,
+ runner: Runner,
+ batch_idx: int,
+ data_batch: Optional[dict] = None,
+ outputs: Optional[Sequence[DetDataSample]] = None) -> None:
+ """Regularly record memory information.
+
+ Args:
+ runner (:obj:`Runner`): The runner of the validation process.
+ batch_idx (int): The index of the current batch in the val loop.
+ data_batch (dict, optional): Data from dataloader.
+ Defaults to None.
+ outputs (Sequence[:obj:`DetDataSample`], optional):
+ Outputs from model. Defaults to None.
+ """
+ if self.every_n_inner_iters(batch_idx, self.interval):
+ self._record_memory_information(runner)
+
+ def after_test_iter(
+ self,
+ runner: Runner,
+ batch_idx: int,
+ data_batch: Optional[dict] = None,
+ outputs: Optional[Sequence[DetDataSample]] = None) -> None:
+ """Regularly record memory information.
+
+ Args:
+ runner (:obj:`Runner`): The runner of the testing process.
+ batch_idx (int): The index of the current batch in the test loop.
+ data_batch (dict, optional): Data from dataloader.
+ Defaults to None.
+ outputs (Sequence[:obj:`DetDataSample`], optional):
+ Outputs from model. Defaults to None.
+ """
+ if self.every_n_inner_iters(batch_idx, self.interval):
+ self._record_memory_information(runner)
diff --git a/mmdet/engine/hooks/num_class_check_hook.py b/mmdet/engine/hooks/num_class_check_hook.py
new file mode 100644
index 0000000000000000000000000000000000000000..6588473acfbd3ffe8e80eb163aa7ee449332e6b8
--- /dev/null
+++ b/mmdet/engine/hooks/num_class_check_hook.py
@@ -0,0 +1,68 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmcv.cnn import VGG
+from mmengine.hooks import Hook
+from mmengine.runner import Runner
+
+from mmdet.registry import HOOKS
+
+
+@HOOKS.register_module()
+class NumClassCheckHook(Hook):
+ """Check whether the `num_classes` in head matches the length of `classes`
+ in `dataset.metainfo`."""
+
+ def _check_head(self, runner: Runner, mode: str) -> None:
+ """Check whether the `num_classes` in head matches the length of
+ `classes` in `dataset.metainfo`.
+
+ Args:
+ runner (:obj:`Runner`): The runner of the training or evaluation
+ process.
+ """
+ assert mode in ['train', 'val']
+ model = runner.model
+ dataset = runner.train_dataloader.dataset if mode == 'train' else \
+ runner.val_dataloader.dataset
+ if dataset.metainfo.get('classes', None) is None:
+ runner.logger.warning(
+ f'Please set `classes` '
+ f'in the {dataset.__class__.__name__} `metainfo` and'
+ f'check if it is consistent with the `num_classes` '
+ f'of head')
+ else:
+ classes = dataset.metainfo['classes']
+ assert type(classes) is not str, \
+ (f'`classes` in {dataset.__class__.__name__}'
+ f'should be a tuple of str.'
+ f'Add comma if number of classes is 1 as '
+ f'classes = ({classes},)')
+ from mmdet.models.roi_heads.mask_heads import FusedSemanticHead
+ for name, module in model.named_modules():
+ if hasattr(module, 'num_classes') and not name.endswith(
+ 'rpn_head') and not isinstance(
+ module, (VGG, FusedSemanticHead)):
+ assert module.num_classes == len(classes), \
+ (f'The `num_classes` ({module.num_classes}) in '
+ f'{module.__class__.__name__} of '
+ f'{model.__class__.__name__} does not matches '
+ f'the length of `classes` '
+ f'{len(classes)}) in '
+ f'{dataset.__class__.__name__}')
+
+ def before_train_epoch(self, runner: Runner) -> None:
+ """Check whether the training dataset is compatible with head.
+
+ Args:
+ runner (:obj:`Runner`): The runner of the training or evaluation
+ process.
+ """
+ self._check_head(runner, 'train')
+
+ def before_val_epoch(self, runner: Runner) -> None:
+ """Check whether the dataset in val epoch is compatible with head.
+
+ Args:
+ runner (:obj:`Runner`): The runner of the training or evaluation
+ process.
+ """
+ self._check_head(runner, 'val')
diff --git a/mmdet/engine/hooks/pipeline_switch_hook.py b/mmdet/engine/hooks/pipeline_switch_hook.py
new file mode 100644
index 0000000000000000000000000000000000000000..4347289fc284c85748ceba17c88490665f99e464
--- /dev/null
+++ b/mmdet/engine/hooks/pipeline_switch_hook.py
@@ -0,0 +1,42 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmcv.transforms import Compose
+from mmengine.hooks import Hook
+
+from mmdet.registry import HOOKS
+
+
+@HOOKS.register_module()
+class PipelineSwitchHook(Hook):
+ """Switch data pipeline at switch_epoch.
+
+ Args:
+ switch_epoch (int): switch pipeline at this epoch.
+ switch_pipeline (list[dict]): the pipeline to switch to.
+ """
+
+ def __init__(self, switch_epoch, switch_pipeline):
+ self.switch_epoch = switch_epoch
+ self.switch_pipeline = switch_pipeline
+ self._restart_dataloader = False
+
+ def before_train_epoch(self, runner):
+ """switch pipeline."""
+ epoch = runner.epoch
+ train_loader = runner.train_dataloader
+ if epoch == self.switch_epoch:
+ runner.logger.info('Switch pipeline now!')
+ # The dataset pipeline cannot be updated when persistent_workers
+ # is True, so we need to force the dataloader's multi-process
+ # restart. This is a very hacky approach.
+ train_loader.dataset.pipeline = Compose(self.switch_pipeline)
+ if hasattr(train_loader, 'persistent_workers'
+ ) and train_loader.persistent_workers is True:
+ train_loader._DataLoader__initialized = False
+ train_loader._iterator = None
+ self._restart_dataloader = True
+
+ else:
+ # Once the restart is complete, we need to restore
+ # the initialization flag.
+ if self._restart_dataloader:
+ train_loader._DataLoader__initialized = True
diff --git a/mmdet/engine/hooks/set_epoch_info_hook.py b/mmdet/engine/hooks/set_epoch_info_hook.py
new file mode 100644
index 0000000000000000000000000000000000000000..183f3167445dc0818e4fa37bdd2049d3876ed031
--- /dev/null
+++ b/mmdet/engine/hooks/set_epoch_info_hook.py
@@ -0,0 +1,17 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmengine.hooks import Hook
+from mmengine.model.wrappers import is_model_wrapper
+
+from mmdet.registry import HOOKS
+
+
+@HOOKS.register_module()
+class SetEpochInfoHook(Hook):
+ """Set runner's epoch information to the model."""
+
+ def before_train_epoch(self, runner):
+ epoch = runner.epoch
+ model = runner.model
+ if is_model_wrapper(model):
+ model = model.module
+ model.set_epoch(epoch)
diff --git a/mmdet/engine/hooks/sync_norm_hook.py b/mmdet/engine/hooks/sync_norm_hook.py
new file mode 100644
index 0000000000000000000000000000000000000000..a1734380c83157c911568098abfce761fb3c9a1f
--- /dev/null
+++ b/mmdet/engine/hooks/sync_norm_hook.py
@@ -0,0 +1,37 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from collections import OrderedDict
+
+from mmengine.dist import get_dist_info
+from mmengine.hooks import Hook
+from torch import nn
+
+from mmdet.registry import HOOKS
+from mmdet.utils import all_reduce_dict
+
+
+def get_norm_states(module: nn.Module) -> OrderedDict:
+ """Get the state_dict of batch norms in the module."""
+ async_norm_states = OrderedDict()
+ for name, child in module.named_modules():
+ if isinstance(child, nn.modules.batchnorm._NormBase):
+ for k, v in child.state_dict().items():
+ async_norm_states['.'.join([name, k])] = v
+ return async_norm_states
+
+
+@HOOKS.register_module()
+class SyncNormHook(Hook):
+ """Synchronize Norm states before validation, currently used in YOLOX."""
+
+ def before_val_epoch(self, runner):
+ """Synchronizing norm."""
+ module = runner.model
+ _, world_size = get_dist_info()
+ if world_size == 1:
+ return
+ norm_states = get_norm_states(module)
+ if len(norm_states) == 0:
+ return
+ # TODO: use `all_reduce_dict` in mmengine
+ norm_states = all_reduce_dict(norm_states, op='mean')
+ module.load_state_dict(norm_states, strict=False)
diff --git a/mmdet/engine/hooks/utils.py b/mmdet/engine/hooks/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..d267cfe77be163c0520568b7b7936f4453914aab
--- /dev/null
+++ b/mmdet/engine/hooks/utils.py
@@ -0,0 +1,19 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+def trigger_visualization_hook(cfg, args):
+ default_hooks = cfg.default_hooks
+ if 'visualization' in default_hooks:
+ visualization_hook = default_hooks['visualization']
+ # Turn on visualization
+ visualization_hook['draw'] = True
+ if args.show:
+ visualization_hook['show'] = True
+ visualization_hook['wait_time'] = args.wait_time
+ if args.show_dir:
+ visualization_hook['test_out_dir'] = args.show_dir
+ else:
+ raise RuntimeError(
+ 'VisualizationHook must be included in default_hooks.'
+ 'refer to usage '
+ '"visualization=dict(type=\'VisualizationHook\')"')
+
+ return cfg
diff --git a/mmdet/engine/hooks/visualization_hook.py b/mmdet/engine/hooks/visualization_hook.py
new file mode 100644
index 0000000000000000000000000000000000000000..a8372433bd3fd3d97f98d39075f1a1354844d008
--- /dev/null
+++ b/mmdet/engine/hooks/visualization_hook.py
@@ -0,0 +1,147 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+import warnings
+from typing import Optional, Sequence
+
+import mmcv
+from mmengine.fileio import get
+from mmengine.hooks import Hook
+from mmengine.runner import Runner
+from mmengine.utils import mkdir_or_exist
+from mmengine.visualization import Visualizer
+
+from mmdet.registry import HOOKS
+from mmdet.structures import DetDataSample
+
+
+@HOOKS.register_module()
+class DetVisualizationHook(Hook):
+ """Detection Visualization Hook. Used to visualize validation and testing
+ process prediction results.
+
+ In the testing phase:
+
+ 1. If ``show`` is True, it means that only the prediction results are
+ visualized without storing data, so ``vis_backends`` needs to
+ be excluded.
+ 2. If ``test_out_dir`` is specified, it means that the prediction results
+ need to be saved to ``test_out_dir``. In order to avoid vis_backends
+ also storing data, so ``vis_backends`` needs to be excluded.
+ 3. ``vis_backends`` takes effect if the user does not specify ``show``
+ and `test_out_dir``. You can set ``vis_backends`` to WandbVisBackend or
+ TensorboardVisBackend to store the prediction result in Wandb or
+ Tensorboard.
+
+ Args:
+ draw (bool): whether to draw prediction results. If it is False,
+ it means that no drawing will be done. Defaults to False.
+ interval (int): The interval of visualization. Defaults to 50.
+ score_thr (float): The threshold to visualize the bboxes
+ and masks. Defaults to 0.3.
+ show (bool): Whether to display the drawn image. Default to False.
+ wait_time (float): The interval of show (s). Defaults to 0.
+ test_out_dir (str, optional): directory where painted images
+ will be saved in testing process.
+ backend_args (dict, optional): Arguments to instantiate the
+ corresponding backend. Defaults to None.
+ """
+
+ def __init__(self,
+ draw: bool = False,
+ interval: int = 50,
+ score_thr: float = 0.3,
+ show: bool = False,
+ wait_time: float = 0.,
+ test_out_dir: Optional[str] = None,
+ backend_args: dict = None):
+ self._visualizer: Visualizer = Visualizer.get_current_instance()
+ self.interval = interval
+ self.score_thr = score_thr
+ self.show = show
+ if self.show:
+ # No need to think about vis backends.
+ self._visualizer._vis_backends = {}
+ warnings.warn('The show is True, it means that only '
+ 'the prediction results are visualized '
+ 'without storing data, so vis_backends '
+ 'needs to be excluded.')
+
+ self.wait_time = wait_time
+ self.backend_args = backend_args
+ self.draw = draw
+ self.test_out_dir = test_out_dir
+ self._test_index = 0
+
+ def after_val_iter(self, runner: Runner, batch_idx: int, data_batch: dict,
+ outputs: Sequence[DetDataSample]) -> None:
+ """Run after every ``self.interval`` validation iterations.
+
+ Args:
+ runner (:obj:`Runner`): The runner of the validation process.
+ batch_idx (int): The index of the current batch in the val loop.
+ data_batch (dict): Data from dataloader.
+ outputs (Sequence[:obj:`DetDataSample`]]): A batch of data samples
+ that contain annotations and predictions.
+ """
+ if self.draw is False:
+ return
+
+ # There is no guarantee that the same batch of images
+ # is visualized for each evaluation.
+ total_curr_iter = runner.iter + batch_idx
+
+ # Visualize only the first data
+ img_path = outputs[0].img_path
+ img_bytes = get(img_path, backend_args=self.backend_args)
+ img = mmcv.imfrombytes(img_bytes, channel_order='rgb')
+
+ if total_curr_iter % self.interval == 0:
+ self._visualizer.add_datasample(
+ osp.basename(img_path) if self.show else 'val_img',
+ img,
+ data_sample=outputs[0],
+ show=self.show,
+ wait_time=self.wait_time,
+ pred_score_thr=self.score_thr,
+ step=total_curr_iter)
+
+ def after_test_iter(self, runner: Runner, batch_idx: int, data_batch: dict,
+ outputs: Sequence[DetDataSample]) -> None:
+ """Run after every testing iterations.
+
+ Args:
+ runner (:obj:`Runner`): The runner of the testing process.
+ batch_idx (int): The index of the current batch in the val loop.
+ data_batch (dict): Data from dataloader.
+ outputs (Sequence[:obj:`DetDataSample`]): A batch of data samples
+ that contain annotations and predictions.
+ """
+ if self.draw is False:
+ return
+
+ if self.test_out_dir is not None:
+ self.test_out_dir = osp.join(runner.work_dir, runner.timestamp,
+ self.test_out_dir)
+ mkdir_or_exist(self.test_out_dir)
+
+ for data_sample in outputs:
+ self._test_index += 1
+
+ img_path = data_sample.img_path
+ img_bytes = get(img_path, backend_args=self.backend_args)
+ img = mmcv.imfrombytes(img_bytes, channel_order='rgb')
+
+ out_file = None
+ if self.test_out_dir is not None:
+ out_file = osp.basename(img_path)
+ out_file = osp.join(self.test_out_dir, out_file)
+
+ self._visualizer.add_datasample(
+ osp.basename(img_path) if self.show else 'test_img',
+ img,
+ data_sample=data_sample,
+ show=self.show,
+ wait_time=self.wait_time,
+ pred_score_thr=self.score_thr,
+ out_file=out_file,
+ step=self._test_index)
diff --git a/mmdet/engine/hooks/yolox_mode_switch_hook.py b/mmdet/engine/hooks/yolox_mode_switch_hook.py
new file mode 100644
index 0000000000000000000000000000000000000000..39aadd94bd05dee6383b2d1365726b2a2df11245
--- /dev/null
+++ b/mmdet/engine/hooks/yolox_mode_switch_hook.py
@@ -0,0 +1,59 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Sequence
+
+from mmengine.hooks import Hook
+from mmengine.model import is_model_wrapper
+
+from mmdet.registry import HOOKS
+
+
+@HOOKS.register_module()
+class YOLOXModeSwitchHook(Hook):
+ """Switch the mode of YOLOX during training.
+
+ This hook turns off the mosaic and mixup data augmentation and switches
+ to use L1 loss in bbox_head.
+
+ Args:
+ num_last_epochs (int): The number of latter epochs in the end of the
+ training to close the data augmentation and switch to L1 loss.
+ Defaults to 15.
+ skip_type_keys (Sequence[str], optional): Sequence of type string to be
+ skip pipeline. Defaults to ('Mosaic', 'RandomAffine', 'MixUp').
+ """
+
+ def __init__(
+ self,
+ num_last_epochs: int = 15,
+ skip_type_keys: Sequence[str] = ('Mosaic', 'RandomAffine', 'MixUp')
+ ) -> None:
+ self.num_last_epochs = num_last_epochs
+ self.skip_type_keys = skip_type_keys
+ self._restart_dataloader = False
+
+ def before_train_epoch(self, runner) -> None:
+ """Close mosaic and mixup augmentation and switches to use L1 loss."""
+ epoch = runner.epoch
+ train_loader = runner.train_dataloader
+ model = runner.model
+ # TODO: refactor after mmengine using model wrapper
+ if is_model_wrapper(model):
+ model = model.module
+ if (epoch + 1) == runner.max_epochs - self.num_last_epochs:
+ runner.logger.info('No mosaic and mixup aug now!')
+ # The dataset pipeline cannot be updated when persistent_workers
+ # is True, so we need to force the dataloader's multi-process
+ # restart. This is a very hacky approach.
+ train_loader.dataset.update_skip_type_keys(self.skip_type_keys)
+ if hasattr(train_loader, 'persistent_workers'
+ ) and train_loader.persistent_workers is True:
+ train_loader._DataLoader__initialized = False
+ train_loader._iterator = None
+ self._restart_dataloader = True
+ runner.logger.info('Add additional L1 loss now!')
+ model.bbox_head.use_l1 = True
+ else:
+ # Once the restart is complete, we need to restore
+ # the initialization flag.
+ if self._restart_dataloader:
+ train_loader._DataLoader__initialized = True
diff --git a/mmdet/engine/optimizers/__init__.py b/mmdet/engine/optimizers/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..83db069ee34cad0888bbf388d3cc7030ba49bbbb
--- /dev/null
+++ b/mmdet/engine/optimizers/__init__.py
@@ -0,0 +1,5 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .layer_decay_optimizer_constructor import \
+ LearningRateDecayOptimizerConstructor
+
+__all__ = ['LearningRateDecayOptimizerConstructor']
diff --git a/mmdet/engine/optimizers/__pycache__/__init__.cpython-37.pyc b/mmdet/engine/optimizers/__pycache__/__init__.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..f3bed76bb01961518b879bf23ee9de838c5ae6d4
Binary files /dev/null and b/mmdet/engine/optimizers/__pycache__/__init__.cpython-37.pyc differ
diff --git a/mmdet/engine/optimizers/__pycache__/layer_decay_optimizer_constructor.cpython-37.pyc b/mmdet/engine/optimizers/__pycache__/layer_decay_optimizer_constructor.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..58703cb88c678086c4ecb770a375c9f851fe311f
Binary files /dev/null and b/mmdet/engine/optimizers/__pycache__/layer_decay_optimizer_constructor.cpython-37.pyc differ
diff --git a/mmdet/engine/optimizers/layer_decay_optimizer_constructor.py b/mmdet/engine/optimizers/layer_decay_optimizer_constructor.py
new file mode 100644
index 0000000000000000000000000000000000000000..73028a0aef698d63dcba8c4935d6ef6c577d0f46
--- /dev/null
+++ b/mmdet/engine/optimizers/layer_decay_optimizer_constructor.py
@@ -0,0 +1,158 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import json
+from typing import List
+
+import torch.nn as nn
+from mmengine.dist import get_dist_info
+from mmengine.logging import MMLogger
+from mmengine.optim import DefaultOptimWrapperConstructor
+
+from mmdet.registry import OPTIM_WRAPPER_CONSTRUCTORS
+
+
+def get_layer_id_for_convnext(var_name, max_layer_id):
+ """Get the layer id to set the different learning rates in ``layer_wise``
+ decay_type.
+
+ Args:
+ var_name (str): The key of the model.
+ max_layer_id (int): Maximum layer id.
+
+ Returns:
+ int: The id number corresponding to different learning rate in
+ ``LearningRateDecayOptimizerConstructor``.
+ """
+
+ if var_name in ('backbone.cls_token', 'backbone.mask_token',
+ 'backbone.pos_embed'):
+ return 0
+ elif var_name.startswith('backbone.downsample_layers'):
+ stage_id = int(var_name.split('.')[2])
+ if stage_id == 0:
+ layer_id = 0
+ elif stage_id == 1:
+ layer_id = 2
+ elif stage_id == 2:
+ layer_id = 3
+ elif stage_id == 3:
+ layer_id = max_layer_id
+ return layer_id
+ elif var_name.startswith('backbone.stages'):
+ stage_id = int(var_name.split('.')[2])
+ block_id = int(var_name.split('.')[3])
+ if stage_id == 0:
+ layer_id = 1
+ elif stage_id == 1:
+ layer_id = 2
+ elif stage_id == 2:
+ layer_id = 3 + block_id // 3
+ elif stage_id == 3:
+ layer_id = max_layer_id
+ return layer_id
+ else:
+ return max_layer_id + 1
+
+
+def get_stage_id_for_convnext(var_name, max_stage_id):
+ """Get the stage id to set the different learning rates in ``stage_wise``
+ decay_type.
+
+ Args:
+ var_name (str): The key of the model.
+ max_stage_id (int): Maximum stage id.
+
+ Returns:
+ int: The id number corresponding to different learning rate in
+ ``LearningRateDecayOptimizerConstructor``.
+ """
+
+ if var_name in ('backbone.cls_token', 'backbone.mask_token',
+ 'backbone.pos_embed'):
+ return 0
+ elif var_name.startswith('backbone.downsample_layers'):
+ return 0
+ elif var_name.startswith('backbone.stages'):
+ stage_id = int(var_name.split('.')[2])
+ return stage_id + 1
+ else:
+ return max_stage_id - 1
+
+
+@OPTIM_WRAPPER_CONSTRUCTORS.register_module()
+class LearningRateDecayOptimizerConstructor(DefaultOptimWrapperConstructor):
+ # Different learning rates are set for different layers of backbone.
+ # Note: Currently, this optimizer constructor is built for ConvNeXt.
+
+ def add_params(self, params: List[dict], module: nn.Module,
+ **kwargs) -> None:
+ """Add all parameters of module to the params list.
+
+ The parameters of the given module will be added to the list of param
+ groups, with specific rules defined by paramwise_cfg.
+
+ Args:
+ params (list[dict]): A list of param groups, it will be modified
+ in place.
+ module (nn.Module): The module to be added.
+ """
+ logger = MMLogger.get_current_instance()
+
+ parameter_groups = {}
+ logger.info(f'self.paramwise_cfg is {self.paramwise_cfg}')
+ num_layers = self.paramwise_cfg.get('num_layers') + 2
+ decay_rate = self.paramwise_cfg.get('decay_rate')
+ decay_type = self.paramwise_cfg.get('decay_type', 'layer_wise')
+ logger.info('Build LearningRateDecayOptimizerConstructor '
+ f'{decay_type} {decay_rate} - {num_layers}')
+ weight_decay = self.base_wd
+ for name, param in module.named_parameters():
+ if not param.requires_grad:
+ continue # frozen weights
+ if len(param.shape) == 1 or name.endswith('.bias') or name in (
+ 'pos_embed', 'cls_token'):
+ group_name = 'no_decay'
+ this_weight_decay = 0.
+ else:
+ group_name = 'decay'
+ this_weight_decay = weight_decay
+ if 'layer_wise' in decay_type:
+ if 'ConvNeXt' in module.backbone.__class__.__name__:
+ layer_id = get_layer_id_for_convnext(
+ name, self.paramwise_cfg.get('num_layers'))
+ logger.info(f'set param {name} as id {layer_id}')
+ else:
+ raise NotImplementedError()
+ elif decay_type == 'stage_wise':
+ if 'ConvNeXt' in module.backbone.__class__.__name__:
+ layer_id = get_stage_id_for_convnext(name, num_layers)
+ logger.info(f'set param {name} as id {layer_id}')
+ else:
+ raise NotImplementedError()
+ group_name = f'layer_{layer_id}_{group_name}'
+
+ if group_name not in parameter_groups:
+ scale = decay_rate**(num_layers - layer_id - 1)
+
+ parameter_groups[group_name] = {
+ 'weight_decay': this_weight_decay,
+ 'params': [],
+ 'param_names': [],
+ 'lr_scale': scale,
+ 'group_name': group_name,
+ 'lr': scale * self.base_lr,
+ }
+
+ parameter_groups[group_name]['params'].append(param)
+ parameter_groups[group_name]['param_names'].append(name)
+ rank, _ = get_dist_info()
+ if rank == 0:
+ to_display = {}
+ for key in parameter_groups:
+ to_display[key] = {
+ 'param_names': parameter_groups[key]['param_names'],
+ 'lr_scale': parameter_groups[key]['lr_scale'],
+ 'lr': parameter_groups[key]['lr'],
+ 'weight_decay': parameter_groups[key]['weight_decay'],
+ }
+ logger.info(f'Param groups = {json.dumps(to_display, indent=2)}')
+ params.extend(parameter_groups.values())
diff --git a/mmdet/engine/runner/__init__.py b/mmdet/engine/runner/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e8bcce4448e48e2d64354ba6770f9f426fb3d869
--- /dev/null
+++ b/mmdet/engine/runner/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .loops import TeacherStudentValLoop
+
+__all__ = ['TeacherStudentValLoop']
diff --git a/mmdet/engine/runner/__pycache__/__init__.cpython-37.pyc b/mmdet/engine/runner/__pycache__/__init__.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..2fb305aa93ef3765d1b5facd7fa23a826957392c
Binary files /dev/null and b/mmdet/engine/runner/__pycache__/__init__.cpython-37.pyc differ
diff --git a/mmdet/engine/runner/__pycache__/loops.cpython-37.pyc b/mmdet/engine/runner/__pycache__/loops.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..c2c710617bfe615a23696added628dd2a18ba696
Binary files /dev/null and b/mmdet/engine/runner/__pycache__/loops.cpython-37.pyc differ
diff --git a/mmdet/engine/runner/loops.py b/mmdet/engine/runner/loops.py
new file mode 100644
index 0000000000000000000000000000000000000000..a32996eceee3a5c4ccbed192f92441038b61c220
--- /dev/null
+++ b/mmdet/engine/runner/loops.py
@@ -0,0 +1,39 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+
+from mmengine.model import is_model_wrapper
+from mmengine.runner import ValLoop
+
+from mmdet.registry import LOOPS
+
+
+@LOOPS.register_module()
+class TeacherStudentValLoop(ValLoop):
+ """Loop for validation of model teacher and student."""
+
+ def run(self):
+ """Launch validation for model teacher and student."""
+ self.runner.call_hook('before_val')
+ self.runner.call_hook('before_val_epoch')
+ self.runner.model.eval()
+
+ model = self.runner.model
+ if is_model_wrapper(model):
+ model = model.module
+ assert hasattr(model, 'teacher')
+ assert hasattr(model, 'student')
+
+ predict_on = model.semi_test_cfg.get('predict_on', None)
+ multi_metrics = dict()
+ for _predict_on in ['teacher', 'student']:
+ model.semi_test_cfg['predict_on'] = _predict_on
+ for idx, data_batch in enumerate(self.dataloader):
+ self.run_iter(idx, data_batch)
+ # compute metrics
+ metrics = self.evaluator.evaluate(len(self.dataloader.dataset))
+ multi_metrics.update(
+ {'/'.join((_predict_on, k)): v
+ for k, v in metrics.items()})
+ model.semi_test_cfg['predict_on'] = predict_on
+
+ self.runner.call_hook('after_val_epoch', metrics=multi_metrics)
+ self.runner.call_hook('after_val')
diff --git a/mmdet/engine/schedulers/__init__.py b/mmdet/engine/schedulers/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..01261646fa8255c643e86ba0517019760a50d387
--- /dev/null
+++ b/mmdet/engine/schedulers/__init__.py
@@ -0,0 +1,8 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .quadratic_warmup import (QuadraticWarmupLR, QuadraticWarmupMomentum,
+ QuadraticWarmupParamScheduler)
+
+__all__ = [
+ 'QuadraticWarmupParamScheduler', 'QuadraticWarmupMomentum',
+ 'QuadraticWarmupLR'
+]
diff --git a/mmdet/engine/schedulers/__pycache__/__init__.cpython-37.pyc b/mmdet/engine/schedulers/__pycache__/__init__.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..67488937c5536014bed6ab1879ffc7c24ac132de
Binary files /dev/null and b/mmdet/engine/schedulers/__pycache__/__init__.cpython-37.pyc differ
diff --git a/mmdet/engine/schedulers/__pycache__/quadratic_warmup.cpython-37.pyc b/mmdet/engine/schedulers/__pycache__/quadratic_warmup.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..f82ce8d7029b121b14827b6599fbbe61a82ed89e
Binary files /dev/null and b/mmdet/engine/schedulers/__pycache__/quadratic_warmup.cpython-37.pyc differ
diff --git a/mmdet/engine/schedulers/quadratic_warmup.py b/mmdet/engine/schedulers/quadratic_warmup.py
new file mode 100644
index 0000000000000000000000000000000000000000..639b47854887786bf3f81d6d0a375033d190d91e
--- /dev/null
+++ b/mmdet/engine/schedulers/quadratic_warmup.py
@@ -0,0 +1,131 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmengine.optim.scheduler.lr_scheduler import LRSchedulerMixin
+from mmengine.optim.scheduler.momentum_scheduler import MomentumSchedulerMixin
+from mmengine.optim.scheduler.param_scheduler import INF, _ParamScheduler
+from torch.optim import Optimizer
+
+from mmdet.registry import PARAM_SCHEDULERS
+
+
+@PARAM_SCHEDULERS.register_module()
+class QuadraticWarmupParamScheduler(_ParamScheduler):
+ r"""Warm up the parameter value of each parameter group by quadratic
+ formula:
+
+ .. math::
+
+ X_{t} = X_{t-1} + \frac{2t+1}{{(end-begin)}^{2}} \times X_{base}
+
+ Args:
+ optimizer (Optimizer): Wrapped optimizer.
+ param_name (str): Name of the parameter to be adjusted, such as
+ ``lr``, ``momentum``.
+ begin (int): Step at which to start updating the parameters.
+ Defaults to 0.
+ end (int): Step at which to stop updating the parameters.
+ Defaults to INF.
+ last_step (int): The index of last step. Used for resume without
+ state dict. Defaults to -1.
+ by_epoch (bool): Whether the scheduled parameters are updated by
+ epochs. Defaults to True.
+ verbose (bool): Whether to print the value for each update.
+ Defaults to False.
+ """
+
+ def __init__(self,
+ optimizer: Optimizer,
+ param_name: str,
+ begin: int = 0,
+ end: int = INF,
+ last_step: int = -1,
+ by_epoch: bool = True,
+ verbose: bool = False):
+ if end >= INF:
+ raise ValueError('``end`` must be less than infinity,'
+ 'Please set ``end`` parameter of '
+ '``QuadraticWarmupScheduler`` as the '
+ 'number of warmup end.')
+ self.total_iters = end - begin
+ super().__init__(
+ optimizer=optimizer,
+ param_name=param_name,
+ begin=begin,
+ end=end,
+ last_step=last_step,
+ by_epoch=by_epoch,
+ verbose=verbose)
+
+ @classmethod
+ def build_iter_from_epoch(cls,
+ *args,
+ begin=0,
+ end=INF,
+ by_epoch=True,
+ epoch_length=None,
+ **kwargs):
+ """Build an iter-based instance of this scheduler from an epoch-based
+ config."""
+ assert by_epoch, 'Only epoch-based kwargs whose `by_epoch=True` can ' \
+ 'be converted to iter-based.'
+ assert epoch_length is not None and epoch_length > 0, \
+ f'`epoch_length` must be a positive integer, ' \
+ f'but got {epoch_length}.'
+ by_epoch = False
+ begin = begin * epoch_length
+ if end != INF:
+ end = end * epoch_length
+ return cls(*args, begin=begin, end=end, by_epoch=by_epoch, **kwargs)
+
+ def _get_value(self):
+ """Compute value using chainable form of the scheduler."""
+ if self.last_step == 0:
+ return [
+ base_value * (2 * self.last_step + 1) / self.total_iters**2
+ for base_value in self.base_values
+ ]
+
+ return [
+ group[self.param_name] + base_value *
+ (2 * self.last_step + 1) / self.total_iters**2
+ for base_value, group in zip(self.base_values,
+ self.optimizer.param_groups)
+ ]
+
+
+@PARAM_SCHEDULERS.register_module()
+class QuadraticWarmupLR(LRSchedulerMixin, QuadraticWarmupParamScheduler):
+ """Warm up the learning rate of each parameter group by quadratic formula.
+
+ Args:
+ optimizer (Optimizer): Wrapped optimizer.
+ begin (int): Step at which to start updating the parameters.
+ Defaults to 0.
+ end (int): Step at which to stop updating the parameters.
+ Defaults to INF.
+ last_step (int): The index of last step. Used for resume without
+ state dict. Defaults to -1.
+ by_epoch (bool): Whether the scheduled parameters are updated by
+ epochs. Defaults to True.
+ verbose (bool): Whether to print the value for each update.
+ Defaults to False.
+ """
+
+
+@PARAM_SCHEDULERS.register_module()
+class QuadraticWarmupMomentum(MomentumSchedulerMixin,
+ QuadraticWarmupParamScheduler):
+ """Warm up the momentum value of each parameter group by quadratic formula.
+
+ Args:
+ optimizer (Optimizer): Wrapped optimizer.
+ begin (int): Step at which to start updating the parameters.
+ Defaults to 0.
+ end (int): Step at which to stop updating the parameters.
+ Defaults to INF.
+ last_step (int): The index of last step. Used for resume without
+ state dict. Defaults to -1.
+ by_epoch (bool): Whether the scheduled parameters are updated by
+ epochs. Defaults to True.
+ verbose (bool): Whether to print the value for each update.
+ Defaults to False.
+ """
diff --git a/mmdet/evaluation/__init__.py b/mmdet/evaluation/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..f70dc226d30f7b8e4ee5a44ca163ad1ae04eabf5
--- /dev/null
+++ b/mmdet/evaluation/__init__.py
@@ -0,0 +1,3 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .functional import * # noqa: F401,F403
+from .metrics import * # noqa: F401,F403
diff --git a/mmdet/evaluation/__pycache__/__init__.cpython-37.pyc b/mmdet/evaluation/__pycache__/__init__.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..c8ac383805da0ccaa05591c22433010c5adbd76e
Binary files /dev/null and b/mmdet/evaluation/__pycache__/__init__.cpython-37.pyc differ
diff --git a/mmdet/evaluation/functional/__init__.py b/mmdet/evaluation/functional/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..6f139f7bc4f53b0c8755b589653313b4a2380256
--- /dev/null
+++ b/mmdet/evaluation/functional/__init__.py
@@ -0,0 +1,24 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .bbox_overlaps import bbox_overlaps
+from .cityscapes_utils import evaluateImgLists
+from .class_names import (cityscapes_classes, coco_classes,
+ coco_panoptic_classes, dataset_aliases, get_classes,
+ imagenet_det_classes, imagenet_vid_classes,
+ objects365v1_classes, objects365v2_classes,
+ oid_challenge_classes, oid_v6_classes, voc_classes)
+from .mean_ap import average_precision, eval_map, print_map_summary
+from .panoptic_utils import (INSTANCE_OFFSET, pq_compute_multi_core,
+ pq_compute_single_core)
+from .recall import (eval_recalls, plot_iou_recall, plot_num_recall,
+ print_recall_summary)
+
+__all__ = [
+ 'voc_classes', 'imagenet_det_classes', 'imagenet_vid_classes',
+ 'coco_classes', 'cityscapes_classes', 'dataset_aliases', 'get_classes',
+ 'average_precision', 'eval_map', 'print_map_summary', 'eval_recalls',
+ 'print_recall_summary', 'plot_num_recall', 'plot_iou_recall',
+ 'oid_v6_classes', 'oid_challenge_classes', 'INSTANCE_OFFSET',
+ 'pq_compute_single_core', 'pq_compute_multi_core', 'bbox_overlaps',
+ 'objects365v1_classes', 'objects365v2_classes', 'coco_panoptic_classes',
+ 'evaluateImgLists'
+]
diff --git a/mmdet/evaluation/functional/__pycache__/__init__.cpython-37.pyc b/mmdet/evaluation/functional/__pycache__/__init__.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..19ff6750ebf41af3318ea9aa1d6e8b4a9f3ef085
Binary files /dev/null and b/mmdet/evaluation/functional/__pycache__/__init__.cpython-37.pyc differ
diff --git a/mmdet/evaluation/functional/__pycache__/bbox_overlaps.cpython-37.pyc b/mmdet/evaluation/functional/__pycache__/bbox_overlaps.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..6c854e1c5ad7e61c45093912ab97fd8786abf631
Binary files /dev/null and b/mmdet/evaluation/functional/__pycache__/bbox_overlaps.cpython-37.pyc differ
diff --git a/mmdet/evaluation/functional/__pycache__/cityscapes_utils.cpython-37.pyc b/mmdet/evaluation/functional/__pycache__/cityscapes_utils.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..5be0c1a9648795035a7e19a9427ac674d58309f8
Binary files /dev/null and b/mmdet/evaluation/functional/__pycache__/cityscapes_utils.cpython-37.pyc differ
diff --git a/mmdet/evaluation/functional/__pycache__/class_names.cpython-37.pyc b/mmdet/evaluation/functional/__pycache__/class_names.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..6b635bcf96c9fedd352c113252aa8cac47c58791
Binary files /dev/null and b/mmdet/evaluation/functional/__pycache__/class_names.cpython-37.pyc differ
diff --git a/mmdet/evaluation/functional/__pycache__/mean_ap.cpython-37.pyc b/mmdet/evaluation/functional/__pycache__/mean_ap.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..758311435d3318739a19c1dd898132251d612086
Binary files /dev/null and b/mmdet/evaluation/functional/__pycache__/mean_ap.cpython-37.pyc differ
diff --git a/mmdet/evaluation/functional/__pycache__/panoptic_utils.cpython-37.pyc b/mmdet/evaluation/functional/__pycache__/panoptic_utils.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..7ee138a7e7ba9a450bd1bf4d08d2c6b5b17230b2
Binary files /dev/null and b/mmdet/evaluation/functional/__pycache__/panoptic_utils.cpython-37.pyc differ
diff --git a/mmdet/evaluation/functional/__pycache__/recall.cpython-37.pyc b/mmdet/evaluation/functional/__pycache__/recall.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..f2634904f78b1c3da587595fdc9adbbfce576a5c
Binary files /dev/null and b/mmdet/evaluation/functional/__pycache__/recall.cpython-37.pyc differ
diff --git a/mmdet/evaluation/functional/bbox_overlaps.py b/mmdet/evaluation/functional/bbox_overlaps.py
new file mode 100644
index 0000000000000000000000000000000000000000..5d6eb82fcfc8d5444dd2a13b7d95b978f8206a55
--- /dev/null
+++ b/mmdet/evaluation/functional/bbox_overlaps.py
@@ -0,0 +1,65 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import numpy as np
+
+
+def bbox_overlaps(bboxes1,
+ bboxes2,
+ mode='iou',
+ eps=1e-6,
+ use_legacy_coordinate=False):
+ """Calculate the ious between each bbox of bboxes1 and bboxes2.
+
+ Args:
+ bboxes1 (ndarray): Shape (n, 4)
+ bboxes2 (ndarray): Shape (k, 4)
+ mode (str): IOU (intersection over union) or IOF (intersection
+ over foreground)
+ use_legacy_coordinate (bool): Whether to use coordinate system in
+ mmdet v1.x. which means width, height should be
+ calculated as 'x2 - x1 + 1` and 'y2 - y1 + 1' respectively.
+ Note when function is used in `VOCDataset`, it should be
+ True to align with the official implementation
+ `http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCdevkit_18-May-2011.tar`
+ Default: False.
+
+ Returns:
+ ious (ndarray): Shape (n, k)
+ """
+
+ assert mode in ['iou', 'iof']
+ if not use_legacy_coordinate:
+ extra_length = 0.
+ else:
+ extra_length = 1.
+ bboxes1 = bboxes1.astype(np.float32)
+ bboxes2 = bboxes2.astype(np.float32)
+ rows = bboxes1.shape[0]
+ cols = bboxes2.shape[0]
+ ious = np.zeros((rows, cols), dtype=np.float32)
+ if rows * cols == 0:
+ return ious
+ exchange = False
+ if bboxes1.shape[0] > bboxes2.shape[0]:
+ bboxes1, bboxes2 = bboxes2, bboxes1
+ ious = np.zeros((cols, rows), dtype=np.float32)
+ exchange = True
+ area1 = (bboxes1[:, 2] - bboxes1[:, 0] + extra_length) * (
+ bboxes1[:, 3] - bboxes1[:, 1] + extra_length)
+ area2 = (bboxes2[:, 2] - bboxes2[:, 0] + extra_length) * (
+ bboxes2[:, 3] - bboxes2[:, 1] + extra_length)
+ for i in range(bboxes1.shape[0]):
+ x_start = np.maximum(bboxes1[i, 0], bboxes2[:, 0])
+ y_start = np.maximum(bboxes1[i, 1], bboxes2[:, 1])
+ x_end = np.minimum(bboxes1[i, 2], bboxes2[:, 2])
+ y_end = np.minimum(bboxes1[i, 3], bboxes2[:, 3])
+ overlap = np.maximum(x_end - x_start + extra_length, 0) * np.maximum(
+ y_end - y_start + extra_length, 0)
+ if mode == 'iou':
+ union = area1[i] + area2 - overlap
+ else:
+ union = area1[i] if not exchange else area2
+ union = np.maximum(union, eps)
+ ious[i, :] = overlap / union
+ if exchange:
+ ious = ious.T
+ return ious
diff --git a/mmdet/evaluation/functional/cityscapes_utils.py b/mmdet/evaluation/functional/cityscapes_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..5ced3680deefe333af7cca3675a6359c02dd96f8
--- /dev/null
+++ b/mmdet/evaluation/functional/cityscapes_utils.py
@@ -0,0 +1,302 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+# Copyright (c) https://github.com/mcordts/cityscapesScripts
+# A wrapper of `cityscapesscripts` which supports loading groundtruth
+# image from `backend_args`.
+import json
+import os
+import sys
+from pathlib import Path
+from typing import Optional, Union
+
+import mmcv
+import numpy as np
+from mmengine.fileio import get
+
+try:
+ import cityscapesscripts.evaluation.evalInstanceLevelSemanticLabeling as CSEval # noqa: E501
+ from cityscapesscripts.evaluation.evalInstanceLevelSemanticLabeling import \
+ CArgs # noqa: E501
+ from cityscapesscripts.evaluation.instance import Instance
+ from cityscapesscripts.helpers.csHelpers import (id2label, labels,
+ writeDict2JSON)
+ HAS_CITYSCAPESAPI = True
+except ImportError:
+ CArgs = object
+ HAS_CITYSCAPESAPI = False
+
+
+def evaluateImgLists(prediction_list: list,
+ groundtruth_list: list,
+ args: CArgs,
+ backend_args: Optional[dict] = None,
+ dump_matches: bool = False) -> dict:
+ """A wrapper of obj:``cityscapesscripts.evaluation.
+
+ evalInstanceLevelSemanticLabeling.evaluateImgLists``. Support loading
+ groundtruth image from file backend.
+ Args:
+ prediction_list (list): A list of prediction txt file.
+ groundtruth_list (list): A list of groundtruth image file.
+ args (CArgs): A global object setting in
+ obj:``cityscapesscripts.evaluation.
+ evalInstanceLevelSemanticLabeling``
+ backend_args (dict, optional): Arguments to instantiate the
+ preifx of uri corresponding backend. Defaults to None.
+ dump_matches (bool): whether dump matches.json. Defaults to False.
+ Returns:
+ dict: The computed metric.
+ """
+ if not HAS_CITYSCAPESAPI:
+ raise RuntimeError('Failed to import `cityscapesscripts`.'
+ 'Please try to install official '
+ 'cityscapesscripts by '
+ '"pip install cityscapesscripts"')
+ # determine labels of interest
+ CSEval.setInstanceLabels(args)
+ # get dictionary of all ground truth instances
+ gt_instances = getGtInstances(
+ groundtruth_list, args, backend_args=backend_args)
+ # match predictions and ground truth
+ matches = matchGtWithPreds(prediction_list, groundtruth_list, gt_instances,
+ args, backend_args)
+ if dump_matches:
+ CSEval.writeDict2JSON(matches, 'matches.json')
+ # evaluate matches
+ apScores = CSEval.evaluateMatches(matches, args)
+ # averages
+ avgDict = CSEval.computeAverages(apScores, args)
+ # result dict
+ resDict = CSEval.prepareJSONDataForResults(avgDict, apScores, args)
+ if args.JSONOutput:
+ # create output folder if necessary
+ path = os.path.dirname(args.exportFile)
+ CSEval.ensurePath(path)
+ # Write APs to JSON
+ CSEval.writeDict2JSON(resDict, args.exportFile)
+
+ CSEval.printResults(avgDict, args)
+
+ return resDict
+
+
+def matchGtWithPreds(prediction_list: list,
+ groundtruth_list: list,
+ gt_instances: dict,
+ args: CArgs,
+ backend_args=None):
+ """A wrapper of obj:``cityscapesscripts.evaluation.
+
+ evalInstanceLevelSemanticLabeling.matchGtWithPreds``. Support loading
+ groundtruth image from file backend.
+ Args:
+ prediction_list (list): A list of prediction txt file.
+ groundtruth_list (list): A list of groundtruth image file.
+ gt_instances (dict): Groundtruth dict.
+ args (CArgs): A global object setting in
+ obj:``cityscapesscripts.evaluation.
+ evalInstanceLevelSemanticLabeling``
+ backend_args (dict, optional): Arguments to instantiate the
+ preifx of uri corresponding backend. Defaults to None.
+ Returns:
+ dict: The processed prediction and groundtruth result.
+ """
+ if not HAS_CITYSCAPESAPI:
+ raise RuntimeError('Failed to import `cityscapesscripts`.'
+ 'Please try to install official '
+ 'cityscapesscripts by '
+ '"pip install cityscapesscripts"')
+ matches: dict = dict()
+ if not args.quiet:
+ print(f'Matching {len(prediction_list)} pairs of images...')
+
+ count = 0
+ for (pred, gt) in zip(prediction_list, groundtruth_list):
+ # Read input files
+ gt_image = readGTImage(gt, backend_args)
+ pred_info = readPredInfo(pred)
+ # Get and filter ground truth instances
+ unfiltered_instances = gt_instances[gt]
+ cur_gt_instances_orig = CSEval.filterGtInstances(
+ unfiltered_instances, args)
+
+ # Try to assign all predictions
+ (cur_gt_instances,
+ cur_pred_instances) = CSEval.assignGt2Preds(cur_gt_instances_orig,
+ gt_image, pred_info, args)
+
+ # append to global dict
+ matches[gt] = {}
+ matches[gt]['groundTruth'] = cur_gt_instances
+ matches[gt]['prediction'] = cur_pred_instances
+
+ count += 1
+ if not args.quiet:
+ print(f'\rImages Processed: {count}', end=' ')
+ sys.stdout.flush()
+
+ if not args.quiet:
+ print('')
+
+ return matches
+
+
+def readGTImage(image_file: Union[str, Path],
+ backend_args: Optional[dict] = None) -> np.ndarray:
+ """Read an image from path.
+
+ Same as obj:``cityscapesscripts.evaluation.
+ evalInstanceLevelSemanticLabeling.readGTImage``, but support loading
+ groundtruth image from file backend.
+ Args:
+ image_file (str or Path): Either a str or pathlib.Path.
+ backend_args (dict, optional): Instantiates the corresponding file
+ backend. It may contain `backend` key to specify the file
+ backend. If it contains, the file backend corresponding to this
+ value will be used and initialized with the remaining values,
+ otherwise the corresponding file backend will be selected
+ based on the prefix of the file path. Defaults to None.
+ Returns:
+ np.ndarray: The groundtruth image.
+ """
+ img_bytes = get(image_file, backend_args=backend_args)
+ img = mmcv.imfrombytes(img_bytes, flag='unchanged', backend='pillow')
+ return img
+
+
+def readPredInfo(prediction_file: str) -> dict:
+ """A wrapper of obj:``cityscapesscripts.evaluation.
+
+ evalInstanceLevelSemanticLabeling.readPredInfo``.
+ Args:
+ prediction_file (str): The prediction txt file.
+ Returns:
+ dict: The processed prediction results.
+ """
+ if not HAS_CITYSCAPESAPI:
+ raise RuntimeError('Failed to import `cityscapesscripts`.'
+ 'Please try to install official '
+ 'cityscapesscripts by '
+ '"pip install cityscapesscripts"')
+ printError = CSEval.printError
+
+ predInfo = {}
+ if (not os.path.isfile(prediction_file)):
+ printError(f"Infofile '{prediction_file}' "
+ 'for the predictions not found.')
+ with open(prediction_file) as f:
+ for line in f:
+ splittedLine = line.split(' ')
+ if len(splittedLine) != 3:
+ printError('Invalid prediction file. Expected content: '
+ 'relPathPrediction1 labelIDPrediction1 '
+ 'confidencePrediction1')
+ if os.path.isabs(splittedLine[0]):
+ printError('Invalid prediction file. First entry in each '
+ 'line must be a relative path.')
+
+ filename = os.path.join(
+ os.path.dirname(prediction_file), splittedLine[0])
+
+ imageInfo = {}
+ imageInfo['labelID'] = int(float(splittedLine[1]))
+ imageInfo['conf'] = float(splittedLine[2]) # type: ignore
+ predInfo[filename] = imageInfo
+
+ return predInfo
+
+
+def getGtInstances(groundtruth_list: list,
+ args: CArgs,
+ backend_args: Optional[dict] = None) -> dict:
+ """A wrapper of obj:``cityscapesscripts.evaluation.
+
+ evalInstanceLevelSemanticLabeling.getGtInstances``. Support loading
+ groundtruth image from file backend.
+ Args:
+ groundtruth_list (list): A list of groundtruth image file.
+ args (CArgs): A global object setting in
+ obj:``cityscapesscripts.evaluation.
+ evalInstanceLevelSemanticLabeling``
+ backend_args (dict, optional): Arguments to instantiate the
+ preifx of uri corresponding backend. Defaults to None.
+ Returns:
+ dict: The computed metric.
+ """
+ if not HAS_CITYSCAPESAPI:
+ raise RuntimeError('Failed to import `cityscapesscripts`.'
+ 'Please try to install official '
+ 'cityscapesscripts by '
+ '"pip install cityscapesscripts"')
+ # if there is a global statistics json, then load it
+ if (os.path.isfile(args.gtInstancesFile)):
+ if not args.quiet:
+ print('Loading ground truth instances from JSON.')
+ with open(args.gtInstancesFile) as json_file:
+ gt_instances = json.load(json_file)
+ # otherwise create it
+ else:
+ if (not args.quiet):
+ print('Creating ground truth instances from png files.')
+ gt_instances = instances2dict(
+ groundtruth_list, args, backend_args=backend_args)
+ writeDict2JSON(gt_instances, args.gtInstancesFile)
+
+ return gt_instances
+
+
+def instances2dict(image_list: list,
+ args: CArgs,
+ backend_args: Optional[dict] = None) -> dict:
+ """A wrapper of obj:``cityscapesscripts.evaluation.
+
+ evalInstanceLevelSemanticLabeling.instances2dict``. Support loading
+ groundtruth image from file backend.
+ Args:
+ image_list (list): A list of image file.
+ args (CArgs): A global object setting in
+ obj:``cityscapesscripts.evaluation.
+ evalInstanceLevelSemanticLabeling``
+ backend_args (dict, optional): Arguments to instantiate the
+ preifx of uri corresponding backend. Defaults to None.
+ Returns:
+ dict: The processed groundtruth results.
+ """
+ if not HAS_CITYSCAPESAPI:
+ raise RuntimeError('Failed to import `cityscapesscripts`.'
+ 'Please try to install official '
+ 'cityscapesscripts by '
+ '"pip install cityscapesscripts"')
+ imgCount = 0
+ instanceDict = {}
+
+ if not isinstance(image_list, list):
+ image_list = [image_list]
+
+ if not args.quiet:
+ print(f'Processing {len(image_list)} images...')
+
+ for image_name in image_list:
+ # Load image
+ img_bytes = get(image_name, backend_args=backend_args)
+ imgNp = mmcv.imfrombytes(img_bytes, flag='unchanged', backend='pillow')
+
+ # Initialize label categories
+ instances: dict = {}
+ for label in labels:
+ instances[label.name] = []
+
+ # Loop through all instance ids in instance image
+ for instanceId in np.unique(imgNp):
+ instanceObj = Instance(imgNp, instanceId)
+
+ instances[id2label[instanceObj.labelID].name].append(
+ instanceObj.toDict())
+
+ instanceDict[image_name] = instances
+ imgCount += 1
+
+ if not args.quiet:
+ print(f'\rImages Processed: {imgCount}', end=' ')
+ sys.stdout.flush()
+
+ return instanceDict
diff --git a/mmdet/evaluation/functional/class_names.py b/mmdet/evaluation/functional/class_names.py
new file mode 100644
index 0000000000000000000000000000000000000000..d0ea7094685de38a9196d1240d23beb1b44d4138
--- /dev/null
+++ b/mmdet/evaluation/functional/class_names.py
@@ -0,0 +1,517 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmengine.utils import is_str
+
+
+def wider_face_classes() -> list:
+ """Class names of WIDERFace."""
+ return ['face']
+
+
+def voc_classes() -> list:
+ """Class names of PASCAL VOC."""
+ return [
+ 'aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat',
+ 'chair', 'cow', 'diningtable', 'dog', 'horse', 'motorbike', 'person',
+ 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor'
+ ]
+
+
+def imagenet_det_classes() -> list:
+ """Class names of ImageNet Det."""
+ return [
+ 'accordion', 'airplane', 'ant', 'antelope', 'apple', 'armadillo',
+ 'artichoke', 'axe', 'baby_bed', 'backpack', 'bagel', 'balance_beam',
+ 'banana', 'band_aid', 'banjo', 'baseball', 'basketball', 'bathing_cap',
+ 'beaker', 'bear', 'bee', 'bell_pepper', 'bench', 'bicycle', 'binder',
+ 'bird', 'bookshelf', 'bow_tie', 'bow', 'bowl', 'brassiere', 'burrito',
+ 'bus', 'butterfly', 'camel', 'can_opener', 'car', 'cart', 'cattle',
+ 'cello', 'centipede', 'chain_saw', 'chair', 'chime', 'cocktail_shaker',
+ 'coffee_maker', 'computer_keyboard', 'computer_mouse', 'corkscrew',
+ 'cream', 'croquet_ball', 'crutch', 'cucumber', 'cup_or_mug', 'diaper',
+ 'digital_clock', 'dishwasher', 'dog', 'domestic_cat', 'dragonfly',
+ 'drum', 'dumbbell', 'electric_fan', 'elephant', 'face_powder', 'fig',
+ 'filing_cabinet', 'flower_pot', 'flute', 'fox', 'french_horn', 'frog',
+ 'frying_pan', 'giant_panda', 'goldfish', 'golf_ball', 'golfcart',
+ 'guacamole', 'guitar', 'hair_dryer', 'hair_spray', 'hamburger',
+ 'hammer', 'hamster', 'harmonica', 'harp', 'hat_with_a_wide_brim',
+ 'head_cabbage', 'helmet', 'hippopotamus', 'horizontal_bar', 'horse',
+ 'hotdog', 'iPod', 'isopod', 'jellyfish', 'koala_bear', 'ladle',
+ 'ladybug', 'lamp', 'laptop', 'lemon', 'lion', 'lipstick', 'lizard',
+ 'lobster', 'maillot', 'maraca', 'microphone', 'microwave', 'milk_can',
+ 'miniskirt', 'monkey', 'motorcycle', 'mushroom', 'nail', 'neck_brace',
+ 'oboe', 'orange', 'otter', 'pencil_box', 'pencil_sharpener', 'perfume',
+ 'person', 'piano', 'pineapple', 'ping-pong_ball', 'pitcher', 'pizza',
+ 'plastic_bag', 'plate_rack', 'pomegranate', 'popsicle', 'porcupine',
+ 'power_drill', 'pretzel', 'printer', 'puck', 'punching_bag', 'purse',
+ 'rabbit', 'racket', 'ray', 'red_panda', 'refrigerator',
+ 'remote_control', 'rubber_eraser', 'rugby_ball', 'ruler',
+ 'salt_or_pepper_shaker', 'saxophone', 'scorpion', 'screwdriver',
+ 'seal', 'sheep', 'ski', 'skunk', 'snail', 'snake', 'snowmobile',
+ 'snowplow', 'soap_dispenser', 'soccer_ball', 'sofa', 'spatula',
+ 'squirrel', 'starfish', 'stethoscope', 'stove', 'strainer',
+ 'strawberry', 'stretcher', 'sunglasses', 'swimming_trunks', 'swine',
+ 'syringe', 'table', 'tape_player', 'tennis_ball', 'tick', 'tie',
+ 'tiger', 'toaster', 'traffic_light', 'train', 'trombone', 'trumpet',
+ 'turtle', 'tv_or_monitor', 'unicycle', 'vacuum', 'violin',
+ 'volleyball', 'waffle_iron', 'washer', 'water_bottle', 'watercraft',
+ 'whale', 'wine_bottle', 'zebra'
+ ]
+
+
+def imagenet_vid_classes() -> list:
+ """Class names of ImageNet VID."""
+ return [
+ 'airplane', 'antelope', 'bear', 'bicycle', 'bird', 'bus', 'car',
+ 'cattle', 'dog', 'domestic_cat', 'elephant', 'fox', 'giant_panda',
+ 'hamster', 'horse', 'lion', 'lizard', 'monkey', 'motorcycle', 'rabbit',
+ 'red_panda', 'sheep', 'snake', 'squirrel', 'tiger', 'train', 'turtle',
+ 'watercraft', 'whale', 'zebra'
+ ]
+
+
+def coco_classes() -> list:
+ """Class names of COCO."""
+ return [
+ 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train',
+ 'truck', 'boat', 'traffic_light', 'fire_hydrant', 'stop_sign',
+ 'parking_meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep',
+ 'cow', 'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella',
+ 'handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard',
+ 'sports_ball', 'kite', 'baseball_bat', 'baseball_glove', 'skateboard',
+ 'surfboard', 'tennis_racket', 'bottle', 'wine_glass', 'cup', 'fork',
+ 'knife', 'spoon', 'bowl', 'banana', 'apple', 'sandwich', 'orange',
+ 'broccoli', 'carrot', 'hot_dog', 'pizza', 'donut', 'cake', 'chair',
+ 'couch', 'potted_plant', 'bed', 'dining_table', 'toilet', 'tv',
+ 'laptop', 'mouse', 'remote', 'keyboard', 'cell_phone', 'microwave',
+ 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase',
+ 'scissors', 'teddy_bear', 'hair_drier', 'toothbrush'
+ ]
+
+
+def coco_panoptic_classes() -> list:
+ """Class names of COCO panoptic."""
+ return [
+ 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train',
+ 'truck', 'boat', 'traffic light', 'fire hydrant', 'stop sign',
+ 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep',
+ 'cow', 'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella',
+ 'handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard',
+ 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard',
+ 'surfboard', 'tennis racket', 'bottle', 'wine glass', 'cup', 'fork',
+ 'knife', 'spoon', 'bowl', 'banana', 'apple', 'sandwich', 'orange',
+ 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair',
+ 'couch', 'potted plant', 'bed', 'dining table', 'toilet', 'tv',
+ 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone', 'microwave',
+ 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase',
+ 'scissors', 'teddy bear', 'hair drier', 'toothbrush', 'banner',
+ 'blanket', 'bridge', 'cardboard', 'counter', 'curtain', 'door-stuff',
+ 'floor-wood', 'flower', 'fruit', 'gravel', 'house', 'light',
+ 'mirror-stuff', 'net', 'pillow', 'platform', 'playingfield',
+ 'railroad', 'river', 'road', 'roof', 'sand', 'sea', 'shelf', 'snow',
+ 'stairs', 'tent', 'towel', 'wall-brick', 'wall-stone', 'wall-tile',
+ 'wall-wood', 'water-other', 'window-blind', 'window-other',
+ 'tree-merged', 'fence-merged', 'ceiling-merged', 'sky-other-merged',
+ 'cabinet-merged', 'table-merged', 'floor-other-merged',
+ 'pavement-merged', 'mountain-merged', 'grass-merged', 'dirt-merged',
+ 'paper-merged', 'food-other-merged', 'building-other-merged',
+ 'rock-merged', 'wall-other-merged', 'rug-merged'
+ ]
+
+
+def cityscapes_classes() -> list:
+ """Class names of Cityscapes."""
+ return [
+ 'person', 'rider', 'car', 'truck', 'bus', 'train', 'motorcycle',
+ 'bicycle'
+ ]
+
+
+def oid_challenge_classes() -> list:
+ """Class names of Open Images Challenge."""
+ return [
+ 'Footwear', 'Jeans', 'House', 'Tree', 'Woman', 'Man', 'Land vehicle',
+ 'Person', 'Wheel', 'Bus', 'Human face', 'Bird', 'Dress', 'Girl',
+ 'Vehicle', 'Building', 'Cat', 'Car', 'Belt', 'Elephant', 'Dessert',
+ 'Butterfly', 'Train', 'Guitar', 'Poster', 'Book', 'Boy', 'Bee',
+ 'Flower', 'Window', 'Hat', 'Human head', 'Dog', 'Human arm', 'Drink',
+ 'Human mouth', 'Human hair', 'Human nose', 'Human hand', 'Table',
+ 'Marine invertebrates', 'Fish', 'Sculpture', 'Rose', 'Street light',
+ 'Glasses', 'Fountain', 'Skyscraper', 'Swimwear', 'Brassiere', 'Drum',
+ 'Duck', 'Countertop', 'Furniture', 'Ball', 'Human leg', 'Boat',
+ 'Balloon', 'Bicycle helmet', 'Goggles', 'Door', 'Human eye', 'Shirt',
+ 'Toy', 'Teddy bear', 'Pasta', 'Tomato', 'Human ear',
+ 'Vehicle registration plate', 'Microphone', 'Musical keyboard',
+ 'Tower', 'Houseplant', 'Flowerpot', 'Fruit', 'Vegetable',
+ 'Musical instrument', 'Suit', 'Motorcycle', 'Bagel', 'French fries',
+ 'Hamburger', 'Chair', 'Salt and pepper shakers', 'Snail', 'Airplane',
+ 'Horse', 'Laptop', 'Computer keyboard', 'Football helmet', 'Cocktail',
+ 'Juice', 'Tie', 'Computer monitor', 'Human beard', 'Bottle',
+ 'Saxophone', 'Lemon', 'Mouse', 'Sock', 'Cowboy hat', 'Sun hat',
+ 'Football', 'Porch', 'Sunglasses', 'Lobster', 'Crab', 'Picture frame',
+ 'Van', 'Crocodile', 'Surfboard', 'Shorts', 'Helicopter', 'Helmet',
+ 'Sports uniform', 'Taxi', 'Swan', 'Goose', 'Coat', 'Jacket', 'Handbag',
+ 'Flag', 'Skateboard', 'Television', 'Tire', 'Spoon', 'Palm tree',
+ 'Stairs', 'Salad', 'Castle', 'Oven', 'Microwave oven', 'Wine',
+ 'Ceiling fan', 'Mechanical fan', 'Cattle', 'Truck', 'Box', 'Ambulance',
+ 'Desk', 'Wine glass', 'Reptile', 'Tank', 'Traffic light', 'Billboard',
+ 'Tent', 'Insect', 'Spider', 'Treadmill', 'Cupboard', 'Shelf',
+ 'Seat belt', 'Human foot', 'Bicycle', 'Bicycle wheel', 'Couch',
+ 'Bookcase', 'Fedora', 'Backpack', 'Bench', 'Oyster',
+ 'Moths and butterflies', 'Lavender', 'Waffle', 'Fork', 'Animal',
+ 'Accordion', 'Mobile phone', 'Plate', 'Coffee cup', 'Saucer',
+ 'Platter', 'Dagger', 'Knife', 'Bull', 'Tortoise', 'Sea turtle', 'Deer',
+ 'Weapon', 'Apple', 'Ski', 'Taco', 'Traffic sign', 'Beer', 'Necklace',
+ 'Sunflower', 'Piano', 'Organ', 'Harpsichord', 'Bed', 'Cabinetry',
+ 'Nightstand', 'Curtain', 'Chest of drawers', 'Drawer', 'Parrot',
+ 'Sandal', 'High heels', 'Tableware', 'Cart', 'Mushroom', 'Kite',
+ 'Missile', 'Seafood', 'Camera', 'Paper towel', 'Toilet paper',
+ 'Sombrero', 'Radish', 'Lighthouse', 'Segway', 'Pig', 'Watercraft',
+ 'Golf cart', 'studio couch', 'Dolphin', 'Whale', 'Earrings', 'Otter',
+ 'Sea lion', 'Whiteboard', 'Monkey', 'Gondola', 'Zebra',
+ 'Baseball glove', 'Scarf', 'Adhesive tape', 'Trousers', 'Scoreboard',
+ 'Lily', 'Carnivore', 'Power plugs and sockets', 'Office building',
+ 'Sandwich', 'Swimming pool', 'Headphones', 'Tin can', 'Crown', 'Doll',
+ 'Cake', 'Frog', 'Beetle', 'Ant', 'Gas stove', 'Canoe', 'Falcon',
+ 'Blue jay', 'Egg', 'Fire hydrant', 'Raccoon', 'Muffin', 'Wall clock',
+ 'Coffee', 'Mug', 'Tea', 'Bear', 'Waste container', 'Home appliance',
+ 'Candle', 'Lion', 'Mirror', 'Starfish', 'Marine mammal', 'Wheelchair',
+ 'Umbrella', 'Alpaca', 'Violin', 'Cello', 'Brown bear', 'Canary', 'Bat',
+ 'Ruler', 'Plastic bag', 'Penguin', 'Watermelon', 'Harbor seal', 'Pen',
+ 'Pumpkin', 'Harp', 'Kitchen appliance', 'Roller skates', 'Bust',
+ 'Coffee table', 'Tennis ball', 'Tennis racket', 'Ladder', 'Boot',
+ 'Bowl', 'Stop sign', 'Volleyball', 'Eagle', 'Paddle', 'Chicken',
+ 'Skull', 'Lamp', 'Beehive', 'Maple', 'Sink', 'Goldfish', 'Tripod',
+ 'Coconut', 'Bidet', 'Tap', 'Bathroom cabinet', 'Toilet',
+ 'Filing cabinet', 'Pretzel', 'Table tennis racket', 'Bronze sculpture',
+ 'Rocket', 'Mouse', 'Hamster', 'Lizard', 'Lifejacket', 'Goat',
+ 'Washing machine', 'Trumpet', 'Horn', 'Trombone', 'Sheep',
+ 'Tablet computer', 'Pillow', 'Kitchen & dining room table',
+ 'Parachute', 'Raven', 'Glove', 'Loveseat', 'Christmas tree',
+ 'Shellfish', 'Rifle', 'Shotgun', 'Sushi', 'Sparrow', 'Bread',
+ 'Toaster', 'Watch', 'Asparagus', 'Artichoke', 'Suitcase', 'Antelope',
+ 'Broccoli', 'Ice cream', 'Racket', 'Banana', 'Cookie', 'Cucumber',
+ 'Dragonfly', 'Lynx', 'Caterpillar', 'Light bulb', 'Office supplies',
+ 'Miniskirt', 'Skirt', 'Fireplace', 'Potato', 'Light switch',
+ 'Croissant', 'Cabbage', 'Ladybug', 'Handgun', 'Luggage and bags',
+ 'Window blind', 'Snowboard', 'Baseball bat', 'Digital clock',
+ 'Serving tray', 'Infant bed', 'Sofa bed', 'Guacamole', 'Fox', 'Pizza',
+ 'Snowplow', 'Jet ski', 'Refrigerator', 'Lantern', 'Convenience store',
+ 'Sword', 'Rugby ball', 'Owl', 'Ostrich', 'Pancake', 'Strawberry',
+ 'Carrot', 'Tart', 'Dice', 'Turkey', 'Rabbit', 'Invertebrate', 'Vase',
+ 'Stool', 'Swim cap', 'Shower', 'Clock', 'Jellyfish', 'Aircraft',
+ 'Chopsticks', 'Orange', 'Snake', 'Sewing machine', 'Kangaroo', 'Mixer',
+ 'Food processor', 'Shrimp', 'Towel', 'Porcupine', 'Jaguar', 'Cannon',
+ 'Limousine', 'Mule', 'Squirrel', 'Kitchen knife', 'Tiara', 'Tiger',
+ 'Bow and arrow', 'Candy', 'Rhinoceros', 'Shark', 'Cricket ball',
+ 'Doughnut', 'Plumbing fixture', 'Camel', 'Polar bear', 'Coin',
+ 'Printer', 'Blender', 'Giraffe', 'Billiard table', 'Kettle',
+ 'Dinosaur', 'Pineapple', 'Zucchini', 'Jug', 'Barge', 'Teapot',
+ 'Golf ball', 'Binoculars', 'Scissors', 'Hot dog', 'Door handle',
+ 'Seahorse', 'Bathtub', 'Leopard', 'Centipede', 'Grapefruit', 'Snowman',
+ 'Cheetah', 'Alarm clock', 'Grape', 'Wrench', 'Wok', 'Bell pepper',
+ 'Cake stand', 'Barrel', 'Woodpecker', 'Flute', 'Corded phone',
+ 'Willow', 'Punching bag', 'Pomegranate', 'Telephone', 'Pear',
+ 'Common fig', 'Bench', 'Wood-burning stove', 'Burrito', 'Nail',
+ 'Turtle', 'Submarine sandwich', 'Drinking straw', 'Peach', 'Popcorn',
+ 'Frying pan', 'Picnic basket', 'Honeycomb', 'Envelope', 'Mango',
+ 'Cutting board', 'Pitcher', 'Stationary bicycle', 'Dumbbell',
+ 'Personal care', 'Dog bed', 'Snowmobile', 'Oboe', 'Briefcase',
+ 'Squash', 'Tick', 'Slow cooker', 'Coffeemaker', 'Measuring cup',
+ 'Crutch', 'Stretcher', 'Screwdriver', 'Flashlight', 'Spatula',
+ 'Pressure cooker', 'Ring binder', 'Beaker', 'Torch', 'Winter melon'
+ ]
+
+
+def oid_v6_classes() -> list:
+ """Class names of Open Images V6."""
+ return [
+ 'Tortoise', 'Container', 'Magpie', 'Sea turtle', 'Football',
+ 'Ambulance', 'Ladder', 'Toothbrush', 'Syringe', 'Sink', 'Toy',
+ 'Organ (Musical Instrument)', 'Cassette deck', 'Apple', 'Human eye',
+ 'Cosmetics', 'Paddle', 'Snowman', 'Beer', 'Chopsticks', 'Human beard',
+ 'Bird', 'Parking meter', 'Traffic light', 'Croissant', 'Cucumber',
+ 'Radish', 'Towel', 'Doll', 'Skull', 'Washing machine', 'Glove', 'Tick',
+ 'Belt', 'Sunglasses', 'Banjo', 'Cart', 'Ball', 'Backpack', 'Bicycle',
+ 'Home appliance', 'Centipede', 'Boat', 'Surfboard', 'Boot',
+ 'Headphones', 'Hot dog', 'Shorts', 'Fast food', 'Bus', 'Boy',
+ 'Screwdriver', 'Bicycle wheel', 'Barge', 'Laptop', 'Miniskirt',
+ 'Drill (Tool)', 'Dress', 'Bear', 'Waffle', 'Pancake', 'Brown bear',
+ 'Woodpecker', 'Blue jay', 'Pretzel', 'Bagel', 'Tower', 'Teapot',
+ 'Person', 'Bow and arrow', 'Swimwear', 'Beehive', 'Brassiere', 'Bee',
+ 'Bat (Animal)', 'Starfish', 'Popcorn', 'Burrito', 'Chainsaw',
+ 'Balloon', 'Wrench', 'Tent', 'Vehicle registration plate', 'Lantern',
+ 'Toaster', 'Flashlight', 'Billboard', 'Tiara', 'Limousine', 'Necklace',
+ 'Carnivore', 'Scissors', 'Stairs', 'Computer keyboard', 'Printer',
+ 'Traffic sign', 'Chair', 'Shirt', 'Poster', 'Cheese', 'Sock',
+ 'Fire hydrant', 'Land vehicle', 'Earrings', 'Tie', 'Watercraft',
+ 'Cabinetry', 'Suitcase', 'Muffin', 'Bidet', 'Snack', 'Snowmobile',
+ 'Clock', 'Medical equipment', 'Cattle', 'Cello', 'Jet ski', 'Camel',
+ 'Coat', 'Suit', 'Desk', 'Cat', 'Bronze sculpture', 'Juice', 'Gondola',
+ 'Beetle', 'Cannon', 'Computer mouse', 'Cookie', 'Office building',
+ 'Fountain', 'Coin', 'Calculator', 'Cocktail', 'Computer monitor',
+ 'Box', 'Stapler', 'Christmas tree', 'Cowboy hat', 'Hiking equipment',
+ 'Studio couch', 'Drum', 'Dessert', 'Wine rack', 'Drink', 'Zucchini',
+ 'Ladle', 'Human mouth', 'Dairy Product', 'Dice', 'Oven', 'Dinosaur',
+ 'Ratchet (Device)', 'Couch', 'Cricket ball', 'Winter melon', 'Spatula',
+ 'Whiteboard', 'Pencil sharpener', 'Door', 'Hat', 'Shower', 'Eraser',
+ 'Fedora', 'Guacamole', 'Dagger', 'Scarf', 'Dolphin', 'Sombrero',
+ 'Tin can', 'Mug', 'Tap', 'Harbor seal', 'Stretcher', 'Can opener',
+ 'Goggles', 'Human body', 'Roller skates', 'Coffee cup',
+ 'Cutting board', 'Blender', 'Plumbing fixture', 'Stop sign',
+ 'Office supplies', 'Volleyball (Ball)', 'Vase', 'Slow cooker',
+ 'Wardrobe', 'Coffee', 'Whisk', 'Paper towel', 'Personal care', 'Food',
+ 'Sun hat', 'Tree house', 'Flying disc', 'Skirt', 'Gas stove',
+ 'Salt and pepper shakers', 'Mechanical fan', 'Face powder', 'Fax',
+ 'Fruit', 'French fries', 'Nightstand', 'Barrel', 'Kite', 'Tart',
+ 'Treadmill', 'Fox', 'Flag', 'French horn', 'Window blind',
+ 'Human foot', 'Golf cart', 'Jacket', 'Egg (Food)', 'Street light',
+ 'Guitar', 'Pillow', 'Human leg', 'Isopod', 'Grape', 'Human ear',
+ 'Power plugs and sockets', 'Panda', 'Giraffe', 'Woman', 'Door handle',
+ 'Rhinoceros', 'Bathtub', 'Goldfish', 'Houseplant', 'Goat',
+ 'Baseball bat', 'Baseball glove', 'Mixing bowl',
+ 'Marine invertebrates', 'Kitchen utensil', 'Light switch', 'House',
+ 'Horse', 'Stationary bicycle', 'Hammer', 'Ceiling fan', 'Sofa bed',
+ 'Adhesive tape', 'Harp', 'Sandal', 'Bicycle helmet', 'Saucer',
+ 'Harpsichord', 'Human hair', 'Heater', 'Harmonica', 'Hamster',
+ 'Curtain', 'Bed', 'Kettle', 'Fireplace', 'Scale', 'Drinking straw',
+ 'Insect', 'Hair dryer', 'Kitchenware', 'Indoor rower', 'Invertebrate',
+ 'Food processor', 'Bookcase', 'Refrigerator', 'Wood-burning stove',
+ 'Punching bag', 'Common fig', 'Cocktail shaker', 'Jaguar (Animal)',
+ 'Golf ball', 'Fashion accessory', 'Alarm clock', 'Filing cabinet',
+ 'Artichoke', 'Table', 'Tableware', 'Kangaroo', 'Koala', 'Knife',
+ 'Bottle', 'Bottle opener', 'Lynx', 'Lavender (Plant)', 'Lighthouse',
+ 'Dumbbell', 'Human head', 'Bowl', 'Humidifier', 'Porch', 'Lizard',
+ 'Billiard table', 'Mammal', 'Mouse', 'Motorcycle',
+ 'Musical instrument', 'Swim cap', 'Frying pan', 'Snowplow',
+ 'Bathroom cabinet', 'Missile', 'Bust', 'Man', 'Waffle iron', 'Milk',
+ 'Ring binder', 'Plate', 'Mobile phone', 'Baked goods', 'Mushroom',
+ 'Crutch', 'Pitcher (Container)', 'Mirror', 'Personal flotation device',
+ 'Table tennis racket', 'Pencil case', 'Musical keyboard', 'Scoreboard',
+ 'Briefcase', 'Kitchen knife', 'Nail (Construction)', 'Tennis ball',
+ 'Plastic bag', 'Oboe', 'Chest of drawers', 'Ostrich', 'Piano', 'Girl',
+ 'Plant', 'Potato', 'Hair spray', 'Sports equipment', 'Pasta',
+ 'Penguin', 'Pumpkin', 'Pear', 'Infant bed', 'Polar bear', 'Mixer',
+ 'Cupboard', 'Jacuzzi', 'Pizza', 'Digital clock', 'Pig', 'Reptile',
+ 'Rifle', 'Lipstick', 'Skateboard', 'Raven', 'High heels', 'Red panda',
+ 'Rose', 'Rabbit', 'Sculpture', 'Saxophone', 'Shotgun', 'Seafood',
+ 'Submarine sandwich', 'Snowboard', 'Sword', 'Picture frame', 'Sushi',
+ 'Loveseat', 'Ski', 'Squirrel', 'Tripod', 'Stethoscope', 'Submarine',
+ 'Scorpion', 'Segway', 'Training bench', 'Snake', 'Coffee table',
+ 'Skyscraper', 'Sheep', 'Television', 'Trombone', 'Tea', 'Tank', 'Taco',
+ 'Telephone', 'Torch', 'Tiger', 'Strawberry', 'Trumpet', 'Tree',
+ 'Tomato', 'Train', 'Tool', 'Picnic basket', 'Cooking spray',
+ 'Trousers', 'Bowling equipment', 'Football helmet', 'Truck',
+ 'Measuring cup', 'Coffeemaker', 'Violin', 'Vehicle', 'Handbag',
+ 'Paper cutter', 'Wine', 'Weapon', 'Wheel', 'Worm', 'Wok', 'Whale',
+ 'Zebra', 'Auto part', 'Jug', 'Pizza cutter', 'Cream', 'Monkey', 'Lion',
+ 'Bread', 'Platter', 'Chicken', 'Eagle', 'Helicopter', 'Owl', 'Duck',
+ 'Turtle', 'Hippopotamus', 'Crocodile', 'Toilet', 'Toilet paper',
+ 'Squid', 'Clothing', 'Footwear', 'Lemon', 'Spider', 'Deer', 'Frog',
+ 'Banana', 'Rocket', 'Wine glass', 'Countertop', 'Tablet computer',
+ 'Waste container', 'Swimming pool', 'Dog', 'Book', 'Elephant', 'Shark',
+ 'Candle', 'Leopard', 'Axe', 'Hand dryer', 'Soap dispenser',
+ 'Porcupine', 'Flower', 'Canary', 'Cheetah', 'Palm tree', 'Hamburger',
+ 'Maple', 'Building', 'Fish', 'Lobster', 'Garden Asparagus',
+ 'Furniture', 'Hedgehog', 'Airplane', 'Spoon', 'Otter', 'Bull',
+ 'Oyster', 'Horizontal bar', 'Convenience store', 'Bomb', 'Bench',
+ 'Ice cream', 'Caterpillar', 'Butterfly', 'Parachute', 'Orange',
+ 'Antelope', 'Beaker', 'Moths and butterflies', 'Window', 'Closet',
+ 'Castle', 'Jellyfish', 'Goose', 'Mule', 'Swan', 'Peach', 'Coconut',
+ 'Seat belt', 'Raccoon', 'Chisel', 'Fork', 'Lamp', 'Camera',
+ 'Squash (Plant)', 'Racket', 'Human face', 'Human arm', 'Vegetable',
+ 'Diaper', 'Unicycle', 'Falcon', 'Chime', 'Snail', 'Shellfish',
+ 'Cabbage', 'Carrot', 'Mango', 'Jeans', 'Flowerpot', 'Pineapple',
+ 'Drawer', 'Stool', 'Envelope', 'Cake', 'Dragonfly', 'Common sunflower',
+ 'Microwave oven', 'Honeycomb', 'Marine mammal', 'Sea lion', 'Ladybug',
+ 'Shelf', 'Watch', 'Candy', 'Salad', 'Parrot', 'Handgun', 'Sparrow',
+ 'Van', 'Grinder', 'Spice rack', 'Light bulb', 'Corded phone',
+ 'Sports uniform', 'Tennis racket', 'Wall clock', 'Serving tray',
+ 'Kitchen & dining room table', 'Dog bed', 'Cake stand',
+ 'Cat furniture', 'Bathroom accessory', 'Facial tissue holder',
+ 'Pressure cooker', 'Kitchen appliance', 'Tire', 'Ruler',
+ 'Luggage and bags', 'Microphone', 'Broccoli', 'Umbrella', 'Pastry',
+ 'Grapefruit', 'Band-aid', 'Animal', 'Bell pepper', 'Turkey', 'Lily',
+ 'Pomegranate', 'Doughnut', 'Glasses', 'Human nose', 'Pen', 'Ant',
+ 'Car', 'Aircraft', 'Human hand', 'Skunk', 'Teddy bear', 'Watermelon',
+ 'Cantaloupe', 'Dishwasher', 'Flute', 'Balance beam', 'Sandwich',
+ 'Shrimp', 'Sewing machine', 'Binoculars', 'Rays and skates', 'Ipod',
+ 'Accordion', 'Willow', 'Crab', 'Crown', 'Seahorse', 'Perfume',
+ 'Alpaca', 'Taxi', 'Canoe', 'Remote control', 'Wheelchair',
+ 'Rugby ball', 'Armadillo', 'Maracas', 'Helmet'
+ ]
+
+
+def objects365v1_classes() -> list:
+ """Class names of Objects365 V1."""
+ return [
+ 'person', 'sneakers', 'chair', 'hat', 'lamp', 'bottle',
+ 'cabinet/shelf', 'cup', 'car', 'glasses', 'picture/frame', 'desk',
+ 'handbag', 'street lights', 'book', 'plate', 'helmet', 'leather shoes',
+ 'pillow', 'glove', 'potted plant', 'bracelet', 'flower', 'tv',
+ 'storage box', 'vase', 'bench', 'wine glass', 'boots', 'bowl',
+ 'dining table', 'umbrella', 'boat', 'flag', 'speaker', 'trash bin/can',
+ 'stool', 'backpack', 'couch', 'belt', 'carpet', 'basket',
+ 'towel/napkin', 'slippers', 'barrel/bucket', 'coffee table', 'suv',
+ 'toy', 'tie', 'bed', 'traffic light', 'pen/pencil', 'microphone',
+ 'sandals', 'canned', 'necklace', 'mirror', 'faucet', 'bicycle',
+ 'bread', 'high heels', 'ring', 'van', 'watch', 'sink', 'horse', 'fish',
+ 'apple', 'camera', 'candle', 'teddy bear', 'cake', 'motorcycle',
+ 'wild bird', 'laptop', 'knife', 'traffic sign', 'cell phone', 'paddle',
+ 'truck', 'cow', 'power outlet', 'clock', 'drum', 'fork', 'bus',
+ 'hanger', 'nightstand', 'pot/pan', 'sheep', 'guitar', 'traffic cone',
+ 'tea pot', 'keyboard', 'tripod', 'hockey', 'fan', 'dog', 'spoon',
+ 'blackboard/whiteboard', 'balloon', 'air conditioner', 'cymbal',
+ 'mouse', 'telephone', 'pickup truck', 'orange', 'banana', 'airplane',
+ 'luggage', 'skis', 'soccer', 'trolley', 'oven', 'remote',
+ 'baseball glove', 'paper towel', 'refrigerator', 'train', 'tomato',
+ 'machinery vehicle', 'tent', 'shampoo/shower gel', 'head phone',
+ 'lantern', 'donut', 'cleaning products', 'sailboat', 'tangerine',
+ 'pizza', 'kite', 'computer box', 'elephant', 'toiletries', 'gas stove',
+ 'broccoli', 'toilet', 'stroller', 'shovel', 'baseball bat',
+ 'microwave', 'skateboard', 'surfboard', 'surveillance camera', 'gun',
+ 'life saver', 'cat', 'lemon', 'liquid soap', 'zebra', 'duck',
+ 'sports car', 'giraffe', 'pumpkin', 'piano', 'stop sign', 'radiator',
+ 'converter', 'tissue ', 'carrot', 'washing machine', 'vent', 'cookies',
+ 'cutting/chopping board', 'tennis racket', 'candy',
+ 'skating and skiing shoes', 'scissors', 'folder', 'baseball',
+ 'strawberry', 'bow tie', 'pigeon', 'pepper', 'coffee machine',
+ 'bathtub', 'snowboard', 'suitcase', 'grapes', 'ladder', 'pear',
+ 'american football', 'basketball', 'potato', 'paint brush', 'printer',
+ 'billiards', 'fire hydrant', 'goose', 'projector', 'sausage',
+ 'fire extinguisher', 'extension cord', 'facial mask', 'tennis ball',
+ 'chopsticks', 'electronic stove and gas stove', 'pie', 'frisbee',
+ 'kettle', 'hamburger', 'golf club', 'cucumber', 'clutch', 'blender',
+ 'tong', 'slide', 'hot dog', 'toothbrush', 'facial cleanser', 'mango',
+ 'deer', 'egg', 'violin', 'marker', 'ship', 'chicken', 'onion',
+ 'ice cream', 'tape', 'wheelchair', 'plum', 'bar soap', 'scale',
+ 'watermelon', 'cabbage', 'router/modem', 'golf ball', 'pine apple',
+ 'crane', 'fire truck', 'peach', 'cello', 'notepaper', 'tricycle',
+ 'toaster', 'helicopter', 'green beans', 'brush', 'carriage', 'cigar',
+ 'earphone', 'penguin', 'hurdle', 'swing', 'radio', 'CD',
+ 'parking meter', 'swan', 'garlic', 'french fries', 'horn', 'avocado',
+ 'saxophone', 'trumpet', 'sandwich', 'cue', 'kiwi fruit', 'bear',
+ 'fishing rod', 'cherry', 'tablet', 'green vegetables', 'nuts', 'corn',
+ 'key', 'screwdriver', 'globe', 'broom', 'pliers', 'volleyball',
+ 'hammer', 'eggplant', 'trophy', 'dates', 'board eraser', 'rice',
+ 'tape measure/ruler', 'dumbbell', 'hamimelon', 'stapler', 'camel',
+ 'lettuce', 'goldfish', 'meat balls', 'medal', 'toothpaste', 'antelope',
+ 'shrimp', 'rickshaw', 'trombone', 'pomegranate', 'coconut',
+ 'jellyfish', 'mushroom', 'calculator', 'treadmill', 'butterfly',
+ 'egg tart', 'cheese', 'pig', 'pomelo', 'race car', 'rice cooker',
+ 'tuba', 'crosswalk sign', 'papaya', 'hair drier', 'green onion',
+ 'chips', 'dolphin', 'sushi', 'urinal', 'donkey', 'electric drill',
+ 'spring rolls', 'tortoise/turtle', 'parrot', 'flute', 'measuring cup',
+ 'shark', 'steak', 'poker card', 'binoculars', 'llama', 'radish',
+ 'noodles', 'yak', 'mop', 'crab', 'microscope', 'barbell', 'bread/bun',
+ 'baozi', 'lion', 'red cabbage', 'polar bear', 'lighter', 'seal',
+ 'mangosteen', 'comb', 'eraser', 'pitaya', 'scallop', 'pencil case',
+ 'saw', 'table tennis paddle', 'okra', 'starfish', 'eagle', 'monkey',
+ 'durian', 'game board', 'rabbit', 'french horn', 'ambulance',
+ 'asparagus', 'hoverboard', 'pasta', 'target', 'hotair balloon',
+ 'chainsaw', 'lobster', 'iron', 'flashlight'
+ ]
+
+
+def objects365v2_classes() -> list:
+ """Class names of Objects365 V2."""
+ return [
+ 'Person', 'Sneakers', 'Chair', 'Other Shoes', 'Hat', 'Car', 'Lamp',
+ 'Glasses', 'Bottle', 'Desk', 'Cup', 'Street Lights', 'Cabinet/shelf',
+ 'Handbag/Satchel', 'Bracelet', 'Plate', 'Picture/Frame', 'Helmet',
+ 'Book', 'Gloves', 'Storage box', 'Boat', 'Leather Shoes', 'Flower',
+ 'Bench', 'Potted Plant', 'Bowl/Basin', 'Flag', 'Pillow', 'Boots',
+ 'Vase', 'Microphone', 'Necklace', 'Ring', 'SUV', 'Wine Glass', 'Belt',
+ 'Moniter/TV', 'Backpack', 'Umbrella', 'Traffic Light', 'Speaker',
+ 'Watch', 'Tie', 'Trash bin Can', 'Slippers', 'Bicycle', 'Stool',
+ 'Barrel/bucket', 'Van', 'Couch', 'Sandals', 'Bakset', 'Drum',
+ 'Pen/Pencil', 'Bus', 'Wild Bird', 'High Heels', 'Motorcycle', 'Guitar',
+ 'Carpet', 'Cell Phone', 'Bread', 'Camera', 'Canned', 'Truck',
+ 'Traffic cone', 'Cymbal', 'Lifesaver', 'Towel', 'Stuffed Toy',
+ 'Candle', 'Sailboat', 'Laptop', 'Awning', 'Bed', 'Faucet', 'Tent',
+ 'Horse', 'Mirror', 'Power outlet', 'Sink', 'Apple', 'Air Conditioner',
+ 'Knife', 'Hockey Stick', 'Paddle', 'Pickup Truck', 'Fork',
+ 'Traffic Sign', 'Ballon', 'Tripod', 'Dog', 'Spoon', 'Clock', 'Pot',
+ 'Cow', 'Cake', 'Dinning Table', 'Sheep', 'Hanger',
+ 'Blackboard/Whiteboard', 'Napkin', 'Other Fish', 'Orange/Tangerine',
+ 'Toiletry', 'Keyboard', 'Tomato', 'Lantern', 'Machinery Vehicle',
+ 'Fan', 'Green Vegetables', 'Banana', 'Baseball Glove', 'Airplane',
+ 'Mouse', 'Train', 'Pumpkin', 'Soccer', 'Skiboard', 'Luggage',
+ 'Nightstand', 'Tea pot', 'Telephone', 'Trolley', 'Head Phone',
+ 'Sports Car', 'Stop Sign', 'Dessert', 'Scooter', 'Stroller', 'Crane',
+ 'Remote', 'Refrigerator', 'Oven', 'Lemon', 'Duck', 'Baseball Bat',
+ 'Surveillance Camera', 'Cat', 'Jug', 'Broccoli', 'Piano', 'Pizza',
+ 'Elephant', 'Skateboard', 'Surfboard', 'Gun',
+ 'Skating and Skiing shoes', 'Gas stove', 'Donut', 'Bow Tie', 'Carrot',
+ 'Toilet', 'Kite', 'Strawberry', 'Other Balls', 'Shovel', 'Pepper',
+ 'Computer Box', 'Toilet Paper', 'Cleaning Products', 'Chopsticks',
+ 'Microwave', 'Pigeon', 'Baseball', 'Cutting/chopping Board',
+ 'Coffee Table', 'Side Table', 'Scissors', 'Marker', 'Pie', 'Ladder',
+ 'Snowboard', 'Cookies', 'Radiator', 'Fire Hydrant', 'Basketball',
+ 'Zebra', 'Grape', 'Giraffe', 'Potato', 'Sausage', 'Tricycle', 'Violin',
+ 'Egg', 'Fire Extinguisher', 'Candy', 'Fire Truck', 'Billards',
+ 'Converter', 'Bathtub', 'Wheelchair', 'Golf Club', 'Briefcase',
+ 'Cucumber', 'Cigar/Cigarette ', 'Paint Brush', 'Pear', 'Heavy Truck',
+ 'Hamburger', 'Extractor', 'Extention Cord', 'Tong', 'Tennis Racket',
+ 'Folder', 'American Football', 'earphone', 'Mask', 'Kettle', 'Tennis',
+ 'Ship', 'Swing', 'Coffee Machine', 'Slide', 'Carriage', 'Onion',
+ 'Green beans', 'Projector', 'Frisbee',
+ 'Washing Machine/Drying Machine', 'Chicken', 'Printer', 'Watermelon',
+ 'Saxophone', 'Tissue', 'Toothbrush', 'Ice cream', 'Hotair ballon',
+ 'Cello', 'French Fries', 'Scale', 'Trophy', 'Cabbage', 'Hot dog',
+ 'Blender', 'Peach', 'Rice', 'Wallet/Purse', 'Volleyball', 'Deer',
+ 'Goose', 'Tape', 'Tablet', 'Cosmetics', 'Trumpet', 'Pineapple',
+ 'Golf Ball', 'Ambulance', 'Parking meter', 'Mango', 'Key', 'Hurdle',
+ 'Fishing Rod', 'Medal', 'Flute', 'Brush', 'Penguin', 'Megaphone',
+ 'Corn', 'Lettuce', 'Garlic', 'Swan', 'Helicopter', 'Green Onion',
+ 'Sandwich', 'Nuts', 'Speed Limit Sign', 'Induction Cooker', 'Broom',
+ 'Trombone', 'Plum', 'Rickshaw', 'Goldfish', 'Kiwi fruit',
+ 'Router/modem', 'Poker Card', 'Toaster', 'Shrimp', 'Sushi', 'Cheese',
+ 'Notepaper', 'Cherry', 'Pliers', 'CD', 'Pasta', 'Hammer', 'Cue',
+ 'Avocado', 'Hamimelon', 'Flask', 'Mushroon', 'Screwdriver', 'Soap',
+ 'Recorder', 'Bear', 'Eggplant', 'Board Eraser', 'Coconut',
+ 'Tape Measur/ Ruler', 'Pig', 'Showerhead', 'Globe', 'Chips', 'Steak',
+ 'Crosswalk Sign', 'Stapler', 'Campel', 'Formula 1 ', 'Pomegranate',
+ 'Dishwasher', 'Crab', 'Hoverboard', 'Meat ball', 'Rice Cooker', 'Tuba',
+ 'Calculator', 'Papaya', 'Antelope', 'Parrot', 'Seal', 'Buttefly',
+ 'Dumbbell', 'Donkey', 'Lion', 'Urinal', 'Dolphin', 'Electric Drill',
+ 'Hair Dryer', 'Egg tart', 'Jellyfish', 'Treadmill', 'Lighter',
+ 'Grapefruit', 'Game board', 'Mop', 'Radish', 'Baozi', 'Target',
+ 'French', 'Spring Rolls', 'Monkey', 'Rabbit', 'Pencil Case', 'Yak',
+ 'Red Cabbage', 'Binoculars', 'Asparagus', 'Barbell', 'Scallop',
+ 'Noddles', 'Comb', 'Dumpling', 'Oyster', 'Table Teniis paddle',
+ 'Cosmetics Brush/Eyeliner Pencil', 'Chainsaw', 'Eraser', 'Lobster',
+ 'Durian', 'Okra', 'Lipstick', 'Cosmetics Mirror', 'Curling',
+ 'Table Tennis '
+ ]
+
+
+dataset_aliases = {
+ 'voc': ['voc', 'pascal_voc', 'voc07', 'voc12'],
+ 'imagenet_det': ['det', 'imagenet_det', 'ilsvrc_det'],
+ 'imagenet_vid': ['vid', 'imagenet_vid', 'ilsvrc_vid'],
+ 'coco': ['coco', 'mscoco', 'ms_coco'],
+ 'coco_panoptic': ['coco_panoptic', 'panoptic'],
+ 'wider_face': ['WIDERFaceDataset', 'wider_face', 'WIDERFace'],
+ 'cityscapes': ['cityscapes'],
+ 'oid_challenge': ['oid_challenge', 'openimages_challenge'],
+ 'oid_v6': ['oid_v6', 'openimages_v6'],
+ 'objects365v1': ['objects365v1', 'obj365v1'],
+ 'objects365v2': ['objects365v2', 'obj365v2']
+}
+
+
+def get_classes(dataset) -> list:
+ """Get class names of a dataset."""
+ alias2name = {}
+ for name, aliases in dataset_aliases.items():
+ for alias in aliases:
+ alias2name[alias] = name
+
+ if is_str(dataset):
+ if dataset in alias2name:
+ labels = eval(alias2name[dataset] + '_classes()')
+ else:
+ raise ValueError(f'Unrecognized dataset: {dataset}')
+ else:
+ raise TypeError(f'dataset must a str, but got {type(dataset)}')
+ return labels
diff --git a/mmdet/evaluation/functional/mean_ap.py b/mmdet/evaluation/functional/mean_ap.py
new file mode 100644
index 0000000000000000000000000000000000000000..989972a48467f74fa915fa6f3807d0db3becdba2
--- /dev/null
+++ b/mmdet/evaluation/functional/mean_ap.py
@@ -0,0 +1,792 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from multiprocessing import Pool
+
+import numpy as np
+from mmengine.logging import print_log
+from mmengine.utils import is_str
+from terminaltables import AsciiTable
+
+from .bbox_overlaps import bbox_overlaps
+from .class_names import get_classes
+
+
+def average_precision(recalls, precisions, mode='area'):
+ """Calculate average precision (for single or multiple scales).
+
+ Args:
+ recalls (ndarray): shape (num_scales, num_dets) or (num_dets, )
+ precisions (ndarray): shape (num_scales, num_dets) or (num_dets, )
+ mode (str): 'area' or '11points', 'area' means calculating the area
+ under precision-recall curve, '11points' means calculating
+ the average precision of recalls at [0, 0.1, ..., 1]
+
+ Returns:
+ float or ndarray: calculated average precision
+ """
+ no_scale = False
+ if recalls.ndim == 1:
+ no_scale = True
+ recalls = recalls[np.newaxis, :]
+ precisions = precisions[np.newaxis, :]
+ assert recalls.shape == precisions.shape and recalls.ndim == 2
+ num_scales = recalls.shape[0]
+ ap = np.zeros(num_scales, dtype=np.float32)
+ if mode == 'area':
+ zeros = np.zeros((num_scales, 1), dtype=recalls.dtype)
+ ones = np.ones((num_scales, 1), dtype=recalls.dtype)
+ mrec = np.hstack((zeros, recalls, ones))
+ mpre = np.hstack((zeros, precisions, zeros))
+ for i in range(mpre.shape[1] - 1, 0, -1):
+ mpre[:, i - 1] = np.maximum(mpre[:, i - 1], mpre[:, i])
+ for i in range(num_scales):
+ ind = np.where(mrec[i, 1:] != mrec[i, :-1])[0]
+ ap[i] = np.sum(
+ (mrec[i, ind + 1] - mrec[i, ind]) * mpre[i, ind + 1])
+ elif mode == '11points':
+ for i in range(num_scales):
+ for thr in np.arange(0, 1 + 1e-3, 0.1):
+ precs = precisions[i, recalls[i, :] >= thr]
+ prec = precs.max() if precs.size > 0 else 0
+ ap[i] += prec
+ ap /= 11
+ else:
+ raise ValueError(
+ 'Unrecognized mode, only "area" and "11points" are supported')
+ if no_scale:
+ ap = ap[0]
+ return ap
+
+
+def tpfp_imagenet(det_bboxes,
+ gt_bboxes,
+ gt_bboxes_ignore=None,
+ default_iou_thr=0.5,
+ area_ranges=None,
+ use_legacy_coordinate=False,
+ **kwargs):
+ """Check if detected bboxes are true positive or false positive.
+
+ Args:
+ det_bbox (ndarray): Detected bboxes of this image, of shape (m, 5).
+ gt_bboxes (ndarray): GT bboxes of this image, of shape (n, 4).
+ gt_bboxes_ignore (ndarray): Ignored gt bboxes of this image,
+ of shape (k, 4). Defaults to None
+ default_iou_thr (float): IoU threshold to be considered as matched for
+ medium and large bboxes (small ones have special rules).
+ Defaults to 0.5.
+ area_ranges (list[tuple] | None): Range of bbox areas to be evaluated,
+ in the format [(min1, max1), (min2, max2), ...]. Defaults to None.
+ use_legacy_coordinate (bool): Whether to use coordinate system in
+ mmdet v1.x. which means width, height should be
+ calculated as 'x2 - x1 + 1` and 'y2 - y1 + 1' respectively.
+ Defaults to False.
+
+ Returns:
+ tuple[np.ndarray]: (tp, fp) whose elements are 0 and 1. The shape of
+ each array is (num_scales, m).
+ """
+
+ if not use_legacy_coordinate:
+ extra_length = 0.
+ else:
+ extra_length = 1.
+
+ # an indicator of ignored gts
+ gt_ignore_inds = np.concatenate(
+ (np.zeros(gt_bboxes.shape[0],
+ dtype=bool), np.ones(gt_bboxes_ignore.shape[0], dtype=bool)))
+ # stack gt_bboxes and gt_bboxes_ignore for convenience
+ gt_bboxes = np.vstack((gt_bboxes, gt_bboxes_ignore))
+
+ num_dets = det_bboxes.shape[0]
+ num_gts = gt_bboxes.shape[0]
+ if area_ranges is None:
+ area_ranges = [(None, None)]
+ num_scales = len(area_ranges)
+ # tp and fp are of shape (num_scales, num_gts), each row is tp or fp
+ # of a certain scale.
+ tp = np.zeros((num_scales, num_dets), dtype=np.float32)
+ fp = np.zeros((num_scales, num_dets), dtype=np.float32)
+ if gt_bboxes.shape[0] == 0:
+ if area_ranges == [(None, None)]:
+ fp[...] = 1
+ else:
+ det_areas = (
+ det_bboxes[:, 2] - det_bboxes[:, 0] + extra_length) * (
+ det_bboxes[:, 3] - det_bboxes[:, 1] + extra_length)
+ for i, (min_area, max_area) in enumerate(area_ranges):
+ fp[i, (det_areas >= min_area) & (det_areas < max_area)] = 1
+ return tp, fp
+ ious = bbox_overlaps(
+ det_bboxes, gt_bboxes - 1, use_legacy_coordinate=use_legacy_coordinate)
+ gt_w = gt_bboxes[:, 2] - gt_bboxes[:, 0] + extra_length
+ gt_h = gt_bboxes[:, 3] - gt_bboxes[:, 1] + extra_length
+ iou_thrs = np.minimum((gt_w * gt_h) / ((gt_w + 10.0) * (gt_h + 10.0)),
+ default_iou_thr)
+ # sort all detections by scores in descending order
+ sort_inds = np.argsort(-det_bboxes[:, -1])
+ for k, (min_area, max_area) in enumerate(area_ranges):
+ gt_covered = np.zeros(num_gts, dtype=bool)
+ # if no area range is specified, gt_area_ignore is all False
+ if min_area is None:
+ gt_area_ignore = np.zeros_like(gt_ignore_inds, dtype=bool)
+ else:
+ gt_areas = gt_w * gt_h
+ gt_area_ignore = (gt_areas < min_area) | (gt_areas >= max_area)
+ for i in sort_inds:
+ max_iou = -1
+ matched_gt = -1
+ # find best overlapped available gt
+ for j in range(num_gts):
+ # different from PASCAL VOC: allow finding other gts if the
+ # best overlapped ones are already matched by other det bboxes
+ if gt_covered[j]:
+ continue
+ elif ious[i, j] >= iou_thrs[j] and ious[i, j] > max_iou:
+ max_iou = ious[i, j]
+ matched_gt = j
+ # there are 4 cases for a det bbox:
+ # 1. it matches a gt, tp = 1, fp = 0
+ # 2. it matches an ignored gt, tp = 0, fp = 0
+ # 3. it matches no gt and within area range, tp = 0, fp = 1
+ # 4. it matches no gt but is beyond area range, tp = 0, fp = 0
+ if matched_gt >= 0:
+ gt_covered[matched_gt] = 1
+ if not (gt_ignore_inds[matched_gt]
+ or gt_area_ignore[matched_gt]):
+ tp[k, i] = 1
+ elif min_area is None:
+ fp[k, i] = 1
+ else:
+ bbox = det_bboxes[i, :4]
+ area = (bbox[2] - bbox[0] + extra_length) * (
+ bbox[3] - bbox[1] + extra_length)
+ if area >= min_area and area < max_area:
+ fp[k, i] = 1
+ return tp, fp
+
+
+def tpfp_default(det_bboxes,
+ gt_bboxes,
+ gt_bboxes_ignore=None,
+ iou_thr=0.5,
+ area_ranges=None,
+ use_legacy_coordinate=False,
+ **kwargs):
+ """Check if detected bboxes are true positive or false positive.
+
+ Args:
+ det_bbox (ndarray): Detected bboxes of this image, of shape (m, 5).
+ gt_bboxes (ndarray): GT bboxes of this image, of shape (n, 4).
+ gt_bboxes_ignore (ndarray): Ignored gt bboxes of this image,
+ of shape (k, 4). Defaults to None
+ iou_thr (float): IoU threshold to be considered as matched.
+ Defaults to 0.5.
+ area_ranges (list[tuple] | None): Range of bbox areas to be
+ evaluated, in the format [(min1, max1), (min2, max2), ...].
+ Defaults to None.
+ use_legacy_coordinate (bool): Whether to use coordinate system in
+ mmdet v1.x. which means width, height should be
+ calculated as 'x2 - x1 + 1` and 'y2 - y1 + 1' respectively.
+ Defaults to False.
+
+ Returns:
+ tuple[np.ndarray]: (tp, fp) whose elements are 0 and 1. The shape of
+ each array is (num_scales, m).
+ """
+
+ if not use_legacy_coordinate:
+ extra_length = 0.
+ else:
+ extra_length = 1.
+
+ # an indicator of ignored gts
+ gt_ignore_inds = np.concatenate(
+ (np.zeros(gt_bboxes.shape[0],
+ dtype=bool), np.ones(gt_bboxes_ignore.shape[0], dtype=bool)))
+ # stack gt_bboxes and gt_bboxes_ignore for convenience
+ gt_bboxes = np.vstack((gt_bboxes, gt_bboxes_ignore))
+
+ num_dets = det_bboxes.shape[0]
+ num_gts = gt_bboxes.shape[0]
+ if area_ranges is None:
+ area_ranges = [(None, None)]
+ num_scales = len(area_ranges)
+ # tp and fp are of shape (num_scales, num_gts), each row is tp or fp of
+ # a certain scale
+ tp = np.zeros((num_scales, num_dets), dtype=np.float32)
+ fp = np.zeros((num_scales, num_dets), dtype=np.float32)
+
+ # if there is no gt bboxes in this image, then all det bboxes
+ # within area range are false positives
+ if gt_bboxes.shape[0] == 0:
+ if area_ranges == [(None, None)]:
+ fp[...] = 1
+ else:
+ det_areas = (
+ det_bboxes[:, 2] - det_bboxes[:, 0] + extra_length) * (
+ det_bboxes[:, 3] - det_bboxes[:, 1] + extra_length)
+ for i, (min_area, max_area) in enumerate(area_ranges):
+ fp[i, (det_areas >= min_area) & (det_areas < max_area)] = 1
+ return tp, fp
+
+ ious = bbox_overlaps(
+ det_bboxes, gt_bboxes, use_legacy_coordinate=use_legacy_coordinate)
+ # for each det, the max iou with all gts
+ ious_max = ious.max(axis=1)
+ # for each det, which gt overlaps most with it
+ ious_argmax = ious.argmax(axis=1)
+ # sort all dets in descending order by scores
+ sort_inds = np.argsort(-det_bboxes[:, -1])
+ for k, (min_area, max_area) in enumerate(area_ranges):
+ gt_covered = np.zeros(num_gts, dtype=bool)
+ # if no area range is specified, gt_area_ignore is all False
+ if min_area is None:
+ gt_area_ignore = np.zeros_like(gt_ignore_inds, dtype=bool)
+ else:
+ gt_areas = (gt_bboxes[:, 2] - gt_bboxes[:, 0] + extra_length) * (
+ gt_bboxes[:, 3] - gt_bboxes[:, 1] + extra_length)
+ gt_area_ignore = (gt_areas < min_area) | (gt_areas >= max_area)
+ for i in sort_inds:
+ if ious_max[i] >= iou_thr:
+ matched_gt = ious_argmax[i]
+ if not (gt_ignore_inds[matched_gt]
+ or gt_area_ignore[matched_gt]):
+ if not gt_covered[matched_gt]:
+ gt_covered[matched_gt] = True
+ tp[k, i] = 1
+ else:
+ fp[k, i] = 1
+ # otherwise ignore this detected bbox, tp = 0, fp = 0
+ elif min_area is None:
+ fp[k, i] = 1
+ else:
+ bbox = det_bboxes[i, :4]
+ area = (bbox[2] - bbox[0] + extra_length) * (
+ bbox[3] - bbox[1] + extra_length)
+ if area >= min_area and area < max_area:
+ fp[k, i] = 1
+ return tp, fp
+
+
+def tpfp_openimages(det_bboxes,
+ gt_bboxes,
+ gt_bboxes_ignore=None,
+ iou_thr=0.5,
+ area_ranges=None,
+ use_legacy_coordinate=False,
+ gt_bboxes_group_of=None,
+ use_group_of=True,
+ ioa_thr=0.5,
+ **kwargs):
+ """Check if detected bboxes are true positive or false positive.
+
+ Args:
+ det_bbox (ndarray): Detected bboxes of this image, of shape (m, 5).
+ gt_bboxes (ndarray): GT bboxes of this image, of shape (n, 4).
+ gt_bboxes_ignore (ndarray): Ignored gt bboxes of this image,
+ of shape (k, 4). Defaults to None
+ iou_thr (float): IoU threshold to be considered as matched.
+ Defaults to 0.5.
+ area_ranges (list[tuple] | None): Range of bbox areas to be
+ evaluated, in the format [(min1, max1), (min2, max2), ...].
+ Defaults to None.
+ use_legacy_coordinate (bool): Whether to use coordinate system in
+ mmdet v1.x. which means width, height should be
+ calculated as 'x2 - x1 + 1` and 'y2 - y1 + 1' respectively.
+ Defaults to False.
+ gt_bboxes_group_of (ndarray): GT group_of of this image, of shape
+ (k, 1). Defaults to None
+ use_group_of (bool): Whether to use group of when calculate TP and FP,
+ which only used in OpenImages evaluation. Defaults to True.
+ ioa_thr (float | None): IoA threshold to be considered as matched,
+ which only used in OpenImages evaluation. Defaults to 0.5.
+
+ Returns:
+ tuple[np.ndarray]: Returns a tuple (tp, fp, det_bboxes), where
+ (tp, fp) whose elements are 0 and 1. The shape of each array is
+ (num_scales, m). (det_bboxes) whose will filter those are not
+ matched by group of gts when processing Open Images evaluation.
+ The shape is (num_scales, m).
+ """
+
+ if not use_legacy_coordinate:
+ extra_length = 0.
+ else:
+ extra_length = 1.
+
+ # an indicator of ignored gts
+ gt_ignore_inds = np.concatenate(
+ (np.zeros(gt_bboxes.shape[0],
+ dtype=bool), np.ones(gt_bboxes_ignore.shape[0], dtype=bool)))
+ # stack gt_bboxes and gt_bboxes_ignore for convenience
+ gt_bboxes = np.vstack((gt_bboxes, gt_bboxes_ignore))
+
+ num_dets = det_bboxes.shape[0]
+ num_gts = gt_bboxes.shape[0]
+ if area_ranges is None:
+ area_ranges = [(None, None)]
+ num_scales = len(area_ranges)
+ # tp and fp are of shape (num_scales, num_gts), each row is tp or fp of
+ # a certain scale
+ tp = np.zeros((num_scales, num_dets), dtype=np.float32)
+ fp = np.zeros((num_scales, num_dets), dtype=np.float32)
+
+ # if there is no gt bboxes in this image, then all det bboxes
+ # within area range are false positives
+ if gt_bboxes.shape[0] == 0:
+ if area_ranges == [(None, None)]:
+ fp[...] = 1
+ else:
+ det_areas = (
+ det_bboxes[:, 2] - det_bboxes[:, 0] + extra_length) * (
+ det_bboxes[:, 3] - det_bboxes[:, 1] + extra_length)
+ for i, (min_area, max_area) in enumerate(area_ranges):
+ fp[i, (det_areas >= min_area) & (det_areas < max_area)] = 1
+ return tp, fp, det_bboxes
+
+ if gt_bboxes_group_of is not None and use_group_of:
+ # if handle group-of boxes, divided gt boxes into two parts:
+ # non-group-of and group-of.Then calculate ious and ioas through
+ # non-group-of group-of gts respectively. This only used in
+ # OpenImages evaluation.
+ assert gt_bboxes_group_of.shape[0] == gt_bboxes.shape[0]
+ non_group_gt_bboxes = gt_bboxes[~gt_bboxes_group_of]
+ group_gt_bboxes = gt_bboxes[gt_bboxes_group_of]
+ num_gts_group = group_gt_bboxes.shape[0]
+ ious = bbox_overlaps(det_bboxes, non_group_gt_bboxes)
+ ioas = bbox_overlaps(det_bboxes, group_gt_bboxes, mode='iof')
+ else:
+ # if not consider group-of boxes, only calculate ious through gt boxes
+ ious = bbox_overlaps(
+ det_bboxes, gt_bboxes, use_legacy_coordinate=use_legacy_coordinate)
+ ioas = None
+
+ if ious.shape[1] > 0:
+ # for each det, the max iou with all gts
+ ious_max = ious.max(axis=1)
+ # for each det, which gt overlaps most with it
+ ious_argmax = ious.argmax(axis=1)
+ # sort all dets in descending order by scores
+ sort_inds = np.argsort(-det_bboxes[:, -1])
+ for k, (min_area, max_area) in enumerate(area_ranges):
+ gt_covered = np.zeros(num_gts, dtype=bool)
+ # if no area range is specified, gt_area_ignore is all False
+ if min_area is None:
+ gt_area_ignore = np.zeros_like(gt_ignore_inds, dtype=bool)
+ else:
+ gt_areas = (
+ gt_bboxes[:, 2] - gt_bboxes[:, 0] + extra_length) * (
+ gt_bboxes[:, 3] - gt_bboxes[:, 1] + extra_length)
+ gt_area_ignore = (gt_areas < min_area) | (gt_areas >= max_area)
+ for i in sort_inds:
+ if ious_max[i] >= iou_thr:
+ matched_gt = ious_argmax[i]
+ if not (gt_ignore_inds[matched_gt]
+ or gt_area_ignore[matched_gt]):
+ if not gt_covered[matched_gt]:
+ gt_covered[matched_gt] = True
+ tp[k, i] = 1
+ else:
+ fp[k, i] = 1
+ # otherwise ignore this detected bbox, tp = 0, fp = 0
+ elif min_area is None:
+ fp[k, i] = 1
+ else:
+ bbox = det_bboxes[i, :4]
+ area = (bbox[2] - bbox[0] + extra_length) * (
+ bbox[3] - bbox[1] + extra_length)
+ if area >= min_area and area < max_area:
+ fp[k, i] = 1
+ else:
+ # if there is no no-group-of gt bboxes in this image,
+ # then all det bboxes within area range are false positives.
+ # Only used in OpenImages evaluation.
+ if area_ranges == [(None, None)]:
+ fp[...] = 1
+ else:
+ det_areas = (
+ det_bboxes[:, 2] - det_bboxes[:, 0] + extra_length) * (
+ det_bboxes[:, 3] - det_bboxes[:, 1] + extra_length)
+ for i, (min_area, max_area) in enumerate(area_ranges):
+ fp[i, (det_areas >= min_area) & (det_areas < max_area)] = 1
+
+ if ioas is None or ioas.shape[1] <= 0:
+ return tp, fp, det_bboxes
+ else:
+ # The evaluation of group-of TP and FP are done in two stages:
+ # 1. All detections are first matched to non group-of boxes; true
+ # positives are determined.
+ # 2. Detections that are determined as false positives are matched
+ # against group-of boxes and calculated group-of TP and FP.
+ # Only used in OpenImages evaluation.
+ det_bboxes_group = np.zeros(
+ (num_scales, ioas.shape[1], det_bboxes.shape[1]), dtype=float)
+ match_group_of = np.zeros((num_scales, num_dets), dtype=bool)
+ tp_group = np.zeros((num_scales, num_gts_group), dtype=np.float32)
+ ioas_max = ioas.max(axis=1)
+ # for each det, which gt overlaps most with it
+ ioas_argmax = ioas.argmax(axis=1)
+ # sort all dets in descending order by scores
+ sort_inds = np.argsort(-det_bboxes[:, -1])
+ for k, (min_area, max_area) in enumerate(area_ranges):
+ box_is_covered = tp[k]
+ # if no area range is specified, gt_area_ignore is all False
+ if min_area is None:
+ gt_area_ignore = np.zeros_like(gt_ignore_inds, dtype=bool)
+ else:
+ gt_areas = (gt_bboxes[:, 2] - gt_bboxes[:, 0]) * (
+ gt_bboxes[:, 3] - gt_bboxes[:, 1])
+ gt_area_ignore = (gt_areas < min_area) | (gt_areas >= max_area)
+ for i in sort_inds:
+ matched_gt = ioas_argmax[i]
+ if not box_is_covered[i]:
+ if ioas_max[i] >= ioa_thr:
+ if not (gt_ignore_inds[matched_gt]
+ or gt_area_ignore[matched_gt]):
+ if not tp_group[k, matched_gt]:
+ tp_group[k, matched_gt] = 1
+ match_group_of[k, i] = True
+ else:
+ match_group_of[k, i] = True
+
+ if det_bboxes_group[k, matched_gt, -1] < \
+ det_bboxes[i, -1]:
+ det_bboxes_group[k, matched_gt] = \
+ det_bboxes[i]
+
+ fp_group = (tp_group <= 0).astype(float)
+ tps = []
+ fps = []
+ # concatenate tp, fp, and det-boxes which not matched group of
+ # gt boxes and tp_group, fp_group, and det_bboxes_group which
+ # matched group of boxes respectively.
+ for i in range(num_scales):
+ tps.append(
+ np.concatenate((tp[i][~match_group_of[i]], tp_group[i])))
+ fps.append(
+ np.concatenate((fp[i][~match_group_of[i]], fp_group[i])))
+ det_bboxes = np.concatenate(
+ (det_bboxes[~match_group_of[i]], det_bboxes_group[i]))
+
+ tp = np.vstack(tps)
+ fp = np.vstack(fps)
+ return tp, fp, det_bboxes
+
+
+def get_cls_results(det_results, annotations, class_id):
+ """Get det results and gt information of a certain class.
+
+ Args:
+ det_results (list[list]): Same as `eval_map()`.
+ annotations (list[dict]): Same as `eval_map()`.
+ class_id (int): ID of a specific class.
+
+ Returns:
+ tuple[list[np.ndarray]]: detected bboxes, gt bboxes, ignored gt bboxes
+ """
+ cls_dets = [img_res[class_id] for img_res in det_results]
+ cls_gts = []
+ cls_gts_ignore = []
+ for ann in annotations:
+ gt_inds = ann['labels'] == class_id
+ cls_gts.append(ann['bboxes'][gt_inds, :])
+
+ if ann.get('labels_ignore', None) is not None:
+ ignore_inds = ann['labels_ignore'] == class_id
+ cls_gts_ignore.append(ann['bboxes_ignore'][ignore_inds, :])
+ else:
+ cls_gts_ignore.append(np.empty((0, 4), dtype=np.float32))
+
+ return cls_dets, cls_gts, cls_gts_ignore
+
+
+def get_cls_group_ofs(annotations, class_id):
+ """Get `gt_group_of` of a certain class, which is used in Open Images.
+
+ Args:
+ annotations (list[dict]): Same as `eval_map()`.
+ class_id (int): ID of a specific class.
+
+ Returns:
+ list[np.ndarray]: `gt_group_of` of a certain class.
+ """
+ gt_group_ofs = []
+ for ann in annotations:
+ gt_inds = ann['labels'] == class_id
+ if ann.get('gt_is_group_ofs', None) is not None:
+ gt_group_ofs.append(ann['gt_is_group_ofs'][gt_inds])
+ else:
+ gt_group_ofs.append(np.empty((0, 1), dtype=bool))
+
+ return gt_group_ofs
+
+
+def eval_map(det_results,
+ annotations,
+ scale_ranges=None,
+ iou_thr=0.5,
+ ioa_thr=None,
+ dataset=None,
+ logger=None,
+ tpfp_fn=None,
+ nproc=4,
+ use_legacy_coordinate=False,
+ use_group_of=False,
+ eval_mode='area'):
+ """Evaluate mAP of a dataset.
+
+ Args:
+ det_results (list[list]): [[cls1_det, cls2_det, ...], ...].
+ The outer list indicates images, and the inner list indicates
+ per-class detected bboxes.
+ annotations (list[dict]): Ground truth annotations where each item of
+ the list indicates an image. Keys of annotations are:
+
+ - `bboxes`: numpy array of shape (n, 4)
+ - `labels`: numpy array of shape (n, )
+ - `bboxes_ignore` (optional): numpy array of shape (k, 4)
+ - `labels_ignore` (optional): numpy array of shape (k, )
+ scale_ranges (list[tuple] | None): Range of scales to be evaluated,
+ in the format [(min1, max1), (min2, max2), ...]. A range of
+ (32, 64) means the area range between (32**2, 64**2).
+ Defaults to None.
+ iou_thr (float): IoU threshold to be considered as matched.
+ Defaults to 0.5.
+ ioa_thr (float | None): IoA threshold to be considered as matched,
+ which only used in OpenImages evaluation. Defaults to None.
+ dataset (list[str] | str | None): Dataset name or dataset classes,
+ there are minor differences in metrics for different datasets, e.g.
+ "voc", "imagenet_det", etc. Defaults to None.
+ logger (logging.Logger | str | None): The way to print the mAP
+ summary. See `mmengine.logging.print_log()` for details.
+ Defaults to None.
+ tpfp_fn (callable | None): The function used to determine true/
+ false positives. If None, :func:`tpfp_default` is used as default
+ unless dataset is 'det' or 'vid' (:func:`tpfp_imagenet` in this
+ case). If it is given as a function, then this function is used
+ to evaluate tp & fp. Default None.
+ nproc (int): Processes used for computing TP and FP.
+ Defaults to 4.
+ use_legacy_coordinate (bool): Whether to use coordinate system in
+ mmdet v1.x. which means width, height should be
+ calculated as 'x2 - x1 + 1` and 'y2 - y1 + 1' respectively.
+ Defaults to False.
+ use_group_of (bool): Whether to use group of when calculate TP and FP,
+ which only used in OpenImages evaluation. Defaults to False.
+ eval_mode (str): 'area' or '11points', 'area' means calculating the
+ area under precision-recall curve, '11points' means calculating
+ the average precision of recalls at [0, 0.1, ..., 1],
+ PASCAL VOC2007 uses `11points` as default evaluate mode, while
+ others are 'area'. Defaults to 'area'.
+
+ Returns:
+ tuple: (mAP, [dict, dict, ...])
+ """
+ assert len(det_results) == len(annotations)
+ assert eval_mode in ['area', '11points'], \
+ f'Unrecognized {eval_mode} mode, only "area" and "11points" ' \
+ 'are supported'
+ if not use_legacy_coordinate:
+ extra_length = 0.
+ else:
+ extra_length = 1.
+
+ num_imgs = len(det_results)
+ num_scales = len(scale_ranges) if scale_ranges is not None else 1
+ num_classes = len(det_results[0]) # positive class num
+ area_ranges = ([(rg[0]**2, rg[1]**2) for rg in scale_ranges]
+ if scale_ranges is not None else None)
+
+ # There is no need to use multi processes to process
+ # when num_imgs = 1 .
+ if num_imgs > 1:
+ assert nproc > 0, 'nproc must be at least one.'
+ nproc = min(nproc, num_imgs)
+ pool = Pool(nproc)
+
+ eval_results = []
+ for i in range(num_classes):
+ # get gt and det bboxes of this class
+ cls_dets, cls_gts, cls_gts_ignore = get_cls_results(
+ det_results, annotations, i)
+ # choose proper function according to datasets to compute tp and fp
+ if tpfp_fn is None:
+ if dataset in ['det', 'vid']:
+ tpfp_fn = tpfp_imagenet
+ elif dataset in ['oid_challenge', 'oid_v6'] \
+ or use_group_of is True:
+ tpfp_fn = tpfp_openimages
+ else:
+ tpfp_fn = tpfp_default
+ if not callable(tpfp_fn):
+ raise ValueError(
+ f'tpfp_fn has to be a function or None, but got {tpfp_fn}')
+
+ if num_imgs > 1:
+ # compute tp and fp for each image with multiple processes
+ args = []
+ if use_group_of:
+ # used in Open Images Dataset evaluation
+ gt_group_ofs = get_cls_group_ofs(annotations, i)
+ args.append(gt_group_ofs)
+ args.append([use_group_of for _ in range(num_imgs)])
+ if ioa_thr is not None:
+ args.append([ioa_thr for _ in range(num_imgs)])
+
+ tpfp = pool.starmap(
+ tpfp_fn,
+ zip(cls_dets, cls_gts, cls_gts_ignore,
+ [iou_thr for _ in range(num_imgs)],
+ [area_ranges for _ in range(num_imgs)],
+ [use_legacy_coordinate for _ in range(num_imgs)], *args))
+ else:
+ tpfp = tpfp_fn(
+ cls_dets[0],
+ cls_gts[0],
+ cls_gts_ignore[0],
+ iou_thr,
+ area_ranges,
+ use_legacy_coordinate,
+ gt_bboxes_group_of=(get_cls_group_ofs(annotations, i)[0]
+ if use_group_of else None),
+ use_group_of=use_group_of,
+ ioa_thr=ioa_thr)
+ tpfp = [tpfp]
+
+ if use_group_of:
+ tp, fp, cls_dets = tuple(zip(*tpfp))
+ else:
+ tp, fp = tuple(zip(*tpfp))
+ # calculate gt number of each scale
+ # ignored gts or gts beyond the specific scale are not counted
+ num_gts = np.zeros(num_scales, dtype=int)
+ for j, bbox in enumerate(cls_gts):
+ if area_ranges is None:
+ num_gts[0] += bbox.shape[0]
+ else:
+ gt_areas = (bbox[:, 2] - bbox[:, 0] + extra_length) * (
+ bbox[:, 3] - bbox[:, 1] + extra_length)
+ for k, (min_area, max_area) in enumerate(area_ranges):
+ num_gts[k] += np.sum((gt_areas >= min_area)
+ & (gt_areas < max_area))
+ # sort all det bboxes by score, also sort tp and fp
+ cls_dets = np.vstack(cls_dets)
+ num_dets = cls_dets.shape[0]
+ sort_inds = np.argsort(-cls_dets[:, -1])
+ tp = np.hstack(tp)[:, sort_inds]
+ fp = np.hstack(fp)[:, sort_inds]
+ # calculate recall and precision with tp and fp
+ tp = np.cumsum(tp, axis=1)
+ fp = np.cumsum(fp, axis=1)
+ eps = np.finfo(np.float32).eps
+ recalls = tp / np.maximum(num_gts[:, np.newaxis], eps)
+ precisions = tp / np.maximum((tp + fp), eps)
+ # calculate AP
+ if scale_ranges is None:
+ recalls = recalls[0, :]
+ precisions = precisions[0, :]
+ num_gts = num_gts.item()
+ ap = average_precision(recalls, precisions, eval_mode)
+ eval_results.append({
+ 'num_gts': num_gts,
+ 'num_dets': num_dets,
+ 'recall': recalls,
+ 'precision': precisions,
+ 'ap': ap
+ })
+
+ if num_imgs > 1:
+ pool.close()
+
+ if scale_ranges is not None:
+ # shape (num_classes, num_scales)
+ all_ap = np.vstack([cls_result['ap'] for cls_result in eval_results])
+ all_num_gts = np.vstack(
+ [cls_result['num_gts'] for cls_result in eval_results])
+ mean_ap = []
+ for i in range(num_scales):
+ if np.any(all_num_gts[:, i] > 0):
+ mean_ap.append(all_ap[all_num_gts[:, i] > 0, i].mean())
+ else:
+ mean_ap.append(0.0)
+ else:
+ aps = []
+ for cls_result in eval_results:
+ if cls_result['num_gts'] > 0:
+ aps.append(cls_result['ap'])
+ mean_ap = np.array(aps).mean().item() if aps else 0.0
+
+ print_map_summary(
+ mean_ap, eval_results, dataset, area_ranges, logger=logger)
+
+ return mean_ap, eval_results
+
+
+def print_map_summary(mean_ap,
+ results,
+ dataset=None,
+ scale_ranges=None,
+ logger=None):
+ """Print mAP and results of each class.
+
+ A table will be printed to show the gts/dets/recall/AP of each class and
+ the mAP.
+
+ Args:
+ mean_ap (float): Calculated from `eval_map()`.
+ results (list[dict]): Calculated from `eval_map()`.
+ dataset (list[str] | str | None): Dataset name or dataset classes.
+ scale_ranges (list[tuple] | None): Range of scales to be evaluated.
+ logger (logging.Logger | str | None): The way to print the mAP
+ summary. See `mmengine.logging.print_log()` for details.
+ Defaults to None.
+ """
+
+ if logger == 'silent':
+ return
+
+ if isinstance(results[0]['ap'], np.ndarray):
+ num_scales = len(results[0]['ap'])
+ else:
+ num_scales = 1
+
+ if scale_ranges is not None:
+ assert len(scale_ranges) == num_scales
+
+ num_classes = len(results)
+
+ recalls = np.zeros((num_scales, num_classes), dtype=np.float32)
+ aps = np.zeros((num_scales, num_classes), dtype=np.float32)
+ num_gts = np.zeros((num_scales, num_classes), dtype=int)
+ for i, cls_result in enumerate(results):
+ if cls_result['recall'].size > 0:
+ recalls[:, i] = np.array(cls_result['recall'], ndmin=2)[:, -1]
+ aps[:, i] = cls_result['ap']
+ num_gts[:, i] = cls_result['num_gts']
+
+ if dataset is None:
+ label_names = [str(i) for i in range(num_classes)]
+ elif is_str(dataset):
+ label_names = get_classes(dataset)
+ else:
+ label_names = dataset
+
+ if not isinstance(mean_ap, list):
+ mean_ap = [mean_ap]
+
+ header = ['class', 'gts', 'dets', 'recall', 'ap']
+ for i in range(num_scales):
+ if scale_ranges is not None:
+ print_log(f'Scale range {scale_ranges[i]}', logger=logger)
+ table_data = [header]
+ for j in range(num_classes):
+ row_data = [
+ label_names[j], num_gts[i, j], results[j]['num_dets'],
+ f'{recalls[i, j]:.3f}', f'{aps[i, j]:.3f}'
+ ]
+ table_data.append(row_data)
+ table_data.append(['mAP', '', '', '', f'{mean_ap[i]:.3f}'])
+ table = AsciiTable(table_data)
+ table.inner_footing_row_border = True
+ print_log('\n' + table.table, logger=logger)
diff --git a/mmdet/evaluation/functional/panoptic_utils.py b/mmdet/evaluation/functional/panoptic_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..6faa8ed52bc46c2cb74b1974b8daa521e616e996
--- /dev/null
+++ b/mmdet/evaluation/functional/panoptic_utils.py
@@ -0,0 +1,228 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+
+# Copyright (c) 2018, Alexander Kirillov
+# This file supports `backend_args` for `panopticapi`,
+# the source code is copied from `panopticapi`,
+# only the way to load the gt images is modified.
+import multiprocessing
+import os
+
+import mmcv
+import numpy as np
+from mmengine.fileio import get
+
+# A custom value to distinguish instance ID and category ID; need to
+# be greater than the number of categories.
+# For a pixel in the panoptic result map:
+# pan_id = ins_id * INSTANCE_OFFSET + cat_id
+INSTANCE_OFFSET = 1000
+
+try:
+ from panopticapi.evaluation import OFFSET, VOID, PQStat
+ from panopticapi.utils import rgb2id
+except ImportError:
+ PQStat = None
+ rgb2id = None
+ VOID = 0
+ OFFSET = 256 * 256 * 256
+
+
+def pq_compute_single_core(proc_id,
+ annotation_set,
+ gt_folder,
+ pred_folder,
+ categories,
+ backend_args=None,
+ print_log=False):
+ """The single core function to evaluate the metric of Panoptic
+ Segmentation.
+
+ Same as the function with the same name in `panopticapi`. Only the function
+ to load the images is changed to use the file client.
+
+ Args:
+ proc_id (int): The id of the mini process.
+ gt_folder (str): The path of the ground truth images.
+ pred_folder (str): The path of the prediction images.
+ categories (str): The categories of the dataset.
+ backend_args (object): The Backend of the dataset. If None,
+ the backend will be set to `local`.
+ print_log (bool): Whether to print the log. Defaults to False.
+ """
+ if PQStat is None:
+ raise RuntimeError(
+ 'panopticapi is not installed, please install it by: '
+ 'pip install git+https://github.com/cocodataset/'
+ 'panopticapi.git.')
+
+ pq_stat = PQStat()
+
+ idx = 0
+ for gt_ann, pred_ann in annotation_set:
+ if print_log and idx % 100 == 0:
+ print('Core: {}, {} from {} images processed'.format(
+ proc_id, idx, len(annotation_set)))
+ idx += 1
+ # The gt images can be on the local disk or `ceph`, so we use
+ # backend here.
+ img_bytes = get(
+ os.path.join(gt_folder, gt_ann['file_name']),
+ backend_args=backend_args)
+ pan_gt = mmcv.imfrombytes(img_bytes, flag='color', channel_order='rgb')
+ pan_gt = rgb2id(pan_gt)
+
+ # The predictions can only be on the local dist now.
+ pan_pred = mmcv.imread(
+ os.path.join(pred_folder, pred_ann['file_name']),
+ flag='color',
+ channel_order='rgb')
+ pan_pred = rgb2id(pan_pred)
+
+ gt_segms = {el['id']: el for el in gt_ann['segments_info']}
+ pred_segms = {el['id']: el for el in pred_ann['segments_info']}
+
+ # predicted segments area calculation + prediction sanity checks
+ pred_labels_set = set(el['id'] for el in pred_ann['segments_info'])
+ labels, labels_cnt = np.unique(pan_pred, return_counts=True)
+ for label, label_cnt in zip(labels, labels_cnt):
+ if label not in pred_segms:
+ if label == VOID:
+ continue
+ raise KeyError(
+ 'In the image with ID {} segment with ID {} is '
+ 'presented in PNG and not presented in JSON.'.format(
+ gt_ann['image_id'], label))
+ pred_segms[label]['area'] = label_cnt
+ pred_labels_set.remove(label)
+ if pred_segms[label]['category_id'] not in categories:
+ raise KeyError(
+ 'In the image with ID {} segment with ID {} has '
+ 'unknown category_id {}.'.format(
+ gt_ann['image_id'], label,
+ pred_segms[label]['category_id']))
+ if len(pred_labels_set) != 0:
+ raise KeyError(
+ 'In the image with ID {} the following segment IDs {} '
+ 'are presented in JSON and not presented in PNG.'.format(
+ gt_ann['image_id'], list(pred_labels_set)))
+
+ # confusion matrix calculation
+ pan_gt_pred = pan_gt.astype(np.uint64) * OFFSET + pan_pred.astype(
+ np.uint64)
+ gt_pred_map = {}
+ labels, labels_cnt = np.unique(pan_gt_pred, return_counts=True)
+ for label, intersection in zip(labels, labels_cnt):
+ gt_id = label // OFFSET
+ pred_id = label % OFFSET
+ gt_pred_map[(gt_id, pred_id)] = intersection
+
+ # count all matched pairs
+ gt_matched = set()
+ pred_matched = set()
+ for label_tuple, intersection in gt_pred_map.items():
+ gt_label, pred_label = label_tuple
+ if gt_label not in gt_segms:
+ continue
+ if pred_label not in pred_segms:
+ continue
+ if gt_segms[gt_label]['iscrowd'] == 1:
+ continue
+ if gt_segms[gt_label]['category_id'] != pred_segms[pred_label][
+ 'category_id']:
+ continue
+
+ union = pred_segms[pred_label]['area'] + gt_segms[gt_label][
+ 'area'] - intersection - gt_pred_map.get((VOID, pred_label), 0)
+ iou = intersection / union
+ if iou > 0.5:
+ pq_stat[gt_segms[gt_label]['category_id']].tp += 1
+ pq_stat[gt_segms[gt_label]['category_id']].iou += iou
+ gt_matched.add(gt_label)
+ pred_matched.add(pred_label)
+
+ # count false positives
+ crowd_labels_dict = {}
+ for gt_label, gt_info in gt_segms.items():
+ if gt_label in gt_matched:
+ continue
+ # crowd segments are ignored
+ if gt_info['iscrowd'] == 1:
+ crowd_labels_dict[gt_info['category_id']] = gt_label
+ continue
+ pq_stat[gt_info['category_id']].fn += 1
+
+ # count false positives
+ for pred_label, pred_info in pred_segms.items():
+ if pred_label in pred_matched:
+ continue
+ # intersection of the segment with VOID
+ intersection = gt_pred_map.get((VOID, pred_label), 0)
+ # plus intersection with corresponding CROWD region if it exists
+ if pred_info['category_id'] in crowd_labels_dict:
+ intersection += gt_pred_map.get(
+ (crowd_labels_dict[pred_info['category_id']], pred_label),
+ 0)
+ # predicted segment is ignored if more than half of
+ # the segment correspond to VOID and CROWD regions
+ if intersection / pred_info['area'] > 0.5:
+ continue
+ pq_stat[pred_info['category_id']].fp += 1
+
+ if print_log:
+ print('Core: {}, all {} images processed'.format(
+ proc_id, len(annotation_set)))
+ return pq_stat
+
+
+def pq_compute_multi_core(matched_annotations_list,
+ gt_folder,
+ pred_folder,
+ categories,
+ backend_args=None,
+ nproc=32):
+ """Evaluate the metrics of Panoptic Segmentation with multithreading.
+
+ Same as the function with the same name in `panopticapi`.
+
+ Args:
+ matched_annotations_list (list): The matched annotation list. Each
+ element is a tuple of annotations of the same image with the
+ format (gt_anns, pred_anns).
+ gt_folder (str): The path of the ground truth images.
+ pred_folder (str): The path of the prediction images.
+ categories (str): The categories of the dataset.
+ backend_args (object): The file client of the dataset. If None,
+ the backend will be set to `local`.
+ nproc (int): Number of processes for panoptic quality computing.
+ Defaults to 32. When `nproc` exceeds the number of cpu cores,
+ the number of cpu cores is used.
+ """
+ if PQStat is None:
+ raise RuntimeError(
+ 'panopticapi is not installed, please install it by: '
+ 'pip install git+https://github.com/cocodataset/'
+ 'panopticapi.git.')
+
+ cpu_num = min(nproc, multiprocessing.cpu_count())
+
+ annotations_split = np.array_split(matched_annotations_list, cpu_num)
+ print('Number of cores: {}, images per core: {}'.format(
+ cpu_num, len(annotations_split[0])))
+ workers = multiprocessing.Pool(processes=cpu_num)
+ processes = []
+ for proc_id, annotation_set in enumerate(annotations_split):
+ p = workers.apply_async(pq_compute_single_core,
+ (proc_id, annotation_set, gt_folder,
+ pred_folder, categories, backend_args))
+ processes.append(p)
+
+ # Close the process pool, otherwise it will lead to memory
+ # leaking problems.
+ workers.close()
+ workers.join()
+
+ pq_stat = PQStat()
+ for p in processes:
+ pq_stat += p.get()
+
+ return pq_stat
diff --git a/mmdet/evaluation/functional/recall.py b/mmdet/evaluation/functional/recall.py
new file mode 100644
index 0000000000000000000000000000000000000000..abbe4e15b833b4c2a6fb3467295cbe9b20d13a6c
--- /dev/null
+++ b/mmdet/evaluation/functional/recall.py
@@ -0,0 +1,199 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from collections.abc import Sequence
+
+import numpy as np
+from mmengine.logging import print_log
+from terminaltables import AsciiTable
+
+from .bbox_overlaps import bbox_overlaps
+
+
+def _recalls(all_ious, proposal_nums, thrs):
+
+ img_num = all_ious.shape[0]
+ total_gt_num = sum([ious.shape[0] for ious in all_ious])
+
+ _ious = np.zeros((proposal_nums.size, total_gt_num), dtype=np.float32)
+ for k, proposal_num in enumerate(proposal_nums):
+ tmp_ious = np.zeros(0)
+ for i in range(img_num):
+ ious = all_ious[i][:, :proposal_num].copy()
+ gt_ious = np.zeros((ious.shape[0]))
+ if ious.size == 0:
+ tmp_ious = np.hstack((tmp_ious, gt_ious))
+ continue
+ for j in range(ious.shape[0]):
+ gt_max_overlaps = ious.argmax(axis=1)
+ max_ious = ious[np.arange(0, ious.shape[0]), gt_max_overlaps]
+ gt_idx = max_ious.argmax()
+ gt_ious[j] = max_ious[gt_idx]
+ box_idx = gt_max_overlaps[gt_idx]
+ ious[gt_idx, :] = -1
+ ious[:, box_idx] = -1
+ tmp_ious = np.hstack((tmp_ious, gt_ious))
+ _ious[k, :] = tmp_ious
+
+ _ious = np.fliplr(np.sort(_ious, axis=1))
+ recalls = np.zeros((proposal_nums.size, thrs.size))
+ for i, thr in enumerate(thrs):
+ recalls[:, i] = (_ious >= thr).sum(axis=1) / float(total_gt_num)
+
+ return recalls
+
+
+def set_recall_param(proposal_nums, iou_thrs):
+ """Check proposal_nums and iou_thrs and set correct format."""
+ if isinstance(proposal_nums, Sequence):
+ _proposal_nums = np.array(proposal_nums)
+ elif isinstance(proposal_nums, int):
+ _proposal_nums = np.array([proposal_nums])
+ else:
+ _proposal_nums = proposal_nums
+
+ if iou_thrs is None:
+ _iou_thrs = np.array([0.5])
+ elif isinstance(iou_thrs, Sequence):
+ _iou_thrs = np.array(iou_thrs)
+ elif isinstance(iou_thrs, float):
+ _iou_thrs = np.array([iou_thrs])
+ else:
+ _iou_thrs = iou_thrs
+
+ return _proposal_nums, _iou_thrs
+
+
+def eval_recalls(gts,
+ proposals,
+ proposal_nums=None,
+ iou_thrs=0.5,
+ logger=None,
+ use_legacy_coordinate=False):
+ """Calculate recalls.
+
+ Args:
+ gts (list[ndarray]): a list of arrays of shape (n, 4)
+ proposals (list[ndarray]): a list of arrays of shape (k, 4) or (k, 5)
+ proposal_nums (int | Sequence[int]): Top N proposals to be evaluated.
+ iou_thrs (float | Sequence[float]): IoU thresholds. Default: 0.5.
+ logger (logging.Logger | str | None): The way to print the recall
+ summary. See `mmengine.logging.print_log()` for details.
+ Default: None.
+ use_legacy_coordinate (bool): Whether use coordinate system
+ in mmdet v1.x. "1" was added to both height and width
+ which means w, h should be
+ computed as 'x2 - x1 + 1` and 'y2 - y1 + 1'. Default: False.
+
+
+ Returns:
+ ndarray: recalls of different ious and proposal nums
+ """
+
+ img_num = len(gts)
+ assert img_num == len(proposals)
+ proposal_nums, iou_thrs = set_recall_param(proposal_nums, iou_thrs)
+ all_ious = []
+ for i in range(img_num):
+ if proposals[i].ndim == 2 and proposals[i].shape[1] == 5:
+ scores = proposals[i][:, 4]
+ sort_idx = np.argsort(scores)[::-1]
+ img_proposal = proposals[i][sort_idx, :]
+ else:
+ img_proposal = proposals[i]
+ prop_num = min(img_proposal.shape[0], proposal_nums[-1])
+ if gts[i] is None or gts[i].shape[0] == 0:
+ ious = np.zeros((0, img_proposal.shape[0]), dtype=np.float32)
+ else:
+ ious = bbox_overlaps(
+ gts[i],
+ img_proposal[:prop_num, :4],
+ use_legacy_coordinate=use_legacy_coordinate)
+ all_ious.append(ious)
+ all_ious = np.array(all_ious, dtype=object)
+ recalls = _recalls(all_ious, proposal_nums, iou_thrs)
+
+ print_recall_summary(recalls, proposal_nums, iou_thrs, logger=logger)
+ return recalls
+
+
+def print_recall_summary(recalls,
+ proposal_nums,
+ iou_thrs,
+ row_idxs=None,
+ col_idxs=None,
+ logger=None):
+ """Print recalls in a table.
+
+ Args:
+ recalls (ndarray): calculated from `bbox_recalls`
+ proposal_nums (ndarray or list): top N proposals
+ iou_thrs (ndarray or list): iou thresholds
+ row_idxs (ndarray): which rows(proposal nums) to print
+ col_idxs (ndarray): which cols(iou thresholds) to print
+ logger (logging.Logger | str | None): The way to print the recall
+ summary. See `mmengine.logging.print_log()` for details.
+ Default: None.
+ """
+ proposal_nums = np.array(proposal_nums, dtype=np.int32)
+ iou_thrs = np.array(iou_thrs)
+ if row_idxs is None:
+ row_idxs = np.arange(proposal_nums.size)
+ if col_idxs is None:
+ col_idxs = np.arange(iou_thrs.size)
+ row_header = [''] + iou_thrs[col_idxs].tolist()
+ table_data = [row_header]
+ for i, num in enumerate(proposal_nums[row_idxs]):
+ row = [f'{val:.3f}' for val in recalls[row_idxs[i], col_idxs].tolist()]
+ row.insert(0, num)
+ table_data.append(row)
+ table = AsciiTable(table_data)
+ print_log('\n' + table.table, logger=logger)
+
+
+def plot_num_recall(recalls, proposal_nums):
+ """Plot Proposal_num-Recalls curve.
+
+ Args:
+ recalls(ndarray or list): shape (k,)
+ proposal_nums(ndarray or list): same shape as `recalls`
+ """
+ if isinstance(proposal_nums, np.ndarray):
+ _proposal_nums = proposal_nums.tolist()
+ else:
+ _proposal_nums = proposal_nums
+ if isinstance(recalls, np.ndarray):
+ _recalls = recalls.tolist()
+ else:
+ _recalls = recalls
+
+ import matplotlib.pyplot as plt
+ f = plt.figure()
+ plt.plot([0] + _proposal_nums, [0] + _recalls)
+ plt.xlabel('Proposal num')
+ plt.ylabel('Recall')
+ plt.axis([0, proposal_nums.max(), 0, 1])
+ f.show()
+
+
+def plot_iou_recall(recalls, iou_thrs):
+ """Plot IoU-Recalls curve.
+
+ Args:
+ recalls(ndarray or list): shape (k,)
+ iou_thrs(ndarray or list): same shape as `recalls`
+ """
+ if isinstance(iou_thrs, np.ndarray):
+ _iou_thrs = iou_thrs.tolist()
+ else:
+ _iou_thrs = iou_thrs
+ if isinstance(recalls, np.ndarray):
+ _recalls = recalls.tolist()
+ else:
+ _recalls = recalls
+
+ import matplotlib.pyplot as plt
+ f = plt.figure()
+ plt.plot(_iou_thrs + [1.0], _recalls + [0.])
+ plt.xlabel('IoU')
+ plt.ylabel('Recall')
+ plt.axis([iou_thrs.min(), 1, 0, 1])
+ f.show()
diff --git a/mmdet/evaluation/metrics/__init__.py b/mmdet/evaluation/metrics/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..da000e0d53581c59a4698b80f67b8064dc68d47f
--- /dev/null
+++ b/mmdet/evaluation/metrics/__init__.py
@@ -0,0 +1,17 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .cityscapes_metric import CityScapesMetric
+from .coco_metric import CocoMetric
+from .coco_occluded_metric import CocoOccludedSeparatedMetric
+from .coco_panoptic_metric import CocoPanopticMetric
+from .crowdhuman_metric import CrowdHumanMetric
+from .dump_det_results import DumpDetResults
+from .dump_proposals_metric import DumpProposals
+from .lvis_metric import LVISMetric
+from .openimages_metric import OpenImagesMetric
+from .voc_metric import VOCMetric
+
+__all__ = [
+ 'CityScapesMetric', 'CocoMetric', 'CocoPanopticMetric', 'OpenImagesMetric',
+ 'VOCMetric', 'LVISMetric', 'CrowdHumanMetric', 'DumpProposals',
+ 'CocoOccludedSeparatedMetric', 'DumpDetResults'
+]
diff --git a/mmdet/evaluation/metrics/__pycache__/__init__.cpython-37.pyc b/mmdet/evaluation/metrics/__pycache__/__init__.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..8c76cca1ca3aba78ebfe31a09388712897fbefe1
Binary files /dev/null and b/mmdet/evaluation/metrics/__pycache__/__init__.cpython-37.pyc differ
diff --git a/mmdet/evaluation/metrics/__pycache__/cityscapes_metric.cpython-37.pyc b/mmdet/evaluation/metrics/__pycache__/cityscapes_metric.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..9706779915ad381caa4c885dc6e36fe7f18c3772
Binary files /dev/null and b/mmdet/evaluation/metrics/__pycache__/cityscapes_metric.cpython-37.pyc differ
diff --git a/mmdet/evaluation/metrics/__pycache__/coco_metric.cpython-37.pyc b/mmdet/evaluation/metrics/__pycache__/coco_metric.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..c2842588eaf7e616c4b229e506aacd44c5590447
Binary files /dev/null and b/mmdet/evaluation/metrics/__pycache__/coco_metric.cpython-37.pyc differ
diff --git a/mmdet/evaluation/metrics/__pycache__/coco_occluded_metric.cpython-37.pyc b/mmdet/evaluation/metrics/__pycache__/coco_occluded_metric.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..9e1f0a3552fb7f6c7ebba8bfb44a2ba852aef8d4
Binary files /dev/null and b/mmdet/evaluation/metrics/__pycache__/coco_occluded_metric.cpython-37.pyc differ
diff --git a/mmdet/evaluation/metrics/__pycache__/coco_panoptic_metric.cpython-37.pyc b/mmdet/evaluation/metrics/__pycache__/coco_panoptic_metric.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..de6f54c2daf7bc9a79ba7970ffbfe43bf48c99c8
Binary files /dev/null and b/mmdet/evaluation/metrics/__pycache__/coco_panoptic_metric.cpython-37.pyc differ
diff --git a/mmdet/evaluation/metrics/__pycache__/crowdhuman_metric.cpython-37.pyc b/mmdet/evaluation/metrics/__pycache__/crowdhuman_metric.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..e6dc2584ec1b17e9d61d3e4b21cb57660d541467
Binary files /dev/null and b/mmdet/evaluation/metrics/__pycache__/crowdhuman_metric.cpython-37.pyc differ
diff --git a/mmdet/evaluation/metrics/__pycache__/dump_det_results.cpython-37.pyc b/mmdet/evaluation/metrics/__pycache__/dump_det_results.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..f4cf3ba04fbb50bfe7db7405ce772250bf7cfab5
Binary files /dev/null and b/mmdet/evaluation/metrics/__pycache__/dump_det_results.cpython-37.pyc differ
diff --git a/mmdet/evaluation/metrics/__pycache__/dump_proposals_metric.cpython-37.pyc b/mmdet/evaluation/metrics/__pycache__/dump_proposals_metric.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..da00c05bfb76781e5f0df4c47abc94ae8b707377
Binary files /dev/null and b/mmdet/evaluation/metrics/__pycache__/dump_proposals_metric.cpython-37.pyc differ
diff --git a/mmdet/evaluation/metrics/__pycache__/lvis_metric.cpython-37.pyc b/mmdet/evaluation/metrics/__pycache__/lvis_metric.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..bc5d49e02fa5c119b4ae07e55cea09f385cf71ef
Binary files /dev/null and b/mmdet/evaluation/metrics/__pycache__/lvis_metric.cpython-37.pyc differ
diff --git a/mmdet/evaluation/metrics/__pycache__/openimages_metric.cpython-37.pyc b/mmdet/evaluation/metrics/__pycache__/openimages_metric.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..95d8e332200bcd01b885d537b2c6b6d52efb228e
Binary files /dev/null and b/mmdet/evaluation/metrics/__pycache__/openimages_metric.cpython-37.pyc differ
diff --git a/mmdet/evaluation/metrics/__pycache__/voc_metric.cpython-37.pyc b/mmdet/evaluation/metrics/__pycache__/voc_metric.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..d6cecea183e1a759ff6fa7a6a79d1a5b0ab21338
Binary files /dev/null and b/mmdet/evaluation/metrics/__pycache__/voc_metric.cpython-37.pyc differ
diff --git a/mmdet/evaluation/metrics/cityscapes_metric.py b/mmdet/evaluation/metrics/cityscapes_metric.py
new file mode 100644
index 0000000000000000000000000000000000000000..e5cdc179a3c76ef3742dd3ee6692c7deb9905459
--- /dev/null
+++ b/mmdet/evaluation/metrics/cityscapes_metric.py
@@ -0,0 +1,205 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+import os.path as osp
+import shutil
+import tempfile
+from collections import OrderedDict
+from typing import Dict, Optional, Sequence
+
+import mmcv
+import numpy as np
+from mmengine.dist import is_main_process
+from mmengine.evaluator import BaseMetric
+from mmengine.logging import MMLogger
+
+from mmdet.registry import METRICS
+
+try:
+ import cityscapesscripts.evaluation.evalInstanceLevelSemanticLabeling as CSEval # noqa: E501
+ import cityscapesscripts.helpers.labels as CSLabels
+
+ from mmdet.evaluation.functional import evaluateImgLists
+ HAS_CITYSCAPESAPI = True
+except ImportError:
+ HAS_CITYSCAPESAPI = False
+
+
+@METRICS.register_module()
+class CityScapesMetric(BaseMetric):
+ """CityScapes metric for instance segmentation.
+
+ Args:
+ outfile_prefix (str): The prefix of txt and png files. The txt and
+ png file will be save in a directory whose path is
+ "outfile_prefix.results/".
+ seg_prefix (str, optional): Path to the directory which contains the
+ cityscapes instance segmentation masks. It's necessary when
+ training and validation. It could be None when infer on test
+ dataset. Defaults to None.
+ format_only (bool): Format the output results without perform
+ evaluation. It is useful when you want to format the result
+ to a specific format and submit it to the test server.
+ Defaults to False.
+ collect_device (str): Device name used for collecting results from
+ different ranks during distributed training. Must be 'cpu' or
+ 'gpu'. Defaults to 'cpu'.
+ prefix (str, optional): The prefix that will be added in the metric
+ names to disambiguate homonymous metrics of different evaluators.
+ If prefix is not provided in the argument, self.default_prefix
+ will be used instead. Defaults to None.
+ dump_matches (bool): Whether dump matches.json file during evaluating.
+ Defaults to False.
+ file_client_args (dict, optional): Arguments to instantiate the
+ corresponding backend in mmdet <= 3.0.0rc6. Defaults to None.
+ backend_args (dict, optional): Arguments to instantiate the
+ corresponding backend. Defaults to None.
+ """
+ default_prefix: Optional[str] = 'cityscapes'
+
+ def __init__(self,
+ outfile_prefix: str,
+ seg_prefix: Optional[str] = None,
+ format_only: bool = False,
+ collect_device: str = 'cpu',
+ prefix: Optional[str] = None,
+ dump_matches: bool = False,
+ file_client_args: dict = None,
+ backend_args: dict = None) -> None:
+
+ if not HAS_CITYSCAPESAPI:
+ raise RuntimeError('Failed to import `cityscapesscripts`.'
+ 'Please try to install official '
+ 'cityscapesscripts by '
+ '"pip install cityscapesscripts"')
+ super().__init__(collect_device=collect_device, prefix=prefix)
+
+ self.tmp_dir = None
+ self.format_only = format_only
+ if self.format_only:
+ assert outfile_prefix is not None, 'outfile_prefix must be not'
+ 'None when format_only is True, otherwise the result files will'
+ 'be saved to a temp directory which will be cleaned up at the end.'
+ else:
+ assert seg_prefix is not None, '`seg_prefix` is necessary when '
+ 'computing the CityScapes metrics'
+
+ if outfile_prefix is None:
+ self.tmp_dir = tempfile.TemporaryDirectory()
+ self.outfile_prefix = osp.join(self.tmp_dir.name, 'results')
+ else:
+ # the directory to save predicted panoptic segmentation mask
+ self.outfile_prefix = osp.join(outfile_prefix, 'results') # type: ignore # yapf: disable # noqa: E501
+
+ dir_name = osp.expanduser(self.outfile_prefix)
+
+ if osp.exists(dir_name) and is_main_process():
+ logger: MMLogger = MMLogger.get_current_instance()
+ logger.info('remove previous results.')
+ shutil.rmtree(dir_name)
+ os.makedirs(dir_name, exist_ok=True)
+
+ self.backend_args = backend_args
+ if file_client_args is not None:
+ raise RuntimeError(
+ 'The `file_client_args` is deprecated, '
+ 'please use `backend_args` instead, please refer to'
+ 'https://github.com/open-mmlab/mmdetection/blob/main/configs/_base_/datasets/coco_detection.py' # noqa: E501
+ )
+
+ self.seg_prefix = seg_prefix
+ self.dump_matches = dump_matches
+
+ def __del__(self) -> None:
+ """Clean up the results if necessary."""
+ if self.tmp_dir is not None:
+ self.tmp_dir.cleanup()
+
+ # TODO: data_batch is no longer needed, consider adjusting the
+ # parameter position
+ def process(self, data_batch: dict, data_samples: Sequence[dict]) -> None:
+ """Process one batch of data samples and predictions. The processed
+ results should be stored in ``self.results``, which will be used to
+ compute the metrics when all batches have been processed.
+
+ Args:
+ data_batch (dict): A batch of data from the dataloader.
+ data_samples (Sequence[dict]): A batch of data samples that
+ contain annotations and predictions.
+ """
+ for data_sample in data_samples:
+ # parse pred
+ result = dict()
+ pred = data_sample['pred_instances']
+ filename = data_sample['img_path']
+ basename = osp.splitext(osp.basename(filename))[0]
+ pred_txt = osp.join(self.outfile_prefix, basename + '_pred.txt')
+ result['pred_txt'] = pred_txt
+ labels = pred['labels'].cpu().numpy()
+ masks = pred['masks'].cpu().numpy().astype(np.uint8)
+ if 'mask_scores' in pred:
+ # some detectors use different scores for bbox and mask
+ mask_scores = pred['mask_scores'].cpu().numpy()
+ else:
+ mask_scores = pred['scores'].cpu().numpy()
+
+ with open(pred_txt, 'w') as f:
+ for i, (label, mask, mask_score) in enumerate(
+ zip(labels, masks, mask_scores)):
+ class_name = self.dataset_meta['classes'][label]
+ class_id = CSLabels.name2label[class_name].id
+ png_filename = osp.join(
+ self.outfile_prefix,
+ basename + f'_{i}_{class_name}.png')
+ mmcv.imwrite(mask, png_filename)
+ f.write(f'{osp.basename(png_filename)} '
+ f'{class_id} {mask_score}\n')
+
+ # parse gt
+ gt = dict()
+ img_path = filename.replace('leftImg8bit.png',
+ 'gtFine_instanceIds.png')
+ gt['file_name'] = img_path.replace('leftImg8bit', 'gtFine')
+
+ self.results.append((gt, result))
+
+ def compute_metrics(self, results: list) -> Dict[str, float]:
+ """Compute the metrics from processed results.
+
+ Args:
+ results (list): The processed results of each batch.
+
+ Returns:
+ Dict[str, float]: The computed metrics. The keys are the names of
+ the metrics, and the values are corresponding results.
+ """
+ logger: MMLogger = MMLogger.get_current_instance()
+
+ if self.format_only:
+ logger.info(
+ f'results are saved to {osp.dirname(self.outfile_prefix)}')
+ return OrderedDict()
+ logger.info('starts to compute metric')
+
+ gts, preds = zip(*results)
+ # set global states in cityscapes evaluation API
+ gt_instances_file = osp.join(self.outfile_prefix, 'gtInstances.json') # type: ignore # yapf: disable # noqa: E501
+ # split gt and prediction list
+ gts, preds = zip(*results)
+ CSEval.args.JSONOutput = False
+ CSEval.args.colorized = False
+ CSEval.args.gtInstancesFile = gt_instances_file
+
+ groundTruthImgList = [gt['file_name'] for gt in gts]
+ predictionImgList = [pred['pred_txt'] for pred in preds]
+ CSEval_results = evaluateImgLists(
+ predictionImgList,
+ groundTruthImgList,
+ CSEval.args,
+ self.backend_args,
+ dump_matches=self.dump_matches)['averages']
+
+ eval_results = OrderedDict()
+ eval_results['mAP'] = CSEval_results['allAp']
+ eval_results['AP@50'] = CSEval_results['allAp50%']
+
+ return eval_results
diff --git a/mmdet/evaluation/metrics/coco_metric.py b/mmdet/evaluation/metrics/coco_metric.py
new file mode 100644
index 0000000000000000000000000000000000000000..f77d6516bfa32bdf616ab0a01dfe331220a814e1
--- /dev/null
+++ b/mmdet/evaluation/metrics/coco_metric.py
@@ -0,0 +1,590 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import datetime
+import itertools
+import os.path as osp
+import tempfile
+from collections import OrderedDict
+from typing import Dict, List, Optional, Sequence, Union
+
+import numpy as np
+import torch
+from mmengine.evaluator import BaseMetric
+from mmengine.fileio import dump, get_local_path, load
+from mmengine.logging import MMLogger
+from terminaltables import AsciiTable
+
+from mmdet.datasets.api_wrappers import COCO, COCOeval
+from mmdet.registry import METRICS
+from mmdet.structures.mask import encode_mask_results
+from ..functional import eval_recalls
+
+
+@METRICS.register_module()
+class CocoMetric(BaseMetric):
+ """COCO evaluation metric.
+
+ Evaluate AR, AP, and mAP for detection tasks including proposal/box
+ detection and instance segmentation. Please refer to
+ https://cocodataset.org/#detection-eval for more details.
+
+ Args:
+ ann_file (str, optional): Path to the coco format annotation file.
+ If not specified, ground truth annotations from the dataset will
+ be converted to coco format. Defaults to None.
+ metric (str | List[str]): Metrics to be evaluated. Valid metrics
+ include 'bbox', 'segm', 'proposal', and 'proposal_fast'.
+ Defaults to 'bbox'.
+ classwise (bool): Whether to evaluate the metric class-wise.
+ Defaults to False.
+ proposal_nums (Sequence[int]): Numbers of proposals to be evaluated.
+ Defaults to (100, 300, 1000).
+ iou_thrs (float | List[float], optional): IoU threshold to compute AP
+ and AR. If not specified, IoUs from 0.5 to 0.95 will be used.
+ Defaults to None.
+ metric_items (List[str], optional): Metric result names to be
+ recorded in the evaluation result. Defaults to None.
+ format_only (bool): Format the output results without perform
+ evaluation. It is useful when you want to format the result
+ to a specific format and submit it to the test server.
+ Defaults to False.
+ outfile_prefix (str, optional): The prefix of json files. It includes
+ the file path and the prefix of filename, e.g., "a/b/prefix".
+ If not specified, a temp file will be created. Defaults to None.
+ file_client_args (dict, optional): Arguments to instantiate the
+ corresponding backend in mmdet <= 3.0.0rc6. Defaults to None.
+ backend_args (dict, optional): Arguments to instantiate the
+ corresponding backend. Defaults to None.
+ collect_device (str): Device name used for collecting results from
+ different ranks during distributed training. Must be 'cpu' or
+ 'gpu'. Defaults to 'cpu'.
+ prefix (str, optional): The prefix that will be added in the metric
+ names to disambiguate homonymous metrics of different evaluators.
+ If prefix is not provided in the argument, self.default_prefix
+ will be used instead. Defaults to None.
+ sort_categories (bool): Whether sort categories in annotations. Only
+ used for `Objects365V1Dataset`. Defaults to False.
+ """
+ default_prefix: Optional[str] = 'coco'
+
+ def __init__(self,
+ ann_file: Optional[str] = None,
+ metric: Union[str, List[str]] = 'bbox',
+ classwise: bool = False,
+ proposal_nums: Sequence[int] = (100, 300, 1000),
+ iou_thrs: Optional[Union[float, Sequence[float]]] = None,
+ metric_items: Optional[Sequence[str]] = None,
+ format_only: bool = False,
+ outfile_prefix: Optional[str] = None,
+ file_client_args: dict = None,
+ backend_args: dict = None,
+ collect_device: str = 'cpu',
+ prefix: Optional[str] = None,
+ sort_categories: bool = False) -> None:
+ super().__init__(collect_device=collect_device, prefix=prefix)
+ # coco evaluation metrics
+ self.metrics = metric if isinstance(metric, list) else [metric]
+ allowed_metrics = ['bbox', 'segm', 'proposal', 'proposal_fast']
+ for metric in self.metrics:
+ if metric not in allowed_metrics:
+ raise KeyError(
+ "metric should be one of 'bbox', 'segm', 'proposal', "
+ f"'proposal_fast', but got {metric}.")
+
+ # do class wise evaluation, default False
+ self.classwise = classwise
+
+ # proposal_nums used to compute recall or precision.
+ self.proposal_nums = list(proposal_nums)
+
+ # iou_thrs used to compute recall or precision.
+ if iou_thrs is None:
+ iou_thrs = np.linspace(
+ .5, 0.95, int(np.round((0.95 - .5) / .05)) + 1, endpoint=True)
+ self.iou_thrs = iou_thrs
+ self.metric_items = metric_items
+ self.format_only = format_only
+ if self.format_only:
+ assert outfile_prefix is not None, 'outfile_prefix must be not'
+ 'None when format_only is True, otherwise the result files will'
+ 'be saved to a temp directory which will be cleaned up at the end.'
+
+ self.outfile_prefix = outfile_prefix
+
+ self.backend_args = backend_args
+ if file_client_args is not None:
+ raise RuntimeError(
+ 'The `file_client_args` is deprecated, '
+ 'please use `backend_args` instead, please refer to'
+ 'https://github.com/open-mmlab/mmdetection/blob/main/configs/_base_/datasets/coco_detection.py' # noqa: E501
+ )
+
+ # if ann_file is not specified,
+ # initialize coco api with the converted dataset
+ if ann_file is not None:
+ with get_local_path(
+ ann_file, backend_args=self.backend_args) as local_path:
+ self._coco_api = COCO(local_path)
+ if sort_categories:
+ # 'categories' list in objects365_train.json and
+ # objects365_val.json is inconsistent, need sort
+ # list(or dict) before get cat_ids.
+ cats = self._coco_api.cats
+ sorted_cats = {i: cats[i] for i in sorted(cats)}
+ self._coco_api.cats = sorted_cats
+ categories = self._coco_api.dataset['categories']
+ sorted_categories = sorted(
+ categories, key=lambda i: i['id'])
+ self._coco_api.dataset['categories'] = sorted_categories
+ else:
+ self._coco_api = None
+
+ # handle dataset lazy init
+ self.cat_ids = None
+ self.img_ids = None
+
+ def fast_eval_recall(self,
+ results: List[dict],
+ proposal_nums: Sequence[int],
+ iou_thrs: Sequence[float],
+ logger: Optional[MMLogger] = None) -> np.ndarray:
+ """Evaluate proposal recall with COCO's fast_eval_recall.
+
+ Args:
+ results (List[dict]): Results of the dataset.
+ proposal_nums (Sequence[int]): Proposal numbers used for
+ evaluation.
+ iou_thrs (Sequence[float]): IoU thresholds used for evaluation.
+ logger (MMLogger, optional): Logger used for logging the recall
+ summary.
+ Returns:
+ np.ndarray: Averaged recall results.
+ """
+ gt_bboxes = []
+ pred_bboxes = [result['bboxes'] for result in results]
+ for i in range(len(self.img_ids)):
+ ann_ids = self._coco_api.get_ann_ids(img_ids=self.img_ids[i])
+ ann_info = self._coco_api.load_anns(ann_ids)
+ if len(ann_info) == 0:
+ gt_bboxes.append(np.zeros((0, 4)))
+ continue
+ bboxes = []
+ for ann in ann_info:
+ if ann.get('ignore', False) or ann['iscrowd']:
+ continue
+ x1, y1, w, h = ann['bbox']
+ bboxes.append([x1, y1, x1 + w, y1 + h])
+ bboxes = np.array(bboxes, dtype=np.float32)
+ if bboxes.shape[0] == 0:
+ bboxes = np.zeros((0, 4))
+ gt_bboxes.append(bboxes)
+
+ recalls = eval_recalls(
+ gt_bboxes, pred_bboxes, proposal_nums, iou_thrs, logger=logger)
+ ar = recalls.mean(axis=1)
+ return ar
+
+ def xyxy2xywh(self, bbox: np.ndarray) -> list:
+ """Convert ``xyxy`` style bounding boxes to ``xywh`` style for COCO
+ evaluation.
+
+ Args:
+ bbox (numpy.ndarray): The bounding boxes, shape (4, ), in
+ ``xyxy`` order.
+
+ Returns:
+ list[float]: The converted bounding boxes, in ``xywh`` order.
+ """
+
+ _bbox: List = bbox.tolist()
+ return [
+ _bbox[0],
+ _bbox[1],
+ _bbox[2] - _bbox[0],
+ _bbox[3] - _bbox[1],
+ ]
+
+ def results2json(self, results: Sequence[dict],
+ outfile_prefix: str) -> dict:
+ """Dump the detection results to a COCO style json file.
+
+ There are 3 types of results: proposals, bbox predictions, mask
+ predictions, and they have different data types. This method will
+ automatically recognize the type, and dump them to json files.
+
+ Args:
+ results (Sequence[dict]): Testing results of the
+ dataset.
+ outfile_prefix (str): The filename prefix of the json files. If the
+ prefix is "somepath/xxx", the json files will be named
+ "somepath/xxx.bbox.json", "somepath/xxx.segm.json",
+ "somepath/xxx.proposal.json".
+
+ Returns:
+ dict: Possible keys are "bbox", "segm", "proposal", and
+ values are corresponding filenames.
+ """
+ bbox_json_results = []
+ segm_json_results = [] if 'masks' in results[0] else None
+ for idx, result in enumerate(results):
+ image_id = result.get('img_id', idx)
+ labels = result['labels']
+ bboxes = result['bboxes']
+ scores = result['scores']
+ # bbox results
+ for i, label in enumerate(labels):
+ data = dict()
+ data['image_id'] = image_id
+ data['bbox'] = self.xyxy2xywh(bboxes[i])
+ data['score'] = float(scores[i])
+ data['category_id'] = self.cat_ids[label]
+ bbox_json_results.append(data)
+
+ if segm_json_results is None:
+ continue
+
+ # segm results
+ masks = result['masks']
+ mask_scores = result.get('mask_scores', scores)
+ for i, label in enumerate(labels):
+ data = dict()
+ data['image_id'] = image_id
+ data['bbox'] = self.xyxy2xywh(bboxes[i])
+ data['score'] = float(mask_scores[i])
+ data['category_id'] = self.cat_ids[label]
+ if isinstance(masks[i]['counts'], bytes):
+ masks[i]['counts'] = masks[i]['counts'].decode()
+ data['segmentation'] = masks[i]
+ segm_json_results.append(data)
+
+ result_files = dict()
+ result_files['bbox'] = f'{outfile_prefix}.bbox.json'
+ result_files['proposal'] = f'{outfile_prefix}.bbox.json'
+ dump(bbox_json_results, result_files['bbox'])
+
+ if segm_json_results is not None:
+ result_files['segm'] = f'{outfile_prefix}.segm.json'
+ dump(segm_json_results, result_files['segm'])
+
+ return result_files
+
+ def gt_to_coco_json(self, gt_dicts: Sequence[dict],
+ outfile_prefix: str) -> str:
+ """Convert ground truth to coco format json file.
+
+ Args:
+ gt_dicts (Sequence[dict]): Ground truth of the dataset.
+ outfile_prefix (str): The filename prefix of the json files. If the
+ prefix is "somepath/xxx", the json file will be named
+ "somepath/xxx.gt.json".
+ Returns:
+ str: The filename of the json file.
+ """
+ categories = [
+ dict(id=id, name=name)
+ for id, name in enumerate(self.dataset_meta['classes'])
+ ]
+ image_infos = []
+ annotations = []
+
+ for idx, gt_dict in enumerate(gt_dicts):
+ img_id = gt_dict.get('img_id', idx)
+ image_info = dict(
+ id=img_id,
+ width=gt_dict['width'],
+ height=gt_dict['height'],
+ file_name='')
+ image_infos.append(image_info)
+ for ann in gt_dict['anns']:
+ label = ann['bbox_label']
+ bbox = ann['bbox']
+ coco_bbox = [
+ bbox[0],
+ bbox[1],
+ bbox[2] - bbox[0],
+ bbox[3] - bbox[1],
+ ]
+
+ annotation = dict(
+ id=len(annotations) +
+ 1, # coco api requires id starts with 1
+ image_id=img_id,
+ bbox=coco_bbox,
+ iscrowd=ann.get('ignore_flag', 0),
+ category_id=int(label),
+ area=coco_bbox[2] * coco_bbox[3])
+ if ann.get('mask', None):
+ mask = ann['mask']
+ # area = mask_util.area(mask)
+ if isinstance(mask, dict) and isinstance(
+ mask['counts'], bytes):
+ mask['counts'] = mask['counts'].decode()
+ annotation['segmentation'] = mask
+ # annotation['area'] = float(area)
+ annotations.append(annotation)
+
+ info = dict(
+ date_created=str(datetime.datetime.now()),
+ description='Coco json file converted by mmdet CocoMetric.')
+ coco_json = dict(
+ info=info,
+ images=image_infos,
+ categories=categories,
+ licenses=None,
+ )
+ if len(annotations) > 0:
+ coco_json['annotations'] = annotations
+ converted_json_path = f'{outfile_prefix}.gt.json'
+ dump(coco_json, converted_json_path)
+ return converted_json_path
+
+ # TODO: data_batch is no longer needed, consider adjusting the
+ # parameter position
+ def process(self, data_batch: dict, data_samples: Sequence[dict]) -> None:
+ """Process one batch of data samples and predictions. The processed
+ results should be stored in ``self.results``, which will be used to
+ compute the metrics when all batches have been processed.
+
+ Args:
+ data_batch (dict): A batch of data from the dataloader.
+ data_samples (Sequence[dict]): A batch of data samples that
+ contain annotations and predictions.
+ """
+ for data_sample in data_samples:
+ result = dict()
+ pred = data_sample['pred_instances']
+ result['img_id'] = data_sample['img_id']
+ result['bboxes'] = pred['bboxes'].cpu().numpy()
+ result['scores'] = pred['scores'].cpu().numpy()
+ result['labels'] = pred['labels'].cpu().numpy()
+ # encode mask to RLE
+ if 'masks' in pred:
+ result['masks'] = encode_mask_results(
+ pred['masks'].detach().cpu().numpy()) if isinstance(
+ pred['masks'], torch.Tensor) else pred['masks']
+ # some detectors use different scores for bbox and mask
+ if 'mask_scores' in pred:
+ result['mask_scores'] = pred['mask_scores'].cpu().numpy()
+
+ # parse gt
+ gt = dict()
+ gt['width'] = data_sample['ori_shape'][1]
+ gt['height'] = data_sample['ori_shape'][0]
+ gt['img_id'] = data_sample['img_id']
+ if self._coco_api is None:
+ # TODO: Need to refactor to support LoadAnnotations
+ assert 'instances' in data_sample, \
+ 'ground truth is required for evaluation when ' \
+ '`ann_file` is not provided'
+ gt['anns'] = data_sample['instances']
+ # add converted result to the results list
+ self.results.append((gt, result))
+
+ def compute_metrics(self, results: list) -> Dict[str, float]:
+ """Compute the metrics from processed results.
+
+ Args:
+ results (list): The processed results of each batch.
+
+ Returns:
+ Dict[str, float]: The computed metrics. The keys are the names of
+ the metrics, and the values are corresponding results.
+ """
+ logger: MMLogger = MMLogger.get_current_instance()
+
+ # split gt and prediction list
+ gts, preds = zip(*results)
+
+ tmp_dir = None
+ if self.outfile_prefix is None:
+ tmp_dir = tempfile.TemporaryDirectory()
+ outfile_prefix = osp.join(tmp_dir.name, 'results')
+ else:
+ outfile_prefix = self.outfile_prefix
+
+ if self._coco_api is None:
+ # use converted gt json file to initialize coco api
+ logger.info('Converting ground truth to coco format...')
+ coco_json_path = self.gt_to_coco_json(
+ gt_dicts=gts, outfile_prefix=outfile_prefix)
+ self._coco_api = COCO(coco_json_path)
+
+ # handle lazy init
+ if self.cat_ids is None:
+ self.cat_ids = self._coco_api.get_cat_ids(
+ cat_names=self.dataset_meta['classes'])
+ if self.img_ids is None:
+ self.img_ids = self._coco_api.get_img_ids()
+
+ # convert predictions to coco format and dump to json file
+ result_files = self.results2json(preds, outfile_prefix)
+
+ eval_results = OrderedDict()
+ if self.format_only:
+ logger.info('results are saved in '
+ f'{osp.dirname(outfile_prefix)}')
+ return eval_results
+
+ for metric in self.metrics:
+ logger.info(f'Evaluating {metric}...')
+
+ # TODO: May refactor fast_eval_recall to an independent metric?
+ # fast eval recall
+ if metric == 'proposal_fast':
+ ar = self.fast_eval_recall(
+ preds, self.proposal_nums, self.iou_thrs, logger=logger)
+ log_msg = []
+ for i, num in enumerate(self.proposal_nums):
+ eval_results[f'AR@{num}'] = ar[i]
+ log_msg.append(f'\nAR@{num}\t{ar[i]:.4f}')
+ log_msg = ''.join(log_msg)
+ logger.info(log_msg)
+ continue
+
+ # evaluate proposal, bbox and segm
+ iou_type = 'bbox' if metric == 'proposal' else metric
+ if metric not in result_files:
+ raise KeyError(f'{metric} is not in results')
+ try:
+ predictions = load(result_files[metric])
+ if iou_type == 'segm':
+ # Refer to https://github.com/cocodataset/cocoapi/blob/master/PythonAPI/pycocotools/coco.py#L331 # noqa
+ # When evaluating mask AP, if the results contain bbox,
+ # cocoapi will use the box area instead of the mask area
+ # for calculating the instance area. Though the overall AP
+ # is not affected, this leads to different
+ # small/medium/large mask AP results.
+ for x in predictions:
+ x.pop('bbox')
+ coco_dt = self._coco_api.loadRes(predictions)
+
+ except IndexError:
+ logger.error(
+ 'The testing results of the whole dataset is empty.')
+ break
+
+ coco_eval = COCOeval(self._coco_api, coco_dt, iou_type)
+
+ coco_eval.params.catIds = self.cat_ids
+ coco_eval.params.imgIds = self.img_ids
+ coco_eval.params.maxDets = list(self.proposal_nums)
+ coco_eval.params.iouThrs = self.iou_thrs
+
+ # mapping of cocoEval.stats
+ coco_metric_names = {
+ 'mAP': 0,
+ 'mAP_50': 1,
+ 'mAP_75': 2,
+ 'mAP_s': 3,
+ 'mAP_m': 4,
+ 'mAP_l': 5,
+ 'AR@100': 6,
+ 'AR@300': 7,
+ 'AR@1000': 8,
+ 'AR_s@1000': 9,
+ 'AR_m@1000': 10,
+ 'AR_l@1000': 11
+ }
+ metric_items = self.metric_items
+ if metric_items is not None:
+ for metric_item in metric_items:
+ if metric_item not in coco_metric_names:
+ raise KeyError(
+ f'metric item "{metric_item}" is not supported')
+
+ if metric == 'proposal':
+ coco_eval.params.useCats = 0
+ coco_eval.evaluate()
+ coco_eval.accumulate()
+ coco_eval.summarize()
+ if metric_items is None:
+ metric_items = [
+ 'AR@100', 'AR@300', 'AR@1000', 'AR_s@1000',
+ 'AR_m@1000', 'AR_l@1000'
+ ]
+
+ for item in metric_items:
+ val = float(
+ f'{coco_eval.stats[coco_metric_names[item]]:.3f}')
+ eval_results[item] = val
+ else:
+ coco_eval.evaluate()
+ coco_eval.accumulate()
+ coco_eval.summarize()
+ if self.classwise: # Compute per-category AP
+ # Compute per-category AP
+ # from https://github.com/facebookresearch/detectron2/
+ precisions = coco_eval.eval['precision']
+ # precision: (iou, recall, cls, area range, max dets)
+ assert len(self.cat_ids) == precisions.shape[2]
+
+ results_per_category = []
+ for idx, cat_id in enumerate(self.cat_ids):
+ t = []
+ # area range index 0: all area ranges
+ # max dets index -1: typically 100 per image
+ nm = self._coco_api.loadCats(cat_id)[0]
+ precision = precisions[:, :, idx, 0, -1]
+ precision = precision[precision > -1]
+ if precision.size:
+ ap = np.mean(precision)
+ else:
+ ap = float('nan')
+ t.append(f'{nm["name"]}')
+ t.append(f'{round(ap, 3)}')
+ eval_results[f'{nm["name"]}_precision'] = round(ap, 3)
+
+ # indexes of IoU @50 and @75
+ for iou in [0, 5]:
+ precision = precisions[iou, :, idx, 0, -1]
+ precision = precision[precision > -1]
+ if precision.size:
+ ap = np.mean(precision)
+ else:
+ ap = float('nan')
+ t.append(f'{round(ap, 3)}')
+
+ # indexes of area of small, median and large
+ for area in [1, 2, 3]:
+ precision = precisions[:, :, idx, area, -1]
+ precision = precision[precision > -1]
+ if precision.size:
+ ap = np.mean(precision)
+ else:
+ ap = float('nan')
+ t.append(f'{round(ap, 3)}')
+ results_per_category.append(tuple(t))
+
+ num_columns = len(results_per_category[0])
+ results_flatten = list(
+ itertools.chain(*results_per_category))
+ headers = [
+ 'category', 'mAP', 'mAP_50', 'mAP_75', 'mAP_s',
+ 'mAP_m', 'mAP_l'
+ ]
+ results_2d = itertools.zip_longest(*[
+ results_flatten[i::num_columns]
+ for i in range(num_columns)
+ ])
+ table_data = [headers]
+ table_data += [result for result in results_2d]
+ table = AsciiTable(table_data)
+ logger.info('\n' + table.table)
+
+ if metric_items is None:
+ metric_items = [
+ 'mAP', 'mAP_50', 'mAP_75', 'mAP_s', 'mAP_m', 'mAP_l'
+ ]
+
+ for metric_item in metric_items:
+ key = f'{metric}_{metric_item}'
+ val = coco_eval.stats[coco_metric_names[metric_item]]
+ eval_results[key] = float(f'{round(val, 3)}')
+
+ ap = coco_eval.stats[:6]
+ logger.info(f'{metric}_mAP_copypaste: {ap[0]:.3f} '
+ f'{ap[1]:.3f} {ap[2]:.3f} {ap[3]:.3f} '
+ f'{ap[4]:.3f} {ap[5]:.3f}')
+
+ if tmp_dir is not None:
+ tmp_dir.cleanup()
+ return eval_results
diff --git a/mmdet/evaluation/metrics/coco_occluded_metric.py b/mmdet/evaluation/metrics/coco_occluded_metric.py
new file mode 100644
index 0000000000000000000000000000000000000000..81235a04e6ee1929cfd6b5cdc284d239765b0d69
--- /dev/null
+++ b/mmdet/evaluation/metrics/coco_occluded_metric.py
@@ -0,0 +1,204 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Optional, Union
+
+import mmengine
+import numpy as np
+from mmengine.fileio import load
+from mmengine.logging import print_log
+from pycocotools import mask as coco_mask
+from terminaltables import AsciiTable
+
+from mmdet.registry import METRICS
+from .coco_metric import CocoMetric
+
+
+@METRICS.register_module()
+class CocoOccludedSeparatedMetric(CocoMetric):
+ """Metric of separated and occluded masks which presented in paper `A Tri-
+ Layer Plugin to Improve Occluded Detection.
+
+ `_.
+
+ Separated COCO and Occluded COCO are automatically generated subsets of
+ COCO val dataset, collecting separated objects and partially occluded
+ objects for a large variety of categories. In this way, we define
+ occlusion into two major categories: separated and partially occluded.
+
+ - Separation: target object segmentation mask is separated into distinct
+ regions by the occluder.
+ - Partial Occlusion: target object is partially occluded but the
+ segmentation mask is connected.
+
+ These two new scalable real-image datasets are to benchmark a model's
+ capability to detect occluded objects of 80 common categories.
+
+ Please cite the paper if you use this dataset:
+
+ @article{zhan2022triocc,
+ title={A Tri-Layer Plugin to Improve Occluded Detection},
+ author={Zhan, Guanqi and Xie, Weidi and Zisserman, Andrew},
+ journal={British Machine Vision Conference},
+ year={2022}
+ }
+
+ Args:
+ occluded_ann (str): Path to the occluded coco annotation file.
+ separated_ann (str): Path to the separated coco annotation file.
+ score_thr (float): Score threshold of the detection masks.
+ Defaults to 0.3.
+ iou_thr (float): IoU threshold for the recall calculation.
+ Defaults to 0.75.
+ metric (str | List[str]): Metrics to be evaluated. Valid metrics
+ include 'bbox', 'segm', 'proposal', and 'proposal_fast'.
+ Defaults to 'bbox'.
+ """
+ default_prefix: Optional[str] = 'coco'
+
+ def __init__(
+ self,
+ *args,
+ occluded_ann:
+ str = 'https://www.robots.ox.ac.uk/~vgg/research/tpod/datasets/occluded_coco.pkl', # noqa
+ separated_ann:
+ str = 'https://www.robots.ox.ac.uk/~vgg/research/tpod/datasets/separated_coco.pkl', # noqa
+ score_thr: float = 0.3,
+ iou_thr: float = 0.75,
+ metric: Union[str, List[str]] = ['bbox', 'segm'],
+ **kwargs) -> None:
+ super().__init__(*args, metric=metric, **kwargs)
+ self.occluded_ann = load(occluded_ann)
+ self.separated_ann = load(separated_ann)
+ self.score_thr = score_thr
+ self.iou_thr = iou_thr
+
+ def compute_metrics(self, results: list) -> Dict[str, float]:
+ """Compute the metrics from processed results.
+
+ Args:
+ results (list): The processed results of each batch.
+
+ Returns:
+ Dict[str, float]: The computed metrics. The keys are the names of
+ the metrics, and the values are corresponding results.
+ """
+ coco_metric_res = super().compute_metrics(results)
+ eval_res = self.evaluate_occluded_separated(results)
+ coco_metric_res.update(eval_res)
+ return coco_metric_res
+
+ def evaluate_occluded_separated(self, results: List[tuple]) -> dict:
+ """Compute the recall of occluded and separated masks.
+
+ Args:
+ results (list[tuple]): Testing results of the dataset.
+
+ Returns:
+ dict[str, float]: The recall of occluded and separated masks.
+ """
+ dict_det = {}
+ print_log('processing detection results...')
+ prog_bar = mmengine.ProgressBar(len(results))
+ for i in range(len(results)):
+ gt, dt = results[i]
+ img_id = dt['img_id']
+ cur_img_name = self._coco_api.imgs[img_id]['file_name']
+ if cur_img_name not in dict_det.keys():
+ dict_det[cur_img_name] = []
+
+ for bbox, score, label, mask in zip(dt['bboxes'], dt['scores'],
+ dt['labels'], dt['masks']):
+ cur_binary_mask = coco_mask.decode(mask)
+ dict_det[cur_img_name].append([
+ score, self.dataset_meta['classes'][label],
+ cur_binary_mask, bbox
+ ])
+ dict_det[cur_img_name].sort(
+ key=lambda x: (-x[0], x[3][0], x[3][1])
+ ) # rank by confidence from high to low, avoid same confidence
+ prog_bar.update()
+ print_log('\ncomputing occluded mask recall...', logger='current')
+ occluded_correct_num, occluded_recall = self.compute_recall(
+ dict_det, gt_ann=self.occluded_ann, is_occ=True)
+ print_log(
+ f'\nCOCO occluded mask recall: {occluded_recall:.2f}%',
+ logger='current')
+ print_log(
+ f'COCO occluded mask success num: {occluded_correct_num}',
+ logger='current')
+ print_log('computing separated mask recall...', logger='current')
+ separated_correct_num, separated_recall = self.compute_recall(
+ dict_det, gt_ann=self.separated_ann, is_occ=False)
+ print_log(
+ f'\nCOCO separated mask recall: {separated_recall:.2f}%',
+ logger='current')
+ print_log(
+ f'COCO separated mask success num: {separated_correct_num}',
+ logger='current')
+ table_data = [
+ ['mask type', 'recall', 'num correct'],
+ ['occluded', f'{occluded_recall:.2f}%', occluded_correct_num],
+ ['separated', f'{separated_recall:.2f}%', separated_correct_num]
+ ]
+ table = AsciiTable(table_data)
+ print_log('\n' + table.table, logger='current')
+ return dict(
+ occluded_recall=occluded_recall, separated_recall=separated_recall)
+
+ def compute_recall(self,
+ result_dict: dict,
+ gt_ann: list,
+ is_occ: bool = True) -> tuple:
+ """Compute the recall of occluded or separated masks.
+
+ Args:
+ result_dict (dict): Processed mask results.
+ gt_ann (list): Occluded or separated coco annotations.
+ is_occ (bool): Whether the annotation is occluded mask.
+ Defaults to True.
+ Returns:
+ tuple: number of correct masks and the recall.
+ """
+ correct = 0
+ prog_bar = mmengine.ProgressBar(len(gt_ann))
+ for iter_i in range(len(gt_ann)):
+ cur_item = gt_ann[iter_i]
+ cur_img_name = cur_item[0]
+ cur_gt_bbox = cur_item[3]
+ if is_occ:
+ cur_gt_bbox = [
+ cur_gt_bbox[0], cur_gt_bbox[1],
+ cur_gt_bbox[0] + cur_gt_bbox[2],
+ cur_gt_bbox[1] + cur_gt_bbox[3]
+ ]
+ cur_gt_class = cur_item[1]
+ cur_gt_mask = coco_mask.decode(cur_item[4])
+
+ assert cur_img_name in result_dict.keys()
+ cur_detections = result_dict[cur_img_name]
+
+ correct_flag = False
+ for i in range(len(cur_detections)):
+ cur_det_confidence = cur_detections[i][0]
+ if cur_det_confidence < self.score_thr:
+ break
+ cur_det_class = cur_detections[i][1]
+ if cur_det_class != cur_gt_class:
+ continue
+ cur_det_mask = cur_detections[i][2]
+ cur_iou = self.mask_iou(cur_det_mask, cur_gt_mask)
+ if cur_iou >= self.iou_thr:
+ correct_flag = True
+ break
+ if correct_flag:
+ correct += 1
+ prog_bar.update()
+ recall = correct / len(gt_ann) * 100
+ return correct, recall
+
+ def mask_iou(self, mask1: np.ndarray, mask2: np.ndarray) -> np.ndarray:
+ """Compute IoU between two masks."""
+ mask1_area = np.count_nonzero(mask1 == 1)
+ mask2_area = np.count_nonzero(mask2 == 1)
+ intersection = np.count_nonzero(np.logical_and(mask1 == 1, mask2 == 1))
+ iou = intersection / (mask1_area + mask2_area - intersection)
+ return iou
diff --git a/mmdet/evaluation/metrics/coco_panoptic_metric.py b/mmdet/evaluation/metrics/coco_panoptic_metric.py
new file mode 100644
index 0000000000000000000000000000000000000000..475e51dbc1979289dff8462bd7178521b6267fdc
--- /dev/null
+++ b/mmdet/evaluation/metrics/coco_panoptic_metric.py
@@ -0,0 +1,612 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import datetime
+import itertools
+import os.path as osp
+import tempfile
+from typing import Dict, Optional, Sequence, Tuple, Union
+
+import mmcv
+import numpy as np
+from mmengine.evaluator import BaseMetric
+from mmengine.fileio import dump, get_local_path, load
+from mmengine.logging import MMLogger, print_log
+from terminaltables import AsciiTable
+
+from mmdet.datasets.api_wrappers import COCOPanoptic
+from mmdet.registry import METRICS
+from ..functional import (INSTANCE_OFFSET, pq_compute_multi_core,
+ pq_compute_single_core)
+
+try:
+ import panopticapi
+ from panopticapi.evaluation import VOID, PQStat
+ from panopticapi.utils import id2rgb, rgb2id
+except ImportError:
+ panopticapi = None
+ id2rgb = None
+ rgb2id = None
+ VOID = None
+ PQStat = None
+
+
+@METRICS.register_module()
+class CocoPanopticMetric(BaseMetric):
+ """COCO panoptic segmentation evaluation metric.
+
+ Evaluate PQ, SQ RQ for panoptic segmentation tasks. Please refer to
+ https://cocodataset.org/#panoptic-eval for more details.
+
+ Args:
+ ann_file (str, optional): Path to the coco format annotation file.
+ If not specified, ground truth annotations from the dataset will
+ be converted to coco format. Defaults to None.
+ seg_prefix (str, optional): Path to the directory which contains the
+ coco panoptic segmentation mask. It should be specified when
+ evaluate. Defaults to None.
+ classwise (bool): Whether to evaluate the metric class-wise.
+ Defaults to False.
+ outfile_prefix (str, optional): The prefix of json files. It includes
+ the file path and the prefix of filename, e.g., "a/b/prefix".
+ If not specified, a temp file will be created.
+ It should be specified when format_only is True. Defaults to None.
+ format_only (bool): Format the output results without perform
+ evaluation. It is useful when you want to format the result
+ to a specific format and submit it to the test server.
+ Defaults to False.
+ nproc (int): Number of processes for panoptic quality computing.
+ Defaults to 32. When ``nproc`` exceeds the number of cpu cores,
+ the number of cpu cores is used.
+ file_client_args (dict, optional): Arguments to instantiate the
+ corresponding backend in mmdet <= 3.0.0rc6. Defaults to None.
+ backend_args (dict, optional): Arguments to instantiate the
+ corresponding backend. Defaults to None.
+ collect_device (str): Device name used for collecting results from
+ different ranks during distributed training. Must be 'cpu' or
+ 'gpu'. Defaults to 'cpu'.
+ prefix (str, optional): The prefix that will be added in the metric
+ names to disambiguate homonymous metrics of different evaluators.
+ If prefix is not provided in the argument, self.default_prefix
+ will be used instead. Defaults to None.
+ """
+ default_prefix: Optional[str] = 'coco_panoptic'
+
+ def __init__(self,
+ ann_file: Optional[str] = None,
+ seg_prefix: Optional[str] = None,
+ classwise: bool = False,
+ format_only: bool = False,
+ outfile_prefix: Optional[str] = None,
+ nproc: int = 32,
+ file_client_args: dict = None,
+ backend_args: dict = None,
+ collect_device: str = 'cpu',
+ prefix: Optional[str] = None) -> None:
+ if panopticapi is None:
+ raise RuntimeError(
+ 'panopticapi is not installed, please install it by: '
+ 'pip install git+https://github.com/cocodataset/'
+ 'panopticapi.git.')
+
+ super().__init__(collect_device=collect_device, prefix=prefix)
+ self.classwise = classwise
+ self.format_only = format_only
+ if self.format_only:
+ assert outfile_prefix is not None, 'outfile_prefix must be not'
+ 'None when format_only is True, otherwise the result files will'
+ 'be saved to a temp directory which will be cleaned up at the end.'
+
+ self.tmp_dir = None
+ # outfile_prefix should be a prefix of a path which points to a shared
+ # storage when train or test with multi nodes.
+ self.outfile_prefix = outfile_prefix
+ if outfile_prefix is None:
+ self.tmp_dir = tempfile.TemporaryDirectory()
+ self.outfile_prefix = osp.join(self.tmp_dir.name, 'results')
+ # the directory to save predicted panoptic segmentation mask
+ self.seg_out_dir = f'{self.outfile_prefix}.panoptic'
+ self.nproc = nproc
+ self.seg_prefix = seg_prefix
+
+ self.cat_ids = None
+ self.cat2label = None
+
+ self.backend_args = backend_args
+ if file_client_args is not None:
+ raise RuntimeError(
+ 'The `file_client_args` is deprecated, '
+ 'please use `backend_args` instead, please refer to'
+ 'https://github.com/open-mmlab/mmdetection/blob/main/configs/_base_/datasets/coco_detection.py' # noqa: E501
+ )
+
+ if ann_file:
+ with get_local_path(
+ ann_file, backend_args=self.backend_args) as local_path:
+ self._coco_api = COCOPanoptic(local_path)
+ self.categories = self._coco_api.cats
+ else:
+ self._coco_api = None
+ self.categories = None
+
+ def __del__(self) -> None:
+ """Clean up."""
+ if self.tmp_dir is not None:
+ self.tmp_dir.cleanup()
+
+ def gt_to_coco_json(self, gt_dicts: Sequence[dict],
+ outfile_prefix: str) -> Tuple[str, str]:
+ """Convert ground truth to coco panoptic segmentation format json file.
+
+ Args:
+ gt_dicts (Sequence[dict]): Ground truth of the dataset.
+ outfile_prefix (str): The filename prefix of the json file. If the
+ prefix is "somepath/xxx", the json file will be named
+ "somepath/xxx.gt.json".
+
+ Returns:
+ Tuple[str, str]: The filename of the json file and the name of the\
+ directory which contains panoptic segmentation masks.
+ """
+ assert len(gt_dicts) > 0, 'gt_dicts is empty.'
+ gt_folder = osp.dirname(gt_dicts[0]['seg_map_path'])
+ converted_json_path = f'{outfile_prefix}.gt.json'
+
+ categories = []
+ for id, name in enumerate(self.dataset_meta['classes']):
+ isthing = 1 if name in self.dataset_meta['thing_classes'] else 0
+ categories.append({'id': id, 'name': name, 'isthing': isthing})
+
+ image_infos = []
+ annotations = []
+ for gt_dict in gt_dicts:
+ img_id = gt_dict['image_id']
+ image_info = {
+ 'id': img_id,
+ 'width': gt_dict['width'],
+ 'height': gt_dict['height'],
+ 'file_name': osp.split(gt_dict['seg_map_path'])[-1]
+ }
+ image_infos.append(image_info)
+
+ pan_png = mmcv.imread(gt_dict['seg_map_path']).squeeze()
+ pan_png = pan_png[:, :, ::-1]
+ pan_png = rgb2id(pan_png)
+ segments_info = []
+ for segment_info in gt_dict['segments_info']:
+ id = segment_info['id']
+ label = segment_info['category']
+ mask = pan_png == id
+ isthing = categories[label]['isthing']
+ if isthing:
+ iscrowd = 1 if not segment_info['is_thing'] else 0
+ else:
+ iscrowd = 0
+
+ new_segment_info = {
+ 'id': id,
+ 'category_id': label,
+ 'isthing': isthing,
+ 'iscrowd': iscrowd,
+ 'area': mask.sum()
+ }
+ segments_info.append(new_segment_info)
+
+ segm_file = image_info['file_name'].replace('jpg', 'png')
+ annotation = dict(
+ image_id=img_id,
+ segments_info=segments_info,
+ file_name=segm_file)
+ annotations.append(annotation)
+ pan_png = id2rgb(pan_png)
+
+ info = dict(
+ date_created=str(datetime.datetime.now()),
+ description='Coco json file converted by mmdet CocoPanopticMetric.'
+ )
+ coco_json = dict(
+ info=info,
+ images=image_infos,
+ categories=categories,
+ licenses=None,
+ )
+ if len(annotations) > 0:
+ coco_json['annotations'] = annotations
+ dump(coco_json, converted_json_path)
+ return converted_json_path, gt_folder
+
+ def result2json(self, results: Sequence[dict],
+ outfile_prefix: str) -> Tuple[str, str]:
+ """Dump the panoptic results to a COCO style json file and a directory.
+
+ Args:
+ results (Sequence[dict]): Testing results of the dataset.
+ outfile_prefix (str): The filename prefix of the json files and the
+ directory.
+
+ Returns:
+ Tuple[str, str]: The json file and the directory which contains \
+ panoptic segmentation masks. The filename of the json is
+ "somepath/xxx.panoptic.json" and name of the directory is
+ "somepath/xxx.panoptic".
+ """
+ label2cat = dict((v, k) for (k, v) in self.cat2label.items())
+ pred_annotations = []
+ for idx in range(len(results)):
+ result = results[idx]
+ for segment_info in result['segments_info']:
+ sem_label = segment_info['category_id']
+ # convert sem_label to json label
+ cat_id = label2cat[sem_label]
+ segment_info['category_id'] = label2cat[sem_label]
+ is_thing = self.categories[cat_id]['isthing']
+ segment_info['isthing'] = is_thing
+ pred_annotations.append(result)
+ pan_json_results = dict(annotations=pred_annotations)
+ json_filename = f'{outfile_prefix}.panoptic.json'
+ dump(pan_json_results, json_filename)
+ return json_filename, (
+ self.seg_out_dir
+ if self.tmp_dir is None else tempfile.gettempdir())
+
+ def _parse_predictions(self,
+ pred: dict,
+ img_id: int,
+ segm_file: str,
+ label2cat=None) -> dict:
+ """Parse panoptic segmentation predictions.
+
+ Args:
+ pred (dict): Panoptic segmentation predictions.
+ img_id (int): Image id.
+ segm_file (str): Segmentation file name.
+ label2cat (dict): Mapping from label to category id.
+ Defaults to None.
+
+ Returns:
+ dict: Parsed predictions.
+ """
+ result = dict()
+ result['img_id'] = img_id
+ # shape (1, H, W) -> (H, W)
+ pan = pred['pred_panoptic_seg']['sem_seg'].cpu().numpy()[0]
+ pan_labels = np.unique(pan)
+ segments_info = []
+ for pan_label in pan_labels:
+ sem_label = pan_label % INSTANCE_OFFSET
+ # We reserve the length of dataset_meta['classes'] for VOID label
+ if sem_label == len(self.dataset_meta['classes']):
+ continue
+ mask = pan == pan_label
+ area = mask.sum()
+ segments_info.append({
+ 'id':
+ int(pan_label),
+ # when ann_file provided, sem_label should be cat_id, otherwise
+ # sem_label should be a continuous id, not the cat_id
+ # defined in dataset
+ 'category_id':
+ label2cat[sem_label] if label2cat else sem_label,
+ 'area':
+ int(area)
+ })
+ # evaluation script uses 0 for VOID label.
+ pan[pan % INSTANCE_OFFSET == len(self.dataset_meta['classes'])] = VOID
+ pan = id2rgb(pan).astype(np.uint8)
+ mmcv.imwrite(pan[:, :, ::-1], osp.join(self.seg_out_dir, segm_file))
+ result = {
+ 'image_id': img_id,
+ 'segments_info': segments_info,
+ 'file_name': segm_file
+ }
+
+ return result
+
+ def _compute_batch_pq_stats(self, data_samples: Sequence[dict]):
+ """Process gts and predictions when ``outfile_prefix`` is not set, gts
+ are from dataset or a json file which is defined by ``ann_file``.
+
+ Intermediate results, ``pq_stats``, are computed here and put into
+ ``self.results``.
+ """
+ if self._coco_api is None:
+ categories = dict()
+ for id, name in enumerate(self.dataset_meta['classes']):
+ isthing = 1 if name in self.dataset_meta['thing_classes']\
+ else 0
+ categories[id] = {'id': id, 'name': name, 'isthing': isthing}
+ label2cat = None
+ else:
+ categories = self.categories
+ cat_ids = self._coco_api.get_cat_ids(
+ cat_names=self.dataset_meta['classes'])
+ label2cat = {i: cat_id for i, cat_id in enumerate(cat_ids)}
+
+ for data_sample in data_samples:
+ # parse pred
+ img_id = data_sample['img_id']
+ segm_file = osp.basename(data_sample['img_path']).replace(
+ 'jpg', 'png')
+ result = self._parse_predictions(
+ pred=data_sample,
+ img_id=img_id,
+ segm_file=segm_file,
+ label2cat=label2cat)
+
+ # parse gt
+ gt = dict()
+ gt['image_id'] = img_id
+ gt['width'] = data_sample['ori_shape'][1]
+ gt['height'] = data_sample['ori_shape'][0]
+ gt['file_name'] = segm_file
+
+ if self._coco_api is None:
+ # get segments_info from data_sample
+ seg_map_path = osp.join(self.seg_prefix, segm_file)
+ pan_png = mmcv.imread(seg_map_path).squeeze()
+ pan_png = pan_png[:, :, ::-1]
+ pan_png = rgb2id(pan_png)
+ segments_info = []
+
+ for segment_info in data_sample['segments_info']:
+ id = segment_info['id']
+ label = segment_info['category']
+ mask = pan_png == id
+ isthing = categories[label]['isthing']
+ if isthing:
+ iscrowd = 1 if not segment_info['is_thing'] else 0
+ else:
+ iscrowd = 0
+
+ new_segment_info = {
+ 'id': id,
+ 'category_id': label,
+ 'isthing': isthing,
+ 'iscrowd': iscrowd,
+ 'area': mask.sum()
+ }
+ segments_info.append(new_segment_info)
+ else:
+ # get segments_info from annotation file
+ segments_info = self._coco_api.imgToAnns[img_id]
+
+ gt['segments_info'] = segments_info
+
+ pq_stats = pq_compute_single_core(
+ proc_id=0,
+ annotation_set=[(gt, result)],
+ gt_folder=self.seg_prefix,
+ pred_folder=self.seg_out_dir,
+ categories=categories,
+ backend_args=self.backend_args)
+
+ self.results.append(pq_stats)
+
+ def _process_gt_and_predictions(self, data_samples: Sequence[dict]):
+ """Process gts and predictions when ``outfile_prefix`` is set.
+
+ The predictions will be saved to directory specified by
+ ``outfile_predfix``. The matched pair (gt, result) will be put into
+ ``self.results``.
+ """
+ for data_sample in data_samples:
+ # parse pred
+ img_id = data_sample['img_id']
+ segm_file = osp.basename(data_sample['img_path']).replace(
+ 'jpg', 'png')
+ result = self._parse_predictions(
+ pred=data_sample, img_id=img_id, segm_file=segm_file)
+
+ # parse gt
+ gt = dict()
+ gt['image_id'] = img_id
+ gt['width'] = data_sample['ori_shape'][1]
+ gt['height'] = data_sample['ori_shape'][0]
+
+ if self._coco_api is None:
+ # get segments_info from dataset
+ gt['segments_info'] = data_sample['segments_info']
+ gt['seg_map_path'] = data_sample['seg_map_path']
+
+ self.results.append((gt, result))
+
+ # TODO: data_batch is no longer needed, consider adjusting the
+ # parameter position
+ def process(self, data_batch: dict, data_samples: Sequence[dict]) -> None:
+ """Process one batch of data samples and predictions. The processed
+ results should be stored in ``self.results``, which will be used to
+ compute the metrics when all batches have been processed.
+
+ Args:
+ data_batch (dict): A batch of data from the dataloader.
+ data_samples (Sequence[dict]): A batch of data samples that
+ contain annotations and predictions.
+ """
+ # If ``self.tmp_dir`` is none, it will save gt and predictions to
+ # self.results, otherwise, it will compute pq_stats here.
+ if self.tmp_dir is None:
+ self._process_gt_and_predictions(data_samples)
+ else:
+ self._compute_batch_pq_stats(data_samples)
+
+ def compute_metrics(self, results: list) -> Dict[str, float]:
+ """Compute the metrics from processed results.
+
+ Args:
+ results (list): The processed results of each batch. There
+ are two cases:
+
+ - When ``outfile_prefix`` is not provided, the elements in
+ results are pq_stats which can be summed directly to get PQ.
+ - When ``outfile_prefix`` is provided, the elements in
+ results are tuples like (gt, pred).
+
+ Returns:
+ Dict[str, float]: The computed metrics. The keys are the names of
+ the metrics, and the values are corresponding results.
+ """
+ logger: MMLogger = MMLogger.get_current_instance()
+
+ if self.tmp_dir is None:
+ # do evaluation after collect all the results
+
+ # split gt and prediction list
+ gts, preds = zip(*results)
+
+ if self._coco_api is None:
+ # use converted gt json file to initialize coco api
+ logger.info('Converting ground truth to coco format...')
+ coco_json_path, gt_folder = self.gt_to_coco_json(
+ gt_dicts=gts, outfile_prefix=self.outfile_prefix)
+ self._coco_api = COCOPanoptic(coco_json_path)
+ else:
+ gt_folder = self.seg_prefix
+
+ self.cat_ids = self._coco_api.get_cat_ids(
+ cat_names=self.dataset_meta['classes'])
+ self.cat2label = {
+ cat_id: i
+ for i, cat_id in enumerate(self.cat_ids)
+ }
+ self.img_ids = self._coco_api.get_img_ids()
+ self.categories = self._coco_api.cats
+
+ # convert predictions to coco format and dump to json file
+ json_filename, pred_folder = self.result2json(
+ results=preds, outfile_prefix=self.outfile_prefix)
+
+ if self.format_only:
+ logger.info('results are saved in '
+ f'{osp.dirname(self.outfile_prefix)}')
+ return dict()
+
+ imgs = self._coco_api.imgs
+ gt_json = self._coco_api.img_ann_map
+ gt_json = [{
+ 'image_id': k,
+ 'segments_info': v,
+ 'file_name': imgs[k]['segm_file']
+ } for k, v in gt_json.items()]
+ pred_json = load(json_filename)
+ pred_json = dict(
+ (el['image_id'], el) for el in pred_json['annotations'])
+
+ # match the gt_anns and pred_anns in the same image
+ matched_annotations_list = []
+ for gt_ann in gt_json:
+ img_id = gt_ann['image_id']
+ if img_id not in pred_json.keys():
+ raise Exception('no prediction for the image'
+ ' with id: {}'.format(img_id))
+ matched_annotations_list.append((gt_ann, pred_json[img_id]))
+
+ pq_stat = pq_compute_multi_core(
+ matched_annotations_list,
+ gt_folder,
+ pred_folder,
+ self.categories,
+ backend_args=self.backend_args,
+ nproc=self.nproc)
+
+ else:
+ # aggregate the results generated in process
+ if self._coco_api is None:
+ categories = dict()
+ for id, name in enumerate(self.dataset_meta['classes']):
+ isthing = 1 if name in self.dataset_meta[
+ 'thing_classes'] else 0
+ categories[id] = {
+ 'id': id,
+ 'name': name,
+ 'isthing': isthing
+ }
+ self.categories = categories
+
+ pq_stat = PQStat()
+ for result in results:
+ pq_stat += result
+
+ metrics = [('All', None), ('Things', True), ('Stuff', False)]
+ pq_results = {}
+
+ for name, isthing in metrics:
+ pq_results[name], classwise_results = pq_stat.pq_average(
+ self.categories, isthing=isthing)
+ if name == 'All':
+ pq_results['classwise'] = classwise_results
+
+ classwise_results = None
+ if self.classwise:
+ classwise_results = {
+ k: v
+ for k, v in zip(self.dataset_meta['classes'],
+ pq_results['classwise'].values())
+ }
+
+ print_panoptic_table(pq_results, classwise_results, logger=logger)
+ results = parse_pq_results(pq_results)
+
+ return results
+
+
+def parse_pq_results(pq_results: dict) -> dict:
+ """Parse the Panoptic Quality results.
+
+ Args:
+ pq_results (dict): Panoptic Quality results.
+
+ Returns:
+ dict: Panoptic Quality results parsed.
+ """
+ result = dict()
+ result['PQ'] = 100 * pq_results['All']['pq']
+ result['SQ'] = 100 * pq_results['All']['sq']
+ result['RQ'] = 100 * pq_results['All']['rq']
+ result['PQ_th'] = 100 * pq_results['Things']['pq']
+ result['SQ_th'] = 100 * pq_results['Things']['sq']
+ result['RQ_th'] = 100 * pq_results['Things']['rq']
+ result['PQ_st'] = 100 * pq_results['Stuff']['pq']
+ result['SQ_st'] = 100 * pq_results['Stuff']['sq']
+ result['RQ_st'] = 100 * pq_results['Stuff']['rq']
+ return result
+
+
+def print_panoptic_table(
+ pq_results: dict,
+ classwise_results: Optional[dict] = None,
+ logger: Optional[Union['MMLogger', str]] = None) -> None:
+ """Print the panoptic evaluation results table.
+
+ Args:
+ pq_results(dict): The Panoptic Quality results.
+ classwise_results(dict, optional): The classwise Panoptic Quality.
+ results. The keys are class names and the values are metrics.
+ Defaults to None.
+ logger (:obj:`MMLogger` | str, optional): Logger used for printing
+ related information during evaluation. Default: None.
+ """
+
+ headers = ['', 'PQ', 'SQ', 'RQ', 'categories']
+ data = [headers]
+ for name in ['All', 'Things', 'Stuff']:
+ numbers = [
+ f'{(pq_results[name][k] * 100):0.3f}' for k in ['pq', 'sq', 'rq']
+ ]
+ row = [name] + numbers + [pq_results[name]['n']]
+ data.append(row)
+ table = AsciiTable(data)
+ print_log('Panoptic Evaluation Results:\n' + table.table, logger=logger)
+
+ if classwise_results is not None:
+ class_metrics = [(name, ) + tuple(f'{(metrics[k] * 100):0.3f}'
+ for k in ['pq', 'sq', 'rq'])
+ for name, metrics in classwise_results.items()]
+ num_columns = min(8, len(class_metrics) * 4)
+ results_flatten = list(itertools.chain(*class_metrics))
+ headers = ['category', 'PQ', 'SQ', 'RQ'] * (num_columns // 4)
+ results_2d = itertools.zip_longest(
+ *[results_flatten[i::num_columns] for i in range(num_columns)])
+ data = [headers]
+ data += [result for result in results_2d]
+ table = AsciiTable(data)
+ print_log(
+ 'Classwise Panoptic Evaluation Results:\n' + table.table,
+ logger=logger)
diff --git a/mmdet/evaluation/metrics/crowdhuman_metric.py b/mmdet/evaluation/metrics/crowdhuman_metric.py
new file mode 100644
index 0000000000000000000000000000000000000000..de2a54edc2b97738a76c8f9cc6c01716f33acdac
--- /dev/null
+++ b/mmdet/evaluation/metrics/crowdhuman_metric.py
@@ -0,0 +1,824 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+import json
+import os.path as osp
+import tempfile
+from collections import OrderedDict
+from multiprocessing import Process, Queue
+from typing import Dict, List, Optional, Sequence, Union
+
+import numpy as np
+from mmengine.evaluator import BaseMetric
+from mmengine.fileio import dump, get_text, load
+from mmengine.logging import MMLogger
+from scipy.sparse import csr_matrix
+from scipy.sparse.csgraph import maximum_bipartite_matching
+
+from mmdet.evaluation.functional.bbox_overlaps import bbox_overlaps
+from mmdet.registry import METRICS
+
+PERSON_CLASSES = ['background', 'person']
+
+
+@METRICS.register_module()
+class CrowdHumanMetric(BaseMetric):
+ """CrowdHuman evaluation metric.
+
+ Evaluate Average Precision (AP), Miss Rate (MR) and Jaccard Index (JI)
+ for detection tasks.
+
+ Args:
+ ann_file (str): Path to the annotation file.
+ metric (str | List[str]): Metrics to be evaluated. Valid metrics
+ include 'AP', 'MR' and 'JI'. Defaults to 'AP'.
+ format_only (bool): Format the output results without perform
+ evaluation. It is useful when you want to format the result
+ to a specific format and submit it to the test server.
+ Defaults to False.
+ outfile_prefix (str, optional): The prefix of json files. It includes
+ the file path and the prefix of filename, e.g., "a/b/prefix".
+ If not specified, a temp file will be created. Defaults to None.
+ file_client_args (dict, optional): Arguments to instantiate the
+ corresponding backend in mmdet <= 3.0.0rc6. Defaults to None.
+ backend_args (dict, optional): Arguments to instantiate the
+ corresponding backend. Defaults to None.
+ collect_device (str): Device name used for collecting results from
+ different ranks during distributed training. Must be 'cpu' or
+ 'gpu'. Defaults to 'cpu'.
+ prefix (str, optional): The prefix that will be added in the metric
+ names to disambiguate homonymous metrics of different evaluators.
+ If prefix is not provided in the argument, self.default_prefix
+ will be used instead. Defaults to None.
+ eval_mode (int): Select the mode of evaluate. Valid mode include
+ 0(just body box), 1(just head box) and 2(both of them).
+ Defaults to 0.
+ iou_thres (float): IoU threshold. Defaults to 0.5.
+ compare_matching_method (str, optional): Matching method to compare
+ the detection results with the ground_truth when compute 'AP'
+ and 'MR'.Valid method include VOC and None(CALTECH). Default to
+ None.
+ mr_ref (str): Different parameter selection to calculate MR. Valid
+ ref include CALTECH_-2 and CALTECH_-4. Defaults to CALTECH_-2.
+ num_ji_process (int): The number of processes to evaluation JI.
+ Defaults to 10.
+ """
+ default_prefix: Optional[str] = 'crowd_human'
+
+ def __init__(self,
+ ann_file: str,
+ metric: Union[str, List[str]] = ['AP', 'MR', 'JI'],
+ format_only: bool = False,
+ outfile_prefix: Optional[str] = None,
+ file_client_args: dict = None,
+ backend_args: dict = None,
+ collect_device: str = 'cpu',
+ prefix: Optional[str] = None,
+ eval_mode: int = 0,
+ iou_thres: float = 0.5,
+ compare_matching_method: Optional[str] = None,
+ mr_ref: str = 'CALTECH_-2',
+ num_ji_process: int = 10) -> None:
+ super().__init__(collect_device=collect_device, prefix=prefix)
+
+ self.ann_file = ann_file
+ # crowdhuman evaluation metrics
+ self.metrics = metric if isinstance(metric, list) else [metric]
+ allowed_metrics = ['MR', 'AP', 'JI']
+ for metric in self.metrics:
+ if metric not in allowed_metrics:
+ raise KeyError(f"metric should be one of 'MR', 'AP', 'JI',"
+ f'but got {metric}.')
+
+ self.format_only = format_only
+ if self.format_only:
+ assert outfile_prefix is not None, 'outfile_prefix must be not'
+ 'None when format_only is True, otherwise the result files will'
+ 'be saved to a temp directory which will be cleaned up at the end.'
+ self.outfile_prefix = outfile_prefix
+ self.backend_args = backend_args
+ if file_client_args is not None:
+ raise RuntimeError(
+ 'The `file_client_args` is deprecated, '
+ 'please use `backend_args` instead, please refer to'
+ 'https://github.com/open-mmlab/mmdetection/blob/main/configs/_base_/datasets/coco_detection.py' # noqa: E501
+ )
+
+ assert eval_mode in [0, 1, 2], \
+ "Unknown eval mode. mr_ref should be one of '0', '1', '2'."
+ assert compare_matching_method is None or \
+ compare_matching_method == 'VOC', \
+ 'The alternative compare_matching_method is VOC.' \
+ 'This parameter defaults to CALTECH(None)'
+ assert mr_ref == 'CALTECH_-2' or mr_ref == 'CALTECH_-4', \
+ "mr_ref should be one of 'CALTECH_-2', 'CALTECH_-4'."
+ self.eval_mode = eval_mode
+ self.iou_thres = iou_thres
+ self.compare_matching_method = compare_matching_method
+ self.mr_ref = mr_ref
+ self.num_ji_process = num_ji_process
+
+ @staticmethod
+ def results2json(results: Sequence[dict], outfile_prefix: str) -> str:
+ """Dump the detection results to a json file."""
+ result_file_path = f'{outfile_prefix}.json'
+ bbox_json_results = []
+ for i, result in enumerate(results):
+ ann, pred = result
+ dump_dict = dict()
+ dump_dict['ID'] = ann['ID']
+ dump_dict['width'] = ann['width']
+ dump_dict['height'] = ann['height']
+ dtboxes = []
+ bboxes = pred.tolist()
+ for _, single_bbox in enumerate(bboxes):
+ temp_dict = dict()
+ x1, y1, x2, y2, score = single_bbox
+ temp_dict['box'] = [x1, y1, x2 - x1, y2 - y1]
+ temp_dict['score'] = score
+ temp_dict['tag'] = 1
+ dtboxes.append(temp_dict)
+ dump_dict['dtboxes'] = dtboxes
+ bbox_json_results.append(dump_dict)
+ dump(bbox_json_results, result_file_path)
+ return result_file_path
+
+ def process(self, data_batch: Sequence[dict],
+ data_samples: Sequence[dict]) -> None:
+ """Process one batch of data samples and predictions. The processed
+ results should be stored in ``self.results``, which will be used to
+ compute the metrics when all batches have been processed.
+
+ Args:
+ data_batch (dict): A batch of data from the dataloader.
+ data_samples (Sequence[dict]): A batch of data samples that
+ contain annotations and predictions.
+ """
+ for data_sample in data_samples:
+ ann = dict()
+ ann['ID'] = data_sample['img_id']
+ ann['width'] = data_sample['ori_shape'][1]
+ ann['height'] = data_sample['ori_shape'][0]
+ pred_bboxes = data_sample['pred_instances']['bboxes'].cpu().numpy()
+ pred_scores = data_sample['pred_instances']['scores'].cpu().numpy()
+
+ pred_bbox_scores = np.hstack(
+ [pred_bboxes, pred_scores.reshape((-1, 1))])
+
+ self.results.append((ann, pred_bbox_scores))
+
+ def compute_metrics(self, results: list) -> Dict[str, float]:
+ """Compute the metrics from processed results.
+
+ Args:
+ results (list): The processed results of each batch.
+
+ Returns:
+ eval_results(Dict[str, float]): The computed metrics.
+ The keys are the names of the metrics, and the values
+ are corresponding results.
+ """
+ logger: MMLogger = MMLogger.get_current_instance()
+
+ tmp_dir = None
+ if self.outfile_prefix is None:
+ tmp_dir = tempfile.TemporaryDirectory()
+ outfile_prefix = osp.join(tmp_dir.name, 'result')
+ else:
+ outfile_prefix = self.outfile_prefix
+
+ # convert predictions to coco format and dump to json file
+ result_file = self.results2json(results, outfile_prefix)
+ eval_results = OrderedDict()
+ if self.format_only:
+ logger.info(f'results are saved in {osp.dirname(outfile_prefix)}')
+ return eval_results
+
+ # load evaluation samples
+ eval_samples = self.load_eval_samples(result_file)
+
+ if 'AP' in self.metrics or 'MR' in self.metrics:
+ score_list = self.compare(eval_samples)
+ gt_num = sum([eval_samples[i].gt_num for i in eval_samples])
+ ign_num = sum([eval_samples[i].ign_num for i in eval_samples])
+ gt_num = gt_num - ign_num
+ img_num = len(eval_samples)
+
+ for metric in self.metrics:
+ logger.info(f'Evaluating {metric}...')
+ if metric == 'AP':
+ AP = self.eval_ap(score_list, gt_num, img_num)
+ eval_results['mAP'] = float(f'{round(AP, 4)}')
+ if metric == 'MR':
+ MR = self.eval_mr(score_list, gt_num, img_num)
+ eval_results['mMR'] = float(f'{round(MR, 4)}')
+ if metric == 'JI':
+ JI = self.eval_ji(eval_samples)
+ eval_results['JI'] = float(f'{round(JI, 4)}')
+ if tmp_dir is not None:
+ tmp_dir.cleanup()
+
+ return eval_results
+
+ def load_eval_samples(self, result_file):
+ """Load data from annotations file and detection results.
+
+ Args:
+ result_file (str): The file path of the saved detection results.
+
+ Returns:
+ Dict[Image]: The detection result packaged by Image
+ """
+ gt_str = get_text(
+ self.ann_file, backend_args=self.backend_args).strip().split('\n')
+ gt_records = [json.loads(line) for line in gt_str]
+
+ pred_records = load(result_file, backend_args=self.backend_args)
+ eval_samples = dict()
+ for gt_record, pred_record in zip(gt_records, pred_records):
+ assert gt_record['ID'] == pred_record['ID'], \
+ 'please set val_dataloader.sampler.shuffle=False and try again'
+ eval_samples[pred_record['ID']] = Image(self.eval_mode)
+ eval_samples[pred_record['ID']].load(gt_record, 'box', None,
+ PERSON_CLASSES, True)
+ eval_samples[pred_record['ID']].load(pred_record, 'box', None,
+ PERSON_CLASSES, False)
+ eval_samples[pred_record['ID']].clip_all_boader()
+ return eval_samples
+
+ def compare(self, samples):
+ """Match the detection results with the ground_truth.
+
+ Args:
+ samples (dict[Image]): The detection result packaged by Image.
+
+ Returns:
+ score_list(list[tuple[ndarray, int, str]]): Matching result.
+ a list of tuples (dtbox, label, imgID) in the descending
+ sort of dtbox.score.
+ """
+ score_list = list()
+ for id in samples:
+ if self.compare_matching_method == 'VOC':
+ result = samples[id].compare_voc(self.iou_thres)
+ else:
+ result = samples[id].compare_caltech(self.iou_thres)
+ score_list.extend(result)
+ # In the descending sort of dtbox score.
+ score_list.sort(key=lambda x: x[0][-1], reverse=True)
+ return score_list
+
+ @staticmethod
+ def eval_ap(score_list, gt_num, img_num):
+ """Evaluate by average precision.
+
+ Args:
+ score_list(list[tuple[ndarray, int, str]]): Matching result.
+ a list of tuples (dtbox, label, imgID) in the descending
+ sort of dtbox.score.
+ gt_num(int): The number of gt boxes in the entire dataset.
+ img_num(int): The number of images in the entire dataset.
+
+ Returns:
+ ap(float): result of average precision.
+ """
+
+ # calculate general ap score
+ def _calculate_map(_recall, _precision):
+ assert len(_recall) == len(_precision)
+ area = 0
+ for k in range(1, len(_recall)):
+ delta_h = (_precision[k - 1] + _precision[k]) / 2
+ delta_w = _recall[k] - _recall[k - 1]
+ area += delta_w * delta_h
+ return area
+
+ tp, fp = 0.0, 0.0
+ rpX, rpY = list(), list()
+
+ fpn = []
+ recalln = []
+ thr = []
+ fppi = []
+ for i, item in enumerate(score_list):
+ if item[1] == 1:
+ tp += 1.0
+ elif item[1] == 0:
+ fp += 1.0
+ fn = gt_num - tp
+ recall = tp / (tp + fn)
+ precision = tp / (tp + fp)
+ rpX.append(recall)
+ rpY.append(precision)
+ fpn.append(fp)
+ recalln.append(tp)
+ thr.append(item[0][-1])
+ fppi.append(fp / img_num)
+
+ ap = _calculate_map(rpX, rpY)
+ return ap
+
+ def eval_mr(self, score_list, gt_num, img_num):
+ """Evaluate by Caltech-style log-average miss rate.
+
+ Args:
+ score_list(list[tuple[ndarray, int, str]]): Matching result.
+ a list of tuples (dtbox, label, imgID) in the descending
+ sort of dtbox.score.
+ gt_num(int): The number of gt boxes in the entire dataset.
+ img_num(int): The number of image in the entire dataset.
+
+ Returns:
+ mr(float): result of miss rate.
+ """
+
+ # find greater_than
+ def _find_gt(lst, target):
+ for idx, _item in enumerate(lst):
+ if _item >= target:
+ return idx
+ return len(lst) - 1
+
+ if self.mr_ref == 'CALTECH_-2':
+ # CALTECH_MRREF_2: anchor points (from 10^-2 to 1) as in
+ # P.Dollar's paper
+ ref = [
+ 0.0100, 0.0178, 0.03160, 0.0562, 0.1000, 0.1778, 0.3162,
+ 0.5623, 1.000
+ ]
+ else:
+ # CALTECH_MRREF_4: anchor points (from 10^-4 to 1) as in
+ # S.Zhang's paper
+ ref = [
+ 0.0001, 0.0003, 0.00100, 0.0032, 0.0100, 0.0316, 0.1000,
+ 0.3162, 1.000
+ ]
+
+ tp, fp = 0.0, 0.0
+ fppiX, fppiY = list(), list()
+ for i, item in enumerate(score_list):
+ if item[1] == 1:
+ tp += 1.0
+ elif item[1] == 0:
+ fp += 1.0
+
+ fn = gt_num - tp
+ recall = tp / (tp + fn)
+ missrate = 1.0 - recall
+ fppi = fp / img_num
+ fppiX.append(fppi)
+ fppiY.append(missrate)
+
+ score = list()
+ for pos in ref:
+ argmin = _find_gt(fppiX, pos)
+ if argmin >= 0:
+ score.append(fppiY[argmin])
+ score = np.array(score)
+ mr = np.exp(np.log(score).mean())
+ return mr
+
+ def eval_ji(self, samples):
+ """Evaluate by JI using multi_process.
+
+ Args:
+ samples(Dict[str, Image]): The detection result packaged by Image.
+
+ Returns:
+ ji(float): result of jaccard index.
+ """
+ import math
+ res_line = []
+ res_ji = []
+ for i in range(10):
+ score_thr = 1e-1 * i
+ total = len(samples)
+ stride = math.ceil(total / self.num_ji_process)
+ result_queue = Queue(10000)
+ results, procs = [], []
+ records = list(samples.items())
+ for i in range(self.num_ji_process):
+ start = i * stride
+ end = np.min([start + stride, total])
+ sample_data = dict(records[start:end])
+ p = Process(
+ target=self.compute_ji_with_ignore,
+ args=(result_queue, sample_data, score_thr))
+ p.start()
+ procs.append(p)
+ for i in range(total):
+ t = result_queue.get()
+ results.append(t)
+ for p in procs:
+ p.join()
+ line, mean_ratio = self.gather(results)
+ line = 'score_thr:{:.1f}, {}'.format(score_thr, line)
+ res_line.append(line)
+ res_ji.append(mean_ratio)
+ return max(res_ji)
+
+ def compute_ji_with_ignore(self, result_queue, dt_result, score_thr):
+ """Compute JI with ignore.
+
+ Args:
+ result_queue(Queue): The Queue for save compute result when
+ multi_process.
+ dt_result(dict[Image]): Detection result packaged by Image.
+ score_thr(float): The threshold of detection score.
+ Returns:
+ dict: compute result.
+ """
+ for ID, record in dt_result.items():
+ gt_boxes = record.gt_boxes
+ dt_boxes = record.dt_boxes
+ keep = dt_boxes[:, -1] > score_thr
+ dt_boxes = dt_boxes[keep][:, :-1]
+
+ gt_tag = np.array(gt_boxes[:, -1] != -1)
+ matches = self.compute_ji_matching(dt_boxes, gt_boxes[gt_tag, :4])
+ # get the unmatched_indices
+ matched_indices = np.array([j for (j, _) in matches])
+ unmatched_indices = list(
+ set(np.arange(dt_boxes.shape[0])) - set(matched_indices))
+ num_ignore_dt = self.get_ignores(dt_boxes[unmatched_indices],
+ gt_boxes[~gt_tag, :4])
+ matched_indices = np.array([j for (_, j) in matches])
+ unmatched_indices = list(
+ set(np.arange(gt_boxes[gt_tag].shape[0])) -
+ set(matched_indices))
+ num_ignore_gt = self.get_ignores(
+ gt_boxes[gt_tag][unmatched_indices], gt_boxes[~gt_tag, :4])
+ # compute results
+ eps = 1e-6
+ k = len(matches)
+ m = gt_tag.sum() - num_ignore_gt
+ n = dt_boxes.shape[0] - num_ignore_dt
+ ratio = k / (m + n - k + eps)
+ recall = k / (m + eps)
+ cover = k / (n + eps)
+ noise = 1 - cover
+ result_dict = dict(
+ ratio=ratio,
+ recall=recall,
+ cover=cover,
+ noise=noise,
+ k=k,
+ m=m,
+ n=n)
+ result_queue.put_nowait(result_dict)
+
+ @staticmethod
+ def gather(results):
+ """Integrate test results."""
+ assert len(results)
+ img_num = 0
+ for result in results:
+ if result['n'] != 0 or result['m'] != 0:
+ img_num += 1
+ mean_ratio = np.sum([rb['ratio'] for rb in results]) / img_num
+ valids = np.sum([rb['k'] for rb in results])
+ total = np.sum([rb['n'] for rb in results])
+ gtn = np.sum([rb['m'] for rb in results])
+ line = 'mean_ratio:{:.4f}, valids:{}, total:{}, gtn:{}'\
+ .format(mean_ratio, valids, total, gtn)
+ return line, mean_ratio
+
+ def compute_ji_matching(self, dt_boxes, gt_boxes):
+ """Match the annotation box for each detection box.
+
+ Args:
+ dt_boxes(ndarray): Detection boxes.
+ gt_boxes(ndarray): Ground_truth boxes.
+
+ Returns:
+ matches_(list[tuple[int, int]]): Match result.
+ """
+ assert dt_boxes.shape[-1] > 3 and gt_boxes.shape[-1] > 3
+ if dt_boxes.shape[0] < 1 or gt_boxes.shape[0] < 1:
+ return list()
+
+ ious = bbox_overlaps(dt_boxes, gt_boxes, mode='iou')
+ input_ = copy.deepcopy(ious)
+ input_[input_ < self.iou_thres] = 0
+ match_scipy = maximum_bipartite_matching(
+ csr_matrix(input_), perm_type='column')
+ matches_ = []
+ for i in range(len(match_scipy)):
+ if match_scipy[i] != -1:
+ matches_.append((i, int(match_scipy[i])))
+ return matches_
+
+ def get_ignores(self, dt_boxes, gt_boxes):
+ """Get the number of ignore bboxes."""
+ if gt_boxes.size:
+ ioas = bbox_overlaps(dt_boxes, gt_boxes, mode='iof')
+ ioas = np.max(ioas, axis=1)
+ rows = np.where(ioas > self.iou_thres)[0]
+ return len(rows)
+ else:
+ return 0
+
+
+class Image(object):
+ """Data structure for evaluation of CrowdHuman.
+
+ Note:
+ This implementation is modified from https://github.com/Purkialo/
+ CrowdDet/blob/master/lib/evaluate/APMRToolkits/image.py
+
+ Args:
+ mode (int): Select the mode of evaluate. Valid mode include
+ 0(just body box), 1(just head box) and 2(both of them).
+ Defaults to 0.
+ """
+
+ def __init__(self, mode):
+ self.ID = None
+ self.width = None
+ self.height = None
+ self.dt_boxes = None
+ self.gt_boxes = None
+ self.eval_mode = mode
+
+ self.ign_num = None
+ self.gt_num = None
+ self.dt_num = None
+
+ def load(self, record, body_key, head_key, class_names, gt_flag):
+ """Loading information for evaluation.
+
+ Args:
+ record (dict): Label information or test results.
+ The format might look something like this:
+ {
+ 'ID': '273271,c9db000d5146c15',
+ 'gtboxes': [
+ {'fbox': [72, 202, 163, 503], 'tag': 'person', ...},
+ {'fbox': [199, 180, 144, 499], 'tag': 'person', ...},
+ ...
+ ]
+ }
+ or:
+ {
+ 'ID': '273271,c9db000d5146c15',
+ 'width': 800,
+ 'height': 1067,
+ 'dtboxes': [
+ {
+ 'box': [306.22, 205.95, 164.05, 394.04],
+ 'score': 0.99,
+ 'tag': 1
+ },
+ {
+ 'box': [403.60, 178.66, 157.15, 421.33],
+ 'score': 0.99,
+ 'tag': 1
+ },
+ ...
+ ]
+ }
+ body_key (str, None): key of detection body box.
+ Valid when loading detection results and self.eval_mode!=1.
+ head_key (str, None): key of detection head box.
+ Valid when loading detection results and self.eval_mode!=0.
+ class_names (list[str]):class names of data set.
+ Defaults to ['background', 'person'].
+ gt_flag (bool): Indicate whether record is ground truth
+ or predicting the outcome.
+ """
+ if 'ID' in record and self.ID is None:
+ self.ID = record['ID']
+ if 'width' in record and self.width is None:
+ self.width = record['width']
+ if 'height' in record and self.height is None:
+ self.height = record['height']
+ if gt_flag:
+ self.gt_num = len(record['gtboxes'])
+ body_bbox, head_bbox = self.load_gt_boxes(record, 'gtboxes',
+ class_names)
+ if self.eval_mode == 0:
+ self.gt_boxes = body_bbox
+ self.ign_num = (body_bbox[:, -1] == -1).sum()
+ elif self.eval_mode == 1:
+ self.gt_boxes = head_bbox
+ self.ign_num = (head_bbox[:, -1] == -1).sum()
+ else:
+ gt_tag = np.array([
+ body_bbox[i, -1] != -1 and head_bbox[i, -1] != -1
+ for i in range(len(body_bbox))
+ ])
+ self.ign_num = (gt_tag == 0).sum()
+ self.gt_boxes = np.hstack(
+ (body_bbox[:, :-1], head_bbox[:, :-1],
+ gt_tag.reshape(-1, 1)))
+
+ if not gt_flag:
+ self.dt_num = len(record['dtboxes'])
+ if self.eval_mode == 0:
+ self.dt_boxes = self.load_det_boxes(record, 'dtboxes',
+ body_key, 'score')
+ elif self.eval_mode == 1:
+ self.dt_boxes = self.load_det_boxes(record, 'dtboxes',
+ head_key, 'score')
+ else:
+ body_dtboxes = self.load_det_boxes(record, 'dtboxes', body_key,
+ 'score')
+ head_dtboxes = self.load_det_boxes(record, 'dtboxes', head_key,
+ 'score')
+ self.dt_boxes = np.hstack((body_dtboxes, head_dtboxes))
+
+ @staticmethod
+ def load_gt_boxes(dict_input, key_name, class_names):
+ """load ground_truth and transform [x, y, w, h] to [x1, y1, x2, y2]"""
+ assert key_name in dict_input
+ if len(dict_input[key_name]) < 1:
+ return np.empty([0, 5])
+ head_bbox = []
+ body_bbox = []
+ for rb in dict_input[key_name]:
+ if rb['tag'] in class_names:
+ body_tag = class_names.index(rb['tag'])
+ head_tag = copy.deepcopy(body_tag)
+ else:
+ body_tag = -1
+ head_tag = -1
+ if 'extra' in rb:
+ if 'ignore' in rb['extra']:
+ if rb['extra']['ignore'] != 0:
+ body_tag = -1
+ head_tag = -1
+ if 'head_attr' in rb:
+ if 'ignore' in rb['head_attr']:
+ if rb['head_attr']['ignore'] != 0:
+ head_tag = -1
+ head_bbox.append(np.hstack((rb['hbox'], head_tag)))
+ body_bbox.append(np.hstack((rb['fbox'], body_tag)))
+ head_bbox = np.array(head_bbox)
+ head_bbox[:, 2:4] += head_bbox[:, :2]
+ body_bbox = np.array(body_bbox)
+ body_bbox[:, 2:4] += body_bbox[:, :2]
+ return body_bbox, head_bbox
+
+ @staticmethod
+ def load_det_boxes(dict_input, key_name, key_box, key_score, key_tag=None):
+ """load detection boxes."""
+ assert key_name in dict_input
+ if len(dict_input[key_name]) < 1:
+ return np.empty([0, 5])
+ else:
+ assert key_box in dict_input[key_name][0]
+ if key_score:
+ assert key_score in dict_input[key_name][0]
+ if key_tag:
+ assert key_tag in dict_input[key_name][0]
+ if key_score:
+ if key_tag:
+ bboxes = np.vstack([
+ np.hstack((rb[key_box], rb[key_score], rb[key_tag]))
+ for rb in dict_input[key_name]
+ ])
+ else:
+ bboxes = np.vstack([
+ np.hstack((rb[key_box], rb[key_score]))
+ for rb in dict_input[key_name]
+ ])
+ else:
+ if key_tag:
+ bboxes = np.vstack([
+ np.hstack((rb[key_box], rb[key_tag]))
+ for rb in dict_input[key_name]
+ ])
+ else:
+ bboxes = np.vstack(
+ [rb[key_box] for rb in dict_input[key_name]])
+ bboxes[:, 2:4] += bboxes[:, :2]
+ return bboxes
+
+ def clip_all_boader(self):
+ """Make sure boxes are within the image range."""
+
+ def _clip_boundary(boxes, height, width):
+ assert boxes.shape[-1] >= 4
+ boxes[:, 0] = np.minimum(np.maximum(boxes[:, 0], 0), width - 1)
+ boxes[:, 1] = np.minimum(np.maximum(boxes[:, 1], 0), height - 1)
+ boxes[:, 2] = np.maximum(np.minimum(boxes[:, 2], width), 0)
+ boxes[:, 3] = np.maximum(np.minimum(boxes[:, 3], height), 0)
+ return boxes
+
+ assert self.dt_boxes.shape[-1] >= 4
+ assert self.gt_boxes.shape[-1] >= 4
+ assert self.width is not None and self.height is not None
+ if self.eval_mode == 2:
+ self.dt_boxes[:, :4] = _clip_boundary(self.dt_boxes[:, :4],
+ self.height, self.width)
+ self.gt_boxes[:, :4] = _clip_boundary(self.gt_boxes[:, :4],
+ self.height, self.width)
+ self.dt_boxes[:, 4:8] = _clip_boundary(self.dt_boxes[:, 4:8],
+ self.height, self.width)
+ self.gt_boxes[:, 4:8] = _clip_boundary(self.gt_boxes[:, 4:8],
+ self.height, self.width)
+ else:
+ self.dt_boxes = _clip_boundary(self.dt_boxes, self.height,
+ self.width)
+ self.gt_boxes = _clip_boundary(self.gt_boxes, self.height,
+ self.width)
+
+ def compare_voc(self, thres):
+ """Match the detection results with the ground_truth by VOC.
+
+ Args:
+ thres (float): IOU threshold.
+
+ Returns:
+ score_list(list[tuple[ndarray, int, str]]): Matching result.
+ a list of tuples (dtbox, label, imgID) in the descending
+ sort of dtbox.score.
+ """
+ if self.dt_boxes is None:
+ return list()
+ dtboxes = self.dt_boxes
+ gtboxes = self.gt_boxes if self.gt_boxes is not None else list()
+ dtboxes.sort(key=lambda x: x.score, reverse=True)
+ gtboxes.sort(key=lambda x: x.ign)
+
+ score_list = list()
+ for i, dt in enumerate(dtboxes):
+ maxpos = -1
+ maxiou = thres
+
+ for j, gt in enumerate(gtboxes):
+ overlap = dt.iou(gt)
+ if overlap > maxiou:
+ maxiou = overlap
+ maxpos = j
+
+ if maxpos >= 0:
+ if gtboxes[maxpos].ign == 0:
+ gtboxes[maxpos].matched = 1
+ dtboxes[i].matched = 1
+ score_list.append((dt, self.ID))
+ else:
+ dtboxes[i].matched = -1
+ else:
+ dtboxes[i].matched = 0
+ score_list.append((dt, self.ID))
+ return score_list
+
+ def compare_caltech(self, thres):
+ """Match the detection results with the ground_truth by Caltech
+ matching strategy.
+
+ Args:
+ thres (float): IOU threshold.
+
+ Returns:
+ score_list(list[tuple[ndarray, int, str]]): Matching result.
+ a list of tuples (dtbox, label, imgID) in the descending
+ sort of dtbox.score.
+ """
+ if self.dt_boxes is None or self.gt_boxes is None:
+ return list()
+
+ dtboxes = self.dt_boxes if self.dt_boxes is not None else list()
+ gtboxes = self.gt_boxes if self.gt_boxes is not None else list()
+ dt_matched = np.zeros(dtboxes.shape[0])
+ gt_matched = np.zeros(gtboxes.shape[0])
+
+ dtboxes = np.array(sorted(dtboxes, key=lambda x: x[-1], reverse=True))
+ gtboxes = np.array(sorted(gtboxes, key=lambda x: x[-1], reverse=True))
+ if len(dtboxes):
+ overlap_iou = bbox_overlaps(dtboxes, gtboxes, mode='iou')
+ overlap_ioa = bbox_overlaps(dtboxes, gtboxes, mode='iof')
+ else:
+ return list()
+
+ score_list = list()
+ for i, dt in enumerate(dtboxes):
+ maxpos = -1
+ maxiou = thres
+ for j, gt in enumerate(gtboxes):
+ if gt_matched[j] == 1:
+ continue
+ if gt[-1] > 0:
+ overlap = overlap_iou[i][j]
+ if overlap > maxiou:
+ maxiou = overlap
+ maxpos = j
+ else:
+ if maxpos >= 0:
+ break
+ else:
+ overlap = overlap_ioa[i][j]
+ if overlap > thres:
+ maxiou = overlap
+ maxpos = j
+ if maxpos >= 0:
+ if gtboxes[maxpos, -1] > 0:
+ gt_matched[maxpos] = 1
+ dt_matched[i] = 1
+ score_list.append((dt, 1, self.ID))
+ else:
+ dt_matched[i] = -1
+ else:
+ dt_matched[i] = 0
+ score_list.append((dt, 0, self.ID))
+ return score_list
diff --git a/mmdet/evaluation/metrics/dump_det_results.py b/mmdet/evaluation/metrics/dump_det_results.py
new file mode 100644
index 0000000000000000000000000000000000000000..f3071d19a6ad0199458d13dfe6f570f181a5ea7f
--- /dev/null
+++ b/mmdet/evaluation/metrics/dump_det_results.py
@@ -0,0 +1,47 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+from typing import Sequence
+
+from mmengine.evaluator import DumpResults
+from mmengine.evaluator.metric import _to_cpu
+
+from mmdet.registry import METRICS
+from mmdet.structures.mask import encode_mask_results
+
+
+@METRICS.register_module()
+class DumpDetResults(DumpResults):
+ """Dump model predictions to a pickle file for offline evaluation.
+
+ Different from `DumpResults` in MMEngine, it compresses instance
+ segmentation masks into RLE format.
+
+ Args:
+ out_file_path (str): Path of the dumped file. Must end with '.pkl'
+ or '.pickle'.
+ collect_device (str): Device name used for collecting results from
+ different ranks during distributed training. Must be 'cpu' or
+ 'gpu'. Defaults to 'cpu'.
+ """
+
+ def process(self, data_batch: dict, data_samples: Sequence[dict]) -> None:
+ """transfer tensors in predictions to CPU."""
+ data_samples = _to_cpu(data_samples)
+ for data_sample in data_samples:
+ # remove gt
+ data_sample.pop('gt_instances', None)
+ data_sample.pop('ignored_instances', None)
+ data_sample.pop('gt_panoptic_seg', None)
+
+ if 'pred_instances' in data_sample:
+ pred = data_sample['pred_instances']
+ # encode mask to RLE
+ if 'masks' in pred:
+ pred['masks'] = encode_mask_results(pred['masks'].numpy())
+ if 'pred_panoptic_seg' in data_sample:
+ warnings.warn(
+ 'Panoptic segmentation map will not be compressed. '
+ 'The dumped file will be extremely large! '
+ 'Suggest using `CocoPanopticMetric` to save the coco '
+ 'format json and segmentation png files directly.')
+ self.results.extend(data_samples)
diff --git a/mmdet/evaluation/metrics/dump_proposals_metric.py b/mmdet/evaluation/metrics/dump_proposals_metric.py
new file mode 100644
index 0000000000000000000000000000000000000000..9e9c53654c15d4b1f7e6555a9a7c53f844cb071f
--- /dev/null
+++ b/mmdet/evaluation/metrics/dump_proposals_metric.py
@@ -0,0 +1,119 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+import os.path as osp
+from typing import Optional, Sequence
+
+from mmengine.dist import is_main_process
+from mmengine.evaluator import BaseMetric
+from mmengine.fileio import dump
+from mmengine.logging import MMLogger
+from mmengine.structures import InstanceData
+
+from mmdet.registry import METRICS
+
+
+@METRICS.register_module()
+class DumpProposals(BaseMetric):
+ """Dump proposals pseudo metric.
+
+ Args:
+ output_dir (str): The root directory for ``proposals_file``.
+ Defaults to ''.
+ proposals_file (str): Proposals file path. Defaults to 'proposals.pkl'.
+ num_max_proposals (int, optional): Maximum number of proposals to dump.
+ If not specified, all proposals will be dumped.
+ file_client_args (dict, optional): Arguments to instantiate the
+ corresponding backend in mmdet <= 3.0.0rc6. Defaults to None.
+ backend_args (dict, optional): Arguments to instantiate the
+ corresponding backend. Defaults to None.
+ collect_device (str): Device name used for collecting results from
+ different ranks during distributed training. Must be 'cpu' or
+ 'gpu'. Defaults to 'cpu'.
+ prefix (str, optional): The prefix that will be added in the metric
+ names to disambiguate homonymous metrics of different evaluators.
+ If prefix is not provided in the argument, self.default_prefix
+ will be used instead. Defaults to None.
+ """
+
+ default_prefix: Optional[str] = 'dump_proposals'
+
+ def __init__(self,
+ output_dir: str = '',
+ proposals_file: str = 'proposals.pkl',
+ num_max_proposals: Optional[int] = None,
+ file_client_args: dict = None,
+ backend_args: dict = None,
+ collect_device: str = 'cpu',
+ prefix: Optional[str] = None) -> None:
+ super().__init__(collect_device=collect_device, prefix=prefix)
+ self.num_max_proposals = num_max_proposals
+ # TODO: update after mmengine finish refactor fileio.
+ self.backend_args = backend_args
+ if file_client_args is not None:
+ raise RuntimeError(
+ 'The `file_client_args` is deprecated, '
+ 'please use `backend_args` instead, please refer to'
+ 'https://github.com/open-mmlab/mmdetection/blob/main/configs/_base_/datasets/coco_detection.py' # noqa: E501
+ )
+ self.output_dir = output_dir
+ assert proposals_file.endswith(('.pkl', '.pickle')), \
+ 'The output file must be a pkl file.'
+
+ self.proposals_file = os.path.join(self.output_dir, proposals_file)
+ if is_main_process():
+ os.makedirs(self.output_dir, exist_ok=True)
+
+ def process(self, data_batch: Sequence[dict],
+ data_samples: Sequence[dict]) -> None:
+ """Process one batch of data samples and predictions. The processed
+ results should be stored in ``self.results``, which will be used to
+ compute the metrics when all batches have been processed.
+
+ Args:
+ data_batch (dict): A batch of data from the dataloader.
+ data_samples (Sequence[dict]): A batch of data samples that
+ contain annotations and predictions.
+ """
+ for data_sample in data_samples:
+ pred = data_sample['pred_instances']
+ # `bboxes` is sorted by `scores`
+ ranked_scores, rank_inds = pred['scores'].sort(descending=True)
+ ranked_bboxes = pred['bboxes'][rank_inds, :]
+
+ ranked_bboxes = ranked_bboxes.cpu().numpy()
+ ranked_scores = ranked_scores.cpu().numpy()
+
+ pred_instance = InstanceData()
+ pred_instance.bboxes = ranked_bboxes
+ pred_instance.scores = ranked_scores
+ if self.num_max_proposals is not None:
+ pred_instance = pred_instance[:self.num_max_proposals]
+
+ img_path = data_sample['img_path']
+ # `file_name` is the key to obtain the proposals from the
+ # `proposals_list`.
+ file_name = osp.join(
+ osp.split(osp.split(img_path)[0])[-1],
+ osp.split(img_path)[-1])
+ result = {file_name: pred_instance}
+ self.results.append(result)
+
+ def compute_metrics(self, results: list) -> dict:
+ """Dump the processed results.
+
+ Args:
+ results (list): The processed results of each batch.
+
+ Returns:
+ dict: An empty dict.
+ """
+ logger: MMLogger = MMLogger.get_current_instance()
+ dump_results = {}
+ for result in results:
+ dump_results.update(result)
+ dump(
+ dump_results,
+ file=self.proposals_file,
+ backend_args=self.backend_args)
+ logger.info(f'Results are saved at {self.proposals_file}')
+ return {}
diff --git a/mmdet/evaluation/metrics/lvis_metric.py b/mmdet/evaluation/metrics/lvis_metric.py
new file mode 100644
index 0000000000000000000000000000000000000000..e4dd6141c0e3f94758a040fd2e2a72ea43ea9b63
--- /dev/null
+++ b/mmdet/evaluation/metrics/lvis_metric.py
@@ -0,0 +1,364 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import itertools
+import os.path as osp
+import tempfile
+import warnings
+from collections import OrderedDict
+from typing import Dict, List, Optional, Sequence, Union
+
+import numpy as np
+from mmengine.fileio import get_local_path
+from mmengine.logging import MMLogger
+from terminaltables import AsciiTable
+
+from mmdet.registry import METRICS
+from mmdet.structures.mask import encode_mask_results
+from ..functional import eval_recalls
+from .coco_metric import CocoMetric
+
+try:
+ import lvis
+ if getattr(lvis, '__version__', '0') >= '10.5.3':
+ warnings.warn(
+ 'mmlvis is deprecated, please install official lvis-api by "pip install git+https://github.com/lvis-dataset/lvis-api.git"', # noqa: E501
+ UserWarning)
+ from lvis import LVIS, LVISEval, LVISResults
+except ImportError:
+ lvis = None
+ LVISEval = None
+ LVISResults = None
+
+
+@METRICS.register_module()
+class LVISMetric(CocoMetric):
+ """LVIS evaluation metric.
+
+ Args:
+ ann_file (str, optional): Path to the coco format annotation file.
+ If not specified, ground truth annotations from the dataset will
+ be converted to coco format. Defaults to None.
+ metric (str | List[str]): Metrics to be evaluated. Valid metrics
+ include 'bbox', 'segm', 'proposal', and 'proposal_fast'.
+ Defaults to 'bbox'.
+ classwise (bool): Whether to evaluate the metric class-wise.
+ Defaults to False.
+ proposal_nums (Sequence[int]): Numbers of proposals to be evaluated.
+ Defaults to (100, 300, 1000).
+ iou_thrs (float | List[float], optional): IoU threshold to compute AP
+ and AR. If not specified, IoUs from 0.5 to 0.95 will be used.
+ Defaults to None.
+ metric_items (List[str], optional): Metric result names to be
+ recorded in the evaluation result. Defaults to None.
+ format_only (bool): Format the output results without perform
+ evaluation. It is useful when you want to format the result
+ to a specific format and submit it to the test server.
+ Defaults to False.
+ outfile_prefix (str, optional): The prefix of json files. It includes
+ the file path and the prefix of filename, e.g., "a/b/prefix".
+ If not specified, a temp file will be created. Defaults to None.
+ collect_device (str): Device name used for collecting results from
+ different ranks during distributed training. Must be 'cpu' or
+ 'gpu'. Defaults to 'cpu'.
+ prefix (str, optional): The prefix that will be added in the metric
+ names to disambiguate homonymous metrics of different evaluators.
+ If prefix is not provided in the argument, self.default_prefix
+ will be used instead. Defaults to None.
+ file_client_args (dict, optional): Arguments to instantiate the
+ corresponding backend in mmdet <= 3.0.0rc6. Defaults to None.
+ backend_args (dict, optional): Arguments to instantiate the
+ corresponding backend. Defaults to None.
+ """
+
+ default_prefix: Optional[str] = 'lvis'
+
+ def __init__(self,
+ ann_file: Optional[str] = None,
+ metric: Union[str, List[str]] = 'bbox',
+ classwise: bool = False,
+ proposal_nums: Sequence[int] = (100, 300, 1000),
+ iou_thrs: Optional[Union[float, Sequence[float]]] = None,
+ metric_items: Optional[Sequence[str]] = None,
+ format_only: bool = False,
+ outfile_prefix: Optional[str] = None,
+ collect_device: str = 'cpu',
+ prefix: Optional[str] = None,
+ file_client_args: dict = None,
+ backend_args: dict = None) -> None:
+ if lvis is None:
+ raise RuntimeError(
+ 'Package lvis is not installed. Please run "pip install '
+ 'git+https://github.com/lvis-dataset/lvis-api.git".')
+ super().__init__(collect_device=collect_device, prefix=prefix)
+ # coco evaluation metrics
+ self.metrics = metric if isinstance(metric, list) else [metric]
+ allowed_metrics = ['bbox', 'segm', 'proposal', 'proposal_fast']
+ for metric in self.metrics:
+ if metric not in allowed_metrics:
+ raise KeyError(
+ "metric should be one of 'bbox', 'segm', 'proposal', "
+ f"'proposal_fast', but got {metric}.")
+
+ # do class wise evaluation, default False
+ self.classwise = classwise
+
+ # proposal_nums used to compute recall or precision.
+ self.proposal_nums = list(proposal_nums)
+
+ # iou_thrs used to compute recall or precision.
+ if iou_thrs is None:
+ iou_thrs = np.linspace(
+ .5, 0.95, int(np.round((0.95 - .5) / .05)) + 1, endpoint=True)
+ self.iou_thrs = iou_thrs
+ self.metric_items = metric_items
+ self.format_only = format_only
+ if self.format_only:
+ assert outfile_prefix is not None, 'outfile_prefix must be not'
+ 'None when format_only is True, otherwise the result files will'
+ 'be saved to a temp directory which will be cleaned up at the end.'
+
+ self.outfile_prefix = outfile_prefix
+ self.backend_args = backend_args
+ if file_client_args is not None:
+ raise RuntimeError(
+ 'The `file_client_args` is deprecated, '
+ 'please use `backend_args` instead, please refer to'
+ 'https://github.com/open-mmlab/mmdetection/blob/main/configs/_base_/datasets/coco_detection.py' # noqa: E501
+ )
+
+ # if ann_file is not specified,
+ # initialize lvis api with the converted dataset
+ if ann_file is not None:
+ with get_local_path(
+ ann_file, backend_args=self.backend_args) as local_path:
+ self._lvis_api = LVIS(local_path)
+ else:
+ self._lvis_api = None
+
+ # handle dataset lazy init
+ self.cat_ids = None
+ self.img_ids = None
+
+ def fast_eval_recall(self,
+ results: List[dict],
+ proposal_nums: Sequence[int],
+ iou_thrs: Sequence[float],
+ logger: Optional[MMLogger] = None) -> np.ndarray:
+ """Evaluate proposal recall with LVIS's fast_eval_recall.
+
+ Args:
+ results (List[dict]): Results of the dataset.
+ proposal_nums (Sequence[int]): Proposal numbers used for
+ evaluation.
+ iou_thrs (Sequence[float]): IoU thresholds used for evaluation.
+ logger (MMLogger, optional): Logger used for logging the recall
+ summary.
+ Returns:
+ np.ndarray: Averaged recall results.
+ """
+ gt_bboxes = []
+ pred_bboxes = [result['bboxes'] for result in results]
+ for i in range(len(self.img_ids)):
+ ann_ids = self._lvis_api.get_ann_ids(img_ids=[self.img_ids[i]])
+ ann_info = self._lvis_api.load_anns(ann_ids)
+ if len(ann_info) == 0:
+ gt_bboxes.append(np.zeros((0, 4)))
+ continue
+ bboxes = []
+ for ann in ann_info:
+ x1, y1, w, h = ann['bbox']
+ bboxes.append([x1, y1, x1 + w, y1 + h])
+ bboxes = np.array(bboxes, dtype=np.float32)
+ if bboxes.shape[0] == 0:
+ bboxes = np.zeros((0, 4))
+ gt_bboxes.append(bboxes)
+
+ recalls = eval_recalls(
+ gt_bboxes, pred_bboxes, proposal_nums, iou_thrs, logger=logger)
+ ar = recalls.mean(axis=1)
+ return ar
+
+ # TODO: data_batch is no longer needed, consider adjusting the
+ # parameter position
+ def process(self, data_batch: dict, data_samples: Sequence[dict]) -> None:
+ """Process one batch of data samples and predictions. The processed
+ results should be stored in ``self.results``, which will be used to
+ compute the metrics when all batches have been processed.
+
+ Args:
+ data_batch (dict): A batch of data from the dataloader.
+ data_samples (Sequence[dict]): A batch of data samples that
+ contain annotations and predictions.
+ """
+ for data_sample in data_samples:
+ result = dict()
+ pred = data_sample['pred_instances']
+ result['img_id'] = data_sample['img_id']
+ result['bboxes'] = pred['bboxes'].cpu().numpy()
+ result['scores'] = pred['scores'].cpu().numpy()
+ result['labels'] = pred['labels'].cpu().numpy()
+ # encode mask to RLE
+ if 'masks' in pred:
+ result['masks'] = encode_mask_results(
+ pred['masks'].detach().cpu().numpy())
+ # some detectors use different scores for bbox and mask
+ if 'mask_scores' in pred:
+ result['mask_scores'] = pred['mask_scores'].cpu().numpy()
+
+ # parse gt
+ gt = dict()
+ gt['width'] = data_sample['ori_shape'][1]
+ gt['height'] = data_sample['ori_shape'][0]
+ gt['img_id'] = data_sample['img_id']
+ if self._lvis_api is None:
+ # TODO: Need to refactor to support LoadAnnotations
+ assert 'instances' in data_sample, \
+ 'ground truth is required for evaluation when ' \
+ '`ann_file` is not provided'
+ gt['anns'] = data_sample['instances']
+ # add converted result to the results list
+ self.results.append((gt, result))
+
+ def compute_metrics(self, results: list) -> Dict[str, float]:
+ """Compute the metrics from processed results.
+
+ Args:
+ results (list): The processed results of each batch.
+
+ Returns:
+ Dict[str, float]: The computed metrics. The keys are the names of
+ the metrics, and the values are corresponding results.
+ """
+ logger: MMLogger = MMLogger.get_current_instance()
+
+ # split gt and prediction list
+ gts, preds = zip(*results)
+
+ tmp_dir = None
+ if self.outfile_prefix is None:
+ tmp_dir = tempfile.TemporaryDirectory()
+ outfile_prefix = osp.join(tmp_dir.name, 'results')
+ else:
+ outfile_prefix = self.outfile_prefix
+
+ if self._lvis_api is None:
+ # use converted gt json file to initialize coco api
+ logger.info('Converting ground truth to coco format...')
+ coco_json_path = self.gt_to_coco_json(
+ gt_dicts=gts, outfile_prefix=outfile_prefix)
+ self._lvis_api = LVIS(coco_json_path)
+
+ # handle lazy init
+ if self.cat_ids is None:
+ self.cat_ids = self._lvis_api.get_cat_ids()
+ if self.img_ids is None:
+ self.img_ids = self._lvis_api.get_img_ids()
+
+ # convert predictions to coco format and dump to json file
+ result_files = self.results2json(preds, outfile_prefix)
+
+ eval_results = OrderedDict()
+ if self.format_only:
+ logger.info('results are saved in '
+ f'{osp.dirname(outfile_prefix)}')
+ return eval_results
+
+ lvis_gt = self._lvis_api
+
+ for metric in self.metrics:
+ logger.info(f'Evaluating {metric}...')
+
+ # TODO: May refactor fast_eval_recall to an independent metric?
+ # fast eval recall
+ if metric == 'proposal_fast':
+ ar = self.fast_eval_recall(
+ preds, self.proposal_nums, self.iou_thrs, logger=logger)
+ log_msg = []
+ for i, num in enumerate(self.proposal_nums):
+ eval_results[f'AR@{num}'] = ar[i]
+ log_msg.append(f'\nAR@{num}\t{ar[i]:.4f}')
+ log_msg = ''.join(log_msg)
+ logger.info(log_msg)
+ continue
+
+ try:
+ lvis_dt = LVISResults(lvis_gt, result_files[metric])
+ except IndexError:
+ logger.info(
+ 'The testing results of the whole dataset is empty.')
+ break
+
+ iou_type = 'bbox' if metric == 'proposal' else metric
+ lvis_eval = LVISEval(lvis_gt, lvis_dt, iou_type)
+ lvis_eval.params.imgIds = self.img_ids
+ metric_items = self.metric_items
+ if metric == 'proposal':
+ lvis_eval.params.useCats = 0
+ lvis_eval.params.maxDets = list(self.proposal_nums)
+ lvis_eval.evaluate()
+ lvis_eval.accumulate()
+ lvis_eval.summarize()
+ if metric_items is None:
+ metric_items = ['AR@300', 'ARs@300', 'ARm@300', 'ARl@300']
+ for k, v in lvis_eval.get_results().items():
+ if k in metric_items:
+ val = float('{:.3f}'.format(float(v)))
+ eval_results[k] = val
+
+ else:
+ lvis_eval.evaluate()
+ lvis_eval.accumulate()
+ lvis_eval.summarize()
+ lvis_results = lvis_eval.get_results()
+ if self.classwise: # Compute per-category AP
+ # Compute per-category AP
+ # from https://github.com/facebookresearch/detectron2/
+ precisions = lvis_eval.eval['precision']
+ # precision: (iou, recall, cls, area range, max dets)
+ assert len(self.cat_ids) == precisions.shape[2]
+
+ results_per_category = []
+ for idx, catId in enumerate(self.cat_ids):
+ # area range index 0: all area ranges
+ # max dets index -1: typically 100 per image
+ # the dimensions of precisions are
+ # [num_thrs, num_recalls, num_cats, num_area_rngs]
+ nm = self._lvis_api.load_cats([catId])[0]
+ precision = precisions[:, :, idx, 0]
+ precision = precision[precision > -1]
+ if precision.size:
+ ap = np.mean(precision)
+ else:
+ ap = float('nan')
+ results_per_category.append(
+ (f'{nm["name"]}', f'{float(ap):0.3f}'))
+ eval_results[f'{nm["name"]}_precision'] = round(ap, 3)
+
+ num_columns = min(6, len(results_per_category) * 2)
+ results_flatten = list(
+ itertools.chain(*results_per_category))
+ headers = ['category', 'AP'] * (num_columns // 2)
+ results_2d = itertools.zip_longest(*[
+ results_flatten[i::num_columns]
+ for i in range(num_columns)
+ ])
+ table_data = [headers]
+ table_data += [result for result in results_2d]
+ table = AsciiTable(table_data)
+ logger.info('\n' + table.table)
+
+ if metric_items is None:
+ metric_items = [
+ 'AP', 'AP50', 'AP75', 'APs', 'APm', 'APl', 'APr',
+ 'APc', 'APf'
+ ]
+
+ for k, v in lvis_results.items():
+ if k in metric_items:
+ key = '{}_{}'.format(metric, k)
+ val = float('{:.3f}'.format(float(v)))
+ eval_results[key] = val
+
+ lvis_eval.print_results()
+ if tmp_dir is not None:
+ tmp_dir.cleanup()
+ return eval_results
diff --git a/mmdet/evaluation/metrics/openimages_metric.py b/mmdet/evaluation/metrics/openimages_metric.py
new file mode 100644
index 0000000000000000000000000000000000000000..d75c59e0e711c90bb1e5fbcc1529e95864e99e9a
--- /dev/null
+++ b/mmdet/evaluation/metrics/openimages_metric.py
@@ -0,0 +1,237 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+from collections import OrderedDict
+from typing import List, Optional, Sequence, Union
+
+import numpy as np
+from mmengine.evaluator import BaseMetric
+from mmengine.logging import MMLogger, print_log
+
+from mmdet.registry import METRICS
+from ..functional import eval_map
+
+
+@METRICS.register_module()
+class OpenImagesMetric(BaseMetric):
+ """OpenImages evaluation metric.
+
+ Evaluate detection mAP for OpenImages. Please refer to
+ https://storage.googleapis.com/openimages/web/evaluation.html for more
+ details.
+
+ Args:
+ iou_thrs (float or List[float]): IoU threshold. Defaults to 0.5.
+ ioa_thrs (float or List[float]): IoA threshold. Defaults to 0.5.
+ scale_ranges (List[tuple], optional): Scale ranges for evaluating
+ mAP. If not specified, all bounding boxes would be included in
+ evaluation. Defaults to None
+ use_group_of (bool): Whether consider group of groud truth bboxes
+ during evaluating. Defaults to True.
+ get_supercategory (bool): Whether to get parent class of the
+ current class. Default: True.
+ filter_labels (bool): Whether filter unannotated classes.
+ Default: True.
+ collect_device (str): Device name used for collecting results from
+ different ranks during distributed training. Must be 'cpu' or
+ 'gpu'. Defaults to 'cpu'.
+ prefix (str, optional): The prefix that will be added in the metric
+ names to disambiguate homonymous metrics of different evaluators.
+ If prefix is not provided in the argument, self.default_prefix
+ will be used instead. Defaults to None.
+ """
+ default_prefix: Optional[str] = 'openimages'
+
+ def __init__(self,
+ iou_thrs: Union[float, List[float]] = 0.5,
+ ioa_thrs: Union[float, List[float]] = 0.5,
+ scale_ranges: Optional[List[tuple]] = None,
+ use_group_of: bool = True,
+ get_supercategory: bool = True,
+ filter_labels: bool = True,
+ collect_device: str = 'cpu',
+ prefix: Optional[str] = None) -> None:
+ super().__init__(collect_device=collect_device, prefix=prefix)
+ self.iou_thrs = [iou_thrs] if isinstance(iou_thrs, float) else iou_thrs
+ self.ioa_thrs = [ioa_thrs] if (isinstance(ioa_thrs, float)
+ or ioa_thrs is None) else ioa_thrs
+ assert isinstance(self.iou_thrs, list) and isinstance(
+ self.ioa_thrs, list)
+ assert len(self.iou_thrs) == len(self.ioa_thrs)
+
+ self.scale_ranges = scale_ranges
+ self.use_group_of = use_group_of
+ self.get_supercategory = get_supercategory
+ self.filter_labels = filter_labels
+
+ def _get_supercategory_ann(self, instances: List[dict]) -> List[dict]:
+ """Get parent classes's annotation of the corresponding class.
+
+ Args:
+ instances (List[dict]): A list of annotations of the instances.
+
+ Returns:
+ List[dict]: Annotations extended with super-category.
+ """
+ supercat_instances = []
+ relation_matrix = self.dataset_meta['RELATION_MATRIX']
+ for instance in instances:
+ labels = np.where(relation_matrix[instance['bbox_label']])[0]
+ for label in labels:
+ if label == instance['bbox_label']:
+ continue
+ new_instance = copy.deepcopy(instance)
+ new_instance['bbox_label'] = label
+ supercat_instances.append(new_instance)
+ return supercat_instances
+
+ def _process_predictions(self, pred_bboxes: np.ndarray,
+ pred_scores: np.ndarray, pred_labels: np.ndarray,
+ gt_instances: list,
+ image_level_labels: np.ndarray) -> tuple:
+ """Process results of the corresponding class of the detection bboxes.
+
+ Note: It will choose to do the following two processing according to
+ the parameters:
+
+ 1. Whether to add parent classes of the corresponding class of the
+ detection bboxes.
+
+ 2. Whether to ignore the classes that unannotated on that image.
+
+ Args:
+ pred_bboxes (np.ndarray): bboxes predicted by the model
+ pred_scores (np.ndarray): scores predicted by the model
+ pred_labels (np.ndarray): labels predicted by the model
+ gt_instances (list): ground truth annotations
+ image_level_labels (np.ndarray): human-verified image level labels
+
+ Returns:
+ tuple: Processed bboxes, scores, and labels.
+ """
+ processed_bboxes = copy.deepcopy(pred_bboxes)
+ processed_scores = copy.deepcopy(pred_scores)
+ processed_labels = copy.deepcopy(pred_labels)
+ gt_labels = np.array([ins['bbox_label'] for ins in gt_instances],
+ dtype=np.int64)
+ if image_level_labels is not None:
+ allowed_classes = np.unique(
+ np.append(gt_labels, image_level_labels))
+ else:
+ allowed_classes = np.unique(gt_labels)
+ relation_matrix = self.dataset_meta['RELATION_MATRIX']
+ pred_classes = np.unique(pred_labels)
+ for pred_class in pred_classes:
+ classes = np.where(relation_matrix[pred_class])[0]
+ for cls in classes:
+ if (cls in allowed_classes and cls != pred_class
+ and self.get_supercategory):
+ # add super-supercategory preds
+ index = np.where(pred_labels == pred_class)[0]
+ processed_scores = np.concatenate(
+ [processed_scores, pred_scores[index]])
+ processed_bboxes = np.concatenate(
+ [processed_bboxes, pred_bboxes[index]])
+ extend_labels = np.full(index.shape, cls, dtype=np.int64)
+ processed_labels = np.concatenate(
+ [processed_labels, extend_labels])
+ elif cls not in allowed_classes and self.filter_labels:
+ # remove unannotated preds
+ index = np.where(processed_labels != cls)[0]
+ processed_scores = processed_scores[index]
+ processed_bboxes = processed_bboxes[index]
+ processed_labels = processed_labels[index]
+ return processed_bboxes, processed_scores, processed_labels
+
+ # TODO: data_batch is no longer needed, consider adjusting the
+ # parameter position
+ def process(self, data_batch: dict, data_samples: Sequence[dict]) -> None:
+ """Process one batch of data samples and predictions. The processed
+ results should be stored in ``self.results``, which will be used to
+ compute the metrics when all batches have been processed.
+
+ Args:
+ data_batch (dict): A batch of data from the dataloader.
+ data_samples (Sequence[dict]): A batch of data samples that
+ contain annotations and predictions.
+ """
+ for data_sample in data_samples:
+ gt = copy.deepcopy(data_sample)
+ # add super-category instances
+ # TODO: Need to refactor to support LoadAnnotations
+ instances = gt['instances']
+ if self.get_supercategory:
+ supercat_instances = self._get_supercategory_ann(instances)
+ instances.extend(supercat_instances)
+ gt_labels = []
+ gt_bboxes = []
+ is_group_ofs = []
+ for ins in instances:
+ gt_labels.append(ins['bbox_label'])
+ gt_bboxes.append(ins['bbox'])
+ is_group_ofs.append(ins['is_group_of'])
+ ann = dict(
+ labels=np.array(gt_labels, dtype=np.int64),
+ bboxes=np.array(gt_bboxes, dtype=np.float32).reshape((-1, 4)),
+ gt_is_group_ofs=np.array(is_group_ofs, dtype=bool))
+
+ image_level_labels = gt.get('image_level_labels', None)
+ pred = data_sample['pred_instances']
+ pred_bboxes = pred['bboxes'].cpu().numpy()
+ pred_scores = pred['scores'].cpu().numpy()
+ pred_labels = pred['labels'].cpu().numpy()
+
+ pred_bboxes, pred_scores, pred_labels = self._process_predictions(
+ pred_bboxes, pred_scores, pred_labels, instances,
+ image_level_labels)
+
+ dets = []
+ for label in range(len(self.dataset_meta['classes'])):
+ index = np.where(pred_labels == label)[0]
+ pred_bbox_scores = np.hstack(
+ [pred_bboxes[index], pred_scores[index].reshape((-1, 1))])
+ dets.append(pred_bbox_scores)
+ self.results.append((ann, dets))
+
+ def compute_metrics(self, results: list) -> dict:
+ """Compute the metrics from processed results.
+
+ Args:
+ results (list): The processed results of each batch.
+
+ Returns:
+ dict: The computed metrics. The keys are the names of the metrics,
+ and the values are corresponding results.
+ """
+ logger = MMLogger.get_current_instance()
+ gts, preds = zip(*results)
+ eval_results = OrderedDict()
+ # get dataset type
+ dataset_type = self.dataset_meta.get('dataset_type')
+ if dataset_type not in ['oid_challenge', 'oid_v6']:
+ dataset_type = 'oid_v6'
+ print_log(
+ 'Cannot infer dataset type from the length of the'
+ ' classes. Set `oid_v6` as dataset type.',
+ logger='current')
+ mean_aps = []
+ for i, (iou_thr,
+ ioa_thr) in enumerate(zip(self.iou_thrs, self.ioa_thrs)):
+ if self.use_group_of:
+ assert ioa_thr is not None, 'ioa_thr must have value when' \
+ ' using group_of in evaluation.'
+ print_log(f'\n{"-" * 15}iou_thr, ioa_thr: {iou_thr}, {ioa_thr}'
+ f'{"-" * 15}')
+ mean_ap, _ = eval_map(
+ preds,
+ gts,
+ scale_ranges=self.scale_ranges,
+ iou_thr=iou_thr,
+ ioa_thr=ioa_thr,
+ dataset=dataset_type,
+ logger=logger,
+ use_group_of=self.use_group_of)
+
+ mean_aps.append(mean_ap)
+ eval_results[f'AP{int(iou_thr * 100):02d}'] = round(mean_ap, 3)
+ eval_results['mAP'] = sum(mean_aps) / len(mean_aps)
+ return eval_results
diff --git a/mmdet/evaluation/metrics/voc_metric.py b/mmdet/evaluation/metrics/voc_metric.py
new file mode 100644
index 0000000000000000000000000000000000000000..d4b7c14af88b67d544ec6e37a4ea4170cf27b490
--- /dev/null
+++ b/mmdet/evaluation/metrics/voc_metric.py
@@ -0,0 +1,176 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+import warnings
+from collections import OrderedDict
+from typing import List, Optional, Sequence, Union
+
+import numpy as np
+from mmengine.evaluator import BaseMetric
+from mmengine.logging import MMLogger
+
+from mmdet.registry import METRICS
+from ..functional import eval_map, eval_recalls
+
+
+@METRICS.register_module()
+class VOCMetric(BaseMetric):
+ """Pascal VOC evaluation metric.
+
+ Args:
+ iou_thrs (float or List[float]): IoU threshold. Defaults to 0.5.
+ scale_ranges (List[tuple], optional): Scale ranges for evaluating
+ mAP. If not specified, all bounding boxes would be included in
+ evaluation. Defaults to None.
+ metric (str | list[str]): Metrics to be evaluated. Options are
+ 'mAP', 'recall'. If is list, the first setting in the list will
+ be used to evaluate metric.
+ proposal_nums (Sequence[int]): Proposal number used for evaluating
+ recalls, such as recall@100, recall@1000.
+ Default: (100, 300, 1000).
+ eval_mode (str): 'area' or '11points', 'area' means calculating the
+ area under precision-recall curve, '11points' means calculating
+ the average precision of recalls at [0, 0.1, ..., 1].
+ The PASCAL VOC2007 defaults to use '11points', while PASCAL
+ VOC2012 defaults to use 'area'.
+ collect_device (str): Device name used for collecting results from
+ different ranks during distributed training. Must be 'cpu' or
+ 'gpu'. Defaults to 'cpu'.
+ prefix (str, optional): The prefix that will be added in the metric
+ names to disambiguate homonymous metrics of different evaluators.
+ If prefix is not provided in the argument, self.default_prefix
+ will be used instead. Defaults to None.
+ """
+
+ default_prefix: Optional[str] = 'pascal_voc'
+
+ def __init__(self,
+ iou_thrs: Union[float, List[float]] = 0.5,
+ scale_ranges: Optional[List[tuple]] = None,
+ metric: Union[str, List[str]] = 'mAP',
+ proposal_nums: Sequence[int] = (100, 300, 1000),
+ eval_mode: str = '11points',
+ collect_device: str = 'cpu',
+ prefix: Optional[str] = None) -> None:
+ super().__init__(collect_device=collect_device, prefix=prefix)
+ self.iou_thrs = [iou_thrs] if isinstance(iou_thrs, float) \
+ else iou_thrs
+ self.scale_ranges = scale_ranges
+ # voc evaluation metrics
+ if not isinstance(metric, str):
+ assert len(metric) == 1
+ metric = metric[0]
+ allowed_metrics = ['recall', 'mAP']
+ if metric not in allowed_metrics:
+ raise KeyError(
+ f"metric should be one of 'recall', 'mAP', but got {metric}.")
+ self.metric = metric
+ self.proposal_nums = proposal_nums
+ assert eval_mode in ['area', '11points'], \
+ 'Unrecognized mode, only "area" and "11points" are supported'
+ self.eval_mode = eval_mode
+
+ # TODO: data_batch is no longer needed, consider adjusting the
+ # parameter position
+ def process(self, data_batch: dict, data_samples: Sequence[dict]) -> None:
+ """Process one batch of data samples and predictions. The processed
+ results should be stored in ``self.results``, which will be used to
+ compute the metrics when all batches have been processed.
+
+ Args:
+ data_batch (dict): A batch of data from the dataloader.
+ data_samples (Sequence[dict]): A batch of data samples that
+ contain annotations and predictions.
+ """
+ for data_sample in data_samples:
+ gt = copy.deepcopy(data_sample)
+ # TODO: Need to refactor to support LoadAnnotations
+ gt_instances = gt['gt_instances']
+ gt_ignore_instances = gt['ignored_instances']
+ ann = dict(
+ labels=gt_instances['labels'].cpu().numpy(),
+ bboxes=gt_instances['bboxes'].cpu().numpy(),
+ bboxes_ignore=gt_ignore_instances['bboxes'].cpu().numpy(),
+ labels_ignore=gt_ignore_instances['labels'].cpu().numpy())
+
+ pred = data_sample['pred_instances']
+ pred_bboxes = pred['bboxes'].cpu().numpy()
+ pred_scores = pred['scores'].cpu().numpy()
+ pred_labels = pred['labels'].cpu().numpy()
+
+ dets = []
+ for label in range(len(self.dataset_meta['classes'])):
+ index = np.where(pred_labels == label)[0]
+ pred_bbox_scores = np.hstack(
+ [pred_bboxes[index], pred_scores[index].reshape((-1, 1))])
+ dets.append(pred_bbox_scores)
+
+ self.results.append((ann, dets))
+
+ def compute_metrics(self, results: list) -> dict:
+ """Compute the metrics from processed results.
+
+ Args:
+ results (list): The processed results of each batch.
+
+ Returns:
+ dict: The computed metrics. The keys are the names of the metrics,
+ and the values are corresponding results.
+ """
+ logger: MMLogger = MMLogger.get_current_instance()
+ gts, preds = zip(*results)
+ eval_results = OrderedDict()
+ if self.metric == 'mAP':
+ assert isinstance(self.iou_thrs, list)
+ dataset_type = self.dataset_meta.get('dataset_type')
+ if dataset_type in ['VOC2007', 'VOC2012']:
+ dataset_name = 'voc'
+ if dataset_type == 'VOC2007' and self.eval_mode != '11points':
+ warnings.warn('Pascal VOC2007 uses `11points` as default '
+ 'evaluate mode, but you are using '
+ f'{self.eval_mode}.')
+ elif dataset_type == 'VOC2012' and self.eval_mode != 'area':
+ warnings.warn('Pascal VOC2012 uses `area` as default '
+ 'evaluate mode, but you are using '
+ f'{self.eval_mode}.')
+ else:
+ dataset_name = self.dataset_meta['classes']
+
+ mean_aps = []
+ for iou_thr in self.iou_thrs:
+ logger.info(f'\n{"-" * 15}iou_thr: {iou_thr}{"-" * 15}')
+ # Follow the official implementation,
+ # http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCdevkit_18-May-2011.tar
+ # we should use the legacy coordinate system in mmdet 1.x,
+ # which means w, h should be computed as 'x2 - x1 + 1` and
+ # `y2 - y1 + 1`
+ mean_ap, _ = eval_map(
+ preds,
+ gts,
+ scale_ranges=self.scale_ranges,
+ iou_thr=iou_thr,
+ dataset=dataset_name,
+ logger=logger,
+ eval_mode=self.eval_mode,
+ use_legacy_coordinate=True)
+ mean_aps.append(mean_ap)
+ eval_results[f'AP{int(iou_thr * 100):02d}'] = round(mean_ap, 3)
+ eval_results['mAP'] = sum(mean_aps) / len(mean_aps)
+ eval_results.move_to_end('mAP', last=False)
+ elif self.metric == 'recall':
+ # TODO: Currently not checked.
+ gt_bboxes = [ann['bboxes'] for ann in self.annotations]
+ recalls = eval_recalls(
+ gt_bboxes,
+ results,
+ self.proposal_nums,
+ self.iou_thrs,
+ logger=logger,
+ use_legacy_coordinate=True)
+ for i, num in enumerate(self.proposal_nums):
+ for j, iou_thr in enumerate(self.iou_thrs):
+ eval_results[f'recall@{num}@{iou_thr}'] = recalls[i, j]
+ if recalls.shape[1] > 1:
+ ar = recalls.mean(axis=1)
+ for i, num in enumerate(self.proposal_nums):
+ eval_results[f'AR@{num}'] = ar[i]
+ return eval_results
diff --git a/mmdet/models/__init__.py b/mmdet/models/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..1fe6ba414bc4ef9d0648ada4573620af6ff18c7b
--- /dev/null
+++ b/mmdet/models/__init__.py
@@ -0,0 +1,12 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .backbones import * # noqa: F401,F403
+from .data_preprocessors import * # noqa: F401,F403
+from .dense_heads import * # noqa: F401,F403
+from .detectors import * # noqa: F401,F403
+from .layers import * # noqa: F401,F403
+from .losses import * # noqa: F401,F403
+from .necks import * # noqa: F401,F403
+from .roi_heads import * # noqa: F401,F403
+from .seg_heads import * # noqa: F401,F403
+from .task_modules import * # noqa: F401,F403
+from .test_time_augs import * # noqa: F401,F403
diff --git a/mmdet/models/__pycache__/__init__.cpython-37.pyc b/mmdet/models/__pycache__/__init__.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..2b45b281812884f7c62d61872bf943c20faadccf
Binary files /dev/null and b/mmdet/models/__pycache__/__init__.cpython-37.pyc differ
diff --git a/mmdet/models/backbones/__init__.py b/mmdet/models/backbones/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..ada3c518ab43cdc887cad89e1d80194678ea45ed
--- /dev/null
+++ b/mmdet/models/backbones/__init__.py
@@ -0,0 +1,31 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .csp_darknet import CSPDarknet
+from .cspnext import CSPNeXt
+from .darknet import Darknet
+from .detectors_resnet import DetectoRS_ResNet
+from .detectors_resnext import DetectoRS_ResNeXt
+from .efficientnet import EfficientNet
+from .hourglass import HourglassNet
+from .hrnet import HRNet
+from .mobilenet_v2 import MobileNetV2
+from .pvt import PyramidVisionTransformer, PyramidVisionTransformerV2
+from .regnet import RegNet
+from .res2net import Res2Net
+from .resnest import ResNeSt
+from .resnet import ResNet, ResNetV1d
+from .resnext import ResNeXt
+from .ssd_vgg import SSDVGG
+from .swin import SwinTransformer
+from .trident_resnet import TridentResNet
+
+# lzx
+from .st_nobackbone import No_backbone_ST
+
+__all__ = [
+ 'RegNet', 'ResNet', 'ResNetV1d', 'ResNeXt', 'SSDVGG', 'HRNet',
+ 'MobileNetV2', 'Res2Net', 'HourglassNet', 'DetectoRS_ResNet',
+ 'DetectoRS_ResNeXt', 'Darknet', 'ResNeSt', 'TridentResNet', 'CSPDarknet',
+ 'SwinTransformer',
+ 'PyramidVisionTransformer',
+ 'PyramidVisionTransformerV2', 'EfficientNet', 'CSPNeXt', 'No_backbone_ST',
+]
diff --git a/mmdet/models/backbones/__pycache__/__init__.cpython-37.pyc b/mmdet/models/backbones/__pycache__/__init__.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..225688f56841dc7fc776c32df671e2fd43fae06a
Binary files /dev/null and b/mmdet/models/backbones/__pycache__/__init__.cpython-37.pyc differ
diff --git a/mmdet/models/backbones/__pycache__/csp_darknet.cpython-37.pyc b/mmdet/models/backbones/__pycache__/csp_darknet.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..6bd9dbe9498d52b4759fd131c89143b56bc6b721
Binary files /dev/null and b/mmdet/models/backbones/__pycache__/csp_darknet.cpython-37.pyc differ
diff --git a/mmdet/models/backbones/__pycache__/cspnext.cpython-37.pyc b/mmdet/models/backbones/__pycache__/cspnext.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..273158d6dc57ad26abfda97271d8c44b3ce990f5
Binary files /dev/null and b/mmdet/models/backbones/__pycache__/cspnext.cpython-37.pyc differ
diff --git a/mmdet/models/backbones/__pycache__/darknet.cpython-37.pyc b/mmdet/models/backbones/__pycache__/darknet.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..e0f870c3daaba942e0894196c33a4ff15f174ab3
Binary files /dev/null and b/mmdet/models/backbones/__pycache__/darknet.cpython-37.pyc differ
diff --git a/mmdet/models/backbones/__pycache__/detectors_resnet.cpython-37.pyc b/mmdet/models/backbones/__pycache__/detectors_resnet.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..46e9359c626bd3b67f9e0c94cb07e48018ad867e
Binary files /dev/null and b/mmdet/models/backbones/__pycache__/detectors_resnet.cpython-37.pyc differ
diff --git a/mmdet/models/backbones/__pycache__/detectors_resnext.cpython-37.pyc b/mmdet/models/backbones/__pycache__/detectors_resnext.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..6c63d643676cf04778688109b9422e65e7f55569
Binary files /dev/null and b/mmdet/models/backbones/__pycache__/detectors_resnext.cpython-37.pyc differ
diff --git a/mmdet/models/backbones/__pycache__/efficientnet.cpython-37.pyc b/mmdet/models/backbones/__pycache__/efficientnet.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..626c8589769a31c7e3c6b5e2d33c902d075af247
Binary files /dev/null and b/mmdet/models/backbones/__pycache__/efficientnet.cpython-37.pyc differ
diff --git a/mmdet/models/backbones/__pycache__/hourglass.cpython-37.pyc b/mmdet/models/backbones/__pycache__/hourglass.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..5e8065d225893833e3cff659d35ecd85849c34bb
Binary files /dev/null and b/mmdet/models/backbones/__pycache__/hourglass.cpython-37.pyc differ
diff --git a/mmdet/models/backbones/__pycache__/hrnet.cpython-37.pyc b/mmdet/models/backbones/__pycache__/hrnet.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..c97d61cd496a0a724f610e4b198624c2556eff63
Binary files /dev/null and b/mmdet/models/backbones/__pycache__/hrnet.cpython-37.pyc differ
diff --git a/mmdet/models/backbones/__pycache__/mobilenet_v2.cpython-37.pyc b/mmdet/models/backbones/__pycache__/mobilenet_v2.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..ecfaefe121a46aefc5866a3dc8d8490d863c3cd2
Binary files /dev/null and b/mmdet/models/backbones/__pycache__/mobilenet_v2.cpython-37.pyc differ
diff --git a/mmdet/models/backbones/__pycache__/pvt.cpython-37.pyc b/mmdet/models/backbones/__pycache__/pvt.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..5bd195a235721ad95335691bef1eb1edb4eba320
Binary files /dev/null and b/mmdet/models/backbones/__pycache__/pvt.cpython-37.pyc differ
diff --git a/mmdet/models/backbones/__pycache__/regnet.cpython-37.pyc b/mmdet/models/backbones/__pycache__/regnet.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..0b77bef99879f65a5e7db00ff0d5449839b518c8
Binary files /dev/null and b/mmdet/models/backbones/__pycache__/regnet.cpython-37.pyc differ
diff --git a/mmdet/models/backbones/__pycache__/res2net.cpython-37.pyc b/mmdet/models/backbones/__pycache__/res2net.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..273cc9dcc6e6f98f4689809d5ccde145aff1bc00
Binary files /dev/null and b/mmdet/models/backbones/__pycache__/res2net.cpython-37.pyc differ
diff --git a/mmdet/models/backbones/__pycache__/resnest.cpython-37.pyc b/mmdet/models/backbones/__pycache__/resnest.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..0c5d2d9e63b6ac68d70299fe836df8c99730ff8d
Binary files /dev/null and b/mmdet/models/backbones/__pycache__/resnest.cpython-37.pyc differ
diff --git a/mmdet/models/backbones/__pycache__/resnet.cpython-37.pyc b/mmdet/models/backbones/__pycache__/resnet.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..0b0f90bdaf6e0f8e1fd9362627bd0d8ff1ca24f0
Binary files /dev/null and b/mmdet/models/backbones/__pycache__/resnet.cpython-37.pyc differ
diff --git a/mmdet/models/backbones/__pycache__/resnext.cpython-37.pyc b/mmdet/models/backbones/__pycache__/resnext.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..5fac41ecf2068fda3231b75fead1f736458462ef
Binary files /dev/null and b/mmdet/models/backbones/__pycache__/resnext.cpython-37.pyc differ
diff --git a/mmdet/models/backbones/__pycache__/ssd_vgg.cpython-37.pyc b/mmdet/models/backbones/__pycache__/ssd_vgg.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..223438b92e343b278c6f460d2bffae7d030e3d46
Binary files /dev/null and b/mmdet/models/backbones/__pycache__/ssd_vgg.cpython-37.pyc differ
diff --git a/mmdet/models/backbones/__pycache__/st_nobackbone.cpython-37.pyc b/mmdet/models/backbones/__pycache__/st_nobackbone.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..63c8d6bee0e25bf0d2b474ddab408fd83ee9f98c
Binary files /dev/null and b/mmdet/models/backbones/__pycache__/st_nobackbone.cpython-37.pyc differ
diff --git a/mmdet/models/backbones/__pycache__/swin.cpython-37.pyc b/mmdet/models/backbones/__pycache__/swin.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..d4a11c63c3cae0273ab43b7f32700c28c095e40c
Binary files /dev/null and b/mmdet/models/backbones/__pycache__/swin.cpython-37.pyc differ
diff --git a/mmdet/models/backbones/__pycache__/trident_resnet.cpython-37.pyc b/mmdet/models/backbones/__pycache__/trident_resnet.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..e9233fdb247e1a3daee88070b07439bc4c224a17
Binary files /dev/null and b/mmdet/models/backbones/__pycache__/trident_resnet.cpython-37.pyc differ
diff --git a/mmdet/models/backbones/csp_darknet.py b/mmdet/models/backbones/csp_darknet.py
new file mode 100644
index 0000000000000000000000000000000000000000..138258787cc6b2ce0ebcc3561fa19168e54a1f1f
--- /dev/null
+++ b/mmdet/models/backbones/csp_darknet.py
@@ -0,0 +1,287 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+
+import torch
+import torch.nn as nn
+from mmcv.cnn import ConvModule, DepthwiseSeparableConvModule
+from mmengine.model import BaseModule
+from torch.nn.modules.batchnorm import _BatchNorm
+
+from mmdet.registry import MODELS
+from ..layers import CSPLayer
+
+
+class Focus(nn.Module):
+ """Focus width and height information into channel space.
+
+ Args:
+ in_channels (int): The input channels of this Module.
+ out_channels (int): The output channels of this Module.
+ kernel_size (int): The kernel size of the convolution. Default: 1
+ stride (int): The stride of the convolution. Default: 1
+ conv_cfg (dict): Config dict for convolution layer. Default: None,
+ which means using conv2d.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='BN', momentum=0.03, eps=0.001).
+ act_cfg (dict): Config dict for activation layer.
+ Default: dict(type='Swish').
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ kernel_size=1,
+ stride=1,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN', momentum=0.03, eps=0.001),
+ act_cfg=dict(type='Swish')):
+ super().__init__()
+ self.conv = ConvModule(
+ in_channels * 4,
+ out_channels,
+ kernel_size,
+ stride,
+ padding=(kernel_size - 1) // 2,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+
+ def forward(self, x):
+ # shape of x (b,c,w,h) -> y(b,4c,w/2,h/2)
+ patch_top_left = x[..., ::2, ::2]
+ patch_top_right = x[..., ::2, 1::2]
+ patch_bot_left = x[..., 1::2, ::2]
+ patch_bot_right = x[..., 1::2, 1::2]
+ x = torch.cat(
+ (
+ patch_top_left,
+ patch_bot_left,
+ patch_top_right,
+ patch_bot_right,
+ ),
+ dim=1,
+ )
+ return self.conv(x)
+
+
+class SPPBottleneck(BaseModule):
+ """Spatial pyramid pooling layer used in YOLOv3-SPP.
+
+ Args:
+ in_channels (int): The input channels of this Module.
+ out_channels (int): The output channels of this Module.
+ kernel_sizes (tuple[int]): Sequential of kernel sizes of pooling
+ layers. Default: (5, 9, 13).
+ conv_cfg (dict): Config dict for convolution layer. Default: None,
+ which means using conv2d.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='BN').
+ act_cfg (dict): Config dict for activation layer.
+ Default: dict(type='Swish').
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ kernel_sizes=(5, 9, 13),
+ conv_cfg=None,
+ norm_cfg=dict(type='BN', momentum=0.03, eps=0.001),
+ act_cfg=dict(type='Swish'),
+ init_cfg=None):
+ super().__init__(init_cfg)
+ mid_channels = in_channels // 2
+ self.conv1 = ConvModule(
+ in_channels,
+ mid_channels,
+ 1,
+ stride=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ self.poolings = nn.ModuleList([
+ nn.MaxPool2d(kernel_size=ks, stride=1, padding=ks // 2)
+ for ks in kernel_sizes
+ ])
+ conv2_channels = mid_channels * (len(kernel_sizes) + 1)
+ self.conv2 = ConvModule(
+ conv2_channels,
+ out_channels,
+ 1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+
+ def forward(self, x):
+ x = self.conv1(x)
+ with torch.cuda.amp.autocast(enabled=False):
+ x = torch.cat(
+ [x] + [pooling(x) for pooling in self.poolings], dim=1)
+ x = self.conv2(x)
+ return x
+
+
+@MODELS.register_module()
+class CSPDarknet(BaseModule):
+ """CSP-Darknet backbone used in YOLOv5 and YOLOX.
+
+ Args:
+ arch (str): Architecture of CSP-Darknet, from {P5, P6}.
+ Default: P5.
+ deepen_factor (float): Depth multiplier, multiply number of
+ blocks in CSP layer by this amount. Default: 1.0.
+ widen_factor (float): Width multiplier, multiply number of
+ channels in each layer by this amount. Default: 1.0.
+ out_indices (Sequence[int]): Output from which stages.
+ Default: (2, 3, 4).
+ frozen_stages (int): Stages to be frozen (stop grad and set eval
+ mode). -1 means not freezing any parameters. Default: -1.
+ use_depthwise (bool): Whether to use depthwise separable convolution.
+ Default: False.
+ arch_ovewrite(list): Overwrite default arch settings. Default: None.
+ spp_kernal_sizes: (tuple[int]): Sequential of kernel sizes of SPP
+ layers. Default: (5, 9, 13).
+ conv_cfg (dict): Config dict for convolution layer. Default: None.
+ norm_cfg (dict): Dictionary to construct and config norm layer.
+ Default: dict(type='BN', requires_grad=True).
+ act_cfg (dict): Config dict for activation layer.
+ Default: dict(type='LeakyReLU', negative_slope=0.1).
+ norm_eval (bool): Whether to set norm layers to eval mode, namely,
+ freeze running stats (mean and var). Note: Effect on Batch Norm
+ and its variants only.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+ Example:
+ >>> from mmdet.models import CSPDarknet
+ >>> import torch
+ >>> self = CSPDarknet(depth=53)
+ >>> self.eval()
+ >>> inputs = torch.rand(1, 3, 416, 416)
+ >>> level_outputs = self.forward(inputs)
+ >>> for level_out in level_outputs:
+ ... print(tuple(level_out.shape))
+ ...
+ (1, 256, 52, 52)
+ (1, 512, 26, 26)
+ (1, 1024, 13, 13)
+ """
+ # From left to right:
+ # in_channels, out_channels, num_blocks, add_identity, use_spp
+ arch_settings = {
+ 'P5': [[64, 128, 3, True, False], [128, 256, 9, True, False],
+ [256, 512, 9, True, False], [512, 1024, 3, False, True]],
+ 'P6': [[64, 128, 3, True, False], [128, 256, 9, True, False],
+ [256, 512, 9, True, False], [512, 768, 3, True, False],
+ [768, 1024, 3, False, True]]
+ }
+
+ def __init__(self,
+ arch='P5',
+ in_channels=3,
+ deepen_factor=1.0,
+ widen_factor=1.0,
+ out_indices=(2, 3, 4),
+ frozen_stages=-1,
+ use_depthwise=False,
+ arch_ovewrite=None,
+ spp_kernal_sizes=(5, 9, 13),
+ conv_cfg=None,
+ norm_cfg=dict(type='BN', momentum=0.03, eps=0.001),
+ act_cfg=dict(type='Swish'),
+ norm_eval=False,
+ init_cfg=dict(
+ type='Kaiming',
+ layer='Conv2d',
+ a=math.sqrt(5),
+ distribution='uniform',
+ mode='fan_in',
+ nonlinearity='leaky_relu')):
+ super().__init__(init_cfg)
+ arch_setting = self.arch_settings[arch]
+ if arch_ovewrite:
+ arch_setting = arch_ovewrite
+ assert set(out_indices).issubset(
+ i for i in range(len(arch_setting) + 1))
+ if frozen_stages not in range(-1, len(arch_setting) + 1):
+ raise ValueError('frozen_stages must be in range(-1, '
+ 'len(arch_setting) + 1). But received '
+ f'{frozen_stages}')
+
+ self.out_indices = out_indices
+ self.frozen_stages = frozen_stages
+ self.use_depthwise = use_depthwise
+ self.norm_eval = norm_eval
+ conv = DepthwiseSeparableConvModule if use_depthwise else ConvModule
+
+ self.stem = Focus(
+ in_channels,
+ int(arch_setting[0][0] * widen_factor),
+ kernel_size=3,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ self.layers = ['stem']
+
+ for i, (in_channels, out_channels, num_blocks, add_identity,
+ use_spp) in enumerate(arch_setting):
+ in_channels = int(in_channels * widen_factor)
+ out_channels = int(out_channels * widen_factor)
+ num_blocks = max(round(num_blocks * deepen_factor), 1)
+ stage = []
+ conv_layer = conv(
+ in_channels,
+ out_channels,
+ 3,
+ stride=2,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ stage.append(conv_layer)
+ if use_spp:
+ spp = SPPBottleneck(
+ out_channels,
+ out_channels,
+ kernel_sizes=spp_kernal_sizes,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ stage.append(spp)
+ csp_layer = CSPLayer(
+ out_channels,
+ out_channels,
+ num_blocks=num_blocks,
+ add_identity=add_identity,
+ use_depthwise=use_depthwise,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ stage.append(csp_layer)
+ self.add_module(f'stage{i + 1}', nn.Sequential(*stage))
+ self.layers.append(f'stage{i + 1}')
+
+ def _freeze_stages(self):
+ if self.frozen_stages >= 0:
+ for i in range(self.frozen_stages + 1):
+ m = getattr(self, self.layers[i])
+ m.eval()
+ for param in m.parameters():
+ param.requires_grad = False
+
+ def train(self, mode=True):
+ super(CSPDarknet, self).train(mode)
+ self._freeze_stages()
+ if mode and self.norm_eval:
+ for m in self.modules():
+ if isinstance(m, _BatchNorm):
+ m.eval()
+
+ def forward(self, x):
+ outs = []
+ for i, layer_name in enumerate(self.layers):
+ layer = getattr(self, layer_name)
+ x = layer(x)
+ if i in self.out_indices:
+ outs.append(x)
+ return tuple(outs)
diff --git a/mmdet/models/backbones/cspnext.py b/mmdet/models/backbones/cspnext.py
new file mode 100644
index 0000000000000000000000000000000000000000..9a02e94ec908b75a0fe7936fd0bc6ded4df1e65f
--- /dev/null
+++ b/mmdet/models/backbones/cspnext.py
@@ -0,0 +1,196 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+from typing import Sequence, Tuple
+
+import torch.nn as nn
+from mmcv.cnn import ConvModule, DepthwiseSeparableConvModule
+from mmengine.model import BaseModule
+from torch import Tensor
+from torch.nn.modules.batchnorm import _BatchNorm
+
+from mmdet.registry import MODELS
+from mmdet.utils import ConfigType, OptConfigType, OptMultiConfig
+from ..layers import CSPLayer
+from .csp_darknet import SPPBottleneck
+
+
+@MODELS.register_module()
+class CSPNeXt(BaseModule):
+ """CSPNeXt backbone used in RTMDet.
+
+ Args:
+ arch (str): Architecture of CSPNeXt, from {P5, P6}.
+ Defaults to P5.
+ expand_ratio (float): Ratio to adjust the number of channels of the
+ hidden layer. Defaults to 0.5.
+ deepen_factor (float): Depth multiplier, multiply number of
+ blocks in CSP layer by this amount. Defaults to 1.0.
+ widen_factor (float): Width multiplier, multiply number of
+ channels in each layer by this amount. Defaults to 1.0.
+ out_indices (Sequence[int]): Output from which stages.
+ Defaults to (2, 3, 4).
+ frozen_stages (int): Stages to be frozen (stop grad and set eval
+ mode). -1 means not freezing any parameters. Defaults to -1.
+ use_depthwise (bool): Whether to use depthwise separable convolution.
+ Defaults to False.
+ arch_ovewrite (list): Overwrite default arch settings.
+ Defaults to None.
+ spp_kernel_sizes: (tuple[int]): Sequential of kernel sizes of SPP
+ layers. Defaults to (5, 9, 13).
+ channel_attention (bool): Whether to add channel attention in each
+ stage. Defaults to True.
+ conv_cfg (:obj:`ConfigDict` or dict, optional): Config dict for
+ convolution layer. Defaults to None.
+ norm_cfg (:obj:`ConfigDict` or dict): Dictionary to construct and
+ config norm layer. Defaults to dict(type='BN', requires_grad=True).
+ act_cfg (:obj:`ConfigDict` or dict): Config dict for activation layer.
+ Defaults to dict(type='SiLU').
+ norm_eval (bool): Whether to set norm layers to eval mode, namely,
+ freeze running stats (mean and var). Note: Effect on Batch Norm
+ and its variants only.
+ init_cfg (:obj:`ConfigDict` or dict or list[dict] or
+ list[:obj:`ConfigDict`]): Initialization config dict.
+ """
+ # From left to right:
+ # in_channels, out_channels, num_blocks, add_identity, use_spp
+ arch_settings = {
+ 'P5': [[64, 128, 3, True, False], [128, 256, 6, True, False],
+ [256, 512, 6, True, False], [512, 1024, 3, False, True]],
+ 'P6': [[64, 128, 3, True, False], [128, 256, 6, True, False],
+ [256, 512, 6, True, False], [512, 768, 3, True, False],
+ [768, 1024, 3, False, True]]
+ }
+
+ def __init__(
+ self,
+ arch: str = 'P5',
+ in_channels: int = 3,
+ deepen_factor: float = 1.0,
+ widen_factor: float = 1.0,
+ out_indices: Sequence[int] = (2, 3, 4),
+ frozen_stages: int = -1,
+ use_depthwise: bool = False,
+ expand_ratio: float = 0.5,
+ arch_ovewrite: dict = None,
+ spp_kernel_sizes: Sequence[int] = (5, 9, 13),
+ channel_attention: bool = True,
+ conv_cfg: OptConfigType = None,
+ norm_cfg: ConfigType = dict(type='BN', momentum=0.03, eps=0.001),
+ act_cfg: ConfigType = dict(type='SiLU'),
+ norm_eval: bool = False,
+ init_cfg: OptMultiConfig = dict(
+ type='Kaiming',
+ layer='Conv2d',
+ a=math.sqrt(5),
+ distribution='uniform',
+ mode='fan_in',
+ nonlinearity='leaky_relu')
+ ) -> None:
+ super().__init__(init_cfg=init_cfg)
+ arch_setting = self.arch_settings[arch]
+ if arch_ovewrite:
+ arch_setting = arch_ovewrite
+ assert set(out_indices).issubset(
+ i for i in range(len(arch_setting) + 1))
+ if frozen_stages not in range(-1, len(arch_setting) + 1):
+ raise ValueError('frozen_stages must be in range(-1, '
+ 'len(arch_setting) + 1). But received '
+ f'{frozen_stages}')
+
+ self.out_indices = out_indices
+ self.frozen_stages = frozen_stages
+ self.use_depthwise = use_depthwise
+ self.norm_eval = norm_eval
+ conv = DepthwiseSeparableConvModule if use_depthwise else ConvModule
+ self.stem = nn.Sequential(
+ ConvModule(
+ in_channels,
+ int(arch_setting[0][0] * widen_factor // 2),
+ 3,
+ padding=1,
+ stride=2,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg),
+ ConvModule(
+ int(arch_setting[0][0] * widen_factor // 2),
+ int(arch_setting[0][0] * widen_factor // 2),
+ 3,
+ padding=1,
+ stride=1,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg),
+ ConvModule(
+ int(arch_setting[0][0] * widen_factor // 2),
+ int(arch_setting[0][0] * widen_factor),
+ 3,
+ padding=1,
+ stride=1,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+ self.layers = ['stem']
+
+ for i, (in_channels, out_channels, num_blocks, add_identity,
+ use_spp) in enumerate(arch_setting):
+ in_channels = int(in_channels * widen_factor)
+ out_channels = int(out_channels * widen_factor)
+ num_blocks = max(round(num_blocks * deepen_factor), 1)
+ stage = []
+ conv_layer = conv(
+ in_channels,
+ out_channels,
+ 3,
+ stride=2,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ stage.append(conv_layer)
+ if use_spp:
+ spp = SPPBottleneck(
+ out_channels,
+ out_channels,
+ kernel_sizes=spp_kernel_sizes,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ stage.append(spp)
+ csp_layer = CSPLayer(
+ out_channels,
+ out_channels,
+ num_blocks=num_blocks,
+ add_identity=add_identity,
+ use_depthwise=use_depthwise,
+ use_cspnext_block=True,
+ expand_ratio=expand_ratio,
+ channel_attention=channel_attention,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ stage.append(csp_layer)
+ self.add_module(f'stage{i + 1}', nn.Sequential(*stage))
+ self.layers.append(f'stage{i + 1}')
+
+ def _freeze_stages(self) -> None:
+ if self.frozen_stages >= 0:
+ for i in range(self.frozen_stages + 1):
+ m = getattr(self, self.layers[i])
+ m.eval()
+ for param in m.parameters():
+ param.requires_grad = False
+
+ def train(self, mode=True) -> None:
+ super().train(mode)
+ self._freeze_stages()
+ if mode and self.norm_eval:
+ for m in self.modules():
+ if isinstance(m, _BatchNorm):
+ m.eval()
+
+ def forward(self, x: Tuple[Tensor, ...]) -> Tuple[Tensor, ...]:
+ outs = []
+ for i, layer_name in enumerate(self.layers):
+ layer = getattr(self, layer_name)
+ x = layer(x)
+ if i in self.out_indices:
+ outs.append(x)
+ return tuple(outs)
diff --git a/mmdet/models/backbones/darknet.py b/mmdet/models/backbones/darknet.py
new file mode 100644
index 0000000000000000000000000000000000000000..73566c1171717016b8d45256689e6c41c1c06cfb
--- /dev/null
+++ b/mmdet/models/backbones/darknet.py
@@ -0,0 +1,212 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+# Copyright (c) 2019 Western Digital Corporation or its affiliates.
+
+import warnings
+
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+from mmengine.model import BaseModule
+from torch.nn.modules.batchnorm import _BatchNorm
+
+from mmdet.registry import MODELS
+
+
+class ResBlock(BaseModule):
+ """The basic residual block used in Darknet. Each ResBlock consists of two
+ ConvModules and the input is added to the final output. Each ConvModule is
+ composed of Conv, BN, and LeakyReLU. In YoloV3 paper, the first convLayer
+ has half of the number of the filters as much as the second convLayer. The
+ first convLayer has filter size of 1x1 and the second one has the filter
+ size of 3x3.
+
+ Args:
+ in_channels (int): The input channels. Must be even.
+ conv_cfg (dict): Config dict for convolution layer. Default: None.
+ norm_cfg (dict): Dictionary to construct and config norm layer.
+ Default: dict(type='BN', requires_grad=True)
+ act_cfg (dict): Config dict for activation layer.
+ Default: dict(type='LeakyReLU', negative_slope=0.1).
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ def __init__(self,
+ in_channels,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ act_cfg=dict(type='LeakyReLU', negative_slope=0.1),
+ init_cfg=None):
+ super(ResBlock, self).__init__(init_cfg)
+ assert in_channels % 2 == 0 # ensure the in_channels is even
+ half_in_channels = in_channels // 2
+ # shortcut
+ cfg = dict(conv_cfg=conv_cfg, norm_cfg=norm_cfg, act_cfg=act_cfg)
+ self.conv1 = ConvModule(in_channels, half_in_channels, 1, **cfg)
+ self.conv2 = ConvModule(
+ half_in_channels, in_channels, 3, padding=1, **cfg)
+
+ def forward(self, x):
+ residual = x
+ out = self.conv1(x)
+ out = self.conv2(out)
+ out = out + residual
+
+ return out
+
+
+@MODELS.register_module()
+class Darknet(BaseModule):
+ """Darknet backbone.
+
+ Args:
+ depth (int): Depth of Darknet. Currently only support 53.
+ out_indices (Sequence[int]): Output from which stages.
+ frozen_stages (int): Stages to be frozen (stop grad and set eval mode).
+ -1 means not freezing any parameters. Default: -1.
+ conv_cfg (dict): Config dict for convolution layer. Default: None.
+ norm_cfg (dict): Dictionary to construct and config norm layer.
+ Default: dict(type='BN', requires_grad=True)
+ act_cfg (dict): Config dict for activation layer.
+ Default: dict(type='LeakyReLU', negative_slope=0.1).
+ norm_eval (bool): Whether to set norm layers to eval mode, namely,
+ freeze running stats (mean and var). Note: Effect on Batch Norm
+ and its variants only.
+ pretrained (str, optional): model pretrained path. Default: None
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+
+ Example:
+ >>> from mmdet.models import Darknet
+ >>> import torch
+ >>> self = Darknet(depth=53)
+ >>> self.eval()
+ >>> inputs = torch.rand(1, 3, 416, 416)
+ >>> level_outputs = self.forward(inputs)
+ >>> for level_out in level_outputs:
+ ... print(tuple(level_out.shape))
+ ...
+ (1, 256, 52, 52)
+ (1, 512, 26, 26)
+ (1, 1024, 13, 13)
+ """
+
+ # Dict(depth: (layers, channels))
+ arch_settings = {
+ 53: ((1, 2, 8, 8, 4), ((32, 64), (64, 128), (128, 256), (256, 512),
+ (512, 1024)))
+ }
+
+ def __init__(self,
+ depth=53,
+ in_channels =3,
+ out_indices=(3, 4, 5),
+ frozen_stages=-1,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ act_cfg=dict(type='LeakyReLU', negative_slope=0.1),
+ norm_eval=True,
+ pretrained=None,
+ init_cfg=None):
+ super(Darknet, self).__init__(init_cfg)
+ if depth not in self.arch_settings:
+ raise KeyError(f'invalid depth {depth} for darknet')
+
+ self.depth = depth
+ self.out_indices = out_indices
+ self.frozen_stages = frozen_stages
+ self.layers, self.channels = self.arch_settings[depth]
+
+ cfg = dict(conv_cfg=conv_cfg, norm_cfg=norm_cfg, act_cfg=act_cfg)
+
+ self.conv1 = ConvModule(in_channels, 32, 3, padding=1, **cfg)
+
+ self.cr_blocks = ['conv1']
+ for i, n_layers in enumerate(self.layers):
+ layer_name = f'conv_res_block{i + 1}'
+ in_c, out_c = self.channels[i]
+ self.add_module(
+ layer_name,
+ self.make_conv_res_block(in_c, out_c, n_layers, **cfg))
+ self.cr_blocks.append(layer_name)
+
+ self.norm_eval = norm_eval
+
+ assert not (init_cfg and pretrained), \
+ 'init_cfg and pretrained cannot be specified at the same time'
+ if isinstance(pretrained, str):
+ warnings.warn('DeprecationWarning: pretrained is deprecated, '
+ 'please use "init_cfg" instead')
+ self.init_cfg = dict(type='Pretrained', checkpoint=pretrained)
+ elif pretrained is None:
+ if init_cfg is None:
+ self.init_cfg = [
+ dict(type='Kaiming', layer='Conv2d'),
+ dict(
+ type='Constant',
+ val=1,
+ layer=['_BatchNorm', 'GroupNorm'])
+ ]
+ else:
+ raise TypeError('pretrained must be a str or None')
+
+ def forward(self, x):
+ outs = []
+ for i, layer_name in enumerate(self.cr_blocks):
+ cr_block = getattr(self, layer_name)
+ x = cr_block(x)
+ if i in self.out_indices:
+ outs.append(x)
+
+ return tuple(outs)
+
+ def _freeze_stages(self):
+ if self.frozen_stages >= 0:
+ for i in range(self.frozen_stages):
+ m = getattr(self, self.cr_blocks[i])
+ m.eval()
+ for param in m.parameters():
+ param.requires_grad = False
+
+ def train(self, mode=True):
+ super(Darknet, self).train(mode)
+ self._freeze_stages()
+ if mode and self.norm_eval:
+ for m in self.modules():
+ if isinstance(m, _BatchNorm):
+ m.eval()
+
+ @staticmethod
+ def make_conv_res_block(in_channels,
+ out_channels,
+ res_repeat,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ act_cfg=dict(type='LeakyReLU',
+ negative_slope=0.1)):
+ """In Darknet backbone, ConvLayer is usually followed by ResBlock. This
+ function will make that. The Conv layers always have 3x3 filters with
+ stride=2. The number of the filters in Conv layer is the same as the
+ out channels of the ResBlock.
+
+ Args:
+ in_channels (int): The number of input channels.
+ out_channels (int): The number of output channels.
+ res_repeat (int): The number of ResBlocks.
+ conv_cfg (dict): Config dict for convolution layer. Default: None.
+ norm_cfg (dict): Dictionary to construct and config norm layer.
+ Default: dict(type='BN', requires_grad=True)
+ act_cfg (dict): Config dict for activation layer.
+ Default: dict(type='LeakyReLU', negative_slope=0.1).
+ """
+
+ cfg = dict(conv_cfg=conv_cfg, norm_cfg=norm_cfg, act_cfg=act_cfg)
+
+ model = nn.Sequential()
+ model.add_module(
+ 'conv',
+ ConvModule(
+ in_channels, out_channels, 3, stride=2, padding=1, **cfg))
+ for idx in range(res_repeat):
+ model.add_module('res{}'.format(idx),
+ ResBlock(out_channels, **cfg))
+ return model
diff --git a/mmdet/models/backbones/detectors_resnet.py b/mmdet/models/backbones/detectors_resnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..f33424fce4a933d675f1f1d3d4ad89e0173c5f9e
--- /dev/null
+++ b/mmdet/models/backbones/detectors_resnet.py
@@ -0,0 +1,353 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch.nn as nn
+import torch.utils.checkpoint as cp
+from mmcv.cnn import build_conv_layer, build_norm_layer
+from mmengine.logging import MMLogger
+from mmengine.model import Sequential, constant_init, kaiming_init
+from mmengine.runner.checkpoint import load_checkpoint
+from torch.nn.modules.batchnorm import _BatchNorm
+
+from mmdet.registry import MODELS
+from .resnet import BasicBlock
+from .resnet import Bottleneck as _Bottleneck
+from .resnet import ResNet
+
+
+class Bottleneck(_Bottleneck):
+ r"""Bottleneck for the ResNet backbone in `DetectoRS
+ `_.
+
+ This bottleneck allows the users to specify whether to use
+ SAC (Switchable Atrous Convolution) and RFP (Recursive Feature Pyramid).
+
+ Args:
+ inplanes (int): The number of input channels.
+ planes (int): The number of output channels before expansion.
+ rfp_inplanes (int, optional): The number of channels from RFP.
+ Default: None. If specified, an additional conv layer will be
+ added for ``rfp_feat``. Otherwise, the structure is the same as
+ base class.
+ sac (dict, optional): Dictionary to construct SAC. Default: None.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+ expansion = 4
+
+ def __init__(self,
+ inplanes,
+ planes,
+ rfp_inplanes=None,
+ sac=None,
+ init_cfg=None,
+ **kwargs):
+ super(Bottleneck, self).__init__(
+ inplanes, planes, init_cfg=init_cfg, **kwargs)
+
+ assert sac is None or isinstance(sac, dict)
+ self.sac = sac
+ self.with_sac = sac is not None
+ if self.with_sac:
+ self.conv2 = build_conv_layer(
+ self.sac,
+ planes,
+ planes,
+ kernel_size=3,
+ stride=self.conv2_stride,
+ padding=self.dilation,
+ dilation=self.dilation,
+ bias=False)
+
+ self.rfp_inplanes = rfp_inplanes
+ if self.rfp_inplanes:
+ self.rfp_conv = build_conv_layer(
+ None,
+ self.rfp_inplanes,
+ planes * self.expansion,
+ 1,
+ stride=1,
+ bias=True)
+ if init_cfg is None:
+ self.init_cfg = dict(
+ type='Constant', val=0, override=dict(name='rfp_conv'))
+
+ def rfp_forward(self, x, rfp_feat):
+ """The forward function that also takes the RFP features as input."""
+
+ def _inner_forward(x):
+ identity = x
+
+ out = self.conv1(x)
+ out = self.norm1(out)
+ out = self.relu(out)
+
+ if self.with_plugins:
+ out = self.forward_plugin(out, self.after_conv1_plugin_names)
+
+ out = self.conv2(out)
+ out = self.norm2(out)
+ out = self.relu(out)
+
+ if self.with_plugins:
+ out = self.forward_plugin(out, self.after_conv2_plugin_names)
+
+ out = self.conv3(out)
+ out = self.norm3(out)
+
+ if self.with_plugins:
+ out = self.forward_plugin(out, self.after_conv3_plugin_names)
+
+ if self.downsample is not None:
+ identity = self.downsample(x)
+
+ out += identity
+
+ return out
+
+ if self.with_cp and x.requires_grad:
+ out = cp.checkpoint(_inner_forward, x)
+ else:
+ out = _inner_forward(x)
+
+ if self.rfp_inplanes:
+ rfp_feat = self.rfp_conv(rfp_feat)
+ out = out + rfp_feat
+
+ out = self.relu(out)
+
+ return out
+
+
+class ResLayer(Sequential):
+ """ResLayer to build ResNet style backbone for RPF in detectoRS.
+
+ The difference between this module and base class is that we pass
+ ``rfp_inplanes`` to the first block.
+
+ Args:
+ block (nn.Module): block used to build ResLayer.
+ inplanes (int): inplanes of block.
+ planes (int): planes of block.
+ num_blocks (int): number of blocks.
+ stride (int): stride of the first block. Default: 1
+ avg_down (bool): Use AvgPool instead of stride conv when
+ downsampling in the bottleneck. Default: False
+ conv_cfg (dict): dictionary to construct and config conv layer.
+ Default: None
+ norm_cfg (dict): dictionary to construct and config norm layer.
+ Default: dict(type='BN')
+ downsample_first (bool): Downsample at the first block or last block.
+ False for Hourglass, True for ResNet. Default: True
+ rfp_inplanes (int, optional): The number of channels from RFP.
+ Default: None. If specified, an additional conv layer will be
+ added for ``rfp_feat``. Otherwise, the structure is the same as
+ base class.
+ """
+
+ def __init__(self,
+ block,
+ inplanes,
+ planes,
+ num_blocks,
+ stride=1,
+ avg_down=False,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ downsample_first=True,
+ rfp_inplanes=None,
+ **kwargs):
+ self.block = block
+ assert downsample_first, f'downsample_first={downsample_first} is ' \
+ 'not supported in DetectoRS'
+
+ downsample = None
+ if stride != 1 or inplanes != planes * block.expansion:
+ downsample = []
+ conv_stride = stride
+ if avg_down and stride != 1:
+ conv_stride = 1
+ downsample.append(
+ nn.AvgPool2d(
+ kernel_size=stride,
+ stride=stride,
+ ceil_mode=True,
+ count_include_pad=False))
+ downsample.extend([
+ build_conv_layer(
+ conv_cfg,
+ inplanes,
+ planes * block.expansion,
+ kernel_size=1,
+ stride=conv_stride,
+ bias=False),
+ build_norm_layer(norm_cfg, planes * block.expansion)[1]
+ ])
+ downsample = nn.Sequential(*downsample)
+
+ layers = []
+ layers.append(
+ block(
+ inplanes=inplanes,
+ planes=planes,
+ stride=stride,
+ downsample=downsample,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ rfp_inplanes=rfp_inplanes,
+ **kwargs))
+ inplanes = planes * block.expansion
+ for _ in range(1, num_blocks):
+ layers.append(
+ block(
+ inplanes=inplanes,
+ planes=planes,
+ stride=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ **kwargs))
+
+ super(ResLayer, self).__init__(*layers)
+
+
+@MODELS.register_module()
+class DetectoRS_ResNet(ResNet):
+ """ResNet backbone for DetectoRS.
+
+ Args:
+ sac (dict, optional): Dictionary to construct SAC (Switchable Atrous
+ Convolution). Default: None.
+ stage_with_sac (list): Which stage to use sac. Default: (False, False,
+ False, False).
+ rfp_inplanes (int, optional): The number of channels from RFP.
+ Default: None. If specified, an additional conv layer will be
+ added for ``rfp_feat``. Otherwise, the structure is the same as
+ base class.
+ output_img (bool): If ``True``, the input image will be inserted into
+ the starting position of output. Default: False.
+ """
+
+ arch_settings = {
+ 50: (Bottleneck, (3, 4, 6, 3)),
+ 101: (Bottleneck, (3, 4, 23, 3)),
+ 152: (Bottleneck, (3, 8, 36, 3))
+ }
+
+ def __init__(self,
+ sac=None,
+ stage_with_sac=(False, False, False, False),
+ rfp_inplanes=None,
+ output_img=False,
+ pretrained=None,
+ init_cfg=None,
+ **kwargs):
+ assert not (init_cfg and pretrained), \
+ 'init_cfg and pretrained cannot be specified at the same time'
+ self.pretrained = pretrained
+ if init_cfg is not None:
+ assert isinstance(init_cfg, dict), \
+ f'init_cfg must be a dict, but got {type(init_cfg)}'
+ if 'type' in init_cfg:
+ assert init_cfg.get('type') == 'Pretrained', \
+ 'Only can initialize module by loading a pretrained model'
+ else:
+ raise KeyError('`init_cfg` must contain the key "type"')
+ self.pretrained = init_cfg.get('checkpoint')
+ self.sac = sac
+ self.stage_with_sac = stage_with_sac
+ self.rfp_inplanes = rfp_inplanes
+ self.output_img = output_img
+ super(DetectoRS_ResNet, self).__init__(**kwargs)
+
+ self.inplanes = self.stem_channels
+ self.res_layers = []
+ for i, num_blocks in enumerate(self.stage_blocks):
+ stride = self.strides[i]
+ dilation = self.dilations[i]
+ dcn = self.dcn if self.stage_with_dcn[i] else None
+ sac = self.sac if self.stage_with_sac[i] else None
+ if self.plugins is not None:
+ stage_plugins = self.make_stage_plugins(self.plugins, i)
+ else:
+ stage_plugins = None
+ planes = self.base_channels * 2**i
+ res_layer = self.make_res_layer(
+ block=self.block,
+ inplanes=self.inplanes,
+ planes=planes,
+ num_blocks=num_blocks,
+ stride=stride,
+ dilation=dilation,
+ style=self.style,
+ avg_down=self.avg_down,
+ with_cp=self.with_cp,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ dcn=dcn,
+ sac=sac,
+ rfp_inplanes=rfp_inplanes if i > 0 else None,
+ plugins=stage_plugins)
+ self.inplanes = planes * self.block.expansion
+ layer_name = f'layer{i + 1}'
+ self.add_module(layer_name, res_layer)
+ self.res_layers.append(layer_name)
+
+ self._freeze_stages()
+
+ # In order to be properly initialized by RFP
+ def init_weights(self):
+ # Calling this method will cause parameter initialization exception
+ # super(DetectoRS_ResNet, self).init_weights()
+
+ if isinstance(self.pretrained, str):
+ logger = MMLogger.get_current_instance()
+ load_checkpoint(self, self.pretrained, strict=False, logger=logger)
+ elif self.pretrained is None:
+ for m in self.modules():
+ if isinstance(m, nn.Conv2d):
+ kaiming_init(m)
+ elif isinstance(m, (_BatchNorm, nn.GroupNorm)):
+ constant_init(m, 1)
+
+ if self.dcn is not None:
+ for m in self.modules():
+ if isinstance(m, Bottleneck) and hasattr(
+ m.conv2, 'conv_offset'):
+ constant_init(m.conv2.conv_offset, 0)
+
+ if self.zero_init_residual:
+ for m in self.modules():
+ if isinstance(m, Bottleneck):
+ constant_init(m.norm3, 0)
+ elif isinstance(m, BasicBlock):
+ constant_init(m.norm2, 0)
+ else:
+ raise TypeError('pretrained must be a str or None')
+
+ def make_res_layer(self, **kwargs):
+ """Pack all blocks in a stage into a ``ResLayer`` for DetectoRS."""
+ return ResLayer(**kwargs)
+
+ def forward(self, x):
+ """Forward function."""
+ outs = list(super(DetectoRS_ResNet, self).forward(x))
+ if self.output_img:
+ outs.insert(0, x)
+ return tuple(outs)
+
+ def rfp_forward(self, x, rfp_feats):
+ """Forward function for RFP."""
+ if self.deep_stem:
+ x = self.stem(x)
+ else:
+ x = self.conv1(x)
+ x = self.norm1(x)
+ x = self.relu(x)
+ x = self.maxpool(x)
+ outs = []
+ for i, layer_name in enumerate(self.res_layers):
+ res_layer = getattr(self, layer_name)
+ rfp_feat = rfp_feats[i] if i > 0 else None
+ for layer in res_layer:
+ x = layer.rfp_forward(x, rfp_feat)
+ if i in self.out_indices:
+ outs.append(x)
+ return tuple(outs)
diff --git a/mmdet/models/backbones/detectors_resnext.py b/mmdet/models/backbones/detectors_resnext.py
new file mode 100644
index 0000000000000000000000000000000000000000..4bbd63154bb47910e27cf6a75e4b359e050063e1
--- /dev/null
+++ b/mmdet/models/backbones/detectors_resnext.py
@@ -0,0 +1,123 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+
+from mmcv.cnn import build_conv_layer, build_norm_layer
+
+from mmdet.registry import MODELS
+from .detectors_resnet import Bottleneck as _Bottleneck
+from .detectors_resnet import DetectoRS_ResNet
+
+
+class Bottleneck(_Bottleneck):
+ expansion = 4
+
+ def __init__(self,
+ inplanes,
+ planes,
+ groups=1,
+ base_width=4,
+ base_channels=64,
+ **kwargs):
+ """Bottleneck block for ResNeXt.
+
+ If style is "pytorch", the stride-two layer is the 3x3 conv layer, if
+ it is "caffe", the stride-two layer is the first 1x1 conv layer.
+ """
+ super(Bottleneck, self).__init__(inplanes, planes, **kwargs)
+
+ if groups == 1:
+ width = self.planes
+ else:
+ width = math.floor(self.planes *
+ (base_width / base_channels)) * groups
+
+ self.norm1_name, norm1 = build_norm_layer(
+ self.norm_cfg, width, postfix=1)
+ self.norm2_name, norm2 = build_norm_layer(
+ self.norm_cfg, width, postfix=2)
+ self.norm3_name, norm3 = build_norm_layer(
+ self.norm_cfg, self.planes * self.expansion, postfix=3)
+
+ self.conv1 = build_conv_layer(
+ self.conv_cfg,
+ self.inplanes,
+ width,
+ kernel_size=1,
+ stride=self.conv1_stride,
+ bias=False)
+ self.add_module(self.norm1_name, norm1)
+ fallback_on_stride = False
+ self.with_modulated_dcn = False
+ if self.with_dcn:
+ fallback_on_stride = self.dcn.pop('fallback_on_stride', False)
+ if self.with_sac:
+ self.conv2 = build_conv_layer(
+ self.sac,
+ width,
+ width,
+ kernel_size=3,
+ stride=self.conv2_stride,
+ padding=self.dilation,
+ dilation=self.dilation,
+ groups=groups,
+ bias=False)
+ elif not self.with_dcn or fallback_on_stride:
+ self.conv2 = build_conv_layer(
+ self.conv_cfg,
+ width,
+ width,
+ kernel_size=3,
+ stride=self.conv2_stride,
+ padding=self.dilation,
+ dilation=self.dilation,
+ groups=groups,
+ bias=False)
+ else:
+ assert self.conv_cfg is None, 'conv_cfg must be None for DCN'
+ self.conv2 = build_conv_layer(
+ self.dcn,
+ width,
+ width,
+ kernel_size=3,
+ stride=self.conv2_stride,
+ padding=self.dilation,
+ dilation=self.dilation,
+ groups=groups,
+ bias=False)
+
+ self.add_module(self.norm2_name, norm2)
+ self.conv3 = build_conv_layer(
+ self.conv_cfg,
+ width,
+ self.planes * self.expansion,
+ kernel_size=1,
+ bias=False)
+ self.add_module(self.norm3_name, norm3)
+
+
+@MODELS.register_module()
+class DetectoRS_ResNeXt(DetectoRS_ResNet):
+ """ResNeXt backbone for DetectoRS.
+
+ Args:
+ groups (int): The number of groups in ResNeXt.
+ base_width (int): The base width of ResNeXt.
+ """
+
+ arch_settings = {
+ 50: (Bottleneck, (3, 4, 6, 3)),
+ 101: (Bottleneck, (3, 4, 23, 3)),
+ 152: (Bottleneck, (3, 8, 36, 3))
+ }
+
+ def __init__(self, groups=1, base_width=4, **kwargs):
+ self.groups = groups
+ self.base_width = base_width
+ super(DetectoRS_ResNeXt, self).__init__(**kwargs)
+
+ def make_res_layer(self, **kwargs):
+ return super().make_res_layer(
+ groups=self.groups,
+ base_width=self.base_width,
+ base_channels=self.base_channels,
+ **kwargs)
diff --git a/mmdet/models/backbones/efficientnet.py b/mmdet/models/backbones/efficientnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..4dd552705714520d5064ffa8862435b1d273dfea
--- /dev/null
+++ b/mmdet/models/backbones/efficientnet.py
@@ -0,0 +1,419 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+import math
+from functools import partial
+
+import torch
+import torch.nn as nn
+import torch.utils.checkpoint as cp
+from mmcv.cnn.bricks import ConvModule, DropPath
+from mmengine.model import BaseModule, Sequential
+
+from mmdet.registry import MODELS
+from ..layers import InvertedResidual, SELayer
+from ..utils import make_divisible
+
+
+class EdgeResidual(BaseModule):
+ """Edge Residual Block.
+
+ Args:
+ in_channels (int): The input channels of this module.
+ out_channels (int): The output channels of this module.
+ mid_channels (int): The input channels of the second convolution.
+ kernel_size (int): The kernel size of the first convolution.
+ Defaults to 3.
+ stride (int): The stride of the first convolution. Defaults to 1.
+ se_cfg (dict, optional): Config dict for se layer. Defaults to None,
+ which means no se layer.
+ with_residual (bool): Use residual connection. Defaults to True.
+ conv_cfg (dict, optional): Config dict for convolution layer.
+ Defaults to None, which means using conv2d.
+ norm_cfg (dict): Config dict for normalization layer.
+ Defaults to ``dict(type='BN')``.
+ act_cfg (dict): Config dict for activation layer.
+ Defaults to ``dict(type='ReLU')``.
+ drop_path_rate (float): stochastic depth rate. Defaults to 0.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Defaults to False.
+ init_cfg (dict | list[dict], optional): Initialization config dict.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ mid_channels,
+ kernel_size=3,
+ stride=1,
+ se_cfg=None,
+ with_residual=True,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ drop_path_rate=0.,
+ with_cp=False,
+ init_cfg=None,
+ **kwargs):
+ super(EdgeResidual, self).__init__(init_cfg=init_cfg)
+ assert stride in [1, 2]
+ self.with_cp = with_cp
+ self.drop_path = DropPath(
+ drop_path_rate) if drop_path_rate > 0 else nn.Identity()
+ self.with_se = se_cfg is not None
+ self.with_residual = (
+ stride == 1 and in_channels == out_channels and with_residual)
+
+ if self.with_se:
+ assert isinstance(se_cfg, dict)
+
+ self.conv1 = ConvModule(
+ in_channels=in_channels,
+ out_channels=mid_channels,
+ kernel_size=kernel_size,
+ stride=1,
+ padding=kernel_size // 2,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+
+ if self.with_se:
+ self.se = SELayer(**se_cfg)
+
+ self.conv2 = ConvModule(
+ in_channels=mid_channels,
+ out_channels=out_channels,
+ kernel_size=1,
+ stride=stride,
+ padding=0,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=None)
+
+ def forward(self, x):
+
+ def _inner_forward(x):
+ out = x
+ out = self.conv1(out)
+
+ if self.with_se:
+ out = self.se(out)
+
+ out = self.conv2(out)
+
+ if self.with_residual:
+ return x + self.drop_path(out)
+ else:
+ return out
+
+ if self.with_cp and x.requires_grad:
+ out = cp.checkpoint(_inner_forward, x)
+ else:
+ out = _inner_forward(x)
+
+ return out
+
+
+def model_scaling(layer_setting, arch_setting):
+ """Scaling operation to the layer's parameters according to the
+ arch_setting."""
+ # scale width
+ new_layer_setting = copy.deepcopy(layer_setting)
+ for layer_cfg in new_layer_setting:
+ for block_cfg in layer_cfg:
+ block_cfg[1] = make_divisible(block_cfg[1] * arch_setting[0], 8)
+
+ # scale depth
+ split_layer_setting = [new_layer_setting[0]]
+ for layer_cfg in new_layer_setting[1:-1]:
+ tmp_index = [0]
+ for i in range(len(layer_cfg) - 1):
+ if layer_cfg[i + 1][1] != layer_cfg[i][1]:
+ tmp_index.append(i + 1)
+ tmp_index.append(len(layer_cfg))
+ for i in range(len(tmp_index) - 1):
+ split_layer_setting.append(layer_cfg[tmp_index[i]:tmp_index[i +
+ 1]])
+ split_layer_setting.append(new_layer_setting[-1])
+
+ num_of_layers = [len(layer_cfg) for layer_cfg in split_layer_setting[1:-1]]
+ new_layers = [
+ int(math.ceil(arch_setting[1] * num)) for num in num_of_layers
+ ]
+
+ merge_layer_setting = [split_layer_setting[0]]
+ for i, layer_cfg in enumerate(split_layer_setting[1:-1]):
+ if new_layers[i] <= num_of_layers[i]:
+ tmp_layer_cfg = layer_cfg[:new_layers[i]]
+ else:
+ tmp_layer_cfg = copy.deepcopy(layer_cfg) + [layer_cfg[-1]] * (
+ new_layers[i] - num_of_layers[i])
+ if tmp_layer_cfg[0][3] == 1 and i != 0:
+ merge_layer_setting[-1] += tmp_layer_cfg.copy()
+ else:
+ merge_layer_setting.append(tmp_layer_cfg.copy())
+ merge_layer_setting.append(split_layer_setting[-1])
+
+ return merge_layer_setting
+
+
+@MODELS.register_module()
+class EfficientNet(BaseModule):
+ """EfficientNet backbone.
+
+ Args:
+ arch (str): Architecture of efficientnet. Defaults to b0.
+ out_indices (Sequence[int]): Output from which stages.
+ Defaults to (6, ).
+ frozen_stages (int): Stages to be frozen (all param fixed).
+ Defaults to 0, which means not freezing any parameters.
+ conv_cfg (dict): Config dict for convolution layer.
+ Defaults to None, which means using conv2d.
+ norm_cfg (dict): Config dict for normalization layer.
+ Defaults to dict(type='BN').
+ act_cfg (dict): Config dict for activation layer.
+ Defaults to dict(type='Swish').
+ norm_eval (bool): Whether to set norm layers to eval mode, namely,
+ freeze running stats (mean and var). Note: Effect on Batch Norm
+ and its variants only. Defaults to False.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Defaults to False.
+ """
+
+ # Parameters to build layers.
+ # 'b' represents the architecture of normal EfficientNet family includes
+ # 'b0', 'b1', 'b2', 'b3', 'b4', 'b5', 'b6', 'b7', 'b8'.
+ # 'e' represents the architecture of EfficientNet-EdgeTPU including 'es',
+ # 'em', 'el'.
+ # 6 parameters are needed to construct a layer, From left to right:
+ # - kernel_size: The kernel size of the block
+ # - out_channel: The number of out_channels of the block
+ # - se_ratio: The sequeeze ratio of SELayer.
+ # - stride: The stride of the block
+ # - expand_ratio: The expand_ratio of the mid_channels
+ # - block_type: -1: Not a block, 0: InvertedResidual, 1: EdgeResidual
+ layer_settings = {
+ 'b': [[[3, 32, 0, 2, 0, -1]],
+ [[3, 16, 4, 1, 1, 0]],
+ [[3, 24, 4, 2, 6, 0],
+ [3, 24, 4, 1, 6, 0]],
+ [[5, 40, 4, 2, 6, 0],
+ [5, 40, 4, 1, 6, 0]],
+ [[3, 80, 4, 2, 6, 0],
+ [3, 80, 4, 1, 6, 0],
+ [3, 80, 4, 1, 6, 0],
+ [5, 112, 4, 1, 6, 0],
+ [5, 112, 4, 1, 6, 0],
+ [5, 112, 4, 1, 6, 0]],
+ [[5, 192, 4, 2, 6, 0],
+ [5, 192, 4, 1, 6, 0],
+ [5, 192, 4, 1, 6, 0],
+ [5, 192, 4, 1, 6, 0],
+ [3, 320, 4, 1, 6, 0]],
+ [[1, 1280, 0, 1, 0, -1]]
+ ],
+ 'e': [[[3, 32, 0, 2, 0, -1]],
+ [[3, 24, 0, 1, 3, 1]],
+ [[3, 32, 0, 2, 8, 1],
+ [3, 32, 0, 1, 8, 1]],
+ [[3, 48, 0, 2, 8, 1],
+ [3, 48, 0, 1, 8, 1],
+ [3, 48, 0, 1, 8, 1],
+ [3, 48, 0, 1, 8, 1]],
+ [[5, 96, 0, 2, 8, 0],
+ [5, 96, 0, 1, 8, 0],
+ [5, 96, 0, 1, 8, 0],
+ [5, 96, 0, 1, 8, 0],
+ [5, 96, 0, 1, 8, 0],
+ [5, 144, 0, 1, 8, 0],
+ [5, 144, 0, 1, 8, 0],
+ [5, 144, 0, 1, 8, 0],
+ [5, 144, 0, 1, 8, 0]],
+ [[5, 192, 0, 2, 8, 0],
+ [5, 192, 0, 1, 8, 0]],
+ [[1, 1280, 0, 1, 0, -1]]
+ ]
+ } # yapf: disable
+
+ # Parameters to build different kinds of architecture.
+ # From left to right: scaling factor for width, scaling factor for depth,
+ # resolution.
+ arch_settings = {
+ 'b0': (1.0, 1.0, 224),
+ 'b1': (1.0, 1.1, 240),
+ 'b2': (1.1, 1.2, 260),
+ 'b3': (1.2, 1.4, 300),
+ 'b4': (1.4, 1.8, 380),
+ 'b5': (1.6, 2.2, 456),
+ 'b6': (1.8, 2.6, 528),
+ 'b7': (2.0, 3.1, 600),
+ 'b8': (2.2, 3.6, 672),
+ 'es': (1.0, 1.0, 224),
+ 'em': (1.0, 1.1, 240),
+ 'el': (1.2, 1.4, 300)
+ }
+
+ def __init__(self,
+ arch='b0',
+ in_channels =3,
+ drop_path_rate=0.,
+ out_indices=(6, ),
+ frozen_stages=0,
+ conv_cfg=dict(type='Conv2dAdaptivePadding'),
+ norm_cfg=dict(type='BN', eps=1e-3),
+ act_cfg=dict(type='Swish'),
+ norm_eval=False,
+ with_cp=False,
+ init_cfg=[
+ dict(type='Kaiming', layer='Conv2d'),
+ dict(
+ type='Constant',
+ layer=['_BatchNorm', 'GroupNorm'],
+ val=1)
+ ]):
+ super(EfficientNet, self).__init__(init_cfg)
+ assert arch in self.arch_settings, \
+ f'"{arch}" is not one of the arch_settings ' \
+ f'({", ".join(self.arch_settings.keys())})'
+ self.arch_setting = self.arch_settings[arch]
+ self.layer_setting = self.layer_settings[arch[:1]]
+ for index in out_indices:
+ if index not in range(0, len(self.layer_setting)):
+ raise ValueError('the item in out_indices must in '
+ f'range(0, {len(self.layer_setting)}). '
+ f'But received {index}')
+
+ if frozen_stages not in range(len(self.layer_setting) + 1):
+ raise ValueError('frozen_stages must be in range(0, '
+ f'{len(self.layer_setting) + 1}). '
+ f'But received {frozen_stages}')
+ self.drop_path_rate = drop_path_rate
+ self.out_indices = out_indices
+ self.frozen_stages = frozen_stages
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.act_cfg = act_cfg
+ self.norm_eval = norm_eval
+ self.with_cp = with_cp
+
+ self.layer_setting = model_scaling(self.layer_setting,
+ self.arch_setting)
+ block_cfg_0 = self.layer_setting[0][0]
+ block_cfg_last = self.layer_setting[-1][0]
+ self.in_channels = make_divisible(block_cfg_0[1], 8)
+ self.out_channels = block_cfg_last[1]
+ self.layers = nn.ModuleList()
+ self.layers.append(
+ ConvModule(
+ in_channels=in_channels,
+ out_channels=self.in_channels,
+ kernel_size=block_cfg_0[0],
+ stride=block_cfg_0[3],
+ padding=block_cfg_0[0] // 2,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg))
+ self.make_layer()
+ # Avoid building unused layers in mmdetection.
+ if len(self.layers) < max(self.out_indices) + 1:
+ self.layers.append(
+ ConvModule(
+ in_channels=self.in_channels,
+ out_channels=self.out_channels,
+ kernel_size=block_cfg_last[0],
+ stride=block_cfg_last[3],
+ padding=block_cfg_last[0] // 2,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg))
+
+ def make_layer(self):
+ # Without the first and the final conv block.
+ layer_setting = self.layer_setting[1:-1]
+
+ total_num_blocks = sum([len(x) for x in layer_setting])
+ block_idx = 0
+ dpr = [
+ x.item()
+ for x in torch.linspace(0, self.drop_path_rate, total_num_blocks)
+ ] # stochastic depth decay rule
+
+ for i, layer_cfg in enumerate(layer_setting):
+ # Avoid building unused layers in mmdetection.
+ if i > max(self.out_indices) - 1:
+ break
+ layer = []
+ for i, block_cfg in enumerate(layer_cfg):
+ (kernel_size, out_channels, se_ratio, stride, expand_ratio,
+ block_type) = block_cfg
+
+ mid_channels = int(self.in_channels * expand_ratio)
+ out_channels = make_divisible(out_channels, 8)
+ if se_ratio <= 0:
+ se_cfg = None
+ else:
+ # In mmdetection, the `divisor` is deleted to align
+ # the logic of SELayer with mmcls.
+ se_cfg = dict(
+ channels=mid_channels,
+ ratio=expand_ratio * se_ratio,
+ act_cfg=(self.act_cfg, dict(type='Sigmoid')))
+ if block_type == 1: # edge tpu
+ if i > 0 and expand_ratio == 3:
+ with_residual = False
+ expand_ratio = 4
+ else:
+ with_residual = True
+ mid_channels = int(self.in_channels * expand_ratio)
+ if se_cfg is not None:
+ # In mmdetection, the `divisor` is deleted to align
+ # the logic of SELayer with mmcls.
+ se_cfg = dict(
+ channels=mid_channels,
+ ratio=se_ratio * expand_ratio,
+ act_cfg=(self.act_cfg, dict(type='Sigmoid')))
+ block = partial(EdgeResidual, with_residual=with_residual)
+ else:
+ block = InvertedResidual
+ layer.append(
+ block(
+ in_channels=self.in_channels,
+ out_channels=out_channels,
+ mid_channels=mid_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ se_cfg=se_cfg,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg,
+ drop_path_rate=dpr[block_idx],
+ with_cp=self.with_cp,
+ # In mmdetection, `with_expand_conv` is set to align
+ # the logic of InvertedResidual with mmcls.
+ with_expand_conv=(mid_channels != self.in_channels)))
+ self.in_channels = out_channels
+ block_idx += 1
+ self.layers.append(Sequential(*layer))
+
+ def forward(self, x):
+ outs = []
+ for i, layer in enumerate(self.layers):
+ x = layer(x)
+ if i in self.out_indices:
+ outs.append(x)
+
+ return tuple(outs)
+
+ def _freeze_stages(self):
+ for i in range(self.frozen_stages):
+ m = self.layers[i]
+ m.eval()
+ for param in m.parameters():
+ param.requires_grad = False
+
+ def train(self, mode=True):
+ super(EfficientNet, self).train(mode)
+ self._freeze_stages()
+ if mode and self.norm_eval:
+ for m in self.modules():
+ if isinstance(m, nn.BatchNorm2d):
+ m.eval()
diff --git a/mmdet/models/backbones/hourglass.py b/mmdet/models/backbones/hourglass.py
new file mode 100644
index 0000000000000000000000000000000000000000..a5bada50aaa01c5c4f7bb7b20494a1b77043bd89
--- /dev/null
+++ b/mmdet/models/backbones/hourglass.py
@@ -0,0 +1,226 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Sequence
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule
+from mmengine.model import BaseModule
+
+from mmdet.registry import MODELS
+from mmdet.utils import ConfigType, OptMultiConfig
+from ..layers import ResLayer
+from .resnet import BasicBlock
+
+
+class HourglassModule(BaseModule):
+ """Hourglass Module for HourglassNet backbone.
+
+ Generate module recursively and use BasicBlock as the base unit.
+
+ Args:
+ depth (int): Depth of current HourglassModule.
+ stage_channels (list[int]): Feature channels of sub-modules in current
+ and follow-up HourglassModule.
+ stage_blocks (list[int]): Number of sub-modules stacked in current and
+ follow-up HourglassModule.
+ norm_cfg (ConfigType): Dictionary to construct and config norm layer.
+ Defaults to `dict(type='BN', requires_grad=True)`
+ upsample_cfg (ConfigType): Config dict for interpolate layer.
+ Defaults to `dict(mode='nearest')`
+ init_cfg (dict or ConfigDict, optional): the config to control the
+ initialization.
+ """
+
+ def __init__(self,
+ depth: int,
+ stage_channels: List[int],
+ stage_blocks: List[int],
+ norm_cfg: ConfigType = dict(type='BN', requires_grad=True),
+ upsample_cfg: ConfigType = dict(mode='nearest'),
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(init_cfg)
+
+ self.depth = depth
+
+ cur_block = stage_blocks[0]
+ next_block = stage_blocks[1]
+
+ cur_channel = stage_channels[0]
+ next_channel = stage_channels[1]
+
+ self.up1 = ResLayer(
+ BasicBlock, cur_channel, cur_channel, cur_block, norm_cfg=norm_cfg)
+
+ self.low1 = ResLayer(
+ BasicBlock,
+ cur_channel,
+ next_channel,
+ cur_block,
+ stride=2,
+ norm_cfg=norm_cfg)
+
+ if self.depth > 1:
+ self.low2 = HourglassModule(depth - 1, stage_channels[1:],
+ stage_blocks[1:])
+ else:
+ self.low2 = ResLayer(
+ BasicBlock,
+ next_channel,
+ next_channel,
+ next_block,
+ norm_cfg=norm_cfg)
+
+ self.low3 = ResLayer(
+ BasicBlock,
+ next_channel,
+ cur_channel,
+ cur_block,
+ norm_cfg=norm_cfg,
+ downsample_first=False)
+
+ self.up2 = F.interpolate
+ self.upsample_cfg = upsample_cfg
+
+ def forward(self, x: torch.Tensor) -> nn.Module:
+ """Forward function."""
+ up1 = self.up1(x)
+ low1 = self.low1(x)
+ low2 = self.low2(low1)
+ low3 = self.low3(low2)
+ # Fixing `scale factor` (e.g. 2) is common for upsampling, but
+ # in some cases the spatial size is mismatched and error will arise.
+ if 'scale_factor' in self.upsample_cfg:
+ up2 = self.up2(low3, **self.upsample_cfg)
+ else:
+ shape = up1.shape[2:]
+ up2 = self.up2(low3, size=shape, **self.upsample_cfg)
+ return up1 + up2
+
+
+@MODELS.register_module()
+class HourglassNet(BaseModule):
+ """HourglassNet backbone.
+
+ Stacked Hourglass Networks for Human Pose Estimation.
+ More details can be found in the `paper
+ `_ .
+
+ Args:
+ downsample_times (int): Downsample times in a HourglassModule.
+ num_stacks (int): Number of HourglassModule modules stacked,
+ 1 for Hourglass-52, 2 for Hourglass-104.
+ stage_channels (Sequence[int]): Feature channel of each sub-module in a
+ HourglassModule.
+ stage_blocks (Sequence[int]): Number of sub-modules stacked in a
+ HourglassModule.
+ feat_channel (int): Feature channel of conv after a HourglassModule.
+ norm_cfg (norm_cfg): Dictionary to construct and config norm layer.
+ init_cfg (dict or ConfigDict, optional): the config to control the
+ initialization.
+
+ Example:
+ >>> from mmdet.models import HourglassNet
+ >>> import torch
+ >>> self = HourglassNet()
+ >>> self.eval()
+ >>> inputs = torch.rand(1, 3, 511, 511)
+ >>> level_outputs = self.forward(inputs)
+ >>> for level_output in level_outputs:
+ ... print(tuple(level_output.shape))
+ (1, 256, 128, 128)
+ (1, 256, 128, 128)
+ """
+
+ def __init__(self,
+ in_channels:int = 3,
+ downsample_times: int = 5,
+ num_stacks: int = 2,
+ stage_channels: Sequence = (256, 256, 384, 384, 384, 512),
+ stage_blocks: Sequence = (2, 2, 2, 2, 2, 4),
+ feat_channel: int = 256,
+ norm_cfg: ConfigType = dict(type='BN', requires_grad=True),
+ init_cfg: OptMultiConfig = None) -> None:
+ assert init_cfg is None, 'To prevent abnormal initialization ' \
+ 'behavior, init_cfg is not allowed to be set'
+ super().__init__(init_cfg)
+
+ self.num_stacks = num_stacks
+ assert self.num_stacks >= 1
+ assert len(stage_channels) == len(stage_blocks)
+ assert len(stage_channels) > downsample_times
+
+ cur_channel = stage_channels[0]
+
+ self.stem = nn.Sequential(
+ ConvModule(
+ in_channels, cur_channel // 2, 7, padding=3, stride=2,
+ norm_cfg=norm_cfg),
+ ResLayer(
+ BasicBlock,
+ cur_channel // 2,
+ cur_channel,
+ 1,
+ stride=2,
+ norm_cfg=norm_cfg))
+
+ self.hourglass_modules = nn.ModuleList([
+ HourglassModule(downsample_times, stage_channels, stage_blocks)
+ for _ in range(num_stacks)
+ ])
+
+ self.inters = ResLayer(
+ BasicBlock,
+ cur_channel,
+ cur_channel,
+ num_stacks - 1,
+ norm_cfg=norm_cfg)
+
+ self.conv1x1s = nn.ModuleList([
+ ConvModule(
+ cur_channel, cur_channel, 1, norm_cfg=norm_cfg, act_cfg=None)
+ for _ in range(num_stacks - 1)
+ ])
+
+ self.out_convs = nn.ModuleList([
+ ConvModule(
+ cur_channel, feat_channel, 3, padding=1, norm_cfg=norm_cfg)
+ for _ in range(num_stacks)
+ ])
+
+ self.remap_convs = nn.ModuleList([
+ ConvModule(
+ feat_channel, cur_channel, 1, norm_cfg=norm_cfg, act_cfg=None)
+ for _ in range(num_stacks - 1)
+ ])
+
+ self.relu = nn.ReLU(inplace=True)
+
+ def init_weights(self) -> None:
+ """Init module weights."""
+ # Training Centripetal Model needs to reset parameters for Conv2d
+ super().init_weights()
+ for m in self.modules():
+ if isinstance(m, nn.Conv2d):
+ m.reset_parameters()
+
+ def forward(self, x: torch.Tensor) -> List[torch.Tensor]:
+ """Forward function."""
+ inter_feat = self.stem(x)
+ out_feats = []
+
+ for ind in range(self.num_stacks):
+ single_hourglass = self.hourglass_modules[ind]
+ out_conv = self.out_convs[ind]
+
+ hourglass_feat = single_hourglass(inter_feat)
+ out_feat = out_conv(hourglass_feat)
+ out_feats.append(out_feat)
+
+ if ind < self.num_stacks - 1:
+ inter_feat = self.conv1x1s[ind](
+ inter_feat) + self.remap_convs[ind](
+ out_feat)
+ inter_feat = self.inters[ind](self.relu(inter_feat))
+
+ return out_feats
diff --git a/mmdet/models/backbones/hrnet.py b/mmdet/models/backbones/hrnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..c0e023d2b5d7eeabcc37bacf9b488aa0f8eed867
--- /dev/null
+++ b/mmdet/models/backbones/hrnet.py
@@ -0,0 +1,590 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+
+import torch.nn as nn
+from mmcv.cnn import build_conv_layer, build_norm_layer
+from mmengine.model import BaseModule, ModuleList, Sequential
+from torch.nn.modules.batchnorm import _BatchNorm
+
+from mmdet.registry import MODELS
+from .resnet import BasicBlock, Bottleneck
+
+
+class HRModule(BaseModule):
+ """High-Resolution Module for HRNet.
+
+ In this module, every branch has 4 BasicBlocks/Bottlenecks. Fusion/Exchange
+ is in this module.
+ """
+
+ def __init__(self,
+ num_branches,
+ blocks,
+ num_blocks,
+ in_channels,
+ num_channels,
+ multiscale_output=True,
+ with_cp=False,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ block_init_cfg=None,
+ init_cfg=None):
+ super(HRModule, self).__init__(init_cfg)
+ self.block_init_cfg = block_init_cfg
+ self._check_branches(num_branches, num_blocks, in_channels,
+ num_channels)
+
+ self.in_channels = in_channels
+ self.num_branches = num_branches
+
+ self.multiscale_output = multiscale_output
+ self.norm_cfg = norm_cfg
+ self.conv_cfg = conv_cfg
+ self.with_cp = with_cp
+ self.branches = self._make_branches(num_branches, blocks, num_blocks,
+ num_channels)
+ self.fuse_layers = self._make_fuse_layers()
+ self.relu = nn.ReLU(inplace=False)
+
+ def _check_branches(self, num_branches, num_blocks, in_channels,
+ num_channels):
+ if num_branches != len(num_blocks):
+ error_msg = f'NUM_BRANCHES({num_branches}) ' \
+ f'!= NUM_BLOCKS({len(num_blocks)})'
+ raise ValueError(error_msg)
+
+ if num_branches != len(num_channels):
+ error_msg = f'NUM_BRANCHES({num_branches}) ' \
+ f'!= NUM_CHANNELS({len(num_channels)})'
+ raise ValueError(error_msg)
+
+ if num_branches != len(in_channels):
+ error_msg = f'NUM_BRANCHES({num_branches}) ' \
+ f'!= NUM_INCHANNELS({len(in_channels)})'
+ raise ValueError(error_msg)
+
+ def _make_one_branch(self,
+ branch_index,
+ block,
+ num_blocks,
+ num_channels,
+ stride=1):
+ downsample = None
+ if stride != 1 or \
+ self.in_channels[branch_index] != \
+ num_channels[branch_index] * block.expansion:
+ downsample = nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ self.in_channels[branch_index],
+ num_channels[branch_index] * block.expansion,
+ kernel_size=1,
+ stride=stride,
+ bias=False),
+ build_norm_layer(self.norm_cfg, num_channels[branch_index] *
+ block.expansion)[1])
+
+ layers = []
+ layers.append(
+ block(
+ self.in_channels[branch_index],
+ num_channels[branch_index],
+ stride,
+ downsample=downsample,
+ with_cp=self.with_cp,
+ norm_cfg=self.norm_cfg,
+ conv_cfg=self.conv_cfg,
+ init_cfg=self.block_init_cfg))
+ self.in_channels[branch_index] = \
+ num_channels[branch_index] * block.expansion
+ for i in range(1, num_blocks[branch_index]):
+ layers.append(
+ block(
+ self.in_channels[branch_index],
+ num_channels[branch_index],
+ with_cp=self.with_cp,
+ norm_cfg=self.norm_cfg,
+ conv_cfg=self.conv_cfg,
+ init_cfg=self.block_init_cfg))
+
+ return Sequential(*layers)
+
+ def _make_branches(self, num_branches, block, num_blocks, num_channels):
+ branches = []
+
+ for i in range(num_branches):
+ branches.append(
+ self._make_one_branch(i, block, num_blocks, num_channels))
+
+ return ModuleList(branches)
+
+ def _make_fuse_layers(self):
+ if self.num_branches == 1:
+ return None
+
+ num_branches = self.num_branches
+ in_channels = self.in_channels
+ fuse_layers = []
+ num_out_branches = num_branches if self.multiscale_output else 1
+ for i in range(num_out_branches):
+ fuse_layer = []
+ for j in range(num_branches):
+ if j > i:
+ fuse_layer.append(
+ nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ in_channels[j],
+ in_channels[i],
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ bias=False),
+ build_norm_layer(self.norm_cfg, in_channels[i])[1],
+ nn.Upsample(
+ scale_factor=2**(j - i), mode='nearest')))
+ elif j == i:
+ fuse_layer.append(None)
+ else:
+ conv_downsamples = []
+ for k in range(i - j):
+ if k == i - j - 1:
+ conv_downsamples.append(
+ nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ in_channels[j],
+ in_channels[i],
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ bias=False),
+ build_norm_layer(self.norm_cfg,
+ in_channels[i])[1]))
+ else:
+ conv_downsamples.append(
+ nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ in_channels[j],
+ in_channels[j],
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ bias=False),
+ build_norm_layer(self.norm_cfg,
+ in_channels[j])[1],
+ nn.ReLU(inplace=False)))
+ fuse_layer.append(nn.Sequential(*conv_downsamples))
+ fuse_layers.append(nn.ModuleList(fuse_layer))
+
+ return nn.ModuleList(fuse_layers)
+
+ def forward(self, x):
+ """Forward function."""
+ if self.num_branches == 1:
+ return [self.branches[0](x[0])]
+
+ for i in range(self.num_branches):
+ x[i] = self.branches[i](x[i])
+
+ x_fuse = []
+ for i in range(len(self.fuse_layers)):
+ y = 0
+ for j in range(self.num_branches):
+ if i == j:
+ y += x[j]
+ else:
+ y += self.fuse_layers[i][j](x[j])
+ x_fuse.append(self.relu(y))
+ return x_fuse
+
+
+@MODELS.register_module()
+class HRNet(BaseModule):
+ """HRNet backbone.
+
+ `High-Resolution Representations for Labeling Pixels and Regions
+ arXiv: `_.
+
+ Args:
+ extra (dict): Detailed configuration for each stage of HRNet.
+ There must be 4 stages, the configuration for each stage must have
+ 5 keys:
+
+ - num_modules(int): The number of HRModule in this stage.
+ - num_branches(int): The number of branches in the HRModule.
+ - block(str): The type of convolution block.
+ - num_blocks(tuple): The number of blocks in each branch.
+ The length must be equal to num_branches.
+ - num_channels(tuple): The number of channels in each branch.
+ The length must be equal to num_branches.
+ in_channels (int): Number of input image channels. Default: 3.
+ conv_cfg (dict): Dictionary to construct and config conv layer.
+ norm_cfg (dict): Dictionary to construct and config norm layer.
+ norm_eval (bool): Whether to set norm layers to eval mode, namely,
+ freeze running stats (mean and var). Note: Effect on Batch Norm
+ and its variants only. Default: True.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False.
+ zero_init_residual (bool): Whether to use zero init for last norm layer
+ in resblocks to let them behave as identity. Default: False.
+ multiscale_output (bool): Whether to output multi-level features
+ produced by multiple branches. If False, only the first level
+ feature will be output. Default: True.
+ pretrained (str, optional): Model pretrained path. Default: None.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+
+ Example:
+ >>> from mmdet.models import HRNet
+ >>> import torch
+ >>> extra = dict(
+ >>> stage1=dict(
+ >>> num_modules=1,
+ >>> num_branches=1,
+ >>> block='BOTTLENECK',
+ >>> num_blocks=(4, ),
+ >>> num_channels=(64, )),
+ >>> stage2=dict(
+ >>> num_modules=1,
+ >>> num_branches=2,
+ >>> block='BASIC',
+ >>> num_blocks=(4, 4),
+ >>> num_channels=(32, 64)),
+ >>> stage3=dict(
+ >>> num_modules=4,
+ >>> num_branches=3,
+ >>> block='BASIC',
+ >>> num_blocks=(4, 4, 4),
+ >>> num_channels=(32, 64, 128)),
+ >>> stage4=dict(
+ >>> num_modules=3,
+ >>> num_branches=4,
+ >>> block='BASIC',
+ >>> num_blocks=(4, 4, 4, 4),
+ >>> num_channels=(32, 64, 128, 256)))
+ >>> self = HRNet(extra, in_channels=1)
+ >>> self.eval()
+ >>> inputs = torch.rand(1, 1, 32, 32)
+ >>> level_outputs = self.forward(inputs)
+ >>> for level_out in level_outputs:
+ ... print(tuple(level_out.shape))
+ (1, 32, 8, 8)
+ (1, 64, 4, 4)
+ (1, 128, 2, 2)
+ (1, 256, 1, 1)
+ """
+
+ blocks_dict = {'BASIC': BasicBlock, 'BOTTLENECK': Bottleneck}
+
+ def __init__(self,
+ extra,
+ in_channels=3,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ norm_eval=True,
+ with_cp=False,
+ zero_init_residual=False,
+ multiscale_output=True,
+ pretrained=None,
+ init_cfg=None):
+ super(HRNet, self).__init__(init_cfg)
+
+ self.pretrained = pretrained
+ assert not (init_cfg and pretrained), \
+ 'init_cfg and pretrained cannot be specified at the same time'
+ if isinstance(pretrained, str):
+ warnings.warn('DeprecationWarning: pretrained is deprecated, '
+ 'please use "init_cfg" instead')
+ self.init_cfg = dict(type='Pretrained', checkpoint=pretrained)
+ elif pretrained is None:
+ if init_cfg is None:
+ self.init_cfg = [
+ dict(type='Kaiming', layer='Conv2d'),
+ dict(
+ type='Constant',
+ val=1,
+ layer=['_BatchNorm', 'GroupNorm'])
+ ]
+ else:
+ raise TypeError('pretrained must be a str or None')
+
+ # Assert configurations of 4 stages are in extra
+ assert 'stage1' in extra and 'stage2' in extra \
+ and 'stage3' in extra and 'stage4' in extra
+ # Assert whether the length of `num_blocks` and `num_channels` are
+ # equal to `num_branches`
+ for i in range(4):
+ cfg = extra[f'stage{i + 1}']
+ assert len(cfg['num_blocks']) == cfg['num_branches'] and \
+ len(cfg['num_channels']) == cfg['num_branches']
+
+ self.extra = extra
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.norm_eval = norm_eval
+ self.with_cp = with_cp
+ self.zero_init_residual = zero_init_residual
+
+ # stem net
+ self.norm1_name, norm1 = build_norm_layer(self.norm_cfg, 64, postfix=1)
+ self.norm2_name, norm2 = build_norm_layer(self.norm_cfg, 64, postfix=2)
+
+ self.conv1 = build_conv_layer(
+ self.conv_cfg,
+ in_channels,
+ 64,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ bias=False)
+
+ self.add_module(self.norm1_name, norm1)
+ self.conv2 = build_conv_layer(
+ self.conv_cfg,
+ 64,
+ 64,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ bias=False)
+
+ self.add_module(self.norm2_name, norm2)
+ self.relu = nn.ReLU(inplace=True)
+
+ # stage 1
+ self.stage1_cfg = self.extra['stage1']
+ num_channels = self.stage1_cfg['num_channels'][0]
+ block_type = self.stage1_cfg['block']
+ num_blocks = self.stage1_cfg['num_blocks'][0]
+
+ block = self.blocks_dict[block_type]
+ stage1_out_channels = num_channels * block.expansion
+ self.layer1 = self._make_layer(block, 64, num_channels, num_blocks)
+
+ # stage 2
+ self.stage2_cfg = self.extra['stage2']
+ num_channels = self.stage2_cfg['num_channels']
+ block_type = self.stage2_cfg['block']
+
+ block = self.blocks_dict[block_type]
+ num_channels = [channel * block.expansion for channel in num_channels]
+ self.transition1 = self._make_transition_layer([stage1_out_channels],
+ num_channels)
+ self.stage2, pre_stage_channels = self._make_stage(
+ self.stage2_cfg, num_channels)
+
+ # stage 3
+ self.stage3_cfg = self.extra['stage3']
+ num_channels = self.stage3_cfg['num_channels']
+ block_type = self.stage3_cfg['block']
+
+ block = self.blocks_dict[block_type]
+ num_channels = [channel * block.expansion for channel in num_channels]
+ self.transition2 = self._make_transition_layer(pre_stage_channels,
+ num_channels)
+ self.stage3, pre_stage_channels = self._make_stage(
+ self.stage3_cfg, num_channels)
+
+ # stage 4
+ self.stage4_cfg = self.extra['stage4']
+ num_channels = self.stage4_cfg['num_channels']
+ block_type = self.stage4_cfg['block']
+
+ block = self.blocks_dict[block_type]
+ num_channels = [channel * block.expansion for channel in num_channels]
+ self.transition3 = self._make_transition_layer(pre_stage_channels,
+ num_channels)
+ self.stage4, pre_stage_channels = self._make_stage(
+ self.stage4_cfg, num_channels, multiscale_output=multiscale_output)
+
+ @property
+ def norm1(self):
+ """nn.Module: the normalization layer named "norm1" """
+ return getattr(self, self.norm1_name)
+
+ @property
+ def norm2(self):
+ """nn.Module: the normalization layer named "norm2" """
+ return getattr(self, self.norm2_name)
+
+ def _make_transition_layer(self, num_channels_pre_layer,
+ num_channels_cur_layer):
+ num_branches_cur = len(num_channels_cur_layer)
+ num_branches_pre = len(num_channels_pre_layer)
+
+ transition_layers = []
+ for i in range(num_branches_cur):
+ if i < num_branches_pre:
+ if num_channels_cur_layer[i] != num_channels_pre_layer[i]:
+ transition_layers.append(
+ nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ num_channels_pre_layer[i],
+ num_channels_cur_layer[i],
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ bias=False),
+ build_norm_layer(self.norm_cfg,
+ num_channels_cur_layer[i])[1],
+ nn.ReLU(inplace=True)))
+ else:
+ transition_layers.append(None)
+ else:
+ conv_downsamples = []
+ for j in range(i + 1 - num_branches_pre):
+ in_channels = num_channels_pre_layer[-1]
+ out_channels = num_channels_cur_layer[i] \
+ if j == i - num_branches_pre else in_channels
+ conv_downsamples.append(
+ nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ in_channels,
+ out_channels,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ bias=False),
+ build_norm_layer(self.norm_cfg, out_channels)[1],
+ nn.ReLU(inplace=True)))
+ transition_layers.append(nn.Sequential(*conv_downsamples))
+
+ return nn.ModuleList(transition_layers)
+
+ def _make_layer(self, block, inplanes, planes, blocks, stride=1):
+ downsample = None
+ if stride != 1 or inplanes != planes * block.expansion:
+ downsample = nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ inplanes,
+ planes * block.expansion,
+ kernel_size=1,
+ stride=stride,
+ bias=False),
+ build_norm_layer(self.norm_cfg, planes * block.expansion)[1])
+
+ layers = []
+ block_init_cfg = None
+ if self.pretrained is None and not hasattr(
+ self, 'init_cfg') and self.zero_init_residual:
+ if block is BasicBlock:
+ block_init_cfg = dict(
+ type='Constant', val=0, override=dict(name='norm2'))
+ elif block is Bottleneck:
+ block_init_cfg = dict(
+ type='Constant', val=0, override=dict(name='norm3'))
+ layers.append(
+ block(
+ inplanes,
+ planes,
+ stride,
+ downsample=downsample,
+ with_cp=self.with_cp,
+ norm_cfg=self.norm_cfg,
+ conv_cfg=self.conv_cfg,
+ init_cfg=block_init_cfg,
+ ))
+ inplanes = planes * block.expansion
+ for i in range(1, blocks):
+ layers.append(
+ block(
+ inplanes,
+ planes,
+ with_cp=self.with_cp,
+ norm_cfg=self.norm_cfg,
+ conv_cfg=self.conv_cfg,
+ init_cfg=block_init_cfg))
+
+ return Sequential(*layers)
+
+ def _make_stage(self, layer_config, in_channels, multiscale_output=True):
+ num_modules = layer_config['num_modules']
+ num_branches = layer_config['num_branches']
+ num_blocks = layer_config['num_blocks']
+ num_channels = layer_config['num_channels']
+ block = self.blocks_dict[layer_config['block']]
+
+ hr_modules = []
+ block_init_cfg = None
+ if self.pretrained is None and not hasattr(
+ self, 'init_cfg') and self.zero_init_residual:
+ if block is BasicBlock:
+ block_init_cfg = dict(
+ type='Constant', val=0, override=dict(name='norm2'))
+ elif block is Bottleneck:
+ block_init_cfg = dict(
+ type='Constant', val=0, override=dict(name='norm3'))
+
+ for i in range(num_modules):
+ # multi_scale_output is only used for the last module
+ if not multiscale_output and i == num_modules - 1:
+ reset_multiscale_output = False
+ else:
+ reset_multiscale_output = True
+
+ hr_modules.append(
+ HRModule(
+ num_branches,
+ block,
+ num_blocks,
+ in_channels,
+ num_channels,
+ reset_multiscale_output,
+ with_cp=self.with_cp,
+ norm_cfg=self.norm_cfg,
+ conv_cfg=self.conv_cfg,
+ block_init_cfg=block_init_cfg))
+
+ return Sequential(*hr_modules), in_channels
+
+ def forward(self, x):
+ """Forward function."""
+
+ x = self.conv1(x) # 尺寸减半
+ x = self.norm1(x)
+ x = self.relu(x)
+ x = self.conv2(x) # 尺寸减半
+ x = self.norm2(x)
+ x = self.relu(x)
+ x = self.layer1(x) # 通道256
+
+ x_list = []
+ for i in range(self.stage2_cfg['num_branches']):
+ if self.transition1[i] is not None:
+ x_list.append(self.transition1[i](x)) # 尺寸不变 尺寸减半
+ else:
+ x_list.append(x)
+ y_list = self.stage2(x_list)
+
+ x_list = [] # 尺寸不变 尺寸减半 尺寸减半
+ for i in range(self.stage3_cfg['num_branches']):
+ if self.transition2[i] is not None:
+ x_list.append(self.transition2[i](y_list[-1]))
+ else:
+ x_list.append(y_list[i])
+ y_list = self.stage3(x_list)
+
+ x_list = [] # 尺寸不变 尺寸减半 尺寸减半 尺寸减半
+ for i in range(self.stage4_cfg['num_branches']):
+ if self.transition3[i] is not None:
+ x_list.append(self.transition3[i](y_list[-1]))
+ else:
+ x_list.append(y_list[i])
+ y_list = self.stage4(x_list)
+
+ return y_list
+
+ def train(self, mode=True):
+ """Convert the model into training mode will keeping the normalization
+ layer freezed."""
+ super(HRNet, self).train(mode)
+ if mode and self.norm_eval:
+ for m in self.modules():
+ # trick: eval have effect on BatchNorm only
+ if isinstance(m, _BatchNorm):
+ m.eval()
diff --git a/mmdet/models/backbones/hrnet_lite.py b/mmdet/models/backbones/hrnet_lite.py
new file mode 100644
index 0000000000000000000000000000000000000000..7f9de518af4273ba8ea8358bc6a0cea15db7d8e0
--- /dev/null
+++ b/mmdet/models/backbones/hrnet_lite.py
@@ -0,0 +1,941 @@
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import (ConvModule, DepthwiseSeparableConvModule,
+ build_conv_layer, build_norm_layer, constant_init,
+ normal_init)
+from torch.nn.modules.batchnorm import _BatchNorm
+import torch.utils.checkpoint as cp
+
+import mmcv
+from mmpose.utils import get_root_logger
+from mmpose.models.registry import BACKBONES
+from mmpose.models.backbones.resnet import BasicBlock, Bottleneck
+from mmpose.models.backbones.utils import load_checkpoint, channel_shuffle
+
+
+def channel_shuffle(x, groups):
+ """Channel Shuffle operation.
+
+ This function enables cross-group information flow for multiple groups
+ convolution layers.
+
+ Args:
+ x (Tensor): The input tensor.
+ groups (int): The number of groups to divide the input tensor
+ in the channel dimension.
+
+ Returns:
+ Tensor: The output tensor after channel shuffle operation.
+ """
+
+ batch_size, num_channels, height, width = x.size()
+ assert (num_channels % groups == 0), ('num_channels should be '
+ 'divisible by groups')
+ channels_per_group = num_channels // groups
+
+ x = x.view(batch_size, groups, channels_per_group, height, width)
+ x = torch.transpose(x, 1, 2).contiguous()
+ x = x.view(batch_size, groups * channels_per_group, height, width)
+
+ return x
+
+class SpatialWeighting(nn.Module):
+
+ def __init__(self,
+ channels,
+ ratio=16,
+ conv_cfg=None,
+ act_cfg=(dict(type='ReLU'), dict(type='Sigmoid'))):
+ super().__init__()
+ if isinstance(act_cfg, dict):
+ act_cfg = (act_cfg, act_cfg)
+ assert len(act_cfg) == 2
+ assert mmcv.is_tuple_of(act_cfg, dict)
+ self.global_avgpool = nn.AdaptiveAvgPool2d(1)
+ self.conv1 = ConvModule(
+ in_channels=channels,
+ out_channels=int(channels / ratio),
+ kernel_size=1,
+ stride=1,
+ conv_cfg=conv_cfg,
+ act_cfg=act_cfg[0])
+ self.conv2 = ConvModule(
+ in_channels=int(channels / ratio),
+ out_channels=channels,
+ kernel_size=1,
+ stride=1,
+ conv_cfg=conv_cfg,
+ act_cfg=act_cfg[1])
+
+ def forward(self, x):
+ out = self.global_avgpool(x)
+ out = self.conv1(out)
+ out = self.conv2(out)
+ return x * out
+
+
+class CrossResolutionWeighting(nn.Module):
+
+ def __init__(self,
+ channels,
+ ratio=16,
+ conv_cfg=None,
+ norm_cfg=None,
+ act_cfg=(dict(type='ReLU'), dict(type='Sigmoid'))):
+ super().__init__()
+ if isinstance(act_cfg, dict):
+ act_cfg = (act_cfg, act_cfg)
+ assert len(act_cfg) == 2
+ assert mmcv.is_tuple_of(act_cfg, dict)
+ self.channels = channels
+ total_channel = sum(channels)
+ self.conv1 = ConvModule(
+ in_channels=total_channel,
+ out_channels=int(total_channel / ratio),
+ kernel_size=1,
+ stride=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg[0])
+ self.conv2 = ConvModule(
+ in_channels=int(total_channel / ratio),
+ out_channels=total_channel,
+ kernel_size=1,
+ stride=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg[1])
+
+ def forward(self, x):
+ mini_size = x[-1].size()[-2:]
+ out = [F.adaptive_avg_pool2d(s, mini_size) for s in x[:-1]] + [x[-1]]
+ out = torch.cat(out, dim=1)
+ out = self.conv1(out)
+ out = self.conv2(out)
+ out = torch.split(out, self.channels, dim=1)
+ out = [
+ s * F.interpolate(a, size=s.size()[-2:], mode='nearest')
+ for s, a in zip(x, out)
+ ]
+ return out
+
+
+class ConditionalChannelWeighting(nn.Module):
+
+ def __init__(self,
+ in_channels,
+ stride,
+ reduce_ratio,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ with_cp=False):
+ super().__init__()
+ self.with_cp = with_cp
+ self.stride = stride
+ assert stride in [1, 2]
+
+ branch_channels = [channel // 2 for channel in in_channels]
+
+ self.cross_resolution_weighting = CrossResolutionWeighting(
+ branch_channels,
+ ratio=reduce_ratio,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg)
+
+ self.depthwise_convs = nn.ModuleList([
+ ConvModule(
+ channel,
+ channel,
+ kernel_size=3,
+ stride=self.stride,
+ padding=1,
+ groups=channel,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=None) for channel in branch_channels
+ ])
+
+ self.spatial_weighting = nn.ModuleList([
+ SpatialWeighting(channels=channel, ratio=4)
+ for channel in branch_channels
+ ])
+
+ def forward(self, x):
+
+ def _inner_forward(x):
+ x = [s.chunk(2, dim=1) for s in x]
+ x1 = [s[0] for s in x]
+ x2 = [s[1] for s in x]
+
+ x2 = self.cross_resolution_weighting(x2)
+ x2 = [dw(s) for s, dw in zip(x2, self.depthwise_convs)]
+ x2 = [sw(s) for s, sw in zip(x2, self.spatial_weighting)]
+
+ out = [torch.cat([s1, s2], dim=1) for s1, s2 in zip(x1, x2)]
+ out = [channel_shuffle(s, 2) for s in out]
+
+ return out
+
+ if self.with_cp and x.requires_grad:
+ out = cp.checkpoint(_inner_forward, x)
+ else:
+ out = _inner_forward(x)
+
+ return out
+
+
+class Stem(nn.Module):
+
+ def __init__(self,
+ in_channels,
+ stem_channels,
+ out_channels,
+ expand_ratio,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ with_cp=False):
+ super().__init__()
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.with_cp = with_cp
+
+ self.conv1 = ConvModule(
+ in_channels=in_channels,
+ out_channels=stem_channels,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=dict(type='ReLU'))
+
+ mid_channels = int(round(stem_channels * expand_ratio))
+ branch_channels = stem_channels // 2
+ if stem_channels == self.out_channels:
+ inc_channels = self.out_channels - branch_channels
+ else:
+ inc_channels = self.out_channels - stem_channels
+
+ self.branch1 = nn.Sequential(
+ ConvModule(
+ branch_channels,
+ branch_channels,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ groups=branch_channels,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=None),
+ ConvModule(
+ branch_channels,
+ inc_channels,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=dict(type='ReLU')),
+ )
+
+ self.expand_conv = ConvModule(
+ branch_channels,
+ mid_channels,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=dict(type='ReLU'))
+ self.depthwise_conv = ConvModule(
+ mid_channels,
+ mid_channels,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ groups=mid_channels,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=None)
+ self.linear_conv = ConvModule(
+ mid_channels,
+ branch_channels
+ if stem_channels == self.out_channels else stem_channels,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=dict(type='ReLU'))
+
+ def forward(self, x):
+
+ def _inner_forward(x):
+ x = self.conv1(x)
+ x1, x2 = x.chunk(2, dim=1)
+
+ x2 = self.expand_conv(x2)
+ x2 = self.depthwise_conv(x2)
+ x2 = self.linear_conv(x2)
+
+ out = torch.cat((self.branch1(x1), x2), dim=1)
+
+ out = channel_shuffle(out, 2)
+
+ return out
+
+ if self.with_cp and x.requires_grad:
+ out = cp.checkpoint(_inner_forward, x)
+ else:
+ out = _inner_forward(x)
+
+ return out
+
+
+class IterativeHead(nn.Module):
+
+ def __init__(self, in_channels, conv_cfg=None, norm_cfg=dict(type='BN')):
+ super().__init__()
+ projects = []
+ num_branchs = len(in_channels)
+ self.in_channels = in_channels[::-1]
+
+ for i in range(num_branchs):
+ if i != num_branchs - 1:
+ projects.append(
+ DepthwiseSeparableConvModule(
+ in_channels=self.in_channels[i],
+ out_channels=self.in_channels[i + 1],
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ norm_cfg=norm_cfg,
+ act_cfg=dict(type='ReLU'),
+ dw_act_cfg=None,
+ pw_act_cfg=dict(type='ReLU')))
+ else:
+ projects.append(
+ DepthwiseSeparableConvModule(
+ in_channels=self.in_channels[i],
+ out_channels=self.in_channels[i],
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ norm_cfg=norm_cfg,
+ act_cfg=dict(type='ReLU'),
+ dw_act_cfg=None,
+ pw_act_cfg=dict(type='ReLU')))
+ self.projects = nn.ModuleList(projects)
+
+ def forward(self, x):
+ x = x[::-1]
+
+ y = []
+ last_x = None
+ for i, s in enumerate(x):
+ if last_x is not None:
+ last_x = F.interpolate(
+ last_x,
+ size=s.size()[-2:],
+ mode='bilinear',
+ align_corners=True)
+ s = s + last_x
+ s = self.projects[i](s)
+ y.append(s)
+ last_x = s
+
+ return y[::-1]
+
+
+class ShuffleUnit(nn.Module):
+ """InvertedResidual block for ShuffleNetV2 backbone.
+
+ Args:
+ in_channels (int): The input channels of the block.
+ out_channels (int): The output channels of the block.
+ stride (int): Stride of the 3x3 convolution layer. Default: 1
+ conv_cfg (dict): Config dict for convolution layer.
+ Default: None, which means using conv2d.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='BN').
+ act_cfg (dict): Config dict for activation layer.
+ Default: dict(type='ReLU').
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ stride=1,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ with_cp=False):
+ super().__init__()
+ self.stride = stride
+ self.with_cp = with_cp
+
+ branch_features = out_channels // 2
+ if self.stride == 1:
+ assert in_channels == branch_features * 2, (
+ f'in_channels ({in_channels}) should equal to '
+ f'branch_features * 2 ({branch_features * 2}) '
+ 'when stride is 1')
+
+ if in_channels != branch_features * 2:
+ assert self.stride != 1, (
+ f'stride ({self.stride}) should not equal 1 when '
+ f'in_channels != branch_features * 2')
+
+ if self.stride > 1:
+ self.branch1 = nn.Sequential(
+ ConvModule(
+ in_channels,
+ in_channels,
+ kernel_size=3,
+ stride=self.stride,
+ padding=1,
+ groups=in_channels,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=None),
+ ConvModule(
+ in_channels,
+ branch_features,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg),
+ )
+
+ self.branch2 = nn.Sequential(
+ ConvModule(
+ in_channels if (self.stride > 1) else branch_features,
+ branch_features,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg),
+ ConvModule(
+ branch_features,
+ branch_features,
+ kernel_size=3,
+ stride=self.stride,
+ padding=1,
+ groups=branch_features,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=None),
+ ConvModule(
+ branch_features,
+ branch_features,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+
+ def forward(self, x):
+
+ def _inner_forward(x):
+ if self.stride > 1:
+ out = torch.cat((self.branch1(x), self.branch2(x)), dim=1)
+ else:
+ x1, x2 = x.chunk(2, dim=1)
+ out = torch.cat((x1, self.branch2(x2)), dim=1)
+
+ out = channel_shuffle(out, 2)
+
+ return out
+
+ if self.with_cp and x.requires_grad:
+ out = cp.checkpoint(_inner_forward, x)
+ else:
+ out = _inner_forward(x)
+
+ return out
+
+
+class LiteHRModule(nn.Module):
+
+ def __init__(
+ self,
+ num_branches,
+ num_blocks,
+ in_channels,
+ reduce_ratio,
+ module_type,
+ multiscale_output=False,
+ with_fuse=True,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ with_cp=False,
+ ):
+ super().__init__()
+ self._check_branches(num_branches, in_channels)
+
+ self.in_channels = in_channels
+ self.num_branches = num_branches
+
+ self.module_type = module_type
+ self.multiscale_output = multiscale_output
+ self.with_fuse = with_fuse
+ self.norm_cfg = norm_cfg
+ self.conv_cfg = conv_cfg
+ self.with_cp = with_cp
+
+ if self.module_type == 'LITE':
+ self.layers = self._make_weighting_blocks(num_blocks, reduce_ratio)
+ elif self.module_type == 'NAIVE':
+ self.layers = self._make_naive_branches(num_branches, num_blocks)
+ if self.with_fuse:
+ self.fuse_layers = self._make_fuse_layers()
+ self.relu = nn.ReLU()
+
+ def _check_branches(self, num_branches, in_channels):
+ """Check input to avoid ValueError."""
+ if num_branches != len(in_channels):
+ error_msg = f'NUM_BRANCHES({num_branches}) ' \
+ f'!= NUM_INCHANNELS({len(in_channels)})'
+ raise ValueError(error_msg)
+
+ def _make_weighting_blocks(self, num_blocks, reduce_ratio, stride=1):
+ layers = []
+ for i in range(num_blocks):
+ layers.append(
+ ConditionalChannelWeighting(
+ self.in_channels,
+ stride=stride,
+ reduce_ratio=reduce_ratio,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ with_cp=self.with_cp))
+
+ return nn.Sequential(*layers)
+
+ def _make_one_branch(self, branch_index, num_blocks, stride=1):
+ """Make one branch."""
+ layers = []
+ layers.append(
+ ShuffleUnit(
+ self.in_channels[branch_index],
+ self.in_channels[branch_index],
+ stride=stride,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=dict(type='ReLU'),
+ with_cp=self.with_cp))
+ for i in range(1, num_blocks):
+ layers.append(
+ ShuffleUnit(
+ self.in_channels[branch_index],
+ self.in_channels[branch_index],
+ stride=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=dict(type='ReLU'),
+ with_cp=self.with_cp))
+
+ return nn.Sequential(*layers)
+
+ def _make_naive_branches(self, num_branches, num_blocks):
+ """Make branches."""
+ branches = []
+
+ for i in range(num_branches):
+ branches.append(self._make_one_branch(i, num_blocks))
+
+ return nn.ModuleList(branches)
+
+ def _make_fuse_layers(self):
+ """Make fuse layer."""
+ if self.num_branches == 1:
+ return None
+
+ num_branches = self.num_branches
+ in_channels = self.in_channels
+ fuse_layers = []
+ num_out_branches = num_branches if self.multiscale_output else 1
+ for i in range(num_out_branches):
+ fuse_layer = []
+ for j in range(num_branches):
+ if j > i:
+ fuse_layer.append(
+ nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ in_channels[j],
+ in_channels[i],
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ bias=False),
+ build_norm_layer(self.norm_cfg, in_channels[i])[1],
+ nn.Upsample(
+ scale_factor=2**(j - i), mode='nearest')))
+ elif j == i:
+ fuse_layer.append(None)
+ else:
+ conv_downsamples = []
+ for k in range(i - j):
+ if k == i - j - 1:
+ conv_downsamples.append(
+ nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ in_channels[j],
+ in_channels[j],
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ groups=in_channels[j],
+ bias=False),
+ build_norm_layer(self.norm_cfg,
+ in_channels[j])[1],
+ build_conv_layer(
+ self.conv_cfg,
+ in_channels[j],
+ in_channels[i],
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ bias=False),
+ build_norm_layer(self.norm_cfg,
+ in_channels[i])[1]))
+ else:
+ conv_downsamples.append(
+ nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ in_channels[j],
+ in_channels[j],
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ groups=in_channels[j],
+ bias=False),
+ build_norm_layer(self.norm_cfg,
+ in_channels[j])[1],
+ build_conv_layer(
+ self.conv_cfg,
+ in_channels[j],
+ in_channels[j],
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ bias=False),
+ build_norm_layer(self.norm_cfg,
+ in_channels[j])[1],
+ nn.ReLU(inplace=True)))
+ fuse_layer.append(nn.Sequential(*conv_downsamples))
+ fuse_layers.append(nn.ModuleList(fuse_layer))
+
+ return nn.ModuleList(fuse_layers)
+
+ def forward(self, x):
+ """Forward function."""
+ if self.num_branches == 1:
+ return [self.layers[0](x[0])]
+
+ if self.module_type == 'LITE':
+ out = self.layers(x)
+ elif self.module_type == 'NAIVE':
+ for i in range(self.num_branches):
+ x[i] = self.layers[i](x[i])
+ out = x
+
+ if self.with_fuse:
+ out_fuse = []
+ for i in range(len(self.fuse_layers)):
+ y = out[0] if i == 0 else self.fuse_layers[i][0](out[0])
+ for j in range(self.num_branches):
+ if i == j:
+ y += out[j]
+ else:
+ y += self.fuse_layers[i][j](out[j])
+ out_fuse.append(self.relu(y))
+ out = out_fuse
+ elif not self.multiscale_output:
+ out = [out[0]]
+ return out
+
+
+@BACKBONES.register_module()
+class LiteHRNet(nn.Module):
+ """Lite-HRNet backbone.
+
+ `High-Resolution Representations for Labeling Pixels and Regions
+ `_
+
+ Args:
+ extra (dict): detailed configuration for each stage of HRNet.
+ in_channels (int): Number of input image channels. Default: 3.
+ conv_cfg (dict): dictionary to construct and config conv layer.
+ norm_cfg (dict): dictionary to construct and config norm layer.
+ norm_eval (bool): Whether to set norm layers to eval mode, namely,
+ freeze running stats (mean and var). Note: Effect on Batch Norm
+ and its variants only. Default: False
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed.
+ zero_init_residual (bool): whether to use zero init for last norm layer
+ in resblocks to let them behave as identity.
+
+ Example:
+ >>> from mmpose.models import HRNet
+ >>> import torch
+ >>> extra = dict(
+ >>> stage1=dict(
+ >>> num_modules=1,
+ >>> num_branches=1,
+ >>> block='BOTTLENECK',
+ >>> num_blocks=(4, ),
+ >>> num_channels=(64, )),
+ >>> stage2=dict(
+ >>> num_modules=1,
+ >>> num_branches=2,
+ >>> block='BASIC',
+ >>> num_blocks=(4, 4),
+ >>> num_channels=(32, 64)),
+ >>> stage3=dict(
+ >>> num_modules=4,
+ >>> num_branches=3,
+ >>> block='BASIC',
+ >>> num_blocks=(4, 4, 4),
+ >>> num_channels=(32, 64, 128)),
+ >>> stage4=dict(
+ >>> num_modules=3,
+ >>> num_branches=4,
+ >>> block='BASIC',
+ >>> num_blocks=(4, 4, 4, 4),
+ >>> num_channels=(32, 64, 128, 256)))
+ >>> self = HRNet(extra, in_channels=1)
+ >>> self.eval()
+ >>> inputs = torch.rand(1, 1, 32, 32)
+ >>> level_outputs = self.forward(inputs)
+ >>> for level_out in level_outputs:
+ ... print(tuple(level_out.shape))
+ (1, 32, 8, 8)
+ (1, 64, 4, 4)
+ (1, 128, 2, 2)
+ (1, 256, 1, 1)
+ """
+
+ def __init__(self,
+ extra,
+ in_channels=3,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ norm_eval=False,
+ with_cp=False,
+ zero_init_residual=False):
+ super().__init__()
+ self.extra = extra
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.norm_eval = norm_eval
+ self.with_cp = with_cp
+ self.zero_init_residual = zero_init_residual
+
+ self.stem = Stem(
+ in_channels,
+ stem_channels=self.extra['stem']['stem_channels'],
+ out_channels=self.extra['stem']['out_channels'],
+ expand_ratio=self.extra['stem']['expand_ratio'],
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg)
+
+ self.num_stages = self.extra['num_stages']
+ self.stages_spec = self.extra['stages_spec']
+
+ num_channels_last = [
+ self.stem.out_channels,
+ ]
+ for i in range(self.num_stages):
+ num_channels = self.stages_spec['num_channels'][i]
+ num_channels = [num_channels[i] for i in range(len(num_channels))]
+ setattr(
+ self, 'transition{}'.format(i),
+ self._make_transition_layer(num_channels_last, num_channels))
+
+ stage, num_channels_last = self._make_stage(
+ self.stages_spec, i, num_channels, multiscale_output=True)
+ setattr(self, 'stage{}'.format(i), stage)
+
+ self.with_head = self.extra['with_head']
+ if self.with_head:
+ self.head_layer = IterativeHead(
+ in_channels=num_channels_last,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ )
+
+ def _make_transition_layer(self, num_channels_pre_layer,
+ num_channels_cur_layer):
+ """Make transition layer."""
+ num_branches_cur = len(num_channels_cur_layer)
+ num_branches_pre = len(num_channels_pre_layer)
+
+ transition_layers = []
+ for i in range(num_branches_cur):
+ if i < num_branches_pre:
+ if num_channels_cur_layer[i] != num_channels_pre_layer[i]:
+ transition_layers.append(
+ nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ num_channels_pre_layer[i],
+ num_channels_pre_layer[i],
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ groups=num_channels_pre_layer[i],
+ bias=False),
+ build_norm_layer(self.norm_cfg,
+ num_channels_pre_layer[i])[1],
+ build_conv_layer(
+ self.conv_cfg,
+ num_channels_pre_layer[i],
+ num_channels_cur_layer[i],
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ bias=False),
+ build_norm_layer(self.norm_cfg,
+ num_channels_cur_layer[i])[1],
+ nn.ReLU()))
+ else:
+ transition_layers.append(None)
+ else:
+ conv_downsamples = []
+ for j in range(i + 1 - num_branches_pre):
+ in_channels = num_channels_pre_layer[-1]
+ out_channels = num_channels_cur_layer[i] \
+ if j == i - num_branches_pre else in_channels
+ conv_downsamples.append(
+ nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ in_channels,
+ in_channels,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ groups=in_channels,
+ bias=False),
+ build_norm_layer(self.norm_cfg, in_channels)[1],
+ build_conv_layer(
+ self.conv_cfg,
+ in_channels,
+ out_channels,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ bias=False),
+ build_norm_layer(self.norm_cfg, out_channels)[1],
+ nn.ReLU()))
+ transition_layers.append(nn.Sequential(*conv_downsamples))
+
+ return nn.ModuleList(transition_layers)
+
+ def _make_stage(self,
+ stages_spec,
+ stage_index,
+ in_channels,
+ multiscale_output=True):
+ num_modules = stages_spec['num_modules'][stage_index]
+ num_branches = stages_spec['num_branches'][stage_index]
+ num_blocks = stages_spec['num_blocks'][stage_index]
+ reduce_ratio = stages_spec['reduce_ratios'][stage_index]
+ with_fuse = stages_spec['with_fuse'][stage_index]
+ module_type = stages_spec['module_type'][stage_index]
+
+ modules = []
+ for i in range(num_modules):
+ # multi_scale_output is only used last module
+ if not multiscale_output and i == num_modules - 1:
+ reset_multiscale_output = False
+ else:
+ reset_multiscale_output = True
+
+ modules.append(
+ LiteHRModule(
+ num_branches,
+ num_blocks,
+ in_channels,
+ reduce_ratio,
+ module_type,
+ multiscale_output=reset_multiscale_output,
+ with_fuse=with_fuse,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ with_cp=self.with_cp))
+ in_channels = modules[-1].in_channels
+
+ return nn.Sequential(*modules), in_channels
+
+ def init_weights(self, pretrained=None):
+ """Initialize the weights in backbone.
+
+ Args:
+ pretrained (str, optional): Path to pre-trained weights.
+ Defaults to None.
+ """
+ if isinstance(pretrained, str):
+ logger = get_root_logger()
+ load_checkpoint(self, pretrained, strict=False, logger=logger)
+ elif pretrained is None:
+ for m in self.modules():
+ if isinstance(m, nn.Conv2d):
+ normal_init(m, std=0.001)
+ elif isinstance(m, (_BatchNorm, nn.GroupNorm)):
+ constant_init(m, 1)
+
+ if self.zero_init_residual:
+ for m in self.modules():
+ if isinstance(m, Bottleneck):
+ constant_init(m.norm3, 0)
+ elif isinstance(m, BasicBlock):
+ constant_init(m.norm2, 0)
+ else:
+ raise TypeError('pretrained must be a str or None')
+
+ def forward(self, x):
+ """Forward function."""
+ x = self.stem(x)
+
+ y_list = [x]
+ for i in range(self.num_stages):
+ x_list = []
+ transition = getattr(self, 'transition{}'.format(i))
+ for j in range(self.stages_spec['num_branches'][i]):
+ if transition[j]:
+ if j >= len(y_list):
+ x_list.append(transition[j](y_list[-1]))
+ else:
+ x_list.append(transition[j](y_list[j]))
+ else:
+ x_list.append(y_list[j])
+ y_list = getattr(self, 'stage{}'.format(i))(x_list)
+
+ x = y_list
+ if self.with_head:
+ x = self.head_layer(x)
+
+ return [x[0]]
+
+ def train(self, mode=True):
+ """Convert the model into training mode."""
+ super().train(mode)
+ if mode and self.norm_eval:
+ for m in self.modules():
+ if isinstance(m, _BatchNorm):
+ m.eval()
\ No newline at end of file
diff --git a/mmdet/models/backbones/mobilenet_v2.py b/mmdet/models/backbones/mobilenet_v2.py
new file mode 100644
index 0000000000000000000000000000000000000000..d9742fa9a79996703f4d51c6a1449f5108eb6108
--- /dev/null
+++ b/mmdet/models/backbones/mobilenet_v2.py
@@ -0,0 +1,199 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+from mmengine.model import BaseModule
+from torch.nn.modules.batchnorm import _BatchNorm
+
+from mmdet.registry import MODELS
+from ..layers import InvertedResidual
+from ..utils import make_divisible
+
+
+@MODELS.register_module()
+class MobileNetV2(BaseModule):
+ """MobileNetV2 backbone.
+
+ Args:
+ widen_factor (float): Width multiplier, multiply number of
+ channels in each layer by this amount. Default: 1.0.
+ out_indices (Sequence[int], optional): Output from which stages.
+ Default: (1, 2, 4, 7).
+ frozen_stages (int): Stages to be frozen (all param fixed).
+ Default: -1, which means not freezing any parameters.
+ conv_cfg (dict, optional): Config dict for convolution layer.
+ Default: None, which means using conv2d.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='BN').
+ act_cfg (dict): Config dict for activation layer.
+ Default: dict(type='ReLU6').
+ norm_eval (bool): Whether to set norm layers to eval mode, namely,
+ freeze running stats (mean and var). Note: Effect on Batch Norm
+ and its variants only. Default: False.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False.
+ pretrained (str, optional): model pretrained path. Default: None
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ # Parameters to build layers. 4 parameters are needed to construct a
+ # layer, from left to right: expand_ratio, channel, num_blocks, stride.
+ arch_settings = [[1, 16, 1, 1], [6, 24, 2, 2], [6, 32, 3, 2],
+ [6, 64, 4, 2], [6, 96, 3, 1], [6, 160, 3, 2],
+ [6, 320, 1, 1]]
+
+ def __init__(self,
+ widen_factor=1.,
+ in_channels =3,
+ out_indices=(1, 2, 4, 7),
+ frozen_stages=-1,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU6'),
+ norm_eval=False,
+ with_cp=False,
+ pretrained=None,
+ init_cfg=None):
+ super(MobileNetV2, self).__init__(init_cfg)
+
+ self.pretrained = pretrained
+ assert not (init_cfg and pretrained), \
+ 'init_cfg and pretrained cannot be specified at the same time'
+ if isinstance(pretrained, str):
+ warnings.warn('DeprecationWarning: pretrained is deprecated, '
+ 'please use "init_cfg" instead')
+ self.init_cfg = dict(type='Pretrained', checkpoint=pretrained)
+ elif pretrained is None:
+ if init_cfg is None:
+ self.init_cfg = [
+ dict(type='Kaiming', layer='Conv2d'),
+ dict(
+ type='Constant',
+ val=1,
+ layer=['_BatchNorm', 'GroupNorm'])
+ ]
+ else:
+ raise TypeError('pretrained must be a str or None')
+
+ self.widen_factor = widen_factor
+ self.out_indices = out_indices
+ if not set(out_indices).issubset(set(range(0, 8))):
+ raise ValueError('out_indices must be a subset of range'
+ f'(0, 8). But received {out_indices}')
+
+ if frozen_stages not in range(-1, 8):
+ raise ValueError('frozen_stages must be in range(-1, 8). '
+ f'But received {frozen_stages}')
+ self.out_indices = out_indices
+ self.frozen_stages = frozen_stages
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.act_cfg = act_cfg
+ self.norm_eval = norm_eval
+ self.with_cp = with_cp
+
+ self.in_channels = make_divisible(32 * widen_factor, 8)
+
+ self.conv1 = ConvModule(
+ in_channels=in_channels,
+ out_channels=self.in_channels,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+
+ self.layers = []
+
+ for i, layer_cfg in enumerate(self.arch_settings):
+ expand_ratio, channel, num_blocks, stride = layer_cfg
+ out_channels = make_divisible(channel * widen_factor, 8)
+ inverted_res_layer = self.make_layer(
+ out_channels=out_channels,
+ num_blocks=num_blocks,
+ stride=stride,
+ expand_ratio=expand_ratio)
+ layer_name = f'layer{i + 1}'
+ self.add_module(layer_name, inverted_res_layer)
+ self.layers.append(layer_name)
+
+ if widen_factor > 1.0:
+ self.out_channel = int(1280 * widen_factor)
+ else:
+ self.out_channel = 1280
+
+ layer = ConvModule(
+ in_channels=self.in_channels,
+ out_channels=self.out_channel,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ self.add_module('conv2', layer)
+ self.layers.append('conv2')
+
+ def make_layer(self, out_channels, num_blocks, stride, expand_ratio):
+ """Stack InvertedResidual blocks to build a layer for MobileNetV2.
+
+ Args:
+ out_channels (int): out_channels of block.
+ num_blocks (int): number of blocks.
+ stride (int): stride of the first block. Default: 1
+ expand_ratio (int): Expand the number of channels of the
+ hidden layer in InvertedResidual by this ratio. Default: 6.
+ """
+ layers = []
+ for i in range(num_blocks):
+ if i >= 1:
+ stride = 1
+ layers.append(
+ InvertedResidual(
+ self.in_channels,
+ out_channels,
+ mid_channels=int(round(self.in_channels * expand_ratio)),
+ stride=stride,
+ with_expand_conv=expand_ratio != 1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg,
+ with_cp=self.with_cp))
+ self.in_channels = out_channels
+
+ return nn.Sequential(*layers)
+
+ def _freeze_stages(self):
+ if self.frozen_stages >= 0:
+ for param in self.conv1.parameters():
+ param.requires_grad = False
+ for i in range(1, self.frozen_stages + 1):
+ layer = getattr(self, f'layer{i}')
+ layer.eval()
+ for param in layer.parameters():
+ param.requires_grad = False
+
+ def forward(self, x):
+ """Forward function."""
+ x = self.conv1(x)
+ outs = []
+ for i, layer_name in enumerate(self.layers):
+ layer = getattr(self, layer_name)
+ x = layer(x)
+ if i in self.out_indices:
+ outs.append(x)
+ return tuple(outs)
+
+ def train(self, mode=True):
+ """Convert the model into training mode while keep normalization layer
+ frozen."""
+ super(MobileNetV2, self).train(mode)
+ self._freeze_stages()
+ if mode and self.norm_eval:
+ for m in self.modules():
+ # trick: eval have effect on BatchNorm only
+ if isinstance(m, _BatchNorm):
+ m.eval()
diff --git a/mmdet/models/backbones/pvt.py b/mmdet/models/backbones/pvt.py
new file mode 100644
index 0000000000000000000000000000000000000000..d452aef630bb42d9c94777a1fe3b6bacd6ee997f
--- /dev/null
+++ b/mmdet/models/backbones/pvt.py
@@ -0,0 +1,665 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+import warnings
+from collections import OrderedDict
+
+import numpy as np
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import Conv2d, build_activation_layer, build_norm_layer
+from mmcv.cnn.bricks.drop import build_dropout
+from mmcv.cnn.bricks.transformer import MultiheadAttention
+from mmengine.logging import MMLogger
+from mmengine.model import (BaseModule, ModuleList, Sequential, constant_init,
+ normal_init, trunc_normal_init)
+from mmengine.model.weight_init import trunc_normal_
+from mmengine.runner.checkpoint import CheckpointLoader, load_state_dict
+from torch.nn.modules.utils import _pair as to_2tuple
+
+from mmdet.registry import MODELS
+from ..layers import PatchEmbed, nchw_to_nlc, nlc_to_nchw
+
+
+class MixFFN(BaseModule):
+ """An implementation of MixFFN of PVT.
+
+ The differences between MixFFN & FFN:
+ 1. Use 1X1 Conv to replace Linear layer.
+ 2. Introduce 3X3 Depth-wise Conv to encode positional information.
+
+ Args:
+ embed_dims (int): The feature dimension. Same as
+ `MultiheadAttention`.
+ feedforward_channels (int): The hidden dimension of FFNs.
+ act_cfg (dict, optional): The activation config for FFNs.
+ Default: dict(type='GELU').
+ ffn_drop (float, optional): Probability of an element to be
+ zeroed in FFN. Default 0.0.
+ dropout_layer (obj:`ConfigDict`): The dropout_layer used
+ when adding the shortcut.
+ Default: None.
+ use_conv (bool): If True, add 3x3 DWConv between two Linear layers.
+ Defaults: False.
+ init_cfg (obj:`mmengine.ConfigDict`): The Config for initialization.
+ Default: None.
+ """
+
+ def __init__(self,
+ embed_dims,
+ feedforward_channels,
+ act_cfg=dict(type='GELU'),
+ ffn_drop=0.,
+ dropout_layer=None,
+ use_conv=False,
+ init_cfg=None):
+ super(MixFFN, self).__init__(init_cfg=init_cfg)
+
+ self.embed_dims = embed_dims
+ self.feedforward_channels = feedforward_channels
+ self.act_cfg = act_cfg
+ activate = build_activation_layer(act_cfg)
+
+ in_channels = embed_dims
+ fc1 = Conv2d(
+ in_channels=in_channels,
+ out_channels=feedforward_channels,
+ kernel_size=1,
+ stride=1,
+ bias=True)
+ if use_conv:
+ # 3x3 depth wise conv to provide positional encode information
+ dw_conv = Conv2d(
+ in_channels=feedforward_channels,
+ out_channels=feedforward_channels,
+ kernel_size=3,
+ stride=1,
+ padding=(3 - 1) // 2,
+ bias=True,
+ groups=feedforward_channels)
+ fc2 = Conv2d(
+ in_channels=feedforward_channels,
+ out_channels=in_channels,
+ kernel_size=1,
+ stride=1,
+ bias=True)
+ drop = nn.Dropout(ffn_drop)
+ layers = [fc1, activate, drop, fc2, drop]
+ if use_conv:
+ layers.insert(1, dw_conv)
+ self.layers = Sequential(*layers)
+ self.dropout_layer = build_dropout(
+ dropout_layer) if dropout_layer else torch.nn.Identity()
+
+ def forward(self, x, hw_shape, identity=None):
+ out = nlc_to_nchw(x, hw_shape)
+ out = self.layers(out)
+ out = nchw_to_nlc(out)
+ if identity is None:
+ identity = x
+ return identity + self.dropout_layer(out)
+
+
+class SpatialReductionAttention(MultiheadAttention):
+ """An implementation of Spatial Reduction Attention of PVT.
+
+ This module is modified from MultiheadAttention which is a module from
+ mmcv.cnn.bricks.transformer.
+
+ Args:
+ embed_dims (int): The embedding dimension.
+ num_heads (int): Parallel attention heads.
+ attn_drop (float): A Dropout layer on attn_output_weights.
+ Default: 0.0.
+ proj_drop (float): A Dropout layer after `nn.MultiheadAttention`.
+ Default: 0.0.
+ dropout_layer (obj:`ConfigDict`): The dropout_layer used
+ when adding the shortcut. Default: None.
+ batch_first (bool): Key, Query and Value are shape of
+ (batch, n, embed_dim)
+ or (n, batch, embed_dim). Default: False.
+ qkv_bias (bool): enable bias for qkv if True. Default: True.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='LN').
+ sr_ratio (int): The ratio of spatial reduction of Spatial Reduction
+ Attention of PVT. Default: 1.
+ init_cfg (obj:`mmengine.ConfigDict`): The Config for initialization.
+ Default: None.
+ """
+
+ def __init__(self,
+ embed_dims,
+ num_heads,
+ attn_drop=0.,
+ proj_drop=0.,
+ dropout_layer=None,
+ batch_first=True,
+ qkv_bias=True,
+ norm_cfg=dict(type='LN'),
+ sr_ratio=1,
+ init_cfg=None):
+ super().__init__(
+ embed_dims,
+ num_heads,
+ attn_drop,
+ proj_drop,
+ batch_first=batch_first,
+ dropout_layer=dropout_layer,
+ bias=qkv_bias,
+ init_cfg=init_cfg)
+
+ self.sr_ratio = sr_ratio
+ if sr_ratio > 1:
+ self.sr = Conv2d(
+ in_channels=embed_dims,
+ out_channels=embed_dims,
+ kernel_size=sr_ratio,
+ stride=sr_ratio)
+ # The ret[0] of build_norm_layer is norm name.
+ self.norm = build_norm_layer(norm_cfg, embed_dims)[1]
+
+ # handle the BC-breaking from https://github.com/open-mmlab/mmcv/pull/1418 # noqa
+ from mmdet import digit_version, mmcv_version
+ if mmcv_version < digit_version('1.3.17'):
+ warnings.warn('The legacy version of forward function in'
+ 'SpatialReductionAttention is deprecated in'
+ 'mmcv>=1.3.17 and will no longer support in the'
+ 'future. Please upgrade your mmcv.')
+ self.forward = self.legacy_forward
+
+ def forward(self, x, hw_shape, identity=None):
+
+ x_q = x
+ if self.sr_ratio > 1:
+ x_kv = nlc_to_nchw(x, hw_shape)
+ x_kv = self.sr(x_kv)
+ x_kv = nchw_to_nlc(x_kv)
+ x_kv = self.norm(x_kv)
+ else:
+ x_kv = x
+
+ if identity is None:
+ identity = x_q
+
+ # Because the dataflow('key', 'query', 'value') of
+ # ``torch.nn.MultiheadAttention`` is (num_queries, batch,
+ # embed_dims), We should adjust the shape of dataflow from
+ # batch_first (batch, num_queries, embed_dims) to num_queries_first
+ # (num_queries ,batch, embed_dims), and recover ``attn_output``
+ # from num_queries_first to batch_first.
+ if self.batch_first:
+ x_q = x_q.transpose(0, 1)
+ x_kv = x_kv.transpose(0, 1)
+
+ out = self.attn(query=x_q, key=x_kv, value=x_kv)[0]
+
+ if self.batch_first:
+ out = out.transpose(0, 1)
+
+ return identity + self.dropout_layer(self.proj_drop(out))
+
+ def legacy_forward(self, x, hw_shape, identity=None):
+ """multi head attention forward in mmcv version < 1.3.17."""
+ x_q = x
+ if self.sr_ratio > 1:
+ x_kv = nlc_to_nchw(x, hw_shape)
+ x_kv = self.sr(x_kv)
+ x_kv = nchw_to_nlc(x_kv)
+ x_kv = self.norm(x_kv)
+ else:
+ x_kv = x
+
+ if identity is None:
+ identity = x_q
+
+ out = self.attn(query=x_q, key=x_kv, value=x_kv)[0]
+
+ return identity + self.dropout_layer(self.proj_drop(out))
+
+
+class PVTEncoderLayer(BaseModule):
+ """Implements one encoder layer in PVT.
+
+ Args:
+ embed_dims (int): The feature dimension.
+ num_heads (int): Parallel attention heads.
+ feedforward_channels (int): The hidden dimension for FFNs.
+ drop_rate (float): Probability of an element to be zeroed.
+ after the feed forward layer. Default: 0.0.
+ attn_drop_rate (float): The drop out rate for attention layer.
+ Default: 0.0.
+ drop_path_rate (float): stochastic depth rate. Default: 0.0.
+ qkv_bias (bool): enable bias for qkv if True.
+ Default: True.
+ act_cfg (dict): The activation config for FFNs.
+ Default: dict(type='GELU').
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='LN').
+ sr_ratio (int): The ratio of spatial reduction of Spatial Reduction
+ Attention of PVT. Default: 1.
+ use_conv_ffn (bool): If True, use Convolutional FFN to replace FFN.
+ Default: False.
+ init_cfg (dict, optional): Initialization config dict.
+ Default: None.
+ """
+
+ def __init__(self,
+ embed_dims,
+ num_heads,
+ feedforward_channels,
+ drop_rate=0.,
+ attn_drop_rate=0.,
+ drop_path_rate=0.,
+ qkv_bias=True,
+ act_cfg=dict(type='GELU'),
+ norm_cfg=dict(type='LN'),
+ sr_ratio=1,
+ use_conv_ffn=False,
+ init_cfg=None):
+ super(PVTEncoderLayer, self).__init__(init_cfg=init_cfg)
+
+ # The ret[0] of build_norm_layer is norm name.
+ self.norm1 = build_norm_layer(norm_cfg, embed_dims)[1]
+
+ self.attn = SpatialReductionAttention(
+ embed_dims=embed_dims,
+ num_heads=num_heads,
+ attn_drop=attn_drop_rate,
+ proj_drop=drop_rate,
+ dropout_layer=dict(type='DropPath', drop_prob=drop_path_rate),
+ qkv_bias=qkv_bias,
+ norm_cfg=norm_cfg,
+ sr_ratio=sr_ratio)
+
+ # The ret[0] of build_norm_layer is norm name.
+ self.norm2 = build_norm_layer(norm_cfg, embed_dims)[1]
+
+ self.ffn = MixFFN(
+ embed_dims=embed_dims,
+ feedforward_channels=feedforward_channels,
+ ffn_drop=drop_rate,
+ dropout_layer=dict(type='DropPath', drop_prob=drop_path_rate),
+ use_conv=use_conv_ffn,
+ act_cfg=act_cfg)
+
+ def forward(self, x, hw_shape):
+ x = self.attn(self.norm1(x), hw_shape, identity=x)
+ x = self.ffn(self.norm2(x), hw_shape, identity=x)
+
+ return x
+
+
+class AbsolutePositionEmbedding(BaseModule):
+ """An implementation of the absolute position embedding in PVT.
+
+ Args:
+ pos_shape (int): The shape of the absolute position embedding.
+ pos_dim (int): The dimension of the absolute position embedding.
+ drop_rate (float): Probability of an element to be zeroed.
+ Default: 0.0.
+ """
+
+ def __init__(self, pos_shape, pos_dim, drop_rate=0., init_cfg=None):
+ super().__init__(init_cfg=init_cfg)
+
+ if isinstance(pos_shape, int):
+ pos_shape = to_2tuple(pos_shape)
+ elif isinstance(pos_shape, tuple):
+ if len(pos_shape) == 1:
+ pos_shape = to_2tuple(pos_shape[0])
+ assert len(pos_shape) == 2, \
+ f'The size of image should have length 1 or 2, ' \
+ f'but got {len(pos_shape)}'
+ self.pos_shape = pos_shape
+ self.pos_dim = pos_dim
+
+ self.pos_embed = nn.Parameter(
+ torch.zeros(1, pos_shape[0] * pos_shape[1], pos_dim))
+ self.drop = nn.Dropout(p=drop_rate)
+
+ def init_weights(self):
+ trunc_normal_(self.pos_embed, std=0.02)
+
+ def resize_pos_embed(self, pos_embed, input_shape, mode='bilinear'):
+ """Resize pos_embed weights.
+
+ Resize pos_embed using bilinear interpolate method.
+
+ Args:
+ pos_embed (torch.Tensor): Position embedding weights.
+ input_shape (tuple): Tuple for (downsampled input image height,
+ downsampled input image width).
+ mode (str): Algorithm used for upsampling:
+ ``'nearest'`` | ``'linear'`` | ``'bilinear'`` | ``'bicubic'`` |
+ ``'trilinear'``. Default: ``'bilinear'``.
+
+ Return:
+ torch.Tensor: The resized pos_embed of shape [B, L_new, C].
+ """
+ assert pos_embed.ndim == 3, 'shape of pos_embed must be [B, L, C]'
+ pos_h, pos_w = self.pos_shape
+ pos_embed_weight = pos_embed[:, (-1 * pos_h * pos_w):]
+ pos_embed_weight = pos_embed_weight.reshape(
+ 1, pos_h, pos_w, self.pos_dim).permute(0, 3, 1, 2).contiguous()
+ pos_embed_weight = F.interpolate(
+ pos_embed_weight, size=input_shape, mode=mode)
+ pos_embed_weight = torch.flatten(pos_embed_weight,
+ 2).transpose(1, 2).contiguous()
+ pos_embed = pos_embed_weight
+
+ return pos_embed
+
+ def forward(self, x, hw_shape, mode='bilinear'):
+ pos_embed = self.resize_pos_embed(self.pos_embed, hw_shape, mode)
+ return self.drop(x + pos_embed)
+
+
+@MODELS.register_module()
+class PyramidVisionTransformer(BaseModule):
+ """Pyramid Vision Transformer (PVT)
+
+ Implementation of `Pyramid Vision Transformer: A Versatile Backbone for
+ Dense Prediction without Convolutions
+ `_.
+
+ Args:
+ pretrain_img_size (int | tuple[int]): The size of input image when
+ pretrain. Defaults: 224.
+ in_channels (int): Number of input channels. Default: 3.
+ embed_dims (int): Embedding dimension. Default: 64.
+ num_stags (int): The num of stages. Default: 4.
+ num_layers (Sequence[int]): The layer number of each transformer encode
+ layer. Default: [3, 4, 6, 3].
+ num_heads (Sequence[int]): The attention heads of each transformer
+ encode layer. Default: [1, 2, 5, 8].
+ patch_sizes (Sequence[int]): The patch_size of each patch embedding.
+ Default: [4, 2, 2, 2].
+ strides (Sequence[int]): The stride of each patch embedding.
+ Default: [4, 2, 2, 2].
+ paddings (Sequence[int]): The padding of each patch embedding.
+ Default: [0, 0, 0, 0].
+ sr_ratios (Sequence[int]): The spatial reduction rate of each
+ transformer encode layer. Default: [8, 4, 2, 1].
+ out_indices (Sequence[int] | int): Output from which stages.
+ Default: (0, 1, 2, 3).
+ mlp_ratios (Sequence[int]): The ratio of the mlp hidden dim to the
+ embedding dim of each transformer encode layer.
+ Default: [8, 8, 4, 4].
+ qkv_bias (bool): Enable bias for qkv if True. Default: True.
+ drop_rate (float): Probability of an element to be zeroed.
+ Default 0.0.
+ attn_drop_rate (float): The drop out rate for attention layer.
+ Default 0.0.
+ drop_path_rate (float): stochastic depth rate. Default 0.1.
+ use_abs_pos_embed (bool): If True, add absolute position embedding to
+ the patch embedding. Defaults: True.
+ use_conv_ffn (bool): If True, use Convolutional FFN to replace FFN.
+ Default: False.
+ act_cfg (dict): The activation config for FFNs.
+ Default: dict(type='GELU').
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='LN').
+ pretrained (str, optional): model pretrained path. Default: None.
+ convert_weights (bool): The flag indicates whether the
+ pre-trained model is from the original repo. We may need
+ to convert some keys to make it compatible.
+ Default: True.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+ """
+
+ def __init__(self,
+ pretrain_img_size=224,
+ in_channels=3,
+ embed_dims=64,
+ num_stages=4,
+ num_layers=[3, 4, 6, 3],
+ num_heads=[1, 2, 5, 8],
+ patch_sizes=[4, 2, 2, 2],
+ strides=[4, 2, 2, 2],
+ paddings=[0, 0, 0, 0],
+ sr_ratios=[8, 4, 2, 1],
+ out_indices=(0, 1, 2, 3),
+ mlp_ratios=[8, 8, 4, 4],
+ qkv_bias=True,
+ drop_rate=0.,
+ attn_drop_rate=0.,
+ drop_path_rate=0.1,
+ use_abs_pos_embed=True,
+ norm_after_stage=False,
+ use_conv_ffn=False,
+ act_cfg=dict(type='GELU'),
+ norm_cfg=dict(type='LN', eps=1e-6),
+ pretrained=None,
+ convert_weights=True,
+ init_cfg=None):
+ super().__init__(init_cfg=init_cfg)
+
+ self.convert_weights = convert_weights
+ if isinstance(pretrain_img_size, int):
+ pretrain_img_size = to_2tuple(pretrain_img_size)
+ elif isinstance(pretrain_img_size, tuple):
+ if len(pretrain_img_size) == 1:
+ pretrain_img_size = to_2tuple(pretrain_img_size[0])
+ assert len(pretrain_img_size) == 2, \
+ f'The size of image should have length 1 or 2, ' \
+ f'but got {len(pretrain_img_size)}'
+
+ assert not (init_cfg and pretrained), \
+ 'init_cfg and pretrained cannot be setting at the same time'
+ if isinstance(pretrained, str):
+ warnings.warn('DeprecationWarning: pretrained is deprecated, '
+ 'please use "init_cfg" instead')
+ self.init_cfg = dict(type='Pretrained', checkpoint=pretrained)
+ elif pretrained is None:
+ self.init_cfg = init_cfg
+ else:
+ raise TypeError('pretrained must be a str or None')
+
+ self.embed_dims = embed_dims
+
+ self.num_stages = num_stages
+ self.num_layers = num_layers
+ self.num_heads = num_heads
+ self.patch_sizes = patch_sizes
+ self.strides = strides
+ self.sr_ratios = sr_ratios
+ assert num_stages == len(num_layers) == len(num_heads) \
+ == len(patch_sizes) == len(strides) == len(sr_ratios)
+
+ self.out_indices = out_indices
+ assert max(out_indices) < self.num_stages
+ self.pretrained = pretrained
+
+ # transformer encoder
+ dpr = [
+ x.item()
+ for x in torch.linspace(0, drop_path_rate, sum(num_layers))
+ ] # stochastic num_layer decay rule
+
+ cur = 0
+ self.layers = ModuleList()
+ for i, num_layer in enumerate(num_layers):
+ embed_dims_i = embed_dims * num_heads[i]
+ patch_embed = PatchEmbed(
+ in_channels=in_channels,
+ embed_dims=embed_dims_i,
+ kernel_size=patch_sizes[i],
+ stride=strides[i],
+ padding=paddings[i],
+ bias=True,
+ norm_cfg=norm_cfg)
+
+ layers = ModuleList()
+ if use_abs_pos_embed:
+ pos_shape = pretrain_img_size // np.prod(patch_sizes[:i + 1])
+ pos_embed = AbsolutePositionEmbedding(
+ pos_shape=pos_shape,
+ pos_dim=embed_dims_i,
+ drop_rate=drop_rate)
+ layers.append(pos_embed)
+ layers.extend([
+ PVTEncoderLayer(
+ embed_dims=embed_dims_i,
+ num_heads=num_heads[i],
+ feedforward_channels=mlp_ratios[i] * embed_dims_i,
+ drop_rate=drop_rate,
+ attn_drop_rate=attn_drop_rate,
+ drop_path_rate=dpr[cur + idx],
+ qkv_bias=qkv_bias,
+ act_cfg=act_cfg,
+ norm_cfg=norm_cfg,
+ sr_ratio=sr_ratios[i],
+ use_conv_ffn=use_conv_ffn) for idx in range(num_layer)
+ ])
+ in_channels = embed_dims_i
+ # The ret[0] of build_norm_layer is norm name.
+ if norm_after_stage:
+ norm = build_norm_layer(norm_cfg, embed_dims_i)[1]
+ else:
+ norm = nn.Identity()
+ self.layers.append(ModuleList([patch_embed, layers, norm]))
+ cur += num_layer
+
+ def init_weights(self):
+ logger = MMLogger.get_current_instance()
+ if self.init_cfg is None:
+ logger.warn(f'No pre-trained weights for '
+ f'{self.__class__.__name__}, '
+ f'training start from scratch')
+ for m in self.modules():
+ if isinstance(m, nn.Linear):
+ trunc_normal_init(m, std=.02, bias=0.)
+ elif isinstance(m, nn.LayerNorm):
+ constant_init(m, 1.0)
+ elif isinstance(m, nn.Conv2d):
+ fan_out = m.kernel_size[0] * m.kernel_size[
+ 1] * m.out_channels
+ fan_out //= m.groups
+ normal_init(m, 0, math.sqrt(2.0 / fan_out))
+ elif isinstance(m, AbsolutePositionEmbedding):
+ m.init_weights()
+ else:
+ assert 'checkpoint' in self.init_cfg, f'Only support ' \
+ f'specify `Pretrained` in ' \
+ f'`init_cfg` in ' \
+ f'{self.__class__.__name__} '
+ checkpoint = CheckpointLoader.load_checkpoint(
+ self.init_cfg.checkpoint, logger=logger, map_location='cpu')
+ logger.warn(f'Load pre-trained model for '
+ f'{self.__class__.__name__} from original repo')
+ if 'state_dict' in checkpoint:
+ state_dict = checkpoint['state_dict']
+ elif 'model' in checkpoint:
+ state_dict = checkpoint['model']
+ else:
+ state_dict = checkpoint
+ if self.convert_weights:
+ # Because pvt backbones are not supported by mmcls,
+ # so we need to convert pre-trained weights to match this
+ # implementation.
+ state_dict = pvt_convert(state_dict)
+ load_state_dict(self, state_dict, strict=False, logger=logger)
+
+ def forward(self, x):
+ outs = []
+
+ for i, layer in enumerate(self.layers):
+ x, hw_shape = layer[0](x)
+
+ for block in layer[1]:
+ x = block(x, hw_shape)
+ x = layer[2](x)
+ x = nlc_to_nchw(x, hw_shape)
+ if i in self.out_indices:
+ outs.append(x)
+
+ return outs
+
+
+@MODELS.register_module()
+class PyramidVisionTransformerV2(PyramidVisionTransformer):
+ """Implementation of `PVTv2: Improved Baselines with Pyramid Vision
+ Transformer `_."""
+
+ def __init__(self, **kwargs):
+ super(PyramidVisionTransformerV2, self).__init__(
+ # patch_sizes=[7, 3, 3, 3],
+ # paddings=[3, 1, 1, 1],
+ use_abs_pos_embed=False,
+ norm_after_stage=True,
+ use_conv_ffn=True,
+ **kwargs)
+
+
+def pvt_convert(ckpt):
+ new_ckpt = OrderedDict()
+ # Process the concat between q linear weights and kv linear weights
+ use_abs_pos_embed = False
+ use_conv_ffn = False
+ for k in ckpt.keys():
+ if k.startswith('pos_embed'):
+ use_abs_pos_embed = True
+ if k.find('dwconv') >= 0:
+ use_conv_ffn = True
+ for k, v in ckpt.items():
+ if k.startswith('head'):
+ continue
+ if k.startswith('norm.'):
+ continue
+ if k.startswith('cls_token'):
+ continue
+ if k.startswith('pos_embed'):
+ stage_i = int(k.replace('pos_embed', ''))
+ new_k = k.replace(f'pos_embed{stage_i}',
+ f'layers.{stage_i - 1}.1.0.pos_embed')
+ if stage_i == 4 and v.size(1) == 50: # 1 (cls token) + 7 * 7
+ new_v = v[:, 1:, :] # remove cls token
+ else:
+ new_v = v
+ elif k.startswith('patch_embed'):
+ stage_i = int(k.split('.')[0].replace('patch_embed', ''))
+ new_k = k.replace(f'patch_embed{stage_i}',
+ f'layers.{stage_i - 1}.0')
+ new_v = v
+ if 'proj.' in new_k:
+ new_k = new_k.replace('proj.', 'projection.')
+ elif k.startswith('block'):
+ stage_i = int(k.split('.')[0].replace('block', ''))
+ layer_i = int(k.split('.')[1])
+ new_layer_i = layer_i + use_abs_pos_embed
+ new_k = k.replace(f'block{stage_i}.{layer_i}',
+ f'layers.{stage_i - 1}.1.{new_layer_i}')
+ new_v = v
+ if 'attn.q.' in new_k:
+ sub_item_k = k.replace('q.', 'kv.')
+ new_k = new_k.replace('q.', 'attn.in_proj_')
+ new_v = torch.cat([v, ckpt[sub_item_k]], dim=0)
+ elif 'attn.kv.' in new_k:
+ continue
+ elif 'attn.proj.' in new_k:
+ new_k = new_k.replace('proj.', 'attn.out_proj.')
+ elif 'attn.sr.' in new_k:
+ new_k = new_k.replace('sr.', 'sr.')
+ elif 'mlp.' in new_k:
+ string = f'{new_k}-'
+ new_k = new_k.replace('mlp.', 'ffn.layers.')
+ if 'fc1.weight' in new_k or 'fc2.weight' in new_k:
+ new_v = v.reshape((*v.shape, 1, 1))
+ new_k = new_k.replace('fc1.', '0.')
+ new_k = new_k.replace('dwconv.dwconv.', '1.')
+ if use_conv_ffn:
+ new_k = new_k.replace('fc2.', '4.')
+ else:
+ new_k = new_k.replace('fc2.', '3.')
+ string += f'{new_k} {v.shape}-{new_v.shape}'
+ elif k.startswith('norm'):
+ stage_i = int(k[4])
+ new_k = k.replace(f'norm{stage_i}', f'layers.{stage_i - 1}.2')
+ new_v = v
+ else:
+ new_k = k
+ new_v = v
+ new_ckpt[new_k] = new_v
+
+ return new_ckpt
diff --git a/mmdet/models/backbones/regnet.py b/mmdet/models/backbones/regnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..55d3ce075f0cec68de4537a71ed569151d684562
--- /dev/null
+++ b/mmdet/models/backbones/regnet.py
@@ -0,0 +1,356 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+
+import numpy as np
+import torch.nn as nn
+from mmcv.cnn import build_conv_layer, build_norm_layer
+
+from mmdet.registry import MODELS
+from .resnet import ResNet
+from .resnext import Bottleneck
+
+
+@MODELS.register_module()
+class RegNet(ResNet):
+ """RegNet backbone.
+
+ More details can be found in `paper `_ .
+
+ Args:
+ arch (dict): The parameter of RegNets.
+
+ - w0 (int): initial width
+ - wa (float): slope of width
+ - wm (float): quantization parameter to quantize the width
+ - depth (int): depth of the backbone
+ - group_w (int): width of group
+ - bot_mul (float): bottleneck ratio, i.e. expansion of bottleneck.
+ strides (Sequence[int]): Strides of the first block of each stage.
+ base_channels (int): Base channels after stem layer.
+ in_channels (int): Number of input image channels. Default: 3.
+ dilations (Sequence[int]): Dilation of each stage.
+ out_indices (Sequence[int]): Output from which stages.
+ style (str): `pytorch` or `caffe`. If set to "pytorch", the stride-two
+ layer is the 3x3 conv layer, otherwise the stride-two layer is
+ the first 1x1 conv layer.
+ frozen_stages (int): Stages to be frozen (all param fixed). -1 means
+ not freezing any parameters.
+ norm_cfg (dict): dictionary to construct and config norm layer.
+ norm_eval (bool): Whether to set norm layers to eval mode, namely,
+ freeze running stats (mean and var). Note: Effect on Batch Norm
+ and its variants only.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed.
+ zero_init_residual (bool): whether to use zero init for last norm layer
+ in resblocks to let them behave as identity.
+ pretrained (str, optional): model pretrained path. Default: None
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+
+ Example:
+ >>> from mmdet.models import RegNet
+ >>> import torch
+ >>> self = RegNet(
+ arch=dict(
+ w0=88,
+ wa=26.31,
+ wm=2.25,
+ group_w=48,
+ depth=25,
+ bot_mul=1.0))
+ >>> self.eval()
+ >>> inputs = torch.rand(1, 3, 32, 32)
+ >>> level_outputs = self.forward(inputs)
+ >>> for level_out in level_outputs:
+ ... print(tuple(level_out.shape))
+ (1, 96, 8, 8)
+ (1, 192, 4, 4)
+ (1, 432, 2, 2)
+ (1, 1008, 1, 1)
+ """
+ arch_settings = {
+ 'regnetx_400mf':
+ dict(w0=24, wa=24.48, wm=2.54, group_w=16, depth=22, bot_mul=1.0),
+ 'regnetx_800mf':
+ dict(w0=56, wa=35.73, wm=2.28, group_w=16, depth=16, bot_mul=1.0),
+ 'regnetx_1.6gf':
+ dict(w0=80, wa=34.01, wm=2.25, group_w=24, depth=18, bot_mul=1.0),
+ 'regnetx_3.2gf':
+ dict(w0=88, wa=26.31, wm=2.25, group_w=48, depth=25, bot_mul=1.0),
+ 'regnetx_4.0gf':
+ dict(w0=96, wa=38.65, wm=2.43, group_w=40, depth=23, bot_mul=1.0),
+ 'regnetx_6.4gf':
+ dict(w0=184, wa=60.83, wm=2.07, group_w=56, depth=17, bot_mul=1.0),
+ 'regnetx_8.0gf':
+ dict(w0=80, wa=49.56, wm=2.88, group_w=120, depth=23, bot_mul=1.0),
+ 'regnetx_12gf':
+ dict(w0=168, wa=73.36, wm=2.37, group_w=112, depth=19, bot_mul=1.0),
+ }
+
+ def __init__(self,
+ arch,
+ in_channels=3,
+ stem_channels=32,
+ base_channels=32,
+ strides=(2, 2, 2, 2),
+ dilations=(1, 1, 1, 1),
+ out_indices=(0, 1, 2, 3),
+ style='pytorch',
+ deep_stem=False,
+ avg_down=False,
+ frozen_stages=-1,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ norm_eval=True,
+ dcn=None,
+ stage_with_dcn=(False, False, False, False),
+ plugins=None,
+ with_cp=False,
+ zero_init_residual=True,
+ pretrained=None,
+ init_cfg=None):
+ super(ResNet, self).__init__(init_cfg)
+
+ # Generate RegNet parameters first
+ if isinstance(arch, str):
+ assert arch in self.arch_settings, \
+ f'"arch": "{arch}" is not one of the' \
+ ' arch_settings'
+ arch = self.arch_settings[arch]
+ elif not isinstance(arch, dict):
+ raise ValueError('Expect "arch" to be either a string '
+ f'or a dict, got {type(arch)}')
+
+ widths, num_stages = self.generate_regnet(
+ arch['w0'],
+ arch['wa'],
+ arch['wm'],
+ arch['depth'],
+ )
+ # Convert to per stage format
+ stage_widths, stage_blocks = self.get_stages_from_blocks(widths)
+ # Generate group widths and bot muls
+ group_widths = [arch['group_w'] for _ in range(num_stages)]
+ self.bottleneck_ratio = [arch['bot_mul'] for _ in range(num_stages)]
+ # Adjust the compatibility of stage_widths and group_widths
+ stage_widths, group_widths = self.adjust_width_group(
+ stage_widths, self.bottleneck_ratio, group_widths)
+
+ # Group params by stage
+ self.stage_widths = stage_widths
+ self.group_widths = group_widths
+ self.depth = sum(stage_blocks)
+ self.stem_channels = stem_channels
+ self.base_channels = base_channels
+ self.num_stages = num_stages
+ assert num_stages >= 1 and num_stages <= 4
+ self.strides = strides
+ self.dilations = dilations
+ assert len(strides) == len(dilations) == num_stages
+ self.out_indices = out_indices
+ assert max(out_indices) < num_stages
+ self.style = style
+ self.deep_stem = deep_stem
+ self.avg_down = avg_down
+ self.frozen_stages = frozen_stages
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.with_cp = with_cp
+ self.norm_eval = norm_eval
+ self.dcn = dcn
+ self.stage_with_dcn = stage_with_dcn
+ if dcn is not None:
+ assert len(stage_with_dcn) == num_stages
+ self.plugins = plugins
+ self.zero_init_residual = zero_init_residual
+ self.block = Bottleneck
+ expansion_bak = self.block.expansion
+ self.block.expansion = 1
+ self.stage_blocks = stage_blocks[:num_stages]
+
+ self._make_stem_layer(in_channels, stem_channels)
+
+ block_init_cfg = None
+ assert not (init_cfg and pretrained), \
+ 'init_cfg and pretrained cannot be specified at the same time'
+ if isinstance(pretrained, str):
+ warnings.warn('DeprecationWarning: pretrained is deprecated, '
+ 'please use "init_cfg" instead')
+ self.init_cfg = dict(type='Pretrained', checkpoint=pretrained)
+ elif pretrained is None:
+ if init_cfg is None:
+ self.init_cfg = [
+ dict(type='Kaiming', layer='Conv2d'),
+ dict(
+ type='Constant',
+ val=1,
+ layer=['_BatchNorm', 'GroupNorm'])
+ ]
+ if self.zero_init_residual:
+ block_init_cfg = dict(
+ type='Constant', val=0, override=dict(name='norm3'))
+ else:
+ raise TypeError('pretrained must be a str or None')
+
+ self.inplanes = stem_channels
+ self.res_layers = []
+ for i, num_blocks in enumerate(self.stage_blocks):
+ stride = self.strides[i]
+ dilation = self.dilations[i]
+ group_width = self.group_widths[i]
+ width = int(round(self.stage_widths[i] * self.bottleneck_ratio[i]))
+ stage_groups = width // group_width
+
+ dcn = self.dcn if self.stage_with_dcn[i] else None
+ if self.plugins is not None:
+ stage_plugins = self.make_stage_plugins(self.plugins, i)
+ else:
+ stage_plugins = None
+
+ res_layer = self.make_res_layer(
+ block=self.block,
+ inplanes=self.inplanes,
+ planes=self.stage_widths[i],
+ num_blocks=num_blocks,
+ stride=stride,
+ dilation=dilation,
+ style=self.style,
+ avg_down=self.avg_down,
+ with_cp=self.with_cp,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ dcn=dcn,
+ plugins=stage_plugins,
+ groups=stage_groups,
+ base_width=group_width,
+ base_channels=self.stage_widths[i],
+ init_cfg=block_init_cfg)
+ self.inplanes = self.stage_widths[i]
+ layer_name = f'layer{i + 1}'
+ self.add_module(layer_name, res_layer)
+ self.res_layers.append(layer_name)
+
+ self._freeze_stages()
+
+ self.feat_dim = stage_widths[-1]
+ self.block.expansion = expansion_bak
+
+ def _make_stem_layer(self, in_channels, base_channels):
+ self.conv1 = build_conv_layer(
+ self.conv_cfg,
+ in_channels,
+ base_channels,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ bias=False)
+ self.norm1_name, norm1 = build_norm_layer(
+ self.norm_cfg, base_channels, postfix=1)
+ self.add_module(self.norm1_name, norm1)
+ self.relu = nn.ReLU(inplace=True)
+
+ def generate_regnet(self,
+ initial_width,
+ width_slope,
+ width_parameter,
+ depth,
+ divisor=8):
+ """Generates per block width from RegNet parameters.
+
+ Args:
+ initial_width ([int]): Initial width of the backbone
+ width_slope ([float]): Slope of the quantized linear function
+ width_parameter ([int]): Parameter used to quantize the width.
+ depth ([int]): Depth of the backbone.
+ divisor (int, optional): The divisor of channels. Defaults to 8.
+
+ Returns:
+ list, int: return a list of widths of each stage and the number \
+ of stages
+ """
+ assert width_slope >= 0
+ assert initial_width > 0
+ assert width_parameter > 1
+ assert initial_width % divisor == 0
+ widths_cont = np.arange(depth) * width_slope + initial_width
+ ks = np.round(
+ np.log(widths_cont / initial_width) / np.log(width_parameter))
+ widths = initial_width * np.power(width_parameter, ks)
+ widths = np.round(np.divide(widths, divisor)) * divisor
+ num_stages = len(np.unique(widths))
+ widths, widths_cont = widths.astype(int).tolist(), widths_cont.tolist()
+ return widths, num_stages
+
+ @staticmethod
+ def quantize_float(number, divisor):
+ """Converts a float to closest non-zero int divisible by divisor.
+
+ Args:
+ number (int): Original number to be quantized.
+ divisor (int): Divisor used to quantize the number.
+
+ Returns:
+ int: quantized number that is divisible by devisor.
+ """
+ return int(round(number / divisor) * divisor)
+
+ def adjust_width_group(self, widths, bottleneck_ratio, groups):
+ """Adjusts the compatibility of widths and groups.
+
+ Args:
+ widths (list[int]): Width of each stage.
+ bottleneck_ratio (float): Bottleneck ratio.
+ groups (int): number of groups in each stage
+
+ Returns:
+ tuple(list): The adjusted widths and groups of each stage.
+ """
+ bottleneck_width = [
+ int(w * b) for w, b in zip(widths, bottleneck_ratio)
+ ]
+ groups = [min(g, w_bot) for g, w_bot in zip(groups, bottleneck_width)]
+ bottleneck_width = [
+ self.quantize_float(w_bot, g)
+ for w_bot, g in zip(bottleneck_width, groups)
+ ]
+ widths = [
+ int(w_bot / b)
+ for w_bot, b in zip(bottleneck_width, bottleneck_ratio)
+ ]
+ return widths, groups
+
+ def get_stages_from_blocks(self, widths):
+ """Gets widths/stage_blocks of network at each stage.
+
+ Args:
+ widths (list[int]): Width in each stage.
+
+ Returns:
+ tuple(list): width and depth of each stage
+ """
+ width_diff = [
+ width != width_prev
+ for width, width_prev in zip(widths + [0], [0] + widths)
+ ]
+ stage_widths = [
+ width for width, diff in zip(widths, width_diff[:-1]) if diff
+ ]
+ stage_blocks = np.diff([
+ depth for depth, diff in zip(range(len(width_diff)), width_diff)
+ if diff
+ ]).tolist()
+ return stage_widths, stage_blocks
+
+ def forward(self, x):
+ """Forward function."""
+ x = self.conv1(x)
+ x = self.norm1(x)
+ x = self.relu(x)
+
+ outs = []
+ for i, layer_name in enumerate(self.res_layers):
+ res_layer = getattr(self, layer_name)
+ x = res_layer(x)
+ if i in self.out_indices:
+ outs.append(x)
+ return tuple(outs)
diff --git a/mmdet/models/backbones/res2net.py b/mmdet/models/backbones/res2net.py
new file mode 100644
index 0000000000000000000000000000000000000000..958fc88465c6769cb4c50907c92335331e8b7834
--- /dev/null
+++ b/mmdet/models/backbones/res2net.py
@@ -0,0 +1,327 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+
+import torch
+import torch.nn as nn
+import torch.utils.checkpoint as cp
+from mmcv.cnn import build_conv_layer, build_norm_layer
+from mmengine.model import Sequential
+
+from mmdet.registry import MODELS
+from .resnet import Bottleneck as _Bottleneck
+from .resnet import ResNet
+
+
+class Bottle2neck(_Bottleneck):
+ expansion = 4
+
+ def __init__(self,
+ inplanes,
+ planes,
+ scales=4,
+ base_width=26,
+ base_channels=64,
+ stage_type='normal',
+ **kwargs):
+ """Bottle2neck block for Res2Net.
+
+ If style is "pytorch", the stride-two layer is the 3x3 conv layer, if
+ it is "caffe", the stride-two layer is the first 1x1 conv layer.
+ """
+ super(Bottle2neck, self).__init__(inplanes, planes, **kwargs)
+ assert scales > 1, 'Res2Net degenerates to ResNet when scales = 1.'
+ width = int(math.floor(self.planes * (base_width / base_channels)))
+
+ self.norm1_name, norm1 = build_norm_layer(
+ self.norm_cfg, width * scales, postfix=1)
+ self.norm3_name, norm3 = build_norm_layer(
+ self.norm_cfg, self.planes * self.expansion, postfix=3)
+
+ self.conv1 = build_conv_layer(
+ self.conv_cfg,
+ self.inplanes,
+ width * scales,
+ kernel_size=1,
+ stride=self.conv1_stride,
+ bias=False)
+ self.add_module(self.norm1_name, norm1)
+
+ if stage_type == 'stage' and self.conv2_stride != 1:
+ self.pool = nn.AvgPool2d(
+ kernel_size=3, stride=self.conv2_stride, padding=1)
+ convs = []
+ bns = []
+
+ fallback_on_stride = False
+ if self.with_dcn:
+ fallback_on_stride = self.dcn.pop('fallback_on_stride', False)
+ if not self.with_dcn or fallback_on_stride:
+ for i in range(scales - 1):
+ convs.append(
+ build_conv_layer(
+ self.conv_cfg,
+ width,
+ width,
+ kernel_size=3,
+ stride=self.conv2_stride,
+ padding=self.dilation,
+ dilation=self.dilation,
+ bias=False))
+ bns.append(
+ build_norm_layer(self.norm_cfg, width, postfix=i + 1)[1])
+ self.convs = nn.ModuleList(convs)
+ self.bns = nn.ModuleList(bns)
+ else:
+ assert self.conv_cfg is None, 'conv_cfg must be None for DCN'
+ for i in range(scales - 1):
+ convs.append(
+ build_conv_layer(
+ self.dcn,
+ width,
+ width,
+ kernel_size=3,
+ stride=self.conv2_stride,
+ padding=self.dilation,
+ dilation=self.dilation,
+ bias=False))
+ bns.append(
+ build_norm_layer(self.norm_cfg, width, postfix=i + 1)[1])
+ self.convs = nn.ModuleList(convs)
+ self.bns = nn.ModuleList(bns)
+
+ self.conv3 = build_conv_layer(
+ self.conv_cfg,
+ width * scales,
+ self.planes * self.expansion,
+ kernel_size=1,
+ bias=False)
+ self.add_module(self.norm3_name, norm3)
+
+ self.stage_type = stage_type
+ self.scales = scales
+ self.width = width
+ delattr(self, 'conv2')
+ delattr(self, self.norm2_name)
+
+ def forward(self, x):
+ """Forward function."""
+
+ def _inner_forward(x):
+ identity = x
+
+ out = self.conv1(x)
+ out = self.norm1(out)
+ out = self.relu(out)
+
+ if self.with_plugins:
+ out = self.forward_plugin(out, self.after_conv1_plugin_names)
+
+ spx = torch.split(out, self.width, 1)
+ sp = self.convs[0](spx[0].contiguous())
+ sp = self.relu(self.bns[0](sp))
+ out = sp
+ for i in range(1, self.scales - 1):
+ if self.stage_type == 'stage':
+ sp = spx[i]
+ else:
+ sp = sp + spx[i]
+ sp = self.convs[i](sp.contiguous())
+ sp = self.relu(self.bns[i](sp))
+ out = torch.cat((out, sp), 1)
+
+ if self.stage_type == 'normal' or self.conv2_stride == 1:
+ out = torch.cat((out, spx[self.scales - 1]), 1)
+ elif self.stage_type == 'stage':
+ out = torch.cat((out, self.pool(spx[self.scales - 1])), 1)
+
+ if self.with_plugins:
+ out = self.forward_plugin(out, self.after_conv2_plugin_names)
+
+ out = self.conv3(out)
+ out = self.norm3(out)
+
+ if self.with_plugins:
+ out = self.forward_plugin(out, self.after_conv3_plugin_names)
+
+ if self.downsample is not None:
+ identity = self.downsample(x)
+
+ out += identity
+
+ return out
+
+ if self.with_cp and x.requires_grad:
+ out = cp.checkpoint(_inner_forward, x)
+ else:
+ out = _inner_forward(x)
+
+ out = self.relu(out)
+
+ return out
+
+
+class Res2Layer(Sequential):
+ """Res2Layer to build Res2Net style backbone.
+
+ Args:
+ block (nn.Module): block used to build ResLayer.
+ inplanes (int): inplanes of block.
+ planes (int): planes of block.
+ num_blocks (int): number of blocks.
+ stride (int): stride of the first block. Default: 1
+ avg_down (bool): Use AvgPool instead of stride conv when
+ downsampling in the bottle2neck. Default: False
+ conv_cfg (dict): dictionary to construct and config conv layer.
+ Default: None
+ norm_cfg (dict): dictionary to construct and config norm layer.
+ Default: dict(type='BN')
+ scales (int): Scales used in Res2Net. Default: 4
+ base_width (int): Basic width of each scale. Default: 26
+ """
+
+ def __init__(self,
+ block,
+ inplanes,
+ planes,
+ num_blocks,
+ stride=1,
+ avg_down=True,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ scales=4,
+ base_width=26,
+ **kwargs):
+ self.block = block
+
+ downsample = None
+ if stride != 1 or inplanes != planes * block.expansion:
+ downsample = nn.Sequential(
+ nn.AvgPool2d(
+ kernel_size=stride,
+ stride=stride,
+ ceil_mode=True,
+ count_include_pad=False),
+ build_conv_layer(
+ conv_cfg,
+ inplanes,
+ planes * block.expansion,
+ kernel_size=1,
+ stride=1,
+ bias=False),
+ build_norm_layer(norm_cfg, planes * block.expansion)[1],
+ )
+
+ layers = []
+ layers.append(
+ block(
+ inplanes=inplanes,
+ planes=planes,
+ stride=stride,
+ downsample=downsample,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ scales=scales,
+ base_width=base_width,
+ stage_type='stage',
+ **kwargs))
+ inplanes = planes * block.expansion
+ for i in range(1, num_blocks):
+ layers.append(
+ block(
+ inplanes=inplanes,
+ planes=planes,
+ stride=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ scales=scales,
+ base_width=base_width,
+ **kwargs))
+ super(Res2Layer, self).__init__(*layers)
+
+
+@MODELS.register_module()
+class Res2Net(ResNet):
+ """Res2Net backbone.
+
+ Args:
+ scales (int): Scales used in Res2Net. Default: 4
+ base_width (int): Basic width of each scale. Default: 26
+ depth (int): Depth of res2net, from {50, 101, 152}.
+ in_channels (int): Number of input image channels. Default: 3.
+ num_stages (int): Res2net stages. Default: 4.
+ strides (Sequence[int]): Strides of the first block of each stage.
+ dilations (Sequence[int]): Dilation of each stage.
+ out_indices (Sequence[int]): Output from which stages.
+ style (str): `pytorch` or `caffe`. If set to "pytorch", the stride-two
+ layer is the 3x3 conv layer, otherwise the stride-two layer is
+ the first 1x1 conv layer.
+ deep_stem (bool): Replace 7x7 conv in input stem with 3 3x3 conv
+ avg_down (bool): Use AvgPool instead of stride conv when
+ downsampling in the bottle2neck.
+ frozen_stages (int): Stages to be frozen (stop grad and set eval mode).
+ -1 means not freezing any parameters.
+ norm_cfg (dict): Dictionary to construct and config norm layer.
+ norm_eval (bool): Whether to set norm layers to eval mode, namely,
+ freeze running stats (mean and var). Note: Effect on Batch Norm
+ and its variants only.
+ plugins (list[dict]): List of plugins for stages, each dict contains:
+
+ - cfg (dict, required): Cfg dict to build plugin.
+ - position (str, required): Position inside block to insert
+ plugin, options are 'after_conv1', 'after_conv2', 'after_conv3'.
+ - stages (tuple[bool], optional): Stages to apply plugin, length
+ should be same as 'num_stages'.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed.
+ zero_init_residual (bool): Whether to use zero init for last norm layer
+ in resblocks to let them behave as identity.
+ pretrained (str, optional): model pretrained path. Default: None
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+
+ Example:
+ >>> from mmdet.models import Res2Net
+ >>> import torch
+ >>> self = Res2Net(depth=50, scales=4, base_width=26)
+ >>> self.eval()
+ >>> inputs = torch.rand(1, 3, 32, 32)
+ >>> level_outputs = self.forward(inputs)
+ >>> for level_out in level_outputs:
+ ... print(tuple(level_out.shape))
+ (1, 256, 8, 8)
+ (1, 512, 4, 4)
+ (1, 1024, 2, 2)
+ (1, 2048, 1, 1)
+ """
+
+ arch_settings = {
+ 50: (Bottle2neck, (3, 4, 6, 3)),
+ 101: (Bottle2neck, (3, 4, 23, 3)),
+ 152: (Bottle2neck, (3, 8, 36, 3))
+ }
+
+ def __init__(self,
+ scales=4,
+ base_width=26,
+ style='pytorch',
+ deep_stem=True,
+ avg_down=True,
+ pretrained=None,
+ init_cfg=None,
+ **kwargs):
+ self.scales = scales
+ self.base_width = base_width
+ super(Res2Net, self).__init__(
+ style='pytorch',
+ deep_stem=True,
+ avg_down=True,
+ pretrained=pretrained,
+ init_cfg=init_cfg,
+ **kwargs)
+
+ def make_res_layer(self, **kwargs):
+ return Res2Layer(
+ scales=self.scales,
+ base_width=self.base_width,
+ base_channels=self.base_channels,
+ **kwargs)
diff --git a/mmdet/models/backbones/resnest.py b/mmdet/models/backbones/resnest.py
new file mode 100644
index 0000000000000000000000000000000000000000..d4466c4cc416237bee1f870b52e3c20a849c5a60
--- /dev/null
+++ b/mmdet/models/backbones/resnest.py
@@ -0,0 +1,322 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+import torch.utils.checkpoint as cp
+from mmcv.cnn import build_conv_layer, build_norm_layer
+from mmengine.model import BaseModule
+
+from mmdet.registry import MODELS
+from ..layers import ResLayer
+from .resnet import Bottleneck as _Bottleneck
+from .resnet import ResNetV1d
+
+
+class RSoftmax(nn.Module):
+ """Radix Softmax module in ``SplitAttentionConv2d``.
+
+ Args:
+ radix (int): Radix of input.
+ groups (int): Groups of input.
+ """
+
+ def __init__(self, radix, groups):
+ super().__init__()
+ self.radix = radix
+ self.groups = groups
+
+ def forward(self, x):
+ batch = x.size(0)
+ if self.radix > 1:
+ x = x.view(batch, self.groups, self.radix, -1).transpose(1, 2)
+ x = F.softmax(x, dim=1)
+ x = x.reshape(batch, -1)
+ else:
+ x = torch.sigmoid(x)
+ return x
+
+
+class SplitAttentionConv2d(BaseModule):
+ """Split-Attention Conv2d in ResNeSt.
+
+ Args:
+ in_channels (int): Number of channels in the input feature map.
+ channels (int): Number of intermediate channels.
+ kernel_size (int | tuple[int]): Size of the convolution kernel.
+ stride (int | tuple[int]): Stride of the convolution.
+ padding (int | tuple[int]): Zero-padding added to both sides of
+ dilation (int | tuple[int]): Spacing between kernel elements.
+ groups (int): Number of blocked connections from input channels to
+ output channels.
+ groups (int): Same as nn.Conv2d.
+ radix (int): Radix of SpltAtConv2d. Default: 2
+ reduction_factor (int): Reduction factor of inter_channels. Default: 4.
+ conv_cfg (dict): Config dict for convolution layer. Default: None,
+ which means using conv2d.
+ norm_cfg (dict): Config dict for normalization layer. Default: None.
+ dcn (dict): Config dict for DCN. Default: None.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ def __init__(self,
+ in_channels,
+ channels,
+ kernel_size,
+ stride=1,
+ padding=0,
+ dilation=1,
+ groups=1,
+ radix=2,
+ reduction_factor=4,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ dcn=None,
+ init_cfg=None):
+ super(SplitAttentionConv2d, self).__init__(init_cfg)
+ inter_channels = max(in_channels * radix // reduction_factor, 32)
+ self.radix = radix
+ self.groups = groups
+ self.channels = channels
+ self.with_dcn = dcn is not None
+ self.dcn = dcn
+ fallback_on_stride = False
+ if self.with_dcn:
+ fallback_on_stride = self.dcn.pop('fallback_on_stride', False)
+ if self.with_dcn and not fallback_on_stride:
+ assert conv_cfg is None, 'conv_cfg must be None for DCN'
+ conv_cfg = dcn
+ self.conv = build_conv_layer(
+ conv_cfg,
+ in_channels,
+ channels * radix,
+ kernel_size,
+ stride=stride,
+ padding=padding,
+ dilation=dilation,
+ groups=groups * radix,
+ bias=False)
+ # To be consistent with original implementation, starting from 0
+ self.norm0_name, norm0 = build_norm_layer(
+ norm_cfg, channels * radix, postfix=0)
+ self.add_module(self.norm0_name, norm0)
+ self.relu = nn.ReLU(inplace=True)
+ self.fc1 = build_conv_layer(
+ None, channels, inter_channels, 1, groups=self.groups)
+ self.norm1_name, norm1 = build_norm_layer(
+ norm_cfg, inter_channels, postfix=1)
+ self.add_module(self.norm1_name, norm1)
+ self.fc2 = build_conv_layer(
+ None, inter_channels, channels * radix, 1, groups=self.groups)
+ self.rsoftmax = RSoftmax(radix, groups)
+
+ @property
+ def norm0(self):
+ """nn.Module: the normalization layer named "norm0" """
+ return getattr(self, self.norm0_name)
+
+ @property
+ def norm1(self):
+ """nn.Module: the normalization layer named "norm1" """
+ return getattr(self, self.norm1_name)
+
+ def forward(self, x):
+ x = self.conv(x)
+ x = self.norm0(x)
+ x = self.relu(x)
+
+ batch, rchannel = x.shape[:2]
+ batch = x.size(0)
+ if self.radix > 1:
+ splits = x.view(batch, self.radix, -1, *x.shape[2:])
+ gap = splits.sum(dim=1)
+ else:
+ gap = x
+ gap = F.adaptive_avg_pool2d(gap, 1)
+ gap = self.fc1(gap)
+
+ gap = self.norm1(gap)
+ gap = self.relu(gap)
+
+ atten = self.fc2(gap)
+ atten = self.rsoftmax(atten).view(batch, -1, 1, 1)
+
+ if self.radix > 1:
+ attens = atten.view(batch, self.radix, -1, *atten.shape[2:])
+ out = torch.sum(attens * splits, dim=1)
+ else:
+ out = atten * x
+ return out.contiguous()
+
+
+class Bottleneck(_Bottleneck):
+ """Bottleneck block for ResNeSt.
+
+ Args:
+ inplane (int): Input planes of this block.
+ planes (int): Middle planes of this block.
+ groups (int): Groups of conv2.
+ base_width (int): Base of width in terms of base channels. Default: 4.
+ base_channels (int): Base of channels for calculating width.
+ Default: 64.
+ radix (int): Radix of SpltAtConv2d. Default: 2
+ reduction_factor (int): Reduction factor of inter_channels in
+ SplitAttentionConv2d. Default: 4.
+ avg_down_stride (bool): Whether to use average pool for stride in
+ Bottleneck. Default: True.
+ kwargs (dict): Key word arguments for base class.
+ """
+ expansion = 4
+
+ def __init__(self,
+ inplanes,
+ planes,
+ groups=1,
+ base_width=4,
+ base_channels=64,
+ radix=2,
+ reduction_factor=4,
+ avg_down_stride=True,
+ **kwargs):
+ """Bottleneck block for ResNeSt."""
+ super(Bottleneck, self).__init__(inplanes, planes, **kwargs)
+
+ if groups == 1:
+ width = self.planes
+ else:
+ width = math.floor(self.planes *
+ (base_width / base_channels)) * groups
+
+ self.avg_down_stride = avg_down_stride and self.conv2_stride > 1
+
+ self.norm1_name, norm1 = build_norm_layer(
+ self.norm_cfg, width, postfix=1)
+ self.norm3_name, norm3 = build_norm_layer(
+ self.norm_cfg, self.planes * self.expansion, postfix=3)
+
+ self.conv1 = build_conv_layer(
+ self.conv_cfg,
+ self.inplanes,
+ width,
+ kernel_size=1,
+ stride=self.conv1_stride,
+ bias=False)
+ self.add_module(self.norm1_name, norm1)
+ self.with_modulated_dcn = False
+ self.conv2 = SplitAttentionConv2d(
+ width,
+ width,
+ kernel_size=3,
+ stride=1 if self.avg_down_stride else self.conv2_stride,
+ padding=self.dilation,
+ dilation=self.dilation,
+ groups=groups,
+ radix=radix,
+ reduction_factor=reduction_factor,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ dcn=self.dcn)
+ delattr(self, self.norm2_name)
+
+ if self.avg_down_stride:
+ self.avd_layer = nn.AvgPool2d(3, self.conv2_stride, padding=1)
+
+ self.conv3 = build_conv_layer(
+ self.conv_cfg,
+ width,
+ self.planes * self.expansion,
+ kernel_size=1,
+ bias=False)
+ self.add_module(self.norm3_name, norm3)
+
+ def forward(self, x):
+
+ def _inner_forward(x):
+ identity = x
+
+ out = self.conv1(x)
+ out = self.norm1(out)
+ out = self.relu(out)
+
+ if self.with_plugins:
+ out = self.forward_plugin(out, self.after_conv1_plugin_names)
+
+ out = self.conv2(out)
+
+ if self.avg_down_stride:
+ out = self.avd_layer(out)
+
+ if self.with_plugins:
+ out = self.forward_plugin(out, self.after_conv2_plugin_names)
+
+ out = self.conv3(out)
+ out = self.norm3(out)
+
+ if self.with_plugins:
+ out = self.forward_plugin(out, self.after_conv3_plugin_names)
+
+ if self.downsample is not None:
+ identity = self.downsample(x)
+
+ out += identity
+
+ return out
+
+ if self.with_cp and x.requires_grad:
+ out = cp.checkpoint(_inner_forward, x)
+ else:
+ out = _inner_forward(x)
+
+ out = self.relu(out)
+
+ return out
+
+
+@MODELS.register_module()
+class ResNeSt(ResNetV1d):
+ """ResNeSt backbone.
+
+ Args:
+ groups (int): Number of groups of Bottleneck. Default: 1
+ base_width (int): Base width of Bottleneck. Default: 4
+ radix (int): Radix of SplitAttentionConv2d. Default: 2
+ reduction_factor (int): Reduction factor of inter_channels in
+ SplitAttentionConv2d. Default: 4.
+ avg_down_stride (bool): Whether to use average pool for stride in
+ Bottleneck. Default: True.
+ kwargs (dict): Keyword arguments for ResNet.
+ """
+
+ arch_settings = {
+ 50: (Bottleneck, (3, 4, 6, 3)),
+ 101: (Bottleneck, (3, 4, 23, 3)),
+ 152: (Bottleneck, (3, 8, 36, 3)),
+ 200: (Bottleneck, (3, 24, 36, 3))
+ }
+
+ def __init__(self,
+ groups=1,
+ base_width=4,
+ radix=2,
+ reduction_factor=4,
+ avg_down_stride=True,
+ **kwargs):
+ self.groups = groups
+ self.base_width = base_width
+ self.radix = radix
+ self.reduction_factor = reduction_factor
+ self.avg_down_stride = avg_down_stride
+ super(ResNeSt, self).__init__(**kwargs)
+
+ def make_res_layer(self, **kwargs):
+ """Pack all blocks in a stage into a ``ResLayer``."""
+ return ResLayer(
+ groups=self.groups,
+ base_width=self.base_width,
+ base_channels=self.base_channels,
+ radix=self.radix,
+ reduction_factor=self.reduction_factor,
+ avg_down_stride=self.avg_down_stride,
+ **kwargs)
diff --git a/mmdet/models/backbones/resnet.py b/mmdet/models/backbones/resnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..ad84a81ecc5510e28bf62c67a4212964071d64cf
--- /dev/null
+++ b/mmdet/models/backbones/resnet.py
@@ -0,0 +1,673 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+
+import torch.nn as nn
+import torch.utils.checkpoint as cp
+from mmcv.cnn import build_conv_layer, build_norm_layer, build_plugin_layer
+from mmengine.model import BaseModule
+from torch.nn.modules.batchnorm import _BatchNorm
+
+from mmdet.registry import MODELS
+from ..layers import ResLayer
+
+
+class BasicBlock(BaseModule):
+ expansion = 1
+
+ def __init__(self,
+ inplanes,
+ planes,
+ stride=1,
+ dilation=1,
+ downsample=None,
+ style='pytorch',
+ with_cp=False,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ dcn=None,
+ plugins=None,
+ init_cfg=None):
+ super(BasicBlock, self).__init__(init_cfg)
+ assert dcn is None, 'Not implemented yet.'
+ assert plugins is None, 'Not implemented yet.'
+
+ self.norm1_name, norm1 = build_norm_layer(norm_cfg, planes, postfix=1)
+ self.norm2_name, norm2 = build_norm_layer(norm_cfg, planes, postfix=2)
+
+ self.conv1 = build_conv_layer(
+ conv_cfg,
+ inplanes,
+ planes,
+ 3,
+ stride=stride,
+ padding=dilation,
+ dilation=dilation,
+ bias=False)
+ self.add_module(self.norm1_name, norm1)
+ self.conv2 = build_conv_layer(
+ conv_cfg, planes, planes, 3, padding=1, bias=False)
+ self.add_module(self.norm2_name, norm2)
+
+ self.relu = nn.ReLU(inplace=True)
+ self.downsample = downsample
+ self.stride = stride
+ self.dilation = dilation
+ self.with_cp = with_cp
+
+ @property
+ def norm1(self):
+ """nn.Module: normalization layer after the first convolution layer"""
+ return getattr(self, self.norm1_name)
+
+ @property
+ def norm2(self):
+ """nn.Module: normalization layer after the second convolution layer"""
+ return getattr(self, self.norm2_name)
+
+ def forward(self, x):
+ """Forward function."""
+
+ def _inner_forward(x):
+ identity = x
+
+ out = self.conv1(x)
+ out = self.norm1(out)
+ out = self.relu(out)
+
+ out = self.conv2(out)
+ out = self.norm2(out)
+
+ if self.downsample is not None:
+ identity = self.downsample(x)
+
+ out += identity
+
+ return out
+
+ if self.with_cp and x.requires_grad:
+ out = cp.checkpoint(_inner_forward, x)
+ else:
+ out = _inner_forward(x)
+
+ out = self.relu(out)
+
+ return out
+
+
+class Bottleneck(BaseModule):
+ expansion = 4
+
+ def __init__(self,
+ inplanes,
+ planes,
+ stride=1,
+ dilation=1,
+ downsample=None,
+ style='pytorch',
+ with_cp=False,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ dcn=None,
+ plugins=None,
+ init_cfg=None):
+ """Bottleneck block for ResNet.
+
+ If style is "pytorch", the stride-two layer is the 3x3 conv layer, if
+ it is "caffe", the stride-two layer is the first 1x1 conv layer.
+ """
+ super(Bottleneck, self).__init__(init_cfg)
+ assert style in ['pytorch', 'caffe']
+ assert dcn is None or isinstance(dcn, dict)
+ assert plugins is None or isinstance(plugins, list)
+ if plugins is not None:
+ allowed_position = ['after_conv1', 'after_conv2', 'after_conv3']
+ assert all(p['position'] in allowed_position for p in plugins)
+
+ self.inplanes = inplanes
+ self.planes = planes
+ self.stride = stride
+ self.dilation = dilation
+ self.style = style
+ self.with_cp = with_cp
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.dcn = dcn
+ self.with_dcn = dcn is not None
+ self.plugins = plugins
+ self.with_plugins = plugins is not None
+
+ if self.with_plugins:
+ # collect plugins for conv1/conv2/conv3
+ self.after_conv1_plugins = [
+ plugin['cfg'] for plugin in plugins
+ if plugin['position'] == 'after_conv1'
+ ]
+ self.after_conv2_plugins = [
+ plugin['cfg'] for plugin in plugins
+ if plugin['position'] == 'after_conv2'
+ ]
+ self.after_conv3_plugins = [
+ plugin['cfg'] for plugin in plugins
+ if plugin['position'] == 'after_conv3'
+ ]
+
+ if self.style == 'pytorch':
+ self.conv1_stride = 1
+ self.conv2_stride = stride
+ else:
+ self.conv1_stride = stride
+ self.conv2_stride = 1
+
+ self.norm1_name, norm1 = build_norm_layer(norm_cfg, planes, postfix=1)
+ self.norm2_name, norm2 = build_norm_layer(norm_cfg, planes, postfix=2)
+ self.norm3_name, norm3 = build_norm_layer(
+ norm_cfg, planes * self.expansion, postfix=3)
+
+ self.conv1 = build_conv_layer(
+ conv_cfg,
+ inplanes,
+ planes,
+ kernel_size=1,
+ stride=self.conv1_stride,
+ bias=False)
+ self.add_module(self.norm1_name, norm1)
+ fallback_on_stride = False
+ if self.with_dcn:
+ fallback_on_stride = dcn.pop('fallback_on_stride', False)
+ if not self.with_dcn or fallback_on_stride:
+ self.conv2 = build_conv_layer(
+ conv_cfg,
+ planes,
+ planes,
+ kernel_size=3,
+ stride=self.conv2_stride,
+ padding=dilation,
+ dilation=dilation,
+ bias=False)
+ else:
+ assert self.conv_cfg is None, 'conv_cfg must be None for DCN'
+ self.conv2 = build_conv_layer(
+ dcn,
+ planes,
+ planes,
+ kernel_size=3,
+ stride=self.conv2_stride,
+ padding=dilation,
+ dilation=dilation,
+ bias=False)
+
+ self.add_module(self.norm2_name, norm2)
+ self.conv3 = build_conv_layer(
+ conv_cfg,
+ planes,
+ planes * self.expansion,
+ kernel_size=1,
+ bias=False)
+ self.add_module(self.norm3_name, norm3)
+
+ self.relu = nn.ReLU(inplace=True)
+ self.downsample = downsample
+
+ if self.with_plugins:
+ self.after_conv1_plugin_names = self.make_block_plugins(
+ planes, self.after_conv1_plugins)
+ self.after_conv2_plugin_names = self.make_block_plugins(
+ planes, self.after_conv2_plugins)
+ self.after_conv3_plugin_names = self.make_block_plugins(
+ planes * self.expansion, self.after_conv3_plugins)
+
+ def make_block_plugins(self, in_channels, plugins):
+ """make plugins for block.
+
+ Args:
+ in_channels (int): Input channels of plugin.
+ plugins (list[dict]): List of plugins cfg to build.
+
+ Returns:
+ list[str]: List of the names of plugin.
+ """
+ assert isinstance(plugins, list)
+ plugin_names = []
+ for plugin in plugins:
+ plugin = plugin.copy()
+ name, layer = build_plugin_layer(
+ plugin,
+ in_channels=in_channels,
+ postfix=plugin.pop('postfix', ''))
+ assert not hasattr(self, name), f'duplicate plugin {name}'
+ self.add_module(name, layer)
+ plugin_names.append(name)
+ return plugin_names
+
+ def forward_plugin(self, x, plugin_names):
+ out = x
+ for name in plugin_names:
+ out = getattr(self, name)(out)
+ return out
+
+ @property
+ def norm1(self):
+ """nn.Module: normalization layer after the first convolution layer"""
+ return getattr(self, self.norm1_name)
+
+ @property
+ def norm2(self):
+ """nn.Module: normalization layer after the second convolution layer"""
+ return getattr(self, self.norm2_name)
+
+ @property
+ def norm3(self):
+ """nn.Module: normalization layer after the third convolution layer"""
+ return getattr(self, self.norm3_name)
+
+ def forward(self, x):
+ """Forward function."""
+
+ def _inner_forward(x):
+ identity = x
+ out = self.conv1(x)
+ out = self.norm1(out)
+ out = self.relu(out)
+
+ if self.with_plugins:
+ out = self.forward_plugin(out, self.after_conv1_plugin_names)
+
+ out = self.conv2(out)
+ out = self.norm2(out)
+ out = self.relu(out)
+
+ if self.with_plugins:
+ out = self.forward_plugin(out, self.after_conv2_plugin_names)
+
+ out = self.conv3(out)
+ out = self.norm3(out)
+
+ if self.with_plugins:
+ out = self.forward_plugin(out, self.after_conv3_plugin_names)
+
+ if self.downsample is not None:
+ identity = self.downsample(x)
+
+ out += identity
+
+ return out
+
+ if self.with_cp and x.requires_grad:
+ out = cp.checkpoint(_inner_forward, x)
+ else:
+ out = _inner_forward(x)
+
+ out = self.relu(out)
+
+ return out
+
+
+@MODELS.register_module()
+class ResNet(BaseModule):
+ """ResNet backbone.
+
+ Args:
+ depth (int): Depth of resnet, from {18, 34, 50, 101, 152}.
+ stem_channels (int | None): Number of stem channels. If not specified,
+ it will be the same as `base_channels`. Default: None.
+ base_channels (int): Number of base channels of res layer. Default: 64.
+ in_channels (int): Number of input image channels. Default: 3.
+ num_stages (int): Resnet stages. Default: 4.
+ strides (Sequence[int]): Strides of the first block of each stage.
+ dilations (Sequence[int]): Dilation of each stage.
+ out_indices (Sequence[int]): Output from which stages.
+ style (str): `pytorch` or `caffe`. If set to "pytorch", the stride-two
+ layer is the 3x3 conv layer, otherwise the stride-two layer is
+ the first 1x1 conv layer.
+ deep_stem (bool): Replace 7x7 conv in input stem with 3 3x3 conv
+ avg_down (bool): Use AvgPool instead of stride conv when
+ downsampling in the bottleneck.
+ frozen_stages (int): Stages to be frozen (stop grad and set eval mode).
+ -1 means not freezing any parameters.
+ norm_cfg (dict): Dictionary to construct and config norm layer.
+ norm_eval (bool): Whether to set norm layers to eval mode, namely,
+ freeze running stats (mean and var). Note: Effect on Batch Norm
+ and its variants only.
+ plugins (list[dict]): List of plugins for stages, each dict contains:
+
+ - cfg (dict, required): Cfg dict to build plugin.
+ - position (str, required): Position inside block to insert
+ plugin, options are 'after_conv1', 'after_conv2', 'after_conv3'.
+ - stages (tuple[bool], optional): Stages to apply plugin, length
+ should be same as 'num_stages'.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed.
+ zero_init_residual (bool): Whether to use zero init for last norm layer
+ in resblocks to let them behave as identity.
+ pretrained (str, optional): model pretrained path. Default: None
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+
+ Example:
+ >>> from mmdet.models import ResNet
+ >>> import torch
+ >>> self = ResNet(depth=18)
+ >>> self.eval()
+ >>> inputs = torch.rand(1, 3, 32, 32)
+ >>> level_outputs = self.forward(inputs)
+ >>> for level_out in level_outputs:
+ ... print(tuple(level_out.shape))
+ (1, 64, 8, 8)
+ (1, 128, 4, 4)
+ (1, 256, 2, 2)
+ (1, 512, 1, 1)
+ """
+
+ arch_settings = {
+ 18: (BasicBlock, (2, 2, 2, 2)),
+ 34: (BasicBlock, (3, 4, 6, 3)),
+ 50: (Bottleneck, (3, 4, 6, 3)),
+ 101: (Bottleneck, (3, 4, 23, 3)),
+ 152: (Bottleneck, (3, 8, 36, 3))
+ }
+
+ def __init__(self,
+ depth,
+ in_channels=3,
+ stem_channels=None,
+ base_channels=64,
+ num_stages=4,
+ strides=(1, 2, 2, 2),
+ dilations=(1, 1, 1, 1),
+ out_indices=(0, 1, 2, 3),
+ style='pytorch',
+ deep_stem=False,
+ avg_down=False,
+ frozen_stages=-1,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ norm_eval=True,
+ dcn=None,
+ stage_with_dcn=(False, False, False, False),
+ plugins=None,
+ with_cp=False,
+ zero_init_residual=True,
+ pretrained=None,
+ init_cfg=None):
+ super(ResNet, self).__init__(init_cfg)
+ self.zero_init_residual = zero_init_residual
+ if depth not in self.arch_settings:
+ raise KeyError(f'invalid depth {depth} for resnet')
+
+ block_init_cfg = None
+ assert not (init_cfg and pretrained), \
+ 'init_cfg and pretrained cannot be specified at the same time'
+ if isinstance(pretrained, str):
+ warnings.warn('DeprecationWarning: pretrained is deprecated, '
+ 'please use "init_cfg" instead')
+ self.init_cfg = dict(type='Pretrained', checkpoint=pretrained)
+ elif pretrained is None:
+ if init_cfg is None:
+ self.init_cfg = [
+ dict(type='Kaiming', layer='Conv2d'),
+ dict(
+ type='Constant',
+ val=1,
+ layer=['_BatchNorm', 'GroupNorm'])
+ ]
+ block = self.arch_settings[depth][0]
+ if self.zero_init_residual:
+ if block is BasicBlock:
+ block_init_cfg = dict(
+ type='Constant',
+ val=0,
+ override=dict(name='norm2'))
+ elif block is Bottleneck:
+ block_init_cfg = dict(
+ type='Constant',
+ val=0,
+ override=dict(name='norm3'))
+ else:
+ raise TypeError('pretrained must be a str or None')
+
+ self.depth = depth
+ if stem_channels is None:
+ stem_channels = base_channels
+ self.stem_channels = stem_channels
+ self.base_channels = base_channels
+ self.num_stages = num_stages
+ assert num_stages >= 1 and num_stages <= 4
+ self.strides = strides
+ self.dilations = dilations
+ assert len(strides) == len(dilations) == num_stages
+ self.out_indices = out_indices
+ assert max(out_indices) < num_stages
+ self.style = style
+ self.deep_stem = deep_stem
+ self.avg_down = avg_down
+ self.frozen_stages = frozen_stages
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.with_cp = with_cp
+ self.norm_eval = norm_eval
+ self.dcn = dcn
+ self.stage_with_dcn = stage_with_dcn
+ if dcn is not None:
+ assert len(stage_with_dcn) == num_stages
+ self.plugins = plugins
+ self.block, stage_blocks = self.arch_settings[depth]
+ self.stage_blocks = stage_blocks[:num_stages]
+ self.inplanes = stem_channels
+
+ self._make_stem_layer(in_channels, stem_channels)
+
+ self.res_layers = []
+ for i, num_blocks in enumerate(self.stage_blocks):
+ stride = strides[i]
+ dilation = dilations[i]
+ dcn = self.dcn if self.stage_with_dcn[i] else None
+ if plugins is not None:
+ stage_plugins = self.make_stage_plugins(plugins, i)
+ else:
+ stage_plugins = None
+ planes = base_channels * 2**i
+ res_layer = self.make_res_layer(
+ block=self.block,
+ inplanes=self.inplanes,
+ planes=planes,
+ num_blocks=num_blocks,
+ stride=stride,
+ dilation=dilation,
+ style=self.style,
+ avg_down=self.avg_down,
+ with_cp=with_cp,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ dcn=dcn,
+ plugins=stage_plugins,
+ init_cfg=block_init_cfg)
+ self.inplanes = planes * self.block.expansion
+ layer_name = f'layer{i + 1}'
+ self.add_module(layer_name, res_layer)
+ self.res_layers.append(layer_name)
+
+ self._freeze_stages()
+
+ self.feat_dim = self.block.expansion * base_channels * 2**(
+ len(self.stage_blocks) - 1)
+
+ def make_stage_plugins(self, plugins, stage_idx):
+ """Make plugins for ResNet ``stage_idx`` th stage.
+
+ Currently we support to insert ``context_block``,
+ ``empirical_attention_block``, ``nonlocal_block`` into the backbone
+ like ResNet/ResNeXt. They could be inserted after conv1/conv2/conv3 of
+ Bottleneck.
+
+ An example of plugins format could be:
+
+ Examples:
+ >>> plugins=[
+ ... dict(cfg=dict(type='xxx', arg1='xxx'),
+ ... stages=(False, True, True, True),
+ ... position='after_conv2'),
+ ... dict(cfg=dict(type='yyy'),
+ ... stages=(True, True, True, True),
+ ... position='after_conv3'),
+ ... dict(cfg=dict(type='zzz', postfix='1'),
+ ... stages=(True, True, True, True),
+ ... position='after_conv3'),
+ ... dict(cfg=dict(type='zzz', postfix='2'),
+ ... stages=(True, True, True, True),
+ ... position='after_conv3')
+ ... ]
+ >>> self = ResNet(depth=18)
+ >>> stage_plugins = self.make_stage_plugins(plugins, 0)
+ >>> assert len(stage_plugins) == 3
+
+ Suppose ``stage_idx=0``, the structure of blocks in the stage would be:
+
+ .. code-block:: none
+
+ conv1-> conv2->conv3->yyy->zzz1->zzz2
+
+ Suppose 'stage_idx=1', the structure of blocks in the stage would be:
+
+ .. code-block:: none
+
+ conv1-> conv2->xxx->conv3->yyy->zzz1->zzz2
+
+ If stages is missing, the plugin would be applied to all stages.
+
+ Args:
+ plugins (list[dict]): List of plugins cfg to build. The postfix is
+ required if multiple same type plugins are inserted.
+ stage_idx (int): Index of stage to build
+
+ Returns:
+ list[dict]: Plugins for current stage
+ """
+ stage_plugins = []
+ for plugin in plugins:
+ plugin = plugin.copy()
+ stages = plugin.pop('stages', None)
+ assert stages is None or len(stages) == self.num_stages
+ # whether to insert plugin into current stage
+ if stages is None or stages[stage_idx]:
+ stage_plugins.append(plugin)
+
+ return stage_plugins
+
+ def make_res_layer(self, **kwargs):
+ """Pack all blocks in a stage into a ``ResLayer``."""
+ return ResLayer(**kwargs)
+
+ @property
+ def norm1(self):
+ """nn.Module: the normalization layer named "norm1" """
+ return getattr(self, self.norm1_name)
+
+ def _make_stem_layer(self, in_channels, stem_channels):
+ if self.deep_stem:
+ self.stem = nn.Sequential(
+ build_conv_layer(
+ self.conv_cfg,
+ in_channels,
+ stem_channels // 2,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ bias=False),
+ build_norm_layer(self.norm_cfg, stem_channels // 2)[1],
+ nn.ReLU(inplace=True),
+ build_conv_layer(
+ self.conv_cfg,
+ stem_channels // 2,
+ stem_channels // 2,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ bias=False),
+ build_norm_layer(self.norm_cfg, stem_channels // 2)[1],
+ nn.ReLU(inplace=True),
+ build_conv_layer(
+ self.conv_cfg,
+ stem_channels // 2,
+ stem_channels,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ bias=False),
+ build_norm_layer(self.norm_cfg, stem_channels)[1],
+ nn.ReLU(inplace=True))
+ else:
+ self.conv1 = build_conv_layer(
+ self.conv_cfg,
+ in_channels,
+ stem_channels,
+ kernel_size=7,
+ stride=2,
+ padding=3,
+ bias=False)
+ self.norm1_name, norm1 = build_norm_layer(
+ self.norm_cfg, stem_channels, postfix=1)
+ self.add_module(self.norm1_name, norm1)
+ self.relu = nn.ReLU(inplace=True)
+ self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
+
+ def _freeze_stages(self):
+ if self.frozen_stages >= 0:
+ if self.deep_stem:
+ self.stem.eval()
+ for param in self.stem.parameters():
+ param.requires_grad = False
+ else:
+ self.norm1.eval()
+ for m in [self.conv1, self.norm1]:
+ for param in m.parameters():
+ param.requires_grad = False
+
+ for i in range(1, self.frozen_stages + 1):
+ m = getattr(self, f'layer{i}')
+ m.eval()
+ for param in m.parameters():
+ param.requires_grad = False
+
+ def forward(self, x):
+ """Forward function."""
+ x=x.float()
+ if self.deep_stem:
+ x = self.stem(x)
+ else:
+ x = self.conv1(x)
+ x = self.norm1(x)
+ x = self.relu(x)
+ x = self.maxpool(x)
+ outs = []
+ for i, layer_name in enumerate(self.res_layers):
+ res_layer = getattr(self, layer_name)
+ x = res_layer(x)
+ if i in self.out_indices:
+ outs.append(x)
+ return tuple(outs)
+
+ def train(self, mode=True):
+ """Convert the model into training mode while keep normalization layer
+ freezed."""
+ super(ResNet, self).train(mode)
+ self._freeze_stages()
+ if mode and self.norm_eval:
+ for m in self.modules():
+ # trick: eval have effect on BatchNorm only
+ if isinstance(m, _BatchNorm):
+ m.eval()
+
+
+@MODELS.register_module()
+class ResNetV1d(ResNet):
+ r"""ResNetV1d variant described in `Bag of Tricks
+ `_.
+
+ Compared with default ResNet(ResNetV1b), ResNetV1d replaces the 7x7 conv in
+ the input stem with three 3x3 convs. And in the downsampling block, a 2x2
+ avg_pool with stride 2 is added before conv, whose stride is changed to 1.
+ """
+
+ def __init__(self, **kwargs):
+ super(ResNetV1d, self).__init__(
+ deep_stem=True, avg_down=True, **kwargs)
diff --git a/mmdet/models/backbones/resnext.py b/mmdet/models/backbones/resnext.py
new file mode 100644
index 0000000000000000000000000000000000000000..df3d79e046c3ab9b289bcfeb6f937c87f6c09bfa
--- /dev/null
+++ b/mmdet/models/backbones/resnext.py
@@ -0,0 +1,154 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+
+from mmcv.cnn import build_conv_layer, build_norm_layer
+
+from mmdet.registry import MODELS
+from ..layers import ResLayer
+from .resnet import Bottleneck as _Bottleneck
+from .resnet import ResNet
+
+
+class Bottleneck(_Bottleneck):
+ expansion = 4
+
+ def __init__(self,
+ inplanes,
+ planes,
+ groups=1,
+ base_width=4,
+ base_channels=64,
+ **kwargs):
+ """Bottleneck block for ResNeXt.
+
+ If style is "pytorch", the stride-two layer is the 3x3 conv layer, if
+ it is "caffe", the stride-two layer is the first 1x1 conv layer.
+ """
+ super(Bottleneck, self).__init__(inplanes, planes, **kwargs)
+
+ if groups == 1:
+ width = self.planes
+ else:
+ width = math.floor(self.planes *
+ (base_width / base_channels)) * groups
+
+ self.norm1_name, norm1 = build_norm_layer(
+ self.norm_cfg, width, postfix=1)
+ self.norm2_name, norm2 = build_norm_layer(
+ self.norm_cfg, width, postfix=2)
+ self.norm3_name, norm3 = build_norm_layer(
+ self.norm_cfg, self.planes * self.expansion, postfix=3)
+
+ self.conv1 = build_conv_layer(
+ self.conv_cfg,
+ self.inplanes,
+ width,
+ kernel_size=1,
+ stride=self.conv1_stride,
+ bias=False)
+ self.add_module(self.norm1_name, norm1)
+ fallback_on_stride = False
+ self.with_modulated_dcn = False
+ if self.with_dcn:
+ fallback_on_stride = self.dcn.pop('fallback_on_stride', False)
+ if not self.with_dcn or fallback_on_stride:
+ self.conv2 = build_conv_layer(
+ self.conv_cfg,
+ width,
+ width,
+ kernel_size=3,
+ stride=self.conv2_stride,
+ padding=self.dilation,
+ dilation=self.dilation,
+ groups=groups,
+ bias=False)
+ else:
+ assert self.conv_cfg is None, 'conv_cfg must be None for DCN'
+ self.conv2 = build_conv_layer(
+ self.dcn,
+ width,
+ width,
+ kernel_size=3,
+ stride=self.conv2_stride,
+ padding=self.dilation,
+ dilation=self.dilation,
+ groups=groups,
+ bias=False)
+
+ self.add_module(self.norm2_name, norm2)
+ self.conv3 = build_conv_layer(
+ self.conv_cfg,
+ width,
+ self.planes * self.expansion,
+ kernel_size=1,
+ bias=False)
+ self.add_module(self.norm3_name, norm3)
+
+ if self.with_plugins:
+ self._del_block_plugins(self.after_conv1_plugin_names +
+ self.after_conv2_plugin_names +
+ self.after_conv3_plugin_names)
+ self.after_conv1_plugin_names = self.make_block_plugins(
+ width, self.after_conv1_plugins)
+ self.after_conv2_plugin_names = self.make_block_plugins(
+ width, self.after_conv2_plugins)
+ self.after_conv3_plugin_names = self.make_block_plugins(
+ self.planes * self.expansion, self.after_conv3_plugins)
+
+ def _del_block_plugins(self, plugin_names):
+ """delete plugins for block if exist.
+
+ Args:
+ plugin_names (list[str]): List of plugins name to delete.
+ """
+ assert isinstance(plugin_names, list)
+ for plugin_name in plugin_names:
+ del self._modules[plugin_name]
+
+
+@MODELS.register_module()
+class ResNeXt(ResNet):
+ """ResNeXt backbone.
+
+ Args:
+ depth (int): Depth of resnet, from {18, 34, 50, 101, 152}.
+ in_channels (int): Number of input image channels. Default: 3.
+ num_stages (int): Resnet stages. Default: 4.
+ groups (int): Group of resnext.
+ base_width (int): Base width of resnext.
+ strides (Sequence[int]): Strides of the first block of each stage.
+ dilations (Sequence[int]): Dilation of each stage.
+ out_indices (Sequence[int]): Output from which stages.
+ style (str): `pytorch` or `caffe`. If set to "pytorch", the stride-two
+ layer is the 3x3 conv layer, otherwise the stride-two layer is
+ the first 1x1 conv layer.
+ frozen_stages (int): Stages to be frozen (all param fixed). -1 means
+ not freezing any parameters.
+ norm_cfg (dict): dictionary to construct and config norm layer.
+ norm_eval (bool): Whether to set norm layers to eval mode, namely,
+ freeze running stats (mean and var). Note: Effect on Batch Norm
+ and its variants only.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed.
+ zero_init_residual (bool): whether to use zero init for last norm layer
+ in resblocks to let them behave as identity.
+ """
+
+ arch_settings = {
+ 50: (Bottleneck, (3, 4, 6, 3)),
+ 101: (Bottleneck, (3, 4, 23, 3)),
+ 152: (Bottleneck, (3, 8, 36, 3))
+ }
+
+ def __init__(self, groups=1, base_width=4, **kwargs):
+ self.groups = groups
+ self.base_width = base_width
+ super(ResNeXt, self).__init__(**kwargs)
+
+ def make_res_layer(self, **kwargs):
+ """Pack all blocks in a stage into a ``ResLayer``"""
+ return ResLayer(
+ groups=self.groups,
+ base_width=self.base_width,
+ base_channels=self.base_channels,
+ **kwargs)
diff --git a/mmdet/models/backbones/ssd_vgg.py b/mmdet/models/backbones/ssd_vgg.py
new file mode 100644
index 0000000000000000000000000000000000000000..b89a9df18b811baa4951d76eef33b1ff924105b3
--- /dev/null
+++ b/mmdet/models/backbones/ssd_vgg.py
@@ -0,0 +1,130 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+
+import torch.nn as nn
+from mmcv.cnn import VGG
+from mmengine.model import BaseModule
+
+from mmdet.registry import MODELS
+from ..necks import ssd_neck
+
+
+@MODELS.register_module()
+class SSDVGG(VGG, BaseModule):
+ """VGG Backbone network for single-shot-detection.
+
+ Args:
+ depth (int): Depth of vgg, from {11, 13, 16, 19}.
+ with_last_pool (bool): Whether to add a pooling layer at the last
+ of the model
+ ceil_mode (bool): When True, will use `ceil` instead of `floor`
+ to compute the output shape.
+ out_indices (Sequence[int]): Output from which stages.
+ out_feature_indices (Sequence[int]): Output from which feature map.
+ pretrained (str, optional): model pretrained path. Default: None
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ input_size (int, optional): Deprecated argumment.
+ Width and height of input, from {300, 512}.
+ l2_norm_scale (float, optional) : Deprecated argumment.
+ L2 normalization layer init scale.
+
+ Example:
+ >>> self = SSDVGG(input_size=300, depth=11)
+ >>> self.eval()
+ >>> inputs = torch.rand(1, 3, 300, 300)
+ >>> level_outputs = self.forward(inputs)
+ >>> for level_out in level_outputs:
+ ... print(tuple(level_out.shape))
+ (1, 1024, 19, 19)
+ (1, 512, 10, 10)
+ (1, 256, 5, 5)
+ (1, 256, 3, 3)
+ (1, 256, 1, 1)
+ """
+ extra_setting = {
+ 300: (256, 'S', 512, 128, 'S', 256, 128, 256, 128, 256),
+ 512: (256, 'S', 512, 128, 'S', 256, 128, 'S', 256, 128, 'S', 256, 128),
+ }
+
+ def __init__(self,
+ depth,
+ inplanes =3,
+ with_last_pool=False,
+ ceil_mode=True,
+ out_indices=(3, 4),
+ out_feature_indices=(22, 34),
+ pretrained=None,
+ init_cfg=None,
+ input_size=None,
+ l2_norm_scale=None):
+ # TODO: in_channels for mmcv.VGG
+ super(SSDVGG, self).__init__(
+ depth,
+ with_last_pool=with_last_pool,
+ inplanes=inplanes,
+ ceil_mode=ceil_mode,
+ out_indices=out_indices)
+
+ self.features.add_module(
+ str(len(self.features)),
+ nn.MaxPool2d(kernel_size=3, stride=1, padding=1))
+ self.features.add_module(
+ str(len(self.features)),
+ nn.Conv2d(512, 1024, kernel_size=3, padding=6, dilation=6))
+ self.features.add_module(
+ str(len(self.features)), nn.ReLU(inplace=True))
+ self.features.add_module(
+ str(len(self.features)), nn.Conv2d(1024, 1024, kernel_size=1))
+ self.features.add_module(
+ str(len(self.features)), nn.ReLU(inplace=True))
+ self.out_feature_indices = out_feature_indices
+
+ assert not (init_cfg and pretrained), \
+ 'init_cfg and pretrained cannot be specified at the same time'
+
+ if init_cfg is not None:
+ self.init_cfg = init_cfg
+ elif isinstance(pretrained, str):
+ warnings.warn('DeprecationWarning: pretrained is deprecated, '
+ 'please use "init_cfg" instead')
+ self.init_cfg = dict(type='Pretrained', checkpoint=pretrained)
+ elif pretrained is None:
+ self.init_cfg = [
+ dict(type='Kaiming', layer='Conv2d'),
+ dict(type='Constant', val=1, layer='BatchNorm2d'),
+ dict(type='Normal', std=0.01, layer='Linear'),
+ ]
+ else:
+ raise TypeError('pretrained must be a str or None')
+
+ if input_size is not None:
+ warnings.warn('DeprecationWarning: input_size is deprecated')
+ if l2_norm_scale is not None:
+ warnings.warn('DeprecationWarning: l2_norm_scale in VGG is '
+ 'deprecated, it has been moved to SSDNeck.')
+
+ def init_weights(self, pretrained=None):
+ super(VGG, self).init_weights()
+
+ def forward(self, x):
+ """Forward function."""
+ outs = []
+ for i, layer in enumerate(self.features):
+ x = layer(x)
+ if i in self.out_feature_indices:
+ outs.append(x)
+
+ if len(outs) == 1:
+ return outs[0]
+ else:
+ return tuple(outs)
+
+
+class L2Norm(ssd_neck.L2Norm):
+
+ def __init__(self, **kwargs):
+ super(L2Norm, self).__init__(**kwargs)
+ warnings.warn('DeprecationWarning: L2Norm in ssd_vgg.py '
+ 'is deprecated, please use L2Norm in '
+ 'mmdet/models/necks/ssd_neck.py instead')
diff --git a/mmdet/models/backbones/st_nobackbone.py b/mmdet/models/backbones/st_nobackbone.py
new file mode 100644
index 0000000000000000000000000000000000000000..91d0b4fa2f199370f97cdc5c4549f57d49bb52c5
--- /dev/null
+++ b/mmdet/models/backbones/st_nobackbone.py
@@ -0,0 +1,119 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+from collections import OrderedDict
+from copy import deepcopy
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+import torch.utils.checkpoint as cp
+from mmcv.cnn import build_norm_layer
+from mmcv.cnn.bricks.transformer import FFN, build_dropout
+from mmengine.logging import MMLogger
+from mmengine.model import BaseModule, ModuleList
+from mmengine.model.weight_init import (constant_init, trunc_normal_,
+ trunc_normal_init)
+from mmengine.runner.checkpoint import CheckpointLoader
+from mmengine.utils import to_2tuple
+from typing import Optional, Sequence, Tuple, Union
+from mmdet.registry import MODELS
+from mmdet.utils import OptConfigType, OptMultiConfig
+from torch import Tensor, nn
+from ..layers import PatchEmbed, PatchMerging,AdaptivePadding
+
+
+def expand_tensor_along_second_dim(x, num):
+ assert x.size(1)<=num
+ # 计算需要重复的次数
+ repeat_times = num // x.size(1)
+ # 使用 repeat 函数对 x 张量进行复制
+ x = x.repeat(1, repeat_times, 1, 1)
+ # 如果 num 不是 x.size(1) 的整数倍,则进行切片操作
+ if num % x.size(1) != 0:
+ x = torch.cat([x, x[:, :num % x.size(1)]], dim=1)
+ return x
+
+def extract_tensor_along_second_dim(x, m):
+ # 计算等间隔的索引
+ idx = torch.linspace(0, x.size(1) - 1, m).long().to(x.device)
+ # 使用 index_select 函数在第二个维度上进行抽取
+ x = torch.index_select(x, 1, idx)
+
+ return x
+
+
+@MODELS.register_module()
+class No_backbone_ST(BaseModule):
+ def __init__(self,
+ in_channels=3,
+ embed_dims=96,
+ strides=(1, 2, 2, 4),
+ patch_size=(1, 2, 2, 4),
+ patch_norm=True,
+ act_cfg=dict(type='GELU'),
+ norm_cfg=dict(type='LN'),
+ pretrained=None,
+ num_levels =2,
+ init_cfg=None):
+ assert not (init_cfg and pretrained), \
+ 'init_cfg and pretrained cannot be specified at the same time'
+ if isinstance(pretrained, str):
+ warnings.warn('DeprecationWarning: pretrained is deprecated, '
+ 'please use "init_cfg" instead')
+ self.init_cfg = dict(type='Pretrained', checkpoint=pretrained)
+ elif pretrained is None:
+ self.init_cfg = init_cfg
+ else:
+ raise TypeError('pretrained must be a str or None')
+
+ super(No_backbone_ST, self).__init__(init_cfg=init_cfg)
+ assert strides[0] == patch_size[0], 'Use non-overlapping patch embed.'
+ self.embed_dims =embed_dims
+ self.in_channels = in_channels
+
+ self.patch_embed = PatchEmbed(
+ in_channels=in_channels,
+ embed_dims=embed_dims,
+ conv_type='Conv2d',
+ kernel_size=patch_size[0],
+ stride=strides[0],
+ norm_cfg=norm_cfg if patch_norm else None,
+ init_cfg=None)
+ self.num_levels = num_levels
+ self.conv = nn.Conv2d(in_channels, embed_dims, kernel_size=1)
+ self.mlp = nn.Sequential(
+ nn.Linear(in_channels, embed_dims),
+ nn.LeakyReLU(negative_slope=0.2),
+ nn.Linear(embed_dims, embed_dims),
+ nn.LeakyReLU(negative_slope=0.2)
+ )
+ if norm_cfg is not None:
+ self.norm = build_norm_layer(norm_cfg, embed_dims)[1]
+ # self.norm = build_norm_layer(norm_cfg, 128*128)[1]
+
+ def train(self, mode=True):
+ """Convert the model into training mode while keep layers freezed."""
+ super(No_backbone_ST, self).train(mode)
+
+ def forward(self, x):
+
+ # x, hw_shape = self.patch_embed(x)
+ # outs = []
+ # out = x.view(-1, *hw_shape, self.embed_dims).permute(0, 3, 1, 2).contiguous()
+
+ if self.in_channels < x.size(1):
+ x = extract_tensor_along_second_dim(x, self.in_channels)
+ outs = []
+ # out = expand_tensor_along_second_dim(x, self.embed_dims)
+ out = self.conv(x)
+ out = self.norm(out.flatten(2).transpose(1, 2))
+ # BN
+ # out = self.norm(out.flatten(2)).transpose(1, 2)
+ # y = x.reshape(x.size(0),x.size(1),-1).permute(0, 2, 1)
+ # out = self.mlp(y)
+ out = out.permute(0, 2, 1).reshape(x.size(0), self.embed_dims,x.size(2),x.size(3)).contiguous()
+ outs.append(out)
+ if self.num_levels > 1:
+ mean = outs[0].mean(dim=(2, 3), keepdim=True).detach()
+ outs.append(mean)
+ return outs
diff --git a/mmdet/models/backbones/swin.py b/mmdet/models/backbones/swin.py
new file mode 100644
index 0000000000000000000000000000000000000000..2b954ab046b20e449aa3092f6c566776437a36b7
--- /dev/null
+++ b/mmdet/models/backbones/swin.py
@@ -0,0 +1,819 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+from collections import OrderedDict
+from copy import deepcopy
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+import torch.utils.checkpoint as cp
+from mmcv.cnn import build_norm_layer
+from mmcv.cnn.bricks.transformer import FFN, build_dropout
+from mmengine.logging import MMLogger
+from mmengine.model import BaseModule, ModuleList
+from mmengine.model.weight_init import (constant_init, trunc_normal_,
+ trunc_normal_init)
+from mmengine.runner.checkpoint import CheckpointLoader
+from mmengine.utils import to_2tuple
+
+from mmdet.registry import MODELS
+from ..layers import PatchEmbed, PatchMerging
+
+
+class WindowMSA(BaseModule):
+ """Window based multi-head self-attention (W-MSA) module with relative
+ position bias.
+
+ Args:
+ embed_dims (int): Number of input channels.
+ num_heads (int): Number of attention heads.
+ window_size (tuple[int]): The height and width of the window.
+ qkv_bias (bool, optional): If True, add a learnable bias to q, k, v.
+ Default: True.
+ qk_scale (float | None, optional): Override default qk scale of
+ head_dim ** -0.5 if set. Default: None.
+ attn_drop_rate (float, optional): Dropout ratio of attention weight.
+ Default: 0.0
+ proj_drop_rate (float, optional): Dropout ratio of output. Default: 0.
+ init_cfg (dict | None, optional): The Config for initialization.
+ Default: None.
+ """
+
+ def __init__(self,
+ embed_dims,
+ num_heads,
+ window_size,
+ qkv_bias=True,
+ qk_scale=None,
+ attn_drop_rate=0.,
+ proj_drop_rate=0.,
+ init_cfg=None):
+
+ super().__init__()
+ self.embed_dims = embed_dims
+ self.window_size = window_size # Wh, Ww
+ self.num_heads = num_heads
+ head_embed_dims = embed_dims // num_heads
+ self.scale = qk_scale or head_embed_dims**-0.5
+ self.init_cfg = init_cfg
+
+ # define a parameter table of relative position bias
+ self.relative_position_bias_table = nn.Parameter(
+ torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1),
+ num_heads)) # 2*Wh-1 * 2*Ww-1, nH
+
+ # About 2x faster than original impl
+ Wh, Ww = self.window_size
+ rel_index_coords = self.double_step_seq(2 * Ww - 1, Wh, 1, Ww)
+ rel_position_index = rel_index_coords + rel_index_coords.T
+ rel_position_index = rel_position_index.flip(1).contiguous()
+ self.register_buffer('relative_position_index', rel_position_index)
+
+ self.qkv = nn.Linear(embed_dims, embed_dims * 3, bias=qkv_bias)
+ self.attn_drop = nn.Dropout(attn_drop_rate)
+ self.proj = nn.Linear(embed_dims, embed_dims)
+ self.proj_drop = nn.Dropout(proj_drop_rate)
+
+ self.softmax = nn.Softmax(dim=-1)
+
+ def init_weights(self):
+ trunc_normal_(self.relative_position_bias_table, std=0.02)
+
+ def forward(self, x, mask=None):
+ """
+ Args:
+
+ x (tensor): input features with shape of (num_windows*B, N, C)
+ mask (tensor | None, Optional): mask with shape of (num_windows,
+ Wh*Ww, Wh*Ww), value should be between (-inf, 0].
+ """
+ B, N, C = x.shape
+ qkv = self.qkv(x).reshape(B, N, 3, self.num_heads,
+ C // self.num_heads).permute(2, 0, 3, 1, 4)
+ # make torchscript happy (cannot use tensor as tuple)
+ q, k, v = qkv[0], qkv[1], qkv[2]
+
+ q = q * self.scale
+ attn = (q @ k.transpose(-2, -1))
+
+ relative_position_bias = self.relative_position_bias_table[
+ self.relative_position_index.view(-1)].view(
+ self.window_size[0] * self.window_size[1],
+ self.window_size[0] * self.window_size[1],
+ -1) # Wh*Ww,Wh*Ww,nH
+ relative_position_bias = relative_position_bias.permute(
+ 2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
+ attn = attn + relative_position_bias.unsqueeze(0)
+
+ if mask is not None:
+ nW = mask.shape[0]
+ attn = attn.view(B // nW, nW, self.num_heads, N,
+ N) + mask.unsqueeze(1).unsqueeze(0)
+ attn = attn.view(-1, self.num_heads, N, N)
+ attn = self.softmax(attn)
+
+ attn = self.attn_drop(attn)
+
+ x = (attn @ v).transpose(1, 2).reshape(B, N, C)
+ x = self.proj(x)
+ x = self.proj_drop(x)
+ return x
+
+ @staticmethod
+ def double_step_seq(step1, len1, step2, len2):
+ seq1 = torch.arange(0, step1 * len1, step1)
+ seq2 = torch.arange(0, step2 * len2, step2)
+ return (seq1[:, None] + seq2[None, :]).reshape(1, -1)
+
+
+class ShiftWindowMSA(BaseModule):
+ """Shifted Window Multihead Self-Attention Module.
+
+ Args:
+ embed_dims (int): Number of input channels.
+ num_heads (int): Number of attention heads.
+ window_size (int): The height and width of the window.
+ shift_size (int, optional): The shift step of each window towards
+ right-bottom. If zero, act as regular window-msa. Defaults to 0.
+ qkv_bias (bool, optional): If True, add a learnable bias to q, k, v.
+ Default: True
+ qk_scale (float | None, optional): Override default qk scale of
+ head_dim ** -0.5 if set. Defaults: None.
+ attn_drop_rate (float, optional): Dropout ratio of attention weight.
+ Defaults: 0.
+ proj_drop_rate (float, optional): Dropout ratio of output.
+ Defaults: 0.
+ dropout_layer (dict, optional): The dropout_layer used before output.
+ Defaults: dict(type='DropPath', drop_prob=0.).
+ init_cfg (dict, optional): The extra config for initialization.
+ Default: None.
+ """
+
+ def __init__(self,
+ embed_dims,
+ num_heads,
+ window_size,
+ shift_size=0,
+ qkv_bias=True,
+ qk_scale=None,
+ attn_drop_rate=0,
+ proj_drop_rate=0,
+ dropout_layer=dict(type='DropPath', drop_prob=0.),
+ init_cfg=None):
+ super().__init__(init_cfg)
+
+ self.window_size = window_size
+ self.shift_size = shift_size
+ assert 0 <= self.shift_size < self.window_size
+
+ self.w_msa = WindowMSA(
+ embed_dims=embed_dims,
+ num_heads=num_heads,
+ window_size=to_2tuple(window_size),
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ attn_drop_rate=attn_drop_rate,
+ proj_drop_rate=proj_drop_rate,
+ init_cfg=None)
+
+ self.drop = build_dropout(dropout_layer)
+
+ def forward(self, query, hw_shape):
+ B, L, C = query.shape
+ H, W = hw_shape
+ assert L == H * W, 'input feature has wrong size'
+ query = query.view(B, H, W, C)
+
+ # pad feature maps to multiples of window size
+ pad_r = (self.window_size - W % self.window_size) % self.window_size
+ pad_b = (self.window_size - H % self.window_size) % self.window_size
+ query = F.pad(query, (0, 0, 0, pad_r, 0, pad_b))
+ H_pad, W_pad = query.shape[1], query.shape[2]
+
+ # cyclic shift
+ if self.shift_size > 0:
+ shifted_query = torch.roll(
+ query,
+ shifts=(-self.shift_size, -self.shift_size),
+ dims=(1, 2))
+
+ # calculate attention mask for SW-MSA
+ img_mask = torch.zeros((1, H_pad, W_pad, 1), device=query.device)
+ h_slices = (slice(0, -self.window_size),
+ slice(-self.window_size,
+ -self.shift_size), slice(-self.shift_size, None))
+ w_slices = (slice(0, -self.window_size),
+ slice(-self.window_size,
+ -self.shift_size), slice(-self.shift_size, None))
+ cnt = 0
+ for h in h_slices:
+ for w in w_slices:
+ img_mask[:, h, w, :] = cnt
+ cnt += 1
+
+ # nW, window_size, window_size, 1
+ mask_windows = self.window_partition(img_mask)
+ mask_windows = mask_windows.view(
+ -1, self.window_size * self.window_size)
+ attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
+ attn_mask = attn_mask.masked_fill(attn_mask != 0,
+ float(-100.0)).masked_fill(
+ attn_mask == 0, float(0.0))
+ else:
+ shifted_query = query
+ attn_mask = None
+
+ # nW*B, window_size, window_size, C
+ query_windows = self.window_partition(shifted_query)
+ # nW*B, window_size*window_size, C
+ query_windows = query_windows.view(-1, self.window_size**2, C)
+
+ # W-MSA/SW-MSA (nW*B, window_size*window_size, C)
+ attn_windows = self.w_msa(query_windows, mask=attn_mask)
+
+ # merge windows
+ attn_windows = attn_windows.view(-1, self.window_size,
+ self.window_size, C)
+
+ # B H' W' C
+ shifted_x = self.window_reverse(attn_windows, H_pad, W_pad)
+ # reverse cyclic shift
+ if self.shift_size > 0:
+ x = torch.roll(
+ shifted_x,
+ shifts=(self.shift_size, self.shift_size),
+ dims=(1, 2))
+ else:
+ x = shifted_x
+
+ if pad_r > 0 or pad_b:
+ x = x[:, :H, :W, :].contiguous()
+
+ x = x.view(B, H * W, C)
+
+ x = self.drop(x)
+ return x
+
+ def window_reverse(self, windows, H, W):
+ """
+ Args:
+ windows: (num_windows*B, window_size, window_size, C)
+ H (int): Height of image
+ W (int): Width of image
+ Returns:
+ x: (B, H, W, C)
+ """
+ window_size = self.window_size
+ B = int(windows.shape[0] / (H * W / window_size / window_size))
+ x = windows.view(B, H // window_size, W // window_size, window_size,
+ window_size, -1)
+ x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
+ return x
+
+ def window_partition(self, x):
+ """
+ Args:
+ x: (B, H, W, C)
+ Returns:
+ windows: (num_windows*B, window_size, window_size, C)
+ """
+ B, H, W, C = x.shape
+ window_size = self.window_size
+ x = x.view(B, H // window_size, window_size, W // window_size,
+ window_size, C)
+ windows = x.permute(0, 1, 3, 2, 4, 5).contiguous()
+ windows = windows.view(-1, window_size, window_size, C)
+ return windows
+
+
+class SwinBlock(BaseModule):
+ """"
+ Args:
+ embed_dims (int): The feature dimension.
+ num_heads (int): Parallel attention heads.
+ feedforward_channels (int): The hidden dimension for FFNs.
+ window_size (int, optional): The local window scale. Default: 7.
+ shift (bool, optional): whether to shift window or not. Default False.
+ qkv_bias (bool, optional): enable bias for qkv if True. Default: True.
+ qk_scale (float | None, optional): Override default qk scale of
+ head_dim ** -0.5 if set. Default: None.
+ drop_rate (float, optional): Dropout rate. Default: 0.
+ attn_drop_rate (float, optional): Attention dropout rate. Default: 0.
+ drop_path_rate (float, optional): Stochastic depth rate. Default: 0.
+ act_cfg (dict, optional): The config dict of activation function.
+ Default: dict(type='GELU').
+ norm_cfg (dict, optional): The config dict of normalization.
+ Default: dict(type='LN').
+ with_cp (bool, optional): Use checkpoint or not. Using checkpoint
+ will save some memory while slowing down the training speed.
+ Default: False.
+ init_cfg (dict | list | None, optional): The init config.
+ Default: None.
+ """
+
+ def __init__(self,
+ embed_dims,
+ num_heads,
+ feedforward_channels,
+ window_size=7,
+ shift=False,
+ qkv_bias=True,
+ qk_scale=None,
+ drop_rate=0.,
+ attn_drop_rate=0.,
+ drop_path_rate=0.,
+ act_cfg=dict(type='GELU'),
+ norm_cfg=dict(type='LN'),
+ with_cp=False,
+ init_cfg=None):
+
+ super(SwinBlock, self).__init__()
+
+ self.init_cfg = init_cfg
+ self.with_cp = with_cp
+
+ self.norm1 = build_norm_layer(norm_cfg, embed_dims)[1]
+ self.attn = ShiftWindowMSA(
+ embed_dims=embed_dims,
+ num_heads=num_heads,
+ window_size=window_size,
+ shift_size=window_size // 2 if shift else 0,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ attn_drop_rate=attn_drop_rate,
+ proj_drop_rate=drop_rate,
+ dropout_layer=dict(type='DropPath', drop_prob=drop_path_rate),
+ init_cfg=None)
+
+ self.norm2 = build_norm_layer(norm_cfg, embed_dims)[1]
+ self.ffn = FFN(
+ embed_dims=embed_dims,
+ feedforward_channels=feedforward_channels,
+ num_fcs=2,
+ ffn_drop=drop_rate,
+ dropout_layer=dict(type='DropPath', drop_prob=drop_path_rate),
+ act_cfg=act_cfg,
+ add_identity=True,
+ init_cfg=None)
+
+ def forward(self, x, hw_shape):
+
+ def _inner_forward(x):
+ identity = x
+ x = self.norm1(x)
+ x = self.attn(x, hw_shape)
+
+ x = x + identity
+
+ identity = x
+ x = self.norm2(x)
+ x = self.ffn(x, identity=identity)
+
+ return x
+
+ if self.with_cp and x.requires_grad:
+ x = cp.checkpoint(_inner_forward, x)
+ else:
+ x = _inner_forward(x)
+
+ return x
+
+
+class SwinBlockSequence(BaseModule):
+ """Implements one stage in Swin Transformer.
+
+ Args:
+ embed_dims (int): The feature dimension.
+ num_heads (int): Parallel attention heads.
+ feedforward_channels (int): The hidden dimension for FFNs.
+ depth (int): The number of blocks in this stage.
+ window_size (int, optional): The local window scale. Default: 7.
+ qkv_bias (bool, optional): enable bias for qkv if True. Default: True.
+ qk_scale (float | None, optional): Override default qk scale of
+ head_dim ** -0.5 if set. Default: None.
+ drop_rate (float, optional): Dropout rate. Default: 0.
+ attn_drop_rate (float, optional): Attention dropout rate. Default: 0.
+ drop_path_rate (float | list[float], optional): Stochastic depth
+ rate. Default: 0.
+ downsample (BaseModule | None, optional): The downsample operation
+ module. Default: None.
+ act_cfg (dict, optional): The config dict of activation function.
+ Default: dict(type='GELU').
+ norm_cfg (dict, optional): The config dict of normalization.
+ Default: dict(type='LN').
+ with_cp (bool, optional): Use checkpoint or not. Using checkpoint
+ will save some memory while slowing down the training speed.
+ Default: False.
+ init_cfg (dict | list | None, optional): The init config.
+ Default: None.
+ """
+
+ def __init__(self,
+ embed_dims,
+ num_heads,
+ feedforward_channels,
+ depth,
+ window_size=7,
+ qkv_bias=True,
+ qk_scale=None,
+ drop_rate=0.,
+ attn_drop_rate=0.,
+ drop_path_rate=0.,
+ downsample=None,
+ act_cfg=dict(type='GELU'),
+ norm_cfg=dict(type='LN'),
+ with_cp=False,
+ init_cfg=None):
+ super().__init__(init_cfg=init_cfg)
+
+ if isinstance(drop_path_rate, list):
+ drop_path_rates = drop_path_rate
+ assert len(drop_path_rates) == depth
+ else:
+ drop_path_rates = [deepcopy(drop_path_rate) for _ in range(depth)]
+
+ self.blocks = ModuleList()
+ for i in range(depth):
+ block = SwinBlock(
+ embed_dims=embed_dims,
+ num_heads=num_heads,
+ feedforward_channels=feedforward_channels,
+ window_size=window_size,
+ shift=False if i % 2 == 0 else True,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ drop_rate=drop_rate,
+ attn_drop_rate=attn_drop_rate,
+ drop_path_rate=drop_path_rates[i],
+ act_cfg=act_cfg,
+ norm_cfg=norm_cfg,
+ with_cp=with_cp,
+ init_cfg=None)
+ self.blocks.append(block)
+
+ self.downsample = downsample
+
+ def forward(self, x, hw_shape):
+ for block in self.blocks:
+ x = block(x, hw_shape)
+
+ if self.downsample:
+ x_down, down_hw_shape = self.downsample(x, hw_shape)
+ return x_down, down_hw_shape, x, hw_shape
+ else:
+ return x, hw_shape, x, hw_shape
+
+
+@MODELS.register_module()
+class SwinTransformer(BaseModule):
+ """ Swin Transformer
+ A PyTorch implement of : `Swin Transformer:
+ Hierarchical Vision Transformer using Shifted Windows` -
+ https://arxiv.org/abs/2103.14030
+
+ Inspiration from
+ https://github.com/microsoft/Swin-Transformer
+
+ Args:
+ pretrain_img_size (int | tuple[int]): The size of input image when
+ pretrain. Defaults: 224.
+ in_channels (int): The num of input channels.
+ Defaults: 3.
+ embed_dims (int): The feature dimension. Default: 96.
+ patch_size (int | tuple[int]): Patch size. Default: 4.
+ window_size (int): Window size. Default: 7.
+ mlp_ratio (int): Ratio of mlp hidden dim to embedding dim.
+ Default: 4.
+ depths (tuple[int]): Depths of each Swin Transformer stage.
+ Default: (2, 2, 6, 2).
+ num_heads (tuple[int]): Parallel attention heads of each Swin
+ Transformer stage. Default: (3, 6, 12, 24).
+ strides (tuple[int]): The patch merging or patch embedding stride of
+ each Swin Transformer stage. (In swin, we set kernel size equal to
+ stride.) Default: (4, 2, 2, 2).
+ out_indices (tuple[int]): Output from which stages.
+ Default: (0, 1, 2, 3).
+ qkv_bias (bool, optional): If True, add a learnable bias to query, key,
+ value. Default: True
+ qk_scale (float | None, optional): Override default qk scale of
+ head_dim ** -0.5 if set. Default: None.
+ patch_norm (bool): If add a norm layer for patch embed and patch
+ merging. Default: True.
+ drop_rate (float): Dropout rate. Defaults: 0.
+ attn_drop_rate (float): Attention dropout rate. Default: 0.
+ drop_path_rate (float): Stochastic depth rate. Defaults: 0.1.
+ use_abs_pos_embed (bool): If True, add absolute position embedding to
+ the patch embedding. Defaults: False.
+ act_cfg (dict): Config dict for activation layer.
+ Default: dict(type='GELU').
+ norm_cfg (dict): Config dict for normalization layer at
+ output of backone. Defaults: dict(type='LN').
+ with_cp (bool, optional): Use checkpoint or not. Using checkpoint
+ will save some memory while slowing down the training speed.
+ Default: False.
+ pretrained (str, optional): model pretrained path. Default: None.
+ convert_weights (bool): The flag indicates whether the
+ pre-trained model is from the original repo. We may need
+ to convert some keys to make it compatible.
+ Default: False.
+ frozen_stages (int): Stages to be frozen (stop grad and set eval mode).
+ Default: -1 (-1 means not freezing any parameters).
+ init_cfg (dict, optional): The Config for initialization.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ pretrain_img_size=224,
+ in_channels=3,
+ embed_dims=96,
+ patch_size=4,
+ window_size=7,
+ mlp_ratio=4,
+ depths=(2, 2, 6, 2),
+ num_heads=(3, 6, 12, 24),
+ strides=(4, 2, 2, 2),
+ out_indices=(0, 1, 2, 3),
+ qkv_bias=True,
+ qk_scale=None,
+ patch_norm=True,
+ drop_rate=0.,
+ attn_drop_rate=0.,
+ drop_path_rate=0.1,
+ use_abs_pos_embed=False,
+ act_cfg=dict(type='GELU'),
+ norm_cfg=dict(type='LN'),
+ with_cp=False,
+ pretrained=None,
+ convert_weights=False,
+ frozen_stages=-1,
+ init_cfg=None):
+ self.convert_weights = convert_weights
+ self.frozen_stages = frozen_stages
+ if isinstance(pretrain_img_size, int):
+ pretrain_img_size = to_2tuple(pretrain_img_size)
+ elif isinstance(pretrain_img_size, tuple):
+ if len(pretrain_img_size) == 1:
+ pretrain_img_size = to_2tuple(pretrain_img_size[0])
+ assert len(pretrain_img_size) == 2, \
+ f'The size of image should have length 1 or 2, ' \
+ f'but got {len(pretrain_img_size)}'
+
+ assert not (init_cfg and pretrained), \
+ 'init_cfg and pretrained cannot be specified at the same time'
+ if isinstance(pretrained, str):
+ warnings.warn('DeprecationWarning: pretrained is deprecated, '
+ 'please use "init_cfg" instead')
+ self.init_cfg = dict(type='Pretrained', checkpoint=pretrained)
+ elif pretrained is None:
+ self.init_cfg = init_cfg
+ else:
+ raise TypeError('pretrained must be a str or None')
+
+ super(SwinTransformer, self).__init__(init_cfg=init_cfg)
+
+ num_layers = len(depths)
+ self.out_indices = out_indices
+ self.use_abs_pos_embed = use_abs_pos_embed
+
+ assert strides[0] == patch_size, 'Use non-overlapping patch embed.'
+
+ self.patch_embed = PatchEmbed(
+ in_channels=in_channels,
+ embed_dims=embed_dims,
+ conv_type='Conv2d',
+ kernel_size=patch_size,
+ stride=strides[0],
+ norm_cfg=norm_cfg if patch_norm else None,
+ init_cfg=None)
+
+ if self.use_abs_pos_embed:
+ patch_row = pretrain_img_size[0] // patch_size
+ patch_col = pretrain_img_size[1] // patch_size
+ num_patches = patch_row * patch_col
+ self.absolute_pos_embed = nn.Parameter(
+ torch.zeros((1, num_patches, embed_dims)))
+
+ self.drop_after_pos = nn.Dropout(p=drop_rate)
+
+ # set stochastic depth decay rule
+ total_depth = sum(depths)
+ dpr = [
+ x.item() for x in torch.linspace(0, drop_path_rate, total_depth)
+ ]
+
+ self.stages = ModuleList()
+ in_channels = embed_dims
+ for i in range(num_layers):
+ if i < num_layers - 1:
+ downsample = PatchMerging(
+ in_channels=in_channels,
+ out_channels=2 * in_channels,
+ stride=strides[i + 1],
+ norm_cfg=norm_cfg if patch_norm else None,
+ init_cfg=None)
+ else:
+ downsample = None
+
+ stage = SwinBlockSequence(
+ embed_dims=in_channels,
+ num_heads=num_heads[i],
+ feedforward_channels=mlp_ratio * in_channels,
+ depth=depths[i],
+ window_size=window_size,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ drop_rate=drop_rate,
+ attn_drop_rate=attn_drop_rate,
+ drop_path_rate=dpr[sum(depths[:i]):sum(depths[:i + 1])],
+ downsample=downsample,
+ act_cfg=act_cfg,
+ norm_cfg=norm_cfg,
+ with_cp=with_cp,
+ init_cfg=None)
+ self.stages.append(stage)
+ if downsample:
+ in_channels = downsample.out_channels
+
+ self.num_features = [int(embed_dims * 2**i) for i in range(num_layers)]
+ # Add a norm layer for each output
+ for i in out_indices:
+ layer = build_norm_layer(norm_cfg, self.num_features[i])[1]
+ layer_name = f'norm{i}'
+ self.add_module(layer_name, layer)
+
+ def train(self, mode=True):
+ """Convert the model into training mode while keep layers freezed."""
+ super(SwinTransformer, self).train(mode)
+ self._freeze_stages()
+
+ def _freeze_stages(self):
+ if self.frozen_stages >= 0:
+ self.patch_embed.eval()
+ for param in self.patch_embed.parameters():
+ param.requires_grad = False
+ if self.use_abs_pos_embed:
+ self.absolute_pos_embed.requires_grad = False
+ self.drop_after_pos.eval()
+
+ for i in range(1, self.frozen_stages + 1):
+
+ if (i - 1) in self.out_indices:
+ norm_layer = getattr(self, f'norm{i-1}')
+ norm_layer.eval()
+ for param in norm_layer.parameters():
+ param.requires_grad = False
+
+ m = self.stages[i - 1]
+ m.eval()
+ for param in m.parameters():
+ param.requires_grad = False
+# changed by lzx
+# def init_weights(self):
+# logger = MMLogger.get_current_instance()
+# if self.init_cfg is None:
+# logger.warn(f'No pre-trained weights for '
+# f'{self.__class__.__name__}, '
+# f'training start from scratch')
+# if self.use_abs_pos_embed:
+# trunc_normal_(self.absolute_pos_embed, std=0.02)
+# for m in self.modules():
+# if isinstance(m, nn.Linear):
+# trunc_normal_init(m, std=.02, bias=0.)
+# elif isinstance(m, nn.LayerNorm):
+# constant_init(m, 1.0)
+# else:
+# assert 'checkpoint' in self.init_cfg, f'Only support ' \
+# f'specify `Pretrained` in ' \
+# f'`init_cfg` in ' \
+# f'{self.__class__.__name__} '
+# ckpt = CheckpointLoader.load_checkpoint(
+# self.init_cfg.checkpoint, logger=logger, map_location='cpu')
+# if 'state_dict' in ckpt:
+# _state_dict = ckpt['state_dict']
+# elif 'model' in ckpt:
+# _state_dict = ckpt['model']
+# else:
+# _state_dict = ckpt
+# if self.convert_weights:
+# # supported loading weight from original repo,
+# _state_dict = swin_converter(_state_dict)
+#
+# state_dict = OrderedDict()
+# for k, v in _state_dict.items():
+# if k.startswith('backbone.'):
+# state_dict[k[9:]] = v
+#
+# # strip prefix of state_dict
+# if list(state_dict.keys())[0].startswith('module.'):
+# state_dict = {k[7:]: v for k, v in state_dict.items()}
+#
+# # reshape absolute position embedding
+# if state_dict.get('absolute_pos_embed') is not None:
+# absolute_pos_embed = state_dict['absolute_pos_embed']
+# N1, L, C1 = absolute_pos_embed.size()
+# N2, C2, H, W = self.absolute_pos_embed.size()
+# if N1 != N2 or C1 != C2 or L != H * W:
+# logger.warning('Error in loading absolute_pos_embed, pass')
+# else:
+# state_dict['absolute_pos_embed'] = absolute_pos_embed.view(
+# N2, H, W, C2).permute(0, 3, 1, 2).contiguous()
+#
+# # interpolate position bias table if needed
+# relative_position_bias_table_keys = [
+# k for k in state_dict.keys()
+# if 'relative_position_bias_table' in k
+# ]
+# for table_key in relative_position_bias_table_keys:
+# table_pretrained = state_dict[table_key]
+# table_current = self.state_dict()[table_key]
+# L1, nH1 = table_pretrained.size()
+# L2, nH2 = table_current.size()
+# if nH1 != nH2:
+# logger.warning(f'Error in loading {table_key}, pass')
+# elif L1 != L2:
+# S1 = int(L1**0.5)
+# S2 = int(L2**0.5)
+# table_pretrained_resized = F.interpolate(
+# table_pretrained.permute(1, 0).reshape(1, nH1, S1, S1),
+# size=(S2, S2),
+# mode='bicubic')
+# state_dict[table_key] = table_pretrained_resized.view(
+# nH2, L2).permute(1, 0).contiguous()
+#
+# # load state_dict
+# self.load_state_dict(state_dict, False)
+
+ def forward(self, x):
+ x, hw_shape = self.patch_embed(x)
+
+ if self.use_abs_pos_embed:
+ x = x + self.absolute_pos_embed
+ x = self.drop_after_pos(x)
+
+ outs = []
+ for i, stage in enumerate(self.stages):
+ x, hw_shape, out, out_hw_shape = stage(x, hw_shape)
+ if i in self.out_indices:
+ norm_layer = getattr(self, f'norm{i}')
+ out = norm_layer(out)
+ out = out.view(-1, *out_hw_shape,
+ self.num_features[i]).permute(0, 3, 1,
+ 2).contiguous()
+ outs.append(out)
+
+ return outs
+
+
+def swin_converter(ckpt):
+
+ new_ckpt = OrderedDict()
+
+ def correct_unfold_reduction_order(x):
+ out_channel, in_channel = x.shape
+ x = x.reshape(out_channel, 4, in_channel // 4)
+ x = x[:, [0, 2, 1, 3], :].transpose(1,
+ 2).reshape(out_channel, in_channel)
+ return x
+
+ def correct_unfold_norm_order(x):
+ in_channel = x.shape[0]
+ x = x.reshape(4, in_channel // 4)
+ x = x[[0, 2, 1, 3], :].transpose(0, 1).reshape(in_channel)
+ return x
+
+ for k, v in ckpt.items():
+ if k.startswith('head'):
+ continue
+ elif k.startswith('layers'):
+ new_v = v
+ if 'attn.' in k:
+ new_k = k.replace('attn.', 'attn.w_msa.')
+ elif 'mlp.' in k:
+ if 'mlp.fc1.' in k:
+ new_k = k.replace('mlp.fc1.', 'ffn.layers.0.0.')
+ elif 'mlp.fc2.' in k:
+ new_k = k.replace('mlp.fc2.', 'ffn.layers.1.')
+ else:
+ new_k = k.replace('mlp.', 'ffn.')
+ elif 'downsample' in k:
+ new_k = k
+ if 'reduction.' in k:
+ new_v = correct_unfold_reduction_order(v)
+ elif 'norm.' in k:
+ new_v = correct_unfold_norm_order(v)
+ else:
+ new_k = k
+ new_k = new_k.replace('layers', 'stages', 1)
+ elif k.startswith('patch_embed'):
+ new_v = v
+ if 'proj' in k:
+ new_k = k.replace('proj', 'projection')
+ else:
+ new_k = k
+ else:
+ new_v = v
+ new_k = k
+
+ new_ckpt['backbone.' + new_k] = new_v
+
+ return new_ckpt
diff --git a/mmdet/models/backbones/trident_resnet.py b/mmdet/models/backbones/trident_resnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..22c76354522ff8533b094df6858ec361ba400c1e
--- /dev/null
+++ b/mmdet/models/backbones/trident_resnet.py
@@ -0,0 +1,298 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+import torch.utils.checkpoint as cp
+from mmcv.cnn import build_conv_layer, build_norm_layer
+from mmengine.model import BaseModule
+from torch.nn.modules.utils import _pair
+
+from mmdet.models.backbones.resnet import Bottleneck, ResNet
+from mmdet.registry import MODELS
+
+
+class TridentConv(BaseModule):
+ """Trident Convolution Module.
+
+ Args:
+ in_channels (int): Number of channels in input.
+ out_channels (int): Number of channels in output.
+ kernel_size (int): Size of convolution kernel.
+ stride (int, optional): Convolution stride. Default: 1.
+ trident_dilations (tuple[int, int, int], optional): Dilations of
+ different trident branch. Default: (1, 2, 3).
+ test_branch_idx (int, optional): In inference, all 3 branches will
+ be used if `test_branch_idx==-1`, otherwise only branch with
+ index `test_branch_idx` will be used. Default: 1.
+ bias (bool, optional): Whether to use bias in convolution or not.
+ Default: False.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ kernel_size,
+ stride=1,
+ trident_dilations=(1, 2, 3),
+ test_branch_idx=1,
+ bias=False,
+ init_cfg=None):
+ super(TridentConv, self).__init__(init_cfg)
+ self.num_branch = len(trident_dilations)
+ self.with_bias = bias
+ self.test_branch_idx = test_branch_idx
+ self.stride = _pair(stride)
+ self.kernel_size = _pair(kernel_size)
+ self.paddings = _pair(trident_dilations)
+ self.dilations = trident_dilations
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.bias = bias
+
+ self.weight = nn.Parameter(
+ torch.Tensor(out_channels, in_channels, *self.kernel_size))
+ if bias:
+ self.bias = nn.Parameter(torch.Tensor(out_channels))
+ else:
+ self.bias = None
+
+ def extra_repr(self):
+ tmpstr = f'in_channels={self.in_channels}'
+ tmpstr += f', out_channels={self.out_channels}'
+ tmpstr += f', kernel_size={self.kernel_size}'
+ tmpstr += f', num_branch={self.num_branch}'
+ tmpstr += f', test_branch_idx={self.test_branch_idx}'
+ tmpstr += f', stride={self.stride}'
+ tmpstr += f', paddings={self.paddings}'
+ tmpstr += f', dilations={self.dilations}'
+ tmpstr += f', bias={self.bias}'
+ return tmpstr
+
+ def forward(self, inputs):
+ if self.training or self.test_branch_idx == -1:
+ outputs = [
+ F.conv2d(input, self.weight, self.bias, self.stride, padding,
+ dilation) for input, dilation, padding in zip(
+ inputs, self.dilations, self.paddings)
+ ]
+ else:
+ assert len(inputs) == 1
+ outputs = [
+ F.conv2d(inputs[0], self.weight, self.bias, self.stride,
+ self.paddings[self.test_branch_idx],
+ self.dilations[self.test_branch_idx])
+ ]
+
+ return outputs
+
+
+# Since TridentNet is defined over ResNet50 and ResNet101, here we
+# only support TridentBottleneckBlock.
+class TridentBottleneck(Bottleneck):
+ """BottleBlock for TridentResNet.
+
+ Args:
+ trident_dilations (tuple[int, int, int]): Dilations of different
+ trident branch.
+ test_branch_idx (int): In inference, all 3 branches will be used
+ if `test_branch_idx==-1`, otherwise only branch with index
+ `test_branch_idx` will be used.
+ concat_output (bool): Whether to concat the output list to a Tensor.
+ `True` only in the last Block.
+ """
+
+ def __init__(self, trident_dilations, test_branch_idx, concat_output,
+ **kwargs):
+
+ super(TridentBottleneck, self).__init__(**kwargs)
+ self.trident_dilations = trident_dilations
+ self.num_branch = len(trident_dilations)
+ self.concat_output = concat_output
+ self.test_branch_idx = test_branch_idx
+ self.conv2 = TridentConv(
+ self.planes,
+ self.planes,
+ kernel_size=3,
+ stride=self.conv2_stride,
+ bias=False,
+ trident_dilations=self.trident_dilations,
+ test_branch_idx=test_branch_idx,
+ init_cfg=dict(
+ type='Kaiming',
+ distribution='uniform',
+ mode='fan_in',
+ override=dict(name='conv2')))
+
+ def forward(self, x):
+
+ def _inner_forward(x):
+ num_branch = (
+ self.num_branch
+ if self.training or self.test_branch_idx == -1 else 1)
+ identity = x
+ if not isinstance(x, list):
+ x = (x, ) * num_branch
+ identity = x
+ if self.downsample is not None:
+ identity = [self.downsample(b) for b in x]
+
+ out = [self.conv1(b) for b in x]
+ out = [self.norm1(b) for b in out]
+ out = [self.relu(b) for b in out]
+
+ if self.with_plugins:
+ for k in range(len(out)):
+ out[k] = self.forward_plugin(out[k],
+ self.after_conv1_plugin_names)
+
+ out = self.conv2(out)
+ out = [self.norm2(b) for b in out]
+ out = [self.relu(b) for b in out]
+ if self.with_plugins:
+ for k in range(len(out)):
+ out[k] = self.forward_plugin(out[k],
+ self.after_conv2_plugin_names)
+
+ out = [self.conv3(b) for b in out]
+ out = [self.norm3(b) for b in out]
+
+ if self.with_plugins:
+ for k in range(len(out)):
+ out[k] = self.forward_plugin(out[k],
+ self.after_conv3_plugin_names)
+
+ out = [
+ out_b + identity_b for out_b, identity_b in zip(out, identity)
+ ]
+ return out
+
+ if self.with_cp and x.requires_grad:
+ out = cp.checkpoint(_inner_forward, x)
+ else:
+ out = _inner_forward(x)
+
+ out = [self.relu(b) for b in out]
+ if self.concat_output:
+ out = torch.cat(out, dim=0)
+ return out
+
+
+def make_trident_res_layer(block,
+ inplanes,
+ planes,
+ num_blocks,
+ stride=1,
+ trident_dilations=(1, 2, 3),
+ style='pytorch',
+ with_cp=False,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ dcn=None,
+ plugins=None,
+ test_branch_idx=-1):
+ """Build Trident Res Layers."""
+
+ downsample = None
+ if stride != 1 or inplanes != planes * block.expansion:
+ downsample = []
+ conv_stride = stride
+ downsample.extend([
+ build_conv_layer(
+ conv_cfg,
+ inplanes,
+ planes * block.expansion,
+ kernel_size=1,
+ stride=conv_stride,
+ bias=False),
+ build_norm_layer(norm_cfg, planes * block.expansion)[1]
+ ])
+ downsample = nn.Sequential(*downsample)
+
+ layers = []
+ for i in range(num_blocks):
+ layers.append(
+ block(
+ inplanes=inplanes,
+ planes=planes,
+ stride=stride if i == 0 else 1,
+ trident_dilations=trident_dilations,
+ downsample=downsample if i == 0 else None,
+ style=style,
+ with_cp=with_cp,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ dcn=dcn,
+ plugins=plugins,
+ test_branch_idx=test_branch_idx,
+ concat_output=True if i == num_blocks - 1 else False))
+ inplanes = planes * block.expansion
+ return nn.Sequential(*layers)
+
+
+@MODELS.register_module()
+class TridentResNet(ResNet):
+ """The stem layer, stage 1 and stage 2 in Trident ResNet are identical to
+ ResNet, while in stage 3, Trident BottleBlock is utilized to replace the
+ normal BottleBlock to yield trident output. Different branch shares the
+ convolution weight but uses different dilations to achieve multi-scale
+ output.
+
+ / stage3(b0) \
+ x - stem - stage1 - stage2 - stage3(b1) - output
+ \ stage3(b2) /
+
+ Args:
+ depth (int): Depth of resnet, from {50, 101, 152}.
+ num_branch (int): Number of branches in TridentNet.
+ test_branch_idx (int): In inference, all 3 branches will be used
+ if `test_branch_idx==-1`, otherwise only branch with index
+ `test_branch_idx` will be used.
+ trident_dilations (tuple[int]): Dilations of different trident branch.
+ len(trident_dilations) should be equal to num_branch.
+ """ # noqa
+
+ def __init__(self, depth, num_branch, test_branch_idx, trident_dilations,
+ **kwargs):
+
+ assert num_branch == len(trident_dilations)
+ assert depth in (50, 101, 152)
+ super(TridentResNet, self).__init__(depth, **kwargs)
+ assert self.num_stages == 3
+ self.test_branch_idx = test_branch_idx
+ self.num_branch = num_branch
+
+ last_stage_idx = self.num_stages - 1
+ stride = self.strides[last_stage_idx]
+ dilation = trident_dilations
+ dcn = self.dcn if self.stage_with_dcn[last_stage_idx] else None
+ if self.plugins is not None:
+ stage_plugins = self.make_stage_plugins(self.plugins,
+ last_stage_idx)
+ else:
+ stage_plugins = None
+ planes = self.base_channels * 2**last_stage_idx
+ res_layer = make_trident_res_layer(
+ TridentBottleneck,
+ inplanes=(self.block.expansion * self.base_channels *
+ 2**(last_stage_idx - 1)),
+ planes=planes,
+ num_blocks=self.stage_blocks[last_stage_idx],
+ stride=stride,
+ trident_dilations=dilation,
+ style=self.style,
+ with_cp=self.with_cp,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ dcn=dcn,
+ plugins=stage_plugins,
+ test_branch_idx=self.test_branch_idx)
+
+ layer_name = f'layer{last_stage_idx + 1}'
+
+ self.__setattr__(layer_name, res_layer)
+ self.res_layers.pop(last_stage_idx)
+ self.res_layers.insert(last_stage_idx, layer_name)
+
+ self._freeze_stages()
diff --git a/mmdet/models/data_preprocessors/HSIdata_preprocessor.py b/mmdet/models/data_preprocessors/HSIdata_preprocessor.py
new file mode 100644
index 0000000000000000000000000000000000000000..2025cbe49f52e3d4829aacebc226471634e5322e
--- /dev/null
+++ b/mmdet/models/data_preprocessors/HSIdata_preprocessor.py
@@ -0,0 +1,368 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import random
+from numbers import Number
+from typing import List, Optional, Sequence, Tuple, Union
+
+import numpy as np
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmengine.dist import barrier, broadcast, get_dist_info
+from mmengine.logging import MessageHub
+from mmengine.model import BaseDataPreprocessor
+from mmengine.structures import PixelData
+from mmengine.utils import is_seq_of
+from mmengine.model.utils import stack_batch
+from torch import Tensor
+
+from mmdet.models.utils import unfold_wo_center
+from mmdet.models.utils.misc import samplelist_boxtype2tensor
+from mmdet.registry import MODELS
+from mmdet.structures import DetDataSample
+from mmdet.structures.mask import BitmapMasks
+from mmdet.utils import ConfigType
+import mmcv
+import math
+
+try:
+ import skimage
+except ImportError:
+ skimage = None
+
+
+
+
+
+@MODELS.register_module()
+class HSIImgDataPreprocessor(BaseDataPreprocessor):
+ """Image pre-processor for normalization and bgr to rgb conversion.
+
+ Accepts the data sampled by the dataloader, and preprocesses it into the
+ format of the model input. ``ImgDataPreprocessor`` provides the
+ basic data pre-processing as follows
+
+ - Collates and moves data to the target device.
+ - Converts inputs from bgr to rgb if the shape of input is (3, H, W).
+ - Normalizes image with defined std and mean.
+ - Pads inputs to the maximum size of current batch with defined
+ ``pad_value``. The padding size can be divisible by a defined
+ ``pad_size_divisor``
+ - Stack inputs to batch_inputs.
+
+ For ``ImgDataPreprocessor``, the dimension of the single inputs must be
+ (3, H, W).
+
+ Note:
+ ``ImgDataPreprocessor`` and its subclass is built in the
+ constructor of :class:`BaseDataset`.
+
+ Args:
+ mean (Sequence[float or int], optional): The pixel mean of image
+ channels. If ``bgr_to_rgb=True`` it means the mean value of R,
+ G, B channels. If the length of `mean` is 1, it means all
+ channels have the same mean value, or the input is a gray image.
+ If it is not specified, images will not be normalized. Defaults
+ None.
+ std (Sequence[float or int], optional): The pixel standard deviation of
+ image channels. If ``bgr_to_rgb=True`` it means the standard
+ deviation of R, G, B channels. If the length of `std` is 1,
+ it means all channels have the same standard deviation, or the
+ input is a gray image. If it is not specified, images will
+ not be normalized. Defaults None.
+ pad_size_divisor (int): The size of padded image should be
+ divisible by ``pad_size_divisor``. Defaults to 1.
+ pad_value (float or int): The padded pixel value. Defaults to 0.
+ bgr_to_rgb (bool): whether to convert image from BGR to RGB.
+ Defaults to False.
+ rgb_to_bgr (bool): whether to convert image from RGB to RGB.
+ Defaults to False.
+ non_blocking (bool): Whether block current process
+ when transferring data to device.
+ New in version v0.3.0.
+
+ Note:
+ if images do not need to be normalized, `std` and `mean` should be
+ both set to None, otherwise both of them should be set to a tuple of
+ corresponding values.
+ """
+
+ def __init__(self,
+ mean: Optional[Sequence[Union[float, int]]] = None,
+ std: Optional[Sequence[Union[float, int]]] = None,
+ pad_size_divisor: int = 1,
+ pad_value: Union[float, int] = 0,
+ non_blocking: Optional[bool] = False):
+ super().__init__(non_blocking)
+ assert (mean is None) == (std is None), (
+ 'mean and std should be both None or tuple')
+ if mean is not None:
+ self._enable_normalize = True
+ self.register_buffer('mean',
+ torch.tensor(mean).view(-1, 1, 1), False)
+ self.register_buffer('std',
+ torch.tensor(std).view(-1, 1, 1), False)
+ else:
+ self._enable_normalize = False
+ self.pad_size_divisor = pad_size_divisor
+ self.pad_value = pad_value
+
+ def forward(self, data: dict, training: bool = False) -> Union[dict, list]:
+ """Performs normalization、padding and bgr2rgb conversion based on
+ ``BaseDataPreprocessor``.
+
+ Args:
+ data (dict): Data sampled from dataset. If the collate
+ function of DataLoader is :obj:`pseudo_collate`, data will be a
+ list of dict. If collate function is :obj:`default_collate`,
+ data will be a tuple with batch input tensor and list of data
+ samples.
+ training (bool): Whether to enable training time augmentation. If
+ subclasses override this method, they can perform different
+ preprocessing strategies for training and testing based on the
+ value of ``training``.
+
+ Returns:
+ dict or list: Data in the same format as the model input.
+ """
+ data = self.cast_data(data) # type: ignore
+ _batch_inputs = data['inputs']
+ # Process data with `pseudo_collate`.
+ if is_seq_of(_batch_inputs, torch.Tensor):
+ batch_inputs = []
+ for _batch_input in _batch_inputs:
+ # efficiency
+ _batch_input = _batch_input.float()
+ # Normalization.
+ batch_inputs.append(_batch_input)
+ # Pad and stack Tensor.
+ batch_inputs = stack_batch(batch_inputs, self.pad_size_divisor,
+ self.pad_value)
+ # Process data with `default_collate`.
+ elif isinstance(_batch_inputs, torch.Tensor):
+ assert _batch_inputs.dim() == 4, (
+ 'The input of `ImgDataPreprocessor` should be a NCHW tensor '
+ 'or a list of tensor, but got a tensor with shape: '
+ f'{_batch_inputs.shape}')
+ # Convert to float after channel conversion to ensure
+ # efficiency
+ _batch_inputs = _batch_inputs.float()
+ h, w = _batch_inputs.shape[2:]
+ target_h = math.ceil(
+ h / self.pad_size_divisor) * self.pad_size_divisor
+ target_w = math.ceil(
+ w / self.pad_size_divisor) * self.pad_size_divisor
+ pad_h = target_h - h
+ pad_w = target_w - w
+ batch_inputs = F.pad(_batch_inputs, (0, pad_w, 0, pad_h),
+ 'constant', self.pad_value)
+ else:
+ raise TypeError('Output of `cast_data` should be a dict of '
+ 'list/tuple with inputs and data_samples, '
+ f'but got {type(data)}: {data}')
+ data['inputs'] = batch_inputs
+ data.setdefault('data_samples', None)
+ return data
+
+@MODELS.register_module()
+class HSIDetDataPreprocessor(HSIImgDataPreprocessor):
+ """Image pre-processor for detection tasks.
+
+ Comparing with the :class:`mmengine.ImgDataPreprocessor`,
+
+ 1. It supports batch augmentations.
+ 2. It will additionally append batch_input_shape and pad_shape
+ to data_samples considering the object detection task.
+
+ It provides the data pre-processing as follows
+
+ - Collate and move data to the target device.
+ - Pad inputs to the maximum size of current batch with defined
+ ``pad_value``. The padding size can be divisible by a defined
+ ``pad_size_divisor``
+ - Stack inputs to batch_inputs.
+ - Convert inputs from bgr to rgb if the shape of input is (3, H, W).
+ - Normalize image with defined std and mean.
+ - Do batch augmentations during training.
+
+ Args:
+ mean (Sequence[Number], optional): The pixel mean of R, G, B channels.
+ Defaults to None.
+ std (Sequence[Number], optional): The pixel standard deviation of
+ R, G, B channels. Defaults to None.
+ pad_size_divisor (int): The size of padded image should be
+ divisible by ``pad_size_divisor``. Defaults to 1.
+ pad_value (Number): The padded pixel value. Defaults to 0.
+ pad_mask (bool): Whether to pad instance masks. Defaults to False.
+ mask_pad_value (int): The padded pixel value for instance masks.
+ Defaults to 0.
+ pad_seg (bool): Whether to pad semantic segmentation maps.
+ Defaults to False.
+ seg_pad_value (int): The padded pixel value for semantic
+ segmentation maps. Defaults to 255.
+ bgr_to_rgb (bool): whether to convert image from BGR to RGB.
+ Defaults to False.
+ rgb_to_bgr (bool): whether to convert image from RGB to RGB.
+ Defaults to False.
+ boxtype2tensor (bool): Whether to keep the ``BaseBoxes`` type of
+ bboxes data or not. Defaults to True.
+ non_blocking (bool): Whether block current process
+ when transferring data to device. Defaults to False.
+ batch_augments (list[dict], optional): Batch-level augmentations
+ """
+
+ def __init__(self,
+ mean: Sequence[Number] = None,
+ std: Sequence[Number] = None,
+ pad_size_divisor: int = 1,
+ pad_value: Union[float, int] = 0,
+ pad_mask: bool = False,
+ mask_pad_value: int = 0,
+ pad_seg: bool = False,
+ seg_pad_value: int = 255,
+ boxtype2tensor: bool = True,
+ non_blocking: Optional[bool] = False,
+ batch_augments: Optional[List[dict]] = None):
+ super().__init__(
+ mean=mean,
+ std=std,
+ pad_size_divisor=pad_size_divisor,
+ pad_value=pad_value,
+ non_blocking=non_blocking)
+ if batch_augments is not None:
+ self.batch_augments = nn.ModuleList(
+ [MODELS.build(aug) for aug in batch_augments])
+ else:
+ self.batch_augments = None
+ self.pad_mask = pad_mask
+ self.mask_pad_value = mask_pad_value
+ self.pad_seg = pad_seg
+ self.seg_pad_value = seg_pad_value
+ self.boxtype2tensor = boxtype2tensor
+
+ def forward(self, data: dict, training: bool = False) -> dict:
+ """Perform normalization、padding and bgr2rgb conversion based on
+ ``BaseDataPreprocessor``.
+
+ Args:
+ data (dict): Data sampled from dataloader.
+ training (bool): Whether to enable training time augmentation.
+
+ Returns:
+ dict: Data in the same format as the model input.
+ """
+ batch_pad_shape = self._get_pad_shape(data)
+ data = super().forward(data=data, training=training)
+ inputs, data_samples = data['inputs'], data['data_samples']
+
+ if data_samples is not None:
+ # NOTE the batched image size information may be useful, e.g.
+ # in DETR, this is needed for the construction of masks, which is
+ # then used for the transformer_head.
+ batch_input_shape = tuple(inputs[0].size()[-2:])
+ for data_sample, pad_shape in zip(data_samples, batch_pad_shape):
+ data_sample.set_metainfo({
+ 'batch_input_shape': batch_input_shape,
+ 'pad_shape': pad_shape
+ })
+
+ if self.boxtype2tensor:
+ samplelist_boxtype2tensor(data_samples)
+
+ if hasattr(data_samples[0].gt_instances, 'masks') and training:
+ self.pad_gt_masks(data_samples)
+ if hasattr(data_samples[0], 'gt_pixel') and training:
+ self.pad_gt_pixel(data_samples)
+ # if self.pad_mask and training:
+ # self.pad_gt_masks(data_samples)
+ if self.pad_seg and training:
+ self.pad_gt_sem_seg(data_samples)
+
+ if training and self.batch_augments is not None:
+ for batch_aug in self.batch_augments:
+ inputs, data_samples = batch_aug(inputs, data_samples)
+
+ return {'inputs': inputs, 'data_samples': data_samples}
+
+ def _get_pad_shape(self, data: dict) -> List[tuple]:
+ """Get the pad_shape of each image based on data and
+ pad_size_divisor."""
+ _batch_inputs = data['inputs']
+ # Process data with `pseudo_collate`.
+ if is_seq_of(_batch_inputs, torch.Tensor):
+ batch_pad_shape = []
+ for ori_input in _batch_inputs:
+ pad_h = int(
+ np.ceil(ori_input.shape[1] /
+ self.pad_size_divisor)) * self.pad_size_divisor
+ pad_w = int(
+ np.ceil(ori_input.shape[2] /
+ self.pad_size_divisor)) * self.pad_size_divisor
+ batch_pad_shape.append((pad_h, pad_w))
+ # Process data with `default_collate`.
+ elif isinstance(_batch_inputs, torch.Tensor):
+ assert _batch_inputs.dim() == 4, (
+ 'The input of `ImgDataPreprocessor` should be a NCHW tensor '
+ 'or a list of tensor, but got a tensor with shape: '
+ f'{_batch_inputs.shape}')
+ pad_h = int(
+ np.ceil(_batch_inputs.shape[1] /
+ self.pad_size_divisor)) * self.pad_size_divisor
+ pad_w = int(
+ np.ceil(_batch_inputs.shape[2] /
+ self.pad_size_divisor)) * self.pad_size_divisor
+ batch_pad_shape = [(pad_h, pad_w)] * _batch_inputs.shape[0]
+ else:
+ raise TypeError('Output of `cast_data` should be a dict '
+ 'or a tuple with inputs and data_samples, but got'
+ f'{type(data)}: {data}')
+ return batch_pad_shape
+
+ def pad_gt_masks(self,
+ batch_data_samples: Sequence[DetDataSample]) -> None:
+ """Pad gt_masks to shape of batch_input_shape."""
+ if 'masks' in batch_data_samples[0].gt_instances:
+ for data_samples in batch_data_samples:
+ masks = data_samples.gt_instances.masks
+ data_samples.gt_instances.masks = masks.pad(
+ data_samples.batch_input_shape,
+ pad_val=self.mask_pad_value)
+
+ def pad_gt_pixel(self,
+ batch_data_samples: Sequence[DetDataSample]) -> None:
+ """Pad gt_masks to shape of batch_input_shape."""
+ for data_samples in batch_data_samples:
+ seg=data_samples.gt_pixel.seg
+ h, w = data_samples.gt_pixel.shape[-2:]
+ pad_h, pad_w = data_samples.batch_input_shape
+ seg = F.pad(
+ seg,
+ pad=(0, max(pad_w - w, 0), 0, max(pad_h - h, 0)),
+ mode='constant',
+ value=0)
+ if hasattr(data_samples.gt_pixel, 'abu'):
+ abu = data_samples.gt_pixel.abu
+ abu = F.pad(
+ abu,
+ pad=(0, max(pad_w - w, 0), 0, max(pad_h - h, 0)),
+ mode='constant',
+ value=0)
+ data_samples.gt_pixel = PixelData(seg=seg, abu=abu)
+ else:
+ data_samples.gt_pixel = PixelData(seg=seg,)
+
+
+ def pad_gt_sem_seg(self,
+ batch_data_samples: Sequence[DetDataSample]) -> None:
+ """Pad gt_sem_seg to shape of batch_input_shape."""
+ if 'gt_sem_seg' in batch_data_samples[0]:
+ for data_samples in batch_data_samples:
+ gt_sem_seg = data_samples.gt_sem_seg.sem_seg
+ h, w = gt_sem_seg.shape[-2:]
+ pad_h, pad_w = data_samples.batch_input_shape
+ gt_sem_seg = F.pad(
+ gt_sem_seg,
+ pad=(0, max(pad_w - w, 0), 0, max(pad_h - h, 0)),
+ mode='constant',
+ value=self.seg_pad_value)
+ data_samples.gt_sem_seg = PixelData(sem_seg=gt_sem_seg)
+
diff --git a/mmdet/models/data_preprocessors/__init__.py b/mmdet/models/data_preprocessors/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..958672edabb0a3aa4447534b40be320ea575a414
--- /dev/null
+++ b/mmdet/models/data_preprocessors/__init__.py
@@ -0,0 +1,13 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .data_preprocessor import (BatchFixedSizePad, BatchResize,
+ BatchSyncRandomResize, BoxInstDataPreprocessor,
+ DetDataPreprocessor,
+ MultiBranchDataPreprocessor,)
+
+from .HSIdata_preprocessor import HSIImgDataPreprocessor,HSIDetDataPreprocessor
+
+__all__ = [
+ 'DetDataPreprocessor', 'BatchSyncRandomResize', 'BatchFixedSizePad',
+ 'MultiBranchDataPreprocessor', 'BatchResize', 'BoxInstDataPreprocessor',
+ 'HSIImgDataPreprocessor', 'HSIDetDataPreprocessor'
+]
diff --git a/mmdet/models/data_preprocessors/__pycache__/HSIdata_preprocessor.cpython-37.pyc b/mmdet/models/data_preprocessors/__pycache__/HSIdata_preprocessor.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..49d8a33c475386a52e60b7b89a942689dac8d367
Binary files /dev/null and b/mmdet/models/data_preprocessors/__pycache__/HSIdata_preprocessor.cpython-37.pyc differ
diff --git a/mmdet/models/data_preprocessors/__pycache__/__init__.cpython-37.pyc b/mmdet/models/data_preprocessors/__pycache__/__init__.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..0cab33f7257bbf221b0f5dd72fb237aad39b109e
Binary files /dev/null and b/mmdet/models/data_preprocessors/__pycache__/__init__.cpython-37.pyc differ
diff --git a/mmdet/models/data_preprocessors/__pycache__/data_preprocessor.cpython-37.pyc b/mmdet/models/data_preprocessors/__pycache__/data_preprocessor.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..6d140901b06f6676a6a0b8b841161d8b00133235
Binary files /dev/null and b/mmdet/models/data_preprocessors/__pycache__/data_preprocessor.cpython-37.pyc differ
diff --git a/mmdet/models/data_preprocessors/data_preprocessor.py b/mmdet/models/data_preprocessors/data_preprocessor.py
new file mode 100644
index 0000000000000000000000000000000000000000..5dbd68c01f186a1a1bbd9546bc86bd648abaf90a
--- /dev/null
+++ b/mmdet/models/data_preprocessors/data_preprocessor.py
@@ -0,0 +1,793 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import random
+from numbers import Number
+from typing import List, Optional, Sequence, Tuple, Union
+
+import numpy as np
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmengine.dist import barrier, broadcast, get_dist_info
+from mmengine.logging import MessageHub
+from mmengine.model import BaseDataPreprocessor, ImgDataPreprocessor
+from mmengine.structures import PixelData
+from mmengine.utils import is_seq_of
+from torch import Tensor
+
+from mmdet.models.utils import unfold_wo_center
+from mmdet.models.utils.misc import samplelist_boxtype2tensor
+from mmdet.registry import MODELS
+from mmdet.structures import DetDataSample
+from mmdet.structures.mask import BitmapMasks
+from mmdet.utils import ConfigType
+
+try:
+ import skimage
+except ImportError:
+ skimage = None
+
+
+@MODELS.register_module()
+class DetDataPreprocessor(ImgDataPreprocessor):
+ """Image pre-processor for detection tasks.
+
+ Comparing with the :class:`mmengine.ImgDataPreprocessor`,
+
+ 1. It supports batch augmentations.
+ 2. It will additionally append batch_input_shape and pad_shape
+ to data_samples considering the object detection task.
+
+ It provides the data pre-processing as follows
+
+ - Collate and move data to the target device.
+ - Pad inputs to the maximum size of current batch with defined
+ ``pad_value``. The padding size can be divisible by a defined
+ ``pad_size_divisor``
+ - Stack inputs to batch_inputs.
+ - Convert inputs from bgr to rgb if the shape of input is (3, H, W).
+ - Normalize image with defined std and mean.
+ - Do batch augmentations during training.
+
+ Args:
+ mean (Sequence[Number], optional): The pixel mean of R, G, B channels.
+ Defaults to None.
+ std (Sequence[Number], optional): The pixel standard deviation of
+ R, G, B channels. Defaults to None.
+ pad_size_divisor (int): The size of padded image should be
+ divisible by ``pad_size_divisor``. Defaults to 1.
+ pad_value (Number): The padded pixel value. Defaults to 0.
+ pad_mask (bool): Whether to pad instance masks. Defaults to False.
+ mask_pad_value (int): The padded pixel value for instance masks.
+ Defaults to 0.
+ pad_seg (bool): Whether to pad semantic segmentation maps.
+ Defaults to False.
+ seg_pad_value (int): The padded pixel value for semantic
+ segmentation maps. Defaults to 255.
+ bgr_to_rgb (bool): whether to convert image from BGR to RGB.
+ Defaults to False.
+ rgb_to_bgr (bool): whether to convert image from RGB to RGB.
+ Defaults to False.
+ boxtype2tensor (bool): Whether to keep the ``BaseBoxes`` type of
+ bboxes data or not. Defaults to True.
+ non_blocking (bool): Whether block current process
+ when transferring data to device. Defaults to False.
+ batch_augments (list[dict], optional): Batch-level augmentations
+ """
+
+ def __init__(self,
+ mean: Sequence[Number] = None,
+ std: Sequence[Number] = None,
+ pad_size_divisor: int = 1,
+ pad_value: Union[float, int] = 0,
+ pad_mask: bool = False,
+ mask_pad_value: int = 0,
+ pad_seg: bool = False,
+ seg_pad_value: int = 255,
+ bgr_to_rgb: bool = False,
+ rgb_to_bgr: bool = False,
+ boxtype2tensor: bool = True,
+ non_blocking: Optional[bool] = False,
+ batch_augments: Optional[List[dict]] = None):
+ super().__init__(
+ mean=mean,
+ std=std,
+ pad_size_divisor=pad_size_divisor,
+ pad_value=pad_value,
+ bgr_to_rgb=bgr_to_rgb,
+ rgb_to_bgr=rgb_to_bgr,
+ non_blocking=non_blocking)
+ if batch_augments is not None:
+ self.batch_augments = nn.ModuleList(
+ [MODELS.build(aug) for aug in batch_augments])
+ else:
+ self.batch_augments = None
+ self.pad_mask = pad_mask
+ self.mask_pad_value = mask_pad_value
+ self.pad_seg = pad_seg
+ self.seg_pad_value = seg_pad_value
+ self.boxtype2tensor = boxtype2tensor
+
+ def forward(self, data: dict, training: bool = False) -> dict:
+ """Perform normalization、padding and bgr2rgb conversion based on
+ ``BaseDataPreprocessor``.
+
+ Args:
+ data (dict): Data sampled from dataloader.
+ training (bool): Whether to enable training time augmentation.
+
+ Returns:
+ dict: Data in the same format as the model input.
+ """
+ batch_pad_shape = self._get_pad_shape(data)
+ data = super().forward(data=data, training=training)
+ inputs, data_samples = data['inputs'], data['data_samples']
+
+ if data_samples is not None:
+ # NOTE the batched image size information may be useful, e.g.
+ # in DETR, this is needed for the construction of masks, which is
+ # then used for the transformer_head.
+ batch_input_shape = tuple(inputs[0].size()[-2:])
+ for data_sample, pad_shape in zip(data_samples, batch_pad_shape):
+ data_sample.set_metainfo({
+ 'batch_input_shape': batch_input_shape,
+ 'pad_shape': pad_shape
+ })
+
+ if self.boxtype2tensor:
+ samplelist_boxtype2tensor(data_samples)
+
+ if self.pad_mask and training:
+ self.pad_gt_masks(data_samples)
+
+ if self.pad_seg and training:
+ self.pad_gt_sem_seg(data_samples)
+
+ if training and self.batch_augments is not None:
+ for batch_aug in self.batch_augments:
+ inputs, data_samples = batch_aug(inputs, data_samples)
+
+ return {'inputs': inputs, 'data_samples': data_samples}
+
+ def _get_pad_shape(self, data: dict) -> List[tuple]:
+ """Get the pad_shape of each image based on data and
+ pad_size_divisor."""
+ _batch_inputs = data['inputs']
+ # Process data with `pseudo_collate`.
+ if is_seq_of(_batch_inputs, torch.Tensor):
+ batch_pad_shape = []
+ for ori_input in _batch_inputs:
+ pad_h = int(
+ np.ceil(ori_input.shape[1] /
+ self.pad_size_divisor)) * self.pad_size_divisor
+ pad_w = int(
+ np.ceil(ori_input.shape[2] /
+ self.pad_size_divisor)) * self.pad_size_divisor
+ batch_pad_shape.append((pad_h, pad_w))
+ # Process data with `default_collate`.
+ elif isinstance(_batch_inputs, torch.Tensor):
+ assert _batch_inputs.dim() == 4, (
+ 'The input of `ImgDataPreprocessor` should be a NCHW tensor '
+ 'or a list of tensor, but got a tensor with shape: '
+ f'{_batch_inputs.shape}')
+ pad_h = int(
+ np.ceil(_batch_inputs.shape[1] /
+ self.pad_size_divisor)) * self.pad_size_divisor
+ pad_w = int(
+ np.ceil(_batch_inputs.shape[2] /
+ self.pad_size_divisor)) * self.pad_size_divisor
+ batch_pad_shape = [(pad_h, pad_w)] * _batch_inputs.shape[0]
+ else:
+ raise TypeError('Output of `cast_data` should be a dict '
+ 'or a tuple with inputs and data_samples, but got'
+ f'{type(data)}: {data}')
+ return batch_pad_shape
+
+ def pad_gt_masks(self,
+ batch_data_samples: Sequence[DetDataSample]) -> None:
+ """Pad gt_masks to shape of batch_input_shape."""
+ if 'masks' in batch_data_samples[0].gt_instances:
+ for data_samples in batch_data_samples:
+ masks = data_samples.gt_instances.masks
+ data_samples.gt_instances.masks = masks.pad(
+ data_samples.batch_input_shape,
+ pad_val=self.mask_pad_value)
+
+ def pad_gt_sem_seg(self,
+ batch_data_samples: Sequence[DetDataSample]) -> None:
+ """Pad gt_sem_seg to shape of batch_input_shape."""
+ if 'gt_sem_seg' in batch_data_samples[0]:
+ for data_samples in batch_data_samples:
+ gt_sem_seg = data_samples.gt_sem_seg.sem_seg
+ h, w = gt_sem_seg.shape[-2:]
+ pad_h, pad_w = data_samples.batch_input_shape
+ gt_sem_seg = F.pad(
+ gt_sem_seg,
+ pad=(0, max(pad_w - w, 0), 0, max(pad_h - h, 0)),
+ mode='constant',
+ value=self.seg_pad_value)
+ data_samples.gt_sem_seg = PixelData(sem_seg=gt_sem_seg)
+
+
+@MODELS.register_module()
+class BatchSyncRandomResize(nn.Module):
+ """Batch random resize which synchronizes the random size across ranks.
+
+ Args:
+ random_size_range (tuple): The multi-scale random range during
+ multi-scale training.
+ interval (int): The iter interval of change
+ image size. Defaults to 10.
+ size_divisor (int): Image size divisible factor.
+ Defaults to 32.
+ """
+
+ def __init__(self,
+ random_size_range: Tuple[int, int],
+ interval: int = 10,
+ size_divisor: int = 32) -> None:
+ super().__init__()
+ self.rank, self.world_size = get_dist_info()
+ self._input_size = None
+ self._random_size_range = (round(random_size_range[0] / size_divisor),
+ round(random_size_range[1] / size_divisor))
+ self._interval = interval
+ self._size_divisor = size_divisor
+
+ def forward(
+ self, inputs: Tensor, data_samples: List[DetDataSample]
+ ) -> Tuple[Tensor, List[DetDataSample]]:
+ """resize a batch of images and bboxes to shape ``self._input_size``"""
+ h, w = inputs.shape[-2:]
+ if self._input_size is None:
+ self._input_size = (h, w)
+ scale_y = self._input_size[0] / h
+ scale_x = self._input_size[1] / w
+ if scale_x != 1 or scale_y != 1:
+ inputs = F.interpolate(
+ inputs,
+ size=self._input_size,
+ mode='bilinear',
+ align_corners=False)
+ for data_sample in data_samples:
+ img_shape = (int(data_sample.img_shape[0] * scale_y),
+ int(data_sample.img_shape[1] * scale_x))
+ pad_shape = (int(data_sample.pad_shape[0] * scale_y),
+ int(data_sample.pad_shape[1] * scale_x))
+ data_sample.set_metainfo({
+ 'img_shape': img_shape,
+ 'pad_shape': pad_shape,
+ 'batch_input_shape': self._input_size
+ })
+ data_sample.gt_instances.bboxes[
+ ...,
+ 0::2] = data_sample.gt_instances.bboxes[...,
+ 0::2] * scale_x
+ data_sample.gt_instances.bboxes[
+ ...,
+ 1::2] = data_sample.gt_instances.bboxes[...,
+ 1::2] * scale_y
+ if 'ignored_instances' in data_sample:
+ data_sample.ignored_instances.bboxes[
+ ..., 0::2] = data_sample.ignored_instances.bboxes[
+ ..., 0::2] * scale_x
+ data_sample.ignored_instances.bboxes[
+ ..., 1::2] = data_sample.ignored_instances.bboxes[
+ ..., 1::2] * scale_y
+ message_hub = MessageHub.get_current_instance()
+ if (message_hub.get_info('iter') + 1) % self._interval == 0:
+ self._input_size = self._get_random_size(
+ aspect_ratio=float(w / h), device=inputs.device)
+ return inputs, data_samples
+
+ def _get_random_size(self, aspect_ratio: float,
+ device: torch.device) -> Tuple[int, int]:
+ """Randomly generate a shape in ``_random_size_range`` and broadcast to
+ all ranks."""
+ tensor = torch.LongTensor(2).to(device)
+ if self.rank == 0:
+ size = random.randint(*self._random_size_range)
+ size = (self._size_divisor * size,
+ self._size_divisor * int(aspect_ratio * size))
+ tensor[0] = size[0]
+ tensor[1] = size[1]
+ barrier()
+ broadcast(tensor, 0)
+ input_size = (tensor[0].item(), tensor[1].item())
+ return input_size
+
+
+@MODELS.register_module()
+class BatchFixedSizePad(nn.Module):
+ """Fixed size padding for batch images.
+
+ Args:
+ size (Tuple[int, int]): Fixed padding size. Expected padding
+ shape (h, w). Defaults to None.
+ img_pad_value (int): The padded pixel value for images.
+ Defaults to 0.
+ pad_mask (bool): Whether to pad instance masks. Defaults to False.
+ mask_pad_value (int): The padded pixel value for instance masks.
+ Defaults to 0.
+ pad_seg (bool): Whether to pad semantic segmentation maps.
+ Defaults to False.
+ seg_pad_value (int): The padded pixel value for semantic
+ segmentation maps. Defaults to 255.
+ """
+
+ def __init__(self,
+ size: Tuple[int, int],
+ img_pad_value: int = 0,
+ pad_mask: bool = False,
+ mask_pad_value: int = 0,
+ pad_seg: bool = False,
+ seg_pad_value: int = 255) -> None:
+ super().__init__()
+ self.size = size
+ self.pad_mask = pad_mask
+ self.pad_seg = pad_seg
+ self.img_pad_value = img_pad_value
+ self.mask_pad_value = mask_pad_value
+ self.seg_pad_value = seg_pad_value
+
+ def forward(
+ self,
+ inputs: Tensor,
+ data_samples: Optional[List[dict]] = None
+ ) -> Tuple[Tensor, Optional[List[dict]]]:
+ """Pad image, instance masks, segmantic segmentation maps."""
+ src_h, src_w = inputs.shape[-2:]
+ dst_h, dst_w = self.size
+
+ if src_h >= dst_h and src_w >= dst_w:
+ return inputs, data_samples
+
+ inputs = F.pad(
+ inputs,
+ pad=(0, max(0, dst_w - src_w), 0, max(0, dst_h - src_h)),
+ mode='constant',
+ value=self.img_pad_value)
+
+ if data_samples is not None:
+ # update batch_input_shape
+ for data_sample in data_samples:
+ data_sample.set_metainfo({
+ 'batch_input_shape': (dst_h, dst_w),
+ 'pad_shape': (dst_h, dst_w)
+ })
+
+ if self.pad_mask:
+ for data_sample in data_samples:
+ masks = data_sample.gt_instances.masks
+ data_sample.gt_instances.masks = masks.pad(
+ (dst_h, dst_w), pad_val=self.mask_pad_value)
+
+ if self.pad_seg:
+ for data_sample in data_samples:
+ gt_sem_seg = data_sample.gt_sem_seg.sem_seg
+ h, w = gt_sem_seg.shape[-2:]
+ gt_sem_seg = F.pad(
+ gt_sem_seg,
+ pad=(0, max(0, dst_w - w), 0, max(0, dst_h - h)),
+ mode='constant',
+ value=self.seg_pad_value)
+ data_sample.gt_sem_seg = PixelData(sem_seg=gt_sem_seg)
+
+ return inputs, data_samples
+
+
+@MODELS.register_module()
+class MultiBranchDataPreprocessor(BaseDataPreprocessor):
+ """DataPreprocessor wrapper for multi-branch data.
+
+ Take semi-supervised object detection as an example, assume that
+ the ratio of labeled data and unlabeled data in a batch is 1:2,
+ `sup` indicates the branch where the labeled data is augmented,
+ `unsup_teacher` and `unsup_student` indicate the branches where
+ the unlabeled data is augmented by different pipeline.
+
+ The input format of multi-branch data is shown as below :
+
+ .. code-block:: none
+ {
+ 'inputs':
+ {
+ 'sup': [Tensor, None, None],
+ 'unsup_teacher': [None, Tensor, Tensor],
+ 'unsup_student': [None, Tensor, Tensor],
+ },
+ 'data_sample':
+ {
+ 'sup': [DetDataSample, None, None],
+ 'unsup_teacher': [None, DetDataSample, DetDataSample],
+ 'unsup_student': [NOne, DetDataSample, DetDataSample],
+ }
+ }
+
+ The format of multi-branch data
+ after filtering None is shown as below :
+
+ .. code-block:: none
+ {
+ 'inputs':
+ {
+ 'sup': [Tensor],
+ 'unsup_teacher': [Tensor, Tensor],
+ 'unsup_student': [Tensor, Tensor],
+ },
+ 'data_sample':
+ {
+ 'sup': [DetDataSample],
+ 'unsup_teacher': [DetDataSample, DetDataSample],
+ 'unsup_student': [DetDataSample, DetDataSample],
+ }
+ }
+
+ In order to reuse `DetDataPreprocessor` for the data
+ from different branches, the format of multi-branch data
+ grouped by branch is as below :
+
+ .. code-block:: none
+ {
+ 'sup':
+ {
+ 'inputs': [Tensor]
+ 'data_sample': [DetDataSample, DetDataSample]
+ },
+ 'unsup_teacher':
+ {
+ 'inputs': [Tensor, Tensor]
+ 'data_sample': [DetDataSample, DetDataSample]
+ },
+ 'unsup_student':
+ {
+ 'inputs': [Tensor, Tensor]
+ 'data_sample': [DetDataSample, DetDataSample]
+ },
+ }
+
+ After preprocessing data from different branches,
+ the multi-branch data needs to be reformatted as:
+
+ .. code-block:: none
+ {
+ 'inputs':
+ {
+ 'sup': [Tensor],
+ 'unsup_teacher': [Tensor, Tensor],
+ 'unsup_student': [Tensor, Tensor],
+ },
+ 'data_sample':
+ {
+ 'sup': [DetDataSample],
+ 'unsup_teacher': [DetDataSample, DetDataSample],
+ 'unsup_student': [DetDataSample, DetDataSample],
+ }
+ }
+
+ Args:
+ data_preprocessor (:obj:`ConfigDict` or dict): Config of
+ :class:`DetDataPreprocessor` to process the input data.
+ """
+
+ def __init__(self, data_preprocessor: ConfigType) -> None:
+ super().__init__()
+ self.data_preprocessor = MODELS.build(data_preprocessor)
+
+ def forward(self, data: dict, training: bool = False) -> dict:
+ """Perform normalization、padding and bgr2rgb conversion based on
+ ``BaseDataPreprocessor`` for multi-branch data.
+
+ Args:
+ data (dict): Data sampled from dataloader.
+ training (bool): Whether to enable training time augmentation.
+
+ Returns:
+ dict:
+
+ - 'inputs' (Dict[str, obj:`torch.Tensor`]): The forward data of
+ models from different branches.
+ - 'data_sample' (Dict[str, obj:`DetDataSample`]): The annotation
+ info of the sample from different branches.
+ """
+
+ if training is False:
+ return self.data_preprocessor(data, training)
+
+ # Filter out branches with a value of None
+ for key in data.keys():
+ for branch in data[key].keys():
+ data[key][branch] = list(
+ filter(lambda x: x is not None, data[key][branch]))
+
+ # Group data by branch
+ multi_branch_data = {}
+ for key in data.keys():
+ for branch in data[key].keys():
+ if multi_branch_data.get(branch, None) is None:
+ multi_branch_data[branch] = {key: data[key][branch]}
+ elif multi_branch_data[branch].get(key, None) is None:
+ multi_branch_data[branch][key] = data[key][branch]
+ else:
+ multi_branch_data[branch][key].append(data[key][branch])
+
+ # Preprocess data from different branches
+ for branch, _data in multi_branch_data.items():
+ multi_branch_data[branch] = self.data_preprocessor(_data, training)
+
+ # Format data by inputs and data_samples
+ format_data = {}
+ for branch in multi_branch_data.keys():
+ for key in multi_branch_data[branch].keys():
+ if format_data.get(key, None) is None:
+ format_data[key] = {branch: multi_branch_data[branch][key]}
+ elif format_data[key].get(branch, None) is None:
+ format_data[key][branch] = multi_branch_data[branch][key]
+ else:
+ format_data[key][branch].append(
+ multi_branch_data[branch][key])
+
+ return format_data
+
+ @property
+ def device(self):
+ return self.data_preprocessor.device
+
+ def to(self, device: Optional[Union[int, torch.device]], *args,
+ **kwargs) -> nn.Module:
+ """Overrides this method to set the :attr:`device`
+
+ Args:
+ device (int or torch.device, optional): The desired device of the
+ parameters and buffers in this module.
+
+ Returns:
+ nn.Module: The model itself.
+ """
+
+ return self.data_preprocessor.to(device, *args, **kwargs)
+
+ def cuda(self, *args, **kwargs) -> nn.Module:
+ """Overrides this method to set the :attr:`device`
+
+ Returns:
+ nn.Module: The model itself.
+ """
+
+ return self.data_preprocessor.cuda(*args, **kwargs)
+
+ def cpu(self, *args, **kwargs) -> nn.Module:
+ """Overrides this method to set the :attr:`device`
+
+ Returns:
+ nn.Module: The model itself.
+ """
+
+ return self.data_preprocessor.cpu(*args, **kwargs)
+
+
+@MODELS.register_module()
+class BatchResize(nn.Module):
+ """Batch resize during training. This implementation is modified from
+ https://github.com/Purkialo/CrowdDet/blob/master/lib/data/CrowdHuman.py.
+
+ It provides the data pre-processing as follows:
+ - A batch of all images will pad to a uniform size and stack them into
+ a torch.Tensor by `DetDataPreprocessor`.
+ - `BatchFixShapeResize` resize all images to the target size.
+ - Padding images to make sure the size of image can be divisible by
+ ``pad_size_divisor``.
+
+ Args:
+ scale (tuple): Images scales for resizing.
+ pad_size_divisor (int): Image size divisible factor.
+ Defaults to 1.
+ pad_value (Number): The padded pixel value. Defaults to 0.
+ """
+
+ def __init__(
+ self,
+ scale: tuple,
+ pad_size_divisor: int = 1,
+ pad_value: Union[float, int] = 0,
+ ) -> None:
+ super().__init__()
+ self.min_size = min(scale)
+ self.max_size = max(scale)
+ self.pad_size_divisor = pad_size_divisor
+ self.pad_value = pad_value
+
+ def forward(
+ self, inputs: Tensor, data_samples: List[DetDataSample]
+ ) -> Tuple[Tensor, List[DetDataSample]]:
+ """resize a batch of images and bboxes."""
+
+ batch_height, batch_width = inputs.shape[-2:]
+ target_height, target_width, scale = self.get_target_size(
+ batch_height, batch_width)
+
+ inputs = F.interpolate(
+ inputs,
+ size=(target_height, target_width),
+ mode='bilinear',
+ align_corners=False)
+
+ inputs = self.get_padded_tensor(inputs, self.pad_value)
+
+ if data_samples is not None:
+ batch_input_shape = tuple(inputs.size()[-2:])
+ for data_sample in data_samples:
+ img_shape = [
+ int(scale * _) for _ in list(data_sample.img_shape)
+ ]
+ data_sample.set_metainfo({
+ 'img_shape': tuple(img_shape),
+ 'batch_input_shape': batch_input_shape,
+ 'pad_shape': batch_input_shape,
+ 'scale_factor': (scale, scale)
+ })
+
+ data_sample.gt_instances.bboxes *= scale
+ data_sample.ignored_instances.bboxes *= scale
+
+ return inputs, data_samples
+
+ def get_target_size(self, height: int,
+ width: int) -> Tuple[int, int, float]:
+ """Get the target size of a batch of images based on data and scale."""
+ im_size_min = np.min([height, width])
+ im_size_max = np.max([height, width])
+ scale = self.min_size / im_size_min
+ if scale * im_size_max > self.max_size:
+ scale = self.max_size / im_size_max
+ target_height, target_width = int(round(height * scale)), int(
+ round(width * scale))
+ return target_height, target_width, scale
+
+ def get_padded_tensor(self, tensor: Tensor, pad_value: int) -> Tensor:
+ """Pad images according to pad_size_divisor."""
+ assert tensor.ndim == 4
+ target_height, target_width = tensor.shape[-2], tensor.shape[-1]
+ divisor = self.pad_size_divisor
+ padded_height = (target_height + divisor - 1) // divisor * divisor
+ padded_width = (target_width + divisor - 1) // divisor * divisor
+ padded_tensor = torch.ones([
+ tensor.shape[0], tensor.shape[1], padded_height, padded_width
+ ]) * pad_value
+ padded_tensor = padded_tensor.type_as(tensor)
+ padded_tensor[:, :, :target_height, :target_width] = tensor
+ return padded_tensor
+
+
+@MODELS.register_module()
+class BoxInstDataPreprocessor(DetDataPreprocessor):
+ """Pseudo mask pre-processor for BoxInst.
+
+ Comparing with the :class:`mmdet.DetDataPreprocessor`,
+
+ 1. It generates masks using box annotations.
+ 2. It computes the images color similarity in LAB color space.
+
+ Args:
+ mask_stride (int): The mask output stride in boxinst. Defaults to 4.
+ pairwise_size (int): The size of neighborhood for each pixel.
+ Defaults to 3.
+ pairwise_dilation (int): The dilation of neighborhood for each pixel.
+ Defaults to 2.
+ pairwise_color_thresh (float): The thresh of image color similarity.
+ Defaults to 0.3.
+ bottom_pixels_removed (int): The length of removed pixels in bottom.
+ It is caused by the annotation error in coco dataset.
+ Defaults to 10.
+ """
+
+ def __init__(self,
+ *arg,
+ mask_stride: int = 4,
+ pairwise_size: int = 3,
+ pairwise_dilation: int = 2,
+ pairwise_color_thresh: float = 0.3,
+ bottom_pixels_removed: int = 10,
+ **kwargs) -> None:
+ super().__init__(*arg, **kwargs)
+ self.mask_stride = mask_stride
+ self.pairwise_size = pairwise_size
+ self.pairwise_dilation = pairwise_dilation
+ self.pairwise_color_thresh = pairwise_color_thresh
+ self.bottom_pixels_removed = bottom_pixels_removed
+
+ if skimage is None:
+ raise RuntimeError('skimage is not installed,\
+ please install it by: pip install scikit-image')
+
+ def get_images_color_similarity(self, inputs: Tensor,
+ image_masks: Tensor) -> Tensor:
+ """Compute the image color similarity in LAB color space."""
+ assert inputs.dim() == 4
+ assert inputs.size(0) == 1
+
+ unfolded_images = unfold_wo_center(
+ inputs,
+ kernel_size=self.pairwise_size,
+ dilation=self.pairwise_dilation)
+ diff = inputs[:, :, None] - unfolded_images
+ similarity = torch.exp(-torch.norm(diff, dim=1) * 0.5)
+
+ unfolded_weights = unfold_wo_center(
+ image_masks[None, None],
+ kernel_size=self.pairwise_size,
+ dilation=self.pairwise_dilation)
+ unfolded_weights = torch.max(unfolded_weights, dim=1)[0]
+
+ return similarity * unfolded_weights
+
+ def forward(self, data: dict, training: bool = False) -> dict:
+ """Get pseudo mask labels using color similarity."""
+ det_data = super().forward(data, training)
+ inputs, data_samples = det_data['inputs'], det_data['data_samples']
+
+ if training:
+ # get image masks and remove bottom pixels
+ b_img_h, b_img_w = data_samples[0].batch_input_shape
+ img_masks = []
+ for i in range(inputs.shape[0]):
+ img_h, img_w = data_samples[i].img_shape
+ img_mask = inputs.new_ones((img_h, img_w))
+ pixels_removed = int(self.bottom_pixels_removed *
+ float(img_h) / float(b_img_h))
+ if pixels_removed > 0:
+ img_mask[-pixels_removed:, :] = 0
+ pad_w = b_img_w - img_w
+ pad_h = b_img_h - img_h
+ img_mask = F.pad(img_mask, (0, pad_w, 0, pad_h), 'constant',
+ 0.)
+ img_masks.append(img_mask)
+ img_masks = torch.stack(img_masks, dim=0)
+ start = int(self.mask_stride // 2)
+ img_masks = img_masks[:, start::self.mask_stride,
+ start::self.mask_stride]
+
+ # Get origin rgb image for color similarity
+ ori_imgs = inputs * self.std + self.mean
+ downsampled_imgs = F.avg_pool2d(
+ ori_imgs.float(),
+ kernel_size=self.mask_stride,
+ stride=self.mask_stride,
+ padding=0)
+
+ # Compute color similarity for pseudo mask generation
+ for im_i, data_sample in enumerate(data_samples):
+ # TODO: Support rgb2lab in mmengine?
+ images_lab = skimage.color.rgb2lab(
+ downsampled_imgs[im_i].byte().permute(1, 2,
+ 0).cpu().numpy())
+ images_lab = torch.as_tensor(
+ images_lab, device=ori_imgs.device, dtype=torch.float32)
+ images_lab = images_lab.permute(2, 0, 1)[None]
+ images_color_similarity = self.get_images_color_similarity(
+ images_lab, img_masks[im_i])
+ pairwise_mask = (images_color_similarity >=
+ self.pairwise_color_thresh).float()
+
+ per_im_bboxes = data_sample.gt_instances.bboxes
+ if per_im_bboxes.shape[0] > 0:
+ per_im_masks = []
+ for per_box in per_im_bboxes:
+ mask_full = torch.zeros((b_img_h, b_img_w),
+ device=self.device).float()
+ mask_full[int(per_box[1]):int(per_box[3] + 1),
+ int(per_box[0]):int(per_box[2] + 1)] = 1.0
+ per_im_masks.append(mask_full)
+ per_im_masks = torch.stack(per_im_masks, dim=0)
+ pairwise_masks = torch.cat(
+ [pairwise_mask for _ in range(per_im_bboxes.shape[0])],
+ dim=0)
+ else:
+ per_im_masks = torch.zeros((0, b_img_h, b_img_w))
+ pairwise_masks = torch.zeros(
+ (0, self.pairwise_size**2 - 1, b_img_h, b_img_w))
+
+ # TODO: Support BitmapMasks with tensor?
+ data_sample.gt_instances.masks = BitmapMasks(
+ per_im_masks.cpu().numpy(), b_img_h, b_img_w)
+ data_sample.gt_instances.pairwise_masks = pairwise_masks
+ return {'inputs': inputs, 'data_samples': data_samples}
diff --git a/mmdet/models/dense_heads/__init__.py b/mmdet/models/dense_heads/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..ccb3fc7cd8f0875f0f5b66524a330cb8632f7fd3
--- /dev/null
+++ b/mmdet/models/dense_heads/__init__.py
@@ -0,0 +1,75 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .anchor_free_head import AnchorFreeHead
+from .anchor_head import AnchorHead
+from .atss_head import ATSSHead
+from .autoassign_head import AutoAssignHead
+from .boxinst_head import BoxInstBboxHead, BoxInstMaskHead
+from .cascade_rpn_head import CascadeRPNHead, StageCascadeRPNHead
+from .centernet_head import CenterNetHead
+from .centernet_update_head import CenterNetUpdateHead
+from .centripetal_head import CentripetalHead
+from .condinst_head import CondInstBboxHead, CondInstMaskHead
+from .conditional_detr_head import ConditionalDETRHead
+from .corner_head import CornerHead
+from .dab_detr_head import DABDETRHead
+from .ddod_head import DDODHead
+from .deformable_detr_head import DeformableDETRHead
+from .detr_head import DETRHead
+from .dino_head import DINOHead
+from .embedding_rpn_head import EmbeddingRPNHead
+from .fcos_head import FCOSHead
+from .fovea_head import FoveaHead
+from .free_anchor_retina_head import FreeAnchorRetinaHead
+from .fsaf_head import FSAFHead
+from .ga_retina_head import GARetinaHead
+from .ga_rpn_head import GARPNHead
+from .gfl_head import GFLHead
+from .guided_anchor_head import FeatureAdaption, GuidedAnchorHead
+from .lad_head import LADHead
+from .ld_head import LDHead
+from .mask2former_head import Mask2FormerHead
+from .maskformer_head import MaskFormerHead
+from .nasfcos_head import NASFCOSHead
+from .paa_head import PAAHead
+from .pisa_retinanet_head import PISARetinaHead
+from .pisa_ssd_head import PISASSDHead
+from .reppoints_head import RepPointsHead
+from .retina_head import RetinaHead
+from .retina_sepbn_head import RetinaSepBNHead
+from .rpn_head import RPNHead
+from .rtmdet_head import RTMDetHead, RTMDetSepBNHead
+from .rtmdet_ins_head import RTMDetInsHead, RTMDetInsSepBNHead
+from .sabl_retina_head import SABLRetinaHead
+from .solo_head import DecoupledSOLOHead, DecoupledSOLOLightHead, SOLOHead
+from .solov2_head import SOLOV2Head
+from .ssd_head import SSDHead
+from .tood_head import TOODHead
+from .vfnet_head import VFNetHead
+from .yolact_head import YOLACTHead, YOLACTProtonet
+from .yolo_head import YOLOV3Head
+from .yolof_head import YOLOFHead
+from .yolox_head import YOLOXHead
+
+# added by lzx
+from .dino_st_head import DINOSTHead
+from .specdetr_head import SpecDetrHead, SpecDetrHead_DN
+from .evolvedet_head import EvloveDetHead
+
+__all__ = [
+ 'AnchorFreeHead', 'AnchorHead', 'GuidedAnchorHead', 'FeatureAdaption',
+ 'RPNHead', 'GARPNHead', 'RetinaHead', 'RetinaSepBNHead', 'GARetinaHead',
+ 'SSDHead', 'FCOSHead', 'RepPointsHead', 'FoveaHead',
+ 'FreeAnchorRetinaHead', 'ATSSHead', 'FSAFHead', 'NASFCOSHead',
+ 'PISARetinaHead', 'PISASSDHead', 'GFLHead', 'CornerHead', 'YOLACTHead',
+ 'YOLACTProtonet', 'YOLOV3Head', 'PAAHead', 'SABLRetinaHead',
+ 'CentripetalHead', 'VFNetHead', 'StageCascadeRPNHead', 'CascadeRPNHead',
+ 'EmbeddingRPNHead', 'LDHead', 'AutoAssignHead', 'DETRHead', 'YOLOFHead',
+ 'DeformableDETRHead', 'CenterNetHead', 'YOLOXHead', 'SOLOHead',
+ 'DecoupledSOLOHead', 'DecoupledSOLOLightHead', 'SOLOV2Head', 'LADHead',
+ 'TOODHead', 'MaskFormerHead', 'Mask2FormerHead', 'DDODHead',
+ 'CenterNetUpdateHead', 'RTMDetHead', 'RTMDetSepBNHead', 'CondInstBboxHead',
+ 'CondInstMaskHead', 'RTMDetInsHead', 'RTMDetInsSepBNHead',
+ 'BoxInstBboxHead', 'BoxInstMaskHead', 'ConditionalDETRHead', 'DINOHead',
+ 'DABDETRHead',
+ 'DINOSTHead','SpecDetrHead','SpecDetrHead_DN', 'EvloveDetHead'
+]
diff --git a/mmdet/models/dense_heads/__pycache__/__init__.cpython-37.pyc b/mmdet/models/dense_heads/__pycache__/__init__.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..a0587a6583e53799891e09842878a34671fddcb3
Binary files /dev/null and b/mmdet/models/dense_heads/__pycache__/__init__.cpython-37.pyc differ
diff --git a/mmdet/models/dense_heads/__pycache__/anchor_free_head.cpython-37.pyc b/mmdet/models/dense_heads/__pycache__/anchor_free_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..93b6ef33fce36566f5dce04267b71088ecf4e839
Binary files /dev/null and b/mmdet/models/dense_heads/__pycache__/anchor_free_head.cpython-37.pyc differ
diff --git a/mmdet/models/dense_heads/__pycache__/anchor_head.cpython-37.pyc b/mmdet/models/dense_heads/__pycache__/anchor_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..0f0df4ece9e83473f9ab200bb02165bb5938bac6
Binary files /dev/null and b/mmdet/models/dense_heads/__pycache__/anchor_head.cpython-37.pyc differ
diff --git a/mmdet/models/dense_heads/__pycache__/atss_head.cpython-37.pyc b/mmdet/models/dense_heads/__pycache__/atss_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..5cc5b49572e850827e68e609a4e1386990933aa0
Binary files /dev/null and b/mmdet/models/dense_heads/__pycache__/atss_head.cpython-37.pyc differ
diff --git a/mmdet/models/dense_heads/__pycache__/autoassign_head.cpython-37.pyc b/mmdet/models/dense_heads/__pycache__/autoassign_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..9759fb857b7b3824ed3c95d9772d0276fbbb8067
Binary files /dev/null and b/mmdet/models/dense_heads/__pycache__/autoassign_head.cpython-37.pyc differ
diff --git a/mmdet/models/dense_heads/__pycache__/base_dense_head.cpython-37.pyc b/mmdet/models/dense_heads/__pycache__/base_dense_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..c5087d777e6ddca0f06fafd950026bf4a26f5782
Binary files /dev/null and b/mmdet/models/dense_heads/__pycache__/base_dense_head.cpython-37.pyc differ
diff --git a/mmdet/models/dense_heads/__pycache__/base_mask_head.cpython-37.pyc b/mmdet/models/dense_heads/__pycache__/base_mask_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..280f998ef5a122f0fd9f7b9a926b5e552119c36e
Binary files /dev/null and b/mmdet/models/dense_heads/__pycache__/base_mask_head.cpython-37.pyc differ
diff --git a/mmdet/models/dense_heads/__pycache__/boxinst_head.cpython-37.pyc b/mmdet/models/dense_heads/__pycache__/boxinst_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..5ba02a67829440caef59f0a5a9e0eadb1a7d5e25
Binary files /dev/null and b/mmdet/models/dense_heads/__pycache__/boxinst_head.cpython-37.pyc differ
diff --git a/mmdet/models/dense_heads/__pycache__/cascade_rpn_head.cpython-37.pyc b/mmdet/models/dense_heads/__pycache__/cascade_rpn_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..7893bd1f9cd2b8b94eac8dc2e663cb03a6e5ffe9
Binary files /dev/null and b/mmdet/models/dense_heads/__pycache__/cascade_rpn_head.cpython-37.pyc differ
diff --git a/mmdet/models/dense_heads/__pycache__/centernet_head.cpython-37.pyc b/mmdet/models/dense_heads/__pycache__/centernet_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..e83538827d047adb68abc17d148d36573ff36795
Binary files /dev/null and b/mmdet/models/dense_heads/__pycache__/centernet_head.cpython-37.pyc differ
diff --git a/mmdet/models/dense_heads/__pycache__/centernet_update_head.cpython-37.pyc b/mmdet/models/dense_heads/__pycache__/centernet_update_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..0472309e54996bcb3137a409b08b7be541915883
Binary files /dev/null and b/mmdet/models/dense_heads/__pycache__/centernet_update_head.cpython-37.pyc differ
diff --git a/mmdet/models/dense_heads/__pycache__/centripetal_head.cpython-37.pyc b/mmdet/models/dense_heads/__pycache__/centripetal_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..7e46cd35eaff4a711638a5ff6733fc80d22968a3
Binary files /dev/null and b/mmdet/models/dense_heads/__pycache__/centripetal_head.cpython-37.pyc differ
diff --git a/mmdet/models/dense_heads/__pycache__/condinst_head.cpython-37.pyc b/mmdet/models/dense_heads/__pycache__/condinst_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..218deebcfb348f0f4b162dec5f487ee284851768
Binary files /dev/null and b/mmdet/models/dense_heads/__pycache__/condinst_head.cpython-37.pyc differ
diff --git a/mmdet/models/dense_heads/__pycache__/conditional_detr_head.cpython-37.pyc b/mmdet/models/dense_heads/__pycache__/conditional_detr_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..02f48727b6fb91fd75d7c79ddd83c8742e2c7540
Binary files /dev/null and b/mmdet/models/dense_heads/__pycache__/conditional_detr_head.cpython-37.pyc differ
diff --git a/mmdet/models/dense_heads/__pycache__/corner_head.cpython-37.pyc b/mmdet/models/dense_heads/__pycache__/corner_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..04033ee03237f9205338cec8529434bd22d34bd3
Binary files /dev/null and b/mmdet/models/dense_heads/__pycache__/corner_head.cpython-37.pyc differ
diff --git a/mmdet/models/dense_heads/__pycache__/dab_detr_head.cpython-37.pyc b/mmdet/models/dense_heads/__pycache__/dab_detr_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..2c3ca612048c46c7f1cc30b35dc9505d72e832ef
Binary files /dev/null and b/mmdet/models/dense_heads/__pycache__/dab_detr_head.cpython-37.pyc differ
diff --git a/mmdet/models/dense_heads/__pycache__/ddod_head.cpython-37.pyc b/mmdet/models/dense_heads/__pycache__/ddod_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..7ddfdbcb2f598f54959bb3b71c1beb228c32ff2f
Binary files /dev/null and b/mmdet/models/dense_heads/__pycache__/ddod_head.cpython-37.pyc differ
diff --git a/mmdet/models/dense_heads/__pycache__/deformable_detr_head.cpython-37.pyc b/mmdet/models/dense_heads/__pycache__/deformable_detr_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..52f4caac822de7bdade03e38f3edc228236b5a6e
Binary files /dev/null and b/mmdet/models/dense_heads/__pycache__/deformable_detr_head.cpython-37.pyc differ
diff --git a/mmdet/models/dense_heads/__pycache__/detr_head.cpython-37.pyc b/mmdet/models/dense_heads/__pycache__/detr_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..c887252846edcd6cba76938375df3dbf852a5c85
Binary files /dev/null and b/mmdet/models/dense_heads/__pycache__/detr_head.cpython-37.pyc differ
diff --git a/mmdet/models/dense_heads/__pycache__/dino_head.cpython-37.pyc b/mmdet/models/dense_heads/__pycache__/dino_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..585e493163fc23c968aff7c5d85d3d2eae9ecedd
Binary files /dev/null and b/mmdet/models/dense_heads/__pycache__/dino_head.cpython-37.pyc differ
diff --git a/mmdet/models/dense_heads/__pycache__/dino_sima_cls_head.cpython-37.pyc b/mmdet/models/dense_heads/__pycache__/dino_sima_cls_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..7d67287348cd13dd2dbf16c448adc8f08a9406e8
Binary files /dev/null and b/mmdet/models/dense_heads/__pycache__/dino_sima_cls_head.cpython-37.pyc differ
diff --git a/mmdet/models/dense_heads/__pycache__/dino_st_head.cpython-37.pyc b/mmdet/models/dense_heads/__pycache__/dino_st_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..532d085582412b0c4338bbfab904807936e82d98
Binary files /dev/null and b/mmdet/models/dense_heads/__pycache__/dino_st_head.cpython-37.pyc differ
diff --git a/mmdet/models/dense_heads/__pycache__/embedding_rpn_head.cpython-37.pyc b/mmdet/models/dense_heads/__pycache__/embedding_rpn_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..20d161a56c31b61cb0a2678a6eb642abdb507288
Binary files /dev/null and b/mmdet/models/dense_heads/__pycache__/embedding_rpn_head.cpython-37.pyc differ
diff --git a/mmdet/models/dense_heads/__pycache__/evolvedet_head.cpython-37.pyc b/mmdet/models/dense_heads/__pycache__/evolvedet_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..0472c791d55765d913a122808ccb32cc1c41d10f
Binary files /dev/null and b/mmdet/models/dense_heads/__pycache__/evolvedet_head.cpython-37.pyc differ
diff --git a/mmdet/models/dense_heads/__pycache__/fcos_head.cpython-37.pyc b/mmdet/models/dense_heads/__pycache__/fcos_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..60ff0ce0e8339f8ffad78877650cd2817dce21ba
Binary files /dev/null and b/mmdet/models/dense_heads/__pycache__/fcos_head.cpython-37.pyc differ
diff --git a/mmdet/models/dense_heads/__pycache__/fovea_head.cpython-37.pyc b/mmdet/models/dense_heads/__pycache__/fovea_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..d104a0259ba3aabc40c9974c0a2a39f808393208
Binary files /dev/null and b/mmdet/models/dense_heads/__pycache__/fovea_head.cpython-37.pyc differ
diff --git a/mmdet/models/dense_heads/__pycache__/free_anchor_retina_head.cpython-37.pyc b/mmdet/models/dense_heads/__pycache__/free_anchor_retina_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..098555d70fe260609cbc4b6e995d5c88619e60e3
Binary files /dev/null and b/mmdet/models/dense_heads/__pycache__/free_anchor_retina_head.cpython-37.pyc differ
diff --git a/mmdet/models/dense_heads/__pycache__/fsaf_head.cpython-37.pyc b/mmdet/models/dense_heads/__pycache__/fsaf_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..93ff829b6e4aa132883565336b6b34ffa00fa190
Binary files /dev/null and b/mmdet/models/dense_heads/__pycache__/fsaf_head.cpython-37.pyc differ
diff --git a/mmdet/models/dense_heads/__pycache__/ga_retina_head.cpython-37.pyc b/mmdet/models/dense_heads/__pycache__/ga_retina_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..690c59e01239bd675b2c2cf9071919a25c3a4575
Binary files /dev/null and b/mmdet/models/dense_heads/__pycache__/ga_retina_head.cpython-37.pyc differ
diff --git a/mmdet/models/dense_heads/__pycache__/ga_rpn_head.cpython-37.pyc b/mmdet/models/dense_heads/__pycache__/ga_rpn_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..68d886e973ab378112f018686ba20fe3e23696ea
Binary files /dev/null and b/mmdet/models/dense_heads/__pycache__/ga_rpn_head.cpython-37.pyc differ
diff --git a/mmdet/models/dense_heads/__pycache__/gfl_head.cpython-37.pyc b/mmdet/models/dense_heads/__pycache__/gfl_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..294f71cae15c34efe6695f109b0117738a49c9fc
Binary files /dev/null and b/mmdet/models/dense_heads/__pycache__/gfl_head.cpython-37.pyc differ
diff --git a/mmdet/models/dense_heads/__pycache__/guided_anchor_head.cpython-37.pyc b/mmdet/models/dense_heads/__pycache__/guided_anchor_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..e6c2e4c6a85787bc1f24e727acb795d9840048f7
Binary files /dev/null and b/mmdet/models/dense_heads/__pycache__/guided_anchor_head.cpython-37.pyc differ
diff --git a/mmdet/models/dense_heads/__pycache__/lad_head.cpython-37.pyc b/mmdet/models/dense_heads/__pycache__/lad_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..b0af483782ee772fe1affb137fe068c31f288b88
Binary files /dev/null and b/mmdet/models/dense_heads/__pycache__/lad_head.cpython-37.pyc differ
diff --git a/mmdet/models/dense_heads/__pycache__/ld_head.cpython-37.pyc b/mmdet/models/dense_heads/__pycache__/ld_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..57ccd6e0fb0e89de372709c6218abda66b106783
Binary files /dev/null and b/mmdet/models/dense_heads/__pycache__/ld_head.cpython-37.pyc differ
diff --git a/mmdet/models/dense_heads/__pycache__/mask2former_head.cpython-37.pyc b/mmdet/models/dense_heads/__pycache__/mask2former_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..08fb245d337a51c30c6735270629f71aebf971da
Binary files /dev/null and b/mmdet/models/dense_heads/__pycache__/mask2former_head.cpython-37.pyc differ
diff --git a/mmdet/models/dense_heads/__pycache__/maskformer_head.cpython-37.pyc b/mmdet/models/dense_heads/__pycache__/maskformer_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..c78e2e1ea9ad0fc4e1370ef519458ca66f42bcd2
Binary files /dev/null and b/mmdet/models/dense_heads/__pycache__/maskformer_head.cpython-37.pyc differ
diff --git a/mmdet/models/dense_heads/__pycache__/nasfcos_head.cpython-37.pyc b/mmdet/models/dense_heads/__pycache__/nasfcos_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..d690b794e4e29350ea58f3d0f844caca488f4b59
Binary files /dev/null and b/mmdet/models/dense_heads/__pycache__/nasfcos_head.cpython-37.pyc differ
diff --git a/mmdet/models/dense_heads/__pycache__/paa_head.cpython-37.pyc b/mmdet/models/dense_heads/__pycache__/paa_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..8f2fd3237da4bc03915a1f748a6104a8611dd58a
Binary files /dev/null and b/mmdet/models/dense_heads/__pycache__/paa_head.cpython-37.pyc differ
diff --git a/mmdet/models/dense_heads/__pycache__/pisa_retinanet_head.cpython-37.pyc b/mmdet/models/dense_heads/__pycache__/pisa_retinanet_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..2339860213a4ced01a03a8c219e8d2d3da98a7bd
Binary files /dev/null and b/mmdet/models/dense_heads/__pycache__/pisa_retinanet_head.cpython-37.pyc differ
diff --git a/mmdet/models/dense_heads/__pycache__/pisa_ssd_head.cpython-37.pyc b/mmdet/models/dense_heads/__pycache__/pisa_ssd_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..f41b32a50c63f917b98da9003f98fe85f6ae120b
Binary files /dev/null and b/mmdet/models/dense_heads/__pycache__/pisa_ssd_head.cpython-37.pyc differ
diff --git a/mmdet/models/dense_heads/__pycache__/reppoints_head.cpython-37.pyc b/mmdet/models/dense_heads/__pycache__/reppoints_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..e640ce4ac4d951d84bb54afff58214c9ad1716c9
Binary files /dev/null and b/mmdet/models/dense_heads/__pycache__/reppoints_head.cpython-37.pyc differ
diff --git a/mmdet/models/dense_heads/__pycache__/retina_head.cpython-37.pyc b/mmdet/models/dense_heads/__pycache__/retina_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..13252bd02cf6486adbedc697cd3b9f95bc31c79a
Binary files /dev/null and b/mmdet/models/dense_heads/__pycache__/retina_head.cpython-37.pyc differ
diff --git a/mmdet/models/dense_heads/__pycache__/retina_sepbn_head.cpython-37.pyc b/mmdet/models/dense_heads/__pycache__/retina_sepbn_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..38920fa7dc5350249d157572c624108917cd6b49
Binary files /dev/null and b/mmdet/models/dense_heads/__pycache__/retina_sepbn_head.cpython-37.pyc differ
diff --git a/mmdet/models/dense_heads/__pycache__/rpn_head.cpython-37.pyc b/mmdet/models/dense_heads/__pycache__/rpn_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..95db2f9d3220ab0dcaab25a7cfe66f90ab14cbcd
Binary files /dev/null and b/mmdet/models/dense_heads/__pycache__/rpn_head.cpython-37.pyc differ
diff --git a/mmdet/models/dense_heads/__pycache__/rtmdet_head.cpython-37.pyc b/mmdet/models/dense_heads/__pycache__/rtmdet_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..e9aa404521ccf9a5f23852815fd5cbfc51d648c3
Binary files /dev/null and b/mmdet/models/dense_heads/__pycache__/rtmdet_head.cpython-37.pyc differ
diff --git a/mmdet/models/dense_heads/__pycache__/rtmdet_ins_head.cpython-37.pyc b/mmdet/models/dense_heads/__pycache__/rtmdet_ins_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..ac365a4a19fa1e5abf1419916ea2dd7bd16b73f7
Binary files /dev/null and b/mmdet/models/dense_heads/__pycache__/rtmdet_ins_head.cpython-37.pyc differ
diff --git a/mmdet/models/dense_heads/__pycache__/sabl_retina_head.cpython-37.pyc b/mmdet/models/dense_heads/__pycache__/sabl_retina_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..7b5044a2f3fec205192afa69d4df600abdd29d36
Binary files /dev/null and b/mmdet/models/dense_heads/__pycache__/sabl_retina_head.cpython-37.pyc differ
diff --git a/mmdet/models/dense_heads/__pycache__/solo_head.cpython-37.pyc b/mmdet/models/dense_heads/__pycache__/solo_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..88c7a6305c16879ba23cdb207f70880eacfcfdfb
Binary files /dev/null and b/mmdet/models/dense_heads/__pycache__/solo_head.cpython-37.pyc differ
diff --git a/mmdet/models/dense_heads/__pycache__/solov2_head.cpython-37.pyc b/mmdet/models/dense_heads/__pycache__/solov2_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..bee6c4a31ba42b1506643a38ce9691da7db42a75
Binary files /dev/null and b/mmdet/models/dense_heads/__pycache__/solov2_head.cpython-37.pyc differ
diff --git a/mmdet/models/dense_heads/__pycache__/ssd_head.cpython-37.pyc b/mmdet/models/dense_heads/__pycache__/ssd_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..0558641056bf51cc5f291dc49cf056f5d5bb8efa
Binary files /dev/null and b/mmdet/models/dense_heads/__pycache__/ssd_head.cpython-37.pyc differ
diff --git a/mmdet/models/dense_heads/__pycache__/tood_head.cpython-37.pyc b/mmdet/models/dense_heads/__pycache__/tood_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..e999ac009aa26cd15482b401b68e14eb3d056f50
Binary files /dev/null and b/mmdet/models/dense_heads/__pycache__/tood_head.cpython-37.pyc differ
diff --git a/mmdet/models/dense_heads/__pycache__/vfnet_head.cpython-37.pyc b/mmdet/models/dense_heads/__pycache__/vfnet_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..99731a3db9ce2defb166cdf5e6b537011461ad98
Binary files /dev/null and b/mmdet/models/dense_heads/__pycache__/vfnet_head.cpython-37.pyc differ
diff --git a/mmdet/models/dense_heads/__pycache__/yolact_head.cpython-37.pyc b/mmdet/models/dense_heads/__pycache__/yolact_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..9ce2abfb43c27bea7b511de6e6bd6415f37d0617
Binary files /dev/null and b/mmdet/models/dense_heads/__pycache__/yolact_head.cpython-37.pyc differ
diff --git a/mmdet/models/dense_heads/__pycache__/yolo_head.cpython-37.pyc b/mmdet/models/dense_heads/__pycache__/yolo_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..c754df4e3db671c758d69438cefe0788c8c32b11
Binary files /dev/null and b/mmdet/models/dense_heads/__pycache__/yolo_head.cpython-37.pyc differ
diff --git a/mmdet/models/dense_heads/__pycache__/yolof_head.cpython-37.pyc b/mmdet/models/dense_heads/__pycache__/yolof_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..4bf678a2663f96c94058c4cdab633596a8fb908e
Binary files /dev/null and b/mmdet/models/dense_heads/__pycache__/yolof_head.cpython-37.pyc differ
diff --git a/mmdet/models/dense_heads/__pycache__/yolox_head.cpython-37.pyc b/mmdet/models/dense_heads/__pycache__/yolox_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..0839355ef438b7b9a2b6b40580f02edf19e2eb69
Binary files /dev/null and b/mmdet/models/dense_heads/__pycache__/yolox_head.cpython-37.pyc differ
diff --git a/mmdet/models/dense_heads/anchor_free_head.py b/mmdet/models/dense_heads/anchor_free_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..90a9b3625b8fef12a2ee3a964c89597b597cb2ec
--- /dev/null
+++ b/mmdet/models/dense_heads/anchor_free_head.py
@@ -0,0 +1,317 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from abc import abstractmethod
+from typing import Any, List, Sequence, Tuple, Union
+
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+from numpy import ndarray
+from torch import Tensor
+
+from mmdet.registry import MODELS, TASK_UTILS
+from mmdet.utils import (ConfigType, InstanceList, MultiConfig, OptConfigType,
+ OptInstanceList)
+from ..task_modules.prior_generators import MlvlPointGenerator
+from ..utils import multi_apply
+from .base_dense_head import BaseDenseHead
+
+StrideType = Union[Sequence[int], Sequence[Tuple[int, int]]]
+
+
+@MODELS.register_module()
+class AnchorFreeHead(BaseDenseHead):
+ """Anchor-free head (FCOS, Fovea, RepPoints, etc.).
+
+ Args:
+ num_classes (int): Number of categories excluding the background
+ category.
+ in_channels (int): Number of channels in the input feature map.
+ feat_channels (int): Number of hidden channels. Used in child classes.
+ stacked_convs (int): Number of stacking convs of the head.
+ strides (Sequence[int] or Sequence[Tuple[int, int]]): Downsample
+ factor of each feature map.
+ dcn_on_last_conv (bool): If true, use dcn in the last layer of
+ towers. Defaults to False.
+ conv_bias (bool or str): If specified as `auto`, it will be decided by
+ the norm_cfg. Bias of conv will be set as True if `norm_cfg` is
+ None, otherwise False. Default: "auto".
+ loss_cls (:obj:`ConfigDict` or dict): Config of classification loss.
+ loss_bbox (:obj:`ConfigDict` or dict): Config of localization loss.
+ bbox_coder (:obj:`ConfigDict` or dict): Config of bbox coder. Defaults
+ 'DistancePointBBoxCoder'.
+ conv_cfg (:obj:`ConfigDict` or dict, Optional): Config dict for
+ convolution layer. Defaults to None.
+ norm_cfg (:obj:`ConfigDict` or dict, Optional): Config dict for
+ normalization layer. Defaults to None.
+ train_cfg (:obj:`ConfigDict` or dict, Optional): Training config of
+ anchor-free head.
+ test_cfg (:obj:`ConfigDict` or dict, Optional): Testing config of
+ anchor-free head.
+ init_cfg (:obj:`ConfigDict` or dict or list[:obj:`ConfigDict` or \
+ dict]): Initialization config dict.
+ """ # noqa: W605
+
+ _version = 1
+
+ def __init__(
+ self,
+ num_classes: int,
+ in_channels: int,
+ feat_channels: int = 256,
+ stacked_convs: int = 4,
+ strides: StrideType = (4, 8, 16, 32, 64),
+ dcn_on_last_conv: bool = False,
+ conv_bias: Union[bool, str] = 'auto',
+ loss_cls: ConfigType = dict(
+ type='FocalLoss',
+ use_sigmoid=True,
+ gamma=2.0,
+ alpha=0.25,
+ loss_weight=1.0),
+ loss_bbox: ConfigType = dict(type='IoULoss', loss_weight=1.0),
+ bbox_coder: ConfigType = dict(type='DistancePointBBoxCoder'),
+ conv_cfg: OptConfigType = None,
+ norm_cfg: OptConfigType = None,
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ init_cfg: MultiConfig = dict(
+ type='Normal',
+ layer='Conv2d',
+ std=0.01,
+ override=dict(
+ type='Normal', name='conv_cls', std=0.01, bias_prob=0.01))
+ ) -> None:
+ super().__init__(init_cfg=init_cfg)
+ self.num_classes = num_classes
+ self.use_sigmoid_cls = loss_cls.get('use_sigmoid', False)
+ if self.use_sigmoid_cls:
+ self.cls_out_channels = num_classes
+ else:
+ self.cls_out_channels = num_classes + 1
+ self.in_channels = in_channels
+ self.feat_channels = feat_channels
+ self.stacked_convs = stacked_convs
+ self.strides = strides
+ self.dcn_on_last_conv = dcn_on_last_conv
+ assert conv_bias == 'auto' or isinstance(conv_bias, bool)
+ self.conv_bias = conv_bias
+ self.loss_cls = MODELS.build(loss_cls)
+ self.loss_bbox = MODELS.build(loss_bbox)
+ self.bbox_coder = TASK_UTILS.build(bbox_coder)
+
+ self.prior_generator = MlvlPointGenerator(strides)
+
+ # In order to keep a more general interface and be consistent with
+ # anchor_head. We can think of point like one anchor
+ self.num_base_priors = self.prior_generator.num_base_priors[0]
+
+ self.train_cfg = train_cfg
+ self.test_cfg = test_cfg
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.fp16_enabled = False
+
+ self._init_layers()
+
+ def _init_layers(self) -> None:
+ """Initialize layers of the head."""
+ self._init_cls_convs()
+ self._init_reg_convs()
+ self._init_predictor()
+
+ def _init_cls_convs(self) -> None:
+ """Initialize classification conv layers of the head."""
+ self.cls_convs = nn.ModuleList()
+ for i in range(self.stacked_convs):
+ chn = self.in_channels if i == 0 else self.feat_channels
+ if self.dcn_on_last_conv and i == self.stacked_convs - 1:
+ conv_cfg = dict(type='DCNv2')
+ else:
+ conv_cfg = self.conv_cfg
+ self.cls_convs.append(
+ ConvModule(
+ chn,
+ self.feat_channels,
+ 3,
+ stride=1,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=self.norm_cfg,
+ bias=self.conv_bias))
+
+ def _init_reg_convs(self) -> None:
+ """Initialize bbox regression conv layers of the head."""
+ self.reg_convs = nn.ModuleList()
+ for i in range(self.stacked_convs):
+ chn = self.in_channels if i == 0 else self.feat_channels
+ if self.dcn_on_last_conv and i == self.stacked_convs - 1:
+ conv_cfg = dict(type='DCNv2')
+ else:
+ conv_cfg = self.conv_cfg
+ self.reg_convs.append(
+ ConvModule(
+ chn,
+ self.feat_channels,
+ 3,
+ stride=1,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=self.norm_cfg,
+ bias=self.conv_bias))
+
+ def _init_predictor(self) -> None:
+ """Initialize predictor layers of the head."""
+ self.conv_cls = nn.Conv2d(
+ self.feat_channels, self.cls_out_channels, 3, padding=1)
+ self.conv_reg = nn.Conv2d(self.feat_channels, 4, 3, padding=1)
+
+ def _load_from_state_dict(self, state_dict: dict, prefix: str,
+ local_metadata: dict, strict: bool,
+ missing_keys: Union[List[str], str],
+ unexpected_keys: Union[List[str], str],
+ error_msgs: Union[List[str], str]) -> None:
+ """Hack some keys of the model state dict so that can load checkpoints
+ of previous version."""
+ version = local_metadata.get('version', None)
+ if version is None:
+ # the key is different in early versions
+ # for example, 'fcos_cls' become 'conv_cls' now
+ bbox_head_keys = [
+ k for k in state_dict.keys() if k.startswith(prefix)
+ ]
+ ori_predictor_keys = []
+ new_predictor_keys = []
+ # e.g. 'fcos_cls' or 'fcos_reg'
+ for key in bbox_head_keys:
+ ori_predictor_keys.append(key)
+ key = key.split('.')
+ if len(key) < 2:
+ conv_name = None
+ elif key[1].endswith('cls'):
+ conv_name = 'conv_cls'
+ elif key[1].endswith('reg'):
+ conv_name = 'conv_reg'
+ elif key[1].endswith('centerness'):
+ conv_name = 'conv_centerness'
+ else:
+ conv_name = None
+ if conv_name is not None:
+ key[1] = conv_name
+ new_predictor_keys.append('.'.join(key))
+ else:
+ ori_predictor_keys.pop(-1)
+ for i in range(len(new_predictor_keys)):
+ state_dict[new_predictor_keys[i]] = state_dict.pop(
+ ori_predictor_keys[i])
+ super()._load_from_state_dict(state_dict, prefix, local_metadata,
+ strict, missing_keys, unexpected_keys,
+ error_msgs)
+
+ def forward(self, x: Tuple[Tensor]) -> Tuple[List[Tensor], List[Tensor]]:
+ """Forward features from the upstream network.
+
+ Args:
+ feats (tuple[Tensor]): Features from the upstream network, each is
+ a 4D-tensor.
+
+ Returns:
+ tuple: Usually contain classification scores and bbox predictions.
+
+ - cls_scores (list[Tensor]): Box scores for each scale level, \
+ each is a 4D-tensor, the channel number is \
+ num_points * num_classes.
+ - bbox_preds (list[Tensor]): Box energies / deltas for each scale \
+ level, each is a 4D-tensor, the channel number is num_points * 4.
+ """
+ return multi_apply(self.forward_single, x)[:2]
+
+ def forward_single(self, x: Tensor) -> Tuple[Tensor, ...]:
+ """Forward features of a single scale level.
+
+ Args:
+ x (Tensor): FPN feature maps of the specified stride.
+
+ Returns:
+ tuple: Scores for each class, bbox predictions, features
+ after classification and regression conv layers, some
+ models needs these features like FCOS.
+ """
+ cls_feat = x
+ reg_feat = x
+
+ for cls_layer in self.cls_convs:
+ cls_feat = cls_layer(cls_feat)
+ cls_score = self.conv_cls(cls_feat)
+
+ for reg_layer in self.reg_convs:
+ reg_feat = reg_layer(reg_feat)
+ bbox_pred = self.conv_reg(reg_feat)
+ return cls_score, bbox_pred, cls_feat, reg_feat
+
+ @abstractmethod
+ def loss_by_feat(
+ self,
+ cls_scores: List[Tensor],
+ bbox_preds: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ batch_gt_instances_ignore: OptInstanceList = None) -> dict:
+ """Calculate the loss based on the features extracted by the detection
+ head.
+
+ Args:
+ cls_scores (list[Tensor]): Box scores for each scale level,
+ each is a 4D-tensor, the channel number is
+ num_points * num_classes.
+ bbox_preds (list[Tensor]): Box energies / deltas for each scale
+ level, each is a 4D-tensor, the channel number is
+ num_points * 4.
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], Optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+ """
+
+ raise NotImplementedError
+
+ @abstractmethod
+ def get_targets(self, points: List[Tensor],
+ batch_gt_instances: InstanceList) -> Any:
+ """Compute regression, classification and centerness targets for points
+ in multiple images.
+
+ Args:
+ points (list[Tensor]): Points of each fpn level, each has shape
+ (num_points, 2).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ """
+ raise NotImplementedError
+
+ # TODO refactor aug_test
+ def aug_test(self,
+ aug_batch_feats: List[Tensor],
+ aug_batch_img_metas: List[List[Tensor]],
+ rescale: bool = False) -> List[ndarray]:
+ """Test function with test time augmentation.
+
+ Args:
+ aug_batch_feats (list[Tensor]): the outer list indicates test-time
+ augmentations and inner Tensor should have a shape NxCxHxW,
+ which contains features for all images in the batch.
+ aug_batch_img_metas (list[list[dict]]): the outer list indicates
+ test-time augs (multiscale, flip, etc.) and the inner list
+ indicates images in a batch. each dict has image information.
+ rescale (bool, optional): Whether to rescale the results.
+ Defaults to False.
+
+ Returns:
+ list[ndarray]: bbox results of each class
+ """
+ return self.aug_test_bboxes(
+ aug_batch_feats, aug_batch_img_metas, rescale=rescale)
diff --git a/mmdet/models/dense_heads/anchor_head.py b/mmdet/models/dense_heads/anchor_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..4578caca818550397875a0df34c128f461e6ec75
--- /dev/null
+++ b/mmdet/models/dense_heads/anchor_head.py
@@ -0,0 +1,530 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+from typing import List, Optional, Tuple, Union
+
+import torch
+import torch.nn as nn
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmdet.registry import MODELS, TASK_UTILS
+from mmdet.structures.bbox import BaseBoxes, cat_boxes, get_box_tensor
+from mmdet.utils import (ConfigType, InstanceList, OptConfigType,
+ OptInstanceList, OptMultiConfig)
+from ..task_modules.prior_generators import (AnchorGenerator,
+ anchor_inside_flags)
+from ..task_modules.samplers import PseudoSampler
+from ..utils import images_to_levels, multi_apply, unmap
+from .base_dense_head import BaseDenseHead
+
+
+@MODELS.register_module()
+class AnchorHead(BaseDenseHead):
+ """Anchor-based head (RPN, RetinaNet, SSD, etc.).
+
+ Args:
+ num_classes (int): Number of categories excluding the background
+ category.
+ in_channels (int): Number of channels in the input feature map.
+ feat_channels (int): Number of hidden channels. Used in child classes.
+ anchor_generator (dict): Config dict for anchor generator
+ bbox_coder (dict): Config of bounding box coder.
+ reg_decoded_bbox (bool): If true, the regression loss would be
+ applied directly on decoded bounding boxes, converting both
+ the predicted boxes and regression targets to absolute
+ coordinates format. Default False. It should be `True` when
+ using `IoULoss`, `GIoULoss`, or `DIoULoss` in the bbox head.
+ loss_cls (dict): Config of classification loss.
+ loss_bbox (dict): Config of localization loss.
+ train_cfg (dict): Training config of anchor head.
+ test_cfg (dict): Testing config of anchor head.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ """ # noqa: W605
+
+ def __init__(
+ self,
+ num_classes: int,
+ in_channels: int,
+ feat_channels: int = 256,
+ anchor_generator: ConfigType = dict(
+ type='AnchorGenerator',
+ scales=[8, 16, 32],
+ ratios=[0.5, 1.0, 2.0],
+ strides=[4, 8, 16, 32, 64]),
+ bbox_coder: ConfigType = dict(
+ type='DeltaXYWHBBoxCoder',
+ clip_border=True,
+ target_means=(.0, .0, .0, .0),
+ target_stds=(1.0, 1.0, 1.0, 1.0)),
+ reg_decoded_bbox: bool = False,
+ loss_cls: ConfigType = dict(
+ type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
+ loss_bbox: ConfigType = dict(
+ type='SmoothL1Loss', beta=1.0 / 9.0, loss_weight=1.0),
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ init_cfg: OptMultiConfig = dict(
+ type='Normal', layer='Conv2d', std=0.01)
+ ) -> None:
+ super().__init__(init_cfg=init_cfg)
+ self.in_channels = in_channels
+ self.num_classes = num_classes
+ self.feat_channels = feat_channels
+ self.use_sigmoid_cls = loss_cls.get('use_sigmoid', False)
+ if self.use_sigmoid_cls:
+ self.cls_out_channels = num_classes
+ else:
+ self.cls_out_channels = num_classes + 1
+
+ if self.cls_out_channels <= 0:
+ raise ValueError(f'num_classes={num_classes} is too small')
+ self.reg_decoded_bbox = reg_decoded_bbox
+
+ self.bbox_coder = TASK_UTILS.build(bbox_coder)
+ self.loss_cls = MODELS.build(loss_cls)
+ self.loss_bbox = MODELS.build(loss_bbox)
+ self.train_cfg = train_cfg
+ self.test_cfg = test_cfg
+ if self.train_cfg:
+ self.assigner = TASK_UTILS.build(self.train_cfg['assigner'])
+ if train_cfg.get('sampler', None) is not None:
+ self.sampler = TASK_UTILS.build(
+ self.train_cfg['sampler'], default_args=dict(context=self))
+ else:
+ self.sampler = PseudoSampler(context=self)
+
+ self.fp16_enabled = False
+
+ self.prior_generator = TASK_UTILS.build(anchor_generator)
+
+ # Usually the numbers of anchors for each level are the same
+ # except SSD detectors. So it is an int in the most dense
+ # heads but a list of int in SSDHead
+ self.num_base_priors = self.prior_generator.num_base_priors[0]
+ self._init_layers()
+
+ @property
+ def num_anchors(self) -> int:
+ warnings.warn('DeprecationWarning: `num_anchors` is deprecated, '
+ 'for consistency or also use '
+ '`num_base_priors` instead')
+ return self.prior_generator.num_base_priors[0]
+
+ @property
+ def anchor_generator(self) -> AnchorGenerator:
+ warnings.warn('DeprecationWarning: anchor_generator is deprecated, '
+ 'please use "prior_generator" instead')
+ return self.prior_generator
+
+ def _init_layers(self) -> None:
+ """Initialize layers of the head."""
+ self.conv_cls = nn.Conv2d(self.in_channels,
+ self.num_base_priors * self.cls_out_channels,
+ 1)
+ reg_dim = self.bbox_coder.encode_size
+ self.conv_reg = nn.Conv2d(self.in_channels,
+ self.num_base_priors * reg_dim, 1)
+
+ def forward_single(self, x: Tensor) -> Tuple[Tensor, Tensor]:
+ """Forward feature of a single scale level.
+
+ Args:
+ x (Tensor): Features of a single scale level.
+
+ Returns:
+ tuple:
+ cls_score (Tensor): Cls scores for a single scale level \
+ the channels number is num_base_priors * num_classes.
+ bbox_pred (Tensor): Box energies / deltas for a single scale \
+ level, the channels number is num_base_priors * 4.
+ """
+ cls_score = self.conv_cls(x)
+ bbox_pred = self.conv_reg(x)
+ return cls_score, bbox_pred
+
+ def forward(self, x: Tuple[Tensor]) -> Tuple[List[Tensor]]:
+ """Forward features from the upstream network.
+
+ Args:
+ x (tuple[Tensor]): Features from the upstream network, each is
+ a 4D-tensor.
+
+ Returns:
+ tuple: A tuple of classification scores and bbox prediction.
+
+ - cls_scores (list[Tensor]): Classification scores for all \
+ scale levels, each is a 4D-tensor, the channels number \
+ is num_base_priors * num_classes.
+ - bbox_preds (list[Tensor]): Box energies / deltas for all \
+ scale levels, each is a 4D-tensor, the channels number \
+ is num_base_priors * 4.
+ """
+ return multi_apply(self.forward_single, x)
+
+ def get_anchors(self,
+ featmap_sizes: List[tuple],
+ batch_img_metas: List[dict],
+ device: Union[torch.device, str] = 'cuda') \
+ -> Tuple[List[List[Tensor]], List[List[Tensor]]]:
+ """Get anchors according to feature map sizes.
+
+ Args:
+ featmap_sizes (list[tuple]): Multi-level feature map sizes.
+ batch_img_metas (list[dict]): Image meta info.
+ device (torch.device | str): Device for returned tensors.
+ Defaults to cuda.
+
+ Returns:
+ tuple:
+
+ - anchor_list (list[list[Tensor]]): Anchors of each image.
+ - valid_flag_list (list[list[Tensor]]): Valid flags of each
+ image.
+ """
+ num_imgs = len(batch_img_metas)
+
+ # since feature map sizes of all images are the same, we only compute
+ # anchors for one time
+ multi_level_anchors = self.prior_generator.grid_priors(
+ featmap_sizes, device=device)
+ anchor_list = [multi_level_anchors for _ in range(num_imgs)]
+
+ # for each image, we compute valid flags of multi level anchors
+ valid_flag_list = []
+ for img_id, img_meta in enumerate(batch_img_metas):
+ multi_level_flags = self.prior_generator.valid_flags(
+ featmap_sizes, img_meta['pad_shape'], device)
+ valid_flag_list.append(multi_level_flags)
+
+ return anchor_list, valid_flag_list
+
+ def _get_targets_single(self,
+ flat_anchors: Union[Tensor, BaseBoxes],
+ valid_flags: Tensor,
+ gt_instances: InstanceData,
+ img_meta: dict,
+ gt_instances_ignore: Optional[InstanceData] = None,
+ unmap_outputs: bool = True) -> tuple:
+ """Compute regression and classification targets for anchors in a
+ single image.
+
+ Args:
+ flat_anchors (Tensor or :obj:`BaseBoxes`): Multi-level anchors
+ of the image, which are concatenated into a single tensor
+ or box type of shape (num_anchors, 4)
+ valid_flags (Tensor): Multi level valid flags of the image,
+ which are concatenated into a single tensor of
+ shape (num_anchors, ).
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It should includes ``bboxes`` and ``labels``
+ attributes.
+ img_meta (dict): Meta information for current image.
+ gt_instances_ignore (:obj:`InstanceData`, optional): Instances
+ to be ignored during training. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+ unmap_outputs (bool): Whether to map outputs back to the original
+ set of anchors. Defaults to True.
+
+ Returns:
+ tuple:
+
+ - labels (Tensor): Labels of each level.
+ - label_weights (Tensor): Label weights of each level.
+ - bbox_targets (Tensor): BBox targets of each level.
+ - bbox_weights (Tensor): BBox weights of each level.
+ - pos_inds (Tensor): positive samples indexes.
+ - neg_inds (Tensor): negative samples indexes.
+ - sampling_result (:obj:`SamplingResult`): Sampling results.
+ """
+ inside_flags = anchor_inside_flags(flat_anchors, valid_flags,
+ img_meta['img_shape'][:2],
+ self.train_cfg['allowed_border'])
+ if not inside_flags.any():
+ raise ValueError(
+ 'There is no valid anchor inside the image boundary. Please '
+ 'check the image size and anchor sizes, or set '
+ '``allowed_border`` to -1 to skip the condition.')
+ # assign gt and sample anchors
+ anchors = flat_anchors[inside_flags]
+
+ pred_instances = InstanceData(priors=anchors)
+ assign_result = self.assigner.assign(pred_instances, gt_instances,
+ gt_instances_ignore)
+ # No sampling is required except for RPN and
+ # Guided Anchoring algorithms
+ sampling_result = self.sampler.sample(assign_result, pred_instances,
+ gt_instances)
+
+ num_valid_anchors = anchors.shape[0]
+ target_dim = gt_instances.bboxes.size(-1) if self.reg_decoded_bbox \
+ else self.bbox_coder.encode_size
+ bbox_targets = anchors.new_zeros(num_valid_anchors, target_dim)
+ bbox_weights = anchors.new_zeros(num_valid_anchors, target_dim)
+
+ # TODO: Considering saving memory, is it necessary to be long?
+ labels = anchors.new_full((num_valid_anchors, ),
+ self.num_classes,
+ dtype=torch.long)
+ label_weights = anchors.new_zeros(num_valid_anchors, dtype=torch.float)
+
+ pos_inds = sampling_result.pos_inds
+ neg_inds = sampling_result.neg_inds
+ # `bbox_coder.encode` accepts tensor or box type inputs and generates
+ # tensor targets. If regressing decoded boxes, the code will convert
+ # box type `pos_bbox_targets` to tensor.
+ if len(pos_inds) > 0:
+ if not self.reg_decoded_bbox:
+ pos_bbox_targets = self.bbox_coder.encode(
+ sampling_result.pos_priors, sampling_result.pos_gt_bboxes)
+ else:
+ pos_bbox_targets = sampling_result.pos_gt_bboxes
+ pos_bbox_targets = get_box_tensor(pos_bbox_targets)
+ bbox_targets[pos_inds, :] = pos_bbox_targets
+ bbox_weights[pos_inds, :] = 1.0
+
+ labels[pos_inds] = sampling_result.pos_gt_labels
+ if self.train_cfg['pos_weight'] <= 0:
+ label_weights[pos_inds] = 1.0
+ else:
+ label_weights[pos_inds] = self.train_cfg['pos_weight']
+ if len(neg_inds) > 0:
+ label_weights[neg_inds] = 1.0
+
+ # map up to original set of anchors
+ if unmap_outputs:
+ num_total_anchors = flat_anchors.size(0)
+ labels = unmap(
+ labels, num_total_anchors, inside_flags,
+ fill=self.num_classes) # fill bg label
+ label_weights = unmap(label_weights, num_total_anchors,
+ inside_flags)
+ bbox_targets = unmap(bbox_targets, num_total_anchors, inside_flags)
+ bbox_weights = unmap(bbox_weights, num_total_anchors, inside_flags)
+
+ return (labels, label_weights, bbox_targets, bbox_weights, pos_inds,
+ neg_inds, sampling_result)
+
+ def get_targets(self,
+ anchor_list: List[List[Tensor]],
+ valid_flag_list: List[List[Tensor]],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ batch_gt_instances_ignore: OptInstanceList = None,
+ unmap_outputs: bool = True,
+ return_sampling_results: bool = False) -> tuple:
+ """Compute regression and classification targets for anchors in
+ multiple images.
+
+ Args:
+ anchor_list (list[list[Tensor]]): Multi level anchors of each
+ image. The outer list indicates images, and the inner list
+ corresponds to feature levels of the image. Each element of
+ the inner list is a tensor of shape (num_anchors, 4).
+ valid_flag_list (list[list[Tensor]]): Multi level valid flags of
+ each image. The outer list indicates images, and the inner list
+ corresponds to feature levels of the image. Each element of
+ the inner list is a tensor of shape (num_anchors, )
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+ unmap_outputs (bool): Whether to map outputs back to the original
+ set of anchors. Defaults to True.
+ return_sampling_results (bool): Whether to return the sampling
+ results. Defaults to False.
+
+ Returns:
+ tuple: Usually returns a tuple containing learning targets.
+
+ - labels_list (list[Tensor]): Labels of each level.
+ - label_weights_list (list[Tensor]): Label weights of each
+ level.
+ - bbox_targets_list (list[Tensor]): BBox targets of each level.
+ - bbox_weights_list (list[Tensor]): BBox weights of each level.
+ - avg_factor (int): Average factor that is used to average
+ the loss. When using sampling method, avg_factor is usually
+ the sum of positive and negative priors. When using
+ `PseudoSampler`, `avg_factor` is usually equal to the number
+ of positive priors.
+
+ additional_returns: This function enables user-defined returns from
+ `self._get_targets_single`. These returns are currently refined
+ to properties at each feature map (i.e. having HxW dimension).
+ The results will be concatenated after the end
+ """
+ num_imgs = len(batch_img_metas)
+ assert len(anchor_list) == len(valid_flag_list) == num_imgs
+
+ if batch_gt_instances_ignore is None:
+ batch_gt_instances_ignore = [None] * num_imgs
+
+ # anchor number of multi levels
+ num_level_anchors = [anchors.size(0) for anchors in anchor_list[0]]
+ # concat all level anchors to a single tensor
+ concat_anchor_list = []
+ concat_valid_flag_list = []
+ for i in range(num_imgs):
+ assert len(anchor_list[i]) == len(valid_flag_list[i])
+ concat_anchor_list.append(cat_boxes(anchor_list[i]))
+ concat_valid_flag_list.append(torch.cat(valid_flag_list[i]))
+
+ # compute targets for each image
+ results = multi_apply(
+ self._get_targets_single,
+ concat_anchor_list,
+ concat_valid_flag_list,
+ batch_gt_instances,
+ batch_img_metas,
+ batch_gt_instances_ignore,
+ unmap_outputs=unmap_outputs)
+ (all_labels, all_label_weights, all_bbox_targets, all_bbox_weights,
+ pos_inds_list, neg_inds_list, sampling_results_list) = results[:7]
+ rest_results = list(results[7:]) # user-added return values
+ # Get `avg_factor` of all images, which calculate in `SamplingResult`.
+ # When using sampling method, avg_factor is usually the sum of
+ # positive and negative priors. When using `PseudoSampler`,
+ # `avg_factor` is usually equal to the number of positive priors.
+ avg_factor = sum(
+ [results.avg_factor for results in sampling_results_list])
+ # update `_raw_positive_infos`, which will be used when calling
+ # `get_positive_infos`.
+ self._raw_positive_infos.update(sampling_results=sampling_results_list)
+ # split targets to a list w.r.t. multiple levels
+ labels_list = images_to_levels(all_labels, num_level_anchors)
+ label_weights_list = images_to_levels(all_label_weights,
+ num_level_anchors)
+ bbox_targets_list = images_to_levels(all_bbox_targets,
+ num_level_anchors)
+ bbox_weights_list = images_to_levels(all_bbox_weights,
+ num_level_anchors)
+ res = (labels_list, label_weights_list, bbox_targets_list,
+ bbox_weights_list, avg_factor)
+ if return_sampling_results:
+ res = res + (sampling_results_list, )
+ for i, r in enumerate(rest_results): # user-added return values
+ rest_results[i] = images_to_levels(r, num_level_anchors)
+
+ return res + tuple(rest_results)
+
+ def loss_by_feat_single(self, cls_score: Tensor, bbox_pred: Tensor,
+ anchors: Tensor, labels: Tensor,
+ label_weights: Tensor, bbox_targets: Tensor,
+ bbox_weights: Tensor, avg_factor: int) -> tuple:
+ """Calculate the loss of a single scale level based on the features
+ extracted by the detection head.
+
+ Args:
+ cls_score (Tensor): Box scores for each scale level
+ Has shape (N, num_anchors * num_classes, H, W).
+ bbox_pred (Tensor): Box energies / deltas for each scale
+ level with shape (N, num_anchors * 4, H, W).
+ anchors (Tensor): Box reference for each scale level with shape
+ (N, num_total_anchors, 4).
+ labels (Tensor): Labels of each anchors with shape
+ (N, num_total_anchors).
+ label_weights (Tensor): Label weights of each anchor with shape
+ (N, num_total_anchors)
+ bbox_targets (Tensor): BBox regression targets of each anchor
+ weight shape (N, num_total_anchors, 4).
+ bbox_weights (Tensor): BBox regression loss weights of each anchor
+ with shape (N, num_total_anchors, 4).
+ avg_factor (int): Average factor that is used to average the loss.
+
+ Returns:
+ tuple: loss components.
+ """
+ # classification loss
+ labels = labels.reshape(-1)
+ label_weights = label_weights.reshape(-1)
+ cls_score = cls_score.permute(0, 2, 3,
+ 1).reshape(-1, self.cls_out_channels)
+ loss_cls = self.loss_cls(
+ cls_score, labels, label_weights, avg_factor=avg_factor)
+ # regression loss
+ target_dim = bbox_targets.size(-1)
+ bbox_targets = bbox_targets.reshape(-1, target_dim)
+ bbox_weights = bbox_weights.reshape(-1, target_dim)
+ bbox_pred = bbox_pred.permute(0, 2, 3,
+ 1).reshape(-1,
+ self.bbox_coder.encode_size)
+ if self.reg_decoded_bbox:
+ # When the regression loss (e.g. `IouLoss`, `GIouLoss`)
+ # is applied directly on the decoded bounding boxes, it
+ # decodes the already encoded coordinates to absolute format.
+ anchors = anchors.reshape(-1, anchors.size(-1))
+ bbox_pred = self.bbox_coder.decode(anchors, bbox_pred)
+ bbox_pred = get_box_tensor(bbox_pred)
+ loss_bbox = self.loss_bbox(
+ bbox_pred, bbox_targets, bbox_weights, avg_factor=avg_factor)
+ return loss_cls, loss_bbox
+
+ def loss_by_feat(
+ self,
+ cls_scores: List[Tensor],
+ bbox_preds: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ batch_gt_instances_ignore: OptInstanceList = None) -> dict:
+ """Calculate the loss based on the features extracted by the detection
+ head.
+
+ Args:
+ cls_scores (list[Tensor]): Box scores for each scale level
+ has shape (N, num_anchors * num_classes, H, W).
+ bbox_preds (list[Tensor]): Box energies / deltas for each scale
+ level with shape (N, num_anchors * 4, H, W).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ dict: A dictionary of loss components.
+ """
+ featmap_sizes = [featmap.size()[-2:] for featmap in cls_scores]
+ assert len(featmap_sizes) == self.prior_generator.num_levels
+
+ device = cls_scores[0].device
+
+ anchor_list, valid_flag_list = self.get_anchors(
+ featmap_sizes, batch_img_metas, device=device)
+ cls_reg_targets = self.get_targets(
+ anchor_list,
+ valid_flag_list,
+ batch_gt_instances,
+ batch_img_metas,
+ batch_gt_instances_ignore=batch_gt_instances_ignore)
+ (labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,
+ avg_factor) = cls_reg_targets
+
+ # anchor number of multi levels
+ num_level_anchors = [anchors.size(0) for anchors in anchor_list[0]]
+ # concat all level anchors and flags to a single tensor
+ concat_anchor_list = []
+ for i in range(len(anchor_list)):
+ concat_anchor_list.append(cat_boxes(anchor_list[i]))
+ all_anchor_list = images_to_levels(concat_anchor_list,
+ num_level_anchors)
+
+ losses_cls, losses_bbox = multi_apply(
+ self.loss_by_feat_single,
+ cls_scores,
+ bbox_preds,
+ all_anchor_list,
+ labels_list,
+ label_weights_list,
+ bbox_targets_list,
+ bbox_weights_list,
+ avg_factor=avg_factor)
+ return dict(loss_cls=losses_cls, loss_bbox=losses_bbox)
diff --git a/mmdet/models/dense_heads/atss_head.py b/mmdet/models/dense_heads/atss_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..d4129a54a9e370a5b1d901040ca4f35dff06d486
--- /dev/null
+++ b/mmdet/models/dense_heads/atss_head.py
@@ -0,0 +1,524 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Optional, Sequence, Tuple
+
+import torch
+import torch.nn as nn
+from mmcv.cnn import ConvModule, Scale
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.utils import (ConfigType, InstanceList, MultiConfig, OptConfigType,
+ OptInstanceList, reduce_mean)
+from ..task_modules.prior_generators import anchor_inside_flags
+from ..utils import images_to_levels, multi_apply, unmap
+from .anchor_head import AnchorHead
+
+
+@MODELS.register_module()
+class ATSSHead(AnchorHead):
+ """Detection Head of `ATSS `_.
+
+ ATSS head structure is similar with FCOS, however ATSS use anchor boxes
+ and assign label by Adaptive Training Sample Selection instead max-iou.
+
+ Args:
+ num_classes (int): Number of categories excluding the background
+ category.
+ in_channels (int): Number of channels in the input feature map.
+ pred_kernel_size (int): Kernel size of ``nn.Conv2d``
+ stacked_convs (int): Number of stacking convs of the head.
+ conv_cfg (:obj:`ConfigDict` or dict, optional): Config dict for
+ convolution layer. Defaults to None.
+ norm_cfg (:obj:`ConfigDict` or dict): Config dict for normalization
+ layer. Defaults to ``dict(type='GN', num_groups=32,
+ requires_grad=True)``.
+ reg_decoded_bbox (bool): If true, the regression loss would be
+ applied directly on decoded bounding boxes, converting both
+ the predicted boxes and regression targets to absolute
+ coordinates format. Defaults to False. It should be `True` when
+ using `IoULoss`, `GIoULoss`, or `DIoULoss` in the bbox head.
+ loss_centerness (:obj:`ConfigDict` or dict): Config of centerness loss.
+ Defaults to ``dict(type='CrossEntropyLoss', use_sigmoid=True,
+ loss_weight=1.0)``.
+ init_cfg (:obj:`ConfigDict` or dict or list[dict] or
+ list[:obj:`ConfigDict`]): Initialization config dict.
+ """
+
+ def __init__(self,
+ num_classes: int,
+ in_channels: int,
+ pred_kernel_size: int = 3,
+ stacked_convs: int = 4,
+ conv_cfg: OptConfigType = None,
+ norm_cfg: ConfigType = dict(
+ type='GN', num_groups=32, requires_grad=True),
+ reg_decoded_bbox: bool = True,
+ loss_centerness: ConfigType = dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=True,
+ loss_weight=1.0),
+ init_cfg: MultiConfig = dict(
+ type='Normal',
+ layer='Conv2d',
+ std=0.01,
+ override=dict(
+ type='Normal',
+ name='atss_cls',
+ std=0.01,
+ bias_prob=0.01)),
+ **kwargs) -> None:
+ self.pred_kernel_size = pred_kernel_size
+ self.stacked_convs = stacked_convs
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ super().__init__(
+ num_classes=num_classes,
+ in_channels=in_channels,
+ reg_decoded_bbox=reg_decoded_bbox,
+ init_cfg=init_cfg,
+ **kwargs)
+
+ self.sampling = False
+ self.loss_centerness = MODELS.build(loss_centerness)
+
+ def _init_layers(self) -> None:
+ """Initialize layers of the head."""
+ self.relu = nn.ReLU(inplace=True)
+ self.cls_convs = nn.ModuleList()
+ self.reg_convs = nn.ModuleList()
+ for i in range(self.stacked_convs):
+ chn = self.in_channels if i == 0 else self.feat_channels
+ self.cls_convs.append(
+ ConvModule(
+ chn,
+ self.feat_channels,
+ 3,
+ stride=1,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg))
+ self.reg_convs.append(
+ ConvModule(
+ chn,
+ self.feat_channels,
+ 3,
+ stride=1,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg))
+ pred_pad_size = self.pred_kernel_size // 2
+ self.atss_cls = nn.Conv2d(
+ self.feat_channels,
+ self.num_anchors * self.cls_out_channels,
+ self.pred_kernel_size,
+ padding=pred_pad_size)
+ self.atss_reg = nn.Conv2d(
+ self.feat_channels,
+ self.num_base_priors * 4,
+ self.pred_kernel_size,
+ padding=pred_pad_size)
+ self.atss_centerness = nn.Conv2d(
+ self.feat_channels,
+ self.num_base_priors * 1,
+ self.pred_kernel_size,
+ padding=pred_pad_size)
+ self.scales = nn.ModuleList(
+ [Scale(1.0) for _ in self.prior_generator.strides])
+
+ def forward(self, x: Tuple[Tensor]) -> Tuple[List[Tensor]]:
+ """Forward features from the upstream network.
+
+ Args:
+ x (tuple[Tensor]): Features from the upstream network, each is
+ a 4D-tensor.
+
+ Returns:
+ tuple: Usually a tuple of classification scores and bbox prediction
+ cls_scores (list[Tensor]): Classification scores for all scale
+ levels, each is a 4D-tensor, the channels number is
+ num_anchors * num_classes.
+ bbox_preds (list[Tensor]): Box energies / deltas for all scale
+ levels, each is a 4D-tensor, the channels number is
+ num_anchors * 4.
+ """
+ return multi_apply(self.forward_single, x, self.scales)
+
+ def forward_single(self, x: Tensor, scale: Scale) -> Sequence[Tensor]:
+ """Forward feature of a single scale level.
+
+ Args:
+ x (Tensor): Features of a single scale level.
+ scale (:obj: `mmcv.cnn.Scale`): Learnable scale module to resize
+ the bbox prediction.
+
+ Returns:
+ tuple:
+ cls_score (Tensor): Cls scores for a single scale level
+ the channels number is num_anchors * num_classes.
+ bbox_pred (Tensor): Box energies / deltas for a single scale
+ level, the channels number is num_anchors * 4.
+ centerness (Tensor): Centerness for a single scale level, the
+ channel number is (N, num_anchors * 1, H, W).
+ """
+ cls_feat = x
+ reg_feat = x
+ for cls_conv in self.cls_convs:
+ cls_feat = cls_conv(cls_feat)
+ for reg_conv in self.reg_convs:
+ reg_feat = reg_conv(reg_feat)
+ cls_score = self.atss_cls(cls_feat)
+ # we just follow atss, not apply exp in bbox_pred
+ bbox_pred = scale(self.atss_reg(reg_feat)).float()
+ centerness = self.atss_centerness(reg_feat)
+ return cls_score, bbox_pred, centerness
+
+ def loss_by_feat_single(self, anchors: Tensor, cls_score: Tensor,
+ bbox_pred: Tensor, centerness: Tensor,
+ labels: Tensor, label_weights: Tensor,
+ bbox_targets: Tensor, avg_factor: float) -> dict:
+ """Calculate the loss of a single scale level based on the features
+ extracted by the detection head.
+
+ Args:
+ cls_score (Tensor): Box scores for each scale level
+ Has shape (N, num_anchors * num_classes, H, W).
+ bbox_pred (Tensor): Box energies / deltas for each scale
+ level with shape (N, num_anchors * 4, H, W).
+ anchors (Tensor): Box reference for each scale level with shape
+ (N, num_total_anchors, 4).
+ labels (Tensor): Labels of each anchors with shape
+ (N, num_total_anchors).
+ label_weights (Tensor): Label weights of each anchor with shape
+ (N, num_total_anchors)
+ bbox_targets (Tensor): BBox regression targets of each anchor
+ weight shape (N, num_total_anchors, 4).
+ avg_factor (float): Average factor that is used to average
+ the loss. When using sampling method, avg_factor is usually
+ the sum of positive and negative priors. When using
+ `PseudoSampler`, `avg_factor` is usually equal to the number
+ of positive priors.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components.
+ """
+
+ anchors = anchors.reshape(-1, 4)
+ cls_score = cls_score.permute(0, 2, 3, 1).reshape(
+ -1, self.cls_out_channels).contiguous()
+ bbox_pred = bbox_pred.permute(0, 2, 3, 1).reshape(-1, 4)
+ centerness = centerness.permute(0, 2, 3, 1).reshape(-1)
+ bbox_targets = bbox_targets.reshape(-1, 4)
+ labels = labels.reshape(-1)
+ label_weights = label_weights.reshape(-1)
+
+ # classification loss
+ loss_cls = self.loss_cls(
+ cls_score, labels, label_weights, avg_factor=avg_factor)
+
+ # FG cat_id: [0, num_classes -1], BG cat_id: num_classes
+ bg_class_ind = self.num_classes
+ pos_inds = ((labels >= 0)
+ & (labels < bg_class_ind)).nonzero().squeeze(1)
+
+ if len(pos_inds) > 0:
+ pos_bbox_targets = bbox_targets[pos_inds]
+ pos_bbox_pred = bbox_pred[pos_inds]
+ pos_anchors = anchors[pos_inds]
+ pos_centerness = centerness[pos_inds]
+
+ centerness_targets = self.centerness_target(
+ pos_anchors, pos_bbox_targets)
+ pos_decode_bbox_pred = self.bbox_coder.decode(
+ pos_anchors, pos_bbox_pred)
+
+ # regression loss
+ loss_bbox = self.loss_bbox(
+ pos_decode_bbox_pred,
+ pos_bbox_targets,
+ weight=centerness_targets,
+ avg_factor=1.0)
+
+ # centerness loss
+ loss_centerness = self.loss_centerness(
+ pos_centerness, centerness_targets, avg_factor=avg_factor)
+
+ else:
+ loss_bbox = bbox_pred.sum() * 0
+ loss_centerness = centerness.sum() * 0
+ centerness_targets = bbox_targets.new_tensor(0.)
+
+ return loss_cls, loss_bbox, loss_centerness, centerness_targets.sum()
+
+ def loss_by_feat(
+ self,
+ cls_scores: List[Tensor],
+ bbox_preds: List[Tensor],
+ centernesses: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ batch_gt_instances_ignore: OptInstanceList = None) -> dict:
+ """Calculate the loss based on the features extracted by the detection
+ head.
+
+ Args:
+ cls_scores (list[Tensor]): Box scores for each scale level
+ Has shape (N, num_anchors * num_classes, H, W)
+ bbox_preds (list[Tensor]): Box energies / deltas for each scale
+ level with shape (N, num_anchors * 4, H, W)
+ centernesses (list[Tensor]): Centerness for each scale
+ level with shape (N, num_anchors * 1, H, W)
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], Optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components.
+ """
+ featmap_sizes = [featmap.size()[-2:] for featmap in cls_scores]
+ assert len(featmap_sizes) == self.prior_generator.num_levels
+
+ device = cls_scores[0].device
+ anchor_list, valid_flag_list = self.get_anchors(
+ featmap_sizes, batch_img_metas, device=device)
+
+ cls_reg_targets = self.get_targets(
+ anchor_list,
+ valid_flag_list,
+ batch_gt_instances,
+ batch_img_metas,
+ batch_gt_instances_ignore=batch_gt_instances_ignore)
+
+ (anchor_list, labels_list, label_weights_list, bbox_targets_list,
+ bbox_weights_list, avg_factor) = cls_reg_targets
+ avg_factor = reduce_mean(
+ torch.tensor(avg_factor, dtype=torch.float, device=device)).item()
+
+ losses_cls, losses_bbox, loss_centerness, \
+ bbox_avg_factor = multi_apply(
+ self.loss_by_feat_single,
+ anchor_list,
+ cls_scores,
+ bbox_preds,
+ centernesses,
+ labels_list,
+ label_weights_list,
+ bbox_targets_list,
+ avg_factor=avg_factor)
+
+ bbox_avg_factor = sum(bbox_avg_factor)
+ bbox_avg_factor = reduce_mean(bbox_avg_factor).clamp_(min=1).item()
+ losses_bbox = list(map(lambda x: x / bbox_avg_factor, losses_bbox))
+ return dict(
+ loss_cls=losses_cls,
+ loss_bbox=losses_bbox,
+ loss_centerness=loss_centerness)
+
+ def centerness_target(self, anchors: Tensor, gts: Tensor) -> Tensor:
+ """Calculate the centerness between anchors and gts.
+
+ Only calculate pos centerness targets, otherwise there may be nan.
+
+ Args:
+ anchors (Tensor): Anchors with shape (N, 4), "xyxy" format.
+ gts (Tensor): Ground truth bboxes with shape (N, 4), "xyxy" format.
+
+ Returns:
+ Tensor: Centerness between anchors and gts.
+ """
+ anchors_cx = (anchors[:, 2] + anchors[:, 0]) / 2
+ anchors_cy = (anchors[:, 3] + anchors[:, 1]) / 2
+ l_ = anchors_cx - gts[:, 0]
+ t_ = anchors_cy - gts[:, 1]
+ r_ = gts[:, 2] - anchors_cx
+ b_ = gts[:, 3] - anchors_cy
+
+ left_right = torch.stack([l_, r_], dim=1)
+ top_bottom = torch.stack([t_, b_], dim=1)
+ centerness = torch.sqrt(
+ (left_right.min(dim=-1)[0] / left_right.max(dim=-1)[0]) *
+ (top_bottom.min(dim=-1)[0] / top_bottom.max(dim=-1)[0]))
+ assert not torch.isnan(centerness).any()
+ return centerness
+
+ def get_targets(self,
+ anchor_list: List[List[Tensor]],
+ valid_flag_list: List[List[Tensor]],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ batch_gt_instances_ignore: OptInstanceList = None,
+ unmap_outputs: bool = True) -> tuple:
+ """Get targets for ATSS head.
+
+ This method is almost the same as `AnchorHead.get_targets()`. Besides
+ returning the targets as the parent method does, it also returns the
+ anchors as the first element of the returned tuple.
+ """
+ num_imgs = len(batch_img_metas)
+ assert len(anchor_list) == len(valid_flag_list) == num_imgs
+
+ # anchor number of multi levels
+ num_level_anchors = [anchors.size(0) for anchors in anchor_list[0]]
+ num_level_anchors_list = [num_level_anchors] * num_imgs
+
+ # concat all level anchors and flags to a single tensor
+ for i in range(num_imgs):
+ assert len(anchor_list[i]) == len(valid_flag_list[i])
+ anchor_list[i] = torch.cat(anchor_list[i])
+ valid_flag_list[i] = torch.cat(valid_flag_list[i])
+
+ # compute targets for each image
+ if batch_gt_instances_ignore is None:
+ batch_gt_instances_ignore = [None] * num_imgs
+ (all_anchors, all_labels, all_label_weights, all_bbox_targets,
+ all_bbox_weights, pos_inds_list, neg_inds_list,
+ sampling_results_list) = multi_apply(
+ self._get_targets_single,
+ anchor_list,
+ valid_flag_list,
+ num_level_anchors_list,
+ batch_gt_instances,
+ batch_img_metas,
+ batch_gt_instances_ignore,
+ unmap_outputs=unmap_outputs)
+ # Get `avg_factor` of all images, which calculate in `SamplingResult`.
+ # When using sampling method, avg_factor is usually the sum of
+ # positive and negative priors. When using `PseudoSampler`,
+ # `avg_factor` is usually equal to the number of positive priors.
+ avg_factor = sum(
+ [results.avg_factor for results in sampling_results_list])
+ # split targets to a list w.r.t. multiple levels
+ anchors_list = images_to_levels(all_anchors, num_level_anchors)
+ labels_list = images_to_levels(all_labels, num_level_anchors)
+ label_weights_list = images_to_levels(all_label_weights,
+ num_level_anchors)
+ bbox_targets_list = images_to_levels(all_bbox_targets,
+ num_level_anchors)
+ bbox_weights_list = images_to_levels(all_bbox_weights,
+ num_level_anchors)
+ return (anchors_list, labels_list, label_weights_list,
+ bbox_targets_list, bbox_weights_list, avg_factor)
+
+ def _get_targets_single(self,
+ flat_anchors: Tensor,
+ valid_flags: Tensor,
+ num_level_anchors: List[int],
+ gt_instances: InstanceData,
+ img_meta: dict,
+ gt_instances_ignore: Optional[InstanceData] = None,
+ unmap_outputs: bool = True) -> tuple:
+ """Compute regression, classification targets for anchors in a single
+ image.
+
+ Args:
+ flat_anchors (Tensor): Multi-level anchors of the image, which are
+ concatenated into a single tensor of shape (num_anchors ,4)
+ valid_flags (Tensor): Multi level valid flags of the image,
+ which are concatenated into a single tensor of
+ shape (num_anchors,).
+ num_level_anchors (List[int]): Number of anchors of each scale
+ level.
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ img_meta (dict): Meta information for current image.
+ gt_instances_ignore (:obj:`InstanceData`, optional): Instances
+ to be ignored during training. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+ unmap_outputs (bool): Whether to map outputs back to the original
+ set of anchors.
+
+ Returns:
+ tuple: N is the number of total anchors in the image.
+ labels (Tensor): Labels of all anchors in the image with shape
+ (N,).
+ label_weights (Tensor): Label weights of all anchor in the
+ image with shape (N,).
+ bbox_targets (Tensor): BBox targets of all anchors in the
+ image with shape (N, 4).
+ bbox_weights (Tensor): BBox weights of all anchors in the
+ image with shape (N, 4)
+ pos_inds (Tensor): Indices of positive anchor with shape
+ (num_pos,).
+ neg_inds (Tensor): Indices of negative anchor with shape
+ (num_neg,).
+ sampling_result (:obj:`SamplingResult`): Sampling results.
+ """
+ inside_flags = anchor_inside_flags(flat_anchors, valid_flags,
+ img_meta['img_shape'][:2],
+ self.train_cfg['allowed_border'])
+ if not inside_flags.any():
+ raise ValueError(
+ 'There is no valid anchor inside the image boundary. Please '
+ 'check the image size and anchor sizes, or set '
+ '``allowed_border`` to -1 to skip the condition.')
+ # assign gt and sample anchors
+ anchors = flat_anchors[inside_flags, :]
+
+ num_level_anchors_inside = self.get_num_level_anchors_inside(
+ num_level_anchors, inside_flags)
+ pred_instances = InstanceData(priors=anchors)
+ assign_result = self.assigner.assign(pred_instances,
+ num_level_anchors_inside,
+ gt_instances, gt_instances_ignore)
+
+ sampling_result = self.sampler.sample(assign_result, pred_instances,
+ gt_instances)
+
+ num_valid_anchors = anchors.shape[0]
+ bbox_targets = torch.zeros_like(anchors)
+ bbox_weights = torch.zeros_like(anchors)
+ labels = anchors.new_full((num_valid_anchors, ),
+ self.num_classes,
+ dtype=torch.long)
+ label_weights = anchors.new_zeros(num_valid_anchors, dtype=torch.float)
+
+ pos_inds = sampling_result.pos_inds
+ neg_inds = sampling_result.neg_inds
+ if len(pos_inds) > 0:
+ if self.reg_decoded_bbox:
+ pos_bbox_targets = sampling_result.pos_gt_bboxes
+ else:
+ pos_bbox_targets = self.bbox_coder.encode(
+ sampling_result.pos_priors, sampling_result.pos_gt_bboxes)
+
+ bbox_targets[pos_inds, :] = pos_bbox_targets
+ bbox_weights[pos_inds, :] = 1.0
+
+ labels[pos_inds] = sampling_result.pos_gt_labels
+ if self.train_cfg['pos_weight'] <= 0:
+ label_weights[pos_inds] = 1.0
+ else:
+ label_weights[pos_inds] = self.train_cfg['pos_weight']
+ if len(neg_inds) > 0:
+ label_weights[neg_inds] = 1.0
+
+ # map up to original set of anchors
+ if unmap_outputs:
+ num_total_anchors = flat_anchors.size(0)
+ anchors = unmap(anchors, num_total_anchors, inside_flags)
+ labels = unmap(
+ labels, num_total_anchors, inside_flags, fill=self.num_classes)
+ label_weights = unmap(label_weights, num_total_anchors,
+ inside_flags)
+ bbox_targets = unmap(bbox_targets, num_total_anchors, inside_flags)
+ bbox_weights = unmap(bbox_weights, num_total_anchors, inside_flags)
+
+ return (anchors, labels, label_weights, bbox_targets, bbox_weights,
+ pos_inds, neg_inds, sampling_result)
+
+ def get_num_level_anchors_inside(self, num_level_anchors, inside_flags):
+ """Get the number of valid anchors in every level."""
+
+ split_inside_flags = torch.split(inside_flags, num_level_anchors)
+ num_level_anchors_inside = [
+ int(flags.sum()) for flags in split_inside_flags
+ ]
+ return num_level_anchors_inside
diff --git a/mmdet/models/dense_heads/autoassign_head.py b/mmdet/models/dense_heads/autoassign_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..a2b30ff0d7d41205f0a92ede7b8eb10a234c5942
--- /dev/null
+++ b/mmdet/models/dense_heads/autoassign_head.py
@@ -0,0 +1,524 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Sequence, Tuple
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import Scale
+from mmengine.model import bias_init_with_prob, normal_init
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.structures.bbox import bbox_overlaps
+from mmdet.utils import InstanceList, OptInstanceList, reduce_mean
+from ..task_modules.prior_generators import MlvlPointGenerator
+from ..utils import levels_to_images, multi_apply
+from .fcos_head import FCOSHead
+
+EPS = 1e-12
+
+
+class CenterPrior(nn.Module):
+ """Center Weighting module to adjust the category-specific prior
+ distributions.
+
+ Args:
+ force_topk (bool): When no point falls into gt_bbox, forcibly
+ select the k points closest to the center to calculate
+ the center prior. Defaults to False.
+ topk (int): The number of points used to calculate the
+ center prior when no point falls in gt_bbox. Only work when
+ force_topk if True. Defaults to 9.
+ num_classes (int): The class number of dataset. Defaults to 80.
+ strides (Sequence[int]): The stride of each input feature map.
+ Defaults to (8, 16, 32, 64, 128).
+ """
+
+ def __init__(
+ self,
+ force_topk: bool = False,
+ topk: int = 9,
+ num_classes: int = 80,
+ strides: Sequence[int] = (8, 16, 32, 64, 128)
+ ) -> None:
+ super().__init__()
+ self.mean = nn.Parameter(torch.zeros(num_classes, 2))
+ self.sigma = nn.Parameter(torch.ones(num_classes, 2))
+ self.strides = strides
+ self.force_topk = force_topk
+ self.topk = topk
+
+ def forward(self, anchor_points_list: List[Tensor],
+ gt_instances: InstanceData,
+ inside_gt_bbox_mask: Tensor) -> Tuple[Tensor, Tensor]:
+ """Get the center prior of each point on the feature map for each
+ instance.
+
+ Args:
+ anchor_points_list (list[Tensor]): list of coordinate
+ of points on feature map. Each with shape
+ (num_points, 2).
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It should includes ``bboxes`` and ``labels``
+ attributes.
+ inside_gt_bbox_mask (Tensor): Tensor of bool type,
+ with shape of (num_points, num_gt), each
+ value is used to mark whether this point falls
+ within a certain gt.
+
+ Returns:
+ tuple[Tensor, Tensor]:
+
+ - center_prior_weights(Tensor): Float tensor with shape of \
+ (num_points, num_gt). Each value represents the center \
+ weighting coefficient.
+ - inside_gt_bbox_mask (Tensor): Tensor of bool type, with shape \
+ of (num_points, num_gt), each value is used to mark whether this \
+ point falls within a certain gt or is the topk nearest points for \
+ a specific gt_bbox.
+ """
+ gt_bboxes = gt_instances.bboxes
+ labels = gt_instances.labels
+
+ inside_gt_bbox_mask = inside_gt_bbox_mask.clone()
+ num_gts = len(labels)
+ num_points = sum([len(item) for item in anchor_points_list])
+ if num_gts == 0:
+ return gt_bboxes.new_zeros(num_points,
+ num_gts), inside_gt_bbox_mask
+ center_prior_list = []
+ for slvl_points, stride in zip(anchor_points_list, self.strides):
+ # slvl_points: points from single level in FPN, has shape (h*w, 2)
+ # single_level_points has shape (h*w, num_gt, 2)
+ single_level_points = slvl_points[:, None, :].expand(
+ (slvl_points.size(0), len(gt_bboxes), 2))
+ gt_center_x = ((gt_bboxes[:, 0] + gt_bboxes[:, 2]) / 2)
+ gt_center_y = ((gt_bboxes[:, 1] + gt_bboxes[:, 3]) / 2)
+ gt_center = torch.stack((gt_center_x, gt_center_y), dim=1)
+ gt_center = gt_center[None]
+ # instance_center has shape (1, num_gt, 2)
+ instance_center = self.mean[labels][None]
+ # instance_sigma has shape (1, num_gt, 2)
+ instance_sigma = self.sigma[labels][None]
+ # distance has shape (num_points, num_gt, 2)
+ distance = (((single_level_points - gt_center) / float(stride) -
+ instance_center)**2)
+ center_prior = torch.exp(-distance /
+ (2 * instance_sigma**2)).prod(dim=-1)
+ center_prior_list.append(center_prior)
+ center_prior_weights = torch.cat(center_prior_list, dim=0)
+
+ if self.force_topk:
+ gt_inds_no_points_inside = torch.nonzero(
+ inside_gt_bbox_mask.sum(0) == 0).reshape(-1)
+ if gt_inds_no_points_inside.numel():
+ topk_center_index = \
+ center_prior_weights[:, gt_inds_no_points_inside].topk(
+ self.topk,
+ dim=0)[1]
+ temp_mask = inside_gt_bbox_mask[:, gt_inds_no_points_inside]
+ inside_gt_bbox_mask[:, gt_inds_no_points_inside] = \
+ torch.scatter(temp_mask,
+ dim=0,
+ index=topk_center_index,
+ src=torch.ones_like(
+ topk_center_index,
+ dtype=torch.bool))
+
+ center_prior_weights[~inside_gt_bbox_mask] = 0
+ return center_prior_weights, inside_gt_bbox_mask
+
+
+@MODELS.register_module()
+class AutoAssignHead(FCOSHead):
+ """AutoAssignHead head used in AutoAssign.
+
+ More details can be found in the `paper
+ `_ .
+
+ Args:
+ force_topk (bool): Used in center prior initialization to
+ handle extremely small gt. Default is False.
+ topk (int): The number of points used to calculate the
+ center prior when no point falls in gt_bbox. Only work when
+ force_topk if True. Defaults to 9.
+ pos_loss_weight (float): The loss weight of positive loss
+ and with default value 0.25.
+ neg_loss_weight (float): The loss weight of negative loss
+ and with default value 0.75.
+ center_loss_weight (float): The loss weight of center prior
+ loss and with default value 0.75.
+ """
+
+ def __init__(self,
+ *args,
+ force_topk: bool = False,
+ topk: int = 9,
+ pos_loss_weight: float = 0.25,
+ neg_loss_weight: float = 0.75,
+ center_loss_weight: float = 0.75,
+ **kwargs) -> None:
+ super().__init__(*args, conv_bias=True, **kwargs)
+ self.center_prior = CenterPrior(
+ force_topk=force_topk,
+ topk=topk,
+ num_classes=self.num_classes,
+ strides=self.strides)
+ self.pos_loss_weight = pos_loss_weight
+ self.neg_loss_weight = neg_loss_weight
+ self.center_loss_weight = center_loss_weight
+ self.prior_generator = MlvlPointGenerator(self.strides, offset=0)
+
+ def init_weights(self) -> None:
+ """Initialize weights of the head.
+
+ In particular, we have special initialization for classified conv's and
+ regression conv's bias
+ """
+
+ super(AutoAssignHead, self).init_weights()
+ bias_cls = bias_init_with_prob(0.02)
+ normal_init(self.conv_cls, std=0.01, bias=bias_cls)
+ normal_init(self.conv_reg, std=0.01, bias=4.0)
+
+ def forward_single(self, x: Tensor, scale: Scale,
+ stride: int) -> Tuple[Tensor, Tensor, Tensor]:
+ """Forward features of a single scale level.
+
+ Args:
+ x (Tensor): FPN feature maps of the specified stride.
+ scale (:obj:`mmcv.cnn.Scale`): Learnable scale module to resize
+ the bbox prediction.
+ stride (int): The corresponding stride for feature maps, only
+ used to normalize the bbox prediction when self.norm_on_bbox
+ is True.
+
+ Returns:
+ tuple[Tensor, Tensor, Tensor]: scores for each class, bbox
+ predictions and centerness predictions of input feature maps.
+ """
+ cls_score, bbox_pred, cls_feat, reg_feat = super(
+ FCOSHead, self).forward_single(x)
+ centerness = self.conv_centerness(reg_feat)
+ # scale the bbox_pred of different level
+ # float to avoid overflow when enabling FP16
+ bbox_pred = scale(bbox_pred).float()
+ # bbox_pred needed for gradient computation has been modified
+ # by F.relu(bbox_pred) when run with PyTorch 1.10. So replace
+ # F.relu(bbox_pred) with bbox_pred.clamp(min=0)
+ bbox_pred = bbox_pred.clamp(min=0)
+ bbox_pred *= stride
+ return cls_score, bbox_pred, centerness
+
+ def get_pos_loss_single(self, cls_score: Tensor, objectness: Tensor,
+ reg_loss: Tensor, gt_instances: InstanceData,
+ center_prior_weights: Tensor) -> Tuple[Tensor]:
+ """Calculate the positive loss of all points in gt_bboxes.
+
+ Args:
+ cls_score (Tensor): All category scores for each point on
+ the feature map. The shape is (num_points, num_class).
+ objectness (Tensor): Foreground probability of all points,
+ has shape (num_points, 1).
+ reg_loss (Tensor): The regression loss of each gt_bbox and each
+ prediction box, has shape of (num_points, num_gt).
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It should includes ``bboxes`` and ``labels``
+ attributes.
+ center_prior_weights (Tensor): Float tensor with shape
+ of (num_points, num_gt). Each value represents
+ the center weighting coefficient.
+
+ Returns:
+ tuple[Tensor]:
+
+ - pos_loss (Tensor): The positive loss of all points in the \
+ gt_bboxes.
+ """
+ gt_labels = gt_instances.labels
+ # p_loc: localization confidence
+ p_loc = torch.exp(-reg_loss)
+ # p_cls: classification confidence
+ p_cls = (cls_score * objectness)[:, gt_labels]
+ # p_pos: joint confidence indicator
+ p_pos = p_cls * p_loc
+
+ # 3 is a hyper-parameter to control the contributions of high and
+ # low confidence locations towards positive losses.
+ confidence_weight = torch.exp(p_pos * 3)
+ p_pos_weight = (confidence_weight * center_prior_weights) / (
+ (confidence_weight * center_prior_weights).sum(
+ 0, keepdim=True)).clamp(min=EPS)
+ reweighted_p_pos = (p_pos * p_pos_weight).sum(0)
+ pos_loss = F.binary_cross_entropy(
+ reweighted_p_pos,
+ torch.ones_like(reweighted_p_pos),
+ reduction='none')
+ pos_loss = pos_loss.sum() * self.pos_loss_weight
+ return pos_loss,
+
+ def get_neg_loss_single(self, cls_score: Tensor, objectness: Tensor,
+ gt_instances: InstanceData, ious: Tensor,
+ inside_gt_bbox_mask: Tensor) -> Tuple[Tensor]:
+ """Calculate the negative loss of all points in feature map.
+
+ Args:
+ cls_score (Tensor): All category scores for each point on
+ the feature map. The shape is (num_points, num_class).
+ objectness (Tensor): Foreground probability of all points
+ and is shape of (num_points, 1).
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It should includes ``bboxes`` and ``labels``
+ attributes.
+ ious (Tensor): Float tensor with shape of (num_points, num_gt).
+ Each value represent the iou of pred_bbox and gt_bboxes.
+ inside_gt_bbox_mask (Tensor): Tensor of bool type,
+ with shape of (num_points, num_gt), each
+ value is used to mark whether this point falls
+ within a certain gt.
+
+ Returns:
+ tuple[Tensor]:
+
+ - neg_loss (Tensor): The negative loss of all points in the \
+ feature map.
+ """
+ gt_labels = gt_instances.labels
+ num_gts = len(gt_labels)
+ joint_conf = (cls_score * objectness)
+ p_neg_weight = torch.ones_like(joint_conf)
+ if num_gts > 0:
+ # the order of dinmension would affect the value of
+ # p_neg_weight, we strictly follow the original
+ # implementation.
+ inside_gt_bbox_mask = inside_gt_bbox_mask.permute(1, 0)
+ ious = ious.permute(1, 0)
+
+ foreground_idxs = torch.nonzero(inside_gt_bbox_mask, as_tuple=True)
+ temp_weight = (1 / (1 - ious[foreground_idxs]).clamp_(EPS))
+
+ def normalize(x):
+ return (x - x.min() + EPS) / (x.max() - x.min() + EPS)
+
+ for instance_idx in range(num_gts):
+ idxs = foreground_idxs[0] == instance_idx
+ if idxs.any():
+ temp_weight[idxs] = normalize(temp_weight[idxs])
+
+ p_neg_weight[foreground_idxs[1],
+ gt_labels[foreground_idxs[0]]] = 1 - temp_weight
+
+ logits = (joint_conf * p_neg_weight)
+ neg_loss = (
+ logits**2 * F.binary_cross_entropy(
+ logits, torch.zeros_like(logits), reduction='none'))
+ neg_loss = neg_loss.sum() * self.neg_loss_weight
+ return neg_loss,
+
+ def loss_by_feat(
+ self,
+ cls_scores: List[Tensor],
+ bbox_preds: List[Tensor],
+ objectnesses: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ batch_gt_instances_ignore: OptInstanceList = None
+ ) -> Dict[str, Tensor]:
+ """Calculate the loss based on the features extracted by the detection
+ head.
+
+ Args:
+ cls_scores (list[Tensor]): Box scores for each scale level,
+ each is a 4D-tensor, the channel number is
+ num_points * num_classes.
+ bbox_preds (list[Tensor]): Box energies / deltas for each scale
+ level, each is a 4D-tensor, the channel number is
+ num_points * 4.
+ objectnesses (list[Tensor]): objectness for each scale level, each
+ is a 4D-tensor, the channel number is num_points * 1.
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components.
+ """
+
+ assert len(cls_scores) == len(bbox_preds) == len(objectnesses)
+ all_num_gt = sum([len(item) for item in batch_gt_instances])
+ featmap_sizes = [featmap.size()[-2:] for featmap in cls_scores]
+ all_level_points = self.prior_generator.grid_priors(
+ featmap_sizes,
+ dtype=bbox_preds[0].dtype,
+ device=bbox_preds[0].device)
+ inside_gt_bbox_mask_list, bbox_targets_list = self.get_targets(
+ all_level_points, batch_gt_instances)
+
+ center_prior_weight_list = []
+ temp_inside_gt_bbox_mask_list = []
+ for gt_instances, inside_gt_bbox_mask in zip(batch_gt_instances,
+ inside_gt_bbox_mask_list):
+ center_prior_weight, inside_gt_bbox_mask = \
+ self.center_prior(all_level_points, gt_instances,
+ inside_gt_bbox_mask)
+ center_prior_weight_list.append(center_prior_weight)
+ temp_inside_gt_bbox_mask_list.append(inside_gt_bbox_mask)
+ inside_gt_bbox_mask_list = temp_inside_gt_bbox_mask_list
+ mlvl_points = torch.cat(all_level_points, dim=0)
+ bbox_preds = levels_to_images(bbox_preds)
+ cls_scores = levels_to_images(cls_scores)
+ objectnesses = levels_to_images(objectnesses)
+
+ reg_loss_list = []
+ ious_list = []
+ num_points = len(mlvl_points)
+
+ for bbox_pred, encoded_targets, inside_gt_bbox_mask in zip(
+ bbox_preds, bbox_targets_list, inside_gt_bbox_mask_list):
+ temp_num_gt = encoded_targets.size(1)
+ expand_mlvl_points = mlvl_points[:, None, :].expand(
+ num_points, temp_num_gt, 2).reshape(-1, 2)
+ encoded_targets = encoded_targets.reshape(-1, 4)
+ expand_bbox_pred = bbox_pred[:, None, :].expand(
+ num_points, temp_num_gt, 4).reshape(-1, 4)
+ decoded_bbox_preds = self.bbox_coder.decode(
+ expand_mlvl_points, expand_bbox_pred)
+ decoded_target_preds = self.bbox_coder.decode(
+ expand_mlvl_points, encoded_targets)
+ with torch.no_grad():
+ ious = bbox_overlaps(
+ decoded_bbox_preds, decoded_target_preds, is_aligned=True)
+ ious = ious.reshape(num_points, temp_num_gt)
+ if temp_num_gt:
+ ious = ious.max(
+ dim=-1, keepdim=True).values.repeat(1, temp_num_gt)
+ else:
+ ious = ious.new_zeros(num_points, temp_num_gt)
+ ious[~inside_gt_bbox_mask] = 0
+ ious_list.append(ious)
+ loss_bbox = self.loss_bbox(
+ decoded_bbox_preds,
+ decoded_target_preds,
+ weight=None,
+ reduction_override='none')
+ reg_loss_list.append(loss_bbox.reshape(num_points, temp_num_gt))
+
+ cls_scores = [item.sigmoid() for item in cls_scores]
+ objectnesses = [item.sigmoid() for item in objectnesses]
+ pos_loss_list, = multi_apply(self.get_pos_loss_single, cls_scores,
+ objectnesses, reg_loss_list,
+ batch_gt_instances,
+ center_prior_weight_list)
+ pos_avg_factor = reduce_mean(
+ bbox_pred.new_tensor(all_num_gt)).clamp_(min=1)
+ pos_loss = sum(pos_loss_list) / pos_avg_factor
+
+ neg_loss_list, = multi_apply(self.get_neg_loss_single, cls_scores,
+ objectnesses, batch_gt_instances,
+ ious_list, inside_gt_bbox_mask_list)
+ neg_avg_factor = sum(item.data.sum()
+ for item in center_prior_weight_list)
+ neg_avg_factor = reduce_mean(neg_avg_factor).clamp_(min=1)
+ neg_loss = sum(neg_loss_list) / neg_avg_factor
+
+ center_loss = []
+ for i in range(len(batch_img_metas)):
+
+ if inside_gt_bbox_mask_list[i].any():
+ center_loss.append(
+ len(batch_gt_instances[i]) /
+ center_prior_weight_list[i].sum().clamp_(min=EPS))
+ # when width or height of gt_bbox is smaller than stride of p3
+ else:
+ center_loss.append(center_prior_weight_list[i].sum() * 0)
+
+ center_loss = torch.stack(center_loss).mean() * self.center_loss_weight
+
+ # avoid dead lock in DDP
+ if all_num_gt == 0:
+ pos_loss = bbox_preds[0].sum() * 0
+ dummy_center_prior_loss = self.center_prior.mean.sum(
+ ) * 0 + self.center_prior.sigma.sum() * 0
+ center_loss = objectnesses[0].sum() * 0 + dummy_center_prior_loss
+
+ loss = dict(
+ loss_pos=pos_loss, loss_neg=neg_loss, loss_center=center_loss)
+
+ return loss
+
+ def get_targets(
+ self, points: List[Tensor], batch_gt_instances: InstanceList
+ ) -> Tuple[List[Tensor], List[Tensor]]:
+ """Compute regression targets and each point inside or outside gt_bbox
+ in multiple images.
+
+ Args:
+ points (list[Tensor]): Points of all fpn level, each has shape
+ (num_points, 2).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+
+ Returns:
+ tuple(list[Tensor], list[Tensor]):
+
+ - inside_gt_bbox_mask_list (list[Tensor]): Each Tensor is with \
+ bool type and shape of (num_points, num_gt), each value is used \
+ to mark whether this point falls within a certain gt.
+ - concat_lvl_bbox_targets (list[Tensor]): BBox targets of each \
+ level. Each tensor has shape (num_points, num_gt, 4).
+ """
+
+ concat_points = torch.cat(points, dim=0)
+ # the number of points per img, per lvl
+ inside_gt_bbox_mask_list, bbox_targets_list = multi_apply(
+ self._get_targets_single, batch_gt_instances, points=concat_points)
+ return inside_gt_bbox_mask_list, bbox_targets_list
+
+ def _get_targets_single(self, gt_instances: InstanceData,
+ points: Tensor) -> Tuple[Tensor, Tensor]:
+ """Compute regression targets and each point inside or outside gt_bbox
+ for a single image.
+
+ Args:
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It should includes ``bboxes`` and ``labels``
+ attributes.
+ points (Tensor): Points of all fpn level, has shape
+ (num_points, 2).
+
+ Returns:
+ tuple[Tensor, Tensor]: Containing the following Tensors:
+
+ - inside_gt_bbox_mask (Tensor): Bool tensor with shape \
+ (num_points, num_gt), each value is used to mark whether this \
+ point falls within a certain gt.
+ - bbox_targets (Tensor): BBox targets of each points with each \
+ gt_bboxes, has shape (num_points, num_gt, 4).
+ """
+ gt_bboxes = gt_instances.bboxes
+ num_points = points.size(0)
+ num_gts = gt_bboxes.size(0)
+ gt_bboxes = gt_bboxes[None].expand(num_points, num_gts, 4)
+ xs, ys = points[:, 0], points[:, 1]
+ xs = xs[:, None]
+ ys = ys[:, None]
+ left = xs - gt_bboxes[..., 0]
+ right = gt_bboxes[..., 2] - xs
+ top = ys - gt_bboxes[..., 1]
+ bottom = gt_bboxes[..., 3] - ys
+ bbox_targets = torch.stack((left, top, right, bottom), -1)
+ if num_gts:
+ inside_gt_bbox_mask = bbox_targets.min(-1)[0] > 0
+ else:
+ inside_gt_bbox_mask = bbox_targets.new_zeros((num_points, num_gts),
+ dtype=torch.bool)
+
+ return inside_gt_bbox_mask, bbox_targets
diff --git a/mmdet/models/dense_heads/base_dense_head.py b/mmdet/models/dense_heads/base_dense_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..02a397c62f9154d10fa5ae254b75a76f041e348d
--- /dev/null
+++ b/mmdet/models/dense_heads/base_dense_head.py
@@ -0,0 +1,577 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+from abc import ABCMeta, abstractmethod
+from inspect import signature
+from typing import List, Optional, Tuple
+
+import torch
+from mmcv.ops import batched_nms
+from mmengine.config import ConfigDict
+from mmengine.model import BaseModule, constant_init
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmdet.structures import SampleList
+from mmdet.structures.bbox import (cat_boxes, get_box_tensor, get_box_wh,
+ scale_boxes)
+from mmdet.utils import InstanceList, OptMultiConfig
+from ..test_time_augs import merge_aug_results
+from ..utils import (filter_scores_and_topk, select_single_mlvl,
+ unpack_gt_instances)
+
+
+class BaseDenseHead(BaseModule, metaclass=ABCMeta):
+ """Base class for DenseHeads.
+
+ 1. The ``init_weights`` method is used to initialize densehead's
+ model parameters. After detector initialization, ``init_weights``
+ is triggered when ``detector.init_weights()`` is called externally.
+
+ 2. The ``loss`` method is used to calculate the loss of densehead,
+ which includes two steps: (1) the densehead model performs forward
+ propagation to obtain the feature maps (2) The ``loss_by_feat`` method
+ is called based on the feature maps to calculate the loss.
+
+ .. code:: text
+
+ loss(): forward() -> loss_by_feat()
+
+ 3. The ``predict`` method is used to predict detection results,
+ which includes two steps: (1) the densehead model performs forward
+ propagation to obtain the feature maps (2) The ``predict_by_feat`` method
+ is called based on the feature maps to predict detection results including
+ post-processing.
+
+ .. code:: text
+
+ predict(): forward() -> predict_by_feat()
+
+ 4. The ``loss_and_predict`` method is used to return loss and detection
+ results at the same time. It will call densehead's ``forward``,
+ ``loss_by_feat`` and ``predict_by_feat`` methods in order. If one-stage is
+ used as RPN, the densehead needs to return both losses and predictions.
+ This predictions is used as the proposal of roihead.
+
+ .. code:: text
+
+ loss_and_predict(): forward() -> loss_by_feat() -> predict_by_feat()
+ """
+
+ def __init__(self, init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(init_cfg=init_cfg)
+ # `_raw_positive_infos` will be used in `get_positive_infos`, which
+ # can get positive information.
+ self._raw_positive_infos = dict()
+
+ def init_weights(self) -> None:
+ """Initialize the weights."""
+ super().init_weights()
+ # avoid init_cfg overwrite the initialization of `conv_offset`
+ for m in self.modules():
+ # DeformConv2dPack, ModulatedDeformConv2dPack
+ if hasattr(m, 'conv_offset'):
+ constant_init(m.conv_offset, 0)
+
+ def get_positive_infos(self) -> InstanceList:
+ """Get positive information from sampling results.
+
+ Returns:
+ list[:obj:`InstanceData`]: Positive information of each image,
+ usually including positive bboxes, positive labels, positive
+ priors, etc.
+ """
+ if len(self._raw_positive_infos) == 0:
+ return None
+
+ sampling_results = self._raw_positive_infos.get(
+ 'sampling_results', None)
+ assert sampling_results is not None
+ positive_infos = []
+ for sampling_result in enumerate(sampling_results):
+ pos_info = InstanceData()
+ pos_info.bboxes = sampling_result.pos_gt_bboxes
+ pos_info.labels = sampling_result.pos_gt_labels
+ pos_info.priors = sampling_result.pos_priors
+ pos_info.pos_assigned_gt_inds = \
+ sampling_result.pos_assigned_gt_inds
+ pos_info.pos_inds = sampling_result.pos_inds
+ positive_infos.append(pos_info)
+ return positive_infos
+
+ def loss(self, x: Tuple[Tensor], batch_data_samples: SampleList) -> dict:
+ """Perform forward propagation and loss calculation of the detection
+ head on the features of the upstream network.
+
+ Args:
+ x (tuple[Tensor]): Features from the upstream network, each is
+ a 4D-tensor.
+ batch_data_samples (List[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+
+ Returns:
+ dict: A dictionary of loss components.
+ """
+ outs = self(x)
+
+ outputs = unpack_gt_instances(batch_data_samples)
+ (batch_gt_instances, batch_gt_instances_ignore,
+ batch_img_metas) = outputs
+
+ loss_inputs = outs + (batch_gt_instances, batch_img_metas,
+ batch_gt_instances_ignore)
+ losses = self.loss_by_feat(*loss_inputs)
+ return losses
+
+ @abstractmethod
+ def loss_by_feat(self, **kwargs) -> dict:
+ """Calculate the loss based on the features extracted by the detection
+ head."""
+ pass
+
+ def loss_and_predict(
+ self,
+ x: Tuple[Tensor],
+ batch_data_samples: SampleList,
+ proposal_cfg: Optional[ConfigDict] = None
+ ) -> Tuple[dict, InstanceList]:
+ """Perform forward propagation of the head, then calculate loss and
+ predictions from the features and data samples.
+
+ Args:
+ x (tuple[Tensor]): Features from FPN.
+ batch_data_samples (list[:obj:`DetDataSample`]): Each item contains
+ the meta information of each image and corresponding
+ annotations.
+ proposal_cfg (ConfigDict, optional): Test / postprocessing
+ configuration, if None, test_cfg would be used.
+ Defaults to None.
+
+ Returns:
+ tuple: the return value is a tuple contains:
+
+ - losses: (dict[str, Tensor]): A dictionary of loss components.
+ - predictions (list[:obj:`InstanceData`]): Detection
+ results of each image after the post process.
+ """
+ outputs = unpack_gt_instances(batch_data_samples)
+ (batch_gt_instances, batch_gt_instances_ignore,
+ batch_img_metas) = outputs
+
+ outs = self(x)
+
+ loss_inputs = outs + (batch_gt_instances, batch_img_metas,
+ batch_gt_instances_ignore)
+ losses = self.loss_by_feat(*loss_inputs)
+
+ predictions = self.predict_by_feat(
+ *outs, batch_img_metas=batch_img_metas, cfg=proposal_cfg)
+ return losses, predictions
+
+ def predict(self,
+ x: Tuple[Tensor],
+ batch_data_samples: SampleList,
+ rescale: bool = False) -> InstanceList:
+ """Perform forward propagation of the detection head and predict
+ detection results on the features of the upstream network.
+
+ Args:
+ x (tuple[Tensor]): Multi-level features from the
+ upstream network, each is a 4D-tensor.
+ batch_data_samples (List[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ rescale (bool, optional): Whether to rescale the results.
+ Defaults to False.
+
+ Returns:
+ list[obj:`InstanceData`]: Detection results of each image
+ after the post process.
+ """
+ batch_img_metas = [
+ data_samples.metainfo for data_samples in batch_data_samples
+ ]
+
+ outs = self(x)
+
+ predictions = self.predict_by_feat(
+ *outs, batch_img_metas=batch_img_metas, rescale=rescale)
+ return predictions
+
+ def predict_by_feat(self,
+ cls_scores: List[Tensor],
+ bbox_preds: List[Tensor],
+ score_factors: Optional[List[Tensor]] = None,
+ batch_img_metas: Optional[List[dict]] = None,
+ cfg: Optional[ConfigDict] = None,
+ rescale: bool = False,
+ with_nms: bool = True) -> InstanceList:
+ """Transform a batch of output features extracted from the head into
+ bbox results.
+
+ Note: When score_factors is not None, the cls_scores are
+ usually multiplied by it then obtain the real score used in NMS,
+ such as CenterNess in FCOS, IoU branch in ATSS.
+
+ Args:
+ cls_scores (list[Tensor]): Classification scores for all
+ scale levels, each is a 4D-tensor, has shape
+ (batch_size, num_priors * num_classes, H, W).
+ bbox_preds (list[Tensor]): Box energies / deltas for all
+ scale levels, each is a 4D-tensor, has shape
+ (batch_size, num_priors * 4, H, W).
+ score_factors (list[Tensor], optional): Score factor for
+ all scale level, each is a 4D-tensor, has shape
+ (batch_size, num_priors * 1, H, W). Defaults to None.
+ batch_img_metas (list[dict], Optional): Batch image meta info.
+ Defaults to None.
+ cfg (ConfigDict, optional): Test / postprocessing
+ configuration, if None, test_cfg would be used.
+ Defaults to None.
+ rescale (bool): If True, return boxes in original image space.
+ Defaults to False.
+ with_nms (bool): If True, do nms before return boxes.
+ Defaults to True.
+
+ Returns:
+ list[:obj:`InstanceData`]: Object detection results of each image
+ after the post process. Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ """
+ assert len(cls_scores) == len(bbox_preds)
+
+ if score_factors is None:
+ # e.g. Retina, FreeAnchor, Foveabox, etc.
+ with_score_factors = False
+ else:
+ # e.g. FCOS, PAA, ATSS, AutoAssign, etc.
+ with_score_factors = True
+ assert len(cls_scores) == len(score_factors)
+
+ num_levels = len(cls_scores)
+
+ featmap_sizes = [cls_scores[i].shape[-2:] for i in range(num_levels)]
+ mlvl_priors = self.prior_generator.grid_priors(
+ featmap_sizes,
+ dtype=cls_scores[0].dtype,
+ device=cls_scores[0].device)
+
+ result_list = []
+
+ for img_id in range(len(batch_img_metas)):
+ img_meta = batch_img_metas[img_id]
+ cls_score_list = select_single_mlvl(
+ cls_scores, img_id, detach=True)
+ bbox_pred_list = select_single_mlvl(
+ bbox_preds, img_id, detach=True)
+ if with_score_factors:
+ score_factor_list = select_single_mlvl(
+ score_factors, img_id, detach=True)
+ else:
+ score_factor_list = [None for _ in range(num_levels)]
+
+ results = self._predict_by_feat_single(
+ cls_score_list=cls_score_list,
+ bbox_pred_list=bbox_pred_list,
+ score_factor_list=score_factor_list,
+ mlvl_priors=mlvl_priors,
+ img_meta=img_meta,
+ cfg=cfg,
+ rescale=rescale,
+ with_nms=with_nms)
+ result_list.append(results)
+ return result_list
+
+ def _predict_by_feat_single(self,
+ cls_score_list: List[Tensor],
+ bbox_pred_list: List[Tensor],
+ score_factor_list: List[Tensor],
+ mlvl_priors: List[Tensor],
+ img_meta: dict,
+ cfg: ConfigDict,
+ rescale: bool = False,
+ with_nms: bool = True) -> InstanceData:
+ """Transform a single image's features extracted from the head into
+ bbox results.
+
+ Args:
+ cls_score_list (list[Tensor]): Box scores from all scale
+ levels of a single image, each item has shape
+ (num_priors * num_classes, H, W).
+ bbox_pred_list (list[Tensor]): Box energies / deltas from
+ all scale levels of a single image, each item has shape
+ (num_priors * 4, H, W).
+ score_factor_list (list[Tensor]): Score factor from all scale
+ levels of a single image, each item has shape
+ (num_priors * 1, H, W).
+ mlvl_priors (list[Tensor]): Each element in the list is
+ the priors of a single level in feature pyramid. In all
+ anchor-based methods, it has shape (num_priors, 4). In
+ all anchor-free methods, it has shape (num_priors, 2)
+ when `with_stride=True`, otherwise it still has shape
+ (num_priors, 4).
+ img_meta (dict): Image meta info.
+ cfg (mmengine.Config): Test / postprocessing configuration,
+ if None, test_cfg would be used.
+ rescale (bool): If True, return boxes in original image space.
+ Defaults to False.
+ with_nms (bool): If True, do nms before return boxes.
+ Defaults to True.
+
+ Returns:
+ :obj:`InstanceData`: Detection results of each image
+ after the post process.
+ Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ """
+ if score_factor_list[0] is None:
+ # e.g. Retina, FreeAnchor, etc.
+ with_score_factors = False
+ else:
+ # e.g. FCOS, PAA, ATSS, etc.
+ with_score_factors = True
+
+ cfg = self.test_cfg if cfg is None else cfg
+ cfg = copy.deepcopy(cfg)
+ img_shape = img_meta['img_shape']
+ nms_pre = cfg.get('nms_pre', -1)
+
+ mlvl_bbox_preds = []
+ mlvl_valid_priors = []
+ mlvl_scores = []
+ mlvl_labels = []
+ if with_score_factors:
+ mlvl_score_factors = []
+ else:
+ mlvl_score_factors = None
+ for level_idx, (cls_score, bbox_pred, score_factor, priors) in \
+ enumerate(zip(cls_score_list, bbox_pred_list,
+ score_factor_list, mlvl_priors)):
+
+ assert cls_score.size()[-2:] == bbox_pred.size()[-2:]
+
+ dim = self.bbox_coder.encode_size
+ bbox_pred = bbox_pred.permute(1, 2, 0).reshape(-1, dim)
+ if with_score_factors:
+ score_factor = score_factor.permute(1, 2,
+ 0).reshape(-1).sigmoid()
+ cls_score = cls_score.permute(1, 2,
+ 0).reshape(-1, self.cls_out_channels)
+ if self.use_sigmoid_cls:
+ scores = cls_score.sigmoid()
+ else:
+ # remind that we set FG labels to [0, num_class-1]
+ # since mmdet v2.0
+ # BG cat_id: num_class
+ scores = cls_score.softmax(-1)[:, :-1]
+
+ # After https://github.com/open-mmlab/mmdetection/pull/6268/,
+ # this operation keeps fewer bboxes under the same `nms_pre`.
+ # There is no difference in performance for most models. If you
+ # find a slight drop in performance, you can set a larger
+ # `nms_pre` than before.
+ score_thr = cfg.get('score_thr', 0)
+
+ results = filter_scores_and_topk(
+ scores, score_thr, nms_pre,
+ dict(bbox_pred=bbox_pred, priors=priors))
+ scores, labels, keep_idxs, filtered_results = results
+
+ bbox_pred = filtered_results['bbox_pred']
+ priors = filtered_results['priors']
+
+ if with_score_factors:
+ score_factor = score_factor[keep_idxs]
+
+ mlvl_bbox_preds.append(bbox_pred)
+ mlvl_valid_priors.append(priors)
+ mlvl_scores.append(scores)
+ mlvl_labels.append(labels)
+
+ if with_score_factors:
+ mlvl_score_factors.append(score_factor)
+
+ bbox_pred = torch.cat(mlvl_bbox_preds)
+ priors = cat_boxes(mlvl_valid_priors)
+ bboxes = self.bbox_coder.decode(priors, bbox_pred, max_shape=img_shape)
+
+ results = InstanceData()
+ results.bboxes = bboxes
+ results.scores = torch.cat(mlvl_scores)
+ results.labels = torch.cat(mlvl_labels)
+ if with_score_factors:
+ results.score_factors = torch.cat(mlvl_score_factors)
+
+ return self._bbox_post_process(
+ results=results,
+ cfg=cfg,
+ rescale=rescale,
+ with_nms=with_nms,
+ img_meta=img_meta)
+
+ def _bbox_post_process(self,
+ results: InstanceData,
+ cfg: ConfigDict,
+ rescale: bool = False,
+ with_nms: bool = True,
+ img_meta: Optional[dict] = None) -> InstanceData:
+ """bbox post-processing method.
+
+ The boxes would be rescaled to the original image scale and do
+ the nms operation. Usually `with_nms` is False is used for aug test.
+
+ Args:
+ results (:obj:`InstaceData`): Detection instance results,
+ each item has shape (num_bboxes, ).
+ cfg (ConfigDict): Test / postprocessing configuration,
+ if None, test_cfg would be used.
+ rescale (bool): If True, return boxes in original image space.
+ Default to False.
+ with_nms (bool): If True, do nms before return boxes.
+ Default to True.
+ img_meta (dict, optional): Image meta info. Defaults to None.
+
+ Returns:
+ :obj:`InstanceData`: Detection results of each image
+ after the post process.
+ Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ """
+ if rescale:
+ assert img_meta.get('scale_factor') is not None
+ scale_factor = [1 / s for s in img_meta['scale_factor']]
+ results.bboxes = scale_boxes(results.bboxes, scale_factor)
+
+ if hasattr(results, 'score_factors'):
+ # TODO: Add sqrt operation in order to be consistent with
+ # the paper.
+ score_factors = results.pop('score_factors')
+ results.scores = results.scores * score_factors
+
+ # filter small size bboxes
+ if cfg.get('min_bbox_size', -1) >= 0:
+ w, h = get_box_wh(results.bboxes)
+ valid_mask = (w > cfg.min_bbox_size) & (h > cfg.min_bbox_size)
+ if not valid_mask.all():
+ results = results[valid_mask]
+
+ # TODO: deal with `with_nms` and `nms_cfg=None` in test_cfg
+ if with_nms and results.bboxes.numel() > 0:
+ bboxes = get_box_tensor(results.bboxes)
+ det_bboxes, keep_idxs = batched_nms(bboxes, results.scores,
+ results.labels, cfg.nms)
+ results = results[keep_idxs]
+ # some nms would reweight the score, such as softnms
+ results.scores = det_bboxes[:, -1]
+ results = results[:cfg.max_per_img]
+
+ return results
+
+ def aug_test(self,
+ aug_batch_feats,
+ aug_batch_img_metas,
+ rescale=False,
+ with_ori_nms=False,
+ **kwargs):
+ """Test function with test time augmentation.
+
+ Args:
+ aug_batch_feats (list[tuple[Tensor]]): The outer list
+ indicates test-time augmentations and inner tuple
+ indicate the multi-level feats from
+ FPN, each Tensor should have a shape (B, C, H, W),
+ aug_batch_img_metas (list[list[dict]]): Meta information
+ of images under the different test-time augs
+ (multiscale, flip, etc.). The outer list indicate
+ the
+ rescale (bool, optional): Whether to rescale the results.
+ Defaults to False.
+ with_ori_nms (bool): Whether execute the nms in original head.
+ Defaults to False. It will be `True` when the head is
+ adopted as `rpn_head`.
+
+ Returns:
+ list(obj:`InstanceData`): Detection results of the
+ input images. Each item usually contains\
+ following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance,)
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances,).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ """
+ # TODO: remove this for detr and deformdetr
+ sig_of_get_results = signature(self.get_results)
+ get_results_args = [
+ p.name for p in sig_of_get_results.parameters.values()
+ ]
+ get_results_single_sig = signature(self._get_results_single)
+ get_results_single_sig_args = [
+ p.name for p in get_results_single_sig.parameters.values()
+ ]
+ assert ('with_nms' in get_results_args) and \
+ ('with_nms' in get_results_single_sig_args), \
+ f'{self.__class__.__name__}' \
+ 'does not support test-time augmentation '
+
+ num_imgs = len(aug_batch_img_metas[0])
+ aug_batch_results = []
+ for x, img_metas in zip(aug_batch_feats, aug_batch_img_metas):
+ outs = self.forward(x)
+ batch_instance_results = self.get_results(
+ *outs,
+ img_metas=img_metas,
+ cfg=self.test_cfg,
+ rescale=False,
+ with_nms=with_ori_nms,
+ **kwargs)
+ aug_batch_results.append(batch_instance_results)
+
+ # after merging, bboxes will be rescaled to the original image
+ batch_results = merge_aug_results(aug_batch_results,
+ aug_batch_img_metas)
+
+ final_results = []
+ for img_id in range(num_imgs):
+ results = batch_results[img_id]
+ det_bboxes, keep_idxs = batched_nms(results.bboxes, results.scores,
+ results.labels,
+ self.test_cfg.nms)
+ results = results[keep_idxs]
+ # some nms operation may reweight the score such as softnms
+ results.scores = det_bboxes[:, -1]
+ results = results[:self.test_cfg.max_per_img]
+ if rescale:
+ # all results have been mapped to the original scale
+ # in `merge_aug_results`, so just pass
+ pass
+ else:
+ # map to the first aug image scale
+ scale_factor = results.bboxes.new_tensor(
+ aug_batch_img_metas[0][img_id]['scale_factor'])
+ results.bboxes = \
+ results.bboxes * scale_factor
+
+ final_results.append(results)
+
+ return final_results
diff --git a/mmdet/models/dense_heads/base_mask_head.py b/mmdet/models/dense_heads/base_mask_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..7183d782829aa15bf12b9e2f7ade999c84d0593f
--- /dev/null
+++ b/mmdet/models/dense_heads/base_mask_head.py
@@ -0,0 +1,128 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from abc import ABCMeta, abstractmethod
+from typing import List, Tuple, Union
+
+from mmengine.model import BaseModule
+from torch import Tensor
+
+from mmdet.structures import SampleList
+from mmdet.utils import InstanceList, OptInstanceList, OptMultiConfig
+from ..utils import unpack_gt_instances
+
+
+class BaseMaskHead(BaseModule, metaclass=ABCMeta):
+ """Base class for mask heads used in One-Stage Instance Segmentation."""
+
+ def __init__(self, init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(init_cfg=init_cfg)
+
+ @abstractmethod
+ def loss_by_feat(self, *args, **kwargs):
+ """Calculate the loss based on the features extracted by the mask
+ head."""
+ pass
+
+ @abstractmethod
+ def predict_by_feat(self, *args, **kwargs):
+ """Transform a batch of output features extracted from the head into
+ mask results."""
+ pass
+
+ def loss(self,
+ x: Union[List[Tensor], Tuple[Tensor]],
+ batch_data_samples: SampleList,
+ positive_infos: OptInstanceList = None,
+ **kwargs) -> dict:
+ """Perform forward propagation and loss calculation of the mask head on
+ the features of the upstream network.
+
+ Args:
+ x (list[Tensor] | tuple[Tensor]): Features from FPN.
+ Each has a shape (B, C, H, W).
+ batch_data_samples (list[:obj:`DetDataSample`]): Each item contains
+ the meta information of each image and corresponding
+ annotations.
+ positive_infos (list[:obj:`InstanceData`], optional): Information
+ of positive samples. Used when the label assignment is
+ done outside the MaskHead, e.g., BboxHead in
+ YOLACT or CondInst, etc. When the label assignment is done in
+ MaskHead, it would be None, like SOLO or SOLOv2. All values
+ in it should have shape (num_positive_samples, *).
+
+
+ Returns:
+ dict: A dictionary of loss components.
+ """
+ if positive_infos is None:
+ outs = self(x)
+ else:
+ outs = self(x, positive_infos)
+
+ assert isinstance(outs, tuple), 'Forward results should be a tuple, ' \
+ 'even if only one item is returned'
+
+ outputs = unpack_gt_instances(batch_data_samples)
+ batch_gt_instances, batch_gt_instances_ignore, batch_img_metas \
+ = outputs
+ for gt_instances, img_metas in zip(batch_gt_instances,
+ batch_img_metas):
+ img_shape = img_metas['batch_input_shape']
+ gt_masks = gt_instances.masks.pad(img_shape)
+ gt_instances.masks = gt_masks
+
+ losses = self.loss_by_feat(
+ *outs,
+ batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas,
+ positive_infos=positive_infos,
+ batch_gt_instances_ignore=batch_gt_instances_ignore,
+ **kwargs)
+ return losses
+
+ def predict(self,
+ x: Tuple[Tensor],
+ batch_data_samples: SampleList,
+ rescale: bool = False,
+ results_list: OptInstanceList = None,
+ **kwargs) -> InstanceList:
+ """Test function without test-time augmentation.
+
+ Args:
+ x (tuple[Tensor]): Multi-level features from the
+ upstream network, each is a 4D-tensor.
+ batch_data_samples (List[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ rescale (bool, optional): Whether to rescale the results.
+ Defaults to False.
+ results_list (list[obj:`InstanceData`], optional): Detection
+ results of each image after the post process. Only exist
+ if there is a `bbox_head`, like `YOLACT`, `CondInst`, etc.
+
+ Returns:
+ list[obj:`InstanceData`]: Instance segmentation
+ results of each image after the post process.
+ Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance,)
+ - labels (Tensor): Has a shape (num_instances,).
+ - masks (Tensor): Processed mask results, has a
+ shape (num_instances, h, w).
+ """
+ batch_img_metas = [
+ data_samples.metainfo for data_samples in batch_data_samples
+ ]
+ if results_list is None:
+ outs = self(x)
+ else:
+ outs = self(x, results_list)
+
+ results_list = self.predict_by_feat(
+ *outs,
+ batch_img_metas=batch_img_metas,
+ rescale=rescale,
+ results_list=results_list,
+ **kwargs)
+
+ return results_list
diff --git a/mmdet/models/dense_heads/boxinst_head.py b/mmdet/models/dense_heads/boxinst_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..7d6e8f7777a852cad89b709e59af2d8e12b343a6
--- /dev/null
+++ b/mmdet/models/dense_heads/boxinst_head.py
@@ -0,0 +1,252 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List
+
+import torch
+import torch.nn.functional as F
+from mmengine import MessageHub
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.utils import InstanceList
+from ..utils.misc import unfold_wo_center
+from .condinst_head import CondInstBboxHead, CondInstMaskHead
+
+
+@MODELS.register_module()
+class BoxInstBboxHead(CondInstBboxHead):
+ """BoxInst box head used in https://arxiv.org/abs/2012.02310."""
+
+ def __init__(self, *args, **kwargs) -> None:
+ super().__init__(*args, **kwargs)
+
+
+@MODELS.register_module()
+class BoxInstMaskHead(CondInstMaskHead):
+ """BoxInst mask head used in https://arxiv.org/abs/2012.02310.
+
+ This head outputs the mask for BoxInst.
+
+ Args:
+ pairwise_size (dict): The size of neighborhood for each pixel.
+ Defaults to 3.
+ pairwise_dilation (int): The dilation of neighborhood for each pixel.
+ Defaults to 2.
+ warmup_iters (int): Warmup iterations for pair-wise loss.
+ Defaults to 10000.
+ """
+
+ def __init__(self,
+ *arg,
+ pairwise_size: int = 3,
+ pairwise_dilation: int = 2,
+ warmup_iters: int = 10000,
+ **kwargs) -> None:
+ self.pairwise_size = pairwise_size
+ self.pairwise_dilation = pairwise_dilation
+ self.warmup_iters = warmup_iters
+ super().__init__(*arg, **kwargs)
+
+ def get_pairwise_affinity(self, mask_logits: Tensor) -> Tensor:
+ """Compute the pairwise affinity for each pixel."""
+ log_fg_prob = F.logsigmoid(mask_logits).unsqueeze(1)
+ log_bg_prob = F.logsigmoid(-mask_logits).unsqueeze(1)
+
+ log_fg_prob_unfold = unfold_wo_center(
+ log_fg_prob,
+ kernel_size=self.pairwise_size,
+ dilation=self.pairwise_dilation)
+ log_bg_prob_unfold = unfold_wo_center(
+ log_bg_prob,
+ kernel_size=self.pairwise_size,
+ dilation=self.pairwise_dilation)
+
+ # the probability of making the same prediction:
+ # p_i * p_j + (1 - p_i) * (1 - p_j)
+ # we compute the the probability in log space
+ # to avoid numerical instability
+ log_same_fg_prob = log_fg_prob[:, :, None] + log_fg_prob_unfold
+ log_same_bg_prob = log_bg_prob[:, :, None] + log_bg_prob_unfold
+
+ # TODO: Figure out the difference between it and directly sum
+ max_ = torch.max(log_same_fg_prob, log_same_bg_prob)
+ log_same_prob = torch.log(
+ torch.exp(log_same_fg_prob - max_) +
+ torch.exp(log_same_bg_prob - max_)) + max_
+
+ return -log_same_prob[:, 0]
+
+ def loss_by_feat(self, mask_preds: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict], positive_infos: InstanceList,
+ **kwargs) -> dict:
+ """Calculate the loss based on the features extracted by the mask head.
+
+ Args:
+ mask_preds (list[Tensor]): List of predicted masks, each has
+ shape (num_classes, H, W).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes``, ``masks``,
+ and ``labels`` attributes.
+ batch_img_metas (list[dict]): Meta information of multiple images.
+ positive_infos (List[:obj:``InstanceData``]): Information of
+ positive samples of each image that are assigned in detection
+ head.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components.
+ """
+ assert positive_infos is not None, \
+ 'positive_infos should not be None in `BoxInstMaskHead`'
+ losses = dict()
+
+ loss_mask_project = 0.
+ loss_mask_pairwise = 0.
+ num_imgs = len(mask_preds)
+ total_pos = 0.
+ avg_fatcor = 0.
+
+ for idx in range(num_imgs):
+ (mask_pred, pos_mask_targets, pos_pairwise_masks, num_pos) = \
+ self._get_targets_single(
+ mask_preds[idx], batch_gt_instances[idx],
+ positive_infos[idx])
+ # mask loss
+ total_pos += num_pos
+ if num_pos == 0 or pos_mask_targets is None:
+ loss_project = mask_pred.new_zeros(1).mean()
+ loss_pairwise = mask_pred.new_zeros(1).mean()
+ avg_fatcor += 0.
+ else:
+ # compute the project term
+ loss_project_x = self.loss_mask(
+ mask_pred.max(dim=1, keepdim=True)[0],
+ pos_mask_targets.max(dim=1, keepdim=True)[0],
+ reduction_override='none').sum()
+ loss_project_y = self.loss_mask(
+ mask_pred.max(dim=2, keepdim=True)[0],
+ pos_mask_targets.max(dim=2, keepdim=True)[0],
+ reduction_override='none').sum()
+ loss_project = loss_project_x + loss_project_y
+ # compute the pairwise term
+ pairwise_affinity = self.get_pairwise_affinity(mask_pred)
+ avg_fatcor += pos_pairwise_masks.sum().clamp(min=1.0)
+ loss_pairwise = (pairwise_affinity * pos_pairwise_masks).sum()
+
+ loss_mask_project += loss_project
+ loss_mask_pairwise += loss_pairwise
+
+ if total_pos == 0:
+ total_pos += 1 # avoid nan
+ if avg_fatcor == 0:
+ avg_fatcor += 1 # avoid nan
+ loss_mask_project = loss_mask_project / total_pos
+ loss_mask_pairwise = loss_mask_pairwise / avg_fatcor
+ message_hub = MessageHub.get_current_instance()
+ iter = message_hub.get_info('iter')
+ warmup_factor = min(iter / float(self.warmup_iters), 1.0)
+ loss_mask_pairwise *= warmup_factor
+
+ losses.update(
+ loss_mask_project=loss_mask_project,
+ loss_mask_pairwise=loss_mask_pairwise)
+ return losses
+
+ def _get_targets_single(self, mask_preds: Tensor,
+ gt_instances: InstanceData,
+ positive_info: InstanceData):
+ """Compute targets for predictions of single image.
+
+ Args:
+ mask_preds (Tensor): Predicted prototypes with shape
+ (num_classes, H, W).
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It should includes ``bboxes``, ``labels``,
+ and ``masks`` attributes.
+ positive_info (:obj:`InstanceData`): Information of positive
+ samples that are assigned in detection head. It usually
+ contains following keys.
+
+ - pos_assigned_gt_inds (Tensor): Assigner GT indexes of
+ positive proposals, has shape (num_pos, )
+ - pos_inds (Tensor): Positive index of image, has
+ shape (num_pos, ).
+ - param_pred (Tensor): Positive param preditions
+ with shape (num_pos, num_params).
+
+ Returns:
+ tuple: Usually returns a tuple containing learning targets.
+
+ - mask_preds (Tensor): Positive predicted mask with shape
+ (num_pos, mask_h, mask_w).
+ - pos_mask_targets (Tensor): Positive mask targets with shape
+ (num_pos, mask_h, mask_w).
+ - pos_pairwise_masks (Tensor): Positive pairwise masks with
+ shape: (num_pos, num_neighborhood, mask_h, mask_w).
+ - num_pos (int): Positive numbers.
+ """
+ gt_bboxes = gt_instances.bboxes
+ device = gt_bboxes.device
+ # Note that gt_masks are generated by full box
+ # from BoxInstDataPreprocessor
+ gt_masks = gt_instances.masks.to_tensor(
+ dtype=torch.bool, device=device).float()
+ # Note that pairwise_masks are generated by image color similarity
+ # from BoxInstDataPreprocessor
+ pairwise_masks = gt_instances.pairwise_masks
+ pairwise_masks = pairwise_masks.to(device=device)
+
+ # process with mask targets
+ pos_assigned_gt_inds = positive_info.get('pos_assigned_gt_inds')
+ scores = positive_info.get('scores')
+ centernesses = positive_info.get('centernesses')
+ num_pos = pos_assigned_gt_inds.size(0)
+
+ if gt_masks.size(0) == 0 or num_pos == 0:
+ return mask_preds, None, None, 0
+ # Since we're producing (near) full image masks,
+ # it'd take too much vram to backprop on every single mask.
+ # Thus we select only a subset.
+ if (self.max_masks_to_train != -1) and \
+ (num_pos > self.max_masks_to_train):
+ perm = torch.randperm(num_pos)
+ select = perm[:self.max_masks_to_train]
+ mask_preds = mask_preds[select]
+ pos_assigned_gt_inds = pos_assigned_gt_inds[select]
+ num_pos = self.max_masks_to_train
+ elif self.topk_masks_per_img != -1:
+ unique_gt_inds = pos_assigned_gt_inds.unique()
+ num_inst_per_gt = max(
+ int(self.topk_masks_per_img / len(unique_gt_inds)), 1)
+
+ keep_mask_preds = []
+ keep_pos_assigned_gt_inds = []
+ for gt_ind in unique_gt_inds:
+ per_inst_pos_inds = (pos_assigned_gt_inds == gt_ind)
+ mask_preds_per_inst = mask_preds[per_inst_pos_inds]
+ gt_inds_per_inst = pos_assigned_gt_inds[per_inst_pos_inds]
+ if sum(per_inst_pos_inds) > num_inst_per_gt:
+ per_inst_scores = scores[per_inst_pos_inds].sigmoid().max(
+ dim=1)[0]
+ per_inst_centerness = centernesses[
+ per_inst_pos_inds].sigmoid().reshape(-1, )
+ select = (per_inst_scores * per_inst_centerness).topk(
+ k=num_inst_per_gt, dim=0)[1]
+ mask_preds_per_inst = mask_preds_per_inst[select]
+ gt_inds_per_inst = gt_inds_per_inst[select]
+ keep_mask_preds.append(mask_preds_per_inst)
+ keep_pos_assigned_gt_inds.append(gt_inds_per_inst)
+ mask_preds = torch.cat(keep_mask_preds)
+ pos_assigned_gt_inds = torch.cat(keep_pos_assigned_gt_inds)
+ num_pos = pos_assigned_gt_inds.size(0)
+
+ # Follow the origin implement
+ start = int(self.mask_out_stride // 2)
+ gt_masks = gt_masks[:, start::self.mask_out_stride,
+ start::self.mask_out_stride]
+ gt_masks = gt_masks.gt(0.5).float()
+ pos_mask_targets = gt_masks[pos_assigned_gt_inds]
+ pos_pairwise_masks = pairwise_masks[pos_assigned_gt_inds]
+ pos_pairwise_masks = pos_pairwise_masks * pos_mask_targets.unsqueeze(1)
+
+ return (mask_preds, pos_mask_targets, pos_pairwise_masks, num_pos)
diff --git a/mmdet/models/dense_heads/cascade_rpn_head.py b/mmdet/models/dense_heads/cascade_rpn_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..a8686cc2c9118094df34a04fdeabd87daa636707
--- /dev/null
+++ b/mmdet/models/dense_heads/cascade_rpn_head.py
@@ -0,0 +1,1110 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from __future__ import division
+import copy
+from typing import Dict, List, Optional, Tuple, Union
+
+import torch
+import torch.nn as nn
+from mmcv.ops import DeformConv2d
+from mmengine.config import ConfigDict
+from mmengine.model import BaseModule, ModuleList
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmdet.registry import MODELS, TASK_UTILS
+from mmdet.structures import SampleList
+from mmdet.utils import (ConfigType, InstanceList, MultiConfig,
+ OptInstanceList, OptMultiConfig)
+from ..task_modules.assigners import RegionAssigner
+from ..task_modules.samplers import PseudoSampler
+from ..utils import (images_to_levels, multi_apply, select_single_mlvl,
+ unpack_gt_instances)
+from .base_dense_head import BaseDenseHead
+from .rpn_head import RPNHead
+
+
+class AdaptiveConv(BaseModule):
+ """AdaptiveConv used to adapt the sampling location with the anchors.
+
+ Args:
+ in_channels (int): Number of channels in the input image.
+ out_channels (int): Number of channels produced by the convolution.
+ kernel_size (int or tuple[int]): Size of the conv kernel.
+ Defaults to 3.
+ stride (int or tuple[int]): Stride of the convolution. Defaults to 1.
+ padding (int or tuple[int]): Zero-padding added to both sides of
+ the input. Defaults to 1.
+ dilation (int or tuple[int]): Spacing between kernel elements.
+ Defaults to 3.
+ groups (int): Number of blocked connections from input channels to
+ output channels. Defaults to 1.
+ bias (bool): If set True, adds a learnable bias to the output.
+ Defaults to False.
+ adapt_type (str): Type of adaptive conv, can be either ``offset``
+ (arbitrary anchors) or 'dilation' (uniform anchor).
+ Defaults to 'dilation'.
+ init_cfg (:obj:`ConfigDict` or list[:obj:`ConfigDict`] or dict or \
+ list[dict]): Initialization config dict.
+ """
+
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ kernel_size: Union[int, Tuple[int]] = 3,
+ stride: Union[int, Tuple[int]] = 1,
+ padding: Union[int, Tuple[int]] = 1,
+ dilation: Union[int, Tuple[int]] = 3,
+ groups: int = 1,
+ bias: bool = False,
+ adapt_type: str = 'dilation',
+ init_cfg: MultiConfig = dict(
+ type='Normal', std=0.01, override=dict(name='conv'))
+ ) -> None:
+ super().__init__(init_cfg=init_cfg)
+ assert adapt_type in ['offset', 'dilation']
+ self.adapt_type = adapt_type
+
+ assert kernel_size == 3, 'Adaptive conv only supports kernels 3'
+ if self.adapt_type == 'offset':
+ assert stride == 1 and padding == 1 and groups == 1, \
+ 'Adaptive conv offset mode only supports padding: {1}, ' \
+ f'stride: {1}, groups: {1}'
+ self.conv = DeformConv2d(
+ in_channels,
+ out_channels,
+ kernel_size,
+ padding=padding,
+ stride=stride,
+ groups=groups,
+ bias=bias)
+ else:
+ self.conv = nn.Conv2d(
+ in_channels,
+ out_channels,
+ kernel_size,
+ padding=dilation,
+ dilation=dilation)
+
+ def forward(self, x: Tensor, offset: Tensor) -> Tensor:
+ """Forward function."""
+ if self.adapt_type == 'offset':
+ N, _, H, W = x.shape
+ assert offset is not None
+ assert H * W == offset.shape[1]
+ # reshape [N, NA, 18] to (N, 18, H, W)
+ offset = offset.permute(0, 2, 1).reshape(N, -1, H, W)
+ offset = offset.contiguous()
+ x = self.conv(x, offset)
+ else:
+ assert offset is None
+ x = self.conv(x)
+ return x
+
+
+@MODELS.register_module()
+class StageCascadeRPNHead(RPNHead):
+ """Stage of CascadeRPNHead.
+
+ Args:
+ in_channels (int): Number of channels in the input feature map.
+ anchor_generator (:obj:`ConfigDict` or dict): anchor generator config.
+ adapt_cfg (:obj:`ConfigDict` or dict): adaptation config.
+ bridged_feature (bool): whether update rpn feature. Defaults to False.
+ with_cls (bool): whether use classification branch. Defaults to True.
+ init_cfg :obj:`ConfigDict` or list[:obj:`ConfigDict`] or dict or
+ list[dict], optional): Initialization config dict.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ in_channels: int,
+ anchor_generator: ConfigType = dict(
+ type='AnchorGenerator',
+ scales=[8],
+ ratios=[1.0],
+ strides=[4, 8, 16, 32, 64]),
+ adapt_cfg: ConfigType = dict(type='dilation', dilation=3),
+ bridged_feature: bool = False,
+ with_cls: bool = True,
+ init_cfg: OptMultiConfig = None,
+ **kwargs) -> None:
+ self.with_cls = with_cls
+ self.anchor_strides = anchor_generator['strides']
+ self.anchor_scales = anchor_generator['scales']
+ self.bridged_feature = bridged_feature
+ self.adapt_cfg = adapt_cfg
+ super().__init__(
+ in_channels=in_channels,
+ anchor_generator=anchor_generator,
+ init_cfg=init_cfg,
+ **kwargs)
+
+ # override sampling and sampler
+ if self.train_cfg:
+ self.assigner = TASK_UTILS.build(self.train_cfg['assigner'])
+ # use PseudoSampler when sampling is False
+ if self.train_cfg.get('sampler', None) is not None:
+ self.sampler = TASK_UTILS.build(
+ self.train_cfg['sampler'], default_args=dict(context=self))
+ else:
+ self.sampler = PseudoSampler(context=self)
+
+ if init_cfg is None:
+ self.init_cfg = dict(
+ type='Normal', std=0.01, override=[dict(name='rpn_reg')])
+ if self.with_cls:
+ self.init_cfg['override'].append(dict(name='rpn_cls'))
+
+ def _init_layers(self) -> None:
+ """Init layers of a CascadeRPN stage."""
+ adapt_cfg = copy.deepcopy(self.adapt_cfg)
+ adapt_cfg['adapt_type'] = adapt_cfg.pop('type')
+ self.rpn_conv = AdaptiveConv(self.in_channels, self.feat_channels,
+ **adapt_cfg)
+ if self.with_cls:
+ self.rpn_cls = nn.Conv2d(self.feat_channels,
+ self.num_anchors * self.cls_out_channels,
+ 1)
+ self.rpn_reg = nn.Conv2d(self.feat_channels, self.num_anchors * 4, 1)
+ self.relu = nn.ReLU(inplace=True)
+
+ def forward_single(self, x: Tensor, offset: Tensor) -> Tuple[Tensor]:
+ """Forward function of single scale."""
+ bridged_x = x
+ x = self.relu(self.rpn_conv(x, offset))
+ if self.bridged_feature:
+ bridged_x = x # update feature
+ cls_score = self.rpn_cls(x) if self.with_cls else None
+ bbox_pred = self.rpn_reg(x)
+ return bridged_x, cls_score, bbox_pred
+
+ def forward(
+ self,
+ feats: List[Tensor],
+ offset_list: Optional[List[Tensor]] = None) -> Tuple[List[Tensor]]:
+ """Forward function."""
+ if offset_list is None:
+ offset_list = [None for _ in range(len(feats))]
+ return multi_apply(self.forward_single, feats, offset_list)
+
+ def _region_targets_single(self, flat_anchors: Tensor, valid_flags: Tensor,
+ gt_instances: InstanceData, img_meta: dict,
+ gt_instances_ignore: InstanceData,
+ featmap_sizes: List[Tuple[int, int]],
+ num_level_anchors: List[int]) -> tuple:
+ """Get anchor targets based on region for single level.
+
+ Args:
+ flat_anchors (Tensor): Multi-level anchors of the image, which are
+ concatenated into a single tensor of shape (num_anchors, 4)
+ valid_flags (Tensor): Multi level valid flags of the image,
+ which are concatenated into a single tensor of
+ shape (num_anchors, ).
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It should includes ``bboxes`` and ``labels``
+ attributes.
+ img_meta (dict): Meta information for current image.
+ gt_instances_ignore (:obj:`InstanceData`, optional): Instances
+ to be ignored during training. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+ featmap_sizes (list[Tuple[int, int]]): Feature map size each level.
+ num_level_anchors (list[int]): The number of anchors in each level.
+
+ Returns:
+ tuple:
+
+ - labels (Tensor): Labels of each level.
+ - label_weights (Tensor): Label weights of each level.
+ - bbox_targets (Tensor): BBox targets of each level.
+ - bbox_weights (Tensor): BBox weights of each level.
+ - pos_inds (Tensor): positive samples indexes.
+ - neg_inds (Tensor): negative samples indexes.
+ - sampling_result (:obj:`SamplingResult`): Sampling results.
+ """
+ pred_instances = InstanceData()
+ pred_instances.priors = flat_anchors
+ pred_instances.valid_flags = valid_flags
+
+ assign_result = self.assigner.assign(
+ pred_instances,
+ gt_instances,
+ img_meta,
+ featmap_sizes,
+ num_level_anchors,
+ self.anchor_scales[0],
+ self.anchor_strides,
+ gt_instances_ignore=gt_instances_ignore,
+ allowed_border=self.train_cfg['allowed_border'])
+ sampling_result = self.sampler.sample(assign_result, pred_instances,
+ gt_instances)
+
+ num_anchors = flat_anchors.shape[0]
+ bbox_targets = torch.zeros_like(flat_anchors)
+ bbox_weights = torch.zeros_like(flat_anchors)
+ labels = flat_anchors.new_zeros(num_anchors, dtype=torch.long)
+ label_weights = flat_anchors.new_zeros(num_anchors, dtype=torch.float)
+
+ pos_inds = sampling_result.pos_inds
+ neg_inds = sampling_result.neg_inds
+ if len(pos_inds) > 0:
+ if not self.reg_decoded_bbox:
+ pos_bbox_targets = self.bbox_coder.encode(
+ sampling_result.pos_bboxes, sampling_result.pos_gt_bboxes)
+ else:
+ pos_bbox_targets = sampling_result.pos_gt_bboxes
+ bbox_targets[pos_inds, :] = pos_bbox_targets
+ bbox_weights[pos_inds, :] = 1.0
+ labels[pos_inds] = sampling_result.pos_gt_labels
+ if self.train_cfg['pos_weight'] <= 0:
+ label_weights[pos_inds] = 1.0
+ else:
+ label_weights[pos_inds] = self.train_cfg['pos_weight']
+ if len(neg_inds) > 0:
+ label_weights[neg_inds] = 1.0
+
+ return (labels, label_weights, bbox_targets, bbox_weights, pos_inds,
+ neg_inds, sampling_result)
+
+ def region_targets(
+ self,
+ anchor_list: List[List[Tensor]],
+ valid_flag_list: List[List[Tensor]],
+ featmap_sizes: List[Tuple[int, int]],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ batch_gt_instances_ignore: OptInstanceList = None,
+ return_sampling_results: bool = False,
+ ) -> tuple:
+ """Compute regression and classification targets for anchors when using
+ RegionAssigner.
+
+ Args:
+ anchor_list (list[list[Tensor]]): Multi level anchors of each
+ image.
+ valid_flag_list (list[list[Tensor]]): Multi level valid flags of
+ each image.
+ featmap_sizes (list[Tuple[int, int]]): Feature map size each level.
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ tuple:
+
+ - labels_list (list[Tensor]): Labels of each level.
+ - label_weights_list (list[Tensor]): Label weights of each
+ level.
+ - bbox_targets_list (list[Tensor]): BBox targets of each level.
+ - bbox_weights_list (list[Tensor]): BBox weights of each level.
+ - avg_factor (int): Average factor that is used to average
+ the loss. When using sampling method, avg_factor is usually
+ the sum of positive and negative priors. When using
+ ``PseudoSampler``, ``avg_factor`` is usually equal to the
+ number of positive priors.
+ """
+ num_imgs = len(batch_img_metas)
+ assert len(anchor_list) == len(valid_flag_list) == num_imgs
+
+ if batch_gt_instances_ignore is None:
+ batch_gt_instances_ignore = [None] * num_imgs
+
+ # anchor number of multi levels
+ num_level_anchors = [anchors.size(0) for anchors in anchor_list[0]]
+ # concat all level anchors to a single tensor
+ concat_anchor_list = []
+ concat_valid_flag_list = []
+ for i in range(num_imgs):
+ assert len(anchor_list[i]) == len(valid_flag_list[i])
+ concat_anchor_list.append(torch.cat(anchor_list[i]))
+ concat_valid_flag_list.append(torch.cat(valid_flag_list[i]))
+
+ # compute targets for each image
+ (all_labels, all_label_weights, all_bbox_targets, all_bbox_weights,
+ pos_inds_list, neg_inds_list, sampling_results_list) = multi_apply(
+ self._region_targets_single,
+ concat_anchor_list,
+ concat_valid_flag_list,
+ batch_gt_instances,
+ batch_img_metas,
+ batch_gt_instances_ignore,
+ featmap_sizes=featmap_sizes,
+ num_level_anchors=num_level_anchors)
+ # no valid anchors
+ if any([labels is None for labels in all_labels]):
+ return None
+ # sampled anchors of all images
+ avg_factor = sum(
+ [results.avg_factor for results in sampling_results_list])
+ # split targets to a list w.r.t. multiple levels
+ labels_list = images_to_levels(all_labels, num_level_anchors)
+ label_weights_list = images_to_levels(all_label_weights,
+ num_level_anchors)
+ bbox_targets_list = images_to_levels(all_bbox_targets,
+ num_level_anchors)
+ bbox_weights_list = images_to_levels(all_bbox_weights,
+ num_level_anchors)
+ res = (labels_list, label_weights_list, bbox_targets_list,
+ bbox_weights_list, avg_factor)
+ if return_sampling_results:
+ res = res + (sampling_results_list, )
+ return res
+
+ def get_targets(
+ self,
+ anchor_list: List[List[Tensor]],
+ valid_flag_list: List[List[Tensor]],
+ featmap_sizes: List[Tuple[int, int]],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ batch_gt_instances_ignore: OptInstanceList = None,
+ return_sampling_results: bool = False,
+ ) -> tuple:
+ """Compute regression and classification targets for anchors.
+
+ Args:
+ anchor_list (list[list[Tensor]]): Multi level anchors of each
+ image.
+ valid_flag_list (list[list[Tensor]]): Multi level valid flags of
+ each image.
+ featmap_sizes (list[Tuple[int, int]]): Feature map size each level.
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+ return_sampling_results (bool): Whether to return the sampling
+ results. Defaults to False.
+
+ Returns:
+ tuple:
+
+ - labels_list (list[Tensor]): Labels of each level.
+ - label_weights_list (list[Tensor]): Label weights of each
+ level.
+ - bbox_targets_list (list[Tensor]): BBox targets of each level.
+ - bbox_weights_list (list[Tensor]): BBox weights of each level.
+ - avg_factor (int): Average factor that is used to average
+ the loss. When using sampling method, avg_factor is usually
+ the sum of positive and negative priors. When using
+ ``PseudoSampler``, ``avg_factor`` is usually equal to the
+ number of positive priors.
+ """
+ if isinstance(self.assigner, RegionAssigner):
+ cls_reg_targets = self.region_targets(
+ anchor_list,
+ valid_flag_list,
+ featmap_sizes,
+ batch_gt_instances,
+ batch_img_metas,
+ batch_gt_instances_ignore=batch_gt_instances_ignore,
+ return_sampling_results=return_sampling_results)
+ else:
+ cls_reg_targets = super().get_targets(
+ anchor_list,
+ valid_flag_list,
+ batch_gt_instances,
+ batch_img_metas,
+ batch_gt_instances_ignore=batch_gt_instances_ignore,
+ return_sampling_results=return_sampling_results)
+ return cls_reg_targets
+
+ def anchor_offset(self, anchor_list: List[List[Tensor]],
+ anchor_strides: List[int],
+ featmap_sizes: List[Tuple[int, int]]) -> List[Tensor]:
+ """ Get offset for deformable conv based on anchor shape
+ NOTE: currently support deformable kernel_size=3 and dilation=1
+
+ Args:
+ anchor_list (list[list[tensor])): [NI, NLVL, NA, 4] list of
+ multi-level anchors
+ anchor_strides (list[int]): anchor stride of each level
+
+ Returns:
+ list[tensor]: offset of DeformConv kernel with shapes of
+ [NLVL, NA, 2, 18].
+ """
+
+ def _shape_offset(anchors, stride, ks=3, dilation=1):
+ # currently support kernel_size=3 and dilation=1
+ assert ks == 3 and dilation == 1
+ pad = (ks - 1) // 2
+ idx = torch.arange(-pad, pad + 1, dtype=dtype, device=device)
+ yy, xx = torch.meshgrid(idx, idx) # return order matters
+ xx = xx.reshape(-1)
+ yy = yy.reshape(-1)
+ w = (anchors[:, 2] - anchors[:, 0]) / stride
+ h = (anchors[:, 3] - anchors[:, 1]) / stride
+ w = w / (ks - 1) - dilation
+ h = h / (ks - 1) - dilation
+ offset_x = w[:, None] * xx # (NA, ks**2)
+ offset_y = h[:, None] * yy # (NA, ks**2)
+ return offset_x, offset_y
+
+ def _ctr_offset(anchors, stride, featmap_size):
+ feat_h, feat_w = featmap_size
+ assert len(anchors) == feat_h * feat_w
+
+ x = (anchors[:, 0] + anchors[:, 2]) * 0.5
+ y = (anchors[:, 1] + anchors[:, 3]) * 0.5
+ # compute centers on feature map
+ x = x / stride
+ y = y / stride
+ # compute predefine centers
+ xx = torch.arange(0, feat_w, device=anchors.device)
+ yy = torch.arange(0, feat_h, device=anchors.device)
+ yy, xx = torch.meshgrid(yy, xx)
+ xx = xx.reshape(-1).type_as(x)
+ yy = yy.reshape(-1).type_as(y)
+
+ offset_x = x - xx # (NA, )
+ offset_y = y - yy # (NA, )
+ return offset_x, offset_y
+
+ num_imgs = len(anchor_list)
+ num_lvls = len(anchor_list[0])
+ dtype = anchor_list[0][0].dtype
+ device = anchor_list[0][0].device
+ num_level_anchors = [anchors.size(0) for anchors in anchor_list[0]]
+
+ offset_list = []
+ for i in range(num_imgs):
+ mlvl_offset = []
+ for lvl in range(num_lvls):
+ c_offset_x, c_offset_y = _ctr_offset(anchor_list[i][lvl],
+ anchor_strides[lvl],
+ featmap_sizes[lvl])
+ s_offset_x, s_offset_y = _shape_offset(anchor_list[i][lvl],
+ anchor_strides[lvl])
+
+ # offset = ctr_offset + shape_offset
+ offset_x = s_offset_x + c_offset_x[:, None]
+ offset_y = s_offset_y + c_offset_y[:, None]
+
+ # offset order (y0, x0, y1, x2, .., y8, x8, y9, x9)
+ offset = torch.stack([offset_y, offset_x], dim=-1)
+ offset = offset.reshape(offset.size(0), -1) # [NA, 2*ks**2]
+ mlvl_offset.append(offset)
+ offset_list.append(torch.cat(mlvl_offset)) # [totalNA, 2*ks**2]
+ offset_list = images_to_levels(offset_list, num_level_anchors)
+ return offset_list
+
+ def loss_by_feat_single(self, cls_score: Tensor, bbox_pred: Tensor,
+ anchors: Tensor, labels: Tensor,
+ label_weights: Tensor, bbox_targets: Tensor,
+ bbox_weights: Tensor, avg_factor: int) -> tuple:
+ """Loss function on single scale."""
+ # classification loss
+ if self.with_cls:
+ labels = labels.reshape(-1)
+ label_weights = label_weights.reshape(-1)
+ cls_score = cls_score.permute(0, 2, 3,
+ 1).reshape(-1, self.cls_out_channels)
+ loss_cls = self.loss_cls(
+ cls_score, labels, label_weights, avg_factor=avg_factor)
+ # regression loss
+ bbox_targets = bbox_targets.reshape(-1, 4)
+ bbox_weights = bbox_weights.reshape(-1, 4)
+ bbox_pred = bbox_pred.permute(0, 2, 3, 1).reshape(-1, 4)
+ if self.reg_decoded_bbox:
+ # When the regression loss (e.g. `IouLoss`, `GIouLoss`)
+ # is applied directly on the decoded bounding boxes, it
+ # decodes the already encoded coordinates to absolute format.
+ anchors = anchors.reshape(-1, 4)
+ bbox_pred = self.bbox_coder.decode(anchors, bbox_pred)
+ loss_reg = self.loss_bbox(
+ bbox_pred, bbox_targets, bbox_weights, avg_factor=avg_factor)
+ if self.with_cls:
+ return loss_cls, loss_reg
+ return None, loss_reg
+
+ def loss_by_feat(
+ self,
+ anchor_list: List[List[Tensor]],
+ valid_flag_list: List[List[Tensor]],
+ cls_scores: List[Tensor],
+ bbox_preds: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ batch_gt_instances_ignore: OptInstanceList = None
+ ) -> Dict[str, Tensor]:
+ """Compute losses of the head.
+
+ Args:
+ anchor_list (list[list[Tensor]]): Multi level anchors of each
+ image.
+ valid_flag_list (list[list[Tensor]]): Multi level valid flags of
+ each image. The outer list indicates images, and the inner list
+ corresponds to feature levels of the image. Each element of
+ the inner list is a tensor of shape (num_anchors, )
+ cls_scores (list[Tensor]): Box scores for each scale level
+ Has shape (N, num_anchors * num_classes, H, W)
+ bbox_preds (list[Tensor]): Box energies / deltas for each scale
+ level with shape (N, num_anchors * 4, H, W)
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components.
+ """
+ featmap_sizes = [featmap.size()[-2:] for featmap in bbox_preds]
+ cls_reg_targets = self.get_targets(
+ anchor_list,
+ valid_flag_list,
+ featmap_sizes,
+ batch_gt_instances,
+ batch_img_metas,
+ batch_gt_instances_ignore=batch_gt_instances_ignore,
+ return_sampling_results=True)
+ (labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,
+ avg_factor, sampling_results_list) = cls_reg_targets
+ if not sampling_results_list[0].avg_factor_with_neg:
+ # 200 is hard-coded average factor,
+ # which follows guided anchoring.
+ avg_factor = sum([label.numel() for label in labels_list]) / 200.0
+
+ # change per image, per level anchor_list to per_level, per_image
+ mlvl_anchor_list = list(zip(*anchor_list))
+ # concat mlvl_anchor_list
+ mlvl_anchor_list = [
+ torch.cat(anchors, dim=0) for anchors in mlvl_anchor_list
+ ]
+
+ losses = multi_apply(
+ self.loss_by_feat_single,
+ cls_scores,
+ bbox_preds,
+ mlvl_anchor_list,
+ labels_list,
+ label_weights_list,
+ bbox_targets_list,
+ bbox_weights_list,
+ avg_factor=avg_factor)
+ if self.with_cls:
+ return dict(loss_rpn_cls=losses[0], loss_rpn_reg=losses[1])
+ return dict(loss_rpn_reg=losses[1])
+
+ def predict_by_feat(self,
+ anchor_list: List[List[Tensor]],
+ cls_scores: List[Tensor],
+ bbox_preds: List[Tensor],
+ batch_img_metas: List[dict],
+ cfg: Optional[ConfigDict] = None,
+ rescale: bool = False) -> InstanceList:
+ """Get proposal predict. Overriding to enable input ``anchor_list``
+ from outside.
+
+ Args:
+ anchor_list (list[list[Tensor]]): Multi level anchors of each
+ image.
+ cls_scores (list[Tensor]): Classification scores for all
+ scale levels, each is a 4D-tensor, has shape
+ (batch_size, num_priors * num_classes, H, W).
+ bbox_preds (list[Tensor]): Box energies / deltas for all
+ scale levels, each is a 4D-tensor, has shape
+ (batch_size, num_priors * 4, H, W).
+ batch_img_metas (list[dict], Optional): Image meta info.
+ cfg (:obj:`ConfigDict`, optional): Test / postprocessing
+ configuration, if None, test_cfg would be used.
+ rescale (bool): If True, return boxes in original image space.
+ Defaults to False.
+
+ Returns:
+ list[:obj:`InstanceData`]: Object detection results of each image
+ after the post process. Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ """
+ assert len(cls_scores) == len(bbox_preds)
+
+ result_list = []
+ for img_id in range(len(batch_img_metas)):
+ cls_score_list = select_single_mlvl(cls_scores, img_id)
+ bbox_pred_list = select_single_mlvl(bbox_preds, img_id)
+ proposals = self._predict_by_feat_single(
+ cls_scores=cls_score_list,
+ bbox_preds=bbox_pred_list,
+ mlvl_anchors=anchor_list[img_id],
+ img_meta=batch_img_metas[img_id],
+ cfg=cfg,
+ rescale=rescale)
+ result_list.append(proposals)
+ return result_list
+
+ def _predict_by_feat_single(self,
+ cls_scores: List[Tensor],
+ bbox_preds: List[Tensor],
+ mlvl_anchors: List[Tensor],
+ img_meta: dict,
+ cfg: ConfigDict,
+ rescale: bool = False) -> InstanceData:
+ """Transform outputs of a single image into bbox predictions.
+
+ Args:
+ cls_scores (list[Tensor]): Box scores from all scale
+ levels of a single image, each item has shape
+ (num_anchors * num_classes, H, W).
+ bbox_preds (list[Tensor]): Box energies / deltas from
+ all scale levels of a single image, each item has
+ shape (num_anchors * 4, H, W).
+ mlvl_anchors (list[Tensor]): Box reference from all scale
+ levels of a single image, each item has shape
+ (num_total_anchors, 4).
+ img_shape (tuple[int]): Shape of the input image,
+ (height, width, 3).
+ scale_factor (ndarray): Scale factor of the image arange as
+ (w_scale, h_scale, w_scale, h_scale).
+ cfg (:obj:`ConfigDict`): Test / postprocessing configuration,
+ if None, test_cfg would be used.
+ rescale (bool): If True, return boxes in original image space.
+ Defaults to False.
+
+ Returns:
+ :obj:`InstanceData`: Detection results of each image
+ after the post process.
+ Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ """
+ cfg = self.test_cfg if cfg is None else cfg
+ cfg = copy.deepcopy(cfg)
+ # bboxes from different level should be independent during NMS,
+ # level_ids are used as labels for batched NMS to separate them
+ level_ids = []
+ mlvl_scores = []
+ mlvl_bbox_preds = []
+ mlvl_valid_anchors = []
+ nms_pre = cfg.get('nms_pre', -1)
+ for idx in range(len(cls_scores)):
+ rpn_cls_score = cls_scores[idx]
+ rpn_bbox_pred = bbox_preds[idx]
+ assert rpn_cls_score.size()[-2:] == rpn_bbox_pred.size()[-2:]
+ rpn_cls_score = rpn_cls_score.permute(1, 2, 0)
+ if self.use_sigmoid_cls:
+ rpn_cls_score = rpn_cls_score.reshape(-1)
+ scores = rpn_cls_score.sigmoid()
+ else:
+ rpn_cls_score = rpn_cls_score.reshape(-1, 2)
+ # We set FG labels to [0, num_class-1] and BG label to
+ # num_class in RPN head since mmdet v2.5, which is unified to
+ # be consistent with other head since mmdet v2.0. In mmdet v2.0
+ # to v2.4 we keep BG label as 0 and FG label as 1 in rpn head.
+ scores = rpn_cls_score.softmax(dim=1)[:, 0]
+ rpn_bbox_pred = rpn_bbox_pred.permute(1, 2, 0).reshape(-1, 4)
+ anchors = mlvl_anchors[idx]
+
+ if 0 < nms_pre < scores.shape[0]:
+ # sort is faster than topk
+ # _, topk_inds = scores.topk(cfg.nms_pre)
+ ranked_scores, rank_inds = scores.sort(descending=True)
+ topk_inds = rank_inds[:nms_pre]
+ scores = ranked_scores[:nms_pre]
+ rpn_bbox_pred = rpn_bbox_pred[topk_inds, :]
+ anchors = anchors[topk_inds, :]
+ mlvl_scores.append(scores)
+ mlvl_bbox_preds.append(rpn_bbox_pred)
+ mlvl_valid_anchors.append(anchors)
+ level_ids.append(
+ scores.new_full((scores.size(0), ), idx, dtype=torch.long))
+
+ anchors = torch.cat(mlvl_valid_anchors)
+ rpn_bbox_pred = torch.cat(mlvl_bbox_preds)
+ bboxes = self.bbox_coder.decode(
+ anchors, rpn_bbox_pred, max_shape=img_meta['img_shape'])
+
+ proposals = InstanceData()
+ proposals.bboxes = bboxes
+ proposals.scores = torch.cat(mlvl_scores)
+ proposals.level_ids = torch.cat(level_ids)
+
+ return self._bbox_post_process(
+ results=proposals, cfg=cfg, rescale=rescale, img_meta=img_meta)
+
+ def refine_bboxes(self, anchor_list: List[List[Tensor]],
+ bbox_preds: List[Tensor],
+ img_metas: List[dict]) -> List[List[Tensor]]:
+ """Refine bboxes through stages."""
+ num_levels = len(bbox_preds)
+ new_anchor_list = []
+ for img_id in range(len(img_metas)):
+ mlvl_anchors = []
+ for i in range(num_levels):
+ bbox_pred = bbox_preds[i][img_id].detach()
+ bbox_pred = bbox_pred.permute(1, 2, 0).reshape(-1, 4)
+ img_shape = img_metas[img_id]['img_shape']
+ bboxes = self.bbox_coder.decode(anchor_list[img_id][i],
+ bbox_pred, img_shape)
+ mlvl_anchors.append(bboxes)
+ new_anchor_list.append(mlvl_anchors)
+ return new_anchor_list
+
+ def loss(self, x: Tuple[Tensor], batch_data_samples: SampleList) -> dict:
+ """Perform forward propagation and loss calculation of the detection
+ head on the features of the upstream network.
+
+ Args:
+ x (tuple[Tensor]): Features from the upstream network, each is
+ a 4D-tensor.
+ batch_data_samples (List[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+
+ Returns:
+ dict: A dictionary of loss components.
+ """
+ outputs = unpack_gt_instances(batch_data_samples)
+ batch_gt_instances, _, batch_img_metas = outputs
+
+ featmap_sizes = [featmap.size()[-2:] for featmap in x]
+ device = x[0].device
+ anchor_list, valid_flag_list = self.get_anchors(
+ featmap_sizes, batch_img_metas, device=device)
+
+ if self.adapt_cfg['type'] == 'offset':
+ offset_list = self.anchor_offset(anchor_list, self.anchor_strides,
+ featmap_sizes)
+ else:
+ offset_list = None
+
+ x, cls_score, bbox_pred = self(x, offset_list)
+ rpn_loss_inputs = (anchor_list, valid_flag_list, cls_score, bbox_pred,
+ batch_gt_instances, batch_img_metas)
+ losses = self.loss_by_feat(*rpn_loss_inputs)
+
+ return losses
+
+ def loss_and_predict(
+ self,
+ x: Tuple[Tensor],
+ batch_data_samples: SampleList,
+ proposal_cfg: Optional[ConfigDict] = None,
+ ) -> Tuple[dict, InstanceList]:
+ """Perform forward propagation of the head, then calculate loss and
+ predictions from the features and data samples.
+
+ Args:
+ x (tuple[Tensor]): Features from FPN.
+ batch_data_samples (list[:obj:`DetDataSample`]): Each item contains
+ the meta information of each image and corresponding
+ annotations.
+ proposal_cfg (:obj`ConfigDict`, optional): Test / postprocessing
+ configuration, if None, test_cfg would be used.
+ Defaults to None.
+
+ Returns:
+ tuple: the return value is a tuple contains:
+
+ - losses: (dict[str, Tensor]): A dictionary of loss components.
+ - predictions (list[:obj:`InstanceData`]): Detection
+ results of each image after the post process.
+ """
+ outputs = unpack_gt_instances(batch_data_samples)
+ batch_gt_instances, _, batch_img_metas = outputs
+
+ featmap_sizes = [featmap.size()[-2:] for featmap in x]
+ device = x[0].device
+ anchor_list, valid_flag_list = self.get_anchors(
+ featmap_sizes, batch_img_metas, device=device)
+
+ if self.adapt_cfg['type'] == 'offset':
+ offset_list = self.anchor_offset(anchor_list, self.anchor_strides,
+ featmap_sizes)
+ else:
+ offset_list = None
+
+ x, cls_score, bbox_pred = self(x, offset_list)
+ rpn_loss_inputs = (anchor_list, valid_flag_list, cls_score, bbox_pred,
+ batch_gt_instances, batch_img_metas)
+ losses = self.loss_by_feat(*rpn_loss_inputs)
+
+ predictions = self.predict_by_feat(
+ anchor_list,
+ cls_score,
+ bbox_pred,
+ batch_img_metas=batch_img_metas,
+ cfg=proposal_cfg)
+ return losses, predictions
+
+ def predict(self,
+ x: Tuple[Tensor],
+ batch_data_samples: SampleList,
+ rescale: bool = False) -> InstanceList:
+ """Perform forward propagation of the detection head and predict
+ detection results on the features of the upstream network.
+
+ Args:
+ x (tuple[Tensor]): Multi-level features from the
+ upstream network, each is a 4D-tensor.
+ batch_data_samples (List[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ rescale (bool, optional): Whether to rescale the results.
+ Defaults to False.
+
+ Returns:
+ list[obj:`InstanceData`]: Detection results of each image
+ after the post process.
+ """
+ batch_img_metas = [
+ data_samples.metainfo for data_samples in batch_data_samples
+ ]
+
+ featmap_sizes = [featmap.size()[-2:] for featmap in x]
+ device = x[0].device
+ anchor_list, _ = self.get_anchors(
+ featmap_sizes, batch_img_metas, device=device)
+
+ if self.adapt_cfg['type'] == 'offset':
+ offset_list = self.anchor_offset(anchor_list, self.anchor_strides,
+ featmap_sizes)
+ else:
+ offset_list = None
+
+ x, cls_score, bbox_pred = self(x, offset_list)
+ predictions = self.stages[-1].predict_by_feat(
+ anchor_list,
+ cls_score,
+ bbox_pred,
+ batch_img_metas=batch_img_metas,
+ rescale=rescale)
+ return predictions
+
+
+@MODELS.register_module()
+class CascadeRPNHead(BaseDenseHead):
+ """The CascadeRPNHead will predict more accurate region proposals, which is
+ required for two-stage detectors (such as Fast/Faster R-CNN). CascadeRPN
+ consists of a sequence of RPNStage to progressively improve the accuracy of
+ the detected proposals.
+
+ More details can be found in ``https://arxiv.org/abs/1909.06720``.
+
+ Args:
+ num_stages (int): number of CascadeRPN stages.
+ stages (list[:obj:`ConfigDict` or dict]): list of configs to build
+ the stages.
+ train_cfg (list[:obj:`ConfigDict` or dict]): list of configs at
+ training time each stage.
+ test_cfg (:obj:`ConfigDict` or dict): config at testing time.
+ init_cfg (:obj:`ConfigDict` or list[:obj:`ConfigDict`] or dict or \
+ list[dict]): Initialization config dict.
+ """
+
+ def __init__(self,
+ num_classes: int,
+ num_stages: int,
+ stages: List[ConfigType],
+ train_cfg: List[ConfigType],
+ test_cfg: ConfigType,
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(init_cfg=init_cfg)
+ assert num_classes == 1, 'Only support num_classes == 1'
+ assert num_stages == len(stages)
+ self.num_stages = num_stages
+ # Be careful! Pretrained weights cannot be loaded when use
+ # nn.ModuleList
+ self.stages = ModuleList()
+ for i in range(len(stages)):
+ train_cfg_i = train_cfg[i] if train_cfg is not None else None
+ stages[i].update(train_cfg=train_cfg_i)
+ stages[i].update(test_cfg=test_cfg)
+ self.stages.append(MODELS.build(stages[i]))
+ self.train_cfg = train_cfg
+ self.test_cfg = test_cfg
+
+ def loss_by_feat(self):
+ """loss_by_feat() is implemented in StageCascadeRPNHead."""
+ pass
+
+ def predict_by_feat(self):
+ """predict_by_feat() is implemented in StageCascadeRPNHead."""
+ pass
+
+ def loss(self, x: Tuple[Tensor], batch_data_samples: SampleList) -> dict:
+ """Perform forward propagation and loss calculation of the detection
+ head on the features of the upstream network.
+
+ Args:
+ x (tuple[Tensor]): Features from the upstream network, each is
+ a 4D-tensor.
+ batch_data_samples (List[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+
+ Returns:
+ dict: A dictionary of loss components.
+ """
+ outputs = unpack_gt_instances(batch_data_samples)
+ batch_gt_instances, _, batch_img_metas = outputs
+
+ featmap_sizes = [featmap.size()[-2:] for featmap in x]
+ device = x[0].device
+ anchor_list, valid_flag_list = self.stages[0].get_anchors(
+ featmap_sizes, batch_img_metas, device=device)
+
+ losses = dict()
+
+ for i in range(self.num_stages):
+ stage = self.stages[i]
+
+ if stage.adapt_cfg['type'] == 'offset':
+ offset_list = stage.anchor_offset(anchor_list,
+ stage.anchor_strides,
+ featmap_sizes)
+ else:
+ offset_list = None
+ x, cls_score, bbox_pred = stage(x, offset_list)
+ rpn_loss_inputs = (anchor_list, valid_flag_list, cls_score,
+ bbox_pred, batch_gt_instances, batch_img_metas)
+ stage_loss = stage.loss_by_feat(*rpn_loss_inputs)
+ for name, value in stage_loss.items():
+ losses['s{}.{}'.format(i, name)] = value
+
+ # refine boxes
+ if i < self.num_stages - 1:
+ anchor_list = stage.refine_bboxes(anchor_list, bbox_pred,
+ batch_img_metas)
+
+ return losses
+
+ def loss_and_predict(
+ self,
+ x: Tuple[Tensor],
+ batch_data_samples: SampleList,
+ proposal_cfg: Optional[ConfigDict] = None,
+ ) -> Tuple[dict, InstanceList]:
+ """Perform forward propagation of the head, then calculate loss and
+ predictions from the features and data samples.
+
+ Args:
+ x (tuple[Tensor]): Features from FPN.
+ batch_data_samples (list[:obj:`DetDataSample`]): Each item contains
+ the meta information of each image and corresponding
+ annotations.
+ proposal_cfg (ConfigDict, optional): Test / postprocessing
+ configuration, if None, test_cfg would be used.
+ Defaults to None.
+
+ Returns:
+ tuple: the return value is a tuple contains:
+
+ - losses: (dict[str, Tensor]): A dictionary of loss components.
+ - predictions (list[:obj:`InstanceData`]): Detection
+ results of each image after the post process.
+ """
+ outputs = unpack_gt_instances(batch_data_samples)
+ batch_gt_instances, _, batch_img_metas = outputs
+
+ featmap_sizes = [featmap.size()[-2:] for featmap in x]
+ device = x[0].device
+ anchor_list, valid_flag_list = self.stages[0].get_anchors(
+ featmap_sizes, batch_img_metas, device=device)
+
+ losses = dict()
+
+ for i in range(self.num_stages):
+ stage = self.stages[i]
+
+ if stage.adapt_cfg['type'] == 'offset':
+ offset_list = stage.anchor_offset(anchor_list,
+ stage.anchor_strides,
+ featmap_sizes)
+ else:
+ offset_list = None
+ x, cls_score, bbox_pred = stage(x, offset_list)
+ rpn_loss_inputs = (anchor_list, valid_flag_list, cls_score,
+ bbox_pred, batch_gt_instances, batch_img_metas)
+ stage_loss = stage.loss_by_feat(*rpn_loss_inputs)
+ for name, value in stage_loss.items():
+ losses['s{}.{}'.format(i, name)] = value
+
+ # refine boxes
+ if i < self.num_stages - 1:
+ anchor_list = stage.refine_bboxes(anchor_list, bbox_pred,
+ batch_img_metas)
+
+ predictions = self.stages[-1].predict_by_feat(
+ anchor_list,
+ cls_score,
+ bbox_pred,
+ batch_img_metas=batch_img_metas,
+ cfg=proposal_cfg)
+ return losses, predictions
+
+ def predict(self,
+ x: Tuple[Tensor],
+ batch_data_samples: SampleList,
+ rescale: bool = False) -> InstanceList:
+ """Perform forward propagation of the detection head and predict
+ detection results on the features of the upstream network.
+
+ Args:
+ x (tuple[Tensor]): Multi-level features from the
+ upstream network, each is a 4D-tensor.
+ batch_data_samples (List[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ rescale (bool, optional): Whether to rescale the results.
+ Defaults to False.
+
+ Returns:
+ list[obj:`InstanceData`]: Detection results of each image
+ after the post process.
+ """
+ batch_img_metas = [
+ data_samples.metainfo for data_samples in batch_data_samples
+ ]
+
+ featmap_sizes = [featmap.size()[-2:] for featmap in x]
+ device = x[0].device
+ anchor_list, _ = self.stages[0].get_anchors(
+ featmap_sizes, batch_img_metas, device=device)
+
+ for i in range(self.num_stages):
+ stage = self.stages[i]
+ if stage.adapt_cfg['type'] == 'offset':
+ offset_list = stage.anchor_offset(anchor_list,
+ stage.anchor_strides,
+ featmap_sizes)
+ else:
+ offset_list = None
+ x, cls_score, bbox_pred = stage(x, offset_list)
+ if i < self.num_stages - 1:
+ anchor_list = stage.refine_bboxes(anchor_list, bbox_pred,
+ batch_img_metas)
+
+ predictions = self.stages[-1].predict_by_feat(
+ anchor_list,
+ cls_score,
+ bbox_pred,
+ batch_img_metas=batch_img_metas,
+ rescale=rescale)
+ return predictions
diff --git a/mmdet/models/dense_heads/centernet_head.py b/mmdet/models/dense_heads/centernet_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..09f3e599eb176965e53f270014cbd326858b7c17
--- /dev/null
+++ b/mmdet/models/dense_heads/centernet_head.py
@@ -0,0 +1,447 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Optional, Tuple
+
+import torch
+import torch.nn as nn
+from mmcv.ops import batched_nms
+from mmengine.config import ConfigDict
+from mmengine.model import bias_init_with_prob, normal_init
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.utils import (ConfigType, InstanceList, OptConfigType,
+ OptInstanceList, OptMultiConfig)
+from ..utils import (gaussian_radius, gen_gaussian_target, get_local_maximum,
+ get_topk_from_heatmap, multi_apply,
+ transpose_and_gather_feat)
+from .base_dense_head import BaseDenseHead
+
+
+@MODELS.register_module()
+class CenterNetHead(BaseDenseHead):
+ """Objects as Points Head. CenterHead use center_point to indicate object's
+ position. Paper link
+
+ Args:
+ in_channels (int): Number of channel in the input feature map.
+ feat_channels (int): Number of channel in the intermediate feature map.
+ num_classes (int): Number of categories excluding the background
+ category.
+ loss_center_heatmap (:obj:`ConfigDict` or dict): Config of center
+ heatmap loss. Defaults to
+ dict(type='GaussianFocalLoss', loss_weight=1.0)
+ loss_wh (:obj:`ConfigDict` or dict): Config of wh loss. Defaults to
+ dict(type='L1Loss', loss_weight=0.1).
+ loss_offset (:obj:`ConfigDict` or dict): Config of offset loss.
+ Defaults to dict(type='L1Loss', loss_weight=1.0).
+ train_cfg (:obj:`ConfigDict` or dict, optional): Training config.
+ Useless in CenterNet, but we keep this variable for
+ SingleStageDetector.
+ test_cfg (:obj:`ConfigDict` or dict, optional): Testing config
+ of CenterNet.
+ init_cfg (:obj:`ConfigDict` or dict or list[dict] or
+ list[:obj:`ConfigDict`], optional): Initialization
+ config dict.
+ """
+
+ def __init__(self,
+ in_channels: int,
+ feat_channels: int,
+ num_classes: int,
+ loss_center_heatmap: ConfigType = dict(
+ type='GaussianFocalLoss', loss_weight=1.0),
+ loss_wh: ConfigType = dict(type='L1Loss', loss_weight=0.1),
+ loss_offset: ConfigType = dict(
+ type='L1Loss', loss_weight=1.0),
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(init_cfg=init_cfg)
+ self.num_classes = num_classes
+ self.heatmap_head = self._build_head(in_channels, feat_channels,
+ num_classes)
+ self.wh_head = self._build_head(in_channels, feat_channels, 2)
+ self.offset_head = self._build_head(in_channels, feat_channels, 2)
+
+ self.loss_center_heatmap = MODELS.build(loss_center_heatmap)
+ self.loss_wh = MODELS.build(loss_wh)
+ self.loss_offset = MODELS.build(loss_offset)
+
+ self.train_cfg = train_cfg
+ self.test_cfg = test_cfg
+ self.fp16_enabled = False
+
+ def _build_head(self, in_channels: int, feat_channels: int,
+ out_channels: int) -> nn.Sequential:
+ """Build head for each branch."""
+ layer = nn.Sequential(
+ nn.Conv2d(in_channels, feat_channels, kernel_size=3, padding=1),
+ nn.ReLU(inplace=True),
+ nn.Conv2d(feat_channels, out_channels, kernel_size=1))
+ return layer
+
+ def init_weights(self) -> None:
+ """Initialize weights of the head."""
+ bias_init = bias_init_with_prob(0.1)
+ self.heatmap_head[-1].bias.data.fill_(bias_init)
+ for head in [self.wh_head, self.offset_head]:
+ for m in head.modules():
+ if isinstance(m, nn.Conv2d):
+ normal_init(m, std=0.001)
+
+ def forward(self, x: Tuple[Tensor, ...]) -> Tuple[List[Tensor]]:
+ """Forward features. Notice CenterNet head does not use FPN.
+
+ Args:
+ x (tuple[Tensor]): Features from the upstream network, each is
+ a 4D-tensor.
+
+ Returns:
+ center_heatmap_preds (list[Tensor]): center predict heatmaps for
+ all levels, the channels number is num_classes.
+ wh_preds (list[Tensor]): wh predicts for all levels, the channels
+ number is 2.
+ offset_preds (list[Tensor]): offset predicts for all levels, the
+ channels number is 2.
+ """
+ return multi_apply(self.forward_single, x)
+
+ def forward_single(self, x: Tensor) -> Tuple[Tensor, ...]:
+ """Forward feature of a single level.
+
+ Args:
+ x (Tensor): Feature of a single level.
+
+ Returns:
+ center_heatmap_pred (Tensor): center predict heatmaps, the
+ channels number is num_classes.
+ wh_pred (Tensor): wh predicts, the channels number is 2.
+ offset_pred (Tensor): offset predicts, the channels number is 2.
+ """
+ center_heatmap_pred = self.heatmap_head(x).sigmoid()
+ wh_pred = self.wh_head(x)
+ offset_pred = self.offset_head(x)
+ return center_heatmap_pred, wh_pred, offset_pred
+
+ def loss_by_feat(
+ self,
+ center_heatmap_preds: List[Tensor],
+ wh_preds: List[Tensor],
+ offset_preds: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ batch_gt_instances_ignore: OptInstanceList = None) -> dict:
+ """Compute losses of the head.
+
+ Args:
+ center_heatmap_preds (list[Tensor]): center predict heatmaps for
+ all levels with shape (B, num_classes, H, W).
+ wh_preds (list[Tensor]): wh predicts for all levels with
+ shape (B, 2, H, W).
+ offset_preds (list[Tensor]): offset predicts for all levels
+ with shape (B, 2, H, W).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ dict[str, Tensor]: which has components below:
+ - loss_center_heatmap (Tensor): loss of center heatmap.
+ - loss_wh (Tensor): loss of hw heatmap
+ - loss_offset (Tensor): loss of offset heatmap.
+ """
+ assert len(center_heatmap_preds) == len(wh_preds) == len(
+ offset_preds) == 1
+ center_heatmap_pred = center_heatmap_preds[0]
+ wh_pred = wh_preds[0]
+ offset_pred = offset_preds[0]
+
+ gt_bboxes = [
+ gt_instances.bboxes for gt_instances in batch_gt_instances
+ ]
+ gt_labels = [
+ gt_instances.labels for gt_instances in batch_gt_instances
+ ]
+ img_shape = batch_img_metas[0]['batch_input_shape']
+ target_result, avg_factor = self.get_targets(gt_bboxes, gt_labels,
+ center_heatmap_pred.shape,
+ img_shape)
+
+ center_heatmap_target = target_result['center_heatmap_target']
+ wh_target = target_result['wh_target']
+ offset_target = target_result['offset_target']
+ wh_offset_target_weight = target_result['wh_offset_target_weight']
+
+ # Since the channel of wh_target and offset_target is 2, the avg_factor
+ # of loss_center_heatmap is always 1/2 of loss_wh and loss_offset.
+ loss_center_heatmap = self.loss_center_heatmap(
+ center_heatmap_pred, center_heatmap_target, avg_factor=avg_factor)
+ loss_wh = self.loss_wh(
+ wh_pred,
+ wh_target,
+ wh_offset_target_weight,
+ avg_factor=avg_factor * 2)
+ loss_offset = self.loss_offset(
+ offset_pred,
+ offset_target,
+ wh_offset_target_weight,
+ avg_factor=avg_factor * 2)
+ return dict(
+ loss_center_heatmap=loss_center_heatmap,
+ loss_wh=loss_wh,
+ loss_offset=loss_offset)
+
+ def get_targets(self, gt_bboxes: List[Tensor], gt_labels: List[Tensor],
+ feat_shape: tuple, img_shape: tuple) -> Tuple[dict, int]:
+ """Compute regression and classification targets in multiple images.
+
+ Args:
+ gt_bboxes (list[Tensor]): Ground truth bboxes for each image with
+ shape (num_gts, 4) in [tl_x, tl_y, br_x, br_y] format.
+ gt_labels (list[Tensor]): class indices corresponding to each box.
+ feat_shape (tuple): feature map shape with value [B, _, H, W]
+ img_shape (tuple): image shape.
+
+ Returns:
+ tuple[dict, float]: The float value is mean avg_factor, the dict
+ has components below:
+ - center_heatmap_target (Tensor): targets of center heatmap, \
+ shape (B, num_classes, H, W).
+ - wh_target (Tensor): targets of wh predict, shape \
+ (B, 2, H, W).
+ - offset_target (Tensor): targets of offset predict, shape \
+ (B, 2, H, W).
+ - wh_offset_target_weight (Tensor): weights of wh and offset \
+ predict, shape (B, 2, H, W).
+ """
+ img_h, img_w = img_shape[:2]
+ bs, _, feat_h, feat_w = feat_shape
+
+ width_ratio = float(feat_w / img_w)
+ height_ratio = float(feat_h / img_h)
+
+ center_heatmap_target = gt_bboxes[-1].new_zeros(
+ [bs, self.num_classes, feat_h, feat_w])
+ wh_target = gt_bboxes[-1].new_zeros([bs, 2, feat_h, feat_w])
+ offset_target = gt_bboxes[-1].new_zeros([bs, 2, feat_h, feat_w])
+ wh_offset_target_weight = gt_bboxes[-1].new_zeros(
+ [bs, 2, feat_h, feat_w])
+
+ for batch_id in range(bs):
+ gt_bbox = gt_bboxes[batch_id]
+ gt_label = gt_labels[batch_id]
+ center_x = (gt_bbox[:, [0]] + gt_bbox[:, [2]]) * width_ratio / 2
+ center_y = (gt_bbox[:, [1]] + gt_bbox[:, [3]]) * height_ratio / 2
+ gt_centers = torch.cat((center_x, center_y), dim=1)
+
+ for j, ct in enumerate(gt_centers):
+ ctx_int, cty_int = ct.int()
+ ctx, cty = ct
+ scale_box_h = (gt_bbox[j][3] - gt_bbox[j][1]) * height_ratio
+ scale_box_w = (gt_bbox[j][2] - gt_bbox[j][0]) * width_ratio
+ radius = gaussian_radius([scale_box_h, scale_box_w],
+ min_overlap=0.3)
+ radius = max(0, int(radius))
+ ind = gt_label[j]
+ gen_gaussian_target(center_heatmap_target[batch_id, ind],
+ [ctx_int, cty_int], radius)
+
+ wh_target[batch_id, 0, cty_int, ctx_int] = scale_box_w
+ wh_target[batch_id, 1, cty_int, ctx_int] = scale_box_h
+
+ offset_target[batch_id, 0, cty_int, ctx_int] = ctx - ctx_int
+ offset_target[batch_id, 1, cty_int, ctx_int] = cty - cty_int
+
+ wh_offset_target_weight[batch_id, :, cty_int, ctx_int] = 1
+
+ avg_factor = max(1, center_heatmap_target.eq(1).sum())
+ target_result = dict(
+ center_heatmap_target=center_heatmap_target,
+ wh_target=wh_target,
+ offset_target=offset_target,
+ wh_offset_target_weight=wh_offset_target_weight)
+ return target_result, avg_factor
+
+ def predict_by_feat(self,
+ center_heatmap_preds: List[Tensor],
+ wh_preds: List[Tensor],
+ offset_preds: List[Tensor],
+ batch_img_metas: Optional[List[dict]] = None,
+ rescale: bool = True,
+ with_nms: bool = False) -> InstanceList:
+ """Transform network output for a batch into bbox predictions.
+
+ Args:
+ center_heatmap_preds (list[Tensor]): Center predict heatmaps for
+ all levels with shape (B, num_classes, H, W).
+ wh_preds (list[Tensor]): WH predicts for all levels with
+ shape (B, 2, H, W).
+ offset_preds (list[Tensor]): Offset predicts for all levels
+ with shape (B, 2, H, W).
+ batch_img_metas (list[dict], optional): Batch image meta info.
+ Defaults to None.
+ rescale (bool): If True, return boxes in original image space.
+ Defaults to True.
+ with_nms (bool): If True, do nms before return boxes.
+ Defaults to False.
+
+ Returns:
+ list[:obj:`InstanceData`]: Instance segmentation
+ results of each image after the post process.
+ Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ """
+ assert len(center_heatmap_preds) == len(wh_preds) == len(
+ offset_preds) == 1
+ result_list = []
+ for img_id in range(len(batch_img_metas)):
+ result_list.append(
+ self._predict_by_feat_single(
+ center_heatmap_preds[0][img_id:img_id + 1, ...],
+ wh_preds[0][img_id:img_id + 1, ...],
+ offset_preds[0][img_id:img_id + 1, ...],
+ batch_img_metas[img_id],
+ rescale=rescale,
+ with_nms=with_nms))
+ return result_list
+
+ def _predict_by_feat_single(self,
+ center_heatmap_pred: Tensor,
+ wh_pred: Tensor,
+ offset_pred: Tensor,
+ img_meta: dict,
+ rescale: bool = True,
+ with_nms: bool = False) -> InstanceData:
+ """Transform outputs of a single image into bbox results.
+
+ Args:
+ center_heatmap_pred (Tensor): Center heatmap for current level with
+ shape (1, num_classes, H, W).
+ wh_pred (Tensor): WH heatmap for current level with shape
+ (1, num_classes, H, W).
+ offset_pred (Tensor): Offset for current level with shape
+ (1, corner_offset_channels, H, W).
+ img_meta (dict): Meta information of current image, e.g.,
+ image size, scaling factor, etc.
+ rescale (bool): If True, return boxes in original image space.
+ Defaults to True.
+ with_nms (bool): If True, do nms before return boxes.
+ Defaults to False.
+
+ Returns:
+ :obj:`InstanceData`: Detection results of each image
+ after the post process.
+ Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ """
+ batch_det_bboxes, batch_labels = self._decode_heatmap(
+ center_heatmap_pred,
+ wh_pred,
+ offset_pred,
+ img_meta['batch_input_shape'],
+ k=self.test_cfg.topk,
+ kernel=self.test_cfg.local_maximum_kernel)
+
+ det_bboxes = batch_det_bboxes.view([-1, 5])
+ det_labels = batch_labels.view(-1)
+
+ batch_border = det_bboxes.new_tensor(img_meta['border'])[...,
+ [2, 0, 2, 0]]
+ det_bboxes[..., :4] -= batch_border
+
+ if rescale and 'scale_factor' in img_meta:
+ det_bboxes[..., :4] /= det_bboxes.new_tensor(
+ img_meta['scale_factor']).repeat((1, 2))
+
+ if with_nms:
+ det_bboxes, det_labels = self._bboxes_nms(det_bboxes, det_labels,
+ self.test_cfg)
+ results = InstanceData()
+ results.bboxes = det_bboxes[..., :4]
+ results.scores = det_bboxes[..., 4]
+ results.labels = det_labels
+ return results
+
+ def _decode_heatmap(self,
+ center_heatmap_pred: Tensor,
+ wh_pred: Tensor,
+ offset_pred: Tensor,
+ img_shape: tuple,
+ k: int = 100,
+ kernel: int = 3) -> Tuple[Tensor, Tensor]:
+ """Transform outputs into detections raw bbox prediction.
+
+ Args:
+ center_heatmap_pred (Tensor): center predict heatmap,
+ shape (B, num_classes, H, W).
+ wh_pred (Tensor): wh predict, shape (B, 2, H, W).
+ offset_pred (Tensor): offset predict, shape (B, 2, H, W).
+ img_shape (tuple): image shape in hw format.
+ k (int): Get top k center keypoints from heatmap. Defaults to 100.
+ kernel (int): Max pooling kernel for extract local maximum pixels.
+ Defaults to 3.
+
+ Returns:
+ tuple[Tensor]: Decoded output of CenterNetHead, containing
+ the following Tensors:
+
+ - batch_bboxes (Tensor): Coords of each box with shape (B, k, 5)
+ - batch_topk_labels (Tensor): Categories of each box with \
+ shape (B, k)
+ """
+ height, width = center_heatmap_pred.shape[2:]
+ inp_h, inp_w = img_shape
+
+ center_heatmap_pred = get_local_maximum(
+ center_heatmap_pred, kernel=kernel)
+
+ *batch_dets, topk_ys, topk_xs = get_topk_from_heatmap(
+ center_heatmap_pred, k=k)
+ batch_scores, batch_index, batch_topk_labels = batch_dets
+
+ wh = transpose_and_gather_feat(wh_pred, batch_index)
+ offset = transpose_and_gather_feat(offset_pred, batch_index)
+ topk_xs = topk_xs + offset[..., 0]
+ topk_ys = topk_ys + offset[..., 1]
+ tl_x = (topk_xs - wh[..., 0] / 2) * (inp_w / width)
+ tl_y = (topk_ys - wh[..., 1] / 2) * (inp_h / height)
+ br_x = (topk_xs + wh[..., 0] / 2) * (inp_w / width)
+ br_y = (topk_ys + wh[..., 1] / 2) * (inp_h / height)
+
+ batch_bboxes = torch.stack([tl_x, tl_y, br_x, br_y], dim=2)
+ batch_bboxes = torch.cat((batch_bboxes, batch_scores[..., None]),
+ dim=-1)
+ return batch_bboxes, batch_topk_labels
+
+ def _bboxes_nms(self, bboxes: Tensor, labels: Tensor,
+ cfg: ConfigDict) -> Tuple[Tensor, Tensor]:
+ """bboxes nms."""
+ if labels.numel() > 0:
+ max_num = cfg.max_per_img
+ bboxes, keep = batched_nms(bboxes[:, :4], bboxes[:,
+ -1].contiguous(),
+ labels, cfg.nms)
+ if max_num > 0:
+ bboxes = bboxes[:max_num]
+ labels = labels[keep][:max_num]
+
+ return bboxes, labels
diff --git a/mmdet/models/dense_heads/centernet_update_head.py b/mmdet/models/dense_heads/centernet_update_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..2eb44edaf8bf811e0e257e7ff2bd42872b19efe4
--- /dev/null
+++ b/mmdet/models/dense_heads/centernet_update_head.py
@@ -0,0 +1,624 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Optional, Sequence, Tuple
+
+import torch
+import torch.nn as nn
+from mmcv.cnn import Scale
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.structures.bbox import bbox2distance
+from mmdet.utils import (ConfigType, InstanceList, OptConfigType,
+ OptInstanceList, reduce_mean)
+from ..utils import multi_apply
+from .anchor_free_head import AnchorFreeHead
+
+INF = 1000000000
+RangeType = Sequence[Tuple[int, int]]
+
+
+def _transpose(tensor_list: List[Tensor],
+ num_point_list: list) -> List[Tensor]:
+ """This function is used to transpose image first tensors to level first
+ ones."""
+ for img_idx in range(len(tensor_list)):
+ tensor_list[img_idx] = torch.split(
+ tensor_list[img_idx], num_point_list, dim=0)
+
+ tensors_level_first = []
+ for targets_per_level in zip(*tensor_list):
+ tensors_level_first.append(torch.cat(targets_per_level, dim=0))
+ return tensors_level_first
+
+
+@MODELS.register_module()
+class CenterNetUpdateHead(AnchorFreeHead):
+ """CenterNetUpdateHead is an improved version of CenterNet in CenterNet2.
+ Paper link ``_.
+
+ Args:
+ num_classes (int): Number of categories excluding the background
+ category.
+ in_channels (int): Number of channel in the input feature map.
+ regress_ranges (Sequence[Tuple[int, int]]): Regress range of multiple
+ level points.
+ hm_min_radius (int): Heatmap target minimum radius of cls branch.
+ Defaults to 4.
+ hm_min_overlap (float): Heatmap target minimum overlap of cls branch.
+ Defaults to 0.8.
+ more_pos_thresh (float): The filtering threshold when the cls branch
+ adds more positive samples. Defaults to 0.2.
+ more_pos_topk (int): The maximum number of additional positive samples
+ added to each gt. Defaults to 9.
+ soft_weight_on_reg (bool): Whether to use the soft target of the
+ cls branch as the soft weight of the bbox branch.
+ Defaults to False.
+ loss_cls (:obj:`ConfigDict` or dict): Config of cls loss. Defaults to
+ dict(type='GaussianFocalLoss', loss_weight=1.0)
+ loss_bbox (:obj:`ConfigDict` or dict): Config of bbox loss. Defaults to
+ dict(type='GIoULoss', loss_weight=2.0).
+ norm_cfg (:obj:`ConfigDict` or dict, optional): dictionary to construct
+ and config norm layer. Defaults to
+ ``norm_cfg=dict(type='GN', num_groups=32, requires_grad=True)``.
+ train_cfg (:obj:`ConfigDict` or dict, optional): Training config.
+ Unused in CenterNet. Reserved for compatibility with
+ SingleStageDetector.
+ test_cfg (:obj:`ConfigDict` or dict, optional): Testing config
+ of CenterNet.
+ """
+
+ def __init__(self,
+ num_classes: int,
+ in_channels: int,
+ regress_ranges: RangeType = ((0, 80), (64, 160), (128, 320),
+ (256, 640), (512, INF)),
+ hm_min_radius: int = 4,
+ hm_min_overlap: float = 0.8,
+ more_pos_thresh: float = 0.2,
+ more_pos_topk: int = 9,
+ soft_weight_on_reg: bool = False,
+ loss_cls: ConfigType = dict(
+ type='GaussianFocalLoss',
+ pos_weight=0.25,
+ neg_weight=0.75,
+ loss_weight=1.0),
+ loss_bbox: ConfigType = dict(
+ type='GIoULoss', loss_weight=2.0),
+ norm_cfg: OptConfigType = dict(
+ type='GN', num_groups=32, requires_grad=True),
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ **kwargs) -> None:
+ super().__init__(
+ num_classes=num_classes,
+ in_channels=in_channels,
+ loss_cls=loss_cls,
+ loss_bbox=loss_bbox,
+ norm_cfg=norm_cfg,
+ train_cfg=train_cfg,
+ test_cfg=test_cfg,
+ **kwargs)
+ self.soft_weight_on_reg = soft_weight_on_reg
+ self.hm_min_radius = hm_min_radius
+ self.more_pos_thresh = more_pos_thresh
+ self.more_pos_topk = more_pos_topk
+ self.delta = (1 - hm_min_overlap) / (1 + hm_min_overlap)
+ self.sigmoid_clamp = 0.0001
+
+ # GaussianFocalLoss must be sigmoid mode
+ self.use_sigmoid_cls = True
+ self.cls_out_channels = num_classes
+
+ self.regress_ranges = regress_ranges
+ self.scales = nn.ModuleList([Scale(1.0) for _ in self.strides])
+
+ def _init_predictor(self) -> None:
+ """Initialize predictor layers of the head."""
+ self.conv_cls = nn.Conv2d(
+ self.feat_channels, self.num_classes, 3, padding=1)
+ self.conv_reg = nn.Conv2d(self.feat_channels, 4, 3, padding=1)
+
+ def forward(self, x: Tuple[Tensor]) -> Tuple[List[Tensor], List[Tensor]]:
+ """Forward features from the upstream network.
+
+ Args:
+ x (tuple[Tensor]): Features from the upstream network, each is
+ a 4D-tensor.
+
+ Returns:
+ tuple: A tuple of each level outputs.
+
+ - cls_scores (list[Tensor]): Box scores for each scale level, \
+ each is a 4D-tensor, the channel number is num_classes.
+ - bbox_preds (list[Tensor]): Box energies / deltas for each \
+ scale level, each is a 4D-tensor, the channel number is 4.
+ """
+ return multi_apply(self.forward_single, x, self.scales, self.strides)
+
+ def forward_single(self, x: Tensor, scale: Scale,
+ stride: int) -> Tuple[Tensor, Tensor]:
+ """Forward features of a single scale level.
+
+ Args:
+ x (Tensor): FPN feature maps of the specified stride.
+ scale (:obj:`mmcv.cnn.Scale`): Learnable scale module to resize
+ the bbox prediction.
+ stride (int): The corresponding stride for feature maps.
+
+ Returns:
+ tuple: scores for each class, bbox predictions of
+ input feature maps.
+ """
+ cls_score, bbox_pred, _, _ = super().forward_single(x)
+ # scale the bbox_pred of different level
+ # float to avoid overflow when enabling FP16
+ bbox_pred = scale(bbox_pred).float()
+ # bbox_pred needed for gradient computation has been modified
+ # by F.relu(bbox_pred) when run with PyTorch 1.10. So replace
+ # F.relu(bbox_pred) with bbox_pred.clamp(min=0)
+ bbox_pred = bbox_pred.clamp(min=0)
+ if not self.training:
+ bbox_pred *= stride
+ return cls_score, bbox_pred
+
+ def loss_by_feat(
+ self,
+ cls_scores: List[Tensor],
+ bbox_preds: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ batch_gt_instances_ignore: OptInstanceList = None
+ ) -> Dict[str, Tensor]:
+ """Calculate the loss based on the features extracted by the detection
+ head.
+
+ Args:
+ cls_scores (list[Tensor]): Box scores for each scale level,
+ each is a 4D-tensor, the channel number is num_classes.
+ bbox_preds (list[Tensor]): Box energies / deltas for each scale
+ level, each is a 4D-tensor, the channel number is 4.
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components.
+ """
+ num_imgs = cls_scores[0].size(0)
+ assert len(cls_scores) == len(bbox_preds)
+ featmap_sizes = [featmap.size()[-2:] for featmap in cls_scores]
+ all_level_points = self.prior_generator.grid_priors(
+ featmap_sizes,
+ dtype=bbox_preds[0].dtype,
+ device=bbox_preds[0].device)
+
+ # 1 flatten outputs
+ flatten_cls_scores = [
+ cls_score.permute(0, 2, 3, 1).reshape(-1, self.cls_out_channels)
+ for cls_score in cls_scores
+ ]
+ flatten_bbox_preds = [
+ bbox_pred.permute(0, 2, 3, 1).reshape(-1, 4)
+ for bbox_pred in bbox_preds
+ ]
+ flatten_cls_scores = torch.cat(flatten_cls_scores)
+ flatten_bbox_preds = torch.cat(flatten_bbox_preds)
+
+ # repeat points to align with bbox_preds
+ flatten_points = torch.cat(
+ [points.repeat(num_imgs, 1) for points in all_level_points])
+
+ assert (torch.isfinite(flatten_bbox_preds).all().item())
+
+ # 2 calc reg and cls branch targets
+ cls_targets, bbox_targets = self.get_targets(all_level_points,
+ batch_gt_instances)
+
+ # 3 add more pos index for cls branch
+ featmap_sizes = flatten_points.new_tensor(featmap_sizes)
+ pos_inds, cls_labels = self.add_cls_pos_inds(flatten_points,
+ flatten_bbox_preds,
+ featmap_sizes,
+ batch_gt_instances)
+
+ # 4 calc cls loss
+ if pos_inds is None:
+ # num_gts=0
+ num_pos_cls = bbox_preds[0].new_tensor(0, dtype=torch.float)
+ else:
+ num_pos_cls = bbox_preds[0].new_tensor(
+ len(pos_inds), dtype=torch.float)
+ num_pos_cls = max(reduce_mean(num_pos_cls), 1.0)
+ flatten_cls_scores = flatten_cls_scores.sigmoid().clamp(
+ min=self.sigmoid_clamp, max=1 - self.sigmoid_clamp)
+ cls_loss = self.loss_cls(
+ flatten_cls_scores,
+ cls_targets,
+ pos_inds=pos_inds,
+ pos_labels=cls_labels,
+ avg_factor=num_pos_cls)
+
+ # 5 calc reg loss
+ pos_bbox_inds = torch.nonzero(
+ bbox_targets.max(dim=1)[0] >= 0).squeeze(1)
+ pos_bbox_preds = flatten_bbox_preds[pos_bbox_inds]
+ pos_bbox_targets = bbox_targets[pos_bbox_inds]
+
+ bbox_weight_map = cls_targets.max(dim=1)[0]
+ bbox_weight_map = bbox_weight_map[pos_bbox_inds]
+ bbox_weight_map = bbox_weight_map if self.soft_weight_on_reg \
+ else torch.ones_like(bbox_weight_map)
+ num_pos_bbox = max(reduce_mean(bbox_weight_map.sum()), 1.0)
+
+ if len(pos_bbox_inds) > 0:
+ pos_points = flatten_points[pos_bbox_inds]
+ pos_decoded_bbox_preds = self.bbox_coder.decode(
+ pos_points, pos_bbox_preds)
+ pos_decoded_target_preds = self.bbox_coder.decode(
+ pos_points, pos_bbox_targets)
+ bbox_loss = self.loss_bbox(
+ pos_decoded_bbox_preds,
+ pos_decoded_target_preds,
+ weight=bbox_weight_map,
+ avg_factor=num_pos_bbox)
+ else:
+ bbox_loss = flatten_bbox_preds.sum() * 0
+
+ return dict(loss_cls=cls_loss, loss_bbox=bbox_loss)
+
+ def get_targets(
+ self,
+ points: List[Tensor],
+ batch_gt_instances: InstanceList,
+ ) -> Tuple[Tensor, Tensor]:
+ """Compute classification and bbox targets for points in multiple
+ images.
+
+ Args:
+ points (list[Tensor]): Points of each fpn level, each has shape
+ (num_points, 2).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+
+ Returns:
+ tuple: Targets of each level.
+
+ - concat_lvl_labels (Tensor): Labels of all level and batch.
+ - concat_lvl_bbox_targets (Tensor): BBox targets of all \
+ level and batch.
+ """
+ assert len(points) == len(self.regress_ranges)
+
+ num_levels = len(points)
+ # the number of points per img, per lvl
+ num_points = [center.size(0) for center in points]
+
+ # expand regress ranges to align with points
+ expanded_regress_ranges = [
+ points[i].new_tensor(self.regress_ranges[i])[None].expand_as(
+ points[i]) for i in range(num_levels)
+ ]
+ # concat all levels points and regress ranges
+ concat_regress_ranges = torch.cat(expanded_regress_ranges, dim=0)
+ concat_points = torch.cat(points, dim=0)
+ concat_strides = torch.cat([
+ concat_points.new_ones(num_points[i]) * self.strides[i]
+ for i in range(num_levels)
+ ])
+
+ # get labels and bbox_targets of each image
+ cls_targets_list, bbox_targets_list = multi_apply(
+ self._get_targets_single,
+ batch_gt_instances,
+ points=concat_points,
+ regress_ranges=concat_regress_ranges,
+ strides=concat_strides)
+
+ bbox_targets_list = _transpose(bbox_targets_list, num_points)
+ cls_targets_list = _transpose(cls_targets_list, num_points)
+ concat_lvl_bbox_targets = torch.cat(bbox_targets_list, 0)
+ concat_lvl_cls_targets = torch.cat(cls_targets_list, dim=0)
+ return concat_lvl_cls_targets, concat_lvl_bbox_targets
+
+ def _get_targets_single(self, gt_instances: InstanceData, points: Tensor,
+ regress_ranges: Tensor,
+ strides: Tensor) -> Tuple[Tensor, Tensor]:
+ """Compute classification and bbox targets for a single image."""
+ num_points = points.size(0)
+ num_gts = len(gt_instances)
+ gt_bboxes = gt_instances.bboxes
+ gt_labels = gt_instances.labels
+
+ if num_gts == 0:
+ return gt_labels.new_full((num_points,
+ self.num_classes),
+ self.num_classes), \
+ gt_bboxes.new_full((num_points, 4), -1)
+
+ # Calculate the regression tblr target corresponding to all points
+ points = points[:, None].expand(num_points, num_gts, 2)
+ gt_bboxes = gt_bboxes[None].expand(num_points, num_gts, 4)
+ strides = strides[:, None, None].expand(num_points, num_gts, 2)
+
+ bbox_target = bbox2distance(points, gt_bboxes) # M x N x 4
+
+ # condition1: inside a gt bbox
+ inside_gt_bbox_mask = bbox_target.min(dim=2)[0] > 0 # M x N
+
+ # condition2: Calculate the nearest points from
+ # the upper, lower, left and right ranges from
+ # the center of the gt bbox
+ centers = ((gt_bboxes[..., [0, 1]] + gt_bboxes[..., [2, 3]]) / 2)
+ centers_discret = ((centers / strides).int() * strides).float() + \
+ strides / 2
+
+ centers_discret_dist = points - centers_discret
+ dist_x = centers_discret_dist[..., 0].abs()
+ dist_y = centers_discret_dist[..., 1].abs()
+ inside_gt_center3x3_mask = (dist_x <= strides[..., 0]) & \
+ (dist_y <= strides[..., 0])
+
+ # condition3: limit the regression range for each location
+ bbox_target_wh = bbox_target[..., :2] + bbox_target[..., 2:]
+ crit = (bbox_target_wh**2).sum(dim=2)**0.5 / 2
+ inside_fpn_level_mask = (crit >= regress_ranges[:, [0]]) & \
+ (crit <= regress_ranges[:, [1]])
+ bbox_target_mask = inside_gt_bbox_mask & \
+ inside_gt_center3x3_mask & \
+ inside_fpn_level_mask
+
+ # Calculate the distance weight map
+ gt_center_peak_mask = ((centers_discret_dist**2).sum(dim=2) == 0)
+ weighted_dist = ((points - centers)**2).sum(dim=2) # M x N
+ weighted_dist[gt_center_peak_mask] = 0
+
+ areas = (gt_bboxes[..., 2] - gt_bboxes[..., 0]) * (
+ gt_bboxes[..., 3] - gt_bboxes[..., 1])
+ radius = self.delta**2 * 2 * areas
+ radius = torch.clamp(radius, min=self.hm_min_radius**2)
+ weighted_dist = weighted_dist / radius
+
+ # Calculate bbox_target
+ bbox_weighted_dist = weighted_dist.clone()
+ bbox_weighted_dist[bbox_target_mask == 0] = INF * 1.0
+ min_dist, min_inds = bbox_weighted_dist.min(dim=1)
+ bbox_target = bbox_target[range(len(bbox_target)),
+ min_inds] # M x N x 4 --> M x 4
+ bbox_target[min_dist == INF] = -INF
+
+ # Convert to feature map scale
+ bbox_target /= strides[:, 0, :].repeat(1, 2)
+
+ # Calculate cls_target
+ cls_target = self._create_heatmaps_from_dist(weighted_dist, gt_labels)
+
+ return cls_target, bbox_target
+
+ @torch.no_grad()
+ def add_cls_pos_inds(
+ self, flatten_points: Tensor, flatten_bbox_preds: Tensor,
+ featmap_sizes: Tensor, batch_gt_instances: InstanceList
+ ) -> Tuple[Optional[Tensor], Optional[Tensor]]:
+ """Provide additional adaptive positive samples to the classification
+ branch.
+
+ Args:
+ flatten_points (Tensor): The point after flatten, including
+ batch image and all levels. The shape is (N, 2).
+ flatten_bbox_preds (Tensor): The bbox predicts after flatten,
+ including batch image and all levels. The shape is (N, 4).
+ featmap_sizes (Tensor): Feature map size of all layers.
+ The shape is (5, 2).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+
+ Returns:
+ tuple:
+
+ - pos_inds (Tensor): Adaptively selected positive sample index.
+ - cls_labels (Tensor): Corresponding positive class label.
+ """
+ outputs = self._get_center3x3_region_index_targets(
+ batch_gt_instances, featmap_sizes)
+ cls_labels, fpn_level_masks, center3x3_inds, \
+ center3x3_bbox_targets, center3x3_masks = outputs
+
+ num_gts, total_level, K = cls_labels.shape[0], len(
+ self.strides), center3x3_masks.shape[-1]
+
+ if num_gts == 0:
+ return None, None
+
+ # The out-of-bounds index is forcibly set to 0
+ # to prevent loss calculation errors
+ center3x3_inds[center3x3_masks == 0] = 0
+ reg_pred_center3x3 = flatten_bbox_preds[center3x3_inds]
+ center3x3_points = flatten_points[center3x3_inds].view(-1, 2)
+
+ center3x3_bbox_targets_expand = center3x3_bbox_targets.view(
+ -1, 4).clamp(min=0)
+
+ pos_decoded_bbox_preds = self.bbox_coder.decode(
+ center3x3_points, reg_pred_center3x3.view(-1, 4))
+ pos_decoded_target_preds = self.bbox_coder.decode(
+ center3x3_points, center3x3_bbox_targets_expand)
+ center3x3_bbox_loss = self.loss_bbox(
+ pos_decoded_bbox_preds,
+ pos_decoded_target_preds,
+ None,
+ reduction_override='none').view(num_gts, total_level,
+ K) / self.loss_bbox.loss_weight
+
+ # Invalid index Loss set to infinity
+ center3x3_bbox_loss[center3x3_masks == 0] = INF
+
+ # 4 is the center point of the sampled 9 points, the center point
+ # of gt bbox after discretization.
+ # The center point of gt bbox after discretization
+ # must be a positive sample, so we force its loss to be set to 0.
+ center3x3_bbox_loss.view(-1, K)[fpn_level_masks.view(-1), 4] = 0
+ center3x3_bbox_loss = center3x3_bbox_loss.view(num_gts, -1)
+
+ loss_thr = torch.kthvalue(
+ center3x3_bbox_loss, self.more_pos_topk, dim=1)[0]
+
+ loss_thr[loss_thr > self.more_pos_thresh] = self.more_pos_thresh
+ new_pos = center3x3_bbox_loss < loss_thr.view(num_gts, 1)
+ pos_inds = center3x3_inds.view(num_gts, -1)[new_pos]
+ cls_labels = cls_labels.view(num_gts,
+ 1).expand(num_gts,
+ total_level * K)[new_pos]
+ return pos_inds, cls_labels
+
+ def _create_heatmaps_from_dist(self, weighted_dist: Tensor,
+ cls_labels: Tensor) -> Tensor:
+ """Generate heatmaps of classification branch based on weighted
+ distance map."""
+ heatmaps = weighted_dist.new_zeros(
+ (weighted_dist.shape[0], self.num_classes))
+ for c in range(self.num_classes):
+ inds = (cls_labels == c) # N
+ if inds.int().sum() == 0:
+ continue
+ heatmaps[:, c] = torch.exp(-weighted_dist[:, inds].min(dim=1)[0])
+ zeros = heatmaps[:, c] < 1e-4
+ heatmaps[zeros, c] = 0
+ return heatmaps
+
+ def _get_center3x3_region_index_targets(self,
+ bacth_gt_instances: InstanceList,
+ shapes_per_level: Tensor) -> tuple:
+ """Get the center (and the 3x3 region near center) locations and target
+ of each objects."""
+ cls_labels = []
+ inside_fpn_level_masks = []
+ center3x3_inds = []
+ center3x3_masks = []
+ center3x3_bbox_targets = []
+
+ total_levels = len(self.strides)
+ batch = len(bacth_gt_instances)
+
+ shapes_per_level = shapes_per_level.long()
+ area_per_level = (shapes_per_level[:, 0] * shapes_per_level[:, 1])
+
+ # Select a total of 9 positions of 3x3 in the center of the gt bbox
+ # as candidate positive samples
+ K = 9
+ dx = shapes_per_level.new_tensor([-1, 0, 1, -1, 0, 1, -1, 0,
+ 1]).view(1, 1, K)
+ dy = shapes_per_level.new_tensor([-1, -1, -1, 0, 0, 0, 1, 1,
+ 1]).view(1, 1, K)
+
+ regress_ranges = shapes_per_level.new_tensor(self.regress_ranges).view(
+ len(self.regress_ranges), 2) # L x 2
+ strides = shapes_per_level.new_tensor(self.strides)
+
+ start_coord_pre_level = []
+ _start = 0
+ for level in range(total_levels):
+ start_coord_pre_level.append(_start)
+ _start = _start + batch * area_per_level[level]
+ start_coord_pre_level = shapes_per_level.new_tensor(
+ start_coord_pre_level).view(1, total_levels, 1)
+ area_per_level = area_per_level.view(1, total_levels, 1)
+
+ for im_i in range(batch):
+ gt_instance = bacth_gt_instances[im_i]
+ gt_bboxes = gt_instance.bboxes
+ gt_labels = gt_instance.labels
+ num_gts = gt_bboxes.shape[0]
+ if num_gts == 0:
+ continue
+
+ cls_labels.append(gt_labels)
+
+ gt_bboxes = gt_bboxes[:, None].expand(num_gts, total_levels, 4)
+ expanded_strides = strides[None, :,
+ None].expand(num_gts, total_levels, 2)
+ expanded_regress_ranges = regress_ranges[None].expand(
+ num_gts, total_levels, 2)
+ expanded_shapes_per_level = shapes_per_level[None].expand(
+ num_gts, total_levels, 2)
+
+ # calc reg_target
+ centers = ((gt_bboxes[..., [0, 1]] + gt_bboxes[..., [2, 3]]) / 2)
+ centers_inds = (centers / expanded_strides).long()
+ centers_discret = centers_inds * expanded_strides \
+ + expanded_strides // 2
+
+ bbox_target = bbox2distance(centers_discret,
+ gt_bboxes) # M x N x 4
+
+ # calc inside_fpn_level_mask
+ bbox_target_wh = bbox_target[..., :2] + bbox_target[..., 2:]
+ crit = (bbox_target_wh**2).sum(dim=2)**0.5 / 2
+ inside_fpn_level_mask = \
+ (crit >= expanded_regress_ranges[..., 0]) & \
+ (crit <= expanded_regress_ranges[..., 1])
+
+ inside_gt_bbox_mask = bbox_target.min(dim=2)[0] >= 0
+ inside_fpn_level_mask = inside_gt_bbox_mask & inside_fpn_level_mask
+ inside_fpn_level_masks.append(inside_fpn_level_mask)
+
+ # calc center3x3_ind and mask
+ expand_ws = expanded_shapes_per_level[..., 1:2].expand(
+ num_gts, total_levels, K)
+ expand_hs = expanded_shapes_per_level[..., 0:1].expand(
+ num_gts, total_levels, K)
+ centers_inds_x = centers_inds[..., 0:1]
+ centers_inds_y = centers_inds[..., 1:2]
+
+ center3x3_idx = start_coord_pre_level + \
+ im_i * area_per_level + \
+ (centers_inds_y + dy) * expand_ws + \
+ (centers_inds_x + dx)
+ center3x3_mask = \
+ ((centers_inds_y + dy) < expand_hs) & \
+ ((centers_inds_y + dy) >= 0) & \
+ ((centers_inds_x + dx) < expand_ws) & \
+ ((centers_inds_x + dx) >= 0)
+
+ # recalc center3x3 region reg target
+ bbox_target = bbox_target / expanded_strides.repeat(1, 1, 2)
+ center3x3_bbox_target = bbox_target[..., None, :].expand(
+ num_gts, total_levels, K, 4).clone()
+ center3x3_bbox_target[..., 0] += dx
+ center3x3_bbox_target[..., 1] += dy
+ center3x3_bbox_target[..., 2] -= dx
+ center3x3_bbox_target[..., 3] -= dy
+ # update center3x3_mask
+ center3x3_mask = center3x3_mask & (
+ center3x3_bbox_target.min(dim=3)[0] >= 0) # n x L x K
+
+ center3x3_inds.append(center3x3_idx)
+ center3x3_masks.append(center3x3_mask)
+ center3x3_bbox_targets.append(center3x3_bbox_target)
+
+ if len(inside_fpn_level_masks) > 0:
+ cls_labels = torch.cat(cls_labels, dim=0)
+ inside_fpn_level_masks = torch.cat(inside_fpn_level_masks, dim=0)
+ center3x3_inds = torch.cat(center3x3_inds, dim=0).long()
+ center3x3_bbox_targets = torch.cat(center3x3_bbox_targets, dim=0)
+ center3x3_masks = torch.cat(center3x3_masks, dim=0)
+ else:
+ cls_labels = shapes_per_level.new_zeros(0).long()
+ inside_fpn_level_masks = shapes_per_level.new_zeros(
+ (0, total_levels)).bool()
+ center3x3_inds = shapes_per_level.new_zeros(
+ (0, total_levels, K)).long()
+ center3x3_bbox_targets = shapes_per_level.new_zeros(
+ (0, total_levels, K, 4)).float()
+ center3x3_masks = shapes_per_level.new_zeros(
+ (0, total_levels, K)).bool()
+ return cls_labels, inside_fpn_level_masks, center3x3_inds, \
+ center3x3_bbox_targets, center3x3_masks
diff --git a/mmdet/models/dense_heads/centripetal_head.py b/mmdet/models/dense_heads/centripetal_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..18f6601ff82394864d53351b10b40f51eb2aec6b
--- /dev/null
+++ b/mmdet/models/dense_heads/centripetal_head.py
@@ -0,0 +1,459 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Optional, Tuple
+
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+from mmcv.ops import DeformConv2d
+from mmengine.model import normal_init
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.utils import (ConfigType, InstanceList, OptInstanceList,
+ OptMultiConfig)
+from ..utils import multi_apply
+from .corner_head import CornerHead
+
+
+@MODELS.register_module()
+class CentripetalHead(CornerHead):
+ """Head of CentripetalNet: Pursuing High-quality Keypoint Pairs for Object
+ Detection.
+
+ CentripetalHead inherits from :class:`CornerHead`. It removes the
+ embedding branch and adds guiding shift and centripetal shift branches.
+ More details can be found in the `paper
+ `_ .
+
+ Args:
+ num_classes (int): Number of categories excluding the background
+ category.
+ in_channels (int): Number of channels in the input feature map.
+ num_feat_levels (int): Levels of feature from the previous module.
+ 2 for HourglassNet-104 and 1 for HourglassNet-52. HourglassNet-104
+ outputs the final feature and intermediate supervision feature and
+ HourglassNet-52 only outputs the final feature. Defaults to 2.
+ corner_emb_channels (int): Channel of embedding vector. Defaults to 1.
+ train_cfg (:obj:`ConfigDict` or dict, optional): Training config.
+ Useless in CornerHead, but we keep this variable for
+ SingleStageDetector.
+ test_cfg (:obj:`ConfigDict` or dict, optional): Testing config of
+ CornerHead.
+ loss_heatmap (:obj:`ConfigDict` or dict): Config of corner heatmap
+ loss. Defaults to GaussianFocalLoss.
+ loss_embedding (:obj:`ConfigDict` or dict): Config of corner embedding
+ loss. Defaults to AssociativeEmbeddingLoss.
+ loss_offset (:obj:`ConfigDict` or dict): Config of corner offset loss.
+ Defaults to SmoothL1Loss.
+ loss_guiding_shift (:obj:`ConfigDict` or dict): Config of
+ guiding shift loss. Defaults to SmoothL1Loss.
+ loss_centripetal_shift (:obj:`ConfigDict` or dict): Config of
+ centripetal shift loss. Defaults to SmoothL1Loss.
+ init_cfg (:obj:`ConfigDict` or dict, optional): the config to control
+ the initialization.
+ """
+
+ def __init__(self,
+ *args,
+ centripetal_shift_channels: int = 2,
+ guiding_shift_channels: int = 2,
+ feat_adaption_conv_kernel: int = 3,
+ loss_guiding_shift: ConfigType = dict(
+ type='SmoothL1Loss', beta=1.0, loss_weight=0.05),
+ loss_centripetal_shift: ConfigType = dict(
+ type='SmoothL1Loss', beta=1.0, loss_weight=1),
+ init_cfg: OptMultiConfig = None,
+ **kwargs) -> None:
+ assert init_cfg is None, 'To prevent abnormal initialization ' \
+ 'behavior, init_cfg is not allowed to be set'
+ assert centripetal_shift_channels == 2, (
+ 'CentripetalHead only support centripetal_shift_channels == 2')
+ self.centripetal_shift_channels = centripetal_shift_channels
+ assert guiding_shift_channels == 2, (
+ 'CentripetalHead only support guiding_shift_channels == 2')
+ self.guiding_shift_channels = guiding_shift_channels
+ self.feat_adaption_conv_kernel = feat_adaption_conv_kernel
+ super().__init__(*args, init_cfg=init_cfg, **kwargs)
+ self.loss_guiding_shift = MODELS.build(loss_guiding_shift)
+ self.loss_centripetal_shift = MODELS.build(loss_centripetal_shift)
+
+ def _init_centripetal_layers(self) -> None:
+ """Initialize centripetal layers.
+
+ Including feature adaption deform convs (feat_adaption), deform offset
+ prediction convs (dcn_off), guiding shift (guiding_shift) and
+ centripetal shift ( centripetal_shift). Each branch has two parts:
+ prefix `tl_` for top-left and `br_` for bottom-right.
+ """
+ self.tl_feat_adaption = nn.ModuleList()
+ self.br_feat_adaption = nn.ModuleList()
+ self.tl_dcn_offset = nn.ModuleList()
+ self.br_dcn_offset = nn.ModuleList()
+ self.tl_guiding_shift = nn.ModuleList()
+ self.br_guiding_shift = nn.ModuleList()
+ self.tl_centripetal_shift = nn.ModuleList()
+ self.br_centripetal_shift = nn.ModuleList()
+
+ for _ in range(self.num_feat_levels):
+ self.tl_feat_adaption.append(
+ DeformConv2d(self.in_channels, self.in_channels,
+ self.feat_adaption_conv_kernel, 1, 1))
+ self.br_feat_adaption.append(
+ DeformConv2d(self.in_channels, self.in_channels,
+ self.feat_adaption_conv_kernel, 1, 1))
+
+ self.tl_guiding_shift.append(
+ self._make_layers(
+ out_channels=self.guiding_shift_channels,
+ in_channels=self.in_channels))
+ self.br_guiding_shift.append(
+ self._make_layers(
+ out_channels=self.guiding_shift_channels,
+ in_channels=self.in_channels))
+
+ self.tl_dcn_offset.append(
+ ConvModule(
+ self.guiding_shift_channels,
+ self.feat_adaption_conv_kernel**2 *
+ self.guiding_shift_channels,
+ 1,
+ bias=False,
+ act_cfg=None))
+ self.br_dcn_offset.append(
+ ConvModule(
+ self.guiding_shift_channels,
+ self.feat_adaption_conv_kernel**2 *
+ self.guiding_shift_channels,
+ 1,
+ bias=False,
+ act_cfg=None))
+
+ self.tl_centripetal_shift.append(
+ self._make_layers(
+ out_channels=self.centripetal_shift_channels,
+ in_channels=self.in_channels))
+ self.br_centripetal_shift.append(
+ self._make_layers(
+ out_channels=self.centripetal_shift_channels,
+ in_channels=self.in_channels))
+
+ def _init_layers(self) -> None:
+ """Initialize layers for CentripetalHead.
+
+ Including two parts: CornerHead layers and CentripetalHead layers
+ """
+ super()._init_layers() # using _init_layers in CornerHead
+ self._init_centripetal_layers()
+
+ def init_weights(self) -> None:
+ super().init_weights()
+ for i in range(self.num_feat_levels):
+ normal_init(self.tl_feat_adaption[i], std=0.01)
+ normal_init(self.br_feat_adaption[i], std=0.01)
+ normal_init(self.tl_dcn_offset[i].conv, std=0.1)
+ normal_init(self.br_dcn_offset[i].conv, std=0.1)
+ _ = [x.conv.reset_parameters() for x in self.tl_guiding_shift[i]]
+ _ = [x.conv.reset_parameters() for x in self.br_guiding_shift[i]]
+ _ = [
+ x.conv.reset_parameters() for x in self.tl_centripetal_shift[i]
+ ]
+ _ = [
+ x.conv.reset_parameters() for x in self.br_centripetal_shift[i]
+ ]
+
+ def forward_single(self, x: Tensor, lvl_ind: int) -> List[Tensor]:
+ """Forward feature of a single level.
+
+ Args:
+ x (Tensor): Feature of a single level.
+ lvl_ind (int): Level index of current feature.
+
+ Returns:
+ tuple[Tensor]: A tuple of CentripetalHead's output for current
+ feature level. Containing the following Tensors:
+
+ - tl_heat (Tensor): Predicted top-left corner heatmap.
+ - br_heat (Tensor): Predicted bottom-right corner heatmap.
+ - tl_off (Tensor): Predicted top-left offset heatmap.
+ - br_off (Tensor): Predicted bottom-right offset heatmap.
+ - tl_guiding_shift (Tensor): Predicted top-left guiding shift
+ heatmap.
+ - br_guiding_shift (Tensor): Predicted bottom-right guiding
+ shift heatmap.
+ - tl_centripetal_shift (Tensor): Predicted top-left centripetal
+ shift heatmap.
+ - br_centripetal_shift (Tensor): Predicted bottom-right
+ centripetal shift heatmap.
+ """
+ tl_heat, br_heat, _, _, tl_off, br_off, tl_pool, br_pool = super(
+ ).forward_single(
+ x, lvl_ind, return_pool=True)
+
+ tl_guiding_shift = self.tl_guiding_shift[lvl_ind](tl_pool)
+ br_guiding_shift = self.br_guiding_shift[lvl_ind](br_pool)
+
+ tl_dcn_offset = self.tl_dcn_offset[lvl_ind](tl_guiding_shift.detach())
+ br_dcn_offset = self.br_dcn_offset[lvl_ind](br_guiding_shift.detach())
+
+ tl_feat_adaption = self.tl_feat_adaption[lvl_ind](tl_pool,
+ tl_dcn_offset)
+ br_feat_adaption = self.br_feat_adaption[lvl_ind](br_pool,
+ br_dcn_offset)
+
+ tl_centripetal_shift = self.tl_centripetal_shift[lvl_ind](
+ tl_feat_adaption)
+ br_centripetal_shift = self.br_centripetal_shift[lvl_ind](
+ br_feat_adaption)
+
+ result_list = [
+ tl_heat, br_heat, tl_off, br_off, tl_guiding_shift,
+ br_guiding_shift, tl_centripetal_shift, br_centripetal_shift
+ ]
+ return result_list
+
+ def loss_by_feat(
+ self,
+ tl_heats: List[Tensor],
+ br_heats: List[Tensor],
+ tl_offs: List[Tensor],
+ br_offs: List[Tensor],
+ tl_guiding_shifts: List[Tensor],
+ br_guiding_shifts: List[Tensor],
+ tl_centripetal_shifts: List[Tensor],
+ br_centripetal_shifts: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ batch_gt_instances_ignore: OptInstanceList = None) -> dict:
+ """Calculate the loss based on the features extracted by the detection
+ head.
+
+ Args:
+ tl_heats (list[Tensor]): Top-left corner heatmaps for each level
+ with shape (N, num_classes, H, W).
+ br_heats (list[Tensor]): Bottom-right corner heatmaps for each
+ level with shape (N, num_classes, H, W).
+ tl_offs (list[Tensor]): Top-left corner offsets for each level
+ with shape (N, corner_offset_channels, H, W).
+ br_offs (list[Tensor]): Bottom-right corner offsets for each level
+ with shape (N, corner_offset_channels, H, W).
+ tl_guiding_shifts (list[Tensor]): Top-left guiding shifts for each
+ level with shape (N, guiding_shift_channels, H, W).
+ br_guiding_shifts (list[Tensor]): Bottom-right guiding shifts for
+ each level with shape (N, guiding_shift_channels, H, W).
+ tl_centripetal_shifts (list[Tensor]): Top-left centripetal shifts
+ for each level with shape (N, centripetal_shift_channels, H,
+ W).
+ br_centripetal_shifts (list[Tensor]): Bottom-right centripetal
+ shifts for each level with shape (N,
+ centripetal_shift_channels, H, W).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], optional):
+ Specify which bounding boxes can be ignored when computing
+ the loss.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components. Containing the
+ following losses:
+
+ - det_loss (list[Tensor]): Corner keypoint losses of all
+ feature levels.
+ - off_loss (list[Tensor]): Corner offset losses of all feature
+ levels.
+ - guiding_loss (list[Tensor]): Guiding shift losses of all
+ feature levels.
+ - centripetal_loss (list[Tensor]): Centripetal shift losses of
+ all feature levels.
+ """
+ gt_bboxes = [
+ gt_instances.bboxes for gt_instances in batch_gt_instances
+ ]
+ gt_labels = [
+ gt_instances.labels for gt_instances in batch_gt_instances
+ ]
+
+ targets = self.get_targets(
+ gt_bboxes,
+ gt_labels,
+ tl_heats[-1].shape,
+ batch_img_metas[0]['batch_input_shape'],
+ with_corner_emb=self.with_corner_emb,
+ with_guiding_shift=True,
+ with_centripetal_shift=True)
+ mlvl_targets = [targets for _ in range(self.num_feat_levels)]
+ [det_losses, off_losses, guiding_losses, centripetal_losses
+ ] = multi_apply(self.loss_by_feat_single, tl_heats, br_heats, tl_offs,
+ br_offs, tl_guiding_shifts, br_guiding_shifts,
+ tl_centripetal_shifts, br_centripetal_shifts,
+ mlvl_targets)
+ loss_dict = dict(
+ det_loss=det_losses,
+ off_loss=off_losses,
+ guiding_loss=guiding_losses,
+ centripetal_loss=centripetal_losses)
+ return loss_dict
+
+ def loss_by_feat_single(self, tl_hmp: Tensor, br_hmp: Tensor,
+ tl_off: Tensor, br_off: Tensor,
+ tl_guiding_shift: Tensor, br_guiding_shift: Tensor,
+ tl_centripetal_shift: Tensor,
+ br_centripetal_shift: Tensor,
+ targets: dict) -> Tuple[Tensor, ...]:
+ """Calculate the loss of a single scale level based on the features
+ extracted by the detection head.
+
+ Args:
+ tl_hmp (Tensor): Top-left corner heatmap for current level with
+ shape (N, num_classes, H, W).
+ br_hmp (Tensor): Bottom-right corner heatmap for current level with
+ shape (N, num_classes, H, W).
+ tl_off (Tensor): Top-left corner offset for current level with
+ shape (N, corner_offset_channels, H, W).
+ br_off (Tensor): Bottom-right corner offset for current level with
+ shape (N, corner_offset_channels, H, W).
+ tl_guiding_shift (Tensor): Top-left guiding shift for current level
+ with shape (N, guiding_shift_channels, H, W).
+ br_guiding_shift (Tensor): Bottom-right guiding shift for current
+ level with shape (N, guiding_shift_channels, H, W).
+ tl_centripetal_shift (Tensor): Top-left centripetal shift for
+ current level with shape (N, centripetal_shift_channels, H, W).
+ br_centripetal_shift (Tensor): Bottom-right centripetal shift for
+ current level with shape (N, centripetal_shift_channels, H, W).
+ targets (dict): Corner target generated by `get_targets`.
+
+ Returns:
+ tuple[torch.Tensor]: Losses of the head's different branches
+ containing the following losses:
+
+ - det_loss (Tensor): Corner keypoint loss.
+ - off_loss (Tensor): Corner offset loss.
+ - guiding_loss (Tensor): Guiding shift loss.
+ - centripetal_loss (Tensor): Centripetal shift loss.
+ """
+ targets['corner_embedding'] = None
+
+ det_loss, _, _, off_loss = super().loss_by_feat_single(
+ tl_hmp, br_hmp, None, None, tl_off, br_off, targets)
+
+ gt_tl_guiding_shift = targets['topleft_guiding_shift']
+ gt_br_guiding_shift = targets['bottomright_guiding_shift']
+ gt_tl_centripetal_shift = targets['topleft_centripetal_shift']
+ gt_br_centripetal_shift = targets['bottomright_centripetal_shift']
+
+ gt_tl_heatmap = targets['topleft_heatmap']
+ gt_br_heatmap = targets['bottomright_heatmap']
+ # We only compute the offset loss at the real corner position.
+ # The value of real corner would be 1 in heatmap ground truth.
+ # The mask is computed in class agnostic mode and its shape is
+ # batch * 1 * width * height.
+ tl_mask = gt_tl_heatmap.eq(1).sum(1).gt(0).unsqueeze(1).type_as(
+ gt_tl_heatmap)
+ br_mask = gt_br_heatmap.eq(1).sum(1).gt(0).unsqueeze(1).type_as(
+ gt_br_heatmap)
+
+ # Guiding shift loss
+ tl_guiding_loss = self.loss_guiding_shift(
+ tl_guiding_shift,
+ gt_tl_guiding_shift,
+ tl_mask,
+ avg_factor=tl_mask.sum())
+ br_guiding_loss = self.loss_guiding_shift(
+ br_guiding_shift,
+ gt_br_guiding_shift,
+ br_mask,
+ avg_factor=br_mask.sum())
+ guiding_loss = (tl_guiding_loss + br_guiding_loss) / 2.0
+ # Centripetal shift loss
+ tl_centripetal_loss = self.loss_centripetal_shift(
+ tl_centripetal_shift,
+ gt_tl_centripetal_shift,
+ tl_mask,
+ avg_factor=tl_mask.sum())
+ br_centripetal_loss = self.loss_centripetal_shift(
+ br_centripetal_shift,
+ gt_br_centripetal_shift,
+ br_mask,
+ avg_factor=br_mask.sum())
+ centripetal_loss = (tl_centripetal_loss + br_centripetal_loss) / 2.0
+
+ return det_loss, off_loss, guiding_loss, centripetal_loss
+
+ def predict_by_feat(self,
+ tl_heats: List[Tensor],
+ br_heats: List[Tensor],
+ tl_offs: List[Tensor],
+ br_offs: List[Tensor],
+ tl_guiding_shifts: List[Tensor],
+ br_guiding_shifts: List[Tensor],
+ tl_centripetal_shifts: List[Tensor],
+ br_centripetal_shifts: List[Tensor],
+ batch_img_metas: Optional[List[dict]] = None,
+ rescale: bool = False,
+ with_nms: bool = True) -> InstanceList:
+ """Transform a batch of output features extracted from the head into
+ bbox results.
+
+ Args:
+ tl_heats (list[Tensor]): Top-left corner heatmaps for each level
+ with shape (N, num_classes, H, W).
+ br_heats (list[Tensor]): Bottom-right corner heatmaps for each
+ level with shape (N, num_classes, H, W).
+ tl_offs (list[Tensor]): Top-left corner offsets for each level
+ with shape (N, corner_offset_channels, H, W).
+ br_offs (list[Tensor]): Bottom-right corner offsets for each level
+ with shape (N, corner_offset_channels, H, W).
+ tl_guiding_shifts (list[Tensor]): Top-left guiding shifts for each
+ level with shape (N, guiding_shift_channels, H, W). Useless in
+ this function, we keep this arg because it's the raw output
+ from CentripetalHead.
+ br_guiding_shifts (list[Tensor]): Bottom-right guiding shifts for
+ each level with shape (N, guiding_shift_channels, H, W).
+ Useless in this function, we keep this arg because it's the
+ raw output from CentripetalHead.
+ tl_centripetal_shifts (list[Tensor]): Top-left centripetal shifts
+ for each level with shape (N, centripetal_shift_channels, H,
+ W).
+ br_centripetal_shifts (list[Tensor]): Bottom-right centripetal
+ shifts for each level with shape (N,
+ centripetal_shift_channels, H, W).
+ batch_img_metas (list[dict], optional): Batch image meta info.
+ Defaults to None.
+ rescale (bool): If True, return boxes in original image space.
+ Defaults to False.
+ with_nms (bool): If True, do nms before return boxes.
+ Defaults to True.
+
+ Returns:
+ list[:obj:`InstanceData`]: Object detection results of each image
+ after the post process. Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ """
+ assert tl_heats[-1].shape[0] == br_heats[-1].shape[0] == len(
+ batch_img_metas)
+ result_list = []
+ for img_id in range(len(batch_img_metas)):
+ result_list.append(
+ self._predict_by_feat_single(
+ tl_heats[-1][img_id:img_id + 1, :],
+ br_heats[-1][img_id:img_id + 1, :],
+ tl_offs[-1][img_id:img_id + 1, :],
+ br_offs[-1][img_id:img_id + 1, :],
+ batch_img_metas[img_id],
+ tl_emb=None,
+ br_emb=None,
+ tl_centripetal_shift=tl_centripetal_shifts[-1][
+ img_id:img_id + 1, :],
+ br_centripetal_shift=br_centripetal_shifts[-1][
+ img_id:img_id + 1, :],
+ rescale=rescale,
+ with_nms=with_nms))
+
+ return result_list
diff --git a/mmdet/models/dense_heads/condinst_head.py b/mmdet/models/dense_heads/condinst_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..35a25e6339a8161314cb0523e7181f9d400023ac
--- /dev/null
+++ b/mmdet/models/dense_heads/condinst_head.py
@@ -0,0 +1,1226 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+from typing import Dict, List, Optional, Tuple
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule, Scale
+from mmengine.config import ConfigDict
+from mmengine.model import BaseModule, kaiming_init
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.structures.bbox import cat_boxes
+from mmdet.utils import (ConfigType, InstanceList, MultiConfig, OptConfigType,
+ OptInstanceList, reduce_mean)
+from ..task_modules.prior_generators import MlvlPointGenerator
+from ..utils import (aligned_bilinear, filter_scores_and_topk, multi_apply,
+ relative_coordinate_maps, select_single_mlvl)
+from ..utils.misc import empty_instances
+from .base_mask_head import BaseMaskHead
+from .fcos_head import FCOSHead
+
+INF = 1e8
+
+
+@MODELS.register_module()
+class CondInstBboxHead(FCOSHead):
+ """CondInst box head used in https://arxiv.org/abs/1904.02689.
+
+ Note that CondInst Bbox Head is a extension of FCOS head.
+ Two differences are described as follows:
+
+ 1. CondInst box head predicts a set of params for each instance.
+ 2. CondInst box head return the pos_gt_inds and pos_inds.
+
+ Args:
+ num_params (int): Number of params for instance segmentation.
+ """
+
+ def __init__(self, *args, num_params: int = 169, **kwargs) -> None:
+ self.num_params = num_params
+ super().__init__(*args, **kwargs)
+
+ def _init_layers(self) -> None:
+ """Initialize layers of the head."""
+ super()._init_layers()
+ self.controller = nn.Conv2d(
+ self.feat_channels, self.num_params, 3, padding=1)
+
+ def forward_single(self, x: Tensor, scale: Scale,
+ stride: int) -> Tuple[Tensor, Tensor, Tensor, Tensor]:
+ """Forward features of a single scale level.
+
+ Args:
+ x (Tensor): FPN feature maps of the specified stride.
+ scale (:obj:`mmcv.cnn.Scale`): Learnable scale module to resize
+ the bbox prediction.
+ stride (int): The corresponding stride for feature maps, only
+ used to normalize the bbox prediction when self.norm_on_bbox
+ is True.
+
+ Returns:
+ tuple: scores for each class, bbox predictions, centerness
+ predictions and param predictions of input feature maps.
+ """
+ cls_score, bbox_pred, cls_feat, reg_feat = \
+ super(FCOSHead, self).forward_single(x)
+ if self.centerness_on_reg:
+ centerness = self.conv_centerness(reg_feat)
+ else:
+ centerness = self.conv_centerness(cls_feat)
+ # scale the bbox_pred of different level
+ # float to avoid overflow when enabling FP16
+ bbox_pred = scale(bbox_pred).float()
+ if self.norm_on_bbox:
+ # bbox_pred needed for gradient computation has been modified
+ # by F.relu(bbox_pred) when run with PyTorch 1.10. So replace
+ # F.relu(bbox_pred) with bbox_pred.clamp(min=0)
+ bbox_pred = bbox_pred.clamp(min=0)
+ if not self.training:
+ bbox_pred *= stride
+ else:
+ bbox_pred = bbox_pred.exp()
+ param_pred = self.controller(reg_feat)
+ return cls_score, bbox_pred, centerness, param_pred
+
+ def loss_by_feat(
+ self,
+ cls_scores: List[Tensor],
+ bbox_preds: List[Tensor],
+ centernesses: List[Tensor],
+ param_preds: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ batch_gt_instances_ignore: OptInstanceList = None
+ ) -> Dict[str, Tensor]:
+ """Calculate the loss based on the features extracted by the detection
+ head.
+
+ Args:
+ cls_scores (list[Tensor]): Box scores for each scale level,
+ each is a 4D-tensor, the channel number is
+ num_points * num_classes.
+ bbox_preds (list[Tensor]): Box energies / deltas for each scale
+ level, each is a 4D-tensor, the channel number is
+ num_points * 4.
+ centernesses (list[Tensor]): centerness for each scale level, each
+ is a 4D-tensor, the channel number is num_points * 1.
+ param_preds (List[Tensor]): param_pred for each scale level, each
+ is a 4D-tensor, the channel number is num_params.
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], Optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components.
+ """
+ assert len(cls_scores) == len(bbox_preds) == len(centernesses)
+ featmap_sizes = [featmap.size()[-2:] for featmap in cls_scores]
+ # Need stride for rel coord compute
+ all_level_points_strides = self.prior_generator.grid_priors(
+ featmap_sizes,
+ dtype=bbox_preds[0].dtype,
+ device=bbox_preds[0].device,
+ with_stride=True)
+ all_level_points = [i[:, :2] for i in all_level_points_strides]
+ all_level_strides = [i[:, 2] for i in all_level_points_strides]
+ labels, bbox_targets, pos_inds_list, pos_gt_inds_list = \
+ self.get_targets(all_level_points, batch_gt_instances)
+
+ num_imgs = cls_scores[0].size(0)
+ # flatten cls_scores, bbox_preds and centerness
+ flatten_cls_scores = [
+ cls_score.permute(0, 2, 3, 1).reshape(-1, self.cls_out_channels)
+ for cls_score in cls_scores
+ ]
+ flatten_bbox_preds = [
+ bbox_pred.permute(0, 2, 3, 1).reshape(-1, 4)
+ for bbox_pred in bbox_preds
+ ]
+ flatten_centerness = [
+ centerness.permute(0, 2, 3, 1).reshape(-1)
+ for centerness in centernesses
+ ]
+ flatten_cls_scores = torch.cat(flatten_cls_scores)
+ flatten_bbox_preds = torch.cat(flatten_bbox_preds)
+ flatten_centerness = torch.cat(flatten_centerness)
+ flatten_labels = torch.cat(labels)
+ flatten_bbox_targets = torch.cat(bbox_targets)
+ # repeat points to align with bbox_preds
+ flatten_points = torch.cat(
+ [points.repeat(num_imgs, 1) for points in all_level_points])
+
+ # FG cat_id: [0, num_classes -1], BG cat_id: num_classes
+ bg_class_ind = self.num_classes
+ pos_inds = ((flatten_labels >= 0)
+ & (flatten_labels < bg_class_ind)).nonzero().reshape(-1)
+ num_pos = torch.tensor(
+ len(pos_inds), dtype=torch.float, device=bbox_preds[0].device)
+ num_pos = max(reduce_mean(num_pos), 1.0)
+ loss_cls = self.loss_cls(
+ flatten_cls_scores, flatten_labels, avg_factor=num_pos)
+
+ pos_bbox_preds = flatten_bbox_preds[pos_inds]
+ pos_centerness = flatten_centerness[pos_inds]
+ pos_bbox_targets = flatten_bbox_targets[pos_inds]
+ pos_centerness_targets = self.centerness_target(pos_bbox_targets)
+ # centerness weighted iou loss
+ centerness_denorm = max(
+ reduce_mean(pos_centerness_targets.sum().detach()), 1e-6)
+
+ if len(pos_inds) > 0:
+ pos_points = flatten_points[pos_inds]
+ pos_decoded_bbox_preds = self.bbox_coder.decode(
+ pos_points, pos_bbox_preds)
+ pos_decoded_target_preds = self.bbox_coder.decode(
+ pos_points, pos_bbox_targets)
+ loss_bbox = self.loss_bbox(
+ pos_decoded_bbox_preds,
+ pos_decoded_target_preds,
+ weight=pos_centerness_targets,
+ avg_factor=centerness_denorm)
+ loss_centerness = self.loss_centerness(
+ pos_centerness, pos_centerness_targets, avg_factor=num_pos)
+ else:
+ loss_bbox = pos_bbox_preds.sum()
+ loss_centerness = pos_centerness.sum()
+
+ self._raw_positive_infos.update(cls_scores=cls_scores)
+ self._raw_positive_infos.update(centernesses=centernesses)
+ self._raw_positive_infos.update(param_preds=param_preds)
+ self._raw_positive_infos.update(all_level_points=all_level_points)
+ self._raw_positive_infos.update(all_level_strides=all_level_strides)
+ self._raw_positive_infos.update(pos_gt_inds_list=pos_gt_inds_list)
+ self._raw_positive_infos.update(pos_inds_list=pos_inds_list)
+
+ return dict(
+ loss_cls=loss_cls,
+ loss_bbox=loss_bbox,
+ loss_centerness=loss_centerness)
+
+ def get_targets(
+ self, points: List[Tensor], batch_gt_instances: InstanceList
+ ) -> Tuple[List[Tensor], List[Tensor], List[Tensor], List[Tensor]]:
+ """Compute regression, classification and centerness targets for points
+ in multiple images.
+
+ Args:
+ points (list[Tensor]): Points of each fpn level, each has shape
+ (num_points, 2).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+
+ Returns:
+ tuple: Targets of each level.
+
+ - concat_lvl_labels (list[Tensor]): Labels of each level.
+ - concat_lvl_bbox_targets (list[Tensor]): BBox targets of each \
+ level.
+ - pos_inds_list (list[Tensor]): pos_inds of each image.
+ - pos_gt_inds_list (List[Tensor]): pos_gt_inds of each image.
+ """
+ assert len(points) == len(self.regress_ranges)
+ num_levels = len(points)
+ # expand regress ranges to align with points
+ expanded_regress_ranges = [
+ points[i].new_tensor(self.regress_ranges[i])[None].expand_as(
+ points[i]) for i in range(num_levels)
+ ]
+ # concat all levels points and regress ranges
+ concat_regress_ranges = torch.cat(expanded_regress_ranges, dim=0)
+ concat_points = torch.cat(points, dim=0)
+
+ # the number of points per img, per lvl
+ num_points = [center.size(0) for center in points]
+
+ # get labels and bbox_targets of each image
+ labels_list, bbox_targets_list, pos_inds_list, pos_gt_inds_list = \
+ multi_apply(
+ self._get_targets_single,
+ batch_gt_instances,
+ points=concat_points,
+ regress_ranges=concat_regress_ranges,
+ num_points_per_lvl=num_points)
+
+ # split to per img, per level
+ labels_list = [labels.split(num_points, 0) for labels in labels_list]
+ bbox_targets_list = [
+ bbox_targets.split(num_points, 0)
+ for bbox_targets in bbox_targets_list
+ ]
+
+ # concat per level image
+ concat_lvl_labels = []
+ concat_lvl_bbox_targets = []
+ for i in range(num_levels):
+ concat_lvl_labels.append(
+ torch.cat([labels[i] for labels in labels_list]))
+ bbox_targets = torch.cat(
+ [bbox_targets[i] for bbox_targets in bbox_targets_list])
+ if self.norm_on_bbox:
+ bbox_targets = bbox_targets / self.strides[i]
+ concat_lvl_bbox_targets.append(bbox_targets)
+ return (concat_lvl_labels, concat_lvl_bbox_targets, pos_inds_list,
+ pos_gt_inds_list)
+
+ def _get_targets_single(
+ self, gt_instances: InstanceData, points: Tensor,
+ regress_ranges: Tensor, num_points_per_lvl: List[int]
+ ) -> Tuple[Tensor, Tensor, Tensor, Tensor]:
+ """Compute regression and classification targets for a single image."""
+ num_points = points.size(0)
+ num_gts = len(gt_instances)
+ gt_bboxes = gt_instances.bboxes
+ gt_labels = gt_instances.labels
+ gt_masks = gt_instances.get('masks', None)
+
+ if num_gts == 0:
+ return gt_labels.new_full((num_points,), self.num_classes), \
+ gt_bboxes.new_zeros((num_points, 4)), \
+ gt_bboxes.new_zeros((0,), dtype=torch.int64), \
+ gt_bboxes.new_zeros((0,), dtype=torch.int64)
+
+ areas = (gt_bboxes[:, 2] - gt_bboxes[:, 0]) * (
+ gt_bboxes[:, 3] - gt_bboxes[:, 1])
+ # TODO: figure out why these two are different
+ # areas = areas[None].expand(num_points, num_gts)
+ areas = areas[None].repeat(num_points, 1)
+ regress_ranges = regress_ranges[:, None, :].expand(
+ num_points, num_gts, 2)
+ gt_bboxes = gt_bboxes[None].expand(num_points, num_gts, 4)
+ xs, ys = points[:, 0], points[:, 1]
+ xs = xs[:, None].expand(num_points, num_gts)
+ ys = ys[:, None].expand(num_points, num_gts)
+
+ left = xs - gt_bboxes[..., 0]
+ right = gt_bboxes[..., 2] - xs
+ top = ys - gt_bboxes[..., 1]
+ bottom = gt_bboxes[..., 3] - ys
+ bbox_targets = torch.stack((left, top, right, bottom), -1)
+
+ if self.center_sampling:
+ # condition1: inside a `center bbox`
+ radius = self.center_sample_radius
+ # if gt_mask not None, use gt mask's centroid to determine
+ # the center region rather than gt_bbox center
+ if gt_masks is None:
+ center_xs = (gt_bboxes[..., 0] + gt_bboxes[..., 2]) / 2
+ center_ys = (gt_bboxes[..., 1] + gt_bboxes[..., 3]) / 2
+ else:
+ h, w = gt_masks.height, gt_masks.width
+ masks = gt_masks.to_tensor(
+ dtype=torch.bool, device=gt_bboxes.device)
+ yys = torch.arange(
+ 0, h, dtype=torch.float32, device=masks.device)
+ xxs = torch.arange(
+ 0, w, dtype=torch.float32, device=masks.device)
+ # m00/m10/m01 represent the moments of a contour
+ # centroid is computed by m00/m10 and m00/m01
+ m00 = masks.sum(dim=-1).sum(dim=-1).clamp(min=1e-6)
+ m10 = (masks * xxs).sum(dim=-1).sum(dim=-1)
+ m01 = (masks * yys[:, None]).sum(dim=-1).sum(dim=-1)
+ center_xs = m10 / m00
+ center_ys = m01 / m00
+
+ center_xs = center_xs[None].expand(num_points, num_gts)
+ center_ys = center_ys[None].expand(num_points, num_gts)
+ center_gts = torch.zeros_like(gt_bboxes)
+ stride = center_xs.new_zeros(center_xs.shape)
+
+ # project the points on current lvl back to the `original` sizes
+ lvl_begin = 0
+ for lvl_idx, num_points_lvl in enumerate(num_points_per_lvl):
+ lvl_end = lvl_begin + num_points_lvl
+ stride[lvl_begin:lvl_end] = self.strides[lvl_idx] * radius
+ lvl_begin = lvl_end
+
+ x_mins = center_xs - stride
+ y_mins = center_ys - stride
+ x_maxs = center_xs + stride
+ y_maxs = center_ys + stride
+ center_gts[..., 0] = torch.where(x_mins > gt_bboxes[..., 0],
+ x_mins, gt_bboxes[..., 0])
+ center_gts[..., 1] = torch.where(y_mins > gt_bboxes[..., 1],
+ y_mins, gt_bboxes[..., 1])
+ center_gts[..., 2] = torch.where(x_maxs > gt_bboxes[..., 2],
+ gt_bboxes[..., 2], x_maxs)
+ center_gts[..., 3] = torch.where(y_maxs > gt_bboxes[..., 3],
+ gt_bboxes[..., 3], y_maxs)
+
+ cb_dist_left = xs - center_gts[..., 0]
+ cb_dist_right = center_gts[..., 2] - xs
+ cb_dist_top = ys - center_gts[..., 1]
+ cb_dist_bottom = center_gts[..., 3] - ys
+ center_bbox = torch.stack(
+ (cb_dist_left, cb_dist_top, cb_dist_right, cb_dist_bottom), -1)
+ inside_gt_bbox_mask = center_bbox.min(-1)[0] > 0
+ else:
+ # condition1: inside a gt bbox
+ inside_gt_bbox_mask = bbox_targets.min(-1)[0] > 0
+
+ # condition2: limit the regression range for each location
+ max_regress_distance = bbox_targets.max(-1)[0]
+ inside_regress_range = (
+ (max_regress_distance >= regress_ranges[..., 0])
+ & (max_regress_distance <= regress_ranges[..., 1]))
+
+ # if there are still more than one objects for a location,
+ # we choose the one with minimal area
+ areas[inside_gt_bbox_mask == 0] = INF
+ areas[inside_regress_range == 0] = INF
+ min_area, min_area_inds = areas.min(dim=1)
+
+ labels = gt_labels[min_area_inds]
+ labels[min_area == INF] = self.num_classes # set as BG
+ bbox_targets = bbox_targets[range(num_points), min_area_inds]
+
+ # return pos_inds & pos_gt_inds
+ bg_class_ind = self.num_classes
+ pos_inds = ((labels >= 0)
+ & (labels < bg_class_ind)).nonzero().reshape(-1)
+ pos_gt_inds = min_area_inds[labels < self.num_classes]
+ return labels, bbox_targets, pos_inds, pos_gt_inds
+
+ def get_positive_infos(self) -> InstanceList:
+ """Get positive information from sampling results.
+
+ Returns:
+ list[:obj:`InstanceData`]: Positive information of each image,
+ usually including positive bboxes, positive labels, positive
+ priors, etc.
+ """
+ assert len(self._raw_positive_infos) > 0
+
+ pos_gt_inds_list = self._raw_positive_infos['pos_gt_inds_list']
+ pos_inds_list = self._raw_positive_infos['pos_inds_list']
+ num_imgs = len(pos_gt_inds_list)
+
+ cls_score_list = []
+ centerness_list = []
+ param_pred_list = []
+ point_list = []
+ stride_list = []
+ for cls_score_per_lvl, centerness_per_lvl, param_pred_per_lvl,\
+ point_per_lvl, stride_per_lvl in \
+ zip(self._raw_positive_infos['cls_scores'],
+ self._raw_positive_infos['centernesses'],
+ self._raw_positive_infos['param_preds'],
+ self._raw_positive_infos['all_level_points'],
+ self._raw_positive_infos['all_level_strides']):
+ cls_score_per_lvl = \
+ cls_score_per_lvl.permute(
+ 0, 2, 3, 1).reshape(num_imgs, -1, self.num_classes)
+ centerness_per_lvl = \
+ centerness_per_lvl.permute(
+ 0, 2, 3, 1).reshape(num_imgs, -1, 1)
+ param_pred_per_lvl = \
+ param_pred_per_lvl.permute(
+ 0, 2, 3, 1).reshape(num_imgs, -1, self.num_params)
+ point_per_lvl = point_per_lvl.unsqueeze(0).repeat(num_imgs, 1, 1)
+ stride_per_lvl = stride_per_lvl.unsqueeze(0).repeat(num_imgs, 1)
+
+ cls_score_list.append(cls_score_per_lvl)
+ centerness_list.append(centerness_per_lvl)
+ param_pred_list.append(param_pred_per_lvl)
+ point_list.append(point_per_lvl)
+ stride_list.append(stride_per_lvl)
+ cls_scores = torch.cat(cls_score_list, dim=1)
+ centernesses = torch.cat(centerness_list, dim=1)
+ param_preds = torch.cat(param_pred_list, dim=1)
+ all_points = torch.cat(point_list, dim=1)
+ all_strides = torch.cat(stride_list, dim=1)
+
+ positive_infos = []
+ for i, (pos_gt_inds,
+ pos_inds) in enumerate(zip(pos_gt_inds_list, pos_inds_list)):
+ pos_info = InstanceData()
+ pos_info.points = all_points[i][pos_inds]
+ pos_info.strides = all_strides[i][pos_inds]
+ pos_info.scores = cls_scores[i][pos_inds]
+ pos_info.centernesses = centernesses[i][pos_inds]
+ pos_info.param_preds = param_preds[i][pos_inds]
+ pos_info.pos_assigned_gt_inds = pos_gt_inds
+ pos_info.pos_inds = pos_inds
+ positive_infos.append(pos_info)
+ return positive_infos
+
+ def predict_by_feat(self,
+ cls_scores: List[Tensor],
+ bbox_preds: List[Tensor],
+ score_factors: Optional[List[Tensor]] = None,
+ param_preds: Optional[List[Tensor]] = None,
+ batch_img_metas: Optional[List[dict]] = None,
+ cfg: Optional[ConfigDict] = None,
+ rescale: bool = False,
+ with_nms: bool = True) -> InstanceList:
+ """Transform a batch of output features extracted from the head into
+ bbox results.
+
+ Note: When score_factors is not None, the cls_scores are
+ usually multiplied by it then obtain the real score used in NMS,
+ such as CenterNess in FCOS, IoU branch in ATSS.
+
+ Args:
+ cls_scores (list[Tensor]): Classification scores for all
+ scale levels, each is a 4D-tensor, has shape
+ (batch_size, num_priors * num_classes, H, W).
+ bbox_preds (list[Tensor]): Box energies / deltas for all
+ scale levels, each is a 4D-tensor, has shape
+ (batch_size, num_priors * 4, H, W).
+ score_factors (list[Tensor], optional): Score factor for
+ all scale level, each is a 4D-tensor, has shape
+ (batch_size, num_priors * 1, H, W). Defaults to None.
+ param_preds (list[Tensor], optional): Params for all scale
+ level, each is a 4D-tensor, has shape
+ (batch_size, num_priors * num_params, H, W)
+ batch_img_metas (list[dict], Optional): Batch image meta info.
+ Defaults to None.
+ cfg (ConfigDict, optional): Test / postprocessing
+ configuration, if None, test_cfg would be used.
+ Defaults to None.
+ rescale (bool): If True, return boxes in original image space.
+ Defaults to False.
+ with_nms (bool): If True, do nms before return boxes.
+ Defaults to True.
+
+ Returns:
+ list[:obj:`InstanceData`]: Object detection results of each image
+ after the post process. Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ """
+ assert len(cls_scores) == len(bbox_preds)
+
+ if score_factors is None:
+ # e.g. Retina, FreeAnchor, Foveabox, etc.
+ with_score_factors = False
+ else:
+ # e.g. FCOS, PAA, ATSS, AutoAssign, etc.
+ with_score_factors = True
+ assert len(cls_scores) == len(score_factors)
+
+ num_levels = len(cls_scores)
+
+ featmap_sizes = [cls_scores[i].shape[-2:] for i in range(num_levels)]
+ all_level_points_strides = self.prior_generator.grid_priors(
+ featmap_sizes,
+ dtype=bbox_preds[0].dtype,
+ device=bbox_preds[0].device,
+ with_stride=True)
+ all_level_points = [i[:, :2] for i in all_level_points_strides]
+ all_level_strides = [i[:, 2] for i in all_level_points_strides]
+
+ result_list = []
+
+ for img_id in range(len(batch_img_metas)):
+ img_meta = batch_img_metas[img_id]
+ cls_score_list = select_single_mlvl(
+ cls_scores, img_id, detach=True)
+ bbox_pred_list = select_single_mlvl(
+ bbox_preds, img_id, detach=True)
+ if with_score_factors:
+ score_factor_list = select_single_mlvl(
+ score_factors, img_id, detach=True)
+ else:
+ score_factor_list = [None for _ in range(num_levels)]
+ param_pred_list = select_single_mlvl(
+ param_preds, img_id, detach=True)
+
+ results = self._predict_by_feat_single(
+ cls_score_list=cls_score_list,
+ bbox_pred_list=bbox_pred_list,
+ score_factor_list=score_factor_list,
+ param_pred_list=param_pred_list,
+ mlvl_points=all_level_points,
+ mlvl_strides=all_level_strides,
+ img_meta=img_meta,
+ cfg=cfg,
+ rescale=rescale,
+ with_nms=with_nms)
+ result_list.append(results)
+ return result_list
+
+ def _predict_by_feat_single(self,
+ cls_score_list: List[Tensor],
+ bbox_pred_list: List[Tensor],
+ score_factor_list: List[Tensor],
+ param_pred_list: List[Tensor],
+ mlvl_points: List[Tensor],
+ mlvl_strides: List[Tensor],
+ img_meta: dict,
+ cfg: ConfigDict,
+ rescale: bool = False,
+ with_nms: bool = True) -> InstanceData:
+ """Transform a single image's features extracted from the head into
+ bbox results.
+
+ Args:
+ cls_score_list (list[Tensor]): Box scores from all scale
+ levels of a single image, each item has shape
+ (num_priors * num_classes, H, W).
+ bbox_pred_list (list[Tensor]): Box energies / deltas from
+ all scale levels of a single image, each item has shape
+ (num_priors * 4, H, W).
+ score_factor_list (list[Tensor]): Score factor from all scale
+ levels of a single image, each item has shape
+ (num_priors * 1, H, W).
+ param_pred_list (List[Tensor]): Param predition from all scale
+ levels of a single image, each item has shape
+ (num_priors * num_params, H, W).
+ mlvl_points (list[Tensor]): Each element in the list is
+ the priors of a single level in feature pyramid.
+ It has shape (num_priors, 2)
+ mlvl_strides (List[Tensor]): Each element in the list is
+ the stride of a single level in feature pyramid.
+ It has shape (num_priors, 1)
+ img_meta (dict): Image meta info.
+ cfg (mmengine.Config): Test / postprocessing configuration,
+ if None, test_cfg would be used.
+ rescale (bool): If True, return boxes in original image space.
+ Defaults to False.
+ with_nms (bool): If True, do nms before return boxes.
+ Defaults to True.
+
+ Returns:
+ :obj:`InstanceData`: Detection results of each image
+ after the post process.
+ Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ """
+ if score_factor_list[0] is None:
+ # e.g. Retina, FreeAnchor, etc.
+ with_score_factors = False
+ else:
+ # e.g. FCOS, PAA, ATSS, etc.
+ with_score_factors = True
+
+ cfg = self.test_cfg if cfg is None else cfg
+ cfg = copy.deepcopy(cfg)
+ img_shape = img_meta['img_shape']
+ nms_pre = cfg.get('nms_pre', -1)
+
+ mlvl_bbox_preds = []
+ mlvl_param_preds = []
+ mlvl_valid_points = []
+ mlvl_valid_strides = []
+ mlvl_scores = []
+ mlvl_labels = []
+ if with_score_factors:
+ mlvl_score_factors = []
+ else:
+ mlvl_score_factors = None
+ for level_idx, (cls_score, bbox_pred, score_factor,
+ param_pred, points, strides) in \
+ enumerate(zip(cls_score_list, bbox_pred_list,
+ score_factor_list, param_pred_list,
+ mlvl_points, mlvl_strides)):
+
+ assert cls_score.size()[-2:] == bbox_pred.size()[-2:]
+
+ dim = self.bbox_coder.encode_size
+ bbox_pred = bbox_pred.permute(1, 2, 0).reshape(-1, dim)
+ if with_score_factors:
+ score_factor = score_factor.permute(1, 2,
+ 0).reshape(-1).sigmoid()
+ cls_score = cls_score.permute(1, 2,
+ 0).reshape(-1, self.cls_out_channels)
+ if self.use_sigmoid_cls:
+ scores = cls_score.sigmoid()
+ else:
+ # remind that we set FG labels to [0, num_class-1]
+ # since mmdet v2.0
+ # BG cat_id: num_class
+ scores = cls_score.softmax(-1)[:, :-1]
+
+ param_pred = param_pred.permute(1, 2,
+ 0).reshape(-1, self.num_params)
+
+ # After https://github.com/open-mmlab/mmdetection/pull/6268/,
+ # this operation keeps fewer bboxes under the same `nms_pre`.
+ # There is no difference in performance for most models. If you
+ # find a slight drop in performance, you can set a larger
+ # `nms_pre` than before.
+ score_thr = cfg.get('score_thr', 0)
+
+ results = filter_scores_and_topk(
+ scores, score_thr, nms_pre,
+ dict(
+ bbox_pred=bbox_pred,
+ param_pred=param_pred,
+ points=points,
+ strides=strides))
+ scores, labels, keep_idxs, filtered_results = results
+
+ bbox_pred = filtered_results['bbox_pred']
+ param_pred = filtered_results['param_pred']
+ points = filtered_results['points']
+ strides = filtered_results['strides']
+
+ if with_score_factors:
+ score_factor = score_factor[keep_idxs]
+
+ mlvl_bbox_preds.append(bbox_pred)
+ mlvl_param_preds.append(param_pred)
+ mlvl_valid_points.append(points)
+ mlvl_valid_strides.append(strides)
+ mlvl_scores.append(scores)
+ mlvl_labels.append(labels)
+
+ if with_score_factors:
+ mlvl_score_factors.append(score_factor)
+
+ bbox_pred = torch.cat(mlvl_bbox_preds)
+ priors = cat_boxes(mlvl_valid_points)
+ bboxes = self.bbox_coder.decode(priors, bbox_pred, max_shape=img_shape)
+
+ results = InstanceData()
+ results.bboxes = bboxes
+ results.scores = torch.cat(mlvl_scores)
+ results.labels = torch.cat(mlvl_labels)
+ results.param_preds = torch.cat(mlvl_param_preds)
+ results.points = torch.cat(mlvl_valid_points)
+ results.strides = torch.cat(mlvl_valid_strides)
+ if with_score_factors:
+ results.score_factors = torch.cat(mlvl_score_factors)
+
+ return self._bbox_post_process(
+ results=results,
+ cfg=cfg,
+ rescale=rescale,
+ with_nms=with_nms,
+ img_meta=img_meta)
+
+
+class MaskFeatModule(BaseModule):
+ """CondInst mask feature map branch used in \
+ https://arxiv.org/abs/1904.02689.
+
+ Args:
+ in_channels (int): Number of channels in the input feature map.
+ feat_channels (int): Number of hidden channels of the mask feature
+ map branch.
+ start_level (int): The starting feature map level from RPN that
+ will be used to predict the mask feature map.
+ end_level (int): The ending feature map level from rpn that
+ will be used to predict the mask feature map.
+ out_channels (int): Number of output channels of the mask feature
+ map branch. This is the channel count of the mask
+ feature map that to be dynamically convolved with the predicted
+ kernel.
+ mask_stride (int): Downsample factor of the mask feature map output.
+ Defaults to 4.
+ num_stacked_convs (int): Number of convs in mask feature branch.
+ conv_cfg (dict): Config dict for convolution layer. Default: None.
+ norm_cfg (dict): Config dict for normalization layer. Default: None.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ """
+
+ def __init__(self,
+ in_channels: int,
+ feat_channels: int,
+ start_level: int,
+ end_level: int,
+ out_channels: int,
+ mask_stride: int = 4,
+ num_stacked_convs: int = 4,
+ conv_cfg: OptConfigType = None,
+ norm_cfg: OptConfigType = None,
+ init_cfg: MultiConfig = [
+ dict(type='Normal', layer='Conv2d', std=0.01)
+ ],
+ **kwargs) -> None:
+ super().__init__(init_cfg=init_cfg)
+ self.in_channels = in_channels
+ self.feat_channels = feat_channels
+ self.start_level = start_level
+ self.end_level = end_level
+ self.mask_stride = mask_stride
+ self.num_stacked_convs = num_stacked_convs
+ assert start_level >= 0 and end_level >= start_level
+ self.out_channels = out_channels
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self._init_layers()
+
+ def _init_layers(self) -> None:
+ """Initialize layers of the head."""
+ self.convs_all_levels = nn.ModuleList()
+ for i in range(self.start_level, self.end_level + 1):
+ convs_per_level = nn.Sequential()
+ convs_per_level.add_module(
+ f'conv{i}',
+ ConvModule(
+ self.in_channels,
+ self.feat_channels,
+ 3,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ inplace=False,
+ bias=False))
+ self.convs_all_levels.append(convs_per_level)
+
+ conv_branch = []
+ for _ in range(self.num_stacked_convs):
+ conv_branch.append(
+ ConvModule(
+ self.feat_channels,
+ self.feat_channels,
+ 3,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ bias=False))
+ self.conv_branch = nn.Sequential(*conv_branch)
+
+ self.conv_pred = nn.Conv2d(
+ self.feat_channels, self.out_channels, 1, stride=1)
+
+ def init_weights(self) -> None:
+ """Initialize weights of the head."""
+ super().init_weights()
+ kaiming_init(self.convs_all_levels, a=1, distribution='uniform')
+ kaiming_init(self.conv_branch, a=1, distribution='uniform')
+ kaiming_init(self.conv_pred, a=1, distribution='uniform')
+
+ def forward(self, x: Tuple[Tensor]) -> Tensor:
+ """Forward features from the upstream network.
+
+ Args:
+ x (tuple[Tensor]): Features from the upstream network, each is
+ a 4D-tensor.
+
+ Returns:
+ Tensor: The predicted mask feature map.
+ """
+ inputs = x[self.start_level:self.end_level + 1]
+ assert len(inputs) == (self.end_level - self.start_level + 1)
+ feature_add_all_level = self.convs_all_levels[0](inputs[0])
+ target_h, target_w = feature_add_all_level.size()[2:]
+ for i in range(1, len(inputs)):
+ input_p = inputs[i]
+ x_p = self.convs_all_levels[i](input_p)
+ h, w = x_p.size()[2:]
+ factor_h = target_h // h
+ factor_w = target_w // w
+ assert factor_h == factor_w
+ feature_per_level = aligned_bilinear(x_p, factor_h)
+ feature_add_all_level = feature_add_all_level + \
+ feature_per_level
+
+ feature_add_all_level = self.conv_branch(feature_add_all_level)
+ feature_pred = self.conv_pred(feature_add_all_level)
+ return feature_pred
+
+
+@MODELS.register_module()
+class CondInstMaskHead(BaseMaskHead):
+ """CondInst mask head used in https://arxiv.org/abs/1904.02689.
+
+ This head outputs the mask for CondInst.
+
+ Args:
+ mask_feature_head (dict): Config of CondInstMaskFeatHead.
+ num_layers (int): Number of dynamic conv layers.
+ feat_channels (int): Number of channels in the dynamic conv.
+ mask_out_stride (int): The stride of the mask feat.
+ size_of_interest (int): The size of the region used in rel coord.
+ max_masks_to_train (int): Maximum number of masks to train for
+ each image.
+ loss_segm (:obj:`ConfigDict` or dict, optional): Config of
+ segmentation loss.
+ train_cfg (:obj:`ConfigDict` or dict, optional): Training config
+ of head.
+ test_cfg (:obj:`ConfigDict` or dict, optional): Testing config of
+ head.
+ """
+
+ def __init__(self,
+ mask_feature_head: ConfigType,
+ num_layers: int = 3,
+ feat_channels: int = 8,
+ mask_out_stride: int = 4,
+ size_of_interest: int = 8,
+ max_masks_to_train: int = -1,
+ topk_masks_per_img: int = -1,
+ loss_mask: ConfigType = None,
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None) -> None:
+ super().__init__()
+ self.mask_feature_head = MaskFeatModule(**mask_feature_head)
+ self.mask_feat_stride = self.mask_feature_head.mask_stride
+ self.in_channels = self.mask_feature_head.out_channels
+ self.num_layers = num_layers
+ self.feat_channels = feat_channels
+ self.size_of_interest = size_of_interest
+ self.mask_out_stride = mask_out_stride
+ self.max_masks_to_train = max_masks_to_train
+ self.topk_masks_per_img = topk_masks_per_img
+ self.prior_generator = MlvlPointGenerator([self.mask_feat_stride])
+
+ self.train_cfg = train_cfg
+ self.test_cfg = test_cfg
+ self.loss_mask = MODELS.build(loss_mask)
+ self._init_layers()
+
+ def _init_layers(self) -> None:
+ """Initialize layers of the head."""
+ weight_nums, bias_nums = [], []
+ for i in range(self.num_layers):
+ if i == 0:
+ weight_nums.append((self.in_channels + 2) * self.feat_channels)
+ bias_nums.append(self.feat_channels)
+ elif i == self.num_layers - 1:
+ weight_nums.append(self.feat_channels * 1)
+ bias_nums.append(1)
+ else:
+ weight_nums.append(self.feat_channels * self.feat_channels)
+ bias_nums.append(self.feat_channels)
+
+ self.weight_nums = weight_nums
+ self.bias_nums = bias_nums
+ self.num_params = sum(weight_nums) + sum(bias_nums)
+
+ def parse_dynamic_params(
+ self, params: Tensor) -> Tuple[List[Tensor], List[Tensor]]:
+ """parse the dynamic params for dynamic conv."""
+ num_insts = params.size(0)
+ params_splits = list(
+ torch.split_with_sizes(
+ params, self.weight_nums + self.bias_nums, dim=1))
+ weight_splits = params_splits[:self.num_layers]
+ bias_splits = params_splits[self.num_layers:]
+ for i in range(self.num_layers):
+ if i < self.num_layers - 1:
+ weight_splits[i] = weight_splits[i].reshape(
+ num_insts * self.in_channels, -1, 1, 1)
+ bias_splits[i] = bias_splits[i].reshape(num_insts *
+ self.in_channels)
+ else:
+ # out_channels x in_channels x 1 x 1
+ weight_splits[i] = weight_splits[i].reshape(
+ num_insts * 1, -1, 1, 1)
+ bias_splits[i] = bias_splits[i].reshape(num_insts)
+
+ return weight_splits, bias_splits
+
+ def dynamic_conv_forward(self, features: Tensor, weights: List[Tensor],
+ biases: List[Tensor], num_insts: int) -> Tensor:
+ """dynamic forward, each layer follow a relu."""
+ n_layers = len(weights)
+ x = features
+ for i, (w, b) in enumerate(zip(weights, biases)):
+ x = F.conv2d(x, w, bias=b, stride=1, padding=0, groups=num_insts)
+ if i < n_layers - 1:
+ x = F.relu(x)
+ return x
+
+ def forward(self, x: tuple, positive_infos: InstanceList) -> tuple:
+ """Forward feature from the upstream network to get prototypes and
+ linearly combine the prototypes, using masks coefficients, into
+ instance masks. Finally, crop the instance masks with given bboxes.
+
+ Args:
+ x (Tuple[Tensor]): Feature from the upstream network, which is
+ a 4D-tensor.
+ positive_infos (List[:obj:``InstanceData``]): Positive information
+ that calculate from detect head.
+
+ Returns:
+ tuple: Predicted instance segmentation masks
+ """
+ mask_feats = self.mask_feature_head(x)
+ return multi_apply(self.forward_single, mask_feats, positive_infos)
+
+ def forward_single(self, mask_feat: Tensor,
+ positive_info: InstanceData) -> Tensor:
+ """Forward features of a each image."""
+ pos_param_preds = positive_info.get('param_preds')
+ pos_points = positive_info.get('points')
+ pos_strides = positive_info.get('strides')
+
+ num_inst = pos_param_preds.shape[0]
+ mask_feat = mask_feat[None].repeat(num_inst, 1, 1, 1)
+ _, _, H, W = mask_feat.size()
+ if num_inst == 0:
+ return (pos_param_preds.new_zeros((0, 1, H, W)), )
+
+ locations = self.prior_generator.single_level_grid_priors(
+ mask_feat.size()[2:], 0, device=mask_feat.device)
+
+ rel_coords = relative_coordinate_maps(locations, pos_points,
+ pos_strides,
+ self.size_of_interest,
+ mask_feat.size()[2:])
+ mask_head_inputs = torch.cat([rel_coords, mask_feat], dim=1)
+ mask_head_inputs = mask_head_inputs.reshape(1, -1, H, W)
+
+ weights, biases = self.parse_dynamic_params(pos_param_preds)
+ mask_preds = self.dynamic_conv_forward(mask_head_inputs, weights,
+ biases, num_inst)
+ mask_preds = mask_preds.reshape(-1, H, W)
+ mask_preds = aligned_bilinear(
+ mask_preds.unsqueeze(0),
+ int(self.mask_feat_stride / self.mask_out_stride)).squeeze(0)
+
+ return (mask_preds, )
+
+ def loss_by_feat(self, mask_preds: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict], positive_infos: InstanceList,
+ **kwargs) -> dict:
+ """Calculate the loss based on the features extracted by the mask head.
+
+ Args:
+ mask_preds (list[Tensor]): List of predicted masks, each has
+ shape (num_classes, H, W).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes``, ``masks``,
+ and ``labels`` attributes.
+ batch_img_metas (list[dict]): Meta information of multiple images.
+ positive_infos (List[:obj:``InstanceData``]): Information of
+ positive samples of each image that are assigned in detection
+ head.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components.
+ """
+ assert positive_infos is not None, \
+ 'positive_infos should not be None in `CondInstMaskHead`'
+ losses = dict()
+
+ loss_mask = 0.
+ num_imgs = len(mask_preds)
+ total_pos = 0
+
+ for idx in range(num_imgs):
+ (mask_pred, pos_mask_targets, num_pos) = \
+ self._get_targets_single(
+ mask_preds[idx], batch_gt_instances[idx],
+ positive_infos[idx])
+ # mask loss
+ total_pos += num_pos
+ if num_pos == 0 or pos_mask_targets is None:
+ loss = mask_pred.new_zeros(1).mean()
+ else:
+ loss = self.loss_mask(
+ mask_pred, pos_mask_targets,
+ reduction_override='none').sum()
+ loss_mask += loss
+
+ if total_pos == 0:
+ total_pos += 1 # avoid nan
+ loss_mask = loss_mask / total_pos
+ losses.update(loss_mask=loss_mask)
+ return losses
+
+ def _get_targets_single(self, mask_preds: Tensor,
+ gt_instances: InstanceData,
+ positive_info: InstanceData):
+ """Compute targets for predictions of single image.
+
+ Args:
+ mask_preds (Tensor): Predicted prototypes with shape
+ (num_classes, H, W).
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It should includes ``bboxes``, ``labels``,
+ and ``masks`` attributes.
+ positive_info (:obj:`InstanceData`): Information of positive
+ samples that are assigned in detection head. It usually
+ contains following keys.
+
+ - pos_assigned_gt_inds (Tensor): Assigner GT indexes of
+ positive proposals, has shape (num_pos, )
+ - pos_inds (Tensor): Positive index of image, has
+ shape (num_pos, ).
+ - param_pred (Tensor): Positive param preditions
+ with shape (num_pos, num_params).
+
+ Returns:
+ tuple: Usually returns a tuple containing learning targets.
+
+ - mask_preds (Tensor): Positive predicted mask with shape
+ (num_pos, mask_h, mask_w).
+ - pos_mask_targets (Tensor): Positive mask targets with shape
+ (num_pos, mask_h, mask_w).
+ - num_pos (int): Positive numbers.
+ """
+ gt_bboxes = gt_instances.bboxes
+ device = gt_bboxes.device
+ gt_masks = gt_instances.masks.to_tensor(
+ dtype=torch.bool, device=device).float()
+
+ # process with mask targets
+ pos_assigned_gt_inds = positive_info.get('pos_assigned_gt_inds')
+ scores = positive_info.get('scores')
+ centernesses = positive_info.get('centernesses')
+ num_pos = pos_assigned_gt_inds.size(0)
+
+ if gt_masks.size(0) == 0 or num_pos == 0:
+ return mask_preds, None, 0
+ # Since we're producing (near) full image masks,
+ # it'd take too much vram to backprop on every single mask.
+ # Thus we select only a subset.
+ if (self.max_masks_to_train != -1) and \
+ (num_pos > self.max_masks_to_train):
+ perm = torch.randperm(num_pos)
+ select = perm[:self.max_masks_to_train]
+ mask_preds = mask_preds[select]
+ pos_assigned_gt_inds = pos_assigned_gt_inds[select]
+ num_pos = self.max_masks_to_train
+ elif self.topk_masks_per_img != -1:
+ unique_gt_inds = pos_assigned_gt_inds.unique()
+ num_inst_per_gt = max(
+ int(self.topk_masks_per_img / len(unique_gt_inds)), 1)
+
+ keep_mask_preds = []
+ keep_pos_assigned_gt_inds = []
+ for gt_ind in unique_gt_inds:
+ per_inst_pos_inds = (pos_assigned_gt_inds == gt_ind)
+ mask_preds_per_inst = mask_preds[per_inst_pos_inds]
+ gt_inds_per_inst = pos_assigned_gt_inds[per_inst_pos_inds]
+ if sum(per_inst_pos_inds) > num_inst_per_gt:
+ per_inst_scores = scores[per_inst_pos_inds].sigmoid().max(
+ dim=1)[0]
+ per_inst_centerness = centernesses[
+ per_inst_pos_inds].sigmoid().reshape(-1, )
+ select = (per_inst_scores * per_inst_centerness).topk(
+ k=num_inst_per_gt, dim=0)[1]
+ mask_preds_per_inst = mask_preds_per_inst[select]
+ gt_inds_per_inst = gt_inds_per_inst[select]
+ keep_mask_preds.append(mask_preds_per_inst)
+ keep_pos_assigned_gt_inds.append(gt_inds_per_inst)
+ mask_preds = torch.cat(keep_mask_preds)
+ pos_assigned_gt_inds = torch.cat(keep_pos_assigned_gt_inds)
+ num_pos = pos_assigned_gt_inds.size(0)
+
+ # Follow the origin implement
+ start = int(self.mask_out_stride // 2)
+ gt_masks = gt_masks[:, start::self.mask_out_stride,
+ start::self.mask_out_stride]
+ gt_masks = gt_masks.gt(0.5).float()
+ pos_mask_targets = gt_masks[pos_assigned_gt_inds]
+
+ return (mask_preds, pos_mask_targets, num_pos)
+
+ def predict_by_feat(self,
+ mask_preds: List[Tensor],
+ results_list: InstanceList,
+ batch_img_metas: List[dict],
+ rescale: bool = True,
+ **kwargs) -> InstanceList:
+ """Transform a batch of output features extracted from the head into
+ mask results.
+
+ Args:
+ mask_preds (list[Tensor]): Predicted prototypes with shape
+ (num_classes, H, W).
+ results_list (List[:obj:``InstanceData``]): BBoxHead results.
+ batch_img_metas (list[dict]): Meta information of all images.
+ rescale (bool, optional): Whether to rescale the results.
+ Defaults to False.
+
+ Returns:
+ list[:obj:`InstanceData`]: Processed results of multiple
+ images.Each :obj:`InstanceData` usually contains
+ following keys.
+
+ - scores (Tensor): Classification scores, has shape
+ (num_instance,).
+ - labels (Tensor): Has shape (num_instances,).
+ - masks (Tensor): Processed mask results, has
+ shape (num_instances, h, w).
+ """
+ assert len(mask_preds) == len(results_list) == len(batch_img_metas)
+
+ for img_id in range(len(batch_img_metas)):
+ img_meta = batch_img_metas[img_id]
+ results = results_list[img_id]
+ bboxes = results.bboxes
+ mask_pred = mask_preds[img_id]
+ if bboxes.shape[0] == 0 or mask_pred.shape[0] == 0:
+ results_list[img_id] = empty_instances(
+ [img_meta],
+ bboxes.device,
+ task_type='mask',
+ instance_results=[results])[0]
+ else:
+ im_mask = self._predict_by_feat_single(
+ mask_preds=mask_pred,
+ bboxes=bboxes,
+ img_meta=img_meta,
+ rescale=rescale)
+ results.masks = im_mask
+ return results_list
+
+ def _predict_by_feat_single(self,
+ mask_preds: Tensor,
+ bboxes: Tensor,
+ img_meta: dict,
+ rescale: bool,
+ cfg: OptConfigType = None):
+ """Transform a single image's features extracted from the head into
+ mask results.
+
+ Args:
+ mask_preds (Tensor): Predicted prototypes, has shape [H, W, N].
+ img_meta (dict): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ rescale (bool): If rescale is False, then returned masks will
+ fit the scale of imgs[0].
+ cfg (dict, optional): Config used in test phase.
+ Defaults to None.
+
+ Returns:
+ :obj:`InstanceData`: Processed results of single image.
+ it usually contains following keys.
+
+ - scores (Tensor): Classification scores, has shape
+ (num_instance,).
+ - labels (Tensor): Has shape (num_instances,).
+ - masks (Tensor): Processed mask results, has
+ shape (num_instances, h, w).
+ """
+ cfg = self.test_cfg if cfg is None else cfg
+ scale_factor = bboxes.new_tensor(img_meta['scale_factor']).repeat(
+ (1, 2))
+ img_h, img_w = img_meta['img_shape'][:2]
+ ori_h, ori_w = img_meta['ori_shape'][:2]
+
+ mask_preds = mask_preds.sigmoid().unsqueeze(0)
+ mask_preds = aligned_bilinear(mask_preds, self.mask_out_stride)
+ mask_preds = mask_preds[:, :, :img_h, :img_w]
+ if rescale: # in-placed rescale the bboxes
+ scale_factor = bboxes.new_tensor(img_meta['scale_factor']).repeat(
+ (1, 2))
+ bboxes /= scale_factor
+
+ masks = F.interpolate(
+ mask_preds, (ori_h, ori_w),
+ mode='bilinear',
+ align_corners=False).squeeze(0) > cfg.mask_thr
+ else:
+ masks = mask_preds.squeeze(0) > cfg.mask_thr
+
+ return masks
diff --git a/mmdet/models/dense_heads/conditional_detr_head.py b/mmdet/models/dense_heads/conditional_detr_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..cc2df2c215667121c5fe329f369510ecd4666faf
--- /dev/null
+++ b/mmdet/models/dense_heads/conditional_detr_head.py
@@ -0,0 +1,168 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Tuple
+
+import torch
+import torch.nn as nn
+from mmengine.model import bias_init_with_prob
+from torch import Tensor
+
+from mmdet.models.layers.transformer import inverse_sigmoid
+from mmdet.registry import MODELS
+from mmdet.structures import SampleList
+from mmdet.utils import InstanceList
+from .detr_head import DETRHead
+
+
+@MODELS.register_module()
+class ConditionalDETRHead(DETRHead):
+ """Head of Conditional DETR. Conditional DETR: Conditional DETR for Fast
+ Training Convergence. More details can be found in the `paper.
+
+ `_ .
+ """
+
+ def init_weights(self):
+ """Initialize weights of the transformer head."""
+ super().init_weights()
+ # The initialization below for transformer head is very
+ # important as we use Focal_loss for loss_cls
+ if self.loss_cls.use_sigmoid:
+ bias_init = bias_init_with_prob(0.01)
+ nn.init.constant_(self.fc_cls.bias, bias_init)
+
+ def forward(self, hidden_states: Tensor,
+ references: Tensor) -> Tuple[Tensor, Tensor]:
+ """"Forward function.
+
+ Args:
+ hidden_states (Tensor): Features from transformer decoder. If
+ `return_intermediate_dec` is True output has shape
+ (num_decoder_layers, bs, num_queries, dim), else has shape (1,
+ bs, num_queries, dim) which only contains the last layer
+ outputs.
+ references (Tensor): References from transformer decoder, has
+ shape (bs, num_queries, 2).
+ Returns:
+ tuple[Tensor]: results of head containing the following tensor.
+
+ - layers_cls_scores (Tensor): Outputs from the classification head,
+ shape (num_decoder_layers, bs, num_queries, cls_out_channels).
+ Note cls_out_channels should include background.
+ - layers_bbox_preds (Tensor): Sigmoid outputs from the regression
+ head with normalized coordinate format (cx, cy, w, h), has shape
+ (num_decoder_layers, bs, num_queries, 4).
+ """
+
+ references_unsigmoid = inverse_sigmoid(references)
+ layers_bbox_preds = []
+ for layer_id in range(hidden_states.shape[0]):
+ tmp_reg_preds = self.fc_reg(
+ self.activate(self.reg_ffn(hidden_states[layer_id])))
+ tmp_reg_preds[..., :2] += references_unsigmoid
+ outputs_coord = tmp_reg_preds.sigmoid()
+ layers_bbox_preds.append(outputs_coord)
+ layers_bbox_preds = torch.stack(layers_bbox_preds)
+
+ layers_cls_scores = self.fc_cls(hidden_states)
+ return layers_cls_scores, layers_bbox_preds
+
+ def loss(self, hidden_states: Tensor, references: Tensor,
+ batch_data_samples: SampleList) -> dict:
+ """Perform forward propagation and loss calculation of the detection
+ head on the features of the upstream network.
+
+ Args:
+ hidden_states (Tensor): Features from the transformer decoder, has
+ shape (num_decoder_layers, bs, num_queries, dim).
+ references (Tensor): References from the transformer decoder, has
+ shape (num_decoder_layers, bs, num_queries, 2).
+ batch_data_samples (List[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+
+ Returns:
+ dict: A dictionary of loss components.
+ """
+ batch_gt_instances = []
+ batch_img_metas = []
+ for data_sample in batch_data_samples:
+ batch_img_metas.append(data_sample.metainfo)
+ batch_gt_instances.append(data_sample.gt_instances)
+
+ outs = self(hidden_states, references)
+ loss_inputs = outs + (batch_gt_instances, batch_img_metas)
+ losses = self.loss_by_feat(*loss_inputs)
+ return losses
+
+ def loss_and_predict(
+ self, hidden_states: Tensor, references: Tensor,
+ batch_data_samples: SampleList) -> Tuple[dict, InstanceList]:
+ """Perform forward propagation of the head, then calculate loss and
+ predictions from the features and data samples. Over-write because
+ img_metas are needed as inputs for bbox_head.
+
+ Args:
+ hidden_states (Tensor): Features from the transformer decoder, has
+ shape (num_decoder_layers, bs, num_queries, dim).
+ references (Tensor): References from the transformer decoder, has
+ shape (num_decoder_layers, bs, num_queries, 2).
+ batch_data_samples (list[:obj:`DetDataSample`]): Each item contains
+ the meta information of each image and corresponding
+ annotations.
+
+ Returns:
+ tuple: The return value is a tuple contains:
+
+ - losses: (dict[str, Tensor]): A dictionary of loss components.
+ - predictions (list[:obj:`InstanceData`]): Detection
+ results of each image after the post process.
+ """
+ batch_gt_instances = []
+ batch_img_metas = []
+ for data_sample in batch_data_samples:
+ batch_img_metas.append(data_sample.metainfo)
+ batch_gt_instances.append(data_sample.gt_instances)
+
+ outs = self(hidden_states, references)
+ loss_inputs = outs + (batch_gt_instances, batch_img_metas)
+ losses = self.loss_by_feat(*loss_inputs)
+
+ predictions = self.predict_by_feat(
+ *outs, batch_img_metas=batch_img_metas)
+ return losses, predictions
+
+ def predict(self,
+ hidden_states: Tensor,
+ references: Tensor,
+ batch_data_samples: SampleList,
+ rescale: bool = True) -> InstanceList:
+ """Perform forward propagation of the detection head and predict
+ detection results on the features of the upstream network. Over-write
+ because img_metas are needed as inputs for bbox_head.
+
+ Args:
+ hidden_states (Tensor): Features from the transformer decoder, has
+ shape (num_decoder_layers, bs, num_queries, dim).
+ references (Tensor): References from the transformer decoder, has
+ shape (num_decoder_layers, bs, num_queries, 2).
+ batch_data_samples (List[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ rescale (bool, optional): Whether to rescale the results.
+ Defaults to True.
+
+ Returns:
+ list[obj:`InstanceData`]: Detection results of each image
+ after the post process.
+ """
+ batch_img_metas = [
+ data_samples.metainfo for data_samples in batch_data_samples
+ ]
+
+ last_layer_hidden_state = hidden_states[-1].unsqueeze(0)
+ outs = self(last_layer_hidden_state, references)
+
+ predictions = self.predict_by_feat(
+ *outs, batch_img_metas=batch_img_metas, rescale=rescale)
+
+ return predictions
diff --git a/mmdet/models/dense_heads/corner_head.py b/mmdet/models/dense_heads/corner_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..bbfd9367a871ce2cf742f0775ceb864d8353befd
--- /dev/null
+++ b/mmdet/models/dense_heads/corner_head.py
@@ -0,0 +1,1082 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from logging import warning
+from math import ceil, log
+from typing import List, Optional, Sequence, Tuple
+
+import torch
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+from mmcv.ops import CornerPool, batched_nms
+from mmengine.config import ConfigDict
+from mmengine.model import BaseModule, bias_init_with_prob
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.utils import (ConfigType, InstanceList, OptConfigType,
+ OptInstanceList, OptMultiConfig)
+from ..utils import (gather_feat, gaussian_radius, gen_gaussian_target,
+ get_local_maximum, get_topk_from_heatmap, multi_apply,
+ transpose_and_gather_feat)
+from .base_dense_head import BaseDenseHead
+
+
+class BiCornerPool(BaseModule):
+ """Bidirectional Corner Pooling Module (TopLeft, BottomRight, etc.)
+
+ Args:
+ in_channels (int): Input channels of module.
+ directions (list[str]): Directions of two CornerPools.
+ out_channels (int): Output channels of module.
+ feat_channels (int): Feature channels of module.
+ norm_cfg (:obj:`ConfigDict` or dict): Dictionary to construct
+ and config norm layer.
+ init_cfg (:obj:`ConfigDict` or dict, optional): the config to
+ control the initialization.
+ """
+
+ def __init__(self,
+ in_channels: int,
+ directions: List[int],
+ feat_channels: int = 128,
+ out_channels: int = 128,
+ norm_cfg: ConfigType = dict(type='BN', requires_grad=True),
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(init_cfg)
+ self.direction1_conv = ConvModule(
+ in_channels, feat_channels, 3, padding=1, norm_cfg=norm_cfg)
+ self.direction2_conv = ConvModule(
+ in_channels, feat_channels, 3, padding=1, norm_cfg=norm_cfg)
+
+ self.aftpool_conv = ConvModule(
+ feat_channels,
+ out_channels,
+ 3,
+ padding=1,
+ norm_cfg=norm_cfg,
+ act_cfg=None)
+
+ self.conv1 = ConvModule(
+ in_channels, out_channels, 1, norm_cfg=norm_cfg, act_cfg=None)
+ self.conv2 = ConvModule(
+ in_channels, out_channels, 3, padding=1, norm_cfg=norm_cfg)
+
+ self.direction1_pool = CornerPool(directions[0])
+ self.direction2_pool = CornerPool(directions[1])
+ self.relu = nn.ReLU(inplace=True)
+
+ def forward(self, x: Tensor) -> Tensor:
+ """Forward features from the upstream network.
+
+ Args:
+ x (tensor): Input feature of BiCornerPool.
+
+ Returns:
+ conv2 (tensor): Output feature of BiCornerPool.
+ """
+ direction1_conv = self.direction1_conv(x)
+ direction2_conv = self.direction2_conv(x)
+ direction1_feat = self.direction1_pool(direction1_conv)
+ direction2_feat = self.direction2_pool(direction2_conv)
+ aftpool_conv = self.aftpool_conv(direction1_feat + direction2_feat)
+ conv1 = self.conv1(x)
+ relu = self.relu(aftpool_conv + conv1)
+ conv2 = self.conv2(relu)
+ return conv2
+
+
+@MODELS.register_module()
+class CornerHead(BaseDenseHead):
+ """Head of CornerNet: Detecting Objects as Paired Keypoints.
+
+ Code is modified from the `official github repo
+ `_ .
+
+ More details can be found in the `paper
+ `_ .
+
+ Args:
+ num_classes (int): Number of categories excluding the background
+ category.
+ in_channels (int): Number of channels in the input feature map.
+ num_feat_levels (int): Levels of feature from the previous module.
+ 2 for HourglassNet-104 and 1 for HourglassNet-52. Because
+ HourglassNet-104 outputs the final feature and intermediate
+ supervision feature and HourglassNet-52 only outputs the final
+ feature. Defaults to 2.
+ corner_emb_channels (int): Channel of embedding vector. Defaults to 1.
+ train_cfg (:obj:`ConfigDict` or dict, optional): Training config.
+ Useless in CornerHead, but we keep this variable for
+ SingleStageDetector.
+ test_cfg (:obj:`ConfigDict` or dict, optional): Testing config of
+ CornerHead.
+ loss_heatmap (:obj:`ConfigDict` or dict): Config of corner heatmap
+ loss. Defaults to GaussianFocalLoss.
+ loss_embedding (:obj:`ConfigDict` or dict): Config of corner embedding
+ loss. Defaults to AssociativeEmbeddingLoss.
+ loss_offset (:obj:`ConfigDict` or dict): Config of corner offset loss.
+ Defaults to SmoothL1Loss.
+ init_cfg (:obj:`ConfigDict` or dict, optional): the config to control
+ the initialization.
+ """
+
+ def __init__(self,
+ num_classes: int,
+ in_channels: int,
+ num_feat_levels: int = 2,
+ corner_emb_channels: int = 1,
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ loss_heatmap: ConfigType = dict(
+ type='GaussianFocalLoss',
+ alpha=2.0,
+ gamma=4.0,
+ loss_weight=1),
+ loss_embedding: ConfigType = dict(
+ type='AssociativeEmbeddingLoss',
+ pull_weight=0.25,
+ push_weight=0.25),
+ loss_offset: ConfigType = dict(
+ type='SmoothL1Loss', beta=1.0, loss_weight=1),
+ init_cfg: OptMultiConfig = None) -> None:
+ assert init_cfg is None, 'To prevent abnormal initialization ' \
+ 'behavior, init_cfg is not allowed to be set'
+ super().__init__(init_cfg=init_cfg)
+ self.num_classes = num_classes
+ self.in_channels = in_channels
+ self.corner_emb_channels = corner_emb_channels
+ self.with_corner_emb = self.corner_emb_channels > 0
+ self.corner_offset_channels = 2
+ self.num_feat_levels = num_feat_levels
+ self.loss_heatmap = MODELS.build(
+ loss_heatmap) if loss_heatmap is not None else None
+ self.loss_embedding = MODELS.build(
+ loss_embedding) if loss_embedding is not None else None
+ self.loss_offset = MODELS.build(
+ loss_offset) if loss_offset is not None else None
+ self.train_cfg = train_cfg
+ self.test_cfg = test_cfg
+
+ self._init_layers()
+
+ def _make_layers(self,
+ out_channels: int,
+ in_channels: int = 256,
+ feat_channels: int = 256) -> nn.Sequential:
+ """Initialize conv sequential for CornerHead."""
+ return nn.Sequential(
+ ConvModule(in_channels, feat_channels, 3, padding=1),
+ ConvModule(
+ feat_channels, out_channels, 1, norm_cfg=None, act_cfg=None))
+
+ def _init_corner_kpt_layers(self) -> None:
+ """Initialize corner keypoint layers.
+
+ Including corner heatmap branch and corner offset branch. Each branch
+ has two parts: prefix `tl_` for top-left and `br_` for bottom-right.
+ """
+ self.tl_pool, self.br_pool = nn.ModuleList(), nn.ModuleList()
+ self.tl_heat, self.br_heat = nn.ModuleList(), nn.ModuleList()
+ self.tl_off, self.br_off = nn.ModuleList(), nn.ModuleList()
+
+ for _ in range(self.num_feat_levels):
+ self.tl_pool.append(
+ BiCornerPool(
+ self.in_channels, ['top', 'left'],
+ out_channels=self.in_channels))
+ self.br_pool.append(
+ BiCornerPool(
+ self.in_channels, ['bottom', 'right'],
+ out_channels=self.in_channels))
+
+ self.tl_heat.append(
+ self._make_layers(
+ out_channels=self.num_classes,
+ in_channels=self.in_channels))
+ self.br_heat.append(
+ self._make_layers(
+ out_channels=self.num_classes,
+ in_channels=self.in_channels))
+
+ self.tl_off.append(
+ self._make_layers(
+ out_channels=self.corner_offset_channels,
+ in_channels=self.in_channels))
+ self.br_off.append(
+ self._make_layers(
+ out_channels=self.corner_offset_channels,
+ in_channels=self.in_channels))
+
+ def _init_corner_emb_layers(self) -> None:
+ """Initialize corner embedding layers.
+
+ Only include corner embedding branch with two parts: prefix `tl_` for
+ top-left and `br_` for bottom-right.
+ """
+ self.tl_emb, self.br_emb = nn.ModuleList(), nn.ModuleList()
+
+ for _ in range(self.num_feat_levels):
+ self.tl_emb.append(
+ self._make_layers(
+ out_channels=self.corner_emb_channels,
+ in_channels=self.in_channels))
+ self.br_emb.append(
+ self._make_layers(
+ out_channels=self.corner_emb_channels,
+ in_channels=self.in_channels))
+
+ def _init_layers(self) -> None:
+ """Initialize layers for CornerHead.
+
+ Including two parts: corner keypoint layers and corner embedding layers
+ """
+ self._init_corner_kpt_layers()
+ if self.with_corner_emb:
+ self._init_corner_emb_layers()
+
+ def init_weights(self) -> None:
+ super().init_weights()
+ bias_init = bias_init_with_prob(0.1)
+ for i in range(self.num_feat_levels):
+ # The initialization of parameters are different between
+ # nn.Conv2d and ConvModule. Our experiments show that
+ # using the original initialization of nn.Conv2d increases
+ # the final mAP by about 0.2%
+ self.tl_heat[i][-1].conv.reset_parameters()
+ self.tl_heat[i][-1].conv.bias.data.fill_(bias_init)
+ self.br_heat[i][-1].conv.reset_parameters()
+ self.br_heat[i][-1].conv.bias.data.fill_(bias_init)
+ self.tl_off[i][-1].conv.reset_parameters()
+ self.br_off[i][-1].conv.reset_parameters()
+ if self.with_corner_emb:
+ self.tl_emb[i][-1].conv.reset_parameters()
+ self.br_emb[i][-1].conv.reset_parameters()
+
+ def forward(self, feats: Tuple[Tensor]) -> tuple:
+ """Forward features from the upstream network.
+
+ Args:
+ feats (tuple[Tensor]): Features from the upstream network, each is
+ a 4D-tensor.
+
+ Returns:
+ tuple: Usually a tuple of corner heatmaps, offset heatmaps and
+ embedding heatmaps.
+ - tl_heats (list[Tensor]): Top-left corner heatmaps for all
+ levels, each is a 4D-tensor, the channels number is
+ num_classes.
+ - br_heats (list[Tensor]): Bottom-right corner heatmaps for all
+ levels, each is a 4D-tensor, the channels number is
+ num_classes.
+ - tl_embs (list[Tensor] | list[None]): Top-left embedding
+ heatmaps for all levels, each is a 4D-tensor or None.
+ If not None, the channels number is corner_emb_channels.
+ - br_embs (list[Tensor] | list[None]): Bottom-right embedding
+ heatmaps for all levels, each is a 4D-tensor or None.
+ If not None, the channels number is corner_emb_channels.
+ - tl_offs (list[Tensor]): Top-left offset heatmaps for all
+ levels, each is a 4D-tensor. The channels number is
+ corner_offset_channels.
+ - br_offs (list[Tensor]): Bottom-right offset heatmaps for all
+ levels, each is a 4D-tensor. The channels number is
+ corner_offset_channels.
+ """
+ lvl_ind = list(range(self.num_feat_levels))
+ return multi_apply(self.forward_single, feats, lvl_ind)
+
+ def forward_single(self,
+ x: Tensor,
+ lvl_ind: int,
+ return_pool: bool = False) -> List[Tensor]:
+ """Forward feature of a single level.
+
+ Args:
+ x (Tensor): Feature of a single level.
+ lvl_ind (int): Level index of current feature.
+ return_pool (bool): Return corner pool feature or not.
+ Defaults to False.
+
+ Returns:
+ tuple[Tensor]: A tuple of CornerHead's output for current feature
+ level. Containing the following Tensors:
+
+ - tl_heat (Tensor): Predicted top-left corner heatmap.
+ - br_heat (Tensor): Predicted bottom-right corner heatmap.
+ - tl_emb (Tensor | None): Predicted top-left embedding heatmap.
+ None for `self.with_corner_emb == False`.
+ - br_emb (Tensor | None): Predicted bottom-right embedding
+ heatmap. None for `self.with_corner_emb == False`.
+ - tl_off (Tensor): Predicted top-left offset heatmap.
+ - br_off (Tensor): Predicted bottom-right offset heatmap.
+ - tl_pool (Tensor): Top-left corner pool feature. Not must
+ have.
+ - br_pool (Tensor): Bottom-right corner pool feature. Not must
+ have.
+ """
+ tl_pool = self.tl_pool[lvl_ind](x)
+ tl_heat = self.tl_heat[lvl_ind](tl_pool)
+ br_pool = self.br_pool[lvl_ind](x)
+ br_heat = self.br_heat[lvl_ind](br_pool)
+
+ tl_emb, br_emb = None, None
+ if self.with_corner_emb:
+ tl_emb = self.tl_emb[lvl_ind](tl_pool)
+ br_emb = self.br_emb[lvl_ind](br_pool)
+
+ tl_off = self.tl_off[lvl_ind](tl_pool)
+ br_off = self.br_off[lvl_ind](br_pool)
+
+ result_list = [tl_heat, br_heat, tl_emb, br_emb, tl_off, br_off]
+ if return_pool:
+ result_list.append(tl_pool)
+ result_list.append(br_pool)
+
+ return result_list
+
+ def get_targets(self,
+ gt_bboxes: List[Tensor],
+ gt_labels: List[Tensor],
+ feat_shape: Sequence[int],
+ img_shape: Sequence[int],
+ with_corner_emb: bool = False,
+ with_guiding_shift: bool = False,
+ with_centripetal_shift: bool = False) -> dict:
+ """Generate corner targets.
+
+ Including corner heatmap, corner offset.
+
+ Optional: corner embedding, corner guiding shift, centripetal shift.
+
+ For CornerNet, we generate corner heatmap, corner offset and corner
+ embedding from this function.
+
+ For CentripetalNet, we generate corner heatmap, corner offset, guiding
+ shift and centripetal shift from this function.
+
+ Args:
+ gt_bboxes (list[Tensor]): Ground truth bboxes of each image, each
+ has shape (num_gt, 4).
+ gt_labels (list[Tensor]): Ground truth labels of each box, each has
+ shape (num_gt, ).
+ feat_shape (Sequence[int]): Shape of output feature,
+ [batch, channel, height, width].
+ img_shape (Sequence[int]): Shape of input image,
+ [height, width, channel].
+ with_corner_emb (bool): Generate corner embedding target or not.
+ Defaults to False.
+ with_guiding_shift (bool): Generate guiding shift target or not.
+ Defaults to False.
+ with_centripetal_shift (bool): Generate centripetal shift target or
+ not. Defaults to False.
+
+ Returns:
+ dict: Ground truth of corner heatmap, corner offset, corner
+ embedding, guiding shift and centripetal shift. Containing the
+ following keys:
+
+ - topleft_heatmap (Tensor): Ground truth top-left corner
+ heatmap.
+ - bottomright_heatmap (Tensor): Ground truth bottom-right
+ corner heatmap.
+ - topleft_offset (Tensor): Ground truth top-left corner offset.
+ - bottomright_offset (Tensor): Ground truth bottom-right corner
+ offset.
+ - corner_embedding (list[list[list[int]]]): Ground truth corner
+ embedding. Not must have.
+ - topleft_guiding_shift (Tensor): Ground truth top-left corner
+ guiding shift. Not must have.
+ - bottomright_guiding_shift (Tensor): Ground truth bottom-right
+ corner guiding shift. Not must have.
+ - topleft_centripetal_shift (Tensor): Ground truth top-left
+ corner centripetal shift. Not must have.
+ - bottomright_centripetal_shift (Tensor): Ground truth
+ bottom-right corner centripetal shift. Not must have.
+ """
+ batch_size, _, height, width = feat_shape
+ img_h, img_w = img_shape[:2]
+
+ width_ratio = float(width / img_w)
+ height_ratio = float(height / img_h)
+
+ gt_tl_heatmap = gt_bboxes[-1].new_zeros(
+ [batch_size, self.num_classes, height, width])
+ gt_br_heatmap = gt_bboxes[-1].new_zeros(
+ [batch_size, self.num_classes, height, width])
+ gt_tl_offset = gt_bboxes[-1].new_zeros([batch_size, 2, height, width])
+ gt_br_offset = gt_bboxes[-1].new_zeros([batch_size, 2, height, width])
+
+ if with_corner_emb:
+ match = []
+
+ # Guiding shift is a kind of offset, from center to corner
+ if with_guiding_shift:
+ gt_tl_guiding_shift = gt_bboxes[-1].new_zeros(
+ [batch_size, 2, height, width])
+ gt_br_guiding_shift = gt_bboxes[-1].new_zeros(
+ [batch_size, 2, height, width])
+ # Centripetal shift is also a kind of offset, from center to corner
+ # and normalized by log.
+ if with_centripetal_shift:
+ gt_tl_centripetal_shift = gt_bboxes[-1].new_zeros(
+ [batch_size, 2, height, width])
+ gt_br_centripetal_shift = gt_bboxes[-1].new_zeros(
+ [batch_size, 2, height, width])
+
+ for batch_id in range(batch_size):
+ # Ground truth of corner embedding per image is a list of coord set
+ corner_match = []
+ for box_id in range(len(gt_labels[batch_id])):
+ left, top, right, bottom = gt_bboxes[batch_id][box_id]
+ center_x = (left + right) / 2.0
+ center_y = (top + bottom) / 2.0
+ label = gt_labels[batch_id][box_id]
+
+ # Use coords in the feature level to generate ground truth
+ scale_left = left * width_ratio
+ scale_right = right * width_ratio
+ scale_top = top * height_ratio
+ scale_bottom = bottom * height_ratio
+ scale_center_x = center_x * width_ratio
+ scale_center_y = center_y * height_ratio
+
+ # Int coords on feature map/ground truth tensor
+ left_idx = int(min(scale_left, width - 1))
+ right_idx = int(min(scale_right, width - 1))
+ top_idx = int(min(scale_top, height - 1))
+ bottom_idx = int(min(scale_bottom, height - 1))
+
+ # Generate gaussian heatmap
+ scale_box_width = ceil(scale_right - scale_left)
+ scale_box_height = ceil(scale_bottom - scale_top)
+ radius = gaussian_radius((scale_box_height, scale_box_width),
+ min_overlap=0.3)
+ radius = max(0, int(radius))
+ gt_tl_heatmap[batch_id, label] = gen_gaussian_target(
+ gt_tl_heatmap[batch_id, label], [left_idx, top_idx],
+ radius)
+ gt_br_heatmap[batch_id, label] = gen_gaussian_target(
+ gt_br_heatmap[batch_id, label], [right_idx, bottom_idx],
+ radius)
+
+ # Generate corner offset
+ left_offset = scale_left - left_idx
+ top_offset = scale_top - top_idx
+ right_offset = scale_right - right_idx
+ bottom_offset = scale_bottom - bottom_idx
+ gt_tl_offset[batch_id, 0, top_idx, left_idx] = left_offset
+ gt_tl_offset[batch_id, 1, top_idx, left_idx] = top_offset
+ gt_br_offset[batch_id, 0, bottom_idx, right_idx] = right_offset
+ gt_br_offset[batch_id, 1, bottom_idx,
+ right_idx] = bottom_offset
+
+ # Generate corner embedding
+ if with_corner_emb:
+ corner_match.append([[top_idx, left_idx],
+ [bottom_idx, right_idx]])
+ # Generate guiding shift
+ if with_guiding_shift:
+ gt_tl_guiding_shift[batch_id, 0, top_idx,
+ left_idx] = scale_center_x - left_idx
+ gt_tl_guiding_shift[batch_id, 1, top_idx,
+ left_idx] = scale_center_y - top_idx
+ gt_br_guiding_shift[batch_id, 0, bottom_idx,
+ right_idx] = right_idx - scale_center_x
+ gt_br_guiding_shift[
+ batch_id, 1, bottom_idx,
+ right_idx] = bottom_idx - scale_center_y
+ # Generate centripetal shift
+ if with_centripetal_shift:
+ gt_tl_centripetal_shift[batch_id, 0, top_idx,
+ left_idx] = log(scale_center_x -
+ scale_left)
+ gt_tl_centripetal_shift[batch_id, 1, top_idx,
+ left_idx] = log(scale_center_y -
+ scale_top)
+ gt_br_centripetal_shift[batch_id, 0, bottom_idx,
+ right_idx] = log(scale_right -
+ scale_center_x)
+ gt_br_centripetal_shift[batch_id, 1, bottom_idx,
+ right_idx] = log(scale_bottom -
+ scale_center_y)
+
+ if with_corner_emb:
+ match.append(corner_match)
+
+ target_result = dict(
+ topleft_heatmap=gt_tl_heatmap,
+ topleft_offset=gt_tl_offset,
+ bottomright_heatmap=gt_br_heatmap,
+ bottomright_offset=gt_br_offset)
+
+ if with_corner_emb:
+ target_result.update(corner_embedding=match)
+ if with_guiding_shift:
+ target_result.update(
+ topleft_guiding_shift=gt_tl_guiding_shift,
+ bottomright_guiding_shift=gt_br_guiding_shift)
+ if with_centripetal_shift:
+ target_result.update(
+ topleft_centripetal_shift=gt_tl_centripetal_shift,
+ bottomright_centripetal_shift=gt_br_centripetal_shift)
+
+ return target_result
+
+ def loss_by_feat(
+ self,
+ tl_heats: List[Tensor],
+ br_heats: List[Tensor],
+ tl_embs: List[Tensor],
+ br_embs: List[Tensor],
+ tl_offs: List[Tensor],
+ br_offs: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ batch_gt_instances_ignore: OptInstanceList = None) -> dict:
+ """Calculate the loss based on the features extracted by the detection
+ head.
+
+ Args:
+ tl_heats (list[Tensor]): Top-left corner heatmaps for each level
+ with shape (N, num_classes, H, W).
+ br_heats (list[Tensor]): Bottom-right corner heatmaps for each
+ level with shape (N, num_classes, H, W).
+ tl_embs (list[Tensor]): Top-left corner embeddings for each level
+ with shape (N, corner_emb_channels, H, W).
+ br_embs (list[Tensor]): Bottom-right corner embeddings for each
+ level with shape (N, corner_emb_channels, H, W).
+ tl_offs (list[Tensor]): Top-left corner offsets for each level
+ with shape (N, corner_offset_channels, H, W).
+ br_offs (list[Tensor]): Bottom-right corner offsets for each level
+ with shape (N, corner_offset_channels, H, W).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], optional):
+ Specify which bounding boxes can be ignored when computing
+ the loss.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components. Containing the
+ following losses:
+
+ - det_loss (list[Tensor]): Corner keypoint losses of all
+ feature levels.
+ - pull_loss (list[Tensor]): Part one of AssociativeEmbedding
+ losses of all feature levels.
+ - push_loss (list[Tensor]): Part two of AssociativeEmbedding
+ losses of all feature levels.
+ - off_loss (list[Tensor]): Corner offset losses of all feature
+ levels.
+ """
+ gt_bboxes = [
+ gt_instances.bboxes for gt_instances in batch_gt_instances
+ ]
+ gt_labels = [
+ gt_instances.labels for gt_instances in batch_gt_instances
+ ]
+
+ targets = self.get_targets(
+ gt_bboxes,
+ gt_labels,
+ tl_heats[-1].shape,
+ batch_img_metas[0]['batch_input_shape'],
+ with_corner_emb=self.with_corner_emb)
+ mlvl_targets = [targets for _ in range(self.num_feat_levels)]
+ det_losses, pull_losses, push_losses, off_losses = multi_apply(
+ self.loss_by_feat_single, tl_heats, br_heats, tl_embs, br_embs,
+ tl_offs, br_offs, mlvl_targets)
+ loss_dict = dict(det_loss=det_losses, off_loss=off_losses)
+ if self.with_corner_emb:
+ loss_dict.update(pull_loss=pull_losses, push_loss=push_losses)
+ return loss_dict
+
+ def loss_by_feat_single(self, tl_hmp: Tensor, br_hmp: Tensor,
+ tl_emb: Optional[Tensor], br_emb: Optional[Tensor],
+ tl_off: Tensor, br_off: Tensor,
+ targets: dict) -> Tuple[Tensor, ...]:
+ """Calculate the loss of a single scale level based on the features
+ extracted by the detection head.
+
+ Args:
+ tl_hmp (Tensor): Top-left corner heatmap for current level with
+ shape (N, num_classes, H, W).
+ br_hmp (Tensor): Bottom-right corner heatmap for current level with
+ shape (N, num_classes, H, W).
+ tl_emb (Tensor, optional): Top-left corner embedding for current
+ level with shape (N, corner_emb_channels, H, W).
+ br_emb (Tensor, optional): Bottom-right corner embedding for
+ current level with shape (N, corner_emb_channels, H, W).
+ tl_off (Tensor): Top-left corner offset for current level with
+ shape (N, corner_offset_channels, H, W).
+ br_off (Tensor): Bottom-right corner offset for current level with
+ shape (N, corner_offset_channels, H, W).
+ targets (dict): Corner target generated by `get_targets`.
+
+ Returns:
+ tuple[torch.Tensor]: Losses of the head's different branches
+ containing the following losses:
+
+ - det_loss (Tensor): Corner keypoint loss.
+ - pull_loss (Tensor): Part one of AssociativeEmbedding loss.
+ - push_loss (Tensor): Part two of AssociativeEmbedding loss.
+ - off_loss (Tensor): Corner offset loss.
+ """
+ gt_tl_hmp = targets['topleft_heatmap']
+ gt_br_hmp = targets['bottomright_heatmap']
+ gt_tl_off = targets['topleft_offset']
+ gt_br_off = targets['bottomright_offset']
+ gt_embedding = targets['corner_embedding']
+
+ # Detection loss
+ tl_det_loss = self.loss_heatmap(
+ tl_hmp.sigmoid(),
+ gt_tl_hmp,
+ avg_factor=max(1, gt_tl_hmp.eq(1).sum()))
+ br_det_loss = self.loss_heatmap(
+ br_hmp.sigmoid(),
+ gt_br_hmp,
+ avg_factor=max(1, gt_br_hmp.eq(1).sum()))
+ det_loss = (tl_det_loss + br_det_loss) / 2.0
+
+ # AssociativeEmbedding loss
+ if self.with_corner_emb and self.loss_embedding is not None:
+ pull_loss, push_loss = self.loss_embedding(tl_emb, br_emb,
+ gt_embedding)
+ else:
+ pull_loss, push_loss = None, None
+
+ # Offset loss
+ # We only compute the offset loss at the real corner position.
+ # The value of real corner would be 1 in heatmap ground truth.
+ # The mask is computed in class agnostic mode and its shape is
+ # batch * 1 * width * height.
+ tl_off_mask = gt_tl_hmp.eq(1).sum(1).gt(0).unsqueeze(1).type_as(
+ gt_tl_hmp)
+ br_off_mask = gt_br_hmp.eq(1).sum(1).gt(0).unsqueeze(1).type_as(
+ gt_br_hmp)
+ tl_off_loss = self.loss_offset(
+ tl_off,
+ gt_tl_off,
+ tl_off_mask,
+ avg_factor=max(1, tl_off_mask.sum()))
+ br_off_loss = self.loss_offset(
+ br_off,
+ gt_br_off,
+ br_off_mask,
+ avg_factor=max(1, br_off_mask.sum()))
+
+ off_loss = (tl_off_loss + br_off_loss) / 2.0
+
+ return det_loss, pull_loss, push_loss, off_loss
+
+ def predict_by_feat(self,
+ tl_heats: List[Tensor],
+ br_heats: List[Tensor],
+ tl_embs: List[Tensor],
+ br_embs: List[Tensor],
+ tl_offs: List[Tensor],
+ br_offs: List[Tensor],
+ batch_img_metas: Optional[List[dict]] = None,
+ rescale: bool = False,
+ with_nms: bool = True) -> InstanceList:
+ """Transform a batch of output features extracted from the head into
+ bbox results.
+
+ Args:
+ tl_heats (list[Tensor]): Top-left corner heatmaps for each level
+ with shape (N, num_classes, H, W).
+ br_heats (list[Tensor]): Bottom-right corner heatmaps for each
+ level with shape (N, num_classes, H, W).
+ tl_embs (list[Tensor]): Top-left corner embeddings for each level
+ with shape (N, corner_emb_channels, H, W).
+ br_embs (list[Tensor]): Bottom-right corner embeddings for each
+ level with shape (N, corner_emb_channels, H, W).
+ tl_offs (list[Tensor]): Top-left corner offsets for each level
+ with shape (N, corner_offset_channels, H, W).
+ br_offs (list[Tensor]): Bottom-right corner offsets for each level
+ with shape (N, corner_offset_channels, H, W).
+ batch_img_metas (list[dict], optional): Batch image meta info.
+ Defaults to None.
+ rescale (bool): If True, return boxes in original image space.
+ Defaults to False.
+ with_nms (bool): If True, do nms before return boxes.
+ Defaults to True.
+
+ Returns:
+ list[:obj:`InstanceData`]: Object detection results of each image
+ after the post process. Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ """
+ assert tl_heats[-1].shape[0] == br_heats[-1].shape[0] == len(
+ batch_img_metas)
+ result_list = []
+ for img_id in range(len(batch_img_metas)):
+ result_list.append(
+ self._predict_by_feat_single(
+ tl_heats[-1][img_id:img_id + 1, :],
+ br_heats[-1][img_id:img_id + 1, :],
+ tl_offs[-1][img_id:img_id + 1, :],
+ br_offs[-1][img_id:img_id + 1, :],
+ batch_img_metas[img_id],
+ tl_emb=tl_embs[-1][img_id:img_id + 1, :],
+ br_emb=br_embs[-1][img_id:img_id + 1, :],
+ rescale=rescale,
+ with_nms=with_nms))
+
+ return result_list
+
+ def _predict_by_feat_single(self,
+ tl_heat: Tensor,
+ br_heat: Tensor,
+ tl_off: Tensor,
+ br_off: Tensor,
+ img_meta: dict,
+ tl_emb: Optional[Tensor] = None,
+ br_emb: Optional[Tensor] = None,
+ tl_centripetal_shift: Optional[Tensor] = None,
+ br_centripetal_shift: Optional[Tensor] = None,
+ rescale: bool = False,
+ with_nms: bool = True) -> InstanceData:
+ """Transform a single image's features extracted from the head into
+ bbox results.
+
+ Args:
+ tl_heat (Tensor): Top-left corner heatmap for current level with
+ shape (N, num_classes, H, W).
+ br_heat (Tensor): Bottom-right corner heatmap for current level
+ with shape (N, num_classes, H, W).
+ tl_off (Tensor): Top-left corner offset for current level with
+ shape (N, corner_offset_channels, H, W).
+ br_off (Tensor): Bottom-right corner offset for current level with
+ shape (N, corner_offset_channels, H, W).
+ img_meta (dict): Meta information of current image, e.g.,
+ image size, scaling factor, etc.
+ tl_emb (Tensor): Top-left corner embedding for current level with
+ shape (N, corner_emb_channels, H, W).
+ br_emb (Tensor): Bottom-right corner embedding for current level
+ with shape (N, corner_emb_channels, H, W).
+ tl_centripetal_shift: Top-left corner's centripetal shift for
+ current level with shape (N, 2, H, W).
+ br_centripetal_shift: Bottom-right corner's centripetal shift for
+ current level with shape (N, 2, H, W).
+ rescale (bool): If True, return boxes in original image space.
+ Defaults to False.
+ with_nms (bool): If True, do nms before return boxes.
+ Defaults to True.
+
+ Returns:
+ :obj:`InstanceData`: Detection results of each image
+ after the post process.
+ Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ """
+ if isinstance(img_meta, (list, tuple)):
+ img_meta = img_meta[0]
+
+ batch_bboxes, batch_scores, batch_clses = self._decode_heatmap(
+ tl_heat=tl_heat.sigmoid(),
+ br_heat=br_heat.sigmoid(),
+ tl_off=tl_off,
+ br_off=br_off,
+ tl_emb=tl_emb,
+ br_emb=br_emb,
+ tl_centripetal_shift=tl_centripetal_shift,
+ br_centripetal_shift=br_centripetal_shift,
+ img_meta=img_meta,
+ k=self.test_cfg.corner_topk,
+ kernel=self.test_cfg.local_maximum_kernel,
+ distance_threshold=self.test_cfg.distance_threshold)
+
+ if rescale and 'scale_factor' in img_meta:
+ batch_bboxes /= batch_bboxes.new_tensor(
+ img_meta['scale_factor']).repeat((1, 2))
+
+ bboxes = batch_bboxes.view([-1, 4])
+ scores = batch_scores.view(-1)
+ clses = batch_clses.view(-1)
+
+ det_bboxes = torch.cat([bboxes, scores.unsqueeze(-1)], -1)
+ keepinds = (det_bboxes[:, -1] > -0.1)
+ det_bboxes = det_bboxes[keepinds]
+ det_labels = clses[keepinds]
+
+ if with_nms:
+ det_bboxes, det_labels = self._bboxes_nms(det_bboxes, det_labels,
+ self.test_cfg)
+
+ results = InstanceData()
+ results.bboxes = det_bboxes[..., :4]
+ results.scores = det_bboxes[..., 4]
+ results.labels = det_labels
+ return results
+
+ def _bboxes_nms(self, bboxes: Tensor, labels: Tensor,
+ cfg: ConfigDict) -> Tuple[Tensor, Tensor]:
+ """bboxes nms."""
+ if 'nms_cfg' in cfg:
+ warning.warn('nms_cfg in test_cfg will be deprecated. '
+ 'Please rename it as nms')
+ if 'nms' not in cfg:
+ cfg.nms = cfg.nms_cfg
+
+ if labels.numel() > 0:
+ max_num = cfg.max_per_img
+ bboxes, keep = batched_nms(bboxes[:, :4], bboxes[:,
+ -1].contiguous(),
+ labels, cfg.nms)
+ if max_num > 0:
+ bboxes = bboxes[:max_num]
+ labels = labels[keep][:max_num]
+
+ return bboxes, labels
+
+ def _decode_heatmap(self,
+ tl_heat: Tensor,
+ br_heat: Tensor,
+ tl_off: Tensor,
+ br_off: Tensor,
+ tl_emb: Optional[Tensor] = None,
+ br_emb: Optional[Tensor] = None,
+ tl_centripetal_shift: Optional[Tensor] = None,
+ br_centripetal_shift: Optional[Tensor] = None,
+ img_meta: Optional[dict] = None,
+ k: int = 100,
+ kernel: int = 3,
+ distance_threshold: float = 0.5,
+ num_dets: int = 1000) -> Tuple[Tensor, Tensor, Tensor]:
+ """Transform outputs into detections raw bbox prediction.
+
+ Args:
+ tl_heat (Tensor): Top-left corner heatmap for current level with
+ shape (N, num_classes, H, W).
+ br_heat (Tensor): Bottom-right corner heatmap for current level
+ with shape (N, num_classes, H, W).
+ tl_off (Tensor): Top-left corner offset for current level with
+ shape (N, corner_offset_channels, H, W).
+ br_off (Tensor): Bottom-right corner offset for current level with
+ shape (N, corner_offset_channels, H, W).
+ tl_emb (Tensor, Optional): Top-left corner embedding for current
+ level with shape (N, corner_emb_channels, H, W).
+ br_emb (Tensor, Optional): Bottom-right corner embedding for
+ current level with shape (N, corner_emb_channels, H, W).
+ tl_centripetal_shift (Tensor, Optional): Top-left centripetal shift
+ for current level with shape (N, 2, H, W).
+ br_centripetal_shift (Tensor, Optional): Bottom-right centripetal
+ shift for current level with shape (N, 2, H, W).
+ img_meta (dict): Meta information of current image, e.g.,
+ image size, scaling factor, etc.
+ k (int): Get top k corner keypoints from heatmap.
+ kernel (int): Max pooling kernel for extract local maximum pixels.
+ distance_threshold (float): Distance threshold. Top-left and
+ bottom-right corner keypoints with feature distance less than
+ the threshold will be regarded as keypoints from same object.
+ num_dets (int): Num of raw boxes before doing nms.
+
+ Returns:
+ tuple[torch.Tensor]: Decoded output of CornerHead, containing the
+ following Tensors:
+
+ - bboxes (Tensor): Coords of each box.
+ - scores (Tensor): Scores of each box.
+ - clses (Tensor): Categories of each box.
+ """
+ with_embedding = tl_emb is not None and br_emb is not None
+ with_centripetal_shift = (
+ tl_centripetal_shift is not None
+ and br_centripetal_shift is not None)
+ assert with_embedding + with_centripetal_shift == 1
+ batch, _, height, width = tl_heat.size()
+ if torch.onnx.is_in_onnx_export():
+ inp_h, inp_w = img_meta['pad_shape_for_onnx'][:2]
+ else:
+ inp_h, inp_w = img_meta['batch_input_shape'][:2]
+
+ # perform nms on heatmaps
+ tl_heat = get_local_maximum(tl_heat, kernel=kernel)
+ br_heat = get_local_maximum(br_heat, kernel=kernel)
+
+ tl_scores, tl_inds, tl_clses, tl_ys, tl_xs = get_topk_from_heatmap(
+ tl_heat, k=k)
+ br_scores, br_inds, br_clses, br_ys, br_xs = get_topk_from_heatmap(
+ br_heat, k=k)
+
+ # We use repeat instead of expand here because expand is a
+ # shallow-copy function. Thus it could cause unexpected testing result
+ # sometimes. Using expand will decrease about 10% mAP during testing
+ # compared to repeat.
+ tl_ys = tl_ys.view(batch, k, 1).repeat(1, 1, k)
+ tl_xs = tl_xs.view(batch, k, 1).repeat(1, 1, k)
+ br_ys = br_ys.view(batch, 1, k).repeat(1, k, 1)
+ br_xs = br_xs.view(batch, 1, k).repeat(1, k, 1)
+
+ tl_off = transpose_and_gather_feat(tl_off, tl_inds)
+ tl_off = tl_off.view(batch, k, 1, 2)
+ br_off = transpose_and_gather_feat(br_off, br_inds)
+ br_off = br_off.view(batch, 1, k, 2)
+
+ tl_xs = tl_xs + tl_off[..., 0]
+ tl_ys = tl_ys + tl_off[..., 1]
+ br_xs = br_xs + br_off[..., 0]
+ br_ys = br_ys + br_off[..., 1]
+
+ if with_centripetal_shift:
+ tl_centripetal_shift = transpose_and_gather_feat(
+ tl_centripetal_shift, tl_inds).view(batch, k, 1, 2).exp()
+ br_centripetal_shift = transpose_and_gather_feat(
+ br_centripetal_shift, br_inds).view(batch, 1, k, 2).exp()
+
+ tl_ctxs = tl_xs + tl_centripetal_shift[..., 0]
+ tl_ctys = tl_ys + tl_centripetal_shift[..., 1]
+ br_ctxs = br_xs - br_centripetal_shift[..., 0]
+ br_ctys = br_ys - br_centripetal_shift[..., 1]
+
+ # all possible boxes based on top k corners (ignoring class)
+ tl_xs *= (inp_w / width)
+ tl_ys *= (inp_h / height)
+ br_xs *= (inp_w / width)
+ br_ys *= (inp_h / height)
+
+ if with_centripetal_shift:
+ tl_ctxs *= (inp_w / width)
+ tl_ctys *= (inp_h / height)
+ br_ctxs *= (inp_w / width)
+ br_ctys *= (inp_h / height)
+
+ x_off, y_off = 0, 0 # no crop
+ if not torch.onnx.is_in_onnx_export():
+ # since `RandomCenterCropPad` is done on CPU with numpy and it's
+ # not dynamic traceable when exporting to ONNX, thus 'border'
+ # does not appears as key in 'img_meta'. As a tmp solution,
+ # we move this 'border' handle part to the postprocess after
+ # finished exporting to ONNX, which is handle in
+ # `mmdet/core/export/model_wrappers.py`. Though difference between
+ # pytorch and exported onnx model, it might be ignored since
+ # comparable performance is achieved between them (e.g. 40.4 vs
+ # 40.6 on COCO val2017, for CornerNet without test-time flip)
+ if 'border' in img_meta:
+ x_off = img_meta['border'][2]
+ y_off = img_meta['border'][0]
+
+ tl_xs -= x_off
+ tl_ys -= y_off
+ br_xs -= x_off
+ br_ys -= y_off
+
+ zeros = tl_xs.new_zeros(*tl_xs.size())
+ tl_xs = torch.where(tl_xs > 0.0, tl_xs, zeros)
+ tl_ys = torch.where(tl_ys > 0.0, tl_ys, zeros)
+ br_xs = torch.where(br_xs > 0.0, br_xs, zeros)
+ br_ys = torch.where(br_ys > 0.0, br_ys, zeros)
+
+ bboxes = torch.stack((tl_xs, tl_ys, br_xs, br_ys), dim=3)
+ area_bboxes = ((br_xs - tl_xs) * (br_ys - tl_ys)).abs()
+
+ if with_centripetal_shift:
+ tl_ctxs -= x_off
+ tl_ctys -= y_off
+ br_ctxs -= x_off
+ br_ctys -= y_off
+
+ tl_ctxs *= tl_ctxs.gt(0.0).type_as(tl_ctxs)
+ tl_ctys *= tl_ctys.gt(0.0).type_as(tl_ctys)
+ br_ctxs *= br_ctxs.gt(0.0).type_as(br_ctxs)
+ br_ctys *= br_ctys.gt(0.0).type_as(br_ctys)
+
+ ct_bboxes = torch.stack((tl_ctxs, tl_ctys, br_ctxs, br_ctys),
+ dim=3)
+ area_ct_bboxes = ((br_ctxs - tl_ctxs) * (br_ctys - tl_ctys)).abs()
+
+ rcentral = torch.zeros_like(ct_bboxes)
+ # magic nums from paper section 4.1
+ mu = torch.ones_like(area_bboxes) / 2.4
+ mu[area_bboxes > 3500] = 1 / 2.1 # large bbox have smaller mu
+
+ bboxes_center_x = (bboxes[..., 0] + bboxes[..., 2]) / 2
+ bboxes_center_y = (bboxes[..., 1] + bboxes[..., 3]) / 2
+ rcentral[..., 0] = bboxes_center_x - mu * (bboxes[..., 2] -
+ bboxes[..., 0]) / 2
+ rcentral[..., 1] = bboxes_center_y - mu * (bboxes[..., 3] -
+ bboxes[..., 1]) / 2
+ rcentral[..., 2] = bboxes_center_x + mu * (bboxes[..., 2] -
+ bboxes[..., 0]) / 2
+ rcentral[..., 3] = bboxes_center_y + mu * (bboxes[..., 3] -
+ bboxes[..., 1]) / 2
+ area_rcentral = ((rcentral[..., 2] - rcentral[..., 0]) *
+ (rcentral[..., 3] - rcentral[..., 1])).abs()
+ dists = area_ct_bboxes / area_rcentral
+
+ tl_ctx_inds = (ct_bboxes[..., 0] <= rcentral[..., 0]) | (
+ ct_bboxes[..., 0] >= rcentral[..., 2])
+ tl_cty_inds = (ct_bboxes[..., 1] <= rcentral[..., 1]) | (
+ ct_bboxes[..., 1] >= rcentral[..., 3])
+ br_ctx_inds = (ct_bboxes[..., 2] <= rcentral[..., 0]) | (
+ ct_bboxes[..., 2] >= rcentral[..., 2])
+ br_cty_inds = (ct_bboxes[..., 3] <= rcentral[..., 1]) | (
+ ct_bboxes[..., 3] >= rcentral[..., 3])
+
+ if with_embedding:
+ tl_emb = transpose_and_gather_feat(tl_emb, tl_inds)
+ tl_emb = tl_emb.view(batch, k, 1)
+ br_emb = transpose_and_gather_feat(br_emb, br_inds)
+ br_emb = br_emb.view(batch, 1, k)
+ dists = torch.abs(tl_emb - br_emb)
+
+ tl_scores = tl_scores.view(batch, k, 1).repeat(1, 1, k)
+ br_scores = br_scores.view(batch, 1, k).repeat(1, k, 1)
+
+ scores = (tl_scores + br_scores) / 2 # scores for all possible boxes
+
+ # tl and br should have same class
+ tl_clses = tl_clses.view(batch, k, 1).repeat(1, 1, k)
+ br_clses = br_clses.view(batch, 1, k).repeat(1, k, 1)
+ cls_inds = (tl_clses != br_clses)
+
+ # reject boxes based on distances
+ dist_inds = dists > distance_threshold
+
+ # reject boxes based on widths and heights
+ width_inds = (br_xs <= tl_xs)
+ height_inds = (br_ys <= tl_ys)
+
+ # No use `scores[cls_inds]`, instead we use `torch.where` here.
+ # Since only 1-D indices with type 'tensor(bool)' are supported
+ # when exporting to ONNX, any other bool indices with more dimensions
+ # (e.g. 2-D bool tensor) as input parameter in node is invalid
+ negative_scores = -1 * torch.ones_like(scores)
+ scores = torch.where(cls_inds, negative_scores, scores)
+ scores = torch.where(width_inds, negative_scores, scores)
+ scores = torch.where(height_inds, negative_scores, scores)
+ scores = torch.where(dist_inds, negative_scores, scores)
+
+ if with_centripetal_shift:
+ scores[tl_ctx_inds] = -1
+ scores[tl_cty_inds] = -1
+ scores[br_ctx_inds] = -1
+ scores[br_cty_inds] = -1
+
+ scores = scores.view(batch, -1)
+ scores, inds = torch.topk(scores, num_dets)
+ scores = scores.unsqueeze(2)
+
+ bboxes = bboxes.view(batch, -1, 4)
+ bboxes = gather_feat(bboxes, inds)
+
+ clses = tl_clses.contiguous().view(batch, -1, 1)
+ clses = gather_feat(clses, inds)
+
+ return bboxes, scores, clses
diff --git a/mmdet/models/dense_heads/dab_detr_head.py b/mmdet/models/dense_heads/dab_detr_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..892833ffce5f17f6f9e82e67b7d32c6b9c1bafc0
--- /dev/null
+++ b/mmdet/models/dense_heads/dab_detr_head.py
@@ -0,0 +1,106 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Tuple
+
+import torch.nn as nn
+from mmcv.cnn import Linear
+from mmengine.model import bias_init_with_prob, constant_init
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.structures import SampleList
+from mmdet.utils import InstanceList
+from ..layers import MLP, inverse_sigmoid
+from .conditional_detr_head import ConditionalDETRHead
+
+
+@MODELS.register_module()
+class DABDETRHead(ConditionalDETRHead):
+ """Head of DAB-DETR. DAB-DETR: Dynamic Anchor Boxes are Better Queries for
+ DETR.
+
+ More details can be found in the `paper
+ `_ .
+ """
+
+ def _init_layers(self) -> None:
+ """Initialize layers of the transformer head."""
+ # cls branch
+ self.fc_cls = Linear(self.embed_dims, self.cls_out_channels)
+ # reg branch
+ self.fc_reg = MLP(self.embed_dims, self.embed_dims, 4, 3)
+
+ def init_weights(self) -> None:
+ """initialize weights."""
+ if self.loss_cls.use_sigmoid:
+ bias_init = bias_init_with_prob(0.01)
+ nn.init.constant_(self.fc_cls.bias, bias_init)
+ constant_init(self.fc_reg.layers[-1], 0., bias=0.)
+
+ def forward(self, hidden_states: Tensor,
+ references: Tensor) -> Tuple[Tensor, Tensor]:
+ """"Forward function.
+
+ Args:
+ hidden_states (Tensor): Features from transformer decoder. If
+ `return_intermediate_dec` is True output has shape
+ (num_decoder_layers, bs, num_queries, dim), else has shape (1,
+ bs, num_queries, dim) which only contains the last layer
+ outputs.
+ references (Tensor): References from transformer decoder. If
+ `return_intermediate_dec` is True output has shape
+ (num_decoder_layers, bs, num_queries, 2/4), else has shape (1,
+ bs, num_queries, 2/4)
+ which only contains the last layer reference.
+ Returns:
+ tuple[Tensor]: results of head containing the following tensor.
+
+ - layers_cls_scores (Tensor): Outputs from the classification head,
+ shape (num_decoder_layers, bs, num_queries, cls_out_channels).
+ Note cls_out_channels should include background.
+ - layers_bbox_preds (Tensor): Sigmoid outputs from the regression
+ head with normalized coordinate format (cx, cy, w, h), has shape
+ (num_decoder_layers, bs, num_queries, 4).
+ """
+ layers_cls_scores = self.fc_cls(hidden_states)
+ references_before_sigmoid = inverse_sigmoid(references, eps=1e-3)
+ tmp_reg_preds = self.fc_reg(hidden_states)
+ tmp_reg_preds[..., :references_before_sigmoid.
+ size(-1)] += references_before_sigmoid
+ layers_bbox_preds = tmp_reg_preds.sigmoid()
+ return layers_cls_scores, layers_bbox_preds
+
+ def predict(self,
+ hidden_states: Tensor,
+ references: Tensor,
+ batch_data_samples: SampleList,
+ rescale: bool = True) -> InstanceList:
+ """Perform forward propagation of the detection head and predict
+ detection results on the features of the upstream network. Over-write
+ because img_metas are needed as inputs for bbox_head.
+
+ Args:
+ hidden_states (Tensor): Feature from the transformer decoder, has
+ shape (num_decoder_layers, bs, num_queries, dim).
+ references (Tensor): references from the transformer decoder, has
+ shape (num_decoder_layers, bs, num_queries, 2/4).
+ batch_data_samples (List[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ rescale (bool, optional): Whether to rescale the results.
+ Defaults to True.
+
+ Returns:
+ list[obj:`InstanceData`]: Detection results of each image
+ after the post process.
+ """
+ batch_img_metas = [
+ data_samples.metainfo for data_samples in batch_data_samples
+ ]
+
+ last_layer_hidden_state = hidden_states[-1].unsqueeze(0)
+ last_layer_reference = references[-1].unsqueeze(0)
+ outs = self(last_layer_hidden_state, last_layer_reference)
+
+ predictions = self.predict_by_feat(
+ *outs, batch_img_metas=batch_img_metas, rescale=rescale)
+ return predictions
diff --git a/mmdet/models/dense_heads/ddod_head.py b/mmdet/models/dense_heads/ddod_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..4ed6933fa965c06b4e75aa5ebd58dcd35b8348fc
--- /dev/null
+++ b/mmdet/models/dense_heads/ddod_head.py
@@ -0,0 +1,794 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Optional, Sequence, Tuple
+
+import torch
+import torch.nn as nn
+from mmcv.cnn import ConvModule, Scale
+from mmengine.model import bias_init_with_prob, normal_init
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmdet.registry import MODELS, TASK_UTILS
+from mmdet.structures.bbox import bbox_overlaps
+from mmdet.utils import (ConfigType, InstanceList, OptConfigType,
+ OptInstanceList, reduce_mean)
+from ..task_modules.prior_generators import anchor_inside_flags
+from ..utils import images_to_levels, multi_apply, unmap
+from .anchor_head import AnchorHead
+
+EPS = 1e-12
+
+
+@MODELS.register_module()
+class DDODHead(AnchorHead):
+ """Detection Head of `DDOD `_.
+
+ DDOD head decomposes conjunctions lying in most current one-stage
+ detectors via label assignment disentanglement, spatial feature
+ disentanglement, and pyramid supervision disentanglement.
+
+ Args:
+ num_classes (int): Number of categories excluding the
+ background category.
+ in_channels (int): Number of channels in the input feature map.
+ stacked_convs (int): The number of stacked Conv. Defaults to 4.
+ conv_cfg (:obj:`ConfigDict` or dict, optional): Config dict for
+ convolution layer. Defaults to None.
+ use_dcn (bool): Use dcn, Same as ATSS when False. Defaults to True.
+ norm_cfg (:obj:`ConfigDict` or dict): Normal config of ddod head.
+ Defaults to dict(type='GN', num_groups=32, requires_grad=True).
+ loss_iou (:obj:`ConfigDict` or dict): Config of IoU loss. Defaults to
+ dict(type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0).
+ """
+
+ def __init__(self,
+ num_classes: int,
+ in_channels: int,
+ stacked_convs: int = 4,
+ conv_cfg: OptConfigType = None,
+ use_dcn: bool = True,
+ norm_cfg: ConfigType = dict(
+ type='GN', num_groups=32, requires_grad=True),
+ loss_iou: ConfigType = dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=True,
+ loss_weight=1.0),
+ **kwargs) -> None:
+ self.stacked_convs = stacked_convs
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.use_dcn = use_dcn
+ super().__init__(num_classes, in_channels, **kwargs)
+
+ if self.train_cfg:
+ self.cls_assigner = TASK_UTILS.build(self.train_cfg['assigner'])
+ self.reg_assigner = TASK_UTILS.build(
+ self.train_cfg['reg_assigner'])
+ self.loss_iou = MODELS.build(loss_iou)
+
+ def _init_layers(self) -> None:
+ """Initialize layers of the head."""
+ self.relu = nn.ReLU(inplace=True)
+ self.cls_convs = nn.ModuleList()
+ self.reg_convs = nn.ModuleList()
+ for i in range(self.stacked_convs):
+ chn = self.in_channels if i == 0 else self.feat_channels
+ self.cls_convs.append(
+ ConvModule(
+ chn,
+ self.feat_channels,
+ 3,
+ stride=1,
+ padding=1,
+ conv_cfg=dict(type='DCN', deform_groups=1)
+ if i == 0 and self.use_dcn else self.conv_cfg,
+ norm_cfg=self.norm_cfg))
+ self.reg_convs.append(
+ ConvModule(
+ chn,
+ self.feat_channels,
+ 3,
+ stride=1,
+ padding=1,
+ conv_cfg=dict(type='DCN', deform_groups=1)
+ if i == 0 and self.use_dcn else self.conv_cfg,
+ norm_cfg=self.norm_cfg))
+ self.atss_cls = nn.Conv2d(
+ self.feat_channels,
+ self.num_base_priors * self.cls_out_channels,
+ 3,
+ padding=1)
+ self.atss_reg = nn.Conv2d(
+ self.feat_channels, self.num_base_priors * 4, 3, padding=1)
+ self.atss_iou = nn.Conv2d(
+ self.feat_channels, self.num_base_priors * 1, 3, padding=1)
+ self.scales = nn.ModuleList(
+ [Scale(1.0) for _ in self.prior_generator.strides])
+
+ # we use the global list in loss
+ self.cls_num_pos_samples_per_level = [
+ 0. for _ in range(len(self.prior_generator.strides))
+ ]
+ self.reg_num_pos_samples_per_level = [
+ 0. for _ in range(len(self.prior_generator.strides))
+ ]
+
+ def init_weights(self) -> None:
+ """Initialize weights of the head."""
+ for m in self.cls_convs:
+ normal_init(m.conv, std=0.01)
+ for m in self.reg_convs:
+ normal_init(m.conv, std=0.01)
+ normal_init(self.atss_reg, std=0.01)
+ normal_init(self.atss_iou, std=0.01)
+ bias_cls = bias_init_with_prob(0.01)
+ normal_init(self.atss_cls, std=0.01, bias=bias_cls)
+
+ def forward(self, x: Tuple[Tensor]) -> Tuple[List[Tensor]]:
+ """Forward features from the upstream network.
+
+ Args:
+ x (tuple[Tensor]): Features from the upstream network, each is
+ a 4D-tensor.
+
+ Returns:
+ tuple: A tuple of classification scores, bbox predictions,
+ and iou predictions.
+
+ - cls_scores (list[Tensor]): Classification scores for all \
+ scale levels, each is a 4D-tensor, the channels number is \
+ num_base_priors * num_classes.
+ - bbox_preds (list[Tensor]): Box energies / deltas for all \
+ scale levels, each is a 4D-tensor, the channels number is \
+ num_base_priors * 4.
+ - iou_preds (list[Tensor]): IoU scores for all scale levels, \
+ each is a 4D-tensor, the channels number is num_base_priors * 1.
+ """
+ return multi_apply(self.forward_single, x, self.scales)
+
+ def forward_single(self, x: Tensor, scale: Scale) -> Sequence[Tensor]:
+ """Forward feature of a single scale level.
+
+ Args:
+ x (Tensor): Features of a single scale level.
+ scale (:obj: `mmcv.cnn.Scale`): Learnable scale module to resize
+ the bbox prediction.
+
+ Returns:
+ tuple:
+
+ - cls_score (Tensor): Cls scores for a single scale level \
+ the channels number is num_base_priors * num_classes.
+ - bbox_pred (Tensor): Box energies / deltas for a single \
+ scale level, the channels number is num_base_priors * 4.
+ - iou_pred (Tensor): Iou for a single scale level, the \
+ channel number is (N, num_base_priors * 1, H, W).
+ """
+ cls_feat = x
+ reg_feat = x
+ for cls_conv in self.cls_convs:
+ cls_feat = cls_conv(cls_feat)
+ for reg_conv in self.reg_convs:
+ reg_feat = reg_conv(reg_feat)
+ cls_score = self.atss_cls(cls_feat)
+ # we just follow atss, not apply exp in bbox_pred
+ bbox_pred = scale(self.atss_reg(reg_feat)).float()
+ iou_pred = self.atss_iou(reg_feat)
+ return cls_score, bbox_pred, iou_pred
+
+ def loss_cls_by_feat_single(self, cls_score: Tensor, labels: Tensor,
+ label_weights: Tensor,
+ reweight_factor: List[float],
+ avg_factor: float) -> Tuple[Tensor]:
+ """Compute cls loss of a single scale level.
+
+ Args:
+ cls_score (Tensor): Box scores for each scale level
+ Has shape (N, num_base_priors * num_classes, H, W).
+ labels (Tensor): Labels of each anchors with shape
+ (N, num_total_anchors).
+ label_weights (Tensor): Label weights of each anchor with shape
+ (N, num_total_anchors)
+ reweight_factor (List[float]): Reweight factor for cls and reg
+ loss.
+ avg_factor (float): Average factor that is used to average
+ the loss. When using sampling method, avg_factor is usually
+ the sum of positive and negative priors. When using
+ `PseudoSampler`, `avg_factor` is usually equal to the number
+ of positive priors.
+
+ Returns:
+ Tuple[Tensor]: A tuple of loss components.
+ """
+ cls_score = cls_score.permute(0, 2, 3, 1).reshape(
+ -1, self.cls_out_channels).contiguous()
+ labels = labels.reshape(-1)
+ label_weights = label_weights.reshape(-1)
+ loss_cls = self.loss_cls(
+ cls_score, labels, label_weights, avg_factor=avg_factor)
+ return reweight_factor * loss_cls,
+
+ def loss_reg_by_feat_single(self, anchors: Tensor, bbox_pred: Tensor,
+ iou_pred: Tensor, labels,
+ label_weights: Tensor, bbox_targets: Tensor,
+ bbox_weights: Tensor,
+ reweight_factor: List[float],
+ avg_factor: float) -> Tuple[Tensor, Tensor]:
+ """Compute reg loss of a single scale level based on the features
+ extracted by the detection head.
+
+ Args:
+ anchors (Tensor): Box reference for each scale level with shape
+ (N, num_total_anchors, 4).
+ bbox_pred (Tensor): Box energies / deltas for each scale
+ level with shape (N, num_base_priors * 4, H, W).
+ iou_pred (Tensor): Iou for a single scale level, the
+ channel number is (N, num_base_priors * 1, H, W).
+ labels (Tensor): Labels of each anchors with shape
+ (N, num_total_anchors).
+ label_weights (Tensor): Label weights of each anchor with shape
+ (N, num_total_anchors)
+ bbox_targets (Tensor): BBox regression targets of each anchor
+ weight shape (N, num_total_anchors, 4).
+ bbox_weights (Tensor): BBox weights of all anchors in the
+ image with shape (N, 4)
+ reweight_factor (List[float]): Reweight factor for cls and reg
+ loss.
+ avg_factor (float): Average factor that is used to average
+ the loss. When using sampling method, avg_factor is usually
+ the sum of positive and negative priors. When using
+ `PseudoSampler`, `avg_factor` is usually equal to the number
+ of positive priors.
+ Returns:
+ Tuple[Tensor, Tensor]: A tuple of loss components.
+ """
+ anchors = anchors.reshape(-1, 4)
+ bbox_pred = bbox_pred.permute(0, 2, 3, 1).reshape(-1, 4)
+ iou_pred = iou_pred.permute(0, 2, 3, 1).reshape(-1, )
+ bbox_targets = bbox_targets.reshape(-1, 4)
+ bbox_weights = bbox_weights.reshape(-1, 4)
+ labels = labels.reshape(-1)
+ label_weights = label_weights.reshape(-1)
+
+ iou_targets = label_weights.new_zeros(labels.shape)
+ iou_weights = label_weights.new_zeros(labels.shape)
+ iou_weights[(bbox_weights.sum(axis=1) > 0).nonzero(
+ as_tuple=False)] = 1.
+
+ # FG cat_id: [0, num_classes -1], BG cat_id: num_classes
+ bg_class_ind = self.num_classes
+ pos_inds = ((labels >= 0)
+ &
+ (labels < bg_class_ind)).nonzero(as_tuple=False).squeeze(1)
+
+ if len(pos_inds) > 0:
+ pos_bbox_targets = bbox_targets[pos_inds]
+ pos_bbox_pred = bbox_pred[pos_inds]
+ pos_anchors = anchors[pos_inds]
+
+ pos_decode_bbox_pred = self.bbox_coder.decode(
+ pos_anchors, pos_bbox_pred)
+ pos_decode_bbox_targets = self.bbox_coder.decode(
+ pos_anchors, pos_bbox_targets)
+
+ # regression loss
+ loss_bbox = self.loss_bbox(
+ pos_decode_bbox_pred,
+ pos_decode_bbox_targets,
+ avg_factor=avg_factor)
+
+ iou_targets[pos_inds] = bbox_overlaps(
+ pos_decode_bbox_pred.detach(),
+ pos_decode_bbox_targets,
+ is_aligned=True)
+ loss_iou = self.loss_iou(
+ iou_pred, iou_targets, iou_weights, avg_factor=avg_factor)
+ else:
+ loss_bbox = bbox_pred.sum() * 0
+ loss_iou = iou_pred.sum() * 0
+
+ return reweight_factor * loss_bbox, reweight_factor * loss_iou
+
+ def calc_reweight_factor(self, labels_list: List[Tensor]) -> List[float]:
+ """Compute reweight_factor for regression and classification loss."""
+ # get pos samples for each level
+ bg_class_ind = self.num_classes
+ for ii, each_level_label in enumerate(labels_list):
+ pos_inds = ((each_level_label >= 0) &
+ (each_level_label < bg_class_ind)).nonzero(
+ as_tuple=False).squeeze(1)
+ self.cls_num_pos_samples_per_level[ii] += len(pos_inds)
+ # get reweight factor from 1 ~ 2 with bilinear interpolation
+ min_pos_samples = min(self.cls_num_pos_samples_per_level)
+ max_pos_samples = max(self.cls_num_pos_samples_per_level)
+ interval = 1. / (max_pos_samples - min_pos_samples + 1e-10)
+ reweight_factor_per_level = []
+ for pos_samples in self.cls_num_pos_samples_per_level:
+ factor = 2. - (pos_samples - min_pos_samples) * interval
+ reweight_factor_per_level.append(factor)
+ return reweight_factor_per_level
+
+ def loss_by_feat(
+ self,
+ cls_scores: List[Tensor],
+ bbox_preds: List[Tensor],
+ iou_preds: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ batch_gt_instances_ignore: OptInstanceList = None) -> dict:
+ """Calculate the loss based on the features extracted by the detection
+ head.
+
+ Args:
+ cls_scores (list[Tensor]): Box scores for each scale level
+ Has shape (N, num_base_priors * num_classes, H, W)
+ bbox_preds (list[Tensor]): Box energies / deltas for each scale
+ level with shape (N, num_base_priors * 4, H, W)
+ iou_preds (list[Tensor]): Score factor for all scale level,
+ each is a 4D-tensor, has shape (batch_size, 1, H, W).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], Optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components.
+ """
+ featmap_sizes = [featmap.size()[-2:] for featmap in cls_scores]
+ assert len(featmap_sizes) == self.prior_generator.num_levels
+
+ device = cls_scores[0].device
+ anchor_list, valid_flag_list = self.get_anchors(
+ featmap_sizes, batch_img_metas, device=device)
+
+ # calculate common vars for cls and reg assigners at once
+ targets_com = self.process_predictions_and_anchors(
+ anchor_list, valid_flag_list, cls_scores, bbox_preds,
+ batch_img_metas, batch_gt_instances_ignore)
+ (anchor_list, valid_flag_list, num_level_anchors_list, cls_score_list,
+ bbox_pred_list, batch_gt_instances_ignore) = targets_com
+
+ # classification branch assigner
+ cls_targets = self.get_cls_targets(
+ anchor_list,
+ valid_flag_list,
+ num_level_anchors_list,
+ cls_score_list,
+ bbox_pred_list,
+ batch_gt_instances,
+ batch_img_metas,
+ batch_gt_instances_ignore=batch_gt_instances_ignore)
+
+ (cls_anchor_list, labels_list, label_weights_list, bbox_targets_list,
+ bbox_weights_list, avg_factor) = cls_targets
+
+ avg_factor = reduce_mean(
+ torch.tensor(avg_factor, dtype=torch.float, device=device)).item()
+ avg_factor = max(avg_factor, 1.0)
+
+ reweight_factor_per_level = self.calc_reweight_factor(labels_list)
+
+ cls_losses_cls, = multi_apply(
+ self.loss_cls_by_feat_single,
+ cls_scores,
+ labels_list,
+ label_weights_list,
+ reweight_factor_per_level,
+ avg_factor=avg_factor)
+
+ # regression branch assigner
+ reg_targets = self.get_reg_targets(
+ anchor_list,
+ valid_flag_list,
+ num_level_anchors_list,
+ cls_score_list,
+ bbox_pred_list,
+ batch_gt_instances,
+ batch_img_metas,
+ batch_gt_instances_ignore=batch_gt_instances_ignore)
+
+ (reg_anchor_list, labels_list, label_weights_list, bbox_targets_list,
+ bbox_weights_list, avg_factor) = reg_targets
+
+ avg_factor = reduce_mean(
+ torch.tensor(avg_factor, dtype=torch.float, device=device)).item()
+ avg_factor = max(avg_factor, 1.0)
+
+ reweight_factor_per_level = self.calc_reweight_factor(labels_list)
+
+ reg_losses_bbox, reg_losses_iou = multi_apply(
+ self.loss_reg_by_feat_single,
+ reg_anchor_list,
+ bbox_preds,
+ iou_preds,
+ labels_list,
+ label_weights_list,
+ bbox_targets_list,
+ bbox_weights_list,
+ reweight_factor_per_level,
+ avg_factor=avg_factor)
+
+ return dict(
+ loss_cls=cls_losses_cls,
+ loss_bbox=reg_losses_bbox,
+ loss_iou=reg_losses_iou)
+
+ def process_predictions_and_anchors(
+ self,
+ anchor_list: List[List[Tensor]],
+ valid_flag_list: List[List[Tensor]],
+ cls_scores: List[Tensor],
+ bbox_preds: List[Tensor],
+ batch_img_metas: List[dict],
+ batch_gt_instances_ignore: OptInstanceList = None) -> tuple:
+ """Compute common vars for regression and classification targets.
+
+ Args:
+ anchor_list (List[List[Tensor]]): anchors of each image.
+ valid_flag_list (List[List[Tensor]]): Valid flags of each image.
+ cls_scores (List[Tensor]): Classification scores for all scale
+ levels, each is a 4D-tensor, the channels number is
+ num_base_priors * num_classes.
+ bbox_preds (list[Tensor]): Box energies / deltas for all scale
+ levels, each is a 4D-tensor, the channels number is
+ num_base_priors * 4.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], Optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+
+ Return:
+ tuple[Tensor]: A tuple of common loss vars.
+ """
+ num_imgs = len(batch_img_metas)
+ assert len(anchor_list) == len(valid_flag_list) == num_imgs
+
+ # anchor number of multi levels
+ num_level_anchors = [anchors.size(0) for anchors in anchor_list[0]]
+ num_level_anchors_list = [num_level_anchors] * num_imgs
+
+ anchor_list_ = []
+ valid_flag_list_ = []
+ # concat all level anchors and flags to a single tensor
+ for i in range(num_imgs):
+ assert len(anchor_list[i]) == len(valid_flag_list[i])
+ anchor_list_.append(torch.cat(anchor_list[i]))
+ valid_flag_list_.append(torch.cat(valid_flag_list[i]))
+
+ # compute targets for each image
+ if batch_gt_instances_ignore is None:
+ batch_gt_instances_ignore = [None for _ in range(num_imgs)]
+
+ num_levels = len(cls_scores)
+ cls_score_list = []
+ bbox_pred_list = []
+
+ mlvl_cls_score_list = [
+ cls_score.permute(0, 2, 3, 1).reshape(
+ num_imgs, -1, self.num_base_priors * self.cls_out_channels)
+ for cls_score in cls_scores
+ ]
+ mlvl_bbox_pred_list = [
+ bbox_pred.permute(0, 2, 3, 1).reshape(num_imgs, -1,
+ self.num_base_priors * 4)
+ for bbox_pred in bbox_preds
+ ]
+
+ for i in range(num_imgs):
+ mlvl_cls_tensor_list = [
+ mlvl_cls_score_list[j][i] for j in range(num_levels)
+ ]
+ mlvl_bbox_tensor_list = [
+ mlvl_bbox_pred_list[j][i] for j in range(num_levels)
+ ]
+ cat_mlvl_cls_score = torch.cat(mlvl_cls_tensor_list, dim=0)
+ cat_mlvl_bbox_pred = torch.cat(mlvl_bbox_tensor_list, dim=0)
+ cls_score_list.append(cat_mlvl_cls_score)
+ bbox_pred_list.append(cat_mlvl_bbox_pred)
+ return (anchor_list_, valid_flag_list_, num_level_anchors_list,
+ cls_score_list, bbox_pred_list, batch_gt_instances_ignore)
+
+ def get_cls_targets(self,
+ anchor_list: List[Tensor],
+ valid_flag_list: List[Tensor],
+ num_level_anchors_list: List[int],
+ cls_score_list: List[Tensor],
+ bbox_pred_list: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ batch_gt_instances_ignore: OptInstanceList = None,
+ unmap_outputs: bool = True) -> tuple:
+ """Get cls targets for DDOD head.
+
+ This method is almost the same as `AnchorHead.get_targets()`.
+ Besides returning the targets as the parent method does,
+ it also returns the anchors as the first element of the
+ returned tuple.
+
+ Args:
+ anchor_list (list[Tensor]): anchors of each image.
+ valid_flag_list (list[Tensor]): Valid flags of each image.
+ num_level_anchors_list (list[Tensor]): Number of anchors of each
+ scale level of all image.
+ cls_score_list (list[Tensor]): Classification scores for all scale
+ levels, each is a 4D-tensor, the channels number is
+ num_base_priors * num_classes.
+ bbox_pred_list (list[Tensor]): Box energies / deltas for all scale
+ levels, each is a 4D-tensor, the channels number is
+ num_base_priors * 4.
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+ unmap_outputs (bool): Whether to map outputs back to the original
+ set of anchors.
+
+ Return:
+ tuple[Tensor]: A tuple of cls targets components.
+ """
+ (all_anchors, all_labels, all_label_weights, all_bbox_targets,
+ all_bbox_weights, pos_inds_list, neg_inds_list,
+ sampling_results_list) = multi_apply(
+ self._get_targets_single,
+ anchor_list,
+ valid_flag_list,
+ cls_score_list,
+ bbox_pred_list,
+ num_level_anchors_list,
+ batch_gt_instances,
+ batch_img_metas,
+ batch_gt_instances_ignore,
+ unmap_outputs=unmap_outputs,
+ is_cls_assigner=True)
+ # Get `avg_factor` of all images, which calculate in `SamplingResult`.
+ # When using sampling method, avg_factor is usually the sum of
+ # positive and negative priors. When using `PseudoSampler`,
+ # `avg_factor` is usually equal to the number of positive priors.
+ avg_factor = sum(
+ [results.avg_factor for results in sampling_results_list])
+ # split targets to a list w.r.t. multiple levels
+ anchors_list = images_to_levels(all_anchors, num_level_anchors_list[0])
+ labels_list = images_to_levels(all_labels, num_level_anchors_list[0])
+ label_weights_list = images_to_levels(all_label_weights,
+ num_level_anchors_list[0])
+ bbox_targets_list = images_to_levels(all_bbox_targets,
+ num_level_anchors_list[0])
+ bbox_weights_list = images_to_levels(all_bbox_weights,
+ num_level_anchors_list[0])
+ return (anchors_list, labels_list, label_weights_list,
+ bbox_targets_list, bbox_weights_list, avg_factor)
+
+ def get_reg_targets(self,
+ anchor_list: List[Tensor],
+ valid_flag_list: List[Tensor],
+ num_level_anchors_list: List[int],
+ cls_score_list: List[Tensor],
+ bbox_pred_list: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ batch_gt_instances_ignore: OptInstanceList = None,
+ unmap_outputs: bool = True) -> tuple:
+ """Get reg targets for DDOD head.
+
+ This method is almost the same as `AnchorHead.get_targets()` when
+ is_cls_assigner is False. Besides returning the targets as the parent
+ method does, it also returns the anchors as the first element of the
+ returned tuple.
+
+ Args:
+ anchor_list (list[Tensor]): anchors of each image.
+ valid_flag_list (list[Tensor]): Valid flags of each image.
+ num_level_anchors_list (list[Tensor]): Number of anchors of each
+ scale level of all image.
+ cls_score_list (list[Tensor]): Classification scores for all scale
+ levels, each is a 4D-tensor, the channels number is
+ num_base_priors * num_classes.
+ bbox_pred_list (list[Tensor]): Box energies / deltas for all scale
+ levels, each is a 4D-tensor, the channels number is
+ num_base_priors * 4.
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+ unmap_outputs (bool): Whether to map outputs back to the original
+ set of anchors.
+
+ Return:
+ tuple[Tensor]: A tuple of reg targets components.
+ """
+ (all_anchors, all_labels, all_label_weights, all_bbox_targets,
+ all_bbox_weights, pos_inds_list, neg_inds_list,
+ sampling_results_list) = multi_apply(
+ self._get_targets_single,
+ anchor_list,
+ valid_flag_list,
+ cls_score_list,
+ bbox_pred_list,
+ num_level_anchors_list,
+ batch_gt_instances,
+ batch_img_metas,
+ batch_gt_instances_ignore,
+ unmap_outputs=unmap_outputs,
+ is_cls_assigner=False)
+ # Get `avg_factor` of all images, which calculate in `SamplingResult`.
+ # When using sampling method, avg_factor is usually the sum of
+ # positive and negative priors. When using `PseudoSampler`,
+ # `avg_factor` is usually equal to the number of positive priors.
+ avg_factor = sum(
+ [results.avg_factor for results in sampling_results_list])
+ # split targets to a list w.r.t. multiple levels
+ anchors_list = images_to_levels(all_anchors, num_level_anchors_list[0])
+ labels_list = images_to_levels(all_labels, num_level_anchors_list[0])
+ label_weights_list = images_to_levels(all_label_weights,
+ num_level_anchors_list[0])
+ bbox_targets_list = images_to_levels(all_bbox_targets,
+ num_level_anchors_list[0])
+ bbox_weights_list = images_to_levels(all_bbox_weights,
+ num_level_anchors_list[0])
+ return (anchors_list, labels_list, label_weights_list,
+ bbox_targets_list, bbox_weights_list, avg_factor)
+
+ def _get_targets_single(self,
+ flat_anchors: Tensor,
+ valid_flags: Tensor,
+ cls_scores: Tensor,
+ bbox_preds: Tensor,
+ num_level_anchors: List[int],
+ gt_instances: InstanceData,
+ img_meta: dict,
+ gt_instances_ignore: Optional[InstanceData] = None,
+ unmap_outputs: bool = True,
+ is_cls_assigner: bool = True) -> tuple:
+ """Compute regression, classification targets for anchors in a single
+ image.
+
+ Args:
+ flat_anchors (Tensor): Multi-level anchors of the image,
+ which are concatenated into a single tensor of shape
+ (num_base_priors, 4).
+ valid_flags (Tensor): Multi level valid flags of the image,
+ which are concatenated into a single tensor of
+ shape (num_base_priors,).
+ cls_scores (Tensor): Classification scores for all scale
+ levels of the image.
+ bbox_preds (Tensor): Box energies / deltas for all scale
+ levels of the image.
+ num_level_anchors (List[int]): Number of anchors of each
+ scale level.
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ img_meta (dict): Meta information for current image.
+ gt_instances_ignore (:obj:`InstanceData`, optional): Instances
+ to be ignored during training. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+ unmap_outputs (bool): Whether to map outputs back to the original
+ set of anchors. Defaults to True.
+ is_cls_assigner (bool): Classification or regression.
+ Defaults to True.
+
+ Returns:
+ tuple: N is the number of total anchors in the image.
+ - anchors (Tensor): all anchors in the image with shape (N, 4).
+ - labels (Tensor): Labels of all anchors in the image with \
+ shape (N, ).
+ - label_weights (Tensor): Label weights of all anchor in the \
+ image with shape (N, ).
+ - bbox_targets (Tensor): BBox targets of all anchors in the \
+ image with shape (N, 4).
+ - bbox_weights (Tensor): BBox weights of all anchors in the \
+ image with shape (N, 4)
+ - pos_inds (Tensor): Indices of positive anchor with shape \
+ (num_pos, ).
+ - neg_inds (Tensor): Indices of negative anchor with shape \
+ (num_neg, ).
+ - sampling_result (:obj:`SamplingResult`): Sampling results.
+ """
+ inside_flags = anchor_inside_flags(flat_anchors, valid_flags,
+ img_meta['img_shape'][:2],
+ self.train_cfg['allowed_border'])
+ if not inside_flags.any():
+ raise ValueError(
+ 'There is no valid anchor inside the image boundary. Please '
+ 'check the image size and anchor sizes, or set '
+ '``allowed_border`` to -1 to skip the condition.')
+ # assign gt and sample anchors
+ anchors = flat_anchors[inside_flags, :]
+
+ num_level_anchors_inside = self.get_num_level_anchors_inside(
+ num_level_anchors, inside_flags)
+ bbox_preds_valid = bbox_preds[inside_flags, :]
+ cls_scores_valid = cls_scores[inside_flags, :]
+
+ assigner = self.cls_assigner if is_cls_assigner else self.reg_assigner
+
+ # decode prediction out of assigner
+ bbox_preds_valid = self.bbox_coder.decode(anchors, bbox_preds_valid)
+ pred_instances = InstanceData(
+ priors=anchors, bboxes=bbox_preds_valid, scores=cls_scores_valid)
+
+ assign_result = assigner.assign(
+ pred_instances=pred_instances,
+ num_level_priors=num_level_anchors_inside,
+ gt_instances=gt_instances,
+ gt_instances_ignore=gt_instances_ignore)
+ sampling_result = self.sampler.sample(
+ assign_result=assign_result,
+ pred_instances=pred_instances,
+ gt_instances=gt_instances)
+
+ num_valid_anchors = anchors.shape[0]
+ bbox_targets = torch.zeros_like(anchors)
+ bbox_weights = torch.zeros_like(anchors)
+ labels = anchors.new_full((num_valid_anchors, ),
+ self.num_classes,
+ dtype=torch.long)
+ label_weights = anchors.new_zeros(num_valid_anchors, dtype=torch.float)
+
+ pos_inds = sampling_result.pos_inds
+ neg_inds = sampling_result.neg_inds
+ if len(pos_inds) > 0:
+ pos_bbox_targets = self.bbox_coder.encode(
+ sampling_result.pos_bboxes, sampling_result.pos_gt_bboxes)
+ bbox_targets[pos_inds, :] = pos_bbox_targets
+ bbox_weights[pos_inds, :] = 1.0
+
+ labels[pos_inds] = sampling_result.pos_gt_labels
+ if self.train_cfg['pos_weight'] <= 0:
+ label_weights[pos_inds] = 1.0
+ else:
+ label_weights[pos_inds] = self.train_cfg['pos_weight']
+ if len(neg_inds) > 0:
+ label_weights[neg_inds] = 1.0
+
+ # map up to original set of anchors
+ if unmap_outputs:
+ num_total_anchors = flat_anchors.size(0)
+ anchors = unmap(anchors, num_total_anchors, inside_flags)
+ labels = unmap(
+ labels, num_total_anchors, inside_flags, fill=self.num_classes)
+ label_weights = unmap(label_weights, num_total_anchors,
+ inside_flags)
+ bbox_targets = unmap(bbox_targets, num_total_anchors, inside_flags)
+ bbox_weights = unmap(bbox_weights, num_total_anchors, inside_flags)
+
+ return (anchors, labels, label_weights, bbox_targets, bbox_weights,
+ pos_inds, neg_inds, sampling_result)
+
+ def get_num_level_anchors_inside(self, num_level_anchors: List[int],
+ inside_flags: Tensor) -> List[int]:
+ """Get the anchors of each scale level inside.
+
+ Args:
+ num_level_anchors (list[int]): Number of anchors of each
+ scale level.
+ inside_flags (Tensor): Multi level inside flags of the image,
+ which are concatenated into a single tensor of
+ shape (num_base_priors,).
+
+ Returns:
+ list[int]: Number of anchors of each scale level inside.
+ """
+ split_inside_flags = torch.split(inside_flags, num_level_anchors)
+ num_level_anchors_inside = [
+ int(flags.sum()) for flags in split_inside_flags
+ ]
+ return num_level_anchors_inside
diff --git a/mmdet/models/dense_heads/deformable_detr_head.py b/mmdet/models/dense_heads/deformable_detr_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..f5b424eec1dc78c15e1fced73ca74cac448663fd
--- /dev/null
+++ b/mmdet/models/dense_heads/deformable_detr_head.py
@@ -0,0 +1,328 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+from typing import Dict, List, Tuple
+
+import torch
+import torch.nn as nn
+from mmcv.cnn import Linear
+from mmengine.model import bias_init_with_prob, constant_init
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.structures import SampleList
+from mmdet.utils import InstanceList, OptInstanceList
+from ..layers import inverse_sigmoid
+from .detr_head import DETRHead
+
+
+@MODELS.register_module()
+class DeformableDETRHead(DETRHead):
+ r"""Head of DeformDETR: Deformable DETR: Deformable Transformers for
+ End-to-End Object Detection.
+
+ Code is modified from the `official github repo
+ `_.
+
+ More details can be found in the `paper
+ `_ .
+
+ Args:
+ share_pred_layer (bool): Whether to share parameters for all the
+ prediction layers. Defaults to `False`.
+ num_pred_layer (int): The number of the prediction layers.
+ Defaults to 6.
+ as_two_stage (bool, optional): Whether to generate the proposal
+ from the outputs of encoder. Defaults to `False`.
+ """
+
+ def __init__(self,
+ *args,
+ share_pred_layer: bool = False,
+ num_pred_layer: int = 6,
+ as_two_stage: bool = False,
+ **kwargs) -> None:
+ self.share_pred_layer = share_pred_layer
+ self.num_pred_layer = num_pred_layer
+ self.as_two_stage = as_two_stage
+
+ super().__init__(*args, **kwargs)
+
+ def _init_layers(self) -> None:
+ """Initialize classification branch and regression branch of head."""
+ fc_cls = Linear(self.embed_dims, self.cls_out_channels)
+ reg_branch = []
+ for _ in range(self.num_reg_fcs):
+ reg_branch.append(Linear(self.embed_dims, self.embed_dims))
+ reg_branch.append(nn.ReLU())
+ reg_branch.append(Linear(self.embed_dims, 4))
+ reg_branch = nn.Sequential(*reg_branch)
+
+ if self.share_pred_layer:
+ self.cls_branches = nn.ModuleList(
+ [fc_cls for _ in range(self.num_pred_layer)])
+ self.reg_branches = nn.ModuleList(
+ [reg_branch for _ in range(self.num_pred_layer)])
+ else:
+ self.cls_branches = nn.ModuleList(
+ [copy.deepcopy(fc_cls) for _ in range(self.num_pred_layer)])
+ self.reg_branches = nn.ModuleList([
+ copy.deepcopy(reg_branch) for _ in range(self.num_pred_layer)
+ ])
+
+ def init_weights(self) -> None:
+ """Initialize weights of the Deformable DETR head."""
+ if self.loss_cls.use_sigmoid:
+ bias_init = bias_init_with_prob(0.01)
+ for m in self.cls_branches:
+ nn.init.constant_(m.bias, bias_init)
+ for m in self.reg_branches:
+ constant_init(m[-1], 0, bias=0)
+ nn.init.constant_(self.reg_branches[0][-1].bias.data[2:], -2.0)
+ if self.as_two_stage:
+ for m in self.reg_branches:
+ nn.init.constant_(m[-1].bias.data[2:], 0.0)
+
+ def forward(self, hidden_states: Tensor,
+ references: List[Tensor]) -> Tuple[Tensor]:
+ """Forward function.
+
+ Args:
+ hidden_states (Tensor): Hidden states output from each decoder
+ layer, has shape (num_decoder_layers, bs, num_queries, dim).
+ references (list[Tensor]): List of the reference from the decoder.
+ The first reference is the `init_reference` (initial) and the
+ other num_decoder_layers(6) references are `inter_references`
+ (intermediate). The `init_reference` has shape (bs,
+ num_queries, 4) when `as_two_stage` of the detector is `True`,
+ otherwise (bs, num_queries, 2). Each `inter_reference` has
+ shape (bs, num_queries, 4) when `with_box_refine` of the
+ detector is `True`, otherwise (bs, num_queries, 2). The
+ coordinates are arranged as (cx, cy) when the last dimension is
+ 2, and (cx, cy, w, h) when it is 4.
+
+ Returns:
+ tuple[Tensor]: results of head containing the following tensor.
+
+ - all_layers_outputs_classes (Tensor): Outputs from the
+ classification head, has shape (num_decoder_layers, bs,
+ num_queries, cls_out_channels).
+ - all_layers_outputs_coords (Tensor): Sigmoid outputs from the
+ regression head with normalized coordinate format (cx, cy, w,
+ h), has shape (num_decoder_layers, bs, num_queries, 4) with the
+ last dimension arranged as (cx, cy, w, h).
+ """
+ all_layers_outputs_classes = []
+ all_layers_outputs_coords = []
+
+ for layer_id in range(hidden_states.shape[0]):
+ reference = inverse_sigmoid(references[layer_id])
+ # NOTE The last reference will not be used.
+ hidden_state = hidden_states[layer_id]
+ outputs_class = self.cls_branches[layer_id](hidden_state)
+ tmp_reg_preds = self.reg_branches[layer_id](hidden_state)
+ if reference.shape[-1] == 4:
+ # When `layer` is 0 and `as_two_stage` of the detector
+ # is `True`, or when `layer` is greater than 0 and
+ # `with_box_refine` of the detector is `True`.
+ tmp_reg_preds += reference
+ else:
+ # When `layer` is 0 and `as_two_stage` of the detector
+ # is `False`, or when `layer` is greater than 0 and
+ # `with_box_refine` of the detector is `False`.
+ assert reference.shape[-1] == 2
+ tmp_reg_preds[..., :2] += reference
+ outputs_coord = tmp_reg_preds.sigmoid()
+ all_layers_outputs_classes.append(outputs_class)
+ all_layers_outputs_coords.append(outputs_coord)
+
+ all_layers_outputs_classes = torch.stack(all_layers_outputs_classes)
+ all_layers_outputs_coords = torch.stack(all_layers_outputs_coords)
+
+ return all_layers_outputs_classes, all_layers_outputs_coords
+
+ def loss(self, hidden_states: Tensor, references: List[Tensor],
+ enc_outputs_class: Tensor, enc_outputs_coord: Tensor,
+ batch_data_samples: SampleList) -> dict:
+ """Perform forward propagation and loss calculation of the detection
+ head on the queries of the upstream network.
+
+ Args:
+ hidden_states (Tensor): Hidden states output from each decoder
+ layer, has shape (num_decoder_layers, num_queries, bs, dim).
+ references (list[Tensor]): List of the reference from the decoder.
+ The first reference is the `init_reference` (initial) and the
+ other num_decoder_layers(6) references are `inter_references`
+ (intermediate). The `init_reference` has shape (bs,
+ num_queries, 4) when `as_two_stage` of the detector is `True`,
+ otherwise (bs, num_queries, 2). Each `inter_reference` has
+ shape (bs, num_queries, 4) when `with_box_refine` of the
+ detector is `True`, otherwise (bs, num_queries, 2). The
+ coordinates are arranged as (cx, cy) when the last dimension is
+ 2, and (cx, cy, w, h) when it is 4.
+ enc_outputs_class (Tensor): The score of each point on encode
+ feature map, has shape (bs, num_feat_points, cls_out_channels).
+ Only when `as_two_stage` is `True` it would be passed in,
+ otherwise it would be `None`.
+ enc_outputs_coord (Tensor): The proposal generate from the encode
+ feature map, has shape (bs, num_feat_points, 4) with the last
+ dimension arranged as (cx, cy, w, h). Only when `as_two_stage`
+ is `True` it would be passed in, otherwise it would be `None`.
+ batch_data_samples (list[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+
+ Returns:
+ dict: A dictionary of loss components.
+ """
+ batch_gt_instances = []
+ batch_img_metas = []
+ for data_sample in batch_data_samples:
+ batch_img_metas.append(data_sample.metainfo)
+ batch_gt_instances.append(data_sample.gt_instances)
+
+ outs = self(hidden_states, references)
+ loss_inputs = outs + (enc_outputs_class, enc_outputs_coord,
+ batch_gt_instances, batch_img_metas)
+ losses = self.loss_by_feat(*loss_inputs)
+ return losses
+
+ def loss_by_feat(
+ self,
+ all_layers_cls_scores: Tensor,
+ all_layers_bbox_preds: Tensor,
+ enc_cls_scores: Tensor,
+ enc_bbox_preds: Tensor,
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ batch_gt_instances_ignore: OptInstanceList = None
+ ) -> Dict[str, Tensor]:
+ """Loss function.
+
+ Args:
+ all_layers_cls_scores (Tensor): Classification scores of all
+ decoder layers, has shape (num_decoder_layers, bs, num_queries,
+ cls_out_channels).
+ all_layers_bbox_preds (Tensor): Regression outputs of all decoder
+ layers. Each is a 4D-tensor with normalized coordinate format
+ (cx, cy, w, h) and has shape (num_decoder_layers, bs,
+ num_queries, 4) with the last dimension arranged as
+ (cx, cy, w, h).
+ enc_cls_scores (Tensor): The score of each point on encode
+ feature map, has shape (bs, num_feat_points, cls_out_channels).
+ Only when `as_two_stage` is `True` it would be passes in,
+ otherwise, it would be `None`.
+ enc_bbox_preds (Tensor): The proposal generate from the encode
+ feature map, has shape (bs, num_feat_points, 4) with the last
+ dimension arranged as (cx, cy, w, h). Only when `as_two_stage`
+ is `True` it would be passed in, otherwise it would be `None`.
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components.
+ """
+ loss_dict = super().loss_by_feat(all_layers_cls_scores,
+ all_layers_bbox_preds,
+ batch_gt_instances, batch_img_metas,
+ batch_gt_instances_ignore)
+
+ # loss of proposal generated from encode feature map.
+ if enc_cls_scores is not None:
+ proposal_gt_instances = copy.deepcopy(batch_gt_instances)
+ for i in range(len(proposal_gt_instances)):
+ proposal_gt_instances[i].labels = torch.zeros_like(
+ proposal_gt_instances[i].labels)
+ enc_loss_cls, enc_losses_bbox, enc_losses_iou = \
+ self.loss_by_feat_single(
+ enc_cls_scores, enc_bbox_preds,
+ batch_gt_instances=proposal_gt_instances,
+ batch_img_metas=batch_img_metas)
+ loss_dict['enc_loss_cls'] = enc_loss_cls
+ loss_dict['enc_loss_bbox'] = enc_losses_bbox
+ loss_dict['enc_loss_iou'] = enc_losses_iou
+ return loss_dict
+
+ def predict(self,
+ hidden_states: Tensor,
+ references: List[Tensor],
+ batch_data_samples: SampleList,
+ rescale: bool = True) -> InstanceList:
+ """Perform forward propagation and loss calculation of the detection
+ head on the queries of the upstream network.
+
+ Args:
+ hidden_states (Tensor): Hidden states output from each decoder
+ layer, has shape (num_decoder_layers, num_queries, bs, dim).
+ references (list[Tensor]): List of the reference from the decoder.
+ The first reference is the `init_reference` (initial) and the
+ other num_decoder_layers(6) references are `inter_references`
+ (intermediate). The `init_reference` has shape (bs,
+ num_queries, 4) when `as_two_stage` of the detector is `True`,
+ otherwise (bs, num_queries, 2). Each `inter_reference` has
+ shape (bs, num_queries, 4) when `with_box_refine` of the
+ detector is `True`, otherwise (bs, num_queries, 2). The
+ coordinates are arranged as (cx, cy) when the last dimension is
+ 2, and (cx, cy, w, h) when it is 4.
+ batch_data_samples (list[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ rescale (bool, optional): If `True`, return boxes in original
+ image space. Defaults to `True`.
+
+ Returns:
+ list[obj:`InstanceData`]: Detection results of each image
+ after the post process.
+ """
+ batch_img_metas = [
+ data_samples.metainfo for data_samples in batch_data_samples
+ ]
+
+ outs = self(hidden_states, references)
+
+ predictions = self.predict_by_feat(
+ *outs, batch_img_metas=batch_img_metas, rescale=rescale)
+ return predictions
+
+ def predict_by_feat(self,
+ all_layers_cls_scores: Tensor,
+ all_layers_bbox_preds: Tensor,
+ batch_img_metas: List[Dict],
+ rescale: bool = False) -> InstanceList:
+ """Transform a batch of output features extracted from the head into
+ bbox results.
+
+ Args:
+ all_layers_cls_scores (Tensor): Classification scores of all
+ decoder layers, has shape (num_decoder_layers, bs, num_queries,
+ cls_out_channels).
+ all_layers_bbox_preds (Tensor): Regression outputs of all decoder
+ layers. Each is a 4D-tensor with normalized coordinate format
+ (cx, cy, w, h) and shape (num_decoder_layers, bs, num_queries,
+ 4) with the last dimension arranged as (cx, cy, w, h).
+ batch_img_metas (list[dict]): Meta information of each image.
+ rescale (bool, optional): If `True`, return boxes in original
+ image space. Default `False`.
+
+ Returns:
+ list[obj:`InstanceData`]: Detection results of each image
+ after the post process.
+ """
+ cls_scores = all_layers_cls_scores[-1]
+ bbox_preds = all_layers_bbox_preds[-1]
+
+ result_list = []
+ for img_id in range(len(batch_img_metas)):
+ cls_score = cls_scores[img_id]
+ bbox_pred = bbox_preds[img_id]
+ img_meta = batch_img_metas[img_id]
+ results = self._predict_by_feat_single(cls_score, bbox_pred,
+ img_meta, rescale)
+ result_list.append(results)
+ return result_list
diff --git a/mmdet/models/dense_heads/dense_test_mixins.py b/mmdet/models/dense_heads/dense_test_mixins.py
new file mode 100644
index 0000000000000000000000000000000000000000..a7526d48430d6bc6b82777980d0bef418e80b91c
--- /dev/null
+++ b/mmdet/models/dense_heads/dense_test_mixins.py
@@ -0,0 +1,215 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import sys
+import warnings
+from inspect import signature
+
+import torch
+from mmcv.ops import batched_nms
+from mmengine.structures import InstanceData
+
+from mmdet.structures.bbox import bbox_mapping_back
+from ..test_time_augs import merge_aug_proposals
+
+if sys.version_info >= (3, 7):
+ from mmdet.utils.contextmanagers import completed
+
+
+class BBoxTestMixin(object):
+ """Mixin class for testing det bboxes via DenseHead."""
+
+ def simple_test_bboxes(self, feats, img_metas, rescale=False):
+ """Test det bboxes without test-time augmentation, can be applied in
+ DenseHead except for ``RPNHead`` and its variants, e.g., ``GARPNHead``,
+ etc.
+
+ Args:
+ feats (tuple[torch.Tensor]): Multi-level features from the
+ upstream network, each is a 4D-tensor.
+ img_metas (list[dict]): List of image information.
+ rescale (bool, optional): Whether to rescale the results.
+ Defaults to False.
+
+ Returns:
+ list[obj:`InstanceData`]: Detection results of each
+ image after the post process. \
+ Each item usually contains following keys. \
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance,)
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances,).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ """
+ warnings.warn('You are calling `simple_test_bboxes` in '
+ '`dense_test_mixins`, but the `dense_test_mixins`'
+ 'will be deprecated soon. Please use '
+ '`simple_test` instead.')
+ outs = self.forward(feats)
+ results_list = self.get_results(
+ *outs, img_metas=img_metas, rescale=rescale)
+ return results_list
+
+ def aug_test_bboxes(self, feats, img_metas, rescale=False):
+ """Test det bboxes with test time augmentation, can be applied in
+ DenseHead except for ``RPNHead`` and its variants, e.g., ``GARPNHead``,
+ etc.
+
+ Args:
+ feats (list[Tensor]): the outer list indicates test-time
+ augmentations and inner Tensor should have a shape NxCxHxW,
+ which contains features for all images in the batch.
+ img_metas (list[list[dict]]): the outer list indicates test-time
+ augs (multiscale, flip, etc.) and the inner list indicates
+ images in a batch. each dict has image information.
+ rescale (bool, optional): Whether to rescale the results.
+ Defaults to False.
+
+ Returns:
+ list[tuple[Tensor, Tensor]]: Each item in result_list is 2-tuple.
+ The first item is ``bboxes`` with shape (n, 5),
+ where 5 represent (tl_x, tl_y, br_x, br_y, score).
+ The shape of the second tensor in the tuple is ``labels``
+ with shape (n,). The length of list should always be 1.
+ """
+
+ warnings.warn('You are calling `aug_test_bboxes` in '
+ '`dense_test_mixins`, but the `dense_test_mixins`'
+ 'will be deprecated soon. Please use '
+ '`aug_test` instead.')
+ # check with_nms argument
+ gb_sig = signature(self.get_results)
+ gb_args = [p.name for p in gb_sig.parameters.values()]
+ gbs_sig = signature(self._get_results_single)
+ gbs_args = [p.name for p in gbs_sig.parameters.values()]
+ assert ('with_nms' in gb_args) and ('with_nms' in gbs_args), \
+ f'{self.__class__.__name__}' \
+ ' does not support test-time augmentation'
+
+ aug_bboxes = []
+ aug_scores = []
+ aug_labels = []
+ for x, img_meta in zip(feats, img_metas):
+ # only one image in the batch
+ outs = self.forward(x)
+ bbox_outputs = self.get_results(
+ *outs,
+ img_metas=img_meta,
+ cfg=self.test_cfg,
+ rescale=False,
+ with_nms=False)[0]
+ aug_bboxes.append(bbox_outputs.bboxes)
+ aug_scores.append(bbox_outputs.scores)
+ if len(bbox_outputs) >= 3:
+ aug_labels.append(bbox_outputs.labels)
+
+ # after merging, bboxes will be rescaled to the original image size
+ merged_bboxes, merged_scores = self.merge_aug_bboxes(
+ aug_bboxes, aug_scores, img_metas)
+ merged_labels = torch.cat(aug_labels, dim=0) if aug_labels else None
+
+ if merged_bboxes.numel() == 0:
+ det_bboxes = torch.cat([merged_bboxes, merged_scores[:, None]], -1)
+ return [
+ (det_bboxes, merged_labels),
+ ]
+
+ det_bboxes, keep_idxs = batched_nms(merged_bboxes, merged_scores,
+ merged_labels, self.test_cfg.nms)
+ det_bboxes = det_bboxes[:self.test_cfg.max_per_img]
+ det_labels = merged_labels[keep_idxs][:self.test_cfg.max_per_img]
+
+ if rescale:
+ _det_bboxes = det_bboxes
+ else:
+ _det_bboxes = det_bboxes.clone()
+ _det_bboxes[:, :4] *= det_bboxes.new_tensor(
+ img_metas[0][0]['scale_factor'])
+
+ results = InstanceData()
+ results.bboxes = _det_bboxes[:, :4]
+ results.scores = _det_bboxes[:, 4]
+ results.labels = det_labels
+ return [results]
+
+ def aug_test_rpn(self, feats, img_metas):
+ """Test with augmentation for only for ``RPNHead`` and its variants,
+ e.g., ``GARPNHead``, etc.
+
+ Args:
+ feats (tuple[Tensor]): Features from the upstream network, each is
+ a 4D-tensor.
+ img_metas (list[dict]): Meta info of each image.
+
+ Returns:
+ list[Tensor]: Proposals of each image, each item has shape (n, 5),
+ where 5 represent (tl_x, tl_y, br_x, br_y, score).
+ """
+ samples_per_gpu = len(img_metas[0])
+ aug_proposals = [[] for _ in range(samples_per_gpu)]
+ for x, img_meta in zip(feats, img_metas):
+ results_list = self.simple_test_rpn(x, img_meta)
+ for i, results in enumerate(results_list):
+ proposals = torch.cat(
+ [results.bboxes, results.scores[:, None]], dim=-1)
+ aug_proposals[i].append(proposals)
+ # reorganize the order of 'img_metas' to match the dimensions
+ # of 'aug_proposals'
+ aug_img_metas = []
+ for i in range(samples_per_gpu):
+ aug_img_meta = []
+ for j in range(len(img_metas)):
+ aug_img_meta.append(img_metas[j][i])
+ aug_img_metas.append(aug_img_meta)
+ # after merging, proposals will be rescaled to the original image size
+
+ merged_proposals = []
+ for proposals, aug_img_meta in zip(aug_proposals, aug_img_metas):
+ merged_proposal = merge_aug_proposals(proposals, aug_img_meta,
+ self.test_cfg)
+ results = InstanceData()
+ results.bboxes = merged_proposal[:, :4]
+ results.scores = merged_proposal[:, 4]
+ merged_proposals.append(results)
+ return merged_proposals
+
+ if sys.version_info >= (3, 7):
+
+ async def async_simple_test_rpn(self, x, img_metas):
+ sleep_interval = self.test_cfg.pop('async_sleep_interval', 0.025)
+ async with completed(
+ __name__, 'rpn_head_forward',
+ sleep_interval=sleep_interval):
+ rpn_outs = self(x)
+
+ proposal_list = self.get_results(*rpn_outs, img_metas=img_metas)
+ return proposal_list
+
+ def merge_aug_bboxes(self, aug_bboxes, aug_scores, img_metas):
+ """Merge augmented detection bboxes and scores.
+
+ Args:
+ aug_bboxes (list[Tensor]): shape (n, 4*#class)
+ aug_scores (list[Tensor] or None): shape (n, #class)
+ img_shapes (list[Tensor]): shape (3, ).
+
+ Returns:
+ tuple[Tensor]: ``bboxes`` with shape (n,4), where
+ 4 represent (tl_x, tl_y, br_x, br_y)
+ and ``scores`` with shape (n,).
+ """
+ recovered_bboxes = []
+ for bboxes, img_info in zip(aug_bboxes, img_metas):
+ img_shape = img_info[0]['img_shape']
+ scale_factor = img_info[0]['scale_factor']
+ flip = img_info[0]['flip']
+ flip_direction = img_info[0]['flip_direction']
+ bboxes = bbox_mapping_back(bboxes, img_shape, scale_factor, flip,
+ flip_direction)
+ recovered_bboxes.append(bboxes)
+ bboxes = torch.cat(recovered_bboxes, dim=0)
+ if aug_scores is None:
+ return bboxes
+ else:
+ scores = torch.cat(aug_scores, dim=0)
+ return bboxes, scores
diff --git a/mmdet/models/dense_heads/detr_head.py b/mmdet/models/dense_heads/detr_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..4f4f12065f4a3580ceb06b6fb159b885329c6e1f
--- /dev/null
+++ b/mmdet/models/dense_heads/detr_head.py
@@ -0,0 +1,643 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Tuple
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import Linear
+from mmcv.cnn.bricks.transformer import FFN
+from mmengine.model import BaseModule
+from mmengine.structures import InstanceData
+from torch import Tensor
+from mmcv.ops.nms import nms
+from mmdet.registry import MODELS, TASK_UTILS
+from mmdet.structures import SampleList
+from mmdet.structures.bbox import bbox_cxcywh_to_xyxy, bbox_xyxy_to_cxcywh
+from mmdet.utils import (ConfigType, InstanceList, OptInstanceList,
+ OptMultiConfig, reduce_mean)
+from ..utils import multi_apply
+
+
+@MODELS.register_module()
+class DETRHead(BaseModule):
+ r"""Head of DETR. DETR:End-to-End Object Detection with Transformers.
+
+ More details can be found in the `paper
+ `_ .
+
+ Args:
+ num_classes (int): Number of categories excluding the background.
+ embed_dims (int): The dims of Transformer embedding.
+ num_reg_fcs (int): Number of fully-connected layers used in `FFN`,
+ which is then used for the regression head. Defaults to 2.
+ sync_cls_avg_factor (bool): Whether to sync the `avg_factor` of
+ all ranks. Default to `False`.
+ loss_cls (:obj:`ConfigDict` or dict): Config of the classification
+ loss. Defaults to `CrossEntropyLoss`.
+ loss_bbox (:obj:`ConfigDict` or dict): Config of the regression bbox
+ loss. Defaults to `L1Loss`.
+ loss_iou (:obj:`ConfigDict` or dict): Config of the regression iou
+ loss. Defaults to `GIoULoss`.
+ train_cfg (:obj:`ConfigDict` or dict): Training config of transformer
+ head.
+ test_cfg (:obj:`ConfigDict` or dict): Testing config of transformer
+ head.
+ init_cfg (:obj:`ConfigDict` or dict, optional): the config to control
+ the initialization. Defaults to None.
+ """
+
+ _version = 2
+
+ def __init__(
+ self,
+ num_classes: int,
+ embed_dims: int = 256,
+ num_reg_fcs: int = 2,
+ sync_cls_avg_factor: bool = False,
+ use_nms: bool = False,
+ neg_cls: bool = True,
+ loss_cls: ConfigType = dict(
+ type='CrossEntropyLoss',
+ bg_cls_weight=0.1,
+ use_sigmoid=False,
+ loss_weight=1.0,
+ class_weight=1.0),
+ loss_bbox: ConfigType = dict(type='L1Loss', loss_weight=5.0),
+ loss_iou: ConfigType = dict(type='GIoULoss', loss_weight=2.0),
+ train_cfg: ConfigType = dict(
+ assigner=dict(
+ type='HungarianAssigner',
+ match_costs=[
+ dict(type='ClassificationCost', weight=1.),
+ dict(type='BBoxL1Cost', weight=5.0, box_format='xywh'),
+ dict(type='IoUCost', iou_mode='giou', weight=2.0)
+ ])),
+ test_cfg: ConfigType = dict(max_per_img=100),
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(init_cfg=init_cfg)
+ self.bg_cls_weight = 0
+ self.sync_cls_avg_factor = sync_cls_avg_factor
+ class_weight = loss_cls.get('class_weight', None)
+ if class_weight is not None and (self.__class__ is DETRHead):
+ assert isinstance(class_weight, float), 'Expected ' \
+ 'class_weight to have type float. Found ' \
+ f'{type(class_weight)}.'
+ # NOTE following the official DETR repo, bg_cls_weight means
+ # relative classification weight of the no-object class.
+ bg_cls_weight = loss_cls.get('bg_cls_weight', class_weight)
+ assert isinstance(bg_cls_weight, float), 'Expected ' \
+ 'bg_cls_weight to have type float. Found ' \
+ f'{type(bg_cls_weight)}.'
+ class_weight = torch.ones(num_classes + 1) * class_weight
+ # set background class as the last indice
+ class_weight[num_classes] = bg_cls_weight
+ loss_cls.update({'class_weight': class_weight})
+ if 'bg_cls_weight' in loss_cls:
+ loss_cls.pop('bg_cls_weight')
+ self.bg_cls_weight = bg_cls_weight
+
+ if train_cfg:
+ assert 'assigner' in train_cfg, 'assigner should be provided ' \
+ 'when train_cfg is set.'
+ assigner = train_cfg['assigner']
+ self.assigner = TASK_UTILS.build(assigner)
+ if train_cfg.get('sampler', None) is not None:
+ raise RuntimeError('DETR do not build sampler.')
+ self.num_classes = num_classes
+ self.embed_dims = embed_dims
+ self.num_reg_fcs = num_reg_fcs
+ self.train_cfg = train_cfg
+ self.test_cfg = test_cfg
+ self.loss_cls = MODELS.build(loss_cls)
+ self.loss_bbox = MODELS.build(loss_bbox)
+ self.loss_iou = MODELS.build(loss_iou)
+ self.use_nms = use_nms
+ self.neg_cls = neg_cls
+ if self.loss_cls.use_sigmoid:
+ self.cls_out_channels = num_classes
+ else:
+ self.cls_out_channels = num_classes + 1
+
+ self._init_layers()
+
+ def _init_layers(self) -> None:
+ """Initialize layers of the transformer head."""
+ # cls branch
+ self.fc_cls = Linear(self.embed_dims, self.cls_out_channels)
+ # reg branch
+ self.activate = nn.ReLU()
+ self.reg_ffn = FFN(
+ self.embed_dims,
+ self.embed_dims,
+ self.num_reg_fcs,
+ dict(type='ReLU', inplace=True),
+ dropout=0.0,
+ add_residual=False)
+ # NOTE the activations of reg_branch here is the same as
+ # those in transformer, but they are actually different
+ # in DAB-DETR (prelu in transformer and relu in reg_branch)
+ self.fc_reg = Linear(self.embed_dims, 4)
+
+ def forward(self, hidden_states: Tensor) -> Tuple[Tensor]:
+ """"Forward function.
+
+ Args:
+ hidden_states (Tensor): Features from transformer decoder. If
+ `return_intermediate_dec` in detr.py is True output has shape
+ (num_decoder_layers, bs, num_queries, dim), else has shape
+ (1, bs, num_queries, dim) which only contains the last layer
+ outputs.
+ Returns:
+ tuple[Tensor]: results of head containing the following tensor.
+
+ - layers_cls_scores (Tensor): Outputs from the classification head,
+ shape (num_decoder_layers, bs, num_queries, cls_out_channels).
+ Note cls_out_channels should include background.
+ - layers_bbox_preds (Tensor): Sigmoid outputs from the regression
+ head with normalized coordinate format (cx, cy, w, h), has shape
+ (num_decoder_layers, bs, num_queries, 4).
+ """
+ layers_cls_scores = self.fc_cls(hidden_states)
+ layers_bbox_preds = self.fc_reg(
+ self.activate(self.reg_ffn(hidden_states))).sigmoid()
+ return layers_cls_scores, layers_bbox_preds
+
+ def loss(self, hidden_states: Tensor,
+ batch_data_samples: SampleList) -> dict:
+ """Perform forward propagation and loss calculation of the detection
+ head on the features of the upstream network.
+
+ Args:
+ hidden_states (Tensor): Feature from the transformer decoder, has
+ shape (num_decoder_layers, bs, num_queries, cls_out_channels)
+ or (num_decoder_layers, num_queries, bs, cls_out_channels).
+ batch_data_samples (List[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+
+ Returns:
+ dict: A dictionary of loss components.
+ """
+ batch_gt_instances = []
+ batch_img_metas = []
+ for data_sample in batch_data_samples:
+ batch_img_metas.append(data_sample.metainfo)
+ batch_gt_instances.append(data_sample.gt_instances)
+
+ outs = self(hidden_states)
+ loss_inputs = outs + (batch_gt_instances, batch_img_metas)
+ losses = self.loss_by_feat(*loss_inputs)
+ return losses
+
+ def loss_by_feat(
+ self,
+ all_layers_cls_scores: Tensor,
+ all_layers_bbox_preds: Tensor,
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ batch_gt_instances_ignore: OptInstanceList = None
+ ) -> Dict[str, Tensor]:
+ """"Loss function.
+
+ Only outputs from the last feature level are used for computing
+ losses by default.
+
+ Args:
+ all_layers_cls_scores (Tensor): Classification outputs
+ of each decoder layers. Each is a 4D-tensor, has shape
+ (num_decoder_layers, bs, num_queries, cls_out_channels).
+ all_layers_bbox_preds (Tensor): Sigmoid regression
+ outputs of each decoder layers. Each is a 4D-tensor with
+ normalized coordinate format (cx, cy, w, h) and shape
+ (num_decoder_layers, bs, num_queries, 4).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components.
+ """
+ assert batch_gt_instances_ignore is None, \
+ f'{self.__class__.__name__} only supports ' \
+ 'for batch_gt_instances_ignore setting to None.'
+
+ losses_cls, losses_bbox, losses_iou = multi_apply(
+ self.loss_by_feat_single,
+ all_layers_cls_scores,
+ all_layers_bbox_preds,
+ batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas)
+
+ loss_dict = dict()
+ # loss from the last decoder layer
+ loss_dict['loss_cls'] = losses_cls[-1]
+ loss_dict['loss_bbox'] = losses_bbox[-1]
+ loss_dict['loss_iou'] = losses_iou[-1]
+ # loss from other decoder layers
+ num_dec_layer = 0
+ for loss_cls_i, loss_bbox_i, loss_iou_i in \
+ zip(losses_cls[:-1], losses_bbox[:-1], losses_iou[:-1]):
+ loss_dict[f'd{num_dec_layer}.loss_cls'] = loss_cls_i
+ loss_dict[f'd{num_dec_layer}.loss_bbox'] = loss_bbox_i
+ loss_dict[f'd{num_dec_layer}.loss_iou'] = loss_iou_i
+ num_dec_layer += 1
+ return loss_dict
+
+ def loss_by_feat_single(self, cls_scores: Tensor, bbox_preds: Tensor,
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict]) -> Tuple[Tensor]:
+ """Loss function for outputs from a single decoder layer of a single
+ feature level.
+
+ Args:
+ cls_scores (Tensor): Box score logits from a single decoder layer
+ for all images, has shape (bs, num_queries, cls_out_channels).
+ bbox_preds (Tensor): Sigmoid outputs from a single decoder layer
+ for all images, with normalized coordinate (cx, cy, w, h) and
+ shape (bs, num_queries, 4).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+
+ Returns:
+ Tuple[Tensor]: A tuple including `loss_cls`, `loss_box` and
+ `loss_iou`.
+ """
+ num_imgs = cls_scores.size(0)
+ cls_scores_list = [cls_scores[i] for i in range(num_imgs)]
+ bbox_preds_list = [bbox_preds[i] for i in range(num_imgs)]
+ cls_reg_targets = self.get_targets(cls_scores_list, bbox_preds_list,
+ batch_gt_instances, batch_img_metas)
+ (labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,
+ num_total_pos, num_total_neg) = cls_reg_targets
+ labels = torch.cat(labels_list, 0)
+ label_weights = torch.cat(label_weights_list, 0)
+ bbox_targets = torch.cat(bbox_targets_list, 0)
+ bbox_weights = torch.cat(bbox_weights_list, 0)
+
+ # classification loss
+ cls_scores = cls_scores.reshape(-1, self.cls_out_channels)
+ # construct weighted avg_factor to match with the official DETR repo
+ cls_avg_factor = num_total_pos * 1.0 + \
+ num_total_neg * self.bg_cls_weight
+
+ if not self.neg_cls:
+ cls_avg_factor = num_total_pos * 1.0
+
+ if self.sync_cls_avg_factor:
+ cls_avg_factor = reduce_mean(
+ cls_scores.new_tensor([cls_avg_factor]))
+ cls_avg_factor = max(cls_avg_factor, 1)
+
+ loss_cls = self.loss_cls(
+ cls_scores, labels, label_weights, avg_factor=cls_avg_factor)
+
+ # Compute the average number of gt boxes across all gpus, for
+ # normalization purposes
+ num_total_pos = loss_cls.new_tensor([num_total_pos])
+ num_total_pos = torch.clamp(reduce_mean(num_total_pos), min=1).item()
+
+ # construct factors used for rescale bboxes
+ factors = []
+ for img_meta, bbox_pred in zip(batch_img_metas, bbox_preds):
+ img_h, img_w, = img_meta['img_shape']
+ factor = bbox_pred.new_tensor([img_w, img_h, img_w,
+ img_h]).unsqueeze(0).repeat(
+ bbox_pred.size(0), 1)
+ factors.append(factor)
+ factors = torch.cat(factors, 0)
+
+ # DETR regress the relative position of boxes (cxcywh) in the image,
+ # thus the learning target is normalized by the image size. So here
+ # we need to re-scale them for calculating IoU loss
+ bbox_preds = bbox_preds.reshape(-1, 4)
+ bboxes = bbox_cxcywh_to_xyxy(bbox_preds) * factors
+ bboxes_gt = bbox_cxcywh_to_xyxy(bbox_targets) * factors
+
+ # regression IoU loss, defaultly GIoU loss
+ loss_iou = self.loss_iou(
+ bboxes, bboxes_gt, bbox_weights, avg_factor=num_total_pos)
+
+ # regression L1 loss
+ loss_bbox = self.loss_bbox(
+ bbox_preds, bbox_targets, bbox_weights, avg_factor=num_total_pos)
+ return loss_cls, loss_bbox, loss_iou
+
+ def get_targets(self, cls_scores_list: List[Tensor],
+ bbox_preds_list: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict]) -> tuple:
+ """Compute regression and classification targets for a batch image.
+
+ Outputs from a single decoder layer of a single feature level are used.
+
+ Args:
+ cls_scores_list (list[Tensor]): Box score logits from a single
+ decoder layer for each image, has shape [num_queries,
+ cls_out_channels].
+ bbox_preds_list (list[Tensor]): Sigmoid outputs from a single
+ decoder layer for each image, with normalized coordinate
+ (cx, cy, w, h) and shape [num_queries, 4].
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+
+ Returns:
+ tuple: a tuple containing the following targets.
+
+ - labels_list (list[Tensor]): Labels for all images.
+ - label_weights_list (list[Tensor]): Label weights for all images.
+ - bbox_targets_list (list[Tensor]): BBox targets for all images.
+ - bbox_weights_list (list[Tensor]): BBox weights for all images.
+ - num_total_pos (int): Number of positive samples in all images.
+ - num_total_neg (int): Number of negative samples in all images.
+ """
+ (labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,
+ pos_inds_list,
+ neg_inds_list) = multi_apply(self._get_targets_single,
+ cls_scores_list, bbox_preds_list,
+ batch_gt_instances, batch_img_metas)
+ num_total_pos = sum((inds.numel() for inds in pos_inds_list))
+ num_total_neg = sum((inds.numel() for inds in neg_inds_list))
+ return (labels_list, label_weights_list, bbox_targets_list,
+ bbox_weights_list, num_total_pos, num_total_neg)
+
+ def _get_targets_single(self, cls_score: Tensor, bbox_pred: Tensor,
+ gt_instances: InstanceData,
+ img_meta: dict) -> tuple:
+ """Compute regression and classification targets for one image.
+
+ Outputs from a single decoder layer of a single feature level are used.
+
+ Args:
+ cls_score (Tensor): Box score logits from a single decoder layer
+ for one image. Shape [num_queries, cls_out_channels].
+ bbox_pred (Tensor): Sigmoid outputs from a single decoder layer
+ for one image, with normalized coordinate (cx, cy, w, h) and
+ shape [num_queries, 4].
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It should includes ``bboxes`` and ``labels``
+ attributes.
+ img_meta (dict): Meta information for one image.
+
+ Returns:
+ tuple[Tensor]: a tuple containing the following for one image.
+
+ - labels (Tensor): Labels of each image.
+ - label_weights (Tensor]): Label weights of each image.
+ - bbox_targets (Tensor): BBox targets of each image.
+ - bbox_weights (Tensor): BBox weights of each image.
+ - pos_inds (Tensor): Sampled positive indices for each image.
+ - neg_inds (Tensor): Sampled negative indices for each image.
+ """
+ img_h, img_w = img_meta['img_shape']
+ factor = bbox_pred.new_tensor([img_w, img_h, img_w,
+ img_h]).unsqueeze(0)
+ num_bboxes = bbox_pred.size(0)
+ # convert bbox_pred from xywh, normalized to xyxy, unnormalized
+ bbox_pred = bbox_cxcywh_to_xyxy(bbox_pred)
+ bbox_pred = bbox_pred * factor
+
+ pred_instances = InstanceData(scores=cls_score, bboxes=bbox_pred)
+ # assigner and sampler
+ assign_result = self.assigner.assign(
+ pred_instances=pred_instances,
+ gt_instances=gt_instances,
+ img_meta=img_meta)
+
+
+
+ gt_bboxes = gt_instances.bboxes
+ gt_labels = gt_instances.labels
+ pos_inds = torch.nonzero(
+ assign_result.gt_inds > 0, as_tuple=False).squeeze(-1).unique()
+ neg_inds = torch.nonzero(
+ assign_result.gt_inds == 0, as_tuple=False).squeeze(-1).unique()
+ pos_assigned_gt_inds = assign_result.gt_inds[pos_inds] - 1
+ pos_gt_bboxes = gt_bboxes[pos_assigned_gt_inds.long(), :]
+
+ # label targets
+ labels = gt_bboxes.new_full((num_bboxes, ),
+ self.num_classes,
+ dtype=torch.long)
+ labels[pos_inds] = gt_labels[pos_assigned_gt_inds]
+ label_weights = gt_bboxes.new_ones(num_bboxes)
+
+ if not self.neg_cls:
+ print('1')
+ label_weights[:] = 0
+ label_weights[pos_inds]=1
+
+
+ # bbox targets
+ bbox_targets = torch.zeros_like(bbox_pred)
+ bbox_weights = torch.zeros_like(bbox_pred)
+ bbox_weights[pos_inds] = 1.0
+
+ # DETR regress the relative position of boxes (cxcywh) in the image.
+ # Thus the learning target should be normalized by the image size, also
+ # the box format should be converted from defaultly x1y1x2y2 to cxcywh.
+ pos_gt_bboxes_normalized = pos_gt_bboxes / factor
+ pos_gt_bboxes_targets = bbox_xyxy_to_cxcywh(pos_gt_bboxes_normalized)
+ bbox_targets[pos_inds] = pos_gt_bboxes_targets
+ return (labels, label_weights, bbox_targets, bbox_weights, pos_inds,
+ neg_inds)
+
+ def loss_and_predict(
+ self, hidden_states: Tuple[Tensor],
+ batch_data_samples: SampleList) -> Tuple[dict, InstanceList]:
+ """Perform forward propagation of the head, then calculate loss and
+ predictions from the features and data samples. Over-write because
+ img_metas are needed as inputs for bbox_head.
+
+ Args:
+ hidden_states (tuple[Tensor]): Feature from the transformer
+ decoder, has shape (num_decoder_layers, bs, num_queries, dim).
+ batch_data_samples (list[:obj:`DetDataSample`]): Each item contains
+ the meta information of each image and corresponding
+ annotations.
+
+ Returns:
+ tuple: the return value is a tuple contains:
+
+ - losses: (dict[str, Tensor]): A dictionary of loss components.
+ - predictions (list[:obj:`InstanceData`]): Detection
+ results of each image after the post process.
+ """
+ batch_gt_instances = []
+ batch_img_metas = []
+ for data_sample in batch_data_samples:
+ batch_img_metas.append(data_sample.metainfo)
+ batch_gt_instances.append(data_sample.gt_instances)
+
+ outs = self(hidden_states)
+ loss_inputs = outs + (batch_gt_instances, batch_img_metas)
+ losses = self.loss_by_feat(*loss_inputs)
+
+ predictions = self.predict_by_feat(
+ *outs, batch_img_metas=batch_img_metas)
+ return losses, predictions
+
+ def predict(self,
+ hidden_states: Tuple[Tensor],
+ batch_data_samples: SampleList,
+ rescale: bool = True) -> InstanceList:
+ """Perform forward propagation of the detection head and predict
+ detection results on the features of the upstream network. Over-write
+ because img_metas are needed as inputs for bbox_head.
+
+ Args:
+ hidden_states (tuple[Tensor]): Multi-level features from the
+ upstream network, each is a 4D-tensor.
+ batch_data_samples (List[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ rescale (bool, optional): Whether to rescale the results.
+ Defaults to True.
+
+ Returns:
+ list[obj:`InstanceData`]: Detection results of each image
+ after the post process.
+ """
+ batch_img_metas = [
+ data_samples.metainfo for data_samples in batch_data_samples
+ ]
+
+ last_layer_hidden_state = hidden_states[-1].unsqueeze(0)
+ outs = self(last_layer_hidden_state)
+
+ predictions = self.predict_by_feat(
+ *outs, batch_img_metas=batch_img_metas, rescale=rescale)
+
+ return predictions
+
+ def predict_by_feat(self,
+ layer_cls_scores: Tensor,
+ layer_bbox_preds: Tensor,
+ batch_img_metas: List[dict],
+ rescale: bool = True) -> InstanceList:
+ """Transform network outputs for a batch into bbox predictions.
+
+ Args:
+ layer_cls_scores (Tensor): Classification outputs of the last or
+ all decoder layer. Each is a 4D-tensor, has shape
+ (num_decoder_layers, bs, num_queries, cls_out_channels).
+ layer_bbox_preds (Tensor): Sigmoid regression outputs of the last
+ or all decoder layer. Each is a 4D-tensor with normalized
+ coordinate format (cx, cy, w, h) and shape
+ (num_decoder_layers, bs, num_queries, 4).
+ batch_img_metas (list[dict]): Meta information of each image.
+ rescale (bool, optional): If `True`, return boxes in original
+ image space. Defaults to `True`.
+
+ Returns:
+ list[:obj:`InstanceData`]: Object detection results of each image
+ after the post process. Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ """
+ # NOTE only using outputs from the last feature level,
+ # and only the outputs from the last decoder layer is used.
+ cls_scores = layer_cls_scores[-1]
+ bbox_preds = layer_bbox_preds[-1]
+
+ result_list = []
+ for img_id in range(len(batch_img_metas)):
+ cls_score = cls_scores[img_id]
+ bbox_pred = bbox_preds[img_id]
+ img_meta = batch_img_metas[img_id]
+ results = self._predict_by_feat_single(cls_score, bbox_pred,
+ img_meta, rescale)
+ result_list.append(results)
+ return result_list
+
+ def _predict_by_feat_single(self,
+ cls_score: Tensor,
+ bbox_pred: Tensor,
+ img_meta: dict,
+ rescale: bool = True) -> InstanceData:
+ """Transform outputs from the last decoder layer into bbox predictions
+ for each image.
+
+ Args:
+ cls_score (Tensor): Box score logits from the last decoder layer
+ for each image. Shape [num_queries, cls_out_channels].
+ bbox_pred (Tensor): Sigmoid outputs from the last decoder layer
+ for each image, with coordinate format (cx, cy, w, h) and
+ shape [num_queries, 4].
+ img_meta (dict): Image meta info.
+ rescale (bool): If True, return boxes in original image
+ space. Default True.
+
+ Returns:
+ :obj:`InstanceData`: Detection results of each image
+ after the post process.
+ Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ """
+ assert len(cls_score) == len(bbox_pred) # num_queries
+ max_per_img = self.test_cfg.get('max_per_img', len(cls_score))
+ img_shape = img_meta['img_shape']
+ # exclude background
+ if self.loss_cls.use_sigmoid:
+ cls_score = cls_score.sigmoid()
+ scores, indexes = cls_score.view(-1).topk(max_per_img)
+ det_labels = indexes % self.num_classes
+ bbox_index = indexes // self.num_classes
+ bbox_pred = bbox_pred[bbox_index]
+ else:
+ scores, det_labels = F.softmax(cls_score, dim=-1)[..., :-1].max(-1)
+ scores, bbox_index = scores.topk(max_per_img)
+ bbox_pred = bbox_pred[bbox_index]
+ det_labels = det_labels[bbox_index]
+
+ det_bboxes = bbox_cxcywh_to_xyxy(bbox_pred)
+ det_bboxes[:, 0::2] = det_bboxes[:, 0::2] * img_shape[1]
+ det_bboxes[:, 1::2] = det_bboxes[:, 1::2] * img_shape[0]
+ det_bboxes[:, 0::2].clamp_(min=0, max=img_shape[1])
+ det_bboxes[:, 1::2].clamp_(min=0, max=img_shape[0])
+
+ if self.use_nms:
+ iou_threshold= 0.01
+ offset = 0
+ score_threshold = 0.0 # torch.mean(cls_score.view(-1))+3*torch.std(cls_score.view(-1))
+ max_num = 300
+ dets, inds = nms(det_bboxes, scores, iou_threshold, offset, score_threshold, max_num)
+ det_bboxes = dets[:,:-1]
+ scores = dets[:,-1]
+ det_labels =det_labels[inds]
+
+ if rescale:
+ # assert img_meta.get('scale_factor') is not None
+ # det_bboxes /= det_bboxes.new_tensor(
+ # img_meta['scale_factor']).repeat((1, 2))
+ # rw by lzx
+ if img_meta.get('scale_factor') is not None:
+ det_bboxes /= det_bboxes.new_tensor(
+ img_meta['scale_factor']).repeat((1, 2))
+ results = InstanceData()
+ results.bboxes = det_bboxes
+ results.scores = scores
+ results.labels = det_labels
+ return results
diff --git a/mmdet/models/dense_heads/dino_head.py b/mmdet/models/dense_heads/dino_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..db03a35767f0dd38f5a747e52e988cabad5de043
--- /dev/null
+++ b/mmdet/models/dense_heads/dino_head.py
@@ -0,0 +1,1304 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+from typing import Dict, List, Tuple
+from torch import Tensor
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import Linear
+from mmcv.ops.nms import nms
+from mmengine.model import bias_init_with_prob, constant_init
+from mmengine.structures import InstanceData
+
+from mmdet.registry import MODELS
+from mmdet.structures import SampleList
+from mmdet.structures.bbox import bbox_cxcywh_to_xyxy, bbox_xyxy_to_cxcywh
+from mmdet.utils import InstanceList, OptInstanceList, reduce_mean
+from ..utils import multi_apply
+from ..layers import inverse_sigmoid
+from .detr_head import DETRHead
+
+
+# def adjust_bbox_to_pixel(bboxes: Tensor):
+# # 向下取整得到目标的左上角坐标
+# adjusted_bboxes = torch.floor(bboxes)
+# # 向上取整得到目标的右下角坐标
+# adjusted_bboxes[:, 2:] = torch.ceil(bboxes[:, 2:])
+# return adjusted_bboxes
+
+
+def adjust_bbox_to_pixel(bboxes: Tensor):
+ # 四舍五入取整坐标
+ adjusted_bboxes = torch.round(bboxes)
+ return adjusted_bboxes
+
+
+
+
+@MODELS.register_module()
+class DINOHead(DETRHead):
+ r"""Head of the DINO: DETR with Improved DeNoising Anchor Boxes
+ for End-to-End Object Detection
+
+ Code is modified from the `official github repo
+ `_.
+
+ More details can be found in the `paper
+ `_ .
+ """
+ def __init__(self,
+ *args,
+ share_pred_layer: bool = False,
+ num_pred_layer: int = 6,
+ as_two_stage: bool = False,
+ pre_bboxes_round: bool = False,
+ **kwargs) -> None:
+ self.share_pred_layer = share_pred_layer
+ self.num_pred_layer = num_pred_layer
+ self.as_two_stage = as_two_stage
+ self.pre_bboxes_round = pre_bboxes_round
+ super().__init__(*args, **kwargs)
+
+ def _init_layers(self) -> None:
+ """Initialize classification branch and regression branch of head."""
+ fc_cls = Linear(self.embed_dims, self.cls_out_channels)
+
+ reg_branch = []
+ for _ in range(self.num_reg_fcs):
+ reg_branch.append(Linear(self.embed_dims, self.embed_dims))
+ reg_branch.append(nn.ReLU())
+ reg_branch.append(Linear(self.embed_dims, 4))
+ reg_branch = nn.Sequential(*reg_branch)
+
+ if self.share_pred_layer:
+ self.cls_branches = nn.ModuleList(
+ [fc_cls for _ in range(self.num_pred_layer)])
+ self.reg_branches = nn.ModuleList(
+ [reg_branch for _ in range(self.num_pred_layer)])
+ else:
+ self.cls_branches = nn.ModuleList(
+ [copy.deepcopy(fc_cls) for _ in range(self.num_pred_layer)])
+ self.reg_branches = nn.ModuleList([
+ copy.deepcopy(reg_branch) for _ in range(self.num_pred_layer)
+ ])
+
+
+ def init_weights(self) -> None:
+ """Initialize weights of the Deformable DETR head."""
+ if self.loss_cls.use_sigmoid:
+ bias_init = bias_init_with_prob(0.01)
+ for m in self.cls_branches:
+ nn.init.constant_(m.bias, bias_init)
+ for m in self.reg_branches:
+ constant_init(m[-1], 0, bias=0)
+ nn.init.constant_(self.reg_branches[0][-1].bias.data[2:], -2.0)
+ if self.as_two_stage:
+ for m in self.reg_branches:
+ nn.init.constant_(m[-1].bias.data[2:], 0.0)
+
+ def forward(self, hidden_states: Tensor,
+ references: List[Tensor]) -> Tuple[Tensor]:
+ """Forward function.
+
+ Args:
+ hidden_states (Tensor): Hidden states output from each decoder
+ layer, has shape (num_decoder_layers, bs, num_queries, dim).
+ references (list[Tensor]): List of the reference from the decoder.
+ The first reference is the `init_reference` (initial) and the
+ other num_decoder_layers(6) references are `inter_references`
+ (intermediate). The `init_reference` has shape (bs,
+ num_queries, 4) when `as_two_stage` of the detector is `True`,
+ otherwise (bs, num_queries, 2). Each `inter_reference` has
+ shape (bs, num_queries, 4) when `with_box_refine` of the
+ detector is `True`, otherwise (bs, num_queries, 2). The
+ coordinates are arranged as (cx, cy) when the last dimension is
+ 2, and (cx, cy, w, h) when it is 4.
+
+ Returns:
+ tuple[Tensor]: results of head containing the following tensor.
+
+ - all_layers_outputs_classes (Tensor): Outputs from the
+ classification head, has shape (num_decoder_layers, bs,
+ num_queries, cls_out_channels).
+ - all_layers_outputs_coords (Tensor): Sigmoid outputs from the
+ regression head with normalized coordinate format (cx, cy, w,
+ h), has shape (num_decoder_layers, bs, num_queries, 4) with the
+ last dimension arranged as (cx, cy, w, h).
+ """
+ all_layers_outputs_classes = []
+ all_layers_outputs_coords = []
+
+ for layer_id in range(hidden_states.shape[0]):
+ reference = inverse_sigmoid(references[layer_id])
+ # NOTE The last reference will not be used.
+ hidden_state = hidden_states[layer_id]
+ outputs_class = self.cls_branches[layer_id](hidden_state)
+ tmp_reg_preds = self.reg_branches[layer_id](hidden_state)
+ if reference.shape[-1] == 4:
+ # When `layer` is 0 and `as_two_stage` of the detector
+ # is `True`, or when `layer` is greater than 0 and
+ # `with_box_refine` of the detector is `True`.
+ tmp_reg_preds += reference
+ else:
+ # When `layer` is 0 and `as_two_stage` of the detector
+ # is `False`, or when `layer` is greater than 0 and
+ # `with_box_refine` of the detector is `False`.
+ assert reference.shape[-1] == 2
+ tmp_reg_preds[..., :2] += reference
+ outputs_coord = tmp_reg_preds.sigmoid()
+ all_layers_outputs_classes.append(outputs_class)
+ all_layers_outputs_coords.append(outputs_coord)
+
+
+
+ all_layers_outputs_classes = torch.stack(all_layers_outputs_classes)
+ all_layers_outputs_coords = torch.stack(all_layers_outputs_coords)
+
+ return all_layers_outputs_classes, all_layers_outputs_coords
+
+ def loss(self, hidden_states: Tensor, references: List[Tensor],
+ enc_outputs_class: Tensor, enc_outputs_coord: Tensor,
+ batch_data_samples: SampleList, dn_meta: Dict[str, int]) -> dict:
+ """Perform forward propagation and loss calculation of the detection
+ head on the queries of the upstream network.
+
+ Args:
+ hidden_states (Tensor): Hidden states output from each decoder
+ layer, has shape (num_decoder_layers, bs, num_queries_total,
+ dim), where `num_queries_total` is the sum of
+ `num_denoising_queries` and `num_matching_queries` when
+ `self.training` is `True`, else `num_matching_queries`.
+ references (list[Tensor]): List of the reference from the decoder.
+ The first reference is the `init_reference` (initial) and the
+ other num_decoder_layers(6) references are `inter_references`
+ (intermediate). The `init_reference` has shape (bs,
+ num_queries_total, 4) and each `inter_reference` has shape
+ (bs, num_queries, 4) with the last dimension arranged as
+ (cx, cy, w, h).
+ enc_outputs_class (Tensor): The score of each point on encode
+ feature map, has shape (bs, num_feat_points, cls_out_channels).
+ enc_outputs_coord (Tensor): The proposal generate from the
+ encode feature map, has shape (bs, num_feat_points, 4) with the
+ last dimension arranged as (cx, cy, w, h).
+ batch_data_samples (list[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ dict: A dictionary of loss components.
+ """
+ batch_gt_instances = []
+ batch_img_metas = []
+ for data_sample in batch_data_samples:
+ batch_img_metas.append(data_sample.metainfo)
+ batch_gt_instances.append(data_sample.gt_instances)
+
+ outs = self(hidden_states, references)
+ loss_inputs = outs + (enc_outputs_class, enc_outputs_coord,
+ batch_gt_instances, batch_img_metas, dn_meta)
+ losses = self.loss_by_feat(*loss_inputs)
+ return losses
+
+ def loss_by_feat(
+ self,
+ all_layers_cls_scores: Tensor,
+ all_layers_bbox_preds: Tensor,
+ enc_cls_scores: Tensor,
+ enc_bbox_preds: Tensor,
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ dn_meta: Dict[str, int],
+ batch_gt_instances_ignore: OptInstanceList = None
+ ) -> Dict[str, Tensor]:
+ """Loss function.
+
+ Args:
+ all_layers_cls_scores (Tensor): Classification scores of all
+ decoder layers, has shape (num_decoder_layers, bs,
+ num_queries_total, cls_out_channels), where
+ `num_queries_total` is the sum of `num_denoising_queries`
+ and `num_matching_queries`.
+ all_layers_bbox_preds (Tensor): Regression outputs of all decoder
+ layers. Each is a 4D-tensor with normalized coordinate format
+ (cx, cy, w, h) and has shape (num_decoder_layers, bs,
+ num_queries_total, 4).
+ enc_cls_scores (Tensor): The score of each point on encode
+ feature map, has shape (bs, num_feat_points, cls_out_channels).
+ enc_bbox_preds (Tensor): The proposal generate from the encode
+ feature map, has shape (bs, num_feat_points, 4) with the last
+ dimension arranged as (cx, cy, w, h).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components.
+ """
+ # extract denoising and matching part of outputs
+ (all_layers_matching_cls_scores, all_layers_matching_bbox_preds,
+ all_layers_denoising_cls_scores, all_layers_denoising_bbox_preds) = \
+ self.split_outputs(
+ all_layers_cls_scores, all_layers_bbox_preds, dn_meta)
+
+ loss_dict = super().loss_by_feat(
+ all_layers_matching_cls_scores, all_layers_matching_bbox_preds,
+ batch_gt_instances, batch_img_metas, batch_gt_instances_ignore)
+ # NOTE DETRHead.loss_by_feat but not DeformableDETRHead.loss_by_feat
+ # is called, because the encoder loss calculations are different
+ # between DINO and DeformableDETR.
+
+ # loss of proposal generated from encode feature map.
+ if enc_cls_scores is not None:
+ # NOTE The enc_loss calculation of the DINO is
+ # different from that of Deformable DETR.
+ enc_loss_cls, enc_losses_bbox, enc_losses_iou = \
+ self.loss_by_feat_single(
+ enc_cls_scores, enc_bbox_preds,
+ batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas)
+ loss_dict['enc_loss_cls'] = enc_loss_cls
+ loss_dict['enc_loss_bbox'] = enc_losses_bbox
+ loss_dict['enc_loss_iou'] = enc_losses_iou
+
+ if all_layers_denoising_cls_scores is not None:
+ # calculate denoising loss from all decoder layers
+ dn_losses_cls, dn_losses_bbox, dn_losses_iou = self.loss_dn(
+ all_layers_denoising_cls_scores,
+ all_layers_denoising_bbox_preds,
+ batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas,
+ dn_meta=dn_meta)
+ # collate denoising loss
+ loss_dict['dn_loss_cls'] = dn_losses_cls[-1]
+ loss_dict['dn_loss_bbox'] = dn_losses_bbox[-1]
+ loss_dict['dn_loss_iou'] = dn_losses_iou[-1]
+ for num_dec_layer, (loss_cls_i, loss_bbox_i, loss_iou_i) in \
+ enumerate(zip(dn_losses_cls[:-1], dn_losses_bbox[:-1],
+ dn_losses_iou[:-1])):
+ loss_dict[f'd{num_dec_layer}.dn_loss_cls'] = loss_cls_i
+ loss_dict[f'd{num_dec_layer}.dn_loss_bbox'] = loss_bbox_i
+ loss_dict[f'd{num_dec_layer}.dn_loss_iou'] = loss_iou_i
+ return loss_dict
+
+ def loss_dn(self, all_layers_denoising_cls_scores: Tensor,
+ all_layers_denoising_bbox_preds: Tensor,
+ batch_gt_instances: InstanceList, batch_img_metas: List[dict],
+ dn_meta: Dict[str, int]) -> Tuple[List[Tensor]]:
+ """Calculate denoising loss.
+
+ Args:
+ all_layers_denoising_cls_scores (Tensor): Classification scores of
+ all decoder layers in denoising part, has shape (
+ num_decoder_layers, bs, num_denoising_queries,
+ cls_out_channels).
+ all_layers_denoising_bbox_preds (Tensor): Regression outputs of all
+ decoder layers in denoising part. Each is a 4D-tensor with
+ normalized coordinate format (cx, cy, w, h) and has shape
+ (num_decoder_layers, bs, num_denoising_queries, 4).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ Tuple[List[Tensor]]: The loss_dn_cls, loss_dn_bbox, and loss_dn_iou
+ of each decoder layers.
+ """
+ return multi_apply(
+ self._loss_dn_single,
+ all_layers_denoising_cls_scores,
+ all_layers_denoising_bbox_preds,
+ batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas,
+ dn_meta=dn_meta)
+
+ def _loss_dn_single(self, dn_cls_scores: Tensor, dn_bbox_preds: Tensor,
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ dn_meta: Dict[str, int]) -> Tuple[Tensor]:
+ """Denoising loss for outputs from a single decoder layer.
+
+ Args:
+ dn_cls_scores (Tensor): Classification scores of a single decoder
+ layer in denoising part, has shape (bs, num_denoising_queries,
+ cls_out_channels).
+ dn_bbox_preds (Tensor): Regression outputs of a single decoder
+ layer in denoising part. Each is a 4D-tensor with normalized
+ coordinate format (cx, cy, w, h) and has shape
+ (bs, num_denoising_queries, 4).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ Tuple[Tensor]: A tuple including `loss_cls`, `loss_box` and
+ `loss_iou`.
+ """
+ cls_reg_targets = self.get_dn_targets(batch_gt_instances,
+ batch_img_metas, dn_meta)
+ (labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,
+ num_total_pos, num_total_neg) = cls_reg_targets
+ labels = torch.cat(labels_list, 0)
+ label_weights = torch.cat(label_weights_list, 0)
+ bbox_targets = torch.cat(bbox_targets_list, 0)
+ bbox_weights = torch.cat(bbox_weights_list, 0)
+
+ # classification loss
+ cls_scores = dn_cls_scores.reshape(-1, self.cls_out_channels)
+ # construct weighted avg_factor to match with the official DETR repo
+ cls_avg_factor = \
+ num_total_pos * 1.0 + num_total_neg * self.bg_cls_weight
+ if self.sync_cls_avg_factor:
+ cls_avg_factor = reduce_mean(
+ cls_scores.new_tensor([cls_avg_factor]))
+ cls_avg_factor = max(cls_avg_factor, 1)
+
+ if len(cls_scores) > 0:
+ loss_cls = self.loss_cls(
+ cls_scores, labels, label_weights, avg_factor=cls_avg_factor)
+ else:
+ loss_cls = torch.zeros(
+ 1, dtype=cls_scores.dtype, device=cls_scores.device)
+
+ # Compute the average number of gt boxes across all gpus, for
+ # normalization purposes
+ num_total_pos = loss_cls.new_tensor([num_total_pos])
+ num_total_pos = torch.clamp(reduce_mean(num_total_pos), min=1).item()
+
+ # construct factors used for rescale bboxes
+ factors = []
+ for img_meta, bbox_pred in zip(batch_img_metas, dn_bbox_preds):
+ img_h, img_w = img_meta['img_shape']
+ factor = bbox_pred.new_tensor([img_w, img_h, img_w,
+ img_h]).unsqueeze(0).repeat(
+ bbox_pred.size(0), 1)
+ factors.append(factor)
+ factors = torch.cat(factors)
+
+ # DETR regress the relative position of boxes (cxcywh) in the image,
+ # thus the learning target is normalized by the image size. So here
+ # we need to re-scale them for calculating IoU loss
+ bbox_preds = dn_bbox_preds.reshape(-1, 4)
+ bboxes = bbox_cxcywh_to_xyxy(bbox_preds) * factors
+ bboxes_gt = bbox_cxcywh_to_xyxy(bbox_targets) * factors
+
+ # regression IoU loss, defaultly GIoU loss
+ loss_iou = self.loss_iou(
+ bboxes, bboxes_gt, bbox_weights, avg_factor=num_total_pos)
+
+ # regression L1 loss
+ loss_bbox = self.loss_bbox(
+ bbox_preds, bbox_targets, bbox_weights, avg_factor=num_total_pos)
+ return loss_cls, loss_bbox, loss_iou
+
+ def get_dn_targets(self, batch_gt_instances: InstanceList,
+ batch_img_metas: dict, dn_meta: Dict[str,
+ int]) -> tuple:
+ """Get targets in denoising part for a batch of images.
+
+ Args:
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ tuple: a tuple containing the following targets.
+
+ - labels_list (list[Tensor]): Labels for all images.
+ - label_weights_list (list[Tensor]): Label weights for all images.
+ - bbox_targets_list (list[Tensor]): BBox targets for all images.
+ - bbox_weights_list (list[Tensor]): BBox weights for all images.
+ - num_total_pos (int): Number of positive samples in all images.
+ - num_total_neg (int): Number of negative samples in all images.
+ """
+ (labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,
+ pos_inds_list, neg_inds_list) = multi_apply(
+ self._get_dn_targets_single,
+ batch_gt_instances,
+ batch_img_metas,
+ dn_meta=dn_meta)
+ num_total_pos = sum((inds.numel() for inds in pos_inds_list))
+ num_total_neg = sum((inds.numel() for inds in neg_inds_list))
+ return (labels_list, label_weights_list, bbox_targets_list,
+ bbox_weights_list, num_total_pos, num_total_neg)
+
+ def _get_dn_targets_single(self, gt_instances: InstanceData,
+ img_meta: dict, dn_meta: Dict[str,
+ int]) -> tuple:
+ """Get targets in denoising part for one image.
+
+ Args:
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It should includes ``bboxes`` and ``labels``
+ attributes.
+ img_meta (dict): Meta information for one image.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ tuple[Tensor]: a tuple containing the following for one image.
+
+ - labels (Tensor): Labels of each image.
+ - label_weights (Tensor]): Label weights of each image.
+ - bbox_targets (Tensor): BBox targets of each image.
+ - bbox_weights (Tensor): BBox weights of each image.
+ - pos_inds (Tensor): Sampled positive indices for each image.
+ - neg_inds (Tensor): Sampled negative indices for each image.
+ """
+ gt_bboxes = gt_instances.bboxes
+ gt_labels = gt_instances.labels
+ num_groups = dn_meta['num_denoising_groups']
+ num_denoising_queries = dn_meta['num_denoising_queries']
+ num_queries_each_group = int(num_denoising_queries / num_groups)
+ device = gt_bboxes.device
+
+ if len(gt_labels) > 0:
+ t = torch.arange(len(gt_labels), dtype=torch.long, device=device)
+ t = t.unsqueeze(0).repeat(num_groups, 1)
+ pos_assigned_gt_inds = t.flatten()
+ pos_inds = torch.arange(
+ num_groups, dtype=torch.long, device=device)
+ pos_inds = pos_inds.unsqueeze(1) * num_queries_each_group + t
+ pos_inds = pos_inds.flatten()
+ else:
+ pos_inds = pos_assigned_gt_inds = \
+ gt_bboxes.new_tensor([], dtype=torch.long)
+
+ neg_inds = pos_inds + num_queries_each_group // 2
+
+ # label targets
+ labels = gt_bboxes.new_full((num_denoising_queries, ),
+ self.num_classes,
+ dtype=torch.long)
+ labels[pos_inds] = gt_labels[pos_assigned_gt_inds]
+ label_weights = gt_bboxes.new_ones(num_denoising_queries)
+
+ # bbox targets
+ bbox_targets = torch.zeros(num_denoising_queries, 4, device=device)
+ bbox_weights = torch.zeros(num_denoising_queries, 4, device=device)
+ bbox_weights[pos_inds] = 1.0
+ img_h, img_w = img_meta['img_shape']
+
+ # DETR regress the relative position of boxes (cxcywh) in the image.
+ # Thus the learning target should be normalized by the image size, also
+ # the box format should be converted from defaultly x1y1x2y2 to cxcywh.
+ factor = gt_bboxes.new_tensor([img_w, img_h, img_w,
+ img_h]).unsqueeze(0)
+ gt_bboxes_normalized = gt_bboxes / factor
+ gt_bboxes_targets = bbox_xyxy_to_cxcywh(gt_bboxes_normalized)
+ bbox_targets[pos_inds] = gt_bboxes_targets.repeat([num_groups, 1])
+
+ return (labels, label_weights, bbox_targets, bbox_weights, pos_inds,
+ neg_inds)
+
+ @staticmethod
+ def split_outputs(all_layers_cls_scores: Tensor,
+ all_layers_bbox_preds: Tensor,
+ dn_meta: Dict[str, int]) -> Tuple[Tensor]:
+ """Split outputs of the denoising part and the matching part.
+
+ For the total outputs of `num_queries_total` length, the former
+ `num_denoising_queries` outputs are from denoising queries, and
+ the rest `num_matching_queries` ones are from matching queries,
+ where `num_queries_total` is the sum of `num_denoising_queries` and
+ `num_matching_queries`.
+
+ Args:
+ all_layers_cls_scores (Tensor): Classification scores of all
+ decoder layers, has shape (num_decoder_layers, bs,
+ num_queries_total, cls_out_channels).
+ all_layers_bbox_preds (Tensor): Regression outputs of all decoder
+ layers. Each is a 4D-tensor with normalized coordinate format
+ (cx, cy, w, h) and has shape (num_decoder_layers, bs,
+ num_queries_total, 4).
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'.
+
+ Returns:
+ Tuple[Tensor]: a tuple containing the following outputs.
+
+ - all_layers_matching_cls_scores (Tensor): Classification scores
+ of all decoder layers in matching part, has shape
+ (num_decoder_layers, bs, num_matching_queries, cls_out_channels).
+ - all_layers_matching_bbox_preds (Tensor): Regression outputs of
+ all decoder layers in matching part. Each is a 4D-tensor with
+ normalized coordinate format (cx, cy, w, h) and has shape
+ (num_decoder_layers, bs, num_matching_queries, 4).
+ - all_layers_denoising_cls_scores (Tensor): Classification scores
+ of all decoder layers in denoising part, has shape
+ (num_decoder_layers, bs, num_denoising_queries,
+ cls_out_channels).
+ - all_layers_denoising_bbox_preds (Tensor): Regression outputs of
+ all decoder layers in denoising part. Each is a 4D-tensor with
+ normalized coordinate format (cx, cy, w, h) and has shape
+ (num_decoder_layers, bs, num_denoising_queries, 4).
+ """
+ num_denoising_queries = dn_meta['num_denoising_queries']
+ if dn_meta is not None:
+ all_layers_denoising_cls_scores = \
+ all_layers_cls_scores[:, :, : num_denoising_queries, :]
+ all_layers_denoising_bbox_preds = \
+ all_layers_bbox_preds[:, :, : num_denoising_queries, :]
+ all_layers_matching_cls_scores = \
+ all_layers_cls_scores[:, :, num_denoising_queries:, :]
+ all_layers_matching_bbox_preds = \
+ all_layers_bbox_preds[:, :, num_denoising_queries:, :]
+ else:
+ all_layers_denoising_cls_scores = None
+ all_layers_denoising_bbox_preds = None
+ all_layers_matching_cls_scores = all_layers_cls_scores
+ all_layers_matching_bbox_preds = all_layers_bbox_preds
+ return (all_layers_matching_cls_scores, all_layers_matching_bbox_preds,
+ all_layers_denoising_cls_scores,
+ all_layers_denoising_bbox_preds)
+
+ def predict(self,
+ hidden_states: Tensor,
+ references: List[Tensor],
+ batch_data_samples: SampleList,
+ rescale: bool = True) -> InstanceList:
+ """Perform forward propagation and loss calculation of the detection
+ head on the queries of the upstream network.
+
+ Args:
+ hidden_states (Tensor): Hidden states output from each decoder
+ layer, has shape (num_decoder_layers, num_queries, bs, dim).
+ references (list[Tensor]): List of the reference from the decoder.
+ The first reference is the `init_reference` (initial) and the
+ other num_decoder_layers(6) references are `inter_references`
+ (intermediate). The `init_reference` has shape (bs,
+ num_queries, 4) when `as_two_stage` of the detector is `True`,
+ otherwise (bs, num_queries, 2). Each `inter_reference` has
+ shape (bs, num_queries, 4) when `with_box_refine` of the
+ detector is `True`, otherwise (bs, num_queries, 2). The
+ coordinates are arranged as (cx, cy) when the last dimension is
+ 2, and (cx, cy, w, h) when it is 4.
+ batch_data_samples (list[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ rescale (bool, optional): If `True`, return boxes in original
+ image space. Defaults to `True`.
+
+ Returns:
+ list[obj:`InstanceData`]: Detection results of each image
+ after the post process.
+ """
+ batch_img_metas = [
+ data_samples.metainfo for data_samples in batch_data_samples
+ ]
+
+ outs = self(hidden_states, references)
+
+ predictions = self.predict_by_feat(
+ *outs, batch_img_metas=batch_img_metas, rescale=rescale)
+ return predictions
+
+ def predict_by_feat(self,
+ all_layers_cls_scores: Tensor,
+ all_layers_bbox_preds: Tensor,
+ batch_img_metas: List[Dict],
+ rescale: bool = False) -> InstanceList:
+ """Transform a batch of output features extracted from the head into
+ bbox results.
+
+ Args:
+ all_layers_cls_scores (Tensor): Classification scores of all
+ decoder layers, has shape (num_decoder_layers, bs, num_queries,
+ cls_out_channels).
+ all_layers_bbox_preds (Tensor): Regression outputs of all decoder
+ layers. Each is a 4D-tensor with normalized coordinate format
+ (cx, cy, w, h) and shape (num_decoder_layers, bs, num_queries,
+ 4) with the last dimension arranged as (cx, cy, w, h).
+ batch_img_metas (list[dict]): Meta information of each image.
+ rescale (bool, optional): If `True`, return boxes in original
+ image space. Default `False`.
+
+ Returns:
+ list[obj:`InstanceData`]: Detection results of each image
+ after the post process.
+ """
+ cls_scores = all_layers_cls_scores[-1]
+ bbox_preds = all_layers_bbox_preds[-1]
+
+ result_list = []
+ for img_id in range(len(batch_img_metas)):
+ cls_score = cls_scores[img_id]
+ bbox_pred = bbox_preds[img_id]
+ img_meta = batch_img_metas[img_id]
+ results = self._predict_by_feat_single(cls_score, bbox_pred,
+ img_meta, rescale)
+ result_list.append(results)
+ return result_list
+
+ def _predict_by_feat_single(self,
+ cls_score: Tensor,
+ bbox_pred: Tensor,
+ img_meta: dict,
+ rescale: bool = True) -> InstanceData:
+ """Transform outputs from the last decoder layer into bbox predictions
+ for each image.
+
+ Args:
+ cls_score (Tensor): Box score logits from the last decoder layer
+ for each image. Shape [num_queries, cls_out_channels].
+ bbox_pred (Tensor): Sigmoid outputs from the last decoder layer
+ for each image, with coordinate format (cx, cy, w, h) and
+ shape [num_queries, 4].
+ img_meta (dict): Image meta info.
+ rescale (bool): If True, return boxes in original image
+ space. Default True.
+
+ Returns:
+ :obj:`InstanceData`: Detection results of each image
+ after the post process.
+ Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ """
+ assert len(cls_score) == len(bbox_pred) # num_queries
+ max_per_img = self.test_cfg.get('max_per_img', len(cls_score))
+ img_shape = img_meta['img_shape']
+ # exclude background
+ if self.loss_cls.use_sigmoid:
+ cls_score = cls_score.sigmoid()
+ scores, indexes = cls_score.view(-1).topk(max_per_img)
+ det_labels = indexes % self.num_classes
+ bbox_index = indexes // self.num_classes
+ bbox_pred = bbox_pred[bbox_index]
+ else:
+ scores, det_labels = F.softmax(cls_score, dim=-1)[..., :-1].max(-1)
+ scores, bbox_index = scores.topk(max_per_img)
+ bbox_pred = bbox_pred[bbox_index]
+ det_labels = det_labels[bbox_index]
+
+ det_bboxes = bbox_cxcywh_to_xyxy(bbox_pred)
+ det_bboxes[:, 0::2] = det_bboxes[:, 0::2] * img_shape[1]
+ det_bboxes[:, 1::2] = det_bboxes[:, 1::2] * img_shape[0]
+ det_bboxes[:, 0::2].clamp_(min=0, max=img_shape[1])
+ det_bboxes[:, 1::2].clamp_(min=0, max=img_shape[0])
+
+ #lzx
+ if self.use_nms:
+ iou_threshold= 0.01
+ offset = 0
+ score_threshold = 0.0 # torch.mean(cls_score.view(-1))+3*torch.std(cls_score.view(-1))
+ max_num = 300
+ dets, inds = nms(det_bboxes, scores, iou_threshold, offset, score_threshold, max_num)
+ det_bboxes = dets[:,:-1]
+ scores = dets[:,-1]
+ det_labels =det_labels[inds]
+
+
+
+ # add by lzx
+ if self.pre_bboxes_round:
+ det_bboxes = adjust_bbox_to_pixel(det_bboxes)
+
+ if rescale:
+ # assert img_meta.get('scale_factor') is not None
+ # det_bboxes /= det_bboxes.new_tensor(
+ # img_meta['scale_factor']).repeat((1, 2))
+ # rw by lzx
+ if img_meta.get('scale_factor') is not None:
+ det_bboxes /= det_bboxes.new_tensor(
+ img_meta['scale_factor']).repeat((1, 2))
+ results = InstanceData()
+ results.bboxes = det_bboxes
+ results.scores = scores
+ results.labels = det_labels
+ return results
+
+
+
+ def loss_group(self, hidden_states: Tensor, references: List[Tensor],
+ enc_outputs_class: Tensor, enc_outputs_coord: Tensor,
+ batch_data_samples: SampleList, dn_meta: Dict[str, int],
+ # match_group_size: Tuple[int, int] = (2, 2),
+ each_match_num_queries: int = 200, ) -> dict:
+ """Perform forward propagation and loss calculation of the detection
+ head on the queries of the upstream network.
+
+ Args:
+ hidden_states (Tensor): Hidden states output from each decoder
+ layer, has shape (num_decoder_layers, bs, num_queries_total,
+ dim), where `num_queries_total` is the sum of
+ `num_denoising_queries` and `num_matching_queries` when
+ `self.training` is `True`, else `num_matching_queries`.
+ references (list[Tensor]): List of the reference from the decoder.
+ The first reference is the `init_reference` (initial) and the
+ other num_decoder_layers(6) references are `inter_references`
+ (intermediate). The `init_reference` has shape (bs,
+ num_queries_total, 4) and each `inter_reference` has shape
+ (bs, num_queries, 4) with the last dimension arranged as
+ (cx, cy, w, h).
+ enc_outputs_class (Tensor): The score of each point on encode
+ feature map, has shape (bs, num_feat_points, cls_out_channels).
+ enc_outputs_coord (Tensor): The proposal generate from the
+ encode feature map, has shape (bs, num_feat_points, 4) with the
+ last dimension arranged as (cx, cy, w, h).
+ batch_data_samples (list[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ dict: A dictionary of loss components.
+ """
+ batch_gt_instances = []
+ batch_img_metas = []
+ for data_sample in batch_data_samples:
+ batch_img_metas.append(data_sample.metainfo)
+ batch_gt_instances.append(data_sample.gt_instances)
+
+ outs = self(hidden_states, references)
+ loss_inputs = outs + (enc_outputs_class, enc_outputs_coord,
+ batch_gt_instances, batch_img_metas, dn_meta,each_match_num_queries)
+ losses = self.loss_by_feat_group(*loss_inputs)
+ return losses
+
+ def loss_by_feat_group(
+ self,
+ all_layers_cls_scores: Tensor,
+ all_layers_bbox_preds: Tensor,
+ enc_cls_scores: Tensor,
+ enc_bbox_preds: Tensor,
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ dn_meta: Dict[str, int],
+ # match_group_size: Tuple[int, int] = (2, 2),
+ each_match_num_queries: int = 200,
+ batch_gt_instances_ignore: OptInstanceList = None,
+ ) -> Dict[str, Tensor]:
+ """Loss function.
+
+ Args:
+ all_layers_cls_scores (Tensor): Classification scores of all
+ decoder layers, has shape (num_decoder_layers, bs,
+ num_queries_total, cls_out_channels), where
+ `num_queries_total` is the sum of `num_denoising_queries`
+ and `num_matching_queries`.
+ all_layers_bbox_preds (Tensor): Regression outputs of all decoder
+ layers. Each is a 4D-tensor with normalized coordinate format
+ (cx, cy, w, h) and has shape (num_decoder_layers, bs,
+ num_queries_total, 4).
+ enc_cls_scores (Tensor): The score of each point on encode
+ feature map, has shape (bs, num_feat_points, cls_out_channels).
+ enc_bbox_preds (Tensor): The proposal generate from the encode
+ feature map, has shape (bs, num_feat_points, 4) with the last
+ dimension arranged as (cx, cy, w, h).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components.
+ """
+ # extract denoising and matching part of outputs
+ (all_layers_matching_cls_scores, all_layers_matching_bbox_preds,
+ all_layers_denoising_cls_scores, all_layers_denoising_bbox_preds) = \
+ self.split_outputs(
+ all_layers_cls_scores, all_layers_bbox_preds, dn_meta)
+ match_group_num = all_layers_matching_cls_scores.shape[2]//each_match_num_queries
+ loss_dict = dict()
+ for id_group in range(match_group_num):
+ all_layers_matching_cls_scores_one_group = all_layers_matching_cls_scores[:, :, id_group * each_match_num_queries:(id_group + 1) * each_match_num_queries, :]
+ all_layers_matching_bbox_preds_one_group = all_layers_matching_bbox_preds[:, :, id_group * each_match_num_queries:(id_group + 1) * each_match_num_queries, :]
+ # 同时计算每一解码层的loss
+ losses_cls, losses_bbox, losses_iou = multi_apply(
+ self.loss_by_feat_single,
+ all_layers_matching_cls_scores_one_group,
+ all_layers_matching_bbox_preds_one_group,
+ batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas)
+ # loss from the last decoder layer
+ loss_dict[f'g{id_group}.loss_cls'] = losses_cls[-1]
+ loss_dict[f'g{id_group}.loss_bbox'] = losses_bbox[-1]
+ loss_dict[f'g{id_group}.loss_iou'] = losses_iou[-1]
+ # loss from other decoder layers
+ num_dec_layer = 0
+ for loss_cls_i, loss_bbox_i, loss_iou_i in \
+ zip(losses_cls[:-1], losses_bbox[:-1], losses_iou[:-1]):
+ loss_dict[f'g{id_group}d{num_dec_layer}.loss_cls'] = loss_cls_i
+ loss_dict[f'g{id_group}d{num_dec_layer}.loss_bbox'] = loss_bbox_i
+ loss_dict[f'g{id_group}d{num_dec_layer}.loss_iou'] = loss_iou_i
+ num_dec_layer += 1
+
+
+ # loss_dict_one_groug = super().loss_by_feat(all_layers_matching_cls_scores_one_group, all_layers_matching_bbox_preds_one_group,
+ # batch_gt_instances, batch_img_metas, batch_gt_instances_ignore)
+ enc_cls_scores_one_group = enc_cls_scores[:, id_group * each_match_num_queries:(id_group + 1) * each_match_num_queries, :]
+ enc_bbox_preds_one_group = enc_bbox_preds[:, id_group * each_match_num_queries:(id_group + 1) * each_match_num_queries, :]
+ if enc_cls_scores is not None:
+ # NOTE The enc_loss calculation of the DINO is
+ # different from that of Deformable DETR.
+ enc_loss_cls, enc_losses_bbox, enc_losses_iou = \
+ self.loss_by_feat_single(enc_cls_scores_one_group,
+ enc_bbox_preds_one_group,
+ batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas)
+ loss_dict[f'g{id_group}.enc_loss_cls'] = enc_loss_cls
+ loss_dict[f'g{id_group}.enc_loss_bbox'] = enc_losses_bbox
+ loss_dict[f'g{id_group}.enc_loss_iou'] = enc_losses_iou
+
+
+ # loss_dict = super().loss_by_feat(
+ # all_layers_matching_cls_scores, all_layers_matching_bbox_preds,
+ # batch_gt_instances, batch_img_metas, batch_gt_instances_ignore)
+ # # NOTE DETRHead.loss_by_feat but not DeformableDETRHead.loss_by_feat
+ # # is called, because the encoder loss calculations are different
+ # # between DINO and DeformableDETR.
+ # # loss of proposal generated from encode feature map.
+ # if enc_cls_scores is not None:
+ # # NOTE The enc_loss calculation of the DINO is
+ # # different from that of Deformable DETR.
+ # enc_loss_cls, enc_losses_bbox, enc_losses_iou = \
+ # self.loss_by_feat_single(
+ # enc_cls_scores, enc_bbox_preds,
+ # batch_gt_instances=batch_gt_instances,
+ # batch_img_metas=batch_img_metas)
+ # loss_dict['enc_loss_cls'] = enc_loss_cls
+ # loss_dict['enc_loss_bbox'] = enc_losses_bbox
+ # loss_dict['enc_loss_iou'] = enc_losses_iou
+
+ if all_layers_denoising_cls_scores is not None:
+ # calculate denoising loss from all decoder layers
+ dn_losses_cls, dn_losses_bbox, dn_losses_iou = self.loss_dn(
+ all_layers_denoising_cls_scores,
+ all_layers_denoising_bbox_preds,
+ batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas,
+ dn_meta=dn_meta)
+ # collate denoising loss
+ loss_dict['dn_loss_cls'] = dn_losses_cls[-1]
+ loss_dict['dn_loss_bbox'] = dn_losses_bbox[-1]
+ loss_dict['dn_loss_iou'] = dn_losses_iou[-1]
+ for num_dec_layer, (loss_cls_i, loss_bbox_i, loss_iou_i) in \
+ enumerate(zip(dn_losses_cls[:-1], dn_losses_bbox[:-1],
+ dn_losses_iou[:-1])):
+ loss_dict[f'd{num_dec_layer}.dn_loss_cls'] = loss_cls_i
+ loss_dict[f'd{num_dec_layer}.dn_loss_bbox'] = loss_bbox_i
+ loss_dict[f'd{num_dec_layer}.dn_loss_iou'] = loss_iou_i
+ return loss_dict
+
+ def loss_ddn(self, hidden_states: Tensor, references: List[Tensor],
+ enc_outputs_class: Tensor, enc_outputs_coord: Tensor,
+ batch_data_samples: SampleList, dn_meta: Dict[str, int]) -> dict:
+ """Perform forward propagation and loss calculation of the detection
+ head on the queries of the upstream network.
+
+ Args:
+ hidden_states (Tensor): Hidden states output from each decoder
+ layer, has shape (num_decoder_layers, bs, num_queries_total,
+ dim), where `num_queries_total` is the sum of
+ `num_denoising_queries` and `num_matching_queries` when
+ `self.training` is `True`, else `num_matching_queries`.
+ references (list[Tensor]): List of the reference from the decoder.
+ The first reference is the `init_reference` (initial) and the
+ other num_decoder_layers(6) references are `inter_references`
+ (intermediate). The `init_reference` has shape (bs,
+ num_queries_total, 4) and each `inter_reference` has shape
+ (bs, num_queries, 4) with the last dimension arranged as
+ (cx, cy, w, h).
+ enc_outputs_class (Tensor): The score of each point on encode
+ feature map, has shape (bs, num_feat_points, cls_out_channels).
+ enc_outputs_coord (Tensor): The proposal generate from the
+ encode feature map, has shape (bs, num_feat_points, 4) with the
+ last dimension arranged as (cx, cy, w, h).
+ batch_data_samples (list[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ dict: A dictionary of loss components.
+ """
+ batch_gt_instances = []
+ batch_img_metas = []
+ for data_sample in batch_data_samples:
+ batch_img_metas.append(data_sample.metainfo)
+ batch_gt_instances.append(data_sample.gt_instances)
+
+ outs = self(hidden_states, references)
+ loss_inputs = outs + (enc_outputs_class, enc_outputs_coord,
+ batch_gt_instances, batch_img_metas, dn_meta)
+ losses,pos_bbox_offsets = self.loss_ddn_by_feat(*loss_inputs)
+ return losses,pos_bbox_offsets
+
+ def loss_ddn_by_feat(
+ self,
+ all_layers_cls_scores: Tensor,
+ all_layers_bbox_preds: Tensor,
+ enc_cls_scores: Tensor,
+ enc_bbox_preds: Tensor,
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ dn_meta: Dict[str, int],
+ # match_group_size: Tuple[int, int] = (2, 2),
+ batch_gt_instances_ignore: OptInstanceList = None,
+ ) -> Tuple[Dict[str, Tensor], List]:
+ """Loss function.
+
+ Args:
+ all_layers_cls_scores (Tensor): Classification scores of all
+ decoder layers, has shape (num_decoder_layers, bs,
+ num_queries_total, cls_out_channels), where
+ `num_queries_total` is the sum of `num_denoising_queries`
+ and `num_matching_queries`.
+ all_layers_bbox_preds (Tensor): Regression outputs of all decoder
+ layers. Each is a 4D-tensor with normalized coordinate format
+ (cx, cy, w, h) and has shape (num_decoder_layers, bs,
+ num_queries_total, 4).
+ enc_cls_scores (Tensor): The score of each point on encode
+ feature map, has shape (bs, num_feat_points, cls_out_channels).
+ enc_bbox_preds (Tensor): The proposal generate from the encode
+ feature map, has shape (bs, num_feat_points, 4) with the last
+ dimension arranged as (cx, cy, w, h).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components.
+ """
+ # extract denoising and matching part of outputs
+ (all_layers_matching_cls_scores, all_layers_matching_bbox_preds,
+ all_layers_denoising_cls_scores, all_layers_denoising_bbox_preds) = \
+ self.split_outputs(
+ all_layers_cls_scores, all_layers_bbox_preds, dn_meta)
+ loss_dict = dict()
+
+ assert batch_gt_instances_ignore is None, \
+ f'{self.__class__.__name__} only supports ' \
+ 'for batch_gt_instances_ignore setting to None.'
+ #同时计算每一解码层的loss
+ losses_cls, losses_bbox, losses_iou, pos_bbox_offsets = multi_apply(
+ self.loss_ddn_by_feat_single,
+ all_layers_matching_cls_scores,
+ all_layers_matching_bbox_preds,
+ batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas)
+ # loss from the last decoder layer
+ loss_dict['loss_cls'] = losses_cls[-1]
+ loss_dict['loss_bbox'] = losses_bbox[-1]
+ loss_dict['loss_iou'] = losses_iou[-1]
+ # loss from other decoder layers
+ num_dec_layer = 0
+ for loss_cls_i, loss_bbox_i, loss_iou_i in \
+ zip(losses_cls[:-1], losses_bbox[:-1], losses_iou[:-1]):
+ loss_dict[f'd{num_dec_layer}.loss_cls'] = loss_cls_i
+ loss_dict[f'd{num_dec_layer}.loss_bbox'] = loss_bbox_i
+ loss_dict[f'd{num_dec_layer}.loss_iou'] = loss_iou_i
+ num_dec_layer += 1
+
+ # NOTE DETRHead.loss_by_feat but not DeformableDETRHead.loss_by_feat
+ # is called, because the encoder loss calculations are different
+ # between DINO and DeformableDETR.
+ # loss of proposal generated from encode feature map.
+ if enc_cls_scores is not None:
+ # NOTE The enc_loss calculation of the DINO is
+ # different from that of Deformable DETR.
+ enc_loss_cls, enc_losses_bbox, enc_losses_iou, pos_bbox_offsets = \
+ self.loss_ddn_by_feat_single(
+ enc_cls_scores, enc_bbox_preds,
+ batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas)
+ loss_dict['enc_loss_cls'] = enc_loss_cls
+ loss_dict['enc_loss_bbox'] = enc_losses_bbox
+ loss_dict['enc_loss_iou'] = enc_losses_iou
+
+ if all_layers_denoising_cls_scores is not None:
+ # calculate denoising loss from all decoder layers
+ dn_losses_cls, dn_losses_bbox, dn_losses_iou = self.loss_dn(
+ all_layers_denoising_cls_scores,
+ all_layers_denoising_bbox_preds,
+ batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas,
+ dn_meta=dn_meta)
+ # collate denoising loss
+ loss_dict['dn_loss_cls'] = dn_losses_cls[-1]
+ loss_dict['dn_loss_bbox'] = dn_losses_bbox[-1]
+ loss_dict['dn_loss_iou'] = dn_losses_iou[-1]
+ for num_dec_layer, (loss_cls_i, loss_bbox_i, loss_iou_i) in \
+ enumerate(zip(dn_losses_cls[:-1], dn_losses_bbox[:-1],
+ dn_losses_iou[:-1])):
+ loss_dict[f'd{num_dec_layer}.dn_loss_cls'] = loss_cls_i
+ loss_dict[f'd{num_dec_layer}.dn_loss_bbox'] = loss_bbox_i
+ loss_dict[f'd{num_dec_layer}.dn_loss_iou'] = loss_iou_i
+ return loss_dict, pos_bbox_offsets
+
+
+ def loss_ddn_by_feat_single(self, cls_scores: Tensor, bbox_preds: Tensor,
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict]) -> Tuple[Tensor, List]:
+ """Loss function for outputs from a single decoder layer of a single
+ feature level.
+
+ Args:
+ cls_scores (Tensor): Box score logits from a single decoder layer
+ for all images, has shape (bs, num_queries, cls_out_channels).
+ bbox_preds (Tensor): Sigmoid outputs from a single decoder layer
+ for all images, with normalized coordinate (cx, cy, w, h) and
+ shape (bs, num_queries, 4).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+
+ Returns:
+ Tuple[Tensor]: A tuple including `loss_cls`, `loss_box` and
+ `loss_iou`.
+ """
+ num_imgs = cls_scores.size(0)
+ cls_scores_list = [cls_scores[i] for i in range(num_imgs)]
+ bbox_preds_list = [bbox_preds[i] for i in range(num_imgs)]
+ cls_reg_targets = self.get_targets_ddn(cls_scores_list, bbox_preds_list,
+ batch_gt_instances, batch_img_metas)
+ (labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,
+ num_total_pos, num_total_neg) = cls_reg_targets
+ labels = torch.cat(labels_list, 0)
+ label_weights = torch.cat(label_weights_list, 0)
+ bbox_targets = torch.cat(bbox_targets_list, 0)
+ bbox_weights = torch.cat(bbox_weights_list, 0)
+
+ # classification loss
+ cls_scores = cls_scores.reshape(-1, self.cls_out_channels)
+ # construct weighted avg_factor to match with the official DETR repo
+ cls_avg_factor = num_total_pos * 1.0 + \
+ num_total_neg * self.bg_cls_weight
+ if self.sync_cls_avg_factor:
+ cls_avg_factor = reduce_mean(
+ cls_scores.new_tensor([cls_avg_factor]))
+ cls_avg_factor = max(cls_avg_factor, 1)
+
+ loss_cls = self.loss_cls(
+ cls_scores, labels, label_weights, avg_factor=cls_avg_factor)
+
+ # Compute the average number of gt boxes across all gpus, for
+ # normalization purposes
+ num_total_pos = loss_cls.new_tensor([num_total_pos])
+ num_total_pos = torch.clamp(reduce_mean(num_total_pos), min=1).item()
+
+ # construct factors used for rescale bboxes
+ factors = []
+ for img_meta, bbox_pred in zip(batch_img_metas, bbox_preds):
+ img_h, img_w, = img_meta['img_shape']
+ factor = bbox_pred.new_tensor([img_w, img_h, img_w,
+ img_h]).unsqueeze(0).repeat(
+ bbox_pred.size(0), 1)
+ factors.append(factor)
+ factors = torch.cat(factors, 0)
+
+ # DETR regress the relative position of boxes (cxcywh) in the image,
+ # thus the learning target is normalized by the image size. So here
+ # we need to re-scale them for calculating IoU loss
+ bbox_preds = bbox_preds.reshape(-1, 4)
+ bboxes = bbox_cxcywh_to_xyxy(bbox_preds) * factors
+ bboxes_gt = bbox_cxcywh_to_xyxy(bbox_targets) * factors
+
+
+ # lzx
+ # 检查bbox_targets中4个值是否全部为0
+ is_target = torch.any(bbox_targets != 0, dim=1)
+ # 获取目标的索引
+ target_indices = torch.nonzero(is_target).squeeze()
+ bbox_targets_only_pos = bbox_targets[target_indices]
+ bbox_preds_only_pos = bbox_preds[target_indices]
+ # factors_only_pos = factors[target_indices]
+ pos_bbox_offset = torch.mean(torch.abs(bbox_targets_only_pos-bbox_preds_only_pos),dim=0).detach().cpu().numpy()
+ pos_bbox_offsets = [(pos_bbox_offset[0]+pos_bbox_offset[1])/2,(pos_bbox_offset[2]+pos_bbox_offset[3])/2]
+ # regression IoU loss, defaultly GIoU loss
+ loss_iou = self.loss_iou(
+ bboxes, bboxes_gt, bbox_weights, avg_factor=num_total_pos)
+
+ # regression L1 loss
+ loss_bbox = self.loss_bbox(
+ bbox_preds, bbox_targets, bbox_weights, avg_factor=num_total_pos)
+ return loss_cls, loss_bbox, loss_iou, pos_bbox_offsets
+
+ def get_targets_ddn(self, cls_scores_list: List[Tensor],
+ bbox_preds_list: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict]) -> tuple:
+ """Compute regression and classification targets for a batch image.
+
+ Outputs from a single decoder layer of a single feature level are used.
+
+ Args:
+ cls_scores_list (list[Tensor]): Box score logits from a single
+ decoder layer for each image, has shape [num_queries,
+ cls_out_channels].
+ bbox_preds_list (list[Tensor]): Sigmoid outputs from a single
+ decoder layer for each image, with normalized coordinate
+ (cx, cy, w, h) and shape [num_queries, 4].
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+
+ Returns:
+ tuple: a tuple containing the following targets.
+
+ - labels_list (list[Tensor]): Labels for all images.
+ - label_weights_list (list[Tensor]): Label weights for all images.
+ - bbox_targets_list (list[Tensor]): BBox targets for all images.
+ - bbox_weights_list (list[Tensor]): BBox weights for all images.
+ - num_total_pos (int): Number of positive samples in all images.
+ - num_total_neg (int): Number of negative samples in all images.
+ """
+ (labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,
+ pos_inds_list,
+ neg_inds_list) = multi_apply(self._get_targets_single_ddn,
+ cls_scores_list, bbox_preds_list,
+ batch_gt_instances, batch_img_metas)
+ num_total_pos = sum((inds.numel() for inds in pos_inds_list))
+ num_total_neg = sum((inds.numel() for inds in neg_inds_list))
+ return (labels_list, label_weights_list, bbox_targets_list,
+ bbox_weights_list, num_total_pos, num_total_neg)
+
+ def _get_targets_single_ddn(self, cls_score: Tensor, bbox_pred: Tensor,
+ gt_instances: InstanceData,
+ img_meta: dict) -> tuple:
+ """Compute regression and classification targets for one image.
+
+ Outputs from a single decoder layer of a single feature level are used.
+
+ Args:
+ cls_score (Tensor): Box score logits from a single decoder layer
+ for one image. Shape [num_queries, cls_out_channels].
+ bbox_pred (Tensor): Sigmoid outputs from a single decoder layer
+ for one image, with normalized coordinate (cx, cy, w, h) and
+ shape [num_queries, 4].
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It should includes ``bboxes`` and ``labels``
+ attributes.
+ img_meta (dict): Meta information for one image.
+
+ Returns:
+ tuple[Tensor]: a tuple containing the following for one image.
+
+ - labels (Tensor): Labels of each image.
+ - label_weights (Tensor]): Label weights of each image.
+ - bbox_targets (Tensor): BBox targets of each image.
+ - bbox_weights (Tensor): BBox weights of each image.
+ - pos_inds (Tensor): Sampled positive indices for each image.
+ - neg_inds (Tensor): Sampled negative indices for each image.
+ """
+ img_h, img_w = img_meta['img_shape']
+ factor = bbox_pred.new_tensor([img_w, img_h, img_w,
+ img_h]).unsqueeze(0)
+ num_bboxes = bbox_pred.size(0)
+ # convert bbox_pred from xywh, normalized to xyxy, unnormalized
+ bbox_pred = bbox_cxcywh_to_xyxy(bbox_pred)
+ bbox_pred = bbox_pred * factor
+
+ pred_instances = InstanceData(scores=cls_score, bboxes=bbox_pred)
+ # assigner and sampler
+ assign_result = self.assigner.assign(
+ pred_instances=pred_instances,
+ gt_instances=gt_instances,
+ img_meta=img_meta)
+
+ # from mmdet.models.task_modules.assigners import MaxIoUAssigner
+ # assigner1 = MaxIoUAssigner(pos_iou_thr=0.5, neg_iou_thr=0.5, min_pos_iou=0.3,match_low_quality=True,ignore_iof_thr=-1)
+ # pred_instances1 = InstanceData()
+ # pred_instances1.priors =pred_instances.bboxes
+ # assign_result = assigner1.assign(pred_instances=pred_instances1, gt_instances=gt_instances, img_meta=img_meta)
+
+
+ gt_bboxes = gt_instances.bboxes
+ gt_labels = gt_instances.labels
+ pos_inds = torch.nonzero(
+ assign_result.gt_inds > 0, as_tuple=False).squeeze(-1).unique()
+ neg_inds = torch.nonzero(
+ assign_result.gt_inds == 0, as_tuple=False).squeeze(-1).unique()
+ pos_assigned_gt_inds = assign_result.gt_inds[pos_inds] - 1
+ pos_gt_bboxes = gt_bboxes[pos_assigned_gt_inds.long(), :]
+
+ # label targets
+ labels = gt_bboxes.new_full((num_bboxes, ),
+ self.num_classes,
+ dtype=torch.long)
+ labels[pos_inds] = gt_labels[pos_assigned_gt_inds]
+ label_weights = gt_bboxes.new_ones(num_bboxes)
+
+ # bbox targets
+ bbox_targets = torch.zeros_like(bbox_pred)
+ bbox_weights = torch.zeros_like(bbox_pred)
+ bbox_weights[pos_inds] = 1.0
+
+ # DETR regress the relative position of boxes (cxcywh) in the image.
+ # Thus the learning target should be normalized by the image size, also
+ # the box format should be converted from defaultly x1y1x2y2 to cxcywh.
+ pos_gt_bboxes_normalized = pos_gt_bboxes / factor
+ pos_gt_bboxes_targets = bbox_xyxy_to_cxcywh(pos_gt_bboxes_normalized)
+ bbox_targets[pos_inds] = pos_gt_bboxes_targets
+ return (labels, label_weights, bbox_targets, bbox_weights, pos_inds,
+ neg_inds)
\ No newline at end of file
diff --git a/mmdet/models/dense_heads/dino_head_copy.py b/mmdet/models/dense_heads/dino_head_copy.py
new file mode 100644
index 0000000000000000000000000000000000000000..889ff38110044bf48332f6b4588dd081d405ab63
--- /dev/null
+++ b/mmdet/models/dense_heads/dino_head_copy.py
@@ -0,0 +1,456 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Tuple
+
+import torch
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.structures import SampleList
+from mmdet.structures.bbox import bbox_cxcywh_to_xyxy, bbox_xyxy_to_cxcywh
+from mmdet.utils import InstanceList, OptInstanceList, reduce_mean
+from ..utils import multi_apply
+from .deformable_detr_head import DeformableDETRHead
+
+
+@MODELS.register_module()
+class DINOHead(DeformableDETRHead):
+ r"""Head of the DINO: DETR with Improved DeNoising Anchor Boxes
+ for End-to-End Object Detection
+
+ Code is modified from the `official github repo
+ `_.
+
+ More details can be found in the `paper
+ `_ .
+ """
+
+ def loss(self, hidden_states: Tensor, references: List[Tensor],
+ enc_outputs_class: Tensor, enc_outputs_coord: Tensor,
+ batch_data_samples: SampleList, dn_meta: Dict[str, int]) -> dict:
+ """Perform forward propagation and loss calculation of the detection
+ head on the queries of the upstream network.
+
+ Args:
+ hidden_states (Tensor): Hidden states output from each decoder
+ layer, has shape (num_decoder_layers, bs, num_queries_total,
+ dim), where `num_queries_total` is the sum of
+ `num_denoising_queries` and `num_matching_queries` when
+ `self.training` is `True`, else `num_matching_queries`.
+ references (list[Tensor]): List of the reference from the decoder.
+ The first reference is the `init_reference` (initial) and the
+ other num_decoder_layers(6) references are `inter_references`
+ (intermediate). The `init_reference` has shape (bs,
+ num_queries_total, 4) and each `inter_reference` has shape
+ (bs, num_queries, 4) with the last dimension arranged as
+ (cx, cy, w, h).
+ enc_outputs_class (Tensor): The score of each point on encode
+ feature map, has shape (bs, num_feat_points, cls_out_channels).
+ enc_outputs_coord (Tensor): The proposal generate from the
+ encode feature map, has shape (bs, num_feat_points, 4) with the
+ last dimension arranged as (cx, cy, w, h).
+ batch_data_samples (list[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ dict: A dictionary of loss components.
+ """
+ batch_gt_instances = []
+ batch_img_metas = []
+ for data_sample in batch_data_samples:
+ batch_img_metas.append(data_sample.metainfo)
+ batch_gt_instances.append(data_sample.gt_instances)
+
+ outs = self(hidden_states, references)
+ loss_inputs = outs + (enc_outputs_class, enc_outputs_coord,
+ batch_gt_instances, batch_img_metas, dn_meta)
+ losses = self.loss_by_feat(*loss_inputs)
+ return losses
+
+ def loss_by_feat(
+ self,
+ all_layers_cls_scores: Tensor,
+ all_layers_bbox_preds: Tensor,
+ enc_cls_scores: Tensor,
+ enc_bbox_preds: Tensor,
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ dn_meta: Dict[str, int],
+ batch_gt_instances_ignore: OptInstanceList = None
+ ) -> Dict[str, Tensor]:
+ """Loss function.
+
+ Args:
+ all_layers_cls_scores (Tensor): Classification scores of all
+ decoder layers, has shape (num_decoder_layers, bs,
+ num_queries_total, cls_out_channels), where
+ `num_queries_total` is the sum of `num_denoising_queries`
+ and `num_matching_queries`.
+ all_layers_bbox_preds (Tensor): Regression outputs of all decoder
+ layers. Each is a 4D-tensor with normalized coordinate format
+ (cx, cy, w, h) and has shape (num_decoder_layers, bs,
+ num_queries_total, 4).
+ enc_cls_scores (Tensor): The score of each point on encode
+ feature map, has shape (bs, num_feat_points, cls_out_channels).
+ enc_bbox_preds (Tensor): The proposal generate from the encode
+ feature map, has shape (bs, num_feat_points, 4) with the last
+ dimension arranged as (cx, cy, w, h).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components.
+ """
+ # extract denoising and matching part of outputs
+ (all_layers_matching_cls_scores, all_layers_matching_bbox_preds,
+ all_layers_denoising_cls_scores, all_layers_denoising_bbox_preds) = \
+ self.split_outputs(
+ all_layers_cls_scores, all_layers_bbox_preds, dn_meta)
+
+ loss_dict = super(DeformableDETRHead, self).loss_by_feat(
+ all_layers_matching_cls_scores, all_layers_matching_bbox_preds,
+ batch_gt_instances, batch_img_metas, batch_gt_instances_ignore)
+ # NOTE DETRHead.loss_by_feat but not DeformableDETRHead.loss_by_feat
+ # is called, because the encoder loss calculations are different
+ # between DINO and DeformableDETR.
+
+ # loss of proposal generated from encode feature map.
+ if enc_cls_scores is not None:
+ # NOTE The enc_loss calculation of the DINO is
+ # different from that of Deformable DETR.
+ enc_loss_cls, enc_losses_bbox, enc_losses_iou = \
+ self.loss_by_feat_single(
+ enc_cls_scores, enc_bbox_preds,
+ batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas)
+ loss_dict['enc_loss_cls'] = enc_loss_cls
+ loss_dict['enc_loss_bbox'] = enc_losses_bbox
+ loss_dict['enc_loss_iou'] = enc_losses_iou
+
+ if all_layers_denoising_cls_scores is not None:
+ # calculate denoising loss from all decoder layers
+ dn_losses_cls, dn_losses_bbox, dn_losses_iou = self.loss_dn(
+ all_layers_denoising_cls_scores,
+ all_layers_denoising_bbox_preds,
+ batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas,
+ dn_meta=dn_meta)
+ # collate denoising loss
+ loss_dict['dn_loss_cls'] = dn_losses_cls[-1]
+ loss_dict['dn_loss_bbox'] = dn_losses_bbox[-1]
+ loss_dict['dn_loss_iou'] = dn_losses_iou[-1]
+ for num_dec_layer, (loss_cls_i, loss_bbox_i, loss_iou_i) in \
+ enumerate(zip(dn_losses_cls[:-1], dn_losses_bbox[:-1],
+ dn_losses_iou[:-1])):
+ loss_dict[f'd{num_dec_layer}.dn_loss_cls'] = loss_cls_i
+ loss_dict[f'd{num_dec_layer}.dn_loss_bbox'] = loss_bbox_i
+ loss_dict[f'd{num_dec_layer}.dn_loss_iou'] = loss_iou_i
+ return loss_dict
+
+ def loss_dn(self, all_layers_denoising_cls_scores: Tensor,
+ all_layers_denoising_bbox_preds: Tensor,
+ batch_gt_instances: InstanceList, batch_img_metas: List[dict],
+ dn_meta: Dict[str, int]) -> Tuple[List[Tensor]]:
+ """Calculate denoising loss.
+
+ Args:
+ all_layers_denoising_cls_scores (Tensor): Classification scores of
+ all decoder layers in denoising part, has shape (
+ num_decoder_layers, bs, num_denoising_queries,
+ cls_out_channels).
+ all_layers_denoising_bbox_preds (Tensor): Regression outputs of all
+ decoder layers in denoising part. Each is a 4D-tensor with
+ normalized coordinate format (cx, cy, w, h) and has shape
+ (num_decoder_layers, bs, num_denoising_queries, 4).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ Tuple[List[Tensor]]: The loss_dn_cls, loss_dn_bbox, and loss_dn_iou
+ of each decoder layers.
+ """
+ return multi_apply(
+ self._loss_dn_single,
+ all_layers_denoising_cls_scores,
+ all_layers_denoising_bbox_preds,
+ batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas,
+ dn_meta=dn_meta)
+
+ def _loss_dn_single(self, dn_cls_scores: Tensor, dn_bbox_preds: Tensor,
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ dn_meta: Dict[str, int]) -> Tuple[Tensor]:
+ """Denoising loss for outputs from a single decoder layer.
+
+ Args:
+ dn_cls_scores (Tensor): Classification scores of a single decoder
+ layer in denoising part, has shape (bs, num_denoising_queries,
+ cls_out_channels).
+ dn_bbox_preds (Tensor): Regression outputs of a single decoder
+ layer in denoising part. Each is a 4D-tensor with normalized
+ coordinate format (cx, cy, w, h) and has shape
+ (bs, num_denoising_queries, 4).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ Tuple[Tensor]: A tuple including `loss_cls`, `loss_box` and
+ `loss_iou`.
+ """
+ cls_reg_targets = self.get_dn_targets(batch_gt_instances,
+ batch_img_metas, dn_meta)
+ (labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,
+ num_total_pos, num_total_neg) = cls_reg_targets
+ labels = torch.cat(labels_list, 0)
+ label_weights = torch.cat(label_weights_list, 0)
+ bbox_targets = torch.cat(bbox_targets_list, 0)
+ bbox_weights = torch.cat(bbox_weights_list, 0)
+
+ # classification loss
+ cls_scores = dn_cls_scores.reshape(-1, self.cls_out_channels)
+ # construct weighted avg_factor to match with the official DETR repo
+ cls_avg_factor = \
+ num_total_pos * 1.0 + num_total_neg * self.bg_cls_weight
+ if self.sync_cls_avg_factor:
+ cls_avg_factor = reduce_mean(
+ cls_scores.new_tensor([cls_avg_factor]))
+ cls_avg_factor = max(cls_avg_factor, 1)
+
+ if len(cls_scores) > 0:
+ loss_cls = self.loss_cls(
+ cls_scores, labels, label_weights, avg_factor=cls_avg_factor)
+ else:
+ loss_cls = torch.zeros(
+ 1, dtype=cls_scores.dtype, device=cls_scores.device)
+
+ # Compute the average number of gt boxes across all gpus, for
+ # normalization purposes
+ num_total_pos = loss_cls.new_tensor([num_total_pos])
+ num_total_pos = torch.clamp(reduce_mean(num_total_pos), min=1).item()
+
+ # construct factors used for rescale bboxes
+ factors = []
+ for img_meta, bbox_pred in zip(batch_img_metas, dn_bbox_preds):
+ img_h, img_w = img_meta['img_shape']
+ factor = bbox_pred.new_tensor([img_w, img_h, img_w,
+ img_h]).unsqueeze(0).repeat(
+ bbox_pred.size(0), 1)
+ factors.append(factor)
+ factors = torch.cat(factors)
+
+ # DETR regress the relative position of boxes (cxcywh) in the image,
+ # thus the learning target is normalized by the image size. So here
+ # we need to re-scale them for calculating IoU loss
+ bbox_preds = dn_bbox_preds.reshape(-1, 4)
+ bboxes = bbox_cxcywh_to_xyxy(bbox_preds) * factors
+ bboxes_gt = bbox_cxcywh_to_xyxy(bbox_targets) * factors
+
+ # regression IoU loss, defaultly GIoU loss
+ loss_iou = self.loss_iou(
+ bboxes, bboxes_gt, bbox_weights, avg_factor=num_total_pos)
+
+ # regression L1 loss
+ loss_bbox = self.loss_bbox(
+ bbox_preds, bbox_targets, bbox_weights, avg_factor=num_total_pos)
+ return loss_cls, loss_bbox, loss_iou
+
+ def get_dn_targets(self, batch_gt_instances: InstanceList,
+ batch_img_metas: dict, dn_meta: Dict[str,
+ int]) -> tuple:
+ """Get targets in denoising part for a batch of images.
+
+ Args:
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ tuple: a tuple containing the following targets.
+
+ - labels_list (list[Tensor]): Labels for all images.
+ - label_weights_list (list[Tensor]): Label weights for all images.
+ - bbox_targets_list (list[Tensor]): BBox targets for all images.
+ - bbox_weights_list (list[Tensor]): BBox weights for all images.
+ - num_total_pos (int): Number of positive samples in all images.
+ - num_total_neg (int): Number of negative samples in all images.
+ """
+ (labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,
+ pos_inds_list, neg_inds_list) = multi_apply(
+ self._get_dn_targets_single,
+ batch_gt_instances,
+ batch_img_metas,
+ dn_meta=dn_meta)
+ num_total_pos = sum((inds.numel() for inds in pos_inds_list))
+ num_total_neg = sum((inds.numel() for inds in neg_inds_list))
+ return (labels_list, label_weights_list, bbox_targets_list,
+ bbox_weights_list, num_total_pos, num_total_neg)
+
+ def _get_dn_targets_single(self, gt_instances: InstanceData,
+ img_meta: dict, dn_meta: Dict[str,
+ int]) -> tuple:
+ """Get targets in denoising part for one image.
+
+ Args:
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It should includes ``bboxes`` and ``labels``
+ attributes.
+ img_meta (dict): Meta information for one image.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ tuple[Tensor]: a tuple containing the following for one image.
+
+ - labels (Tensor): Labels of each image.
+ - label_weights (Tensor]): Label weights of each image.
+ - bbox_targets (Tensor): BBox targets of each image.
+ - bbox_weights (Tensor): BBox weights of each image.
+ - pos_inds (Tensor): Sampled positive indices for each image.
+ - neg_inds (Tensor): Sampled negative indices for each image.
+ """
+ gt_bboxes = gt_instances.bboxes
+ gt_labels = gt_instances.labels
+ num_groups = dn_meta['num_denoising_groups']
+ num_denoising_queries = dn_meta['num_denoising_queries']
+ num_queries_each_group = int(num_denoising_queries / num_groups)
+ device = gt_bboxes.device
+
+ if len(gt_labels) > 0:
+ t = torch.arange(len(gt_labels), dtype=torch.long, device=device)
+ t = t.unsqueeze(0).repeat(num_groups, 1)
+ pos_assigned_gt_inds = t.flatten()
+ pos_inds = torch.arange(
+ num_groups, dtype=torch.long, device=device)
+ pos_inds = pos_inds.unsqueeze(1) * num_queries_each_group + t
+ pos_inds = pos_inds.flatten()
+ else:
+ pos_inds = pos_assigned_gt_inds = \
+ gt_bboxes.new_tensor([], dtype=torch.long)
+
+ neg_inds = pos_inds + num_queries_each_group // 2
+
+ # label targets
+ labels = gt_bboxes.new_full((num_denoising_queries, ),
+ self.num_classes,
+ dtype=torch.long)
+ labels[pos_inds] = gt_labels[pos_assigned_gt_inds]
+ label_weights = gt_bboxes.new_ones(num_denoising_queries)
+
+ # bbox targets
+ bbox_targets = torch.zeros(num_denoising_queries, 4, device=device)
+ bbox_weights = torch.zeros(num_denoising_queries, 4, device=device)
+ bbox_weights[pos_inds] = 1.0
+ img_h, img_w = img_meta['img_shape']
+
+ # DETR regress the relative position of boxes (cxcywh) in the image.
+ # Thus the learning target should be normalized by the image size, also
+ # the box format should be converted from defaultly x1y1x2y2 to cxcywh.
+ factor = gt_bboxes.new_tensor([img_w, img_h, img_w,
+ img_h]).unsqueeze(0)
+ gt_bboxes_normalized = gt_bboxes / factor
+ gt_bboxes_targets = bbox_xyxy_to_cxcywh(gt_bboxes_normalized)
+ bbox_targets[pos_inds] = gt_bboxes_targets.repeat([num_groups, 1])
+
+ return (labels, label_weights, bbox_targets, bbox_weights, pos_inds,
+ neg_inds)
+
+ @staticmethod
+ def split_outputs(all_layers_cls_scores: Tensor,
+ all_layers_bbox_preds: Tensor,
+ dn_meta: Dict[str, int]) -> Tuple[Tensor]:
+ """Split outputs of the denoising part and the matching part.
+
+ For the total outputs of `num_queries_total` length, the former
+ `num_denoising_queries` outputs are from denoising queries, and
+ the rest `num_matching_queries` ones are from matching queries,
+ where `num_queries_total` is the sum of `num_denoising_queries` and
+ `num_matching_queries`.
+
+ Args:
+ all_layers_cls_scores (Tensor): Classification scores of all
+ decoder layers, has shape (num_decoder_layers, bs,
+ num_queries_total, cls_out_channels).
+ all_layers_bbox_preds (Tensor): Regression outputs of all decoder
+ layers. Each is a 4D-tensor with normalized coordinate format
+ (cx, cy, w, h) and has shape (num_decoder_layers, bs,
+ num_queries_total, 4).
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'.
+
+ Returns:
+ Tuple[Tensor]: a tuple containing the following outputs.
+
+ - all_layers_matching_cls_scores (Tensor): Classification scores
+ of all decoder layers in matching part, has shape
+ (num_decoder_layers, bs, num_matching_queries, cls_out_channels).
+ - all_layers_matching_bbox_preds (Tensor): Regression outputs of
+ all decoder layers in matching part. Each is a 4D-tensor with
+ normalized coordinate format (cx, cy, w, h) and has shape
+ (num_decoder_layers, bs, num_matching_queries, 4).
+ - all_layers_denoising_cls_scores (Tensor): Classification scores
+ of all decoder layers in denoising part, has shape
+ (num_decoder_layers, bs, num_denoising_queries,
+ cls_out_channels).
+ - all_layers_denoising_bbox_preds (Tensor): Regression outputs of
+ all decoder layers in denoising part. Each is a 4D-tensor with
+ normalized coordinate format (cx, cy, w, h) and has shape
+ (num_decoder_layers, bs, num_denoising_queries, 4).
+ """
+ num_denoising_queries = dn_meta['num_denoising_queries']
+ if dn_meta is not None:
+ all_layers_denoising_cls_scores = \
+ all_layers_cls_scores[:, :, : num_denoising_queries, :]
+ all_layers_denoising_bbox_preds = \
+ all_layers_bbox_preds[:, :, : num_denoising_queries, :]
+ all_layers_matching_cls_scores = \
+ all_layers_cls_scores[:, :, num_denoising_queries:, :]
+ all_layers_matching_bbox_preds = \
+ all_layers_bbox_preds[:, :, num_denoising_queries:, :]
+ else:
+ all_layers_denoising_cls_scores = None
+ all_layers_denoising_bbox_preds = None
+ all_layers_matching_cls_scores = all_layers_cls_scores
+ all_layers_matching_bbox_preds = all_layers_bbox_preds
+ return (all_layers_matching_cls_scores, all_layers_matching_bbox_preds,
+ all_layers_denoising_cls_scores,
+ all_layers_denoising_bbox_preds)
diff --git a/mmdet/models/dense_heads/dino_head_rm_deform_copy.py b/mmdet/models/dense_heads/dino_head_rm_deform_copy.py
new file mode 100644
index 0000000000000000000000000000000000000000..cd40790ab93e75938710ee3c3951f0de65d91cef
--- /dev/null
+++ b/mmdet/models/dense_heads/dino_head_rm_deform_copy.py
@@ -0,0 +1,645 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+from typing import Dict, List, Tuple
+from torch import Tensor
+
+import torch
+import torch.nn as nn
+from mmcv.cnn import Linear
+from mmengine.model import bias_init_with_prob, constant_init
+from mmengine.structures import InstanceData
+
+from mmdet.registry import MODELS
+from mmdet.structures import SampleList
+from mmdet.structures.bbox import bbox_cxcywh_to_xyxy, bbox_xyxy_to_cxcywh
+from mmdet.utils import InstanceList, OptInstanceList, reduce_mean
+from ..utils import multi_apply
+from ..layers import inverse_sigmoid
+from .detr_head import DETRHead
+
+
+@MODELS.register_module()
+class DINOHead(DETRHead):
+ r"""Head of the DINO: DETR with Improved DeNoising Anchor Boxes
+ for End-to-End Object Detection
+
+ Code is modified from the `official github repo
+ `_.
+
+ More details can be found in the `paper
+ `_ .
+ """
+ def __init__(self,
+ *args,
+ share_pred_layer: bool = False,
+ num_pred_layer: int = 6,
+ as_two_stage: bool = False,
+ **kwargs) -> None:
+ self.share_pred_layer = share_pred_layer
+ self.num_pred_layer = num_pred_layer
+ self.as_two_stage = as_two_stage
+
+ super().__init__(*args, **kwargs)
+
+ def _init_layers(self) -> None:
+ """Initialize classification branch and regression branch of head."""
+ fc_cls = Linear(self.embed_dims, self.cls_out_channels)
+ reg_branch = []
+ for _ in range(self.num_reg_fcs):
+ reg_branch.append(Linear(self.embed_dims, self.embed_dims))
+ reg_branch.append(nn.ReLU())
+ reg_branch.append(Linear(self.embed_dims, 4))
+ reg_branch = nn.Sequential(*reg_branch)
+
+ if self.share_pred_layer:
+ self.cls_branches = nn.ModuleList(
+ [fc_cls for _ in range(self.num_pred_layer)])
+ self.reg_branches = nn.ModuleList(
+ [reg_branch for _ in range(self.num_pred_layer)])
+ else:
+ self.cls_branches = nn.ModuleList(
+ [copy.deepcopy(fc_cls) for _ in range(self.num_pred_layer)])
+ self.reg_branches = nn.ModuleList([
+ copy.deepcopy(reg_branch) for _ in range(self.num_pred_layer)
+ ])
+
+ def init_weights(self) -> None:
+ """Initialize weights of the Deformable DETR head."""
+ if self.loss_cls.use_sigmoid:
+ bias_init = bias_init_with_prob(0.01)
+ for m in self.cls_branches:
+ nn.init.constant_(m.bias, bias_init)
+ for m in self.reg_branches:
+ constant_init(m[-1], 0, bias=0)
+ nn.init.constant_(self.reg_branches[0][-1].bias.data[2:], -2.0)
+ if self.as_two_stage:
+ for m in self.reg_branches:
+ nn.init.constant_(m[-1].bias.data[2:], 0.0)
+
+ def forward(self, hidden_states: Tensor,
+ references: List[Tensor]) -> Tuple[Tensor]:
+ """Forward function.
+
+ Args:
+ hidden_states (Tensor): Hidden states output from each decoder
+ layer, has shape (num_decoder_layers, bs, num_queries, dim).
+ references (list[Tensor]): List of the reference from the decoder.
+ The first reference is the `init_reference` (initial) and the
+ other num_decoder_layers(6) references are `inter_references`
+ (intermediate). The `init_reference` has shape (bs,
+ num_queries, 4) when `as_two_stage` of the detector is `True`,
+ otherwise (bs, num_queries, 2). Each `inter_reference` has
+ shape (bs, num_queries, 4) when `with_box_refine` of the
+ detector is `True`, otherwise (bs, num_queries, 2). The
+ coordinates are arranged as (cx, cy) when the last dimension is
+ 2, and (cx, cy, w, h) when it is 4.
+
+ Returns:
+ tuple[Tensor]: results of head containing the following tensor.
+
+ - all_layers_outputs_classes (Tensor): Outputs from the
+ classification head, has shape (num_decoder_layers, bs,
+ num_queries, cls_out_channels).
+ - all_layers_outputs_coords (Tensor): Sigmoid outputs from the
+ regression head with normalized coordinate format (cx, cy, w,
+ h), has shape (num_decoder_layers, bs, num_queries, 4) with the
+ last dimension arranged as (cx, cy, w, h).
+ """
+ all_layers_outputs_classes = []
+ all_layers_outputs_coords = []
+
+ for layer_id in range(hidden_states.shape[0]):
+ reference = inverse_sigmoid(references[layer_id])
+ # NOTE The last reference will not be used.
+ hidden_state = hidden_states[layer_id]
+ outputs_class = self.cls_branches[layer_id](hidden_state)
+ tmp_reg_preds = self.reg_branches[layer_id](hidden_state)
+ if reference.shape[-1] == 4:
+ # When `layer` is 0 and `as_two_stage` of the detector
+ # is `True`, or when `layer` is greater than 0 and
+ # `with_box_refine` of the detector is `True`.
+ tmp_reg_preds += reference
+ else:
+ # When `layer` is 0 and `as_two_stage` of the detector
+ # is `False`, or when `layer` is greater than 0 and
+ # `with_box_refine` of the detector is `False`.
+ assert reference.shape[-1] == 2
+ tmp_reg_preds[..., :2] += reference
+ outputs_coord = tmp_reg_preds.sigmoid()
+ all_layers_outputs_classes.append(outputs_class)
+ all_layers_outputs_coords.append(outputs_coord)
+
+
+
+ all_layers_outputs_classes = torch.stack(all_layers_outputs_classes)
+ all_layers_outputs_coords = torch.stack(all_layers_outputs_coords)
+
+ return all_layers_outputs_classes, all_layers_outputs_coords
+
+ def loss(self, hidden_states: Tensor, references: List[Tensor],
+ enc_outputs_class: Tensor, enc_outputs_coord: Tensor,
+ batch_data_samples: SampleList, dn_meta: Dict[str, int]) -> dict:
+ """Perform forward propagation and loss calculation of the detection
+ head on the queries of the upstream network.
+
+ Args:
+ hidden_states (Tensor): Hidden states output from each decoder
+ layer, has shape (num_decoder_layers, bs, num_queries_total,
+ dim), where `num_queries_total` is the sum of
+ `num_denoising_queries` and `num_matching_queries` when
+ `self.training` is `True`, else `num_matching_queries`.
+ references (list[Tensor]): List of the reference from the decoder.
+ The first reference is the `init_reference` (initial) and the
+ other num_decoder_layers(6) references are `inter_references`
+ (intermediate). The `init_reference` has shape (bs,
+ num_queries_total, 4) and each `inter_reference` has shape
+ (bs, num_queries, 4) with the last dimension arranged as
+ (cx, cy, w, h).
+ enc_outputs_class (Tensor): The score of each point on encode
+ feature map, has shape (bs, num_feat_points, cls_out_channels).
+ enc_outputs_coord (Tensor): The proposal generate from the
+ encode feature map, has shape (bs, num_feat_points, 4) with the
+ last dimension arranged as (cx, cy, w, h).
+ batch_data_samples (list[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ dict: A dictionary of loss components.
+ """
+ batch_gt_instances = []
+ batch_img_metas = []
+ for data_sample in batch_data_samples:
+ batch_img_metas.append(data_sample.metainfo)
+ batch_gt_instances.append(data_sample.gt_instances)
+
+ outs = self(hidden_states, references)
+ loss_inputs = outs + (enc_outputs_class, enc_outputs_coord,
+ batch_gt_instances, batch_img_metas, dn_meta)
+ losses = self.loss_by_feat(*loss_inputs)
+ return losses
+
+ def loss_by_feat(
+ self,
+ all_layers_cls_scores: Tensor,
+ all_layers_bbox_preds: Tensor,
+ enc_cls_scores: Tensor,
+ enc_bbox_preds: Tensor,
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ dn_meta: Dict[str, int],
+ batch_gt_instances_ignore: OptInstanceList = None
+ ) -> Dict[str, Tensor]:
+ """Loss function.
+
+ Args:
+ all_layers_cls_scores (Tensor): Classification scores of all
+ decoder layers, has shape (num_decoder_layers, bs,
+ num_queries_total, cls_out_channels), where
+ `num_queries_total` is the sum of `num_denoising_queries`
+ and `num_matching_queries`.
+ all_layers_bbox_preds (Tensor): Regression outputs of all decoder
+ layers. Each is a 4D-tensor with normalized coordinate format
+ (cx, cy, w, h) and has shape (num_decoder_layers, bs,
+ num_queries_total, 4).
+ enc_cls_scores (Tensor): The score of each point on encode
+ feature map, has shape (bs, num_feat_points, cls_out_channels).
+ enc_bbox_preds (Tensor): The proposal generate from the encode
+ feature map, has shape (bs, num_feat_points, 4) with the last
+ dimension arranged as (cx, cy, w, h).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components.
+ """
+ # extract denoising and matching part of outputs
+ (all_layers_matching_cls_scores, all_layers_matching_bbox_preds,
+ all_layers_denoising_cls_scores, all_layers_denoising_bbox_preds) = \
+ self.split_outputs(
+ all_layers_cls_scores, all_layers_bbox_preds, dn_meta)
+
+ loss_dict = super().loss_by_feat(
+ all_layers_matching_cls_scores, all_layers_matching_bbox_preds,
+ batch_gt_instances, batch_img_metas, batch_gt_instances_ignore)
+ # NOTE DETRHead.loss_by_feat but not DeformableDETRHead.loss_by_feat
+ # is called, because the encoder loss calculations are different
+ # between DINO and DeformableDETR.
+
+ # loss of proposal generated from encode feature map.
+ if enc_cls_scores is not None:
+ # NOTE The enc_loss calculation of the DINO is
+ # different from that of Deformable DETR.
+ enc_loss_cls, enc_losses_bbox, enc_losses_iou = \
+ self.loss_by_feat_single(
+ enc_cls_scores, enc_bbox_preds,
+ batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas)
+ loss_dict['enc_loss_cls'] = enc_loss_cls
+ loss_dict['enc_loss_bbox'] = enc_losses_bbox
+ loss_dict['enc_loss_iou'] = enc_losses_iou
+
+ if all_layers_denoising_cls_scores is not None:
+ # calculate denoising loss from all decoder layers
+ dn_losses_cls, dn_losses_bbox, dn_losses_iou = self.loss_dn(
+ all_layers_denoising_cls_scores,
+ all_layers_denoising_bbox_preds,
+ batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas,
+ dn_meta=dn_meta)
+ # collate denoising loss
+ loss_dict['dn_loss_cls'] = dn_losses_cls[-1]
+ loss_dict['dn_loss_bbox'] = dn_losses_bbox[-1]
+ loss_dict['dn_loss_iou'] = dn_losses_iou[-1]
+ for num_dec_layer, (loss_cls_i, loss_bbox_i, loss_iou_i) in \
+ enumerate(zip(dn_losses_cls[:-1], dn_losses_bbox[:-1],
+ dn_losses_iou[:-1])):
+ loss_dict[f'd{num_dec_layer}.dn_loss_cls'] = loss_cls_i
+ loss_dict[f'd{num_dec_layer}.dn_loss_bbox'] = loss_bbox_i
+ loss_dict[f'd{num_dec_layer}.dn_loss_iou'] = loss_iou_i
+ return loss_dict
+
+ def loss_dn(self, all_layers_denoising_cls_scores: Tensor,
+ all_layers_denoising_bbox_preds: Tensor,
+ batch_gt_instances: InstanceList, batch_img_metas: List[dict],
+ dn_meta: Dict[str, int]) -> Tuple[List[Tensor]]:
+ """Calculate denoising loss.
+
+ Args:
+ all_layers_denoising_cls_scores (Tensor): Classification scores of
+ all decoder layers in denoising part, has shape (
+ num_decoder_layers, bs, num_denoising_queries,
+ cls_out_channels).
+ all_layers_denoising_bbox_preds (Tensor): Regression outputs of all
+ decoder layers in denoising part. Each is a 4D-tensor with
+ normalized coordinate format (cx, cy, w, h) and has shape
+ (num_decoder_layers, bs, num_denoising_queries, 4).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ Tuple[List[Tensor]]: The loss_dn_cls, loss_dn_bbox, and loss_dn_iou
+ of each decoder layers.
+ """
+ return multi_apply(
+ self._loss_dn_single,
+ all_layers_denoising_cls_scores,
+ all_layers_denoising_bbox_preds,
+ batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas,
+ dn_meta=dn_meta)
+
+ def _loss_dn_single(self, dn_cls_scores: Tensor, dn_bbox_preds: Tensor,
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ dn_meta: Dict[str, int]) -> Tuple[Tensor]:
+ """Denoising loss for outputs from a single decoder layer.
+
+ Args:
+ dn_cls_scores (Tensor): Classification scores of a single decoder
+ layer in denoising part, has shape (bs, num_denoising_queries,
+ cls_out_channels).
+ dn_bbox_preds (Tensor): Regression outputs of a single decoder
+ layer in denoising part. Each is a 4D-tensor with normalized
+ coordinate format (cx, cy, w, h) and has shape
+ (bs, num_denoising_queries, 4).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ Tuple[Tensor]: A tuple including `loss_cls`, `loss_box` and
+ `loss_iou`.
+ """
+ cls_reg_targets = self.get_dn_targets(batch_gt_instances,
+ batch_img_metas, dn_meta)
+ (labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,
+ num_total_pos, num_total_neg) = cls_reg_targets
+ labels = torch.cat(labels_list, 0)
+ label_weights = torch.cat(label_weights_list, 0)
+ bbox_targets = torch.cat(bbox_targets_list, 0)
+ bbox_weights = torch.cat(bbox_weights_list, 0)
+
+ # classification loss
+ cls_scores = dn_cls_scores.reshape(-1, self.cls_out_channels)
+ # construct weighted avg_factor to match with the official DETR repo
+ cls_avg_factor = \
+ num_total_pos * 1.0 + num_total_neg * self.bg_cls_weight
+ if self.sync_cls_avg_factor:
+ cls_avg_factor = reduce_mean(
+ cls_scores.new_tensor([cls_avg_factor]))
+ cls_avg_factor = max(cls_avg_factor, 1)
+
+ if len(cls_scores) > 0:
+ loss_cls = self.loss_cls(
+ cls_scores, labels, label_weights, avg_factor=cls_avg_factor)
+ else:
+ loss_cls = torch.zeros(
+ 1, dtype=cls_scores.dtype, device=cls_scores.device)
+
+ # Compute the average number of gt boxes across all gpus, for
+ # normalization purposes
+ num_total_pos = loss_cls.new_tensor([num_total_pos])
+ num_total_pos = torch.clamp(reduce_mean(num_total_pos), min=1).item()
+
+ # construct factors used for rescale bboxes
+ factors = []
+ for img_meta, bbox_pred in zip(batch_img_metas, dn_bbox_preds):
+ img_h, img_w = img_meta['img_shape']
+ factor = bbox_pred.new_tensor([img_w, img_h, img_w,
+ img_h]).unsqueeze(0).repeat(
+ bbox_pred.size(0), 1)
+ factors.append(factor)
+ factors = torch.cat(factors)
+
+ # DETR regress the relative position of boxes (cxcywh) in the image,
+ # thus the learning target is normalized by the image size. So here
+ # we need to re-scale them for calculating IoU loss
+ bbox_preds = dn_bbox_preds.reshape(-1, 4)
+ bboxes = bbox_cxcywh_to_xyxy(bbox_preds) * factors
+ bboxes_gt = bbox_cxcywh_to_xyxy(bbox_targets) * factors
+
+ # regression IoU loss, defaultly GIoU loss
+ loss_iou = self.loss_iou(
+ bboxes, bboxes_gt, bbox_weights, avg_factor=num_total_pos)
+
+ # regression L1 loss
+ loss_bbox = self.loss_bbox(
+ bbox_preds, bbox_targets, bbox_weights, avg_factor=num_total_pos)
+ return loss_cls, loss_bbox, loss_iou
+
+ def get_dn_targets(self, batch_gt_instances: InstanceList,
+ batch_img_metas: dict, dn_meta: Dict[str,
+ int]) -> tuple:
+ """Get targets in denoising part for a batch of images.
+
+ Args:
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ tuple: a tuple containing the following targets.
+
+ - labels_list (list[Tensor]): Labels for all images.
+ - label_weights_list (list[Tensor]): Label weights for all images.
+ - bbox_targets_list (list[Tensor]): BBox targets for all images.
+ - bbox_weights_list (list[Tensor]): BBox weights for all images.
+ - num_total_pos (int): Number of positive samples in all images.
+ - num_total_neg (int): Number of negative samples in all images.
+ """
+ (labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,
+ pos_inds_list, neg_inds_list) = multi_apply(
+ self._get_dn_targets_single,
+ batch_gt_instances,
+ batch_img_metas,
+ dn_meta=dn_meta)
+ num_total_pos = sum((inds.numel() for inds in pos_inds_list))
+ num_total_neg = sum((inds.numel() for inds in neg_inds_list))
+ return (labels_list, label_weights_list, bbox_targets_list,
+ bbox_weights_list, num_total_pos, num_total_neg)
+
+ def _get_dn_targets_single(self, gt_instances: InstanceData,
+ img_meta: dict, dn_meta: Dict[str,
+ int]) -> tuple:
+ """Get targets in denoising part for one image.
+
+ Args:
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It should includes ``bboxes`` and ``labels``
+ attributes.
+ img_meta (dict): Meta information for one image.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ tuple[Tensor]: a tuple containing the following for one image.
+
+ - labels (Tensor): Labels of each image.
+ - label_weights (Tensor]): Label weights of each image.
+ - bbox_targets (Tensor): BBox targets of each image.
+ - bbox_weights (Tensor): BBox weights of each image.
+ - pos_inds (Tensor): Sampled positive indices for each image.
+ - neg_inds (Tensor): Sampled negative indices for each image.
+ """
+ gt_bboxes = gt_instances.bboxes
+ gt_labels = gt_instances.labels
+ num_groups = dn_meta['num_denoising_groups']
+ num_denoising_queries = dn_meta['num_denoising_queries']
+ num_queries_each_group = int(num_denoising_queries / num_groups)
+ device = gt_bboxes.device
+
+ if len(gt_labels) > 0:
+ t = torch.arange(len(gt_labels), dtype=torch.long, device=device)
+ t = t.unsqueeze(0).repeat(num_groups, 1)
+ pos_assigned_gt_inds = t.flatten()
+ pos_inds = torch.arange(
+ num_groups, dtype=torch.long, device=device)
+ pos_inds = pos_inds.unsqueeze(1) * num_queries_each_group + t
+ pos_inds = pos_inds.flatten()
+ else:
+ pos_inds = pos_assigned_gt_inds = \
+ gt_bboxes.new_tensor([], dtype=torch.long)
+
+ neg_inds = pos_inds + num_queries_each_group // 2
+
+ # label targets
+ labels = gt_bboxes.new_full((num_denoising_queries, ),
+ self.num_classes,
+ dtype=torch.long)
+ labels[pos_inds] = gt_labels[pos_assigned_gt_inds]
+ label_weights = gt_bboxes.new_ones(num_denoising_queries)
+
+ # bbox targets
+ bbox_targets = torch.zeros(num_denoising_queries, 4, device=device)
+ bbox_weights = torch.zeros(num_denoising_queries, 4, device=device)
+ bbox_weights[pos_inds] = 1.0
+ img_h, img_w = img_meta['img_shape']
+
+ # DETR regress the relative position of boxes (cxcywh) in the image.
+ # Thus the learning target should be normalized by the image size, also
+ # the box format should be converted from defaultly x1y1x2y2 to cxcywh.
+ factor = gt_bboxes.new_tensor([img_w, img_h, img_w,
+ img_h]).unsqueeze(0)
+ gt_bboxes_normalized = gt_bboxes / factor
+ gt_bboxes_targets = bbox_xyxy_to_cxcywh(gt_bboxes_normalized)
+ bbox_targets[pos_inds] = gt_bboxes_targets.repeat([num_groups, 1])
+
+ return (labels, label_weights, bbox_targets, bbox_weights, pos_inds,
+ neg_inds)
+
+ @staticmethod
+ def split_outputs(all_layers_cls_scores: Tensor,
+ all_layers_bbox_preds: Tensor,
+ dn_meta: Dict[str, int]) -> Tuple[Tensor]:
+ """Split outputs of the denoising part and the matching part.
+
+ For the total outputs of `num_queries_total` length, the former
+ `num_denoising_queries` outputs are from denoising queries, and
+ the rest `num_matching_queries` ones are from matching queries,
+ where `num_queries_total` is the sum of `num_denoising_queries` and
+ `num_matching_queries`.
+
+ Args:
+ all_layers_cls_scores (Tensor): Classification scores of all
+ decoder layers, has shape (num_decoder_layers, bs,
+ num_queries_total, cls_out_channels).
+ all_layers_bbox_preds (Tensor): Regression outputs of all decoder
+ layers. Each is a 4D-tensor with normalized coordinate format
+ (cx, cy, w, h) and has shape (num_decoder_layers, bs,
+ num_queries_total, 4).
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'.
+
+ Returns:
+ Tuple[Tensor]: a tuple containing the following outputs.
+
+ - all_layers_matching_cls_scores (Tensor): Classification scores
+ of all decoder layers in matching part, has shape
+ (num_decoder_layers, bs, num_matching_queries, cls_out_channels).
+ - all_layers_matching_bbox_preds (Tensor): Regression outputs of
+ all decoder layers in matching part. Each is a 4D-tensor with
+ normalized coordinate format (cx, cy, w, h) and has shape
+ (num_decoder_layers, bs, num_matching_queries, 4).
+ - all_layers_denoising_cls_scores (Tensor): Classification scores
+ of all decoder layers in denoising part, has shape
+ (num_decoder_layers, bs, num_denoising_queries,
+ cls_out_channels).
+ - all_layers_denoising_bbox_preds (Tensor): Regression outputs of
+ all decoder layers in denoising part. Each is a 4D-tensor with
+ normalized coordinate format (cx, cy, w, h) and has shape
+ (num_decoder_layers, bs, num_denoising_queries, 4).
+ """
+ num_denoising_queries = dn_meta['num_denoising_queries']
+ if dn_meta is not None:
+ all_layers_denoising_cls_scores = \
+ all_layers_cls_scores[:, :, : num_denoising_queries, :]
+ all_layers_denoising_bbox_preds = \
+ all_layers_bbox_preds[:, :, : num_denoising_queries, :]
+ all_layers_matching_cls_scores = \
+ all_layers_cls_scores[:, :, num_denoising_queries:, :]
+ all_layers_matching_bbox_preds = \
+ all_layers_bbox_preds[:, :, num_denoising_queries:, :]
+ else:
+ all_layers_denoising_cls_scores = None
+ all_layers_denoising_bbox_preds = None
+ all_layers_matching_cls_scores = all_layers_cls_scores
+ all_layers_matching_bbox_preds = all_layers_bbox_preds
+ return (all_layers_matching_cls_scores, all_layers_matching_bbox_preds,
+ all_layers_denoising_cls_scores,
+ all_layers_denoising_bbox_preds)
+
+ def predict(self,
+ hidden_states: Tensor,
+ references: List[Tensor],
+ batch_data_samples: SampleList,
+ rescale: bool = True) -> InstanceList:
+ """Perform forward propagation and loss calculation of the detection
+ head on the queries of the upstream network.
+
+ Args:
+ hidden_states (Tensor): Hidden states output from each decoder
+ layer, has shape (num_decoder_layers, num_queries, bs, dim).
+ references (list[Tensor]): List of the reference from the decoder.
+ The first reference is the `init_reference` (initial) and the
+ other num_decoder_layers(6) references are `inter_references`
+ (intermediate). The `init_reference` has shape (bs,
+ num_queries, 4) when `as_two_stage` of the detector is `True`,
+ otherwise (bs, num_queries, 2). Each `inter_reference` has
+ shape (bs, num_queries, 4) when `with_box_refine` of the
+ detector is `True`, otherwise (bs, num_queries, 2). The
+ coordinates are arranged as (cx, cy) when the last dimension is
+ 2, and (cx, cy, w, h) when it is 4.
+ batch_data_samples (list[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ rescale (bool, optional): If `True`, return boxes in original
+ image space. Defaults to `True`.
+
+ Returns:
+ list[obj:`InstanceData`]: Detection results of each image
+ after the post process.
+ """
+ batch_img_metas = [
+ data_samples.metainfo for data_samples in batch_data_samples
+ ]
+
+ outs = self(hidden_states, references)
+
+ predictions = self.predict_by_feat(
+ *outs, batch_img_metas=batch_img_metas, rescale=rescale)
+ return predictions
+
+ def predict_by_feat(self,
+ all_layers_cls_scores: Tensor,
+ all_layers_bbox_preds: Tensor,
+ batch_img_metas: List[Dict],
+ rescale: bool = False) -> InstanceList:
+ """Transform a batch of output features extracted from the head into
+ bbox results.
+
+ Args:
+ all_layers_cls_scores (Tensor): Classification scores of all
+ decoder layers, has shape (num_decoder_layers, bs, num_queries,
+ cls_out_channels).
+ all_layers_bbox_preds (Tensor): Regression outputs of all decoder
+ layers. Each is a 4D-tensor with normalized coordinate format
+ (cx, cy, w, h) and shape (num_decoder_layers, bs, num_queries,
+ 4) with the last dimension arranged as (cx, cy, w, h).
+ batch_img_metas (list[dict]): Meta information of each image.
+ rescale (bool, optional): If `True`, return boxes in original
+ image space. Default `False`.
+
+ Returns:
+ list[obj:`InstanceData`]: Detection results of each image
+ after the post process.
+ """
+ cls_scores = all_layers_cls_scores[-1]
+ bbox_preds = all_layers_bbox_preds[-1]
+
+ result_list = []
+ for img_id in range(len(batch_img_metas)):
+ cls_score = cls_scores[img_id]
+ bbox_pred = bbox_preds[img_id]
+ img_meta = batch_img_metas[img_id]
+ results = self._predict_by_feat_single(cls_score, bbox_pred,
+ img_meta, rescale)
+ result_list.append(results)
+ return result_list
\ No newline at end of file
diff --git a/mmdet/models/dense_heads/dino_sima_cls_head.py b/mmdet/models/dense_heads/dino_sima_cls_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..b67051a04f8aed75a0d9871a0b394b19f4220148
--- /dev/null
+++ b/mmdet/models/dense_heads/dino_sima_cls_head.py
@@ -0,0 +1,1383 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+from typing import Dict, List, Tuple
+from torch import Tensor
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import Linear
+from mmcv.ops.nms import nms
+from mmengine.model import bias_init_with_prob, constant_init
+from mmengine.structures import InstanceData
+
+from mmdet.registry import MODELS
+from mmdet.structures import SampleList
+from mmdet.structures.bbox import bbox_cxcywh_to_xyxy, bbox_xyxy_to_cxcywh
+from mmdet.utils import InstanceList, OptInstanceList, reduce_mean
+from ..utils import multi_apply
+from ..layers import inverse_sigmoid
+from .detr_head import DETRHead
+
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from torch.nn import Transformer
+
+# def adjust_bbox_to_pixel(bboxes: Tensor):
+# # 向下取整得到目标的左上角坐标
+# adjusted_bboxes = torch.floor(bboxes)
+# # 向上取整得到目标的右下角坐标
+# adjusted_bboxes[:, 2:] = torch.ceil(bboxes[:, 2:])
+# return adjusted_bboxes
+
+
+def adjust_bbox_to_pixel(bboxes: Tensor):
+ # 四舍五入取整坐标
+ adjusted_bboxes = torch.round(bboxes)
+ return adjusted_bboxes
+
+
+
+class SiameseClassifier(nn.Module):
+ def __init__(self, embed_dims, num_references=5):
+ super(SiameseClassifier, self).__init__()
+ self.embed_dims = embed_dims
+ self.num_references = num_references
+ self.out_features = self.num_references
+ self.transformer = nn.TransformerEncoder(
+ nn.TransformerEncoderLayer(d_model=embed_dims, nhead=1),
+ num_layers=1
+ )
+ self.mlp = nn.Sequential(
+ nn.Linear(embed_dims, 256),
+ nn.LeakyReLU(),
+ nn.Linear(256, 256),
+ nn.LeakyReLU(),
+ nn.Linear(256, embed_dims)
+ )
+ self.out = nn.ModuleList([nn.Linear(embed_dims, 1 ) for _ in range(num_references)])
+ for layer in self.out:
+ layer.bias.data.fill_(bias_init_with_prob(0.01))
+ # self.out1 = nn.Linear(embed_dims, num_references)
+ # self.out1.bias.data.fill_(bias_init_with_prob(0.01))
+ self.references = nn.Parameter(torch.randn(num_references, embed_dims))
+
+ def forward(self, x):
+ batch_size = x.size(0)
+ sample_num = x.size(1)
+ # Expand references to match batch size
+ references = self.references.unsqueeze(0)
+
+ # Pass inputs and references through transformer
+ # x_transformed = self.transformer(x)
+ # references_transformed = self.transformer(references)
+
+ x_transformed = self.mlp(x.reshape(-1, self.embed_dims)).reshape(batch_size,sample_num, -1)
+ references_transformed = self.mlp(references)
+
+ # Concatenate transformed_x and references_transformed
+ # references_transformed_expanded = references_transformed.unsqueeze(1).expand(batch_size, x_transformed.size(1), -1, -1)
+ # x_transformed = x_transformed.unsqueeze(2).expand(-1, -1, self.out_features, -1)
+ # concatenated = torch.cat([x_transformed, references_transformed_expanded], dim=3)
+ # # Pass through MLPs
+ # outputs = []
+ # for i in range(self.out_features):
+ # output = self.out[i](concatenated[:,:,i,:].reshape(-1,self.embed_dims*2))
+ # outputs.append(output.view(batch_size,-1,1))
+ # output = torch.cat(outputs, dim=2)
+ references_transformed_expanded = references_transformed.unsqueeze(1).expand(batch_size,sample_num,
+ -1, -1).unsqueeze(-1)
+ x_transformed = x_transformed.unsqueeze(2).expand(-1, -1, self.out_features, -1).unsqueeze(-1)
+ concatenated = torch.cat([x_transformed, references_transformed_expanded], dim=4)
+ concatenated = torch.mean(concatenated, dim=4)
+ # Pass through MLPs
+ outputs = []
+ for i in range(self.out_features):
+ output = self.out[i](concatenated[:,:,i,:].reshape(-1,concatenated.size(3)))
+ outputs.append(output.view(batch_size,-1,1))
+ output = torch.cat(outputs, dim=2)
+ # references_transformed_expanded = references_transformed.unsqueeze(1).expand(batch_size, x_transformed.size(1), -1, -1) #.reshape(batch_size, x_transformed.size(1), -1)
+ # x_transformed = x_transformed.unsqueeze(2)
+ # concatenated = torch.cat([x_transformed, references_transformed_expanded], dim=2)
+ # concatenated = torch.mean(concatenated,dim=2)
+ # output = self.out1(concatenated.reshape(-1,self.embed_dims)).view(x.size(0),x.size(1),-1)
+ return output
+
+ #
+ # def forward(self, x):
+ # batch_size = x.size(0)
+ # outputs = []
+ # for i in range(self.out_features):
+ # output = self.out[i](x.reshape(-1, self.embed_dims))
+ # outputs.append(output.view(batch_size, x.size(1),-1))
+ # output = torch.cat(outputs, dim=2)
+ # return output
+
+
+@MODELS.register_module()
+class DINOSiamClsHead(DETRHead):
+ r"""Head of the DINO: DETR with Improved DeNoising Anchor Boxes
+ for End-to-End Object Detection
+
+ Code is modified from the `official github repo
+ `_.
+
+ More details can be found in the `paper
+ `_ .
+ """
+ def __init__(self,
+ *args,
+ share_pred_layer: bool = False,
+ num_pred_layer: int = 6,
+ as_two_stage: bool = False,
+ siamese_cls: bool = False,
+ **kwargs) -> None:
+ self.share_pred_layer = share_pred_layer
+ self.num_pred_layer = num_pred_layer
+ self.as_two_stage = as_two_stage
+ self.siamese_cls = siamese_cls
+
+ super().__init__(*args, **kwargs)
+
+ def _init_layers(self) -> None:
+ """Initialize classification branch and regression branch of head."""
+ # fc_cls = Linear(self.embed_dims, self.cls_out_channels)
+
+ fc_cls = SiameseClassifier(self.embed_dims, self.cls_out_channels)
+ reg_branch = []
+ for _ in range(self.num_reg_fcs):
+ reg_branch.append(Linear(self.embed_dims, self.embed_dims))
+ reg_branch.append(nn.ReLU())
+ reg_branch.append(Linear(self.embed_dims, 4))
+ reg_branch = nn.Sequential(*reg_branch)
+
+ if self.share_pred_layer:
+ self.cls_branches = nn.ModuleList(
+ [fc_cls for _ in range(self.num_pred_layer)])
+ self.reg_branches = nn.ModuleList(
+ [reg_branch for _ in range(self.num_pred_layer)])
+ else:
+ self.cls_branches = nn.ModuleList(
+ [copy.deepcopy(fc_cls) for _ in range(self.num_pred_layer)])
+ self.reg_branches = nn.ModuleList([
+ copy.deepcopy(reg_branch) for _ in range(self.num_pred_layer)
+ ])
+
+
+ def init_weights(self) -> None:
+ """Initialize weights of the Deformable DETR head."""
+ # if self.loss_cls.use_sigmoid:
+ # bias_init = bias_init_with_prob(0.01)
+ # for m in self.cls_branches:
+ # nn.init.constant_(m.bias, bias_init)
+
+ for m in self.reg_branches:
+ constant_init(m[-1], 0, bias=0)
+ nn.init.constant_(self.reg_branches[0][-1].bias.data[2:], -2.0)
+ if self.as_two_stage:
+ for m in self.reg_branches:
+ nn.init.constant_(m[-1].bias.data[2:], 0.0)
+
+ def forward(self, hidden_states: Tensor,
+ references: List[Tensor]) -> Tuple[Tensor]:
+ """Forward function.
+
+ Args:
+ hidden_states (Tensor): Hidden states output from each decoder
+ layer, has shape (num_decoder_layers, bs, num_queries, dim).
+ references (list[Tensor]): List of the reference from the decoder.
+ The first reference is the `init_reference` (initial) and the
+ other num_decoder_layers(6) references are `inter_references`
+ (intermediate). The `init_reference` has shape (bs,
+ num_queries, 4) when `as_two_stage` of the detector is `True`,
+ otherwise (bs, num_queries, 2). Each `inter_reference` has
+ shape (bs, num_queries, 4) when `with_box_refine` of the
+ detector is `True`, otherwise (bs, num_queries, 2). The
+ coordinates are arranged as (cx, cy) when the last dimension is
+ 2, and (cx, cy, w, h) when it is 4.
+
+ Returns:
+ tuple[Tensor]: results of head containing the following tensor.
+
+ - all_layers_outputs_classes (Tensor): Outputs from the
+ classification head, has shape (num_decoder_layers, bs,
+ num_queries, cls_out_channels).
+ - all_layers_outputs_coords (Tensor): Sigmoid outputs from the
+ regression head with normalized coordinate format (cx, cy, w,
+ h), has shape (num_decoder_layers, bs, num_queries, 4) with the
+ last dimension arranged as (cx, cy, w, h).
+ """
+ all_layers_outputs_classes = []
+ all_layers_outputs_coords = []
+
+ for layer_id in range(hidden_states.shape[0]):
+ reference = inverse_sigmoid(references[layer_id])
+ # NOTE The last reference will not be used.
+ hidden_state = hidden_states[layer_id]
+ outputs_class = self.cls_branches[layer_id](hidden_state)
+ tmp_reg_preds = self.reg_branches[layer_id](hidden_state)
+ if reference.shape[-1] == 4:
+ # When `layer` is 0 and `as_two_stage` of the detector
+ # is `True`, or when `layer` is greater than 0 and
+ # `with_box_refine` of the detector is `True`.
+ tmp_reg_preds += reference
+ else:
+ # When `layer` is 0 and `as_two_stage` of the detector
+ # is `False`, or when `layer` is greater than 0 and
+ # `with_box_refine` of the detector is `False`.
+ assert reference.shape[-1] == 2
+ tmp_reg_preds[..., :2] += reference
+ outputs_coord = tmp_reg_preds.sigmoid()
+ all_layers_outputs_classes.append(outputs_class)
+ all_layers_outputs_coords.append(outputs_coord)
+
+
+
+ all_layers_outputs_classes = torch.stack(all_layers_outputs_classes)
+ all_layers_outputs_coords = torch.stack(all_layers_outputs_coords)
+
+ return all_layers_outputs_classes, all_layers_outputs_coords
+
+ def loss(self, hidden_states: Tensor, references: List[Tensor],
+ enc_outputs_class: Tensor, enc_outputs_coord: Tensor,
+ batch_data_samples: SampleList, dn_meta: Dict[str, int]) -> dict:
+ """Perform forward propagation and loss calculation of the detection
+ head on the queries of the upstream network.
+
+ Args:
+ hidden_states (Tensor): Hidden states output from each decoder
+ layer, has shape (num_decoder_layers, bs, num_queries_total,
+ dim), where `num_queries_total` is the sum of
+ `num_denoising_queries` and `num_matching_queries` when
+ `self.training` is `True`, else `num_matching_queries`.
+ references (list[Tensor]): List of the reference from the decoder.
+ The first reference is the `init_reference` (initial) and the
+ other num_decoder_layers(6) references are `inter_references`
+ (intermediate). The `init_reference` has shape (bs,
+ num_queries_total, 4) and each `inter_reference` has shape
+ (bs, num_queries, 4) with the last dimension arranged as
+ (cx, cy, w, h).
+ enc_outputs_class (Tensor): The score of each point on encode
+ feature map, has shape (bs, num_feat_points, cls_out_channels).
+ enc_outputs_coord (Tensor): The proposal generate from the
+ encode feature map, has shape (bs, num_feat_points, 4) with the
+ last dimension arranged as (cx, cy, w, h).
+ batch_data_samples (list[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ dict: A dictionary of loss components.
+ """
+ batch_gt_instances = []
+ batch_img_metas = []
+ for data_sample in batch_data_samples:
+ batch_img_metas.append(data_sample.metainfo)
+ batch_gt_instances.append(data_sample.gt_instances)
+
+ outs = self(hidden_states, references)
+ loss_inputs = outs + (enc_outputs_class, enc_outputs_coord,
+ batch_gt_instances, batch_img_metas, dn_meta)
+ losses = self.loss_by_feat(*loss_inputs)
+ return losses
+
+ def loss_by_feat(
+ self,
+ all_layers_cls_scores: Tensor,
+ all_layers_bbox_preds: Tensor,
+ enc_cls_scores: Tensor,
+ enc_bbox_preds: Tensor,
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ dn_meta: Dict[str, int],
+ batch_gt_instances_ignore: OptInstanceList = None
+ ) -> Dict[str, Tensor]:
+ """Loss function.
+
+ Args:
+ all_layers_cls_scores (Tensor): Classification scores of all
+ decoder layers, has shape (num_decoder_layers, bs,
+ num_queries_total, cls_out_channels), where
+ `num_queries_total` is the sum of `num_denoising_queries`
+ and `num_matching_queries`.
+ all_layers_bbox_preds (Tensor): Regression outputs of all decoder
+ layers. Each is a 4D-tensor with normalized coordinate format
+ (cx, cy, w, h) and has shape (num_decoder_layers, bs,
+ num_queries_total, 4).
+ enc_cls_scores (Tensor): The score of each point on encode
+ feature map, has shape (bs, num_feat_points, cls_out_channels).
+ enc_bbox_preds (Tensor): The proposal generate from the encode
+ feature map, has shape (bs, num_feat_points, 4) with the last
+ dimension arranged as (cx, cy, w, h).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components.
+ """
+ # extract denoising and matching part of outputs
+ (all_layers_matching_cls_scores, all_layers_matching_bbox_preds,
+ all_layers_denoising_cls_scores, all_layers_denoising_bbox_preds) = \
+ self.split_outputs(
+ all_layers_cls_scores, all_layers_bbox_preds, dn_meta)
+
+ loss_dict = super().loss_by_feat(
+ all_layers_matching_cls_scores, all_layers_matching_bbox_preds,
+ batch_gt_instances, batch_img_metas, batch_gt_instances_ignore)
+ # NOTE DETRHead.loss_by_feat but not DeformableDETRHead.loss_by_feat
+ # is called, because the encoder loss calculations are different
+ # between DINO and DeformableDETR.
+
+ # loss of proposal generated from encode feature map.
+ if enc_cls_scores is not None:
+ # NOTE The enc_loss calculation of the DINO is
+ # different from that of Deformable DETR.
+ enc_loss_cls, enc_losses_bbox, enc_losses_iou = \
+ self.loss_by_feat_single(
+ enc_cls_scores, enc_bbox_preds,
+ batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas)
+ loss_dict['enc_loss_cls'] = enc_loss_cls
+ loss_dict['enc_loss_bbox'] = enc_losses_bbox
+ loss_dict['enc_loss_iou'] = enc_losses_iou
+
+ if all_layers_denoising_cls_scores is not None:
+ # calculate denoising loss from all decoder layers
+ dn_losses_cls, dn_losses_bbox, dn_losses_iou = self.loss_dn(
+ all_layers_denoising_cls_scores,
+ all_layers_denoising_bbox_preds,
+ batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas,
+ dn_meta=dn_meta)
+ # collate denoising loss
+ loss_dict['dn_loss_cls'] = dn_losses_cls[-1]
+ loss_dict['dn_loss_bbox'] = dn_losses_bbox[-1]
+ loss_dict['dn_loss_iou'] = dn_losses_iou[-1]
+ for num_dec_layer, (loss_cls_i, loss_bbox_i, loss_iou_i) in \
+ enumerate(zip(dn_losses_cls[:-1], dn_losses_bbox[:-1],
+ dn_losses_iou[:-1])):
+ loss_dict[f'd{num_dec_layer}.dn_loss_cls'] = loss_cls_i
+ loss_dict[f'd{num_dec_layer}.dn_loss_bbox'] = loss_bbox_i
+ loss_dict[f'd{num_dec_layer}.dn_loss_iou'] = loss_iou_i
+ return loss_dict
+
+ def loss_dn(self, all_layers_denoising_cls_scores: Tensor,
+ all_layers_denoising_bbox_preds: Tensor,
+ batch_gt_instances: InstanceList, batch_img_metas: List[dict],
+ dn_meta: Dict[str, int]) -> Tuple[List[Tensor]]:
+ """Calculate denoising loss.
+
+ Args:
+ all_layers_denoising_cls_scores (Tensor): Classification scores of
+ all decoder layers in denoising part, has shape (
+ num_decoder_layers, bs, num_denoising_queries,
+ cls_out_channels).
+ all_layers_denoising_bbox_preds (Tensor): Regression outputs of all
+ decoder layers in denoising part. Each is a 4D-tensor with
+ normalized coordinate format (cx, cy, w, h) and has shape
+ (num_decoder_layers, bs, num_denoising_queries, 4).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ Tuple[List[Tensor]]: The loss_dn_cls, loss_dn_bbox, and loss_dn_iou
+ of each decoder layers.
+ """
+ return multi_apply(
+ self._loss_dn_single,
+ all_layers_denoising_cls_scores,
+ all_layers_denoising_bbox_preds,
+ batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas,
+ dn_meta=dn_meta)
+
+ def _loss_dn_single(self, dn_cls_scores: Tensor, dn_bbox_preds: Tensor,
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ dn_meta: Dict[str, int]) -> Tuple[Tensor]:
+ """Denoising loss for outputs from a single decoder layer.
+
+ Args:
+ dn_cls_scores (Tensor): Classification scores of a single decoder
+ layer in denoising part, has shape (bs, num_denoising_queries,
+ cls_out_channels).
+ dn_bbox_preds (Tensor): Regression outputs of a single decoder
+ layer in denoising part. Each is a 4D-tensor with normalized
+ coordinate format (cx, cy, w, h) and has shape
+ (bs, num_denoising_queries, 4).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ Tuple[Tensor]: A tuple including `loss_cls`, `loss_box` and
+ `loss_iou`.
+ """
+ cls_reg_targets = self.get_dn_targets(batch_gt_instances,
+ batch_img_metas, dn_meta)
+ (labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,
+ num_total_pos, num_total_neg) = cls_reg_targets
+ labels = torch.cat(labels_list, 0)
+ label_weights = torch.cat(label_weights_list, 0)
+ bbox_targets = torch.cat(bbox_targets_list, 0)
+ bbox_weights = torch.cat(bbox_weights_list, 0)
+
+ # classification loss
+ cls_scores = dn_cls_scores.reshape(-1, self.cls_out_channels)
+ # construct weighted avg_factor to match with the official DETR repo
+ cls_avg_factor = \
+ num_total_pos * 1.0 + num_total_neg * self.bg_cls_weight
+ if self.sync_cls_avg_factor:
+ cls_avg_factor = reduce_mean(
+ cls_scores.new_tensor([cls_avg_factor]))
+ cls_avg_factor = max(cls_avg_factor, 1)
+
+ if len(cls_scores) > 0:
+ loss_cls = self.loss_cls(
+ cls_scores, labels, label_weights, avg_factor=cls_avg_factor)
+ else:
+ loss_cls = torch.zeros(
+ 1, dtype=cls_scores.dtype, device=cls_scores.device)
+
+ # Compute the average number of gt boxes across all gpus, for
+ # normalization purposes
+ num_total_pos = loss_cls.new_tensor([num_total_pos])
+ num_total_pos = torch.clamp(reduce_mean(num_total_pos), min=1).item()
+
+ # construct factors used for rescale bboxes
+ factors = []
+ for img_meta, bbox_pred in zip(batch_img_metas, dn_bbox_preds):
+ img_h, img_w = img_meta['img_shape']
+ factor = bbox_pred.new_tensor([img_w, img_h, img_w,
+ img_h]).unsqueeze(0).repeat(
+ bbox_pred.size(0), 1)
+ factors.append(factor)
+ factors = torch.cat(factors)
+
+ # DETR regress the relative position of boxes (cxcywh) in the image,
+ # thus the learning target is normalized by the image size. So here
+ # we need to re-scale them for calculating IoU loss
+ bbox_preds = dn_bbox_preds.reshape(-1, 4)
+ bboxes = bbox_cxcywh_to_xyxy(bbox_preds) * factors
+ bboxes_gt = bbox_cxcywh_to_xyxy(bbox_targets) * factors
+
+ # regression IoU loss, defaultly GIoU loss
+ loss_iou = self.loss_iou(
+ bboxes, bboxes_gt, bbox_weights, avg_factor=num_total_pos)
+
+ # regression L1 loss
+ loss_bbox = self.loss_bbox(
+ bbox_preds, bbox_targets, bbox_weights, avg_factor=num_total_pos)
+ return loss_cls, loss_bbox, loss_iou
+
+ def get_dn_targets(self, batch_gt_instances: InstanceList,
+ batch_img_metas: dict, dn_meta: Dict[str,
+ int]) -> tuple:
+ """Get targets in denoising part for a batch of images.
+
+ Args:
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ tuple: a tuple containing the following targets.
+
+ - labels_list (list[Tensor]): Labels for all images.
+ - label_weights_list (list[Tensor]): Label weights for all images.
+ - bbox_targets_list (list[Tensor]): BBox targets for all images.
+ - bbox_weights_list (list[Tensor]): BBox weights for all images.
+ - num_total_pos (int): Number of positive samples in all images.
+ - num_total_neg (int): Number of negative samples in all images.
+ """
+ (labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,
+ pos_inds_list, neg_inds_list) = multi_apply(
+ self._get_dn_targets_single,
+ batch_gt_instances,
+ batch_img_metas,
+ dn_meta=dn_meta)
+ num_total_pos = sum((inds.numel() for inds in pos_inds_list))
+ num_total_neg = sum((inds.numel() for inds in neg_inds_list))
+ return (labels_list, label_weights_list, bbox_targets_list,
+ bbox_weights_list, num_total_pos, num_total_neg)
+
+ def _get_dn_targets_single(self, gt_instances: InstanceData,
+ img_meta: dict, dn_meta: Dict[str,
+ int]) -> tuple:
+ """Get targets in denoising part for one image.
+
+ Args:
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It should includes ``bboxes`` and ``labels``
+ attributes.
+ img_meta (dict): Meta information for one image.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ tuple[Tensor]: a tuple containing the following for one image.
+
+ - labels (Tensor): Labels of each image.
+ - label_weights (Tensor]): Label weights of each image.
+ - bbox_targets (Tensor): BBox targets of each image.
+ - bbox_weights (Tensor): BBox weights of each image.
+ - pos_inds (Tensor): Sampled positive indices for each image.
+ - neg_inds (Tensor): Sampled negative indices for each image.
+ """
+ gt_bboxes = gt_instances.bboxes
+ gt_labels = gt_instances.labels
+ num_groups = dn_meta['num_denoising_groups']
+ num_denoising_queries = dn_meta['num_denoising_queries']
+ num_queries_each_group = int(num_denoising_queries / num_groups)
+ device = gt_bboxes.device
+
+ if len(gt_labels) > 0:
+ t = torch.arange(len(gt_labels), dtype=torch.long, device=device)
+ t = t.unsqueeze(0).repeat(num_groups, 1)
+ pos_assigned_gt_inds = t.flatten()
+ pos_inds = torch.arange(
+ num_groups, dtype=torch.long, device=device)
+ pos_inds = pos_inds.unsqueeze(1) * num_queries_each_group + t
+ pos_inds = pos_inds.flatten()
+ else:
+ pos_inds = pos_assigned_gt_inds = \
+ gt_bboxes.new_tensor([], dtype=torch.long)
+
+ neg_inds = pos_inds + num_queries_each_group // 2
+
+ # label targets
+ labels = gt_bboxes.new_full((num_denoising_queries, ),
+ self.num_classes,
+ dtype=torch.long)
+ labels[pos_inds] = gt_labels[pos_assigned_gt_inds]
+ label_weights = gt_bboxes.new_ones(num_denoising_queries)
+
+ # bbox targets
+ bbox_targets = torch.zeros(num_denoising_queries, 4, device=device)
+ bbox_weights = torch.zeros(num_denoising_queries, 4, device=device)
+ bbox_weights[pos_inds] = 1.0
+ img_h, img_w = img_meta['img_shape']
+
+ # DETR regress the relative position of boxes (cxcywh) in the image.
+ # Thus the learning target should be normalized by the image size, also
+ # the box format should be converted from defaultly x1y1x2y2 to cxcywh.
+ factor = gt_bboxes.new_tensor([img_w, img_h, img_w,
+ img_h]).unsqueeze(0)
+ gt_bboxes_normalized = gt_bboxes / factor
+ gt_bboxes_targets = bbox_xyxy_to_cxcywh(gt_bboxes_normalized)
+ bbox_targets[pos_inds] = gt_bboxes_targets.repeat([num_groups, 1])
+
+ return (labels, label_weights, bbox_targets, bbox_weights, pos_inds,
+ neg_inds)
+
+ @staticmethod
+ def split_outputs(all_layers_cls_scores: Tensor,
+ all_layers_bbox_preds: Tensor,
+ dn_meta: Dict[str, int]) -> Tuple[Tensor]:
+ """Split outputs of the denoising part and the matching part.
+
+ For the total outputs of `num_queries_total` length, the former
+ `num_denoising_queries` outputs are from denoising queries, and
+ the rest `num_matching_queries` ones are from matching queries,
+ where `num_queries_total` is the sum of `num_denoising_queries` and
+ `num_matching_queries`.
+
+ Args:
+ all_layers_cls_scores (Tensor): Classification scores of all
+ decoder layers, has shape (num_decoder_layers, bs,
+ num_queries_total, cls_out_channels).
+ all_layers_bbox_preds (Tensor): Regression outputs of all decoder
+ layers. Each is a 4D-tensor with normalized coordinate format
+ (cx, cy, w, h) and has shape (num_decoder_layers, bs,
+ num_queries_total, 4).
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'.
+
+ Returns:
+ Tuple[Tensor]: a tuple containing the following outputs.
+
+ - all_layers_matching_cls_scores (Tensor): Classification scores
+ of all decoder layers in matching part, has shape
+ (num_decoder_layers, bs, num_matching_queries, cls_out_channels).
+ - all_layers_matching_bbox_preds (Tensor): Regression outputs of
+ all decoder layers in matching part. Each is a 4D-tensor with
+ normalized coordinate format (cx, cy, w, h) and has shape
+ (num_decoder_layers, bs, num_matching_queries, 4).
+ - all_layers_denoising_cls_scores (Tensor): Classification scores
+ of all decoder layers in denoising part, has shape
+ (num_decoder_layers, bs, num_denoising_queries,
+ cls_out_channels).
+ - all_layers_denoising_bbox_preds (Tensor): Regression outputs of
+ all decoder layers in denoising part. Each is a 4D-tensor with
+ normalized coordinate format (cx, cy, w, h) and has shape
+ (num_decoder_layers, bs, num_denoising_queries, 4).
+ """
+ num_denoising_queries = dn_meta['num_denoising_queries']
+ if dn_meta is not None:
+ all_layers_denoising_cls_scores = \
+ all_layers_cls_scores[:, :, : num_denoising_queries, :]
+ all_layers_denoising_bbox_preds = \
+ all_layers_bbox_preds[:, :, : num_denoising_queries, :]
+ all_layers_matching_cls_scores = \
+ all_layers_cls_scores[:, :, num_denoising_queries:, :]
+ all_layers_matching_bbox_preds = \
+ all_layers_bbox_preds[:, :, num_denoising_queries:, :]
+ else:
+ all_layers_denoising_cls_scores = None
+ all_layers_denoising_bbox_preds = None
+ all_layers_matching_cls_scores = all_layers_cls_scores
+ all_layers_matching_bbox_preds = all_layers_bbox_preds
+ return (all_layers_matching_cls_scores, all_layers_matching_bbox_preds,
+ all_layers_denoising_cls_scores,
+ all_layers_denoising_bbox_preds)
+
+ def predict(self,
+ hidden_states: Tensor,
+ references: List[Tensor],
+ batch_data_samples: SampleList,
+ rescale: bool = True) -> InstanceList:
+ """Perform forward propagation and loss calculation of the detection
+ head on the queries of the upstream network.
+
+ Args:
+ hidden_states (Tensor): Hidden states output from each decoder
+ layer, has shape (num_decoder_layers, num_queries, bs, dim).
+ references (list[Tensor]): List of the reference from the decoder.
+ The first reference is the `init_reference` (initial) and the
+ other num_decoder_layers(6) references are `inter_references`
+ (intermediate). The `init_reference` has shape (bs,
+ num_queries, 4) when `as_two_stage` of the detector is `True`,
+ otherwise (bs, num_queries, 2). Each `inter_reference` has
+ shape (bs, num_queries, 4) when `with_box_refine` of the
+ detector is `True`, otherwise (bs, num_queries, 2). The
+ coordinates are arranged as (cx, cy) when the last dimension is
+ 2, and (cx, cy, w, h) when it is 4.
+ batch_data_samples (list[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ rescale (bool, optional): If `True`, return boxes in original
+ image space. Defaults to `True`.
+
+ Returns:
+ list[obj:`InstanceData`]: Detection results of each image
+ after the post process.
+ """
+ batch_img_metas = [
+ data_samples.metainfo for data_samples in batch_data_samples
+ ]
+
+ outs = self(hidden_states, references)
+
+ predictions = self.predict_by_feat(
+ *outs, batch_img_metas=batch_img_metas, rescale=rescale)
+ return predictions
+
+ def predict_by_feat(self,
+ all_layers_cls_scores: Tensor,
+ all_layers_bbox_preds: Tensor,
+ batch_img_metas: List[Dict],
+ rescale: bool = False) -> InstanceList:
+ """Transform a batch of output features extracted from the head into
+ bbox results.
+
+ Args:
+ all_layers_cls_scores (Tensor): Classification scores of all
+ decoder layers, has shape (num_decoder_layers, bs, num_queries,
+ cls_out_channels).
+ all_layers_bbox_preds (Tensor): Regression outputs of all decoder
+ layers. Each is a 4D-tensor with normalized coordinate format
+ (cx, cy, w, h) and shape (num_decoder_layers, bs, num_queries,
+ 4) with the last dimension arranged as (cx, cy, w, h).
+ batch_img_metas (list[dict]): Meta information of each image.
+ rescale (bool, optional): If `True`, return boxes in original
+ image space. Default `False`.
+
+ Returns:
+ list[obj:`InstanceData`]: Detection results of each image
+ after the post process.
+ """
+ cls_scores = all_layers_cls_scores[-1]
+ bbox_preds = all_layers_bbox_preds[-1]
+
+ result_list = []
+ for img_id in range(len(batch_img_metas)):
+ cls_score = cls_scores[img_id]
+ bbox_pred = bbox_preds[img_id]
+ img_meta = batch_img_metas[img_id]
+ results = self._predict_by_feat_single(cls_score, bbox_pred,
+ img_meta, rescale)
+ result_list.append(results)
+ return result_list
+
+ def _predict_by_feat_single(self,
+ cls_score: Tensor,
+ bbox_pred: Tensor,
+ img_meta: dict,
+ rescale: bool = True) -> InstanceData:
+ """Transform outputs from the last decoder layer into bbox predictions
+ for each image.
+
+ Args:
+ cls_score (Tensor): Box score logits from the last decoder layer
+ for each image. Shape [num_queries, cls_out_channels].
+ bbox_pred (Tensor): Sigmoid outputs from the last decoder layer
+ for each image, with coordinate format (cx, cy, w, h) and
+ shape [num_queries, 4].
+ img_meta (dict): Image meta info.
+ rescale (bool): If True, return boxes in original image
+ space. Default True.
+
+ Returns:
+ :obj:`InstanceData`: Detection results of each image
+ after the post process.
+ Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ """
+ assert len(cls_score) == len(bbox_pred) # num_queries
+ max_per_img = self.test_cfg.get('max_per_img', len(cls_score))
+ img_shape = img_meta['img_shape']
+ # exclude background
+ if self.loss_cls.use_sigmoid:
+ cls_score = cls_score.sigmoid()
+ scores, indexes = cls_score.view(-1).topk(max_per_img)
+ det_labels = indexes % self.num_classes
+ bbox_index = indexes // self.num_classes
+ bbox_pred = bbox_pred[bbox_index]
+ else:
+ scores, det_labels = F.softmax(cls_score, dim=-1)[..., :-1].max(-1)
+ scores, bbox_index = scores.topk(max_per_img)
+ bbox_pred = bbox_pred[bbox_index]
+ det_labels = det_labels[bbox_index]
+
+ det_bboxes = bbox_cxcywh_to_xyxy(bbox_pred)
+ det_bboxes[:, 0::2] = det_bboxes[:, 0::2] * img_shape[1]
+ det_bboxes[:, 1::2] = det_bboxes[:, 1::2] * img_shape[0]
+ det_bboxes[:, 0::2].clamp_(min=0, max=img_shape[1])
+ det_bboxes[:, 1::2].clamp_(min=0, max=img_shape[0])
+
+ #lzx
+ iou_threshold= 0.01
+ offset = 0
+ score_threshold = 0.05 # torch.mean(cls_score.view(-1))+3*torch.std(cls_score.view(-1))
+ max_num = 300
+ dets, inds = nms(det_bboxes, scores, iou_threshold, offset, score_threshold, max_num)
+ det_bboxes = dets[:,:-1]
+ scores = dets[:,-1]
+ det_labels =det_labels[inds]
+
+ # add by lzx
+ det_bboxes = adjust_bbox_to_pixel(det_bboxes)
+
+ if rescale:
+ # assert img_meta.get('scale_factor') is not None
+ # det_bboxes /= det_bboxes.new_tensor(
+ # img_meta['scale_factor']).repeat((1, 2))
+ # rw by lzx
+ if img_meta.get('scale_factor') is not None:
+ det_bboxes /= det_bboxes.new_tensor(
+ img_meta['scale_factor']).repeat((1, 2))
+ results = InstanceData()
+ results.bboxes = det_bboxes
+ results.scores = scores
+ results.labels = det_labels
+ return results
+
+
+
+ def loss_group(self, hidden_states: Tensor, references: List[Tensor],
+ enc_outputs_class: Tensor, enc_outputs_coord: Tensor,
+ batch_data_samples: SampleList, dn_meta: Dict[str, int],
+ # match_group_size: Tuple[int, int] = (2, 2),
+ each_match_num_queries: int = 200, ) -> dict:
+ """Perform forward propagation and loss calculation of the detection
+ head on the queries of the upstream network.
+
+ Args:
+ hidden_states (Tensor): Hidden states output from each decoder
+ layer, has shape (num_decoder_layers, bs, num_queries_total,
+ dim), where `num_queries_total` is the sum of
+ `num_denoising_queries` and `num_matching_queries` when
+ `self.training` is `True`, else `num_matching_queries`.
+ references (list[Tensor]): List of the reference from the decoder.
+ The first reference is the `init_reference` (initial) and the
+ other num_decoder_layers(6) references are `inter_references`
+ (intermediate). The `init_reference` has shape (bs,
+ num_queries_total, 4) and each `inter_reference` has shape
+ (bs, num_queries, 4) with the last dimension arranged as
+ (cx, cy, w, h).
+ enc_outputs_class (Tensor): The score of each point on encode
+ feature map, has shape (bs, num_feat_points, cls_out_channels).
+ enc_outputs_coord (Tensor): The proposal generate from the
+ encode feature map, has shape (bs, num_feat_points, 4) with the
+ last dimension arranged as (cx, cy, w, h).
+ batch_data_samples (list[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ dict: A dictionary of loss components.
+ """
+ batch_gt_instances = []
+ batch_img_metas = []
+ for data_sample in batch_data_samples:
+ batch_img_metas.append(data_sample.metainfo)
+ batch_gt_instances.append(data_sample.gt_instances)
+
+ outs = self(hidden_states, references)
+ loss_inputs = outs + (enc_outputs_class, enc_outputs_coord,
+ batch_gt_instances, batch_img_metas, dn_meta,each_match_num_queries)
+ losses = self.loss_by_feat_group(*loss_inputs)
+ return losses
+
+ def loss_by_feat_group(
+ self,
+ all_layers_cls_scores: Tensor,
+ all_layers_bbox_preds: Tensor,
+ enc_cls_scores: Tensor,
+ enc_bbox_preds: Tensor,
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ dn_meta: Dict[str, int],
+ # match_group_size: Tuple[int, int] = (2, 2),
+ each_match_num_queries: int = 200,
+ batch_gt_instances_ignore: OptInstanceList = None,
+ ) -> Dict[str, Tensor]:
+ """Loss function.
+
+ Args:
+ all_layers_cls_scores (Tensor): Classification scores of all
+ decoder layers, has shape (num_decoder_layers, bs,
+ num_queries_total, cls_out_channels), where
+ `num_queries_total` is the sum of `num_denoising_queries`
+ and `num_matching_queries`.
+ all_layers_bbox_preds (Tensor): Regression outputs of all decoder
+ layers. Each is a 4D-tensor with normalized coordinate format
+ (cx, cy, w, h) and has shape (num_decoder_layers, bs,
+ num_queries_total, 4).
+ enc_cls_scores (Tensor): The score of each point on encode
+ feature map, has shape (bs, num_feat_points, cls_out_channels).
+ enc_bbox_preds (Tensor): The proposal generate from the encode
+ feature map, has shape (bs, num_feat_points, 4) with the last
+ dimension arranged as (cx, cy, w, h).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components.
+ """
+ # extract denoising and matching part of outputs
+ (all_layers_matching_cls_scores, all_layers_matching_bbox_preds,
+ all_layers_denoising_cls_scores, all_layers_denoising_bbox_preds) = \
+ self.split_outputs(
+ all_layers_cls_scores, all_layers_bbox_preds, dn_meta)
+ match_group_num = all_layers_matching_cls_scores.shape[2]//each_match_num_queries
+ loss_dict = dict()
+ for id_group in range(match_group_num):
+ all_layers_matching_cls_scores_one_group = all_layers_matching_cls_scores[:, :, id_group * each_match_num_queries:(id_group + 1) * each_match_num_queries, :]
+ all_layers_matching_bbox_preds_one_group = all_layers_matching_bbox_preds[:, :, id_group * each_match_num_queries:(id_group + 1) * each_match_num_queries, :]
+ # 同时计算每一解码层的loss
+ losses_cls, losses_bbox, losses_iou = multi_apply(
+ self.loss_by_feat_single,
+ all_layers_matching_cls_scores_one_group,
+ all_layers_matching_bbox_preds_one_group,
+ batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas)
+ # loss from the last decoder layer
+ loss_dict[f'g{id_group}.loss_cls'] = losses_cls[-1]
+ loss_dict[f'g{id_group}.loss_bbox'] = losses_bbox[-1]
+ loss_dict[f'g{id_group}.loss_iou'] = losses_iou[-1]
+ # loss from other decoder layers
+ num_dec_layer = 0
+ for loss_cls_i, loss_bbox_i, loss_iou_i in \
+ zip(losses_cls[:-1], losses_bbox[:-1], losses_iou[:-1]):
+ loss_dict[f'g{id_group}d{num_dec_layer}.loss_cls'] = loss_cls_i
+ loss_dict[f'g{id_group}d{num_dec_layer}.loss_bbox'] = loss_bbox_i
+ loss_dict[f'g{id_group}d{num_dec_layer}.loss_iou'] = loss_iou_i
+ num_dec_layer += 1
+
+
+ # loss_dict_one_groug = super().loss_by_feat(all_layers_matching_cls_scores_one_group, all_layers_matching_bbox_preds_one_group,
+ # batch_gt_instances, batch_img_metas, batch_gt_instances_ignore)
+ enc_cls_scores_one_group = enc_cls_scores[:, id_group * each_match_num_queries:(id_group + 1) * each_match_num_queries, :]
+ enc_bbox_preds_one_group = enc_bbox_preds[:, id_group * each_match_num_queries:(id_group + 1) * each_match_num_queries, :]
+ if enc_cls_scores is not None:
+ # NOTE The enc_loss calculation of the DINO is
+ # different from that of Deformable DETR.
+ enc_loss_cls, enc_losses_bbox, enc_losses_iou = \
+ self.loss_by_feat_single(enc_cls_scores_one_group,
+ enc_bbox_preds_one_group,
+ batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas)
+ loss_dict[f'g{id_group}.enc_loss_cls'] = enc_loss_cls
+ loss_dict[f'g{id_group}.enc_loss_bbox'] = enc_losses_bbox
+ loss_dict[f'g{id_group}.enc_loss_iou'] = enc_losses_iou
+
+
+ # loss_dict = super().loss_by_feat(
+ # all_layers_matching_cls_scores, all_layers_matching_bbox_preds,
+ # batch_gt_instances, batch_img_metas, batch_gt_instances_ignore)
+ # # NOTE DETRHead.loss_by_feat but not DeformableDETRHead.loss_by_feat
+ # # is called, because the encoder loss calculations are different
+ # # between DINO and DeformableDETR.
+ # # loss of proposal generated from encode feature map.
+ # if enc_cls_scores is not None:
+ # # NOTE The enc_loss calculation of the DINO is
+ # # different from that of Deformable DETR.
+ # enc_loss_cls, enc_losses_bbox, enc_losses_iou = \
+ # self.loss_by_feat_single(
+ # enc_cls_scores, enc_bbox_preds,
+ # batch_gt_instances=batch_gt_instances,
+ # batch_img_metas=batch_img_metas)
+ # loss_dict['enc_loss_cls'] = enc_loss_cls
+ # loss_dict['enc_loss_bbox'] = enc_losses_bbox
+ # loss_dict['enc_loss_iou'] = enc_losses_iou
+
+ if all_layers_denoising_cls_scores is not None:
+ # calculate denoising loss from all decoder layers
+ dn_losses_cls, dn_losses_bbox, dn_losses_iou = self.loss_dn(
+ all_layers_denoising_cls_scores,
+ all_layers_denoising_bbox_preds,
+ batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas,
+ dn_meta=dn_meta)
+ # collate denoising loss
+ loss_dict['dn_loss_cls'] = dn_losses_cls[-1]
+ loss_dict['dn_loss_bbox'] = dn_losses_bbox[-1]
+ loss_dict['dn_loss_iou'] = dn_losses_iou[-1]
+ for num_dec_layer, (loss_cls_i, loss_bbox_i, loss_iou_i) in \
+ enumerate(zip(dn_losses_cls[:-1], dn_losses_bbox[:-1],
+ dn_losses_iou[:-1])):
+ loss_dict[f'd{num_dec_layer}.dn_loss_cls'] = loss_cls_i
+ loss_dict[f'd{num_dec_layer}.dn_loss_bbox'] = loss_bbox_i
+ loss_dict[f'd{num_dec_layer}.dn_loss_iou'] = loss_iou_i
+ return loss_dict
+
+ def loss_ddn(self, hidden_states: Tensor, references: List[Tensor],
+ enc_outputs_class: Tensor, enc_outputs_coord: Tensor,
+ batch_data_samples: SampleList, dn_meta: Dict[str, int]) -> dict:
+ """Perform forward propagation and loss calculation of the detection
+ head on the queries of the upstream network.
+
+ Args:
+ hidden_states (Tensor): Hidden states output from each decoder
+ layer, has shape (num_decoder_layers, bs, num_queries_total,
+ dim), where `num_queries_total` is the sum of
+ `num_denoising_queries` and `num_matching_queries` when
+ `self.training` is `True`, else `num_matching_queries`.
+ references (list[Tensor]): List of the reference from the decoder.
+ The first reference is the `init_reference` (initial) and the
+ other num_decoder_layers(6) references are `inter_references`
+ (intermediate). The `init_reference` has shape (bs,
+ num_queries_total, 4) and each `inter_reference` has shape
+ (bs, num_queries, 4) with the last dimension arranged as
+ (cx, cy, w, h).
+ enc_outputs_class (Tensor): The score of each point on encode
+ feature map, has shape (bs, num_feat_points, cls_out_channels).
+ enc_outputs_coord (Tensor): The proposal generate from the
+ encode feature map, has shape (bs, num_feat_points, 4) with the
+ last dimension arranged as (cx, cy, w, h).
+ batch_data_samples (list[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ dict: A dictionary of loss components.
+ """
+ batch_gt_instances = []
+ batch_img_metas = []
+ for data_sample in batch_data_samples:
+ batch_img_metas.append(data_sample.metainfo)
+ batch_gt_instances.append(data_sample.gt_instances)
+
+ outs = self(hidden_states, references)
+ loss_inputs = outs + (enc_outputs_class, enc_outputs_coord,
+ batch_gt_instances, batch_img_metas, dn_meta)
+ losses,pos_bbox_offsets = self.loss_ddn_by_feat(*loss_inputs)
+ return losses,pos_bbox_offsets
+
+ def loss_ddn_by_feat(
+ self,
+ all_layers_cls_scores: Tensor,
+ all_layers_bbox_preds: Tensor,
+ enc_cls_scores: Tensor,
+ enc_bbox_preds: Tensor,
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ dn_meta: Dict[str, int],
+ # match_group_size: Tuple[int, int] = (2, 2),
+ batch_gt_instances_ignore: OptInstanceList = None,
+ ) -> Tuple[Dict[str, Tensor], List]:
+ """Loss function.
+
+ Args:
+ all_layers_cls_scores (Tensor): Classification scores of all
+ decoder layers, has shape (num_decoder_layers, bs,
+ num_queries_total, cls_out_channels), where
+ `num_queries_total` is the sum of `num_denoising_queries`
+ and `num_matching_queries`.
+ all_layers_bbox_preds (Tensor): Regression outputs of all decoder
+ layers. Each is a 4D-tensor with normalized coordinate format
+ (cx, cy, w, h) and has shape (num_decoder_layers, bs,
+ num_queries_total, 4).
+ enc_cls_scores (Tensor): The score of each point on encode
+ feature map, has shape (bs, num_feat_points, cls_out_channels).
+ enc_bbox_preds (Tensor): The proposal generate from the encode
+ feature map, has shape (bs, num_feat_points, 4) with the last
+ dimension arranged as (cx, cy, w, h).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components.
+ """
+ # extract denoising and matching part of outputs
+ (all_layers_matching_cls_scores, all_layers_matching_bbox_preds,
+ all_layers_denoising_cls_scores, all_layers_denoising_bbox_preds) = \
+ self.split_outputs(
+ all_layers_cls_scores, all_layers_bbox_preds, dn_meta)
+ loss_dict = dict()
+
+ assert batch_gt_instances_ignore is None, \
+ f'{self.__class__.__name__} only supports ' \
+ 'for batch_gt_instances_ignore setting to None.'
+ #同时计算每一解码层的loss
+ losses_cls, losses_bbox, losses_iou, pos_bbox_offsets = multi_apply(
+ self.loss_ddn_by_feat_single,
+ all_layers_matching_cls_scores,
+ all_layers_matching_bbox_preds,
+ batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas)
+ # loss from the last decoder layer
+ loss_dict['loss_cls'] = losses_cls[-1]
+ loss_dict['loss_bbox'] = losses_bbox[-1]
+ loss_dict['loss_iou'] = losses_iou[-1]
+ # loss from other decoder layers
+ num_dec_layer = 0
+ for loss_cls_i, loss_bbox_i, loss_iou_i in \
+ zip(losses_cls[:-1], losses_bbox[:-1], losses_iou[:-1]):
+ loss_dict[f'd{num_dec_layer}.loss_cls'] = loss_cls_i
+ loss_dict[f'd{num_dec_layer}.loss_bbox'] = loss_bbox_i
+ loss_dict[f'd{num_dec_layer}.loss_iou'] = loss_iou_i
+ num_dec_layer += 1
+
+ # NOTE DETRHead.loss_by_feat but not DeformableDETRHead.loss_by_feat
+ # is called, because the encoder loss calculations are different
+ # between DINO and DeformableDETR.
+ # loss of proposal generated from encode feature map.
+ if enc_cls_scores is not None:
+ # NOTE The enc_loss calculation of the DINO is
+ # different from that of Deformable DETR.
+ enc_loss_cls, enc_losses_bbox, enc_losses_iou, pos_bbox_offsets = \
+ self.loss_ddn_by_feat_single(
+ enc_cls_scores, enc_bbox_preds,
+ batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas)
+ loss_dict['enc_loss_cls'] = enc_loss_cls
+ loss_dict['enc_loss_bbox'] = enc_losses_bbox
+ loss_dict['enc_loss_iou'] = enc_losses_iou
+
+ if all_layers_denoising_cls_scores is not None:
+ # calculate denoising loss from all decoder layers
+ dn_losses_cls, dn_losses_bbox, dn_losses_iou = self.loss_dn(
+ all_layers_denoising_cls_scores,
+ all_layers_denoising_bbox_preds,
+ batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas,
+ dn_meta=dn_meta)
+ # collate denoising loss
+ loss_dict['dn_loss_cls'] = dn_losses_cls[-1]
+ loss_dict['dn_loss_bbox'] = dn_losses_bbox[-1]
+ loss_dict['dn_loss_iou'] = dn_losses_iou[-1]
+ for num_dec_layer, (loss_cls_i, loss_bbox_i, loss_iou_i) in \
+ enumerate(zip(dn_losses_cls[:-1], dn_losses_bbox[:-1],
+ dn_losses_iou[:-1])):
+ loss_dict[f'd{num_dec_layer}.dn_loss_cls'] = loss_cls_i
+ loss_dict[f'd{num_dec_layer}.dn_loss_bbox'] = loss_bbox_i
+ loss_dict[f'd{num_dec_layer}.dn_loss_iou'] = loss_iou_i
+ return loss_dict, pos_bbox_offsets
+
+
+ def loss_ddn_by_feat_single(self, cls_scores: Tensor, bbox_preds: Tensor,
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict]) -> Tuple[Tensor, List]:
+ """Loss function for outputs from a single decoder layer of a single
+ feature level.
+
+ Args:
+ cls_scores (Tensor): Box score logits from a single decoder layer
+ for all images, has shape (bs, num_queries, cls_out_channels).
+ bbox_preds (Tensor): Sigmoid outputs from a single decoder layer
+ for all images, with normalized coordinate (cx, cy, w, h) and
+ shape (bs, num_queries, 4).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+
+ Returns:
+ Tuple[Tensor]: A tuple including `loss_cls`, `loss_box` and
+ `loss_iou`.
+ """
+ num_imgs = cls_scores.size(0)
+ cls_scores_list = [cls_scores[i] for i in range(num_imgs)]
+ bbox_preds_list = [bbox_preds[i] for i in range(num_imgs)]
+ cls_reg_targets = self.get_targets_ddn(cls_scores_list, bbox_preds_list,
+ batch_gt_instances, batch_img_metas)
+ (labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,
+ num_total_pos, num_total_neg) = cls_reg_targets
+ labels = torch.cat(labels_list, 0)
+ label_weights = torch.cat(label_weights_list, 0)
+ bbox_targets = torch.cat(bbox_targets_list, 0)
+ bbox_weights = torch.cat(bbox_weights_list, 0)
+
+ # classification loss
+ cls_scores = cls_scores.reshape(-1, self.cls_out_channels)
+ # construct weighted avg_factor to match with the official DETR repo
+ cls_avg_factor = num_total_pos * 1.0 + \
+ num_total_neg * self.bg_cls_weight
+ if self.sync_cls_avg_factor:
+ cls_avg_factor = reduce_mean(
+ cls_scores.new_tensor([cls_avg_factor]))
+ cls_avg_factor = max(cls_avg_factor, 1)
+
+ loss_cls = self.loss_cls(
+ cls_scores, labels, label_weights, avg_factor=cls_avg_factor)
+
+ # Compute the average number of gt boxes across all gpus, for
+ # normalization purposes
+ num_total_pos = loss_cls.new_tensor([num_total_pos])
+ num_total_pos = torch.clamp(reduce_mean(num_total_pos), min=1).item()
+
+ # construct factors used for rescale bboxes
+ factors = []
+ for img_meta, bbox_pred in zip(batch_img_metas, bbox_preds):
+ img_h, img_w, = img_meta['img_shape']
+ factor = bbox_pred.new_tensor([img_w, img_h, img_w,
+ img_h]).unsqueeze(0).repeat(
+ bbox_pred.size(0), 1)
+ factors.append(factor)
+ factors = torch.cat(factors, 0)
+
+ # DETR regress the relative position of boxes (cxcywh) in the image,
+ # thus the learning target is normalized by the image size. So here
+ # we need to re-scale them for calculating IoU loss
+ bbox_preds = bbox_preds.reshape(-1, 4)
+ bboxes = bbox_cxcywh_to_xyxy(bbox_preds) * factors
+ bboxes_gt = bbox_cxcywh_to_xyxy(bbox_targets) * factors
+
+
+ # lzx
+ # 检查bbox_targets中4个值是否全部为0
+ is_target = torch.any(bbox_targets != 0, dim=1)
+ # 获取目标的索引
+ target_indices = torch.nonzero(is_target).squeeze()
+ bbox_targets_only_pos = bbox_targets[target_indices]
+ bbox_preds_only_pos = bbox_preds[target_indices]
+ # factors_only_pos = factors[target_indices]
+ pos_bbox_offset = torch.mean(torch.abs(bbox_targets_only_pos-bbox_preds_only_pos),dim=0).detach().cpu().numpy()
+ pos_bbox_offsets = [(pos_bbox_offset[0]+pos_bbox_offset[1])/2,(pos_bbox_offset[2]+pos_bbox_offset[3])/2]
+ # regression IoU loss, defaultly GIoU loss
+ loss_iou = self.loss_iou(
+ bboxes, bboxes_gt, bbox_weights, avg_factor=num_total_pos)
+
+ # regression L1 loss
+ loss_bbox = self.loss_bbox(
+ bbox_preds, bbox_targets, bbox_weights, avg_factor=num_total_pos)
+ return loss_cls, loss_bbox, loss_iou, pos_bbox_offsets
+
+ def get_targets_ddn(self, cls_scores_list: List[Tensor],
+ bbox_preds_list: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict]) -> tuple:
+ """Compute regression and classification targets for a batch image.
+
+ Outputs from a single decoder layer of a single feature level are used.
+
+ Args:
+ cls_scores_list (list[Tensor]): Box score logits from a single
+ decoder layer for each image, has shape [num_queries,
+ cls_out_channels].
+ bbox_preds_list (list[Tensor]): Sigmoid outputs from a single
+ decoder layer for each image, with normalized coordinate
+ (cx, cy, w, h) and shape [num_queries, 4].
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+
+ Returns:
+ tuple: a tuple containing the following targets.
+
+ - labels_list (list[Tensor]): Labels for all images.
+ - label_weights_list (list[Tensor]): Label weights for all images.
+ - bbox_targets_list (list[Tensor]): BBox targets for all images.
+ - bbox_weights_list (list[Tensor]): BBox weights for all images.
+ - num_total_pos (int): Number of positive samples in all images.
+ - num_total_neg (int): Number of negative samples in all images.
+ """
+ (labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,
+ pos_inds_list,
+ neg_inds_list) = multi_apply(self._get_targets_single_ddn,
+ cls_scores_list, bbox_preds_list,
+ batch_gt_instances, batch_img_metas)
+ num_total_pos = sum((inds.numel() for inds in pos_inds_list))
+ num_total_neg = sum((inds.numel() for inds in neg_inds_list))
+ return (labels_list, label_weights_list, bbox_targets_list,
+ bbox_weights_list, num_total_pos, num_total_neg)
+
+ def _get_targets_single_ddn(self, cls_score: Tensor, bbox_pred: Tensor,
+ gt_instances: InstanceData,
+ img_meta: dict) -> tuple:
+ """Compute regression and classification targets for one image.
+
+ Outputs from a single decoder layer of a single feature level are used.
+
+ Args:
+ cls_score (Tensor): Box score logits from a single decoder layer
+ for one image. Shape [num_queries, cls_out_channels].
+ bbox_pred (Tensor): Sigmoid outputs from a single decoder layer
+ for one image, with normalized coordinate (cx, cy, w, h) and
+ shape [num_queries, 4].
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It should includes ``bboxes`` and ``labels``
+ attributes.
+ img_meta (dict): Meta information for one image.
+
+ Returns:
+ tuple[Tensor]: a tuple containing the following for one image.
+
+ - labels (Tensor): Labels of each image.
+ - label_weights (Tensor]): Label weights of each image.
+ - bbox_targets (Tensor): BBox targets of each image.
+ - bbox_weights (Tensor): BBox weights of each image.
+ - pos_inds (Tensor): Sampled positive indices for each image.
+ - neg_inds (Tensor): Sampled negative indices for each image.
+ """
+ img_h, img_w = img_meta['img_shape']
+ factor = bbox_pred.new_tensor([img_w, img_h, img_w,
+ img_h]).unsqueeze(0)
+ num_bboxes = bbox_pred.size(0)
+ # convert bbox_pred from xywh, normalized to xyxy, unnormalized
+ bbox_pred = bbox_cxcywh_to_xyxy(bbox_pred)
+ bbox_pred = bbox_pred * factor
+
+ pred_instances = InstanceData(scores=cls_score, bboxes=bbox_pred)
+ # assigner and sampler
+ assign_result = self.assigner.assign(
+ pred_instances=pred_instances,
+ gt_instances=gt_instances,
+ img_meta=img_meta)
+
+ # from mmdet.models.task_modules.assigners import MaxIoUAssigner
+ # assigner1 = MaxIoUAssigner(pos_iou_thr=0.5, neg_iou_thr=0.5, min_pos_iou=0.3,match_low_quality=True,ignore_iof_thr=-1)
+ # pred_instances1 = InstanceData()
+ # pred_instances1.priors =pred_instances.bboxes
+ # assign_result = assigner1.assign(pred_instances=pred_instances1, gt_instances=gt_instances, img_meta=img_meta)
+
+
+ gt_bboxes = gt_instances.bboxes
+ gt_labels = gt_instances.labels
+ pos_inds = torch.nonzero(
+ assign_result.gt_inds > 0, as_tuple=False).squeeze(-1).unique()
+ neg_inds = torch.nonzero(
+ assign_result.gt_inds == 0, as_tuple=False).squeeze(-1).unique()
+ pos_assigned_gt_inds = assign_result.gt_inds[pos_inds] - 1
+ pos_gt_bboxes = gt_bboxes[pos_assigned_gt_inds.long(), :]
+
+ # label targets
+ labels = gt_bboxes.new_full((num_bboxes, ),
+ self.num_classes,
+ dtype=torch.long)
+ labels[pos_inds] = gt_labels[pos_assigned_gt_inds]
+ label_weights = gt_bboxes.new_ones(num_bboxes)
+
+ # bbox targets
+ bbox_targets = torch.zeros_like(bbox_pred)
+ bbox_weights = torch.zeros_like(bbox_pred)
+ bbox_weights[pos_inds] = 1.0
+
+ # DETR regress the relative position of boxes (cxcywh) in the image.
+ # Thus the learning target should be normalized by the image size, also
+ # the box format should be converted from defaultly x1y1x2y2 to cxcywh.
+ pos_gt_bboxes_normalized = pos_gt_bboxes / factor
+ pos_gt_bboxes_targets = bbox_xyxy_to_cxcywh(pos_gt_bboxes_normalized)
+ bbox_targets[pos_inds] = pos_gt_bboxes_targets
+ return (labels, label_weights, bbox_targets, bbox_weights, pos_inds,
+ neg_inds)
\ No newline at end of file
diff --git a/mmdet/models/dense_heads/dino_st_head.py b/mmdet/models/dense_heads/dino_st_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..80d44bfb7a22684054f62ab066e4e5a927932ae4
--- /dev/null
+++ b/mmdet/models/dense_heads/dino_st_head.py
@@ -0,0 +1,217 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Tuple
+
+import torch
+from mmengine.structures import InstanceData
+from torch import Tensor
+import torch.nn.functional as F
+from mmdet.registry import MODELS
+from mmdet.structures import SampleList
+from mmdet.structures.bbox import bbox_cxcywh_to_xyxy, bbox_xyxy_to_cxcywh
+from mmdet.utils import InstanceList, OptInstanceList, reduce_mean
+from ..utils import multi_apply
+from .deformable_detr_head import DeformableDETRHead
+from .dino_head import DINOHead
+
+# def bbox_cxcywh_to_xyxy_1pixel(bbox: Tensor, factors: Tensor) -> Tensor:
+# """Convert bbox coordinates from (cx, cy, w, h) to (x1, y1, x2, y2).
+#
+# Args:
+# bbox (Tensor): Shape (n, 4) for bboxes.
+#
+# Returns:
+# Tensor: Converted bboxes.
+#
+# """
+# bbox1 = bbox*factors
+# cx, cy, w, h = bbox.split((1, 1, 1, 1), dim=-1)
+#
+# bbox_new = [(cx - 0.5 * w), (cy - 0.5 * h), (cx + 0.5 * w), (cy + 0.5 * h)]
+# return torch.cat(bbox_new, dim=-1)
+
+def adjust_bbox_to_pixel(bboxes: Tensor):
+ # 向下取整得到目标的左上角坐标
+ adjusted_bboxes = torch.floor(bboxes)
+ # 向上取整得到目标的右下角坐标
+ adjusted_bboxes[:, 2:] = torch.ceil(bboxes[:, 2:])
+ return adjusted_bboxes
+
+def adjust_bbox_to_pixelV2(bboxes: Tensor):
+ # 向下取整得到目标的左上角坐标
+ adjusted_bboxes = torch.floor(bboxes)
+ # 向上取整得到目标的右下角坐标
+ adjusted_bboxes[:, 2:] = torch.ceil(bboxes[:, 2:])
+ return adjusted_bboxes
+
+@MODELS.register_module()
+class DINOSTHead(DINOHead):
+ def __init__(self,
+ *args,
+ round_coord: bool = False,
+ **kwargs) -> None:
+ self.round_coord = round_coord
+ super().__init__(*args, **kwargs)
+
+ def loss_by_feat_single(self, cls_scores: Tensor, bbox_preds: Tensor,
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict]) -> Tuple[Tensor]:
+ """Loss function for outputs from a single decoder layer of a single
+ feature level.
+
+ Args:
+ cls_scores (Tensor): Box score logits from a single decoder layer
+ for all images, has shape (bs, num_queries, cls_out_channels).
+ bbox_preds (Tensor): Sigmoid outputs from a single decoder layer
+ for all images, with normalized coordinate (cx, cy, w, h) and
+ shape (bs, num_queries, 4).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+
+ Returns:
+ Tuple[Tensor]: A tuple including `loss_cls`, `loss_box` and
+ `loss_iou`.
+ """
+ num_imgs = cls_scores.size(0)
+ cls_scores_list = [cls_scores[i] for i in range(num_imgs)]
+ bbox_preds_list = [bbox_preds[i] for i in range(num_imgs)]
+ cls_reg_targets = self.get_targets(cls_scores_list, bbox_preds_list,
+ batch_gt_instances, batch_img_metas)
+ (labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,
+ num_total_pos, num_total_neg) = cls_reg_targets
+ labels = torch.cat(labels_list, 0)
+ label_weights = torch.cat(label_weights_list, 0)
+ bbox_targets = torch.cat(bbox_targets_list, 0)
+ bbox_weights = torch.cat(bbox_weights_list, 0)
+
+ # classification loss
+ cls_scores = cls_scores.reshape(-1, self.cls_out_channels)
+ # construct weighted avg_factor to match with the official DETR repo
+ cls_avg_factor = num_total_pos * 1.0 + \
+ num_total_neg * self.bg_cls_weight
+ if self.sync_cls_avg_factor:
+ cls_avg_factor = reduce_mean(
+ cls_scores.new_tensor([cls_avg_factor]))
+ cls_avg_factor = max(cls_avg_factor, 1)
+
+ loss_cls = self.loss_cls(
+ cls_scores, labels, label_weights, avg_factor=cls_avg_factor)
+
+ # Compute the average number of gt boxes across all gpus, for
+ # normalization purposes
+ num_total_pos = loss_cls.new_tensor([num_total_pos])
+ num_total_pos = torch.clamp(reduce_mean(num_total_pos), min=1).item()
+
+ # construct factors used for rescale bboxes
+ factors = []
+ for img_meta, bbox_pred in zip(batch_img_metas, bbox_preds):
+ img_h, img_w, = img_meta['img_shape']
+ factor = bbox_pred.new_tensor([img_w, img_h, img_w,
+ img_h]).unsqueeze(0).repeat(
+ bbox_pred.size(0), 1)
+ factors.append(factor)
+ factors = torch.cat(factors, 0)
+
+ # DETR regress the relative position of boxes (cxcywh) in the image,
+ # thus the learning target is normalized by the image size. So here
+ # we need to re-scale them for calculating IoU loss
+ bbox_preds = bbox_preds.reshape(-1, 4)
+ bboxes = bbox_cxcywh_to_xyxy(bbox_preds) * factors
+ bboxes=adjust_bbox_to_pixel(bboxes)
+ bboxes_gt = bbox_cxcywh_to_xyxy(bbox_targets) * factors
+ #
+ # regression IoU loss, defaultly GIoU loss
+ loss_iou = self.loss_iou(
+ bboxes, bboxes_gt, bbox_weights, avg_factor=num_total_pos)
+
+ # regression L1 loss
+ loss_bbox = self.loss_bbox(
+ bbox_preds, bbox_targets, bbox_weights, avg_factor=num_total_pos)
+ return loss_cls, loss_bbox, loss_iou
+
+
+ def _predict_by_feat_single(self,
+ cls_score: Tensor,
+ bbox_pred: Tensor,
+ img_meta: dict,
+ rescale: bool = True) -> InstanceData:
+ """Transform outputs from the last decoder layer into bbox predictions
+ for each image.
+
+ Args:
+ cls_score (Tensor): Box score logits from the last decoder layer
+ for each image. Shape [num_queries, cls_out_channels].
+ bbox_pred (Tensor): Sigmoid outputs from the last decoder layer
+ for each image, with coordinate format (cx, cy, w, h) and
+ shape [num_queries, 4].
+ img_meta (dict): Image meta info.
+ rescale (bool): If True, return boxes in original image
+ space. Default True.
+
+ Returns:
+ :obj:`InstanceData`: Detection results of each image
+ after the post process.
+ Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ """
+ assert len(cls_score) == len(bbox_pred) # num_queries
+ max_per_img = self.test_cfg.get('max_per_img', len(cls_score))
+ img_shape = img_meta['img_shape']
+ # exclude background
+ if self.loss_cls.use_sigmoid:
+ cls_score = cls_score.sigmoid()
+ scores, indexes = cls_score.view(-1).topk(max_per_img)
+ det_labels = indexes % self.num_classes
+ bbox_index = indexes // self.num_classes
+ bbox_pred = bbox_pred[bbox_index]
+ else:
+ scores, det_labels = F.softmax(cls_score, dim=-1)[..., :-1].max(-1)
+ scores, bbox_index = scores.topk(max_per_img)
+ bbox_pred = bbox_pred[bbox_index]
+ det_labels = det_labels[bbox_index]
+
+ det_bboxes = bbox_cxcywh_to_xyxy(bbox_pred)
+ det_bboxes[:, 0::2] = det_bboxes[:, 0::2] * img_shape[1]
+ det_bboxes[:, 1::2] = det_bboxes[:, 1::2] * img_shape[0]
+ det_bboxes[:, 0::2].clamp_(min=0, max=img_shape[1])
+ det_bboxes[:, 1::2].clamp_(min=0, max=img_shape[0])
+
+ if rescale:
+ # assert img_meta.get('scale_factor') is not None
+ # det_bboxes /= det_bboxes.new_tensor(
+ # img_meta['scale_factor']).repeat((1, 2))
+ # rw by lzx
+ if img_meta.get('scale_factor') is not None:
+ det_bboxes /= det_bboxes.new_tensor(
+ img_meta['scale_factor']).repeat((1, 2))
+
+ results = InstanceData()
+ results.bboxes = det_bboxes
+ results.scores = scores
+ results.labels = det_labels
+ return results
+
+
+ """
+import matplotlib.pyplot as plt
+
+# 绘制直方图
+bboxes_gt
+bboxes_gt_np = bboxes_gt.detach().cpu().numpy()
+result = bbox_preds.detach().cpu().numpy()
+result = (bboxes[:, 2] - bboxes[:, 0]) * (bboxes[:, 3] - bboxes[:, 1])
+result = result.detach().cpu().numpy()
+plt.hist(result, bins=50, edgecolor='black')
+plt.xlabel('Result')
+plt.ylabel('Frequency')
+plt.title('Histogram of Result')
+plt.show()
+ """
\ No newline at end of file
diff --git a/mmdet/models/dense_heads/embedding_rpn_head.py b/mmdet/models/dense_heads/embedding_rpn_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..97e84fa83b892c0274615d582fe43a6693541617
--- /dev/null
+++ b/mmdet/models/dense_heads/embedding_rpn_head.py
@@ -0,0 +1,132 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List
+
+import torch
+import torch.nn as nn
+from mmengine.model import BaseModule
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.structures.bbox import bbox_cxcywh_to_xyxy
+from mmdet.structures.det_data_sample import SampleList
+from mmdet.utils import InstanceList, OptConfigType
+
+
+@MODELS.register_module()
+class EmbeddingRPNHead(BaseModule):
+ """RPNHead in the `Sparse R-CNN `_ .
+
+ Unlike traditional RPNHead, this module does not need FPN input, but just
+ decode `init_proposal_bboxes` and expand the first dimension of
+ `init_proposal_bboxes` and `init_proposal_features` to the batch_size.
+
+ Args:
+ num_proposals (int): Number of init_proposals. Defaults to 100.
+ proposal_feature_channel (int): Channel number of
+ init_proposal_feature. Defaults to 256.
+ init_cfg (:obj:`ConfigDict` or dict or list[:obj:`ConfigDict` or \
+ dict]): Initialization config dict. Defaults to None.
+ """
+
+ def __init__(self,
+ num_proposals: int = 100,
+ proposal_feature_channel: int = 256,
+ init_cfg: OptConfigType = None,
+ **kwargs) -> None:
+ # `**kwargs` is necessary to avoid some potential error.
+ assert init_cfg is None, 'To prevent abnormal initialization ' \
+ 'behavior, init_cfg is not allowed to be set'
+ super().__init__(init_cfg=init_cfg)
+ self.num_proposals = num_proposals
+ self.proposal_feature_channel = proposal_feature_channel
+ self._init_layers()
+
+ def _init_layers(self) -> None:
+ """Initialize a sparse set of proposal boxes and proposal features."""
+ self.init_proposal_bboxes = nn.Embedding(self.num_proposals, 4)
+ self.init_proposal_features = nn.Embedding(
+ self.num_proposals, self.proposal_feature_channel)
+
+ def init_weights(self) -> None:
+ """Initialize the init_proposal_bboxes as normalized.
+
+ [c_x, c_y, w, h], and we initialize it to the size of the entire
+ image.
+ """
+ super().init_weights()
+ nn.init.constant_(self.init_proposal_bboxes.weight[:, :2], 0.5)
+ nn.init.constant_(self.init_proposal_bboxes.weight[:, 2:], 1)
+
+ def _decode_init_proposals(self, x: List[Tensor],
+ batch_data_samples: SampleList) -> InstanceList:
+ """Decode init_proposal_bboxes according to the size of images and
+ expand dimension of init_proposal_features to batch_size.
+
+ Args:
+ x (list[Tensor]): List of FPN features.
+ batch_data_samples (List[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+
+ Returns:
+ List[:obj:`InstanceData`:] Detection results of each image.
+ Each item usually contains following keys.
+
+ - proposals: Decoded proposal bboxes,
+ has shape (num_proposals, 4).
+ - features: init_proposal_features, expanded proposal
+ features, has shape
+ (num_proposals, proposal_feature_channel).
+ - imgs_whwh: Tensor with shape
+ (num_proposals, 4), the dimension means
+ [img_width, img_height, img_width, img_height].
+ """
+ batch_img_metas = []
+ for data_sample in batch_data_samples:
+ batch_img_metas.append(data_sample.metainfo)
+
+ proposals = self.init_proposal_bboxes.weight.clone()
+ proposals = bbox_cxcywh_to_xyxy(proposals)
+ imgs_whwh = []
+ for meta in batch_img_metas:
+ h, w = meta['img_shape'][:2]
+ imgs_whwh.append(x[0].new_tensor([[w, h, w, h]]))
+ imgs_whwh = torch.cat(imgs_whwh, dim=0)
+ imgs_whwh = imgs_whwh[:, None, :]
+ proposals = proposals * imgs_whwh
+
+ rpn_results_list = []
+ for idx in range(len(batch_img_metas)):
+ rpn_results = InstanceData()
+ rpn_results.bboxes = proposals[idx]
+ rpn_results.imgs_whwh = imgs_whwh[idx].repeat(
+ self.num_proposals, 1)
+ rpn_results.features = self.init_proposal_features.weight.clone()
+ rpn_results_list.append(rpn_results)
+ return rpn_results_list
+
+ def loss(self, *args, **kwargs):
+ """Perform forward propagation and loss calculation of the detection
+ head on the features of the upstream network."""
+ raise NotImplementedError(
+ 'EmbeddingRPNHead does not have `loss`, please use '
+ '`predict` or `loss_and_predict` instead.')
+
+ def predict(self, x: List[Tensor], batch_data_samples: SampleList,
+ **kwargs) -> InstanceList:
+ """Perform forward propagation of the detection head and predict
+ detection results on the features of the upstream network."""
+ # `**kwargs` is necessary to avoid some potential error.
+ return self._decode_init_proposals(
+ x=x, batch_data_samples=batch_data_samples)
+
+ def loss_and_predict(self, x: List[Tensor], batch_data_samples: SampleList,
+ **kwargs) -> tuple:
+ """Perform forward propagation of the head, then calculate loss and
+ predictions from the features and data samples."""
+ # `**kwargs` is necessary to avoid some potential error.
+ predictions = self._decode_init_proposals(
+ x=x, batch_data_samples=batch_data_samples)
+
+ return dict(), predictions
diff --git a/mmdet/models/dense_heads/evolvedet_head.py b/mmdet/models/dense_heads/evolvedet_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..098535c101a915778cff90825a910b70a21ba971
--- /dev/null
+++ b/mmdet/models/dense_heads/evolvedet_head.py
@@ -0,0 +1,1569 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+import os.path
+from typing import Dict, List, Tuple, Optional
+from torch import Tensor
+from mmcv.cnn import Linear
+from mmengine.model import bias_init_with_prob, constant_init
+from mmengine.structures import InstanceData
+from mmengine.model import BaseModule
+from mmdet.registry import MODELS
+from mmdet.structures import SampleList
+from mmdet.structures.bbox import bbox_cxcywh_to_xyxy, bbox_xyxy_to_cxcywh, bbox_overlaps
+from mmdet.utils import InstanceList, OptInstanceList, reduce_mean
+from ..utils import multi_apply
+from ..layers import inverse_sigmoid
+from .detr_head import DETRHead
+from mmdet.registry import MODELS, TASK_UTILS
+from mmdet.utils import (ConfigType, InstanceList, OptInstanceList,OptConfigType,
+ OptMultiConfig, reduce_mean)
+from mmcv.ops import nms, batched_nms
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from torch.nn import Transformer
+import scipy.io as sio
+import os
+from ..losses import QualityFocalLoss
+# def adjust_bbox_to_pixel(bboxes: Tensor):
+# # 向下取整得到目标的左上角坐标
+# adjusted_bboxes = torch.floor(bboxes)
+# # 向上取整得到目标的右下角坐标
+# adjusted_bboxes[:, 2:] = torch.ceil(bboxes[:, 2:])
+# return adjusted_bboxes
+
+
+def adjust_bbox_to_pixel(bboxes: Tensor):
+ # 四舍五入取整坐标
+ adjusted_bboxes = torch.round(bboxes)
+ return adjusted_bboxes
+
+@MODELS.register_module()
+class EvloveDetHead(BaseModule):
+ r"""Head of the DINO: DETR with Improved DeNoising Anchor Boxes
+ for End-to-End Object Detection
+
+ Code is modified from the `official github repo
+ `_.
+
+ More details can be found in the `paper
+ `_ .
+ """
+
+ def __init__(self,
+ num_classes: int,
+ embed_dims: int = 256,
+ decoder_embed_dims: int = 256,
+ num_reg_fcs: int = 2,
+ center_feat_indice: int=1,
+ sync_cls_avg_factor: bool = False,
+ use_nms: bool = False,
+ score_threshold: float = 0.0,
+ class_wise_nms: bool = True,
+ test_nms: OptConfigType = dict(type='nms', iou_threshold=0.01, ),
+ loss_cls: ConfigType = dict(
+ type='FocalLoss',
+ use_sigmoid=True,
+ gamma=2.0,
+ alpha=0.25,
+ loss_weight=1.0),
+ loss_center_cls: ConfigType = dict(
+ type='FocalLoss',
+ use_sigmoid=True,
+ gamma=2.0,
+ alpha=0.25,
+ loss_weight=1.0),
+ loss_bbox: ConfigType = dict(type='L1Loss', loss_weight=5.0),
+ loss_iou: OptConfigType = None,
+ loss_seg: ConfigType = dict(
+ type='FocalLoss',
+ use_sigmoid=True,
+ gamma=2.0,
+ alpha=0.25,
+ loss_weight=1.0),
+ # loss_seg: ConfigType = dict(type='L1Loss', loss_weight=1.0),
+ loss_abu: ConfigType = dict(type='L1Loss', loss_weight=1.0),
+ train_cfg: ConfigType = dict(
+ assigner=dict(
+ type='HungarianAssigner',
+ match_costs=[
+ dict(type='ClassificationCost', weight=1.),
+ dict(type='BBoxL1Cost', weight=5.0, box_format='xywh'),
+ dict(type='IoUCost', iou_mode='giou', weight=2.0)
+ ])),
+ test_cfg: ConfigType = dict(max_per_img=100),
+ init_cfg: OptMultiConfig = None,
+ share_pred_layer: bool = False,
+ num_pred_layer: int = 6,
+ as_two_stage: bool = False,
+ pre_bboxes_round: bool = True,
+ neg_hard_num: int = 0,
+ seg_neg_hard_num: int = 0,
+ loss_center_th: float = 0.2,
+ loss_iou_th: float = 0.3,
+ center_ds_ratio: int = 1,
+ use_center: bool = True,
+ predict_segmentation: bool = False,
+ predict_abundance: bool = False,
+ save_path: Optional[str]= None,
+ mask_threshold:float = 0.5,
+ mask_extend_pixel: int = 2,
+ ) -> None:
+ self.share_pred_layer = share_pred_layer
+ self.num_pred_layer = num_pred_layer
+ self.as_two_stage = as_two_stage
+ self.pre_bboxes_round = pre_bboxes_round
+ self.score_threshold = score_threshold
+ self.loss_center_th = loss_center_th
+ self.loss_iou_th = loss_iou_th
+ self.center_feat_indice = center_feat_indice
+ self.center_ds_ratio = center_ds_ratio
+ super().__init__(init_cfg=init_cfg)
+ self.bg_cls_weight = 0
+ self.sync_cls_avg_factor = sync_cls_avg_factor
+ class_weight = loss_cls.get('class_weight', None)
+ if class_weight is not None and (self.__class__ is DETRHead):
+ assert isinstance(class_weight, float), 'Expected ' \
+ 'class_weight to have type float. Found ' \
+ f'{type(class_weight)}.'
+ # NOTE following the official DETR repo, bg_cls_weight means
+ # relative classification weight of the no-object class.
+ bg_cls_weight = loss_cls.get('bg_cls_weight', class_weight)
+ assert isinstance(bg_cls_weight, float), 'Expected ' \
+ 'bg_cls_weight to have type float. Found ' \
+ f'{type(bg_cls_weight)}.'
+ class_weight = torch.ones(num_classes + 1) * class_weight
+ # set background class as the last indice
+ class_weight[num_classes] = bg_cls_weight
+ loss_cls.update({'class_weight': class_weight})
+ if 'bg_cls_weight' in loss_cls:
+ loss_cls.pop('bg_cls_weight')
+ self.bg_cls_weight = bg_cls_weight
+ if train_cfg:
+ assert 'assigner' in train_cfg, 'assigner should be provided ' \
+ 'when train_cfg is set.'
+ assigner = train_cfg['assigner']
+ self.assigner = TASK_UTILS.build(assigner)
+ if train_cfg.get('sampler', None) is not None:
+ raise RuntimeError('DETR do not build sampler.')
+ # self.bbox_assigner = TASK_UTILS.build(bbox_assigner)
+ # self.dn_assigner = TASK_UTILS.build(dn_assigner)
+ self.num_classes = num_classes
+ self.embed_dims = embed_dims
+ self.num_reg_fcs = num_reg_fcs
+ self.train_cfg = train_cfg
+ self.test_cfg = test_cfg
+ self.loss_cls = MODELS.build(loss_cls)
+ self.loss_center_cls = MODELS.build(loss_center_cls)
+ self.loss_bbox = MODELS.build(loss_bbox)
+ if loss_iou is not None:
+ self.loss_iou = MODELS.build(loss_iou)
+ else:
+ self.loss_iou = None
+ self.loss_seg = MODELS.build(loss_seg)
+ self.loss_abu = MODELS.build(loss_abu)
+ self.use_nms = use_nms
+ self.class_wise_nms = class_wise_nms
+ self.score_threshold = score_threshold
+ self.test_nms = test_nms
+ if self.loss_cls.use_sigmoid:
+ self.cls_out_channels = num_classes
+ else:
+ self.cls_out_channels = num_classes + 1
+ self.neg_hard_num = neg_hard_num
+ self.seg_neg_hard_num = neg_hard_num
+ self.use_center = use_center
+ self.decoder_embed_dims = decoder_embed_dims
+ self.predict_segmentation = predict_segmentation
+ self.predict_abundance = predict_abundance
+ self.save_path = save_path
+ if self.save_path is not None:
+ os.makedirs(self.save_path,exist_ok=True)
+ self.mask_threshold = mask_threshold
+ self.mask_extend_pixel = mask_extend_pixel
+ self._init_layers()
+
+ def _init_layers(self) -> None:
+ """Initialize classification branch and regression branch of head."""
+ # fc_cls = Linear(self.embed_dims, self.cls_out_channels)
+ fc_cls = []
+ for _ in range(2):
+ fc_cls.append(Linear(self.embed_dims, self.embed_dims))
+ fc_cls.append(Linear(self.embed_dims, self.cls_out_channels))
+ fc_cls = nn.Sequential(*fc_cls)
+ self.cls_branch = fc_cls
+ if self.predict_segmentation:
+ fc_cls = []
+ for _ in range(2):
+ fc_cls.append(Linear(self.embed_dims, self.embed_dims))
+ fc_cls.append(Linear(self.embed_dims, 1))
+ fc_cls = nn.Sequential(*fc_cls)
+ self.seg_branch = fc_cls
+ if self.predict_abundance:
+ fc_cls = []
+ for _ in range(2):
+ fc_cls.append(Linear(self.embed_dims, self.embed_dims))
+ fc_cls.append(Linear(self.embed_dims, 1))
+ fc_cls = nn.Sequential(*fc_cls)
+ self.abu_branch = fc_cls
+
+ reg_branch = []
+ ratio=2
+ reg_branch.append(Linear(self.decoder_embed_dims, self.decoder_embed_dims*ratio))
+ reg_branch.append(nn.ReLU())
+ for _ in range(self.num_reg_fcs-1):
+ reg_branch.append(Linear(self.decoder_embed_dims*ratio, self.decoder_embed_dims*ratio))
+ reg_branch.append(nn.ReLU())
+ reg_branch.append(Linear(self.decoder_embed_dims*ratio, 4))
+ reg_branch = nn.Sequential(*reg_branch)
+ if self.share_pred_layer:
+ self.reg_branches = nn.ModuleList(
+ [reg_branch for _ in range(self.num_pred_layer)])
+ else:
+ self.reg_branches = nn.ModuleList([
+ copy.deepcopy(reg_branch) for _ in range(self.num_pred_layer)
+ ])
+
+ if self.use_center:
+ center_cls = []
+ for _ in range(2):
+ center_cls.append(Linear(self.embed_dims, self.embed_dims))
+ center_cls.append(Linear(self.embed_dims, 1))
+ center_cls = nn.Sequential(*center_cls)
+ self.center_branch = center_cls
+
+
+ def init_weights(self) -> None:
+ """Initialize weights of the Deformable DETR head."""
+ if self.loss_cls.use_sigmoid:
+ bias_init = bias_init_with_prob(0.01)
+ # for m in self.cls_branches:
+ nn.init.constant_(self.cls_branch.bias, bias_init)
+ if self.use_center:
+ nn.init.constant_(self.center_branch.bias, bias_init)
+ if self.predict_segmentation:
+ nn.init.constant_(self.seg_branch.bias, bias_init)
+ if self.predict_abundance:
+ nn.init.constant_(self.abu_branch.bias, bias_init)
+ for m in self.reg_branches:
+ constant_init(m[-1], 0, bias=0)
+ nn.init.constant_(m[-1].bias.data[2:], 0.0)
+ nn.init.constant_(self.reg_branches[0][-1].bias.data[2:], -2.0)
+
+
+
+ # def _get_targets_single(self, cls_score: Tensor, bbox_pred: Tensor,
+ # gt_instances: InstanceData,
+ # img_meta: dict,
+ # with_neg_cls:bool=True,
+ # assigner_type:str = None) -> tuple:
+ # """Compute regression and classification targets for one image.
+ #
+ # Outputs from a single decoder layer of a single feature level are used.
+ #
+ # Args:
+ # cls_score (Tensor): Box score logits from a single decoder layer
+ # for one image. Shape [num_queries, cls_out_channels].
+ # bbox_pred (Tensor): Sigmoid outputs from a single decoder layer
+ # for one image, with normalized coordinate (cx, cy, w, h) and
+ # shape [num_queries, 4].
+ # gt_instances (:obj:`InstanceData`): Ground truth of instance
+ # annotations. It should includes ``bboxes`` and ``labels``
+ # attributes.
+ # img_meta (dict): Meta information for one image.
+ #
+ # Returns:
+ # tuple[Tensor]: a tuple containing the following for one image.
+ #
+ # - labels (Tensor): Labels of each image.
+ # - label_weights (Tensor]): Label weights of each image.
+ # - bbox_targets (Tensor): BBox targets of each image.
+ # - bbox_weights (Tensor): BBox weights of each image.
+ # - pos_inds (Tensor): Sampled positive indices for each image.
+ # - neg_inds (Tensor): Sampled negative indices for each image.
+ # """
+ # img_h, img_w = img_meta['img_shape']
+ # factor = bbox_pred.new_tensor([img_w, img_h, img_w,
+ # img_h]).unsqueeze(0)
+ # num_bboxes = bbox_pred.size(0)
+ # # convert bbox_pred from xywh, normalized to xyxy, unnormalized
+ # bbox_pred = bbox_cxcywh_to_xyxy(bbox_pred)
+ # bbox_pred = bbox_pred * factor
+ #
+ # pred_instances = InstanceData(scores=cls_score, bboxes=bbox_pred,priors=bbox_pred)
+ # # assigner and sampler
+ # if assigner_type == 'dn':
+ # assign_result = self.dn_assigner.assign(
+ # pred_instances=pred_instances,
+ # gt_instances=gt_instances,
+ # img_meta=img_meta)
+ # else:
+ # assign_result = self.assigner.assign(
+ # pred_instances=pred_instances,
+ # gt_instances=gt_instances,
+ # img_meta=img_meta)
+ #
+ # gt_bboxes = gt_instances.bboxes
+ # gt_labels = gt_instances.labels
+ # pos_inds = torch.nonzero(
+ # assign_result.gt_inds > 0, as_tuple=False).squeeze(-1).unique()
+ # neg_inds = torch.nonzero(
+ # assign_result.gt_inds == 0, as_tuple=False).squeeze(-1).unique()
+ # pos_assigned_gt_inds = assign_result.gt_inds[pos_inds] - 1
+ # pos_gt_bboxes = gt_bboxes[pos_assigned_gt_inds.long(), :]
+ # # label targets
+ # labels = gt_bboxes.new_full((num_bboxes,),
+ # self.num_classes,
+ # dtype=torch.long)
+ # labels[pos_inds] = gt_labels[pos_assigned_gt_inds]
+ # label_weights = gt_bboxes.new_zeros(num_bboxes)
+ # label_weights[pos_inds] = 1
+ # label_weights[neg_inds] = 1
+ # if not with_neg_cls:
+ # label_weights[neg_inds] = 0
+ # # bbox targets
+ # bbox_targets = torch.zeros_like(bbox_pred)
+ # bbox_weights = torch.zeros_like(bbox_pred)
+ # bbox_weights[pos_inds] = 1.0
+ # # DETR regress the relative position of boxes (cxcywh) in the image.
+ # # Thus the learning target should be normalized by the image size, also
+ # # the box format should be converted from defaultly x1y1x2y2 to cxcywh.
+ # pos_gt_bboxes_normalized = pos_gt_bboxes / factor
+ # pos_gt_bboxes_targets = bbox_xyxy_to_cxcywh(pos_gt_bboxes_normalized)
+ # bbox_targets[pos_inds] = pos_gt_bboxes_targets
+ # return (labels, label_weights, bbox_targets, bbox_weights, pos_inds,
+ # neg_inds)
+
+ def _get_targets_single_center(self,
+ center: Tensor,
+ center_scores: Tensor,
+ cls_scores: Tensor,
+ spatial_shapes: Tensor,
+ gt_instances: InstanceData,
+ img_meta: dict) -> tuple:
+ """Compute regression and classification targets for one image.
+
+ Outputs from a single decoder layer of a single feature level are used.
+
+ Args:
+ cls_score (Tensor): Box score logits from a single decoder layer
+ for one image. Shape [num_queries, cls_out_channels].
+ bbox_pred (Tensor): Sigmoid outputs from a single decoder layer
+ for one image, with normalized coordinate (cx, cy, w, h) and
+ shape [num_queries, 4].
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It should includes ``bboxes`` and ``labels``
+ attributes.
+ img_meta (dict): Meta information for one image.
+
+ Returns:
+ tuple[Tensor]: a tuple containing the following for one image.
+
+ - labels (Tensor): Labels of each image.
+ - label_weights (Tensor]): Label weights of each image.
+ - bbox_targets (Tensor): BBox targets of each image.
+ - bbox_weights (Tensor): BBox weights of each image.
+ - pos_inds (Tensor): Sampled positive indices for each image.
+ - neg_inds (Tensor): Sampled negative indices for each image.
+ """
+ img_h, img_w = img_meta['img_shape']
+ feat_h = int(spatial_shapes[self.center_feat_indice][0]/self.center_ds_ratio)
+ feat_w = int(spatial_shapes[self.center_feat_indice][1]/self.center_ds_ratio)
+ factor = spatial_shapes.new_tensor([feat_w, feat_h]).unsqueeze(0)
+ # factor = center.new_tensor([img_w, img_h,]).unsqueeze(0)
+ gt_bboxes = gt_instances.bboxes
+ gt_labels = gt_instances.labels
+ gt_cxcy = bbox_xyxy_to_cxcywh(gt_bboxes)[:, :2]
+ gt_cxcy[:, 0] = gt_cxcy[:, 0] * feat_w / img_w
+ gt_cxcy[:, 1] = gt_cxcy[:, 1] * feat_h / img_h
+ gt_cxcy= gt_cxcy.long()
+ gt_bboxes[:, 2:] -= 0.1
+ gt_bboxes_x = gt_bboxes[:, 0::2]
+ gt_bboxes_y = gt_bboxes[:, 1::2]
+ gt_bboxes_x = torch.floor(gt_bboxes_x * feat_w / img_w)
+ gt_bboxes_y = torch.floor(gt_bboxes_y * feat_h / img_h)
+ gt_bboxes_x = gt_bboxes_x.long()
+ gt_bboxes_y = gt_bboxes_y.long()
+ heat_map = gt_bboxes.new_full((feat_h, feat_w), 0, dtype=torch.long)
+ for t_i in range(gt_bboxes.size(0)):
+ # if gt_bboxes_x[t_i, 1] - gt_bboxes_x[t_i, 0] > 3:
+ # gt_bboxes_x[t_i,1] = gt_cxcy[t_i, 0] + 1
+ # gt_bboxes_x[t_i,0] = gt_cxcy[t_i, 0] - 1
+ # if gt_bboxes_y[t_i,1] - gt_bboxes_y[t_i,0] > 3:
+ # gt_bboxes_y[t_i,1] = gt_cxcy[t_i, 1] + 1
+ # gt_bboxes_y[t_i,0] = gt_cxcy[t_i, 1] - 1
+ grid_y, grid_x = torch.meshgrid(
+ torch.linspace(gt_bboxes_y[t_i, 0], gt_bboxes_y[t_i, 1], gt_bboxes_y[t_i, 1]+1-gt_bboxes_y[t_i, 0],
+ dtype=torch.long, device=gt_cxcy.device),
+ torch.linspace(gt_bboxes_x[t_i, 0], gt_bboxes_x[t_i, 1], gt_bboxes_x[t_i, 1]+1-gt_bboxes_x[t_i, 0],
+ dtype=torch.long, device=gt_cxcy.device))
+ grid = torch.cat([grid_y.unsqueeze(-1), grid_x.unsqueeze(-1)], -1)
+ grid = grid.view(-1, 2)
+ value_input = gt_bboxes.new_full((grid.size(0),), -1, dtype=torch.long)
+ heat_map.index_put_((grid[:,0],grid[:,1]), value_input)
+ # cls_labels.index_put_((grid[:,0],grid[:,1]), value_input)
+ value_input = gt_bboxes.new_full((gt_cxcy.size(0),), 1, dtype=torch.long)
+ heat_map = heat_map.index_put_((gt_cxcy[:,1], gt_cxcy[:,0]), value_input)
+ heat_map = heat_map.view(-1)
+ mask = heat_map != -1
+ # new_center_score = center_score[mask]
+ # heat_map = heat_map[mask]
+ pos_inds = torch.where(heat_map == 1)[0]
+ ignore_inds = torch.where(heat_map == -1)[0]
+ neg_inds = torch.where(heat_map == 0)[0]
+ cls_labels = gt_bboxes.new_full((feat_h, feat_w), self.num_classes, dtype=torch.long)
+ cls_labels = cls_labels.index_put_((gt_cxcy[:,1], gt_cxcy[:,0]), gt_labels)
+ cls_labels = cls_labels.view(-1)
+ center_labels = gt_bboxes.new_full((heat_map.size(0),), 1, dtype=torch.long)
+ center_labels[pos_inds] = 0
+ label_weights = gt_bboxes.new_ones(heat_map.size(0))
+ if ignore_inds.numel() > 0:
+ label_weights[ignore_inds] = 0
+ if self.neg_hard_num>0:
+ if self.use_center:
+ _, indices = torch.sort(center_scores, dim=0, descending=True)
+ else:
+ cls_scores_max = torch.max(cls_scores, dim=-1, keepdim=True)[0]
+ _, indices = torch.sort(cls_scores_max, dim=0, descending=True)
+ sorted_inds = indices.squeeze()
+ non_neg_inds = torch.cat([pos_inds,ignore_inds],dim=0)
+ mask = torch.isin(sorted_inds, non_neg_inds)
+ remaining_inds = sorted_inds[~mask]
+ neg_hard_inds = remaining_inds[:self.neg_hard_num]
+ new_inds = torch.cat([pos_inds, neg_hard_inds], dim=0)
+ neg_inds = neg_hard_inds
+ center_labels = center_labels[new_inds]
+ cls_labels = cls_labels[new_inds]
+ center_scores = center_scores[new_inds]
+ cls_scores = cls_scores[new_inds]
+ label_weights = gt_bboxes.new_ones(new_inds.size(0))
+ return (center_labels, cls_labels, center_scores, cls_scores, label_weights, pos_inds, neg_inds)
+
+ def _get_targets_single_pixel(self,
+ seg_scores: Tensor,
+ abu_scores: Optional[Tensor],
+ spatial_shapes: Tensor,
+ gt_seg: Tensor,
+ gt_abu: Optional[Tensor],
+ img_meta: dict) -> tuple:
+ assert seg_scores.shape[0] == gt_seg.numel()
+ assert spatial_shapes[0][0]*spatial_shapes[0][1] == gt_seg.numel()
+ gt_seg = gt_seg.view(-1,1)
+ pos_inds = torch.where(gt_seg >0)[0]
+ seg_labels = gt_seg.detach().clone()
+ seg_labels[gt_seg >0] = 0
+ seg_labels[gt_seg == 0] = 1
+ seg_labels = seg_labels.long()
+ # gt_abu= gt_abu.view(-1,1)
+ # pos_inds = torch.where(gt_abu > 0)[0]
+ if self.seg_neg_hard_num== 0:
+ neg_inds = torch.where(gt_seg == 0)[0]
+ seg_label_weights = seg_scores.new_ones(seg_labels.size(0))
+ else:
+ seg_scores_max = torch.max(seg_scores, dim=-1, keepdim=True)[0]
+ _, indices = torch.sort(seg_scores_max, dim=0, descending=True)
+ sorted_inds = indices.squeeze()
+ mask = torch.isin(sorted_inds, pos_inds)
+ remaining_inds = sorted_inds[~mask]
+ neg_hard_inds = remaining_inds[:self.seg_neg_hard_num]
+ neg_inds = neg_hard_inds
+ new_inds = torch.cat([pos_inds, neg_hard_inds], dim=0)
+ seg_scores = seg_scores[new_inds]
+ seg_labels = seg_labels[new_inds]
+ seg_label_weights = seg_scores.new_ones(seg_labels.size(0))
+ if self.predict_abundance:
+ gt_abu = gt_abu.view(-1,1)
+ abu_scores = abu_scores[pos_inds]
+ abu_labels = gt_abu[pos_inds]*0.5+0.25
+ abu_label_weights = seg_scores.new_ones(abu_labels.size(0))
+ else:
+ abu_scores = None
+ abu_labels = None
+ abu_label_weights = None
+ return seg_scores, seg_labels, seg_label_weights,abu_scores, abu_labels, abu_label_weights, pos_inds, neg_inds
+
+
+ # def _get_targets_single_bbox(self,
+ # cls_score: Tensor,
+ # bbox_pred: Tensor,
+ # gt_instances: InstanceData,
+ # img_meta: dict) -> tuple:
+ # """Compute regression and classification targets for one image.
+ #
+ # Outputs from a single decoder layer of a single feature level are used.
+ #
+ # Args:
+ # cls_score (Tensor): Box score logits from a single decoder layer
+ # for one image. Shape [num_queries, cls_out_channels].
+ # bbox_pred (Tensor): Sigmoid outputs from a single decoder layer
+ # for one image, with normalized coordinate (cx, cy, w, h) and
+ # shape [num_queries, 4].
+ # gt_instances (:obj:`InstanceData`): Ground truth of instance
+ # annotations. It should includes ``bboxes`` and ``labels``
+ # attributes.
+ # img_meta (dict): Meta information for one image.
+ #
+ # Returns:
+ # tuple[Tensor]: a tuple containing the following for one image.
+ #
+ # - labels (Tensor): Labels of each image.
+ # - label_weights (Tensor]): Label weights of each image.
+ # - bbox_targets (Tensor): BBox targets of each image.
+ # - bbox_weights (Tensor): BBox weights of each image.
+ # - pos_inds (Tensor): Sampled positive indices for each image.
+ # - neg_inds (Tensor): Sampled negative indices for each image.
+ # """
+ # img_h, img_w = img_meta['img_shape']
+ # factor = bbox_pred.new_tensor([img_w, img_h, img_w,
+ # img_h]).unsqueeze(0)
+ # num_bboxes = bbox_pred.size(0)
+ # # convert bbox_pred from xywh, normalized to xyxy, unnormalized
+ # bbox_pred = bbox_cxcywh_to_xyxy(bbox_pred)
+ # bbox_pred = bbox_pred * factor
+ #
+ # pred_instances = InstanceData(scores=cls_score, bboxes=bbox_pred,priors=bbox_pred)
+ # # assigner and sampler
+ # assign_result = self.bbox_assigner.assign(
+ # pred_instances=pred_instances,
+ # gt_instances=gt_instances,
+ # img_meta=img_meta)
+ # gt_bboxes = gt_instances.bboxes
+ # gt_labels = gt_instances.labels
+ # pos_inds = torch.nonzero(
+ # assign_result.gt_inds > 0, as_tuple=False).squeeze(-1).unique()
+ # neg_inds = torch.nonzero(
+ # assign_result.gt_inds == 0, as_tuple=False).squeeze(-1).unique()
+ # pos_assigned_gt_inds = assign_result.gt_inds[pos_inds] - 1
+ # pos_gt_bboxes = gt_bboxes[pos_assigned_gt_inds.long(), :]
+ #
+ # # bbox targets
+ # bbox_targets = torch.zeros_like(bbox_pred)
+ # bbox_weights = torch.zeros_like(bbox_pred)
+ # bbox_weights[pos_inds] = 1.0
+ #
+ # # DETR regress the relative position of boxes (cxcywh) in the image.
+ # # Thus the learning target should be normalized by the image size, also
+ # # the box format should be converted from defaultly x1y1x2y2 to cxcywh.
+ # pos_gt_bboxes_normalized = pos_gt_bboxes / factor
+ # pos_gt_bboxes_targets = bbox_xyxy_to_cxcywh(pos_gt_bboxes_normalized)
+ # bbox_targets[pos_inds] = pos_gt_bboxes_targets
+ # return (bbox_targets, bbox_weights, pos_inds, neg_inds)
+
+ def loss_and_predict(
+ self, hidden_states: Tuple[Tensor],
+ batch_data_samples: SampleList) -> Tuple[dict, InstanceList]:
+ """Perform forward propagation of the head, then calculate loss and
+ predictions from the features and data samples. Over-write because
+ img_metas are needed as inputs for bbox_head.
+
+ Args:
+ hidden_states (tuple[Tensor]): Feature from the transformer
+ decoder, has shape (num_decoder_layers, bs, num_queries, dim).
+ batch_data_samples (list[:obj:`DetDataSample`]): Each item contains
+ the meta information of each image and corresponding
+ annotations.
+
+ Returns:
+ tuple: the return value is a tuple contains:
+
+ - losses: (dict[str, Tensor]): A dictionary of loss components.
+ - predictions (list[:obj:`InstanceData`]): Detection
+ results of each image after the post process.
+ """
+ batch_gt_instances = []
+ batch_img_metas = []
+ for data_sample in batch_data_samples:
+ batch_img_metas.append(data_sample.metainfo)
+ batch_gt_instances.append(data_sample.gt_instances)
+ outs = self(hidden_states)
+ loss_inputs = outs + (batch_gt_instances, batch_img_metas)
+ losses = self.loss_by_feat(*loss_inputs)
+ predictions = self.predict_by_feat(
+ *outs, batch_img_metas=batch_img_metas)
+ return losses, predictions
+
+ def forward(self, hidden_states: Tensor,
+ references: List[Tensor],
+ topk_cls_scores: Tensor,) -> Tuple[Tensor]:
+ """Forward function.
+
+ Args:
+ hidden_states (Tensor): Hidden states output from each decoder
+ layer, has shape (num_decoder_layers, bs, num_queries, dim).
+ references (list[Tensor]): List of the reference from the decoder.
+ The first reference is the `init_reference` (initial) and the
+ other num_decoder_layers(6) references are `inter_references`
+ (intermediate). The `init_reference` has shape (bs,
+ num_queries, 4) when `as_two_stage` of the detector is `True`,
+ otherwise (bs, num_queries, 2). Each `inter_reference` has
+ shape (bs, num_queries, 4) when `with_box_refine` of the
+ detector is `True`, otherwise (bs, num_queries, 2). The
+ coordinates are arranged as (cx, cy) when the last dimension is
+ 2, and (cx, cy, w, h) when it is 4.
+
+ Returns:
+ tuple[Tensor]: results of head containing the following tensor.
+
+ - all_layers_outputs_classes (Tensor): Outputs from the
+ classification head, has shape (num_decoder_layers, bs,
+ num_queries, cls_out_channels).
+ - all_layers_outputs_coords (Tensor): Sigmoid outputs from the
+ regression head with normalized coordinate format (cx, cy, w,
+ h), has shape (num_decoder_layers, bs, num_queries, 4) with the
+ last dimension arranged as (cx, cy, w, h).
+ """
+ all_layers_outputs_coords = []
+ for layer_id in range(hidden_states.shape[0]):
+ reference = inverse_sigmoid(references[layer_id])
+ # NOTE The last reference will not be used.
+ hidden_state = hidden_states[layer_id]
+ tmp_reg_preds = self.reg_branches[layer_id](hidden_state)
+ if reference.shape[-1] == 4:
+ # When `layer` is 0 and `as_two_stage` of the detector
+ # is `True`, or when `layer` is greater than 0 and
+ # `with_box_refine` of the detector is `True`.
+ tmp_reg_preds += reference
+ else:
+ # When `layer` is 0 and `as_two_stage` of the detector
+ # is `False`, or when `layer` is greater than 0 and
+ # `with_box_refine` of the detector is `False`.
+ assert reference.shape[-1] == 2
+ tmp_reg_preds[..., :2] += reference
+ outputs_coord = tmp_reg_preds.sigmoid()
+ all_layers_outputs_coords.append(outputs_coord)
+ all_layers_outputs_classes = topk_cls_scores.unsqueeze(0).repeat(hidden_states.shape[0],1,1,1)
+ all_layers_outputs_coords = torch.stack(all_layers_outputs_coords)
+ return all_layers_outputs_classes, all_layers_outputs_coords
+
+ def loss(self, hidden_states: Tensor,
+ references: List[Tensor],
+ centers: Tensor,
+ center_scores: Tensor,
+ topk_centers_scores: Tensor,
+ cls_scores: Tensor,
+ topk_cls_scores: Tensor,
+ seg_scores:Optional[Tensor],
+ abu_scores: Optional[Tensor],
+ batch_data_samples: SampleList,
+ dn_meta: Dict[str, int],
+ spatial_shapes: Tensor) -> dict:
+ """Perform forward propagation and loss calculation of the detection
+ head on the queries of the upstream network.
+
+ Args:
+ hidden_states (Tensor): Hidden states output from each decoder
+ layer, has shape (num_decoder_layers, bs, num_queries_total,
+ dim), where `num_queries_total` is the sum of
+ `num_denoising_queries` and `num_matching_queries` when
+ `self.training` is `True`, else `num_matching_queries`.
+ references (list[Tensor]): List of the reference from the decoder.
+ The first reference is the `init_reference` (initial) and the
+ other num_decoder_layers(6) references are `inter_references`
+ (intermediate). The `init_reference` has shape (bs,
+ num_queries_total, 4) and each `inter_reference` has shape
+ (bs, num_queries, 4) with the last dimension arranged as
+ (cx, cy, w, h).
+ enc_outputs_class (Tensor): The score of each point on encode
+ feature map, has shape (bs, num_feat_points, cls_out_channels).
+ enc_outputs_coord (Tensor): The proposal generate from the
+ encode feature map, has shape (bs, num_feat_points, 4) with the
+ last dimension arranged as (cx, cy, w, h).
+ batch_data_samples (list[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ dict: A dictionary of loss components.
+ """
+ batch_gt_instances = []
+ batch_img_metas = []
+ batch_gt_seg = []
+ batch_gt_abu = []
+ for data_sample in batch_data_samples:
+ batch_img_metas.append(data_sample.metainfo)
+ batch_gt_instances.append(data_sample.gt_instances)
+ if self.predict_segmentation:
+ batch_gt_seg.append(data_sample.gt_pixel.seg)
+ else:
+ batch_gt_seg.append(None)
+ if self.predict_abundance:
+ batch_gt_abu.append(data_sample.gt_pixel.abu)
+ else:
+ batch_gt_abu.append(None)
+ outs = self(hidden_states, references, topk_cls_scores)
+ loss_inputs = outs + (centers, center_scores, topk_centers_scores, cls_scores, topk_cls_scores,
+ seg_scores,abu_scores,
+ batch_gt_instances, batch_img_metas, dn_meta, spatial_shapes,batch_gt_seg,batch_gt_abu)
+ losses = self.loss_by_feat(*loss_inputs)
+ return losses
+
+ def loss_by_feat(
+ self,
+ all_layers_cls_scores: Tensor,
+ all_layers_bbox_preds: Tensor,
+ centers: Tensor,
+ center_scores: Tensor,
+ topk_centers_scores: Tensor,
+ cls_scores: Tensor,
+ topk_cls_scores: Tensor,
+ seg_scores: Optional[Tensor],
+ abu_scores: Optional[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ dn_meta: Dict[str, int],
+ spatial_shapes: Tensor,
+ batch_gt_seg: List,
+ batch_gt_abu: List,
+ batch_gt_instances_ignore: OptInstanceList = None,
+ ) -> Dict[str, Tensor]:
+ """Loss function.
+
+ Args:
+ all_layers_cls_scores (Tensor): Classification scores of all
+ decoder layers, has shape (num_decoder_layers, bs,
+ num_queries_total, cls_out_channels), where
+ `num_queries_total` is the sum of `num_denoising_queries`
+ and `num_matching_queries`.
+ all_layers_bbox_preds (Tensor): Regression outputs of all decoder
+ layers. Each is a 4D-tensor with normalized coordinate format
+ (cx, cy, w, h) and has shape (num_decoder_layers, bs,
+ num_queries_total, 4).
+ enc_cls_scores (Tensor): The score of each point on encode
+ feature map, has shape (bs, num_feat_points, cls_out_channels).
+ enc_bbox_preds (Tensor): The proposal generate from the encode
+ feature map, has shape (bs, num_feat_points, 4) with the last
+ dimension arranged as (cx, cy, w, h).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components.
+ """
+ # extract denoising and matching part of outputs
+ weight_bbox = 0
+ weight_cls = 0
+ # (all_layers_matching_cls_scores, all_layers_matching_bbox_preds,
+ # all_layers_denoising_cls_scores, all_layers_denoising_bbox_preds) = \
+ # self.split_outputs(all_layers_cls_scores, all_layers_bbox_preds, dn_meta)
+
+ # (matching_cls_scores, all_layers_matching_bbox_preds,
+ # denoising_cls_scores, all_layers_denoising_bbox_preds) = \
+ # self.split_outputsv1(cls_scores, all_layers_bbox_preds, dn_meta)
+ loss_dict = dict()
+ loss_center, loss_cls = self.loss_center(centers,
+ center_scores,
+ cls_scores,
+ spatial_shapes,
+ batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas)
+ if self.use_center:
+ loss_dict['loss_center'] = loss_center
+ loss_dict['loss_cls'] = loss_cls
+ if loss_cls <= self.loss_center_th:
+ weight_bbox = 1
+ if self.predict_segmentation:
+ # seg_scores = seg_scores.sigmoid()
+ if self.predict_abundance:
+ abu_scores = abu_scores.sigmoid()
+ loss_seg, loss_abu = self.loss_pixel(seg_scores, abu_scores, spatial_shapes,
+ batch_gt_seg,batch_gt_abu,
+ batch_img_metas=batch_img_metas)
+ loss_dict['loss_seg'] = loss_seg*weight_bbox
+ if self.predict_abundance:
+ loss_dict['loss_abu'] = loss_abu*weight_bbox
+ reg_targets = self.get_dn_targets(batch_gt_instances, batch_img_metas, dn_meta)
+ dn_losses_bbox, dn_losses_iou = multi_apply(
+ self._loss_dn_single,
+ all_layers_bbox_preds,
+ reg_targets=reg_targets,
+ batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas,
+ dn_meta=dn_meta)
+ for num_dec_layer, (loss_bbox_i, loss_iou_i) in \
+ enumerate(zip(dn_losses_bbox, dn_losses_iou)):
+ loss_dict[f'd{num_dec_layer+1}.dn_loss_bbox'] = loss_bbox_i*weight_bbox
+ if self.loss_iou is not None:
+ loss_dict[f'd{num_dec_layer+1}.dn_loss_iou'] = loss_iou_i*weight_bbox
+ return loss_dict
+
+
+ # def loss_by_feat_single(self, cls_scores: Tensor, bbox_preds: Tensor,
+ # batch_gt_instances: InstanceList,
+ # batch_img_metas: List[dict]) -> Tuple[Tensor]:
+ # """Loss function for outputs from a single decoder layer of a single
+ # feature level.
+ #
+ # Args:
+ # cls_scores (Tensor): Box score logits from a single decoder layer
+ # for all images, has shape (bs, num_queries, cls_out_channels).
+ # bbox_preds (Tensor): Sigmoid outputs from a single decoder layer
+ # for all images, with normalized coordinate (cx, cy, w, h) and
+ # shape (bs, num_queries, 4).
+ # batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ # gt_instance. It usually includes ``bboxes`` and ``labels``
+ # attributes.
+ # batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ # image size, scaling factor, etc.
+ #
+ # Returns:
+ # Tuple[Tensor]: A tuple including `loss_cls`, `loss_box` and
+ # `loss_iou`.
+ # """
+ # num_imgs = cls_scores.size(0)
+ # cls_scores_list = [cls_scores[i] for i in range(num_imgs)]
+ # bbox_preds_list = [bbox_preds[i] for i in range(num_imgs)]
+ # cls_reg_targets = self.get_targets_bbox(cls_scores_list, bbox_preds_list,
+ # batch_gt_instances, batch_img_metas)
+ # (bbox_targets_list, bbox_weights_list,
+ # num_total_pos, num_total_neg) = cls_reg_targets
+ # bbox_targets = torch.cat(bbox_targets_list, 0)
+ # bbox_weights = torch.cat(bbox_weights_list, 0)
+ #
+ #
+ # # Compute the average number of gt boxes across all gpus, for
+ # # normalization purposes
+ # num_total_pos = bbox_targets.new_tensor([num_total_pos])
+ # num_total_pos = torch.clamp(reduce_mean(num_total_pos), min=1).item()
+ #
+ # # construct factors used for rescale bboxes
+ # factors = []
+ # for img_meta, bbox_pred in zip(batch_img_metas, bbox_preds):
+ # img_h, img_w, = img_meta['img_shape']
+ # factor = bbox_pred.new_tensor([img_w, img_h, img_w,
+ # img_h]).unsqueeze(0).repeat(
+ # bbox_pred.size(0), 1)
+ # factors.append(factor)
+ # factors = torch.cat(factors, 0)
+ #
+ # # DETR regress the relative position of boxes (cxcywh) in the image,
+ # # thus the learning target is normalized by the image size. So here
+ # # we need to re-scale them for calculating IoU loss
+ # bbox_preds = bbox_preds.reshape(-1, 4)
+ # bboxes = bbox_cxcywh_to_xyxy(bbox_preds) * factors
+ # bboxes_gt = bbox_cxcywh_to_xyxy(bbox_targets) * factors
+ #
+ # # regression IoU loss, defaultly GIoU loss
+ # loss_iou = self.loss_iou(
+ # bboxes, bboxes_gt, bbox_weights, avg_factor=num_total_pos)
+ #
+ # # regression L1 loss
+ # loss_bbox = self.loss_bbox(
+ # bbox_preds, bbox_targets, bbox_weights, avg_factor=num_total_pos)
+ # return loss_bbox, loss_iou
+
+
+
+ def loss_center(self,
+ centers: Tensor,
+ center_scores: Tensor,
+ cls_scores: Tensor,
+ spatial_shapes: Tensor,
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict]) -> Tuple[Tensor]:
+ """Loss function for outputs from a single decoder layer of a single
+ feature level.
+
+ Args:
+ cls_scores (Tensor): Box score logits from a single decoder layer
+ for all images, has shape (bs, num_queries, cls_out_channels).
+ bbox_preds (Tensor): Sigmoid outputs from a single decoder layer
+ for all images, with normalized coordinate (cx, cy, w, h) and
+ shape (bs, num_queries, 4).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+
+ Returns:
+ Tuple[Tensor]: A tuple including `loss_cls`, `loss_box` and
+ `loss_iou`.
+ """
+ num_imgs = centers.size(0)
+ if center_scores is None:
+ center_scores_list = [cls_scores[i] for i in range(num_imgs)]
+ else:
+ center_scores_list = [center_scores[i] for i in range(num_imgs)]
+
+ cls_scores_list = [cls_scores[i] for i in range(num_imgs)]
+ # center_scores =center_scores.view(-1, center_scores.shape[2])
+ # cls_scores = cls_scores.view(-1, cls_scores.shape[2])
+ centers_list = [centers[i] for i in range(num_imgs)]
+ spatial_shapes_list = [spatial_shapes for i in range(num_imgs)]
+ (center_labels_list, cls_labels_list, center_scores_list, cls_scores_list, label_weights_list, pos_inds_list, neg_inds_list,) = multi_apply(self._get_targets_single_center,
+ centers_list, center_scores_list, cls_scores_list, spatial_shapes_list, batch_gt_instances, batch_img_metas)
+ num_total_pos = sum((inds.numel() for inds in pos_inds_list))
+ num_total_neg = sum((inds.numel() for inds in neg_inds_list))
+ center_labels = torch.cat(center_labels_list, 0)
+ cls_labels = torch.cat(cls_labels_list, 0)
+ center_scores = torch.cat(center_scores_list, 0)
+ cls_scores = torch.cat(cls_scores_list, 0)
+ label_weights = torch.cat(label_weights_list, 0)
+ # construct weighted avg_factor to match with the official DETR repo
+ cls_avg_factor = num_total_pos * 1.0 + \
+ num_total_neg * 0
+ if self.sync_cls_avg_factor:
+ cls_avg_factor = reduce_mean(
+ centers.new_tensor([cls_avg_factor]))
+ cls_avg_factor = max(cls_avg_factor, 1)
+ if self.use_center:
+ loss_center = self.loss_center_cls(
+ center_scores, center_labels, label_weights, avg_factor=cls_avg_factor)
+ else:
+ loss_center = None
+ loss_cls = self.loss_cls(
+ cls_scores, cls_labels, label_weights, avg_factor=cls_avg_factor)
+ return loss_center, loss_cls
+
+ def loss_pixel(self,
+ seg_scores: Tensor,
+ abu_scores: Tensor,
+ spatial_shapes: Tensor,
+ batch_gt_seg: List,
+ batch_gt_abu: List,
+ batch_img_metas: List) -> Tuple[Tensor]:
+ num_imgs = seg_scores.size(0)
+ seg_scores_list = [seg_scores[i] for i in range(num_imgs)]
+ if abu_scores is not None:
+ abu_scores_list = [abu_scores[i] for i in range(num_imgs)]
+ else:
+ abu_scores_list = [None for i in range(num_imgs)]
+ spatial_shapes_list = [spatial_shapes for i in range(num_imgs)]
+ (seg_scores_list, seg_labels_list, seg_label_weights_list,abu_scores_list, abu_labels_list, abu_label_weights_list, pos_inds_list, neg_inds_list) = multi_apply(self._get_targets_single_pixel,
+ seg_scores_list, abu_scores_list,
+ spatial_shapes_list,
+ batch_gt_seg,
+ batch_gt_abu,
+ batch_img_metas)
+ num_total_pos = sum((inds.numel() for inds in pos_inds_list))
+ num_total_neg = sum((inds.numel() for inds in neg_inds_list))
+ seg_scores = torch.cat(seg_scores_list, 0)
+ seg_labels = torch.cat(seg_labels_list, 0)
+ seg_label_weights = torch.cat(seg_label_weights_list, 0)
+ cls_avg_factor = num_total_pos * 1.0 + num_total_neg * 0
+ if self.sync_cls_avg_factor:
+ cls_avg_factor = reduce_mean(
+ seg_scores.new_tensor([cls_avg_factor]))
+ cls_avg_factor = max(cls_avg_factor, 1)
+ loss_seg = self.loss_seg(
+ seg_scores, seg_labels, seg_label_weights, avg_factor=cls_avg_factor)
+ if self.predict_abundance:
+ abu_scores = torch.cat(abu_scores_list, 0)
+ abu_labels = torch.cat(abu_labels_list, 0)
+ abu_label_weights = torch.cat(abu_label_weights_list, 0)
+ # cls_avg_factor = num_total_pos * 1.0
+ # if self.sync_cls_avg_factor:
+ # cls_avg_factor = reduce_mean(
+ # seg_scores.new_tensor([cls_avg_factor]))
+ # cls_avg_factor = max(cls_avg_factor, 1)
+ loss_abu = self.loss_abu(
+ abu_scores, abu_labels, abu_label_weights)
+ else:
+ loss_abu = None
+ return loss_seg, loss_abu
+
+ # def get_targets(self, cls_scores_list: List[Tensor],
+ # bbox_preds_list: List[Tensor],
+ # batch_gt_instances: InstanceList,
+ # batch_img_metas: List[dict],
+ # with_neg_cls:bool=True,
+ # assigner_type:str = None) -> tuple:
+ # """Compute regression and classification targets for a batch image.
+ #
+ # Outputs from a single decoder layer of a single feature level are used.
+ #
+ # Args:
+ # cls_scores_list (list[Tensor]): Box score logits from a single
+ # decoder layer for each image, has shape [num_queries,
+ # cls_out_channels].
+ # bbox_preds_list (list[Tensor]): Sigmoid outputs from a single
+ # decoder layer for each image, with normalized coordinate
+ # (cx, cy, w, h) and shape [num_queries, 4].
+ # batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ # gt_instance. It usually includes ``bboxes`` and ``labels``
+ # attributes.
+ # batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ # image size, scaling factor, etc.
+ #
+ # Returns:
+ # tuple: a tuple containing the following targets.
+ #
+ # - labels_list (list[Tensor]): Labels for all images.
+ # - label_weights_list (list[Tensor]): Label weights for all images.
+ # - bbox_targets_list (list[Tensor]): BBox targets for all images.
+ # - bbox_weights_list (list[Tensor]): BBox weights for all images.
+ # - num_total_pos (int): Number of positive samples in all images.
+ # - num_total_neg (int): Number of negative samples in all images.
+ # """
+ # (labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,
+ # pos_inds_list,
+ # neg_inds_list) = multi_apply(self._get_targets_single,
+ # cls_scores_list, bbox_preds_list,
+ # batch_gt_instances, batch_img_metas,
+ # with_neg_cls=with_neg_cls,
+ # assigner_type= assigner_type)
+ # num_total_pos = sum((inds.numel() for inds in pos_inds_list))
+ # num_total_neg = sum((inds.numel() for inds in neg_inds_list))
+ # if not with_neg_cls:
+ # num_total_neg = 0
+ # return (labels_list, label_weights_list, bbox_targets_list,
+ # bbox_weights_list, num_total_pos, num_total_neg)
+
+ # def get_targets_bbox(self,
+ # cls_scores_list: List[Tensor],
+ # bbox_preds_list: List[Tensor],
+ # batch_gt_instances: InstanceList,
+ # batch_img_metas: List[dict]) -> tuple:
+ # """Compute regression and classification targets for a batch image.
+ #
+ # Outputs from a single decoder layer of a single feature level are used.
+ #
+ # Args:
+ # cls_scores_list (list[Tensor]): Box score logits from a single
+ # decoder layer for each image, has shape [num_queries,
+ # cls_out_channels].
+ # bbox_preds_list (list[Tensor]): Sigmoid outputs from a single
+ # decoder layer for each image, with normalized coordinate
+ # (cx, cy, w, h) and shape [num_queries, 4].
+ # batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ # gt_instance. It usually includes ``bboxes`` and ``labels``
+ # attributes.
+ # batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ # image size, scaling factor, etc.
+ #
+ # Returns:
+ # tuple: a tuple containing the following targets.
+ #
+ # - labels_list (list[Tensor]): Labels for all images.
+ # - label_weights_list (list[Tensor]): Label weights for all images.
+ # - bbox_targets_list (list[Tensor]): BBox targets for all images.
+ # - bbox_weights_list (list[Tensor]): BBox weights for all images.
+ # - num_total_pos (int): Number of positive samples in all images.
+ # - num_total_neg (int): Number of negative samples in all images.
+ # """
+ # (bbox_targets_list, bbox_weights_list, pos_inds_list,
+ # neg_inds_list) = multi_apply(self._get_targets_single_bbox, cls_scores_list,
+ # bbox_preds_list,
+ # batch_gt_instances, batch_img_metas)
+ # num_total_pos = sum((inds.numel() for inds in pos_inds_list))
+ # num_total_neg = sum((inds.numel() for inds in neg_inds_list))
+ # return (bbox_targets_list, bbox_weights_list, num_total_pos, num_total_neg)
+
+
+ def _loss_dn_single(self, dn_bbox_preds: Tensor,
+ reg_targets: Tuple[list, int],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ dn_meta: Dict[str, int]) -> Tuple[Tensor]:
+ """Denoising loss for outputs from a single decoder layer.
+
+ Args:
+ dn_cls_scores (Tensor): Classification scores of a single decoder
+ layer in denoising part, has shape (bs, num_denoising_queries,
+ cls_out_channels).
+ dn_bbox_preds (Tensor): Regression outputs of a single decoder
+ layer in denoising part. Each is a 4D-tensor with normalized
+ coordinate format (cx, cy, w, h) and has shape
+ (bs, num_denoising_queries, 4).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ Tuple[Tensor]: A tuple including `loss_cls`, `loss_box` and
+ `loss_iou`.
+ """
+ (labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,num_total_pos) = reg_targets
+ bbox_targets = torch.cat(bbox_targets_list, 0)
+ bbox_weights = torch.cat(bbox_weights_list, 0)
+
+ # Compute the average number of gt boxes across all gpus, for
+ # normalization purposes
+ num_total_pos = dn_bbox_preds.new_tensor([num_total_pos])
+ num_total_pos = torch.clamp(reduce_mean(num_total_pos), min=1).item()
+
+ # construct factors used for rescale bboxes
+ factors = []
+ for img_meta, bbox_pred in zip(batch_img_metas, dn_bbox_preds):
+ img_h, img_w = img_meta['img_shape']
+ factor = bbox_pred.new_tensor([img_w, img_h, img_w,
+ img_h]).unsqueeze(0).repeat(
+ bbox_pred.size(0), 1)
+ factors.append(factor)
+ factors = torch.cat(factors)
+ # DETR regress the relative position of boxes (cxcywh) in the image,
+ # thus the learning target is normalized by the image size. So here
+ # we need to re-scale them for calculating IoU loss
+ bbox_preds = dn_bbox_preds.reshape(-1, 4)
+ bboxes = bbox_cxcywh_to_xyxy(bbox_preds) * factors
+ bboxes_gt = bbox_cxcywh_to_xyxy(bbox_targets) * factors
+ # regression IoU loss, defaultly GIoU loss
+ if self.loss_iou is not None:
+ loss_iou = self.loss_iou(
+ bboxes, bboxes_gt, bbox_weights, avg_factor=num_total_pos)
+ else:
+ loss_iou = None
+ # regression L1 loss
+ loss_bbox = self.loss_bbox(
+ bbox_preds, bbox_targets, bbox_weights, avg_factor=num_total_pos)
+ return loss_bbox, loss_iou
+
+ def get_dn_targets(self, batch_gt_instances: InstanceList,
+ batch_img_metas: dict, dn_meta: Dict[str,
+ int]) -> tuple:
+ """Get targets in denoising part for a batch of images.
+
+ Args:
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ tuple: a tuple containing the following targets.
+
+ - labels_list (list[Tensor]): Labels for all images.
+ - label_weights_list (list[Tensor]): Label weights for all images.
+ - bbox_targets_list (list[Tensor]): BBox targets for all images.
+ - bbox_weights_list (list[Tensor]): BBox weights for all images.
+ - num_total_pos (int): Number of positive samples in all images.
+ - num_total_neg (int): Number of negative samples in all images.
+ """
+ (labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,pos_inds_list) = multi_apply(
+ self._get_dn_targets_single,
+ batch_gt_instances,
+ batch_img_metas,
+ dn_meta=dn_meta)
+ num_total_pos = sum((inds.numel() for inds in pos_inds_list))
+ return (labels_list, label_weights_list, bbox_targets_list, bbox_weights_list, num_total_pos,)
+
+ def _get_dn_targets_single(self, gt_instances: InstanceData,
+ img_meta: dict, dn_meta: Dict[str,
+ int]) -> tuple:
+ """Get targets in denoising part for one image.
+
+ Args:
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It should includes ``bboxes`` and ``labels``
+ attributes.
+ img_meta (dict): Meta information for one image.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ tuple[Tensor]: a tuple containing the following for one image.
+
+ - labels (Tensor): Labels of each image.
+ - label_weights (Tensor]): Label weights of each image.
+ - bbox_targets (Tensor): BBox targets of each image.
+ - bbox_weights (Tensor): BBox weights of each image.
+ - pos_inds (Tensor): Sampled positive indices for each image.
+ - neg_inds (Tensor): Sampled negative indices for each image.
+ """
+ gt_bboxes = gt_instances.bboxes
+ gt_labels = gt_instances.labels
+ num_groups = dn_meta['num_denoising_groups']
+ num_denoising_queries = dn_meta['num_denoising_queries']
+ num_queries_each_group = int(num_denoising_queries / num_groups)
+ device = gt_bboxes.device
+
+ if len(gt_labels) > 0:
+ t = torch.arange(len(gt_labels), dtype=torch.long, device=device)
+ t = t.unsqueeze(0).repeat(num_groups, 1)
+ pos_assigned_gt_inds = t.flatten()
+ pos_inds = torch.arange(num_groups, dtype=torch.long, device=device)
+ pos_inds = pos_inds.unsqueeze(1) * num_queries_each_group + t
+ pos_inds = pos_inds.flatten()
+ else:
+ pos_inds = pos_assigned_gt_inds = \
+ gt_bboxes.new_tensor([], dtype=torch.long)
+
+ # label targets
+ labels = gt_bboxes.new_full((num_denoising_queries, ),
+ self.num_classes,
+ dtype=torch.long)
+ labels[pos_inds] = gt_labels[pos_assigned_gt_inds]
+ label_weights = gt_bboxes.new_zeros(num_denoising_queries)
+ label_weights[pos_inds] = 1.0
+ # bbox targets
+ bbox_targets = torch.zeros(num_denoising_queries, 4, device=device)
+ bbox_weights = torch.zeros(num_denoising_queries, 4, device=device)
+ bbox_weights[pos_inds] = 1.0
+ img_h, img_w = img_meta['img_shape']
+
+ # DETR regress the relative position of boxes (cxcywh) in the image.
+ # Thus the learning target should be normalized by the image size, also
+ # the box format should be converted from defaultly x1y1x2y2 to cxcywh.
+ factor = gt_bboxes.new_tensor([img_w, img_h, img_w,
+ img_h]).unsqueeze(0)
+ gt_bboxes_normalized = gt_bboxes / factor
+ gt_bboxes_targets = bbox_xyxy_to_cxcywh(gt_bboxes_normalized)
+ bbox_targets[pos_inds] = gt_bboxes_targets.repeat([num_groups, 1])
+
+ return (labels, label_weights,bbox_targets, bbox_weights, pos_inds)
+
+
+ @staticmethod
+ def split_outputs(all_layers_cls_scores: Tensor,
+ all_layers_bbox_preds: Tensor,
+ dn_meta: Dict[str, int]) -> Tuple[Tensor]:
+ """Split outputs of the denoising part and the matching part.
+
+ For the total outputs of `num_queries_total` length, the former
+ `num_denoising_queries` outputs are from denoising queries, and
+ the rest `num_matching_queries` ones are from matching queries,
+ where `num_queries_total` is the sum of `num_denoising_queries` and
+ `num_matching_queries`.
+
+ Args:
+ all_layers_cls_scores (Tensor): Classification scores of all
+ decoder layers, has shape (num_decoder_layers, bs,
+ num_queries_total, cls_out_channels).
+ all_layers_bbox_preds (Tensor): Regression outputs of all decoder
+ layers. Each is a 4D-tensor with normalized coordinate format
+ (cx, cy, w, h) and has shape (num_decoder_layers, bs,
+ num_queries_total, 4).
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'.
+
+ Returns:
+ Tuple[Tensor]: a tuple containing the following outputs.
+
+ - all_layers_matching_cls_scores (Tensor): Classification scores
+ of all decoder layers in matching part, has shape
+ (num_decoder_layers, bs, num_matching_queries, cls_out_channels).
+ - all_layers_matching_bbox_preds (Tensor): Regression outputs of
+ all decoder layers in matching part. Each is a 4D-tensor with
+ normalized coordinate format (cx, cy, w, h) and has shape
+ (num_decoder_layers, bs, num_matching_queries, 4).
+ - all_layers_denoising_cls_scores (Tensor): Classification scores
+ of all decoder layers in denoising part, has shape
+ (num_decoder_layers, bs, num_denoising_queries,
+ cls_out_channels).
+ - all_layers_denoising_bbox_preds (Tensor): Regression outputs of
+ all decoder layers in denoising part. Each is a 4D-tensor with
+ normalized coordinate format (cx, cy, w, h) and has shape
+ (num_decoder_layers, bs, num_denoising_queries, 4).
+ """
+ if dn_meta is not None:
+ num_denoising_queries = dn_meta['num_denoising_queries']
+ all_layers_denoising_cls_scores = \
+ all_layers_cls_scores[:,:, : num_denoising_queries, :]
+ all_layers_denoising_bbox_preds = \
+ all_layers_bbox_preds[:, :, : num_denoising_queries, :]
+ all_layers_matching_cls_scores = \
+ all_layers_cls_scores[:, :, num_denoising_queries:, :]
+ all_layers_matching_bbox_preds = \
+ all_layers_bbox_preds[:, :, num_denoising_queries:, :]
+ else:
+ all_layers_denoising_cls_scores = None
+ all_layers_denoising_bbox_preds = None
+ all_layers_matching_cls_scores = all_layers_cls_scores
+ all_layers_matching_bbox_preds = all_layers_bbox_preds
+ return (all_layers_matching_cls_scores, all_layers_matching_bbox_preds,
+ all_layers_denoising_cls_scores,
+ all_layers_denoising_bbox_preds)
+
+
+ @staticmethod
+ def split_outputsv1(all_layers_cls_scores: Tensor,
+ all_layers_bbox_preds: Tensor,
+ dn_meta: Dict[str, int]) -> Tuple[Tensor]:
+ """Split outputs of the denoising part and the matching part.
+
+ For the total outputs of `num_queries_total` length, the former
+ `num_denoising_queries` outputs are from denoising queries, and
+ the rest `num_matching_queries` ones are from matching queries,
+ where `num_queries_total` is the sum of `num_denoising_queries` and
+ `num_matching_queries`.
+
+ Args:
+ all_layers_cls_scores (Tensor): Classification scores of all
+ decoder layers, has shape (num_decoder_layers, bs,
+ num_queries_total, cls_out_channels).
+ all_layers_bbox_preds (Tensor): Regression outputs of all decoder
+ layers. Each is a 4D-tensor with normalized coordinate format
+ (cx, cy, w, h) and has shape (num_decoder_layers, bs,
+ num_queries_total, 4).
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'.
+
+ Returns:
+ Tuple[Tensor]: a tuple containing the following outputs.
+
+ - all_layers_matching_cls_scores (Tensor): Classification scores
+ of all decoder layers in matching part, has shape
+ (num_decoder_layers, bs, num_matching_queries, cls_out_channels).
+ - all_layers_matching_bbox_preds (Tensor): Regression outputs of
+ all decoder layers in matching part. Each is a 4D-tensor with
+ normalized coordinate format (cx, cy, w, h) and has shape
+ (num_decoder_layers, bs, num_matching_queries, 4).
+ - all_layers_denoising_cls_scores (Tensor): Classification scores
+ of all decoder layers in denoising part, has shape
+ (num_decoder_layers, bs, num_denoising_queries,
+ cls_out_channels).
+ - all_layers_denoising_bbox_preds (Tensor): Regression outputs of
+ all decoder layers in denoising part. Each is a 4D-tensor with
+ normalized coordinate format (cx, cy, w, h) and has shape
+ (num_decoder_layers, bs, num_denoising_queries, 4).
+ """
+ if dn_meta is not None:
+ num_denoising_queries = dn_meta['num_denoising_queries']
+ all_layers_denoising_cls_scores = \
+ all_layers_cls_scores[:, : num_denoising_queries, :]
+ all_layers_denoising_bbox_preds = \
+ all_layers_bbox_preds[:, :, : num_denoising_queries, :]
+ all_layers_matching_cls_scores = \
+ all_layers_cls_scores[:, num_denoising_queries:, :]
+ all_layers_matching_bbox_preds = \
+ all_layers_bbox_preds[:, :, num_denoising_queries:, :]
+ else:
+ all_layers_denoising_cls_scores = None
+ all_layers_denoising_bbox_preds = None
+ all_layers_matching_cls_scores = all_layers_cls_scores
+ all_layers_matching_bbox_preds = all_layers_bbox_preds
+ return (all_layers_matching_cls_scores, all_layers_matching_bbox_preds,
+ all_layers_denoising_cls_scores,
+ all_layers_denoising_bbox_preds)
+
+ def predict(self,
+ hidden_states: Tensor,
+ references: List[Tensor],
+ centers: Tensor,
+ center_scores: Tensor,
+ topk_centers_scores: Tensor,
+ cls_scores: Tensor,
+ topk_cls_scores: Tensor,
+ seg_scores: Optional[Tensor],
+ abu_scores: Optional[Tensor],
+ batch_data_samples: SampleList,
+ rescale: bool = True) -> InstanceList:
+ """Perform forward propagation and loss calculation of the detection
+ head on the queries of the upstream network.
+
+ Args:
+ hidden_states (Tensor): Hidden states output from each decoder
+ layer, has shape (num_decoder_layers, num_queries, bs, dim).
+ references (list[Tensor]): List of the reference from the decoder.
+ The first reference is the `init_reference` (initial) and the
+ other num_decoder_layers(6) references are `inter_references`
+ (intermediate). The `init_reference` has shape (bs,
+ num_queries, 4) when `as_two_stage` of the detector is `True`,
+ otherwise (bs, num_queries, 2). Each `inter_reference` has
+ shape (bs, num_queries, 4) when `with_box_refine` of the
+ detector is `True`, otherwise (bs, num_queries, 2). The
+ coordinates are arranged as (cx, cy) when the last dimension is
+ 2, and (cx, cy, w, h) when it is 4.
+ batch_data_samples (list[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ rescale (bool, optional): If `True`, return boxes in original
+ image space. Defaults to `True`.
+
+ Returns:
+ list[obj:`InstanceData`]: Detection results of each image
+ after the post process.
+ """
+ batch_img_metas = [
+ data_samples.metainfo for data_samples in batch_data_samples
+ ]
+ outs = self(hidden_states, references, topk_cls_scores)
+ if self.predict_segmentation:
+ seg_scores = seg_scores.sigmoid()
+ if self.predict_abundance:
+ abu_scores = torch.clamp((abu_scores.sigmoid()-0.25)*2,0,1)
+ predictions = self.predict_by_feat(
+ *outs,seg_scores,abu_scores, batch_img_metas=batch_img_metas, rescale=rescale)
+ return predictions
+
+ def predict_by_feat(self,
+ all_layers_cls_scores: Tensor,
+ all_layers_bbox_preds: Tensor,
+ seg_scores: Optional[Tensor],
+ abu_scores: Optional[Tensor],
+ batch_img_metas: List[Dict],
+ rescale: bool = False) -> InstanceList:
+ """Transform a batch of output features extracted from the head into
+ bbox results.
+
+ Args:
+ all_layers_cls_scores (Tensor): Classification scores of all
+ decoder layers, has shape (num_decoder_layers, bs, num_queries,
+ cls_out_channels).
+ all_layers_bbox_preds (Tensor): Regression outputs of all decoder
+ layers. Each is a 4D-tensor with normalized coordinate format
+ (cx, cy, w, h) and shape (num_decoder_layers, bs, num_queries,
+ 4) with the last dimension arranged as (cx, cy, w, h).
+ batch_img_metas (list[dict]): Meta information of each image.
+ rescale (bool, optional): If `True`, return boxes in original
+ image space. Default `False`.
+
+ Returns:
+ list[obj:`InstanceData`]: Detection results of each image
+ after the post process.
+ """
+ cls_scores = all_layers_cls_scores[-1]
+ bbox_preds = all_layers_bbox_preds[-1]
+
+ result_list = []
+ for img_id in range(len(batch_img_metas)):
+ cls_score = cls_scores[img_id]
+ bbox_pred = bbox_preds[img_id]
+ img_meta = batch_img_metas[img_id]
+ if self.predict_segmentation:
+ seg_score = seg_scores[img_id]
+ else:
+ seg_score = None
+ if self.predict_abundance:
+ abu_score = abu_scores[img_id]
+ else:
+ abu_score = None
+ results = self._predict_by_feat_single(cls_score, bbox_pred,
+ seg_score,abu_score,
+ img_meta, rescale)
+ result_list.append(results)
+ return result_list
+
+ def _predict_by_feat_single(self,
+ cls_score: Tensor,
+ bbox_pred: Tensor,
+ seg_score: Optional[Tensor],
+ abu_score: Optional[Tensor],
+ img_meta: dict,
+ rescale: bool = True) -> InstanceData:
+ """Transform outputs from the last decoder layer into bbox predictions
+ for each image.
+
+ Args:
+ cls_score (Tensor): Box score logits from the last decoder layer
+ for each image. Shape [num_queries, cls_out_channels].
+ bbox_pred (Tensor): Sigmoid outputs from the last decoder layer
+ for each image, with coordinate format (cx, cy, w, h) and
+ shape [num_queries, 4].
+ img_meta (dict): Image meta info.
+ rescale (bool): If True, return boxes in original image
+ space. Default True.
+
+ Returns:
+ :obj:`InstanceData`: Detection results of each image
+ after the post process.
+ Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ """
+ assert len(cls_score) == len(bbox_pred) # num_queries
+ max_per_img = self.test_cfg.get('max_per_img', len(cls_score))
+
+ img_shape = img_meta['img_shape']
+ assert self.loss_cls.use_sigmoid
+ cls_score = cls_score.sigmoid()
+ # scores, indexes = cls_score.view(-1).topk(max_per_img)
+ scores, indexes = torch.sort(cls_score.view(-1), descending=True)
+ # indexes = indexes[scores > self.score_threshold]
+ # scores = scores[scores > self.score_threshold]
+ det_labels = indexes % self.num_classes
+ bbox_index = torch.div(indexes, self.num_classes, rounding_mode='trunc')
+ bbox_pred = bbox_pred[bbox_index]
+ det_bboxes = bbox_cxcywh_to_xyxy(bbox_pred)
+ det_bboxes[:, 0::2] = det_bboxes[:, 0::2] * img_shape[1]
+ det_bboxes[:, 1::2] = det_bboxes[:, 1::2] * img_shape[0]
+ det_bboxes[:, 0::2].clamp_(min=0, max=img_shape[1])
+ det_bboxes[:, 1::2].clamp_(min=0, max=img_shape[0])
+ if self.use_nms:
+ if det_labels.numel() > 0:
+ bboxes_scores, keep = batched_nms(det_bboxes, scores.contiguous(), det_labels, self.test_nms, class_agnostic=(not self.class_wise_nms))
+ if keep.numel() > max_per_img:
+ bboxes_scores = bboxes_scores[:max_per_img]
+ det_labels = det_labels[keep][:max_per_img]
+ else:
+ det_labels = det_labels[keep]
+ det_bboxes = bboxes_scores[:, :-1]
+ scores = bboxes_scores[:, -1]
+ if self.pre_bboxes_round:
+ det_bboxes = adjust_bbox_to_pixel(det_bboxes)
+ if rescale:
+ # assert img_meta.get('scale_factor') is not None
+ # det_bboxes /= det_bboxes.new_tensor(
+ # img_meta['scale_factor']).repeat((1, 2))
+ # rw by lzx
+ if img_meta.get('scale_factor') is not None:
+ det_bboxes /= det_bboxes.new_tensor(
+ img_meta['scale_factor']).repeat((1, 2))
+
+ if self.predict_segmentation:
+ img_h, img_w = img_meta['ori_shape'][:2]
+ seg_score = seg_score.view(img_h, img_w)
+ seg_mask=seg_score>self.mask_threshold
+ N = det_bboxes.size(0)
+ im_mask = torch.zeros(
+ N,
+ img_shape[0],
+ img_shape[1],
+ device=det_bboxes.device,
+ dtype=torch.bool)
+ for i in range(N):
+ x0, y0, x1, y1 = det_bboxes[i,:]
+ x0 = max(int(x0)-self.mask_extend_pixel,0)
+ x1 = min(int(x1)+self.mask_extend_pixel,img_w)
+ y0 = max(int(y0)-self.mask_extend_pixel,0)
+ y1 = min(int(y1)+self.mask_extend_pixel,img_h)
+ im_mask[i, y0:y1,x0:x1] =seg_mask[y0:y1,x0:x1 ]
+ new_mask = torch.sum(im_mask,dim=0)
+ seg_score_new = seg_score.clone().detach()
+ seg_score_new[new_mask==0] = 0
+ if self.save_path is not None:
+ img_name=img_meta['img_path'].split('/')[-1].replace('.npy','').replace('.png','').replace('.jpg','').replace('.mat','')
+ sio.savemat(os.path.join(self.save_path,img_name+'_seg_scoremap.mat'),
+ {'data':seg_score.detach().cpu().numpy()})
+ sio.savemat(os.path.join(self.save_path,img_name+'_seg_predictionmap.mat'),
+ {'data':seg_score_new.detach().cpu().numpy()})
+ if self.predict_abundance:
+ abu_score = abu_score.view(img_h, img_w)
+ abu_score_new = abu_score.clone().detach()
+ abu_score_new[new_mask == 0] = 0
+ sio.savemat(os.path.join(self.save_path, img_name + '_abu_scoremap.mat'),
+ {'data': abu_score.detach().cpu().numpy()})
+ sio.savemat(os.path.join(self.save_path, img_name + '_abu_predictionmap.mat'),
+ {'data': seg_score_new.detach().cpu().numpy()})
+ results = InstanceData()
+ results.bboxes = det_bboxes
+ results.scores = scores
+ results.labels = det_labels
+ if self.predict_segmentation:
+ results.masks = im_mask
+ return results
diff --git a/mmdet/models/dense_heads/evolvedet_headv1.py b/mmdet/models/dense_heads/evolvedet_headv1.py
new file mode 100644
index 0000000000000000000000000000000000000000..a168300dd08e79b48f52545a58f510476fbd7fd2
--- /dev/null
+++ b/mmdet/models/dense_heads/evolvedet_headv1.py
@@ -0,0 +1,1741 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+from typing import Dict, List, Tuple
+from torch import Tensor
+from mmcv.cnn import Linear
+from mmengine.model import bias_init_with_prob, constant_init
+from mmengine.structures import InstanceData
+from mmengine.model import BaseModule
+from mmdet.registry import MODELS
+from mmdet.structures import SampleList
+from mmdet.structures.bbox import bbox_cxcywh_to_xyxy, bbox_xyxy_to_cxcywh, bbox_overlaps
+from mmdet.utils import InstanceList, OptInstanceList, reduce_mean
+from ..utils import multi_apply
+from ..layers import inverse_sigmoid
+from .detr_head import DETRHead
+from mmdet.registry import MODELS, TASK_UTILS
+from mmdet.utils import (ConfigType, InstanceList, OptInstanceList,OptConfigType,
+ OptMultiConfig, reduce_mean)
+from mmcv.ops import nms, batched_nms
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from torch.nn import Transformer
+from ..losses import QualityFocalLoss
+# def adjust_bbox_to_pixel(bboxes: Tensor):
+# # 向下取整得到目标的左上角坐标
+# adjusted_bboxes = torch.floor(bboxes)
+# # 向上取整得到目标的右下角坐标
+# adjusted_bboxes[:, 2:] = torch.ceil(bboxes[:, 2:])
+# return adjusted_bboxes
+
+
+def adjust_bbox_to_pixel(bboxes: Tensor):
+ # 四舍五入取整坐标
+ adjusted_bboxes = torch.round(bboxes)
+
+ return adjusted_bboxes
+
+@MODELS.register_module()
+class EvloveDetHead(BaseModule):
+ r"""Head of the DINO: DETR with Improved DeNoising Anchor Boxes
+ for End-to-End Object Detection
+
+ Code is modified from the `official github repo
+ `_.
+
+ More details can be found in the `paper
+ `_ .
+ """
+
+ def __init__(self,
+ num_classes: int,
+ embed_dims: int = 256,
+ num_reg_fcs: int = 2,
+ center_feat_indice: int=1,
+ sync_cls_avg_factor: bool = False,
+ use_nms: bool = False,
+ iou_threshold: float = 0.01,
+ score_threshold: float = 0.0,
+ class_wise_nms: bool = True,
+ test_nms: OptConfigType = dict(type='nms', iou_threshold=0.01, ),
+ neg_cls: bool = True,
+ loss_cls: ConfigType = dict(
+ type='CrossEntropyLoss',
+ bg_cls_weight=0.1,
+ use_sigmoid=False,
+ loss_weight=1.0,
+ class_weight=1.0),
+ loss_center_cls: ConfigType = dict(
+ type='CrossEntropyLoss',
+ bg_cls_weight=0.1,
+ use_sigmoid=False,
+ loss_weight=1.0,
+ class_weight=1.0),
+ loss_bbox: ConfigType = dict(type='L1Loss', loss_weight=5.0),
+ loss_iou: ConfigType = dict(type='GIoULoss', loss_weight=2.0),
+ train_cfg: ConfigType = dict(
+ assigner=dict(
+ type='HungarianAssigner',
+ match_costs=[
+ dict(type='ClassificationCost', weight=1.),
+ dict(type='BBoxL1Cost', weight=5.0, box_format='xywh'),
+ dict(type='IoUCost', iou_mode='giou', weight=2.0)
+ ])),
+ bbox_assigner: ConfigType = dict(type='MaxIoUAssigner',
+ pos_iou_thr=0.01,
+ neg_iou_thr=0.01,
+ min_pos_iou=0.01,
+ match_low_quality=False,
+ ignore_iof_thr=-1),
+ dn_assigner: ConfigType = dict(type='MaxIoUAssigner',
+ pos_iou_thr=0.9,
+ neg_iou_thr=0.9,
+ min_pos_iou=0.9,
+ match_low_quality=False,
+ ignore_iof_thr=-1),
+ test_cfg: ConfigType = dict(max_per_img=100),
+ init_cfg: OptMultiConfig = None,
+ share_pred_layer: bool = False,
+ num_pred_layer: int = 6,
+ as_two_stage: bool = False,
+ pre_bboxes_round: bool = True,
+ decoupe_dn: bool = False,
+ dn_only_pos: bool = False,
+ dn_loss_weight: List[float] = [1, 1, 1], # [1,1,1]
+ center_neg_hard_num: int = 300,
+ center_neg_rand_num: int = 300,
+ loss_center_th: float = 0.2,
+ loss_iou_th: float = 0.3,
+ center_ds_ratio: int = 1
+ ) -> None:
+ self.share_pred_layer = share_pred_layer
+ self.num_pred_layer = num_pred_layer
+ self.as_two_stage = as_two_stage
+ self.pre_bboxes_round = pre_bboxes_round
+ assert not (decoupe_dn and dn_only_pos), "Both decoupe_dn and dn_only_pos cannot be True at the same time."
+ self.decoupe_dn = decoupe_dn
+ self.dn_only_pos = dn_only_pos
+ self.dn_loss_weight = dn_loss_weight
+ self.iou_threshold = iou_threshold
+ self.loss_center_th = loss_center_th
+ self.loss_iou_th = loss_iou_th
+ self.center_feat_indice = center_feat_indice
+ self.center_ds_ratio = center_ds_ratio
+ super().__init__(init_cfg=init_cfg)
+ self.bg_cls_weight = 0
+ self.sync_cls_avg_factor = sync_cls_avg_factor
+ class_weight = loss_cls.get('class_weight', None)
+ if class_weight is not None and (self.__class__ is DETRHead):
+ assert isinstance(class_weight, float), 'Expected ' \
+ 'class_weight to have type float. Found ' \
+ f'{type(class_weight)}.'
+ # NOTE following the official DETR repo, bg_cls_weight means
+ # relative classification weight of the no-object class.
+ bg_cls_weight = loss_cls.get('bg_cls_weight', class_weight)
+ assert isinstance(bg_cls_weight, float), 'Expected ' \
+ 'bg_cls_weight to have type float. Found ' \
+ f'{type(bg_cls_weight)}.'
+ class_weight = torch.ones(num_classes + 1) * class_weight
+ # set background class as the last indice
+ class_weight[num_classes] = bg_cls_weight
+ loss_cls.update({'class_weight': class_weight})
+ if 'bg_cls_weight' in loss_cls:
+ loss_cls.pop('bg_cls_weight')
+ self.bg_cls_weight = bg_cls_weight
+ if train_cfg:
+ assert 'assigner' in train_cfg, 'assigner should be provided ' \
+ 'when train_cfg is set.'
+ assigner = train_cfg['assigner']
+ self.assigner = TASK_UTILS.build(assigner)
+ if train_cfg.get('sampler', None) is not None:
+ raise RuntimeError('DETR do not build sampler.')
+ self.bbox_assigner = TASK_UTILS.build(bbox_assigner)
+ self.dn_assigner = TASK_UTILS.build(dn_assigner)
+ self.num_classes = num_classes
+ self.embed_dims = embed_dims
+ self.num_reg_fcs = num_reg_fcs
+ self.train_cfg = train_cfg
+ self.test_cfg = test_cfg
+ self.loss_cls = MODELS.build(loss_cls)
+ self.loss_center_cls = MODELS.build(loss_center_cls)
+ self.loss_bbox = MODELS.build(loss_bbox)
+ self.loss_iou = MODELS.build(loss_iou)
+ self.use_nms = use_nms
+ self.class_wise_nms = class_wise_nms
+ self.score_threshold = score_threshold
+ self.test_nms = test_nms
+ self.neg_cls = neg_cls
+ if self.loss_cls.use_sigmoid:
+ self.cls_out_channels = num_classes
+ else:
+ self.cls_out_channels = num_classes + 1
+ self.center_neg_hard_num = center_neg_hard_num
+ self.center_neg_rand_num = center_neg_rand_num
+ self._init_layers()
+
+ def _init_layers(self) -> None:
+ """Initialize classification branch and regression branch of head."""
+ # fc_cls = Linear(self.embed_dims, self.cls_out_channels)
+ fc_cls = []
+ # for _ in range(self.num_reg_fcs):
+ # fc_cls.append(Linear(self.embed_dims, self.embed_dims))
+ # fc_cls.append(nn.ReLU())
+ fc_cls.append(Linear(self.embed_dims, self.cls_out_channels))
+ # fc_cls.append(Linear(self.embed_dims, 1))
+ fc_cls = nn.Sequential(*fc_cls)
+ self.cls_branches = nn.ModuleList([fc_cls])
+ reg_branch = []
+ for _ in range(self.num_reg_fcs):
+ reg_branch.append(Linear(self.embed_dims, self.embed_dims))
+ reg_branch.append(nn.ReLU())
+ reg_branch.append(Linear(self.embed_dims, 4))
+ reg_branch = nn.Sequential(*reg_branch)
+ if self.share_pred_layer:
+ self.reg_branches = nn.ModuleList(
+ [reg_branch for _ in range(self.num_pred_layer)])
+ else:
+ self.reg_branches = nn.ModuleList([
+ copy.deepcopy(reg_branch) for _ in range(self.num_pred_layer)
+ ])
+ center_cls = []
+ # for _ in range(self.num_reg_fcs):
+ # center_cls.append(Linear(self.embed_dims, self.embed_dims))
+ # center_cls.append(nn.ReLU())
+ center_cls.append(Linear(self.embed_dims, 1))
+ center_cls = nn.Sequential(*center_cls)
+ self.center_cls = center_cls
+ self.cls_embedding = nn.Embedding(1, self.embed_dims)
+ # self.cls_embedding = nn.Embedding(self.cls_out_channels, self.embed_dims)
+
+ def init_weights(self) -> None:
+ """Initialize weights of the Deformable DETR head."""
+ if self.loss_cls.use_sigmoid:
+ bias_init = bias_init_with_prob(0.01)
+ for m in self.cls_branches:
+ nn.init.constant_(m.bias, bias_init)
+ nn.init.constant_(self.center_cls.bias, bias_init)
+ for m in self.reg_branches:
+ constant_init(m[-1], 0, bias=0)
+ nn.init.constant_(self.reg_branches[0][-1].bias.data[2:], -2.0)
+ if self.as_two_stage:
+ for m in self.reg_branches:
+ nn.init.constant_(m[-1].bias.data[2:], 0.0)
+ nn.init.xavier_uniform_(self.cls_embedding)
+
+ def _get_targets_single(self, cls_score: Tensor, bbox_pred: Tensor,
+ gt_instances: InstanceData,
+ img_meta: dict,
+ with_neg_cls:bool=True,
+ assigner_type:str = None) -> tuple:
+ """Compute regression and classification targets for one image.
+
+ Outputs from a single decoder layer of a single feature level are used.
+
+ Args:
+ cls_score (Tensor): Box score logits from a single decoder layer
+ for one image. Shape [num_queries, cls_out_channels].
+ bbox_pred (Tensor): Sigmoid outputs from a single decoder layer
+ for one image, with normalized coordinate (cx, cy, w, h) and
+ shape [num_queries, 4].
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It should includes ``bboxes`` and ``labels``
+ attributes.
+ img_meta (dict): Meta information for one image.
+
+ Returns:
+ tuple[Tensor]: a tuple containing the following for one image.
+
+ - labels (Tensor): Labels of each image.
+ - label_weights (Tensor]): Label weights of each image.
+ - bbox_targets (Tensor): BBox targets of each image.
+ - bbox_weights (Tensor): BBox weights of each image.
+ - pos_inds (Tensor): Sampled positive indices for each image.
+ - neg_inds (Tensor): Sampled negative indices for each image.
+ """
+ img_h, img_w = img_meta['img_shape']
+ factor = bbox_pred.new_tensor([img_w, img_h, img_w,
+ img_h]).unsqueeze(0)
+ num_bboxes = bbox_pred.size(0)
+ # convert bbox_pred from xywh, normalized to xyxy, unnormalized
+ bbox_pred = bbox_cxcywh_to_xyxy(bbox_pred)
+ bbox_pred = bbox_pred * factor
+
+ pred_instances = InstanceData(scores=cls_score, bboxes=bbox_pred,priors=bbox_pred)
+ # assigner and sampler
+ if assigner_type == 'dn':
+ assign_result = self.dn_assigner.assign(
+ pred_instances=pred_instances,
+ gt_instances=gt_instances,
+ img_meta=img_meta)
+ else:
+ assign_result = self.assigner.assign(
+ pred_instances=pred_instances,
+ gt_instances=gt_instances,
+ img_meta=img_meta)
+
+ gt_bboxes = gt_instances.bboxes
+ gt_labels = gt_instances.labels
+ pos_inds = torch.nonzero(
+ assign_result.gt_inds > 0, as_tuple=False).squeeze(-1).unique()
+ neg_inds = torch.nonzero(
+ assign_result.gt_inds == 0, as_tuple=False).squeeze(-1).unique()
+ pos_assigned_gt_inds = assign_result.gt_inds[pos_inds] - 1
+ pos_gt_bboxes = gt_bboxes[pos_assigned_gt_inds.long(), :]
+ # label targets
+ labels = gt_bboxes.new_full((num_bboxes,),
+ self.num_classes,
+ dtype=torch.long)
+ labels[pos_inds] = gt_labels[pos_assigned_gt_inds]
+ label_weights = gt_bboxes.new_zeros(num_bboxes)
+ label_weights[pos_inds] = 1
+ label_weights[neg_inds] = 1
+ if not with_neg_cls:
+ label_weights[neg_inds] = 0
+ # bbox targets
+ bbox_targets = torch.zeros_like(bbox_pred)
+ bbox_weights = torch.zeros_like(bbox_pred)
+ bbox_weights[pos_inds] = 1.0
+ # DETR regress the relative position of boxes (cxcywh) in the image.
+ # Thus the learning target should be normalized by the image size, also
+ # the box format should be converted from defaultly x1y1x2y2 to cxcywh.
+ pos_gt_bboxes_normalized = pos_gt_bboxes / factor
+ pos_gt_bboxes_targets = bbox_xyxy_to_cxcywh(pos_gt_bboxes_normalized)
+ bbox_targets[pos_inds] = pos_gt_bboxes_targets
+ return (labels, label_weights, bbox_targets, bbox_weights, pos_inds,
+ neg_inds)
+
+ # def _get_targets_single_center(self, center_score: Tensor, center: Tensor,
+ # spatial_shapes: Tensor,
+ # gt_instances: InstanceData,
+ # img_meta: dict) -> tuple:
+ # """Compute regression and classification targets for one image.
+ #
+ # Outputs from a single decoder layer of a single feature level are used.
+ #
+ # Args:
+ # cls_score (Tensor): Box score logits from a single decoder layer
+ # for one image. Shape [num_queries, cls_out_channels].
+ # bbox_pred (Tensor): Sigmoid outputs from a single decoder layer
+ # for one image, with normalized coordinate (cx, cy, w, h) and
+ # shape [num_queries, 4].
+ # gt_instances (:obj:`InstanceData`): Ground truth of instance
+ # annotations. It should includes ``bboxes`` and ``labels``
+ # attributes.
+ # img_meta (dict): Meta information for one image.
+ #
+ # Returns:
+ # tuple[Tensor]: a tuple containing the following for one image.
+ #
+ # - labels (Tensor): Labels of each image.
+ # - label_weights (Tensor]): Label weights of each image.
+ # - bbox_targets (Tensor): BBox targets of each image.
+ # - bbox_weights (Tensor): BBox weights of each image.
+ # - pos_inds (Tensor): Sampled positive indices for each image.
+ # - neg_inds (Tensor): Sampled negative indices for each image.
+ # """
+ # img_h, img_w = img_meta['img_shape']
+ # feat_w = int(spatial_shapes[self.center_feat_indice][0])
+ # feat_h = int(spatial_shapes[self.center_feat_indice][1])
+ # factor = center.new_tensor([feat_w, feat_h]).unsqueeze(0)
+ # # factor = center.new_tensor([img_w, img_h,]).unsqueeze(0)
+ # num_center = center.size(0)
+ # # convert bbox_pred from xywh, normalized to xyxy, unnormalized
+ # # bbox_pred = center
+ # center = center * factor
+ # gt_bboxes = gt_instances.bboxes
+ # gt_cxcy = bbox_xyxy_to_cxcywh(gt_bboxes)[:, :2]
+ # gt_cxcy[:, 0] = gt_cxcy[:, 0] * feat_w / img_w
+ # gt_cxcy[:, 1] = gt_cxcy[:, 1] * feat_h / img_h
+ # gt_cxcy_int = torch.floor(gt_cxcy+0.5)-0.5
+ # grid_y, grid_x = torch.meshgrid(
+ # torch.linspace(-1, 1, 3, dtype=gt_cxcy.dtype, device=gt_cxcy.device),
+ # torch.linspace(-1, 1, 3, dtype=gt_cxcy.dtype, device=gt_cxcy.device))
+ # grid = torch.cat([grid_x.unsqueeze(-1), grid_y.unsqueeze(-1)], -1)
+ # grid = grid.view(-1, 2).unsqueeze(0).repeat(gt_cxcy.size(0), 1, 1)
+ # candidate_point = gt_cxcy_int.unsqueeze(1).repeat(1, grid.size(1), 1)+grid
+ # gt_cxcy_expand = gt_cxcy.unsqueeze(1).repeat(1, grid.size(1), 1)
+ # dis = torch.sum((candidate_point-gt_cxcy_expand)**2, dim=2)
+ # dis_min_indices = dis.argmin(dim=1)
+ # dis_min_indices += torch.arange(len(dis_min_indices), device=dis_min_indices.device) * grid.size(1)
+ # candidate_point = candidate_point.view(-1, 2)
+ # target_point = candidate_point[dis_min_indices, :]
+ # target_point[target_point<0.5]=0.5
+ # pos_index = torch.floor(target_point[:, 0]) + torch.floor(target_point[:, 1]) * feat_w
+ # pos_index = pos_index.to(torch.long)
+ # mask = (candidate_point > 0).all(dim=1) & (candidate_point[:, 0] <= feat_w) & (candidate_point[:, 1] <= feat_h)
+ # candidate_point = candidate_point[mask]
+ # candidate_index = torch.floor(candidate_point[:, 0]) + torch.floor(candidate_point[:, 1]) * feat_w
+ # candidate_index = candidate_index.to(torch.long)
+ # candidate_index = torch.unique(candidate_index)
+ # _, indices = torch.sort(center_score,dim=0, descending=True)
+ # sorted_indices = indices.squeeze()
+ # mask = torch.isin(sorted_indices, candidate_index)
+ # remaining_index = sorted_indices[~mask]
+ # neg_index1 = remaining_index[:self.center_neg_hard_num]
+ # neg_index2 = torch.randperm(remaining_index[self.center_neg_hard_num:].size(0), device=center.device)[:self.center_neg_rand_num ]
+ # # neg_index = torch.cat([neg_index1, neg_index2], dim=0)
+ # neg_index = neg_index2
+ # new_index = torch.cat([pos_index, neg_index], dim=0)
+ # # new_center = center[new_index]
+ # new_center_score = center_score[new_index]
+ # pos_inds = torch.arange(0, pos_index.size(0))
+ # neg_inds = torch.arange(pos_index.size(0), new_index.size(0))
+ # labels = gt_bboxes.new_full((new_index.size(0),), 1, dtype=torch.long)
+ # labels[:pos_index.size(0),] = 0
+ # label_weights = gt_bboxes.new_ones(new_index.size(0))
+ #
+ # return (labels, label_weights, pos_inds, neg_inds, new_center_score)
+
+ def _get_targets_single_center(self, center_score: Tensor, center: Tensor,
+ spatial_shapes: Tensor,
+ gt_instances: InstanceData,
+ img_meta: dict) -> tuple:
+ """Compute regression and classification targets for one image.
+
+ Outputs from a single decoder layer of a single feature level are used.
+
+ Args:
+ cls_score (Tensor): Box score logits from a single decoder layer
+ for one image. Shape [num_queries, cls_out_channels].
+ bbox_pred (Tensor): Sigmoid outputs from a single decoder layer
+ for one image, with normalized coordinate (cx, cy, w, h) and
+ shape [num_queries, 4].
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It should includes ``bboxes`` and ``labels``
+ attributes.
+ img_meta (dict): Meta information for one image.
+
+ Returns:
+ tuple[Tensor]: a tuple containing the following for one image.
+
+ - labels (Tensor): Labels of each image.
+ - label_weights (Tensor]): Label weights of each image.
+ - bbox_targets (Tensor): BBox targets of each image.
+ - bbox_weights (Tensor): BBox weights of each image.
+ - pos_inds (Tensor): Sampled positive indices for each image.
+ - neg_inds (Tensor): Sampled negative indices for each image.
+ """
+ img_h, img_w = img_meta['img_shape']
+ feat_h = int(spatial_shapes[self.center_feat_indice][0]/self.center_ds_ratio)
+ feat_w = int(spatial_shapes[self.center_feat_indice][1]/self.center_ds_ratio)
+ factor = center.new_tensor([feat_w, feat_h]).unsqueeze(0)
+ # factor = center.new_tensor([img_w, img_h,]).unsqueeze(0)
+ num_center = center.size(0)
+ # convert bbox_pred from xywh, normalized to xyxy, unnormalized
+ # bbox_pred = center
+ center = center * factor
+ gt_bboxes = gt_instances.bboxes
+ gt_cxcy = bbox_xyxy_to_cxcywh(gt_bboxes)[:, :2]
+ gt_cxcy[:, 0] = gt_cxcy[:, 0] * feat_w / img_w
+ gt_cxcy[:, 1] = gt_cxcy[:, 1] * feat_h / img_h
+ gt_cxcy= gt_cxcy.long()
+ gt_bboxes[:, 2:] -= 0.1
+ gt_bboxes_x = gt_bboxes[:, 0::2]
+ gt_bboxes_y = gt_bboxes[:, 1::2]
+ gt_bboxes_x = torch.floor(gt_bboxes_x * feat_w / img_w)
+ gt_bboxes_y = torch.floor(gt_bboxes_y * feat_h / img_h)
+ gt_bboxes_x = gt_bboxes_x.long()
+ gt_bboxes_y = gt_bboxes_y.long()
+ heat_map = gt_bboxes.new_full((feat_h, feat_w), 0, dtype=torch.long)
+ for t_i in range(gt_bboxes.size(0)):
+ grid_y, grid_x = torch.meshgrid(
+ torch.linspace(gt_bboxes_y[t_i, 0], gt_bboxes_y[t_i, 1], gt_bboxes_y[t_i, 1]+1-gt_bboxes_y[t_i, 0],
+ dtype=torch.long, device=gt_cxcy.device),
+ torch.linspace(gt_bboxes_x[t_i, 0], gt_bboxes_x[t_i, 1], gt_bboxes_x[t_i, 1]+1-gt_bboxes_x[t_i, 0],
+ dtype=torch.long, device=gt_cxcy.device))
+ grid = torch.cat([grid_y.unsqueeze(-1), grid_x.unsqueeze(-1)], -1)
+ grid = grid.view(-1, 2)
+ a = gt_bboxes.new_full((grid.size(0),), -1, dtype=torch.long)
+ heat_map.index_put_((grid[:,0],grid[:,1]), a)
+ a = gt_bboxes.new_full((gt_cxcy.size(0),), 1, dtype=torch.long)
+ heat_map = heat_map.index_put_((gt_cxcy[:,1], gt_cxcy[:,0]), a)
+ heat_map = heat_map.view(-1)
+ mask = heat_map != -1
+ new_center_score = center_score[mask]
+ heat_map = heat_map[mask]
+ pos_inds = torch.where(heat_map == 1)[0]
+ neg_inds = torch.where(heat_map == 0)[0]
+ labels = gt_bboxes.new_full((heat_map.size(0),), 1, dtype=torch.long)
+ labels[pos_inds] = 0
+ label_weights = gt_bboxes.new_ones(heat_map.size(0))
+ return (labels, label_weights, pos_inds, neg_inds, new_center_score)
+
+
+ def _get_targets_single_bbox(self,cls_score: Tensor, bbox_pred: Tensor,
+ gt_instances: InstanceData,
+ img_meta: dict) -> tuple:
+ """Compute regression and classification targets for one image.
+
+ Outputs from a single decoder layer of a single feature level are used.
+
+ Args:
+ cls_score (Tensor): Box score logits from a single decoder layer
+ for one image. Shape [num_queries, cls_out_channels].
+ bbox_pred (Tensor): Sigmoid outputs from a single decoder layer
+ for one image, with normalized coordinate (cx, cy, w, h) and
+ shape [num_queries, 4].
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It should includes ``bboxes`` and ``labels``
+ attributes.
+ img_meta (dict): Meta information for one image.
+
+ Returns:
+ tuple[Tensor]: a tuple containing the following for one image.
+
+ - labels (Tensor): Labels of each image.
+ - label_weights (Tensor]): Label weights of each image.
+ - bbox_targets (Tensor): BBox targets of each image.
+ - bbox_weights (Tensor): BBox weights of each image.
+ - pos_inds (Tensor): Sampled positive indices for each image.
+ - neg_inds (Tensor): Sampled negative indices for each image.
+ """
+ img_h, img_w = img_meta['img_shape']
+ factor = bbox_pred.new_tensor([img_w, img_h, img_w,
+ img_h]).unsqueeze(0)
+ num_bboxes = bbox_pred.size(0)
+ # convert bbox_pred from xywh, normalized to xyxy, unnormalized
+ bbox_pred = bbox_cxcywh_to_xyxy(bbox_pred)
+ bbox_pred = bbox_pred * factor
+
+ pred_instances = InstanceData(scores=cls_score, bboxes=bbox_pred,priors=bbox_pred)
+ # assigner and sampler
+ assign_result = self.bbox_assigner.assign(
+ pred_instances=pred_instances,
+ gt_instances=gt_instances,
+ img_meta=img_meta)
+ gt_bboxes = gt_instances.bboxes
+ gt_labels = gt_instances.labels
+ pos_inds = torch.nonzero(
+ assign_result.gt_inds > 0, as_tuple=False).squeeze(-1).unique()
+ neg_inds = torch.nonzero(
+ assign_result.gt_inds == 0, as_tuple=False).squeeze(-1).unique()
+ pos_assigned_gt_inds = assign_result.gt_inds[pos_inds] - 1
+ pos_gt_bboxes = gt_bboxes[pos_assigned_gt_inds.long(), :]
+
+ # bbox targets
+ bbox_targets = torch.zeros_like(bbox_pred)
+ bbox_weights = torch.zeros_like(bbox_pred)
+ bbox_weights[pos_inds] = 1.0
+
+ # DETR regress the relative position of boxes (cxcywh) in the image.
+ # Thus the learning target should be normalized by the image size, also
+ # the box format should be converted from defaultly x1y1x2y2 to cxcywh.
+ pos_gt_bboxes_normalized = pos_gt_bboxes / factor
+ pos_gt_bboxes_targets = bbox_xyxy_to_cxcywh(pos_gt_bboxes_normalized)
+ bbox_targets[pos_inds] = pos_gt_bboxes_targets
+ return (bbox_targets, bbox_weights, pos_inds, neg_inds)
+
+ def loss_and_predict(
+ self, hidden_states: Tuple[Tensor],
+ batch_data_samples: SampleList) -> Tuple[dict, InstanceList]:
+ """Perform forward propagation of the head, then calculate loss and
+ predictions from the features and data samples. Over-write because
+ img_metas are needed as inputs for bbox_head.
+
+ Args:
+ hidden_states (tuple[Tensor]): Feature from the transformer
+ decoder, has shape (num_decoder_layers, bs, num_queries, dim).
+ batch_data_samples (list[:obj:`DetDataSample`]): Each item contains
+ the meta information of each image and corresponding
+ annotations.
+
+ Returns:
+ tuple: the return value is a tuple contains:
+
+ - losses: (dict[str, Tensor]): A dictionary of loss components.
+ - predictions (list[:obj:`InstanceData`]): Detection
+ results of each image after the post process.
+ """
+ batch_gt_instances = []
+ batch_img_metas = []
+ for data_sample in batch_data_samples:
+ batch_img_metas.append(data_sample.metainfo)
+ batch_gt_instances.append(data_sample.gt_instances)
+ outs = self(hidden_states)
+ loss_inputs = outs + (batch_gt_instances, batch_img_metas)
+ losses = self.loss_by_feat(*loss_inputs)
+ predictions = self.predict_by_feat(
+ *outs, batch_img_metas=batch_img_metas)
+ return losses, predictions
+
+ def forward(self, hidden_states: Tensor,
+ references: List[Tensor],
+ cls_feats: Tensor,) -> Tuple[Tensor]:
+ """Forward function.
+
+ Args:
+ hidden_states (Tensor): Hidden states output from each decoder
+ layer, has shape (num_decoder_layers, bs, num_queries, dim).
+ references (list[Tensor]): List of the reference from the decoder.
+ The first reference is the `init_reference` (initial) and the
+ other num_decoder_layers(6) references are `inter_references`
+ (intermediate). The `init_reference` has shape (bs,
+ num_queries, 4) when `as_two_stage` of the detector is `True`,
+ otherwise (bs, num_queries, 2). Each `inter_reference` has
+ shape (bs, num_queries, 4) when `with_box_refine` of the
+ detector is `True`, otherwise (bs, num_queries, 2). The
+ coordinates are arranged as (cx, cy) when the last dimension is
+ 2, and (cx, cy, w, h) when it is 4.
+
+ Returns:
+ tuple[Tensor]: results of head containing the following tensor.
+
+ - all_layers_outputs_classes (Tensor): Outputs from the
+ classification head, has shape (num_decoder_layers, bs,
+ num_queries, cls_out_channels).
+ - all_layers_outputs_coords (Tensor): Sigmoid outputs from the
+ regression head with normalized coordinate format (cx, cy, w,
+ h), has shape (num_decoder_layers, bs, num_queries, 4) with the
+ last dimension arranged as (cx, cy, w, h).
+ """
+ all_layers_outputs_coords = []
+ for layer_id in range(hidden_states.shape[0]):
+ reference = inverse_sigmoid(references[layer_id])
+ # NOTE The last reference will not be used.
+ hidden_state = hidden_states[layer_id]
+ tmp_reg_preds = self.reg_branches[layer_id](hidden_state)
+ if reference.shape[-1] == 4:
+ # When `layer` is 0 and `as_two_stage` of the detector
+ # is `True`, or when `layer` is greater than 0 and
+ # `with_box_refine` of the detector is `True`.
+ tmp_reg_preds += reference
+ else:
+ # When `layer` is 0 and `as_two_stage` of the detector
+ # is `False`, or when `layer` is greater than 0 and
+ # `with_box_refine` of the detector is `False`.
+ assert reference.shape[-1] == 2
+ tmp_reg_preds[..., :2] += reference
+ outputs_coord = tmp_reg_preds.sigmoid()
+ all_layers_outputs_coords.append(outputs_coord)
+ # cls_embedding = self.cls_embedding.weight[:, None, :]
+ # cls_embedding = cls_embedding.transpose(0, 1).unsqueeze(0).repeat(cls_feats.size(0),cls_feats.size(1),1,1)
+ # cls_feats = cls_feats.unsqueeze(2).repeat(1, 1, self.cls_out_channels, 1)
+ # cls_feats = cls_feats+cls_embedding
+ # cls_feats = cls_feats.reshape(cls_feats.size(0), -1, cls_feats.size(3))
+ # outputs_classes = self.cls_branches[-1](cls_feats)
+ # outputs_classes = outputs_classes.squeeze(dim=-1).transpose(1, 2).view(cls_feats.size(0),-1,self.cls_out_channels)
+ # cls_feats = cls_feats *self.cls_embedding.weight[:, None, :]
+ outputs_classes = self.cls_branches[-1](cls_feats)
+ all_layers_outputs_classes = outputs_classes.unsqueeze(0).repeat(hidden_states.shape[0],1,1,1)
+ all_layers_outputs_coords = torch.stack(all_layers_outputs_coords)
+ inputs_coords = references[0]
+ return outputs_classes, inputs_coords, all_layers_outputs_classes, all_layers_outputs_coords
+
+ def loss(self, hidden_states: Tensor, references: List[Tensor],
+ centers: Tensor,
+ center_scores: Tensor,
+ topk_centers_scores: Tensor,
+ cls_feats: Tensor,
+ batch_data_samples: SampleList,
+ dn_meta: Dict[str, int],
+ spatial_shapes: Tensor) -> dict:
+ """Perform forward propagation and loss calculation of the detection
+ head on the queries of the upstream network.
+
+ Args:
+ hidden_states (Tensor): Hidden states output from each decoder
+ layer, has shape (num_decoder_layers, bs, num_queries_total,
+ dim), where `num_queries_total` is the sum of
+ `num_denoising_queries` and `num_matching_queries` when
+ `self.training` is `True`, else `num_matching_queries`.
+ references (list[Tensor]): List of the reference from the decoder.
+ The first reference is the `init_reference` (initial) and the
+ other num_decoder_layers(6) references are `inter_references`
+ (intermediate). The `init_reference` has shape (bs,
+ num_queries_total, 4) and each `inter_reference` has shape
+ (bs, num_queries, 4) with the last dimension arranged as
+ (cx, cy, w, h).
+ enc_outputs_class (Tensor): The score of each point on encode
+ feature map, has shape (bs, num_feat_points, cls_out_channels).
+ enc_outputs_coord (Tensor): The proposal generate from the
+ encode feature map, has shape (bs, num_feat_points, 4) with the
+ last dimension arranged as (cx, cy, w, h).
+ batch_data_samples (list[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ dict: A dictionary of loss components.
+ """
+ batch_gt_instances = []
+ batch_img_metas = []
+ for data_sample in batch_data_samples:
+ batch_img_metas.append(data_sample.metainfo)
+ batch_gt_instances.append(data_sample.gt_instances)
+ outs = self(hidden_states, references, cls_feats)
+ loss_inputs = outs + (center_scores, centers, topk_centers_scores,
+ batch_gt_instances, batch_img_metas, dn_meta, spatial_shapes)
+ losses = self.loss_by_feat(*loss_inputs)
+ return losses
+
+ def loss_by_feat(
+ self,
+ cls_scores: Tensor,
+ inputs_coords: Tensor,
+ all_layers_cls_scores: Tensor,
+ all_layers_bbox_preds: Tensor,
+ center_scores: Tensor,
+ centers: Tensor,
+ topk_centers_scores: Tensor,
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ dn_meta: Dict[str, int],
+ spatial_shapes: Tensor,
+ batch_gt_instances_ignore: OptInstanceList = None
+ ) -> Dict[str, Tensor]:
+ """Loss function.
+
+ Args:
+ all_layers_cls_scores (Tensor): Classification scores of all
+ decoder layers, has shape (num_decoder_layers, bs,
+ num_queries_total, cls_out_channels), where
+ `num_queries_total` is the sum of `num_denoising_queries`
+ and `num_matching_queries`.
+ all_layers_bbox_preds (Tensor): Regression outputs of all decoder
+ layers. Each is a 4D-tensor with normalized coordinate format
+ (cx, cy, w, h) and has shape (num_decoder_layers, bs,
+ num_queries_total, 4).
+ enc_cls_scores (Tensor): The score of each point on encode
+ feature map, has shape (bs, num_feat_points, cls_out_channels).
+ enc_bbox_preds (Tensor): The proposal generate from the encode
+ feature map, has shape (bs, num_feat_points, 4) with the last
+ dimension arranged as (cx, cy, w, h).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components.
+ """
+ # extract denoising and matching part of outputs
+ weight_bbox = 0
+ weight_cls = 0
+ (all_layers_matching_cls_scores, all_layers_matching_bbox_preds,
+ all_layers_denoising_cls_scores, all_layers_denoising_bbox_preds) = \
+ self.split_outputs(all_layers_cls_scores, all_layers_bbox_preds, dn_meta)
+
+ (matching_cls_scores, all_layers_matching_bbox_preds,
+ denoising_cls_scores, all_layers_denoising_bbox_preds) = \
+ self.split_outputsv1(cls_scores, all_layers_bbox_preds, dn_meta)
+ loss_dict = dict()
+ center_loss_cls = self.loss_center(center_scores, centers, spatial_shapes, batch_gt_instances=batch_gt_instances, batch_img_metas=batch_img_metas)
+ loss_dict['center_loss_cls'] = center_loss_cls
+ if center_loss_cls <= self.loss_center_th:
+ weight_bbox = 1
+ # num_imgs = centers.size(0)
+ # bbox_preds_list = [inputs_coords[i][dn_meta['num_denoising_queries']:] for i in range(num_imgs)]
+ # cls_scores_list = [all_layers_matching_cls_scores[-1][i] for i in range(num_imgs)]
+ # reg_targets = self.get_targets_bbox(cls_scores_list, bbox_preds_list, batch_gt_instances, batch_img_metas)
+ # losses_bbox, losses_iou = multi_apply(
+ # self.loss_bbox_by_feat_single,
+ # all_layers_matching_bbox_preds,
+ # reg_targets=reg_targets,
+ # batch_gt_instances=batch_gt_instances,
+ # batch_img_metas=batch_img_metas)
+ # # loss from other decoder layers
+ # num_dec_layer = 1
+ # for loss_bbox_i, loss_iou_i in zip(losses_bbox, losses_iou):
+ # loss_dict[f'd{num_dec_layer}.loss_bbox'] = loss_bbox_i*weight_bbox
+ # loss_dict[f'd{num_dec_layer}.loss_iou'] = loss_iou_i*weight_bbox
+ # num_dec_layer += 1
+ reg_targets = self.get_dn_targets(batch_gt_instances, batch_img_metas, dn_meta)
+ dn_losses_bbox, dn_losses_iou = multi_apply(
+ self._loss_dn_single,
+ all_layers_denoising_bbox_preds,
+ reg_targets=reg_targets,
+ batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas,
+ dn_meta=dn_meta)
+ for num_dec_layer, (loss_bbox_i, loss_iou_i) in \
+ enumerate(zip(dn_losses_bbox, dn_losses_iou)):
+ loss_dict[f'd{num_dec_layer+1}.dn_loss_bbox'] = loss_bbox_i*weight_bbox
+ loss_dict[f'd{num_dec_layer+1}.dn_loss_iou'] = loss_iou_i*weight_bbox
+ if weight_bbox == 1 and loss_iou_i <= self.loss_iou_th:
+ weight_cls = 1
+ # loss_cls = self.cls_loss(cls_scores, all_layers_bbox_preds[-1], batch_gt_instances=batch_gt_instances,
+ # batch_img_metas=batch_img_metas)
+ loss_cls = self.cls_loss(all_layers_matching_cls_scores[-1], all_layers_matching_bbox_preds[-1], batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas)
+ # loss_cls = self.cls_loss_dn_match(matching_cls_scores, all_layers_matching_bbox_preds[-1],
+ # denoising_cls_scores, all_layers_denoising_bbox_preds[-1], reg_targets, batch_gt_instances=batch_gt_instances,
+ # batch_img_metas=batch_img_metas)
+ loss_dict['match_loss_cls'] = loss_cls*weight_cls
+ if self.cls_out_channels > 0:
+ dn_loss_cls = self.cls_loss_dn(all_layers_denoising_cls_scores[-1], all_layers_denoising_bbox_preds[-1], reg_targets,
+ batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas)
+ loss_dict['dn_loss_cls'] = dn_loss_cls * weight_cls
+ return loss_dict
+
+ def loss_by_feat_single(self, cls_scores: Tensor, bbox_preds: Tensor,
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict]) -> Tuple[Tensor]:
+ """Loss function for outputs from a single decoder layer of a single
+ feature level.
+
+ Args:
+ cls_scores (Tensor): Box score logits from a single decoder layer
+ for all images, has shape (bs, num_queries, cls_out_channels).
+ bbox_preds (Tensor): Sigmoid outputs from a single decoder layer
+ for all images, with normalized coordinate (cx, cy, w, h) and
+ shape (bs, num_queries, 4).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+
+ Returns:
+ Tuple[Tensor]: A tuple including `loss_cls`, `loss_box` and
+ `loss_iou`.
+ """
+ num_imgs = cls_scores.size(0)
+ cls_scores_list = [cls_scores[i] for i in range(num_imgs)]
+ bbox_preds_list = [bbox_preds[i] for i in range(num_imgs)]
+ cls_reg_targets = self.get_targets(cls_scores_list, bbox_preds_list,
+ batch_gt_instances, batch_img_metas)
+ (labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,
+ num_total_pos, num_total_neg) = cls_reg_targets
+ labels = torch.cat(labels_list, 0)
+ label_weights = torch.cat(label_weights_list, 0)
+ bbox_targets = torch.cat(bbox_targets_list, 0)
+ bbox_weights = torch.cat(bbox_weights_list, 0)
+
+ # classification loss
+ cls_scores = cls_scores.reshape(-1, self.cls_out_channels)
+ # construct weighted avg_factor to match with the official DETR repo
+ cls_avg_factor = num_total_pos * 1.0 + \
+ num_total_neg * self.bg_cls_weight
+
+ if not self.neg_cls:
+ cls_avg_factor = num_total_pos * 1.0
+
+ if self.sync_cls_avg_factor:
+ cls_avg_factor = reduce_mean(
+ cls_scores.new_tensor([cls_avg_factor]))
+ cls_avg_factor = max(cls_avg_factor, 1)
+
+ loss_cls = self.loss_cls(
+ cls_scores, labels, label_weights, avg_factor=cls_avg_factor)
+
+ # Compute the average number of gt boxes across all gpus, for
+ # normalization purposes
+ num_total_pos = loss_cls.new_tensor([num_total_pos])
+ num_total_pos = torch.clamp(reduce_mean(num_total_pos), min=1).item()
+
+ # construct factors used for rescale bboxes
+ factors = []
+ for img_meta, bbox_pred in zip(batch_img_metas, bbox_preds):
+ img_h, img_w, = img_meta['img_shape']
+ factor = bbox_pred.new_tensor([img_w, img_h, img_w,
+ img_h]).unsqueeze(0).repeat(
+ bbox_pred.size(0), 1)
+ factors.append(factor)
+ factors = torch.cat(factors, 0)
+
+ # DETR regress the relative position of boxes (cxcywh) in the image,
+ # thus the learning target is normalized by the image size. So here
+ # we need to re-scale them for calculating IoU loss
+ bbox_preds = bbox_preds.reshape(-1, 4)
+ bboxes = bbox_cxcywh_to_xyxy(bbox_preds) * factors
+ bboxes_gt = bbox_cxcywh_to_xyxy(bbox_targets) * factors
+
+ # regression IoU loss, defaultly GIoU loss
+ loss_iou = self.loss_iou(
+ bboxes, bboxes_gt, bbox_weights, avg_factor=num_total_pos)
+
+ # regression L1 loss
+ loss_bbox = self.loss_bbox(
+ bbox_preds, bbox_targets, bbox_weights, avg_factor=num_total_pos)
+ return loss_cls, loss_bbox, loss_iou
+
+ def cls_loss(self, cls_scores: Tensor, bbox_preds: Tensor,
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict]) -> Tuple[Tensor]:
+ """Loss function for outputs from a single decoder layer of a single
+ feature level.
+
+ Args:
+ cls_scores (Tensor): Box score logits from a single decoder layer
+ for all images, has shape (bs, num_queries, cls_out_channels).
+ bbox_preds (Tensor): Sigmoid outputs from a single decoder layer
+ for all images, with normalized coordinate (cx, cy, w, h) and
+ shape (bs, num_queries, 4).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+
+ Returns:
+ Tuple[Tensor]: A tuple including `loss_cls`, `loss_box` and
+ `loss_iou`.
+ """
+ num_imgs = cls_scores.size(0)
+ cls_scores_list = [cls_scores[i] for i in range(num_imgs)]
+ bbox_preds_list = [bbox_preds[i] for i in range(num_imgs)]
+ cls_reg_targets = self.get_targets(cls_scores_list, bbox_preds_list,
+ batch_gt_instances, batch_img_metas)
+ (labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,
+ num_total_pos, num_total_neg) = cls_reg_targets
+ labels = torch.cat(labels_list, 0)
+ label_weights = torch.cat(label_weights_list, 0)
+ bbox_targets = torch.cat(bbox_targets_list, 0)
+ bbox_weights = torch.cat(bbox_weights_list, 0)
+
+ # classification loss
+ cls_scores = cls_scores.reshape(-1, self.cls_out_channels)
+ # construct weighted avg_factor to match with the official DETR repo
+ cls_avg_factor = num_total_pos * 1.0 + \
+ num_total_neg * self.bg_cls_weight
+ if self.sync_cls_avg_factor:
+ cls_avg_factor = reduce_mean(
+ cls_scores.new_tensor([cls_avg_factor]))
+ cls_avg_factor = max(cls_avg_factor, 1)
+ if isinstance(self.loss_cls, QualityFocalLoss):
+ bg_class_ind = self.num_classes
+ pos_inds = ((labels >= 0) & (labels < bg_class_ind)).nonzero().squeeze(1)
+ scores = label_weights.new_zeros(labels.shape)
+ pos_bbox_targets = bbox_targets[pos_inds]
+ pos_decode_bbox_targets = bbox_cxcywh_to_xyxy(pos_bbox_targets)
+ pos_bbox_pred = bbox_preds.reshape(-1, 4)[pos_inds]
+ pos_decode_bbox_pred = bbox_cxcywh_to_xyxy(pos_bbox_pred)
+ scores[pos_inds] = bbox_overlaps(
+ pos_decode_bbox_pred.detach(),
+ pos_decode_bbox_targets,
+ is_aligned=True)
+ loss_cls = self.loss_cls(
+ cls_scores, (labels, scores),
+ label_weights,
+ avg_factor=cls_avg_factor)
+ else:
+ loss_cls = self.loss_cls(
+ cls_scores, labels, label_weights, avg_factor=cls_avg_factor)
+ # loss_cls = self.loss_cls(
+ # cls_scores, labels, label_weights, avg_factor=cls_avg_factor)
+ if num_total_pos == 0:
+ loss_cls = loss_cls*0
+ return loss_cls
+
+ def cls_loss_dn_match(self, matching_cls_scores: Tensor,
+ matching_bbox_preds: Tensor,
+ denoising_cls_scores: Tensor,
+ denoising_bbox_preds: Tensor,
+ dn_targets: Tuple[list, int],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict]) -> Tuple[Tensor]:
+ """Loss function for outputs from a single decoder layer of a single
+ feature level.
+
+ Args:
+ cls_scores (Tensor): Box score logits from a single decoder layer
+ for all images, has shape (bs, num_queries, cls_out_channels).
+ bbox_preds (Tensor): Sigmoid outputs from a single decoder layer
+ for all images, with normalized coordinate (cx, cy, w, h) and
+ shape (bs, num_queries, 4).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+
+ Returns:
+ Tuple[Tensor]: A tuple including `loss_cls`, `loss_box` and
+ `loss_iou`.
+ """
+
+ cls_scores= torch.cat([matching_cls_scores,denoising_cls_scores],dim=1)
+ bbox_preds = torch.cat([matching_bbox_preds, denoising_bbox_preds], dim=1)
+
+ # cls_scores = matching_cls_scores
+ # bbox_preds = matching_bbox_preds
+ num_imgs = cls_scores.size(0)
+ cls_scores_list = [cls_scores[i] for i in range(num_imgs)]
+ bbox_preds_list = [bbox_preds[i] for i in range(num_imgs)]
+
+ matching_cls_scores_list = [matching_cls_scores[i] for i in range(num_imgs)]
+ matching_bbox_preds_list = [matching_bbox_preds[i] for i in range(num_imgs)]
+ denoising_cls_scores_list = [denoising_cls_scores[i] for i in range(num_imgs)]
+ denoising_bbox_preds_list = [denoising_bbox_preds[i] for i in range(num_imgs)]
+ cls_reg_targets = self.get_targets(matching_cls_scores_list, matching_bbox_preds_list,
+ batch_gt_instances, batch_img_metas)
+
+ (labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,
+ num_total_pos, num_total_neg) = cls_reg_targets
+ cls_reg_targets_dn = self.get_targets(denoising_cls_scores_list, denoising_bbox_preds_list,
+ batch_gt_instances, batch_img_metas, with_neg_cls=False, assigner_type='dn')
+ (labels_list_dn, label_weights_list_dn, bbox_targets_list_dn, bbox_weights_list_dn,
+ num_total_pos_dn, num_total_neg_dn) = cls_reg_targets_dn
+ # (labels_list_dn, label_weights_list_dn,bbox_targets_list_dn, bbox_weights_list_dn, num_total_pos_dn) = dn_targets
+ for i in range(num_imgs):
+ labels_list[i] = torch.cat([labels_list[i], labels_list_dn[i]], 0)
+ label_weights_list[i] = torch.cat([label_weights_list[i], label_weights_list_dn[i]], 0)
+ bbox_targets_list[i] = torch.cat([bbox_targets_list[i], bbox_targets_list_dn[i]], 0)
+ bbox_weights_list[i] = torch.cat([bbox_weights_list[i], bbox_weights_list_dn[i]], 0)
+ num_total_pos = num_total_pos+num_total_pos_dn
+ labels = torch.cat(labels_list, 0)
+ label_weights = torch.cat(label_weights_list, 0)
+ bbox_targets = torch.cat(bbox_targets_list, 0)
+ # bbox_weights = torch.cat(bbox_weights_list, 0)
+ cls_scores = cls_scores.reshape(-1, self.cls_out_channels)
+ labels = labels[label_weights != 0]
+ cls_scores = cls_scores[label_weights != 0]
+ bbox_targets = bbox_targets[label_weights != 0]
+ label_weights = label_weights[label_weights!= 0]
+ # construct weighted avg_factor to match with the official DETR repo
+ cls_avg_factor = num_total_pos * 1.0 + \
+ num_total_neg * self.bg_cls_weight
+ if self.sync_cls_avg_factor:
+ cls_avg_factor = reduce_mean(
+ cls_scores.new_tensor([cls_avg_factor]))
+ cls_avg_factor = max(cls_avg_factor, 1)
+ if isinstance(self.loss_cls, QualityFocalLoss):
+ bg_class_ind = self.num_classes
+ pos_inds = ((labels >= 0)
+ & (labels < bg_class_ind)).nonzero().squeeze(1)
+ scores = label_weights.new_zeros(labels.shape)
+ pos_bbox_targets = bbox_targets[pos_inds]
+ pos_decode_bbox_targets = bbox_cxcywh_to_xyxy(pos_bbox_targets)
+ pos_bbox_pred = bbox_preds.reshape(-1, 4)[pos_inds]
+ pos_decode_bbox_pred = bbox_cxcywh_to_xyxy(pos_bbox_pred)
+ scores[pos_inds] = bbox_overlaps(
+ pos_decode_bbox_pred.detach(),
+ pos_decode_bbox_targets,
+ is_aligned=True)
+ loss_cls = self.loss_cls(
+ cls_scores, (labels, scores),
+ label_weights,
+ avg_factor=cls_avg_factor)
+ else:
+ loss_cls = self.loss_cls(
+ cls_scores, labels, label_weights, avg_factor=cls_avg_factor)
+ # loss_cls = self.loss_cls(
+ # cls_scores, labels, label_weights, avg_factor=cls_avg_factor)
+ if num_total_pos == 0:
+ loss_cls = loss_cls*0
+ return loss_cls
+
+ def cls_loss_dn(self,denoising_cls_scores: Tensor,
+ denoising_bbox_preds: Tensor,
+ dn_targets: Tuple[list, int],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict]) -> Tuple[Tensor]:
+ """Loss function for outputs from a single decoder layer of a single
+ feature level.
+
+ Args:
+ cls_scores (Tensor): Box score logits from a single decoder layer
+ for all images, has shape (bs, num_queries, cls_out_channels).
+ bbox_preds (Tensor): Sigmoid outputs from a single decoder layer
+ for all images, with normalized coordinate (cx, cy, w, h) and
+ shape (bs, num_queries, 4).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+
+ Returns:
+ Tuple[Tensor]: A tuple including `loss_cls`, `loss_box` and
+ `loss_iou`.
+ """
+ cls_scores = denoising_cls_scores
+ bbox_preds = denoising_bbox_preds
+ num_imgs = cls_scores.size(0)
+ cls_scores_list = [cls_scores[i] for i in range(num_imgs)]
+ bbox_preds_list = [bbox_preds[i] for i in range(num_imgs)]
+ cls_reg_targets = self.get_targets(cls_scores_list, bbox_preds_list,
+ batch_gt_instances, batch_img_metas, with_neg_cls=False, assigner_type='dn')
+ (labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,
+ num_total_pos, num_total_neg) = cls_reg_targets
+ # (labels_list, label_weights_list,bbox_targets_list, bbox_weights_list, num_total_pos) = dn_targets
+ labels = torch.cat(labels_list, 0)
+ label_weights = torch.cat(label_weights_list, 0)
+ bbox_targets = torch.cat(bbox_targets_list, 0)
+ bbox_weights = torch.cat(bbox_weights_list, 0)
+ # classification loss
+ cls_scores = cls_scores.reshape(-1, self.cls_out_channels)
+ # construct weighted avg_factor to match with the official DETR repo
+ cls_avg_factor = num_total_pos * 1.0 + \
+ num_total_neg * self.bg_cls_weight
+ if self.sync_cls_avg_factor:
+ cls_avg_factor = reduce_mean(
+ cls_scores.new_tensor([cls_avg_factor]))
+ cls_avg_factor = max(cls_avg_factor, 1)
+ if isinstance(self.loss_cls, QualityFocalLoss):
+ bg_class_ind = self.num_classes
+ pos_inds = ((labels >= 0)
+ & (labels < bg_class_ind)).nonzero().squeeze(1)
+ scores = label_weights.new_zeros(labels.shape)
+ pos_bbox_targets = bbox_targets[pos_inds]
+ pos_decode_bbox_targets = bbox_cxcywh_to_xyxy(pos_bbox_targets)
+ pos_bbox_pred = bbox_preds.reshape(-1, 4)[pos_inds]
+ pos_decode_bbox_pred = bbox_cxcywh_to_xyxy(pos_bbox_pred)
+ scores[pos_inds] = bbox_overlaps(
+ pos_decode_bbox_pred.detach(),
+ pos_decode_bbox_targets,
+ is_aligned=True)
+ loss_cls = self.loss_cls(
+ cls_scores, (labels, scores),
+ label_weights,
+ avg_factor=cls_avg_factor)
+ else:
+ loss_cls = self.loss_cls(
+ cls_scores, labels, label_weights, avg_factor=cls_avg_factor)
+ # loss_cls = self.loss_cls(
+ # cls_scores, labels, label_weights, avg_factor=cls_avg_factor)
+ if num_total_pos == 0:
+ loss_cls = loss_cls*0
+ return loss_cls
+
+ def loss_center(self, center_scores: Tensor,
+ centers: Tensor,
+ spatial_shapes: Tensor,
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict]) -> Tuple[Tensor]:
+ """Loss function for outputs from a single decoder layer of a single
+ feature level.
+
+ Args:
+ cls_scores (Tensor): Box score logits from a single decoder layer
+ for all images, has shape (bs, num_queries, cls_out_channels).
+ bbox_preds (Tensor): Sigmoid outputs from a single decoder layer
+ for all images, with normalized coordinate (cx, cy, w, h) and
+ shape (bs, num_queries, 4).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+
+ Returns:
+ Tuple[Tensor]: A tuple including `loss_cls`, `loss_box` and
+ `loss_iou`.
+ """
+ num_imgs = center_scores.size(0)
+ center_scores_list = [center_scores[i] for i in range(num_imgs)]
+ centers_list = [centers[i] for i in range(num_imgs)]
+ spatial_shapes_list = [spatial_shapes for i in range(num_imgs)]
+ (labels_list, label_weights_list, pos_inds_list, neg_inds_list, new_center_scores_list) = multi_apply(self._get_targets_single_center,
+ center_scores_list, centers_list, spatial_shapes_list, batch_gt_instances, batch_img_metas)
+ num_total_pos = sum((inds.numel() for inds in pos_inds_list))
+ num_total_neg = sum((inds.numel() for inds in neg_inds_list))
+ labels = torch.cat(labels_list, 0)
+ label_weights = torch.cat(label_weights_list, 0)
+ new_center_scores = torch.cat(new_center_scores_list, 0)
+ # construct weighted avg_factor to match with the official DETR repo
+ cls_avg_factor = num_total_pos * 1.0 + \
+ num_total_neg * self.bg_cls_weight
+ if self.sync_cls_avg_factor:
+ cls_avg_factor = reduce_mean(
+ new_center_scores.new_tensor([cls_avg_factor]))
+ cls_avg_factor = max(cls_avg_factor, 1)
+ loss_cls = self.loss_center_cls(
+ new_center_scores, labels, label_weights, avg_factor=cls_avg_factor)
+ return loss_cls
+
+ def loss_bbox_by_feat_single(self, bbox_preds: Tensor,
+ reg_targets: Tuple[list,int],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict]) -> Tuple[Tensor]:
+ """Loss function for outputs from a single decoder layer of a single
+ feature level.
+
+ Args:
+ cls_scores (Tensor): Box score logits from a single decoder layer
+ for all images, has shape (bs, num_queries, cls_out_channels).
+ bbox_preds (Tensor): Sigmoid outputs from a single decoder layer
+ for all images, with normalized coordinate (cx, cy, w, h) and
+ shape (bs, num_queries, 4).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+
+ Returns:
+ Tuple[Tensor]: A tuple including `loss_cls`, `loss_box` and
+ `loss_iou`.
+ """
+ num_imgs = bbox_preds.size(0)
+ (bbox_targets_list, bbox_weights_list, num_total_pos, num_total_neg) = reg_targets
+ bbox_targets = torch.cat(bbox_targets_list, 0)
+ bbox_weights = torch.cat(bbox_weights_list, 0)
+
+ # Compute the average number of gt boxes across all gpus, for
+ # normalization purposes
+ num_total_pos = bbox_targets.new_tensor([num_total_pos])
+ num_total_pos = torch.clamp(reduce_mean(num_total_pos), min=1).item()
+
+ # construct factors used for rescale bboxes
+ factors = []
+ for img_meta, bbox_pred in zip(batch_img_metas, bbox_preds):
+ img_h, img_w, = img_meta['img_shape']
+ factor = bbox_pred.new_tensor([img_w, img_h, img_w,
+ img_h]).unsqueeze(0).repeat(
+ bbox_pred.size(0), 1)
+ factors.append(factor)
+ factors = torch.cat(factors, 0)
+
+ # DETR regress the relative position of boxes (cxcywh) in the image,
+ # thus the learning target is normalized by the image size. So here
+ # we need to re-scale them for calculating IoU loss
+ bbox_preds = bbox_preds.reshape(-1, 4)
+ bboxes = bbox_cxcywh_to_xyxy(bbox_preds) * factors
+ bboxes_gt = bbox_cxcywh_to_xyxy(bbox_targets) * factors
+ # regression IoU loss, defaultly GIoU loss
+ loss_iou = self.loss_iou(
+ bboxes, bboxes_gt, bbox_weights, avg_factor=num_total_pos)
+ # regression L1 loss
+ loss_bbox = self.loss_bbox(
+ bbox_preds, bbox_targets, bbox_weights, avg_factor=num_total_pos)
+ return loss_bbox, loss_iou
+
+ def get_targets(self, cls_scores_list: List[Tensor],
+ bbox_preds_list: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ with_neg_cls:bool=True,
+ assigner_type:str = None) -> tuple:
+ """Compute regression and classification targets for a batch image.
+
+ Outputs from a single decoder layer of a single feature level are used.
+
+ Args:
+ cls_scores_list (list[Tensor]): Box score logits from a single
+ decoder layer for each image, has shape [num_queries,
+ cls_out_channels].
+ bbox_preds_list (list[Tensor]): Sigmoid outputs from a single
+ decoder layer for each image, with normalized coordinate
+ (cx, cy, w, h) and shape [num_queries, 4].
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+
+ Returns:
+ tuple: a tuple containing the following targets.
+
+ - labels_list (list[Tensor]): Labels for all images.
+ - label_weights_list (list[Tensor]): Label weights for all images.
+ - bbox_targets_list (list[Tensor]): BBox targets for all images.
+ - bbox_weights_list (list[Tensor]): BBox weights for all images.
+ - num_total_pos (int): Number of positive samples in all images.
+ - num_total_neg (int): Number of negative samples in all images.
+ """
+ (labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,
+ pos_inds_list,
+ neg_inds_list) = multi_apply(self._get_targets_single,
+ cls_scores_list, bbox_preds_list,
+ batch_gt_instances, batch_img_metas,
+ with_neg_cls=with_neg_cls,
+ assigner_type= assigner_type)
+ num_total_pos = sum((inds.numel() for inds in pos_inds_list))
+ num_total_neg = sum((inds.numel() for inds in neg_inds_list))
+ if not with_neg_cls:
+ num_total_neg = 0
+ return (labels_list, label_weights_list, bbox_targets_list,
+ bbox_weights_list, num_total_pos, num_total_neg)
+
+ def get_targets_bbox(self,
+ cls_scores_list: List[Tensor],
+ bbox_preds_list: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict]) -> tuple:
+ """Compute regression and classification targets for a batch image.
+
+ Outputs from a single decoder layer of a single feature level are used.
+
+ Args:
+ cls_scores_list (list[Tensor]): Box score logits from a single
+ decoder layer for each image, has shape [num_queries,
+ cls_out_channels].
+ bbox_preds_list (list[Tensor]): Sigmoid outputs from a single
+ decoder layer for each image, with normalized coordinate
+ (cx, cy, w, h) and shape [num_queries, 4].
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+
+ Returns:
+ tuple: a tuple containing the following targets.
+
+ - labels_list (list[Tensor]): Labels for all images.
+ - label_weights_list (list[Tensor]): Label weights for all images.
+ - bbox_targets_list (list[Tensor]): BBox targets for all images.
+ - bbox_weights_list (list[Tensor]): BBox weights for all images.
+ - num_total_pos (int): Number of positive samples in all images.
+ - num_total_neg (int): Number of negative samples in all images.
+ """
+ (bbox_targets_list, bbox_weights_list, pos_inds_list,
+ neg_inds_list) = multi_apply(self._get_targets_single_bbox, cls_scores_list,
+ bbox_preds_list,
+ batch_gt_instances, batch_img_metas)
+ num_total_pos = sum((inds.numel() for inds in pos_inds_list))
+ num_total_neg = sum((inds.numel() for inds in neg_inds_list))
+ return (bbox_targets_list, bbox_weights_list, num_total_pos, num_total_neg)
+
+
+ def _loss_dn_single(self, dn_bbox_preds: Tensor,
+ reg_targets: Tuple[list, int],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ dn_meta: Dict[str, int]) -> Tuple[Tensor]:
+ """Denoising loss for outputs from a single decoder layer.
+
+ Args:
+ dn_cls_scores (Tensor): Classification scores of a single decoder
+ layer in denoising part, has shape (bs, num_denoising_queries,
+ cls_out_channels).
+ dn_bbox_preds (Tensor): Regression outputs of a single decoder
+ layer in denoising part. Each is a 4D-tensor with normalized
+ coordinate format (cx, cy, w, h) and has shape
+ (bs, num_denoising_queries, 4).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ Tuple[Tensor]: A tuple including `loss_cls`, `loss_box` and
+ `loss_iou`.
+ """
+ (labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,num_total_pos) = reg_targets
+ bbox_targets = torch.cat(bbox_targets_list, 0)
+ bbox_weights = torch.cat(bbox_weights_list, 0)
+
+ # Compute the average number of gt boxes across all gpus, for
+ # normalization purposes
+ num_total_pos = dn_bbox_preds.new_tensor([num_total_pos])
+ num_total_pos = torch.clamp(reduce_mean(num_total_pos), min=1).item()
+
+ # construct factors used for rescale bboxes
+ factors = []
+ for img_meta, bbox_pred in zip(batch_img_metas, dn_bbox_preds):
+ img_h, img_w = img_meta['img_shape']
+ factor = bbox_pred.new_tensor([img_w, img_h, img_w,
+ img_h]).unsqueeze(0).repeat(
+ bbox_pred.size(0), 1)
+ factors.append(factor)
+ factors = torch.cat(factors)
+ # DETR regress the relative position of boxes (cxcywh) in the image,
+ # thus the learning target is normalized by the image size. So here
+ # we need to re-scale them for calculating IoU loss
+ bbox_preds = dn_bbox_preds.reshape(-1, 4)
+ bboxes = bbox_cxcywh_to_xyxy(bbox_preds) * factors
+ bboxes_gt = bbox_cxcywh_to_xyxy(bbox_targets) * factors
+ # regression IoU loss, defaultly GIoU loss
+ loss_iou = self.loss_iou(
+ bboxes, bboxes_gt, bbox_weights, avg_factor=num_total_pos)
+ # regression L1 loss
+ loss_bbox = self.loss_bbox(
+ bbox_preds, bbox_targets, bbox_weights, avg_factor=num_total_pos)
+ return loss_bbox, loss_iou
+
+ def get_dn_targets(self, batch_gt_instances: InstanceList,
+ batch_img_metas: dict, dn_meta: Dict[str,
+ int]) -> tuple:
+ """Get targets in denoising part for a batch of images.
+
+ Args:
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ tuple: a tuple containing the following targets.
+
+ - labels_list (list[Tensor]): Labels for all images.
+ - label_weights_list (list[Tensor]): Label weights for all images.
+ - bbox_targets_list (list[Tensor]): BBox targets for all images.
+ - bbox_weights_list (list[Tensor]): BBox weights for all images.
+ - num_total_pos (int): Number of positive samples in all images.
+ - num_total_neg (int): Number of negative samples in all images.
+ """
+ (labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,pos_inds_list) = multi_apply(
+ self._get_dn_targets_single,
+ batch_gt_instances,
+ batch_img_metas,
+ dn_meta=dn_meta)
+ num_total_pos = sum((inds.numel() for inds in pos_inds_list))
+ return (labels_list, label_weights_list, bbox_targets_list, bbox_weights_list, num_total_pos,)
+
+ def _get_dn_targets_single(self, gt_instances: InstanceData,
+ img_meta: dict, dn_meta: Dict[str,
+ int]) -> tuple:
+ """Get targets in denoising part for one image.
+
+ Args:
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It should includes ``bboxes`` and ``labels``
+ attributes.
+ img_meta (dict): Meta information for one image.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ tuple[Tensor]: a tuple containing the following for one image.
+
+ - labels (Tensor): Labels of each image.
+ - label_weights (Tensor]): Label weights of each image.
+ - bbox_targets (Tensor): BBox targets of each image.
+ - bbox_weights (Tensor): BBox weights of each image.
+ - pos_inds (Tensor): Sampled positive indices for each image.
+ - neg_inds (Tensor): Sampled negative indices for each image.
+ """
+ gt_bboxes = gt_instances.bboxes
+ gt_labels = gt_instances.labels
+ num_groups = dn_meta['num_denoising_groups']
+ num_denoising_queries = dn_meta['num_denoising_queries']
+ num_queries_each_group = int(num_denoising_queries / num_groups)
+ device = gt_bboxes.device
+
+ if len(gt_labels) > 0:
+ t = torch.arange(len(gt_labels), dtype=torch.long, device=device)
+ t = t.unsqueeze(0).repeat(num_groups, 1)
+ pos_assigned_gt_inds = t.flatten()
+ pos_inds = torch.arange(num_groups, dtype=torch.long, device=device)
+ pos_inds = pos_inds.unsqueeze(1) * num_queries_each_group + t
+ pos_inds = pos_inds.flatten()
+ else:
+ pos_inds = pos_assigned_gt_inds = \
+ gt_bboxes.new_tensor([], dtype=torch.long)
+
+ # label targets
+ labels = gt_bboxes.new_full((num_denoising_queries, ),
+ self.num_classes,
+ dtype=torch.long)
+ labels[pos_inds] = gt_labels[pos_assigned_gt_inds]
+ label_weights = gt_bboxes.new_zeros(num_denoising_queries)
+ label_weights[pos_inds] = 1.0
+ # bbox targets
+ bbox_targets = torch.zeros(num_denoising_queries, 4, device=device)
+ bbox_weights = torch.zeros(num_denoising_queries, 4, device=device)
+ bbox_weights[pos_inds] = 1.0
+ img_h, img_w = img_meta['img_shape']
+
+ # DETR regress the relative position of boxes (cxcywh) in the image.
+ # Thus the learning target should be normalized by the image size, also
+ # the box format should be converted from defaultly x1y1x2y2 to cxcywh.
+ factor = gt_bboxes.new_tensor([img_w, img_h, img_w,
+ img_h]).unsqueeze(0)
+ gt_bboxes_normalized = gt_bboxes / factor
+ gt_bboxes_targets = bbox_xyxy_to_cxcywh(gt_bboxes_normalized)
+ bbox_targets[pos_inds] = gt_bboxes_targets.repeat([num_groups, 1])
+
+ return (labels, label_weights,bbox_targets, bbox_weights, pos_inds)
+
+
+ @staticmethod
+ def split_outputs(all_layers_cls_scores: Tensor,
+ all_layers_bbox_preds: Tensor,
+ dn_meta: Dict[str, int]) -> Tuple[Tensor]:
+ """Split outputs of the denoising part and the matching part.
+
+ For the total outputs of `num_queries_total` length, the former
+ `num_denoising_queries` outputs are from denoising queries, and
+ the rest `num_matching_queries` ones are from matching queries,
+ where `num_queries_total` is the sum of `num_denoising_queries` and
+ `num_matching_queries`.
+
+ Args:
+ all_layers_cls_scores (Tensor): Classification scores of all
+ decoder layers, has shape (num_decoder_layers, bs,
+ num_queries_total, cls_out_channels).
+ all_layers_bbox_preds (Tensor): Regression outputs of all decoder
+ layers. Each is a 4D-tensor with normalized coordinate format
+ (cx, cy, w, h) and has shape (num_decoder_layers, bs,
+ num_queries_total, 4).
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'.
+
+ Returns:
+ Tuple[Tensor]: a tuple containing the following outputs.
+
+ - all_layers_matching_cls_scores (Tensor): Classification scores
+ of all decoder layers in matching part, has shape
+ (num_decoder_layers, bs, num_matching_queries, cls_out_channels).
+ - all_layers_matching_bbox_preds (Tensor): Regression outputs of
+ all decoder layers in matching part. Each is a 4D-tensor with
+ normalized coordinate format (cx, cy, w, h) and has shape
+ (num_decoder_layers, bs, num_matching_queries, 4).
+ - all_layers_denoising_cls_scores (Tensor): Classification scores
+ of all decoder layers in denoising part, has shape
+ (num_decoder_layers, bs, num_denoising_queries,
+ cls_out_channels).
+ - all_layers_denoising_bbox_preds (Tensor): Regression outputs of
+ all decoder layers in denoising part. Each is a 4D-tensor with
+ normalized coordinate format (cx, cy, w, h) and has shape
+ (num_decoder_layers, bs, num_denoising_queries, 4).
+ """
+ if dn_meta is not None:
+ num_denoising_queries = dn_meta['num_denoising_queries']
+ all_layers_denoising_cls_scores = \
+ all_layers_cls_scores[:,:, : num_denoising_queries, :]
+ all_layers_denoising_bbox_preds = \
+ all_layers_bbox_preds[:, :, : num_denoising_queries, :]
+ all_layers_matching_cls_scores = \
+ all_layers_cls_scores[:, :, num_denoising_queries:, :]
+ all_layers_matching_bbox_preds = \
+ all_layers_bbox_preds[:, :, num_denoising_queries:, :]
+ else:
+ all_layers_denoising_cls_scores = None
+ all_layers_denoising_bbox_preds = None
+ all_layers_matching_cls_scores = all_layers_cls_scores
+ all_layers_matching_bbox_preds = all_layers_bbox_preds
+ return (all_layers_matching_cls_scores, all_layers_matching_bbox_preds,
+ all_layers_denoising_cls_scores,
+ all_layers_denoising_bbox_preds)
+
+
+ @staticmethod
+ def split_outputsv1(all_layers_cls_scores: Tensor,
+ all_layers_bbox_preds: Tensor,
+ dn_meta: Dict[str, int]) -> Tuple[Tensor]:
+ """Split outputs of the denoising part and the matching part.
+
+ For the total outputs of `num_queries_total` length, the former
+ `num_denoising_queries` outputs are from denoising queries, and
+ the rest `num_matching_queries` ones are from matching queries,
+ where `num_queries_total` is the sum of `num_denoising_queries` and
+ `num_matching_queries`.
+
+ Args:
+ all_layers_cls_scores (Tensor): Classification scores of all
+ decoder layers, has shape (num_decoder_layers, bs,
+ num_queries_total, cls_out_channels).
+ all_layers_bbox_preds (Tensor): Regression outputs of all decoder
+ layers. Each is a 4D-tensor with normalized coordinate format
+ (cx, cy, w, h) and has shape (num_decoder_layers, bs,
+ num_queries_total, 4).
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'.
+
+ Returns:
+ Tuple[Tensor]: a tuple containing the following outputs.
+
+ - all_layers_matching_cls_scores (Tensor): Classification scores
+ of all decoder layers in matching part, has shape
+ (num_decoder_layers, bs, num_matching_queries, cls_out_channels).
+ - all_layers_matching_bbox_preds (Tensor): Regression outputs of
+ all decoder layers in matching part. Each is a 4D-tensor with
+ normalized coordinate format (cx, cy, w, h) and has shape
+ (num_decoder_layers, bs, num_matching_queries, 4).
+ - all_layers_denoising_cls_scores (Tensor): Classification scores
+ of all decoder layers in denoising part, has shape
+ (num_decoder_layers, bs, num_denoising_queries,
+ cls_out_channels).
+ - all_layers_denoising_bbox_preds (Tensor): Regression outputs of
+ all decoder layers in denoising part. Each is a 4D-tensor with
+ normalized coordinate format (cx, cy, w, h) and has shape
+ (num_decoder_layers, bs, num_denoising_queries, 4).
+ """
+ if dn_meta is not None:
+ num_denoising_queries = dn_meta['num_denoising_queries']
+ all_layers_denoising_cls_scores = \
+ all_layers_cls_scores[:, : num_denoising_queries, :]
+ all_layers_denoising_bbox_preds = \
+ all_layers_bbox_preds[:, :, : num_denoising_queries, :]
+ all_layers_matching_cls_scores = \
+ all_layers_cls_scores[:, num_denoising_queries:, :]
+ all_layers_matching_bbox_preds = \
+ all_layers_bbox_preds[:, :, num_denoising_queries:, :]
+ else:
+ all_layers_denoising_cls_scores = None
+ all_layers_denoising_bbox_preds = None
+ all_layers_matching_cls_scores = all_layers_cls_scores
+ all_layers_matching_bbox_preds = all_layers_bbox_preds
+ return (all_layers_matching_cls_scores, all_layers_matching_bbox_preds,
+ all_layers_denoising_cls_scores,
+ all_layers_denoising_bbox_preds)
+
+ def predict(self,
+ hidden_states: Tensor,
+ references: List[Tensor],
+ centers: Tensor,
+ center_scores: Tensor,
+ topk_centers_scores: Tensor,
+ cls_feats: Tensor,
+ batch_data_samples: SampleList,
+ rescale: bool = True) -> InstanceList:
+ """Perform forward propagation and loss calculation of the detection
+ head on the queries of the upstream network.
+
+ Args:
+ hidden_states (Tensor): Hidden states output from each decoder
+ layer, has shape (num_decoder_layers, num_queries, bs, dim).
+ references (list[Tensor]): List of the reference from the decoder.
+ The first reference is the `init_reference` (initial) and the
+ other num_decoder_layers(6) references are `inter_references`
+ (intermediate). The `init_reference` has shape (bs,
+ num_queries, 4) when `as_two_stage` of the detector is `True`,
+ otherwise (bs, num_queries, 2). Each `inter_reference` has
+ shape (bs, num_queries, 4) when `with_box_refine` of the
+ detector is `True`, otherwise (bs, num_queries, 2). The
+ coordinates are arranged as (cx, cy) when the last dimension is
+ 2, and (cx, cy, w, h) when it is 4.
+ batch_data_samples (list[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ rescale (bool, optional): If `True`, return boxes in original
+ image space. Defaults to `True`.
+
+ Returns:
+ list[obj:`InstanceData`]: Detection results of each image
+ after the post process.
+ """
+ batch_img_metas = [
+ data_samples.metainfo for data_samples in batch_data_samples
+ ]
+
+ outs = self(hidden_states, references, cls_feats)
+
+ predictions = self.predict_by_feat(
+ *outs, batch_img_metas=batch_img_metas, rescale=rescale)
+ return predictions
+
+ def predict_by_feat(self,
+ cls_scores: Tensor,
+ inputs_coords: Tensor,
+ all_layers_cls_scores: Tensor,
+ all_layers_bbox_preds: Tensor,
+ batch_img_metas: List[Dict],
+ rescale: bool = False) -> InstanceList:
+ """Transform a batch of output features extracted from the head into
+ bbox results.
+
+ Args:
+ all_layers_cls_scores (Tensor): Classification scores of all
+ decoder layers, has shape (num_decoder_layers, bs, num_queries,
+ cls_out_channels).
+ all_layers_bbox_preds (Tensor): Regression outputs of all decoder
+ layers. Each is a 4D-tensor with normalized coordinate format
+ (cx, cy, w, h) and shape (num_decoder_layers, bs, num_queries,
+ 4) with the last dimension arranged as (cx, cy, w, h).
+ batch_img_metas (list[dict]): Meta information of each image.
+ rescale (bool, optional): If `True`, return boxes in original
+ image space. Default `False`.
+
+ Returns:
+ list[obj:`InstanceData`]: Detection results of each image
+ after the post process.
+ """
+ cls_scores = all_layers_cls_scores[-1]
+ bbox_preds = all_layers_bbox_preds[-1]
+
+ result_list = []
+ for img_id in range(len(batch_img_metas)):
+ cls_score = cls_scores[img_id]
+ bbox_pred = bbox_preds[img_id]
+ img_meta = batch_img_metas[img_id]
+ results = self._predict_by_feat_single(cls_score, bbox_pred,
+ img_meta, rescale)
+ result_list.append(results)
+ return result_list
+
+ def _predict_by_feat_single(self,
+ cls_score: Tensor,
+ bbox_pred: Tensor,
+ img_meta: dict,
+ rescale: bool = True) -> InstanceData:
+ """Transform outputs from the last decoder layer into bbox predictions
+ for each image.
+
+ Args:
+ cls_score (Tensor): Box score logits from the last decoder layer
+ for each image. Shape [num_queries, cls_out_channels].
+ bbox_pred (Tensor): Sigmoid outputs from the last decoder layer
+ for each image, with coordinate format (cx, cy, w, h) and
+ shape [num_queries, 4].
+ img_meta (dict): Image meta info.
+ rescale (bool): If True, return boxes in original image
+ space. Default True.
+
+ Returns:
+ :obj:`InstanceData`: Detection results of each image
+ after the post process.
+ Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ """
+ assert len(cls_score) == len(bbox_pred) # num_queries
+ max_per_img = self.test_cfg.get('max_per_img', len(cls_score))
+ img_shape = img_meta['img_shape']
+ assert self.loss_cls.use_sigmoid
+ cls_score = cls_score.sigmoid()
+ # scores, indexes = cls_score.view(-1).topk(max_per_img)
+ scores, indexes = torch.sort(cls_score.view(-1), descending=True)
+ indexes = indexes[scores > self.iou_threshold]
+ scores = scores[scores > self.iou_threshold]
+ det_labels = indexes % self.num_classes
+ bbox_index = torch.div(indexes, self.num_classes, rounding_mode='trunc')
+ bbox_pred = bbox_pred[bbox_index]
+
+ det_bboxes = bbox_cxcywh_to_xyxy(bbox_pred)
+ det_bboxes[:, 0::2] = det_bboxes[:, 0::2] * img_shape[1]
+ det_bboxes[:, 1::2] = det_bboxes[:, 1::2] * img_shape[0]
+ det_bboxes[:, 0::2].clamp_(min=0, max=img_shape[1])
+ det_bboxes[:, 1::2].clamp_(min=0, max=img_shape[0])
+ if self.use_nms:
+ if det_labels.numel() > 0:
+ bboxes_scores, keep = batched_nms(det_bboxes, scores.contiguous(), det_labels, self.test_nms, class_agnostic=(not self.class_wise_nms))
+ if keep.numel() > max_per_img:
+ bboxes_scores = bboxes_scores[:max_per_img]
+ det_labels = det_labels[keep][:max_per_img]
+ else:
+ det_labels = det_labels[keep]
+ det_bboxes = bboxes_scores[:, :-1]
+ scores = bboxes_scores[:, -1]
+ if self.pre_bboxes_round:
+ det_bboxes = adjust_bbox_to_pixel(det_bboxes)
+ if rescale:
+ # assert img_meta.get('scale_factor') is not None
+ # det_bboxes /= det_bboxes.new_tensor(
+ # img_meta['scale_factor']).repeat((1, 2))
+ # rw by lzx
+ if img_meta.get('scale_factor') is not None:
+ det_bboxes /= det_bboxes.new_tensor(
+ img_meta['scale_factor']).repeat((1, 2))
+ results = InstanceData()
+ results.bboxes = det_bboxes
+ results.scores = scores
+ results.labels = det_labels
+ return results
diff --git a/mmdet/models/dense_heads/fcos_head.py b/mmdet/models/dense_heads/fcos_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..f3206877a1e3684e7ecf90799bb234c59838f294
--- /dev/null
+++ b/mmdet/models/dense_heads/fcos_head.py
@@ -0,0 +1,455 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Tuple
+
+import torch
+import torch.nn as nn
+from mmcv.cnn import Scale
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.utils import (ConfigType, InstanceList, MultiConfig,
+ OptInstanceList, RangeType, reduce_mean)
+from ..utils import multi_apply
+from .anchor_free_head import AnchorFreeHead
+
+INF = 1e8
+
+
+@MODELS.register_module()
+class FCOSHead(AnchorFreeHead):
+ """Anchor-free head used in `FCOS `_.
+
+ The FCOS head does not use anchor boxes. Instead bounding boxes are
+ predicted at each pixel and a centerness measure is used to suppress
+ low-quality predictions.
+ Here norm_on_bbox, centerness_on_reg, dcn_on_last_conv are training
+ tricks used in official repo, which will bring remarkable mAP gains
+ of up to 4.9. Please see https://github.com/tianzhi0549/FCOS for
+ more detail.
+
+ Args:
+ num_classes (int): Number of categories excluding the background
+ category.
+ in_channels (int): Number of channels in the input feature map.
+ strides (Sequence[int] or Sequence[Tuple[int, int]]): Strides of points
+ in multiple feature levels. Defaults to (4, 8, 16, 32, 64).
+ regress_ranges (Sequence[Tuple[int, int]]): Regress range of multiple
+ level points.
+ center_sampling (bool): If true, use center sampling.
+ Defaults to False.
+ center_sample_radius (float): Radius of center sampling.
+ Defaults to 1.5.
+ norm_on_bbox (bool): If true, normalize the regression targets with
+ FPN strides. Defaults to False.
+ centerness_on_reg (bool): If true, position centerness on the
+ regress branch. Please refer to https://github.com/tianzhi0549/FCOS/issues/89#issuecomment-516877042.
+ Defaults to False.
+ conv_bias (bool or str): If specified as `auto`, it will be decided by
+ the norm_cfg. Bias of conv will be set as True if `norm_cfg` is
+ None, otherwise False. Defaults to "auto".
+ loss_cls (:obj:`ConfigDict` or dict): Config of classification loss.
+ loss_bbox (:obj:`ConfigDict` or dict): Config of localization loss.
+ loss_centerness (:obj:`ConfigDict`, or dict): Config of centerness
+ loss.
+ norm_cfg (:obj:`ConfigDict` or dict): dictionary to construct and
+ config norm layer. Defaults to
+ ``norm_cfg=dict(type='GN', num_groups=32, requires_grad=True)``.
+ init_cfg (:obj:`ConfigDict` or dict or list[:obj:`ConfigDict` or \
+ dict]): Initialization config dict.
+
+ Example:
+ >>> self = FCOSHead(11, 7)
+ >>> feats = [torch.rand(1, 7, s, s) for s in [4, 8, 16, 32, 64]]
+ >>> cls_score, bbox_pred, centerness = self.forward(feats)
+ >>> assert len(cls_score) == len(self.scales)
+ """ # noqa: E501
+
+ def __init__(self,
+ num_classes: int,
+ in_channels: int,
+ regress_ranges: RangeType = ((-1, 64), (64, 128), (128, 256),
+ (256, 512), (512, INF)),
+ center_sampling: bool = False,
+ center_sample_radius: float = 1.5,
+ norm_on_bbox: bool = False,
+ centerness_on_reg: bool = False,
+ loss_cls: ConfigType = dict(
+ type='FocalLoss',
+ use_sigmoid=True,
+ gamma=2.0,
+ alpha=0.25,
+ loss_weight=1.0),
+ loss_bbox: ConfigType = dict(type='IoULoss', loss_weight=1.0),
+ loss_centerness: ConfigType = dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=True,
+ loss_weight=1.0),
+ norm_cfg: ConfigType = dict(
+ type='GN', num_groups=32, requires_grad=True),
+ init_cfg: MultiConfig = dict(
+ type='Normal',
+ layer='Conv2d',
+ std=0.01,
+ override=dict(
+ type='Normal',
+ name='conv_cls',
+ std=0.01,
+ bias_prob=0.01)),
+ **kwargs) -> None:
+ self.regress_ranges = regress_ranges
+ self.center_sampling = center_sampling
+ self.center_sample_radius = center_sample_radius
+ self.norm_on_bbox = norm_on_bbox
+ self.centerness_on_reg = centerness_on_reg
+ super().__init__(
+ num_classes=num_classes,
+ in_channels=in_channels,
+ loss_cls=loss_cls,
+ loss_bbox=loss_bbox,
+ norm_cfg=norm_cfg,
+ init_cfg=init_cfg,
+ **kwargs)
+ self.loss_centerness = MODELS.build(loss_centerness)
+
+ def _init_layers(self) -> None:
+ """Initialize layers of the head."""
+ super()._init_layers()
+ self.conv_centerness = nn.Conv2d(self.feat_channels, 1, 3, padding=1)
+ self.scales = nn.ModuleList([Scale(1.0) for _ in self.strides])
+
+ def forward(
+ self, x: Tuple[Tensor]
+ ) -> Tuple[List[Tensor], List[Tensor], List[Tensor]]:
+ """Forward features from the upstream network.
+
+ Args:
+ feats (tuple[Tensor]): Features from the upstream network, each is
+ a 4D-tensor.
+
+ Returns:
+ tuple: A tuple of each level outputs.
+
+ - cls_scores (list[Tensor]): Box scores for each scale level, \
+ each is a 4D-tensor, the channel number is \
+ num_points * num_classes.
+ - bbox_preds (list[Tensor]): Box energies / deltas for each \
+ scale level, each is a 4D-tensor, the channel number is \
+ num_points * 4.
+ - centernesses (list[Tensor]): centerness for each scale level, \
+ each is a 4D-tensor, the channel number is num_points * 1.
+ """
+ return multi_apply(self.forward_single, x, self.scales, self.strides)
+
+ def forward_single(self, x: Tensor, scale: Scale,
+ stride: int) -> Tuple[Tensor, Tensor, Tensor]:
+ """Forward features of a single scale level.
+
+ Args:
+ x (Tensor): FPN feature maps of the specified stride.
+ scale (:obj:`mmcv.cnn.Scale`): Learnable scale module to resize
+ the bbox prediction.
+ stride (int): The corresponding stride for feature maps, only
+ used to normalize the bbox prediction when self.norm_on_bbox
+ is True.
+
+ Returns:
+ tuple: scores for each class, bbox predictions and centerness
+ predictions of input feature maps.
+ """
+ cls_score, bbox_pred, cls_feat, reg_feat = super().forward_single(x)
+ if self.centerness_on_reg:
+ centerness = self.conv_centerness(reg_feat)
+ else:
+ centerness = self.conv_centerness(cls_feat)
+ # scale the bbox_pred of different level
+ # float to avoid overflow when enabling FP16
+ bbox_pred = scale(bbox_pred).float()
+ if self.norm_on_bbox:
+ # bbox_pred needed for gradient computation has been modified
+ # by F.relu(bbox_pred) when run with PyTorch 1.10. So replace
+ # F.relu(bbox_pred) with bbox_pred.clamp(min=0)
+ bbox_pred = bbox_pred.clamp(min=0)
+ if not self.training:
+ bbox_pred *= stride
+ else:
+ bbox_pred = bbox_pred.exp()
+ return cls_score, bbox_pred, centerness
+
+ def loss_by_feat(
+ self,
+ cls_scores: List[Tensor],
+ bbox_preds: List[Tensor],
+ centernesses: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ batch_gt_instances_ignore: OptInstanceList = None
+ ) -> Dict[str, Tensor]:
+ """Calculate the loss based on the features extracted by the detection
+ head.
+
+ Args:
+ cls_scores (list[Tensor]): Box scores for each scale level,
+ each is a 4D-tensor, the channel number is
+ num_points * num_classes.
+ bbox_preds (list[Tensor]): Box energies / deltas for each scale
+ level, each is a 4D-tensor, the channel number is
+ num_points * 4.
+ centernesses (list[Tensor]): centerness for each scale level, each
+ is a 4D-tensor, the channel number is num_points * 1.
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], Optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components.
+ """
+ assert len(cls_scores) == len(bbox_preds) == len(centernesses)
+ featmap_sizes = [featmap.size()[-2:] for featmap in cls_scores]
+ all_level_points = self.prior_generator.grid_priors(
+ featmap_sizes,
+ dtype=bbox_preds[0].dtype,
+ device=bbox_preds[0].device)
+ labels, bbox_targets = self.get_targets(all_level_points,
+ batch_gt_instances)
+
+ num_imgs = cls_scores[0].size(0)
+ # flatten cls_scores, bbox_preds and centerness
+ flatten_cls_scores = [
+ cls_score.permute(0, 2, 3, 1).reshape(-1, self.cls_out_channels)
+ for cls_score in cls_scores
+ ]
+ flatten_bbox_preds = [
+ bbox_pred.permute(0, 2, 3, 1).reshape(-1, 4)
+ for bbox_pred in bbox_preds
+ ]
+ flatten_centerness = [
+ centerness.permute(0, 2, 3, 1).reshape(-1)
+ for centerness in centernesses
+ ]
+ flatten_cls_scores = torch.cat(flatten_cls_scores)
+ flatten_bbox_preds = torch.cat(flatten_bbox_preds)
+ flatten_centerness = torch.cat(flatten_centerness)
+ flatten_labels = torch.cat(labels)
+ flatten_bbox_targets = torch.cat(bbox_targets)
+ # repeat points to align with bbox_preds
+ flatten_points = torch.cat(
+ [points.repeat(num_imgs, 1) for points in all_level_points])
+
+ # FG cat_id: [0, num_classes -1], BG cat_id: num_classes
+ bg_class_ind = self.num_classes
+ pos_inds = ((flatten_labels >= 0)
+ & (flatten_labels < bg_class_ind)).nonzero().reshape(-1)
+ num_pos = torch.tensor(
+ len(pos_inds), dtype=torch.float, device=bbox_preds[0].device)
+ num_pos = max(reduce_mean(num_pos), 1.0)
+ loss_cls = self.loss_cls(
+ flatten_cls_scores, flatten_labels, avg_factor=num_pos)
+
+ pos_bbox_preds = flatten_bbox_preds[pos_inds]
+ pos_centerness = flatten_centerness[pos_inds]
+ pos_bbox_targets = flatten_bbox_targets[pos_inds]
+ pos_centerness_targets = self.centerness_target(pos_bbox_targets)
+ # centerness weighted iou loss
+ centerness_denorm = max(
+ reduce_mean(pos_centerness_targets.sum().detach()), 1e-6)
+
+ if len(pos_inds) > 0:
+ pos_points = flatten_points[pos_inds]
+ pos_decoded_bbox_preds = self.bbox_coder.decode(
+ pos_points, pos_bbox_preds)
+ pos_decoded_target_preds = self.bbox_coder.decode(
+ pos_points, pos_bbox_targets)
+ loss_bbox = self.loss_bbox(
+ pos_decoded_bbox_preds,
+ pos_decoded_target_preds,
+ weight=pos_centerness_targets,
+ avg_factor=centerness_denorm)
+ loss_centerness = self.loss_centerness(
+ pos_centerness, pos_centerness_targets, avg_factor=num_pos)
+ else:
+ loss_bbox = pos_bbox_preds.sum()
+ loss_centerness = pos_centerness.sum()
+
+ return dict(
+ loss_cls=loss_cls,
+ loss_bbox=loss_bbox,
+ loss_centerness=loss_centerness)
+
+ def get_targets(
+ self, points: List[Tensor], batch_gt_instances: InstanceList
+ ) -> Tuple[List[Tensor], List[Tensor]]:
+ """Compute regression, classification and centerness targets for points
+ in multiple images.
+
+ Args:
+ points (list[Tensor]): Points of each fpn level, each has shape
+ (num_points, 2).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+
+ Returns:
+ tuple: Targets of each level.
+
+ - concat_lvl_labels (list[Tensor]): Labels of each level.
+ - concat_lvl_bbox_targets (list[Tensor]): BBox targets of each \
+ level.
+ """
+ assert len(points) == len(self.regress_ranges)
+ num_levels = len(points)
+ # expand regress ranges to align with points
+ expanded_regress_ranges = [
+ points[i].new_tensor(self.regress_ranges[i])[None].expand_as(
+ points[i]) for i in range(num_levels)
+ ]
+ # concat all levels points and regress ranges
+ concat_regress_ranges = torch.cat(expanded_regress_ranges, dim=0)
+ concat_points = torch.cat(points, dim=0)
+
+ # the number of points per img, per lvl
+ num_points = [center.size(0) for center in points]
+
+ # get labels and bbox_targets of each image
+ labels_list, bbox_targets_list = multi_apply(
+ self._get_targets_single,
+ batch_gt_instances,
+ points=concat_points,
+ regress_ranges=concat_regress_ranges,
+ num_points_per_lvl=num_points)
+
+ # split to per img, per level
+ labels_list = [labels.split(num_points, 0) for labels in labels_list]
+ bbox_targets_list = [
+ bbox_targets.split(num_points, 0)
+ for bbox_targets in bbox_targets_list
+ ]
+
+ # concat per level image
+ concat_lvl_labels = []
+ concat_lvl_bbox_targets = []
+ for i in range(num_levels):
+ concat_lvl_labels.append(
+ torch.cat([labels[i] for labels in labels_list]))
+ bbox_targets = torch.cat(
+ [bbox_targets[i] for bbox_targets in bbox_targets_list])
+ if self.norm_on_bbox:
+ bbox_targets = bbox_targets / self.strides[i]
+ concat_lvl_bbox_targets.append(bbox_targets)
+ return concat_lvl_labels, concat_lvl_bbox_targets
+
+ def _get_targets_single(
+ self, gt_instances: InstanceData, points: Tensor,
+ regress_ranges: Tensor,
+ num_points_per_lvl: List[int]) -> Tuple[Tensor, Tensor]:
+ """Compute regression and classification targets for a single image."""
+ num_points = points.size(0)
+ num_gts = len(gt_instances)
+ gt_bboxes = gt_instances.bboxes
+ gt_labels = gt_instances.labels
+
+ if num_gts == 0:
+ return gt_labels.new_full((num_points,), self.num_classes), \
+ gt_bboxes.new_zeros((num_points, 4))
+
+ areas = (gt_bboxes[:, 2] - gt_bboxes[:, 0]) * (
+ gt_bboxes[:, 3] - gt_bboxes[:, 1])
+ # TODO: figure out why these two are different
+ # areas = areas[None].expand(num_points, num_gts)
+ areas = areas[None].repeat(num_points, 1)
+ regress_ranges = regress_ranges[:, None, :].expand(
+ num_points, num_gts, 2)
+ gt_bboxes = gt_bboxes[None].expand(num_points, num_gts, 4)
+ xs, ys = points[:, 0], points[:, 1]
+ xs = xs[:, None].expand(num_points, num_gts)
+ ys = ys[:, None].expand(num_points, num_gts)
+
+ left = xs - gt_bboxes[..., 0]
+ right = gt_bboxes[..., 2] - xs
+ top = ys - gt_bboxes[..., 1]
+ bottom = gt_bboxes[..., 3] - ys
+ bbox_targets = torch.stack((left, top, right, bottom), -1)
+
+ if self.center_sampling:
+ # condition1: inside a `center bbox`
+ radius = self.center_sample_radius
+ center_xs = (gt_bboxes[..., 0] + gt_bboxes[..., 2]) / 2
+ center_ys = (gt_bboxes[..., 1] + gt_bboxes[..., 3]) / 2
+ center_gts = torch.zeros_like(gt_bboxes)
+ stride = center_xs.new_zeros(center_xs.shape)
+
+ # project the points on current lvl back to the `original` sizes
+ lvl_begin = 0
+ for lvl_idx, num_points_lvl in enumerate(num_points_per_lvl):
+ lvl_end = lvl_begin + num_points_lvl
+ stride[lvl_begin:lvl_end] = self.strides[lvl_idx] * radius
+ lvl_begin = lvl_end
+
+ x_mins = center_xs - stride
+ y_mins = center_ys - stride
+ x_maxs = center_xs + stride
+ y_maxs = center_ys + stride
+ center_gts[..., 0] = torch.where(x_mins > gt_bboxes[..., 0],
+ x_mins, gt_bboxes[..., 0])
+ center_gts[..., 1] = torch.where(y_mins > gt_bboxes[..., 1],
+ y_mins, gt_bboxes[..., 1])
+ center_gts[..., 2] = torch.where(x_maxs > gt_bboxes[..., 2],
+ gt_bboxes[..., 2], x_maxs)
+ center_gts[..., 3] = torch.where(y_maxs > gt_bboxes[..., 3],
+ gt_bboxes[..., 3], y_maxs)
+
+ cb_dist_left = xs - center_gts[..., 0]
+ cb_dist_right = center_gts[..., 2] - xs
+ cb_dist_top = ys - center_gts[..., 1]
+ cb_dist_bottom = center_gts[..., 3] - ys
+ center_bbox = torch.stack(
+ (cb_dist_left, cb_dist_top, cb_dist_right, cb_dist_bottom), -1)
+ inside_gt_bbox_mask = center_bbox.min(-1)[0] > 0
+ else:
+ # condition1: inside a gt bbox
+ inside_gt_bbox_mask = bbox_targets.min(-1)[0] > 0
+
+ # condition2: limit the regression range for each location
+ max_regress_distance = bbox_targets.max(-1)[0]
+ inside_regress_range = (
+ (max_regress_distance >= regress_ranges[..., 0])
+ & (max_regress_distance <= regress_ranges[..., 1]))
+
+ # if there are still more than one objects for a location,
+ # we choose the one with minimal area
+ areas[inside_gt_bbox_mask == 0] = INF
+ areas[inside_regress_range == 0] = INF
+ min_area, min_area_inds = areas.min(dim=1)
+
+ labels = gt_labels[min_area_inds]
+ labels[min_area == INF] = self.num_classes # set as BG
+ bbox_targets = bbox_targets[range(num_points), min_area_inds]
+
+ return labels, bbox_targets
+
+ def centerness_target(self, pos_bbox_targets: Tensor) -> Tensor:
+ """Compute centerness targets.
+
+ Args:
+ pos_bbox_targets (Tensor): BBox targets of positive bboxes in shape
+ (num_pos, 4)
+
+ Returns:
+ Tensor: Centerness target.
+ """
+ # only calculate pos centerness targets, otherwise there may be nan
+ left_right = pos_bbox_targets[:, [0, 2]]
+ top_bottom = pos_bbox_targets[:, [1, 3]]
+ if len(left_right) == 0:
+ centerness_targets = left_right[..., 0]
+ else:
+ centerness_targets = (
+ left_right.min(dim=-1)[0] / left_right.max(dim=-1)[0]) * (
+ top_bottom.min(dim=-1)[0] / top_bottom.max(dim=-1)[0])
+ return torch.sqrt(centerness_targets)
diff --git a/mmdet/models/dense_heads/fovea_head.py b/mmdet/models/dense_heads/fovea_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..89353deac7f0189c1e464288521ee8e4238f0107
--- /dev/null
+++ b/mmdet/models/dense_heads/fovea_head.py
@@ -0,0 +1,509 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Optional, Tuple
+
+import torch
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+from mmcv.ops import DeformConv2d
+from mmengine.config import ConfigDict
+from mmengine.model import BaseModule
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.utils import InstanceList, OptInstanceList, OptMultiConfig
+from ..utils import filter_scores_and_topk, multi_apply
+from .anchor_free_head import AnchorFreeHead
+
+INF = 1e8
+
+
+class FeatureAlign(BaseModule):
+ """Feature Align Module.
+
+ Feature Align Module is implemented based on DCN v1.
+ It uses anchor shape prediction rather than feature map to
+ predict offsets of deform conv layer.
+
+ Args:
+ in_channels (int): Number of channels in the input feature map.
+ out_channels (int): Number of channels in the output feature map.
+ kernel_size (int): Size of the convolution kernel.
+ ``norm_cfg=dict(type='GN', num_groups=32, requires_grad=True)``.
+ deform_groups: (int): Group number of DCN in
+ FeatureAdaption module.
+ init_cfg (:obj:`ConfigDict` or dict or list[:obj:`ConfigDict` or \
+ dict], optional): Initialization config dict.
+ """
+
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ kernel_size: int = 3,
+ deform_groups: int = 4,
+ init_cfg: OptMultiConfig = dict(
+ type='Normal',
+ layer='Conv2d',
+ std=0.1,
+ override=dict(type='Normal', name='conv_adaption', std=0.01))
+ ) -> None:
+ super().__init__(init_cfg=init_cfg)
+ offset_channels = kernel_size * kernel_size * 2
+ self.conv_offset = nn.Conv2d(
+ 4, deform_groups * offset_channels, 1, bias=False)
+ self.conv_adaption = DeformConv2d(
+ in_channels,
+ out_channels,
+ kernel_size=kernel_size,
+ padding=(kernel_size - 1) // 2,
+ deform_groups=deform_groups)
+ self.relu = nn.ReLU(inplace=True)
+
+ def forward(self, x: Tensor, shape: Tensor) -> Tensor:
+ """Forward function of feature align module.
+
+ Args:
+ x (Tensor): Features from the upstream network.
+ shape (Tensor): Exponential of bbox predictions.
+
+ Returns:
+ x (Tensor): The aligned features.
+ """
+ offset = self.conv_offset(shape)
+ x = self.relu(self.conv_adaption(x, offset))
+ return x
+
+
+@MODELS.register_module()
+class FoveaHead(AnchorFreeHead):
+ """Detection Head of `FoveaBox: Beyond Anchor-based Object Detector.
+
+ `_.
+
+ Args:
+ num_classes (int): Number of categories excluding the background
+ category.
+ in_channels (int): Number of channels in the input feature map.
+ base_edge_list (list[int]): List of edges.
+ scale_ranges (list[tuple]): Range of scales.
+ sigma (float): Super parameter of ``FoveaHead``.
+ with_deform (bool): Whether use deform conv.
+ deform_groups (int): Deformable conv group size.
+ init_cfg (:obj:`ConfigDict` or dict or list[:obj:`ConfigDict` or \
+ dict], optional): Initialization config dict.
+ """
+
+ def __init__(self,
+ num_classes: int,
+ in_channels: int,
+ base_edge_list: List[int] = (16, 32, 64, 128, 256),
+ scale_ranges: List[tuple] = ((8, 32), (16, 64), (32, 128),
+ (64, 256), (128, 512)),
+ sigma: float = 0.4,
+ with_deform: bool = False,
+ deform_groups: int = 4,
+ init_cfg: OptMultiConfig = dict(
+ type='Normal',
+ layer='Conv2d',
+ std=0.01,
+ override=dict(
+ type='Normal',
+ name='conv_cls',
+ std=0.01,
+ bias_prob=0.01)),
+ **kwargs) -> None:
+ self.base_edge_list = base_edge_list
+ self.scale_ranges = scale_ranges
+ self.sigma = sigma
+ self.with_deform = with_deform
+ self.deform_groups = deform_groups
+ super().__init__(
+ num_classes=num_classes,
+ in_channels=in_channels,
+ init_cfg=init_cfg,
+ **kwargs)
+
+ def _init_layers(self) -> None:
+ """Initialize layers of the head."""
+ # box branch
+ super()._init_reg_convs()
+ self.conv_reg = nn.Conv2d(self.feat_channels, 4, 3, padding=1)
+
+ # cls branch
+ if not self.with_deform:
+ super()._init_cls_convs()
+ self.conv_cls = nn.Conv2d(
+ self.feat_channels, self.cls_out_channels, 3, padding=1)
+ else:
+ self.cls_convs = nn.ModuleList()
+ self.cls_convs.append(
+ ConvModule(
+ self.feat_channels, (self.feat_channels * 4),
+ 3,
+ stride=1,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ bias=self.norm_cfg is None))
+ self.cls_convs.append(
+ ConvModule((self.feat_channels * 4), (self.feat_channels * 4),
+ 1,
+ stride=1,
+ padding=0,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ bias=self.norm_cfg is None))
+ self.feature_adaption = FeatureAlign(
+ self.feat_channels,
+ self.feat_channels,
+ kernel_size=3,
+ deform_groups=self.deform_groups)
+ self.conv_cls = nn.Conv2d(
+ int(self.feat_channels * 4),
+ self.cls_out_channels,
+ 3,
+ padding=1)
+
+ def forward_single(self, x: Tensor) -> Tuple[Tensor, Tensor]:
+ """Forward features of a single scale level.
+
+ Args:
+ x (Tensor): FPN feature maps of the specified stride.
+
+ Returns:
+ tuple: scores for each class and bbox predictions of input
+ feature maps.
+ """
+ cls_feat = x
+ reg_feat = x
+ for reg_layer in self.reg_convs:
+ reg_feat = reg_layer(reg_feat)
+ bbox_pred = self.conv_reg(reg_feat)
+ if self.with_deform:
+ cls_feat = self.feature_adaption(cls_feat, bbox_pred.exp())
+ for cls_layer in self.cls_convs:
+ cls_feat = cls_layer(cls_feat)
+ cls_score = self.conv_cls(cls_feat)
+ return cls_score, bbox_pred
+
+ def loss_by_feat(
+ self,
+ cls_scores: List[Tensor],
+ bbox_preds: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ batch_gt_instances_ignore: OptInstanceList = None
+ ) -> Dict[str, Tensor]:
+ """Calculate the loss based on the features extracted by the detection
+ head.
+
+ Args:
+ cls_scores (list[Tensor]): Box scores for each scale level,
+ each is a 4D-tensor, the channel number is
+ num_priors * num_classes.
+ bbox_preds (list[Tensor]): Box energies / deltas for each scale
+ level, each is a 4D-tensor, the channel number is
+ num_priors * 4.
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], Optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components.
+ """
+ assert len(cls_scores) == len(bbox_preds)
+
+ featmap_sizes = [featmap.size()[-2:] for featmap in cls_scores]
+ priors = self.prior_generator.grid_priors(
+ featmap_sizes,
+ dtype=bbox_preds[0].dtype,
+ device=bbox_preds[0].device)
+ num_imgs = cls_scores[0].size(0)
+ flatten_cls_scores = [
+ cls_score.permute(0, 2, 3, 1).reshape(-1, self.cls_out_channels)
+ for cls_score in cls_scores
+ ]
+ flatten_bbox_preds = [
+ bbox_pred.permute(0, 2, 3, 1).reshape(-1, 4)
+ for bbox_pred in bbox_preds
+ ]
+ flatten_cls_scores = torch.cat(flatten_cls_scores)
+ flatten_bbox_preds = torch.cat(flatten_bbox_preds)
+ flatten_labels, flatten_bbox_targets = self.get_targets(
+ batch_gt_instances, featmap_sizes, priors)
+
+ # FG cat_id: [0, num_classes -1], BG cat_id: num_classes
+ pos_inds = ((flatten_labels >= 0)
+ & (flatten_labels < self.num_classes)).nonzero().view(-1)
+ num_pos = len(pos_inds)
+
+ loss_cls = self.loss_cls(
+ flatten_cls_scores, flatten_labels, avg_factor=num_pos + num_imgs)
+ if num_pos > 0:
+ pos_bbox_preds = flatten_bbox_preds[pos_inds]
+ pos_bbox_targets = flatten_bbox_targets[pos_inds]
+ pos_weights = pos_bbox_targets.new_ones(pos_bbox_targets.size())
+ loss_bbox = self.loss_bbox(
+ pos_bbox_preds,
+ pos_bbox_targets,
+ pos_weights,
+ avg_factor=num_pos)
+ else:
+ loss_bbox = torch.tensor(
+ 0,
+ dtype=flatten_bbox_preds.dtype,
+ device=flatten_bbox_preds.device)
+ return dict(loss_cls=loss_cls, loss_bbox=loss_bbox)
+
+ def get_targets(
+ self, batch_gt_instances: InstanceList, featmap_sizes: List[tuple],
+ priors_list: List[Tensor]) -> Tuple[List[Tensor], List[Tensor]]:
+ """Compute regression and classification for priors in multiple images.
+
+ Args:
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ featmap_sizes (list[tuple]): Size tuple of feature maps.
+ priors_list (list[Tensor]): Priors list of each fpn level, each has
+ shape (num_priors, 2).
+
+ Returns:
+ tuple: Targets of each level.
+
+ - flatten_labels (list[Tensor]): Labels of each level.
+ - flatten_bbox_targets (list[Tensor]): BBox targets of each
+ level.
+ """
+ label_list, bbox_target_list = multi_apply(
+ self._get_targets_single,
+ batch_gt_instances,
+ featmap_size_list=featmap_sizes,
+ priors_list=priors_list)
+ flatten_labels = [
+ torch.cat([
+ labels_level_img.flatten() for labels_level_img in labels_level
+ ]) for labels_level in zip(*label_list)
+ ]
+ flatten_bbox_targets = [
+ torch.cat([
+ bbox_targets_level_img.reshape(-1, 4)
+ for bbox_targets_level_img in bbox_targets_level
+ ]) for bbox_targets_level in zip(*bbox_target_list)
+ ]
+ flatten_labels = torch.cat(flatten_labels)
+ flatten_bbox_targets = torch.cat(flatten_bbox_targets)
+ return flatten_labels, flatten_bbox_targets
+
+ def _get_targets_single(self,
+ gt_instances: InstanceData,
+ featmap_size_list: List[tuple] = None,
+ priors_list: List[Tensor] = None) -> tuple:
+ """Compute regression and classification targets for a single image.
+
+ Args:
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ featmap_size_list (list[tuple]): Size tuple of feature maps.
+ priors_list (list[Tensor]): Priors of each fpn level, each has
+ shape (num_priors, 2).
+
+ Returns:
+ tuple:
+
+ - label_list (list[Tensor]): Labels of all anchors in the image.
+ - box_target_list (list[Tensor]): BBox targets of all anchors in
+ the image.
+ """
+ gt_bboxes_raw = gt_instances.bboxes
+ gt_labels_raw = gt_instances.labels
+ gt_areas = torch.sqrt((gt_bboxes_raw[:, 2] - gt_bboxes_raw[:, 0]) *
+ (gt_bboxes_raw[:, 3] - gt_bboxes_raw[:, 1]))
+ label_list = []
+ bbox_target_list = []
+ # for each pyramid, find the cls and box target
+ for base_len, (lower_bound, upper_bound), stride, featmap_size, \
+ priors in zip(self.base_edge_list, self.scale_ranges,
+ self.strides, featmap_size_list, priors_list):
+ # FG cat_id: [0, num_classes -1], BG cat_id: num_classes
+ priors = priors.view(*featmap_size, 2)
+ x, y = priors[..., 0], priors[..., 1]
+ labels = gt_labels_raw.new_full(featmap_size, self.num_classes)
+ bbox_targets = gt_bboxes_raw.new_ones(featmap_size[0],
+ featmap_size[1], 4)
+ # scale assignment
+ hit_indices = ((gt_areas >= lower_bound) &
+ (gt_areas <= upper_bound)).nonzero().flatten()
+ if len(hit_indices) == 0:
+ label_list.append(labels)
+ bbox_target_list.append(torch.log(bbox_targets))
+ continue
+ _, hit_index_order = torch.sort(-gt_areas[hit_indices])
+ hit_indices = hit_indices[hit_index_order]
+ gt_bboxes = gt_bboxes_raw[hit_indices, :] / stride
+ gt_labels = gt_labels_raw[hit_indices]
+ half_w = 0.5 * (gt_bboxes[:, 2] - gt_bboxes[:, 0])
+ half_h = 0.5 * (gt_bboxes[:, 3] - gt_bboxes[:, 1])
+ # valid fovea area: left, right, top, down
+ pos_left = torch.ceil(
+ gt_bboxes[:, 0] + (1 - self.sigma) * half_w - 0.5).long(). \
+ clamp(0, featmap_size[1] - 1)
+ pos_right = torch.floor(
+ gt_bboxes[:, 0] + (1 + self.sigma) * half_w - 0.5).long(). \
+ clamp(0, featmap_size[1] - 1)
+ pos_top = torch.ceil(
+ gt_bboxes[:, 1] + (1 - self.sigma) * half_h - 0.5).long(). \
+ clamp(0, featmap_size[0] - 1)
+ pos_down = torch.floor(
+ gt_bboxes[:, 1] + (1 + self.sigma) * half_h - 0.5).long(). \
+ clamp(0, featmap_size[0] - 1)
+ for px1, py1, px2, py2, label, (gt_x1, gt_y1, gt_x2, gt_y2) in \
+ zip(pos_left, pos_top, pos_right, pos_down, gt_labels,
+ gt_bboxes_raw[hit_indices, :]):
+ labels[py1:py2 + 1, px1:px2 + 1] = label
+ bbox_targets[py1:py2 + 1, px1:px2 + 1, 0] = \
+ (x[py1:py2 + 1, px1:px2 + 1] - gt_x1) / base_len
+ bbox_targets[py1:py2 + 1, px1:px2 + 1, 1] = \
+ (y[py1:py2 + 1, px1:px2 + 1] - gt_y1) / base_len
+ bbox_targets[py1:py2 + 1, px1:px2 + 1, 2] = \
+ (gt_x2 - x[py1:py2 + 1, px1:px2 + 1]) / base_len
+ bbox_targets[py1:py2 + 1, px1:px2 + 1, 3] = \
+ (gt_y2 - y[py1:py2 + 1, px1:px2 + 1]) / base_len
+ bbox_targets = bbox_targets.clamp(min=1. / 16, max=16.)
+ label_list.append(labels)
+ bbox_target_list.append(torch.log(bbox_targets))
+ return label_list, bbox_target_list
+
+ # Same as base_dense_head/_predict_by_feat_single except self._bbox_decode
+ def _predict_by_feat_single(self,
+ cls_score_list: List[Tensor],
+ bbox_pred_list: List[Tensor],
+ score_factor_list: List[Tensor],
+ mlvl_priors: List[Tensor],
+ img_meta: dict,
+ cfg: Optional[ConfigDict] = None,
+ rescale: bool = False,
+ with_nms: bool = True) -> InstanceData:
+ """Transform a single image's features extracted from the head into
+ bbox results.
+
+ Args:
+ cls_score_list (list[Tensor]): Box scores from all scale
+ levels of a single image, each item has shape
+ (num_priors * num_classes, H, W).
+ bbox_pred_list (list[Tensor]): Box energies / deltas from
+ all scale levels of a single image, each item has shape
+ (num_priors * 4, H, W).
+ score_factor_list (list[Tensor]): Score factor from all scale
+ levels of a single image, each item has shape
+ (num_priors * 1, H, W).
+ mlvl_priors (list[Tensor]): Each element in the list is
+ the priors of a single level in feature pyramid, has shape
+ (num_priors, 2).
+ img_meta (dict): Image meta info.
+ cfg (ConfigDict, optional): Test / postprocessing
+ configuration, if None, test_cfg would be used.
+ Defaults to None.
+ rescale (bool): If True, return boxes in original image space.
+ Defaults to False.
+ with_nms (bool): If True, do nms before return boxes.
+ Defaults to True.
+
+ Returns:
+ :obj:`InstanceData`: Detection results of each image
+ after the post process.
+ Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ """
+ cfg = self.test_cfg if cfg is None else cfg
+ assert len(cls_score_list) == len(bbox_pred_list)
+ img_shape = img_meta['img_shape']
+ nms_pre = cfg.get('nms_pre', -1)
+
+ mlvl_bboxes = []
+ mlvl_scores = []
+ mlvl_labels = []
+ for level_idx, (cls_score, bbox_pred, stride, base_len, priors) in \
+ enumerate(zip(cls_score_list, bbox_pred_list, self.strides,
+ self.base_edge_list, mlvl_priors)):
+ assert cls_score.size()[-2:] == bbox_pred.size()[-2:]
+ bbox_pred = bbox_pred.permute(1, 2, 0).reshape(-1, 4)
+
+ scores = cls_score.permute(1, 2, 0).reshape(
+ -1, self.cls_out_channels).sigmoid()
+
+ # After https://github.com/open-mmlab/mmdetection/pull/6268/,
+ # this operation keeps fewer bboxes under the same `nms_pre`.
+ # There is no difference in performance for most models. If you
+ # find a slight drop in performance, you can set a larger
+ # `nms_pre` than before.
+ results = filter_scores_and_topk(
+ scores, cfg.score_thr, nms_pre,
+ dict(bbox_pred=bbox_pred, priors=priors))
+ scores, labels, _, filtered_results = results
+
+ bbox_pred = filtered_results['bbox_pred']
+ priors = filtered_results['priors']
+
+ bboxes = self._bbox_decode(priors, bbox_pred, base_len, img_shape)
+
+ mlvl_bboxes.append(bboxes)
+ mlvl_scores.append(scores)
+ mlvl_labels.append(labels)
+
+ results = InstanceData()
+ results.bboxes = torch.cat(mlvl_bboxes)
+ results.scores = torch.cat(mlvl_scores)
+ results.labels = torch.cat(mlvl_labels)
+
+ return self._bbox_post_process(
+ results=results,
+ cfg=cfg,
+ rescale=rescale,
+ with_nms=with_nms,
+ img_meta=img_meta)
+
+ def _bbox_decode(self, priors: Tensor, bbox_pred: Tensor, base_len: int,
+ max_shape: int) -> Tensor:
+ """Function to decode bbox.
+
+ Args:
+ priors (Tensor): Center proiors of an image, has shape
+ (num_instances, 2).
+ bbox_preds (Tensor): Box energies / deltas for all instances,
+ has shape (batch_size, num_instances, 4).
+ base_len (int): The base length.
+ max_shape (int): The max shape of bbox.
+
+ Returns:
+ Tensor: Decoded bboxes in (tl_x, tl_y, br_x, br_y) format. Has
+ shape (batch_size, num_instances, 4).
+ """
+ bbox_pred = bbox_pred.exp()
+
+ y = priors[:, 1]
+ x = priors[:, 0]
+ x1 = (x - base_len * bbox_pred[:, 0]). \
+ clamp(min=0, max=max_shape[1] - 1)
+ y1 = (y - base_len * bbox_pred[:, 1]). \
+ clamp(min=0, max=max_shape[0] - 1)
+ x2 = (x + base_len * bbox_pred[:, 2]). \
+ clamp(min=0, max=max_shape[1] - 1)
+ y2 = (y + base_len * bbox_pred[:, 3]). \
+ clamp(min=0, max=max_shape[0] - 1)
+ decoded_bboxes = torch.stack([x1, y1, x2, y2], -1)
+ return decoded_bboxes
diff --git a/mmdet/models/dense_heads/free_anchor_retina_head.py b/mmdet/models/dense_heads/free_anchor_retina_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..df6fb9202c32735121bf7738e332fbfc5ac7e6bd
--- /dev/null
+++ b/mmdet/models/dense_heads/free_anchor_retina_head.py
@@ -0,0 +1,312 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List
+
+import torch
+import torch.nn.functional as F
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.structures.bbox import bbox_overlaps
+from mmdet.utils import InstanceList, OptConfigType, OptInstanceList
+from ..utils import multi_apply
+from .retina_head import RetinaHead
+
+EPS = 1e-12
+
+
+@MODELS.register_module()
+class FreeAnchorRetinaHead(RetinaHead):
+ """FreeAnchor RetinaHead used in https://arxiv.org/abs/1909.02466.
+
+ Args:
+ num_classes (int): Number of categories excluding the background
+ category.
+ in_channels (int): Number of channels in the input feature map.
+ stacked_convs (int): Number of conv layers in cls and reg tower.
+ Defaults to 4.
+ conv_cfg (:obj:`ConfigDict` or dict, optional): dictionary to
+ construct and config conv layer. Defaults to None.
+ norm_cfg (:obj:`ConfigDict` or dict, optional): dictionary to
+ construct and config norm layer. Defaults to
+ norm_cfg=dict(type='GN', num_groups=32, requires_grad=True).
+ pre_anchor_topk (int): Number of boxes that be token in each bag.
+ Defaults to 50
+ bbox_thr (float): The threshold of the saturated linear function.
+ It is usually the same with the IoU threshold used in NMS.
+ Defaults to 0.6.
+ gamma (float): Gamma parameter in focal loss. Defaults to 2.0.
+ alpha (float): Alpha parameter in focal loss. Defaults to 0.5.
+ """
+
+ def __init__(self,
+ num_classes: int,
+ in_channels: int,
+ stacked_convs: int = 4,
+ conv_cfg: OptConfigType = None,
+ norm_cfg: OptConfigType = None,
+ pre_anchor_topk: int = 50,
+ bbox_thr: float = 0.6,
+ gamma: float = 2.0,
+ alpha: float = 0.5,
+ **kwargs) -> None:
+ super().__init__(
+ num_classes=num_classes,
+ in_channels=in_channels,
+ stacked_convs=stacked_convs,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ **kwargs)
+
+ self.pre_anchor_topk = pre_anchor_topk
+ self.bbox_thr = bbox_thr
+ self.gamma = gamma
+ self.alpha = alpha
+
+ def loss_by_feat(
+ self,
+ cls_scores: List[Tensor],
+ bbox_preds: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ batch_gt_instances_ignore: OptInstanceList = None) -> dict:
+ """Calculate the loss based on the features extracted by the detection
+ head.
+
+ Args:
+ cls_scores (list[Tensor]): Box scores for each scale level
+ has shape (N, num_anchors * num_classes, H, W).
+ bbox_preds (list[Tensor]): Box energies / deltas for each scale
+ level with shape (N, num_anchors * 4, H, W).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ dict: A dictionary of loss components.
+ """
+ featmap_sizes = [featmap.size()[-2:] for featmap in cls_scores]
+ assert len(featmap_sizes) == self.prior_generator.num_levels
+
+ device = cls_scores[0].device
+
+ anchor_list, _ = self.get_anchors(
+ featmap_sizes=featmap_sizes,
+ batch_img_metas=batch_img_metas,
+ device=device)
+ concat_anchor_list = [torch.cat(anchor) for anchor in anchor_list]
+
+ # concatenate each level
+ cls_scores = [
+ cls.permute(0, 2, 3,
+ 1).reshape(cls.size(0), -1, self.cls_out_channels)
+ for cls in cls_scores
+ ]
+ bbox_preds = [
+ bbox_pred.permute(0, 2, 3, 1).reshape(bbox_pred.size(0), -1, 4)
+ for bbox_pred in bbox_preds
+ ]
+ cls_scores = torch.cat(cls_scores, dim=1)
+ cls_probs = torch.sigmoid(cls_scores)
+ bbox_preds = torch.cat(bbox_preds, dim=1)
+
+ box_probs, positive_losses, num_pos_list = multi_apply(
+ self.positive_loss_single, cls_probs, bbox_preds,
+ concat_anchor_list, batch_gt_instances)
+
+ num_pos = sum(num_pos_list)
+ positive_loss = torch.cat(positive_losses).sum() / max(1, num_pos)
+
+ # box_prob: P{a_{j} \in A_{+}}
+ box_probs = torch.stack(box_probs, dim=0)
+
+ # negative_loss:
+ # \sum_{j}{ FL((1 - P{a_{j} \in A_{+}}) * (1 - P_{j}^{bg})) } / n||B||
+ negative_loss = self.negative_bag_loss(cls_probs, box_probs).sum() / \
+ max(1, num_pos * self.pre_anchor_topk)
+
+ # avoid the absence of gradients in regression subnet
+ # when no ground-truth in a batch
+ if num_pos == 0:
+ positive_loss = bbox_preds.sum() * 0
+
+ losses = {
+ 'positive_bag_loss': positive_loss,
+ 'negative_bag_loss': negative_loss
+ }
+ return losses
+
+ def positive_loss_single(self, cls_prob: Tensor, bbox_pred: Tensor,
+ flat_anchors: Tensor,
+ gt_instances: InstanceData) -> tuple:
+ """Compute positive loss.
+
+ Args:
+ cls_prob (Tensor): Classification probability of shape
+ (num_anchors, num_classes).
+ bbox_pred (Tensor): Box probability of shape (num_anchors, 4).
+ flat_anchors (Tensor): Multi-level anchors of the image, which are
+ concatenated into a single tensor of shape (num_anchors, 4)
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It should includes ``bboxes`` and ``labels``
+ attributes.
+
+ Returns:
+ tuple:
+
+ - box_prob (Tensor): Box probability of shape (num_anchors, 4).
+ - positive_loss (Tensor): Positive loss of shape (num_pos, ).
+ - num_pos (int): positive samples indexes.
+ """
+
+ gt_bboxes = gt_instances.bboxes
+ gt_labels = gt_instances.labels
+ with torch.no_grad():
+ if len(gt_bboxes) == 0:
+ image_box_prob = torch.zeros(
+ flat_anchors.size(0),
+ self.cls_out_channels).type_as(bbox_pred)
+ else:
+ # box_localization: a_{j}^{loc}, shape: [j, 4]
+ pred_boxes = self.bbox_coder.decode(flat_anchors, bbox_pred)
+
+ # object_box_iou: IoU_{ij}^{loc}, shape: [i, j]
+ object_box_iou = bbox_overlaps(gt_bboxes, pred_boxes)
+
+ # object_box_prob: P{a_{j} -> b_{i}}, shape: [i, j]
+ t1 = self.bbox_thr
+ t2 = object_box_iou.max(
+ dim=1, keepdim=True).values.clamp(min=t1 + 1e-12)
+ object_box_prob = ((object_box_iou - t1) / (t2 - t1)).clamp(
+ min=0, max=1)
+
+ # object_cls_box_prob: P{a_{j} -> b_{i}}, shape: [i, c, j]
+ num_obj = gt_labels.size(0)
+ indices = torch.stack(
+ [torch.arange(num_obj).type_as(gt_labels), gt_labels],
+ dim=0)
+ object_cls_box_prob = torch.sparse_coo_tensor(
+ indices, object_box_prob)
+
+ # image_box_iou: P{a_{j} \in A_{+}}, shape: [c, j]
+ """
+ from "start" to "end" implement:
+ image_box_iou = torch.sparse.max(object_cls_box_prob,
+ dim=0).t()
+
+ """
+ # start
+ box_cls_prob = torch.sparse.sum(
+ object_cls_box_prob, dim=0).to_dense()
+
+ indices = torch.nonzero(box_cls_prob, as_tuple=False).t_()
+ if indices.numel() == 0:
+ image_box_prob = torch.zeros(
+ flat_anchors.size(0),
+ self.cls_out_channels).type_as(object_box_prob)
+ else:
+ nonzero_box_prob = torch.where(
+ (gt_labels.unsqueeze(dim=-1) == indices[0]),
+ object_box_prob[:, indices[1]],
+ torch.tensor(
+ [0]).type_as(object_box_prob)).max(dim=0).values
+
+ # upmap to shape [j, c]
+ image_box_prob = torch.sparse_coo_tensor(
+ indices.flip([0]),
+ nonzero_box_prob,
+ size=(flat_anchors.size(0),
+ self.cls_out_channels)).to_dense()
+ # end
+ box_prob = image_box_prob
+
+ # construct bags for objects
+ match_quality_matrix = bbox_overlaps(gt_bboxes, flat_anchors)
+ _, matched = torch.topk(
+ match_quality_matrix, self.pre_anchor_topk, dim=1, sorted=False)
+ del match_quality_matrix
+
+ # matched_cls_prob: P_{ij}^{cls}
+ matched_cls_prob = torch.gather(
+ cls_prob[matched], 2,
+ gt_labels.view(-1, 1, 1).repeat(1, self.pre_anchor_topk,
+ 1)).squeeze(2)
+
+ # matched_box_prob: P_{ij}^{loc}
+ matched_anchors = flat_anchors[matched]
+ matched_object_targets = self.bbox_coder.encode(
+ matched_anchors,
+ gt_bboxes.unsqueeze(dim=1).expand_as(matched_anchors))
+ loss_bbox = self.loss_bbox(
+ bbox_pred[matched],
+ matched_object_targets,
+ reduction_override='none').sum(-1)
+ matched_box_prob = torch.exp(-loss_bbox)
+
+ # positive_losses: {-log( Mean-max(P_{ij}^{cls} * P_{ij}^{loc}) )}
+ num_pos = len(gt_bboxes)
+ positive_loss = self.positive_bag_loss(matched_cls_prob,
+ matched_box_prob)
+
+ return box_prob, positive_loss, num_pos
+
+ def positive_bag_loss(self, matched_cls_prob: Tensor,
+ matched_box_prob: Tensor) -> Tensor:
+ """Compute positive bag loss.
+
+ :math:`-log( Mean-max(P_{ij}^{cls} * P_{ij}^{loc}) )`.
+
+ :math:`P_{ij}^{cls}`: matched_cls_prob, classification probability of matched samples.
+
+ :math:`P_{ij}^{loc}`: matched_box_prob, box probability of matched samples.
+
+ Args:
+ matched_cls_prob (Tensor): Classification probability of matched
+ samples in shape (num_gt, pre_anchor_topk).
+ matched_box_prob (Tensor): BBox probability of matched samples,
+ in shape (num_gt, pre_anchor_topk).
+
+ Returns:
+ Tensor: Positive bag loss in shape (num_gt,).
+ """ # noqa: E501, W605
+ # bag_prob = Mean-max(matched_prob)
+ matched_prob = matched_cls_prob * matched_box_prob
+ weight = 1 / torch.clamp(1 - matched_prob, 1e-12, None)
+ weight /= weight.sum(dim=1).unsqueeze(dim=-1)
+ bag_prob = (weight * matched_prob).sum(dim=1)
+ # positive_bag_loss = -self.alpha * log(bag_prob)
+ return self.alpha * F.binary_cross_entropy(
+ bag_prob, torch.ones_like(bag_prob), reduction='none')
+
+ def negative_bag_loss(self, cls_prob: Tensor, box_prob: Tensor) -> Tensor:
+ """Compute negative bag loss.
+
+ :math:`FL((1 - P_{a_{j} \in A_{+}}) * (1 - P_{j}^{bg}))`.
+
+ :math:`P_{a_{j} \in A_{+}}`: Box_probability of matched samples.
+
+ :math:`P_{j}^{bg}`: Classification probability of negative samples.
+
+ Args:
+ cls_prob (Tensor): Classification probability, in shape
+ (num_img, num_anchors, num_classes).
+ box_prob (Tensor): Box probability, in shape
+ (num_img, num_anchors, num_classes).
+
+ Returns:
+ Tensor: Negative bag loss in shape (num_img, num_anchors,
+ num_classes).
+ """ # noqa: E501, W605
+ prob = cls_prob * (1 - box_prob)
+ # There are some cases when neg_prob = 0.
+ # This will cause the neg_prob.log() to be inf without clamp.
+ prob = prob.clamp(min=EPS, max=1 - EPS)
+ negative_bag_loss = prob**self.gamma * F.binary_cross_entropy(
+ prob, torch.zeros_like(prob), reduction='none')
+ return (1 - self.alpha) * negative_bag_loss
diff --git a/mmdet/models/dense_heads/fsaf_head.py b/mmdet/models/dense_heads/fsaf_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..0a01c487406693253eb17b883cac9ed06cf95802
--- /dev/null
+++ b/mmdet/models/dense_heads/fsaf_head.py
@@ -0,0 +1,458 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Optional, Tuple
+
+import numpy as np
+import torch
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.utils import InstanceList, OptInstanceList, OptMultiConfig
+from ..losses.accuracy import accuracy
+from ..losses.utils import weight_reduce_loss
+from ..task_modules.prior_generators import anchor_inside_flags
+from ..utils import images_to_levels, multi_apply, unmap
+from .retina_head import RetinaHead
+
+
+@MODELS.register_module()
+class FSAFHead(RetinaHead):
+ """Anchor-free head used in `FSAF `_.
+
+ The head contains two subnetworks. The first classifies anchor boxes and
+ the second regresses deltas for the anchors (num_anchors is 1 for anchor-
+ free methods)
+
+ Args:
+ *args: Same as its base class in :class:`RetinaHead`
+ score_threshold (float, optional): The score_threshold to calculate
+ positive recall. If given, prediction scores lower than this value
+ is counted as incorrect prediction. Defaults to None.
+ init_cfg (:obj:`ConfigDict` or dict or list[:obj:`ConfigDict` or \
+ dict]): Initialization config dict.
+ **kwargs: Same as its base class in :class:`RetinaHead`
+
+ Example:
+ >>> import torch
+ >>> self = FSAFHead(11, 7)
+ >>> x = torch.rand(1, 7, 32, 32)
+ >>> cls_score, bbox_pred = self.forward_single(x)
+ >>> # Each anchor predicts a score for each class except background
+ >>> cls_per_anchor = cls_score.shape[1] / self.num_anchors
+ >>> box_per_anchor = bbox_pred.shape[1] / self.num_anchors
+ >>> assert cls_per_anchor == self.num_classes
+ >>> assert box_per_anchor == 4
+ """
+
+ def __init__(self,
+ *args,
+ score_threshold: Optional[float] = None,
+ init_cfg: OptMultiConfig = None,
+ **kwargs) -> None:
+ # The positive bias in self.retina_reg conv is to prevent predicted \
+ # bbox with 0 area
+ if init_cfg is None:
+ init_cfg = dict(
+ type='Normal',
+ layer='Conv2d',
+ std=0.01,
+ override=[
+ dict(
+ type='Normal',
+ name='retina_cls',
+ std=0.01,
+ bias_prob=0.01),
+ dict(
+ type='Normal', name='retina_reg', std=0.01, bias=0.25)
+ ])
+ super().__init__(*args, init_cfg=init_cfg, **kwargs)
+ self.score_threshold = score_threshold
+
+ def forward_single(self, x: Tensor) -> Tuple[Tensor, Tensor]:
+ """Forward feature map of a single scale level.
+
+ Args:
+ x (Tensor): Feature map of a single scale level.
+
+ Returns:
+ tuple[Tensor, Tensor]:
+
+ - cls_score (Tensor): Box scores for each scale level Has \
+ shape (N, num_points * num_classes, H, W).
+ - bbox_pred (Tensor): Box energies / deltas for each scale \
+ level with shape (N, num_points * 4, H, W).
+ """
+ cls_score, bbox_pred = super().forward_single(x)
+ # relu: TBLR encoder only accepts positive bbox_pred
+ return cls_score, self.relu(bbox_pred)
+
+ def _get_targets_single(self,
+ flat_anchors: Tensor,
+ valid_flags: Tensor,
+ gt_instances: InstanceData,
+ img_meta: dict,
+ gt_instances_ignore: Optional[InstanceData] = None,
+ unmap_outputs: bool = True) -> tuple:
+ """Compute regression and classification targets for anchors in a
+ single image.
+
+ Most of the codes are the same with the base class :obj: `AnchorHead`,
+ except that it also collects and returns the matched gt index in the
+ image (from 0 to num_gt-1). If the anchor bbox is not matched to any
+ gt, the corresponding value in pos_gt_inds is -1.
+
+ Args:
+ flat_anchors (Tensor): Multi-level anchors of the image, which are
+ concatenated into a single tensor of shape (num_anchors, 4)
+ valid_flags (Tensor): Multi level valid flags of the image,
+ which are concatenated into a single tensor of
+ shape (num_anchors, ).
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It should includes ``bboxes`` and ``labels``
+ attributes.
+ img_meta (dict): Meta information for current image.
+ gt_instances_ignore (:obj:`InstanceData`, optional): Instances
+ to be ignored during training. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+ unmap_outputs (bool): Whether to map outputs back to the original
+ set of anchors. Defaults to True.
+ """
+ inside_flags = anchor_inside_flags(flat_anchors, valid_flags,
+ img_meta['img_shape'][:2],
+ self.train_cfg['allowed_border'])
+ if not inside_flags.any():
+ raise ValueError(
+ 'There is no valid anchor inside the image boundary. Please '
+ 'check the image size and anchor sizes, or set '
+ '``allowed_border`` to -1 to skip the condition.')
+ # Assign gt and sample anchors
+ anchors = flat_anchors[inside_flags.type(torch.bool), :]
+
+ pred_instances = InstanceData(priors=anchors)
+ assign_result = self.assigner.assign(pred_instances, gt_instances,
+ gt_instances_ignore)
+ sampling_result = self.sampler.sample(assign_result, pred_instances,
+ gt_instances)
+
+ num_valid_anchors = anchors.shape[0]
+ bbox_targets = torch.zeros_like(anchors)
+ bbox_weights = torch.zeros_like(anchors)
+ labels = anchors.new_full((num_valid_anchors, ),
+ self.num_classes,
+ dtype=torch.long)
+ label_weights = anchors.new_zeros(
+ (num_valid_anchors, self.cls_out_channels), dtype=torch.float)
+ pos_gt_inds = anchors.new_full((num_valid_anchors, ),
+ -1,
+ dtype=torch.long)
+
+ pos_inds = sampling_result.pos_inds
+ neg_inds = sampling_result.neg_inds
+
+ if len(pos_inds) > 0:
+ if not self.reg_decoded_bbox:
+ pos_bbox_targets = self.bbox_coder.encode(
+ sampling_result.pos_bboxes, sampling_result.pos_gt_bboxes)
+ else:
+ # When the regression loss (e.g. `IouLoss`, `GIouLoss`)
+ # is applied directly on the decoded bounding boxes, both
+ # the predicted boxes and regression targets should be with
+ # absolute coordinate format.
+ pos_bbox_targets = sampling_result.pos_gt_bboxes
+ bbox_targets[pos_inds, :] = pos_bbox_targets
+ bbox_weights[pos_inds, :] = 1.0
+ # The assigned gt_index for each anchor. (0-based)
+ pos_gt_inds[pos_inds] = sampling_result.pos_assigned_gt_inds
+ labels[pos_inds] = sampling_result.pos_gt_labels
+ if self.train_cfg['pos_weight'] <= 0:
+ label_weights[pos_inds] = 1.0
+ else:
+ label_weights[pos_inds] = self.train_cfg['pos_weight']
+
+ if len(neg_inds) > 0:
+ label_weights[neg_inds] = 1.0
+
+ # shadowed_labels is a tensor composed of tuples
+ # (anchor_inds, class_label) that indicate those anchors lying in the
+ # outer region of a gt or overlapped by another gt with a smaller
+ # area.
+ #
+ # Therefore, only the shadowed labels are ignored for loss calculation.
+ # the key `shadowed_labels` is defined in :obj:`CenterRegionAssigner`
+ shadowed_labels = assign_result.get_extra_property('shadowed_labels')
+ if shadowed_labels is not None and shadowed_labels.numel():
+ if len(shadowed_labels.shape) == 2:
+ idx_, label_ = shadowed_labels[:, 0], shadowed_labels[:, 1]
+ assert (labels[idx_] != label_).all(), \
+ 'One label cannot be both positive and ignored'
+ label_weights[idx_, label_] = 0
+ else:
+ label_weights[shadowed_labels] = 0
+
+ # map up to original set of anchors
+ if unmap_outputs:
+ num_total_anchors = flat_anchors.size(0)
+ labels = unmap(
+ labels, num_total_anchors, inside_flags,
+ fill=self.num_classes) # fill bg label
+ label_weights = unmap(label_weights, num_total_anchors,
+ inside_flags)
+ bbox_targets = unmap(bbox_targets, num_total_anchors, inside_flags)
+ bbox_weights = unmap(bbox_weights, num_total_anchors, inside_flags)
+ pos_gt_inds = unmap(
+ pos_gt_inds, num_total_anchors, inside_flags, fill=-1)
+
+ return (labels, label_weights, bbox_targets, bbox_weights, pos_inds,
+ neg_inds, sampling_result, pos_gt_inds)
+
+ def loss_by_feat(
+ self,
+ cls_scores: List[Tensor],
+ bbox_preds: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ batch_gt_instances_ignore: OptInstanceList = None
+ ) -> Dict[str, Tensor]:
+ """Compute loss of the head.
+
+ Args:
+ cls_scores (list[Tensor]): Box scores for each scale level
+ Has shape (N, num_points * num_classes, H, W).
+ bbox_preds (list[Tensor]): Box energies / deltas for each scale
+ level with shape (N, num_points * 4, H, W).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components.
+ """
+ for i in range(len(bbox_preds)): # loop over fpn level
+ # avoid 0 area of the predicted bbox
+ bbox_preds[i] = bbox_preds[i].clamp(min=1e-4)
+ # TODO: It may directly use the base-class loss function.
+ featmap_sizes = [featmap.size()[-2:] for featmap in cls_scores]
+ assert len(featmap_sizes) == self.prior_generator.num_levels
+ batch_size = len(batch_img_metas)
+ device = cls_scores[0].device
+ anchor_list, valid_flag_list = self.get_anchors(
+ featmap_sizes, batch_img_metas, device=device)
+ cls_reg_targets = self.get_targets(
+ anchor_list,
+ valid_flag_list,
+ batch_gt_instances,
+ batch_img_metas,
+ batch_gt_instances_ignore=batch_gt_instances_ignore,
+ return_sampling_results=True)
+ (labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,
+ avg_factor, sampling_results_list,
+ pos_assigned_gt_inds_list) = cls_reg_targets
+
+ num_gts = np.array(list(map(len, batch_gt_instances)))
+ # anchor number of multi levels
+ num_level_anchors = [anchors.size(0) for anchors in anchor_list[0]]
+ # concat all level anchors and flags to a single tensor
+ concat_anchor_list = []
+ for i in range(len(anchor_list)):
+ concat_anchor_list.append(torch.cat(anchor_list[i]))
+ all_anchor_list = images_to_levels(concat_anchor_list,
+ num_level_anchors)
+ losses_cls, losses_bbox = multi_apply(
+ self.loss_by_feat_single,
+ cls_scores,
+ bbox_preds,
+ all_anchor_list,
+ labels_list,
+ label_weights_list,
+ bbox_targets_list,
+ bbox_weights_list,
+ avg_factor=avg_factor)
+
+ # `pos_assigned_gt_inds_list` (length: fpn_levels) stores the assigned
+ # gt index of each anchor bbox in each fpn level.
+ cum_num_gts = list(np.cumsum(num_gts)) # length of batch_size
+ for i, assign in enumerate(pos_assigned_gt_inds_list):
+ # loop over fpn levels
+ for j in range(1, batch_size):
+ # loop over batch size
+ # Convert gt indices in each img to those in the batch
+ assign[j][assign[j] >= 0] += int(cum_num_gts[j - 1])
+ pos_assigned_gt_inds_list[i] = assign.flatten()
+ labels_list[i] = labels_list[i].flatten()
+ num_gts = num_gts.sum() # total number of gt in the batch
+ # The unique label index of each gt in the batch
+ label_sequence = torch.arange(num_gts, device=device)
+ # Collect the average loss of each gt in each level
+ with torch.no_grad():
+ loss_levels, = multi_apply(
+ self.collect_loss_level_single,
+ losses_cls,
+ losses_bbox,
+ pos_assigned_gt_inds_list,
+ labels_seq=label_sequence)
+ # Shape: (fpn_levels, num_gts). Loss of each gt at each fpn level
+ loss_levels = torch.stack(loss_levels, dim=0)
+ # Locate the best fpn level for loss back-propagation
+ if loss_levels.numel() == 0: # zero gt
+ argmin = loss_levels.new_empty((num_gts, ), dtype=torch.long)
+ else:
+ _, argmin = loss_levels.min(dim=0)
+
+ # Reweight the loss of each (anchor, label) pair, so that only those
+ # at the best gt level are back-propagated.
+ losses_cls, losses_bbox, pos_inds = multi_apply(
+ self.reweight_loss_single,
+ losses_cls,
+ losses_bbox,
+ pos_assigned_gt_inds_list,
+ labels_list,
+ list(range(len(losses_cls))),
+ min_levels=argmin)
+ num_pos = torch.cat(pos_inds, 0).sum().float()
+ pos_recall = self.calculate_pos_recall(cls_scores, labels_list,
+ pos_inds)
+
+ if num_pos == 0: # No gt
+ num_total_neg = sum(
+ [results.num_neg for results in sampling_results_list])
+ avg_factor = num_pos + num_total_neg
+ else:
+ avg_factor = num_pos
+ for i in range(len(losses_cls)):
+ losses_cls[i] /= avg_factor
+ losses_bbox[i] /= avg_factor
+ return dict(
+ loss_cls=losses_cls,
+ loss_bbox=losses_bbox,
+ num_pos=num_pos / batch_size,
+ pos_recall=pos_recall)
+
+ def calculate_pos_recall(self, cls_scores: List[Tensor],
+ labels_list: List[Tensor],
+ pos_inds: List[Tensor]) -> Tensor:
+ """Calculate positive recall with score threshold.
+
+ Args:
+ cls_scores (list[Tensor]): Classification scores at all fpn levels.
+ Each tensor is in shape (N, num_classes * num_anchors, H, W)
+ labels_list (list[Tensor]): The label that each anchor is assigned
+ to. Shape (N * H * W * num_anchors, )
+ pos_inds (list[Tensor]): List of bool tensors indicating whether
+ the anchor is assigned to a positive label.
+ Shape (N * H * W * num_anchors, )
+
+ Returns:
+ Tensor: A single float number indicating the positive recall.
+ """
+ with torch.no_grad():
+ num_class = self.num_classes
+ scores = [
+ cls.permute(0, 2, 3, 1).reshape(-1, num_class)[pos]
+ for cls, pos in zip(cls_scores, pos_inds)
+ ]
+ labels = [
+ label.reshape(-1)[pos]
+ for label, pos in zip(labels_list, pos_inds)
+ ]
+ scores = torch.cat(scores, dim=0)
+ labels = torch.cat(labels, dim=0)
+ if self.use_sigmoid_cls:
+ scores = scores.sigmoid()
+ else:
+ scores = scores.softmax(dim=1)
+
+ return accuracy(scores, labels, thresh=self.score_threshold)
+
+ def collect_loss_level_single(self, cls_loss: Tensor, reg_loss: Tensor,
+ assigned_gt_inds: Tensor,
+ labels_seq: Tensor) -> Tensor:
+ """Get the average loss in each FPN level w.r.t. each gt label.
+
+ Args:
+ cls_loss (Tensor): Classification loss of each feature map pixel,
+ shape (num_anchor, num_class)
+ reg_loss (Tensor): Regression loss of each feature map pixel,
+ shape (num_anchor, 4)
+ assigned_gt_inds (Tensor): It indicates which gt the prior is
+ assigned to (0-based, -1: no assignment). shape (num_anchor),
+ labels_seq: The rank of labels. shape (num_gt)
+
+ Returns:
+ Tensor: shape (num_gt), average loss of each gt in this level
+ """
+ if len(reg_loss.shape) == 2: # iou loss has shape (num_prior, 4)
+ reg_loss = reg_loss.sum(dim=-1) # sum loss in tblr dims
+ if len(cls_loss.shape) == 2:
+ cls_loss = cls_loss.sum(dim=-1) # sum loss in class dims
+ loss = cls_loss + reg_loss
+ assert loss.size(0) == assigned_gt_inds.size(0)
+ # Default loss value is 1e6 for a layer where no anchor is positive
+ # to ensure it will not be chosen to back-propagate gradient
+ losses_ = loss.new_full(labels_seq.shape, 1e6)
+ for i, l in enumerate(labels_seq):
+ match = assigned_gt_inds == l
+ if match.any():
+ losses_[i] = loss[match].mean()
+ return losses_,
+
+ def reweight_loss_single(self, cls_loss: Tensor, reg_loss: Tensor,
+ assigned_gt_inds: Tensor, labels: Tensor,
+ level: int, min_levels: Tensor) -> tuple:
+ """Reweight loss values at each level.
+
+ Reassign loss values at each level by masking those where the
+ pre-calculated loss is too large. Then return the reduced losses.
+
+ Args:
+ cls_loss (Tensor): Element-wise classification loss.
+ Shape: (num_anchors, num_classes)
+ reg_loss (Tensor): Element-wise regression loss.
+ Shape: (num_anchors, 4)
+ assigned_gt_inds (Tensor): The gt indices that each anchor bbox
+ is assigned to. -1 denotes a negative anchor, otherwise it is the
+ gt index (0-based). Shape: (num_anchors, ),
+ labels (Tensor): Label assigned to anchors. Shape: (num_anchors, ).
+ level (int): The current level index in the pyramid
+ (0-4 for RetinaNet)
+ min_levels (Tensor): The best-matching level for each gt.
+ Shape: (num_gts, ),
+
+ Returns:
+ tuple:
+
+ - cls_loss: Reduced corrected classification loss. Scalar.
+ - reg_loss: Reduced corrected regression loss. Scalar.
+ - pos_flags (Tensor): Corrected bool tensor indicating the \
+ final positive anchors. Shape: (num_anchors, ).
+ """
+ loc_weight = torch.ones_like(reg_loss)
+ cls_weight = torch.ones_like(cls_loss)
+ pos_flags = assigned_gt_inds >= 0 # positive pixel flag
+ pos_indices = torch.nonzero(pos_flags, as_tuple=False).flatten()
+
+ if pos_flags.any(): # pos pixels exist
+ pos_assigned_gt_inds = assigned_gt_inds[pos_flags]
+ zeroing_indices = (min_levels[pos_assigned_gt_inds] != level)
+ neg_indices = pos_indices[zeroing_indices]
+
+ if neg_indices.numel():
+ pos_flags[neg_indices] = 0
+ loc_weight[neg_indices] = 0
+ # Only the weight corresponding to the label is
+ # zeroed out if not selected
+ zeroing_labels = labels[neg_indices]
+ assert (zeroing_labels >= 0).all()
+ cls_weight[neg_indices, zeroing_labels] = 0
+
+ # Weighted loss for both cls and reg loss
+ cls_loss = weight_reduce_loss(cls_loss, cls_weight, reduction='sum')
+ reg_loss = weight_reduce_loss(reg_loss, loc_weight, reduction='sum')
+
+ return cls_loss, reg_loss, pos_flags
diff --git a/mmdet/models/dense_heads/ga_retina_head.py b/mmdet/models/dense_heads/ga_retina_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..569910b365126e90638256f0d10addfa230fd141
--- /dev/null
+++ b/mmdet/models/dense_heads/ga_retina_head.py
@@ -0,0 +1,120 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Tuple
+
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+from mmcv.ops import MaskedConv2d
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.utils import OptConfigType, OptMultiConfig
+from .guided_anchor_head import FeatureAdaption, GuidedAnchorHead
+
+
+@MODELS.register_module()
+class GARetinaHead(GuidedAnchorHead):
+ """Guided-Anchor-based RetinaNet head."""
+
+ def __init__(self,
+ num_classes: int,
+ in_channels: int,
+ stacked_convs: int = 4,
+ conv_cfg: OptConfigType = None,
+ norm_cfg: OptConfigType = None,
+ init_cfg: OptMultiConfig = None,
+ **kwargs) -> None:
+ if init_cfg is None:
+ init_cfg = dict(
+ type='Normal',
+ layer='Conv2d',
+ std=0.01,
+ override=[
+ dict(
+ type='Normal',
+ name='conv_loc',
+ std=0.01,
+ bias_prob=0.01),
+ dict(
+ type='Normal',
+ name='retina_cls',
+ std=0.01,
+ bias_prob=0.01)
+ ])
+ self.stacked_convs = stacked_convs
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ super().__init__(
+ num_classes=num_classes,
+ in_channels=in_channels,
+ init_cfg=init_cfg,
+ **kwargs)
+
+ def _init_layers(self) -> None:
+ """Initialize layers of the head."""
+ self.relu = nn.ReLU(inplace=True)
+ self.cls_convs = nn.ModuleList()
+ self.reg_convs = nn.ModuleList()
+ for i in range(self.stacked_convs):
+ chn = self.in_channels if i == 0 else self.feat_channels
+ self.cls_convs.append(
+ ConvModule(
+ chn,
+ self.feat_channels,
+ 3,
+ stride=1,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg))
+ self.reg_convs.append(
+ ConvModule(
+ chn,
+ self.feat_channels,
+ 3,
+ stride=1,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg))
+
+ self.conv_loc = nn.Conv2d(self.feat_channels, 1, 1)
+ num_anchors = self.square_anchor_generator.num_base_priors[0]
+ self.conv_shape = nn.Conv2d(self.feat_channels, num_anchors * 2, 1)
+ self.feature_adaption_cls = FeatureAdaption(
+ self.feat_channels,
+ self.feat_channels,
+ kernel_size=3,
+ deform_groups=self.deform_groups)
+ self.feature_adaption_reg = FeatureAdaption(
+ self.feat_channels,
+ self.feat_channels,
+ kernel_size=3,
+ deform_groups=self.deform_groups)
+ self.retina_cls = MaskedConv2d(
+ self.feat_channels,
+ self.num_base_priors * self.cls_out_channels,
+ 3,
+ padding=1)
+ self.retina_reg = MaskedConv2d(
+ self.feat_channels, self.num_base_priors * 4, 3, padding=1)
+
+ def forward_single(self, x: Tensor) -> Tuple[Tensor]:
+ """Forward feature map of a single scale level."""
+ cls_feat = x
+ reg_feat = x
+ for cls_conv in self.cls_convs:
+ cls_feat = cls_conv(cls_feat)
+ for reg_conv in self.reg_convs:
+ reg_feat = reg_conv(reg_feat)
+
+ loc_pred = self.conv_loc(cls_feat)
+ shape_pred = self.conv_shape(reg_feat)
+
+ cls_feat = self.feature_adaption_cls(cls_feat, shape_pred)
+ reg_feat = self.feature_adaption_reg(reg_feat, shape_pred)
+
+ if not self.training:
+ mask = loc_pred.sigmoid()[0] >= self.loc_filter_thr
+ else:
+ mask = None
+ cls_score = self.retina_cls(cls_feat, mask)
+ bbox_pred = self.retina_reg(reg_feat, mask)
+ return cls_score, bbox_pred, shape_pred, loc_pred
diff --git a/mmdet/models/dense_heads/ga_rpn_head.py b/mmdet/models/dense_heads/ga_rpn_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..9614463165533358b8465420a87dfa47e7de1177
--- /dev/null
+++ b/mmdet/models/dense_heads/ga_rpn_head.py
@@ -0,0 +1,222 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+from typing import List, Tuple
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.ops import nms
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.utils import ConfigType, InstanceList, MultiConfig, OptInstanceList
+from .guided_anchor_head import GuidedAnchorHead
+
+
+@MODELS.register_module()
+class GARPNHead(GuidedAnchorHead):
+ """Guided-Anchor-based RPN head."""
+
+ def __init__(self,
+ in_channels: int,
+ num_classes: int = 1,
+ init_cfg: MultiConfig = dict(
+ type='Normal',
+ layer='Conv2d',
+ std=0.01,
+ override=dict(
+ type='Normal',
+ name='conv_loc',
+ std=0.01,
+ bias_prob=0.01)),
+ **kwargs) -> None:
+ super().__init__(
+ num_classes=num_classes,
+ in_channels=in_channels,
+ init_cfg=init_cfg,
+ **kwargs)
+
+ def _init_layers(self) -> None:
+ """Initialize layers of the head."""
+ self.rpn_conv = nn.Conv2d(
+ self.in_channels, self.feat_channels, 3, padding=1)
+ super(GARPNHead, self)._init_layers()
+
+ def forward_single(self, x: Tensor) -> Tuple[Tensor]:
+ """Forward feature of a single scale level."""
+
+ x = self.rpn_conv(x)
+ x = F.relu(x, inplace=True)
+ (cls_score, bbox_pred, shape_pred,
+ loc_pred) = super().forward_single(x)
+ return cls_score, bbox_pred, shape_pred, loc_pred
+
+ def loss_by_feat(
+ self,
+ cls_scores: List[Tensor],
+ bbox_preds: List[Tensor],
+ shape_preds: List[Tensor],
+ loc_preds: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ batch_gt_instances_ignore: OptInstanceList = None) -> dict:
+ """Calculate the loss based on the features extracted by the detection
+ head.
+
+ Args:
+ cls_scores (list[Tensor]): Box scores for each scale level
+ has shape (N, num_anchors * num_classes, H, W).
+ bbox_preds (list[Tensor]): Box energies / deltas for each scale
+ level with shape (N, num_anchors * 4, H, W).
+ shape_preds (list[Tensor]): shape predictions for each scale
+ level with shape (N, 1, H, W).
+ loc_preds (list[Tensor]): location predictions for each scale
+ level with shape (N, num_anchors * 2, H, W).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ dict: A dictionary of loss components.
+ """
+ losses = super().loss_by_feat(
+ cls_scores,
+ bbox_preds,
+ shape_preds,
+ loc_preds,
+ batch_gt_instances,
+ batch_img_metas,
+ batch_gt_instances_ignore=batch_gt_instances_ignore)
+ return dict(
+ loss_rpn_cls=losses['loss_cls'],
+ loss_rpn_bbox=losses['loss_bbox'],
+ loss_anchor_shape=losses['loss_shape'],
+ loss_anchor_loc=losses['loss_loc'])
+
+ def _predict_by_feat_single(self,
+ cls_scores: List[Tensor],
+ bbox_preds: List[Tensor],
+ mlvl_anchors: List[Tensor],
+ mlvl_masks: List[Tensor],
+ img_meta: dict,
+ cfg: ConfigType,
+ rescale: bool = False) -> InstanceData:
+ """Transform a single image's features extracted from the head into
+ bbox results.
+
+ Args:
+ cls_scores (list[Tensor]): Box scores from all scale
+ levels of a single image, each item has shape
+ (num_priors * num_classes, H, W).
+ bbox_preds (list[Tensor]): Box energies / deltas from
+ all scale levels of a single image, each item has shape
+ (num_priors * 4, H, W).
+ mlvl_anchors (list[Tensor]): Each element in the list is
+ the anchors of a single level in feature pyramid. it has
+ shape (num_priors, 4).
+ mlvl_masks (list[Tensor]): Each element in the list is location
+ masks of a single level.
+ img_meta (dict): Image meta info.
+ cfg (:obj:`ConfigDict` or dict): Test / postprocessing
+ configuration, if None, test_cfg would be used.
+ rescale (bool): If True, return boxes in original image space.
+ Defaults to False.
+
+ Returns:
+ :obj:`InstanceData`: Detection results of each image
+ after the post process.
+ Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4), the last
+ dimension 4 arrange as (x1, y1, x2, y2).
+ """
+ cfg = self.test_cfg if cfg is None else cfg
+ cfg = copy.deepcopy(cfg)
+ assert cfg.nms.get('type', 'nms') == 'nms', 'GARPNHead only support ' \
+ 'naive nms.'
+
+ mlvl_proposals = []
+ for idx in range(len(cls_scores)):
+ rpn_cls_score = cls_scores[idx]
+ rpn_bbox_pred = bbox_preds[idx]
+ anchors = mlvl_anchors[idx]
+ mask = mlvl_masks[idx]
+ assert rpn_cls_score.size()[-2:] == rpn_bbox_pred.size()[-2:]
+ # if no location is kept, end.
+ if mask.sum() == 0:
+ continue
+ rpn_cls_score = rpn_cls_score.permute(1, 2, 0)
+ if self.use_sigmoid_cls:
+ rpn_cls_score = rpn_cls_score.reshape(-1)
+ scores = rpn_cls_score.sigmoid()
+ else:
+ rpn_cls_score = rpn_cls_score.reshape(-1, 2)
+ # remind that we set FG labels to [0, num_class-1]
+ # since mmdet v2.0
+ # BG cat_id: num_class
+ scores = rpn_cls_score.softmax(dim=1)[:, :-1]
+ # filter scores, bbox_pred w.r.t. mask.
+ # anchors are filtered in get_anchors() beforehand.
+ scores = scores[mask]
+ rpn_bbox_pred = rpn_bbox_pred.permute(1, 2, 0).reshape(-1,
+ 4)[mask, :]
+ if scores.dim() == 0:
+ rpn_bbox_pred = rpn_bbox_pred.unsqueeze(0)
+ anchors = anchors.unsqueeze(0)
+ scores = scores.unsqueeze(0)
+ # filter anchors, bbox_pred, scores w.r.t. scores
+ if cfg.nms_pre > 0 and scores.shape[0] > cfg.nms_pre:
+ _, topk_inds = scores.topk(cfg.nms_pre)
+ rpn_bbox_pred = rpn_bbox_pred[topk_inds, :]
+ anchors = anchors[topk_inds, :]
+ scores = scores[topk_inds]
+ # get proposals w.r.t. anchors and rpn_bbox_pred
+ proposals = self.bbox_coder.decode(
+ anchors, rpn_bbox_pred, max_shape=img_meta['img_shape'])
+ # filter out too small bboxes
+ if cfg.min_bbox_size >= 0:
+ w = proposals[:, 2] - proposals[:, 0]
+ h = proposals[:, 3] - proposals[:, 1]
+ valid_mask = (w > cfg.min_bbox_size) & (h > cfg.min_bbox_size)
+ if not valid_mask.all():
+ proposals = proposals[valid_mask]
+ scores = scores[valid_mask]
+
+ # NMS in current level
+ proposals, _ = nms(proposals, scores, cfg.nms.iou_threshold)
+ proposals = proposals[:cfg.nms_post, :]
+ mlvl_proposals.append(proposals)
+ proposals = torch.cat(mlvl_proposals, 0)
+ if cfg.get('nms_across_levels', False):
+ # NMS across multi levels
+ proposals, _ = nms(proposals[:, :4], proposals[:, -1],
+ cfg.nms.iou_threshold)
+ proposals = proposals[:cfg.max_per_img, :]
+ else:
+ scores = proposals[:, 4]
+ num = min(cfg.max_per_img, proposals.shape[0])
+ _, topk_inds = scores.topk(num)
+ proposals = proposals[topk_inds, :]
+
+ bboxes = proposals[:, :-1]
+ scores = proposals[:, -1]
+ if rescale:
+ assert img_meta.get('scale_factor') is not None
+ bboxes /= bboxes.new_tensor(img_meta['scale_factor']).repeat(
+ (1, 2))
+
+ results = InstanceData()
+ results.bboxes = bboxes
+ results.scores = scores
+ results.labels = scores.new_zeros(scores.size(0), dtype=torch.long)
+ return results
diff --git a/mmdet/models/dense_heads/gfl_head.py b/mmdet/models/dense_heads/gfl_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..6d2947a894892575c7f86ba6725456e6571f7585
--- /dev/null
+++ b/mmdet/models/dense_heads/gfl_head.py
@@ -0,0 +1,667 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Optional, Sequence, Tuple
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule, Scale
+from mmengine.config import ConfigDict
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmdet.registry import MODELS, TASK_UTILS
+from mmdet.structures.bbox import bbox_overlaps
+from mmdet.utils import (ConfigType, InstanceList, MultiConfig, OptConfigType,
+ OptInstanceList, reduce_mean)
+from ..task_modules.prior_generators import anchor_inside_flags
+from ..task_modules.samplers import PseudoSampler
+from ..utils import (filter_scores_and_topk, images_to_levels, multi_apply,
+ unmap)
+from .anchor_head import AnchorHead
+
+
+class Integral(nn.Module):
+ """A fixed layer for calculating integral result from distribution.
+
+ This layer calculates the target location by :math: ``sum{P(y_i) * y_i}``,
+ P(y_i) denotes the softmax vector that represents the discrete distribution
+ y_i denotes the discrete set, usually {0, 1, 2, ..., reg_max}
+
+ Args:
+ reg_max (int): The maximal value of the discrete set. Defaults to 16.
+ You may want to reset it according to your new dataset or related
+ settings.
+ """
+
+ def __init__(self, reg_max: int = 16) -> None:
+ super().__init__()
+ self.reg_max = reg_max
+ self.register_buffer('project',
+ torch.linspace(0, self.reg_max, self.reg_max + 1))
+
+ def forward(self, x: Tensor) -> Tensor:
+ """Forward feature from the regression head to get integral result of
+ bounding box location.
+
+ Args:
+ x (Tensor): Features of the regression head, shape (N, 4*(n+1)),
+ n is self.reg_max.
+
+ Returns:
+ x (Tensor): Integral result of box locations, i.e., distance
+ offsets from the box center in four directions, shape (N, 4).
+ """
+ x = F.softmax(x.reshape(-1, self.reg_max + 1), dim=1)
+ x = F.linear(x, self.project.type_as(x)).reshape(-1, 4)
+ return x
+
+
+@MODELS.register_module()
+class GFLHead(AnchorHead):
+ """Generalized Focal Loss: Learning Qualified and Distributed Bounding
+ Boxes for Dense Object Detection.
+
+ GFL head structure is similar with ATSS, however GFL uses
+ 1) joint representation for classification and localization quality, and
+ 2) flexible General distribution for bounding box locations,
+ which are supervised by
+ Quality Focal Loss (QFL) and Distribution Focal Loss (DFL), respectively
+
+ https://arxiv.org/abs/2006.04388
+
+ Args:
+ num_classes (int): Number of categories excluding the background
+ category.
+ in_channels (int): Number of channels in the input feature map.
+ stacked_convs (int): Number of conv layers in cls and reg tower.
+ Defaults to 4.
+ conv_cfg (:obj:`ConfigDict` or dict, optional): dictionary to construct
+ and config conv layer. Defaults to None.
+ norm_cfg (:obj:`ConfigDict` or dict): dictionary to construct and
+ config norm layer. Default: dict(type='GN', num_groups=32,
+ requires_grad=True).
+ loss_qfl (:obj:`ConfigDict` or dict): Config of Quality Focal Loss
+ (QFL).
+ bbox_coder (:obj:`ConfigDict` or dict): Config of bbox coder. Defaults
+ to 'DistancePointBBoxCoder'.
+ reg_max (int): Max value of integral set :math: ``{0, ..., reg_max}``
+ in QFL setting. Defaults to 16.
+ init_cfg (:obj:`ConfigDict` or dict or list[dict] or
+ list[:obj:`ConfigDict`]): Initialization config dict.
+ Example:
+ >>> self = GFLHead(11, 7)
+ >>> feats = [torch.rand(1, 7, s, s) for s in [4, 8, 16, 32, 64]]
+ >>> cls_quality_score, bbox_pred = self.forward(feats)
+ >>> assert len(cls_quality_score) == len(self.scales)
+ """
+
+ def __init__(self,
+ num_classes: int,
+ in_channels: int,
+ stacked_convs: int = 4,
+ conv_cfg: OptConfigType = None,
+ norm_cfg: ConfigType = dict(
+ type='GN', num_groups=32, requires_grad=True),
+ loss_dfl: ConfigType = dict(
+ type='DistributionFocalLoss', loss_weight=0.25),
+ bbox_coder: ConfigType = dict(type='DistancePointBBoxCoder'),
+ reg_max: int = 16,
+ init_cfg: MultiConfig = dict(
+ type='Normal',
+ layer='Conv2d',
+ std=0.01,
+ override=dict(
+ type='Normal',
+ name='gfl_cls',
+ std=0.01,
+ bias_prob=0.01)),
+ **kwargs) -> None:
+ self.stacked_convs = stacked_convs
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.reg_max = reg_max
+ super().__init__(
+ num_classes=num_classes,
+ in_channels=in_channels,
+ bbox_coder=bbox_coder,
+ init_cfg=init_cfg,
+ **kwargs)
+
+ if self.train_cfg:
+ self.assigner = TASK_UTILS.build(self.train_cfg['assigner'])
+ if self.train_cfg.get('sampler', None) is not None:
+ self.sampler = TASK_UTILS.build(
+ self.train_cfg['sampler'], default_args=dict(context=self))
+ else:
+ self.sampler = PseudoSampler(context=self)
+
+ self.integral = Integral(self.reg_max)
+ self.loss_dfl = MODELS.build(loss_dfl)
+
+ def _init_layers(self) -> None:
+ """Initialize layers of the head."""
+ self.relu = nn.ReLU()
+ self.cls_convs = nn.ModuleList()
+ self.reg_convs = nn.ModuleList()
+ for i in range(self.stacked_convs):
+ chn = self.in_channels if i == 0 else self.feat_channels
+ self.cls_convs.append(
+ ConvModule(
+ chn,
+ self.feat_channels,
+ 3,
+ stride=1,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg))
+ self.reg_convs.append(
+ ConvModule(
+ chn,
+ self.feat_channels,
+ 3,
+ stride=1,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg))
+ assert self.num_anchors == 1, 'anchor free version'
+ self.gfl_cls = nn.Conv2d(
+ self.feat_channels, self.cls_out_channels, 3, padding=1)
+ self.gfl_reg = nn.Conv2d(
+ self.feat_channels, 4 * (self.reg_max + 1), 3, padding=1)
+ self.scales = nn.ModuleList(
+ [Scale(1.0) for _ in self.prior_generator.strides])
+
+ def forward(self, x: Tuple[Tensor]) -> Tuple[List[Tensor]]:
+ """Forward features from the upstream network.
+
+ Args:
+ x (tuple[Tensor]): Features from the upstream network, each is
+ a 4D-tensor.
+
+ Returns:
+ tuple: Usually a tuple of classification scores and bbox prediction
+
+ - cls_scores (list[Tensor]): Classification and quality (IoU)
+ joint scores for all scale levels, each is a 4D-tensor,
+ the channel number is num_classes.
+ - bbox_preds (list[Tensor]): Box distribution logits for all
+ scale levels, each is a 4D-tensor, the channel number is
+ 4*(n+1), n is max value of integral set.
+ """
+ return multi_apply(self.forward_single, x, self.scales)
+
+ def forward_single(self, x: Tensor, scale: Scale) -> Sequence[Tensor]:
+ """Forward feature of a single scale level.
+
+ Args:
+ x (Tensor): Features of a single scale level.
+ scale (:obj: `mmcv.cnn.Scale`): Learnable scale module to resize
+ the bbox prediction.
+
+ Returns:
+ tuple:
+
+ - cls_score (Tensor): Cls and quality joint scores for a single
+ scale level the channel number is num_classes.
+ - bbox_pred (Tensor): Box distribution logits for a single scale
+ level, the channel number is 4*(n+1), n is max value of
+ integral set.
+ """
+ cls_feat = x
+ reg_feat = x
+ for cls_conv in self.cls_convs:
+ cls_feat = cls_conv(cls_feat)
+ for reg_conv in self.reg_convs:
+ reg_feat = reg_conv(reg_feat)
+ cls_score = self.gfl_cls(cls_feat)
+ bbox_pred = scale(self.gfl_reg(reg_feat)).float()
+ return cls_score, bbox_pred
+
+ def anchor_center(self, anchors: Tensor) -> Tensor:
+ """Get anchor centers from anchors.
+
+ Args:
+ anchors (Tensor): Anchor list with shape (N, 4), ``xyxy`` format.
+
+ Returns:
+ Tensor: Anchor centers with shape (N, 2), ``xy`` format.
+ """
+ anchors_cx = (anchors[..., 2] + anchors[..., 0]) / 2
+ anchors_cy = (anchors[..., 3] + anchors[..., 1]) / 2
+ return torch.stack([anchors_cx, anchors_cy], dim=-1)
+
+ def loss_by_feat_single(self, anchors: Tensor, cls_score: Tensor,
+ bbox_pred: Tensor, labels: Tensor,
+ label_weights: Tensor, bbox_targets: Tensor,
+ stride: Tuple[int], avg_factor: int) -> dict:
+ """Calculate the loss of a single scale level based on the features
+ extracted by the detection head.
+
+ Args:
+ anchors (Tensor): Box reference for each scale level with shape
+ (N, num_total_anchors, 4).
+ cls_score (Tensor): Cls and quality joint scores for each scale
+ level has shape (N, num_classes, H, W).
+ bbox_pred (Tensor): Box distribution logits for each scale
+ level with shape (N, 4*(n+1), H, W), n is max value of integral
+ set.
+ labels (Tensor): Labels of each anchors with shape
+ (N, num_total_anchors).
+ label_weights (Tensor): Label weights of each anchor with shape
+ (N, num_total_anchors)
+ bbox_targets (Tensor): BBox regression targets of each anchor
+ weight shape (N, num_total_anchors, 4).
+ stride (Tuple[int]): Stride in this scale level.
+ avg_factor (int): Average factor that is used to average
+ the loss. When using sampling method, avg_factor is usually
+ the sum of positive and negative priors. When using
+ `PseudoSampler`, `avg_factor` is usually equal to the number
+ of positive priors.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components.
+ """
+ assert stride[0] == stride[1], 'h stride is not equal to w stride!'
+ anchors = anchors.reshape(-1, 4)
+ cls_score = cls_score.permute(0, 2, 3,
+ 1).reshape(-1, self.cls_out_channels)
+ bbox_pred = bbox_pred.permute(0, 2, 3,
+ 1).reshape(-1, 4 * (self.reg_max + 1))
+ bbox_targets = bbox_targets.reshape(-1, 4)
+ labels = labels.reshape(-1)
+ label_weights = label_weights.reshape(-1)
+
+ # FG cat_id: [0, num_classes -1], BG cat_id: num_classes
+ bg_class_ind = self.num_classes
+ pos_inds = ((labels >= 0)
+ & (labels < bg_class_ind)).nonzero().squeeze(1)
+ score = label_weights.new_zeros(labels.shape)
+
+ if len(pos_inds) > 0:
+ pos_bbox_targets = bbox_targets[pos_inds]
+ pos_bbox_pred = bbox_pred[pos_inds]
+ pos_anchors = anchors[pos_inds]
+ pos_anchor_centers = self.anchor_center(pos_anchors) / stride[0]
+
+ weight_targets = cls_score.detach().sigmoid()
+ weight_targets = weight_targets.max(dim=1)[0][pos_inds]
+ pos_bbox_pred_corners = self.integral(pos_bbox_pred)
+ pos_decode_bbox_pred = self.bbox_coder.decode(
+ pos_anchor_centers, pos_bbox_pred_corners)
+ pos_decode_bbox_targets = pos_bbox_targets / stride[0]
+ score[pos_inds] = bbox_overlaps(
+ pos_decode_bbox_pred.detach(),
+ pos_decode_bbox_targets,
+ is_aligned=True)
+ pred_corners = pos_bbox_pred.reshape(-1, self.reg_max + 1)
+ target_corners = self.bbox_coder.encode(pos_anchor_centers,
+ pos_decode_bbox_targets,
+ self.reg_max).reshape(-1)
+
+ # regression loss
+ loss_bbox = self.loss_bbox(
+ pos_decode_bbox_pred,
+ pos_decode_bbox_targets,
+ weight=weight_targets,
+ avg_factor=1.0)
+
+ # dfl loss
+ loss_dfl = self.loss_dfl(
+ pred_corners,
+ target_corners,
+ weight=weight_targets[:, None].expand(-1, 4).reshape(-1),
+ avg_factor=4.0)
+ else:
+ loss_bbox = bbox_pred.sum() * 0
+ loss_dfl = bbox_pred.sum() * 0
+ weight_targets = bbox_pred.new_tensor(0)
+
+ # cls (qfl) loss
+ loss_cls = self.loss_cls(
+ cls_score, (labels, score),
+ weight=label_weights,
+ avg_factor=avg_factor)
+
+ return loss_cls, loss_bbox, loss_dfl, weight_targets.sum()
+
+ def loss_by_feat(
+ self,
+ cls_scores: List[Tensor],
+ bbox_preds: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ batch_gt_instances_ignore: OptInstanceList = None) -> dict:
+ """Calculate the loss based on the features extracted by the detection
+ head.
+
+ Args:
+ cls_scores (list[Tensor]): Cls and quality scores for each scale
+ level has shape (N, num_classes, H, W).
+ bbox_preds (list[Tensor]): Box distribution logits for each scale
+ level with shape (N, 4*(n+1), H, W), n is max value of integral
+ set.
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], Optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components.
+ """
+
+ featmap_sizes = [featmap.size()[-2:] for featmap in cls_scores]
+ assert len(featmap_sizes) == self.prior_generator.num_levels
+
+ device = cls_scores[0].device
+ anchor_list, valid_flag_list = self.get_anchors(
+ featmap_sizes, batch_img_metas, device=device)
+
+ cls_reg_targets = self.get_targets(
+ anchor_list,
+ valid_flag_list,
+ batch_gt_instances,
+ batch_img_metas,
+ batch_gt_instances_ignore=batch_gt_instances_ignore)
+
+ (anchor_list, labels_list, label_weights_list, bbox_targets_list,
+ bbox_weights_list, avg_factor) = cls_reg_targets
+
+ avg_factor = reduce_mean(
+ torch.tensor(avg_factor, dtype=torch.float, device=device)).item()
+
+ losses_cls, losses_bbox, losses_dfl,\
+ avg_factor = multi_apply(
+ self.loss_by_feat_single,
+ anchor_list,
+ cls_scores,
+ bbox_preds,
+ labels_list,
+ label_weights_list,
+ bbox_targets_list,
+ self.prior_generator.strides,
+ avg_factor=avg_factor)
+
+ avg_factor = sum(avg_factor)
+ avg_factor = reduce_mean(avg_factor).clamp_(min=1).item()
+ losses_bbox = list(map(lambda x: x / avg_factor, losses_bbox))
+ losses_dfl = list(map(lambda x: x / avg_factor, losses_dfl))
+ return dict(
+ loss_cls=losses_cls, loss_bbox=losses_bbox, loss_dfl=losses_dfl)
+
+ def _predict_by_feat_single(self,
+ cls_score_list: List[Tensor],
+ bbox_pred_list: List[Tensor],
+ score_factor_list: List[Tensor],
+ mlvl_priors: List[Tensor],
+ img_meta: dict,
+ cfg: ConfigDict,
+ rescale: bool = False,
+ with_nms: bool = True) -> InstanceData:
+ """Transform a single image's features extracted from the head into
+ bbox results.
+
+ Args:
+ cls_score_list (list[Tensor]): Box scores from all scale
+ levels of a single image, each item has shape
+ (num_priors * num_classes, H, W).
+ bbox_pred_list (list[Tensor]): Box energies / deltas from
+ all scale levels of a single image, each item has shape
+ (num_priors * 4, H, W).
+ score_factor_list (list[Tensor]): Score factor from all scale
+ levels of a single image. GFL head does not need this value.
+ mlvl_priors (list[Tensor]): Each element in the list is
+ the priors of a single level in feature pyramid, has shape
+ (num_priors, 4).
+ img_meta (dict): Image meta info.
+ cfg (:obj: `ConfigDict`): Test / postprocessing configuration,
+ if None, test_cfg would be used.
+ rescale (bool): If True, return boxes in original image space.
+ Defaults to False.
+ with_nms (bool): If True, do nms before return boxes.
+ Defaults to True.
+
+ Returns:
+ tuple[Tensor]: Results of detected bboxes and labels. If with_nms
+ is False and mlvl_score_factor is None, return mlvl_bboxes and
+ mlvl_scores, else return mlvl_bboxes, mlvl_scores and
+ mlvl_score_factor. Usually with_nms is False is used for aug
+ test. If with_nms is True, then return the following format
+
+ - det_bboxes (Tensor): Predicted bboxes with shape
+ [num_bboxes, 5], where the first 4 columns are bounding
+ box positions (tl_x, tl_y, br_x, br_y) and the 5-th
+ column are scores between 0 and 1.
+ - det_labels (Tensor): Predicted labels of the corresponding
+ box with shape [num_bboxes].
+ """
+ cfg = self.test_cfg if cfg is None else cfg
+ img_shape = img_meta['img_shape']
+ nms_pre = cfg.get('nms_pre', -1)
+
+ mlvl_bboxes = []
+ mlvl_scores = []
+ mlvl_labels = []
+ for level_idx, (cls_score, bbox_pred, stride, priors) in enumerate(
+ zip(cls_score_list, bbox_pred_list,
+ self.prior_generator.strides, mlvl_priors)):
+ assert cls_score.size()[-2:] == bbox_pred.size()[-2:]
+ assert stride[0] == stride[1]
+
+ bbox_pred = bbox_pred.permute(1, 2, 0)
+ bbox_pred = self.integral(bbox_pred) * stride[0]
+
+ scores = cls_score.permute(1, 2, 0).reshape(
+ -1, self.cls_out_channels).sigmoid()
+
+ # After https://github.com/open-mmlab/mmdetection/pull/6268/,
+ # this operation keeps fewer bboxes under the same `nms_pre`.
+ # There is no difference in performance for most models. If you
+ # find a slight drop in performance, you can set a larger
+ # `nms_pre` than before.
+ results = filter_scores_and_topk(
+ scores, cfg.score_thr, nms_pre,
+ dict(bbox_pred=bbox_pred, priors=priors))
+ scores, labels, _, filtered_results = results
+
+ bbox_pred = filtered_results['bbox_pred']
+ priors = filtered_results['priors']
+
+ bboxes = self.bbox_coder.decode(
+ self.anchor_center(priors), bbox_pred, max_shape=img_shape)
+ mlvl_bboxes.append(bboxes)
+ mlvl_scores.append(scores)
+ mlvl_labels.append(labels)
+
+ results = InstanceData()
+ results.bboxes = torch.cat(mlvl_bboxes)
+ results.scores = torch.cat(mlvl_scores)
+ results.labels = torch.cat(mlvl_labels)
+
+ return self._bbox_post_process(
+ results=results,
+ cfg=cfg,
+ rescale=rescale,
+ with_nms=with_nms,
+ img_meta=img_meta)
+
+ def get_targets(self,
+ anchor_list: List[Tensor],
+ valid_flag_list: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ batch_gt_instances_ignore: OptInstanceList = None,
+ unmap_outputs=True) -> tuple:
+ """Get targets for GFL head.
+
+ This method is almost the same as `AnchorHead.get_targets()`. Besides
+ returning the targets as the parent method does, it also returns the
+ anchors as the first element of the returned tuple.
+ """
+ num_imgs = len(batch_img_metas)
+ assert len(anchor_list) == len(valid_flag_list) == num_imgs
+
+ # anchor number of multi levels
+ num_level_anchors = [anchors.size(0) for anchors in anchor_list[0]]
+ num_level_anchors_list = [num_level_anchors] * num_imgs
+
+ # concat all level anchors and flags to a single tensor
+ for i in range(num_imgs):
+ assert len(anchor_list[i]) == len(valid_flag_list[i])
+ anchor_list[i] = torch.cat(anchor_list[i])
+ valid_flag_list[i] = torch.cat(valid_flag_list[i])
+
+ # compute targets for each image
+ if batch_gt_instances_ignore is None:
+ batch_gt_instances_ignore = [None] * num_imgs
+ (all_anchors, all_labels, all_label_weights, all_bbox_targets,
+ all_bbox_weights, pos_inds_list, neg_inds_list,
+ sampling_results_list) = multi_apply(
+ self._get_targets_single,
+ anchor_list,
+ valid_flag_list,
+ num_level_anchors_list,
+ batch_gt_instances,
+ batch_img_metas,
+ batch_gt_instances_ignore,
+ unmap_outputs=unmap_outputs)
+ # Get `avg_factor` of all images, which calculate in `SamplingResult`.
+ # When using sampling method, avg_factor is usually the sum of
+ # positive and negative priors. When using `PseudoSampler`,
+ # `avg_factor` is usually equal to the number of positive priors.
+ avg_factor = sum(
+ [results.avg_factor for results in sampling_results_list])
+ # split targets to a list w.r.t. multiple levels
+ anchors_list = images_to_levels(all_anchors, num_level_anchors)
+ labels_list = images_to_levels(all_labels, num_level_anchors)
+ label_weights_list = images_to_levels(all_label_weights,
+ num_level_anchors)
+ bbox_targets_list = images_to_levels(all_bbox_targets,
+ num_level_anchors)
+ bbox_weights_list = images_to_levels(all_bbox_weights,
+ num_level_anchors)
+ return (anchors_list, labels_list, label_weights_list,
+ bbox_targets_list, bbox_weights_list, avg_factor)
+
+ def _get_targets_single(self,
+ flat_anchors: Tensor,
+ valid_flags: Tensor,
+ num_level_anchors: List[int],
+ gt_instances: InstanceData,
+ img_meta: dict,
+ gt_instances_ignore: Optional[InstanceData] = None,
+ unmap_outputs: bool = True) -> tuple:
+ """Compute regression, classification targets for anchors in a single
+ image.
+
+ Args:
+ flat_anchors (Tensor): Multi-level anchors of the image, which are
+ concatenated into a single tensor of shape (num_anchors, 4)
+ valid_flags (Tensor): Multi level valid flags of the image,
+ which are concatenated into a single tensor of
+ shape (num_anchors,).
+ num_level_anchors (list[int]): Number of anchors of each scale
+ level.
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ img_meta (dict): Meta information for current image.
+ gt_instances_ignore (:obj:`InstanceData`, optional): Instances
+ to be ignored during training. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+ unmap_outputs (bool): Whether to map outputs back to the original
+ set of anchors. Defaults to True.
+
+ Returns:
+ tuple: N is the number of total anchors in the image.
+
+ - anchors (Tensor): All anchors in the image with shape (N, 4).
+ - labels (Tensor): Labels of all anchors in the image with
+ shape (N,).
+ - label_weights (Tensor): Label weights of all anchor in the
+ image with shape (N,).
+ - bbox_targets (Tensor): BBox targets of all anchors in the
+ image with shape (N, 4).
+ - bbox_weights (Tensor): BBox weights of all anchors in the
+ image with shape (N, 4).
+ - pos_inds (Tensor): Indices of positive anchor with shape
+ (num_pos,).
+ - neg_inds (Tensor): Indices of negative anchor with shape
+ (num_neg,).
+ - sampling_result (:obj:`SamplingResult`): Sampling results.
+ """
+ inside_flags = anchor_inside_flags(flat_anchors, valid_flags,
+ img_meta['img_shape'][:2],
+ self.train_cfg['allowed_border'])
+ if not inside_flags.any():
+ raise ValueError(
+ 'There is no valid anchor inside the image boundary. Please '
+ 'check the image size and anchor sizes, or set '
+ '``allowed_border`` to -1 to skip the condition.')
+ # assign gt and sample anchors
+ anchors = flat_anchors[inside_flags, :]
+ num_level_anchors_inside = self.get_num_level_anchors_inside(
+ num_level_anchors, inside_flags)
+ pred_instances = InstanceData(priors=anchors)
+ assign_result = self.assigner.assign(
+ pred_instances=pred_instances,
+ num_level_priors=num_level_anchors_inside,
+ gt_instances=gt_instances,
+ gt_instances_ignore=gt_instances_ignore)
+
+ sampling_result = self.sampler.sample(
+ assign_result=assign_result,
+ pred_instances=pred_instances,
+ gt_instances=gt_instances)
+
+ num_valid_anchors = anchors.shape[0]
+ bbox_targets = torch.zeros_like(anchors)
+ bbox_weights = torch.zeros_like(anchors)
+ labels = anchors.new_full((num_valid_anchors, ),
+ self.num_classes,
+ dtype=torch.long)
+ label_weights = anchors.new_zeros(num_valid_anchors, dtype=torch.float)
+
+ pos_inds = sampling_result.pos_inds
+ neg_inds = sampling_result.neg_inds
+ if len(pos_inds) > 0:
+ pos_bbox_targets = sampling_result.pos_gt_bboxes
+ bbox_targets[pos_inds, :] = pos_bbox_targets
+ bbox_weights[pos_inds, :] = 1.0
+
+ labels[pos_inds] = sampling_result.pos_gt_labels
+ if self.train_cfg['pos_weight'] <= 0:
+ label_weights[pos_inds] = 1.0
+ else:
+ label_weights[pos_inds] = self.train_cfg['pos_weight']
+ if len(neg_inds) > 0:
+ label_weights[neg_inds] = 1.0
+
+ # map up to original set of anchors
+ if unmap_outputs:
+ num_total_anchors = flat_anchors.size(0)
+ anchors = unmap(anchors, num_total_anchors, inside_flags)
+ labels = unmap(
+ labels, num_total_anchors, inside_flags, fill=self.num_classes)
+ label_weights = unmap(label_weights, num_total_anchors,
+ inside_flags)
+ bbox_targets = unmap(bbox_targets, num_total_anchors, inside_flags)
+ bbox_weights = unmap(bbox_weights, num_total_anchors, inside_flags)
+
+ return (anchors, labels, label_weights, bbox_targets, bbox_weights,
+ pos_inds, neg_inds, sampling_result)
+
+ def get_num_level_anchors_inside(self, num_level_anchors: List[int],
+ inside_flags: Tensor) -> List[int]:
+ """Get the number of valid anchors in every level."""
+
+ split_inside_flags = torch.split(inside_flags, num_level_anchors)
+ num_level_anchors_inside = [
+ int(flags.sum()) for flags in split_inside_flags
+ ]
+ return num_level_anchors_inside
diff --git a/mmdet/models/dense_heads/guided_anchor_head.py b/mmdet/models/dense_heads/guided_anchor_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..59f6dd3336e66065dc88b702e925965d4089c72f
--- /dev/null
+++ b/mmdet/models/dense_heads/guided_anchor_head.py
@@ -0,0 +1,994 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Optional, Tuple
+
+import torch
+import torch.nn as nn
+from mmcv.ops import DeformConv2d, MaskedConv2d
+from mmengine.model import BaseModule
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmdet.registry import MODELS, TASK_UTILS
+from mmdet.utils import (ConfigType, InstanceList, MultiConfig, OptConfigType,
+ OptInstanceList)
+from ..layers import multiclass_nms
+from ..task_modules.prior_generators import anchor_inside_flags, calc_region
+from ..task_modules.samplers import PseudoSampler
+from ..utils import images_to_levels, multi_apply, unmap
+from .anchor_head import AnchorHead
+
+
+class FeatureAdaption(BaseModule):
+ """Feature Adaption Module.
+
+ Feature Adaption Module is implemented based on DCN v1.
+ It uses anchor shape prediction rather than feature map to
+ predict offsets of deform conv layer.
+
+ Args:
+ in_channels (int): Number of channels in the input feature map.
+ out_channels (int): Number of channels in the output feature map.
+ kernel_size (int): Deformable conv kernel size. Defaults to 3.
+ deform_groups (int): Deformable conv group size. Defaults to 4.
+ init_cfg (:obj:`ConfigDict` or list[:obj:`ConfigDict`] or dict or \
+ list[dict], optional): Initialization config dict.
+ """
+
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ kernel_size: int = 3,
+ deform_groups: int = 4,
+ init_cfg: MultiConfig = dict(
+ type='Normal',
+ layer='Conv2d',
+ std=0.1,
+ override=dict(type='Normal', name='conv_adaption', std=0.01))
+ ) -> None:
+ super().__init__(init_cfg=init_cfg)
+ offset_channels = kernel_size * kernel_size * 2
+ self.conv_offset = nn.Conv2d(
+ 2, deform_groups * offset_channels, 1, bias=False)
+ self.conv_adaption = DeformConv2d(
+ in_channels,
+ out_channels,
+ kernel_size=kernel_size,
+ padding=(kernel_size - 1) // 2,
+ deform_groups=deform_groups)
+ self.relu = nn.ReLU(inplace=True)
+
+ def forward(self, x: Tensor, shape: Tensor) -> Tensor:
+ offset = self.conv_offset(shape.detach())
+ x = self.relu(self.conv_adaption(x, offset))
+ return x
+
+
+@MODELS.register_module()
+class GuidedAnchorHead(AnchorHead):
+ """Guided-Anchor-based head (GA-RPN, GA-RetinaNet, etc.).
+
+ This GuidedAnchorHead will predict high-quality feature guided
+ anchors and locations where anchors will be kept in inference.
+ There are mainly 3 categories of bounding-boxes.
+
+ - Sampled 9 pairs for target assignment. (approxes)
+ - The square boxes where the predicted anchors are based on. (squares)
+ - Guided anchors.
+
+ Please refer to https://arxiv.org/abs/1901.03278 for more details.
+
+ Args:
+ num_classes (int): Number of classes.
+ in_channels (int): Number of channels in the input feature map.
+ feat_channels (int): Number of hidden channels. Defaults to 256.
+ approx_anchor_generator (:obj:`ConfigDict` or dict): Config dict
+ for approx generator
+ square_anchor_generator (:obj:`ConfigDict` or dict): Config dict
+ for square generator
+ anchor_coder (:obj:`ConfigDict` or dict): Config dict for anchor coder
+ bbox_coder (:obj:`ConfigDict` or dict): Config dict for bbox coder
+ reg_decoded_bbox (bool): If true, the regression loss would be
+ applied directly on decoded bounding boxes, converting both
+ the predicted boxes and regression targets to absolute
+ coordinates format. Defaults to False. It should be `True` when
+ using `IoULoss`, `GIoULoss`, or `DIoULoss` in the bbox head.
+ deform_groups: (int): Group number of DCN in FeatureAdaption module.
+ Defaults to 4.
+ loc_filter_thr (float): Threshold to filter out unconcerned regions.
+ Defaults to 0.01.
+ loss_loc (:obj:`ConfigDict` or dict): Config of location loss.
+ loss_shape (:obj:`ConfigDict` or dict): Config of anchor shape loss.
+ loss_cls (:obj:`ConfigDict` or dict): Config of classification loss.
+ loss_bbox (:obj:`ConfigDict` or dict): Config of bbox regression loss.
+ init_cfg (:obj:`ConfigDict` or list[:obj:`ConfigDict`] or dict or \
+ list[dict], optional): Initialization config dict.
+ """
+
+ def __init__(
+ self,
+ num_classes: int,
+ in_channels: int,
+ feat_channels: int = 256,
+ approx_anchor_generator: ConfigType = dict(
+ type='AnchorGenerator',
+ octave_base_scale=8,
+ scales_per_octave=3,
+ ratios=[0.5, 1.0, 2.0],
+ strides=[4, 8, 16, 32, 64]),
+ square_anchor_generator: ConfigType = dict(
+ type='AnchorGenerator',
+ ratios=[1.0],
+ scales=[8],
+ strides=[4, 8, 16, 32, 64]),
+ anchor_coder: ConfigType = dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[.0, .0, .0, .0],
+ target_stds=[1.0, 1.0, 1.0, 1.0]),
+ bbox_coder: ConfigType = dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[.0, .0, .0, .0],
+ target_stds=[1.0, 1.0, 1.0, 1.0]),
+ reg_decoded_bbox: bool = False,
+ deform_groups: int = 4,
+ loc_filter_thr: float = 0.01,
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ loss_loc: ConfigType = dict(
+ type='FocalLoss',
+ use_sigmoid=True,
+ gamma=2.0,
+ alpha=0.25,
+ loss_weight=1.0),
+ loss_shape: ConfigType = dict(
+ type='BoundedIoULoss', beta=0.2, loss_weight=1.0),
+ loss_cls: ConfigType = dict(
+ type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
+ loss_bbox: ConfigType = dict(
+ type='SmoothL1Loss', beta=1.0, loss_weight=1.0),
+ init_cfg: MultiConfig = dict(
+ type='Normal',
+ layer='Conv2d',
+ std=0.01,
+ override=dict(
+ type='Normal', name='conv_loc', std=0.01, lbias_prob=0.01))
+ ) -> None:
+ super(AnchorHead, self).__init__(init_cfg=init_cfg)
+ self.in_channels = in_channels
+ self.num_classes = num_classes
+ self.feat_channels = feat_channels
+ self.deform_groups = deform_groups
+ self.loc_filter_thr = loc_filter_thr
+
+ # build approx_anchor_generator and square_anchor_generator
+ assert (approx_anchor_generator['octave_base_scale'] ==
+ square_anchor_generator['scales'][0])
+ assert (approx_anchor_generator['strides'] ==
+ square_anchor_generator['strides'])
+ self.approx_anchor_generator = TASK_UTILS.build(
+ approx_anchor_generator)
+ self.square_anchor_generator = TASK_UTILS.build(
+ square_anchor_generator)
+ self.approxs_per_octave = self.approx_anchor_generator \
+ .num_base_priors[0]
+
+ self.reg_decoded_bbox = reg_decoded_bbox
+
+ # one anchor per location
+ self.num_base_priors = self.square_anchor_generator.num_base_priors[0]
+
+ self.use_sigmoid_cls = loss_cls.get('use_sigmoid', False)
+ self.loc_focal_loss = loss_loc['type'] in ['FocalLoss']
+ if self.use_sigmoid_cls:
+ self.cls_out_channels = self.num_classes
+ else:
+ self.cls_out_channels = self.num_classes + 1
+
+ # build bbox_coder
+ self.anchor_coder = TASK_UTILS.build(anchor_coder)
+ self.bbox_coder = TASK_UTILS.build(bbox_coder)
+
+ # build losses
+ self.loss_loc = MODELS.build(loss_loc)
+ self.loss_shape = MODELS.build(loss_shape)
+ self.loss_cls = MODELS.build(loss_cls)
+ self.loss_bbox = MODELS.build(loss_bbox)
+
+ self.train_cfg = train_cfg
+ self.test_cfg = test_cfg
+
+ if self.train_cfg:
+ self.assigner = TASK_UTILS.build(self.train_cfg['assigner'])
+ # use PseudoSampler when no sampler in train_cfg
+ if train_cfg.get('sampler', None) is not None:
+ self.sampler = TASK_UTILS.build(
+ self.train_cfg['sampler'], default_args=dict(context=self))
+ else:
+ self.sampler = PseudoSampler()
+
+ self.ga_assigner = TASK_UTILS.build(self.train_cfg['ga_assigner'])
+ if train_cfg.get('ga_sampler', None) is not None:
+ self.ga_sampler = TASK_UTILS.build(
+ self.train_cfg['ga_sampler'],
+ default_args=dict(context=self))
+ else:
+ self.ga_sampler = PseudoSampler()
+
+ self._init_layers()
+
+ def _init_layers(self) -> None:
+ """Initialize layers of the head."""
+ self.relu = nn.ReLU(inplace=True)
+ self.conv_loc = nn.Conv2d(self.in_channels, 1, 1)
+ self.conv_shape = nn.Conv2d(self.in_channels, self.num_base_priors * 2,
+ 1)
+ self.feature_adaption = FeatureAdaption(
+ self.in_channels,
+ self.feat_channels,
+ kernel_size=3,
+ deform_groups=self.deform_groups)
+ self.conv_cls = MaskedConv2d(
+ self.feat_channels, self.num_base_priors * self.cls_out_channels,
+ 1)
+ self.conv_reg = MaskedConv2d(self.feat_channels,
+ self.num_base_priors * 4, 1)
+
+ def forward_single(self, x: Tensor) -> Tuple[Tensor]:
+ """Forward feature of a single scale level."""
+ loc_pred = self.conv_loc(x)
+ shape_pred = self.conv_shape(x)
+ x = self.feature_adaption(x, shape_pred)
+ # masked conv is only used during inference for speed-up
+ if not self.training:
+ mask = loc_pred.sigmoid()[0] >= self.loc_filter_thr
+ else:
+ mask = None
+ cls_score = self.conv_cls(x, mask)
+ bbox_pred = self.conv_reg(x, mask)
+ return cls_score, bbox_pred, shape_pred, loc_pred
+
+ def forward(self, x: List[Tensor]) -> Tuple[List[Tensor]]:
+ """Forward features from the upstream network."""
+ return multi_apply(self.forward_single, x)
+
+ def get_sampled_approxs(self,
+ featmap_sizes: List[Tuple[int, int]],
+ batch_img_metas: List[dict],
+ device: str = 'cuda') -> tuple:
+ """Get sampled approxs and inside flags according to feature map sizes.
+
+ Args:
+ featmap_sizes (list[tuple]): Multi-level feature map sizes.
+ batch_img_metas (list[dict]): Image meta info.
+ device (str): device for returned tensors
+
+ Returns:
+ tuple: approxes of each image, inside flags of each image
+ """
+ num_imgs = len(batch_img_metas)
+
+ # since feature map sizes of all images are the same, we only compute
+ # approxes for one time
+ multi_level_approxs = self.approx_anchor_generator.grid_priors(
+ featmap_sizes, device=device)
+ approxs_list = [multi_level_approxs for _ in range(num_imgs)]
+
+ # for each image, we compute inside flags of multi level approxes
+ inside_flag_list = []
+ for img_id, img_meta in enumerate(batch_img_metas):
+ multi_level_flags = []
+ multi_level_approxs = approxs_list[img_id]
+
+ # obtain valid flags for each approx first
+ multi_level_approx_flags = self.approx_anchor_generator \
+ .valid_flags(featmap_sizes,
+ img_meta['pad_shape'],
+ device=device)
+
+ for i, flags in enumerate(multi_level_approx_flags):
+ approxs = multi_level_approxs[i]
+ inside_flags_list = []
+ for j in range(self.approxs_per_octave):
+ split_valid_flags = flags[j::self.approxs_per_octave]
+ split_approxs = approxs[j::self.approxs_per_octave, :]
+ inside_flags = anchor_inside_flags(
+ split_approxs, split_valid_flags,
+ img_meta['img_shape'][:2],
+ self.train_cfg['allowed_border'])
+ inside_flags_list.append(inside_flags)
+ # inside_flag for a position is true if any anchor in this
+ # position is true
+ inside_flags = (
+ torch.stack(inside_flags_list, 0).sum(dim=0) > 0)
+ multi_level_flags.append(inside_flags)
+ inside_flag_list.append(multi_level_flags)
+ return approxs_list, inside_flag_list
+
+ def get_anchors(self,
+ featmap_sizes: List[Tuple[int, int]],
+ shape_preds: List[Tensor],
+ loc_preds: List[Tensor],
+ batch_img_metas: List[dict],
+ use_loc_filter: bool = False,
+ device: str = 'cuda') -> tuple:
+ """Get squares according to feature map sizes and guided anchors.
+
+ Args:
+ featmap_sizes (list[tuple]): Multi-level feature map sizes.
+ shape_preds (list[tensor]): Multi-level shape predictions.
+ loc_preds (list[tensor]): Multi-level location predictions.
+ batch_img_metas (list[dict]): Image meta info.
+ use_loc_filter (bool): Use loc filter or not. Defaults to False
+ device (str): device for returned tensors.
+ Defaults to `cuda`.
+
+ Returns:
+ tuple: square approxs of each image, guided anchors of each image,
+ loc masks of each image.
+ """
+ num_imgs = len(batch_img_metas)
+ num_levels = len(featmap_sizes)
+
+ # since feature map sizes of all images are the same, we only compute
+ # squares for one time
+ multi_level_squares = self.square_anchor_generator.grid_priors(
+ featmap_sizes, device=device)
+ squares_list = [multi_level_squares for _ in range(num_imgs)]
+
+ # for each image, we compute multi level guided anchors
+ guided_anchors_list = []
+ loc_mask_list = []
+ for img_id, img_meta in enumerate(batch_img_metas):
+ multi_level_guided_anchors = []
+ multi_level_loc_mask = []
+ for i in range(num_levels):
+ squares = squares_list[img_id][i]
+ shape_pred = shape_preds[i][img_id]
+ loc_pred = loc_preds[i][img_id]
+ guided_anchors, loc_mask = self._get_guided_anchors_single(
+ squares,
+ shape_pred,
+ loc_pred,
+ use_loc_filter=use_loc_filter)
+ multi_level_guided_anchors.append(guided_anchors)
+ multi_level_loc_mask.append(loc_mask)
+ guided_anchors_list.append(multi_level_guided_anchors)
+ loc_mask_list.append(multi_level_loc_mask)
+ return squares_list, guided_anchors_list, loc_mask_list
+
+ def _get_guided_anchors_single(
+ self,
+ squares: Tensor,
+ shape_pred: Tensor,
+ loc_pred: Tensor,
+ use_loc_filter: bool = False) -> Tuple[Tensor]:
+ """Get guided anchors and loc masks for a single level.
+
+ Args:
+ squares (tensor): Squares of a single level.
+ shape_pred (tensor): Shape predictions of a single level.
+ loc_pred (tensor): Loc predictions of a single level.
+ use_loc_filter (list[tensor]): Use loc filter or not.
+ Defaults to False.
+
+ Returns:
+ tuple: guided anchors, location masks
+ """
+ # calculate location filtering mask
+ loc_pred = loc_pred.sigmoid().detach()
+ if use_loc_filter:
+ loc_mask = loc_pred >= self.loc_filter_thr
+ else:
+ loc_mask = loc_pred >= 0.0
+ mask = loc_mask.permute(1, 2, 0).expand(-1, -1, self.num_base_priors)
+ mask = mask.contiguous().view(-1)
+ # calculate guided anchors
+ squares = squares[mask]
+ anchor_deltas = shape_pred.permute(1, 2, 0).contiguous().view(
+ -1, 2).detach()[mask]
+ bbox_deltas = anchor_deltas.new_full(squares.size(), 0)
+ bbox_deltas[:, 2:] = anchor_deltas
+ guided_anchors = self.anchor_coder.decode(
+ squares, bbox_deltas, wh_ratio_clip=1e-6)
+ return guided_anchors, mask
+
+ def ga_loc_targets(self, batch_gt_instances: InstanceList,
+ featmap_sizes: List[Tuple[int, int]]) -> tuple:
+ """Compute location targets for guided anchoring.
+
+ Each feature map is divided into positive, negative and ignore regions.
+ - positive regions: target 1, weight 1
+ - ignore regions: target 0, weight 0
+ - negative regions: target 0, weight 0.1
+
+ Args:
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ featmap_sizes (list[tuple]): Multi level sizes of each feature
+ maps.
+
+ Returns:
+ tuple: Returns a tuple containing location targets.
+ """
+ anchor_scale = self.approx_anchor_generator.octave_base_scale
+ anchor_strides = self.approx_anchor_generator.strides
+ # Currently only supports same stride in x and y direction.
+ for stride in anchor_strides:
+ assert (stride[0] == stride[1])
+ anchor_strides = [stride[0] for stride in anchor_strides]
+
+ center_ratio = self.train_cfg['center_ratio']
+ ignore_ratio = self.train_cfg['ignore_ratio']
+ img_per_gpu = len(batch_gt_instances)
+ num_lvls = len(featmap_sizes)
+ r1 = (1 - center_ratio) / 2
+ r2 = (1 - ignore_ratio) / 2
+ all_loc_targets = []
+ all_loc_weights = []
+ all_ignore_map = []
+ for lvl_id in range(num_lvls):
+ h, w = featmap_sizes[lvl_id]
+ loc_targets = torch.zeros(
+ img_per_gpu,
+ 1,
+ h,
+ w,
+ device=batch_gt_instances[0].bboxes.device,
+ dtype=torch.float32)
+ loc_weights = torch.full_like(loc_targets, -1)
+ ignore_map = torch.zeros_like(loc_targets)
+ all_loc_targets.append(loc_targets)
+ all_loc_weights.append(loc_weights)
+ all_ignore_map.append(ignore_map)
+ for img_id in range(img_per_gpu):
+ gt_bboxes = batch_gt_instances[img_id].bboxes
+ scale = torch.sqrt((gt_bboxes[:, 2] - gt_bboxes[:, 0]) *
+ (gt_bboxes[:, 3] - gt_bboxes[:, 1]))
+ min_anchor_size = scale.new_full(
+ (1, ), float(anchor_scale * anchor_strides[0]))
+ # assign gt bboxes to different feature levels w.r.t. their scales
+ target_lvls = torch.floor(
+ torch.log2(scale) - torch.log2(min_anchor_size) + 0.5)
+ target_lvls = target_lvls.clamp(min=0, max=num_lvls - 1).long()
+ for gt_id in range(gt_bboxes.size(0)):
+ lvl = target_lvls[gt_id].item()
+ # rescaled to corresponding feature map
+ gt_ = gt_bboxes[gt_id, :4] / anchor_strides[lvl]
+ # calculate ignore regions
+ ignore_x1, ignore_y1, ignore_x2, ignore_y2 = calc_region(
+ gt_, r2, featmap_sizes[lvl])
+ # calculate positive (center) regions
+ ctr_x1, ctr_y1, ctr_x2, ctr_y2 = calc_region(
+ gt_, r1, featmap_sizes[lvl])
+ all_loc_targets[lvl][img_id, 0, ctr_y1:ctr_y2 + 1,
+ ctr_x1:ctr_x2 + 1] = 1
+ all_loc_weights[lvl][img_id, 0, ignore_y1:ignore_y2 + 1,
+ ignore_x1:ignore_x2 + 1] = 0
+ all_loc_weights[lvl][img_id, 0, ctr_y1:ctr_y2 + 1,
+ ctr_x1:ctr_x2 + 1] = 1
+ # calculate ignore map on nearby low level feature
+ if lvl > 0:
+ d_lvl = lvl - 1
+ # rescaled to corresponding feature map
+ gt_ = gt_bboxes[gt_id, :4] / anchor_strides[d_lvl]
+ ignore_x1, ignore_y1, ignore_x2, ignore_y2 = calc_region(
+ gt_, r2, featmap_sizes[d_lvl])
+ all_ignore_map[d_lvl][img_id, 0, ignore_y1:ignore_y2 + 1,
+ ignore_x1:ignore_x2 + 1] = 1
+ # calculate ignore map on nearby high level feature
+ if lvl < num_lvls - 1:
+ u_lvl = lvl + 1
+ # rescaled to corresponding feature map
+ gt_ = gt_bboxes[gt_id, :4] / anchor_strides[u_lvl]
+ ignore_x1, ignore_y1, ignore_x2, ignore_y2 = calc_region(
+ gt_, r2, featmap_sizes[u_lvl])
+ all_ignore_map[u_lvl][img_id, 0, ignore_y1:ignore_y2 + 1,
+ ignore_x1:ignore_x2 + 1] = 1
+ for lvl_id in range(num_lvls):
+ # ignore negative regions w.r.t. ignore map
+ all_loc_weights[lvl_id][(all_loc_weights[lvl_id] < 0)
+ & (all_ignore_map[lvl_id] > 0)] = 0
+ # set negative regions with weight 0.1
+ all_loc_weights[lvl_id][all_loc_weights[lvl_id] < 0] = 0.1
+ # loc average factor to balance loss
+ loc_avg_factor = sum(
+ [t.size(0) * t.size(-1) * t.size(-2)
+ for t in all_loc_targets]) / 200
+ return all_loc_targets, all_loc_weights, loc_avg_factor
+
+ def _ga_shape_target_single(self,
+ flat_approxs: Tensor,
+ inside_flags: Tensor,
+ flat_squares: Tensor,
+ gt_instances: InstanceData,
+ gt_instances_ignore: Optional[InstanceData],
+ img_meta: dict,
+ unmap_outputs: bool = True) -> tuple:
+ """Compute guided anchoring targets.
+
+ This function returns sampled anchors and gt bboxes directly
+ rather than calculates regression targets.
+
+ Args:
+ flat_approxs (Tensor): flat approxs of a single image,
+ shape (n, 4)
+ inside_flags (Tensor): inside flags of a single image,
+ shape (n, ).
+ flat_squares (Tensor): flat squares of a single image,
+ shape (approxs_per_octave * n, 4)
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ gt_instances_ignore (:obj:`InstanceData`, optional): Instances
+ to be ignored during training. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ img_meta (dict): Meta info of a single image.
+ unmap_outputs (bool): unmap outputs or not.
+
+ Returns:
+ tuple: Returns a tuple containing shape targets of each image.
+ """
+ if not inside_flags.any():
+ raise ValueError(
+ 'There is no valid anchor inside the image boundary. Please '
+ 'check the image size and anchor sizes, or set '
+ '``allowed_border`` to -1 to skip the condition.')
+ # assign gt and sample anchors
+ num_square = flat_squares.size(0)
+ approxs = flat_approxs.view(num_square, self.approxs_per_octave, 4)
+ approxs = approxs[inside_flags, ...]
+ squares = flat_squares[inside_flags, :]
+
+ pred_instances = InstanceData()
+ pred_instances.priors = squares
+ pred_instances.approxs = approxs
+
+ assign_result = self.ga_assigner.assign(
+ pred_instances=pred_instances,
+ gt_instances=gt_instances,
+ gt_instances_ignore=gt_instances_ignore)
+ sampling_result = self.ga_sampler.sample(
+ assign_result=assign_result,
+ pred_instances=pred_instances,
+ gt_instances=gt_instances)
+
+ bbox_anchors = torch.zeros_like(squares)
+ bbox_gts = torch.zeros_like(squares)
+ bbox_weights = torch.zeros_like(squares)
+
+ pos_inds = sampling_result.pos_inds
+ neg_inds = sampling_result.neg_inds
+ if len(pos_inds) > 0:
+ bbox_anchors[pos_inds, :] = sampling_result.pos_bboxes
+ bbox_gts[pos_inds, :] = sampling_result.pos_gt_bboxes
+ bbox_weights[pos_inds, :] = 1.0
+
+ # map up to original set of anchors
+ if unmap_outputs:
+ num_total_anchors = flat_squares.size(0)
+ bbox_anchors = unmap(bbox_anchors, num_total_anchors, inside_flags)
+ bbox_gts = unmap(bbox_gts, num_total_anchors, inside_flags)
+ bbox_weights = unmap(bbox_weights, num_total_anchors, inside_flags)
+
+ return (bbox_anchors, bbox_gts, bbox_weights, pos_inds, neg_inds,
+ sampling_result)
+
+ def ga_shape_targets(self,
+ approx_list: List[List[Tensor]],
+ inside_flag_list: List[List[Tensor]],
+ square_list: List[List[Tensor]],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ batch_gt_instances_ignore: OptInstanceList = None,
+ unmap_outputs: bool = True) -> tuple:
+ """Compute guided anchoring targets.
+
+ Args:
+ approx_list (list[list[Tensor]]): Multi level approxs of each
+ image.
+ inside_flag_list (list[list[Tensor]]): Multi level inside flags
+ of each image.
+ square_list (list[list[Tensor]]): Multi level squares of each
+ image.
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+ unmap_outputs (bool): unmap outputs or not. Defaults to None.
+
+ Returns:
+ tuple: Returns a tuple containing shape targets.
+ """
+ num_imgs = len(batch_img_metas)
+ assert len(approx_list) == len(inside_flag_list) == len(
+ square_list) == num_imgs
+ # anchor number of multi levels
+ num_level_squares = [squares.size(0) for squares in square_list[0]]
+ # concat all level anchors and flags to a single tensor
+ inside_flag_flat_list = []
+ approx_flat_list = []
+ square_flat_list = []
+ for i in range(num_imgs):
+ assert len(square_list[i]) == len(inside_flag_list[i])
+ inside_flag_flat_list.append(torch.cat(inside_flag_list[i]))
+ approx_flat_list.append(torch.cat(approx_list[i]))
+ square_flat_list.append(torch.cat(square_list[i]))
+
+ # compute targets for each image
+ if batch_gt_instances_ignore is None:
+ batch_gt_instances_ignore = [None for _ in range(num_imgs)]
+ (all_bbox_anchors, all_bbox_gts, all_bbox_weights, pos_inds_list,
+ neg_inds_list, sampling_results_list) = multi_apply(
+ self._ga_shape_target_single,
+ approx_flat_list,
+ inside_flag_flat_list,
+ square_flat_list,
+ batch_gt_instances,
+ batch_gt_instances_ignore,
+ batch_img_metas,
+ unmap_outputs=unmap_outputs)
+ # sampled anchors of all images
+ avg_factor = sum(
+ [results.avg_factor for results in sampling_results_list])
+ # split targets to a list w.r.t. multiple levels
+ bbox_anchors_list = images_to_levels(all_bbox_anchors,
+ num_level_squares)
+ bbox_gts_list = images_to_levels(all_bbox_gts, num_level_squares)
+ bbox_weights_list = images_to_levels(all_bbox_weights,
+ num_level_squares)
+ return (bbox_anchors_list, bbox_gts_list, bbox_weights_list,
+ avg_factor)
+
+ def loss_shape_single(self, shape_pred: Tensor, bbox_anchors: Tensor,
+ bbox_gts: Tensor, anchor_weights: Tensor,
+ avg_factor: int) -> Tensor:
+ """Compute shape loss in single level."""
+ shape_pred = shape_pred.permute(0, 2, 3, 1).contiguous().view(-1, 2)
+ bbox_anchors = bbox_anchors.contiguous().view(-1, 4)
+ bbox_gts = bbox_gts.contiguous().view(-1, 4)
+ anchor_weights = anchor_weights.contiguous().view(-1, 4)
+ bbox_deltas = bbox_anchors.new_full(bbox_anchors.size(), 0)
+ bbox_deltas[:, 2:] += shape_pred
+ # filter out negative samples to speed-up weighted_bounded_iou_loss
+ inds = torch.nonzero(
+ anchor_weights[:, 0] > 0, as_tuple=False).squeeze(1)
+ bbox_deltas_ = bbox_deltas[inds]
+ bbox_anchors_ = bbox_anchors[inds]
+ bbox_gts_ = bbox_gts[inds]
+ anchor_weights_ = anchor_weights[inds]
+ pred_anchors_ = self.anchor_coder.decode(
+ bbox_anchors_, bbox_deltas_, wh_ratio_clip=1e-6)
+ loss_shape = self.loss_shape(
+ pred_anchors_, bbox_gts_, anchor_weights_, avg_factor=avg_factor)
+ return loss_shape
+
+ def loss_loc_single(self, loc_pred: Tensor, loc_target: Tensor,
+ loc_weight: Tensor, avg_factor: float) -> Tensor:
+ """Compute location loss in single level."""
+ loss_loc = self.loss_loc(
+ loc_pred.reshape(-1, 1),
+ loc_target.reshape(-1).long(),
+ loc_weight.reshape(-1),
+ avg_factor=avg_factor)
+ return loss_loc
+
+ def loss_by_feat(
+ self,
+ cls_scores: List[Tensor],
+ bbox_preds: List[Tensor],
+ shape_preds: List[Tensor],
+ loc_preds: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ batch_gt_instances_ignore: OptInstanceList = None) -> dict:
+ """Calculate the loss based on the features extracted by the detection
+ head.
+
+ Args:
+ cls_scores (list[Tensor]): Box scores for each scale level
+ has shape (N, num_anchors * num_classes, H, W).
+ bbox_preds (list[Tensor]): Box energies / deltas for each scale
+ level with shape (N, num_anchors * 4, H, W).
+ shape_preds (list[Tensor]): shape predictions for each scale
+ level with shape (N, 1, H, W).
+ loc_preds (list[Tensor]): location predictions for each scale
+ level with shape (N, num_anchors * 2, H, W).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ dict: A dictionary of loss components.
+ """
+
+ featmap_sizes = [featmap.size()[-2:] for featmap in cls_scores]
+ assert len(featmap_sizes) == self.approx_anchor_generator.num_levels
+
+ device = cls_scores[0].device
+
+ # get loc targets
+ loc_targets, loc_weights, loc_avg_factor = self.ga_loc_targets(
+ batch_gt_instances, featmap_sizes)
+
+ # get sampled approxes
+ approxs_list, inside_flag_list = self.get_sampled_approxs(
+ featmap_sizes, batch_img_metas, device=device)
+ # get squares and guided anchors
+ squares_list, guided_anchors_list, _ = self.get_anchors(
+ featmap_sizes,
+ shape_preds,
+ loc_preds,
+ batch_img_metas,
+ device=device)
+
+ # get shape targets
+ shape_targets = self.ga_shape_targets(approxs_list, inside_flag_list,
+ squares_list, batch_gt_instances,
+ batch_img_metas)
+ (bbox_anchors_list, bbox_gts_list, anchor_weights_list,
+ ga_avg_factor) = shape_targets
+
+ # get anchor targets
+ cls_reg_targets = self.get_targets(
+ guided_anchors_list,
+ inside_flag_list,
+ batch_gt_instances,
+ batch_img_metas,
+ batch_gt_instances_ignore=batch_gt_instances_ignore)
+ (labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,
+ avg_factor) = cls_reg_targets
+
+ # anchor number of multi levels
+ num_level_anchors = [
+ anchors.size(0) for anchors in guided_anchors_list[0]
+ ]
+ # concat all level anchors to a single tensor
+ concat_anchor_list = []
+ for i in range(len(guided_anchors_list)):
+ concat_anchor_list.append(torch.cat(guided_anchors_list[i]))
+ all_anchor_list = images_to_levels(concat_anchor_list,
+ num_level_anchors)
+
+ # get classification and bbox regression losses
+ losses_cls, losses_bbox = multi_apply(
+ self.loss_by_feat_single,
+ cls_scores,
+ bbox_preds,
+ all_anchor_list,
+ labels_list,
+ label_weights_list,
+ bbox_targets_list,
+ bbox_weights_list,
+ avg_factor=avg_factor)
+
+ # get anchor location loss
+ losses_loc = []
+ for i in range(len(loc_preds)):
+ loss_loc = self.loss_loc_single(
+ loc_preds[i],
+ loc_targets[i],
+ loc_weights[i],
+ avg_factor=loc_avg_factor)
+ losses_loc.append(loss_loc)
+
+ # get anchor shape loss
+ losses_shape = []
+ for i in range(len(shape_preds)):
+ loss_shape = self.loss_shape_single(
+ shape_preds[i],
+ bbox_anchors_list[i],
+ bbox_gts_list[i],
+ anchor_weights_list[i],
+ avg_factor=ga_avg_factor)
+ losses_shape.append(loss_shape)
+
+ return dict(
+ loss_cls=losses_cls,
+ loss_bbox=losses_bbox,
+ loss_shape=losses_shape,
+ loss_loc=losses_loc)
+
+ def predict_by_feat(self,
+ cls_scores: List[Tensor],
+ bbox_preds: List[Tensor],
+ shape_preds: List[Tensor],
+ loc_preds: List[Tensor],
+ batch_img_metas: List[dict],
+ cfg: OptConfigType = None,
+ rescale: bool = False) -> InstanceList:
+ """Transform a batch of output features extracted from the head into
+ bbox results.
+
+ Args:
+ cls_scores (list[Tensor]): Classification scores for all
+ scale levels, each is a 4D-tensor, has shape
+ (batch_size, num_priors * num_classes, H, W).
+ bbox_preds (list[Tensor]): Box energies / deltas for all
+ scale levels, each is a 4D-tensor, has shape
+ (batch_size, num_priors * 4, H, W).
+ shape_preds (list[Tensor]): shape predictions for each scale
+ level with shape (N, 1, H, W).
+ loc_preds (list[Tensor]): location predictions for each scale
+ level with shape (N, num_anchors * 2, H, W).
+ batch_img_metas (list[dict], Optional): Batch image meta info.
+ Defaults to None.
+ cfg (ConfigDict, optional): Test / postprocessing
+ configuration, if None, test_cfg would be used.
+ Defaults to None.
+ rescale (bool): If True, return boxes in original image space.
+ Defaults to False.
+
+ Returns:
+ list[:obj:`InstanceData`]: Object detection results of each image
+ after the post process. Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4), the last
+ dimension 4 arrange as (x1, y1, x2, y2).
+ """
+ assert len(cls_scores) == len(bbox_preds) == len(shape_preds) == len(
+ loc_preds)
+ num_levels = len(cls_scores)
+ featmap_sizes = [featmap.size()[-2:] for featmap in cls_scores]
+ device = cls_scores[0].device
+ # get guided anchors
+ _, guided_anchors, loc_masks = self.get_anchors(
+ featmap_sizes,
+ shape_preds,
+ loc_preds,
+ batch_img_metas,
+ use_loc_filter=not self.training,
+ device=device)
+ result_list = []
+ for img_id in range(len(batch_img_metas)):
+ cls_score_list = [
+ cls_scores[i][img_id].detach() for i in range(num_levels)
+ ]
+ bbox_pred_list = [
+ bbox_preds[i][img_id].detach() for i in range(num_levels)
+ ]
+ guided_anchor_list = [
+ guided_anchors[img_id][i].detach() for i in range(num_levels)
+ ]
+ loc_mask_list = [
+ loc_masks[img_id][i].detach() for i in range(num_levels)
+ ]
+ proposals = self._predict_by_feat_single(
+ cls_scores=cls_score_list,
+ bbox_preds=bbox_pred_list,
+ mlvl_anchors=guided_anchor_list,
+ mlvl_masks=loc_mask_list,
+ img_meta=batch_img_metas[img_id],
+ cfg=cfg,
+ rescale=rescale)
+ result_list.append(proposals)
+ return result_list
+
+ def _predict_by_feat_single(self,
+ cls_scores: List[Tensor],
+ bbox_preds: List[Tensor],
+ mlvl_anchors: List[Tensor],
+ mlvl_masks: List[Tensor],
+ img_meta: dict,
+ cfg: ConfigType,
+ rescale: bool = False) -> InstanceData:
+ """Transform a single image's features extracted from the head into
+ bbox results.
+
+ Args:
+ cls_scores (list[Tensor]): Box scores from all scale
+ levels of a single image, each item has shape
+ (num_priors * num_classes, H, W).
+ bbox_preds (list[Tensor]): Box energies / deltas from
+ all scale levels of a single image, each item has shape
+ (num_priors * 4, H, W).
+ mlvl_anchors (list[Tensor]): Each element in the list is
+ the anchors of a single level in feature pyramid. it has
+ shape (num_priors, 4).
+ mlvl_masks (list[Tensor]): Each element in the list is location
+ masks of a single level.
+ img_meta (dict): Image meta info.
+ cfg (:obj:`ConfigDict` or dict): Test / postprocessing
+ configuration, if None, test_cfg would be used.
+ rescale (bool): If True, return boxes in original image space.
+ Defaults to False.
+
+ Returns:
+ :obj:`InstanceData`: Detection results of each image
+ after the post process.
+ Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4), the last
+ dimension 4 arrange as (x1, y1, x2, y2).
+ """
+ cfg = self.test_cfg if cfg is None else cfg
+ assert len(cls_scores) == len(bbox_preds) == len(mlvl_anchors)
+ mlvl_bbox_preds = []
+ mlvl_valid_anchors = []
+ mlvl_scores = []
+ for cls_score, bbox_pred, anchors, mask in zip(cls_scores, bbox_preds,
+ mlvl_anchors,
+ mlvl_masks):
+ assert cls_score.size()[-2:] == bbox_pred.size()[-2:]
+ # if no location is kept, end.
+ if mask.sum() == 0:
+ continue
+ # reshape scores and bbox_pred
+ cls_score = cls_score.permute(1, 2,
+ 0).reshape(-1, self.cls_out_channels)
+ if self.use_sigmoid_cls:
+ scores = cls_score.sigmoid()
+ else:
+ scores = cls_score.softmax(-1)
+ bbox_pred = bbox_pred.permute(1, 2, 0).reshape(-1, 4)
+ # filter scores, bbox_pred w.r.t. mask.
+ # anchors are filtered in get_anchors() beforehand.
+ scores = scores[mask, :]
+ bbox_pred = bbox_pred[mask, :]
+ if scores.dim() == 0:
+ anchors = anchors.unsqueeze(0)
+ scores = scores.unsqueeze(0)
+ bbox_pred = bbox_pred.unsqueeze(0)
+ # filter anchors, bbox_pred, scores w.r.t. scores
+ nms_pre = cfg.get('nms_pre', -1)
+ if nms_pre > 0 and scores.shape[0] > nms_pre:
+ if self.use_sigmoid_cls:
+ max_scores, _ = scores.max(dim=1)
+ else:
+ # remind that we set FG labels to [0, num_class-1]
+ # since mmdet v2.0
+ # BG cat_id: num_class
+ max_scores, _ = scores[:, :-1].max(dim=1)
+ _, topk_inds = max_scores.topk(nms_pre)
+ anchors = anchors[topk_inds, :]
+ bbox_pred = bbox_pred[topk_inds, :]
+ scores = scores[topk_inds, :]
+
+ mlvl_bbox_preds.append(bbox_pred)
+ mlvl_valid_anchors.append(anchors)
+ mlvl_scores.append(scores)
+
+ mlvl_bbox_preds = torch.cat(mlvl_bbox_preds)
+ mlvl_anchors = torch.cat(mlvl_valid_anchors)
+ mlvl_scores = torch.cat(mlvl_scores)
+ mlvl_bboxes = self.bbox_coder.decode(
+ mlvl_anchors, mlvl_bbox_preds, max_shape=img_meta['img_shape'])
+
+ if rescale:
+ assert img_meta.get('scale_factor') is not None
+ mlvl_bboxes /= mlvl_bboxes.new_tensor(
+ img_meta['scale_factor']).repeat((1, 2))
+
+ if self.use_sigmoid_cls:
+ # Add a dummy background class to the backend when using sigmoid
+ # remind that we set FG labels to [0, num_class-1] since mmdet v2.0
+ # BG cat_id: num_class
+ padding = mlvl_scores.new_zeros(mlvl_scores.shape[0], 1)
+ mlvl_scores = torch.cat([mlvl_scores, padding], dim=1)
+ # multi class NMS
+ det_bboxes, det_labels = multiclass_nms(mlvl_bboxes, mlvl_scores,
+ cfg.score_thr, cfg.nms,
+ cfg.max_per_img)
+
+ results = InstanceData()
+ results.bboxes = det_bboxes[:, :-1]
+ results.scores = det_bboxes[:, -1]
+ results.labels = det_labels
+ return results
diff --git a/mmdet/models/dense_heads/lad_head.py b/mmdet/models/dense_heads/lad_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..d1218e1f88206704d4f414d151ccd34a189ac5d0
--- /dev/null
+++ b/mmdet/models/dense_heads/lad_head.py
@@ -0,0 +1,226 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Optional
+
+import torch
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.structures import SampleList
+from mmdet.structures.bbox import bbox_overlaps
+from mmdet.utils import InstanceList, OptInstanceList
+from ..utils import levels_to_images, multi_apply, unpack_gt_instances
+from .paa_head import PAAHead
+
+
+@MODELS.register_module()
+class LADHead(PAAHead):
+ """Label Assignment Head from the paper: `Improving Object Detection by
+ Label Assignment Distillation `_"""
+
+ def get_label_assignment(
+ self,
+ cls_scores: List[Tensor],
+ bbox_preds: List[Tensor],
+ iou_preds: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ batch_gt_instances_ignore: OptInstanceList = None) -> tuple:
+ """Get label assignment (from teacher).
+
+ Args:
+ cls_scores (list[Tensor]): Box scores for each scale level
+ Has shape (N, num_anchors * num_classes, H, W)
+ bbox_preds (list[Tensor]): Box energies / deltas for each scale
+ level with shape (N, num_anchors * 4, H, W)
+ iou_preds (list[Tensor]): iou_preds for each scale
+ level with shape (N, num_anchors * 1, H, W)
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ tuple: Returns a tuple containing label assignment variables.
+
+ - labels (Tensor): Labels of all anchors, each with
+ shape (num_anchors,).
+ - labels_weight (Tensor): Label weights of all anchor.
+ each with shape (num_anchors,).
+ - bboxes_target (Tensor): BBox targets of all anchors.
+ each with shape (num_anchors, 4).
+ - bboxes_weight (Tensor): BBox weights of all anchors.
+ each with shape (num_anchors, 4).
+ - pos_inds_flatten (Tensor): Contains all index of positive
+ sample in all anchor.
+ - pos_anchors (Tensor): Positive anchors.
+ - num_pos (int): Number of positive anchors.
+ """
+
+ featmap_sizes = [featmap.size()[-2:] for featmap in cls_scores]
+ assert len(featmap_sizes) == self.prior_generator.num_levels
+
+ device = cls_scores[0].device
+ anchor_list, valid_flag_list = self.get_anchors(
+ featmap_sizes, batch_img_metas, device=device)
+ cls_reg_targets = self.get_targets(
+ anchor_list,
+ valid_flag_list,
+ batch_gt_instances,
+ batch_img_metas,
+ batch_gt_instances_ignore=batch_gt_instances_ignore,
+ )
+ (labels, labels_weight, bboxes_target, bboxes_weight, pos_inds,
+ pos_gt_index) = cls_reg_targets
+ cls_scores = levels_to_images(cls_scores)
+ cls_scores = [
+ item.reshape(-1, self.cls_out_channels) for item in cls_scores
+ ]
+ bbox_preds = levels_to_images(bbox_preds)
+ bbox_preds = [item.reshape(-1, 4) for item in bbox_preds]
+ pos_losses_list, = multi_apply(self.get_pos_loss, anchor_list,
+ cls_scores, bbox_preds, labels,
+ labels_weight, bboxes_target,
+ bboxes_weight, pos_inds)
+
+ with torch.no_grad():
+ reassign_labels, reassign_label_weight, \
+ reassign_bbox_weights, num_pos = multi_apply(
+ self.paa_reassign,
+ pos_losses_list,
+ labels,
+ labels_weight,
+ bboxes_weight,
+ pos_inds,
+ pos_gt_index,
+ anchor_list)
+ num_pos = sum(num_pos)
+ # convert all tensor list to a flatten tensor
+ labels = torch.cat(reassign_labels, 0).view(-1)
+ flatten_anchors = torch.cat(
+ [torch.cat(item, 0) for item in anchor_list])
+ labels_weight = torch.cat(reassign_label_weight, 0).view(-1)
+ bboxes_target = torch.cat(bboxes_target,
+ 0).view(-1, bboxes_target[0].size(-1))
+
+ pos_inds_flatten = ((labels >= 0)
+ &
+ (labels < self.num_classes)).nonzero().reshape(-1)
+
+ if num_pos:
+ pos_anchors = flatten_anchors[pos_inds_flatten]
+ else:
+ pos_anchors = None
+
+ label_assignment_results = (labels, labels_weight, bboxes_target,
+ bboxes_weight, pos_inds_flatten,
+ pos_anchors, num_pos)
+ return label_assignment_results
+
+ def loss(self, x: List[Tensor], label_assignment_results: tuple,
+ batch_data_samples: SampleList) -> dict:
+ """Forward train with the available label assignment (student receives
+ from teacher).
+
+ Args:
+ x (list[Tensor]): Features from FPN.
+ label_assignment_results (tuple): As the outputs defined in the
+ function `self.get_label_assignment`.
+ batch_data_samples (list[:obj:`DetDataSample`]): The batch
+ data samples. It usually includes information such
+ as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
+
+ Returns:
+ losses: (dict[str, Tensor]): A dictionary of loss components.
+ """
+ outputs = unpack_gt_instances(batch_data_samples)
+ batch_gt_instances, batch_gt_instances_ignore, batch_img_metas \
+ = outputs
+
+ outs = self(x)
+ loss_inputs = outs + (batch_gt_instances, batch_img_metas)
+ losses = self.loss_by_feat(
+ *loss_inputs,
+ batch_gt_instances_ignore=batch_gt_instances_ignore,
+ label_assignment_results=label_assignment_results)
+ return losses
+
+ def loss_by_feat(self,
+ cls_scores: List[Tensor],
+ bbox_preds: List[Tensor],
+ iou_preds: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ batch_gt_instances_ignore: OptInstanceList = None,
+ label_assignment_results: Optional[tuple] = None) -> dict:
+ """Compute losses of the head.
+
+ Args:
+ cls_scores (list[Tensor]): Box scores for each scale level
+ Has shape (N, num_anchors * num_classes, H, W)
+ bbox_preds (list[Tensor]): Box energies / deltas for each scale
+ level with shape (N, num_anchors * 4, H, W)
+ iou_preds (list[Tensor]): iou_preds for each scale
+ level with shape (N, num_anchors * 1, H, W)
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+ label_assignment_results (tuple, optional): As the outputs defined
+ in the function `self.get_
+ label_assignment`.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss gmm_assignment.
+ """
+
+ (labels, labels_weight, bboxes_target, bboxes_weight, pos_inds_flatten,
+ pos_anchors, num_pos) = label_assignment_results
+
+ cls_scores = levels_to_images(cls_scores)
+ cls_scores = [
+ item.reshape(-1, self.cls_out_channels) for item in cls_scores
+ ]
+ bbox_preds = levels_to_images(bbox_preds)
+ bbox_preds = [item.reshape(-1, 4) for item in bbox_preds]
+ iou_preds = levels_to_images(iou_preds)
+ iou_preds = [item.reshape(-1, 1) for item in iou_preds]
+
+ # convert all tensor list to a flatten tensor
+ cls_scores = torch.cat(cls_scores, 0).view(-1, cls_scores[0].size(-1))
+ bbox_preds = torch.cat(bbox_preds, 0).view(-1, bbox_preds[0].size(-1))
+ iou_preds = torch.cat(iou_preds, 0).view(-1, iou_preds[0].size(-1))
+
+ losses_cls = self.loss_cls(
+ cls_scores,
+ labels,
+ labels_weight,
+ avg_factor=max(num_pos, len(batch_img_metas))) # avoid num_pos=0
+ if num_pos:
+ pos_bbox_pred = self.bbox_coder.decode(
+ pos_anchors, bbox_preds[pos_inds_flatten])
+ pos_bbox_target = bboxes_target[pos_inds_flatten]
+ iou_target = bbox_overlaps(
+ pos_bbox_pred.detach(), pos_bbox_target, is_aligned=True)
+ losses_iou = self.loss_centerness(
+ iou_preds[pos_inds_flatten],
+ iou_target.unsqueeze(-1),
+ avg_factor=num_pos)
+ losses_bbox = self.loss_bbox(
+ pos_bbox_pred, pos_bbox_target, avg_factor=num_pos)
+
+ else:
+ losses_iou = iou_preds.sum() * 0
+ losses_bbox = bbox_preds.sum() * 0
+
+ return dict(
+ loss_cls=losses_cls, loss_bbox=losses_bbox, loss_iou=losses_iou)
diff --git a/mmdet/models/dense_heads/ld_head.py b/mmdet/models/dense_heads/ld_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..b5679179c79c8d4e6606e63bd745729c841bef19
--- /dev/null
+++ b/mmdet/models/dense_heads/ld_head.py
@@ -0,0 +1,257 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Tuple
+
+import torch
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.structures import SampleList
+from mmdet.structures.bbox import bbox_overlaps
+from mmdet.utils import ConfigType, InstanceList, OptInstanceList, reduce_mean
+from ..utils import multi_apply, unpack_gt_instances
+from .gfl_head import GFLHead
+
+
+@MODELS.register_module()
+class LDHead(GFLHead):
+ """Localization distillation Head. (Short description)
+
+ It utilizes the learned bbox distributions to transfer the localization
+ dark knowledge from teacher to student. Original paper: `Localization
+ Distillation for Object Detection. `_
+
+ Args:
+ num_classes (int): Number of categories excluding the background
+ category.
+ in_channels (int): Number of channels in the input feature map.
+ loss_ld (:obj:`ConfigDict` or dict): Config of Localization
+ Distillation Loss (LD), T is the temperature for distillation.
+ """
+
+ def __init__(self,
+ num_classes: int,
+ in_channels: int,
+ loss_ld: ConfigType = dict(
+ type='LocalizationDistillationLoss',
+ loss_weight=0.25,
+ T=10),
+ **kwargs) -> dict:
+
+ super().__init__(
+ num_classes=num_classes, in_channels=in_channels, **kwargs)
+ self.loss_ld = MODELS.build(loss_ld)
+
+ def loss_by_feat_single(self, anchors: Tensor, cls_score: Tensor,
+ bbox_pred: Tensor, labels: Tensor,
+ label_weights: Tensor, bbox_targets: Tensor,
+ stride: Tuple[int], soft_targets: Tensor,
+ avg_factor: int):
+ """Calculate the loss of a single scale level based on the features
+ extracted by the detection head.
+
+ Args:
+ anchors (Tensor): Box reference for each scale level with shape
+ (N, num_total_anchors, 4).
+ cls_score (Tensor): Cls and quality joint scores for each scale
+ level has shape (N, num_classes, H, W).
+ bbox_pred (Tensor): Box distribution logits for each scale
+ level with shape (N, 4*(n+1), H, W), n is max value of integral
+ set.
+ labels (Tensor): Labels of each anchors with shape
+ (N, num_total_anchors).
+ label_weights (Tensor): Label weights of each anchor with shape
+ (N, num_total_anchors)
+ bbox_targets (Tensor): BBox regression targets of each anchor
+ weight shape (N, num_total_anchors, 4).
+ stride (tuple): Stride in this scale level.
+ soft_targets (Tensor): Soft BBox regression targets.
+ avg_factor (int): Average factor that is used to average
+ the loss. When using sampling method, avg_factor is usually
+ the sum of positive and negative priors. When using
+ `PseudoSampler`, `avg_factor` is usually equal to the number
+ of positive priors.
+
+ Returns:
+ dict[tuple, Tensor]: Loss components and weight targets.
+ """
+ assert stride[0] == stride[1], 'h stride is not equal to w stride!'
+ anchors = anchors.reshape(-1, 4)
+ cls_score = cls_score.permute(0, 2, 3,
+ 1).reshape(-1, self.cls_out_channels)
+ bbox_pred = bbox_pred.permute(0, 2, 3,
+ 1).reshape(-1, 4 * (self.reg_max + 1))
+ soft_targets = soft_targets.permute(0, 2, 3,
+ 1).reshape(-1,
+ 4 * (self.reg_max + 1))
+
+ bbox_targets = bbox_targets.reshape(-1, 4)
+ labels = labels.reshape(-1)
+ label_weights = label_weights.reshape(-1)
+
+ # FG cat_id: [0, num_classes -1], BG cat_id: num_classes
+ bg_class_ind = self.num_classes
+ pos_inds = ((labels >= 0)
+ & (labels < bg_class_ind)).nonzero().squeeze(1)
+ score = label_weights.new_zeros(labels.shape)
+
+ if len(pos_inds) > 0:
+ pos_bbox_targets = bbox_targets[pos_inds]
+ pos_bbox_pred = bbox_pred[pos_inds]
+ pos_anchors = anchors[pos_inds]
+ pos_anchor_centers = self.anchor_center(pos_anchors) / stride[0]
+
+ weight_targets = cls_score.detach().sigmoid()
+ weight_targets = weight_targets.max(dim=1)[0][pos_inds]
+ pos_bbox_pred_corners = self.integral(pos_bbox_pred)
+ pos_decode_bbox_pred = self.bbox_coder.decode(
+ pos_anchor_centers, pos_bbox_pred_corners)
+ pos_decode_bbox_targets = pos_bbox_targets / stride[0]
+ score[pos_inds] = bbox_overlaps(
+ pos_decode_bbox_pred.detach(),
+ pos_decode_bbox_targets,
+ is_aligned=True)
+ pred_corners = pos_bbox_pred.reshape(-1, self.reg_max + 1)
+ pos_soft_targets = soft_targets[pos_inds]
+ soft_corners = pos_soft_targets.reshape(-1, self.reg_max + 1)
+
+ target_corners = self.bbox_coder.encode(pos_anchor_centers,
+ pos_decode_bbox_targets,
+ self.reg_max).reshape(-1)
+
+ # regression loss
+ loss_bbox = self.loss_bbox(
+ pos_decode_bbox_pred,
+ pos_decode_bbox_targets,
+ weight=weight_targets,
+ avg_factor=1.0)
+
+ # dfl loss
+ loss_dfl = self.loss_dfl(
+ pred_corners,
+ target_corners,
+ weight=weight_targets[:, None].expand(-1, 4).reshape(-1),
+ avg_factor=4.0)
+
+ # ld loss
+ loss_ld = self.loss_ld(
+ pred_corners,
+ soft_corners,
+ weight=weight_targets[:, None].expand(-1, 4).reshape(-1),
+ avg_factor=4.0)
+
+ else:
+ loss_ld = bbox_pred.sum() * 0
+ loss_bbox = bbox_pred.sum() * 0
+ loss_dfl = bbox_pred.sum() * 0
+ weight_targets = bbox_pred.new_tensor(0)
+
+ # cls (qfl) loss
+ loss_cls = self.loss_cls(
+ cls_score, (labels, score),
+ weight=label_weights,
+ avg_factor=avg_factor)
+
+ return loss_cls, loss_bbox, loss_dfl, loss_ld, weight_targets.sum()
+
+ def loss(self, x: List[Tensor], out_teacher: Tuple[Tensor],
+ batch_data_samples: SampleList) -> dict:
+ """
+ Args:
+ x (list[Tensor]): Features from FPN.
+ out_teacher (tuple[Tensor]): The output of teacher.
+ batch_data_samples (list[:obj:`DetDataSample`]): The batch
+ data samples. It usually includes information such
+ as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
+
+ Returns:
+ tuple[dict, list]: The loss components and proposals of each image.
+
+ - losses (dict[str, Tensor]): A dictionary of loss components.
+ - proposal_list (list[Tensor]): Proposals of each image.
+ """
+ outputs = unpack_gt_instances(batch_data_samples)
+ batch_gt_instances, batch_gt_instances_ignore, batch_img_metas \
+ = outputs
+
+ outs = self(x)
+ soft_targets = out_teacher[1]
+ loss_inputs = outs + (batch_gt_instances, batch_img_metas,
+ soft_targets)
+ losses = self.loss_by_feat(
+ *loss_inputs, batch_gt_instances_ignore=batch_gt_instances_ignore)
+
+ return losses
+
+ def loss_by_feat(
+ self,
+ cls_scores: List[Tensor],
+ bbox_preds: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ soft_targets: List[Tensor],
+ batch_gt_instances_ignore: OptInstanceList = None) -> dict:
+ """Compute losses of the head.
+
+ Args:
+ cls_scores (list[Tensor]): Cls and quality scores for each scale
+ level has shape (N, num_classes, H, W).
+ bbox_preds (list[Tensor]): Box distribution logits for each scale
+ level with shape (N, 4*(n+1), H, W), n is max value of integral
+ set.
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ soft_targets (list[Tensor]): Soft BBox regression targets.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], Optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components.
+ """
+
+ featmap_sizes = [featmap.size()[-2:] for featmap in cls_scores]
+ assert len(featmap_sizes) == self.prior_generator.num_levels
+
+ device = cls_scores[0].device
+ anchor_list, valid_flag_list = self.get_anchors(
+ featmap_sizes, batch_img_metas, device=device)
+
+ cls_reg_targets = self.get_targets(
+ anchor_list,
+ valid_flag_list,
+ batch_gt_instances,
+ batch_img_metas,
+ batch_gt_instances_ignore=batch_gt_instances_ignore)
+
+ (anchor_list, labels_list, label_weights_list, bbox_targets_list,
+ bbox_weights_list, avg_factor) = cls_reg_targets
+
+ avg_factor = reduce_mean(
+ torch.tensor(avg_factor, dtype=torch.float, device=device)).item()
+
+ losses_cls, losses_bbox, losses_dfl, losses_ld, \
+ avg_factor = multi_apply(
+ self.loss_by_feat_single,
+ anchor_list,
+ cls_scores,
+ bbox_preds,
+ labels_list,
+ label_weights_list,
+ bbox_targets_list,
+ self.prior_generator.strides,
+ soft_targets,
+ avg_factor=avg_factor)
+
+ avg_factor = sum(avg_factor) + 1e-6
+ avg_factor = reduce_mean(avg_factor).item()
+ losses_bbox = [x / avg_factor for x in losses_bbox]
+ losses_dfl = [x / avg_factor for x in losses_dfl]
+ return dict(
+ loss_cls=losses_cls,
+ loss_bbox=losses_bbox,
+ loss_dfl=losses_dfl,
+ loss_ld=losses_ld)
diff --git a/mmdet/models/dense_heads/mask2former_head.py b/mmdet/models/dense_heads/mask2former_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..0d45f7828fb335760dcce5b27f3364d75db472fd
--- /dev/null
+++ b/mmdet/models/dense_heads/mask2former_head.py
@@ -0,0 +1,465 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+from typing import List, Tuple
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import Conv2d
+from mmcv.ops import point_sample
+from mmengine.model import ModuleList, caffe2_xavier_init
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmdet.registry import MODELS, TASK_UTILS
+from mmdet.structures import SampleList
+from mmdet.utils import ConfigType, OptConfigType, OptMultiConfig, reduce_mean
+from ..layers import Mask2FormerTransformerDecoder, SinePositionalEncoding
+from ..utils import get_uncertain_point_coords_with_randomness
+from .anchor_free_head import AnchorFreeHead
+from .maskformer_head import MaskFormerHead
+
+
+@MODELS.register_module()
+class Mask2FormerHead(MaskFormerHead):
+ """Implements the Mask2Former head.
+
+ See `Masked-attention Mask Transformer for Universal Image
+ Segmentation `_ for details.
+
+ Args:
+ in_channels (list[int]): Number of channels in the input feature map.
+ feat_channels (int): Number of channels for features.
+ out_channels (int): Number of channels for output.
+ num_things_classes (int): Number of things.
+ num_stuff_classes (int): Number of stuff.
+ num_queries (int): Number of query in Transformer decoder.
+ pixel_decoder (:obj:`ConfigDict` or dict): Config for pixel
+ decoder. Defaults to None.
+ enforce_decoder_input_project (bool, optional): Whether to add
+ a layer to change the embed_dim of tranformer encoder in
+ pixel decoder to the embed_dim of transformer decoder.
+ Defaults to False.
+ transformer_decoder (:obj:`ConfigDict` or dict): Config for
+ transformer decoder. Defaults to None.
+ positional_encoding (:obj:`ConfigDict` or dict): Config for
+ transformer decoder position encoding. Defaults to
+ dict(num_feats=128, normalize=True).
+ loss_cls (:obj:`ConfigDict` or dict): Config of the classification
+ loss. Defaults to None.
+ loss_mask (:obj:`ConfigDict` or dict): Config of the mask loss.
+ Defaults to None.
+ loss_dice (:obj:`ConfigDict` or dict): Config of the dice loss.
+ Defaults to None.
+ train_cfg (:obj:`ConfigDict` or dict, optional): Training config of
+ Mask2Former head.
+ test_cfg (:obj:`ConfigDict` or dict, optional): Testing config of
+ Mask2Former head.
+ init_cfg (:obj:`ConfigDict` or dict or list[:obj:`ConfigDict` or \
+ dict], optional): Initialization config dict. Defaults to None.
+ """
+
+ def __init__(self,
+ in_channels: List[int],
+ strides: List[int],
+ feat_channels: int,
+ out_channels: int,
+ num_things_classes: int = 80,
+ num_stuff_classes: int = 53,
+ num_queries: int = 100,
+ num_transformer_feat_level: int = 3,
+ pixel_decoder: ConfigType = ...,
+ enforce_decoder_input_project: bool = False,
+ transformer_decoder: ConfigType = ...,
+ positional_encoding: ConfigType = dict(
+ num_feats=128, normalize=True),
+ loss_cls: ConfigType = dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=False,
+ loss_weight=2.0,
+ reduction='mean',
+ class_weight=[1.0] * 133 + [0.1]),
+ loss_mask: ConfigType = dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=True,
+ reduction='mean',
+ loss_weight=5.0),
+ loss_dice: ConfigType = dict(
+ type='DiceLoss',
+ use_sigmoid=True,
+ activate=True,
+ reduction='mean',
+ naive_dice=True,
+ eps=1.0,
+ loss_weight=5.0),
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ init_cfg: OptMultiConfig = None,
+ **kwargs) -> None:
+ super(AnchorFreeHead, self).__init__(init_cfg=init_cfg)
+ self.num_things_classes = num_things_classes
+ self.num_stuff_classes = num_stuff_classes
+ self.num_classes = self.num_things_classes + self.num_stuff_classes
+ self.num_queries = num_queries
+ self.num_transformer_feat_level = num_transformer_feat_level
+ self.num_heads = transformer_decoder.layer_cfg.cross_attn_cfg.num_heads
+ self.num_transformer_decoder_layers = transformer_decoder.num_layers
+ assert pixel_decoder.encoder.layer_cfg. \
+ self_attn_cfg.num_levels == num_transformer_feat_level
+ pixel_decoder_ = copy.deepcopy(pixel_decoder)
+ pixel_decoder_.update(
+ in_channels=in_channels,
+ strides =strides,
+ feat_channels=feat_channels,
+ out_channels=out_channels)
+ self.pixel_decoder = MODELS.build(pixel_decoder_)
+ self.transformer_decoder = Mask2FormerTransformerDecoder(
+ **transformer_decoder)
+ self.decoder_embed_dims = self.transformer_decoder.embed_dims
+
+ self.decoder_input_projs = ModuleList()
+ # from low resolution to high resolution
+ for _ in range(num_transformer_feat_level):
+ if (self.decoder_embed_dims != feat_channels
+ or enforce_decoder_input_project):
+ self.decoder_input_projs.append(
+ Conv2d(
+ feat_channels, self.decoder_embed_dims, kernel_size=1))
+ else:
+ self.decoder_input_projs.append(nn.Identity())
+ self.decoder_positional_encoding = SinePositionalEncoding(
+ **positional_encoding)
+ self.query_embed = nn.Embedding(self.num_queries, feat_channels)
+ self.query_feat = nn.Embedding(self.num_queries, feat_channels)
+ # from low resolution to high resolution
+ self.level_embed = nn.Embedding(self.num_transformer_feat_level,
+ feat_channels)
+
+ self.cls_embed = nn.Linear(feat_channels, self.num_classes + 1)
+ self.mask_embed = nn.Sequential(
+ nn.Linear(feat_channels, feat_channels), nn.ReLU(inplace=True),
+ nn.Linear(feat_channels, feat_channels), nn.ReLU(inplace=True),
+ nn.Linear(feat_channels, out_channels))
+
+ self.test_cfg = test_cfg
+ self.train_cfg = train_cfg
+ if train_cfg:
+ self.assigner = TASK_UTILS.build(self.train_cfg['assigner'])
+ self.sampler = TASK_UTILS.build(
+ self.train_cfg['sampler'], default_args=dict(context=self))
+ self.num_points = self.train_cfg.get('num_points', 12544)
+ self.oversample_ratio = self.train_cfg.get('oversample_ratio', 3.0)
+ self.importance_sample_ratio = self.train_cfg.get(
+ 'importance_sample_ratio', 0.75)
+
+ self.class_weight = loss_cls.class_weight
+ self.loss_cls = MODELS.build(loss_cls)
+ self.loss_mask = MODELS.build(loss_mask)
+ self.loss_dice = MODELS.build(loss_dice)
+
+ def init_weights(self) -> None:
+ for m in self.decoder_input_projs:
+ if isinstance(m, Conv2d):
+ caffe2_xavier_init(m, bias=0)
+
+ self.pixel_decoder.init_weights()
+
+ for p in self.transformer_decoder.parameters():
+ if p.dim() > 1:
+ nn.init.xavier_normal_(p)
+
+ def _get_targets_single(self, cls_score: Tensor, mask_pred: Tensor,
+ gt_instances: InstanceData,
+ img_meta: dict) -> Tuple[Tensor]:
+ """Compute classification and mask targets for one image.
+
+ Args:
+ cls_score (Tensor): Mask score logits from a single decoder layer
+ for one image. Shape (num_queries, cls_out_channels).
+ mask_pred (Tensor): Mask logits for a single decoder layer for one
+ image. Shape (num_queries, h, w).
+ gt_instances (:obj:`InstanceData`): It contains ``labels`` and
+ ``masks``.
+ img_meta (dict): Image informtation.
+
+ Returns:
+ tuple[Tensor]: A tuple containing the following for one image.
+
+ - labels (Tensor): Labels of each image. \
+ shape (num_queries, ).
+ - label_weights (Tensor): Label weights of each image. \
+ shape (num_queries, ).
+ - mask_targets (Tensor): Mask targets of each image. \
+ shape (num_queries, h, w).
+ - mask_weights (Tensor): Mask weights of each image. \
+ shape (num_queries, ).
+ - pos_inds (Tensor): Sampled positive indices for each \
+ image.
+ - neg_inds (Tensor): Sampled negative indices for each \
+ image.
+ - sampling_result (:obj:`SamplingResult`): Sampling results.
+ """
+ gt_labels = gt_instances.labels
+ gt_masks = gt_instances.masks
+ # sample points
+ num_queries = cls_score.shape[0]
+ num_gts = gt_labels.shape[0]
+
+ point_coords = torch.rand((1, self.num_points, 2),
+ device=cls_score.device)
+ # shape (num_queries, num_points)
+ mask_points_pred = point_sample(
+ mask_pred.unsqueeze(1), point_coords.repeat(num_queries, 1,
+ 1)).squeeze(1)
+ # shape (num_gts, num_points)
+ gt_points_masks = point_sample(
+ gt_masks.unsqueeze(1).float(), point_coords.repeat(num_gts, 1,
+ 1)).squeeze(1)
+
+ sampled_gt_instances = InstanceData(
+ labels=gt_labels, masks=gt_points_masks)
+ sampled_pred_instances = InstanceData(
+ scores=cls_score, masks=mask_points_pred)
+ # assign and sample
+ assign_result = self.assigner.assign(
+ pred_instances=sampled_pred_instances,
+ gt_instances=sampled_gt_instances,
+ img_meta=img_meta)
+ pred_instances = InstanceData(scores=cls_score, masks=mask_pred)
+ sampling_result = self.sampler.sample(
+ assign_result=assign_result,
+ pred_instances=pred_instances,
+ gt_instances=gt_instances)
+ pos_inds = sampling_result.pos_inds
+ neg_inds = sampling_result.neg_inds
+
+ # label target
+ labels = gt_labels.new_full((self.num_queries, ),
+ self.num_classes,
+ dtype=torch.long)
+ labels[pos_inds] = gt_labels[sampling_result.pos_assigned_gt_inds]
+ label_weights = gt_labels.new_ones((self.num_queries, ))
+
+ # mask target
+ mask_targets = gt_masks[sampling_result.pos_assigned_gt_inds]
+ mask_weights = mask_pred.new_zeros((self.num_queries, ))
+ mask_weights[pos_inds] = 1.0
+
+ return (labels, label_weights, mask_targets, mask_weights, pos_inds,
+ neg_inds, sampling_result)
+
+ def _loss_by_feat_single(self, cls_scores: Tensor, mask_preds: Tensor,
+ batch_gt_instances: List[InstanceData],
+ batch_img_metas: List[dict]) -> Tuple[Tensor]:
+ """Loss function for outputs from a single decoder layer.
+
+ Args:
+ cls_scores (Tensor): Mask score logits from a single decoder layer
+ for all images. Shape (batch_size, num_queries,
+ cls_out_channels). Note `cls_out_channels` should includes
+ background.
+ mask_preds (Tensor): Mask logits for a pixel decoder for all
+ images. Shape (batch_size, num_queries, h, w).
+ batch_gt_instances (list[obj:`InstanceData`]): each contains
+ ``labels`` and ``masks``.
+ batch_img_metas (list[dict]): List of image meta information.
+
+ Returns:
+ tuple[Tensor]: Loss components for outputs from a single \
+ decoder layer.
+ """
+ num_imgs = cls_scores.size(0)
+ cls_scores_list = [cls_scores[i] for i in range(num_imgs)]
+ mask_preds_list = [mask_preds[i] for i in range(num_imgs)]
+ (labels_list, label_weights_list, mask_targets_list, mask_weights_list,
+ avg_factor) = self.get_targets(cls_scores_list, mask_preds_list,
+ batch_gt_instances, batch_img_metas)
+ # shape (batch_size, num_queries)
+ labels = torch.stack(labels_list, dim=0)
+ # shape (batch_size, num_queries)
+ label_weights = torch.stack(label_weights_list, dim=0)
+ # shape (num_total_gts, h, w)
+ mask_targets = torch.cat(mask_targets_list, dim=0)
+ # shape (batch_size, num_queries)
+ mask_weights = torch.stack(mask_weights_list, dim=0)
+
+ # classfication loss
+ # shape (batch_size * num_queries, )
+ cls_scores = cls_scores.flatten(0, 1)
+ labels = labels.flatten(0, 1)
+ label_weights = label_weights.flatten(0, 1)
+
+ class_weight = cls_scores.new_tensor(self.class_weight)
+ loss_cls = self.loss_cls(
+ cls_scores,
+ labels,
+ label_weights,
+ avg_factor=class_weight[labels].sum())
+
+ num_total_masks = reduce_mean(cls_scores.new_tensor([avg_factor]))
+ num_total_masks = max(num_total_masks, 1)
+
+ # extract positive ones
+ # shape (batch_size, num_queries, h, w) -> (num_total_gts, h, w)
+ mask_preds = mask_preds[mask_weights > 0]
+
+ if mask_targets.shape[0] == 0:
+ # zero match
+ loss_dice = mask_preds.sum()
+ loss_mask = mask_preds.sum()
+ return loss_cls, loss_mask, loss_dice
+
+ with torch.no_grad():
+ points_coords = get_uncertain_point_coords_with_randomness(
+ mask_preds.unsqueeze(1), None, self.num_points,
+ self.oversample_ratio, self.importance_sample_ratio)
+ # shape (num_total_gts, h, w) -> (num_total_gts, num_points)
+ mask_point_targets = point_sample(
+ mask_targets.unsqueeze(1).float(), points_coords).squeeze(1)
+ # shape (num_queries, h, w) -> (num_queries, num_points)
+ mask_point_preds = point_sample(
+ mask_preds.unsqueeze(1), points_coords).squeeze(1)
+
+ # dice loss
+ loss_dice = self.loss_dice(
+ mask_point_preds, mask_point_targets, avg_factor=num_total_masks)
+
+ # mask loss
+ # shape (num_queries, num_points) -> (num_queries * num_points, )
+ mask_point_preds = mask_point_preds.reshape(-1)
+ # shape (num_total_gts, num_points) -> (num_total_gts * num_points, )
+ mask_point_targets = mask_point_targets.reshape(-1)
+ loss_mask = self.loss_mask(
+ mask_point_preds,
+ mask_point_targets,
+ avg_factor=num_total_masks * self.num_points)
+
+ return loss_cls, loss_mask, loss_dice
+
+ def _forward_head(self, decoder_out: Tensor, mask_feature: Tensor,
+ attn_mask_target_size: Tuple[int, int]) -> Tuple[Tensor]:
+ """Forward for head part which is called after every decoder layer.
+
+ Args:
+ decoder_out (Tensor): in shape (batch_size, num_queries, c).
+ mask_feature (Tensor): in shape (batch_size, c, h, w).
+ attn_mask_target_size (tuple[int, int]): target attention
+ mask size.
+
+ Returns:
+ tuple: A tuple contain three elements.
+
+ - cls_pred (Tensor): Classification scores in shape \
+ (batch_size, num_queries, cls_out_channels). \
+ Note `cls_out_channels` should includes background.
+ - mask_pred (Tensor): Mask scores in shape \
+ (batch_size, num_queries,h, w).
+ - attn_mask (Tensor): Attention mask in shape \
+ (batch_size * num_heads, num_queries, h, w).
+ """
+ decoder_out = self.transformer_decoder.post_norm(decoder_out)
+ # shape (num_queries, batch_size, c)
+ cls_pred = self.cls_embed(decoder_out)
+ # shape (num_queries, batch_size, c)
+ mask_embed = self.mask_embed(decoder_out)
+ # shape (num_queries, batch_size, h, w)
+ mask_pred = torch.einsum('bqc,bchw->bqhw', mask_embed, mask_feature)
+ attn_mask = F.interpolate(
+ mask_pred,
+ attn_mask_target_size,
+ mode='bilinear',
+ align_corners=False)
+ # shape (num_queries, batch_size, h, w) ->
+ # (batch_size * num_head, num_queries, h, w)
+ attn_mask = attn_mask.flatten(2).unsqueeze(1).repeat(
+ (1, self.num_heads, 1, 1)).flatten(0, 1)
+ attn_mask = attn_mask.sigmoid() < 0.5
+ attn_mask = attn_mask.detach()
+
+ return cls_pred, mask_pred, attn_mask
+
+ def forward(self, x: List[Tensor],
+ batch_data_samples: SampleList) -> Tuple[List[Tensor]]:
+ """Forward function.
+
+ Args:
+ x (list[Tensor]): Multi scale Features from the
+ upstream network, each is a 4D-tensor.
+ batch_data_samples (List[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+
+ Returns:
+ tuple[list[Tensor]]: A tuple contains two elements.
+
+ - cls_pred_list (list[Tensor)]: Classification logits \
+ for each decoder layer. Each is a 3D-tensor with shape \
+ (batch_size, num_queries, cls_out_channels). \
+ Note `cls_out_channels` should includes background.
+ - mask_pred_list (list[Tensor]): Mask logits for each \
+ decoder layer. Each with shape (batch_size, num_queries, \
+ h, w).
+ """
+ batch_img_metas = [
+ data_sample.metainfo for data_sample in batch_data_samples
+ ]
+ batch_size = len(batch_img_metas)
+ mask_features, multi_scale_memorys = self.pixel_decoder(x)
+ # multi_scale_memorys (from low resolution to high resolution)
+ decoder_inputs = []
+ decoder_positional_encodings = []
+ for i in range(self.num_transformer_feat_level):
+ decoder_input = self.decoder_input_projs[i](multi_scale_memorys[i])
+ # shape (batch_size, c, h, w) -> (batch_size, h*w, c)
+ decoder_input = decoder_input.flatten(2).permute(0, 2, 1)
+ level_embed = self.level_embed.weight[i].view(1, 1, -1)
+ decoder_input = decoder_input + level_embed
+ # shape (batch_size, c, h, w) -> (batch_size, h*w, c)
+ mask = decoder_input.new_zeros(
+ (batch_size, ) + multi_scale_memorys[i].shape[-2:],
+ dtype=torch.bool)
+ decoder_positional_encoding = self.decoder_positional_encoding(
+ mask)
+ decoder_positional_encoding = decoder_positional_encoding.flatten(
+ 2).permute(0, 2, 1)
+ decoder_inputs.append(decoder_input)
+ decoder_positional_encodings.append(decoder_positional_encoding)
+ # shape (num_queries, c) -> (batch_size, num_queries, c)
+ query_feat = self.query_feat.weight.unsqueeze(0).repeat(
+ (batch_size, 1, 1))
+ query_embed = self.query_embed.weight.unsqueeze(0).repeat(
+ (batch_size, 1, 1))
+
+ cls_pred_list = []
+ mask_pred_list = []
+ cls_pred, mask_pred, attn_mask = self._forward_head(
+ query_feat, mask_features, multi_scale_memorys[0].shape[-2:])
+ cls_pred_list.append(cls_pred)
+ mask_pred_list.append(mask_pred)
+
+ for i in range(self.num_transformer_decoder_layers):
+ level_idx = i % self.num_transformer_feat_level
+ # if a mask is all True(all background), then set it all False.
+ attn_mask[torch.where(
+ attn_mask.sum(-1) == attn_mask.shape[-1])] = False
+
+ # cross_attn + self_attn
+ layer = self.transformer_decoder.layers[i]
+ query_feat = layer(
+ query=query_feat,
+ key=decoder_inputs[level_idx],
+ value=decoder_inputs[level_idx],
+ query_pos=query_embed,
+ key_pos=decoder_positional_encodings[level_idx],
+ cross_attn_mask=attn_mask,
+ query_key_padding_mask=None,
+ # here we do not apply masking on padded region
+ key_padding_mask=None)
+ cls_pred, mask_pred, attn_mask = self._forward_head(
+ query_feat, mask_features, multi_scale_memorys[
+ (i + 1) % self.num_transformer_feat_level].shape[-2:])
+
+ cls_pred_list.append(cls_pred)
+ mask_pred_list.append(mask_pred)
+
+ return cls_pred_list, mask_pred_list
diff --git a/mmdet/models/dense_heads/maskformer_head.py b/mmdet/models/dense_heads/maskformer_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..cfa97297bac01ba05eb4bbb55d8a6c736afe4ec4
--- /dev/null
+++ b/mmdet/models/dense_heads/maskformer_head.py
@@ -0,0 +1,601 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Optional, Tuple, Union
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import Conv2d
+from mmengine.model import caffe2_xavier_init
+from mmengine.structures import InstanceData, PixelData
+from torch import Tensor
+
+from mmdet.models.layers.pixel_decoder import PixelDecoder
+from mmdet.registry import MODELS, TASK_UTILS
+from mmdet.structures import SampleList
+from mmdet.utils import (ConfigType, InstanceList, OptConfigType,
+ OptMultiConfig, reduce_mean)
+from ..layers import DetrTransformerDecoder, SinePositionalEncoding
+from ..utils import multi_apply, preprocess_panoptic_gt
+from .anchor_free_head import AnchorFreeHead
+
+
+@MODELS.register_module()
+class MaskFormerHead(AnchorFreeHead):
+ """Implements the MaskFormer head.
+
+ See `Per-Pixel Classification is Not All You Need for Semantic
+ Segmentation `_ for details.
+
+ Args:
+ in_channels (list[int]): Number of channels in the input feature map.
+ feat_channels (int): Number of channels for feature.
+ out_channels (int): Number of channels for output.
+ num_things_classes (int): Number of things.
+ num_stuff_classes (int): Number of stuff.
+ num_queries (int): Number of query in Transformer.
+ pixel_decoder (:obj:`ConfigDict` or dict): Config for pixel
+ decoder.
+ enforce_decoder_input_project (bool): Whether to add a layer
+ to change the embed_dim of transformer encoder in pixel decoder to
+ the embed_dim of transformer decoder. Defaults to False.
+ transformer_decoder (:obj:`ConfigDict` or dict): Config for
+ transformer decoder.
+ positional_encoding (:obj:`ConfigDict` or dict): Config for
+ transformer decoder position encoding.
+ loss_cls (:obj:`ConfigDict` or dict): Config of the classification
+ loss. Defaults to `CrossEntropyLoss`.
+ loss_mask (:obj:`ConfigDict` or dict): Config of the mask loss.
+ Defaults to `FocalLoss`.
+ loss_dice (:obj:`ConfigDict` or dict): Config of the dice loss.
+ Defaults to `DiceLoss`.
+ train_cfg (:obj:`ConfigDict` or dict, optional): Training config of
+ MaskFormer head.
+ test_cfg (:obj:`ConfigDict` or dict, optional): Testing config of
+ MaskFormer head.
+ init_cfg (:obj:`ConfigDict` or dict or list[:obj:`ConfigDict` or \
+ dict], optional): Initialization config dict. Defaults to None.
+ """
+
+ def __init__(self,
+ in_channels: List[int],
+ feat_channels: int,
+ out_channels: int,
+ num_things_classes: int = 80,
+ num_stuff_classes: int = 53,
+ num_queries: int = 100,
+ pixel_decoder: ConfigType = ...,
+ enforce_decoder_input_project: bool = False,
+ transformer_decoder: ConfigType = ...,
+ positional_encoding: ConfigType = dict(
+ num_feats=128, normalize=True),
+ loss_cls: ConfigType = dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=False,
+ loss_weight=1.0,
+ class_weight=[1.0] * 133 + [0.1]),
+ loss_mask: ConfigType = dict(
+ type='FocalLoss',
+ use_sigmoid=True,
+ gamma=2.0,
+ alpha=0.25,
+ loss_weight=20.0),
+ loss_dice: ConfigType = dict(
+ type='DiceLoss',
+ use_sigmoid=True,
+ activate=True,
+ naive_dice=True,
+ loss_weight=1.0),
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ init_cfg: OptMultiConfig = None,
+ **kwargs) -> None:
+ super(AnchorFreeHead, self).__init__(init_cfg=init_cfg)
+ self.num_things_classes = num_things_classes
+ self.num_stuff_classes = num_stuff_classes
+ self.num_classes = self.num_things_classes + self.num_stuff_classes
+ self.num_queries = num_queries
+
+ pixel_decoder.update(
+ in_channels=in_channels,
+ feat_channels=feat_channels,
+ out_channels=out_channels)
+ self.pixel_decoder = MODELS.build(pixel_decoder)
+ self.transformer_decoder = DetrTransformerDecoder(
+ **transformer_decoder)
+ self.decoder_embed_dims = self.transformer_decoder.embed_dims
+ if type(self.pixel_decoder) == PixelDecoder and (
+ self.decoder_embed_dims != in_channels[-1]
+ or enforce_decoder_input_project):
+ self.decoder_input_proj = Conv2d(
+ in_channels[-1], self.decoder_embed_dims, kernel_size=1)
+ else:
+ self.decoder_input_proj = nn.Identity()
+ self.decoder_pe = SinePositionalEncoding(**positional_encoding)
+ self.query_embed = nn.Embedding(self.num_queries, out_channels)
+
+ self.cls_embed = nn.Linear(feat_channels, self.num_classes + 1)
+ self.mask_embed = nn.Sequential(
+ nn.Linear(feat_channels, feat_channels), nn.ReLU(inplace=True),
+ nn.Linear(feat_channels, feat_channels), nn.ReLU(inplace=True),
+ nn.Linear(feat_channels, out_channels))
+
+ self.test_cfg = test_cfg
+ self.train_cfg = train_cfg
+ if train_cfg:
+ self.assigner = TASK_UTILS.build(train_cfg['assigner'])
+ self.sampler = TASK_UTILS.build(
+ train_cfg['sampler'], default_args=dict(context=self))
+
+ self.class_weight = loss_cls.class_weight
+ self.loss_cls = MODELS.build(loss_cls)
+ self.loss_mask = MODELS.build(loss_mask)
+ self.loss_dice = MODELS.build(loss_dice)
+
+ def init_weights(self) -> None:
+ if isinstance(self.decoder_input_proj, Conv2d):
+ caffe2_xavier_init(self.decoder_input_proj, bias=0)
+
+ self.pixel_decoder.init_weights()
+
+ for p in self.transformer_decoder.parameters():
+ if p.dim() > 1:
+ nn.init.xavier_uniform_(p)
+
+ def preprocess_gt(
+ self, batch_gt_instances: InstanceList,
+ batch_gt_semantic_segs: List[Optional[PixelData]]) -> InstanceList:
+ """Preprocess the ground truth for all images.
+
+ Args:
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``labels``, each is
+ ground truth labels of each bbox, with shape (num_gts, )
+ and ``masks``, each is ground truth masks of each instances
+ of a image, shape (num_gts, h, w).
+ gt_semantic_seg (list[Optional[PixelData]]): Ground truth of
+ semantic segmentation, each with the shape (1, h, w).
+ [0, num_thing_class - 1] means things,
+ [num_thing_class, num_class-1] means stuff,
+ 255 means VOID. It's None when training instance segmentation.
+
+ Returns:
+ list[obj:`InstanceData`]: each contains the following keys
+
+ - labels (Tensor): Ground truth class indices\
+ for a image, with shape (n, ), n is the sum of\
+ number of stuff type and number of instance in a image.
+ - masks (Tensor): Ground truth mask for a\
+ image, with shape (n, h, w).
+ """
+ num_things_list = [self.num_things_classes] * len(batch_gt_instances)
+ num_stuff_list = [self.num_stuff_classes] * len(batch_gt_instances)
+ gt_labels_list = [
+ gt_instances['labels'] for gt_instances in batch_gt_instances
+ ]
+ gt_masks_list = [
+ gt_instances['masks'] for gt_instances in batch_gt_instances
+ ]
+ gt_semantic_segs = [
+ None if gt_semantic_seg is None else gt_semantic_seg.sem_seg
+ for gt_semantic_seg in batch_gt_semantic_segs
+ ]
+ targets = multi_apply(preprocess_panoptic_gt, gt_labels_list,
+ gt_masks_list, gt_semantic_segs, num_things_list,
+ num_stuff_list)
+ labels, masks = targets
+ batch_gt_instances = [
+ InstanceData(labels=label, masks=mask)
+ for label, mask in zip(labels, masks)
+ ]
+ return batch_gt_instances
+
+ def get_targets(
+ self,
+ cls_scores_list: List[Tensor],
+ mask_preds_list: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ return_sampling_results: bool = False
+ ) -> Tuple[List[Union[Tensor, int]]]:
+ """Compute classification and mask targets for all images for a decoder
+ layer.
+
+ Args:
+ cls_scores_list (list[Tensor]): Mask score logits from a single
+ decoder layer for all images. Each with shape (num_queries,
+ cls_out_channels).
+ mask_preds_list (list[Tensor]): Mask logits from a single decoder
+ layer for all images. Each with shape (num_queries, h, w).
+ batch_gt_instances (list[obj:`InstanceData`]): each contains
+ ``labels`` and ``masks``.
+ batch_img_metas (list[dict]): List of image meta information.
+ return_sampling_results (bool): Whether to return the sampling
+ results. Defaults to False.
+
+ Returns:
+ tuple: a tuple containing the following targets.
+
+ - labels_list (list[Tensor]): Labels of all images.\
+ Each with shape (num_queries, ).
+ - label_weights_list (list[Tensor]): Label weights\
+ of all images. Each with shape (num_queries, ).
+ - mask_targets_list (list[Tensor]): Mask targets of\
+ all images. Each with shape (num_queries, h, w).
+ - mask_weights_list (list[Tensor]): Mask weights of\
+ all images. Each with shape (num_queries, ).
+ - avg_factor (int): Average factor that is used to average\
+ the loss. When using sampling method, avg_factor is
+ usually the sum of positive and negative priors. When
+ using `MaskPseudoSampler`, `avg_factor` is usually equal
+ to the number of positive priors.
+
+ additional_returns: This function enables user-defined returns from
+ `self._get_targets_single`. These returns are currently refined
+ to properties at each feature map (i.e. having HxW dimension).
+ The results will be concatenated after the end.
+ """
+ results = multi_apply(self._get_targets_single, cls_scores_list,
+ mask_preds_list, batch_gt_instances,
+ batch_img_metas)
+ (labels_list, label_weights_list, mask_targets_list, mask_weights_list,
+ pos_inds_list, neg_inds_list, sampling_results_list) = results[:7]
+ rest_results = list(results[7:])
+
+ avg_factor = sum(
+ [results.avg_factor for results in sampling_results_list])
+
+ res = (labels_list, label_weights_list, mask_targets_list,
+ mask_weights_list, avg_factor)
+ if return_sampling_results:
+ res = res + (sampling_results_list)
+
+ return res + tuple(rest_results)
+
+ def _get_targets_single(self, cls_score: Tensor, mask_pred: Tensor,
+ gt_instances: InstanceData,
+ img_meta: dict) -> Tuple[Tensor]:
+ """Compute classification and mask targets for one image.
+
+ Args:
+ cls_score (Tensor): Mask score logits from a single decoder layer
+ for one image. Shape (num_queries, cls_out_channels).
+ mask_pred (Tensor): Mask logits for a single decoder layer for one
+ image. Shape (num_queries, h, w).
+ gt_instances (:obj:`InstanceData`): It contains ``labels`` and
+ ``masks``.
+ img_meta (dict): Image informtation.
+
+ Returns:
+ tuple: a tuple containing the following for one image.
+
+ - labels (Tensor): Labels of each image.
+ shape (num_queries, ).
+ - label_weights (Tensor): Label weights of each image.
+ shape (num_queries, ).
+ - mask_targets (Tensor): Mask targets of each image.
+ shape (num_queries, h, w).
+ - mask_weights (Tensor): Mask weights of each image.
+ shape (num_queries, ).
+ - pos_inds (Tensor): Sampled positive indices for each image.
+ - neg_inds (Tensor): Sampled negative indices for each image.
+ - sampling_result (:obj:`SamplingResult`): Sampling results.
+ """
+ gt_masks = gt_instances.masks
+ gt_labels = gt_instances.labels
+
+ target_shape = mask_pred.shape[-2:]
+ if gt_masks.shape[0] > 0:
+ gt_masks_downsampled = F.interpolate(
+ gt_masks.unsqueeze(1).float(), target_shape,
+ mode='nearest').squeeze(1).long()
+ else:
+ gt_masks_downsampled = gt_masks
+
+ pred_instances = InstanceData(scores=cls_score, masks=mask_pred)
+ downsampled_gt_instances = InstanceData(
+ labels=gt_labels, masks=gt_masks_downsampled)
+ # assign and sample
+ assign_result = self.assigner.assign(
+ pred_instances=pred_instances,
+ gt_instances=downsampled_gt_instances,
+ img_meta=img_meta)
+ sampling_result = self.sampler.sample(
+ assign_result=assign_result,
+ pred_instances=pred_instances,
+ gt_instances=gt_instances)
+ pos_inds = sampling_result.pos_inds
+ neg_inds = sampling_result.neg_inds
+
+ # label target
+ labels = gt_labels.new_full((self.num_queries, ),
+ self.num_classes,
+ dtype=torch.long)
+ labels[pos_inds] = gt_labels[sampling_result.pos_assigned_gt_inds]
+ label_weights = gt_labels.new_ones(self.num_queries)
+
+ # mask target
+ mask_targets = gt_masks[sampling_result.pos_assigned_gt_inds]
+ mask_weights = mask_pred.new_zeros((self.num_queries, ))
+ mask_weights[pos_inds] = 1.0
+
+ return (labels, label_weights, mask_targets, mask_weights, pos_inds,
+ neg_inds, sampling_result)
+
+ def loss_by_feat(self, all_cls_scores: Tensor, all_mask_preds: Tensor,
+ batch_gt_instances: List[InstanceData],
+ batch_img_metas: List[dict]) -> Dict[str, Tensor]:
+ """Loss function.
+
+ Args:
+ all_cls_scores (Tensor): Classification scores for all decoder
+ layers with shape (num_decoder, batch_size, num_queries,
+ cls_out_channels). Note `cls_out_channels` should includes
+ background.
+ all_mask_preds (Tensor): Mask scores for all decoder layers with
+ shape (num_decoder, batch_size, num_queries, h, w).
+ batch_gt_instances (list[obj:`InstanceData`]): each contains
+ ``labels`` and ``masks``.
+ batch_img_metas (list[dict]): List of image meta information.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components.
+ """
+ num_dec_layers = len(all_cls_scores)
+ batch_gt_instances_list = [
+ batch_gt_instances for _ in range(num_dec_layers)
+ ]
+ img_metas_list = [batch_img_metas for _ in range(num_dec_layers)]
+ losses_cls, losses_mask, losses_dice = multi_apply(
+ self._loss_by_feat_single, all_cls_scores, all_mask_preds,
+ batch_gt_instances_list, img_metas_list)
+
+ loss_dict = dict()
+ # loss from the last decoder layer
+ loss_dict['loss_cls'] = losses_cls[-1]
+ loss_dict['loss_mask'] = losses_mask[-1]
+ loss_dict['loss_dice'] = losses_dice[-1]
+ # loss from other decoder layers
+ num_dec_layer = 0
+ for loss_cls_i, loss_mask_i, loss_dice_i in zip(
+ losses_cls[:-1], losses_mask[:-1], losses_dice[:-1]):
+ loss_dict[f'd{num_dec_layer}.loss_cls'] = loss_cls_i
+ loss_dict[f'd{num_dec_layer}.loss_mask'] = loss_mask_i
+ loss_dict[f'd{num_dec_layer}.loss_dice'] = loss_dice_i
+ num_dec_layer += 1
+ return loss_dict
+
+ def _loss_by_feat_single(self, cls_scores: Tensor, mask_preds: Tensor,
+ batch_gt_instances: List[InstanceData],
+ batch_img_metas: List[dict]) -> Tuple[Tensor]:
+ """Loss function for outputs from a single decoder layer.
+
+ Args:
+ cls_scores (Tensor): Mask score logits from a single decoder layer
+ for all images. Shape (batch_size, num_queries,
+ cls_out_channels). Note `cls_out_channels` should includes
+ background.
+ mask_preds (Tensor): Mask logits for a pixel decoder for all
+ images. Shape (batch_size, num_queries, h, w).
+ batch_gt_instances (list[obj:`InstanceData`]): each contains
+ ``labels`` and ``masks``.
+ batch_img_metas (list[dict]): List of image meta information.
+
+ Returns:
+ tuple[Tensor]: Loss components for outputs from a single decoder\
+ layer.
+ """
+ num_imgs = cls_scores.size(0)
+ cls_scores_list = [cls_scores[i] for i in range(num_imgs)]
+ mask_preds_list = [mask_preds[i] for i in range(num_imgs)]
+
+ (labels_list, label_weights_list, mask_targets_list, mask_weights_list,
+ avg_factor) = self.get_targets(cls_scores_list, mask_preds_list,
+ batch_gt_instances, batch_img_metas)
+ # shape (batch_size, num_queries)
+ labels = torch.stack(labels_list, dim=0)
+ # shape (batch_size, num_queries)
+ label_weights = torch.stack(label_weights_list, dim=0)
+ # shape (num_total_gts, h, w)
+ mask_targets = torch.cat(mask_targets_list, dim=0)
+ # shape (batch_size, num_queries)
+ mask_weights = torch.stack(mask_weights_list, dim=0)
+
+ # classfication loss
+ # shape (batch_size * num_queries, )
+ cls_scores = cls_scores.flatten(0, 1)
+ labels = labels.flatten(0, 1)
+ label_weights = label_weights.flatten(0, 1)
+
+ class_weight = cls_scores.new_tensor(self.class_weight)
+ loss_cls = self.loss_cls(
+ cls_scores,
+ labels,
+ label_weights,
+ avg_factor=class_weight[labels].sum())
+
+ num_total_masks = reduce_mean(cls_scores.new_tensor([avg_factor]))
+ num_total_masks = max(num_total_masks, 1)
+
+ # extract positive ones
+ # shape (batch_size, num_queries, h, w) -> (num_total_gts, h, w)
+ mask_preds = mask_preds[mask_weights > 0]
+ target_shape = mask_targets.shape[-2:]
+
+ if mask_targets.shape[0] == 0:
+ # zero match
+ loss_dice = mask_preds.sum()
+ loss_mask = mask_preds.sum()
+ return loss_cls, loss_mask, loss_dice
+
+ # upsample to shape of target
+ # shape (num_total_gts, h, w)
+ mask_preds = F.interpolate(
+ mask_preds.unsqueeze(1),
+ target_shape,
+ mode='bilinear',
+ align_corners=False).squeeze(1)
+
+ # dice loss
+ loss_dice = self.loss_dice(
+ mask_preds, mask_targets, avg_factor=num_total_masks)
+
+ # mask loss
+ # FocalLoss support input of shape (n, num_class)
+ h, w = mask_preds.shape[-2:]
+ # shape (num_total_gts, h, w) -> (num_total_gts * h * w, 1)
+ mask_preds = mask_preds.reshape(-1, 1)
+ # shape (num_total_gts, h, w) -> (num_total_gts * h * w)
+ mask_targets = mask_targets.reshape(-1)
+ # target is (1 - mask_targets) !!!
+ loss_mask = self.loss_mask(
+ mask_preds, 1 - mask_targets, avg_factor=num_total_masks * h * w)
+
+ return loss_cls, loss_mask, loss_dice
+
+ def forward(self, x: Tuple[Tensor],
+ batch_data_samples: SampleList) -> Tuple[Tensor]:
+ """Forward function.
+
+ Args:
+ x (tuple[Tensor]): Features from the upstream network, each
+ is a 4D-tensor.
+ batch_data_samples (List[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+
+ Returns:
+ tuple[Tensor]: a tuple contains two elements.
+
+ - all_cls_scores (Tensor): Classification scores for each\
+ scale level. Each is a 4D-tensor with shape\
+ (num_decoder, batch_size, num_queries, cls_out_channels).\
+ Note `cls_out_channels` should includes background.
+ - all_mask_preds (Tensor): Mask scores for each decoder\
+ layer. Each with shape (num_decoder, batch_size,\
+ num_queries, h, w).
+ """
+ batch_img_metas = [
+ data_sample.metainfo for data_sample in batch_data_samples
+ ]
+ batch_size = len(batch_img_metas)
+ input_img_h, input_img_w = batch_img_metas[0]['batch_input_shape']
+ padding_mask = x[-1].new_ones((batch_size, input_img_h, input_img_w),
+ dtype=torch.float32)
+ for i in range(batch_size):
+ img_h, img_w = batch_img_metas[i]['img_shape']
+ padding_mask[i, :img_h, :img_w] = 0
+ padding_mask = F.interpolate(
+ padding_mask.unsqueeze(1), size=x[-1].shape[-2:],
+ mode='nearest').to(torch.bool).squeeze(1)
+ # when backbone is swin, memory is output of last stage of swin.
+ # when backbone is r50, memory is output of tranformer encoder.
+ mask_features, memory = self.pixel_decoder(x, batch_img_metas)
+ pos_embed = self.decoder_pe(padding_mask)
+ memory = self.decoder_input_proj(memory)
+ # shape (batch_size, c, h, w) -> (batch_size, h*w, c)
+ memory = memory.flatten(2).permute(0, 2, 1)
+ pos_embed = pos_embed.flatten(2).permute(0, 2, 1)
+ # shape (batch_size, h * w)
+ padding_mask = padding_mask.flatten(1)
+ # shape = (num_queries, embed_dims)
+ query_embed = self.query_embed.weight
+ # shape = (batch_size, num_queries, embed_dims)
+ query_embed = query_embed.unsqueeze(0).repeat(batch_size, 1, 1)
+ target = torch.zeros_like(query_embed)
+ # shape (num_decoder, num_queries, batch_size, embed_dims)
+ out_dec = self.transformer_decoder(
+ query=target,
+ key=memory,
+ value=memory,
+ query_pos=query_embed,
+ key_pos=pos_embed,
+ key_padding_mask=padding_mask)
+
+ # cls_scores
+ all_cls_scores = self.cls_embed(out_dec)
+
+ # mask_preds
+ mask_embed = self.mask_embed(out_dec)
+ all_mask_preds = torch.einsum('lbqc,bchw->lbqhw', mask_embed,
+ mask_features)
+
+ return all_cls_scores, all_mask_preds
+
+ def loss(
+ self,
+ x: Tuple[Tensor],
+ batch_data_samples: SampleList,
+ ) -> Dict[str, Tensor]:
+ """Perform forward propagation and loss calculation of the panoptic
+ head on the features of the upstream network.
+
+ Args:
+ x (tuple[Tensor]): Multi-level features from the upstream
+ network, each is a 4D-tensor.
+ batch_data_samples (List[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+
+ Returns:
+ dict[str, Tensor]: a dictionary of loss components
+ """
+ batch_img_metas = []
+ batch_gt_instances = []
+ batch_gt_semantic_segs = []
+ for data_sample in batch_data_samples:
+ batch_img_metas.append(data_sample.metainfo)
+ batch_gt_instances.append(data_sample.gt_instances)
+ if 'gt_sem_seg' in data_sample:
+ batch_gt_semantic_segs.append(data_sample.gt_sem_seg)
+ else:
+ batch_gt_semantic_segs.append(None)
+
+ # forward
+ all_cls_scores, all_mask_preds = self(x, batch_data_samples)
+
+ # preprocess ground truth
+ batch_gt_instances = self.preprocess_gt(batch_gt_instances,
+ batch_gt_semantic_segs)
+
+ # loss
+ losses = self.loss_by_feat(all_cls_scores, all_mask_preds,
+ batch_gt_instances, batch_img_metas)
+
+ return losses
+
+ def predict(self, x: Tuple[Tensor],
+ batch_data_samples: SampleList) -> Tuple[Tensor]:
+ """Test without augmentaton.
+
+ Args:
+ x (tuple[Tensor]): Multi-level features from the
+ upstream network, each is a 4D-tensor.
+ batch_data_samples (List[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+
+ Returns:
+ tuple[Tensor]: A tuple contains two tensors.
+
+ - mask_cls_results (Tensor): Mask classification logits,\
+ shape (batch_size, num_queries, cls_out_channels).
+ Note `cls_out_channels` should includes background.
+ - mask_pred_results (Tensor): Mask logits, shape \
+ (batch_size, num_queries, h, w).
+ """
+ batch_img_metas = [
+ data_sample.metainfo for data_sample in batch_data_samples
+ ]
+ all_cls_scores, all_mask_preds = self(x, batch_data_samples)
+ mask_cls_results = all_cls_scores[-1]
+ mask_pred_results = all_mask_preds[-1]
+
+ # upsample masks
+ img_shape = batch_img_metas[0]['batch_input_shape']
+ mask_pred_results = F.interpolate(
+ mask_pred_results,
+ size=(img_shape[0], img_shape[1]),
+ mode='bilinear',
+ align_corners=False)
+
+ return mask_cls_results, mask_pred_results
diff --git a/mmdet/models/dense_heads/nasfcos_head.py b/mmdet/models/dense_heads/nasfcos_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..14ee62a7910d90a108fefb2acef00c91ab83ecc8
--- /dev/null
+++ b/mmdet/models/dense_heads/nasfcos_head.py
@@ -0,0 +1,114 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+
+import torch.nn as nn
+from mmcv.cnn import ConvModule, Scale
+
+from mmdet.models.dense_heads.fcos_head import FCOSHead
+from mmdet.registry import MODELS
+from mmdet.utils import OptMultiConfig
+
+
+@MODELS.register_module()
+class NASFCOSHead(FCOSHead):
+ """Anchor-free head used in `NASFCOS `_.
+
+ It is quite similar with FCOS head, except for the searched structure of
+ classification branch and bbox regression branch, where a structure of
+ "dconv3x3, conv3x3, dconv3x3, conv1x1" is utilized instead.
+
+ Args:
+ num_classes (int): Number of categories excluding the background
+ category.
+ in_channels (int): Number of channels in the input feature map.
+ strides (Sequence[int] or Sequence[Tuple[int, int]]): Strides of points
+ in multiple feature levels. Defaults to (4, 8, 16, 32, 64).
+ regress_ranges (Sequence[Tuple[int, int]]): Regress range of multiple
+ level points.
+ center_sampling (bool): If true, use center sampling.
+ Defaults to False.
+ center_sample_radius (float): Radius of center sampling.
+ Defaults to 1.5.
+ norm_on_bbox (bool): If true, normalize the regression targets with
+ FPN strides. Defaults to False.
+ centerness_on_reg (bool): If true, position centerness on the
+ regress branch. Please refer to https://github.com/tianzhi0549/FCOS/issues/89#issuecomment-516877042.
+ Defaults to False.
+ conv_bias (bool or str): If specified as `auto`, it will be decided by
+ the norm_cfg. Bias of conv will be set as True if `norm_cfg` is
+ None, otherwise False. Defaults to "auto".
+ loss_cls (:obj:`ConfigDict` or dict): Config of classification loss.
+ loss_bbox (:obj:`ConfigDict` or dict): Config of localization loss.
+ loss_centerness (:obj:`ConfigDict`, or dict): Config of centerness
+ loss.
+ norm_cfg (:obj:`ConfigDict` or dict): dictionary to construct and
+ config norm layer. Defaults to
+ ``norm_cfg=dict(type='GN', num_groups=32, requires_grad=True)``.
+ init_cfg (:obj:`ConfigDict` or dict or list[:obj:`ConfigDict` or \
+ dict], opitonal): Initialization config dict.
+ """ # noqa: E501
+
+ def __init__(self,
+ *args,
+ init_cfg: OptMultiConfig = None,
+ **kwargs) -> None:
+ if init_cfg is None:
+ init_cfg = [
+ dict(type='Caffe2Xavier', layer=['ConvModule', 'Conv2d']),
+ dict(
+ type='Normal',
+ std=0.01,
+ override=[
+ dict(name='conv_reg'),
+ dict(name='conv_centerness'),
+ dict(
+ name='conv_cls',
+ type='Normal',
+ std=0.01,
+ bias_prob=0.01)
+ ]),
+ ]
+ super().__init__(*args, init_cfg=init_cfg, **kwargs)
+
+ def _init_layers(self) -> None:
+ """Initialize layers of the head."""
+ dconv3x3_config = dict(
+ type='DCNv2',
+ kernel_size=3,
+ use_bias=True,
+ deform_groups=2,
+ padding=1)
+ conv3x3_config = dict(type='Conv', kernel_size=3, padding=1)
+ conv1x1_config = dict(type='Conv', kernel_size=1)
+
+ self.arch_config = [
+ dconv3x3_config, conv3x3_config, dconv3x3_config, conv1x1_config
+ ]
+ self.cls_convs = nn.ModuleList()
+ self.reg_convs = nn.ModuleList()
+ for i, op_ in enumerate(self.arch_config):
+ op = copy.deepcopy(op_)
+ chn = self.in_channels if i == 0 else self.feat_channels
+ assert isinstance(op, dict)
+ use_bias = op.pop('use_bias', False)
+ padding = op.pop('padding', 0)
+ kernel_size = op.pop('kernel_size')
+ module = ConvModule(
+ chn,
+ self.feat_channels,
+ kernel_size,
+ stride=1,
+ padding=padding,
+ norm_cfg=self.norm_cfg,
+ bias=use_bias,
+ conv_cfg=op)
+
+ self.cls_convs.append(copy.deepcopy(module))
+ self.reg_convs.append(copy.deepcopy(module))
+
+ self.conv_cls = nn.Conv2d(
+ self.feat_channels, self.cls_out_channels, 3, padding=1)
+ self.conv_reg = nn.Conv2d(self.feat_channels, 4, 3, padding=1)
+ self.conv_centerness = nn.Conv2d(self.feat_channels, 1, 3, padding=1)
+
+ self.scales = nn.ModuleList([Scale(1.0) for _ in self.strides])
diff --git a/mmdet/models/dense_heads/paa_head.py b/mmdet/models/dense_heads/paa_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..3c1f453d2788b354970254e8875068e824c370d4
--- /dev/null
+++ b/mmdet/models/dense_heads/paa_head.py
@@ -0,0 +1,730 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Optional, Tuple
+
+import numpy as np
+import torch
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.structures.bbox import bbox_overlaps
+from mmdet.utils import (ConfigType, InstanceList, OptConfigType,
+ OptInstanceList)
+from ..layers import multiclass_nms
+from ..utils import levels_to_images, multi_apply
+from . import ATSSHead
+
+EPS = 1e-12
+try:
+ import sklearn.mixture as skm
+except ImportError:
+ skm = None
+
+
+@MODELS.register_module()
+class PAAHead(ATSSHead):
+ """Head of PAAAssignment: Probabilistic Anchor Assignment with IoU
+ Prediction for Object Detection.
+
+ Code is modified from the `official github repo
+ `_.
+
+ More details can be found in the `paper
+ `_ .
+
+ Args:
+ topk (int): Select topk samples with smallest loss in
+ each level.
+ score_voting (bool): Whether to use score voting in post-process.
+ covariance_type : String describing the type of covariance parameters
+ to be used in :class:`sklearn.mixture.GaussianMixture`.
+ It must be one of:
+
+ - 'full': each component has its own general covariance matrix
+ - 'tied': all components share the same general covariance matrix
+ - 'diag': each component has its own diagonal covariance matrix
+ - 'spherical': each component has its own single variance
+ Default: 'diag'. From 'full' to 'spherical', the gmm fitting
+ process is faster yet the performance could be influenced. For most
+ cases, 'diag' should be a good choice.
+ """
+
+ def __init__(self,
+ *args,
+ topk: int = 9,
+ score_voting: bool = True,
+ covariance_type: str = 'diag',
+ **kwargs):
+ # topk used in paa reassign process
+ self.topk = topk
+ self.with_score_voting = score_voting
+ self.covariance_type = covariance_type
+ super().__init__(*args, **kwargs)
+
+ def loss_by_feat(
+ self,
+ cls_scores: List[Tensor],
+ bbox_preds: List[Tensor],
+ iou_preds: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ batch_gt_instances_ignore: OptInstanceList = None) -> dict:
+ """Calculate the loss based on the features extracted by the detection
+ head.
+
+ Args:
+ cls_scores (list[Tensor]): Box scores for each scale level
+ Has shape (N, num_anchors * num_classes, H, W)
+ bbox_preds (list[Tensor]): Box energies / deltas for each scale
+ level with shape (N, num_anchors * 4, H, W)
+ iou_preds (list[Tensor]): iou_preds for each scale
+ level with shape (N, num_anchors * 1, H, W)
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss gmm_assignment.
+ """
+
+ featmap_sizes = [featmap.size()[-2:] for featmap in cls_scores]
+ assert len(featmap_sizes) == self.prior_generator.num_levels
+
+ device = cls_scores[0].device
+ anchor_list, valid_flag_list = self.get_anchors(
+ featmap_sizes, batch_img_metas, device=device)
+ cls_reg_targets = self.get_targets(
+ anchor_list,
+ valid_flag_list,
+ batch_gt_instances,
+ batch_img_metas,
+ batch_gt_instances_ignore=batch_gt_instances_ignore,
+ )
+ (labels, labels_weight, bboxes_target, bboxes_weight, pos_inds,
+ pos_gt_index) = cls_reg_targets
+ cls_scores = levels_to_images(cls_scores)
+ cls_scores = [
+ item.reshape(-1, self.cls_out_channels) for item in cls_scores
+ ]
+ bbox_preds = levels_to_images(bbox_preds)
+ bbox_preds = [item.reshape(-1, 4) for item in bbox_preds]
+ iou_preds = levels_to_images(iou_preds)
+ iou_preds = [item.reshape(-1, 1) for item in iou_preds]
+ pos_losses_list, = multi_apply(self.get_pos_loss, anchor_list,
+ cls_scores, bbox_preds, labels,
+ labels_weight, bboxes_target,
+ bboxes_weight, pos_inds)
+
+ with torch.no_grad():
+ reassign_labels, reassign_label_weight, \
+ reassign_bbox_weights, num_pos = multi_apply(
+ self.paa_reassign,
+ pos_losses_list,
+ labels,
+ labels_weight,
+ bboxes_weight,
+ pos_inds,
+ pos_gt_index,
+ anchor_list)
+ num_pos = sum(num_pos)
+ # convert all tensor list to a flatten tensor
+ cls_scores = torch.cat(cls_scores, 0).view(-1, cls_scores[0].size(-1))
+ bbox_preds = torch.cat(bbox_preds, 0).view(-1, bbox_preds[0].size(-1))
+ iou_preds = torch.cat(iou_preds, 0).view(-1, iou_preds[0].size(-1))
+ labels = torch.cat(reassign_labels, 0).view(-1)
+ flatten_anchors = torch.cat(
+ [torch.cat(item, 0) for item in anchor_list])
+ labels_weight = torch.cat(reassign_label_weight, 0).view(-1)
+ bboxes_target = torch.cat(bboxes_target,
+ 0).view(-1, bboxes_target[0].size(-1))
+
+ pos_inds_flatten = ((labels >= 0)
+ &
+ (labels < self.num_classes)).nonzero().reshape(-1)
+
+ losses_cls = self.loss_cls(
+ cls_scores,
+ labels,
+ labels_weight,
+ avg_factor=max(num_pos, len(batch_img_metas))) # avoid num_pos=0
+ if num_pos:
+ pos_bbox_pred = self.bbox_coder.decode(
+ flatten_anchors[pos_inds_flatten],
+ bbox_preds[pos_inds_flatten])
+ pos_bbox_target = bboxes_target[pos_inds_flatten]
+ iou_target = bbox_overlaps(
+ pos_bbox_pred.detach(), pos_bbox_target, is_aligned=True)
+ losses_iou = self.loss_centerness(
+ iou_preds[pos_inds_flatten],
+ iou_target.unsqueeze(-1),
+ avg_factor=num_pos)
+ losses_bbox = self.loss_bbox(
+ pos_bbox_pred,
+ pos_bbox_target,
+ iou_target.clamp(min=EPS),
+ avg_factor=iou_target.sum())
+ else:
+ losses_iou = iou_preds.sum() * 0
+ losses_bbox = bbox_preds.sum() * 0
+
+ return dict(
+ loss_cls=losses_cls, loss_bbox=losses_bbox, loss_iou=losses_iou)
+
+ def get_pos_loss(self, anchors: List[Tensor], cls_score: Tensor,
+ bbox_pred: Tensor, label: Tensor, label_weight: Tensor,
+ bbox_target: dict, bbox_weight: Tensor,
+ pos_inds: Tensor) -> Tensor:
+ """Calculate loss of all potential positive samples obtained from first
+ match process.
+
+ Args:
+ anchors (list[Tensor]): Anchors of each scale.
+ cls_score (Tensor): Box scores of single image with shape
+ (num_anchors, num_classes)
+ bbox_pred (Tensor): Box energies / deltas of single image
+ with shape (num_anchors, 4)
+ label (Tensor): classification target of each anchor with
+ shape (num_anchors,)
+ label_weight (Tensor): Classification loss weight of each
+ anchor with shape (num_anchors).
+ bbox_target (dict): Regression target of each anchor with
+ shape (num_anchors, 4).
+ bbox_weight (Tensor): Bbox weight of each anchor with shape
+ (num_anchors, 4).
+ pos_inds (Tensor): Index of all positive samples got from
+ first assign process.
+
+ Returns:
+ Tensor: Losses of all positive samples in single image.
+ """
+ if not len(pos_inds):
+ return cls_score.new([]),
+ anchors_all_level = torch.cat(anchors, 0)
+ pos_scores = cls_score[pos_inds]
+ pos_bbox_pred = bbox_pred[pos_inds]
+ pos_label = label[pos_inds]
+ pos_label_weight = label_weight[pos_inds]
+ pos_bbox_target = bbox_target[pos_inds]
+ pos_bbox_weight = bbox_weight[pos_inds]
+ pos_anchors = anchors_all_level[pos_inds]
+ pos_bbox_pred = self.bbox_coder.decode(pos_anchors, pos_bbox_pred)
+
+ # to keep loss dimension
+ loss_cls = self.loss_cls(
+ pos_scores,
+ pos_label,
+ pos_label_weight,
+ avg_factor=1.0,
+ reduction_override='none')
+
+ loss_bbox = self.loss_bbox(
+ pos_bbox_pred,
+ pos_bbox_target,
+ pos_bbox_weight,
+ avg_factor=1.0, # keep same loss weight before reassign
+ reduction_override='none')
+
+ loss_cls = loss_cls.sum(-1)
+ pos_loss = loss_bbox + loss_cls
+ return pos_loss,
+
+ def paa_reassign(self, pos_losses: Tensor, label: Tensor,
+ label_weight: Tensor, bbox_weight: Tensor,
+ pos_inds: Tensor, pos_gt_inds: Tensor,
+ anchors: List[Tensor]) -> tuple:
+ """Fit loss to GMM distribution and separate positive, ignore, negative
+ samples again with GMM model.
+
+ Args:
+ pos_losses (Tensor): Losses of all positive samples in
+ single image.
+ label (Tensor): classification target of each anchor with
+ shape (num_anchors,)
+ label_weight (Tensor): Classification loss weight of each
+ anchor with shape (num_anchors).
+ bbox_weight (Tensor): Bbox weight of each anchor with shape
+ (num_anchors, 4).
+ pos_inds (Tensor): Index of all positive samples got from
+ first assign process.
+ pos_gt_inds (Tensor): Gt_index of all positive samples got
+ from first assign process.
+ anchors (list[Tensor]): Anchors of each scale.
+
+ Returns:
+ tuple: Usually returns a tuple containing learning targets.
+
+ - label (Tensor): classification target of each anchor after
+ paa assign, with shape (num_anchors,)
+ - label_weight (Tensor): Classification loss weight of each
+ anchor after paa assign, with shape (num_anchors).
+ - bbox_weight (Tensor): Bbox weight of each anchor with shape
+ (num_anchors, 4).
+ - num_pos (int): The number of positive samples after paa
+ assign.
+ """
+ if not len(pos_inds):
+ return label, label_weight, bbox_weight, 0
+ label = label.clone()
+ label_weight = label_weight.clone()
+ bbox_weight = bbox_weight.clone()
+ num_gt = pos_gt_inds.max() + 1
+ num_level = len(anchors)
+ num_anchors_each_level = [item.size(0) for item in anchors]
+ num_anchors_each_level.insert(0, 0)
+ inds_level_interval = np.cumsum(num_anchors_each_level)
+ pos_level_mask = []
+ for i in range(num_level):
+ mask = (pos_inds >= inds_level_interval[i]) & (
+ pos_inds < inds_level_interval[i + 1])
+ pos_level_mask.append(mask)
+ pos_inds_after_paa = [label.new_tensor([])]
+ ignore_inds_after_paa = [label.new_tensor([])]
+ for gt_ind in range(num_gt):
+ pos_inds_gmm = []
+ pos_loss_gmm = []
+ gt_mask = pos_gt_inds == gt_ind
+ for level in range(num_level):
+ level_mask = pos_level_mask[level]
+ level_gt_mask = level_mask & gt_mask
+ value, topk_inds = pos_losses[level_gt_mask].topk(
+ min(level_gt_mask.sum(), self.topk), largest=False)
+ pos_inds_gmm.append(pos_inds[level_gt_mask][topk_inds])
+ pos_loss_gmm.append(value)
+ pos_inds_gmm = torch.cat(pos_inds_gmm)
+ pos_loss_gmm = torch.cat(pos_loss_gmm)
+ # fix gmm need at least two sample
+ if len(pos_inds_gmm) < 2:
+ continue
+ device = pos_inds_gmm.device
+ pos_loss_gmm, sort_inds = pos_loss_gmm.sort()
+ pos_inds_gmm = pos_inds_gmm[sort_inds]
+ pos_loss_gmm = pos_loss_gmm.view(-1, 1).cpu().numpy()
+ min_loss, max_loss = pos_loss_gmm.min(), pos_loss_gmm.max()
+ means_init = np.array([min_loss, max_loss]).reshape(2, 1)
+ weights_init = np.array([0.5, 0.5])
+ precisions_init = np.array([1.0, 1.0]).reshape(2, 1, 1) # full
+ if self.covariance_type == 'spherical':
+ precisions_init = precisions_init.reshape(2)
+ elif self.covariance_type == 'diag':
+ precisions_init = precisions_init.reshape(2, 1)
+ elif self.covariance_type == 'tied':
+ precisions_init = np.array([[1.0]])
+ if skm is None:
+ raise ImportError('Please run "pip install sklearn" '
+ 'to install sklearn first.')
+ gmm = skm.GaussianMixture(
+ 2,
+ weights_init=weights_init,
+ means_init=means_init,
+ precisions_init=precisions_init,
+ covariance_type=self.covariance_type)
+ gmm.fit(pos_loss_gmm)
+ gmm_assignment = gmm.predict(pos_loss_gmm)
+ scores = gmm.score_samples(pos_loss_gmm)
+ gmm_assignment = torch.from_numpy(gmm_assignment).to(device)
+ scores = torch.from_numpy(scores).to(device)
+
+ pos_inds_temp, ignore_inds_temp = self.gmm_separation_scheme(
+ gmm_assignment, scores, pos_inds_gmm)
+ pos_inds_after_paa.append(pos_inds_temp)
+ ignore_inds_after_paa.append(ignore_inds_temp)
+
+ pos_inds_after_paa = torch.cat(pos_inds_after_paa)
+ ignore_inds_after_paa = torch.cat(ignore_inds_after_paa)
+ reassign_mask = (pos_inds.unsqueeze(1) != pos_inds_after_paa).all(1)
+ reassign_ids = pos_inds[reassign_mask]
+ label[reassign_ids] = self.num_classes
+ label_weight[ignore_inds_after_paa] = 0
+ bbox_weight[reassign_ids] = 0
+ num_pos = len(pos_inds_after_paa)
+ return label, label_weight, bbox_weight, num_pos
+
+ def gmm_separation_scheme(self, gmm_assignment: Tensor, scores: Tensor,
+ pos_inds_gmm: Tensor) -> Tuple[Tensor, Tensor]:
+ """A general separation scheme for gmm model.
+
+ It separates a GMM distribution of candidate samples into three
+ parts, 0 1 and uncertain areas, and you can implement other
+ separation schemes by rewriting this function.
+
+ Args:
+ gmm_assignment (Tensor): The prediction of GMM which is of shape
+ (num_samples,). The 0/1 value indicates the distribution
+ that each sample comes from.
+ scores (Tensor): The probability of sample coming from the
+ fit GMM distribution. The tensor is of shape (num_samples,).
+ pos_inds_gmm (Tensor): All the indexes of samples which are used
+ to fit GMM model. The tensor is of shape (num_samples,)
+
+ Returns:
+ tuple[Tensor, Tensor]: The indices of positive and ignored samples.
+
+ - pos_inds_temp (Tensor): Indices of positive samples.
+ - ignore_inds_temp (Tensor): Indices of ignore samples.
+ """
+ # The implementation is (c) in Fig.3 in origin paper instead of (b).
+ # You can refer to issues such as
+ # https://github.com/kkhoot/PAA/issues/8 and
+ # https://github.com/kkhoot/PAA/issues/9.
+ fgs = gmm_assignment == 0
+ pos_inds_temp = fgs.new_tensor([], dtype=torch.long)
+ ignore_inds_temp = fgs.new_tensor([], dtype=torch.long)
+ if fgs.nonzero().numel():
+ _, pos_thr_ind = scores[fgs].topk(1)
+ pos_inds_temp = pos_inds_gmm[fgs][:pos_thr_ind + 1]
+ ignore_inds_temp = pos_inds_gmm.new_tensor([])
+ return pos_inds_temp, ignore_inds_temp
+
+ def get_targets(self,
+ anchor_list: List[List[Tensor]],
+ valid_flag_list: List[List[Tensor]],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ batch_gt_instances_ignore: OptInstanceList = None,
+ unmap_outputs: bool = True) -> tuple:
+ """Get targets for PAA head.
+
+ This method is almost the same as `AnchorHead.get_targets()`. We direct
+ return the results from _get_targets_single instead map it to levels
+ by images_to_levels function.
+
+ Args:
+ anchor_list (list[list[Tensor]]): Multi level anchors of each
+ image. The outer list indicates images, and the inner list
+ corresponds to feature levels of the image. Each element of
+ the inner list is a tensor of shape (num_anchors, 4).
+ valid_flag_list (list[list[Tensor]]): Multi level valid flags of
+ each image. The outer list indicates images, and the inner list
+ corresponds to feature levels of the image. Each element of
+ the inner list is a tensor of shape (num_anchors, )
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+ unmap_outputs (bool): Whether to map outputs back to the original
+ set of anchors. Defaults to True.
+
+ Returns:
+ tuple: Usually returns a tuple containing learning targets.
+
+ - labels (list[Tensor]): Labels of all anchors, each with
+ shape (num_anchors,).
+ - label_weights (list[Tensor]): Label weights of all anchor.
+ each with shape (num_anchors,).
+ - bbox_targets (list[Tensor]): BBox targets of all anchors.
+ each with shape (num_anchors, 4).
+ - bbox_weights (list[Tensor]): BBox weights of all anchors.
+ each with shape (num_anchors, 4).
+ - pos_inds (list[Tensor]): Contains all index of positive
+ sample in all anchor.
+ - gt_inds (list[Tensor]): Contains all gt_index of positive
+ sample in all anchor.
+ """
+
+ num_imgs = len(batch_img_metas)
+ assert len(anchor_list) == len(valid_flag_list) == num_imgs
+ concat_anchor_list = []
+ concat_valid_flag_list = []
+ for i in range(num_imgs):
+ assert len(anchor_list[i]) == len(valid_flag_list[i])
+ concat_anchor_list.append(torch.cat(anchor_list[i]))
+ concat_valid_flag_list.append(torch.cat(valid_flag_list[i]))
+
+ # compute targets for each image
+ if batch_gt_instances_ignore is None:
+ batch_gt_instances_ignore = [None] * num_imgs
+ results = multi_apply(
+ self._get_targets_single,
+ concat_anchor_list,
+ concat_valid_flag_list,
+ batch_gt_instances,
+ batch_img_metas,
+ batch_gt_instances_ignore,
+ unmap_outputs=unmap_outputs)
+
+ (labels, label_weights, bbox_targets, bbox_weights, valid_pos_inds,
+ valid_neg_inds, sampling_result) = results
+
+ # Due to valid flag of anchors, we have to calculate the real pos_inds
+ # in origin anchor set.
+ pos_inds = []
+ for i, single_labels in enumerate(labels):
+ pos_mask = (0 <= single_labels) & (
+ single_labels < self.num_classes)
+ pos_inds.append(pos_mask.nonzero().view(-1))
+
+ gt_inds = [item.pos_assigned_gt_inds for item in sampling_result]
+ return (labels, label_weights, bbox_targets, bbox_weights, pos_inds,
+ gt_inds)
+
+ def _get_targets_single(self,
+ flat_anchors: Tensor,
+ valid_flags: Tensor,
+ gt_instances: InstanceData,
+ img_meta: dict,
+ gt_instances_ignore: Optional[InstanceData] = None,
+ unmap_outputs: bool = True) -> tuple:
+ """Compute regression and classification targets for anchors in a
+ single image.
+
+ This method is same as `AnchorHead._get_targets_single()`.
+ """
+ assert unmap_outputs, 'We must map outputs back to the original' \
+ 'set of anchors in PAAhead'
+ return super(ATSSHead, self)._get_targets_single(
+ flat_anchors,
+ valid_flags,
+ gt_instances,
+ img_meta,
+ gt_instances_ignore,
+ unmap_outputs=True)
+
+ def predict_by_feat(self,
+ cls_scores: List[Tensor],
+ bbox_preds: List[Tensor],
+ score_factors: Optional[List[Tensor]] = None,
+ batch_img_metas: Optional[List[dict]] = None,
+ cfg: OptConfigType = None,
+ rescale: bool = False,
+ with_nms: bool = True) -> InstanceList:
+ """Transform a batch of output features extracted from the head into
+ bbox results.
+
+ This method is same as `BaseDenseHead.get_results()`.
+ """
+ assert with_nms, 'PAA only supports "with_nms=True" now and it ' \
+ 'means PAAHead does not support ' \
+ 'test-time augmentation'
+ return super().predict_by_feat(
+ cls_scores=cls_scores,
+ bbox_preds=bbox_preds,
+ score_factors=score_factors,
+ batch_img_metas=batch_img_metas,
+ cfg=cfg,
+ rescale=rescale,
+ with_nms=with_nms)
+
+ def _predict_by_feat_single(self,
+ cls_score_list: List[Tensor],
+ bbox_pred_list: List[Tensor],
+ score_factor_list: List[Tensor],
+ mlvl_priors: List[Tensor],
+ img_meta: dict,
+ cfg: OptConfigType = None,
+ rescale: bool = False,
+ with_nms: bool = True) -> InstanceData:
+ """Transform a single image's features extracted from the head into
+ bbox results.
+
+ Args:
+ cls_score_list (list[Tensor]): Box scores from all scale
+ levels of a single image, each item has shape
+ (num_priors * num_classes, H, W).
+ bbox_pred_list (list[Tensor]): Box energies / deltas from
+ all scale levels of a single image, each item has shape
+ (num_priors * 4, H, W).
+ score_factor_list (list[Tensor]): Score factors from all scale
+ levels of a single image, each item has shape
+ (num_priors * 1, H, W).
+ mlvl_priors (list[Tensor]): Each element in the list is
+ the priors of a single level in feature pyramid, has shape
+ (num_priors, 4).
+ img_meta (dict): Image meta info.
+ cfg (:obj:`ConfigDict` or dict, optional): Test / postprocessing
+ configuration, if None, test_cfg would be used.
+ rescale (bool): If True, return boxes in original image space.
+ Default: False.
+ with_nms (bool): If True, do nms before return boxes.
+ Default: True.
+
+ Returns:
+ :obj:`InstanceData`: Detection results of each image
+ after the post process.
+ Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ """
+ cfg = self.test_cfg if cfg is None else cfg
+ img_shape = img_meta['img_shape']
+ nms_pre = cfg.get('nms_pre', -1)
+
+ mlvl_bboxes = []
+ mlvl_scores = []
+ mlvl_score_factors = []
+ for level_idx, (cls_score, bbox_pred, score_factor, priors) in \
+ enumerate(zip(cls_score_list, bbox_pred_list,
+ score_factor_list, mlvl_priors)):
+ assert cls_score.size()[-2:] == bbox_pred.size()[-2:]
+
+ scores = cls_score.permute(1, 2, 0).reshape(
+ -1, self.cls_out_channels).sigmoid()
+ bbox_pred = bbox_pred.permute(1, 2, 0).reshape(-1, 4)
+ score_factor = score_factor.permute(1, 2, 0).reshape(-1).sigmoid()
+
+ if 0 < nms_pre < scores.shape[0]:
+ max_scores, _ = (scores *
+ score_factor[:, None]).sqrt().max(dim=1)
+ _, topk_inds = max_scores.topk(nms_pre)
+ priors = priors[topk_inds, :]
+ bbox_pred = bbox_pred[topk_inds, :]
+ scores = scores[topk_inds, :]
+ score_factor = score_factor[topk_inds]
+
+ bboxes = self.bbox_coder.decode(
+ priors, bbox_pred, max_shape=img_shape)
+ mlvl_bboxes.append(bboxes)
+ mlvl_scores.append(scores)
+ mlvl_score_factors.append(score_factor)
+
+ results = InstanceData()
+ results.bboxes = torch.cat(mlvl_bboxes)
+ results.scores = torch.cat(mlvl_scores)
+ results.score_factors = torch.cat(mlvl_score_factors)
+
+ return self._bbox_post_process(results, cfg, rescale, with_nms,
+ img_meta)
+
+ def _bbox_post_process(self,
+ results: InstanceData,
+ cfg: ConfigType,
+ rescale: bool = False,
+ with_nms: bool = True,
+ img_meta: Optional[dict] = None):
+ """bbox post-processing method.
+
+ The boxes would be rescaled to the original image scale and do
+ the nms operation. Usually with_nms is False is used for aug test.
+
+ Args:
+ results (:obj:`InstaceData`): Detection instance results,
+ each item has shape (num_bboxes, ).
+ cfg (:obj:`ConfigDict` or dict): Test / postprocessing
+ configuration, if None, test_cfg would be used.
+ rescale (bool): If True, return boxes in original image space.
+ Default: False.
+ with_nms (bool): If True, do nms before return boxes.
+ Default: True.
+ img_meta (dict, optional): Image meta info. Defaults to None.
+
+ Returns:
+ :obj:`InstanceData`: Detection results of each image
+ after the post process.
+ Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ """
+ if rescale:
+ results.bboxes /= results.bboxes.new_tensor(
+ img_meta['scale_factor']).repeat((1, 2))
+ # Add a dummy background class to the backend when using sigmoid
+ # remind that we set FG labels to [0, num_class-1] since mmdet v2.0
+ # BG cat_id: num_class
+ padding = results.scores.new_zeros(results.scores.shape[0], 1)
+ mlvl_scores = torch.cat([results.scores, padding], dim=1)
+
+ mlvl_nms_scores = (mlvl_scores * results.score_factors[:, None]).sqrt()
+ det_bboxes, det_labels = multiclass_nms(
+ results.bboxes,
+ mlvl_nms_scores,
+ cfg.score_thr,
+ cfg.nms,
+ cfg.max_per_img,
+ score_factors=None)
+ if self.with_score_voting and len(det_bboxes) > 0:
+ det_bboxes, det_labels = self.score_voting(det_bboxes, det_labels,
+ results.bboxes,
+ mlvl_nms_scores,
+ cfg.score_thr)
+ nms_results = InstanceData()
+ nms_results.bboxes = det_bboxes[:, :-1]
+ nms_results.scores = det_bboxes[:, -1]
+ nms_results.labels = det_labels
+ return nms_results
+
+ def score_voting(self, det_bboxes: Tensor, det_labels: Tensor,
+ mlvl_bboxes: Tensor, mlvl_nms_scores: Tensor,
+ score_thr: float) -> Tuple[Tensor, Tensor]:
+ """Implementation of score voting method works on each remaining boxes
+ after NMS procedure.
+
+ Args:
+ det_bboxes (Tensor): Remaining boxes after NMS procedure,
+ with shape (k, 5), each dimension means
+ (x1, y1, x2, y2, score).
+ det_labels (Tensor): The label of remaining boxes, with shape
+ (k, 1),Labels are 0-based.
+ mlvl_bboxes (Tensor): All boxes before the NMS procedure,
+ with shape (num_anchors,4).
+ mlvl_nms_scores (Tensor): The scores of all boxes which is used
+ in the NMS procedure, with shape (num_anchors, num_class)
+ score_thr (float): The score threshold of bboxes.
+
+ Returns:
+ tuple: Usually returns a tuple containing voting results.
+
+ - det_bboxes_voted (Tensor): Remaining boxes after
+ score voting procedure, with shape (k, 5), each
+ dimension means (x1, y1, x2, y2, score).
+ - det_labels_voted (Tensor): Label of remaining bboxes
+ after voting, with shape (num_anchors,).
+ """
+ candidate_mask = mlvl_nms_scores > score_thr
+ candidate_mask_nonzeros = candidate_mask.nonzero(as_tuple=False)
+ candidate_inds = candidate_mask_nonzeros[:, 0]
+ candidate_labels = candidate_mask_nonzeros[:, 1]
+ candidate_bboxes = mlvl_bboxes[candidate_inds]
+ candidate_scores = mlvl_nms_scores[candidate_mask]
+ det_bboxes_voted = []
+ det_labels_voted = []
+ for cls in range(self.cls_out_channels):
+ candidate_cls_mask = candidate_labels == cls
+ if not candidate_cls_mask.any():
+ continue
+ candidate_cls_scores = candidate_scores[candidate_cls_mask]
+ candidate_cls_bboxes = candidate_bboxes[candidate_cls_mask]
+ det_cls_mask = det_labels == cls
+ det_cls_bboxes = det_bboxes[det_cls_mask].view(
+ -1, det_bboxes.size(-1))
+ det_candidate_ious = bbox_overlaps(det_cls_bboxes[:, :4],
+ candidate_cls_bboxes)
+ for det_ind in range(len(det_cls_bboxes)):
+ single_det_ious = det_candidate_ious[det_ind]
+ pos_ious_mask = single_det_ious > 0.01
+ pos_ious = single_det_ious[pos_ious_mask]
+ pos_bboxes = candidate_cls_bboxes[pos_ious_mask]
+ pos_scores = candidate_cls_scores[pos_ious_mask]
+ pis = (torch.exp(-(1 - pos_ious)**2 / 0.025) *
+ pos_scores)[:, None]
+ voted_box = torch.sum(
+ pis * pos_bboxes, dim=0) / torch.sum(
+ pis, dim=0)
+ voted_score = det_cls_bboxes[det_ind][-1:][None, :]
+ det_bboxes_voted.append(
+ torch.cat((voted_box[None, :], voted_score), dim=1))
+ det_labels_voted.append(cls)
+
+ det_bboxes_voted = torch.cat(det_bboxes_voted, dim=0)
+ det_labels_voted = det_labels.new_tensor(det_labels_voted)
+ return det_bboxes_voted, det_labels_voted
diff --git a/mmdet/models/dense_heads/pisa_retinanet_head.py b/mmdet/models/dense_heads/pisa_retinanet_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..85fd54f5be3605d0994c2a2d4d9d7deac4c0f284
--- /dev/null
+++ b/mmdet/models/dense_heads/pisa_retinanet_head.py
@@ -0,0 +1,154 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List
+
+import torch
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.utils import InstanceList, OptInstanceList
+from ..losses import carl_loss, isr_p
+from ..utils import images_to_levels
+from .retina_head import RetinaHead
+
+
+@MODELS.register_module()
+class PISARetinaHead(RetinaHead):
+ """PISA Retinanet Head.
+
+ The head owns the same structure with Retinanet Head, but differs in two
+ aspects:
+ 1. Importance-based Sample Reweighting Positive (ISR-P) is applied to
+ change the positive loss weights.
+ 2. Classification-aware regression loss is adopted as a third loss.
+ """
+
+ def loss_by_feat(
+ self,
+ cls_scores: List[Tensor],
+ bbox_preds: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ batch_gt_instances_ignore: OptInstanceList = None) -> dict:
+ """Compute losses of the head.
+
+ Args:
+ cls_scores (list[Tensor]): Box scores for each scale level
+ Has shape (N, num_anchors * num_classes, H, W)
+ bbox_preds (list[Tensor]): Box energies / deltas for each scale
+ level with shape (N, num_anchors * 4, H, W)
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ dict: Loss dict, comprise classification loss, regression loss and
+ carl loss.
+ """
+ featmap_sizes = [featmap.size()[-2:] for featmap in cls_scores]
+ assert len(featmap_sizes) == self.prior_generator.num_levels
+
+ device = cls_scores[0].device
+
+ anchor_list, valid_flag_list = self.get_anchors(
+ featmap_sizes, batch_img_metas, device=device)
+ label_channels = self.cls_out_channels if self.use_sigmoid_cls else 1
+ cls_reg_targets = self.get_targets(
+ anchor_list,
+ valid_flag_list,
+ batch_gt_instances,
+ batch_img_metas,
+ batch_gt_instances_ignore=batch_gt_instances_ignore,
+ return_sampling_results=True)
+ if cls_reg_targets is None:
+ return None
+ (labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,
+ avg_factor, sampling_results_list) = cls_reg_targets
+
+ # anchor number of multi levels
+ num_level_anchors = [anchors.size(0) for anchors in anchor_list[0]]
+ # concat all level anchors and flags to a single tensor
+ concat_anchor_list = []
+ for i in range(len(anchor_list)):
+ concat_anchor_list.append(torch.cat(anchor_list[i]))
+ all_anchor_list = images_to_levels(concat_anchor_list,
+ num_level_anchors)
+
+ num_imgs = len(batch_img_metas)
+ flatten_cls_scores = [
+ cls_score.permute(0, 2, 3, 1).reshape(num_imgs, -1, label_channels)
+ for cls_score in cls_scores
+ ]
+ flatten_cls_scores = torch.cat(
+ flatten_cls_scores, dim=1).reshape(-1,
+ flatten_cls_scores[0].size(-1))
+ flatten_bbox_preds = [
+ bbox_pred.permute(0, 2, 3, 1).reshape(num_imgs, -1, 4)
+ for bbox_pred in bbox_preds
+ ]
+ flatten_bbox_preds = torch.cat(
+ flatten_bbox_preds, dim=1).view(-1, flatten_bbox_preds[0].size(-1))
+ flatten_labels = torch.cat(labels_list, dim=1).reshape(-1)
+ flatten_label_weights = torch.cat(
+ label_weights_list, dim=1).reshape(-1)
+ flatten_anchors = torch.cat(all_anchor_list, dim=1).reshape(-1, 4)
+ flatten_bbox_targets = torch.cat(
+ bbox_targets_list, dim=1).reshape(-1, 4)
+ flatten_bbox_weights = torch.cat(
+ bbox_weights_list, dim=1).reshape(-1, 4)
+
+ # Apply ISR-P
+ isr_cfg = self.train_cfg.get('isr', None)
+ if isr_cfg is not None:
+ all_targets = (flatten_labels, flatten_label_weights,
+ flatten_bbox_targets, flatten_bbox_weights)
+ with torch.no_grad():
+ all_targets = isr_p(
+ flatten_cls_scores,
+ flatten_bbox_preds,
+ all_targets,
+ flatten_anchors,
+ sampling_results_list,
+ bbox_coder=self.bbox_coder,
+ loss_cls=self.loss_cls,
+ num_class=self.num_classes,
+ **self.train_cfg['isr'])
+ (flatten_labels, flatten_label_weights, flatten_bbox_targets,
+ flatten_bbox_weights) = all_targets
+
+ # For convenience we compute loss once instead separating by fpn level,
+ # so that we don't need to separate the weights by level again.
+ # The result should be the same
+ losses_cls = self.loss_cls(
+ flatten_cls_scores,
+ flatten_labels,
+ flatten_label_weights,
+ avg_factor=avg_factor)
+ losses_bbox = self.loss_bbox(
+ flatten_bbox_preds,
+ flatten_bbox_targets,
+ flatten_bbox_weights,
+ avg_factor=avg_factor)
+ loss_dict = dict(loss_cls=losses_cls, loss_bbox=losses_bbox)
+
+ # CARL Loss
+ carl_cfg = self.train_cfg.get('carl', None)
+ if carl_cfg is not None:
+ loss_carl = carl_loss(
+ flatten_cls_scores,
+ flatten_labels,
+ flatten_bbox_preds,
+ flatten_bbox_targets,
+ self.loss_bbox,
+ **self.train_cfg['carl'],
+ avg_factor=avg_factor,
+ sigmoid=True,
+ num_class=self.num_classes)
+ loss_dict.update(loss_carl)
+
+ return loss_dict
diff --git a/mmdet/models/dense_heads/pisa_ssd_head.py b/mmdet/models/dense_heads/pisa_ssd_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..ec09cb40a9c95d3f9889d736b80dfccef07f6fd1
--- /dev/null
+++ b/mmdet/models/dense_heads/pisa_ssd_head.py
@@ -0,0 +1,182 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Union
+
+import torch
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.utils import InstanceList, OptInstanceList
+from ..losses import CrossEntropyLoss, SmoothL1Loss, carl_loss, isr_p
+from ..utils import multi_apply
+from .ssd_head import SSDHead
+
+
+# TODO: add loss evaluator for SSD
+@MODELS.register_module()
+class PISASSDHead(SSDHead):
+ """Implementation of `PISA SSD head `_
+
+ Args:
+ num_classes (int): Number of categories excluding the background
+ category.
+ in_channels (Sequence[int]): Number of channels in the input feature
+ map.
+ stacked_convs (int): Number of conv layers in cls and reg tower.
+ Defaults to 0.
+ feat_channels (int): Number of hidden channels when stacked_convs
+ > 0. Defaults to 256.
+ use_depthwise (bool): Whether to use DepthwiseSeparableConv.
+ Defaults to False.
+ conv_cfg (:obj:`ConfigDict` or dict, Optional): Dictionary to construct
+ and config conv layer. Defaults to None.
+ norm_cfg (:obj:`ConfigDict` or dict, Optional): Dictionary to construct
+ and config norm layer. Defaults to None.
+ act_cfg (:obj:`ConfigDict` or dict, Optional): Dictionary to construct
+ and config activation layer. Defaults to None.
+ anchor_generator (:obj:`ConfigDict` or dict): Config dict for anchor
+ generator.
+ bbox_coder (:obj:`ConfigDict` or dict): Config of bounding box coder.
+ reg_decoded_bbox (bool): If true, the regression loss would be
+ applied directly on decoded bounding boxes, converting both
+ the predicted boxes and regression targets to absolute
+ coordinates format. Defaults to False. It should be `True` when
+ using `IoULoss`, `GIoULoss`, or `DIoULoss` in the bbox head.
+ train_cfg (:obj:`ConfigDict` or dict, Optional): Training config of
+ anchor head.
+ test_cfg (:obj:`ConfigDict` or dict, Optional): Testing config of
+ anchor head.
+ init_cfg (:obj:`ConfigDict` or dict or list[:obj:`ConfigDict` or \
+ dict], Optional): Initialization config dict.
+ """ # noqa: W605
+
+ def loss_by_feat(
+ self,
+ cls_scores: List[Tensor],
+ bbox_preds: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ batch_gt_instances_ignore: OptInstanceList = None
+ ) -> Dict[str, Union[List[Tensor], Tensor]]:
+ """Compute losses of the head.
+
+ Args:
+ cls_scores (list[Tensor]): Box scores for each scale level
+ Has shape (N, num_anchors * num_classes, H, W)
+ bbox_preds (list[Tensor]): Box energies / deltas for each scale
+ level with shape (N, num_anchors * 4, H, W)
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], Optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ dict[str, Union[List[Tensor], Tensor]]: A dictionary of loss
+ components. the dict has components below:
+
+ - loss_cls (list[Tensor]): A list containing each feature map \
+ classification loss.
+ - loss_bbox (list[Tensor]): A list containing each feature map \
+ regression loss.
+ - loss_carl (Tensor): The loss of CARL.
+ """
+ featmap_sizes = [featmap.size()[-2:] for featmap in cls_scores]
+ assert len(featmap_sizes) == self.prior_generator.num_levels
+
+ device = cls_scores[0].device
+
+ anchor_list, valid_flag_list = self.get_anchors(
+ featmap_sizes, batch_img_metas, device=device)
+ cls_reg_targets = self.get_targets(
+ anchor_list,
+ valid_flag_list,
+ batch_gt_instances,
+ batch_img_metas,
+ batch_gt_instances_ignore=batch_gt_instances_ignore,
+ unmap_outputs=False,
+ return_sampling_results=True)
+ (labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,
+ avg_factor, sampling_results_list) = cls_reg_targets
+
+ num_images = len(batch_img_metas)
+ all_cls_scores = torch.cat([
+ s.permute(0, 2, 3, 1).reshape(
+ num_images, -1, self.cls_out_channels) for s in cls_scores
+ ], 1)
+ all_labels = torch.cat(labels_list, -1).view(num_images, -1)
+ all_label_weights = torch.cat(label_weights_list,
+ -1).view(num_images, -1)
+ all_bbox_preds = torch.cat([
+ b.permute(0, 2, 3, 1).reshape(num_images, -1, 4)
+ for b in bbox_preds
+ ], -2)
+ all_bbox_targets = torch.cat(bbox_targets_list,
+ -2).view(num_images, -1, 4)
+ all_bbox_weights = torch.cat(bbox_weights_list,
+ -2).view(num_images, -1, 4)
+
+ # concat all level anchors to a single tensor
+ all_anchors = []
+ for i in range(num_images):
+ all_anchors.append(torch.cat(anchor_list[i]))
+
+ isr_cfg = self.train_cfg.get('isr', None)
+ all_targets = (all_labels.view(-1), all_label_weights.view(-1),
+ all_bbox_targets.view(-1,
+ 4), all_bbox_weights.view(-1, 4))
+ # apply ISR-P
+ if isr_cfg is not None:
+ all_targets = isr_p(
+ all_cls_scores.view(-1, all_cls_scores.size(-1)),
+ all_bbox_preds.view(-1, 4),
+ all_targets,
+ torch.cat(all_anchors),
+ sampling_results_list,
+ loss_cls=CrossEntropyLoss(),
+ bbox_coder=self.bbox_coder,
+ **self.train_cfg['isr'],
+ num_class=self.num_classes)
+ (new_labels, new_label_weights, new_bbox_targets,
+ new_bbox_weights) = all_targets
+ all_labels = new_labels.view(all_labels.shape)
+ all_label_weights = new_label_weights.view(all_label_weights.shape)
+ all_bbox_targets = new_bbox_targets.view(all_bbox_targets.shape)
+ all_bbox_weights = new_bbox_weights.view(all_bbox_weights.shape)
+
+ # add CARL loss
+ carl_loss_cfg = self.train_cfg.get('carl', None)
+ if carl_loss_cfg is not None:
+ loss_carl = carl_loss(
+ all_cls_scores.view(-1, all_cls_scores.size(-1)),
+ all_targets[0],
+ all_bbox_preds.view(-1, 4),
+ all_targets[2],
+ SmoothL1Loss(beta=1.),
+ **self.train_cfg['carl'],
+ avg_factor=avg_factor,
+ num_class=self.num_classes)
+
+ # check NaN and Inf
+ assert torch.isfinite(all_cls_scores).all().item(), \
+ 'classification scores become infinite or NaN!'
+ assert torch.isfinite(all_bbox_preds).all().item(), \
+ 'bbox predications become infinite or NaN!'
+
+ losses_cls, losses_bbox = multi_apply(
+ self.loss_by_feat_single,
+ all_cls_scores,
+ all_bbox_preds,
+ all_anchors,
+ all_labels,
+ all_label_weights,
+ all_bbox_targets,
+ all_bbox_weights,
+ avg_factor=avg_factor)
+ loss_dict = dict(loss_cls=losses_cls, loss_bbox=losses_bbox)
+ if carl_loss_cfg is not None:
+ loss_dict.update(loss_carl)
+ return loss_dict
diff --git a/mmdet/models/dense_heads/reppoints_head.py b/mmdet/models/dense_heads/reppoints_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..22f3e3401a4abd9cc35b41d24efe23e5655a905e
--- /dev/null
+++ b/mmdet/models/dense_heads/reppoints_head.py
@@ -0,0 +1,885 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Sequence, Tuple
+
+import numpy as np
+import torch
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+from mmcv.ops import DeformConv2d
+from mmengine.config import ConfigDict
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmdet.registry import MODELS, TASK_UTILS
+from mmdet.utils import ConfigType, InstanceList, MultiConfig, OptInstanceList
+from ..task_modules.prior_generators import MlvlPointGenerator
+from ..task_modules.samplers import PseudoSampler
+from ..utils import (filter_scores_and_topk, images_to_levels, multi_apply,
+ unmap)
+from .anchor_free_head import AnchorFreeHead
+
+
+@MODELS.register_module()
+class RepPointsHead(AnchorFreeHead):
+ """RepPoint head.
+
+ Args:
+ num_classes (int): Number of categories excluding the background
+ category.
+ in_channels (int): Number of channels in the input feature map.
+ point_feat_channels (int): Number of channels of points features.
+ num_points (int): Number of points.
+ gradient_mul (float): The multiplier to gradients from
+ points refinement and recognition.
+ point_strides (Sequence[int]): points strides.
+ point_base_scale (int): bbox scale for assigning labels.
+ loss_cls (:obj:`ConfigDict` or dict): Config of classification loss.
+ loss_bbox_init (:obj:`ConfigDict` or dict): Config of initial points
+ loss.
+ loss_bbox_refine (:obj:`ConfigDict` or dict): Config of points loss in
+ refinement.
+ use_grid_points (bool): If we use bounding box representation, the
+ reppoints is represented as grid points on the bounding box.
+ center_init (bool): Whether to use center point assignment.
+ transform_method (str): The methods to transform RepPoints to bbox.
+ init_cfg (:obj:`ConfigDict` or dict or list[:obj:`ConfigDict` or \
+ dict]): Initialization config dict.
+ """ # noqa: W605
+
+ def __init__(self,
+ num_classes: int,
+ in_channels: int,
+ point_feat_channels: int = 256,
+ num_points: int = 9,
+ gradient_mul: float = 0.1,
+ point_strides: Sequence[int] = [8, 16, 32, 64, 128],
+ point_base_scale: int = 4,
+ loss_cls: ConfigType = dict(
+ type='FocalLoss',
+ use_sigmoid=True,
+ gamma=2.0,
+ alpha=0.25,
+ loss_weight=1.0),
+ loss_bbox_init: ConfigType = dict(
+ type='SmoothL1Loss', beta=1.0 / 9.0, loss_weight=0.5),
+ loss_bbox_refine: ConfigType = dict(
+ type='SmoothL1Loss', beta=1.0 / 9.0, loss_weight=1.0),
+ use_grid_points: bool = False,
+ center_init: bool = True,
+ transform_method: str = 'moment',
+ moment_mul: float = 0.01,
+ init_cfg: MultiConfig = dict(
+ type='Normal',
+ layer='Conv2d',
+ std=0.01,
+ override=dict(
+ type='Normal',
+ name='reppoints_cls_out',
+ std=0.01,
+ bias_prob=0.01)),
+ **kwargs) -> None:
+ self.num_points = num_points
+ self.point_feat_channels = point_feat_channels
+ self.use_grid_points = use_grid_points
+ self.center_init = center_init
+
+ # we use deform conv to extract points features
+ self.dcn_kernel = int(np.sqrt(num_points))
+ self.dcn_pad = int((self.dcn_kernel - 1) / 2)
+ assert self.dcn_kernel * self.dcn_kernel == num_points, \
+ 'The points number should be a square number.'
+ assert self.dcn_kernel % 2 == 1, \
+ 'The points number should be an odd square number.'
+ dcn_base = np.arange(-self.dcn_pad,
+ self.dcn_pad + 1).astype(np.float64)
+ dcn_base_y = np.repeat(dcn_base, self.dcn_kernel)
+ dcn_base_x = np.tile(dcn_base, self.dcn_kernel)
+ dcn_base_offset = np.stack([dcn_base_y, dcn_base_x], axis=1).reshape(
+ (-1))
+ self.dcn_base_offset = torch.tensor(dcn_base_offset).view(1, -1, 1, 1)
+
+ super().__init__(
+ num_classes=num_classes,
+ in_channels=in_channels,
+ loss_cls=loss_cls,
+ init_cfg=init_cfg,
+ **kwargs)
+
+ self.gradient_mul = gradient_mul
+ self.point_base_scale = point_base_scale
+ self.point_strides = point_strides
+ self.prior_generator = MlvlPointGenerator(
+ self.point_strides, offset=0.)
+
+ if self.train_cfg:
+ self.init_assigner = TASK_UTILS.build(
+ self.train_cfg['init']['assigner'])
+ self.refine_assigner = TASK_UTILS.build(
+ self.train_cfg['refine']['assigner'])
+
+ if self.train_cfg.get('sampler', None) is not None:
+ self.sampler = TASK_UTILS.build(
+ self.train_cfg['sampler'], default_args=dict(context=self))
+ else:
+ self.sampler = PseudoSampler(context=self)
+
+ self.transform_method = transform_method
+ if self.transform_method == 'moment':
+ self.moment_transfer = nn.Parameter(
+ data=torch.zeros(2), requires_grad=True)
+ self.moment_mul = moment_mul
+
+ self.use_sigmoid_cls = loss_cls.get('use_sigmoid', False)
+ if self.use_sigmoid_cls:
+ self.cls_out_channels = self.num_classes
+ else:
+ self.cls_out_channels = self.num_classes + 1
+ self.loss_bbox_init = MODELS.build(loss_bbox_init)
+ self.loss_bbox_refine = MODELS.build(loss_bbox_refine)
+
+ def _init_layers(self) -> None:
+ """Initialize layers of the head."""
+ self.relu = nn.ReLU(inplace=True)
+ self.cls_convs = nn.ModuleList()
+ self.reg_convs = nn.ModuleList()
+ for i in range(self.stacked_convs):
+ chn = self.in_channels if i == 0 else self.feat_channels
+ self.cls_convs.append(
+ ConvModule(
+ chn,
+ self.feat_channels,
+ 3,
+ stride=1,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg))
+ self.reg_convs.append(
+ ConvModule(
+ chn,
+ self.feat_channels,
+ 3,
+ stride=1,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg))
+ pts_out_dim = 4 if self.use_grid_points else 2 * self.num_points
+ self.reppoints_cls_conv = DeformConv2d(self.feat_channels,
+ self.point_feat_channels,
+ self.dcn_kernel, 1,
+ self.dcn_pad)
+ self.reppoints_cls_out = nn.Conv2d(self.point_feat_channels,
+ self.cls_out_channels, 1, 1, 0)
+ self.reppoints_pts_init_conv = nn.Conv2d(self.feat_channels,
+ self.point_feat_channels, 3,
+ 1, 1)
+ self.reppoints_pts_init_out = nn.Conv2d(self.point_feat_channels,
+ pts_out_dim, 1, 1, 0)
+ self.reppoints_pts_refine_conv = DeformConv2d(self.feat_channels,
+ self.point_feat_channels,
+ self.dcn_kernel, 1,
+ self.dcn_pad)
+ self.reppoints_pts_refine_out = nn.Conv2d(self.point_feat_channels,
+ pts_out_dim, 1, 1, 0)
+
+ def points2bbox(self, pts: Tensor, y_first: bool = True) -> Tensor:
+ """Converting the points set into bounding box.
+
+ Args:
+ pts (Tensor): the input points sets (fields), each points
+ set (fields) is represented as 2n scalar.
+ y_first (bool): if y_first=True, the point set is
+ represented as [y1, x1, y2, x2 ... yn, xn], otherwise
+ the point set is represented as
+ [x1, y1, x2, y2 ... xn, yn]. Defaults to True.
+
+ Returns:
+ Tensor: each points set is converting to a bbox [x1, y1, x2, y2].
+ """
+ pts_reshape = pts.view(pts.shape[0], -1, 2, *pts.shape[2:])
+ pts_y = pts_reshape[:, :, 0, ...] if y_first else pts_reshape[:, :, 1,
+ ...]
+ pts_x = pts_reshape[:, :, 1, ...] if y_first else pts_reshape[:, :, 0,
+ ...]
+ if self.transform_method == 'minmax':
+ bbox_left = pts_x.min(dim=1, keepdim=True)[0]
+ bbox_right = pts_x.max(dim=1, keepdim=True)[0]
+ bbox_up = pts_y.min(dim=1, keepdim=True)[0]
+ bbox_bottom = pts_y.max(dim=1, keepdim=True)[0]
+ bbox = torch.cat([bbox_left, bbox_up, bbox_right, bbox_bottom],
+ dim=1)
+ elif self.transform_method == 'partial_minmax':
+ pts_y = pts_y[:, :4, ...]
+ pts_x = pts_x[:, :4, ...]
+ bbox_left = pts_x.min(dim=1, keepdim=True)[0]
+ bbox_right = pts_x.max(dim=1, keepdim=True)[0]
+ bbox_up = pts_y.min(dim=1, keepdim=True)[0]
+ bbox_bottom = pts_y.max(dim=1, keepdim=True)[0]
+ bbox = torch.cat([bbox_left, bbox_up, bbox_right, bbox_bottom],
+ dim=1)
+ elif self.transform_method == 'moment':
+ pts_y_mean = pts_y.mean(dim=1, keepdim=True)
+ pts_x_mean = pts_x.mean(dim=1, keepdim=True)
+ pts_y_std = torch.std(pts_y - pts_y_mean, dim=1, keepdim=True)
+ pts_x_std = torch.std(pts_x - pts_x_mean, dim=1, keepdim=True)
+ moment_transfer = (self.moment_transfer * self.moment_mul) + (
+ self.moment_transfer.detach() * (1 - self.moment_mul))
+ moment_width_transfer = moment_transfer[0]
+ moment_height_transfer = moment_transfer[1]
+ half_width = pts_x_std * torch.exp(moment_width_transfer)
+ half_height = pts_y_std * torch.exp(moment_height_transfer)
+ bbox = torch.cat([
+ pts_x_mean - half_width, pts_y_mean - half_height,
+ pts_x_mean + half_width, pts_y_mean + half_height
+ ],
+ dim=1)
+ else:
+ raise NotImplementedError
+ return bbox
+
+ def gen_grid_from_reg(self, reg: Tensor,
+ previous_boxes: Tensor) -> Tuple[Tensor]:
+ """Base on the previous bboxes and regression values, we compute the
+ regressed bboxes and generate the grids on the bboxes.
+
+ Args:
+ reg (Tensor): the regression value to previous bboxes.
+ previous_boxes (Tensor): previous bboxes.
+
+ Returns:
+ Tuple[Tensor]: generate grids on the regressed bboxes.
+ """
+ b, _, h, w = reg.shape
+ bxy = (previous_boxes[:, :2, ...] + previous_boxes[:, 2:, ...]) / 2.
+ bwh = (previous_boxes[:, 2:, ...] -
+ previous_boxes[:, :2, ...]).clamp(min=1e-6)
+ grid_topleft = bxy + bwh * reg[:, :2, ...] - 0.5 * bwh * torch.exp(
+ reg[:, 2:, ...])
+ grid_wh = bwh * torch.exp(reg[:, 2:, ...])
+ grid_left = grid_topleft[:, [0], ...]
+ grid_top = grid_topleft[:, [1], ...]
+ grid_width = grid_wh[:, [0], ...]
+ grid_height = grid_wh[:, [1], ...]
+ intervel = torch.linspace(0., 1., self.dcn_kernel).view(
+ 1, self.dcn_kernel, 1, 1).type_as(reg)
+ grid_x = grid_left + grid_width * intervel
+ grid_x = grid_x.unsqueeze(1).repeat(1, self.dcn_kernel, 1, 1, 1)
+ grid_x = grid_x.view(b, -1, h, w)
+ grid_y = grid_top + grid_height * intervel
+ grid_y = grid_y.unsqueeze(2).repeat(1, 1, self.dcn_kernel, 1, 1)
+ grid_y = grid_y.view(b, -1, h, w)
+ grid_yx = torch.stack([grid_y, grid_x], dim=2)
+ grid_yx = grid_yx.view(b, -1, h, w)
+ regressed_bbox = torch.cat([
+ grid_left, grid_top, grid_left + grid_width, grid_top + grid_height
+ ], 1)
+ return grid_yx, regressed_bbox
+
+ def forward(self, feats: Tuple[Tensor]) -> Tuple[Tensor]:
+ return multi_apply(self.forward_single, feats)
+
+ def forward_single(self, x: Tensor) -> Tuple[Tensor]:
+ """Forward feature map of a single FPN level."""
+ dcn_base_offset = self.dcn_base_offset.type_as(x)
+ # If we use center_init, the initial reppoints is from center points.
+ # If we use bounding bbox representation, the initial reppoints is
+ # from regular grid placed on a pre-defined bbox.
+ if self.use_grid_points or not self.center_init:
+ scale = self.point_base_scale / 2
+ points_init = dcn_base_offset / dcn_base_offset.max() * scale
+ bbox_init = x.new_tensor([-scale, -scale, scale,
+ scale]).view(1, 4, 1, 1)
+ else:
+ points_init = 0
+ cls_feat = x
+ pts_feat = x
+ for cls_conv in self.cls_convs:
+ cls_feat = cls_conv(cls_feat)
+ for reg_conv in self.reg_convs:
+ pts_feat = reg_conv(pts_feat)
+ # initialize reppoints
+ pts_out_init = self.reppoints_pts_init_out(
+ self.relu(self.reppoints_pts_init_conv(pts_feat)))
+ if self.use_grid_points:
+ pts_out_init, bbox_out_init = self.gen_grid_from_reg(
+ pts_out_init, bbox_init.detach())
+ else:
+ pts_out_init = pts_out_init + points_init
+ # refine and classify reppoints
+ pts_out_init_grad_mul = (1 - self.gradient_mul) * pts_out_init.detach(
+ ) + self.gradient_mul * pts_out_init
+ dcn_offset = pts_out_init_grad_mul - dcn_base_offset
+ cls_out = self.reppoints_cls_out(
+ self.relu(self.reppoints_cls_conv(cls_feat, dcn_offset)))
+ pts_out_refine = self.reppoints_pts_refine_out(
+ self.relu(self.reppoints_pts_refine_conv(pts_feat, dcn_offset)))
+ if self.use_grid_points:
+ pts_out_refine, bbox_out_refine = self.gen_grid_from_reg(
+ pts_out_refine, bbox_out_init.detach())
+ else:
+ pts_out_refine = pts_out_refine + pts_out_init.detach()
+
+ if self.training:
+ return cls_out, pts_out_init, pts_out_refine
+ else:
+ return cls_out, self.points2bbox(pts_out_refine)
+
+ def get_points(self, featmap_sizes: List[Tuple[int]],
+ batch_img_metas: List[dict], device: str) -> tuple:
+ """Get points according to feature map sizes.
+
+ Args:
+ featmap_sizes (list[tuple]): Multi-level feature map sizes.
+ batch_img_metas (list[dict]): Image meta info.
+
+ Returns:
+ tuple: points of each image, valid flags of each image
+ """
+ num_imgs = len(batch_img_metas)
+
+ # since feature map sizes of all images are the same, we only compute
+ # points center for one time
+ multi_level_points = self.prior_generator.grid_priors(
+ featmap_sizes, device=device, with_stride=True)
+ points_list = [[point.clone() for point in multi_level_points]
+ for _ in range(num_imgs)]
+
+ # for each image, we compute valid flags of multi level grids
+ valid_flag_list = []
+ for img_id, img_meta in enumerate(batch_img_metas):
+ multi_level_flags = self.prior_generator.valid_flags(
+ featmap_sizes, img_meta['pad_shape'], device=device)
+ valid_flag_list.append(multi_level_flags)
+
+ return points_list, valid_flag_list
+
+ def centers_to_bboxes(self, point_list: List[Tensor]) -> List[Tensor]:
+ """Get bboxes according to center points.
+
+ Only used in :class:`MaxIoUAssigner`.
+ """
+ bbox_list = []
+ for i_img, point in enumerate(point_list):
+ bbox = []
+ for i_lvl in range(len(self.point_strides)):
+ scale = self.point_base_scale * self.point_strides[i_lvl] * 0.5
+ bbox_shift = torch.Tensor([-scale, -scale, scale,
+ scale]).view(1, 4).type_as(point[0])
+ bbox_center = torch.cat(
+ [point[i_lvl][:, :2], point[i_lvl][:, :2]], dim=1)
+ bbox.append(bbox_center + bbox_shift)
+ bbox_list.append(bbox)
+ return bbox_list
+
+ def offset_to_pts(self, center_list: List[Tensor],
+ pred_list: List[Tensor]) -> List[Tensor]:
+ """Change from point offset to point coordinate."""
+ pts_list = []
+ for i_lvl in range(len(self.point_strides)):
+ pts_lvl = []
+ for i_img in range(len(center_list)):
+ pts_center = center_list[i_img][i_lvl][:, :2].repeat(
+ 1, self.num_points)
+ pts_shift = pred_list[i_lvl][i_img]
+ yx_pts_shift = pts_shift.permute(1, 2, 0).view(
+ -1, 2 * self.num_points)
+ y_pts_shift = yx_pts_shift[..., 0::2]
+ x_pts_shift = yx_pts_shift[..., 1::2]
+ xy_pts_shift = torch.stack([x_pts_shift, y_pts_shift], -1)
+ xy_pts_shift = xy_pts_shift.view(*yx_pts_shift.shape[:-1], -1)
+ pts = xy_pts_shift * self.point_strides[i_lvl] + pts_center
+ pts_lvl.append(pts)
+ pts_lvl = torch.stack(pts_lvl, 0)
+ pts_list.append(pts_lvl)
+ return pts_list
+
+ def _get_targets_single(self,
+ flat_proposals: Tensor,
+ valid_flags: Tensor,
+ gt_instances: InstanceData,
+ gt_instances_ignore: InstanceData,
+ stage: str = 'init',
+ unmap_outputs: bool = True) -> tuple:
+ """Compute corresponding GT box and classification targets for
+ proposals.
+
+ Args:
+ flat_proposals (Tensor): Multi level points of a image.
+ valid_flags (Tensor): Multi level valid flags of a image.
+ gt_instances (InstanceData): It usually includes ``bboxes`` and
+ ``labels`` attributes.
+ gt_instances_ignore (InstanceData): It includes ``bboxes``
+ attribute data that is ignored during training and testing.
+ stage (str): 'init' or 'refine'. Generate target for
+ init stage or refine stage. Defaults to 'init'.
+ unmap_outputs (bool): Whether to map outputs back to
+ the original set of anchors. Defaults to True.
+
+ Returns:
+ tuple:
+
+ - labels (Tensor): Labels of each level.
+ - label_weights (Tensor): Label weights of each level.
+ - bbox_targets (Tensor): BBox targets of each level.
+ - bbox_weights (Tensor): BBox weights of each level.
+ - pos_inds (Tensor): positive samples indexes.
+ - neg_inds (Tensor): negative samples indexes.
+ - sampling_result (:obj:`SamplingResult`): Sampling results.
+ """
+ inside_flags = valid_flags
+ if not inside_flags.any():
+ raise ValueError(
+ 'There is no valid proposal inside the image boundary. Please '
+ 'check the image size.')
+ # assign gt and sample proposals
+ proposals = flat_proposals[inside_flags, :]
+ pred_instances = InstanceData(priors=proposals)
+
+ if stage == 'init':
+ assigner = self.init_assigner
+ pos_weight = self.train_cfg['init']['pos_weight']
+ else:
+ assigner = self.refine_assigner
+ pos_weight = self.train_cfg['refine']['pos_weight']
+
+ assign_result = assigner.assign(pred_instances, gt_instances,
+ gt_instances_ignore)
+ sampling_result = self.sampler.sample(assign_result, pred_instances,
+ gt_instances)
+
+ num_valid_proposals = proposals.shape[0]
+ bbox_gt = proposals.new_zeros([num_valid_proposals, 4])
+ pos_proposals = torch.zeros_like(proposals)
+ proposals_weights = proposals.new_zeros([num_valid_proposals, 4])
+ labels = proposals.new_full((num_valid_proposals, ),
+ self.num_classes,
+ dtype=torch.long)
+ label_weights = proposals.new_zeros(
+ num_valid_proposals, dtype=torch.float)
+
+ pos_inds = sampling_result.pos_inds
+ neg_inds = sampling_result.neg_inds
+ if len(pos_inds) > 0:
+ bbox_gt[pos_inds, :] = sampling_result.pos_gt_bboxes
+ pos_proposals[pos_inds, :] = proposals[pos_inds, :]
+ proposals_weights[pos_inds, :] = 1.0
+
+ labels[pos_inds] = sampling_result.pos_gt_labels
+ if pos_weight <= 0:
+ label_weights[pos_inds] = 1.0
+ else:
+ label_weights[pos_inds] = pos_weight
+ if len(neg_inds) > 0:
+ label_weights[neg_inds] = 1.0
+
+ # map up to original set of proposals
+ if unmap_outputs:
+ num_total_proposals = flat_proposals.size(0)
+ labels = unmap(
+ labels,
+ num_total_proposals,
+ inside_flags,
+ fill=self.num_classes) # fill bg label
+ label_weights = unmap(label_weights, num_total_proposals,
+ inside_flags)
+ bbox_gt = unmap(bbox_gt, num_total_proposals, inside_flags)
+ pos_proposals = unmap(pos_proposals, num_total_proposals,
+ inside_flags)
+ proposals_weights = unmap(proposals_weights, num_total_proposals,
+ inside_flags)
+
+ return (labels, label_weights, bbox_gt, pos_proposals,
+ proposals_weights, pos_inds, neg_inds, sampling_result)
+
+ def get_targets(self,
+ proposals_list: List[Tensor],
+ valid_flag_list: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ batch_gt_instances_ignore: OptInstanceList = None,
+ stage: str = 'init',
+ unmap_outputs: bool = True,
+ return_sampling_results: bool = False) -> tuple:
+ """Compute corresponding GT box and classification targets for
+ proposals.
+
+ Args:
+ proposals_list (list[Tensor]): Multi level points/bboxes of each
+ image.
+ valid_flag_list (list[Tensor]): Multi level valid flags of each
+ image.
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+ stage (str): 'init' or 'refine'. Generate target for init stage or
+ refine stage.
+ unmap_outputs (bool): Whether to map outputs back to the original
+ set of anchors.
+ return_sampling_results (bool): Whether to return the sampling
+ results. Defaults to False.
+
+ Returns:
+ tuple:
+
+ - labels_list (list[Tensor]): Labels of each level.
+ - label_weights_list (list[Tensor]): Label weights of each
+ level.
+ - bbox_gt_list (list[Tensor]): Ground truth bbox of each level.
+ - proposals_list (list[Tensor]): Proposals(points/bboxes) of
+ each level.
+ - proposal_weights_list (list[Tensor]): Proposal weights of
+ each level.
+ - avg_factor (int): Average factor that is used to average
+ the loss. When using sampling method, avg_factor is usually
+ the sum of positive and negative priors. When using
+ `PseudoSampler`, `avg_factor` is usually equal to the number
+ of positive priors.
+ """
+ assert stage in ['init', 'refine']
+ num_imgs = len(batch_img_metas)
+ assert len(proposals_list) == len(valid_flag_list) == num_imgs
+
+ # points number of multi levels
+ num_level_proposals = [points.size(0) for points in proposals_list[0]]
+
+ # concat all level points and flags to a single tensor
+ for i in range(num_imgs):
+ assert len(proposals_list[i]) == len(valid_flag_list[i])
+ proposals_list[i] = torch.cat(proposals_list[i])
+ valid_flag_list[i] = torch.cat(valid_flag_list[i])
+
+ if batch_gt_instances_ignore is None:
+ batch_gt_instances_ignore = [None] * num_imgs
+
+ (all_labels, all_label_weights, all_bbox_gt, all_proposals,
+ all_proposal_weights, pos_inds_list, neg_inds_list,
+ sampling_results_list) = multi_apply(
+ self._get_targets_single,
+ proposals_list,
+ valid_flag_list,
+ batch_gt_instances,
+ batch_gt_instances_ignore,
+ stage=stage,
+ unmap_outputs=unmap_outputs)
+
+ # sampled points of all images
+ avg_refactor = sum(
+ [results.avg_factor for results in sampling_results_list])
+ labels_list = images_to_levels(all_labels, num_level_proposals)
+ label_weights_list = images_to_levels(all_label_weights,
+ num_level_proposals)
+ bbox_gt_list = images_to_levels(all_bbox_gt, num_level_proposals)
+ proposals_list = images_to_levels(all_proposals, num_level_proposals)
+ proposal_weights_list = images_to_levels(all_proposal_weights,
+ num_level_proposals)
+ res = (labels_list, label_weights_list, bbox_gt_list, proposals_list,
+ proposal_weights_list, avg_refactor)
+ if return_sampling_results:
+ res = res + (sampling_results_list, )
+
+ return res
+
+ def loss_by_feat_single(self, cls_score: Tensor, pts_pred_init: Tensor,
+ pts_pred_refine: Tensor, labels: Tensor,
+ label_weights, bbox_gt_init: Tensor,
+ bbox_weights_init: Tensor, bbox_gt_refine: Tensor,
+ bbox_weights_refine: Tensor, stride: int,
+ avg_factor_init: int,
+ avg_factor_refine: int) -> Tuple[Tensor]:
+ """Calculate the loss of a single scale level based on the features
+ extracted by the detection head.
+
+ Args:
+ cls_score (Tensor): Box scores for each scale level
+ Has shape (N, num_classes, h_i, w_i).
+ pts_pred_init (Tensor): Points of shape
+ (batch_size, h_i * w_i, num_points * 2).
+ pts_pred_refine (Tensor): Points refined of shape
+ (batch_size, h_i * w_i, num_points * 2).
+ labels (Tensor): Ground truth class indices with shape
+ (batch_size, h_i * w_i).
+ label_weights (Tensor): Label weights of shape
+ (batch_size, h_i * w_i).
+ bbox_gt_init (Tensor): BBox regression targets in the init stage
+ of shape (batch_size, h_i * w_i, 4).
+ bbox_weights_init (Tensor): BBox regression loss weights in the
+ init stage of shape (batch_size, h_i * w_i, 4).
+ bbox_gt_refine (Tensor): BBox regression targets in the refine
+ stage of shape (batch_size, h_i * w_i, 4).
+ bbox_weights_refine (Tensor): BBox regression loss weights in the
+ refine stage of shape (batch_size, h_i * w_i, 4).
+ stride (int): Point stride.
+ avg_factor_init (int): Average factor that is used to average
+ the loss in the init stage.
+ avg_factor_refine (int): Average factor that is used to average
+ the loss in the refine stage.
+
+ Returns:
+ Tuple[Tensor]: loss components.
+ """
+ # classification loss
+ labels = labels.reshape(-1)
+ label_weights = label_weights.reshape(-1)
+ cls_score = cls_score.permute(0, 2, 3,
+ 1).reshape(-1, self.cls_out_channels)
+ cls_score = cls_score.contiguous()
+ loss_cls = self.loss_cls(
+ cls_score, labels, label_weights, avg_factor=avg_factor_refine)
+
+ # points loss
+ bbox_gt_init = bbox_gt_init.reshape(-1, 4)
+ bbox_weights_init = bbox_weights_init.reshape(-1, 4)
+ bbox_pred_init = self.points2bbox(
+ pts_pred_init.reshape(-1, 2 * self.num_points), y_first=False)
+ bbox_gt_refine = bbox_gt_refine.reshape(-1, 4)
+ bbox_weights_refine = bbox_weights_refine.reshape(-1, 4)
+ bbox_pred_refine = self.points2bbox(
+ pts_pred_refine.reshape(-1, 2 * self.num_points), y_first=False)
+ normalize_term = self.point_base_scale * stride
+ loss_pts_init = self.loss_bbox_init(
+ bbox_pred_init / normalize_term,
+ bbox_gt_init / normalize_term,
+ bbox_weights_init,
+ avg_factor=avg_factor_init)
+ loss_pts_refine = self.loss_bbox_refine(
+ bbox_pred_refine / normalize_term,
+ bbox_gt_refine / normalize_term,
+ bbox_weights_refine,
+ avg_factor=avg_factor_refine)
+ return loss_cls, loss_pts_init, loss_pts_refine
+
+ def loss_by_feat(
+ self,
+ cls_scores: List[Tensor],
+ pts_preds_init: List[Tensor],
+ pts_preds_refine: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ batch_gt_instances_ignore: OptInstanceList = None
+ ) -> Dict[str, Tensor]:
+ """Calculate the loss based on the features extracted by the detection
+ head.
+
+ Args:
+ cls_scores (list[Tensor]): Box scores for each scale level,
+ each is a 4D-tensor, of shape (batch_size, num_classes, h, w).
+ pts_preds_init (list[Tensor]): Points for each scale level, each is
+ a 3D-tensor, of shape (batch_size, h_i * w_i, num_points * 2).
+ pts_preds_refine (list[Tensor]): Points refined for each scale
+ level, each is a 3D-tensor, of shape
+ (batch_size, h_i * w_i, num_points * 2).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], Optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components.
+ """
+ featmap_sizes = [featmap.size()[-2:] for featmap in cls_scores]
+ device = cls_scores[0].device
+
+ # target for initial stage
+ center_list, valid_flag_list = self.get_points(featmap_sizes,
+ batch_img_metas, device)
+ pts_coordinate_preds_init = self.offset_to_pts(center_list,
+ pts_preds_init)
+ if self.train_cfg['init']['assigner']['type'] == 'PointAssigner':
+ # Assign target for center list
+ candidate_list = center_list
+ else:
+ # transform center list to bbox list and
+ # assign target for bbox list
+ bbox_list = self.centers_to_bboxes(center_list)
+ candidate_list = bbox_list
+ cls_reg_targets_init = self.get_targets(
+ proposals_list=candidate_list,
+ valid_flag_list=valid_flag_list,
+ batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas,
+ batch_gt_instances_ignore=batch_gt_instances_ignore,
+ stage='init',
+ return_sampling_results=False)
+ (*_, bbox_gt_list_init, candidate_list_init, bbox_weights_list_init,
+ avg_factor_init) = cls_reg_targets_init
+
+ # target for refinement stage
+ center_list, valid_flag_list = self.get_points(featmap_sizes,
+ batch_img_metas, device)
+ pts_coordinate_preds_refine = self.offset_to_pts(
+ center_list, pts_preds_refine)
+ bbox_list = []
+ for i_img, center in enumerate(center_list):
+ bbox = []
+ for i_lvl in range(len(pts_preds_refine)):
+ bbox_preds_init = self.points2bbox(
+ pts_preds_init[i_lvl].detach())
+ bbox_shift = bbox_preds_init * self.point_strides[i_lvl]
+ bbox_center = torch.cat(
+ [center[i_lvl][:, :2], center[i_lvl][:, :2]], dim=1)
+ bbox.append(bbox_center +
+ bbox_shift[i_img].permute(1, 2, 0).reshape(-1, 4))
+ bbox_list.append(bbox)
+ cls_reg_targets_refine = self.get_targets(
+ proposals_list=bbox_list,
+ valid_flag_list=valid_flag_list,
+ batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas,
+ batch_gt_instances_ignore=batch_gt_instances_ignore,
+ stage='refine',
+ return_sampling_results=False)
+ (labels_list, label_weights_list, bbox_gt_list_refine,
+ candidate_list_refine, bbox_weights_list_refine,
+ avg_factor_refine) = cls_reg_targets_refine
+
+ # compute loss
+ losses_cls, losses_pts_init, losses_pts_refine = multi_apply(
+ self.loss_by_feat_single,
+ cls_scores,
+ pts_coordinate_preds_init,
+ pts_coordinate_preds_refine,
+ labels_list,
+ label_weights_list,
+ bbox_gt_list_init,
+ bbox_weights_list_init,
+ bbox_gt_list_refine,
+ bbox_weights_list_refine,
+ self.point_strides,
+ avg_factor_init=avg_factor_init,
+ avg_factor_refine=avg_factor_refine)
+ loss_dict_all = {
+ 'loss_cls': losses_cls,
+ 'loss_pts_init': losses_pts_init,
+ 'loss_pts_refine': losses_pts_refine
+ }
+ return loss_dict_all
+
+ # Same as base_dense_head/_get_bboxes_single except self._bbox_decode
+ def _predict_by_feat_single(self,
+ cls_score_list: List[Tensor],
+ bbox_pred_list: List[Tensor],
+ score_factor_list: List[Tensor],
+ mlvl_priors: List[Tensor],
+ img_meta: dict,
+ cfg: ConfigDict,
+ rescale: bool = False,
+ with_nms: bool = True) -> InstanceData:
+ """Transform outputs of a single image into bbox predictions.
+
+ Args:
+ cls_score_list (list[Tensor]): Box scores from all scale
+ levels of a single image, each item has shape
+ (num_priors * num_classes, H, W).
+ bbox_pred_list (list[Tensor]): Box energies / deltas from
+ all scale levels of a single image, each item has shape
+ (num_priors * 4, H, W).
+ score_factor_list (list[Tensor]): Score factor from all scale
+ levels of a single image. RepPoints head does not need
+ this value.
+ mlvl_priors (list[Tensor]): Each element in the list is
+ the priors of a single level in feature pyramid, has shape
+ (num_priors, 2).
+ img_meta (dict): Image meta info.
+ cfg (:obj:`ConfigDict`): Test / postprocessing configuration,
+ if None, test_cfg would be used.
+ rescale (bool): If True, return boxes in original image space.
+ Defaults to False.
+ with_nms (bool): If True, do nms before return boxes.
+ Defaults to True.
+
+ Returns:
+ :obj:`InstanceData`: Detection results of each image
+ after the post process.
+ Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ """
+ cfg = self.test_cfg if cfg is None else cfg
+ assert len(cls_score_list) == len(bbox_pred_list)
+ img_shape = img_meta['img_shape']
+ nms_pre = cfg.get('nms_pre', -1)
+
+ mlvl_bboxes = []
+ mlvl_scores = []
+ mlvl_labels = []
+ for level_idx, (cls_score, bbox_pred, priors) in enumerate(
+ zip(cls_score_list, bbox_pred_list, mlvl_priors)):
+ assert cls_score.size()[-2:] == bbox_pred.size()[-2:]
+ bbox_pred = bbox_pred.permute(1, 2, 0).reshape(-1, 4)
+
+ cls_score = cls_score.permute(1, 2,
+ 0).reshape(-1, self.cls_out_channels)
+ if self.use_sigmoid_cls:
+ scores = cls_score.sigmoid()
+ else:
+ scores = cls_score.softmax(-1)[:, :-1]
+
+ # After https://github.com/open-mmlab/mmdetection/pull/6268/,
+ # this operation keeps fewer bboxes under the same `nms_pre`.
+ # There is no difference in performance for most models. If you
+ # find a slight drop in performance, you can set a larger
+ # `nms_pre` than before.
+ results = filter_scores_and_topk(
+ scores, cfg.score_thr, nms_pre,
+ dict(bbox_pred=bbox_pred, priors=priors))
+ scores, labels, _, filtered_results = results
+
+ bbox_pred = filtered_results['bbox_pred']
+ priors = filtered_results['priors']
+
+ bboxes = self._bbox_decode(priors, bbox_pred,
+ self.point_strides[level_idx],
+ img_shape)
+
+ mlvl_bboxes.append(bboxes)
+ mlvl_scores.append(scores)
+ mlvl_labels.append(labels)
+
+ results = InstanceData()
+ results.bboxes = torch.cat(mlvl_bboxes)
+ results.scores = torch.cat(mlvl_scores)
+ results.labels = torch.cat(mlvl_labels)
+
+ return self._bbox_post_process(
+ results=results,
+ cfg=cfg,
+ rescale=rescale,
+ with_nms=with_nms,
+ img_meta=img_meta)
+
+ def _bbox_decode(self, points: Tensor, bbox_pred: Tensor, stride: int,
+ max_shape: Tuple[int, int]) -> Tensor:
+ """Decode the prediction to bounding box.
+
+ Args:
+ points (Tensor): shape (h_i * w_i, 2).
+ bbox_pred (Tensor): shape (h_i * w_i, 4).
+ stride (int): Stride for bbox_pred in different level.
+ max_shape (Tuple[int, int]): image shape.
+
+ Returns:
+ Tensor: Bounding boxes decoded.
+ """
+ bbox_pos_center = torch.cat([points[:, :2], points[:, :2]], dim=1)
+ bboxes = bbox_pred * stride + bbox_pos_center
+ x1 = bboxes[:, 0].clamp(min=0, max=max_shape[1])
+ y1 = bboxes[:, 1].clamp(min=0, max=max_shape[0])
+ x2 = bboxes[:, 2].clamp(min=0, max=max_shape[1])
+ y2 = bboxes[:, 3].clamp(min=0, max=max_shape[0])
+ decoded_bboxes = torch.stack([x1, y1, x2, y2], dim=-1)
+ return decoded_bboxes
diff --git a/mmdet/models/dense_heads/retina_head.py b/mmdet/models/dense_heads/retina_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..be3ae74d81ba38609646f0d0406098ecbdcef688
--- /dev/null
+++ b/mmdet/models/dense_heads/retina_head.py
@@ -0,0 +1,120 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+
+from mmdet.registry import MODELS
+from .anchor_head import AnchorHead
+
+
+@MODELS.register_module()
+class RetinaHead(AnchorHead):
+ r"""An anchor-based head used in `RetinaNet
+ `_.
+
+ The head contains two subnetworks. The first classifies anchor boxes and
+ the second regresses deltas for the anchors.
+
+ Example:
+ >>> import torch
+ >>> self = RetinaHead(11, 7)
+ >>> x = torch.rand(1, 7, 32, 32)
+ >>> cls_score, bbox_pred = self.forward_single(x)
+ >>> # Each anchor predicts a score for each class except background
+ >>> cls_per_anchor = cls_score.shape[1] / self.num_anchors
+ >>> box_per_anchor = bbox_pred.shape[1] / self.num_anchors
+ >>> assert cls_per_anchor == (self.num_classes)
+ >>> assert box_per_anchor == 4
+ """
+
+ def __init__(self,
+ num_classes,
+ in_channels,
+ stacked_convs=4,
+ conv_cfg=None,
+ norm_cfg=None,
+ anchor_generator=dict(
+ type='AnchorGenerator',
+ octave_base_scale=4,
+ scales_per_octave=3,
+ ratios=[0.5, 1.0, 2.0],
+ strides=[8, 16, 32, 64, 128]),
+ init_cfg=dict(
+ type='Normal',
+ layer='Conv2d',
+ std=0.01,
+ override=dict(
+ type='Normal',
+ name='retina_cls',
+ std=0.01,
+ bias_prob=0.01)),
+ **kwargs):
+ assert stacked_convs >= 0, \
+ '`stacked_convs` must be non-negative integers, ' \
+ f'but got {stacked_convs} instead.'
+ self.stacked_convs = stacked_convs
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ super(RetinaHead, self).__init__(
+ num_classes,
+ in_channels,
+ anchor_generator=anchor_generator,
+ init_cfg=init_cfg,
+ **kwargs)
+
+ def _init_layers(self):
+ """Initialize layers of the head."""
+ self.relu = nn.ReLU(inplace=True)
+ self.cls_convs = nn.ModuleList()
+ self.reg_convs = nn.ModuleList()
+ in_channels = self.in_channels
+ for i in range(self.stacked_convs):
+ self.cls_convs.append(
+ ConvModule(
+ in_channels,
+ self.feat_channels,
+ 3,
+ stride=1,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg))
+ self.reg_convs.append(
+ ConvModule(
+ in_channels,
+ self.feat_channels,
+ 3,
+ stride=1,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg))
+ in_channels = self.feat_channels
+ self.retina_cls = nn.Conv2d(
+ in_channels,
+ self.num_base_priors * self.cls_out_channels,
+ 3,
+ padding=1)
+ reg_dim = self.bbox_coder.encode_size
+ self.retina_reg = nn.Conv2d(
+ in_channels, self.num_base_priors * reg_dim, 3, padding=1)
+
+ def forward_single(self, x):
+ """Forward feature of a single scale level.
+
+ Args:
+ x (Tensor): Features of a single scale level.
+
+ Returns:
+ tuple:
+ cls_score (Tensor): Cls scores for a single scale level
+ the channels number is num_anchors * num_classes.
+ bbox_pred (Tensor): Box energies / deltas for a single scale
+ level, the channels number is num_anchors * 4.
+ """
+ cls_feat = x
+ reg_feat = x
+ for cls_conv in self.cls_convs:
+ cls_feat = cls_conv(cls_feat)
+ for reg_conv in self.reg_convs:
+ reg_feat = reg_conv(reg_feat)
+ cls_score = self.retina_cls(cls_feat)
+ bbox_pred = self.retina_reg(reg_feat)
+ return cls_score, bbox_pred
diff --git a/mmdet/models/dense_heads/retina_sepbn_head.py b/mmdet/models/dense_heads/retina_sepbn_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..681a39983a08670adaa3e24a4099c4f26bc967ce
--- /dev/null
+++ b/mmdet/models/dense_heads/retina_sepbn_head.py
@@ -0,0 +1,127 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Tuple
+
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+from mmengine.model import bias_init_with_prob, normal_init
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.utils import OptConfigType, OptMultiConfig
+from .anchor_head import AnchorHead
+
+
+@MODELS.register_module()
+class RetinaSepBNHead(AnchorHead):
+ """"RetinaHead with separate BN.
+
+ In RetinaHead, conv/norm layers are shared across different FPN levels,
+ while in RetinaSepBNHead, conv layers are shared across different FPN
+ levels, but BN layers are separated.
+ """
+
+ def __init__(self,
+ num_classes: int,
+ num_ins: int,
+ in_channels: int,
+ stacked_convs: int = 4,
+ conv_cfg: OptConfigType = None,
+ norm_cfg: OptConfigType = None,
+ init_cfg: OptMultiConfig = None,
+ **kwargs) -> None:
+ assert init_cfg is None, 'To prevent abnormal initialization ' \
+ 'behavior, init_cfg is not allowed to be set'
+ self.stacked_convs = stacked_convs
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.num_ins = num_ins
+ super().__init__(
+ num_classes=num_classes,
+ in_channels=in_channels,
+ init_cfg=init_cfg,
+ **kwargs)
+
+ def _init_layers(self) -> None:
+ """Initialize layers of the head."""
+ self.relu = nn.ReLU(inplace=True)
+ self.cls_convs = nn.ModuleList()
+ self.reg_convs = nn.ModuleList()
+ for i in range(self.num_ins):
+ cls_convs = nn.ModuleList()
+ reg_convs = nn.ModuleList()
+ for j in range(self.stacked_convs):
+ chn = self.in_channels if j == 0 else self.feat_channels
+ cls_convs.append(
+ ConvModule(
+ chn,
+ self.feat_channels,
+ 3,
+ stride=1,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg))
+ reg_convs.append(
+ ConvModule(
+ chn,
+ self.feat_channels,
+ 3,
+ stride=1,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg))
+ self.cls_convs.append(cls_convs)
+ self.reg_convs.append(reg_convs)
+ for i in range(self.stacked_convs):
+ for j in range(1, self.num_ins):
+ self.cls_convs[j][i].conv = self.cls_convs[0][i].conv
+ self.reg_convs[j][i].conv = self.reg_convs[0][i].conv
+ self.retina_cls = nn.Conv2d(
+ self.feat_channels,
+ self.num_base_priors * self.cls_out_channels,
+ 3,
+ padding=1)
+ self.retina_reg = nn.Conv2d(
+ self.feat_channels, self.num_base_priors * 4, 3, padding=1)
+
+ def init_weights(self) -> None:
+ """Initialize weights of the head."""
+ super().init_weights()
+ for m in self.cls_convs[0]:
+ normal_init(m.conv, std=0.01)
+ for m in self.reg_convs[0]:
+ normal_init(m.conv, std=0.01)
+ bias_cls = bias_init_with_prob(0.01)
+ normal_init(self.retina_cls, std=0.01, bias=bias_cls)
+ normal_init(self.retina_reg, std=0.01)
+
+ def forward(self, feats: Tuple[Tensor]) -> tuple:
+ """Forward features from the upstream network.
+
+ Args:
+ feats (tuple[Tensor]): Features from the upstream network, each is
+ a 4D-tensor.
+
+ Returns:
+ tuple: Usually a tuple of classification scores and bbox prediction
+
+ - cls_scores (list[Tensor]): Classification scores for all
+ scale levels, each is a 4D-tensor, the channels number is
+ num_anchors * num_classes.
+ - bbox_preds (list[Tensor]): Box energies / deltas for all
+ scale levels, each is a 4D-tensor, the channels number is
+ num_anchors * 4.
+ """
+ cls_scores = []
+ bbox_preds = []
+ for i, x in enumerate(feats):
+ cls_feat = feats[i]
+ reg_feat = feats[i]
+ for cls_conv in self.cls_convs[i]:
+ cls_feat = cls_conv(cls_feat)
+ for reg_conv in self.reg_convs[i]:
+ reg_feat = reg_conv(reg_feat)
+ cls_score = self.retina_cls(cls_feat)
+ bbox_pred = self.retina_reg(reg_feat)
+ cls_scores.append(cls_score)
+ bbox_preds.append(bbox_pred)
+ return cls_scores, bbox_preds
diff --git a/mmdet/models/dense_heads/rpn_head.py b/mmdet/models/dense_heads/rpn_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..6b544009d2ffc4c3c9065707a0a8a72c577eb432
--- /dev/null
+++ b/mmdet/models/dense_heads/rpn_head.py
@@ -0,0 +1,302 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+from typing import List, Optional, Tuple
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule
+from mmcv.ops import batched_nms
+from mmengine.config import ConfigDict
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.structures.bbox import (cat_boxes, empty_box_as, get_box_tensor,
+ get_box_wh, scale_boxes)
+from mmdet.utils import InstanceList, MultiConfig, OptInstanceList
+from .anchor_head import AnchorHead
+
+
+@MODELS.register_module()
+class RPNHead(AnchorHead):
+ """Implementation of RPN head.
+
+ Args:
+ in_channels (int): Number of channels in the input feature map.
+ num_classes (int): Number of categories excluding the background
+ category. Defaults to 1.
+ init_cfg (:obj:`ConfigDict` or list[:obj:`ConfigDict`] or dict or \
+ list[dict]): Initialization config dict.
+ num_convs (int): Number of convolution layers in the head.
+ Defaults to 1.
+ """ # noqa: W605
+
+ def __init__(self,
+ in_channels: int,
+ num_classes: int = 1,
+ init_cfg: MultiConfig = dict(
+ type='Normal', layer='Conv2d', std=0.01),
+ num_convs: int = 1,
+ **kwargs) -> None:
+ self.num_convs = num_convs
+ assert num_classes == 1
+ super().__init__(
+ num_classes=num_classes,
+ in_channels=in_channels,
+ init_cfg=init_cfg,
+ **kwargs)
+
+ def _init_layers(self) -> None:
+ """Initialize layers of the head."""
+ if self.num_convs > 1:
+ rpn_convs = []
+ for i in range(self.num_convs):
+ if i == 0:
+ in_channels = self.in_channels
+ else:
+ in_channels = self.feat_channels
+ # use ``inplace=False`` to avoid error: one of the variables
+ # needed for gradient computation has been modified by an
+ # inplace operation.
+ rpn_convs.append(
+ ConvModule(
+ in_channels,
+ self.feat_channels,
+ 3,
+ padding=1,
+ inplace=False))
+ self.rpn_conv = nn.Sequential(*rpn_convs)
+ else:
+ self.rpn_conv = nn.Conv2d(
+ self.in_channels, self.feat_channels, 3, padding=1)
+ self.rpn_cls = nn.Conv2d(self.feat_channels,
+ self.num_base_priors * self.cls_out_channels,
+ 1)
+ reg_dim = self.bbox_coder.encode_size
+ self.rpn_reg = nn.Conv2d(self.feat_channels,
+ self.num_base_priors * reg_dim, 1)
+
+ def forward_single(self, x: Tensor) -> Tuple[Tensor, Tensor]:
+ """Forward feature of a single scale level.
+
+ Args:
+ x (Tensor): Features of a single scale level.
+
+ Returns:
+ tuple:
+ cls_score (Tensor): Cls scores for a single scale level \
+ the channels number is num_base_priors * num_classes.
+ bbox_pred (Tensor): Box energies / deltas for a single scale \
+ level, the channels number is num_base_priors * 4.
+ """
+ x = self.rpn_conv(x)
+ x = F.relu(x)
+ rpn_cls_score = self.rpn_cls(x)
+ rpn_bbox_pred = self.rpn_reg(x)
+ return rpn_cls_score, rpn_bbox_pred
+
+ def loss_by_feat(self,
+ cls_scores: List[Tensor],
+ bbox_preds: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ batch_gt_instances_ignore: OptInstanceList = None) \
+ -> dict:
+ """Calculate the loss based on the features extracted by the detection
+ head.
+
+ Args:
+ cls_scores (list[Tensor]): Box scores for each scale level,
+ has shape (N, num_anchors * num_classes, H, W).
+ bbox_preds (list[Tensor]): Box energies / deltas for each scale
+ level with shape (N, num_anchors * 4, H, W).
+ batch_gt_instances (list[obj:InstanceData]): Batch of gt_instance.
+ It usually includes ``bboxes`` and ``labels`` attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ batch_gt_instances_ignore (list[obj:InstanceData], Optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components.
+ """
+ losses = super().loss_by_feat(
+ cls_scores,
+ bbox_preds,
+ batch_gt_instances,
+ batch_img_metas,
+ batch_gt_instances_ignore=batch_gt_instances_ignore)
+ return dict(
+ loss_rpn_cls=losses['loss_cls'], loss_rpn_bbox=losses['loss_bbox'])
+
+ def _predict_by_feat_single(self,
+ cls_score_list: List[Tensor],
+ bbox_pred_list: List[Tensor],
+ score_factor_list: List[Tensor],
+ mlvl_priors: List[Tensor],
+ img_meta: dict,
+ cfg: ConfigDict,
+ rescale: bool = False,
+ with_nms: bool = True) -> InstanceData:
+ """Transform a single image's features extracted from the head into
+ bbox results.
+
+ Args:
+ cls_score_list (list[Tensor]): Box scores from all scale
+ levels of a single image, each item has shape
+ (num_priors * num_classes, H, W).
+ bbox_pred_list (list[Tensor]): Box energies / deltas from
+ all scale levels of a single image, each item has shape
+ (num_priors * 4, H, W).
+ score_factor_list (list[Tensor]): Be compatible with
+ BaseDenseHead. Not used in RPNHead.
+ mlvl_priors (list[Tensor]): Each element in the list is
+ the priors of a single level in feature pyramid. In all
+ anchor-based methods, it has shape (num_priors, 4). In
+ all anchor-free methods, it has shape (num_priors, 2)
+ when `with_stride=True`, otherwise it still has shape
+ (num_priors, 4).
+ img_meta (dict): Image meta info.
+ cfg (ConfigDict, optional): Test / postprocessing configuration,
+ if None, test_cfg would be used.
+ rescale (bool): If True, return boxes in original image space.
+ Defaults to False.
+
+ Returns:
+ :obj:`InstanceData`: Detection results of each image
+ after the post process.
+ Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ """
+ cfg = self.test_cfg if cfg is None else cfg
+ cfg = copy.deepcopy(cfg)
+ img_shape = img_meta['img_shape']
+ nms_pre = cfg.get('nms_pre', -1)
+
+ mlvl_bbox_preds = []
+ mlvl_valid_priors = []
+ mlvl_scores = []
+ level_ids = []
+ for level_idx, (cls_score, bbox_pred, priors) in \
+ enumerate(zip(cls_score_list, bbox_pred_list,
+ mlvl_priors)):
+ assert cls_score.size()[-2:] == bbox_pred.size()[-2:]
+
+ reg_dim = self.bbox_coder.encode_size
+ bbox_pred = bbox_pred.permute(1, 2, 0).reshape(-1, reg_dim)
+ cls_score = cls_score.permute(1, 2,
+ 0).reshape(-1, self.cls_out_channels)
+ if self.use_sigmoid_cls:
+ scores = cls_score.sigmoid()
+ else:
+ # remind that we set FG labels to [0] since mmdet v2.0
+ # BG cat_id: 1
+ scores = cls_score.softmax(-1)[:, :-1]
+
+ scores = torch.squeeze(scores)
+ if 0 < nms_pre < scores.shape[0]:
+ # sort is faster than topk
+ # _, topk_inds = scores.topk(cfg.nms_pre)
+ ranked_scores, rank_inds = scores.sort(descending=True)
+ topk_inds = rank_inds[:nms_pre]
+ scores = ranked_scores[:nms_pre]
+ bbox_pred = bbox_pred[topk_inds, :]
+ priors = priors[topk_inds]
+
+ mlvl_bbox_preds.append(bbox_pred)
+ mlvl_valid_priors.append(priors)
+ mlvl_scores.append(scores)
+
+ # use level id to implement the separate level nms
+ level_ids.append(
+ scores.new_full((scores.size(0), ),
+ level_idx,
+ dtype=torch.long))
+
+ bbox_pred = torch.cat(mlvl_bbox_preds)
+ priors = cat_boxes(mlvl_valid_priors)
+ bboxes = self.bbox_coder.decode(priors, bbox_pred, max_shape=img_shape)
+
+ results = InstanceData()
+ results.bboxes = bboxes
+ results.scores = torch.cat(mlvl_scores)
+ results.level_ids = torch.cat(level_ids)
+
+ return self._bbox_post_process(
+ results=results, cfg=cfg, rescale=rescale, img_meta=img_meta)
+
+ def _bbox_post_process(self,
+ results: InstanceData,
+ cfg: ConfigDict,
+ rescale: bool = False,
+ with_nms: bool = True,
+ img_meta: Optional[dict] = None) -> InstanceData:
+ """bbox post-processing method.
+
+ The boxes would be rescaled to the original image scale and do
+ the nms operation.
+
+ Args:
+ results (:obj:`InstaceData`): Detection instance results,
+ each item has shape (num_bboxes, ).
+ cfg (ConfigDict): Test / postprocessing configuration.
+ rescale (bool): If True, return boxes in original image space.
+ Defaults to False.
+ with_nms (bool): If True, do nms before return boxes.
+ Default to True.
+ img_meta (dict, optional): Image meta info. Defaults to None.
+
+ Returns:
+ :obj:`InstanceData`: Detection results of each image
+ after the post process.
+ Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ """
+ assert with_nms, '`with_nms` must be True in RPNHead'
+ if rescale:
+ assert img_meta.get('scale_factor') is not None
+ scale_factor = [1 / s for s in img_meta['scale_factor']]
+ results.bboxes = scale_boxes(results.bboxes, scale_factor)
+
+ # filter small size bboxes
+ if cfg.get('min_bbox_size', -1) >= 0:
+ w, h = get_box_wh(results.bboxes)
+ valid_mask = (w > cfg.min_bbox_size) & (h > cfg.min_bbox_size)
+ if not valid_mask.all():
+ results = results[valid_mask]
+
+ if results.bboxes.numel() > 0:
+ bboxes = get_box_tensor(results.bboxes)
+ det_bboxes, keep_idxs = batched_nms(bboxes, results.scores,
+ results.level_ids, cfg.nms)
+ results = results[keep_idxs]
+ # some nms would reweight the score, such as softnms
+ results.scores = det_bboxes[:, -1]
+ results = results[:cfg.max_per_img]
+ # TODO: This would unreasonably show the 0th class label
+ # in visualization
+ results.labels = results.scores.new_zeros(
+ len(results), dtype=torch.long)
+ del results.level_ids
+ else:
+ # To avoid some potential error
+ results_ = InstanceData()
+ results_.bboxes = empty_box_as(results.bboxes)
+ results_.scores = results.scores.new_zeros(0)
+ results_.labels = results.scores.new_zeros(0)
+ results = results_
+ return results
diff --git a/mmdet/models/dense_heads/rtmdet_head.py b/mmdet/models/dense_heads/rtmdet_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..ae0ee6d2f35a0fa46ba0b8de21054433d0420b65
--- /dev/null
+++ b/mmdet/models/dense_heads/rtmdet_head.py
@@ -0,0 +1,692 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Optional, Tuple, Union
+
+import torch
+import torch.nn as nn
+from mmcv.cnn import ConvModule, DepthwiseSeparableConvModule, Scale, is_norm
+from mmengine.model import bias_init_with_prob, constant_init, normal_init
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmdet.registry import MODELS, TASK_UTILS
+from mmdet.structures.bbox import distance2bbox
+from mmdet.utils import ConfigType, InstanceList, OptInstanceList, reduce_mean
+from ..layers.transformer import inverse_sigmoid
+from ..task_modules import anchor_inside_flags
+from ..utils import (images_to_levels, multi_apply, sigmoid_geometric_mean,
+ unmap)
+from .atss_head import ATSSHead
+
+
+@MODELS.register_module()
+class RTMDetHead(ATSSHead):
+ """Detection Head of RTMDet.
+
+ Args:
+ num_classes (int): Number of categories excluding the background
+ category.
+ in_channels (int): Number of channels in the input feature map.
+ with_objectness (bool): Whether to add an objectness branch.
+ Defaults to True.
+ act_cfg (:obj:`ConfigDict` or dict): Config dict for activation layer.
+ Default: dict(type='ReLU')
+ """
+
+ def __init__(self,
+ num_classes: int,
+ in_channels: int,
+ with_objectness: bool = True,
+ act_cfg: ConfigType = dict(type='ReLU'),
+ **kwargs) -> None:
+ self.act_cfg = act_cfg
+ self.with_objectness = with_objectness
+ super().__init__(num_classes, in_channels, **kwargs)
+ if self.train_cfg:
+ self.assigner = TASK_UTILS.build(self.train_cfg['assigner'])
+
+ def _init_layers(self):
+ """Initialize layers of the head."""
+ self.cls_convs = nn.ModuleList()
+ self.reg_convs = nn.ModuleList()
+ for i in range(self.stacked_convs):
+ chn = self.in_channels if i == 0 else self.feat_channels
+ self.cls_convs.append(
+ ConvModule(
+ chn,
+ self.feat_channels,
+ 3,
+ stride=1,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg))
+ self.reg_convs.append(
+ ConvModule(
+ chn,
+ self.feat_channels,
+ 3,
+ stride=1,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg))
+ pred_pad_size = self.pred_kernel_size // 2
+ self.rtm_cls = nn.Conv2d(
+ self.feat_channels,
+ self.num_base_priors * self.cls_out_channels,
+ self.pred_kernel_size,
+ padding=pred_pad_size)
+ self.rtm_reg = nn.Conv2d(
+ self.feat_channels,
+ self.num_base_priors * 4,
+ self.pred_kernel_size,
+ padding=pred_pad_size)
+ if self.with_objectness:
+ self.rtm_obj = nn.Conv2d(
+ self.feat_channels,
+ 1,
+ self.pred_kernel_size,
+ padding=pred_pad_size)
+
+ self.scales = nn.ModuleList(
+ [Scale(1.0) for _ in self.prior_generator.strides])
+
+ def init_weights(self) -> None:
+ """Initialize weights of the head."""
+ for m in self.modules():
+ if isinstance(m, nn.Conv2d):
+ normal_init(m, mean=0, std=0.01)
+ if is_norm(m):
+ constant_init(m, 1)
+ bias_cls = bias_init_with_prob(0.01)
+ normal_init(self.rtm_cls, std=0.01, bias=bias_cls)
+ normal_init(self.rtm_reg, std=0.01)
+ if self.with_objectness:
+ normal_init(self.rtm_obj, std=0.01, bias=bias_cls)
+
+ def forward(self, feats: Tuple[Tensor, ...]) -> tuple:
+ """Forward features from the upstream network.
+
+ Args:
+ feats (tuple[Tensor]): Features from the upstream network, each is
+ a 4D-tensor.
+
+ Returns:
+ tuple: Usually a tuple of classification scores and bbox prediction
+ - cls_scores (list[Tensor]): Classification scores for all scale
+ levels, each is a 4D-tensor, the channels number is
+ num_base_priors * num_classes.
+ - bbox_preds (list[Tensor]): Box energies / deltas for all scale
+ levels, each is a 4D-tensor, the channels number is
+ num_base_priors * 4.
+ """
+
+ cls_scores = []
+ bbox_preds = []
+ for idx, (x, scale, stride) in enumerate(
+ zip(feats, self.scales, self.prior_generator.strides)):
+ cls_feat = x
+ reg_feat = x
+
+ for cls_layer in self.cls_convs:
+ cls_feat = cls_layer(cls_feat)
+ cls_score = self.rtm_cls(cls_feat)
+
+ for reg_layer in self.reg_convs:
+ reg_feat = reg_layer(reg_feat)
+
+ if self.with_objectness:
+ objectness = self.rtm_obj(reg_feat)
+ cls_score = inverse_sigmoid(
+ sigmoid_geometric_mean(cls_score, objectness))
+
+ reg_dist = scale(self.rtm_reg(reg_feat).exp()).float() * stride[0]
+
+ cls_scores.append(cls_score)
+ bbox_preds.append(reg_dist)
+ return tuple(cls_scores), tuple(bbox_preds)
+
+ def loss_by_feat_single(self, cls_score: Tensor, bbox_pred: Tensor,
+ labels: Tensor, label_weights: Tensor,
+ bbox_targets: Tensor, assign_metrics: Tensor,
+ stride: List[int]):
+ """Compute loss of a single scale level.
+
+ Args:
+ cls_score (Tensor): Box scores for each scale level
+ Has shape (N, num_anchors * num_classes, H, W).
+ bbox_pred (Tensor): Decoded bboxes for each scale
+ level with shape (N, num_anchors * 4, H, W).
+ labels (Tensor): Labels of each anchors with shape
+ (N, num_total_anchors).
+ label_weights (Tensor): Label weights of each anchor with shape
+ (N, num_total_anchors).
+ bbox_targets (Tensor): BBox regression targets of each anchor with
+ shape (N, num_total_anchors, 4).
+ assign_metrics (Tensor): Assign metrics with shape
+ (N, num_total_anchors).
+ stride (List[int]): Downsample stride of the feature map.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components.
+ """
+ assert stride[0] == stride[1], 'h stride is not equal to w stride!'
+ cls_score = cls_score.permute(0, 2, 3, 1).reshape(
+ -1, self.cls_out_channels).contiguous()
+ bbox_pred = bbox_pred.reshape(-1, 4)
+ bbox_targets = bbox_targets.reshape(-1, 4)
+ labels = labels.reshape(-1)
+ assign_metrics = assign_metrics.reshape(-1)
+ label_weights = label_weights.reshape(-1)
+ targets = (labels, assign_metrics)
+
+ loss_cls = self.loss_cls(
+ cls_score, targets, label_weights, avg_factor=1.0)
+
+ # FG cat_id: [0, num_classes -1], BG cat_id: num_classes
+ bg_class_ind = self.num_classes
+ pos_inds = ((labels >= 0)
+ & (labels < bg_class_ind)).nonzero().squeeze(1)
+
+ if len(pos_inds) > 0:
+ pos_bbox_targets = bbox_targets[pos_inds]
+ pos_bbox_pred = bbox_pred[pos_inds]
+
+ pos_decode_bbox_pred = pos_bbox_pred
+ pos_decode_bbox_targets = pos_bbox_targets
+
+ # regression loss
+ pos_bbox_weight = assign_metrics[pos_inds]
+
+ loss_bbox = self.loss_bbox(
+ pos_decode_bbox_pred,
+ pos_decode_bbox_targets,
+ weight=pos_bbox_weight,
+ avg_factor=1.0)
+ else:
+ loss_bbox = bbox_pred.sum() * 0
+ pos_bbox_weight = bbox_targets.new_tensor(0.)
+
+ return loss_cls, loss_bbox, assign_metrics.sum(), pos_bbox_weight.sum()
+
+ def loss_by_feat(self,
+ cls_scores: List[Tensor],
+ bbox_preds: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ batch_gt_instances_ignore: OptInstanceList = None):
+ """Compute losses of the head.
+
+ Args:
+ cls_scores (list[Tensor]): Box scores for each scale level
+ Has shape (N, num_anchors * num_classes, H, W)
+ bbox_preds (list[Tensor]): Decoded box for each scale
+ level with shape (N, num_anchors * 4, H, W) in
+ [tl_x, tl_y, br_x, br_y] format.
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], Optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components.
+ """
+ num_imgs = len(batch_img_metas)
+ featmap_sizes = [featmap.size()[-2:] for featmap in cls_scores]
+ assert len(featmap_sizes) == self.prior_generator.num_levels
+
+ device = cls_scores[0].device
+ anchor_list, valid_flag_list = self.get_anchors(
+ featmap_sizes, batch_img_metas, device=device)
+ flatten_cls_scores = torch.cat([
+ cls_score.permute(0, 2, 3, 1).reshape(num_imgs, -1,
+ self.cls_out_channels)
+ for cls_score in cls_scores
+ ], 1)
+ decoded_bboxes = []
+ for anchor, bbox_pred in zip(anchor_list[0], bbox_preds):
+ anchor = anchor.reshape(-1, 4)
+ bbox_pred = bbox_pred.permute(0, 2, 3, 1).reshape(num_imgs, -1, 4)
+ bbox_pred = distance2bbox(anchor, bbox_pred)
+ decoded_bboxes.append(bbox_pred)
+
+ flatten_bboxes = torch.cat(decoded_bboxes, 1)
+
+ cls_reg_targets = self.get_targets(
+ flatten_cls_scores,
+ flatten_bboxes,
+ anchor_list,
+ valid_flag_list,
+ batch_gt_instances,
+ batch_img_metas,
+ batch_gt_instances_ignore=batch_gt_instances_ignore)
+ (anchor_list, labels_list, label_weights_list, bbox_targets_list,
+ assign_metrics_list, sampling_results_list) = cls_reg_targets
+
+ losses_cls, losses_bbox,\
+ cls_avg_factors, bbox_avg_factors = multi_apply(
+ self.loss_by_feat_single,
+ cls_scores,
+ decoded_bboxes,
+ labels_list,
+ label_weights_list,
+ bbox_targets_list,
+ assign_metrics_list,
+ self.prior_generator.strides)
+
+ cls_avg_factor = reduce_mean(sum(cls_avg_factors)).clamp_(min=1).item()
+ losses_cls = list(map(lambda x: x / cls_avg_factor, losses_cls))
+
+ bbox_avg_factor = reduce_mean(
+ sum(bbox_avg_factors)).clamp_(min=1).item()
+ losses_bbox = list(map(lambda x: x / bbox_avg_factor, losses_bbox))
+ return dict(loss_cls=losses_cls, loss_bbox=losses_bbox)
+
+ def get_targets(self,
+ cls_scores: Tensor,
+ bbox_preds: Tensor,
+ anchor_list: List[List[Tensor]],
+ valid_flag_list: List[List[Tensor]],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ batch_gt_instances_ignore: OptInstanceList = None,
+ unmap_outputs=True):
+ """Compute regression and classification targets for anchors in
+ multiple images.
+
+ Args:
+ cls_scores (Tensor): Classification predictions of images,
+ a 3D-Tensor with shape [num_imgs, num_priors, num_classes].
+ bbox_preds (Tensor): Decoded bboxes predictions of one image,
+ a 3D-Tensor with shape [num_imgs, num_priors, 4] in [tl_x,
+ tl_y, br_x, br_y] format.
+ anchor_list (list[list[Tensor]]): Multi level anchors of each
+ image. The outer list indicates images, and the inner list
+ corresponds to feature levels of the image. Each element of
+ the inner list is a tensor of shape (num_anchors, 4).
+ valid_flag_list (list[list[Tensor]]): Multi level valid flags of
+ each image. The outer list indicates images, and the inner list
+ corresponds to feature levels of the image. Each element of
+ the inner list is a tensor of shape (num_anchors, )
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], Optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+ unmap_outputs (bool): Whether to map outputs back to the original
+ set of anchors. Defaults to True.
+
+ Returns:
+ tuple: a tuple containing learning targets.
+
+ - anchors_list (list[list[Tensor]]): Anchors of each level.
+ - labels_list (list[Tensor]): Labels of each level.
+ - label_weights_list (list[Tensor]): Label weights of each
+ level.
+ - bbox_targets_list (list[Tensor]): BBox targets of each level.
+ - assign_metrics_list (list[Tensor]): alignment metrics of each
+ level.
+ """
+ num_imgs = len(batch_img_metas)
+ assert len(anchor_list) == len(valid_flag_list) == num_imgs
+
+ # anchor number of multi levels
+ num_level_anchors = [anchors.size(0) for anchors in anchor_list[0]]
+
+ # concat all level anchors and flags to a single tensor
+ for i in range(num_imgs):
+ assert len(anchor_list[i]) == len(valid_flag_list[i])
+ anchor_list[i] = torch.cat(anchor_list[i])
+ valid_flag_list[i] = torch.cat(valid_flag_list[i])
+
+ # compute targets for each image
+ if batch_gt_instances_ignore is None:
+ batch_gt_instances_ignore = [None] * num_imgs
+ # anchor_list: list(b * [-1, 4])
+ (all_anchors, all_labels, all_label_weights, all_bbox_targets,
+ all_assign_metrics, sampling_results_list) = multi_apply(
+ self._get_targets_single,
+ cls_scores.detach(),
+ bbox_preds.detach(),
+ anchor_list,
+ valid_flag_list,
+ batch_gt_instances,
+ batch_img_metas,
+ batch_gt_instances_ignore,
+ unmap_outputs=unmap_outputs)
+ # no valid anchors
+ if any([labels is None for labels in all_labels]):
+ return None
+
+ # split targets to a list w.r.t. multiple levels
+ anchors_list = images_to_levels(all_anchors, num_level_anchors)
+ labels_list = images_to_levels(all_labels, num_level_anchors)
+ label_weights_list = images_to_levels(all_label_weights,
+ num_level_anchors)
+ bbox_targets_list = images_to_levels(all_bbox_targets,
+ num_level_anchors)
+ assign_metrics_list = images_to_levels(all_assign_metrics,
+ num_level_anchors)
+
+ return (anchors_list, labels_list, label_weights_list,
+ bbox_targets_list, assign_metrics_list, sampling_results_list)
+
+ def _get_targets_single(self,
+ cls_scores: Tensor,
+ bbox_preds: Tensor,
+ flat_anchors: Tensor,
+ valid_flags: Tensor,
+ gt_instances: InstanceData,
+ img_meta: dict,
+ gt_instances_ignore: Optional[InstanceData] = None,
+ unmap_outputs=True):
+ """Compute regression, classification targets for anchors in a single
+ image.
+
+ Args:
+ cls_scores (list(Tensor)): Box scores for each image.
+ bbox_preds (list(Tensor)): Box energies / deltas for each image.
+ flat_anchors (Tensor): Multi-level anchors of the image, which are
+ concatenated into a single tensor of shape (num_anchors ,4)
+ valid_flags (Tensor): Multi level valid flags of the image,
+ which are concatenated into a single tensor of
+ shape (num_anchors,).
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ img_meta (dict): Meta information for current image.
+ gt_instances_ignore (:obj:`InstanceData`, optional): Instances
+ to be ignored during training. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+ unmap_outputs (bool): Whether to map outputs back to the original
+ set of anchors. Defaults to True.
+
+ Returns:
+ tuple: N is the number of total anchors in the image.
+
+ - anchors (Tensor): All anchors in the image with shape (N, 4).
+ - labels (Tensor): Labels of all anchors in the image with shape
+ (N,).
+ - label_weights (Tensor): Label weights of all anchor in the
+ image with shape (N,).
+ - bbox_targets (Tensor): BBox targets of all anchors in the
+ image with shape (N, 4).
+ - norm_alignment_metrics (Tensor): Normalized alignment metrics
+ of all priors in the image with shape (N,).
+ """
+ inside_flags = anchor_inside_flags(flat_anchors, valid_flags,
+ img_meta['img_shape'][:2],
+ self.train_cfg['allowed_border'])
+ if not inside_flags.any():
+ return (None, ) * 7
+ # assign gt and sample anchors
+ anchors = flat_anchors[inside_flags, :]
+
+ pred_instances = InstanceData(
+ scores=cls_scores[inside_flags, :],
+ bboxes=bbox_preds[inside_flags, :],
+ priors=anchors)
+
+ assign_result = self.assigner.assign(pred_instances, gt_instances,
+ gt_instances_ignore)
+
+ sampling_result = self.sampler.sample(assign_result, pred_instances,
+ gt_instances)
+
+ num_valid_anchors = anchors.shape[0]
+ bbox_targets = torch.zeros_like(anchors)
+ labels = anchors.new_full((num_valid_anchors, ),
+ self.num_classes,
+ dtype=torch.long)
+ label_weights = anchors.new_zeros(num_valid_anchors, dtype=torch.float)
+ assign_metrics = anchors.new_zeros(
+ num_valid_anchors, dtype=torch.float)
+
+ pos_inds = sampling_result.pos_inds
+ neg_inds = sampling_result.neg_inds
+ if len(pos_inds) > 0:
+ # point-based
+ pos_bbox_targets = sampling_result.pos_gt_bboxes
+ bbox_targets[pos_inds, :] = pos_bbox_targets
+
+ labels[pos_inds] = sampling_result.pos_gt_labels
+ if self.train_cfg['pos_weight'] <= 0:
+ label_weights[pos_inds] = 1.0
+ else:
+ label_weights[pos_inds] = self.train_cfg['pos_weight']
+ if len(neg_inds) > 0:
+ label_weights[neg_inds] = 1.0
+
+ class_assigned_gt_inds = torch.unique(
+ sampling_result.pos_assigned_gt_inds)
+ for gt_inds in class_assigned_gt_inds:
+ gt_class_inds = pos_inds[sampling_result.pos_assigned_gt_inds ==
+ gt_inds]
+ assign_metrics[gt_class_inds] = assign_result.max_overlaps[
+ gt_class_inds]
+
+ # map up to original set of anchors
+ if unmap_outputs:
+ num_total_anchors = flat_anchors.size(0)
+ anchors = unmap(anchors, num_total_anchors, inside_flags)
+ labels = unmap(
+ labels, num_total_anchors, inside_flags, fill=self.num_classes)
+ label_weights = unmap(label_weights, num_total_anchors,
+ inside_flags)
+ bbox_targets = unmap(bbox_targets, num_total_anchors, inside_flags)
+ assign_metrics = unmap(assign_metrics, num_total_anchors,
+ inside_flags)
+ return (anchors, labels, label_weights, bbox_targets, assign_metrics,
+ sampling_result)
+
+ def get_anchors(self,
+ featmap_sizes: List[tuple],
+ batch_img_metas: List[dict],
+ device: Union[torch.device, str] = 'cuda') \
+ -> Tuple[List[List[Tensor]], List[List[Tensor]]]:
+ """Get anchors according to feature map sizes.
+
+ Args:
+ featmap_sizes (list[tuple]): Multi-level feature map sizes.
+ batch_img_metas (list[dict]): Image meta info.
+ device (torch.device or str): Device for returned tensors.
+ Defaults to cuda.
+
+ Returns:
+ tuple:
+
+ - anchor_list (list[list[Tensor]]): Anchors of each image.
+ - valid_flag_list (list[list[Tensor]]): Valid flags of each
+ image.
+ """
+ num_imgs = len(batch_img_metas)
+
+ # since feature map sizes of all images are the same, we only compute
+ # anchors for one time
+ multi_level_anchors = self.prior_generator.grid_priors(
+ featmap_sizes, device=device, with_stride=True)
+ anchor_list = [multi_level_anchors for _ in range(num_imgs)]
+
+ # for each image, we compute valid flags of multi level anchors
+ valid_flag_list = []
+ for img_id, img_meta in enumerate(batch_img_metas):
+ multi_level_flags = self.prior_generator.valid_flags(
+ featmap_sizes, img_meta['pad_shape'], device)
+ valid_flag_list.append(multi_level_flags)
+ return anchor_list, valid_flag_list
+
+
+@MODELS.register_module()
+class RTMDetSepBNHead(RTMDetHead):
+ """RTMDetHead with separated BN layers and shared conv layers.
+
+ Args:
+ num_classes (int): Number of categories excluding the background
+ category.
+ in_channels (int): Number of channels in the input feature map.
+ share_conv (bool): Whether to share conv layers between stages.
+ Defaults to True.
+ use_depthwise (bool): Whether to use depthwise separable convolution in
+ head. Defaults to False.
+ norm_cfg (:obj:`ConfigDict` or dict)): Config dict for normalization
+ layer. Defaults to dict(type='BN', momentum=0.03, eps=0.001).
+ act_cfg (:obj:`ConfigDict` or dict)): Config dict for activation layer.
+ Defaults to dict(type='SiLU').
+ pred_kernel_size (int): Kernel size of prediction layer. Defaults to 1.
+ """
+
+ def __init__(self,
+ num_classes: int,
+ in_channels: int,
+ share_conv: bool = True,
+ use_depthwise: bool = False,
+ norm_cfg: ConfigType = dict(
+ type='BN', momentum=0.03, eps=0.001),
+ act_cfg: ConfigType = dict(type='SiLU'),
+ pred_kernel_size: int = 1,
+ exp_on_reg=False,
+ **kwargs) -> None:
+ self.share_conv = share_conv
+ self.exp_on_reg = exp_on_reg
+ self.use_depthwise = use_depthwise
+ super().__init__(
+ num_classes,
+ in_channels,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ pred_kernel_size=pred_kernel_size,
+ **kwargs)
+
+ def _init_layers(self) -> None:
+ """Initialize layers of the head."""
+ conv = DepthwiseSeparableConvModule \
+ if self.use_depthwise else ConvModule
+ self.cls_convs = nn.ModuleList()
+ self.reg_convs = nn.ModuleList()
+
+ self.rtm_cls = nn.ModuleList()
+ self.rtm_reg = nn.ModuleList()
+ if self.with_objectness:
+ self.rtm_obj = nn.ModuleList()
+ for n in range(len(self.prior_generator.strides)):
+ cls_convs = nn.ModuleList()
+ reg_convs = nn.ModuleList()
+ for i in range(self.stacked_convs):
+ chn = self.in_channels if i == 0 else self.feat_channels
+ cls_convs.append(
+ conv(
+ chn,
+ self.feat_channels,
+ 3,
+ stride=1,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg))
+ reg_convs.append(
+ conv(
+ chn,
+ self.feat_channels,
+ 3,
+ stride=1,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg))
+ self.cls_convs.append(cls_convs)
+ self.reg_convs.append(reg_convs)
+
+ self.rtm_cls.append(
+ nn.Conv2d(
+ self.feat_channels,
+ self.num_base_priors * self.cls_out_channels,
+ self.pred_kernel_size,
+ padding=self.pred_kernel_size // 2))
+ self.rtm_reg.append(
+ nn.Conv2d(
+ self.feat_channels,
+ self.num_base_priors * 4,
+ self.pred_kernel_size,
+ padding=self.pred_kernel_size // 2))
+ if self.with_objectness:
+ self.rtm_obj.append(
+ nn.Conv2d(
+ self.feat_channels,
+ 1,
+ self.pred_kernel_size,
+ padding=self.pred_kernel_size // 2))
+
+ if self.share_conv:
+ for n in range(len(self.prior_generator.strides)):
+ for i in range(self.stacked_convs):
+ self.cls_convs[n][i].conv = self.cls_convs[0][i].conv
+ self.reg_convs[n][i].conv = self.reg_convs[0][i].conv
+
+ def init_weights(self) -> None:
+ """Initialize weights of the head."""
+ for m in self.modules():
+ if isinstance(m, nn.Conv2d):
+ normal_init(m, mean=0, std=0.01)
+ if is_norm(m):
+ constant_init(m, 1)
+ bias_cls = bias_init_with_prob(0.01)
+ for rtm_cls, rtm_reg in zip(self.rtm_cls, self.rtm_reg):
+ normal_init(rtm_cls, std=0.01, bias=bias_cls)
+ normal_init(rtm_reg, std=0.01)
+ if self.with_objectness:
+ for rtm_obj in self.rtm_obj:
+ normal_init(rtm_obj, std=0.01, bias=bias_cls)
+
+ def forward(self, feats: Tuple[Tensor, ...]) -> tuple:
+ """Forward features from the upstream network.
+
+ Args:
+ feats (tuple[Tensor]): Features from the upstream network, each is
+ a 4D-tensor.
+
+ Returns:
+ tuple: Usually a tuple of classification scores and bbox prediction
+
+ - cls_scores (tuple[Tensor]): Classification scores for all scale
+ levels, each is a 4D-tensor, the channels number is
+ num_anchors * num_classes.
+ - bbox_preds (tuple[Tensor]): Box energies / deltas for all scale
+ levels, each is a 4D-tensor, the channels number is
+ num_anchors * 4.
+ """
+
+ cls_scores = []
+ bbox_preds = []
+ for idx, (x, stride) in enumerate(
+ zip(feats, self.prior_generator.strides)):
+ cls_feat = x
+ reg_feat = x
+
+ for cls_layer in self.cls_convs[idx]:
+ cls_feat = cls_layer(cls_feat)
+ cls_score = self.rtm_cls[idx](cls_feat)
+
+ for reg_layer in self.reg_convs[idx]:
+ reg_feat = reg_layer(reg_feat)
+
+ if self.with_objectness:
+ objectness = self.rtm_obj[idx](reg_feat)
+ cls_score = inverse_sigmoid(
+ sigmoid_geometric_mean(cls_score, objectness))
+ if self.exp_on_reg:
+ reg_dist = self.rtm_reg[idx](reg_feat).exp() * stride[0]
+ else:
+ reg_dist = self.rtm_reg[idx](reg_feat) * stride[0]
+ cls_scores.append(cls_score)
+ bbox_preds.append(reg_dist)
+ return tuple(cls_scores), tuple(bbox_preds)
diff --git a/mmdet/models/dense_heads/rtmdet_ins_head.py b/mmdet/models/dense_heads/rtmdet_ins_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..729a4492f0b40d0ad007822cc3ddb0ea0ae0faec
--- /dev/null
+++ b/mmdet/models/dense_heads/rtmdet_ins_head.py
@@ -0,0 +1,1034 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+import math
+from typing import List, Optional, Tuple
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule, is_norm
+from mmcv.ops import batched_nms
+from mmengine.model import (BaseModule, bias_init_with_prob, constant_init,
+ normal_init)
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmdet.models.layers.transformer import inverse_sigmoid
+from mmdet.models.utils import (filter_scores_and_topk, multi_apply,
+ select_single_mlvl, sigmoid_geometric_mean)
+from mmdet.registry import MODELS
+from mmdet.structures.bbox import (cat_boxes, distance2bbox, get_box_tensor,
+ get_box_wh, scale_boxes)
+from mmdet.utils import ConfigType, InstanceList, OptInstanceList, reduce_mean
+from .rtmdet_head import RTMDetHead
+
+
+@MODELS.register_module()
+class RTMDetInsHead(RTMDetHead):
+ """Detection Head of RTMDet-Ins.
+
+ Args:
+ num_prototypes (int): Number of mask prototype features extracted
+ from the mask head. Defaults to 8.
+ dyconv_channels (int): Channel of the dynamic conv layers.
+ Defaults to 8.
+ num_dyconvs (int): Number of the dynamic convolution layers.
+ Defaults to 3.
+ mask_loss_stride (int): Down sample stride of the masks for loss
+ computation. Defaults to 4.
+ loss_mask (:obj:`ConfigDict` or dict): Config dict for mask loss.
+ """
+
+ def __init__(self,
+ *args,
+ num_prototypes: int = 8,
+ dyconv_channels: int = 8,
+ num_dyconvs: int = 3,
+ mask_loss_stride: int = 4,
+ loss_mask=dict(
+ type='DiceLoss',
+ loss_weight=2.0,
+ eps=5e-6,
+ reduction='mean'),
+ **kwargs) -> None:
+ self.num_prototypes = num_prototypes
+ self.num_dyconvs = num_dyconvs
+ self.dyconv_channels = dyconv_channels
+ self.mask_loss_stride = mask_loss_stride
+ super().__init__(*args, **kwargs)
+ self.loss_mask = MODELS.build(loss_mask)
+
+ def _init_layers(self) -> None:
+ """Initialize layers of the head."""
+ super()._init_layers()
+ # a branch to predict kernels of dynamic convs
+ self.kernel_convs = nn.ModuleList()
+ # calculate num dynamic parameters
+ weight_nums, bias_nums = [], []
+ for i in range(self.num_dyconvs):
+ if i == 0:
+ weight_nums.append(
+ # mask prototype and coordinate features
+ (self.num_prototypes + 2) * self.dyconv_channels)
+ bias_nums.append(self.dyconv_channels * 1)
+ elif i == self.num_dyconvs - 1:
+ weight_nums.append(self.dyconv_channels * 1)
+ bias_nums.append(1)
+ else:
+ weight_nums.append(self.dyconv_channels * self.dyconv_channels)
+ bias_nums.append(self.dyconv_channels * 1)
+ self.weight_nums = weight_nums
+ self.bias_nums = bias_nums
+ self.num_gen_params = sum(weight_nums) + sum(bias_nums)
+
+ for i in range(self.stacked_convs):
+ chn = self.in_channels if i == 0 else self.feat_channels
+ self.kernel_convs.append(
+ ConvModule(
+ chn,
+ self.feat_channels,
+ 3,
+ stride=1,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg))
+ pred_pad_size = self.pred_kernel_size // 2
+ self.rtm_kernel = nn.Conv2d(
+ self.feat_channels,
+ self.num_gen_params,
+ self.pred_kernel_size,
+ padding=pred_pad_size)
+ self.mask_head = MaskFeatModule(
+ in_channels=self.in_channels,
+ feat_channels=self.feat_channels,
+ stacked_convs=4,
+ num_levels=len(self.prior_generator.strides),
+ num_prototypes=self.num_prototypes,
+ act_cfg=self.act_cfg,
+ norm_cfg=self.norm_cfg)
+
+ def forward(self, feats: Tuple[Tensor, ...]) -> tuple:
+ """Forward features from the upstream network.
+
+ Args:
+ feats (tuple[Tensor]): Features from the upstream network, each is
+ a 4D-tensor.
+
+ Returns:
+ tuple: Usually a tuple of classification scores and bbox prediction
+ - cls_scores (list[Tensor]): Classification scores for all scale
+ levels, each is a 4D-tensor, the channels number is
+ num_base_priors * num_classes.
+ - bbox_preds (list[Tensor]): Box energies / deltas for all scale
+ levels, each is a 4D-tensor, the channels number is
+ num_base_priors * 4.
+ - kernel_preds (list[Tensor]): Dynamic conv kernels for all scale
+ levels, each is a 4D-tensor, the channels number is
+ num_gen_params.
+ - mask_feat (Tensor): Output feature of the mask head. Each is a
+ 4D-tensor, the channels number is num_prototypes.
+ """
+ mask_feat = self.mask_head(feats)
+
+ cls_scores = []
+ bbox_preds = []
+ kernel_preds = []
+ for idx, (x, scale, stride) in enumerate(
+ zip(feats, self.scales, self.prior_generator.strides)):
+ cls_feat = x
+ reg_feat = x
+ kernel_feat = x
+
+ for cls_layer in self.cls_convs:
+ cls_feat = cls_layer(cls_feat)
+ cls_score = self.rtm_cls(cls_feat)
+
+ for kernel_layer in self.kernel_convs:
+ kernel_feat = kernel_layer(kernel_feat)
+ kernel_pred = self.rtm_kernel(kernel_feat)
+
+ for reg_layer in self.reg_convs:
+ reg_feat = reg_layer(reg_feat)
+
+ if self.with_objectness:
+ objectness = self.rtm_obj(reg_feat)
+ cls_score = inverse_sigmoid(
+ sigmoid_geometric_mean(cls_score, objectness))
+
+ reg_dist = scale(self.rtm_reg(reg_feat)) * stride[0]
+
+ cls_scores.append(cls_score)
+ bbox_preds.append(reg_dist)
+ kernel_preds.append(kernel_pred)
+ return tuple(cls_scores), tuple(bbox_preds), tuple(
+ kernel_preds), mask_feat
+
+ def predict_by_feat(self,
+ cls_scores: List[Tensor],
+ bbox_preds: List[Tensor],
+ kernel_preds: List[Tensor],
+ mask_feat: Tensor,
+ score_factors: Optional[List[Tensor]] = None,
+ batch_img_metas: Optional[List[dict]] = None,
+ cfg: Optional[ConfigType] = None,
+ rescale: bool = False,
+ with_nms: bool = True) -> InstanceList:
+ """Transform a batch of output features extracted from the head into
+ bbox results.
+
+ Note: When score_factors is not None, the cls_scores are
+ usually multiplied by it then obtain the real score used in NMS,
+ such as CenterNess in FCOS, IoU branch in ATSS.
+
+ Args:
+ cls_scores (list[Tensor]): Classification scores for all
+ scale levels, each is a 4D-tensor, has shape
+ (batch_size, num_priors * num_classes, H, W).
+ bbox_preds (list[Tensor]): Box energies / deltas for all
+ scale levels, each is a 4D-tensor, has shape
+ (batch_size, num_priors * 4, H, W).
+ kernel_preds (list[Tensor]): Kernel predictions of dynamic
+ convs for all scale levels, each is a 4D-tensor, has shape
+ (batch_size, num_params, H, W).
+ mask_feat (Tensor): Mask prototype features extracted from the
+ mask head, has shape (batch_size, num_prototypes, H, W).
+ score_factors (list[Tensor], optional): Score factor for
+ all scale level, each is a 4D-tensor, has shape
+ (batch_size, num_priors * 1, H, W). Defaults to None.
+ batch_img_metas (list[dict], Optional): Batch image meta info.
+ Defaults to None.
+ cfg (ConfigDict, optional): Test / postprocessing
+ configuration, if None, test_cfg would be used.
+ Defaults to None.
+ rescale (bool): If True, return boxes in original image space.
+ Defaults to False.
+ with_nms (bool): If True, do nms before return boxes.
+ Defaults to True.
+
+ Returns:
+ list[:obj:`InstanceData`]: Object detection results of each image
+ after the post process. Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ - masks (Tensor): Has a shape (num_instances, h, w).
+ """
+ assert len(cls_scores) == len(bbox_preds)
+
+ if score_factors is None:
+ # e.g. Retina, FreeAnchor, Foveabox, etc.
+ with_score_factors = False
+ else:
+ # e.g. FCOS, PAA, ATSS, AutoAssign, etc.
+ with_score_factors = True
+ assert len(cls_scores) == len(score_factors)
+
+ num_levels = len(cls_scores)
+
+ featmap_sizes = [cls_scores[i].shape[-2:] for i in range(num_levels)]
+ mlvl_priors = self.prior_generator.grid_priors(
+ featmap_sizes,
+ dtype=cls_scores[0].dtype,
+ device=cls_scores[0].device,
+ with_stride=True)
+
+ result_list = []
+
+ for img_id in range(len(batch_img_metas)):
+ img_meta = batch_img_metas[img_id]
+ cls_score_list = select_single_mlvl(
+ cls_scores, img_id, detach=True)
+ bbox_pred_list = select_single_mlvl(
+ bbox_preds, img_id, detach=True)
+ kernel_pred_list = select_single_mlvl(
+ kernel_preds, img_id, detach=True)
+ if with_score_factors:
+ score_factor_list = select_single_mlvl(
+ score_factors, img_id, detach=True)
+ else:
+ score_factor_list = [None for _ in range(num_levels)]
+
+ results = self._predict_by_feat_single(
+ cls_score_list=cls_score_list,
+ bbox_pred_list=bbox_pred_list,
+ kernel_pred_list=kernel_pred_list,
+ mask_feat=mask_feat[img_id],
+ score_factor_list=score_factor_list,
+ mlvl_priors=mlvl_priors,
+ img_meta=img_meta,
+ cfg=cfg,
+ rescale=rescale,
+ with_nms=with_nms)
+ result_list.append(results)
+ return result_list
+
+ def _predict_by_feat_single(self,
+ cls_score_list: List[Tensor],
+ bbox_pred_list: List[Tensor],
+ kernel_pred_list: List[Tensor],
+ mask_feat: Tensor,
+ score_factor_list: List[Tensor],
+ mlvl_priors: List[Tensor],
+ img_meta: dict,
+ cfg: ConfigType,
+ rescale: bool = False,
+ with_nms: bool = True) -> InstanceData:
+ """Transform a single image's features extracted from the head into
+ bbox and mask results.
+
+ Args:
+ cls_score_list (list[Tensor]): Box scores from all scale
+ levels of a single image, each item has shape
+ (num_priors * num_classes, H, W).
+ bbox_pred_list (list[Tensor]): Box energies / deltas from
+ all scale levels of a single image, each item has shape
+ (num_priors * 4, H, W).
+ kernel_preds (list[Tensor]): Kernel predictions of dynamic
+ convs for all scale levels of a single image, each is a
+ 4D-tensor, has shape (num_params, H, W).
+ mask_feat (Tensor): Mask prototype features of a single image
+ extracted from the mask head, has shape (num_prototypes, H, W).
+ score_factor_list (list[Tensor]): Score factor from all scale
+ levels of a single image, each item has shape
+ (num_priors * 1, H, W).
+ mlvl_priors (list[Tensor]): Each element in the list is
+ the priors of a single level in feature pyramid. In all
+ anchor-based methods, it has shape (num_priors, 4). In
+ all anchor-free methods, it has shape (num_priors, 2)
+ when `with_stride=True`, otherwise it still has shape
+ (num_priors, 4).
+ img_meta (dict): Image meta info.
+ cfg (mmengine.Config): Test / postprocessing configuration,
+ if None, test_cfg would be used.
+ rescale (bool): If True, return boxes in original image space.
+ Defaults to False.
+ with_nms (bool): If True, do nms before return boxes.
+ Defaults to True.
+
+ Returns:
+ :obj:`InstanceData`: Detection results of each image
+ after the post process.
+ Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ - masks (Tensor): Has a shape (num_instances, h, w).
+ """
+ if score_factor_list[0] is None:
+ # e.g. Retina, FreeAnchor, etc.
+ with_score_factors = False
+ else:
+ # e.g. FCOS, PAA, ATSS, etc.
+ with_score_factors = True
+
+ cfg = self.test_cfg if cfg is None else cfg
+ cfg = copy.deepcopy(cfg)
+ img_shape = img_meta['img_shape']
+ nms_pre = cfg.get('nms_pre', -1)
+
+ mlvl_bbox_preds = []
+ mlvl_kernels = []
+ mlvl_valid_priors = []
+ mlvl_scores = []
+ mlvl_labels = []
+ if with_score_factors:
+ mlvl_score_factors = []
+ else:
+ mlvl_score_factors = None
+
+ for level_idx, (cls_score, bbox_pred, kernel_pred,
+ score_factor, priors) in \
+ enumerate(zip(cls_score_list, bbox_pred_list, kernel_pred_list,
+ score_factor_list, mlvl_priors)):
+
+ assert cls_score.size()[-2:] == bbox_pred.size()[-2:]
+
+ dim = self.bbox_coder.encode_size
+ bbox_pred = bbox_pred.permute(1, 2, 0).reshape(-1, dim)
+ if with_score_factors:
+ score_factor = score_factor.permute(1, 2,
+ 0).reshape(-1).sigmoid()
+ cls_score = cls_score.permute(1, 2,
+ 0).reshape(-1, self.cls_out_channels)
+ kernel_pred = kernel_pred.permute(1, 2, 0).reshape(
+ -1, self.num_gen_params)
+ if self.use_sigmoid_cls:
+ scores = cls_score.sigmoid()
+ else:
+ # remind that we set FG labels to [0, num_class-1]
+ # since mmdet v2.0
+ # BG cat_id: num_class
+ scores = cls_score.softmax(-1)[:, :-1]
+
+ # After https://github.com/open-mmlab/mmdetection/pull/6268/,
+ # this operation keeps fewer bboxes under the same `nms_pre`.
+ # There is no difference in performance for most models. If you
+ # find a slight drop in performance, you can set a larger
+ # `nms_pre` than before.
+ score_thr = cfg.get('score_thr', 0)
+
+ results = filter_scores_and_topk(
+ scores, score_thr, nms_pre,
+ dict(
+ bbox_pred=bbox_pred,
+ priors=priors,
+ kernel_pred=kernel_pred))
+ scores, labels, keep_idxs, filtered_results = results
+
+ bbox_pred = filtered_results['bbox_pred']
+ priors = filtered_results['priors']
+ kernel_pred = filtered_results['kernel_pred']
+
+ if with_score_factors:
+ score_factor = score_factor[keep_idxs]
+
+ mlvl_bbox_preds.append(bbox_pred)
+ mlvl_valid_priors.append(priors)
+ mlvl_scores.append(scores)
+ mlvl_labels.append(labels)
+ mlvl_kernels.append(kernel_pred)
+
+ if with_score_factors:
+ mlvl_score_factors.append(score_factor)
+
+ bbox_pred = torch.cat(mlvl_bbox_preds)
+ priors = cat_boxes(mlvl_valid_priors)
+ bboxes = self.bbox_coder.decode(
+ priors[..., :2], bbox_pred, max_shape=img_shape)
+
+ results = InstanceData()
+ results.bboxes = bboxes
+ results.priors = priors
+ results.scores = torch.cat(mlvl_scores)
+ results.labels = torch.cat(mlvl_labels)
+ results.kernels = torch.cat(mlvl_kernels)
+ if with_score_factors:
+ results.score_factors = torch.cat(mlvl_score_factors)
+
+ return self._bbox_mask_post_process(
+ results=results,
+ mask_feat=mask_feat,
+ cfg=cfg,
+ rescale=rescale,
+ with_nms=with_nms,
+ img_meta=img_meta)
+
+ def _bbox_mask_post_process(
+ self,
+ results: InstanceData,
+ mask_feat,
+ cfg: ConfigType,
+ rescale: bool = False,
+ with_nms: bool = True,
+ img_meta: Optional[dict] = None) -> InstanceData:
+ """bbox and mask post-processing method.
+
+ The boxes would be rescaled to the original image scale and do
+ the nms operation. Usually `with_nms` is False is used for aug test.
+
+ Args:
+ results (:obj:`InstaceData`): Detection instance results,
+ each item has shape (num_bboxes, ).
+ cfg (ConfigDict): Test / postprocessing configuration,
+ if None, test_cfg would be used.
+ rescale (bool): If True, return boxes in original image space.
+ Default to False.
+ with_nms (bool): If True, do nms before return boxes.
+ Default to True.
+ img_meta (dict, optional): Image meta info. Defaults to None.
+
+ Returns:
+ :obj:`InstanceData`: Detection results of each image
+ after the post process.
+ Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ - masks (Tensor): Has a shape (num_instances, h, w).
+ """
+ stride = self.prior_generator.strides[0][0]
+ if rescale:
+ assert img_meta.get('scale_factor') is not None
+ scale_factor = [1 / s for s in img_meta['scale_factor']]
+ results.bboxes = scale_boxes(results.bboxes, scale_factor)
+
+ if hasattr(results, 'score_factors'):
+ # TODO: Add sqrt operation in order to be consistent with
+ # the paper.
+ score_factors = results.pop('score_factors')
+ results.scores = results.scores * score_factors
+
+ # filter small size bboxes
+ if cfg.get('min_bbox_size', -1) >= 0:
+ w, h = get_box_wh(results.bboxes)
+ valid_mask = (w > cfg.min_bbox_size) & (h > cfg.min_bbox_size)
+ if not valid_mask.all():
+ results = results[valid_mask]
+
+ # TODO: deal with `with_nms` and `nms_cfg=None` in test_cfg
+ assert with_nms, 'with_nms must be True for RTMDet-Ins'
+ if results.bboxes.numel() > 0:
+ bboxes = get_box_tensor(results.bboxes)
+ det_bboxes, keep_idxs = batched_nms(bboxes, results.scores,
+ results.labels, cfg.nms)
+ results = results[keep_idxs]
+ # some nms would reweight the score, such as softnms
+ results.scores = det_bboxes[:, -1]
+ results = results[:cfg.max_per_img]
+
+ # process masks
+ mask_logits = self._mask_predict_by_feat_single(
+ mask_feat, results.kernels, results.priors)
+
+ mask_logits = F.interpolate(
+ mask_logits.unsqueeze(0), scale_factor=stride, mode='bilinear')
+ if rescale:
+ ori_h, ori_w = img_meta['ori_shape'][:2]
+ mask_logits = F.interpolate(
+ mask_logits,
+ size=[
+ math.ceil(mask_logits.shape[-2] * scale_factor[0]),
+ math.ceil(mask_logits.shape[-1] * scale_factor[1])
+ ],
+ mode='bilinear',
+ align_corners=False)[..., :ori_h, :ori_w]
+ masks = mask_logits.sigmoid().squeeze(0)
+ masks = masks > cfg.mask_thr_binary
+ results.masks = masks
+ else:
+ h, w = img_meta['ori_shape'][:2] if rescale else img_meta[
+ 'img_shape'][:2]
+ results.masks = torch.zeros(
+ size=(results.bboxes.shape[0], h, w),
+ dtype=torch.bool,
+ device=results.bboxes.device)
+
+ return results
+
+ def parse_dynamic_params(self, flatten_kernels: Tensor) -> tuple:
+ """split kernel head prediction to conv weight and bias."""
+ n_inst = flatten_kernels.size(0)
+ n_layers = len(self.weight_nums)
+ params_splits = list(
+ torch.split_with_sizes(
+ flatten_kernels, self.weight_nums + self.bias_nums, dim=1))
+ weight_splits = params_splits[:n_layers]
+ bias_splits = params_splits[n_layers:]
+ for i in range(n_layers):
+ if i < n_layers - 1:
+ weight_splits[i] = weight_splits[i].reshape(
+ n_inst * self.dyconv_channels, -1, 1, 1)
+ bias_splits[i] = bias_splits[i].reshape(n_inst *
+ self.dyconv_channels)
+ else:
+ weight_splits[i] = weight_splits[i].reshape(n_inst, -1, 1, 1)
+ bias_splits[i] = bias_splits[i].reshape(n_inst)
+
+ return weight_splits, bias_splits
+
+ def _mask_predict_by_feat_single(self, mask_feat: Tensor, kernels: Tensor,
+ priors: Tensor) -> Tensor:
+ """Generate mask logits from mask features with dynamic convs.
+
+ Args:
+ mask_feat (Tensor): Mask prototype features.
+ Has shape (num_prototypes, H, W).
+ kernels (Tensor): Kernel parameters for each instance.
+ Has shape (num_instance, num_params)
+ priors (Tensor): Center priors for each instance.
+ Has shape (num_instance, 4).
+ Returns:
+ Tensor: Instance segmentation masks for each instance.
+ Has shape (num_instance, H, W).
+ """
+ num_inst = priors.shape[0]
+ h, w = mask_feat.size()[-2:]
+ if num_inst < 1:
+ return torch.empty(
+ size=(num_inst, h, w),
+ dtype=mask_feat.dtype,
+ device=mask_feat.device)
+ if len(mask_feat.shape) < 4:
+ mask_feat.unsqueeze(0)
+
+ coord = self.prior_generator.single_level_grid_priors(
+ (h, w), level_idx=0, device=mask_feat.device).reshape(1, -1, 2)
+ num_inst = priors.shape[0]
+ points = priors[:, :2].reshape(-1, 1, 2)
+ strides = priors[:, 2:].reshape(-1, 1, 2)
+ relative_coord = (points - coord).permute(0, 2, 1) / (
+ strides[..., 0].reshape(-1, 1, 1) * 8)
+ relative_coord = relative_coord.reshape(num_inst, 2, h, w)
+
+ mask_feat = torch.cat(
+ [relative_coord,
+ mask_feat.repeat(num_inst, 1, 1, 1)], dim=1)
+ weights, biases = self.parse_dynamic_params(kernels)
+
+ n_layers = len(weights)
+ x = mask_feat.reshape(1, -1, h, w)
+ for i, (weight, bias) in enumerate(zip(weights, biases)):
+ x = F.conv2d(
+ x, weight, bias=bias, stride=1, padding=0, groups=num_inst)
+ if i < n_layers - 1:
+ x = F.relu(x)
+ x = x.reshape(num_inst, h, w)
+ return x
+
+ def loss_mask_by_feat(self, mask_feats: Tensor, flatten_kernels: Tensor,
+ sampling_results_list: list,
+ batch_gt_instances: InstanceList) -> Tensor:
+ """Compute instance segmentation loss.
+
+ Args:
+ mask_feats (list[Tensor]): Mask prototype features extracted from
+ the mask head. Has shape (N, num_prototypes, H, W)
+ flatten_kernels (list[Tensor]): Kernels of the dynamic conv layers.
+ Has shape (N, num_instances, num_params)
+ sampling_results_list (list[:obj:`SamplingResults`]) Batch of
+ assignment results.
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+
+ Returns:
+ Tensor: The mask loss tensor.
+ """
+ batch_pos_mask_logits = []
+ pos_gt_masks = []
+ for idx, (mask_feat, kernels, sampling_results,
+ gt_instances) in enumerate(
+ zip(mask_feats, flatten_kernels, sampling_results_list,
+ batch_gt_instances)):
+ pos_priors = sampling_results.pos_priors
+ pos_inds = sampling_results.pos_inds
+ pos_kernels = kernels[pos_inds] # n_pos, num_gen_params
+ pos_mask_logits = self._mask_predict_by_feat_single(
+ mask_feat, pos_kernels, pos_priors)
+ if gt_instances.masks.numel() == 0:
+ gt_masks = torch.empty_like(gt_instances.masks)
+ else:
+ gt_masks = gt_instances.masks[
+ sampling_results.pos_assigned_gt_inds, :]
+ batch_pos_mask_logits.append(pos_mask_logits)
+ pos_gt_masks.append(gt_masks)
+
+ pos_gt_masks = torch.cat(pos_gt_masks, 0)
+ batch_pos_mask_logits = torch.cat(batch_pos_mask_logits, 0)
+
+ # avg_factor
+ num_pos = batch_pos_mask_logits.shape[0]
+ num_pos = reduce_mean(mask_feats.new_tensor([num_pos
+ ])).clamp_(min=1).item()
+
+ if batch_pos_mask_logits.shape[0] == 0:
+ return mask_feats.sum() * 0
+
+ scale = self.prior_generator.strides[0][0] // self.mask_loss_stride
+ # upsample pred masks
+ batch_pos_mask_logits = F.interpolate(
+ batch_pos_mask_logits.unsqueeze(0),
+ scale_factor=scale,
+ mode='bilinear',
+ align_corners=False).squeeze(0)
+ # downsample gt masks
+ pos_gt_masks = pos_gt_masks[:, self.mask_loss_stride //
+ 2::self.mask_loss_stride,
+ self.mask_loss_stride //
+ 2::self.mask_loss_stride]
+
+ loss_mask = self.loss_mask(
+ batch_pos_mask_logits,
+ pos_gt_masks,
+ weight=None,
+ avg_factor=num_pos)
+
+ return loss_mask
+
+ def loss_by_feat(self,
+ cls_scores: List[Tensor],
+ bbox_preds: List[Tensor],
+ kernel_preds: List[Tensor],
+ mask_feat: Tensor,
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ batch_gt_instances_ignore: OptInstanceList = None):
+ """Compute losses of the head.
+
+ Args:
+ cls_scores (list[Tensor]): Box scores for each scale level
+ Has shape (N, num_anchors * num_classes, H, W)
+ bbox_preds (list[Tensor]): Decoded box for each scale
+ level with shape (N, num_anchors * 4, H, W) in
+ [tl_x, tl_y, br_x, br_y] format.
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], Optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components.
+ """
+ num_imgs = len(batch_img_metas)
+ featmap_sizes = [featmap.size()[-2:] for featmap in cls_scores]
+ assert len(featmap_sizes) == self.prior_generator.num_levels
+
+ device = cls_scores[0].device
+ anchor_list, valid_flag_list = self.get_anchors(
+ featmap_sizes, batch_img_metas, device=device)
+ flatten_cls_scores = torch.cat([
+ cls_score.permute(0, 2, 3, 1).reshape(num_imgs, -1,
+ self.cls_out_channels)
+ for cls_score in cls_scores
+ ], 1)
+ flatten_kernels = torch.cat([
+ kernel_pred.permute(0, 2, 3, 1).reshape(num_imgs, -1,
+ self.num_gen_params)
+ for kernel_pred in kernel_preds
+ ], 1)
+ decoded_bboxes = []
+ for anchor, bbox_pred in zip(anchor_list[0], bbox_preds):
+ anchor = anchor.reshape(-1, 4)
+ bbox_pred = bbox_pred.permute(0, 2, 3, 1).reshape(num_imgs, -1, 4)
+ bbox_pred = distance2bbox(anchor, bbox_pred)
+ decoded_bboxes.append(bbox_pred)
+
+ flatten_bboxes = torch.cat(decoded_bboxes, 1)
+ for gt_instances in batch_gt_instances:
+ gt_instances.masks = gt_instances.masks.to_tensor(
+ dtype=torch.bool, device=device)
+
+ cls_reg_targets = self.get_targets(
+ flatten_cls_scores,
+ flatten_bboxes,
+ anchor_list,
+ valid_flag_list,
+ batch_gt_instances,
+ batch_img_metas,
+ batch_gt_instances_ignore=batch_gt_instances_ignore)
+ (anchor_list, labels_list, label_weights_list, bbox_targets_list,
+ assign_metrics_list, sampling_results_list) = cls_reg_targets
+
+ losses_cls, losses_bbox,\
+ cls_avg_factors, bbox_avg_factors = multi_apply(
+ self.loss_by_feat_single,
+ cls_scores,
+ decoded_bboxes,
+ labels_list,
+ label_weights_list,
+ bbox_targets_list,
+ assign_metrics_list,
+ self.prior_generator.strides)
+
+ cls_avg_factor = reduce_mean(sum(cls_avg_factors)).clamp_(min=1).item()
+ losses_cls = list(map(lambda x: x / cls_avg_factor, losses_cls))
+
+ bbox_avg_factor = reduce_mean(
+ sum(bbox_avg_factors)).clamp_(min=1).item()
+ losses_bbox = list(map(lambda x: x / bbox_avg_factor, losses_bbox))
+
+ loss_mask = self.loss_mask_by_feat(mask_feat, flatten_kernels,
+ sampling_results_list,
+ batch_gt_instances)
+ loss = dict(
+ loss_cls=losses_cls, loss_bbox=losses_bbox, loss_mask=loss_mask)
+ return loss
+
+
+class MaskFeatModule(BaseModule):
+ """Mask feature head used in RTMDet-Ins.
+
+ Args:
+ in_channels (int): Number of channels in the input feature map.
+ feat_channels (int): Number of hidden channels of the mask feature
+ map branch.
+ num_levels (int): The starting feature map level from RPN that
+ will be used to predict the mask feature map.
+ num_prototypes (int): Number of output channel of the mask feature
+ map branch. This is the channel count of the mask
+ feature map that to be dynamically convolved with the predicted
+ kernel.
+ stacked_convs (int): Number of convs in mask feature branch.
+ act_cfg (:obj:`ConfigDict` or dict): Config dict for activation layer.
+ Default: dict(type='ReLU', inplace=True)
+ norm_cfg (dict): Config dict for normalization layer. Default: None.
+ """
+
+ def __init__(
+ self,
+ in_channels: int,
+ feat_channels: int = 256,
+ stacked_convs: int = 4,
+ num_levels: int = 3,
+ num_prototypes: int = 8,
+ act_cfg: ConfigType = dict(type='ReLU', inplace=True),
+ norm_cfg: ConfigType = dict(type='BN')
+ ) -> None:
+ super().__init__(init_cfg=None)
+ self.num_levels = num_levels
+ self.fusion_conv = nn.Conv2d(num_levels * in_channels, in_channels, 1)
+ convs = []
+ for i in range(stacked_convs):
+ in_c = in_channels if i == 0 else feat_channels
+ convs.append(
+ ConvModule(
+ in_c,
+ feat_channels,
+ 3,
+ padding=1,
+ act_cfg=act_cfg,
+ norm_cfg=norm_cfg))
+ self.stacked_convs = nn.Sequential(*convs)
+ self.projection = nn.Conv2d(
+ feat_channels, num_prototypes, kernel_size=1)
+
+ def forward(self, features: Tuple[Tensor, ...]) -> Tensor:
+ # multi-level feature fusion
+ fusion_feats = [features[0]]
+ size = features[0].shape[-2:]
+ for i in range(1, self.num_levels):
+ f = F.interpolate(features[i], size=size, mode='bilinear')
+ fusion_feats.append(f)
+ fusion_feats = torch.cat(fusion_feats, dim=1)
+ fusion_feats = self.fusion_conv(fusion_feats)
+ # pred mask feats
+ mask_features = self.stacked_convs(fusion_feats)
+ mask_features = self.projection(mask_features)
+ return mask_features
+
+
+@MODELS.register_module()
+class RTMDetInsSepBNHead(RTMDetInsHead):
+ """Detection Head of RTMDet-Ins with sep-bn layers.
+
+ Args:
+ num_classes (int): Number of categories excluding the background
+ category.
+ in_channels (int): Number of channels in the input feature map.
+ share_conv (bool): Whether to share conv layers between stages.
+ Defaults to True.
+ norm_cfg (:obj:`ConfigDict` or dict)): Config dict for normalization
+ layer. Defaults to dict(type='BN').
+ act_cfg (:obj:`ConfigDict` or dict)): Config dict for activation layer.
+ Defaults to dict(type='SiLU', inplace=True).
+ pred_kernel_size (int): Kernel size of prediction layer. Defaults to 1.
+ """
+
+ def __init__(self,
+ num_classes: int,
+ in_channels: int,
+ share_conv: bool = True,
+ with_objectness: bool = False,
+ norm_cfg: ConfigType = dict(type='BN', requires_grad=True),
+ act_cfg: ConfigType = dict(type='SiLU', inplace=True),
+ pred_kernel_size: int = 1,
+ **kwargs) -> None:
+ self.share_conv = share_conv
+ super().__init__(
+ num_classes,
+ in_channels,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ pred_kernel_size=pred_kernel_size,
+ with_objectness=with_objectness,
+ **kwargs)
+
+ def _init_layers(self) -> None:
+ """Initialize layers of the head."""
+ self.cls_convs = nn.ModuleList()
+ self.reg_convs = nn.ModuleList()
+ self.kernel_convs = nn.ModuleList()
+
+ self.rtm_cls = nn.ModuleList()
+ self.rtm_reg = nn.ModuleList()
+ self.rtm_kernel = nn.ModuleList()
+ self.rtm_obj = nn.ModuleList()
+
+ # calculate num dynamic parameters
+ weight_nums, bias_nums = [], []
+ for i in range(self.num_dyconvs):
+ if i == 0:
+ weight_nums.append(
+ (self.num_prototypes + 2) * self.dyconv_channels)
+ bias_nums.append(self.dyconv_channels)
+ elif i == self.num_dyconvs - 1:
+ weight_nums.append(self.dyconv_channels)
+ bias_nums.append(1)
+ else:
+ weight_nums.append(self.dyconv_channels * self.dyconv_channels)
+ bias_nums.append(self.dyconv_channels)
+ self.weight_nums = weight_nums
+ self.bias_nums = bias_nums
+ self.num_gen_params = sum(weight_nums) + sum(bias_nums)
+ pred_pad_size = self.pred_kernel_size // 2
+
+ for n in range(len(self.prior_generator.strides)):
+ cls_convs = nn.ModuleList()
+ reg_convs = nn.ModuleList()
+ kernel_convs = nn.ModuleList()
+ for i in range(self.stacked_convs):
+ chn = self.in_channels if i == 0 else self.feat_channels
+ cls_convs.append(
+ ConvModule(
+ chn,
+ self.feat_channels,
+ 3,
+ stride=1,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg))
+ reg_convs.append(
+ ConvModule(
+ chn,
+ self.feat_channels,
+ 3,
+ stride=1,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg))
+ kernel_convs.append(
+ ConvModule(
+ chn,
+ self.feat_channels,
+ 3,
+ stride=1,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg))
+ self.cls_convs.append(cls_convs)
+ self.reg_convs.append(cls_convs)
+ self.kernel_convs.append(kernel_convs)
+
+ self.rtm_cls.append(
+ nn.Conv2d(
+ self.feat_channels,
+ self.num_base_priors * self.cls_out_channels,
+ self.pred_kernel_size,
+ padding=pred_pad_size))
+ self.rtm_reg.append(
+ nn.Conv2d(
+ self.feat_channels,
+ self.num_base_priors * 4,
+ self.pred_kernel_size,
+ padding=pred_pad_size))
+ self.rtm_kernel.append(
+ nn.Conv2d(
+ self.feat_channels,
+ self.num_gen_params,
+ self.pred_kernel_size,
+ padding=pred_pad_size))
+ if self.with_objectness:
+ self.rtm_obj.append(
+ nn.Conv2d(
+ self.feat_channels,
+ 1,
+ self.pred_kernel_size,
+ padding=pred_pad_size))
+
+ if self.share_conv:
+ for n in range(len(self.prior_generator.strides)):
+ for i in range(self.stacked_convs):
+ self.cls_convs[n][i].conv = self.cls_convs[0][i].conv
+ self.reg_convs[n][i].conv = self.reg_convs[0][i].conv
+
+ self.mask_head = MaskFeatModule(
+ in_channels=self.in_channels,
+ feat_channels=self.feat_channels,
+ stacked_convs=4,
+ num_levels=len(self.prior_generator.strides),
+ num_prototypes=self.num_prototypes,
+ act_cfg=self.act_cfg,
+ norm_cfg=self.norm_cfg)
+
+ def init_weights(self) -> None:
+ """Initialize weights of the head."""
+ for m in self.modules():
+ if isinstance(m, nn.Conv2d):
+ normal_init(m, mean=0, std=0.01)
+ if is_norm(m):
+ constant_init(m, 1)
+ bias_cls = bias_init_with_prob(0.01)
+ for rtm_cls, rtm_reg, rtm_kernel in zip(self.rtm_cls, self.rtm_reg,
+ self.rtm_kernel):
+ normal_init(rtm_cls, std=0.01, bias=bias_cls)
+ normal_init(rtm_reg, std=0.01, bias=1)
+ if self.with_objectness:
+ for rtm_obj in self.rtm_obj:
+ normal_init(rtm_obj, std=0.01, bias=bias_cls)
+
+ def forward(self, feats: Tuple[Tensor, ...]) -> tuple:
+ """Forward features from the upstream network.
+
+ Args:
+ feats (tuple[Tensor]): Features from the upstream network, each is
+ a 4D-tensor.
+
+ Returns:
+ tuple: Usually a tuple of classification scores and bbox prediction
+ - cls_scores (list[Tensor]): Classification scores for all scale
+ levels, each is a 4D-tensor, the channels number is
+ num_base_priors * num_classes.
+ - bbox_preds (list[Tensor]): Box energies / deltas for all scale
+ levels, each is a 4D-tensor, the channels number is
+ num_base_priors * 4.
+ - kernel_preds (list[Tensor]): Dynamic conv kernels for all scale
+ levels, each is a 4D-tensor, the channels number is
+ num_gen_params.
+ - mask_feat (Tensor): Output feature of the mask head. Each is a
+ 4D-tensor, the channels number is num_prototypes.
+ """
+ mask_feat = self.mask_head(feats)
+
+ cls_scores = []
+ bbox_preds = []
+ kernel_preds = []
+ for idx, (x, stride) in enumerate(
+ zip(feats, self.prior_generator.strides)):
+ cls_feat = x
+ reg_feat = x
+ kernel_feat = x
+
+ for cls_layer in self.cls_convs[idx]:
+ cls_feat = cls_layer(cls_feat)
+ cls_score = self.rtm_cls[idx](cls_feat)
+
+ for kernel_layer in self.kernel_convs[idx]:
+ kernel_feat = kernel_layer(kernel_feat)
+ kernel_pred = self.rtm_kernel[idx](kernel_feat)
+
+ for reg_layer in self.reg_convs[idx]:
+ reg_feat = reg_layer(reg_feat)
+
+ if self.with_objectness:
+ objectness = self.rtm_obj[idx](reg_feat)
+ cls_score = inverse_sigmoid(
+ sigmoid_geometric_mean(cls_score, objectness))
+
+ reg_dist = F.relu(self.rtm_reg[idx](reg_feat)) * stride[0]
+
+ cls_scores.append(cls_score)
+ bbox_preds.append(reg_dist)
+ kernel_preds.append(kernel_pred)
+ return tuple(cls_scores), tuple(bbox_preds), tuple(
+ kernel_preds), mask_feat
diff --git a/mmdet/models/dense_heads/sabl_retina_head.py b/mmdet/models/dense_heads/sabl_retina_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..8cd1b71cc2c80035a0378180da70caddf853375d
--- /dev/null
+++ b/mmdet/models/dense_heads/sabl_retina_head.py
@@ -0,0 +1,706 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Optional, Tuple, Union
+
+import numpy as np
+import torch
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+from mmengine.config import ConfigDict
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmdet.registry import MODELS, TASK_UTILS
+from mmdet.utils import (ConfigType, InstanceList, MultiConfig, OptConfigType,
+ OptInstanceList)
+from ..task_modules.samplers import PseudoSampler
+from ..utils import (filter_scores_and_topk, images_to_levels, multi_apply,
+ unmap)
+from .base_dense_head import BaseDenseHead
+from .guided_anchor_head import GuidedAnchorHead
+
+
+@MODELS.register_module()
+class SABLRetinaHead(BaseDenseHead):
+ """Side-Aware Boundary Localization (SABL) for RetinaNet.
+
+ The anchor generation, assigning and sampling in SABLRetinaHead
+ are the same as GuidedAnchorHead for guided anchoring.
+
+ Please refer to https://arxiv.org/abs/1912.04260 for more details.
+
+ Args:
+ num_classes (int): Number of classes.
+ in_channels (int): Number of channels in the input feature map.
+ stacked_convs (int): Number of Convs for classification and
+ regression branches. Defaults to 4.
+ feat_channels (int): Number of hidden channels. Defaults to 256.
+ approx_anchor_generator (:obj:`ConfigType` or dict): Config dict for
+ approx generator.
+ square_anchor_generator (:obj:`ConfigDict` or dict): Config dict for
+ square generator.
+ conv_cfg (:obj:`ConfigDict` or dict, optional): Config dict for
+ ConvModule. Defaults to None.
+ norm_cfg (:obj:`ConfigDict` or dict, optional): Config dict for
+ Norm Layer. Defaults to None.
+ bbox_coder (:obj:`ConfigDict` or dict): Config dict for bbox coder.
+ reg_decoded_bbox (bool): If true, the regression loss would be
+ applied directly on decoded bounding boxes, converting both
+ the predicted boxes and regression targets to absolute
+ coordinates format. Default False. It should be ``True`` when
+ using ``IoULoss``, ``GIoULoss``, or ``DIoULoss`` in the bbox head.
+ train_cfg (:obj:`ConfigDict` or dict, optional): Training config of
+ SABLRetinaHead.
+ test_cfg (:obj:`ConfigDict` or dict, optional): Testing config of
+ SABLRetinaHead.
+ loss_cls (:obj:`ConfigDict` or dict): Config of classification loss.
+ loss_bbox_cls (:obj:`ConfigDict` or dict): Config of classification
+ loss for bbox branch.
+ loss_bbox_reg (:obj:`ConfigDict` or dict): Config of regression loss
+ for bbox branch.
+ init_cfg (:obj:`ConfigDict` or dict or list[:obj:`ConfigDict` or \
+ dict], optional): Initialization config dict.
+ """
+
+ def __init__(
+ self,
+ num_classes: int,
+ in_channels: int,
+ stacked_convs: int = 4,
+ feat_channels: int = 256,
+ approx_anchor_generator: ConfigType = dict(
+ type='AnchorGenerator',
+ octave_base_scale=4,
+ scales_per_octave=3,
+ ratios=[0.5, 1.0, 2.0],
+ strides=[8, 16, 32, 64, 128]),
+ square_anchor_generator: ConfigType = dict(
+ type='AnchorGenerator',
+ ratios=[1.0],
+ scales=[4],
+ strides=[8, 16, 32, 64, 128]),
+ conv_cfg: OptConfigType = None,
+ norm_cfg: OptConfigType = None,
+ bbox_coder: ConfigType = dict(
+ type='BucketingBBoxCoder', num_buckets=14, scale_factor=3.0),
+ reg_decoded_bbox: bool = False,
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ loss_cls: ConfigType = dict(
+ type='FocalLoss',
+ use_sigmoid=True,
+ gamma=2.0,
+ alpha=0.25,
+ loss_weight=1.0),
+ loss_bbox_cls: ConfigType = dict(
+ type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.5),
+ loss_bbox_reg: ConfigType = dict(
+ type='SmoothL1Loss', beta=1.0 / 9.0, loss_weight=1.5),
+ init_cfg: MultiConfig = dict(
+ type='Normal',
+ layer='Conv2d',
+ std=0.01,
+ override=dict(
+ type='Normal', name='retina_cls', std=0.01, bias_prob=0.01))
+ ) -> None:
+ super().__init__(init_cfg=init_cfg)
+ self.in_channels = in_channels
+ self.num_classes = num_classes
+ self.feat_channels = feat_channels
+ self.num_buckets = bbox_coder['num_buckets']
+ self.side_num = int(np.ceil(self.num_buckets / 2))
+
+ assert (approx_anchor_generator['octave_base_scale'] ==
+ square_anchor_generator['scales'][0])
+ assert (approx_anchor_generator['strides'] ==
+ square_anchor_generator['strides'])
+
+ self.approx_anchor_generator = TASK_UTILS.build(
+ approx_anchor_generator)
+ self.square_anchor_generator = TASK_UTILS.build(
+ square_anchor_generator)
+ self.approxs_per_octave = (
+ self.approx_anchor_generator.num_base_priors[0])
+
+ # one anchor per location
+ self.num_base_priors = self.square_anchor_generator.num_base_priors[0]
+
+ self.stacked_convs = stacked_convs
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+
+ self.reg_decoded_bbox = reg_decoded_bbox
+
+ self.use_sigmoid_cls = loss_cls.get('use_sigmoid', False)
+ if self.use_sigmoid_cls:
+ self.cls_out_channels = num_classes
+ else:
+ self.cls_out_channels = num_classes + 1
+
+ self.bbox_coder = TASK_UTILS.build(bbox_coder)
+ self.loss_cls = MODELS.build(loss_cls)
+ self.loss_bbox_cls = MODELS.build(loss_bbox_cls)
+ self.loss_bbox_reg = MODELS.build(loss_bbox_reg)
+
+ self.train_cfg = train_cfg
+ self.test_cfg = test_cfg
+
+ if self.train_cfg:
+ self.assigner = TASK_UTILS.build(self.train_cfg['assigner'])
+ # use PseudoSampler when sampling is False
+ if 'sampler' in self.train_cfg:
+ self.sampler = TASK_UTILS.build(
+ self.train_cfg['sampler'], default_args=dict(context=self))
+ else:
+ self.sampler = PseudoSampler(context=self)
+
+ self._init_layers()
+
+ def _init_layers(self) -> None:
+ self.relu = nn.ReLU(inplace=True)
+ self.cls_convs = nn.ModuleList()
+ self.reg_convs = nn.ModuleList()
+ for i in range(self.stacked_convs):
+ chn = self.in_channels if i == 0 else self.feat_channels
+ self.cls_convs.append(
+ ConvModule(
+ chn,
+ self.feat_channels,
+ 3,
+ stride=1,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg))
+ self.reg_convs.append(
+ ConvModule(
+ chn,
+ self.feat_channels,
+ 3,
+ stride=1,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg))
+ self.retina_cls = nn.Conv2d(
+ self.feat_channels, self.cls_out_channels, 3, padding=1)
+ self.retina_bbox_reg = nn.Conv2d(
+ self.feat_channels, self.side_num * 4, 3, padding=1)
+ self.retina_bbox_cls = nn.Conv2d(
+ self.feat_channels, self.side_num * 4, 3, padding=1)
+
+ def forward_single(self, x: Tensor) -> Tuple[Tensor, Tensor]:
+ cls_feat = x
+ reg_feat = x
+ for cls_conv in self.cls_convs:
+ cls_feat = cls_conv(cls_feat)
+ for reg_conv in self.reg_convs:
+ reg_feat = reg_conv(reg_feat)
+ cls_score = self.retina_cls(cls_feat)
+ bbox_cls_pred = self.retina_bbox_cls(reg_feat)
+ bbox_reg_pred = self.retina_bbox_reg(reg_feat)
+ bbox_pred = (bbox_cls_pred, bbox_reg_pred)
+ return cls_score, bbox_pred
+
+ def forward(self, feats: List[Tensor]) -> Tuple[List[Tensor]]:
+ return multi_apply(self.forward_single, feats)
+
+ def get_anchors(
+ self,
+ featmap_sizes: List[tuple],
+ img_metas: List[dict],
+ device: Union[torch.device, str] = 'cuda'
+ ) -> Tuple[List[List[Tensor]], List[List[Tensor]]]:
+ """Get squares according to feature map sizes and guided anchors.
+
+ Args:
+ featmap_sizes (list[tuple]): Multi-level feature map sizes.
+ img_metas (list[dict]): Image meta info.
+ device (torch.device | str): device for returned tensors
+
+ Returns:
+ tuple: square approxs of each image
+ """
+ num_imgs = len(img_metas)
+
+ # since feature map sizes of all images are the same, we only compute
+ # squares for one time
+ multi_level_squares = self.square_anchor_generator.grid_priors(
+ featmap_sizes, device=device)
+ squares_list = [multi_level_squares for _ in range(num_imgs)]
+
+ return squares_list
+
+ def get_targets(self,
+ approx_list: List[List[Tensor]],
+ inside_flag_list: List[List[Tensor]],
+ square_list: List[List[Tensor]],
+ batch_gt_instances: InstanceList,
+ batch_img_metas,
+ batch_gt_instances_ignore: OptInstanceList = None,
+ unmap_outputs=True) -> tuple:
+ """Compute bucketing targets.
+
+ Args:
+ approx_list (list[list[Tensor]]): Multi level approxs of each
+ image.
+ inside_flag_list (list[list[Tensor]]): Multi level inside flags of
+ each image.
+ square_list (list[list[Tensor]]): Multi level squares of each
+ image.
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+ unmap_outputs (bool): Whether to map outputs back to the original
+ set of anchors. Defaults to True.
+
+ Returns:
+ tuple: Returns a tuple containing learning targets.
+
+ - labels_list (list[Tensor]): Labels of each level.
+ - label_weights_list (list[Tensor]): Label weights of each level.
+ - bbox_cls_targets_list (list[Tensor]): BBox cls targets of \
+ each level.
+ - bbox_cls_weights_list (list[Tensor]): BBox cls weights of \
+ each level.
+ - bbox_reg_targets_list (list[Tensor]): BBox reg targets of \
+ each level.
+ - bbox_reg_weights_list (list[Tensor]): BBox reg weights of \
+ each level.
+ - num_total_pos (int): Number of positive samples in all images.
+ - num_total_neg (int): Number of negative samples in all images.
+ """
+ num_imgs = len(batch_img_metas)
+ assert len(approx_list) == len(inside_flag_list) == len(
+ square_list) == num_imgs
+ # anchor number of multi levels
+ num_level_squares = [squares.size(0) for squares in square_list[0]]
+ # concat all level anchors and flags to a single tensor
+ inside_flag_flat_list = []
+ approx_flat_list = []
+ square_flat_list = []
+ for i in range(num_imgs):
+ assert len(square_list[i]) == len(inside_flag_list[i])
+ inside_flag_flat_list.append(torch.cat(inside_flag_list[i]))
+ approx_flat_list.append(torch.cat(approx_list[i]))
+ square_flat_list.append(torch.cat(square_list[i]))
+
+ # compute targets for each image
+ if batch_gt_instances_ignore is None:
+ batch_gt_instances_ignore = [None for _ in range(num_imgs)]
+ (all_labels, all_label_weights, all_bbox_cls_targets,
+ all_bbox_cls_weights, all_bbox_reg_targets, all_bbox_reg_weights,
+ pos_inds_list, neg_inds_list, sampling_results_list) = multi_apply(
+ self._get_targets_single,
+ approx_flat_list,
+ inside_flag_flat_list,
+ square_flat_list,
+ batch_gt_instances,
+ batch_img_metas,
+ batch_gt_instances_ignore,
+ unmap_outputs=unmap_outputs)
+
+ # sampled anchors of all images
+ avg_factor = sum(
+ [results.avg_factor for results in sampling_results_list])
+ # split targets to a list w.r.t. multiple levels
+ labels_list = images_to_levels(all_labels, num_level_squares)
+ label_weights_list = images_to_levels(all_label_weights,
+ num_level_squares)
+ bbox_cls_targets_list = images_to_levels(all_bbox_cls_targets,
+ num_level_squares)
+ bbox_cls_weights_list = images_to_levels(all_bbox_cls_weights,
+ num_level_squares)
+ bbox_reg_targets_list = images_to_levels(all_bbox_reg_targets,
+ num_level_squares)
+ bbox_reg_weights_list = images_to_levels(all_bbox_reg_weights,
+ num_level_squares)
+ return (labels_list, label_weights_list, bbox_cls_targets_list,
+ bbox_cls_weights_list, bbox_reg_targets_list,
+ bbox_reg_weights_list, avg_factor)
+
+ def _get_targets_single(self,
+ flat_approxs: Tensor,
+ inside_flags: Tensor,
+ flat_squares: Tensor,
+ gt_instances: InstanceData,
+ img_meta: dict,
+ gt_instances_ignore: Optional[InstanceData] = None,
+ unmap_outputs: bool = True) -> tuple:
+ """Compute regression and classification targets for anchors in a
+ single image.
+
+ Args:
+ flat_approxs (Tensor): flat approxs of a single image,
+ shape (n, 4)
+ inside_flags (Tensor): inside flags of a single image,
+ shape (n, ).
+ flat_squares (Tensor): flat squares of a single image,
+ shape (approxs_per_octave * n, 4)
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It should includes ``bboxes`` and ``labels``
+ attributes.
+ img_meta (dict): Meta information for current image.
+ gt_instances_ignore (:obj:`InstanceData`, optional): Instances
+ to be ignored during training. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+ unmap_outputs (bool): Whether to map outputs back to the original
+ set of anchors. Defaults to True.
+
+ Returns:
+ tuple:
+
+ - labels_list (Tensor): Labels in a single image.
+ - label_weights (Tensor): Label weights in a single image.
+ - bbox_cls_targets (Tensor): BBox cls targets in a single image.
+ - bbox_cls_weights (Tensor): BBox cls weights in a single image.
+ - bbox_reg_targets (Tensor): BBox reg targets in a single image.
+ - bbox_reg_weights (Tensor): BBox reg weights in a single image.
+ - num_total_pos (int): Number of positive samples in a single \
+ image.
+ - num_total_neg (int): Number of negative samples in a single \
+ image.
+ - sampling_result (:obj:`SamplingResult`): Sampling result object.
+ """
+ if not inside_flags.any():
+ raise ValueError(
+ 'There is no valid anchor inside the image boundary. Please '
+ 'check the image size and anchor sizes, or set '
+ '``allowed_border`` to -1 to skip the condition.')
+ # assign gt and sample anchors
+ num_square = flat_squares.size(0)
+ approxs = flat_approxs.view(num_square, self.approxs_per_octave, 4)
+ approxs = approxs[inside_flags, ...]
+ squares = flat_squares[inside_flags, :]
+
+ pred_instances = InstanceData()
+ pred_instances.priors = squares
+ pred_instances.approxs = approxs
+ assign_result = self.assigner.assign(pred_instances, gt_instances,
+ gt_instances_ignore)
+ sampling_result = self.sampler.sample(assign_result, pred_instances,
+ gt_instances)
+
+ num_valid_squares = squares.shape[0]
+ bbox_cls_targets = squares.new_zeros(
+ (num_valid_squares, self.side_num * 4))
+ bbox_cls_weights = squares.new_zeros(
+ (num_valid_squares, self.side_num * 4))
+ bbox_reg_targets = squares.new_zeros(
+ (num_valid_squares, self.side_num * 4))
+ bbox_reg_weights = squares.new_zeros(
+ (num_valid_squares, self.side_num * 4))
+ labels = squares.new_full((num_valid_squares, ),
+ self.num_classes,
+ dtype=torch.long)
+ label_weights = squares.new_zeros(num_valid_squares, dtype=torch.float)
+
+ pos_inds = sampling_result.pos_inds
+ neg_inds = sampling_result.neg_inds
+ if len(pos_inds) > 0:
+ (pos_bbox_reg_targets, pos_bbox_reg_weights, pos_bbox_cls_targets,
+ pos_bbox_cls_weights) = self.bbox_coder.encode(
+ sampling_result.pos_bboxes, sampling_result.pos_gt_bboxes)
+
+ bbox_cls_targets[pos_inds, :] = pos_bbox_cls_targets
+ bbox_reg_targets[pos_inds, :] = pos_bbox_reg_targets
+ bbox_cls_weights[pos_inds, :] = pos_bbox_cls_weights
+ bbox_reg_weights[pos_inds, :] = pos_bbox_reg_weights
+ labels[pos_inds] = sampling_result.pos_gt_labels
+ if self.train_cfg['pos_weight'] <= 0:
+ label_weights[pos_inds] = 1.0
+ else:
+ label_weights[pos_inds] = self.train_cfg['pos_weight']
+ if len(neg_inds) > 0:
+ label_weights[neg_inds] = 1.0
+
+ # map up to original set of anchors
+ if unmap_outputs:
+ num_total_anchors = flat_squares.size(0)
+ labels = unmap(
+ labels, num_total_anchors, inside_flags, fill=self.num_classes)
+ label_weights = unmap(label_weights, num_total_anchors,
+ inside_flags)
+ bbox_cls_targets = unmap(bbox_cls_targets, num_total_anchors,
+ inside_flags)
+ bbox_cls_weights = unmap(bbox_cls_weights, num_total_anchors,
+ inside_flags)
+ bbox_reg_targets = unmap(bbox_reg_targets, num_total_anchors,
+ inside_flags)
+ bbox_reg_weights = unmap(bbox_reg_weights, num_total_anchors,
+ inside_flags)
+ return (labels, label_weights, bbox_cls_targets, bbox_cls_weights,
+ bbox_reg_targets, bbox_reg_weights, pos_inds, neg_inds,
+ sampling_result)
+
+ def loss_by_feat_single(self, cls_score: Tensor, bbox_pred: Tensor,
+ labels: Tensor, label_weights: Tensor,
+ bbox_cls_targets: Tensor, bbox_cls_weights: Tensor,
+ bbox_reg_targets: Tensor, bbox_reg_weights: Tensor,
+ avg_factor: float) -> Tuple[Tensor]:
+ """Calculate the loss of a single scale level based on the features
+ extracted by the detection head.
+
+ Args:
+ cls_score (Tensor): Box scores for each scale level
+ Has shape (N, num_anchors * num_classes, H, W).
+ bbox_pred (Tensor): Box energies / deltas for each scale
+ level with shape (N, num_anchors * 4, H, W).
+ labels (Tensor): Labels in a single image.
+ label_weights (Tensor): Label weights in a single level.
+ bbox_cls_targets (Tensor): BBox cls targets in a single level.
+ bbox_cls_weights (Tensor): BBox cls weights in a single level.
+ bbox_reg_targets (Tensor): BBox reg targets in a single level.
+ bbox_reg_weights (Tensor): BBox reg weights in a single level.
+ avg_factor (int): Average factor that is used to average the loss.
+
+ Returns:
+ tuple: loss components.
+ """
+ # classification loss
+ labels = labels.reshape(-1)
+ label_weights = label_weights.reshape(-1)
+ cls_score = cls_score.permute(0, 2, 3,
+ 1).reshape(-1, self.cls_out_channels)
+ loss_cls = self.loss_cls(
+ cls_score, labels, label_weights, avg_factor=avg_factor)
+ # regression loss
+ bbox_cls_targets = bbox_cls_targets.reshape(-1, self.side_num * 4)
+ bbox_cls_weights = bbox_cls_weights.reshape(-1, self.side_num * 4)
+ bbox_reg_targets = bbox_reg_targets.reshape(-1, self.side_num * 4)
+ bbox_reg_weights = bbox_reg_weights.reshape(-1, self.side_num * 4)
+ (bbox_cls_pred, bbox_reg_pred) = bbox_pred
+ bbox_cls_pred = bbox_cls_pred.permute(0, 2, 3, 1).reshape(
+ -1, self.side_num * 4)
+ bbox_reg_pred = bbox_reg_pred.permute(0, 2, 3, 1).reshape(
+ -1, self.side_num * 4)
+ loss_bbox_cls = self.loss_bbox_cls(
+ bbox_cls_pred,
+ bbox_cls_targets.long(),
+ bbox_cls_weights,
+ avg_factor=avg_factor * 4 * self.side_num)
+ loss_bbox_reg = self.loss_bbox_reg(
+ bbox_reg_pred,
+ bbox_reg_targets,
+ bbox_reg_weights,
+ avg_factor=avg_factor * 4 * self.bbox_coder.offset_topk)
+ return loss_cls, loss_bbox_cls, loss_bbox_reg
+
+ def loss_by_feat(
+ self,
+ cls_scores: List[Tensor],
+ bbox_preds: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ batch_gt_instances_ignore: OptInstanceList = None) -> dict:
+ """Calculate the loss based on the features extracted by the detection
+ head.
+
+ Args:
+ cls_scores (list[Tensor]): Box scores for each scale level
+ has shape (N, num_anchors * num_classes, H, W).
+ bbox_preds (list[Tensor]): Box energies / deltas for each scale
+ level with shape (N, num_anchors * 4, H, W).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ dict: A dictionary of loss components.
+ """
+ featmap_sizes = [featmap.size()[-2:] for featmap in cls_scores]
+ assert len(featmap_sizes) == self.approx_anchor_generator.num_levels
+
+ device = cls_scores[0].device
+
+ # get sampled approxes
+ approxs_list, inside_flag_list = GuidedAnchorHead.get_sampled_approxs(
+ self, featmap_sizes, batch_img_metas, device=device)
+
+ square_list = self.get_anchors(
+ featmap_sizes, batch_img_metas, device=device)
+
+ cls_reg_targets = self.get_targets(
+ approxs_list,
+ inside_flag_list,
+ square_list,
+ batch_gt_instances,
+ batch_img_metas,
+ batch_gt_instances_ignore=batch_gt_instances_ignore)
+ (labels_list, label_weights_list, bbox_cls_targets_list,
+ bbox_cls_weights_list, bbox_reg_targets_list, bbox_reg_weights_list,
+ avg_factor) = cls_reg_targets
+
+ losses_cls, losses_bbox_cls, losses_bbox_reg = multi_apply(
+ self.loss_by_feat_single,
+ cls_scores,
+ bbox_preds,
+ labels_list,
+ label_weights_list,
+ bbox_cls_targets_list,
+ bbox_cls_weights_list,
+ bbox_reg_targets_list,
+ bbox_reg_weights_list,
+ avg_factor=avg_factor)
+ return dict(
+ loss_cls=losses_cls,
+ loss_bbox_cls=losses_bbox_cls,
+ loss_bbox_reg=losses_bbox_reg)
+
+ def predict_by_feat(self,
+ cls_scores: List[Tensor],
+ bbox_preds: List[Tensor],
+ batch_img_metas: List[dict],
+ cfg: Optional[ConfigDict] = None,
+ rescale: bool = False,
+ with_nms: bool = True) -> InstanceList:
+ """Transform a batch of output features extracted from the head into
+ bbox results.
+
+ Note: When score_factors is not None, the cls_scores are
+ usually multiplied by it then obtain the real score used in NMS,
+ such as CenterNess in FCOS, IoU branch in ATSS.
+
+ Args:
+ cls_scores (list[Tensor]): Classification scores for all
+ scale levels, each is a 4D-tensor, has shape
+ (batch_size, num_priors * num_classes, H, W).
+ bbox_preds (list[Tensor]): Box energies / deltas for all
+ scale levels, each is a 4D-tensor, has shape
+ (batch_size, num_priors * 4, H, W).
+ batch_img_metas (list[dict], Optional): Batch image meta info.
+ cfg (:obj:`ConfigDict`, optional): Test / postprocessing
+ configuration, if None, test_cfg would be used.
+ Defaults to None.
+ rescale (bool): If True, return boxes in original image space.
+ Defaults to False.
+ with_nms (bool): If True, do nms before return boxes.
+ Defaults to True.
+
+ Returns:
+ list[:obj:`InstanceData`]: Object detection results of each image
+ after the post process. Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ """
+ assert len(cls_scores) == len(bbox_preds)
+ num_levels = len(cls_scores)
+ featmap_sizes = [featmap.size()[-2:] for featmap in cls_scores]
+
+ device = cls_scores[0].device
+ mlvl_anchors = self.get_anchors(
+ featmap_sizes, batch_img_metas, device=device)
+ result_list = []
+ for img_id in range(len(batch_img_metas)):
+ cls_score_list = [
+ cls_scores[i][img_id].detach() for i in range(num_levels)
+ ]
+ bbox_cls_pred_list = [
+ bbox_preds[i][0][img_id].detach() for i in range(num_levels)
+ ]
+ bbox_reg_pred_list = [
+ bbox_preds[i][1][img_id].detach() for i in range(num_levels)
+ ]
+ proposals = self._predict_by_feat_single(
+ cls_scores=cls_score_list,
+ bbox_cls_preds=bbox_cls_pred_list,
+ bbox_reg_preds=bbox_reg_pred_list,
+ mlvl_anchors=mlvl_anchors[img_id],
+ img_meta=batch_img_metas[img_id],
+ cfg=cfg,
+ rescale=rescale,
+ with_nms=with_nms)
+ result_list.append(proposals)
+ return result_list
+
+ def _predict_by_feat_single(self,
+ cls_scores: List[Tensor],
+ bbox_cls_preds: List[Tensor],
+ bbox_reg_preds: List[Tensor],
+ mlvl_anchors: List[Tensor],
+ img_meta: dict,
+ cfg: ConfigDict,
+ rescale: bool = False,
+ with_nms: bool = True) -> InstanceData:
+ cfg = self.test_cfg if cfg is None else cfg
+ nms_pre = cfg.get('nms_pre', -1)
+
+ mlvl_bboxes = []
+ mlvl_scores = []
+ mlvl_confids = []
+ mlvl_labels = []
+ assert len(cls_scores) == len(bbox_cls_preds) == len(
+ bbox_reg_preds) == len(mlvl_anchors)
+ for cls_score, bbox_cls_pred, bbox_reg_pred, anchors in zip(
+ cls_scores, bbox_cls_preds, bbox_reg_preds, mlvl_anchors):
+ assert cls_score.size()[-2:] == bbox_cls_pred.size(
+ )[-2:] == bbox_reg_pred.size()[-2::]
+ cls_score = cls_score.permute(1, 2,
+ 0).reshape(-1, self.cls_out_channels)
+ if self.use_sigmoid_cls:
+ scores = cls_score.sigmoid()
+ else:
+ scores = cls_score.softmax(-1)[:, :-1]
+ bbox_cls_pred = bbox_cls_pred.permute(1, 2, 0).reshape(
+ -1, self.side_num * 4)
+ bbox_reg_pred = bbox_reg_pred.permute(1, 2, 0).reshape(
+ -1, self.side_num * 4)
+
+ # After https://github.com/open-mmlab/mmdetection/pull/6268/,
+ # this operation keeps fewer bboxes under the same `nms_pre`.
+ # There is no difference in performance for most models. If you
+ # find a slight drop in performance, you can set a larger
+ # `nms_pre` than before.
+ results = filter_scores_and_topk(
+ scores, cfg.score_thr, nms_pre,
+ dict(
+ anchors=anchors,
+ bbox_cls_pred=bbox_cls_pred,
+ bbox_reg_pred=bbox_reg_pred))
+ scores, labels, _, filtered_results = results
+
+ anchors = filtered_results['anchors']
+ bbox_cls_pred = filtered_results['bbox_cls_pred']
+ bbox_reg_pred = filtered_results['bbox_reg_pred']
+
+ bbox_preds = [
+ bbox_cls_pred.contiguous(),
+ bbox_reg_pred.contiguous()
+ ]
+ bboxes, confids = self.bbox_coder.decode(
+ anchors.contiguous(),
+ bbox_preds,
+ max_shape=img_meta['img_shape'])
+
+ mlvl_bboxes.append(bboxes)
+ mlvl_scores.append(scores)
+ mlvl_confids.append(confids)
+ mlvl_labels.append(labels)
+
+ results = InstanceData()
+ results.bboxes = torch.cat(mlvl_bboxes)
+ results.scores = torch.cat(mlvl_scores)
+ results.score_factors = torch.cat(mlvl_confids)
+ results.labels = torch.cat(mlvl_labels)
+
+ return self._bbox_post_process(
+ results=results,
+ cfg=cfg,
+ rescale=rescale,
+ with_nms=with_nms,
+ img_meta=img_meta)
diff --git a/mmdet/models/dense_heads/solo_head.py b/mmdet/models/dense_heads/solo_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..6444ed788c691dd458d73b1a9a801935e2081791
--- /dev/null
+++ b/mmdet/models/dense_heads/solo_head.py
@@ -0,0 +1,1262 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Optional, Tuple
+
+import mmcv
+import numpy as np
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmdet.models.utils.misc import floordiv
+from mmdet.registry import MODELS
+from mmdet.utils import ConfigType, InstanceList, MultiConfig, OptConfigType
+from ..layers import mask_matrix_nms
+from ..utils import center_of_mass, generate_coordinate, multi_apply
+from .base_mask_head import BaseMaskHead
+
+
+@MODELS.register_module()
+class SOLOHead(BaseMaskHead):
+ """SOLO mask head used in `SOLO: Segmenting Objects by Locations.
+
+ `_
+
+ Args:
+ num_classes (int): Number of categories excluding the background
+ category.
+ in_channels (int): Number of channels in the input feature map.
+ feat_channels (int): Number of hidden channels. Used in child classes.
+ Defaults to 256.
+ stacked_convs (int): Number of stacking convs of the head.
+ Defaults to 4.
+ strides (tuple): Downsample factor of each feature map.
+ scale_ranges (tuple[tuple[int, int]]): Area range of multiple
+ level masks, in the format [(min1, max1), (min2, max2), ...].
+ A range of (16, 64) means the area range between (16, 64).
+ pos_scale (float): Constant scale factor to control the center region.
+ num_grids (list[int]): Divided image into a uniform grids, each
+ feature map has a different grid value. The number of output
+ channels is grid ** 2. Defaults to [40, 36, 24, 16, 12].
+ cls_down_index (int): The index of downsample operation in
+ classification branch. Defaults to 0.
+ loss_mask (dict): Config of mask loss.
+ loss_cls (dict): Config of classification loss.
+ norm_cfg (dict): Dictionary to construct and config norm layer.
+ Defaults to norm_cfg=dict(type='GN', num_groups=32,
+ requires_grad=True).
+ train_cfg (dict): Training config of head.
+ test_cfg (dict): Testing config of head.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ """
+
+ def __init__(
+ self,
+ num_classes: int,
+ in_channels: int,
+ feat_channels: int = 256,
+ stacked_convs: int = 4,
+ strides: tuple = (4, 8, 16, 32, 64),
+ scale_ranges: tuple = ((8, 32), (16, 64), (32, 128), (64, 256), (128,
+ 512)),
+ pos_scale: float = 0.2,
+ num_grids: list = [40, 36, 24, 16, 12],
+ cls_down_index: int = 0,
+ loss_mask: ConfigType = dict(
+ type='DiceLoss', use_sigmoid=True, loss_weight=3.0),
+ loss_cls: ConfigType = dict(
+ type='FocalLoss',
+ use_sigmoid=True,
+ gamma=2.0,
+ alpha=0.25,
+ loss_weight=1.0),
+ norm_cfg: ConfigType = dict(
+ type='GN', num_groups=32, requires_grad=True),
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ init_cfg: MultiConfig = [
+ dict(type='Normal', layer='Conv2d', std=0.01),
+ dict(
+ type='Normal',
+ std=0.01,
+ bias_prob=0.01,
+ override=dict(name='conv_mask_list')),
+ dict(
+ type='Normal',
+ std=0.01,
+ bias_prob=0.01,
+ override=dict(name='conv_cls'))
+ ]
+ ) -> None:
+ super().__init__(init_cfg=init_cfg)
+ self.num_classes = num_classes
+ self.cls_out_channels = self.num_classes
+ self.in_channels = in_channels
+ self.feat_channels = feat_channels
+ self.stacked_convs = stacked_convs
+ self.strides = strides
+ self.num_grids = num_grids
+ # number of FPN feats
+ self.num_levels = len(strides)
+ assert self.num_levels == len(scale_ranges) == len(num_grids)
+ self.scale_ranges = scale_ranges
+ self.pos_scale = pos_scale
+
+ self.cls_down_index = cls_down_index
+ self.loss_cls = MODELS.build(loss_cls)
+ self.loss_mask = MODELS.build(loss_mask)
+ self.norm_cfg = norm_cfg
+ self.init_cfg = init_cfg
+ self.train_cfg = train_cfg
+ self.test_cfg = test_cfg
+ self._init_layers()
+
+ def _init_layers(self) -> None:
+ """Initialize layers of the head."""
+ self.mask_convs = nn.ModuleList()
+ self.cls_convs = nn.ModuleList()
+ for i in range(self.stacked_convs):
+ chn = self.in_channels + 2 if i == 0 else self.feat_channels
+ self.mask_convs.append(
+ ConvModule(
+ chn,
+ self.feat_channels,
+ 3,
+ stride=1,
+ padding=1,
+ norm_cfg=self.norm_cfg))
+ chn = self.in_channels if i == 0 else self.feat_channels
+ self.cls_convs.append(
+ ConvModule(
+ chn,
+ self.feat_channels,
+ 3,
+ stride=1,
+ padding=1,
+ norm_cfg=self.norm_cfg))
+ self.conv_mask_list = nn.ModuleList()
+ for num_grid in self.num_grids:
+ self.conv_mask_list.append(
+ nn.Conv2d(self.feat_channels, num_grid**2, 1))
+
+ self.conv_cls = nn.Conv2d(
+ self.feat_channels, self.cls_out_channels, 3, padding=1)
+
+ def resize_feats(self, x: Tuple[Tensor]) -> List[Tensor]:
+ """Downsample the first feat and upsample last feat in feats.
+
+ Args:
+ x (tuple[Tensor]): Features from the upstream network, each is
+ a 4D-tensor.
+
+ Returns:
+ list[Tensor]: Features after resizing, each is a 4D-tensor.
+ """
+ out = []
+ for i in range(len(x)):
+ if i == 0:
+ out.append(
+ F.interpolate(x[0], scale_factor=0.5, mode='bilinear'))
+ elif i == len(x) - 1:
+ out.append(
+ F.interpolate(
+ x[i], size=x[i - 1].shape[-2:], mode='bilinear'))
+ else:
+ out.append(x[i])
+ return out
+
+ def forward(self, x: Tuple[Tensor]) -> tuple:
+ """Forward features from the upstream network.
+
+ Args:
+ x (tuple[Tensor]): Features from the upstream network, each is
+ a 4D-tensor.
+
+ Returns:
+ tuple: A tuple of classification scores and mask prediction.
+
+ - mlvl_mask_preds (list[Tensor]): Multi-level mask prediction.
+ Each element in the list has shape
+ (batch_size, num_grids**2 ,h ,w).
+ - mlvl_cls_preds (list[Tensor]): Multi-level scores.
+ Each element in the list has shape
+ (batch_size, num_classes, num_grids ,num_grids).
+ """
+ assert len(x) == self.num_levels
+ feats = self.resize_feats(x)
+ mlvl_mask_preds = []
+ mlvl_cls_preds = []
+ for i in range(self.num_levels):
+ x = feats[i]
+ mask_feat = x
+ cls_feat = x
+ # generate and concat the coordinate
+ coord_feat = generate_coordinate(mask_feat.size(),
+ mask_feat.device)
+ mask_feat = torch.cat([mask_feat, coord_feat], 1)
+
+ for mask_layer in (self.mask_convs):
+ mask_feat = mask_layer(mask_feat)
+
+ mask_feat = F.interpolate(
+ mask_feat, scale_factor=2, mode='bilinear')
+ mask_preds = self.conv_mask_list[i](mask_feat)
+
+ # cls branch
+ for j, cls_layer in enumerate(self.cls_convs):
+ if j == self.cls_down_index:
+ num_grid = self.num_grids[i]
+ cls_feat = F.interpolate(
+ cls_feat, size=num_grid, mode='bilinear')
+ cls_feat = cls_layer(cls_feat)
+
+ cls_pred = self.conv_cls(cls_feat)
+
+ if not self.training:
+ feat_wh = feats[0].size()[-2:]
+ upsampled_size = (feat_wh[0] * 2, feat_wh[1] * 2)
+ mask_preds = F.interpolate(
+ mask_preds.sigmoid(), size=upsampled_size, mode='bilinear')
+ cls_pred = cls_pred.sigmoid()
+ # get local maximum
+ local_max = F.max_pool2d(cls_pred, 2, stride=1, padding=1)
+ keep_mask = local_max[:, :, :-1, :-1] == cls_pred
+ cls_pred = cls_pred * keep_mask
+
+ mlvl_mask_preds.append(mask_preds)
+ mlvl_cls_preds.append(cls_pred)
+ return mlvl_mask_preds, mlvl_cls_preds
+
+ def loss_by_feat(self, mlvl_mask_preds: List[Tensor],
+ mlvl_cls_preds: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict], **kwargs) -> dict:
+ """Calculate the loss based on the features extracted by the mask head.
+
+ Args:
+ mlvl_mask_preds (list[Tensor]): Multi-level mask prediction.
+ Each element in the list has shape
+ (batch_size, num_grids**2 ,h ,w).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes``, ``masks``,
+ and ``labels`` attributes.
+ batch_img_metas (list[dict]): Meta information of multiple images.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components.
+ """
+ num_levels = self.num_levels
+ num_imgs = len(batch_img_metas)
+
+ featmap_sizes = [featmap.size()[-2:] for featmap in mlvl_mask_preds]
+
+ # `BoolTensor` in `pos_masks` represent
+ # whether the corresponding point is
+ # positive
+ pos_mask_targets, labels, pos_masks = multi_apply(
+ self._get_targets_single,
+ batch_gt_instances,
+ featmap_sizes=featmap_sizes)
+
+ # change from the outside list meaning multi images
+ # to the outside list meaning multi levels
+ mlvl_pos_mask_targets = [[] for _ in range(num_levels)]
+ mlvl_pos_mask_preds = [[] for _ in range(num_levels)]
+ mlvl_pos_masks = [[] for _ in range(num_levels)]
+ mlvl_labels = [[] for _ in range(num_levels)]
+ for img_id in range(num_imgs):
+ assert num_levels == len(pos_mask_targets[img_id])
+ for lvl in range(num_levels):
+ mlvl_pos_mask_targets[lvl].append(
+ pos_mask_targets[img_id][lvl])
+ mlvl_pos_mask_preds[lvl].append(
+ mlvl_mask_preds[lvl][img_id, pos_masks[img_id][lvl], ...])
+ mlvl_pos_masks[lvl].append(pos_masks[img_id][lvl].flatten())
+ mlvl_labels[lvl].append(labels[img_id][lvl].flatten())
+
+ # cat multiple image
+ temp_mlvl_cls_preds = []
+ for lvl in range(num_levels):
+ mlvl_pos_mask_targets[lvl] = torch.cat(
+ mlvl_pos_mask_targets[lvl], dim=0)
+ mlvl_pos_mask_preds[lvl] = torch.cat(
+ mlvl_pos_mask_preds[lvl], dim=0)
+ mlvl_pos_masks[lvl] = torch.cat(mlvl_pos_masks[lvl], dim=0)
+ mlvl_labels[lvl] = torch.cat(mlvl_labels[lvl], dim=0)
+ temp_mlvl_cls_preds.append(mlvl_cls_preds[lvl].permute(
+ 0, 2, 3, 1).reshape(-1, self.cls_out_channels))
+
+ num_pos = sum(item.sum() for item in mlvl_pos_masks)
+ # dice loss
+ loss_mask = []
+ for pred, target in zip(mlvl_pos_mask_preds, mlvl_pos_mask_targets):
+ if pred.size()[0] == 0:
+ loss_mask.append(pred.sum().unsqueeze(0))
+ continue
+ loss_mask.append(
+ self.loss_mask(pred, target, reduction_override='none'))
+ if num_pos > 0:
+ loss_mask = torch.cat(loss_mask).sum() / num_pos
+ else:
+ loss_mask = torch.cat(loss_mask).mean()
+
+ flatten_labels = torch.cat(mlvl_labels)
+ flatten_cls_preds = torch.cat(temp_mlvl_cls_preds)
+ loss_cls = self.loss_cls(
+ flatten_cls_preds, flatten_labels, avg_factor=num_pos + 1)
+ return dict(loss_mask=loss_mask, loss_cls=loss_cls)
+
+ def _get_targets_single(self,
+ gt_instances: InstanceData,
+ featmap_sizes: Optional[list] = None) -> tuple:
+ """Compute targets for predictions of single image.
+
+ Args:
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It should includes ``bboxes``, ``labels``,
+ and ``masks`` attributes.
+ featmap_sizes (list[:obj:`torch.size`]): Size of each
+ feature map from feature pyramid, each element
+ means (feat_h, feat_w). Defaults to None.
+
+ Returns:
+ Tuple: Usually returns a tuple containing targets for predictions.
+
+ - mlvl_pos_mask_targets (list[Tensor]): Each element represent
+ the binary mask targets for positive points in this
+ level, has shape (num_pos, out_h, out_w).
+ - mlvl_labels (list[Tensor]): Each element is
+ classification labels for all
+ points in this level, has shape
+ (num_grid, num_grid).
+ - mlvl_pos_masks (list[Tensor]): Each element is
+ a `BoolTensor` to represent whether the
+ corresponding point in single level
+ is positive, has shape (num_grid **2).
+ """
+ gt_labels = gt_instances.labels
+ device = gt_labels.device
+
+ gt_bboxes = gt_instances.bboxes
+ gt_areas = torch.sqrt((gt_bboxes[:, 2] - gt_bboxes[:, 0]) *
+ (gt_bboxes[:, 3] - gt_bboxes[:, 1]))
+
+ gt_masks = gt_instances.masks.to_tensor(
+ dtype=torch.bool, device=device)
+
+ mlvl_pos_mask_targets = []
+ mlvl_labels = []
+ mlvl_pos_masks = []
+ for (lower_bound, upper_bound), stride, featmap_size, num_grid \
+ in zip(self.scale_ranges, self.strides,
+ featmap_sizes, self.num_grids):
+
+ mask_target = torch.zeros(
+ [num_grid**2, featmap_size[0], featmap_size[1]],
+ dtype=torch.uint8,
+ device=device)
+ # FG cat_id: [0, num_classes -1], BG cat_id: num_classes
+ labels = torch.zeros([num_grid, num_grid],
+ dtype=torch.int64,
+ device=device) + self.num_classes
+ pos_mask = torch.zeros([num_grid**2],
+ dtype=torch.bool,
+ device=device)
+
+ gt_inds = ((gt_areas >= lower_bound) &
+ (gt_areas <= upper_bound)).nonzero().flatten()
+ if len(gt_inds) == 0:
+ mlvl_pos_mask_targets.append(
+ mask_target.new_zeros(0, featmap_size[0], featmap_size[1]))
+ mlvl_labels.append(labels)
+ mlvl_pos_masks.append(pos_mask)
+ continue
+ hit_gt_bboxes = gt_bboxes[gt_inds]
+ hit_gt_labels = gt_labels[gt_inds]
+ hit_gt_masks = gt_masks[gt_inds, ...]
+
+ pos_w_ranges = 0.5 * (hit_gt_bboxes[:, 2] -
+ hit_gt_bboxes[:, 0]) * self.pos_scale
+ pos_h_ranges = 0.5 * (hit_gt_bboxes[:, 3] -
+ hit_gt_bboxes[:, 1]) * self.pos_scale
+
+ # Make sure hit_gt_masks has a value
+ valid_mask_flags = hit_gt_masks.sum(dim=-1).sum(dim=-1) > 0
+ output_stride = stride #/ 2
+
+ for gt_mask, gt_label, pos_h_range, pos_w_range, \
+ valid_mask_flag in \
+ zip(hit_gt_masks, hit_gt_labels, pos_h_ranges,
+ pos_w_ranges, valid_mask_flags):
+ if not valid_mask_flag:
+ continue
+ upsampled_size = (featmap_sizes[0][0] * 4,
+ featmap_sizes[0][1] * 4)
+ center_h, center_w = center_of_mass(gt_mask)
+
+ coord_w = int(
+ floordiv((center_w / upsampled_size[1]), (1. / num_grid),
+ rounding_mode='trunc'))
+ coord_h = int(
+ floordiv((center_h / upsampled_size[0]), (1. / num_grid),
+ rounding_mode='trunc'))
+
+ # left, top, right, down
+ top_box = max(
+ 0,
+ int(
+ floordiv(
+ (center_h - pos_h_range) / upsampled_size[0],
+ (1. / num_grid),
+ rounding_mode='trunc')))
+ down_box = min(
+ num_grid - 1,
+ int(
+ floordiv(
+ (center_h + pos_h_range) / upsampled_size[0],
+ (1. / num_grid),
+ rounding_mode='trunc')))
+ left_box = max(
+ 0,
+ int(
+ floordiv(
+ (center_w - pos_w_range) / upsampled_size[1],
+ (1. / num_grid),
+ rounding_mode='trunc')))
+ right_box = min(
+ num_grid - 1,
+ int(
+ floordiv(
+ (center_w + pos_w_range) / upsampled_size[1],
+ (1. / num_grid),
+ rounding_mode='trunc')))
+
+ top = max(top_box, coord_h - 1)
+ down = min(down_box, coord_h + 1)
+ left = max(coord_w - 1, left_box)
+ right = min(right_box, coord_w + 1)
+
+ labels[top:(down + 1), left:(right + 1)] = gt_label
+ # ins
+ gt_mask = np.uint8(gt_mask.cpu().numpy())
+ # Follow the original implementation, F.interpolate is
+ # different from cv2 and opencv
+ gt_mask = mmcv.imrescale(gt_mask, scale=1. / output_stride)
+ gt_mask = torch.from_numpy(gt_mask).to(device=device)
+
+ for i in range(top, down + 1):
+ for j in range(left, right + 1):
+ index = int(i * num_grid + j)
+ mask_target[index, :gt_mask.shape[0], :gt_mask.shape[1]] = gt_mask
+ pos_mask[index] = True
+ mlvl_pos_mask_targets.append(mask_target[pos_mask])
+ mlvl_labels.append(labels)
+ mlvl_pos_masks.append(pos_mask)
+ return mlvl_pos_mask_targets, mlvl_labels, mlvl_pos_masks
+
+ def predict_by_feat(self, mlvl_mask_preds: List[Tensor],
+ mlvl_cls_scores: List[Tensor],
+ batch_img_metas: List[dict], **kwargs) -> InstanceList:
+ """Transform a batch of output features extracted from the head into
+ mask results.
+
+ Args:
+ mlvl_mask_preds (list[Tensor]): Multi-level mask prediction.
+ Each element in the list has shape
+ (batch_size, num_grids**2 ,h ,w).
+ mlvl_cls_scores (list[Tensor]): Multi-level scores. Each element
+ in the list has shape
+ (batch_size, num_classes, num_grids ,num_grids).
+ batch_img_metas (list[dict]): Meta information of all images.
+
+ Returns:
+ list[:obj:`InstanceData`]: Processed results of multiple
+ images.Each :obj:`InstanceData` usually contains
+ following keys.
+
+ - scores (Tensor): Classification scores, has shape
+ (num_instance,).
+ - labels (Tensor): Has shape (num_instances,).
+ - masks (Tensor): Processed mask results, has
+ shape (num_instances, h, w).
+ """
+ mlvl_cls_scores = [
+ item.permute(0, 2, 3, 1) for item in mlvl_cls_scores
+ ]
+ assert len(mlvl_mask_preds) == len(mlvl_cls_scores)
+ num_levels = len(mlvl_cls_scores)
+
+ results_list = []
+ for img_id in range(len(batch_img_metas)):
+ cls_pred_list = [
+ mlvl_cls_scores[lvl][img_id].view(-1, self.cls_out_channels)
+ for lvl in range(num_levels)
+ ]
+ mask_pred_list = [
+ mlvl_mask_preds[lvl][img_id] for lvl in range(num_levels)
+ ]
+
+ cls_pred_list = torch.cat(cls_pred_list, dim=0)
+ mask_pred_list = torch.cat(mask_pred_list, dim=0)
+ img_meta = batch_img_metas[img_id]
+
+ results = self._predict_by_feat_single(
+ cls_pred_list, mask_pred_list, img_meta=img_meta)
+ results_list.append(results)
+
+ return results_list
+
+ def _predict_by_feat_single(self,
+ cls_scores: Tensor,
+ mask_preds: Tensor,
+ img_meta: dict,
+ cfg: OptConfigType = None) -> InstanceData:
+ """Transform a single image's features extracted from the head into
+ mask results.
+
+ Args:
+ cls_scores (Tensor): Classification score of all points
+ in single image, has shape (num_points, num_classes).
+ mask_preds (Tensor): Mask prediction of all points in
+ single image, has shape (num_points, feat_h, feat_w).
+ img_meta (dict): Meta information of corresponding image.
+ cfg (dict, optional): Config used in test phase.
+ Defaults to None.
+
+ Returns:
+ :obj:`InstanceData`: Processed results of single image.
+ it usually contains following keys.
+
+ - scores (Tensor): Classification scores, has shape
+ (num_instance,).
+ - labels (Tensor): Has shape (num_instances,).
+ - masks (Tensor): Processed mask results, has
+ shape (num_instances, h, w).
+ """
+
+ def empty_results(cls_scores, ori_shape):
+ """Generate a empty results."""
+ results = InstanceData()
+ results.scores = cls_scores.new_ones(0)
+ results.masks = cls_scores.new_zeros(0, *ori_shape)
+ results.labels = cls_scores.new_ones(0)
+ results.bboxes = cls_scores.new_zeros(0, 4)
+ return results
+
+ cfg = self.test_cfg if cfg is None else cfg
+ assert len(cls_scores) == len(mask_preds)
+
+ featmap_size = mask_preds.size()[-2:]
+
+ h, w = img_meta['img_shape'][:2]
+ upsampled_size = (featmap_size[0] * 4, featmap_size[1] * 4)
+
+ score_mask = (cls_scores > cfg.score_thr)
+ cls_scores = cls_scores[score_mask]
+ if len(cls_scores) == 0:
+ return empty_results(cls_scores, img_meta['ori_shape'][:2])
+
+ inds = score_mask.nonzero()
+ cls_labels = inds[:, 1]
+
+ # Filter the mask mask with an area is smaller than
+ # stride of corresponding feature level
+ lvl_interval = cls_labels.new_tensor(self.num_grids).pow(2).cumsum(0)
+ strides = cls_scores.new_ones(lvl_interval[-1])
+ strides[:lvl_interval[0]] *= self.strides[0]
+ for lvl in range(1, self.num_levels):
+ strides[lvl_interval[lvl -
+ 1]:lvl_interval[lvl]] *= self.strides[lvl]
+ strides = strides[inds[:, 0]]
+ mask_preds = mask_preds[inds[:, 0]]
+
+ masks = mask_preds > cfg.mask_thr
+ sum_masks = masks.sum((1, 2)).float()
+ keep = sum_masks > strides
+ if keep.sum() == 0:
+ return empty_results(cls_scores, img_meta['ori_shape'][:2])
+ masks = masks[keep]
+ mask_preds = mask_preds[keep]
+ sum_masks = sum_masks[keep]
+ cls_scores = cls_scores[keep]
+ cls_labels = cls_labels[keep]
+
+ # maskness.
+ mask_scores = (mask_preds * masks).sum((1, 2)) / sum_masks
+ cls_scores *= mask_scores
+
+ scores, labels, _, keep_inds = mask_matrix_nms(
+ masks,
+ cls_labels,
+ cls_scores,
+ mask_area=sum_masks,
+ nms_pre=cfg.nms_pre,
+ max_num=cfg.max_per_img,
+ kernel=cfg.kernel,
+ sigma=cfg.sigma,
+ filter_thr=cfg.filter_thr)
+ # mask_matrix_nms may return an empty Tensor
+ if len(keep_inds) == 0:
+ return empty_results(cls_scores, img_meta['ori_shape'][:2])
+ mask_preds = mask_preds[keep_inds]
+ mask_preds = F.interpolate(
+ mask_preds.unsqueeze(0), size=upsampled_size,
+ mode='bilinear')[:, :, :h, :w]
+ mask_preds = F.interpolate(
+ mask_preds, size=img_meta['ori_shape'][:2],
+ mode='bilinear').squeeze(0)
+ masks = mask_preds > cfg.mask_thr
+
+ results = InstanceData()
+ results.masks = masks
+ results.labels = labels
+ results.scores = scores
+ # create an empty bbox in InstanceData to avoid bugs when
+ # calculating metrics.
+ results.bboxes = results.scores.new_zeros(len(scores), 4)
+ return results
+
+
+@MODELS.register_module()
+class DecoupledSOLOHead(SOLOHead):
+ """Decoupled SOLO mask head used in `SOLO: Segmenting Objects by Locations.
+
+ `_
+
+ Args:
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ """
+
+ def __init__(self,
+ *args,
+ init_cfg: MultiConfig = [
+ dict(type='Normal', layer='Conv2d', std=0.01),
+ dict(
+ type='Normal',
+ std=0.01,
+ bias_prob=0.01,
+ override=dict(name='conv_mask_list_x')),
+ dict(
+ type='Normal',
+ std=0.01,
+ bias_prob=0.01,
+ override=dict(name='conv_mask_list_y')),
+ dict(
+ type='Normal',
+ std=0.01,
+ bias_prob=0.01,
+ override=dict(name='conv_cls'))
+ ],
+ **kwargs) -> None:
+ super().__init__(*args, init_cfg=init_cfg, **kwargs)
+
+ def _init_layers(self) -> None:
+ self.mask_convs_x = nn.ModuleList()
+ self.mask_convs_y = nn.ModuleList()
+ self.cls_convs = nn.ModuleList()
+
+ for i in range(self.stacked_convs):
+ chn = self.in_channels + 1 if i == 0 else self.feat_channels
+ self.mask_convs_x.append(
+ ConvModule(
+ chn,
+ self.feat_channels,
+ 3,
+ stride=1,
+ padding=1,
+ norm_cfg=self.norm_cfg))
+ self.mask_convs_y.append(
+ ConvModule(
+ chn,
+ self.feat_channels,
+ 3,
+ stride=1,
+ padding=1,
+ norm_cfg=self.norm_cfg))
+
+ chn = self.in_channels if i == 0 else self.feat_channels
+ self.cls_convs.append(
+ ConvModule(
+ chn,
+ self.feat_channels,
+ 3,
+ stride=1,
+ padding=1,
+ norm_cfg=self.norm_cfg))
+
+ self.conv_mask_list_x = nn.ModuleList()
+ self.conv_mask_list_y = nn.ModuleList()
+ for num_grid in self.num_grids:
+ self.conv_mask_list_x.append(
+ nn.Conv2d(self.feat_channels, num_grid, 3, padding=1))
+ self.conv_mask_list_y.append(
+ nn.Conv2d(self.feat_channels, num_grid, 3, padding=1))
+ self.conv_cls = nn.Conv2d(
+ self.feat_channels, self.cls_out_channels, 3, padding=1)
+
+ def forward(self, x: Tuple[Tensor]) -> Tuple:
+ """Forward features from the upstream network.
+
+ Args:
+ x (tuple[Tensor]): Features from the upstream network, each is
+ a 4D-tensor.
+
+ Returns:
+ tuple: A tuple of classification scores and mask prediction.
+
+ - mlvl_mask_preds_x (list[Tensor]): Multi-level mask prediction
+ from x branch. Each element in the list has shape
+ (batch_size, num_grids ,h ,w).
+ - mlvl_mask_preds_y (list[Tensor]): Multi-level mask prediction
+ from y branch. Each element in the list has shape
+ (batch_size, num_grids ,h ,w).
+ - mlvl_cls_preds (list[Tensor]): Multi-level scores.
+ Each element in the list has shape
+ (batch_size, num_classes, num_grids ,num_grids).
+ """
+ assert len(x) == self.num_levels
+ feats = self.resize_feats(x)
+ mask_preds_x = []
+ mask_preds_y = []
+ cls_preds = []
+ for i in range(self.num_levels):
+ x = feats[i]
+ mask_feat = x
+ cls_feat = x
+ # generate and concat the coordinate
+ coord_feat = generate_coordinate(mask_feat.size(),
+ mask_feat.device)
+ mask_feat_x = torch.cat([mask_feat, coord_feat[:, 0:1, ...]], 1)
+ mask_feat_y = torch.cat([mask_feat, coord_feat[:, 1:2, ...]], 1)
+
+ for mask_layer_x, mask_layer_y in \
+ zip(self.mask_convs_x, self.mask_convs_y):
+ mask_feat_x = mask_layer_x(mask_feat_x)
+ mask_feat_y = mask_layer_y(mask_feat_y)
+
+ mask_feat_x = F.interpolate(
+ mask_feat_x, scale_factor=2, mode='bilinear')
+ mask_feat_y = F.interpolate(
+ mask_feat_y, scale_factor=2, mode='bilinear')
+
+ mask_pred_x = self.conv_mask_list_x[i](mask_feat_x)
+ mask_pred_y = self.conv_mask_list_y[i](mask_feat_y)
+
+ # cls branch
+ for j, cls_layer in enumerate(self.cls_convs):
+ if j == self.cls_down_index:
+ num_grid = self.num_grids[i]
+ cls_feat = F.interpolate(
+ cls_feat, size=num_grid, mode='bilinear')
+ cls_feat = cls_layer(cls_feat)
+
+ cls_pred = self.conv_cls(cls_feat)
+
+ if not self.training:
+ feat_wh = feats[0].size()[-2:]
+ upsampled_size = (feat_wh[0] * 2, feat_wh[1] * 2)
+ mask_pred_x = F.interpolate(
+ mask_pred_x.sigmoid(),
+ size=upsampled_size,
+ mode='bilinear')
+ mask_pred_y = F.interpolate(
+ mask_pred_y.sigmoid(),
+ size=upsampled_size,
+ mode='bilinear')
+ cls_pred = cls_pred.sigmoid()
+ # get local maximum
+ local_max = F.max_pool2d(cls_pred, 2, stride=1, padding=1)
+ keep_mask = local_max[:, :, :-1, :-1] == cls_pred
+ cls_pred = cls_pred * keep_mask
+
+ mask_preds_x.append(mask_pred_x)
+ mask_preds_y.append(mask_pred_y)
+ cls_preds.append(cls_pred)
+ return mask_preds_x, mask_preds_y, cls_preds
+
+ def loss_by_feat(self, mlvl_mask_preds_x: List[Tensor],
+ mlvl_mask_preds_y: List[Tensor],
+ mlvl_cls_preds: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict], **kwargs) -> dict:
+ """Calculate the loss based on the features extracted by the mask head.
+
+ Args:
+ mlvl_mask_preds_x (list[Tensor]): Multi-level mask prediction
+ from x branch. Each element in the list has shape
+ (batch_size, num_grids ,h ,w).
+ mlvl_mask_preds_y (list[Tensor]): Multi-level mask prediction
+ from y branch. Each element in the list has shape
+ (batch_size, num_grids ,h ,w).
+ mlvl_cls_preds (list[Tensor]): Multi-level scores. Each element
+ in the list has shape
+ (batch_size, num_classes, num_grids ,num_grids).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes``, ``masks``,
+ and ``labels`` attributes.
+ batch_img_metas (list[dict]): Meta information of multiple images.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components.
+ """
+ num_levels = self.num_levels
+ num_imgs = len(batch_img_metas)
+ featmap_sizes = [featmap.size()[-2:] for featmap in mlvl_mask_preds_x]
+
+ pos_mask_targets, labels, xy_pos_indexes = multi_apply(
+ self._get_targets_single,
+ batch_gt_instances,
+ featmap_sizes=featmap_sizes)
+
+ # change from the outside list meaning multi images
+ # to the outside list meaning multi levels
+ mlvl_pos_mask_targets = [[] for _ in range(num_levels)]
+ mlvl_pos_mask_preds_x = [[] for _ in range(num_levels)]
+ mlvl_pos_mask_preds_y = [[] for _ in range(num_levels)]
+ mlvl_labels = [[] for _ in range(num_levels)]
+ for img_id in range(num_imgs):
+
+ for lvl in range(num_levels):
+ mlvl_pos_mask_targets[lvl].append(
+ pos_mask_targets[img_id][lvl])
+ mlvl_pos_mask_preds_x[lvl].append(
+ mlvl_mask_preds_x[lvl][img_id,
+ xy_pos_indexes[img_id][lvl][:, 1]])
+ mlvl_pos_mask_preds_y[lvl].append(
+ mlvl_mask_preds_y[lvl][img_id,
+ xy_pos_indexes[img_id][lvl][:, 0]])
+ mlvl_labels[lvl].append(labels[img_id][lvl].flatten())
+
+ # cat multiple image
+ temp_mlvl_cls_preds = []
+ for lvl in range(num_levels):
+ mlvl_pos_mask_targets[lvl] = torch.cat(
+ mlvl_pos_mask_targets[lvl], dim=0)
+ mlvl_pos_mask_preds_x[lvl] = torch.cat(
+ mlvl_pos_mask_preds_x[lvl], dim=0)
+ mlvl_pos_mask_preds_y[lvl] = torch.cat(
+ mlvl_pos_mask_preds_y[lvl], dim=0)
+ mlvl_labels[lvl] = torch.cat(mlvl_labels[lvl], dim=0)
+ temp_mlvl_cls_preds.append(mlvl_cls_preds[lvl].permute(
+ 0, 2, 3, 1).reshape(-1, self.cls_out_channels))
+
+ num_pos = 0.
+ # dice loss
+ loss_mask = []
+ for pred_x, pred_y, target in \
+ zip(mlvl_pos_mask_preds_x,
+ mlvl_pos_mask_preds_y, mlvl_pos_mask_targets):
+ num_masks = pred_x.size(0)
+ if num_masks == 0:
+ # make sure can get grad
+ loss_mask.append((pred_x.sum() + pred_y.sum()).unsqueeze(0))
+ continue
+ num_pos += num_masks
+ pred_mask = pred_y.sigmoid() * pred_x.sigmoid()
+ loss_mask.append(
+ self.loss_mask(pred_mask, target, reduction_override='none'))
+ if num_pos > 0:
+ loss_mask = torch.cat(loss_mask).sum() / num_pos
+ else:
+ loss_mask = torch.cat(loss_mask).mean()
+
+ # cate
+ flatten_labels = torch.cat(mlvl_labels)
+ flatten_cls_preds = torch.cat(temp_mlvl_cls_preds)
+
+ loss_cls = self.loss_cls(
+ flatten_cls_preds, flatten_labels, avg_factor=num_pos + 1)
+ return dict(loss_mask=loss_mask, loss_cls=loss_cls)
+
+ def _get_targets_single(self,
+ gt_instances: InstanceData,
+ featmap_sizes: Optional[list] = None) -> tuple:
+ """Compute targets for predictions of single image.
+
+ Args:
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It should includes ``bboxes``, ``labels``,
+ and ``masks`` attributes.
+ featmap_sizes (list[:obj:`torch.size`]): Size of each
+ feature map from feature pyramid, each element
+ means (feat_h, feat_w). Defaults to None.
+
+ Returns:
+ Tuple: Usually returns a tuple containing targets for predictions.
+
+ - mlvl_pos_mask_targets (list[Tensor]): Each element represent
+ the binary mask targets for positive points in this
+ level, has shape (num_pos, out_h, out_w).
+ - mlvl_labels (list[Tensor]): Each element is
+ classification labels for all
+ points in this level, has shape
+ (num_grid, num_grid).
+ - mlvl_xy_pos_indexes (list[Tensor]): Each element
+ in the list contains the index of positive samples in
+ corresponding level, has shape (num_pos, 2), last
+ dimension 2 present (index_x, index_y).
+ """
+ mlvl_pos_mask_targets, mlvl_labels, mlvl_pos_masks = \
+ super()._get_targets_single(gt_instances,
+ featmap_sizes=featmap_sizes)
+
+ mlvl_xy_pos_indexes = [(item - self.num_classes).nonzero()
+ for item in mlvl_labels]
+
+ return mlvl_pos_mask_targets, mlvl_labels, mlvl_xy_pos_indexes
+
+ def predict_by_feat(self, mlvl_mask_preds_x: List[Tensor],
+ mlvl_mask_preds_y: List[Tensor],
+ mlvl_cls_scores: List[Tensor],
+ batch_img_metas: List[dict], **kwargs) -> InstanceList:
+ """Transform a batch of output features extracted from the head into
+ mask results.
+
+ Args:
+ mlvl_mask_preds_x (list[Tensor]): Multi-level mask prediction
+ from x branch. Each element in the list has shape
+ (batch_size, num_grids ,h ,w).
+ mlvl_mask_preds_y (list[Tensor]): Multi-level mask prediction
+ from y branch. Each element in the list has shape
+ (batch_size, num_grids ,h ,w).
+ mlvl_cls_scores (list[Tensor]): Multi-level scores. Each element
+ in the list has shape
+ (batch_size, num_classes ,num_grids ,num_grids).
+ batch_img_metas (list[dict]): Meta information of all images.
+
+ Returns:
+ list[:obj:`InstanceData`]: Processed results of multiple
+ images.Each :obj:`InstanceData` usually contains
+ following keys.
+
+ - scores (Tensor): Classification scores, has shape
+ (num_instance,).
+ - labels (Tensor): Has shape (num_instances,).
+ - masks (Tensor): Processed mask results, has
+ shape (num_instances, h, w).
+ """
+ mlvl_cls_scores = [
+ item.permute(0, 2, 3, 1) for item in mlvl_cls_scores
+ ]
+ assert len(mlvl_mask_preds_x) == len(mlvl_cls_scores)
+ num_levels = len(mlvl_cls_scores)
+
+ results_list = []
+ for img_id in range(len(batch_img_metas)):
+ cls_pred_list = [
+ mlvl_cls_scores[i][img_id].view(
+ -1, self.cls_out_channels).detach()
+ for i in range(num_levels)
+ ]
+ mask_pred_list_x = [
+ mlvl_mask_preds_x[i][img_id] for i in range(num_levels)
+ ]
+ mask_pred_list_y = [
+ mlvl_mask_preds_y[i][img_id] for i in range(num_levels)
+ ]
+
+ cls_pred_list = torch.cat(cls_pred_list, dim=0)
+ mask_pred_list_x = torch.cat(mask_pred_list_x, dim=0)
+ mask_pred_list_y = torch.cat(mask_pred_list_y, dim=0)
+ img_meta = batch_img_metas[img_id]
+
+ results = self._predict_by_feat_single(
+ cls_pred_list,
+ mask_pred_list_x,
+ mask_pred_list_y,
+ img_meta=img_meta)
+ results_list.append(results)
+ return results_list
+
+ def _predict_by_feat_single(self,
+ cls_scores: Tensor,
+ mask_preds_x: Tensor,
+ mask_preds_y: Tensor,
+ img_meta: dict,
+ cfg: OptConfigType = None) -> InstanceData:
+ """Transform a single image's features extracted from the head into
+ mask results.
+
+ Args:
+ cls_scores (Tensor): Classification score of all points
+ in single image, has shape (num_points, num_classes).
+ mask_preds_x (Tensor): Mask prediction of x branch of
+ all points in single image, has shape
+ (sum_num_grids, feat_h, feat_w).
+ mask_preds_y (Tensor): Mask prediction of y branch of
+ all points in single image, has shape
+ (sum_num_grids, feat_h, feat_w).
+ img_meta (dict): Meta information of corresponding image.
+ cfg (dict): Config used in test phase.
+
+ Returns:
+ :obj:`InstanceData`: Processed results of single image.
+ it usually contains following keys.
+
+ - scores (Tensor): Classification scores, has shape
+ (num_instance,).
+ - labels (Tensor): Has shape (num_instances,).
+ - masks (Tensor): Processed mask results, has
+ shape (num_instances, h, w).
+ """
+
+ def empty_results(cls_scores, ori_shape):
+ """Generate a empty results."""
+ results = InstanceData()
+ results.scores = cls_scores.new_ones(0)
+ results.masks = cls_scores.new_zeros(0, *ori_shape)
+ results.labels = cls_scores.new_ones(0)
+ results.bboxes = cls_scores.new_zeros(0, 4)
+ return results
+
+ cfg = self.test_cfg if cfg is None else cfg
+
+ featmap_size = mask_preds_x.size()[-2:]
+
+ h, w = img_meta['img_shape'][:2]
+ upsampled_size = (featmap_size[0] * 4, featmap_size[1] * 4)
+
+ score_mask = (cls_scores > cfg.score_thr)
+ cls_scores = cls_scores[score_mask]
+ inds = score_mask.nonzero()
+ lvl_interval = inds.new_tensor(self.num_grids).pow(2).cumsum(0)
+ num_all_points = lvl_interval[-1]
+ lvl_start_index = inds.new_ones(num_all_points)
+ num_grids = inds.new_ones(num_all_points)
+ seg_size = inds.new_tensor(self.num_grids).cumsum(0)
+ mask_lvl_start_index = inds.new_ones(num_all_points)
+ strides = inds.new_ones(num_all_points)
+
+ lvl_start_index[:lvl_interval[0]] *= 0
+ mask_lvl_start_index[:lvl_interval[0]] *= 0
+ num_grids[:lvl_interval[0]] *= self.num_grids[0]
+ strides[:lvl_interval[0]] *= self.strides[0]
+
+ for lvl in range(1, self.num_levels):
+ lvl_start_index[lvl_interval[lvl - 1]:lvl_interval[lvl]] *= \
+ lvl_interval[lvl - 1]
+ mask_lvl_start_index[lvl_interval[lvl - 1]:lvl_interval[lvl]] *= \
+ seg_size[lvl - 1]
+ num_grids[lvl_interval[lvl - 1]:lvl_interval[lvl]] *= \
+ self.num_grids[lvl]
+ strides[lvl_interval[lvl - 1]:lvl_interval[lvl]] *= \
+ self.strides[lvl]
+
+ lvl_start_index = lvl_start_index[inds[:, 0]]
+ mask_lvl_start_index = mask_lvl_start_index[inds[:, 0]]
+ num_grids = num_grids[inds[:, 0]]
+ strides = strides[inds[:, 0]]
+
+ y_lvl_offset = (inds[:, 0] - lvl_start_index) // num_grids
+ x_lvl_offset = (inds[:, 0] - lvl_start_index) % num_grids
+ y_inds = mask_lvl_start_index + y_lvl_offset
+ x_inds = mask_lvl_start_index + x_lvl_offset
+
+ cls_labels = inds[:, 1]
+ mask_preds = mask_preds_x[x_inds, ...] * mask_preds_y[y_inds, ...]
+
+ masks = mask_preds > cfg.mask_thr
+ sum_masks = masks.sum((1, 2)).float()
+ keep = sum_masks > strides
+ if keep.sum() == 0:
+ return empty_results(cls_scores, img_meta['ori_shape'][:2])
+
+ masks = masks[keep]
+ mask_preds = mask_preds[keep]
+ sum_masks = sum_masks[keep]
+ cls_scores = cls_scores[keep]
+ cls_labels = cls_labels[keep]
+
+ # maskness.
+ mask_scores = (mask_preds * masks).sum((1, 2)) / sum_masks
+ cls_scores *= mask_scores
+
+ scores, labels, _, keep_inds = mask_matrix_nms(
+ masks,
+ cls_labels,
+ cls_scores,
+ mask_area=sum_masks,
+ nms_pre=cfg.nms_pre,
+ max_num=cfg.max_per_img,
+ kernel=cfg.kernel,
+ sigma=cfg.sigma,
+ filter_thr=cfg.filter_thr)
+ # mask_matrix_nms may return an empty Tensor
+ if len(keep_inds) == 0:
+ return empty_results(cls_scores, img_meta['ori_shape'][:2])
+ mask_preds = mask_preds[keep_inds]
+ mask_preds = F.interpolate(
+ mask_preds.unsqueeze(0), size=upsampled_size,
+ mode='bilinear')[:, :, :h, :w]
+ mask_preds = F.interpolate(
+ mask_preds, size=img_meta['ori_shape'][:2],
+ mode='bilinear').squeeze(0)
+ masks = mask_preds > cfg.mask_thr
+
+ results = InstanceData()
+ results.masks = masks
+ results.labels = labels
+ results.scores = scores
+ # create an empty bbox in InstanceData to avoid bugs when
+ # calculating metrics.
+ results.bboxes = results.scores.new_zeros(len(scores), 4)
+
+ return results
+
+
+@MODELS.register_module()
+class DecoupledSOLOLightHead(DecoupledSOLOHead):
+ """Decoupled Light SOLO mask head used in `SOLO: Segmenting Objects by
+ Locations `_
+
+ Args:
+ with_dcn (bool): Whether use dcn in mask_convs and cls_convs,
+ Defaults to False.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ """
+
+ def __init__(self,
+ *args,
+ dcn_cfg: OptConfigType = None,
+ init_cfg: MultiConfig = [
+ dict(type='Normal', layer='Conv2d', std=0.01),
+ dict(
+ type='Normal',
+ std=0.01,
+ bias_prob=0.01,
+ override=dict(name='conv_mask_list_x')),
+ dict(
+ type='Normal',
+ std=0.01,
+ bias_prob=0.01,
+ override=dict(name='conv_mask_list_y')),
+ dict(
+ type='Normal',
+ std=0.01,
+ bias_prob=0.01,
+ override=dict(name='conv_cls'))
+ ],
+ **kwargs) -> None:
+ assert dcn_cfg is None or isinstance(dcn_cfg, dict)
+ self.dcn_cfg = dcn_cfg
+ super().__init__(*args, init_cfg=init_cfg, **kwargs)
+
+ def _init_layers(self) -> None:
+ self.mask_convs = nn.ModuleList()
+ self.cls_convs = nn.ModuleList()
+
+ for i in range(self.stacked_convs):
+ if self.dcn_cfg is not None \
+ and i == self.stacked_convs - 1:
+ conv_cfg = self.dcn_cfg
+ else:
+ conv_cfg = None
+
+ chn = self.in_channels + 2 if i == 0 else self.feat_channels
+ self.mask_convs.append(
+ ConvModule(
+ chn,
+ self.feat_channels,
+ 3,
+ stride=1,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=self.norm_cfg))
+
+ chn = self.in_channels if i == 0 else self.feat_channels
+ self.cls_convs.append(
+ ConvModule(
+ chn,
+ self.feat_channels,
+ 3,
+ stride=1,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=self.norm_cfg))
+
+ self.conv_mask_list_x = nn.ModuleList()
+ self.conv_mask_list_y = nn.ModuleList()
+ for num_grid in self.num_grids:
+ self.conv_mask_list_x.append(
+ nn.Conv2d(self.feat_channels, num_grid, 3, padding=1))
+ self.conv_mask_list_y.append(
+ nn.Conv2d(self.feat_channels, num_grid, 3, padding=1))
+ self.conv_cls = nn.Conv2d(
+ self.feat_channels, self.cls_out_channels, 3, padding=1)
+
+ def forward(self, x: Tuple[Tensor]) -> Tuple:
+ """Forward features from the upstream network.
+
+ Args:
+ x (tuple[Tensor]): Features from the upstream network, each is
+ a 4D-tensor.
+
+ Returns:
+ tuple: A tuple of classification scores and mask prediction.
+
+ - mlvl_mask_preds_x (list[Tensor]): Multi-level mask prediction
+ from x branch. Each element in the list has shape
+ (batch_size, num_grids ,h ,w).
+ - mlvl_mask_preds_y (list[Tensor]): Multi-level mask prediction
+ from y branch. Each element in the list has shape
+ (batch_size, num_grids ,h ,w).
+ - mlvl_cls_preds (list[Tensor]): Multi-level scores.
+ Each element in the list has shape
+ (batch_size, num_classes, num_grids ,num_grids).
+ """
+ assert len(x) == self.num_levels
+ feats = self.resize_feats(x)
+ mask_preds_x = []
+ mask_preds_y = []
+ cls_preds = []
+ for i in range(self.num_levels):
+ x = feats[i]
+ mask_feat = x
+ cls_feat = x
+ # generate and concat the coordinate
+ coord_feat = generate_coordinate(mask_feat.size(),
+ mask_feat.device)
+ mask_feat = torch.cat([mask_feat, coord_feat], 1)
+
+ for mask_layer in self.mask_convs:
+ mask_feat = mask_layer(mask_feat)
+
+ mask_feat = F.interpolate(
+ mask_feat, scale_factor=2, mode='bilinear')
+
+ mask_pred_x = self.conv_mask_list_x[i](mask_feat)
+ mask_pred_y = self.conv_mask_list_y[i](mask_feat)
+
+ # cls branch
+ for j, cls_layer in enumerate(self.cls_convs):
+ if j == self.cls_down_index:
+ num_grid = self.num_grids[i]
+ cls_feat = F.interpolate(
+ cls_feat, size=num_grid, mode='bilinear')
+ cls_feat = cls_layer(cls_feat)
+
+ cls_pred = self.conv_cls(cls_feat)
+
+ if not self.training:
+ feat_wh = feats[0].size()[-2:]
+ upsampled_size = (feat_wh[0] * 2, feat_wh[1] * 2)
+ mask_pred_x = F.interpolate(
+ mask_pred_x.sigmoid(),
+ size=upsampled_size,
+ mode='bilinear')
+ mask_pred_y = F.interpolate(
+ mask_pred_y.sigmoid(),
+ size=upsampled_size,
+ mode='bilinear')
+ cls_pred = cls_pred.sigmoid()
+ # get local maximum
+ local_max = F.max_pool2d(cls_pred, 2, stride=1, padding=1)
+ keep_mask = local_max[:, :, :-1, :-1] == cls_pred
+ cls_pred = cls_pred * keep_mask
+
+ mask_preds_x.append(mask_pred_x)
+ mask_preds_y.append(mask_pred_y)
+ cls_preds.append(cls_pred)
+ return mask_preds_x, mask_preds_y, cls_preds
diff --git a/mmdet/models/dense_heads/solov2_head.py b/mmdet/models/dense_heads/solov2_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..35b9df0c45148cb18e8afb659b10dd0b9e866b99
--- /dev/null
+++ b/mmdet/models/dense_heads/solov2_head.py
@@ -0,0 +1,799 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+from typing import List, Optional, Tuple
+
+import mmcv
+import numpy as np
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule
+from mmengine.model import BaseModule
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmdet.models.utils.misc import floordiv
+from mmdet.registry import MODELS
+from mmdet.utils import ConfigType, InstanceList, MultiConfig, OptConfigType
+from ..layers import mask_matrix_nms
+from ..utils import center_of_mass, generate_coordinate, multi_apply
+from .solo_head import SOLOHead
+
+
+class MaskFeatModule(BaseModule):
+ """SOLOv2 mask feature map branch used in `SOLOv2: Dynamic and Fast
+ Instance Segmentation. `_
+
+ Args:
+ in_channels (int): Number of channels in the input feature map.
+ feat_channels (int): Number of hidden channels of the mask feature
+ map branch.
+ start_level (int): The starting feature map level from RPN that
+ will be used to predict the mask feature map.
+ end_level (int): The ending feature map level from rpn that
+ will be used to predict the mask feature map.
+ out_channels (int): Number of output channels of the mask feature
+ map branch. This is the channel count of the mask
+ feature map that to be dynamically convolved with the predicted
+ kernel.
+ mask_stride (int): Downsample factor of the mask feature map output.
+ Defaults to 4.
+ conv_cfg (dict): Config dict for convolution layer. Default: None.
+ norm_cfg (dict): Config dict for normalization layer. Default: None.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ """
+
+ def __init__(
+ self,
+ in_channels: int,
+ feat_channels: int,
+ start_level: int,
+ end_level: int,
+ out_channels: int,
+ mask_stride: int = 4,
+ conv_cfg: OptConfigType = None,
+ norm_cfg: OptConfigType = None,
+ init_cfg: MultiConfig = [
+ dict(type='Normal', layer='Conv2d', std=0.01)
+ ]
+ ) -> None:
+ super().__init__(init_cfg=init_cfg)
+ self.in_channels = in_channels
+ self.feat_channels = feat_channels
+ self.start_level = start_level
+ self.end_level = end_level
+ self.mask_stride = mask_stride
+ assert start_level >= 0 and end_level >= start_level
+ self.out_channels = out_channels
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self._init_layers()
+ self.fp16_enabled = False
+
+ def _init_layers(self) -> None:
+ """Initialize layers of the head."""
+ self.convs_all_levels = nn.ModuleList()
+ for i in range(self.start_level, self.end_level + 1):
+ convs_per_level = nn.Sequential()
+ if i == 0:
+ convs_per_level.add_module(
+ f'conv{i}',
+ ConvModule(
+ self.in_channels,
+ self.feat_channels,
+ 3,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ inplace=False))
+ self.convs_all_levels.append(convs_per_level)
+ continue
+
+ for j in range(i):
+ if j == 0:
+ if i == self.end_level:
+ chn = self.in_channels + 2
+ else:
+ chn = self.in_channels
+ convs_per_level.add_module(
+ f'conv{j}',
+ ConvModule(
+ chn,
+ self.feat_channels,
+ 3,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ inplace=False))
+ convs_per_level.add_module(
+ f'upsample{j}',
+ nn.Upsample(
+ scale_factor=2,
+ mode='bilinear',
+ align_corners=False))
+ continue
+
+ convs_per_level.add_module(
+ f'conv{j}',
+ ConvModule(
+ self.feat_channels,
+ self.feat_channels,
+ 3,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ inplace=False))
+ convs_per_level.add_module(
+ f'upsample{j}',
+ nn.Upsample(
+ scale_factor=2, mode='bilinear', align_corners=False))
+
+ self.convs_all_levels.append(convs_per_level)
+
+ self.conv_pred = ConvModule(
+ self.feat_channels,
+ self.out_channels,
+ 1,
+ padding=0,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg)
+
+ def forward(self, x: Tuple[Tensor]) -> Tensor:
+ """Forward features from the upstream network.
+
+ Args:
+ x (tuple[Tensor]): Features from the upstream network, each is
+ a 4D-tensor.
+
+ Returns:
+ Tensor: The predicted mask feature map.
+ """
+ inputs = x[self.start_level:self.end_level + 1]
+ assert len(inputs) == (self.end_level - self.start_level + 1)
+ feature_add_all_level = self.convs_all_levels[0](inputs[0])
+ for i in range(1, len(inputs)):
+ input_p = inputs[i]
+ if i == len(inputs) - 1:
+ coord_feat = generate_coordinate(input_p.size(),
+ input_p.device)
+ input_p = torch.cat([input_p, coord_feat], 1)
+
+ feature_add_all_level = feature_add_all_level + \
+ self.convs_all_levels[i](input_p)
+
+ feature_pred = self.conv_pred(feature_add_all_level)
+ return feature_pred
+
+
+@MODELS.register_module()
+class SOLOV2Head(SOLOHead):
+ """SOLOv2 mask head used in `SOLOv2: Dynamic and Fast Instance
+ Segmentation. `_
+
+ Args:
+ mask_feature_head (dict): Config of SOLOv2MaskFeatHead.
+ dynamic_conv_size (int): Dynamic Conv kernel size. Defaults to 1.
+ dcn_cfg (dict): Dcn conv configurations in kernel_convs and cls_conv.
+ Defaults to None.
+ dcn_apply_to_all_conv (bool): Whether to use dcn in every layer of
+ kernel_convs and cls_convs, or only the last layer. It shall be set
+ `True` for the normal version of SOLOv2 and `False` for the
+ light-weight version. Defaults to True.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ """
+
+ def __init__(self,
+ *args,
+ mask_feature_head: ConfigType,
+ dynamic_conv_size: int = 1,
+ dcn_cfg: OptConfigType = None,
+ dcn_apply_to_all_conv: bool = True,
+ init_cfg: MultiConfig = [
+ dict(type='Normal', layer='Conv2d', std=0.01),
+ dict(
+ type='Normal',
+ std=0.01,
+ bias_prob=0.01,
+ override=dict(name='conv_cls'))
+ ],
+ **kwargs) -> None:
+ assert dcn_cfg is None or isinstance(dcn_cfg, dict)
+ self.dcn_cfg = dcn_cfg
+ self.with_dcn = dcn_cfg is not None
+ self.dcn_apply_to_all_conv = dcn_apply_to_all_conv
+ self.dynamic_conv_size = dynamic_conv_size
+ mask_out_channels = mask_feature_head.get('out_channels')
+ self.kernel_out_channels = \
+ mask_out_channels * self.dynamic_conv_size * self.dynamic_conv_size
+
+ super().__init__(*args, init_cfg=init_cfg, **kwargs)
+
+ # update the in_channels of mask_feature_head
+ if mask_feature_head.get('in_channels', None) is not None:
+ if mask_feature_head.in_channels != self.in_channels:
+ warnings.warn('The `in_channels` of SOLOv2MaskFeatHead and '
+ 'SOLOv2Head should be same, changing '
+ 'mask_feature_head.in_channels to '
+ f'{self.in_channels}')
+ mask_feature_head.update(in_channels=self.in_channels)
+ else:
+ mask_feature_head.update(in_channels=self.in_channels)
+
+ self.mask_feature_head = MaskFeatModule(**mask_feature_head)
+ self.mask_stride = self.mask_feature_head.mask_stride
+ self.fp16_enabled = False
+
+ def _init_layers(self) -> None:
+ """Initialize layers of the head."""
+ self.cls_convs = nn.ModuleList()
+ self.kernel_convs = nn.ModuleList()
+ conv_cfg = None
+ for i in range(self.stacked_convs):
+ if self.with_dcn:
+ if self.dcn_apply_to_all_conv:
+ conv_cfg = self.dcn_cfg
+ elif i == self.stacked_convs - 1:
+ # light head
+ conv_cfg = self.dcn_cfg
+
+ chn = self.in_channels + 2 if i == 0 else self.feat_channels
+ self.kernel_convs.append(
+ ConvModule(
+ chn,
+ self.feat_channels,
+ 3,
+ stride=1,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=self.norm_cfg,
+ bias=self.norm_cfg is None))
+
+ chn = self.in_channels if i == 0 else self.feat_channels
+ self.cls_convs.append(
+ ConvModule(
+ chn,
+ self.feat_channels,
+ 3,
+ stride=1,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=self.norm_cfg,
+ bias=self.norm_cfg is None))
+
+ self.conv_cls = nn.Conv2d(
+ self.feat_channels, self.cls_out_channels, 3, padding=1)
+
+ self.conv_kernel = nn.Conv2d(
+ self.feat_channels, self.kernel_out_channels, 3, padding=1)
+
+ def forward(self, x):
+ """Forward features from the upstream network.
+
+ Args:
+ x (tuple[Tensor]): Features from the upstream network, each is
+ a 4D-tensor.
+
+ Returns:
+ tuple: A tuple of classification scores, mask prediction,
+ and mask features.
+
+ - mlvl_kernel_preds (list[Tensor]): Multi-level dynamic kernel
+ prediction. The kernel is used to generate instance
+ segmentation masks by dynamic convolution. Each element in
+ the list has shape
+ (batch_size, kernel_out_channels, num_grids, num_grids).
+ - mlvl_cls_preds (list[Tensor]): Multi-level scores. Each
+ element in the list has shape
+ (batch_size, num_classes, num_grids, num_grids).
+ - mask_feats (Tensor): Unified mask feature map used to
+ generate instance segmentation masks by dynamic convolution.
+ Has shape (batch_size, mask_out_channels, h, w).
+ """
+ assert len(x) == self.num_levels
+ mask_feats = self.mask_feature_head(x)
+ ins_kernel_feats = self.resize_feats(x)
+ mlvl_kernel_preds = []
+ mlvl_cls_preds = []
+ for i in range(self.num_levels):
+ ins_kernel_feat = ins_kernel_feats[i]
+ # ins branch
+ # concat coord
+ coord_feat = generate_coordinate(ins_kernel_feat.size(),
+ ins_kernel_feat.device)
+ ins_kernel_feat = torch.cat([ins_kernel_feat, coord_feat], 1)
+
+ # kernel branch
+ kernel_feat = ins_kernel_feat
+ kernel_feat = F.interpolate(
+ kernel_feat,
+ size=self.num_grids[i],
+ mode='bilinear',
+ align_corners=False)
+
+ cate_feat = kernel_feat[:, :-2, :, :]
+
+ kernel_feat = kernel_feat.contiguous()
+ for i, kernel_conv in enumerate(self.kernel_convs):
+ kernel_feat = kernel_conv(kernel_feat)
+ kernel_pred = self.conv_kernel(kernel_feat)
+
+ # cate branch
+ cate_feat = cate_feat.contiguous()
+ for i, cls_conv in enumerate(self.cls_convs):
+ cate_feat = cls_conv(cate_feat)
+ cate_pred = self.conv_cls(cate_feat)
+
+ mlvl_kernel_preds.append(kernel_pred)
+ mlvl_cls_preds.append(cate_pred)
+
+ return mlvl_kernel_preds, mlvl_cls_preds, mask_feats
+
+ def _get_targets_single(self,
+ gt_instances: InstanceData,
+ featmap_sizes: Optional[list] = None) -> tuple:
+ """Compute targets for predictions of single image.
+
+ Args:
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It should includes ``bboxes``, ``labels``,
+ and ``masks`` attributes.
+ featmap_sizes (list[:obj:`torch.size`]): Size of each
+ feature map from feature pyramid, each element
+ means (feat_h, feat_w). Defaults to None.
+
+ Returns:
+ Tuple: Usually returns a tuple containing targets for predictions.
+
+ - mlvl_pos_mask_targets (list[Tensor]): Each element represent
+ the binary mask targets for positive points in this
+ level, has shape (num_pos, out_h, out_w).
+ - mlvl_labels (list[Tensor]): Each element is
+ classification labels for all
+ points in this level, has shape
+ (num_grid, num_grid).
+ - mlvl_pos_masks (list[Tensor]): Each element is
+ a `BoolTensor` to represent whether the
+ corresponding point in single level
+ is positive, has shape (num_grid **2).
+ - mlvl_pos_indexes (list[list]): Each element
+ in the list contains the positive index in
+ corresponding level, has shape (num_pos).
+ """
+ gt_labels = gt_instances.labels
+ device = gt_labels.device
+
+ gt_bboxes = gt_instances.bboxes
+ gt_areas = torch.sqrt((gt_bboxes[:, 2] - gt_bboxes[:, 0]) *
+ (gt_bboxes[:, 3] - gt_bboxes[:, 1]))
+ gt_masks = gt_instances.masks.to_tensor(
+ dtype=torch.bool, device=device)
+
+ mlvl_pos_mask_targets = []
+ mlvl_pos_indexes = []
+ mlvl_labels = []
+ mlvl_pos_masks = []
+ for (lower_bound, upper_bound), num_grid \
+ in zip(self.scale_ranges, self.num_grids):
+ mask_target = []
+ # FG cat_id: [0, num_classes -1], BG cat_id: num_classes
+ pos_index = []
+ labels = torch.zeros([num_grid, num_grid],
+ dtype=torch.int64,
+ device=device) + self.num_classes
+ pos_mask = torch.zeros([num_grid**2],
+ dtype=torch.bool,
+ device=device)
+
+ gt_inds = ((gt_areas >= lower_bound) &
+ (gt_areas <= upper_bound)).nonzero().flatten()
+ if len(gt_inds) == 0:
+ mlvl_pos_mask_targets.append(
+ torch.zeros([0, featmap_sizes[0], featmap_sizes[1]],
+ dtype=torch.uint8,
+ device=device))
+ mlvl_labels.append(labels)
+ mlvl_pos_masks.append(pos_mask)
+ mlvl_pos_indexes.append([])
+ continue
+ hit_gt_bboxes = gt_bboxes[gt_inds]
+ hit_gt_labels = gt_labels[gt_inds]
+ hit_gt_masks = gt_masks[gt_inds, ...]
+
+ pos_w_ranges = 0.5 * (hit_gt_bboxes[:, 2] -
+ hit_gt_bboxes[:, 0]) * self.pos_scale
+ pos_h_ranges = 0.5 * (hit_gt_bboxes[:, 3] -
+ hit_gt_bboxes[:, 1]) * self.pos_scale
+
+ # Make sure hit_gt_masks has a value
+ valid_mask_flags = hit_gt_masks.sum(dim=-1).sum(dim=-1) > 0
+
+ for gt_mask, gt_label, pos_h_range, pos_w_range, \
+ valid_mask_flag in \
+ zip(hit_gt_masks, hit_gt_labels, pos_h_ranges,
+ pos_w_ranges, valid_mask_flags):
+ if not valid_mask_flag:
+ continue
+ upsampled_size = (featmap_sizes[0] * self.mask_stride,
+ featmap_sizes[1] * self.mask_stride)
+ center_h, center_w = center_of_mass(gt_mask)
+
+ coord_w = int(
+ floordiv((center_w / upsampled_size[1]), (1. / num_grid),
+ rounding_mode='trunc'))
+ coord_h = int(
+ floordiv((center_h / upsampled_size[0]), (1. / num_grid),
+ rounding_mode='trunc'))
+
+ # left, top, right, down
+ top_box = max(
+ 0,
+ int(
+ floordiv(
+ (center_h - pos_h_range) / upsampled_size[0],
+ (1. / num_grid),
+ rounding_mode='trunc')))
+ down_box = min(
+ num_grid - 1,
+ int(
+ floordiv(
+ (center_h + pos_h_range) / upsampled_size[0],
+ (1. / num_grid),
+ rounding_mode='trunc')))
+ left_box = max(
+ 0,
+ int(
+ floordiv(
+ (center_w - pos_w_range) / upsampled_size[1],
+ (1. / num_grid),
+ rounding_mode='trunc')))
+ right_box = min(
+ num_grid - 1,
+ int(
+ floordiv(
+ (center_w + pos_w_range) / upsampled_size[1],
+ (1. / num_grid),
+ rounding_mode='trunc')))
+
+ top = max(top_box, coord_h - 1)
+ down = min(down_box, coord_h + 1)
+ left = max(coord_w - 1, left_box)
+ right = min(right_box, coord_w + 1)
+
+ labels[top:(down + 1), left:(right + 1)] = gt_label
+ # ins
+ gt_mask = np.uint8(gt_mask.cpu().numpy())
+ # Follow the original implementation, F.interpolate is
+ # different from cv2 and opencv
+ gt_mask = mmcv.imrescale(gt_mask, scale=1. / self.mask_stride)
+ gt_mask = torch.from_numpy(gt_mask).to(device=device)
+
+ for i in range(top, down + 1):
+ for j in range(left, right + 1):
+ index = int(i * num_grid + j)
+ this_mask_target = torch.zeros(
+ [featmap_sizes[0], featmap_sizes[1]],
+ dtype=torch.uint8,
+ device=device)
+ this_mask_target[:gt_mask.shape[0], :gt_mask.
+ shape[1]] = gt_mask
+ mask_target.append(this_mask_target)
+ pos_mask[index] = True
+ pos_index.append(index)
+ if len(mask_target) == 0:
+ mask_target = torch.zeros(
+ [0, featmap_sizes[0], featmap_sizes[1]],
+ dtype=torch.uint8,
+ device=device)
+ else:
+ mask_target = torch.stack(mask_target, 0)
+ mlvl_pos_mask_targets.append(mask_target)
+ mlvl_labels.append(labels)
+ mlvl_pos_masks.append(pos_mask)
+ mlvl_pos_indexes.append(pos_index)
+ return (mlvl_pos_mask_targets, mlvl_labels, mlvl_pos_masks,
+ mlvl_pos_indexes)
+
+ def loss_by_feat(self, mlvl_kernel_preds: List[Tensor],
+ mlvl_cls_preds: List[Tensor], mask_feats: Tensor,
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict], **kwargs) -> dict:
+ """Calculate the loss based on the features extracted by the mask head.
+
+ Args:
+ mlvl_kernel_preds (list[Tensor]): Multi-level dynamic kernel
+ prediction. The kernel is used to generate instance
+ segmentation masks by dynamic convolution. Each element in the
+ list has shape
+ (batch_size, kernel_out_channels, num_grids, num_grids).
+ mlvl_cls_preds (list[Tensor]): Multi-level scores. Each element
+ in the list has shape
+ (batch_size, num_classes, num_grids, num_grids).
+ mask_feats (Tensor): Unified mask feature map used to generate
+ instance segmentation masks by dynamic convolution. Has shape
+ (batch_size, mask_out_channels, h, w).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes``, ``masks``,
+ and ``labels`` attributes.
+ batch_img_metas (list[dict]): Meta information of multiple images.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components.
+ """
+ featmap_sizes = mask_feats.size()[-2:]
+
+ pos_mask_targets, labels, pos_masks, pos_indexes = multi_apply(
+ self._get_targets_single,
+ batch_gt_instances,
+ featmap_sizes=featmap_sizes)
+
+ mlvl_mask_targets = [
+ torch.cat(lvl_mask_targets, 0)
+ for lvl_mask_targets in zip(*pos_mask_targets)
+ ]
+
+ mlvl_pos_kernel_preds = []
+ for lvl_kernel_preds, lvl_pos_indexes in zip(mlvl_kernel_preds,
+ zip(*pos_indexes)):
+ lvl_pos_kernel_preds = []
+ for img_lvl_kernel_preds, img_lvl_pos_indexes in zip(
+ lvl_kernel_preds, lvl_pos_indexes):
+ img_lvl_pos_kernel_preds = img_lvl_kernel_preds.view(
+ img_lvl_kernel_preds.shape[0], -1)[:, img_lvl_pos_indexes]
+ lvl_pos_kernel_preds.append(img_lvl_pos_kernel_preds)
+ mlvl_pos_kernel_preds.append(lvl_pos_kernel_preds)
+
+ # make multilevel mlvl_mask_pred
+ mlvl_mask_preds = []
+ for lvl_pos_kernel_preds in mlvl_pos_kernel_preds:
+ lvl_mask_preds = []
+ for img_id, img_lvl_pos_kernel_pred in enumerate(
+ lvl_pos_kernel_preds):
+ if img_lvl_pos_kernel_pred.size()[-1] == 0:
+ continue
+ img_mask_feats = mask_feats[[img_id]]
+ h, w = img_mask_feats.shape[-2:]
+ num_kernel = img_lvl_pos_kernel_pred.shape[1]
+ img_lvl_mask_pred = F.conv2d(
+ img_mask_feats,
+ img_lvl_pos_kernel_pred.permute(1, 0).view(
+ num_kernel, -1, self.dynamic_conv_size,
+ self.dynamic_conv_size),
+ stride=1).view(-1, h, w)
+ lvl_mask_preds.append(img_lvl_mask_pred)
+ if len(lvl_mask_preds) == 0:
+ lvl_mask_preds = None
+ else:
+ lvl_mask_preds = torch.cat(lvl_mask_preds, 0)
+ mlvl_mask_preds.append(lvl_mask_preds)
+ # dice loss
+ num_pos = 0
+ for img_pos_masks in pos_masks:
+ for lvl_img_pos_masks in img_pos_masks:
+ # Fix `Tensor` object has no attribute `count_nonzero()`
+ # in PyTorch 1.6, the type of `lvl_img_pos_masks`
+ # should be `torch.bool`.
+ num_pos += lvl_img_pos_masks.nonzero().numel()
+ loss_mask = []
+ for lvl_mask_preds, lvl_mask_targets in zip(mlvl_mask_preds,
+ mlvl_mask_targets):
+ if lvl_mask_preds is None:
+ continue
+ loss_mask.append(
+ self.loss_mask(
+ lvl_mask_preds,
+ lvl_mask_targets,
+ reduction_override='none'))
+ if num_pos > 0:
+ loss_mask = torch.cat(loss_mask).sum() / num_pos
+ else:
+ loss_mask = mask_feats.sum() * 0
+
+ # cate
+ flatten_labels = [
+ torch.cat(
+ [img_lvl_labels.flatten() for img_lvl_labels in lvl_labels])
+ for lvl_labels in zip(*labels)
+ ]
+ flatten_labels = torch.cat(flatten_labels)
+
+ flatten_cls_preds = [
+ lvl_cls_preds.permute(0, 2, 3, 1).reshape(-1, self.num_classes)
+ for lvl_cls_preds in mlvl_cls_preds
+ ]
+ flatten_cls_preds = torch.cat(flatten_cls_preds)
+
+ loss_cls = self.loss_cls(
+ flatten_cls_preds, flatten_labels, avg_factor=num_pos + 1)
+ return dict(loss_mask=loss_mask, loss_cls=loss_cls)
+
+ def predict_by_feat(self, mlvl_kernel_preds: List[Tensor],
+ mlvl_cls_scores: List[Tensor], mask_feats: Tensor,
+ batch_img_metas: List[dict], **kwargs) -> InstanceList:
+ """Transform a batch of output features extracted from the head into
+ mask results.
+
+ Args:
+ mlvl_kernel_preds (list[Tensor]): Multi-level dynamic kernel
+ prediction. The kernel is used to generate instance
+ segmentation masks by dynamic convolution. Each element in the
+ list has shape
+ (batch_size, kernel_out_channels, num_grids, num_grids).
+ mlvl_cls_scores (list[Tensor]): Multi-level scores. Each element
+ in the list has shape
+ (batch_size, num_classes, num_grids, num_grids).
+ mask_feats (Tensor): Unified mask feature map used to generate
+ instance segmentation masks by dynamic convolution. Has shape
+ (batch_size, mask_out_channels, h, w).
+ batch_img_metas (list[dict]): Meta information of all images.
+
+ Returns:
+ list[:obj:`InstanceData`]: Processed results of multiple
+ images.Each :obj:`InstanceData` usually contains
+ following keys.
+
+ - scores (Tensor): Classification scores, has shape
+ (num_instance,).
+ - labels (Tensor): Has shape (num_instances,).
+ - masks (Tensor): Processed mask results, has
+ shape (num_instances, h, w).
+ """
+ num_levels = len(mlvl_cls_scores)
+ assert len(mlvl_kernel_preds) == len(mlvl_cls_scores)
+
+ for lvl in range(num_levels):
+ cls_scores = mlvl_cls_scores[lvl]
+ cls_scores = cls_scores.sigmoid()
+ local_max = F.max_pool2d(cls_scores, 2, stride=1, padding=1)
+ keep_mask = local_max[:, :, :-1, :-1] == cls_scores
+ cls_scores = cls_scores * keep_mask
+ mlvl_cls_scores[lvl] = cls_scores.permute(0, 2, 3, 1)
+
+ result_list = []
+ for img_id in range(len(batch_img_metas)):
+ img_cls_pred = [
+ mlvl_cls_scores[lvl][img_id].view(-1, self.cls_out_channels)
+ for lvl in range(num_levels)
+ ]
+ img_mask_feats = mask_feats[[img_id]]
+ img_kernel_pred = [
+ mlvl_kernel_preds[lvl][img_id].permute(1, 2, 0).view(
+ -1, self.kernel_out_channels) for lvl in range(num_levels)
+ ]
+ img_cls_pred = torch.cat(img_cls_pred, dim=0)
+ img_kernel_pred = torch.cat(img_kernel_pred, dim=0)
+ result = self._predict_by_feat_single(
+ img_kernel_pred,
+ img_cls_pred,
+ img_mask_feats,
+ img_meta=batch_img_metas[img_id])
+ result_list.append(result)
+ return result_list
+
+ def _predict_by_feat_single(self,
+ kernel_preds: Tensor,
+ cls_scores: Tensor,
+ mask_feats: Tensor,
+ img_meta: dict,
+ cfg: OptConfigType = None) -> InstanceData:
+ """Transform a single image's features extracted from the head into
+ mask results.
+
+ Args:
+ kernel_preds (Tensor): Dynamic kernel prediction of all points
+ in single image, has shape
+ (num_points, kernel_out_channels).
+ cls_scores (Tensor): Classification score of all points
+ in single image, has shape (num_points, num_classes).
+ mask_feats (Tensor): Mask prediction of all points in
+ single image, has shape (num_points, feat_h, feat_w).
+ img_meta (dict): Meta information of corresponding image.
+ cfg (dict, optional): Config used in test phase.
+ Defaults to None.
+
+ Returns:
+ :obj:`InstanceData`: Processed results of single image.
+ it usually contains following keys.
+
+ - scores (Tensor): Classification scores, has shape
+ (num_instance,).
+ - labels (Tensor): Has shape (num_instances,).
+ - masks (Tensor): Processed mask results, has
+ shape (num_instances, h, w).
+ """
+
+ def empty_results(cls_scores, ori_shape):
+ """Generate a empty results."""
+ results = InstanceData()
+ results.scores = cls_scores.new_ones(0)
+ results.masks = cls_scores.new_zeros(0, *ori_shape)
+ results.labels = cls_scores.new_ones(0)
+ results.bboxes = cls_scores.new_zeros(0, 4)
+ return results
+
+ cfg = self.test_cfg if cfg is None else cfg
+ assert len(kernel_preds) == len(cls_scores)
+
+ featmap_size = mask_feats.size()[-2:]
+
+ # overall info
+ h, w = img_meta['img_shape'][:2]
+ upsampled_size = (featmap_size[0] * self.mask_stride,
+ featmap_size[1] * self.mask_stride)
+
+ # process.
+ score_mask = (cls_scores > cfg.score_thr)
+ cls_scores = cls_scores[score_mask]
+ if len(cls_scores) == 0:
+ return empty_results(cls_scores, img_meta['ori_shape'][:2])
+
+ # cate_labels & kernel_preds
+ inds = score_mask.nonzero()
+ cls_labels = inds[:, 1]
+ kernel_preds = kernel_preds[inds[:, 0]]
+
+ # trans vector.
+ lvl_interval = cls_labels.new_tensor(self.num_grids).pow(2).cumsum(0)
+ strides = kernel_preds.new_ones(lvl_interval[-1])
+
+ strides[:lvl_interval[0]] *= self.strides[0]
+ for lvl in range(1, self.num_levels):
+ strides[lvl_interval[lvl -
+ 1]:lvl_interval[lvl]] *= self.strides[lvl]
+ strides = strides[inds[:, 0]]
+
+ # mask encoding.
+ kernel_preds = kernel_preds.view(
+ kernel_preds.size(0), -1, self.dynamic_conv_size,
+ self.dynamic_conv_size)
+ mask_preds = F.conv2d(
+ mask_feats, kernel_preds, stride=1).squeeze(0).sigmoid()
+ # mask.
+ masks = mask_preds > cfg.mask_thr
+ sum_masks = masks.sum((1, 2)).float()
+ keep = sum_masks > strides
+ if keep.sum() == 0:
+ return empty_results(cls_scores, img_meta['ori_shape'][:2])
+ masks = masks[keep]
+ mask_preds = mask_preds[keep]
+ sum_masks = sum_masks[keep]
+ cls_scores = cls_scores[keep]
+ cls_labels = cls_labels[keep]
+
+ # maskness.
+ mask_scores = (mask_preds * masks).sum((1, 2)) / sum_masks
+ cls_scores *= mask_scores
+
+ scores, labels, _, keep_inds = mask_matrix_nms(
+ masks,
+ cls_labels,
+ cls_scores,
+ mask_area=sum_masks,
+ nms_pre=cfg.nms_pre,
+ max_num=cfg.max_per_img,
+ kernel=cfg.kernel,
+ sigma=cfg.sigma,
+ filter_thr=cfg.filter_thr)
+ if len(keep_inds) == 0:
+ return empty_results(cls_scores, img_meta['ori_shape'][:2])
+ mask_preds = mask_preds[keep_inds]
+ mask_preds = F.interpolate(
+ mask_preds.unsqueeze(0),
+ size=upsampled_size,
+ mode='bilinear',
+ align_corners=False)[:, :, :h, :w]
+ mask_preds = F.interpolate(
+ mask_preds,
+ size=img_meta['ori_shape'][:2],
+ mode='bilinear',
+ align_corners=False).squeeze(0)
+ masks = mask_preds > cfg.mask_thr
+
+ results = InstanceData()
+ results.masks = masks
+ results.labels = labels
+ results.scores = scores
+ # create an empty bbox in InstanceData to avoid bugs when
+ # calculating metrics.
+ results.bboxes = results.scores.new_zeros(len(scores), 4)
+
+ return results
diff --git a/mmdet/models/dense_heads/specdetr_head.py b/mmdet/models/dense_heads/specdetr_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..e723dbfc460cea6b34dc54b54873195362ddc21d
--- /dev/null
+++ b/mmdet/models/dense_heads/specdetr_head.py
@@ -0,0 +1,3354 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+from typing import Dict, List, Tuple
+from torch import Tensor
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import Linear
+from mmcv.ops.nms import nms
+from mmengine.model import bias_init_with_prob, constant_init
+from mmengine.structures import InstanceData
+
+from mmdet.registry import MODELS
+from mmdet.structures import SampleList
+from mmdet.structures.bbox import bbox_cxcywh_to_xyxy, bbox_xyxy_to_cxcywh
+from mmdet.utils import InstanceList, OptInstanceList, reduce_mean
+from ..utils import multi_apply
+from ..layers import inverse_sigmoid
+from .detr_head import DETRHead
+
+import math
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from torch.nn import Transformer
+import numpy as np
+# def adjust_bbox_to_pixel(bboxes: Tensor):
+# # 向下取整得到目标的左上角坐标
+# adjusted_bboxes = torch.floor(bboxes)
+# # 向上取整得到目标的右下角坐标
+# adjusted_bboxes[:, 2:] = torch.ceil(bboxes[:, 2:])
+# return adjusted_bboxes
+
+
+def adjust_bbox_to_pixel(bboxes: Tensor):
+ # 四舍五入取整坐标
+ adjusted_bboxes = torch.round(bboxes)
+ return adjusted_bboxes
+
+@MODELS.register_module()
+class SpecDetrHead(DETRHead):
+ r"""Head of the DINO: DETR with Improved DeNoising Anchor Boxes
+ for End-to-End Object Detection
+
+ Code is modified from the `official github repo
+ `_.
+
+ More details can be found in the `paper
+ `_ .
+ """
+
+ def __init__(self,
+ *args,
+ share_pred_layer: bool = False,
+ num_pred_layer: int = 6,
+ as_two_stage: bool = False,
+ pre_bboxes_round: bool = True,
+ decoupe_dn: bool = False,
+ dn_only_pos: bool = False,
+ dn_loss_weight: List[float] = [1, 1, 1], # [1,1,1]
+ iou_threshold: float = 0.01,
+ # use_nms : bool = True,
+ **kwargs) -> None:
+ self.share_pred_layer = share_pred_layer
+ self.num_pred_layer = num_pred_layer
+ self.as_two_stage = as_two_stage
+ self.pre_bboxes_round = pre_bboxes_round
+ assert not (decoupe_dn and dn_only_pos), "Both decoupe_dn and dn_only_pos cannot be True at the same time."
+ self.decoupe_dn = decoupe_dn
+ self.dn_only_pos = dn_only_pos
+ self.dn_loss_weight = dn_loss_weight
+ self.iou_threshold = iou_threshold
+ super().__init__(*args, **kwargs)
+ # self.use_nms = use_nms
+
+ def _init_layers(self) -> None:
+ """Initialize classification branch and regression branch of head."""
+ fc_cls = Linear(self.embed_dims, self.cls_out_channels)
+ reg_branch = []
+ for _ in range(self.num_reg_fcs):
+ reg_branch.append(Linear(self.embed_dims, self.embed_dims))
+ reg_branch.append(nn.ReLU())
+ reg_branch.append(Linear(self.embed_dims, 4))
+ reg_branch = nn.Sequential(*reg_branch)
+
+ if self.share_pred_layer:
+ self.cls_branches = nn.ModuleList(
+ [fc_cls for _ in range(self.num_pred_layer)])
+ self.reg_branches = nn.ModuleList(
+ [reg_branch for _ in range(self.num_pred_layer)])
+ else:
+ self.cls_branches = nn.ModuleList(
+ [copy.deepcopy(fc_cls) for _ in range(self.num_pred_layer)])
+ self.reg_branches = nn.ModuleList([
+ copy.deepcopy(reg_branch) for _ in range(self.num_pred_layer)
+ ])
+
+ def init_weights(self) -> None:
+ """Initialize weights of the Deformable DETR head."""
+ if self.loss_cls.use_sigmoid:
+ bias_init = bias_init_with_prob(0.01)
+ for m in self.cls_branches:
+ nn.init.constant_(m.bias, bias_init)
+ for m in self.reg_branches:
+ constant_init(m[-1], 0, bias=0)
+ nn.init.constant_(self.reg_branches[0][-1].bias.data[2:], -2.0)
+ if self.as_two_stage:
+ for m in self.reg_branches:
+ nn.init.constant_(m[-1].bias.data[2:], 0.0)
+
+ def _get_targets_single(self, cls_score: Tensor, bbox_pred: Tensor,
+ gt_instances: InstanceData,
+ img_meta: dict) -> tuple:
+ """Compute regression and classification targets for one image.
+
+ Outputs from a single decoder layer of a single feature level are used.
+
+ Args:
+ cls_score (Tensor): Box score logits from a single decoder layer
+ for one image. Shape [num_queries, cls_out_channels].
+ bbox_pred (Tensor): Sigmoid outputs from a single decoder layer
+ for one image, with normalized coordinate (cx, cy, w, h) and
+ shape [num_queries, 4].
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It should includes ``bboxes`` and ``labels``
+ attributes.
+ img_meta (dict): Meta information for one image.
+
+ Returns:
+ tuple[Tensor]: a tuple containing the following for one image.
+
+ - labels (Tensor): Labels of each image.
+ - label_weights (Tensor]): Label weights of each image.
+ - bbox_targets (Tensor): BBox targets of each image.
+ - bbox_weights (Tensor): BBox weights of each image.
+ - pos_inds (Tensor): Sampled positive indices for each image.
+ - neg_inds (Tensor): Sampled negative indices for each image.
+ """
+ img_h, img_w = img_meta['img_shape']
+ factor = bbox_pred.new_tensor([img_w, img_h, img_w,
+ img_h]).unsqueeze(0)
+ num_bboxes = bbox_pred.size(0)
+ # convert bbox_pred from xywh, normalized to xyxy, unnormalized
+ bbox_pred = bbox_cxcywh_to_xyxy(bbox_pred)
+ bbox_pred = bbox_pred * factor
+
+ pred_instances = InstanceData(scores=cls_score, bboxes=bbox_pred,priors=bbox_pred)
+ # assigner and sampler
+ assign_result = self.assigner.assign(
+ pred_instances=pred_instances,
+ gt_instances=gt_instances,
+ img_meta=img_meta)
+
+ gt_bboxes = gt_instances.bboxes
+ gt_labels = gt_instances.labels
+ pos_inds = torch.nonzero(
+ assign_result.gt_inds > 0, as_tuple=False).squeeze(-1).unique()
+ neg_inds = torch.nonzero(
+ assign_result.gt_inds == 0, as_tuple=False).squeeze(-1).unique()
+ pos_assigned_gt_inds = assign_result.gt_inds[pos_inds] - 1
+ pos_gt_bboxes = gt_bboxes[pos_assigned_gt_inds.long(), :]
+
+ # label targets
+ labels = gt_bboxes.new_full((num_bboxes,),
+ self.num_classes,
+ dtype=torch.long)
+ labels[pos_inds] = gt_labels[pos_assigned_gt_inds]
+ label_weights = gt_bboxes.new_ones(num_bboxes)
+
+ if not self.neg_cls:
+ label_weights[:] = 0
+ label_weights[pos_inds]=1
+ # bbox targets
+ bbox_targets = torch.zeros_like(bbox_pred)
+ bbox_weights = torch.zeros_like(bbox_pred)
+ bbox_weights[pos_inds] = 1.0
+
+ # DETR regress the relative position of boxes (cxcywh) in the image.
+ # Thus the learning target should be normalized by the image size, also
+ # the box format should be converted from defaultly x1y1x2y2 to cxcywh.
+ pos_gt_bboxes_normalized = pos_gt_bboxes / factor
+ pos_gt_bboxes_targets = bbox_xyxy_to_cxcywh(pos_gt_bboxes_normalized)
+ bbox_targets[pos_inds] = pos_gt_bboxes_targets
+ return (labels, label_weights, bbox_targets, bbox_weights, pos_inds,
+ neg_inds)
+
+ def forward(self, hidden_states: Tensor,
+ references: List[Tensor]) -> Tuple[Tensor]:
+ """Forward function.
+
+ Args:
+ hidden_states (Tensor): Hidden states output from each decoder
+ layer, has shape (num_decoder_layers, bs, num_queries, dim).
+ references (list[Tensor]): List of the reference from the decoder.
+ The first reference is the `init_reference` (initial) and the
+ other num_decoder_layers(6) references are `inter_references`
+ (intermediate). The `init_reference` has shape (bs,
+ num_queries, 4) when `as_two_stage` of the detector is `True`,
+ otherwise (bs, num_queries, 2). Each `inter_reference` has
+ shape (bs, num_queries, 4) when `with_box_refine` of the
+ detector is `True`, otherwise (bs, num_queries, 2). The
+ coordinates are arranged as (cx, cy) when the last dimension is
+ 2, and (cx, cy, w, h) when it is 4.
+
+ Returns:
+ tuple[Tensor]: results of head containing the following tensor.
+
+ - all_layers_outputs_classes (Tensor): Outputs from the
+ classification head, has shape (num_decoder_layers, bs,
+ num_queries, cls_out_channels).
+ - all_layers_outputs_coords (Tensor): Sigmoid outputs from the
+ regression head with normalized coordinate format (cx, cy, w,
+ h), has shape (num_decoder_layers, bs, num_queries, 4) with the
+ last dimension arranged as (cx, cy, w, h).
+ """
+ all_layers_outputs_classes = []
+ all_layers_outputs_coords = []
+
+ for layer_id in range(hidden_states.shape[0]):
+ reference = inverse_sigmoid(references[layer_id])
+ # NOTE The last reference will not be used.
+ hidden_state = hidden_states[layer_id]
+ outputs_class = self.cls_branches[layer_id](hidden_state)
+ tmp_reg_preds = self.reg_branches[layer_id](hidden_state)
+ if reference.shape[-1] == 4:
+ # When `layer` is 0 and `as_two_stage` of the detector
+ # is `True`, or when `layer` is greater than 0 and
+ # `with_box_refine` of the detector is `True`.
+ tmp_reg_preds += reference
+ else:
+ # When `layer` is 0 and `as_two_stage` of the detector
+ # is `False`, or when `layer` is greater than 0 and
+ # `with_box_refine` of the detector is `False`.
+ assert reference.shape[-1] == 2
+ tmp_reg_preds[..., :2] += reference
+ outputs_coord = tmp_reg_preds.sigmoid()
+ all_layers_outputs_classes.append(outputs_class)
+ all_layers_outputs_coords.append(outputs_coord)
+
+ all_layers_outputs_classes = torch.stack(all_layers_outputs_classes)
+ all_layers_outputs_coords = torch.stack(all_layers_outputs_coords)
+
+ return all_layers_outputs_classes, all_layers_outputs_coords
+
+ def loss(self, hidden_states: Tensor, references: List[Tensor],
+ enc_outputs_class: Tensor, enc_outputs_coord: Tensor,
+ batch_data_samples: SampleList, dn_meta: Dict[str, int]) -> dict:
+ """Perform forward propagation and loss calculation of the detection
+ head on the queries of the upstream network.
+
+ Args:
+ hidden_states (Tensor): Hidden states output from each decoder
+ layer, has shape (num_decoder_layers, bs, num_queries_total,
+ dim), where `num_queries_total` is the sum of
+ `num_denoising_queries` and `num_matching_queries` when
+ `self.training` is `True`, else `num_matching_queries`.
+ references (list[Tensor]): List of the reference from the decoder.
+ The first reference is the `init_reference` (initial) and the
+ other num_decoder_layers(6) references are `inter_references`
+ (intermediate). The `init_reference` has shape (bs,
+ num_queries_total, 4) and each `inter_reference` has shape
+ (bs, num_queries, 4) with the last dimension arranged as
+ (cx, cy, w, h).
+ enc_outputs_class (Tensor): The score of each point on encode
+ feature map, has shape (bs, num_feat_points, cls_out_channels).
+ enc_outputs_coord (Tensor): The proposal generate from the
+ encode feature map, has shape (bs, num_feat_points, 4) with the
+ last dimension arranged as (cx, cy, w, h).
+ batch_data_samples (list[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ dict: A dictionary of loss components.
+ """
+ batch_gt_instances = []
+ batch_img_metas = []
+ for data_sample in batch_data_samples:
+ batch_img_metas.append(data_sample.metainfo)
+ batch_gt_instances.append(data_sample.gt_instances)
+
+ outs = self(hidden_states, references)
+ loss_inputs = outs + (enc_outputs_class, enc_outputs_coord,
+ batch_gt_instances, batch_img_metas, dn_meta)
+ losses = self.loss_by_feat(*loss_inputs)
+ return losses
+
+ def loss_by_feat(
+ self,
+ all_layers_cls_scores: Tensor,
+ all_layers_bbox_preds: Tensor,
+ enc_cls_scores: Tensor,
+ enc_bbox_preds: Tensor,
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ dn_meta: Dict[str, int],
+ batch_gt_instances_ignore: OptInstanceList = None
+ ) -> Dict[str, Tensor]:
+ """Loss function.
+
+ Args:
+ all_layers_cls_scores (Tensor): Classification scores of all
+ decoder layers, has shape (num_decoder_layers, bs,
+ num_queries_total, cls_out_channels), where
+ `num_queries_total` is the sum of `num_denoising_queries`
+ and `num_matching_queries`.
+ all_layers_bbox_preds (Tensor): Regression outputs of all decoder
+ layers. Each is a 4D-tensor with normalized coordinate format
+ (cx, cy, w, h) and has shape (num_decoder_layers, bs,
+ num_queries_total, 4).
+ enc_cls_scores (Tensor): The score of each point on encode
+ feature map, has shape (bs, num_feat_points, cls_out_channels).
+ enc_bbox_preds (Tensor): The proposal generate from the encode
+ feature map, has shape (bs, num_feat_points, 4) with the last
+ dimension arranged as (cx, cy, w, h).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components.
+ """
+ # extract denoising and matching part of outputs
+ (all_layers_matching_cls_scores, all_layers_matching_bbox_preds,
+ all_layers_denoising_cls_scores, all_layers_denoising_bbox_preds) = \
+ self.split_outputs(
+ all_layers_cls_scores, all_layers_bbox_preds, dn_meta)
+
+ if all_layers_matching_cls_scores.numel() >0: # for dnd
+ loss_dict = super().loss_by_feat(
+ all_layers_matching_cls_scores, all_layers_matching_bbox_preds,
+ batch_gt_instances, batch_img_metas, batch_gt_instances_ignore)
+ else:
+ loss_dict = dict()
+
+ # # NOTE DETRHead.loss_by_feat but not DeformableDETRHead.loss_by_feat
+ # # is called, because the encoder loss calculations are different
+ # # between DINO and DeformableDETR.
+ # loss_dict = dict()
+ # loss of proposal generated from encode feature map.
+ if enc_cls_scores is not None:
+ # NOTE The enc_loss calculation of the DINO is
+ # different from that of Deformable DETR.
+ enc_loss_cls, enc_losses_bbox, enc_losses_iou = \
+ self.loss_by_feat_single(
+ enc_cls_scores, enc_bbox_preds,
+ batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas)
+ loss_dict['enc_loss_cls'] = enc_loss_cls
+ loss_dict['enc_loss_bbox'] = enc_losses_bbox
+ loss_dict['enc_loss_iou'] = enc_losses_iou
+
+ if all_layers_denoising_cls_scores is not None:
+ dn_losses_cls, dn_losses_bbox, dn_losses_iou = self.loss_dn(
+ all_layers_denoising_cls_scores,
+ all_layers_denoising_bbox_preds,
+ batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas,
+ dn_meta=dn_meta)
+ loss_dict['dn_loss_cls'] = dn_losses_cls[-1]
+ loss_dict['dn_loss_bbox'] = dn_losses_bbox[-1]
+ loss_dict['dn_loss_iou'] = dn_losses_iou[-1]
+ for num_dec_layer, (loss_cls_i, loss_bbox_i, loss_iou_i) in \
+ enumerate(zip(dn_losses_cls[:-1], dn_losses_bbox[:-1],
+ dn_losses_iou[:-1])):
+ loss_dict[f'd{num_dec_layer}.dn_loss_cls'] = loss_cls_i
+ loss_dict[f'd{num_dec_layer}.dn_loss_bbox'] = loss_bbox_i
+ loss_dict[f'd{num_dec_layer}.dn_loss_iou'] = loss_iou_i
+
+ # a = 0
+ # b = 1
+ # if all_layers_denoising_cls_scores is not None:
+ # # calculate denoising loss from all decoder layers
+ # dn_losses_cls, dn_losses_bbox, dn_losses_iou = self.loss_dn(
+ # all_layers_denoising_cls_scores,
+ # all_layers_denoising_bbox_preds,
+ # batch_gt_instances=batch_gt_instances,
+ # batch_img_metas=batch_img_metas,
+ # dn_meta=dn_meta)
+ # # collate denoising loss
+ # loss_dict['dn_loss_cls'] = dn_losses_cls[-1]
+ # loss_dict['dn_loss_bbox'] = dn_losses_bbox[-1]
+ # loss_dict['dn_loss_iou'] = dn_losses_iou[-1]
+ # # if loss_dict['loss_cls']>loss_dict['dn_loss_cls']:
+ # # cls_w = 1
+ # # else:
+ # # cls_w = loss_dict['loss_cls']/loss_dict['dn_loss_cls']
+ # # cls_w = (cls_w**a).detach()
+ # if loss_dict['loss_bbox']*b>loss_dict['dn_loss_bbox']:
+ # bbox_w = 1
+ # else:
+ # bbox_w = loss_dict['loss_bbox']/loss_dict['dn_loss_bbox']
+ # bbox_w = (bbox_w**a).detach()
+ # if loss_dict['loss_iou']*b>loss_dict['dn_loss_iou']:
+ # iou_w = 1
+ # else:
+ # iou_w = loss_dict['loss_iou']/loss_dict['dn_loss_iou']
+ # iou_w = (iou_w**a).detach()
+ # # cls_w = loss_dict['loss_cls'] / loss_dict['dn_loss_cls']
+ # # cls_w = (cls_w ** a).detach()
+ # # bbox_w = loss_dict['loss_bbox'] / loss_dict['dn_loss_bbox']
+ # # bbox_w = (bbox_w ** a).detach()
+ # # iou_w = loss_dict['loss_iou'] / loss_dict['dn_loss_iou']
+ # # iou_w = (iou_w ** a).detach()
+ # # loss_dict['dn_loss_cls'] *= cls_w
+ # loss_dict['dn_loss_bbox'] *= bbox_w
+ # loss_dict['dn_loss_iou'] *= iou_w
+ #
+ # for num_dec_layer, (loss_cls_i, loss_bbox_i, loss_iou_i) in \
+ # enumerate(zip(dn_losses_cls[:-1], dn_losses_bbox[:-1],
+ # dn_losses_iou[:-1])):
+ # loss_dict[f'd{num_dec_layer}.dn_loss_cls'] = loss_cls_i
+ # loss_dict[f'd{num_dec_layer}.dn_loss_bbox'] = loss_bbox_i
+ # loss_dict[f'd{num_dec_layer}.dn_loss_iou'] = loss_iou_i
+ # # if loss_dict[f'd{num_dec_layer}.loss_cls']> loss_dict[f'd{num_dec_layer}.dn_loss_cls']:
+ # # cls_w = 1
+ # # else:
+ # # cls_w = loss_dict[f'd{num_dec_layer}.loss_cls'] / loss_dict[f'd{num_dec_layer}.dn_loss_cls']
+ # # cls_w = (cls_w**a).detach()
+ # if loss_dict[f'd{num_dec_layer}.loss_bbox']*b> loss_dict[f'd{num_dec_layer}.dn_loss_bbox']:
+ # bbox_w = 1
+ # else:
+ # bbox_w = loss_dict[f'd{num_dec_layer}.loss_bbox'] / loss_dict[f'd{num_dec_layer}.dn_loss_bbox']
+ # bbox_w = (bbox_w**a).detach()
+ # if loss_dict[f'd{num_dec_layer}.loss_iou']*b> loss_dict[f'd{num_dec_layer}.dn_loss_iou']:
+ # iou_w = 1
+ # else:
+ # iou_w = loss_dict[f'd{num_dec_layer}.loss_iou'] / loss_dict[f'd{num_dec_layer}.dn_loss_iou']
+ # iou_w = (iou_w**a).detach()
+ # # cls_w = loss_dict[f'd{num_dec_layer}.loss_cls'] / loss_dict[f'd{num_dec_layer}.dn_loss_cls']
+ # # cls_w = (cls_w ** a).detach()
+ # # bbox_w = loss_dict[f'd{num_dec_layer}.loss_bbox'] / loss_dict[f'd{num_dec_layer}.dn_loss_bbox']
+ # # bbox_w = (bbox_w ** a).detach()
+ # # iou_w = loss_dict[f'd{num_dec_layer}.loss_iou'] / loss_dict[f'd{num_dec_layer}.dn_loss_iou']
+ # # iou_w = (iou_w ** a).detach()
+ # # loss_dict[f'd{num_dec_layer}.dn_loss_cls'] *= cls_w
+ # loss_dict[f'd{num_dec_layer}.dn_loss_bbox'] *= bbox_w
+ # loss_dict[f'd{num_dec_layer}.dn_loss_iou'] *= iou_w
+
+ return loss_dict
+
+ def loss_dn(self, all_layers_denoising_cls_scores: Tensor,
+ all_layers_denoising_bbox_preds: Tensor,
+ batch_gt_instances: InstanceList, batch_img_metas: List[dict],
+ dn_meta: Dict[str, int]) -> Tuple[List[Tensor]]:
+ """Calculate denoising loss.
+
+ Args:
+ all_layers_denoising_cls_scores (Tensor): Classification scores of
+ all decoder layers in denoising part, has shape (
+ num_decoder_layers, bs, num_denoising_queries,
+ cls_out_channels).
+ all_layers_denoising_bbox_preds (Tensor): Regression outputs of all
+ decoder layers in denoising part. Each is a 4D-tensor with
+ normalized coordinate format (cx, cy, w, h) and has shape
+ (num_decoder_layers, bs, num_denoising_queries, 4).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ Tuple[List[Tensor]]: The loss_dn_cls, loss_dn_bbox, and loss_dn_iou
+ of each decoder layers.
+ """
+ return multi_apply(
+ self._loss_dn_single,
+ all_layers_denoising_cls_scores,
+ all_layers_denoising_bbox_preds,
+ batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas,
+ dn_meta=dn_meta)
+
+
+ def _loss_dn_single(self, dn_cls_scores: Tensor, dn_bbox_preds: Tensor,
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ dn_meta: Dict[str, int]) -> Tuple[Tensor]:
+ """Denoising loss for outputs from a single decoder layer.
+
+ Args:
+ dn_cls_scores (Tensor): Classification scores of a single decoder
+ layer in denoising part, has shape (bs, num_denoising_queries,
+ cls_out_channels).
+ dn_bbox_preds (Tensor): Regression outputs of a single decoder
+ layer in denoising part. Each is a 4D-tensor with normalized
+ coordinate format (cx, cy, w, h) and has shape
+ (bs, num_denoising_queries, 4).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ Tuple[Tensor]: A tuple including `loss_cls`, `loss_box` and
+ `loss_iou`.
+ """
+ cls_reg_targets = self.get_dn_targets(batch_gt_instances,
+ batch_img_metas, dn_meta)
+ (labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,
+ num_total_pos, num_total_neg) = cls_reg_targets
+ labels = torch.cat(labels_list, 0)
+ label_weights = torch.cat(label_weights_list, 0)
+ bbox_targets = torch.cat(bbox_targets_list, 0)
+ bbox_weights = torch.cat(bbox_weights_list, 0)
+
+ # classification loss
+ cls_scores = dn_cls_scores.reshape(-1, self.cls_out_channels)
+ # construct weighted avg_factor to match with the official DETR repo
+ cls_avg_factor = \
+ num_total_pos * 1.0 + num_total_neg * self.bg_cls_weight
+ if self.sync_cls_avg_factor:
+ cls_avg_factor = reduce_mean(
+ cls_scores.new_tensor([cls_avg_factor]))
+ cls_avg_factor = max(cls_avg_factor, 1)
+
+ if len(cls_scores) > 0:
+ loss_cls = self.loss_cls(
+ cls_scores, labels, label_weights, avg_factor=cls_avg_factor)
+ else:
+ loss_cls = torch.zeros(
+ 1, dtype=cls_scores.dtype, device=cls_scores.device)
+
+ # Compute the average number of gt boxes across all gpus, for
+ # normalization purposes
+ num_total_pos = loss_cls.new_tensor([num_total_pos])
+ num_total_pos = torch.clamp(reduce_mean(num_total_pos), min=1).item()
+
+ # construct factors used for rescale bboxes
+ factors = []
+ for img_meta, bbox_pred in zip(batch_img_metas, dn_bbox_preds):
+ img_h, img_w = img_meta['img_shape']
+ factor = bbox_pred.new_tensor([img_w, img_h, img_w,
+ img_h]).unsqueeze(0).repeat(
+ bbox_pred.size(0), 1)
+ factors.append(factor)
+ factors = torch.cat(factors)
+
+ # DETR regress the relative position of boxes (cxcywh) in the image,
+ # thus the learning target is normalized by the image size. So here
+ # we need to re-scale them for calculating IoU loss
+ bbox_preds = dn_bbox_preds.reshape(-1, 4)
+ bboxes = bbox_cxcywh_to_xyxy(bbox_preds) * factors
+ bboxes_gt = bbox_cxcywh_to_xyxy(bbox_targets) * factors
+
+ # regression IoU loss, defaultly GIoU loss
+ loss_iou = self.loss_iou(
+ bboxes, bboxes_gt, bbox_weights, avg_factor=num_total_pos)
+
+ # regression L1 loss
+ loss_bbox = self.loss_bbox(
+ bbox_preds, bbox_targets, bbox_weights, avg_factor=num_total_pos)
+ return loss_cls, loss_bbox, loss_iou
+
+ def get_dn_targets(self, batch_gt_instances: InstanceList,
+ batch_img_metas: dict, dn_meta: Dict[str,
+ int]) -> tuple:
+ """Get targets in denoising part for a batch of images.
+
+ Args:
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ tuple: a tuple containing the following targets.
+
+ - labels_list (list[Tensor]): Labels for all images.
+ - label_weights_list (list[Tensor]): Label weights for all images.
+ - bbox_targets_list (list[Tensor]): BBox targets for all images.
+ - bbox_weights_list (list[Tensor]): BBox weights for all images.
+ - num_total_pos (int): Number of positive samples in all images.
+ - num_total_neg (int): Number of negative samples in all images.
+ """
+ (labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,
+ pos_inds_list, neg_inds_list) = multi_apply(
+ self._get_dn_targets_single,
+ batch_gt_instances,
+ batch_img_metas,
+ dn_meta=dn_meta)
+ num_total_pos = sum((inds.numel() for inds in pos_inds_list))
+ num_total_neg = sum((inds.numel() for inds in neg_inds_list))
+ return (labels_list, label_weights_list, bbox_targets_list,
+ bbox_weights_list, num_total_pos, num_total_neg)
+
+ def _get_dn_targets_single(self, gt_instances: InstanceData,
+ img_meta: dict, dn_meta: Dict[str,
+ int]) -> tuple:
+ """Get targets in denoising part for one image.
+
+ Args:
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It should includes ``bboxes`` and ``labels``
+ attributes.
+ img_meta (dict): Meta information for one image.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ tuple[Tensor]: a tuple containing the following for one image.
+
+ - labels (Tensor): Labels of each image.
+ - label_weights (Tensor]): Label weights of each image.
+ - bbox_targets (Tensor): BBox targets of each image.
+ - bbox_weights (Tensor): BBox weights of each image.
+ - pos_inds (Tensor): Sampled positive indices for each image.
+ - neg_inds (Tensor): Sampled negative indices for each image.
+ """
+ gt_bboxes = gt_instances.bboxes
+ gt_labels = gt_instances.labels
+ num_groups = dn_meta['num_denoising_groups']
+ num_denoising_queries = dn_meta['num_denoising_queries']
+ num_queries_each_group = int(num_denoising_queries / num_groups)
+ device = gt_bboxes.device
+
+ if len(gt_labels) > 0:
+ t = torch.arange(len(gt_labels), dtype=torch.long, device=device)
+ t = t.unsqueeze(0).repeat(num_groups, 1)
+ pos_assigned_gt_inds = t.flatten()
+ pos_inds = torch.arange(
+ num_groups, dtype=torch.long, device=device)
+ pos_inds = pos_inds.unsqueeze(1) * num_queries_each_group + t
+ pos_inds = pos_inds.flatten()
+ else:
+ pos_inds = pos_assigned_gt_inds = \
+ gt_bboxes.new_tensor([], dtype=torch.long)
+
+ neg_inds = pos_inds + num_queries_each_group // 2
+
+ # label targets
+ labels = gt_bboxes.new_full((num_denoising_queries, ),
+ self.num_classes,
+ dtype=torch.long)
+ labels[pos_inds] = gt_labels[pos_assigned_gt_inds]
+ label_weights = gt_bboxes.new_ones(num_denoising_queries)
+
+ # bbox targets
+ bbox_targets = torch.zeros(num_denoising_queries, 4, device=device)
+ bbox_weights = torch.zeros(num_denoising_queries, 4, device=device)
+ bbox_weights[pos_inds] = 1.0
+ img_h, img_w = img_meta['img_shape']
+
+ # DETR regress the relative position of boxes (cxcywh) in the image.
+ # Thus the learning target should be normalized by the image size, also
+ # the box format should be converted from defaultly x1y1x2y2 to cxcywh.
+ factor = gt_bboxes.new_tensor([img_w, img_h, img_w,
+ img_h]).unsqueeze(0)
+ gt_bboxes_normalized = gt_bboxes / factor
+ gt_bboxes_targets = bbox_xyxy_to_cxcywh(gt_bboxes_normalized)
+ bbox_targets[pos_inds] = gt_bboxes_targets.repeat([num_groups, 1])
+
+ return (labels, label_weights, bbox_targets, bbox_weights, pos_inds,
+ neg_inds)
+
+
+ @staticmethod
+ def split_outputs(all_layers_cls_scores: Tensor,
+ all_layers_bbox_preds: Tensor,
+ dn_meta: Dict[str, int]) -> Tuple[Tensor]:
+ """Split outputs of the denoising part and the matching part.
+
+ For the total outputs of `num_queries_total` length, the former
+ `num_denoising_queries` outputs are from denoising queries, and
+ the rest `num_matching_queries` ones are from matching queries,
+ where `num_queries_total` is the sum of `num_denoising_queries` and
+ `num_matching_queries`.
+
+ Args:
+ all_layers_cls_scores (Tensor): Classification scores of all
+ decoder layers, has shape (num_decoder_layers, bs,
+ num_queries_total, cls_out_channels).
+ all_layers_bbox_preds (Tensor): Regression outputs of all decoder
+ layers. Each is a 4D-tensor with normalized coordinate format
+ (cx, cy, w, h) and has shape (num_decoder_layers, bs,
+ num_queries_total, 4).
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'.
+
+ Returns:
+ Tuple[Tensor]: a tuple containing the following outputs.
+
+ - all_layers_matching_cls_scores (Tensor): Classification scores
+ of all decoder layers in matching part, has shape
+ (num_decoder_layers, bs, num_matching_queries, cls_out_channels).
+ - all_layers_matching_bbox_preds (Tensor): Regression outputs of
+ all decoder layers in matching part. Each is a 4D-tensor with
+ normalized coordinate format (cx, cy, w, h) and has shape
+ (num_decoder_layers, bs, num_matching_queries, 4).
+ - all_layers_denoising_cls_scores (Tensor): Classification scores
+ of all decoder layers in denoising part, has shape
+ (num_decoder_layers, bs, num_denoising_queries,
+ cls_out_channels).
+ - all_layers_denoising_bbox_preds (Tensor): Regression outputs of
+ all decoder layers in denoising part. Each is a 4D-tensor with
+ normalized coordinate format (cx, cy, w, h) and has shape
+ (num_decoder_layers, bs, num_denoising_queries, 4).
+ """
+ if dn_meta is not None:
+ num_denoising_queries = dn_meta['num_denoising_queries']
+ all_layers_denoising_cls_scores = \
+ all_layers_cls_scores[:, :, : num_denoising_queries, :]
+ all_layers_denoising_bbox_preds = \
+ all_layers_bbox_preds[:, :, : num_denoising_queries, :]
+ all_layers_matching_cls_scores = \
+ all_layers_cls_scores[:, :, num_denoising_queries:, :]
+ all_layers_matching_bbox_preds = \
+ all_layers_bbox_preds[:, :, num_denoising_queries:, :]
+ else:
+ all_layers_denoising_cls_scores = None
+ all_layers_denoising_bbox_preds = None
+ all_layers_matching_cls_scores = all_layers_cls_scores
+ all_layers_matching_bbox_preds = all_layers_bbox_preds
+ return (all_layers_matching_cls_scores, all_layers_matching_bbox_preds,
+ all_layers_denoising_cls_scores,
+ all_layers_denoising_bbox_preds)
+
+ def predict(self,
+ hidden_states: Tensor,
+ references: List[Tensor],
+ batch_data_samples: SampleList,
+ rescale: bool = True) -> InstanceList:
+ """Perform forward propagation and loss calculation of the detection
+ head on the queries of the upstream network.
+
+ Args:
+ hidden_states (Tensor): Hidden states output from each decoder
+ layer, has shape (num_decoder_layers, num_queries, bs, dim).
+ references (list[Tensor]): List of the reference from the decoder.
+ The first reference is the `init_reference` (initial) and the
+ other num_decoder_layers(6) references are `inter_references`
+ (intermediate). The `init_reference` has shape (bs,
+ num_queries, 4) when `as_two_stage` of the detector is `True`,
+ otherwise (bs, num_queries, 2). Each `inter_reference` has
+ shape (bs, num_queries, 4) when `with_box_refine` of the
+ detector is `True`, otherwise (bs, num_queries, 2). The
+ coordinates are arranged as (cx, cy) when the last dimension is
+ 2, and (cx, cy, w, h) when it is 4.
+ batch_data_samples (list[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ rescale (bool, optional): If `True`, return boxes in original
+ image space. Defaults to `True`.
+
+ Returns:
+ list[obj:`InstanceData`]: Detection results of each image
+ after the post process.
+ """
+ batch_img_metas = [
+ data_samples.metainfo for data_samples in batch_data_samples
+ ]
+
+ outs = self(hidden_states, references)
+
+ predictions = self.predict_by_feat(
+ *outs, batch_img_metas=batch_img_metas, rescale=rescale)
+ return predictions
+
+ def predict_by_feat(self,
+ all_layers_cls_scores: Tensor,
+ all_layers_bbox_preds: Tensor,
+ batch_img_metas: List[Dict],
+ rescale: bool = False) -> InstanceList:
+ """Transform a batch of output features extracted from the head into
+ bbox results.
+
+ Args:
+ all_layers_cls_scores (Tensor): Classification scores of all
+ decoder layers, has shape (num_decoder_layers, bs, num_queries,
+ cls_out_channels).
+ all_layers_bbox_preds (Tensor): Regression outputs of all decoder
+ layers. Each is a 4D-tensor with normalized coordinate format
+ (cx, cy, w, h) and shape (num_decoder_layers, bs, num_queries,
+ 4) with the last dimension arranged as (cx, cy, w, h).
+ batch_img_metas (list[dict]): Meta information of each image.
+ rescale (bool, optional): If `True`, return boxes in original
+ image space. Default `False`.
+
+ Returns:
+ list[obj:`InstanceData`]: Detection results of each image
+ after the post process.
+ """
+ cls_scores = all_layers_cls_scores[-1]
+ bbox_preds = all_layers_bbox_preds[-1]
+
+ result_list = []
+ for img_id in range(len(batch_img_metas)):
+ cls_score = cls_scores[img_id]
+ bbox_pred = bbox_preds[img_id]
+ img_meta = batch_img_metas[img_id]
+ results = self._predict_by_feat_single(cls_score, bbox_pred,
+ img_meta, rescale)
+ result_list.append(results)
+ return result_list
+
+ def _predict_by_feat_single(self,
+ cls_score: Tensor,
+ bbox_pred: Tensor,
+ img_meta: dict,
+ rescale: bool = True) -> InstanceData:
+ """Transform outputs from the last decoder layer into bbox predictions
+ for each image.
+
+ Args:
+ cls_score (Tensor): Box score logits from the last decoder layer
+ for each image. Shape [num_queries, cls_out_channels].
+ bbox_pred (Tensor): Sigmoid outputs from the last decoder layer
+ for each image, with coordinate format (cx, cy, w, h) and
+ shape [num_queries, 4].
+ img_meta (dict): Image meta info.
+ rescale (bool): If True, return boxes in original image
+ space. Default True.
+
+ Returns:
+ :obj:`InstanceData`: Detection results of each image
+ after the post process.
+ Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ """
+ assert len(cls_score) == len(bbox_pred) # num_queries
+ max_per_img = self.test_cfg.get('max_per_img', len(cls_score))
+ img_shape = img_meta['img_shape']
+ # # exclude background
+ if self.loss_cls.use_sigmoid:
+ cls_score = cls_score.sigmoid()
+ scores, indexes = cls_score.view(-1).topk(max_per_img)
+ det_labels = indexes % self.num_classes
+ bbox_index = indexes // self.num_classes
+ bbox_pred = bbox_pred[bbox_index]
+ else:
+ scores, det_labels = F.softmax(cls_score, dim=-1)[..., :-1].max(-1)
+ scores, bbox_index = scores.topk(max_per_img)
+ bbox_pred = bbox_pred[bbox_index]
+ det_labels = det_labels[bbox_index]
+
+
+ det_bboxes = bbox_cxcywh_to_xyxy(bbox_pred)
+ det_bboxes[:, 0::2] = det_bboxes[:, 0::2] * img_shape[1]
+ det_bboxes[:, 1::2] = det_bboxes[:, 1::2] * img_shape[0]
+ det_bboxes[:, 0::2].clamp_(min=0, max=img_shape[1])
+ det_bboxes[:, 1::2].clamp_(min=0, max=img_shape[0])
+
+ if self.use_nms:
+ iou_threshold = self.iou_threshold
+ offset = 0
+ score_threshold = 0.0 # torch.mean(cls_score.view(-1))+3*torch.std(cls_score.view(-1))
+
+ # max_num = 300
+ dets, inds = nms(det_bboxes, scores, iou_threshold, offset, score_threshold)
+ det_bboxes = dets[:, :-1]
+ scores = dets[:, -1]
+ det_labels = det_labels[inds]
+
+ # add by lzx
+ if self.pre_bboxes_round:
+ det_bboxes = adjust_bbox_to_pixel(det_bboxes)
+
+ if rescale:
+ # assert img_meta.get('scale_factor') is not None
+ # det_bboxes /= det_bboxes.new_tensor(
+ # img_meta['scale_factor']).repeat((1, 2))
+ # rw by lzx
+ if img_meta.get('scale_factor') is not None:
+ det_bboxes /= det_bboxes.new_tensor(
+ img_meta['scale_factor']).repeat((1, 2))
+ results = InstanceData()
+ results.bboxes = det_bboxes
+ results.scores = scores
+ results.labels = det_labels
+ return results
+
+
+def bbox_iou_numpy(bbox1, bbox2):
+ """
+ 计算两个边界框的IoU。这里bbox1和bbox2都是NumPy数组。
+ """
+ # 计算交集的坐标
+ x1 = np.maximum(bbox1[:, 0], bbox2[:, 0])
+ y1 = np.maximum(bbox1[:, 1], bbox2[:, 1])
+ x2 = np.minimum(bbox1[:, 2], bbox2[:, 2])
+ y2 = np.minimum(bbox1[:, 3], bbox2[:, 3])
+
+ # 计算交集和并集的面积
+ inter_area = np.maximum(x2 - x1, 0) * np.maximum(y2 - y1, 0)
+ bbox1_area = (bbox1[:, 2] - bbox1[:, 0]) * (bbox1[:, 3] - bbox1[:, 1])
+ bbox2_area = (bbox2[:, 2] - bbox2[:, 0]) * (bbox2[:, 3] - bbox2[:, 1])
+
+ # 计算IoU
+ union_area = bbox1_area + bbox2_area - inter_area
+ # iou = inter_area / bbox2_area
+ iou = inter_area / union_area
+ iob2 = inter_area / bbox2_area
+ return iou,iob2
+
+@MODELS.register_module()
+class SpecDetrHead_DN(DETRHead):
+ r"""Head of the DINO: DETR with Improved DeNoising Anchor Boxes
+ for End-to-End Object Detection
+
+ Code is modified from the `official github repo
+ `_.
+
+ More details can be found in the `paper
+ `_ .
+ """
+
+ def __init__(self,
+ *args,
+ share_pred_layer: bool = False,
+ num_pred_layer: int = 6,
+ as_two_stage: bool = False,
+ pre_bboxes_round: bool = True,
+ decoupe_dn: bool = False,
+ dn_only_pos: bool = False,
+ dn_loss_weight: List[float] = [1, 1, 1], # [1,1,1]
+ # use_nms : bool = True,
+ **kwargs) -> None:
+ self.share_pred_layer = share_pred_layer
+ self.num_pred_layer = num_pred_layer
+ self.as_two_stage = as_two_stage
+ self.pre_bboxes_round = pre_bboxes_round
+ assert not (decoupe_dn and dn_only_pos), "Both decoupe_dn and dn_only_pos cannot be True at the same time."
+ self.decoupe_dn = decoupe_dn
+ self.dn_only_pos = dn_only_pos
+ self.dn_loss_weight = dn_loss_weight
+ super().__init__(*args, **kwargs)
+ # self.use_nms = use_nms
+
+ def _init_layers(self) -> None:
+ """Initialize classification branch and regression branch of head."""
+ fc_cls = Linear(self.embed_dims, self.cls_out_channels)
+ reg_branch = []
+ for _ in range(self.num_reg_fcs):
+ reg_branch.append(Linear(self.embed_dims, self.embed_dims))
+ reg_branch.append(nn.ReLU())
+ reg_branch.append(Linear(self.embed_dims, 4))
+ reg_branch = nn.Sequential(*reg_branch)
+
+ if self.share_pred_layer:
+ self.cls_branches = nn.ModuleList(
+ [fc_cls for _ in range(self.num_pred_layer)])
+ self.reg_branches = nn.ModuleList(
+ [reg_branch for _ in range(self.num_pred_layer)])
+ else:
+ self.cls_branches = nn.ModuleList(
+ [copy.deepcopy(fc_cls) for _ in range(self.num_pred_layer)])
+ self.reg_branches = nn.ModuleList([
+ copy.deepcopy(reg_branch) for _ in range(self.num_pred_layer)
+ ])
+
+ def init_weights(self) -> None:
+ """Initialize weights of the Deformable DETR head."""
+ if self.loss_cls.use_sigmoid:
+ bias_init = bias_init_with_prob(0.01)
+ for m in self.cls_branches:
+ nn.init.constant_(m.bias, bias_init)
+ for m in self.reg_branches:
+ constant_init(m[-1], 0, bias=0)
+ nn.init.constant_(self.reg_branches[0][-1].bias.data[2:], -2.0)
+ if self.as_two_stage:
+ for m in self.reg_branches:
+ nn.init.constant_(m[-1].bias.data[2:], 0.0)
+
+ def _get_targets_single(self, cls_score: Tensor, bbox_pred: Tensor,
+ gt_instances: InstanceData,
+ img_meta: dict) -> tuple:
+ """Compute regression and classification targets for one image.
+
+ Outputs from a single decoder layer of a single feature level are used.
+
+ Args:
+ cls_score (Tensor): Box score logits from a single decoder layer
+ for one image. Shape [num_queries, cls_out_channels].
+ bbox_pred (Tensor): Sigmoid outputs from a single decoder layer
+ for one image, with normalized coordinate (cx, cy, w, h) and
+ shape [num_queries, 4].
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It should includes ``bboxes`` and ``labels``
+ attributes.
+ img_meta (dict): Meta information for one image.
+
+ Returns:
+ tuple[Tensor]: a tuple containing the following for one image.
+
+ - labels (Tensor): Labels of each image.
+ - label_weights (Tensor]): Label weights of each image.
+ - bbox_targets (Tensor): BBox targets of each image.
+ - bbox_weights (Tensor): BBox weights of each image.
+ - pos_inds (Tensor): Sampled positive indices for each image.
+ - neg_inds (Tensor): Sampled negative indices for each image.
+ """
+ img_h, img_w = img_meta['img_shape']
+ factor = bbox_pred.new_tensor([img_w, img_h, img_w,
+ img_h]).unsqueeze(0)
+ num_bboxes = bbox_pred.size(0)
+ # convert bbox_pred from xywh, normalized to xyxy, unnormalized
+ bbox_pred = bbox_cxcywh_to_xyxy(bbox_pred)
+ bbox_pred = bbox_pred * factor
+
+ pred_instances = InstanceData(scores=cls_score, bboxes=bbox_pred,priors=bbox_pred)
+ # assigner and sampler
+ assign_result = self.assigner.assign(
+ pred_instances=pred_instances,
+ gt_instances=gt_instances,
+ img_meta=img_meta)
+
+ gt_bboxes = gt_instances.bboxes
+ gt_labels = gt_instances.labels
+ pos_inds = torch.nonzero(
+ assign_result.gt_inds > 0, as_tuple=False).squeeze(-1).unique()
+ neg_inds = torch.nonzero(
+ assign_result.gt_inds == 0, as_tuple=False).squeeze(-1).unique()
+ pos_assigned_gt_inds = assign_result.gt_inds[pos_inds] - 1
+ pos_gt_bboxes = gt_bboxes[pos_assigned_gt_inds.long(), :]
+
+ # label targets
+ labels = gt_bboxes.new_full((num_bboxes,),
+ self.num_classes,
+ dtype=torch.long)
+ labels[pos_inds] = gt_labels[pos_assigned_gt_inds]
+ label_weights = gt_bboxes.new_ones(num_bboxes)
+ if not self.neg_cls:
+ label_weights[:] = 0
+ label_weights[pos_inds]=1
+ # bbox targets
+ bbox_targets = torch.zeros_like(bbox_pred)
+ bbox_weights = torch.zeros_like(bbox_pred)
+ bbox_weights[pos_inds] = 1.0
+
+ # DETR regress the relative position of boxes (cxcywh) in the image.
+ # Thus the learning target should be normalized by the image size, also
+ # the box format should be converted from defaultly x1y1x2y2 to cxcywh.
+ pos_gt_bboxes_normalized = pos_gt_bboxes / factor
+ pos_gt_bboxes_targets = bbox_xyxy_to_cxcywh(pos_gt_bboxes_normalized)
+ bbox_targets[pos_inds] = pos_gt_bboxes_targets
+ return (labels, label_weights, bbox_targets, bbox_weights, pos_inds,
+ neg_inds)
+
+ def forward(self, hidden_states: Tensor,
+ references: List[Tensor]) -> Tuple[Tensor]:
+ """Forward function.
+
+ Args:
+ hidden_states (Tensor): Hidden states output from each decoder
+ layer, has shape (num_decoder_layers, bs, num_queries, dim).
+ references (list[Tensor]): List of the reference from the decoder.
+ The first reference is the `init_reference` (initial) and the
+ other num_decoder_layers(6) references are `inter_references`
+ (intermediate). The `init_reference` has shape (bs,
+ num_queries, 4) when `as_two_stage` of the detector is `True`,
+ otherwise (bs, num_queries, 2). Each `inter_reference` has
+ shape (bs, num_queries, 4) when `with_box_refine` of the
+ detector is `True`, otherwise (bs, num_queries, 2). The
+ coordinates are arranged as (cx, cy) when the last dimension is
+ 2, and (cx, cy, w, h) when it is 4.
+
+ Returns:
+ tuple[Tensor]: results of head containing the following tensor.
+
+ - all_layers_outputs_classes (Tensor): Outputs from the
+ classification head, has shape (num_decoder_layers, bs,
+ num_queries, cls_out_channels).
+ - all_layers_outputs_coords (Tensor): Sigmoid outputs from the
+ regression head with normalized coordinate format (cx, cy, w,
+ h), has shape (num_decoder_layers, bs, num_queries, 4) with the
+ last dimension arranged as (cx, cy, w, h).
+ """
+ all_layers_outputs_classes = []
+ all_layers_outputs_coords = []
+
+ for layer_id in range(hidden_states.shape[0]):
+ reference = inverse_sigmoid(references[layer_id])
+ # NOTE The last reference will not be used.
+ hidden_state = hidden_states[layer_id]
+ outputs_class = self.cls_branches[layer_id](hidden_state)
+ tmp_reg_preds = self.reg_branches[layer_id](hidden_state)
+ if reference.shape[-1] == 4:
+ # When `layer` is 0 and `as_two_stage` of the detector
+ # is `True`, or when `layer` is greater than 0 and
+ # `with_box_refine` of the detector is `True`.
+ tmp_reg_preds += reference
+ else:
+ # When `layer` is 0 and `as_two_stage` of the detector
+ # is `False`, or when `layer` is greater than 0 and
+ # `with_box_refine` of the detector is `False`.
+ assert reference.shape[-1] == 2
+ tmp_reg_preds[..., :2] += reference
+ outputs_coord = tmp_reg_preds.sigmoid()
+ all_layers_outputs_classes.append(outputs_class)
+ all_layers_outputs_coords.append(outputs_coord)
+
+ all_layers_outputs_classes = torch.stack(all_layers_outputs_classes)
+ all_layers_outputs_coords = torch.stack(all_layers_outputs_coords)
+
+ return all_layers_outputs_classes, all_layers_outputs_coords
+
+ def loss(self, hidden_states: Tensor, references: List[Tensor],
+ enc_outputs_class: Tensor, enc_outputs_coord: Tensor,
+ batch_data_samples: SampleList, dn_meta: Dict[str, int]) -> dict:
+ """Perform forward propagation and loss calculation of the detection
+ head on the queries of the upstream network.
+
+ Args:
+ hidden_states (Tensor): Hidden states output from each decoder
+ layer, has shape (num_decoder_layers, bs, num_queries_total,
+ dim), where `num_queries_total` is the sum of
+ `num_denoising_queries` and `num_matching_queries` when
+ `self.training` is `True`, else `num_matching_queries`.
+ references (list[Tensor]): List of the reference from the decoder.
+ The first reference is the `init_reference` (initial) and the
+ other num_decoder_layers(6) references are `inter_references`
+ (intermediate). The `init_reference` has shape (bs,
+ num_queries_total, 4) and each `inter_reference` has shape
+ (bs, num_queries, 4) with the last dimension arranged as
+ (cx, cy, w, h).
+ enc_outputs_class (Tensor): The score of each point on encode
+ feature map, has shape (bs, num_feat_points, cls_out_channels).
+ enc_outputs_coord (Tensor): The proposal generate from the
+ encode feature map, has shape (bs, num_feat_points, 4) with the
+ last dimension arranged as (cx, cy, w, h).
+ batch_data_samples (list[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ dict: A dictionary of loss components.
+ """
+ batch_gt_instances = []
+ batch_img_metas = []
+ for data_sample in batch_data_samples:
+ batch_img_metas.append(data_sample.metainfo)
+ batch_gt_instances.append(data_sample.gt_instances)
+
+ outs = self(hidden_states, references)
+ loss_inputs = outs + (enc_outputs_class, enc_outputs_coord,
+ batch_gt_instances, batch_img_metas, dn_meta)
+ losses = self.loss_by_feat(*loss_inputs)
+ return losses
+
+ def loss_by_feat(
+ self,
+ all_layers_cls_scores: Tensor,
+ all_layers_bbox_preds: Tensor,
+ enc_cls_scores: Tensor,
+ enc_bbox_preds: Tensor,
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ dn_meta: Dict[str, int],
+ batch_gt_instances_ignore: OptInstanceList = None
+ ) -> Dict[str, Tensor]:
+ """Loss function.
+
+ Args:
+ all_layers_cls_scores (Tensor): Classification scores of all
+ decoder layers, has shape (num_decoder_layers, bs,
+ num_queries_total, cls_out_channels), where
+ `num_queries_total` is the sum of `num_denoising_queries`
+ and `num_matching_queries`.
+ all_layers_bbox_preds (Tensor): Regression outputs of all decoder
+ layers. Each is a 4D-tensor with normalized coordinate format
+ (cx, cy, w, h) and has shape (num_decoder_layers, bs,
+ num_queries_total, 4).
+ enc_cls_scores (Tensor): The score of each point on encode
+ feature map, has shape (bs, num_feat_points, cls_out_channels).
+ enc_bbox_preds (Tensor): The proposal generate from the encode
+ feature map, has shape (bs, num_feat_points, 4) with the last
+ dimension arranged as (cx, cy, w, h).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components.
+ """
+ # extract denoising and matching part of outputs
+ (all_layers_matching_cls_scores, all_layers_matching_bbox_preds,
+ all_layers_denoising_cls_scores, all_layers_denoising_bbox_preds) = \
+ self.split_outputs(
+ all_layers_cls_scores, all_layers_bbox_preds, dn_meta)
+ if all_layers_matching_cls_scores.numel() >0: # for dnd
+ loss_dict = super().loss_by_feat(
+ all_layers_matching_cls_scores, all_layers_matching_bbox_preds,
+ batch_gt_instances, batch_img_metas, batch_gt_instances_ignore)
+ else:
+ loss_dict = dict()
+ # # NOTE DETRHead.loss_by_feat but not DeformableDETRHead.loss_by_feat
+ # # is called, because the encoder loss calculations are different
+ # # between DINO and DeformableDETR.
+ # loss_dict = dict()
+ # loss of proposal generated from encode feature map.
+ if enc_cls_scores is not None:
+ # NOTE The enc_loss calculation of the DINO is
+ # different from that of Deformable DETR.
+ enc_loss_cls, enc_losses_bbox, enc_losses_iou = \
+ self.loss_by_feat_single(
+ enc_cls_scores, enc_bbox_preds,
+ batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas)
+ loss_dict['enc_loss_cls'] = enc_loss_cls
+ loss_dict['enc_loss_bbox'] = enc_losses_bbox
+ loss_dict['enc_loss_iou'] = enc_losses_iou
+
+ if all_layers_denoising_cls_scores is not None:
+ # calculate denoising loss from all decoder layers
+ dn_losses_cls, dn_losses_bbox, dn_losses_iou = self.loss_dn(
+ all_layers_denoising_cls_scores,
+ all_layers_denoising_bbox_preds,
+ batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas,
+ dn_meta=dn_meta)
+ # collate denoising loss
+ loss_dict['dn_loss_cls'] = dn_losses_cls[-1]
+ loss_dict['dn_loss_bbox'] = dn_losses_bbox[-1]
+ loss_dict['dn_loss_iou'] = dn_losses_iou[-1]
+ for num_dec_layer, (loss_cls_i, loss_bbox_i, loss_iou_i) in \
+ enumerate(zip(dn_losses_cls[:-1], dn_losses_bbox[:-1],
+ dn_losses_iou[:-1])):
+ loss_dict[f'd{num_dec_layer}.dn_loss_cls'] = loss_cls_i
+ loss_dict[f'd{num_dec_layer}.dn_loss_bbox'] = loss_bbox_i
+ loss_dict[f'd{num_dec_layer}.dn_loss_iou'] = loss_iou_i
+ # a = 0
+ # b = 1
+ # if all_layers_denoising_cls_scores is not None:
+ # # calculate denoising loss from all decoder layers
+ # dn_losses_cls, dn_losses_bbox, dn_losses_iou = self.loss_dn(
+ # all_layers_denoising_cls_scores,
+ # all_layers_denoising_bbox_preds,
+ # batch_gt_instances=batch_gt_instances,
+ # batch_img_metas=batch_img_metas,
+ # dn_meta=dn_meta)
+ # # collate denoising loss
+ # loss_dict['dn_loss_cls'] = dn_losses_cls[-1]
+ # loss_dict['dn_loss_bbox'] = dn_losses_bbox[-1]
+ # loss_dict['dn_loss_iou'] = dn_losses_iou[-1]
+ # # if loss_dict['loss_cls']>loss_dict['dn_loss_cls']:
+ # # cls_w = 1
+ # # else:
+ # # cls_w = loss_dict['loss_cls']/loss_dict['dn_loss_cls']
+ # # cls_w = (cls_w**a).detach()
+ # if loss_dict['loss_bbox']*b>loss_dict['dn_loss_bbox']:
+ # bbox_w = 1
+ # else:
+ # bbox_w = loss_dict['loss_bbox']/loss_dict['dn_loss_bbox']
+ # bbox_w = (bbox_w**a).detach()
+ # if loss_dict['loss_iou']*b>loss_dict['dn_loss_iou']:
+ # iou_w = 1
+ # else:
+ # iou_w = loss_dict['loss_iou']/loss_dict['dn_loss_iou']
+ # iou_w = (iou_w**a).detach()
+ # # cls_w = loss_dict['loss_cls'] / loss_dict['dn_loss_cls']
+ # # cls_w = (cls_w ** a).detach()
+ # # bbox_w = loss_dict['loss_bbox'] / loss_dict['dn_loss_bbox']
+ # # bbox_w = (bbox_w ** a).detach()
+ # # iou_w = loss_dict['loss_iou'] / loss_dict['dn_loss_iou']
+ # # iou_w = (iou_w ** a).detach()
+ # # loss_dict['dn_loss_cls'] *= cls_w
+ # loss_dict['dn_loss_bbox'] *= bbox_w
+ # loss_dict['dn_loss_iou'] *= iou_w
+ #
+ # for num_dec_layer, (loss_cls_i, loss_bbox_i, loss_iou_i) in \
+ # enumerate(zip(dn_losses_cls[:-1], dn_losses_bbox[:-1],
+ # dn_losses_iou[:-1])):
+ # loss_dict[f'd{num_dec_layer}.dn_loss_cls'] = loss_cls_i
+ # loss_dict[f'd{num_dec_layer}.dn_loss_bbox'] = loss_bbox_i
+ # loss_dict[f'd{num_dec_layer}.dn_loss_iou'] = loss_iou_i
+ # # if loss_dict[f'd{num_dec_layer}.loss_cls']> loss_dict[f'd{num_dec_layer}.dn_loss_cls']:
+ # # cls_w = 1
+ # # else:
+ # # cls_w = loss_dict[f'd{num_dec_layer}.loss_cls'] / loss_dict[f'd{num_dec_layer}.dn_loss_cls']
+ # # cls_w = (cls_w**a).detach()
+ # if loss_dict[f'd{num_dec_layer}.loss_bbox']*b> loss_dict[f'd{num_dec_layer}.dn_loss_bbox']:
+ # bbox_w = 1
+ # else:
+ # bbox_w = loss_dict[f'd{num_dec_layer}.loss_bbox'] / loss_dict[f'd{num_dec_layer}.dn_loss_bbox']
+ # bbox_w = (bbox_w**a).detach()
+ # if loss_dict[f'd{num_dec_layer}.loss_iou']*b> loss_dict[f'd{num_dec_layer}.dn_loss_iou']:
+ # iou_w = 1
+ # else:
+ # iou_w = loss_dict[f'd{num_dec_layer}.loss_iou'] / loss_dict[f'd{num_dec_layer}.dn_loss_iou']
+ # iou_w = (iou_w**a).detach()
+ # # cls_w = loss_dict[f'd{num_dec_layer}.loss_cls'] / loss_dict[f'd{num_dec_layer}.dn_loss_cls']
+ # # cls_w = (cls_w ** a).detach()
+ # # bbox_w = loss_dict[f'd{num_dec_layer}.loss_bbox'] / loss_dict[f'd{num_dec_layer}.dn_loss_bbox']
+ # # bbox_w = (bbox_w ** a).detach()
+ # # iou_w = loss_dict[f'd{num_dec_layer}.loss_iou'] / loss_dict[f'd{num_dec_layer}.dn_loss_iou']
+ # # iou_w = (iou_w ** a).detach()
+ # # loss_dict[f'd{num_dec_layer}.dn_loss_cls'] *= cls_w
+ # loss_dict[f'd{num_dec_layer}.dn_loss_bbox'] *= bbox_w
+ # loss_dict[f'd{num_dec_layer}.dn_loss_iou'] *= iou_w
+
+ return loss_dict
+
+ def loss_dn(self, all_layers_denoising_cls_scores: Tensor,
+ all_layers_denoising_bbox_preds: Tensor,
+ batch_gt_instances: InstanceList, batch_img_metas: List[dict],
+ dn_meta: Dict[str, int]) -> Tuple[List[Tensor]]:
+ """Calculate denoising loss.
+
+ Args:
+ all_layers_denoising_cls_scores (Tensor): Classification scores of
+ all decoder layers in denoising part, has shape (
+ num_decoder_layers, bs, num_denoising_queries,
+ cls_out_channels).
+ all_layers_denoising_bbox_preds (Tensor): Regression outputs of all
+ decoder layers in denoising part. Each is a 4D-tensor with
+ normalized coordinate format (cx, cy, w, h) and has shape
+ (num_decoder_layers, bs, num_denoising_queries, 4).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ Tuple[List[Tensor]]: The loss_dn_cls, loss_dn_bbox, and loss_dn_iou
+ of each decoder layers.
+ """
+ return multi_apply(
+ self._loss_dn_single,
+ all_layers_denoising_cls_scores,
+ all_layers_denoising_bbox_preds,
+ batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas,
+ dn_meta=dn_meta)
+
+
+ def _loss_dn_single(self, dn_cls_scores: Tensor, dn_bbox_preds: Tensor,
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ dn_meta: Dict[str, int]) -> Tuple[Tensor]:
+ """Denoising loss for outputs from a single decoder layer.
+
+ Args:
+ dn_cls_scores (Tensor): Classification scores of a single decoder
+ layer in denoising part, has shape (bs, num_denoising_queries,
+ cls_out_channels).
+ dn_bbox_preds (Tensor): Regression outputs of a single decoder
+ layer in denoising part. Each is a 4D-tensor with normalized
+ coordinate format (cx, cy, w, h) and has shape
+ (bs, num_denoising_queries, 4).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ Tuple[Tensor]: A tuple including `loss_cls`, `loss_box` and
+ `loss_iou`.
+ """
+ cls_reg_targets = self.get_dn_targets(batch_gt_instances,
+ batch_img_metas, dn_meta)
+ (labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,
+ num_total_pos) = cls_reg_targets
+ labels = torch.cat(labels_list, 0)
+ label_weights = torch.cat(label_weights_list, 0)
+ bbox_targets = torch.cat(bbox_targets_list, 0)
+ bbox_weights = torch.cat(bbox_weights_list, 0)
+
+ # classification loss
+ cls_scores = dn_cls_scores.reshape(-1, self.cls_out_channels)
+ # construct weighted avg_factor to match with the official DETR repo
+ cls_avg_factor = num_total_pos
+
+ if self.sync_cls_avg_factor:
+ cls_avg_factor = reduce_mean(
+ cls_scores.new_tensor([cls_avg_factor]))
+ cls_avg_factor = max(cls_avg_factor, 1)
+
+ if len(cls_scores) > 0:
+ loss_cls = self.loss_cls(
+ cls_scores, labels, label_weights, avg_factor=cls_avg_factor)
+ else:
+ loss_cls = torch.zeros(
+ 1, dtype=cls_scores.dtype, device=cls_scores.device)
+
+ # Compute the average number of gt boxes across all gpus, for
+ # normalization purposes
+ num_total_pos = loss_cls.new_tensor([num_total_pos])
+ num_total_pos = torch.clamp(reduce_mean(num_total_pos), min=1).item()
+
+ # construct factors used for rescale bboxes
+ factors = []
+ for img_meta, bbox_pred in zip(batch_img_metas, dn_bbox_preds):
+ img_h, img_w = img_meta['img_shape']
+ factor = bbox_pred.new_tensor([img_w, img_h, img_w,
+ img_h]).unsqueeze(0).repeat(
+ bbox_pred.size(0), 1)
+ factors.append(factor)
+ factors = torch.cat(factors)
+
+ # DETR regress the relative position of boxes (cxcywh) in the image,
+ # thus the learning target is normalized by the image size. So here
+ # we need to re-scale them for calculating IoU loss
+ bbox_preds = dn_bbox_preds.reshape(-1, 4)
+ bboxes = bbox_cxcywh_to_xyxy(bbox_preds) * factors
+ bboxes_gt = bbox_cxcywh_to_xyxy(bbox_targets) * factors
+ # regression IoU loss, defaultly GIoU loss
+ loss_iou = self.loss_iou(
+ bboxes, bboxes_gt, bbox_weights, avg_factor=num_total_pos) # lzx
+
+ # regression L1 loss
+ loss_bbox = self.loss_bbox(
+ bbox_preds, bbox_targets, bbox_weights, avg_factor=num_total_pos) # lzx
+ # return loss_cls*self.dn_loss_weight[0], loss_bbox**self.dn_loss_weight[1], loss_iou*self.dn_loss_weight[2]
+
+ return loss_cls, loss_bbox , loss_iou
+
+ def get_dn_targets(self, batch_gt_instances: InstanceList,
+ batch_img_metas: dict, dn_meta: Dict[str,
+ int]) -> tuple:
+ """Get targets in denoising part for a batch of images.
+
+ Args:
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ tuple: a tuple containing the following targets.
+
+ - labels_list (list[Tensor]): Labels for all images.
+ - label_weights_list (list[Tensor]): Label weights for all images.
+ - bbox_targets_list (list[Tensor]): BBox targets for all images.
+ - bbox_weights_list (list[Tensor]): BBox weights for all images.
+ - num_total_pos (int): Number of positive samples in all images.
+ - num_total_neg (int): Number of negative samples in all images.
+ """
+ (labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,
+ pos_inds_list,) = multi_apply(
+ self._get_dn_targets_single,
+ batch_gt_instances,
+ batch_img_metas,
+ dn_meta=dn_meta)
+ num_total_pos = sum((inds.numel() for inds in pos_inds_list))
+ return (labels_list, label_weights_list, bbox_targets_list,
+ bbox_weights_list, num_total_pos)
+
+
+
+ def _get_dn_targets_single(self, gt_instances: InstanceData,
+ img_meta: dict, dn_meta: Dict[str,
+ int]) -> tuple:
+ """Get targets in denoising part for one image.
+
+ Args:
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It should includes ``bboxes`` and ``labels``
+ attributes.
+ img_meta (dict): Meta information for one image.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ tuple[Tensor]: a tuple containing the following for one image.
+
+ - labels (Tensor): Labels of each image.
+ - label_weights (Tensor]): Label weights of each image.
+ - bbox_targets (Tensor): BBox targets of each image.
+ - bbox_weights (Tensor): BBox weights of each image.
+ - pos_inds (Tensor): Sampled positive indices for each image.
+ - neg_inds (Tensor): Sampled negative indices for each image.
+ """
+ gt_bboxes = gt_instances.bboxes
+ gt_labels = gt_instances.labels
+ num_groups = dn_meta['num_denoising_groups']
+ num_denoising_queries = dn_meta['num_denoising_queries']
+ num_queries_each_group = int(num_denoising_queries / num_groups)
+ device = gt_bboxes.device
+
+ if len(gt_labels) > 0:
+ t = torch.arange(len(gt_labels), dtype=torch.long, device=device)
+ t = t.unsqueeze(0).repeat(num_groups, 1)
+ pos_assigned_gt_inds = t.flatten()
+ pos_inds = torch.arange(
+ num_groups, dtype=torch.long, device=device)
+ pos_inds = pos_inds.unsqueeze(1) * num_queries_each_group + t
+ pos_inds = pos_inds.flatten()
+ else:
+ pos_inds = pos_assigned_gt_inds = \
+ gt_bboxes.new_tensor([], dtype=torch.long)
+
+ # label targets
+ labels = gt_bboxes.new_full((num_denoising_queries,),
+ self.num_classes,
+ dtype=torch.long)
+ labels[pos_inds] = gt_labels[pos_assigned_gt_inds]
+ label_weights = torch.zeros(num_denoising_queries, device=device)
+ label_weights[pos_inds] = 1.0
+ # bbox targets
+ bbox_targets = torch.zeros(num_denoising_queries, 4, device=device)
+ bbox_weights = torch.zeros(num_denoising_queries, 4, device=device)
+ bbox_weights[pos_inds] = 1.0
+ img_h, img_w = img_meta['img_shape']
+ # DETR regress the relative position of boxes (cxcywh) in the image.
+ # Thus the learning target should be normalized by the image size, also
+ # the box format should be converted from defaultly x1y1x2y2 to cxcywh.
+ factor = gt_bboxes.new_tensor([img_w, img_h, img_w,
+ img_h]).unsqueeze(0)
+ gt_bboxes_normalized = gt_bboxes / factor
+ gt_bboxes_targets = bbox_xyxy_to_cxcywh(gt_bboxes_normalized)
+ bbox_targets[pos_inds] = gt_bboxes_targets.repeat([num_groups, 1])
+ return (labels, label_weights, bbox_targets, bbox_weights, pos_inds,)
+
+
+ @staticmethod
+ def split_outputs(all_layers_cls_scores: Tensor,
+ all_layers_bbox_preds: Tensor,
+ dn_meta: Dict[str, int]) -> Tuple[Tensor]:
+ """Split outputs of the denoising part and the matching part.
+
+ For the total outputs of `num_queries_total` length, the former
+ `num_denoising_queries` outputs are from denoising queries, and
+ the rest `num_matching_queries` ones are from matching queries,
+ where `num_queries_total` is the sum of `num_denoising_queries` and
+ `num_matching_queries`.
+
+ Args:
+ all_layers_cls_scores (Tensor): Classification scores of all
+ decoder layers, has shape (num_decoder_layers, bs,
+ num_queries_total, cls_out_channels).
+ all_layers_bbox_preds (Tensor): Regression outputs of all decoder
+ layers. Each is a 4D-tensor with normalized coordinate format
+ (cx, cy, w, h) and has shape (num_decoder_layers, bs,
+ num_queries_total, 4).
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'.
+
+ Returns:
+ Tuple[Tensor]: a tuple containing the following outputs.
+
+ - all_layers_matching_cls_scores (Tensor): Classification scores
+ of all decoder layers in matching part, has shape
+ (num_decoder_layers, bs, num_matching_queries, cls_out_channels).
+ - all_layers_matching_bbox_preds (Tensor): Regression outputs of
+ all decoder layers in matching part. Each is a 4D-tensor with
+ normalized coordinate format (cx, cy, w, h) and has shape
+ (num_decoder_layers, bs, num_matching_queries, 4).
+ - all_layers_denoising_cls_scores (Tensor): Classification scores
+ of all decoder layers in denoising part, has shape
+ (num_decoder_layers, bs, num_denoising_queries,
+ cls_out_channels).
+ - all_layers_denoising_bbox_preds (Tensor): Regression outputs of
+ all decoder layers in denoising part. Each is a 4D-tensor with
+ normalized coordinate format (cx, cy, w, h) and has shape
+ (num_decoder_layers, bs, num_denoising_queries, 4).
+ """
+ if dn_meta is not None:
+ num_denoising_queries = dn_meta['num_denoising_queries']
+ all_layers_denoising_cls_scores = \
+ all_layers_cls_scores[:, :, : num_denoising_queries, :]
+ all_layers_denoising_bbox_preds = \
+ all_layers_bbox_preds[:, :, : num_denoising_queries, :]
+ all_layers_matching_cls_scores = \
+ all_layers_cls_scores[:, :, num_denoising_queries:, :]
+ all_layers_matching_bbox_preds = \
+ all_layers_bbox_preds[:, :, num_denoising_queries:, :]
+ else:
+ all_layers_denoising_cls_scores = None
+ all_layers_denoising_bbox_preds = None
+ all_layers_matching_cls_scores = all_layers_cls_scores
+ all_layers_matching_bbox_preds = all_layers_bbox_preds
+ return (all_layers_matching_cls_scores, all_layers_matching_bbox_preds,
+ all_layers_denoising_cls_scores,
+ all_layers_denoising_bbox_preds)
+
+ def predict(self,
+ hidden_states: Tensor,
+ references: List[Tensor],
+ batch_data_samples: SampleList,
+ rescale: bool = True) -> InstanceList:
+ """Perform forward propagation and loss calculation of the detection
+ head on the queries of the upstream network.
+
+ Args:
+ hidden_states (Tensor): Hidden states output from each decoder
+ layer, has shape (num_decoder_layers, num_queries, bs, dim).
+ references (list[Tensor]): List of the reference from the decoder.
+ The first reference is the `init_reference` (initial) and the
+ other num_decoder_layers(6) references are `inter_references`
+ (intermediate). The `init_reference` has shape (bs,
+ num_queries, 4) when `as_two_stage` of the detector is `True`,
+ otherwise (bs, num_queries, 2). Each `inter_reference` has
+ shape (bs, num_queries, 4) when `with_box_refine` of the
+ detector is `True`, otherwise (bs, num_queries, 2). The
+ coordinates are arranged as (cx, cy) when the last dimension is
+ 2, and (cx, cy, w, h) when it is 4.
+ batch_data_samples (list[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ rescale (bool, optional): If `True`, return boxes in original
+ image space. Defaults to `True`.
+
+ Returns:
+ list[obj:`InstanceData`]: Detection results of each image
+ after the post process.
+ """
+ batch_img_metas = [
+ data_samples.metainfo for data_samples in batch_data_samples
+ ]
+
+ outs = self(hidden_states, references)
+
+ predictions = self.predict_by_feat(
+ *outs, batch_img_metas=batch_img_metas, rescale=rescale)
+ return predictions
+
+ def predict_by_feat(self,
+ all_layers_cls_scores: Tensor,
+ all_layers_bbox_preds: Tensor,
+ batch_img_metas: List[Dict],
+ rescale: bool = False) -> InstanceList:
+ """Transform a batch of output features extracted from the head into
+ bbox results.
+
+ Args:
+ all_layers_cls_scores (Tensor): Classification scores of all
+ decoder layers, has shape (num_decoder_layers, bs, num_queries,
+ cls_out_channels).
+ all_layers_bbox_preds (Tensor): Regression outputs of all decoder
+ layers. Each is a 4D-tensor with normalized coordinate format
+ (cx, cy, w, h) and shape (num_decoder_layers, bs, num_queries,
+ 4) with the last dimension arranged as (cx, cy, w, h).
+ batch_img_metas (list[dict]): Meta information of each image.
+ rescale (bool, optional): If `True`, return boxes in original
+ image space. Default `False`.
+
+ Returns:
+ list[obj:`InstanceData`]: Detection results of each image
+ after the post process.
+ """
+ cls_scores = all_layers_cls_scores[-1]
+ bbox_preds = all_layers_bbox_preds[-1]
+
+ result_list = []
+ for img_id in range(len(batch_img_metas)):
+ cls_score = cls_scores[img_id]
+ bbox_pred = bbox_preds[img_id]
+ img_meta = batch_img_metas[img_id]
+ results = self._predict_by_feat_single(cls_score, bbox_pred,
+ img_meta, rescale)
+ result_list.append(results)
+ return result_list
+
+ def _predict_by_feat_single(self,
+ cls_score: Tensor,
+ bbox_pred: Tensor,
+ img_meta: dict,
+ rescale: bool = True) -> InstanceData:
+ """Transform outputs from the last decoder layer into bbox predictions
+ for each image.
+
+ Args:
+ cls_score (Tensor): Box score logits from the last decoder layer
+ for each image. Shape [num_queries, cls_out_channels].
+ bbox_pred (Tensor): Sigmoid outputs from the last decoder layer
+ for each image, with coordinate format (cx, cy, w, h) and
+ shape [num_queries, 4].
+ img_meta (dict): Image meta info.
+ rescale (bool): If True, return boxes in original image
+ space. Default True.
+
+ Returns:
+ :obj:`InstanceData`: Detection results of each image
+ after the post process.
+ Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ """
+ assert len(cls_score) == len(bbox_pred) # num_queries
+ max_per_img = self.test_cfg.get('max_per_img', len(cls_score))
+ img_shape = img_meta['img_shape']
+ # exclude background
+ if self.loss_cls.use_sigmoid:
+ cls_score = cls_score.sigmoid()
+ scores, indexes = cls_score.view(-1).topk(max_per_img)
+ det_labels = indexes % self.num_classes
+ bbox_index = indexes // self.num_classes
+ bbox_pred = bbox_pred[bbox_index]
+ else:
+ scores, det_labels = F.softmax(cls_score, dim=-1)[..., :-1].max(-1)
+ scores, bbox_index = scores.topk(max_per_img)
+ bbox_pred = bbox_pred[bbox_index]
+ det_labels = det_labels[bbox_index]
+
+ det_bboxes = bbox_cxcywh_to_xyxy(bbox_pred)
+ det_bboxes[:, 0::2] = det_bboxes[:, 0::2] * img_shape[1]
+ det_bboxes[:, 1::2] = det_bboxes[:, 1::2] * img_shape[0]
+ det_bboxes[:, 0::2].clamp_(min=0, max=img_shape[1])
+ det_bboxes[:, 1::2].clamp_(min=0, max=img_shape[0])
+
+ if self.use_nms:
+ iou_threshold = 0.01
+ offset = 0
+ score_threshold = 0.0 # torch.mean(cls_score.view(-1))+3*torch.std(cls_score.view(-1))
+ # max_num = 300
+ dets, inds = nms(det_bboxes, scores, iou_threshold, offset, score_threshold)
+ det_bboxes = dets[:, :-1]
+ scores = dets[:, -1]
+ det_labels = det_labels[inds]
+
+ # add by lzx
+ if self.pre_bboxes_round:
+ det_bboxes = adjust_bbox_to_pixel(det_bboxes)
+
+ if rescale:
+ # assert img_meta.get('scale_factor') is not None
+ # det_bboxes /= det_bboxes.new_tensor(
+ # img_meta['scale_factor']).repeat((1, 2))
+ # rw by lzx
+ if img_meta.get('scale_factor') is not None:
+ det_bboxes /= det_bboxes.new_tensor(
+ img_meta['scale_factor']).repeat((1, 2))
+ results = InstanceData()
+ results.bboxes = det_bboxes
+ results.scores = scores
+ results.labels = det_labels
+ return results
+@MODELS.register_module()
+class SpecDetrHeadv2(DETRHead):
+ r"""Head of the DINO: DETR with Improved DeNoising Anchor Boxes
+ for End-to-End Object Detection
+
+ Code is modified from the `official github repo
+ `_.
+
+ More details can be found in the `paper
+ `_ .
+ """
+
+ def __init__(self,
+ *args,
+ share_pred_layer: bool = False,
+ num_pred_layer: int = 6,
+ as_two_stage: bool = False,
+ pre_bboxes_round: bool = True,
+ decoupe_dn: bool = False,
+ dn_only_pos: bool = False,
+ dn_loss_weight: List[float] = [1, 1, 1], # [1,1,1]
+ # use_nms : bool = True,
+ **kwargs) -> None:
+ self.share_pred_layer = share_pred_layer
+ self.num_pred_layer = num_pred_layer
+ self.as_two_stage = as_two_stage
+ self.pre_bboxes_round = pre_bboxes_round
+ assert not (decoupe_dn and dn_only_pos), "Both decoupe_dn and dn_only_pos cannot be True at the same time."
+ self.decoupe_dn = decoupe_dn
+ self.dn_only_pos = dn_only_pos
+ self.dn_loss_weight = dn_loss_weight
+ super().__init__(*args, **kwargs)
+ # self.use_nms = use_nms
+
+ def _init_layers(self) -> None:
+ """Initialize classification branch and regression branch of head."""
+ fc_cls = Linear(self.embed_dims, self.cls_out_channels)
+ reg_branch = []
+ for _ in range(self.num_reg_fcs):
+ reg_branch.append(Linear(self.embed_dims, self.embed_dims))
+ reg_branch.append(nn.ReLU())
+ reg_branch.append(Linear(self.embed_dims, 4))
+ reg_branch = nn.Sequential(*reg_branch)
+
+ if self.share_pred_layer:
+ self.cls_branches = nn.ModuleList(
+ [fc_cls for _ in range(self.num_pred_layer)])
+ self.reg_branches = nn.ModuleList(
+ [reg_branch for _ in range(self.num_pred_layer)])
+ else:
+ self.cls_branches = nn.ModuleList(
+ [copy.deepcopy(fc_cls) for _ in range(self.num_pred_layer)])
+ self.reg_branches = nn.ModuleList([
+ copy.deepcopy(reg_branch) for _ in range(self.num_pred_layer)
+ ])
+
+ def init_weights(self) -> None:
+ """Initialize weights of the Deformable DETR head."""
+ if self.loss_cls.use_sigmoid:
+ bias_init = bias_init_with_prob(0.01)
+ for m in self.cls_branches:
+ nn.init.constant_(m.bias, bias_init)
+ for m in self.reg_branches:
+ constant_init(m[-1], 0, bias=0)
+ nn.init.constant_(self.reg_branches[0][-1].bias.data[2:], -2.0)
+ if self.as_two_stage:
+ for m in self.reg_branches:
+ nn.init.constant_(m[-1].bias.data[2:], 0.0)
+
+ def forward(self, hidden_states: Tensor,
+ references: List[Tensor]) -> Tuple[Tensor]:
+ """Forward function.
+
+ Args:
+ hidden_states (Tensor): Hidden states output from each decoder
+ layer, has shape (num_decoder_layers, bs, num_queries, dim).
+ references (list[Tensor]): List of the reference from the decoder.
+ The first reference is the `init_reference` (initial) and the
+ other num_decoder_layers(6) references are `inter_references`
+ (intermediate). The `init_reference` has shape (bs,
+ num_queries, 4) when `as_two_stage` of the detector is `True`,
+ otherwise (bs, num_queries, 2). Each `inter_reference` has
+ shape (bs, num_queries, 4) when `with_box_refine` of the
+ detector is `True`, otherwise (bs, num_queries, 2). The
+ coordinates are arranged as (cx, cy) when the last dimension is
+ 2, and (cx, cy, w, h) when it is 4.
+
+ Returns:
+ tuple[Tensor]: results of head containing the following tensor.
+
+ - all_layers_outputs_classes (Tensor): Outputs from the
+ classification head, has shape (num_decoder_layers, bs,
+ num_queries, cls_out_channels).
+ - all_layers_outputs_coords (Tensor): Sigmoid outputs from the
+ regression head with normalized coordinate format (cx, cy, w,
+ h), has shape (num_decoder_layers, bs, num_queries, 4) with the
+ last dimension arranged as (cx, cy, w, h).
+ """
+ all_layers_outputs_classes = []
+ all_layers_outputs_coords = []
+
+ for layer_id in range(hidden_states.shape[0]):
+ reference = inverse_sigmoid(references[layer_id])
+ # NOTE The last reference will not be used.
+ hidden_state = hidden_states[layer_id]
+ outputs_class = self.cls_branches[layer_id](hidden_state)
+ tmp_reg_preds = self.reg_branches[layer_id](hidden_state)
+ if reference.shape[-1] == 4:
+ # When `layer` is 0 and `as_two_stage` of the detector
+ # is `True`, or when `layer` is greater than 0 and
+ # `with_box_refine` of the detector is `True`.
+ tmp_reg_preds += reference
+ else:
+ # When `layer` is 0 and `as_two_stage` of the detector
+ # is `False`, or when `layer` is greater than 0 and
+ # `with_box_refine` of the detector is `False`.
+ assert reference.shape[-1] == 2
+ tmp_reg_preds[..., :2] += reference
+ outputs_coord = tmp_reg_preds.sigmoid()
+ all_layers_outputs_classes.append(outputs_class)
+ all_layers_outputs_coords.append(outputs_coord)
+
+ all_layers_outputs_classes = torch.stack(all_layers_outputs_classes)
+ all_layers_outputs_coords = torch.stack(all_layers_outputs_coords)
+
+ return all_layers_outputs_classes, all_layers_outputs_coords
+
+ def loss(self, hidden_states: Tensor, references: List[Tensor],
+ enc_outputs_class: Tensor, enc_outputs_coord: Tensor,
+ batch_data_samples: SampleList, dn_meta: Dict[str, int]) -> dict:
+ """Perform forward propagation and loss calculation of the detection
+ head on the queries of the upstream network.
+
+ Args:
+ hidden_states (Tensor): Hidden states output from each decoder
+ layer, has shape (num_decoder_layers, bs, num_queries_total,
+ dim), where `num_queries_total` is the sum of
+ `num_denoising_queries` and `num_matching_queries` when
+ `self.training` is `True`, else `num_matching_queries`.
+ references (list[Tensor]): List of the reference from the decoder.
+ The first reference is the `init_reference` (initial) and the
+ other num_decoder_layers(6) references are `inter_references`
+ (intermediate). The `init_reference` has shape (bs,
+ num_queries_total, 4) and each `inter_reference` has shape
+ (bs, num_queries, 4) with the last dimension arranged as
+ (cx, cy, w, h).
+ enc_outputs_class (Tensor): The score of each point on encode
+ feature map, has shape (bs, num_feat_points, cls_out_channels).
+ enc_outputs_coord (Tensor): The proposal generate from the
+ encode feature map, has shape (bs, num_feat_points, 4) with the
+ last dimension arranged as (cx, cy, w, h).
+ batch_data_samples (list[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ dict: A dictionary of loss components.
+ """
+ batch_gt_instances = []
+ batch_img_metas = []
+ for data_sample in batch_data_samples:
+ batch_img_metas.append(data_sample.metainfo)
+ batch_gt_instances.append(data_sample.gt_instances)
+
+ outs = self(hidden_states, references)
+ loss_inputs = outs + (enc_outputs_class, enc_outputs_coord,
+ batch_gt_instances, batch_img_metas, dn_meta)
+ losses = self.loss_by_feat(*loss_inputs)
+ return losses
+
+ def loss_by_feat(
+ self,
+ all_layers_cls_scores: Tensor,
+ all_layers_bbox_preds: Tensor,
+ enc_cls_scores: Tensor,
+ enc_bbox_preds: Tensor,
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ dn_meta: Dict[str, int],
+ batch_gt_instances_ignore: OptInstanceList = None
+ ) -> Dict[str, Tensor]:
+ """Loss function.
+
+ Args:
+ all_layers_cls_scores (Tensor): Classification scores of all
+ decoder layers, has shape (num_decoder_layers, bs,
+ num_queries_total, cls_out_channels), where
+ `num_queries_total` is the sum of `num_denoising_queries`
+ and `num_matching_queries`.
+ all_layers_bbox_preds (Tensor): Regression outputs of all decoder
+ layers. Each is a 4D-tensor with normalized coordinate format
+ (cx, cy, w, h) and has shape (num_decoder_layers, bs,
+ num_queries_total, 4).
+ enc_cls_scores (Tensor): The score of each point on encode
+ feature map, has shape (bs, num_feat_points, cls_out_channels).
+ enc_bbox_preds (Tensor): The proposal generate from the encode
+ feature map, has shape (bs, num_feat_points, 4) with the last
+ dimension arranged as (cx, cy, w, h).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components.
+ """
+ # extract denoising and matching part of outputs
+ (all_layers_matching_cls_scores, all_layers_matching_bbox_preds,
+ all_layers_denoising_cls_scores, all_layers_denoising_bbox_preds) = \
+ self.split_outputs(
+ all_layers_cls_scores, all_layers_bbox_preds, dn_meta)
+
+ loss_dict = super().loss_by_feat(
+ all_layers_matching_cls_scores, all_layers_matching_bbox_preds,
+ batch_gt_instances, batch_img_metas, batch_gt_instances_ignore)
+ # # NOTE DETRHead.loss_by_feat but not DeformableDETRHead.loss_by_feat
+ # # is called, because the encoder loss calculations are different
+ # # between DINO and DeformableDETR.
+ # loss_dict = dict()
+ # loss of proposal generated from encode feature map.
+ if enc_cls_scores is not None:
+ # NOTE The enc_loss calculation of the DINO is
+ # different from that of Deformable DETR.
+ enc_loss_cls, enc_losses_bbox, enc_losses_iou = \
+ self.loss_by_feat_single(
+ enc_cls_scores, enc_bbox_preds,
+ batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas)
+ loss_dict['enc_loss_cls'] = enc_loss_cls
+ loss_dict['enc_loss_bbox'] = enc_losses_bbox
+ loss_dict['enc_loss_iou'] = enc_losses_iou
+ a = 1
+ if all_layers_denoising_cls_scores is not None:
+ # calculate denoising loss from all decoder layers
+ dn_losses_cls, dn_losses_bbox, dn_losses_iou = self.loss_dn(
+ all_layers_denoising_cls_scores,
+ all_layers_denoising_bbox_preds,
+ batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas,
+ dn_meta=dn_meta)
+ # collate denoising loss
+ loss_dict['dn_loss_cls'] = dn_losses_cls[-1]
+ loss_dict['dn_loss_bbox'] = dn_losses_bbox[-1]
+ loss_dict['dn_loss_iou'] = dn_losses_iou[-1]
+ # if loss_dict['loss_cls']>loss_dict['dn_loss_cls']:
+ # cls_w = 1
+ # else:
+ # cls_w = loss_dict['loss_cls']/loss_dict['dn_loss_cls']
+ # cls_w = (cls_w**a).detach()
+ if loss_dict['loss_bbox']>loss_dict['dn_loss_bbox']:
+ bbox_w = 1
+ else:
+ bbox_w = loss_dict['loss_bbox']/loss_dict['dn_loss_bbox']
+ bbox_w = (bbox_w**a).detach()
+ if loss_dict['loss_iou']>loss_dict['dn_loss_iou']:
+ iou_w = 1
+ else:
+ iou_w = loss_dict['loss_iou']/loss_dict['dn_loss_iou']
+ iou_w = (iou_w**a).detach()
+ # cls_w = loss_dict['loss_cls'] / loss_dict['dn_loss_cls']
+ # cls_w = (cls_w ** a).detach()
+ # bbox_w = loss_dict['loss_bbox'] / loss_dict['dn_loss_bbox']
+ # bbox_w = (bbox_w ** a).detach()
+ # iou_w = loss_dict['loss_iou'] / loss_dict['dn_loss_iou']
+ # iou_w = (iou_w ** a).detach()
+ # loss_dict['dn_loss_cls'] *= cls_w
+ loss_dict['dn_loss_bbox'] *= bbox_w
+ loss_dict['dn_loss_iou'] *= iou_w
+
+ for num_dec_layer, (loss_cls_i, loss_bbox_i, loss_iou_i) in \
+ enumerate(zip(dn_losses_cls[:-1], dn_losses_bbox[:-1],
+ dn_losses_iou[:-1])):
+ loss_dict[f'd{num_dec_layer}.dn_loss_cls'] = loss_cls_i
+ loss_dict[f'd{num_dec_layer}.dn_loss_bbox'] = loss_bbox_i
+ loss_dict[f'd{num_dec_layer}.dn_loss_iou'] = loss_iou_i
+ # if loss_dict[f'd{num_dec_layer}.loss_cls']> loss_dict[f'd{num_dec_layer}.dn_loss_cls']:
+ # cls_w = 1
+ # else:
+ # cls_w = loss_dict[f'd{num_dec_layer}.loss_cls'] / loss_dict[f'd{num_dec_layer}.dn_loss_cls']
+ # cls_w = (cls_w**a).detach()
+ if loss_dict[f'd{num_dec_layer}.loss_bbox']> loss_dict[f'd{num_dec_layer}.dn_loss_bbox']:
+ bbox_w = 1
+ else:
+ bbox_w = loss_dict[f'd{num_dec_layer}.loss_bbox'] / loss_dict[f'd{num_dec_layer}.dn_loss_bbox']
+ bbox_w = (bbox_w**a).detach()
+ if loss_dict[f'd{num_dec_layer}.loss_iou']> loss_dict[f'd{num_dec_layer}.dn_loss_iou']:
+ iou_w = 1
+ else:
+ iou_w = loss_dict[f'd{num_dec_layer}.loss_iou'] / loss_dict[f'd{num_dec_layer}.dn_loss_iou']
+ iou_w = (iou_w**a).detach()
+ # cls_w = loss_dict[f'd{num_dec_layer}.loss_cls'] / loss_dict[f'd{num_dec_layer}.dn_loss_cls']
+ # cls_w = (cls_w ** a).detach()
+ # bbox_w = loss_dict[f'd{num_dec_layer}.loss_bbox'] / loss_dict[f'd{num_dec_layer}.dn_loss_bbox']
+ # bbox_w = (bbox_w ** a).detach()
+ # iou_w = loss_dict[f'd{num_dec_layer}.loss_iou'] / loss_dict[f'd{num_dec_layer}.dn_loss_iou']
+ # iou_w = (iou_w ** a).detach()
+ # loss_dict[f'd{num_dec_layer}.dn_loss_cls'] *= cls_w
+ loss_dict[f'd{num_dec_layer}.dn_loss_bbox'] *= bbox_w
+ loss_dict[f'd{num_dec_layer}.dn_loss_iou'] *= iou_w
+
+ return loss_dict
+
+ def loss_dn(self, all_layers_denoising_cls_scores: Tensor,
+ all_layers_denoising_bbox_preds: Tensor,
+ batch_gt_instances: InstanceList, batch_img_metas: List[dict],
+ dn_meta: Dict[str, int]) -> Tuple[List[Tensor]]:
+ """Calculate denoising loss.
+
+ Args:
+ all_layers_denoising_cls_scores (Tensor): Classification scores of
+ all decoder layers in denoising part, has shape (
+ num_decoder_layers, bs, num_denoising_queries,
+ cls_out_channels).
+ all_layers_denoising_bbox_preds (Tensor): Regression outputs of all
+ decoder layers in denoising part. Each is a 4D-tensor with
+ normalized coordinate format (cx, cy, w, h) and has shape
+ (num_decoder_layers, bs, num_denoising_queries, 4).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ Tuple[List[Tensor]]: The loss_dn_cls, loss_dn_bbox, and loss_dn_iou
+ of each decoder layers.
+ """
+ return multi_apply(
+ self._loss_dn_single,
+ all_layers_denoising_cls_scores,
+ all_layers_denoising_bbox_preds,
+ batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas,
+ dn_meta=dn_meta)
+
+
+ def _loss_dn_single(self, dn_cls_scores: Tensor, dn_bbox_preds: Tensor,
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ dn_meta: Dict[str, int]) -> Tuple[Tensor]:
+ """Denoising loss for outputs from a single decoder layer.
+
+ Args:
+ dn_cls_scores (Tensor): Classification scores of a single decoder
+ layer in denoising part, has shape (bs, num_denoising_queries,
+ cls_out_channels).
+ dn_bbox_preds (Tensor): Regression outputs of a single decoder
+ layer in denoising part. Each is a 4D-tensor with normalized
+ coordinate format (cx, cy, w, h) and has shape
+ (bs, num_denoising_queries, 4).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ Tuple[Tensor]: A tuple including `loss_cls`, `loss_box` and
+ `loss_iou`.
+ """
+ cls_reg_targets = self.get_dn_targets(batch_gt_instances,
+ batch_img_metas, dn_meta)
+ (labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,
+ num_total_pos) = cls_reg_targets
+ labels = torch.cat(labels_list, 0)
+ label_weights = torch.cat(label_weights_list, 0)
+ bbox_targets = torch.cat(bbox_targets_list, 0)
+ bbox_weights = torch.cat(bbox_weights_list, 0)
+
+ # classification loss
+ cls_scores = dn_cls_scores.reshape(-1, self.cls_out_channels)
+ # construct weighted avg_factor to match with the official DETR repo
+ cls_avg_factor = \
+ num_total_pos # + num_total_neg * self.bg_cls_weight #lzx
+
+ if self.sync_cls_avg_factor:
+ cls_avg_factor = reduce_mean(
+ cls_scores.new_tensor([cls_avg_factor]))
+ cls_avg_factor = max(cls_avg_factor, 1)
+
+ if len(cls_scores) > 0:
+ loss_cls = self.loss_cls(
+ cls_scores, labels, label_weights, avg_factor=cls_avg_factor)
+ else:
+ loss_cls = torch.zeros(
+ 1, dtype=cls_scores.dtype, device=cls_scores.device)
+
+ # Compute the average number of gt boxes across all gpus, for
+ # normalization purposes
+ num_total_pos = loss_cls.new_tensor([num_total_pos])
+ num_total_pos = torch.clamp(reduce_mean(num_total_pos), min=1).item()
+
+ # construct factors used for rescale bboxes
+ factors = []
+ for img_meta, bbox_pred in zip(batch_img_metas, dn_bbox_preds):
+ img_h, img_w = img_meta['img_shape']
+ factor = bbox_pred.new_tensor([img_w, img_h, img_w,
+ img_h]).unsqueeze(0).repeat(
+ bbox_pred.size(0), 1)
+ factors.append(factor)
+ factors = torch.cat(factors)
+
+ # DETR regress the relative position of boxes (cxcywh) in the image,
+ # thus the learning target is normalized by the image size. So here
+ # we need to re-scale them for calculating IoU loss
+ bbox_preds = dn_bbox_preds.reshape(-1, 4)
+ bboxes = bbox_cxcywh_to_xyxy(bbox_preds) * factors
+ bboxes_gt = bbox_cxcywh_to_xyxy(bbox_targets) * factors
+ # regression IoU loss, defaultly GIoU loss
+ loss_iou = self.loss_iou(
+ bboxes, bboxes_gt, bbox_weights, avg_factor=num_total_pos) # lzx
+
+ # regression L1 loss
+ loss_bbox = self.loss_bbox(
+ bbox_preds, bbox_targets, bbox_weights, avg_factor=num_total_pos) # lzx
+
+ return loss_cls, loss_bbox, loss_iou
+
+ def get_dn_targets(self, batch_gt_instances: InstanceList,
+ batch_img_metas: dict, dn_meta: Dict[str,
+ int]) -> tuple:
+ """Get targets in denoising part for a batch of images.
+
+ Args:
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ tuple: a tuple containing the following targets.
+
+ - labels_list (list[Tensor]): Labels for all images.
+ - label_weights_list (list[Tensor]): Label weights for all images.
+ - bbox_targets_list (list[Tensor]): BBox targets for all images.
+ - bbox_weights_list (list[Tensor]): BBox weights for all images.
+ - num_total_pos (int): Number of positive samples in all images.
+ - num_total_neg (int): Number of negative samples in all images.
+ """
+ (labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,
+ num_pos) = multi_apply(
+ self._get_dn_targets_single,
+ batch_gt_instances,
+ batch_img_metas,
+ dn_meta=dn_meta)
+ num_total_pos =sum(num_pos)
+ return (labels_list, label_weights_list, bbox_targets_list,
+ bbox_weights_list, num_total_pos,)
+
+ def _get_dn_targets_single(self, gt_instances: InstanceData,
+ img_meta: dict, dn_meta: Dict[str,
+ int]) -> tuple:
+ """Get targets in denoising part for one image.
+
+ Args:
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It should includes ``bboxes`` and ``labels``
+ attributes.
+ img_meta (dict): Meta information for one image.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ tuple[Tensor]: a tuple containing the following for one image.
+
+ - labels (Tensor): Labels of each image.
+ - label_weights (Tensor]): Label weights of each image.
+ - bbox_targets (Tensor): BBox targets of each image.
+ - bbox_weights (Tensor): BBox weights of each image.
+ - pos_inds (Tensor): Sampled positive indices for each image.
+ - neg_inds (Tensor): Sampled negative indices for each image.
+ """
+ gt_bboxes = gt_instances.bboxes
+ gt_labels = gt_instances.labels
+ num_groups = dn_meta['num_denoising_groups']
+ num_denoising_queries = dn_meta['num_denoising_queries']
+ # num_queries_each_group = int(num_denoising_queries / num_groups)
+ device = gt_bboxes.device
+ num_repeats = math.ceil(num_denoising_queries/ gt_bboxes.size(0))
+ # 将 gt_bboxes 扩展为形状为 [num_repeats, 4] 的张量,复制次数为 num_repeats
+ labels = gt_labels.repeat(num_repeats)
+ labels =labels[:num_denoising_queries]
+ labels = labels.long()
+ # if len(gt_labels) > 0:
+ # t = torch.arange(len(gt_labels), dtype=torch.long, device=device)
+ # t = t.unsqueeze(0).repeat(num_groups, 1)
+ # pos_assigned_gt_inds = t.flatten()
+ # pos_inds = torch.arange(
+ # num_groups, dtype=torch.long, device=device)
+ # pos_inds = pos_inds.unsqueeze(1) * num_queries_each_group + t
+ # pos_inds = pos_inds.flatten()
+ # else:
+ # pos_inds = pos_assigned_gt_inds = \
+ # gt_bboxes.new_tensor([], dtype=torch.long)
+ #
+ # neg_inds = pos_inds + num_queries_each_group // 2
+
+ # label targets
+
+ # labels = gt_bboxes.new_full((num_denoising_queries,),
+ # self.num_classes,
+ # dtype=torch.long)
+ # labels[pos_inds] = gt_labels[pos_assigned_gt_inds]
+
+ # labels[neg_inds] = gt_labels[pos_assigned_gt_inds]
+ # label_weights[neg_inds] = 0.0
+ # label_weights[pos_inds] = 1.0
+ # label_weights = gt_bboxes.new_ones(num_denoising_queries)
+ label_weights = torch.ones(num_denoising_queries, device=device)
+ img_h, img_w = img_meta['img_shape']
+ # DETR regress the relative position of boxes (cxcywh) in the image.
+ # Thus the learning target should be normalized by the image size, also
+ # the box format should be converted from defaultly x1y1x2y2 to cxcywh.
+ factor = gt_bboxes.new_tensor([img_w, img_h, img_w,
+ img_h]).unsqueeze(0)
+ gt_bboxes_normalized = gt_bboxes / factor
+ gt_bboxes_targets = bbox_xyxy_to_cxcywh(gt_bboxes_normalized)
+ bbox_targets = gt_bboxes_targets.repeat(num_repeats, 1)
+ bbox_targets =bbox_targets[:num_denoising_queries]
+ bbox_weights = torch.ones(num_denoising_queries, 4, device=device)
+
+ return (labels, label_weights, bbox_targets, bbox_weights, labels.size(0))
+
+ @staticmethod
+ def split_outputs(all_layers_cls_scores: Tensor,
+ all_layers_bbox_preds: Tensor,
+ dn_meta: Dict[str, int]) -> Tuple[Tensor]:
+ """Split outputs of the denoising part and the matching part.
+
+ For the total outputs of `num_queries_total` length, the former
+ `num_denoising_queries` outputs are from denoising queries, and
+ the rest `num_matching_queries` ones are from matching queries,
+ where `num_queries_total` is the sum of `num_denoising_queries` and
+ `num_matching_queries`.
+
+ Args:
+ all_layers_cls_scores (Tensor): Classification scores of all
+ decoder layers, has shape (num_decoder_layers, bs,
+ num_queries_total, cls_out_channels).
+ all_layers_bbox_preds (Tensor): Regression outputs of all decoder
+ layers. Each is a 4D-tensor with normalized coordinate format
+ (cx, cy, w, h) and has shape (num_decoder_layers, bs,
+ num_queries_total, 4).
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'.
+
+ Returns:
+ Tuple[Tensor]: a tuple containing the following outputs.
+
+ - all_layers_matching_cls_scores (Tensor): Classification scores
+ of all decoder layers in matching part, has shape
+ (num_decoder_layers, bs, num_matching_queries, cls_out_channels).
+ - all_layers_matching_bbox_preds (Tensor): Regression outputs of
+ all decoder layers in matching part. Each is a 4D-tensor with
+ normalized coordinate format (cx, cy, w, h) and has shape
+ (num_decoder_layers, bs, num_matching_queries, 4).
+ - all_layers_denoising_cls_scores (Tensor): Classification scores
+ of all decoder layers in denoising part, has shape
+ (num_decoder_layers, bs, num_denoising_queries,
+ cls_out_channels).
+ - all_layers_denoising_bbox_preds (Tensor): Regression outputs of
+ all decoder layers in denoising part. Each is a 4D-tensor with
+ normalized coordinate format (cx, cy, w, h) and has shape
+ (num_decoder_layers, bs, num_denoising_queries, 4).
+ """
+ if dn_meta is not None:
+ num_denoising_queries = dn_meta['num_denoising_queries']
+ all_layers_denoising_cls_scores = \
+ all_layers_cls_scores[:, :, : num_denoising_queries, :]
+ all_layers_denoising_bbox_preds = \
+ all_layers_bbox_preds[:, :, : num_denoising_queries, :]
+ all_layers_matching_cls_scores = \
+ all_layers_cls_scores[:, :, num_denoising_queries:, :]
+ all_layers_matching_bbox_preds = \
+ all_layers_bbox_preds[:, :, num_denoising_queries:, :]
+ else:
+ all_layers_denoising_cls_scores = None
+ all_layers_denoising_bbox_preds = None
+ all_layers_matching_cls_scores = all_layers_cls_scores
+ all_layers_matching_bbox_preds = all_layers_bbox_preds
+ return (all_layers_matching_cls_scores, all_layers_matching_bbox_preds,
+ all_layers_denoising_cls_scores,
+ all_layers_denoising_bbox_preds)
+
+ def predict(self,
+ hidden_states: Tensor,
+ references: List[Tensor],
+ batch_data_samples: SampleList,
+ rescale: bool = True) -> InstanceList:
+ """Perform forward propagation and loss calculation of the detection
+ head on the queries of the upstream network.
+
+ Args:
+ hidden_states (Tensor): Hidden states output from each decoder
+ layer, has shape (num_decoder_layers, num_queries, bs, dim).
+ references (list[Tensor]): List of the reference from the decoder.
+ The first reference is the `init_reference` (initial) and the
+ other num_decoder_layers(6) references are `inter_references`
+ (intermediate). The `init_reference` has shape (bs,
+ num_queries, 4) when `as_two_stage` of the detector is `True`,
+ otherwise (bs, num_queries, 2). Each `inter_reference` has
+ shape (bs, num_queries, 4) when `with_box_refine` of the
+ detector is `True`, otherwise (bs, num_queries, 2). The
+ coordinates are arranged as (cx, cy) when the last dimension is
+ 2, and (cx, cy, w, h) when it is 4.
+ batch_data_samples (list[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ rescale (bool, optional): If `True`, return boxes in original
+ image space. Defaults to `True`.
+
+ Returns:
+ list[obj:`InstanceData`]: Detection results of each image
+ after the post process.
+ """
+ batch_img_metas = [
+ data_samples.metainfo for data_samples in batch_data_samples
+ ]
+
+ outs = self(hidden_states, references)
+
+ predictions = self.predict_by_feat(
+ *outs, batch_img_metas=batch_img_metas, rescale=rescale)
+ return predictions
+
+ def predict_by_feat(self,
+ all_layers_cls_scores: Tensor,
+ all_layers_bbox_preds: Tensor,
+ batch_img_metas: List[Dict],
+ rescale: bool = False) -> InstanceList:
+ """Transform a batch of output features extracted from the head into
+ bbox results.
+
+ Args:
+ all_layers_cls_scores (Tensor): Classification scores of all
+ decoder layers, has shape (num_decoder_layers, bs, num_queries,
+ cls_out_channels).
+ all_layers_bbox_preds (Tensor): Regression outputs of all decoder
+ layers. Each is a 4D-tensor with normalized coordinate format
+ (cx, cy, w, h) and shape (num_decoder_layers, bs, num_queries,
+ 4) with the last dimension arranged as (cx, cy, w, h).
+ batch_img_metas (list[dict]): Meta information of each image.
+ rescale (bool, optional): If `True`, return boxes in original
+ image space. Default `False`.
+
+ Returns:
+ list[obj:`InstanceData`]: Detection results of each image
+ after the post process.
+ """
+ cls_scores = all_layers_cls_scores[-1]
+ bbox_preds = all_layers_bbox_preds[-1]
+
+ result_list = []
+ for img_id in range(len(batch_img_metas)):
+ cls_score = cls_scores[img_id]
+ bbox_pred = bbox_preds[img_id]
+ img_meta = batch_img_metas[img_id]
+ results = self._predict_by_feat_single(cls_score, bbox_pred,
+ img_meta, rescale)
+ result_list.append(results)
+ return result_list
+
+ def _predict_by_feat_single(self,
+ cls_score: Tensor,
+ bbox_pred: Tensor,
+ img_meta: dict,
+ rescale: bool = True) -> InstanceData:
+ """Transform outputs from the last decoder layer into bbox predictions
+ for each image.
+
+ Args:
+ cls_score (Tensor): Box score logits from the last decoder layer
+ for each image. Shape [num_queries, cls_out_channels].
+ bbox_pred (Tensor): Sigmoid outputs from the last decoder layer
+ for each image, with coordinate format (cx, cy, w, h) and
+ shape [num_queries, 4].
+ img_meta (dict): Image meta info.
+ rescale (bool): If True, return boxes in original image
+ space. Default True.
+
+ Returns:
+ :obj:`InstanceData`: Detection results of each image
+ after the post process.
+ Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ """
+ assert len(cls_score) == len(bbox_pred) # num_queries
+ max_per_img = self.test_cfg.get('max_per_img', len(cls_score))
+ img_shape = img_meta['img_shape']
+ # exclude background
+ if self.loss_cls.use_sigmoid:
+ cls_score = cls_score.sigmoid()
+ scores, indexes = cls_score.view(-1).topk(max_per_img)
+ det_labels = indexes % self.num_classes
+ bbox_index = indexes // self.num_classes
+ bbox_pred = bbox_pred[bbox_index]
+ else:
+ scores, det_labels = F.softmax(cls_score, dim=-1)[..., :-1].max(-1)
+ scores, bbox_index = scores.topk(max_per_img)
+ bbox_pred = bbox_pred[bbox_index]
+ det_labels = det_labels[bbox_index]
+
+ det_bboxes = bbox_cxcywh_to_xyxy(bbox_pred)
+ det_bboxes[:, 0::2] = det_bboxes[:, 0::2] * img_shape[1]
+ det_bboxes[:, 1::2] = det_bboxes[:, 1::2] * img_shape[0]
+ det_bboxes[:, 0::2].clamp_(min=0, max=img_shape[1])
+ det_bboxes[:, 1::2].clamp_(min=0, max=img_shape[0])
+
+ if self.use_nms:
+ iou_threshold = 0.01
+ offset = 0
+ score_threshold = 0.0 # torch.mean(cls_score.view(-1))+3*torch.std(cls_score.view(-1))
+ # max_num = 300
+ dets, inds = nms(det_bboxes, scores, iou_threshold, offset, score_threshold)
+ det_bboxes = dets[:, :-1]
+ scores = dets[:, -1]
+ det_labels = det_labels[inds]
+
+ # add by lzx
+ if self.pre_bboxes_round:
+ det_bboxes = adjust_bbox_to_pixel(det_bboxes)
+
+ if rescale:
+ # assert img_meta.get('scale_factor') is not None
+ # det_bboxes /= det_bboxes.new_tensor(
+ # img_meta['scale_factor']).repeat((1, 2))
+ # rw by lzx
+ if img_meta.get('scale_factor') is not None:
+ det_bboxes /= det_bboxes.new_tensor(
+ img_meta['scale_factor']).repeat((1, 2))
+ results = InstanceData()
+ results.bboxes = det_bboxes
+ results.scores = scores
+ results.labels = det_labels
+ return results
+
+
+
+@MODELS.register_module()
+class SpecDetrHead_V1(DETRHead):
+ r"""Head of the DINO: DETR with Improved DeNoising Anchor Boxes
+ for End-to-End Object Detection
+
+ Code is modified from the `official github repo
+ `_.
+
+ More details can be found in the `paper
+ `_ .
+ """
+ def __init__(self,
+ *args,
+ share_pred_layer: bool = False,
+ num_pred_layer: int = 6,
+ as_two_stage: bool = False,
+ pre_bboxes_round : bool = True,
+ decoupe_dn: bool = False,
+ dn_only_pos: bool =False,
+ dn_loss_weight: List[float] = [1,1,1], #[1,1,1]
+ # use_nms : bool = True,
+ **kwargs) -> None:
+ self.share_pred_layer = share_pred_layer
+ self.num_pred_layer = num_pred_layer
+ self.as_two_stage = as_two_stage
+ self.pre_bboxes_round = pre_bboxes_round
+ assert not (decoupe_dn and dn_only_pos), "Both decoupe_dn and dn_only_pos cannot be True at the same time."
+ self.decoupe_dn = decoupe_dn
+ self.dn_only_pos = dn_only_pos
+ self.dn_loss_weight = dn_loss_weight
+ super().__init__(*args, **kwargs)
+ # self.use_nms = use_nms
+
+
+ def _init_layers(self) -> None:
+ """Initialize classification branch and regression branch of head."""
+ fc_cls = Linear(self.embed_dims, self.cls_out_channels)
+ reg_branch = []
+ for _ in range(self.num_reg_fcs):
+ reg_branch.append(Linear(self.embed_dims, self.embed_dims))
+ reg_branch.append(nn.ReLU())
+ reg_branch.append(Linear(self.embed_dims, 4))
+ reg_branch = nn.Sequential(*reg_branch)
+
+ if self.share_pred_layer:
+ self.cls_branches = nn.ModuleList(
+ [fc_cls for _ in range(self.num_pred_layer)])
+ self.reg_branches = nn.ModuleList(
+ [reg_branch for _ in range(self.num_pred_layer)])
+ else:
+ self.cls_branches = nn.ModuleList(
+ [copy.deepcopy(fc_cls) for _ in range(self.num_pred_layer)])
+ self.reg_branches = nn.ModuleList([
+ copy.deepcopy(reg_branch) for _ in range(self.num_pred_layer)
+ ])
+
+
+ def init_weights(self) -> None:
+ """Initialize weights of the Deformable DETR head."""
+ if self.loss_cls.use_sigmoid:
+ bias_init = bias_init_with_prob(0.01)
+ for m in self.cls_branches:
+ nn.init.constant_(m.bias, bias_init)
+ for m in self.reg_branches:
+ constant_init(m[-1], 0, bias=0)
+ nn.init.constant_(self.reg_branches[0][-1].bias.data[2:], -2.0)
+ if self.as_two_stage:
+ for m in self.reg_branches:
+ nn.init.constant_(m[-1].bias.data[2:], 0.0)
+
+ def forward(self, hidden_states: Tensor,
+ references: List[Tensor]) -> Tuple[Tensor]:
+ """Forward function.
+
+ Args:
+ hidden_states (Tensor): Hidden states output from each decoder
+ layer, has shape (num_decoder_layers, bs, num_queries, dim).
+ references (list[Tensor]): List of the reference from the decoder.
+ The first reference is the `init_reference` (initial) and the
+ other num_decoder_layers(6) references are `inter_references`
+ (intermediate). The `init_reference` has shape (bs,
+ num_queries, 4) when `as_two_stage` of the detector is `True`,
+ otherwise (bs, num_queries, 2). Each `inter_reference` has
+ shape (bs, num_queries, 4) when `with_box_refine` of the
+ detector is `True`, otherwise (bs, num_queries, 2). The
+ coordinates are arranged as (cx, cy) when the last dimension is
+ 2, and (cx, cy, w, h) when it is 4.
+
+ Returns:
+ tuple[Tensor]: results of head containing the following tensor.
+
+ - all_layers_outputs_classes (Tensor): Outputs from the
+ classification head, has shape (num_decoder_layers, bs,
+ num_queries, cls_out_channels).
+ - all_layers_outputs_coords (Tensor): Sigmoid outputs from the
+ regression head with normalized coordinate format (cx, cy, w,
+ h), has shape (num_decoder_layers, bs, num_queries, 4) with the
+ last dimension arranged as (cx, cy, w, h).
+ """
+ all_layers_outputs_classes = []
+ all_layers_outputs_coords = []
+
+ for layer_id in range(hidden_states.shape[0]):
+ reference = inverse_sigmoid(references[layer_id])
+ # NOTE The last reference will not be used.
+ hidden_state = hidden_states[layer_id]
+ outputs_class = self.cls_branches[layer_id](hidden_state)
+ tmp_reg_preds = self.reg_branches[layer_id](hidden_state)
+ if reference.shape[-1] == 4:
+ # When `layer` is 0 and `as_two_stage` of the detector
+ # is `True`, or when `layer` is greater than 0 and
+ # `with_box_refine` of the detector is `True`.
+ tmp_reg_preds += reference
+ else:
+ # When `layer` is 0 and `as_two_stage` of the detector
+ # is `False`, or when `layer` is greater than 0 and
+ # `with_box_refine` of the detector is `False`.
+ assert reference.shape[-1] == 2
+ tmp_reg_preds[..., :2] += reference
+ outputs_coord = tmp_reg_preds.sigmoid()
+ all_layers_outputs_classes.append(outputs_class)
+ all_layers_outputs_coords.append(outputs_coord)
+
+
+
+ all_layers_outputs_classes = torch.stack(all_layers_outputs_classes)
+ all_layers_outputs_coords = torch.stack(all_layers_outputs_coords)
+
+ return all_layers_outputs_classes, all_layers_outputs_coords
+
+ def loss(self, hidden_states: Tensor, references: List[Tensor],
+ enc_outputs_class: Tensor, enc_outputs_coord: Tensor,
+ batch_data_samples: SampleList, dn_meta: Dict[str, int]) -> dict:
+ """Perform forward propagation and loss calculation of the detection
+ head on the queries of the upstream network.
+
+ Args:
+ hidden_states (Tensor): Hidden states output from each decoder
+ layer, has shape (num_decoder_layers, bs, num_queries_total,
+ dim), where `num_queries_total` is the sum of
+ `num_denoising_queries` and `num_matching_queries` when
+ `self.training` is `True`, else `num_matching_queries`.
+ references (list[Tensor]): List of the reference from the decoder.
+ The first reference is the `init_reference` (initial) and the
+ other num_decoder_layers(6) references are `inter_references`
+ (intermediate). The `init_reference` has shape (bs,
+ num_queries_total, 4) and each `inter_reference` has shape
+ (bs, num_queries, 4) with the last dimension arranged as
+ (cx, cy, w, h).
+ enc_outputs_class (Tensor): The score of each point on encode
+ feature map, has shape (bs, num_feat_points, cls_out_channels).
+ enc_outputs_coord (Tensor): The proposal generate from the
+ encode feature map, has shape (bs, num_feat_points, 4) with the
+ last dimension arranged as (cx, cy, w, h).
+ batch_data_samples (list[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ dict: A dictionary of loss components.
+ """
+ batch_gt_instances = []
+ batch_img_metas = []
+ for data_sample in batch_data_samples:
+ batch_img_metas.append(data_sample.metainfo)
+ batch_gt_instances.append(data_sample.gt_instances)
+
+ outs = self(hidden_states, references)
+ loss_inputs = outs + (enc_outputs_class, enc_outputs_coord,
+ batch_gt_instances, batch_img_metas, dn_meta)
+ losses = self.loss_by_feat(*loss_inputs)
+ return losses
+
+ def loss_by_feat(
+ self,
+ all_layers_cls_scores: Tensor,
+ all_layers_bbox_preds: Tensor,
+ enc_cls_scores: Tensor,
+ enc_bbox_preds: Tensor,
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ dn_meta: Dict[str, int],
+ batch_gt_instances_ignore: OptInstanceList = None
+ ) -> Dict[str, Tensor]:
+ """Loss function.
+
+ Args:
+ all_layers_cls_scores (Tensor): Classification scores of all
+ decoder layers, has shape (num_decoder_layers, bs,
+ num_queries_total, cls_out_channels), where
+ `num_queries_total` is the sum of `num_denoising_queries`
+ and `num_matching_queries`.
+ all_layers_bbox_preds (Tensor): Regression outputs of all decoder
+ layers. Each is a 4D-tensor with normalized coordinate format
+ (cx, cy, w, h) and has shape (num_decoder_layers, bs,
+ num_queries_total, 4).
+ enc_cls_scores (Tensor): The score of each point on encode
+ feature map, has shape (bs, num_feat_points, cls_out_channels).
+ enc_bbox_preds (Tensor): The proposal generate from the encode
+ feature map, has shape (bs, num_feat_points, 4) with the last
+ dimension arranged as (cx, cy, w, h).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components.
+ """
+ # extract denoising and matching part of outputs
+ (all_layers_matching_cls_scores, all_layers_matching_bbox_preds,
+ all_layers_denoising_cls_scores, all_layers_denoising_bbox_preds) = \
+ self.split_outputs(
+ all_layers_cls_scores, all_layers_bbox_preds, dn_meta)
+
+ loss_dict = super().loss_by_feat(
+ all_layers_matching_cls_scores, all_layers_matching_bbox_preds,
+ batch_gt_instances, batch_img_metas, batch_gt_instances_ignore)
+ # # NOTE DETRHead.loss_by_feat but not DeformableDETRHead.loss_by_feat
+ # # is called, because the encoder loss calculations are different
+ # # between DINO and DeformableDETR.
+ # loss_dict = dict()
+ # loss of proposal generated from encode feature map.
+ if enc_cls_scores is not None:
+ # NOTE The enc_loss calculation of the DINO is
+ # different from that of Deformable DETR.
+ enc_loss_cls, enc_losses_bbox, enc_losses_iou = \
+ self.loss_by_feat_single(
+ enc_cls_scores, enc_bbox_preds,
+ batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas)
+ loss_dict['enc_loss_cls'] = enc_loss_cls
+ loss_dict['enc_loss_bbox'] = enc_losses_bbox
+ loss_dict['enc_loss_iou'] = enc_losses_iou
+ a = 1
+ if all_layers_denoising_cls_scores is not None:
+ # calculate denoising loss from all decoder layers
+ dn_losses_cls, dn_losses_bbox, dn_losses_iou = self.loss_dn(
+ all_layers_denoising_cls_scores,
+ all_layers_denoising_bbox_preds,
+ batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas,
+ dn_meta=dn_meta)
+ # collate denoising loss
+ loss_dict['dn_loss_cls'] = dn_losses_cls[-1]
+ loss_dict['dn_loss_bbox'] = dn_losses_bbox[-1]
+ loss_dict['dn_loss_iou'] = dn_losses_iou[-1]
+# if loss_dict['loss_cls']>loss_dict['dn_loss_cls']:
+# cls_w = 1
+# else:
+# cls_w = loss_dict['loss_cls']/loss_dict['dn_loss_cls']
+# cls_w = (cls_w**a).detach()
+
+# if loss_dict['loss_bbox']>loss_dict['dn_loss_bbox']:
+# bbox_w = 1
+# else:
+# bbox_w = loss_dict['loss_bbox']/loss_dict['dn_loss_bbox']
+# bbox_w = (bbox_w**a).detach()
+# if loss_dict['loss_iou']>loss_dict['dn_loss_iou']:
+# iou_w = 1
+# else:
+# iou_w = loss_dict['loss_iou']/loss_dict['dn_loss_iou']
+# iou_w = (iou_w**a).detach()
+ cls_w = loss_dict['loss_cls'] / loss_dict['dn_loss_cls']
+ cls_w = (cls_w ** a).detach()
+ bbox_w = loss_dict['loss_bbox'] / loss_dict['dn_loss_bbox']
+ bbox_w = (bbox_w ** a).detach()
+ iou_w = loss_dict['loss_iou'] / loss_dict['dn_loss_iou']
+ iou_w = (iou_w ** a).detach()
+ loss_dict['dn_loss_cls'] *= cls_w
+ loss_dict['dn_loss_bbox'] *= bbox_w
+ loss_dict['dn_loss_iou'] *= iou_w
+
+ for num_dec_layer, (loss_cls_i, loss_bbox_i, loss_iou_i) in \
+ enumerate(zip(dn_losses_cls[:-1], dn_losses_bbox[:-1],
+ dn_losses_iou[:-1])):
+ loss_dict[f'd{num_dec_layer}.dn_loss_cls'] = loss_cls_i
+ loss_dict[f'd{num_dec_layer}.dn_loss_bbox'] = loss_bbox_i
+ loss_dict[f'd{num_dec_layer}.dn_loss_iou'] = loss_iou_i
+# if loss_dict[f'd{num_dec_layer}.loss_cls']> loss_dict[f'd{num_dec_layer}.dn_loss_cls']:
+# cls_w = 1
+# else:
+# cls_w = loss_dict[f'd{num_dec_layer}.loss_cls'] / loss_dict[f'd{num_dec_layer}.dn_loss_cls']
+# cls_w = (cls_w**a).detach()
+# if loss_dict[f'd{num_dec_layer}.loss_bbox']> loss_dict[f'd{num_dec_layer}.dn_loss_bbox']:
+# bbox_w = 1
+# else:
+# bbox_w = loss_dict[f'd{num_dec_layer}.loss_bbox'] / loss_dict[f'd{num_dec_layer}.dn_loss_bbox']
+# bbox_w = (bbox_w**a).detach()
+# if loss_dict[f'd{num_dec_layer}.loss_iou']> loss_dict[f'd{num_dec_layer}.dn_loss_iou']:
+# iou_w = 1
+# else:
+# iou_w = loss_dict[f'd{num_dec_layer}.loss_iou'] / loss_dict[f'd{num_dec_layer}.dn_loss_iou']
+# iou_w = (iou_w**a).detach()
+ cls_w = loss_dict[f'd{num_dec_layer}.loss_cls'] / loss_dict[f'd{num_dec_layer}.dn_loss_cls']
+ cls_w = (cls_w ** a).detach()
+ bbox_w = loss_dict[f'd{num_dec_layer}.loss_bbox'] / loss_dict[f'd{num_dec_layer}.dn_loss_bbox']
+ bbox_w = (bbox_w ** a).detach()
+ iou_w = loss_dict[f'd{num_dec_layer}.loss_iou'] / loss_dict[f'd{num_dec_layer}.dn_loss_iou']
+ iou_w = (iou_w ** a).detach()
+ loss_dict[f'd{num_dec_layer}.dn_loss_cls'] *= cls_w
+ loss_dict[f'd{num_dec_layer}.dn_loss_bbox'] *= bbox_w
+ loss_dict[f'd{num_dec_layer}.dn_loss_iou'] *= iou_w
+
+
+ return loss_dict
+
+ def loss_dn(self, all_layers_denoising_cls_scores: Tensor,
+ all_layers_denoising_bbox_preds: Tensor,
+ batch_gt_instances: InstanceList, batch_img_metas: List[dict],
+ dn_meta: Dict[str, int]) -> Tuple[List[Tensor]]:
+ """Calculate denoising loss.
+
+ Args:
+ all_layers_denoising_cls_scores (Tensor): Classification scores of
+ all decoder layers in denoising part, has shape (
+ num_decoder_layers, bs, num_denoising_queries,
+ cls_out_channels).
+ all_layers_denoising_bbox_preds (Tensor): Regression outputs of all
+ decoder layers in denoising part. Each is a 4D-tensor with
+ normalized coordinate format (cx, cy, w, h) and has shape
+ (num_decoder_layers, bs, num_denoising_queries, 4).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ Tuple[List[Tensor]]: The loss_dn_cls, loss_dn_bbox, and loss_dn_iou
+ of each decoder layers.
+ """
+ return multi_apply(
+ self._loss_dn_single,
+ all_layers_denoising_cls_scores,
+ all_layers_denoising_bbox_preds,
+ batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas,
+ dn_meta=dn_meta)
+
+ def _loss_dn_single(self, dn_cls_scores: Tensor, dn_bbox_preds: Tensor,
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ dn_meta: Dict[str, int]) -> Tuple[Tensor]:
+ """Denoising loss for outputs from a single decoder layer.
+
+ Args:
+ dn_cls_scores (Tensor): Classification scores of a single decoder
+ layer in denoising part, has shape (bs, num_denoising_queries,
+ cls_out_channels).
+ dn_bbox_preds (Tensor): Regression outputs of a single decoder
+ layer in denoising part. Each is a 4D-tensor with normalized
+ coordinate format (cx, cy, w, h) and has shape
+ (bs, num_denoising_queries, 4).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ Tuple[Tensor]: A tuple including `loss_cls`, `loss_box` and
+ `loss_iou`.
+ """
+ cls_reg_targets = self.get_dn_targets(batch_gt_instances,
+ batch_img_metas, dn_meta)
+ (labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,
+ num_total_pos, num_total_neg) = cls_reg_targets
+ labels = torch.cat(labels_list, 0)
+ label_weights = torch.cat(label_weights_list, 0)
+ bbox_targets = torch.cat(bbox_targets_list, 0)
+ bbox_weights = torch.cat(bbox_weights_list, 0)
+
+ # classification loss
+ cls_scores = dn_cls_scores.reshape(-1, self.cls_out_channels)
+ # construct weighted avg_factor to match with the official DETR repo
+ cls_avg_factor = \
+ num_total_pos # + num_total_neg * self.bg_cls_weight #lzx
+
+ if self.sync_cls_avg_factor:
+ cls_avg_factor = reduce_mean(
+ cls_scores.new_tensor([cls_avg_factor]))
+ cls_avg_factor = max(cls_avg_factor, 1)
+
+ if len(cls_scores) > 0:
+ loss_cls = self.loss_cls(
+ cls_scores, labels, label_weights, avg_factor=cls_avg_factor)
+ else:
+ loss_cls = torch.zeros(
+ 1, dtype=cls_scores.dtype, device=cls_scores.device)
+
+ # Compute the average number of gt boxes across all gpus, for
+ # normalization purposes
+ num_total_pos = loss_cls.new_tensor([num_total_pos])
+ num_total_pos = torch.clamp(reduce_mean(num_total_pos), min=1).item()
+
+ # construct factors used for rescale bboxes
+ factors = []
+ for img_meta, bbox_pred in zip(batch_img_metas, dn_bbox_preds):
+ img_h, img_w = img_meta['img_shape']
+ factor = bbox_pred.new_tensor([img_w, img_h, img_w,
+ img_h]).unsqueeze(0).repeat(
+ bbox_pred.size(0), 1)
+ factors.append(factor)
+ factors = torch.cat(factors)
+
+ # DETR regress the relative position of boxes (cxcywh) in the image,
+ # thus the learning target is normalized by the image size. So here
+ # we need to re-scale them for calculating IoU loss
+ bbox_preds = dn_bbox_preds.reshape(-1, 4)
+ bboxes = bbox_cxcywh_to_xyxy(bbox_preds) * factors
+ bboxes_gt = bbox_cxcywh_to_xyxy(bbox_targets) * factors
+ # regression IoU loss, defaultly GIoU loss
+ loss_iou = self.loss_iou(
+ bboxes, bboxes_gt, bbox_weights, avg_factor=num_total_pos) # lzx
+
+ # regression L1 loss
+ loss_bbox = self.loss_bbox(
+ bbox_preds, bbox_targets, bbox_weights, avg_factor=num_total_pos) # lzx
+ # return loss_cls*self.dn_loss_weight[0], loss_bbox**self.dn_loss_weight[1], loss_iou*self.dn_loss_weight[2]
+
+ return loss_cls, loss_bbox , loss_iou
+
+ def get_dn_targets(self, batch_gt_instances: InstanceList,
+ batch_img_metas: dict, dn_meta: Dict[str,
+ int]) -> tuple:
+ """Get targets in denoising part for a batch of images.
+
+ Args:
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ tuple: a tuple containing the following targets.
+
+ - labels_list (list[Tensor]): Labels for all images.
+ - label_weights_list (list[Tensor]): Label weights for all images.
+ - bbox_targets_list (list[Tensor]): BBox targets for all images.
+ - bbox_weights_list (list[Tensor]): BBox weights for all images.
+ - num_total_pos (int): Number of positive samples in all images.
+ - num_total_neg (int): Number of negative samples in all images.
+ """
+ (labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,
+ pos_inds_list, neg_inds_list) = multi_apply(
+ self._get_dn_targets_single,
+ batch_gt_instances,
+ batch_img_metas,
+ dn_meta=dn_meta)
+ num_total_pos = sum((inds.numel() for inds in pos_inds_list))
+ num_total_neg = sum((inds.numel() for inds in neg_inds_list))
+ return (labels_list, label_weights_list, bbox_targets_list,
+ bbox_weights_list, num_total_pos, num_total_neg)
+
+
+
+ def _get_dn_targets_single(self, gt_instances: InstanceData,
+ img_meta: dict, dn_meta: Dict[str,
+ int]) -> tuple:
+ """Get targets in denoising part for one image.
+
+ Args:
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It should includes ``bboxes`` and ``labels``
+ attributes.
+ img_meta (dict): Meta information for one image.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ tuple[Tensor]: a tuple containing the following for one image.
+
+ - labels (Tensor): Labels of each image.
+ - label_weights (Tensor]): Label weights of each image.
+ - bbox_targets (Tensor): BBox targets of each image.
+ - bbox_weights (Tensor): BBox weights of each image.
+ - pos_inds (Tensor): Sampled positive indices for each image.
+ - neg_inds (Tensor): Sampled negative indices for each image.
+ """
+ gt_bboxes = gt_instances.bboxes
+ gt_labels = gt_instances.labels
+ num_groups = dn_meta['num_denoising_groups']
+ num_denoising_queries = dn_meta['num_denoising_queries']
+ num_queries_each_group = int(num_denoising_queries / num_groups)
+ device = gt_bboxes.device
+
+ if len(gt_labels) > 0:
+ t = torch.arange(len(gt_labels), dtype=torch.long, device=device)
+ t = t.unsqueeze(0).repeat(num_groups, 1)
+ pos_assigned_gt_inds = t.flatten()
+ pos_inds = torch.arange(
+ num_groups, dtype=torch.long, device=device)
+ pos_inds = pos_inds.unsqueeze(1) * num_queries_each_group + t
+ pos_inds = pos_inds.flatten()
+ else:
+ pos_inds = pos_assigned_gt_inds = \
+ gt_bboxes.new_tensor([], dtype=torch.long)
+
+ neg_inds = pos_inds + num_queries_each_group // 2
+
+ # label targets
+ labels = gt_bboxes.new_full((num_denoising_queries,),
+ self.num_classes,
+ dtype=torch.long)
+ labels[pos_inds] = gt_labels[pos_assigned_gt_inds]
+
+ # labels[neg_inds] = gt_labels[pos_assigned_gt_inds]
+ # label_weights[neg_inds] = 0.0
+ # label_weights[pos_inds] = 1.0
+ # label_weights = gt_bboxes.new_ones(num_denoising_queries)
+ label_weights = torch.zeros(num_denoising_queries, device=device)
+ label_weights[pos_inds] = 1.0
+ # if self.dn_only_pos:
+ # label_weights[neg_inds] = 1.0
+ # labels[neg_inds] = gt_labels[pos_assigned_gt_inds]
+ # label_weights[pos_inds] = 0.0
+
+ # bbox targets
+ bbox_targets = torch.zeros(num_denoising_queries, 4, device=device)
+ bbox_weights = torch.zeros(num_denoising_queries, 4, device=device)
+ bbox_weights[pos_inds] = 1.0
+ # if self.decoupe_dn:
+ # bbox_weights[neg_inds] = 1.0
+ # if self.dn_only_pos:
+ # bbox_weights[pos_inds] = 1.0
+ # bbox_weights[neg_inds] = 1.0
+ img_h, img_w = img_meta['img_shape']
+ # DETR regress the relative position of boxes (cxcywh) in the image.
+ # Thus the learning target should be normalized by the image size, also
+ # the box format should be converted from defaultly x1y1x2y2 to cxcywh.
+ factor = gt_bboxes.new_tensor([img_w, img_h, img_w,
+ img_h]).unsqueeze(0)
+ gt_bboxes_normalized = gt_bboxes / factor
+ gt_bboxes_targets = bbox_xyxy_to_cxcywh(gt_bboxes_normalized)
+ bbox_targets[pos_inds] = gt_bboxes_targets.repeat([num_groups, 1])
+ bbox_targets[neg_inds] = gt_bboxes_targets.repeat([num_groups, 1])
+ return (labels, label_weights, bbox_targets, bbox_weights, pos_inds,
+ neg_inds)
+ @staticmethod
+ def split_outputs(all_layers_cls_scores: Tensor,
+ all_layers_bbox_preds: Tensor,
+ dn_meta: Dict[str, int]) -> Tuple[Tensor]:
+ """Split outputs of the denoising part and the matching part.
+
+ For the total outputs of `num_queries_total` length, the former
+ `num_denoising_queries` outputs are from denoising queries, and
+ the rest `num_matching_queries` ones are from matching queries,
+ where `num_queries_total` is the sum of `num_denoising_queries` and
+ `num_matching_queries`.
+
+ Args:
+ all_layers_cls_scores (Tensor): Classification scores of all
+ decoder layers, has shape (num_decoder_layers, bs,
+ num_queries_total, cls_out_channels).
+ all_layers_bbox_preds (Tensor): Regression outputs of all decoder
+ layers. Each is a 4D-tensor with normalized coordinate format
+ (cx, cy, w, h) and has shape (num_decoder_layers, bs,
+ num_queries_total, 4).
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'.
+
+ Returns:
+ Tuple[Tensor]: a tuple containing the following outputs.
+
+ - all_layers_matching_cls_scores (Tensor): Classification scores
+ of all decoder layers in matching part, has shape
+ (num_decoder_layers, bs, num_matching_queries, cls_out_channels).
+ - all_layers_matching_bbox_preds (Tensor): Regression outputs of
+ all decoder layers in matching part. Each is a 4D-tensor with
+ normalized coordinate format (cx, cy, w, h) and has shape
+ (num_decoder_layers, bs, num_matching_queries, 4).
+ - all_layers_denoising_cls_scores (Tensor): Classification scores
+ of all decoder layers in denoising part, has shape
+ (num_decoder_layers, bs, num_denoising_queries,
+ cls_out_channels).
+ - all_layers_denoising_bbox_preds (Tensor): Regression outputs of
+ all decoder layers in denoising part. Each is a 4D-tensor with
+ normalized coordinate format (cx, cy, w, h) and has shape
+ (num_decoder_layers, bs, num_denoising_queries, 4).
+ """
+ if dn_meta is not None:
+ num_denoising_queries = dn_meta['num_denoising_queries']
+ all_layers_denoising_cls_scores = \
+ all_layers_cls_scores[:, :, : num_denoising_queries, :]
+ all_layers_denoising_bbox_preds = \
+ all_layers_bbox_preds[:, :, : num_denoising_queries, :]
+ all_layers_matching_cls_scores = \
+ all_layers_cls_scores[:, :, num_denoising_queries:, :]
+ all_layers_matching_bbox_preds = \
+ all_layers_bbox_preds[:, :, num_denoising_queries:, :]
+ else:
+ all_layers_denoising_cls_scores = None
+ all_layers_denoising_bbox_preds = None
+ all_layers_matching_cls_scores = all_layers_cls_scores
+ all_layers_matching_bbox_preds = all_layers_bbox_preds
+ return (all_layers_matching_cls_scores, all_layers_matching_bbox_preds,
+ all_layers_denoising_cls_scores,
+ all_layers_denoising_bbox_preds)
+
+ def predict(self,
+ hidden_states: Tensor,
+ references: List[Tensor],
+ batch_data_samples: SampleList,
+ rescale: bool = True) -> InstanceList:
+ """Perform forward propagation and loss calculation of the detection
+ head on the queries of the upstream network.
+
+ Args:
+ hidden_states (Tensor): Hidden states output from each decoder
+ layer, has shape (num_decoder_layers, num_queries, bs, dim).
+ references (list[Tensor]): List of the reference from the decoder.
+ The first reference is the `init_reference` (initial) and the
+ other num_decoder_layers(6) references are `inter_references`
+ (intermediate). The `init_reference` has shape (bs,
+ num_queries, 4) when `as_two_stage` of the detector is `True`,
+ otherwise (bs, num_queries, 2). Each `inter_reference` has
+ shape (bs, num_queries, 4) when `with_box_refine` of the
+ detector is `True`, otherwise (bs, num_queries, 2). The
+ coordinates are arranged as (cx, cy) when the last dimension is
+ 2, and (cx, cy, w, h) when it is 4.
+ batch_data_samples (list[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ rescale (bool, optional): If `True`, return boxes in original
+ image space. Defaults to `True`.
+
+ Returns:
+ list[obj:`InstanceData`]: Detection results of each image
+ after the post process.
+ """
+ batch_img_metas = [
+ data_samples.metainfo for data_samples in batch_data_samples
+ ]
+
+ outs = self(hidden_states, references)
+
+ predictions = self.predict_by_feat(
+ *outs, batch_img_metas=batch_img_metas, rescale=rescale)
+ return predictions
+
+ def predict_by_feat(self,
+ all_layers_cls_scores: Tensor,
+ all_layers_bbox_preds: Tensor,
+ batch_img_metas: List[Dict],
+ rescale: bool = False) -> InstanceList:
+ """Transform a batch of output features extracted from the head into
+ bbox results.
+
+ Args:
+ all_layers_cls_scores (Tensor): Classification scores of all
+ decoder layers, has shape (num_decoder_layers, bs, num_queries,
+ cls_out_channels).
+ all_layers_bbox_preds (Tensor): Regression outputs of all decoder
+ layers. Each is a 4D-tensor with normalized coordinate format
+ (cx, cy, w, h) and shape (num_decoder_layers, bs, num_queries,
+ 4) with the last dimension arranged as (cx, cy, w, h).
+ batch_img_metas (list[dict]): Meta information of each image.
+ rescale (bool, optional): If `True`, return boxes in original
+ image space. Default `False`.
+
+ Returns:
+ list[obj:`InstanceData`]: Detection results of each image
+ after the post process.
+ """
+ cls_scores = all_layers_cls_scores[-1]
+ bbox_preds = all_layers_bbox_preds[-1]
+
+ result_list = []
+ for img_id in range(len(batch_img_metas)):
+ cls_score = cls_scores[img_id]
+ bbox_pred = bbox_preds[img_id]
+ img_meta = batch_img_metas[img_id]
+ results = self._predict_by_feat_single(cls_score, bbox_pred,
+ img_meta, rescale)
+ result_list.append(results)
+ return result_list
+
+ def _predict_by_feat_single(self,
+ cls_score: Tensor,
+ bbox_pred: Tensor,
+ img_meta: dict,
+ rescale: bool = True) -> InstanceData:
+ """Transform outputs from the last decoder layer into bbox predictions
+ for each image.
+
+ Args:
+ cls_score (Tensor): Box score logits from the last decoder layer
+ for each image. Shape [num_queries, cls_out_channels].
+ bbox_pred (Tensor): Sigmoid outputs from the last decoder layer
+ for each image, with coordinate format (cx, cy, w, h) and
+ shape [num_queries, 4].
+ img_meta (dict): Image meta info.
+ rescale (bool): If True, return boxes in original image
+ space. Default True.
+
+ Returns:
+ :obj:`InstanceData`: Detection results of each image
+ after the post process.
+ Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ """
+ assert len(cls_score) == len(bbox_pred) # num_queries
+ max_per_img = self.test_cfg.get('max_per_img', len(cls_score))
+ img_shape = img_meta['img_shape']
+ # exclude background
+ if self.loss_cls.use_sigmoid:
+ cls_score = cls_score.sigmoid()
+ scores, indexes = cls_score.view(-1).topk(max_per_img)
+ det_labels = indexes % self.num_classes
+ bbox_index = indexes // self.num_classes
+ bbox_pred = bbox_pred[bbox_index]
+ else:
+ scores, det_labels = F.softmax(cls_score, dim=-1)[..., :-1].max(-1)
+ scores, bbox_index = scores.topk(max_per_img)
+ bbox_pred = bbox_pred[bbox_index]
+ det_labels = det_labels[bbox_index]
+
+ det_bboxes = bbox_cxcywh_to_xyxy(bbox_pred)
+ det_bboxes[:, 0::2] = det_bboxes[:, 0::2] * img_shape[1]
+ det_bboxes[:, 1::2] = det_bboxes[:, 1::2] * img_shape[0]
+ det_bboxes[:, 0::2].clamp_(min=0, max=img_shape[1])
+ det_bboxes[:, 1::2].clamp_(min=0, max=img_shape[0])
+
+
+ if self.use_nms:
+ iou_threshold= 0.01
+ offset = 0
+ score_threshold = 0.0 # torch.mean(cls_score.view(-1))+3*torch.std(cls_score.view(-1))
+ # max_num = 300
+ dets, inds = nms(det_bboxes, scores, iou_threshold, offset, score_threshold)
+ det_bboxes = dets[:,:-1]
+ scores = dets[:,-1]
+ det_labels =det_labels[inds]
+
+ # add by lzx
+ if self.pre_bboxes_round:
+ det_bboxes = adjust_bbox_to_pixel(det_bboxes)
+
+ if rescale:
+ # assert img_meta.get('scale_factor') is not None
+ # det_bboxes /= det_bboxes.new_tensor(
+ # img_meta['scale_factor']).repeat((1, 2))
+ # rw by lzx
+ if img_meta.get('scale_factor') is not None:
+ det_bboxes /= det_bboxes.new_tensor(
+ img_meta['scale_factor']).repeat((1, 2))
+ results = InstanceData()
+ results.bboxes = det_bboxes
+ results.scores = scores
+ results.labels = det_labels
+ return results
+
diff --git a/mmdet/models/dense_heads/specdetr_headV1.py b/mmdet/models/dense_heads/specdetr_headV1.py
new file mode 100644
index 0000000000000000000000000000000000000000..ef9bafafc67910434cc8a645aa0a6f3c833ea583
--- /dev/null
+++ b/mmdet/models/dense_heads/specdetr_headV1.py
@@ -0,0 +1,1820 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+from typing import Dict, List, Tuple
+from torch import Tensor
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import Linear
+from mmcv.ops.nms import nms
+from mmengine.model import bias_init_with_prob, constant_init
+from mmengine.structures import InstanceData
+
+from mmdet.registry import MODELS
+from mmdet.structures import SampleList
+from mmdet.structures.bbox import bbox_cxcywh_to_xyxy, bbox_xyxy_to_cxcywh
+from mmdet.utils import InstanceList, OptInstanceList, reduce_mean
+from ..utils import multi_apply
+from ..layers import inverse_sigmoid
+from .detr_head import DETRHead
+
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from torch.nn import Transformer
+
+# def adjust_bbox_to_pixel(bboxes: Tensor):
+# # 向下取整得到目标的左上角坐标
+# adjusted_bboxes = torch.floor(bboxes)
+# # 向上取整得到目标的右下角坐标
+# adjusted_bboxes[:, 2:] = torch.ceil(bboxes[:, 2:])
+# return adjusted_bboxes
+
+
+def adjust_bbox_to_pixel(bboxes: Tensor):
+ # 四舍五入取整坐标
+ adjusted_bboxes = torch.round(bboxes)
+ return adjusted_bboxes
+
+
+
+class SiameseClassifier(nn.Module):
+ def __init__(self, embed_dims, num_references=5):
+ super(SiameseClassifier, self).__init__()
+ self.embed_dims = embed_dims
+ self.out_dims =64
+ self.num_references = num_references
+ self.out_features = self.num_references
+ self.transformer = nn.TransformerEncoder(
+ nn.TransformerEncoderLayer(d_model=embed_dims, nhead=1),
+ num_layers=1
+ )
+ self.mlp = nn.Sequential(
+ nn.Linear(embed_dims, 256),
+ nn.LeakyReLU(),
+ # nn.Linear(256, 128),
+ # nn.LeakyReLU(),
+ nn.Linear(256, self.out_dims),
+ )
+ self.out = nn.ModuleList([nn.Linear(self.out_dims, 1 ) for _ in range(num_references)])
+
+ # for layer in self.mlp:
+ # layer.bias.data.fill_(bias_init_with_prob(0.01))
+ for layer in self.out:
+ layer.bias.data.fill_(bias_init_with_prob(0.01))
+ # self.out1 = nn.Linear(embed_dims, num_references)
+ # self.out1.bias.data.fill_(bias_init_with_prob(0.01))
+
+ # self.references = nn.Parameter(torch.randn(num_references, embed_dims))
+
+ # 使用 nn.Embedding 创建嵌入层
+ self.references = nn.Embedding(num_references, embed_dims)
+ # 初始化嵌入权重(随机初始化)
+ nn.init.normal_(self.references.weight)
+ # self.references = self.references.unsqueeze(0)
+ self.init_references = False
+
+ def forward(self, x):
+ batch_size = x.size(0)
+ sample_num = x.size(1)
+ # Expand references to match batch size
+
+
+ # Pass inputs and references through transformer
+ # x_transformed = self.transformer(x)
+ # references_transformed = self.transformer(references)
+
+ x_transformed = self.mlp(x.reshape(batch_size*sample_num, -1)).reshape(batch_size,sample_num, -1)
+
+ # if not self.init_references:
+ # x_mean = torch.mean(x,dim=(0,1)).detach()
+ # self.references = nn.Parameter(x_mean.repeat(self.num_references, 1))
+ # self.init_references = True
+ #
+ references_transformed = self.references(torch.arange(self.num_references).to(x.device))
+ references_transformed = self.mlp(references_transformed)
+ # Concatenate transformed_x and references_transformed
+ # references_transformed_expanded = references_transformed.unsqueeze(1).expand(batch_size, x_transformed.size(1), -1, -1)
+ # x_transformed = x_transformed.unsqueeze(2).expand(-1, -1, self.out_features, -1)
+ # concatenated = torch.cat([x_transformed, references_transformed_expanded], dim=3)
+ # # Pass through MLPs
+ # outputs = []
+ # for i in range(self.out_features):
+ # output = self.out[i](concatenated[:,:,i,:].reshape(-1,self.embed_dims*2))
+ # outputs.append(output.view(batch_size,-1,1))
+ # output = torch.cat(outputs, dim=2)
+
+ references_transformed_expanded = references_transformed.unsqueeze(0).unsqueeze(0).expand(batch_size,sample_num,
+ -1, -1)
+ x_transformed = x_transformed.unsqueeze(2).expand(-1, -1, self.out_features, -1)
+ # concatenated = torch.cat([x_transformed, references_transformed_expanded], dim=4)
+ # concatenated = torch.mean(concatenated, dim=4)
+ concatenated = references_transformed_expanded-x_transformed
+ # Pass through MLPs
+ outputs = []
+ for i in range(self.out_features):
+ output = self.out[i](concatenated[:,:,i,:].reshape(-1,concatenated.size(3)))
+ outputs.append(output.view(batch_size,-1,1))
+ output = torch.cat(outputs, dim=2)
+
+ return output
+
+ # references_transformed_expanded = references_transformed.unsqueeze(1).expand(batch_size, x_transformed.size(1), -1, -1) #.reshape(batch_size, x_transformed.size(1), -1)
+ # x_transformed = x_transformed.unsqueeze(2)
+ # concatenated = torch.cat([x_transformed, references_transformed_expanded], dim=2)
+ # concatenated = torch.mean(concatenated,dim=2)
+ # output = self.out1(concatenated.reshape(-1,self.embed_dims)).view(x.size(0),x.size(1),-1)
+ #
+ # def forward(self, x):
+ # batch_size = x.size(0)
+ # outputs = []
+ # for i in range(self.out_features):
+ # output = self.out[i](x.reshape(-1, self.embed_dims))
+ # outputs.append(output.view(batch_size, x.size(1),-1))
+ # output = torch.cat(outputs, dim=2)
+ # return output
+
+
+@MODELS.register_module()
+class SpecDetrHead(DETRHead):
+ r"""Head of the DINO: DETR with Improved DeNoising Anchor Boxes
+ for End-to-End Object Detection
+
+ Code is modified from the `official github repo
+ `_.
+
+ More details can be found in the `paper
+ `_ .
+ """
+ def __init__(self,
+ *args,
+ share_pred_layer: bool = False,
+ num_pred_layer: int = 6,
+ as_two_stage: bool = False,
+ siamese_cls: bool = True,
+ pre_bboxes_round : bool = True,
+ use_nms : bool = True,
+ **kwargs) -> None:
+ self.share_pred_layer = share_pred_layer
+ self.num_pred_layer = num_pred_layer
+ self.as_two_stage = as_two_stage
+ self.siamese_cls = siamese_cls
+ self.pre_bboxes_round = pre_bboxes_round
+ self.use_nms = use_nms
+ super().__init__(*args, **kwargs)
+
+ def _init_layers(self) -> None:
+ """Initialize classification branch and regression branch of head."""
+ if self.siamese_cls:
+ fc_cls = SiameseClassifier(self.embed_dims, self.cls_out_channels)
+ else:
+ fc_cls = Linear(self.embed_dims, self.cls_out_channels)
+ reg_branch = []
+ for _ in range(self.num_reg_fcs):
+ reg_branch.append(Linear(self.embed_dims, self.embed_dims))
+ reg_branch.append(nn.ReLU())
+ reg_branch.append(Linear(self.embed_dims, 4))
+ reg_branch = nn.Sequential(*reg_branch)
+
+ if self.share_pred_layer:
+ self.cls_branches = nn.ModuleList(
+ [fc_cls for _ in range(self.num_pred_layer)])
+ self.reg_branches = nn.ModuleList(
+ [reg_branch for _ in range(self.num_pred_layer)])
+ else:
+ self.cls_branches = nn.ModuleList(
+ [copy.deepcopy(fc_cls) for _ in range(self.num_pred_layer)])
+ self.reg_branches = nn.ModuleList([
+ copy.deepcopy(reg_branch) for _ in range(self.num_pred_layer)
+ ])
+
+
+ def init_weights(self) -> None:
+ """Initialize weights of the Deformable DETR head."""
+ if not self.siamese_cls:
+ if self.loss_cls.use_sigmoid:
+ bias_init = bias_init_with_prob(0.01)
+ for m in self.cls_branches:
+ nn.init.constant_(m.bias, bias_init)
+ for m in self.reg_branches:
+ constant_init(m[-1], 0, bias=0)
+ nn.init.constant_(self.reg_branches[0][-1].bias.data[2:], -2.0)
+ if self.as_two_stage:
+ for m in self.reg_branches:
+ nn.init.constant_(m[-1].bias.data[2:], 0.0)
+
+ def forward(self, hidden_states: Tensor,
+ references: List[Tensor]) -> Tuple[Tensor]:
+ """Forward function.
+
+ Args:
+ hidden_states (Tensor): Hidden states output from each decoder
+ layer, has shape (num_decoder_layers, bs, num_queries, dim).
+ references (list[Tensor]): List of the reference from the decoder.
+ The first reference is the `init_reference` (initial) and the
+ other num_decoder_layers(6) references are `inter_references`
+ (intermediate). The `init_reference` has shape (bs,
+ num_queries, 4) when `as_two_stage` of the detector is `True`,
+ otherwise (bs, num_queries, 2). Each `inter_reference` has
+ shape (bs, num_queries, 4) when `with_box_refine` of the
+ detector is `True`, otherwise (bs, num_queries, 2). The
+ coordinates are arranged as (cx, cy) when the last dimension is
+ 2, and (cx, cy, w, h) when it is 4.
+
+ Returns:
+ tuple[Tensor]: results of head containing the following tensor.
+
+ - all_layers_outputs_classes (Tensor): Outputs from the
+ classification head, has shape (num_decoder_layers, bs,
+ num_queries, cls_out_channels).
+ - all_layers_outputs_coords (Tensor): Sigmoid outputs from the
+ regression head with normalized coordinate format (cx, cy, w,
+ h), has shape (num_decoder_layers, bs, num_queries, 4) with the
+ last dimension arranged as (cx, cy, w, h).
+ """
+ all_layers_outputs_classes = []
+ all_layers_outputs_coords = []
+
+ for layer_id in range(hidden_states.shape[0]):
+ reference = inverse_sigmoid(references[layer_id])
+ # NOTE The last reference will not be used.
+ hidden_state = hidden_states[layer_id]
+ outputs_class = self.cls_branches[layer_id](hidden_state)
+ tmp_reg_preds = self.reg_branches[layer_id](hidden_state)
+ if reference.shape[-1] == 4:
+ # When `layer` is 0 and `as_two_stage` of the detector
+ # is `True`, or when `layer` is greater than 0 and
+ # `with_box_refine` of the detector is `True`.
+ tmp_reg_preds += reference
+ else:
+ # When `layer` is 0 and `as_two_stage` of the detector
+ # is `False`, or when `layer` is greater than 0 and
+ # `with_box_refine` of the detector is `False`.
+ assert reference.shape[-1] == 2
+ tmp_reg_preds[..., :2] += reference
+ outputs_coord = tmp_reg_preds.sigmoid()
+ all_layers_outputs_classes.append(outputs_class)
+ all_layers_outputs_coords.append(outputs_coord)
+
+
+
+ all_layers_outputs_classes = torch.stack(all_layers_outputs_classes)
+ all_layers_outputs_coords = torch.stack(all_layers_outputs_coords)
+
+ return all_layers_outputs_classes, all_layers_outputs_coords
+
+ def loss(self, hidden_states: Tensor, references: List[Tensor],
+ enc_outputs_class: Tensor, enc_outputs_coord: Tensor,
+ batch_data_samples: SampleList, dn_meta: Dict[str, int]) -> dict:
+ """Perform forward propagation and loss calculation of the detection
+ head on the queries of the upstream network.
+
+ Args:
+ hidden_states (Tensor): Hidden states output from each decoder
+ layer, has shape (num_decoder_layers, bs, num_queries_total,
+ dim), where `num_queries_total` is the sum of
+ `num_denoising_queries` and `num_matching_queries` when
+ `self.training` is `True`, else `num_matching_queries`.
+ references (list[Tensor]): List of the reference from the decoder.
+ The first reference is the `init_reference` (initial) and the
+ other num_decoder_layers(6) references are `inter_references`
+ (intermediate). The `init_reference` has shape (bs,
+ num_queries_total, 4) and each `inter_reference` has shape
+ (bs, num_queries, 4) with the last dimension arranged as
+ (cx, cy, w, h).
+ enc_outputs_class (Tensor): The score of each point on encode
+ feature map, has shape (bs, num_feat_points, cls_out_channels).
+ enc_outputs_coord (Tensor): The proposal generate from the
+ encode feature map, has shape (bs, num_feat_points, 4) with the
+ last dimension arranged as (cx, cy, w, h).
+ batch_data_samples (list[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ dict: A dictionary of loss components.
+ """
+ batch_gt_instances = []
+ batch_img_metas = []
+ for data_sample in batch_data_samples:
+ batch_img_metas.append(data_sample.metainfo)
+ batch_gt_instances.append(data_sample.gt_instances)
+
+ outs = self(hidden_states, references)
+ loss_inputs = outs + (enc_outputs_class, enc_outputs_coord,
+ batch_gt_instances, batch_img_metas, dn_meta)
+ losses = self.loss_by_feat(*loss_inputs)
+ return losses
+
+ def loss_by_feat(
+ self,
+ all_layers_cls_scores: Tensor,
+ all_layers_bbox_preds: Tensor,
+ enc_cls_scores: Tensor,
+ enc_bbox_preds: Tensor,
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ dn_meta: Dict[str, int],
+ batch_gt_instances_ignore: OptInstanceList = None
+ ) -> Dict[str, Tensor]:
+ """Loss function.
+
+ Args:
+ all_layers_cls_scores (Tensor): Classification scores of all
+ decoder layers, has shape (num_decoder_layers, bs,
+ num_queries_total, cls_out_channels), where
+ `num_queries_total` is the sum of `num_denoising_queries`
+ and `num_matching_queries`.
+ all_layers_bbox_preds (Tensor): Regression outputs of all decoder
+ layers. Each is a 4D-tensor with normalized coordinate format
+ (cx, cy, w, h) and has shape (num_decoder_layers, bs,
+ num_queries_total, 4).
+ enc_cls_scores (Tensor): The score of each point on encode
+ feature map, has shape (bs, num_feat_points, cls_out_channels).
+ enc_bbox_preds (Tensor): The proposal generate from the encode
+ feature map, has shape (bs, num_feat_points, 4) with the last
+ dimension arranged as (cx, cy, w, h).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components.
+ """
+ # extract denoising and matching part of outputs
+ (all_layers_matching_cls_scores, all_layers_matching_bbox_preds,
+ all_layers_denoising_cls_scores, all_layers_denoising_bbox_preds) = \
+ self.split_outputs(
+ all_layers_cls_scores, all_layers_bbox_preds, dn_meta)
+
+ loss_dict = super().loss_by_feat(
+ all_layers_matching_cls_scores, all_layers_matching_bbox_preds,
+ batch_gt_instances, batch_img_metas, batch_gt_instances_ignore)
+ # # NOTE DETRHead.loss_by_feat but not DeformableDETRHead.loss_by_feat
+ # # is called, because the encoder loss calculations are different
+ # # between DINO and DeformableDETR.
+ # loss_dict = dict()
+ # loss of proposal generated from encode feature map.
+ if enc_cls_scores is not None:
+ # NOTE The enc_loss calculation of the DINO is
+ # different from that of Deformable DETR.
+ enc_loss_cls, enc_losses_bbox, enc_losses_iou = \
+ self.loss_by_feat_single(
+ enc_cls_scores, enc_bbox_preds,
+ batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas)
+ loss_dict['enc_loss_cls'] = enc_loss_cls
+ loss_dict['enc_loss_bbox'] = enc_losses_bbox
+ loss_dict['enc_loss_iou'] = enc_losses_iou
+ # loss_dict = dict()
+ if all_layers_denoising_cls_scores is not None:
+ # calculate denoising loss from all decoder layers
+ dn_losses_cls, dn_losses_bbox, dn_losses_iou = self.loss_dn(
+ all_layers_denoising_cls_scores,
+ all_layers_denoising_bbox_preds,
+ batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas,
+ dn_meta=dn_meta)
+ # collate denoising loss
+ loss_dict['dn_loss_cls'] = dn_losses_cls[-1]
+ loss_dict['dn_loss_bbox'] = dn_losses_bbox[-1]
+ loss_dict['dn_loss_iou'] = dn_losses_iou[-1]
+ for num_dec_layer, (loss_cls_i, loss_bbox_i, loss_iou_i) in \
+ enumerate(zip(dn_losses_cls[:-1], dn_losses_bbox[:-1],
+ dn_losses_iou[:-1])):
+ loss_dict[f'd{num_dec_layer}.dn_loss_cls'] = loss_cls_i
+ # loss_dict[f'd{num_dec_layer}.dn_loss_bbox'] = loss_bbox_i
+ # loss_dict[f'd{num_dec_layer}.dn_loss_iou'] = loss_iou_i
+ return loss_dict
+
+ def loss_dn(self, all_layers_denoising_cls_scores: Tensor,
+ all_layers_denoising_bbox_preds: Tensor,
+ batch_gt_instances: InstanceList, batch_img_metas: List[dict],
+ dn_meta: Dict[str, int]) -> Tuple[List[Tensor]]:
+ """Calculate denoising loss.
+
+ Args:
+ all_layers_denoising_cls_scores (Tensor): Classification scores of
+ all decoder layers in denoising part, has shape (
+ num_decoder_layers, bs, num_denoising_queries,
+ cls_out_channels).
+ all_layers_denoising_bbox_preds (Tensor): Regression outputs of all
+ decoder layers in denoising part. Each is a 4D-tensor with
+ normalized coordinate format (cx, cy, w, h) and has shape
+ (num_decoder_layers, bs, num_denoising_queries, 4).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ Tuple[List[Tensor]]: The loss_dn_cls, loss_dn_bbox, and loss_dn_iou
+ of each decoder layers.
+ """
+ return multi_apply(
+ self._loss_dn_single,
+ all_layers_denoising_cls_scores,
+ all_layers_denoising_bbox_preds,
+ batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas,
+ dn_meta=dn_meta)
+
+ def _loss_dn_single(self, dn_cls_scores: Tensor, dn_bbox_preds: Tensor,
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ dn_meta: Dict[str, int]) -> Tuple[Tensor]:
+ """Denoising loss for outputs from a single decoder layer.
+
+ Args:
+ dn_cls_scores (Tensor): Classification scores of a single decoder
+ layer in denoising part, has shape (bs, num_denoising_queries,
+ cls_out_channels).
+ dn_bbox_preds (Tensor): Regression outputs of a single decoder
+ layer in denoising part. Each is a 4D-tensor with normalized
+ coordinate format (cx, cy, w, h) and has shape
+ (bs, num_denoising_queries, 4).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ Tuple[Tensor]: A tuple including `loss_cls`, `loss_box` and
+ `loss_iou`.
+ """
+ cls_reg_targets = self.get_dn_targets(batch_gt_instances,
+ batch_img_metas, dn_meta)
+ (labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,
+ num_total_pos, num_total_neg) = cls_reg_targets
+ labels = torch.cat(labels_list, 0)
+ label_weights = torch.cat(label_weights_list, 0)
+ bbox_targets = torch.cat(bbox_targets_list, 0)
+ bbox_weights = torch.cat(bbox_weights_list, 0)
+
+ # classification loss
+ cls_scores = dn_cls_scores.reshape(-1, self.cls_out_channels)
+ # construct weighted avg_factor to match with the official DETR repo
+ cls_avg_factor = \
+ num_total_pos * 1.0 + num_total_neg * self.bg_cls_weight
+ if self.sync_cls_avg_factor:
+ cls_avg_factor = reduce_mean(
+ cls_scores.new_tensor([cls_avg_factor]))
+ cls_avg_factor = max(cls_avg_factor, 1)
+
+ if len(cls_scores) > 0:
+ loss_cls = self.loss_cls(
+ cls_scores, labels, label_weights, avg_factor=cls_avg_factor)
+ else:
+ loss_cls = torch.zeros(
+ 1, dtype=cls_scores.dtype, device=cls_scores.device)
+
+ # Compute the average number of gt boxes across all gpus, for
+ # normalization purposes
+ num_total_pos = loss_cls.new_tensor([num_total_pos])
+ num_total_pos = torch.clamp(reduce_mean(num_total_pos), min=1).item()
+
+ # construct factors used for rescale bboxes
+ factors = []
+ for img_meta, bbox_pred in zip(batch_img_metas, dn_bbox_preds):
+ img_h, img_w = img_meta['img_shape']
+ factor = bbox_pred.new_tensor([img_w, img_h, img_w,
+ img_h]).unsqueeze(0).repeat(
+ bbox_pred.size(0), 1)
+ factors.append(factor)
+ factors = torch.cat(factors)
+
+ # DETR regress the relative position of boxes (cxcywh) in the image,
+ # thus the learning target is normalized by the image size. So here
+ # we need to re-scale them for calculating IoU loss
+ bbox_preds = dn_bbox_preds.reshape(-1, 4)
+ bboxes = bbox_cxcywh_to_xyxy(bbox_preds) * factors
+ bboxes_gt = bbox_cxcywh_to_xyxy(bbox_targets) * factors
+
+ # regression IoU loss, defaultly GIoU loss
+ loss_iou = self.loss_iou(
+ bboxes, bboxes_gt, bbox_weights, avg_factor=num_total_pos)
+
+ # regression L1 loss
+ loss_bbox = self.loss_bbox(
+ bbox_preds, bbox_targets, bbox_weights, avg_factor=num_total_pos)
+ return loss_cls, loss_bbox, loss_iou
+
+ def get_dn_targets(self, batch_gt_instances: InstanceList,
+ batch_img_metas: dict, dn_meta: Dict[str,
+ int]) -> tuple:
+ """Get targets in denoising part for a batch of images.
+
+ Args:
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ tuple: a tuple containing the following targets.
+
+ - labels_list (list[Tensor]): Labels for all images.
+ - label_weights_list (list[Tensor]): Label weights for all images.
+ - bbox_targets_list (list[Tensor]): BBox targets for all images.
+ - bbox_weights_list (list[Tensor]): BBox weights for all images.
+ - num_total_pos (int): Number of positive samples in all images.
+ - num_total_neg (int): Number of negative samples in all images.
+ """
+ (labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,
+ pos_inds_list, neg_inds_list) = multi_apply(
+ self._get_dn_targets_single,
+ batch_gt_instances,
+ batch_img_metas,
+ dn_meta=dn_meta)
+ num_total_pos = sum((inds.numel() for inds in pos_inds_list))
+ num_total_neg = sum((inds.numel() for inds in neg_inds_list))
+ return (labels_list, label_weights_list, bbox_targets_list,
+ bbox_weights_list, num_total_pos, num_total_neg)
+
+ def _get_dn_targets_single(self, gt_instances: InstanceData,
+ img_meta: dict, dn_meta: Dict[str,
+ int]) -> tuple:
+ """Get targets in denoising part for one image.
+
+ Args:
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It should includes ``bboxes`` and ``labels``
+ attributes.
+ img_meta (dict): Meta information for one image.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ tuple[Tensor]: a tuple containing the following for one image.
+
+ - labels (Tensor): Labels of each image.
+ - label_weights (Tensor]): Label weights of each image.
+ - bbox_targets (Tensor): BBox targets of each image.
+ - bbox_weights (Tensor): BBox weights of each image.
+ - pos_inds (Tensor): Sampled positive indices for each image.
+ - neg_inds (Tensor): Sampled negative indices for each image.
+ """
+ gt_bboxes = gt_instances.bboxes
+ gt_labels = gt_instances.labels
+ num_groups = dn_meta['num_denoising_groups']
+ num_denoising_queries = dn_meta['num_denoising_queries']
+ num_queries_each_group = int(num_denoising_queries / num_groups)
+ device = gt_bboxes.device
+
+ if len(gt_labels) > 0:
+ t = torch.arange(len(gt_labels), dtype=torch.long, device=device)
+ t = t.unsqueeze(0).repeat(num_groups, 1)
+ pos_assigned_gt_inds = t.flatten()
+ pos_inds = torch.arange(
+ num_groups, dtype=torch.long, device=device)
+ pos_inds = pos_inds.unsqueeze(1) * num_queries_each_group + t
+ pos_inds = pos_inds.flatten()
+ else:
+ pos_inds = pos_assigned_gt_inds = \
+ gt_bboxes.new_tensor([], dtype=torch.long)
+
+ neg_inds = pos_inds + num_queries_each_group // 2
+
+ # label targets
+ labels = gt_bboxes.new_full((num_denoising_queries, ),
+ self.num_classes,
+ dtype=torch.long)
+ labels[pos_inds] = gt_labels[pos_assigned_gt_inds]
+ label_weights = gt_bboxes.new_ones(num_denoising_queries)
+
+ # bbox targets
+ bbox_targets = torch.zeros(num_denoising_queries, 4, device=device)
+ bbox_weights = torch.zeros(num_denoising_queries, 4, device=device)
+ bbox_weights[pos_inds] = 1.0
+ img_h, img_w = img_meta['img_shape']
+
+ # DETR regress the relative position of boxes (cxcywh) in the image.
+ # Thus the learning target should be normalized by the image size, also
+ # the box format should be converted from defaultly x1y1x2y2 to cxcywh.
+ factor = gt_bboxes.new_tensor([img_w, img_h, img_w,
+ img_h]).unsqueeze(0)
+ gt_bboxes_normalized = gt_bboxes / factor
+ gt_bboxes_targets = bbox_xyxy_to_cxcywh(gt_bboxes_normalized)
+ bbox_targets[pos_inds] = gt_bboxes_targets.repeat([num_groups, 1])
+
+ return (labels, label_weights, bbox_targets, bbox_weights, pos_inds,
+ neg_inds)
+
+ @staticmethod
+ def split_outputs(all_layers_cls_scores: Tensor,
+ all_layers_bbox_preds: Tensor,
+ dn_meta: Dict[str, int]) -> Tuple[Tensor]:
+ """Split outputs of the denoising part and the matching part.
+
+ For the total outputs of `num_queries_total` length, the former
+ `num_denoising_queries` outputs are from denoising queries, and
+ the rest `num_matching_queries` ones are from matching queries,
+ where `num_queries_total` is the sum of `num_denoising_queries` and
+ `num_matching_queries`.
+
+ Args:
+ all_layers_cls_scores (Tensor): Classification scores of all
+ decoder layers, has shape (num_decoder_layers, bs,
+ num_queries_total, cls_out_channels).
+ all_layers_bbox_preds (Tensor): Regression outputs of all decoder
+ layers. Each is a 4D-tensor with normalized coordinate format
+ (cx, cy, w, h) and has shape (num_decoder_layers, bs,
+ num_queries_total, 4).
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'.
+
+ Returns:
+ Tuple[Tensor]: a tuple containing the following outputs.
+
+ - all_layers_matching_cls_scores (Tensor): Classification scores
+ of all decoder layers in matching part, has shape
+ (num_decoder_layers, bs, num_matching_queries, cls_out_channels).
+ - all_layers_matching_bbox_preds (Tensor): Regression outputs of
+ all decoder layers in matching part. Each is a 4D-tensor with
+ normalized coordinate format (cx, cy, w, h) and has shape
+ (num_decoder_layers, bs, num_matching_queries, 4).
+ - all_layers_denoising_cls_scores (Tensor): Classification scores
+ of all decoder layers in denoising part, has shape
+ (num_decoder_layers, bs, num_denoising_queries,
+ cls_out_channels).
+ - all_layers_denoising_bbox_preds (Tensor): Regression outputs of
+ all decoder layers in denoising part. Each is a 4D-tensor with
+ normalized coordinate format (cx, cy, w, h) and has shape
+ (num_decoder_layers, bs, num_denoising_queries, 4).
+ """
+ if dn_meta is not None:
+ num_denoising_queries = dn_meta['num_denoising_queries']
+ all_layers_denoising_cls_scores = \
+ all_layers_cls_scores[:, :, : num_denoising_queries, :]
+ all_layers_denoising_bbox_preds = \
+ all_layers_bbox_preds[:, :, : num_denoising_queries, :]
+ all_layers_matching_cls_scores = \
+ all_layers_cls_scores[:, :, num_denoising_queries:, :]
+ all_layers_matching_bbox_preds = \
+ all_layers_bbox_preds[:, :, num_denoising_queries:, :]
+ else:
+ all_layers_denoising_cls_scores = None
+ all_layers_denoising_bbox_preds = None
+ all_layers_matching_cls_scores = all_layers_cls_scores
+ all_layers_matching_bbox_preds = all_layers_bbox_preds
+ return (all_layers_matching_cls_scores, all_layers_matching_bbox_preds,
+ all_layers_denoising_cls_scores,
+ all_layers_denoising_bbox_preds)
+
+ def predict(self,
+ hidden_states: Tensor,
+ references: List[Tensor],
+ batch_data_samples: SampleList,
+ rescale: bool = True) -> InstanceList:
+ """Perform forward propagation and loss calculation of the detection
+ head on the queries of the upstream network.
+
+ Args:
+ hidden_states (Tensor): Hidden states output from each decoder
+ layer, has shape (num_decoder_layers, num_queries, bs, dim).
+ references (list[Tensor]): List of the reference from the decoder.
+ The first reference is the `init_reference` (initial) and the
+ other num_decoder_layers(6) references are `inter_references`
+ (intermediate). The `init_reference` has shape (bs,
+ num_queries, 4) when `as_two_stage` of the detector is `True`,
+ otherwise (bs, num_queries, 2). Each `inter_reference` has
+ shape (bs, num_queries, 4) when `with_box_refine` of the
+ detector is `True`, otherwise (bs, num_queries, 2). The
+ coordinates are arranged as (cx, cy) when the last dimension is
+ 2, and (cx, cy, w, h) when it is 4.
+ batch_data_samples (list[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ rescale (bool, optional): If `True`, return boxes in original
+ image space. Defaults to `True`.
+
+ Returns:
+ list[obj:`InstanceData`]: Detection results of each image
+ after the post process.
+ """
+ batch_img_metas = [
+ data_samples.metainfo for data_samples in batch_data_samples
+ ]
+
+ outs = self(hidden_states, references)
+
+ predictions = self.predict_by_feat(
+ *outs, batch_img_metas=batch_img_metas, rescale=rescale)
+ return predictions
+
+ def predict_by_feat(self,
+ all_layers_cls_scores: Tensor,
+ all_layers_bbox_preds: Tensor,
+ batch_img_metas: List[Dict],
+ rescale: bool = False) -> InstanceList:
+ """Transform a batch of output features extracted from the head into
+ bbox results.
+
+ Args:
+ all_layers_cls_scores (Tensor): Classification scores of all
+ decoder layers, has shape (num_decoder_layers, bs, num_queries,
+ cls_out_channels).
+ all_layers_bbox_preds (Tensor): Regression outputs of all decoder
+ layers. Each is a 4D-tensor with normalized coordinate format
+ (cx, cy, w, h) and shape (num_decoder_layers, bs, num_queries,
+ 4) with the last dimension arranged as (cx, cy, w, h).
+ batch_img_metas (list[dict]): Meta information of each image.
+ rescale (bool, optional): If `True`, return boxes in original
+ image space. Default `False`.
+
+ Returns:
+ list[obj:`InstanceData`]: Detection results of each image
+ after the post process.
+ """
+ cls_scores = all_layers_cls_scores[-1]
+ bbox_preds = all_layers_bbox_preds[-1]
+
+ result_list = []
+ for img_id in range(len(batch_img_metas)):
+ cls_score = cls_scores[img_id]
+ bbox_pred = bbox_preds[img_id]
+ img_meta = batch_img_metas[img_id]
+ results = self._predict_by_feat_single(cls_score, bbox_pred,
+ img_meta, rescale)
+ result_list.append(results)
+ return result_list
+
+ def _predict_by_feat_single(self,
+ cls_score: Tensor,
+ bbox_pred: Tensor,
+ img_meta: dict,
+ rescale: bool = True) -> InstanceData:
+ """Transform outputs from the last decoder layer into bbox predictions
+ for each image.
+
+ Args:
+ cls_score (Tensor): Box score logits from the last decoder layer
+ for each image. Shape [num_queries, cls_out_channels].
+ bbox_pred (Tensor): Sigmoid outputs from the last decoder layer
+ for each image, with coordinate format (cx, cy, w, h) and
+ shape [num_queries, 4].
+ img_meta (dict): Image meta info.
+ rescale (bool): If True, return boxes in original image
+ space. Default True.
+
+ Returns:
+ :obj:`InstanceData`: Detection results of each image
+ after the post process.
+ Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ """
+ assert len(cls_score) == len(bbox_pred) # num_queries
+ max_per_img = self.test_cfg.get('max_per_img', len(cls_score))
+ img_shape = img_meta['img_shape']
+ # exclude background
+ if self.loss_cls.use_sigmoid:
+ cls_score = cls_score.sigmoid()
+ scores, indexes = cls_score.view(-1).topk(max_per_img)
+ det_labels = indexes % self.num_classes
+ bbox_index = indexes // self.num_classes
+ bbox_pred = bbox_pred[bbox_index]
+ else:
+ scores, det_labels = F.softmax(cls_score, dim=-1)[..., :-1].max(-1)
+ scores, bbox_index = scores.topk(max_per_img)
+ bbox_pred = bbox_pred[bbox_index]
+ det_labels = det_labels[bbox_index]
+
+ det_bboxes = bbox_cxcywh_to_xyxy(bbox_pred)
+ det_bboxes[:, 0::2] = det_bboxes[:, 0::2] * img_shape[1]
+ det_bboxes[:, 1::2] = det_bboxes[:, 1::2] * img_shape[0]
+ det_bboxes[:, 0::2].clamp_(min=0, max=img_shape[1])
+ det_bboxes[:, 1::2].clamp_(min=0, max=img_shape[0])
+
+
+ if self.use_nms:
+ iou_threshold= 0.01
+ offset = 0
+ score_threshold = 0.0 # torch.mean(cls_score.view(-1))+3*torch.std(cls_score.view(-1))
+ max_num = 300
+ dets, inds = nms(det_bboxes, scores, iou_threshold, offset, score_threshold, max_num)
+ det_bboxes = dets[:,:-1]
+ scores = dets[:,-1]
+ det_labels =det_labels[inds]
+
+ # add by lzx
+ if self.pre_bboxes_round:
+ det_bboxes = adjust_bbox_to_pixel(det_bboxes)
+
+ if rescale:
+ # assert img_meta.get('scale_factor') is not None
+ # det_bboxes /= det_bboxes.new_tensor(
+ # img_meta['scale_factor']).repeat((1, 2))
+ # rw by lzx
+ if img_meta.get('scale_factor') is not None:
+ det_bboxes /= det_bboxes.new_tensor(
+ img_meta['scale_factor']).repeat((1, 2))
+ results = InstanceData()
+ results.bboxes = det_bboxes
+ results.scores = scores
+ results.labels = det_labels
+ return results
+
+
+
+ def loss_group(self, hidden_states: Tensor, references: List[Tensor],
+ enc_outputs_class: Tensor, enc_outputs_coord: Tensor,
+ batch_data_samples: SampleList, dn_meta: Dict[str, int],
+ # match_group_size: Tuple[int, int] = (2, 2),
+ each_match_num_queries: int = 200, ) -> dict:
+ """Perform forward propagation and loss calculation of the detection
+ head on the queries of the upstream network.
+
+ Args:
+ hidden_states (Tensor): Hidden states output from each decoder
+ layer, has shape (num_decoder_layers, bs, num_queries_total,
+ dim), where `num_queries_total` is the sum of
+ `num_denoising_queries` and `num_matching_queries` when
+ `self.training` is `True`, else `num_matching_queries`.
+ references (list[Tensor]): List of the reference from the decoder.
+ The first reference is the `init_reference` (initial) and the
+ other num_decoder_layers(6) references are `inter_references`
+ (intermediate). The `init_reference` has shape (bs,
+ num_queries_total, 4) and each `inter_reference` has shape
+ (bs, num_queries, 4) with the last dimension arranged as
+ (cx, cy, w, h).
+ enc_outputs_class (Tensor): The score of each point on encode
+ feature map, has shape (bs, num_feat_points, cls_out_channels).
+ enc_outputs_coord (Tensor): The proposal generate from the
+ encode feature map, has shape (bs, num_feat_points, 4) with the
+ last dimension arranged as (cx, cy, w, h).
+ batch_data_samples (list[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ dict: A dictionary of loss components.
+ """
+ batch_gt_instances = []
+ batch_img_metas = []
+ for data_sample in batch_data_samples:
+ batch_img_metas.append(data_sample.metainfo)
+ batch_gt_instances.append(data_sample.gt_instances)
+
+ outs = self(hidden_states, references)
+ loss_inputs = outs + (enc_outputs_class, enc_outputs_coord,
+ batch_gt_instances, batch_img_metas, dn_meta,each_match_num_queries)
+ losses = self.loss_by_feat_group(*loss_inputs)
+ return losses
+
+ def loss_by_feat_group(
+ self,
+ all_layers_cls_scores: Tensor,
+ all_layers_bbox_preds: Tensor,
+ enc_cls_scores: Tensor,
+ enc_bbox_preds: Tensor,
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ dn_meta: Dict[str, int],
+ # match_group_size: Tuple[int, int] = (2, 2),
+ each_match_num_queries: int = 200,
+ batch_gt_instances_ignore: OptInstanceList = None,
+ ) -> Dict[str, Tensor]:
+ """Loss function.
+
+ Args:
+ all_layers_cls_scores (Tensor): Classification scores of all
+ decoder layers, has shape (num_decoder_layers, bs,
+ num_queries_total, cls_out_channels), where
+ `num_queries_total` is the sum of `num_denoising_queries`
+ and `num_matching_queries`.
+ all_layers_bbox_preds (Tensor): Regression outputs of all decoder
+ layers. Each is a 4D-tensor with normalized coordinate format
+ (cx, cy, w, h) and has shape (num_decoder_layers, bs,
+ num_queries_total, 4).
+ enc_cls_scores (Tensor): The score of each point on encode
+ feature map, has shape (bs, num_feat_points, cls_out_channels).
+ enc_bbox_preds (Tensor): The proposal generate from the encode
+ feature map, has shape (bs, num_feat_points, 4) with the last
+ dimension arranged as (cx, cy, w, h).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components.
+ """
+ # extract denoising and matching part of outputs
+ (all_layers_matching_cls_scores, all_layers_matching_bbox_preds,
+ all_layers_denoising_cls_scores, all_layers_denoising_bbox_preds) = \
+ self.split_outputs(
+ all_layers_cls_scores, all_layers_bbox_preds, dn_meta)
+ match_group_num = all_layers_matching_cls_scores.shape[2]//each_match_num_queries
+ loss_dict = dict()
+ for id_group in range(match_group_num):
+ all_layers_matching_cls_scores_one_group = all_layers_matching_cls_scores[:, :, id_group * each_match_num_queries:(id_group + 1) * each_match_num_queries, :]
+ all_layers_matching_bbox_preds_one_group = all_layers_matching_bbox_preds[:, :, id_group * each_match_num_queries:(id_group + 1) * each_match_num_queries, :]
+ # 同时计算每一解码层的loss
+ losses_cls, losses_bbox, losses_iou = multi_apply(
+ self.loss_by_feat_single,
+ all_layers_matching_cls_scores_one_group,
+ all_layers_matching_bbox_preds_one_group,
+ batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas)
+ # loss from the last decoder layer
+ loss_dict[f'g{id_group}.loss_cls'] = losses_cls[-1]
+ loss_dict[f'g{id_group}.loss_bbox'] = losses_bbox[-1]
+ loss_dict[f'g{id_group}.loss_iou'] = losses_iou[-1]
+ # loss from other decoder layers
+ num_dec_layer = 0
+ for loss_cls_i, loss_bbox_i, loss_iou_i in \
+ zip(losses_cls[:-1], losses_bbox[:-1], losses_iou[:-1]):
+ loss_dict[f'g{id_group}d{num_dec_layer}.loss_cls'] = loss_cls_i
+ loss_dict[f'g{id_group}d{num_dec_layer}.loss_bbox'] = loss_bbox_i
+ loss_dict[f'g{id_group}d{num_dec_layer}.loss_iou'] = loss_iou_i
+ num_dec_layer += 1
+
+
+ # loss_dict_one_groug = super().loss_by_feat(all_layers_matching_cls_scores_one_group, all_layers_matching_bbox_preds_one_group,
+ # batch_gt_instances, batch_img_metas, batch_gt_instances_ignore)
+ enc_cls_scores_one_group = enc_cls_scores[:, id_group * each_match_num_queries:(id_group + 1) * each_match_num_queries, :]
+ enc_bbox_preds_one_group = enc_bbox_preds[:, id_group * each_match_num_queries:(id_group + 1) * each_match_num_queries, :]
+ if enc_cls_scores is not None:
+ # NOTE The enc_loss calculation of the DINO is
+ # different from that of Deformable DETR.
+ enc_loss_cls, enc_losses_bbox, enc_losses_iou = \
+ self.loss_by_feat_single(enc_cls_scores_one_group,
+ enc_bbox_preds_one_group,
+ batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas)
+ loss_dict[f'g{id_group}.enc_loss_cls'] = enc_loss_cls
+ loss_dict[f'g{id_group}.enc_loss_bbox'] = enc_losses_bbox
+ loss_dict[f'g{id_group}.enc_loss_iou'] = enc_losses_iou
+
+
+ # loss_dict = super().loss_by_feat(
+ # all_layers_matching_cls_scores, all_layers_matching_bbox_preds,
+ # batch_gt_instances, batch_img_metas, batch_gt_instances_ignore)
+ # # NOTE DETRHead.loss_by_feat but not DeformableDETRHead.loss_by_feat
+ # # is called, because the encoder loss calculations are different
+ # # between DINO and DeformableDETR.
+ # # loss of proposal generated from encode feature map.
+ # if enc_cls_scores is not None:
+ # # NOTE The enc_loss calculation of the DINO is
+ # # different from that of Deformable DETR.
+ # enc_loss_cls, enc_losses_bbox, enc_losses_iou = \
+ # self.loss_by_feat_single(
+ # enc_cls_scores, enc_bbox_preds,
+ # batch_gt_instances=batch_gt_instances,
+ # batch_img_metas=batch_img_metas)
+ # loss_dict['enc_loss_cls'] = enc_loss_cls
+ # loss_dict['enc_loss_bbox'] = enc_losses_bbox
+ # loss_dict['enc_loss_iou'] = enc_losses_iou
+
+ if all_layers_denoising_cls_scores is not None:
+ # calculate denoising loss from all decoder layers
+ dn_losses_cls, dn_losses_bbox, dn_losses_iou = self.loss_dn(
+ all_layers_denoising_cls_scores,
+ all_layers_denoising_bbox_preds,
+ batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas,
+ dn_meta=dn_meta)
+ # collate denoising loss
+ loss_dict['dn_loss_cls'] = dn_losses_cls[-1]
+ loss_dict['dn_loss_bbox'] = dn_losses_bbox[-1]
+ loss_dict['dn_loss_iou'] = dn_losses_iou[-1]
+ for num_dec_layer, (loss_cls_i, loss_bbox_i, loss_iou_i) in \
+ enumerate(zip(dn_losses_cls[:-1], dn_losses_bbox[:-1],
+ dn_losses_iou[:-1])):
+ loss_dict[f'd{num_dec_layer}.dn_loss_cls'] = loss_cls_i
+ loss_dict[f'd{num_dec_layer}.dn_loss_bbox'] = loss_bbox_i
+ loss_dict[f'd{num_dec_layer}.dn_loss_iou'] = loss_iou_i
+ return loss_dict
+
+ def loss_ddn(self, hidden_states: Tensor, references: List[Tensor],
+ enc_outputs_class: Tensor, enc_outputs_coord: Tensor,
+ batch_data_samples: SampleList, dn_meta: Dict[str, int]) -> dict:
+ """Perform forward propagation and loss calculation of the detection
+ head on the queries of the upstream network.
+
+ Args:
+ hidden_states (Tensor): Hidden states output from each decoder
+ layer, has shape (num_decoder_layers, bs, num_queries_total,
+ dim), where `num_queries_total` is the sum of
+ `num_denoising_queries` and `num_matching_queries` when
+ `self.training` is `True`, else `num_matching_queries`.
+ references (list[Tensor]): List of the reference from the decoder.
+ The first reference is the `init_reference` (initial) and the
+ other num_decoder_layers(6) references are `inter_references`
+ (intermediate). The `init_reference` has shape (bs,
+ num_queries_total, 4) and each `inter_reference` has shape
+ (bs, num_queries, 4) with the last dimension arranged as
+ (cx, cy, w, h).
+ enc_outputs_class (Tensor): The score of each point on encode
+ feature map, has shape (bs, num_feat_points, cls_out_channels).
+ enc_outputs_coord (Tensor): The proposal generate from the
+ encode feature map, has shape (bs, num_feat_points, 4) with the
+ last dimension arranged as (cx, cy, w, h).
+ batch_data_samples (list[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ dict: A dictionary of loss components.
+ """
+ batch_gt_instances = []
+ batch_img_metas = []
+ for data_sample in batch_data_samples:
+ batch_img_metas.append(data_sample.metainfo)
+ batch_gt_instances.append(data_sample.gt_instances)
+
+ outs = self(hidden_states, references)
+ loss_inputs = outs + (enc_outputs_class, enc_outputs_coord,
+ batch_gt_instances, batch_img_metas, dn_meta)
+ losses,pos_bbox_offsets = self.loss_ddn_by_feat(*loss_inputs)
+ return losses, pos_bbox_offsets
+
+ def loss_ddn_by_feat(
+ self,
+ all_layers_cls_scores: Tensor,
+ all_layers_bbox_preds: Tensor,
+ enc_cls_scores: Tensor,
+ enc_bbox_preds: Tensor,
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ dn_meta: Dict[str, int],
+ # match_group_size: Tuple[int, int] = (2, 2),
+ batch_gt_instances_ignore: OptInstanceList = None,
+ ) -> Tuple[Dict[str, Tensor], List]:
+ """Loss function.
+
+ Args:
+ all_layers_cls_scores (Tensor): Classification scores of all
+ decoder layers, has shape (num_decoder_layers, bs,
+ num_queries_total, cls_out_channels), where
+ `num_queries_total` is the sum of `num_denoising_queries`
+ and `num_matching_queries`.
+ all_layers_bbox_preds (Tensor): Regression outputs of all decoder
+ layers. Each is a 4D-tensor with normalized coordinate format
+ (cx, cy, w, h) and has shape (num_decoder_layers, bs,
+ num_queries_total, 4).
+ enc_cls_scores (Tensor): The score of each point on encode
+ feature map, has shape (bs, num_feat_points, cls_out_channels).
+ enc_bbox_preds (Tensor): The proposal generate from the encode
+ feature map, has shape (bs, num_feat_points, 4) with the last
+ dimension arranged as (cx, cy, w, h).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components.
+ """
+ # extract denoising and matching part of outputs
+ (all_layers_matching_cls_scores, all_layers_matching_bbox_preds,
+ all_layers_denoising_cls_scores, all_layers_denoising_bbox_preds) = \
+ self.split_outputs(
+ all_layers_cls_scores, all_layers_bbox_preds, dn_meta)
+ loss_dict = dict()
+
+ assert batch_gt_instances_ignore is None, \
+ f'{self.__class__.__name__} only supports ' \
+ 'for batch_gt_instances_ignore setting to None.'
+ #同时计算每一解码层的loss
+ losses_cls, losses_bbox, losses_iou, pos_bbox_offsets = multi_apply(
+ self.loss_ddn_by_feat_single,
+ all_layers_matching_cls_scores,
+ all_layers_matching_bbox_preds,
+ batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas)
+ pos_bbox_offsets = pos_bbox_offsets[-1]
+ # loss from the last decoder layer
+ loss_dict['loss_cls'] = losses_cls[-1]
+ loss_dict['loss_bbox'] = losses_bbox[-1]
+ loss_dict['loss_iou'] = losses_iou[-1]
+ # loss from other decoder layers
+ num_dec_layer = 0
+ for loss_cls_i, loss_bbox_i, loss_iou_i in \
+ zip(losses_cls[:-1], losses_bbox[:-1], losses_iou[:-1]):
+ loss_dict[f'd{num_dec_layer}.loss_cls'] = loss_cls_i
+ loss_dict[f'd{num_dec_layer}.loss_bbox'] = loss_bbox_i
+ loss_dict[f'd{num_dec_layer}.loss_iou'] = loss_iou_i
+ num_dec_layer += 1
+
+
+ # NOTE DETRHead.loss_by_feat but not DeformableDETRHead.loss_by_feat
+ # is called, because the encoder loss calculations are different
+ # between DINO and DeformableDETR.
+ # loss of proposal generated from encode feature map.
+ if enc_cls_scores is not None:
+ # NOTE The enc_loss calculation of the DINO is
+ # different from that of Deformable DETR.
+ enc_loss_cls, enc_losses_bbox, enc_losses_iou, pos_bbox_offsets = \
+ self.loss_ddn_by_feat_single(
+ enc_cls_scores, enc_bbox_preds,
+ batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas)
+ loss_dict['enc_loss_cls'] = enc_loss_cls
+ loss_dict['enc_loss_bbox'] = enc_losses_bbox
+ loss_dict['enc_loss_iou'] = enc_losses_iou
+ # loss_dict = dict()
+ if all_layers_denoising_cls_scores is not None:
+ # calculate denoising loss from all decoder layers
+ dn_losses_cls, dn_losses_bbox, dn_losses_iou = self.loss_dn(
+ all_layers_denoising_cls_scores,
+ all_layers_denoising_bbox_preds,
+ batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas,
+ dn_meta=dn_meta)
+ # collate denoising loss
+ loss_dict['dn_loss_cls'] = dn_losses_cls[-1]
+ loss_dict['dn_loss_bbox'] = dn_losses_bbox[-1]
+ loss_dict['dn_loss_iou'] = dn_losses_iou[-1]
+ for num_dec_layer, (loss_cls_i, loss_bbox_i, loss_iou_i) in \
+ enumerate(zip(dn_losses_cls[:-1], dn_losses_bbox[:-1],
+ dn_losses_iou[:-1])):
+ loss_dict[f'd{num_dec_layer}.dn_loss_cls'] = loss_cls_i
+ loss_dict[f'd{num_dec_layer}.dn_loss_bbox'] = loss_bbox_i
+ loss_dict[f'd{num_dec_layer}.dn_loss_iou'] = loss_iou_i
+ return loss_dict, pos_bbox_offsets
+
+
+ def loss_ddn_by_feat_single(self, cls_scores: Tensor, bbox_preds: Tensor,
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict]) -> Tuple[Tensor, List]:
+ """Loss function for outputs from a single decoder layer of a single
+ feature level.
+
+ Args:
+ cls_scores (Tensor): Box score logits from a single decoder layer
+ for all images, has shape (bs, num_queries, cls_out_channels).
+ bbox_preds (Tensor): Sigmoid outputs from a single decoder layer
+ for all images, with normalized coordinate (cx, cy, w, h) and
+ shape (bs, num_queries, 4).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+
+ Returns:
+ Tuple[Tensor]: A tuple including `loss_cls`, `loss_box` and
+ `loss_iou`.
+ """
+ num_imgs = cls_scores.size(0)
+ cls_scores_list = [cls_scores[i] for i in range(num_imgs)]
+ bbox_preds_list = [bbox_preds[i] for i in range(num_imgs)]
+ cls_reg_targets = self.get_targets_ddn(cls_scores_list, bbox_preds_list,
+ batch_gt_instances, batch_img_metas)
+ (labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,
+ num_total_pos, num_total_neg) = cls_reg_targets
+ labels = torch.cat(labels_list, 0)
+ label_weights = torch.cat(label_weights_list, 0)
+ bbox_targets = torch.cat(bbox_targets_list, 0)
+ bbox_weights = torch.cat(bbox_weights_list, 0)
+
+ # classification loss
+ cls_scores = cls_scores.reshape(-1, self.cls_out_channels)
+ # construct weighted avg_factor to match with the official DETR repo
+ cls_avg_factor = num_total_pos * 1.0 + \
+ num_total_neg * self.bg_cls_weight
+ if self.sync_cls_avg_factor:
+ cls_avg_factor = reduce_mean(
+ cls_scores.new_tensor([cls_avg_factor]))
+ cls_avg_factor = max(cls_avg_factor, 1)
+
+ loss_cls = self.loss_cls(
+ cls_scores, labels, label_weights, avg_factor=cls_avg_factor)
+
+ # Compute the average number of gt boxes across all gpus, for
+ # normalization purposes
+ num_total_pos = loss_cls.new_tensor([num_total_pos])
+ num_total_pos = torch.clamp(reduce_mean(num_total_pos), min=1).item()
+
+ # construct factors used for rescale bboxes
+ factors = []
+ for img_meta, bbox_pred in zip(batch_img_metas, bbox_preds):
+ img_h, img_w, = img_meta['img_shape']
+ factor = bbox_pred.new_tensor([img_w, img_h, img_w,
+ img_h]).unsqueeze(0).repeat(
+ bbox_pred.size(0), 1)
+ factors.append(factor)
+ factors = torch.cat(factors, 0)
+
+ # DETR regress the relative position of boxes (cxcywh) in the image,
+ # thus the learning target is normalized by the image size. So here
+ # we need to re-scale them for calculating IoU loss
+ bbox_preds = bbox_preds.reshape(-1, 4)
+ bboxes = bbox_cxcywh_to_xyxy(bbox_preds) * factors
+ bboxes_gt = bbox_cxcywh_to_xyxy(bbox_targets) * factors
+
+
+ # lzx
+ # 检查bbox_targets中4个值是否全部为0
+ is_target = torch.any(bbox_targets != 0, dim=1)
+ # 获取目标的索引
+ target_indices = torch.nonzero(is_target).squeeze()
+ bbox_targets_only_pos = bbox_targets[target_indices]
+ bbox_preds_only_pos = bbox_preds[target_indices]
+ # factors_only_pos = factors[target_indices]
+ # if bbox_targets_only_pos.dim()>1:
+ # pos_bbox_offset = torch.mean(torch.abs(bbox_targets_only_pos-bbox_preds_only_pos),dim=0).detach().cpu().numpy()
+ # else:
+ # pos_bbox_offset = torch.abs(bbox_targets_only_pos - bbox_preds_only_pos).detach().cpu().numpy()
+ # pos_bbox_offsets = [(pos_bbox_offset[0] + pos_bbox_offset[1]) / 2,
+ # (pos_bbox_offset[2] + pos_bbox_offset[3]) / 2]
+ pos_bbox_offset = torch.abs(bbox_targets_only_pos - bbox_preds_only_pos).detach().cpu().numpy()
+ if bbox_targets_only_pos.dim()>1:
+ pos_bbox_offsets = [pos_bbox_offset[b_i] for b_i in range(pos_bbox_offset.shape[0])]
+ else:
+ pos_bbox_offsets = [pos_bbox_offset]
+
+ # zero_indices = torch.nonzero(is_target == 0).squeeze()
+ # bbox_targets_only_neg = bbox_targets[zero_indices]
+ # bbox_preds_only_neg = bbox_preds[zero_indices]
+ # pos_bbox_offset = torch.abs(bbox_targets_only_neg - bbox_preds_only_neg).detach().cpu().numpy()
+ # if bbox_targets_only_pos.dim()>1:
+ # neg_bbox_offsets = [pos_bbox_offset[b_i] for b_i in range(pos_bbox_offset.shape[0])]
+ # else:
+ # neg_bbox_offsets = [pos_bbox_offset]
+ # pos_bbox_offsets = neg_bbox_offsets
+ # regression IoU loss, defaultly GIoU loss
+ # if self.pre_bboxes_round:
+ # bboxes_r = adjust_bbox_to_pixel(bboxes)
+ # loss_iou = self.loss_iou(
+ # bboxes_r, bboxes_gt, bbox_weights, avg_factor=num_total_pos)
+ # # bboxes = bbox_cxcywh_to_xyxy(bbox_preds) * factors
+ # bbox_preds_r = bbox_xyxy_to_cxcywh(bboxes_r/factors)
+ # # regression L1 loss
+ # loss_bbox = self.loss_bbox(
+ # bbox_preds_r, bbox_targets, bbox_weights, avg_factor=num_total_pos)
+ # else:
+
+ loss_iou = self.loss_iou(
+ bboxes, bboxes_gt, bbox_weights, avg_factor=num_total_pos)
+
+ # regression L1 loss
+ loss_bbox = self.loss_bbox(
+ bbox_preds, bbox_targets, bbox_weights, avg_factor=num_total_pos)
+ return loss_cls, loss_bbox, loss_iou, pos_bbox_offsets
+
+ def get_targets_ddn(self, cls_scores_list: List[Tensor],
+ bbox_preds_list: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict]) -> tuple:
+ """Compute regression and classification targets for a batch image.
+
+ Outputs from a single decoder layer of a single feature level are used.
+
+ Args:
+ cls_scores_list (list[Tensor]): Box score logits from a single
+ decoder layer for each image, has shape [num_queries,
+ cls_out_channels].
+ bbox_preds_list (list[Tensor]): Sigmoid outputs from a single
+ decoder layer for each image, with normalized coordinate
+ (cx, cy, w, h) and shape [num_queries, 4].
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+
+ Returns:
+ tuple: a tuple containing the following targets.
+
+ - labels_list (list[Tensor]): Labels for all images.
+ - label_weights_list (list[Tensor]): Label weights for all images.
+ - bbox_targets_list (list[Tensor]): BBox targets for all images.
+ - bbox_weights_list (list[Tensor]): BBox weights for all images.
+ - num_total_pos (int): Number of positive samples in all images.
+ - num_total_neg (int): Number of negative samples in all images.
+ """
+ (labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,
+ pos_inds_list,
+ neg_inds_list) = multi_apply(self._get_targets_single_ddn,
+ cls_scores_list, bbox_preds_list,
+ batch_gt_instances, batch_img_metas)
+ num_total_pos = sum((inds.numel() for inds in pos_inds_list))
+ num_total_neg = sum((inds.numel() for inds in neg_inds_list))
+ return (labels_list, label_weights_list, bbox_targets_list,
+ bbox_weights_list, num_total_pos, num_total_neg)
+
+ def _get_targets_single_ddn(self, cls_score: Tensor, bbox_pred: Tensor,
+ gt_instances: InstanceData,
+ img_meta: dict) -> tuple:
+ """Compute regression and classification targets for one image.
+
+ Outputs from a single decoder layer of a single feature level are used.
+
+ Args:
+ cls_score (Tensor): Box score logits from a single decoder layer
+ for one image. Shape [num_queries, cls_out_channels].
+ bbox_pred (Tensor): Sigmoid outputs from a single decoder layer
+ for one image, with normalized coordinate (cx, cy, w, h) and
+ shape [num_queries, 4].
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It should includes ``bboxes`` and ``labels``
+ attributes.
+ img_meta (dict): Meta information for one image.
+
+ Returns:
+ tuple[Tensor]: a tuple containing the following for one image.
+
+ - labels (Tensor): Labels of each image.
+ - label_weights (Tensor]): Label weights of each image.
+ - bbox_targets (Tensor): BBox targets of each image.
+ - bbox_weights (Tensor): BBox weights of each image.
+ - pos_inds (Tensor): Sampled positive indices for each image.
+ - neg_inds (Tensor): Sampled negative indices for each image.
+ """
+ img_h, img_w = img_meta['img_shape']
+ factor = bbox_pred.new_tensor([img_w, img_h, img_w,
+ img_h]).unsqueeze(0)
+ num_bboxes = bbox_pred.size(0)
+ # convert bbox_pred from xywh, normalized to xyxy, unnormalized
+ bbox_pred = bbox_cxcywh_to_xyxy(bbox_pred)
+ bbox_pred = bbox_pred * factor
+
+ pred_instances = InstanceData(scores=cls_score, bboxes=bbox_pred)
+ # assigner and sampler
+ assign_result = self.assigner.assign(
+ pred_instances=pred_instances,
+ gt_instances=gt_instances,
+ img_meta=img_meta)
+
+ # from mmdet.models.task_modules.assigners import MaxIoUAssigner
+ # assigner1 = MaxIoUAssigner(pos_iou_thr=0.5, neg_iou_thr=0.5, min_pos_iou=0.3,match_low_quality=True,ignore_iof_thr=-1)
+ # pred_instances1 = InstanceData()
+ # pred_instances1.priors =pred_instances.bboxes
+ # assign_result = assigner1.assign(pred_instances=pred_instances1, gt_instances=gt_instances, img_meta=img_meta)
+
+
+ gt_bboxes = gt_instances.bboxes
+ gt_labels = gt_instances.labels
+ pos_inds = torch.nonzero(
+ assign_result.gt_inds > 0, as_tuple=False).squeeze(-1).unique()
+ neg_inds = torch.nonzero(
+ assign_result.gt_inds == 0, as_tuple=False).squeeze(-1).unique()
+ pos_assigned_gt_inds = assign_result.gt_inds[pos_inds] - 1
+ pos_gt_bboxes = gt_bboxes[pos_assigned_gt_inds.long(), :]
+
+ # label targets
+ labels = gt_bboxes.new_full((num_bboxes, ),
+ self.num_classes,
+ dtype=torch.long)
+ labels[pos_inds] = gt_labels[pos_assigned_gt_inds]
+ label_weights = gt_bboxes.new_ones(num_bboxes)
+
+ # bbox targets
+ bbox_targets = torch.zeros_like(bbox_pred)
+ bbox_weights = torch.zeros_like(bbox_pred)
+ bbox_weights[pos_inds] = 1.0
+
+ # DETR regress the relative position of boxes (cxcywh) in the image.
+ # Thus the learning target should be normalized by the image size, also
+ # the box format should be converted from defaultly x1y1x2y2 to cxcywh.
+ pos_gt_bboxes_normalized = pos_gt_bboxes / factor
+ pos_gt_bboxes_targets = bbox_xyxy_to_cxcywh(pos_gt_bboxes_normalized)
+ bbox_targets[pos_inds] = pos_gt_bboxes_targets
+ return (labels, label_weights, bbox_targets, bbox_weights, pos_inds,
+ neg_inds)
+
+
+
+
+
+
+
+
+ # for only positive dn
+ def loss_p(self, hidden_states: Tensor, references: List[Tensor],
+ enc_outputs_class: Tensor, enc_outputs_coord: Tensor,
+ batch_data_samples: SampleList, dn_meta: Dict[str, int]) -> dict:
+ """Perform forward propagation and loss calculation of the detection
+ head on the queries of the upstream network.
+
+ Args:
+ hidden_states (Tensor): Hidden states output from each decoder
+ layer, has shape (num_decoder_layers, bs, num_queries_total,
+ dim), where `num_queries_total` is the sum of
+ `num_denoising_queries` and `num_matching_queries` when
+ `self.training` is `True`, else `num_matching_queries`.
+ references (list[Tensor]): List of the reference from the decoder.
+ The first reference is the `init_reference` (initial) and the
+ other num_decoder_layers(6) references are `inter_references`
+ (intermediate). The `init_reference` has shape (bs,
+ num_queries_total, 4) and each `inter_reference` has shape
+ (bs, num_queries, 4) with the last dimension arranged as
+ (cx, cy, w, h).
+ enc_outputs_class (Tensor): The score of each point on encode
+ feature map, has shape (bs, num_feat_points, cls_out_channels).
+ enc_outputs_coord (Tensor): The proposal generate from the
+ encode feature map, has shape (bs, num_feat_points, 4) with the
+ last dimension arranged as (cx, cy, w, h).
+ batch_data_samples (list[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ dict: A dictionary of loss components.
+ """
+ batch_gt_instances = []
+ batch_img_metas = []
+ for data_sample in batch_data_samples:
+ batch_img_metas.append(data_sample.metainfo)
+ batch_gt_instances.append(data_sample.gt_instances)
+
+ outs = self(hidden_states, references)
+ loss_inputs = outs + (enc_outputs_class, enc_outputs_coord,
+ batch_gt_instances, batch_img_metas, dn_meta)
+ losses = self.loss_by_feat_p(*loss_inputs)
+ return losses
+
+ def loss_by_feat_p(
+ self,
+ all_layers_cls_scores: Tensor,
+ all_layers_bbox_preds: Tensor,
+ enc_cls_scores: Tensor,
+ enc_bbox_preds: Tensor,
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ dn_meta: Dict[str, int],
+ batch_gt_instances_ignore: OptInstanceList = None
+ ) -> Dict[str, Tensor]:
+ """Loss function.
+
+ Args:
+ all_layers_cls_scores (Tensor): Classification scores of all
+ decoder layers, has shape (num_decoder_layers, bs,
+ num_queries_total, cls_out_channels), where
+ `num_queries_total` is the sum of `num_denoising_queries`
+ and `num_matching_queries`.
+ all_layers_bbox_preds (Tensor): Regression outputs of all decoder
+ layers. Each is a 4D-tensor with normalized coordinate format
+ (cx, cy, w, h) and has shape (num_decoder_layers, bs,
+ num_queries_total, 4).
+ enc_cls_scores (Tensor): The score of each point on encode
+ feature map, has shape (bs, num_feat_points, cls_out_channels).
+ enc_bbox_preds (Tensor): The proposal generate from the encode
+ feature map, has shape (bs, num_feat_points, 4) with the last
+ dimension arranged as (cx, cy, w, h).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components.
+ """
+ # extract denoising and matching part of outputs
+ (all_layers_matching_cls_scores, all_layers_matching_bbox_preds,
+ all_layers_denoising_cls_scores, all_layers_denoising_bbox_preds) = \
+ self.split_outputs(
+ all_layers_cls_scores, all_layers_bbox_preds, dn_meta)
+
+ loss_dict = super().loss_by_feat(
+ all_layers_matching_cls_scores, all_layers_matching_bbox_preds,
+ batch_gt_instances, batch_img_metas, batch_gt_instances_ignore)
+ # # NOTE DETRHead.loss_by_feat but not DeformableDETRHead.loss_by_feat
+ # # is called, because the encoder loss calculations are different
+ # # between DINO and DeformableDETR.
+ # loss_dict = dict()
+ # loss of proposal generated from encode feature map.
+ if enc_cls_scores is not None:
+ # NOTE The enc_loss calculation of the DINO is
+ # different from that of Deformable DETR.
+ enc_loss_cls, enc_losses_bbox, enc_losses_iou = \
+ self.loss_by_feat_single(
+ enc_cls_scores, enc_bbox_preds,
+ batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas)
+ loss_dict['enc_loss_cls'] = enc_loss_cls
+ loss_dict['enc_loss_bbox'] = enc_losses_bbox
+ loss_dict['enc_loss_iou'] = enc_losses_iou
+ # loss_dict = dict()
+ if all_layers_denoising_cls_scores is not None:
+ # calculate denoising loss from all decoder layers
+ dn_losses_cls, dn_losses_bbox, dn_losses_iou = self.loss_dn_p(
+ all_layers_denoising_cls_scores,
+ all_layers_denoising_bbox_preds,
+ batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas,
+ dn_meta=dn_meta)
+ # collate denoising loss
+ loss_dict['dn_loss_cls'] = dn_losses_cls[-1]
+ loss_dict['dn_loss_bbox'] = dn_losses_bbox[-1]
+ loss_dict['dn_loss_iou'] = dn_losses_iou[-1]
+ for num_dec_layer, (loss_cls_i, loss_bbox_i, loss_iou_i) in \
+ enumerate(zip(dn_losses_cls[:-1], dn_losses_bbox[:-1],
+ dn_losses_iou[:-1])):
+ loss_dict[f'd{num_dec_layer}.dn_loss_cls'] = loss_cls_i
+ # loss_dict[f'd{num_dec_layer}.dn_loss_bbox'] = loss_bbox_i
+ # loss_dict[f'd{num_dec_layer}.dn_loss_iou'] = loss_iou_i
+ return loss_dict
+
+ def loss_dn_p(self, all_layers_denoising_cls_scores: Tensor,
+ all_layers_denoising_bbox_preds: Tensor,
+ batch_gt_instances: InstanceList, batch_img_metas: List[dict],
+ dn_meta: Dict[str, int]) -> Tuple[List[Tensor]]:
+ """Calculate denoising loss.
+
+ Args:
+ all_layers_denoising_cls_scores (Tensor): Classification scores of
+ all decoder layers in denoising part, has shape (
+ num_decoder_layers, bs, num_denoising_queries,
+ cls_out_channels).
+ all_layers_denoising_bbox_preds (Tensor): Regression outputs of all
+ decoder layers in denoising part. Each is a 4D-tensor with
+ normalized coordinate format (cx, cy, w, h) and has shape
+ (num_decoder_layers, bs, num_denoising_queries, 4).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ Tuple[List[Tensor]]: The loss_dn_cls, loss_dn_bbox, and loss_dn_iou
+ of each decoder layers.
+ """
+ return multi_apply(
+ self._loss_dn_single_p,
+ all_layers_denoising_cls_scores,
+ all_layers_denoising_bbox_preds,
+ batch_gt_instances=batch_gt_instances,
+ batch_img_metas=batch_img_metas,
+ dn_meta=dn_meta)
+
+ def _loss_dn_single_p(self, dn_cls_scores: Tensor, dn_bbox_preds: Tensor,
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ dn_meta: Dict[str, int]) -> Tuple[Tensor]:
+ """Denoising loss for outputs from a single decoder layer.
+
+ Args:
+ dn_cls_scores (Tensor): Classification scores of a single decoder
+ layer in denoising part, has shape (bs, num_denoising_queries,
+ cls_out_channels).
+ dn_bbox_preds (Tensor): Regression outputs of a single decoder
+ layer in denoising part. Each is a 4D-tensor with normalized
+ coordinate format (cx, cy, w, h) and has shape
+ (bs, num_denoising_queries, 4).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ Tuple[Tensor]: A tuple including `loss_cls`, `loss_box` and
+ `loss_iou`.
+ """
+ cls_reg_targets = self.get_dn_targets_p(batch_gt_instances,
+ batch_img_metas, dn_meta)
+ (labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,
+ num_total_pos, num_total_neg) = cls_reg_targets
+ labels = torch.cat(labels_list, 0)
+ label_weights = torch.cat(label_weights_list, 0)
+ bbox_targets = torch.cat(bbox_targets_list, 0)
+ bbox_weights = torch.cat(bbox_weights_list, 0)
+
+ # classification loss
+ cls_scores = dn_cls_scores.reshape(-1, self.cls_out_channels)
+ # construct weighted avg_factor to match with the official DETR repo
+ cls_avg_factor = \
+ num_total_pos * 1.0 + num_total_neg * self.bg_cls_weight
+ # cls_avg_factor = \
+ # num_total_pos * 1.0
+ if self.sync_cls_avg_factor:
+ cls_avg_factor = reduce_mean(
+ cls_scores.new_tensor([cls_avg_factor]))
+ cls_avg_factor = max(cls_avg_factor, 1)
+
+ if len(cls_scores) > 0:
+ loss_cls = self.loss_cls(
+ cls_scores, labels, label_weights, avg_factor=cls_avg_factor)
+ else:
+ loss_cls = torch.zeros(
+ 1, dtype=cls_scores.dtype, device=cls_scores.device)
+
+ # Compute the average number of gt boxes across all gpus, for
+ # normalization purposes
+ num_total_pos = loss_cls.new_tensor([num_total_pos])
+ num_total_pos = torch.clamp(reduce_mean(num_total_pos), min=1).item()
+
+ # construct factors used for rescale bboxes
+ factors = []
+ for img_meta, bbox_pred in zip(batch_img_metas, dn_bbox_preds):
+ img_h, img_w = img_meta['img_shape']
+ factor = bbox_pred.new_tensor([img_w, img_h, img_w,
+ img_h]).unsqueeze(0).repeat(
+ bbox_pred.size(0), 1)
+ factors.append(factor)
+ factors = torch.cat(factors)
+
+ # DETR regress the relative position of boxes (cxcywh) in the image,
+ # thus the learning target is normalized by the image size. So here
+ # we need to re-scale them for calculating IoU loss
+ bbox_preds = dn_bbox_preds.reshape(-1, 4)
+ bboxes = bbox_cxcywh_to_xyxy(bbox_preds) * factors
+ bboxes_gt = bbox_cxcywh_to_xyxy(bbox_targets) * factors
+
+ # regression IoU loss, defaultly GIoU loss
+ loss_iou = self.loss_iou(
+ bboxes, bboxes_gt, bbox_weights, avg_factor=num_total_pos)
+
+ # regression L1 loss
+ loss_bbox = self.loss_bbox(
+ bbox_preds, bbox_targets, bbox_weights, avg_factor=num_total_pos)
+ return loss_cls, loss_bbox, loss_iou
+
+ def get_dn_targets_p(self, batch_gt_instances: InstanceList,
+ batch_img_metas: dict, dn_meta: Dict[str,
+ int]) -> tuple:
+ """Get targets in denoising part for a batch of images.
+
+ Args:
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ tuple: a tuple containing the following targets.
+
+ - labels_list (list[Tensor]): Labels for all images.
+ - label_weights_list (list[Tensor]): Label weights for all images.
+ - bbox_targets_list (list[Tensor]): BBox targets for all images.
+ - bbox_weights_list (list[Tensor]): BBox weights for all images.
+ - num_total_pos (int): Number of positive samples in all images.
+ - num_total_neg (int): Number of negative samples in all images.
+ """
+ (labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,
+ pos_inds_list, neg_inds_list) = multi_apply(
+ self._get_dn_targets_single_p,
+ batch_gt_instances,
+ batch_img_metas,
+ dn_meta=dn_meta)
+ num_total_pos = sum((inds.numel() for inds in pos_inds_list))
+ num_total_neg = sum((inds.numel() for inds in neg_inds_list)) # num_total_neg is not used
+ return (labels_list, label_weights_list, bbox_targets_list,
+ bbox_weights_list, num_total_pos, num_total_neg)
+
+ def _get_dn_targets_single_p(self, gt_instances: InstanceData,
+ img_meta: dict, dn_meta: Dict[str,
+ int]) -> tuple:
+ """Get targets in denoising part for one image.
+
+ Args:
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It should includes ``bboxes`` and ``labels``
+ attributes.
+ img_meta (dict): Meta information for one image.
+ dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ Returns:
+ tuple[Tensor]: a tuple containing the following for one image.
+
+ - labels (Tensor): Labels of each image.
+ - label_weights (Tensor]): Label weights of each image.
+ - bbox_targets (Tensor): BBox targets of each image.
+ - bbox_weights (Tensor): BBox weights of each image.
+ - pos_inds (Tensor): Sampled positive indices for each image.
+ - neg_inds (Tensor): Sampled negative indices for each image.
+ """
+ gt_bboxes = gt_instances.bboxes
+ gt_labels = gt_instances.labels
+ num_groups = dn_meta['num_denoising_groups']
+ num_denoising_queries = dn_meta['num_denoising_queries']
+ num_queries_each_group = int(num_denoising_queries / num_groups)
+ device = gt_bboxes.device
+
+ if len(gt_labels) > 0:
+ t = torch.arange(len(gt_labels), dtype=torch.long, device=device)
+ t = t.unsqueeze(0).repeat(num_groups, 1)
+ pos_assigned_gt_inds = t.flatten()
+ pos_inds = torch.arange(
+ num_groups, dtype=torch.long, device=device)
+ pos_inds = pos_inds.unsqueeze(1) * num_queries_each_group + t
+ pos_inds = pos_inds.flatten()
+ else:
+ pos_inds = pos_assigned_gt_inds = \
+ gt_bboxes.new_tensor([], dtype=torch.long)
+
+ neg_inds = pos_inds + num_queries_each_group // 2
+
+ # label targets
+ labels = gt_bboxes.new_full((num_denoising_queries, ),
+ self.num_classes,
+ dtype=torch.long)
+ labels[pos_inds] = gt_labels[pos_assigned_gt_inds]
+ label_weights = gt_bboxes.new_ones(num_denoising_queries)
+
+ # bbox targets
+ bbox_targets = torch.zeros(num_denoising_queries, 4, device=device)
+ bbox_weights = torch.zeros(num_denoising_queries, 4, device=device)
+ bbox_weights[pos_inds] = 1.0
+ img_h, img_w = img_meta['img_shape']
+
+ # DETR regress the relative position of boxes (cxcywh) in the image.
+ # Thus the learning target should be normalized by the image size, also
+ # the box format should be converted from defaultly x1y1x2y2 to cxcywh.
+ factor = gt_bboxes.new_tensor([img_w, img_h, img_w,
+ img_h]).unsqueeze(0)
+ gt_bboxes_normalized = gt_bboxes / factor
+ gt_bboxes_targets = bbox_xyxy_to_cxcywh(gt_bboxes_normalized)
+ bbox_targets[pos_inds] = gt_bboxes_targets.repeat([num_groups, 1])
+
+ return (labels, label_weights, bbox_targets, bbox_weights, pos_inds,
+ neg_inds)
diff --git a/mmdet/models/dense_heads/ssd_head.py b/mmdet/models/dense_heads/ssd_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..c3b46fa3d8942ff1eb41e067b8e9b361542b6362
--- /dev/null
+++ b/mmdet/models/dense_heads/ssd_head.py
@@ -0,0 +1,362 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Optional, Sequence, Tuple
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule, DepthwiseSeparableConvModule
+from torch import Tensor
+
+from mmdet.registry import MODELS, TASK_UTILS
+from mmdet.utils import ConfigType, InstanceList, MultiConfig, OptInstanceList
+from ..losses import smooth_l1_loss
+from ..task_modules.samplers import PseudoSampler
+from ..utils import multi_apply
+from .anchor_head import AnchorHead
+
+
+# TODO: add loss evaluator for SSD
+@MODELS.register_module()
+class SSDHead(AnchorHead):
+ """Implementation of `SSD head `_
+
+ Args:
+ num_classes (int): Number of categories excluding the background
+ category.
+ in_channels (Sequence[int]): Number of channels in the input feature
+ map.
+ stacked_convs (int): Number of conv layers in cls and reg tower.
+ Defaults to 0.
+ feat_channels (int): Number of hidden channels when stacked_convs
+ > 0. Defaults to 256.
+ use_depthwise (bool): Whether to use DepthwiseSeparableConv.
+ Defaults to False.
+ conv_cfg (:obj:`ConfigDict` or dict, Optional): Dictionary to construct
+ and config conv layer. Defaults to None.
+ norm_cfg (:obj:`ConfigDict` or dict, Optional): Dictionary to construct
+ and config norm layer. Defaults to None.
+ act_cfg (:obj:`ConfigDict` or dict, Optional): Dictionary to construct
+ and config activation layer. Defaults to None.
+ anchor_generator (:obj:`ConfigDict` or dict): Config dict for anchor
+ generator.
+ bbox_coder (:obj:`ConfigDict` or dict): Config of bounding box coder.
+ reg_decoded_bbox (bool): If true, the regression loss would be
+ applied directly on decoded bounding boxes, converting both
+ the predicted boxes and regression targets to absolute
+ coordinates format. Defaults to False. It should be `True` when
+ using `IoULoss`, `GIoULoss`, or `DIoULoss` in the bbox head.
+ train_cfg (:obj:`ConfigDict` or dict, Optional): Training config of
+ anchor head.
+ test_cfg (:obj:`ConfigDict` or dict, Optional): Testing config of
+ anchor head.
+ init_cfg (:obj:`ConfigDict` or dict or list[:obj:`ConfigDict` or \
+ dict], Optional): Initialization config dict.
+ """ # noqa: W605
+
+ def __init__(
+ self,
+ num_classes: int = 80,
+ in_channels: Sequence[int] = (512, 1024, 512, 256, 256, 256),
+ stacked_convs: int = 0,
+ feat_channels: int = 256,
+ use_depthwise: bool = False,
+ conv_cfg: Optional[ConfigType] = None,
+ norm_cfg: Optional[ConfigType] = None,
+ act_cfg: Optional[ConfigType] = None,
+ anchor_generator: ConfigType = dict(
+ type='SSDAnchorGenerator',
+ scale_major=False,
+ input_size=300,
+ strides=[8, 16, 32, 64, 100, 300],
+ ratios=([2], [2, 3], [2, 3], [2, 3], [2], [2]),
+ basesize_ratio_range=(0.1, 0.9)),
+ bbox_coder: ConfigType = dict(
+ type='DeltaXYWHBBoxCoder',
+ clip_border=True,
+ target_means=[.0, .0, .0, .0],
+ target_stds=[1.0, 1.0, 1.0, 1.0],
+ ),
+ reg_decoded_bbox: bool = False,
+ train_cfg: Optional[ConfigType] = None,
+ test_cfg: Optional[ConfigType] = None,
+ init_cfg: MultiConfig = dict(
+ type='Xavier', layer='Conv2d', distribution='uniform', bias=0)
+ ) -> None:
+ super(AnchorHead, self).__init__(init_cfg=init_cfg)
+ self.num_classes = num_classes
+ self.in_channels = in_channels
+ self.stacked_convs = stacked_convs
+ self.feat_channels = feat_channels
+ self.use_depthwise = use_depthwise
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.act_cfg = act_cfg
+
+ self.cls_out_channels = num_classes + 1 # add background class
+ self.prior_generator = TASK_UTILS.build(anchor_generator)
+
+ # Usually the numbers of anchors for each level are the same
+ # except SSD detectors. So it is an int in the most dense
+ # heads but a list of int in SSDHead
+ self.num_base_priors = self.prior_generator.num_base_priors
+
+ self._init_layers()
+
+ self.bbox_coder = TASK_UTILS.build(bbox_coder)
+ self.reg_decoded_bbox = reg_decoded_bbox
+ self.use_sigmoid_cls = False
+ self.cls_focal_loss = False
+ self.train_cfg = train_cfg
+ self.test_cfg = test_cfg
+ if self.train_cfg:
+ self.assigner = TASK_UTILS.build(self.train_cfg['assigner'])
+ if self.train_cfg.get('sampler', None) is not None:
+ self.sampler = TASK_UTILS.build(
+ self.train_cfg['sampler'], default_args=dict(context=self))
+ else:
+ self.sampler = PseudoSampler(context=self)
+
+ def _init_layers(self) -> None:
+ """Initialize layers of the head."""
+ self.cls_convs = nn.ModuleList()
+ self.reg_convs = nn.ModuleList()
+ # TODO: Use registry to choose ConvModule type
+ conv = DepthwiseSeparableConvModule \
+ if self.use_depthwise else ConvModule
+
+ for channel, num_base_priors in zip(self.in_channels,
+ self.num_base_priors):
+ cls_layers = []
+ reg_layers = []
+ in_channel = channel
+ # build stacked conv tower, not used in default ssd
+ for i in range(self.stacked_convs):
+ cls_layers.append(
+ conv(
+ in_channel,
+ self.feat_channels,
+ 3,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg))
+ reg_layers.append(
+ conv(
+ in_channel,
+ self.feat_channels,
+ 3,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg))
+ in_channel = self.feat_channels
+ # SSD-Lite head
+ if self.use_depthwise:
+ cls_layers.append(
+ ConvModule(
+ in_channel,
+ in_channel,
+ 3,
+ padding=1,
+ groups=in_channel,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg))
+ reg_layers.append(
+ ConvModule(
+ in_channel,
+ in_channel,
+ 3,
+ padding=1,
+ groups=in_channel,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg))
+ cls_layers.append(
+ nn.Conv2d(
+ in_channel,
+ num_base_priors * self.cls_out_channels,
+ kernel_size=1 if self.use_depthwise else 3,
+ padding=0 if self.use_depthwise else 1))
+ reg_layers.append(
+ nn.Conv2d(
+ in_channel,
+ num_base_priors * 4,
+ kernel_size=1 if self.use_depthwise else 3,
+ padding=0 if self.use_depthwise else 1))
+ self.cls_convs.append(nn.Sequential(*cls_layers))
+ self.reg_convs.append(nn.Sequential(*reg_layers))
+
+ def forward(self, x: Tuple[Tensor]) -> Tuple[List[Tensor], List[Tensor]]:
+ """Forward features from the upstream network.
+
+ Args:
+ x (tuple[Tensor]): Features from the upstream network, each is
+ a 4D-tensor.
+
+ Returns:
+ tuple[list[Tensor], list[Tensor]]: A tuple of cls_scores list and
+ bbox_preds list.
+
+ - cls_scores (list[Tensor]): Classification scores for all scale \
+ levels, each is a 4D-tensor, the channels number is \
+ num_anchors * num_classes.
+ - bbox_preds (list[Tensor]): Box energies / deltas for all scale \
+ levels, each is a 4D-tensor, the channels number is \
+ num_anchors * 4.
+ """
+ cls_scores = []
+ bbox_preds = []
+ for feat, reg_conv, cls_conv in zip(x, self.reg_convs, self.cls_convs):
+ cls_scores.append(cls_conv(feat))
+ bbox_preds.append(reg_conv(feat))
+ return cls_scores, bbox_preds
+
+ def loss_by_feat_single(self, cls_score: Tensor, bbox_pred: Tensor,
+ anchor: Tensor, labels: Tensor,
+ label_weights: Tensor, bbox_targets: Tensor,
+ bbox_weights: Tensor,
+ avg_factor: int) -> Tuple[Tensor, Tensor]:
+ """Compute loss of a single image.
+
+ Args:
+ cls_score (Tensor): Box scores for eachimage
+ Has shape (num_total_anchors, num_classes).
+ bbox_pred (Tensor): Box energies / deltas for each image
+ level with shape (num_total_anchors, 4).
+ anchors (Tensor): Box reference for each scale level with shape
+ (num_total_anchors, 4).
+ labels (Tensor): Labels of each anchors with shape
+ (num_total_anchors,).
+ label_weights (Tensor): Label weights of each anchor with shape
+ (num_total_anchors,)
+ bbox_targets (Tensor): BBox regression targets of each anchor
+ weight shape (num_total_anchors, 4).
+ bbox_weights (Tensor): BBox regression loss weights of each anchor
+ with shape (num_total_anchors, 4).
+ avg_factor (int): Average factor that is used to average
+ the loss. When using sampling method, avg_factor is usually
+ the sum of positive and negative priors. When using
+ `PseudoSampler`, `avg_factor` is usually equal to the number
+ of positive priors.
+
+ Returns:
+ Tuple[Tensor, Tensor]: A tuple of cls loss and bbox loss of one
+ feature map.
+ """
+
+ loss_cls_all = F.cross_entropy(
+ cls_score, labels, reduction='none') * label_weights
+ # FG cat_id: [0, num_classes -1], BG cat_id: num_classes
+ pos_inds = ((labels >= 0) & (labels < self.num_classes)).nonzero(
+ as_tuple=False).reshape(-1)
+ neg_inds = (labels == self.num_classes).nonzero(
+ as_tuple=False).view(-1)
+
+ num_pos_samples = pos_inds.size(0)
+ num_neg_samples = self.train_cfg['neg_pos_ratio'] * num_pos_samples
+ if num_neg_samples > neg_inds.size(0):
+ num_neg_samples = neg_inds.size(0)
+ topk_loss_cls_neg, _ = loss_cls_all[neg_inds].topk(num_neg_samples)
+ loss_cls_pos = loss_cls_all[pos_inds].sum()
+ loss_cls_neg = topk_loss_cls_neg.sum()
+ loss_cls = (loss_cls_pos + loss_cls_neg) / avg_factor
+
+ if self.reg_decoded_bbox:
+ # When the regression loss (e.g. `IouLoss`, `GIouLoss`)
+ # is applied directly on the decoded bounding boxes, it
+ # decodes the already encoded coordinates to absolute format.
+ bbox_pred = self.bbox_coder.decode(anchor, bbox_pred)
+
+ loss_bbox = smooth_l1_loss(
+ bbox_pred,
+ bbox_targets,
+ bbox_weights,
+ beta=self.train_cfg['smoothl1_beta'],
+ avg_factor=avg_factor)
+ return loss_cls[None], loss_bbox
+
+ def loss_by_feat(
+ self,
+ cls_scores: List[Tensor],
+ bbox_preds: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ batch_gt_instances_ignore: OptInstanceList = None
+ ) -> Dict[str, List[Tensor]]:
+ """Compute losses of the head.
+
+ Args:
+ cls_scores (list[Tensor]): Box scores for each scale level
+ Has shape (N, num_anchors * num_classes, H, W)
+ bbox_preds (list[Tensor]): Box energies / deltas for each scale
+ level with shape (N, num_anchors * 4, H, W)
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], Optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ dict[str, list[Tensor]]: A dictionary of loss components. the dict
+ has components below:
+
+ - loss_cls (list[Tensor]): A list containing each feature map \
+ classification loss.
+ - loss_bbox (list[Tensor]): A list containing each feature map \
+ regression loss.
+ """
+ featmap_sizes = [featmap.size()[-2:] for featmap in cls_scores]
+ assert len(featmap_sizes) == self.prior_generator.num_levels
+
+ device = cls_scores[0].device
+
+ anchor_list, valid_flag_list = self.get_anchors(
+ featmap_sizes, batch_img_metas, device=device)
+ cls_reg_targets = self.get_targets(
+ anchor_list,
+ valid_flag_list,
+ batch_gt_instances,
+ batch_img_metas,
+ batch_gt_instances_ignore=batch_gt_instances_ignore,
+ unmap_outputs=True)
+ (labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,
+ avg_factor) = cls_reg_targets
+
+ num_images = len(batch_img_metas)
+ all_cls_scores = torch.cat([
+ s.permute(0, 2, 3, 1).reshape(
+ num_images, -1, self.cls_out_channels) for s in cls_scores
+ ], 1)
+ all_labels = torch.cat(labels_list, -1).view(num_images, -1)
+ all_label_weights = torch.cat(label_weights_list,
+ -1).view(num_images, -1)
+ all_bbox_preds = torch.cat([
+ b.permute(0, 2, 3, 1).reshape(num_images, -1, 4)
+ for b in bbox_preds
+ ], -2)
+ all_bbox_targets = torch.cat(bbox_targets_list,
+ -2).view(num_images, -1, 4)
+ all_bbox_weights = torch.cat(bbox_weights_list,
+ -2).view(num_images, -1, 4)
+
+ # concat all level anchors to a single tensor
+ all_anchors = []
+ for i in range(num_images):
+ all_anchors.append(torch.cat(anchor_list[i]))
+
+ losses_cls, losses_bbox = multi_apply(
+ self.loss_by_feat_single,
+ all_cls_scores,
+ all_bbox_preds,
+ all_anchors,
+ all_labels,
+ all_label_weights,
+ all_bbox_targets,
+ all_bbox_weights,
+ avg_factor=avg_factor)
+ return dict(loss_cls=losses_cls, loss_bbox=losses_bbox)
diff --git a/mmdet/models/dense_heads/tood_head.py b/mmdet/models/dense_heads/tood_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..8c59598d89289df6d1a87c7b6fde112429ac8f45
--- /dev/null
+++ b/mmdet/models/dense_heads/tood_head.py
@@ -0,0 +1,805 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Optional, Tuple
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule, Scale
+from mmcv.ops import deform_conv2d
+from mmengine import MessageHub
+from mmengine.config import ConfigDict
+from mmengine.model import bias_init_with_prob, normal_init
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmdet.registry import MODELS, TASK_UTILS
+from mmdet.structures.bbox import distance2bbox
+from mmdet.utils import (ConfigType, InstanceList, OptConfigType,
+ OptInstanceList, reduce_mean)
+from ..task_modules.prior_generators import anchor_inside_flags
+from ..utils import (filter_scores_and_topk, images_to_levels, multi_apply,
+ sigmoid_geometric_mean, unmap)
+from .atss_head import ATSSHead
+
+
+class TaskDecomposition(nn.Module):
+ """Task decomposition module in task-aligned predictor of TOOD.
+
+ Args:
+ feat_channels (int): Number of feature channels in TOOD head.
+ stacked_convs (int): Number of conv layers in TOOD head.
+ la_down_rate (int): Downsample rate of layer attention.
+ Defaults to 8.
+ conv_cfg (:obj:`ConfigDict` or dict, optional): Config dict for
+ convolution layer. Defaults to None.
+ norm_cfg (:obj:`ConfigDict` or dict, optional): Config dict for
+ normalization layer. Defaults to None.
+ """
+
+ def __init__(self,
+ feat_channels: int,
+ stacked_convs: int,
+ la_down_rate: int = 8,
+ conv_cfg: OptConfigType = None,
+ norm_cfg: OptConfigType = None) -> None:
+ super().__init__()
+ self.feat_channels = feat_channels
+ self.stacked_convs = stacked_convs
+ self.in_channels = self.feat_channels * self.stacked_convs
+ self.norm_cfg = norm_cfg
+ self.layer_attention = nn.Sequential(
+ nn.Conv2d(self.in_channels, self.in_channels // la_down_rate, 1),
+ nn.ReLU(inplace=True),
+ nn.Conv2d(
+ self.in_channels // la_down_rate,
+ self.stacked_convs,
+ 1,
+ padding=0), nn.Sigmoid())
+
+ self.reduction_conv = ConvModule(
+ self.in_channels,
+ self.feat_channels,
+ 1,
+ stride=1,
+ padding=0,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ bias=norm_cfg is None)
+
+ def init_weights(self) -> None:
+ """Initialize the parameters."""
+ for m in self.layer_attention.modules():
+ if isinstance(m, nn.Conv2d):
+ normal_init(m, std=0.001)
+ normal_init(self.reduction_conv.conv, std=0.01)
+
+ def forward(self,
+ feat: Tensor,
+ avg_feat: Optional[Tensor] = None) -> Tensor:
+ """Forward function of task decomposition module."""
+ b, c, h, w = feat.shape
+ if avg_feat is None:
+ avg_feat = F.adaptive_avg_pool2d(feat, (1, 1))
+ weight = self.layer_attention(avg_feat)
+
+ # here we first compute the product between layer attention weight and
+ # conv weight, and then compute the convolution between new conv weight
+ # and feature map, in order to save memory and FLOPs.
+ conv_weight = weight.reshape(
+ b, 1, self.stacked_convs,
+ 1) * self.reduction_conv.conv.weight.reshape(
+ 1, self.feat_channels, self.stacked_convs, self.feat_channels)
+ conv_weight = conv_weight.reshape(b, self.feat_channels,
+ self.in_channels)
+ feat = feat.reshape(b, self.in_channels, h * w)
+ feat = torch.bmm(conv_weight, feat).reshape(b, self.feat_channels, h,
+ w)
+ if self.norm_cfg is not None:
+ feat = self.reduction_conv.norm(feat)
+ feat = self.reduction_conv.activate(feat)
+
+ return feat
+
+
+@MODELS.register_module()
+class TOODHead(ATSSHead):
+ """TOODHead used in `TOOD: Task-aligned One-stage Object Detection.
+
+ `_.
+
+ TOOD uses Task-aligned head (T-head) and is optimized by Task Alignment
+ Learning (TAL).
+
+ Args:
+ num_classes (int): Number of categories excluding the background
+ category.
+ in_channels (int): Number of channels in the input feature map.
+ num_dcn (int): Number of deformable convolution in the head.
+ Defaults to 0.
+ anchor_type (str): If set to ``anchor_free``, the head will use centers
+ to regress bboxes. If set to ``anchor_based``, the head will
+ regress bboxes based on anchors. Defaults to ``anchor_free``.
+ initial_loss_cls (:obj:`ConfigDict` or dict): Config of initial loss.
+
+ Example:
+ >>> self = TOODHead(11, 7)
+ >>> feats = [torch.rand(1, 7, s, s) for s in [4, 8, 16, 32, 64]]
+ >>> cls_score, bbox_pred = self.forward(feats)
+ >>> assert len(cls_score) == len(self.scales)
+ """
+
+ def __init__(self,
+ num_classes: int,
+ in_channels: int,
+ num_dcn: int = 0,
+ anchor_type: str = 'anchor_free',
+ initial_loss_cls: ConfigType = dict(
+ type='FocalLoss',
+ use_sigmoid=True,
+ activated=True,
+ gamma=2.0,
+ alpha=0.25,
+ loss_weight=1.0),
+ **kwargs) -> None:
+ assert anchor_type in ['anchor_free', 'anchor_based']
+ self.num_dcn = num_dcn
+ self.anchor_type = anchor_type
+ super().__init__(
+ num_classes=num_classes, in_channels=in_channels, **kwargs)
+
+ if self.train_cfg:
+ self.initial_epoch = self.train_cfg['initial_epoch']
+ self.initial_assigner = TASK_UTILS.build(
+ self.train_cfg['initial_assigner'])
+ self.initial_loss_cls = MODELS.build(initial_loss_cls)
+ self.assigner = self.initial_assigner
+ self.alignment_assigner = TASK_UTILS.build(
+ self.train_cfg['assigner'])
+ self.alpha = self.train_cfg['alpha']
+ self.beta = self.train_cfg['beta']
+
+ def _init_layers(self) -> None:
+ """Initialize layers of the head."""
+ self.relu = nn.ReLU(inplace=True)
+ self.inter_convs = nn.ModuleList()
+ for i in range(self.stacked_convs):
+ if i < self.num_dcn:
+ conv_cfg = dict(type='DCNv2', deform_groups=4)
+ else:
+ conv_cfg = self.conv_cfg
+ chn = self.in_channels if i == 0 else self.feat_channels
+ self.inter_convs.append(
+ ConvModule(
+ chn,
+ self.feat_channels,
+ 3,
+ stride=1,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=self.norm_cfg))
+
+ self.cls_decomp = TaskDecomposition(self.feat_channels,
+ self.stacked_convs,
+ self.stacked_convs * 8,
+ self.conv_cfg, self.norm_cfg)
+ self.reg_decomp = TaskDecomposition(self.feat_channels,
+ self.stacked_convs,
+ self.stacked_convs * 8,
+ self.conv_cfg, self.norm_cfg)
+
+ self.tood_cls = nn.Conv2d(
+ self.feat_channels,
+ self.num_base_priors * self.cls_out_channels,
+ 3,
+ padding=1)
+ self.tood_reg = nn.Conv2d(
+ self.feat_channels, self.num_base_priors * 4, 3, padding=1)
+
+ self.cls_prob_module = nn.Sequential(
+ nn.Conv2d(self.feat_channels * self.stacked_convs,
+ self.feat_channels // 4, 1), nn.ReLU(inplace=True),
+ nn.Conv2d(self.feat_channels // 4, 1, 3, padding=1))
+ self.reg_offset_module = nn.Sequential(
+ nn.Conv2d(self.feat_channels * self.stacked_convs,
+ self.feat_channels // 4, 1), nn.ReLU(inplace=True),
+ nn.Conv2d(self.feat_channels // 4, 4 * 2, 3, padding=1))
+
+ self.scales = nn.ModuleList(
+ [Scale(1.0) for _ in self.prior_generator.strides])
+
+ def init_weights(self) -> None:
+ """Initialize weights of the head."""
+ bias_cls = bias_init_with_prob(0.01)
+ for m in self.inter_convs:
+ normal_init(m.conv, std=0.01)
+ for m in self.cls_prob_module:
+ if isinstance(m, nn.Conv2d):
+ normal_init(m, std=0.01)
+ for m in self.reg_offset_module:
+ if isinstance(m, nn.Conv2d):
+ normal_init(m, std=0.001)
+ normal_init(self.cls_prob_module[-1], std=0.01, bias=bias_cls)
+
+ self.cls_decomp.init_weights()
+ self.reg_decomp.init_weights()
+
+ normal_init(self.tood_cls, std=0.01, bias=bias_cls)
+ normal_init(self.tood_reg, std=0.01)
+
+ def forward(self, feats: Tuple[Tensor]) -> Tuple[List[Tensor]]:
+ """Forward features from the upstream network.
+
+ Args:
+ feats (tuple[Tensor]): Features from the upstream network, each is
+ a 4D-tensor.
+
+ Returns:
+ tuple: Usually a tuple of classification scores and bbox prediction
+ cls_scores (list[Tensor]): Classification scores for all scale
+ levels, each is a 4D-tensor, the channels number is
+ num_anchors * num_classes.
+ bbox_preds (list[Tensor]): Decoded box for all scale levels,
+ each is a 4D-tensor, the channels number is
+ num_anchors * 4. In [tl_x, tl_y, br_x, br_y] format.
+ """
+ cls_scores = []
+ bbox_preds = []
+ for idx, (x, scale, stride) in enumerate(
+ zip(feats, self.scales, self.prior_generator.strides)):
+ b, c, h, w = x.shape
+ anchor = self.prior_generator.single_level_grid_priors(
+ (h, w), idx, device=x.device)
+ anchor = torch.cat([anchor for _ in range(b)])
+ # extract task interactive features
+ inter_feats = []
+ for inter_conv in self.inter_convs:
+ x = inter_conv(x)
+ inter_feats.append(x)
+ feat = torch.cat(inter_feats, 1)
+
+ # task decomposition
+ avg_feat = F.adaptive_avg_pool2d(feat, (1, 1))
+ cls_feat = self.cls_decomp(feat, avg_feat)
+ reg_feat = self.reg_decomp(feat, avg_feat)
+
+ # cls prediction and alignment
+ cls_logits = self.tood_cls(cls_feat)
+ cls_prob = self.cls_prob_module(feat)
+ cls_score = sigmoid_geometric_mean(cls_logits, cls_prob)
+
+ # reg prediction and alignment
+ if self.anchor_type == 'anchor_free':
+ reg_dist = scale(self.tood_reg(reg_feat).exp()).float()
+ reg_dist = reg_dist.permute(0, 2, 3, 1).reshape(-1, 4)
+ reg_bbox = distance2bbox(
+ self.anchor_center(anchor) / stride[0],
+ reg_dist).reshape(b, h, w, 4).permute(0, 3, 1,
+ 2) # (b, c, h, w)
+ elif self.anchor_type == 'anchor_based':
+ reg_dist = scale(self.tood_reg(reg_feat)).float()
+ reg_dist = reg_dist.permute(0, 2, 3, 1).reshape(-1, 4)
+ reg_bbox = self.bbox_coder.decode(anchor, reg_dist).reshape(
+ b, h, w, 4).permute(0, 3, 1, 2) / stride[0]
+ else:
+ raise NotImplementedError(
+ f'Unknown anchor type: {self.anchor_type}.'
+ f'Please use `anchor_free` or `anchor_based`.')
+ reg_offset = self.reg_offset_module(feat)
+ bbox_pred = self.deform_sampling(reg_bbox.contiguous(),
+ reg_offset.contiguous())
+
+ # After deform_sampling, some boxes will become invalid (The
+ # left-top point is at the right or bottom of the right-bottom
+ # point), which will make the GIoULoss negative.
+ invalid_bbox_idx = (bbox_pred[:, [0]] > bbox_pred[:, [2]]) | \
+ (bbox_pred[:, [1]] > bbox_pred[:, [3]])
+ invalid_bbox_idx = invalid_bbox_idx.expand_as(bbox_pred)
+ bbox_pred = torch.where(invalid_bbox_idx, reg_bbox, bbox_pred)
+
+ cls_scores.append(cls_score)
+ bbox_preds.append(bbox_pred)
+ return tuple(cls_scores), tuple(bbox_preds)
+
+ def deform_sampling(self, feat: Tensor, offset: Tensor) -> Tensor:
+ """Sampling the feature x according to offset.
+
+ Args:
+ feat (Tensor): Feature
+ offset (Tensor): Spatial offset for feature sampling
+ """
+ # it is an equivalent implementation of bilinear interpolation
+ b, c, h, w = feat.shape
+ weight = feat.new_ones(c, 1, 1, 1)
+ y = deform_conv2d(feat, offset, weight, 1, 0, 1, c, c)
+ return y
+
+ def anchor_center(self, anchors: Tensor) -> Tensor:
+ """Get anchor centers from anchors.
+
+ Args:
+ anchors (Tensor): Anchor list with shape (N, 4), "xyxy" format.
+
+ Returns:
+ Tensor: Anchor centers with shape (N, 2), "xy" format.
+ """
+ anchors_cx = (anchors[:, 2] + anchors[:, 0]) / 2
+ anchors_cy = (anchors[:, 3] + anchors[:, 1]) / 2
+ return torch.stack([anchors_cx, anchors_cy], dim=-1)
+
+ def loss_by_feat_single(self, anchors: Tensor, cls_score: Tensor,
+ bbox_pred: Tensor, labels: Tensor,
+ label_weights: Tensor, bbox_targets: Tensor,
+ alignment_metrics: Tensor,
+ stride: Tuple[int, int]) -> dict:
+ """Calculate the loss of a single scale level based on the features
+ extracted by the detection head.
+
+ Args:
+ anchors (Tensor): Box reference for each scale level with shape
+ (N, num_total_anchors, 4).
+ cls_score (Tensor): Box scores for each scale level
+ Has shape (N, num_anchors * num_classes, H, W).
+ bbox_pred (Tensor): Decoded bboxes for each scale
+ level with shape (N, num_anchors * 4, H, W).
+ labels (Tensor): Labels of each anchors with shape
+ (N, num_total_anchors).
+ label_weights (Tensor): Label weights of each anchor with shape
+ (N, num_total_anchors).
+ bbox_targets (Tensor): BBox regression targets of each anchor with
+ shape (N, num_total_anchors, 4).
+ alignment_metrics (Tensor): Alignment metrics with shape
+ (N, num_total_anchors).
+ stride (Tuple[int, int]): Downsample stride of the feature map.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components.
+ """
+ assert stride[0] == stride[1], 'h stride is not equal to w stride!'
+ anchors = anchors.reshape(-1, 4)
+ cls_score = cls_score.permute(0, 2, 3, 1).reshape(
+ -1, self.cls_out_channels).contiguous()
+ bbox_pred = bbox_pred.permute(0, 2, 3, 1).reshape(-1, 4)
+ bbox_targets = bbox_targets.reshape(-1, 4)
+ labels = labels.reshape(-1)
+ alignment_metrics = alignment_metrics.reshape(-1)
+ label_weights = label_weights.reshape(-1)
+ targets = labels if self.epoch < self.initial_epoch else (
+ labels, alignment_metrics)
+ cls_loss_func = self.initial_loss_cls \
+ if self.epoch < self.initial_epoch else self.loss_cls
+
+ loss_cls = cls_loss_func(
+ cls_score, targets, label_weights, avg_factor=1.0)
+
+ # FG cat_id: [0, num_classes -1], BG cat_id: num_classes
+ bg_class_ind = self.num_classes
+ pos_inds = ((labels >= 0)
+ & (labels < bg_class_ind)).nonzero().squeeze(1)
+
+ if len(pos_inds) > 0:
+ pos_bbox_targets = bbox_targets[pos_inds]
+ pos_bbox_pred = bbox_pred[pos_inds]
+ pos_anchors = anchors[pos_inds]
+
+ pos_decode_bbox_pred = pos_bbox_pred
+ pos_decode_bbox_targets = pos_bbox_targets / stride[0]
+
+ # regression loss
+ pos_bbox_weight = self.centerness_target(
+ pos_anchors, pos_bbox_targets
+ ) if self.epoch < self.initial_epoch else alignment_metrics[
+ pos_inds]
+
+ loss_bbox = self.loss_bbox(
+ pos_decode_bbox_pred,
+ pos_decode_bbox_targets,
+ weight=pos_bbox_weight,
+ avg_factor=1.0)
+ else:
+ loss_bbox = bbox_pred.sum() * 0
+ pos_bbox_weight = bbox_targets.new_tensor(0.)
+
+ return loss_cls, loss_bbox, alignment_metrics.sum(
+ ), pos_bbox_weight.sum()
+
+ def loss_by_feat(
+ self,
+ cls_scores: List[Tensor],
+ bbox_preds: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ batch_gt_instances_ignore: OptInstanceList = None) -> dict:
+ """Calculate the loss based on the features extracted by the detection
+ head.
+
+ Args:
+ cls_scores (list[Tensor]): Box scores for each scale level
+ Has shape (N, num_anchors * num_classes, H, W)
+ bbox_preds (list[Tensor]): Decoded box for each scale
+ level with shape (N, num_anchors * 4, H, W) in
+ [tl_x, tl_y, br_x, br_y] format.
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], Optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components.
+ """
+ num_imgs = len(batch_img_metas)
+ featmap_sizes = [featmap.size()[-2:] for featmap in cls_scores]
+ assert len(featmap_sizes) == self.prior_generator.num_levels
+
+ device = cls_scores[0].device
+ anchor_list, valid_flag_list = self.get_anchors(
+ featmap_sizes, batch_img_metas, device=device)
+
+ flatten_cls_scores = torch.cat([
+ cls_score.permute(0, 2, 3, 1).reshape(num_imgs, -1,
+ self.cls_out_channels)
+ for cls_score in cls_scores
+ ], 1)
+ flatten_bbox_preds = torch.cat([
+ bbox_pred.permute(0, 2, 3, 1).reshape(num_imgs, -1, 4) * stride[0]
+ for bbox_pred, stride in zip(bbox_preds,
+ self.prior_generator.strides)
+ ], 1)
+
+ cls_reg_targets = self.get_targets(
+ flatten_cls_scores,
+ flatten_bbox_preds,
+ anchor_list,
+ valid_flag_list,
+ batch_gt_instances,
+ batch_img_metas,
+ batch_gt_instances_ignore=batch_gt_instances_ignore)
+ (anchor_list, labels_list, label_weights_list, bbox_targets_list,
+ alignment_metrics_list) = cls_reg_targets
+
+ losses_cls, losses_bbox, \
+ cls_avg_factors, bbox_avg_factors = multi_apply(
+ self.loss_by_feat_single,
+ anchor_list,
+ cls_scores,
+ bbox_preds,
+ labels_list,
+ label_weights_list,
+ bbox_targets_list,
+ alignment_metrics_list,
+ self.prior_generator.strides)
+
+ cls_avg_factor = reduce_mean(sum(cls_avg_factors)).clamp_(min=1).item()
+ losses_cls = list(map(lambda x: x / cls_avg_factor, losses_cls))
+
+ bbox_avg_factor = reduce_mean(
+ sum(bbox_avg_factors)).clamp_(min=1).item()
+ losses_bbox = list(map(lambda x: x / bbox_avg_factor, losses_bbox))
+ return dict(loss_cls=losses_cls, loss_bbox=losses_bbox)
+
+ def _predict_by_feat_single(self,
+ cls_score_list: List[Tensor],
+ bbox_pred_list: List[Tensor],
+ score_factor_list: List[Tensor],
+ mlvl_priors: List[Tensor],
+ img_meta: dict,
+ cfg: Optional[ConfigDict] = None,
+ rescale: bool = False,
+ with_nms: bool = True) -> InstanceData:
+ """Transform a single image's features extracted from the head into
+ bbox results.
+
+ Args:
+ cls_score_list (list[Tensor]): Box scores from all scale
+ levels of a single image, each item has shape
+ (num_priors * num_classes, H, W).
+ bbox_pred_list (list[Tensor]): Box energies / deltas from
+ all scale levels of a single image, each item has shape
+ (num_priors * 4, H, W).
+ score_factor_list (list[Tensor]): Score factor from all scale
+ levels of a single image, each item has shape
+ (num_priors * 1, H, W).
+ mlvl_priors (list[Tensor]): Each element in the list is
+ the priors of a single level in feature pyramid. In all
+ anchor-based methods, it has shape (num_priors, 4). In
+ all anchor-free methods, it has shape (num_priors, 2)
+ when `with_stride=True`, otherwise it still has shape
+ (num_priors, 4).
+ img_meta (dict): Image meta info.
+ cfg (:obj:`ConfigDict`, optional): Test / postprocessing
+ configuration, if None, test_cfg would be used.
+ rescale (bool): If True, return boxes in original image space.
+ Defaults to False.
+ with_nms (bool): If True, do nms before return boxes.
+ Defaults to True.
+
+ Returns:
+ tuple[Tensor]: Results of detected bboxes and labels. If with_nms
+ is False and mlvl_score_factor is None, return mlvl_bboxes and
+ mlvl_scores, else return mlvl_bboxes, mlvl_scores and
+ mlvl_score_factor. Usually with_nms is False is used for aug
+ test. If with_nms is True, then return the following format
+
+ - det_bboxes (Tensor): Predicted bboxes with shape \
+ [num_bboxes, 5], where the first 4 columns are bounding \
+ box positions (tl_x, tl_y, br_x, br_y) and the 5-th \
+ column are scores between 0 and 1.
+ - det_labels (Tensor): Predicted labels of the corresponding \
+ box with shape [num_bboxes].
+ """
+
+ cfg = self.test_cfg if cfg is None else cfg
+ nms_pre = cfg.get('nms_pre', -1)
+
+ mlvl_bboxes = []
+ mlvl_scores = []
+ mlvl_labels = []
+ for cls_score, bbox_pred, priors, stride in zip(
+ cls_score_list, bbox_pred_list, mlvl_priors,
+ self.prior_generator.strides):
+ assert cls_score.size()[-2:] == bbox_pred.size()[-2:]
+
+ bbox_pred = bbox_pred.permute(1, 2, 0).reshape(-1, 4) * stride[0]
+ scores = cls_score.permute(1, 2,
+ 0).reshape(-1, self.cls_out_channels)
+
+ # After https://github.com/open-mmlab/mmdetection/pull/6268/,
+ # this operation keeps fewer bboxes under the same `nms_pre`.
+ # There is no difference in performance for most models. If you
+ # find a slight drop in performance, you can set a larger
+ # `nms_pre` than before.
+ results = filter_scores_and_topk(
+ scores, cfg.score_thr, nms_pre,
+ dict(bbox_pred=bbox_pred, priors=priors))
+ scores, labels, keep_idxs, filtered_results = results
+
+ bboxes = filtered_results['bbox_pred']
+
+ mlvl_bboxes.append(bboxes)
+ mlvl_scores.append(scores)
+ mlvl_labels.append(labels)
+
+ results = InstanceData()
+ results.bboxes = torch.cat(mlvl_bboxes)
+ results.scores = torch.cat(mlvl_scores)
+ results.labels = torch.cat(mlvl_labels)
+
+ return self._bbox_post_process(
+ results=results,
+ cfg=cfg,
+ rescale=rescale,
+ with_nms=with_nms,
+ img_meta=img_meta)
+
+ def get_targets(self,
+ cls_scores: List[List[Tensor]],
+ bbox_preds: List[List[Tensor]],
+ anchor_list: List[List[Tensor]],
+ valid_flag_list: List[List[Tensor]],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ batch_gt_instances_ignore: OptInstanceList = None,
+ unmap_outputs: bool = True) -> tuple:
+ """Compute regression and classification targets for anchors in
+ multiple images.
+
+ Args:
+ cls_scores (list[list[Tensor]]): Classification predictions of
+ images, a 3D-Tensor with shape [num_imgs, num_priors,
+ num_classes].
+ bbox_preds (list[list[Tensor]]): Decoded bboxes predictions of one
+ image, a 3D-Tensor with shape [num_imgs, num_priors, 4] in
+ [tl_x, tl_y, br_x, br_y] format.
+ anchor_list (list[list[Tensor]]): Multi level anchors of each
+ image. The outer list indicates images, and the inner list
+ corresponds to feature levels of the image. Each element of
+ the inner list is a tensor of shape (num_anchors, 4).
+ valid_flag_list (list[list[Tensor]]): Multi level valid flags of
+ each image. The outer list indicates images, and the inner list
+ corresponds to feature levels of the image. Each element of
+ the inner list is a tensor of shape (num_anchors, )
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], Optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+ unmap_outputs (bool): Whether to map outputs back to the original
+ set of anchors.
+
+ Returns:
+ tuple: a tuple containing learning targets.
+
+ - anchors_list (list[list[Tensor]]): Anchors of each level.
+ - labels_list (list[Tensor]): Labels of each level.
+ - label_weights_list (list[Tensor]): Label weights of each
+ level.
+ - bbox_targets_list (list[Tensor]): BBox targets of each level.
+ - norm_alignment_metrics_list (list[Tensor]): Normalized
+ alignment metrics of each level.
+ """
+ num_imgs = len(batch_img_metas)
+ assert len(anchor_list) == len(valid_flag_list) == num_imgs
+
+ # anchor number of multi levels
+ num_level_anchors = [anchors.size(0) for anchors in anchor_list[0]]
+ num_level_anchors_list = [num_level_anchors] * num_imgs
+
+ # concat all level anchors and flags to a single tensor
+ for i in range(num_imgs):
+ assert len(anchor_list[i]) == len(valid_flag_list[i])
+ anchor_list[i] = torch.cat(anchor_list[i])
+ valid_flag_list[i] = torch.cat(valid_flag_list[i])
+
+ # compute targets for each image
+ if batch_gt_instances_ignore is None:
+ batch_gt_instances_ignore = [None] * num_imgs
+ # anchor_list: list(b * [-1, 4])
+
+ # get epoch information from message hub
+ message_hub = MessageHub.get_current_instance()
+ self.epoch = message_hub.get_info('epoch')
+
+ if self.epoch < self.initial_epoch:
+ (all_anchors, all_labels, all_label_weights, all_bbox_targets,
+ all_bbox_weights, pos_inds_list, neg_inds_list,
+ sampling_result) = multi_apply(
+ super()._get_targets_single,
+ anchor_list,
+ valid_flag_list,
+ num_level_anchors_list,
+ batch_gt_instances,
+ batch_img_metas,
+ batch_gt_instances_ignore,
+ unmap_outputs=unmap_outputs)
+ all_assign_metrics = [
+ weight[..., 0] for weight in all_bbox_weights
+ ]
+ else:
+ (all_anchors, all_labels, all_label_weights, all_bbox_targets,
+ all_assign_metrics) = multi_apply(
+ self._get_targets_single,
+ cls_scores,
+ bbox_preds,
+ anchor_list,
+ valid_flag_list,
+ batch_gt_instances,
+ batch_img_metas,
+ batch_gt_instances_ignore,
+ unmap_outputs=unmap_outputs)
+
+ # split targets to a list w.r.t. multiple levels
+ anchors_list = images_to_levels(all_anchors, num_level_anchors)
+ labels_list = images_to_levels(all_labels, num_level_anchors)
+ label_weights_list = images_to_levels(all_label_weights,
+ num_level_anchors)
+ bbox_targets_list = images_to_levels(all_bbox_targets,
+ num_level_anchors)
+ norm_alignment_metrics_list = images_to_levels(all_assign_metrics,
+ num_level_anchors)
+
+ return (anchors_list, labels_list, label_weights_list,
+ bbox_targets_list, norm_alignment_metrics_list)
+
+ def _get_targets_single(self,
+ cls_scores: Tensor,
+ bbox_preds: Tensor,
+ flat_anchors: Tensor,
+ valid_flags: Tensor,
+ gt_instances: InstanceData,
+ img_meta: dict,
+ gt_instances_ignore: Optional[InstanceData] = None,
+ unmap_outputs: bool = True) -> tuple:
+ """Compute regression, classification targets for anchors in a single
+ image.
+
+ Args:
+ cls_scores (Tensor): Box scores for each image.
+ bbox_preds (Tensor): Box energies / deltas for each image.
+ flat_anchors (Tensor): Multi-level anchors of the image, which are
+ concatenated into a single tensor of shape (num_anchors ,4)
+ valid_flags (Tensor): Multi level valid flags of the image,
+ which are concatenated into a single tensor of
+ shape (num_anchors,).
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ img_meta (dict): Meta information for current image.
+ gt_instances_ignore (:obj:`InstanceData`, optional): Instances
+ to be ignored during training. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+ unmap_outputs (bool): Whether to map outputs back to the original
+ set of anchors.
+
+ Returns:
+ tuple: N is the number of total anchors in the image.
+ anchors (Tensor): All anchors in the image with shape (N, 4).
+ labels (Tensor): Labels of all anchors in the image with shape
+ (N,).
+ label_weights (Tensor): Label weights of all anchor in the
+ image with shape (N,).
+ bbox_targets (Tensor): BBox targets of all anchors in the
+ image with shape (N, 4).
+ norm_alignment_metrics (Tensor): Normalized alignment metrics
+ of all priors in the image with shape (N,).
+ """
+ inside_flags = anchor_inside_flags(flat_anchors, valid_flags,
+ img_meta['img_shape'][:2],
+ self.train_cfg['allowed_border'])
+ if not inside_flags.any():
+ raise ValueError(
+ 'There is no valid anchor inside the image boundary. Please '
+ 'check the image size and anchor sizes, or set '
+ '``allowed_border`` to -1 to skip the condition.')
+ # assign gt and sample anchors
+ anchors = flat_anchors[inside_flags, :]
+ pred_instances = InstanceData(
+ priors=anchors,
+ scores=cls_scores[inside_flags, :],
+ bboxes=bbox_preds[inside_flags, :])
+ assign_result = self.alignment_assigner.assign(pred_instances,
+ gt_instances,
+ gt_instances_ignore,
+ self.alpha, self.beta)
+ assign_ious = assign_result.max_overlaps
+ assign_metrics = assign_result.assign_metrics
+
+ sampling_result = self.sampler.sample(assign_result, pred_instances,
+ gt_instances)
+
+ num_valid_anchors = anchors.shape[0]
+ bbox_targets = torch.zeros_like(anchors)
+ labels = anchors.new_full((num_valid_anchors, ),
+ self.num_classes,
+ dtype=torch.long)
+ label_weights = anchors.new_zeros(num_valid_anchors, dtype=torch.float)
+ norm_alignment_metrics = anchors.new_zeros(
+ num_valid_anchors, dtype=torch.float)
+
+ pos_inds = sampling_result.pos_inds
+ neg_inds = sampling_result.neg_inds
+ if len(pos_inds) > 0:
+ # point-based
+ pos_bbox_targets = sampling_result.pos_gt_bboxes
+ bbox_targets[pos_inds, :] = pos_bbox_targets
+
+ labels[pos_inds] = sampling_result.pos_gt_labels
+ if self.train_cfg['pos_weight'] <= 0:
+ label_weights[pos_inds] = 1.0
+ else:
+ label_weights[pos_inds] = self.train_cfg['pos_weight']
+ if len(neg_inds) > 0:
+ label_weights[neg_inds] = 1.0
+
+ class_assigned_gt_inds = torch.unique(
+ sampling_result.pos_assigned_gt_inds)
+ for gt_inds in class_assigned_gt_inds:
+ gt_class_inds = pos_inds[sampling_result.pos_assigned_gt_inds ==
+ gt_inds]
+ pos_alignment_metrics = assign_metrics[gt_class_inds]
+ pos_ious = assign_ious[gt_class_inds]
+ pos_norm_alignment_metrics = pos_alignment_metrics / (
+ pos_alignment_metrics.max() + 10e-8) * pos_ious.max()
+ norm_alignment_metrics[gt_class_inds] = pos_norm_alignment_metrics
+
+ # map up to original set of anchors
+ if unmap_outputs:
+ num_total_anchors = flat_anchors.size(0)
+ anchors = unmap(anchors, num_total_anchors, inside_flags)
+ labels = unmap(
+ labels, num_total_anchors, inside_flags, fill=self.num_classes)
+ label_weights = unmap(label_weights, num_total_anchors,
+ inside_flags)
+ bbox_targets = unmap(bbox_targets, num_total_anchors, inside_flags)
+ norm_alignment_metrics = unmap(norm_alignment_metrics,
+ num_total_anchors, inside_flags)
+ return (anchors, labels, label_weights, bbox_targets,
+ norm_alignment_metrics)
diff --git a/mmdet/models/dense_heads/vfnet_head.py b/mmdet/models/dense_heads/vfnet_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..430b06d085d94760d56a7ea083eaf23bd32b1f53
--- /dev/null
+++ b/mmdet/models/dense_heads/vfnet_head.py
@@ -0,0 +1,722 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Tuple, Union
+
+import numpy as np
+import torch
+import torch.nn as nn
+from mmcv.cnn import ConvModule, Scale
+from mmcv.ops import DeformConv2d
+from torch import Tensor
+
+from mmdet.registry import MODELS, TASK_UTILS
+from mmdet.structures.bbox import bbox_overlaps
+from mmdet.utils import (ConfigType, InstanceList, MultiConfig,
+ OptInstanceList, RangeType, reduce_mean)
+from ..task_modules.prior_generators import MlvlPointGenerator
+from ..task_modules.samplers import PseudoSampler
+from ..utils import multi_apply
+from .atss_head import ATSSHead
+from .fcos_head import FCOSHead
+
+INF = 1e8
+
+
+@MODELS.register_module()
+class VFNetHead(ATSSHead, FCOSHead):
+ """Head of `VarifocalNet (VFNet): An IoU-aware Dense Object
+ Detector.`_.
+
+ The VFNet predicts IoU-aware classification scores which mix the
+ object presence confidence and object localization accuracy as the
+ detection score. It is built on the FCOS architecture and uses ATSS
+ for defining positive/negative training examples. The VFNet is trained
+ with Varifocal Loss and empolys star-shaped deformable convolution to
+ extract features for a bbox.
+
+ Args:
+ num_classes (int): Number of categories excluding the background
+ category.
+ in_channels (int): Number of channels in the input feature map.
+ regress_ranges (Sequence[Tuple[int, int]]): Regress range of multiple
+ level points.
+ center_sampling (bool): If true, use center sampling. Defaults to False.
+ center_sample_radius (float): Radius of center sampling. Defaults to 1.5.
+ sync_num_pos (bool): If true, synchronize the number of positive
+ examples across GPUs. Defaults to True
+ gradient_mul (float): The multiplier to gradients from bbox refinement
+ and recognition. Defaults to 0.1.
+ bbox_norm_type (str): The bbox normalization type, 'reg_denom' or
+ 'stride'. Defaults to reg_denom
+ loss_cls_fl (:obj:`ConfigDict` or dict): Config of focal loss.
+ use_vfl (bool): If true, use varifocal loss for training.
+ Defaults to True.
+ loss_cls (:obj:`ConfigDict` or dict): Config of varifocal loss.
+ loss_bbox (:obj:`ConfigDict` or dict): Config of localization loss,
+ GIoU Loss.
+ loss_bbox (:obj:`ConfigDict` or dict): Config of localization
+ refinement loss, GIoU Loss.
+ norm_cfg (:obj:`ConfigDict` or dict): dictionary to construct and
+ config norm layer. Defaults to norm_cfg=dict(type='GN',
+ num_groups=32, requires_grad=True).
+ use_atss (bool): If true, use ATSS to define positive/negative
+ examples. Defaults to True.
+ anchor_generator (:obj:`ConfigDict` or dict): Config of anchor
+ generator for ATSS.
+ init_cfg (:obj:`ConfigDict` or dict or list[dict] or
+ list[:obj:`ConfigDict`]): Initialization config dict.
+
+ Example:
+ >>> self = VFNetHead(11, 7)
+ >>> feats = [torch.rand(1, 7, s, s) for s in [4, 8, 16, 32, 64]]
+ >>> cls_score, bbox_pred, bbox_pred_refine= self.forward(feats)
+ >>> assert len(cls_score) == len(self.scales)
+ """ # noqa: E501
+
+ def __init__(self,
+ num_classes: int,
+ in_channels: int,
+ regress_ranges: RangeType = ((-1, 64), (64, 128), (128, 256),
+ (256, 512), (512, INF)),
+ center_sampling: bool = False,
+ center_sample_radius: float = 1.5,
+ sync_num_pos: bool = True,
+ gradient_mul: float = 0.1,
+ bbox_norm_type: str = 'reg_denom',
+ loss_cls_fl: ConfigType = dict(
+ type='FocalLoss',
+ use_sigmoid=True,
+ gamma=2.0,
+ alpha=0.25,
+ loss_weight=1.0),
+ use_vfl: bool = True,
+ loss_cls: ConfigType = dict(
+ type='VarifocalLoss',
+ use_sigmoid=True,
+ alpha=0.75,
+ gamma=2.0,
+ iou_weighted=True,
+ loss_weight=1.0),
+ loss_bbox: ConfigType = dict(
+ type='GIoULoss', loss_weight=1.5),
+ loss_bbox_refine: ConfigType = dict(
+ type='GIoULoss', loss_weight=2.0),
+ norm_cfg: ConfigType = dict(
+ type='GN', num_groups=32, requires_grad=True),
+ use_atss: bool = True,
+ reg_decoded_bbox: bool = True,
+ anchor_generator: ConfigType = dict(
+ type='AnchorGenerator',
+ ratios=[1.0],
+ octave_base_scale=8,
+ scales_per_octave=1,
+ center_offset=0.0,
+ strides=[8, 16, 32, 64, 128]),
+ init_cfg: MultiConfig = dict(
+ type='Normal',
+ layer='Conv2d',
+ std=0.01,
+ override=dict(
+ type='Normal',
+ name='vfnet_cls',
+ std=0.01,
+ bias_prob=0.01)),
+ **kwargs) -> None:
+ # dcn base offsets, adapted from reppoints_head.py
+ self.num_dconv_points = 9
+ self.dcn_kernel = int(np.sqrt(self.num_dconv_points))
+ self.dcn_pad = int((self.dcn_kernel - 1) / 2)
+ dcn_base = np.arange(-self.dcn_pad,
+ self.dcn_pad + 1).astype(np.float64)
+ dcn_base_y = np.repeat(dcn_base, self.dcn_kernel)
+ dcn_base_x = np.tile(dcn_base, self.dcn_kernel)
+ dcn_base_offset = np.stack([dcn_base_y, dcn_base_x], axis=1).reshape(
+ (-1))
+ self.dcn_base_offset = torch.tensor(dcn_base_offset).view(1, -1, 1, 1)
+
+ super(FCOSHead, self).__init__(
+ num_classes=num_classes,
+ in_channels=in_channels,
+ norm_cfg=norm_cfg,
+ init_cfg=init_cfg,
+ **kwargs)
+ self.regress_ranges = regress_ranges
+ self.reg_denoms = [
+ regress_range[-1] for regress_range in regress_ranges
+ ]
+ self.reg_denoms[-1] = self.reg_denoms[-2] * 2
+ self.center_sampling = center_sampling
+ self.center_sample_radius = center_sample_radius
+ self.sync_num_pos = sync_num_pos
+ self.bbox_norm_type = bbox_norm_type
+ self.gradient_mul = gradient_mul
+ self.use_vfl = use_vfl
+ if self.use_vfl:
+ self.loss_cls = MODELS.build(loss_cls)
+ else:
+ self.loss_cls = MODELS.build(loss_cls_fl)
+ self.loss_bbox = MODELS.build(loss_bbox)
+ self.loss_bbox_refine = MODELS.build(loss_bbox_refine)
+
+ # for getting ATSS targets
+ self.use_atss = use_atss
+ self.reg_decoded_bbox = reg_decoded_bbox
+ self.use_sigmoid_cls = loss_cls.get('use_sigmoid', False)
+
+ self.anchor_center_offset = anchor_generator['center_offset']
+
+ self.num_base_priors = self.prior_generator.num_base_priors[0]
+
+ if self.train_cfg:
+ self.assigner = TASK_UTILS.build(self.train_cfg['assigner'])
+ if self.train_cfg.get('sampler', None) is not None:
+ self.sampler = TASK_UTILS.build(
+ self.train_cfg['sampler'], default_args=dict(context=self))
+ else:
+ self.sampler = PseudoSampler()
+ # only be used in `get_atss_targets` when `use_atss` is True
+ self.atss_prior_generator = TASK_UTILS.build(anchor_generator)
+
+ self.fcos_prior_generator = MlvlPointGenerator(
+ anchor_generator['strides'],
+ self.anchor_center_offset if self.use_atss else 0.5)
+
+ # In order to reuse the `get_bboxes` in `BaseDenseHead.
+ # Only be used in testing phase.
+ self.prior_generator = self.fcos_prior_generator
+
+ def _init_layers(self) -> None:
+ """Initialize layers of the head."""
+ super(FCOSHead, self)._init_cls_convs()
+ super(FCOSHead, self)._init_reg_convs()
+ self.relu = nn.ReLU()
+ self.vfnet_reg_conv = ConvModule(
+ self.feat_channels,
+ self.feat_channels,
+ 3,
+ stride=1,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ bias=self.conv_bias)
+ self.vfnet_reg = nn.Conv2d(self.feat_channels, 4, 3, padding=1)
+ self.scales = nn.ModuleList([Scale(1.0) for _ in self.strides])
+
+ self.vfnet_reg_refine_dconv = DeformConv2d(
+ self.feat_channels,
+ self.feat_channels,
+ self.dcn_kernel,
+ 1,
+ padding=self.dcn_pad)
+ self.vfnet_reg_refine = nn.Conv2d(self.feat_channels, 4, 3, padding=1)
+ self.scales_refine = nn.ModuleList([Scale(1.0) for _ in self.strides])
+
+ self.vfnet_cls_dconv = DeformConv2d(
+ self.feat_channels,
+ self.feat_channels,
+ self.dcn_kernel,
+ 1,
+ padding=self.dcn_pad)
+ self.vfnet_cls = nn.Conv2d(
+ self.feat_channels, self.cls_out_channels, 3, padding=1)
+
+ def forward(self, x: Tuple[Tensor]) -> Tuple[List[Tensor]]:
+ """Forward features from the upstream network.
+
+ Args:
+ x (tuple[Tensor]): Features from the upstream network, each is
+ a 4D-tensor.
+
+ Returns:
+ tuple:
+
+ - cls_scores (list[Tensor]): Box iou-aware scores for each scale
+ level, each is a 4D-tensor, the channel number is
+ num_points * num_classes.
+ - bbox_preds (list[Tensor]): Box offsets for each
+ scale level, each is a 4D-tensor, the channel number is
+ num_points * 4.
+ - bbox_preds_refine (list[Tensor]): Refined Box offsets for
+ each scale level, each is a 4D-tensor, the channel
+ number is num_points * 4.
+ """
+ return multi_apply(self.forward_single, x, self.scales,
+ self.scales_refine, self.strides, self.reg_denoms)
+
+ def forward_single(self, x: Tensor, scale: Scale, scale_refine: Scale,
+ stride: int, reg_denom: int) -> tuple:
+ """Forward features of a single scale level.
+
+ Args:
+ x (Tensor): FPN feature maps of the specified stride.
+ scale (:obj: `mmcv.cnn.Scale`): Learnable scale module to resize
+ the bbox prediction.
+ scale_refine (:obj: `mmcv.cnn.Scale`): Learnable scale module to
+ resize the refined bbox prediction.
+ stride (int): The corresponding stride for feature maps,
+ used to normalize the bbox prediction when
+ bbox_norm_type = 'stride'.
+ reg_denom (int): The corresponding regression range for feature
+ maps, only used to normalize the bbox prediction when
+ bbox_norm_type = 'reg_denom'.
+
+ Returns:
+ tuple: iou-aware cls scores for each box, bbox predictions and
+ refined bbox predictions of input feature maps.
+ """
+ cls_feat = x
+ reg_feat = x
+
+ for cls_layer in self.cls_convs:
+ cls_feat = cls_layer(cls_feat)
+
+ for reg_layer in self.reg_convs:
+ reg_feat = reg_layer(reg_feat)
+
+ # predict the bbox_pred of different level
+ reg_feat_init = self.vfnet_reg_conv(reg_feat)
+ if self.bbox_norm_type == 'reg_denom':
+ bbox_pred = scale(
+ self.vfnet_reg(reg_feat_init)).float().exp() * reg_denom
+ elif self.bbox_norm_type == 'stride':
+ bbox_pred = scale(
+ self.vfnet_reg(reg_feat_init)).float().exp() * stride
+ else:
+ raise NotImplementedError
+
+ # compute star deformable convolution offsets
+ # converting dcn_offset to reg_feat.dtype thus VFNet can be
+ # trained with FP16
+ dcn_offset = self.star_dcn_offset(bbox_pred, self.gradient_mul,
+ stride).to(reg_feat.dtype)
+
+ # refine the bbox_pred
+ reg_feat = self.relu(self.vfnet_reg_refine_dconv(reg_feat, dcn_offset))
+ bbox_pred_refine = scale_refine(
+ self.vfnet_reg_refine(reg_feat)).float().exp()
+ bbox_pred_refine = bbox_pred_refine * bbox_pred.detach()
+
+ # predict the iou-aware cls score
+ cls_feat = self.relu(self.vfnet_cls_dconv(cls_feat, dcn_offset))
+ cls_score = self.vfnet_cls(cls_feat)
+
+ if self.training:
+ return cls_score, bbox_pred, bbox_pred_refine
+ else:
+ return cls_score, bbox_pred_refine
+
+ def star_dcn_offset(self, bbox_pred: Tensor, gradient_mul: float,
+ stride: int) -> Tensor:
+ """Compute the star deformable conv offsets.
+
+ Args:
+ bbox_pred (Tensor): Predicted bbox distance offsets (l, r, t, b).
+ gradient_mul (float): Gradient multiplier.
+ stride (int): The corresponding stride for feature maps,
+ used to project the bbox onto the feature map.
+
+ Returns:
+ Tensor: The offsets for deformable convolution.
+ """
+ dcn_base_offset = self.dcn_base_offset.type_as(bbox_pred)
+ bbox_pred_grad_mul = (1 - gradient_mul) * bbox_pred.detach() + \
+ gradient_mul * bbox_pred
+ # map to the feature map scale
+ bbox_pred_grad_mul = bbox_pred_grad_mul / stride
+ N, C, H, W = bbox_pred.size()
+
+ x1 = bbox_pred_grad_mul[:, 0, :, :]
+ y1 = bbox_pred_grad_mul[:, 1, :, :]
+ x2 = bbox_pred_grad_mul[:, 2, :, :]
+ y2 = bbox_pred_grad_mul[:, 3, :, :]
+ bbox_pred_grad_mul_offset = bbox_pred.new_zeros(
+ N, 2 * self.num_dconv_points, H, W)
+ bbox_pred_grad_mul_offset[:, 0, :, :] = -1.0 * y1 # -y1
+ bbox_pred_grad_mul_offset[:, 1, :, :] = -1.0 * x1 # -x1
+ bbox_pred_grad_mul_offset[:, 2, :, :] = -1.0 * y1 # -y1
+ bbox_pred_grad_mul_offset[:, 4, :, :] = -1.0 * y1 # -y1
+ bbox_pred_grad_mul_offset[:, 5, :, :] = x2 # x2
+ bbox_pred_grad_mul_offset[:, 7, :, :] = -1.0 * x1 # -x1
+ bbox_pred_grad_mul_offset[:, 11, :, :] = x2 # x2
+ bbox_pred_grad_mul_offset[:, 12, :, :] = y2 # y2
+ bbox_pred_grad_mul_offset[:, 13, :, :] = -1.0 * x1 # -x1
+ bbox_pred_grad_mul_offset[:, 14, :, :] = y2 # y2
+ bbox_pred_grad_mul_offset[:, 16, :, :] = y2 # y2
+ bbox_pred_grad_mul_offset[:, 17, :, :] = x2 # x2
+ dcn_offset = bbox_pred_grad_mul_offset - dcn_base_offset
+
+ return dcn_offset
+
+ def loss_by_feat(
+ self,
+ cls_scores: List[Tensor],
+ bbox_preds: List[Tensor],
+ bbox_preds_refine: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ batch_gt_instances_ignore: OptInstanceList = None) -> dict:
+ """Compute loss of the head.
+
+ Args:
+ cls_scores (list[Tensor]): Box iou-aware scores for each scale
+ level, each is a 4D-tensor, the channel number is
+ num_points * num_classes.
+ bbox_preds (list[Tensor]): Box offsets for each
+ scale level, each is a 4D-tensor, the channel number is
+ num_points * 4.
+ bbox_preds_refine (list[Tensor]): Refined Box offsets for
+ each scale level, each is a 4D-tensor, the channel
+ number is num_points * 4.
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], Optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components.
+ """
+ assert len(cls_scores) == len(bbox_preds) == len(bbox_preds_refine)
+ featmap_sizes = [featmap.size()[-2:] for featmap in cls_scores]
+ all_level_points = self.fcos_prior_generator.grid_priors(
+ featmap_sizes, bbox_preds[0].dtype, bbox_preds[0].device)
+ labels, label_weights, bbox_targets, bbox_weights = self.get_targets(
+ cls_scores,
+ all_level_points,
+ batch_gt_instances,
+ batch_img_metas,
+ batch_gt_instances_ignore=batch_gt_instances_ignore)
+
+ num_imgs = cls_scores[0].size(0)
+ # flatten cls_scores, bbox_preds and bbox_preds_refine
+ flatten_cls_scores = [
+ cls_score.permute(0, 2, 3,
+ 1).reshape(-1,
+ self.cls_out_channels).contiguous()
+ for cls_score in cls_scores
+ ]
+ flatten_bbox_preds = [
+ bbox_pred.permute(0, 2, 3, 1).reshape(-1, 4).contiguous()
+ for bbox_pred in bbox_preds
+ ]
+ flatten_bbox_preds_refine = [
+ bbox_pred_refine.permute(0, 2, 3, 1).reshape(-1, 4).contiguous()
+ for bbox_pred_refine in bbox_preds_refine
+ ]
+ flatten_cls_scores = torch.cat(flatten_cls_scores)
+ flatten_bbox_preds = torch.cat(flatten_bbox_preds)
+ flatten_bbox_preds_refine = torch.cat(flatten_bbox_preds_refine)
+ flatten_labels = torch.cat(labels)
+ flatten_bbox_targets = torch.cat(bbox_targets)
+ # repeat points to align with bbox_preds
+ flatten_points = torch.cat(
+ [points.repeat(num_imgs, 1) for points in all_level_points])
+
+ # FG cat_id: [0, num_classes - 1], BG cat_id: num_classes
+ bg_class_ind = self.num_classes
+ pos_inds = torch.where(
+ ((flatten_labels >= 0) & (flatten_labels < bg_class_ind)) > 0)[0]
+ num_pos = len(pos_inds)
+
+ pos_bbox_preds = flatten_bbox_preds[pos_inds]
+ pos_bbox_preds_refine = flatten_bbox_preds_refine[pos_inds]
+ pos_labels = flatten_labels[pos_inds]
+
+ # sync num_pos across all gpus
+ if self.sync_num_pos:
+ num_pos_avg_per_gpu = reduce_mean(
+ pos_inds.new_tensor(num_pos).float()).item()
+ num_pos_avg_per_gpu = max(num_pos_avg_per_gpu, 1.0)
+ else:
+ num_pos_avg_per_gpu = num_pos
+
+ pos_bbox_targets = flatten_bbox_targets[pos_inds]
+ pos_points = flatten_points[pos_inds]
+
+ pos_decoded_bbox_preds = self.bbox_coder.decode(
+ pos_points, pos_bbox_preds)
+ pos_decoded_target_preds = self.bbox_coder.decode(
+ pos_points, pos_bbox_targets)
+ iou_targets_ini = bbox_overlaps(
+ pos_decoded_bbox_preds,
+ pos_decoded_target_preds.detach(),
+ is_aligned=True).clamp(min=1e-6)
+ bbox_weights_ini = iou_targets_ini.clone().detach()
+ bbox_avg_factor_ini = reduce_mean(
+ bbox_weights_ini.sum()).clamp_(min=1).item()
+
+ pos_decoded_bbox_preds_refine = \
+ self.bbox_coder.decode(pos_points, pos_bbox_preds_refine)
+ iou_targets_rf = bbox_overlaps(
+ pos_decoded_bbox_preds_refine,
+ pos_decoded_target_preds.detach(),
+ is_aligned=True).clamp(min=1e-6)
+ bbox_weights_rf = iou_targets_rf.clone().detach()
+ bbox_avg_factor_rf = reduce_mean(
+ bbox_weights_rf.sum()).clamp_(min=1).item()
+
+ if num_pos > 0:
+ loss_bbox = self.loss_bbox(
+ pos_decoded_bbox_preds,
+ pos_decoded_target_preds.detach(),
+ weight=bbox_weights_ini,
+ avg_factor=bbox_avg_factor_ini)
+
+ loss_bbox_refine = self.loss_bbox_refine(
+ pos_decoded_bbox_preds_refine,
+ pos_decoded_target_preds.detach(),
+ weight=bbox_weights_rf,
+ avg_factor=bbox_avg_factor_rf)
+
+ # build IoU-aware cls_score targets
+ if self.use_vfl:
+ pos_ious = iou_targets_rf.clone().detach()
+ cls_iou_targets = torch.zeros_like(flatten_cls_scores)
+ cls_iou_targets[pos_inds, pos_labels] = pos_ious
+ else:
+ loss_bbox = pos_bbox_preds.sum() * 0
+ loss_bbox_refine = pos_bbox_preds_refine.sum() * 0
+ if self.use_vfl:
+ cls_iou_targets = torch.zeros_like(flatten_cls_scores)
+
+ if self.use_vfl:
+ loss_cls = self.loss_cls(
+ flatten_cls_scores,
+ cls_iou_targets,
+ avg_factor=num_pos_avg_per_gpu)
+ else:
+ loss_cls = self.loss_cls(
+ flatten_cls_scores,
+ flatten_labels,
+ weight=label_weights,
+ avg_factor=num_pos_avg_per_gpu)
+
+ return dict(
+ loss_cls=loss_cls,
+ loss_bbox=loss_bbox,
+ loss_bbox_rf=loss_bbox_refine)
+
+ def get_targets(
+ self,
+ cls_scores: List[Tensor],
+ mlvl_points: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ batch_gt_instances_ignore: OptInstanceList = None) -> tuple:
+ """A wrapper for computing ATSS and FCOS targets for points in multiple
+ images.
+
+ Args:
+ cls_scores (list[Tensor]): Box iou-aware scores for each scale
+ level with shape (N, num_points * num_classes, H, W).
+ mlvl_points (list[Tensor]): Points of each fpn level, each has
+ shape (num_points, 2).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], Optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ tuple:
+
+ - labels_list (list[Tensor]): Labels of each level.
+ - label_weights (Tensor/None): Label weights of all levels.
+ - bbox_targets_list (list[Tensor]): Regression targets of each
+ level, (l, t, r, b).
+ - bbox_weights (Tensor/None): Bbox weights of all levels.
+ """
+ if self.use_atss:
+ return self.get_atss_targets(cls_scores, mlvl_points,
+ batch_gt_instances, batch_img_metas,
+ batch_gt_instances_ignore)
+ else:
+ self.norm_on_bbox = False
+ return self.get_fcos_targets(mlvl_points, batch_gt_instances)
+
+ def _get_targets_single(self, *args, **kwargs):
+ """Avoid ambiguity in multiple inheritance."""
+ if self.use_atss:
+ return ATSSHead._get_targets_single(self, *args, **kwargs)
+ else:
+ return FCOSHead._get_targets_single(self, *args, **kwargs)
+
+ def get_fcos_targets(self, points: List[Tensor],
+ batch_gt_instances: InstanceList) -> tuple:
+ """Compute FCOS regression and classification targets for points in
+ multiple images.
+
+ Args:
+ points (list[Tensor]): Points of each fpn level, each has shape
+ (num_points, 2).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+
+ Returns:
+ tuple:
+
+ - labels (list[Tensor]): Labels of each level.
+ - label_weights: None, to be compatible with ATSS targets.
+ - bbox_targets (list[Tensor]): BBox targets of each level.
+ - bbox_weights: None, to be compatible with ATSS targets.
+ """
+ labels, bbox_targets = FCOSHead.get_targets(self, points,
+ batch_gt_instances)
+ label_weights = None
+ bbox_weights = None
+ return labels, label_weights, bbox_targets, bbox_weights
+
+ def get_anchors(self,
+ featmap_sizes: List[Tuple],
+ batch_img_metas: List[dict],
+ device: str = 'cuda') -> tuple:
+ """Get anchors according to feature map sizes.
+
+ Args:
+ featmap_sizes (list[tuple]): Multi-level feature map sizes.
+ batch_img_metas (list[dict]): Image meta info.
+ device (str): Device for returned tensors
+
+ Returns:
+ tuple:
+
+ - anchor_list (list[Tensor]): Anchors of each image.
+ - valid_flag_list (list[Tensor]): Valid flags of each image.
+ """
+ num_imgs = len(batch_img_metas)
+
+ # since feature map sizes of all images are the same, we only compute
+ # anchors for one time
+ multi_level_anchors = self.atss_prior_generator.grid_priors(
+ featmap_sizes, device=device)
+ anchor_list = [multi_level_anchors for _ in range(num_imgs)]
+
+ # for each image, we compute valid flags of multi level anchors
+ valid_flag_list = []
+ for img_id, img_meta in enumerate(batch_img_metas):
+ multi_level_flags = self.atss_prior_generator.valid_flags(
+ featmap_sizes, img_meta['pad_shape'], device=device)
+ valid_flag_list.append(multi_level_flags)
+
+ return anchor_list, valid_flag_list
+
+ def get_atss_targets(
+ self,
+ cls_scores: List[Tensor],
+ mlvl_points: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ batch_gt_instances_ignore: OptInstanceList = None) -> tuple:
+ """A wrapper for computing ATSS targets for points in multiple images.
+
+ Args:
+ cls_scores (list[Tensor]): Box iou-aware scores for each scale
+ level with shape (N, num_points * num_classes, H, W).
+ mlvl_points (list[Tensor]): Points of each fpn level, each has
+ shape (num_points, 2).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], Optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ tuple:
+
+ - labels_list (list[Tensor]): Labels of each level.
+ - label_weights (Tensor): Label weights of all levels.
+ - bbox_targets_list (list[Tensor]): Regression targets of each
+ level, (l, t, r, b).
+ - bbox_weights (Tensor): Bbox weights of all levels.
+ """
+ featmap_sizes = [featmap.size()[-2:] for featmap in cls_scores]
+ assert len(
+ featmap_sizes
+ ) == self.atss_prior_generator.num_levels == \
+ self.fcos_prior_generator.num_levels
+
+ device = cls_scores[0].device
+
+ anchor_list, valid_flag_list = self.get_anchors(
+ featmap_sizes, batch_img_metas, device=device)
+
+ cls_reg_targets = ATSSHead.get_targets(
+ self,
+ anchor_list,
+ valid_flag_list,
+ batch_gt_instances,
+ batch_img_metas,
+ batch_gt_instances_ignore,
+ unmap_outputs=True)
+
+ (anchor_list, labels_list, label_weights_list, bbox_targets_list,
+ bbox_weights_list, avg_factor) = cls_reg_targets
+
+ bbox_targets_list = [
+ bbox_targets.reshape(-1, 4) for bbox_targets in bbox_targets_list
+ ]
+
+ num_imgs = len(batch_img_metas)
+ # transform bbox_targets (x1, y1, x2, y2) into (l, t, r, b) format
+ bbox_targets_list = self.transform_bbox_targets(
+ bbox_targets_list, mlvl_points, num_imgs)
+
+ labels_list = [labels.reshape(-1) for labels in labels_list]
+ label_weights_list = [
+ label_weights.reshape(-1) for label_weights in label_weights_list
+ ]
+ bbox_weights_list = [
+ bbox_weights.reshape(-1) for bbox_weights in bbox_weights_list
+ ]
+ label_weights = torch.cat(label_weights_list)
+ bbox_weights = torch.cat(bbox_weights_list)
+ return labels_list, label_weights, bbox_targets_list, bbox_weights
+
+ def transform_bbox_targets(self, decoded_bboxes: List[Tensor],
+ mlvl_points: List[Tensor],
+ num_imgs: int) -> List[Tensor]:
+ """Transform bbox_targets (x1, y1, x2, y2) into (l, t, r, b) format.
+
+ Args:
+ decoded_bboxes (list[Tensor]): Regression targets of each level,
+ in the form of (x1, y1, x2, y2).
+ mlvl_points (list[Tensor]): Points of each fpn level, each has
+ shape (num_points, 2).
+ num_imgs (int): the number of images in a batch.
+
+ Returns:
+ bbox_targets (list[Tensor]): Regression targets of each level in
+ the form of (l, t, r, b).
+ """
+ # TODO: Re-implemented in Class PointCoder
+ assert len(decoded_bboxes) == len(mlvl_points)
+ num_levels = len(decoded_bboxes)
+ mlvl_points = [points.repeat(num_imgs, 1) for points in mlvl_points]
+ bbox_targets = []
+ for i in range(num_levels):
+ bbox_target = self.bbox_coder.encode(mlvl_points[i],
+ decoded_bboxes[i])
+ bbox_targets.append(bbox_target)
+
+ return bbox_targets
+
+ def _load_from_state_dict(self, state_dict: dict, prefix: str,
+ local_metadata: dict, strict: bool,
+ missing_keys: Union[List[str], str],
+ unexpected_keys: Union[List[str], str],
+ error_msgs: Union[List[str], str]) -> None:
+ """Override the method in the parent class to avoid changing para's
+ name."""
+ pass
diff --git a/mmdet/models/dense_heads/yolact_head.py b/mmdet/models/dense_heads/yolact_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..b004013e9f0f4b977757fba2e6840e0d589e312f
--- /dev/null
+++ b/mmdet/models/dense_heads/yolact_head.py
@@ -0,0 +1,1193 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+from typing import List, Optional
+
+import numpy as np
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule
+from mmengine.model import BaseModule, ModuleList
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.utils import (ConfigType, InstanceList, OptConfigType,
+ OptInstanceList, OptMultiConfig)
+from ..layers import fast_nms
+from ..utils import images_to_levels, multi_apply, select_single_mlvl
+from ..utils.misc import empty_instances
+from .anchor_head import AnchorHead
+from .base_mask_head import BaseMaskHead
+
+
+@MODELS.register_module()
+class YOLACTHead(AnchorHead):
+ """YOLACT box head used in https://arxiv.org/abs/1904.02689.
+
+ Note that YOLACT head is a light version of RetinaNet head.
+ Four differences are described as follows:
+
+ 1. YOLACT box head has three-times fewer anchors.
+ 2. YOLACT box head shares the convs for box and cls branches.
+ 3. YOLACT box head uses OHEM instead of Focal loss.
+ 4. YOLACT box head predicts a set of mask coefficients for each box.
+
+ Args:
+ num_classes (int): Number of categories excluding the background
+ category.
+ in_channels (int): Number of channels in the input feature map.
+ anchor_generator (:obj:`ConfigDict` or dict): Config dict for
+ anchor generator
+ loss_cls (:obj:`ConfigDict` or dict): Config of classification loss.
+ loss_bbox (:obj:`ConfigDict` or dict): Config of localization loss.
+ num_head_convs (int): Number of the conv layers shared by
+ box and cls branches.
+ num_protos (int): Number of the mask coefficients.
+ use_ohem (bool): If true, ``loss_single_OHEM`` will be used for
+ cls loss calculation. If false, ``loss_single`` will be used.
+ conv_cfg (:obj:`ConfigDict` or dict, optional): Dictionary to
+ construct and config conv layer.
+ norm_cfg (:obj:`ConfigDict` or dict, optional): Dictionary to
+ construct and config norm layer.
+ init_cfg (:obj:`ConfigDict` or list[:obj:`ConfigDict`] or dict or
+ list[dict], optional): Initialization config dict.
+ """
+
+ def __init__(self,
+ num_classes: int,
+ in_channels: int,
+ anchor_generator: ConfigType = dict(
+ type='AnchorGenerator',
+ octave_base_scale=3,
+ scales_per_octave=1,
+ ratios=[0.5, 1.0, 2.0],
+ strides=[8, 16, 32, 64, 128]),
+ loss_cls: ConfigType = dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=False,
+ reduction='none',
+ loss_weight=1.0),
+ loss_bbox: ConfigType = dict(
+ type='SmoothL1Loss', beta=1.0, loss_weight=1.5),
+ num_head_convs: int = 1,
+ num_protos: int = 32,
+ use_ohem: bool = True,
+ conv_cfg: OptConfigType = None,
+ norm_cfg: OptConfigType = None,
+ init_cfg: OptMultiConfig = dict(
+ type='Xavier',
+ distribution='uniform',
+ bias=0,
+ layer='Conv2d'),
+ **kwargs) -> None:
+ self.num_head_convs = num_head_convs
+ self.num_protos = num_protos
+ self.use_ohem = use_ohem
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ super().__init__(
+ num_classes=num_classes,
+ in_channels=in_channels,
+ loss_cls=loss_cls,
+ loss_bbox=loss_bbox,
+ anchor_generator=anchor_generator,
+ init_cfg=init_cfg,
+ **kwargs)
+
+ def _init_layers(self) -> None:
+ """Initialize layers of the head."""
+ self.relu = nn.ReLU(inplace=True)
+ self.head_convs = ModuleList()
+ for i in range(self.num_head_convs):
+ chn = self.in_channels if i == 0 else self.feat_channels
+ self.head_convs.append(
+ ConvModule(
+ chn,
+ self.feat_channels,
+ 3,
+ stride=1,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg))
+ self.conv_cls = nn.Conv2d(
+ self.feat_channels,
+ self.num_base_priors * self.cls_out_channels,
+ 3,
+ padding=1)
+ self.conv_reg = nn.Conv2d(
+ self.feat_channels, self.num_base_priors * 4, 3, padding=1)
+ self.conv_coeff = nn.Conv2d(
+ self.feat_channels,
+ self.num_base_priors * self.num_protos,
+ 3,
+ padding=1)
+
+ def forward_single(self, x: Tensor) -> tuple:
+ """Forward feature of a single scale level.
+
+ Args:
+ x (Tensor): Features of a single scale level.
+
+ Returns:
+ tuple:
+
+ - cls_score (Tensor): Cls scores for a single scale level
+ the channels number is num_anchors * num_classes.
+ - bbox_pred (Tensor): Box energies / deltas for a single scale
+ level, the channels number is num_anchors * 4.
+ - coeff_pred (Tensor): Mask coefficients for a single scale
+ level, the channels number is num_anchors * num_protos.
+ """
+ for head_conv in self.head_convs:
+ x = head_conv(x)
+ cls_score = self.conv_cls(x)
+ bbox_pred = self.conv_reg(x)
+ coeff_pred = self.conv_coeff(x).tanh()
+ return cls_score, bbox_pred, coeff_pred
+
+ def loss_by_feat(
+ self,
+ cls_scores: List[Tensor],
+ bbox_preds: List[Tensor],
+ coeff_preds: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ batch_gt_instances_ignore: OptInstanceList = None) -> dict:
+ """Calculate the loss based on the features extracted by the bbox head.
+
+ When ``self.use_ohem == True``, it functions like ``SSDHead.loss``,
+ otherwise, it follows ``AnchorHead.loss``.
+
+ Args:
+ cls_scores (list[Tensor]): Box scores for each scale level
+ has shape (N, num_anchors * num_classes, H, W).
+ bbox_preds (list[Tensor]): Box energies / deltas for each scale
+ level with shape (N, num_anchors * 4, H, W).
+ coeff_preds (list[Tensor]): Mask coefficients for each scale
+ level with shape (N, num_anchors * num_protos, H, W)
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ dict: A dictionary of loss components.
+ """
+ featmap_sizes = [featmap.size()[-2:] for featmap in cls_scores]
+ assert len(featmap_sizes) == self.prior_generator.num_levels
+
+ device = cls_scores[0].device
+
+ anchor_list, valid_flag_list = self.get_anchors(
+ featmap_sizes, batch_img_metas, device=device)
+ cls_reg_targets = self.get_targets(
+ anchor_list,
+ valid_flag_list,
+ batch_gt_instances,
+ batch_img_metas,
+ batch_gt_instances_ignore=batch_gt_instances_ignore,
+ unmap_outputs=not self.use_ohem,
+ return_sampling_results=True)
+ (labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,
+ avg_factor, sampling_results) = cls_reg_targets
+
+ if self.use_ohem:
+ num_images = len(batch_img_metas)
+ all_cls_scores = torch.cat([
+ s.permute(0, 2, 3, 1).reshape(
+ num_images, -1, self.cls_out_channels) for s in cls_scores
+ ], 1)
+ all_labels = torch.cat(labels_list, -1).view(num_images, -1)
+ all_label_weights = torch.cat(label_weights_list,
+ -1).view(num_images, -1)
+ all_bbox_preds = torch.cat([
+ b.permute(0, 2, 3, 1).reshape(num_images, -1, 4)
+ for b in bbox_preds
+ ], -2)
+ all_bbox_targets = torch.cat(bbox_targets_list,
+ -2).view(num_images, -1, 4)
+ all_bbox_weights = torch.cat(bbox_weights_list,
+ -2).view(num_images, -1, 4)
+
+ # concat all level anchors to a single tensor
+ all_anchors = []
+ for i in range(num_images):
+ all_anchors.append(torch.cat(anchor_list[i]))
+
+ # check NaN and Inf
+ assert torch.isfinite(all_cls_scores).all().item(), \
+ 'classification scores become infinite or NaN!'
+ assert torch.isfinite(all_bbox_preds).all().item(), \
+ 'bbox predications become infinite or NaN!'
+
+ losses_cls, losses_bbox = multi_apply(
+ self.OHEMloss_by_feat_single,
+ all_cls_scores,
+ all_bbox_preds,
+ all_anchors,
+ all_labels,
+ all_label_weights,
+ all_bbox_targets,
+ all_bbox_weights,
+ avg_factor=avg_factor)
+ else:
+ # anchor number of multi levels
+ num_level_anchors = [anchors.size(0) for anchors in anchor_list[0]]
+ # concat all level anchors and flags to a single tensor
+ concat_anchor_list = []
+ for i in range(len(anchor_list)):
+ concat_anchor_list.append(torch.cat(anchor_list[i]))
+ all_anchor_list = images_to_levels(concat_anchor_list,
+ num_level_anchors)
+ losses_cls, losses_bbox = multi_apply(
+ self.loss_by_feat_single,
+ cls_scores,
+ bbox_preds,
+ all_anchor_list,
+ labels_list,
+ label_weights_list,
+ bbox_targets_list,
+ bbox_weights_list,
+ avg_factor=avg_factor)
+ losses = dict(loss_cls=losses_cls, loss_bbox=losses_bbox)
+ # update `_raw_positive_infos`, which will be used when calling
+ # `get_positive_infos`.
+ self._raw_positive_infos.update(coeff_preds=coeff_preds)
+ return losses
+
+ def OHEMloss_by_feat_single(self, cls_score: Tensor, bbox_pred: Tensor,
+ anchors: Tensor, labels: Tensor,
+ label_weights: Tensor, bbox_targets: Tensor,
+ bbox_weights: Tensor,
+ avg_factor: int) -> tuple:
+ """Compute loss of a single image. Similar to
+ func:``SSDHead.loss_by_feat_single``
+
+ Args:
+ cls_score (Tensor): Box scores for eachimage
+ Has shape (num_total_anchors, num_classes).
+ bbox_pred (Tensor): Box energies / deltas for each image
+ level with shape (num_total_anchors, 4).
+ anchors (Tensor): Box reference for each scale level with shape
+ (num_total_anchors, 4).
+ labels (Tensor): Labels of each anchors with shape
+ (num_total_anchors,).
+ label_weights (Tensor): Label weights of each anchor with shape
+ (num_total_anchors,)
+ bbox_targets (Tensor): BBox regression targets of each anchor
+ weight shape (num_total_anchors, 4).
+ bbox_weights (Tensor): BBox regression loss weights of each anchor
+ with shape (num_total_anchors, 4).
+ avg_factor (int): Average factor that is used to average
+ the loss. When using sampling method, avg_factor is usually
+ the sum of positive and negative priors. When using
+ `PseudoSampler`, `avg_factor` is usually equal to the number
+ of positive priors.
+
+ Returns:
+ Tuple[Tensor, Tensor]: A tuple of cls loss and bbox loss of one
+ feature map.
+ """
+
+ loss_cls_all = self.loss_cls(cls_score, labels, label_weights)
+
+ # FG cat_id: [0, num_classes -1], BG cat_id: num_classes
+ pos_inds = ((labels >= 0) & (labels < self.num_classes)).nonzero(
+ as_tuple=False).reshape(-1)
+ neg_inds = (labels == self.num_classes).nonzero(
+ as_tuple=False).view(-1)
+
+ num_pos_samples = pos_inds.size(0)
+ if num_pos_samples == 0:
+ num_neg_samples = neg_inds.size(0)
+ else:
+ num_neg_samples = self.train_cfg['neg_pos_ratio'] * \
+ num_pos_samples
+ if num_neg_samples > neg_inds.size(0):
+ num_neg_samples = neg_inds.size(0)
+ topk_loss_cls_neg, _ = loss_cls_all[neg_inds].topk(num_neg_samples)
+ loss_cls_pos = loss_cls_all[pos_inds].sum()
+ loss_cls_neg = topk_loss_cls_neg.sum()
+ loss_cls = (loss_cls_pos + loss_cls_neg) / avg_factor
+ if self.reg_decoded_bbox:
+ # When the regression loss (e.g. `IouLoss`, `GIouLoss`)
+ # is applied directly on the decoded bounding boxes, it
+ # decodes the already encoded coordinates to absolute format.
+ bbox_pred = self.bbox_coder.decode(anchors, bbox_pred)
+ loss_bbox = self.loss_bbox(
+ bbox_pred, bbox_targets, bbox_weights, avg_factor=avg_factor)
+ return loss_cls[None], loss_bbox
+
+ def get_positive_infos(self) -> InstanceList:
+ """Get positive information from sampling results.
+
+ Returns:
+ list[:obj:`InstanceData`]: Positive Information of each image,
+ usually including positive bboxes, positive labels, positive
+ priors, positive coeffs, etc.
+ """
+ assert len(self._raw_positive_infos) > 0
+ sampling_results = self._raw_positive_infos['sampling_results']
+ num_imgs = len(sampling_results)
+
+ coeff_pred_list = []
+ for coeff_pred_per_level in self._raw_positive_infos['coeff_preds']:
+ coeff_pred_per_level = \
+ coeff_pred_per_level.permute(
+ 0, 2, 3, 1).reshape(num_imgs, -1, self.num_protos)
+ coeff_pred_list.append(coeff_pred_per_level)
+ coeff_preds = torch.cat(coeff_pred_list, dim=1)
+
+ pos_info_list = []
+ for idx, sampling_result in enumerate(sampling_results):
+ pos_info = InstanceData()
+ coeff_preds_single = coeff_preds[idx]
+ pos_info.pos_assigned_gt_inds = \
+ sampling_result.pos_assigned_gt_inds
+ pos_info.pos_inds = sampling_result.pos_inds
+ pos_info.coeffs = coeff_preds_single[sampling_result.pos_inds]
+ pos_info.bboxes = sampling_result.pos_gt_bboxes
+ pos_info_list.append(pos_info)
+ return pos_info_list
+
+ def predict_by_feat(self,
+ cls_scores,
+ bbox_preds,
+ coeff_preds,
+ batch_img_metas,
+ cfg=None,
+ rescale=True,
+ **kwargs):
+ """Similar to func:``AnchorHead.get_bboxes``, but additionally
+ processes coeff_preds.
+
+ Args:
+ cls_scores (list[Tensor]): Box scores for each scale level
+ with shape (N, num_anchors * num_classes, H, W)
+ bbox_preds (list[Tensor]): Box energies / deltas for each scale
+ level with shape (N, num_anchors * 4, H, W)
+ coeff_preds (list[Tensor]): Mask coefficients for each scale
+ level with shape (N, num_anchors * num_protos, H, W)
+ batch_img_metas (list[dict]): Batch image meta info.
+ cfg (:obj:`Config` | None): Test / postprocessing configuration,
+ if None, test_cfg would be used
+ rescale (bool): If True, return boxes in original image space.
+ Defaults to True.
+
+ Returns:
+ list[:obj:`InstanceData`]: Object detection results of each image
+ after the post process. Each item usually contains following keys.
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ - coeffs (Tensor): the predicted mask coefficients of
+ instance inside the corresponding box has a shape
+ (n, num_protos).
+ """
+ assert len(cls_scores) == len(bbox_preds)
+ num_levels = len(cls_scores)
+
+ device = cls_scores[0].device
+ featmap_sizes = [cls_scores[i].shape[-2:] for i in range(num_levels)]
+ mlvl_priors = self.prior_generator.grid_priors(
+ featmap_sizes, device=device)
+
+ result_list = []
+ for img_id in range(len(batch_img_metas)):
+ img_meta = batch_img_metas[img_id]
+ cls_score_list = select_single_mlvl(cls_scores, img_id)
+ bbox_pred_list = select_single_mlvl(bbox_preds, img_id)
+ coeff_pred_list = select_single_mlvl(coeff_preds, img_id)
+ results = self._predict_by_feat_single(
+ cls_score_list=cls_score_list,
+ bbox_pred_list=bbox_pred_list,
+ coeff_preds_list=coeff_pred_list,
+ mlvl_priors=mlvl_priors,
+ img_meta=img_meta,
+ cfg=cfg,
+ rescale=rescale)
+ result_list.append(results)
+ return result_list
+
+ def _predict_by_feat_single(self,
+ cls_score_list: List[Tensor],
+ bbox_pred_list: List[Tensor],
+ coeff_preds_list: List[Tensor],
+ mlvl_priors: List[Tensor],
+ img_meta: dict,
+ cfg: ConfigType,
+ rescale: bool = True) -> InstanceData:
+ """Transform a single image's features extracted from the head into
+ bbox results. Similar to func:``AnchorHead._predict_by_feat_single``,
+ but additionally processes coeff_preds_list and uses fast NMS instead
+ of traditional NMS.
+
+ Args:
+ cls_score_list (list[Tensor]): Box scores for a single scale level
+ Has shape (num_priors * num_classes, H, W).
+ bbox_pred_list (list[Tensor]): Box energies / deltas for a single
+ scale level with shape (num_priors * 4, H, W).
+ coeff_preds_list (list[Tensor]): Mask coefficients for a single
+ scale level with shape (num_priors * num_protos, H, W).
+ mlvl_priors (list[Tensor]): Each element in the list is
+ the priors of a single level in feature pyramid,
+ has shape (num_priors, 4).
+ img_meta (dict): Image meta info.
+ cfg (mmengine.Config): Test / postprocessing configuration,
+ if None, test_cfg would be used.
+ rescale (bool): If True, return boxes in original image space.
+ Defaults to False.
+
+ Returns:
+ :obj:`InstanceData`: Detection results of each image
+ after the post process.
+ Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ - coeffs (Tensor): the predicted mask coefficients of
+ instance inside the corresponding box has a shape
+ (n, num_protos).
+ """
+ assert len(cls_score_list) == len(bbox_pred_list) == len(mlvl_priors)
+
+ cfg = self.test_cfg if cfg is None else cfg
+ cfg = copy.deepcopy(cfg)
+ img_shape = img_meta['img_shape']
+ nms_pre = cfg.get('nms_pre', -1)
+
+ mlvl_bbox_preds = []
+ mlvl_valid_priors = []
+ mlvl_scores = []
+ mlvl_coeffs = []
+ for cls_score, bbox_pred, coeff_pred, priors in \
+ zip(cls_score_list, bbox_pred_list,
+ coeff_preds_list, mlvl_priors):
+ assert cls_score.size()[-2:] == bbox_pred.size()[-2:]
+ cls_score = cls_score.permute(1, 2,
+ 0).reshape(-1, self.cls_out_channels)
+ if self.use_sigmoid_cls:
+ scores = cls_score.sigmoid()
+ else:
+ scores = cls_score.softmax(-1)
+ bbox_pred = bbox_pred.permute(1, 2, 0).reshape(-1, 4)
+ coeff_pred = coeff_pred.permute(1, 2,
+ 0).reshape(-1, self.num_protos)
+
+ if 0 < nms_pre < scores.shape[0]:
+ # Get maximum scores for foreground classes.
+ if self.use_sigmoid_cls:
+ max_scores, _ = scores.max(dim=1)
+ else:
+ # remind that we set FG labels to [0, num_class-1]
+ # since mmdet v2.0
+ # BG cat_id: num_class
+ max_scores, _ = scores[:, :-1].max(dim=1)
+ _, topk_inds = max_scores.topk(nms_pre)
+ priors = priors[topk_inds, :]
+ bbox_pred = bbox_pred[topk_inds, :]
+ scores = scores[topk_inds, :]
+ coeff_pred = coeff_pred[topk_inds, :]
+
+ mlvl_bbox_preds.append(bbox_pred)
+ mlvl_valid_priors.append(priors)
+ mlvl_scores.append(scores)
+ mlvl_coeffs.append(coeff_pred)
+
+ bbox_pred = torch.cat(mlvl_bbox_preds)
+ priors = torch.cat(mlvl_valid_priors)
+ multi_bboxes = self.bbox_coder.decode(
+ priors, bbox_pred, max_shape=img_shape)
+
+ multi_scores = torch.cat(mlvl_scores)
+ multi_coeffs = torch.cat(mlvl_coeffs)
+
+ return self._bbox_post_process(
+ multi_bboxes=multi_bboxes,
+ multi_scores=multi_scores,
+ multi_coeffs=multi_coeffs,
+ cfg=cfg,
+ rescale=rescale,
+ img_meta=img_meta)
+
+ def _bbox_post_process(self,
+ multi_bboxes: Tensor,
+ multi_scores: Tensor,
+ multi_coeffs: Tensor,
+ cfg: ConfigType,
+ rescale: bool = False,
+ img_meta: Optional[dict] = None,
+ **kwargs) -> InstanceData:
+ """bbox post-processing method.
+
+ The boxes would be rescaled to the original image scale and do
+ the nms operation. Usually `with_nms` is False is used for aug test.
+
+ Args:
+ multi_bboxes (Tensor): Predicted bbox that concat all levels.
+ multi_scores (Tensor): Bbox scores that concat all levels.
+ multi_coeffs (Tensor): Mask coefficients that concat all levels.
+ cfg (ConfigDict): Test / postprocessing configuration,
+ if None, test_cfg would be used.
+ rescale (bool): If True, return boxes in original image space.
+ Default to False.
+ img_meta (dict, optional): Image meta info. Defaults to None.
+
+ Returns:
+ :obj:`InstanceData`: Detection results of each image
+ after the post process.
+ Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ - coeffs (Tensor): the predicted mask coefficients of
+ instance inside the corresponding box has a shape
+ (n, num_protos).
+ """
+ if rescale:
+ assert img_meta.get('scale_factor') is not None
+ multi_bboxes /= multi_bboxes.new_tensor(
+ img_meta['scale_factor']).repeat((1, 2))
+ # mlvl_bboxes /= mlvl_bboxes.new_tensor(scale_factor)
+
+ if self.use_sigmoid_cls:
+ # Add a dummy background class to the backend when using sigmoid
+ # remind that we set FG labels to [0, num_class-1] since mmdet v2.0
+ # BG cat_id: num_class
+
+ padding = multi_scores.new_zeros(multi_scores.shape[0], 1)
+ multi_scores = torch.cat([multi_scores, padding], dim=1)
+ det_bboxes, det_labels, det_coeffs = fast_nms(
+ multi_bboxes, multi_scores, multi_coeffs, cfg.score_thr,
+ cfg.iou_thr, cfg.top_k, cfg.max_per_img)
+ results = InstanceData()
+ results.bboxes = det_bboxes[:, :4]
+ results.scores = det_bboxes[:, -1]
+ results.labels = det_labels
+ results.coeffs = det_coeffs
+ return results
+
+
+@MODELS.register_module()
+class YOLACTProtonet(BaseMaskHead):
+ """YOLACT mask head used in https://arxiv.org/abs/1904.02689.
+
+ This head outputs the mask prototypes for YOLACT.
+
+ Args:
+ in_channels (int): Number of channels in the input feature map.
+ proto_channels (tuple[int]): Output channels of protonet convs.
+ proto_kernel_sizes (tuple[int]): Kernel sizes of protonet convs.
+ include_last_relu (bool): If keep the last relu of protonet.
+ num_protos (int): Number of prototypes.
+ num_classes (int): Number of categories excluding the background
+ category.
+ loss_mask_weight (float): Reweight the mask loss by this factor.
+ max_masks_to_train (int): Maximum number of masks to train for
+ each image.
+ with_seg_branch (bool): Whether to apply a semantic segmentation
+ branch and calculate loss during training to increase
+ performance with no speed penalty. Defaults to True.
+ loss_segm (:obj:`ConfigDict` or dict, optional): Config of
+ semantic segmentation loss.
+ train_cfg (:obj:`ConfigDict` or dict, optional): Training config
+ of head.
+ test_cfg (:obj:`ConfigDict` or dict, optional): Testing config of
+ head.
+ init_cfg (:obj:`ConfigDict` or list[:obj:`ConfigDict`] or dict or
+ list[dict], optional): Initialization config dict.
+ """
+
+ def __init__(
+ self,
+ num_classes: int,
+ in_channels: int = 256,
+ proto_channels: tuple = (256, 256, 256, None, 256, 32),
+ proto_kernel_sizes: tuple = (3, 3, 3, -2, 3, 1),
+ include_last_relu: bool = True,
+ num_protos: int = 32,
+ loss_mask_weight: float = 1.0,
+ max_masks_to_train: int = 100,
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ with_seg_branch: bool = True,
+ loss_segm: ConfigType = dict(
+ type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
+ init_cfg=dict(
+ type='Xavier',
+ distribution='uniform',
+ override=dict(name='protonet'))
+ ) -> None:
+ super().__init__(init_cfg=init_cfg)
+ self.in_channels = in_channels
+ self.proto_channels = proto_channels
+ self.proto_kernel_sizes = proto_kernel_sizes
+ self.include_last_relu = include_last_relu
+
+ # Segmentation branch
+ self.with_seg_branch = with_seg_branch
+ self.segm_branch = SegmentationModule(
+ num_classes=num_classes, in_channels=in_channels) \
+ if with_seg_branch else None
+ self.loss_segm = MODELS.build(loss_segm) if with_seg_branch else None
+
+ self.loss_mask_weight = loss_mask_weight
+ self.num_protos = num_protos
+ self.num_classes = num_classes
+ self.max_masks_to_train = max_masks_to_train
+ self.train_cfg = train_cfg
+ self.test_cfg = test_cfg
+ self._init_layers()
+
+ def _init_layers(self) -> None:
+ """Initialize layers of the head."""
+ # Possible patterns:
+ # ( 256, 3) -> conv
+ # ( 256,-2) -> deconv
+ # (None,-2) -> bilinear interpolate
+ in_channels = self.in_channels
+ protonets = ModuleList()
+ for num_channels, kernel_size in zip(self.proto_channels,
+ self.proto_kernel_sizes):
+ if kernel_size > 0:
+ layer = nn.Conv2d(
+ in_channels,
+ num_channels,
+ kernel_size,
+ padding=kernel_size // 2)
+ else:
+ if num_channels is None:
+ layer = InterpolateModule(
+ scale_factor=-kernel_size,
+ mode='bilinear',
+ align_corners=False)
+ else:
+ layer = nn.ConvTranspose2d(
+ in_channels,
+ num_channels,
+ -kernel_size,
+ padding=kernel_size // 2)
+ protonets.append(layer)
+ protonets.append(nn.ReLU(inplace=True))
+ in_channels = num_channels if num_channels is not None \
+ else in_channels
+ if not self.include_last_relu:
+ protonets = protonets[:-1]
+ self.protonet = nn.Sequential(*protonets)
+
+ def forward(self, x: tuple, positive_infos: InstanceList) -> tuple:
+ """Forward feature from the upstream network to get prototypes and
+ linearly combine the prototypes, using masks coefficients, into
+ instance masks. Finally, crop the instance masks with given bboxes.
+
+ Args:
+ x (Tuple[Tensor]): Feature from the upstream network, which is
+ a 4D-tensor.
+ positive_infos (List[:obj:``InstanceData``]): Positive information
+ that calculate from detect head.
+
+ Returns:
+ tuple: Predicted instance segmentation masks and
+ semantic segmentation map.
+ """
+ # YOLACT used single feature map to get segmentation masks
+ single_x = x[0]
+
+ # YOLACT segmentation branch, if not training or segmentation branch
+ # is None, will not process the forward function.
+ if self.segm_branch is not None and self.training:
+ segm_preds = self.segm_branch(single_x)
+ else:
+ segm_preds = None
+ # YOLACT mask head
+ prototypes = self.protonet(single_x)
+ prototypes = prototypes.permute(0, 2, 3, 1).contiguous()
+
+ num_imgs = single_x.size(0)
+
+ mask_pred_list = []
+ for idx in range(num_imgs):
+ cur_prototypes = prototypes[idx]
+ pos_coeffs = positive_infos[idx].coeffs
+
+ # Linearly combine the prototypes with the mask coefficients
+ mask_preds = cur_prototypes @ pos_coeffs.t()
+ mask_preds = torch.sigmoid(mask_preds)
+ mask_pred_list.append(mask_preds)
+ return mask_pred_list, segm_preds
+
+ def loss_by_feat(self, mask_preds: List[Tensor], segm_preds: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict], positive_infos: InstanceList,
+ **kwargs) -> dict:
+ """Calculate the loss based on the features extracted by the mask head.
+
+ Args:
+ mask_preds (list[Tensor]): List of predicted prototypes, each has
+ shape (num_classes, H, W).
+ segm_preds (Tensor): Predicted semantic segmentation map with
+ shape (N, num_classes, H, W)
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes``, ``masks``,
+ and ``labels`` attributes.
+ batch_img_metas (list[dict]): Meta information of multiple images.
+ positive_infos (List[:obj:``InstanceData``]): Information of
+ positive samples of each image that are assigned in detection
+ head.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components.
+ """
+ assert positive_infos is not None, \
+ 'positive_infos should not be None in `YOLACTProtonet`'
+ losses = dict()
+
+ # crop
+ croped_mask_pred = self.crop_mask_preds(mask_preds, batch_img_metas,
+ positive_infos)
+
+ loss_mask = []
+ loss_segm = []
+ num_imgs, _, mask_h, mask_w = segm_preds.size()
+ assert num_imgs == len(croped_mask_pred)
+ segm_avg_factor = num_imgs * mask_h * mask_w
+ total_pos = 0
+
+ if self.segm_branch is not None:
+ assert segm_preds is not None
+
+ for idx in range(num_imgs):
+ img_meta = batch_img_metas[idx]
+
+ (mask_preds, pos_mask_targets, segm_targets, num_pos,
+ gt_bboxes_for_reweight) = self._get_targets_single(
+ croped_mask_pred[idx], segm_preds[idx],
+ batch_gt_instances[idx], positive_infos[idx])
+
+ # segmentation loss
+ if self.with_seg_branch:
+ if segm_targets is None:
+ loss = segm_preds[idx].sum() * 0.
+ else:
+ loss = self.loss_segm(
+ segm_preds[idx],
+ segm_targets,
+ avg_factor=segm_avg_factor)
+ loss_segm.append(loss)
+ # mask loss
+ total_pos += num_pos
+ if num_pos == 0 or pos_mask_targets is None:
+ loss = mask_preds.sum() * 0.
+ else:
+ mask_preds = torch.clamp(mask_preds, 0, 1)
+ loss = F.binary_cross_entropy(
+ mask_preds, pos_mask_targets,
+ reduction='none') * self.loss_mask_weight
+
+ h, w = img_meta['img_shape'][:2]
+ gt_bboxes_width = (gt_bboxes_for_reweight[:, 2] -
+ gt_bboxes_for_reweight[:, 0]) / w
+ gt_bboxes_height = (gt_bboxes_for_reweight[:, 3] -
+ gt_bboxes_for_reweight[:, 1]) / h
+ loss = loss.mean(dim=(1,
+ 2)) / gt_bboxes_width / gt_bboxes_height
+ loss = torch.sum(loss)
+ loss_mask.append(loss)
+
+ if total_pos == 0:
+ total_pos += 1 # avoid nan
+ loss_mask = [x / total_pos for x in loss_mask]
+
+ losses.update(loss_mask=loss_mask)
+ if self.with_seg_branch:
+ losses.update(loss_segm=loss_segm)
+
+ return losses
+
+ def _get_targets_single(self, mask_preds: Tensor, segm_pred: Tensor,
+ gt_instances: InstanceData,
+ positive_info: InstanceData):
+ """Compute targets for predictions of single image.
+
+ Args:
+ mask_preds (Tensor): Predicted prototypes with shape
+ (num_classes, H, W).
+ segm_pred (Tensor): Predicted semantic segmentation map
+ with shape (num_classes, H, W).
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It should includes ``bboxes``, ``labels``,
+ and ``masks`` attributes.
+ positive_info (:obj:`InstanceData`): Information of positive
+ samples that are assigned in detection head. It usually
+ contains following keys.
+
+ - pos_assigned_gt_inds (Tensor): Assigner GT indexes of
+ positive proposals, has shape (num_pos, )
+ - pos_inds (Tensor): Positive index of image, has
+ shape (num_pos, ).
+ - coeffs (Tensor): Positive mask coefficients
+ with shape (num_pos, num_protos).
+ - bboxes (Tensor): Positive bboxes with shape
+ (num_pos, 4)
+
+ Returns:
+ tuple: Usually returns a tuple containing learning targets.
+
+ - mask_preds (Tensor): Positive predicted mask with shape
+ (num_pos, mask_h, mask_w).
+ - pos_mask_targets (Tensor): Positive mask targets with shape
+ (num_pos, mask_h, mask_w).
+ - segm_targets (Tensor): Semantic segmentation targets with shape
+ (num_classes, segm_h, segm_w).
+ - num_pos (int): Positive numbers.
+ - gt_bboxes_for_reweight (Tensor): GT bboxes that match to the
+ positive priors has shape (num_pos, 4).
+ """
+ gt_bboxes = gt_instances.bboxes
+ gt_labels = gt_instances.labels
+ device = gt_bboxes.device
+ gt_masks = gt_instances.masks.to_tensor(
+ dtype=torch.bool, device=device).float()
+ if gt_masks.size(0) == 0:
+ return mask_preds, None, None, 0, None
+
+ # process with semantic segmentation targets
+ if segm_pred is not None:
+ num_classes, segm_h, segm_w = segm_pred.size()
+ with torch.no_grad():
+ downsampled_masks = F.interpolate(
+ gt_masks.unsqueeze(0), (segm_h, segm_w),
+ mode='bilinear',
+ align_corners=False).squeeze(0)
+ downsampled_masks = downsampled_masks.gt(0.5).float()
+ segm_targets = torch.zeros_like(segm_pred, requires_grad=False)
+ for obj_idx in range(downsampled_masks.size(0)):
+ segm_targets[gt_labels[obj_idx] - 1] = torch.max(
+ segm_targets[gt_labels[obj_idx] - 1],
+ downsampled_masks[obj_idx])
+ else:
+ segm_targets = None
+ # process with mask targets
+ pos_assigned_gt_inds = positive_info.pos_assigned_gt_inds
+ num_pos = pos_assigned_gt_inds.size(0)
+ # Since we're producing (near) full image masks,
+ # it'd take too much vram to backprop on every single mask.
+ # Thus we select only a subset.
+ if num_pos > self.max_masks_to_train:
+ perm = torch.randperm(num_pos)
+ select = perm[:self.max_masks_to_train]
+ mask_preds = mask_preds[select]
+ pos_assigned_gt_inds = pos_assigned_gt_inds[select]
+ num_pos = self.max_masks_to_train
+
+ gt_bboxes_for_reweight = gt_bboxes[pos_assigned_gt_inds]
+
+ mask_h, mask_w = mask_preds.shape[-2:]
+ gt_masks = F.interpolate(
+ gt_masks.unsqueeze(0), (mask_h, mask_w),
+ mode='bilinear',
+ align_corners=False).squeeze(0)
+ gt_masks = gt_masks.gt(0.5).float()
+ pos_mask_targets = gt_masks[pos_assigned_gt_inds]
+
+ return (mask_preds, pos_mask_targets, segm_targets, num_pos,
+ gt_bboxes_for_reweight)
+
+ def crop_mask_preds(self, mask_preds: List[Tensor],
+ batch_img_metas: List[dict],
+ positive_infos: InstanceList) -> list:
+ """Crop predicted masks by zeroing out everything not in the predicted
+ bbox.
+
+ Args:
+ mask_preds (list[Tensor]): Predicted prototypes with shape
+ (num_classes, H, W).
+ batch_img_metas (list[dict]): Meta information of multiple images.
+ positive_infos (List[:obj:``InstanceData``]): Positive
+ information that calculate from detect head.
+
+ Returns:
+ list: The cropped masks.
+ """
+ croped_mask_preds = []
+ for img_meta, mask_preds, cur_info in zip(batch_img_metas, mask_preds,
+ positive_infos):
+ bboxes_for_cropping = copy.deepcopy(cur_info.bboxes)
+ h, w = img_meta['img_shape'][:2]
+ bboxes_for_cropping[:, 0::2] /= w
+ bboxes_for_cropping[:, 1::2] /= h
+ mask_preds = self.crop_single(mask_preds, bboxes_for_cropping)
+ mask_preds = mask_preds.permute(2, 0, 1).contiguous()
+ croped_mask_preds.append(mask_preds)
+ return croped_mask_preds
+
+ def crop_single(self,
+ masks: Tensor,
+ boxes: Tensor,
+ padding: int = 1) -> Tensor:
+ """Crop single predicted masks by zeroing out everything not in the
+ predicted bbox.
+
+ Args:
+ masks (Tensor): Predicted prototypes, has shape [H, W, N].
+ boxes (Tensor): Bbox coords in relative point form with
+ shape [N, 4].
+ padding (int): Image padding size.
+
+ Return:
+ Tensor: The cropped masks.
+ """
+ h, w, n = masks.size()
+ x1, x2 = self.sanitize_coordinates(
+ boxes[:, 0], boxes[:, 2], w, padding, cast=False)
+ y1, y2 = self.sanitize_coordinates(
+ boxes[:, 1], boxes[:, 3], h, padding, cast=False)
+
+ rows = torch.arange(
+ w, device=masks.device, dtype=x1.dtype).view(1, -1,
+ 1).expand(h, w, n)
+ cols = torch.arange(
+ h, device=masks.device, dtype=x1.dtype).view(-1, 1,
+ 1).expand(h, w, n)
+
+ masks_left = rows >= x1.view(1, 1, -1)
+ masks_right = rows < x2.view(1, 1, -1)
+ masks_up = cols >= y1.view(1, 1, -1)
+ masks_down = cols < y2.view(1, 1, -1)
+
+ crop_mask = masks_left * masks_right * masks_up * masks_down
+
+ return masks * crop_mask.float()
+
+ def sanitize_coordinates(self,
+ x1: Tensor,
+ x2: Tensor,
+ img_size: int,
+ padding: int = 0,
+ cast: bool = True) -> tuple:
+ """Sanitizes the input coordinates so that x1 < x2, x1 != x2, x1 >= 0,
+ and x2 <= image_size. Also converts from relative to absolute
+ coordinates and casts the results to long tensors.
+
+ Warning: this does things in-place behind the scenes so
+ copy if necessary.
+
+ Args:
+ x1 (Tensor): shape (N, ).
+ x2 (Tensor): shape (N, ).
+ img_size (int): Size of the input image.
+ padding (int): x1 >= padding, x2 <= image_size-padding.
+ cast (bool): If cast is false, the result won't be cast to longs.
+
+ Returns:
+ tuple:
+
+ - x1 (Tensor): Sanitized _x1.
+ - x2 (Tensor): Sanitized _x2.
+ """
+ x1 = x1 * img_size
+ x2 = x2 * img_size
+ if cast:
+ x1 = x1.long()
+ x2 = x2.long()
+ x1 = torch.min(x1, x2)
+ x2 = torch.max(x1, x2)
+ x1 = torch.clamp(x1 - padding, min=0)
+ x2 = torch.clamp(x2 + padding, max=img_size)
+ return x1, x2
+
+ def predict_by_feat(self,
+ mask_preds: List[Tensor],
+ segm_preds: Tensor,
+ results_list: InstanceList,
+ batch_img_metas: List[dict],
+ rescale: bool = True,
+ **kwargs) -> InstanceList:
+ """Transform a batch of output features extracted from the head into
+ mask results.
+
+ Args:
+ mask_preds (list[Tensor]): Predicted prototypes with shape
+ (num_classes, H, W).
+ results_list (List[:obj:``InstanceData``]): BBoxHead results.
+ batch_img_metas (list[dict]): Meta information of all images.
+ rescale (bool, optional): Whether to rescale the results.
+ Defaults to False.
+
+ Returns:
+ list[:obj:`InstanceData`]: Processed results of multiple
+ images.Each :obj:`InstanceData` usually contains
+ following keys.
+
+ - scores (Tensor): Classification scores, has shape
+ (num_instance,).
+ - labels (Tensor): Has shape (num_instances,).
+ - masks (Tensor): Processed mask results, has
+ shape (num_instances, h, w).
+ """
+ assert len(mask_preds) == len(results_list) == len(batch_img_metas)
+
+ croped_mask_pred = self.crop_mask_preds(mask_preds, batch_img_metas,
+ results_list)
+
+ for img_id in range(len(batch_img_metas)):
+ img_meta = batch_img_metas[img_id]
+ results = results_list[img_id]
+ bboxes = results.bboxes
+ mask_preds = croped_mask_pred[img_id]
+ if bboxes.shape[0] == 0 or mask_preds.shape[0] == 0:
+ results_list[img_id] = empty_instances(
+ [img_meta],
+ bboxes.device,
+ task_type='mask',
+ instance_results=[results])[0]
+ else:
+ im_mask = self._predict_by_feat_single(
+ mask_preds=croped_mask_pred[img_id],
+ bboxes=bboxes,
+ img_meta=img_meta,
+ rescale=rescale)
+ results.masks = im_mask
+ return results_list
+
+ def _predict_by_feat_single(self,
+ mask_preds: Tensor,
+ bboxes: Tensor,
+ img_meta: dict,
+ rescale: bool,
+ cfg: OptConfigType = None):
+ """Transform a single image's features extracted from the head into
+ mask results.
+
+ Args:
+ mask_preds (Tensor): Predicted prototypes, has shape [H, W, N].
+ bboxes (Tensor): Bbox coords in relative point form with
+ shape [N, 4].
+ img_meta (dict): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ rescale (bool): If rescale is False, then returned masks will
+ fit the scale of imgs[0].
+ cfg (dict, optional): Config used in test phase.
+ Defaults to None.
+
+ Returns:
+ :obj:`InstanceData`: Processed results of single image.
+ it usually contains following keys.
+
+ - scores (Tensor): Classification scores, has shape
+ (num_instance,).
+ - labels (Tensor): Has shape (num_instances,).
+ - masks (Tensor): Processed mask results, has
+ shape (num_instances, h, w).
+ """
+ cfg = self.test_cfg if cfg is None else cfg
+ scale_factor = bboxes.new_tensor(img_meta['scale_factor']).repeat(
+ (1, 2))
+ img_h, img_w = img_meta['ori_shape'][:2]
+ if rescale: # in-placed rescale the bboxes
+ scale_factor = bboxes.new_tensor(img_meta['scale_factor']).repeat(
+ (1, 2))
+ bboxes /= scale_factor
+ else:
+ w_scale, h_scale = scale_factor[0, 0], scale_factor[0, 1]
+ img_h = np.round(img_h * h_scale.item()).astype(np.int32)
+ img_w = np.round(img_w * w_scale.item()).astype(np.int32)
+
+ masks = F.interpolate(
+ mask_preds.unsqueeze(0), (img_h, img_w),
+ mode='bilinear',
+ align_corners=False).squeeze(0) > cfg.mask_thr
+
+ if cfg.mask_thr_binary < 0:
+ # for visualization and debugging
+ masks = (masks * 255).to(dtype=torch.uint8)
+
+ return masks
+
+
+class SegmentationModule(BaseModule):
+ """YOLACT segmentation branch used in `_
+
+ In mmdet v2.x `segm_loss` is calculated in YOLACTSegmHead, while in
+ mmdet v3.x `SegmentationModule` is used to obtain the predicted semantic
+ segmentation map and `segm_loss` is calculated in YOLACTProtonet.
+
+ Args:
+ num_classes (int): Number of categories excluding the background
+ category.
+ in_channels (int): Number of channels in the input feature map.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ """
+
+ def __init__(
+ self,
+ num_classes: int,
+ in_channels: int = 256,
+ init_cfg: ConfigType = dict(
+ type='Xavier',
+ distribution='uniform',
+ override=dict(name='segm_conv'))
+ ) -> None:
+ super().__init__(init_cfg=init_cfg)
+ self.in_channels = in_channels
+ self.num_classes = num_classes
+ self._init_layers()
+
+ def _init_layers(self) -> None:
+ """Initialize layers of the head."""
+ self.segm_conv = nn.Conv2d(
+ self.in_channels, self.num_classes, kernel_size=1)
+
+ def forward(self, x: Tensor) -> Tensor:
+ """Forward feature from the upstream network.
+
+ Args:
+ x (Tensor): Feature from the upstream network, which is
+ a 4D-tensor.
+
+ Returns:
+ Tensor: Predicted semantic segmentation map with shape
+ (N, num_classes, H, W).
+ """
+ return self.segm_conv(x)
+
+
+class InterpolateModule(BaseModule):
+ """This is a module version of F.interpolate.
+
+ Any arguments you give it just get passed along for the ride.
+ """
+
+ def __init__(self, *args, init_cfg=None, **kwargs) -> None:
+ super().__init__(init_cfg=init_cfg)
+ self.args = args
+ self.kwargs = kwargs
+
+ def forward(self, x: Tensor) -> Tensor:
+ """Forward features from the upstream network.
+
+ Args:
+ x (Tensor): Feature from the upstream network, which is
+ a 4D-tensor.
+
+ Returns:
+ Tensor: A 4D-tensor feature map.
+ """
+ return F.interpolate(x, *self.args, **self.kwargs)
diff --git a/mmdet/models/dense_heads/yolo_head.py b/mmdet/models/dense_heads/yolo_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..0f63afbbc94353e16e4c67ec5bc0b6cd1200de07
--- /dev/null
+++ b/mmdet/models/dense_heads/yolo_head.py
@@ -0,0 +1,527 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+# Copyright (c) 2019 Western Digital Corporation or its affiliates.
+
+import copy
+import warnings
+from typing import List, Optional, Sequence, Tuple
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule, is_norm
+from mmengine.model import bias_init_with_prob, constant_init, normal_init
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmdet.registry import MODELS, TASK_UTILS
+from mmdet.utils import (ConfigType, InstanceList, OptConfigType,
+ OptInstanceList)
+from ..task_modules.samplers import PseudoSampler
+from ..utils import filter_scores_and_topk, images_to_levels, multi_apply
+from .base_dense_head import BaseDenseHead
+
+
+@MODELS.register_module()
+class YOLOV3Head(BaseDenseHead):
+ """YOLOV3Head Paper link: https://arxiv.org/abs/1804.02767.
+
+ Args:
+ num_classes (int): The number of object classes (w/o background)
+ in_channels (Sequence[int]): Number of input channels per scale.
+ out_channels (Sequence[int]): The number of output channels per scale
+ before the final 1x1 layer. Default: (1024, 512, 256).
+ anchor_generator (:obj:`ConfigDict` or dict): Config dict for anchor
+ generator.
+ bbox_coder (:obj:`ConfigDict` or dict): Config of bounding box coder.
+ featmap_strides (Sequence[int]): The stride of each scale.
+ Should be in descending order. Defaults to (32, 16, 8).
+ one_hot_smoother (float): Set a non-zero value to enable label-smooth
+ Defaults to 0.
+ conv_cfg (:obj:`ConfigDict` or dict, optional): Config dict for
+ convolution layer. Defaults to None.
+ norm_cfg (:obj:`ConfigDict` or dict): Dictionary to construct and
+ config norm layer. Defaults to dict(type='BN', requires_grad=True).
+ act_cfg (:obj:`ConfigDict` or dict): Config dict for activation layer.
+ Defaults to dict(type='LeakyReLU', negative_slope=0.1).
+ loss_cls (:obj:`ConfigDict` or dict): Config of classification loss.
+ loss_conf (:obj:`ConfigDict` or dict): Config of confidence loss.
+ loss_xy (:obj:`ConfigDict` or dict): Config of xy coordinate loss.
+ loss_wh (:obj:`ConfigDict` or dict): Config of wh coordinate loss.
+ train_cfg (:obj:`ConfigDict` or dict, optional): Training config of
+ YOLOV3 head. Defaults to None.
+ test_cfg (:obj:`ConfigDict` or dict, optional): Testing config of
+ YOLOV3 head. Defaults to None.
+ """
+
+ def __init__(self,
+ num_classes: int,
+ in_channels: Sequence[int],
+ out_channels: Sequence[int] = (1024, 512, 256),
+ anchor_generator: ConfigType = dict(
+ type='YOLOAnchorGenerator',
+ base_sizes=[[(116, 90), (156, 198), (373, 326)],
+ [(30, 61), (62, 45), (59, 119)],
+ [(10, 13), (16, 30), (33, 23)]],
+ strides=[32, 16, 8]),
+ bbox_coder: ConfigType = dict(type='YOLOBBoxCoder'),
+ featmap_strides: Sequence[int] = (32, 16, 8),
+ one_hot_smoother: float = 0.,
+ conv_cfg: OptConfigType = None,
+ norm_cfg: ConfigType = dict(type='BN', requires_grad=True),
+ act_cfg: ConfigType = dict(
+ type='LeakyReLU', negative_slope=0.1),
+ loss_cls: ConfigType = dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=True,
+ loss_weight=1.0),
+ loss_conf: ConfigType = dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=True,
+ loss_weight=1.0),
+ loss_xy: ConfigType = dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=True,
+ loss_weight=1.0),
+ loss_wh: ConfigType = dict(type='MSELoss', loss_weight=1.0),
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None) -> None:
+ super().__init__(init_cfg=None)
+ # Check params
+ assert (len(in_channels) == len(out_channels) == len(featmap_strides))
+
+ self.num_classes = num_classes
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.featmap_strides = featmap_strides
+ self.train_cfg = train_cfg
+ self.test_cfg = test_cfg
+ if self.train_cfg:
+ self.assigner = TASK_UTILS.build(self.train_cfg['assigner'])
+ if train_cfg.get('sampler', None) is not None:
+ self.sampler = TASK_UTILS.build(
+ self.train_cfg['sampler'], context=self)
+ else:
+ self.sampler = PseudoSampler()
+
+ self.one_hot_smoother = one_hot_smoother
+
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.act_cfg = act_cfg
+
+ self.bbox_coder = TASK_UTILS.build(bbox_coder)
+
+ self.prior_generator = TASK_UTILS.build(anchor_generator)
+
+ self.loss_cls = MODELS.build(loss_cls)
+ self.loss_conf = MODELS.build(loss_conf)
+ self.loss_xy = MODELS.build(loss_xy)
+ self.loss_wh = MODELS.build(loss_wh)
+
+ self.num_base_priors = self.prior_generator.num_base_priors[0]
+ assert len(
+ self.prior_generator.num_base_priors) == len(featmap_strides)
+ self._init_layers()
+
+ @property
+ def num_levels(self) -> int:
+ """int: number of feature map levels"""
+ return len(self.featmap_strides)
+
+ @property
+ def num_attrib(self) -> int:
+ """int: number of attributes in pred_map, bboxes (4) +
+ objectness (1) + num_classes"""
+
+ return 5 + self.num_classes
+
+ def _init_layers(self) -> None:
+ """initialize conv layers in YOLOv3 head."""
+ self.convs_bridge = nn.ModuleList()
+ self.convs_pred = nn.ModuleList()
+ for i in range(self.num_levels):
+ conv_bridge = ConvModule(
+ self.in_channels[i],
+ self.out_channels[i],
+ 3,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ conv_pred = nn.Conv2d(self.out_channels[i],
+ self.num_base_priors * self.num_attrib, 1)
+
+ self.convs_bridge.append(conv_bridge)
+ self.convs_pred.append(conv_pred)
+
+ def init_weights(self) -> None:
+ """initialize weights."""
+ for m in self.modules():
+ if isinstance(m, nn.Conv2d):
+ normal_init(m, mean=0, std=0.01)
+ if is_norm(m):
+ constant_init(m, 1)
+
+ # Use prior in model initialization to improve stability
+ for conv_pred, stride in zip(self.convs_pred, self.featmap_strides):
+ bias = conv_pred.bias.reshape(self.num_base_priors, -1)
+ # init objectness with prior of 8 objects per feature map
+ # refer to https://github.com/ultralytics/yolov3
+ nn.init.constant_(bias.data[:, 4],
+ bias_init_with_prob(8 / (608 / stride)**2))
+ nn.init.constant_(bias.data[:, 5:], bias_init_with_prob(0.01))
+
+ def forward(self, x: Tuple[Tensor, ...]) -> tuple:
+ """Forward features from the upstream network.
+
+ Args:
+ x (tuple[Tensor]): Features from the upstream network, each is
+ a 4D-tensor.
+
+ Returns:
+ tuple[Tensor]: A tuple of multi-level predication map, each is a
+ 4D-tensor of shape (batch_size, 5+num_classes, height, width).
+ """
+
+ assert len(x) == self.num_levels
+ pred_maps = []
+ for i in range(self.num_levels):
+ feat = x[i]
+ feat = self.convs_bridge[i](feat)
+ pred_map = self.convs_pred[i](feat)
+ pred_maps.append(pred_map)
+
+ return tuple(pred_maps),
+
+ def predict_by_feat(self,
+ pred_maps: Sequence[Tensor],
+ batch_img_metas: Optional[List[dict]],
+ cfg: OptConfigType = None,
+ rescale: bool = False,
+ with_nms: bool = True) -> InstanceList:
+ """Transform a batch of output features extracted from the head into
+ bbox results. It has been accelerated since PR #5991.
+
+ Args:
+ pred_maps (Sequence[Tensor]): Raw predictions for a batch of
+ images.
+ batch_img_metas (list[dict], Optional): Batch image meta info.
+ Defaults to None.
+ cfg (:obj:`ConfigDict` or dict, optional): Test / postprocessing
+ configuration, if None, test_cfg would be used.
+ Defaults to None.
+ rescale (bool): If True, return boxes in original image space.
+ Defaults to False.
+ with_nms (bool): If True, do nms before return boxes.
+ Defaults to True.
+
+ Returns:
+ list[:obj:`InstanceData`]: Object detection results of each image
+ after the post process. Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ """
+ assert len(pred_maps) == self.num_levels
+ cfg = self.test_cfg if cfg is None else cfg
+ cfg = copy.deepcopy(cfg)
+
+ num_imgs = len(batch_img_metas)
+ featmap_sizes = [pred_map.shape[-2:] for pred_map in pred_maps]
+
+ mlvl_anchors = self.prior_generator.grid_priors(
+ featmap_sizes, device=pred_maps[0].device)
+ flatten_preds = []
+ flatten_strides = []
+ for pred, stride in zip(pred_maps, self.featmap_strides):
+ pred = pred.permute(0, 2, 3, 1).reshape(num_imgs, -1,
+ self.num_attrib)
+ pred[..., :2].sigmoid_()
+ flatten_preds.append(pred)
+ flatten_strides.append(
+ pred.new_tensor(stride).expand(pred.size(1)))
+
+ flatten_preds = torch.cat(flatten_preds, dim=1)
+ flatten_bbox_preds = flatten_preds[..., :4]
+ flatten_objectness = flatten_preds[..., 4].sigmoid()
+ flatten_cls_scores = flatten_preds[..., 5:].sigmoid()
+ flatten_anchors = torch.cat(mlvl_anchors)
+ flatten_strides = torch.cat(flatten_strides)
+ flatten_bboxes = self.bbox_coder.decode(flatten_anchors,
+ flatten_bbox_preds,
+ flatten_strides.unsqueeze(-1))
+ results_list = []
+ for (bboxes, scores, objectness,
+ img_meta) in zip(flatten_bboxes, flatten_cls_scores,
+ flatten_objectness, batch_img_metas):
+ # Filtering out all predictions with conf < conf_thr
+ conf_thr = cfg.get('conf_thr', -1)
+ if conf_thr > 0:
+ conf_inds = objectness >= conf_thr
+ bboxes = bboxes[conf_inds, :]
+ scores = scores[conf_inds, :]
+ objectness = objectness[conf_inds]
+
+ score_thr = cfg.get('score_thr', 0)
+ nms_pre = cfg.get('nms_pre', -1)
+ scores, labels, keep_idxs, _ = filter_scores_and_topk(
+ scores, score_thr, nms_pre)
+
+ results = InstanceData(
+ scores=scores,
+ labels=labels,
+ bboxes=bboxes[keep_idxs],
+ score_factors=objectness[keep_idxs],
+ )
+ results = self._bbox_post_process(
+ results=results,
+ cfg=cfg,
+ rescale=rescale,
+ with_nms=with_nms,
+ img_meta=img_meta)
+ results_list.append(results)
+ return results_list
+
+ def loss_by_feat(
+ self,
+ pred_maps: Sequence[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ batch_gt_instances_ignore: OptInstanceList = None) -> dict:
+ """Calculate the loss based on the features extracted by the detection
+ head.
+
+ Args:
+ pred_maps (list[Tensor]): Prediction map for each scale level,
+ shape (N, num_anchors * num_attrib, H, W)
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ dict: A dictionary of loss components.
+ """
+ num_imgs = len(batch_img_metas)
+ device = pred_maps[0][0].device
+
+ featmap_sizes = [
+ pred_maps[i].shape[-2:] for i in range(self.num_levels)
+ ]
+ mlvl_anchors = self.prior_generator.grid_priors(
+ featmap_sizes, device=device)
+ anchor_list = [mlvl_anchors for _ in range(num_imgs)]
+
+ responsible_flag_list = []
+ for img_id in range(num_imgs):
+ responsible_flag_list.append(
+ self.responsible_flags(featmap_sizes,
+ batch_gt_instances[img_id].bboxes,
+ device))
+
+ target_maps_list, neg_maps_list = self.get_targets(
+ anchor_list, responsible_flag_list, batch_gt_instances)
+
+ losses_cls, losses_conf, losses_xy, losses_wh = multi_apply(
+ self.loss_by_feat_single, pred_maps, target_maps_list,
+ neg_maps_list)
+
+ return dict(
+ loss_cls=losses_cls,
+ loss_conf=losses_conf,
+ loss_xy=losses_xy,
+ loss_wh=losses_wh)
+
+ def loss_by_feat_single(self, pred_map: Tensor, target_map: Tensor,
+ neg_map: Tensor) -> tuple:
+ """Calculate the loss of a single scale level based on the features
+ extracted by the detection head.
+
+ Args:
+ pred_map (Tensor): Raw predictions for a single level.
+ target_map (Tensor): The Ground-Truth target for a single level.
+ neg_map (Tensor): The negative masks for a single level.
+
+ Returns:
+ tuple:
+ loss_cls (Tensor): Classification loss.
+ loss_conf (Tensor): Confidence loss.
+ loss_xy (Tensor): Regression loss of x, y coordinate.
+ loss_wh (Tensor): Regression loss of w, h coordinate.
+ """
+
+ num_imgs = len(pred_map)
+ pred_map = pred_map.permute(0, 2, 3,
+ 1).reshape(num_imgs, -1, self.num_attrib)
+ neg_mask = neg_map.float()
+ pos_mask = target_map[..., 4]
+ pos_and_neg_mask = neg_mask + pos_mask
+ pos_mask = pos_mask.unsqueeze(dim=-1)
+ if torch.max(pos_and_neg_mask) > 1.:
+ warnings.warn('There is overlap between pos and neg sample.')
+ pos_and_neg_mask = pos_and_neg_mask.clamp(min=0., max=1.)
+
+ pred_xy = pred_map[..., :2]
+ pred_wh = pred_map[..., 2:4]
+ pred_conf = pred_map[..., 4]
+ pred_label = pred_map[..., 5:]
+
+ target_xy = target_map[..., :2]
+ target_wh = target_map[..., 2:4]
+ target_conf = target_map[..., 4]
+ target_label = target_map[..., 5:]
+
+ loss_cls = self.loss_cls(pred_label, target_label, weight=pos_mask)
+ loss_conf = self.loss_conf(
+ pred_conf, target_conf, weight=pos_and_neg_mask)
+ loss_xy = self.loss_xy(pred_xy, target_xy, weight=pos_mask)
+ loss_wh = self.loss_wh(pred_wh, target_wh, weight=pos_mask)
+
+ return loss_cls, loss_conf, loss_xy, loss_wh
+
+ def get_targets(self, anchor_list: List[List[Tensor]],
+ responsible_flag_list: List[List[Tensor]],
+ batch_gt_instances: List[InstanceData]) -> tuple:
+ """Compute target maps for anchors in multiple images.
+
+ Args:
+ anchor_list (list[list[Tensor]]): Multi level anchors of each
+ image. The outer list indicates images, and the inner list
+ corresponds to feature levels of the image. Each element of
+ the inner list is a tensor of shape (num_total_anchors, 4).
+ responsible_flag_list (list[list[Tensor]]): Multi level responsible
+ flags of each image. Each element is a tensor of shape
+ (num_total_anchors, )
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+
+ Returns:
+ tuple: Usually returns a tuple containing learning targets.
+ - target_map_list (list[Tensor]): Target map of each level.
+ - neg_map_list (list[Tensor]): Negative map of each level.
+ """
+ num_imgs = len(anchor_list)
+
+ # anchor number of multi levels
+ num_level_anchors = [anchors.size(0) for anchors in anchor_list[0]]
+
+ results = multi_apply(self._get_targets_single, anchor_list,
+ responsible_flag_list, batch_gt_instances)
+
+ all_target_maps, all_neg_maps = results
+ assert num_imgs == len(all_target_maps) == len(all_neg_maps)
+ target_maps_list = images_to_levels(all_target_maps, num_level_anchors)
+ neg_maps_list = images_to_levels(all_neg_maps, num_level_anchors)
+
+ return target_maps_list, neg_maps_list
+
+ def _get_targets_single(self, anchors: List[Tensor],
+ responsible_flags: List[Tensor],
+ gt_instances: InstanceData) -> tuple:
+ """Generate matching bounding box prior and converted GT.
+
+ Args:
+ anchors (List[Tensor]): Multi-level anchors of the image.
+ responsible_flags (List[Tensor]): Multi-level responsible flags of
+ anchors
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It should includes ``bboxes`` and ``labels``
+ attributes.
+
+ Returns:
+ tuple:
+ target_map (Tensor): Predication target map of each
+ scale level, shape (num_total_anchors,
+ 5+num_classes)
+ neg_map (Tensor): Negative map of each scale level,
+ shape (num_total_anchors,)
+ """
+ gt_bboxes = gt_instances.bboxes
+ gt_labels = gt_instances.labels
+ anchor_strides = []
+ for i in range(len(anchors)):
+ anchor_strides.append(
+ torch.tensor(self.featmap_strides[i],
+ device=gt_bboxes.device).repeat(len(anchors[i])))
+ concat_anchors = torch.cat(anchors)
+ concat_responsible_flags = torch.cat(responsible_flags)
+
+ anchor_strides = torch.cat(anchor_strides)
+ assert len(anchor_strides) == len(concat_anchors) == \
+ len(concat_responsible_flags)
+ pred_instances = InstanceData(
+ priors=concat_anchors, responsible_flags=concat_responsible_flags)
+
+ assign_result = self.assigner.assign(pred_instances, gt_instances)
+ sampling_result = self.sampler.sample(assign_result, pred_instances,
+ gt_instances)
+
+ target_map = concat_anchors.new_zeros(
+ concat_anchors.size(0), self.num_attrib)
+
+ target_map[sampling_result.pos_inds, :4] = self.bbox_coder.encode(
+ sampling_result.pos_priors, sampling_result.pos_gt_bboxes,
+ anchor_strides[sampling_result.pos_inds])
+
+ target_map[sampling_result.pos_inds, 4] = 1
+
+ gt_labels_one_hot = F.one_hot(
+ gt_labels, num_classes=self.num_classes).float()
+ if self.one_hot_smoother != 0: # label smooth
+ gt_labels_one_hot = gt_labels_one_hot * (
+ 1 - self.one_hot_smoother
+ ) + self.one_hot_smoother / self.num_classes
+ target_map[sampling_result.pos_inds, 5:] = gt_labels_one_hot[
+ sampling_result.pos_assigned_gt_inds]
+
+ neg_map = concat_anchors.new_zeros(
+ concat_anchors.size(0), dtype=torch.uint8)
+ neg_map[sampling_result.neg_inds] = 1
+
+ return target_map, neg_map
+
+ def responsible_flags(self, featmap_sizes: List[tuple], gt_bboxes: Tensor,
+ device: str) -> List[Tensor]:
+ """Generate responsible anchor flags of grid cells in multiple scales.
+
+ Args:
+ featmap_sizes (List[tuple]): List of feature map sizes in multiple
+ feature levels.
+ gt_bboxes (Tensor): Ground truth boxes, shape (n, 4).
+ device (str): Device where the anchors will be put on.
+
+ Return:
+ List[Tensor]: responsible flags of anchors in multiple level
+ """
+ assert self.num_levels == len(featmap_sizes)
+ multi_level_responsible_flags = []
+ for i in range(self.num_levels):
+ anchor_stride = self.prior_generator.strides[i]
+ feat_h, feat_w = featmap_sizes[i]
+ gt_cx = ((gt_bboxes[:, 0] + gt_bboxes[:, 2]) * 0.5).to(device)
+ gt_cy = ((gt_bboxes[:, 1] + gt_bboxes[:, 3]) * 0.5).to(device)
+ gt_grid_x = torch.floor(gt_cx / anchor_stride[0]).long()
+ gt_grid_y = torch.floor(gt_cy / anchor_stride[1]).long()
+ # row major indexing
+ gt_bboxes_grid_idx = gt_grid_y * feat_w + gt_grid_x
+
+ responsible_grid = torch.zeros(
+ feat_h * feat_w, dtype=torch.uint8, device=device)
+ responsible_grid[gt_bboxes_grid_idx] = 1
+
+ responsible_grid = responsible_grid[:, None].expand(
+ responsible_grid.size(0),
+ self.prior_generator.num_base_priors[i]).contiguous().view(-1)
+
+ multi_level_responsible_flags.append(responsible_grid)
+ return multi_level_responsible_flags
diff --git a/mmdet/models/dense_heads/yolof_head.py b/mmdet/models/dense_heads/yolof_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..bef4d8803c9311447588589a89fbd6a4b1f09a54
--- /dev/null
+++ b/mmdet/models/dense_heads/yolof_head.py
@@ -0,0 +1,399 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Optional, Tuple
+
+import torch
+import torch.nn as nn
+from mmcv.cnn import ConvModule, is_norm
+from mmengine.model import bias_init_with_prob, constant_init, normal_init
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.utils import ConfigType, InstanceList, OptInstanceList, reduce_mean
+from ..task_modules.prior_generators import anchor_inside_flags
+from ..utils import levels_to_images, multi_apply, unmap
+from .anchor_head import AnchorHead
+
+INF = 1e8
+
+
+@MODELS.register_module()
+class YOLOFHead(AnchorHead):
+ """Detection Head of `YOLOF `_
+
+ Args:
+ num_classes (int): The number of object classes (w/o background)
+ in_channels (list[int]): The number of input channels per scale.
+ cls_num_convs (int): The number of convolutions of cls branch.
+ Defaults to 2.
+ reg_num_convs (int): The number of convolutions of reg branch.
+ Defaults to 4.
+ norm_cfg (:obj:`ConfigDict` or dict): Config dict for normalization
+ layer. Defaults to ``dict(type='BN', requires_grad=True)``.
+ """
+
+ def __init__(self,
+ num_classes: int,
+ in_channels: List[int],
+ num_cls_convs: int = 2,
+ num_reg_convs: int = 4,
+ norm_cfg: ConfigType = dict(type='BN', requires_grad=True),
+ **kwargs) -> None:
+ self.num_cls_convs = num_cls_convs
+ self.num_reg_convs = num_reg_convs
+ self.norm_cfg = norm_cfg
+ super().__init__(
+ num_classes=num_classes, in_channels=in_channels, **kwargs)
+
+ def _init_layers(self) -> None:
+ cls_subnet = []
+ bbox_subnet = []
+ for i in range(self.num_cls_convs):
+ cls_subnet.append(
+ ConvModule(
+ self.in_channels,
+ self.in_channels,
+ kernel_size=3,
+ padding=1,
+ norm_cfg=self.norm_cfg))
+ for i in range(self.num_reg_convs):
+ bbox_subnet.append(
+ ConvModule(
+ self.in_channels,
+ self.in_channels,
+ kernel_size=3,
+ padding=1,
+ norm_cfg=self.norm_cfg))
+ self.cls_subnet = nn.Sequential(*cls_subnet)
+ self.bbox_subnet = nn.Sequential(*bbox_subnet)
+ self.cls_score = nn.Conv2d(
+ self.in_channels,
+ self.num_base_priors * self.num_classes,
+ kernel_size=3,
+ stride=1,
+ padding=1)
+ self.bbox_pred = nn.Conv2d(
+ self.in_channels,
+ self.num_base_priors * 4,
+ kernel_size=3,
+ stride=1,
+ padding=1)
+ self.object_pred = nn.Conv2d(
+ self.in_channels,
+ self.num_base_priors,
+ kernel_size=3,
+ stride=1,
+ padding=1)
+
+ def init_weights(self) -> None:
+ for m in self.modules():
+ if isinstance(m, nn.Conv2d):
+ normal_init(m, mean=0, std=0.01)
+ if is_norm(m):
+ constant_init(m, 1)
+
+ # Use prior in model initialization to improve stability
+ bias_cls = bias_init_with_prob(0.01)
+ torch.nn.init.constant_(self.cls_score.bias, bias_cls)
+
+ def forward_single(self, x: Tensor) -> Tuple[Tensor, Tensor]:
+ """Forward feature of a single scale level.
+
+ Args:
+ x (Tensor): Features of a single scale level.
+
+ Returns:
+ tuple:
+ normalized_cls_score (Tensor): Normalized Cls scores for a \
+ single scale level, the channels number is \
+ num_base_priors * num_classes.
+ bbox_reg (Tensor): Box energies / deltas for a single scale \
+ level, the channels number is num_base_priors * 4.
+ """
+ cls_score = self.cls_score(self.cls_subnet(x))
+ N, _, H, W = cls_score.shape
+ cls_score = cls_score.view(N, -1, self.num_classes, H, W)
+
+ reg_feat = self.bbox_subnet(x)
+ bbox_reg = self.bbox_pred(reg_feat)
+ objectness = self.object_pred(reg_feat)
+
+ # implicit objectness
+ objectness = objectness.view(N, -1, 1, H, W)
+ normalized_cls_score = cls_score + objectness - torch.log(
+ 1. + torch.clamp(cls_score.exp(), max=INF) +
+ torch.clamp(objectness.exp(), max=INF))
+ normalized_cls_score = normalized_cls_score.view(N, -1, H, W)
+ return normalized_cls_score, bbox_reg
+
+ def loss_by_feat(
+ self,
+ cls_scores: List[Tensor],
+ bbox_preds: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ batch_gt_instances_ignore: OptInstanceList = None) -> dict:
+ """Calculate the loss based on the features extracted by the detection
+ head.
+
+ Args:
+ cls_scores (list[Tensor]): Box scores for each scale level
+ has shape (N, num_anchors * num_classes, H, W).
+ bbox_preds (list[Tensor]): Box energies / deltas for each scale
+ level with shape (N, num_anchors * 4, H, W).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ dict: A dictionary of loss components.
+ """
+ assert len(cls_scores) == 1
+ assert self.prior_generator.num_levels == 1
+
+ device = cls_scores[0].device
+ featmap_sizes = [featmap.size()[-2:] for featmap in cls_scores]
+ anchor_list, valid_flag_list = self.get_anchors(
+ featmap_sizes, batch_img_metas, device=device)
+
+ # The output level is always 1
+ anchor_list = [anchors[0] for anchors in anchor_list]
+ valid_flag_list = [valid_flags[0] for valid_flags in valid_flag_list]
+
+ cls_scores_list = levels_to_images(cls_scores)
+ bbox_preds_list = levels_to_images(bbox_preds)
+
+ cls_reg_targets = self.get_targets(
+ cls_scores_list,
+ bbox_preds_list,
+ anchor_list,
+ valid_flag_list,
+ batch_gt_instances,
+ batch_img_metas,
+ batch_gt_instances_ignore=batch_gt_instances_ignore)
+ if cls_reg_targets is None:
+ return None
+ (batch_labels, batch_label_weights, avg_factor, batch_bbox_weights,
+ batch_pos_predicted_boxes, batch_target_boxes) = cls_reg_targets
+
+ flatten_labels = batch_labels.reshape(-1)
+ batch_label_weights = batch_label_weights.reshape(-1)
+ cls_score = cls_scores[0].permute(0, 2, 3,
+ 1).reshape(-1, self.cls_out_channels)
+
+ avg_factor = reduce_mean(
+ torch.tensor(avg_factor, dtype=torch.float, device=device)).item()
+
+ # classification loss
+ loss_cls = self.loss_cls(
+ cls_score,
+ flatten_labels,
+ batch_label_weights,
+ avg_factor=avg_factor)
+
+ # regression loss
+ if batch_pos_predicted_boxes.shape[0] == 0:
+ # no pos sample
+ loss_bbox = batch_pos_predicted_boxes.sum() * 0
+ else:
+ loss_bbox = self.loss_bbox(
+ batch_pos_predicted_boxes,
+ batch_target_boxes,
+ batch_bbox_weights.float(),
+ avg_factor=avg_factor)
+
+ return dict(loss_cls=loss_cls, loss_bbox=loss_bbox)
+
+ def get_targets(self,
+ cls_scores_list: List[Tensor],
+ bbox_preds_list: List[Tensor],
+ anchor_list: List[Tensor],
+ valid_flag_list: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ batch_gt_instances_ignore: OptInstanceList = None,
+ unmap_outputs: bool = True):
+ """Compute regression and classification targets for anchors in
+ multiple images.
+
+ Args:
+ cls_scores_list (list[Tensor]): Classification scores of
+ each image. each is a 4D-tensor, the shape is
+ (h * w, num_anchors * num_classes).
+ bbox_preds_list (list[Tensor]): Bbox preds of each image.
+ each is a 4D-tensor, the shape is (h * w, num_anchors * 4).
+ anchor_list (list[Tensor]): Anchors of each image. Each element of
+ is a tensor of shape (h * w * num_anchors, 4).
+ valid_flag_list (list[Tensor]): Valid flags of each image. Each
+ element of is a tensor of shape (h * w * num_anchors, )
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+ unmap_outputs (bool): Whether to map outputs back to the original
+ set of anchors.
+
+ Returns:
+ tuple: Usually returns a tuple containing learning targets.
+
+ - batch_labels (Tensor): Label of all images. Each element \
+ of is a tensor of shape (batch, h * w * num_anchors)
+ - batch_label_weights (Tensor): Label weights of all images \
+ of is a tensor of shape (batch, h * w * num_anchors)
+ - num_total_pos (int): Number of positive samples in all \
+ images.
+ - num_total_neg (int): Number of negative samples in all \
+ images.
+ additional_returns: This function enables user-defined returns from
+ `self._get_targets_single`. These returns are currently refined
+ to properties at each feature map (i.e. having HxW dimension).
+ The results will be concatenated after the end
+ """
+ num_imgs = len(batch_img_metas)
+ assert len(anchor_list) == len(valid_flag_list) == num_imgs
+
+ # compute targets for each image
+ if batch_gt_instances_ignore is None:
+ batch_gt_instances_ignore = [None] * num_imgs
+ results = multi_apply(
+ self._get_targets_single,
+ bbox_preds_list,
+ anchor_list,
+ valid_flag_list,
+ batch_gt_instances,
+ batch_img_metas,
+ batch_gt_instances_ignore,
+ unmap_outputs=unmap_outputs)
+ (all_labels, all_label_weights, pos_inds, neg_inds,
+ sampling_results_list) = results[:5]
+ # Get `avg_factor` of all images, which calculate in `SamplingResult`.
+ # When using sampling method, avg_factor is usually the sum of
+ # positive and negative priors. When using `PseudoSampler`,
+ # `avg_factor` is usually equal to the number of positive priors.
+ avg_factor = sum(
+ [results.avg_factor for results in sampling_results_list])
+ rest_results = list(results[5:]) # user-added return values
+
+ batch_labels = torch.stack(all_labels, 0)
+ batch_label_weights = torch.stack(all_label_weights, 0)
+
+ res = (batch_labels, batch_label_weights, avg_factor)
+ for i, rests in enumerate(rest_results): # user-added return values
+ rest_results[i] = torch.cat(rests, 0)
+
+ return res + tuple(rest_results)
+
+ def _get_targets_single(self,
+ bbox_preds: Tensor,
+ flat_anchors: Tensor,
+ valid_flags: Tensor,
+ gt_instances: InstanceData,
+ img_meta: dict,
+ gt_instances_ignore: Optional[InstanceData] = None,
+ unmap_outputs: bool = True) -> tuple:
+ """Compute regression and classification targets for anchors in a
+ single image.
+
+ Args:
+ bbox_preds (Tensor): Bbox prediction of the image, which
+ shape is (h * w ,4)
+ flat_anchors (Tensor): Anchors of the image, which shape is
+ (h * w * num_anchors ,4)
+ valid_flags (Tensor): Valid flags of the image, which shape is
+ (h * w * num_anchors,).
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It should includes ``bboxes`` and ``labels``
+ attributes.
+ img_meta (dict): Meta information for current image.
+ gt_instances_ignore (:obj:`InstanceData`, optional): Instances
+ to be ignored during training. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+ unmap_outputs (bool): Whether to map outputs back to the original
+ set of anchors.
+
+ Returns:
+ tuple:
+ labels (Tensor): Labels of image, which shape is
+ (h * w * num_anchors, ).
+ label_weights (Tensor): Label weights of image, which shape is
+ (h * w * num_anchors, ).
+ pos_inds (Tensor): Pos index of image.
+ neg_inds (Tensor): Neg index of image.
+ sampling_result (obj:`SamplingResult`): Sampling result.
+ pos_bbox_weights (Tensor): The Weight of using to calculate
+ the bbox branch loss, which shape is (num, ).
+ pos_predicted_boxes (Tensor): boxes predicted value of
+ using to calculate the bbox branch loss, which shape is
+ (num, 4).
+ pos_target_boxes (Tensor): boxes target value of
+ using to calculate the bbox branch loss, which shape is
+ (num, 4).
+ """
+ inside_flags = anchor_inside_flags(flat_anchors, valid_flags,
+ img_meta['img_shape'][:2],
+ self.train_cfg['allowed_border'])
+ if not inside_flags.any():
+ raise ValueError(
+ 'There is no valid anchor inside the image boundary. Please '
+ 'check the image size and anchor sizes, or set '
+ '``allowed_border`` to -1 to skip the condition.')
+
+ # assign gt and sample anchors
+ anchors = flat_anchors[inside_flags, :]
+ bbox_preds = bbox_preds.reshape(-1, 4)
+ bbox_preds = bbox_preds[inside_flags, :]
+
+ # decoded bbox
+ decoder_bbox_preds = self.bbox_coder.decode(anchors, bbox_preds)
+ pred_instances = InstanceData(
+ priors=anchors, decoder_priors=decoder_bbox_preds)
+ assign_result = self.assigner.assign(pred_instances, gt_instances,
+ gt_instances_ignore)
+
+ pos_bbox_weights = assign_result.get_extra_property('pos_idx')
+ pos_predicted_boxes = assign_result.get_extra_property(
+ 'pos_predicted_boxes')
+ pos_target_boxes = assign_result.get_extra_property('target_boxes')
+
+ sampling_result = self.sampler.sample(assign_result, pred_instances,
+ gt_instances)
+ num_valid_anchors = anchors.shape[0]
+ labels = anchors.new_full((num_valid_anchors, ),
+ self.num_classes,
+ dtype=torch.long)
+ label_weights = anchors.new_zeros(num_valid_anchors, dtype=torch.float)
+
+ pos_inds = sampling_result.pos_inds
+ neg_inds = sampling_result.neg_inds
+ if len(pos_inds) > 0:
+ labels[pos_inds] = sampling_result.pos_gt_labels
+ if self.train_cfg['pos_weight'] <= 0:
+ label_weights[pos_inds] = 1.0
+ else:
+ label_weights[pos_inds] = self.train_cfg['pos_weight']
+ if len(neg_inds) > 0:
+ label_weights[neg_inds] = 1.0
+
+ # map up to original set of anchors
+ if unmap_outputs:
+ num_total_anchors = flat_anchors.size(0)
+ labels = unmap(
+ labels, num_total_anchors, inside_flags,
+ fill=self.num_classes) # fill bg label
+ label_weights = unmap(label_weights, num_total_anchors,
+ inside_flags)
+
+ return (labels, label_weights, pos_inds, neg_inds, sampling_result,
+ pos_bbox_weights, pos_predicted_boxes, pos_target_boxes)
diff --git a/mmdet/models/dense_heads/yolox_head.py b/mmdet/models/dense_heads/yolox_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..00fe1e42766e4ca0052cf31d2e940dfab73fb200
--- /dev/null
+++ b/mmdet/models/dense_heads/yolox_head.py
@@ -0,0 +1,618 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+from typing import List, Optional, Sequence, Tuple, Union
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule, DepthwiseSeparableConvModule
+from mmcv.ops.nms import batched_nms
+from mmengine.config import ConfigDict
+from mmengine.model import bias_init_with_prob
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmdet.registry import MODELS, TASK_UTILS
+from mmdet.structures.bbox import bbox_xyxy_to_cxcywh
+from mmdet.utils import (ConfigType, OptConfigType, OptInstanceList,
+ OptMultiConfig, reduce_mean)
+from ..task_modules.prior_generators import MlvlPointGenerator
+from ..task_modules.samplers import PseudoSampler
+from ..utils import multi_apply
+from .base_dense_head import BaseDenseHead
+
+
+@MODELS.register_module()
+class YOLOXHead(BaseDenseHead):
+ """YOLOXHead head used in `YOLOX `_.
+
+ Args:
+ num_classes (int): Number of categories excluding the background
+ category.
+ in_channels (int): Number of channels in the input feature map.
+ feat_channels (int): Number of hidden channels in stacking convs.
+ Defaults to 256
+ stacked_convs (int): Number of stacking convs of the head.
+ Defaults to (8, 16, 32).
+ strides (Sequence[int]): Downsample factor of each feature map.
+ Defaults to None.
+ use_depthwise (bool): Whether to depthwise separable convolution in
+ blocks. Defaults to False.
+ dcn_on_last_conv (bool): If true, use dcn in the last layer of
+ towers. Defaults to False.
+ conv_bias (bool or str): If specified as `auto`, it will be decided by
+ the norm_cfg. Bias of conv will be set as True if `norm_cfg` is
+ None, otherwise False. Defaults to "auto".
+ conv_cfg (:obj:`ConfigDict` or dict, optional): Config dict for
+ convolution layer. Defaults to None.
+ norm_cfg (:obj:`ConfigDict` or dict): Config dict for normalization
+ layer. Defaults to dict(type='BN', momentum=0.03, eps=0.001).
+ act_cfg (:obj:`ConfigDict` or dict): Config dict for activation layer.
+ Defaults to None.
+ loss_cls (:obj:`ConfigDict` or dict): Config of classification loss.
+ loss_bbox (:obj:`ConfigDict` or dict): Config of localization loss.
+ loss_obj (:obj:`ConfigDict` or dict): Config of objectness loss.
+ loss_l1 (:obj:`ConfigDict` or dict): Config of L1 loss.
+ train_cfg (:obj:`ConfigDict` or dict, optional): Training config of
+ anchor head. Defaults to None.
+ test_cfg (:obj:`ConfigDict` or dict, optional): Testing config of
+ anchor head. Defaults to None.
+ init_cfg (:obj:`ConfigDict` or list[:obj:`ConfigDict`] or dict or
+ list[dict], optional): Initialization config dict.
+ Defaults to None.
+ """
+
+ def __init__(
+ self,
+ num_classes: int,
+ in_channels: int,
+ feat_channels: int = 256,
+ stacked_convs: int = 2,
+ strides: Sequence[int] = (8, 16, 32),
+ use_depthwise: bool = False,
+ dcn_on_last_conv: bool = False,
+ conv_bias: Union[bool, str] = 'auto',
+ conv_cfg: OptConfigType = None,
+ norm_cfg: ConfigType = dict(type='BN', momentum=0.03, eps=0.001),
+ act_cfg: ConfigType = dict(type='Swish'),
+ loss_cls: ConfigType = dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=True,
+ reduction='sum',
+ loss_weight=1.0),
+ loss_bbox: ConfigType = dict(
+ type='IoULoss',
+ mode='square',
+ eps=1e-16,
+ reduction='sum',
+ loss_weight=5.0),
+ loss_obj: ConfigType = dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=True,
+ reduction='sum',
+ loss_weight=1.0),
+ loss_l1: ConfigType = dict(
+ type='L1Loss', reduction='sum', loss_weight=1.0),
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ init_cfg: OptMultiConfig = dict(
+ type='Kaiming',
+ layer='Conv2d',
+ a=math.sqrt(5),
+ distribution='uniform',
+ mode='fan_in',
+ nonlinearity='leaky_relu')
+ ) -> None:
+
+ super().__init__(init_cfg=init_cfg)
+ self.num_classes = num_classes
+ self.cls_out_channels = num_classes
+ self.in_channels = in_channels
+ self.feat_channels = feat_channels
+ self.stacked_convs = stacked_convs
+ self.strides = strides
+ self.use_depthwise = use_depthwise
+ self.dcn_on_last_conv = dcn_on_last_conv
+ assert conv_bias == 'auto' or isinstance(conv_bias, bool)
+ self.conv_bias = conv_bias
+ self.use_sigmoid_cls = True
+
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.act_cfg = act_cfg
+
+ self.loss_cls: nn.Module = MODELS.build(loss_cls)
+ self.loss_bbox: nn.Module = MODELS.build(loss_bbox)
+ self.loss_obj: nn.Module = MODELS.build(loss_obj)
+
+ self.use_l1 = False # This flag will be modified by hooks.
+ self.loss_l1: nn.Module = MODELS.build(loss_l1)
+
+ self.prior_generator = MlvlPointGenerator(strides, offset=0)
+
+ self.test_cfg = test_cfg
+ self.train_cfg = train_cfg
+
+ if self.train_cfg:
+ self.assigner = TASK_UTILS.build(self.train_cfg['assigner'])
+ # YOLOX does not support sampling
+ self.sampler = PseudoSampler()
+
+ self._init_layers()
+
+ def _init_layers(self) -> None:
+ """Initialize heads for all level feature maps."""
+ self.multi_level_cls_convs = nn.ModuleList()
+ self.multi_level_reg_convs = nn.ModuleList()
+ self.multi_level_conv_cls = nn.ModuleList()
+ self.multi_level_conv_reg = nn.ModuleList()
+ self.multi_level_conv_obj = nn.ModuleList()
+ for _ in self.strides:
+ self.multi_level_cls_convs.append(self._build_stacked_convs())
+ self.multi_level_reg_convs.append(self._build_stacked_convs())
+ conv_cls, conv_reg, conv_obj = self._build_predictor()
+ self.multi_level_conv_cls.append(conv_cls)
+ self.multi_level_conv_reg.append(conv_reg)
+ self.multi_level_conv_obj.append(conv_obj)
+
+ def _build_stacked_convs(self) -> nn.Sequential:
+ """Initialize conv layers of a single level head."""
+ conv = DepthwiseSeparableConvModule \
+ if self.use_depthwise else ConvModule
+ stacked_convs = []
+ for i in range(self.stacked_convs):
+ chn = self.in_channels if i == 0 else self.feat_channels
+ if self.dcn_on_last_conv and i == self.stacked_convs - 1:
+ conv_cfg = dict(type='DCNv2')
+ else:
+ conv_cfg = self.conv_cfg
+ stacked_convs.append(
+ conv(
+ chn,
+ self.feat_channels,
+ 3,
+ stride=1,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg,
+ bias=self.conv_bias))
+ return nn.Sequential(*stacked_convs)
+
+ def _build_predictor(self) -> Tuple[nn.Module, nn.Module, nn.Module]:
+ """Initialize predictor layers of a single level head."""
+ conv_cls = nn.Conv2d(self.feat_channels, self.cls_out_channels, 1)
+ conv_reg = nn.Conv2d(self.feat_channels, 4, 1)
+ conv_obj = nn.Conv2d(self.feat_channels, 1, 1)
+ return conv_cls, conv_reg, conv_obj
+
+ def init_weights(self) -> None:
+ """Initialize weights of the head."""
+ super(YOLOXHead, self).init_weights()
+ # Use prior in model initialization to improve stability
+ bias_init = bias_init_with_prob(0.01)
+ for conv_cls, conv_obj in zip(self.multi_level_conv_cls,
+ self.multi_level_conv_obj):
+ conv_cls.bias.data.fill_(bias_init)
+ conv_obj.bias.data.fill_(bias_init)
+
+ def forward_single(self, x: Tensor, cls_convs: nn.Module,
+ reg_convs: nn.Module, conv_cls: nn.Module,
+ conv_reg: nn.Module,
+ conv_obj: nn.Module) -> Tuple[Tensor, Tensor, Tensor]:
+ """Forward feature of a single scale level."""
+
+ cls_feat = cls_convs(x)
+ reg_feat = reg_convs(x)
+
+ cls_score = conv_cls(cls_feat)
+ bbox_pred = conv_reg(reg_feat)
+ objectness = conv_obj(reg_feat)
+
+ return cls_score, bbox_pred, objectness
+
+ def forward(self, x: Tuple[Tensor]) -> Tuple[List]:
+ """Forward features from the upstream network.
+
+ Args:
+ x (Tuple[Tensor]): Features from the upstream network, each is
+ a 4D-tensor.
+ Returns:
+ Tuple[List]: A tuple of multi-level classification scores, bbox
+ predictions, and objectnesses.
+ """
+
+ return multi_apply(self.forward_single, x, self.multi_level_cls_convs,
+ self.multi_level_reg_convs,
+ self.multi_level_conv_cls,
+ self.multi_level_conv_reg,
+ self.multi_level_conv_obj)
+
+ def predict_by_feat(self,
+ cls_scores: List[Tensor],
+ bbox_preds: List[Tensor],
+ objectnesses: Optional[List[Tensor]],
+ batch_img_metas: Optional[List[dict]] = None,
+ cfg: Optional[ConfigDict] = None,
+ rescale: bool = False,
+ with_nms: bool = True) -> List[InstanceData]:
+ """Transform a batch of output features extracted by the head into
+ bbox results.
+ Args:
+ cls_scores (list[Tensor]): Classification scores for all
+ scale levels, each is a 4D-tensor, has shape
+ (batch_size, num_priors * num_classes, H, W).
+ bbox_preds (list[Tensor]): Box energies / deltas for all
+ scale levels, each is a 4D-tensor, has shape
+ (batch_size, num_priors * 4, H, W).
+ objectnesses (list[Tensor], Optional): Score factor for
+ all scale level, each is a 4D-tensor, has shape
+ (batch_size, 1, H, W).
+ batch_img_metas (list[dict], Optional): Batch image meta info.
+ Defaults to None.
+ cfg (ConfigDict, optional): Test / postprocessing
+ configuration, if None, test_cfg would be used.
+ Defaults to None.
+ rescale (bool): If True, return boxes in original image space.
+ Defaults to False.
+ with_nms (bool): If True, do nms before return boxes.
+ Defaults to True.
+
+ Returns:
+ list[:obj:`InstanceData`]: Object detection results of each image
+ after the post process. Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ """
+ assert len(cls_scores) == len(bbox_preds) == len(objectnesses)
+ cfg = self.test_cfg if cfg is None else cfg
+
+ num_imgs = len(batch_img_metas)
+ featmap_sizes = [cls_score.shape[2:] for cls_score in cls_scores]
+ mlvl_priors = self.prior_generator.grid_priors(
+ featmap_sizes,
+ dtype=cls_scores[0].dtype,
+ device=cls_scores[0].device,
+ with_stride=True)
+
+ # flatten cls_scores, bbox_preds and objectness
+ flatten_cls_scores = [
+ cls_score.permute(0, 2, 3, 1).reshape(num_imgs, -1,
+ self.cls_out_channels)
+ for cls_score in cls_scores
+ ]
+ flatten_bbox_preds = [
+ bbox_pred.permute(0, 2, 3, 1).reshape(num_imgs, -1, 4)
+ for bbox_pred in bbox_preds
+ ]
+ flatten_objectness = [
+ objectness.permute(0, 2, 3, 1).reshape(num_imgs, -1)
+ for objectness in objectnesses
+ ]
+
+ flatten_cls_scores = torch.cat(flatten_cls_scores, dim=1).sigmoid()
+ flatten_bbox_preds = torch.cat(flatten_bbox_preds, dim=1)
+ flatten_objectness = torch.cat(flatten_objectness, dim=1).sigmoid()
+ flatten_priors = torch.cat(mlvl_priors)
+
+ flatten_bboxes = self._bbox_decode(flatten_priors, flatten_bbox_preds)
+
+ result_list = []
+ for img_id, img_meta in enumerate(batch_img_metas):
+ max_scores, labels = torch.max(flatten_cls_scores[img_id], 1)
+ valid_mask = flatten_objectness[
+ img_id] * max_scores >= cfg.score_thr
+ results = InstanceData(
+ bboxes=flatten_bboxes[img_id][valid_mask],
+ scores=max_scores[valid_mask] *
+ flatten_objectness[img_id][valid_mask],
+ labels=labels[valid_mask])
+
+ result_list.append(
+ self._bbox_post_process(
+ results=results,
+ cfg=cfg,
+ rescale=rescale,
+ with_nms=with_nms,
+ img_meta=img_meta))
+
+ return result_list
+
+ def _bbox_decode(self, priors: Tensor, bbox_preds: Tensor) -> Tensor:
+ """Decode regression results (delta_x, delta_x, w, h) to bboxes (tl_x,
+ tl_y, br_x, br_y).
+
+ Args:
+ priors (Tensor): Center proiors of an image, has shape
+ (num_instances, 2).
+ bbox_preds (Tensor): Box energies / deltas for all instances,
+ has shape (batch_size, num_instances, 4).
+
+ Returns:
+ Tensor: Decoded bboxes in (tl_x, tl_y, br_x, br_y) format. Has
+ shape (batch_size, num_instances, 4).
+ """
+ xys = (bbox_preds[..., :2] * priors[:, 2:]) + priors[:, :2]
+ whs = bbox_preds[..., 2:].exp() * priors[:, 2:]
+
+ tl_x = (xys[..., 0] - whs[..., 0] / 2)
+ tl_y = (xys[..., 1] - whs[..., 1] / 2)
+ br_x = (xys[..., 0] + whs[..., 0] / 2)
+ br_y = (xys[..., 1] + whs[..., 1] / 2)
+
+ decoded_bboxes = torch.stack([tl_x, tl_y, br_x, br_y], -1)
+ return decoded_bboxes
+
+ def _bbox_post_process(self,
+ results: InstanceData,
+ cfg: ConfigDict,
+ rescale: bool = False,
+ with_nms: bool = True,
+ img_meta: Optional[dict] = None) -> InstanceData:
+ """bbox post-processing method.
+
+ The boxes would be rescaled to the original image scale and do
+ the nms operation. Usually `with_nms` is False is used for aug test.
+
+ Args:
+ results (:obj:`InstaceData`): Detection instance results,
+ each item has shape (num_bboxes, ).
+ cfg (mmengine.Config): Test / postprocessing configuration,
+ if None, test_cfg would be used.
+ rescale (bool): If True, return boxes in original image space.
+ Default to False.
+ with_nms (bool): If True, do nms before return boxes.
+ Default to True.
+ img_meta (dict, optional): Image meta info. Defaults to None.
+
+ Returns:
+ :obj:`InstanceData`: Detection results of each image
+ after the post process.
+ Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ """
+
+ if rescale:
+ assert img_meta.get('scale_factor') is not None
+ results.bboxes /= results.bboxes.new_tensor(
+ img_meta['scale_factor']).repeat((1, 2))
+
+ if with_nms and results.bboxes.numel() > 0:
+ det_bboxes, keep_idxs = batched_nms(results.bboxes, results.scores,
+ results.labels, cfg.nms)
+ results = results[keep_idxs]
+ # some nms would reweight the score, such as softnms
+ results.scores = det_bboxes[:, -1]
+ return results
+
+ def loss_by_feat(
+ self,
+ cls_scores: Sequence[Tensor],
+ bbox_preds: Sequence[Tensor],
+ objectnesses: Sequence[Tensor],
+ batch_gt_instances: Sequence[InstanceData],
+ batch_img_metas: Sequence[dict],
+ batch_gt_instances_ignore: OptInstanceList = None) -> dict:
+ """Calculate the loss based on the features extracted by the detection
+ head.
+
+ Args:
+ cls_scores (Sequence[Tensor]): Box scores for each scale level,
+ each is a 4D-tensor, the channel number is
+ num_priors * num_classes.
+ bbox_preds (Sequence[Tensor]): Box energies / deltas for each scale
+ level, each is a 4D-tensor, the channel number is
+ num_priors * 4.
+ objectnesses (Sequence[Tensor]): Score factor for
+ all scale level, each is a 4D-tensor, has shape
+ (batch_size, 1, H, W).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+ Returns:
+ dict[str, Tensor]: A dictionary of losses.
+ """
+ num_imgs = len(batch_img_metas)
+ if batch_gt_instances_ignore is None:
+ batch_gt_instances_ignore = [None] * num_imgs
+
+ featmap_sizes = [cls_score.shape[2:] for cls_score in cls_scores]
+ mlvl_priors = self.prior_generator.grid_priors(
+ featmap_sizes,
+ dtype=cls_scores[0].dtype,
+ device=cls_scores[0].device,
+ with_stride=True)
+
+ flatten_cls_preds = [
+ cls_pred.permute(0, 2, 3, 1).reshape(num_imgs, -1,
+ self.cls_out_channels)
+ for cls_pred in cls_scores
+ ]
+ flatten_bbox_preds = [
+ bbox_pred.permute(0, 2, 3, 1).reshape(num_imgs, -1, 4)
+ for bbox_pred in bbox_preds
+ ]
+ flatten_objectness = [
+ objectness.permute(0, 2, 3, 1).reshape(num_imgs, -1)
+ for objectness in objectnesses
+ ]
+
+ flatten_cls_preds = torch.cat(flatten_cls_preds, dim=1)
+ flatten_bbox_preds = torch.cat(flatten_bbox_preds, dim=1)
+ flatten_objectness = torch.cat(flatten_objectness, dim=1)
+ flatten_priors = torch.cat(mlvl_priors)
+ flatten_bboxes = self._bbox_decode(flatten_priors, flatten_bbox_preds)
+
+ (pos_masks, cls_targets, obj_targets, bbox_targets, l1_targets,
+ num_fg_imgs) = multi_apply(
+ self._get_targets_single,
+ flatten_priors.unsqueeze(0).repeat(num_imgs, 1, 1),
+ flatten_cls_preds.detach(), flatten_bboxes.detach(),
+ flatten_objectness.detach(), batch_gt_instances, batch_img_metas,
+ batch_gt_instances_ignore)
+
+ # The experimental results show that 'reduce_mean' can improve
+ # performance on the COCO dataset.
+ num_pos = torch.tensor(
+ sum(num_fg_imgs),
+ dtype=torch.float,
+ device=flatten_cls_preds.device)
+ num_total_samples = max(reduce_mean(num_pos), 1.0)
+
+ pos_masks = torch.cat(pos_masks, 0)
+ cls_targets = torch.cat(cls_targets, 0)
+ obj_targets = torch.cat(obj_targets, 0)
+ bbox_targets = torch.cat(bbox_targets, 0)
+ if self.use_l1:
+ l1_targets = torch.cat(l1_targets, 0)
+
+ loss_obj = self.loss_obj(flatten_objectness.view(-1, 1),
+ obj_targets) / num_total_samples
+ if num_pos > 0:
+ loss_cls = self.loss_cls(
+ flatten_cls_preds.view(-1, self.num_classes)[pos_masks],
+ cls_targets) / num_total_samples
+ loss_bbox = self.loss_bbox(
+ flatten_bboxes.view(-1, 4)[pos_masks],
+ bbox_targets) / num_total_samples
+ else:
+ # Avoid cls and reg branch not participating in the gradient
+ # propagation when there is no ground-truth in the images.
+ # For more details, please refer to
+ # https://github.com/open-mmlab/mmdetection/issues/7298
+ loss_cls = flatten_cls_preds.sum() * 0
+ loss_bbox = flatten_bboxes.sum() * 0
+
+ loss_dict = dict(
+ loss_cls=loss_cls, loss_bbox=loss_bbox, loss_obj=loss_obj)
+
+ if self.use_l1:
+ if num_pos > 0:
+ loss_l1 = self.loss_l1(
+ flatten_bbox_preds.view(-1, 4)[pos_masks],
+ l1_targets) / num_total_samples
+ else:
+ # Avoid cls and reg branch not participating in the gradient
+ # propagation when there is no ground-truth in the images.
+ # For more details, please refer to
+ # https://github.com/open-mmlab/mmdetection/issues/7298
+ loss_l1 = flatten_bbox_preds.sum() * 0
+ loss_dict.update(loss_l1=loss_l1)
+
+ return loss_dict
+
+ @torch.no_grad()
+ def _get_targets_single(
+ self,
+ priors: Tensor,
+ cls_preds: Tensor,
+ decoded_bboxes: Tensor,
+ objectness: Tensor,
+ gt_instances: InstanceData,
+ img_meta: dict,
+ gt_instances_ignore: Optional[InstanceData] = None) -> tuple:
+ """Compute classification, regression, and objectness targets for
+ priors in a single image.
+
+ Args:
+ priors (Tensor): All priors of one image, a 2D-Tensor with shape
+ [num_priors, 4] in [cx, xy, stride_w, stride_y] format.
+ cls_preds (Tensor): Classification predictions of one image,
+ a 2D-Tensor with shape [num_priors, num_classes]
+ decoded_bboxes (Tensor): Decoded bboxes predictions of one image,
+ a 2D-Tensor with shape [num_priors, 4] in [tl_x, tl_y,
+ br_x, br_y] format.
+ objectness (Tensor): Objectness predictions of one image,
+ a 1D-Tensor with shape [num_priors]
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It should includes ``bboxes`` and ``labels``
+ attributes.
+ img_meta (dict): Meta information for current image.
+ gt_instances_ignore (:obj:`InstanceData`, optional): Instances
+ to be ignored during training. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+ Returns:
+ tuple:
+ foreground_mask (list[Tensor]): Binary mask of foreground
+ targets.
+ cls_target (list[Tensor]): Classification targets of an image.
+ obj_target (list[Tensor]): Objectness targets of an image.
+ bbox_target (list[Tensor]): BBox targets of an image.
+ l1_target (int): BBox L1 targets of an image.
+ num_pos_per_img (int): Number of positive samples in an image.
+ """
+
+ num_priors = priors.size(0)
+ num_gts = len(gt_instances)
+ # No target
+ if num_gts == 0:
+ cls_target = cls_preds.new_zeros((0, self.num_classes))
+ bbox_target = cls_preds.new_zeros((0, 4))
+ l1_target = cls_preds.new_zeros((0, 4))
+ obj_target = cls_preds.new_zeros((num_priors, 1))
+ foreground_mask = cls_preds.new_zeros(num_priors).bool()
+ return (foreground_mask, cls_target, obj_target, bbox_target,
+ l1_target, 0)
+
+ # YOLOX uses center priors with 0.5 offset to assign targets,
+ # but use center priors without offset to regress bboxes.
+ offset_priors = torch.cat(
+ [priors[:, :2] + priors[:, 2:] * 0.5, priors[:, 2:]], dim=-1)
+
+ scores = cls_preds.sigmoid() * objectness.unsqueeze(1).sigmoid()
+ pred_instances = InstanceData(
+ bboxes=decoded_bboxes, scores=scores.sqrt_(), priors=offset_priors)
+ assign_result = self.assigner.assign(
+ pred_instances=pred_instances,
+ gt_instances=gt_instances,
+ gt_instances_ignore=gt_instances_ignore)
+
+ sampling_result = self.sampler.sample(assign_result, pred_instances,
+ gt_instances)
+ pos_inds = sampling_result.pos_inds
+ num_pos_per_img = pos_inds.size(0)
+
+ pos_ious = assign_result.max_overlaps[pos_inds]
+ # IOU aware classification score
+ cls_target = F.one_hot(sampling_result.pos_gt_labels,
+ self.num_classes) * pos_ious.unsqueeze(-1)
+ obj_target = torch.zeros_like(objectness).unsqueeze(-1)
+ obj_target[pos_inds] = 1
+ bbox_target = sampling_result.pos_gt_bboxes
+ l1_target = cls_preds.new_zeros((num_pos_per_img, 4))
+ if self.use_l1:
+ l1_target = self._get_l1_target(l1_target, bbox_target,
+ priors[pos_inds])
+ foreground_mask = torch.zeros_like(objectness).to(torch.bool)
+ foreground_mask[pos_inds] = 1
+ return (foreground_mask, cls_target, obj_target, bbox_target,
+ l1_target, num_pos_per_img)
+
+ def _get_l1_target(self,
+ l1_target: Tensor,
+ gt_bboxes: Tensor,
+ priors: Tensor,
+ eps: float = 1e-8) -> Tensor:
+ """Convert gt bboxes to center offset and log width height."""
+ gt_cxcywh = bbox_xyxy_to_cxcywh(gt_bboxes)
+ l1_target[:, :2] = (gt_cxcywh[:, :2] - priors[:, :2]) / priors[:, 2:]
+ l1_target[:, 2:] = torch.log(gt_cxcywh[:, 2:] / priors[:, 2:] + eps)
+ return l1_target
diff --git a/mmdet/models/detectors/__init__.py b/mmdet/models/detectors/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..1cffe289ef93d6caeb61f6b28cd1067f7c326815
--- /dev/null
+++ b/mmdet/models/detectors/__init__.py
@@ -0,0 +1,75 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .atss import ATSS
+from .autoassign import AutoAssign
+from .base import BaseDetector
+from .base_detr import DetectionTransformer
+from .boxinst import BoxInst
+from .cascade_rcnn import CascadeRCNN
+from .centernet import CenterNet
+from .condinst import CondInst
+from .conditional_detr import ConditionalDETR
+from .cornernet import CornerNet
+from .crowddet import CrowdDet
+from .d2_wrapper import Detectron2Wrapper
+from .dab_detr import DABDETR
+from .ddod import DDOD
+from .deformable_detr import DeformableDETR
+from .detr import DETR
+from .dino import DINO
+from .fast_rcnn import FastRCNN
+from .faster_rcnn import FasterRCNN
+from .fcos import FCOS
+from .fovea import FOVEA
+from .fsaf import FSAF
+from .gfl import GFL
+from .grid_rcnn import GridRCNN
+from .htc import HybridTaskCascade
+from .kd_one_stage import KnowledgeDistillationSingleStageDetector
+from .lad import LAD
+from .mask2former import Mask2Former
+from .mask_rcnn import MaskRCNN
+from .mask_scoring_rcnn import MaskScoringRCNN
+from .maskformer import MaskFormer
+from .nasfcos import NASFCOS
+from .paa import PAA
+from .panoptic_fpn import PanopticFPN
+from .panoptic_two_stage_segmentor import TwoStagePanopticSegmentor
+from .point_rend import PointRend
+from .queryinst import QueryInst
+from .reppoints_detector import RepPointsDetector
+from .retinanet import RetinaNet
+from .rpn import RPN
+from .rtmdet import RTMDet
+from .scnet import SCNet
+from .semi_base import SemiBaseDetector
+from .single_stage import SingleStageDetector
+from .soft_teacher import SoftTeacher
+from .solo import SOLO
+from .solov2 import SOLOv2
+from .sparse_rcnn import SparseRCNN
+from .tood import TOOD
+from .trident_faster_rcnn import TridentFasterRCNN
+from .two_stage import TwoStageDetector
+from .vfnet import VFNet
+from .yolact import YOLACT
+from .yolo import YOLOV3
+from .yolof import YOLOF
+from .yolox import YOLOX
+
+# lzx
+from .specdetr import SpecDetr
+
+__all__ = [
+ 'ATSS', 'BaseDetector', 'SingleStageDetector', 'TwoStageDetector', 'RPN',
+ 'KnowledgeDistillationSingleStageDetector', 'FastRCNN', 'FasterRCNN',
+ 'MaskRCNN', 'CascadeRCNN', 'HybridTaskCascade', 'RetinaNet', 'FCOS',
+ 'GridRCNN', 'MaskScoringRCNN', 'RepPointsDetector', 'FOVEA', 'FSAF',
+ 'NASFCOS', 'PointRend', 'GFL', 'CornerNet', 'PAA', 'YOLOV3', 'YOLACT',
+ 'VFNet', 'DETR', 'TridentFasterRCNN', 'SparseRCNN', 'SCNet', 'SOLO',
+ 'SOLOv2', 'DeformableDETR', 'AutoAssign', 'YOLOF', 'CenterNet', 'YOLOX',
+ 'TwoStagePanopticSegmentor', 'PanopticFPN', 'QueryInst', 'LAD', 'TOOD',
+ 'MaskFormer', 'DDOD', 'Mask2Former', 'SemiBaseDetector', 'SoftTeacher',
+ 'RTMDet', 'Detectron2Wrapper', 'CrowdDet', 'CondInst', 'BoxInst',
+ 'DetectionTransformer', 'ConditionalDETR', 'DINO', 'DABDETR',
+ 'SpecDetr',
+]
diff --git a/mmdet/models/detectors/__pycache__/__init__.cpython-37.pyc b/mmdet/models/detectors/__pycache__/__init__.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..53f8d39d06f1ac8b34c7620d5ba68dd008062c06
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/__init__.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/atss.cpython-37.pyc b/mmdet/models/detectors/__pycache__/atss.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..181a90138c70ea3de7ed94fb23165b81ed47f7dd
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/atss.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/autoassign.cpython-37.pyc b/mmdet/models/detectors/__pycache__/autoassign.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..f038e4727badafb0d87d30a6b3a10a3c4dda3311
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/autoassign.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/base.cpython-37.pyc b/mmdet/models/detectors/__pycache__/base.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..e041675e5fc07c9a4a615c30c559bad0f15a5a97
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/base.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/base_detr.cpython-37.pyc b/mmdet/models/detectors/__pycache__/base_detr.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..e65b839e8e82921a643754ac696c9043a66300e7
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/base_detr.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/boxinst.cpython-37.pyc b/mmdet/models/detectors/__pycache__/boxinst.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..9ffc0b2497709455535f192debd4fd5bf3418f6d
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/boxinst.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/cascade_rcnn.cpython-37.pyc b/mmdet/models/detectors/__pycache__/cascade_rcnn.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..1f48d89f02f42352976556dee167331f1669768b
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/cascade_rcnn.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/centernet.cpython-37.pyc b/mmdet/models/detectors/__pycache__/centernet.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..2538aa7326e3c1ecb02c67911862a22766299848
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/centernet.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/condinst.cpython-37.pyc b/mmdet/models/detectors/__pycache__/condinst.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..33d74e2e4d83ac1b3a83759205f3a324f52cf420
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/condinst.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/conditional_detr.cpython-37.pyc b/mmdet/models/detectors/__pycache__/conditional_detr.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..b4cd852f1ac83926ca62a453f0538690ea969e16
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/conditional_detr.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/cornernet.cpython-37.pyc b/mmdet/models/detectors/__pycache__/cornernet.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..b2f773bdb8017e86b0e32f522c992c53debb3969
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/cornernet.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/crowddet.cpython-37.pyc b/mmdet/models/detectors/__pycache__/crowddet.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..708f039c262bff89e436026f8fb26540f7473373
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/crowddet.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/d2_wrapper.cpython-37.pyc b/mmdet/models/detectors/__pycache__/d2_wrapper.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..b101d67208cad34379d97da2db355db0fcb78360
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/d2_wrapper.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/dab_detr.cpython-37.pyc b/mmdet/models/detectors/__pycache__/dab_detr.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..121dddc5f77316ffee4080d22488a8427d2d0671
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/dab_detr.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/ddod.cpython-37.pyc b/mmdet/models/detectors/__pycache__/ddod.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..e6cb7d279ecf543151e1bd77c852ef8c82a3962f
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/ddod.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/deformable_detr.cpython-37.pyc b/mmdet/models/detectors/__pycache__/deformable_detr.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..561c209fd91bbfffc2a01bc6a10efd486179289d
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/deformable_detr.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/detr.cpython-37.pyc b/mmdet/models/detectors/__pycache__/detr.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..5680762a930e099abda67e809d86d5f5073d5722
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/detr.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/dino.cpython-37.pyc b/mmdet/models/detectors/__pycache__/dino.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..f9aae38e1b35520ea1c53ddee63aacef7d9a4ce5
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/dino.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/fast_rcnn.cpython-37.pyc b/mmdet/models/detectors/__pycache__/fast_rcnn.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..9d91ca3dd4fa29c8035c62dc6ee7c2f84dfc4a4c
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/fast_rcnn.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/faster_rcnn.cpython-37.pyc b/mmdet/models/detectors/__pycache__/faster_rcnn.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..e024b68ddb8bc029e77532861b0caf74fd2d6ab8
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/faster_rcnn.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/fcos.cpython-37.pyc b/mmdet/models/detectors/__pycache__/fcos.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..37f93d0964f05663abc713c0d39d4ef69a5ec992
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/fcos.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/fovea.cpython-37.pyc b/mmdet/models/detectors/__pycache__/fovea.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..b5fb517706b03632ab5ea5df1646e921b184c5f5
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/fovea.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/fsaf.cpython-37.pyc b/mmdet/models/detectors/__pycache__/fsaf.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..01eee464540104824c8bfebdf55f98358c9719c0
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/fsaf.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/gfl.cpython-37.pyc b/mmdet/models/detectors/__pycache__/gfl.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..f64e7ea3784ebcd612e220733144f94b74ed34ed
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/gfl.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/grid_rcnn.cpython-37.pyc b/mmdet/models/detectors/__pycache__/grid_rcnn.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..1f1db8b06718f9cfc94781313c48d347ac9242ba
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/grid_rcnn.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/htc.cpython-37.pyc b/mmdet/models/detectors/__pycache__/htc.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..1365835fe6951c47d3c90fa6252861131179e02c
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/htc.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/kd_one_stage.cpython-37.pyc b/mmdet/models/detectors/__pycache__/kd_one_stage.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..3ff9c71d21ee3b63a12790fe99521916816787f2
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/kd_one_stage.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/lad.cpython-37.pyc b/mmdet/models/detectors/__pycache__/lad.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..e67124d89a50a2fc7c08e8aa089671ad9362a24e
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/lad.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/mask2former.cpython-37.pyc b/mmdet/models/detectors/__pycache__/mask2former.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..9a75979792415cfec4b1f006ebf45ecbccf84e48
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/mask2former.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/mask_rcnn.cpython-37.pyc b/mmdet/models/detectors/__pycache__/mask_rcnn.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..eb6567bc5ab8fc8f85d0895796e4be135486c7b7
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/mask_rcnn.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/mask_scoring_rcnn.cpython-37.pyc b/mmdet/models/detectors/__pycache__/mask_scoring_rcnn.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..d42e403ed6f9d601c24f2b49483371aeb399bd0f
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/mask_scoring_rcnn.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/maskformer.cpython-37.pyc b/mmdet/models/detectors/__pycache__/maskformer.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..5994a8430340da32af6f1809878c86899db5b0b4
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/maskformer.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/nasfcos.cpython-37.pyc b/mmdet/models/detectors/__pycache__/nasfcos.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..84b0b35a95e72f553c18a602cc5db21ffb84fd12
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/nasfcos.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/paa.cpython-37.pyc b/mmdet/models/detectors/__pycache__/paa.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..354cbf90d10c9b29312c5cd21141b5de486ad6c2
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/paa.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/panoptic_fpn.cpython-37.pyc b/mmdet/models/detectors/__pycache__/panoptic_fpn.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..367696fa417c9191ac8eaae9a1aad8db0943e205
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/panoptic_fpn.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/panoptic_two_stage_segmentor.cpython-37.pyc b/mmdet/models/detectors/__pycache__/panoptic_two_stage_segmentor.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..cbececdde019e0dd1e9dc086e306c7dd4bc1b328
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/panoptic_two_stage_segmentor.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/point_rend.cpython-37.pyc b/mmdet/models/detectors/__pycache__/point_rend.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..d6d32d99ae74d625e84fd3bcbc3d292127bc95b8
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/point_rend.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/queryinst.cpython-37.pyc b/mmdet/models/detectors/__pycache__/queryinst.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..60900ec88c4947379b560e1a75167972d0a953fc
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/queryinst.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/reppoints_detector.cpython-37.pyc b/mmdet/models/detectors/__pycache__/reppoints_detector.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..c83365b24a6f2b2eb6c1828542764f6b40393a1a
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/reppoints_detector.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/retinanet.cpython-37.pyc b/mmdet/models/detectors/__pycache__/retinanet.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..db3595cb72366c2fc7496850938842a671d0d327
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/retinanet.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/rpn.cpython-37.pyc b/mmdet/models/detectors/__pycache__/rpn.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..39991b24c7265461ed0db2c5d7717319012115cd
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/rpn.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/rtmdet.cpython-37.pyc b/mmdet/models/detectors/__pycache__/rtmdet.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..0ae54f0d59b5d4c6779c0188f7dc1a27674ee1ce
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/rtmdet.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/scnet.cpython-37.pyc b/mmdet/models/detectors/__pycache__/scnet.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..a890e84a2d347d69e39ca0ccace197c9abc742d0
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/scnet.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/semi_base.cpython-37.pyc b/mmdet/models/detectors/__pycache__/semi_base.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..57103a4ac79c61033540ee42dd726f17d35c80e9
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/semi_base.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/single_stage.cpython-37.pyc b/mmdet/models/detectors/__pycache__/single_stage.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..1620b3ca33bda89a7f4cad1295dc71c9a92f1dba
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/single_stage.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/single_stage_instance_seg.cpython-37.pyc b/mmdet/models/detectors/__pycache__/single_stage_instance_seg.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..493c38d9895f85e2f74c2dfc451186f018d267a4
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/single_stage_instance_seg.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/soft_teacher.cpython-37.pyc b/mmdet/models/detectors/__pycache__/soft_teacher.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..04bd60f6626896be36a71cdcbaadbcfc1929ca08
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/soft_teacher.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/solo.cpython-37.pyc b/mmdet/models/detectors/__pycache__/solo.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..05e09a99eeba86fce6331f41dceadab0675570be
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/solo.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/solov2.cpython-37.pyc b/mmdet/models/detectors/__pycache__/solov2.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..a9ad9e158d5ea4e65ffb9dfe0d8655ea26f248f2
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/solov2.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/sparse_rcnn.cpython-37.pyc b/mmdet/models/detectors/__pycache__/sparse_rcnn.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..d6738d7fee832d368e4a8da3eaf6eaeb9c38b07f
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/sparse_rcnn.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/specdetr.cpython-37.pyc b/mmdet/models/detectors/__pycache__/specdetr.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..5b9c8851325fe867e731a2f51a2a87d41176088a
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/specdetr.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/tood.cpython-37.pyc b/mmdet/models/detectors/__pycache__/tood.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..c59c25d6b08f248b03daced0cab14db3b27347f5
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/tood.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/trident_faster_rcnn.cpython-37.pyc b/mmdet/models/detectors/__pycache__/trident_faster_rcnn.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..989645aaf9d6893c1ca9fcea743986dd5655f930
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/trident_faster_rcnn.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/two_stage.cpython-37.pyc b/mmdet/models/detectors/__pycache__/two_stage.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..9a39cbc468bcbcbf10abc5a99231034fe1d75940
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/two_stage.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/vfnet.cpython-37.pyc b/mmdet/models/detectors/__pycache__/vfnet.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..952ea429e5afdc0184dabdc66ca73e409c2685c9
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/vfnet.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/yolact.cpython-37.pyc b/mmdet/models/detectors/__pycache__/yolact.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..ccfb97a841e5b2bffec44de3966d0366f9b5a84b
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/yolact.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/yolo.cpython-37.pyc b/mmdet/models/detectors/__pycache__/yolo.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..97fe8c617949f4fa5cb4ec96c38ad7d6c7a8b169
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/yolo.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/yolof.cpython-37.pyc b/mmdet/models/detectors/__pycache__/yolof.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..d489a1354790460f58850a67ea15a26c387c1466
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/yolof.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/__pycache__/yolox.cpython-37.pyc b/mmdet/models/detectors/__pycache__/yolox.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..a978acb04b2f837634e3ab41f9d09115afcd0954
Binary files /dev/null and b/mmdet/models/detectors/__pycache__/yolox.cpython-37.pyc differ
diff --git a/mmdet/models/detectors/atss.py b/mmdet/models/detectors/atss.py
new file mode 100644
index 0000000000000000000000000000000000000000..0bfcc728dc4cc33c0b705a2ab22a4e3f4ad7386d
--- /dev/null
+++ b/mmdet/models/detectors/atss.py
@@ -0,0 +1,41 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmdet.registry import MODELS
+from mmdet.utils import ConfigType, OptConfigType, OptMultiConfig
+from .single_stage import SingleStageDetector
+
+
+@MODELS.register_module()
+class ATSS(SingleStageDetector):
+ """Implementation of `ATSS `_
+
+ Args:
+ backbone (:obj:`ConfigDict` or dict): The backbone module.
+ neck (:obj:`ConfigDict` or dict): The neck module.
+ bbox_head (:obj:`ConfigDict` or dict): The bbox head module.
+ train_cfg (:obj:`ConfigDict` or dict, optional): The training config
+ of ATSS. Defaults to None.
+ test_cfg (:obj:`ConfigDict` or dict, optional): The testing config
+ of ATSS. Defaults to None.
+ data_preprocessor (:obj:`ConfigDict` or dict, optional): Config of
+ :class:`DetDataPreprocessor` to process the input data.
+ Defaults to None.
+ init_cfg (:obj:`ConfigDict` or dict, optional): the config to control
+ the initialization. Defaults to None.
+ """
+
+ def __init__(self,
+ backbone: ConfigType,
+ neck: ConfigType,
+ bbox_head: ConfigType,
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ data_preprocessor: OptConfigType = None,
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(
+ backbone=backbone,
+ neck=neck,
+ bbox_head=bbox_head,
+ train_cfg=train_cfg,
+ test_cfg=test_cfg,
+ data_preprocessor=data_preprocessor,
+ init_cfg=init_cfg)
diff --git a/mmdet/models/detectors/autoassign.py b/mmdet/models/detectors/autoassign.py
new file mode 100644
index 0000000000000000000000000000000000000000..a0b3570fe6e0c3812a72bc677038bb4e76b05576
--- /dev/null
+++ b/mmdet/models/detectors/autoassign.py
@@ -0,0 +1,43 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmdet.registry import MODELS
+from mmdet.utils import ConfigType, OptConfigType, OptMultiConfig
+from .single_stage import SingleStageDetector
+
+
+@MODELS.register_module()
+class AutoAssign(SingleStageDetector):
+ """Implementation of `AutoAssign: Differentiable Label Assignment for Dense
+ Object Detection `_
+
+ Args:
+ backbone (:obj:`ConfigDict` or dict): The backbone config.
+ neck (:obj:`ConfigDict` or dict): The neck config.
+ bbox_head (:obj:`ConfigDict` or dict): The bbox head config.
+ train_cfg (:obj:`ConfigDict` or dict, optional): The training config
+ of AutoAssign. Defaults to None.
+ test_cfg (:obj:`ConfigDict` or dict, optional): The testing config
+ of AutoAssign. Defaults to None.
+ data_preprocessor (:obj:`ConfigDict` or dict, optional): Config of
+ :class:`DetDataPreprocessor` to process the input data.
+ Defaults to None.
+ init_cfg (:obj:`ConfigDict` or list[:obj:`ConfigDict`] or dict or
+ list[dict], optional): Initialization config dict.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ backbone: ConfigType,
+ neck: ConfigType,
+ bbox_head: ConfigType,
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ data_preprocessor: OptConfigType = None,
+ init_cfg: OptMultiConfig = None):
+ super().__init__(
+ backbone=backbone,
+ neck=neck,
+ bbox_head=bbox_head,
+ train_cfg=train_cfg,
+ test_cfg=test_cfg,
+ data_preprocessor=data_preprocessor,
+ init_cfg=init_cfg)
diff --git a/mmdet/models/detectors/base.py b/mmdet/models/detectors/base.py
new file mode 100644
index 0000000000000000000000000000000000000000..1a193b0ca9ca3d2b42fda452004d5c97421f426c
--- /dev/null
+++ b/mmdet/models/detectors/base.py
@@ -0,0 +1,156 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from abc import ABCMeta, abstractmethod
+from typing import Dict, List, Tuple, Union
+
+import torch
+from mmengine.model import BaseModel
+from torch import Tensor
+
+from mmdet.structures import DetDataSample, OptSampleList, SampleList
+from mmdet.utils import InstanceList, OptConfigType, OptMultiConfig
+from ..utils import samplelist_boxtype2tensor
+
+ForwardResults = Union[Dict[str, torch.Tensor], List[DetDataSample],
+ Tuple[torch.Tensor], torch.Tensor]
+
+
+class BaseDetector(BaseModel, metaclass=ABCMeta):
+ """Base class for detectors.
+
+ Args:
+ data_preprocessor (dict or ConfigDict, optional): The pre-process
+ config of :class:`BaseDataPreprocessor`. it usually includes,
+ ``pad_size_divisor``, ``pad_value``, ``mean`` and ``std``.
+ init_cfg (dict or ConfigDict, optional): the config to control the
+ initialization. Defaults to None.
+ """
+
+ def __init__(self,
+ data_preprocessor: OptConfigType = None,
+ init_cfg: OptMultiConfig = None):
+ super().__init__(
+ data_preprocessor=data_preprocessor, init_cfg=init_cfg)
+
+ @property
+ def with_neck(self) -> bool:
+ """bool: whether the detector has a neck"""
+ return hasattr(self, 'neck') and self.neck is not None
+
+ # TODO: these properties need to be carefully handled
+ # for both single stage & two stage detectors
+ @property
+ def with_shared_head(self) -> bool:
+ """bool: whether the detector has a shared head in the RoI Head"""
+ return hasattr(self, 'roi_head') and self.roi_head.with_shared_head
+
+ @property
+ def with_bbox(self) -> bool:
+ """bool: whether the detector has a bbox head"""
+ return ((hasattr(self, 'roi_head') and self.roi_head.with_bbox)
+ or (hasattr(self, 'bbox_head') and self.bbox_head is not None))
+
+ @property
+ def with_mask(self) -> bool:
+ """bool: whether the detector has a mask head"""
+ return ((hasattr(self, 'roi_head') and self.roi_head.with_mask)
+ or (hasattr(self, 'mask_head') and self.mask_head is not None))
+
+ def forward(self,
+ inputs: torch.Tensor,
+ data_samples: OptSampleList = None,
+ mode: str = 'tensor') -> ForwardResults:
+ """The unified entry for a forward process in both training and test.
+
+ The method should accept three modes: "tensor", "predict" and "loss":
+
+ - "tensor": Forward the whole network and return tensor or tuple of
+ tensor without any post-processing, same as a common nn.Module.
+ - "predict": Forward and return the predictions, which are fully
+ processed to a list of :obj:`DetDataSample`.
+ - "loss": Forward and return a dict of losses according to the given
+ inputs and data samples.
+
+ Note that this method doesn't handle either back propagation or
+ parameter update, which are supposed to be done in :meth:`train_step`.
+
+ Args:
+ inputs (torch.Tensor): The input tensor with shape
+ (N, C, ...) in general.
+ data_samples (list[:obj:`DetDataSample`], optional): A batch of
+ data samples that contain annotations and predictions.
+ Defaults to None.
+ mode (str): Return what kind of value. Defaults to 'tensor'.
+
+ Returns:
+ The return type depends on ``mode``.
+
+ - If ``mode="tensor"``, return a tensor or a tuple of tensor.
+ - If ``mode="predict"``, return a list of :obj:`DetDataSample`.
+ - If ``mode="loss"``, return a dict of tensor.
+ """
+ if mode == 'loss':
+ return self.loss(inputs, data_samples)
+ elif mode == 'predict':
+ return self.predict(inputs, data_samples)
+ elif mode == 'tensor':
+ return self._forward(inputs, data_samples)
+ else:
+ raise RuntimeError(f'Invalid mode "{mode}". '
+ 'Only supports loss, predict and tensor mode')
+
+ @abstractmethod
+ def loss(self, batch_inputs: Tensor,
+ batch_data_samples: SampleList) -> Union[dict, tuple]:
+ """Calculate losses from a batch of inputs and data samples."""
+ pass
+
+ @abstractmethod
+ def predict(self, batch_inputs: Tensor,
+ batch_data_samples: SampleList) -> SampleList:
+ """Predict results from a batch of inputs and data samples with post-
+ processing."""
+ pass
+
+ @abstractmethod
+ def _forward(self,
+ batch_inputs: Tensor,
+ batch_data_samples: OptSampleList = None):
+ """Network forward process.
+
+ Usually includes backbone, neck and head forward without any post-
+ processing.
+ """
+ pass
+
+ @abstractmethod
+ def extract_feat(self, batch_inputs: Tensor):
+ """Extract features from images."""
+ pass
+
+ def add_pred_to_datasample(self, data_samples: SampleList,
+ results_list: InstanceList) -> SampleList:
+ """Add predictions to `DetDataSample`.
+
+ Args:
+ data_samples (list[:obj:`DetDataSample`], optional): A batch of
+ data samples that contain annotations and predictions.
+ results_list (list[:obj:`InstanceData`]): Detection results of
+ each image.
+
+ Returns:
+ list[:obj:`DetDataSample`]: Detection results of the
+ input images. Each DetDataSample usually contain
+ 'pred_instances'. And the ``pred_instances`` usually
+ contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ """
+ for data_sample, pred_instances in zip(data_samples, results_list):
+ data_sample.pred_instances = pred_instances
+ samplelist_boxtype2tensor(data_samples)
+ return data_samples
diff --git a/mmdet/models/detectors/base_detr.py b/mmdet/models/detectors/base_detr.py
new file mode 100644
index 0000000000000000000000000000000000000000..fb298fd96ef67e93f3e87f6e0d369d1c5115b1de
--- /dev/null
+++ b/mmdet/models/detectors/base_detr.py
@@ -0,0 +1,332 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from abc import ABCMeta, abstractmethod
+from typing import Dict, List, Tuple, Union
+
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.structures import OptSampleList, SampleList
+from mmdet.utils import ConfigType, OptConfigType, OptMultiConfig
+from .base import BaseDetector
+
+
+@MODELS.register_module()
+class DetectionTransformer(BaseDetector, metaclass=ABCMeta):
+ r"""Base class for Detection Transformer.
+
+ In Detection Transformer, an encoder is used to process output features of
+ neck, then several queries interact with the encoder features using a
+ decoder and do the regression and classification with the bounding box
+ head.
+
+ Args:
+ backbone (:obj:`ConfigDict` or dict): Config of the backbone.
+ neck (:obj:`ConfigDict` or dict, optional): Config of the neck.
+ Defaults to None.
+ encoder (:obj:`ConfigDict` or dict, optional): Config of the
+ Transformer encoder. Defaults to None.
+ decoder (:obj:`ConfigDict` or dict, optional): Config of the
+ Transformer decoder. Defaults to None.
+ bbox_head (:obj:`ConfigDict` or dict, optional): Config for the
+ bounding box head module. Defaults to None.
+ positional_encoding (:obj:`ConfigDict` or dict, optional): Config
+ of the positional encoding module. Defaults to None.
+ num_queries (int, optional): Number of decoder query in Transformer.
+ Defaults to 100.
+ train_cfg (:obj:`ConfigDict` or dict, optional): Training config of
+ the bounding box head module. Defaults to None.
+ test_cfg (:obj:`ConfigDict` or dict, optional): Testing config of
+ the bounding box head module. Defaults to None.
+ data_preprocessor (dict or ConfigDict, optional): The pre-process
+ config of :class:`BaseDataPreprocessor`. it usually includes,
+ ``pad_size_divisor``, ``pad_value``, ``mean`` and ``std``.
+ Defaults to None.
+ init_cfg (:obj:`ConfigDict` or dict, optional): the config to control
+ the initialization. Defaults to None.
+ """
+
+ def __init__(self,
+ backbone: ConfigType,
+ neck: OptConfigType = None,
+ encoder: OptConfigType = None,
+ decoder: OptConfigType = None,
+ bbox_head: OptConfigType = None,
+ positional_encoding: OptConfigType = None,
+ num_queries: int = 100,
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ data_preprocessor: OptConfigType = None,
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(
+ data_preprocessor=data_preprocessor, init_cfg=init_cfg)
+ # process args
+ bbox_head.update(train_cfg=train_cfg)
+ bbox_head.update(test_cfg=test_cfg)
+ self.train_cfg = train_cfg
+ self.test_cfg = test_cfg
+ self.encoder = encoder
+ self.decoder = decoder
+ self.positional_encoding = positional_encoding
+ self.num_queries = num_queries
+ self.encoder_layers_num=encoder['num_layers']
+ # init model layers
+ self.backbone = MODELS.build(backbone)
+ if neck is not None:
+ self.neck = MODELS.build(neck)
+ self.bbox_head = MODELS.build(bbox_head)
+ self._init_layers()
+
+ @abstractmethod
+ def _init_layers(self) -> None:
+ """Initialize layers except for backbone, neck and bbox_head."""
+ pass
+
+ def loss(self, batch_inputs: Tensor,
+ batch_data_samples: SampleList) -> Union[dict, list]:
+ """Calculate losses from a batch of inputs and data samples.
+
+ Args:
+ batch_inputs (Tensor): Input images of shape (bs, dim, H, W).
+ These should usually be mean centered and std scaled.
+ batch_data_samples (List[:obj:`DetDataSample`]): The batch
+ data samples. It usually includes information such
+ as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
+
+ Returns:
+ dict: A dictionary of loss components
+ """
+ img_feats = self.extract_feat(batch_inputs)
+ head_inputs_dict = self.forward_transformer(img_feats,
+ batch_data_samples)
+ losses = self.bbox_head.loss(
+ **head_inputs_dict, batch_data_samples=batch_data_samples)
+
+ return losses
+
+ def predict(self,
+ batch_inputs: Tensor,
+ batch_data_samples: SampleList,
+ rescale: bool = True) -> SampleList:
+ """Predict results from a batch of inputs and data samples with post-
+ processing.
+
+ Args:
+ batch_inputs (Tensor): Inputs, has shape (bs, dim, H, W).
+ batch_data_samples (List[:obj:`DetDataSample`]): The batch
+ data samples. It usually includes information such
+ as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
+ rescale (bool): Whether to rescale the results.
+ Defaults to True.
+
+ Returns:
+ list[:obj:`DetDataSample`]: Detection results of the input images.
+ Each DetDataSample usually contain 'pred_instances'. And the
+ `pred_instances` usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ """
+ img_feats = self.extract_feat(batch_inputs)
+ head_inputs_dict = self.forward_transformer(img_feats,
+ batch_data_samples)
+ results_list = self.bbox_head.predict(
+ **head_inputs_dict,
+ rescale=rescale,
+ batch_data_samples=batch_data_samples)
+ batch_data_samples = self.add_pred_to_datasample(
+ batch_data_samples, results_list)
+ return batch_data_samples
+
+ def _forward(
+ self,
+ batch_inputs: Tensor,
+ batch_data_samples: OptSampleList = None) -> Tuple[List[Tensor]]:
+ """Network forward process. Usually includes backbone, neck and head
+ forward without any post-processing.
+
+ Args:
+ batch_inputs (Tensor): Inputs, has shape (bs, dim, H, W).
+ batch_data_samples (List[:obj:`DetDataSample`], optional): The
+ batch data samples. It usually includes information such
+ as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
+ Defaults to None.
+
+ Returns:
+ tuple[Tensor]: A tuple of features from ``bbox_head`` forward.
+ """
+ img_feats = self.extract_feat(batch_inputs)
+ head_inputs_dict = self.forward_transformer(img_feats,
+ batch_data_samples)
+ results = self.bbox_head.forward(**head_inputs_dict)
+ return results
+
+ def forward_transformer(self,
+ img_feats: Tuple[Tensor],
+ batch_data_samples: OptSampleList = None) -> Dict:
+ """Forward process of Transformer, which includes four steps:
+ 'pre_transformer' -> 'encoder' -> 'pre_decoder' -> 'decoder'. We
+ summarized the parameters flow of the existing DETR-like detector,
+ which can be illustrated as follow:
+
+ .. code:: text
+
+ img_feats & batch_data_samples
+ |
+ V
+ +-----------------+
+ | pre_transformer |
+ +-----------------+
+ | |
+ | V
+ | +-----------------+
+ | | forward_encoder |
+ | +-----------------+
+ | |
+ | V
+ | +---------------+
+ | | pre_decoder |
+ | +---------------+
+ | | |
+ V V |
+ +-----------------+ |
+ | forward_decoder | |
+ +-----------------+ |
+ | |
+ V V
+ head_inputs_dict
+
+ Args:
+ img_feats (tuple[Tensor]): Tuple of feature maps from neck. Each
+ feature map has shape (bs, dim, H, W).
+ batch_data_samples (list[:obj:`DetDataSample`], optional): The
+ batch data samples. It usually includes information such
+ as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
+ Defaults to None.
+
+ Returns:
+ dict: The dictionary of bbox_head function inputs, which always
+ includes the `hidden_states` of the decoder output and may contain
+ `references` including the initial and intermediate references.
+ """
+ encoder_inputs_dict, decoder_inputs_dict = self.pre_transformer(
+ img_feats, batch_data_samples)
+
+ encoder_outputs_dict = self.forward_encoder(**encoder_inputs_dict)
+
+ tmp_dec_in, head_inputs_dict = self.pre_decoder(**encoder_outputs_dict)
+ decoder_inputs_dict.update(tmp_dec_in)
+
+ decoder_outputs_dict = self.forward_decoder(**decoder_inputs_dict)
+ head_inputs_dict.update(decoder_outputs_dict)
+ return head_inputs_dict
+
+ def extract_feat(self, batch_inputs: Tensor) -> Tuple[Tensor]:
+ """Extract features.
+
+ Args:
+ batch_inputs (Tensor): Image tensor, has shape (bs, dim, H, W).
+
+ Returns:
+ tuple[Tensor]: Tuple of feature maps from neck. Each feature map
+ has shape (bs, dim, H, W).
+ """
+ x = self.backbone(batch_inputs)
+ if self.with_neck:
+ x = self.neck(x)
+ return x
+
+ @abstractmethod
+ def pre_transformer(
+ self,
+ img_feats: Tuple[Tensor],
+ batch_data_samples: OptSampleList = None) -> Tuple[Dict, Dict]:
+ """Process image features before feeding them to the transformer.
+
+ Args:
+ img_feats (tuple[Tensor]): Tuple of feature maps from neck. Each
+ feature map has shape (bs, dim, H, W).
+ batch_data_samples (list[:obj:`DetDataSample`], optional): The
+ batch data samples. It usually includes information such
+ as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
+ Defaults to None.
+
+ Returns:
+ tuple[dict, dict]: The first dict contains the inputs of encoder
+ and the second dict contains the inputs of decoder.
+
+ - encoder_inputs_dict (dict): The keyword args dictionary of
+ `self.forward_encoder()`, which includes 'feat', 'feat_mask',
+ 'feat_pos', and other algorithm-specific arguments.
+ - decoder_inputs_dict (dict): The keyword args dictionary of
+ `self.forward_decoder()`, which includes 'memory_mask', and
+ other algorithm-specific arguments.
+ """
+ pass
+
+ @abstractmethod
+ def forward_encoder(self, feat: Tensor, feat_mask: Tensor,
+ feat_pos: Tensor, **kwargs) -> Dict:
+ """Forward with Transformer encoder.
+
+ Args:
+ feat (Tensor): Sequential features, has shape (bs, num_feat_points,
+ dim).
+ feat_mask (Tensor): ByteTensor, the padding mask of the features,
+ has shape (bs, num_feat_points).
+ feat_pos (Tensor): The positional embeddings of the features, has
+ shape (bs, num_feat_points, dim).
+
+ Returns:
+ dict: The dictionary of encoder outputs, which includes the
+ `memory` of the encoder output and other algorithm-specific
+ arguments.
+ """
+ pass
+
+ @abstractmethod
+ def pre_decoder(self, memory: Tensor, **kwargs) -> Tuple[Dict, Dict]:
+ """Prepare intermediate variables before entering Transformer decoder,
+ such as `query`, `query_pos`, and `reference_points`.
+
+ Args:
+ memory (Tensor): The output embeddings of the Transformer encoder,
+ has shape (bs, num_feat_points, dim).
+
+ Returns:
+ tuple[dict, dict]: The first dict contains the inputs of decoder
+ and the second dict contains the inputs of the bbox_head function.
+
+ - decoder_inputs_dict (dict): The keyword dictionary args of
+ `self.forward_decoder()`, which includes 'query', 'query_pos',
+ 'memory', and other algorithm-specific arguments.
+ - head_inputs_dict (dict): The keyword dictionary args of the
+ bbox_head functions, which is usually empty, or includes
+ `enc_outputs_class` and `enc_outputs_class` when the detector
+ support 'two stage' or 'query selection' strategies.
+ """
+ pass
+
+ @abstractmethod
+ def forward_decoder(self, query: Tensor, query_pos: Tensor, memory: Tensor,
+ **kwargs) -> Dict:
+ """Forward with Transformer decoder.
+
+ Args:
+ query (Tensor): The queries of decoder inputs, has shape
+ (bs, num_queries, dim).
+ query_pos (Tensor): The positional queries of decoder inputs,
+ has shape (bs, num_queries, dim).
+ memory (Tensor): The output embeddings of the Transformer encoder,
+ has shape (bs, num_feat_points, dim).
+
+ Returns:
+ dict: The dictionary of decoder outputs, which includes the
+ `hidden_states` of the decoder output, `references` including
+ the initial and intermediate reference_points, and other
+ algorithm-specific arguments.
+ """
+ pass
diff --git a/mmdet/models/detectors/boxinst.py b/mmdet/models/detectors/boxinst.py
new file mode 100644
index 0000000000000000000000000000000000000000..ca6b0bdd90a2a7e78f429a6822dbde6f809426da
--- /dev/null
+++ b/mmdet/models/detectors/boxinst.py
@@ -0,0 +1,28 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmdet.registry import MODELS
+from mmdet.utils import ConfigType, OptConfigType, OptMultiConfig
+from .single_stage_instance_seg import SingleStageInstanceSegmentor
+
+
+@MODELS.register_module()
+class BoxInst(SingleStageInstanceSegmentor):
+ """Implementation of `BoxInst `_"""
+
+ def __init__(self,
+ backbone: ConfigType,
+ neck: ConfigType,
+ bbox_head: ConfigType,
+ mask_head: ConfigType,
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ data_preprocessor: OptConfigType = None,
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(
+ backbone=backbone,
+ neck=neck,
+ bbox_head=bbox_head,
+ mask_head=mask_head,
+ train_cfg=train_cfg,
+ test_cfg=test_cfg,
+ data_preprocessor=data_preprocessor,
+ init_cfg=init_cfg)
diff --git a/mmdet/models/detectors/cascade_rcnn.py b/mmdet/models/detectors/cascade_rcnn.py
new file mode 100644
index 0000000000000000000000000000000000000000..ecf733ff104b99436fcc74130b0ccea12a0fa6d0
--- /dev/null
+++ b/mmdet/models/detectors/cascade_rcnn.py
@@ -0,0 +1,29 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmdet.registry import MODELS
+from mmdet.utils import ConfigType, OptConfigType, OptMultiConfig
+from .two_stage import TwoStageDetector
+
+
+@MODELS.register_module()
+class CascadeRCNN(TwoStageDetector):
+ r"""Implementation of `Cascade R-CNN: Delving into High Quality Object
+ Detection `_"""
+
+ def __init__(self,
+ backbone: ConfigType,
+ neck: OptConfigType = None,
+ rpn_head: OptConfigType = None,
+ roi_head: OptConfigType = None,
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ data_preprocessor: OptConfigType = None,
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(
+ backbone=backbone,
+ neck=neck,
+ rpn_head=rpn_head,
+ roi_head=roi_head,
+ train_cfg=train_cfg,
+ test_cfg=test_cfg,
+ data_preprocessor=data_preprocessor,
+ init_cfg=init_cfg)
diff --git a/mmdet/models/detectors/centernet.py b/mmdet/models/detectors/centernet.py
new file mode 100644
index 0000000000000000000000000000000000000000..9c6622d6280227ecba9ede4aabf72c22a764e11d
--- /dev/null
+++ b/mmdet/models/detectors/centernet.py
@@ -0,0 +1,29 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmdet.registry import MODELS
+from mmdet.utils import ConfigType, OptConfigType, OptMultiConfig
+from .single_stage import SingleStageDetector
+
+
+@MODELS.register_module()
+class CenterNet(SingleStageDetector):
+ """Implementation of CenterNet(Objects as Points)
+
+ .
+ """
+
+ def __init__(self,
+ backbone: ConfigType,
+ neck: ConfigType,
+ bbox_head: ConfigType,
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ data_preprocessor: OptConfigType = None,
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(
+ backbone=backbone,
+ neck=neck,
+ bbox_head=bbox_head,
+ train_cfg=train_cfg,
+ test_cfg=test_cfg,
+ data_preprocessor=data_preprocessor,
+ init_cfg=init_cfg)
diff --git a/mmdet/models/detectors/condinst.py b/mmdet/models/detectors/condinst.py
new file mode 100644
index 0000000000000000000000000000000000000000..ed2dc99eea3faf7b03a3970d46a372d28eb89fe1
--- /dev/null
+++ b/mmdet/models/detectors/condinst.py
@@ -0,0 +1,28 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmdet.registry import MODELS
+from mmdet.utils import ConfigType, OptConfigType, OptMultiConfig
+from .single_stage_instance_seg import SingleStageInstanceSegmentor
+
+
+@MODELS.register_module()
+class CondInst(SingleStageInstanceSegmentor):
+ """Implementation of `CondInst `_"""
+
+ def __init__(self,
+ backbone: ConfigType,
+ neck: ConfigType,
+ bbox_head: ConfigType,
+ mask_head: ConfigType,
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ data_preprocessor: OptConfigType = None,
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(
+ backbone=backbone,
+ neck=neck,
+ bbox_head=bbox_head,
+ mask_head=mask_head,
+ train_cfg=train_cfg,
+ test_cfg=test_cfg,
+ data_preprocessor=data_preprocessor,
+ init_cfg=init_cfg)
diff --git a/mmdet/models/detectors/conditional_detr.py b/mmdet/models/detectors/conditional_detr.py
new file mode 100644
index 0000000000000000000000000000000000000000..d57868e63a2ece085a7e5b67ee93c921ba334830
--- /dev/null
+++ b/mmdet/models/detectors/conditional_detr.py
@@ -0,0 +1,74 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict
+
+import torch.nn as nn
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from ..layers import (ConditionalDetrTransformerDecoder,
+ DetrTransformerEncoder, SinePositionalEncoding)
+from .detr import DETR
+
+
+@MODELS.register_module()
+class ConditionalDETR(DETR):
+ r"""Implementation of `Conditional DETR for Fast Training Convergence.
+
+ `_.
+
+ Code is modified from the `official github repo
+ `_.
+ """
+
+ def _init_layers(self) -> None:
+ """Initialize layers except for backbone, neck and bbox_head."""
+ self.positional_encoding = SinePositionalEncoding(
+ **self.positional_encoding)
+ self.encoder = DetrTransformerEncoder(**self.encoder)
+ self.decoder = ConditionalDetrTransformerDecoder(**self.decoder)
+ self.embed_dims = self.encoder.embed_dims
+ # NOTE The embed_dims is typically passed from the inside out.
+ # For example in DETR, The embed_dims is passed as
+ # self_attn -> the first encoder layer -> encoder -> detector.
+ self.query_embedding = nn.Embedding(self.num_queries, self.embed_dims)
+
+ num_feats = self.positional_encoding.num_feats
+ assert num_feats * 2 == self.embed_dims, \
+ f'embed_dims should be exactly 2 times of num_feats. ' \
+ f'Found {self.embed_dims} and {num_feats}.'
+
+ def forward_decoder(self, query: Tensor, query_pos: Tensor, memory: Tensor,
+ memory_mask: Tensor, memory_pos: Tensor) -> Dict:
+ """Forward with Transformer decoder.
+
+ Args:
+ query (Tensor): The queries of decoder inputs, has shape
+ (bs, num_queries, dim).
+ query_pos (Tensor): The positional queries of decoder inputs,
+ has shape (bs, num_queries, dim).
+ memory (Tensor): The output embeddings of the Transformer encoder,
+ has shape (bs, num_feat_points, dim).
+ memory_mask (Tensor): ByteTensor, the padding mask of the memory,
+ has shape (bs, num_feat_points).
+ memory_pos (Tensor): The positional embeddings of memory, has
+ shape (bs, num_feat_points, dim).
+
+ Returns:
+ dict: The dictionary of decoder outputs, which includes the
+ `hidden_states` and `references` of the decoder output.
+
+ - hidden_states (Tensor): Has shape
+ (num_decoder_layers, bs, num_queries, dim)
+ - references (Tensor): Has shape
+ (bs, num_queries, 2)
+ """
+
+ hidden_states, references = self.decoder(
+ query=query,
+ key=memory,
+ query_pos=query_pos,
+ key_pos=memory_pos,
+ key_padding_mask=memory_mask)
+ head_inputs_dict = dict(
+ hidden_states=hidden_states, references=references)
+ return head_inputs_dict
diff --git a/mmdet/models/detectors/cornernet.py b/mmdet/models/detectors/cornernet.py
new file mode 100644
index 0000000000000000000000000000000000000000..946af4dbe6ae339d44f8db265ff7f11b9e02d239
--- /dev/null
+++ b/mmdet/models/detectors/cornernet.py
@@ -0,0 +1,30 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmdet.registry import MODELS
+from mmdet.utils import ConfigType, OptConfigType, OptMultiConfig
+from .single_stage import SingleStageDetector
+
+
+@MODELS.register_module()
+class CornerNet(SingleStageDetector):
+ """CornerNet.
+
+ This detector is the implementation of the paper `CornerNet: Detecting
+ Objects as Paired Keypoints `_ .
+ """
+
+ def __init__(self,
+ backbone: ConfigType,
+ neck: ConfigType,
+ bbox_head: ConfigType,
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ data_preprocessor: OptConfigType = None,
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(
+ backbone=backbone,
+ neck=neck,
+ bbox_head=bbox_head,
+ train_cfg=train_cfg,
+ test_cfg=test_cfg,
+ data_preprocessor=data_preprocessor,
+ init_cfg=init_cfg)
diff --git a/mmdet/models/detectors/crowddet.py b/mmdet/models/detectors/crowddet.py
new file mode 100644
index 0000000000000000000000000000000000000000..4f43bc08aa95756324381ee4182f001a008613c8
--- /dev/null
+++ b/mmdet/models/detectors/crowddet.py
@@ -0,0 +1,45 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmdet.registry import MODELS
+from mmdet.utils import ConfigType, OptConfigType, OptMultiConfig
+from .two_stage import TwoStageDetector
+
+
+@MODELS.register_module()
+class CrowdDet(TwoStageDetector):
+ """Implementation of `CrowdDet `_
+
+ Args:
+ backbone (:obj:`ConfigDict` or dict): The backbone config.
+ rpn_head (:obj:`ConfigDict` or dict): The rpn config.
+ roi_head (:obj:`ConfigDict` or dict): The roi config.
+ train_cfg (:obj:`ConfigDict` or dict, optional): The training config
+ of FCOS. Defaults to None.
+ test_cfg (:obj:`ConfigDict` or dict, optional): The testing config
+ of FCOS. Defaults to None.
+ neck (:obj:`ConfigDict` or dict): The neck config.
+ data_preprocessor (:obj:`ConfigDict` or dict, optional): Config of
+ :class:`DetDataPreprocessor` to process the input data.
+ Defaults to None.
+ init_cfg (:obj:`ConfigDict` or list[:obj:`ConfigDict`] or dict or
+ list[dict], optional): Initialization config dict.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ backbone: ConfigType,
+ rpn_head: ConfigType,
+ roi_head: ConfigType,
+ train_cfg: ConfigType,
+ test_cfg: ConfigType,
+ neck: OptConfigType = None,
+ data_preprocessor: OptConfigType = None,
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(
+ backbone=backbone,
+ neck=neck,
+ rpn_head=rpn_head,
+ roi_head=roi_head,
+ train_cfg=train_cfg,
+ test_cfg=test_cfg,
+ init_cfg=init_cfg,
+ data_preprocessor=data_preprocessor)
diff --git a/mmdet/models/detectors/d2_wrapper.py b/mmdet/models/detectors/d2_wrapper.py
new file mode 100644
index 0000000000000000000000000000000000000000..3a2daa413e8fe0397ec37008d781ce449e7a26fd
--- /dev/null
+++ b/mmdet/models/detectors/d2_wrapper.py
@@ -0,0 +1,291 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Union
+
+from mmengine.config import ConfigDict
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.structures import SampleList
+from mmdet.structures.bbox import BaseBoxes
+from mmdet.structures.mask import BitmapMasks, PolygonMasks
+from mmdet.utils import ConfigType
+from .base import BaseDetector
+
+try:
+ import detectron2
+ from detectron2.config import get_cfg
+ from detectron2.modeling import build_model
+ from detectron2.structures.masks import BitMasks as D2_BitMasks
+ from detectron2.structures.masks import PolygonMasks as D2_PolygonMasks
+ from detectron2.utils.events import EventStorage
+except ImportError:
+ detectron2 = None
+
+
+def _to_cfgnode_list(cfg: ConfigType,
+ config_list: list = [],
+ father_name: str = 'MODEL') -> tuple:
+ """Convert the key and value of mmengine.ConfigDict into a list.
+
+ Args:
+ cfg (ConfigDict): The detectron2 model config.
+ config_list (list): A list contains the key and value of ConfigDict.
+ Defaults to [].
+ father_name (str): The father name add before the key.
+ Defaults to "MODEL".
+
+ Returns:
+ tuple:
+
+ - config_list: A list contains the key and value of ConfigDict.
+ - father_name (str): The father name add before the key.
+ Defaults to "MODEL".
+ """
+ for key, value in cfg.items():
+ name = f'{father_name}.{key.upper()}'
+ if isinstance(value, ConfigDict) or isinstance(value, dict):
+ config_list, fater_name = \
+ _to_cfgnode_list(value, config_list, name)
+ else:
+ config_list.append(name)
+ config_list.append(value)
+
+ return config_list, father_name
+
+
+def convert_d2_pred_to_datasample(data_samples: SampleList,
+ d2_results_list: list) -> SampleList:
+ """Convert the Detectron2's result to DetDataSample.
+
+ Args:
+ data_samples (list[:obj:`DetDataSample`]): The batch
+ data samples. It usually includes information such
+ as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
+ d2_results_list (list): The list of the results of Detectron2's model.
+
+ Returns:
+ list[:obj:`DetDataSample`]: Detection results of the
+ input images. Each DetDataSample usually contain
+ 'pred_instances'. And the ``pred_instances`` usually
+ contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ """
+ assert len(data_samples) == len(d2_results_list)
+ for data_sample, d2_results in zip(data_samples, d2_results_list):
+ d2_instance = d2_results['instances']
+
+ results = InstanceData()
+ results.bboxes = d2_instance.pred_boxes.tensor
+ results.scores = d2_instance.scores
+ results.labels = d2_instance.pred_classes
+
+ if d2_instance.has('pred_masks'):
+ results.masks = d2_instance.pred_masks
+ data_sample.pred_instances = results
+
+ return data_samples
+
+
+@MODELS.register_module()
+class Detectron2Wrapper(BaseDetector):
+ """Wrapper of a Detectron2 model. Input/output formats of this class follow
+ MMDetection's convention, so a Detectron2 model can be trained and
+ evaluated in MMDetection.
+
+ Args:
+ detector (:obj:`ConfigDict` or dict): The module config of
+ Detectron2.
+ bgr_to_rgb (bool): whether to convert image from BGR to RGB.
+ Defaults to False.
+ rgb_to_bgr (bool): whether to convert image from RGB to BGR.
+ Defaults to False.
+ """
+
+ def __init__(self,
+ detector: ConfigType,
+ bgr_to_rgb: bool = False,
+ rgb_to_bgr: bool = False) -> None:
+ if detectron2 is None:
+ raise ImportError('Please install Detectron2 first')
+ assert not (bgr_to_rgb and rgb_to_bgr), (
+ '`bgr2rgb` and `rgb2bgr` cannot be set to True at the same time')
+ super().__init__()
+ self._channel_conversion = rgb_to_bgr or bgr_to_rgb
+ cfgnode_list, _ = _to_cfgnode_list(detector)
+ self.cfg = get_cfg()
+ self.cfg.merge_from_list(cfgnode_list)
+ self.d2_model = build_model(self.cfg)
+ self.storage = EventStorage()
+
+ def init_weights(self) -> None:
+ """Initialization Backbone.
+
+ NOTE: The initialization of other layers are in Detectron2,
+ if users want to change the initialization way, please
+ change the code in Detectron2.
+ """
+ from detectron2.checkpoint import DetectionCheckpointer
+ checkpointer = DetectionCheckpointer(model=self.d2_model)
+ checkpointer.load(self.cfg.MODEL.WEIGHTS, checkpointables=[])
+
+ def loss(self, batch_inputs: Tensor,
+ batch_data_samples: SampleList) -> Union[dict, tuple]:
+ """Calculate losses from a batch of inputs and data samples.
+
+ The inputs will first convert to the Detectron2 type and feed into
+ D2 models.
+
+ Args:
+ batch_inputs (Tensor): Input images of shape (N, C, H, W).
+ These should usually be mean centered and std scaled.
+ batch_data_samples (list[:obj:`DetDataSample`]): The batch
+ data samples. It usually includes information such
+ as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
+
+ Returns:
+ dict: A dictionary of loss components.
+ """
+ d2_batched_inputs = self._convert_to_d2_inputs(
+ batch_inputs=batch_inputs,
+ batch_data_samples=batch_data_samples,
+ training=True)
+
+ with self.storage as storage: # noqa
+ losses = self.d2_model(d2_batched_inputs)
+ # storage contains some training information, such as cls_accuracy.
+ # you can use storage.latest() to get the detail information
+ return losses
+
+ def predict(self, batch_inputs: Tensor,
+ batch_data_samples: SampleList) -> SampleList:
+ """Predict results from a batch of inputs and data samples with post-
+ processing.
+
+ The inputs will first convert to the Detectron2 type and feed into
+ D2 models. And the results will convert back to the MMDet type.
+
+ Args:
+ batch_inputs (Tensor): Input images of shape (N, C, H, W).
+ These should usually be mean centered and std scaled.
+ batch_data_samples (list[:obj:`DetDataSample`]): The batch
+ data samples. It usually includes information such
+ as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
+
+
+ Returns:
+ list[:obj:`DetDataSample`]: Detection results of the
+ input images. Each DetDataSample usually contain
+ 'pred_instances'. And the ``pred_instances`` usually
+ contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ """
+ d2_batched_inputs = self._convert_to_d2_inputs(
+ batch_inputs=batch_inputs,
+ batch_data_samples=batch_data_samples,
+ training=False)
+ # results in detectron2 has already rescale
+ d2_results_list = self.d2_model(d2_batched_inputs)
+ batch_data_samples = convert_d2_pred_to_datasample(
+ data_samples=batch_data_samples, d2_results_list=d2_results_list)
+
+ return batch_data_samples
+
+ def _forward(self, *args, **kwargs):
+ """Network forward process.
+
+ Usually includes backbone, neck and head forward without any post-
+ processing.
+ """
+ raise NotImplementedError(
+ f'`_forward` is not implemented in {self.__class__.__name__}')
+
+ def extract_feat(self, *args, **kwargs):
+ """Extract features from images.
+
+ `extract_feat` will not be used in obj:``Detectron2Wrapper``.
+ """
+ pass
+
+ def _convert_to_d2_inputs(self,
+ batch_inputs: Tensor,
+ batch_data_samples: SampleList,
+ training=True) -> list:
+ """Convert inputs type to support Detectron2's model.
+
+ Args:
+ batch_inputs (Tensor): Input images of shape (N, C, H, W).
+ These should usually be mean centered and std scaled.
+ batch_data_samples (list[:obj:`DetDataSample`]): The batch
+ data samples. It usually includes information such
+ as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
+ training (bool): Whether to enable training time processing.
+
+ Returns:
+ list[dict]: A list of dict, which will be fed into Detectron2's
+ model. And the dict usually contains following keys.
+
+ - image (Tensor): Image in (C, H, W) format.
+ - instances (Instances): GT Instance.
+ - height (int): the output height resolution of the model
+ - width (int): the output width resolution of the model
+ """
+ from detectron2.data.detection_utils import filter_empty_instances
+ from detectron2.structures import Boxes, Instances
+
+ batched_d2_inputs = []
+ for image, data_samples in zip(batch_inputs, batch_data_samples):
+ d2_inputs = dict()
+ # deal with metainfo
+ meta_info = data_samples.metainfo
+ d2_inputs['file_name'] = meta_info['img_path']
+ d2_inputs['height'], d2_inputs['width'] = meta_info['ori_shape']
+ d2_inputs['image_id'] = meta_info['img_id']
+ # deal with image
+ if self._channel_conversion:
+ image = image[[2, 1, 0], ...]
+ d2_inputs['image'] = image
+ # deal with gt_instances
+ gt_instances = data_samples.gt_instances
+ d2_instances = Instances(meta_info['img_shape'])
+
+ gt_boxes = gt_instances.bboxes
+ # TODO: use mmdet.structures.box.get_box_tensor after PR 8658
+ # has merged
+ if isinstance(gt_boxes, BaseBoxes):
+ gt_boxes = gt_boxes.tensor
+ d2_instances.gt_boxes = Boxes(gt_boxes)
+
+ d2_instances.gt_classes = gt_instances.labels
+ if gt_instances.get('masks', None) is not None:
+ gt_masks = gt_instances.masks
+ if isinstance(gt_masks, PolygonMasks):
+ d2_instances.gt_masks = D2_PolygonMasks(gt_masks.masks)
+ elif isinstance(gt_masks, BitmapMasks):
+ d2_instances.gt_masks = D2_BitMasks(gt_masks.masks)
+ else:
+ raise TypeError('The type of `gt_mask` can be '
+ '`PolygonMasks` or `BitMasks`, but get '
+ f'{type(gt_masks)}.')
+ # convert to cpu and convert back to cuda to avoid
+ # some potential error
+ if training:
+ device = gt_boxes.device
+ d2_instances = filter_empty_instances(
+ d2_instances.to('cpu')).to(device)
+ d2_inputs['instances'] = d2_instances
+ batched_d2_inputs.append(d2_inputs)
+
+ return batched_d2_inputs
diff --git a/mmdet/models/detectors/dab_detr.py b/mmdet/models/detectors/dab_detr.py
new file mode 100644
index 0000000000000000000000000000000000000000..b61301cf6660924f0832f4068841a4664797c585
--- /dev/null
+++ b/mmdet/models/detectors/dab_detr.py
@@ -0,0 +1,139 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, Tuple
+
+from mmengine.model import uniform_init
+from torch import Tensor, nn
+
+from mmdet.registry import MODELS
+from ..layers import SinePositionalEncoding
+from ..layers.transformer import (DABDetrTransformerDecoder,
+ DABDetrTransformerEncoder, inverse_sigmoid)
+from .detr import DETR
+
+
+@MODELS.register_module()
+class DABDETR(DETR):
+ r"""Implementation of `DAB-DETR:
+ Dynamic Anchor Boxes are Better Queries for DETR.
+
+ `_.
+
+ Code is modified from the `official github repo
+ `_.
+
+ Args:
+ with_random_refpoints (bool): Whether to randomly initialize query
+ embeddings and not update them during training.
+ Defaults to False.
+ num_patterns (int): Inspired by Anchor-DETR. Defaults to 0.
+ """
+
+ def __init__(self,
+ *args,
+ with_random_refpoints: bool = False,
+ num_patterns: int = 0,
+ **kwargs) -> None:
+ self.with_random_refpoints = with_random_refpoints
+ assert isinstance(num_patterns, int), \
+ f'num_patterns should be int but {num_patterns}.'
+ self.num_patterns = num_patterns
+
+ super().__init__(*args, **kwargs)
+
+ def _init_layers(self) -> None:
+ """Initialize layers except for backbone, neck and bbox_head."""
+ self.positional_encoding = SinePositionalEncoding(
+ **self.positional_encoding)
+ self.encoder = DABDetrTransformerEncoder(**self.encoder)
+ self.decoder = DABDetrTransformerDecoder(**self.decoder)
+ self.embed_dims = self.encoder.embed_dims
+ self.query_dim = self.decoder.query_dim
+ self.query_embedding = nn.Embedding(self.num_queries, self.query_dim)
+ if self.num_patterns > 0:
+ self.patterns = nn.Embedding(self.num_patterns, self.embed_dims)
+
+ num_feats = self.positional_encoding.num_feats
+ assert num_feats * 2 == self.embed_dims, \
+ f'embed_dims should be exactly 2 times of num_feats. ' \
+ f'Found {self.embed_dims} and {num_feats}.'
+
+ def init_weights(self) -> None:
+ """Initialize weights for Transformer and other components."""
+ super(DABDETR, self).init_weights()
+ if self.with_random_refpoints:
+ uniform_init(self.query_embedding)
+ self.query_embedding.weight.data[:, :2] = \
+ inverse_sigmoid(self.query_embedding.weight.data[:, :2])
+ self.query_embedding.weight.data[:, :2].requires_grad = False
+
+ def pre_decoder(self, memory: Tensor) -> Tuple[Dict, Dict]:
+ """Prepare intermediate variables before entering Transformer decoder,
+ such as `query`, `query_pos`.
+
+ Args:
+ memory (Tensor): The output embeddings of the Transformer encoder,
+ has shape (bs, num_feat_points, dim).
+
+ Returns:
+ tuple[dict, dict]: The first dict contains the inputs of decoder
+ and the second dict contains the inputs of the bbox_head function.
+
+ - decoder_inputs_dict (dict): The keyword args dictionary of
+ `self.forward_decoder()`, which includes 'query', 'query_pos',
+ 'memory' and 'reg_branches'.
+ - head_inputs_dict (dict): The keyword args dictionary of the
+ bbox_head functions, which is usually empty, or includes
+ `enc_outputs_class` and `enc_outputs_class` when the detector
+ support 'two stage' or 'query selection' strategies.
+ """
+ batch_size = memory.size(0)
+ query_pos = self.query_embedding.weight
+ query_pos = query_pos.unsqueeze(0).repeat(batch_size, 1, 1)
+ if self.num_patterns == 0:
+ query = query_pos.new_zeros(batch_size, self.num_queries,
+ self.embed_dims)
+ else:
+ query = self.patterns.weight[:, None, None, :]\
+ .repeat(1, self.num_queries, batch_size, 1)\
+ .view(-1, batch_size, self.embed_dims)\
+ .permute(1, 0, 2)
+ query_pos = query_pos.repeat(1, self.num_patterns, 1)
+
+ decoder_inputs_dict = dict(
+ query_pos=query_pos, query=query, memory=memory)
+ head_inputs_dict = dict()
+ return decoder_inputs_dict, head_inputs_dict
+
+ def forward_decoder(self, query: Tensor, query_pos: Tensor, memory: Tensor,
+ memory_mask: Tensor, memory_pos: Tensor) -> Dict:
+ """Forward with Transformer decoder.
+
+ Args:
+ query (Tensor): The queries of decoder inputs, has shape
+ (bs, num_queries, dim).
+ query_pos (Tensor): The positional queries of decoder inputs,
+ has shape (bs, num_queries, dim).
+ memory (Tensor): The output embeddings of the Transformer encoder,
+ has shape (bs, num_feat_points, dim).
+ memory_mask (Tensor): ByteTensor, the padding mask of the memory,
+ has shape (bs, num_feat_points).
+ memory_pos (Tensor): The positional embeddings of memory, has
+ shape (bs, num_feat_points, dim).
+
+ Returns:
+ dict: The dictionary of decoder outputs, which includes the
+ `hidden_states` and `references` of the decoder output.
+ """
+
+ hidden_states, references = self.decoder(
+ query=query,
+ key=memory,
+ query_pos=query_pos,
+ key_pos=memory_pos,
+ key_padding_mask=memory_mask,
+ reg_branches=self.bbox_head.
+ fc_reg # iterative refinement for anchor boxes
+ )
+ head_inputs_dict = dict(
+ hidden_states=hidden_states, references=references)
+ return head_inputs_dict
diff --git a/mmdet/models/detectors/ddod.py b/mmdet/models/detectors/ddod.py
new file mode 100644
index 0000000000000000000000000000000000000000..3503a40c8eb6d6c0496ea0f31740acecf774113a
--- /dev/null
+++ b/mmdet/models/detectors/ddod.py
@@ -0,0 +1,41 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmdet.registry import MODELS
+from mmdet.utils import ConfigType, OptConfigType, OptMultiConfig
+from .single_stage import SingleStageDetector
+
+
+@MODELS.register_module()
+class DDOD(SingleStageDetector):
+ """Implementation of `DDOD `_.
+
+ Args:
+ backbone (:obj:`ConfigDict` or dict): The backbone module.
+ neck (:obj:`ConfigDict` or dict): The neck module.
+ bbox_head (:obj:`ConfigDict` or dict): The bbox head module.
+ train_cfg (:obj:`ConfigDict` or dict, optional): The training config
+ of ATSS. Defaults to None.
+ test_cfg (:obj:`ConfigDict` or dict, optional): The testing config
+ of ATSS. Defaults to None.
+ data_preprocessor (:obj:`ConfigDict` or dict, optional): Config of
+ :class:`DetDataPreprocessor` to process the input data.
+ Defaults to None.
+ init_cfg (:obj:`ConfigDict` or dict, optional): the config to control
+ the initialization. Defaults to None.
+ """
+
+ def __init__(self,
+ backbone: ConfigType,
+ neck: ConfigType,
+ bbox_head: ConfigType,
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ data_preprocessor: OptConfigType = None,
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(
+ backbone=backbone,
+ neck=neck,
+ bbox_head=bbox_head,
+ train_cfg=train_cfg,
+ test_cfg=test_cfg,
+ data_preprocessor=data_preprocessor,
+ init_cfg=init_cfg)
diff --git a/mmdet/models/detectors/deformable_detr.py b/mmdet/models/detectors/deformable_detr.py
new file mode 100644
index 0000000000000000000000000000000000000000..99c9e4a643c1d82222ce05f79a7d3e5d42a59ae6
--- /dev/null
+++ b/mmdet/models/detectors/deformable_detr.py
@@ -0,0 +1,547 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+from typing import Dict, Tuple
+
+import torch
+import torch.nn.functional as F
+from mmcv.cnn.bricks.transformer import MultiScaleDeformableAttention
+from mmengine.model import xavier_init
+from torch import Tensor, nn
+from torch.nn.init import normal_
+
+from mmdet.registry import MODELS
+from mmdet.structures import OptSampleList
+from mmdet.utils import OptConfigType
+from ..layers import (DeformableDetrTransformerDecoder,
+ DeformableDetrTransformerEncoder, SinePositionalEncoding)
+from .base_detr import DetectionTransformer
+
+
+@MODELS.register_module()
+class DeformableDETR(DetectionTransformer):
+ r"""Implementation of `Deformable DETR: Deformable Transformers for
+ End-to-End Object Detection `_
+
+ Code is modified from the `official github repo
+ `_.
+
+ Args:
+ decoder (:obj:`ConfigDict` or dict, optional): Config of the
+ Transformer decoder. Defaults to None.
+ bbox_head (:obj:`ConfigDict` or dict, optional): Config for the
+ bounding box head module. Defaults to None.
+ with_box_refine (bool, optional): Whether to refine the references
+ in the decoder. Defaults to `False`.
+ as_two_stage (bool, optional): Whether to generate the proposal
+ from the outputs of encoder. Defaults to `False`.
+ num_feature_levels (int, optional): Number of feature levels.
+ Defaults to 4.
+ """
+
+ def __init__(self,
+ *args,
+ decoder: OptConfigType = None,
+ bbox_head: OptConfigType = None,
+ with_box_refine: bool = False,
+ as_two_stage: bool = False,
+ num_feature_levels: int = 4,
+ **kwargs) -> None:
+ self.with_box_refine = with_box_refine
+ self.as_two_stage = as_two_stage
+ self.num_feature_levels = num_feature_levels
+
+ if bbox_head is not None:
+ assert 'share_pred_layer' not in bbox_head and \
+ 'num_pred_layer' not in bbox_head and \
+ 'as_two_stage' not in bbox_head, \
+ 'The two keyword args `share_pred_layer`, `num_pred_layer`, ' \
+ 'and `as_two_stage are set in `detector.__init__()`, users ' \
+ 'should not set them in `bbox_head` config.'
+ # The last prediction layer is used to generate proposal
+ # from encode feature map when `as_two_stage` is `True`.
+ # And all the prediction layers should share parameters
+ # when `with_box_refine` is `True`.
+ bbox_head['share_pred_layer'] = not with_box_refine
+ bbox_head['num_pred_layer'] = (decoder['num_layers'] + 1) \
+ if self.as_two_stage else decoder['num_layers']
+ bbox_head['as_two_stage'] = as_two_stage
+
+ super().__init__(*args, decoder=decoder, bbox_head=bbox_head, **kwargs)
+
+ def _init_layers(self) -> None:
+ """Initialize layers except for backbone, neck and bbox_head."""
+ self.positional_encoding = SinePositionalEncoding(
+ **self.positional_encoding)
+ if self.encoder_layers_num>0:
+ self.encoder = DeformableDetrTransformerEncoder(**self.encoder)
+ self.decoder = DeformableDetrTransformerDecoder(**self.decoder)
+ self.embed_dims = self.encoder.embed_dims
+ if not self.as_two_stage:
+ self.query_embedding = nn.Embedding(self.num_queries,
+ self.embed_dims * 2)
+ # NOTE The query_embedding will be split into query and query_pos
+ # in self.pre_decoder, hence, the embed_dims are doubled.
+
+ num_feats = self.positional_encoding.num_feats
+ assert num_feats * 2 == self.embed_dims, \
+ 'embed_dims should be exactly 2 times of num_feats. ' \
+ f'Found {self.embed_dims} and {num_feats}.'
+
+ self.level_embed = nn.Parameter(
+ torch.Tensor(self.num_feature_levels, self.embed_dims))
+
+ if self.as_two_stage:
+ self.memory_trans_fc = nn.Linear(self.embed_dims, self.embed_dims)
+ self.memory_trans_norm = nn.LayerNorm(self.embed_dims)
+ self.pos_trans_fc = nn.Linear(self.embed_dims * 2,
+ self.embed_dims * 2)
+ self.pos_trans_norm = nn.LayerNorm(self.embed_dims * 2)
+ else:
+ self.reference_points_fc = nn.Linear(self.embed_dims, 2)
+
+ def init_weights(self) -> None:
+ """Initialize weights for Transformer and other components."""
+ super().init_weights()
+ if self.encoder_layers_num>0:
+ for coder in self.encoder, self.decoder:
+ for p in coder.parameters():
+ if p.dim() > 1:
+ nn.init.xavier_uniform_(p)
+ else:
+ for p in self.decoder.parameters():
+ if p.dim() > 1:
+ nn.init.xavier_uniform_(p)
+ for m in self.modules():
+ if isinstance(m, MultiScaleDeformableAttention):
+ m.init_weights()
+ if self.as_two_stage:
+ nn.init.xavier_uniform_(self.memory_trans_fc.weight)
+ nn.init.xavier_uniform_(self.pos_trans_fc.weight)
+ else:
+ xavier_init(
+ self.reference_points_fc, distribution='uniform', bias=0.)
+ normal_(self.level_embed)
+
+ def pre_transformer(
+ self,
+ mlvl_feats: Tuple[Tensor],
+ batch_data_samples: OptSampleList = None) -> Tuple[Dict]:
+ """Process image features before feeding them to the transformer.
+
+ The forward procedure of the transformer is defined as:
+ 'pre_transformer' -> 'encoder' -> 'pre_decoder' -> 'decoder'
+ More details can be found at `TransformerDetector.forward_transformer`
+ in `mmdet/detector/base_detr.py`.
+
+ Args:
+ mlvl_feats (tuple[Tensor]): Multi-level features that may have
+ different resolutions, output from neck. Each feature has
+ shape (bs, dim, h_lvl, w_lvl), where 'lvl' means 'layer'.
+ batch_data_samples (list[:obj:`DetDataSample`], optional): The
+ batch data samples. It usually includes information such
+ as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
+ Defaults to None.
+
+ Returns:
+ tuple[dict]: The first dict contains the inputs of encoder and the
+ second dict contains the inputs of decoder.
+
+ - encoder_inputs_dict (dict): The keyword args dictionary of
+ `self.forward_encoder()`, which includes 'feat', 'feat_mask',
+ and 'feat_pos'.
+ - decoder_inputs_dict (dict): The keyword args dictionary of
+ `self.forward_decoder()`, which includes 'memory_mask'.
+ """
+ batch_size = mlvl_feats[0].size(0)
+
+ # construct binary masks for the transformer.
+ assert batch_data_samples is not None
+ batch_input_shape = batch_data_samples[0].batch_input_shape
+ img_shape_list = [sample.img_shape for sample in batch_data_samples]
+ input_img_h, input_img_w = batch_input_shape
+ masks = mlvl_feats[0].new_ones((batch_size, input_img_h, input_img_w))
+ for img_id in range(batch_size):
+ img_h, img_w = img_shape_list[img_id]
+ masks[img_id, :img_h, :img_w] = 0
+ # NOTE following the official DETR repo, non-zero values representing
+ # ignored positions, while zero values means valid positions.
+
+ mlvl_masks = []
+ mlvl_pos_embeds = []
+ for feat in mlvl_feats:
+ mlvl_masks.append(
+ F.interpolate(masks[None],
+ size=feat.shape[-2:]).to(torch.bool).squeeze(0))
+ mlvl_pos_embeds.append(self.positional_encoding(mlvl_masks[-1]))
+
+ feat_flatten = []
+ lvl_pos_embed_flatten = []
+ mask_flatten = []
+ spatial_shapes = []
+ for lvl, (feat, mask, pos_embed) in enumerate(
+ zip(mlvl_feats, mlvl_masks, mlvl_pos_embeds)):
+ batch_size, c, h, w = feat.shape
+ # [bs, c, h_lvl, w_lvl] -> [bs, h_lvl*w_lvl, c]
+ feat = feat.view(batch_size, c, -1).permute(0, 2, 1)
+ pos_embed = pos_embed.view(batch_size, c, -1).permute(0, 2, 1)
+ lvl_pos_embed = pos_embed + self.level_embed[lvl].view(1, 1, -1)
+ # [bs, h_lvl, w_lvl] -> [bs, h_lvl*w_lvl]
+ mask = mask.flatten(1)
+ spatial_shape = (h, w)
+
+ feat_flatten.append(feat)
+ lvl_pos_embed_flatten.append(lvl_pos_embed)
+ mask_flatten.append(mask)
+ spatial_shapes.append(spatial_shape)
+
+ # (bs, num_feat_points, dim)
+ feat_flatten = torch.cat(feat_flatten, 1)
+ lvl_pos_embed_flatten = torch.cat(lvl_pos_embed_flatten, 1)
+ # (bs, num_feat_points), where num_feat_points = sum_lvl(h_lvl*w_lvl)
+ mask_flatten = torch.cat(mask_flatten, 1)
+
+ spatial_shapes = torch.as_tensor( # (num_level, 2)
+ spatial_shapes,
+ dtype=torch.long,
+ device=feat_flatten.device)
+ level_start_index = torch.cat((
+ spatial_shapes.new_zeros((1, )), # (num_level)
+ spatial_shapes.prod(1).cumsum(0)[:-1]))
+ valid_ratios = torch.stack( # (bs, num_level, 2)
+ [self.get_valid_ratio(m) for m in mlvl_masks], 1)
+
+ encoder_inputs_dict = dict(
+ feat=feat_flatten,
+ feat_mask=mask_flatten,
+ feat_pos=lvl_pos_embed_flatten,
+ spatial_shapes=spatial_shapes,
+ level_start_index=level_start_index,
+ valid_ratios=valid_ratios)
+ decoder_inputs_dict = dict(
+ memory_mask=mask_flatten,
+ spatial_shapes=spatial_shapes,
+ level_start_index=level_start_index,
+ valid_ratios=valid_ratios)
+ return encoder_inputs_dict, decoder_inputs_dict
+
+ def forward_encoder(self, feat: Tensor, feat_mask: Tensor,
+ feat_pos: Tensor, spatial_shapes: Tensor,
+ level_start_index: Tensor,
+ valid_ratios: Tensor) -> Dict:
+ """Forward with Transformer encoder.
+
+ The forward procedure of the transformer is defined as:
+ 'pre_transformer' -> 'encoder' -> 'pre_decoder' -> 'decoder'
+ More details can be found at `TransformerDetector.forward_transformer`
+ in `mmdet/detector/base_detr.py`.
+
+ Args:
+ feat (Tensor): Sequential features, has shape (bs, num_feat_points,
+ dim).
+ feat_mask (Tensor): ByteTensor, the padding mask of the features,
+ has shape (bs, num_feat_points).
+ feat_pos (Tensor): The positional embeddings of the features, has
+ shape (bs, num_feat_points, dim).
+ spatial_shapes (Tensor): Spatial shapes of features in all levels,
+ has shape (num_levels, 2), last dimension represents (h, w).
+ level_start_index (Tensor): The start index of each level.
+ A tensor has shape (num_levels, ) and can be represented
+ as [0, h_0*w_0, h_0*w_0+h_1*w_1, ...].
+ valid_ratios (Tensor): The ratios of the valid width and the valid
+ height relative to the width and the height of features in all
+ levels, has shape (bs, num_levels, 2).
+
+ Returns:
+ dict: The dictionary of encoder outputs, which includes the
+ `memory` of the encoder output.
+ """
+ memory = self.encoder(
+ query=feat,
+ query_pos=feat_pos,
+ key_padding_mask=feat_mask, # for self_attn
+ spatial_shapes=spatial_shapes,
+ level_start_index=level_start_index,
+ valid_ratios=valid_ratios)
+ encoder_outputs_dict = dict(
+ memory=memory,
+ memory_mask=feat_mask,
+ spatial_shapes=spatial_shapes)
+ return encoder_outputs_dict
+
+ def pre_decoder(self, memory: Tensor, memory_mask: Tensor,
+ spatial_shapes: Tensor) -> Tuple[Dict, Dict]:
+ """Prepare intermediate variables before entering Transformer decoder,
+ such as `query`, `query_pos`, and `reference_points`.
+
+ The forward procedure of the transformer is defined as:
+ 'pre_transformer' -> 'encoder' -> 'pre_decoder' -> 'decoder'
+ More details can be found at `TransformerDetector.forward_transformer`
+ in `mmdet/detector/base_detr.py`.
+
+ Args:
+ memory (Tensor): The output embeddings of the Transformer encoder,
+ has shape (bs, num_feat_points, dim).
+ memory_mask (Tensor): ByteTensor, the padding mask of the memory,
+ has shape (bs, num_feat_points). It will only be used when
+ `as_two_stage` is `True`.
+ spatial_shapes (Tensor): Spatial shapes of features in all levels,
+ has shape (num_levels, 2), last dimension represents (h, w).
+ It will only be used when `as_two_stage` is `True`.
+
+ Returns:
+ tuple[dict, dict]: The decoder_inputs_dict and head_inputs_dict.
+
+ - decoder_inputs_dict (dict): The keyword dictionary args of
+ `self.forward_decoder()`, which includes 'query', 'query_pos',
+ 'memory', and `reference_points`. The reference_points of
+ decoder input here are 4D boxes when `as_two_stage` is `True`,
+ otherwise 2D points, although it has `points` in its name.
+ The reference_points in encoder is always 2D points.
+ - head_inputs_dict (dict): The keyword dictionary args of the
+ bbox_head functions, which includes `enc_outputs_class` and
+ `enc_outputs_coord`. They are both `None` when 'as_two_stage'
+ is `False`. The dict is empty when `self.training` is `False`.
+ """
+ batch_size, _, c = memory.shape
+ if self.as_two_stage:
+ output_memory, output_proposals = \
+ self.gen_encoder_output_proposals(
+ memory, memory_mask, spatial_shapes)
+ enc_outputs_class = self.bbox_head.cls_branches[
+ self.decoder.num_layers](
+ output_memory)
+ enc_outputs_coord_unact = self.bbox_head.reg_branches[
+ self.decoder.num_layers](output_memory) + output_proposals
+ enc_outputs_coord = enc_outputs_coord_unact.sigmoid()
+ # We only use the first channel in enc_outputs_class as foreground,
+ # the other (num_classes - 1) channels are actually not used.
+ # Its targets are set to be 0s, which indicates the first
+ # class (foreground) because we use [0, num_classes - 1] to
+ # indicate class labels, background class is indicated by
+ # num_classes (similar convention in RPN).
+ # See https://github.com/open-mmlab/mmdetection/blob/master/mmdet/models/dense_heads/deformable_detr_head.py#L241 # noqa
+ # This follows the official implementation of Deformable DETR.
+ topk_proposals = torch.topk(
+ enc_outputs_class[..., 0], self.num_queries, dim=1)[1]
+ topk_coords_unact = torch.gather(
+ enc_outputs_coord_unact, 1,
+ topk_proposals.unsqueeze(-1).repeat(1, 1, 4))
+ topk_coords_unact = topk_coords_unact.detach()
+ reference_points = topk_coords_unact.sigmoid()
+ pos_trans_out = self.pos_trans_fc(
+ self.get_proposal_pos_embed(topk_coords_unact))
+ pos_trans_out = self.pos_trans_norm(pos_trans_out)
+ query_pos, query = torch.split(pos_trans_out, c, dim=2)
+ else:
+ enc_outputs_class, enc_outputs_coord = None, None
+ query_embed = self.query_embedding.weight
+ query_pos, query = torch.split(query_embed, c, dim=1)
+ query_pos = query_pos.unsqueeze(0).expand(batch_size, -1, -1)
+ query = query.unsqueeze(0).expand(batch_size, -1, -1)
+ reference_points = self.reference_points_fc(query_pos).sigmoid()
+
+ decoder_inputs_dict = dict(
+ query=query,
+ query_pos=query_pos,
+ memory=memory,
+ reference_points=reference_points)
+ head_inputs_dict = dict(
+ enc_outputs_class=enc_outputs_class,
+ enc_outputs_coord=enc_outputs_coord) if self.training else dict()
+ return decoder_inputs_dict, head_inputs_dict
+
+ def forward_decoder(self, query: Tensor, query_pos: Tensor, memory: Tensor,
+ memory_mask: Tensor, reference_points: Tensor,
+ spatial_shapes: Tensor, level_start_index: Tensor,
+ valid_ratios: Tensor) -> Dict:
+ """Forward with Transformer decoder.
+
+ The forward procedure of the transformer is defined as:
+ 'pre_transformer' -> 'encoder' -> 'pre_decoder' -> 'decoder'
+ More details can be found at `TransformerDetector.forward_transformer`
+ in `mmdet/detector/base_detr.py`.
+
+ Args:
+ query (Tensor): The queries of decoder inputs, has shape
+ (bs, num_queries, dim).
+ query_pos (Tensor): The positional queries of decoder inputs,
+ has shape (bs, num_queries, dim).
+ memory (Tensor): The output embeddings of the Transformer encoder,
+ has shape (bs, num_feat_points, dim).
+ memory_mask (Tensor): ByteTensor, the padding mask of the memory,
+ has shape (bs, num_feat_points).
+ reference_points (Tensor): The initial reference, has shape
+ (bs, num_queries, 4) with the last dimension arranged as
+ (cx, cy, w, h) when `as_two_stage` is `True`, otherwise has
+ shape (bs, num_queries, 2) with the last dimension arranged as
+ (cx, cy).
+ spatial_shapes (Tensor): Spatial shapes of features in all levels,
+ has shape (num_levels, 2), last dimension represents (h, w).
+ level_start_index (Tensor): The start index of each level.
+ A tensor has shape (num_levels, ) and can be represented
+ as [0, h_0*w_0, h_0*w_0+h_1*w_1, ...].
+ valid_ratios (Tensor): The ratios of the valid width and the valid
+ height relative to the width and the height of features in all
+ levels, has shape (bs, num_levels, 2).
+
+ Returns:
+ dict: The dictionary of decoder outputs, which includes the
+ `hidden_states` of the decoder output and `references` including
+ the initial and intermediate reference_points.
+ """
+ inter_states, inter_references = self.decoder(
+ query=query,
+ value=memory,
+ query_pos=query_pos,
+ key_padding_mask=memory_mask, # for cross_attn
+ reference_points=reference_points,
+ spatial_shapes=spatial_shapes,
+ level_start_index=level_start_index,
+ valid_ratios=valid_ratios,
+ reg_branches=self.bbox_head.reg_branches
+ if self.with_box_refine else None)
+ references = [reference_points, *inter_references]
+ decoder_outputs_dict = dict(
+ hidden_states=inter_states, references=references)
+ return decoder_outputs_dict
+
+ @staticmethod
+ def get_valid_ratio(mask: Tensor) -> Tensor:
+ """Get the valid radios of feature map in a level.
+
+ .. code:: text
+
+ |---> valid_W <---|
+ ---+-----------------+-----+---
+ A | | | A
+ | | | | |
+ | | | | |
+ valid_H | | | |
+ | | | | H
+ | | | | |
+ V | | | |
+ ---+-----------------+ | |
+ | | V
+ +-----------------------+---
+ |---------> W <---------|
+
+ The valid_ratios are defined as:
+ r_h = valid_H / H, r_w = valid_W / W
+ They are the factors to re-normalize the relative coordinates of the
+ image to the relative coordinates of the current level feature map.
+
+ Args:
+ mask (Tensor): Binary mask of a feature map, has shape (bs, H, W).
+
+ Returns:
+ Tensor: valid ratios [r_w, r_h] of a feature map, has shape (1, 2).
+ """
+ _, H, W = mask.shape
+ valid_H = torch.sum(~mask[:, :, 0], 1)
+ valid_W = torch.sum(~mask[:, 0, :], 1)
+ valid_ratio_h = valid_H.float() / H
+ valid_ratio_w = valid_W.float() / W
+ valid_ratio = torch.stack([valid_ratio_w, valid_ratio_h], -1)
+ return valid_ratio
+
+ def gen_encoder_output_proposals(
+ self, memory: Tensor, memory_mask: Tensor,
+ spatial_shapes: Tensor) -> Tuple[Tensor, Tensor]:
+ """Generate proposals from encoded memory. The function will only be
+ used when `as_two_stage` is `True`.
+
+ Args:
+ memory (Tensor): The output embeddings of the Transformer encoder,
+ has shape (bs, num_feat_points, dim).
+ memory_mask (Tensor): ByteTensor, the padding mask of the memory,
+ has shape (bs, num_feat_points).
+ spatial_shapes (Tensor): Spatial shapes of features in all levels,
+ has shape (num_levels, 2), last dimension represents (h, w).
+
+ Returns:
+ tuple: A tuple of transformed memory and proposals.
+
+ - output_memory (Tensor): The transformed memory for obtaining
+ top-k proposals, has shape (bs, num_feat_points, dim).
+ - output_proposals (Tensor): The inverse-normalized proposal, has
+ shape (batch_size, num_keys, 4) with the last dimension arranged
+ as (cx, cy, w, h).
+ """
+
+ bs = memory.size(0)
+ proposals = []
+ _cur = 0 # start index in the sequence of the current level
+ for lvl, (H, W) in enumerate(spatial_shapes):
+ mask_flatten_ = memory_mask[:,
+ _cur:(_cur + H * W)].view(bs, H, W, 1)
+ valid_H = torch.sum(~mask_flatten_[:, :, 0, 0], 1).unsqueeze(-1)
+ valid_W = torch.sum(~mask_flatten_[:, 0, :, 0], 1).unsqueeze(-1)
+
+ grid_y, grid_x = torch.meshgrid(
+ torch.linspace(
+ 0, H - 1, H, dtype=torch.float32, device=memory.device),
+ torch.linspace(
+ 0, W - 1, W, dtype=torch.float32, device=memory.device))
+ grid = torch.cat([grid_x.unsqueeze(-1), grid_y.unsqueeze(-1)], -1)
+
+ scale = torch.cat([valid_W, valid_H], 1).view(bs, 1, 1, 2)
+ grid = (grid.unsqueeze(0).expand(bs, -1, -1, -1) + 0.5) / scale
+ wh = torch.ones_like(grid) * 0.05 * (2.0**lvl)
+ proposal = torch.cat((grid, wh), -1).view(bs, -1, 4)
+ proposals.append(proposal)
+ _cur += (H * W)
+ output_proposals = torch.cat(proposals, 1)
+ output_proposals_valid = ((output_proposals > 0.01) &
+ (output_proposals < 0.99)).all(
+ -1, keepdim=True)
+ # inverse_sigmoid
+ output_proposals = torch.log(output_proposals / (1 - output_proposals))
+ output_proposals = output_proposals.masked_fill(
+ memory_mask.unsqueeze(-1), float('inf'))
+ output_proposals = output_proposals.masked_fill(
+ ~output_proposals_valid, float('inf'))
+
+ output_memory = memory
+ output_memory = output_memory.masked_fill(
+ memory_mask.unsqueeze(-1), float(0))
+ output_memory = output_memory.masked_fill(~output_proposals_valid,
+ float(0))
+ output_memory = self.memory_trans_fc(output_memory)
+ output_memory = self.memory_trans_norm(output_memory)
+ # [bs, sum(hw), 2]
+ return output_memory, output_proposals
+
+ @staticmethod
+ def get_proposal_pos_embed(proposals: Tensor,
+ num_pos_feats: int = 128,
+ temperature: int = 10000) -> Tensor:
+ """Get the position embedding of the proposal.
+
+ Args:
+ proposals (Tensor): Not normalized proposals, has shape
+ (bs, num_queries, 4) with the last dimension arranged as
+ (cx, cy, w, h).
+ num_pos_feats (int, optional): The feature dimension for each
+ position along x, y, w, and h-axis. Note the final returned
+ dimension for each position is 4 times of num_pos_feats.
+ Default to 128.
+ temperature (int, optional): The temperature used for scaling the
+ position embedding. Defaults to 10000.
+
+ Returns:
+ Tensor: The position embedding of proposal, has shape
+ (bs, num_queries, num_pos_feats * 4), with the last dimension
+ arranged as (cx, cy, w, h)
+ """
+ scale = 2 * math.pi
+ dim_t = torch.arange(
+ num_pos_feats, dtype=torch.float32, device=proposals.device)
+ dim_t = temperature**(2 * (dim_t // 2) / num_pos_feats)
+ # N, L, 4
+ proposals = proposals.sigmoid() * scale
+ # N, L, 4, 128
+ pos = proposals[:, :, :, None] / dim_t
+ # N, L, 4, 64, 2
+ pos = torch.stack((pos[:, :, :, 0::2].sin(), pos[:, :, :, 1::2].cos()),
+ dim=4).flatten(2)
+ return pos
diff --git a/mmdet/models/detectors/detr.py b/mmdet/models/detectors/detr.py
new file mode 100644
index 0000000000000000000000000000000000000000..07fed2951ef23b377344d46d0372ac0befaaa8fa
--- /dev/null
+++ b/mmdet/models/detectors/detr.py
@@ -0,0 +1,216 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, Tuple
+
+import torch
+import torch.nn.functional as F
+from torch import Tensor, nn
+
+from mmdet.registry import MODELS
+from mmdet.structures import OptSampleList
+from ..layers import (DetrTransformerDecoder, DetrTransformerEncoder,
+ SinePositionalEncoding)
+from .base_detr import DetectionTransformer
+
+
+@MODELS.register_module()
+class DETR(DetectionTransformer):
+ r"""Implementation of `DETR: End-to-End Object Detection with Transformers.
+
+ `_.
+
+ Code is modified from the `official github repo
+ `_.
+ """
+
+ def _init_layers(self) -> None:
+ """Initialize layers except for backbone, neck and bbox_head."""
+ self.positional_encoding = SinePositionalEncoding(
+ **self.positional_encoding)
+ self.encoder = DetrTransformerEncoder(**self.encoder)
+ self.decoder = DetrTransformerDecoder(**self.decoder)
+ self.embed_dims = self.encoder.embed_dims
+ # NOTE The embed_dims is typically passed from the inside out.
+ # For example in DETR, The embed_dims is passed as
+ # self_attn -> the first encoder layer -> encoder -> detector.
+ self.query_embedding = nn.Embedding(self.num_queries, self.embed_dims)
+
+ num_feats = self.positional_encoding.num_feats
+ assert num_feats * 2 == self.embed_dims, \
+ 'embed_dims should be exactly 2 times of num_feats. ' \
+ f'Found {self.embed_dims} and {num_feats}.'
+
+ def init_weights(self) -> None:
+ """Initialize weights for Transformer and other components."""
+ super().init_weights()
+ for coder in self.encoder, self.decoder:
+ for p in coder.parameters():
+ if p.dim() > 1:
+ nn.init.xavier_uniform_(p)
+
+ def pre_transformer(
+ self,
+ img_feats: Tuple[Tensor],
+ batch_data_samples: OptSampleList = None) -> Tuple[Dict, Dict]:
+ """Prepare the inputs of the Transformer.
+
+ The forward procedure of the transformer is defined as:
+ 'pre_transformer' -> 'encoder' -> 'pre_decoder' -> 'decoder'
+ More details can be found at `TransformerDetector.forward_transformer`
+ in `mmdet/detector/base_detr.py`.
+
+ Args:
+ img_feats (Tuple[Tensor]): Tuple of features output from the neck,
+ has shape (bs, c, h, w).
+ batch_data_samples (List[:obj:`DetDataSample`]): The batch
+ data samples. It usually includes information such as
+ `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
+ Defaults to None.
+
+ Returns:
+ tuple[dict, dict]: The first dict contains the inputs of encoder
+ and the second dict contains the inputs of decoder.
+
+ - encoder_inputs_dict (dict): The keyword args dictionary of
+ `self.forward_encoder()`, which includes 'feat', 'feat_mask',
+ and 'feat_pos'.
+ - decoder_inputs_dict (dict): The keyword args dictionary of
+ `self.forward_decoder()`, which includes 'memory_mask',
+ and 'memory_pos'.
+ """
+
+ feat = img_feats[-1] # NOTE img_feats contains only one feature.
+ batch_size, feat_dim, _, _ = feat.shape
+ # construct binary masks which for the transformer.
+ assert batch_data_samples is not None
+ batch_input_shape = batch_data_samples[0].batch_input_shape
+ img_shape_list = [sample.img_shape for sample in batch_data_samples]
+
+ input_img_h, input_img_w = batch_input_shape
+ masks = feat.new_ones((batch_size, input_img_h, input_img_w))
+ for img_id in range(batch_size):
+ img_h, img_w = img_shape_list[img_id]
+ masks[img_id, :img_h, :img_w] = 0
+ # NOTE following the official DETR repo, non-zero values represent
+ # ignored positions, while zero values mean valid positions.
+
+ masks = F.interpolate(
+ masks.unsqueeze(1), size=feat.shape[-2:]).to(torch.bool).squeeze(1)
+ # [batch_size, embed_dim, h, w]
+ pos_embed = self.positional_encoding(masks)
+
+ # use `view` instead of `flatten` for dynamically exporting to ONNX
+ # [bs, c, h, w] -> [bs, h*w, c]
+ feat = feat.view(batch_size, feat_dim, -1).permute(0, 2, 1)
+ pos_embed = pos_embed.view(batch_size, feat_dim, -1).permute(0, 2, 1)
+ # [bs, h, w] -> [bs, h*w]
+ masks = masks.view(batch_size, -1)
+
+ # prepare transformer_inputs_dict
+ encoder_inputs_dict = dict(
+ feat=feat, feat_mask=masks, feat_pos=pos_embed)
+ decoder_inputs_dict = dict(memory_mask=masks, memory_pos=pos_embed)
+ return encoder_inputs_dict, decoder_inputs_dict
+
+ def forward_encoder(self, feat: Tensor, feat_mask: Tensor,
+ feat_pos: Tensor) -> Dict:
+ """Forward with Transformer encoder.
+
+ The forward procedure of the transformer is defined as:
+ 'pre_transformer' -> 'encoder' -> 'pre_decoder' -> 'decoder'
+ More details can be found at `TransformerDetector.forward_transformer`
+ in `mmdet/detector/base_detr.py`.
+
+ Args:
+ feat (Tensor): Sequential features, has shape (bs, num_feat_points,
+ dim).
+ feat_mask (Tensor): ByteTensor, the padding mask of the features,
+ has shape (bs, num_feat_points).
+ feat_pos (Tensor): The positional embeddings of the features, has
+ shape (bs, num_feat_points, dim).
+
+ Returns:
+ dict: The dictionary of encoder outputs, which includes the
+ `memory` of the encoder output.
+ """
+ memory = self.encoder(
+ query=feat, query_pos=feat_pos,
+ key_padding_mask=feat_mask) # for self_attn
+ encoder_outputs_dict = dict(memory=memory)
+ return encoder_outputs_dict
+
+ def pre_decoder(self, memory: Tensor) -> Tuple[Dict, Dict]:
+ """Prepare intermediate variables before entering Transformer decoder,
+ such as `query`, `query_pos`.
+
+ The forward procedure of the transformer is defined as:
+ 'pre_transformer' -> 'encoder' -> 'pre_decoder' -> 'decoder'
+ More details can be found at `TransformerDetector.forward_transformer`
+ in `mmdet/detector/base_detr.py`.
+
+ Args:
+ memory (Tensor): The output embeddings of the Transformer encoder,
+ has shape (bs, num_feat_points, dim).
+
+ Returns:
+ tuple[dict, dict]: The first dict contains the inputs of decoder
+ and the second dict contains the inputs of the bbox_head function.
+
+ - decoder_inputs_dict (dict): The keyword args dictionary of
+ `self.forward_decoder()`, which includes 'query', 'query_pos',
+ 'memory'.
+ - head_inputs_dict (dict): The keyword args dictionary of the
+ bbox_head functions, which is usually empty, or includes
+ `enc_outputs_class` and `enc_outputs_class` when the detector
+ support 'two stage' or 'query selection' strategies.
+ """
+
+ batch_size = memory.size(0) # (bs, num_feat_points, dim)
+ query_pos = self.query_embedding.weight
+ # (num_queries, dim) -> (bs, num_queries, dim)
+ query_pos = query_pos.unsqueeze(0).repeat(batch_size, 1, 1)
+ query = torch.zeros_like(query_pos)
+
+ decoder_inputs_dict = dict(
+ query_pos=query_pos, query=query, memory=memory)
+ head_inputs_dict = dict()
+ return decoder_inputs_dict, head_inputs_dict
+
+ def forward_decoder(self, query: Tensor, query_pos: Tensor, memory: Tensor,
+ memory_mask: Tensor, memory_pos: Tensor) -> Dict:
+ """Forward with Transformer decoder.
+
+ The forward procedure of the transformer is defined as:
+ 'pre_transformer' -> 'encoder' -> 'pre_decoder' -> 'decoder'
+ More details can be found at `TransformerDetector.forward_transformer`
+ in `mmdet/detector/base_detr.py`.
+
+ Args:
+ query (Tensor): The queries of decoder inputs, has shape
+ (bs, num_queries, dim).
+ query_pos (Tensor): The positional queries of decoder inputs,
+ has shape (bs, num_queries, dim).
+ memory (Tensor): The output embeddings of the Transformer encoder,
+ has shape (bs, num_feat_points, dim).
+ memory_mask (Tensor): ByteTensor, the padding mask of the memory,
+ has shape (bs, num_feat_points).
+ memory_pos (Tensor): The positional embeddings of memory, has
+ shape (bs, num_feat_points, dim).
+
+ Returns:
+ dict: The dictionary of decoder outputs, which includes the
+ `hidden_states` of the decoder output.
+
+ - hidden_states (Tensor): Has shape
+ (num_decoder_layers, bs, num_queries, dim)
+ """
+
+ hidden_states = self.decoder(
+ query=query,
+ key=memory,
+ value=memory,
+ query_pos=query_pos,
+ key_pos=memory_pos,
+ key_padding_mask=memory_mask) # for cross_attn
+
+ head_inputs_dict = dict(hidden_states=hidden_states)
+ return head_inputs_dict
diff --git a/mmdet/models/detectors/dino.py b/mmdet/models/detectors/dino.py
new file mode 100644
index 0000000000000000000000000000000000000000..78c9ab307cdef594e1eb955922dc8da95598c0c2
--- /dev/null
+++ b/mmdet/models/detectors/dino.py
@@ -0,0 +1,689 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+
+# 修改版本,增加了框缩放,默认不缩放,
+from typing import Dict, Optional, Tuple,List, Union
+
+import torch
+from torch import Tensor, nn
+import torch.nn.functional as F
+from torch.nn.init import normal_
+from mmdet.registry import MODELS
+from mmdet.structures import OptSampleList, SampleList
+from mmdet.utils import OptConfigType
+# from ..layers import (CdnQueryGenerator, DeformableDetrTransformerEncoder,
+# DinoTransformerDecoder, SinePositionalEncoding)
+from ..layers import SinePositionalEncoding
+from ..layers.transformer.dino_layers import (CdnQueryGenerator, DeformableDetrTransformerEncoder,
+ DinoTransformerDecoder)
+from .deformable_detr import DeformableDETR, MultiScaleDeformableAttention
+
+
+
+
+@MODELS.register_module()
+class DINO(DeformableDETR):
+ r"""Implementation of `DINO: DETR with Improved DeNoising Anchor Boxes
+ for End-to-End Object Detection `_
+
+ Code is modified from the `official github repo
+ `_.
+
+ Args:
+ dn_cfg (:obj:`ConfigDict` or dict, optional): Config of denoising
+ query generator. Defaults to `None`.
+ """
+
+ def __init__(self, *args, dn_cfg: OptConfigType = None,
+ candidate_bboxes_size: float = 0.05,
+ scale_gt_bboxes_size: float = 0,
+ htd_2s: int = False,
+ **kwargs) -> None:
+ super().__init__(*args, **kwargs)
+ assert self.as_two_stage, 'as_two_stage must be True for DINO'
+ assert self.with_box_refine, 'with_box_refine must be True for DINO'
+
+ if dn_cfg is not None:
+ assert 'num_classes' not in dn_cfg and \
+ 'num_queries' not in dn_cfg and \
+ 'hidden_dim' not in dn_cfg, \
+ 'The three keyword args `num_classes`, `embed_dims`, and ' \
+ '`num_matching_queries` are set in `detector.__init__()`, ' \
+ 'users should not set them in `dn_cfg` config.'
+ dn_cfg['num_classes'] = self.bbox_head.num_classes
+ dn_cfg['embed_dims'] = self.embed_dims
+ dn_cfg['num_matching_queries'] = self.num_queries
+ self.dn_query_generator = CdnQueryGenerator(**dn_cfg)
+ self.scale_gt_bboxes_size = scale_gt_bboxes_size
+ self.candidate_bboxes_size = candidate_bboxes_size
+ self.htd_2s = htd_2s
+ def _init_layers(self) -> None:
+ """Initialize layers except for backbone, neck and bbox_head."""
+ self.positional_encoding = SinePositionalEncoding(
+ **self.positional_encoding)
+ self.encoder = DeformableDetrTransformerEncoder(**self.encoder)
+ self.decoder = DinoTransformerDecoder(**self.decoder)
+ self.embed_dims = self.encoder.embed_dims
+ self.query_embedding = nn.Embedding(self.num_queries, self.embed_dims)
+ # NOTE In DINO, the query_embedding only contains content
+ # queries, while in Deformable DETR, the query_embedding
+ # contains both content and spatial queries, and in DETR,
+ # it only contains spatial queries.
+
+ num_feats = self.positional_encoding.num_feats
+ assert num_feats * 2 == self.embed_dims, \
+ f'embed_dims should be exactly 2 times of num_feats. ' \
+ f'Found {self.embed_dims} and {num_feats}.'
+
+ self.level_embed = nn.Parameter(
+ torch.Tensor(self.num_feature_levels, self.embed_dims))
+ self.memory_trans_fc = nn.Linear(self.embed_dims, self.embed_dims)
+ self.memory_trans_norm = nn.LayerNorm(self.embed_dims)
+
+ def init_weights(self) -> None:
+ """Initialize weights for Transformer and other components."""
+ super(DeformableDETR, self).init_weights()
+ for coder in self.encoder, self.decoder:
+ for p in coder.parameters():
+ if p.dim() > 1:
+ nn.init.xavier_uniform_(p)
+ for m in self.modules():
+ if isinstance(m, MultiScaleDeformableAttention):
+ m.init_weights()
+ nn.init.xavier_uniform_(self.memory_trans_fc.weight)
+ nn.init.xavier_uniform_(self.query_embedding.weight)
+ normal_(self.level_embed)
+
+
+ def extract_feat(self, batch_inputs: Tensor) -> Tuple[Tensor]:
+ """Extract features.
+
+ Args:
+ batch_inputs (Tensor): Image tensor, has shape (bs, dim, H, W).
+
+ Returns:
+ tuple[Tensor]: Tuple of feature maps from neck. Each feature map
+ has shape (bs, dim, H, W).
+ """
+ x = self.backbone(batch_inputs)
+ if self.with_neck:
+ x = self.neck(x)
+ return x
+
+ def loss(self, batch_inputs: Tensor,
+ batch_data_samples: SampleList) -> Union[dict, list]:
+ """Calculate losses from a batch of inputs and data samples.
+
+ Args:
+ batch_inputs (Tensor): Input images of shape (bs, dim, H, W).
+ These should usually be mean centered and std scaled.
+ batch_data_samples (List[:obj:`DetDataSample`]): The batch
+ data samples. It usually includes information such
+ as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
+
+ Returns:
+ dict: A dictionary of loss components
+ """
+ # add by lzx
+ if self.scale_gt_bboxes_size>0:
+ batch_data_samples = self.rescale_gt_bboxes(batch_data_samples, self.scale_gt_bboxes_size)
+
+ img_feats = self.extract_feat(batch_inputs)
+ head_inputs_dict = self.forward_transformer(img_feats,
+ batch_data_samples)
+ losses = self.bbox_head.loss(
+ **head_inputs_dict, batch_data_samples=batch_data_samples)
+
+ return losses
+
+
+ def predict(self,
+ batch_inputs: Tensor,
+ batch_data_samples: SampleList,
+ rescale: bool = True) -> SampleList:
+ """Predict results from a batch of inputs and data samples with post-
+ processing.
+
+ Args:
+ batch_inputs (Tensor): Inputs, has shape (bs, dim, H, W).
+ batch_data_samples (List[:obj:`DetDataSample`]): The batch
+ data samples. It usually includes information such
+ as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
+ rescale (bool): Whether to rescale the results.
+ Defaults to True.
+
+ Returns:
+ list[:obj:`DetDataSample`]: Detection results of the input images.
+ Each DetDataSample usually contain 'pred_instances'. And the
+ `pred_instances` usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ """
+ img_feats = self.extract_feat(batch_inputs)
+ head_inputs_dict = self.forward_transformer(img_feats,
+ batch_data_samples)
+ results_list = self.bbox_head.predict(
+ **head_inputs_dict,
+ rescale=rescale,
+ batch_data_samples=batch_data_samples)
+ batch_data_samples = self.add_pred_to_datasample(
+ batch_data_samples, results_list)
+ return batch_data_samples
+
+ def _forward(self,
+ batch_inputs: Tensor,
+ batch_data_samples: OptSampleList = None) -> Tuple[List[Tensor]]:
+ """Network forward process. Usually includes backbone, neck and head
+ forward without any post-processing.
+
+ Args:
+ batch_inputs (Tensor): Inputs, has shape (bs, dim, H, W).
+ batch_data_samples (List[:obj:`DetDataSample`], optional): The
+ batch data samples. It usually includes information such
+ as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
+ Defaults to None.
+
+ Returns:
+ tuple[Tensor]: A tuple of features from ``bbox_head`` forward.
+ """
+ img_feats = self.extract_feat(batch_inputs)
+ head_inputs_dict = self.forward_transformer(img_feats,
+ batch_data_samples)
+ results = self.bbox_head.forward(**head_inputs_dict)
+ return results
+
+ def forward_transformer(
+ self,
+ img_feats: Tuple[Tensor],
+ batch_data_samples: OptSampleList = None,
+ ) -> Dict:
+ """Forward process of Transformer.
+
+ The forward procedure of the transformer is defined as:
+ 'pre_transformer' -> 'encoder' -> 'pre_decoder' -> 'decoder'
+ More details can be found at `TransformerDetector.forward_transformer`
+ in `mmdet/detector/base_detr.py`.
+ The difference is that the ground truth in `batch_data_samples` is
+ required for the `pre_decoder` to prepare the query of DINO.
+ Additionally, DINO inherits the `pre_transformer` method and the
+ `forward_encoder` method of DeformableDETR. More details about the
+ two methods can be found in `mmdet/detector/deformable_detr.py`.
+
+ Args:
+ img_feats (tuple[Tensor]): Tuple of feature maps from neck. Each
+ feature map has shape (bs, dim, H, W).
+ batch_data_samples (list[:obj:`DetDataSample`]): The batch
+ data samples. It usually includes information such
+ as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
+ Defaults to None.
+
+ Returns:
+ dict: The dictionary of bbox_head function inputs, which always
+ includes the `hidden_states` of the decoder output and may contain
+ `references` including the initial and intermediate references.
+ """
+ encoder_inputs_dict, decoder_inputs_dict = self.pre_transformer(
+ img_feats, batch_data_samples)
+
+ encoder_outputs_dict = self.forward_encoder(**encoder_inputs_dict)
+
+ tmp_dec_in, head_inputs_dict = self.pre_decoder(
+ **encoder_outputs_dict, batch_data_samples=batch_data_samples)
+ decoder_inputs_dict.update(tmp_dec_in)
+
+ decoder_outputs_dict = self.forward_decoder(**decoder_inputs_dict)
+ head_inputs_dict.update(decoder_outputs_dict)
+ return head_inputs_dict
+
+ def pre_transformer(
+ self,
+ mlvl_feats: Tuple[Tensor],
+ batch_data_samples: OptSampleList = None) -> Tuple[Dict]:
+ """Process image features before feeding them to the transformer.
+
+ The forward procedure of the transformer is defined as:
+ 'pre_transformer' -> 'encoder' -> 'pre_decoder' -> 'decoder'
+ More details can be found at `TransformerDetector.forward_transformer`
+ in `mmdet/detector/base_detr.py`.
+
+ Args:
+ mlvl_feats (tuple[Tensor]): Multi-level features that may have
+ different resolutions, output from neck. Each feature has
+ shape (bs, dim, h_lvl, w_lvl), where 'lvl' means 'layer'.
+ batch_data_samples (list[:obj:`DetDataSample`], optional): The
+ batch data samples. It usually includes information such
+ as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
+ Defaults to None.
+
+ Returns:
+ tuple[dict]: The first dict contains the inputs of encoder and the
+ second dict contains the inputs of decoder.
+
+ - encoder_inputs_dict (dict): The keyword args dictionary of
+ `self.forward_encoder()`, which includes 'feat', 'feat_mask',
+ and 'feat_pos'.
+ - decoder_inputs_dict (dict): The keyword args dictionary of
+ `self.forward_decoder()`, which includes 'memory_mask'.
+ """
+ batch_size = mlvl_feats[0].size(0)
+
+ # construct binary masks for the transformer.
+ assert batch_data_samples is not None
+ batch_input_shape = batch_data_samples[0].batch_input_shape
+ img_shape_list = [sample.img_shape for sample in batch_data_samples]
+ input_img_h, input_img_w = batch_input_shape
+ masks = mlvl_feats[0].new_ones((batch_size, input_img_h, input_img_w))
+ for img_id in range(batch_size):
+ img_h, img_w = img_shape_list[img_id]
+ masks[img_id, :img_h, :img_w] = 0
+ # NOTE following the official DETR repo, non-zero values representing
+ # ignored positions, while zero values means valid positions.
+
+ mlvl_masks = []
+ mlvl_pos_embeds = []
+ for feat in mlvl_feats:
+ mlvl_masks.append(
+ F.interpolate(masks[None],
+ size=feat.shape[-2:]).to(torch.bool).squeeze(0))
+ mlvl_pos_embeds.append(self.positional_encoding(mlvl_masks[-1]))
+
+ feat_flatten = []
+ lvl_pos_embed_flatten = []
+ mask_flatten = []
+ spatial_shapes = []
+ for lvl, (feat, mask, pos_embed) in enumerate(
+ zip(mlvl_feats, mlvl_masks, mlvl_pos_embeds)):
+ batch_size, c, h, w = feat.shape
+ # [bs, c, h_lvl, w_lvl] -> [bs, h_lvl*w_lvl, c]
+ feat = feat.view(batch_size, c, -1).permute(0, 2, 1)
+ pos_embed = pos_embed.view(batch_size, c, -1).permute(0, 2, 1)
+ lvl_pos_embed = pos_embed + self.level_embed[lvl].view(1, 1, -1)
+ # [bs, h_lvl, w_lvl] -> [bs, h_lvl*w_lvl]
+ mask = mask.flatten(1)
+ spatial_shape = (h, w)
+
+ feat_flatten.append(feat)
+ lvl_pos_embed_flatten.append(lvl_pos_embed)
+ mask_flatten.append(mask)
+ spatial_shapes.append(spatial_shape)
+
+ # (bs, num_feat_points, dim)
+ feat_flatten = torch.cat(feat_flatten, 1)
+ lvl_pos_embed_flatten = torch.cat(lvl_pos_embed_flatten, 1)
+ # (bs, num_feat_points), where num_feat_points = sum_lvl(h_lvl*w_lvl)
+ mask_flatten = torch.cat(mask_flatten, 1)
+
+ spatial_shapes = torch.as_tensor( # (num_level, 2)
+ spatial_shapes,
+ dtype=torch.long,
+ device=feat_flatten.device)
+ level_start_index = torch.cat((
+ spatial_shapes.new_zeros((1, )), # (num_level)
+ spatial_shapes.prod(1).cumsum(0)[:-1]))
+ valid_ratios = torch.stack( # (bs, num_level, 2)
+ [self.get_valid_ratio(m) for m in mlvl_masks], 1)
+
+ encoder_inputs_dict = dict(
+ feat=feat_flatten,
+ feat_mask=mask_flatten,
+ feat_pos=lvl_pos_embed_flatten,
+ spatial_shapes=spatial_shapes,
+ level_start_index=level_start_index,
+ valid_ratios=valid_ratios)
+ decoder_inputs_dict = dict(
+ memory_mask=mask_flatten,
+ spatial_shapes=spatial_shapes,
+ level_start_index=level_start_index,
+ valid_ratios=valid_ratios)
+ return encoder_inputs_dict, decoder_inputs_dict
+
+ def forward_encoder(self, feat: Tensor, feat_mask: Tensor,
+ feat_pos: Tensor, spatial_shapes: Tensor,
+ level_start_index: Tensor,
+ valid_ratios: Tensor) -> Dict:
+ """Forward with Transformer encoder.
+
+ The forward procedure of the transformer is defined as:
+ 'pre_transformer' -> 'encoder' -> 'pre_decoder' -> 'decoder'
+ More details can be found at `TransformerDetector.forward_transformer`
+ in `mmdet/detector/base_detr.py`.
+
+ Args:
+ feat (Tensor): Sequential features, has shape (bs, num_feat_points,
+ dim).
+ feat_mask (Tensor): ByteTensor, the padding mask of the features,
+ has shape (bs, num_feat_points).
+ feat_pos (Tensor): The positional embeddings of the features, has
+ shape (bs, num_feat_points, dim).
+ spatial_shapes (Tensor): Spatial shapes of features in all levels,
+ has shape (num_levels, 2), last dimension represents (h, w).
+ level_start_index (Tensor): The start index of each level.
+ A tensor has shape (num_levels, ) and can be represented
+ as [0, h_0*w_0, h_0*w_0+h_1*w_1, ...].
+ valid_ratios (Tensor): The ratios of the valid width and the valid
+ height relative to the width and the height of features in all
+ levels, has shape (bs, num_levels, 2).
+
+ Returns:
+ dict: The dictionary of encoder outputs, which includes the
+ `memory` of the encoder output.
+ """
+ memory = self.encoder(
+ query=feat,
+ query_pos=feat_pos,
+ key_padding_mask=feat_mask, # for self_attn
+ spatial_shapes=spatial_shapes,
+ level_start_index=level_start_index,
+ valid_ratios=valid_ratios)
+ encoder_outputs_dict = dict(
+ memory=memory,
+ memory_mask=feat_mask,
+ spatial_shapes=spatial_shapes)
+ return encoder_outputs_dict
+
+ def pre_decoder(
+ self,
+ memory: Tensor,
+ memory_mask: Tensor,
+ spatial_shapes: Tensor,
+ batch_data_samples: OptSampleList = None,
+ ) -> Tuple[Dict]:
+ """Prepare intermediate variables before entering Transformer decoder,
+ such as `query`, `query_pos`, and `reference_points`.
+
+ Args:
+ memory (Tensor): The output embeddings of the Transformer encoder,
+ has shape (bs, num_feat_points, dim).
+ memory_mask (Tensor): ByteTensor, the padding mask of the memory,
+ has shape (bs, num_feat_points). Will only be used when
+ `as_two_stage` is `True`.
+ spatial_shapes (Tensor): Spatial shapes of features in all levels.
+ With shape (num_levels, 2), last dimension represents (h, w).
+ Will only be used when `as_two_stage` is `True`.
+ batch_data_samples (list[:obj:`DetDataSample`]): The batch
+ data samples. It usually includes information such
+ as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
+ Defaults to None.
+
+ Returns:
+ tuple[dict]: The decoder_inputs_dict and head_inputs_dict.
+
+ - decoder_inputs_dict (dict): The keyword dictionary args of
+ `self.forward_decoder()`, which includes 'query', 'memory',
+ `reference_points`, and `dn_mask`. The reference points of
+ decoder input here are 4D boxes, although it has `points`
+ in its name.
+ - head_inputs_dict (dict): The keyword dictionary args of the
+ bbox_head functions, which includes `topk_score`, `topk_coords`,
+ and `dn_meta` when `self.training` is `True`, else is empty.
+ """
+ bs, _, c = memory.shape
+ cls_out_features = self.bbox_head.cls_branches[
+ self.decoder.num_layers].out_features
+
+ output_memory, output_proposals = self.gen_encoder_output_proposals(
+ memory, memory_mask, spatial_shapes)
+
+ output_memory = output_memory[:,:-1,:]
+ output_proposals = output_proposals[:,:-1,:]
+
+ enc_outputs_class = self.bbox_head.cls_branches[
+ self.decoder.num_layers](
+ output_memory)
+ enc_outputs_coord_unact = self.bbox_head.reg_branches[
+ self.decoder.num_layers](output_memory) + output_proposals
+
+ # NOTE The DINO selects top-k proposals according to scores of
+ # multi-class classification, while DeformDETR, where the input
+ # is `enc_outputs_class[..., 0]` selects according to scores of
+ # binary classification.
+ topk_indices = torch.topk(
+ enc_outputs_class.max(-1)[0], k=self.num_queries, dim=1)[1]
+ topk_score = torch.gather(
+ enc_outputs_class, 1,
+ topk_indices.unsqueeze(-1).repeat(1, 1, cls_out_features))
+ topk_coords_unact = torch.gather(
+ enc_outputs_coord_unact, 1,
+ topk_indices.unsqueeze(-1).repeat(1, 1, 4))
+ topk_coords = topk_coords_unact.sigmoid()
+ topk_coords_unact = topk_coords_unact.detach()
+
+ query = self.query_embedding.weight[:, None, :]
+ query = query.repeat(1, bs, 1).transpose(0, 1)
+ if self.training:
+ dn_label_query, dn_bbox_query, dn_mask, dn_meta = \
+ self.dn_query_generator(batch_data_samples)
+ query = torch.cat([dn_label_query, query], dim=1)
+ reference_points = torch.cat([dn_bbox_query, topk_coords_unact],
+ dim=1)
+ else:
+ reference_points = topk_coords_unact
+ dn_mask, dn_meta = None, None
+ reference_points = reference_points.sigmoid()
+
+ decoder_inputs_dict = dict(
+ query=query,
+ memory=memory,
+ reference_points=reference_points,
+ dn_mask=dn_mask)
+ # NOTE DINO calculates encoder losses on scores and coordinates
+ # of selected top-k encoder queries, while DeformDETR is of all
+ # encoder queries.
+ head_inputs_dict = dict(
+ enc_outputs_class=topk_score,
+ enc_outputs_coord=topk_coords,
+ dn_meta=dn_meta) if self.training else dict()
+ return decoder_inputs_dict, head_inputs_dict
+
+ def forward_decoder(self,
+ query: Tensor,
+ memory: Tensor,
+ memory_mask: Tensor,
+ reference_points: Tensor,
+ spatial_shapes: Tensor,
+ level_start_index: Tensor,
+ valid_ratios: Tensor,
+ dn_mask: Optional[Tensor] = None) -> Dict:
+ """Forward with Transformer decoder.
+
+ The forward procedure of the transformer is defined as:
+ 'pre_transformer' -> 'encoder' -> 'pre_decoder' -> 'decoder'
+ More details can be found at `TransformerDetector.forward_transformer`
+ in `mmdet/detector/base_detr.py`.
+
+ Args:
+ query (Tensor): The queries of decoder inputs, has shape
+ (bs, num_queries_total, dim), where `num_queries_total` is the
+ sum of `num_denoising_queries` and `num_matching_queries` when
+ `self.training` is `True`, else `num_matching_queries`.
+ memory (Tensor): The output embeddings of the Transformer encoder,
+ has shape (bs, num_feat_points, dim).
+ memory_mask (Tensor): ByteTensor, the padding mask of the memory,
+ has shape (bs, num_feat_points).
+ reference_points (Tensor): The initial reference, has shape
+ (bs, num_queries_total, 4) with the last dimension arranged as
+ (cx, cy, w, h).
+ spatial_shapes (Tensor): Spatial shapes of features in all levels,
+ has shape (num_levels, 2), last dimension represents (h, w).
+ level_start_index (Tensor): The start index of each level.
+ A tensor has shape (num_levels, ) and can be represented
+ as [0, h_0*w_0, h_0*w_0+h_1*w_1, ...].
+ valid_ratios (Tensor): The ratios of the valid width and the valid
+ height relative to the width and the height of features in all
+ levels, has shape (bs, num_levels, 2).
+ dn_mask (Tensor, optional): The attention mask to prevent
+ information leakage from different denoising groups and
+ matching parts, will be used as `self_attn_mask` of the
+ `self.decoder`, has shape (num_queries_total,
+ num_queries_total).
+ It is `None` when `self.training` is `False`.
+
+ Returns:
+ dict: The dictionary of decoder outputs, which includes the
+ `hidden_states` of the decoder output and `references` including
+ the initial and intermediate reference_points.
+ """
+ inter_states, references = self.decoder(
+ query=query,
+ value=memory,
+ key_padding_mask=memory_mask,
+ self_attn_mask=dn_mask,
+ reference_points=reference_points,
+ spatial_shapes=spatial_shapes,
+ level_start_index=level_start_index,
+ valid_ratios=valid_ratios,
+ reg_branches=self.bbox_head.reg_branches)
+
+
+ # inter_states, references = self.decoder(
+ # query=query,
+ # value=memory[:,:-1,:],
+ # key_padding_mask=memory_mask[:,:-1],
+ # self_attn_mask=dn_mask,
+ # reference_points=reference_points,
+ # spatial_shapes=spatial_shapes[:-1],
+ # level_start_index=level_start_index[:-1],
+ # valid_ratios=valid_ratios[:,:-1, :],
+ # reg_branches=self.bbox_head.reg_branches)
+
+
+ if len(query) == self.num_queries:
+ # NOTE: This is to make sure label_embeding can be involved to
+ # produce loss even if there is no denoising query (no ground truth
+ # target in this GPU), otherwise, this will raise runtime error in
+ # distributed training.
+ inter_states[0] += \
+ self.dn_query_generator.label_embedding.weight[0, 0] * 0.0
+
+ decoder_outputs_dict = dict(
+ hidden_states=inter_states, references=list(references))
+ return decoder_outputs_dict
+
+
+ @staticmethod
+ def get_valid_ratio(mask: Tensor) -> Tensor:
+ """Get the valid radios of feature map in a level.
+
+ .. code:: text
+
+ |---> valid_W <---|
+ ---+-----------------+-----+---
+ A | | | A
+ | | | | |
+ | | | | |
+ valid_H | | | |
+ | | | | H
+ | | | | |
+ V | | | |
+ ---+-----------------+ | |
+ | | V
+ +-----------------------+---
+ |---------> W <---------|
+
+ The valid_ratios are defined as:
+ r_h = valid_H / H, r_w = valid_W / W
+ They are the factors to re-normalize the relative coordinates of the
+ image to the relative coordinates of the current level feature map.
+
+ Args:
+ mask (Tensor): Binary mask of a feature map, has shape (bs, H, W).
+
+ Returns:
+ Tensor: valid ratios [r_w, r_h] of a feature map, has shape (1, 2).
+ """
+ _, H, W = mask.shape
+ valid_H = torch.sum(~mask[:, :, 0], 1)
+ valid_W = torch.sum(~mask[:, 0, :], 1)
+ valid_ratio_h = valid_H.float() / H
+ valid_ratio_w = valid_W.float() / W
+ valid_ratio = torch.stack([valid_ratio_w, valid_ratio_h], -1)
+ return valid_ratio
+
+ def gen_encoder_output_proposals(
+ self, memory: Tensor, memory_mask: Tensor,
+ spatial_shapes: Tensor) -> Tuple[Tensor, Tensor]:
+ """Generate proposals from encoded memory. The function will only be
+ used when `as_two_stage` is `True`.
+
+ Args:
+ memory (Tensor): The output embeddings of the Transformer encoder,
+ has shape (bs, num_feat_points, dim).
+ memory_mask (Tensor): ByteTensor, the padding mask of the memory,
+ has shape (bs, num_feat_points).
+ spatial_shapes (Tensor): Spatial shapes of features in all levels,
+ has shape (num_levels, 2), last dimension represents (h, w).
+
+ Returns:
+ tuple: A tuple of transformed memory and proposals.
+
+ - output_memory (Tensor): The transformed memory for obtaining
+ top-k proposals, has shape (bs, num_feat_points, dim).
+ - output_proposals (Tensor): The inverse-normalized proposal, has
+ shape (batch_size, num_keys, 4) with the last dimension arranged
+ as (cx, cy, w, h).
+ """
+
+ bs = memory.size(0)
+ proposals = []
+ # memory_mask[:,-1] =True
+ _cur = 0 # start index in the sequence of the current level
+ for lvl, (H, W) in enumerate(spatial_shapes):
+ mask_flatten_ = memory_mask[:,
+ _cur:(_cur + H * W)].view(bs, H, W, 1)
+ valid_H = torch.sum(~mask_flatten_[:, :, 0, 0], 1).unsqueeze(-1)
+ valid_W = torch.sum(~mask_flatten_[:, 0, :, 0], 1).unsqueeze(-1)
+
+ grid_y, grid_x = torch.meshgrid(
+ torch.linspace(
+ 0, H - 1, H, dtype=torch.float32, device=memory.device),
+ torch.linspace(
+ 0, W - 1, W, dtype=torch.float32, device=memory.device))
+ grid = torch.cat([grid_x.unsqueeze(-1), grid_y.unsqueeze(-1)], -1)
+
+ scale = torch.cat([valid_W, valid_H], 1).view(bs, 1, 1, 2)
+ grid = (grid.unsqueeze(0).expand(bs, -1, -1, -1) + 0.5) / scale
+ wh = torch.ones_like(grid) * self.candidate_bboxes_size * (2.0 ** lvl)
+ # wh = torch.ones_like(grid) * 0.05 * (2.0**lvl)
+ proposal = torch.cat((grid, wh), -1).view(bs, -1, 4)
+ proposals.append(proposal)
+ _cur += (H * W)
+ output_proposals = torch.cat(proposals, 1)
+ output_proposals_valid = ((output_proposals > 0.01) &
+ (output_proposals < 0.99)).all(
+ -1, keepdim=True)
+
+ if self.htd_2s:
+ output_proposals_valid = ((output_proposals > 0.0001) &
+ (output_proposals < 0.9999)).all(
+ -1, keepdim=True)
+ # inverse_sigmoid
+ output_proposals = torch.log(output_proposals / (1 - output_proposals))
+ output_proposals = output_proposals.masked_fill(
+ memory_mask.unsqueeze(-1), float('inf'))
+ output_proposals = output_proposals.masked_fill(
+ ~output_proposals_valid, float('inf'))
+ output_memory = memory
+ output_memory = output_memory.masked_fill(
+ memory_mask.unsqueeze(-1), float(0))
+ output_memory = output_memory.masked_fill(~output_proposals_valid,
+ float(0))
+ output_memory = self.memory_trans_fc(output_memory)
+ output_memory = self.memory_trans_norm(output_memory)
+ # [bs, sum(hw), 2]
+ return output_memory, output_proposals
+
+
+ @staticmethod
+ def rescale_gt_bboxes(batch_data_samples:OptSampleList, scale_gt_bboxes_size:float = 0.25) -> OptSampleList:
+ for i_sample in range(len(batch_data_samples)):
+ gt_bboxes = batch_data_samples[i_sample].gt_instances.bboxes
+ gt_bboxes[:, :2] = gt_bboxes[:, :2] +scale_gt_bboxes_size
+ gt_bboxes[:, 2:] = gt_bboxes[:, 2:] - scale_gt_bboxes_size
+ # batch_data_samples[i_sample]['gt_instances']['bboxes'] = gt_bboxes
+ return batch_data_samples
+
+
diff --git a/mmdet/models/detectors/fast_rcnn.py b/mmdet/models/detectors/fast_rcnn.py
new file mode 100644
index 0000000000000000000000000000000000000000..5b39050fdc2989eb5c870704e1c1417987d53d46
--- /dev/null
+++ b/mmdet/models/detectors/fast_rcnn.py
@@ -0,0 +1,26 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmdet.registry import MODELS
+from mmdet.utils import ConfigType, OptConfigType, OptMultiConfig
+from .two_stage import TwoStageDetector
+
+
+@MODELS.register_module()
+class FastRCNN(TwoStageDetector):
+ """Implementation of `Fast R-CNN `_"""
+
+ def __init__(self,
+ backbone: ConfigType,
+ roi_head: ConfigType,
+ train_cfg: ConfigType,
+ test_cfg: ConfigType,
+ neck: OptConfigType = None,
+ data_preprocessor: OptConfigType = None,
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(
+ backbone=backbone,
+ neck=neck,
+ roi_head=roi_head,
+ train_cfg=train_cfg,
+ test_cfg=test_cfg,
+ init_cfg=init_cfg,
+ data_preprocessor=data_preprocessor)
diff --git a/mmdet/models/detectors/faster_rcnn.py b/mmdet/models/detectors/faster_rcnn.py
new file mode 100644
index 0000000000000000000000000000000000000000..36109e3200a2d8e7d8a1032f7028e47a7699fb6a
--- /dev/null
+++ b/mmdet/models/detectors/faster_rcnn.py
@@ -0,0 +1,28 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmdet.registry import MODELS
+from mmdet.utils import ConfigType, OptConfigType, OptMultiConfig
+from .two_stage import TwoStageDetector
+
+
+@MODELS.register_module()
+class FasterRCNN(TwoStageDetector):
+ """Implementation of `Faster R-CNN `_"""
+
+ def __init__(self,
+ backbone: ConfigType,
+ rpn_head: ConfigType,
+ roi_head: ConfigType,
+ train_cfg: ConfigType,
+ test_cfg: ConfigType,
+ neck: OptConfigType = None,
+ data_preprocessor: OptConfigType = None,
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(
+ backbone=backbone,
+ neck=neck,
+ rpn_head=rpn_head,
+ roi_head=roi_head,
+ train_cfg=train_cfg,
+ test_cfg=test_cfg,
+ init_cfg=init_cfg,
+ data_preprocessor=data_preprocessor)
diff --git a/mmdet/models/detectors/fcos.py b/mmdet/models/detectors/fcos.py
new file mode 100644
index 0000000000000000000000000000000000000000..c628059313ac80644ec2ba2c806e7baf2e418a41
--- /dev/null
+++ b/mmdet/models/detectors/fcos.py
@@ -0,0 +1,42 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmdet.registry import MODELS
+from mmdet.utils import ConfigType, OptConfigType, OptMultiConfig
+from .single_stage import SingleStageDetector
+
+
+@MODELS.register_module()
+class FCOS(SingleStageDetector):
+ """Implementation of `FCOS `_
+
+ Args:
+ backbone (:obj:`ConfigDict` or dict): The backbone config.
+ neck (:obj:`ConfigDict` or dict): The neck config.
+ bbox_head (:obj:`ConfigDict` or dict): The bbox head config.
+ train_cfg (:obj:`ConfigDict` or dict, optional): The training config
+ of FCOS. Defaults to None.
+ test_cfg (:obj:`ConfigDict` or dict, optional): The testing config
+ of FCOS. Defaults to None.
+ data_preprocessor (:obj:`ConfigDict` or dict, optional): Config of
+ :class:`DetDataPreprocessor` to process the input data.
+ Defaults to None.
+ init_cfg (:obj:`ConfigDict` or list[:obj:`ConfigDict`] or dict or
+ list[dict], optional): Initialization config dict.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ backbone: ConfigType,
+ neck: ConfigType,
+ bbox_head: ConfigType,
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ data_preprocessor: OptConfigType = None,
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(
+ backbone=backbone,
+ neck=neck,
+ bbox_head=bbox_head,
+ train_cfg=train_cfg,
+ test_cfg=test_cfg,
+ data_preprocessor=data_preprocessor,
+ init_cfg=init_cfg)
diff --git a/mmdet/models/detectors/fovea.py b/mmdet/models/detectors/fovea.py
new file mode 100644
index 0000000000000000000000000000000000000000..5e4f21caa239147e3b81e66280aa1da043715b42
--- /dev/null
+++ b/mmdet/models/detectors/fovea.py
@@ -0,0 +1,41 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmdet.registry import MODELS
+from mmdet.utils import ConfigType, OptConfigType, OptMultiConfig
+from .single_stage import SingleStageDetector
+
+
+@MODELS.register_module()
+class FOVEA(SingleStageDetector):
+ """Implementation of `FoveaBox `_
+ Args:
+ backbone (:obj:`ConfigDict` or dict): The backbone config.
+ neck (:obj:`ConfigDict` or dict): The neck config.
+ bbox_head (:obj:`ConfigDict` or dict): The bbox head config.
+ train_cfg (:obj:`ConfigDict` or dict, optional): The training config
+ of FOVEA. Defaults to None.
+ test_cfg (:obj:`ConfigDict` or dict, optional): The testing config
+ of FOVEA. Defaults to None.
+ data_preprocessor (:obj:`ConfigDict` or dict, optional): Config of
+ :class:`DetDataPreprocessor` to process the input data.
+ Defaults to None.
+ init_cfg (:obj:`ConfigDict` or list[:obj:`ConfigDict`] or dict or
+ list[dict], optional): Initialization config dict.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ backbone: ConfigType,
+ neck: ConfigType,
+ bbox_head: ConfigType,
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ data_preprocessor: OptConfigType = None,
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(
+ backbone=backbone,
+ neck=neck,
+ bbox_head=bbox_head,
+ train_cfg=train_cfg,
+ test_cfg=test_cfg,
+ data_preprocessor=data_preprocessor,
+ init_cfg=init_cfg)
diff --git a/mmdet/models/detectors/fsaf.py b/mmdet/models/detectors/fsaf.py
new file mode 100644
index 0000000000000000000000000000000000000000..01b40273341f2a85cfa427f8adfc945a1b7da58a
--- /dev/null
+++ b/mmdet/models/detectors/fsaf.py
@@ -0,0 +1,26 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmdet.registry import MODELS
+from mmdet.utils import ConfigType, OptConfigType, OptMultiConfig
+from .single_stage import SingleStageDetector
+
+
+@MODELS.register_module()
+class FSAF(SingleStageDetector):
+ """Implementation of `FSAF `_"""
+
+ def __init__(self,
+ backbone: ConfigType,
+ neck: ConfigType,
+ bbox_head: ConfigType,
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ data_preprocessor: OptConfigType = None,
+ init_cfg: OptMultiConfig = None):
+ super().__init__(
+ backbone=backbone,
+ neck=neck,
+ bbox_head=bbox_head,
+ train_cfg=train_cfg,
+ test_cfg=test_cfg,
+ data_preprocessor=data_preprocessor,
+ init_cfg=init_cfg)
diff --git a/mmdet/models/detectors/gfl.py b/mmdet/models/detectors/gfl.py
new file mode 100644
index 0000000000000000000000000000000000000000..c26821af68c224d4b55a1ca3d2be4c6e1d1b155d
--- /dev/null
+++ b/mmdet/models/detectors/gfl.py
@@ -0,0 +1,41 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmdet.registry import MODELS
+from mmdet.utils import ConfigType, OptConfigType, OptMultiConfig
+from .single_stage import SingleStageDetector
+
+
+@MODELS.register_module()
+class GFL(SingleStageDetector):
+ """Implementation of `GFL `_
+
+ Args:
+ backbone (:obj:`ConfigDict` or dict): The backbone module.
+ neck (:obj:`ConfigDict` or dict): The neck module.
+ bbox_head (:obj:`ConfigDict` or dict): The bbox head module.
+ train_cfg (:obj:`ConfigDict` or dict, optional): The training config
+ of GFL. Defaults to None.
+ test_cfg (:obj:`ConfigDict` or dict, optional): The testing config
+ of GFL. Defaults to None.
+ data_preprocessor (:obj:`ConfigDict` or dict, optional): Config of
+ :class:`DetDataPreprocessor` to process the input data.
+ Defaults to None.
+ init_cfg (:obj:`ConfigDict` or dict, optional): the config to control
+ the initialization. Defaults to None.
+ """
+
+ def __init__(self,
+ backbone: ConfigType,
+ neck: ConfigType,
+ bbox_head: ConfigType,
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ data_preprocessor: OptConfigType = None,
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(
+ backbone=backbone,
+ neck=neck,
+ bbox_head=bbox_head,
+ train_cfg=train_cfg,
+ test_cfg=test_cfg,
+ data_preprocessor=data_preprocessor,
+ init_cfg=init_cfg)
diff --git a/mmdet/models/detectors/grid_rcnn.py b/mmdet/models/detectors/grid_rcnn.py
new file mode 100644
index 0000000000000000000000000000000000000000..7bcb5b033edc620f1cf61b986c345961b719e6f1
--- /dev/null
+++ b/mmdet/models/detectors/grid_rcnn.py
@@ -0,0 +1,33 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmdet.registry import MODELS
+from mmdet.utils import ConfigType, OptConfigType, OptMultiConfig
+from .two_stage import TwoStageDetector
+
+
+@MODELS.register_module()
+class GridRCNN(TwoStageDetector):
+ """Grid R-CNN.
+
+ This detector is the implementation of:
+ - Grid R-CNN (https://arxiv.org/abs/1811.12030)
+ - Grid R-CNN Plus: Faster and Better (https://arxiv.org/abs/1906.05688)
+ """
+
+ def __init__(self,
+ backbone: ConfigType,
+ rpn_head: ConfigType,
+ roi_head: ConfigType,
+ train_cfg: ConfigType,
+ test_cfg: ConfigType,
+ neck: OptConfigType = None,
+ data_preprocessor: OptConfigType = None,
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(
+ backbone=backbone,
+ neck=neck,
+ rpn_head=rpn_head,
+ roi_head=roi_head,
+ train_cfg=train_cfg,
+ test_cfg=test_cfg,
+ data_preprocessor=data_preprocessor,
+ init_cfg=init_cfg)
diff --git a/mmdet/models/detectors/htc.py b/mmdet/models/detectors/htc.py
new file mode 100644
index 0000000000000000000000000000000000000000..22a2aa889a59fd0e0afeb95a7369028def6e4fa9
--- /dev/null
+++ b/mmdet/models/detectors/htc.py
@@ -0,0 +1,16 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmdet.registry import MODELS
+from .cascade_rcnn import CascadeRCNN
+
+
+@MODELS.register_module()
+class HybridTaskCascade(CascadeRCNN):
+ """Implementation of `HTC `_"""
+
+ def __init__(self, **kwargs) -> None:
+ super().__init__(**kwargs)
+
+ @property
+ def with_semantic(self) -> bool:
+ """bool: whether the detector has a semantic head"""
+ return self.roi_head.with_semantic
diff --git a/mmdet/models/detectors/kd_one_stage.py b/mmdet/models/detectors/kd_one_stage.py
new file mode 100644
index 0000000000000000000000000000000000000000..8a4a1bb564c0f6e4cabe32a5c01cfea252ecfb7d
--- /dev/null
+++ b/mmdet/models/detectors/kd_one_stage.py
@@ -0,0 +1,122 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from pathlib import Path
+from typing import Any, Optional, Union
+
+import torch
+import torch.nn as nn
+from mmengine.config import Config
+from mmengine.runner import load_checkpoint
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.structures import SampleList
+from mmdet.utils import ConfigType, OptConfigType
+from .single_stage import SingleStageDetector
+
+
+@MODELS.register_module()
+class KnowledgeDistillationSingleStageDetector(SingleStageDetector):
+ r"""Implementation of `Distilling the Knowledge in a Neural Network.
+ `_.
+
+ Args:
+ backbone (:obj:`ConfigDict` or dict): The backbone module.
+ neck (:obj:`ConfigDict` or dict): The neck module.
+ bbox_head (:obj:`ConfigDict` or dict): The bbox head module.
+ teacher_config (:obj:`ConfigDict` | dict | str | Path): Config file
+ path or the config object of teacher model.
+ teacher_ckpt (str, optional): Checkpoint path of teacher model.
+ If left as None, the model will not load any weights.
+ Defaults to True.
+ eval_teacher (bool): Set the train mode for teacher.
+ Defaults to True.
+ train_cfg (:obj:`ConfigDict` or dict, optional): The training config
+ of ATSS. Defaults to None.
+ test_cfg (:obj:`ConfigDict` or dict, optional): The testing config
+ of ATSS. Defaults to None.
+ data_preprocessor (:obj:`ConfigDict` or dict, optional): Config of
+ :class:`DetDataPreprocessor` to process the input data.
+ Defaults to None.
+ """
+
+ def __init__(
+ self,
+ backbone: ConfigType,
+ neck: ConfigType,
+ bbox_head: ConfigType,
+ teacher_config: Union[ConfigType, str, Path],
+ teacher_ckpt: Optional[str] = None,
+ eval_teacher: bool = True,
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ data_preprocessor: OptConfigType = None,
+ ) -> None:
+ super().__init__(
+ backbone=backbone,
+ neck=neck,
+ bbox_head=bbox_head,
+ train_cfg=train_cfg,
+ test_cfg=test_cfg,
+ data_preprocessor=data_preprocessor)
+ self.eval_teacher = eval_teacher
+ # Build teacher model
+ if isinstance(teacher_config, (str, Path)):
+ teacher_config = Config.fromfile(teacher_config)
+ self.teacher_model = MODELS.build(teacher_config['model'])
+ if teacher_ckpt is not None:
+ load_checkpoint(
+ self.teacher_model, teacher_ckpt, map_location='cpu')
+
+ def loss(self, batch_inputs: Tensor,
+ batch_data_samples: SampleList) -> dict:
+ """
+ Args:
+ batch_inputs (Tensor): Input images of shape (N, C, H, W).
+ These should usually be mean centered and std scaled.
+ batch_data_samples (list[:obj:`DetDataSample`]): The batch
+ data samples. It usually includes information such
+ as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components.
+ """
+ x = self.extract_feat(batch_inputs)
+ with torch.no_grad():
+ teacher_x = self.teacher_model.extract_feat(batch_inputs)
+ out_teacher = self.teacher_model.bbox_head(teacher_x)
+ losses = self.bbox_head.loss(x, out_teacher, batch_data_samples)
+ return losses
+
+ def cuda(self, device: Optional[str] = None) -> nn.Module:
+ """Since teacher_model is registered as a plain object, it is necessary
+ to put the teacher model to cuda when calling ``cuda`` function."""
+ self.teacher_model.cuda(device=device)
+ return super().cuda(device=device)
+
+ def to(self, device: Optional[str] = None) -> nn.Module:
+ """Since teacher_model is registered as a plain object, it is necessary
+ to put the teacher model to other device when calling ``to``
+ function."""
+ self.teacher_model.to(device=device)
+ return super().to(device=device)
+
+ def train(self, mode: bool = True) -> None:
+ """Set the same train mode for teacher and student model."""
+ if self.eval_teacher:
+ self.teacher_model.train(False)
+ else:
+ self.teacher_model.train(mode)
+ super().train(mode)
+
+ def __setattr__(self, name: str, value: Any) -> None:
+ """Set attribute, i.e. self.name = value
+
+ This reloading prevent the teacher model from being registered as a
+ nn.Module. The teacher module is registered as a plain object, so that
+ the teacher parameters will not show up when calling
+ ``self.parameters``, ``self.modules``, ``self.children`` methods.
+ """
+ if name == 'teacher_model':
+ object.__setattr__(self, name, value)
+ else:
+ super().__setattr__(name, value)
diff --git a/mmdet/models/detectors/lad.py b/mmdet/models/detectors/lad.py
new file mode 100644
index 0000000000000000000000000000000000000000..008f898772988715c67783d9218ff39c4dd95d80
--- /dev/null
+++ b/mmdet/models/detectors/lad.py
@@ -0,0 +1,93 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional
+
+import torch
+import torch.nn as nn
+from mmengine.runner import load_checkpoint
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.structures import SampleList
+from mmdet.utils import ConfigType, OptConfigType
+from ..utils.misc import unpack_gt_instances
+from .kd_one_stage import KnowledgeDistillationSingleStageDetector
+
+
+@MODELS.register_module()
+class LAD(KnowledgeDistillationSingleStageDetector):
+ """Implementation of `LAD `_."""
+
+ def __init__(self,
+ backbone: ConfigType,
+ neck: ConfigType,
+ bbox_head: ConfigType,
+ teacher_backbone: ConfigType,
+ teacher_neck: ConfigType,
+ teacher_bbox_head: ConfigType,
+ teacher_ckpt: Optional[str] = None,
+ eval_teacher: bool = True,
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ data_preprocessor: OptConfigType = None) -> None:
+ super(KnowledgeDistillationSingleStageDetector, self).__init__(
+ backbone=backbone,
+ neck=neck,
+ bbox_head=bbox_head,
+ train_cfg=train_cfg,
+ test_cfg=test_cfg,
+ data_preprocessor=data_preprocessor)
+ self.eval_teacher = eval_teacher
+ self.teacher_model = nn.Module()
+ self.teacher_model.backbone = MODELS.build(teacher_backbone)
+ if teacher_neck is not None:
+ self.teacher_model.neck = MODELS.build(teacher_neck)
+ teacher_bbox_head.update(train_cfg=train_cfg)
+ teacher_bbox_head.update(test_cfg=test_cfg)
+ self.teacher_model.bbox_head = MODELS.build(teacher_bbox_head)
+ if teacher_ckpt is not None:
+ load_checkpoint(
+ self.teacher_model, teacher_ckpt, map_location='cpu')
+
+ @property
+ def with_teacher_neck(self) -> bool:
+ """bool: whether the detector has a teacher_neck"""
+ return hasattr(self.teacher_model, 'neck') and \
+ self.teacher_model.neck is not None
+
+ def extract_teacher_feat(self, batch_inputs: Tensor) -> Tensor:
+ """Directly extract teacher features from the backbone+neck."""
+ x = self.teacher_model.backbone(batch_inputs)
+ if self.with_teacher_neck:
+ x = self.teacher_model.neck(x)
+ return x
+
+ def loss(self, batch_inputs: Tensor,
+ batch_data_samples: SampleList) -> dict:
+ """
+ Args:
+ batch_inputs (Tensor): Input images of shape (N, C, H, W).
+ These should usually be mean centered and std scaled.
+ batch_data_samples (list[:obj:`DetDataSample`]): The batch
+ data samples. It usually includes information such
+ as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components.
+ """
+ outputs = unpack_gt_instances(batch_data_samples)
+ batch_gt_instances, batch_gt_instances_ignore, batch_img_metas \
+ = outputs
+ # get label assignment from the teacher
+ with torch.no_grad():
+ x_teacher = self.extract_teacher_feat(batch_inputs)
+ outs_teacher = self.teacher_model.bbox_head(x_teacher)
+ label_assignment_results = \
+ self.teacher_model.bbox_head.get_label_assignment(
+ *outs_teacher, batch_gt_instances, batch_img_metas,
+ batch_gt_instances_ignore)
+
+ # the student use the label assignment from the teacher to learn
+ x = self.extract_feat(batch_inputs)
+ losses = self.bbox_head.loss(x, label_assignment_results,
+ batch_data_samples)
+ return losses
diff --git a/mmdet/models/detectors/mask2former.py b/mmdet/models/detectors/mask2former.py
new file mode 100644
index 0000000000000000000000000000000000000000..4f38ef44e482039fdf7476d048eee5df2a96fd9b
--- /dev/null
+++ b/mmdet/models/detectors/mask2former.py
@@ -0,0 +1,30 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmdet.registry import MODELS
+from mmdet.utils import ConfigType, OptConfigType, OptMultiConfig
+from .maskformer import MaskFormer
+
+
+@MODELS.register_module()
+class Mask2Former(MaskFormer):
+ r"""Implementation of `Masked-attention Mask
+ Transformer for Universal Image Segmentation
+ `_."""
+
+ def __init__(self,
+ backbone: ConfigType,
+ neck: OptConfigType = None,
+ panoptic_head: OptConfigType = None,
+ panoptic_fusion_head: OptConfigType = None,
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ data_preprocessor: OptConfigType = None,
+ init_cfg: OptMultiConfig = None):
+ super().__init__(
+ backbone=backbone,
+ neck=neck,
+ panoptic_head=panoptic_head,
+ panoptic_fusion_head=panoptic_fusion_head,
+ train_cfg=train_cfg,
+ test_cfg=test_cfg,
+ data_preprocessor=data_preprocessor,
+ init_cfg=init_cfg)
diff --git a/mmdet/models/detectors/mask_rcnn.py b/mmdet/models/detectors/mask_rcnn.py
new file mode 100644
index 0000000000000000000000000000000000000000..880ee1e8ac3926d618ef47985549d3214175ee73
--- /dev/null
+++ b/mmdet/models/detectors/mask_rcnn.py
@@ -0,0 +1,30 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmengine.config import ConfigDict
+
+from mmdet.registry import MODELS
+from mmdet.utils import OptConfigType, OptMultiConfig
+from .two_stage import TwoStageDetector
+
+
+@MODELS.register_module()
+class MaskRCNN(TwoStageDetector):
+ """Implementation of `Mask R-CNN `_"""
+
+ def __init__(self,
+ backbone: ConfigDict,
+ rpn_head: ConfigDict,
+ roi_head: ConfigDict,
+ train_cfg: ConfigDict,
+ test_cfg: ConfigDict,
+ neck: OptConfigType = None,
+ data_preprocessor: OptConfigType = None,
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(
+ backbone=backbone,
+ neck=neck,
+ rpn_head=rpn_head,
+ roi_head=roi_head,
+ train_cfg=train_cfg,
+ test_cfg=test_cfg,
+ init_cfg=init_cfg,
+ data_preprocessor=data_preprocessor)
diff --git a/mmdet/models/detectors/mask_scoring_rcnn.py b/mmdet/models/detectors/mask_scoring_rcnn.py
new file mode 100644
index 0000000000000000000000000000000000000000..e09d3a1041f929113962e42bdf8b169e52dabe25
--- /dev/null
+++ b/mmdet/models/detectors/mask_scoring_rcnn.py
@@ -0,0 +1,31 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmdet.registry import MODELS
+from mmdet.utils import ConfigType, OptConfigType, OptMultiConfig
+from .two_stage import TwoStageDetector
+
+
+@MODELS.register_module()
+class MaskScoringRCNN(TwoStageDetector):
+ """Mask Scoring RCNN.
+
+ https://arxiv.org/abs/1903.00241
+ """
+
+ def __init__(self,
+ backbone: ConfigType,
+ rpn_head: ConfigType,
+ roi_head: ConfigType,
+ train_cfg: ConfigType,
+ test_cfg: ConfigType,
+ neck: OptConfigType = None,
+ data_preprocessor: OptConfigType = None,
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(
+ backbone=backbone,
+ neck=neck,
+ rpn_head=rpn_head,
+ roi_head=roi_head,
+ train_cfg=train_cfg,
+ test_cfg=test_cfg,
+ data_preprocessor=data_preprocessor,
+ init_cfg=init_cfg)
diff --git a/mmdet/models/detectors/maskformer.py b/mmdet/models/detectors/maskformer.py
new file mode 100644
index 0000000000000000000000000000000000000000..7493c00e1b87cf9b2fbd2c80f1e642f6eb2bea55
--- /dev/null
+++ b/mmdet/models/detectors/maskformer.py
@@ -0,0 +1,170 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Tuple
+
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.structures import SampleList
+from mmdet.utils import ConfigType, OptConfigType, OptMultiConfig
+from .single_stage import SingleStageDetector
+
+
+@MODELS.register_module()
+class MaskFormer(SingleStageDetector):
+ r"""Implementation of `Per-Pixel Classification is
+ NOT All You Need for Semantic Segmentation
+ `_."""
+
+ def __init__(self,
+ backbone: ConfigType,
+ neck: OptConfigType = None,
+ panoptic_head: OptConfigType = None,
+ panoptic_fusion_head: OptConfigType = None,
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ data_preprocessor: OptConfigType = None,
+ init_cfg: OptMultiConfig = None):
+ super(SingleStageDetector, self).__init__(
+ data_preprocessor=data_preprocessor, init_cfg=init_cfg)
+ self.backbone = MODELS.build(backbone)
+ if neck is not None:
+ self.neck = MODELS.build(neck)
+
+ panoptic_head_ = panoptic_head.deepcopy()
+ panoptic_head_.update(train_cfg=train_cfg)
+ panoptic_head_.update(test_cfg=test_cfg)
+ self.panoptic_head = MODELS.build(panoptic_head_)
+
+ panoptic_fusion_head_ = panoptic_fusion_head.deepcopy()
+ panoptic_fusion_head_.update(test_cfg=test_cfg)
+ self.panoptic_fusion_head = MODELS.build(panoptic_fusion_head_)
+
+ self.num_things_classes = self.panoptic_head.num_things_classes
+ self.num_stuff_classes = self.panoptic_head.num_stuff_classes
+ self.num_classes = self.panoptic_head.num_classes
+
+ self.train_cfg = train_cfg
+ self.test_cfg = test_cfg
+
+ def loss(self, batch_inputs: Tensor,
+ batch_data_samples: SampleList) -> Dict[str, Tensor]:
+ """
+ Args:
+ batch_inputs (Tensor): Input images of shape (N, C, H, W).
+ These should usually be mean centered and std scaled.
+ batch_data_samples (list[:obj:`DetDataSample`]): The batch
+ data samples. It usually includes information such
+ as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
+
+ Returns:
+ dict[str, Tensor]: a dictionary of loss components
+ """
+ x = self.extract_feat(batch_inputs)
+ losses = self.panoptic_head.loss(x, batch_data_samples)
+ return losses
+
+ def predict(self,
+ batch_inputs: Tensor,
+ batch_data_samples: SampleList,
+ rescale: bool = True) -> SampleList:
+ """Predict results from a batch of inputs and data samples with post-
+ processing.
+
+ Args:
+ batch_inputs (Tensor): Inputs with shape (N, C, H, W).
+ batch_data_samples (List[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ rescale (bool): Whether to rescale the results.
+ Defaults to True.
+
+ Returns:
+ list[:obj:`DetDataSample`]: Detection results of the
+ input images. Each DetDataSample usually contain
+ 'pred_instances' and `pred_panoptic_seg`. And the
+ ``pred_instances`` usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ - masks (Tensor): Has a shape (num_instances, H, W).
+
+ And the ``pred_panoptic_seg`` contains the following key
+
+ - sem_seg (Tensor): panoptic segmentation mask, has a
+ shape (1, h, w).
+ """
+ feats = self.extract_feat(batch_inputs)
+ mask_cls_results, mask_pred_results = self.panoptic_head.predict(
+ feats, batch_data_samples)
+ results_list = self.panoptic_fusion_head.predict(
+ mask_cls_results,
+ mask_pred_results,
+ batch_data_samples,
+ rescale=rescale)
+ results = self.add_pred_to_datasample(batch_data_samples, results_list)
+
+ return results
+
+ def add_pred_to_datasample(self, data_samples: SampleList,
+ results_list: List[dict]) -> SampleList:
+ """Add predictions to `DetDataSample`.
+
+ Args:
+ data_samples (list[:obj:`DetDataSample`], optional): A batch of
+ data samples that contain annotations and predictions.
+ results_list (List[dict]): Instance segmentation, segmantic
+ segmentation and panoptic segmentation results.
+
+ Returns:
+ list[:obj:`DetDataSample`]: Detection results of the
+ input images. Each DetDataSample usually contain
+ 'pred_instances' and `pred_panoptic_seg`. And the
+ ``pred_instances`` usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ - masks (Tensor): Has a shape (num_instances, H, W).
+
+ And the ``pred_panoptic_seg`` contains the following key
+
+ - sem_seg (Tensor): panoptic segmentation mask, has a
+ shape (1, h, w).
+ """
+ for data_sample, pred_results in zip(data_samples, results_list):
+ if 'pan_results' in pred_results:
+ data_sample.pred_panoptic_seg = pred_results['pan_results']
+
+ if 'ins_results' in pred_results:
+ data_sample.pred_instances = pred_results['ins_results']
+
+ assert 'sem_results' not in pred_results, 'segmantic ' \
+ 'segmentation results are not supported yet.'
+
+ return data_samples
+
+ def _forward(self, batch_inputs: Tensor,
+ batch_data_samples: SampleList) -> Tuple[List[Tensor]]:
+ """Network forward process. Usually includes backbone, neck and head
+ forward without any post-processing.
+
+ Args:
+ batch_inputs (Tensor): Inputs with shape (N, C, H, W).
+ batch_data_samples (list[:obj:`DetDataSample`]): The batch
+ data samples. It usually includes information such
+ as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
+
+ Returns:
+ tuple[List[Tensor]]: A tuple of features from ``panoptic_head``
+ forward.
+ """
+ feats = self.extract_feat(batch_inputs)
+ results = self.panoptic_head.forward(feats, batch_data_samples)
+ return results
diff --git a/mmdet/models/detectors/nasfcos.py b/mmdet/models/detectors/nasfcos.py
new file mode 100644
index 0000000000000000000000000000000000000000..da2b911bcfc6b0ba51b00d9b3948a3df7af2e74f
--- /dev/null
+++ b/mmdet/models/detectors/nasfcos.py
@@ -0,0 +1,43 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmdet.registry import MODELS
+from mmdet.utils import ConfigType, OptConfigType, OptMultiConfig
+from .single_stage import SingleStageDetector
+
+
+@MODELS.register_module()
+class NASFCOS(SingleStageDetector):
+ """Implementation of `NAS-FCOS: Fast Neural Architecture Search for Object
+ Detection. `_
+
+ Args:
+ backbone (:obj:`ConfigDict` or dict): The backbone config.
+ neck (:obj:`ConfigDict` or dict): The neck config.
+ bbox_head (:obj:`ConfigDict` or dict): The bbox head config.
+ train_cfg (:obj:`ConfigDict` or dict, optional): The training config
+ of NASFCOS. Defaults to None.
+ test_cfg (:obj:`ConfigDict` or dict, optional): The testing config
+ of NASFCOS. Defaults to None.
+ data_preprocessor (:obj:`ConfigDict` or dict, optional): Config of
+ :class:`DetDataPreprocessor` to process the input data.
+ Defaults to None.
+ init_cfg (:obj:`ConfigDict` or list[:obj:`ConfigDict`] or dict or
+ list[dict], optional): Initialization config dict.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ backbone: ConfigType,
+ neck: ConfigType,
+ bbox_head: ConfigType,
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ data_preprocessor: OptConfigType = None,
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(
+ backbone=backbone,
+ neck=neck,
+ bbox_head=bbox_head,
+ train_cfg=train_cfg,
+ test_cfg=test_cfg,
+ data_preprocessor=data_preprocessor,
+ init_cfg=init_cfg)
diff --git a/mmdet/models/detectors/paa.py b/mmdet/models/detectors/paa.py
new file mode 100644
index 0000000000000000000000000000000000000000..094306b2fbd18ba45536470ec80443e4ff793e67
--- /dev/null
+++ b/mmdet/models/detectors/paa.py
@@ -0,0 +1,41 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmdet.registry import MODELS
+from mmdet.utils import ConfigType, OptConfigType, OptMultiConfig
+from .single_stage import SingleStageDetector
+
+
+@MODELS.register_module()
+class PAA(SingleStageDetector):
+ """Implementation of `PAA `_
+
+ Args:
+ backbone (:obj:`ConfigDict` or dict): The backbone module.
+ neck (:obj:`ConfigDict` or dict): The neck module.
+ bbox_head (:obj:`ConfigDict` or dict): The bbox head module.
+ train_cfg (:obj:`ConfigDict` or dict, optional): The training config
+ of PAA. Defaults to None.
+ test_cfg (:obj:`ConfigDict` or dict, optional): The testing config
+ of PAA. Defaults to None.
+ data_preprocessor (:obj:`ConfigDict` or dict, optional): Config of
+ :class:`DetDataPreprocessor` to process the input data.
+ Defaults to None.
+ init_cfg (:obj:`ConfigDict` or dict, optional): the config to control
+ the initialization. Defaults to None.
+ """
+
+ def __init__(self,
+ backbone: ConfigType,
+ neck: ConfigType,
+ bbox_head: ConfigType,
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ data_preprocessor: OptConfigType = None,
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(
+ backbone=backbone,
+ neck=neck,
+ bbox_head=bbox_head,
+ train_cfg=train_cfg,
+ test_cfg=test_cfg,
+ data_preprocessor=data_preprocessor,
+ init_cfg=init_cfg)
diff --git a/mmdet/models/detectors/panoptic_fpn.py b/mmdet/models/detectors/panoptic_fpn.py
new file mode 100644
index 0000000000000000000000000000000000000000..ae63ccc38931daa60b4e62f94dcf9f44574d3669
--- /dev/null
+++ b/mmdet/models/detectors/panoptic_fpn.py
@@ -0,0 +1,35 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmdet.registry import MODELS
+from mmdet.utils import ConfigType, OptConfigType, OptMultiConfig
+from .panoptic_two_stage_segmentor import TwoStagePanopticSegmentor
+
+
+@MODELS.register_module()
+class PanopticFPN(TwoStagePanopticSegmentor):
+ r"""Implementation of `Panoptic feature pyramid
+ networks `_"""
+
+ def __init__(
+ self,
+ backbone: ConfigType,
+ neck: OptConfigType = None,
+ rpn_head: OptConfigType = None,
+ roi_head: OptConfigType = None,
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ data_preprocessor: OptConfigType = None,
+ init_cfg: OptMultiConfig = None,
+ # for panoptic segmentation
+ semantic_head: OptConfigType = None,
+ panoptic_fusion_head: OptMultiConfig = None) -> None:
+ super().__init__(
+ backbone=backbone,
+ neck=neck,
+ rpn_head=rpn_head,
+ roi_head=roi_head,
+ train_cfg=train_cfg,
+ test_cfg=test_cfg,
+ data_preprocessor=data_preprocessor,
+ init_cfg=init_cfg,
+ semantic_head=semantic_head,
+ panoptic_fusion_head=panoptic_fusion_head)
diff --git a/mmdet/models/detectors/panoptic_two_stage_segmentor.py b/mmdet/models/detectors/panoptic_two_stage_segmentor.py
new file mode 100644
index 0000000000000000000000000000000000000000..879edbe1ac6a0f482fdd740f4058e508e728414d
--- /dev/null
+++ b/mmdet/models/detectors/panoptic_two_stage_segmentor.py
@@ -0,0 +1,234 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+from typing import List
+
+import torch
+from mmengine.structures import PixelData
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.structures import SampleList
+from mmdet.utils import ConfigType, OptConfigType, OptMultiConfig
+from .two_stage import TwoStageDetector
+
+
+@MODELS.register_module()
+class TwoStagePanopticSegmentor(TwoStageDetector):
+ """Base class of Two-stage Panoptic Segmentor.
+
+ As well as the components in TwoStageDetector, Panoptic Segmentor has extra
+ semantic_head and panoptic_fusion_head.
+ """
+
+ def __init__(
+ self,
+ backbone: ConfigType,
+ neck: OptConfigType = None,
+ rpn_head: OptConfigType = None,
+ roi_head: OptConfigType = None,
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ data_preprocessor: OptConfigType = None,
+ init_cfg: OptMultiConfig = None,
+ # for panoptic segmentation
+ semantic_head: OptConfigType = None,
+ panoptic_fusion_head: OptConfigType = None) -> None:
+ super().__init__(
+ backbone=backbone,
+ neck=neck,
+ rpn_head=rpn_head,
+ roi_head=roi_head,
+ train_cfg=train_cfg,
+ test_cfg=test_cfg,
+ data_preprocessor=data_preprocessor,
+ init_cfg=init_cfg)
+
+ if semantic_head is not None:
+ self.semantic_head = MODELS.build(semantic_head)
+
+ if panoptic_fusion_head is not None:
+ panoptic_cfg = test_cfg.panoptic if test_cfg is not None else None
+ panoptic_fusion_head_ = panoptic_fusion_head.deepcopy()
+ panoptic_fusion_head_.update(test_cfg=panoptic_cfg)
+ self.panoptic_fusion_head = MODELS.build(panoptic_fusion_head_)
+
+ self.num_things_classes = self.panoptic_fusion_head.\
+ num_things_classes
+ self.num_stuff_classes = self.panoptic_fusion_head.\
+ num_stuff_classes
+ self.num_classes = self.panoptic_fusion_head.num_classes
+
+ @property
+ def with_semantic_head(self) -> bool:
+ """bool: whether the detector has semantic head"""
+ return hasattr(self,
+ 'semantic_head') and self.semantic_head is not None
+
+ @property
+ def with_panoptic_fusion_head(self) -> bool:
+ """bool: whether the detector has panoptic fusion head"""
+ return hasattr(self, 'panoptic_fusion_head') and \
+ self.panoptic_fusion_head is not None
+
+ def loss(self, batch_inputs: Tensor,
+ batch_data_samples: SampleList) -> dict:
+ """
+ Args:
+ batch_inputs (Tensor): Input images of shape (N, C, H, W).
+ These should usually be mean centered and std scaled.
+ batch_data_samples (list[:obj:`DetDataSample`]): The batch
+ data samples. It usually includes information such
+ as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
+
+ Returns:
+ dict: A dictionary of loss components.
+ """
+ x = self.extract_feat(batch_inputs)
+
+ losses = dict()
+
+ # RPN forward and loss
+ if self.with_rpn:
+ proposal_cfg = self.train_cfg.get('rpn_proposal',
+ self.test_cfg.rpn)
+ rpn_data_samples = copy.deepcopy(batch_data_samples)
+ # set cat_id of gt_labels to 0 in RPN
+ for data_sample in rpn_data_samples:
+ data_sample.gt_instances.labels = \
+ torch.zeros_like(data_sample.gt_instances.labels)
+
+ rpn_losses, rpn_results_list = self.rpn_head.loss_and_predict(
+ x, rpn_data_samples, proposal_cfg=proposal_cfg)
+ # avoid get same name with roi_head loss
+ keys = rpn_losses.keys()
+ for key in list(keys):
+ if 'loss' in key and 'rpn' not in key:
+ rpn_losses[f'rpn_{key}'] = rpn_losses.pop(key)
+ losses.update(rpn_losses)
+ else:
+ # TODO: Not support currently, should have a check at Fast R-CNN
+ assert batch_data_samples[0].get('proposals', None) is not None
+ # use pre-defined proposals in InstanceData for the second stage
+ # to extract ROI features.
+ rpn_results_list = [
+ data_sample.proposals for data_sample in batch_data_samples
+ ]
+
+ roi_losses = self.roi_head.loss(x, rpn_results_list,
+ batch_data_samples)
+ losses.update(roi_losses)
+
+ semantic_loss = self.semantic_head.loss(x, batch_data_samples)
+ losses.update(semantic_loss)
+
+ return losses
+
+ def predict(self,
+ batch_inputs: Tensor,
+ batch_data_samples: SampleList,
+ rescale: bool = True) -> SampleList:
+ """Predict results from a batch of inputs and data samples with post-
+ processing.
+
+ Args:
+ batch_inputs (Tensor): Inputs with shape (N, C, H, W).
+ batch_data_samples (List[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ rescale (bool): Whether to rescale the results.
+ Defaults to True.
+
+ Returns:
+ List[:obj:`DetDataSample`]: Return the packed panoptic segmentation
+ results of input images. Each DetDataSample usually contains
+ 'pred_panoptic_seg'. And the 'pred_panoptic_seg' has a key
+ ``sem_seg``, which is a tensor of shape (1, h, w).
+ """
+ batch_img_metas = [
+ data_samples.metainfo for data_samples in batch_data_samples
+ ]
+
+ x = self.extract_feat(batch_inputs)
+
+ # If there are no pre-defined proposals, use RPN to get proposals
+ if batch_data_samples[0].get('proposals', None) is None:
+ rpn_results_list = self.rpn_head.predict(
+ x, batch_data_samples, rescale=False)
+ else:
+ rpn_results_list = [
+ data_sample.proposals for data_sample in batch_data_samples
+ ]
+
+ results_list = self.roi_head.predict(
+ x, rpn_results_list, batch_data_samples, rescale=rescale)
+
+ seg_preds = self.semantic_head.predict(x, batch_img_metas, rescale)
+
+ results_list = self.panoptic_fusion_head.predict(
+ results_list, seg_preds)
+
+ batch_data_samples = self.add_pred_to_datasample(
+ batch_data_samples, results_list)
+ return batch_data_samples
+
+ # TODO the code has not been verified and needs to be refactored later.
+ def _forward(self, batch_inputs: Tensor,
+ batch_data_samples: SampleList) -> tuple:
+ """Network forward process. Usually includes backbone, neck and head
+ forward without any post-processing.
+
+ Args:
+ batch_inputs (Tensor): Inputs with shape (N, C, H, W).
+
+ Returns:
+ tuple: A tuple of features from ``rpn_head``, ``roi_head`` and
+ ``semantic_head`` forward.
+ """
+ results = ()
+ x = self.extract_feat(batch_inputs)
+ rpn_outs = self.rpn_head.forward(x)
+ results = results + (rpn_outs)
+
+ # If there are no pre-defined proposals, use RPN to get proposals
+ if batch_data_samples[0].get('proposals', None) is None:
+ batch_img_metas = [
+ data_samples.metainfo for data_samples in batch_data_samples
+ ]
+ rpn_results_list = self.rpn_head.predict_by_feat(
+ *rpn_outs, batch_img_metas=batch_img_metas, rescale=False)
+ else:
+ # TODO: Not checked currently.
+ rpn_results_list = [
+ data_sample.proposals for data_sample in batch_data_samples
+ ]
+
+ # roi_head
+ roi_outs = self.roi_head(x, rpn_results_list)
+ results = results + (roi_outs)
+
+ # semantic_head
+ sem_outs = self.semantic_head.forward(x)
+ results = results + (sem_outs['seg_preds'], )
+
+ return results
+
+ def add_pred_to_datasample(self, data_samples: SampleList,
+ results_list: List[PixelData]) -> SampleList:
+ """Add predictions to `DetDataSample`.
+
+ Args:
+ data_samples (list[:obj:`DetDataSample`]): The
+ annotation data of every samples.
+ results_list (List[PixelData]): Panoptic segmentation results of
+ each image.
+
+ Returns:
+ List[:obj:`DetDataSample`]: Return the packed panoptic segmentation
+ results of input images. Each DetDataSample usually contains
+ 'pred_panoptic_seg'. And the 'pred_panoptic_seg' has a key
+ ``sem_seg``, which is a tensor of shape (1, h, w).
+ """
+
+ for data_sample, pred_panoptic_seg in zip(data_samples, results_list):
+ data_sample.pred_panoptic_seg = pred_panoptic_seg
+ return data_samples
diff --git a/mmdet/models/detectors/point_rend.py b/mmdet/models/detectors/point_rend.py
new file mode 100644
index 0000000000000000000000000000000000000000..5062ac0c945e79bd53e66e1642aec51113475cad
--- /dev/null
+++ b/mmdet/models/detectors/point_rend.py
@@ -0,0 +1,35 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmengine.config import ConfigDict
+
+from mmdet.registry import MODELS
+from mmdet.utils import OptConfigType, OptMultiConfig
+from .two_stage import TwoStageDetector
+
+
+@MODELS.register_module()
+class PointRend(TwoStageDetector):
+ """PointRend: Image Segmentation as Rendering
+
+ This detector is the implementation of
+ `PointRend `_.
+
+ """
+
+ def __init__(self,
+ backbone: ConfigDict,
+ rpn_head: ConfigDict,
+ roi_head: ConfigDict,
+ train_cfg: ConfigDict,
+ test_cfg: ConfigDict,
+ neck: OptConfigType = None,
+ data_preprocessor: OptConfigType = None,
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(
+ backbone=backbone,
+ neck=neck,
+ rpn_head=rpn_head,
+ roi_head=roi_head,
+ train_cfg=train_cfg,
+ test_cfg=test_cfg,
+ init_cfg=init_cfg,
+ data_preprocessor=data_preprocessor)
diff --git a/mmdet/models/detectors/queryinst.py b/mmdet/models/detectors/queryinst.py
new file mode 100644
index 0000000000000000000000000000000000000000..400ce20c01f5c3825e343f2d32accf740c5dd55c
--- /dev/null
+++ b/mmdet/models/detectors/queryinst.py
@@ -0,0 +1,29 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmdet.registry import MODELS
+from mmdet.utils import ConfigType, OptConfigType, OptMultiConfig
+from .sparse_rcnn import SparseRCNN
+
+
+@MODELS.register_module()
+class QueryInst(SparseRCNN):
+ r"""Implementation of
+ `Instances as Queries `_"""
+
+ def __init__(self,
+ backbone: ConfigType,
+ rpn_head: ConfigType,
+ roi_head: ConfigType,
+ train_cfg: ConfigType,
+ test_cfg: ConfigType,
+ neck: OptConfigType = None,
+ data_preprocessor: OptConfigType = None,
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(
+ backbone=backbone,
+ neck=neck,
+ rpn_head=rpn_head,
+ roi_head=roi_head,
+ train_cfg=train_cfg,
+ test_cfg=test_cfg,
+ data_preprocessor=data_preprocessor,
+ init_cfg=init_cfg)
diff --git a/mmdet/models/detectors/reppoints_detector.py b/mmdet/models/detectors/reppoints_detector.py
new file mode 100644
index 0000000000000000000000000000000000000000..d86cec2ecda0671939e227c50f00379e81d3ac9c
--- /dev/null
+++ b/mmdet/models/detectors/reppoints_detector.py
@@ -0,0 +1,30 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmdet.registry import MODELS
+from mmdet.utils import ConfigType, OptConfigType, OptMultiConfig
+from .single_stage import SingleStageDetector
+
+
+@MODELS.register_module()
+class RepPointsDetector(SingleStageDetector):
+ """RepPoints: Point Set Representation for Object Detection.
+
+ This detector is the implementation of:
+ - RepPoints detector (https://arxiv.org/pdf/1904.11490)
+ """
+
+ def __init__(self,
+ backbone: ConfigType,
+ neck: ConfigType,
+ bbox_head: ConfigType,
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ data_preprocessor: OptConfigType = None,
+ init_cfg: OptMultiConfig = None):
+ super().__init__(
+ backbone=backbone,
+ neck=neck,
+ bbox_head=bbox_head,
+ train_cfg=train_cfg,
+ test_cfg=test_cfg,
+ data_preprocessor=data_preprocessor,
+ init_cfg=init_cfg)
diff --git a/mmdet/models/detectors/retinanet.py b/mmdet/models/detectors/retinanet.py
new file mode 100644
index 0000000000000000000000000000000000000000..03e3cb20e5bda603e9384d83688a56fa590e6de8
--- /dev/null
+++ b/mmdet/models/detectors/retinanet.py
@@ -0,0 +1,26 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmdet.registry import MODELS
+from mmdet.utils import ConfigType, OptConfigType, OptMultiConfig
+from .single_stage import SingleStageDetector
+
+
+@MODELS.register_module()
+class RetinaNet(SingleStageDetector):
+ """Implementation of `RetinaNet `_"""
+
+ def __init__(self,
+ backbone: ConfigType,
+ neck: ConfigType,
+ bbox_head: ConfigType,
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ data_preprocessor: OptConfigType = None,
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(
+ backbone=backbone,
+ neck=neck,
+ bbox_head=bbox_head,
+ train_cfg=train_cfg,
+ test_cfg=test_cfg,
+ data_preprocessor=data_preprocessor,
+ init_cfg=init_cfg)
diff --git a/mmdet/models/detectors/rpn.py b/mmdet/models/detectors/rpn.py
new file mode 100644
index 0000000000000000000000000000000000000000..72fe8521fcc9bc796801b2dd68269bb57aaab984
--- /dev/null
+++ b/mmdet/models/detectors/rpn.py
@@ -0,0 +1,81 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+import warnings
+
+import torch
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.structures import SampleList
+from mmdet.utils import ConfigType, OptConfigType, OptMultiConfig
+from .single_stage import SingleStageDetector
+
+
+@MODELS.register_module()
+class RPN(SingleStageDetector):
+ """Implementation of Region Proposal Network.
+
+ Args:
+ backbone (:obj:`ConfigDict` or dict): The backbone config.
+ neck (:obj:`ConfigDict` or dict): The neck config.
+ bbox_head (:obj:`ConfigDict` or dict): The bbox head config.
+ train_cfg (:obj:`ConfigDict` or dict, optional): The training config.
+ test_cfg (:obj:`ConfigDict` or dict, optional): The testing config.
+ data_preprocessor (:obj:`ConfigDict` or dict, optional): Config of
+ :class:`DetDataPreprocessor` to process the input data.
+ Defaults to None.
+ init_cfg (:obj:`ConfigDict` or list[:obj:`ConfigDict`] or dict or
+ list[dict], optional): Initialization config dict.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ backbone: ConfigType,
+ neck: ConfigType,
+ rpn_head: ConfigType,
+ train_cfg: ConfigType,
+ test_cfg: ConfigType,
+ data_preprocessor: OptConfigType = None,
+ init_cfg: OptMultiConfig = None,
+ **kwargs) -> None:
+ super(SingleStageDetector, self).__init__(
+ data_preprocessor=data_preprocessor, init_cfg=init_cfg)
+ self.backbone = MODELS.build(backbone)
+ self.neck = MODELS.build(neck) if neck is not None else None
+ rpn_train_cfg = train_cfg['rpn'] if train_cfg is not None else None
+ rpn_head_num_classes = rpn_head.get('num_classes', 1)
+ if rpn_head_num_classes != 1:
+ warnings.warn('The `num_classes` should be 1 in RPN, but get '
+ f'{rpn_head_num_classes}, please set '
+ 'rpn_head.num_classes = 1 in your config file.')
+ rpn_head.update(num_classes=1)
+ rpn_head.update(train_cfg=rpn_train_cfg)
+ rpn_head.update(test_cfg=test_cfg['rpn'])
+ self.bbox_head = MODELS.build(rpn_head)
+ self.train_cfg = train_cfg
+ self.test_cfg = test_cfg
+
+ def loss(self, batch_inputs: Tensor,
+ batch_data_samples: SampleList) -> dict:
+ """Calculate losses from a batch of inputs and data samples.
+
+ Args:
+ batch_inputs (Tensor): Input images of shape (N, C, H, W).
+ These should usually be mean centered and std scaled.
+ batch_data_samples (list[:obj:`DetDataSample`]): The batch
+ data samples. It usually includes information such
+ as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components.
+ """
+ x = self.extract_feat(batch_inputs)
+
+ # set cat_id of gt_labels to 0 in RPN
+ rpn_data_samples = copy.deepcopy(batch_data_samples)
+ for data_sample in rpn_data_samples:
+ data_sample.gt_instances.labels = \
+ torch.zeros_like(data_sample.gt_instances.labels)
+
+ losses = self.bbox_head.loss(x, rpn_data_samples)
+ return losses
diff --git a/mmdet/models/detectors/rtmdet.py b/mmdet/models/detectors/rtmdet.py
new file mode 100644
index 0000000000000000000000000000000000000000..cb10f76dd57d79761e9b58c310293eedba1e00d5
--- /dev/null
+++ b/mmdet/models/detectors/rtmdet.py
@@ -0,0 +1,52 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+from mmengine.dist import get_world_size
+from mmengine.logging import print_log
+
+from mmdet.registry import MODELS
+from mmdet.utils import ConfigType, OptConfigType, OptMultiConfig
+from .single_stage import SingleStageDetector
+
+
+@MODELS.register_module()
+class RTMDet(SingleStageDetector):
+ """Implementation of RTMDet.
+
+ Args:
+ backbone (:obj:`ConfigDict` or dict): The backbone module.
+ neck (:obj:`ConfigDict` or dict): The neck module.
+ bbox_head (:obj:`ConfigDict` or dict): The bbox head module.
+ train_cfg (:obj:`ConfigDict` or dict, optional): The training config
+ of ATSS. Defaults to None.
+ test_cfg (:obj:`ConfigDict` or dict, optional): The testing config
+ of ATSS. Defaults to None.
+ data_preprocessor (:obj:`ConfigDict` or dict, optional): Config of
+ :class:`DetDataPreprocessor` to process the input data.
+ Defaults to None.
+ init_cfg (:obj:`ConfigDict` or dict, optional): the config to control
+ the initialization. Defaults to None.
+ use_syncbn (bool): Whether to use SyncBatchNorm. Defaults to True.
+ """
+
+ def __init__(self,
+ backbone: ConfigType,
+ neck: ConfigType,
+ bbox_head: ConfigType,
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ data_preprocessor: OptConfigType = None,
+ init_cfg: OptMultiConfig = None,
+ use_syncbn: bool = True) -> None:
+ super().__init__(
+ backbone=backbone,
+ neck=neck,
+ bbox_head=bbox_head,
+ train_cfg=train_cfg,
+ test_cfg=test_cfg,
+ data_preprocessor=data_preprocessor,
+ init_cfg=init_cfg)
+
+ # TODO: Waiting for mmengine support
+ if use_syncbn and get_world_size() > 1:
+ torch.nn.SyncBatchNorm.convert_sync_batchnorm(self)
+ print_log('Using SyncBatchNorm()', 'current')
diff --git a/mmdet/models/detectors/scnet.py b/mmdet/models/detectors/scnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..606a0203869f1731a21d811f06c4781f5cd90d8d
--- /dev/null
+++ b/mmdet/models/detectors/scnet.py
@@ -0,0 +1,11 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmdet.registry import MODELS
+from .cascade_rcnn import CascadeRCNN
+
+
+@MODELS.register_module()
+class SCNet(CascadeRCNN):
+ """Implementation of `SCNet `_"""
+
+ def __init__(self, **kwargs) -> None:
+ super().__init__(**kwargs)
diff --git a/mmdet/models/detectors/semi_base.py b/mmdet/models/detectors/semi_base.py
new file mode 100644
index 0000000000000000000000000000000000000000..f3f0c8c030830e188bf3ad245d5b3cb471ecb04f
--- /dev/null
+++ b/mmdet/models/detectors/semi_base.py
@@ -0,0 +1,266 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+from typing import Dict, List, Optional, Tuple, Union
+
+import torch
+import torch.nn as nn
+from torch import Tensor
+
+from mmdet.models.utils import (filter_gt_instances, rename_loss_dict,
+ reweight_loss_dict)
+from mmdet.registry import MODELS
+from mmdet.structures import SampleList
+from mmdet.structures.bbox import bbox_project
+from mmdet.utils import ConfigType, OptConfigType, OptMultiConfig
+from .base import BaseDetector
+
+
+@MODELS.register_module()
+class SemiBaseDetector(BaseDetector):
+ """Base class for semi-supervised detectors.
+
+ Semi-supervised detectors typically consisting of a teacher model
+ updated by exponential moving average and a student model updated
+ by gradient descent.
+
+ Args:
+ detector (:obj:`ConfigDict` or dict): The detector config.
+ semi_train_cfg (:obj:`ConfigDict` or dict, optional):
+ The semi-supervised training config.
+ semi_test_cfg (:obj:`ConfigDict` or dict, optional):
+ The semi-supervised testing config.
+ data_preprocessor (:obj:`ConfigDict` or dict, optional): Config of
+ :class:`DetDataPreprocessor` to process the input data.
+ Defaults to None.
+ init_cfg (:obj:`ConfigDict` or list[:obj:`ConfigDict`] or dict or
+ list[dict], optional): Initialization config dict.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ detector: ConfigType,
+ semi_train_cfg: OptConfigType = None,
+ semi_test_cfg: OptConfigType = None,
+ data_preprocessor: OptConfigType = None,
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(
+ data_preprocessor=data_preprocessor, init_cfg=init_cfg)
+ self.student = MODELS.build(detector)
+ self.teacher = MODELS.build(detector)
+ self.semi_train_cfg = semi_train_cfg
+ self.semi_test_cfg = semi_test_cfg
+ if self.semi_train_cfg.get('freeze_teacher', True) is True:
+ self.freeze(self.teacher)
+
+ @staticmethod
+ def freeze(model: nn.Module):
+ """Freeze the model."""
+ model.eval()
+ for param in model.parameters():
+ param.requires_grad = False
+
+ def loss(self, multi_batch_inputs: Dict[str, Tensor],
+ multi_batch_data_samples: Dict[str, SampleList]) -> dict:
+ """Calculate losses from multi-branch inputs and data samples.
+
+ Args:
+ multi_batch_inputs (Dict[str, Tensor]): The dict of multi-branch
+ input images, each value with shape (N, C, H, W).
+ Each value should usually be mean centered and std scaled.
+ multi_batch_data_samples (Dict[str, List[:obj:`DetDataSample`]]):
+ The dict of multi-branch data samples.
+
+ Returns:
+ dict: A dictionary of loss components
+ """
+ losses = dict()
+ losses.update(**self.loss_by_gt_instances(
+ multi_batch_inputs['sup'], multi_batch_data_samples['sup']))
+
+ origin_pseudo_data_samples, batch_info = self.get_pseudo_instances(
+ multi_batch_inputs['unsup_teacher'],
+ multi_batch_data_samples['unsup_teacher'])
+ multi_batch_data_samples[
+ 'unsup_student'] = self.project_pseudo_instances(
+ origin_pseudo_data_samples,
+ multi_batch_data_samples['unsup_student'])
+ losses.update(**self.loss_by_pseudo_instances(
+ multi_batch_inputs['unsup_student'],
+ multi_batch_data_samples['unsup_student'], batch_info))
+ return losses
+
+ def loss_by_gt_instances(self, batch_inputs: Tensor,
+ batch_data_samples: SampleList) -> dict:
+ """Calculate losses from a batch of inputs and ground-truth data
+ samples.
+
+ Args:
+ batch_inputs (Tensor): Input images of shape (N, C, H, W).
+ These should usually be mean centered and std scaled.
+ batch_data_samples (List[:obj:`DetDataSample`]): The batch
+ data samples. It usually includes information such
+ as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
+
+ Returns:
+ dict: A dictionary of loss components
+ """
+
+ losses = self.student.loss(batch_inputs, batch_data_samples)
+ sup_weight = self.semi_train_cfg.get('sup_weight', 1.)
+ return rename_loss_dict('sup_', reweight_loss_dict(losses, sup_weight))
+
+ def loss_by_pseudo_instances(self,
+ batch_inputs: Tensor,
+ batch_data_samples: SampleList,
+ batch_info: Optional[dict] = None) -> dict:
+ """Calculate losses from a batch of inputs and pseudo data samples.
+
+ Args:
+ batch_inputs (Tensor): Input images of shape (N, C, H, W).
+ These should usually be mean centered and std scaled.
+ batch_data_samples (List[:obj:`DetDataSample`]): The batch
+ data samples. It usually includes information such
+ as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`,
+ which are `pseudo_instance` or `pseudo_panoptic_seg`
+ or `pseudo_sem_seg` in fact.
+ batch_info (dict): Batch information of teacher model
+ forward propagation process. Defaults to None.
+
+ Returns:
+ dict: A dictionary of loss components
+ """
+ batch_data_samples = filter_gt_instances(
+ batch_data_samples, score_thr=self.semi_train_cfg.cls_pseudo_thr)
+ losses = self.student.loss(batch_inputs, batch_data_samples)
+ pseudo_instances_num = sum([
+ len(data_samples.gt_instances)
+ for data_samples in batch_data_samples
+ ])
+ unsup_weight = self.semi_train_cfg.get(
+ 'unsup_weight', 1.) if pseudo_instances_num > 0 else 0.
+ return rename_loss_dict('unsup_',
+ reweight_loss_dict(losses, unsup_weight))
+
+ @torch.no_grad()
+ def get_pseudo_instances(
+ self, batch_inputs: Tensor, batch_data_samples: SampleList
+ ) -> Tuple[SampleList, Optional[dict]]:
+ """Get pseudo instances from teacher model."""
+ self.teacher.eval()
+ results_list = self.teacher.predict(
+ batch_inputs, batch_data_samples, rescale=False)
+ batch_info = {}
+ for data_samples, results in zip(batch_data_samples, results_list):
+ data_samples.gt_instances = results.pred_instances
+ data_samples.gt_instances.bboxes = bbox_project(
+ data_samples.gt_instances.bboxes,
+ torch.from_numpy(data_samples.homography_matrix).inverse().to(
+ self.data_preprocessor.device), data_samples.ori_shape)
+ return batch_data_samples, batch_info
+
+ def project_pseudo_instances(self, batch_pseudo_instances: SampleList,
+ batch_data_samples: SampleList) -> SampleList:
+ """Project pseudo instances."""
+ for pseudo_instances, data_samples in zip(batch_pseudo_instances,
+ batch_data_samples):
+ data_samples.gt_instances = copy.deepcopy(
+ pseudo_instances.gt_instances)
+ data_samples.gt_instances.bboxes = bbox_project(
+ data_samples.gt_instances.bboxes,
+ torch.tensor(data_samples.homography_matrix).to(
+ self.data_preprocessor.device), data_samples.img_shape)
+ wh_thr = self.semi_train_cfg.get('min_pseudo_bbox_wh', (1e-2, 1e-2))
+ return filter_gt_instances(batch_data_samples, wh_thr=wh_thr)
+
+ def predict(self, batch_inputs: Tensor,
+ batch_data_samples: SampleList) -> SampleList:
+ """Predict results from a batch of inputs and data samples with post-
+ processing.
+
+ Args:
+ batch_inputs (Tensor): Inputs with shape (N, C, H, W).
+ batch_data_samples (List[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ rescale (bool): Whether to rescale the results.
+ Defaults to True.
+
+ Returns:
+ list[:obj:`DetDataSample`]: Return the detection results of the
+ input images. The returns value is DetDataSample,
+ which usually contain 'pred_instances'. And the
+ ``pred_instances`` usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ - masks (Tensor): Has a shape (num_instances, H, W).
+ """
+ if self.semi_test_cfg.get('predict_on', 'teacher') == 'teacher':
+ return self.teacher(
+ batch_inputs, batch_data_samples, mode='predict')
+ else:
+ return self.student(
+ batch_inputs, batch_data_samples, mode='predict')
+
+ def _forward(self, batch_inputs: Tensor,
+ batch_data_samples: SampleList) -> SampleList:
+ """Network forward process. Usually includes backbone, neck and head
+ forward without any post-processing.
+
+ Args:
+ batch_inputs (Tensor): Inputs with shape (N, C, H, W).
+
+ Returns:
+ tuple: A tuple of features from ``rpn_head`` and ``roi_head``
+ forward.
+ """
+ if self.semi_test_cfg.get('forward_on', 'teacher') == 'teacher':
+ return self.teacher(
+ batch_inputs, batch_data_samples, mode='tensor')
+ else:
+ return self.student(
+ batch_inputs, batch_data_samples, mode='tensor')
+
+ def extract_feat(self, batch_inputs: Tensor) -> Tuple[Tensor]:
+ """Extract features.
+
+ Args:
+ batch_inputs (Tensor): Image tensor with shape (N, C, H ,W).
+
+ Returns:
+ tuple[Tensor]: Multi-level features that may have
+ different resolutions.
+ """
+ if self.semi_test_cfg.get('extract_feat_on', 'teacher') == 'teacher':
+ return self.teacher.extract_feat(batch_inputs)
+ else:
+ return self.student.extract_feat(batch_inputs)
+
+ def _load_from_state_dict(self, state_dict: dict, prefix: str,
+ local_metadata: dict, strict: bool,
+ missing_keys: Union[List[str], str],
+ unexpected_keys: Union[List[str], str],
+ error_msgs: Union[List[str], str]) -> None:
+ """Add teacher and student prefixes to model parameter names."""
+ if not any([
+ 'student' in key or 'teacher' in key
+ for key in state_dict.keys()
+ ]):
+ keys = list(state_dict.keys())
+ state_dict.update({'teacher.' + k: state_dict[k] for k in keys})
+ state_dict.update({'student.' + k: state_dict[k] for k in keys})
+ for k in keys:
+ state_dict.pop(k)
+ return super()._load_from_state_dict(
+ state_dict,
+ prefix,
+ local_metadata,
+ strict,
+ missing_keys,
+ unexpected_keys,
+ error_msgs,
+ )
diff --git a/mmdet/models/detectors/single_stage.py b/mmdet/models/detectors/single_stage.py
new file mode 100644
index 0000000000000000000000000000000000000000..06c074085967bbc9040d93e5eb446b67a006087e
--- /dev/null
+++ b/mmdet/models/detectors/single_stage.py
@@ -0,0 +1,149 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Tuple, Union
+
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.structures import OptSampleList, SampleList
+from mmdet.utils import ConfigType, OptConfigType, OptMultiConfig
+from .base import BaseDetector
+
+
+@MODELS.register_module()
+class SingleStageDetector(BaseDetector):
+ """Base class for single-stage detectors.
+
+ Single-stage detectors directly and densely predict bounding boxes on the
+ output features of the backbone+neck.
+ """
+
+ def __init__(self,
+ backbone: ConfigType,
+ neck: OptConfigType = None,
+ bbox_head: OptConfigType = None,
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ data_preprocessor: OptConfigType = None,
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(
+ data_preprocessor=data_preprocessor, init_cfg=init_cfg)
+ self.backbone = MODELS.build(backbone)
+ if neck is not None:
+ self.neck = MODELS.build(neck)
+ bbox_head.update(train_cfg=train_cfg)
+ bbox_head.update(test_cfg=test_cfg)
+ self.bbox_head = MODELS.build(bbox_head)
+ self.train_cfg = train_cfg
+ self.test_cfg = test_cfg
+
+ def _load_from_state_dict(self, state_dict: dict, prefix: str,
+ local_metadata: dict, strict: bool,
+ missing_keys: Union[List[str], str],
+ unexpected_keys: Union[List[str], str],
+ error_msgs: Union[List[str], str]) -> None:
+ """Exchange bbox_head key to rpn_head key when loading two-stage
+ weights into single-stage model."""
+ bbox_head_prefix = prefix + '.bbox_head' if prefix else 'bbox_head'
+ bbox_head_keys = [
+ k for k in state_dict.keys() if k.startswith(bbox_head_prefix)
+ ]
+ rpn_head_prefix = prefix + '.rpn_head' if prefix else 'rpn_head'
+ rpn_head_keys = [
+ k for k in state_dict.keys() if k.startswith(rpn_head_prefix)
+ ]
+ if len(bbox_head_keys) == 0 and len(rpn_head_keys) != 0:
+ for rpn_head_key in rpn_head_keys:
+ bbox_head_key = bbox_head_prefix + \
+ rpn_head_key[len(rpn_head_prefix):]
+ state_dict[bbox_head_key] = state_dict.pop(rpn_head_key)
+ super()._load_from_state_dict(state_dict, prefix, local_metadata,
+ strict, missing_keys, unexpected_keys,
+ error_msgs)
+
+ def loss(self, batch_inputs: Tensor,
+ batch_data_samples: SampleList) -> Union[dict, list]:
+ """Calculate losses from a batch of inputs and data samples.
+
+ Args:
+ batch_inputs (Tensor): Input images of shape (N, C, H, W).
+ These should usually be mean centered and std scaled.
+ batch_data_samples (list[:obj:`DetDataSample`]): The batch
+ data samples. It usually includes information such
+ as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
+
+ Returns:
+ dict: A dictionary of loss components.
+ """
+ x = self.extract_feat(batch_inputs)
+ losses = self.bbox_head.loss(x, batch_data_samples)
+ return losses
+
+ def predict(self,
+ batch_inputs: Tensor,
+ batch_data_samples: SampleList,
+ rescale: bool = True) -> SampleList:
+ """Predict results from a batch of inputs and data samples with post-
+ processing.
+
+ Args:
+ batch_inputs (Tensor): Inputs with shape (N, C, H, W).
+ batch_data_samples (List[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ rescale (bool): Whether to rescale the results.
+ Defaults to True.
+
+ Returns:
+ list[:obj:`DetDataSample`]: Detection results of the
+ input images. Each DetDataSample usually contain
+ 'pred_instances'. And the ``pred_instances`` usually
+ contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ """
+ x = self.extract_feat(batch_inputs)
+ results_list = self.bbox_head.predict(
+ x, batch_data_samples, rescale=rescale)
+ batch_data_samples = self.add_pred_to_datasample(
+ batch_data_samples, results_list)
+ return batch_data_samples
+
+ def _forward(
+ self,
+ batch_inputs: Tensor,
+ batch_data_samples: OptSampleList = None) -> Tuple[List[Tensor]]:
+ """Network forward process. Usually includes backbone, neck and head
+ forward without any post-processing.
+
+ Args:
+ batch_inputs (Tensor): Inputs with shape (N, C, H, W).
+ batch_data_samples (list[:obj:`DetDataSample`]): Each item contains
+ the meta information of each image and corresponding
+ annotations.
+
+ Returns:
+ tuple[list]: A tuple of features from ``bbox_head`` forward.
+ """
+ x = self.extract_feat(batch_inputs)
+ results = self.bbox_head.forward(x)
+ return results
+
+ def extract_feat(self, batch_inputs: Tensor) -> Tuple[Tensor]:
+ """Extract features.
+
+ Args:
+ batch_inputs (Tensor): Image tensor with shape (N, C, H ,W).
+
+ Returns:
+ tuple[Tensor]: Multi-level features that may have
+ different resolutions.
+ """
+ x = self.backbone(batch_inputs)
+ if self.with_neck:
+ x = self.neck(x)
+ return x
diff --git a/mmdet/models/detectors/single_stage_instance_seg.py b/mmdet/models/detectors/single_stage_instance_seg.py
new file mode 100644
index 0000000000000000000000000000000000000000..acb5f0d2f8e4636b86b4b66cbf5c4916d0dae16f
--- /dev/null
+++ b/mmdet/models/detectors/single_stage_instance_seg.py
@@ -0,0 +1,180 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+from typing import Tuple
+
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.structures import OptSampleList, SampleList
+from mmdet.utils import ConfigType, OptConfigType, OptMultiConfig
+from .base import BaseDetector
+
+INF = 1e8
+
+
+@MODELS.register_module()
+class SingleStageInstanceSegmentor(BaseDetector):
+ """Base class for single-stage instance segmentors."""
+
+ def __init__(self,
+ backbone: ConfigType,
+ neck: OptConfigType = None,
+ bbox_head: OptConfigType = None,
+ mask_head: OptConfigType = None,
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ data_preprocessor: OptConfigType = None,
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(
+ data_preprocessor=data_preprocessor, init_cfg=init_cfg)
+ self.backbone = MODELS.build(backbone)
+ if neck is not None:
+ self.neck = MODELS.build(neck)
+ else:
+ self.neck = None
+ if bbox_head is not None:
+ bbox_head.update(train_cfg=copy.deepcopy(train_cfg))
+ bbox_head.update(test_cfg=copy.deepcopy(test_cfg))
+ self.bbox_head = MODELS.build(bbox_head)
+ else:
+ self.bbox_head = None
+
+ assert mask_head, f'`mask_head` must ' \
+ f'be implemented in {self.__class__.__name__}'
+ mask_head.update(train_cfg=copy.deepcopy(train_cfg))
+ mask_head.update(test_cfg=copy.deepcopy(test_cfg))
+ self.mask_head = MODELS.build(mask_head)
+
+ self.train_cfg = train_cfg
+ self.test_cfg = test_cfg
+
+ def extract_feat(self, batch_inputs: Tensor) -> Tuple[Tensor]:
+ """Extract features.
+
+ Args:
+ batch_inputs (Tensor): Image tensor with shape (N, C, H ,W).
+
+ Returns:
+ tuple[Tensor]: Multi-level features that may have different
+ resolutions.
+ """
+ x = self.backbone(batch_inputs)
+ if self.with_neck:
+ x = self.neck(x)
+ return x
+
+ def _forward(self,
+ batch_inputs: Tensor,
+ batch_data_samples: OptSampleList = None,
+ **kwargs) -> tuple:
+ """Network forward process. Usually includes backbone, neck and head
+ forward without any post-processing.
+
+ Args:
+ batch_inputs (Tensor): Inputs with shape (N, C, H, W).
+
+ Returns:
+ tuple: A tuple of features from ``bbox_head`` forward.
+ """
+ outs = ()
+ # backbone
+ x = self.extract_feat(batch_inputs)
+ # bbox_head
+ positive_infos = None
+ if self.with_bbox:
+ assert batch_data_samples is not None
+ bbox_outs = self.bbox_head.forward(x)
+ outs = outs + (bbox_outs, )
+ # It is necessary to use `bbox_head.loss` to update
+ # `_raw_positive_infos` which will be used in `get_positive_infos`
+ # positive_infos will be used in the following mask head.
+ _ = self.bbox_head.loss(x, batch_data_samples, **kwargs)
+ positive_infos = self.bbox_head.get_positive_infos()
+ # mask_head
+ if positive_infos is None:
+ mask_outs = self.mask_head.forward(x)
+ else:
+ mask_outs = self.mask_head.forward(x, positive_infos)
+ outs = outs + (mask_outs, )
+ return outs
+
+ def loss(self, batch_inputs: Tensor, batch_data_samples: SampleList,
+ **kwargs) -> dict:
+ """
+ Args:
+ batch_inputs (Tensor): Input images of shape (N, C, H, W).
+ These should usually be mean centered and std scaled.
+ batch_data_samples (list[:obj:`DetDataSample`]): The batch
+ data samples. It usually includes information such
+ as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
+
+ Returns:
+ dict: A dictionary of loss components.
+ """
+ x = self.extract_feat(batch_inputs)
+ losses = dict()
+
+ positive_infos = None
+ # CondInst and YOLACT have bbox_head
+ if self.with_bbox:
+ bbox_losses = self.bbox_head.loss(x, batch_data_samples, **kwargs)
+ losses.update(bbox_losses)
+ # get positive information from bbox head, which will be used
+ # in the following mask head.
+ positive_infos = self.bbox_head.get_positive_infos()
+
+ mask_loss = self.mask_head.loss(
+ x, batch_data_samples, positive_infos=positive_infos, **kwargs)
+ # avoid loss override
+ assert not set(mask_loss.keys()) & set(losses.keys())
+
+ losses.update(mask_loss)
+ return losses
+
+ def predict(self,
+ batch_inputs: Tensor,
+ batch_data_samples: SampleList,
+ rescale: bool = True,
+ **kwargs) -> SampleList:
+ """Perform forward propagation of the mask head and predict mask
+ results on the features of the upstream network.
+
+ Args:
+ batch_inputs (Tensor): Inputs with shape (N, C, H, W).
+ batch_data_samples (List[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ rescale (bool): Whether to rescale the results.
+ Defaults to False.
+
+ Returns:
+ list[:obj:`DetDataSample`]: Detection results of the
+ input images. Each DetDataSample usually contain
+ 'pred_instances'. And the ``pred_instances`` usually
+ contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ - masks (Tensor): Has a shape (num_instances, H, W).
+ """
+ x = self.extract_feat(batch_inputs)
+ if self.with_bbox:
+ # the bbox branch does not need to be scaled to the original
+ # image scale, because the mask branch will scale both bbox
+ # and mask at the same time.
+ bbox_rescale = rescale if not self.with_mask else False
+ results_list = self.bbox_head.predict(
+ x, batch_data_samples, rescale=bbox_rescale)
+ else:
+ results_list = None
+
+ results_list = self.mask_head.predict(
+ x, batch_data_samples, rescale=rescale, results_list=results_list)
+
+ batch_data_samples = self.add_pred_to_datasample(
+ batch_data_samples, results_list)
+ return batch_data_samples
diff --git a/mmdet/models/detectors/soft_teacher.py b/mmdet/models/detectors/soft_teacher.py
new file mode 100644
index 0000000000000000000000000000000000000000..80853f1d8399c70008923067777a2581671ede0b
--- /dev/null
+++ b/mmdet/models/detectors/soft_teacher.py
@@ -0,0 +1,378 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+from typing import List, Optional, Tuple
+
+import torch
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmdet.models.utils import (filter_gt_instances, rename_loss_dict,
+ reweight_loss_dict)
+from mmdet.registry import MODELS
+from mmdet.structures import SampleList
+from mmdet.structures.bbox import bbox2roi, bbox_project
+from mmdet.utils import ConfigType, InstanceList, OptConfigType, OptMultiConfig
+from ..utils.misc import unpack_gt_instances
+from .semi_base import SemiBaseDetector
+
+
+@MODELS.register_module()
+class SoftTeacher(SemiBaseDetector):
+ r"""Implementation of `End-to-End Semi-Supervised Object Detection
+ with Soft Teacher `_
+
+ Args:
+ detector (:obj:`ConfigDict` or dict): The detector config.
+ semi_train_cfg (:obj:`ConfigDict` or dict, optional):
+ The semi-supervised training config.
+ semi_test_cfg (:obj:`ConfigDict` or dict, optional):
+ The semi-supervised testing config.
+ data_preprocessor (:obj:`ConfigDict` or dict, optional): Config of
+ :class:`DetDataPreprocessor` to process the input data.
+ Defaults to None.
+ init_cfg (:obj:`ConfigDict` or list[:obj:`ConfigDict`] or dict or
+ list[dict], optional): Initialization config dict.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ detector: ConfigType,
+ semi_train_cfg: OptConfigType = None,
+ semi_test_cfg: OptConfigType = None,
+ data_preprocessor: OptConfigType = None,
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(
+ detector=detector,
+ semi_train_cfg=semi_train_cfg,
+ semi_test_cfg=semi_test_cfg,
+ data_preprocessor=data_preprocessor,
+ init_cfg=init_cfg)
+
+ def loss_by_pseudo_instances(self,
+ batch_inputs: Tensor,
+ batch_data_samples: SampleList,
+ batch_info: Optional[dict] = None) -> dict:
+ """Calculate losses from a batch of inputs and pseudo data samples.
+
+ Args:
+ batch_inputs (Tensor): Input images of shape (N, C, H, W).
+ These should usually be mean centered and std scaled.
+ batch_data_samples (List[:obj:`DetDataSample`]): The batch
+ data samples. It usually includes information such
+ as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`,
+ which are `pseudo_instance` or `pseudo_panoptic_seg`
+ or `pseudo_sem_seg` in fact.
+ batch_info (dict): Batch information of teacher model
+ forward propagation process. Defaults to None.
+
+ Returns:
+ dict: A dictionary of loss components
+ """
+
+ x = self.student.extract_feat(batch_inputs)
+
+ losses = {}
+ rpn_losses, rpn_results_list = self.rpn_loss_by_pseudo_instances(
+ x, batch_data_samples)
+ losses.update(**rpn_losses)
+ losses.update(**self.rcnn_cls_loss_by_pseudo_instances(
+ x, rpn_results_list, batch_data_samples, batch_info))
+ losses.update(**self.rcnn_reg_loss_by_pseudo_instances(
+ x, rpn_results_list, batch_data_samples))
+ unsup_weight = self.semi_train_cfg.get('unsup_weight', 1.)
+ return rename_loss_dict('unsup_',
+ reweight_loss_dict(losses, unsup_weight))
+
+ @torch.no_grad()
+ def get_pseudo_instances(
+ self, batch_inputs: Tensor, batch_data_samples: SampleList
+ ) -> Tuple[SampleList, Optional[dict]]:
+ """Get pseudo instances from teacher model."""
+ assert self.teacher.with_bbox, 'Bbox head must be implemented.'
+ x = self.teacher.extract_feat(batch_inputs)
+
+ # If there are no pre-defined proposals, use RPN to get proposals
+ if batch_data_samples[0].get('proposals', None) is None:
+ rpn_results_list = self.teacher.rpn_head.predict(
+ x, batch_data_samples, rescale=False)
+ else:
+ rpn_results_list = [
+ data_sample.proposals for data_sample in batch_data_samples
+ ]
+
+ results_list = self.teacher.roi_head.predict(
+ x, rpn_results_list, batch_data_samples, rescale=False)
+
+ for data_samples, results in zip(batch_data_samples, results_list):
+ data_samples.gt_instances = results
+
+ batch_data_samples = filter_gt_instances(
+ batch_data_samples,
+ score_thr=self.semi_train_cfg.pseudo_label_initial_score_thr)
+
+ reg_uncs_list = self.compute_uncertainty_with_aug(
+ x, batch_data_samples)
+
+ for data_samples, reg_uncs in zip(batch_data_samples, reg_uncs_list):
+ data_samples.gt_instances['reg_uncs'] = reg_uncs
+ data_samples.gt_instances.bboxes = bbox_project(
+ data_samples.gt_instances.bboxes,
+ torch.from_numpy(data_samples.homography_matrix).inverse().to(
+ self.data_preprocessor.device), data_samples.ori_shape)
+
+ batch_info = {
+ 'feat': x,
+ 'img_shape': [],
+ 'homography_matrix': [],
+ 'metainfo': []
+ }
+ for data_samples in batch_data_samples:
+ batch_info['img_shape'].append(data_samples.img_shape)
+ batch_info['homography_matrix'].append(
+ torch.from_numpy(data_samples.homography_matrix).to(
+ self.data_preprocessor.device))
+ batch_info['metainfo'].append(data_samples.metainfo)
+ return batch_data_samples, batch_info
+
+ def rpn_loss_by_pseudo_instances(self, x: Tuple[Tensor],
+ batch_data_samples: SampleList) -> dict:
+ """Calculate rpn loss from a batch of inputs and pseudo data samples.
+
+ Args:
+ x (tuple[Tensor]): Features from FPN.
+ batch_data_samples (List[:obj:`DetDataSample`]): The batch
+ data samples. It usually includes information such
+ as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`,
+ which are `pseudo_instance` or `pseudo_panoptic_seg`
+ or `pseudo_sem_seg` in fact.
+ Returns:
+ dict: A dictionary of rpn loss components
+ """
+
+ rpn_data_samples = copy.deepcopy(batch_data_samples)
+ rpn_data_samples = filter_gt_instances(
+ rpn_data_samples, score_thr=self.semi_train_cfg.rpn_pseudo_thr)
+ proposal_cfg = self.student.train_cfg.get('rpn_proposal',
+ self.student.test_cfg.rpn)
+ # set cat_id of gt_labels to 0 in RPN
+ for data_sample in rpn_data_samples:
+ data_sample.gt_instances.labels = \
+ torch.zeros_like(data_sample.gt_instances.labels)
+
+ rpn_losses, rpn_results_list = self.student.rpn_head.loss_and_predict(
+ x, rpn_data_samples, proposal_cfg=proposal_cfg)
+ for key in rpn_losses.keys():
+ if 'loss' in key and 'rpn' not in key:
+ rpn_losses[f'rpn_{key}'] = rpn_losses.pop(key)
+ return rpn_losses, rpn_results_list
+
+ def rcnn_cls_loss_by_pseudo_instances(self, x: Tuple[Tensor],
+ unsup_rpn_results_list: InstanceList,
+ batch_data_samples: SampleList,
+ batch_info: dict) -> dict:
+ """Calculate classification loss from a batch of inputs and pseudo data
+ samples.
+
+ Args:
+ x (tuple[Tensor]): List of multi-level img features.
+ unsup_rpn_results_list (list[:obj:`InstanceData`]):
+ List of region proposals.
+ batch_data_samples (List[:obj:`DetDataSample`]): The batch
+ data samples. It usually includes information such
+ as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`,
+ which are `pseudo_instance` or `pseudo_panoptic_seg`
+ or `pseudo_sem_seg` in fact.
+ batch_info (dict): Batch information of teacher model
+ forward propagation process.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of rcnn
+ classification loss components
+ """
+ rpn_results_list = copy.deepcopy(unsup_rpn_results_list)
+ cls_data_samples = copy.deepcopy(batch_data_samples)
+ cls_data_samples = filter_gt_instances(
+ cls_data_samples, score_thr=self.semi_train_cfg.cls_pseudo_thr)
+
+ outputs = unpack_gt_instances(cls_data_samples)
+ batch_gt_instances, batch_gt_instances_ignore, _ = outputs
+
+ # assign gts and sample proposals
+ num_imgs = len(cls_data_samples)
+ sampling_results = []
+ for i in range(num_imgs):
+ # rename rpn_results.bboxes to rpn_results.priors
+ rpn_results = rpn_results_list[i]
+ rpn_results.priors = rpn_results.pop('bboxes')
+ assign_result = self.student.roi_head.bbox_assigner.assign(
+ rpn_results, batch_gt_instances[i],
+ batch_gt_instances_ignore[i])
+ sampling_result = self.student.roi_head.bbox_sampler.sample(
+ assign_result,
+ rpn_results,
+ batch_gt_instances[i],
+ feats=[lvl_feat[i][None] for lvl_feat in x])
+ sampling_results.append(sampling_result)
+
+ selected_bboxes = [res.priors for res in sampling_results]
+ rois = bbox2roi(selected_bboxes)
+ bbox_results = self.student.roi_head._bbox_forward(x, rois)
+ # cls_reg_targets is a tuple of labels, label_weights,
+ # and bbox_targets, bbox_weights
+ cls_reg_targets = self.student.roi_head.bbox_head.get_targets(
+ sampling_results, self.student.train_cfg.rcnn)
+
+ selected_results_list = []
+ for bboxes, data_samples, teacher_matrix, teacher_img_shape in zip(
+ selected_bboxes, batch_data_samples,
+ batch_info['homography_matrix'], batch_info['img_shape']):
+ student_matrix = torch.tensor(
+ data_samples.homography_matrix, device=teacher_matrix.device)
+ homography_matrix = teacher_matrix @ student_matrix.inverse()
+ projected_bboxes = bbox_project(bboxes, homography_matrix,
+ teacher_img_shape)
+ selected_results_list.append(InstanceData(bboxes=projected_bboxes))
+
+ with torch.no_grad():
+ results_list = self.teacher.roi_head.predict_bbox(
+ batch_info['feat'],
+ batch_info['metainfo'],
+ selected_results_list,
+ rcnn_test_cfg=None,
+ rescale=False)
+ bg_score = torch.cat(
+ [results.scores[:, -1] for results in results_list])
+ # cls_reg_targets[0] is labels
+ neg_inds = cls_reg_targets[
+ 0] == self.student.roi_head.bbox_head.num_classes
+ # cls_reg_targets[1] is label_weights
+ cls_reg_targets[1][neg_inds] = bg_score[neg_inds].detach()
+
+ losses = self.student.roi_head.bbox_head.loss(
+ bbox_results['cls_score'], bbox_results['bbox_pred'], rois,
+ *cls_reg_targets)
+ # cls_reg_targets[1] is label_weights
+ losses['loss_cls'] = losses['loss_cls'] * len(
+ cls_reg_targets[1]) / max(sum(cls_reg_targets[1]), 1.0)
+ return losses
+
+ def rcnn_reg_loss_by_pseudo_instances(
+ self, x: Tuple[Tensor], unsup_rpn_results_list: InstanceList,
+ batch_data_samples: SampleList) -> dict:
+ """Calculate rcnn regression loss from a batch of inputs and pseudo
+ data samples.
+
+ Args:
+ x (tuple[Tensor]): List of multi-level img features.
+ unsup_rpn_results_list (list[:obj:`InstanceData`]):
+ List of region proposals.
+ batch_data_samples (List[:obj:`DetDataSample`]): The batch
+ data samples. It usually includes information such
+ as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`,
+ which are `pseudo_instance` or `pseudo_panoptic_seg`
+ or `pseudo_sem_seg` in fact.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of rcnn
+ regression loss components
+ """
+ rpn_results_list = copy.deepcopy(unsup_rpn_results_list)
+ reg_data_samples = copy.deepcopy(batch_data_samples)
+ for data_samples in reg_data_samples:
+ if data_samples.gt_instances.bboxes.shape[0] > 0:
+ data_samples.gt_instances = data_samples.gt_instances[
+ data_samples.gt_instances.reg_uncs <
+ self.semi_train_cfg.reg_pseudo_thr]
+ roi_losses = self.student.roi_head.loss(x, rpn_results_list,
+ reg_data_samples)
+ return {'loss_bbox': roi_losses['loss_bbox']}
+
+ def compute_uncertainty_with_aug(
+ self, x: Tuple[Tensor],
+ batch_data_samples: SampleList) -> List[Tensor]:
+ """Compute uncertainty with augmented bboxes.
+
+ Args:
+ x (tuple[Tensor]): List of multi-level img features.
+ batch_data_samples (List[:obj:`DetDataSample`]): The batch
+ data samples. It usually includes information such
+ as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`,
+ which are `pseudo_instance` or `pseudo_panoptic_seg`
+ or `pseudo_sem_seg` in fact.
+
+ Returns:
+ list[Tensor]: A list of uncertainty for pseudo bboxes.
+ """
+ auged_results_list = self.aug_box(batch_data_samples,
+ self.semi_train_cfg.jitter_times,
+ self.semi_train_cfg.jitter_scale)
+ # flatten
+ auged_results_list = [
+ InstanceData(bboxes=auged.reshape(-1, auged.shape[-1]))
+ for auged in auged_results_list
+ ]
+
+ self.teacher.roi_head.test_cfg = None
+ results_list = self.teacher.roi_head.predict(
+ x, auged_results_list, batch_data_samples, rescale=False)
+ self.teacher.roi_head.test_cfg = self.teacher.test_cfg.rcnn
+
+ reg_channel = max(
+ [results.bboxes.shape[-1] for results in results_list]) // 4
+ bboxes = [
+ results.bboxes.reshape(self.semi_train_cfg.jitter_times, -1,
+ results.bboxes.shape[-1])
+ if results.bboxes.numel() > 0 else results.bboxes.new_zeros(
+ self.semi_train_cfg.jitter_times, 0, 4 * reg_channel).float()
+ for results in results_list
+ ]
+
+ box_unc = [bbox.std(dim=0) for bbox in bboxes]
+ bboxes = [bbox.mean(dim=0) for bbox in bboxes]
+ labels = [
+ data_samples.gt_instances.labels
+ for data_samples in batch_data_samples
+ ]
+ if reg_channel != 1:
+ bboxes = [
+ bbox.reshape(bbox.shape[0], reg_channel,
+ 4)[torch.arange(bbox.shape[0]), label]
+ for bbox, label in zip(bboxes, labels)
+ ]
+ box_unc = [
+ unc.reshape(unc.shape[0], reg_channel,
+ 4)[torch.arange(unc.shape[0]), label]
+ for unc, label in zip(box_unc, labels)
+ ]
+
+ box_shape = [(bbox[:, 2:4] - bbox[:, :2]).clamp(min=1.0)
+ for bbox in bboxes]
+ box_unc = [
+ torch.mean(
+ unc / wh[:, None, :].expand(-1, 2, 2).reshape(-1, 4), dim=-1)
+ if wh.numel() > 0 else unc for unc, wh in zip(box_unc, box_shape)
+ ]
+ return box_unc
+
+ @staticmethod
+ def aug_box(batch_data_samples, times, frac):
+ """Augment bboxes with jitter."""
+
+ def _aug_single(box):
+ box_scale = box[:, 2:4] - box[:, :2]
+ box_scale = (
+ box_scale.clamp(min=1)[:, None, :].expand(-1, 2,
+ 2).reshape(-1, 4))
+ aug_scale = box_scale * frac # [n,4]
+
+ offset = (
+ torch.randn(times, box.shape[0], 4, device=box.device) *
+ aug_scale[None, ...])
+ new_box = box.clone()[None, ...].expand(times, box.shape[0],
+ -1) + offset
+ return new_box
+
+ return [
+ _aug_single(data_samples.gt_instances.bboxes)
+ for data_samples in batch_data_samples
+ ]
diff --git a/mmdet/models/detectors/solo.py b/mmdet/models/detectors/solo.py
new file mode 100644
index 0000000000000000000000000000000000000000..6bf47ba24941e09fd795b241a3f6aa0b67ae3380
--- /dev/null
+++ b/mmdet/models/detectors/solo.py
@@ -0,0 +1,31 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmdet.registry import MODELS
+from mmdet.utils import ConfigType, OptConfigType, OptMultiConfig
+from .single_stage_instance_seg import SingleStageInstanceSegmentor
+
+
+@MODELS.register_module()
+class SOLO(SingleStageInstanceSegmentor):
+ """`SOLO: Segmenting Objects by Locations
+ `_
+
+ """
+
+ def __init__(self,
+ backbone: ConfigType,
+ neck: OptConfigType = None,
+ bbox_head: OptConfigType = None,
+ mask_head: OptConfigType = None,
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ data_preprocessor: OptConfigType = None,
+ init_cfg: OptMultiConfig = None):
+ super().__init__(
+ backbone=backbone,
+ neck=neck,
+ bbox_head=bbox_head,
+ mask_head=mask_head,
+ train_cfg=train_cfg,
+ test_cfg=test_cfg,
+ data_preprocessor=data_preprocessor,
+ init_cfg=init_cfg)
diff --git a/mmdet/models/detectors/solov2.py b/mmdet/models/detectors/solov2.py
new file mode 100644
index 0000000000000000000000000000000000000000..1eefe4c532267be1480d13b8d73fc54bf694e81c
--- /dev/null
+++ b/mmdet/models/detectors/solov2.py
@@ -0,0 +1,31 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmdet.registry import MODELS
+from mmdet.utils import ConfigType, OptConfigType, OptMultiConfig
+from .single_stage_instance_seg import SingleStageInstanceSegmentor
+
+
+@MODELS.register_module()
+class SOLOv2(SingleStageInstanceSegmentor):
+ """`SOLOv2: Dynamic and Fast Instance Segmentation
+ `_
+
+ """
+
+ def __init__(self,
+ backbone: ConfigType,
+ neck: OptConfigType = None,
+ bbox_head: OptConfigType = None,
+ mask_head: OptConfigType = None,
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ data_preprocessor: OptConfigType = None,
+ init_cfg: OptMultiConfig = None):
+ super().__init__(
+ backbone=backbone,
+ neck=neck,
+ bbox_head=bbox_head,
+ mask_head=mask_head,
+ train_cfg=train_cfg,
+ test_cfg=test_cfg,
+ data_preprocessor=data_preprocessor,
+ init_cfg=init_cfg)
diff --git a/mmdet/models/detectors/sparse_rcnn.py b/mmdet/models/detectors/sparse_rcnn.py
new file mode 100644
index 0000000000000000000000000000000000000000..75442a69e472953854ded9fc8c30ac4ab30535d3
--- /dev/null
+++ b/mmdet/models/detectors/sparse_rcnn.py
@@ -0,0 +1,31 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmdet.registry import MODELS
+from mmdet.utils import ConfigType, OptConfigType, OptMultiConfig
+from .two_stage import TwoStageDetector
+
+
+@MODELS.register_module()
+class SparseRCNN(TwoStageDetector):
+ r"""Implementation of `Sparse R-CNN: End-to-End Object Detection with
+ Learnable Proposals `_"""
+
+ def __init__(self,
+ backbone: ConfigType,
+ neck: OptConfigType = None,
+ rpn_head: OptConfigType = None,
+ roi_head: OptConfigType = None,
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ data_preprocessor: OptConfigType = None,
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(
+ backbone=backbone,
+ neck=neck,
+ rpn_head=rpn_head,
+ roi_head=roi_head,
+ train_cfg=train_cfg,
+ test_cfg=test_cfg,
+ data_preprocessor=data_preprocessor,
+ init_cfg=init_cfg)
+ assert self.with_rpn, 'Sparse R-CNN and QueryInst ' \
+ 'do not support external proposals'
diff --git a/mmdet/models/detectors/specdetr.py b/mmdet/models/detectors/specdetr.py
new file mode 100644
index 0000000000000000000000000000000000000000..96c40ecab0c3f7064a7d6689996d9c62695557a0
--- /dev/null
+++ b/mmdet/models/detectors/specdetr.py
@@ -0,0 +1,719 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, Optional, Tuple,List, Union
+
+import torch
+from torch import Tensor, nn
+import torch.nn.functional as F
+from torch.nn.init import normal_
+from mmdet.registry import MODELS
+from mmdet.structures import OptSampleList, SampleList
+from mmdet.utils import OptConfigType
+# from ..layers import (CdnQueryGenerator, DeformableDetrTransformerEncoder,
+# DinoTransformerDecoder, SinePositionalEncoding)
+from ..layers import SinePositionalEncoding
+from ..layers.transformer.specdetr_layers import (CdnQueryGenerator, SpecDetrTransformerEncoder,
+ SpecDetrTransformerDecoder, )
+from .deformable_detr import DeformableDETR
+
+from ..layers.transformer.specdetr_atten import MultiScaleDeformableAttention_1 as MultiScaleDeformableAttention
+
+import itertools
+import numpy as np
+
+@MODELS.register_module()
+class SpecDetr(DeformableDETR):
+ r"""Implementation of `DINO: DETR with Improved DeNoising Anchor Boxes
+ for End-to-End Object Detection `_
+
+ Code is modified from the `official github repo
+ `_.
+
+ Args:
+ dn_cfg (:obj:`ConfigDict` or dict, optional): Config of denoising
+ query generator. Defaults to `None`.
+ """
+
+ def __init__(self, *args,
+ candidate_bboxes_size: float = 0.01,
+ scale_gt_bboxes_size: float = 0,
+ training_dn: bool = True,
+ dn_only_pos: bool = False,
+ remove_last_candidate: bool = False,
+ num_query_per_cat:int = 0,
+ num_fix_query :int= 0,
+ anchor_iou_th: float = 0.5,
+ query_interval: int =1,
+ dn_type: str = 'CDN',
+ query_initial: str = 'one',
+ dn_cfg: OptConfigType = None, **kwargs) -> None:
+ self.query_initial = query_initial
+ super().__init__(*args, **kwargs)
+ assert self.as_two_stage, 'as_two_stage must be True for DINO'
+ assert self.with_box_refine, 'with_box_refine must be True for DINO'
+
+ if dn_cfg is not None:
+ assert 'num_classes' not in dn_cfg and \
+ 'num_queries' not in dn_cfg and \
+ 'hidden_dim' not in dn_cfg, \
+ 'The three keyword args `num_classes`, `embed_dims`, and ' \
+ '`num_matching_queries` are set in `detector.__init__()`, ' \
+ 'users should not set them in `dn_cfg` config.'
+ dn_cfg['num_classes'] = self.bbox_head.num_classes
+ dn_cfg['embed_dims'] = self.embed_dims
+ dn_cfg['num_matching_queries'] = self.num_queries
+
+ self.candidate_bboxes_size =candidate_bboxes_size
+ # self.scale_gt_bboxes_size = scale_gt_bboxes_size
+ self.remove_last_candidate = remove_last_candidate
+ self.dn_query_generator = CdnQueryGenerator(**dn_cfg)
+
+ self.pos_bbox_offsets = []
+ self.training_dn =training_dn
+ self.dn_only_pos = dn_only_pos
+ self.num_query_per_cat = num_query_per_cat
+ self.num_fix_query = num_fix_query
+ # self.anchor_iou_th = anchor_iou_th
+ self.save_id = 0
+ self.query_interval = query_interval
+
+ def _init_layers(self) -> None:
+ """Initialize layers except for backbone, neck and bbox_head."""
+ self.positional_encoding = SinePositionalEncoding(
+ **self.positional_encoding)
+ if self.encoder_layers_num > 0:
+ self.encoder = SpecDetrTransformerEncoder(**self.encoder)
+ self.decoder = SpecDetrTransformerDecoder(**self.decoder)
+ self.embed_dims = self.decoder.embed_dims
+ if self.query_initial == 'embed':
+ self.query_embedding = nn.Embedding(self.num_queries, self.embed_dims)
+ # NOTE In DINO, the query_embedding only contains content
+ # queries, while in Deformable DETR, the query_embedding
+ # contains both content and spatial queries, and in DETR,
+ # it only contains spatial queries.
+
+ num_feats = self.positional_encoding.num_feats
+ assert num_feats * 2 == self.embed_dims, \
+ f'embed_dims should be exactly 2 times of num_feats. ' \
+ f'Found {self.embed_dims} and {num_feats}.'
+
+ self.level_embed = nn.Parameter(
+ torch.Tensor(self.num_feature_levels, self.embed_dims))
+ self.memory_trans_fc = nn.Linear(self.embed_dims, self.embed_dims)
+ self.memory_trans_norm = nn.LayerNorm(self.embed_dims)
+
+ def init_weights(self) -> None:
+ """Initialize weights for Transformer and other components."""
+ super(DeformableDETR, self).init_weights()
+ if self.encoder_layers_num>0:
+ for coder in self.encoder, self.decoder:
+ for p in coder.parameters():
+ if p.dim() > 1:
+ nn.init.xavier_uniform_(p)
+ else:
+ for p in self.decoder.parameters():
+ if p.dim() > 1:
+ nn.init.xavier_uniform_(p)
+ for m in self.modules():
+ if isinstance(m, MultiScaleDeformableAttention):
+ m.init_weights()
+ nn.init.xavier_uniform_(self.memory_trans_fc.weight)
+ # nn.init.xavier_uniform_(self.query_embedding.weight)
+ normal_(self.level_embed)
+
+
+ def extract_feat(self, batch_inputs: Tensor) -> Tuple[Tensor]:
+ """Extract features.
+
+ Args:
+ batch_inputs (Tensor): Image tensor, has shape (bs, dim, H, W).
+
+ Returns:
+ tuple[Tensor]: Tuple of feature maps from neck. Each feature map
+ has shape (bs, dim, H, W).
+ """
+ x = self.backbone(batch_inputs)
+ if self.with_neck:
+ x = self.neck(x)
+ self.save_id += 1
+
+ return x
+
+ def loss(self, batch_inputs: Tensor,
+ batch_data_samples: SampleList) -> Union[dict, list]:
+ """Calculate losses from a batch of inputs and data samples.
+
+ Args:
+ batch_inputs (Tensor): Input images of shape (bs, dim, H, W).
+ These should usually be mean centered and std scaled.
+ batch_data_samples (List[:obj:`DetDataSample`]): The batch
+ data samples. It usually includes information such
+ as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
+
+ Returns:
+ dict: A dictionary of loss components
+ """
+
+ img_feats = self.extract_feat(batch_inputs)
+ head_inputs_dict = self.forward_transformer(img_feats,
+ batch_data_samples)
+ losses = self.bbox_head.loss(
+ **head_inputs_dict, batch_data_samples=batch_data_samples)
+
+
+ return losses
+
+
+ def predict(self,
+ batch_inputs: Tensor,
+ batch_data_samples: SampleList,
+ rescale: bool = True) -> SampleList:
+ """Predict results from a batch of inputs and data samples with post-
+ processing.
+
+ Args:
+ batch_inputs (Tensor): Inputs, has shape (bs, dim, H, W).
+ batch_data_samples (List[:obj:`DetDataSample`]): The batch
+ data samples. It usually includes information such
+ as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
+ rescale (bool): Whether to rescale the results.
+ Defaults to True.
+
+ Returns:
+ list[:obj:`DetDataSample`]: Detection results of the input images.
+ Each DetDataSample usually contain 'pred_instances'. And the
+ `pred_instances` usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ """
+ img_feats = self.extract_feat(batch_inputs)
+ head_inputs_dict = self.forward_transformer(img_feats,
+ batch_data_samples)
+ results_list = self.bbox_head.predict(
+ **head_inputs_dict,
+ rescale=rescale,
+ batch_data_samples=batch_data_samples)
+ batch_data_samples = self.add_pred_to_datasample(
+ batch_data_samples, results_list)
+ return batch_data_samples
+
+ def _forward(self,
+ batch_inputs: Tensor,
+ batch_data_samples: OptSampleList = None) -> Tuple[List[Tensor]]:
+ """Network forward process. Usually includes backbone, neck and head
+ forward without any post-processing.
+
+ Args:
+ batch_inputs (Tensor): Inputs, has shape (bs, dim, H, W).
+ batch_data_samples (List[:obj:`DetDataSample`], optional): The
+ batch data samples. It usually includes information such
+ as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
+ Defaults to None.
+
+ Returns:
+ tuple[Tensor]: A tuple of features from ``bbox_head`` forward.
+ """
+ img_feats = self.extract_feat(batch_inputs)
+ head_inputs_dict = self.forward_transformer(img_feats,
+ batch_data_samples)
+ results = self.bbox_head.forward(**head_inputs_dict)
+ return results
+
+ def forward_transformer(
+ self,
+ img_feats: Tuple[Tensor],
+ batch_data_samples: OptSampleList = None,
+ ) -> Dict:
+ """Forward process of Transformer.
+
+ The forward procedure of the transformer is defined as:
+ 'pre_transformer' -> 'encoder' -> 'pre_decoder' -> 'decoder'
+ More details can be found at `TransformerDetector.forward_transformer`
+ in `mmdet/detector/base_detr.py`.
+ The difference is that the ground truth in `batch_data_samples` is
+ required for the `pre_decoder` to prepare the query of DINO.
+ Additionally, DINO inherits the `pre_transformer` method and the
+ `forward_encoder` method of DeformableDETR. More details about the
+ two methods can be found in `mmdet/detector/deformable_detr.py`.
+
+ Args:
+ img_feats (tuple[Tensor]): Tuple of feature maps from neck. Each
+ feature map has shape (bs, dim, H, W).
+ batch_data_samples (list[:obj:`DetDataSample`]): The batch
+ data samples. It usually includes information such
+ as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
+ Defaults to None.
+
+ Returns:
+ dict: The dictionary of bbox_head function inputs, which always
+ includes the `hidden_states` of the decoder output and may contain
+ `references` including the initial and intermediate references.
+ """
+ encoder_inputs_dict, decoder_inputs_dict = self.pre_transformer(
+ img_feats, batch_data_samples)
+
+ encoder_outputs_dict = self.forward_encoder(**encoder_inputs_dict)
+
+ tmp_dec_in, head_inputs_dict = self.pre_decoder(
+ **encoder_outputs_dict, batch_data_samples=batch_data_samples)
+ decoder_inputs_dict.update(tmp_dec_in)
+
+ decoder_outputs_dict = self.forward_decoder(**decoder_inputs_dict)
+ head_inputs_dict.update(decoder_outputs_dict)
+ return head_inputs_dict
+
+ def pre_transformer(
+ self,
+ mlvl_feats: Tuple[Tensor],
+ batch_data_samples: OptSampleList = None) -> Tuple[Dict]:
+ """Process image features before feeding them to the transformer.
+
+ The forward procedure of the transformer is defined as:
+ 'pre_transformer' -> 'encoder' -> 'pre_decoder' -> 'decoder'
+ More details can be found at `TransformerDetector.forward_transformer`
+ in `mmdet/detector/base_detr.py`.
+
+ Args:
+ mlvl_feats (tuple[Tensor]): Multi-level features that may have
+ different resolutions, output from neck. Each feature has
+ shape (bs, dim, h_lvl, w_lvl), where 'lvl' means 'layer'.
+ batch_data_samples (list[:obj:`DetDataSample`], optional): The
+ batch data samples. It usually includes information such
+ as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
+ Defaults to None.
+
+ Returns:
+ tuple[dict]: The first dict contains the inputs of encoder and the
+ second dict contains the inputs of decoder.
+
+ - encoder_inputs_dict (dict): The keyword args dictionary of
+ `self.forward_encoder()`, which includes 'feat', 'feat_mask',
+ and 'feat_pos'.
+ - decoder_inputs_dict (dict): The keyword args dictionary of
+ `self.forward_decoder()`, which includes 'memory_mask'.
+ """
+ batch_size = mlvl_feats[0].size(0)
+
+ # construct binary masks for the transformer.
+ assert batch_data_samples is not None
+ batch_input_shape = batch_data_samples[0].batch_input_shape
+ img_shape_list = [sample.img_shape for sample in batch_data_samples]
+ input_img_h, input_img_w = batch_input_shape
+ masks = mlvl_feats[0].new_ones((batch_size, input_img_h, input_img_w))
+ for img_id in range(batch_size):
+ img_h, img_w = img_shape_list[img_id]
+ masks[img_id, :img_h, :img_w] = 0
+ # NOTE following the official DETR repo, non-zero values representing
+ # ignored positions, while zero values means valid positions.
+
+ mlvl_masks = []
+ mlvl_pos_embeds = []
+ for feat in mlvl_feats:
+ mlvl_masks.append(
+ F.interpolate(masks[None],
+ size=feat.shape[-2:]).to(torch.bool).squeeze(0))
+ mlvl_pos_embeds.append(self.positional_encoding(mlvl_masks[-1]))
+
+ feat_flatten = []
+ lvl_pos_embed_flatten = []
+ mask_flatten = []
+ spatial_shapes = []
+ for lvl, (feat, mask, pos_embed) in enumerate(
+ zip(mlvl_feats, mlvl_masks, mlvl_pos_embeds)):
+ batch_size, c, h, w = feat.shape
+ # [bs, c, h_lvl, w_lvl] -> [bs, h_lvl*w_lvl, c]
+ feat = feat.view(batch_size, c, -1).permute(0, 2, 1)
+ pos_embed = pos_embed.view(batch_size, c, -1).permute(0, 2, 1)
+ lvl_pos_embed = pos_embed + self.level_embed[lvl].view(1, 1, -1)
+ # [bs, h_lvl, w_lvl] -> [bs, h_lvl*w_lvl]
+ mask = mask.flatten(1)
+ spatial_shape = (h, w)
+
+ feat_flatten.append(feat)
+ lvl_pos_embed_flatten.append(lvl_pos_embed)
+ mask_flatten.append(mask)
+ spatial_shapes.append(spatial_shape)
+
+ # (bs, num_feat_points, dim)
+ feat_flatten = torch.cat(feat_flatten, 1)
+ lvl_pos_embed_flatten = torch.cat(lvl_pos_embed_flatten, 1)
+ # (bs, num_feat_points), where num_feat_points = sum_lvl(h_lvl*w_lvl)
+ mask_flatten = torch.cat(mask_flatten, 1)
+
+ spatial_shapes = torch.as_tensor( # (num_level, 2)
+ spatial_shapes,
+ dtype=torch.long,
+ device=feat_flatten.device)
+ level_start_index = torch.cat((
+ spatial_shapes.new_zeros((1, )), # (num_level)
+ spatial_shapes.prod(1).cumsum(0)[:-1]))
+ valid_ratios = torch.stack( # (bs, num_level, 2)
+ [self.get_valid_ratio(m) for m in mlvl_masks], 1)
+
+ encoder_inputs_dict = dict(
+ feat=feat_flatten,
+ feat_mask=mask_flatten,
+ feat_pos=lvl_pos_embed_flatten,
+ spatial_shapes=spatial_shapes,
+ level_start_index=level_start_index,
+ valid_ratios=valid_ratios)
+ decoder_inputs_dict = dict(
+ memory_mask=mask_flatten,
+ spatial_shapes=spatial_shapes,
+ level_start_index=level_start_index,
+ valid_ratios=valid_ratios)
+ return encoder_inputs_dict, decoder_inputs_dict
+
+ def forward_encoder(self, feat: Tensor, feat_mask: Tensor,
+ feat_pos: Tensor, spatial_shapes: Tensor,
+ level_start_index: Tensor,
+ valid_ratios: Tensor) -> Dict:
+ """Forward with Transformer encoder.
+
+ The forward procedure of the transformer is defined as:
+ 'pre_transformer' -> 'encoder' -> 'pre_decoder' -> 'decoder'
+ More details can be found at `TransformerDetector.forward_transformer`
+ in `mmdet/detector/base_detr.py`.
+
+ Args:
+ feat (Tensor): Sequential features, has shape (bs, num_feat_points,
+ dim).
+ feat_mask (Tensor): ByteTensor, the padding mask of the features,
+ has shape (bs, num_feat_points).
+ feat_pos (Tensor): The positional embeddings of the features, has
+ shape (bs, num_feat_points, dim).
+ spatial_shapes (Tensor): Spatial shapes of features in all levels,
+ has shape (num_levels, 2), last dimension represents (h, w).
+ level_start_index (Tensor): The start index of each level.
+ A tensor has shape (num_levels, ) and can be represented
+ as [0, h_0*w_0, h_0*w_0+h_1*w_1, ...].
+ valid_ratios (Tensor): The ratios of the valid width and the valid
+ height relative to the width and the height of features in all
+ levels, has shape (bs, num_levels, 2).
+
+ Returns:
+ dict: The dictionary of encoder outputs, which includes the
+ `memory` of the encoder output.
+ """
+ if self.encoder_layers_num > 0:
+ memory = self.encoder(
+ query=feat,
+ query_pos=feat_pos,
+ key_padding_mask=feat_mask, # for self_attn
+ spatial_shapes=spatial_shapes,
+ level_start_index=level_start_index,
+ valid_ratios=valid_ratios)
+ encoder_outputs_dict = dict(
+ memory=memory,
+ memory_mask=feat_mask,
+ spatial_shapes=spatial_shapes)
+ else:
+ encoder_outputs_dict = dict(
+ memory=feat,
+ memory_mask=feat_mask,
+ spatial_shapes=spatial_shapes)
+ return encoder_outputs_dict
+
+
+
+ def pre_decoder(
+ self,
+ memory: Tensor,
+ memory_mask: Tensor,
+ spatial_shapes: Tensor,
+ batch_data_samples: OptSampleList = None,
+
+ ) -> Tuple[Dict]:
+ """Prepare intermediate variables before entering Transformer decoder,
+ such as `query`, `query_pos`, and `reference_points`.
+
+ Args:
+ memory (Tensor): The output embeddings of the Transformer encoder,
+ has shape (bs, num_feat_points, dim).
+ memory_mask (Tensor): ByteTensor, the padding mask of the memory,
+ has shape (bs, num_feat_points). Will only be used when
+ `as_two_stage` is `True`.
+ spatial_shapes (Tensor): Spatial shapes of features in all levels.
+ With shape (num_levels, 2), last dimension represents (h, w).
+ Will only be used when `as_two_stage` is `True`.
+ batch_data_samples (list[:obj:`DetDataSample`]): The batch
+ data samples. It usually includes information such
+ as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
+ Defaults to None.
+
+ Returns:
+ tuple[dict]: The decoder_inputs_dict and head_inputs_dict.
+
+ - decoder_inputs_dict (dict): The keyword dictionary args of
+ `self.forward_decoder()`, which includes 'query', 'memory',
+ `reference_points`, and `dn_mask`. The reference points of
+ decoder input here are 4D boxes, although it has `points`
+ in its name.
+ - head_inputs_dict (dict): The keyword dictionary args of the
+ bbox_head functions, which includes `topk_score`, `topk_coords`,
+ and `dn_meta` when `self.training` is `True`, else is empty.
+ """
+ bs, num_fea, c = memory.shape
+ cls_out_features = self.bbox_head.cls_branches[
+ self.decoder.num_layers].out_features
+
+ output_memory, output_proposals = self.gen_encoder_output_proposals(
+ memory, memory_mask, spatial_shapes)
+
+ if self.remove_last_candidate:
+ output_memory = output_memory[:,:-1,:]
+ output_proposals = output_proposals[:,:-1,:]
+
+ enc_outputs_class = self.bbox_head.cls_branches[
+ self.decoder.num_layers](
+ output_memory)
+ enc_outputs_coord_unact = self.bbox_head.reg_branches[
+ self.decoder.num_layers](output_memory) + output_proposals
+
+ # NOTE The DINO selects top-k proposals according to scores of
+ # multi-class classification, while DeformDETR, where the input
+ # is `enc_outputs_class[..., 0]` selects according to scores of
+ # binary classification.
+ assert self.num_query_per_cat*cls_out_features<=self.num_queries
+
+ topk_indices = torch.topk(
+ enc_outputs_class.max(-1)[0], k=self.num_queries, dim=1)[1]
+
+ topk_score = torch.gather(
+ enc_outputs_class, 1,
+ topk_indices.unsqueeze(-1).repeat(1, 1, cls_out_features))
+ topk_coords_unact = torch.gather(
+ enc_outputs_coord_unact, 1,
+ topk_indices.unsqueeze(-1).repeat(1, 1, 4))
+ topk_coords = topk_coords_unact.sigmoid()
+ topk_coords_unact = topk_coords_unact.detach()
+
+
+ if self.query_initial == 'one':
+ query = torch.ones((self.num_queries, 1, self.embed_dims), device=memory.device)
+ elif self.query_initial == 'random':
+ query = torch.rand((self.num_queries, 1, self.embed_dims), device=memory.device)
+ elif self.query_initial == 'embed':
+ query = self.query_embedding.weight[:, None, :]
+ query = query.repeat(1, bs, 1).transpose(0, 1)
+
+ if self.training:
+ if self.training_dn:
+ dn_label_query, dn_bbox_query, dn_mask, dn_meta = \
+ self.dn_query_generator(batch_data_samples)
+
+ query = torch.cat([dn_label_query, query], dim=1)
+ reference_points = torch.cat([dn_bbox_query, topk_coords_unact],
+ dim=1)
+ else:
+ dn_mask, dn_meta = None, None
+ reference_points = topk_coords_unact
+ else:
+ reference_points = topk_coords_unact
+ dn_mask, dn_meta = None, None
+
+ reference_points = reference_points.sigmoid()
+
+ decoder_inputs_dict = dict(
+ query=query,
+ memory=memory,
+ reference_points=reference_points,
+ dn_mask=dn_mask)
+ # NOTE DINO calculates encoder losses on scores and coordinates
+ # of selected top-k encoder queries, while DeformDETR is of all
+ # encoder queries.
+ head_inputs_dict = dict(
+ enc_outputs_class=topk_score,
+ enc_outputs_coord=topk_coords,
+ dn_meta=dn_meta) if self.training else dict()
+ return decoder_inputs_dict, head_inputs_dict
+
+ def forward_decoder(self,
+ query: Tensor,
+ memory: Tensor,
+ memory_mask: Tensor,
+ reference_points: Tensor,
+ spatial_shapes: Tensor,
+ level_start_index: Tensor,
+ valid_ratios: Tensor,
+ dn_mask: Optional[Tensor] = None) -> Dict:
+ """Forward with Transformer decoder.
+
+ The forward procedure of the transformer is defined as:
+ 'pre_transformer' -> 'encoder' -> 'pre_decoder' -> 'decoder'
+ More details can be found at `TransformerDetector.forward_transformer`
+ in `mmdet/detector/base_detr.py`.
+
+ Args:
+ query (Tensor): The queries of decoder inputs, has shape
+ (bs, num_queries_total, dim), where `num_queries_total` is the
+ sum of `num_denoising_queries` and `num_matching_queries` when
+ `self.training` is `True`, else `num_matching_queries`.
+ memory (Tensor): The output embeddings of the Transformer encoder,
+ has shape (bs, num_feat_points, dim).
+ memory_mask (Tensor): ByteTensor, the padding mask of the memory,
+ has shape (bs, num_feat_points).
+ reference_points (Tensor): The initial reference, has shape
+ (bs, num_queries_total, 4) with the last dimension arranged as
+ (cx, cy, w, h).
+ spatial_shapes (Tensor): Spatial shapes of features in all levels,
+ has shape (num_levels, 2), last dimension represents (h, w).
+ level_start_index (Tensor): The start index of each level.
+ A tensor has shape (num_levels, ) and can be represented
+ as [0, h_0*w_0, h_0*w_0+h_1*w_1, ...].
+ valid_ratios (Tensor): The ratios of the valid width and the valid
+ height relative to the width and the height of features in all
+ levels, has shape (bs, num_levels, 2).
+ dn_mask (Tensor, optional): The attention mask to prevent
+ information leakage from different denoising groups and
+ matching parts, will be used as `self_attn_mask` of the
+ `self.decoder`, has shape (num_queries_total,
+ num_queries_total).
+ It is `None` when `self.training` is `False`.
+
+ Returns:
+ dict: The dictionary of decoder outputs, which includes the
+ `hidden_states` of the decoder output and `references` including
+ the initial and intermediate reference_points.
+ """
+ inter_states, references = self.decoder(
+ query=query,
+ value=memory,
+ key_padding_mask=memory_mask,
+ self_attn_mask=dn_mask,
+ reference_points=reference_points,
+ spatial_shapes=spatial_shapes,
+ level_start_index=level_start_index,
+ valid_ratios=valid_ratios,
+ reg_branches=self.bbox_head.reg_branches)
+
+
+
+ if len(query) == self.num_queries:
+ # NOTE: This is to make sure label_embeding can be involved to
+ # produce loss even if there is no denoising query (no ground truth
+ # target in this GPU), otherwise, this will raise runtime error in
+ # distributed training.
+ inter_states[0] += \
+ self.dn_query_generator.label_embedding.weight[0, 0] * 0.0
+
+ decoder_outputs_dict = dict(
+ hidden_states=inter_states, references=list(references))
+ return decoder_outputs_dict
+
+
+ @staticmethod
+ def get_valid_ratio(mask: Tensor) -> Tensor:
+ """Get the valid radios of feature map in a level.
+
+ .. code:: text
+
+ |---> valid_W <---|
+ ---+-----------------+-----+---
+ A | | | A
+ | | | | |
+ | | | | |
+ valid_H | | | |
+ | | | | H
+ | | | | |
+ V | | | |
+ ---+-----------------+ | |
+ | | V
+ +-----------------------+---
+ |---------> W <---------|
+
+ The valid_ratios are defined as:
+ r_h = valid_H / H, r_w = valid_W / W
+ They are the factors to re-normalize the relative coordinates of the
+ image to the relative coordinates of the current level feature map.
+
+ Args:
+ mask (Tensor): Binary mask of a feature map, has shape (bs, H, W).
+
+ Returns:
+ Tensor: valid ratios [r_w, r_h] of a feature map, has shape (1, 2).
+ """
+ _, H, W = mask.shape
+ valid_H = torch.sum(~mask[:, :, 0], 1)
+ valid_W = torch.sum(~mask[:, 0, :], 1)
+ valid_ratio_h = valid_H.float() / H
+ valid_ratio_w = valid_W.float() / W
+ valid_ratio = torch.stack([valid_ratio_w, valid_ratio_h], -1)
+ return valid_ratio
+
+ def gen_encoder_output_proposals(
+ self, memory: Tensor, memory_mask: Tensor,
+ spatial_shapes: Tensor) -> Tuple[Tensor, Tensor]:
+ """Generate proposals from encoded memory. The function will only be
+ used when `as_two_stage` is `True`.
+
+ Args:
+ memory (Tensor): The output embeddings of the Transformer encoder,
+ has shape (bs, num_feat_points, dim).
+ memory_mask (Tensor): ByteTensor, the padding mask of the memory,
+ has shape (bs, num_feat_points).
+ spatial_shapes (Tensor): Spatial shapes of features in all levels,
+ has shape (num_levels, 2), last dimension represents (h, w).
+
+ Returns:
+ tuple: A tuple of transformed memory and proposals.
+
+ - output_memory (Tensor): The transformed memory for obtaining
+ top-k proposals, has shape (bs, num_feat_points, dim).
+ - output_proposals (Tensor): The inverse-normalized proposal, has
+ shape (batch_size, num_keys, 4) with the last dimension arranged
+ as (cx, cy, w, h).
+ """
+
+ bs = memory.size(0)
+ proposals = []
+ # memory_mask[:,-1] =True
+ _cur = 0 # start index in the sequence of the current level
+ for lvl, (H, W) in enumerate(spatial_shapes):
+ mask_flatten_ = memory_mask[:,
+ _cur:(_cur + H * W)].view(bs, H, W, 1)
+ valid_H = torch.sum(~mask_flatten_[:, :, 0, 0], 1).unsqueeze(-1)
+ valid_W = torch.sum(~mask_flatten_[:, 0, :, 0], 1).unsqueeze(-1)
+ grid_y, grid_x = torch.meshgrid(
+ torch.linspace(
+ 0, H - 1, H, dtype=torch.float32, device=memory.device),
+ torch.linspace(
+ 0, W - 1, W, dtype=torch.float32, device=memory.device))
+ grid = torch.cat([grid_x.unsqueeze(-1), grid_y.unsqueeze(-1)], -1)
+ scale = torch.cat([valid_W, valid_H], 1).view(bs, 1, 1, 2)
+ grid = (grid.unsqueeze(0).expand(bs, -1, -1, -1) + 0.5) / scale
+ # wh = torch.ones_like(grid) * 0.05 * (2.0**lvl)
+ # by lzx
+ wh = torch.ones_like(grid) * self.candidate_bboxes_size * (2.0 ** lvl) # ori
+ proposal = torch.cat((grid, wh), -1).view(bs, -1, 4)
+ proposals.append(proposal)
+ _cur += (H * W)
+ output_proposals = torch.cat(proposals, 1)
+ output_proposals_valid = ((output_proposals > 0.0001) &
+ (output_proposals < 0.9999)).all(
+ -1, keepdim=True)
+ # inverse_sigmoid
+ output_proposals = torch.log(output_proposals / (1 - output_proposals))
+ output_proposals = output_proposals.masked_fill(
+ memory_mask.unsqueeze(-1), float('inf'))
+ output_proposals = output_proposals.masked_fill(
+ ~output_proposals_valid, float('inf'))
+ output_memory = memory
+ output_memory = output_memory.masked_fill(
+ memory_mask.unsqueeze(-1), float(0))
+ output_memory = output_memory.masked_fill(~output_proposals_valid,
+ float(0))
+ output_memory = self.memory_trans_fc(output_memory)
+ output_memory = self.memory_trans_norm(output_memory)
+ # [bs, sum(hw), 2]
+ return output_memory, output_proposals
+
+
+
+
+
+
diff --git a/mmdet/models/detectors/tood.py b/mmdet/models/detectors/tood.py
new file mode 100644
index 0000000000000000000000000000000000000000..38720482c5451471f5a66a6cf689dbed6100c9fa
--- /dev/null
+++ b/mmdet/models/detectors/tood.py
@@ -0,0 +1,42 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmdet.registry import MODELS
+from mmdet.utils import ConfigType, OptConfigType, OptMultiConfig
+from .single_stage import SingleStageDetector
+
+
+@MODELS.register_module()
+class TOOD(SingleStageDetector):
+ r"""Implementation of `TOOD: Task-aligned One-stage Object Detection.
+ `_
+
+ Args:
+ backbone (:obj:`ConfigDict` or dict): The backbone module.
+ neck (:obj:`ConfigDict` or dict): The neck module.
+ bbox_head (:obj:`ConfigDict` or dict): The bbox head module.
+ train_cfg (:obj:`ConfigDict` or dict, optional): The training config
+ of TOOD. Defaults to None.
+ test_cfg (:obj:`ConfigDict` or dict, optional): The testing config
+ of TOOD. Defaults to None.
+ data_preprocessor (:obj:`ConfigDict` or dict, optional): Config of
+ :class:`DetDataPreprocessor` to process the input data.
+ Defaults to None.
+ init_cfg (:obj:`ConfigDict` or dict, optional): the config to control
+ the initialization. Defaults to None.
+ """
+
+ def __init__(self,
+ backbone: ConfigType,
+ neck: ConfigType,
+ bbox_head: ConfigType,
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ data_preprocessor: OptConfigType = None,
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(
+ backbone=backbone,
+ neck=neck,
+ bbox_head=bbox_head,
+ train_cfg=train_cfg,
+ test_cfg=test_cfg,
+ data_preprocessor=data_preprocessor,
+ init_cfg=init_cfg)
diff --git a/mmdet/models/detectors/trident_faster_rcnn.py b/mmdet/models/detectors/trident_faster_rcnn.py
new file mode 100644
index 0000000000000000000000000000000000000000..4244925beaebea820f836b41ab5463f5f499f4d0
--- /dev/null
+++ b/mmdet/models/detectors/trident_faster_rcnn.py
@@ -0,0 +1,81 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.structures import SampleList
+from mmdet.utils import ConfigType, OptConfigType, OptMultiConfig
+from .faster_rcnn import FasterRCNN
+
+
+@MODELS.register_module()
+class TridentFasterRCNN(FasterRCNN):
+ """Implementation of `TridentNet `_"""
+
+ def __init__(self,
+ backbone: ConfigType,
+ rpn_head: ConfigType,
+ roi_head: ConfigType,
+ train_cfg: ConfigType,
+ test_cfg: ConfigType,
+ neck: OptConfigType = None,
+ data_preprocessor: OptConfigType = None,
+ init_cfg: OptMultiConfig = None) -> None:
+
+ super().__init__(
+ backbone=backbone,
+ neck=neck,
+ rpn_head=rpn_head,
+ roi_head=roi_head,
+ train_cfg=train_cfg,
+ test_cfg=test_cfg,
+ data_preprocessor=data_preprocessor,
+ init_cfg=init_cfg)
+ assert self.backbone.num_branch == self.roi_head.num_branch
+ assert self.backbone.test_branch_idx == self.roi_head.test_branch_idx
+ self.num_branch = self.backbone.num_branch
+ self.test_branch_idx = self.backbone.test_branch_idx
+
+ def _forward(self, batch_inputs: Tensor,
+ batch_data_samples: SampleList) -> tuple:
+ """copy the ``batch_data_samples`` to fit multi-branch."""
+ num_branch = self.num_branch \
+ if self.training or self.test_branch_idx == -1 else 1
+ trident_data_samples = batch_data_samples * num_branch
+ return super()._forward(
+ batch_inputs=batch_inputs, batch_data_samples=trident_data_samples)
+
+ def loss(self, batch_inputs: Tensor,
+ batch_data_samples: SampleList) -> dict:
+ """copy the ``batch_data_samples`` to fit multi-branch."""
+ num_branch = self.num_branch \
+ if self.training or self.test_branch_idx == -1 else 1
+ trident_data_samples = batch_data_samples * num_branch
+ return super().loss(
+ batch_inputs=batch_inputs, batch_data_samples=trident_data_samples)
+
+ def predict(self,
+ batch_inputs: Tensor,
+ batch_data_samples: SampleList,
+ rescale: bool = True) -> SampleList:
+ """copy the ``batch_data_samples`` to fit multi-branch."""
+ num_branch = self.num_branch \
+ if self.training or self.test_branch_idx == -1 else 1
+ trident_data_samples = batch_data_samples * num_branch
+ return super().predict(
+ batch_inputs=batch_inputs,
+ batch_data_samples=trident_data_samples,
+ rescale=rescale)
+
+ # TODO need to refactor
+ def aug_test(self, imgs, img_metas, rescale=False):
+ """Test with augmentations.
+
+ If rescale is False, then returned bboxes and masks will fit the scale
+ of imgs[0].
+ """
+ x = self.extract_feats(imgs)
+ num_branch = (self.num_branch if self.test_branch_idx == -1 else 1)
+ trident_img_metas = [img_metas * num_branch for img_metas in img_metas]
+ proposal_list = self.rpn_head.aug_test_rpn(x, trident_img_metas)
+ return self.roi_head.aug_test(
+ x, proposal_list, img_metas, rescale=rescale)
diff --git a/mmdet/models/detectors/two_stage.py b/mmdet/models/detectors/two_stage.py
new file mode 100644
index 0000000000000000000000000000000000000000..4e83df9eb5ce837636e10c4592fe26a7edce1657
--- /dev/null
+++ b/mmdet/models/detectors/two_stage.py
@@ -0,0 +1,243 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+import warnings
+from typing import List, Tuple, Union
+
+import torch
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.structures import SampleList
+from mmdet.utils import ConfigType, OptConfigType, OptMultiConfig
+from .base import BaseDetector
+
+
+@MODELS.register_module()
+class TwoStageDetector(BaseDetector):
+ """Base class for two-stage detectors.
+
+ Two-stage detectors typically consisting of a region proposal network and a
+ task-specific regression head.
+ """
+
+ def __init__(self,
+ backbone: ConfigType,
+ neck: OptConfigType = None,
+ rpn_head: OptConfigType = None,
+ roi_head: OptConfigType = None,
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ data_preprocessor: OptConfigType = None,
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(
+ data_preprocessor=data_preprocessor, init_cfg=init_cfg)
+ self.backbone = MODELS.build(backbone)
+
+ if neck is not None:
+ self.neck = MODELS.build(neck)
+
+ if rpn_head is not None:
+ rpn_train_cfg = train_cfg.rpn if train_cfg is not None else None
+ rpn_head_ = rpn_head.copy()
+ rpn_head_.update(train_cfg=rpn_train_cfg, test_cfg=test_cfg.rpn)
+ rpn_head_num_classes = rpn_head_.get('num_classes', None)
+ if rpn_head_num_classes is None:
+ rpn_head_.update(num_classes=1)
+ else:
+ if rpn_head_num_classes != 1:
+ warnings.warn(
+ 'The `num_classes` should be 1 in RPN, but get '
+ f'{rpn_head_num_classes}, please set '
+ 'rpn_head.num_classes = 1 in your config file.')
+ rpn_head_.update(num_classes=1)
+ self.rpn_head = MODELS.build(rpn_head_)
+
+ if roi_head is not None:
+ # update train and test cfg here for now
+ # TODO: refactor assigner & sampler
+ rcnn_train_cfg = train_cfg.rcnn if train_cfg is not None else None
+ roi_head.update(train_cfg=rcnn_train_cfg)
+ roi_head.update(test_cfg=test_cfg.rcnn)
+ self.roi_head = MODELS.build(roi_head)
+
+ self.train_cfg = train_cfg
+ self.test_cfg = test_cfg
+
+ def _load_from_state_dict(self, state_dict: dict, prefix: str,
+ local_metadata: dict, strict: bool,
+ missing_keys: Union[List[str], str],
+ unexpected_keys: Union[List[str], str],
+ error_msgs: Union[List[str], str]) -> None:
+ """Exchange bbox_head key to rpn_head key when loading single-stage
+ weights into two-stage model."""
+ bbox_head_prefix = prefix + '.bbox_head' if prefix else 'bbox_head'
+ bbox_head_keys = [
+ k for k in state_dict.keys() if k.startswith(bbox_head_prefix)
+ ]
+ rpn_head_prefix = prefix + '.rpn_head' if prefix else 'rpn_head'
+ rpn_head_keys = [
+ k for k in state_dict.keys() if k.startswith(rpn_head_prefix)
+ ]
+ if len(bbox_head_keys) != 0 and len(rpn_head_keys) == 0:
+ for bbox_head_key in bbox_head_keys:
+ rpn_head_key = rpn_head_prefix + \
+ bbox_head_key[len(bbox_head_prefix):]
+ state_dict[rpn_head_key] = state_dict.pop(bbox_head_key)
+ super()._load_from_state_dict(state_dict, prefix, local_metadata,
+ strict, missing_keys, unexpected_keys,
+ error_msgs)
+
+ @property
+ def with_rpn(self) -> bool:
+ """bool: whether the detector has RPN"""
+ return hasattr(self, 'rpn_head') and self.rpn_head is not None
+
+ @property
+ def with_roi_head(self) -> bool:
+ """bool: whether the detector has a RoI head"""
+ return hasattr(self, 'roi_head') and self.roi_head is not None
+
+ def extract_feat(self, batch_inputs: Tensor) -> Tuple[Tensor]:
+ """Extract features.
+
+ Args:
+ batch_inputs (Tensor): Image tensor with shape (N, C, H ,W).
+
+ Returns:
+ tuple[Tensor]: Multi-level features that may have
+ different resolutions.
+ """
+ x = self.backbone(batch_inputs)
+ if self.with_neck:
+ x = self.neck(x)
+ return x
+
+ def _forward(self, batch_inputs: Tensor,
+ batch_data_samples: SampleList) -> tuple:
+ """Network forward process. Usually includes backbone, neck and head
+ forward without any post-processing.
+
+ Args:
+ batch_inputs (Tensor): Inputs with shape (N, C, H, W).
+ batch_data_samples (list[:obj:`DetDataSample`]): Each item contains
+ the meta information of each image and corresponding
+ annotations.
+
+ Returns:
+ tuple: A tuple of features from ``rpn_head`` and ``roi_head``
+ forward.
+ """
+ results = ()
+ x = self.extract_feat(batch_inputs)
+
+ if self.with_rpn:
+ rpn_results_list = self.rpn_head.predict(
+ x, batch_data_samples, rescale=False)
+ else:
+ assert batch_data_samples[0].get('proposals', None) is not None
+ rpn_results_list = [
+ data_sample.proposals for data_sample in batch_data_samples
+ ]
+ roi_outs = self.roi_head.forward(x, rpn_results_list,
+ batch_data_samples)
+ results = results + (roi_outs, )
+ return results
+
+ def loss(self, batch_inputs: Tensor,
+ batch_data_samples: SampleList) -> dict:
+ """Calculate losses from a batch of inputs and data samples.
+
+ Args:
+ batch_inputs (Tensor): Input images of shape (N, C, H, W).
+ These should usually be mean centered and std scaled.
+ batch_data_samples (List[:obj:`DetDataSample`]): The batch
+ data samples. It usually includes information such
+ as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
+
+ Returns:
+ dict: A dictionary of loss components
+ """
+ x = self.extract_feat(batch_inputs)
+
+ losses = dict()
+
+ # RPN forward and loss
+ if self.with_rpn:
+ proposal_cfg = self.train_cfg.get('rpn_proposal',
+ self.test_cfg.rpn)
+ rpn_data_samples = copy.deepcopy(batch_data_samples)
+ # set cat_id of gt_labels to 0 in RPN
+ for data_sample in rpn_data_samples:
+ data_sample.gt_instances.labels = \
+ torch.zeros_like(data_sample.gt_instances.labels)
+
+ rpn_losses, rpn_results_list = self.rpn_head.loss_and_predict(
+ x, rpn_data_samples, proposal_cfg=proposal_cfg)
+ # avoid get same name with roi_head loss
+ keys = rpn_losses.keys()
+ for key in list(keys):
+ if 'loss' in key and 'rpn' not in key:
+ rpn_losses[f'rpn_{key}'] = rpn_losses.pop(key)
+ losses.update(rpn_losses)
+ else:
+ assert batch_data_samples[0].get('proposals', None) is not None
+ # use pre-defined proposals in InstanceData for the second stage
+ # to extract ROI features.
+ rpn_results_list = [
+ data_sample.proposals for data_sample in batch_data_samples
+ ]
+
+ roi_losses = self.roi_head.loss(x, rpn_results_list,
+ batch_data_samples)
+ losses.update(roi_losses)
+
+ return losses
+
+ def predict(self,
+ batch_inputs: Tensor,
+ batch_data_samples: SampleList,
+ rescale: bool = True) -> SampleList:
+ """Predict results from a batch of inputs and data samples with post-
+ processing.
+
+ Args:
+ batch_inputs (Tensor): Inputs with shape (N, C, H, W).
+ batch_data_samples (List[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ rescale (bool): Whether to rescale the results.
+ Defaults to True.
+
+ Returns:
+ list[:obj:`DetDataSample`]: Return the detection results of the
+ input images. The returns value is DetDataSample,
+ which usually contain 'pred_instances'. And the
+ ``pred_instances`` usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ - masks (Tensor): Has a shape (num_instances, H, W).
+ """
+
+ assert self.with_bbox, 'Bbox head must be implemented.'
+ x = self.extract_feat(batch_inputs)
+
+ # If there are no pre-defined proposals, use RPN to get proposals
+ if batch_data_samples[0].get('proposals', None) is None:
+ rpn_results_list = self.rpn_head.predict(
+ x, batch_data_samples, rescale=False)
+ else:
+ rpn_results_list = [
+ data_sample.proposals for data_sample in batch_data_samples
+ ]
+
+ results_list = self.roi_head.predict(
+ x, rpn_results_list, batch_data_samples, rescale=rescale)
+
+ batch_data_samples = self.add_pred_to_datasample(
+ batch_data_samples, results_list)
+ return batch_data_samples
diff --git a/mmdet/models/detectors/vfnet.py b/mmdet/models/detectors/vfnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..a695513faa7d37756d7716cbca0e457060400518
--- /dev/null
+++ b/mmdet/models/detectors/vfnet.py
@@ -0,0 +1,42 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmdet.registry import MODELS
+from mmdet.utils import ConfigType, OptConfigType, OptMultiConfig
+from .single_stage import SingleStageDetector
+
+
+@MODELS.register_module()
+class VFNet(SingleStageDetector):
+ """Implementation of `VarifocalNet
+ (VFNet).`_
+
+ Args:
+ backbone (:obj:`ConfigDict` or dict): The backbone module.
+ neck (:obj:`ConfigDict` or dict): The neck module.
+ bbox_head (:obj:`ConfigDict` or dict): The bbox head module.
+ train_cfg (:obj:`ConfigDict` or dict, optional): The training config
+ of VFNet. Defaults to None.
+ test_cfg (:obj:`ConfigDict` or dict, optional): The testing config
+ of VFNet. Defaults to None.
+ data_preprocessor (:obj:`ConfigDict` or dict, optional): Config of
+ :class:`DetDataPreprocessor` to process the input data.
+ Defaults to None.
+ init_cfg (:obj:`ConfigDict` or dict, optional): the config to control
+ the initialization. Defaults to None.
+ """
+
+ def __init__(self,
+ backbone: ConfigType,
+ neck: ConfigType,
+ bbox_head: ConfigType,
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ data_preprocessor: OptConfigType = None,
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(
+ backbone=backbone,
+ neck=neck,
+ bbox_head=bbox_head,
+ train_cfg=train_cfg,
+ test_cfg=test_cfg,
+ data_preprocessor=data_preprocessor,
+ init_cfg=init_cfg)
diff --git a/mmdet/models/detectors/yolact.py b/mmdet/models/detectors/yolact.py
new file mode 100644
index 0000000000000000000000000000000000000000..f15fb7b70263b0c4018751067771b1365af96f67
--- /dev/null
+++ b/mmdet/models/detectors/yolact.py
@@ -0,0 +1,28 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmdet.registry import MODELS
+from mmdet.utils import ConfigType, OptConfigType, OptMultiConfig
+from .single_stage_instance_seg import SingleStageInstanceSegmentor
+
+
+@MODELS.register_module()
+class YOLACT(SingleStageInstanceSegmentor):
+ """Implementation of `YOLACT `_"""
+
+ def __init__(self,
+ backbone: ConfigType,
+ neck: ConfigType,
+ bbox_head: ConfigType,
+ mask_head: ConfigType,
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ data_preprocessor: OptConfigType = None,
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(
+ backbone=backbone,
+ neck=neck,
+ bbox_head=bbox_head,
+ mask_head=mask_head,
+ train_cfg=train_cfg,
+ test_cfg=test_cfg,
+ data_preprocessor=data_preprocessor,
+ init_cfg=init_cfg)
diff --git a/mmdet/models/detectors/yolo.py b/mmdet/models/detectors/yolo.py
new file mode 100644
index 0000000000000000000000000000000000000000..5cb9a9cd250a2c26af22032b1ed4bb5a7a8af605
--- /dev/null
+++ b/mmdet/models/detectors/yolo.py
@@ -0,0 +1,45 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+# Copyright (c) 2019 Western Digital Corporation or its affiliates.
+
+from mmdet.registry import MODELS
+from mmdet.utils import ConfigType, OptConfigType, OptMultiConfig
+from .single_stage import SingleStageDetector
+
+
+@MODELS.register_module()
+class YOLOV3(SingleStageDetector):
+ r"""Implementation of `Yolov3: An incremental improvement
+ `_
+
+ Args:
+ backbone (:obj:`ConfigDict` or dict): The backbone module.
+ neck (:obj:`ConfigDict` or dict): The neck module.
+ bbox_head (:obj:`ConfigDict` or dict): The bbox head module.
+ train_cfg (:obj:`ConfigDict` or dict, optional): The training config
+ of YOLOX. Default: None.
+ test_cfg (:obj:`ConfigDict` or dict, optional): The testing config
+ of YOLOX. Default: None.
+ data_preprocessor (:obj:`ConfigDict` or dict, optional):
+ Model preprocessing config for processing the input data.
+ it usually includes ``to_rgb``, ``pad_size_divisor``,
+ ``pad_value``, ``mean`` and ``std``. Defaults to None.
+ init_cfg (:obj:`ConfigDict` or dict, optional): the config to control
+ the initialization. Defaults to None.
+ """
+
+ def __init__(self,
+ backbone: ConfigType,
+ neck: ConfigType,
+ bbox_head: ConfigType,
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ data_preprocessor: OptConfigType = None,
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(
+ backbone=backbone,
+ neck=neck,
+ bbox_head=bbox_head,
+ train_cfg=train_cfg,
+ test_cfg=test_cfg,
+ data_preprocessor=data_preprocessor,
+ init_cfg=init_cfg)
diff --git a/mmdet/models/detectors/yolof.py b/mmdet/models/detectors/yolof.py
new file mode 100644
index 0000000000000000000000000000000000000000..c6d98b9134a7f422fa7ea1f1a1e0d548d36603e8
--- /dev/null
+++ b/mmdet/models/detectors/yolof.py
@@ -0,0 +1,43 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmdet.registry import MODELS
+from mmdet.utils import ConfigType, OptConfigType, OptMultiConfig
+from .single_stage import SingleStageDetector
+
+
+@MODELS.register_module()
+class YOLOF(SingleStageDetector):
+ r"""Implementation of `You Only Look One-level Feature
+ `_
+
+ Args:
+ backbone (:obj:`ConfigDict` or dict): The backbone module.
+ neck (:obj:`ConfigDict` or dict): The neck module.
+ bbox_head (:obj:`ConfigDict` or dict): The bbox head module.
+ train_cfg (:obj:`ConfigDict` or dict, optional): The training config
+ of YOLOF. Defaults to None.
+ test_cfg (:obj:`ConfigDict` or dict, optional): The testing config
+ of YOLOF. Defaults to None.
+ data_preprocessor (:obj:`ConfigDict` or dict, optional):
+ Model preprocessing config for processing the input data.
+ it usually includes ``to_rgb``, ``pad_size_divisor``,
+ ``pad_value``, ``mean`` and ``std``. Defaults to None.
+ init_cfg (:obj:`ConfigDict` or dict, optional): the config to control
+ the initialization. Defaults to None.
+ """
+
+ def __init__(self,
+ backbone: ConfigType,
+ neck: ConfigType,
+ bbox_head: ConfigType,
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ data_preprocessor: OptConfigType = None,
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(
+ backbone=backbone,
+ neck=neck,
+ bbox_head=bbox_head,
+ train_cfg=train_cfg,
+ test_cfg=test_cfg,
+ data_preprocessor=data_preprocessor,
+ init_cfg=init_cfg)
diff --git a/mmdet/models/detectors/yolox.py b/mmdet/models/detectors/yolox.py
new file mode 100644
index 0000000000000000000000000000000000000000..df9190c93f7b043910fbce3bd5ee8dc0ef7b5f68
--- /dev/null
+++ b/mmdet/models/detectors/yolox.py
@@ -0,0 +1,43 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmdet.registry import MODELS
+from mmdet.utils import ConfigType, OptConfigType, OptMultiConfig
+from .single_stage import SingleStageDetector
+
+
+@MODELS.register_module()
+class YOLOX(SingleStageDetector):
+ r"""Implementation of `YOLOX: Exceeding YOLO Series in 2021
+ `_
+
+ Args:
+ backbone (:obj:`ConfigDict` or dict): The backbone config.
+ neck (:obj:`ConfigDict` or dict): The neck config.
+ bbox_head (:obj:`ConfigDict` or dict): The bbox head config.
+ train_cfg (:obj:`ConfigDict` or dict, optional): The training config
+ of YOLOX. Defaults to None.
+ test_cfg (:obj:`ConfigDict` or dict, optional): The testing config
+ of YOLOX. Defaults to None.
+ data_preprocessor (:obj:`ConfigDict` or dict, optional): Config of
+ :class:`DetDataPreprocessor` to process the input data.
+ Defaults to None.
+ init_cfg (:obj:`ConfigDict` or list[:obj:`ConfigDict`] or dict or
+ list[dict], optional): Initialization config dict.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ backbone: ConfigType,
+ neck: ConfigType,
+ bbox_head: ConfigType,
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ data_preprocessor: OptConfigType = None,
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(
+ backbone=backbone,
+ neck=neck,
+ bbox_head=bbox_head,
+ train_cfg=train_cfg,
+ test_cfg=test_cfg,
+ data_preprocessor=data_preprocessor,
+ init_cfg=init_cfg)
diff --git a/mmdet/models/layers/__init__.py b/mmdet/models/layers/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..c8fc99df1ce51e4e5e9cce67d58530be4d945791
--- /dev/null
+++ b/mmdet/models/layers/__init__.py
@@ -0,0 +1,61 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .activations import SiLU
+from .bbox_nms import fast_nms, multiclass_nms
+from .brick_wrappers import AdaptiveAvgPool2d, adaptive_avg_pool2d
+from .conv_upsample import ConvUpsample
+from .csp_layer import CSPLayer
+from .dropblock import DropBlock
+from .ema import ExpMomentumEMA
+from .inverted_residual import InvertedResidual
+from .matrix_nms import mask_matrix_nms
+from .msdeformattn_pixel_decoder import MSDeformAttnPixelDecoder
+from .normed_predictor import NormedConv2d, NormedLinear
+from .pixel_decoder import PixelDecoder, TransformerEncoderPixelDecoder
+from .positional_encoding import (LearnedPositionalEncoding,
+ SinePositionalEncoding)
+from .res_layer import ResLayer, SimplifiedBasicBlock
+from .se_layer import ChannelAttention, DyReLU, SELayer
+# yapf: disable
+from .transformer import (MLP, AdaptivePadding, CdnQueryGenerator,
+ ConditionalAttention,
+ ConditionalDetrTransformerDecoder,
+ ConditionalDetrTransformerDecoderLayer,
+ DABDetrTransformerDecoder,
+ DABDetrTransformerDecoderLayer,
+ DABDetrTransformerEncoder,
+ DeformableDetrTransformerDecoder,
+ DeformableDetrTransformerDecoderLayer,
+ DeformableDetrTransformerEncoder,
+ DeformableDetrTransformerEncoderLayer,
+ DetrTransformerDecoder, DetrTransformerDecoderLayer,
+ DetrTransformerEncoder, DetrTransformerEncoderLayer,
+ DinoTransformerDecoder, DynamicConv,
+ Mask2FormerTransformerDecoder,
+ Mask2FormerTransformerDecoderLayer,
+ Mask2FormerTransformerEncoder, PatchEmbed,
+ PatchMerging, coordinate_to_encoding,
+ inverse_sigmoid, nchw_to_nlc, nlc_to_nchw)
+
+# yapf: enable
+
+__all__ = [
+ 'fast_nms', 'multiclass_nms', 'mask_matrix_nms', 'DropBlock',
+ 'PixelDecoder', 'TransformerEncoderPixelDecoder',
+ 'MSDeformAttnPixelDecoder', 'ResLayer', 'PatchMerging',
+ 'SinePositionalEncoding', 'LearnedPositionalEncoding', 'DynamicConv',
+ 'SimplifiedBasicBlock', 'NormedLinear', 'NormedConv2d', 'InvertedResidual',
+ 'SELayer', 'ConvUpsample', 'CSPLayer', 'adaptive_avg_pool2d',
+ 'AdaptiveAvgPool2d', 'PatchEmbed', 'nchw_to_nlc', 'nlc_to_nchw', 'DyReLU',
+ 'ExpMomentumEMA', 'inverse_sigmoid', 'ChannelAttention', 'SiLU', 'MLP',
+ 'DetrTransformerEncoderLayer', 'DetrTransformerDecoderLayer',
+ 'DetrTransformerEncoder', 'DetrTransformerDecoder',
+ 'DeformableDetrTransformerEncoder', 'DeformableDetrTransformerDecoder',
+ 'DeformableDetrTransformerEncoderLayer',
+ 'DeformableDetrTransformerDecoderLayer', 'AdaptivePadding',
+ 'coordinate_to_encoding', 'ConditionalAttention',
+ 'DABDetrTransformerDecoderLayer', 'DABDetrTransformerDecoder',
+ 'DABDetrTransformerEncoder', 'ConditionalDetrTransformerDecoder',
+ 'ConditionalDetrTransformerDecoderLayer', 'DinoTransformerDecoder',
+ 'CdnQueryGenerator', 'Mask2FormerTransformerEncoder',
+ 'Mask2FormerTransformerDecoderLayer', 'Mask2FormerTransformerDecoder'
+]
diff --git a/mmdet/models/layers/__pycache__/__init__.cpython-37.pyc b/mmdet/models/layers/__pycache__/__init__.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..b773d8fbfba03054ecadfd14ac06bd881e65fef6
Binary files /dev/null and b/mmdet/models/layers/__pycache__/__init__.cpython-37.pyc differ
diff --git a/mmdet/models/layers/__pycache__/activations.cpython-37.pyc b/mmdet/models/layers/__pycache__/activations.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..b4f4af8fa554101f8e342a74d7f90276c8f4abf2
Binary files /dev/null and b/mmdet/models/layers/__pycache__/activations.cpython-37.pyc differ
diff --git a/mmdet/models/layers/__pycache__/bbox_nms.cpython-37.pyc b/mmdet/models/layers/__pycache__/bbox_nms.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..78261544a8360f7df2acb01663870445af9cde0c
Binary files /dev/null and b/mmdet/models/layers/__pycache__/bbox_nms.cpython-37.pyc differ
diff --git a/mmdet/models/layers/__pycache__/brick_wrappers.cpython-37.pyc b/mmdet/models/layers/__pycache__/brick_wrappers.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..dd33e10ef283abe5c9f58e1d0ae47ce81d21901b
Binary files /dev/null and b/mmdet/models/layers/__pycache__/brick_wrappers.cpython-37.pyc differ
diff --git a/mmdet/models/layers/__pycache__/conv_upsample.cpython-37.pyc b/mmdet/models/layers/__pycache__/conv_upsample.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..4c60ebb09b3d5aabf7b3068829383d534aca15dd
Binary files /dev/null and b/mmdet/models/layers/__pycache__/conv_upsample.cpython-37.pyc differ
diff --git a/mmdet/models/layers/__pycache__/csp_layer.cpython-37.pyc b/mmdet/models/layers/__pycache__/csp_layer.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..103d946b758054471761e063e3e6b3b669914c02
Binary files /dev/null and b/mmdet/models/layers/__pycache__/csp_layer.cpython-37.pyc differ
diff --git a/mmdet/models/layers/__pycache__/dropblock.cpython-37.pyc b/mmdet/models/layers/__pycache__/dropblock.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..d65159099bf2286c2c232937ebf8d9f747346a2e
Binary files /dev/null and b/mmdet/models/layers/__pycache__/dropblock.cpython-37.pyc differ
diff --git a/mmdet/models/layers/__pycache__/ema.cpython-37.pyc b/mmdet/models/layers/__pycache__/ema.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..62ee3aa285afb83984cc88e9d7e4334125c9eaa7
Binary files /dev/null and b/mmdet/models/layers/__pycache__/ema.cpython-37.pyc differ
diff --git a/mmdet/models/layers/__pycache__/inverted_residual.cpython-37.pyc b/mmdet/models/layers/__pycache__/inverted_residual.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..15da02e05878534684f943f606a1b89f27e14994
Binary files /dev/null and b/mmdet/models/layers/__pycache__/inverted_residual.cpython-37.pyc differ
diff --git a/mmdet/models/layers/__pycache__/matrix_nms.cpython-37.pyc b/mmdet/models/layers/__pycache__/matrix_nms.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..ec5e56e50bc39e677c97ed82ed36493aa122808e
Binary files /dev/null and b/mmdet/models/layers/__pycache__/matrix_nms.cpython-37.pyc differ
diff --git a/mmdet/models/layers/__pycache__/msdeformattn_pixel_decoder.cpython-37.pyc b/mmdet/models/layers/__pycache__/msdeformattn_pixel_decoder.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..2920fbe7cc3574b44b6d0a9d2b656de707a54caf
Binary files /dev/null and b/mmdet/models/layers/__pycache__/msdeformattn_pixel_decoder.cpython-37.pyc differ
diff --git a/mmdet/models/layers/__pycache__/normed_predictor.cpython-37.pyc b/mmdet/models/layers/__pycache__/normed_predictor.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..ed06488120caa62289c3d74ac85636ed13c764fc
Binary files /dev/null and b/mmdet/models/layers/__pycache__/normed_predictor.cpython-37.pyc differ
diff --git a/mmdet/models/layers/__pycache__/pixel_decoder.cpython-37.pyc b/mmdet/models/layers/__pycache__/pixel_decoder.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..1461eb8cf3ac21d8048eb0adcfb2458cfc7b4770
Binary files /dev/null and b/mmdet/models/layers/__pycache__/pixel_decoder.cpython-37.pyc differ
diff --git a/mmdet/models/layers/__pycache__/positional_encoding.cpython-37.pyc b/mmdet/models/layers/__pycache__/positional_encoding.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..ee64cc314631dcc50fc526c0a8fb5059b46a41a2
Binary files /dev/null and b/mmdet/models/layers/__pycache__/positional_encoding.cpython-37.pyc differ
diff --git a/mmdet/models/layers/__pycache__/res_layer.cpython-37.pyc b/mmdet/models/layers/__pycache__/res_layer.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..6d4def673d1ad27064fab7a664f42f7dac71411f
Binary files /dev/null and b/mmdet/models/layers/__pycache__/res_layer.cpython-37.pyc differ
diff --git a/mmdet/models/layers/__pycache__/se_layer.cpython-37.pyc b/mmdet/models/layers/__pycache__/se_layer.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..e0d483383888dfed982e88ebac8ffa8e932a48af
Binary files /dev/null and b/mmdet/models/layers/__pycache__/se_layer.cpython-37.pyc differ
diff --git a/mmdet/models/layers/activations.py b/mmdet/models/layers/activations.py
new file mode 100644
index 0000000000000000000000000000000000000000..9e73ef42180ccd3dddb4bcca224c0b4eb5da807c
--- /dev/null
+++ b/mmdet/models/layers/activations.py
@@ -0,0 +1,22 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+from mmengine.utils import digit_version
+
+from mmdet.registry import MODELS
+
+if digit_version(torch.__version__) >= digit_version('1.7.0'):
+ from torch.nn import SiLU
+else:
+
+ class SiLU(nn.Module):
+ """Sigmoid Weighted Liner Unit."""
+
+ def __init__(self, inplace=True):
+ super().__init__()
+
+ def forward(self, inputs) -> torch.Tensor:
+ return inputs * torch.sigmoid(inputs)
+
+
+MODELS.register_module(module=SiLU, name='SiLU')
diff --git a/mmdet/models/layers/bbox_nms.py b/mmdet/models/layers/bbox_nms.py
new file mode 100644
index 0000000000000000000000000000000000000000..fd67a45f60ca98c354e095127ab7dbb9653deca5
--- /dev/null
+++ b/mmdet/models/layers/bbox_nms.py
@@ -0,0 +1,184 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Tuple, Union
+
+import torch
+from mmcv.ops.nms import batched_nms
+from torch import Tensor
+
+from mmdet.structures.bbox import bbox_overlaps
+from mmdet.utils import ConfigType
+
+
+def multiclass_nms(
+ multi_bboxes: Tensor,
+ multi_scores: Tensor,
+ score_thr: float,
+ nms_cfg: ConfigType,
+ max_num: int = -1,
+ score_factors: Optional[Tensor] = None,
+ return_inds: bool = False,
+ box_dim: int = 4
+) -> Union[Tuple[Tensor, Tensor, Tensor], Tuple[Tensor, Tensor]]:
+ """NMS for multi-class bboxes.
+
+ Args:
+ multi_bboxes (Tensor): shape (n, #class*4) or (n, 4)
+ multi_scores (Tensor): shape (n, #class), where the last column
+ contains scores of the background class, but this will be ignored.
+ score_thr (float): bbox threshold, bboxes with scores lower than it
+ will not be considered.
+ nms_cfg (Union[:obj:`ConfigDict`, dict]): a dict that contains
+ the arguments of nms operations.
+ max_num (int, optional): if there are more than max_num bboxes after
+ NMS, only top max_num will be kept. Default to -1.
+ score_factors (Tensor, optional): The factors multiplied to scores
+ before applying NMS. Default to None.
+ return_inds (bool, optional): Whether return the indices of kept
+ bboxes. Default to False.
+ box_dim (int): The dimension of boxes. Defaults to 4.
+
+ Returns:
+ Union[Tuple[Tensor, Tensor, Tensor], Tuple[Tensor, Tensor]]:
+ (dets, labels, indices (optional)), tensors of shape (k, 5),
+ (k), and (k). Dets are boxes with scores. Labels are 0-based.
+ """
+ num_classes = multi_scores.size(1) - 1
+ # exclude background category
+ if multi_bboxes.shape[1] > box_dim:
+ bboxes = multi_bboxes.view(multi_scores.size(0), -1, box_dim)
+ else:
+ bboxes = multi_bboxes[:, None].expand(
+ multi_scores.size(0), num_classes, box_dim)
+
+ scores = multi_scores[:, :-1]
+
+ labels = torch.arange(num_classes, dtype=torch.long, device=scores.device)
+ labels = labels.view(1, -1).expand_as(scores)
+
+ bboxes = bboxes.reshape(-1, box_dim)
+ scores = scores.reshape(-1)
+ labels = labels.reshape(-1)
+
+ if not torch.onnx.is_in_onnx_export():
+ # NonZero not supported in TensorRT
+ # remove low scoring boxes
+ valid_mask = scores > score_thr
+ # multiply score_factor after threshold to preserve more bboxes, improve
+ # mAP by 1% for YOLOv3
+ if score_factors is not None:
+ # expand the shape to match original shape of score
+ score_factors = score_factors.view(-1, 1).expand(
+ multi_scores.size(0), num_classes)
+ score_factors = score_factors.reshape(-1)
+ scores = scores * score_factors
+
+ if not torch.onnx.is_in_onnx_export():
+ # NonZero not supported in TensorRT
+ inds = valid_mask.nonzero(as_tuple=False).squeeze(1)
+ bboxes, scores, labels = bboxes[inds], scores[inds], labels[inds]
+ else:
+ # TensorRT NMS plugin has invalid output filled with -1
+ # add dummy data to make detection output correct.
+ bboxes = torch.cat([bboxes, bboxes.new_zeros(1, box_dim)], dim=0)
+ scores = torch.cat([scores, scores.new_zeros(1)], dim=0)
+ labels = torch.cat([labels, labels.new_zeros(1)], dim=0)
+
+ if bboxes.numel() == 0:
+ if torch.onnx.is_in_onnx_export():
+ raise RuntimeError('[ONNX Error] Can not record NMS '
+ 'as it has not been executed this time')
+ dets = torch.cat([bboxes, scores[:, None]], -1)
+ if return_inds:
+ return dets, labels, inds
+ else:
+ return dets, labels
+
+ dets, keep = batched_nms(bboxes, scores, labels, nms_cfg)
+
+ if max_num > 0:
+ dets = dets[:max_num]
+ keep = keep[:max_num]
+
+ if return_inds:
+ return dets, labels[keep], inds[keep]
+ else:
+ return dets, labels[keep]
+
+
+def fast_nms(
+ multi_bboxes: Tensor,
+ multi_scores: Tensor,
+ multi_coeffs: Tensor,
+ score_thr: float,
+ iou_thr: float,
+ top_k: int,
+ max_num: int = -1
+) -> Union[Tuple[Tensor, Tensor, Tensor], Tuple[Tensor, Tensor]]:
+ """Fast NMS in `YOLACT `_.
+
+ Fast NMS allows already-removed detections to suppress other detections so
+ that every instance can be decided to be kept or discarded in parallel,
+ which is not possible in traditional NMS. This relaxation allows us to
+ implement Fast NMS entirely in standard GPU-accelerated matrix operations.
+
+ Args:
+ multi_bboxes (Tensor): shape (n, #class*4) or (n, 4)
+ multi_scores (Tensor): shape (n, #class+1), where the last column
+ contains scores of the background class, but this will be ignored.
+ multi_coeffs (Tensor): shape (n, #class*coeffs_dim).
+ score_thr (float): bbox threshold, bboxes with scores lower than it
+ will not be considered.
+ iou_thr (float): IoU threshold to be considered as conflicted.
+ top_k (int): if there are more than top_k bboxes before NMS,
+ only top top_k will be kept.
+ max_num (int): if there are more than max_num bboxes after NMS,
+ only top max_num will be kept. If -1, keep all the bboxes.
+ Default: -1.
+
+ Returns:
+ Union[Tuple[Tensor, Tensor, Tensor], Tuple[Tensor, Tensor]]:
+ (dets, labels, coefficients), tensors of shape (k, 5), (k, 1),
+ and (k, coeffs_dim). Dets are boxes with scores.
+ Labels are 0-based.
+ """
+
+ scores = multi_scores[:, :-1].t() # [#class, n]
+ scores, idx = scores.sort(1, descending=True)
+
+ idx = idx[:, :top_k].contiguous()
+ scores = scores[:, :top_k] # [#class, topk]
+ num_classes, num_dets = idx.size()
+ boxes = multi_bboxes[idx.view(-1), :].view(num_classes, num_dets, 4)
+ coeffs = multi_coeffs[idx.view(-1), :].view(num_classes, num_dets, -1)
+
+ iou = bbox_overlaps(boxes, boxes) # [#class, topk, topk]
+ iou.triu_(diagonal=1)
+ iou_max, _ = iou.max(dim=1)
+
+ # Now just filter out the ones higher than the threshold
+ keep = iou_max <= iou_thr
+
+ # Second thresholding introduces 0.2 mAP gain at negligible time cost
+ keep *= scores > score_thr
+
+ # Assign each kept detection to its corresponding class
+ classes = torch.arange(
+ num_classes, device=boxes.device)[:, None].expand_as(keep)
+ classes = classes[keep]
+
+ boxes = boxes[keep]
+ coeffs = coeffs[keep]
+ scores = scores[keep]
+
+ # Only keep the top max_num highest scores across all classes
+ scores, idx = scores.sort(0, descending=True)
+ if max_num > 0:
+ idx = idx[:max_num]
+ scores = scores[:max_num]
+
+ classes = classes[idx]
+ boxes = boxes[idx]
+ coeffs = coeffs[idx]
+
+ cls_dets = torch.cat([boxes, scores[:, None]], dim=1)
+ return cls_dets, classes, coeffs
diff --git a/mmdet/models/layers/brick_wrappers.py b/mmdet/models/layers/brick_wrappers.py
new file mode 100644
index 0000000000000000000000000000000000000000..fa0279ab60d0943bf68ea2616df9dad87e220db4
--- /dev/null
+++ b/mmdet/models/layers/brick_wrappers.py
@@ -0,0 +1,51 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn.bricks.wrappers import NewEmptyTensorOp, obsolete_torch_version
+
+if torch.__version__ == 'parrots':
+ TORCH_VERSION = torch.__version__
+else:
+ # torch.__version__ could be 1.3.1+cu92, we only need the first two
+ # for comparison
+ TORCH_VERSION = tuple(int(x) for x in torch.__version__.split('.')[:2])
+
+
+def adaptive_avg_pool2d(input, output_size):
+ """Handle empty batch dimension to adaptive_avg_pool2d.
+
+ Args:
+ input (tensor): 4D tensor.
+ output_size (int, tuple[int,int]): the target output size.
+ """
+ if input.numel() == 0 and obsolete_torch_version(TORCH_VERSION, (1, 9)):
+ if isinstance(output_size, int):
+ output_size = [output_size, output_size]
+ output_size = [*input.shape[:2], *output_size]
+ empty = NewEmptyTensorOp.apply(input, output_size)
+ return empty
+ else:
+ return F.adaptive_avg_pool2d(input, output_size)
+
+
+class AdaptiveAvgPool2d(nn.AdaptiveAvgPool2d):
+ """Handle empty batch dimension to AdaptiveAvgPool2d."""
+
+ def forward(self, x):
+ # PyTorch 1.9 does not support empty tensor inference yet
+ if x.numel() == 0 and obsolete_torch_version(TORCH_VERSION, (1, 9)):
+ output_size = self.output_size
+ if isinstance(output_size, int):
+ output_size = [output_size, output_size]
+ else:
+ output_size = [
+ v if v is not None else d
+ for v, d in zip(output_size,
+ x.size()[-2:])
+ ]
+ output_size = [*x.shape[:2], *output_size]
+ empty = NewEmptyTensorOp.apply(x, output_size)
+ return empty
+
+ return super().forward(x)
diff --git a/mmdet/models/layers/conv_upsample.py b/mmdet/models/layers/conv_upsample.py
new file mode 100644
index 0000000000000000000000000000000000000000..32505875a2162330ed7d00455f088d08d94f679e
--- /dev/null
+++ b/mmdet/models/layers/conv_upsample.py
@@ -0,0 +1,67 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule
+from mmengine.model import BaseModule, ModuleList
+
+
+class ConvUpsample(BaseModule):
+ """ConvUpsample performs 2x upsampling after Conv.
+
+ There are several `ConvModule` layers. In the first few layers, upsampling
+ will be applied after each layer of convolution. The number of upsampling
+ must be no more than the number of ConvModule layers.
+
+ Args:
+ in_channels (int): Number of channels in the input feature map.
+ inner_channels (int): Number of channels produced by the convolution.
+ num_layers (int): Number of convolution layers.
+ num_upsample (int | optional): Number of upsampling layer. Must be no
+ more than num_layers. Upsampling will be applied after the first
+ ``num_upsample`` layers of convolution. Default: ``num_layers``.
+ conv_cfg (dict): Config dict for convolution layer. Default: None,
+ which means using conv2d.
+ norm_cfg (dict): Config dict for normalization layer. Default: None.
+ init_cfg (dict): Config dict for initialization. Default: None.
+ kwargs (key word augments): Other augments used in ConvModule.
+ """
+
+ def __init__(self,
+ in_channels,
+ inner_channels,
+ num_layers=1,
+ num_upsample=None,
+ conv_cfg=None,
+ norm_cfg=None,
+ init_cfg=None,
+ **kwargs):
+ super(ConvUpsample, self).__init__(init_cfg)
+ if num_upsample is None:
+ num_upsample = num_layers
+ assert num_upsample <= num_layers, \
+ f'num_upsample({num_upsample})must be no more than ' \
+ f'num_layers({num_layers})'
+ self.num_layers = num_layers
+ self.num_upsample = num_upsample
+ self.conv = ModuleList()
+ for i in range(num_layers):
+ self.conv.append(
+ ConvModule(
+ in_channels,
+ inner_channels,
+ 3,
+ padding=1,
+ stride=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ **kwargs))
+ in_channels = inner_channels
+
+ def forward(self, x):
+ num_upsample = self.num_upsample
+ for i in range(self.num_layers):
+ x = self.conv[i](x)
+ if num_upsample > 0:
+ num_upsample -= 1
+ x = F.interpolate(
+ x, scale_factor=2, mode='bilinear', align_corners=False)
+ return x
diff --git a/mmdet/models/layers/csp_layer.py b/mmdet/models/layers/csp_layer.py
new file mode 100644
index 0000000000000000000000000000000000000000..c8b547b8994862bfe14739033bb6b254ef886f29
--- /dev/null
+++ b/mmdet/models/layers/csp_layer.py
@@ -0,0 +1,246 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+from mmcv.cnn import ConvModule, DepthwiseSeparableConvModule
+from mmengine.model import BaseModule
+from torch import Tensor
+
+from mmdet.utils import ConfigType, OptConfigType, OptMultiConfig
+from .se_layer import ChannelAttention
+
+
+class DarknetBottleneck(BaseModule):
+ """The basic bottleneck block used in Darknet.
+
+ Each ResBlock consists of two ConvModules and the input is added to the
+ final output. Each ConvModule is composed of Conv, BN, and LeakyReLU.
+ The first convLayer has filter size of 1x1 and the second one has the
+ filter size of 3x3.
+
+ Args:
+ in_channels (int): The input channels of this Module.
+ out_channels (int): The output channels of this Module.
+ expansion (float): The kernel size of the convolution.
+ Defaults to 0.5.
+ add_identity (bool): Whether to add identity to the out.
+ Defaults to True.
+ use_depthwise (bool): Whether to use depthwise separable convolution.
+ Defaults to False.
+ conv_cfg (dict): Config dict for convolution layer. Defaults to None,
+ which means using conv2d.
+ norm_cfg (dict): Config dict for normalization layer.
+ Defaults to dict(type='BN').
+ act_cfg (dict): Config dict for activation layer.
+ Defaults to dict(type='Swish').
+ """
+
+ def __init__(self,
+ in_channels: int,
+ out_channels: int,
+ expansion: float = 0.5,
+ add_identity: bool = True,
+ use_depthwise: bool = False,
+ conv_cfg: OptConfigType = None,
+ norm_cfg: ConfigType = dict(
+ type='BN', momentum=0.03, eps=0.001),
+ act_cfg: ConfigType = dict(type='Swish'),
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(init_cfg=init_cfg)
+ hidden_channels = int(out_channels * expansion)
+ conv = DepthwiseSeparableConvModule if use_depthwise else ConvModule
+ self.conv1 = ConvModule(
+ in_channels,
+ hidden_channels,
+ 1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ self.conv2 = conv(
+ hidden_channels,
+ out_channels,
+ 3,
+ stride=1,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ self.add_identity = \
+ add_identity and in_channels == out_channels
+
+ def forward(self, x: Tensor) -> Tensor:
+ """Forward function."""
+ identity = x
+ out = self.conv1(x)
+ out = self.conv2(out)
+
+ if self.add_identity:
+ return out + identity
+ else:
+ return out
+
+
+class CSPNeXtBlock(BaseModule):
+ """The basic bottleneck block used in CSPNeXt.
+
+ Args:
+ in_channels (int): The input channels of this Module.
+ out_channels (int): The output channels of this Module.
+ expansion (float): Expand ratio of the hidden channel. Defaults to 0.5.
+ add_identity (bool): Whether to add identity to the out. Only works
+ when in_channels == out_channels. Defaults to True.
+ use_depthwise (bool): Whether to use depthwise separable convolution.
+ Defaults to False.
+ kernel_size (int): The kernel size of the second convolution layer.
+ Defaults to 5.
+ conv_cfg (dict): Config dict for convolution layer. Defaults to None,
+ which means using conv2d.
+ norm_cfg (dict): Config dict for normalization layer.
+ Defaults to dict(type='BN', momentum=0.03, eps=0.001).
+ act_cfg (dict): Config dict for activation layer.
+ Defaults to dict(type='SiLU').
+ init_cfg (:obj:`ConfigDict` or dict or list[dict] or
+ list[:obj:`ConfigDict`], optional): Initialization config dict.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ in_channels: int,
+ out_channels: int,
+ expansion: float = 0.5,
+ add_identity: bool = True,
+ use_depthwise: bool = False,
+ kernel_size: int = 5,
+ conv_cfg: OptConfigType = None,
+ norm_cfg: ConfigType = dict(
+ type='BN', momentum=0.03, eps=0.001),
+ act_cfg: ConfigType = dict(type='SiLU'),
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(init_cfg=init_cfg)
+ hidden_channels = int(out_channels * expansion)
+ conv = DepthwiseSeparableConvModule if use_depthwise else ConvModule
+ self.conv1 = conv(
+ in_channels,
+ hidden_channels,
+ 3,
+ stride=1,
+ padding=1,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ self.conv2 = DepthwiseSeparableConvModule(
+ hidden_channels,
+ out_channels,
+ kernel_size,
+ stride=1,
+ padding=kernel_size // 2,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ self.add_identity = \
+ add_identity and in_channels == out_channels
+
+ def forward(self, x: Tensor) -> Tensor:
+ """Forward function."""
+ identity = x
+ out = self.conv1(x)
+ out = self.conv2(out)
+
+ if self.add_identity:
+ return out + identity
+ else:
+ return out
+
+
+class CSPLayer(BaseModule):
+ """Cross Stage Partial Layer.
+
+ Args:
+ in_channels (int): The input channels of the CSP layer.
+ out_channels (int): The output channels of the CSP layer.
+ expand_ratio (float): Ratio to adjust the number of channels of the
+ hidden layer. Defaults to 0.5.
+ num_blocks (int): Number of blocks. Defaults to 1.
+ add_identity (bool): Whether to add identity in blocks.
+ Defaults to True.
+ use_cspnext_block (bool): Whether to use CSPNeXt block.
+ Defaults to False.
+ use_depthwise (bool): Whether to use depthwise separable convolution in
+ blocks. Defaults to False.
+ channel_attention (bool): Whether to add channel attention in each
+ stage. Defaults to True.
+ conv_cfg (dict, optional): Config dict for convolution layer.
+ Defaults to None, which means using conv2d.
+ norm_cfg (dict): Config dict for normalization layer.
+ Defaults to dict(type='BN')
+ act_cfg (dict): Config dict for activation layer.
+ Defaults to dict(type='Swish')
+ init_cfg (:obj:`ConfigDict` or dict or list[dict] or
+ list[:obj:`ConfigDict`], optional): Initialization config dict.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ in_channels: int,
+ out_channels: int,
+ expand_ratio: float = 0.5,
+ num_blocks: int = 1,
+ add_identity: bool = True,
+ use_depthwise: bool = False,
+ use_cspnext_block: bool = False,
+ channel_attention: bool = False,
+ conv_cfg: OptConfigType = None,
+ norm_cfg: ConfigType = dict(
+ type='BN', momentum=0.03, eps=0.001),
+ act_cfg: ConfigType = dict(type='Swish'),
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(init_cfg=init_cfg)
+ block = CSPNeXtBlock if use_cspnext_block else DarknetBottleneck
+ mid_channels = int(out_channels * expand_ratio)
+ self.channel_attention = channel_attention
+ self.main_conv = ConvModule(
+ in_channels,
+ mid_channels,
+ 1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ self.short_conv = ConvModule(
+ in_channels,
+ mid_channels,
+ 1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ self.final_conv = ConvModule(
+ 2 * mid_channels,
+ out_channels,
+ 1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+
+ self.blocks = nn.Sequential(*[
+ block(
+ mid_channels,
+ mid_channels,
+ 1.0,
+ add_identity,
+ use_depthwise,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg) for _ in range(num_blocks)
+ ])
+ if channel_attention:
+ self.attention = ChannelAttention(2 * mid_channels)
+
+ def forward(self, x: Tensor) -> Tensor:
+ """Forward function."""
+ x_short = self.short_conv(x)
+
+ x_main = self.main_conv(x)
+ x_main = self.blocks(x_main)
+
+ x_final = torch.cat((x_main, x_short), dim=1)
+
+ if self.channel_attention:
+ x_final = self.attention(x_final)
+ return self.final_conv(x_final)
diff --git a/mmdet/models/layers/dropblock.py b/mmdet/models/layers/dropblock.py
new file mode 100644
index 0000000000000000000000000000000000000000..7938199b761d637afdb1b2c62dbca01d1bf629eb
--- /dev/null
+++ b/mmdet/models/layers/dropblock.py
@@ -0,0 +1,86 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from mmdet.registry import MODELS
+
+eps = 1e-6
+
+
+@MODELS.register_module()
+class DropBlock(nn.Module):
+ """Randomly drop some regions of feature maps.
+
+ Please refer to the method proposed in `DropBlock
+ `_ for details.
+
+ Args:
+ drop_prob (float): The probability of dropping each block.
+ block_size (int): The size of dropped blocks.
+ warmup_iters (int): The drop probability will linearly increase
+ from `0` to `drop_prob` during the first `warmup_iters` iterations.
+ Default: 2000.
+ """
+
+ def __init__(self, drop_prob, block_size, warmup_iters=2000, **kwargs):
+ super(DropBlock, self).__init__()
+ assert block_size % 2 == 1
+ assert 0 < drop_prob <= 1
+ assert warmup_iters >= 0
+ self.drop_prob = drop_prob
+ self.block_size = block_size
+ self.warmup_iters = warmup_iters
+ self.iter_cnt = 0
+
+ def forward(self, x):
+ """
+ Args:
+ x (Tensor): Input feature map on which some areas will be randomly
+ dropped.
+
+ Returns:
+ Tensor: The tensor after DropBlock layer.
+ """
+ if not self.training:
+ return x
+ self.iter_cnt += 1
+ N, C, H, W = list(x.shape)
+ gamma = self._compute_gamma((H, W))
+ mask_shape = (N, C, H - self.block_size + 1, W - self.block_size + 1)
+ mask = torch.bernoulli(torch.full(mask_shape, gamma, device=x.device))
+
+ mask = F.pad(mask, [self.block_size // 2] * 4, value=0)
+ mask = F.max_pool2d(
+ input=mask,
+ stride=(1, 1),
+ kernel_size=(self.block_size, self.block_size),
+ padding=self.block_size // 2)
+ mask = 1 - mask
+ x = x * mask * mask.numel() / (eps + mask.sum())
+ return x
+
+ def _compute_gamma(self, feat_size):
+ """Compute the value of gamma according to paper. gamma is the
+ parameter of bernoulli distribution, which controls the number of
+ features to drop.
+
+ gamma = (drop_prob * fm_area) / (drop_area * keep_area)
+
+ Args:
+ feat_size (tuple[int, int]): The height and width of feature map.
+
+ Returns:
+ float: The value of gamma.
+ """
+ gamma = (self.drop_prob * feat_size[0] * feat_size[1])
+ gamma /= ((feat_size[0] - self.block_size + 1) *
+ (feat_size[1] - self.block_size + 1))
+ gamma /= (self.block_size**2)
+ factor = (1.0 if self.iter_cnt > self.warmup_iters else self.iter_cnt /
+ self.warmup_iters)
+ return gamma * factor
+
+ def extra_repr(self):
+ return (f'drop_prob={self.drop_prob}, block_size={self.block_size}, '
+ f'warmup_iters={self.warmup_iters}')
diff --git a/mmdet/models/layers/ema.py b/mmdet/models/layers/ema.py
new file mode 100644
index 0000000000000000000000000000000000000000..bce503c4641f7391a7bd7d722c05f4e49bd07db9
--- /dev/null
+++ b/mmdet/models/layers/ema.py
@@ -0,0 +1,66 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+from typing import Optional
+
+import torch
+import torch.nn as nn
+from mmengine.model import ExponentialMovingAverage
+from torch import Tensor
+
+from mmdet.registry import MODELS
+
+
+@MODELS.register_module()
+class ExpMomentumEMA(ExponentialMovingAverage):
+ """Exponential moving average (EMA) with exponential momentum strategy,
+ which is used in YOLOX.
+
+ Args:
+ model (nn.Module): The model to be averaged.
+ momentum (float): The momentum used for updating ema parameter.
+ Ema's parameter are updated with the formula:
+ `averaged_param = (1-momentum) * averaged_param + momentum *
+ source_param`. Defaults to 0.0002.
+ gamma (int): Use a larger momentum early in training and gradually
+ annealing to a smaller value to update the ema model smoothly. The
+ momentum is calculated as
+ `(1 - momentum) * exp(-(1 + steps) / gamma) + momentum`.
+ Defaults to 2000.
+ interval (int): Interval between two updates. Defaults to 1.
+ device (torch.device, optional): If provided, the averaged model will
+ be stored on the :attr:`device`. Defaults to None.
+ update_buffers (bool): if True, it will compute running averages for
+ both the parameters and the buffers of the model. Defaults to
+ False.
+ """
+
+ def __init__(self,
+ model: nn.Module,
+ momentum: float = 0.0002,
+ gamma: int = 2000,
+ interval=1,
+ device: Optional[torch.device] = None,
+ update_buffers: bool = False) -> None:
+ super().__init__(
+ model=model,
+ momentum=momentum,
+ interval=interval,
+ device=device,
+ update_buffers=update_buffers)
+ assert gamma > 0, f'gamma must be greater than 0, but got {gamma}'
+ self.gamma = gamma
+
+ def avg_func(self, averaged_param: Tensor, source_param: Tensor,
+ steps: int) -> None:
+ """Compute the moving average of the parameters using the exponential
+ momentum strategy.
+
+ Args:
+ averaged_param (Tensor): The averaged parameters.
+ source_param (Tensor): The source parameters.
+ steps (int): The number of times the parameters have been
+ updated.
+ """
+ momentum = (1 - self.momentum) * math.exp(
+ -float(1 + steps) / self.gamma) + self.momentum
+ averaged_param.mul_(1 - momentum).add_(source_param, alpha=momentum)
diff --git a/mmdet/models/layers/inverted_residual.py b/mmdet/models/layers/inverted_residual.py
new file mode 100644
index 0000000000000000000000000000000000000000..a34e72d85784de84ee30132065e8376719b5d91f
--- /dev/null
+++ b/mmdet/models/layers/inverted_residual.py
@@ -0,0 +1,130 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch.nn as nn
+import torch.utils.checkpoint as cp
+from mmcv.cnn import ConvModule
+from mmcv.cnn.bricks import DropPath
+from mmengine.model import BaseModule
+
+from .se_layer import SELayer
+
+
+class InvertedResidual(BaseModule):
+ """Inverted Residual Block.
+
+ Args:
+ in_channels (int): The input channels of this Module.
+ out_channels (int): The output channels of this Module.
+ mid_channels (int): The input channels of the depthwise convolution.
+ kernel_size (int): The kernel size of the depthwise convolution.
+ Default: 3.
+ stride (int): The stride of the depthwise convolution. Default: 1.
+ se_cfg (dict): Config dict for se layer. Default: None, which means no
+ se layer.
+ with_expand_conv (bool): Use expand conv or not. If set False,
+ mid_channels must be the same with in_channels.
+ Default: True.
+ conv_cfg (dict): Config dict for convolution layer. Default: None,
+ which means using conv2d.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='BN').
+ act_cfg (dict): Config dict for activation layer.
+ Default: dict(type='ReLU').
+ drop_path_rate (float): stochastic depth rate. Defaults to 0.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+
+ Returns:
+ Tensor: The output tensor.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ mid_channels,
+ kernel_size=3,
+ stride=1,
+ se_cfg=None,
+ with_expand_conv=True,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ drop_path_rate=0.,
+ with_cp=False,
+ init_cfg=None):
+ super(InvertedResidual, self).__init__(init_cfg)
+ self.with_res_shortcut = (stride == 1 and in_channels == out_channels)
+ # assert stride in [1, 2], f'stride must in [1, 2]. ' \
+ # f'But received {stride}.'
+ self.with_cp = with_cp
+ self.drop_path = DropPath(
+ drop_path_rate) if drop_path_rate > 0 else nn.Identity()
+ self.with_se = se_cfg is not None
+ self.with_expand_conv = with_expand_conv
+
+ if self.with_se:
+ assert isinstance(se_cfg, dict)
+ if not self.with_expand_conv:
+ assert mid_channels == in_channels
+
+ if self.with_expand_conv:
+ self.expand_conv = ConvModule(
+ in_channels=in_channels,
+ out_channels=mid_channels,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ self.depthwise_conv = ConvModule(
+ in_channels=mid_channels,
+ out_channels=mid_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=kernel_size // 2,
+ groups=mid_channels,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+
+ if self.with_se:
+ self.se = SELayer(**se_cfg)
+
+ self.linear_conv = ConvModule(
+ in_channels=mid_channels,
+ out_channels=out_channels,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=None)
+
+ def forward(self, x):
+
+ def _inner_forward(x):
+ out = x
+
+ if self.with_expand_conv:
+ out = self.expand_conv(out)
+
+ out = self.depthwise_conv(out)
+
+ if self.with_se:
+ out = self.se(out)
+
+ out = self.linear_conv(out)
+
+ if self.with_res_shortcut:
+ return x + self.drop_path(out)
+ else:
+ return out
+
+ if self.with_cp and x.requires_grad:
+ out = cp.checkpoint(_inner_forward, x)
+ else:
+ out = _inner_forward(x)
+
+ return out
diff --git a/mmdet/models/layers/matrix_nms.py b/mmdet/models/layers/matrix_nms.py
new file mode 100644
index 0000000000000000000000000000000000000000..9dc8c4f74e28127fb69ccc684f0bdb2bd3943b20
--- /dev/null
+++ b/mmdet/models/layers/matrix_nms.py
@@ -0,0 +1,121 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+
+
+def mask_matrix_nms(masks,
+ labels,
+ scores,
+ filter_thr=-1,
+ nms_pre=-1,
+ max_num=-1,
+ kernel='gaussian',
+ sigma=2.0,
+ mask_area=None):
+ """Matrix NMS for multi-class masks.
+
+ Args:
+ masks (Tensor): Has shape (num_instances, h, w)
+ labels (Tensor): Labels of corresponding masks,
+ has shape (num_instances,).
+ scores (Tensor): Mask scores of corresponding masks,
+ has shape (num_instances).
+ filter_thr (float): Score threshold to filter the masks
+ after matrix nms. Default: -1, which means do not
+ use filter_thr.
+ nms_pre (int): The max number of instances to do the matrix nms.
+ Default: -1, which means do not use nms_pre.
+ max_num (int, optional): If there are more than max_num masks after
+ matrix, only top max_num will be kept. Default: -1, which means
+ do not use max_num.
+ kernel (str): 'linear' or 'gaussian'.
+ sigma (float): std in gaussian method.
+ mask_area (Tensor): The sum of seg_masks.
+
+ Returns:
+ tuple(Tensor): Processed mask results.
+
+ - scores (Tensor): Updated scores, has shape (n,).
+ - labels (Tensor): Remained labels, has shape (n,).
+ - masks (Tensor): Remained masks, has shape (n, w, h).
+ - keep_inds (Tensor): The indices number of
+ the remaining mask in the input mask, has shape (n,).
+ """
+ assert len(labels) == len(masks) == len(scores)
+ if len(labels) == 0:
+ return scores.new_zeros(0), labels.new_zeros(0), masks.new_zeros(
+ 0, *masks.shape[-2:]), labels.new_zeros(0)
+ if mask_area is None:
+ mask_area = masks.sum((1, 2)).float()
+ else:
+ assert len(masks) == len(mask_area)
+
+ # sort and keep top nms_pre
+ scores, sort_inds = torch.sort(scores, descending=True)
+
+ keep_inds = sort_inds
+ if nms_pre > 0 and len(sort_inds) > nms_pre:
+ sort_inds = sort_inds[:nms_pre]
+ keep_inds = keep_inds[:nms_pre]
+ scores = scores[:nms_pre]
+ masks = masks[sort_inds]
+ mask_area = mask_area[sort_inds]
+ labels = labels[sort_inds]
+
+ num_masks = len(labels)
+ flatten_masks = masks.reshape(num_masks, -1).float()
+ # inter.
+ inter_matrix = torch.mm(flatten_masks, flatten_masks.transpose(1, 0))
+ expanded_mask_area = mask_area.expand(num_masks, num_masks)
+ # Upper triangle iou matrix.
+ iou_matrix = (inter_matrix /
+ (expanded_mask_area + expanded_mask_area.transpose(1, 0) -
+ inter_matrix)).triu(diagonal=1)
+ # label_specific matrix.
+ expanded_labels = labels.expand(num_masks, num_masks)
+ # Upper triangle label matrix.
+ label_matrix = (expanded_labels == expanded_labels.transpose(
+ 1, 0)).triu(diagonal=1)
+
+ # IoU compensation
+ compensate_iou, _ = (iou_matrix * label_matrix).max(0)
+ compensate_iou = compensate_iou.expand(num_masks,
+ num_masks).transpose(1, 0)
+
+ # IoU decay
+ decay_iou = iou_matrix * label_matrix
+
+ # Calculate the decay_coefficient
+ if kernel == 'gaussian':
+ decay_matrix = torch.exp(-1 * sigma * (decay_iou**2))
+ compensate_matrix = torch.exp(-1 * sigma * (compensate_iou**2))
+ decay_coefficient, _ = (decay_matrix / compensate_matrix).min(0)
+ elif kernel == 'linear':
+ decay_matrix = (1 - decay_iou) / (1 - compensate_iou)
+ decay_coefficient, _ = decay_matrix.min(0)
+ else:
+ raise NotImplementedError(
+ f'{kernel} kernel is not supported in matrix nms!')
+ # update the score.
+ scores = scores * decay_coefficient
+
+ if filter_thr > 0:
+ keep = scores >= filter_thr
+ keep_inds = keep_inds[keep]
+ if not keep.any():
+ return scores.new_zeros(0), labels.new_zeros(0), masks.new_zeros(
+ 0, *masks.shape[-2:]), labels.new_zeros(0)
+ masks = masks[keep]
+ scores = scores[keep]
+ labels = labels[keep]
+
+ # sort and keep top max_num
+ scores, sort_inds = torch.sort(scores, descending=True)
+ keep_inds = keep_inds[sort_inds]
+ if max_num > 0 and len(sort_inds) > max_num:
+ sort_inds = sort_inds[:max_num]
+ keep_inds = keep_inds[:max_num]
+ scores = scores[:max_num]
+ masks = masks[sort_inds]
+ labels = labels[sort_inds]
+
+ return scores, labels, masks, keep_inds
diff --git a/mmdet/models/layers/msdeformattn_pixel_decoder.py b/mmdet/models/layers/msdeformattn_pixel_decoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..93a1c8e731d2153c9c9110afea72fc4ae045f0ae
--- /dev/null
+++ b/mmdet/models/layers/msdeformattn_pixel_decoder.py
@@ -0,0 +1,247 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Tuple, Union
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import Conv2d, ConvModule
+from mmcv.cnn.bricks.transformer import MultiScaleDeformableAttention
+from mmengine.model import (BaseModule, ModuleList, caffe2_xavier_init,
+ normal_init, xavier_init)
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.utils import ConfigType, OptMultiConfig
+from ..task_modules.prior_generators import MlvlPointGenerator
+from .positional_encoding import SinePositionalEncoding
+from .transformer import Mask2FormerTransformerEncoder
+
+
+@MODELS.register_module()
+class MSDeformAttnPixelDecoder(BaseModule):
+ """Pixel decoder with multi-scale deformable attention.
+
+ Args:
+ in_channels (list[int] | tuple[int]): Number of channels in the
+ input feature maps.
+ strides (list[int] | tuple[int]): Output strides of feature from
+ backbone.
+ feat_channels (int): Number of channels for feature.
+ out_channels (int): Number of channels for output.
+ num_outs (int): Number of output scales.
+ norm_cfg (:obj:`ConfigDict` or dict): Config for normalization.
+ Defaults to dict(type='GN', num_groups=32).
+ act_cfg (:obj:`ConfigDict` or dict): Config for activation.
+ Defaults to dict(type='ReLU').
+ encoder (:obj:`ConfigDict` or dict): Config for transformer
+ encoder. Defaults to None.
+ positional_encoding (:obj:`ConfigDict` or dict): Config for
+ transformer encoder position encoding. Defaults to
+ dict(num_feats=128, normalize=True).
+ init_cfg (:obj:`ConfigDict` or dict or list[:obj:`ConfigDict` or \
+ dict], optional): Initialization config dict. Defaults to None.
+ """
+
+ def __init__(self,
+ in_channels: Union[List[int],
+ Tuple[int]] = [256, 512, 1024, 2048],
+ strides: Union[List[int], Tuple[int]] = [4, 8, 16, 32],
+ feat_channels: int = 256,
+ out_channels: int = 256,
+ num_outs: int = 3,
+ norm_cfg: ConfigType = dict(type='GN', num_groups=32),
+ act_cfg: ConfigType = dict(type='ReLU'),
+ encoder: ConfigType = None,
+ positional_encoding: ConfigType = dict(
+ num_feats=128, normalize=True),
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(init_cfg=init_cfg)
+ self.strides = strides
+ self.num_input_levels = len(in_channels)
+ self.num_encoder_levels = \
+ encoder.layer_cfg.self_attn_cfg.num_levels
+ assert self.num_encoder_levels >= 1, \
+ 'num_levels in attn_cfgs must be at least one'
+ input_conv_list = []
+ # from top to down (low to high resolution)
+ for i in range(self.num_input_levels - 1,
+ self.num_input_levels - self.num_encoder_levels - 1,
+ -1):
+ input_conv = ConvModule(
+ in_channels[i],
+ feat_channels,
+ kernel_size=1,
+ norm_cfg=norm_cfg,
+ act_cfg=None,
+ bias=True)
+ input_conv_list.append(input_conv)
+ self.input_convs = ModuleList(input_conv_list)
+
+ self.encoder = Mask2FormerTransformerEncoder(**encoder)
+ self.postional_encoding = SinePositionalEncoding(**positional_encoding)
+ # high resolution to low resolution
+ self.level_encoding = nn.Embedding(self.num_encoder_levels,
+ feat_channels)
+
+ # fpn-like structure
+ self.lateral_convs = ModuleList()
+ self.output_convs = ModuleList()
+ self.use_bias = norm_cfg is None
+ # from top to down (low to high resolution)
+ # fpn for the rest features that didn't pass in encoder
+ for i in range(self.num_input_levels - self.num_encoder_levels - 1, -1,
+ -1):
+ lateral_conv = ConvModule(
+ in_channels[i],
+ feat_channels,
+ kernel_size=1,
+ bias=self.use_bias,
+ norm_cfg=norm_cfg,
+ act_cfg=None)
+ output_conv = ConvModule(
+ feat_channels,
+ feat_channels,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ bias=self.use_bias,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ self.lateral_convs.append(lateral_conv)
+ self.output_convs.append(output_conv)
+
+ self.mask_feature = Conv2d(
+ feat_channels, out_channels, kernel_size=1, stride=1, padding=0)
+
+ self.num_outs = num_outs
+ self.point_generator = MlvlPointGenerator(strides)
+
+ def init_weights(self) -> None:
+ """Initialize weights."""
+ for i in range(0, self.num_encoder_levels):
+ xavier_init(
+ self.input_convs[i].conv,
+ gain=1,
+ bias=0,
+ distribution='uniform')
+
+ for i in range(0, self.num_input_levels - self.num_encoder_levels):
+ caffe2_xavier_init(self.lateral_convs[i].conv, bias=0)
+ caffe2_xavier_init(self.output_convs[i].conv, bias=0)
+
+ caffe2_xavier_init(self.mask_feature, bias=0)
+
+ normal_init(self.level_encoding, mean=0, std=1)
+ for p in self.encoder.parameters():
+ if p.dim() > 1:
+ nn.init.xavier_normal_(p)
+
+ # init_weights defined in MultiScaleDeformableAttention
+ for m in self.encoder.layers.modules():
+ if isinstance(m, MultiScaleDeformableAttention):
+ m.init_weights()
+
+ def forward(self, feats: List[Tensor]) -> Tuple[Tensor, Tensor]:
+ """
+ Args:
+ feats (list[Tensor]): Feature maps of each level. Each has
+ shape of (batch_size, c, h, w).
+
+ Returns:
+ tuple: A tuple containing the following:
+
+ - mask_feature (Tensor): shape (batch_size, c, h, w).
+ - multi_scale_features (list[Tensor]): Multi scale \
+ features, each in shape (batch_size, c, h, w).
+ """
+ # generate padding mask for each level, for each image
+ batch_size = feats[0].shape[0]
+ encoder_input_list = []
+ padding_mask_list = []
+ level_positional_encoding_list = []
+ spatial_shapes = []
+ reference_points_list = []
+ for i in range(self.num_encoder_levels):
+ level_idx = self.num_input_levels - i - 1
+ feat = feats[level_idx]
+ feat_projected = self.input_convs[i](feat)
+ h, w = feat.shape[-2:]
+
+ # no padding
+ padding_mask_resized = feat.new_zeros(
+ (batch_size, ) + feat.shape[-2:], dtype=torch.bool)
+ pos_embed = self.postional_encoding(padding_mask_resized)
+ level_embed = self.level_encoding.weight[i]
+ level_pos_embed = level_embed.view(1, -1, 1, 1) + pos_embed
+ # (h_i * w_i, 2)
+ reference_points = self.point_generator.single_level_grid_priors(
+ feat.shape[-2:], level_idx, device=feat.device)
+ # normalize
+ factor = feat.new_tensor([[w, h]]) * self.strides[level_idx]
+ reference_points = reference_points / factor
+
+ # shape (batch_size, c, h_i, w_i) -> (h_i * w_i, batch_size, c)
+ feat_projected = feat_projected.flatten(2).permute(0, 2, 1)
+ level_pos_embed = level_pos_embed.flatten(2).permute(0, 2, 1)
+ padding_mask_resized = padding_mask_resized.flatten(1)
+
+ encoder_input_list.append(feat_projected)
+ padding_mask_list.append(padding_mask_resized)
+ level_positional_encoding_list.append(level_pos_embed)
+ spatial_shapes.append(feat.shape[-2:])
+ reference_points_list.append(reference_points)
+ # shape (batch_size, total_num_queries),
+ # total_num_queries=sum([., h_i * w_i,.])
+ padding_masks = torch.cat(padding_mask_list, dim=1)
+ # shape (total_num_queries, batch_size, c)
+ encoder_inputs = torch.cat(encoder_input_list, dim=1)
+ level_positional_encodings = torch.cat(
+ level_positional_encoding_list, dim=1)
+ device = encoder_inputs.device
+ # shape (num_encoder_levels, 2), from low
+ # resolution to high resolution
+ spatial_shapes = torch.as_tensor(
+ spatial_shapes, dtype=torch.long, device=device)
+ # shape (0, h_0*w_0, h_0*w_0+h_1*w_1, ...)
+ level_start_index = torch.cat((spatial_shapes.new_zeros(
+ (1, )), spatial_shapes.prod(1).cumsum(0)[:-1]))
+ reference_points = torch.cat(reference_points_list, dim=0)
+ reference_points = reference_points[None, :, None].repeat(
+ batch_size, 1, self.num_encoder_levels, 1)
+ valid_radios = reference_points.new_ones(
+ (batch_size, self.num_encoder_levels, 2))
+ # shape (num_total_queries, batch_size, c)
+ memory = self.encoder(
+ query=encoder_inputs,
+ query_pos=level_positional_encodings,
+ key_padding_mask=padding_masks,
+ spatial_shapes=spatial_shapes,
+ reference_points=reference_points,
+ level_start_index=level_start_index,
+ valid_ratios=valid_radios)
+ # (batch_size, c, num_total_queries)
+ memory = memory.permute(0, 2, 1)
+
+ # from low resolution to high resolution
+ num_queries_per_level = [e[0] * e[1] for e in spatial_shapes]
+ outs = torch.split(memory, num_queries_per_level, dim=-1)
+ outs = [
+ x.reshape(batch_size, -1, spatial_shapes[i][0],
+ spatial_shapes[i][1]) for i, x in enumerate(outs)
+ ]
+
+ for i in range(self.num_input_levels - self.num_encoder_levels - 1, -1,
+ -1):
+ x = feats[i]
+ cur_feat = self.lateral_convs[i](x)
+ y = cur_feat + F.interpolate(
+ outs[-1],
+ size=cur_feat.shape[-2:],
+ mode='bilinear',
+ align_corners=False)
+ y = self.output_convs[i](y)
+ outs.append(y)
+ multi_scale_features = outs[:self.num_outs]
+
+ mask_feature = self.mask_feature(outs[-1])
+ return mask_feature, multi_scale_features
diff --git a/mmdet/models/layers/normed_predictor.py b/mmdet/models/layers/normed_predictor.py
new file mode 100644
index 0000000000000000000000000000000000000000..9fb40c71c425ee1e01af255186be7517cd63552a
--- /dev/null
+++ b/mmdet/models/layers/normed_predictor.py
@@ -0,0 +1,98 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from torch import Tensor
+
+from mmdet.registry import MODELS
+
+MODELS.register_module('Linear', module=nn.Linear)
+
+
+@MODELS.register_module(name='NormedLinear')
+class NormedLinear(nn.Linear):
+ """Normalized Linear Layer.
+
+ Args:
+ tempeature (float, optional): Tempeature term. Defaults to 20.
+ power (int, optional): Power term. Defaults to 1.0.
+ eps (float, optional): The minimal value of divisor to
+ keep numerical stability. Defaults to 1e-6.
+ """
+
+ def __init__(self,
+ *args,
+ tempearture: float = 20,
+ power: int = 1.0,
+ eps: float = 1e-6,
+ **kwargs) -> None:
+ super().__init__(*args, **kwargs)
+ self.tempearture = tempearture
+ self.power = power
+ self.eps = eps
+ self.init_weights()
+
+ def init_weights(self) -> None:
+ """Initialize the weights."""
+ nn.init.normal_(self.weight, mean=0, std=0.01)
+ if self.bias is not None:
+ nn.init.constant_(self.bias, 0)
+
+ def forward(self, x: Tensor) -> Tensor:
+ """Forward function for `NormedLinear`."""
+ weight_ = self.weight / (
+ self.weight.norm(dim=1, keepdim=True).pow(self.power) + self.eps)
+ x_ = x / (x.norm(dim=1, keepdim=True).pow(self.power) + self.eps)
+ x_ = x_ * self.tempearture
+
+ return F.linear(x_, weight_, self.bias)
+
+
+@MODELS.register_module(name='NormedConv2d')
+class NormedConv2d(nn.Conv2d):
+ """Normalized Conv2d Layer.
+
+ Args:
+ tempeature (float, optional): Tempeature term. Defaults to 20.
+ power (int, optional): Power term. Defaults to 1.0.
+ eps (float, optional): The minimal value of divisor to
+ keep numerical stability. Defaults to 1e-6.
+ norm_over_kernel (bool, optional): Normalize over kernel.
+ Defaults to False.
+ """
+
+ def __init__(self,
+ *args,
+ tempearture: float = 20,
+ power: int = 1.0,
+ eps: float = 1e-6,
+ norm_over_kernel: bool = False,
+ **kwargs) -> None:
+ super().__init__(*args, **kwargs)
+ self.tempearture = tempearture
+ self.power = power
+ self.norm_over_kernel = norm_over_kernel
+ self.eps = eps
+
+ def forward(self, x: Tensor) -> Tensor:
+ """Forward function for `NormedConv2d`."""
+ if not self.norm_over_kernel:
+ weight_ = self.weight / (
+ self.weight.norm(dim=1, keepdim=True).pow(self.power) +
+ self.eps)
+ else:
+ weight_ = self.weight / (
+ self.weight.view(self.weight.size(0), -1).norm(
+ dim=1, keepdim=True).pow(self.power)[..., None, None] +
+ self.eps)
+ x_ = x / (x.norm(dim=1, keepdim=True).pow(self.power) + self.eps)
+ x_ = x_ * self.tempearture
+
+ if hasattr(self, 'conv2d_forward'):
+ x_ = self.conv2d_forward(x_, weight_)
+ else:
+ if torch.__version__ >= '1.8':
+ x_ = self._conv_forward(x_, weight_, self.bias)
+ else:
+ x_ = self._conv_forward(x_, weight_)
+ return x_
diff --git a/mmdet/models/layers/pixel_decoder.py b/mmdet/models/layers/pixel_decoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..fb61434045eb9996276518577800132e4a25eb3e
--- /dev/null
+++ b/mmdet/models/layers/pixel_decoder.py
@@ -0,0 +1,249 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Tuple, Union
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import Conv2d, ConvModule
+from mmengine.model import BaseModule, ModuleList, caffe2_xavier_init
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.utils import ConfigType, OptMultiConfig
+from .positional_encoding import SinePositionalEncoding
+from .transformer import DetrTransformerEncoder
+
+
+@MODELS.register_module()
+class PixelDecoder(BaseModule):
+ """Pixel decoder with a structure like fpn.
+
+ Args:
+ in_channels (list[int] | tuple[int]): Number of channels in the
+ input feature maps.
+ feat_channels (int): Number channels for feature.
+ out_channels (int): Number channels for output.
+ norm_cfg (:obj:`ConfigDict` or dict): Config for normalization.
+ Defaults to dict(type='GN', num_groups=32).
+ act_cfg (:obj:`ConfigDict` or dict): Config for activation.
+ Defaults to dict(type='ReLU').
+ encoder (:obj:`ConfigDict` or dict): Config for transorformer
+ encoder.Defaults to None.
+ positional_encoding (:obj:`ConfigDict` or dict): Config for
+ transformer encoder position encoding. Defaults to
+ dict(type='SinePositionalEncoding', num_feats=128,
+ normalize=True).
+ init_cfg (:obj:`ConfigDict` or dict or list[:obj:`ConfigDict` or \
+ dict], optional): Initialization config dict. Defaults to None.
+ """
+
+ def __init__(self,
+ in_channels: Union[List[int], Tuple[int]],
+ feat_channels: int,
+ out_channels: int,
+ norm_cfg: ConfigType = dict(type='GN', num_groups=32),
+ act_cfg: ConfigType = dict(type='ReLU'),
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(init_cfg=init_cfg)
+ self.in_channels = in_channels
+ self.num_inputs = len(in_channels)
+ self.lateral_convs = ModuleList()
+ self.output_convs = ModuleList()
+ self.use_bias = norm_cfg is None
+ for i in range(0, self.num_inputs - 1):
+ lateral_conv = ConvModule(
+ in_channels[i],
+ feat_channels,
+ kernel_size=1,
+ bias=self.use_bias,
+ norm_cfg=norm_cfg,
+ act_cfg=None)
+ output_conv = ConvModule(
+ feat_channels,
+ feat_channels,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ bias=self.use_bias,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ self.lateral_convs.append(lateral_conv)
+ self.output_convs.append(output_conv)
+
+ self.last_feat_conv = ConvModule(
+ in_channels[-1],
+ feat_channels,
+ kernel_size=3,
+ padding=1,
+ stride=1,
+ bias=self.use_bias,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ self.mask_feature = Conv2d(
+ feat_channels, out_channels, kernel_size=3, stride=1, padding=1)
+
+ def init_weights(self) -> None:
+ """Initialize weights."""
+ for i in range(0, self.num_inputs - 2):
+ caffe2_xavier_init(self.lateral_convs[i].conv, bias=0)
+ caffe2_xavier_init(self.output_convs[i].conv, bias=0)
+
+ caffe2_xavier_init(self.mask_feature, bias=0)
+ caffe2_xavier_init(self.last_feat_conv, bias=0)
+
+ def forward(self, feats: List[Tensor],
+ batch_img_metas: List[dict]) -> Tuple[Tensor, Tensor]:
+ """
+ Args:
+ feats (list[Tensor]): Feature maps of each level. Each has
+ shape of (batch_size, c, h, w).
+ batch_img_metas (list[dict]): List of image information.
+ Pass in for creating more accurate padding mask. Not
+ used here.
+
+ Returns:
+ tuple[Tensor, Tensor]: a tuple containing the following:
+
+ - mask_feature (Tensor): Shape (batch_size, c, h, w).
+ - memory (Tensor): Output of last stage of backbone.\
+ Shape (batch_size, c, h, w).
+ """
+ y = self.last_feat_conv(feats[-1])
+ for i in range(self.num_inputs - 2, -1, -1):
+ x = feats[i]
+ cur_feat = self.lateral_convs[i](x)
+ y = cur_feat + \
+ F.interpolate(y, size=cur_feat.shape[-2:], mode='nearest')
+ y = self.output_convs[i](y)
+
+ mask_feature = self.mask_feature(y)
+ memory = feats[-1]
+ return mask_feature, memory
+
+
+@MODELS.register_module()
+class TransformerEncoderPixelDecoder(PixelDecoder):
+ """Pixel decoder with transormer encoder inside.
+
+ Args:
+ in_channels (list[int] | tuple[int]): Number of channels in the
+ input feature maps.
+ feat_channels (int): Number channels for feature.
+ out_channels (int): Number channels for output.
+ norm_cfg (:obj:`ConfigDict` or dict): Config for normalization.
+ Defaults to dict(type='GN', num_groups=32).
+ act_cfg (:obj:`ConfigDict` or dict): Config for activation.
+ Defaults to dict(type='ReLU').
+ encoder (:obj:`ConfigDict` or dict): Config for transformer encoder.
+ Defaults to None.
+ positional_encoding (:obj:`ConfigDict` or dict): Config for
+ transformer encoder position encoding. Defaults to
+ dict(num_feats=128, normalize=True).
+ init_cfg (:obj:`ConfigDict` or dict or list[:obj:`ConfigDict` or \
+ dict], optional): Initialization config dict. Defaults to None.
+ """
+
+ def __init__(self,
+ in_channels: Union[List[int], Tuple[int]],
+ feat_channels: int,
+ out_channels: int,
+ norm_cfg: ConfigType = dict(type='GN', num_groups=32),
+ act_cfg: ConfigType = dict(type='ReLU'),
+ encoder: ConfigType = None,
+ positional_encoding: ConfigType = dict(
+ num_feats=128, normalize=True),
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(
+ in_channels=in_channels,
+ feat_channels=feat_channels,
+ out_channels=out_channels,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ init_cfg=init_cfg)
+ self.last_feat_conv = None
+
+ self.encoder = DetrTransformerEncoder(**encoder)
+ self.encoder_embed_dims = self.encoder.embed_dims
+ assert self.encoder_embed_dims == feat_channels, 'embed_dims({}) of ' \
+ 'tranformer encoder must equal to feat_channels({})'.format(
+ feat_channels, self.encoder_embed_dims)
+ self.positional_encoding = SinePositionalEncoding(
+ **positional_encoding)
+ self.encoder_in_proj = Conv2d(
+ in_channels[-1], feat_channels, kernel_size=1)
+ self.encoder_out_proj = ConvModule(
+ feat_channels,
+ feat_channels,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ bias=self.use_bias,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+
+ def init_weights(self) -> None:
+ """Initialize weights."""
+ for i in range(0, self.num_inputs - 2):
+ caffe2_xavier_init(self.lateral_convs[i].conv, bias=0)
+ caffe2_xavier_init(self.output_convs[i].conv, bias=0)
+
+ caffe2_xavier_init(self.mask_feature, bias=0)
+ caffe2_xavier_init(self.encoder_in_proj, bias=0)
+ caffe2_xavier_init(self.encoder_out_proj.conv, bias=0)
+
+ for p in self.encoder.parameters():
+ if p.dim() > 1:
+ nn.init.xavier_uniform_(p)
+
+ def forward(self, feats: List[Tensor],
+ batch_img_metas: List[dict]) -> Tuple[Tensor, Tensor]:
+ """
+ Args:
+ feats (list[Tensor]): Feature maps of each level. Each has
+ shape of (batch_size, c, h, w).
+ batch_img_metas (list[dict]): List of image information. Pass in
+ for creating more accurate padding mask.
+
+ Returns:
+ tuple: a tuple containing the following:
+
+ - mask_feature (Tensor): shape (batch_size, c, h, w).
+ - memory (Tensor): shape (batch_size, c, h, w).
+ """
+ feat_last = feats[-1]
+ bs, c, h, w = feat_last.shape
+ input_img_h, input_img_w = batch_img_metas[0]['batch_input_shape']
+ padding_mask = feat_last.new_ones((bs, input_img_h, input_img_w),
+ dtype=torch.float32)
+ for i in range(bs):
+ img_h, img_w = batch_img_metas[i]['img_shape']
+ padding_mask[i, :img_h, :img_w] = 0
+ padding_mask = F.interpolate(
+ padding_mask.unsqueeze(1),
+ size=feat_last.shape[-2:],
+ mode='nearest').to(torch.bool).squeeze(1)
+
+ pos_embed = self.positional_encoding(padding_mask)
+ feat_last = self.encoder_in_proj(feat_last)
+ # (batch_size, c, h, w) -> (batch_size, num_queries, c)
+ feat_last = feat_last.flatten(2).permute(0, 2, 1)
+ pos_embed = pos_embed.flatten(2).permute(0, 2, 1)
+ # (batch_size, h, w) -> (batch_size, h*w)
+ padding_mask = padding_mask.flatten(1)
+ memory = self.encoder(
+ query=feat_last,
+ query_pos=pos_embed,
+ key_padding_mask=padding_mask)
+ # (batch_size, num_queries, c) -> (batch_size, c, h, w)
+ memory = memory.permute(0, 2, 1).view(bs, self.encoder_embed_dims, h,
+ w)
+ y = self.encoder_out_proj(memory)
+ for i in range(self.num_inputs - 2, -1, -1):
+ x = feats[i]
+ cur_feat = self.lateral_convs[i](x)
+ y = cur_feat + \
+ F.interpolate(y, size=cur_feat.shape[-2:], mode='nearest')
+ y = self.output_convs[i](y)
+
+ mask_feature = self.mask_feature(y)
+ return mask_feature, memory
diff --git a/mmdet/models/layers/positional_encoding.py b/mmdet/models/layers/positional_encoding.py
new file mode 100644
index 0000000000000000000000000000000000000000..9367f0aaf0ca5fddda66e9c7df425654c56e4776
--- /dev/null
+++ b/mmdet/models/layers/positional_encoding.py
@@ -0,0 +1,168 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+
+import torch
+import torch.nn as nn
+from mmengine.model import BaseModule
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.utils import MultiConfig, OptMultiConfig
+
+
+@MODELS.register_module()
+class SinePositionalEncoding(BaseModule):
+ """Position encoding with sine and cosine functions.
+
+ See `End-to-End Object Detection with Transformers
+ `_ for details.
+
+ Args:
+ num_feats (int): The feature dimension for each position
+ along x-axis or y-axis. Note the final returned dimension
+ for each position is 2 times of this value.
+ temperature (int, optional): The temperature used for scaling
+ the position embedding. Defaults to 10000.
+ normalize (bool, optional): Whether to normalize the position
+ embedding. Defaults to False.
+ scale (float, optional): A scale factor that scales the position
+ embedding. The scale will be used only when `normalize` is True.
+ Defaults to 2*pi.
+ eps (float, optional): A value added to the denominator for
+ numerical stability. Defaults to 1e-6.
+ offset (float): offset add to embed when do the normalization.
+ Defaults to 0.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Defaults to None
+ """
+
+ def __init__(self,
+ num_feats: int,
+ temperature: int = 10000,
+ normalize: bool = False,
+ scale: float = 2 * math.pi,
+ eps: float = 1e-6,
+ offset: float = 0.,
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(init_cfg=init_cfg)
+ if normalize:
+ assert isinstance(scale, (float, int)), 'when normalize is set,' \
+ 'scale should be provided and in float or int type, ' \
+ f'found {type(scale)}'
+ self.num_feats = num_feats
+ self.temperature = temperature
+ self.normalize = normalize
+ self.scale = scale
+ self.eps = eps
+ self.offset = offset
+
+ def forward(self, mask: Tensor) -> Tensor:
+ """Forward function for `SinePositionalEncoding`.
+
+ Args:
+ mask (Tensor): ByteTensor mask. Non-zero values representing
+ ignored positions, while zero values means valid positions
+ for this image. Shape [bs, h, w].
+
+ Returns:
+ pos (Tensor): Returned position embedding with shape
+ [bs, num_feats*2, h, w].
+ """
+ # For convenience of exporting to ONNX, it's required to convert
+ # `masks` from bool to int.
+ mask = mask.to(torch.int)
+ not_mask = 1 - mask # logical_not
+ y_embed = not_mask.cumsum(1, dtype=torch.float32)
+ x_embed = not_mask.cumsum(2, dtype=torch.float32)
+ if self.normalize:
+ y_embed = (y_embed + self.offset) / \
+ (y_embed[:, -1:, :] + self.eps) * self.scale
+ x_embed = (x_embed + self.offset) / \
+ (x_embed[:, :, -1:] + self.eps) * self.scale
+ dim_t = torch.arange(
+ self.num_feats, dtype=torch.float32, device=mask.device)
+ dim_t = self.temperature**(2 * (dim_t // 2) / self.num_feats)
+ pos_x = x_embed[:, :, :, None] / dim_t
+ pos_y = y_embed[:, :, :, None] / dim_t
+ # use `view` instead of `flatten` for dynamically exporting to ONNX
+ B, H, W = mask.size()
+ pos_x = torch.stack(
+ (pos_x[:, :, :, 0::2].sin(), pos_x[:, :, :, 1::2].cos()),
+ dim=4).view(B, H, W, -1)
+ pos_y = torch.stack(
+ (pos_y[:, :, :, 0::2].sin(), pos_y[:, :, :, 1::2].cos()),
+ dim=4).view(B, H, W, -1)
+ pos = torch.cat((pos_y, pos_x), dim=3).permute(0, 3, 1, 2)
+ return pos
+
+ def __repr__(self) -> str:
+ """str: a string that describes the module"""
+ repr_str = self.__class__.__name__
+ repr_str += f'(num_feats={self.num_feats}, '
+ repr_str += f'temperature={self.temperature}, '
+ repr_str += f'normalize={self.normalize}, '
+ repr_str += f'scale={self.scale}, '
+ repr_str += f'eps={self.eps})'
+ return repr_str
+
+
+@MODELS.register_module()
+class LearnedPositionalEncoding(BaseModule):
+ """Position embedding with learnable embedding weights.
+
+ Args:
+ num_feats (int): The feature dimension for each position
+ along x-axis or y-axis. The final returned dimension for
+ each position is 2 times of this value.
+ row_num_embed (int, optional): The dictionary size of row embeddings.
+ Defaults to 50.
+ col_num_embed (int, optional): The dictionary size of col embeddings.
+ Defaults to 50.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ """
+
+ def __init__(
+ self,
+ num_feats: int,
+ row_num_embed: int = 50,
+ col_num_embed: int = 50,
+ init_cfg: MultiConfig = dict(type='Uniform', layer='Embedding')
+ ) -> None:
+ super().__init__(init_cfg=init_cfg)
+ self.row_embed = nn.Embedding(row_num_embed, num_feats)
+ self.col_embed = nn.Embedding(col_num_embed, num_feats)
+ self.num_feats = num_feats
+ self.row_num_embed = row_num_embed
+ self.col_num_embed = col_num_embed
+
+ def forward(self, mask: Tensor) -> Tensor:
+ """Forward function for `LearnedPositionalEncoding`.
+
+ Args:
+ mask (Tensor): ByteTensor mask. Non-zero values representing
+ ignored positions, while zero values means valid positions
+ for this image. Shape [bs, h, w].
+
+ Returns:
+ pos (Tensor): Returned position embedding with shape
+ [bs, num_feats*2, h, w].
+ """
+ h, w = mask.shape[-2:]
+ x = torch.arange(w, device=mask.device)
+ y = torch.arange(h, device=mask.device)
+ x_embed = self.col_embed(x)
+ y_embed = self.row_embed(y)
+ pos = torch.cat(
+ (x_embed.unsqueeze(0).repeat(h, 1, 1), y_embed.unsqueeze(1).repeat(
+ 1, w, 1)),
+ dim=-1).permute(2, 0,
+ 1).unsqueeze(0).repeat(mask.shape[0], 1, 1, 1)
+ return pos
+
+ def __repr__(self) -> str:
+ """str: a string that describes the module"""
+ repr_str = self.__class__.__name__
+ repr_str += f'(num_feats={self.num_feats}, '
+ repr_str += f'row_num_embed={self.row_num_embed}, '
+ repr_str += f'col_num_embed={self.col_num_embed})'
+ return repr_str
diff --git a/mmdet/models/layers/res_layer.py b/mmdet/models/layers/res_layer.py
new file mode 100644
index 0000000000000000000000000000000000000000..ff24d3e8562d1c3c724b35f7dc10cafe48e47650
--- /dev/null
+++ b/mmdet/models/layers/res_layer.py
@@ -0,0 +1,195 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional
+
+from mmcv.cnn import build_conv_layer, build_norm_layer
+from mmengine.model import BaseModule, Sequential
+from torch import Tensor
+from torch import nn as nn
+
+from mmdet.utils import ConfigType, OptConfigType, OptMultiConfig
+
+
+class ResLayer(Sequential):
+ """ResLayer to build ResNet style backbone.
+
+ Args:
+ block (nn.Module): block used to build ResLayer.
+ inplanes (int): inplanes of block.
+ planes (int): planes of block.
+ num_blocks (int): number of blocks.
+ stride (int): stride of the first block. Defaults to 1
+ avg_down (bool): Use AvgPool instead of stride conv when
+ downsampling in the bottleneck. Defaults to False
+ conv_cfg (dict): dictionary to construct and config conv layer.
+ Defaults to None
+ norm_cfg (dict): dictionary to construct and config norm layer.
+ Defaults to dict(type='BN')
+ downsample_first (bool): Downsample at the first block or last block.
+ False for Hourglass, True for ResNet. Defaults to True
+ """
+
+ def __init__(self,
+ block: BaseModule,
+ inplanes: int,
+ planes: int,
+ num_blocks: int,
+ stride: int = 1,
+ avg_down: bool = False,
+ conv_cfg: OptConfigType = None,
+ norm_cfg: ConfigType = dict(type='BN'),
+ downsample_first: bool = True,
+ **kwargs) -> None:
+ self.block = block
+
+ downsample = None
+ if stride != 1 or inplanes != planes * block.expansion:
+ downsample = []
+ conv_stride = stride
+ if avg_down:
+ conv_stride = 1
+ downsample.append(
+ nn.AvgPool2d(
+ kernel_size=stride,
+ stride=stride,
+ ceil_mode=True,
+ count_include_pad=False))
+ downsample.extend([
+ build_conv_layer(
+ conv_cfg,
+ inplanes,
+ planes * block.expansion,
+ kernel_size=1,
+ stride=conv_stride,
+ bias=False),
+ build_norm_layer(norm_cfg, planes * block.expansion)[1]
+ ])
+ downsample = nn.Sequential(*downsample)
+
+ layers = []
+ if downsample_first:
+ layers.append(
+ block(
+ inplanes=inplanes,
+ planes=planes,
+ stride=stride,
+ downsample=downsample,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ **kwargs))
+ inplanes = planes * block.expansion
+ for _ in range(1, num_blocks):
+ layers.append(
+ block(
+ inplanes=inplanes,
+ planes=planes,
+ stride=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ **kwargs))
+
+ else: # downsample_first=False is for HourglassModule
+ for _ in range(num_blocks - 1):
+ layers.append(
+ block(
+ inplanes=inplanes,
+ planes=inplanes,
+ stride=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ **kwargs))
+ layers.append(
+ block(
+ inplanes=inplanes,
+ planes=planes,
+ stride=stride,
+ downsample=downsample,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ **kwargs))
+ super().__init__(*layers)
+
+
+class SimplifiedBasicBlock(BaseModule):
+ """Simplified version of original basic residual block. This is used in
+ `SCNet `_.
+
+ - Norm layer is now optional
+ - Last ReLU in forward function is removed
+ """
+ expansion = 1
+
+ def __init__(self,
+ inplanes: int,
+ planes: int,
+ stride: int = 1,
+ dilation: int = 1,
+ downsample: Optional[Sequential] = None,
+ style: ConfigType = 'pytorch',
+ with_cp: bool = False,
+ conv_cfg: OptConfigType = None,
+ norm_cfg: ConfigType = dict(type='BN'),
+ dcn: OptConfigType = None,
+ plugins: OptConfigType = None,
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(init_cfg=init_cfg)
+ assert dcn is None, 'Not implemented yet.'
+ assert plugins is None, 'Not implemented yet.'
+ assert not with_cp, 'Not implemented yet.'
+ self.with_norm = norm_cfg is not None
+ with_bias = True if norm_cfg is None else False
+ self.conv1 = build_conv_layer(
+ conv_cfg,
+ inplanes,
+ planes,
+ 3,
+ stride=stride,
+ padding=dilation,
+ dilation=dilation,
+ bias=with_bias)
+ if self.with_norm:
+ self.norm1_name, norm1 = build_norm_layer(
+ norm_cfg, planes, postfix=1)
+ self.add_module(self.norm1_name, norm1)
+ self.conv2 = build_conv_layer(
+ conv_cfg, planes, planes, 3, padding=1, bias=with_bias)
+ if self.with_norm:
+ self.norm2_name, norm2 = build_norm_layer(
+ norm_cfg, planes, postfix=2)
+ self.add_module(self.norm2_name, norm2)
+
+ self.relu = nn.ReLU(inplace=True)
+ self.downsample = downsample
+ self.stride = stride
+ self.dilation = dilation
+ self.with_cp = with_cp
+
+ @property
+ def norm1(self) -> Optional[BaseModule]:
+ """nn.Module: normalization layer after the first convolution layer"""
+ return getattr(self, self.norm1_name) if self.with_norm else None
+
+ @property
+ def norm2(self) -> Optional[BaseModule]:
+ """nn.Module: normalization layer after the second convolution layer"""
+ return getattr(self, self.norm2_name) if self.with_norm else None
+
+ def forward(self, x: Tensor) -> Tensor:
+ """Forward function for SimplifiedBasicBlock."""
+
+ identity = x
+
+ out = self.conv1(x)
+ if self.with_norm:
+ out = self.norm1(out)
+ out = self.relu(out)
+
+ out = self.conv2(out)
+ if self.with_norm:
+ out = self.norm2(out)
+
+ if self.downsample is not None:
+ identity = self.downsample(x)
+
+ out += identity
+
+ return out
diff --git a/mmdet/models/layers/se_layer.py b/mmdet/models/layers/se_layer.py
new file mode 100644
index 0000000000000000000000000000000000000000..5598dabaf6f3b3a09f4348fcd65ff39897b7068f
--- /dev/null
+++ b/mmdet/models/layers/se_layer.py
@@ -0,0 +1,162 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+from mmengine.model import BaseModule
+from mmengine.utils import digit_version, is_tuple_of
+from torch import Tensor
+
+from mmdet.utils import MultiConfig, OptConfigType, OptMultiConfig
+
+
+class SELayer(BaseModule):
+ """Squeeze-and-Excitation Module.
+
+ Args:
+ channels (int): The input (and output) channels of the SE layer.
+ ratio (int): Squeeze ratio in SELayer, the intermediate channel will be
+ ``int(channels/ratio)``. Defaults to 16.
+ conv_cfg (None or dict): Config dict for convolution layer.
+ Defaults to None, which means using conv2d.
+ act_cfg (dict or Sequence[dict]): Config dict for activation layer.
+ If act_cfg is a dict, two activation layers will be configurated
+ by this dict. If act_cfg is a sequence of dicts, the first
+ activation layer will be configurated by the first dict and the
+ second activation layer will be configurated by the second dict.
+ Defaults to (dict(type='ReLU'), dict(type='Sigmoid'))
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Defaults to None
+ """
+
+ def __init__(self,
+ channels: int,
+ ratio: int = 16,
+ conv_cfg: OptConfigType = None,
+ act_cfg: MultiConfig = (dict(type='ReLU'),
+ dict(type='Sigmoid')),
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(init_cfg=init_cfg)
+ if isinstance(act_cfg, dict):
+ act_cfg = (act_cfg, act_cfg)
+ assert len(act_cfg) == 2
+ assert is_tuple_of(act_cfg, dict)
+ self.global_avgpool = nn.AdaptiveAvgPool2d(1)
+ self.conv1 = ConvModule(
+ in_channels=channels,
+ out_channels=int(channels / ratio),
+ kernel_size=1,
+ stride=1,
+ conv_cfg=conv_cfg,
+ act_cfg=act_cfg[0])
+ self.conv2 = ConvModule(
+ in_channels=int(channels / ratio),
+ out_channels=channels,
+ kernel_size=1,
+ stride=1,
+ conv_cfg=conv_cfg,
+ act_cfg=act_cfg[1])
+
+ def forward(self, x: Tensor) -> Tensor:
+ """Forward function for SELayer."""
+ out = self.global_avgpool(x)
+ out = self.conv1(out)
+ out = self.conv2(out)
+ return x * out
+
+
+class DyReLU(BaseModule):
+ """Dynamic ReLU (DyReLU) module.
+
+ See `Dynamic ReLU `_ for details.
+ Current implementation is specialized for task-aware attention in DyHead.
+ HSigmoid arguments in default act_cfg follow DyHead official code.
+ https://github.com/microsoft/DynamicHead/blob/master/dyhead/dyrelu.py
+
+ Args:
+ channels (int): The input (and output) channels of DyReLU module.
+ ratio (int): Squeeze ratio in Squeeze-and-Excitation-like module,
+ the intermediate channel will be ``int(channels/ratio)``.
+ Defaults to 4.
+ conv_cfg (None or dict): Config dict for convolution layer.
+ Defaults to None, which means using conv2d.
+ act_cfg (dict or Sequence[dict]): Config dict for activation layer.
+ If act_cfg is a dict, two activation layers will be configurated
+ by this dict. If act_cfg is a sequence of dicts, the first
+ activation layer will be configurated by the first dict and the
+ second activation layer will be configurated by the second dict.
+ Defaults to (dict(type='ReLU'), dict(type='HSigmoid', bias=3.0,
+ divisor=6.0))
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Defaults to None
+ """
+
+ def __init__(self,
+ channels: int,
+ ratio: int = 4,
+ conv_cfg: OptConfigType = None,
+ act_cfg: MultiConfig = (dict(type='ReLU'),
+ dict(
+ type='HSigmoid',
+ bias=3.0,
+ divisor=6.0)),
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(init_cfg=init_cfg)
+ if isinstance(act_cfg, dict):
+ act_cfg = (act_cfg, act_cfg)
+ assert len(act_cfg) == 2
+ assert is_tuple_of(act_cfg, dict)
+ self.channels = channels
+ self.expansion = 4 # for a1, b1, a2, b2
+ self.global_avgpool = nn.AdaptiveAvgPool2d(1)
+ self.conv1 = ConvModule(
+ in_channels=channels,
+ out_channels=int(channels / ratio),
+ kernel_size=1,
+ stride=1,
+ conv_cfg=conv_cfg,
+ act_cfg=act_cfg[0])
+ self.conv2 = ConvModule(
+ in_channels=int(channels / ratio),
+ out_channels=channels * self.expansion,
+ kernel_size=1,
+ stride=1,
+ conv_cfg=conv_cfg,
+ act_cfg=act_cfg[1])
+
+ def forward(self, x: Tensor) -> Tensor:
+ """Forward function."""
+ coeffs = self.global_avgpool(x)
+ coeffs = self.conv1(coeffs)
+ coeffs = self.conv2(coeffs) - 0.5 # value range: [-0.5, 0.5]
+ a1, b1, a2, b2 = torch.split(coeffs, self.channels, dim=1)
+ a1 = a1 * 2.0 + 1.0 # [-1.0, 1.0] + 1.0
+ a2 = a2 * 2.0 # [-1.0, 1.0]
+ out = torch.max(x * a1 + b1, x * a2 + b2)
+ return out
+
+
+class ChannelAttention(BaseModule):
+ """Channel attention Module.
+
+ Args:
+ channels (int): The input (and output) channels of the attention layer.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Defaults to None
+ """
+
+ def __init__(self, channels: int, init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(init_cfg=init_cfg)
+ self.global_avgpool = nn.AdaptiveAvgPool2d(1)
+ self.fc = nn.Conv2d(channels, channels, 1, 1, 0, bias=True)
+ if digit_version(torch.__version__) < (1, 7, 0):
+ self.act = nn.Hardsigmoid()
+ else:
+ self.act = nn.Hardsigmoid(inplace=True)
+
+ def forward(self, x: Tensor) -> Tensor:
+ """Forward function for ChannelAttention."""
+ with torch.cuda.amp.autocast(enabled=False):
+ out = self.global_avgpool(x)
+ out = self.fc(out)
+ out = self.act(out)
+ return x * out
diff --git a/mmdet/models/layers/transformer/__init__.py b/mmdet/models/layers/transformer/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..0d70f845f8f48d1cabaab63ee33d65569d28a13e
--- /dev/null
+++ b/mmdet/models/layers/transformer/__init__.py
@@ -0,0 +1,35 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .conditional_detr_layers import (ConditionalDetrTransformerDecoder,
+ ConditionalDetrTransformerDecoderLayer)
+from .dab_detr_layers import (DABDetrTransformerDecoder,
+ DABDetrTransformerDecoderLayer,
+ DABDetrTransformerEncoder)
+from .deformable_detr_layers import (DeformableDetrTransformerDecoder,
+ DeformableDetrTransformerDecoderLayer,
+ DeformableDetrTransformerEncoder,
+ DeformableDetrTransformerEncoderLayer)
+from .detr_layers import (DetrTransformerDecoder, DetrTransformerDecoderLayer,
+ DetrTransformerEncoder, DetrTransformerEncoderLayer)
+from .dino_layers import CdnQueryGenerator, DinoTransformerDecoder
+from .mask2former_layers import (Mask2FormerTransformerDecoder,
+ Mask2FormerTransformerDecoderLayer,
+ Mask2FormerTransformerEncoder)
+from .utils import (MLP, AdaptivePadding, ConditionalAttention, DynamicConv,
+ PatchEmbed, PatchMerging, coordinate_to_encoding,
+ inverse_sigmoid, nchw_to_nlc, nlc_to_nchw)
+
+__all__ = [
+ 'nlc_to_nchw', 'nchw_to_nlc', 'AdaptivePadding', 'PatchEmbed',
+ 'PatchMerging', 'inverse_sigmoid', 'DynamicConv', 'MLP',
+ 'DetrTransformerEncoder', 'DetrTransformerDecoder',
+ 'DetrTransformerEncoderLayer', 'DetrTransformerDecoderLayer',
+ 'DeformableDetrTransformerEncoder', 'DeformableDetrTransformerDecoder',
+ 'DeformableDetrTransformerEncoderLayer',
+ 'DeformableDetrTransformerDecoderLayer', 'coordinate_to_encoding',
+ 'ConditionalAttention', 'DABDetrTransformerDecoderLayer',
+ 'DABDetrTransformerDecoder', 'DABDetrTransformerEncoder',
+ 'ConditionalDetrTransformerDecoder',
+ 'ConditionalDetrTransformerDecoderLayer', 'DinoTransformerDecoder',
+ 'CdnQueryGenerator', 'Mask2FormerTransformerEncoder',
+ 'Mask2FormerTransformerDecoderLayer', 'Mask2FormerTransformerDecoder'
+]
diff --git a/mmdet/models/layers/transformer/__pycache__/__init__.cpython-37.pyc b/mmdet/models/layers/transformer/__pycache__/__init__.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..9d914ed73cd54be0f6e2496f0b304905fe3e51f1
Binary files /dev/null and b/mmdet/models/layers/transformer/__pycache__/__init__.cpython-37.pyc differ
diff --git a/mmdet/models/layers/transformer/__pycache__/conditional_detr_layers.cpython-37.pyc b/mmdet/models/layers/transformer/__pycache__/conditional_detr_layers.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..7ec4cd5e64dd0ca919d0f2ec02c4665fe8a1b9e2
Binary files /dev/null and b/mmdet/models/layers/transformer/__pycache__/conditional_detr_layers.cpython-37.pyc differ
diff --git a/mmdet/models/layers/transformer/__pycache__/dab_detr_layers.cpython-37.pyc b/mmdet/models/layers/transformer/__pycache__/dab_detr_layers.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..917fa0596330ee95bf8cbb757977e6479cac656d
Binary files /dev/null and b/mmdet/models/layers/transformer/__pycache__/dab_detr_layers.cpython-37.pyc differ
diff --git a/mmdet/models/layers/transformer/__pycache__/deformable_detr_layers.cpython-37.pyc b/mmdet/models/layers/transformer/__pycache__/deformable_detr_layers.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..9f0dfd4b8a2b4525408e453232d2d85ab8940ce8
Binary files /dev/null and b/mmdet/models/layers/transformer/__pycache__/deformable_detr_layers.cpython-37.pyc differ
diff --git a/mmdet/models/layers/transformer/__pycache__/detr_layers.cpython-37.pyc b/mmdet/models/layers/transformer/__pycache__/detr_layers.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..4541d203b201f0e6c66ceeea8130f57ce00b3f35
Binary files /dev/null and b/mmdet/models/layers/transformer/__pycache__/detr_layers.cpython-37.pyc differ
diff --git a/mmdet/models/layers/transformer/__pycache__/dino_layers.cpython-37.pyc b/mmdet/models/layers/transformer/__pycache__/dino_layers.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..e6a93d140475b6fc5419727e1a2ae67ba428ba27
Binary files /dev/null and b/mmdet/models/layers/transformer/__pycache__/dino_layers.cpython-37.pyc differ
diff --git a/mmdet/models/layers/transformer/__pycache__/mask2former_layers.cpython-37.pyc b/mmdet/models/layers/transformer/__pycache__/mask2former_layers.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..18fe5c38892abbbc76b0f23dffb4e39da360b0e1
Binary files /dev/null and b/mmdet/models/layers/transformer/__pycache__/mask2former_layers.cpython-37.pyc differ
diff --git a/mmdet/models/layers/transformer/__pycache__/specdetr_atten.cpython-37.pyc b/mmdet/models/layers/transformer/__pycache__/specdetr_atten.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..102494353ed21b271c5cefb0cc7a08fc0eee4ee4
Binary files /dev/null and b/mmdet/models/layers/transformer/__pycache__/specdetr_atten.cpython-37.pyc differ
diff --git a/mmdet/models/layers/transformer/__pycache__/specdetr_layers.cpython-37.pyc b/mmdet/models/layers/transformer/__pycache__/specdetr_layers.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..599c2fc7075bbbc6d95a9b738716c8556525695a
Binary files /dev/null and b/mmdet/models/layers/transformer/__pycache__/specdetr_layers.cpython-37.pyc differ
diff --git a/mmdet/models/layers/transformer/__pycache__/utils.cpython-37.pyc b/mmdet/models/layers/transformer/__pycache__/utils.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..fee6a04a15e70242707947f4451034dd8c45b7e7
Binary files /dev/null and b/mmdet/models/layers/transformer/__pycache__/utils.cpython-37.pyc differ
diff --git a/mmdet/models/layers/transformer/conditional_detr_layers.py b/mmdet/models/layers/transformer/conditional_detr_layers.py
new file mode 100644
index 0000000000000000000000000000000000000000..6db12a1340c758996e8c0e96f0b21cbc6fa928c9
--- /dev/null
+++ b/mmdet/models/layers/transformer/conditional_detr_layers.py
@@ -0,0 +1,170 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+from mmcv.cnn import build_norm_layer
+from mmcv.cnn.bricks.transformer import FFN
+from torch import Tensor
+from torch.nn import ModuleList
+
+from .detr_layers import DetrTransformerDecoder, DetrTransformerDecoderLayer
+from .utils import MLP, ConditionalAttention, coordinate_to_encoding
+
+
+class ConditionalDetrTransformerDecoder(DetrTransformerDecoder):
+ """Decoder of Conditional DETR."""
+
+ def _init_layers(self) -> None:
+ """Initialize decoder layers and other layers."""
+ self.layers = ModuleList([
+ ConditionalDetrTransformerDecoderLayer(**self.layer_cfg)
+ for _ in range(self.num_layers)
+ ])
+ self.embed_dims = self.layers[0].embed_dims
+ self.post_norm = build_norm_layer(self.post_norm_cfg,
+ self.embed_dims)[1]
+ # conditional detr affline
+ self.query_scale = MLP(self.embed_dims, self.embed_dims,
+ self.embed_dims, 2)
+ self.ref_point_head = MLP(self.embed_dims, self.embed_dims, 2, 2)
+ # we have substitute 'qpos_proj' with 'qpos_sine_proj' except for
+ # the first decoder layer), so 'qpos_proj' should be deleted
+ # in other layers.
+ for layer_id in range(self.num_layers - 1):
+ self.layers[layer_id + 1].cross_attn.qpos_proj = None
+
+ def forward(self,
+ query: Tensor,
+ key: Tensor = None,
+ query_pos: Tensor = None,
+ key_pos: Tensor = None,
+ key_padding_mask: Tensor = None):
+ """Forward function of decoder.
+
+ Args:
+ query (Tensor): The input query with shape
+ (bs, num_queries, dim).
+ key (Tensor): The input key with shape (bs, num_keys, dim) If
+ `None`, the `query` will be used. Defaults to `None`.
+ query_pos (Tensor): The positional encoding for `query`, with the
+ same shape as `query`. If not `None`, it will be added to
+ `query` before forward function. Defaults to `None`.
+ key_pos (Tensor): The positional encoding for `key`, with the
+ same shape as `key`. If not `None`, it will be added to
+ `key` before forward function. If `None`, and `query_pos`
+ has the same shape as `key`, then `query_pos` will be used
+ as `key_pos`. Defaults to `None`.
+ key_padding_mask (Tensor): ByteTensor with shape (bs, num_keys).
+ Defaults to `None`.
+ Returns:
+ List[Tensor]: forwarded results with shape (num_decoder_layers,
+ bs, num_queries, dim) if `return_intermediate` is True, otherwise
+ with shape (1, bs, num_queries, dim). References with shape
+ (bs, num_queries, 2).
+ """
+ reference_unsigmoid = self.ref_point_head(
+ query_pos) # [bs, num_queries, 2]
+ reference = reference_unsigmoid.sigmoid()
+ reference_xy = reference[..., :2]
+ intermediate = []
+ for layer_id, layer in enumerate(self.layers):
+ if layer_id == 0:
+ pos_transformation = 1
+ else:
+ pos_transformation = self.query_scale(query)
+ # get sine embedding for the query reference
+ ref_sine_embed = coordinate_to_encoding(coord_tensor=reference_xy)
+ # apply transformation
+ ref_sine_embed = ref_sine_embed * pos_transformation
+ query = layer(
+ query,
+ key=key,
+ query_pos=query_pos,
+ key_pos=key_pos,
+ key_padding_mask=key_padding_mask,
+ ref_sine_embed=ref_sine_embed,
+ is_first=(layer_id == 0))
+ if self.return_intermediate:
+ intermediate.append(self.post_norm(query))
+
+ if self.return_intermediate:
+ return torch.stack(intermediate), reference
+
+ query = self.post_norm(query)
+ return query.unsqueeze(0), reference
+
+
+class ConditionalDetrTransformerDecoderLayer(DetrTransformerDecoderLayer):
+ """Implements decoder layer in Conditional DETR transformer."""
+
+ def _init_layers(self):
+ """Initialize self-attention, cross-attention, FFN, and
+ normalization."""
+ self.self_attn = ConditionalAttention(**self.self_attn_cfg)
+ self.cross_attn = ConditionalAttention(**self.cross_attn_cfg)
+ self.embed_dims = self.self_attn.embed_dims
+ self.ffn = FFN(**self.ffn_cfg)
+ norms_list = [
+ build_norm_layer(self.norm_cfg, self.embed_dims)[1]
+ for _ in range(3)
+ ]
+ self.norms = ModuleList(norms_list)
+
+ def forward(self,
+ query: Tensor,
+ key: Tensor = None,
+ query_pos: Tensor = None,
+ key_pos: Tensor = None,
+ self_attn_masks: Tensor = None,
+ cross_attn_masks: Tensor = None,
+ key_padding_mask: Tensor = None,
+ ref_sine_embed: Tensor = None,
+ is_first: bool = False):
+ """
+ Args:
+ query (Tensor): The input query, has shape (bs, num_queries, dim)
+ key (Tensor, optional): The input key, has shape (bs, num_keys,
+ dim). If `None`, the `query` will be used. Defaults to `None`.
+ query_pos (Tensor, optional): The positional encoding for `query`,
+ has the same shape as `query`. If not `None`, it will be
+ added to `query` before forward function. Defaults to `None`.
+ ref_sine_embed (Tensor): The positional encoding for query in
+ cross attention, with the same shape as `x`. Defaults to None.
+ key_pos (Tensor, optional): The positional encoding for `key`, has
+ the same shape as `key`. If not None, it will be added to
+ `key` before forward function. If None, and `query_pos` has
+ the same shape as `key`, then `query_pos` will be used for
+ `key_pos`. Defaults to None.
+ self_attn_masks (Tensor, optional): ByteTensor mask, has shape
+ (num_queries, num_keys), Same in `nn.MultiheadAttention.
+ forward`. Defaults to None.
+ cross_attn_masks (Tensor, optional): ByteTensor mask, has shape
+ (num_queries, num_keys), Same in `nn.MultiheadAttention.
+ forward`. Defaults to None.
+ key_padding_mask (Tensor, optional): ByteTensor, has shape
+ (bs, num_keys). Defaults to None.
+ is_first (bool): A indicator to tell whether the current layer
+ is the first layer of the decoder. Defaults to False.
+
+ Returns:
+ Tensor: Forwarded results, has shape (bs, num_queries, dim).
+ """
+ query = self.self_attn(
+ query=query,
+ key=query,
+ query_pos=query_pos,
+ key_pos=query_pos,
+ attn_mask=self_attn_masks)
+ query = self.norms[0](query)
+ query = self.cross_attn(
+ query=query,
+ key=key,
+ query_pos=query_pos,
+ key_pos=key_pos,
+ attn_mask=cross_attn_masks,
+ key_padding_mask=key_padding_mask,
+ ref_sine_embed=ref_sine_embed,
+ is_first=is_first)
+ query = self.norms[1](query)
+ query = self.ffn(query)
+ query = self.norms[2](query)
+
+ return query
diff --git a/mmdet/models/layers/transformer/dab_detr_layers.py b/mmdet/models/layers/transformer/dab_detr_layers.py
new file mode 100644
index 0000000000000000000000000000000000000000..b8a6e7724a1b1ca18f26dd10455f3e3a4d696460
--- /dev/null
+++ b/mmdet/models/layers/transformer/dab_detr_layers.py
@@ -0,0 +1,298 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List
+
+import torch
+import torch.nn as nn
+from mmcv.cnn import build_norm_layer
+from mmcv.cnn.bricks.transformer import FFN
+from mmengine.model import ModuleList
+from torch import Tensor
+
+from .detr_layers import (DetrTransformerDecoder, DetrTransformerDecoderLayer,
+ DetrTransformerEncoder, DetrTransformerEncoderLayer)
+from .utils import (MLP, ConditionalAttention, coordinate_to_encoding,
+ inverse_sigmoid)
+
+
+class DABDetrTransformerDecoderLayer(DetrTransformerDecoderLayer):
+ """Implements decoder layer in DAB-DETR transformer."""
+
+ def _init_layers(self):
+ """Initialize self-attention, cross-attention, FFN, normalization and
+ others."""
+ self.self_attn = ConditionalAttention(**self.self_attn_cfg)
+ self.cross_attn = ConditionalAttention(**self.cross_attn_cfg)
+ self.embed_dims = self.self_attn.embed_dims
+ self.ffn = FFN(**self.ffn_cfg)
+ norms_list = [
+ build_norm_layer(self.norm_cfg, self.embed_dims)[1]
+ for _ in range(3)
+ ]
+ self.norms = ModuleList(norms_list)
+ self.keep_query_pos = self.cross_attn.keep_query_pos
+
+ def forward(self,
+ query: Tensor,
+ key: Tensor,
+ query_pos: Tensor,
+ key_pos: Tensor,
+ ref_sine_embed: Tensor = None,
+ self_attn_masks: Tensor = None,
+ cross_attn_masks: Tensor = None,
+ key_padding_mask: Tensor = None,
+ is_first: bool = False,
+ **kwargs) -> Tensor:
+ """
+ Args:
+ query (Tensor): The input query with shape [bs, num_queries,
+ dim].
+ key (Tensor): The key tensor with shape [bs, num_keys,
+ dim].
+ query_pos (Tensor): The positional encoding for query in self
+ attention, with the same shape as `x`.
+ key_pos (Tensor): The positional encoding for `key`, with the
+ same shape as `key`.
+ ref_sine_embed (Tensor): The positional encoding for query in
+ cross attention, with the same shape as `x`.
+ Defaults to None.
+ self_attn_masks (Tensor): ByteTensor mask with shape [num_queries,
+ num_keys]. Same in `nn.MultiheadAttention.forward`.
+ Defaults to None.
+ cross_attn_masks (Tensor): ByteTensor mask with shape [num_queries,
+ num_keys]. Same in `nn.MultiheadAttention.forward`.
+ Defaults to None.
+ key_padding_mask (Tensor): ByteTensor with shape [bs, num_keys].
+ Defaults to None.
+ is_first (bool): A indicator to tell whether the current layer
+ is the first layer of the decoder.
+ Defaults to False.
+
+ Returns:
+ Tensor: forwarded results with shape
+ [bs, num_queries, dim].
+ """
+
+ query = self.self_attn(
+ query=query,
+ key=query,
+ query_pos=query_pos,
+ key_pos=query_pos,
+ attn_mask=self_attn_masks,
+ **kwargs)
+ query = self.norms[0](query)
+ query = self.cross_attn(
+ query=query,
+ key=key,
+ query_pos=query_pos,
+ key_pos=key_pos,
+ ref_sine_embed=ref_sine_embed,
+ attn_mask=cross_attn_masks,
+ key_padding_mask=key_padding_mask,
+ is_first=is_first,
+ **kwargs)
+ query = self.norms[1](query)
+ query = self.ffn(query)
+ query = self.norms[2](query)
+
+ return query
+
+
+class DABDetrTransformerDecoder(DetrTransformerDecoder):
+ """Decoder of DAB-DETR.
+
+ Args:
+ query_dim (int): The last dimension of query pos,
+ 4 for anchor format, 2 for point format.
+ Defaults to 4.
+ query_scale_type (str): Type of transformation applied
+ to content query. Defaults to `cond_elewise`.
+ with_modulated_hw_attn (bool): Whether to inject h&w info
+ during cross conditional attention. Defaults to True.
+ """
+
+ def __init__(self,
+ *args,
+ query_dim: int = 4,
+ query_scale_type: str = 'cond_elewise',
+ with_modulated_hw_attn: bool = True,
+ **kwargs):
+
+ self.query_dim = query_dim
+ self.query_scale_type = query_scale_type
+ self.with_modulated_hw_attn = with_modulated_hw_attn
+
+ super().__init__(*args, **kwargs)
+
+ def _init_layers(self):
+ """Initialize decoder layers and other layers."""
+ assert self.query_dim in [2, 4], \
+ f'{"dab-detr only supports anchor prior or reference point prior"}'
+ assert self.query_scale_type in [
+ 'cond_elewise', 'cond_scalar', 'fix_elewise'
+ ]
+
+ self.layers = ModuleList([
+ DABDetrTransformerDecoderLayer(**self.layer_cfg)
+ for _ in range(self.num_layers)
+ ])
+
+ embed_dims = self.layers[0].embed_dims
+ self.embed_dims = embed_dims
+
+ self.post_norm = build_norm_layer(self.post_norm_cfg, embed_dims)[1]
+ if self.query_scale_type == 'cond_elewise':
+ self.query_scale = MLP(embed_dims, embed_dims, embed_dims, 2)
+ elif self.query_scale_type == 'cond_scalar':
+ self.query_scale = MLP(embed_dims, embed_dims, 1, 2)
+ elif self.query_scale_type == 'fix_elewise':
+ self.query_scale = nn.Embedding(self.num_layers, embed_dims)
+ else:
+ raise NotImplementedError('Unknown query_scale_type: {}'.format(
+ self.query_scale_type))
+
+ self.ref_point_head = MLP(self.query_dim // 2 * embed_dims, embed_dims,
+ embed_dims, 2)
+
+ if self.with_modulated_hw_attn and self.query_dim == 4:
+ self.ref_anchor_head = MLP(embed_dims, embed_dims, 2, 2)
+
+ self.keep_query_pos = self.layers[0].keep_query_pos
+ if not self.keep_query_pos:
+ for layer_id in range(self.num_layers - 1):
+ self.layers[layer_id + 1].cross_attn.qpos_proj = None
+
+ def forward(self,
+ query: Tensor,
+ key: Tensor,
+ query_pos: Tensor,
+ key_pos: Tensor,
+ reg_branches: nn.Module,
+ key_padding_mask: Tensor = None,
+ **kwargs) -> List[Tensor]:
+ """Forward function of decoder.
+
+ Args:
+ query (Tensor): The input query with shape (bs, num_queries, dim).
+ key (Tensor): The input key with shape (bs, num_keys, dim).
+ query_pos (Tensor): The positional encoding for `query`, with the
+ same shape as `query`.
+ key_pos (Tensor): The positional encoding for `key`, with the
+ same shape as `key`.
+ reg_branches (nn.Module): The regression branch for dynamically
+ updating references in each layer.
+ key_padding_mask (Tensor): ByteTensor with shape (bs, num_keys).
+ Defaults to `None`.
+
+ Returns:
+ List[Tensor]: forwarded results with shape (num_decoder_layers,
+ bs, num_queries, dim) if `return_intermediate` is True, otherwise
+ with shape (1, bs, num_queries, dim). references with shape
+ (num_decoder_layers, bs, num_queries, 2/4).
+ """
+ output = query
+ unsigmoid_references = query_pos
+
+ reference_points = unsigmoid_references.sigmoid()
+ intermediate_reference_points = [reference_points]
+
+ intermediate = []
+ for layer_id, layer in enumerate(self.layers):
+ obj_center = reference_points[..., :self.query_dim]
+ ref_sine_embed = coordinate_to_encoding(
+ coord_tensor=obj_center, num_feats=self.embed_dims // 2)
+ query_pos = self.ref_point_head(
+ ref_sine_embed) # [bs, nq, 2c] -> [bs, nq, c]
+ # For the first decoder layer, do not apply transformation
+ if self.query_scale_type != 'fix_elewise':
+ if layer_id == 0:
+ pos_transformation = 1
+ else:
+ pos_transformation = self.query_scale(output)
+ else:
+ pos_transformation = self.query_scale.weight[layer_id]
+ # apply transformation
+ ref_sine_embed = ref_sine_embed[
+ ..., :self.embed_dims] * pos_transformation
+ # modulated height and weight attention
+ if self.with_modulated_hw_attn:
+ assert obj_center.size(-1) == 4
+ ref_hw = self.ref_anchor_head(output).sigmoid()
+ ref_sine_embed[..., self.embed_dims // 2:] *= \
+ (ref_hw[..., 0] / obj_center[..., 2]).unsqueeze(-1)
+ ref_sine_embed[..., : self.embed_dims // 2] *= \
+ (ref_hw[..., 1] / obj_center[..., 3]).unsqueeze(-1)
+
+ output = layer(
+ output,
+ key,
+ query_pos=query_pos,
+ ref_sine_embed=ref_sine_embed,
+ key_pos=key_pos,
+ key_padding_mask=key_padding_mask,
+ is_first=(layer_id == 0),
+ **kwargs)
+ # iter update
+ tmp_reg_preds = reg_branches(output)
+ tmp_reg_preds[..., :self.query_dim] += inverse_sigmoid(
+ reference_points)
+ new_reference_points = tmp_reg_preds[
+ ..., :self.query_dim].sigmoid()
+ if layer_id != self.num_layers - 1:
+ intermediate_reference_points.append(new_reference_points)
+ reference_points = new_reference_points.detach()
+
+ if self.return_intermediate:
+ intermediate.append(self.post_norm(output))
+
+ output = self.post_norm(output)
+
+ if self.return_intermediate:
+ return [
+ torch.stack(intermediate),
+ torch.stack(intermediate_reference_points),
+ ]
+ else:
+ return [
+ output.unsqueeze(0),
+ torch.stack(intermediate_reference_points)
+ ]
+
+
+class DABDetrTransformerEncoder(DetrTransformerEncoder):
+ """Encoder of DAB-DETR."""
+
+ def _init_layers(self):
+ """Initialize encoder layers."""
+ self.layers = ModuleList([
+ DetrTransformerEncoderLayer(**self.layer_cfg)
+ for _ in range(self.num_layers)
+ ])
+ embed_dims = self.layers[0].embed_dims
+ self.embed_dims = embed_dims
+ self.query_scale = MLP(embed_dims, embed_dims, embed_dims, 2)
+
+ def forward(self, query: Tensor, query_pos: Tensor,
+ key_padding_mask: Tensor, **kwargs):
+ """Forward function of encoder.
+
+ Args:
+ query (Tensor): Input queries of encoder, has shape
+ (bs, num_queries, dim).
+ query_pos (Tensor): The positional embeddings of the queries, has
+ shape (bs, num_feat_points, dim).
+ key_padding_mask (Tensor): ByteTensor, the key padding mask
+ of the queries, has shape (bs, num_feat_points).
+
+ Returns:
+ Tensor: With shape (num_queries, bs, dim).
+ """
+
+ for layer in self.layers:
+ pos_scales = self.query_scale(query)
+ query = layer(
+ query,
+ query_pos=query_pos * pos_scales,
+ key_padding_mask=key_padding_mask,
+ **kwargs)
+
+ return query
diff --git a/mmdet/models/layers/transformer/deformable_detr_layers.py b/mmdet/models/layers/transformer/deformable_detr_layers.py
new file mode 100644
index 0000000000000000000000000000000000000000..f337e7fd01ba05ace0a74441192d4e58299bbd93
--- /dev/null
+++ b/mmdet/models/layers/transformer/deformable_detr_layers.py
@@ -0,0 +1,250 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Tuple, Union
+
+import torch
+from mmcv.cnn import build_norm_layer
+from mmcv.cnn.bricks.transformer import FFN, MultiheadAttention
+from mmcv.ops import MultiScaleDeformableAttention
+from mmengine.model import ModuleList
+from torch import Tensor, nn
+
+from .detr_layers import (DetrTransformerDecoder, DetrTransformerDecoderLayer,
+ DetrTransformerEncoder, DetrTransformerEncoderLayer)
+from .utils import inverse_sigmoid
+
+
+class DeformableDetrTransformerEncoder(DetrTransformerEncoder):
+ """Transformer encoder of Deformable DETR."""
+
+ def _init_layers(self) -> None:
+ """Initialize encoder layers."""
+ self.layers = ModuleList([
+ DeformableDetrTransformerEncoderLayer(**self.layer_cfg)
+ for _ in range(self.num_layers)
+ ])
+ self.embed_dims = self.layers[0].embed_dims
+
+ def forward(self, query: Tensor, query_pos: Tensor,
+ key_padding_mask: Tensor, spatial_shapes: Tensor,
+ level_start_index: Tensor, valid_ratios: Tensor,
+ **kwargs) -> Tensor:
+ """Forward function of Transformer encoder.
+
+ Args:
+ query (Tensor): The input query, has shape (bs, num_queries, dim).
+ query_pos (Tensor): The positional encoding for query, has shape
+ (bs, num_queries, dim).
+ key_padding_mask (Tensor): The `key_padding_mask` of `self_attn`
+ input. ByteTensor, has shape (bs, num_queries).
+ spatial_shapes (Tensor): Spatial shapes of features in all levels,
+ has shape (num_levels, 2), last dimension represents (h, w).
+ level_start_index (Tensor): The start index of each level.
+ A tensor has shape (num_levels, ) and can be represented
+ as [0, h_0*w_0, h_0*w_0+h_1*w_1, ...].
+ valid_ratios (Tensor): The ratios of the valid width and the valid
+ height relative to the width and the height of features in all
+ levels, has shape (bs, num_levels, 2).
+
+ Returns:
+ Tensor: Output queries of Transformer encoder, which is also
+ called 'encoder output embeddings' or 'memory', has shape
+ (bs, num_queries, dim)
+ """
+ reference_points = self.get_encoder_reference_points(
+ spatial_shapes, valid_ratios, device=query.device)
+ for layer in self.layers:
+ query = layer(
+ query=query,
+ query_pos=query_pos,
+ key_padding_mask=key_padding_mask,
+ spatial_shapes=spatial_shapes,
+ level_start_index=level_start_index,
+ valid_ratios=valid_ratios,
+ reference_points=reference_points,
+ **kwargs)
+ return query
+
+ @staticmethod
+ def get_encoder_reference_points(
+ spatial_shapes: Tensor, valid_ratios: Tensor,
+ device: Union[torch.device, str]) -> Tensor:
+ """Get the reference points used in encoder.
+
+ Args:
+ spatial_shapes (Tensor): Spatial shapes of features in all levels,
+ has shape (num_levels, 2), last dimension represents (h, w).
+ valid_ratios (Tensor): The ratios of the valid width and the valid
+ height relative to the width and the height of features in all
+ levels, has shape (bs, num_levels, 2).
+ device (obj:`device` or str): The device acquired by the
+ `reference_points`.
+
+ Returns:
+ Tensor: Reference points used in decoder, has shape (bs, length,
+ num_levels, 2).
+ """
+
+ reference_points_list = []
+ for lvl, (H, W) in enumerate(spatial_shapes):
+ ref_y, ref_x = torch.meshgrid(
+ torch.linspace(
+ 0.5, H - 0.5, H, dtype=torch.float32, device=device),
+ torch.linspace(
+ 0.5, W - 0.5, W, dtype=torch.float32, device=device))
+ ref_y = ref_y.reshape(-1)[None] / (
+ valid_ratios[:, None, lvl, 1] * H)
+ ref_x = ref_x.reshape(-1)[None] / (
+ valid_ratios[:, None, lvl, 0] * W)
+ ref = torch.stack((ref_x, ref_y), -1)
+ reference_points_list.append(ref)
+ reference_points = torch.cat(reference_points_list, 1)
+ # [bs, sum(hw), num_level, 2]
+ reference_points = reference_points[:, :, None] * valid_ratios[:, None]
+ return reference_points
+
+
+class DeformableDetrTransformerDecoder(DetrTransformerDecoder):
+ """Transformer Decoder of Deformable DETR."""
+
+ def _init_layers(self) -> None:
+ """Initialize decoder layers."""
+ self.layers = ModuleList([
+ DeformableDetrTransformerDecoderLayer(**self.layer_cfg)
+ for _ in range(self.num_layers)
+ ])
+ self.embed_dims = self.layers[0].embed_dims
+ if self.post_norm_cfg is not None:
+ raise ValueError('There is not post_norm in '
+ f'{self._get_name()}')
+
+ def forward(self,
+ query: Tensor,
+ query_pos: Tensor,
+ value: Tensor,
+ key_padding_mask: Tensor,
+ reference_points: Tensor,
+ spatial_shapes: Tensor,
+ level_start_index: Tensor,
+ valid_ratios: Tensor,
+ reg_branches: Optional[nn.Module] = None,
+ **kwargs) -> Tuple[Tensor]:
+ """Forward function of Transformer decoder.
+
+ Args:
+ query (Tensor): The input queries, has shape (bs, num_queries,
+ dim).
+ query_pos (Tensor): The input positional query, has shape
+ (bs, num_queries, dim). It will be added to `query` before
+ forward function.
+ value (Tensor): The input values, has shape (bs, num_value, dim).
+ key_padding_mask (Tensor): The `key_padding_mask` of `cross_attn`
+ input. ByteTensor, has shape (bs, num_value).
+ reference_points (Tensor): The initial reference, has shape
+ (bs, num_queries, 4) with the last dimension arranged as
+ (cx, cy, w, h) when `as_two_stage` is `True`, otherwise has
+ shape (bs, num_queries, 2) with the last dimension arranged
+ as (cx, cy).
+ spatial_shapes (Tensor): Spatial shapes of features in all levels,
+ has shape (num_levels, 2), last dimension represents (h, w).
+ level_start_index (Tensor): The start index of each level.
+ A tensor has shape (num_levels, ) and can be represented
+ as [0, h_0*w_0, h_0*w_0+h_1*w_1, ...].
+ valid_ratios (Tensor): The ratios of the valid width and the valid
+ height relative to the width and the height of features in all
+ levels, has shape (bs, num_levels, 2).
+ reg_branches: (obj:`nn.ModuleList`, optional): Used for refining
+ the regression results. Only would be passed when
+ `with_box_refine` is `True`, otherwise would be `None`.
+
+ Returns:
+ tuple[Tensor]: Outputs of Deformable Transformer Decoder.
+
+ - output (Tensor): Output embeddings of the last decoder, has
+ shape (num_queries, bs, embed_dims) when `return_intermediate`
+ is `False`. Otherwise, Intermediate output embeddings of all
+ decoder layers, has shape (num_decoder_layers, num_queries, bs,
+ embed_dims).
+ - reference_points (Tensor): The reference of the last decoder
+ layer, has shape (bs, num_queries, 4) when `return_intermediate`
+ is `False`. Otherwise, Intermediate references of all decoder
+ layers, has shape (num_decoder_layers, bs, num_queries, 4). The
+ coordinates are arranged as (cx, cy, w, h)
+ """
+ output = query
+ intermediate = []
+ intermediate_reference_points = []
+ for layer_id, layer in enumerate(self.layers):
+ if reference_points.shape[-1] == 4:
+ reference_points_input = \
+ reference_points[:, :, None] * \
+ torch.cat([valid_ratios, valid_ratios], -1)[:, None]
+ else:
+ assert reference_points.shape[-1] == 2
+ reference_points_input = \
+ reference_points[:, :, None] * \
+ valid_ratios[:, None]
+ output = layer(
+ output,
+ query_pos=query_pos,
+ value=value,
+ key_padding_mask=key_padding_mask,
+ spatial_shapes=spatial_shapes,
+ level_start_index=level_start_index,
+ valid_ratios=valid_ratios,
+ reference_points=reference_points_input,
+ **kwargs)
+
+ if reg_branches is not None:
+ tmp_reg_preds = reg_branches[layer_id](output)
+ if reference_points.shape[-1] == 4:
+ new_reference_points = tmp_reg_preds + inverse_sigmoid(
+ reference_points)
+ new_reference_points = new_reference_points.sigmoid()
+ else:
+ assert reference_points.shape[-1] == 2
+ new_reference_points = tmp_reg_preds
+ new_reference_points[..., :2] = tmp_reg_preds[
+ ..., :2] + inverse_sigmoid(reference_points)
+ new_reference_points = new_reference_points.sigmoid()
+ reference_points = new_reference_points.detach()
+
+ if self.return_intermediate:
+ intermediate.append(output)
+ intermediate_reference_points.append(reference_points)
+
+ if self.return_intermediate:
+ return torch.stack(intermediate), torch.stack(
+ intermediate_reference_points)
+
+ return output, reference_points
+
+
+class DeformableDetrTransformerEncoderLayer(DetrTransformerEncoderLayer):
+ """Encoder layer of Deformable DETR."""
+
+ def _init_layers(self) -> None:
+ """Initialize self_attn, ffn, and norms."""
+ self.self_attn = MultiScaleDeformableAttention(**self.self_attn_cfg)
+ self.embed_dims = self.self_attn.embed_dims
+ self.ffn = FFN(**self.ffn_cfg)
+ norms_list = [
+ build_norm_layer(self.norm_cfg, self.embed_dims)[1]
+ for _ in range(2)
+ ]
+ self.norms = ModuleList(norms_list)
+
+
+class DeformableDetrTransformerDecoderLayer(DetrTransformerDecoderLayer):
+ """Decoder layer of Deformable DETR."""
+
+ def _init_layers(self) -> None:
+ """Initialize self_attn, cross-attn, ffn, and norms."""
+ self.self_attn = MultiheadAttention(**self.self_attn_cfg)
+ self.cross_attn = MultiScaleDeformableAttention(**self.cross_attn_cfg)
+ self.embed_dims = self.self_attn.embed_dims
+ self.ffn = FFN(**self.ffn_cfg)
+ norms_list = [
+ build_norm_layer(self.norm_cfg, self.embed_dims)[1]
+ for _ in range(3)
+ ]
+ self.norms = ModuleList(norms_list)
diff --git a/mmdet/models/layers/transformer/detr_layers.py b/mmdet/models/layers/transformer/detr_layers.py
new file mode 100644
index 0000000000000000000000000000000000000000..43c2ffdb631ec854c2e7a6e66d28c1840b1b32ee
--- /dev/null
+++ b/mmdet/models/layers/transformer/detr_layers.py
@@ -0,0 +1,354 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Union
+
+import torch
+from mmcv.cnn import build_norm_layer
+from mmcv.cnn.bricks.transformer import FFN, MultiheadAttention
+from mmengine import ConfigDict
+from mmengine.model import BaseModule, ModuleList
+from torch import Tensor
+
+from mmdet.utils import ConfigType, OptConfigType
+
+
+class DetrTransformerEncoder(BaseModule):
+ """Encoder of DETR.
+
+ Args:
+ num_layers (int): Number of encoder layers.
+ layer_cfg (:obj:`ConfigDict` or dict): the config of each encoder
+ layer. All the layers will share the same config.
+ init_cfg (:obj:`ConfigDict` or dict, optional): the config to control
+ the initialization. Defaults to None.
+ """
+
+ def __init__(self,
+ num_layers: int,
+ layer_cfg: ConfigType,
+ init_cfg: OptConfigType = None) -> None:
+
+ super().__init__(init_cfg=init_cfg)
+ self.num_layers = num_layers
+ self.layer_cfg = layer_cfg
+ self._init_layers()
+
+ def _init_layers(self) -> None:
+ """Initialize encoder layers."""
+ self.layers = ModuleList([
+ DetrTransformerEncoderLayer(**self.layer_cfg)
+ for _ in range(self.num_layers)
+ ])
+ self.embed_dims = self.layers[0].embed_dims
+
+ def forward(self, query: Tensor, query_pos: Tensor,
+ key_padding_mask: Tensor, **kwargs) -> Tensor:
+ """Forward function of encoder.
+
+ Args:
+ query (Tensor): Input queries of encoder, has shape
+ (bs, num_queries, dim).
+ query_pos (Tensor): The positional embeddings of the queries, has
+ shape (bs, num_queries, dim).
+ key_padding_mask (Tensor): The `key_padding_mask` of `self_attn`
+ input. ByteTensor, has shape (bs, num_queries).
+
+ Returns:
+ Tensor: Has shape (bs, num_queries, dim) if `batch_first` is
+ `True`, otherwise (num_queries, bs, dim).
+ """
+ for layer in self.layers:
+ query = layer(query, query_pos, key_padding_mask, **kwargs)
+ return query
+
+
+class DetrTransformerDecoder(BaseModule):
+ """Decoder of DETR.
+
+ Args:
+ num_layers (int): Number of decoder layers.
+ layer_cfg (:obj:`ConfigDict` or dict): the config of each encoder
+ layer. All the layers will share the same config.
+ post_norm_cfg (:obj:`ConfigDict` or dict, optional): Config of the
+ post normalization layer. Defaults to `LN`.
+ return_intermediate (bool, optional): Whether to return outputs of
+ intermediate layers. Defaults to `True`,
+ init_cfg (:obj:`ConfigDict` or dict, optional): the config to control
+ the initialization. Defaults to None.
+ """
+
+ def __init__(self,
+ num_layers: int,
+ layer_cfg: ConfigType,
+ post_norm_cfg: OptConfigType = dict(type='LN'),
+ return_intermediate: bool = True,
+ init_cfg: Union[dict, ConfigDict] = None) -> None:
+ super().__init__(init_cfg=init_cfg)
+ self.layer_cfg = layer_cfg
+ self.num_layers = num_layers
+ self.post_norm_cfg = post_norm_cfg
+ self.return_intermediate = return_intermediate
+ self._init_layers()
+
+ def _init_layers(self) -> None:
+ """Initialize decoder layers."""
+ self.layers = ModuleList([
+ DetrTransformerDecoderLayer(**self.layer_cfg)
+ for _ in range(self.num_layers)
+ ])
+ self.embed_dims = self.layers[0].embed_dims
+ self.post_norm = build_norm_layer(self.post_norm_cfg,
+ self.embed_dims)[1]
+
+ def forward(self, query: Tensor, key: Tensor, value: Tensor,
+ query_pos: Tensor, key_pos: Tensor, key_padding_mask: Tensor,
+ **kwargs) -> Tensor:
+ """Forward function of decoder
+ Args:
+ query (Tensor): The input query, has shape (bs, num_queries, dim).
+ key (Tensor): The input key, has shape (bs, num_keys, dim).
+ value (Tensor): The input value with the same shape as `key`.
+ query_pos (Tensor): The positional encoding for `query`, with the
+ same shape as `query`.
+ key_pos (Tensor): The positional encoding for `key`, with the
+ same shape as `key`.
+ key_padding_mask (Tensor): The `key_padding_mask` of `cross_attn`
+ input. ByteTensor, has shape (bs, num_value).
+
+ Returns:
+ Tensor: The forwarded results will have shape
+ (num_decoder_layers, bs, num_queries, dim) if
+ `return_intermediate` is `True` else (1, bs, num_queries, dim).
+ """
+ intermediate = []
+ for layer in self.layers:
+ query = layer(
+ query,
+ key=key,
+ value=value,
+ query_pos=query_pos,
+ key_pos=key_pos,
+ key_padding_mask=key_padding_mask,
+ **kwargs)
+ if self.return_intermediate:
+ intermediate.append(self.post_norm(query))
+ query = self.post_norm(query)
+
+ if self.return_intermediate:
+ return torch.stack(intermediate)
+
+ return query.unsqueeze(0)
+
+
+class DetrTransformerEncoderLayer(BaseModule):
+ """Implements encoder layer in DETR transformer.
+
+ Args:
+ self_attn_cfg (:obj:`ConfigDict` or dict, optional): Config for self
+ attention.
+ ffn_cfg (:obj:`ConfigDict` or dict, optional): Config for FFN.
+ norm_cfg (:obj:`ConfigDict` or dict, optional): Config for
+ normalization layers. All the layers will share the same
+ config. Defaults to `LN`.
+ init_cfg (:obj:`ConfigDict` or dict, optional): Config to control
+ the initialization. Defaults to None.
+ """
+
+ def __init__(self,
+ self_attn_cfg: OptConfigType = dict(
+ embed_dims=256, num_heads=8, dropout=0.0),
+ ffn_cfg: OptConfigType = dict(
+ embed_dims=256,
+ feedforward_channels=1024,
+ num_fcs=2,
+ ffn_drop=0.,
+ act_cfg=dict(type='ReLU', inplace=True)),
+ norm_cfg: OptConfigType = dict(type='LN'),
+ init_cfg: OptConfigType = None) -> None:
+
+ super().__init__(init_cfg=init_cfg)
+
+ self.self_attn_cfg = self_attn_cfg
+ if 'batch_first' not in self.self_attn_cfg:
+ self.self_attn_cfg['batch_first'] = True
+ else:
+ assert self.self_attn_cfg['batch_first'] is True, 'First \
+ dimension of all DETRs in mmdet is `batch`, \
+ please set `batch_first` flag.'
+
+ self.ffn_cfg = ffn_cfg
+ self.norm_cfg = norm_cfg
+ self._init_layers()
+
+ def _init_layers(self) -> None:
+ """Initialize self-attention, FFN, and normalization."""
+ self.self_attn = MultiheadAttention(**self.self_attn_cfg)
+ self.embed_dims = self.self_attn.embed_dims
+ self.ffn = FFN(**self.ffn_cfg)
+ norms_list = [
+ build_norm_layer(self.norm_cfg, self.embed_dims)[1]
+ for _ in range(2)
+ ]
+ self.norms = ModuleList(norms_list)
+
+ def forward(self, query: Tensor, query_pos: Tensor,
+ key_padding_mask: Tensor, **kwargs) -> Tensor:
+ """Forward function of an encoder layer.
+
+ Args:
+ query (Tensor): The input query, has shape (bs, num_queries, dim).
+ query_pos (Tensor): The positional encoding for query, with
+ the same shape as `query`.
+ key_padding_mask (Tensor): The `key_padding_mask` of `self_attn`
+ input. ByteTensor. has shape (bs, num_queries).
+ Returns:
+ Tensor: forwarded results, has shape (bs, num_queries, dim).
+ """
+ query = self.self_attn(
+ query=query,
+ key=query,
+ value=query,
+ query_pos=query_pos,
+ key_pos=query_pos,
+ key_padding_mask=key_padding_mask,
+ **kwargs)
+ query = self.norms[0](query)
+ query = self.ffn(query)
+ query = self.norms[1](query)
+
+ return query
+
+
+class DetrTransformerDecoderLayer(BaseModule):
+ """Implements decoder layer in DETR transformer.
+
+ Args:
+ self_attn_cfg (:obj:`ConfigDict` or dict, optional): Config for self
+ attention.
+ cross_attn_cfg (:obj:`ConfigDict` or dict, optional): Config for cross
+ attention.
+ ffn_cfg (:obj:`ConfigDict` or dict, optional): Config for FFN.
+ norm_cfg (:obj:`ConfigDict` or dict, optional): Config for
+ normalization layers. All the layers will share the same
+ config. Defaults to `LN`.
+ init_cfg (:obj:`ConfigDict` or dict, optional): Config to control
+ the initialization. Defaults to None.
+ """
+
+ def __init__(self,
+ self_attn_cfg: OptConfigType = dict(
+ embed_dims=256,
+ num_heads=8,
+ dropout=0.0,
+ batch_first=True),
+ cross_attn_cfg: OptConfigType = dict(
+ embed_dims=256,
+ num_heads=8,
+ dropout=0.0,
+ batch_first=True),
+ ffn_cfg: OptConfigType = dict(
+ embed_dims=256,
+ feedforward_channels=1024,
+ num_fcs=2,
+ ffn_drop=0.,
+ act_cfg=dict(type='ReLU', inplace=True),
+ ),
+ norm_cfg: OptConfigType = dict(type='LN'),
+ init_cfg: OptConfigType = None) -> None:
+
+ super().__init__(init_cfg=init_cfg)
+
+ self.self_attn_cfg = self_attn_cfg
+ self.cross_attn_cfg = cross_attn_cfg
+ if 'batch_first' not in self.self_attn_cfg:
+ self.self_attn_cfg['batch_first'] = True
+ else:
+ assert self.self_attn_cfg['batch_first'] is True, 'First \
+ dimension of all DETRs in mmdet is `batch`, \
+ please set `batch_first` flag.'
+
+ if 'batch_first' not in self.cross_attn_cfg:
+ self.cross_attn_cfg['batch_first'] = True
+ else:
+ assert self.cross_attn_cfg['batch_first'] is True, 'First \
+ dimension of all DETRs in mmdet is `batch`, \
+ please set `batch_first` flag.'
+
+ self.ffn_cfg = ffn_cfg
+ self.norm_cfg = norm_cfg
+ self._init_layers()
+
+ def _init_layers(self) -> None:
+ """Initialize self-attention, FFN, and normalization."""
+ self.self_attn = MultiheadAttention(**self.self_attn_cfg)
+ self.cross_attn = MultiheadAttention(**self.cross_attn_cfg)
+ self.embed_dims = self.self_attn.embed_dims
+ self.ffn = FFN(**self.ffn_cfg)
+ norms_list = [
+ build_norm_layer(self.norm_cfg, self.embed_dims)[1]
+ for _ in range(3)
+ ]
+ self.norms = ModuleList(norms_list)
+
+ def forward(self,
+ query: Tensor,
+ key: Tensor = None,
+ value: Tensor = None,
+ query_pos: Tensor = None,
+ key_pos: Tensor = None,
+ self_attn_mask: Tensor = None,
+ cross_attn_mask: Tensor = None,
+ key_padding_mask: Tensor = None,
+ **kwargs) -> Tensor:
+ """
+ Args:
+ query (Tensor): The input query, has shape (bs, num_queries, dim).
+ key (Tensor, optional): The input key, has shape (bs, num_keys,
+ dim). If `None`, the `query` will be used. Defaults to `None`.
+ value (Tensor, optional): The input value, has the same shape as
+ `key`, as in `nn.MultiheadAttention.forward`. If `None`, the
+ `key` will be used. Defaults to `None`.
+ query_pos (Tensor, optional): The positional encoding for `query`,
+ has the same shape as `query`. If not `None`, it will be added
+ to `query` before forward function. Defaults to `None`.
+ key_pos (Tensor, optional): The positional encoding for `key`, has
+ the same shape as `key`. If not `None`, it will be added to
+ `key` before forward function. If None, and `query_pos` has the
+ same shape as `key`, then `query_pos` will be used for
+ `key_pos`. Defaults to None.
+ self_attn_mask (Tensor, optional): ByteTensor mask, has shape
+ (num_queries, num_keys), as in `nn.MultiheadAttention.forward`.
+ Defaults to None.
+ cross_attn_mask (Tensor, optional): ByteTensor mask, has shape
+ (num_queries, num_keys), as in `nn.MultiheadAttention.forward`.
+ Defaults to None.
+ key_padding_mask (Tensor, optional): The `key_padding_mask` of
+ `self_attn` input. ByteTensor, has shape (bs, num_value).
+ Defaults to None.
+
+ Returns:
+ Tensor: forwarded results, has shape (bs, num_queries, dim).
+ """
+
+ query = self.self_attn(
+ query=query,
+ key=query,
+ value=query,
+ query_pos=query_pos,
+ key_pos=query_pos,
+ attn_mask=self_attn_mask,
+ **kwargs)
+ query = self.norms[0](query)
+ query = self.cross_attn(
+ query=query,
+ key=key,
+ value=value,
+ query_pos=query_pos,
+ key_pos=key_pos,
+ attn_mask=cross_attn_mask,
+ key_padding_mask=key_padding_mask,
+ **kwargs)
+ query = self.norms[1](query)
+ query = self.ffn(query)
+ query = self.norms[2](query)
+
+ return query
diff --git a/mmdet/models/layers/transformer/dino_layers.py b/mmdet/models/layers/transformer/dino_layers.py
new file mode 100644
index 0000000000000000000000000000000000000000..c3f83b3a169620e6110681fa8d7e3ca797da4598
--- /dev/null
+++ b/mmdet/models/layers/transformer/dino_layers.py
@@ -0,0 +1,944 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+
+from typing import Optional, Tuple, Union
+import torch
+from mmcv.cnn import build_norm_layer
+from mmcv.cnn.bricks.transformer import FFN, MultiheadAttention
+from mmcv.ops import MultiScaleDeformableAttention
+from mmengine.model import ModuleList
+from torch import Tensor, nn
+from mmengine.model import BaseModule
+
+from mmdet.structures import SampleList
+from mmdet.structures.bbox import bbox_xyxy_to_cxcywh
+from mmengine import ConfigDict
+from mmdet.utils import ConfigType, OptConfigType
+# from .detr_layers import (DetrTransformerDecoder, DetrTransformerDecoderLayer,
+# DetrTransformerEncoder, DetrTransformerEncoderLayer)
+from .utils import MLP, coordinate_to_encoding, inverse_sigmoid
+
+
+class DeformableDetrTransformerEncoder(BaseModule):
+ """Transformer encoder of Deformable DETR.Encoder of DETR.
+
+ Args:
+ num_layers (int): Number of encoder layers.
+ layer_cfg (:obj:`ConfigDict` or dict): the config of each encoder
+ layer. All the layers will share the same config.
+ init_cfg (:obj:`ConfigDict` or dict, optional): the config to control
+ the initialization. Defaults to None.
+ """
+
+ def __init__(self,
+ num_layers: int,
+ layer_cfg: ConfigType,
+ init_cfg: OptConfigType = None) -> None:
+
+ super().__init__(init_cfg=init_cfg)
+ self.num_layers = num_layers
+ self.layer_cfg = layer_cfg
+ self._init_layers()
+
+
+ def _init_layers(self) -> None:
+ """Initialize encoder layers."""
+ self.layers = ModuleList([
+ DeformableDetrTransformerEncoderLayer(**self.layer_cfg)
+ for _ in range(self.num_layers)
+ ])
+ self.embed_dims = self.layers[0].embed_dims
+
+ def forward(self, query: Tensor, query_pos: Tensor,
+ key_padding_mask: Tensor, spatial_shapes: Tensor,
+ level_start_index: Tensor, valid_ratios: Tensor,
+ **kwargs) -> Tensor:
+ """Forward function of Transformer encoder.
+
+ Args:
+ query (Tensor): The input query, has shape (bs, num_queries, dim).
+ query_pos (Tensor): The positional encoding for query, has shape
+ (bs, num_queries, dim).
+ key_padding_mask (Tensor): The `key_padding_mask` of `self_attn`
+ input. ByteTensor, has shape (bs, num_queries).
+ spatial_shapes (Tensor): Spatial shapes of features in all levels,
+ has shape (num_levels, 2), last dimension represents (h, w).
+ level_start_index (Tensor): The start index of each level.
+ A tensor has shape (num_levels, ) and can be represented
+ as [0, h_0*w_0, h_0*w_0+h_1*w_1, ...].
+ valid_ratios (Tensor): The ratios of the valid width and the valid
+ height relative to the width and the height of features in all
+ levels, has shape (bs, num_levels, 2).
+
+ Returns:
+ Tensor: Output queries of Transformer encoder, which is also
+ called 'encoder output embeddings' or 'memory', has shape
+ (bs, num_queries, dim)
+ """
+ reference_points = self.get_encoder_reference_points(
+ spatial_shapes, valid_ratios, device=query.device)
+ for layer in self.layers:
+ query = layer(
+ query=query,
+ query_pos=query_pos,
+ key_padding_mask=key_padding_mask,
+ spatial_shapes=spatial_shapes,
+ level_start_index=level_start_index,
+ valid_ratios=valid_ratios,
+ reference_points=reference_points,
+ **kwargs)
+ return query
+
+ @staticmethod
+ def get_encoder_reference_points(
+ spatial_shapes: Tensor, valid_ratios: Tensor,
+ device: Union[torch.device, str]) -> Tensor:
+ """Get the reference points used in encoder.
+
+ Args:
+ spatial_shapes (Tensor): Spatial shapes of features in all levels,
+ has shape (num_levels, 2), last dimension represents (h, w).
+ valid_ratios (Tensor): The ratios of the valid width and the valid
+ height relative to the width and the height of features in all
+ levels, has shape (bs, num_levels, 2).
+ device (obj:`device` or str): The device acquired by the
+ `reference_points`.
+
+ Returns:
+ Tensor: Reference points used in decoder, has shape (bs, length,
+ num_levels, 2).
+ """
+
+ reference_points_list = []
+ for lvl, (H, W) in enumerate(spatial_shapes):
+ ref_y, ref_x = torch.meshgrid(
+ torch.linspace(
+ 0.5, H - 0.5, H, dtype=torch.float32, device=device),
+ torch.linspace(
+ 0.5, W - 0.5, W, dtype=torch.float32, device=device))
+ ref_y = ref_y.reshape(-1)[None] / (
+ valid_ratios[:, None, lvl, 1] * H)
+ ref_x = ref_x.reshape(-1)[None] / (
+ valid_ratios[:, None, lvl, 0] * W)
+ ref = torch.stack((ref_x, ref_y), -1)
+ reference_points_list.append(ref)
+ reference_points = torch.cat(reference_points_list, 1)
+ # [bs, sum(hw), num_level, 2]
+ reference_points = reference_points[:, :, None] * valid_ratios[:, None]
+ return reference_points
+
+
+class DinoTransformerDecoder(BaseModule):
+ """Transformer encoder of DINO.Decoder of DETR.
+
+ Args:
+ num_layers (int): Number of decoder layers.
+ layer_cfg (:obj:`ConfigDict` or dict): the config of each encoder
+ layer. All the layers will share the same config.
+ post_norm_cfg (:obj:`ConfigDict` or dict, optional): Config of the
+ post normalization layer. Defaults to `LN`.
+ return_intermediate (bool, optional): Whether to return outputs of
+ intermediate layers. Defaults to `True`,
+ init_cfg (:obj:`ConfigDict` or dict, optional): the config to control
+ the initialization. Defaults to None.
+ """
+
+ def __init__(self,
+ num_layers: int,
+ layer_cfg: ConfigType,
+ post_norm_cfg: OptConfigType = dict(type='LN'),
+ return_intermediate: bool = True,
+ init_cfg: Union[dict, ConfigDict] = None) -> None:
+ super().__init__(init_cfg=init_cfg)
+ self.layer_cfg = layer_cfg
+ self.num_layers = num_layers
+ self.post_norm_cfg = post_norm_cfg
+ self.return_intermediate = return_intermediate
+ self._init_layers()
+
+ def _init_layers(self) -> None:
+ """Initialize decoder layers."""
+ self.layers = ModuleList([
+ DeformableDetrTransformerDecoderLayer(**self.layer_cfg)
+ for _ in range(self.num_layers)
+ ])
+ self.embed_dims = self.layers[0].embed_dims
+ if self.post_norm_cfg is not None:
+ raise ValueError('There is not post_norm in '
+ f'{self._get_name()}')
+ self.ref_point_head = MLP(self.embed_dims * 2, self.embed_dims,
+ self.embed_dims, 2)
+ self.norm = nn.LayerNorm(self.embed_dims)
+
+ def forward(self, query: Tensor, value: Tensor, key_padding_mask: Tensor,
+ self_attn_mask: Tensor, reference_points: Tensor,
+ spatial_shapes: Tensor, level_start_index: Tensor,
+ valid_ratios: Tensor, reg_branches: nn.ModuleList,
+ **kwargs) -> Tensor:
+ """Forward function of Transformer encoder.
+
+ Args:
+ query (Tensor): The input query, has shape (num_queries, bs, dim).
+ value (Tensor): The input values, has shape (num_value, bs, dim).
+ key_padding_mask (Tensor): The `key_padding_mask` of `self_attn`
+ input. ByteTensor, has shape (num_queries, bs).
+ self_attn_mask (Tensor): The attention mask to prevent information
+ leakage from different denoising groups and matching parts, has
+ shape (num_queries_total, num_queries_total). It is `None` when
+ `self.training` is `False`.
+ reference_points (Tensor): The initial reference, has shape
+ (bs, num_queries, 4) with the last dimension arranged as
+ (cx, cy, w, h).
+ spatial_shapes (Tensor): Spatial shapes of features in all levels,
+ has shape (num_levels, 2), last dimension represents (h, w).
+ level_start_index (Tensor): The start index of each level.
+ A tensor has shape (num_levels, ) and can be represented
+ as [0, h_0*w_0, h_0*w_0+h_1*w_1, ...].
+ valid_ratios (Tensor): The ratios of the valid width and the valid
+ height relative to the width and the height of features in all
+ levels, has shape (bs, num_levels, 2).
+ reg_branches: (obj:`nn.ModuleList`): Used for refining the
+ regression results.
+
+ Returns:
+ Tensor: Output queries of Transformer encoder, which is also
+ called 'encoder output embeddings' or 'memory', has shape
+ (num_queries, bs, dim)
+ """
+ intermediate = []
+ intermediate_reference_points = [reference_points]
+ for lid, layer in enumerate(self.layers):
+ if reference_points.shape[-1] == 4:
+ reference_points_input = \
+ reference_points[:, :, None] * torch.cat(
+ [valid_ratios, valid_ratios], -1)[:, None]
+ else:
+ assert reference_points.shape[-1] == 2
+ reference_points_input = \
+ reference_points[:, :, None] * valid_ratios[:, None]
+
+ query_sine_embed = coordinate_to_encoding(
+ reference_points_input[:, :, 0, :])
+ query_pos = self.ref_point_head(query_sine_embed)
+
+ query = layer(
+ query,
+ query_pos=query_pos,
+ value=value,
+ key_padding_mask=key_padding_mask,
+ self_attn_mask=self_attn_mask,
+ spatial_shapes=spatial_shapes,
+ level_start_index=level_start_index,
+ valid_ratios=valid_ratios,
+ reference_points=reference_points_input,
+ **kwargs)
+
+ if reg_branches is not None:
+ tmp = reg_branches[lid](query)
+ assert reference_points.shape[-1] == 4
+ new_reference_points = tmp + inverse_sigmoid(
+ reference_points, eps=1e-3)
+ new_reference_points = new_reference_points.sigmoid()
+ reference_points = new_reference_points.detach()
+
+ if self.return_intermediate:
+ intermediate.append(self.norm(query))
+ intermediate_reference_points.append(new_reference_points)
+ # NOTE this is for the "Look Forward Twice" module,
+ # in the DeformDETR, reference_points was appended.
+
+ if self.return_intermediate:
+ return torch.stack(intermediate), torch.stack(
+ intermediate_reference_points)
+
+ return query, reference_points
+
+
+class DeformableDetrTransformerEncoderLayer(BaseModule):
+ """Encoder layer of Deformable DETR.
+ Implements encoder layer in DETR transformer.
+
+ Args:
+ self_attn_cfg (:obj:`ConfigDict` or dict, optional): Config for self
+ attention.
+ ffn_cfg (:obj:`ConfigDict` or dict, optional): Config for FFN.
+ norm_cfg (:obj:`ConfigDict` or dict, optional): Config for
+ normalization layers. All the layers will share the same
+ config. Defaults to `LN`.
+ init_cfg (:obj:`ConfigDict` or dict, optional): Config to control
+ the initialization. Defaults to None.
+ """
+
+ def __init__(self,
+ self_attn_cfg: OptConfigType = dict(
+ embed_dims=256, num_heads=8, dropout=0.0),
+ ffn_cfg: OptConfigType = dict(
+ embed_dims=256,
+ feedforward_channels=1024,
+ num_fcs=2,
+ ffn_drop=0.,
+ act_cfg=dict(type='ReLU', inplace=True)),
+ norm_cfg: OptConfigType = dict(type='LN'),
+ init_cfg: OptConfigType = None) -> None:
+
+ super().__init__(init_cfg=init_cfg)
+
+ self.self_attn_cfg = self_attn_cfg
+ if 'batch_first' not in self.self_attn_cfg:
+ self.self_attn_cfg['batch_first'] = True
+ else:
+ assert self.self_attn_cfg['batch_first'] is True, 'First \
+ dimension of all DETRs in mmdet is `batch`, \
+ please set `batch_first` flag.'
+
+ self.ffn_cfg = ffn_cfg
+ self.norm_cfg = norm_cfg
+ self._init_layers()
+
+ def _init_layers(self) -> None:
+ """Initialize self_attn, ffn, and norms."""
+ self.self_attn = MultiScaleDeformableAttention(**self.self_attn_cfg)
+ self.embed_dims = self.self_attn.embed_dims
+ self.ffn = FFN(**self.ffn_cfg)
+ norms_list = [
+ build_norm_layer(self.norm_cfg, self.embed_dims)[1]
+ for _ in range(2)
+ ]
+ # IN spectra
+ # norms_list = [
+ # build_norm_layer(self.norm_cfg, 128*128+1)[1]
+ # for _ in range(2)
+ # ]
+ self.norms = ModuleList(norms_list)
+
+ def forward(self, query: Tensor, query_pos: Tensor,
+ key_padding_mask: Tensor, **kwargs) -> Tensor:
+ """Forward function of an encoder layer.
+
+ Args:
+ query (Tensor): The input query, has shape (bs, num_queries, dim).
+ query_pos (Tensor): The positional encoding for query, with
+ the same shape as `query`.
+ key_padding_mask (Tensor): The `key_padding_mask` of `self_attn`
+ input. ByteTensor. has shape (bs, num_queries).
+ Returns:
+ Tensor: forwarded results, has shape (bs, num_queries, dim).
+ """
+ query = self.self_attn(
+ query=query,
+ key=query,
+ value=query,
+ query_pos=query_pos,
+ key_pos=query_pos,
+ key_padding_mask=key_padding_mask,
+ **kwargs)
+ query = self.norms[0](query)
+ query = self.ffn(query)
+ query = self.norms[1](query)
+ # BN
+ # query = self.norms[0](query.transpose(1, 2)).transpose(1, 2)
+ # query = self.ffn(query)
+ # query = self.norms[1](query.transpose(1, 2)).transpose(1, 2)
+ return query
+
+
+class DeformableDetrTransformerDecoderLayer(BaseModule):
+ """Decoder layer of Deformable DETR.
+ Implements decoder layer in DETR transformer.
+ Args:
+ self_attn_cfg (:obj:`ConfigDict` or dict, optional): Config for self
+ attention.
+ cross_attn_cfg (:obj:`ConfigDict` or dict, optional): Config for cross
+ attention.
+ ffn_cfg (:obj:`ConfigDict` or dict, optional): Config for FFN.
+ norm_cfg (:obj:`ConfigDict` or dict, optional): Config for
+ normalization layers. All the layers will share the same
+ config. Defaults to `LN`.
+ init_cfg (:obj:`ConfigDict` or dict, optional): Config to control
+ the initialization. Defaults to None.
+ """
+
+ def __init__(self,
+ self_attn_cfg: OptConfigType = dict(
+ embed_dims=256,
+ num_heads=8,
+ dropout=0.0,
+ batch_first=True),
+ cross_attn_cfg: OptConfigType = dict(
+ embed_dims=256,
+ num_heads=8,
+ dropout=0.0,
+ batch_first=True),
+ ffn_cfg: OptConfigType = dict(
+ embed_dims=256,
+ feedforward_channels=1024,
+ num_fcs=2,
+ ffn_drop=0.,
+ act_cfg=dict(type='ReLU', inplace=True),
+ ),
+ norm_cfg: OptConfigType = dict(type='LN'),
+ init_cfg: OptConfigType = None) -> None:
+
+ super().__init__(init_cfg=init_cfg)
+
+ self.self_attn_cfg = self_attn_cfg
+ self.cross_attn_cfg = cross_attn_cfg
+ if 'batch_first' not in self.self_attn_cfg:
+ self.self_attn_cfg['batch_first'] = True
+ else:
+ assert self.self_attn_cfg['batch_first'] is True, 'First \
+ dimension of all DETRs in mmdet is `batch`, \
+ please set `batch_first` flag.'
+
+ if 'batch_first' not in self.cross_attn_cfg:
+ self.cross_attn_cfg['batch_first'] = True
+ else:
+ assert self.cross_attn_cfg['batch_first'] is True, 'First \
+ dimension of all DETRs in mmdet is `batch`, \
+ please set `batch_first` flag.'
+
+ self.ffn_cfg = ffn_cfg
+ self.norm_cfg = norm_cfg
+ self._init_layers()
+
+
+ def _init_layers(self) -> None:
+ """Initialize self_attn, cross-attn, ffn, and norms."""
+ self.self_attn = MultiheadAttention(**self.self_attn_cfg)
+ self.cross_attn = MultiScaleDeformableAttention(**self.cross_attn_cfg)
+ self.embed_dims = self.self_attn.embed_dims
+ self.ffn = FFN(**self.ffn_cfg)
+ norms_list = [
+ build_norm_layer(self.norm_cfg, self.embed_dims)[1]
+ for _ in range(3)
+ ]
+ # IN spectra
+ # norms_list = [
+ # build_norm_layer(self.norm_cfg, 128*128+1)[1]
+ # for _ in range(3)
+ # ]
+ self.norms = ModuleList(norms_list)
+
+ def forward(self,
+ query: Tensor,
+ key: Tensor = None,
+ value: Tensor = None,
+ query_pos: Tensor = None,
+ key_pos: Tensor = None,
+ self_attn_mask: Tensor = None,
+ cross_attn_mask: Tensor = None,
+ key_padding_mask: Tensor = None,
+ **kwargs) -> Tensor:
+ """
+ Args:
+ query (Tensor): The input query, has shape (bs, num_queries, dim).
+ key (Tensor, optional): The input key, has shape (bs, num_keys,
+ dim). If `None`, the `query` will be used. Defaults to `None`.
+ value (Tensor, optional): The input value, has the same shape as
+ `key`, as in `nn.MultiheadAttention.forward`. If `None`, the
+ `key` will be used. Defaults to `None`.
+ query_pos (Tensor, optional): The positional encoding for `query`,
+ has the same shape as `query`. If not `None`, it will be added
+ to `query` before forward function. Defaults to `None`.
+ key_pos (Tensor, optional): The positional encoding for `key`, has
+ the same shape as `key`. If not `None`, it will be added to
+ `key` before forward function. If None, and `query_pos` has the
+ same shape as `key`, then `query_pos` will be used for
+ `key_pos`. Defaults to None.
+ self_attn_mask (Tensor, optional): ByteTensor mask, has shape
+ (num_queries, num_keys), as in `nn.MultiheadAttention.forward`.
+ Defaults to None.
+ cross_attn_mask (Tensor, optional): ByteTensor mask, has shape
+ (num_queries, num_keys), as in `nn.MultiheadAttention.forward`.
+ Defaults to None.
+ key_padding_mask (Tensor, optional): The `key_padding_mask` of
+ `self_attn` input. ByteTensor, has shape (bs, num_value).
+ Defaults to None.
+
+ Returns:
+ Tensor: forwarded results, has shape (bs, num_queries, dim).
+ """
+
+ query = self.self_attn(
+ query=query,
+ key=query,
+ value=query,
+ query_pos=query_pos,
+ key_pos=query_pos,
+ attn_mask=self_attn_mask,
+ **kwargs)
+ query = self.norms[0](query)
+ # query = self.norms[0](query.transpose(1, 2)).transpose(1, 2)
+
+ query = self.cross_attn(
+ query=query,
+ key=key,
+ value=value,
+ query_pos=query_pos,
+ key_pos=key_pos,
+ attn_mask=cross_attn_mask,
+ key_padding_mask=key_padding_mask,
+ **kwargs)
+ query = self.norms[1](query)
+ query = self.ffn(query)
+ query = self.norms[2](query)
+ # BN
+ # query = self.norms[1](query.transpose(1, 2)).transpose(1, 2)
+ # query = self.ffn(query)
+ # query = self.norms[2](query.transpose(1, 2)).transpose(1, 2)
+ return query
+
+
+class CdnQueryGenerator(BaseModule):
+ """Implement query generator of the Contrastive denoising (CDN) proposed in
+ `DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object
+ Detection `_
+
+ Code is modified from the `official github repo
+ `_.
+
+ Args:
+ num_classes (int): Number of object classes.
+ embed_dims (int): The embedding dimensions of the generated queries.
+ num_matching_queries (int): The queries number of the matching part.
+ Used for generating dn_mask.
+ label_noise_scale (float): The scale of label noise, defaults to 0.5.
+ box_noise_scale (float): The scale of box noise, defaults to 1.0.
+ group_cfg (:obj:`ConfigDict` or dict, optional): The config of the
+ denoising queries grouping, includes `dynamic`, `num_dn_queries`,
+ and `num_groups`. Two grouping strategies, 'static dn groups' and
+ 'dynamic dn groups', are supported. When `dynamic` is `False`,
+ the `num_groups` should be set, and the number of denoising query
+ groups will always be `num_groups`. When `dynamic` is `True`, the
+ `num_dn_queries` should be set, and the group number will be
+ dynamic to ensure that the denoising queries number will not exceed
+ `num_dn_queries` to prevent large fluctuations of memory. Defaults
+ to `None`.
+ """
+
+ def __init__(self,
+ num_classes: int,
+ embed_dims: int,
+ num_matching_queries: int,
+ label_noise_scale: float = 0.5,
+ box_noise_scale: float = 1.0,
+ group_cfg: OptConfigType = None) -> None:
+ super().__init__()
+ self.num_classes = num_classes
+ self.embed_dims = embed_dims
+ self.num_matching_queries = num_matching_queries
+ self.label_noise_scale = label_noise_scale
+ self.box_noise_scale = box_noise_scale
+
+ # prepare grouping strategy
+ group_cfg = {} if group_cfg is None else group_cfg
+ self.dynamic_dn_groups = group_cfg.get('dynamic', True)
+ if self.dynamic_dn_groups:
+ if 'num_dn_queries' not in group_cfg:
+ warnings.warn("'num_dn_queries' should be set when using "
+ 'dynamic dn groups, use 100 as default.')
+ self.num_dn_queries = group_cfg.get('num_dn_queries', 100)
+ assert isinstance(self.num_dn_queries, int), \
+ f'Expected the num_dn_queries to have type int, but got ' \
+ f'{self.num_dn_queries}({type(self.num_dn_queries)}). '
+ else:
+ assert 'num_groups' in group_cfg, \
+ 'num_groups should be set when using static dn groups'
+ self.num_groups = group_cfg['num_groups']
+ assert isinstance(self.num_groups, int), \
+ f'Expected the num_groups to have type int, but got ' \
+ f'{self.num_groups}({type(self.num_groups)}). '
+
+ # NOTE The original repo of DINO set the num_embeddings 92 for coco,
+ # 91 (0~90) of which represents target classes and the 92 (91)
+ # indicates `Unknown` class. However, the embedding of `unknown` class
+ # is not used in the original DINO.
+ # TODO: num_classes + 1 or num_classes ?
+ self.label_embedding = nn.Embedding(self.num_classes, self.embed_dims)
+
+ def __call__(self, batch_data_samples: SampleList) -> tuple:
+ """Generate contrastive denoising (cdn) queries with ground truth.
+ max_num_target 为一个batch内各个图像目标数量的最大值
+ Descriptions of the Number Values in code and comments:
+ - num_target_total: the total target number of the input batch
+ samples.
+ - max_num_target: the max target number of the input batch samples.
+ - num_noisy_targets: the total targets number after adding noise,
+ i.e., num_target_total * num_groups * 2.
+ - num_denoising_queries: the length of the output batched queries,
+ i.e., max_num_target * num_groups * 2.
+
+ NOTE The format of input bboxes in batch_data_samples is unnormalized
+ (x, y, x, y), and the output bbox queries are embedded by normalized
+ (cx, cy, w, h) format bboxes going through inverse_sigmoid.
+
+ Args:
+ batch_data_samples (list[:obj:`DetDataSample`]): List of the batch
+ data samples, each includes `gt_instance` which has attributes
+ `bboxes` and `labels`. The `bboxes` has unnormalized coordinate
+ format (x, y, x, y).
+
+ Returns:
+ tuple: The outputs of the dn query generator.
+
+ - dn_label_query (Tensor): The output content queries for denoising
+ part, has shape (bs, num_denoising_queries, dim), where
+ `num_denoising_queries = max_num_target * num_groups * 2`.
+ - dn_bbox_query (Tensor): The output reference bboxes as positions
+ of queries for denoising part, which are embedded by normalized
+ (cx, cy, w, h) format bboxes going through inverse_sigmoid, has
+ shape (bs, num_denoising_queries, 4) with the last dimension
+ arranged as (cx, cy, w, h).
+ - attn_mask (Tensor): The attention mask to prevent information
+ leakage from different denoising groups and matching parts,
+ will be used as `self_attn_mask` of the `decoder`, has shape
+ (num_queries_total, num_queries_total), where `num_queries_total`
+ is the sum of `num_denoising_queries` and `num_matching_queries`.
+ - dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ """
+ # normalize bbox and collate ground truth (gt)
+ gt_labels_list = []
+ gt_bboxes_list = []
+ for sample in batch_data_samples:
+ img_h, img_w = sample.img_shape
+ bboxes = sample.gt_instances.bboxes
+ factor = bboxes.new_tensor([img_w, img_h, img_w,
+ img_h]).unsqueeze(0)
+ bboxes_normalized = bboxes / factor
+ gt_bboxes_list.append(bboxes_normalized)
+ gt_labels_list.append(sample.gt_instances.labels)
+ gt_labels = torch.cat(gt_labels_list) # (num_target_total, 4)
+ gt_bboxes = torch.cat(gt_bboxes_list)
+
+ num_target_list = [len(bboxes) for bboxes in gt_bboxes_list]
+ max_num_target = max(num_target_list)
+ num_groups = self.get_num_groups(max_num_target)
+
+ dn_label_query = self.generate_dn_label_query(gt_labels, num_groups)
+ dn_bbox_query = self.generate_dn_bbox_query(gt_bboxes, num_groups)
+ # dn_bbox_query数量为batch内图像目标总数 * 组数 * 2 (正样本和负样本各占一半)
+ # dn_label_query数量为batch内图像目标总数 * 组数 * 2, 随机选择一定数量的样本设为错误类比标签
+ # The `batch_idx` saves the batch index of the corresponding sample
+ # for each target, has shape (num_target_total).
+ batch_idx = torch.cat([
+ torch.full_like(t.long(), i) for i, t in enumerate(gt_labels_list)
+ ])
+
+
+ # dn_label_query, dn_bbox_query目前将一个batch内所有图像的正负样本拼接在一起,需要按batch size分开
+ # 每一张图目标数目不一样,数目同一设为最大目标数*group*2
+ dn_label_query, dn_bbox_query = self.collate_dn_queries(
+ dn_label_query, dn_bbox_query, batch_idx, len(batch_data_samples),
+ num_groups)
+
+ # 匹配部分查询和去噪组的查询不做注意力,去噪组与组之间也不做注意力
+ attn_mask = self.generate_dn_mask(
+ max_num_target, num_groups, device=dn_label_query.device)
+
+ dn_meta = dict(
+ num_denoising_queries=int(max_num_target * 2 * num_groups),
+ num_denoising_groups=num_groups)
+
+ return dn_label_query, dn_bbox_query, attn_mask, dn_meta
+
+ def get_num_groups(self, max_num_target: int = None) -> int:
+ """Calculate denoising query groups number.
+
+ Two grouping strategies, 'static dn groups' and 'dynamic dn groups',
+ are supported. When `self.dynamic_dn_groups` is `False`, the number
+ of denoising query groups will always be `self.num_groups`. When
+ `self.dynamic_dn_groups` is `True`, the group number will be dynamic,
+ ensuring the denoising queries number will not exceed
+ `self.num_dn_queries` to prevent large fluctuations of memory.
+
+ NOTE The `num_group` is shared for different samples in a batch. When
+ the target numbers in the samples varies, the denoising queries of the
+ samples containing fewer targets are padded to the max length.
+
+ Args:
+ max_num_target (int, optional): The max target number of the batch
+ samples. It will only be used when `self.dynamic_dn_groups` is
+ `True`. Defaults to `None`.
+
+ Returns:
+ int: The denoising group number of the current batch.
+ """
+ if self.dynamic_dn_groups:
+ assert max_num_target is not None, \
+ 'group_queries should be provided when using ' \
+ 'dynamic dn groups'
+ if max_num_target == 0:
+ num_groups = 1
+ else:
+ num_groups = self.num_dn_queries // max_num_target
+ else:
+ num_groups = self.num_groups
+ if num_groups < 1:
+ num_groups = 1
+ return int(num_groups)
+
+ def generate_dn_label_query(self, gt_labels: Tensor,
+ num_groups: int) -> Tensor:
+ """Generate noisy labels and their query embeddings.
+
+ The strategy for generating noisy labels is: Randomly choose labels of
+ `self.label_noise_scale * 0.5` proportion and override each of them
+ with a random object category label.
+
+ NOTE Not add noise to all labels. Besides, the `self.label_noise_scale
+ * 0.5` arg is the ratio of the chosen positions, which is higher than
+ the actual proportion of noisy labels, because the labels to override
+ may be correct. And the gap becomes larger as the number of target
+ categories decreases. The users should notice this and modify the scale
+ arg or the corresponding logic according to specific dataset.
+
+ Args:
+ gt_labels (Tensor): The concatenated gt labels of all samples
+ in the batch, has shape (num_target_total, ) where
+ `num_target_total = sum(num_target_list)`.
+ num_groups (int): The number of denoising query groups.
+
+ Returns:
+ Tensor: The query embeddings of noisy labels, has shape
+ (num_noisy_targets, embed_dims), where `num_noisy_targets =
+ num_target_total * num_groups * 2`.
+ """
+ assert self.label_noise_scale > 0
+ gt_labels_expand = gt_labels.repeat(2 * num_groups,
+ 1).view(-1) # Note `* 2` # noqa
+ p = torch.rand_like(gt_labels_expand.float())
+ chosen_indice = torch.nonzero(p < (self.label_noise_scale * 0.5)).view(
+ -1) # Note `* 0.5`
+ new_labels = torch.randint_like(chosen_indice, 0, self.num_classes)
+ noisy_labels_expand = gt_labels_expand.scatter(0, chosen_indice,
+ new_labels)
+ dn_label_query = self.label_embedding(noisy_labels_expand)
+ return dn_label_query
+
+ def generate_dn_bbox_query(self, gt_bboxes: Tensor,
+ num_groups: int) -> Tensor:
+ """Generate noisy bboxes and their query embeddings.
+
+ The strategy for generating noisy bboxes is as follow:
+
+ .. code:: text
+
+ +--------------------+
+ | negative |
+ | +----------+ |
+ | | positive | |
+ | | +-----|----+------------+
+ | | | | | |
+ | +----+-----+ | |
+ | | | |
+ +---------+----------+ |
+ | |
+ | gt bbox |
+ | |
+ | +---------+----------+
+ | | | |
+ | | +----+-----+ |
+ | | | | | |
+ +-------------|--- +----+ | |
+ | | positive | |
+ | +----------+ |
+ | negative |
+ +--------------------+
+
+ The random noise is added to the top-left and down-right point
+ positions, hence, normalized (x, y, x, y) format of bboxes are
+ required. The noisy bboxes of positive queries have the points
+ both within the inner square, while those of negative queries
+ have the points both between the inner and outer squares.
+
+ Besides, the length of outer square is twice as long as that of
+ the inner square, i.e., self.box_noise_scale * w_or_h / 2.
+ NOTE The noise is added to all the bboxes. Moreover, there is still
+ unconsidered case when one point is within the positive square and
+ the others is between the inner and outer squares.
+
+ Args:
+ gt_bboxes (Tensor): The concatenated gt bboxes of all samples
+ in the batch, has shape (num_target_total, 4) with the last
+ dimension arranged as (cx, cy, w, h) where
+ `num_target_total = sum(num_target_list)`.
+ num_groups (int): The number of denoising query groups.
+
+ Returns:
+ Tensor: The output noisy bboxes, which are embedded by normalized
+ (cx, cy, w, h) format bboxes going through inverse_sigmoid, has
+ shape (num_noisy_targets, 4) with the last dimension arranged as
+ (cx, cy, w, h), where
+ `num_noisy_targets = num_target_total * num_groups * 2`.
+ """
+ assert self.box_noise_scale > 0
+ device = gt_bboxes.device
+
+ # expand gt_bboxes as groups
+ gt_bboxes_expand = gt_bboxes.repeat(2 * num_groups, 1) # xyxy
+
+ # obtain index of negative queries in gt_bboxes_expand
+ positive_idx = torch.arange(
+ len(gt_bboxes), dtype=torch.long, device=device)
+ positive_idx = positive_idx.unsqueeze(0).repeat(num_groups, 1)
+ positive_idx += 2 * len(gt_bboxes) * torch.arange(
+ num_groups, dtype=torch.long, device=device)[:, None]
+ positive_idx = positive_idx.flatten()
+ negative_idx = positive_idx + len(gt_bboxes)
+
+ # determine the sign of each element in the random part of the added
+ # noise to be positive or negative randomly.
+ rand_sign = torch.randint_like(
+ gt_bboxes_expand, low=0, high=2,
+ dtype=torch.float32) * 2.0 - 1.0 # [low, high), 1 or -1, randomly
+
+ # calculate the random part of the added noise
+ rand_part = torch.rand_like(gt_bboxes_expand) # [0, 1)
+ rand_part[negative_idx] += 1.0 # pos: [0, 1); neg: [1, 2)
+ rand_part *= rand_sign # pos: (-1, 1); neg: (-2, -1] U [1, 2)
+
+ # add noise to the bboxes
+ bboxes_whwh = bbox_xyxy_to_cxcywh(gt_bboxes_expand)[:, 2:].repeat(1, 2) #[num,4] 宽高宽高
+ noisy_bboxes_expand = gt_bboxes_expand + torch.mul(
+ rand_part, bboxes_whwh) * self.box_noise_scale / 2 # xyxy
+ noisy_bboxes_expand = noisy_bboxes_expand.clamp(min=0.0, max=1.0)
+ noisy_bboxes_expand = bbox_xyxy_to_cxcywh(noisy_bboxes_expand)
+
+ # random_numbers = 0.98 * torch.rand_like(gt_bboxes_expand[:, :2]) + 0.01
+ # noisy_bboxes_expand[negative_idx, :2] = random_numbers[negative_idx]
+
+ dn_bbox_query = inverse_sigmoid(noisy_bboxes_expand, eps=1e-3)
+ return dn_bbox_query
+
+ def collate_dn_queries(self, input_label_query: Tensor,
+ input_bbox_query: Tensor, batch_idx: Tensor,
+ batch_size: int, num_groups: int) -> Tuple[Tensor]:
+ """Collate generated queries to obtain batched dn queries.
+
+ The strategy for query collation is as follow:
+
+ .. code:: text
+
+ input_queries (num_target_total, query_dim)
+ P_A1 P_B1 P_B2 N_A1 N_B1 N_B2 P'A1 P'B1 P'B2 N'A1 N'B1 N'B2
+ |________ group1 ________| |________ group2 ________|
+ |
+ V
+ P_A1 Pad0 N_A1 Pad0 P'A1 Pad0 N'A1 Pad0
+ P_B1 P_B2 N_B1 N_B2 P'B1 P'B2 N'B1 N'B2
+ |____ group1 ____| |____ group2 ____|
+ batched_queries (batch_size, max_num_target, query_dim)
+
+ where query_dim is 4 for bbox and self.embed_dims for label.
+ Notation: _-group 1; '-group 2;
+ A-Sample1(has 1 target); B-sample2(has 2 targets)
+
+ Args:
+ input_label_query (Tensor): The generated label queries of all
+ targets, has shape (num_target_total, embed_dims) where
+ `num_target_total = sum(num_target_list)`.
+ input_bbox_query (Tensor): The generated bbox queries of all
+ targets, has shape (num_target_total, 4) with the last
+ dimension arranged as (cx, cy, w, h).
+ batch_idx (Tensor): The batch index of the corresponding sample
+ for each target, has shape (num_target_total).
+ batch_size (int): The size of the input batch.
+ num_groups (int): The number of denoising query groups.
+
+ Returns:
+ tuple[Tensor]: Output batched label and bbox queries.
+ - batched_label_query (Tensor): The output batched label queries,
+ has shape (batch_size, max_num_target, embed_dims).
+ - batched_bbox_query (Tensor): The output batched bbox queries,
+ has shape (batch_size, max_num_target, 4) with the last dimension
+ arranged as (cx, cy, w, h).
+ """
+ device = input_label_query.device
+ num_target_list = [
+ torch.sum(batch_idx == idx) for idx in range(batch_size)
+ ]
+ max_num_target = max(num_target_list)
+ num_denoising_queries = int(max_num_target * 2 * num_groups)
+
+ map_query_index = torch.cat([
+ torch.arange(num_target, device=device)
+ for num_target in num_target_list
+ ])
+ map_query_index = torch.cat([
+ map_query_index + max_num_target * i for i in range(2 * num_groups)
+ ]).long()
+ batch_idx_expand = batch_idx.repeat(2 * num_groups, 1).view(-1)
+ mapper = (batch_idx_expand, map_query_index)
+
+ batched_label_query = torch.zeros(
+ batch_size, num_denoising_queries, self.embed_dims, device=device)
+ batched_bbox_query = torch.zeros(
+ batch_size, num_denoising_queries, 4, device=device)
+
+ batched_label_query[mapper] = input_label_query
+ batched_bbox_query[mapper] = input_bbox_query
+ return batched_label_query, batched_bbox_query
+
+ def generate_dn_mask(self, max_num_target: int, num_groups: int,
+ device: Union[torch.device, str]) -> Tensor:
+ """Generate attention mask to prevent information leakage from
+ different denoising groups and matching parts.
+
+ .. code:: text
+
+ 0 0 0 0 1 1 1 1 0 0 0 0 0
+ 0 0 0 0 1 1 1 1 0 0 0 0 0
+ 0 0 0 0 1 1 1 1 0 0 0 0 0
+ 0 0 0 0 1 1 1 1 0 0 0 0 0
+ 1 1 1 1 0 0 0 0 0 0 0 0 0
+ 1 1 1 1 0 0 0 0 0 0 0 0 0
+ 1 1 1 1 0 0 0 0 0 0 0 0 0
+ 1 1 1 1 0 0 0 0 0 0 0 0 0
+ 1 1 1 1 1 1 1 1 0 0 0 0 0
+ 1 1 1 1 1 1 1 1 0 0 0 0 0
+ 1 1 1 1 1 1 1 1 0 0 0 0 0
+ 1 1 1 1 1 1 1 1 0 0 0 0 0
+ 1 1 1 1 1 1 1 1 0 0 0 0 0
+ max_num_target |_| |_________| num_matching_queries
+ |_____________| num_denoising_queries
+
+ 1 -> True (Masked), means 'can not see'.
+ 0 -> False (UnMasked), means 'can see'.
+
+ Args:
+ max_num_target (int): The max target number of the input batch
+ samples.
+ num_groups (int): The number of denoising query groups.
+ device (obj:`device` or str): The device of generated mask.
+
+ Returns:
+ Tensor: The attention mask to prevent information leakage from
+ different denoising groups and matching parts, will be used as
+ `self_attn_mask` of the `decoder`, has shape (num_queries_total,
+ num_queries_total), where `num_queries_total` is the sum of
+ `num_denoising_queries` and `num_matching_queries`.
+ """
+ num_denoising_queries = int(max_num_target * 2 * num_groups)
+ num_queries_total = num_denoising_queries + self.num_matching_queries
+ attn_mask = torch.zeros(
+ num_queries_total,
+ num_queries_total,
+ device=device,
+ dtype=torch.bool)
+ # Make the matching part cannot see the denoising groups 匹配部分的查询不能看到去噪组查询
+ attn_mask[num_denoising_queries:, :num_denoising_queries] = True
+ # Make the denoising groups cannot see each other
+ for i in range(num_groups):
+ # Mask rows of one group per step.
+ row_scope = slice(max_num_target * 2 * i,
+ max_num_target * 2 * (i + 1))
+ left_scope = slice(max_num_target * 2 * i)
+ right_scope = slice(max_num_target * 2 * (i + 1),
+ num_denoising_queries)
+ attn_mask[row_scope, right_scope] = True
+ attn_mask[row_scope, left_scope] = True
+ return attn_mask
diff --git a/mmdet/models/layers/transformer/dino_layers_copy.py b/mmdet/models/layers/transformer/dino_layers_copy.py
new file mode 100644
index 0000000000000000000000000000000000000000..74ebec1e1d940a5d056977c40c6257438fafca03
--- /dev/null
+++ b/mmdet/models/layers/transformer/dino_layers_copy.py
@@ -0,0 +1,941 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+
+from typing import Optional, Tuple, Union
+import torch
+from mmcv.cnn import build_norm_layer
+from mmcv.cnn.bricks.transformer import FFN, MultiheadAttention
+from mmcv.ops import MultiScaleDeformableAttention
+from mmengine.model import ModuleList
+from torch import Tensor, nn
+from mmengine.model import BaseModule
+
+from mmdet.structures import SampleList
+from mmdet.structures.bbox import bbox_xyxy_to_cxcywh
+from mmengine import ConfigDict
+from mmdet.utils import ConfigType, OptConfigType
+# from .detr_layers import (DetrTransformerDecoder, DetrTransformerDecoderLayer,
+# DetrTransformerEncoder, DetrTransformerEncoderLayer)
+from .utils import MLP, coordinate_to_encoding, inverse_sigmoid
+
+
+class DeformableDetrTransformerEncoder(BaseModule):
+ """Transformer encoder of Deformable DETR.Encoder of DETR.
+
+ Args:
+ num_layers (int): Number of encoder layers.
+ layer_cfg (:obj:`ConfigDict` or dict): the config of each encoder
+ layer. All the layers will share the same config.
+ init_cfg (:obj:`ConfigDict` or dict, optional): the config to control
+ the initialization. Defaults to None.
+ """
+
+ def __init__(self,
+ num_layers: int,
+ layer_cfg: ConfigType,
+ init_cfg: OptConfigType = None) -> None:
+
+ super().__init__(init_cfg=init_cfg)
+ self.num_layers = num_layers
+ self.layer_cfg = layer_cfg
+ self._init_layers()
+
+
+ def _init_layers(self) -> None:
+ """Initialize encoder layers."""
+ self.layers = ModuleList([
+ DeformableDetrTransformerEncoderLayer(**self.layer_cfg)
+ for _ in range(self.num_layers)
+ ])
+ self.embed_dims = self.layers[0].embed_dims
+
+ def forward(self, query: Tensor, query_pos: Tensor,
+ key_padding_mask: Tensor, spatial_shapes: Tensor,
+ level_start_index: Tensor, valid_ratios: Tensor,
+ **kwargs) -> Tensor:
+ """Forward function of Transformer encoder.
+
+ Args:
+ query (Tensor): The input query, has shape (bs, num_queries, dim).
+ query_pos (Tensor): The positional encoding for query, has shape
+ (bs, num_queries, dim).
+ key_padding_mask (Tensor): The `key_padding_mask` of `self_attn`
+ input. ByteTensor, has shape (bs, num_queries).
+ spatial_shapes (Tensor): Spatial shapes of features in all levels,
+ has shape (num_levels, 2), last dimension represents (h, w).
+ level_start_index (Tensor): The start index of each level.
+ A tensor has shape (num_levels, ) and can be represented
+ as [0, h_0*w_0, h_0*w_0+h_1*w_1, ...].
+ valid_ratios (Tensor): The ratios of the valid width and the valid
+ height relative to the width and the height of features in all
+ levels, has shape (bs, num_levels, 2).
+
+ Returns:
+ Tensor: Output queries of Transformer encoder, which is also
+ called 'encoder output embeddings' or 'memory', has shape
+ (bs, num_queries, dim)
+ """
+ reference_points = self.get_encoder_reference_points(
+ spatial_shapes, valid_ratios, device=query.device)
+ for layer in self.layers:
+ query = layer(
+ query=query,
+ query_pos=query_pos,
+ key_padding_mask=key_padding_mask,
+ spatial_shapes=spatial_shapes,
+ level_start_index=level_start_index,
+ valid_ratios=valid_ratios,
+ reference_points=reference_points,
+ **kwargs)
+ return query
+
+ @staticmethod
+ def get_encoder_reference_points(
+ spatial_shapes: Tensor, valid_ratios: Tensor,
+ device: Union[torch.device, str]) -> Tensor:
+ """Get the reference points used in encoder.
+
+ Args:
+ spatial_shapes (Tensor): Spatial shapes of features in all levels,
+ has shape (num_levels, 2), last dimension represents (h, w).
+ valid_ratios (Tensor): The ratios of the valid width and the valid
+ height relative to the width and the height of features in all
+ levels, has shape (bs, num_levels, 2).
+ device (obj:`device` or str): The device acquired by the
+ `reference_points`.
+
+ Returns:
+ Tensor: Reference points used in decoder, has shape (bs, length,
+ num_levels, 2).
+ """
+
+ reference_points_list = []
+ for lvl, (H, W) in enumerate(spatial_shapes):
+ ref_y, ref_x = torch.meshgrid(
+ torch.linspace(
+ 0.5, H - 0.5, H, dtype=torch.float32, device=device),
+ torch.linspace(
+ 0.5, W - 0.5, W, dtype=torch.float32, device=device))
+ ref_y = ref_y.reshape(-1)[None] / (
+ valid_ratios[:, None, lvl, 1] * H)
+ ref_x = ref_x.reshape(-1)[None] / (
+ valid_ratios[:, None, lvl, 0] * W)
+ ref = torch.stack((ref_x, ref_y), -1)
+ reference_points_list.append(ref)
+ reference_points = torch.cat(reference_points_list, 1)
+ # [bs, sum(hw), num_level, 2]
+ reference_points = reference_points[:, :, None] * valid_ratios[:, None]
+ return reference_points
+
+
+class DinoTransformerDecoder(BaseModule):
+ """Transformer encoder of DINO.Decoder of DETR.
+
+ Args:
+ num_layers (int): Number of decoder layers.
+ layer_cfg (:obj:`ConfigDict` or dict): the config of each encoder
+ layer. All the layers will share the same config.
+ post_norm_cfg (:obj:`ConfigDict` or dict, optional): Config of the
+ post normalization layer. Defaults to `LN`.
+ return_intermediate (bool, optional): Whether to return outputs of
+ intermediate layers. Defaults to `True`,
+ init_cfg (:obj:`ConfigDict` or dict, optional): the config to control
+ the initialization. Defaults to None.
+ """
+
+ def __init__(self,
+ num_layers: int,
+ layer_cfg: ConfigType,
+ post_norm_cfg: OptConfigType = dict(type='LN'),
+ return_intermediate: bool = True,
+ init_cfg: Union[dict, ConfigDict] = None) -> None:
+ super().__init__(init_cfg=init_cfg)
+ self.layer_cfg = layer_cfg
+ self.num_layers = num_layers
+ self.post_norm_cfg = post_norm_cfg
+ self.return_intermediate = return_intermediate
+ self._init_layers()
+
+ def _init_layers(self) -> None:
+ """Initialize decoder layers."""
+ self.layers = ModuleList([
+ DeformableDetrTransformerDecoderLayer(**self.layer_cfg)
+ for _ in range(self.num_layers)
+ ])
+ self.embed_dims = self.layers[0].embed_dims
+ if self.post_norm_cfg is not None:
+ raise ValueError('There is not post_norm in '
+ f'{self._get_name()}')
+ self.ref_point_head = MLP(self.embed_dims * 2, self.embed_dims,
+ self.embed_dims, 2)
+ self.norm = nn.LayerNorm(self.embed_dims)
+
+ def forward(self, query: Tensor, value: Tensor, key_padding_mask: Tensor,
+ self_attn_mask: Tensor, reference_points: Tensor,
+ spatial_shapes: Tensor, level_start_index: Tensor,
+ valid_ratios: Tensor, reg_branches: nn.ModuleList,
+ **kwargs) -> Tensor:
+ """Forward function of Transformer encoder.
+
+ Args:
+ query (Tensor): The input query, has shape (num_queries, bs, dim).
+ value (Tensor): The input values, has shape (num_value, bs, dim).
+ key_padding_mask (Tensor): The `key_padding_mask` of `self_attn`
+ input. ByteTensor, has shape (num_queries, bs).
+ self_attn_mask (Tensor): The attention mask to prevent information
+ leakage from different denoising groups and matching parts, has
+ shape (num_queries_total, num_queries_total). It is `None` when
+ `self.training` is `False`.
+ reference_points (Tensor): The initial reference, has shape
+ (bs, num_queries, 4) with the last dimension arranged as
+ (cx, cy, w, h).
+ spatial_shapes (Tensor): Spatial shapes of features in all levels,
+ has shape (num_levels, 2), last dimension represents (h, w).
+ level_start_index (Tensor): The start index of each level.
+ A tensor has shape (num_levels, ) and can be represented
+ as [0, h_0*w_0, h_0*w_0+h_1*w_1, ...].
+ valid_ratios (Tensor): The ratios of the valid width and the valid
+ height relative to the width and the height of features in all
+ levels, has shape (bs, num_levels, 2).
+ reg_branches: (obj:`nn.ModuleList`): Used for refining the
+ regression results.
+
+ Returns:
+ Tensor: Output queries of Transformer encoder, which is also
+ called 'encoder output embeddings' or 'memory', has shape
+ (num_queries, bs, dim)
+ """
+ intermediate = []
+ intermediate_reference_points = [reference_points]
+ for lid, layer in enumerate(self.layers):
+ if reference_points.shape[-1] == 4:
+ reference_points_input = \
+ reference_points[:, :, None] * torch.cat(
+ [valid_ratios, valid_ratios], -1)[:, None]
+ else:
+ assert reference_points.shape[-1] == 2
+ reference_points_input = \
+ reference_points[:, :, None] * valid_ratios[:, None]
+
+ query_sine_embed = coordinate_to_encoding(
+ reference_points_input[:, :, 0, :])
+ query_pos = self.ref_point_head(query_sine_embed)
+
+ query = layer(
+ query,
+ query_pos=query_pos,
+ value=value,
+ key_padding_mask=key_padding_mask,
+ self_attn_mask=self_attn_mask,
+ spatial_shapes=spatial_shapes,
+ level_start_index=level_start_index,
+ valid_ratios=valid_ratios,
+ reference_points=reference_points_input,
+ **kwargs)
+
+ if reg_branches is not None:
+ tmp = reg_branches[lid](query)
+ assert reference_points.shape[-1] == 4
+ new_reference_points = tmp + inverse_sigmoid(
+ reference_points, eps=1e-3)
+ new_reference_points = new_reference_points.sigmoid()
+ reference_points = new_reference_points.detach()
+
+ if self.return_intermediate:
+ intermediate.append(self.norm(query))
+ intermediate_reference_points.append(new_reference_points)
+ # NOTE this is for the "Look Forward Twice" module,
+ # in the DeformDETR, reference_points was appended.
+
+ if self.return_intermediate:
+ return torch.stack(intermediate), torch.stack(
+ intermediate_reference_points)
+
+ return query, reference_points
+
+
+class DeformableDetrTransformerEncoderLayer(BaseModule):
+ """Encoder layer of Deformable DETR.
+ Implements encoder layer in DETR transformer.
+
+ Args:
+ self_attn_cfg (:obj:`ConfigDict` or dict, optional): Config for self
+ attention.
+ ffn_cfg (:obj:`ConfigDict` or dict, optional): Config for FFN.
+ norm_cfg (:obj:`ConfigDict` or dict, optional): Config for
+ normalization layers. All the layers will share the same
+ config. Defaults to `LN`.
+ init_cfg (:obj:`ConfigDict` or dict, optional): Config to control
+ the initialization. Defaults to None.
+ """
+
+ def __init__(self,
+ self_attn_cfg: OptConfigType = dict(
+ embed_dims=256, num_heads=8, dropout=0.0),
+ ffn_cfg: OptConfigType = dict(
+ embed_dims=256,
+ feedforward_channels=1024,
+ num_fcs=2,
+ ffn_drop=0.,
+ act_cfg=dict(type='ReLU', inplace=True)),
+ norm_cfg: OptConfigType = dict(type='LN'),
+ init_cfg: OptConfigType = None) -> None:
+
+ super().__init__(init_cfg=init_cfg)
+
+ self.self_attn_cfg = self_attn_cfg
+ if 'batch_first' not in self.self_attn_cfg:
+ self.self_attn_cfg['batch_first'] = True
+ else:
+ assert self.self_attn_cfg['batch_first'] is True, 'First \
+ dimension of all DETRs in mmdet is `batch`, \
+ please set `batch_first` flag.'
+
+ self.ffn_cfg = ffn_cfg
+ self.norm_cfg = norm_cfg
+ self._init_layers()
+
+ def _init_layers(self) -> None:
+ """Initialize self_attn, ffn, and norms."""
+ self.self_attn = MultiScaleDeformableAttention(**self.self_attn_cfg)
+ self.embed_dims = self.self_attn.embed_dims
+ self.ffn = FFN(**self.ffn_cfg)
+ norms_list = [
+ build_norm_layer(self.norm_cfg, self.embed_dims)[1]
+ for _ in range(2)
+ ]
+ # IN spectra
+ # norms_list = [
+ # build_norm_layer(self.norm_cfg, 128*128+1)[1]
+ # for _ in range(2)
+ # ]
+ self.norms = ModuleList(norms_list)
+
+ def forward(self, query: Tensor, query_pos: Tensor,
+ key_padding_mask: Tensor, **kwargs) -> Tensor:
+ """Forward function of an encoder layer.
+
+ Args:
+ query (Tensor): The input query, has shape (bs, num_queries, dim).
+ query_pos (Tensor): The positional encoding for query, with
+ the same shape as `query`.
+ key_padding_mask (Tensor): The `key_padding_mask` of `self_attn`
+ input. ByteTensor. has shape (bs, num_queries).
+ Returns:
+ Tensor: forwarded results, has shape (bs, num_queries, dim).
+ """
+ query = self.self_attn(
+ query=query,
+ key=query,
+ value=query,
+ query_pos=query_pos,
+ key_pos=query_pos,
+ key_padding_mask=key_padding_mask,
+ **kwargs)
+ query = self.norms[0](query)
+ query = self.ffn(query)
+ query = self.norms[1](query)
+ # BN
+ # query = self.norms[0](query.transpose(1, 2)).transpose(1, 2)
+ # query = self.ffn(query)
+ # query = self.norms[1](query.transpose(1, 2)).transpose(1, 2)
+ return query
+
+
+class DeformableDetrTransformerDecoderLayer(BaseModule):
+ """Decoder layer of Deformable DETR.
+ Implements decoder layer in DETR transformer.
+ Args:
+ self_attn_cfg (:obj:`ConfigDict` or dict, optional): Config for self
+ attention.
+ cross_attn_cfg (:obj:`ConfigDict` or dict, optional): Config for cross
+ attention.
+ ffn_cfg (:obj:`ConfigDict` or dict, optional): Config for FFN.
+ norm_cfg (:obj:`ConfigDict` or dict, optional): Config for
+ normalization layers. All the layers will share the same
+ config. Defaults to `LN`.
+ init_cfg (:obj:`ConfigDict` or dict, optional): Config to control
+ the initialization. Defaults to None.
+ """
+
+ def __init__(self,
+ self_attn_cfg: OptConfigType = dict(
+ embed_dims=256,
+ num_heads=8,
+ dropout=0.0,
+ batch_first=True),
+ cross_attn_cfg: OptConfigType = dict(
+ embed_dims=256,
+ num_heads=8,
+ dropout=0.0,
+ batch_first=True),
+ ffn_cfg: OptConfigType = dict(
+ embed_dims=256,
+ feedforward_channels=1024,
+ num_fcs=2,
+ ffn_drop=0.,
+ act_cfg=dict(type='ReLU', inplace=True),
+ ),
+ norm_cfg: OptConfigType = dict(type='LN'),
+ init_cfg: OptConfigType = None) -> None:
+
+ super().__init__(init_cfg=init_cfg)
+
+ self.self_attn_cfg = self_attn_cfg
+ self.cross_attn_cfg = cross_attn_cfg
+ if 'batch_first' not in self.self_attn_cfg:
+ self.self_attn_cfg['batch_first'] = True
+ else:
+ assert self.self_attn_cfg['batch_first'] is True, 'First \
+ dimension of all DETRs in mmdet is `batch`, \
+ please set `batch_first` flag.'
+
+ if 'batch_first' not in self.cross_attn_cfg:
+ self.cross_attn_cfg['batch_first'] = True
+ else:
+ assert self.cross_attn_cfg['batch_first'] is True, 'First \
+ dimension of all DETRs in mmdet is `batch`, \
+ please set `batch_first` flag.'
+
+ self.ffn_cfg = ffn_cfg
+ self.norm_cfg = norm_cfg
+ self._init_layers()
+
+
+ def _init_layers(self) -> None:
+ """Initialize self_attn, cross-attn, ffn, and norms."""
+ self.self_attn = MultiheadAttention(**self.self_attn_cfg)
+ self.cross_attn = MultiScaleDeformableAttention(**self.cross_attn_cfg)
+ self.embed_dims = self.self_attn.embed_dims
+ self.ffn = FFN(**self.ffn_cfg)
+ norms_list = [
+ build_norm_layer(self.norm_cfg, self.embed_dims)[1]
+ for _ in range(3)
+ ]
+ # IN spectra
+ # norms_list = [
+ # build_norm_layer(self.norm_cfg, 128*128+1)[1]
+ # for _ in range(3)
+ # ]
+ self.norms = ModuleList(norms_list)
+
+ def forward(self,
+ query: Tensor,
+ key: Tensor = None,
+ value: Tensor = None,
+ query_pos: Tensor = None,
+ key_pos: Tensor = None,
+ self_attn_mask: Tensor = None,
+ cross_attn_mask: Tensor = None,
+ key_padding_mask: Tensor = None,
+ **kwargs) -> Tensor:
+ """
+ Args:
+ query (Tensor): The input query, has shape (bs, num_queries, dim).
+ key (Tensor, optional): The input key, has shape (bs, num_keys,
+ dim). If `None`, the `query` will be used. Defaults to `None`.
+ value (Tensor, optional): The input value, has the same shape as
+ `key`, as in `nn.MultiheadAttention.forward`. If `None`, the
+ `key` will be used. Defaults to `None`.
+ query_pos (Tensor, optional): The positional encoding for `query`,
+ has the same shape as `query`. If not `None`, it will be added
+ to `query` before forward function. Defaults to `None`.
+ key_pos (Tensor, optional): The positional encoding for `key`, has
+ the same shape as `key`. If not `None`, it will be added to
+ `key` before forward function. If None, and `query_pos` has the
+ same shape as `key`, then `query_pos` will be used for
+ `key_pos`. Defaults to None.
+ self_attn_mask (Tensor, optional): ByteTensor mask, has shape
+ (num_queries, num_keys), as in `nn.MultiheadAttention.forward`.
+ Defaults to None.
+ cross_attn_mask (Tensor, optional): ByteTensor mask, has shape
+ (num_queries, num_keys), as in `nn.MultiheadAttention.forward`.
+ Defaults to None.
+ key_padding_mask (Tensor, optional): The `key_padding_mask` of
+ `self_attn` input. ByteTensor, has shape (bs, num_value).
+ Defaults to None.
+
+ Returns:
+ Tensor: forwarded results, has shape (bs, num_queries, dim).
+ """
+
+ query = self.self_attn(
+ query=query,
+ key=query,
+ value=query,
+ query_pos=query_pos,
+ key_pos=query_pos,
+ attn_mask=self_attn_mask,
+ **kwargs)
+ # query = self.norms[0](query)
+ query = self.norms[0](query.transpose(1, 2)).transpose(1, 2)
+
+ query = self.cross_attn(
+ query=query,
+ key=key,
+ value=value,
+ query_pos=query_pos,
+ key_pos=key_pos,
+ attn_mask=cross_attn_mask,
+ key_padding_mask=key_padding_mask,
+ **kwargs)
+ query = self.norms[1](query)
+ query = self.ffn(query)
+ query = self.norms[2](query)
+ # BN
+ # query = self.norms[1](query.transpose(1, 2)).transpose(1, 2)
+ # query = self.ffn(query)
+ # query = self.norms[2](query.transpose(1, 2)).transpose(1, 2)
+ return query
+
+
+class CdnQueryGenerator(BaseModule):
+ """Implement query generator of the Contrastive denoising (CDN) proposed in
+ `DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object
+ Detection `_
+
+ Code is modified from the `official github repo
+ `_.
+
+ Args:
+ num_classes (int): Number of object classes.
+ embed_dims (int): The embedding dimensions of the generated queries.
+ num_matching_queries (int): The queries number of the matching part.
+ Used for generating dn_mask.
+ label_noise_scale (float): The scale of label noise, defaults to 0.5.
+ box_noise_scale (float): The scale of box noise, defaults to 1.0.
+ group_cfg (:obj:`ConfigDict` or dict, optional): The config of the
+ denoising queries grouping, includes `dynamic`, `num_dn_queries`,
+ and `num_groups`. Two grouping strategies, 'static dn groups' and
+ 'dynamic dn groups', are supported. When `dynamic` is `False`,
+ the `num_groups` should be set, and the number of denoising query
+ groups will always be `num_groups`. When `dynamic` is `True`, the
+ `num_dn_queries` should be set, and the group number will be
+ dynamic to ensure that the denoising queries number will not exceed
+ `num_dn_queries` to prevent large fluctuations of memory. Defaults
+ to `None`.
+ """
+
+ def __init__(self,
+ num_classes: int,
+ embed_dims: int,
+ num_matching_queries: int,
+ label_noise_scale: float = 0.5,
+ box_noise_scale: float = 1.0,
+ group_cfg: OptConfigType = None) -> None:
+ super().__init__()
+ self.num_classes = num_classes
+ self.embed_dims = embed_dims
+ self.num_matching_queries = num_matching_queries
+ self.label_noise_scale = label_noise_scale
+ self.box_noise_scale = box_noise_scale
+
+ # prepare grouping strategy
+ group_cfg = {} if group_cfg is None else group_cfg
+ self.dynamic_dn_groups = group_cfg.get('dynamic', True)
+ if self.dynamic_dn_groups:
+ if 'num_dn_queries' not in group_cfg:
+ warnings.warn("'num_dn_queries' should be set when using "
+ 'dynamic dn groups, use 100 as default.')
+ self.num_dn_queries = group_cfg.get('num_dn_queries', 100)
+ assert isinstance(self.num_dn_queries, int), \
+ f'Expected the num_dn_queries to have type int, but got ' \
+ f'{self.num_dn_queries}({type(self.num_dn_queries)}). '
+ else:
+ assert 'num_groups' in group_cfg, \
+ 'num_groups should be set when using static dn groups'
+ self.num_groups = group_cfg['num_groups']
+ assert isinstance(self.num_groups, int), \
+ f'Expected the num_groups to have type int, but got ' \
+ f'{self.num_groups}({type(self.num_groups)}). '
+
+ # NOTE The original repo of DINO set the num_embeddings 92 for coco,
+ # 91 (0~90) of which represents target classes and the 92 (91)
+ # indicates `Unknown` class. However, the embedding of `unknown` class
+ # is not used in the original DINO.
+ # TODO: num_classes + 1 or num_classes ?
+ self.label_embedding = nn.Embedding(self.num_classes, self.embed_dims)
+
+ def __call__(self, batch_data_samples: SampleList) -> tuple:
+ """Generate contrastive denoising (cdn) queries with ground truth.
+ max_num_target 为一个batch内各个图像目标数量的最大值
+ Descriptions of the Number Values in code and comments:
+ - num_target_total: the total target number of the input batch
+ samples.
+ - max_num_target: the max target number of the input batch samples.
+ - num_noisy_targets: the total targets number after adding noise,
+ i.e., num_target_total * num_groups * 2.
+ - num_denoising_queries: the length of the output batched queries,
+ i.e., max_num_target * num_groups * 2.
+
+ NOTE The format of input bboxes in batch_data_samples is unnormalized
+ (x, y, x, y), and the output bbox queries are embedded by normalized
+ (cx, cy, w, h) format bboxes going through inverse_sigmoid.
+
+ Args:
+ batch_data_samples (list[:obj:`DetDataSample`]): List of the batch
+ data samples, each includes `gt_instance` which has attributes
+ `bboxes` and `labels`. The `bboxes` has unnormalized coordinate
+ format (x, y, x, y).
+
+ Returns:
+ tuple: The outputs of the dn query generator.
+
+ - dn_label_query (Tensor): The output content queries for denoising
+ part, has shape (bs, num_denoising_queries, dim), where
+ `num_denoising_queries = max_num_target * num_groups * 2`.
+ - dn_bbox_query (Tensor): The output reference bboxes as positions
+ of queries for denoising part, which are embedded by normalized
+ (cx, cy, w, h) format bboxes going through inverse_sigmoid, has
+ shape (bs, num_denoising_queries, 4) with the last dimension
+ arranged as (cx, cy, w, h).
+ - attn_mask (Tensor): The attention mask to prevent information
+ leakage from different denoising groups and matching parts,
+ will be used as `self_attn_mask` of the `decoder`, has shape
+ (num_queries_total, num_queries_total), where `num_queries_total`
+ is the sum of `num_denoising_queries` and `num_matching_queries`.
+ - dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ """
+ # normalize bbox and collate ground truth (gt)
+ gt_labels_list = []
+ gt_bboxes_list = []
+ for sample in batch_data_samples:
+ img_h, img_w = sample.img_shape
+ bboxes = sample.gt_instances.bboxes
+ factor = bboxes.new_tensor([img_w, img_h, img_w,
+ img_h]).unsqueeze(0)
+ bboxes_normalized = bboxes / factor
+ gt_bboxes_list.append(bboxes_normalized)
+ gt_labels_list.append(sample.gt_instances.labels)
+ gt_labels = torch.cat(gt_labels_list) # (num_target_total, 4)
+ gt_bboxes = torch.cat(gt_bboxes_list)
+
+ num_target_list = [len(bboxes) for bboxes in gt_bboxes_list]
+ max_num_target = max(num_target_list)
+ num_groups = self.get_num_groups(max_num_target)
+
+ dn_label_query = self.generate_dn_label_query(gt_labels, num_groups)
+ dn_bbox_query = self.generate_dn_bbox_query(gt_bboxes, num_groups)
+ # dn_bbox_query数量为batch内图像目标总数 * 组数 * 2 (正样本和负样本各占一半)
+ # dn_label_query数量为batch内图像目标总数 * 组数 * 2, 随机选择一定数量的样本设为错误类比标签
+ # The `batch_idx` saves the batch index of the corresponding sample
+ # for each target, has shape (num_target_total).
+ batch_idx = torch.cat([
+ torch.full_like(t.long(), i) for i, t in enumerate(gt_labels_list)
+ ])
+
+
+ # dn_label_query, dn_bbox_query目前将一个batch内所有图像的正负样本拼接在一起,需要按batch size分开
+ # 每一张图目标数目不一样,数目同一设为最大目标数*group*2
+ dn_label_query, dn_bbox_query = self.collate_dn_queries(
+ dn_label_query, dn_bbox_query, batch_idx, len(batch_data_samples),
+ num_groups)
+
+ # 匹配部分查询和去噪组的查询不做注意力,去噪组与组之间也不做注意力
+ attn_mask = self.generate_dn_mask(
+ max_num_target, num_groups, device=dn_label_query.device)
+
+ dn_meta = dict(
+ num_denoising_queries=int(max_num_target * 2 * num_groups),
+ num_denoising_groups=num_groups)
+
+ return dn_label_query, dn_bbox_query, attn_mask, dn_meta
+
+ def get_num_groups(self, max_num_target: int = None) -> int:
+ """Calculate denoising query groups number.
+
+ Two grouping strategies, 'static dn groups' and 'dynamic dn groups',
+ are supported. When `self.dynamic_dn_groups` is `False`, the number
+ of denoising query groups will always be `self.num_groups`. When
+ `self.dynamic_dn_groups` is `True`, the group number will be dynamic,
+ ensuring the denoising queries number will not exceed
+ `self.num_dn_queries` to prevent large fluctuations of memory.
+
+ NOTE The `num_group` is shared for different samples in a batch. When
+ the target numbers in the samples varies, the denoising queries of the
+ samples containing fewer targets are padded to the max length.
+
+ Args:
+ max_num_target (int, optional): The max target number of the batch
+ samples. It will only be used when `self.dynamic_dn_groups` is
+ `True`. Defaults to `None`.
+
+ Returns:
+ int: The denoising group number of the current batch.
+ """
+ if self.dynamic_dn_groups:
+ assert max_num_target is not None, \
+ 'group_queries should be provided when using ' \
+ 'dynamic dn groups'
+ if max_num_target == 0:
+ num_groups = 1
+ else:
+ num_groups = self.num_dn_queries // max_num_target
+ else:
+ num_groups = self.num_groups
+ if num_groups < 1:
+ num_groups = 1
+ return int(num_groups)
+
+ def generate_dn_label_query(self, gt_labels: Tensor,
+ num_groups: int) -> Tensor:
+ """Generate noisy labels and their query embeddings.
+
+ The strategy for generating noisy labels is: Randomly choose labels of
+ `self.label_noise_scale * 0.5` proportion and override each of them
+ with a random object category label.
+
+ NOTE Not add noise to all labels. Besides, the `self.label_noise_scale
+ * 0.5` arg is the ratio of the chosen positions, which is higher than
+ the actual proportion of noisy labels, because the labels to override
+ may be correct. And the gap becomes larger as the number of target
+ categories decreases. The users should notice this and modify the scale
+ arg or the corresponding logic according to specific dataset.
+
+ Args:
+ gt_labels (Tensor): The concatenated gt labels of all samples
+ in the batch, has shape (num_target_total, ) where
+ `num_target_total = sum(num_target_list)`.
+ num_groups (int): The number of denoising query groups.
+
+ Returns:
+ Tensor: The query embeddings of noisy labels, has shape
+ (num_noisy_targets, embed_dims), where `num_noisy_targets =
+ num_target_total * num_groups * 2`.
+ """
+ assert self.label_noise_scale > 0
+ gt_labels_expand = gt_labels.repeat(2 * num_groups,
+ 1).view(-1) # Note `* 2` # noqa
+ p = torch.rand_like(gt_labels_expand.float())
+ chosen_indice = torch.nonzero(p < (self.label_noise_scale * 0.5)).view(
+ -1) # Note `* 0.5`
+ new_labels = torch.randint_like(chosen_indice, 0, self.num_classes)
+ noisy_labels_expand = gt_labels_expand.scatter(0, chosen_indice,
+ new_labels)
+ dn_label_query = self.label_embedding(noisy_labels_expand)
+ return dn_label_query
+
+ def generate_dn_bbox_query(self, gt_bboxes: Tensor,
+ num_groups: int) -> Tensor:
+ """Generate noisy bboxes and their query embeddings.
+
+ The strategy for generating noisy bboxes is as follow:
+
+ .. code:: text
+
+ +--------------------+
+ | negative |
+ | +----------+ |
+ | | positive | |
+ | | +-----|----+------------+
+ | | | | | |
+ | +----+-----+ | |
+ | | | |
+ +---------+----------+ |
+ | |
+ | gt bbox |
+ | |
+ | +---------+----------+
+ | | | |
+ | | +----+-----+ |
+ | | | | | |
+ +-------------|--- +----+ | |
+ | | positive | |
+ | +----------+ |
+ | negative |
+ +--------------------+
+
+ The random noise is added to the top-left and down-right point
+ positions, hence, normalized (x, y, x, y) format of bboxes are
+ required. The noisy bboxes of positive queries have the points
+ both within the inner square, while those of negative queries
+ have the points both between the inner and outer squares.
+
+ Besides, the length of outer square is twice as long as that of
+ the inner square, i.e., self.box_noise_scale * w_or_h / 2.
+ NOTE The noise is added to all the bboxes. Moreover, there is still
+ unconsidered case when one point is within the positive square and
+ the others is between the inner and outer squares.
+
+ Args:
+ gt_bboxes (Tensor): The concatenated gt bboxes of all samples
+ in the batch, has shape (num_target_total, 4) with the last
+ dimension arranged as (cx, cy, w, h) where
+ `num_target_total = sum(num_target_list)`.
+ num_groups (int): The number of denoising query groups.
+
+ Returns:
+ Tensor: The output noisy bboxes, which are embedded by normalized
+ (cx, cy, w, h) format bboxes going through inverse_sigmoid, has
+ shape (num_noisy_targets, 4) with the last dimension arranged as
+ (cx, cy, w, h), where
+ `num_noisy_targets = num_target_total * num_groups * 2`.
+ """
+ assert self.box_noise_scale > 0
+ device = gt_bboxes.device
+
+ # expand gt_bboxes as groups
+ gt_bboxes_expand = gt_bboxes.repeat(2 * num_groups, 1) # xyxy
+
+ # obtain index of negative queries in gt_bboxes_expand
+ positive_idx = torch.arange(
+ len(gt_bboxes), dtype=torch.long, device=device)
+ positive_idx = positive_idx.unsqueeze(0).repeat(num_groups, 1)
+ positive_idx += 2 * len(gt_bboxes) * torch.arange(
+ num_groups, dtype=torch.long, device=device)[:, None]
+ positive_idx = positive_idx.flatten()
+ negative_idx = positive_idx + len(gt_bboxes)
+
+ # determine the sign of each element in the random part of the added
+ # noise to be positive or negative randomly.
+ rand_sign = torch.randint_like(
+ gt_bboxes_expand, low=0, high=2,
+ dtype=torch.float32) * 2.0 - 1.0 # [low, high), 1 or -1, randomly
+
+ # calculate the random part of the added noise
+ rand_part = torch.rand_like(gt_bboxes_expand) # [0, 1)
+ rand_part[negative_idx] += 1.0 # pos: [0, 1); neg: [1, 2)
+ rand_part *= rand_sign # pos: (-1, 1); neg: (-2, -1] U [1, 2)
+
+ # add noise to the bboxes
+ bboxes_whwh = bbox_xyxy_to_cxcywh(gt_bboxes_expand)[:, 2:].repeat(1, 2) #[num,4] 宽高宽高
+ noisy_bboxes_expand = gt_bboxes_expand + torch.mul(
+ rand_part, bboxes_whwh) * self.box_noise_scale / 2 # xyxy
+ noisy_bboxes_expand = noisy_bboxes_expand.clamp(min=0.0, max=1.0)
+ noisy_bboxes_expand = bbox_xyxy_to_cxcywh(noisy_bboxes_expand)
+
+ dn_bbox_query = inverse_sigmoid(noisy_bboxes_expand, eps=1e-3)
+ return dn_bbox_query
+
+ def collate_dn_queries(self, input_label_query: Tensor,
+ input_bbox_query: Tensor, batch_idx: Tensor,
+ batch_size: int, num_groups: int) -> Tuple[Tensor]:
+ """Collate generated queries to obtain batched dn queries.
+
+ The strategy for query collation is as follow:
+
+ .. code:: text
+
+ input_queries (num_target_total, query_dim)
+ P_A1 P_B1 P_B2 N_A1 N_B1 N_B2 P'A1 P'B1 P'B2 N'A1 N'B1 N'B2
+ |________ group1 ________| |________ group2 ________|
+ |
+ V
+ P_A1 Pad0 N_A1 Pad0 P'A1 Pad0 N'A1 Pad0
+ P_B1 P_B2 N_B1 N_B2 P'B1 P'B2 N'B1 N'B2
+ |____ group1 ____| |____ group2 ____|
+ batched_queries (batch_size, max_num_target, query_dim)
+
+ where query_dim is 4 for bbox and self.embed_dims for label.
+ Notation: _-group 1; '-group 2;
+ A-Sample1(has 1 target); B-sample2(has 2 targets)
+
+ Args:
+ input_label_query (Tensor): The generated label queries of all
+ targets, has shape (num_target_total, embed_dims) where
+ `num_target_total = sum(num_target_list)`.
+ input_bbox_query (Tensor): The generated bbox queries of all
+ targets, has shape (num_target_total, 4) with the last
+ dimension arranged as (cx, cy, w, h).
+ batch_idx (Tensor): The batch index of the corresponding sample
+ for each target, has shape (num_target_total).
+ batch_size (int): The size of the input batch.
+ num_groups (int): The number of denoising query groups.
+
+ Returns:
+ tuple[Tensor]: Output batched label and bbox queries.
+ - batched_label_query (Tensor): The output batched label queries,
+ has shape (batch_size, max_num_target, embed_dims).
+ - batched_bbox_query (Tensor): The output batched bbox queries,
+ has shape (batch_size, max_num_target, 4) with the last dimension
+ arranged as (cx, cy, w, h).
+ """
+ device = input_label_query.device
+ num_target_list = [
+ torch.sum(batch_idx == idx) for idx in range(batch_size)
+ ]
+ max_num_target = max(num_target_list)
+ num_denoising_queries = int(max_num_target * 2 * num_groups)
+
+ map_query_index = torch.cat([
+ torch.arange(num_target, device=device)
+ for num_target in num_target_list
+ ])
+ map_query_index = torch.cat([
+ map_query_index + max_num_target * i for i in range(2 * num_groups)
+ ]).long()
+ batch_idx_expand = batch_idx.repeat(2 * num_groups, 1).view(-1)
+ mapper = (batch_idx_expand, map_query_index)
+
+ batched_label_query = torch.zeros(
+ batch_size, num_denoising_queries, self.embed_dims, device=device)
+ batched_bbox_query = torch.zeros(
+ batch_size, num_denoising_queries, 4, device=device)
+
+ batched_label_query[mapper] = input_label_query
+ batched_bbox_query[mapper] = input_bbox_query
+ return batched_label_query, batched_bbox_query
+
+ def generate_dn_mask(self, max_num_target: int, num_groups: int,
+ device: Union[torch.device, str]) -> Tensor:
+ """Generate attention mask to prevent information leakage from
+ different denoising groups and matching parts.
+
+ .. code:: text
+
+ 0 0 0 0 1 1 1 1 0 0 0 0 0
+ 0 0 0 0 1 1 1 1 0 0 0 0 0
+ 0 0 0 0 1 1 1 1 0 0 0 0 0
+ 0 0 0 0 1 1 1 1 0 0 0 0 0
+ 1 1 1 1 0 0 0 0 0 0 0 0 0
+ 1 1 1 1 0 0 0 0 0 0 0 0 0
+ 1 1 1 1 0 0 0 0 0 0 0 0 0
+ 1 1 1 1 0 0 0 0 0 0 0 0 0
+ 1 1 1 1 1 1 1 1 0 0 0 0 0
+ 1 1 1 1 1 1 1 1 0 0 0 0 0
+ 1 1 1 1 1 1 1 1 0 0 0 0 0
+ 1 1 1 1 1 1 1 1 0 0 0 0 0
+ 1 1 1 1 1 1 1 1 0 0 0 0 0
+ max_num_target |_| |_________| num_matching_queries
+ |_____________| num_denoising_queries
+
+ 1 -> True (Masked), means 'can not see'.
+ 0 -> False (UnMasked), means 'can see'.
+
+ Args:
+ max_num_target (int): The max target number of the input batch
+ samples.
+ num_groups (int): The number of denoising query groups.
+ device (obj:`device` or str): The device of generated mask.
+
+ Returns:
+ Tensor: The attention mask to prevent information leakage from
+ different denoising groups and matching parts, will be used as
+ `self_attn_mask` of the `decoder`, has shape (num_queries_total,
+ num_queries_total), where `num_queries_total` is the sum of
+ `num_denoising_queries` and `num_matching_queries`.
+ """
+ num_denoising_queries = int(max_num_target * 2 * num_groups)
+ num_queries_total = num_denoising_queries + self.num_matching_queries
+ attn_mask = torch.zeros(
+ num_queries_total,
+ num_queries_total,
+ device=device,
+ dtype=torch.bool)
+ # Make the matching part cannot see the denoising groups 匹配部分的查询不能看到去噪组查询
+ attn_mask[num_denoising_queries:, :num_denoising_queries] = True
+ # Make the denoising groups cannot see each other
+ for i in range(num_groups):
+ # Mask rows of one group per step.
+ row_scope = slice(max_num_target * 2 * i,
+ max_num_target * 2 * (i + 1))
+ left_scope = slice(max_num_target * 2 * i)
+ right_scope = slice(max_num_target * 2 * (i + 1),
+ num_denoising_queries)
+ attn_mask[row_scope, right_scope] = True
+ attn_mask[row_scope, left_scope] = True
+ return attn_mask
diff --git a/mmdet/models/layers/transformer/mask2former_layers.py b/mmdet/models/layers/transformer/mask2former_layers.py
new file mode 100644
index 0000000000000000000000000000000000000000..dcc604e277d91151334ed520d78e6a5a8f388036
--- /dev/null
+++ b/mmdet/models/layers/transformer/mask2former_layers.py
@@ -0,0 +1,135 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmcv.cnn import build_norm_layer
+from mmengine.model import ModuleList
+from torch import Tensor
+
+from .deformable_detr_layers import DeformableDetrTransformerEncoder
+from .detr_layers import DetrTransformerDecoder, DetrTransformerDecoderLayer
+
+
+class Mask2FormerTransformerEncoder(DeformableDetrTransformerEncoder):
+ """Encoder in PixelDecoder of Mask2Former."""
+
+ def forward(self, query: Tensor, query_pos: Tensor,
+ key_padding_mask: Tensor, spatial_shapes: Tensor,
+ level_start_index: Tensor, valid_ratios: Tensor,
+ reference_points: Tensor, **kwargs) -> Tensor:
+ """Forward function of Transformer encoder.
+
+ Args:
+ query (Tensor): The input query, has shape (bs, num_queries, dim).
+ query_pos (Tensor): The positional encoding for query, has shape
+ (bs, num_queries, dim). If not None, it will be added to the
+ `query` before forward function. Defaults to None.
+ key_padding_mask (Tensor): The `key_padding_mask` of `self_attn`
+ input. ByteTensor, has shape (bs, num_queries).
+ spatial_shapes (Tensor): Spatial shapes of features in all levels,
+ has shape (num_levels, 2), last dimension represents (h, w).
+ level_start_index (Tensor): The start index of each level.
+ A tensor has shape (num_levels, ) and can be represented
+ as [0, h_0*w_0, h_0*w_0+h_1*w_1, ...].
+ valid_ratios (Tensor): The ratios of the valid width and the valid
+ height relative to the width and the height of features in all
+ levels, has shape (bs, num_levels, 2).
+ reference_points (Tensor): The initial reference, has shape
+ (bs, num_queries, 2) with the last dimension arranged
+ as (cx, cy).
+
+ Returns:
+ Tensor: Output queries of Transformer encoder, which is also
+ called 'encoder output embeddings' or 'memory', has shape
+ (bs, num_queries, dim)
+ """
+ for layer in self.layers:
+ query = layer(
+ query=query,
+ query_pos=query_pos,
+ key_padding_mask=key_padding_mask,
+ spatial_shapes=spatial_shapes,
+ level_start_index=level_start_index,
+ valid_ratios=valid_ratios,
+ reference_points=reference_points,
+ **kwargs)
+ return query
+
+
+class Mask2FormerTransformerDecoder(DetrTransformerDecoder):
+ """Decoder of Mask2Former."""
+
+ def _init_layers(self) -> None:
+ """Initialize decoder layers."""
+ self.layers = ModuleList([
+ Mask2FormerTransformerDecoderLayer(**self.layer_cfg)
+ for _ in range(self.num_layers)
+ ])
+ self.embed_dims = self.layers[0].embed_dims
+ self.post_norm = build_norm_layer(self.post_norm_cfg,
+ self.embed_dims)[1]
+
+
+class Mask2FormerTransformerDecoderLayer(DetrTransformerDecoderLayer):
+ """Implements decoder layer in Mask2Former transformer."""
+
+ def forward(self,
+ query: Tensor,
+ key: Tensor = None,
+ value: Tensor = None,
+ query_pos: Tensor = None,
+ key_pos: Tensor = None,
+ self_attn_mask: Tensor = None,
+ cross_attn_mask: Tensor = None,
+ key_padding_mask: Tensor = None,
+ **kwargs) -> Tensor:
+ """
+ Args:
+ query (Tensor): The input query, has shape (bs, num_queries, dim).
+ key (Tensor, optional): The input key, has shape (bs, num_keys,
+ dim). If `None`, the `query` will be used. Defaults to `None`.
+ value (Tensor, optional): The input value, has the same shape as
+ `key`, as in `nn.MultiheadAttention.forward`. If `None`, the
+ `key` will be used. Defaults to `None`.
+ query_pos (Tensor, optional): The positional encoding for `query`,
+ has the same shape as `query`. If not `None`, it will be added
+ to `query` before forward function. Defaults to `None`.
+ key_pos (Tensor, optional): The positional encoding for `key`, has
+ the same shape as `key`. If not `None`, it will be added to
+ `key` before forward function. If None, and `query_pos` has the
+ same shape as `key`, then `query_pos` will be used for
+ `key_pos`. Defaults to None.
+ self_attn_mask (Tensor, optional): ByteTensor mask, has shape
+ (num_queries, num_keys), as in `nn.MultiheadAttention.forward`.
+ Defaults to None.
+ cross_attn_mask (Tensor, optional): ByteTensor mask, has shape
+ (num_queries, num_keys), as in `nn.MultiheadAttention.forward`.
+ Defaults to None.
+ key_padding_mask (Tensor, optional): The `key_padding_mask` of
+ `self_attn` input. ByteTensor, has shape (bs, num_value).
+ Defaults to None.
+
+ Returns:
+ Tensor: forwarded results, has shape (bs, num_queries, dim).
+ """
+
+ query = self.cross_attn(
+ query=query,
+ key=key,
+ value=value,
+ query_pos=query_pos,
+ key_pos=key_pos,
+ attn_mask=cross_attn_mask,
+ key_padding_mask=key_padding_mask,
+ **kwargs)
+ query = self.norms[0](query)
+ query = self.self_attn(
+ query=query,
+ key=query,
+ value=query,
+ query_pos=query_pos,
+ key_pos=query_pos,
+ attn_mask=self_attn_mask,
+ **kwargs)
+ query = self.norms[1](query)
+ query = self.ffn(query)
+ query = self.norms[2](query)
+
+ return query
diff --git a/mmdet/models/layers/transformer/specdetr_atten.py b/mmdet/models/layers/transformer/specdetr_atten.py
new file mode 100644
index 0000000000000000000000000000000000000000..8d63de02c7d856200cd60368cafb4e8bb443efcd
--- /dev/null
+++ b/mmdet/models/layers/transformer/specdetr_atten.py
@@ -0,0 +1,469 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+import warnings
+from typing import Optional, no_type_check
+import mmengine
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmengine.model import BaseModule, constant_init, xavier_init
+from mmengine.registry import MODELS
+from mmengine.utils import deprecated_api_warning
+from torch.autograd.function import Function, once_differentiable
+from mmcv.utils import IS_CUDA_AVAILABLE, IS_MLU_AVAILABLE
+from mmcv.utils import ext_loader
+
+
+ext_module = ext_loader.load_ext(
+ '_ext', ['ms_deform_attn_backward', 'ms_deform_attn_forward'])
+
+
+class MultiScaleDeformableAttnFunction(Function):
+
+ @staticmethod
+ def forward(ctx, value: torch.Tensor, value_spatial_shapes: torch.Tensor,
+ value_level_start_index: torch.Tensor,
+ sampling_locations: torch.Tensor,
+ attention_weights: torch.Tensor,
+ im2col_step: torch.Tensor) -> torch.Tensor:
+ """GPU/MLU version of multi-scale deformable attention.
+
+ Args:
+ value (torch.Tensor): The value has shape
+ (bs, num_keys, mum_heads, embed_dims//num_heads)
+ value_spatial_shapes (torch.Tensor): Spatial shape of
+ each feature map, has shape (num_levels, 2),
+ last dimension 2 represent (h, w)
+ sampling_locations (torch.Tensor): The location of sampling points,
+ has shape
+ (bs ,num_queries, num_heads, num_levels, num_points, 2),
+ the last dimension 2 represent (x, y).
+ attention_weights (torch.Tensor): The weight of sampling points
+ used when calculate the attention, has shape
+ (bs ,num_queries, num_heads, num_levels, num_points),
+ im2col_step (torch.Tensor): The step used in image to column.
+
+ Returns:
+ torch.Tensor: has shape (bs, num_queries, embed_dims)
+ """
+
+ ctx.im2col_step = im2col_step
+
+ # When pytorch version >= 1.6.0, amp is adopted for fp16 mode;
+ # amp won't cast the type of sampling_locations, attention_weights
+ # (float32), but "value" is cast to float16, leading to the type
+ # mismatch with input (when it is float32) or weight.
+ # The flag for whether to use fp16 or amp is the type of "value",
+ # we cast sampling_locations and attention_weights to
+ # temporarily support fp16 and amp whatever the
+ # pytorch version is.
+ sampling_locations = sampling_locations.type_as(value)
+ attention_weights = attention_weights.type_as(value)
+
+ output = ext_module.ms_deform_attn_forward(
+ value,
+ value_spatial_shapes,
+ value_level_start_index,
+ sampling_locations,
+ attention_weights,
+ im2col_step=ctx.im2col_step)
+ ctx.save_for_backward(value, value_spatial_shapes,
+ value_level_start_index, sampling_locations,
+ attention_weights)
+ return output
+
+ @staticmethod
+ @once_differentiable
+ def backward(ctx, grad_output: torch.Tensor) -> tuple:
+ """GPU/MLU version of backward function.
+
+ Args:
+ grad_output (torch.Tensor): Gradient of output tensor of forward.
+
+ Returns:
+ tuple[Tensor]: Gradient of input tensors in forward.
+ """
+ value, value_spatial_shapes, value_level_start_index,\
+ sampling_locations, attention_weights = ctx.saved_tensors
+ grad_value = torch.zeros_like(value)
+ grad_sampling_loc = torch.zeros_like(sampling_locations)
+ grad_attn_weight = torch.zeros_like(attention_weights)
+
+ ext_module.ms_deform_attn_backward(
+ value,
+ value_spatial_shapes,
+ value_level_start_index,
+ sampling_locations,
+ attention_weights,
+ grad_output.contiguous(),
+ grad_value,
+ grad_sampling_loc,
+ grad_attn_weight,
+ im2col_step=ctx.im2col_step)
+
+ return grad_value, None, None, \
+ grad_sampling_loc, grad_attn_weight, None
+
+
+def multi_scale_deformable_attn_pytorch(
+ value: torch.Tensor, value_spatial_shapes: torch.Tensor,
+ sampling_locations: torch.Tensor,
+ attention_weights: torch.Tensor) -> torch.Tensor:
+ """CPU version of multi-scale deformable attention.
+
+ Args:
+ value (torch.Tensor): The value has shape
+ (bs, num_keys, num_heads, embed_dims//num_heads)
+ value_spatial_shapes (torch.Tensor): Spatial shape of
+ each feature map, has shape (num_levels, 2),
+ last dimension 2 represent (h, w)
+ sampling_locations (torch.Tensor): The location of sampling points,
+ has shape
+ (bs ,num_queries, num_heads, num_levels, num_points, 2),
+ the last dimension 2 represent (x, y).
+ attention_weights (torch.Tensor): The weight of sampling points used
+ when calculate the attention, has shape
+ (bs ,num_queries, num_heads, num_levels, num_points),
+
+ Returns:
+ torch.Tensor: has shape (bs, num_queries, embed_dims)
+ """
+
+ bs, _, num_heads, embed_dims = value.shape
+ _, num_queries, num_heads, num_levels, num_points, _ =\
+ sampling_locations.shape
+ value_list = value.split([H_ * W_ for H_, W_ in value_spatial_shapes],
+ dim=1)
+ sampling_grids = 2 * sampling_locations - 1
+ sampling_value_list = []
+ for level, (H_, W_) in enumerate(value_spatial_shapes):
+ # bs, H_*W_, num_heads, embed_dims ->
+ # bs, H_*W_, num_heads*embed_dims ->
+ # bs, num_heads*embed_dims, H_*W_ ->
+ # bs*num_heads, embed_dims, H_, W_
+ value_l_ = value_list[level].flatten(2).transpose(1, 2).reshape(
+ bs * num_heads, embed_dims, H_, W_)
+ # bs, num_queries, num_heads, num_points, 2 ->
+ # bs, num_heads, num_queries, num_points, 2 ->
+ # bs*num_heads, num_queries, num_points, 2
+ sampling_grid_l_ = sampling_grids[:, :, :,
+ level].transpose(1, 2).flatten(0, 1)
+ # bs*num_heads, embed_dims, num_queries, num_points
+ sampling_value_l_ = F.grid_sample(
+ value_l_,
+ sampling_grid_l_,
+ mode='bilinear',
+ padding_mode='zeros',
+ align_corners=False)
+ sampling_value_list.append(sampling_value_l_)
+ # (bs, num_queries, num_heads, num_levels, num_points) ->
+ # (bs, num_heads, num_queries, num_levels, num_points) ->
+ # (bs, num_heads, 1, num_queries, num_levels*num_points)
+ attention_weights = attention_weights.transpose(1, 2).reshape(
+ bs * num_heads, 1, num_queries, num_levels * num_points)
+ output = (torch.stack(sampling_value_list, dim=-2).flatten(-2) *
+ attention_weights).sum(-1).view(bs, num_heads * embed_dims,
+ num_queries)
+ return output.transpose(1, 2).contiguous()
+
+
+@MODELS.register_module()
+class MultiScaleDeformableAttention_1(BaseModule):
+ """An attention module used in Deformable-Detr.
+
+ `Deformable DETR: Deformable Transformers for End-to-End Object Detection.
+ `_.
+
+ Args:
+ embed_dims (int): The embedding dimension of Attention.
+ Default: 256.
+ num_heads (int): Parallel attention heads. Default: 8.
+ num_levels (int): The number of feature map used in
+ Attention. Default: 4.
+ num_points (int): The number of sampling points for
+ each query in each head. Default: 4.
+ im2col_step (int): The step used in image_to_column.
+ Default: 64.
+ dropout (float): A Dropout layer on `inp_identity`.
+ Default: 0.1.
+ batch_first (bool): Key, Query and Value are shape of
+ (batch, n, embed_dim)
+ or (n, batch, embed_dim). Default to False.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: None.
+ init_cfg (obj:`mmcv.ConfigDict`): The Config for initialization.
+ Default: None.
+ value_proj_ratio (float): The expansion ratio of value_proj.
+ Default: 1.0.
+ """
+
+ def __init__(self,
+ embed_dims: int = 256,
+ num_heads: int = 8,
+ num_levels: int = 4,
+ num_points: int = 4,
+ im2col_step: int = 64,
+ dropout: float = 0.1,
+ local_attn_type: str = 'initial_version', # 'fix_same_orientation' 'fix_same_distance' 'initial_version' bbox_fine'
+ batch_first: bool = False,
+ norm_cfg: Optional[dict] = None,
+ init_cfg: Optional[mmengine.ConfigDict] = None,
+ value_proj_ratio: float = 1.0):
+ super().__init__(init_cfg)
+ if embed_dims % num_heads != 0:
+ raise ValueError(f'embed_dims must be divisible by num_heads, '
+ f'but got {embed_dims} and {num_heads}')
+ dim_per_head = embed_dims // num_heads
+ self.norm_cfg = norm_cfg
+ self.dropout = nn.Dropout(dropout)
+ self.batch_first = batch_first
+ self.local_attn_type = local_attn_type
+ # you'd better set dim_per_head to a power of 2
+ # which is more efficient in the CUDA implementation
+ def _is_power_of_2(n):
+ if (not isinstance(n, int)) or (n < 0):
+ raise ValueError(
+ 'invalid input for _is_power_of_2: {} (type: {})'.format(
+ n, type(n)))
+ return (n & (n - 1) == 0) and n != 0
+
+ if not _is_power_of_2(dim_per_head):
+ warnings.warn(
+ "You'd better set embed_dims in "
+ 'MultiScaleDeformAttention to make '
+ 'the dimension of each attention head a power of 2 '
+ 'which is more efficient in our CUDA implementation.')
+
+ self.im2col_step = im2col_step
+ self.embed_dims = embed_dims
+ self.num_levels = num_levels
+ self.num_heads = num_heads
+ self.num_points = num_points
+ if local_attn_type == 'initial_version' or self.local_attn_type == 'bbox_fine':
+ self.sampling_offsets = nn.Linear(
+ embed_dims, num_heads * num_levels * num_points * 2)
+ else:
+ #修改
+ self.sampling_offsets = torch.zeros(num_heads * num_levels * num_points * 2)
+
+ self.attention_weights = nn.Linear(embed_dims,
+ num_heads * num_levels * num_points)
+ value_proj_size = int(embed_dims * value_proj_ratio)
+ self.value_proj = nn.Linear(embed_dims, value_proj_size)
+ self.output_proj = nn.Linear(value_proj_size, embed_dims)
+ self.init_weights()
+
+
+ def init_weights(self) -> None:
+ """Default initialization for Parameters of Module."""
+ if self.local_attn_type == 'initial_version' or self.local_attn_type == 'bbox_fine':
+ constant_init(self.sampling_offsets, 0.)
+ device = next(self.parameters()).device
+ if self.local_attn_type == 'initial_version' or self.local_attn_type == 'bbox_fine':
+ thetas = torch.arange(
+ self.num_heads, dtype=torch.float32,
+ device=device) * (2.0 * math.pi / self.num_heads)
+ grid_init = torch.stack([thetas.cos(), thetas.sin()], -1)
+ grid_init = (grid_init /
+ grid_init.abs().max(-1, keepdim=True)[0]).view(
+ self.num_heads, 1, 1,
+ 2).repeat(1, self.num_levels, self.num_points, 1)
+ for i in range(self.num_points):
+ grid_init[:, :, i, :] *= i + 1
+ self.sampling_offsets.bias.data = grid_init.view(-1)
+ # self.sampling_offsets.bias.data = grid_init.view(-1)
+ # constant_init(self.attention_weights, val=0., bias=0.)
+ # xavier_init(self.value_proj, distribution='uniform', bias=0.)
+ # xavier_init(self.output_proj, distribution='uniform', bias=0.)
+ # self._is_init = True
+
+ elif self.local_attn_type == 'fix_same_orientation':
+ # 每个head四个点在同一方向上
+ thetas = torch.arange(
+ self.num_heads, dtype=torch.float32,
+ device=device) * (2.0 * math.pi / self.num_heads)
+ grid_init = torch.stack([thetas.cos(), thetas.sin()], -1)
+ grid_init = (grid_init /
+ grid_init.abs().max(-1, keepdim=True)[0]).view(
+ self.num_heads, 1, 1,
+ 2).repeat(1, self.num_levels, self.num_points, 1)
+ for i in range(self.num_points):
+ grid_init[:, :, i, :] *= i + 1
+ self.sampling_offsets1 = grid_init.view(-1)
+ elif self.local_attn_type == 'fix_same_distance':
+ # changed by lzx
+ # 每个head四个点与中心点距离相同
+ assert self.num_points == 4
+ grid_init = torch.zeros(self.num_heads, 1, self.num_points, 2)
+ grid_init[0, :, :, :] = torch.Tensor([[1, 0], [0, 1], [-1, 0], [0, -1]])
+ grid_init[1, :, :, :] = torch.Tensor([[1,1],[-1,1],[-1,-1],[1,-1]])
+ for i in range(2, self.num_heads):
+ if i % 2 == 0:
+ grid_init[i, :, :, :] = grid_init[0, :, :, :] * (i//2+1)
+ else:
+ grid_init[i, :, :, :] = grid_init[1, :, :, :] * (i//2+1)
+ grid_init = grid_init.repeat(1, self.num_levels, 1, 1)
+ self.sampling_offsets1 = grid_init.view(-1)
+ # 每个head四个点与中心点螺旋延伸
+ # assert self.num_points == 4
+ # grid_init = torch.zeros(self.num_heads, 1, self.num_points, 2)
+ # grid_init_old = torch.Tensor([[1, 0], [0, 1], [-1, 0], [0, -1]])
+ # grid_init_even = torch.Tensor([[1,1],[-1,1],[-1,-1],[1,-1]])
+ # for i in range(self.num_heads):
+ # if i % 2 == 0:
+ # for p_i in range(4):
+ # grid_init[i, :, p_i, :] = (grid_init_old[p_i, :]) * ((i//2+p_i)%4+1)
+ # else:
+ # for p_i in range(4):
+ # grid_init[i, :, p_i, :] = (grid_init_even[p_i, :]) * ((i//2+p_i)%4+1)
+ # grid_init = grid_init.repeat(1, self.num_levels, 1, 1)
+
+
+ constant_init(self.attention_weights, val=0., bias=0.)
+ xavier_init(self.value_proj, distribution='uniform', bias=0.)
+ xavier_init(self.output_proj, distribution='uniform', bias=0.)
+ self._is_init = True
+
+ @no_type_check
+ @deprecated_api_warning({'residual': 'identity'},
+ cls_name='MultiScaleDeformableAttention')
+ def forward(self,
+ query: torch.Tensor,
+ key: Optional[torch.Tensor] = None,
+ value: Optional[torch.Tensor] = None,
+ identity: Optional[torch.Tensor] = None,
+ query_pos: Optional[torch.Tensor] = None,
+ key_padding_mask: Optional[torch.Tensor] = None,
+ reference_points: Optional[torch.Tensor] = None,
+ spatial_shapes: Optional[torch.Tensor] = None,
+ level_start_index: Optional[torch.Tensor] = None,
+ **kwargs) -> torch.Tensor:
+ """Forward Function of MultiScaleDeformAttention.
+
+ Args:
+ query (torch.Tensor): Query of Transformer with shape
+ (num_query, bs, embed_dims).
+ key (torch.Tensor): The key tensor with shape
+ `(num_key, bs, embed_dims)`.
+ value (torch.Tensor): The value tensor with shape
+ `(num_key, bs, embed_dims)`.
+ identity (torch.Tensor): The tensor used for addition, with the
+ same shape as `query`. Default None. If None,
+ `query` will be used.
+ query_pos (torch.Tensor): The positional encoding for `query`.
+ Default: None.
+ key_padding_mask (torch.Tensor): ByteTensor for `query`, with
+ shape [bs, num_key].
+ reference_points (torch.Tensor): The normalized reference
+ points with shape (bs, num_query, num_levels, 2),
+ all elements is range in [0, 1], top-left (0,0),
+ bottom-right (1, 1), including padding area.
+ or (N, Length_{query}, num_levels, 4), add
+ additional two dimensions is (w, h) to
+ form reference boxes.
+ spatial_shapes (torch.Tensor): Spatial shape of features in
+ different levels. With shape (num_levels, 2),
+ last dimension represents (h, w).
+ level_start_index (torch.Tensor): The start index of each level.
+ A tensor has shape ``(num_levels, )`` and can be represented
+ as [0, h_0*w_0, h_0*w_0+h_1*w_1, ...].
+
+ Returns:
+ torch.Tensor: forwarded results with shape
+ [num_query, bs, embed_dims].
+ """
+
+ if value is None:
+ value = query
+
+ if identity is None:
+ identity = query
+ if query_pos is not None:
+ query = query + query_pos
+ if not self.batch_first:
+ # change to (bs, num_query ,embed_dims)
+ query = query.permute(1, 0, 2)
+ value = value.permute(1, 0, 2)
+
+ bs, num_query, _ = query.shape
+ bs, num_value, _ = value.shape
+ assert (spatial_shapes[:, 0] * spatial_shapes[:, 1]).sum() == num_value
+
+ value = self.value_proj(value)
+ if key_padding_mask is not None:
+ value = value.masked_fill(key_padding_mask[..., None], 0.0)
+ value = value.view(bs, num_value, self.num_heads, -1)
+
+ if self.local_attn_type == 'initial_version'or self.local_attn_type == 'bbox_fine':
+ sampling_offsets = self.sampling_offsets(query).view(
+ bs, num_query, self.num_heads, self.num_levels, self.num_points, 2)
+ # sampling_offsets = self.sampling_offsets(torch.ones_like(query[0,0,:])).view(self.num_heads, self.num_levels, self.num_points, 2).repeat( bs, num_query, 1,1,1,1)
+ else:
+ # # 修改部分:将原先的 sampling_offsets 修改为 sampling_offsets_weight
+ sampling_offsets = self.sampling_offsets1.view(
+ 1, 1, self.num_heads, self.num_levels, self.num_points, 2)
+ sampling_offsets =sampling_offsets.repeat(
+ bs, num_query, 1, 1, 1, 1)
+ sampling_offsets = sampling_offsets.to(query.device)
+
+ attention_weights = self.attention_weights(query).view(
+ bs, num_query, self.num_heads, self.num_levels * self.num_points)
+ attention_weights = attention_weights.softmax(-1)
+ attention_weights = attention_weights.view(bs, num_query,
+ self.num_heads,
+ self.num_levels,
+ self.num_points)
+ if reference_points.shape[-1] == 2:
+ if self.local_attn_type == 'initial_version':
+ offset_normalizer = torch.stack(
+ [spatial_shapes[..., 1], spatial_shapes[..., 0]], -1)
+ sampling_locations = reference_points[:, :, None, :, None, :] \
+ + sampling_offsets \
+ / offset_normalizer[None, None, None, :, None, :]
+ else:
+ offset_normalizer = torch.stack(
+ [spatial_shapes[..., 1], spatial_shapes[..., 0]], -1)
+ sampling_locations = reference_points[:, :, None, :, None, :] \
+ + sampling_offsets \
+ / offset_normalizer[None, None, None, :, None, :]
+ elif reference_points.shape[-1] == 4:
+ # ori
+ # sampling_locations = reference_points[:, :, None, :, None, :2] \
+ # + sampling_offsets / self.num_points \
+ # * reference_points[:, :, None, :, None, 2:] \
+ # * 0.5
+ if self.local_attn_type == 'initial_version':
+ sampling_locations = reference_points[:, :, None, :, None, :2] \
+ + sampling_offsets / self.num_points \
+ * reference_points[:, :, None, :, None, 2:] \
+ * 0.5
+ elif self.local_attn_type == 'bbox_fine':
+ sampling_locations = reference_points[:, :, None, :, None, :2] \
+ + reference_points[:, :, None, :, None, 2:] *0.5*0.6+ sampling_offsets / self.num_points \
+ * reference_points[:, :, None, :, None, 2:] *0.5*0.8
+ else:
+ sampling_locations = reference_points[:, :, None, :, None, :2] \
+ + reference_points[:, :, None, :, None, 2:] * 0.25+ sampling_offsets / self.num_points \
+ * reference_points[:, :, None, :, None, 2:] * 0.5
+ else:
+ raise ValueError(
+ f'Last dim of reference_points must be'
+ f' 2 or 4, but get {reference_points.shape[-1]} instead.')
+ if ((IS_CUDA_AVAILABLE and value.is_cuda)
+ or (IS_MLU_AVAILABLE and value.is_mlu)):
+ output = MultiScaleDeformableAttnFunction.apply(
+ value, spatial_shapes, level_start_index, sampling_locations,
+ attention_weights, self.im2col_step)
+ # output = multi_scale_deformable_attn_pytorch(
+ # value, spatial_shapes, sampling_locations, attention_weights)
+ else:
+ output = multi_scale_deformable_attn_pytorch(
+ value, spatial_shapes, sampling_locations, attention_weights)
+
+ output = self.output_proj(output)
+
+ if not self.batch_first:
+ # (num_query, bs ,embed_dims)
+ output = output.permute(1, 0, 2)
+
+ return self.dropout(output) + identity
diff --git a/mmdet/models/layers/transformer/specdetr_layers.py b/mmdet/models/layers/transformer/specdetr_layers.py
new file mode 100644
index 0000000000000000000000000000000000000000..04d998b75747ca7af0c1966dd4767c9196d4eca9
--- /dev/null
+++ b/mmdet/models/layers/transformer/specdetr_layers.py
@@ -0,0 +1,932 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+import numpy as np
+from typing import Optional, Tuple, Union,List
+import torch
+from mmcv.cnn import build_norm_layer
+from mmcv.cnn.bricks.transformer import FFN, MultiheadAttention
+# from mmcv.ops import MultiScaleDeformableAttention
+from .specdetr_atten import MultiScaleDeformableAttention_1 as MultiScaleDeformableAttention
+from mmengine.model import ModuleList
+from torch import Tensor, nn
+from mmengine.model import BaseModule
+
+from mmdet.structures import SampleList
+from mmdet.structures.bbox import bbox_xyxy_to_cxcywh,bbox_cxcywh_to_xyxy
+from mmengine import ConfigDict
+from mmdet.utils import ConfigType, OptConfigType
+# from .detr_layers import (DetrTransformerDecoder, DetrTransformerDecoderLayer,
+# DetrTransformerEncoder, DetrTransformerEncoderLayer)
+from .utils import MLP, coordinate_to_encoding, inverse_sigmoid
+import random
+import math
+
+
+class SpecDetrTransformerEncoder(BaseModule):
+ """Transformer encoder of Deformable DETR.Encoder of DETR.
+
+ Args:
+ num_layers (int): Number of encoder layers.
+ layer_cfg (:obj:`ConfigDict` or dict): the config of each encoder
+ layer. All the layers will share the same config.
+ init_cfg (:obj:`ConfigDict` or dict, optional): the config to control
+ the initialization. Defaults to None.
+ """
+
+ def __init__(self,
+ num_layers: int,
+ layer_cfg: ConfigType,
+ init_cfg: OptConfigType = None) -> None:
+
+ super().__init__(init_cfg=init_cfg)
+ self.num_layers = num_layers
+ self.layer_cfg = layer_cfg
+ self._init_layers()
+ self.save_id = 0
+
+
+ def _init_layers(self) -> None:
+ """Initialize encoder layers."""
+ self.layers = ModuleList([
+ SpecDetrTransformerEncoderLayer(**self.layer_cfg)
+ for _ in range(self.num_layers)
+ ])
+ self.embed_dims = self.layers[0].embed_dims
+
+ def forward(self, query: Tensor, query_pos: Tensor,
+ key_padding_mask: Tensor, spatial_shapes: Tensor,
+ level_start_index: Tensor, valid_ratios: Tensor,
+ **kwargs) -> Tensor:
+ """Forward function of Transformer encoder.
+
+ Args:
+ query (Tensor): The input query, has shape (bs, num_queries, dim).
+ query_pos (Tensor): The positional encoding for query, has shape
+ (bs, num_queries, dim).
+ key_padding_mask (Tensor): The `key_padding_mask` of `self_attn`
+ input. ByteTensor, has shape (bs, num_queries).
+ spatial_shapes (Tensor): Spatial shapes of features in all levels,
+ has shape (num_levels, 2), last dimension represents (h, w).
+ level_start_index (Tensor): The start index of each level.
+ A tensor has shape (num_levels, ) and can be represented
+ as [0, h_0*w_0, h_0*w_0+h_1*w_1, ...].
+ valid_ratios (Tensor): The ratios of the valid width and the valid
+ height relative to the width and the height of features in all
+ levels, has shape (bs, num_levels, 2).
+
+ Returns:
+ Tensor: Output queries of Transformer encoder, which is also
+ called 'encoder output embeddings' or 'memory', has shape
+ (bs, num_queries, dim)
+ """
+ reference_points = self.get_encoder_reference_points(
+ spatial_shapes, valid_ratios, device=query.device)
+
+ for i, layer in enumerate(self.layers):
+ if self.save_id in [21] and i == 5:
+ []
+ query = layer(
+ query=query,
+ query_pos=query_pos,
+ key_padding_mask=key_padding_mask,
+ spatial_shapes=spatial_shapes,
+ level_start_index=level_start_index,
+ valid_ratios=valid_ratios,
+ reference_points=reference_points,
+ **kwargs)
+ # if self.save_id in [5,50,100,150,200,250,300,350,400,450]:
+ # np.save('/media/ubuntu/data/my_HTD_dataset/paper_fig/feat_map1/f'+str(i+1)+'_'+'{:03d}'.format(self.save_id), query[:,:-1].view(128,128,256).detach().cpu().numpy())
+ # np.save(
+ # '/media/ubuntu/data/my_HTD_dataset/paper_fig/feat_map1/g' + str(i+1) + '_' + '{:03d}'.format(
+ # self.save_id),
+ # np.squeeze(query[:,-1].detach().cpu().numpy()))
+ self.save_id += 1
+ return query
+
+ @staticmethod
+ def get_encoder_reference_points(
+ spatial_shapes: Tensor, valid_ratios: Tensor,
+ device: Union[torch.device, str]) -> Tensor:
+ """Get the reference points used in encoder.
+
+ Args:
+ spatial_shapes (Tensor): Spatial shapes of features in all levels,
+ has shape (num_levels, 2), last dimension represents (h, w).
+ valid_ratios (Tensor): The ratios of the valid width and the valid
+ height relative to the width and the height of features in all
+ levels, has shape (bs, num_levels, 2).
+ device (obj:`device` or str): The device acquired by the
+ `reference_points`.
+
+ Returns:
+ Tensor: Reference points used in decoder, has shape (bs, length,
+ num_levels, 2).
+ """
+
+ reference_points_list = []
+ for lvl, (H, W) in enumerate(spatial_shapes):
+ ref_y, ref_x = torch.meshgrid(
+ torch.linspace(
+ 0.5, H - 0.5, H, dtype=torch.float32, device=device),
+ torch.linspace(
+ 0.5, W - 0.5, W, dtype=torch.float32, device=device))
+ ref_y = ref_y.reshape(-1)[None] / (
+ valid_ratios[:, None, lvl, 1] * H)
+ ref_x = ref_x.reshape(-1)[None] / (
+ valid_ratios[:, None, lvl, 0] * W)
+ ref = torch.stack((ref_x, ref_y), -1)
+ reference_points_list.append(ref)
+ reference_points = torch.cat(reference_points_list, 1)
+ # [bs, sum(hw), num_level, 2]
+ reference_points = reference_points[:, :, None] * valid_ratios[:, None]
+ return reference_points
+
+
+class SpecDetrTransformerDecoder(BaseModule):
+ """Transformer encoder of DINO.Decoder of DETR.
+
+ Args:
+ num_layers (int): Number of decoder layers.
+ layer_cfg (:obj:`ConfigDict` or dict): the config of each encoder
+ layer. All the layers will share the same config.
+ post_norm_cfg (:obj:`ConfigDict` or dict, optional): Config of the
+ post normalization layer. Defaults to `LN`.
+ return_intermediate (bool, optional): Whether to return outputs of
+ intermediate layers. Defaults to `True`,
+ init_cfg (:obj:`ConfigDict` or dict, optional): the config to control
+ the initialization. Defaults to None.
+ """
+
+ def __init__(self,
+ num_layers: int,
+ layer_cfg: ConfigType,
+ post_norm_cfg: OptConfigType = dict(type='LN'),
+ return_intermediate: bool = True,
+ init_cfg: Union[dict, ConfigDict] = None) -> None:
+ super().__init__(init_cfg=init_cfg)
+ self.layer_cfg = layer_cfg
+ self.num_layers = num_layers
+ self.post_norm_cfg = post_norm_cfg
+ self.return_intermediate = return_intermediate
+ self._init_layers()
+
+ def _init_layers(self) -> None:
+ """Initialize decoder layers."""
+ self.layers = ModuleList([
+ SpecDetrTransformerDecoderLayer(**self.layer_cfg)
+ for _ in range(self.num_layers)
+ ])
+ self.embed_dims = self.layers[0].embed_dims
+ if self.post_norm_cfg is not None:
+ raise ValueError('There is not post_norm in '
+ f'{self._get_name()}')
+ self.ref_point_head = MLP(self.embed_dims * 2, self.embed_dims,
+ self.embed_dims, 2)
+ self.norm = nn.LayerNorm(self.embed_dims)
+
+ def forward(self, query: Tensor, value: Tensor, key_padding_mask: Tensor,
+ self_attn_mask: Tensor, reference_points: Tensor,
+ spatial_shapes: Tensor, level_start_index: Tensor,
+ valid_ratios: Tensor, reg_branches: nn.ModuleList,
+ **kwargs) -> Tensor:
+ """Forward function of Transformer encoder.
+
+ Args:
+ query (Tensor): The input query, has shape (num_queries, bs, dim).
+ value (Tensor): The input values, has shape (num_value, bs, dim).
+ key_padding_mask (Tensor): The `key_padding_mask` of `self_attn`
+ input. ByteTensor, has shape (num_queries, bs).
+ self_attn_mask (Tensor): The attention mask to prevent information
+ leakage from different denoising groups and matching parts, has
+ shape (num_queries_total, num_queries_total). It is `None` when
+ `self.training` is `False`.
+ reference_points (Tensor): The initial reference, has shape
+ (bs, num_queries, 4) with the last dimension arranged as
+ (cx, cy, w, h).
+ spatial_shapes (Tensor): Spatial shapes of features in all levels,
+ has shape (num_levels, 2), last dimension represents (h, w).
+ level_start_index (Tensor): The start index of each level.
+ A tensor has shape (num_levels, ) and can be represented
+ as [0, h_0*w_0, h_0*w_0+h_1*w_1, ...].
+ valid_ratios (Tensor): The ratios of the valid width and the valid
+ height relative to the width and the height of features in all
+ levels, has shape (bs, num_levels, 2).
+ reg_branches: (obj:`nn.ModuleList`): Used for refining the
+ regression results.
+
+ Returns:
+ Tensor: Output queries of Transformer encoder, which is also
+ called 'encoder output embeddings' or 'memory', has shape
+ (num_queries, bs, dim)
+ """
+ intermediate = []
+ intermediate_reference_points = [reference_points]
+ for lid, layer in enumerate(self.layers):
+ if reference_points.shape[-1] == 4:
+ reference_points_input = \
+ reference_points[:, :, None] * torch.cat(
+ [valid_ratios, valid_ratios], -1)[:, None]
+ else:
+ assert reference_points.shape[-1] == 2
+ reference_points_input = \
+ reference_points[:, :, None] * valid_ratios[:, None]
+
+ query_sine_embed = coordinate_to_encoding(
+ reference_points_input[:, :, 0, :], self.embed_dims/2 )
+ query_pos = self.ref_point_head(query_sine_embed)
+
+ query = layer(
+ query,
+ query_pos=query_pos,
+ value=value,
+ key_padding_mask=key_padding_mask,
+ self_attn_mask=self_attn_mask,
+ spatial_shapes=spatial_shapes,
+ level_start_index=level_start_index,
+ valid_ratios=valid_ratios,
+ reference_points=reference_points_input,
+ **kwargs)
+
+ if reg_branches is not None:
+ tmp = reg_branches[lid](query)
+ assert reference_points.shape[-1] == 4
+ new_reference_points = tmp + inverse_sigmoid(
+ reference_points, eps=1e-3)
+ new_reference_points = new_reference_points.sigmoid()
+ reference_points = new_reference_points.detach()
+
+ if self.return_intermediate:
+ intermediate.append(self.norm(query))
+ intermediate_reference_points.append(new_reference_points)
+ # NOTE this is for the "Look Forward Twice" module,
+ # in the DeformDETR, reference_points was appended.
+
+ if self.return_intermediate:
+ return torch.stack(intermediate), torch.stack(
+ intermediate_reference_points)
+
+ return query, reference_points
+
+
+class SpecDetrTransformerEncoderLayer(BaseModule):
+ """Encoder layer of Deformable DETR.
+ Implements encoder layer in DETR transformer.
+
+ Args:
+ self_attn_cfg (:obj:`ConfigDict` or dict, optional): Config for self
+ attention.
+ ffn_cfg (:obj:`ConfigDict` or dict, optional): Config for FFN.
+ norm_cfg (:obj:`ConfigDict` or dict, optional): Config for
+ normalization layers. All the layers will share the same
+ config. Defaults to `LN`.
+ init_cfg (:obj:`ConfigDict` or dict, optional): Config to control
+ the initialization. Defaults to None.
+ """
+
+ def __init__(self,
+ self_attn_cfg: OptConfigType = dict(
+ embed_dims=256, num_heads=8, dropout=0.0),
+ ffn_cfg: OptConfigType = dict(
+ embed_dims=256,
+ feedforward_channels=1024,
+ num_fcs=2,
+ ffn_drop=0.,
+ act_cfg=dict(type='ReLU', inplace=True)),
+ norm_cfg: OptConfigType = dict(type='LN'),
+ init_cfg: OptConfigType = None) -> None:
+
+ super().__init__(init_cfg=init_cfg)
+
+ self.self_attn_cfg = self_attn_cfg
+ if 'batch_first' not in self.self_attn_cfg:
+ self.self_attn_cfg['batch_first'] = True
+ else:
+ assert self.self_attn_cfg['batch_first'] is True, 'First \
+ dimension of all DETRs in mmdet is `batch`, \
+ please set `batch_first` flag.'
+
+ self.ffn_cfg = ffn_cfg
+ self.norm_cfg = norm_cfg
+ self._init_layers()
+
+ def _init_layers(self) -> None:
+ """Initialize self_attn, ffn, and norms."""
+ self.self_attn = MultiScaleDeformableAttention(**self.self_attn_cfg)
+ self.embed_dims = self.self_attn.embed_dims
+ self.ffn = FFN(**self.ffn_cfg)
+ norms_list = [
+ build_norm_layer(self.norm_cfg, self.embed_dims)[1]
+ for _ in range(2)
+ ]
+ self.norms = ModuleList(norms_list)
+
+ def forward(self, query: Tensor, query_pos: Tensor,
+ key_padding_mask: Tensor, **kwargs) -> Tensor:
+ """Forward function of an encoder layer.
+
+ Args:
+ query (Tensor): The input query, has shape (bs, num_queries, dim).
+ query_pos (Tensor): The positional encoding for query, with
+ the same shape as `query`.
+ key_padding_mask (Tensor): The `key_padding_mask` of `self_attn`
+ input. ByteTensor. has shape (bs, num_queries).
+ Returns:
+ Tensor: forwarded results, has shape (bs, num_queries, dim).
+ """
+ query = self.self_attn(
+ query=query,
+ key=query,
+ value=query,
+ query_pos=query_pos,
+ key_pos=query_pos,
+ key_padding_mask=key_padding_mask,
+ **kwargs)
+ query = self.norms[0](query)
+ query = self.ffn(query)
+ query = self.norms[1](query)
+ return query
+
+
+class SpecDetrTransformerDecoderLayer(BaseModule):
+ """Decoder layer of Deformable DETR.
+ Implements decoder layer in DETR transformer.
+ Args:
+ self_attn_cfg (:obj:`ConfigDict` or dict, optional): Config for self
+ attention.
+ cross_attn_cfg (:obj:`ConfigDict` or dict, optional): Config for cross
+ attention.
+ ffn_cfg (:obj:`ConfigDict` or dict, optional): Config for FFN.
+ norm_cfg (:obj:`ConfigDict` or dict, optional): Config for
+ normalization layers. All the layers will share the same
+ config. Defaults to `LN`.
+ init_cfg (:obj:`ConfigDict` or dict, optional): Config to control
+ the initialization. Defaults to None.
+ """
+
+ def __init__(self,
+ self_attn_cfg: OptConfigType = dict(
+ embed_dims=256,
+ num_heads=8,
+ dropout=0.0,
+ batch_first=True),
+ cross_attn_cfg: OptConfigType = dict(
+ embed_dims=256,
+ num_heads=8,
+ dropout=0.0,
+ batch_first=True),
+ ffn_cfg: OptConfigType = dict(
+ embed_dims=256,
+ feedforward_channels=1024,
+ num_fcs=2,
+ ffn_drop=0.,
+ act_cfg=dict(type='ReLU', inplace=True),
+ ),
+ norm_cfg: OptConfigType = dict(type='LN'),
+ init_cfg: OptConfigType = None) -> None:
+
+ super().__init__(init_cfg=init_cfg)
+
+ self.self_attn_cfg = self_attn_cfg
+ self.cross_attn_cfg = cross_attn_cfg
+ if 'batch_first' not in self.self_attn_cfg:
+ self.self_attn_cfg['batch_first'] = True
+ else:
+ assert self.self_attn_cfg['batch_first'] is True, 'First \
+ dimension of all DETRs in mmdet is `batch`, \
+ please set `batch_first` flag.'
+
+ if 'batch_first' not in self.cross_attn_cfg:
+ self.cross_attn_cfg['batch_first'] = True
+ else:
+ assert self.cross_attn_cfg['batch_first'] is True, 'First \
+ dimension of all DETRs in mmdet is `batch`, \
+ please set `batch_first` flag.'
+
+ self.ffn_cfg = ffn_cfg
+ self.norm_cfg = norm_cfg
+ self._init_layers()
+
+
+ def _init_layers(self) -> None:
+ """Initialize self_attn, cross-attn, ffn, and norms."""
+ # self.self_attn = MultiheadAttention(**self.self_attn_cfg)
+ self.cross_attn = MultiScaleDeformableAttention(**self.cross_attn_cfg)
+ self.embed_dims = self.cross_attn.embed_dims
+ self.ffn = FFN(**self.ffn_cfg)
+ norms_list = [
+ build_norm_layer(self.norm_cfg, self.embed_dims)[1]
+ for _ in range(2)
+ ]
+ self.norms = ModuleList(norms_list)
+
+ def forward(self,
+ query: Tensor,
+ key: Tensor = None,
+ value: Tensor = None,
+ query_pos: Tensor = None,
+ key_pos: Tensor = None,
+ self_attn_mask: Tensor = None,
+ cross_attn_mask: Tensor = None,
+ key_padding_mask: Tensor = None,
+ **kwargs) -> Tensor:
+ """
+ Args:
+ query (Tensor): The input query, has shape (bs, num_queries, dim).
+ key (Tensor, optional): The input key, has shape (bs, num_keys,
+ dim). If `None`, the `query` will be used. Defaults to `None`.
+ value (Tensor, optional): The input value, has the same shape as
+ `key`, as in `nn.MultiheadAttention.forward`. If `None`, the
+ `key` will be used. Defaults to `None`.
+ query_pos (Tensor, optional): The positional encoding for `query`,
+ has the same shape as `query`. If not `None`, it will be added
+ to `query` before forward function. Defaults to `None`.
+ key_pos (Tensor, optional): The positional encoding for `key`, has
+ the same shape as `key`. If not `None`, it will be added to
+ `key` before forward function. If None, and `query_pos` has the
+ same shape as `key`, then `query_pos` will be used for
+ `key_pos`. Defaults to None.
+ self_attn_mask (Tensor, optional): ByteTensor mask, has shape
+ (num_queries, num_keys), as in `nn.MultiheadAttention.forward`.
+ Defaults to None.
+ cross_attn_mask (Tensor, optional): ByteTensor mask, has shape
+ (num_queries, num_keys), as in `nn.MultiheadAttention.forward`.
+ Defaults to None.
+ key_padding_mask (Tensor, optional): The `key_padding_mask` of
+ `self_attn` input. ByteTensor, has shape (bs, num_value).
+ Defaults to None.
+
+ Returns:
+ Tensor: forwarded results, has shape (bs, num_queries, dim).
+ """
+
+ # query = self.self_attn(
+ # query=query,
+ # key=query,
+ # value=query,
+ # query_pos=query_pos,
+ # key_pos=query_pos,
+ # attn_mask=self_attn_mask,
+ # **kwargs)
+ # query = self.norms[0](query)
+ query = self.cross_attn(
+ query=query,
+ key=key,
+ value=value,
+ query_pos=query_pos,
+ key_pos=key_pos,
+ attn_mask=cross_attn_mask,
+ key_padding_mask=key_padding_mask,
+ **kwargs)
+ query = self.norms[0](query)
+ query = self.ffn(query)
+ query = self.norms[1](query)
+ return query
+
+
+class CdnQueryGenerator(BaseModule):
+ """Implement query generator of the Contrastive denoising (CDN) proposed in
+ `DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object
+ Detection `_
+
+ Code is modified from the `official github repo
+ `_.
+
+ Args:
+ num_classes (int): Number of object classes.
+ embed_dims (int): The embedding dimensions of the generated queries.
+ num_matching_queries (int): The queries number of the matching part.
+ Used for generating dn_mask.
+ label_noise_scale (float): The scale of label noise, defaults to 0.5.
+ box_noise_scale (float): The scale of box noise, defaults to 1.0.
+ group_cfg (:obj:`ConfigDict` or dict, optional): The config of the
+ denoising queries grouping, includes `dynamic`, `num_dn_queries`,
+ and `num_groups`. Two grouping strategies, 'static dn groups' and
+ 'dynamic dn groups', are supported. When `dynamic` is `False`,
+ the `num_groups` should be set, and the number of denoising query
+ groups will always be `num_groups`. When `dynamic` is `True`, the
+ `num_dn_queries` should be set, and the group number will be
+ dynamic to ensure that the denoising queries number will not exceed
+ `num_dn_queries` to prevent large fluctuations of memory. Defaults
+ to `None`.
+ """
+
+ def __init__(self,
+ num_classes: int,
+ embed_dims: int,
+ num_matching_queries: int,
+ label_noise_scale: float = 0.5,
+ box_noise_scale: float = 1.0,
+ query_initial: str = 'one',
+ group_cfg: OptConfigType = None) -> None:
+ super().__init__()
+ self.num_classes = num_classes
+ self.embed_dims = embed_dims
+ self.num_matching_queries = num_matching_queries
+ self.label_noise_scale = label_noise_scale
+ self.box_noise_scale = box_noise_scale
+
+ # prepare grouping strategy
+ group_cfg = {} if group_cfg is None else group_cfg
+ self.dynamic_dn_groups = group_cfg.get('dynamic', True)
+ if self.dynamic_dn_groups:
+ if 'num_dn_queries' not in group_cfg:
+ warnings.warn("'num_dn_queries' should be set when using "
+ 'dynamic dn groups, use 100 as default.')
+ self.num_dn_queries = group_cfg.get('num_dn_queries', 100)
+ assert isinstance(self.num_dn_queries, int), \
+ f'Expected the num_dn_queries to have type int, but got ' \
+ f'{self.num_dn_queries}({type(self.num_dn_queries)}). '
+ else:
+ assert 'num_groups' in group_cfg, \
+ 'num_groups should be set when using static dn groups'
+ self.num_groups = group_cfg['num_groups']
+ assert isinstance(self.num_groups, int), \
+ f'Expected the num_groups to have type int, but got ' \
+ f'{self.num_groups}({type(self.num_groups)}). '
+
+ # NOTE The original repo of DINO set the num_embeddings 92 for coco,
+ # 91 (0~90) of which represents target classes and the 92 (91)
+ # indicates `Unknown` class. However, the embedding of `unknown` class
+ # is not used in the original DINO.
+ # TODO: num_classes + 1 or num_classes ?
+ self.query_initial =query_initial
+ if self.query_initial == 'embed':
+ self.label_embedding = nn.Embedding(self.num_classes, self.embed_dims)
+
+ def __call__(self, batch_data_samples: SampleList) -> tuple:
+ """Generate contrastive denoising (cdn) queries with ground truth.
+ max_num_target 为一个batch内各个图像目标数量的最大值
+ Descriptions of the Number Values in code and comments:
+ - num_target_total: the total target number of the input batch
+ samples.
+ - max_num_target: the max target number of the input batch samples.
+ - num_noisy_targets: the total targets number after adding noise,
+ i.e., num_target_total * num_groups * 2.
+ - num_denoising_queries: the length of the output batched queries,
+ i.e., max_num_target * num_groups * 2.
+
+ NOTE The format of input bboxes in batch_data_samples is unnormalized
+ (x, y, x, y), and the output bbox queries are embedded by normalized
+ (cx, cy, w, h) format bboxes going through inverse_sigmoid.
+
+ Args:
+ batch_data_samples (list[:obj:`DetDataSample`]): List of the batch
+ data samples, each includes `gt_instance` which has attributes
+ `bboxes` and `labels`. The `bboxes` has unnormalized coordinate
+ format (x, y, x, y).
+
+ Returns:
+ tuple: The outputs of the dn query generator.
+
+ - dn_label_query (Tensor): The output content queries for denoising
+ part, has shape (bs, num_denoising_queries, dim), where
+ `num_denoising_queries = max_num_target * num_groups * 2`.
+ - dn_bbox_query (Tensor): The output reference bboxes as positions
+ of queries for denoising part, which are embedded by normalized
+ (cx, cy, w, h) format bboxes going through inverse_sigmoid, has
+ shape (bs, num_denoising_queries, 4) with the last dimension
+ arranged as (cx, cy, w, h).
+ - attn_mask (Tensor): The attention mask to prevent information
+ leakage from different denoising groups and matching parts,
+ will be used as `self_attn_mask` of the `decoder`, has shape
+ (num_queries_total, num_queries_total), where `num_queries_total`
+ is the sum of `num_denoising_queries` and `num_matching_queries`.
+ - dn_meta (Dict[str, int]): The dictionary saves information about
+ group collation, including 'num_denoising_queries' and
+ 'num_denoising_groups'. It will be used for split outputs of
+ denoising and matching parts and loss calculation.
+
+ """
+ # normalize bbox and collate ground truth (gt)
+ gt_labels_list = []
+ gt_bboxes_list = []
+ for sample in batch_data_samples:
+ img_h, img_w = sample.img_shape
+ bboxes = sample.gt_instances.bboxes
+ factor = bboxes.new_tensor([img_w, img_h, img_w,
+ img_h]).unsqueeze(0)
+ bboxes_normalized = bboxes / factor
+ gt_bboxes_list.append(bboxes_normalized)
+ gt_labels_list.append(sample.gt_instances.labels)
+ gt_labels = torch.cat(gt_labels_list) # (num_target_total, 4)
+ gt_bboxes = torch.cat(gt_bboxes_list)
+
+ num_target_list = [len(bboxes) for bboxes in gt_bboxes_list]
+ max_num_target = max(num_target_list)
+ num_groups = self.get_num_groups(max_num_target)
+
+ dn_label_query = self.generate_dn_label_query(gt_labels, num_groups)
+ dn_bbox_query = self.generate_dn_bbox_query(gt_bboxes, num_groups)
+ # dn_bbox_query数量为batch内图像目标总数 * 组数 * 2 (正样本和负样本各占一半)
+ # dn_label_query数量为batch内图像目标总数 * 组数 * 2, 随机选择一定数量的样本设为错误类比标签
+ # The `batch_idx` saves the batch index of the corresponding sample
+ # for each target, has shape (num_target_total).
+ batch_idx = torch.cat([
+ torch.full_like(t.long(), i) for i, t in enumerate(gt_labels_list)
+ ])
+
+
+ # dn_label_query, dn_bbox_query目前将一个batch内所有图像的正负样本拼接在一起,需要按batch size分开
+ # 每一张图目标数目不一样,数目同一设为最大目标数*group*2
+ dn_label_query, dn_bbox_query = self.collate_dn_queries(
+ dn_label_query, dn_bbox_query, batch_idx, len(batch_data_samples),
+ num_groups)
+
+ # 匹配部分查询和去噪组的查询不做注意力,去噪组与组之间也不做注意力
+ attn_mask = self.generate_dn_mask(
+ max_num_target, num_groups, device=dn_label_query.device)
+
+ dn_meta = dict(
+ num_denoising_queries=int(max_num_target * 2 * num_groups),
+ num_denoising_groups=num_groups)
+
+ return dn_label_query, dn_bbox_query, attn_mask, dn_meta
+
+ def get_num_groups(self, max_num_target: int = None) -> int:
+ """Calculate denoising query groups number.
+
+ Two grouping strategies, 'static dn groups' and 'dynamic dn groups',
+ are supported. When `self.dynamic_dn_groups` is `False`, the number
+ of denoising query groups will always be `self.num_groups`. When
+ `self.dynamic_dn_groups` is `True`, the group number will be dynamic,
+ ensuring the denoising queries number will not exceed
+ `self.num_dn_queries` to prevent large fluctuations of memory.
+
+ NOTE The `num_group` is shared for different samples in a batch. When
+ the target numbers in the samples varies, the denoising queries of the
+ samples containing fewer targets are padded to the max length.
+
+ Args:
+ max_num_target (int, optional): The max target number of the batch
+ samples. It will only be used when `self.dynamic_dn_groups` is
+ `True`. Defaults to `None`.
+
+ Returns:
+ int: The denoising group number of the current batch.
+ """
+ if self.dynamic_dn_groups:
+ assert max_num_target is not None, \
+ 'group_queries should be provided when using ' \
+ 'dynamic dn groups'
+ if max_num_target == 0:
+ num_groups = 1
+ else:
+ num_groups = self.num_dn_queries // max_num_target
+ else:
+ num_groups = self.num_groups
+ if num_groups < 1:
+ num_groups = 1
+ return int(num_groups)
+
+ def generate_dn_label_query(self, gt_labels: Tensor,
+ num_groups: int) -> Tensor:
+ """Generate noisy labels and their query embeddings.
+
+ The strategy for generating noisy labels is: Randomly choose labels of
+ `self.label_noise_scale * 0.5` proportion and override each of them
+ with a random object category label.
+
+ NOTE Not add noise to all labels. Besides, the `self.label_noise_scale
+ * 0.5` arg is the ratio of the chosen positions, which is higher than
+ the actual proportion of noisy labels, because the labels to override
+ may be correct. And the gap becomes larger as the number of target
+ categories decreases. The users should notice this and modify the scale
+ arg or the corresponding logic according to specific dataset.
+
+ Args:
+ gt_labels (Tensor): The concatenated gt labels of all samples
+ in the batch, has shape (num_target_total, ) where
+ `num_target_total = sum(num_target_list)`.
+ num_groups (int): The number of denoising query groups.
+
+ Returns:
+ Tensor: The query embeddings of noisy labels, has shape
+ (num_noisy_targets, embed_dims), where `num_noisy_targets =
+ num_target_total * num_groups * 2`.
+ """
+ if self.query_initial == 'one':
+ dn_label_query = torch.ones((gt_labels.size(0)*num_groups*2, self.embed_dims), device=gt_labels.device)
+ elif self.query_initial == 'random':
+ dn_label_query = torch.rand((gt_labels.size(0)*num_groups*2, self.embed_dims), device=gt_labels.device)
+ elif self.query_initial == 'embed':
+ gt_labels_expand = gt_labels.repeat(2 * num_groups,
+ 1).view(-1)
+ dn_label_query = self.label_embedding(gt_labels_expand)
+ return dn_label_query
+
+
+
+ def generate_dn_bbox_query(self, gt_bboxes: Tensor,
+ num_groups: int) -> Tensor:
+ """Generate noisy bboxes and their query embeddings.
+
+ The strategy for generating noisy bboxes is as follow:
+
+ .. code:: text
+
+ +--------------------+
+ | negative |
+ | +----------+ |
+ | | positive | |
+ | | +-----|----+------------+
+ | | | | | |
+ | +----+-----+ | |
+ | | | |
+ +---------+----------+ |
+ | |
+ | gt bbox |
+ | |
+ | +---------+----------+
+ | | | |
+ | | +----+-----+ |
+ | | | | | |
+ +-------------|--- +----+ | |
+ | | positive | |
+ | +----------+ |
+ | negative |
+ +--------------------+
+
+ The random noise is added to the top-left and down-right point
+ positions, hence, normalized (x, y, x, y) format of bboxes are
+ required. The noisy bboxes of positive queries have the points
+ both within the inner square, while those of negative queries
+ have the points both between the inner and outer squares.
+
+ Besides, the length of outer square is twice as long as that of
+ the inner square, i.e., self.box_noise_scale * w_or_h / 2.
+ NOTE The noise is added to all the bboxes. Moreover, there is still
+ unconsidered case when one point is within the positive square and
+ the others is between the inner and outer squares.
+
+ Args:
+ gt_bboxes (Tensor): The concatenated gt bboxes of all samples
+ in the batch, has shape (num_target_total, 4) with the last
+ dimension arranged as (cx, cy, w, h) where
+ `num_target_total = sum(num_target_list)`.
+ num_groups (int): The number of denoising query groups.
+
+ Returns:
+ Tensor: The output noisy bboxes, which are embedded by normalized
+ (cx, cy, w, h) format bboxes going through inverse_sigmoid, has
+ shape (num_noisy_targets, 4) with the last dimension arranged as
+ (cx, cy, w, h), where
+ `num_noisy_targets = num_target_total * num_groups * 2`.
+ """
+ assert self.box_noise_scale > 0
+ device = gt_bboxes.device
+
+ # expand gt_bboxes as groups
+ gt_bboxes_expand = gt_bboxes.repeat(2 * num_groups, 1) # xyxy
+
+ # obtain index of negative queries in gt_bboxes_expand
+ positive_idx = torch.arange(
+ len(gt_bboxes), dtype=torch.long, device=device)
+ positive_idx = positive_idx.unsqueeze(0).repeat(num_groups, 1)
+ positive_idx += 2 * len(gt_bboxes) * torch.arange(
+ num_groups, dtype=torch.long, device=device)[:, None]
+ positive_idx = positive_idx.flatten()
+ negative_idx = positive_idx + len(gt_bboxes)
+
+
+ bboxes_cxcywh_expand = bbox_xyxy_to_cxcywh(gt_bboxes_expand)
+ bboxes_whwh = bbox_xyxy_to_cxcywh(gt_bboxes_expand)[:, 2:].repeat(1, 2)
+ rand_part = torch.rand_like(gt_bboxes_expand) * 2.0 - 1.0
+ rand_part[:,:2] *= self.label_noise_scale
+ rand_part[:, 2:] *= self.box_noise_scale
+ noisy_bboxes_expand = bboxes_cxcywh_expand + torch.mul(rand_part, bboxes_whwh)/2
+
+ rand_sign = torch.randint_like(
+ gt_bboxes_expand, low=0, high=2,
+ dtype=torch.float32) * 2.0 - 1.0 # [low, high), 1 or -1, randomly
+ # calculate the random part of the added noise
+ rand_part = torch.rand_like(gt_bboxes_expand) # [0, 1)
+ # rand_part = self.label_noise_scale + rand_part *(1-self.label_noise_scale)
+ rand_part = self.label_noise_scale + rand_part * self.label_noise_scale
+ # rand_part = 2 + rand_part * 1
+ rand_part *= rand_sign
+ noisy_bboxes_expand[negative_idx,:2] = bboxes_cxcywh_expand[negative_idx,:2]+torch.mul(rand_part[negative_idx,2:],bboxes_cxcywh_expand[negative_idx,2:]*0.5)
+ noisy_bboxes_expand = bbox_cxcywh_to_xyxy(noisy_bboxes_expand)
+ noisy_bboxes_expand = noisy_bboxes_expand.clamp(min=0.0, max=1.0)
+ noisy_bboxes_expand = bbox_xyxy_to_cxcywh(noisy_bboxes_expand)
+
+ dn_bbox_query = inverse_sigmoid(noisy_bboxes_expand, eps=1e-3)
+ return dn_bbox_query
+
+
+ def collate_dn_queries(self, input_label_query: Tensor,
+ input_bbox_query: Tensor, batch_idx: Tensor,
+ batch_size: int, num_groups: int) -> Tuple[Tensor]:
+ """Collate generated queries to obtain batched dn queries.
+
+ The strategy for query collation is as follow:
+
+ .. code:: text
+
+ input_queries (num_target_total, query_dim)
+ P_A1 P_B1 P_B2 N_A1 N_B1 N_B2 P'A1 P'B1 P'B2 N'A1 N'B1 N'B2
+ |________ group1 ________| |________ group2 ________|
+ |
+ V
+ P_A1 Pad0 N_A1 Pad0 P'A1 Pad0 N'A1 Pad0
+ P_B1 P_B2 N_B1 N_B2 P'B1 P'B2 N'B1 N'B2
+ |____ group1 ____| |____ group2 ____|
+ batched_queries (batch_size, max_num_target, query_dim)
+
+ where query_dim is 4 for bbox and self.embed_dims for label.
+ Notation: _-group 1; '-group 2;
+ A-Sample1(has 1 target); B-sample2(has 2 targets)
+
+ Args:
+ input_label_query (Tensor): The generated label queries of all
+ targets, has shape (num_target_total, embed_dims) where
+ `num_target_total = sum(num_target_list)`.
+ input_bbox_query (Tensor): The generated bbox queries of all
+ targets, has shape (num_target_total, 4) with the last
+ dimension arranged as (cx, cy, w, h).
+ batch_idx (Tensor): The batch index of the corresponding sample
+ for each target, has shape (num_target_total).
+ batch_size (int): The size of the input batch.
+ num_groups (int): The number of denoising query groups.
+
+ Returns:
+ tuple[Tensor]: Output batched label and bbox queries.
+ - batched_label_query (Tensor): The output batched label queries,
+ has shape (batch_size, max_num_target, embed_dims).
+ - batched_bbox_query (Tensor): The output batched bbox queries,
+ has shape (batch_size, max_num_target, 4) with the last dimension
+ arranged as (cx, cy, w, h).
+ """
+ device = input_label_query.device
+ num_target_list = [
+ torch.sum(batch_idx == idx) for idx in range(batch_size)
+ ]
+ max_num_target = max(num_target_list)
+ num_denoising_queries = int(max_num_target * 2 * num_groups)
+
+ map_query_index = torch.cat([
+ torch.arange(num_target, device=device)
+ for num_target in num_target_list
+ ])
+ map_query_index = torch.cat([
+ map_query_index + max_num_target * i for i in range(2 * num_groups)
+ ]).long()
+ batch_idx_expand = batch_idx.repeat(2 * num_groups, 1).view(-1)
+ mapper = (batch_idx_expand, map_query_index)
+
+ batched_label_query = torch.zeros(
+ batch_size, num_denoising_queries, self.embed_dims, device=device)
+ batched_bbox_query = torch.zeros(
+ batch_size, num_denoising_queries, 4, device=device)
+
+ batched_label_query[mapper] = input_label_query
+ batched_bbox_query[mapper] = input_bbox_query
+ return batched_label_query, batched_bbox_query
+
+ def generate_dn_mask(self, max_num_target: int, num_groups: int,
+ device: Union[torch.device, str]) -> Tensor:
+ """Generate attention mask to prevent information leakage from
+ different denoising groups and matching parts.
+
+ .. code:: text
+
+ 0 0 0 0 1 1 1 1 0 0 0 0 0
+ 0 0 0 0 1 1 1 1 0 0 0 0 0
+ 0 0 0 0 1 1 1 1 0 0 0 0 0
+ 0 0 0 0 1 1 1 1 0 0 0 0 0
+ 1 1 1 1 0 0 0 0 0 0 0 0 0
+ 1 1 1 1 0 0 0 0 0 0 0 0 0
+ 1 1 1 1 0 0 0 0 0 0 0 0 0
+ 1 1 1 1 0 0 0 0 0 0 0 0 0
+ 1 1 1 1 1 1 1 1 0 0 0 0 0
+ 1 1 1 1 1 1 1 1 0 0 0 0 0
+ 1 1 1 1 1 1 1 1 0 0 0 0 0
+ 1 1 1 1 1 1 1 1 0 0 0 0 0
+ 1 1 1 1 1 1 1 1 0 0 0 0 0
+ max_num_target |_| |_________| num_matching_queries
+ |_____________| num_denoising_queries
+
+ 1 -> True (Masked), means 'can not see'.
+ 0 -> False (UnMasked), means 'can see'.
+
+ Args:
+ max_num_target (int): The max target number of the input batch
+ samples.
+ num_groups (int): The number of denoising query groups.
+ device (obj:`device` or str): The device of generated mask.
+
+ Returns:
+ Tensor: The attention mask to prevent information leakage from
+ different denoising groups and matching parts, will be used as
+ `self_attn_mask` of the `decoder`, has shape (num_queries_total,
+ num_queries_total), where `num_queries_total` is the sum of
+ `num_denoising_queries` and `num_matching_queries`.
+ """
+ num_denoising_queries = int(max_num_target * 2 * num_groups)
+ num_queries_total = num_denoising_queries + self.num_matching_queries
+ attn_mask = torch.zeros(
+ num_queries_total,
+ num_queries_total,
+ device=device,
+ dtype=torch.bool)
+ return attn_mask
+
diff --git a/mmdet/models/layers/transformer/utils.py b/mmdet/models/layers/transformer/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..3ba8a824a245e1c3b98ac27b34cfbd354ddcb0a3
--- /dev/null
+++ b/mmdet/models/layers/transformer/utils.py
@@ -0,0 +1,876 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+import warnings
+from typing import Optional, Sequence, Tuple, Union
+
+import torch
+import torch.nn.functional as F
+from mmcv.cnn import (Linear, build_activation_layer, build_conv_layer,
+ build_norm_layer)
+from mmcv.cnn.bricks.drop import Dropout
+from mmengine.model import BaseModule, ModuleList
+from mmengine.utils import to_2tuple
+from torch import Tensor, nn
+
+from mmdet.registry import MODELS
+from mmdet.utils import OptConfigType, OptMultiConfig
+
+
+def nlc_to_nchw(x: Tensor, hw_shape: Sequence[int]) -> Tensor:
+ """Convert [N, L, C] shape tensor to [N, C, H, W] shape tensor.
+
+ Args:
+ x (Tensor): The input tensor of shape [N, L, C] before conversion.
+ hw_shape (Sequence[int]): The height and width of output feature map.
+
+ Returns:
+ Tensor: The output tensor of shape [N, C, H, W] after conversion.
+ """
+ H, W = hw_shape
+ assert len(x.shape) == 3
+ B, L, C = x.shape
+ assert L == H * W, 'The seq_len does not match H, W'
+ return x.transpose(1, 2).reshape(B, C, H, W).contiguous()
+
+
+def nchw_to_nlc(x):
+ """Flatten [N, C, H, W] shape tensor to [N, L, C] shape tensor.
+
+ Args:
+ x (Tensor): The input tensor of shape [N, C, H, W] before conversion.
+
+ Returns:
+ Tensor: The output tensor of shape [N, L, C] after conversion.
+ """
+ assert len(x.shape) == 4
+ return x.flatten(2).transpose(1, 2).contiguous()
+
+
+def coordinate_to_encoding(coord_tensor: Tensor,
+ num_feats: int = 128,
+ temperature: int = 10000,
+ scale: float = 2 * math.pi):
+ """Convert coordinate tensor to positional encoding.
+
+ Args:
+ coord_tensor (Tensor): Coordinate tensor to be converted to
+ positional encoding. With the last dimension as 2 or 4.
+ num_feats (int, optional): The feature dimension for each position
+ along x-axis or y-axis. Note the final returned dimension
+ for each position is 2 times of this value. Defaults to 128.
+ temperature (int, optional): The temperature used for scaling
+ the position embedding. Defaults to 10000.
+ scale (float, optional): A scale factor that scales the position
+ embedding. The scale will be used only when `normalize` is True.
+ Defaults to 2*pi.
+ Returns:
+ Tensor: Returned encoded positional tensor.
+ """
+ dim_t = torch.arange(
+ num_feats, dtype=torch.float32, device=coord_tensor.device)
+ dim_t = temperature**(2 * (dim_t // 2) / num_feats)
+ x_embed = coord_tensor[..., 0] * scale
+ y_embed = coord_tensor[..., 1] * scale
+ pos_x = x_embed[..., None] / dim_t
+ pos_y = y_embed[..., None] / dim_t
+ pos_x = torch.stack((pos_x[..., 0::2].sin(), pos_x[..., 1::2].cos()),
+ dim=-1).flatten(2)
+ pos_y = torch.stack((pos_y[..., 0::2].sin(), pos_y[..., 1::2].cos()),
+ dim=-1).flatten(2)
+ if coord_tensor.size(-1) == 2:
+ pos = torch.cat((pos_y, pos_x), dim=-1)
+ elif coord_tensor.size(-1) == 4:
+ w_embed = coord_tensor[..., 2] * scale
+ pos_w = w_embed[..., None] / dim_t
+ pos_w = torch.stack((pos_w[..., 0::2].sin(), pos_w[..., 1::2].cos()),
+ dim=-1).flatten(2)
+
+ h_embed = coord_tensor[..., 3] * scale
+ pos_h = h_embed[..., None] / dim_t
+ pos_h = torch.stack((pos_h[..., 0::2].sin(), pos_h[..., 1::2].cos()),
+ dim=-1).flatten(2)
+
+ pos = torch.cat((pos_y, pos_x, pos_w, pos_h), dim=-1)
+ else:
+ raise ValueError('Unknown pos_tensor shape(-1):{}'.format(
+ coord_tensor.size(-1)))
+ return pos
+
+
+def inverse_sigmoid(x: Tensor, eps: float = 1e-5) -> Tensor:
+ """Inverse function of sigmoid.
+
+ Args:
+ x (Tensor): The tensor to do the inverse.
+ eps (float): EPS avoid numerical overflow. Defaults 1e-5.
+ Returns:
+ Tensor: The x has passed the inverse function of sigmoid, has the same
+ shape with input.
+ """
+ x = x.clamp(min=0, max=1)
+ x1 = x.clamp(min=eps)
+ x2 = (1 - x).clamp(min=eps)
+ return torch.log(x1 / x2)
+
+
+class AdaptivePadding(nn.Module):
+ """Applies padding to input (if needed) so that input can get fully covered
+ by filter you specified. It support two modes "same" and "corner". The
+ "same" mode is same with "SAME" padding mode in TensorFlow, pad zero around
+ input. The "corner" mode would pad zero to bottom right.
+
+ Args:
+ kernel_size (int | tuple): Size of the kernel:
+ stride (int | tuple): Stride of the filter. Default: 1:
+ dilation (int | tuple): Spacing between kernel elements.
+ Default: 1
+ padding (str): Support "same" and "corner", "corner" mode
+ would pad zero to bottom right, and "same" mode would
+ pad zero around input. Default: "corner".
+ Example:
+ >>> kernel_size = 16
+ >>> stride = 16
+ >>> dilation = 1
+ >>> input = torch.rand(1, 1, 15, 17)
+ >>> adap_pad = AdaptivePadding(
+ >>> kernel_size=kernel_size,
+ >>> stride=stride,
+ >>> dilation=dilation,
+ >>> padding="corner")
+ >>> out = adap_pad(input)
+ >>> assert (out.shape[2], out.shape[3]) == (16, 32)
+ >>> input = torch.rand(1, 1, 16, 17)
+ >>> out = adap_pad(input)
+ >>> assert (out.shape[2], out.shape[3]) == (16, 32)
+ """
+
+ def __init__(self, kernel_size=1, stride=1, dilation=1, padding='corner'):
+
+ super(AdaptivePadding, self).__init__()
+
+ assert padding in ('same', 'corner')
+
+ kernel_size = to_2tuple(kernel_size)
+ stride = to_2tuple(stride)
+ padding = to_2tuple(padding)
+ dilation = to_2tuple(dilation)
+
+ self.padding = padding
+ self.kernel_size = kernel_size
+ self.stride = stride
+ self.dilation = dilation
+
+ def get_pad_shape(self, input_shape):
+ input_h, input_w = input_shape
+ kernel_h, kernel_w = self.kernel_size
+ stride_h, stride_w = self.stride
+ output_h = math.ceil(input_h / stride_h)
+ output_w = math.ceil(input_w / stride_w)
+ pad_h = max((output_h - 1) * stride_h +
+ (kernel_h - 1) * self.dilation[0] + 1 - input_h, 0)
+ pad_w = max((output_w - 1) * stride_w +
+ (kernel_w - 1) * self.dilation[1] + 1 - input_w, 0)
+ return pad_h, pad_w
+
+ def forward(self, x):
+ pad_h, pad_w = self.get_pad_shape(x.size()[-2:])
+ if pad_h > 0 or pad_w > 0:
+ if self.padding == 'corner':
+ x = F.pad(x, [0, pad_w, 0, pad_h])
+ elif self.padding == 'same':
+ x = F.pad(x, [
+ pad_w // 2, pad_w - pad_w // 2, pad_h // 2,
+ pad_h - pad_h // 2
+ ])
+ return x
+
+
+class PatchEmbed(BaseModule):
+ """Image to Patch Embedding.
+
+ We use a conv layer to implement PatchEmbed.
+
+ Args:
+ in_channels (int): The num of input channels. Default: 3
+ embed_dims (int): The dimensions of embedding. Default: 768
+ conv_type (str): The config dict for embedding
+ conv layer type selection. Default: "Conv2d.
+ kernel_size (int): The kernel_size of embedding conv. Default: 16.
+ stride (int): The slide stride of embedding conv.
+ Default: None (Would be set as `kernel_size`).
+ padding (int | tuple | string ): The padding length of
+ embedding conv. When it is a string, it means the mode
+ of adaptive padding, support "same" and "corner" now.
+ Default: "corner".
+ dilation (int): The dilation rate of embedding conv. Default: 1.
+ bias (bool): Bias of embed conv. Default: True.
+ norm_cfg (dict, optional): Config dict for normalization layer.
+ Default: None.
+ input_size (int | tuple | None): The size of input, which will be
+ used to calculate the out size. Only work when `dynamic_size`
+ is False. Default: None.
+ init_cfg (`mmengine.ConfigDict`, optional): The Config for
+ initialization. Default: None.
+ """
+
+ def __init__(self,
+ in_channels: int = 3,
+ embed_dims: int = 768,
+ conv_type: str = 'Conv2d',
+ kernel_size: int = 16,
+ stride: int = 16,
+ padding: Union[int, tuple, str] = 'corner',
+ dilation: int = 1,
+ bias: bool = True,
+ norm_cfg: OptConfigType = None,
+ input_size: Union[int, tuple] = None,
+ init_cfg: OptConfigType = None) -> None:
+ super(PatchEmbed, self).__init__(init_cfg=init_cfg)
+
+ self.embed_dims = embed_dims
+ if stride is None:
+ stride = kernel_size
+
+ kernel_size = to_2tuple(kernel_size)
+ stride = to_2tuple(stride)
+ dilation = to_2tuple(dilation)
+
+ if isinstance(padding, str):
+ self.adap_padding = AdaptivePadding(
+ kernel_size=kernel_size,
+ stride=stride,
+ dilation=dilation,
+ padding=padding)
+ # disable the padding of conv
+ padding = 0
+ else:
+ self.adap_padding = None
+ padding = to_2tuple(padding)
+
+ self.projection = build_conv_layer(
+ dict(type=conv_type),
+ in_channels=in_channels,
+ out_channels=embed_dims,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ dilation=dilation,
+ bias=bias)
+
+ if norm_cfg is not None:
+ self.norm = build_norm_layer(norm_cfg, embed_dims)[1]
+ else:
+ self.norm = None
+
+ if input_size:
+ input_size = to_2tuple(input_size)
+ # `init_out_size` would be used outside to
+ # calculate the num_patches
+ # when `use_abs_pos_embed` outside
+ self.init_input_size = input_size
+ if self.adap_padding:
+ pad_h, pad_w = self.adap_padding.get_pad_shape(input_size)
+ input_h, input_w = input_size
+ input_h = input_h + pad_h
+ input_w = input_w + pad_w
+ input_size = (input_h, input_w)
+
+ # https://pytorch.org/docs/stable/generated/torch.nn.Conv2d.html
+ h_out = (input_size[0] + 2 * padding[0] - dilation[0] *
+ (kernel_size[0] - 1) - 1) // stride[0] + 1
+ w_out = (input_size[1] + 2 * padding[1] - dilation[1] *
+ (kernel_size[1] - 1) - 1) // stride[1] + 1
+ self.init_out_size = (h_out, w_out)
+ else:
+ self.init_input_size = None
+ self.init_out_size = None
+
+ def forward(self, x: Tensor) -> Tuple[Tensor, Tuple[int]]:
+ """
+ Args:
+ x (Tensor): Has shape (B, C, H, W). In most case, C is 3.
+
+ Returns:
+ tuple: Contains merged results and its spatial shape.
+
+ - x (Tensor): Has shape (B, out_h * out_w, embed_dims)
+ - out_size (tuple[int]): Spatial shape of x, arrange as
+ (out_h, out_w).
+ """
+
+ if self.adap_padding:
+ x = self.adap_padding(x)
+
+ x = self.projection(x)
+ out_size = (x.shape[2], x.shape[3])
+ x = x.flatten(2).transpose(1, 2)
+ if self.norm is not None:
+ x = self.norm(x)
+ return x, out_size
+
+
+class PatchMerging(BaseModule):
+ """Merge patch feature map.
+
+ This layer groups feature map by kernel_size, and applies norm and linear
+ layers to the grouped feature map. Our implementation uses `nn.Unfold` to
+ merge patch, which is about 25% faster than original implementation.
+ Instead, we need to modify pretrained models for compatibility.
+
+ Args:
+ in_channels (int): The num of input channels.
+ to gets fully covered by filter and stride you specified..
+ Default: True.
+ out_channels (int): The num of output channels.
+ kernel_size (int | tuple, optional): the kernel size in the unfold
+ layer. Defaults to 2.
+ stride (int | tuple, optional): the stride of the sliding blocks in the
+ unfold layer. Default: None. (Would be set as `kernel_size`)
+ padding (int | tuple | string ): The padding length of
+ embedding conv. When it is a string, it means the mode
+ of adaptive padding, support "same" and "corner" now.
+ Default: "corner".
+ dilation (int | tuple, optional): dilation parameter in the unfold
+ layer. Default: 1.
+ bias (bool, optional): Whether to add bias in linear layer or not.
+ Defaults: False.
+ norm_cfg (dict, optional): Config dict for normalization layer.
+ Default: dict(type='LN').
+ init_cfg (dict, optional): The extra config for initialization.
+ Default: None.
+ """
+
+ def __init__(self,
+ in_channels: int,
+ out_channels: int,
+ kernel_size: Optional[Union[int, tuple]] = 2,
+ stride: Optional[Union[int, tuple]] = None,
+ padding: Union[int, tuple, str] = 'corner',
+ dilation: Optional[Union[int, tuple]] = 1,
+ bias: Optional[bool] = False,
+ norm_cfg: OptConfigType = dict(type='LN'),
+ init_cfg: OptConfigType = None) -> None:
+ super().__init__(init_cfg=init_cfg)
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ if stride:
+ stride = stride
+ else:
+ stride = kernel_size
+
+ kernel_size = to_2tuple(kernel_size)
+ stride = to_2tuple(stride)
+ dilation = to_2tuple(dilation)
+
+ if isinstance(padding, str):
+ self.adap_padding = AdaptivePadding(
+ kernel_size=kernel_size,
+ stride=stride,
+ dilation=dilation,
+ padding=padding)
+ # disable the padding of unfold
+ padding = 0
+ else:
+ self.adap_padding = None
+
+ padding = to_2tuple(padding)
+ self.sampler = nn.Unfold(
+ kernel_size=kernel_size,
+ dilation=dilation,
+ padding=padding,
+ stride=stride)
+
+ sample_dim = kernel_size[0] * kernel_size[1] * in_channels
+
+ if norm_cfg is not None:
+ self.norm = build_norm_layer(norm_cfg, sample_dim)[1]
+ else:
+ self.norm = None
+
+ self.reduction = nn.Linear(sample_dim, out_channels, bias=bias)
+
+ def forward(self, x: Tensor,
+ input_size: Tuple[int]) -> Tuple[Tensor, Tuple[int]]:
+ """
+ Args:
+ x (Tensor): Has shape (B, H*W, C_in).
+ input_size (tuple[int]): The spatial shape of x, arrange as (H, W).
+ Default: None.
+
+ Returns:
+ tuple: Contains merged results and its spatial shape.
+
+ - x (Tensor): Has shape (B, Merged_H * Merged_W, C_out)
+ - out_size (tuple[int]): Spatial shape of x, arrange as
+ (Merged_H, Merged_W).
+ """
+ B, L, C = x.shape
+ assert isinstance(input_size, Sequence), f'Expect ' \
+ f'input_size is ' \
+ f'`Sequence` ' \
+ f'but get {input_size}'
+
+ H, W = input_size
+ assert L == H * W, 'input feature has wrong size'
+
+ x = x.view(B, H, W, C).permute([0, 3, 1, 2]) # B, C, H, W
+ # Use nn.Unfold to merge patch. About 25% faster than original method,
+ # but need to modify pretrained model for compatibility
+
+ if self.adap_padding:
+ x = self.adap_padding(x)
+ H, W = x.shape[-2:]
+
+ x = self.sampler(x)
+ # if kernel_size=2 and stride=2, x should has shape (B, 4*C, H/2*W/2)
+
+ out_h = (H + 2 * self.sampler.padding[0] - self.sampler.dilation[0] *
+ (self.sampler.kernel_size[0] - 1) -
+ 1) // self.sampler.stride[0] + 1
+ out_w = (W + 2 * self.sampler.padding[1] - self.sampler.dilation[1] *
+ (self.sampler.kernel_size[1] - 1) -
+ 1) // self.sampler.stride[1] + 1
+
+ output_size = (out_h, out_w)
+ x = x.transpose(1, 2) # B, H/2*W/2, 4*C
+ x = self.norm(x) if self.norm else x
+ x = self.reduction(x)
+ return x, output_size
+
+
+class ConditionalAttention(BaseModule):
+ """A wrapper of conditional attention, dropout and residual connection.
+
+ Args:
+ embed_dims (int): The embedding dimension.
+ num_heads (int): Parallel attention heads.
+ attn_drop (float): A Dropout layer on attn_output_weights.
+ Default: 0.0.
+ proj_drop: A Dropout layer after `nn.MultiheadAttention`.
+ Default: 0.0.
+ cross_attn (bool): Whether the attention module is for cross attention.
+ Default: False
+ keep_query_pos (bool): Whether to transform query_pos before cross
+ attention.
+ Default: False.
+ batch_first (bool): When it is True, Key, Query and Value are shape of
+ (batch, n, embed_dim), otherwise (n, batch, embed_dim).
+ Default: True.
+ init_cfg (obj:`mmcv.ConfigDict`): The Config for initialization.
+ Default: None.
+ """
+
+ def __init__(self,
+ embed_dims: int,
+ num_heads: int,
+ attn_drop: float = 0.,
+ proj_drop: float = 0.,
+ cross_attn: bool = False,
+ keep_query_pos: bool = False,
+ batch_first: bool = True,
+ init_cfg: OptMultiConfig = None):
+ super().__init__(init_cfg=init_cfg)
+
+ assert batch_first is True, 'Set `batch_first`\
+ to False is NOT supported in ConditionalAttention. \
+ First dimension of all DETRs in mmdet is `batch`, \
+ please set `batch_first` to True.'
+
+ self.cross_attn = cross_attn
+ self.keep_query_pos = keep_query_pos
+ self.embed_dims = embed_dims
+ self.num_heads = num_heads
+ self.attn_drop = Dropout(attn_drop)
+ self.proj_drop = Dropout(proj_drop)
+
+ self._init_layers()
+
+ def _init_layers(self):
+ """Initialize layers for qkv projection."""
+ embed_dims = self.embed_dims
+ self.qcontent_proj = Linear(embed_dims, embed_dims)
+ self.qpos_proj = Linear(embed_dims, embed_dims)
+ self.kcontent_proj = Linear(embed_dims, embed_dims)
+ self.kpos_proj = Linear(embed_dims, embed_dims)
+ self.v_proj = Linear(embed_dims, embed_dims)
+ if self.cross_attn:
+ self.qpos_sine_proj = Linear(embed_dims, embed_dims)
+ self.out_proj = Linear(embed_dims, embed_dims)
+
+ nn.init.constant_(self.out_proj.bias, 0.)
+
+ def forward_attn(self,
+ query: Tensor,
+ key: Tensor,
+ value: Tensor,
+ attn_mask: Tensor = None,
+ key_padding_mask: Tensor = None) -> Tuple[Tensor]:
+ """Forward process for `ConditionalAttention`.
+
+ Args:
+ query (Tensor): The input query with shape [bs, num_queries,
+ embed_dims].
+ key (Tensor): The key tensor with shape [bs, num_keys,
+ embed_dims].
+ If None, the `query` will be used. Defaults to None.
+ value (Tensor): The value tensor with same shape as `key`.
+ Same in `nn.MultiheadAttention.forward`. Defaults to None.
+ If None, the `key` will be used.
+ attn_mask (Tensor): ByteTensor mask with shape [num_queries,
+ num_keys]. Same in `nn.MultiheadAttention.forward`.
+ Defaults to None.
+ key_padding_mask (Tensor): ByteTensor with shape [bs, num_keys].
+ Defaults to None.
+ Returns:
+ Tuple[Tensor]: Attention outputs of shape :math:`(N, L, E)`,
+ where :math:`N` is the batch size, :math:`L` is the target
+ sequence length , and :math:`E` is the embedding dimension
+ `embed_dim`. Attention weights per head of shape :math:`
+ (num_heads, L, S)`. where :math:`N` is batch size, :math:`L`
+ is target sequence length, and :math:`S` is the source sequence
+ length.
+ """
+ assert key.size(1) == value.size(1), \
+ f'{"key, value must have the same sequence length"}'
+ assert query.size(0) == key.size(0) == value.size(0), \
+ f'{"batch size must be equal for query, key, value"}'
+ assert query.size(2) == key.size(2), \
+ f'{"q_dims, k_dims must be equal"}'
+ assert value.size(2) == self.embed_dims, \
+ f'{"v_dims must be equal to embed_dims"}'
+
+ bs, tgt_len, hidden_dims = query.size()
+ _, src_len, _ = key.size()
+ head_dims = hidden_dims // self.num_heads
+ v_head_dims = self.embed_dims // self.num_heads
+ assert head_dims * self.num_heads == hidden_dims, \
+ f'{"hidden_dims must be divisible by num_heads"}'
+ scaling = float(head_dims)**-0.5
+
+ q = query * scaling
+ k = key
+ v = value
+
+ if attn_mask is not None:
+ assert attn_mask.dtype == torch.float32 or \
+ attn_mask.dtype == torch.float64 or \
+ attn_mask.dtype == torch.float16 or \
+ attn_mask.dtype == torch.uint8 or \
+ attn_mask.dtype == torch.bool, \
+ 'Only float, byte, and bool types are supported for \
+ attn_mask'
+
+ if attn_mask.dtype == torch.uint8:
+ warnings.warn('Byte tensor for attn_mask is deprecated.\
+ Use bool tensor instead.')
+ attn_mask = attn_mask.to(torch.bool)
+ if attn_mask.dim() == 2:
+ attn_mask = attn_mask.unsqueeze(0)
+ if list(attn_mask.size()) != [1, query.size(1), key.size(1)]:
+ raise RuntimeError(
+ 'The size of the 2D attn_mask is not correct.')
+ elif attn_mask.dim() == 3:
+ if list(attn_mask.size()) != [
+ bs * self.num_heads,
+ query.size(1),
+ key.size(1)
+ ]:
+ raise RuntimeError(
+ 'The size of the 3D attn_mask is not correct.')
+ else:
+ raise RuntimeError(
+ "attn_mask's dimension {} is not supported".format(
+ attn_mask.dim()))
+ # attn_mask's dim is 3 now.
+
+ if key_padding_mask is not None and key_padding_mask.dtype == int:
+ key_padding_mask = key_padding_mask.to(torch.bool)
+
+ q = q.contiguous().view(bs, tgt_len, self.num_heads,
+ head_dims).permute(0, 2, 1, 3).flatten(0, 1)
+ if k is not None:
+ k = k.contiguous().view(bs, src_len, self.num_heads,
+ head_dims).permute(0, 2, 1,
+ 3).flatten(0, 1)
+ if v is not None:
+ v = v.contiguous().view(bs, src_len, self.num_heads,
+ v_head_dims).permute(0, 2, 1,
+ 3).flatten(0, 1)
+
+ if key_padding_mask is not None:
+ assert key_padding_mask.size(0) == bs
+ assert key_padding_mask.size(1) == src_len
+
+ attn_output_weights = torch.bmm(q, k.transpose(1, 2))
+ assert list(attn_output_weights.size()) == [
+ bs * self.num_heads, tgt_len, src_len
+ ]
+
+ if attn_mask is not None:
+ if attn_mask.dtype == torch.bool:
+ attn_output_weights.masked_fill_(attn_mask, float('-inf'))
+ else:
+ attn_output_weights += attn_mask
+
+ if key_padding_mask is not None:
+ attn_output_weights = attn_output_weights.view(
+ bs, self.num_heads, tgt_len, src_len)
+ attn_output_weights = attn_output_weights.masked_fill(
+ key_padding_mask.unsqueeze(1).unsqueeze(2),
+ float('-inf'),
+ )
+ attn_output_weights = attn_output_weights.view(
+ bs * self.num_heads, tgt_len, src_len)
+
+ attn_output_weights = F.softmax(
+ attn_output_weights -
+ attn_output_weights.max(dim=-1, keepdim=True)[0],
+ dim=-1)
+ attn_output_weights = self.attn_drop(attn_output_weights)
+
+ attn_output = torch.bmm(attn_output_weights, v)
+ assert list(
+ attn_output.size()) == [bs * self.num_heads, tgt_len, v_head_dims]
+ attn_output = attn_output.view(bs, self.num_heads, tgt_len,
+ v_head_dims).permute(0, 2, 1,
+ 3).flatten(2)
+ attn_output = self.out_proj(attn_output)
+
+ # average attention weights over heads
+ attn_output_weights = attn_output_weights.view(bs, self.num_heads,
+ tgt_len, src_len)
+ return attn_output, attn_output_weights.sum(dim=1) / self.num_heads
+
+ def forward(self,
+ query: Tensor,
+ key: Tensor,
+ query_pos: Tensor = None,
+ ref_sine_embed: Tensor = None,
+ key_pos: Tensor = None,
+ attn_mask: Tensor = None,
+ key_padding_mask: Tensor = None,
+ is_first: bool = False) -> Tensor:
+ """Forward function for `ConditionalAttention`.
+ Args:
+ query (Tensor): The input query with shape [bs, num_queries,
+ embed_dims].
+ key (Tensor): The key tensor with shape [bs, num_keys,
+ embed_dims].
+ If None, the `query` will be used. Defaults to None.
+ query_pos (Tensor): The positional encoding for query in self
+ attention, with the same shape as `x`. If not None, it will
+ be added to `x` before forward function.
+ Defaults to None.
+ query_sine_embed (Tensor): The positional encoding for query in
+ cross attention, with the same shape as `x`. If not None, it
+ will be added to `x` before forward function.
+ Defaults to None.
+ key_pos (Tensor): The positional encoding for `key`, with the
+ same shape as `key`. Defaults to None. If not None, it will
+ be added to `key` before forward function. If None, and
+ `query_pos` has the same shape as `key`, then `query_pos`
+ will be used for `key_pos`. Defaults to None.
+ attn_mask (Tensor): ByteTensor mask with shape [num_queries,
+ num_keys]. Same in `nn.MultiheadAttention.forward`.
+ Defaults to None.
+ key_padding_mask (Tensor): ByteTensor with shape [bs, num_keys].
+ Defaults to None.
+ is_first (bool): A indicator to tell whether the current layer
+ is the first layer of the decoder.
+ Defaults to False.
+ Returns:
+ Tensor: forwarded results with shape
+ [bs, num_queries, embed_dims].
+ """
+
+ if self.cross_attn:
+ q_content = self.qcontent_proj(query)
+ k_content = self.kcontent_proj(key)
+ v = self.v_proj(key)
+
+ bs, nq, c = q_content.size()
+ _, hw, _ = k_content.size()
+
+ k_pos = self.kpos_proj(key_pos)
+ if is_first or self.keep_query_pos:
+ q_pos = self.qpos_proj(query_pos)
+ q = q_content + q_pos
+ k = k_content + k_pos
+ else:
+ q = q_content
+ k = k_content
+ q = q.view(bs, nq, self.num_heads, c // self.num_heads)
+ query_sine_embed = self.qpos_sine_proj(ref_sine_embed)
+ query_sine_embed = query_sine_embed.view(bs, nq, self.num_heads,
+ c // self.num_heads)
+ q = torch.cat([q, query_sine_embed], dim=3).view(bs, nq, 2 * c)
+ k = k.view(bs, hw, self.num_heads, c // self.num_heads)
+ k_pos = k_pos.view(bs, hw, self.num_heads, c // self.num_heads)
+ k = torch.cat([k, k_pos], dim=3).view(bs, hw, 2 * c)
+ ca_output = self.forward_attn(
+ query=q,
+ key=k,
+ value=v,
+ attn_mask=attn_mask,
+ key_padding_mask=key_padding_mask)[0]
+ query = query + self.proj_drop(ca_output)
+ else:
+ q_content = self.qcontent_proj(query)
+ q_pos = self.qpos_proj(query_pos)
+ k_content = self.kcontent_proj(query)
+ k_pos = self.kpos_proj(query_pos)
+ v = self.v_proj(query)
+ q = q_content if q_pos is None else q_content + q_pos
+ k = k_content if k_pos is None else k_content + k_pos
+ sa_output = self.forward_attn(
+ query=q,
+ key=k,
+ value=v,
+ attn_mask=attn_mask,
+ key_padding_mask=key_padding_mask)[0]
+ query = query + self.proj_drop(sa_output)
+
+ return query
+
+
+class MLP(BaseModule):
+ """Very simple multi-layer perceptron (also called FFN) with relu. Mostly
+ used in DETR series detectors.
+
+ Args:
+ input_dim (int): Feature dim of the input tensor.
+ hidden_dim (int): Feature dim of the hidden layer.
+ output_dim (int): Feature dim of the output tensor.
+ num_layers (int): Number of FFN layers. As the last
+ layer of MLP only contains FFN (Linear).
+ """
+
+ def __init__(self, input_dim: int, hidden_dim: int, output_dim: int,
+ num_layers: int) -> None:
+ super().__init__()
+ self.num_layers = num_layers
+ h = [hidden_dim] * (num_layers - 1)
+ self.layers = ModuleList(
+ Linear(n, k) for n, k in zip([input_dim] + h, h + [output_dim]))
+
+ def forward(self, x: Tensor) -> Tensor:
+ """Forward function of MLP.
+
+ Args:
+ x (Tensor): The input feature, has shape
+ (num_queries, bs, input_dim).
+ Returns:
+ Tensor: The output feature, has shape
+ (num_queries, bs, output_dim).
+ """
+ for i, layer in enumerate(self.layers):
+ x = F.relu(layer(x)) if i < self.num_layers - 1 else layer(x)
+ return x
+
+
+@MODELS.register_module()
+class DynamicConv(BaseModule):
+ """Implements Dynamic Convolution.
+
+ This module generate parameters for each sample and
+ use bmm to implement 1*1 convolution. Code is modified
+ from the `official github repo `_ .
+
+ Args:
+ in_channels (int): The input feature channel.
+ Defaults to 256.
+ feat_channels (int): The inner feature channel.
+ Defaults to 64.
+ out_channels (int, optional): The output feature channel.
+ When not specified, it will be set to `in_channels`
+ by default
+ input_feat_shape (int): The shape of input feature.
+ Defaults to 7.
+ with_proj (bool): Project two-dimentional feature to
+ one-dimentional feature. Default to True.
+ act_cfg (dict): The activation config for DynamicConv.
+ norm_cfg (dict): Config dict for normalization layer. Default
+ layer normalization.
+ init_cfg (obj:`mmengine.ConfigDict`): The Config for initialization.
+ Default: None.
+ """
+
+ def __init__(self,
+ in_channels: int = 256,
+ feat_channels: int = 64,
+ out_channels: Optional[int] = None,
+ input_feat_shape: int = 7,
+ with_proj: bool = True,
+ act_cfg: OptConfigType = dict(type='ReLU', inplace=True),
+ norm_cfg: OptConfigType = dict(type='LN'),
+ init_cfg: OptConfigType = None) -> None:
+ super(DynamicConv, self).__init__(init_cfg)
+ self.in_channels = in_channels
+ self.feat_channels = feat_channels
+ self.out_channels_raw = out_channels
+ self.input_feat_shape = input_feat_shape
+ self.with_proj = with_proj
+ self.act_cfg = act_cfg
+ self.norm_cfg = norm_cfg
+ self.out_channels = out_channels if out_channels else in_channels
+
+ self.num_params_in = self.in_channels * self.feat_channels
+ self.num_params_out = self.out_channels * self.feat_channels
+ self.dynamic_layer = nn.Linear(
+ self.in_channels, self.num_params_in + self.num_params_out)
+
+ self.norm_in = build_norm_layer(norm_cfg, self.feat_channels)[1]
+ self.norm_out = build_norm_layer(norm_cfg, self.out_channels)[1]
+
+ self.activation = build_activation_layer(act_cfg)
+
+ num_output = self.out_channels * input_feat_shape**2
+ if self.with_proj:
+ self.fc_layer = nn.Linear(num_output, self.out_channels)
+ self.fc_norm = build_norm_layer(norm_cfg, self.out_channels)[1]
+
+ def forward(self, param_feature: Tensor, input_feature: Tensor) -> Tensor:
+ """Forward function for `DynamicConv`.
+
+ Args:
+ param_feature (Tensor): The feature can be used
+ to generate the parameter, has shape
+ (num_all_proposals, in_channels).
+ input_feature (Tensor): Feature that
+ interact with parameters, has shape
+ (num_all_proposals, in_channels, H, W).
+
+ Returns:
+ Tensor: The output feature has shape
+ (num_all_proposals, out_channels).
+ """
+ input_feature = input_feature.flatten(2).permute(2, 0, 1)
+
+ input_feature = input_feature.permute(1, 0, 2)
+ parameters = self.dynamic_layer(param_feature)
+
+ param_in = parameters[:, :self.num_params_in].view(
+ -1, self.in_channels, self.feat_channels)
+ param_out = parameters[:, -self.num_params_out:].view(
+ -1, self.feat_channels, self.out_channels)
+
+ # input_feature has shape (num_all_proposals, H*W, in_channels)
+ # param_in has shape (num_all_proposals, in_channels, feat_channels)
+ # feature has shape (num_all_proposals, H*W, feat_channels)
+ features = torch.bmm(input_feature, param_in)
+ features = self.norm_in(features)
+ features = self.activation(features)
+
+ # param_out has shape (batch_size, feat_channels, out_channels)
+ features = torch.bmm(features, param_out)
+ features = self.norm_out(features)
+ features = self.activation(features)
+
+ if self.with_proj:
+ features = features.flatten(1)
+ features = self.fc_layer(features)
+ features = self.fc_norm(features)
+ features = self.activation(features)
+
+ return features
diff --git a/mmdet/models/losses/__init__.py b/mmdet/models/losses/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..a6faefd34dd21bb6be9ca415130ef8da7728b9d3
--- /dev/null
+++ b/mmdet/models/losses/__init__.py
@@ -0,0 +1,33 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .accuracy import Accuracy, accuracy
+from .ae_loss import AssociativeEmbeddingLoss
+from .balanced_l1_loss import BalancedL1Loss, balanced_l1_loss
+from .cross_entropy_loss import (CrossEntropyLoss, binary_cross_entropy,
+ cross_entropy, mask_cross_entropy)
+from .dice_loss import DiceLoss
+from .focal_loss import FocalLoss, sigmoid_focal_loss
+from .gaussian_focal_loss import GaussianFocalLoss
+from .gfocal_loss import DistributionFocalLoss, QualityFocalLoss
+from .ghm_loss import GHMC, GHMR
+from .iou_loss import (BoundedIoULoss, CIoULoss, DIoULoss, EIoULoss, GIoULoss,
+ IoULoss, bounded_iou_loss, iou_loss, WassersteinLoss)
+from .kd_loss import KnowledgeDistillationKLDivLoss
+from .mse_loss import MSELoss, mse_loss
+from .pisa_loss import carl_loss, isr_p
+from .seesaw_loss import SeesawLoss
+from .smooth_l1_loss import L1Loss, SmoothL1Loss, l1_loss, smooth_l1_loss
+from .utils import reduce_loss, weight_reduce_loss, weighted_loss
+from .varifocal_loss import VarifocalLoss
+
+__all__ = [
+ 'accuracy', 'Accuracy', 'cross_entropy', 'binary_cross_entropy',
+ 'mask_cross_entropy', 'CrossEntropyLoss', 'sigmoid_focal_loss',
+ 'FocalLoss', 'smooth_l1_loss', 'SmoothL1Loss', 'balanced_l1_loss',
+ 'BalancedL1Loss', 'mse_loss', 'MSELoss', 'iou_loss', 'bounded_iou_loss',
+ 'IoULoss', 'BoundedIoULoss', 'GIoULoss', 'DIoULoss', 'CIoULoss',
+ 'EIoULoss', 'GHMC', 'GHMR', 'reduce_loss', 'weight_reduce_loss',
+ 'weighted_loss', 'L1Loss', 'l1_loss', 'isr_p', 'carl_loss',
+ 'AssociativeEmbeddingLoss', 'GaussianFocalLoss', 'QualityFocalLoss',
+ 'DistributionFocalLoss', 'VarifocalLoss', 'KnowledgeDistillationKLDivLoss','WassersteinLoss',
+ 'SeesawLoss', 'DiceLoss'
+]
diff --git a/mmdet/models/losses/__pycache__/__init__.cpython-37.pyc b/mmdet/models/losses/__pycache__/__init__.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..2f5128a5ab4db2d9e59dd4f4eab0c6ea1012df3f
Binary files /dev/null and b/mmdet/models/losses/__pycache__/__init__.cpython-37.pyc differ
diff --git a/mmdet/models/losses/__pycache__/accuracy.cpython-37.pyc b/mmdet/models/losses/__pycache__/accuracy.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..a50ea75d030fab4e837ca30e53d1d3f2ccc84178
Binary files /dev/null and b/mmdet/models/losses/__pycache__/accuracy.cpython-37.pyc differ
diff --git a/mmdet/models/losses/__pycache__/ae_loss.cpython-37.pyc b/mmdet/models/losses/__pycache__/ae_loss.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..e364edea67d8bc119976aac8a7bf47c97c2712ca
Binary files /dev/null and b/mmdet/models/losses/__pycache__/ae_loss.cpython-37.pyc differ
diff --git a/mmdet/models/losses/__pycache__/balanced_l1_loss.cpython-37.pyc b/mmdet/models/losses/__pycache__/balanced_l1_loss.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..2d34d530911af7a8b4ef2d7922bde761909a29de
Binary files /dev/null and b/mmdet/models/losses/__pycache__/balanced_l1_loss.cpython-37.pyc differ
diff --git a/mmdet/models/losses/__pycache__/cross_entropy_loss.cpython-37.pyc b/mmdet/models/losses/__pycache__/cross_entropy_loss.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..d7b006a4fb9c90a2016cedc7bb2f5d814a488767
Binary files /dev/null and b/mmdet/models/losses/__pycache__/cross_entropy_loss.cpython-37.pyc differ
diff --git a/mmdet/models/losses/__pycache__/dice_loss.cpython-37.pyc b/mmdet/models/losses/__pycache__/dice_loss.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..b077b9f4ac24ea916a1cc604cc0a7237e6b020b9
Binary files /dev/null and b/mmdet/models/losses/__pycache__/dice_loss.cpython-37.pyc differ
diff --git a/mmdet/models/losses/__pycache__/focal_loss.cpython-37.pyc b/mmdet/models/losses/__pycache__/focal_loss.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..2ab382648bb737394ce29e3218390f48cfe5e493
Binary files /dev/null and b/mmdet/models/losses/__pycache__/focal_loss.cpython-37.pyc differ
diff --git a/mmdet/models/losses/__pycache__/gaussian_focal_loss.cpython-37.pyc b/mmdet/models/losses/__pycache__/gaussian_focal_loss.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..8b9ce94ab9e8be2b7699cbcd70e9f49723da1e7a
Binary files /dev/null and b/mmdet/models/losses/__pycache__/gaussian_focal_loss.cpython-37.pyc differ
diff --git a/mmdet/models/losses/__pycache__/gfocal_loss.cpython-37.pyc b/mmdet/models/losses/__pycache__/gfocal_loss.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..688d3ba8e28ff2b004b7c7b10df45858501eeb6a
Binary files /dev/null and b/mmdet/models/losses/__pycache__/gfocal_loss.cpython-37.pyc differ
diff --git a/mmdet/models/losses/__pycache__/ghm_loss.cpython-37.pyc b/mmdet/models/losses/__pycache__/ghm_loss.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..7e4e7ca0b45454d8b15f6b909a1f91a1c952d45a
Binary files /dev/null and b/mmdet/models/losses/__pycache__/ghm_loss.cpython-37.pyc differ
diff --git a/mmdet/models/losses/__pycache__/iou_loss.cpython-37.pyc b/mmdet/models/losses/__pycache__/iou_loss.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..35441b3d244db4da1d5d36a15635ebfa55bbd424
Binary files /dev/null and b/mmdet/models/losses/__pycache__/iou_loss.cpython-37.pyc differ
diff --git a/mmdet/models/losses/__pycache__/kd_loss.cpython-37.pyc b/mmdet/models/losses/__pycache__/kd_loss.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..57322c766c83c83c459eb22dc0805779d9686ea4
Binary files /dev/null and b/mmdet/models/losses/__pycache__/kd_loss.cpython-37.pyc differ
diff --git a/mmdet/models/losses/__pycache__/mse_loss.cpython-37.pyc b/mmdet/models/losses/__pycache__/mse_loss.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..04cbdf6edd920e0cf5a90d78d25c9c046a3c146d
Binary files /dev/null and b/mmdet/models/losses/__pycache__/mse_loss.cpython-37.pyc differ
diff --git a/mmdet/models/losses/__pycache__/pisa_loss.cpython-37.pyc b/mmdet/models/losses/__pycache__/pisa_loss.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..83c1a2f668973c41499550996cc22b43af8f71df
Binary files /dev/null and b/mmdet/models/losses/__pycache__/pisa_loss.cpython-37.pyc differ
diff --git a/mmdet/models/losses/__pycache__/seesaw_loss.cpython-37.pyc b/mmdet/models/losses/__pycache__/seesaw_loss.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..2b35ef0e664c508f96e8d3a61df74b3a561f5d9b
Binary files /dev/null and b/mmdet/models/losses/__pycache__/seesaw_loss.cpython-37.pyc differ
diff --git a/mmdet/models/losses/__pycache__/smooth_l1_loss.cpython-37.pyc b/mmdet/models/losses/__pycache__/smooth_l1_loss.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..8fc1b2099d10e6989e508955f3a55ca2c1c13a2f
Binary files /dev/null and b/mmdet/models/losses/__pycache__/smooth_l1_loss.cpython-37.pyc differ
diff --git a/mmdet/models/losses/__pycache__/utils.cpython-37.pyc b/mmdet/models/losses/__pycache__/utils.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..d6c9d8644008591dfeba00cb60711be660dc14be
Binary files /dev/null and b/mmdet/models/losses/__pycache__/utils.cpython-37.pyc differ
diff --git a/mmdet/models/losses/__pycache__/varifocal_loss.cpython-37.pyc b/mmdet/models/losses/__pycache__/varifocal_loss.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..11efc03cf140a5f7cd8ad6d5f2c29e700219ce8a
Binary files /dev/null and b/mmdet/models/losses/__pycache__/varifocal_loss.cpython-37.pyc differ
diff --git a/mmdet/models/losses/accuracy.py b/mmdet/models/losses/accuracy.py
new file mode 100644
index 0000000000000000000000000000000000000000..d68484e13965ced3bd6b104071d22657a9b3fde6
--- /dev/null
+++ b/mmdet/models/losses/accuracy.py
@@ -0,0 +1,77 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch.nn as nn
+
+
+def accuracy(pred, target, topk=1, thresh=None):
+ """Calculate accuracy according to the prediction and target.
+
+ Args:
+ pred (torch.Tensor): The model prediction, shape (N, num_class)
+ target (torch.Tensor): The target of each prediction, shape (N, )
+ topk (int | tuple[int], optional): If the predictions in ``topk``
+ matches the target, the predictions will be regarded as
+ correct ones. Defaults to 1.
+ thresh (float, optional): If not None, predictions with scores under
+ this threshold are considered incorrect. Default to None.
+
+ Returns:
+ float | tuple[float]: If the input ``topk`` is a single integer,
+ the function will return a single float as accuracy. If
+ ``topk`` is a tuple containing multiple integers, the
+ function will return a tuple containing accuracies of
+ each ``topk`` number.
+ """
+ assert isinstance(topk, (int, tuple))
+ if isinstance(topk, int):
+ topk = (topk, )
+ return_single = True
+ else:
+ return_single = False
+
+ maxk = max(topk)
+ if pred.size(0) == 0:
+ accu = [pred.new_tensor(0.) for i in range(len(topk))]
+ return accu[0] if return_single else accu
+ assert pred.ndim == 2 and target.ndim == 1
+ assert pred.size(0) == target.size(0)
+ assert maxk <= pred.size(1), \
+ f'maxk {maxk} exceeds pred dimension {pred.size(1)}'
+ pred_value, pred_label = pred.topk(maxk, dim=1)
+ pred_label = pred_label.t() # transpose to shape (maxk, N)
+ correct = pred_label.eq(target.view(1, -1).expand_as(pred_label))
+ if thresh is not None:
+ # Only prediction values larger than thresh are counted as correct
+ correct = correct & (pred_value > thresh).t()
+ res = []
+ for k in topk:
+ correct_k = correct[:k].reshape(-1).float().sum(0, keepdim=True)
+ res.append(correct_k.mul_(100.0 / pred.size(0)))
+ return res[0] if return_single else res
+
+
+class Accuracy(nn.Module):
+
+ def __init__(self, topk=(1, ), thresh=None):
+ """Module to calculate the accuracy.
+
+ Args:
+ topk (tuple, optional): The criterion used to calculate the
+ accuracy. Defaults to (1,).
+ thresh (float, optional): If not None, predictions with scores
+ under this threshold are considered incorrect. Default to None.
+ """
+ super().__init__()
+ self.topk = topk
+ self.thresh = thresh
+
+ def forward(self, pred, target):
+ """Forward function to calculate accuracy.
+
+ Args:
+ pred (torch.Tensor): Prediction of models.
+ target (torch.Tensor): Target for each prediction.
+
+ Returns:
+ tuple[float]: The accuracies under different topk criterions.
+ """
+ return accuracy(pred, target, self.topk, self.thresh)
diff --git a/mmdet/models/losses/ae_loss.py b/mmdet/models/losses/ae_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..2aa7d696be4b937a2d45545a8309aaa936fe5f22
--- /dev/null
+++ b/mmdet/models/losses/ae_loss.py
@@ -0,0 +1,101 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from mmdet.registry import MODELS
+
+
+def ae_loss_per_image(tl_preds, br_preds, match):
+ """Associative Embedding Loss in one image.
+
+ Associative Embedding Loss including two parts: pull loss and push loss.
+ Pull loss makes embedding vectors from same object closer to each other.
+ Push loss distinguish embedding vector from different objects, and makes
+ the gap between them is large enough.
+
+ During computing, usually there are 3 cases:
+ - no object in image: both pull loss and push loss will be 0.
+ - one object in image: push loss will be 0 and pull loss is computed
+ by the two corner of the only object.
+ - more than one objects in image: pull loss is computed by corner pairs
+ from each object, push loss is computed by each object with all
+ other objects. We use confusion matrix with 0 in diagonal to
+ compute the push loss.
+
+ Args:
+ tl_preds (tensor): Embedding feature map of left-top corner.
+ br_preds (tensor): Embedding feature map of bottim-right corner.
+ match (list): Downsampled coordinates pair of each ground truth box.
+ """
+
+ tl_list, br_list, me_list = [], [], []
+ if len(match) == 0: # no object in image
+ pull_loss = tl_preds.sum() * 0.
+ push_loss = tl_preds.sum() * 0.
+ else:
+ for m in match:
+ [tl_y, tl_x], [br_y, br_x] = m
+ tl_e = tl_preds[:, tl_y, tl_x].view(-1, 1)
+ br_e = br_preds[:, br_y, br_x].view(-1, 1)
+ tl_list.append(tl_e)
+ br_list.append(br_e)
+ me_list.append((tl_e + br_e) / 2.0)
+
+ tl_list = torch.cat(tl_list)
+ br_list = torch.cat(br_list)
+ me_list = torch.cat(me_list)
+
+ assert tl_list.size() == br_list.size()
+
+ # N is object number in image, M is dimension of embedding vector
+ N, M = tl_list.size()
+
+ pull_loss = (tl_list - me_list).pow(2) + (br_list - me_list).pow(2)
+ pull_loss = pull_loss.sum() / N
+
+ margin = 1 # exp setting of CornerNet, details in section 3.3 of paper
+
+ # confusion matrix of push loss
+ conf_mat = me_list.expand((N, N, M)).permute(1, 0, 2) - me_list
+ conf_weight = 1 - torch.eye(N).type_as(me_list)
+ conf_mat = conf_weight * (margin - conf_mat.sum(-1).abs())
+
+ if N > 1: # more than one object in current image
+ push_loss = F.relu(conf_mat).sum() / (N * (N - 1))
+ else:
+ push_loss = tl_preds.sum() * 0.
+
+ return pull_loss, push_loss
+
+
+@MODELS.register_module()
+class AssociativeEmbeddingLoss(nn.Module):
+ """Associative Embedding Loss.
+
+ More details can be found in
+ `Associative Embedding `_ and
+ `CornerNet `_ .
+ Code is modified from `kp_utils.py `_ # noqa: E501
+
+ Args:
+ pull_weight (float): Loss weight for corners from same object.
+ push_weight (float): Loss weight for corners from different object.
+ """
+
+ def __init__(self, pull_weight=0.25, push_weight=0.25):
+ super(AssociativeEmbeddingLoss, self).__init__()
+ self.pull_weight = pull_weight
+ self.push_weight = push_weight
+
+ def forward(self, pred, target, match):
+ """Forward function."""
+ batch = pred.size(0)
+ pull_all, push_all = 0.0, 0.0
+ for i in range(batch):
+ pull, push = ae_loss_per_image(pred[i], target[i], match[i])
+
+ pull_all += self.pull_weight * pull
+ push_all += self.push_weight * push
+
+ return pull_all, push_all
diff --git a/mmdet/models/losses/balanced_l1_loss.py b/mmdet/models/losses/balanced_l1_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..25adaab2239e871476d9d4e3cbb1a238c3043041
--- /dev/null
+++ b/mmdet/models/losses/balanced_l1_loss.py
@@ -0,0 +1,122 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import numpy as np
+import torch
+import torch.nn as nn
+
+from mmdet.registry import MODELS
+from .utils import weighted_loss
+
+
+@weighted_loss
+def balanced_l1_loss(pred,
+ target,
+ beta=1.0,
+ alpha=0.5,
+ gamma=1.5,
+ reduction='mean'):
+ """Calculate balanced L1 loss.
+
+ Please see the `Libra R-CNN `_
+
+ Args:
+ pred (torch.Tensor): The prediction with shape (N, 4).
+ target (torch.Tensor): The learning target of the prediction with
+ shape (N, 4).
+ beta (float): The loss is a piecewise function of prediction and target
+ and ``beta`` serves as a threshold for the difference between the
+ prediction and target. Defaults to 1.0.
+ alpha (float): The denominator ``alpha`` in the balanced L1 loss.
+ Defaults to 0.5.
+ gamma (float): The ``gamma`` in the balanced L1 loss.
+ Defaults to 1.5.
+ reduction (str, optional): The method that reduces the loss to a
+ scalar. Options are "none", "mean" and "sum".
+
+ Returns:
+ torch.Tensor: The calculated loss
+ """
+ assert beta > 0
+ if target.numel() == 0:
+ return pred.sum() * 0
+
+ assert pred.size() == target.size()
+
+ diff = torch.abs(pred - target)
+ b = np.e**(gamma / alpha) - 1
+ loss = torch.where(
+ diff < beta, alpha / b *
+ (b * diff + 1) * torch.log(b * diff / beta + 1) - alpha * diff,
+ gamma * diff + gamma / b - alpha * beta)
+
+ return loss
+
+
+@MODELS.register_module()
+class BalancedL1Loss(nn.Module):
+ """Balanced L1 Loss.
+
+ arXiv: https://arxiv.org/pdf/1904.02701.pdf (CVPR 2019)
+
+ Args:
+ alpha (float): The denominator ``alpha`` in the balanced L1 loss.
+ Defaults to 0.5.
+ gamma (float): The ``gamma`` in the balanced L1 loss. Defaults to 1.5.
+ beta (float, optional): The loss is a piecewise function of prediction
+ and target. ``beta`` serves as a threshold for the difference
+ between the prediction and target. Defaults to 1.0.
+ reduction (str, optional): The method that reduces the loss to a
+ scalar. Options are "none", "mean" and "sum".
+ loss_weight (float, optional): The weight of the loss. Defaults to 1.0
+ """
+
+ def __init__(self,
+ alpha=0.5,
+ gamma=1.5,
+ beta=1.0,
+ reduction='mean',
+ loss_weight=1.0):
+ super(BalancedL1Loss, self).__init__()
+ self.alpha = alpha
+ self.gamma = gamma
+ self.beta = beta
+ self.reduction = reduction
+ self.loss_weight = loss_weight
+
+ def forward(self,
+ pred,
+ target,
+ weight=None,
+ avg_factor=None,
+ reduction_override=None,
+ **kwargs):
+ """Forward function of loss.
+
+ Args:
+ pred (torch.Tensor): The prediction with shape (N, 4).
+ target (torch.Tensor): The learning target of the prediction with
+ shape (N, 4).
+ weight (torch.Tensor, optional): Sample-wise loss weight with
+ shape (N, ).
+ avg_factor (int, optional): Average factor that is used to average
+ the loss. Defaults to None.
+ reduction_override (str, optional): The reduction method used to
+ override the original reduction method of the loss.
+ Options are "none", "mean" and "sum".
+
+ Returns:
+ torch.Tensor: The calculated loss
+ """
+ assert reduction_override in (None, 'none', 'mean', 'sum')
+ reduction = (
+ reduction_override if reduction_override else self.reduction)
+ loss_bbox = self.loss_weight * balanced_l1_loss(
+ pred,
+ target,
+ weight,
+ alpha=self.alpha,
+ gamma=self.gamma,
+ beta=self.beta,
+ reduction=reduction,
+ avg_factor=avg_factor,
+ **kwargs)
+ return loss_bbox
diff --git a/mmdet/models/losses/cross_entropy_loss.py b/mmdet/models/losses/cross_entropy_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..b057e560a9eb237a3732d809c21e58e53559352a
--- /dev/null
+++ b/mmdet/models/losses/cross_entropy_loss.py
@@ -0,0 +1,301 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from mmdet.registry import MODELS
+from .utils import weight_reduce_loss
+
+
+def cross_entropy(pred,
+ label,
+ weight=None,
+ reduction='mean',
+ avg_factor=None,
+ class_weight=None,
+ ignore_index=-100,
+ avg_non_ignore=False):
+ """Calculate the CrossEntropy loss.
+
+ Args:
+ pred (torch.Tensor): The prediction with shape (N, C), C is the number
+ of classes.
+ label (torch.Tensor): The learning label of the prediction.
+ weight (torch.Tensor, optional): Sample-wise loss weight.
+ reduction (str, optional): The method used to reduce the loss.
+ avg_factor (int, optional): Average factor that is used to average
+ the loss. Defaults to None.
+ class_weight (list[float], optional): The weight for each class.
+ ignore_index (int | None): The label index to be ignored.
+ If None, it will be set to default value. Default: -100.
+ avg_non_ignore (bool): The flag decides to whether the loss is
+ only averaged over non-ignored targets. Default: False.
+
+ Returns:
+ torch.Tensor: The calculated loss
+ """
+ # The default value of ignore_index is the same as F.cross_entropy
+ ignore_index = -100 if ignore_index is None else ignore_index
+ # element-wise losses
+ loss = F.cross_entropy(
+ pred,
+ label,
+ weight=class_weight,
+ reduction='none',
+ ignore_index=ignore_index)
+
+ # average loss over non-ignored elements
+ # pytorch's official cross_entropy average loss over non-ignored elements
+ # refer to https://github.com/pytorch/pytorch/blob/56b43f4fec1f76953f15a627694d4bba34588969/torch/nn/functional.py#L2660 # noqa
+ if (avg_factor is None) and avg_non_ignore and reduction == 'mean':
+ avg_factor = label.numel() - (label == ignore_index).sum().item()
+
+ # apply weights and do the reduction
+ if weight is not None:
+ weight = weight.float()
+ loss = weight_reduce_loss(
+ loss, weight=weight, reduction=reduction, avg_factor=avg_factor)
+
+ return loss
+
+
+def _expand_onehot_labels(labels, label_weights, label_channels, ignore_index):
+ """Expand onehot labels to match the size of prediction."""
+ bin_labels = labels.new_full((labels.size(0), label_channels), 0)
+ valid_mask = (labels >= 0) & (labels != ignore_index)
+ inds = torch.nonzero(
+ valid_mask & (labels < label_channels), as_tuple=False)
+
+ if inds.numel() > 0:
+ bin_labels[inds, labels[inds]] = 1
+
+ valid_mask = valid_mask.view(-1, 1).expand(labels.size(0),
+ label_channels).float()
+ if label_weights is None:
+ bin_label_weights = valid_mask
+ else:
+ bin_label_weights = label_weights.view(-1, 1).repeat(1, label_channels)
+ bin_label_weights *= valid_mask
+
+ return bin_labels, bin_label_weights, valid_mask
+
+
+def binary_cross_entropy(pred,
+ label,
+ weight=None,
+ reduction='mean',
+ avg_factor=None,
+ class_weight=None,
+ ignore_index=-100,
+ avg_non_ignore=False):
+ """Calculate the binary CrossEntropy loss.
+
+ Args:
+ pred (torch.Tensor): The prediction with shape (N, 1) or (N, ).
+ When the shape of pred is (N, 1), label will be expanded to
+ one-hot format, and when the shape of pred is (N, ), label
+ will not be expanded to one-hot format.
+ label (torch.Tensor): The learning label of the prediction,
+ with shape (N, ).
+ weight (torch.Tensor, optional): Sample-wise loss weight.
+ reduction (str, optional): The method used to reduce the loss.
+ Options are "none", "mean" and "sum".
+ avg_factor (int, optional): Average factor that is used to average
+ the loss. Defaults to None.
+ class_weight (list[float], optional): The weight for each class.
+ ignore_index (int | None): The label index to be ignored.
+ If None, it will be set to default value. Default: -100.
+ avg_non_ignore (bool): The flag decides to whether the loss is
+ only averaged over non-ignored targets. Default: False.
+
+ Returns:
+ torch.Tensor: The calculated loss.
+ """
+ # The default value of ignore_index is the same as F.cross_entropy
+ ignore_index = -100 if ignore_index is None else ignore_index
+
+ if pred.dim() != label.dim():
+ label, weight, valid_mask = _expand_onehot_labels(
+ label, weight, pred.size(-1), ignore_index)
+ else:
+ # should mask out the ignored elements
+ valid_mask = ((label >= 0) & (label != ignore_index)).float()
+ if weight is not None:
+ # The inplace writing method will have a mismatched broadcast
+ # shape error if the weight and valid_mask dimensions
+ # are inconsistent such as (B,N,1) and (B,N,C).
+ weight = weight * valid_mask
+ else:
+ weight = valid_mask
+
+ # average loss over non-ignored elements
+ if (avg_factor is None) and avg_non_ignore and reduction == 'mean':
+ avg_factor = valid_mask.sum().item()
+
+ # weighted element-wise losses
+ weight = weight.float()
+ loss = F.binary_cross_entropy_with_logits(
+ pred, label.float(), pos_weight=class_weight, reduction='none')
+ # do the reduction for the weighted loss
+ loss = weight_reduce_loss(
+ loss, weight, reduction=reduction, avg_factor=avg_factor)
+
+ return loss
+
+
+def mask_cross_entropy(pred,
+ target,
+ label,
+ reduction='mean',
+ avg_factor=None,
+ class_weight=None,
+ ignore_index=None,
+ **kwargs):
+ """Calculate the CrossEntropy loss for masks.
+
+ Args:
+ pred (torch.Tensor): The prediction with shape (N, C, *), C is the
+ number of classes. The trailing * indicates arbitrary shape.
+ target (torch.Tensor): The learning label of the prediction.
+ label (torch.Tensor): ``label`` indicates the class label of the mask
+ corresponding object. This will be used to select the mask in the
+ of the class which the object belongs to when the mask prediction
+ if not class-agnostic.
+ reduction (str, optional): The method used to reduce the loss.
+ Options are "none", "mean" and "sum".
+ avg_factor (int, optional): Average factor that is used to average
+ the loss. Defaults to None.
+ class_weight (list[float], optional): The weight for each class.
+ ignore_index (None): Placeholder, to be consistent with other loss.
+ Default: None.
+
+ Returns:
+ torch.Tensor: The calculated loss
+
+ Example:
+ >>> N, C = 3, 11
+ >>> H, W = 2, 2
+ >>> pred = torch.randn(N, C, H, W) * 1000
+ >>> target = torch.rand(N, H, W)
+ >>> label = torch.randint(0, C, size=(N,))
+ >>> reduction = 'mean'
+ >>> avg_factor = None
+ >>> class_weights = None
+ >>> loss = mask_cross_entropy(pred, target, label, reduction,
+ >>> avg_factor, class_weights)
+ >>> assert loss.shape == (1,)
+ """
+ assert ignore_index is None, 'BCE loss does not support ignore_index'
+ # TODO: handle these two reserved arguments
+ assert reduction == 'mean' and avg_factor is None
+ num_rois = pred.size()[0]
+ inds = torch.arange(0, num_rois, dtype=torch.long, device=pred.device)
+ pred_slice = pred[inds, label].squeeze(1)
+ return F.binary_cross_entropy_with_logits(
+ pred_slice, target, weight=class_weight, reduction='mean')[None]
+
+
+@MODELS.register_module()
+class CrossEntropyLoss(nn.Module):
+
+ def __init__(self,
+ use_sigmoid=False,
+ use_mask=False,
+ reduction='mean',
+ class_weight=None,
+ ignore_index=None,
+ loss_weight=1.0,
+ avg_non_ignore=False):
+ """CrossEntropyLoss.
+
+ Args:
+ use_sigmoid (bool, optional): Whether the prediction uses sigmoid
+ of softmax. Defaults to False.
+ use_mask (bool, optional): Whether to use mask cross entropy loss.
+ Defaults to False.
+ reduction (str, optional): . Defaults to 'mean'.
+ Options are "none", "mean" and "sum".
+ class_weight (list[float], optional): Weight of each class.
+ Defaults to None.
+ ignore_index (int | None): The label index to be ignored.
+ Defaults to None.
+ loss_weight (float, optional): Weight of the loss. Defaults to 1.0.
+ avg_non_ignore (bool): The flag decides to whether the loss is
+ only averaged over non-ignored targets. Default: False.
+ """
+ super(CrossEntropyLoss, self).__init__()
+ assert (use_sigmoid is False) or (use_mask is False)
+ self.use_sigmoid = use_sigmoid
+ self.use_mask = use_mask
+ self.reduction = reduction
+ self.loss_weight = loss_weight
+ self.class_weight = class_weight
+ self.ignore_index = ignore_index
+ self.avg_non_ignore = avg_non_ignore
+ if ((ignore_index is not None) and not self.avg_non_ignore
+ and self.reduction == 'mean'):
+ warnings.warn(
+ 'Default ``avg_non_ignore`` is False, if you would like to '
+ 'ignore the certain label and average loss over non-ignore '
+ 'labels, which is the same with PyTorch official '
+ 'cross_entropy, set ``avg_non_ignore=True``.')
+
+ if self.use_sigmoid:
+ self.cls_criterion = binary_cross_entropy
+ elif self.use_mask:
+ self.cls_criterion = mask_cross_entropy
+ else:
+ self.cls_criterion = cross_entropy
+
+ def extra_repr(self):
+ """Extra repr."""
+ s = f'avg_non_ignore={self.avg_non_ignore}'
+ return s
+
+ def forward(self,
+ cls_score,
+ label,
+ weight=None,
+ avg_factor=None,
+ reduction_override=None,
+ ignore_index=None,
+ **kwargs):
+ """Forward function.
+
+ Args:
+ cls_score (torch.Tensor): The prediction.
+ label (torch.Tensor): The learning label of the prediction.
+ weight (torch.Tensor, optional): Sample-wise loss weight.
+ avg_factor (int, optional): Average factor that is used to average
+ the loss. Defaults to None.
+ reduction_override (str, optional): The method used to reduce the
+ loss. Options are "none", "mean" and "sum".
+ ignore_index (int | None): The label index to be ignored.
+ If not None, it will override the default value. Default: None.
+ Returns:
+ torch.Tensor: The calculated loss.
+ """
+ assert reduction_override in (None, 'none', 'mean', 'sum')
+ reduction = (
+ reduction_override if reduction_override else self.reduction)
+ if ignore_index is None:
+ ignore_index = self.ignore_index
+
+ if self.class_weight is not None:
+ class_weight = cls_score.new_tensor(
+ self.class_weight, device=cls_score.device)
+ else:
+ class_weight = None
+ loss_cls = self.loss_weight * self.cls_criterion(
+ cls_score,
+ label,
+ weight,
+ class_weight=class_weight,
+ reduction=reduction,
+ avg_factor=avg_factor,
+ ignore_index=ignore_index,
+ avg_non_ignore=self.avg_non_ignore,
+ **kwargs)
+ return loss_cls
diff --git a/mmdet/models/losses/dice_loss.py b/mmdet/models/losses/dice_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..1d5cac1e9710a6a72fe0401db22b8b72cfe058f9
--- /dev/null
+++ b/mmdet/models/losses/dice_loss.py
@@ -0,0 +1,146 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+
+from mmdet.registry import MODELS
+from .utils import weight_reduce_loss
+
+
+def dice_loss(pred,
+ target,
+ weight=None,
+ eps=1e-3,
+ reduction='mean',
+ naive_dice=False,
+ avg_factor=None):
+ """Calculate dice loss, there are two forms of dice loss is supported:
+
+ - the one proposed in `V-Net: Fully Convolutional Neural
+ Networks for Volumetric Medical Image Segmentation
+ `_.
+ - the dice loss in which the power of the number in the
+ denominator is the first power instead of the second
+ power.
+
+ Args:
+ pred (torch.Tensor): The prediction, has a shape (n, *)
+ target (torch.Tensor): The learning label of the prediction,
+ shape (n, *), same shape of pred.
+ weight (torch.Tensor, optional): The weight of loss for each
+ prediction, has a shape (n,). Defaults to None.
+ eps (float): Avoid dividing by zero. Default: 1e-3.
+ reduction (str, optional): The method used to reduce the loss into
+ a scalar. Defaults to 'mean'.
+ Options are "none", "mean" and "sum".
+ naive_dice (bool, optional): If false, use the dice
+ loss defined in the V-Net paper, otherwise, use the
+ naive dice loss in which the power of the number in the
+ denominator is the first power instead of the second
+ power.Defaults to False.
+ avg_factor (int, optional): Average factor that is used to average
+ the loss. Defaults to None.
+ """
+
+ input = pred.flatten(1)
+ target = target.flatten(1).float()
+
+ a = torch.sum(input * target, 1)
+ if naive_dice:
+ b = torch.sum(input, 1)
+ c = torch.sum(target, 1)
+ d = (2 * a + eps) / (b + c + eps)
+ else:
+ b = torch.sum(input * input, 1) + eps
+ c = torch.sum(target * target, 1) + eps
+ d = (2 * a) / (b + c)
+
+ loss = 1 - d
+ if weight is not None:
+ assert weight.ndim == loss.ndim
+ assert len(weight) == len(pred)
+ loss = weight_reduce_loss(loss, weight, reduction, avg_factor)
+ return loss
+
+
+@MODELS.register_module()
+class DiceLoss(nn.Module):
+
+ def __init__(self,
+ use_sigmoid=True,
+ activate=True,
+ reduction='mean',
+ naive_dice=False,
+ loss_weight=1.0,
+ eps=1e-3):
+ """Compute dice loss.
+
+ Args:
+ use_sigmoid (bool, optional): Whether to the prediction is
+ used for sigmoid or softmax. Defaults to True.
+ activate (bool): Whether to activate the predictions inside,
+ this will disable the inside sigmoid operation.
+ Defaults to True.
+ reduction (str, optional): The method used
+ to reduce the loss. Options are "none",
+ "mean" and "sum". Defaults to 'mean'.
+ naive_dice (bool, optional): If false, use the dice
+ loss defined in the V-Net paper, otherwise, use the
+ naive dice loss in which the power of the number in the
+ denominator is the first power instead of the second
+ power. Defaults to False.
+ loss_weight (float, optional): Weight of loss. Defaults to 1.0.
+ eps (float): Avoid dividing by zero. Defaults to 1e-3.
+ """
+
+ super(DiceLoss, self).__init__()
+ self.use_sigmoid = use_sigmoid
+ self.reduction = reduction
+ self.naive_dice = naive_dice
+ self.loss_weight = loss_weight
+ self.eps = eps
+ self.activate = activate
+
+ def forward(self,
+ pred,
+ target,
+ weight=None,
+ reduction_override=None,
+ avg_factor=None):
+ """Forward function.
+
+ Args:
+ pred (torch.Tensor): The prediction, has a shape (n, *).
+ target (torch.Tensor): The label of the prediction,
+ shape (n, *), same shape of pred.
+ weight (torch.Tensor, optional): The weight of loss for each
+ prediction, has a shape (n,). Defaults to None.
+ avg_factor (int, optional): Average factor that is used to average
+ the loss. Defaults to None.
+ reduction_override (str, optional): The reduction method used to
+ override the original reduction method of the loss.
+ Options are "none", "mean" and "sum".
+
+ Returns:
+ torch.Tensor: The calculated loss
+ """
+
+ assert reduction_override in (None, 'none', 'mean', 'sum')
+ reduction = (
+ reduction_override if reduction_override else self.reduction)
+
+ if self.activate:
+ if self.use_sigmoid:
+ pred = pred.sigmoid()
+ else:
+ raise NotImplementedError
+
+ loss = self.loss_weight * dice_loss(
+ pred,
+ target,
+ weight,
+ eps=self.eps,
+ reduction=reduction,
+ naive_dice=self.naive_dice,
+ avg_factor=avg_factor)
+
+ return loss
diff --git a/mmdet/models/losses/focal_loss.py b/mmdet/models/losses/focal_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..9c7cc3f0f8e236e7a51107dd4e9acbde2b178682
--- /dev/null
+++ b/mmdet/models/losses/focal_loss.py
@@ -0,0 +1,251 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.ops import sigmoid_focal_loss as _sigmoid_focal_loss
+
+from mmdet.registry import MODELS
+from .utils import weight_reduce_loss
+
+
+# This method is only for debugging
+def py_sigmoid_focal_loss(pred,
+ target,
+ weight=None,
+ gamma=2.0,
+ alpha=0.25,
+ reduction='mean',
+ avg_factor=None):
+ """PyTorch version of `Focal Loss `_.
+
+ Args:
+ pred (torch.Tensor): The prediction with shape (N, C), C is the
+ number of classes
+ target (torch.Tensor): The learning label of the prediction.
+ weight (torch.Tensor, optional): Sample-wise loss weight.
+ gamma (float, optional): The gamma for calculating the modulating
+ factor. Defaults to 2.0.
+ alpha (float, optional): A balanced form for Focal Loss.
+ Defaults to 0.25.
+ reduction (str, optional): The method used to reduce the loss into
+ a scalar. Defaults to 'mean'.
+ avg_factor (int, optional): Average factor that is used to average
+ the loss. Defaults to None.
+ """
+ pred_sigmoid = pred.sigmoid()
+ target = target.type_as(pred)
+ pt = (1 - pred_sigmoid) * target + pred_sigmoid * (1 - target)
+ focal_weight = (alpha * target + (1 - alpha) *
+ (1 - target)) * pt.pow(gamma)
+ loss = F.binary_cross_entropy_with_logits(
+ pred, target, reduction='none') * focal_weight
+ if weight is not None:
+ if weight.shape != loss.shape:
+ if weight.size(0) == loss.size(0):
+ # For most cases, weight is of shape (num_priors, ),
+ # which means it does not have the second axis num_class
+ weight = weight.view(-1, 1)
+ else:
+ # Sometimes, weight per anchor per class is also needed. e.g.
+ # in FSAF. But it may be flattened of shape
+ # (num_priors x num_class, ), while loss is still of shape
+ # (num_priors, num_class).
+ assert weight.numel() == loss.numel()
+ weight = weight.view(loss.size(0), -1)
+ assert weight.ndim == loss.ndim
+ loss = weight_reduce_loss(loss, weight, reduction, avg_factor)
+ return loss
+
+
+def py_focal_loss_with_prob(pred,
+ target,
+ weight=None,
+ gamma=2.0,
+ alpha=0.25,
+ reduction='mean',
+ avg_factor=None):
+ """PyTorch version of `Focal Loss `_.
+ Different from `py_sigmoid_focal_loss`, this function accepts probability
+ as input.
+
+ Args:
+ pred (torch.Tensor): The prediction probability with shape (N, C),
+ C is the number of classes.
+ target (torch.Tensor): The learning label of the prediction.
+ The target shape support (N,C) or (N,), (N,C) means one-hot form.
+ weight (torch.Tensor, optional): Sample-wise loss weight.
+ gamma (float, optional): The gamma for calculating the modulating
+ factor. Defaults to 2.0.
+ alpha (float, optional): A balanced form for Focal Loss.
+ Defaults to 0.25.
+ reduction (str, optional): The method used to reduce the loss into
+ a scalar. Defaults to 'mean'.
+ avg_factor (int, optional): Average factor that is used to average
+ the loss. Defaults to None.
+ """
+ if pred.dim() != target.dim():
+ num_classes = pred.size(1)
+ target = F.one_hot(target, num_classes=num_classes + 1)
+ target = target[:, :num_classes]
+
+ target = target.type_as(pred)
+ pt = (1 - pred) * target + pred * (1 - target)
+ focal_weight = (alpha * target + (1 - alpha) *
+ (1 - target)) * pt.pow(gamma)
+ loss = F.binary_cross_entropy(
+ pred, target, reduction='none') * focal_weight
+ if weight is not None:
+ if weight.shape != loss.shape:
+ if weight.size(0) == loss.size(0):
+ # For most cases, weight is of shape (num_priors, ),
+ # which means it does not have the second axis num_class
+ weight = weight.view(-1, 1)
+ else:
+ # Sometimes, weight per anchor per class is also needed. e.g.
+ # in FSAF. But it may be flattened of shape
+ # (num_priors x num_class, ), while loss is still of shape
+ # (num_priors, num_class).
+ assert weight.numel() == loss.numel()
+ weight = weight.view(loss.size(0), -1)
+ assert weight.ndim == loss.ndim
+ loss = weight_reduce_loss(loss, weight, reduction, avg_factor)
+ return loss
+
+
+def sigmoid_focal_loss(pred,
+ target,
+ weight=None,
+ gamma=2.0,
+ alpha=0.25,
+ reduction='mean',
+ avg_factor=None):
+ r"""A wrapper of cuda version `Focal Loss
+ `_.
+
+ Args:
+ pred (torch.Tensor): The prediction with shape (N, C), C is the number
+ of classes.
+ target (torch.Tensor): The learning label of the prediction.
+ weight (torch.Tensor, optional): Sample-wise loss weight.
+ gamma (float, optional): The gamma for calculating the modulating
+ factor. Defaults to 2.0.
+ alpha (float, optional): A balanced form for Focal Loss.
+ Defaults to 0.25.
+ reduction (str, optional): The method used to reduce the loss into
+ a scalar. Defaults to 'mean'. Options are "none", "mean" and "sum".
+ avg_factor (int, optional): Average factor that is used to average
+ the loss. Defaults to None.
+ """
+ # Function.apply does not accept keyword arguments, so the decorator
+ # "weighted_loss" is not applicable
+ loss = _sigmoid_focal_loss(pred.contiguous(), target.contiguous(), gamma,
+ alpha, None, 'none')
+ if weight is not None:
+ if weight.shape != loss.shape:
+ if weight.size(0) == loss.size(0):
+ # For most cases, weight is of shape (num_priors, ),
+ # which means it does not have the second axis num_class
+ weight = weight.view(-1, 1)
+ else:
+ # Sometimes, weight per anchor per class is also needed. e.g.
+ # in FSAF. But it may be flattened of shape
+ # (num_priors x num_class, ), while loss is still of shape
+ # (num_priors, num_class).
+ assert weight.numel() == loss.numel()
+ weight = weight.view(loss.size(0), -1)
+ assert weight.ndim == loss.ndim
+ loss = weight_reduce_loss(loss, weight, reduction, avg_factor)
+ return loss
+
+
+@MODELS.register_module()
+class FocalLoss(nn.Module):
+
+ def __init__(self,
+ use_sigmoid=True,
+ gamma=2.0,
+ alpha=0.25,
+ reduction='mean',
+ loss_weight=1.0,
+ activated=False):
+ """`Focal Loss `_
+
+ Args:
+ use_sigmoid (bool, optional): Whether to the prediction is
+ used for sigmoid or softmax. Defaults to True.
+ gamma (float, optional): The gamma for calculating the modulating
+ factor. Defaults to 2.0.
+ alpha (float, optional): A balanced form for Focal Loss.
+ Defaults to 0.25.
+ reduction (str, optional): The method used to reduce the loss into
+ a scalar. Defaults to 'mean'. Options are "none", "mean" and
+ "sum".
+ loss_weight (float, optional): Weight of loss. Defaults to 1.0.
+ activated (bool, optional): Whether the input is activated.
+ If True, it means the input has been activated and can be
+ treated as probabilities. Else, it should be treated as logits.
+ Defaults to False.
+ """
+ super(FocalLoss, self).__init__()
+ assert use_sigmoid is True, 'Only sigmoid focal loss supported now.'
+ self.use_sigmoid = use_sigmoid
+ self.gamma = gamma
+ self.alpha = alpha
+ self.reduction = reduction
+ self.loss_weight = loss_weight
+ self.activated = activated
+
+ def forward(self,
+ pred,
+ target,
+ weight=None,
+ avg_factor=None,
+ reduction_override=None):
+ """Forward function.
+
+ Args:
+ pred (torch.Tensor): The prediction.
+ target (torch.Tensor): The learning label of the prediction.
+ The target shape support (N,C) or (N,), (N,C) means
+ one-hot form.
+ weight (torch.Tensor, optional): The weight of loss for each
+ prediction. Defaults to None.
+ avg_factor (int, optional): Average factor that is used to average
+ the loss. Defaults to None.
+ reduction_override (str, optional): The reduction method used to
+ override the original reduction method of the loss.
+ Options are "none", "mean" and "sum".
+
+ Returns:
+ torch.Tensor: The calculated loss
+ """
+ assert reduction_override in (None, 'none', 'mean', 'sum')
+ reduction = (
+ reduction_override if reduction_override else self.reduction)
+ if self.use_sigmoid:
+ if self.activated:
+ calculate_loss_func = py_focal_loss_with_prob
+ else:
+ if pred.dim() == target.dim():
+ # this means that target is already in One-Hot form.
+ calculate_loss_func = py_sigmoid_focal_loss
+ elif torch.cuda.is_available() and pred.is_cuda:
+ calculate_loss_func = sigmoid_focal_loss
+ else:
+ num_classes = pred.size(1)
+ target = F.one_hot(target, num_classes=num_classes + 1)
+ target = target[:, :num_classes]
+ calculate_loss_func = py_sigmoid_focal_loss
+
+ loss_cls = self.loss_weight * calculate_loss_func(
+ pred,
+ target,
+ weight,
+ gamma=self.gamma,
+ alpha=self.alpha,
+ reduction=reduction,
+ avg_factor=avg_factor)
+
+ else:
+ raise NotImplementedError
+ return loss_cls
diff --git a/mmdet/models/losses/gaussian_focal_loss.py b/mmdet/models/losses/gaussian_focal_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..14fa8da462a5e7cabde2166878a1b9f2ccc16d62
--- /dev/null
+++ b/mmdet/models/losses/gaussian_focal_loss.py
@@ -0,0 +1,186 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Union
+
+import torch.nn as nn
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from .utils import weight_reduce_loss, weighted_loss
+
+
+@weighted_loss
+def gaussian_focal_loss(pred: Tensor,
+ gaussian_target: Tensor,
+ alpha: float = 2.0,
+ gamma: float = 4.0,
+ pos_weight: float = 1.0,
+ neg_weight: float = 1.0) -> Tensor:
+ """`Focal Loss `_ for targets in gaussian
+ distribution.
+
+ Args:
+ pred (torch.Tensor): The prediction.
+ gaussian_target (torch.Tensor): The learning target of the prediction
+ in gaussian distribution.
+ alpha (float, optional): A balanced form for Focal Loss.
+ Defaults to 2.0.
+ gamma (float, optional): The gamma for calculating the modulating
+ factor. Defaults to 4.0.
+ pos_weight(float): Positive sample loss weight. Defaults to 1.0.
+ neg_weight(float): Negative sample loss weight. Defaults to 1.0.
+ """
+ eps = 1e-12
+ pos_weights = gaussian_target.eq(1)
+ neg_weights = (1 - gaussian_target).pow(gamma)
+ pos_loss = -(pred + eps).log() * (1 - pred).pow(alpha) * pos_weights
+ neg_loss = -(1 - pred + eps).log() * pred.pow(alpha) * neg_weights
+ return pos_weight * pos_loss + neg_weight * neg_loss
+
+
+def gaussian_focal_loss_with_pos_inds(
+ pred: Tensor,
+ gaussian_target: Tensor,
+ pos_inds: Tensor,
+ pos_labels: Tensor,
+ alpha: float = 2.0,
+ gamma: float = 4.0,
+ pos_weight: float = 1.0,
+ neg_weight: float = 1.0,
+ reduction: str = 'mean',
+ avg_factor: Optional[Union[int, float]] = None) -> Tensor:
+ """`Focal Loss `_ for targets in gaussian
+ distribution.
+
+ Note: The index with a value of 1 in ``gaussian_target`` in the
+ ``gaussian_focal_loss`` function is a positive sample, but in
+ ``gaussian_focal_loss_with_pos_inds`` the positive sample is passed
+ in through the ``pos_inds`` parameter.
+
+ Args:
+ pred (torch.Tensor): The prediction. The shape is (N, num_classes).
+ gaussian_target (torch.Tensor): The learning target of the prediction
+ in gaussian distribution. The shape is (N, num_classes).
+ pos_inds (torch.Tensor): The positive sample index.
+ The shape is (M, ).
+ pos_labels (torch.Tensor): The label corresponding to the positive
+ sample index. The shape is (M, ).
+ alpha (float, optional): A balanced form for Focal Loss.
+ Defaults to 2.0.
+ gamma (float, optional): The gamma for calculating the modulating
+ factor. Defaults to 4.0.
+ pos_weight(float): Positive sample loss weight. Defaults to 1.0.
+ neg_weight(float): Negative sample loss weight. Defaults to 1.0.
+ reduction (str): Options are "none", "mean" and "sum".
+ Defaults to 'mean`.
+ avg_factor (int, float, optional): Average factor that is used to
+ average the loss. Defaults to None.
+ """
+ eps = 1e-12
+ neg_weights = (1 - gaussian_target).pow(gamma)
+
+ pos_pred_pix = pred[pos_inds]
+ pos_pred = pos_pred_pix.gather(1, pos_labels.unsqueeze(1))
+ pos_loss = -(pos_pred + eps).log() * (1 - pos_pred).pow(alpha)
+ pos_loss = weight_reduce_loss(pos_loss, None, reduction, avg_factor)
+
+ neg_loss = -(1 - pred + eps).log() * pred.pow(alpha) * neg_weights
+ neg_loss = weight_reduce_loss(neg_loss, None, reduction, avg_factor)
+
+ return pos_weight * pos_loss + neg_weight * neg_loss
+
+
+@MODELS.register_module()
+class GaussianFocalLoss(nn.Module):
+ """GaussianFocalLoss is a variant of focal loss.
+
+ More details can be found in the `paper
+ `_
+ Code is modified from `kp_utils.py
+ `_ # noqa: E501
+ Please notice that the target in GaussianFocalLoss is a gaussian heatmap,
+ not 0/1 binary target.
+
+ Args:
+ alpha (float): Power of prediction.
+ gamma (float): Power of target for negative samples.
+ reduction (str): Options are "none", "mean" and "sum".
+ loss_weight (float): Loss weight of current loss.
+ pos_weight(float): Positive sample loss weight. Defaults to 1.0.
+ neg_weight(float): Negative sample loss weight. Defaults to 1.0.
+ """
+
+ def __init__(self,
+ alpha: float = 2.0,
+ gamma: float = 4.0,
+ reduction: str = 'mean',
+ loss_weight: float = 1.0,
+ pos_weight: float = 1.0,
+ neg_weight: float = 1.0) -> None:
+ super().__init__()
+ self.alpha = alpha
+ self.gamma = gamma
+ self.reduction = reduction
+ self.loss_weight = loss_weight
+ self.pos_weight = pos_weight
+ self.neg_weight = neg_weight
+
+ def forward(self,
+ pred: Tensor,
+ target: Tensor,
+ pos_inds: Optional[Tensor] = None,
+ pos_labels: Optional[Tensor] = None,
+ weight: Optional[Tensor] = None,
+ avg_factor: Optional[Union[int, float]] = None,
+ reduction_override: Optional[str] = None) -> Tensor:
+ """Forward function.
+
+ If you want to manually determine which positions are
+ positive samples, you can set the pos_index and pos_label
+ parameter. Currently, only the CenterNet update version uses
+ the parameter.
+
+ Args:
+ pred (torch.Tensor): The prediction. The shape is (N, num_classes).
+ target (torch.Tensor): The learning target of the prediction
+ in gaussian distribution. The shape is (N, num_classes).
+ pos_inds (torch.Tensor): The positive sample index.
+ Defaults to None.
+ pos_labels (torch.Tensor): The label corresponding to the positive
+ sample index. Defaults to None.
+ weight (torch.Tensor, optional): The weight of loss for each
+ prediction. Defaults to None.
+ avg_factor (int, float, optional): Average factor that is used to
+ average the loss. Defaults to None.
+ reduction_override (str, optional): The reduction method used to
+ override the original reduction method of the loss.
+ Defaults to None.
+ """
+ assert reduction_override in (None, 'none', 'mean', 'sum')
+ reduction = (
+ reduction_override if reduction_override else self.reduction)
+ if pos_inds is not None:
+ assert pos_labels is not None
+ # Only used by centernet update version
+ loss_reg = self.loss_weight * gaussian_focal_loss_with_pos_inds(
+ pred,
+ target,
+ pos_inds,
+ pos_labels,
+ alpha=self.alpha,
+ gamma=self.gamma,
+ pos_weight=self.pos_weight,
+ neg_weight=self.neg_weight,
+ reduction=reduction,
+ avg_factor=avg_factor)
+ else:
+ loss_reg = self.loss_weight * gaussian_focal_loss(
+ pred,
+ target,
+ weight,
+ alpha=self.alpha,
+ gamma=self.gamma,
+ pos_weight=self.pos_weight,
+ neg_weight=self.neg_weight,
+ reduction=reduction,
+ avg_factor=avg_factor)
+ return loss_reg
diff --git a/mmdet/models/losses/gfocal_loss.py b/mmdet/models/losses/gfocal_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..b3a1172207e859039ca5ed7e0604d8b787131c29
--- /dev/null
+++ b/mmdet/models/losses/gfocal_loss.py
@@ -0,0 +1,295 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from functools import partial
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from mmdet.models.losses.utils import weighted_loss
+from mmdet.registry import MODELS
+
+
+@weighted_loss
+def quality_focal_loss(pred, target, beta=2.0):
+ r"""Quality Focal Loss (QFL) is from `Generalized Focal Loss: Learning
+ Qualified and Distributed Bounding Boxes for Dense Object Detection
+ `_.
+
+ Args:
+ pred (torch.Tensor): Predicted joint representation of classification
+ and quality (IoU) estimation with shape (N, C), C is the number of
+ classes.
+ target (tuple([torch.Tensor])): Target category label with shape (N,)
+ and target quality label with shape (N,).
+ beta (float): The beta parameter for calculating the modulating factor.
+ Defaults to 2.0.
+
+ Returns:
+ torch.Tensor: Loss tensor with shape (N,).
+ """
+ assert len(target) == 2, """target for QFL must be a tuple of two elements,
+ including category label and quality label, respectively"""
+ # label denotes the category id, score denotes the quality score
+ label, score = target
+
+ # negatives are supervised by 0 quality score
+ pred_sigmoid = pred.sigmoid()
+ scale_factor = pred_sigmoid
+ zerolabel = scale_factor.new_zeros(pred.shape)
+ loss = F.binary_cross_entropy_with_logits(
+ pred, zerolabel, reduction='none') * scale_factor.pow(beta)
+
+ # FG cat_id: [0, num_classes -1], BG cat_id: num_classes
+ bg_class_ind = pred.size(1)
+ pos = ((label >= 0) & (label < bg_class_ind)).nonzero().squeeze(1)
+ pos_label = label[pos].long()
+ # positives are supervised by bbox quality (IoU) score
+ scale_factor = score[pos] - pred_sigmoid[pos, pos_label]
+ loss[pos, pos_label] = F.binary_cross_entropy_with_logits(
+ pred[pos, pos_label], score[pos],
+ reduction='none') * scale_factor.abs().pow(beta)
+
+ loss = loss.sum(dim=1, keepdim=False)
+ return loss
+
+
+@weighted_loss
+def quality_focal_loss_tensor_target(pred, target, beta=2.0, activated=False):
+ """`QualityFocal Loss `_
+ Args:
+ pred (torch.Tensor): The prediction with shape (N, C), C is the
+ number of classes
+ target (torch.Tensor): The learning target of the iou-aware
+ classification score with shape (N, C), C is the number of classes.
+ beta (float): The beta parameter for calculating the modulating factor.
+ Defaults to 2.0.
+ activated (bool): Whether the input is activated.
+ If True, it means the input has been activated and can be
+ treated as probabilities. Else, it should be treated as logits.
+ Defaults to False.
+ """
+ # pred and target should be of the same size
+ assert pred.size() == target.size()
+ if activated:
+ pred_sigmoid = pred
+ loss_function = F.binary_cross_entropy
+ else:
+ pred_sigmoid = pred.sigmoid()
+ loss_function = F.binary_cross_entropy_with_logits
+
+ scale_factor = pred_sigmoid
+ target = target.type_as(pred)
+
+ zerolabel = scale_factor.new_zeros(pred.shape)
+ loss = loss_function(
+ pred, zerolabel, reduction='none') * scale_factor.pow(beta)
+
+ pos = (target != 0)
+ scale_factor = target[pos] - pred_sigmoid[pos]
+ loss[pos] = loss_function(
+ pred[pos], target[pos],
+ reduction='none') * scale_factor.abs().pow(beta)
+
+ loss = loss.sum(dim=1, keepdim=False)
+ return loss
+
+
+@weighted_loss
+def quality_focal_loss_with_prob(pred, target, beta=2.0):
+ r"""Quality Focal Loss (QFL) is from `Generalized Focal Loss: Learning
+ Qualified and Distributed Bounding Boxes for Dense Object Detection
+ `_.
+ Different from `quality_focal_loss`, this function accepts probability
+ as input.
+
+ Args:
+ pred (torch.Tensor): Predicted joint representation of classification
+ and quality (IoU) estimation with shape (N, C), C is the number of
+ classes.
+ target (tuple([torch.Tensor])): Target category label with shape (N,)
+ and target quality label with shape (N,).
+ beta (float): The beta parameter for calculating the modulating factor.
+ Defaults to 2.0.
+
+ Returns:
+ torch.Tensor: Loss tensor with shape (N,).
+ """
+ assert len(target) == 2, """target for QFL must be a tuple of two elements,
+ including category label and quality label, respectively"""
+ # label denotes the category id, score denotes the quality score
+ label, score = target
+
+ # negatives are supervised by 0 quality score
+ pred_sigmoid = pred
+ scale_factor = pred_sigmoid
+ zerolabel = scale_factor.new_zeros(pred.shape)
+ loss = F.binary_cross_entropy(
+ pred, zerolabel, reduction='none') * scale_factor.pow(beta)
+
+ # FG cat_id: [0, num_classes -1], BG cat_id: num_classes
+ bg_class_ind = pred.size(1)
+ pos = ((label >= 0) & (label < bg_class_ind)).nonzero().squeeze(1)
+ pos_label = label[pos].long()
+ # positives are supervised by bbox quality (IoU) score
+ scale_factor = score[pos] - pred_sigmoid[pos, pos_label]
+ loss[pos, pos_label] = F.binary_cross_entropy(
+ pred[pos, pos_label], score[pos],
+ reduction='none') * scale_factor.abs().pow(beta)
+
+ loss = loss.sum(dim=1, keepdim=False)
+ return loss
+
+
+@weighted_loss
+def distribution_focal_loss(pred, label):
+ r"""Distribution Focal Loss (DFL) is from `Generalized Focal Loss: Learning
+ Qualified and Distributed Bounding Boxes for Dense Object Detection
+ `_.
+
+ Args:
+ pred (torch.Tensor): Predicted general distribution of bounding boxes
+ (before softmax) with shape (N, n+1), n is the max value of the
+ integral set `{0, ..., n}` in paper.
+ label (torch.Tensor): Target distance label for bounding boxes with
+ shape (N,).
+
+ Returns:
+ torch.Tensor: Loss tensor with shape (N,).
+ """
+ dis_left = label.long()
+ dis_right = dis_left + 1
+ weight_left = dis_right.float() - label
+ weight_right = label - dis_left.float()
+ loss = F.cross_entropy(pred, dis_left, reduction='none') * weight_left \
+ + F.cross_entropy(pred, dis_right, reduction='none') * weight_right
+ return loss
+
+
+@MODELS.register_module()
+class QualityFocalLoss(nn.Module):
+ r"""Quality Focal Loss (QFL) is a variant of `Generalized Focal Loss:
+ Learning Qualified and Distributed Bounding Boxes for Dense Object
+ Detection `_.
+
+ Args:
+ use_sigmoid (bool): Whether sigmoid operation is conducted in QFL.
+ Defaults to True.
+ beta (float): The beta parameter for calculating the modulating factor.
+ Defaults to 2.0.
+ reduction (str): Options are "none", "mean" and "sum".
+ loss_weight (float): Loss weight of current loss.
+ activated (bool, optional): Whether the input is activated.
+ If True, it means the input has been activated and can be
+ treated as probabilities. Else, it should be treated as logits.
+ Defaults to False.
+ """
+
+ def __init__(self,
+ use_sigmoid=True,
+ beta=2.0,
+ reduction='mean',
+ loss_weight=1.0,
+ activated=False):
+ super(QualityFocalLoss, self).__init__()
+ assert use_sigmoid is True, 'Only sigmoid in QFL supported now.'
+ self.use_sigmoid = use_sigmoid
+ self.beta = beta
+ self.reduction = reduction
+ self.loss_weight = loss_weight
+ self.activated = activated
+
+ def forward(self,
+ pred,
+ target,
+ weight=None,
+ avg_factor=None,
+ reduction_override=None):
+ """Forward function.
+
+ Args:
+ pred (torch.Tensor): Predicted joint representation of
+ classification and quality (IoU) estimation with shape (N, C),
+ C is the number of classes.
+ target (Union(tuple([torch.Tensor]),Torch.Tensor)): The type is
+ tuple, it should be included Target category label with
+ shape (N,) and target quality label with shape (N,).The type
+ is torch.Tensor, the target should be one-hot form with
+ soft weights.
+ weight (torch.Tensor, optional): The weight of loss for each
+ prediction. Defaults to None.
+ avg_factor (int, optional): Average factor that is used to average
+ the loss. Defaults to None.
+ reduction_override (str, optional): The reduction method used to
+ override the original reduction method of the loss.
+ Defaults to None.
+ """
+ assert reduction_override in (None, 'none', 'mean', 'sum')
+ reduction = (
+ reduction_override if reduction_override else self.reduction)
+ if self.use_sigmoid:
+ if self.activated:
+ calculate_loss_func = quality_focal_loss_with_prob
+ else:
+ calculate_loss_func = quality_focal_loss
+ if isinstance(target, torch.Tensor):
+ # the target shape with (N,C) or (N,C,...), which means
+ # the target is one-hot form with soft weights.
+ calculate_loss_func = partial(
+ quality_focal_loss_tensor_target, activated=self.activated)
+
+ loss_cls = self.loss_weight * calculate_loss_func(
+ pred,
+ target,
+ weight,
+ beta=self.beta,
+ reduction=reduction,
+ avg_factor=avg_factor)
+ else:
+ raise NotImplementedError
+ return loss_cls
+
+
+@MODELS.register_module()
+class DistributionFocalLoss(nn.Module):
+ r"""Distribution Focal Loss (DFL) is a variant of `Generalized Focal Loss:
+ Learning Qualified and Distributed Bounding Boxes for Dense Object
+ Detection `_.
+
+ Args:
+ reduction (str): Options are `'none'`, `'mean'` and `'sum'`.
+ loss_weight (float): Loss weight of current loss.
+ """
+
+ def __init__(self, reduction='mean', loss_weight=1.0):
+ super(DistributionFocalLoss, self).__init__()
+ self.reduction = reduction
+ self.loss_weight = loss_weight
+
+ def forward(self,
+ pred,
+ target,
+ weight=None,
+ avg_factor=None,
+ reduction_override=None):
+ """Forward function.
+
+ Args:
+ pred (torch.Tensor): Predicted general distribution of bounding
+ boxes (before softmax) with shape (N, n+1), n is the max value
+ of the integral set `{0, ..., n}` in paper.
+ target (torch.Tensor): Target distance label for bounding boxes
+ with shape (N,).
+ weight (torch.Tensor, optional): The weight of loss for each
+ prediction. Defaults to None.
+ avg_factor (int, optional): Average factor that is used to average
+ the loss. Defaults to None.
+ reduction_override (str, optional): The reduction method used to
+ override the original reduction method of the loss.
+ Defaults to None.
+ """
+ assert reduction_override in (None, 'none', 'mean', 'sum')
+ reduction = (
+ reduction_override if reduction_override else self.reduction)
+ loss_cls = self.loss_weight * distribution_focal_loss(
+ pred, target, weight, reduction=reduction, avg_factor=avg_factor)
+ return loss_cls
diff --git a/mmdet/models/losses/ghm_loss.py b/mmdet/models/losses/ghm_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..a874c0038cc4a77769705a3a06a95a56d3e8dd2d
--- /dev/null
+++ b/mmdet/models/losses/ghm_loss.py
@@ -0,0 +1,213 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from mmdet.registry import MODELS
+from .utils import weight_reduce_loss
+
+
+def _expand_onehot_labels(labels, label_weights, label_channels):
+ bin_labels = labels.new_full((labels.size(0), label_channels), 0)
+ inds = torch.nonzero(
+ (labels >= 0) & (labels < label_channels), as_tuple=False).squeeze()
+ if inds.numel() > 0:
+ bin_labels[inds, labels[inds]] = 1
+ bin_label_weights = label_weights.view(-1, 1).expand(
+ label_weights.size(0), label_channels)
+ return bin_labels, bin_label_weights
+
+
+# TODO: code refactoring to make it consistent with other losses
+@MODELS.register_module()
+class GHMC(nn.Module):
+ """GHM Classification Loss.
+
+ Details of the theorem can be viewed in the paper
+ `Gradient Harmonized Single-stage Detector
+ `_.
+
+ Args:
+ bins (int): Number of the unit regions for distribution calculation.
+ momentum (float): The parameter for moving average.
+ use_sigmoid (bool): Can only be true for BCE based loss now.
+ loss_weight (float): The weight of the total GHM-C loss.
+ reduction (str): Options are "none", "mean" and "sum".
+ Defaults to "mean"
+ """
+
+ def __init__(self,
+ bins=10,
+ momentum=0,
+ use_sigmoid=True,
+ loss_weight=1.0,
+ reduction='mean'):
+ super(GHMC, self).__init__()
+ self.bins = bins
+ self.momentum = momentum
+ edges = torch.arange(bins + 1).float() / bins
+ self.register_buffer('edges', edges)
+ self.edges[-1] += 1e-6
+ if momentum > 0:
+ acc_sum = torch.zeros(bins)
+ self.register_buffer('acc_sum', acc_sum)
+ self.use_sigmoid = use_sigmoid
+ if not self.use_sigmoid:
+ raise NotImplementedError
+ self.loss_weight = loss_weight
+ self.reduction = reduction
+
+ def forward(self,
+ pred,
+ target,
+ label_weight,
+ reduction_override=None,
+ **kwargs):
+ """Calculate the GHM-C loss.
+
+ Args:
+ pred (float tensor of size [batch_num, class_num]):
+ The direct prediction of classification fc layer.
+ target (float tensor of size [batch_num, class_num]):
+ Binary class target for each sample.
+ label_weight (float tensor of size [batch_num, class_num]):
+ the value is 1 if the sample is valid and 0 if ignored.
+ reduction_override (str, optional): The reduction method used to
+ override the original reduction method of the loss.
+ Defaults to None.
+ Returns:
+ The gradient harmonized loss.
+ """
+ assert reduction_override in (None, 'none', 'mean', 'sum')
+ reduction = (
+ reduction_override if reduction_override else self.reduction)
+ # the target should be binary class label
+ if pred.dim() != target.dim():
+ target, label_weight = _expand_onehot_labels(
+ target, label_weight, pred.size(-1))
+ target, label_weight = target.float(), label_weight.float()
+ edges = self.edges
+ mmt = self.momentum
+ weights = torch.zeros_like(pred)
+
+ # gradient length
+ g = torch.abs(pred.sigmoid().detach() - target)
+
+ valid = label_weight > 0
+ tot = max(valid.float().sum().item(), 1.0)
+ n = 0 # n valid bins
+ for i in range(self.bins):
+ inds = (g >= edges[i]) & (g < edges[i + 1]) & valid
+ num_in_bin = inds.sum().item()
+ if num_in_bin > 0:
+ if mmt > 0:
+ self.acc_sum[i] = mmt * self.acc_sum[i] \
+ + (1 - mmt) * num_in_bin
+ weights[inds] = tot / self.acc_sum[i]
+ else:
+ weights[inds] = tot / num_in_bin
+ n += 1
+ if n > 0:
+ weights = weights / n
+
+ loss = F.binary_cross_entropy_with_logits(
+ pred, target, reduction='none')
+ loss = weight_reduce_loss(
+ loss, weights, reduction=reduction, avg_factor=tot)
+ return loss * self.loss_weight
+
+
+# TODO: code refactoring to make it consistent with other losses
+@MODELS.register_module()
+class GHMR(nn.Module):
+ """GHM Regression Loss.
+
+ Details of the theorem can be viewed in the paper
+ `Gradient Harmonized Single-stage Detector
+ `_.
+
+ Args:
+ mu (float): The parameter for the Authentic Smooth L1 loss.
+ bins (int): Number of the unit regions for distribution calculation.
+ momentum (float): The parameter for moving average.
+ loss_weight (float): The weight of the total GHM-R loss.
+ reduction (str): Options are "none", "mean" and "sum".
+ Defaults to "mean"
+ """
+
+ def __init__(self,
+ mu=0.02,
+ bins=10,
+ momentum=0,
+ loss_weight=1.0,
+ reduction='mean'):
+ super(GHMR, self).__init__()
+ self.mu = mu
+ self.bins = bins
+ edges = torch.arange(bins + 1).float() / bins
+ self.register_buffer('edges', edges)
+ self.edges[-1] = 1e3
+ self.momentum = momentum
+ if momentum > 0:
+ acc_sum = torch.zeros(bins)
+ self.register_buffer('acc_sum', acc_sum)
+ self.loss_weight = loss_weight
+ self.reduction = reduction
+
+ # TODO: support reduction parameter
+ def forward(self,
+ pred,
+ target,
+ label_weight,
+ avg_factor=None,
+ reduction_override=None):
+ """Calculate the GHM-R loss.
+
+ Args:
+ pred (float tensor of size [batch_num, 4 (* class_num)]):
+ The prediction of box regression layer. Channel number can be 4
+ or 4 * class_num depending on whether it is class-agnostic.
+ target (float tensor of size [batch_num, 4 (* class_num)]):
+ The target regression values with the same size of pred.
+ label_weight (float tensor of size [batch_num, 4 (* class_num)]):
+ The weight of each sample, 0 if ignored.
+ reduction_override (str, optional): The reduction method used to
+ override the original reduction method of the loss.
+ Defaults to None.
+ Returns:
+ The gradient harmonized loss.
+ """
+ assert reduction_override in (None, 'none', 'mean', 'sum')
+ reduction = (
+ reduction_override if reduction_override else self.reduction)
+ mu = self.mu
+ edges = self.edges
+ mmt = self.momentum
+
+ # ASL1 loss
+ diff = pred - target
+ loss = torch.sqrt(diff * diff + mu * mu) - mu
+
+ # gradient length
+ g = torch.abs(diff / torch.sqrt(mu * mu + diff * diff)).detach()
+ weights = torch.zeros_like(g)
+
+ valid = label_weight > 0
+ tot = max(label_weight.float().sum().item(), 1.0)
+ n = 0 # n: valid bins
+ for i in range(self.bins):
+ inds = (g >= edges[i]) & (g < edges[i + 1]) & valid
+ num_in_bin = inds.sum().item()
+ if num_in_bin > 0:
+ n += 1
+ if mmt > 0:
+ self.acc_sum[i] = mmt * self.acc_sum[i] \
+ + (1 - mmt) * num_in_bin
+ weights[inds] = tot / self.acc_sum[i]
+ else:
+ weights[inds] = tot / num_in_bin
+ if n > 0:
+ weights /= n
+ loss = weight_reduce_loss(
+ loss, weights, reduction=reduction, avg_factor=tot)
+ return loss * self.loss_weight
diff --git a/mmdet/models/losses/iou_loss.py b/mmdet/models/losses/iou_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..e8ad49cad89d582d4b2da361defcc875b11575d6
--- /dev/null
+++ b/mmdet/models/losses/iou_loss.py
@@ -0,0 +1,836 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+import warnings
+from typing import Optional
+
+import torch
+import torch.nn as nn
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.structures.bbox import bbox_overlaps
+from .utils import weighted_loss
+
+
+@weighted_loss
+def iou_loss(pred: Tensor,
+ target: Tensor,
+ linear: bool = False,
+ mode: str = 'log',
+ eps: float = 1e-6) -> Tensor:
+ """IoU loss.
+
+ Computing the IoU loss between a set of predicted bboxes and target bboxes.
+ The loss is calculated as negative log of IoU.
+
+ Args:
+ pred (Tensor): Predicted bboxes of format (x1, y1, x2, y2),
+ shape (n, 4).
+ target (Tensor): Corresponding gt bboxes, shape (n, 4).
+ linear (bool, optional): If True, use linear scale of loss instead of
+ log scale. Default: False.
+ mode (str): Loss scaling mode, including "linear", "square", and "log".
+ Default: 'log'
+ eps (float): Epsilon to avoid log(0).
+
+ Return:
+ Tensor: Loss tensor.
+ """
+ assert mode in ['linear', 'square', 'log']
+ if linear:
+ mode = 'linear'
+ warnings.warn('DeprecationWarning: Setting "linear=True" in '
+ 'iou_loss is deprecated, please use "mode=`linear`" '
+ 'instead.')
+ ious = bbox_overlaps(pred, target, is_aligned=True).clamp(min=eps)
+ if mode == 'linear':
+ loss = 1 - ious
+ elif mode == 'square':
+ loss = 1 - ious**2
+ elif mode == 'log':
+ loss = -ious.log()
+ else:
+ raise NotImplementedError
+ return loss
+
+
+@weighted_loss
+def bounded_iou_loss(pred: Tensor,
+ target: Tensor,
+ beta: float = 0.2,
+ eps: float = 1e-3) -> Tensor:
+ """BIoULoss.
+
+ This is an implementation of paper
+ `Improving Object Localization with Fitness NMS and Bounded IoU Loss.
+ `_.
+
+ Args:
+ pred (Tensor): Predicted bboxes of format (x1, y1, x2, y2),
+ shape (n, 4).
+ target (Tensor): Corresponding gt bboxes, shape (n, 4).
+ beta (float, optional): Beta parameter in smoothl1.
+ eps (float, optional): Epsilon to avoid NaN values.
+
+ Return:
+ Tensor: Loss tensor.
+ """
+ pred_ctrx = (pred[:, 0] + pred[:, 2]) * 0.5
+ pred_ctry = (pred[:, 1] + pred[:, 3]) * 0.5
+ pred_w = pred[:, 2] - pred[:, 0]
+ pred_h = pred[:, 3] - pred[:, 1]
+ with torch.no_grad():
+ target_ctrx = (target[:, 0] + target[:, 2]) * 0.5
+ target_ctry = (target[:, 1] + target[:, 3]) * 0.5
+ target_w = target[:, 2] - target[:, 0]
+ target_h = target[:, 3] - target[:, 1]
+
+ dx = target_ctrx - pred_ctrx
+ dy = target_ctry - pred_ctry
+
+ loss_dx = 1 - torch.max(
+ (target_w - 2 * dx.abs()) /
+ (target_w + 2 * dx.abs() + eps), torch.zeros_like(dx))
+ loss_dy = 1 - torch.max(
+ (target_h - 2 * dy.abs()) /
+ (target_h + 2 * dy.abs() + eps), torch.zeros_like(dy))
+ loss_dw = 1 - torch.min(target_w / (pred_w + eps), pred_w /
+ (target_w + eps))
+ loss_dh = 1 - torch.min(target_h / (pred_h + eps), pred_h /
+ (target_h + eps))
+ # view(..., -1) does not work for empty tensor
+ loss_comb = torch.stack([loss_dx, loss_dy, loss_dw, loss_dh],
+ dim=-1).flatten(1)
+
+ loss = torch.where(loss_comb < beta, 0.5 * loss_comb * loss_comb / beta,
+ loss_comb - 0.5 * beta)
+ return loss
+
+
+@weighted_loss
+def giou_loss(pred: Tensor, target: Tensor, eps: float = 1e-7) -> Tensor:
+ r"""`Generalized Intersection over Union: A Metric and A Loss for Bounding
+ Box Regression `_.
+
+ Args:
+ pred (Tensor): Predicted bboxes of format (x1, y1, x2, y2),
+ shape (n, 4).
+ target (Tensor): Corresponding gt bboxes, shape (n, 4).
+ eps (float): Epsilon to avoid log(0).
+
+ Return:
+ Tensor: Loss tensor.
+ """
+ gious = bbox_overlaps(pred, target, mode='giou', is_aligned=True, eps=eps)
+ loss = 1 - gious
+ return loss
+
+
+@weighted_loss
+def diou_loss(pred: Tensor, target: Tensor, eps: float = 1e-7) -> Tensor:
+ r"""Implementation of `Distance-IoU Loss: Faster and Better
+ Learning for Bounding Box Regression https://arxiv.org/abs/1911.08287`_.
+
+ Code is modified from https://github.com/Zzh-tju/DIoU.
+
+ Args:
+ pred (Tensor): Predicted bboxes of format (x1, y1, x2, y2),
+ shape (n, 4).
+ target (Tensor): Corresponding gt bboxes, shape (n, 4).
+ eps (float): Epsilon to avoid log(0).
+
+ Return:
+ Tensor: Loss tensor.
+ """
+ # overlap
+ lt = torch.max(pred[:, :2], target[:, :2])
+ rb = torch.min(pred[:, 2:], target[:, 2:])
+ wh = (rb - lt).clamp(min=0)
+ overlap = wh[:, 0] * wh[:, 1]
+
+ # union
+ ap = (pred[:, 2] - pred[:, 0]) * (pred[:, 3] - pred[:, 1])
+ ag = (target[:, 2] - target[:, 0]) * (target[:, 3] - target[:, 1])
+ union = ap + ag - overlap + eps
+
+ # IoU
+ ious = overlap / union
+
+ # enclose area
+ enclose_x1y1 = torch.min(pred[:, :2], target[:, :2])
+ enclose_x2y2 = torch.max(pred[:, 2:], target[:, 2:])
+ enclose_wh = (enclose_x2y2 - enclose_x1y1).clamp(min=0)
+
+ cw = enclose_wh[:, 0]
+ ch = enclose_wh[:, 1]
+
+ c2 = cw**2 + ch**2 + eps
+
+ b1_x1, b1_y1 = pred[:, 0], pred[:, 1]
+ b1_x2, b1_y2 = pred[:, 2], pred[:, 3]
+ b2_x1, b2_y1 = target[:, 0], target[:, 1]
+ b2_x2, b2_y2 = target[:, 2], target[:, 3]
+
+ left = ((b2_x1 + b2_x2) - (b1_x1 + b1_x2))**2 / 4
+ right = ((b2_y1 + b2_y2) - (b1_y1 + b1_y2))**2 / 4
+ rho2 = left + right
+
+ # DIoU
+ dious = ious - rho2 / c2
+ loss = 1 - dious
+ return loss
+
+
+@weighted_loss
+def ciou_loss(pred: Tensor, target: Tensor, eps: float = 1e-7) -> Tensor:
+ r"""`Implementation of paper `Enhancing Geometric Factors into
+ Model Learning and Inference for Object Detection and Instance
+ Segmentation `_.
+
+ Code is modified from https://github.com/Zzh-tju/CIoU.
+
+ Args:
+ pred (Tensor): Predicted bboxes of format (x1, y1, x2, y2),
+ shape (n, 4).
+ target (Tensor): Corresponding gt bboxes, shape (n, 4).
+ eps (float): Epsilon to avoid log(0).
+
+ Return:
+ Tensor: Loss tensor.
+ """
+ # overlap
+ lt = torch.max(pred[:, :2], target[:, :2])
+ rb = torch.min(pred[:, 2:], target[:, 2:])
+ wh = (rb - lt).clamp(min=0)
+ overlap = wh[:, 0] * wh[:, 1]
+
+ # union
+ ap = (pred[:, 2] - pred[:, 0]) * (pred[:, 3] - pred[:, 1])
+ ag = (target[:, 2] - target[:, 0]) * (target[:, 3] - target[:, 1])
+ union = ap + ag - overlap + eps
+
+ # IoU
+ ious = overlap / union
+
+ # enclose area
+ enclose_x1y1 = torch.min(pred[:, :2], target[:, :2])
+ enclose_x2y2 = torch.max(pred[:, 2:], target[:, 2:])
+ enclose_wh = (enclose_x2y2 - enclose_x1y1).clamp(min=0)
+
+ cw = enclose_wh[:, 0]
+ ch = enclose_wh[:, 1]
+
+ c2 = cw**2 + ch**2 + eps
+
+ b1_x1, b1_y1 = pred[:, 0], pred[:, 1]
+ b1_x2, b1_y2 = pred[:, 2], pred[:, 3]
+ b2_x1, b2_y1 = target[:, 0], target[:, 1]
+ b2_x2, b2_y2 = target[:, 2], target[:, 3]
+
+ w1, h1 = b1_x2 - b1_x1, b1_y2 - b1_y1 + eps
+ w2, h2 = b2_x2 - b2_x1, b2_y2 - b2_y1 + eps
+
+ left = ((b2_x1 + b2_x2) - (b1_x1 + b1_x2))**2 / 4
+ right = ((b2_y1 + b2_y2) - (b1_y1 + b1_y2))**2 / 4
+ rho2 = left + right
+
+ factor = 4 / math.pi**2
+ v = factor * torch.pow(torch.atan(w2 / h2) - torch.atan(w1 / h1), 2)
+
+ with torch.no_grad():
+ alpha = (ious > 0.5).float() * v / (1 - ious + v)
+
+ # CIoU
+ cious = ious - (rho2 / c2 + alpha * v)
+ loss = 1 - cious.clamp(min=-1.0, max=1.0)
+ return loss
+
+
+@weighted_loss
+def eiou_loss(pred: Tensor,
+ target: Tensor,
+ smooth_point: float = 0.1,
+ eps: float = 1e-7) -> Tensor:
+ r"""Implementation of paper `Extended-IoU Loss: A Systematic
+ IoU-Related Method: Beyond Simplified Regression for Better
+ Localization `_
+
+ Code is modified from https://github.com//ShiqiYu/libfacedetection.train.
+
+ Args:
+ pred (Tensor): Predicted bboxes of format (x1, y1, x2, y2),
+ shape (n, 4).
+ target (Tensor): Corresponding gt bboxes, shape (n, 4).
+ smooth_point (float): hyperparameter, default is 0.1.
+ eps (float): Epsilon to avoid log(0).
+
+ Return:
+ Tensor: Loss tensor.
+ """
+ px1, py1, px2, py2 = pred[:, 0], pred[:, 1], pred[:, 2], pred[:, 3]
+ tx1, ty1, tx2, ty2 = target[:, 0], target[:, 1], target[:, 2], target[:, 3]
+
+ # extent top left
+ ex1 = torch.min(px1, tx1)
+ ey1 = torch.min(py1, ty1)
+
+ # intersection coordinates
+ ix1 = torch.max(px1, tx1)
+ iy1 = torch.max(py1, ty1)
+ ix2 = torch.min(px2, tx2)
+ iy2 = torch.min(py2, ty2)
+
+ # extra
+ xmin = torch.min(ix1, ix2)
+ ymin = torch.min(iy1, iy2)
+ xmax = torch.max(ix1, ix2)
+ ymax = torch.max(iy1, iy2)
+
+ # Intersection
+ intersection = (ix2 - ex1) * (iy2 - ey1) + (xmin - ex1) * (ymin - ey1) - (
+ ix1 - ex1) * (ymax - ey1) - (xmax - ex1) * (
+ iy1 - ey1)
+ # Union
+ union = (px2 - px1) * (py2 - py1) + (tx2 - tx1) * (
+ ty2 - ty1) - intersection + eps
+ # IoU
+ ious = 1 - (intersection / union)
+
+ # Smooth-EIoU
+ smooth_sign = (ious < smooth_point).detach().float()
+ loss = 0.5 * smooth_sign * (ious**2) / smooth_point + (1 - smooth_sign) * (
+ ious - 0.5 * smooth_point)
+ return loss
+
+@weighted_loss
+def wasserstein_loss(pred, target, eps=1e-7, mode='exp', gamma=1, constant=12.8):
+ r"""`Implementation of paper `Enhancing Geometric Factors into
+ Model Learning and Inference for Object Detection and Instance
+ Segmentation `_.
+
+ Code is modified from https://github.com/Zzh-tju/CIoU.
+
+ Args:
+ pred (Tensor): Predicted bboxes of format (x1, y1, x2, y2),
+ shape (n, 4).
+ target (Tensor): Corresponding gt bboxes, shape (n, 4).
+ eps (float): Eps to avoid log(0).
+ Return:
+ Tensor: Loss tensor.
+ """
+ center1 = (pred[:, :2] + pred[:, 2:]) / 2
+ center2 = (target[:, :2] + target[:, 2:]) / 2
+
+ whs = center1[:, :2] - center2[:, :2]
+
+ center_distance = whs[:, 0] * whs[:, 0] + whs[:, 1] * whs[:, 1] + eps #
+
+ w1 = pred[:, 2] - pred[:, 0] + eps
+ h1 = pred[:, 3] - pred[:, 1] + eps
+ w2 = target[:, 2] - target[:, 0] + eps
+ h2 = target[:, 3] - target[:, 1] + eps
+
+ wh_distance = ((w1 - w2) ** 2 + (h1 - h2) ** 2) / 4
+
+ wasserstein_2 = center_distance + wh_distance
+
+ if mode == 'exp':
+ normalized_wasserstein = torch.exp(-torch.sqrt(wasserstein_2) / constant)
+ wloss = 1 - normalized_wasserstein
+
+ if mode == 'sqrt':
+ wloss = torch.sqrt(wasserstein_2)
+
+ if mode == 'log':
+ wloss = torch.log(wasserstein_2 + 1)
+
+ if mode == 'norm_sqrt':
+ wloss = 1 - 1 / (gamma + torch.sqrt(wasserstein_2))
+
+ if mode == 'w2':
+ wloss = wasserstein_2
+
+ return wloss
+
+
+@MODELS.register_module()
+class IoULoss(nn.Module):
+ """IoULoss.
+
+ Computing the IoU loss between a set of predicted bboxes and target bboxes.
+
+ Args:
+ linear (bool): If True, use linear scale of loss else determined
+ by mode. Default: False.
+ eps (float): Epsilon to avoid log(0).
+ reduction (str): Options are "none", "mean" and "sum".
+ loss_weight (float): Weight of loss.
+ mode (str): Loss scaling mode, including "linear", "square", and "log".
+ Default: 'log'
+ """
+
+ def __init__(self,
+ linear: bool = False,
+ eps: float = 1e-6,
+ reduction: str = 'mean',
+ loss_weight: float = 1.0,
+ mode: str = 'log') -> None:
+ super().__init__()
+ assert mode in ['linear', 'square', 'log']
+ if linear:
+ mode = 'linear'
+ warnings.warn('DeprecationWarning: Setting "linear=True" in '
+ 'IOULoss is deprecated, please use "mode=`linear`" '
+ 'instead.')
+ self.mode = mode
+ self.linear = linear
+ self.eps = eps
+ self.reduction = reduction
+ self.loss_weight = loss_weight
+
+ def forward(self,
+ pred: Tensor,
+ target: Tensor,
+ weight: Optional[Tensor] = None,
+ avg_factor: Optional[int] = None,
+ reduction_override: Optional[str] = None,
+ **kwargs) -> Tensor:
+ """Forward function.
+
+ Args:
+ pred (Tensor): Predicted bboxes of format (x1, y1, x2, y2),
+ shape (n, 4).
+ target (Tensor): The learning target of the prediction,
+ shape (n, 4).
+ weight (Tensor, optional): The weight of loss for each
+ prediction. Defaults to None.
+ avg_factor (int, optional): Average factor that is used to average
+ the loss. Defaults to None.
+ reduction_override (str, optional): The reduction method used to
+ override the original reduction method of the loss.
+ Defaults to None. Options are "none", "mean" and "sum".
+
+ Return:
+ Tensor: Loss tensor.
+ """
+ assert reduction_override in (None, 'none', 'mean', 'sum')
+ reduction = (
+ reduction_override if reduction_override else self.reduction)
+ if (weight is not None) and (not torch.any(weight > 0)) and (
+ reduction != 'none'):
+ if pred.dim() == weight.dim() + 1:
+ weight = weight.unsqueeze(1)
+ return (pred * weight).sum() # 0
+ if weight is not None and weight.dim() > 1:
+ # TODO: remove this in the future
+ # reduce the weight of shape (n, 4) to (n,) to match the
+ # iou_loss of shape (n,)
+ assert weight.shape == pred.shape
+ weight = weight.mean(-1)
+ loss = self.loss_weight * iou_loss(
+ pred,
+ target,
+ weight,
+ mode=self.mode,
+ eps=self.eps,
+ reduction=reduction,
+ avg_factor=avg_factor,
+ **kwargs)
+ return loss
+
+
+@MODELS.register_module()
+class BoundedIoULoss(nn.Module):
+ """BIoULoss.
+
+ This is an implementation of paper
+ `Improving Object Localization with Fitness NMS and Bounded IoU Loss.
+ `_.
+
+ Args:
+ beta (float, optional): Beta parameter in smoothl1.
+ eps (float, optional): Epsilon to avoid NaN values.
+ reduction (str): Options are "none", "mean" and "sum".
+ loss_weight (float): Weight of loss.
+ """
+
+ def __init__(self,
+ beta: float = 0.2,
+ eps: float = 1e-3,
+ reduction: str = 'mean',
+ loss_weight: float = 1.0) -> None:
+ super().__init__()
+ self.beta = beta
+ self.eps = eps
+ self.reduction = reduction
+ self.loss_weight = loss_weight
+
+ def forward(self,
+ pred: Tensor,
+ target: Tensor,
+ weight: Optional[Tensor] = None,
+ avg_factor: Optional[int] = None,
+ reduction_override: Optional[str] = None,
+ **kwargs) -> Tensor:
+ """Forward function.
+
+ Args:
+ pred (Tensor): Predicted bboxes of format (x1, y1, x2, y2),
+ shape (n, 4).
+ target (Tensor): The learning target of the prediction,
+ shape (n, 4).
+ weight (Optional[Tensor], optional): The weight of loss for each
+ prediction. Defaults to None.
+ avg_factor (Optional[int], optional): Average factor that is used
+ to average the loss. Defaults to None.
+ reduction_override (Optional[str], optional): The reduction method
+ used to override the original reduction method of the loss.
+ Defaults to None. Options are "none", "mean" and "sum".
+
+ Returns:
+ Tensor: Loss tensor.
+ """
+ if weight is not None and not torch.any(weight > 0):
+ if pred.dim() == weight.dim() + 1:
+ weight = weight.unsqueeze(1)
+ return (pred * weight).sum() # 0
+ assert reduction_override in (None, 'none', 'mean', 'sum')
+ reduction = (
+ reduction_override if reduction_override else self.reduction)
+ loss = self.loss_weight * bounded_iou_loss(
+ pred,
+ target,
+ weight,
+ beta=self.beta,
+ eps=self.eps,
+ reduction=reduction,
+ avg_factor=avg_factor,
+ **kwargs)
+ return loss
+
+
+@MODELS.register_module()
+class GIoULoss(nn.Module):
+ r"""`Generalized Intersection over Union: A Metric and A Loss for Bounding
+ Box Regression `_.
+
+ Args:
+ eps (float): Epsilon to avoid log(0).
+ reduction (str): Options are "none", "mean" and "sum".
+ loss_weight (float): Weight of loss.
+ """
+
+ def __init__(self,
+ eps: float = 1e-6,
+ reduction: str = 'mean',
+ loss_weight: float = 1.0) -> None:
+ super().__init__()
+ self.eps = eps
+ self.reduction = reduction
+ self.loss_weight = loss_weight
+
+ def forward(self,
+ pred: Tensor,
+ target: Tensor,
+ weight: Optional[Tensor] = None,
+ avg_factor: Optional[int] = None,
+ reduction_override: Optional[str] = None,
+ **kwargs) -> Tensor:
+ """Forward function.
+
+ Args:
+ pred (Tensor): Predicted bboxes of format (x1, y1, x2, y2),
+ shape (n, 4).
+ target (Tensor): The learning target of the prediction,
+ shape (n, 4).
+ weight (Optional[Tensor], optional): The weight of loss for each
+ prediction. Defaults to None.
+ avg_factor (Optional[int], optional): Average factor that is used
+ to average the loss. Defaults to None.
+ reduction_override (Optional[str], optional): The reduction method
+ used to override the original reduction method of the loss.
+ Defaults to None. Options are "none", "mean" and "sum".
+
+ Returns:
+ Tensor: Loss tensor.
+ """
+ if weight is not None and not torch.any(weight > 0):
+ if pred.dim() == weight.dim() + 1:
+ weight = weight.unsqueeze(1)
+ return (pred * weight).sum() # 0
+ assert reduction_override in (None, 'none', 'mean', 'sum')
+ reduction = (
+ reduction_override if reduction_override else self.reduction)
+ if weight is not None and weight.dim() > 1:
+ # TODO: remove this in the future
+ # reduce the weight of shape (n, 4) to (n,) to match the
+ # giou_loss of shape (n,)
+ assert weight.shape == pred.shape
+ weight = weight.mean(-1)
+ loss = self.loss_weight * giou_loss(
+ pred,
+ target,
+ weight,
+ eps=self.eps,
+ reduction=reduction,
+ avg_factor=avg_factor,
+ **kwargs)
+ return loss
+
+
+@MODELS.register_module()
+class DIoULoss(nn.Module):
+ r"""Implementation of `Distance-IoU Loss: Faster and Better
+ Learning for Bounding Box Regression https://arxiv.org/abs/1911.08287`_.
+
+ Code is modified from https://github.com/Zzh-tju/DIoU.
+
+ Args:
+ eps (float): Epsilon to avoid log(0).
+ reduction (str): Options are "none", "mean" and "sum".
+ loss_weight (float): Weight of loss.
+ """
+
+ def __init__(self,
+ eps: float = 1e-6,
+ reduction: str = 'mean',
+ loss_weight: float = 1.0) -> None:
+ super().__init__()
+ self.eps = eps
+ self.reduction = reduction
+ self.loss_weight = loss_weight
+
+ def forward(self,
+ pred: Tensor,
+ target: Tensor,
+ weight: Optional[Tensor] = None,
+ avg_factor: Optional[int] = None,
+ reduction_override: Optional[str] = None,
+ **kwargs) -> Tensor:
+ """Forward function.
+
+ Args:
+ pred (Tensor): Predicted bboxes of format (x1, y1, x2, y2),
+ shape (n, 4).
+ target (Tensor): The learning target of the prediction,
+ shape (n, 4).
+ weight (Optional[Tensor], optional): The weight of loss for each
+ prediction. Defaults to None.
+ avg_factor (Optional[int], optional): Average factor that is used
+ to average the loss. Defaults to None.
+ reduction_override (Optional[str], optional): The reduction method
+ used to override the original reduction method of the loss.
+ Defaults to None. Options are "none", "mean" and "sum".
+
+ Returns:
+ Tensor: Loss tensor.
+ """
+ if weight is not None and not torch.any(weight > 0):
+ if pred.dim() == weight.dim() + 1:
+ weight = weight.unsqueeze(1)
+ return (pred * weight).sum() # 0
+ assert reduction_override in (None, 'none', 'mean', 'sum')
+ reduction = (
+ reduction_override if reduction_override else self.reduction)
+ if weight is not None and weight.dim() > 1:
+ # TODO: remove this in the future
+ # reduce the weight of shape (n, 4) to (n,) to match the
+ # giou_loss of shape (n,)
+ assert weight.shape == pred.shape
+ weight = weight.mean(-1)
+ loss = self.loss_weight * diou_loss(
+ pred,
+ target,
+ weight,
+ eps=self.eps,
+ reduction=reduction,
+ avg_factor=avg_factor,
+ **kwargs)
+ return loss
+
+
+@MODELS.register_module()
+class CIoULoss(nn.Module):
+ r"""`Implementation of paper `Enhancing Geometric Factors into
+ Model Learning and Inference for Object Detection and Instance
+ Segmentation `_.
+
+ Code is modified from https://github.com/Zzh-tju/CIoU.
+
+ Args:
+ eps (float): Epsilon to avoid log(0).
+ reduction (str): Options are "none", "mean" and "sum".
+ loss_weight (float): Weight of loss.
+ """
+
+ def __init__(self,
+ eps: float = 1e-6,
+ reduction: str = 'mean',
+ loss_weight: float = 1.0) -> None:
+ super().__init__()
+ self.eps = eps
+ self.reduction = reduction
+ self.loss_weight = loss_weight
+
+ def forward(self,
+ pred: Tensor,
+ target: Tensor,
+ weight: Optional[Tensor] = None,
+ avg_factor: Optional[int] = None,
+ reduction_override: Optional[str] = None,
+ **kwargs) -> Tensor:
+ """Forward function.
+
+ Args:
+ pred (Tensor): Predicted bboxes of format (x1, y1, x2, y2),
+ shape (n, 4).
+ target (Tensor): The learning target of the prediction,
+ shape (n, 4).
+ weight (Optional[Tensor], optional): The weight of loss for each
+ prediction. Defaults to None.
+ avg_factor (Optional[int], optional): Average factor that is used
+ to average the loss. Defaults to None.
+ reduction_override (Optional[str], optional): The reduction method
+ used to override the original reduction method of the loss.
+ Defaults to None. Options are "none", "mean" and "sum".
+
+ Returns:
+ Tensor: Loss tensor.
+ """
+ if weight is not None and not torch.any(weight > 0):
+ if pred.dim() == weight.dim() + 1:
+ weight = weight.unsqueeze(1)
+ return (pred * weight).sum() # 0
+ assert reduction_override in (None, 'none', 'mean', 'sum')
+ reduction = (
+ reduction_override if reduction_override else self.reduction)
+ if weight is not None and weight.dim() > 1:
+ # TODO: remove this in the future
+ # reduce the weight of shape (n, 4) to (n,) to match the
+ # giou_loss of shape (n,)
+ assert weight.shape == pred.shape
+ weight = weight.mean(-1)
+ loss = self.loss_weight * ciou_loss(
+ pred,
+ target,
+ weight,
+ eps=self.eps,
+ reduction=reduction,
+ avg_factor=avg_factor,
+ **kwargs)
+ return loss
+
+
+@MODELS.register_module()
+class EIoULoss(nn.Module):
+ r"""Implementation of paper `Extended-IoU Loss: A Systematic
+ IoU-Related Method: Beyond Simplified Regression for Better
+ Localization `_
+
+ Code is modified from https://github.com//ShiqiYu/libfacedetection.train.
+
+ Args:
+ eps (float): Epsilon to avoid log(0).
+ reduction (str): Options are "none", "mean" and "sum".
+ loss_weight (float): Weight of loss.
+ smooth_point (float): hyperparameter, default is 0.1.
+ """
+
+ def __init__(self,
+ eps: float = 1e-6,
+ reduction: str = 'mean',
+ loss_weight: float = 1.0,
+ smooth_point: float = 0.1) -> None:
+ super().__init__()
+ self.eps = eps
+ self.reduction = reduction
+ self.loss_weight = loss_weight
+ self.smooth_point = smooth_point
+
+ def forward(self,
+ pred: Tensor,
+ target: Tensor,
+ weight: Optional[Tensor] = None,
+ avg_factor: Optional[int] = None,
+ reduction_override: Optional[str] = None,
+ **kwargs) -> Tensor:
+ """Forward function.
+
+ Args:
+ pred (Tensor): Predicted bboxes of format (x1, y1, x2, y2),
+ shape (n, 4).
+ target (Tensor): The learning target of the prediction,
+ shape (n, 4).
+ weight (Optional[Tensor], optional): The weight of loss for each
+ prediction. Defaults to None.
+ avg_factor (Optional[int], optional): Average factor that is used
+ to average the loss. Defaults to None.
+ reduction_override (Optional[str], optional): The reduction method
+ used to override the original reduction method of the loss.
+ Defaults to None. Options are "none", "mean" and "sum".
+
+ Returns:
+ Tensor: Loss tensor.
+ """
+ if weight is not None and not torch.any(weight > 0):
+ if pred.dim() == weight.dim() + 1:
+ weight = weight.unsqueeze(1)
+ return (pred * weight).sum() # 0
+ assert reduction_override in (None, 'none', 'mean', 'sum')
+ reduction = (
+ reduction_override if reduction_override else self.reduction)
+ if weight is not None and weight.dim() > 1:
+ assert weight.shape == pred.shape
+ weight = weight.mean(-1)
+ loss = self.loss_weight * eiou_loss(
+ pred,
+ target,
+ weight,
+ smooth_point=self.smooth_point,
+ eps=self.eps,
+ reduction=reduction,
+ avg_factor=avg_factor,
+ **kwargs)
+ return loss
+
+
+@MODELS.register_module()
+class WassersteinLoss(nn.Module):
+ def __init__(self, eps=1e-6, reduction='mean', loss_weight=1.0, mode='exp', gamma=2, constant=12.8):
+ super(WassersteinLoss, self).__init__()
+ self.eps = eps
+ self.reduction = reduction
+ self.loss_weight = loss_weight
+ self.mode = mode
+ self.gamma = gamma
+ self.constant = constant # constant = 12.8 for AI-TOD
+ def forward(self,
+ pred,
+ target,
+ weight=None,
+ avg_factor=None,
+ reduction_override=None,
+ **kwargs):
+ if weight is not None and not torch.any(weight > 0):
+ return (pred * weight).sum() # 0
+ assert reduction_override in (None, 'none', 'mean', 'sum')
+ reduction = (
+ reduction_override if reduction_override else self.reduction)
+ if weight is not None and weight.dim() > 1:
+ # TODO: remove this in the future
+ # reduce the weight of shape (n, 4) to (n,) to match the
+ # giou_loss of shape (n,)
+ assert weight.shape == pred.shape
+ weight = weight.mean(-1)
+ loss = self.loss_weight * wasserstein_loss(
+ pred,
+ target,
+ weight,
+ eps=self.eps,
+ reduction=reduction,
+ avg_factor=avg_factor,
+ mode=self.mode,
+ gamma=self.gamma,
+ constant=self.constant,
+ **kwargs)
+ return loss
\ No newline at end of file
diff --git a/mmdet/models/losses/kd_loss.py b/mmdet/models/losses/kd_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..0a7d5ef24a0b0d7d7390a27c7cd9cbfdbe61d823
--- /dev/null
+++ b/mmdet/models/losses/kd_loss.py
@@ -0,0 +1,95 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional
+
+import torch.nn as nn
+import torch.nn.functional as F
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from .utils import weighted_loss
+
+
+@weighted_loss
+def knowledge_distillation_kl_div_loss(pred: Tensor,
+ soft_label: Tensor,
+ T: int,
+ detach_target: bool = True) -> Tensor:
+ r"""Loss function for knowledge distilling using KL divergence.
+
+ Args:
+ pred (Tensor): Predicted logits with shape (N, n + 1).
+ soft_label (Tensor): Target logits with shape (N, N + 1).
+ T (int): Temperature for distillation.
+ detach_target (bool): Remove soft_label from automatic differentiation
+
+ Returns:
+ Tensor: Loss tensor with shape (N,).
+ """
+ assert pred.size() == soft_label.size()
+ target = F.softmax(soft_label / T, dim=1)
+ if detach_target:
+ target = target.detach()
+
+ kd_loss = F.kl_div(
+ F.log_softmax(pred / T, dim=1), target, reduction='none').mean(1) * (
+ T * T)
+
+ return kd_loss
+
+
+@MODELS.register_module()
+class KnowledgeDistillationKLDivLoss(nn.Module):
+ """Loss function for knowledge distilling using KL divergence.
+
+ Args:
+ reduction (str): Options are `'none'`, `'mean'` and `'sum'`.
+ loss_weight (float): Loss weight of current loss.
+ T (int): Temperature for distillation.
+ """
+
+ def __init__(self,
+ reduction: str = 'mean',
+ loss_weight: float = 1.0,
+ T: int = 10) -> None:
+ super().__init__()
+ assert T >= 1
+ self.reduction = reduction
+ self.loss_weight = loss_weight
+ self.T = T
+
+ def forward(self,
+ pred: Tensor,
+ soft_label: Tensor,
+ weight: Optional[Tensor] = None,
+ avg_factor: Optional[int] = None,
+ reduction_override: Optional[str] = None) -> Tensor:
+ """Forward function.
+
+ Args:
+ pred (Tensor): Predicted logits with shape (N, n + 1).
+ soft_label (Tensor): Target logits with shape (N, N + 1).
+ weight (Tensor, optional): The weight of loss for each
+ prediction. Defaults to None.
+ avg_factor (int, optional): Average factor that is used to average
+ the loss. Defaults to None.
+ reduction_override (str, optional): The reduction method used to
+ override the original reduction method of the loss.
+ Defaults to None.
+
+ Returns:
+ Tensor: Loss tensor.
+ """
+ assert reduction_override in (None, 'none', 'mean', 'sum')
+
+ reduction = (
+ reduction_override if reduction_override else self.reduction)
+
+ loss_kd = self.loss_weight * knowledge_distillation_kl_div_loss(
+ pred,
+ soft_label,
+ weight,
+ reduction=reduction,
+ avg_factor=avg_factor,
+ T=self.T)
+
+ return loss_kd
diff --git a/mmdet/models/losses/mse_loss.py b/mmdet/models/losses/mse_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..6048218ad36a8105e7fa182f40fae93ef7c9268f
--- /dev/null
+++ b/mmdet/models/losses/mse_loss.py
@@ -0,0 +1,69 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional
+
+import torch.nn as nn
+import torch.nn.functional as F
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from .utils import weighted_loss
+
+
+@weighted_loss
+def mse_loss(pred: Tensor, target: Tensor) -> Tensor:
+ """A Wrapper of MSE loss.
+ Args:
+ pred (Tensor): The prediction.
+ target (Tensor): The learning target of the prediction.
+
+ Returns:
+ Tensor: loss Tensor
+ """
+ return F.mse_loss(pred, target, reduction='none')
+
+
+@MODELS.register_module()
+class MSELoss(nn.Module):
+ """MSELoss.
+
+ Args:
+ reduction (str, optional): The method that reduces the loss to a
+ scalar. Options are "none", "mean" and "sum".
+ loss_weight (float, optional): The weight of the loss. Defaults to 1.0
+ """
+
+ def __init__(self,
+ reduction: str = 'mean',
+ loss_weight: float = 1.0) -> None:
+ super().__init__()
+ self.reduction = reduction
+ self.loss_weight = loss_weight
+
+ def forward(self,
+ pred: Tensor,
+ target: Tensor,
+ weight: Optional[Tensor] = None,
+ avg_factor: Optional[int] = None,
+ reduction_override: Optional[str] = None) -> Tensor:
+ """Forward function of loss.
+
+ Args:
+ pred (Tensor): The prediction.
+ target (Tensor): The learning target of the prediction.
+ weight (Tensor, optional): Weight of the loss for each
+ prediction. Defaults to None.
+ avg_factor (int, optional): Average factor that is used to average
+ the loss. Defaults to None.
+ reduction_override (str, optional): The reduction method used to
+ override the original reduction method of the loss.
+ Defaults to None.
+
+ Returns:
+ Tensor: The calculated loss.
+ """
+ assert reduction_override in (None, 'none', 'mean', 'sum')
+ reduction = (
+ reduction_override if reduction_override else self.reduction)
+ loss = self.loss_weight * mse_loss(
+ pred, target, weight, reduction=reduction, avg_factor=avg_factor)
+ return loss
diff --git a/mmdet/models/losses/pisa_loss.py b/mmdet/models/losses/pisa_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..b192aa0dbc7eb554755eb2f242eab0ea7f1fc650
--- /dev/null
+++ b/mmdet/models/losses/pisa_loss.py
@@ -0,0 +1,187 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Optional, Tuple
+
+import torch
+import torch.nn as nn
+from torch import Tensor
+
+from mmdet.structures.bbox import bbox_overlaps
+from ..task_modules.coders import BaseBBoxCoder
+from ..task_modules.samplers import SamplingResult
+
+
+def isr_p(cls_score: Tensor,
+ bbox_pred: Tensor,
+ bbox_targets: Tuple[Tensor],
+ rois: Tensor,
+ sampling_results: List[SamplingResult],
+ loss_cls: nn.Module,
+ bbox_coder: BaseBBoxCoder,
+ k: float = 2,
+ bias: float = 0,
+ num_class: int = 80) -> tuple:
+ """Importance-based Sample Reweighting (ISR_P), positive part.
+
+ Args:
+ cls_score (Tensor): Predicted classification scores.
+ bbox_pred (Tensor): Predicted bbox deltas.
+ bbox_targets (tuple[Tensor]): A tuple of bbox targets, the are
+ labels, label_weights, bbox_targets, bbox_weights, respectively.
+ rois (Tensor): Anchors (single_stage) in shape (n, 4) or RoIs
+ (two_stage) in shape (n, 5).
+ sampling_results (:obj:`SamplingResult`): Sampling results.
+ loss_cls (:obj:`nn.Module`): Classification loss func of the head.
+ bbox_coder (:obj:`BaseBBoxCoder`): BBox coder of the head.
+ k (float): Power of the non-linear mapping. Defaults to 2.
+ bias (float): Shift of the non-linear mapping. Defaults to 0.
+ num_class (int): Number of classes, defaults to 80.
+
+ Return:
+ tuple([Tensor]): labels, imp_based_label_weights, bbox_targets,
+ bbox_target_weights
+ """
+
+ labels, label_weights, bbox_targets, bbox_weights = bbox_targets
+ pos_label_inds = ((labels >= 0) &
+ (labels < num_class)).nonzero().reshape(-1)
+ pos_labels = labels[pos_label_inds]
+
+ # if no positive samples, return the original targets
+ num_pos = float(pos_label_inds.size(0))
+ if num_pos == 0:
+ return labels, label_weights, bbox_targets, bbox_weights
+
+ # merge pos_assigned_gt_inds of per image to a single tensor
+ gts = list()
+ last_max_gt = 0
+ for i in range(len(sampling_results)):
+ gt_i = sampling_results[i].pos_assigned_gt_inds
+ gts.append(gt_i + last_max_gt)
+ if len(gt_i) != 0:
+ last_max_gt = gt_i.max() + 1
+ gts = torch.cat(gts)
+ assert len(gts) == num_pos
+
+ cls_score = cls_score.detach()
+ bbox_pred = bbox_pred.detach()
+
+ # For single stage detectors, rois here indicate anchors, in shape (N, 4)
+ # For two stage detectors, rois are in shape (N, 5)
+ if rois.size(-1) == 5:
+ pos_rois = rois[pos_label_inds][:, 1:]
+ else:
+ pos_rois = rois[pos_label_inds]
+
+ if bbox_pred.size(-1) > 4:
+ bbox_pred = bbox_pred.view(bbox_pred.size(0), -1, 4)
+ pos_delta_pred = bbox_pred[pos_label_inds, pos_labels].view(-1, 4)
+ else:
+ pos_delta_pred = bbox_pred[pos_label_inds].view(-1, 4)
+
+ # compute iou of the predicted bbox and the corresponding GT
+ pos_delta_target = bbox_targets[pos_label_inds].view(-1, 4)
+ pos_bbox_pred = bbox_coder.decode(pos_rois, pos_delta_pred)
+ target_bbox_pred = bbox_coder.decode(pos_rois, pos_delta_target)
+ ious = bbox_overlaps(pos_bbox_pred, target_bbox_pred, is_aligned=True)
+
+ pos_imp_weights = label_weights[pos_label_inds]
+ # Two steps to compute IoU-HLR. Samples are first sorted by IoU locally,
+ # then sorted again within the same-rank group
+ max_l_num = pos_labels.bincount().max()
+ for label in pos_labels.unique():
+ l_inds = (pos_labels == label).nonzero().view(-1)
+ l_gts = gts[l_inds]
+ for t in l_gts.unique():
+ t_inds = l_inds[l_gts == t]
+ t_ious = ious[t_inds]
+ _, t_iou_rank_idx = t_ious.sort(descending=True)
+ _, t_iou_rank = t_iou_rank_idx.sort()
+ ious[t_inds] += max_l_num - t_iou_rank.float()
+ l_ious = ious[l_inds]
+ _, l_iou_rank_idx = l_ious.sort(descending=True)
+ _, l_iou_rank = l_iou_rank_idx.sort() # IoU-HLR
+ # linearly map HLR to label weights
+ pos_imp_weights[l_inds] *= (max_l_num - l_iou_rank.float()) / max_l_num
+
+ pos_imp_weights = (bias + pos_imp_weights * (1 - bias)).pow(k)
+
+ # normalize to make the new weighted loss value equal to the original loss
+ pos_loss_cls = loss_cls(
+ cls_score[pos_label_inds], pos_labels, reduction_override='none')
+ if pos_loss_cls.dim() > 1:
+ ori_pos_loss_cls = pos_loss_cls * label_weights[pos_label_inds][:,
+ None]
+ new_pos_loss_cls = pos_loss_cls * pos_imp_weights[:, None]
+ else:
+ ori_pos_loss_cls = pos_loss_cls * label_weights[pos_label_inds]
+ new_pos_loss_cls = pos_loss_cls * pos_imp_weights
+ pos_loss_cls_ratio = ori_pos_loss_cls.sum() / new_pos_loss_cls.sum()
+ pos_imp_weights = pos_imp_weights * pos_loss_cls_ratio
+ label_weights[pos_label_inds] = pos_imp_weights
+
+ bbox_targets = labels, label_weights, bbox_targets, bbox_weights
+ return bbox_targets
+
+
+def carl_loss(cls_score: Tensor,
+ labels: Tensor,
+ bbox_pred: Tensor,
+ bbox_targets: Tensor,
+ loss_bbox: nn.Module,
+ k: float = 1,
+ bias: float = 0.2,
+ avg_factor: Optional[int] = None,
+ sigmoid: bool = False,
+ num_class: int = 80) -> dict:
+ """Classification-Aware Regression Loss (CARL).
+
+ Args:
+ cls_score (Tensor): Predicted classification scores.
+ labels (Tensor): Targets of classification.
+ bbox_pred (Tensor): Predicted bbox deltas.
+ bbox_targets (Tensor): Target of bbox regression.
+ loss_bbox (func): Regression loss func of the head.
+ bbox_coder (obj): BBox coder of the head.
+ k (float): Power of the non-linear mapping. Defaults to 1.
+ bias (float): Shift of the non-linear mapping. Defaults to 0.2.
+ avg_factor (int, optional): Average factor used in regression loss.
+ sigmoid (bool): Activation of the classification score.
+ num_class (int): Number of classes, defaults to 80.
+
+ Return:
+ dict: CARL loss dict.
+ """
+ pos_label_inds = ((labels >= 0) &
+ (labels < num_class)).nonzero().reshape(-1)
+ if pos_label_inds.numel() == 0:
+ return dict(loss_carl=cls_score.sum()[None] * 0.)
+ pos_labels = labels[pos_label_inds]
+
+ # multiply pos_cls_score with the corresponding bbox weight
+ # and remain gradient
+ if sigmoid:
+ pos_cls_score = cls_score.sigmoid()[pos_label_inds, pos_labels]
+ else:
+ pos_cls_score = cls_score.softmax(-1)[pos_label_inds, pos_labels]
+ carl_loss_weights = (bias + (1 - bias) * pos_cls_score).pow(k)
+
+ # normalize carl_loss_weight to make its sum equal to num positive
+ num_pos = float(pos_cls_score.size(0))
+ weight_ratio = num_pos / carl_loss_weights.sum()
+ carl_loss_weights *= weight_ratio
+
+ if avg_factor is None:
+ avg_factor = bbox_targets.size(0)
+ # if is class agnostic, bbox pred is in shape (N, 4)
+ # otherwise, bbox pred is in shape (N, #classes, 4)
+ if bbox_pred.size(-1) > 4:
+ bbox_pred = bbox_pred.view(bbox_pred.size(0), -1, 4)
+ pos_bbox_preds = bbox_pred[pos_label_inds, pos_labels]
+ else:
+ pos_bbox_preds = bbox_pred[pos_label_inds]
+ ori_loss_reg = loss_bbox(
+ pos_bbox_preds,
+ bbox_targets[pos_label_inds],
+ reduction_override='none') / avg_factor
+ loss_carl = (ori_loss_reg * carl_loss_weights[:, None]).sum()
+ return dict(loss_carl=loss_carl[None])
diff --git a/mmdet/models/losses/seesaw_loss.py b/mmdet/models/losses/seesaw_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..4dec62b0afdc01e848e0c7f53ba0b6b10b899ea4
--- /dev/null
+++ b/mmdet/models/losses/seesaw_loss.py
@@ -0,0 +1,278 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, Optional, Tuple, Union
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from .accuracy import accuracy
+from .cross_entropy_loss import cross_entropy
+from .utils import weight_reduce_loss
+
+
+def seesaw_ce_loss(cls_score: Tensor,
+ labels: Tensor,
+ label_weights: Tensor,
+ cum_samples: Tensor,
+ num_classes: int,
+ p: float,
+ q: float,
+ eps: float,
+ reduction: str = 'mean',
+ avg_factor: Optional[int] = None) -> Tensor:
+ """Calculate the Seesaw CrossEntropy loss.
+
+ Args:
+ cls_score (Tensor): The prediction with shape (N, C),
+ C is the number of classes.
+ labels (Tensor): The learning label of the prediction.
+ label_weights (Tensor): Sample-wise loss weight.
+ cum_samples (Tensor): Cumulative samples for each category.
+ num_classes (int): The number of classes.
+ p (float): The ``p`` in the mitigation factor.
+ q (float): The ``q`` in the compenstation factor.
+ eps (float): The minimal value of divisor to smooth
+ the computation of compensation factor
+ reduction (str, optional): The method used to reduce the loss.
+ avg_factor (int, optional): Average factor that is used to average
+ the loss. Defaults to None.
+
+ Returns:
+ Tensor: The calculated loss
+ """
+ assert cls_score.size(-1) == num_classes
+ assert len(cum_samples) == num_classes
+
+ onehot_labels = F.one_hot(labels, num_classes)
+ seesaw_weights = cls_score.new_ones(onehot_labels.size())
+
+ # mitigation factor
+ if p > 0:
+ sample_ratio_matrix = cum_samples[None, :].clamp(
+ min=1) / cum_samples[:, None].clamp(min=1)
+ index = (sample_ratio_matrix < 1.0).float()
+ sample_weights = sample_ratio_matrix.pow(p) * index + (1 - index)
+ mitigation_factor = sample_weights[labels.long(), :]
+ seesaw_weights = seesaw_weights * mitigation_factor
+
+ # compensation factor
+ if q > 0:
+ scores = F.softmax(cls_score.detach(), dim=1)
+ self_scores = scores[
+ torch.arange(0, len(scores)).to(scores.device).long(),
+ labels.long()]
+ score_matrix = scores / self_scores[:, None].clamp(min=eps)
+ index = (score_matrix > 1.0).float()
+ compensation_factor = score_matrix.pow(q) * index + (1 - index)
+ seesaw_weights = seesaw_weights * compensation_factor
+
+ cls_score = cls_score + (seesaw_weights.log() * (1 - onehot_labels))
+
+ loss = F.cross_entropy(cls_score, labels, weight=None, reduction='none')
+
+ if label_weights is not None:
+ label_weights = label_weights.float()
+ loss = weight_reduce_loss(
+ loss, weight=label_weights, reduction=reduction, avg_factor=avg_factor)
+ return loss
+
+
+@MODELS.register_module()
+class SeesawLoss(nn.Module):
+ """
+ Seesaw Loss for Long-Tailed Instance Segmentation (CVPR 2021)
+ arXiv: https://arxiv.org/abs/2008.10032
+
+ Args:
+ use_sigmoid (bool, optional): Whether the prediction uses sigmoid
+ of softmax. Only False is supported.
+ p (float, optional): The ``p`` in the mitigation factor.
+ Defaults to 0.8.
+ q (float, optional): The ``q`` in the compenstation factor.
+ Defaults to 2.0.
+ num_classes (int, optional): The number of classes.
+ Default to 1203 for LVIS v1 dataset.
+ eps (float, optional): The minimal value of divisor to smooth
+ the computation of compensation factor
+ reduction (str, optional): The method that reduces the loss to a
+ scalar. Options are "none", "mean" and "sum".
+ loss_weight (float, optional): The weight of the loss. Defaults to 1.0
+ return_dict (bool, optional): Whether return the losses as a dict.
+ Default to True.
+ """
+
+ def __init__(self,
+ use_sigmoid: bool = False,
+ p: float = 0.8,
+ q: float = 2.0,
+ num_classes: int = 1203,
+ eps: float = 1e-2,
+ reduction: str = 'mean',
+ loss_weight: float = 1.0,
+ return_dict: bool = True) -> None:
+ super().__init__()
+ assert not use_sigmoid
+ self.use_sigmoid = False
+ self.p = p
+ self.q = q
+ self.num_classes = num_classes
+ self.eps = eps
+ self.reduction = reduction
+ self.loss_weight = loss_weight
+ self.return_dict = return_dict
+
+ # 0 for pos, 1 for neg
+ self.cls_criterion = seesaw_ce_loss
+
+ # cumulative samples for each category
+ self.register_buffer(
+ 'cum_samples',
+ torch.zeros(self.num_classes + 1, dtype=torch.float))
+
+ # custom output channels of the classifier
+ self.custom_cls_channels = True
+ # custom activation of cls_score
+ self.custom_activation = True
+ # custom accuracy of the classsifier
+ self.custom_accuracy = True
+
+ def _split_cls_score(self, cls_score: Tensor) -> Tuple[Tensor, Tensor]:
+ """split cls_score.
+
+ Args:
+ cls_score (Tensor): The prediction with shape (N, C + 2).
+
+ Returns:
+ Tuple[Tensor, Tensor]: The score for classes and objectness,
+ respectively
+ """
+ # split cls_score to cls_score_classes and cls_score_objectness
+ assert cls_score.size(-1) == self.num_classes + 2
+ cls_score_classes = cls_score[..., :-2]
+ cls_score_objectness = cls_score[..., -2:]
+ return cls_score_classes, cls_score_objectness
+
+ def get_cls_channels(self, num_classes: int) -> int:
+ """Get custom classification channels.
+
+ Args:
+ num_classes (int): The number of classes.
+
+ Returns:
+ int: The custom classification channels.
+ """
+ assert num_classes == self.num_classes
+ return num_classes + 2
+
+ def get_activation(self, cls_score: Tensor) -> Tensor:
+ """Get custom activation of cls_score.
+
+ Args:
+ cls_score (Tensor): The prediction with shape (N, C + 2).
+
+ Returns:
+ Tensor: The custom activation of cls_score with shape
+ (N, C + 1).
+ """
+ cls_score_classes, cls_score_objectness = self._split_cls_score(
+ cls_score)
+ score_classes = F.softmax(cls_score_classes, dim=-1)
+ score_objectness = F.softmax(cls_score_objectness, dim=-1)
+ score_pos = score_objectness[..., [0]]
+ score_neg = score_objectness[..., [1]]
+ score_classes = score_classes * score_pos
+ scores = torch.cat([score_classes, score_neg], dim=-1)
+ return scores
+
+ def get_accuracy(self, cls_score: Tensor,
+ labels: Tensor) -> Dict[str, Tensor]:
+ """Get custom accuracy w.r.t. cls_score and labels.
+
+ Args:
+ cls_score (Tensor): The prediction with shape (N, C + 2).
+ labels (Tensor): The learning label of the prediction.
+
+ Returns:
+ Dict [str, Tensor]: The accuracy for objectness and classes,
+ respectively.
+ """
+ pos_inds = labels < self.num_classes
+ obj_labels = (labels == self.num_classes).long()
+ cls_score_classes, cls_score_objectness = self._split_cls_score(
+ cls_score)
+ acc_objectness = accuracy(cls_score_objectness, obj_labels)
+ acc_classes = accuracy(cls_score_classes[pos_inds], labels[pos_inds])
+ acc = dict()
+ acc['acc_objectness'] = acc_objectness
+ acc['acc_classes'] = acc_classes
+ return acc
+
+ def forward(
+ self,
+ cls_score: Tensor,
+ labels: Tensor,
+ label_weights: Optional[Tensor] = None,
+ avg_factor: Optional[int] = None,
+ reduction_override: Optional[str] = None
+ ) -> Union[Tensor, Dict[str, Tensor]]:
+ """Forward function.
+
+ Args:
+ cls_score (Tensor): The prediction with shape (N, C + 2).
+ labels (Tensor): The learning label of the prediction.
+ label_weights (Tensor, optional): Sample-wise loss weight.
+ avg_factor (int, optional): Average factor that is used to average
+ the loss. Defaults to None.
+ reduction (str, optional): The method used to reduce the loss.
+ Options are "none", "mean" and "sum".
+
+ Returns:
+ Tensor | Dict [str, Tensor]:
+ if return_dict == False: The calculated loss |
+ if return_dict == True: The dict of calculated losses
+ for objectness and classes, respectively.
+ """
+ assert reduction_override in (None, 'none', 'mean', 'sum')
+ reduction = (
+ reduction_override if reduction_override else self.reduction)
+ assert cls_score.size(-1) == self.num_classes + 2
+ pos_inds = labels < self.num_classes
+ # 0 for pos, 1 for neg
+ obj_labels = (labels == self.num_classes).long()
+
+ # accumulate the samples for each category
+ unique_labels = labels.unique()
+ for u_l in unique_labels:
+ inds_ = labels == u_l.item()
+ self.cum_samples[u_l] += inds_.sum()
+
+ if label_weights is not None:
+ label_weights = label_weights.float()
+ else:
+ label_weights = labels.new_ones(labels.size(), dtype=torch.float)
+
+ cls_score_classes, cls_score_objectness = self._split_cls_score(
+ cls_score)
+ # calculate loss_cls_classes (only need pos samples)
+ if pos_inds.sum() > 0:
+ loss_cls_classes = self.loss_weight * self.cls_criterion(
+ cls_score_classes[pos_inds], labels[pos_inds],
+ label_weights[pos_inds], self.cum_samples[:self.num_classes],
+ self.num_classes, self.p, self.q, self.eps, reduction,
+ avg_factor)
+ else:
+ loss_cls_classes = cls_score_classes[pos_inds].sum()
+ # calculate loss_cls_objectness
+ loss_cls_objectness = self.loss_weight * cross_entropy(
+ cls_score_objectness, obj_labels, label_weights, reduction,
+ avg_factor)
+
+ if self.return_dict:
+ loss_cls = dict()
+ loss_cls['loss_cls_objectness'] = loss_cls_objectness
+ loss_cls['loss_cls_classes'] = loss_cls_classes
+ else:
+ loss_cls = loss_cls_classes + loss_cls_objectness
+ return loss_cls
diff --git a/mmdet/models/losses/smooth_l1_loss.py b/mmdet/models/losses/smooth_l1_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..fd5f043b8f6886276ab1de574752f78158797e51
--- /dev/null
+++ b/mmdet/models/losses/smooth_l1_loss.py
@@ -0,0 +1,157 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional
+
+import torch
+import torch.nn as nn
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from .utils import weighted_loss
+
+
+@weighted_loss
+def smooth_l1_loss(pred: Tensor, target: Tensor, beta: float = 1.0) -> Tensor:
+ """Smooth L1 loss.
+
+ Args:
+ pred (Tensor): The prediction.
+ target (Tensor): The learning target of the prediction.
+ beta (float, optional): The threshold in the piecewise function.
+ Defaults to 1.0.
+
+ Returns:
+ Tensor: Calculated loss
+ """
+ assert beta > 0
+ if target.numel() == 0:
+ return pred.sum() * 0
+
+ assert pred.size() == target.size()
+ diff = torch.abs(pred - target)
+ loss = torch.where(diff < beta, 0.5 * diff * diff / beta,
+ diff - 0.5 * beta)
+ return loss
+
+
+@weighted_loss
+def l1_loss(pred: Tensor, target: Tensor) -> Tensor:
+ """L1 loss.
+
+ Args:
+ pred (Tensor): The prediction.
+ target (Tensor): The learning target of the prediction.
+
+ Returns:
+ Tensor: Calculated loss
+ """
+ if target.numel() == 0:
+ return pred.sum() * 0
+
+ assert pred.size() == target.size()
+ loss = torch.abs(pred - target)
+ return loss
+
+
+@MODELS.register_module()
+class SmoothL1Loss(nn.Module):
+ """Smooth L1 loss.
+
+ Args:
+ beta (float, optional): The threshold in the piecewise function.
+ Defaults to 1.0.
+ reduction (str, optional): The method to reduce the loss.
+ Options are "none", "mean" and "sum". Defaults to "mean".
+ loss_weight (float, optional): The weight of loss.
+ """
+
+ def __init__(self,
+ beta: float = 1.0,
+ reduction: str = 'mean',
+ loss_weight: float = 1.0) -> None:
+ super().__init__()
+ self.beta = beta
+ self.reduction = reduction
+ self.loss_weight = loss_weight
+
+ def forward(self,
+ pred: Tensor,
+ target: Tensor,
+ weight: Optional[Tensor] = None,
+ avg_factor: Optional[int] = None,
+ reduction_override: Optional[str] = None,
+ **kwargs) -> Tensor:
+ """Forward function.
+
+ Args:
+ pred (Tensor): The prediction.
+ target (Tensor): The learning target of the prediction.
+ weight (Tensor, optional): The weight of loss for each
+ prediction. Defaults to None.
+ avg_factor (int, optional): Average factor that is used to average
+ the loss. Defaults to None.
+ reduction_override (str, optional): The reduction method used to
+ override the original reduction method of the loss.
+ Defaults to None.
+
+ Returns:
+ Tensor: Calculated loss
+ """
+ assert reduction_override in (None, 'none', 'mean', 'sum')
+ reduction = (
+ reduction_override if reduction_override else self.reduction)
+ loss_bbox = self.loss_weight * smooth_l1_loss(
+ pred,
+ target,
+ weight,
+ beta=self.beta,
+ reduction=reduction,
+ avg_factor=avg_factor,
+ **kwargs)
+ return loss_bbox
+
+
+@MODELS.register_module()
+class L1Loss(nn.Module):
+ """L1 loss.
+
+ Args:
+ reduction (str, optional): The method to reduce the loss.
+ Options are "none", "mean" and "sum".
+ loss_weight (float, optional): The weight of loss.
+ """
+
+ def __init__(self,
+ reduction: str = 'mean',
+ loss_weight: float = 1.0) -> None:
+ super().__init__()
+ self.reduction = reduction
+ self.loss_weight = loss_weight
+
+ def forward(self,
+ pred: Tensor,
+ target: Tensor,
+ weight: Optional[Tensor] = None,
+ avg_factor: Optional[int] = None,
+ reduction_override: Optional[str] = None) -> Tensor:
+ """Forward function.
+
+ Args:
+ pred (Tensor): The prediction.
+ target (Tensor): The learning target of the prediction.
+ weight (Tensor, optional): The weight of loss for each
+ prediction. Defaults to None.
+ avg_factor (int, optional): Average factor that is used to average
+ the loss. Defaults to None.
+ reduction_override (str, optional): The reduction method used to
+ override the original reduction method of the loss.
+ Defaults to None.
+
+ Returns:
+ Tensor: Calculated loss
+ """
+ assert reduction_override in (None, 'none', 'mean', 'sum')
+ reduction = (
+ reduction_override if reduction_override else self.reduction)
+ loss_bbox = self.loss_weight * l1_loss(
+ pred, target, weight, reduction=reduction, avg_factor=avg_factor)
+ return loss_bbox
diff --git a/mmdet/models/losses/utils.py b/mmdet/models/losses/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..5e6e7859f353f3e5456f0cfc1f66b4b0ad535427
--- /dev/null
+++ b/mmdet/models/losses/utils.py
@@ -0,0 +1,125 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import functools
+from typing import Callable, Optional
+
+import torch
+import torch.nn.functional as F
+from torch import Tensor
+
+
+def reduce_loss(loss: Tensor, reduction: str) -> Tensor:
+ """Reduce loss as specified.
+
+ Args:
+ loss (Tensor): Elementwise loss tensor.
+ reduction (str): Options are "none", "mean" and "sum".
+
+ Return:
+ Tensor: Reduced loss tensor.
+ """
+ reduction_enum = F._Reduction.get_enum(reduction)
+ # none: 0, elementwise_mean:1, sum: 2
+ if reduction_enum == 0:
+ return loss
+ elif reduction_enum == 1:
+ return loss.mean()
+ elif reduction_enum == 2:
+ return loss.sum()
+
+
+def weight_reduce_loss(loss: Tensor,
+ weight: Optional[Tensor] = None,
+ reduction: str = 'mean',
+ avg_factor: Optional[float] = None) -> Tensor:
+ """Apply element-wise weight and reduce loss.
+
+ Args:
+ loss (Tensor): Element-wise loss.
+ weight (Optional[Tensor], optional): Element-wise weights.
+ Defaults to None.
+ reduction (str, optional): Same as built-in losses of PyTorch.
+ Defaults to 'mean'.
+ avg_factor (Optional[float], optional): Average factor when
+ computing the mean of losses. Defaults to None.
+
+ Returns:
+ Tensor: Processed loss values.
+ """
+ # if weight is specified, apply element-wise weight
+ if weight is not None:
+ loss = loss * weight
+
+ # if avg_factor is not specified, just reduce the loss
+ if avg_factor is None:
+ loss = reduce_loss(loss, reduction)
+ else:
+ # if reduction is mean, then average the loss by avg_factor
+ if reduction == 'mean':
+ # Avoid causing ZeroDivisionError when avg_factor is 0.0,
+ # i.e., all labels of an image belong to ignore index.
+ eps = torch.finfo(torch.float32).eps
+ loss = loss.sum() / (avg_factor + eps)
+ # if reduction is 'none', then do nothing, otherwise raise an error
+ elif reduction != 'none':
+ raise ValueError('avg_factor can not be used with reduction="sum"')
+ return loss
+
+
+def weighted_loss(loss_func: Callable) -> Callable:
+ """Create a weighted version of a given loss function.
+
+ To use this decorator, the loss function must have the signature like
+ `loss_func(pred, target, **kwargs)`. The function only needs to compute
+ element-wise loss without any reduction. This decorator will add weight
+ and reduction arguments to the function. The decorated function will have
+ the signature like `loss_func(pred, target, weight=None, reduction='mean',
+ avg_factor=None, **kwargs)`.
+
+ :Example:
+
+ >>> import torch
+ >>> @weighted_loss
+ >>> def l1_loss(pred, target):
+ >>> return (pred - target).abs()
+
+ >>> pred = torch.Tensor([0, 2, 3])
+ >>> target = torch.Tensor([1, 1, 1])
+ >>> weight = torch.Tensor([1, 0, 1])
+
+ >>> l1_loss(pred, target)
+ tensor(1.3333)
+ >>> l1_loss(pred, target, weight)
+ tensor(1.)
+ >>> l1_loss(pred, target, reduction='none')
+ tensor([1., 1., 2.])
+ >>> l1_loss(pred, target, weight, avg_factor=2)
+ tensor(1.5000)
+ """
+
+ @functools.wraps(loss_func)
+ def wrapper(pred: Tensor,
+ target: Tensor,
+ weight: Optional[Tensor] = None,
+ reduction: str = 'mean',
+ avg_factor: Optional[int] = None,
+ **kwargs) -> Tensor:
+ """
+ Args:
+ pred (Tensor): The prediction.
+ target (Tensor): Target bboxes.
+ weight (Optional[Tensor], optional): The weight of loss for each
+ prediction. Defaults to None.
+ reduction (str, optional): Options are "none", "mean" and "sum".
+ Defaults to 'mean'.
+ avg_factor (Optional[int], optional): Average factor that is used
+ to average the loss. Defaults to None.
+
+ Returns:
+ Tensor: Loss tensor.
+ """
+ # get element-wise loss
+ loss = loss_func(pred, target, **kwargs)
+ loss = weight_reduce_loss(loss, weight, reduction, avg_factor)
+ return loss
+
+ return wrapper
diff --git a/mmdet/models/losses/varifocal_loss.py b/mmdet/models/losses/varifocal_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..58ab167352e1ae32566f5e731339966d5fd10759
--- /dev/null
+++ b/mmdet/models/losses/varifocal_loss.py
@@ -0,0 +1,141 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional
+
+import torch.nn as nn
+import torch.nn.functional as F
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from .utils import weight_reduce_loss
+
+
+def varifocal_loss(pred: Tensor,
+ target: Tensor,
+ weight: Optional[Tensor] = None,
+ alpha: float = 0.75,
+ gamma: float = 2.0,
+ iou_weighted: bool = True,
+ reduction: str = 'mean',
+ avg_factor: Optional[int] = None) -> Tensor:
+ """`Varifocal Loss `_
+
+ Args:
+ pred (Tensor): The prediction with shape (N, C), C is the
+ number of classes.
+ target (Tensor): The learning target of the iou-aware
+ classification score with shape (N, C), C is the number of classes.
+ weight (Tensor, optional): The weight of loss for each
+ prediction. Defaults to None.
+ alpha (float, optional): A balance factor for the negative part of
+ Varifocal Loss, which is different from the alpha of Focal Loss.
+ Defaults to 0.75.
+ gamma (float, optional): The gamma for calculating the modulating
+ factor. Defaults to 2.0.
+ iou_weighted (bool, optional): Whether to weight the loss of the
+ positive example with the iou target. Defaults to True.
+ reduction (str, optional): The method used to reduce the loss into
+ a scalar. Defaults to 'mean'. Options are "none", "mean" and
+ "sum".
+ avg_factor (int, optional): Average factor that is used to average
+ the loss. Defaults to None.
+
+ Returns:
+ Tensor: Loss tensor.
+ """
+ # pred and target should be of the same size
+ assert pred.size() == target.size()
+ pred_sigmoid = pred.sigmoid()
+ target = target.type_as(pred)
+ if iou_weighted:
+ focal_weight = target * (target > 0.0).float() + \
+ alpha * (pred_sigmoid - target).abs().pow(gamma) * \
+ (target <= 0.0).float()
+ else:
+ focal_weight = (target > 0.0).float() + \
+ alpha * (pred_sigmoid - target).abs().pow(gamma) * \
+ (target <= 0.0).float()
+ loss = F.binary_cross_entropy_with_logits(
+ pred, target, reduction='none') * focal_weight
+ loss = weight_reduce_loss(loss, weight, reduction, avg_factor)
+ return loss
+
+
+@MODELS.register_module()
+class VarifocalLoss(nn.Module):
+
+ def __init__(self,
+ use_sigmoid: bool = True,
+ alpha: float = 0.75,
+ gamma: float = 2.0,
+ iou_weighted: bool = True,
+ reduction: str = 'mean',
+ loss_weight: float = 1.0) -> None:
+ """`Varifocal Loss `_
+
+ Args:
+ use_sigmoid (bool, optional): Whether the prediction is
+ used for sigmoid or softmax. Defaults to True.
+ alpha (float, optional): A balance factor for the negative part of
+ Varifocal Loss, which is different from the alpha of Focal
+ Loss. Defaults to 0.75.
+ gamma (float, optional): The gamma for calculating the modulating
+ factor. Defaults to 2.0.
+ iou_weighted (bool, optional): Whether to weight the loss of the
+ positive examples with the iou target. Defaults to True.
+ reduction (str, optional): The method used to reduce the loss into
+ a scalar. Defaults to 'mean'. Options are "none", "mean" and
+ "sum".
+ loss_weight (float, optional): Weight of loss. Defaults to 1.0.
+ """
+ super().__init__()
+ assert use_sigmoid is True, \
+ 'Only sigmoid varifocal loss supported now.'
+ assert alpha >= 0.0
+ self.use_sigmoid = use_sigmoid
+ self.alpha = alpha
+ self.gamma = gamma
+ self.iou_weighted = iou_weighted
+ self.reduction = reduction
+ self.loss_weight = loss_weight
+
+ def forward(self,
+ pred: Tensor,
+ target: Tensor,
+ weight: Optional[Tensor] = None,
+ avg_factor: Optional[int] = None,
+ reduction_override: Optional[str] = None) -> Tensor:
+ """Forward function.
+
+ Args:
+ pred (Tensor): The prediction with shape (N, C), C is the
+ number of classes.
+ target (Tensor): The learning target of the iou-aware
+ classification score with shape (N, C), C is
+ the number of classes.
+ weight (Tensor, optional): The weight of loss for each
+ prediction. Defaults to None.
+ avg_factor (int, optional): Average factor that is used to average
+ the loss. Defaults to None.
+ reduction_override (str, optional): The reduction method used to
+ override the original reduction method of the loss.
+ Options are "none", "mean" and "sum".
+
+ Returns:
+ Tensor: The calculated loss
+ """
+ assert reduction_override in (None, 'none', 'mean', 'sum')
+ reduction = (
+ reduction_override if reduction_override else self.reduction)
+ if self.use_sigmoid:
+ loss_cls = self.loss_weight * varifocal_loss(
+ pred,
+ target,
+ weight,
+ alpha=self.alpha,
+ gamma=self.gamma,
+ iou_weighted=self.iou_weighted,
+ reduction=reduction,
+ avg_factor=avg_factor)
+ else:
+ raise NotImplementedError
+ return loss_cls
diff --git a/mmdet/models/necks/__init__.py b/mmdet/models/necks/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..9bc7cadce2bd0e115464bdafdef2d4718ecb332b
--- /dev/null
+++ b/mmdet/models/necks/__init__.py
@@ -0,0 +1,29 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .bfp import BFP
+from .channel_mapper import ChannelMapper
+from .cspnext_pafpn import CSPNeXtPAFPN
+from .ct_resnet_neck import CTResNetNeck
+from .dilated_encoder import DilatedEncoder
+from .dyhead import DyHead
+from .fpg import FPG
+from .fpn import FPN
+from .fpn_carafe import FPN_CARAFE
+from .hrfpn import HRFPN
+from .nas_fpn import NASFPN
+from .nasfcos_fpn import NASFCOS_FPN
+from .pafpn import PAFPN
+from .rfp import RFP
+from .ssd_neck import SSDNeck
+from .ssh import SSH
+from .yolo_neck import YOLOV3Neck
+from .yolox_pafpn import YOLOXPAFPN
+
+# added by lzx
+from .channel_mapper_st import ChannelMapperST
+
+__all__ = [
+ 'FPN', 'BFP', 'ChannelMapper', 'HRFPN', 'NASFPN', 'FPN_CARAFE', 'PAFPN',
+ 'NASFCOS_FPN', 'RFP', 'YOLOV3Neck', 'FPG', 'DilatedEncoder',
+ 'CTResNetNeck', 'SSDNeck', 'YOLOXPAFPN', 'DyHead', 'CSPNeXtPAFPN', 'SSH',
+ 'ChannelMapperST'
+]
diff --git a/mmdet/models/necks/__pycache__/__init__.cpython-37.pyc b/mmdet/models/necks/__pycache__/__init__.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..85dc8ddc2f84f236bfc5032edd488949b87ce2e9
Binary files /dev/null and b/mmdet/models/necks/__pycache__/__init__.cpython-37.pyc differ
diff --git a/mmdet/models/necks/__pycache__/bfp.cpython-37.pyc b/mmdet/models/necks/__pycache__/bfp.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..48d80b5b8094518026aca6df3608d4d035b01aae
Binary files /dev/null and b/mmdet/models/necks/__pycache__/bfp.cpython-37.pyc differ
diff --git a/mmdet/models/necks/__pycache__/channel_mapper.cpython-37.pyc b/mmdet/models/necks/__pycache__/channel_mapper.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..69723e1302734b1ccf64894c8ba59d19508b8fb5
Binary files /dev/null and b/mmdet/models/necks/__pycache__/channel_mapper.cpython-37.pyc differ
diff --git a/mmdet/models/necks/__pycache__/channel_mapper_st.cpython-37.pyc b/mmdet/models/necks/__pycache__/channel_mapper_st.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..d5e369268b06bb6cfff4c09179c75a86068b0832
Binary files /dev/null and b/mmdet/models/necks/__pycache__/channel_mapper_st.cpython-37.pyc differ
diff --git a/mmdet/models/necks/__pycache__/cspnext_pafpn.cpython-37.pyc b/mmdet/models/necks/__pycache__/cspnext_pafpn.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..85d34df1d5cf396dbc7ff05fcedd636664df096d
Binary files /dev/null and b/mmdet/models/necks/__pycache__/cspnext_pafpn.cpython-37.pyc differ
diff --git a/mmdet/models/necks/__pycache__/ct_resnet_neck.cpython-37.pyc b/mmdet/models/necks/__pycache__/ct_resnet_neck.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..0d437c37038dacc08a745e86938a72fe280001f9
Binary files /dev/null and b/mmdet/models/necks/__pycache__/ct_resnet_neck.cpython-37.pyc differ
diff --git a/mmdet/models/necks/__pycache__/dilated_encoder.cpython-37.pyc b/mmdet/models/necks/__pycache__/dilated_encoder.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..5c5d243eb71feed114ccfe26148f852b6db3d25c
Binary files /dev/null and b/mmdet/models/necks/__pycache__/dilated_encoder.cpython-37.pyc differ
diff --git a/mmdet/models/necks/__pycache__/dyhead.cpython-37.pyc b/mmdet/models/necks/__pycache__/dyhead.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..0e459bf2b2e431dea24ceab11cfa9a391668a429
Binary files /dev/null and b/mmdet/models/necks/__pycache__/dyhead.cpython-37.pyc differ
diff --git a/mmdet/models/necks/__pycache__/fpg.cpython-37.pyc b/mmdet/models/necks/__pycache__/fpg.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..23970cf2684dff26845f91f9800be1d745793520
Binary files /dev/null and b/mmdet/models/necks/__pycache__/fpg.cpython-37.pyc differ
diff --git a/mmdet/models/necks/__pycache__/fpn.cpython-37.pyc b/mmdet/models/necks/__pycache__/fpn.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..19a6c5c7967e87a90f36ce54e1ec2291c4ab4667
Binary files /dev/null and b/mmdet/models/necks/__pycache__/fpn.cpython-37.pyc differ
diff --git a/mmdet/models/necks/__pycache__/fpn_carafe.cpython-37.pyc b/mmdet/models/necks/__pycache__/fpn_carafe.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..66383ab1202b6fded438f967b6302ee49a268558
Binary files /dev/null and b/mmdet/models/necks/__pycache__/fpn_carafe.cpython-37.pyc differ
diff --git a/mmdet/models/necks/__pycache__/hrfpn.cpython-37.pyc b/mmdet/models/necks/__pycache__/hrfpn.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..cf78cbc0d08d3dc43e8a536c2432a2f20216d9b6
Binary files /dev/null and b/mmdet/models/necks/__pycache__/hrfpn.cpython-37.pyc differ
diff --git a/mmdet/models/necks/__pycache__/nas_fpn.cpython-37.pyc b/mmdet/models/necks/__pycache__/nas_fpn.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..279dfa42ee1e74f5cb934d45fd86c94fe997117a
Binary files /dev/null and b/mmdet/models/necks/__pycache__/nas_fpn.cpython-37.pyc differ
diff --git a/mmdet/models/necks/__pycache__/nasfcos_fpn.cpython-37.pyc b/mmdet/models/necks/__pycache__/nasfcos_fpn.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..c82aa0742c92ca1ae475d76773d53979c5aea98f
Binary files /dev/null and b/mmdet/models/necks/__pycache__/nasfcos_fpn.cpython-37.pyc differ
diff --git a/mmdet/models/necks/__pycache__/pafpn.cpython-37.pyc b/mmdet/models/necks/__pycache__/pafpn.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..02dbd05775ee14c90598c68ee5158183b7381649
Binary files /dev/null and b/mmdet/models/necks/__pycache__/pafpn.cpython-37.pyc differ
diff --git a/mmdet/models/necks/__pycache__/rfp.cpython-37.pyc b/mmdet/models/necks/__pycache__/rfp.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..6ae4533440e7c0dbc9ab2c550534f9341731729e
Binary files /dev/null and b/mmdet/models/necks/__pycache__/rfp.cpython-37.pyc differ
diff --git a/mmdet/models/necks/__pycache__/ssd_neck.cpython-37.pyc b/mmdet/models/necks/__pycache__/ssd_neck.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..d19f2ec1ff9eaab4446e34099a3622ef6baadded
Binary files /dev/null and b/mmdet/models/necks/__pycache__/ssd_neck.cpython-37.pyc differ
diff --git a/mmdet/models/necks/__pycache__/ssh.cpython-37.pyc b/mmdet/models/necks/__pycache__/ssh.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..df8a84ce563a5c01faeb4e1a39893446da118f88
Binary files /dev/null and b/mmdet/models/necks/__pycache__/ssh.cpython-37.pyc differ
diff --git a/mmdet/models/necks/__pycache__/yolo_neck.cpython-37.pyc b/mmdet/models/necks/__pycache__/yolo_neck.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..bc4450f3e42a3381975be4aea7ff50bc47f0dffb
Binary files /dev/null and b/mmdet/models/necks/__pycache__/yolo_neck.cpython-37.pyc differ
diff --git a/mmdet/models/necks/__pycache__/yolox_pafpn.cpython-37.pyc b/mmdet/models/necks/__pycache__/yolox_pafpn.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..141e9a86050f7f186fb5ef2cc9c32151d19afec8
Binary files /dev/null and b/mmdet/models/necks/__pycache__/yolox_pafpn.cpython-37.pyc differ
diff --git a/mmdet/models/necks/bfp.py b/mmdet/models/necks/bfp.py
new file mode 100644
index 0000000000000000000000000000000000000000..401cdb0f552b06c9e8eb185c3e8ae0ba7112a9d8
--- /dev/null
+++ b/mmdet/models/necks/bfp.py
@@ -0,0 +1,111 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Tuple
+
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule
+from mmcv.cnn.bricks import NonLocal2d
+from mmengine.model import BaseModule
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.utils import OptConfigType, OptMultiConfig
+
+
+@MODELS.register_module()
+class BFP(BaseModule):
+ """BFP (Balanced Feature Pyramids)
+
+ BFP takes multi-level features as inputs and gather them into a single one,
+ then refine the gathered feature and scatter the refined results to
+ multi-level features. This module is used in Libra R-CNN (CVPR 2019), see
+ the paper `Libra R-CNN: Towards Balanced Learning for Object Detection
+ `_ for details.
+
+ Args:
+ in_channels (int): Number of input channels (feature maps of all levels
+ should have the same channels).
+ num_levels (int): Number of input feature levels.
+ refine_level (int): Index of integration and refine level of BSF in
+ multi-level features from bottom to top.
+ refine_type (str): Type of the refine op, currently support
+ [None, 'conv', 'non_local'].
+ conv_cfg (:obj:`ConfigDict` or dict, optional): The config dict for
+ convolution layers.
+ norm_cfg (:obj:`ConfigDict` or dict, optional): The config dict for
+ normalization layers.
+ init_cfg (:obj:`ConfigDict` or dict or list[:obj:`ConfigDict` or
+ dict], optional): Initialization config dict.
+ """
+
+ def __init__(
+ self,
+ in_channels: int,
+ num_levels: int,
+ refine_level: int = 2,
+ refine_type: str = None,
+ conv_cfg: OptConfigType = None,
+ norm_cfg: OptConfigType = None,
+ init_cfg: OptMultiConfig = dict(
+ type='Xavier', layer='Conv2d', distribution='uniform')
+ ) -> None:
+ super().__init__(init_cfg=init_cfg)
+ assert refine_type in [None, 'conv', 'non_local']
+
+ self.in_channels = in_channels
+ self.num_levels = num_levels
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+
+ self.refine_level = refine_level
+ self.refine_type = refine_type
+ assert 0 <= self.refine_level < self.num_levels
+
+ if self.refine_type == 'conv':
+ self.refine = ConvModule(
+ self.in_channels,
+ self.in_channels,
+ 3,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg)
+ elif self.refine_type == 'non_local':
+ self.refine = NonLocal2d(
+ self.in_channels,
+ reduction=1,
+ use_scale=False,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg)
+
+ def forward(self, inputs: Tuple[Tensor]) -> Tuple[Tensor]:
+ """Forward function."""
+ assert len(inputs) == self.num_levels
+
+ # step 1: gather multi-level features by resize and average
+ feats = []
+ gather_size = inputs[self.refine_level].size()[2:]
+ for i in range(self.num_levels):
+ if i < self.refine_level:
+ gathered = F.adaptive_max_pool2d(
+ inputs[i], output_size=gather_size)
+ else:
+ gathered = F.interpolate(
+ inputs[i], size=gather_size, mode='nearest')
+ feats.append(gathered)
+
+ bsf = sum(feats) / len(feats)
+
+ # step 2: refine gathered features
+ if self.refine_type is not None:
+ bsf = self.refine(bsf)
+
+ # step 3: scatter refined features to multi-levels by a residual path
+ outs = []
+ for i in range(self.num_levels):
+ out_size = inputs[i].size()[2:]
+ if i < self.refine_level:
+ residual = F.interpolate(bsf, size=out_size, mode='nearest')
+ else:
+ residual = F.adaptive_max_pool2d(bsf, output_size=out_size)
+ outs.append(residual + inputs[i])
+
+ return tuple(outs)
diff --git a/mmdet/models/necks/channel_mapper.py b/mmdet/models/necks/channel_mapper.py
new file mode 100644
index 0000000000000000000000000000000000000000..9700a2b3e7296661cc0c988d86152fe8fb03eaf6
--- /dev/null
+++ b/mmdet/models/necks/channel_mapper.py
@@ -0,0 +1,106 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Tuple
+
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+from mmengine.model import BaseModule
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.utils import OptConfigType, OptMultiConfig
+
+
+@MODELS.register_module()
+class ChannelMapper(BaseModule):
+ """Channel Mapper to reduce/increase channels of backbone features.
+
+ This is used to reduce/increase channels of backbone features.
+
+ Args:
+ in_channels (List[int]): Number of input channels per scale.
+ out_channels (int): Number of output channels (used at each scale).
+ kernel_size (int, optional): kernel_size for reducing channels (used
+ at each scale). Default: 3.
+ conv_cfg (:obj:`ConfigDict` or dict, optional): Config dict for
+ convolution layer. Default: None.
+ norm_cfg (:obj:`ConfigDict` or dict, optional): Config dict for
+ normalization layer. Default: None.
+ act_cfg (:obj:`ConfigDict` or dict, optional): Config dict for
+ activation layer in ConvModule. Default: dict(type='ReLU').
+ num_outs (int, optional): Number of output feature maps. There would
+ be extra_convs when num_outs larger than the length of in_channels.
+ init_cfg (:obj:`ConfigDict` or dict or list[:obj:`ConfigDict` or dict],
+ optional): Initialization config dict.
+ Example:
+ >>> import torch
+ >>> in_channels = [2, 3, 5, 7]
+ >>> scales = [340, 170, 84, 43]
+ >>> inputs = [torch.rand(1, c, s, s)
+ ... for c, s in zip(in_channels, scales)]
+ >>> self = ChannelMapper(in_channels, 11, 3).eval()
+ >>> outputs = self.forward(inputs)
+ >>> for i in range(len(outputs)):
+ ... print(f'outputs[{i}].shape = {outputs[i].shape}')
+ outputs[0].shape = torch.Size([1, 11, 340, 340])
+ outputs[1].shape = torch.Size([1, 11, 170, 170])
+ outputs[2].shape = torch.Size([1, 11, 84, 84])
+ outputs[3].shape = torch.Size([1, 11, 43, 43])
+ """
+
+ def __init__(
+ self,
+ in_channels: List[int],
+ out_channels: int,
+ kernel_size: int = 3,
+ conv_cfg: OptConfigType = None,
+ norm_cfg: OptConfigType = None,
+ act_cfg: OptConfigType = dict(type='ReLU'),
+ num_outs: int = None,
+ init_cfg: OptMultiConfig = dict(
+ type='Xavier', layer='Conv2d', distribution='uniform')
+ ) -> None:
+ super().__init__(init_cfg=init_cfg)
+ assert isinstance(in_channels, list)
+ self.extra_convs = None
+ if num_outs is None:
+ num_outs = len(in_channels)
+ self.convs = nn.ModuleList()
+ for in_channel in in_channels:
+ self.convs.append(
+ ConvModule(
+ in_channel,
+ out_channels,
+ kernel_size,
+ padding=(kernel_size - 1) // 2,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+ if num_outs > len(in_channels):
+ self.extra_convs = nn.ModuleList()
+ for i in range(len(in_channels), num_outs):
+ if i == len(in_channels):
+ in_channel = in_channels[-1]
+ else:
+ in_channel = out_channels
+ self.extra_convs.append(
+ ConvModule(
+ in_channel,
+ out_channels,
+ 3,
+ stride=2,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+
+ def forward(self, inputs: Tuple[Tensor]) -> Tuple[Tensor]:
+ """Forward function."""
+ assert len(inputs) == len(self.convs)
+ outs = [self.convs[i](inputs[i]) for i in range(len(inputs))]
+ if self.extra_convs:
+ for i in range(len(self.extra_convs)):
+ if i == 0:
+ outs.append(self.extra_convs[0](inputs[-1]))
+ else:
+ outs.append(self.extra_convs[i](outs[-1]))
+ return tuple(outs)
diff --git a/mmdet/models/necks/channel_mapper1.py b/mmdet/models/necks/channel_mapper1.py
new file mode 100644
index 0000000000000000000000000000000000000000..0b182aa29b3ef339029391024a3739c59a7b9549
--- /dev/null
+++ b/mmdet/models/necks/channel_mapper1.py
@@ -0,0 +1,127 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Tuple
+
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+from mmengine.model import BaseModule
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.utils import OptConfigType, OptMultiConfig
+
+
+@MODELS.register_module()
+class ChannelMapper(BaseModule):
+ """Channel Mapper to reduce/increase channels of backbone features.
+
+ This is used to reduce/increase channels of backbone features.
+
+ Args:
+ in_channels (List[int]): Number of input channels per scale.
+ out_channels (int): Number of output channels (used at each scale).
+ kernel_size (int, optional): kernel_size for reducing channels (used
+ at each scale). Default: 3.
+ conv_cfg (:obj:`ConfigDict` or dict, optional): Config dict for
+ convolution layer. Default: None.
+ norm_cfg (:obj:`ConfigDict` or dict, optional): Config dict for
+ normalization layer. Default: None.
+ act_cfg (:obj:`ConfigDict` or dict, optional): Config dict for
+ activation layer in ConvModule. Default: dict(type='ReLU').
+ num_outs (int, optional): Number of output feature maps. There would
+ be extra_convs when num_outs larger than the length of in_channels.
+ init_cfg (:obj:`ConfigDict` or dict or list[:obj:`ConfigDict` or dict],
+ optional): Initialization config dict.
+ Example:
+ >>> import torch
+ >>> in_channels = [2, 3, 5, 7]
+ >>> scales = [340, 170, 84, 43]
+ >>> inputs = [torch.rand(1, c, s, s)
+ ... for c, s in zip(in_channels, scales)]
+ >>> self = ChannelMapper(in_channels, 11, 3).eval()
+ >>> outputs = self.forward(inputs)
+ >>> for i in range(len(outputs)):
+ ... print(f'outputs[{i}].shape = {outputs[i].shape}')
+ outputs[0].shape = torch.Size([1, 11, 340, 340])
+ outputs[1].shape = torch.Size([1, 11, 170, 170])
+ outputs[2].shape = torch.Size([1, 11, 84, 84])
+ outputs[3].shape = torch.Size([1, 11, 43, 43])
+ """
+
+ def __init__(
+ self,
+ in_channels: List[int],
+ out_channels: int,
+ kernel_size: int = 3,
+ conv_cfg: OptConfigType = None,
+ norm_cfg: OptConfigType = None,
+ act_cfg: OptConfigType = dict(type='ReLU'),
+ num_outs: int = None,
+ init_cfg: OptMultiConfig = dict(
+ type='Xavier', layer='Conv2d', distribution='uniform')
+ ) -> None:
+ super().__init__(init_cfg=init_cfg)
+ assert isinstance(in_channels, list)
+ self.extra_convs = None
+ if num_outs is None:
+ num_outs = len(in_channels)
+ self.convs = nn.ModuleList()
+ for in_channel in in_channels:
+ self.convs.append(
+ ConvModule(
+ in_channel,
+ out_channels,
+ kernel_size,
+ padding=(kernel_size - 1) // 2,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+ if num_outs > len(in_channels):
+ self.extra_convs = nn.ModuleList()
+ for i in range(len(in_channels), num_outs):
+ if i == len(in_channels):
+ in_channel = in_channels[-1]
+ else:
+ in_channel = out_channels
+ # self.extra_convs.append(
+ # ConvModule(
+ # in_channel,
+ # out_channels,
+ # 3,
+ # stride=2,
+ # padding=1,
+ # conv_cfg=conv_cfg,
+ # norm_cfg=norm_cfg,
+ # act_cfg=act_cfg))
+ self.extra_convs.append(
+ ConvModule(
+ in_channel,
+ out_channels,
+ 32,
+ stride=32,
+ padding=0,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+ self.extra_convs.append(
+ ConvModule(
+ out_channels,
+ out_channels,
+ 4,
+ stride=4,
+ padding=0,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+
+ def forward(self, inputs: Tuple[Tensor]) -> Tuple[Tensor]:
+ """Forward function."""
+ assert len(inputs) == len(self.convs)
+ outs = [self.convs[i](inputs[i]) for i in range(len(inputs))]
+ if self.extra_convs:
+ outs.append(self.extra_convs[1](self.extra_convs[0](inputs[-1])))
+ # for i in range(len(self.extra_convs)):
+ # if i == 0:
+ # outs.append(self.extra_convs[0](inputs[-1]))
+ # else:
+ # outs.append(self.extra_convs[i](outs[-1]))
+ return tuple(outs)
diff --git a/mmdet/models/necks/channel_mapper_st.py b/mmdet/models/necks/channel_mapper_st.py
new file mode 100644
index 0000000000000000000000000000000000000000..0a64db6cf039243d0385cc7e5ab78b845b530d7e
--- /dev/null
+++ b/mmdet/models/necks/channel_mapper_st.py
@@ -0,0 +1,131 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Tuple
+
+import torch.nn as nn
+import torch
+from mmcv.cnn import ConvModule
+from mmengine.model import BaseModule
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.utils import OptConfigType, OptMultiConfig
+
+
+@MODELS.register_module()
+class ChannelMapperST(BaseModule):
+ """Channel Mapper to reduce/increase channels of backbone features.
+
+ This is used to reduce/increase channels of backbone features.
+
+ Args:
+ in_channels (List[int]): Number of input channels per scale.
+ out_channels (int): Number of output channels (used at each scale).
+ kernel_size (int, optional): kernel_size for reducing channels (used
+ at each scale). Default: 3.
+ conv_cfg (:obj:`ConfigDict` or dict, optional): Config dict for
+ convolution layer. Default: None.
+ norm_cfg (:obj:`ConfigDict` or dict, optional): Config dict for
+ normalization layer. Default: None.
+ act_cfg (:obj:`ConfigDict` or dict, optional): Config dict for
+ activation layer in ConvModule. Default: dict(type='ReLU').
+ num_outs (int, optional): Number of output feature maps. There would
+ be extra_convs when num_outs larger than the length of in_channels.
+ init_cfg (:obj:`ConfigDict` or dict or list[:obj:`ConfigDict` or dict],
+ optional): Initialization config dict.
+ Example:
+ >>> import torch
+ >>> in_channels = [2, 3, 5, 7]
+ >>> scales = [340, 170, 84, 43]
+ >>> inputs = [torch.rand(1, c, s, s)
+ ... for c, s in zip(in_channels, scales)]
+ >>> self = ChannelMapper(in_channels, 11, 3).eval()
+ >>> outputs = self.forward(inputs)
+ >>> for i in range(len(outputs)):
+ ... print(f'outputs[{i}].shape = {outputs[i].shape}')
+ outputs[0].shape = torch.Size([1, 11, 340, 340])
+ outputs[1].shape = torch.Size([1, 11, 170, 170])
+ outputs[2].shape = torch.Size([1, 11, 84, 84])
+ outputs[3].shape = torch.Size([1, 11, 43, 43])
+ """
+
+ def __init__(
+ self,
+ in_channels: List[int],
+ out_channels: int,
+ kernel_size: int = 3,
+ conv_cfg: OptConfigType = None,
+ norm_cfg: OptConfigType = None,
+ act_cfg: OptConfigType = dict(type='ReLU'),
+ num_outs: int = None,
+ init_cfg: OptMultiConfig = dict(
+ type='Xavier', layer='Conv2d', distribution='uniform')
+ ) -> None:
+ super().__init__(init_cfg=init_cfg)
+ assert isinstance(in_channels, list)
+ self.extra_convs = None
+ if num_outs is None:
+ num_outs = len(in_channels)
+ self.convs = nn.ModuleList()
+ for in_channel in in_channels:
+ self.convs.append(
+ ConvModule(
+ in_channel,
+ out_channels,
+ kernel_size,
+ padding=(kernel_size - 1) // 2,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+ if num_outs > len(in_channels):
+ self.extra_convs = nn.ModuleList()
+ for i in range(len(in_channels), num_outs):
+ if i == len(in_channels):
+ in_channel = in_channels[-1]
+ else:
+ in_channel = out_channels
+ # self.extra_convs.append(
+ # ConvModule(
+ # in_channel,
+ # out_channels,
+ # 3,
+ # stride=2,
+ # padding=1,
+ # conv_cfg=conv_cfg,
+ # norm_cfg=norm_cfg,
+ # act_cfg=act_cfg))
+ self.extra_convs.append(
+ ConvModule(
+ in_channel,
+ out_channels,
+ 32,
+ stride=32,
+ padding=0,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+ self.extra_convs.append(
+ ConvModule(
+ out_channels,
+ out_channels,
+ 4,
+ stride=4,
+ padding=0,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+
+ def forward(self, inputs: Tuple[Tensor]) -> Tuple[Tensor]:
+ """Forward function."""
+ assert len(inputs) == len(self.convs)
+ outs = [self.convs[i](inputs[i]) for i in range(len(inputs))]
+ # outs = inputs
+ mean = outs[0].mean(dim=(2, 3), keepdim=True).detach()
+ outs.append(mean)
+ # if self.extra_convs:
+ # outs.append(self.extra_convs[1](self.extra_convs[0](inputs[-1])))
+ # for i in range(len(self.extra_convs)):
+ # if i == 0:
+ # outs.append(self.extra_convs[0](inputs[-1]))
+ # else:
+ # outs.append(self.extra_convs[i](outs[-1]))
+ return tuple(outs)
diff --git a/mmdet/models/necks/cspnext_pafpn.py b/mmdet/models/necks/cspnext_pafpn.py
new file mode 100644
index 0000000000000000000000000000000000000000..a52ba72d9b3e48c4866fb16507bc2118eb23010e
--- /dev/null
+++ b/mmdet/models/necks/cspnext_pafpn.py
@@ -0,0 +1,170 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+from typing import Sequence, Tuple
+
+import torch
+import torch.nn as nn
+from mmcv.cnn import ConvModule, DepthwiseSeparableConvModule
+from mmengine.model import BaseModule
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.utils import ConfigType, OptMultiConfig
+from ..layers import CSPLayer
+
+
+@MODELS.register_module()
+class CSPNeXtPAFPN(BaseModule):
+ """Path Aggregation Network with CSPNeXt blocks.
+
+ Args:
+ in_channels (Sequence[int]): Number of input channels per scale.
+ out_channels (int): Number of output channels (used at each scale)
+ num_csp_blocks (int): Number of bottlenecks in CSPLayer.
+ Defaults to 3.
+ use_depthwise (bool): Whether to use depthwise separable convolution in
+ blocks. Defaults to False.
+ expand_ratio (float): Ratio to adjust the number of channels of the
+ hidden layer. Default: 0.5
+ upsample_cfg (dict): Config dict for interpolate layer.
+ Default: `dict(scale_factor=2, mode='nearest')`
+ conv_cfg (dict, optional): Config dict for convolution layer.
+ Default: None, which means using conv2d.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='BN')
+ act_cfg (dict): Config dict for activation layer.
+ Default: dict(type='Swish')
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+ """
+
+ def __init__(
+ self,
+ in_channels: Sequence[int],
+ out_channels: int,
+ num_csp_blocks: int = 3,
+ use_depthwise: bool = False,
+ expand_ratio: float = 0.5,
+ upsample_cfg: ConfigType = dict(scale_factor=2, mode='nearest'),
+ conv_cfg: bool = None,
+ norm_cfg: ConfigType = dict(type='BN', momentum=0.03, eps=0.001),
+ act_cfg: ConfigType = dict(type='Swish'),
+ init_cfg: OptMultiConfig = dict(
+ type='Kaiming',
+ layer='Conv2d',
+ a=math.sqrt(5),
+ distribution='uniform',
+ mode='fan_in',
+ nonlinearity='leaky_relu')
+ ) -> None:
+ super().__init__(init_cfg)
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+
+ conv = DepthwiseSeparableConvModule if use_depthwise else ConvModule
+
+ # build top-down blocks
+ self.upsample = nn.Upsample(**upsample_cfg)
+ self.reduce_layers = nn.ModuleList()
+ self.top_down_blocks = nn.ModuleList()
+ for idx in range(len(in_channels) - 1, 0, -1):
+ self.reduce_layers.append(
+ ConvModule(
+ in_channels[idx],
+ in_channels[idx - 1],
+ 1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+ self.top_down_blocks.append(
+ CSPLayer(
+ in_channels[idx - 1] * 2,
+ in_channels[idx - 1],
+ num_blocks=num_csp_blocks,
+ add_identity=False,
+ use_depthwise=use_depthwise,
+ use_cspnext_block=True,
+ expand_ratio=expand_ratio,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+
+ # build bottom-up blocks
+ self.downsamples = nn.ModuleList()
+ self.bottom_up_blocks = nn.ModuleList()
+ for idx in range(len(in_channels) - 1):
+ self.downsamples.append(
+ conv(
+ in_channels[idx],
+ in_channels[idx],
+ 3,
+ stride=2,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+ self.bottom_up_blocks.append(
+ CSPLayer(
+ in_channels[idx] * 2,
+ in_channels[idx + 1],
+ num_blocks=num_csp_blocks,
+ add_identity=False,
+ use_depthwise=use_depthwise,
+ use_cspnext_block=True,
+ expand_ratio=expand_ratio,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+
+ self.out_convs = nn.ModuleList()
+ for i in range(len(in_channels)):
+ self.out_convs.append(
+ conv(
+ in_channels[i],
+ out_channels,
+ 3,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+
+ def forward(self, inputs: Tuple[Tensor, ...]) -> Tuple[Tensor, ...]:
+ """
+ Args:
+ inputs (tuple[Tensor]): input features.
+
+ Returns:
+ tuple[Tensor]: YOLOXPAFPN features.
+ """
+ assert len(inputs) == len(self.in_channels)
+
+ # top-down path
+ inner_outs = [inputs[-1]]
+ for idx in range(len(self.in_channels) - 1, 0, -1):
+ feat_heigh = inner_outs[0]
+ feat_low = inputs[idx - 1]
+ feat_heigh = self.reduce_layers[len(self.in_channels) - 1 - idx](
+ feat_heigh)
+ inner_outs[0] = feat_heigh
+
+ upsample_feat = self.upsample(feat_heigh)
+
+ inner_out = self.top_down_blocks[len(self.in_channels) - 1 - idx](
+ torch.cat([upsample_feat, feat_low], 1))
+ inner_outs.insert(0, inner_out)
+
+ # bottom-up path
+ outs = [inner_outs[0]]
+ for idx in range(len(self.in_channels) - 1):
+ feat_low = outs[-1]
+ feat_height = inner_outs[idx + 1]
+ downsample_feat = self.downsamples[idx](feat_low)
+ out = self.bottom_up_blocks[idx](
+ torch.cat([downsample_feat, feat_height], 1))
+ outs.append(out)
+
+ # out convs
+ for idx, conv in enumerate(self.out_convs):
+ outs[idx] = conv(outs[idx])
+
+ return tuple(outs)
diff --git a/mmdet/models/necks/ct_resnet_neck.py b/mmdet/models/necks/ct_resnet_neck.py
new file mode 100644
index 0000000000000000000000000000000000000000..9109fe79290fafecd954f223d5365ef619c0c301
--- /dev/null
+++ b/mmdet/models/necks/ct_resnet_neck.py
@@ -0,0 +1,102 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+from typing import Sequence, Tuple
+
+import torch
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+from mmengine.model import BaseModule
+
+from mmdet.registry import MODELS
+from mmdet.utils import OptMultiConfig
+
+
+@MODELS.register_module()
+class CTResNetNeck(BaseModule):
+ """The neck used in `CenterNet `_ for
+ object classification and box regression.
+
+ Args:
+ in_channels (int): Number of input channels.
+ num_deconv_filters (tuple[int]): Number of filters per stage.
+ num_deconv_kernels (tuple[int]): Number of kernels per stage.
+ use_dcn (bool): If True, use DCNv2. Defaults to True.
+ init_cfg (:obj:`ConfigDict` or dict or list[dict] or
+ list[:obj:`ConfigDict`], optional): Initialization
+ config dict.
+ """
+
+ def __init__(self,
+ in_channels: int,
+ num_deconv_filters: Tuple[int, ...],
+ num_deconv_kernels: Tuple[int, ...],
+ use_dcn: bool = True,
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(init_cfg=init_cfg)
+ assert len(num_deconv_filters) == len(num_deconv_kernels)
+ self.fp16_enabled = False
+ self.use_dcn = use_dcn
+ self.in_channels = in_channels
+ self.deconv_layers = self._make_deconv_layer(num_deconv_filters,
+ num_deconv_kernels)
+
+ def _make_deconv_layer(
+ self, num_deconv_filters: Tuple[int, ...],
+ num_deconv_kernels: Tuple[int, ...]) -> nn.Sequential:
+ """use deconv layers to upsample backbone's output."""
+ layers = []
+ for i in range(len(num_deconv_filters)):
+ feat_channels = num_deconv_filters[i]
+ conv_module = ConvModule(
+ self.in_channels,
+ feat_channels,
+ 3,
+ padding=1,
+ conv_cfg=dict(type='DCNv2') if self.use_dcn else None,
+ norm_cfg=dict(type='BN'))
+ layers.append(conv_module)
+ upsample_module = ConvModule(
+ feat_channels,
+ feat_channels,
+ num_deconv_kernels[i],
+ stride=2,
+ padding=1,
+ conv_cfg=dict(type='deconv'),
+ norm_cfg=dict(type='BN'))
+ layers.append(upsample_module)
+ self.in_channels = feat_channels
+
+ return nn.Sequential(*layers)
+
+ def init_weights(self) -> None:
+ """Initialize the parameters."""
+ for m in self.modules():
+ if isinstance(m, nn.ConvTranspose2d):
+ # In order to be consistent with the source code,
+ # reset the ConvTranspose2d initialization parameters
+ m.reset_parameters()
+ # Simulated bilinear upsampling kernel
+ w = m.weight.data
+ f = math.ceil(w.size(2) / 2)
+ c = (2 * f - 1 - f % 2) / (2. * f)
+ for i in range(w.size(2)):
+ for j in range(w.size(3)):
+ w[0, 0, i, j] = \
+ (1 - math.fabs(i / f - c)) * (
+ 1 - math.fabs(j / f - c))
+ for c in range(1, w.size(0)):
+ w[c, 0, :, :] = w[0, 0, :, :]
+ elif isinstance(m, nn.BatchNorm2d):
+ nn.init.constant_(m.weight, 1)
+ nn.init.constant_(m.bias, 0)
+ # self.use_dcn is False
+ elif not self.use_dcn and isinstance(m, nn.Conv2d):
+ # In order to be consistent with the source code,
+ # reset the Conv2d initialization parameters
+ m.reset_parameters()
+
+ def forward(self, x: Sequence[torch.Tensor]) -> Tuple[torch.Tensor]:
+ """model forward."""
+ assert isinstance(x, (list, tuple))
+ outs = self.deconv_layers(x[-1])
+ return outs,
diff --git a/mmdet/models/necks/dilated_encoder.py b/mmdet/models/necks/dilated_encoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..e9beb3ea9b4289da8d0100ae7759927f045829bb
--- /dev/null
+++ b/mmdet/models/necks/dilated_encoder.py
@@ -0,0 +1,109 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch.nn as nn
+from mmcv.cnn import ConvModule, is_norm
+from mmengine.model import caffe2_xavier_init, constant_init, normal_init
+from torch.nn import BatchNorm2d
+
+from mmdet.registry import MODELS
+
+
+class Bottleneck(nn.Module):
+ """Bottleneck block for DilatedEncoder used in `YOLOF.
+
+ `.
+
+ The Bottleneck contains three ConvLayers and one residual connection.
+
+ Args:
+ in_channels (int): The number of input channels.
+ mid_channels (int): The number of middle output channels.
+ dilation (int): Dilation rate.
+ norm_cfg (dict): Dictionary to construct and config norm layer.
+ """
+
+ def __init__(self,
+ in_channels,
+ mid_channels,
+ dilation,
+ norm_cfg=dict(type='BN', requires_grad=True)):
+ super(Bottleneck, self).__init__()
+ self.conv1 = ConvModule(
+ in_channels, mid_channels, 1, norm_cfg=norm_cfg)
+ self.conv2 = ConvModule(
+ mid_channels,
+ mid_channels,
+ 3,
+ padding=dilation,
+ dilation=dilation,
+ norm_cfg=norm_cfg)
+ self.conv3 = ConvModule(
+ mid_channels, in_channels, 1, norm_cfg=norm_cfg)
+
+ def forward(self, x):
+ identity = x
+ out = self.conv1(x)
+ out = self.conv2(out)
+ out = self.conv3(out)
+ out = out + identity
+ return out
+
+
+@MODELS.register_module()
+class DilatedEncoder(nn.Module):
+ """Dilated Encoder for YOLOF `.
+
+ This module contains two types of components:
+ - the original FPN lateral convolution layer and fpn convolution layer,
+ which are 1x1 conv + 3x3 conv
+ - the dilated residual block
+
+ Args:
+ in_channels (int): The number of input channels.
+ out_channels (int): The number of output channels.
+ block_mid_channels (int): The number of middle block output channels
+ num_residual_blocks (int): The number of residual blocks.
+ block_dilations (list): The list of residual blocks dilation.
+ """
+
+ def __init__(self, in_channels, out_channels, block_mid_channels,
+ num_residual_blocks, block_dilations):
+ super(DilatedEncoder, self).__init__()
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.block_mid_channels = block_mid_channels
+ self.num_residual_blocks = num_residual_blocks
+ self.block_dilations = block_dilations
+ self._init_layers()
+
+ def _init_layers(self):
+ self.lateral_conv = nn.Conv2d(
+ self.in_channels, self.out_channels, kernel_size=1)
+ self.lateral_norm = BatchNorm2d(self.out_channels)
+ self.fpn_conv = nn.Conv2d(
+ self.out_channels, self.out_channels, kernel_size=3, padding=1)
+ self.fpn_norm = BatchNorm2d(self.out_channels)
+ encoder_blocks = []
+ for i in range(self.num_residual_blocks):
+ dilation = self.block_dilations[i]
+ encoder_blocks.append(
+ Bottleneck(
+ self.out_channels,
+ self.block_mid_channels,
+ dilation=dilation))
+ self.dilated_encoder_blocks = nn.Sequential(*encoder_blocks)
+
+ def init_weights(self):
+ caffe2_xavier_init(self.lateral_conv)
+ caffe2_xavier_init(self.fpn_conv)
+ for m in [self.lateral_norm, self.fpn_norm]:
+ constant_init(m, 1)
+ for m in self.dilated_encoder_blocks.modules():
+ if isinstance(m, nn.Conv2d):
+ normal_init(m, mean=0, std=0.01)
+ if is_norm(m):
+ constant_init(m, 1)
+
+ def forward(self, feature):
+ out = self.lateral_norm(self.lateral_conv(feature[-1]))
+ out = self.fpn_norm(self.fpn_conv(out))
+ return self.dilated_encoder_blocks(out),
diff --git a/mmdet/models/necks/dyhead.py b/mmdet/models/necks/dyhead.py
new file mode 100644
index 0000000000000000000000000000000000000000..5f5ae0b285c20558a0c7bcc59cbb7b214684eab2
--- /dev/null
+++ b/mmdet/models/necks/dyhead.py
@@ -0,0 +1,173 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import build_activation_layer, build_norm_layer
+from mmcv.ops.modulated_deform_conv import ModulatedDeformConv2d
+from mmengine.model import BaseModule, constant_init, normal_init
+
+from mmdet.registry import MODELS
+from ..layers import DyReLU
+
+# Reference:
+# https://github.com/microsoft/DynamicHead
+# https://github.com/jshilong/SEPC
+
+
+class DyDCNv2(nn.Module):
+ """ModulatedDeformConv2d with normalization layer used in DyHead.
+
+ This module cannot be configured with `conv_cfg=dict(type='DCNv2')`
+ because DyHead calculates offset and mask from middle-level feature.
+
+ Args:
+ in_channels (int): Number of input channels.
+ out_channels (int): Number of output channels.
+ stride (int | tuple[int], optional): Stride of the convolution.
+ Default: 1.
+ norm_cfg (dict, optional): Config dict for normalization layer.
+ Default: dict(type='GN', num_groups=16, requires_grad=True).
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ stride=1,
+ norm_cfg=dict(type='GN', num_groups=16, requires_grad=True)):
+ super().__init__()
+ self.with_norm = norm_cfg is not None
+ bias = not self.with_norm
+ self.conv = ModulatedDeformConv2d(
+ in_channels, out_channels, 3, stride=stride, padding=1, bias=bias)
+ if self.with_norm:
+ self.norm = build_norm_layer(norm_cfg, out_channels)[1]
+
+ def forward(self, x, offset, mask):
+ """Forward function."""
+ x = self.conv(x.contiguous(), offset, mask)
+ if self.with_norm:
+ x = self.norm(x)
+ return x
+
+
+class DyHeadBlock(nn.Module):
+ """DyHead Block with three types of attention.
+
+ HSigmoid arguments in default act_cfg follow official code, not paper.
+ https://github.com/microsoft/DynamicHead/blob/master/dyhead/dyrelu.py
+
+ Args:
+ in_channels (int): Number of input channels.
+ out_channels (int): Number of output channels.
+ zero_init_offset (bool, optional): Whether to use zero init for
+ `spatial_conv_offset`. Default: True.
+ act_cfg (dict, optional): Config dict for the last activation layer of
+ scale-aware attention. Default: dict(type='HSigmoid', bias=3.0,
+ divisor=6.0).
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ zero_init_offset=True,
+ act_cfg=dict(type='HSigmoid', bias=3.0, divisor=6.0)):
+ super().__init__()
+ self.zero_init_offset = zero_init_offset
+ # (offset_x, offset_y, mask) * kernel_size_y * kernel_size_x
+ self.offset_and_mask_dim = 3 * 3 * 3
+ self.offset_dim = 2 * 3 * 3
+
+ self.spatial_conv_high = DyDCNv2(in_channels, out_channels)
+ self.spatial_conv_mid = DyDCNv2(in_channels, out_channels)
+ self.spatial_conv_low = DyDCNv2(in_channels, out_channels, stride=2)
+ self.spatial_conv_offset = nn.Conv2d(
+ in_channels, self.offset_and_mask_dim, 3, padding=1)
+ self.scale_attn_module = nn.Sequential(
+ nn.AdaptiveAvgPool2d(1), nn.Conv2d(out_channels, 1, 1),
+ nn.ReLU(inplace=True), build_activation_layer(act_cfg))
+ self.task_attn_module = DyReLU(out_channels)
+ self._init_weights()
+
+ def _init_weights(self):
+ for m in self.modules():
+ if isinstance(m, nn.Conv2d):
+ normal_init(m, 0, 0.01)
+ if self.zero_init_offset:
+ constant_init(self.spatial_conv_offset, 0)
+
+ def forward(self, x):
+ """Forward function."""
+ outs = []
+ for level in range(len(x)):
+ # calculate offset and mask of DCNv2 from middle-level feature
+ offset_and_mask = self.spatial_conv_offset(x[level])
+ offset = offset_and_mask[:, :self.offset_dim, :, :]
+ mask = offset_and_mask[:, self.offset_dim:, :, :].sigmoid()
+
+ mid_feat = self.spatial_conv_mid(x[level], offset, mask)
+ sum_feat = mid_feat * self.scale_attn_module(mid_feat)
+ summed_levels = 1
+ if level > 0:
+ low_feat = self.spatial_conv_low(x[level - 1], offset, mask)
+ sum_feat += low_feat * self.scale_attn_module(low_feat)
+ summed_levels += 1
+ if level < len(x) - 1:
+ # this upsample order is weird, but faster than natural order
+ # https://github.com/microsoft/DynamicHead/issues/25
+ high_feat = F.interpolate(
+ self.spatial_conv_high(x[level + 1], offset, mask),
+ size=x[level].shape[-2:],
+ mode='bilinear',
+ align_corners=True)
+ sum_feat += high_feat * self.scale_attn_module(high_feat)
+ summed_levels += 1
+ outs.append(self.task_attn_module(sum_feat / summed_levels))
+
+ return outs
+
+
+@MODELS.register_module()
+class DyHead(BaseModule):
+ """DyHead neck consisting of multiple DyHead Blocks.
+
+ See `Dynamic Head: Unifying Object Detection Heads with Attentions
+ `_ for details.
+
+ Args:
+ in_channels (int): Number of input channels.
+ out_channels (int): Number of output channels.
+ num_blocks (int, optional): Number of DyHead Blocks. Default: 6.
+ zero_init_offset (bool, optional): Whether to use zero init for
+ `spatial_conv_offset`. Default: True.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ num_blocks=6,
+ zero_init_offset=True,
+ init_cfg=None):
+ assert init_cfg is None, 'To prevent abnormal initialization ' \
+ 'behavior, init_cfg is not allowed to be set'
+ super().__init__(init_cfg=init_cfg)
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.num_blocks = num_blocks
+ self.zero_init_offset = zero_init_offset
+
+ dyhead_blocks = []
+ for i in range(num_blocks):
+ in_channels = self.in_channels if i == 0 else self.out_channels
+ dyhead_blocks.append(
+ DyHeadBlock(
+ in_channels,
+ self.out_channels,
+ zero_init_offset=zero_init_offset))
+ self.dyhead_blocks = nn.Sequential(*dyhead_blocks)
+
+ def forward(self, inputs):
+ """Forward function."""
+ assert isinstance(inputs, (tuple, list))
+ outs = self.dyhead_blocks(inputs)
+ return tuple(outs)
diff --git a/mmdet/models/necks/fpg.py b/mmdet/models/necks/fpg.py
new file mode 100644
index 0000000000000000000000000000000000000000..73ee799bb83645ab2556fe871dcd8b1c5bbff89e
--- /dev/null
+++ b/mmdet/models/necks/fpg.py
@@ -0,0 +1,406 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule
+from mmengine.model import BaseModule
+
+from mmdet.registry import MODELS
+
+
+class Transition(BaseModule):
+ """Base class for transition.
+
+ Args:
+ in_channels (int): Number of input channels.
+ out_channels (int): Number of output channels.
+ """
+
+ def __init__(self, in_channels, out_channels, init_cfg=None):
+ super().__init__(init_cfg)
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+
+ def forward(x):
+ pass
+
+
+class UpInterpolationConv(Transition):
+ """A transition used for up-sampling.
+
+ Up-sample the input by interpolation then refines the feature by
+ a convolution layer.
+
+ Args:
+ in_channels (int): Number of input channels.
+ out_channels (int): Number of output channels.
+ scale_factor (int): Up-sampling factor. Default: 2.
+ mode (int): Interpolation mode. Default: nearest.
+ align_corners (bool): Whether align corners when interpolation.
+ Default: None.
+ kernel_size (int): Kernel size for the conv. Default: 3.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ scale_factor=2,
+ mode='nearest',
+ align_corners=None,
+ kernel_size=3,
+ init_cfg=None,
+ **kwargs):
+ super().__init__(in_channels, out_channels, init_cfg)
+ self.mode = mode
+ self.scale_factor = scale_factor
+ self.align_corners = align_corners
+ self.conv = ConvModule(
+ in_channels,
+ out_channels,
+ kernel_size,
+ padding=(kernel_size - 1) // 2,
+ **kwargs)
+
+ def forward(self, x):
+ x = F.interpolate(
+ x,
+ scale_factor=self.scale_factor,
+ mode=self.mode,
+ align_corners=self.align_corners)
+ x = self.conv(x)
+ return x
+
+
+class LastConv(Transition):
+ """A transition used for refining the output of the last stage.
+
+ Args:
+ in_channels (int): Number of input channels.
+ out_channels (int): Number of output channels.
+ num_inputs (int): Number of inputs of the FPN features.
+ kernel_size (int): Kernel size for the conv. Default: 3.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ num_inputs,
+ kernel_size=3,
+ init_cfg=None,
+ **kwargs):
+ super().__init__(in_channels, out_channels, init_cfg)
+ self.num_inputs = num_inputs
+ self.conv_out = ConvModule(
+ in_channels,
+ out_channels,
+ kernel_size,
+ padding=(kernel_size - 1) // 2,
+ **kwargs)
+
+ def forward(self, inputs):
+ assert len(inputs) == self.num_inputs
+ return self.conv_out(inputs[-1])
+
+
+@MODELS.register_module()
+class FPG(BaseModule):
+ """FPG.
+
+ Implementation of `Feature Pyramid Grids (FPG)
+ `_.
+ This implementation only gives the basic structure stated in the paper.
+ But users can implement different type of transitions to fully explore the
+ the potential power of the structure of FPG.
+
+ Args:
+ in_channels (int): Number of input channels (feature maps of all levels
+ should have the same channels).
+ out_channels (int): Number of output channels (used at each scale)
+ num_outs (int): Number of output scales.
+ stack_times (int): The number of times the pyramid architecture will
+ be stacked.
+ paths (list[str]): Specify the path order of each stack level.
+ Each element in the list should be either 'bu' (bottom-up) or
+ 'td' (top-down).
+ inter_channels (int): Number of inter channels.
+ same_up_trans (dict): Transition that goes down at the same stage.
+ same_down_trans (dict): Transition that goes up at the same stage.
+ across_lateral_trans (dict): Across-pathway same-stage
+ across_down_trans (dict): Across-pathway bottom-up connection.
+ across_up_trans (dict): Across-pathway top-down connection.
+ across_skip_trans (dict): Across-pathway skip connection.
+ output_trans (dict): Transition that trans the output of the
+ last stage.
+ start_level (int): Index of the start input backbone level used to
+ build the feature pyramid. Default: 0.
+ end_level (int): Index of the end input backbone level (exclusive) to
+ build the feature pyramid. Default: -1, which means the last level.
+ add_extra_convs (bool): It decides whether to add conv
+ layers on top of the original feature maps. Default to False.
+ If True, its actual mode is specified by `extra_convs_on_inputs`.
+ norm_cfg (dict): Config dict for normalization layer. Default: None.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ """
+
+ transition_types = {
+ 'conv': ConvModule,
+ 'interpolation_conv': UpInterpolationConv,
+ 'last_conv': LastConv,
+ }
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ num_outs,
+ stack_times,
+ paths,
+ inter_channels=None,
+ same_down_trans=None,
+ same_up_trans=dict(
+ type='conv', kernel_size=3, stride=2, padding=1),
+ across_lateral_trans=dict(type='conv', kernel_size=1),
+ across_down_trans=dict(type='conv', kernel_size=3),
+ across_up_trans=None,
+ across_skip_trans=dict(type='identity'),
+ output_trans=dict(type='last_conv', kernel_size=3),
+ start_level=0,
+ end_level=-1,
+ add_extra_convs=False,
+ norm_cfg=None,
+ skip_inds=None,
+ init_cfg=[
+ dict(type='Caffe2Xavier', layer='Conv2d'),
+ dict(
+ type='Constant',
+ layer=[
+ '_BatchNorm', '_InstanceNorm', 'GroupNorm',
+ 'LayerNorm'
+ ],
+ val=1.0)
+ ]):
+ super(FPG, self).__init__(init_cfg)
+ assert isinstance(in_channels, list)
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.num_ins = len(in_channels)
+ self.num_outs = num_outs
+ if inter_channels is None:
+ self.inter_channels = [out_channels for _ in range(num_outs)]
+ elif isinstance(inter_channels, int):
+ self.inter_channels = [inter_channels for _ in range(num_outs)]
+ else:
+ assert isinstance(inter_channels, list)
+ assert len(inter_channels) == num_outs
+ self.inter_channels = inter_channels
+ self.stack_times = stack_times
+ self.paths = paths
+ assert isinstance(paths, list) and len(paths) == stack_times
+ for d in paths:
+ assert d in ('bu', 'td')
+
+ self.same_down_trans = same_down_trans
+ self.same_up_trans = same_up_trans
+ self.across_lateral_trans = across_lateral_trans
+ self.across_down_trans = across_down_trans
+ self.across_up_trans = across_up_trans
+ self.output_trans = output_trans
+ self.across_skip_trans = across_skip_trans
+
+ self.with_bias = norm_cfg is None
+ # skip inds must be specified if across skip trans is not None
+ if self.across_skip_trans is not None:
+ skip_inds is not None
+ self.skip_inds = skip_inds
+ assert len(self.skip_inds[0]) <= self.stack_times
+
+ if end_level == -1 or end_level == self.num_ins - 1:
+ self.backbone_end_level = self.num_ins
+ assert num_outs >= self.num_ins - start_level
+ else:
+ # if end_level is not the last level, no extra level is allowed
+ self.backbone_end_level = end_level + 1
+ assert end_level < self.num_ins
+ assert num_outs == end_level - start_level + 1
+ self.start_level = start_level
+ self.end_level = end_level
+ self.add_extra_convs = add_extra_convs
+
+ # build lateral 1x1 convs to reduce channels
+ self.lateral_convs = nn.ModuleList()
+ for i in range(self.start_level, self.backbone_end_level):
+ l_conv = nn.Conv2d(self.in_channels[i],
+ self.inter_channels[i - self.start_level], 1)
+ self.lateral_convs.append(l_conv)
+
+ extra_levels = num_outs - self.backbone_end_level + self.start_level
+ self.extra_downsamples = nn.ModuleList()
+ for i in range(extra_levels):
+ if self.add_extra_convs:
+ fpn_idx = self.backbone_end_level - self.start_level + i
+ extra_conv = nn.Conv2d(
+ self.inter_channels[fpn_idx - 1],
+ self.inter_channels[fpn_idx],
+ 3,
+ stride=2,
+ padding=1)
+ self.extra_downsamples.append(extra_conv)
+ else:
+ self.extra_downsamples.append(nn.MaxPool2d(1, stride=2))
+
+ self.fpn_transitions = nn.ModuleList() # stack times
+ for s in range(self.stack_times):
+ stage_trans = nn.ModuleList() # num of feature levels
+ for i in range(self.num_outs):
+ # same, across_lateral, across_down, across_up
+ trans = nn.ModuleDict()
+ if s in self.skip_inds[i]:
+ stage_trans.append(trans)
+ continue
+ # build same-stage down trans (used in bottom-up paths)
+ if i == 0 or self.same_up_trans is None:
+ same_up_trans = None
+ else:
+ same_up_trans = self.build_trans(
+ self.same_up_trans, self.inter_channels[i - 1],
+ self.inter_channels[i])
+ trans['same_up'] = same_up_trans
+ # build same-stage up trans (used in top-down paths)
+ if i == self.num_outs - 1 or self.same_down_trans is None:
+ same_down_trans = None
+ else:
+ same_down_trans = self.build_trans(
+ self.same_down_trans, self.inter_channels[i + 1],
+ self.inter_channels[i])
+ trans['same_down'] = same_down_trans
+ # build across lateral trans
+ across_lateral_trans = self.build_trans(
+ self.across_lateral_trans, self.inter_channels[i],
+ self.inter_channels[i])
+ trans['across_lateral'] = across_lateral_trans
+ # build across down trans
+ if i == self.num_outs - 1 or self.across_down_trans is None:
+ across_down_trans = None
+ else:
+ across_down_trans = self.build_trans(
+ self.across_down_trans, self.inter_channels[i + 1],
+ self.inter_channels[i])
+ trans['across_down'] = across_down_trans
+ # build across up trans
+ if i == 0 or self.across_up_trans is None:
+ across_up_trans = None
+ else:
+ across_up_trans = self.build_trans(
+ self.across_up_trans, self.inter_channels[i - 1],
+ self.inter_channels[i])
+ trans['across_up'] = across_up_trans
+ if self.across_skip_trans is None:
+ across_skip_trans = None
+ else:
+ across_skip_trans = self.build_trans(
+ self.across_skip_trans, self.inter_channels[i - 1],
+ self.inter_channels[i])
+ trans['across_skip'] = across_skip_trans
+ # build across_skip trans
+ stage_trans.append(trans)
+ self.fpn_transitions.append(stage_trans)
+
+ self.output_transition = nn.ModuleList() # output levels
+ for i in range(self.num_outs):
+ trans = self.build_trans(
+ self.output_trans,
+ self.inter_channels[i],
+ self.out_channels,
+ num_inputs=self.stack_times + 1)
+ self.output_transition.append(trans)
+
+ self.relu = nn.ReLU(inplace=True)
+
+ def build_trans(self, cfg, in_channels, out_channels, **extra_args):
+ cfg_ = cfg.copy()
+ trans_type = cfg_.pop('type')
+ trans_cls = self.transition_types[trans_type]
+ return trans_cls(in_channels, out_channels, **cfg_, **extra_args)
+
+ def fuse(self, fuse_dict):
+ out = None
+ for item in fuse_dict.values():
+ if item is not None:
+ if out is None:
+ out = item
+ else:
+ out = out + item
+ return out
+
+ def forward(self, inputs):
+ assert len(inputs) == len(self.in_channels)
+
+ # build all levels from original feature maps
+ feats = [
+ lateral_conv(inputs[i + self.start_level])
+ for i, lateral_conv in enumerate(self.lateral_convs)
+ ]
+ for downsample in self.extra_downsamples:
+ feats.append(downsample(feats[-1]))
+
+ outs = [feats]
+
+ for i in range(self.stack_times):
+ current_outs = outs[-1]
+ next_outs = []
+ direction = self.paths[i]
+ for j in range(self.num_outs):
+ if i in self.skip_inds[j]:
+ next_outs.append(outs[-1][j])
+ continue
+ # feature level
+ if direction == 'td':
+ lvl = self.num_outs - j - 1
+ else:
+ lvl = j
+ # get transitions
+ if direction == 'td':
+ same_trans = self.fpn_transitions[i][lvl]['same_down']
+ else:
+ same_trans = self.fpn_transitions[i][lvl]['same_up']
+ across_lateral_trans = self.fpn_transitions[i][lvl][
+ 'across_lateral']
+ across_down_trans = self.fpn_transitions[i][lvl]['across_down']
+ across_up_trans = self.fpn_transitions[i][lvl]['across_up']
+ across_skip_trans = self.fpn_transitions[i][lvl]['across_skip']
+ # init output
+ to_fuse = dict(
+ same=None, lateral=None, across_up=None, across_down=None)
+ # same downsample/upsample
+ if same_trans is not None:
+ to_fuse['same'] = same_trans(next_outs[-1])
+ # across lateral
+ if across_lateral_trans is not None:
+ to_fuse['lateral'] = across_lateral_trans(
+ current_outs[lvl])
+ # across downsample
+ if lvl > 0 and across_up_trans is not None:
+ to_fuse['across_up'] = across_up_trans(current_outs[lvl -
+ 1])
+ # across upsample
+ if (lvl < self.num_outs - 1 and across_down_trans is not None):
+ to_fuse['across_down'] = across_down_trans(
+ current_outs[lvl + 1])
+ if across_skip_trans is not None:
+ to_fuse['across_skip'] = across_skip_trans(outs[0][lvl])
+ x = self.fuse(to_fuse)
+ next_outs.append(x)
+
+ if direction == 'td':
+ outs.append(next_outs[::-1])
+ else:
+ outs.append(next_outs)
+
+ # output trans
+ final_outs = []
+ for i in range(self.num_outs):
+ lvl_out_list = []
+ for s in range(len(outs)):
+ lvl_out_list.append(outs[s][i])
+ lvl_out = self.output_transition[i](lvl_out_list)
+ final_outs.append(lvl_out)
+
+ return final_outs
diff --git a/mmdet/models/necks/fpn.py b/mmdet/models/necks/fpn.py
new file mode 100644
index 0000000000000000000000000000000000000000..67bd8879641f8539f329e6ffb94f88d25e417244
--- /dev/null
+++ b/mmdet/models/necks/fpn.py
@@ -0,0 +1,221 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Tuple, Union
+
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule
+from mmengine.model import BaseModule
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.utils import ConfigType, MultiConfig, OptConfigType
+
+
+@MODELS.register_module()
+class FPN(BaseModule):
+ r"""Feature Pyramid Network.
+
+ This is an implementation of paper `Feature Pyramid Networks for Object
+ Detection `_.
+
+ Args:
+ in_channels (list[int]): Number of input channels per scale.
+ out_channels (int): Number of output channels (used at each scale).
+ num_outs (int): Number of output scales.
+ start_level (int): Index of the start input backbone level used to
+ build the feature pyramid. Defaults to 0.
+ end_level (int): Index of the end input backbone level (exclusive) to
+ build the feature pyramid. Defaults to -1, which means the
+ last level.
+ add_extra_convs (bool | str): If bool, it decides whether to add conv
+ layers on top of the original feature maps. Defaults to False.
+ If True, it is equivalent to `add_extra_convs='on_input'`.
+ If str, it specifies the source feature map of the extra convs.
+ Only the following options are allowed
+
+ - 'on_input': Last feat map of neck inputs (i.e. backbone feature).
+ - 'on_lateral': Last feature map after lateral convs.
+ - 'on_output': The last output feature map after fpn convs.
+ relu_before_extra_convs (bool): Whether to apply relu before the extra
+ conv. Defaults to False.
+ no_norm_on_lateral (bool): Whether to apply norm on lateral.
+ Defaults to False.
+ conv_cfg (:obj:`ConfigDict` or dict, optional): Config dict for
+ convolution layer. Defaults to None.
+ norm_cfg (:obj:`ConfigDict` or dict, optional): Config dict for
+ normalization layer. Defaults to None.
+ act_cfg (:obj:`ConfigDict` or dict, optional): Config dict for
+ activation layer in ConvModule. Defaults to None.
+ upsample_cfg (:obj:`ConfigDict` or dict, optional): Config dict
+ for interpolate layer. Defaults to dict(mode='nearest').
+ init_cfg (:obj:`ConfigDict` or dict or list[:obj:`ConfigDict` or \
+ dict]): Initialization config dict.
+
+ Example:
+ >>> import torch
+ >>> in_channels = [2, 3, 5, 7]
+ >>> scales = [340, 170, 84, 43]
+ >>> inputs = [torch.rand(1, c, s, s)
+ ... for c, s in zip(in_channels, scales)]
+ >>> self = FPN(in_channels, 11, len(in_channels)).eval()
+ >>> outputs = self.forward(inputs)
+ >>> for i in range(len(outputs)):
+ ... print(f'outputs[{i}].shape = {outputs[i].shape}')
+ outputs[0].shape = torch.Size([1, 11, 340, 340])
+ outputs[1].shape = torch.Size([1, 11, 170, 170])
+ outputs[2].shape = torch.Size([1, 11, 84, 84])
+ outputs[3].shape = torch.Size([1, 11, 43, 43])
+ """
+
+ def __init__(
+ self,
+ in_channels: List[int],
+ out_channels: int,
+ num_outs: int,
+ start_level: int = 0,
+ end_level: int = -1,
+ add_extra_convs: Union[bool, str] = False,
+ relu_before_extra_convs: bool = False,
+ no_norm_on_lateral: bool = False,
+ conv_cfg: OptConfigType = None,
+ norm_cfg: OptConfigType = None,
+ act_cfg: OptConfigType = None,
+ upsample_cfg: ConfigType = dict(mode='nearest'),
+ init_cfg: MultiConfig = dict(
+ type='Xavier', layer='Conv2d', distribution='uniform')
+ ) -> None:
+ super().__init__(init_cfg=init_cfg)
+ assert isinstance(in_channels, list)
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.num_ins = len(in_channels)
+ self.num_outs = num_outs
+ self.relu_before_extra_convs = relu_before_extra_convs
+ self.no_norm_on_lateral = no_norm_on_lateral
+ self.fp16_enabled = False
+ self.upsample_cfg = upsample_cfg.copy()
+
+ if end_level == -1 or end_level == self.num_ins - 1:
+ self.backbone_end_level = self.num_ins
+ assert num_outs >= self.num_ins - start_level
+ else:
+ # if end_level is not the last level, no extra level is allowed
+ self.backbone_end_level = end_level + 1
+ assert end_level < self.num_ins
+ assert num_outs == end_level - start_level + 1
+ self.start_level = start_level
+ self.end_level = end_level
+ self.add_extra_convs = add_extra_convs
+ assert isinstance(add_extra_convs, (str, bool))
+ if isinstance(add_extra_convs, str):
+ # Extra_convs_source choices: 'on_input', 'on_lateral', 'on_output'
+ assert add_extra_convs in ('on_input', 'on_lateral', 'on_output')
+ elif add_extra_convs: # True
+ self.add_extra_convs = 'on_input'
+
+ self.lateral_convs = nn.ModuleList()
+ self.fpn_convs = nn.ModuleList()
+
+ for i in range(self.start_level, self.backbone_end_level):
+ l_conv = ConvModule(
+ in_channels[i],
+ out_channels,
+ 1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg if not self.no_norm_on_lateral else None,
+ act_cfg=act_cfg,
+ inplace=False)
+ fpn_conv = ConvModule(
+ out_channels,
+ out_channels,
+ 3,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ inplace=False)
+
+ self.lateral_convs.append(l_conv)
+ self.fpn_convs.append(fpn_conv)
+
+ # add extra conv layers (e.g., RetinaNet)
+ extra_levels = num_outs - self.backbone_end_level + self.start_level
+ if self.add_extra_convs and extra_levels >= 1:
+ for i in range(extra_levels):
+ if i == 0 and self.add_extra_convs == 'on_input':
+ in_channels = self.in_channels[self.backbone_end_level - 1]
+ else:
+ in_channels = out_channels
+ extra_fpn_conv = ConvModule(
+ in_channels,
+ out_channels,
+ 3,
+ stride=2,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ inplace=False)
+ self.fpn_convs.append(extra_fpn_conv)
+
+ def forward(self, inputs: Tuple[Tensor]) -> tuple:
+ """Forward function.
+
+ Args:
+ inputs (tuple[Tensor]): Features from the upstream network, each
+ is a 4D-tensor.
+
+ Returns:
+ tuple: Feature maps, each is a 4D-tensor.
+ """
+ assert len(inputs) == len(self.in_channels)
+
+ # build laterals
+ laterals = [
+ lateral_conv(inputs[i + self.start_level])
+ for i, lateral_conv in enumerate(self.lateral_convs)
+ ]
+
+ # build top-down path
+ used_backbone_levels = len(laterals)
+ for i in range(used_backbone_levels - 1, 0, -1):
+ # In some cases, fixing `scale factor` (e.g. 2) is preferred, but
+ # it cannot co-exist with `size` in `F.interpolate`.
+ if 'scale_factor' in self.upsample_cfg:
+ # fix runtime error of "+=" inplace operation in PyTorch 1.10
+ laterals[i - 1] = laterals[i - 1] + F.interpolate(
+ laterals[i], **self.upsample_cfg)
+ else:
+ prev_shape = laterals[i - 1].shape[2:]
+ laterals[i - 1] = laterals[i - 1] + F.interpolate(
+ laterals[i], size=prev_shape, **self.upsample_cfg)
+
+ # build outputs
+ # part 1: from original levels
+ outs = [
+ self.fpn_convs[i](laterals[i]) for i in range(used_backbone_levels)
+ ]
+ # part 2: add extra levels
+ if self.num_outs > len(outs):
+ # use max pool to get more levels on top of outputs
+ # (e.g., Faster R-CNN, Mask R-CNN)
+ if not self.add_extra_convs:
+ for i in range(self.num_outs - used_backbone_levels):
+ outs.append(F.max_pool2d(outs[-1], 1, stride=2))
+ # add conv layers on top of original feature maps (RetinaNet)
+ else:
+ if self.add_extra_convs == 'on_input':
+ extra_source = inputs[self.backbone_end_level - 1]
+ elif self.add_extra_convs == 'on_lateral':
+ extra_source = laterals[-1]
+ elif self.add_extra_convs == 'on_output':
+ extra_source = outs[-1]
+ else:
+ raise NotImplementedError
+ outs.append(self.fpn_convs[used_backbone_levels](extra_source))
+ for i in range(used_backbone_levels + 1, self.num_outs):
+ if self.relu_before_extra_convs:
+ outs.append(self.fpn_convs[i](F.relu(outs[-1])))
+ else:
+ outs.append(self.fpn_convs[i](outs[-1]))
+ return tuple(outs)
diff --git a/mmdet/models/necks/fpn_carafe.py b/mmdet/models/necks/fpn_carafe.py
new file mode 100644
index 0000000000000000000000000000000000000000..b393ff7c340c0c343fc4c91a4d87d341f66a3177
--- /dev/null
+++ b/mmdet/models/necks/fpn_carafe.py
@@ -0,0 +1,275 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch.nn as nn
+from mmcv.cnn import ConvModule, build_upsample_layer
+from mmcv.ops.carafe import CARAFEPack
+from mmengine.model import BaseModule, ModuleList, xavier_init
+
+from mmdet.registry import MODELS
+
+
+@MODELS.register_module()
+class FPN_CARAFE(BaseModule):
+ """FPN_CARAFE is a more flexible implementation of FPN. It allows more
+ choice for upsample methods during the top-down pathway.
+
+ It can reproduce the performance of ICCV 2019 paper
+ CARAFE: Content-Aware ReAssembly of FEatures
+ Please refer to https://arxiv.org/abs/1905.02188 for more details.
+
+ Args:
+ in_channels (list[int]): Number of channels for each input feature map.
+ out_channels (int): Output channels of feature pyramids.
+ num_outs (int): Number of output stages.
+ start_level (int): Start level of feature pyramids.
+ (Default: 0)
+ end_level (int): End level of feature pyramids.
+ (Default: -1 indicates the last level).
+ norm_cfg (dict): Dictionary to construct and config norm layer.
+ activate (str): Type of activation function in ConvModule
+ (Default: None indicates w/o activation).
+ order (dict): Order of components in ConvModule.
+ upsample (str): Type of upsample layer.
+ upsample_cfg (dict): Dictionary to construct and config upsample layer.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ num_outs,
+ start_level=0,
+ end_level=-1,
+ norm_cfg=None,
+ act_cfg=None,
+ order=('conv', 'norm', 'act'),
+ upsample_cfg=dict(
+ type='carafe',
+ up_kernel=5,
+ up_group=1,
+ encoder_kernel=3,
+ encoder_dilation=1),
+ init_cfg=None):
+ assert init_cfg is None, 'To prevent abnormal initialization ' \
+ 'behavior, init_cfg is not allowed to be set'
+ super(FPN_CARAFE, self).__init__(init_cfg)
+ assert isinstance(in_channels, list)
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.num_ins = len(in_channels)
+ self.num_outs = num_outs
+ self.norm_cfg = norm_cfg
+ self.act_cfg = act_cfg
+ self.with_bias = norm_cfg is None
+ self.upsample_cfg = upsample_cfg.copy()
+ self.upsample = self.upsample_cfg.get('type')
+ self.relu = nn.ReLU(inplace=False)
+
+ self.order = order
+ assert order in [('conv', 'norm', 'act'), ('act', 'conv', 'norm')]
+
+ assert self.upsample in [
+ 'nearest', 'bilinear', 'deconv', 'pixel_shuffle', 'carafe', None
+ ]
+ if self.upsample in ['deconv', 'pixel_shuffle']:
+ assert hasattr(
+ self.upsample_cfg,
+ 'upsample_kernel') and self.upsample_cfg.upsample_kernel > 0
+ self.upsample_kernel = self.upsample_cfg.pop('upsample_kernel')
+
+ if end_level == -1 or end_level == self.num_ins - 1:
+ self.backbone_end_level = self.num_ins
+ assert num_outs >= self.num_ins - start_level
+ else:
+ # if end_level is not the last level, no extra level is allowed
+ self.backbone_end_level = end_level + 1
+ assert end_level < self.num_ins
+ assert num_outs == end_level - start_level + 1
+ self.start_level = start_level
+ self.end_level = end_level
+
+ self.lateral_convs = ModuleList()
+ self.fpn_convs = ModuleList()
+ self.upsample_modules = ModuleList()
+
+ for i in range(self.start_level, self.backbone_end_level):
+ l_conv = ConvModule(
+ in_channels[i],
+ out_channels,
+ 1,
+ norm_cfg=norm_cfg,
+ bias=self.with_bias,
+ act_cfg=act_cfg,
+ inplace=False,
+ order=self.order)
+ fpn_conv = ConvModule(
+ out_channels,
+ out_channels,
+ 3,
+ padding=1,
+ norm_cfg=self.norm_cfg,
+ bias=self.with_bias,
+ act_cfg=act_cfg,
+ inplace=False,
+ order=self.order)
+ if i != self.backbone_end_level - 1:
+ upsample_cfg_ = self.upsample_cfg.copy()
+ if self.upsample == 'deconv':
+ upsample_cfg_.update(
+ in_channels=out_channels,
+ out_channels=out_channels,
+ kernel_size=self.upsample_kernel,
+ stride=2,
+ padding=(self.upsample_kernel - 1) // 2,
+ output_padding=(self.upsample_kernel - 1) // 2)
+ elif self.upsample == 'pixel_shuffle':
+ upsample_cfg_.update(
+ in_channels=out_channels,
+ out_channels=out_channels,
+ scale_factor=2,
+ upsample_kernel=self.upsample_kernel)
+ elif self.upsample == 'carafe':
+ upsample_cfg_.update(channels=out_channels, scale_factor=2)
+ else:
+ # suppress warnings
+ align_corners = (None
+ if self.upsample == 'nearest' else False)
+ upsample_cfg_.update(
+ scale_factor=2,
+ mode=self.upsample,
+ align_corners=align_corners)
+ upsample_module = build_upsample_layer(upsample_cfg_)
+ self.upsample_modules.append(upsample_module)
+ self.lateral_convs.append(l_conv)
+ self.fpn_convs.append(fpn_conv)
+
+ # add extra conv layers (e.g., RetinaNet)
+ extra_out_levels = (
+ num_outs - self.backbone_end_level + self.start_level)
+ if extra_out_levels >= 1:
+ for i in range(extra_out_levels):
+ in_channels = (
+ self.in_channels[self.backbone_end_level -
+ 1] if i == 0 else out_channels)
+ extra_l_conv = ConvModule(
+ in_channels,
+ out_channels,
+ 3,
+ stride=2,
+ padding=1,
+ norm_cfg=norm_cfg,
+ bias=self.with_bias,
+ act_cfg=act_cfg,
+ inplace=False,
+ order=self.order)
+ if self.upsample == 'deconv':
+ upsampler_cfg_ = dict(
+ in_channels=out_channels,
+ out_channels=out_channels,
+ kernel_size=self.upsample_kernel,
+ stride=2,
+ padding=(self.upsample_kernel - 1) // 2,
+ output_padding=(self.upsample_kernel - 1) // 2)
+ elif self.upsample == 'pixel_shuffle':
+ upsampler_cfg_ = dict(
+ in_channels=out_channels,
+ out_channels=out_channels,
+ scale_factor=2,
+ upsample_kernel=self.upsample_kernel)
+ elif self.upsample == 'carafe':
+ upsampler_cfg_ = dict(
+ channels=out_channels,
+ scale_factor=2,
+ **self.upsample_cfg)
+ else:
+ # suppress warnings
+ align_corners = (None
+ if self.upsample == 'nearest' else False)
+ upsampler_cfg_ = dict(
+ scale_factor=2,
+ mode=self.upsample,
+ align_corners=align_corners)
+ upsampler_cfg_['type'] = self.upsample
+ upsample_module = build_upsample_layer(upsampler_cfg_)
+ extra_fpn_conv = ConvModule(
+ out_channels,
+ out_channels,
+ 3,
+ padding=1,
+ norm_cfg=self.norm_cfg,
+ bias=self.with_bias,
+ act_cfg=act_cfg,
+ inplace=False,
+ order=self.order)
+ self.upsample_modules.append(upsample_module)
+ self.fpn_convs.append(extra_fpn_conv)
+ self.lateral_convs.append(extra_l_conv)
+
+ # default init_weights for conv(msra) and norm in ConvModule
+ def init_weights(self):
+ """Initialize the weights of module."""
+ super(FPN_CARAFE, self).init_weights()
+ for m in self.modules():
+ if isinstance(m, (nn.Conv2d, nn.ConvTranspose2d)):
+ xavier_init(m, distribution='uniform')
+ for m in self.modules():
+ if isinstance(m, CARAFEPack):
+ m.init_weights()
+
+ def slice_as(self, src, dst):
+ """Slice ``src`` as ``dst``
+
+ Note:
+ ``src`` should have the same or larger size than ``dst``.
+
+ Args:
+ src (torch.Tensor): Tensors to be sliced.
+ dst (torch.Tensor): ``src`` will be sliced to have the same
+ size as ``dst``.
+
+ Returns:
+ torch.Tensor: Sliced tensor.
+ """
+ assert (src.size(2) >= dst.size(2)) and (src.size(3) >= dst.size(3))
+ if src.size(2) == dst.size(2) and src.size(3) == dst.size(3):
+ return src
+ else:
+ return src[:, :, :dst.size(2), :dst.size(3)]
+
+ def tensor_add(self, a, b):
+ """Add tensors ``a`` and ``b`` that might have different sizes."""
+ if a.size() == b.size():
+ c = a + b
+ else:
+ c = a + self.slice_as(b, a)
+ return c
+
+ def forward(self, inputs):
+ """Forward function."""
+ assert len(inputs) == len(self.in_channels)
+
+ # build laterals
+ laterals = []
+ for i, lateral_conv in enumerate(self.lateral_convs):
+ if i <= self.backbone_end_level - self.start_level:
+ input = inputs[min(i + self.start_level, len(inputs) - 1)]
+ else:
+ input = laterals[-1]
+ lateral = lateral_conv(input)
+ laterals.append(lateral)
+
+ # build top-down path
+ for i in range(len(laterals) - 1, 0, -1):
+ if self.upsample is not None:
+ upsample_feat = self.upsample_modules[i - 1](laterals[i])
+ else:
+ upsample_feat = laterals[i]
+ laterals[i - 1] = self.tensor_add(laterals[i - 1], upsample_feat)
+
+ # build outputs
+ num_conv_outs = len(self.fpn_convs)
+ outs = []
+ for i in range(num_conv_outs):
+ out = self.fpn_convs[i](laterals[i])
+ outs.append(out)
+ return tuple(outs)
diff --git a/mmdet/models/necks/hrfpn.py b/mmdet/models/necks/hrfpn.py
new file mode 100644
index 0000000000000000000000000000000000000000..d2627549b4cb8acc6833bc40425e459c28aa5c20
--- /dev/null
+++ b/mmdet/models/necks/hrfpn.py
@@ -0,0 +1,100 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule
+from mmengine.model import BaseModule
+from torch.utils.checkpoint import checkpoint
+
+from mmdet.registry import MODELS
+
+
+@MODELS.register_module()
+class HRFPN(BaseModule):
+ """HRFPN (High Resolution Feature Pyramids)
+
+ paper: `High-Resolution Representations for Labeling Pixels and Regions
+ `_.
+
+ Args:
+ in_channels (list): number of channels for each branch.
+ out_channels (int): output channels of feature pyramids.
+ num_outs (int): number of output stages.
+ pooling_type (str): pooling for generating feature pyramids
+ from {MAX, AVG}.
+ conv_cfg (dict): dictionary to construct and config conv layer.
+ norm_cfg (dict): dictionary to construct and config norm layer.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed.
+ stride (int): stride of 3x3 convolutional layers
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ num_outs=5,
+ pooling_type='AVG',
+ conv_cfg=None,
+ norm_cfg=None,
+ with_cp=False,
+ stride=1,
+ init_cfg=dict(type='Caffe2Xavier', layer='Conv2d')):
+ super(HRFPN, self).__init__(init_cfg)
+ assert isinstance(in_channels, list)
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.num_ins = len(in_channels)
+ self.num_outs = num_outs
+ self.with_cp = with_cp
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+
+ self.reduction_conv = ConvModule(
+ sum(in_channels),
+ out_channels,
+ kernel_size=1,
+ conv_cfg=self.conv_cfg,
+ act_cfg=None)
+
+ self.fpn_convs = nn.ModuleList()
+ for i in range(self.num_outs):
+ self.fpn_convs.append(
+ ConvModule(
+ out_channels,
+ out_channels,
+ kernel_size=3,
+ padding=1,
+ stride=stride,
+ conv_cfg=self.conv_cfg,
+ act_cfg=None))
+
+ if pooling_type == 'MAX':
+ self.pooling = F.max_pool2d
+ else:
+ self.pooling = F.avg_pool2d
+
+ def forward(self, inputs):
+ """Forward function."""
+ assert len(inputs) == self.num_ins
+ outs = [inputs[0]]
+ for i in range(1, self.num_ins):
+ outs.append(
+ F.interpolate(inputs[i], scale_factor=2**i, mode='bilinear'))
+ out = torch.cat(outs, dim=1)
+ if out.requires_grad and self.with_cp:
+ out = checkpoint(self.reduction_conv, out)
+ else:
+ out = self.reduction_conv(out)
+ outs = [out]
+ for i in range(1, self.num_outs):
+ outs.append(self.pooling(out, kernel_size=2**i, stride=2**i))
+ outputs = []
+
+ for i in range(self.num_outs):
+ if outs[i].requires_grad and self.with_cp:
+ tmp_out = checkpoint(self.fpn_convs[i], outs[i])
+ else:
+ tmp_out = self.fpn_convs[i](outs[i])
+ outputs.append(tmp_out)
+ return tuple(outputs)
diff --git a/mmdet/models/necks/nas_fpn.py b/mmdet/models/necks/nas_fpn.py
new file mode 100644
index 0000000000000000000000000000000000000000..8ec90cd6eed3aa65a3a192d332cbfd8c16d5bc36
--- /dev/null
+++ b/mmdet/models/necks/nas_fpn.py
@@ -0,0 +1,171 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Tuple
+
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+from mmcv.ops.merge_cells import GlobalPoolingCell, SumCell
+from mmengine.model import BaseModule, ModuleList
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.utils import MultiConfig, OptConfigType
+
+
+@MODELS.register_module()
+class NASFPN(BaseModule):
+ """NAS-FPN.
+
+ Implementation of `NAS-FPN: Learning Scalable Feature Pyramid Architecture
+ for Object Detection `_
+
+ Args:
+ in_channels (List[int]): Number of input channels per scale.
+ out_channels (int): Number of output channels (used at each scale)
+ num_outs (int): Number of output scales.
+ stack_times (int): The number of times the pyramid architecture will
+ be stacked.
+ start_level (int): Index of the start input backbone level used to
+ build the feature pyramid. Defaults to 0.
+ end_level (int): Index of the end input backbone level (exclusive) to
+ build the feature pyramid. Defaults to -1, which means the
+ last level.
+ norm_cfg (:obj:`ConfigDict` or dict, optional): Config dict for
+ normalization layer. Defaults to None.
+ init_cfg (:obj:`ConfigDict` or dict or list[:obj:`ConfigDict` or \
+ dict]): Initialization config dict.
+ """
+
+ def __init__(
+ self,
+ in_channels: List[int],
+ out_channels: int,
+ num_outs: int,
+ stack_times: int,
+ start_level: int = 0,
+ end_level: int = -1,
+ norm_cfg: OptConfigType = None,
+ init_cfg: MultiConfig = dict(type='Caffe2Xavier', layer='Conv2d')
+ ) -> None:
+ super().__init__(init_cfg=init_cfg)
+ assert isinstance(in_channels, list)
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.num_ins = len(in_channels) # num of input feature levels
+ self.num_outs = num_outs # num of output feature levels
+ self.stack_times = stack_times
+ self.norm_cfg = norm_cfg
+
+ if end_level == -1 or end_level == self.num_ins - 1:
+ self.backbone_end_level = self.num_ins
+ assert num_outs >= self.num_ins - start_level
+ else:
+ # if end_level is not the last level, no extra level is allowed
+ self.backbone_end_level = end_level + 1
+ assert end_level < self.num_ins
+ assert num_outs == end_level - start_level + 1
+ self.start_level = start_level
+ self.end_level = end_level
+
+ # add lateral connections
+ self.lateral_convs = nn.ModuleList()
+ for i in range(self.start_level, self.backbone_end_level):
+ l_conv = ConvModule(
+ in_channels[i],
+ out_channels,
+ 1,
+ norm_cfg=norm_cfg,
+ act_cfg=None)
+ self.lateral_convs.append(l_conv)
+
+ # add extra downsample layers (stride-2 pooling or conv)
+ extra_levels = num_outs - self.backbone_end_level + self.start_level
+ self.extra_downsamples = nn.ModuleList()
+ for i in range(extra_levels):
+ extra_conv = ConvModule(
+ out_channels, out_channels, 1, norm_cfg=norm_cfg, act_cfg=None)
+ self.extra_downsamples.append(
+ nn.Sequential(extra_conv, nn.MaxPool2d(2, 2)))
+
+ # add NAS FPN connections
+ self.fpn_stages = ModuleList()
+ for _ in range(self.stack_times):
+ stage = nn.ModuleDict()
+ # gp(p6, p4) -> p4_1
+ stage['gp_64_4'] = GlobalPoolingCell(
+ in_channels=out_channels,
+ out_channels=out_channels,
+ out_norm_cfg=norm_cfg)
+ # sum(p4_1, p4) -> p4_2
+ stage['sum_44_4'] = SumCell(
+ in_channels=out_channels,
+ out_channels=out_channels,
+ out_norm_cfg=norm_cfg)
+ # sum(p4_2, p3) -> p3_out
+ stage['sum_43_3'] = SumCell(
+ in_channels=out_channels,
+ out_channels=out_channels,
+ out_norm_cfg=norm_cfg)
+ # sum(p3_out, p4_2) -> p4_out
+ stage['sum_34_4'] = SumCell(
+ in_channels=out_channels,
+ out_channels=out_channels,
+ out_norm_cfg=norm_cfg)
+ # sum(p5, gp(p4_out, p3_out)) -> p5_out
+ stage['gp_43_5'] = GlobalPoolingCell(with_out_conv=False)
+ stage['sum_55_5'] = SumCell(
+ in_channels=out_channels,
+ out_channels=out_channels,
+ out_norm_cfg=norm_cfg)
+ # sum(p7, gp(p5_out, p4_2)) -> p7_out
+ stage['gp_54_7'] = GlobalPoolingCell(with_out_conv=False)
+ stage['sum_77_7'] = SumCell(
+ in_channels=out_channels,
+ out_channels=out_channels,
+ out_norm_cfg=norm_cfg)
+ # gp(p7_out, p5_out) -> p6_out
+ stage['gp_75_6'] = GlobalPoolingCell(
+ in_channels=out_channels,
+ out_channels=out_channels,
+ out_norm_cfg=norm_cfg)
+ self.fpn_stages.append(stage)
+
+ def forward(self, inputs: Tuple[Tensor]) -> tuple:
+ """Forward function.
+
+ Args:
+ inputs (tuple[Tensor]): Features from the upstream network, each
+ is a 4D-tensor.
+
+ Returns:
+ tuple: Feature maps, each is a 4D-tensor.
+ """
+ # build P3-P5
+ feats = [
+ lateral_conv(inputs[i + self.start_level])
+ for i, lateral_conv in enumerate(self.lateral_convs)
+ ]
+ # build P6-P7 on top of P5
+ for downsample in self.extra_downsamples:
+ feats.append(downsample(feats[-1]))
+
+ p3, p4, p5, p6, p7 = feats
+
+ for stage in self.fpn_stages:
+ # gp(p6, p4) -> p4_1
+ p4_1 = stage['gp_64_4'](p6, p4, out_size=p4.shape[-2:])
+ # sum(p4_1, p4) -> p4_2
+ p4_2 = stage['sum_44_4'](p4_1, p4, out_size=p4.shape[-2:])
+ # sum(p4_2, p3) -> p3_out
+ p3 = stage['sum_43_3'](p4_2, p3, out_size=p3.shape[-2:])
+ # sum(p3_out, p4_2) -> p4_out
+ p4 = stage['sum_34_4'](p3, p4_2, out_size=p4.shape[-2:])
+ # sum(p5, gp(p4_out, p3_out)) -> p5_out
+ p5_tmp = stage['gp_43_5'](p4, p3, out_size=p5.shape[-2:])
+ p5 = stage['sum_55_5'](p5, p5_tmp, out_size=p5.shape[-2:])
+ # sum(p7, gp(p5_out, p4_2)) -> p7_out
+ p7_tmp = stage['gp_54_7'](p5, p4_2, out_size=p7.shape[-2:])
+ p7 = stage['sum_77_7'](p7, p7_tmp, out_size=p7.shape[-2:])
+ # gp(p7_out, p5_out) -> p6_out
+ p6 = stage['gp_75_6'](p7, p5, out_size=p6.shape[-2:])
+
+ return p3, p4, p5, p6, p7
diff --git a/mmdet/models/necks/nasfcos_fpn.py b/mmdet/models/necks/nasfcos_fpn.py
new file mode 100644
index 0000000000000000000000000000000000000000..12d0848f7634bb0113e0b5a16b5b65ba8b7ebb9c
--- /dev/null
+++ b/mmdet/models/necks/nasfcos_fpn.py
@@ -0,0 +1,170 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule
+from mmcv.ops.merge_cells import ConcatCell
+from mmengine.model import BaseModule, caffe2_xavier_init
+
+from mmdet.registry import MODELS
+
+
+@MODELS.register_module()
+class NASFCOS_FPN(BaseModule):
+ """FPN structure in NASFPN.
+
+ Implementation of paper `NAS-FCOS: Fast Neural Architecture Search for
+ Object Detection `_
+
+ Args:
+ in_channels (List[int]): Number of input channels per scale.
+ out_channels (int): Number of output channels (used at each scale)
+ num_outs (int): Number of output scales.
+ start_level (int): Index of the start input backbone level used to
+ build the feature pyramid. Default: 0.
+ end_level (int): Index of the end input backbone level (exclusive) to
+ build the feature pyramid. Default: -1, which means the last level.
+ add_extra_convs (bool): It decides whether to add conv
+ layers on top of the original feature maps. Default to False.
+ If True, its actual mode is specified by `extra_convs_on_inputs`.
+ conv_cfg (dict): dictionary to construct and config conv layer.
+ norm_cfg (dict): dictionary to construct and config norm layer.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ num_outs,
+ start_level=1,
+ end_level=-1,
+ add_extra_convs=False,
+ conv_cfg=None,
+ norm_cfg=None,
+ init_cfg=None):
+ assert init_cfg is None, 'To prevent abnormal initialization ' \
+ 'behavior, init_cfg is not allowed to be set'
+ super(NASFCOS_FPN, self).__init__(init_cfg)
+ assert isinstance(in_channels, list)
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.num_ins = len(in_channels)
+ self.num_outs = num_outs
+ self.norm_cfg = norm_cfg
+ self.conv_cfg = conv_cfg
+
+ if end_level == -1 or end_level == self.num_ins - 1:
+ self.backbone_end_level = self.num_ins
+ assert num_outs >= self.num_ins - start_level
+ else:
+ # if end_level is not the last level, no extra level is allowed
+ self.backbone_end_level = end_level + 1
+ assert end_level < self.num_ins
+ assert num_outs == end_level - start_level + 1
+ self.start_level = start_level
+ self.end_level = end_level
+ self.add_extra_convs = add_extra_convs
+
+ self.adapt_convs = nn.ModuleList()
+ for i in range(self.start_level, self.backbone_end_level):
+ adapt_conv = ConvModule(
+ in_channels[i],
+ out_channels,
+ 1,
+ stride=1,
+ padding=0,
+ bias=False,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU', inplace=False))
+ self.adapt_convs.append(adapt_conv)
+
+ # C2 is omitted according to the paper
+ extra_levels = num_outs - self.backbone_end_level + self.start_level
+
+ def build_concat_cell(with_input1_conv, with_input2_conv):
+ cell_conv_cfg = dict(
+ kernel_size=1, padding=0, bias=False, groups=out_channels)
+ return ConcatCell(
+ in_channels=out_channels,
+ out_channels=out_channels,
+ with_out_conv=True,
+ out_conv_cfg=cell_conv_cfg,
+ out_norm_cfg=dict(type='BN'),
+ out_conv_order=('norm', 'act', 'conv'),
+ with_input1_conv=with_input1_conv,
+ with_input2_conv=with_input2_conv,
+ input_conv_cfg=conv_cfg,
+ input_norm_cfg=norm_cfg,
+ upsample_mode='nearest')
+
+ # Denote c3=f0, c4=f1, c5=f2 for convince
+ self.fpn = nn.ModuleDict()
+ self.fpn['c22_1'] = build_concat_cell(True, True)
+ self.fpn['c22_2'] = build_concat_cell(True, True)
+ self.fpn['c32'] = build_concat_cell(True, False)
+ self.fpn['c02'] = build_concat_cell(True, False)
+ self.fpn['c42'] = build_concat_cell(True, True)
+ self.fpn['c36'] = build_concat_cell(True, True)
+ self.fpn['c61'] = build_concat_cell(True, True) # f9
+ self.extra_downsamples = nn.ModuleList()
+ for i in range(extra_levels):
+ extra_act_cfg = None if i == 0 \
+ else dict(type='ReLU', inplace=False)
+ self.extra_downsamples.append(
+ ConvModule(
+ out_channels,
+ out_channels,
+ 3,
+ stride=2,
+ padding=1,
+ act_cfg=extra_act_cfg,
+ order=('act', 'norm', 'conv')))
+
+ def forward(self, inputs):
+ """Forward function."""
+ feats = [
+ adapt_conv(inputs[i + self.start_level])
+ for i, adapt_conv in enumerate(self.adapt_convs)
+ ]
+
+ for (i, module_name) in enumerate(self.fpn):
+ idx_1, idx_2 = int(module_name[1]), int(module_name[2])
+ res = self.fpn[module_name](feats[idx_1], feats[idx_2])
+ feats.append(res)
+
+ ret = []
+ for (idx, input_idx) in zip([9, 8, 7], [1, 2, 3]): # add P3, P4, P5
+ feats1, feats2 = feats[idx], feats[5]
+ feats2_resize = F.interpolate(
+ feats2,
+ size=feats1.size()[2:],
+ mode='bilinear',
+ align_corners=False)
+
+ feats_sum = feats1 + feats2_resize
+ ret.append(
+ F.interpolate(
+ feats_sum,
+ size=inputs[input_idx].size()[2:],
+ mode='bilinear',
+ align_corners=False))
+
+ for submodule in self.extra_downsamples:
+ ret.append(submodule(ret[-1]))
+
+ return tuple(ret)
+
+ def init_weights(self):
+ """Initialize the weights of module."""
+ super(NASFCOS_FPN, self).init_weights()
+ for module in self.fpn.values():
+ if hasattr(module, 'conv_out'):
+ caffe2_xavier_init(module.out_conv.conv)
+
+ for modules in [
+ self.adapt_convs.modules(),
+ self.extra_downsamples.modules()
+ ]:
+ for module in modules:
+ if isinstance(module, nn.Conv2d):
+ caffe2_xavier_init(module)
diff --git a/mmdet/models/necks/pafpn.py b/mmdet/models/necks/pafpn.py
new file mode 100644
index 0000000000000000000000000000000000000000..557638f48a629691f780d3e1466e234bbe987518
--- /dev/null
+++ b/mmdet/models/necks/pafpn.py
@@ -0,0 +1,157 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule
+
+from mmdet.registry import MODELS
+from .fpn import FPN
+
+
+@MODELS.register_module()
+class PAFPN(FPN):
+ """Path Aggregation Network for Instance Segmentation.
+
+ This is an implementation of the `PAFPN in Path Aggregation Network
+ `_.
+
+ Args:
+ in_channels (List[int]): Number of input channels per scale.
+ out_channels (int): Number of output channels (used at each scale)
+ num_outs (int): Number of output scales.
+ start_level (int): Index of the start input backbone level used to
+ build the feature pyramid. Default: 0.
+ end_level (int): Index of the end input backbone level (exclusive) to
+ build the feature pyramid. Default: -1, which means the last level.
+ add_extra_convs (bool | str): If bool, it decides whether to add conv
+ layers on top of the original feature maps. Default to False.
+ If True, it is equivalent to `add_extra_convs='on_input'`.
+ If str, it specifies the source feature map of the extra convs.
+ Only the following options are allowed
+
+ - 'on_input': Last feat map of neck inputs (i.e. backbone feature).
+ - 'on_lateral': Last feature map after lateral convs.
+ - 'on_output': The last output feature map after fpn convs.
+ relu_before_extra_convs (bool): Whether to apply relu before the extra
+ conv. Default: False.
+ no_norm_on_lateral (bool): Whether to apply norm on lateral.
+ Default: False.
+ conv_cfg (dict): Config dict for convolution layer. Default: None.
+ norm_cfg (dict): Config dict for normalization layer. Default: None.
+ act_cfg (str): Config dict for activation layer in ConvModule.
+ Default: None.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ num_outs,
+ start_level=0,
+ end_level=-1,
+ add_extra_convs=False,
+ relu_before_extra_convs=False,
+ no_norm_on_lateral=False,
+ conv_cfg=None,
+ norm_cfg=None,
+ act_cfg=None,
+ init_cfg=dict(
+ type='Xavier', layer='Conv2d', distribution='uniform')):
+ super(PAFPN, self).__init__(
+ in_channels,
+ out_channels,
+ num_outs,
+ start_level,
+ end_level,
+ add_extra_convs,
+ relu_before_extra_convs,
+ no_norm_on_lateral,
+ conv_cfg,
+ norm_cfg,
+ act_cfg,
+ init_cfg=init_cfg)
+ # add extra bottom up pathway
+ self.downsample_convs = nn.ModuleList()
+ self.pafpn_convs = nn.ModuleList()
+ for i in range(self.start_level + 1, self.backbone_end_level):
+ d_conv = ConvModule(
+ out_channels,
+ out_channels,
+ 3,
+ stride=2,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ inplace=False)
+ pafpn_conv = ConvModule(
+ out_channels,
+ out_channels,
+ 3,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ inplace=False)
+ self.downsample_convs.append(d_conv)
+ self.pafpn_convs.append(pafpn_conv)
+
+ def forward(self, inputs):
+ """Forward function."""
+ assert len(inputs) == len(self.in_channels)
+
+ # build laterals
+ laterals = [
+ lateral_conv(inputs[i + self.start_level])
+ for i, lateral_conv in enumerate(self.lateral_convs)
+ ]
+
+ # build top-down path
+ used_backbone_levels = len(laterals)
+ for i in range(used_backbone_levels - 1, 0, -1):
+ prev_shape = laterals[i - 1].shape[2:]
+ laterals[i - 1] = laterals[i - 1] + F.interpolate(
+ laterals[i], size=prev_shape, mode='nearest')
+
+ # build outputs
+ # part 1: from original levels
+ inter_outs = [
+ self.fpn_convs[i](laterals[i]) for i in range(used_backbone_levels)
+ ]
+
+ # part 2: add bottom-up path
+ for i in range(0, used_backbone_levels - 1):
+ inter_outs[i + 1] = inter_outs[i + 1] + \
+ self.downsample_convs[i](inter_outs[i])
+
+ outs = []
+ outs.append(inter_outs[0])
+ outs.extend([
+ self.pafpn_convs[i - 1](inter_outs[i])
+ for i in range(1, used_backbone_levels)
+ ])
+
+ # part 3: add extra levels
+ if self.num_outs > len(outs):
+ # use max pool to get more levels on top of outputs
+ # (e.g., Faster R-CNN, Mask R-CNN)
+ if not self.add_extra_convs:
+ for i in range(self.num_outs - used_backbone_levels):
+ outs.append(F.max_pool2d(outs[-1], 1, stride=2))
+ # add conv layers on top of original feature maps (RetinaNet)
+ else:
+ if self.add_extra_convs == 'on_input':
+ orig = inputs[self.backbone_end_level - 1]
+ outs.append(self.fpn_convs[used_backbone_levels](orig))
+ elif self.add_extra_convs == 'on_lateral':
+ outs.append(self.fpn_convs[used_backbone_levels](
+ laterals[-1]))
+ elif self.add_extra_convs == 'on_output':
+ outs.append(self.fpn_convs[used_backbone_levels](outs[-1]))
+ else:
+ raise NotImplementedError
+ for i in range(used_backbone_levels + 1, self.num_outs):
+ if self.relu_before_extra_convs:
+ outs.append(self.fpn_convs[i](F.relu(outs[-1])))
+ else:
+ outs.append(self.fpn_convs[i](outs[-1]))
+ return tuple(outs)
diff --git a/mmdet/models/necks/rfp.py b/mmdet/models/necks/rfp.py
new file mode 100644
index 0000000000000000000000000000000000000000..7ec9b3753c5031bb12a2b4c88733f13bf27c44e2
--- /dev/null
+++ b/mmdet/models/necks/rfp.py
@@ -0,0 +1,134 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmengine.model import BaseModule, ModuleList, constant_init, xavier_init
+
+from mmdet.registry import MODELS
+from .fpn import FPN
+
+
+class ASPP(BaseModule):
+ """ASPP (Atrous Spatial Pyramid Pooling)
+
+ This is an implementation of the ASPP module used in DetectoRS
+ (https://arxiv.org/pdf/2006.02334.pdf)
+
+ Args:
+ in_channels (int): Number of input channels.
+ out_channels (int): Number of channels produced by this module
+ dilations (tuple[int]): Dilations of the four branches.
+ Default: (1, 3, 6, 1)
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ dilations=(1, 3, 6, 1),
+ init_cfg=dict(type='Kaiming', layer='Conv2d')):
+ super().__init__(init_cfg)
+ assert dilations[-1] == 1
+ self.aspp = nn.ModuleList()
+ for dilation in dilations:
+ kernel_size = 3 if dilation > 1 else 1
+ padding = dilation if dilation > 1 else 0
+ conv = nn.Conv2d(
+ in_channels,
+ out_channels,
+ kernel_size=kernel_size,
+ stride=1,
+ dilation=dilation,
+ padding=padding,
+ bias=True)
+ self.aspp.append(conv)
+ self.gap = nn.AdaptiveAvgPool2d(1)
+
+ def forward(self, x):
+ avg_x = self.gap(x)
+ out = []
+ for aspp_idx in range(len(self.aspp)):
+ inp = avg_x if (aspp_idx == len(self.aspp) - 1) else x
+ out.append(F.relu_(self.aspp[aspp_idx](inp)))
+ out[-1] = out[-1].expand_as(out[-2])
+ out = torch.cat(out, dim=1)
+ return out
+
+
+@MODELS.register_module()
+class RFP(FPN):
+ """RFP (Recursive Feature Pyramid)
+
+ This is an implementation of RFP in `DetectoRS
+ `_. Different from standard FPN, the
+ input of RFP should be multi level features along with origin input image
+ of backbone.
+
+ Args:
+ rfp_steps (int): Number of unrolled steps of RFP.
+ rfp_backbone (dict): Configuration of the backbone for RFP.
+ aspp_out_channels (int): Number of output channels of ASPP module.
+ aspp_dilations (tuple[int]): Dilation rates of four branches.
+ Default: (1, 3, 6, 1)
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ def __init__(self,
+ rfp_steps,
+ rfp_backbone,
+ aspp_out_channels,
+ aspp_dilations=(1, 3, 6, 1),
+ init_cfg=None,
+ **kwargs):
+ assert init_cfg is None, 'To prevent abnormal initialization ' \
+ 'behavior, init_cfg is not allowed to be set'
+ super().__init__(init_cfg=init_cfg, **kwargs)
+ self.rfp_steps = rfp_steps
+ # Be careful! Pretrained weights cannot be loaded when use
+ # nn.ModuleList
+ self.rfp_modules = ModuleList()
+ for rfp_idx in range(1, rfp_steps):
+ rfp_module = MODELS.build(rfp_backbone)
+ self.rfp_modules.append(rfp_module)
+ self.rfp_aspp = ASPP(self.out_channels, aspp_out_channels,
+ aspp_dilations)
+ self.rfp_weight = nn.Conv2d(
+ self.out_channels,
+ 1,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ bias=True)
+
+ def init_weights(self):
+ # Avoid using super().init_weights(), which may alter the default
+ # initialization of the modules in self.rfp_modules that have missing
+ # keys in the pretrained checkpoint.
+ for convs in [self.lateral_convs, self.fpn_convs]:
+ for m in convs.modules():
+ if isinstance(m, nn.Conv2d):
+ xavier_init(m, distribution='uniform')
+ for rfp_idx in range(self.rfp_steps - 1):
+ self.rfp_modules[rfp_idx].init_weights()
+ constant_init(self.rfp_weight, 0)
+
+ def forward(self, inputs):
+ inputs = list(inputs)
+ assert len(inputs) == len(self.in_channels) + 1 # +1 for input image
+ img = inputs.pop(0)
+ # FPN forward
+ x = super().forward(tuple(inputs))
+ for rfp_idx in range(self.rfp_steps - 1):
+ rfp_feats = [x[0]] + list(
+ self.rfp_aspp(x[i]) for i in range(1, len(x)))
+ x_idx = self.rfp_modules[rfp_idx].rfp_forward(img, rfp_feats)
+ # FPN forward
+ x_idx = super().forward(x_idx)
+ x_new = []
+ for ft_idx in range(len(x_idx)):
+ add_weight = torch.sigmoid(self.rfp_weight(x_idx[ft_idx]))
+ x_new.append(add_weight * x_idx[ft_idx] +
+ (1 - add_weight) * x[ft_idx])
+ x = x_new
+ return x
diff --git a/mmdet/models/necks/ssd_neck.py b/mmdet/models/necks/ssd_neck.py
new file mode 100644
index 0000000000000000000000000000000000000000..17ba319370b988b9c7e2d98c2f10607ff8f8b5c3
--- /dev/null
+++ b/mmdet/models/necks/ssd_neck.py
@@ -0,0 +1,129 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+from mmcv.cnn import ConvModule, DepthwiseSeparableConvModule
+from mmengine.model import BaseModule
+
+from mmdet.registry import MODELS
+
+
+@MODELS.register_module()
+class SSDNeck(BaseModule):
+ """Extra layers of SSD backbone to generate multi-scale feature maps.
+
+ Args:
+ in_channels (Sequence[int]): Number of input channels per scale.
+ out_channels (Sequence[int]): Number of output channels per scale.
+ level_strides (Sequence[int]): Stride of 3x3 conv per level.
+ level_paddings (Sequence[int]): Padding size of 3x3 conv per level.
+ l2_norm_scale (float|None): L2 normalization layer init scale.
+ If None, not use L2 normalization on the first input feature.
+ last_kernel_size (int): Kernel size of the last conv layer.
+ Default: 3.
+ use_depthwise (bool): Whether to use DepthwiseSeparableConv.
+ Default: False.
+ conv_cfg (dict): Config dict for convolution layer. Default: None.
+ norm_cfg (dict): Dictionary to construct and config norm layer.
+ Default: None.
+ act_cfg (dict): Config dict for activation layer.
+ Default: dict(type='ReLU').
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ level_strides,
+ level_paddings,
+ l2_norm_scale=20.,
+ last_kernel_size=3,
+ use_depthwise=False,
+ conv_cfg=None,
+ norm_cfg=None,
+ act_cfg=dict(type='ReLU'),
+ init_cfg=[
+ dict(
+ type='Xavier', distribution='uniform',
+ layer='Conv2d'),
+ dict(type='Constant', val=1, layer='BatchNorm2d'),
+ ]):
+ super(SSDNeck, self).__init__(init_cfg)
+ assert len(out_channels) > len(in_channels)
+ assert len(out_channels) - len(in_channels) == len(level_strides)
+ assert len(level_strides) == len(level_paddings)
+ assert in_channels == out_channels[:len(in_channels)]
+
+ if l2_norm_scale:
+ self.l2_norm = L2Norm(in_channels[0], l2_norm_scale)
+ self.init_cfg += [
+ dict(
+ type='Constant',
+ val=self.l2_norm.scale,
+ override=dict(name='l2_norm'))
+ ]
+
+ self.extra_layers = nn.ModuleList()
+ extra_layer_channels = out_channels[len(in_channels):]
+ second_conv = DepthwiseSeparableConvModule if \
+ use_depthwise else ConvModule
+
+ for i, (out_channel, stride, padding) in enumerate(
+ zip(extra_layer_channels, level_strides, level_paddings)):
+ kernel_size = last_kernel_size \
+ if i == len(extra_layer_channels) - 1 else 3
+ per_lvl_convs = nn.Sequential(
+ ConvModule(
+ out_channels[len(in_channels) - 1 + i],
+ out_channel // 2,
+ 1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg),
+ second_conv(
+ out_channel // 2,
+ out_channel,
+ kernel_size,
+ stride=stride,
+ padding=padding,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+ self.extra_layers.append(per_lvl_convs)
+
+ def forward(self, inputs):
+ """Forward function."""
+ outs = [feat for feat in inputs]
+ if hasattr(self, 'l2_norm'):
+ outs[0] = self.l2_norm(outs[0])
+
+ feat = outs[-1]
+ for layer in self.extra_layers:
+ feat = layer(feat)
+ outs.append(feat)
+ return tuple(outs)
+
+
+class L2Norm(nn.Module):
+
+ def __init__(self, n_dims, scale=20., eps=1e-10):
+ """L2 normalization layer.
+
+ Args:
+ n_dims (int): Number of dimensions to be normalized
+ scale (float, optional): Defaults to 20..
+ eps (float, optional): Used to avoid division by zero.
+ Defaults to 1e-10.
+ """
+ super(L2Norm, self).__init__()
+ self.n_dims = n_dims
+ self.weight = nn.Parameter(torch.Tensor(self.n_dims))
+ self.eps = eps
+ self.scale = scale
+
+ def forward(self, x):
+ """Forward function."""
+ # normalization layer convert to FP32 in FP16 training
+ x_float = x.float()
+ norm = x_float.pow(2).sum(1, keepdim=True).sqrt() + self.eps
+ return (self.weight[None, :, None, None].float().expand_as(x_float) *
+ x_float / norm).type_as(x)
diff --git a/mmdet/models/necks/ssh.py b/mmdet/models/necks/ssh.py
new file mode 100644
index 0000000000000000000000000000000000000000..75a6561489d8d3634fc34829dafe819bbf066ed4
--- /dev/null
+++ b/mmdet/models/necks/ssh.py
@@ -0,0 +1,216 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Tuple
+
+import torch
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule
+from mmengine.model import BaseModule
+
+from mmdet.registry import MODELS
+from mmdet.utils import ConfigType, OptConfigType, OptMultiConfig
+
+
+class SSHContextModule(BaseModule):
+ """This is an implementation of `SSH context module` described in `SSH:
+ Single Stage Headless Face Detector.
+
+ `_.
+
+ Args:
+ in_channels (int): Number of input channels used at each scale.
+ out_channels (int): Number of output channels used at each scale.
+ conv_cfg (:obj:`ConfigDict` or dict, optional): Config dict for
+ convolution layer. Defaults to None.
+ norm_cfg (:obj:`ConfigDict` or dict): Config dict for normalization
+ layer. Defaults to dict(type='BN').
+ init_cfg (:obj:`ConfigDict` or list[:obj:`ConfigDict`] or dict or
+ list[dict], optional): Initialization config dict.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ in_channels: int,
+ out_channels: int,
+ conv_cfg: OptConfigType = None,
+ norm_cfg: ConfigType = dict(type='BN'),
+ init_cfg: OptMultiConfig = None):
+ super().__init__(init_cfg=init_cfg)
+ assert out_channels % 4 == 0
+
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+
+ self.conv5x5_1 = ConvModule(
+ self.in_channels,
+ self.out_channels // 4,
+ 3,
+ stride=1,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ )
+
+ self.conv5x5_2 = ConvModule(
+ self.out_channels // 4,
+ self.out_channels // 4,
+ 3,
+ stride=1,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=None)
+
+ self.conv7x7_2 = ConvModule(
+ self.out_channels // 4,
+ self.out_channels // 4,
+ 3,
+ stride=1,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ )
+
+ self.conv7x7_3 = ConvModule(
+ self.out_channels // 4,
+ self.out_channels // 4,
+ 3,
+ stride=1,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=None,
+ )
+
+ def forward(self, x: torch.Tensor) -> tuple:
+ conv5x5_1 = self.conv5x5_1(x)
+ conv5x5 = self.conv5x5_2(conv5x5_1)
+ conv7x7_2 = self.conv7x7_2(conv5x5_1)
+ conv7x7 = self.conv7x7_3(conv7x7_2)
+
+ return (conv5x5, conv7x7)
+
+
+class SSHDetModule(BaseModule):
+ """This is an implementation of `SSH detection module` described in `SSH:
+ Single Stage Headless Face Detector.
+
+ `_.
+
+ Args:
+ in_channels (int): Number of input channels used at each scale.
+ out_channels (int): Number of output channels used at each scale.
+ conv_cfg (:obj:`ConfigDict` or dict, optional): Config dict for
+ convolution layer. Defaults to None.
+ norm_cfg (:obj:`ConfigDict` or dict): Config dict for normalization
+ layer. Defaults to dict(type='BN').
+ init_cfg (:obj:`ConfigDict` or list[:obj:`ConfigDict`] or dict or
+ list[dict], optional): Initialization config dict.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ in_channels: int,
+ out_channels: int,
+ conv_cfg: OptConfigType = None,
+ norm_cfg: ConfigType = dict(type='BN'),
+ init_cfg: OptMultiConfig = None):
+ super().__init__(init_cfg=init_cfg)
+ assert out_channels % 4 == 0
+
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+
+ self.conv3x3 = ConvModule(
+ self.in_channels,
+ self.out_channels // 2,
+ 3,
+ stride=1,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=None)
+
+ self.context_module = SSHContextModule(
+ in_channels=self.in_channels,
+ out_channels=self.out_channels,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg)
+
+ def forward(self, x: torch.Tensor) -> torch.Tensor:
+ conv3x3 = self.conv3x3(x)
+ conv5x5, conv7x7 = self.context_module(x)
+ out = torch.cat([conv3x3, conv5x5, conv7x7], dim=1)
+ out = F.relu(out)
+
+ return out
+
+
+@MODELS.register_module()
+class SSH(BaseModule):
+ """`SSH Neck` used in `SSH: Single Stage Headless Face Detector.
+
+ `_.
+
+ Args:
+ num_scales (int): The number of scales / stages.
+ in_channels (list[int]): The number of input channels per scale.
+ out_channels (list[int]): The number of output channels per scale.
+ conv_cfg (:obj:`ConfigDict` or dict, optional): Config dict for
+ convolution layer. Defaults to None.
+ norm_cfg (:obj:`ConfigDict` or dict): Config dict for normalization
+ layer. Defaults to dict(type='BN').
+ init_cfg (:obj:`ConfigDict` or list[:obj:`ConfigDict`] or dict or
+ list[dict], optional): Initialization config dict.
+
+ Example:
+ >>> import torch
+ >>> in_channels = [8, 16, 32, 64]
+ >>> out_channels = [16, 32, 64, 128]
+ >>> scales = [340, 170, 84, 43]
+ >>> inputs = [torch.rand(1, c, s, s)
+ ... for c, s in zip(in_channels, scales)]
+ >>> self = SSH(num_scales=4, in_channels=in_channels,
+ ... out_channels=out_channels)
+ >>> outputs = self.forward(inputs)
+ >>> for i in range(len(outputs)):
+ ... print(f'outputs[{i}].shape = {outputs[i].shape}')
+ outputs[0].shape = torch.Size([1, 16, 340, 340])
+ outputs[1].shape = torch.Size([1, 32, 170, 170])
+ outputs[2].shape = torch.Size([1, 64, 84, 84])
+ outputs[3].shape = torch.Size([1, 128, 43, 43])
+ """
+
+ def __init__(self,
+ num_scales: int,
+ in_channels: List[int],
+ out_channels: List[int],
+ conv_cfg: OptConfigType = None,
+ norm_cfg: ConfigType = dict(type='BN'),
+ init_cfg: OptMultiConfig = dict(
+ type='Xavier', layer='Conv2d', distribution='uniform')):
+ super().__init__(init_cfg=init_cfg)
+ assert (num_scales == len(in_channels) == len(out_channels))
+ self.num_scales = num_scales
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+
+ for idx in range(self.num_scales):
+ in_c, out_c = self.in_channels[idx], self.out_channels[idx]
+ self.add_module(
+ f'ssh_module{idx}',
+ SSHDetModule(
+ in_channels=in_c,
+ out_channels=out_c,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg))
+
+ def forward(self, inputs: Tuple[torch.Tensor]) -> tuple:
+ assert len(inputs) == self.num_scales
+
+ outs = []
+ for idx, x in enumerate(inputs):
+ ssh_module = getattr(self, f'ssh_module{idx}')
+ out = ssh_module(x)
+ outs.append(out)
+
+ return tuple(outs)
diff --git a/mmdet/models/necks/yolo_neck.py b/mmdet/models/necks/yolo_neck.py
new file mode 100644
index 0000000000000000000000000000000000000000..48a6b1a4897c85083aa1e1e7d692263f66de67c3
--- /dev/null
+++ b/mmdet/models/necks/yolo_neck.py
@@ -0,0 +1,145 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+# Copyright (c) 2019 Western Digital Corporation or its affiliates.
+from typing import List, Tuple
+
+import torch
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule
+from mmengine.model import BaseModule
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.utils import ConfigType, OptConfigType, OptMultiConfig
+
+
+class DetectionBlock(BaseModule):
+ """Detection block in YOLO neck.
+
+ Let out_channels = n, the DetectionBlock contains:
+ Six ConvLayers, 1 Conv2D Layer and 1 YoloLayer.
+ The first 6 ConvLayers are formed the following way:
+ 1x1xn, 3x3x2n, 1x1xn, 3x3x2n, 1x1xn, 3x3x2n.
+ The Conv2D layer is 1x1x255.
+ Some block will have branch after the fifth ConvLayer.
+ The input channel is arbitrary (in_channels)
+
+ Args:
+ in_channels (int): The number of input channels.
+ out_channels (int): The number of output channels.
+ conv_cfg (dict): Config dict for convolution layer. Default: None.
+ norm_cfg (dict): Dictionary to construct and config norm layer.
+ Default: dict(type='BN', requires_grad=True)
+ act_cfg (dict): Config dict for activation layer.
+ Default: dict(type='LeakyReLU', negative_slope=0.1).
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ def __init__(self,
+ in_channels: int,
+ out_channels: int,
+ conv_cfg: OptConfigType = None,
+ norm_cfg: ConfigType = dict(type='BN', requires_grad=True),
+ act_cfg: ConfigType = dict(
+ type='LeakyReLU', negative_slope=0.1),
+ init_cfg: OptMultiConfig = None) -> None:
+ super(DetectionBlock, self).__init__(init_cfg)
+ double_out_channels = out_channels * 2
+
+ # shortcut
+ cfg = dict(conv_cfg=conv_cfg, norm_cfg=norm_cfg, act_cfg=act_cfg)
+ self.conv1 = ConvModule(in_channels, out_channels, 1, **cfg)
+ self.conv2 = ConvModule(
+ out_channels, double_out_channels, 3, padding=1, **cfg)
+ self.conv3 = ConvModule(double_out_channels, out_channels, 1, **cfg)
+ self.conv4 = ConvModule(
+ out_channels, double_out_channels, 3, padding=1, **cfg)
+ self.conv5 = ConvModule(double_out_channels, out_channels, 1, **cfg)
+
+ def forward(self, x: Tensor) -> Tensor:
+ tmp = self.conv1(x)
+ tmp = self.conv2(tmp)
+ tmp = self.conv3(tmp)
+ tmp = self.conv4(tmp)
+ out = self.conv5(tmp)
+ return out
+
+
+@MODELS.register_module()
+class YOLOV3Neck(BaseModule):
+ """The neck of YOLOV3.
+
+ It can be treated as a simplified version of FPN. It
+ will take the result from Darknet backbone and do some upsampling and
+ concatenation. It will finally output the detection result.
+
+ Note:
+ The input feats should be from top to bottom.
+ i.e., from high-lvl to low-lvl
+ But YOLOV3Neck will process them in reversed order.
+ i.e., from bottom (high-lvl) to top (low-lvl)
+
+ Args:
+ num_scales (int): The number of scales / stages.
+ in_channels (List[int]): The number of input channels per scale.
+ out_channels (List[int]): The number of output channels per scale.
+ conv_cfg (dict, optional): Config dict for convolution layer.
+ Default: None.
+ norm_cfg (dict, optional): Dictionary to construct and config norm
+ layer. Default: dict(type='BN', requires_grad=True)
+ act_cfg (dict, optional): Config dict for activation layer.
+ Default: dict(type='LeakyReLU', negative_slope=0.1).
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None
+ """
+
+ def __init__(self,
+ num_scales: int,
+ in_channels: List[int],
+ out_channels: List[int],
+ conv_cfg: OptConfigType = None,
+ norm_cfg: ConfigType = dict(type='BN', requires_grad=True),
+ act_cfg: ConfigType = dict(
+ type='LeakyReLU', negative_slope=0.1),
+ init_cfg: OptMultiConfig = None) -> None:
+ super(YOLOV3Neck, self).__init__(init_cfg)
+ assert (num_scales == len(in_channels) == len(out_channels))
+ self.num_scales = num_scales
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+
+ # shortcut
+ cfg = dict(conv_cfg=conv_cfg, norm_cfg=norm_cfg, act_cfg=act_cfg)
+
+ # To support arbitrary scales, the code looks awful, but it works.
+ # Better solution is welcomed.
+ self.detect1 = DetectionBlock(in_channels[0], out_channels[0], **cfg)
+ for i in range(1, self.num_scales):
+ in_c, out_c = self.in_channels[i], self.out_channels[i]
+ inter_c = out_channels[i - 1]
+ self.add_module(f'conv{i}', ConvModule(inter_c, out_c, 1, **cfg))
+ # in_c + out_c : High-lvl feats will be cat with low-lvl feats
+ self.add_module(f'detect{i+1}',
+ DetectionBlock(in_c + out_c, out_c, **cfg))
+
+ def forward(self, feats=Tuple[Tensor]) -> Tuple[Tensor]:
+ assert len(feats) == self.num_scales
+
+ # processed from bottom (high-lvl) to top (low-lvl)
+ outs = []
+ out = self.detect1(feats[-1])
+ outs.append(out)
+
+ for i, x in enumerate(reversed(feats[:-1])):
+ conv = getattr(self, f'conv{i+1}')
+ tmp = conv(out)
+
+ # Cat with low-lvl feats
+ tmp = F.interpolate(tmp, scale_factor=2)
+ tmp = torch.cat((tmp, x), 1)
+
+ detect = getattr(self, f'detect{i+2}')
+ out = detect(tmp)
+ outs.append(out)
+
+ return tuple(outs)
diff --git a/mmdet/models/necks/yolox_pafpn.py b/mmdet/models/necks/yolox_pafpn.py
new file mode 100644
index 0000000000000000000000000000000000000000..8ec3d12bfde8158c1a817fbf223a8eea94798667
--- /dev/null
+++ b/mmdet/models/necks/yolox_pafpn.py
@@ -0,0 +1,156 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+
+import torch
+import torch.nn as nn
+from mmcv.cnn import ConvModule, DepthwiseSeparableConvModule
+from mmengine.model import BaseModule
+
+from mmdet.registry import MODELS
+from ..layers import CSPLayer
+
+
+@MODELS.register_module()
+class YOLOXPAFPN(BaseModule):
+ """Path Aggregation Network used in YOLOX.
+
+ Args:
+ in_channels (List[int]): Number of input channels per scale.
+ out_channels (int): Number of output channels (used at each scale)
+ num_csp_blocks (int): Number of bottlenecks in CSPLayer. Default: 3
+ use_depthwise (bool): Whether to depthwise separable convolution in
+ blocks. Default: False
+ upsample_cfg (dict): Config dict for interpolate layer.
+ Default: `dict(scale_factor=2, mode='nearest')`
+ conv_cfg (dict, optional): Config dict for convolution layer.
+ Default: None, which means using conv2d.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='BN')
+ act_cfg (dict): Config dict for activation layer.
+ Default: dict(type='Swish')
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Default: None.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ num_csp_blocks=3,
+ use_depthwise=False,
+ upsample_cfg=dict(scale_factor=2, mode='nearest'),
+ conv_cfg=None,
+ norm_cfg=dict(type='BN', momentum=0.03, eps=0.001),
+ act_cfg=dict(type='Swish'),
+ init_cfg=dict(
+ type='Kaiming',
+ layer='Conv2d',
+ a=math.sqrt(5),
+ distribution='uniform',
+ mode='fan_in',
+ nonlinearity='leaky_relu')):
+ super(YOLOXPAFPN, self).__init__(init_cfg)
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+
+ conv = DepthwiseSeparableConvModule if use_depthwise else ConvModule
+
+ # build top-down blocks
+ self.upsample = nn.Upsample(**upsample_cfg)
+ self.reduce_layers = nn.ModuleList()
+ self.top_down_blocks = nn.ModuleList()
+ for idx in range(len(in_channels) - 1, 0, -1):
+ self.reduce_layers.append(
+ ConvModule(
+ in_channels[idx],
+ in_channels[idx - 1],
+ 1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+ self.top_down_blocks.append(
+ CSPLayer(
+ in_channels[idx - 1] * 2,
+ in_channels[idx - 1],
+ num_blocks=num_csp_blocks,
+ add_identity=False,
+ use_depthwise=use_depthwise,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+
+ # build bottom-up blocks
+ self.downsamples = nn.ModuleList()
+ self.bottom_up_blocks = nn.ModuleList()
+ for idx in range(len(in_channels) - 1):
+ self.downsamples.append(
+ conv(
+ in_channels[idx],
+ in_channels[idx],
+ 3,
+ stride=2,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+ self.bottom_up_blocks.append(
+ CSPLayer(
+ in_channels[idx] * 2,
+ in_channels[idx + 1],
+ num_blocks=num_csp_blocks,
+ add_identity=False,
+ use_depthwise=use_depthwise,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+
+ self.out_convs = nn.ModuleList()
+ for i in range(len(in_channels)):
+ self.out_convs.append(
+ ConvModule(
+ in_channels[i],
+ out_channels,
+ 1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+
+ def forward(self, inputs):
+ """
+ Args:
+ inputs (tuple[Tensor]): input features.
+
+ Returns:
+ tuple[Tensor]: YOLOXPAFPN features.
+ """
+ assert len(inputs) == len(self.in_channels)
+
+ # top-down path
+ inner_outs = [inputs[-1]]
+ for idx in range(len(self.in_channels) - 1, 0, -1):
+ feat_heigh = inner_outs[0]
+ feat_low = inputs[idx - 1]
+ feat_heigh = self.reduce_layers[len(self.in_channels) - 1 - idx](
+ feat_heigh)
+ inner_outs[0] = feat_heigh
+
+ upsample_feat = self.upsample(feat_heigh)
+
+ inner_out = self.top_down_blocks[len(self.in_channels) - 1 - idx](
+ torch.cat([upsample_feat, feat_low], 1))
+ inner_outs.insert(0, inner_out)
+
+ # bottom-up path
+ outs = [inner_outs[0]]
+ for idx in range(len(self.in_channels) - 1):
+ feat_low = outs[-1]
+ feat_height = inner_outs[idx + 1]
+ downsample_feat = self.downsamples[idx](feat_low)
+ out = self.bottom_up_blocks[idx](
+ torch.cat([downsample_feat, feat_height], 1))
+ outs.append(out)
+
+ # out convs
+ for idx, conv in enumerate(self.out_convs):
+ outs[idx] = conv(outs[idx])
+
+ return tuple(outs)
diff --git a/mmdet/models/roi_heads/__init__.py b/mmdet/models/roi_heads/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..bba5664cc5ae5229ddebcb42f7583364ca9f77d8
--- /dev/null
+++ b/mmdet/models/roi_heads/__init__.py
@@ -0,0 +1,38 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .base_roi_head import BaseRoIHead
+from .bbox_heads import (BBoxHead, ConvFCBBoxHead, DIIHead,
+ DoubleConvFCBBoxHead, SABLHead, SCNetBBoxHead,
+ Shared2FCBBoxHead, Shared4Conv1FCBBoxHead)
+from .cascade_roi_head import CascadeRoIHead
+from .double_roi_head import DoubleHeadRoIHead
+from .dynamic_roi_head import DynamicRoIHead
+from .grid_roi_head import GridRoIHead
+from .htc_roi_head import HybridTaskCascadeRoIHead
+from .mask_heads import (CoarseMaskHead, FCNMaskHead, FeatureRelayHead,
+ FusedSemanticHead, GlobalContextHead, GridHead,
+ HTCMaskHead, MaskIoUHead, MaskPointHead,
+ SCNetMaskHead, SCNetSemanticHead)
+from .mask_scoring_roi_head import MaskScoringRoIHead
+from .multi_instance_roi_head import MultiInstanceRoIHead
+from .pisa_roi_head import PISARoIHead
+from .point_rend_roi_head import PointRendRoIHead
+from .roi_extractors import (BaseRoIExtractor, GenericRoIExtractor,
+ SingleRoIExtractor)
+from .scnet_roi_head import SCNetRoIHead
+from .shared_heads import ResLayer
+from .sparse_roi_head import SparseRoIHead
+from .standard_roi_head import StandardRoIHead
+from .trident_roi_head import TridentRoIHead
+
+__all__ = [
+ 'BaseRoIHead', 'CascadeRoIHead', 'DoubleHeadRoIHead', 'MaskScoringRoIHead',
+ 'HybridTaskCascadeRoIHead', 'GridRoIHead', 'ResLayer', 'BBoxHead',
+ 'ConvFCBBoxHead', 'DIIHead', 'SABLHead', 'Shared2FCBBoxHead',
+ 'StandardRoIHead', 'Shared4Conv1FCBBoxHead', 'DoubleConvFCBBoxHead',
+ 'FCNMaskHead', 'HTCMaskHead', 'FusedSemanticHead', 'GridHead',
+ 'MaskIoUHead', 'BaseRoIExtractor', 'GenericRoIExtractor',
+ 'SingleRoIExtractor', 'PISARoIHead', 'PointRendRoIHead', 'MaskPointHead',
+ 'CoarseMaskHead', 'DynamicRoIHead', 'SparseRoIHead', 'TridentRoIHead',
+ 'SCNetRoIHead', 'SCNetMaskHead', 'SCNetSemanticHead', 'SCNetBBoxHead',
+ 'FeatureRelayHead', 'GlobalContextHead', 'MultiInstanceRoIHead'
+]
diff --git a/mmdet/models/roi_heads/__pycache__/__init__.cpython-37.pyc b/mmdet/models/roi_heads/__pycache__/__init__.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..4640c59bab3c13470601f7b40461217bdf68deea
Binary files /dev/null and b/mmdet/models/roi_heads/__pycache__/__init__.cpython-37.pyc differ
diff --git a/mmdet/models/roi_heads/__pycache__/base_roi_head.cpython-37.pyc b/mmdet/models/roi_heads/__pycache__/base_roi_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..38ef48f98693b7e5e54389c9692cf573b46cbf84
Binary files /dev/null and b/mmdet/models/roi_heads/__pycache__/base_roi_head.cpython-37.pyc differ
diff --git a/mmdet/models/roi_heads/__pycache__/cascade_roi_head.cpython-37.pyc b/mmdet/models/roi_heads/__pycache__/cascade_roi_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..a2c7654989c4cd5b7f4e6bf423a5306b9ea7e550
Binary files /dev/null and b/mmdet/models/roi_heads/__pycache__/cascade_roi_head.cpython-37.pyc differ
diff --git a/mmdet/models/roi_heads/__pycache__/double_roi_head.cpython-37.pyc b/mmdet/models/roi_heads/__pycache__/double_roi_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..e2ff2688edc47fc64d3b27fe2183ac0f4076c056
Binary files /dev/null and b/mmdet/models/roi_heads/__pycache__/double_roi_head.cpython-37.pyc differ
diff --git a/mmdet/models/roi_heads/__pycache__/dynamic_roi_head.cpython-37.pyc b/mmdet/models/roi_heads/__pycache__/dynamic_roi_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..bb718863cbc1c6d2f0b3d787c35b6c98a08a9ee1
Binary files /dev/null and b/mmdet/models/roi_heads/__pycache__/dynamic_roi_head.cpython-37.pyc differ
diff --git a/mmdet/models/roi_heads/__pycache__/grid_roi_head.cpython-37.pyc b/mmdet/models/roi_heads/__pycache__/grid_roi_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..d59f530f05031804091516954074119d09cb421c
Binary files /dev/null and b/mmdet/models/roi_heads/__pycache__/grid_roi_head.cpython-37.pyc differ
diff --git a/mmdet/models/roi_heads/__pycache__/htc_roi_head.cpython-37.pyc b/mmdet/models/roi_heads/__pycache__/htc_roi_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..b8129ad8dbfade910a6662bd0c6fa52d78958613
Binary files /dev/null and b/mmdet/models/roi_heads/__pycache__/htc_roi_head.cpython-37.pyc differ
diff --git a/mmdet/models/roi_heads/__pycache__/mask_scoring_roi_head.cpython-37.pyc b/mmdet/models/roi_heads/__pycache__/mask_scoring_roi_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..3ccc98456f4702b89055190212739b7bb56390a5
Binary files /dev/null and b/mmdet/models/roi_heads/__pycache__/mask_scoring_roi_head.cpython-37.pyc differ
diff --git a/mmdet/models/roi_heads/__pycache__/multi_instance_roi_head.cpython-37.pyc b/mmdet/models/roi_heads/__pycache__/multi_instance_roi_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..1c5d10f0254333d0b590c1193742b8d76216fd78
Binary files /dev/null and b/mmdet/models/roi_heads/__pycache__/multi_instance_roi_head.cpython-37.pyc differ
diff --git a/mmdet/models/roi_heads/__pycache__/pisa_roi_head.cpython-37.pyc b/mmdet/models/roi_heads/__pycache__/pisa_roi_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..3804a25af5b75d625b5cb3d64dcef5dda5e93ead
Binary files /dev/null and b/mmdet/models/roi_heads/__pycache__/pisa_roi_head.cpython-37.pyc differ
diff --git a/mmdet/models/roi_heads/__pycache__/point_rend_roi_head.cpython-37.pyc b/mmdet/models/roi_heads/__pycache__/point_rend_roi_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..c0b4c54694313a2ae43665cf1fbde4b69350e1df
Binary files /dev/null and b/mmdet/models/roi_heads/__pycache__/point_rend_roi_head.cpython-37.pyc differ
diff --git a/mmdet/models/roi_heads/__pycache__/scnet_roi_head.cpython-37.pyc b/mmdet/models/roi_heads/__pycache__/scnet_roi_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..4cbb1200725595052ae0ecf76b64be079edf0452
Binary files /dev/null and b/mmdet/models/roi_heads/__pycache__/scnet_roi_head.cpython-37.pyc differ
diff --git a/mmdet/models/roi_heads/__pycache__/sparse_roi_head.cpython-37.pyc b/mmdet/models/roi_heads/__pycache__/sparse_roi_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..4148287bf3a704620c8c7912d6a70cad8131909d
Binary files /dev/null and b/mmdet/models/roi_heads/__pycache__/sparse_roi_head.cpython-37.pyc differ
diff --git a/mmdet/models/roi_heads/__pycache__/standard_roi_head.cpython-37.pyc b/mmdet/models/roi_heads/__pycache__/standard_roi_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..d0160697004563fb2520f0b9202b2b9558b9f1c4
Binary files /dev/null and b/mmdet/models/roi_heads/__pycache__/standard_roi_head.cpython-37.pyc differ
diff --git a/mmdet/models/roi_heads/__pycache__/trident_roi_head.cpython-37.pyc b/mmdet/models/roi_heads/__pycache__/trident_roi_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..de302a78ad958b56ff9878b1708d8410713aaabd
Binary files /dev/null and b/mmdet/models/roi_heads/__pycache__/trident_roi_head.cpython-37.pyc differ
diff --git a/mmdet/models/roi_heads/base_roi_head.py b/mmdet/models/roi_heads/base_roi_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..405f80a73ecc5db7343d81ca55518160fcbc2b63
--- /dev/null
+++ b/mmdet/models/roi_heads/base_roi_head.py
@@ -0,0 +1,129 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from abc import ABCMeta, abstractmethod
+from typing import Tuple
+
+from mmengine.model import BaseModule
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.structures import SampleList
+from mmdet.utils import InstanceList, OptConfigType, OptMultiConfig
+
+
+class BaseRoIHead(BaseModule, metaclass=ABCMeta):
+ """Base class for RoIHeads."""
+
+ def __init__(self,
+ bbox_roi_extractor: OptMultiConfig = None,
+ bbox_head: OptMultiConfig = None,
+ mask_roi_extractor: OptMultiConfig = None,
+ mask_head: OptMultiConfig = None,
+ shared_head: OptConfigType = None,
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(init_cfg=init_cfg)
+ self.train_cfg = train_cfg
+ self.test_cfg = test_cfg
+ if shared_head is not None:
+ self.shared_head = MODELS.build(shared_head)
+
+ if bbox_head is not None:
+ self.init_bbox_head(bbox_roi_extractor, bbox_head)
+
+ if mask_head is not None:
+ self.init_mask_head(mask_roi_extractor, mask_head)
+
+ self.init_assigner_sampler()
+
+ @property
+ def with_bbox(self) -> bool:
+ """bool: whether the RoI head contains a `bbox_head`"""
+ return hasattr(self, 'bbox_head') and self.bbox_head is not None
+
+ @property
+ def with_mask(self) -> bool:
+ """bool: whether the RoI head contains a `mask_head`"""
+ return hasattr(self, 'mask_head') and self.mask_head is not None
+
+ @property
+ def with_shared_head(self) -> bool:
+ """bool: whether the RoI head contains a `shared_head`"""
+ return hasattr(self, 'shared_head') and self.shared_head is not None
+
+ @abstractmethod
+ def init_bbox_head(self, *args, **kwargs):
+ """Initialize ``bbox_head``"""
+ pass
+
+ @abstractmethod
+ def init_mask_head(self, *args, **kwargs):
+ """Initialize ``mask_head``"""
+ pass
+
+ @abstractmethod
+ def init_assigner_sampler(self, *args, **kwargs):
+ """Initialize assigner and sampler."""
+ pass
+
+ @abstractmethod
+ def loss(self, x: Tuple[Tensor], rpn_results_list: InstanceList,
+ batch_data_samples: SampleList):
+ """Perform forward propagation and loss calculation of the roi head on
+ the features of the upstream network."""
+
+ def predict(self,
+ x: Tuple[Tensor],
+ rpn_results_list: InstanceList,
+ batch_data_samples: SampleList,
+ rescale: bool = False) -> InstanceList:
+ """Perform forward propagation of the roi head and predict detection
+ results on the features of the upstream network.
+
+ Args:
+ x (tuple[Tensor]): Features from upstream network. Each
+ has shape (N, C, H, W).
+ rpn_results_list (list[:obj:`InstanceData`]): list of region
+ proposals.
+ batch_data_samples (List[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ rescale (bool): Whether to rescale the results to
+ the original image. Defaults to True.
+
+ Returns:
+ list[obj:`InstanceData`]: Detection results of each image.
+ Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ - masks (Tensor): Has a shape (num_instances, H, W).
+ """
+ assert self.with_bbox, 'Bbox head must be implemented.'
+ batch_img_metas = [
+ data_samples.metainfo for data_samples in batch_data_samples
+ ]
+
+ # TODO: nms_op in mmcv need be enhanced, the bbox result may get
+ # difference when not rescale in bbox_head
+
+ # If it has the mask branch, the bbox branch does not need
+ # to be scaled to the original image scale, because the mask
+ # branch will scale both bbox and mask at the same time.
+ bbox_rescale = rescale if not self.with_mask else False
+ results_list = self.predict_bbox(
+ x,
+ batch_img_metas,
+ rpn_results_list,
+ rcnn_test_cfg=self.test_cfg,
+ rescale=bbox_rescale)
+
+ if self.with_mask:
+ results_list = self.predict_mask(
+ x, batch_img_metas, results_list, rescale=rescale)
+
+ return results_list
diff --git a/mmdet/models/roi_heads/bbox_heads/__init__.py b/mmdet/models/roi_heads/bbox_heads/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..d9e742abfecfc9dfe37b78822407fc92e9d64cc3
--- /dev/null
+++ b/mmdet/models/roi_heads/bbox_heads/__init__.py
@@ -0,0 +1,15 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .bbox_head import BBoxHead
+from .convfc_bbox_head import (ConvFCBBoxHead, Shared2FCBBoxHead,
+ Shared4Conv1FCBBoxHead)
+from .dii_head import DIIHead
+from .double_bbox_head import DoubleConvFCBBoxHead
+from .multi_instance_bbox_head import MultiInstanceBBoxHead
+from .sabl_head import SABLHead
+from .scnet_bbox_head import SCNetBBoxHead
+
+__all__ = [
+ 'BBoxHead', 'ConvFCBBoxHead', 'Shared2FCBBoxHead',
+ 'Shared4Conv1FCBBoxHead', 'DoubleConvFCBBoxHead', 'SABLHead', 'DIIHead',
+ 'SCNetBBoxHead', 'MultiInstanceBBoxHead'
+]
diff --git a/mmdet/models/roi_heads/bbox_heads/__pycache__/__init__.cpython-37.pyc b/mmdet/models/roi_heads/bbox_heads/__pycache__/__init__.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..b6e0391d652ee16992aa9b444a0c2e8e83da432a
Binary files /dev/null and b/mmdet/models/roi_heads/bbox_heads/__pycache__/__init__.cpython-37.pyc differ
diff --git a/mmdet/models/roi_heads/bbox_heads/__pycache__/bbox_head.cpython-37.pyc b/mmdet/models/roi_heads/bbox_heads/__pycache__/bbox_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..fd855625d7addf76dbfdeefb783d654999cf940a
Binary files /dev/null and b/mmdet/models/roi_heads/bbox_heads/__pycache__/bbox_head.cpython-37.pyc differ
diff --git a/mmdet/models/roi_heads/bbox_heads/__pycache__/convfc_bbox_head.cpython-37.pyc b/mmdet/models/roi_heads/bbox_heads/__pycache__/convfc_bbox_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..2dc2802406e544cce0919f8d3bdb6d6c6e69a53f
Binary files /dev/null and b/mmdet/models/roi_heads/bbox_heads/__pycache__/convfc_bbox_head.cpython-37.pyc differ
diff --git a/mmdet/models/roi_heads/bbox_heads/__pycache__/dii_head.cpython-37.pyc b/mmdet/models/roi_heads/bbox_heads/__pycache__/dii_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..bb9f155bef5a2e86d0462aa8874dfbc5a6773075
Binary files /dev/null and b/mmdet/models/roi_heads/bbox_heads/__pycache__/dii_head.cpython-37.pyc differ
diff --git a/mmdet/models/roi_heads/bbox_heads/__pycache__/double_bbox_head.cpython-37.pyc b/mmdet/models/roi_heads/bbox_heads/__pycache__/double_bbox_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..a9f1bafd2e8a994f8155b72450e9cfe6ae617a29
Binary files /dev/null and b/mmdet/models/roi_heads/bbox_heads/__pycache__/double_bbox_head.cpython-37.pyc differ
diff --git a/mmdet/models/roi_heads/bbox_heads/__pycache__/multi_instance_bbox_head.cpython-37.pyc b/mmdet/models/roi_heads/bbox_heads/__pycache__/multi_instance_bbox_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..509cd57c1fd2bbb8c4fdb02b53e5d402ed7bdee7
Binary files /dev/null and b/mmdet/models/roi_heads/bbox_heads/__pycache__/multi_instance_bbox_head.cpython-37.pyc differ
diff --git a/mmdet/models/roi_heads/bbox_heads/__pycache__/sabl_head.cpython-37.pyc b/mmdet/models/roi_heads/bbox_heads/__pycache__/sabl_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..a6f09501fc5f38796770674614d1c65cdc73a7d3
Binary files /dev/null and b/mmdet/models/roi_heads/bbox_heads/__pycache__/sabl_head.cpython-37.pyc differ
diff --git a/mmdet/models/roi_heads/bbox_heads/__pycache__/scnet_bbox_head.cpython-37.pyc b/mmdet/models/roi_heads/bbox_heads/__pycache__/scnet_bbox_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..ce6149b1291d8334159f7ab88b1c1f7c555a77ec
Binary files /dev/null and b/mmdet/models/roi_heads/bbox_heads/__pycache__/scnet_bbox_head.cpython-37.pyc differ
diff --git a/mmdet/models/roi_heads/bbox_heads/bbox_head.py b/mmdet/models/roi_heads/bbox_heads/bbox_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..3b2e8aae0833ae0351b544099d79d296f082a76e
--- /dev/null
+++ b/mmdet/models/roi_heads/bbox_heads/bbox_head.py
@@ -0,0 +1,708 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Optional, Tuple, Union
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmengine.config import ConfigDict
+from mmengine.model import BaseModule
+from mmengine.structures import InstanceData
+from torch import Tensor
+from torch.nn.modules.utils import _pair
+
+from mmdet.models.layers import multiclass_nms
+from mmdet.models.losses import accuracy
+from mmdet.models.task_modules.samplers import SamplingResult
+from mmdet.models.utils import empty_instances, multi_apply
+from mmdet.registry import MODELS, TASK_UTILS
+from mmdet.structures.bbox import get_box_tensor, scale_boxes
+from mmdet.utils import ConfigType, InstanceList, OptMultiConfig
+
+
+@MODELS.register_module()
+class BBoxHead(BaseModule):
+ """Simplest RoI head, with only two fc layers for classification and
+ regression respectively."""
+
+ def __init__(self,
+ with_avg_pool: bool = False,
+ with_cls: bool = True,
+ with_reg: bool = True,
+ roi_feat_size: int = 7,
+ in_channels: int = 256,
+ num_classes: int = 80,
+ bbox_coder: ConfigType = dict(
+ type='DeltaXYWHBBoxCoder',
+ clip_border=True,
+ target_means=[0., 0., 0., 0.],
+ target_stds=[0.1, 0.1, 0.2, 0.2]),
+ predict_box_type: str = 'hbox',
+ reg_class_agnostic: bool = False,
+ reg_decoded_bbox: bool = False,
+ reg_predictor_cfg: ConfigType = dict(type='Linear'),
+ cls_predictor_cfg: ConfigType = dict(type='Linear'),
+ loss_cls: ConfigType = dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=False,
+ loss_weight=1.0),
+ loss_bbox: ConfigType = dict(
+ type='SmoothL1Loss', beta=1.0, loss_weight=1.0),
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(init_cfg=init_cfg)
+ assert with_cls or with_reg
+ self.with_avg_pool = with_avg_pool
+ self.with_cls = with_cls
+ self.with_reg = with_reg
+ self.roi_feat_size = _pair(roi_feat_size)
+ self.roi_feat_area = self.roi_feat_size[0] * self.roi_feat_size[1]
+ self.in_channels = in_channels
+ self.num_classes = num_classes
+ self.predict_box_type = predict_box_type
+ self.reg_class_agnostic = reg_class_agnostic
+ self.reg_decoded_bbox = reg_decoded_bbox
+ self.reg_predictor_cfg = reg_predictor_cfg
+ self.cls_predictor_cfg = cls_predictor_cfg
+
+ self.bbox_coder = TASK_UTILS.build(bbox_coder)
+ self.loss_cls = MODELS.build(loss_cls)
+ self.loss_bbox = MODELS.build(loss_bbox)
+
+ in_channels = self.in_channels
+ if self.with_avg_pool:
+ self.avg_pool = nn.AvgPool2d(self.roi_feat_size)
+ else:
+ in_channels *= self.roi_feat_area
+ if self.with_cls:
+ # need to add background class
+ if self.custom_cls_channels:
+ cls_channels = self.loss_cls.get_cls_channels(self.num_classes)
+ else:
+ cls_channels = num_classes + 1
+ cls_predictor_cfg_ = self.cls_predictor_cfg.copy()
+ cls_predictor_cfg_.update(
+ in_features=in_channels, out_features=cls_channels)
+ self.fc_cls = MODELS.build(cls_predictor_cfg_)
+ if self.with_reg:
+ box_dim = self.bbox_coder.encode_size
+ out_dim_reg = box_dim if reg_class_agnostic else \
+ box_dim * num_classes
+ reg_predictor_cfg_ = self.reg_predictor_cfg.copy()
+ if isinstance(reg_predictor_cfg_, (dict, ConfigDict)):
+ reg_predictor_cfg_.update(
+ in_features=in_channels, out_features=out_dim_reg)
+ self.fc_reg = MODELS.build(reg_predictor_cfg_)
+ self.debug_imgs = None
+ if init_cfg is None:
+ self.init_cfg = []
+ if self.with_cls:
+ self.init_cfg += [
+ dict(
+ type='Normal', std=0.01, override=dict(name='fc_cls'))
+ ]
+ if self.with_reg:
+ self.init_cfg += [
+ dict(
+ type='Normal', std=0.001, override=dict(name='fc_reg'))
+ ]
+
+ # TODO: Create a SeasawBBoxHead to simplified logic in BBoxHead
+ @property
+ def custom_cls_channels(self) -> bool:
+ """get custom_cls_channels from loss_cls."""
+ return getattr(self.loss_cls, 'custom_cls_channels', False)
+
+ # TODO: Create a SeasawBBoxHead to simplified logic in BBoxHead
+ @property
+ def custom_activation(self) -> bool:
+ """get custom_activation from loss_cls."""
+ return getattr(self.loss_cls, 'custom_activation', False)
+
+ # TODO: Create a SeasawBBoxHead to simplified logic in BBoxHead
+ @property
+ def custom_accuracy(self) -> bool:
+ """get custom_accuracy from loss_cls."""
+ return getattr(self.loss_cls, 'custom_accuracy', False)
+
+ def forward(self, x: Tuple[Tensor]) -> tuple:
+ """Forward features from the upstream network.
+
+ Args:
+ x (tuple[Tensor]): Features from the upstream network, each is
+ a 4D-tensor.
+
+ Returns:
+ tuple: A tuple of classification scores and bbox prediction.
+
+ - cls_score (Tensor): Classification scores for all
+ scale levels, each is a 4D-tensor, the channels number
+ is num_base_priors * num_classes.
+ - bbox_pred (Tensor): Box energies / deltas for all
+ scale levels, each is a 4D-tensor, the channels number
+ is num_base_priors * 4.
+ """
+ if self.with_avg_pool:
+ if x.numel() > 0:
+ x = self.avg_pool(x)
+ x = x.view(x.size(0), -1)
+ else:
+ # avg_pool does not support empty tensor,
+ # so use torch.mean instead it
+ x = torch.mean(x, dim=(-1, -2))
+ cls_score = self.fc_cls(x) if self.with_cls else None
+ bbox_pred = self.fc_reg(x) if self.with_reg else None
+ return cls_score, bbox_pred
+
+ def _get_targets_single(self, pos_priors: Tensor, neg_priors: Tensor,
+ pos_gt_bboxes: Tensor, pos_gt_labels: Tensor,
+ cfg: ConfigDict) -> tuple:
+ """Calculate the ground truth for proposals in the single image
+ according to the sampling results.
+
+ Args:
+ pos_priors (Tensor): Contains all the positive boxes,
+ has shape (num_pos, 4), the last dimension 4
+ represents [tl_x, tl_y, br_x, br_y].
+ neg_priors (Tensor): Contains all the negative boxes,
+ has shape (num_neg, 4), the last dimension 4
+ represents [tl_x, tl_y, br_x, br_y].
+ pos_gt_bboxes (Tensor): Contains gt_boxes for
+ all positive samples, has shape (num_pos, 4),
+ the last dimension 4
+ represents [tl_x, tl_y, br_x, br_y].
+ pos_gt_labels (Tensor): Contains gt_labels for
+ all positive samples, has shape (num_pos, ).
+ cfg (obj:`ConfigDict`): `train_cfg` of R-CNN.
+
+ Returns:
+ Tuple[Tensor]: Ground truth for proposals
+ in a single image. Containing the following Tensors:
+
+ - labels(Tensor): Gt_labels for all proposals, has
+ shape (num_proposals,).
+ - label_weights(Tensor): Labels_weights for all
+ proposals, has shape (num_proposals,).
+ - bbox_targets(Tensor):Regression target for all
+ proposals, has shape (num_proposals, 4), the
+ last dimension 4 represents [tl_x, tl_y, br_x, br_y].
+ - bbox_weights(Tensor):Regression weights for all
+ proposals, has shape (num_proposals, 4).
+ """
+ num_pos = pos_priors.size(0)
+ num_neg = neg_priors.size(0)
+ num_samples = num_pos + num_neg
+
+ # original implementation uses new_zeros since BG are set to be 0
+ # now use empty & fill because BG cat_id = num_classes,
+ # FG cat_id = [0, num_classes-1]
+ labels = pos_priors.new_full((num_samples, ),
+ self.num_classes,
+ dtype=torch.long)
+ reg_dim = pos_gt_bboxes.size(-1) if self.reg_decoded_bbox \
+ else self.bbox_coder.encode_size
+ label_weights = pos_priors.new_zeros(num_samples)
+ bbox_targets = pos_priors.new_zeros(num_samples, reg_dim)
+ bbox_weights = pos_priors.new_zeros(num_samples, reg_dim)
+ if num_pos > 0:
+ labels[:num_pos] = pos_gt_labels
+ pos_weight = 1.0 if cfg.pos_weight <= 0 else cfg.pos_weight
+ label_weights[:num_pos] = pos_weight
+ if not self.reg_decoded_bbox:
+ pos_bbox_targets = self.bbox_coder.encode(
+ pos_priors, pos_gt_bboxes)
+ else:
+ # When the regression loss (e.g. `IouLoss`, `GIouLoss`)
+ # is applied directly on the decoded bounding boxes, both
+ # the predicted boxes and regression targets should be with
+ # absolute coordinate format.
+ pos_bbox_targets = get_box_tensor(pos_gt_bboxes)
+ bbox_targets[:num_pos, :] = pos_bbox_targets
+ bbox_weights[:num_pos, :] = 1
+ if num_neg > 0:
+ label_weights[-num_neg:] = 1.0
+
+ return labels, label_weights, bbox_targets, bbox_weights
+
+ def get_targets(self,
+ sampling_results: List[SamplingResult],
+ rcnn_train_cfg: ConfigDict,
+ concat: bool = True) -> tuple:
+ """Calculate the ground truth for all samples in a batch according to
+ the sampling_results.
+
+ Almost the same as the implementation in bbox_head, we passed
+ additional parameters pos_inds_list and neg_inds_list to
+ `_get_targets_single` function.
+
+ Args:
+ sampling_results (List[obj:SamplingResult]): Assign results of
+ all images in a batch after sampling.
+ rcnn_train_cfg (obj:ConfigDict): `train_cfg` of RCNN.
+ concat (bool): Whether to concatenate the results of all
+ the images in a single batch.
+
+ Returns:
+ Tuple[Tensor]: Ground truth for proposals in a single image.
+ Containing the following list of Tensors:
+
+ - labels (list[Tensor],Tensor): Gt_labels for all
+ proposals in a batch, each tensor in list has
+ shape (num_proposals,) when `concat=False`, otherwise
+ just a single tensor has shape (num_all_proposals,).
+ - label_weights (list[Tensor]): Labels_weights for
+ all proposals in a batch, each tensor in list has
+ shape (num_proposals,) when `concat=False`, otherwise
+ just a single tensor has shape (num_all_proposals,).
+ - bbox_targets (list[Tensor],Tensor): Regression target
+ for all proposals in a batch, each tensor in list
+ has shape (num_proposals, 4) when `concat=False`,
+ otherwise just a single tensor has shape
+ (num_all_proposals, 4), the last dimension 4 represents
+ [tl_x, tl_y, br_x, br_y].
+ - bbox_weights (list[tensor],Tensor): Regression weights for
+ all proposals in a batch, each tensor in list has shape
+ (num_proposals, 4) when `concat=False`, otherwise just a
+ single tensor has shape (num_all_proposals, 4).
+ """
+ pos_priors_list = [res.pos_priors for res in sampling_results]
+ neg_priors_list = [res.neg_priors for res in sampling_results]
+ pos_gt_bboxes_list = [res.pos_gt_bboxes for res in sampling_results]
+ pos_gt_labels_list = [res.pos_gt_labels for res in sampling_results]
+ labels, label_weights, bbox_targets, bbox_weights = multi_apply(
+ self._get_targets_single,
+ pos_priors_list,
+ neg_priors_list,
+ pos_gt_bboxes_list,
+ pos_gt_labels_list,
+ cfg=rcnn_train_cfg)
+
+ if concat:
+ labels = torch.cat(labels, 0)
+ label_weights = torch.cat(label_weights, 0)
+ bbox_targets = torch.cat(bbox_targets, 0)
+ bbox_weights = torch.cat(bbox_weights, 0)
+ return labels, label_weights, bbox_targets, bbox_weights
+
+ def loss_and_target(self,
+ cls_score: Tensor,
+ bbox_pred: Tensor,
+ rois: Tensor,
+ sampling_results: List[SamplingResult],
+ rcnn_train_cfg: ConfigDict,
+ concat: bool = True,
+ reduction_override: Optional[str] = None) -> dict:
+ """Calculate the loss based on the features extracted by the bbox head.
+
+ Args:
+ cls_score (Tensor): Classification prediction
+ results of all class, has shape
+ (batch_size * num_proposals_single_image, num_classes)
+ bbox_pred (Tensor): Regression prediction results,
+ has shape
+ (batch_size * num_proposals_single_image, 4), the last
+ dimension 4 represents [tl_x, tl_y, br_x, br_y].
+ rois (Tensor): RoIs with the shape
+ (batch_size * num_proposals_single_image, 5) where the first
+ column indicates batch id of each RoI.
+ sampling_results (List[obj:SamplingResult]): Assign results of
+ all images in a batch after sampling.
+ rcnn_train_cfg (obj:ConfigDict): `train_cfg` of RCNN.
+ concat (bool): Whether to concatenate the results of all
+ the images in a single batch. Defaults to True.
+ reduction_override (str, optional): The reduction
+ method used to override the original reduction
+ method of the loss. Options are "none",
+ "mean" and "sum". Defaults to None,
+
+ Returns:
+ dict: A dictionary of loss and targets components.
+ The targets are only used for cascade rcnn.
+ """
+
+ cls_reg_targets = self.get_targets(
+ sampling_results, rcnn_train_cfg, concat=concat)
+ losses = self.loss(
+ cls_score,
+ bbox_pred,
+ rois,
+ *cls_reg_targets,
+ reduction_override=reduction_override)
+
+ # cls_reg_targets is only for cascade rcnn
+ return dict(loss_bbox=losses, bbox_targets=cls_reg_targets)
+
+ def loss(self,
+ cls_score: Tensor,
+ bbox_pred: Tensor,
+ rois: Tensor,
+ labels: Tensor,
+ label_weights: Tensor,
+ bbox_targets: Tensor,
+ bbox_weights: Tensor,
+ reduction_override: Optional[str] = None) -> dict:
+ """Calculate the loss based on the network predictions and targets.
+
+ Args:
+ cls_score (Tensor): Classification prediction
+ results of all class, has shape
+ (batch_size * num_proposals_single_image, num_classes)
+ bbox_pred (Tensor): Regression prediction results,
+ has shape
+ (batch_size * num_proposals_single_image, 4), the last
+ dimension 4 represents [tl_x, tl_y, br_x, br_y].
+ rois (Tensor): RoIs with the shape
+ (batch_size * num_proposals_single_image, 5) where the first
+ column indicates batch id of each RoI.
+ labels (Tensor): Gt_labels for all proposals in a batch, has
+ shape (batch_size * num_proposals_single_image, ).
+ label_weights (Tensor): Labels_weights for all proposals in a
+ batch, has shape (batch_size * num_proposals_single_image, ).
+ bbox_targets (Tensor): Regression target for all proposals in a
+ batch, has shape (batch_size * num_proposals_single_image, 4),
+ the last dimension 4 represents [tl_x, tl_y, br_x, br_y].
+ bbox_weights (Tensor): Regression weights for all proposals in a
+ batch, has shape (batch_size * num_proposals_single_image, 4).
+ reduction_override (str, optional): The reduction
+ method used to override the original reduction
+ method of the loss. Options are "none",
+ "mean" and "sum". Defaults to None,
+
+ Returns:
+ dict: A dictionary of loss.
+ """
+
+ losses = dict()
+
+ if cls_score is not None:
+ avg_factor = max(torch.sum(label_weights > 0).float().item(), 1.)
+ if cls_score.numel() > 0:
+ loss_cls_ = self.loss_cls(
+ cls_score,
+ labels,
+ label_weights,
+ avg_factor=avg_factor,
+ reduction_override=reduction_override)
+ if isinstance(loss_cls_, dict):
+ losses.update(loss_cls_)
+ else:
+ losses['loss_cls'] = loss_cls_
+ if self.custom_activation:
+ acc_ = self.loss_cls.get_accuracy(cls_score, labels)
+ losses.update(acc_)
+ else:
+ losses['acc'] = accuracy(cls_score, labels)
+ if bbox_pred is not None:
+ bg_class_ind = self.num_classes
+ # 0~self.num_classes-1 are FG, self.num_classes is BG
+ pos_inds = (labels >= 0) & (labels < bg_class_ind)
+ # do not perform bounding box regression for BG anymore.
+ if pos_inds.any():
+ if self.reg_decoded_bbox:
+ # When the regression loss (e.g. `IouLoss`,
+ # `GIouLoss`, `DIouLoss`) is applied directly on
+ # the decoded bounding boxes, it decodes the
+ # already encoded coordinates to absolute format.
+ bbox_pred = self.bbox_coder.decode(rois[:, 1:], bbox_pred)
+ bbox_pred = get_box_tensor(bbox_pred)
+ if self.reg_class_agnostic:
+ pos_bbox_pred = bbox_pred.view(
+ bbox_pred.size(0), -1)[pos_inds.type(torch.bool)]
+ else:
+ pos_bbox_pred = bbox_pred.view(
+ bbox_pred.size(0), self.num_classes,
+ -1)[pos_inds.type(torch.bool),
+ labels[pos_inds.type(torch.bool)]]
+ losses['loss_bbox'] = self.loss_bbox(
+ pos_bbox_pred,
+ bbox_targets[pos_inds.type(torch.bool)],
+ bbox_weights[pos_inds.type(torch.bool)],
+ avg_factor=bbox_targets.size(0),
+ reduction_override=reduction_override)
+ else:
+ losses['loss_bbox'] = bbox_pred[pos_inds].sum()
+
+ return losses
+
+ def predict_by_feat(self,
+ rois: Tuple[Tensor],
+ cls_scores: Tuple[Tensor],
+ bbox_preds: Tuple[Tensor],
+ batch_img_metas: List[dict],
+ rcnn_test_cfg: Optional[ConfigDict] = None,
+ rescale: bool = False) -> InstanceList:
+ """Transform a batch of output features extracted from the head into
+ bbox results.
+
+ Args:
+ rois (tuple[Tensor]): Tuple of boxes to be transformed.
+ Each has shape (num_boxes, 5). last dimension 5 arrange as
+ (batch_index, x1, y1, x2, y2).
+ cls_scores (tuple[Tensor]): Tuple of box scores, each has shape
+ (num_boxes, num_classes + 1).
+ bbox_preds (tuple[Tensor]): Tuple of box energies / deltas, each
+ has shape (num_boxes, num_classes * 4).
+ batch_img_metas (list[dict]): List of image information.
+ rcnn_test_cfg (obj:`ConfigDict`, optional): `test_cfg` of R-CNN.
+ Defaults to None.
+ rescale (bool): If True, return boxes in original image space.
+ Defaults to False.
+
+ Returns:
+ list[:obj:`InstanceData`]: Instance segmentation
+ results of each image after the post process.
+ Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ """
+ assert len(cls_scores) == len(bbox_preds)
+ result_list = []
+ for img_id in range(len(batch_img_metas)):
+ img_meta = batch_img_metas[img_id]
+ results = self._predict_by_feat_single(
+ roi=rois[img_id],
+ cls_score=cls_scores[img_id],
+ bbox_pred=bbox_preds[img_id],
+ img_meta=img_meta,
+ rescale=rescale,
+ rcnn_test_cfg=rcnn_test_cfg)
+ result_list.append(results)
+
+ return result_list
+
+ def _predict_by_feat_single(
+ self,
+ roi: Tensor,
+ cls_score: Tensor,
+ bbox_pred: Tensor,
+ img_meta: dict,
+ rescale: bool = False,
+ rcnn_test_cfg: Optional[ConfigDict] = None) -> InstanceData:
+ """Transform a single image's features extracted from the head into
+ bbox results.
+
+ Args:
+ roi (Tensor): Boxes to be transformed. Has shape (num_boxes, 5).
+ last dimension 5 arrange as (batch_index, x1, y1, x2, y2).
+ cls_score (Tensor): Box scores, has shape
+ (num_boxes, num_classes + 1).
+ bbox_pred (Tensor): Box energies / deltas.
+ has shape (num_boxes, num_classes * 4).
+ img_meta (dict): image information.
+ rescale (bool): If True, return boxes in original image space.
+ Defaults to False.
+ rcnn_test_cfg (obj:`ConfigDict`): `test_cfg` of Bbox Head.
+ Defaults to None
+
+ Returns:
+ :obj:`InstanceData`: Detection results of each image\
+ Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ """
+ results = InstanceData()
+ if roi.shape[0] == 0:
+ return empty_instances([img_meta],
+ roi.device,
+ task_type='bbox',
+ instance_results=[results],
+ box_type=self.predict_box_type,
+ use_box_type=False,
+ num_classes=self.num_classes,
+ score_per_cls=rcnn_test_cfg is None)[0]
+
+ # some loss (Seesaw loss..) may have custom activation
+ if self.custom_cls_channels:
+ scores = self.loss_cls.get_activation(cls_score)
+ else:
+ scores = F.softmax(
+ cls_score, dim=-1) if cls_score is not None else None
+
+ img_shape = img_meta['img_shape']
+ num_rois = roi.size(0)
+ # bbox_pred would be None in some detector when with_reg is False,
+ # e.g. Grid R-CNN.
+ if bbox_pred is not None:
+ num_classes = 1 if self.reg_class_agnostic else self.num_classes
+ roi = roi.repeat_interleave(num_classes, dim=0)
+ bbox_pred = bbox_pred.view(-1, self.bbox_coder.encode_size)
+ bboxes = self.bbox_coder.decode(
+ roi[..., 1:], bbox_pred, max_shape=img_shape)
+ else:
+ bboxes = roi[:, 1:].clone()
+ if img_shape is not None and bboxes.size(-1) == 4:
+ bboxes[:, [0, 2]].clamp_(min=0, max=img_shape[1])
+ bboxes[:, [1, 3]].clamp_(min=0, max=img_shape[0])
+
+ if rescale and bboxes.size(0) > 0:
+ assert img_meta.get('scale_factor') is not None
+ scale_factor = [1 / s for s in img_meta['scale_factor']]
+ bboxes = scale_boxes(bboxes, scale_factor)
+
+ # Get the inside tensor when `bboxes` is a box type
+ bboxes = get_box_tensor(bboxes)
+ box_dim = bboxes.size(-1)
+ bboxes = bboxes.view(num_rois, -1)
+
+ if rcnn_test_cfg is None:
+ # This means that it is aug test.
+ # It needs to return the raw results without nms.
+ results.bboxes = bboxes
+ results.scores = scores
+ else:
+ det_bboxes, det_labels = multiclass_nms(
+ bboxes,
+ scores,
+ rcnn_test_cfg.score_thr,
+ rcnn_test_cfg.nms,
+ rcnn_test_cfg.max_per_img,
+ box_dim=box_dim)
+ results.bboxes = det_bboxes[:, :-1]
+ results.scores = det_bboxes[:, -1]
+ results.labels = det_labels
+ return results
+
+ def refine_bboxes(self, sampling_results: Union[List[SamplingResult],
+ InstanceList],
+ bbox_results: dict,
+ batch_img_metas: List[dict]) -> InstanceList:
+ """Refine bboxes during training.
+
+ Args:
+ sampling_results (List[:obj:`SamplingResult`] or
+ List[:obj:`InstanceData`]): Sampling results.
+ :obj:`SamplingResult` is the real sampling results
+ calculate from bbox_head, while :obj:`InstanceData` is
+ fake sampling results, e.g., in Sparse R-CNN or QueryInst, etc.
+ bbox_results (dict): Usually is a dictionary with keys:
+
+ - `cls_score` (Tensor): Classification scores.
+ - `bbox_pred` (Tensor): Box energies / deltas.
+ - `rois` (Tensor): RoIs with the shape (n, 5) where the first
+ column indicates batch id of each RoI.
+ - `bbox_targets` (tuple): Ground truth for proposals in a
+ single image. Containing the following list of Tensors:
+ (labels, label_weights, bbox_targets, bbox_weights)
+ batch_img_metas (List[dict]): List of image information.
+
+ Returns:
+ list[:obj:`InstanceData`]: Refined bboxes of each image.
+
+ Example:
+ >>> # xdoctest: +REQUIRES(module:kwarray)
+ >>> import numpy as np
+ >>> from mmdet.models.task_modules.samplers.
+ ... sampling_result import random_boxes
+ >>> from mmdet.models.task_modules.samplers import SamplingResult
+ >>> self = BBoxHead(reg_class_agnostic=True)
+ >>> n_roi = 2
+ >>> n_img = 4
+ >>> scale = 512
+ >>> rng = np.random.RandomState(0)
+ ... batch_img_metas = [{'img_shape': (scale, scale)}
+ >>> for _ in range(n_img)]
+ >>> sampling_results = [SamplingResult.random(rng=10)
+ ... for _ in range(n_img)]
+ >>> # Create rois in the expected format
+ >>> roi_boxes = random_boxes(n_roi, scale=scale, rng=rng)
+ >>> img_ids = torch.randint(0, n_img, (n_roi,))
+ >>> img_ids = img_ids.float()
+ >>> rois = torch.cat([img_ids[:, None], roi_boxes], dim=1)
+ >>> # Create other args
+ >>> labels = torch.randint(0, 81, (scale,)).long()
+ >>> bbox_preds = random_boxes(n_roi, scale=scale, rng=rng)
+ >>> cls_score = torch.randn((scale, 81))
+ ... # For each image, pretend random positive boxes are gts
+ >>> bbox_targets = (labels, None, None, None)
+ ... bbox_results = dict(rois=rois, bbox_pred=bbox_preds,
+ ... cls_score=cls_score,
+ ... bbox_targets=bbox_targets)
+ >>> bboxes_list = self.refine_bboxes(sampling_results,
+ ... bbox_results,
+ ... batch_img_metas)
+ >>> print(bboxes_list)
+ """
+ pos_is_gts = [res.pos_is_gt for res in sampling_results]
+ # bbox_targets is a tuple
+ labels = bbox_results['bbox_targets'][0]
+ cls_scores = bbox_results['cls_score']
+ rois = bbox_results['rois']
+ bbox_preds = bbox_results['bbox_pred']
+ if self.custom_activation:
+ # TODO: Create a SeasawBBoxHead to simplified logic in BBoxHead
+ cls_scores = self.loss_cls.get_activation(cls_scores)
+ if cls_scores.numel() == 0:
+ return None
+ if cls_scores.shape[-1] == self.num_classes + 1:
+ # remove background class
+ cls_scores = cls_scores[:, :-1]
+ elif cls_scores.shape[-1] != self.num_classes:
+ raise ValueError('The last dim of `cls_scores` should equal to '
+ '`num_classes` or `num_classes + 1`,'
+ f'but got {cls_scores.shape[-1]}.')
+ labels = torch.where(labels == self.num_classes, cls_scores.argmax(1),
+ labels)
+
+ img_ids = rois[:, 0].long().unique(sorted=True)
+ assert img_ids.numel() <= len(batch_img_metas)
+
+ results_list = []
+ for i in range(len(batch_img_metas)):
+ inds = torch.nonzero(
+ rois[:, 0] == i, as_tuple=False).squeeze(dim=1)
+ num_rois = inds.numel()
+
+ bboxes_ = rois[inds, 1:]
+ label_ = labels[inds]
+ bbox_pred_ = bbox_preds[inds]
+ img_meta_ = batch_img_metas[i]
+ pos_is_gts_ = pos_is_gts[i]
+
+ bboxes = self.regress_by_class(bboxes_, label_, bbox_pred_,
+ img_meta_)
+ # filter gt bboxes
+ pos_keep = 1 - pos_is_gts_
+ keep_inds = pos_is_gts_.new_ones(num_rois)
+ keep_inds[:len(pos_is_gts_)] = pos_keep
+ results = InstanceData(bboxes=bboxes[keep_inds.type(torch.bool)])
+ results_list.append(results)
+
+ return results_list
+
+ def regress_by_class(self, priors: Tensor, label: Tensor,
+ bbox_pred: Tensor, img_meta: dict) -> Tensor:
+ """Regress the bbox for the predicted class. Used in Cascade R-CNN.
+
+ Args:
+ priors (Tensor): Priors from `rpn_head` or last stage
+ `bbox_head`, has shape (num_proposals, 4).
+ label (Tensor): Only used when `self.reg_class_agnostic`
+ is False, has shape (num_proposals, ).
+ bbox_pred (Tensor): Regression prediction of
+ current stage `bbox_head`. When `self.reg_class_agnostic`
+ is False, it has shape (n, num_classes * 4), otherwise
+ it has shape (n, 4).
+ img_meta (dict): Image meta info.
+
+ Returns:
+ Tensor: Regressed bboxes, the same shape as input rois.
+ """
+ reg_dim = self.bbox_coder.encode_size
+ if not self.reg_class_agnostic:
+ label = label * reg_dim
+ inds = torch.stack([label + i for i in range(reg_dim)], 1)
+ bbox_pred = torch.gather(bbox_pred, 1, inds)
+ assert bbox_pred.size()[1] == reg_dim
+
+ max_shape = img_meta['img_shape']
+ regressed_bboxes = self.bbox_coder.decode(
+ priors, bbox_pred, max_shape=max_shape)
+ return regressed_bboxes
diff --git a/mmdet/models/roi_heads/bbox_heads/convfc_bbox_head.py b/mmdet/models/roi_heads/bbox_heads/convfc_bbox_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..cb6aadd86d34af3605d432492931442026432cc8
--- /dev/null
+++ b/mmdet/models/roi_heads/bbox_heads/convfc_bbox_head.py
@@ -0,0 +1,249 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Tuple, Union
+
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+from mmengine.config import ConfigDict
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from .bbox_head import BBoxHead
+
+
+@MODELS.register_module()
+class ConvFCBBoxHead(BBoxHead):
+ r"""More general bbox head, with shared conv and fc layers and two optional
+ separated branches.
+
+ .. code-block:: none
+
+ /-> cls convs -> cls fcs -> cls
+ shared convs -> shared fcs
+ \-> reg convs -> reg fcs -> reg
+ """ # noqa: W605
+
+ def __init__(self,
+ num_shared_convs: int = 0,
+ num_shared_fcs: int = 0,
+ num_cls_convs: int = 0,
+ num_cls_fcs: int = 0,
+ num_reg_convs: int = 0,
+ num_reg_fcs: int = 0,
+ conv_out_channels: int = 256,
+ fc_out_channels: int = 1024,
+ conv_cfg: Optional[Union[dict, ConfigDict]] = None,
+ norm_cfg: Optional[Union[dict, ConfigDict]] = None,
+ init_cfg: Optional[Union[dict, ConfigDict]] = None,
+ *args,
+ **kwargs) -> None:
+ super().__init__(*args, init_cfg=init_cfg, **kwargs)
+ assert (num_shared_convs + num_shared_fcs + num_cls_convs +
+ num_cls_fcs + num_reg_convs + num_reg_fcs > 0)
+ if num_cls_convs > 0 or num_reg_convs > 0:
+ assert num_shared_fcs == 0
+ if not self.with_cls:
+ assert num_cls_convs == 0 and num_cls_fcs == 0
+ if not self.with_reg:
+ assert num_reg_convs == 0 and num_reg_fcs == 0
+ self.num_shared_convs = num_shared_convs
+ self.num_shared_fcs = num_shared_fcs
+ self.num_cls_convs = num_cls_convs
+ self.num_cls_fcs = num_cls_fcs
+ self.num_reg_convs = num_reg_convs
+ self.num_reg_fcs = num_reg_fcs
+ self.conv_out_channels = conv_out_channels
+ self.fc_out_channels = fc_out_channels
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+
+ # add shared convs and fcs
+ self.shared_convs, self.shared_fcs, last_layer_dim = \
+ self._add_conv_fc_branch(
+ self.num_shared_convs, self.num_shared_fcs, self.in_channels,
+ True)
+ self.shared_out_channels = last_layer_dim
+
+ # add cls specific branch
+ self.cls_convs, self.cls_fcs, self.cls_last_dim = \
+ self._add_conv_fc_branch(
+ self.num_cls_convs, self.num_cls_fcs, self.shared_out_channels)
+
+ # add reg specific branch
+ self.reg_convs, self.reg_fcs, self.reg_last_dim = \
+ self._add_conv_fc_branch(
+ self.num_reg_convs, self.num_reg_fcs, self.shared_out_channels)
+
+ if self.num_shared_fcs == 0 and not self.with_avg_pool:
+ if self.num_cls_fcs == 0:
+ self.cls_last_dim *= self.roi_feat_area
+ if self.num_reg_fcs == 0:
+ self.reg_last_dim *= self.roi_feat_area
+
+ self.relu = nn.ReLU(inplace=True)
+ # reconstruct fc_cls and fc_reg since input channels are changed
+ if self.with_cls:
+ if self.custom_cls_channels:
+ cls_channels = self.loss_cls.get_cls_channels(self.num_classes)
+ else:
+ cls_channels = self.num_classes + 1
+ cls_predictor_cfg_ = self.cls_predictor_cfg.copy()
+ cls_predictor_cfg_.update(
+ in_features=self.cls_last_dim, out_features=cls_channels)
+ self.fc_cls = MODELS.build(cls_predictor_cfg_)
+ if self.with_reg:
+ box_dim = self.bbox_coder.encode_size
+ out_dim_reg = box_dim if self.reg_class_agnostic else \
+ box_dim * self.num_classes
+ reg_predictor_cfg_ = self.reg_predictor_cfg.copy()
+ if isinstance(reg_predictor_cfg_, (dict, ConfigDict)):
+ reg_predictor_cfg_.update(
+ in_features=self.reg_last_dim, out_features=out_dim_reg)
+ self.fc_reg = MODELS.build(reg_predictor_cfg_)
+
+ if init_cfg is None:
+ # when init_cfg is None,
+ # It has been set to
+ # [[dict(type='Normal', std=0.01, override=dict(name='fc_cls'))],
+ # [dict(type='Normal', std=0.001, override=dict(name='fc_reg'))]
+ # after `super(ConvFCBBoxHead, self).__init__()`
+ # we only need to append additional configuration
+ # for `shared_fcs`, `cls_fcs` and `reg_fcs`
+ self.init_cfg += [
+ dict(
+ type='Xavier',
+ distribution='uniform',
+ override=[
+ dict(name='shared_fcs'),
+ dict(name='cls_fcs'),
+ dict(name='reg_fcs')
+ ])
+ ]
+
+ def _add_conv_fc_branch(self,
+ num_branch_convs: int,
+ num_branch_fcs: int,
+ in_channels: int,
+ is_shared: bool = False) -> tuple:
+ """Add shared or separable branch.
+
+ convs -> avg pool (optional) -> fcs
+ """
+ last_layer_dim = in_channels
+ # add branch specific conv layers
+ branch_convs = nn.ModuleList()
+ if num_branch_convs > 0:
+ for i in range(num_branch_convs):
+ conv_in_channels = (
+ last_layer_dim if i == 0 else self.conv_out_channels)
+ branch_convs.append(
+ ConvModule(
+ conv_in_channels,
+ self.conv_out_channels,
+ 3,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg))
+ last_layer_dim = self.conv_out_channels
+ # add branch specific fc layers
+ branch_fcs = nn.ModuleList()
+ if num_branch_fcs > 0:
+ # for shared branch, only consider self.with_avg_pool
+ # for separated branches, also consider self.num_shared_fcs
+ if (is_shared
+ or self.num_shared_fcs == 0) and not self.with_avg_pool:
+ last_layer_dim *= self.roi_feat_area
+ for i in range(num_branch_fcs):
+ fc_in_channels = (
+ last_layer_dim if i == 0 else self.fc_out_channels)
+ branch_fcs.append(
+ nn.Linear(fc_in_channels, self.fc_out_channels))
+ last_layer_dim = self.fc_out_channels
+ return branch_convs, branch_fcs, last_layer_dim
+
+ def forward(self, x: Tuple[Tensor]) -> tuple:
+ """Forward features from the upstream network.
+
+ Args:
+ x (tuple[Tensor]): Features from the upstream network, each is
+ a 4D-tensor.
+
+ Returns:
+ tuple: A tuple of classification scores and bbox prediction.
+
+ - cls_score (Tensor): Classification scores for all \
+ scale levels, each is a 4D-tensor, the channels number \
+ is num_base_priors * num_classes.
+ - bbox_pred (Tensor): Box energies / deltas for all \
+ scale levels, each is a 4D-tensor, the channels number \
+ is num_base_priors * 4.
+ """
+ # shared part
+ if self.num_shared_convs > 0:
+ for conv in self.shared_convs:
+ x = conv(x)
+
+ if self.num_shared_fcs > 0:
+ if self.with_avg_pool:
+ x = self.avg_pool(x)
+
+ x = x.flatten(1)
+
+ for fc in self.shared_fcs:
+ x = self.relu(fc(x))
+ # separate branches
+ x_cls = x
+ x_reg = x
+
+ for conv in self.cls_convs:
+ x_cls = conv(x_cls)
+ if x_cls.dim() > 2:
+ if self.with_avg_pool:
+ x_cls = self.avg_pool(x_cls)
+ x_cls = x_cls.flatten(1)
+ for fc in self.cls_fcs:
+ x_cls = self.relu(fc(x_cls))
+
+ for conv in self.reg_convs:
+ x_reg = conv(x_reg)
+ if x_reg.dim() > 2:
+ if self.with_avg_pool:
+ x_reg = self.avg_pool(x_reg)
+ x_reg = x_reg.flatten(1)
+ for fc in self.reg_fcs:
+ x_reg = self.relu(fc(x_reg))
+
+ cls_score = self.fc_cls(x_cls) if self.with_cls else None
+ bbox_pred = self.fc_reg(x_reg) if self.with_reg else None
+ return cls_score, bbox_pred
+
+
+@MODELS.register_module()
+class Shared2FCBBoxHead(ConvFCBBoxHead):
+
+ def __init__(self, fc_out_channels: int = 1024, *args, **kwargs) -> None:
+ super().__init__(
+ num_shared_convs=0,
+ num_shared_fcs=2,
+ num_cls_convs=0,
+ num_cls_fcs=0,
+ num_reg_convs=0,
+ num_reg_fcs=0,
+ fc_out_channels=fc_out_channels,
+ *args,
+ **kwargs)
+
+
+@MODELS.register_module()
+class Shared4Conv1FCBBoxHead(ConvFCBBoxHead):
+
+ def __init__(self, fc_out_channels: int = 1024, *args, **kwargs) -> None:
+ super().__init__(
+ num_shared_convs=4,
+ num_shared_fcs=1,
+ num_cls_convs=0,
+ num_cls_fcs=0,
+ num_reg_convs=0,
+ num_reg_fcs=0,
+ fc_out_channels=fc_out_channels,
+ *args,
+ **kwargs)
diff --git a/mmdet/models/roi_heads/bbox_heads/dii_head.py b/mmdet/models/roi_heads/bbox_heads/dii_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..ae9a31bbeb2a8f1da62b457363fa05031d21925a
--- /dev/null
+++ b/mmdet/models/roi_heads/bbox_heads/dii_head.py
@@ -0,0 +1,422 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List
+
+import torch
+import torch.nn as nn
+from mmcv.cnn import build_activation_layer, build_norm_layer
+from mmcv.cnn.bricks.transformer import FFN, MultiheadAttention
+from mmengine.config import ConfigDict
+from mmengine.model import bias_init_with_prob
+from torch import Tensor
+
+from mmdet.models.losses import accuracy
+from mmdet.models.task_modules import SamplingResult
+from mmdet.models.utils import multi_apply
+from mmdet.registry import MODELS
+from mmdet.utils import ConfigType, OptConfigType, reduce_mean
+from .bbox_head import BBoxHead
+
+
+@MODELS.register_module()
+class DIIHead(BBoxHead):
+ r"""Dynamic Instance Interactive Head for `Sparse R-CNN: End-to-End Object
+ Detection with Learnable Proposals `_
+
+ Args:
+ num_classes (int): Number of class in dataset.
+ Defaults to 80.
+ num_ffn_fcs (int): The number of fully-connected
+ layers in FFNs. Defaults to 2.
+ num_heads (int): The hidden dimension of FFNs.
+ Defaults to 8.
+ num_cls_fcs (int): The number of fully-connected
+ layers in classification subnet. Defaults to 1.
+ num_reg_fcs (int): The number of fully-connected
+ layers in regression subnet. Defaults to 3.
+ feedforward_channels (int): The hidden dimension
+ of FFNs. Defaults to 2048
+ in_channels (int): Hidden_channels of MultiheadAttention.
+ Defaults to 256.
+ dropout (float): Probability of drop the channel.
+ Defaults to 0.0
+ ffn_act_cfg (:obj:`ConfigDict` or dict): The activation config
+ for FFNs.
+ dynamic_conv_cfg (:obj:`ConfigDict` or dict): The convolution
+ config for DynamicConv.
+ loss_iou (:obj:`ConfigDict` or dict): The config for iou or
+ giou loss.
+ init_cfg (:obj:`ConfigDict` or dict or list[:obj:`ConfigDict` or \
+ dict]): Initialization config dict. Defaults to None.
+ """
+
+ def __init__(self,
+ num_classes: int = 80,
+ num_ffn_fcs: int = 2,
+ num_heads: int = 8,
+ num_cls_fcs: int = 1,
+ num_reg_fcs: int = 3,
+ feedforward_channels: int = 2048,
+ in_channels: int = 256,
+ dropout: float = 0.0,
+ ffn_act_cfg: ConfigType = dict(type='ReLU', inplace=True),
+ dynamic_conv_cfg: ConfigType = dict(
+ type='DynamicConv',
+ in_channels=256,
+ feat_channels=64,
+ out_channels=256,
+ input_feat_shape=7,
+ act_cfg=dict(type='ReLU', inplace=True),
+ norm_cfg=dict(type='LN')),
+ loss_iou: ConfigType = dict(type='GIoULoss', loss_weight=2.0),
+ init_cfg: OptConfigType = None,
+ **kwargs) -> None:
+ assert init_cfg is None, 'To prevent abnormal initialization ' \
+ 'behavior, init_cfg is not allowed to be set'
+ super().__init__(
+ num_classes=num_classes,
+ reg_decoded_bbox=True,
+ reg_class_agnostic=True,
+ init_cfg=init_cfg,
+ **kwargs)
+ self.loss_iou = MODELS.build(loss_iou)
+ self.in_channels = in_channels
+ self.fp16_enabled = False
+ self.attention = MultiheadAttention(in_channels, num_heads, dropout)
+ self.attention_norm = build_norm_layer(dict(type='LN'), in_channels)[1]
+
+ self.instance_interactive_conv = MODELS.build(dynamic_conv_cfg)
+ self.instance_interactive_conv_dropout = nn.Dropout(dropout)
+ self.instance_interactive_conv_norm = build_norm_layer(
+ dict(type='LN'), in_channels)[1]
+
+ self.ffn = FFN(
+ in_channels,
+ feedforward_channels,
+ num_ffn_fcs,
+ act_cfg=ffn_act_cfg,
+ dropout=dropout)
+ self.ffn_norm = build_norm_layer(dict(type='LN'), in_channels)[1]
+
+ self.cls_fcs = nn.ModuleList()
+ for _ in range(num_cls_fcs):
+ self.cls_fcs.append(
+ nn.Linear(in_channels, in_channels, bias=False))
+ self.cls_fcs.append(
+ build_norm_layer(dict(type='LN'), in_channels)[1])
+ self.cls_fcs.append(
+ build_activation_layer(dict(type='ReLU', inplace=True)))
+
+ # over load the self.fc_cls in BBoxHead
+ if self.loss_cls.use_sigmoid:
+ self.fc_cls = nn.Linear(in_channels, self.num_classes)
+ else:
+ self.fc_cls = nn.Linear(in_channels, self.num_classes + 1)
+
+ self.reg_fcs = nn.ModuleList()
+ for _ in range(num_reg_fcs):
+ self.reg_fcs.append(
+ nn.Linear(in_channels, in_channels, bias=False))
+ self.reg_fcs.append(
+ build_norm_layer(dict(type='LN'), in_channels)[1])
+ self.reg_fcs.append(
+ build_activation_layer(dict(type='ReLU', inplace=True)))
+ # over load the self.fc_cls in BBoxHead
+ self.fc_reg = nn.Linear(in_channels, 4)
+
+ assert self.reg_class_agnostic, 'DIIHead only ' \
+ 'suppport `reg_class_agnostic=True` '
+ assert self.reg_decoded_bbox, 'DIIHead only ' \
+ 'suppport `reg_decoded_bbox=True`'
+
+ def init_weights(self) -> None:
+ """Use xavier initialization for all weight parameter and set
+ classification head bias as a specific value when use focal loss."""
+ super().init_weights()
+ for p in self.parameters():
+ if p.dim() > 1:
+ nn.init.xavier_uniform_(p)
+ else:
+ # adopt the default initialization for
+ # the weight and bias of the layer norm
+ pass
+ if self.loss_cls.use_sigmoid:
+ bias_init = bias_init_with_prob(0.01)
+ nn.init.constant_(self.fc_cls.bias, bias_init)
+
+ def forward(self, roi_feat: Tensor, proposal_feat: Tensor) -> tuple:
+ """Forward function of Dynamic Instance Interactive Head.
+
+ Args:
+ roi_feat (Tensor): Roi-pooling features with shape
+ (batch_size*num_proposals, feature_dimensions,
+ pooling_h , pooling_w).
+ proposal_feat (Tensor): Intermediate feature get from
+ diihead in last stage, has shape
+ (batch_size, num_proposals, feature_dimensions)
+
+ Returns:
+ tuple[Tensor]: Usually a tuple of classification scores
+ and bbox prediction and a intermediate feature.
+
+ - cls_scores (Tensor): Classification scores for
+ all proposals, has shape
+ (batch_size, num_proposals, num_classes).
+ - bbox_preds (Tensor): Box energies / deltas for
+ all proposals, has shape
+ (batch_size, num_proposals, 4).
+ - obj_feat (Tensor): Object feature before classification
+ and regression subnet, has shape
+ (batch_size, num_proposal, feature_dimensions).
+ - attn_feats (Tensor): Intermediate feature.
+ """
+ N, num_proposals = proposal_feat.shape[:2]
+
+ # Self attention
+ proposal_feat = proposal_feat.permute(1, 0, 2)
+ proposal_feat = self.attention_norm(self.attention(proposal_feat))
+ attn_feats = proposal_feat.permute(1, 0, 2)
+
+ # instance interactive
+ proposal_feat = attn_feats.reshape(-1, self.in_channels)
+ proposal_feat_iic = self.instance_interactive_conv(
+ proposal_feat, roi_feat)
+ proposal_feat = proposal_feat + self.instance_interactive_conv_dropout(
+ proposal_feat_iic)
+ obj_feat = self.instance_interactive_conv_norm(proposal_feat)
+
+ # FFN
+ obj_feat = self.ffn_norm(self.ffn(obj_feat))
+
+ cls_feat = obj_feat
+ reg_feat = obj_feat
+
+ for cls_layer in self.cls_fcs:
+ cls_feat = cls_layer(cls_feat)
+ for reg_layer in self.reg_fcs:
+ reg_feat = reg_layer(reg_feat)
+
+ cls_score = self.fc_cls(cls_feat).view(
+ N, num_proposals, self.num_classes
+ if self.loss_cls.use_sigmoid else self.num_classes + 1)
+ bbox_delta = self.fc_reg(reg_feat).view(N, num_proposals, 4)
+
+ return cls_score, bbox_delta, obj_feat.view(
+ N, num_proposals, self.in_channels), attn_feats
+
+ def loss_and_target(self,
+ cls_score: Tensor,
+ bbox_pred: Tensor,
+ sampling_results: List[SamplingResult],
+ rcnn_train_cfg: ConfigType,
+ imgs_whwh: Tensor,
+ concat: bool = True,
+ reduction_override: str = None) -> dict:
+ """Calculate the loss based on the features extracted by the DIIHead.
+
+ Args:
+ cls_score (Tensor): Classification prediction
+ results of all class, has shape
+ (batch_size * num_proposals_single_image, num_classes)
+ bbox_pred (Tensor): Regression prediction results, has shape
+ (batch_size * num_proposals_single_image, 4), the last
+ dimension 4 represents [tl_x, tl_y, br_x, br_y].
+ sampling_results (List[obj:SamplingResult]): Assign results of
+ all images in a batch after sampling.
+ rcnn_train_cfg (obj:ConfigDict): `train_cfg` of RCNN.
+ imgs_whwh (Tensor): imgs_whwh (Tensor): Tensor with\
+ shape (batch_size, num_proposals, 4), the last
+ dimension means
+ [img_width,img_height, img_width, img_height].
+ concat (bool): Whether to concatenate the results of all
+ the images in a single batch. Defaults to True.
+ reduction_override (str, optional): The reduction
+ method used to override the original reduction
+ method of the loss. Options are "none",
+ "mean" and "sum". Defaults to None.
+
+ Returns:
+ dict: A dictionary of loss and targets components.
+ The targets are only used for cascade rcnn.
+ """
+ cls_reg_targets = self.get_targets(
+ sampling_results=sampling_results,
+ rcnn_train_cfg=rcnn_train_cfg,
+ concat=concat)
+ (labels, label_weights, bbox_targets, bbox_weights) = cls_reg_targets
+
+ losses = dict()
+ bg_class_ind = self.num_classes
+ # note in spare rcnn num_gt == num_pos
+ pos_inds = (labels >= 0) & (labels < bg_class_ind)
+ num_pos = pos_inds.sum().float()
+ avg_factor = reduce_mean(num_pos)
+ if cls_score is not None:
+ if cls_score.numel() > 0:
+ losses['loss_cls'] = self.loss_cls(
+ cls_score,
+ labels,
+ label_weights,
+ avg_factor=avg_factor,
+ reduction_override=reduction_override)
+ losses['pos_acc'] = accuracy(cls_score[pos_inds],
+ labels[pos_inds])
+ if bbox_pred is not None:
+ # 0~self.num_classes-1 are FG, self.num_classes is BG
+ # do not perform bounding box regression for BG anymore.
+ if pos_inds.any():
+ pos_bbox_pred = bbox_pred.reshape(bbox_pred.size(0),
+ 4)[pos_inds.type(torch.bool)]
+ imgs_whwh = imgs_whwh.reshape(bbox_pred.size(0),
+ 4)[pos_inds.type(torch.bool)]
+ losses['loss_bbox'] = self.loss_bbox(
+ pos_bbox_pred / imgs_whwh,
+ bbox_targets[pos_inds.type(torch.bool)] / imgs_whwh,
+ bbox_weights[pos_inds.type(torch.bool)],
+ avg_factor=avg_factor)
+ losses['loss_iou'] = self.loss_iou(
+ pos_bbox_pred,
+ bbox_targets[pos_inds.type(torch.bool)],
+ bbox_weights[pos_inds.type(torch.bool)],
+ avg_factor=avg_factor)
+ else:
+ losses['loss_bbox'] = bbox_pred.sum() * 0
+ losses['loss_iou'] = bbox_pred.sum() * 0
+ return dict(loss_bbox=losses, bbox_targets=cls_reg_targets)
+
+ def _get_targets_single(self, pos_inds: Tensor, neg_inds: Tensor,
+ pos_priors: Tensor, neg_priors: Tensor,
+ pos_gt_bboxes: Tensor, pos_gt_labels: Tensor,
+ cfg: ConfigDict) -> tuple:
+ """Calculate the ground truth for proposals in the single image
+ according to the sampling results.
+
+ Almost the same as the implementation in `bbox_head`,
+ we add pos_inds and neg_inds to select positive and
+ negative samples instead of selecting the first num_pos
+ as positive samples.
+
+ Args:
+ pos_inds (Tensor): The length is equal to the
+ positive sample numbers contain all index
+ of the positive sample in the origin proposal set.
+ neg_inds (Tensor): The length is equal to the
+ negative sample numbers contain all index
+ of the negative sample in the origin proposal set.
+ pos_priors (Tensor): Contains all the positive boxes,
+ has shape (num_pos, 4), the last dimension 4
+ represents [tl_x, tl_y, br_x, br_y].
+ neg_priors (Tensor): Contains all the negative boxes,
+ has shape (num_neg, 4), the last dimension 4
+ represents [tl_x, tl_y, br_x, br_y].
+ pos_gt_bboxes (Tensor): Contains gt_boxes for
+ all positive samples, has shape (num_pos, 4),
+ the last dimension 4
+ represents [tl_x, tl_y, br_x, br_y].
+ pos_gt_labels (Tensor): Contains gt_labels for
+ all positive samples, has shape (num_pos, ).
+ cfg (obj:`ConfigDict`): `train_cfg` of R-CNN.
+
+ Returns:
+ Tuple[Tensor]: Ground truth for proposals in a single image.
+ Containing the following Tensors:
+
+ - labels(Tensor): Gt_labels for all proposals, has
+ shape (num_proposals,).
+ - label_weights(Tensor): Labels_weights for all proposals, has
+ shape (num_proposals,).
+ - bbox_targets(Tensor):Regression target for all proposals, has
+ shape (num_proposals, 4), the last dimension 4
+ represents [tl_x, tl_y, br_x, br_y].
+ - bbox_weights(Tensor):Regression weights for all proposals,
+ has shape (num_proposals, 4).
+ """
+ num_pos = pos_priors.size(0)
+ num_neg = neg_priors.size(0)
+ num_samples = num_pos + num_neg
+
+ # original implementation uses new_zeros since BG are set to be 0
+ # now use empty & fill because BG cat_id = num_classes,
+ # FG cat_id = [0, num_classes-1]
+ labels = pos_priors.new_full((num_samples, ),
+ self.num_classes,
+ dtype=torch.long)
+ label_weights = pos_priors.new_zeros(num_samples)
+ bbox_targets = pos_priors.new_zeros(num_samples, 4)
+ bbox_weights = pos_priors.new_zeros(num_samples, 4)
+ if num_pos > 0:
+ labels[pos_inds] = pos_gt_labels
+ pos_weight = 1.0 if cfg.pos_weight <= 0 else cfg.pos_weight
+ label_weights[pos_inds] = pos_weight
+ if not self.reg_decoded_bbox:
+ pos_bbox_targets = self.bbox_coder.encode(
+ pos_priors, pos_gt_bboxes)
+ else:
+ pos_bbox_targets = pos_gt_bboxes
+ bbox_targets[pos_inds, :] = pos_bbox_targets
+ bbox_weights[pos_inds, :] = 1
+ if num_neg > 0:
+ label_weights[neg_inds] = 1.0
+
+ return labels, label_weights, bbox_targets, bbox_weights
+
+ def get_targets(self,
+ sampling_results: List[SamplingResult],
+ rcnn_train_cfg: ConfigDict,
+ concat: bool = True) -> tuple:
+ """Calculate the ground truth for all samples in a batch according to
+ the sampling_results.
+
+ Almost the same as the implementation in bbox_head, we passed
+ additional parameters pos_inds_list and neg_inds_list to
+ `_get_targets_single` function.
+
+ Args:
+ sampling_results (List[obj:SamplingResult]): Assign results of
+ all images in a batch after sampling.
+ rcnn_train_cfg (obj:ConfigDict): `train_cfg` of RCNN.
+ concat (bool): Whether to concatenate the results of all
+ the images in a single batch.
+
+ Returns:
+ Tuple[Tensor]: Ground truth for proposals in a single image.
+ Containing the following list of Tensors:
+
+ - labels (list[Tensor],Tensor): Gt_labels for all
+ proposals in a batch, each tensor in list has
+ shape (num_proposals,) when `concat=False`, otherwise just
+ a single tensor has shape (num_all_proposals,).
+ - label_weights (list[Tensor]): Labels_weights for
+ all proposals in a batch, each tensor in list has shape
+ (num_proposals,) when `concat=False`, otherwise just a
+ single tensor has shape (num_all_proposals,).
+ - bbox_targets (list[Tensor],Tensor): Regression target
+ for all proposals in a batch, each tensor in list has
+ shape (num_proposals, 4) when `concat=False`, otherwise
+ just a single tensor has shape (num_all_proposals, 4),
+ the last dimension 4 represents [tl_x, tl_y, br_x, br_y].
+ - bbox_weights (list[tensor],Tensor): Regression weights for
+ all proposals in a batch, each tensor in list has shape
+ (num_proposals, 4) when `concat=False`, otherwise just a
+ single tensor has shape (num_all_proposals, 4).
+ """
+ pos_inds_list = [res.pos_inds for res in sampling_results]
+ neg_inds_list = [res.neg_inds for res in sampling_results]
+ pos_priors_list = [res.pos_priors for res in sampling_results]
+ neg_priors_list = [res.neg_priors for res in sampling_results]
+ pos_gt_bboxes_list = [res.pos_gt_bboxes for res in sampling_results]
+ pos_gt_labels_list = [res.pos_gt_labels for res in sampling_results]
+ labels, label_weights, bbox_targets, bbox_weights = multi_apply(
+ self._get_targets_single,
+ pos_inds_list,
+ neg_inds_list,
+ pos_priors_list,
+ neg_priors_list,
+ pos_gt_bboxes_list,
+ pos_gt_labels_list,
+ cfg=rcnn_train_cfg)
+ if concat:
+ labels = torch.cat(labels, 0)
+ label_weights = torch.cat(label_weights, 0)
+ bbox_targets = torch.cat(bbox_targets, 0)
+ bbox_weights = torch.cat(bbox_weights, 0)
+ return labels, label_weights, bbox_targets, bbox_weights
diff --git a/mmdet/models/roi_heads/bbox_heads/double_bbox_head.py b/mmdet/models/roi_heads/bbox_heads/double_bbox_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..076c35843375c7aef5e58786d55ebacd281d54a3
--- /dev/null
+++ b/mmdet/models/roi_heads/bbox_heads/double_bbox_head.py
@@ -0,0 +1,199 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Tuple
+
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+from mmengine.model import BaseModule, ModuleList
+from torch import Tensor
+
+from mmdet.models.backbones.resnet import Bottleneck
+from mmdet.registry import MODELS
+from mmdet.utils import ConfigType, MultiConfig, OptConfigType, OptMultiConfig
+from .bbox_head import BBoxHead
+
+
+class BasicResBlock(BaseModule):
+ """Basic residual block.
+
+ This block is a little different from the block in the ResNet backbone.
+ The kernel size of conv1 is 1 in this block while 3 in ResNet BasicBlock.
+
+ Args:
+ in_channels (int): Channels of the input feature map.
+ out_channels (int): Channels of the output feature map.
+ conv_cfg (:obj:`ConfigDict` or dict, optional): The config dict
+ for convolution layers.
+ norm_cfg (:obj:`ConfigDict` or dict): The config dict for
+ normalization layers.
+ init_cfg (:obj:`ConfigDict` or dict or list[:obj:`ConfigDict` or \
+ dict], optional): Initialization config dict. Defaults to None
+ """
+
+ def __init__(self,
+ in_channels: int,
+ out_channels: int,
+ conv_cfg: OptConfigType = None,
+ norm_cfg: ConfigType = dict(type='BN'),
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(init_cfg=init_cfg)
+
+ # main path
+ self.conv1 = ConvModule(
+ in_channels,
+ in_channels,
+ kernel_size=3,
+ padding=1,
+ bias=False,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg)
+ self.conv2 = ConvModule(
+ in_channels,
+ out_channels,
+ kernel_size=1,
+ bias=False,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=None)
+
+ # identity path
+ self.conv_identity = ConvModule(
+ in_channels,
+ out_channels,
+ kernel_size=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=None)
+
+ self.relu = nn.ReLU(inplace=True)
+
+ def forward(self, x: Tensor) -> Tensor:
+ """Forward function."""
+ identity = x
+
+ x = self.conv1(x)
+ x = self.conv2(x)
+
+ identity = self.conv_identity(identity)
+ out = x + identity
+
+ out = self.relu(out)
+ return out
+
+
+@MODELS.register_module()
+class DoubleConvFCBBoxHead(BBoxHead):
+ r"""Bbox head used in Double-Head R-CNN
+
+ .. code-block:: none
+
+ /-> cls
+ /-> shared convs ->
+ \-> reg
+ roi features
+ /-> cls
+ \-> shared fc ->
+ \-> reg
+ """ # noqa: W605
+
+ def __init__(self,
+ num_convs: int = 0,
+ num_fcs: int = 0,
+ conv_out_channels: int = 1024,
+ fc_out_channels: int = 1024,
+ conv_cfg: OptConfigType = None,
+ norm_cfg: ConfigType = dict(type='BN'),
+ init_cfg: MultiConfig = dict(
+ type='Normal',
+ override=[
+ dict(type='Normal', name='fc_cls', std=0.01),
+ dict(type='Normal', name='fc_reg', std=0.001),
+ dict(
+ type='Xavier',
+ name='fc_branch',
+ distribution='uniform')
+ ]),
+ **kwargs) -> None:
+ kwargs.setdefault('with_avg_pool', True)
+ super().__init__(init_cfg=init_cfg, **kwargs)
+ assert self.with_avg_pool
+ assert num_convs > 0
+ assert num_fcs > 0
+ self.num_convs = num_convs
+ self.num_fcs = num_fcs
+ self.conv_out_channels = conv_out_channels
+ self.fc_out_channels = fc_out_channels
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+
+ # increase the channel of input features
+ self.res_block = BasicResBlock(self.in_channels,
+ self.conv_out_channels)
+
+ # add conv heads
+ self.conv_branch = self._add_conv_branch()
+ # add fc heads
+ self.fc_branch = self._add_fc_branch()
+
+ out_dim_reg = 4 if self.reg_class_agnostic else 4 * self.num_classes
+ self.fc_reg = nn.Linear(self.conv_out_channels, out_dim_reg)
+
+ self.fc_cls = nn.Linear(self.fc_out_channels, self.num_classes + 1)
+ self.relu = nn.ReLU()
+
+ def _add_conv_branch(self) -> None:
+ """Add the fc branch which consists of a sequential of conv layers."""
+ branch_convs = ModuleList()
+ for i in range(self.num_convs):
+ branch_convs.append(
+ Bottleneck(
+ inplanes=self.conv_out_channels,
+ planes=self.conv_out_channels // 4,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg))
+ return branch_convs
+
+ def _add_fc_branch(self) -> None:
+ """Add the fc branch which consists of a sequential of fc layers."""
+ branch_fcs = ModuleList()
+ for i in range(self.num_fcs):
+ fc_in_channels = (
+ self.in_channels *
+ self.roi_feat_area if i == 0 else self.fc_out_channels)
+ branch_fcs.append(nn.Linear(fc_in_channels, self.fc_out_channels))
+ return branch_fcs
+
+ def forward(self, x_cls: Tensor, x_reg: Tensor) -> Tuple[Tensor]:
+ """Forward features from the upstream network.
+
+ Args:
+ x_cls (Tensor): Classification features of rois
+ x_reg (Tensor): Regression features from the upstream network.
+
+ Returns:
+ tuple: A tuple of classification scores and bbox prediction.
+
+ - cls_score (Tensor): Classification score predictions of rois.
+ each roi predicts num_classes + 1 channels.
+ - bbox_pred (Tensor): BBox deltas predictions of rois. each roi
+ predicts 4 * num_classes channels.
+ """
+ # conv head
+ x_conv = self.res_block(x_reg)
+
+ for conv in self.conv_branch:
+ x_conv = conv(x_conv)
+
+ if self.with_avg_pool:
+ x_conv = self.avg_pool(x_conv)
+
+ x_conv = x_conv.view(x_conv.size(0), -1)
+ bbox_pred = self.fc_reg(x_conv)
+
+ # fc head
+ x_fc = x_cls.view(x_cls.size(0), -1)
+ for fc in self.fc_branch:
+ x_fc = self.relu(fc(x_fc))
+
+ cls_score = self.fc_cls(x_fc)
+
+ return cls_score, bbox_pred
diff --git a/mmdet/models/roi_heads/bbox_heads/multi_instance_bbox_head.py b/mmdet/models/roi_heads/bbox_heads/multi_instance_bbox_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..1c888f1e78d60433bf0333c642cc2f89e6d95614
--- /dev/null
+++ b/mmdet/models/roi_heads/bbox_heads/multi_instance_bbox_head.py
@@ -0,0 +1,622 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Optional, Tuple, Union
+
+import numpy as np
+import torch
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule
+from mmengine.config import ConfigDict
+from mmengine.structures import InstanceData
+from torch import Tensor, nn
+
+from mmdet.models.roi_heads.bbox_heads.bbox_head import BBoxHead
+from mmdet.models.task_modules.samplers import SamplingResult
+from mmdet.models.utils import empty_instances
+from mmdet.registry import MODELS
+from mmdet.structures.bbox import bbox_overlaps
+
+
+@MODELS.register_module()
+class MultiInstanceBBoxHead(BBoxHead):
+ r"""Bbox head used in CrowdDet.
+
+ .. code-block:: none
+
+ /-> cls convs_1 -> cls fcs_1 -> cls_1
+ |--
+ | \-> reg convs_1 -> reg fcs_1 -> reg_1
+ |
+ | /-> cls convs_2 -> cls fcs_2 -> cls_2
+ shared convs -> shared fcs |--
+ | \-> reg convs_2 -> reg fcs_2 -> reg_2
+ |
+ | ...
+ |
+ | /-> cls convs_k -> cls fcs_k -> cls_k
+ |--
+ \-> reg convs_k -> reg fcs_k -> reg_k
+
+
+ Args:
+ num_instance (int): The number of branches after shared fcs.
+ Defaults to 2.
+ with_refine (bool): Whether to use refine module. Defaults to False.
+ num_shared_convs (int): The number of shared convs. Defaults to 0.
+ num_shared_fcs (int): The number of shared fcs. Defaults to 2.
+ num_cls_convs (int): The number of cls convs. Defaults to 0.
+ num_cls_fcs (int): The number of cls fcs. Defaults to 0.
+ num_reg_convs (int): The number of reg convs. Defaults to 0.
+ num_reg_fcs (int): The number of reg fcs. Defaults to 0.
+ conv_out_channels (int): The number of conv out channels.
+ Defaults to 256.
+ fc_out_channels (int): The number of fc out channels. Defaults to 1024.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Defaults to None.
+ """ # noqa: W605
+
+ def __init__(self,
+ num_instance: int = 2,
+ with_refine: bool = False,
+ num_shared_convs: int = 0,
+ num_shared_fcs: int = 2,
+ num_cls_convs: int = 0,
+ num_cls_fcs: int = 0,
+ num_reg_convs: int = 0,
+ num_reg_fcs: int = 0,
+ conv_out_channels: int = 256,
+ fc_out_channels: int = 1024,
+ init_cfg: Optional[Union[dict, ConfigDict]] = None,
+ *args,
+ **kwargs) -> None:
+ super().__init__(*args, init_cfg=init_cfg, **kwargs)
+ assert (num_shared_convs + num_shared_fcs + num_cls_convs +
+ num_cls_fcs + num_reg_convs + num_reg_fcs > 0)
+ assert num_instance == 2, 'Currently only 2 instances are supported'
+ if num_cls_convs > 0 or num_reg_convs > 0:
+ assert num_shared_fcs == 0
+ if not self.with_cls:
+ assert num_cls_convs == 0 and num_cls_fcs == 0
+ if not self.with_reg:
+ assert num_reg_convs == 0 and num_reg_fcs == 0
+ self.num_instance = num_instance
+ self.num_shared_convs = num_shared_convs
+ self.num_shared_fcs = num_shared_fcs
+ self.num_cls_convs = num_cls_convs
+ self.num_cls_fcs = num_cls_fcs
+ self.num_reg_convs = num_reg_convs
+ self.num_reg_fcs = num_reg_fcs
+ self.conv_out_channels = conv_out_channels
+ self.fc_out_channels = fc_out_channels
+ self.with_refine = with_refine
+
+ # add shared convs and fcs
+ self.shared_convs, self.shared_fcs, last_layer_dim = \
+ self._add_conv_fc_branch(
+ self.num_shared_convs, self.num_shared_fcs, self.in_channels,
+ True)
+ self.shared_out_channels = last_layer_dim
+ self.relu = nn.ReLU(inplace=True)
+
+ if self.with_refine:
+ refine_model_cfg = {
+ 'type': 'Linear',
+ 'in_features': self.shared_out_channels + 20,
+ 'out_features': self.shared_out_channels
+ }
+ self.shared_fcs_ref = MODELS.build(refine_model_cfg)
+ self.fc_cls_ref = nn.ModuleList()
+ self.fc_reg_ref = nn.ModuleList()
+
+ self.cls_convs = nn.ModuleList()
+ self.cls_fcs = nn.ModuleList()
+ self.reg_convs = nn.ModuleList()
+ self.reg_fcs = nn.ModuleList()
+ self.cls_last_dim = list()
+ self.reg_last_dim = list()
+ self.fc_cls = nn.ModuleList()
+ self.fc_reg = nn.ModuleList()
+ for k in range(self.num_instance):
+ # add cls specific branch
+ cls_convs, cls_fcs, cls_last_dim = self._add_conv_fc_branch(
+ self.num_cls_convs, self.num_cls_fcs, self.shared_out_channels)
+ self.cls_convs.append(cls_convs)
+ self.cls_fcs.append(cls_fcs)
+ self.cls_last_dim.append(cls_last_dim)
+
+ # add reg specific branch
+ reg_convs, reg_fcs, reg_last_dim = self._add_conv_fc_branch(
+ self.num_reg_convs, self.num_reg_fcs, self.shared_out_channels)
+ self.reg_convs.append(reg_convs)
+ self.reg_fcs.append(reg_fcs)
+ self.reg_last_dim.append(reg_last_dim)
+
+ if self.num_shared_fcs == 0 and not self.with_avg_pool:
+ if self.num_cls_fcs == 0:
+ self.cls_last_dim *= self.roi_feat_area
+ if self.num_reg_fcs == 0:
+ self.reg_last_dim *= self.roi_feat_area
+
+ if self.with_cls:
+ if self.custom_cls_channels:
+ cls_channels = self.loss_cls.get_cls_channels(
+ self.num_classes)
+ else:
+ cls_channels = self.num_classes + 1
+ cls_predictor_cfg_ = self.cls_predictor_cfg.copy() # deepcopy
+ cls_predictor_cfg_.update(
+ in_features=self.cls_last_dim[k],
+ out_features=cls_channels)
+ self.fc_cls.append(MODELS.build(cls_predictor_cfg_))
+ if self.with_refine:
+ self.fc_cls_ref.append(MODELS.build(cls_predictor_cfg_))
+
+ if self.with_reg:
+ out_dim_reg = (4 if self.reg_class_agnostic else 4 *
+ self.num_classes)
+ reg_predictor_cfg_ = self.reg_predictor_cfg.copy()
+ reg_predictor_cfg_.update(
+ in_features=self.reg_last_dim[k], out_features=out_dim_reg)
+ self.fc_reg.append(MODELS.build(reg_predictor_cfg_))
+ if self.with_refine:
+ self.fc_reg_ref.append(MODELS.build(reg_predictor_cfg_))
+
+ if init_cfg is None:
+ # when init_cfg is None,
+ # It has been set to
+ # [[dict(type='Normal', std=0.01, override=dict(name='fc_cls'))],
+ # [dict(type='Normal', std=0.001, override=dict(name='fc_reg'))]
+ # after `super(ConvFCBBoxHead, self).__init__()`
+ # we only need to append additional configuration
+ # for `shared_fcs`, `cls_fcs` and `reg_fcs`
+ self.init_cfg += [
+ dict(
+ type='Xavier',
+ distribution='uniform',
+ override=[
+ dict(name='shared_fcs'),
+ dict(name='cls_fcs'),
+ dict(name='reg_fcs')
+ ])
+ ]
+
+ def _add_conv_fc_branch(self,
+ num_branch_convs: int,
+ num_branch_fcs: int,
+ in_channels: int,
+ is_shared: bool = False) -> tuple:
+ """Add shared or separable branch.
+
+ convs -> avg pool (optional) -> fcs
+ """
+ last_layer_dim = in_channels
+ # add branch specific conv layers
+ branch_convs = nn.ModuleList()
+ if num_branch_convs > 0:
+ for i in range(num_branch_convs):
+ conv_in_channels = (
+ last_layer_dim if i == 0 else self.conv_out_channels)
+ branch_convs.append(
+ ConvModule(
+ conv_in_channels, self.conv_out_channels, 3,
+ padding=1))
+ last_layer_dim = self.conv_out_channels
+ # add branch specific fc layers
+ branch_fcs = nn.ModuleList()
+ if num_branch_fcs > 0:
+ # for shared branch, only consider self.with_avg_pool
+ # for separated branches, also consider self.num_shared_fcs
+ if (is_shared
+ or self.num_shared_fcs == 0) and not self.with_avg_pool:
+ last_layer_dim *= self.roi_feat_area
+ for i in range(num_branch_fcs):
+ fc_in_channels = (
+ last_layer_dim if i == 0 else self.fc_out_channels)
+ branch_fcs.append(
+ nn.Linear(fc_in_channels, self.fc_out_channels))
+ last_layer_dim = self.fc_out_channels
+ return branch_convs, branch_fcs, last_layer_dim
+
+ def forward(self, x: Tuple[Tensor]) -> tuple:
+ """Forward features from the upstream network.
+
+ Args:
+ x (tuple[Tensor]): Features from the upstream network, each is
+ a 4D-tensor.
+
+ Returns:
+ tuple: A tuple of classification scores and bbox prediction.
+
+ - cls_score (Tensor): Classification scores for all scale
+ levels, each is a 4D-tensor, the channels number is
+ num_base_priors * num_classes.
+ - bbox_pred (Tensor): Box energies / deltas for all scale
+ levels, each is a 4D-tensor, the channels number is
+ num_base_priors * 4.
+ - cls_score_ref (Tensor): The cls_score after refine model.
+ - bbox_pred_ref (Tensor): The bbox_pred after refine model.
+ """
+ # shared part
+ if self.num_shared_convs > 0:
+ for conv in self.shared_convs:
+ x = conv(x)
+
+ if self.num_shared_fcs > 0:
+ if self.with_avg_pool:
+ x = self.avg_pool(x)
+
+ x = x.flatten(1)
+ for fc in self.shared_fcs:
+ x = self.relu(fc(x))
+
+ x_cls = x
+ x_reg = x
+ # separate branches
+ cls_score = list()
+ bbox_pred = list()
+ for k in range(self.num_instance):
+ for conv in self.cls_convs[k]:
+ x_cls = conv(x_cls)
+ if x_cls.dim() > 2:
+ if self.with_avg_pool:
+ x_cls = self.avg_pool(x_cls)
+ x_cls = x_cls.flatten(1)
+ for fc in self.cls_fcs[k]:
+ x_cls = self.relu(fc(x_cls))
+
+ for conv in self.reg_convs[k]:
+ x_reg = conv(x_reg)
+ if x_reg.dim() > 2:
+ if self.with_avg_pool:
+ x_reg = self.avg_pool(x_reg)
+ x_reg = x_reg.flatten(1)
+ for fc in self.reg_fcs[k]:
+ x_reg = self.relu(fc(x_reg))
+
+ cls_score.append(self.fc_cls[k](x_cls) if self.with_cls else None)
+ bbox_pred.append(self.fc_reg[k](x_reg) if self.with_reg else None)
+
+ if self.with_refine:
+ x_ref = x
+ cls_score_ref = list()
+ bbox_pred_ref = list()
+ for k in range(self.num_instance):
+ feat_ref = cls_score[k].softmax(dim=-1)
+ feat_ref = torch.cat((bbox_pred[k], feat_ref[:, 1][:, None]),
+ dim=1).repeat(1, 4)
+ feat_ref = torch.cat((x_ref, feat_ref), dim=1)
+ feat_ref = F.relu_(self.shared_fcs_ref(feat_ref))
+
+ cls_score_ref.append(self.fc_cls_ref[k](feat_ref))
+ bbox_pred_ref.append(self.fc_reg_ref[k](feat_ref))
+
+ cls_score = torch.cat(cls_score, dim=1)
+ bbox_pred = torch.cat(bbox_pred, dim=1)
+ cls_score_ref = torch.cat(cls_score_ref, dim=1)
+ bbox_pred_ref = torch.cat(bbox_pred_ref, dim=1)
+ return cls_score, bbox_pred, cls_score_ref, bbox_pred_ref
+
+ cls_score = torch.cat(cls_score, dim=1)
+ bbox_pred = torch.cat(bbox_pred, dim=1)
+
+ return cls_score, bbox_pred
+
+ def get_targets(self,
+ sampling_results: List[SamplingResult],
+ rcnn_train_cfg: ConfigDict,
+ concat: bool = True) -> tuple:
+ """Calculate the ground truth for all samples in a batch according to
+ the sampling_results.
+
+ Almost the same as the implementation in bbox_head, we passed
+ additional parameters pos_inds_list and neg_inds_list to
+ `_get_targets_single` function.
+
+ Args:
+ sampling_results (List[obj:SamplingResult]): Assign results of
+ all images in a batch after sampling.
+ rcnn_train_cfg (obj:ConfigDict): `train_cfg` of RCNN.
+ concat (bool): Whether to concatenate the results of all
+ the images in a single batch.
+
+ Returns:
+ Tuple[Tensor]: Ground truth for proposals in a single image.
+ Containing the following list of Tensors:
+
+ - labels (list[Tensor],Tensor): Gt_labels for all proposals in a
+ batch, each tensor in list has shape (num_proposals,) when
+ `concat=False`, otherwise just a single tensor has shape
+ (num_all_proposals,).
+ - label_weights (list[Tensor]): Labels_weights for
+ all proposals in a batch, each tensor in list has shape
+ (num_proposals,) when `concat=False`, otherwise just a single
+ tensor has shape (num_all_proposals,).
+ - bbox_targets (list[Tensor],Tensor): Regression target for all
+ proposals in a batch, each tensor in list has shape
+ (num_proposals, 4) when `concat=False`, otherwise just a single
+ tensor has shape (num_all_proposals, 4), the last dimension 4
+ represents [tl_x, tl_y, br_x, br_y].
+ - bbox_weights (list[tensor],Tensor): Regression weights for
+ all proposals in a batch, each tensor in list has shape
+ (num_proposals, 4) when `concat=False`, otherwise just a
+ single tensor has shape (num_all_proposals, 4).
+ """
+ labels = []
+ bbox_targets = []
+ bbox_weights = []
+ label_weights = []
+ for i in range(len(sampling_results)):
+ sample_bboxes = torch.cat([
+ sampling_results[i].pos_gt_bboxes,
+ sampling_results[i].neg_gt_bboxes
+ ])
+ sample_priors = sampling_results[i].priors
+ sample_priors = sample_priors.repeat(1, self.num_instance).reshape(
+ -1, 4)
+ sample_bboxes = sample_bboxes.reshape(-1, 4)
+
+ if not self.reg_decoded_bbox:
+ _bbox_targets = self.bbox_coder.encode(sample_priors,
+ sample_bboxes)
+ else:
+ _bbox_targets = sample_priors
+ _bbox_targets = _bbox_targets.reshape(-1, self.num_instance * 4)
+ _bbox_weights = torch.ones(_bbox_targets.shape)
+ _labels = torch.cat([
+ sampling_results[i].pos_gt_labels,
+ sampling_results[i].neg_gt_labels
+ ])
+ _labels_weights = torch.ones(_labels.shape)
+
+ bbox_targets.append(_bbox_targets)
+ bbox_weights.append(_bbox_weights)
+ labels.append(_labels)
+ label_weights.append(_labels_weights)
+
+ if concat:
+ labels = torch.cat(labels, 0)
+ label_weights = torch.cat(label_weights, 0)
+ bbox_targets = torch.cat(bbox_targets, 0)
+ bbox_weights = torch.cat(bbox_weights, 0)
+ return labels, label_weights, bbox_targets, bbox_weights
+
+ def loss(self, cls_score: Tensor, bbox_pred: Tensor, rois: Tensor,
+ labels: Tensor, label_weights: Tensor, bbox_targets: Tensor,
+ bbox_weights: Tensor, **kwargs) -> dict:
+ """Calculate the loss based on the network predictions and targets.
+
+ Args:
+ cls_score (Tensor): Classification prediction results of all class,
+ has shape (batch_size * num_proposals_single_image,
+ (num_classes + 1) * k), k represents the number of prediction
+ boxes generated by each proposal box.
+ bbox_pred (Tensor): Regression prediction results, has shape
+ (batch_size * num_proposals_single_image, 4 * k), the last
+ dimension 4 represents [tl_x, tl_y, br_x, br_y].
+ rois (Tensor): RoIs with the shape
+ (batch_size * num_proposals_single_image, 5) where the first
+ column indicates batch id of each RoI.
+ labels (Tensor): Gt_labels for all proposals in a batch, has
+ shape (batch_size * num_proposals_single_image, k).
+ label_weights (Tensor): Labels_weights for all proposals in a
+ batch, has shape (batch_size * num_proposals_single_image, k).
+ bbox_targets (Tensor): Regression target for all proposals in a
+ batch, has shape (batch_size * num_proposals_single_image,
+ 4 * k), the last dimension 4 represents [tl_x, tl_y, br_x,
+ br_y].
+ bbox_weights (Tensor): Regression weights for all proposals in a
+ batch, has shape (batch_size * num_proposals_single_image,
+ 4 * k).
+
+ Returns:
+ dict: A dictionary of loss.
+ """
+ losses = dict()
+ if bbox_pred.numel():
+ loss_0 = self.emd_loss(bbox_pred[:, 0:4], cls_score[:, 0:2],
+ bbox_pred[:, 4:8], cls_score[:, 2:4],
+ bbox_targets, labels)
+ loss_1 = self.emd_loss(bbox_pred[:, 4:8], cls_score[:, 2:4],
+ bbox_pred[:, 0:4], cls_score[:, 0:2],
+ bbox_targets, labels)
+ loss = torch.cat([loss_0, loss_1], dim=1)
+ _, min_indices = loss.min(dim=1)
+ loss_emd = loss[torch.arange(loss.shape[0]), min_indices]
+ loss_emd = loss_emd.mean()
+ else:
+ loss_emd = bbox_pred.sum()
+ losses['loss_rcnn_emd'] = loss_emd
+ return losses
+
+ def emd_loss(self, bbox_pred_0: Tensor, cls_score_0: Tensor,
+ bbox_pred_1: Tensor, cls_score_1: Tensor, targets: Tensor,
+ labels: Tensor) -> Tensor:
+ """Calculate the emd loss.
+
+ Note:
+ This implementation is modified from https://github.com/Purkialo/
+ CrowdDet/blob/master/lib/det_oprs/loss_opr.py
+
+ Args:
+ bbox_pred_0 (Tensor): Part of regression prediction results, has
+ shape (batch_size * num_proposals_single_image, 4), the last
+ dimension 4 represents [tl_x, tl_y, br_x, br_y].
+ cls_score_0 (Tensor): Part of classification prediction results,
+ has shape (batch_size * num_proposals_single_image,
+ (num_classes + 1)), where 1 represents the background.
+ bbox_pred_1 (Tensor): The other part of regression prediction
+ results, has shape (batch_size*num_proposals_single_image, 4).
+ cls_score_1 (Tensor):The other part of classification prediction
+ results, has shape (batch_size * num_proposals_single_image,
+ (num_classes + 1)).
+ targets (Tensor):Regression target for all proposals in a
+ batch, has shape (batch_size * num_proposals_single_image,
+ 4 * k), the last dimension 4 represents [tl_x, tl_y, br_x,
+ br_y], k represents the number of prediction boxes generated
+ by each proposal box.
+ labels (Tensor): Gt_labels for all proposals in a batch, has
+ shape (batch_size * num_proposals_single_image, k).
+
+ Returns:
+ torch.Tensor: The calculated loss.
+ """
+
+ bbox_pred = torch.cat([bbox_pred_0, bbox_pred_1],
+ dim=1).reshape(-1, bbox_pred_0.shape[-1])
+ cls_score = torch.cat([cls_score_0, cls_score_1],
+ dim=1).reshape(-1, cls_score_0.shape[-1])
+ targets = targets.reshape(-1, 4)
+ labels = labels.long().flatten()
+
+ # masks
+ valid_masks = labels >= 0
+ fg_masks = labels > 0
+
+ # multiple class
+ bbox_pred = bbox_pred.reshape(-1, self.num_classes, 4)
+ fg_gt_classes = labels[fg_masks]
+ bbox_pred = bbox_pred[fg_masks, fg_gt_classes - 1, :]
+
+ # loss for regression
+ loss_bbox = self.loss_bbox(bbox_pred, targets[fg_masks])
+ loss_bbox = loss_bbox.sum(dim=1)
+
+ # loss for classification
+ labels = labels * valid_masks
+ loss_cls = self.loss_cls(cls_score, labels)
+
+ loss_cls[fg_masks] = loss_cls[fg_masks] + loss_bbox
+ loss = loss_cls.reshape(-1, 2).sum(dim=1)
+ return loss.reshape(-1, 1)
+
+ def _predict_by_feat_single(
+ self,
+ roi: Tensor,
+ cls_score: Tensor,
+ bbox_pred: Tensor,
+ img_meta: dict,
+ rescale: bool = False,
+ rcnn_test_cfg: Optional[ConfigDict] = None) -> InstanceData:
+ """Transform a single image's features extracted from the head into
+ bbox results.
+
+ Args:
+ roi (Tensor): Boxes to be transformed. Has shape (num_boxes, 5).
+ last dimension 5 arrange as (batch_index, x1, y1, x2, y2).
+ cls_score (Tensor): Box scores, has shape
+ (num_boxes, num_classes + 1).
+ bbox_pred (Tensor): Box energies / deltas. has shape
+ (num_boxes, num_classes * 4).
+ img_meta (dict): image information.
+ rescale (bool): If True, return boxes in original image space.
+ Defaults to False.
+ rcnn_test_cfg (obj:`ConfigDict`): `test_cfg` of Bbox Head.
+ Defaults to None
+
+ Returns:
+ :obj:`InstanceData`: Detection results of each image.
+ Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ """
+
+ cls_score = cls_score.reshape(-1, self.num_classes + 1)
+ bbox_pred = bbox_pred.reshape(-1, 4)
+ roi = roi.repeat_interleave(self.num_instance, dim=0)
+
+ results = InstanceData()
+ if roi.shape[0] == 0:
+ return empty_instances([img_meta],
+ roi.device,
+ task_type='bbox',
+ instance_results=[results])[0]
+
+ scores = cls_score.softmax(dim=-1) if cls_score is not None else None
+ img_shape = img_meta['img_shape']
+ bboxes = self.bbox_coder.decode(
+ roi[..., 1:], bbox_pred, max_shape=img_shape)
+
+ if rescale and bboxes.size(0) > 0:
+ assert img_meta.get('scale_factor') is not None
+ scale_factor = bboxes.new_tensor(img_meta['scale_factor']).repeat(
+ (1, 2))
+ bboxes = (bboxes.view(bboxes.size(0), -1, 4) / scale_factor).view(
+ bboxes.size()[0], -1)
+
+ if rcnn_test_cfg is None:
+ # This means that it is aug test.
+ # It needs to return the raw results without nms.
+ results.bboxes = bboxes
+ results.scores = scores
+ else:
+ roi_idx = np.tile(
+ np.arange(bboxes.shape[0] / self.num_instance)[:, None],
+ (1, self.num_instance)).reshape(-1, 1)[:, 0]
+ roi_idx = torch.from_numpy(roi_idx).to(bboxes.device).reshape(
+ -1, 1)
+ bboxes = torch.cat([bboxes, roi_idx], dim=1)
+ det_bboxes, det_scores = self.set_nms(
+ bboxes, scores[:, 1], rcnn_test_cfg.score_thr,
+ rcnn_test_cfg.nms['iou_threshold'], rcnn_test_cfg.max_per_img)
+
+ results.bboxes = det_bboxes[:, :-1]
+ results.scores = det_scores
+ results.labels = torch.zeros_like(det_scores)
+
+ return results
+
+ @staticmethod
+ def set_nms(bboxes: Tensor,
+ scores: Tensor,
+ score_thr: float,
+ iou_threshold: float,
+ max_num: int = -1) -> Tuple[Tensor, Tensor]:
+ """NMS for multi-instance prediction. Please refer to
+ https://github.com/Purkialo/CrowdDet for more details.
+
+ Args:
+ bboxes (Tensor): predict bboxes.
+ scores (Tensor): The score of each predict bbox.
+ score_thr (float): bbox threshold, bboxes with scores lower than it
+ will not be considered.
+ iou_threshold (float): IoU threshold to be considered as
+ conflicted.
+ max_num (int, optional): if there are more than max_num bboxes
+ after NMS, only top max_num will be kept. Default to -1.
+
+ Returns:
+ Tuple[Tensor, Tensor]: (bboxes, scores).
+ """
+
+ bboxes = bboxes[scores > score_thr]
+ scores = scores[scores > score_thr]
+
+ ordered_scores, order = scores.sort(descending=True)
+ ordered_bboxes = bboxes[order]
+ roi_idx = ordered_bboxes[:, -1]
+
+ keep = torch.ones(len(ordered_bboxes)) == 1
+ ruler = torch.arange(len(ordered_bboxes))
+ while ruler.shape[0] > 0:
+ basement = ruler[0]
+ ruler = ruler[1:]
+ idx = roi_idx[basement]
+ # calculate the body overlap
+ basement_bbox = ordered_bboxes[:, :4][basement].reshape(-1, 4)
+ ruler_bbox = ordered_bboxes[:, :4][ruler].reshape(-1, 4)
+ overlap = bbox_overlaps(basement_bbox, ruler_bbox)
+ indices = torch.where(overlap > iou_threshold)[1]
+ loc = torch.where(roi_idx[ruler][indices] == idx)
+ # the mask won't change in the step
+ mask = keep[ruler[indices][loc]]
+ keep[ruler[indices]] = False
+ keep[ruler[indices][loc][mask]] = True
+ ruler[~keep[ruler]] = -1
+ ruler = ruler[ruler > 0]
+
+ keep = keep[order.sort()[1]]
+ return bboxes[keep][:max_num, :], scores[keep][:max_num]
diff --git a/mmdet/models/roi_heads/bbox_heads/sabl_head.py b/mmdet/models/roi_heads/bbox_heads/sabl_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..9a9ee6aba9669514ec8ce7218e8c97e026830f6c
--- /dev/null
+++ b/mmdet/models/roi_heads/bbox_heads/sabl_head.py
@@ -0,0 +1,684 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Optional, Sequence, Tuple
+
+import numpy as np
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule
+from mmengine.config import ConfigDict
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmdet.models.layers import multiclass_nms
+from mmdet.models.losses import accuracy
+from mmdet.models.task_modules import SamplingResult
+from mmdet.models.utils import multi_apply
+from mmdet.registry import MODELS, TASK_UTILS
+from mmdet.utils import ConfigType, InstanceList, OptConfigType, OptMultiConfig
+from .bbox_head import BBoxHead
+
+
+@MODELS.register_module()
+class SABLHead(BBoxHead):
+ """Side-Aware Boundary Localization (SABL) for RoI-Head.
+
+ Side-Aware features are extracted by conv layers
+ with an attention mechanism.
+ Boundary Localization with Bucketing and Bucketing Guided Rescoring
+ are implemented in BucketingBBoxCoder.
+
+ Please refer to https://arxiv.org/abs/1912.04260 for more details.
+
+ Args:
+ cls_in_channels (int): Input channels of cls RoI feature. \
+ Defaults to 256.
+ reg_in_channels (int): Input channels of reg RoI feature. \
+ Defaults to 256.
+ roi_feat_size (int): Size of RoI features. Defaults to 7.
+ reg_feat_up_ratio (int): Upsample ratio of reg features. \
+ Defaults to 2.
+ reg_pre_kernel (int): Kernel of 2D conv layers before \
+ attention pooling. Defaults to 3.
+ reg_post_kernel (int): Kernel of 1D conv layers after \
+ attention pooling. Defaults to 3.
+ reg_pre_num (int): Number of pre convs. Defaults to 2.
+ reg_post_num (int): Number of post convs. Defaults to 1.
+ num_classes (int): Number of classes in dataset. Defaults to 80.
+ cls_out_channels (int): Hidden channels in cls fcs. Defaults to 1024.
+ reg_offset_out_channels (int): Hidden and output channel \
+ of reg offset branch. Defaults to 256.
+ reg_cls_out_channels (int): Hidden and output channel \
+ of reg cls branch. Defaults to 256.
+ num_cls_fcs (int): Number of fcs for cls branch. Defaults to 1.
+ num_reg_fcs (int): Number of fcs for reg branch.. Defaults to 0.
+ reg_class_agnostic (bool): Class agnostic regression or not. \
+ Defaults to True.
+ norm_cfg (dict): Config of norm layers. Defaults to None.
+ bbox_coder (dict): Config of bbox coder. Defaults 'BucketingBBoxCoder'.
+ loss_cls (dict): Config of classification loss.
+ loss_bbox_cls (dict): Config of classification loss for bbox branch.
+ loss_bbox_reg (dict): Config of regression loss for bbox branch.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ num_classes: int,
+ cls_in_channels: int = 256,
+ reg_in_channels: int = 256,
+ roi_feat_size: int = 7,
+ reg_feat_up_ratio: int = 2,
+ reg_pre_kernel: int = 3,
+ reg_post_kernel: int = 3,
+ reg_pre_num: int = 2,
+ reg_post_num: int = 1,
+ cls_out_channels: int = 1024,
+ reg_offset_out_channels: int = 256,
+ reg_cls_out_channels: int = 256,
+ num_cls_fcs: int = 1,
+ num_reg_fcs: int = 0,
+ reg_class_agnostic: bool = True,
+ norm_cfg: OptConfigType = None,
+ bbox_coder: ConfigType = dict(
+ type='BucketingBBoxCoder',
+ num_buckets=14,
+ scale_factor=1.7),
+ loss_cls: ConfigType = dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=False,
+ loss_weight=1.0),
+ loss_bbox_cls: ConfigType = dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=True,
+ loss_weight=1.0),
+ loss_bbox_reg: ConfigType = dict(
+ type='SmoothL1Loss', beta=0.1, loss_weight=1.0),
+ init_cfg: OptMultiConfig = None) -> None:
+ super(BBoxHead, self).__init__(init_cfg=init_cfg)
+ self.cls_in_channels = cls_in_channels
+ self.reg_in_channels = reg_in_channels
+ self.roi_feat_size = roi_feat_size
+ self.reg_feat_up_ratio = int(reg_feat_up_ratio)
+ self.num_buckets = bbox_coder['num_buckets']
+ assert self.reg_feat_up_ratio // 2 >= 1
+ self.up_reg_feat_size = roi_feat_size * self.reg_feat_up_ratio
+ assert self.up_reg_feat_size == bbox_coder['num_buckets']
+ self.reg_pre_kernel = reg_pre_kernel
+ self.reg_post_kernel = reg_post_kernel
+ self.reg_pre_num = reg_pre_num
+ self.reg_post_num = reg_post_num
+ self.num_classes = num_classes
+ self.cls_out_channels = cls_out_channels
+ self.reg_offset_out_channels = reg_offset_out_channels
+ self.reg_cls_out_channels = reg_cls_out_channels
+ self.num_cls_fcs = num_cls_fcs
+ self.num_reg_fcs = num_reg_fcs
+ self.reg_class_agnostic = reg_class_agnostic
+ assert self.reg_class_agnostic
+ self.norm_cfg = norm_cfg
+
+ self.bbox_coder = TASK_UTILS.build(bbox_coder)
+ self.loss_cls = MODELS.build(loss_cls)
+ self.loss_bbox_cls = MODELS.build(loss_bbox_cls)
+ self.loss_bbox_reg = MODELS.build(loss_bbox_reg)
+
+ self.cls_fcs = self._add_fc_branch(self.num_cls_fcs,
+ self.cls_in_channels,
+ self.roi_feat_size,
+ self.cls_out_channels)
+
+ self.side_num = int(np.ceil(self.num_buckets / 2))
+
+ if self.reg_feat_up_ratio > 1:
+ self.upsample_x = nn.ConvTranspose1d(
+ reg_in_channels,
+ reg_in_channels,
+ self.reg_feat_up_ratio,
+ stride=self.reg_feat_up_ratio)
+ self.upsample_y = nn.ConvTranspose1d(
+ reg_in_channels,
+ reg_in_channels,
+ self.reg_feat_up_ratio,
+ stride=self.reg_feat_up_ratio)
+
+ self.reg_pre_convs = nn.ModuleList()
+ for i in range(self.reg_pre_num):
+ reg_pre_conv = ConvModule(
+ reg_in_channels,
+ reg_in_channels,
+ kernel_size=reg_pre_kernel,
+ padding=reg_pre_kernel // 2,
+ norm_cfg=norm_cfg,
+ act_cfg=dict(type='ReLU'))
+ self.reg_pre_convs.append(reg_pre_conv)
+
+ self.reg_post_conv_xs = nn.ModuleList()
+ for i in range(self.reg_post_num):
+ reg_post_conv_x = ConvModule(
+ reg_in_channels,
+ reg_in_channels,
+ kernel_size=(1, reg_post_kernel),
+ padding=(0, reg_post_kernel // 2),
+ norm_cfg=norm_cfg,
+ act_cfg=dict(type='ReLU'))
+ self.reg_post_conv_xs.append(reg_post_conv_x)
+ self.reg_post_conv_ys = nn.ModuleList()
+ for i in range(self.reg_post_num):
+ reg_post_conv_y = ConvModule(
+ reg_in_channels,
+ reg_in_channels,
+ kernel_size=(reg_post_kernel, 1),
+ padding=(reg_post_kernel // 2, 0),
+ norm_cfg=norm_cfg,
+ act_cfg=dict(type='ReLU'))
+ self.reg_post_conv_ys.append(reg_post_conv_y)
+
+ self.reg_conv_att_x = nn.Conv2d(reg_in_channels, 1, 1)
+ self.reg_conv_att_y = nn.Conv2d(reg_in_channels, 1, 1)
+
+ self.fc_cls = nn.Linear(self.cls_out_channels, self.num_classes + 1)
+ self.relu = nn.ReLU(inplace=True)
+
+ self.reg_cls_fcs = self._add_fc_branch(self.num_reg_fcs,
+ self.reg_in_channels, 1,
+ self.reg_cls_out_channels)
+ self.reg_offset_fcs = self._add_fc_branch(self.num_reg_fcs,
+ self.reg_in_channels, 1,
+ self.reg_offset_out_channels)
+ self.fc_reg_cls = nn.Linear(self.reg_cls_out_channels, 1)
+ self.fc_reg_offset = nn.Linear(self.reg_offset_out_channels, 1)
+
+ if init_cfg is None:
+ self.init_cfg = [
+ dict(
+ type='Xavier',
+ layer='Linear',
+ distribution='uniform',
+ override=[
+ dict(type='Normal', name='reg_conv_att_x', std=0.01),
+ dict(type='Normal', name='reg_conv_att_y', std=0.01),
+ dict(type='Normal', name='fc_reg_cls', std=0.01),
+ dict(type='Normal', name='fc_cls', std=0.01),
+ dict(type='Normal', name='fc_reg_offset', std=0.001)
+ ])
+ ]
+ if self.reg_feat_up_ratio > 1:
+ self.init_cfg += [
+ dict(
+ type='Kaiming',
+ distribution='normal',
+ override=[
+ dict(name='upsample_x'),
+ dict(name='upsample_y')
+ ])
+ ]
+
+ def _add_fc_branch(self, num_branch_fcs: int, in_channels: int,
+ roi_feat_size: int,
+ fc_out_channels: int) -> nn.ModuleList:
+ """build fc layers."""
+ in_channels = in_channels * roi_feat_size * roi_feat_size
+ branch_fcs = nn.ModuleList()
+ for i in range(num_branch_fcs):
+ fc_in_channels = (in_channels if i == 0 else fc_out_channels)
+ branch_fcs.append(nn.Linear(fc_in_channels, fc_out_channels))
+ return branch_fcs
+
+ def cls_forward(self, cls_x: Tensor) -> Tensor:
+ """forward of classification fc layers."""
+ cls_x = cls_x.view(cls_x.size(0), -1)
+ for fc in self.cls_fcs:
+ cls_x = self.relu(fc(cls_x))
+ cls_score = self.fc_cls(cls_x)
+ return cls_score
+
+ def attention_pool(self, reg_x: Tensor) -> tuple:
+ """Extract direction-specific features fx and fy with attention
+ methanism."""
+ reg_fx = reg_x
+ reg_fy = reg_x
+ reg_fx_att = self.reg_conv_att_x(reg_fx).sigmoid()
+ reg_fy_att = self.reg_conv_att_y(reg_fy).sigmoid()
+ reg_fx_att = reg_fx_att / reg_fx_att.sum(dim=2).unsqueeze(2)
+ reg_fy_att = reg_fy_att / reg_fy_att.sum(dim=3).unsqueeze(3)
+ reg_fx = (reg_fx * reg_fx_att).sum(dim=2)
+ reg_fy = (reg_fy * reg_fy_att).sum(dim=3)
+ return reg_fx, reg_fy
+
+ def side_aware_feature_extractor(self, reg_x: Tensor) -> tuple:
+ """Refine and extract side-aware features without split them."""
+ for reg_pre_conv in self.reg_pre_convs:
+ reg_x = reg_pre_conv(reg_x)
+ reg_fx, reg_fy = self.attention_pool(reg_x)
+
+ if self.reg_post_num > 0:
+ reg_fx = reg_fx.unsqueeze(2)
+ reg_fy = reg_fy.unsqueeze(3)
+ for i in range(self.reg_post_num):
+ reg_fx = self.reg_post_conv_xs[i](reg_fx)
+ reg_fy = self.reg_post_conv_ys[i](reg_fy)
+ reg_fx = reg_fx.squeeze(2)
+ reg_fy = reg_fy.squeeze(3)
+ if self.reg_feat_up_ratio > 1:
+ reg_fx = self.relu(self.upsample_x(reg_fx))
+ reg_fy = self.relu(self.upsample_y(reg_fy))
+ reg_fx = torch.transpose(reg_fx, 1, 2)
+ reg_fy = torch.transpose(reg_fy, 1, 2)
+ return reg_fx.contiguous(), reg_fy.contiguous()
+
+ def reg_pred(self, x: Tensor, offset_fcs: nn.ModuleList,
+ cls_fcs: nn.ModuleList) -> tuple:
+ """Predict bucketing estimation (cls_pred) and fine regression (offset
+ pred) with side-aware features."""
+ x_offset = x.view(-1, self.reg_in_channels)
+ x_cls = x.view(-1, self.reg_in_channels)
+
+ for fc in offset_fcs:
+ x_offset = self.relu(fc(x_offset))
+ for fc in cls_fcs:
+ x_cls = self.relu(fc(x_cls))
+ offset_pred = self.fc_reg_offset(x_offset)
+ cls_pred = self.fc_reg_cls(x_cls)
+
+ offset_pred = offset_pred.view(x.size(0), -1)
+ cls_pred = cls_pred.view(x.size(0), -1)
+
+ return offset_pred, cls_pred
+
+ def side_aware_split(self, feat: Tensor) -> Tensor:
+ """Split side-aware features aligned with orders of bucketing
+ targets."""
+ l_end = int(np.ceil(self.up_reg_feat_size / 2))
+ r_start = int(np.floor(self.up_reg_feat_size / 2))
+ feat_fl = feat[:, :l_end]
+ feat_fr = feat[:, r_start:].flip(dims=(1, ))
+ feat_fl = feat_fl.contiguous()
+ feat_fr = feat_fr.contiguous()
+ feat = torch.cat([feat_fl, feat_fr], dim=-1)
+ return feat
+
+ def bbox_pred_split(self, bbox_pred: tuple,
+ num_proposals_per_img: Sequence[int]) -> tuple:
+ """Split batch bbox prediction back to each image."""
+ bucket_cls_preds, bucket_offset_preds = bbox_pred
+ bucket_cls_preds = bucket_cls_preds.split(num_proposals_per_img, 0)
+ bucket_offset_preds = bucket_offset_preds.split(
+ num_proposals_per_img, 0)
+ bbox_pred = tuple(zip(bucket_cls_preds, bucket_offset_preds))
+ return bbox_pred
+
+ def reg_forward(self, reg_x: Tensor) -> tuple:
+ """forward of regression branch."""
+ outs = self.side_aware_feature_extractor(reg_x)
+ edge_offset_preds = []
+ edge_cls_preds = []
+ reg_fx = outs[0]
+ reg_fy = outs[1]
+ offset_pred_x, cls_pred_x = self.reg_pred(reg_fx, self.reg_offset_fcs,
+ self.reg_cls_fcs)
+ offset_pred_y, cls_pred_y = self.reg_pred(reg_fy, self.reg_offset_fcs,
+ self.reg_cls_fcs)
+ offset_pred_x = self.side_aware_split(offset_pred_x)
+ offset_pred_y = self.side_aware_split(offset_pred_y)
+ cls_pred_x = self.side_aware_split(cls_pred_x)
+ cls_pred_y = self.side_aware_split(cls_pred_y)
+ edge_offset_preds = torch.cat([offset_pred_x, offset_pred_y], dim=-1)
+ edge_cls_preds = torch.cat([cls_pred_x, cls_pred_y], dim=-1)
+
+ return edge_cls_preds, edge_offset_preds
+
+ def forward(self, x: Tensor) -> tuple:
+ """Forward features from the upstream network."""
+ bbox_pred = self.reg_forward(x)
+ cls_score = self.cls_forward(x)
+
+ return cls_score, bbox_pred
+
+ def get_targets(self,
+ sampling_results: List[SamplingResult],
+ rcnn_train_cfg: ConfigDict,
+ concat: bool = True) -> tuple:
+ """Calculate the ground truth for all samples in a batch according to
+ the sampling_results."""
+ pos_proposals = [res.pos_bboxes for res in sampling_results]
+ neg_proposals = [res.neg_bboxes for res in sampling_results]
+ pos_gt_bboxes = [res.pos_gt_bboxes for res in sampling_results]
+ pos_gt_labels = [res.pos_gt_labels for res in sampling_results]
+ cls_reg_targets = self.bucket_target(
+ pos_proposals,
+ neg_proposals,
+ pos_gt_bboxes,
+ pos_gt_labels,
+ rcnn_train_cfg,
+ concat=concat)
+ (labels, label_weights, bucket_cls_targets, bucket_cls_weights,
+ bucket_offset_targets, bucket_offset_weights) = cls_reg_targets
+ return (labels, label_weights, (bucket_cls_targets,
+ bucket_offset_targets),
+ (bucket_cls_weights, bucket_offset_weights))
+
+ def bucket_target(self,
+ pos_proposals_list: list,
+ neg_proposals_list: list,
+ pos_gt_bboxes_list: list,
+ pos_gt_labels_list: list,
+ rcnn_train_cfg: ConfigDict,
+ concat: bool = True) -> tuple:
+ """Compute bucketing estimation targets and fine regression targets for
+ a batch of images."""
+ (labels, label_weights, bucket_cls_targets, bucket_cls_weights,
+ bucket_offset_targets, bucket_offset_weights) = multi_apply(
+ self._bucket_target_single,
+ pos_proposals_list,
+ neg_proposals_list,
+ pos_gt_bboxes_list,
+ pos_gt_labels_list,
+ cfg=rcnn_train_cfg)
+
+ if concat:
+ labels = torch.cat(labels, 0)
+ label_weights = torch.cat(label_weights, 0)
+ bucket_cls_targets = torch.cat(bucket_cls_targets, 0)
+ bucket_cls_weights = torch.cat(bucket_cls_weights, 0)
+ bucket_offset_targets = torch.cat(bucket_offset_targets, 0)
+ bucket_offset_weights = torch.cat(bucket_offset_weights, 0)
+ return (labels, label_weights, bucket_cls_targets, bucket_cls_weights,
+ bucket_offset_targets, bucket_offset_weights)
+
+ def _bucket_target_single(self, pos_proposals: Tensor,
+ neg_proposals: Tensor, pos_gt_bboxes: Tensor,
+ pos_gt_labels: Tensor, cfg: ConfigDict) -> tuple:
+ """Compute bucketing estimation targets and fine regression targets for
+ a single image.
+
+ Args:
+ pos_proposals (Tensor): positive proposals of a single image,
+ Shape (n_pos, 4)
+ neg_proposals (Tensor): negative proposals of a single image,
+ Shape (n_neg, 4).
+ pos_gt_bboxes (Tensor): gt bboxes assigned to positive proposals
+ of a single image, Shape (n_pos, 4).
+ pos_gt_labels (Tensor): gt labels assigned to positive proposals
+ of a single image, Shape (n_pos, ).
+ cfg (dict): Config of calculating targets
+
+ Returns:
+ tuple:
+
+ - labels (Tensor): Labels in a single image. Shape (n,).
+ - label_weights (Tensor): Label weights in a single image.
+ Shape (n,)
+ - bucket_cls_targets (Tensor): Bucket cls targets in
+ a single image. Shape (n, num_buckets*2).
+ - bucket_cls_weights (Tensor): Bucket cls weights in
+ a single image. Shape (n, num_buckets*2).
+ - bucket_offset_targets (Tensor): Bucket offset targets
+ in a single image. Shape (n, num_buckets*2).
+ - bucket_offset_targets (Tensor): Bucket offset weights
+ in a single image. Shape (n, num_buckets*2).
+ """
+ num_pos = pos_proposals.size(0)
+ num_neg = neg_proposals.size(0)
+ num_samples = num_pos + num_neg
+ labels = pos_gt_bboxes.new_full((num_samples, ),
+ self.num_classes,
+ dtype=torch.long)
+ label_weights = pos_proposals.new_zeros(num_samples)
+ bucket_cls_targets = pos_proposals.new_zeros(num_samples,
+ 4 * self.side_num)
+ bucket_cls_weights = pos_proposals.new_zeros(num_samples,
+ 4 * self.side_num)
+ bucket_offset_targets = pos_proposals.new_zeros(
+ num_samples, 4 * self.side_num)
+ bucket_offset_weights = pos_proposals.new_zeros(
+ num_samples, 4 * self.side_num)
+ if num_pos > 0:
+ labels[:num_pos] = pos_gt_labels
+ label_weights[:num_pos] = 1.0
+ (pos_bucket_offset_targets, pos_bucket_offset_weights,
+ pos_bucket_cls_targets,
+ pos_bucket_cls_weights) = self.bbox_coder.encode(
+ pos_proposals, pos_gt_bboxes)
+ bucket_cls_targets[:num_pos, :] = pos_bucket_cls_targets
+ bucket_cls_weights[:num_pos, :] = pos_bucket_cls_weights
+ bucket_offset_targets[:num_pos, :] = pos_bucket_offset_targets
+ bucket_offset_weights[:num_pos, :] = pos_bucket_offset_weights
+ if num_neg > 0:
+ label_weights[-num_neg:] = 1.0
+ return (labels, label_weights, bucket_cls_targets, bucket_cls_weights,
+ bucket_offset_targets, bucket_offset_weights)
+
+ def loss(self,
+ cls_score: Tensor,
+ bbox_pred: Tuple[Tensor, Tensor],
+ rois: Tensor,
+ labels: Tensor,
+ label_weights: Tensor,
+ bbox_targets: Tuple[Tensor, Tensor],
+ bbox_weights: Tuple[Tensor, Tensor],
+ reduction_override: Optional[str] = None) -> dict:
+ """Calculate the loss based on the network predictions and targets.
+
+ Args:
+ cls_score (Tensor): Classification prediction
+ results of all class, has shape
+ (batch_size * num_proposals_single_image, num_classes)
+ bbox_pred (Tensor): A tuple of regression prediction results
+ containing `bucket_cls_preds and` `bucket_offset_preds`.
+ rois (Tensor): RoIs with the shape
+ (batch_size * num_proposals_single_image, 5) where the first
+ column indicates batch id of each RoI.
+ labels (Tensor): Gt_labels for all proposals in a batch, has
+ shape (batch_size * num_proposals_single_image, ).
+ label_weights (Tensor): Labels_weights for all proposals in a
+ batch, has shape (batch_size * num_proposals_single_image, ).
+ bbox_targets (Tuple[Tensor, Tensor]): A tuple of regression target
+ containing `bucket_cls_targets` and `bucket_offset_targets`.
+ the last dimension 4 represents [tl_x, tl_y, br_x, br_y].
+ bbox_weights (Tuple[Tensor, Tensor]): A tuple of regression
+ weights containing `bucket_cls_weights` and
+ `bucket_offset_weights`.
+ reduction_override (str, optional): The reduction
+ method used to override the original reduction
+ method of the loss. Options are "none",
+ "mean" and "sum". Defaults to None,
+
+ Returns:
+ dict: A dictionary of loss.
+ """
+ losses = dict()
+ if cls_score is not None:
+ avg_factor = max(torch.sum(label_weights > 0).float().item(), 1.)
+ losses['loss_cls'] = self.loss_cls(
+ cls_score,
+ labels,
+ label_weights,
+ avg_factor=avg_factor,
+ reduction_override=reduction_override)
+ losses['acc'] = accuracy(cls_score, labels)
+
+ if bbox_pred is not None:
+ bucket_cls_preds, bucket_offset_preds = bbox_pred
+ bucket_cls_targets, bucket_offset_targets = bbox_targets
+ bucket_cls_weights, bucket_offset_weights = bbox_weights
+ # edge cls
+ bucket_cls_preds = bucket_cls_preds.view(-1, self.side_num)
+ bucket_cls_targets = bucket_cls_targets.view(-1, self.side_num)
+ bucket_cls_weights = bucket_cls_weights.view(-1, self.side_num)
+ losses['loss_bbox_cls'] = self.loss_bbox_cls(
+ bucket_cls_preds,
+ bucket_cls_targets,
+ bucket_cls_weights,
+ avg_factor=bucket_cls_targets.size(0),
+ reduction_override=reduction_override)
+
+ losses['loss_bbox_reg'] = self.loss_bbox_reg(
+ bucket_offset_preds,
+ bucket_offset_targets,
+ bucket_offset_weights,
+ avg_factor=bucket_offset_targets.size(0),
+ reduction_override=reduction_override)
+
+ return losses
+
+ def _predict_by_feat_single(
+ self,
+ roi: Tensor,
+ cls_score: Tensor,
+ bbox_pred: Tuple[Tensor, Tensor],
+ img_meta: dict,
+ rescale: bool = False,
+ rcnn_test_cfg: Optional[ConfigDict] = None) -> InstanceData:
+ """Transform a single image's features extracted from the head into
+ bbox results.
+
+ Args:
+ roi (Tensor): Boxes to be transformed. Has shape (num_boxes, 5).
+ last dimension 5 arrange as (batch_index, x1, y1, x2, y2).
+ cls_score (Tensor): Box scores, has shape
+ (num_boxes, num_classes + 1).
+ bbox_pred (Tuple[Tensor, Tensor]): Box cls preds and offset preds.
+ img_meta (dict): image information.
+ rescale (bool): If True, return boxes in original image space.
+ Defaults to False.
+ rcnn_test_cfg (obj:`ConfigDict`): `test_cfg` of Bbox Head.
+ Defaults to None
+
+ Returns:
+ :obj:`InstanceData`: Detection results of each image
+ Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ """
+ results = InstanceData()
+ if isinstance(cls_score, list):
+ cls_score = sum(cls_score) / float(len(cls_score))
+ scores = F.softmax(cls_score, dim=1) if cls_score is not None else None
+ img_shape = img_meta['img_shape']
+ if bbox_pred is not None:
+ bboxes, confidences = self.bbox_coder.decode(
+ roi[:, 1:], bbox_pred, img_shape)
+ else:
+ bboxes = roi[:, 1:].clone()
+ confidences = None
+ if img_shape is not None:
+ bboxes[:, [0, 2]].clamp_(min=0, max=img_shape[1] - 1)
+ bboxes[:, [1, 3]].clamp_(min=0, max=img_shape[0] - 1)
+
+ if rescale and bboxes.size(0) > 0:
+ assert img_meta.get('scale_factor') is not None
+ scale_factor = bboxes.new_tensor(img_meta['scale_factor']).repeat(
+ (1, 2))
+ bboxes = (bboxes.view(bboxes.size(0), -1, 4) / scale_factor).view(
+ bboxes.size()[0], -1)
+
+ if rcnn_test_cfg is None:
+ results.bboxes = bboxes
+ results.scores = scores
+ else:
+ det_bboxes, det_labels = multiclass_nms(
+ bboxes,
+ scores,
+ rcnn_test_cfg.score_thr,
+ rcnn_test_cfg.nms,
+ rcnn_test_cfg.max_per_img,
+ score_factors=confidences)
+ results.bboxes = det_bboxes[:, :4]
+ results.scores = det_bboxes[:, -1]
+ results.labels = det_labels
+ return results
+
+ def refine_bboxes(self, sampling_results: List[SamplingResult],
+ bbox_results: dict,
+ batch_img_metas: List[dict]) -> InstanceList:
+ """Refine bboxes during training.
+
+ Args:
+ sampling_results (List[:obj:`SamplingResult`]): Sampling results.
+ bbox_results (dict): Usually is a dictionary with keys:
+
+ - `cls_score` (Tensor): Classification scores.
+ - `bbox_pred` (Tensor): Box energies / deltas.
+ - `rois` (Tensor): RoIs with the shape (n, 5) where the first
+ column indicates batch id of each RoI.
+ - `bbox_targets` (tuple): Ground truth for proposals in a
+ single image. Containing the following list of Tensors:
+ (labels, label_weights, bbox_targets, bbox_weights)
+ batch_img_metas (List[dict]): List of image information.
+
+ Returns:
+ list[:obj:`InstanceData`]: Refined bboxes of each image.
+ """
+ pos_is_gts = [res.pos_is_gt for res in sampling_results]
+ # bbox_targets is a tuple
+ labels = bbox_results['bbox_targets'][0]
+ cls_scores = bbox_results['cls_score']
+ rois = bbox_results['rois']
+ bbox_preds = bbox_results['bbox_pred']
+
+ if cls_scores.numel() == 0:
+ return None
+
+ labels = torch.where(labels == self.num_classes,
+ cls_scores[:, :-1].argmax(1), labels)
+
+ img_ids = rois[:, 0].long().unique(sorted=True)
+ assert img_ids.numel() <= len(batch_img_metas)
+
+ results_list = []
+ for i in range(len(batch_img_metas)):
+ inds = torch.nonzero(
+ rois[:, 0] == i, as_tuple=False).squeeze(dim=1)
+ num_rois = inds.numel()
+
+ bboxes_ = rois[inds, 1:]
+ label_ = labels[inds]
+ edge_cls_preds, edge_offset_preds = bbox_preds
+ edge_cls_preds_ = edge_cls_preds[inds]
+ edge_offset_preds_ = edge_offset_preds[inds]
+ bbox_pred_ = (edge_cls_preds_, edge_offset_preds_)
+ img_meta_ = batch_img_metas[i]
+ pos_is_gts_ = pos_is_gts[i]
+
+ bboxes = self.regress_by_class(bboxes_, label_, bbox_pred_,
+ img_meta_)
+ # filter gt bboxes
+ pos_keep = 1 - pos_is_gts_
+ keep_inds = pos_is_gts_.new_ones(num_rois)
+ keep_inds[:len(pos_is_gts_)] = pos_keep
+ results = InstanceData(bboxes=bboxes[keep_inds.type(torch.bool)])
+ results_list.append(results)
+
+ return results_list
+
+ def regress_by_class(self, rois: Tensor, label: Tensor, bbox_pred: tuple,
+ img_meta: dict) -> Tensor:
+ """Regress the bbox for the predicted class. Used in Cascade R-CNN.
+
+ Args:
+ rois (Tensor): shape (n, 4) or (n, 5)
+ label (Tensor): shape (n, )
+ bbox_pred (Tuple[Tensor]): shape [(n, num_buckets *2), \
+ (n, num_buckets *2)]
+ img_meta (dict): Image meta info.
+
+ Returns:
+ Tensor: Regressed bboxes, the same shape as input rois.
+ """
+ assert rois.size(1) == 4 or rois.size(1) == 5
+
+ if rois.size(1) == 4:
+ new_rois, _ = self.bbox_coder.decode(rois, bbox_pred,
+ img_meta['img_shape'])
+ else:
+ bboxes, _ = self.bbox_coder.decode(rois[:, 1:], bbox_pred,
+ img_meta['img_shape'])
+ new_rois = torch.cat((rois[:, [0]], bboxes), dim=1)
+
+ return new_rois
diff --git a/mmdet/models/roi_heads/bbox_heads/scnet_bbox_head.py b/mmdet/models/roi_heads/bbox_heads/scnet_bbox_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..790b08fb207970927c7925cb8b3fb365bc183dc4
--- /dev/null
+++ b/mmdet/models/roi_heads/bbox_heads/scnet_bbox_head.py
@@ -0,0 +1,101 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Tuple, Union
+
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from .convfc_bbox_head import ConvFCBBoxHead
+
+
+@MODELS.register_module()
+class SCNetBBoxHead(ConvFCBBoxHead):
+ """BBox head for `SCNet `_.
+
+ This inherits ``ConvFCBBoxHead`` with modified forward() function, allow us
+ to get intermediate shared feature.
+ """
+
+ def _forward_shared(self, x: Tensor) -> Tensor:
+ """Forward function for shared part.
+
+ Args:
+ x (Tensor): Input feature.
+
+ Returns:
+ Tensor: Shared feature.
+ """
+ if self.num_shared_convs > 0:
+ for conv in self.shared_convs:
+ x = conv(x)
+
+ if self.num_shared_fcs > 0:
+ if self.with_avg_pool:
+ x = self.avg_pool(x)
+
+ x = x.flatten(1)
+
+ for fc in self.shared_fcs:
+ x = self.relu(fc(x))
+
+ return x
+
+ def _forward_cls_reg(self, x: Tensor) -> Tuple[Tensor]:
+ """Forward function for classification and regression parts.
+
+ Args:
+ x (Tensor): Input feature.
+
+ Returns:
+ tuple[Tensor]:
+
+ - cls_score (Tensor): classification prediction.
+ - bbox_pred (Tensor): bbox prediction.
+ """
+ x_cls = x
+ x_reg = x
+
+ for conv in self.cls_convs:
+ x_cls = conv(x_cls)
+ if x_cls.dim() > 2:
+ if self.with_avg_pool:
+ x_cls = self.avg_pool(x_cls)
+ x_cls = x_cls.flatten(1)
+ for fc in self.cls_fcs:
+ x_cls = self.relu(fc(x_cls))
+
+ for conv in self.reg_convs:
+ x_reg = conv(x_reg)
+ if x_reg.dim() > 2:
+ if self.with_avg_pool:
+ x_reg = self.avg_pool(x_reg)
+ x_reg = x_reg.flatten(1)
+ for fc in self.reg_fcs:
+ x_reg = self.relu(fc(x_reg))
+
+ cls_score = self.fc_cls(x_cls) if self.with_cls else None
+ bbox_pred = self.fc_reg(x_reg) if self.with_reg else None
+
+ return cls_score, bbox_pred
+
+ def forward(
+ self,
+ x: Tensor,
+ return_shared_feat: bool = False) -> Union[Tensor, Tuple[Tensor]]:
+ """Forward function.
+
+ Args:
+ x (Tensor): input features
+ return_shared_feat (bool): If True, return cls-reg-shared feature.
+
+ Return:
+ out (tuple[Tensor]): contain ``cls_score`` and ``bbox_pred``,
+ if ``return_shared_feat`` is True, append ``x_shared`` to the
+ returned tuple.
+ """
+ x_shared = self._forward_shared(x)
+ out = self._forward_cls_reg(x_shared)
+
+ if return_shared_feat:
+ out += (x_shared, )
+
+ return out
diff --git a/mmdet/models/roi_heads/cascade_roi_head.py b/mmdet/models/roi_heads/cascade_roi_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..81db671113a63beb7849abdc0e432a738ee46f5e
--- /dev/null
+++ b/mmdet/models/roi_heads/cascade_roi_head.py
@@ -0,0 +1,568 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Sequence, Tuple, Union
+
+import torch
+import torch.nn as nn
+from mmengine.model import ModuleList
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmdet.models.task_modules.samplers import SamplingResult
+from mmdet.models.test_time_augs import merge_aug_masks
+from mmdet.registry import MODELS, TASK_UTILS
+from mmdet.structures import SampleList
+from mmdet.structures.bbox import bbox2roi, get_box_tensor
+from mmdet.utils import (ConfigType, InstanceList, MultiConfig, OptConfigType,
+ OptMultiConfig)
+from ..utils.misc import empty_instances, unpack_gt_instances
+from .base_roi_head import BaseRoIHead
+
+
+@MODELS.register_module()
+class CascadeRoIHead(BaseRoIHead):
+ """Cascade roi head including one bbox head and one mask head.
+
+ https://arxiv.org/abs/1712.00726
+ """
+
+ def __init__(self,
+ num_stages: int,
+ stage_loss_weights: Union[List[float], Tuple[float]],
+ bbox_roi_extractor: OptMultiConfig = None,
+ bbox_head: OptMultiConfig = None,
+ mask_roi_extractor: OptMultiConfig = None,
+ mask_head: OptMultiConfig = None,
+ shared_head: OptConfigType = None,
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ init_cfg: OptMultiConfig = None) -> None:
+ assert bbox_roi_extractor is not None
+ assert bbox_head is not None
+ assert shared_head is None, \
+ 'Shared head is not supported in Cascade RCNN anymore'
+
+ self.num_stages = num_stages
+ self.stage_loss_weights = stage_loss_weights
+ super().__init__(
+ bbox_roi_extractor=bbox_roi_extractor,
+ bbox_head=bbox_head,
+ mask_roi_extractor=mask_roi_extractor,
+ mask_head=mask_head,
+ shared_head=shared_head,
+ train_cfg=train_cfg,
+ test_cfg=test_cfg,
+ init_cfg=init_cfg)
+
+ def init_bbox_head(self, bbox_roi_extractor: MultiConfig,
+ bbox_head: MultiConfig) -> None:
+ """Initialize box head and box roi extractor.
+
+ Args:
+ bbox_roi_extractor (:obj:`ConfigDict`, dict or list):
+ Config of box roi extractor.
+ bbox_head (:obj:`ConfigDict`, dict or list): Config
+ of box in box head.
+ """
+ self.bbox_roi_extractor = ModuleList()
+ self.bbox_head = ModuleList()
+ if not isinstance(bbox_roi_extractor, list):
+ bbox_roi_extractor = [
+ bbox_roi_extractor for _ in range(self.num_stages)
+ ]
+ if not isinstance(bbox_head, list):
+ bbox_head = [bbox_head for _ in range(self.num_stages)]
+ assert len(bbox_roi_extractor) == len(bbox_head) == self.num_stages
+ for roi_extractor, head in zip(bbox_roi_extractor, bbox_head):
+ self.bbox_roi_extractor.append(MODELS.build(roi_extractor))
+ self.bbox_head.append(MODELS.build(head))
+
+ def init_mask_head(self, mask_roi_extractor: MultiConfig,
+ mask_head: MultiConfig) -> None:
+ """Initialize mask head and mask roi extractor.
+
+ Args:
+ mask_head (dict): Config of mask in mask head.
+ mask_roi_extractor (:obj:`ConfigDict`, dict or list):
+ Config of mask roi extractor.
+ """
+ self.mask_head = nn.ModuleList()
+ if not isinstance(mask_head, list):
+ mask_head = [mask_head for _ in range(self.num_stages)]
+ assert len(mask_head) == self.num_stages
+ for head in mask_head:
+ self.mask_head.append(MODELS.build(head))
+ if mask_roi_extractor is not None:
+ self.share_roi_extractor = False
+ self.mask_roi_extractor = ModuleList()
+ if not isinstance(mask_roi_extractor, list):
+ mask_roi_extractor = [
+ mask_roi_extractor for _ in range(self.num_stages)
+ ]
+ assert len(mask_roi_extractor) == self.num_stages
+ for roi_extractor in mask_roi_extractor:
+ self.mask_roi_extractor.append(MODELS.build(roi_extractor))
+ else:
+ self.share_roi_extractor = True
+ self.mask_roi_extractor = self.bbox_roi_extractor
+
+ def init_assigner_sampler(self) -> None:
+ """Initialize assigner and sampler for each stage."""
+ self.bbox_assigner = []
+ self.bbox_sampler = []
+ if self.train_cfg is not None:
+ for idx, rcnn_train_cfg in enumerate(self.train_cfg):
+ self.bbox_assigner.append(
+ TASK_UTILS.build(rcnn_train_cfg.assigner))
+ self.current_stage = idx
+ self.bbox_sampler.append(
+ TASK_UTILS.build(
+ rcnn_train_cfg.sampler,
+ default_args=dict(context=self)))
+
+ def _bbox_forward(self, stage: int, x: Tuple[Tensor],
+ rois: Tensor) -> dict:
+ """Box head forward function used in both training and testing.
+
+ Args:
+ stage (int): The current stage in Cascade RoI Head.
+ x (tuple[Tensor]): List of multi-level img features.
+ rois (Tensor): RoIs with the shape (n, 5) where the first
+ column indicates batch id of each RoI.
+
+ Returns:
+ dict[str, Tensor]: Usually returns a dictionary with keys:
+
+ - `cls_score` (Tensor): Classification scores.
+ - `bbox_pred` (Tensor): Box energies / deltas.
+ - `bbox_feats` (Tensor): Extract bbox RoI features.
+ """
+ bbox_roi_extractor = self.bbox_roi_extractor[stage]
+ bbox_head = self.bbox_head[stage]
+ bbox_feats = bbox_roi_extractor(x[:bbox_roi_extractor.num_inputs],
+ rois)
+ # do not support caffe_c4 model anymore
+ cls_score, bbox_pred = bbox_head(bbox_feats)
+
+ bbox_results = dict(
+ cls_score=cls_score, bbox_pred=bbox_pred, bbox_feats=bbox_feats)
+ return bbox_results
+
+ def bbox_loss(self, stage: int, x: Tuple[Tensor],
+ sampling_results: List[SamplingResult]) -> dict:
+ """Run forward function and calculate loss for box head in training.
+
+ Args:
+ stage (int): The current stage in Cascade RoI Head.
+ x (tuple[Tensor]): List of multi-level img features.
+ sampling_results (list["obj:`SamplingResult`]): Sampling results.
+
+ Returns:
+ dict: Usually returns a dictionary with keys:
+
+ - `cls_score` (Tensor): Classification scores.
+ - `bbox_pred` (Tensor): Box energies / deltas.
+ - `bbox_feats` (Tensor): Extract bbox RoI features.
+ - `loss_bbox` (dict): A dictionary of bbox loss components.
+ - `rois` (Tensor): RoIs with the shape (n, 5) where the first
+ column indicates batch id of each RoI.
+ - `bbox_targets` (tuple): Ground truth for proposals in a
+ single image. Containing the following list of Tensors:
+ (labels, label_weights, bbox_targets, bbox_weights)
+ """
+ bbox_head = self.bbox_head[stage]
+ rois = bbox2roi([res.priors for res in sampling_results])
+ bbox_results = self._bbox_forward(stage, x, rois)
+ bbox_results.update(rois=rois)
+
+ bbox_loss_and_target = bbox_head.loss_and_target(
+ cls_score=bbox_results['cls_score'],
+ bbox_pred=bbox_results['bbox_pred'],
+ rois=rois,
+ sampling_results=sampling_results,
+ rcnn_train_cfg=self.train_cfg[stage])
+ bbox_results.update(bbox_loss_and_target)
+
+ return bbox_results
+
+ def _mask_forward(self, stage: int, x: Tuple[Tensor],
+ rois: Tensor) -> dict:
+ """Mask head forward function used in both training and testing.
+
+ Args:
+ stage (int): The current stage in Cascade RoI Head.
+ x (tuple[Tensor]): Tuple of multi-level img features.
+ rois (Tensor): RoIs with the shape (n, 5) where the first
+ column indicates batch id of each RoI.
+
+ Returns:
+ dict: Usually returns a dictionary with keys:
+
+ - `mask_preds` (Tensor): Mask prediction.
+ """
+ mask_roi_extractor = self.mask_roi_extractor[stage]
+ mask_head = self.mask_head[stage]
+ mask_feats = mask_roi_extractor(x[:mask_roi_extractor.num_inputs],
+ rois)
+ # do not support caffe_c4 model anymore
+ mask_preds = mask_head(mask_feats)
+
+ mask_results = dict(mask_preds=mask_preds)
+ return mask_results
+
+ def mask_loss(self, stage: int, x: Tuple[Tensor],
+ sampling_results: List[SamplingResult],
+ batch_gt_instances: InstanceList) -> dict:
+ """Run forward function and calculate loss for mask head in training.
+
+ Args:
+ stage (int): The current stage in Cascade RoI Head.
+ x (tuple[Tensor]): Tuple of multi-level img features.
+ sampling_results (list["obj:`SamplingResult`]): Sampling results.
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes``, ``labels``, and
+ ``masks`` attributes.
+
+ Returns:
+ dict: Usually returns a dictionary with keys:
+
+ - `mask_preds` (Tensor): Mask prediction.
+ - `loss_mask` (dict): A dictionary of mask loss components.
+ """
+ pos_rois = bbox2roi([res.pos_priors for res in sampling_results])
+ mask_results = self._mask_forward(stage, x, pos_rois)
+
+ mask_head = self.mask_head[stage]
+
+ mask_loss_and_target = mask_head.loss_and_target(
+ mask_preds=mask_results['mask_preds'],
+ sampling_results=sampling_results,
+ batch_gt_instances=batch_gt_instances,
+ rcnn_train_cfg=self.train_cfg[stage])
+ mask_results.update(mask_loss_and_target)
+
+ return mask_results
+
+ def loss(self, x: Tuple[Tensor], rpn_results_list: InstanceList,
+ batch_data_samples: SampleList) -> dict:
+ """Perform forward propagation and loss calculation of the detection
+ roi on the features of the upstream network.
+
+ Args:
+ x (tuple[Tensor]): List of multi-level img features.
+ rpn_results_list (list[:obj:`InstanceData`]): List of region
+ proposals.
+ batch_data_samples (list[:obj:`DetDataSample`]): The batch
+ data samples. It usually includes information such
+ as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components
+ """
+ # TODO: May add a new function in baseroihead
+ assert len(rpn_results_list) == len(batch_data_samples)
+ outputs = unpack_gt_instances(batch_data_samples)
+ batch_gt_instances, batch_gt_instances_ignore, batch_img_metas \
+ = outputs
+
+ num_imgs = len(batch_data_samples)
+ losses = dict()
+ results_list = rpn_results_list
+ for stage in range(self.num_stages):
+ self.current_stage = stage
+
+ stage_loss_weight = self.stage_loss_weights[stage]
+
+ # assign gts and sample proposals
+ sampling_results = []
+ if self.with_bbox or self.with_mask:
+ bbox_assigner = self.bbox_assigner[stage]
+ bbox_sampler = self.bbox_sampler[stage]
+
+ for i in range(num_imgs):
+ results = results_list[i]
+ # rename rpn_results.bboxes to rpn_results.priors
+ results.priors = results.pop('bboxes')
+
+ assign_result = bbox_assigner.assign(
+ results, batch_gt_instances[i],
+ batch_gt_instances_ignore[i])
+
+ sampling_result = bbox_sampler.sample(
+ assign_result,
+ results,
+ batch_gt_instances[i],
+ feats=[lvl_feat[i][None] for lvl_feat in x])
+ sampling_results.append(sampling_result)
+
+ # bbox head forward and loss
+ bbox_results = self.bbox_loss(stage, x, sampling_results)
+
+ for name, value in bbox_results['loss_bbox'].items():
+ losses[f's{stage}.{name}'] = (
+ value * stage_loss_weight if 'loss' in name else value)
+
+ # mask head forward and loss
+ if self.with_mask:
+ mask_results = self.mask_loss(stage, x, sampling_results,
+ batch_gt_instances)
+ for name, value in mask_results['loss_mask'].items():
+ losses[f's{stage}.{name}'] = (
+ value * stage_loss_weight if 'loss' in name else value)
+
+ # refine bboxes
+ if stage < self.num_stages - 1:
+ bbox_head = self.bbox_head[stage]
+ with torch.no_grad():
+ results_list = bbox_head.refine_bboxes(
+ sampling_results, bbox_results, batch_img_metas)
+ # Empty proposal
+ if results_list is None:
+ break
+ return losses
+
+ def predict_bbox(self,
+ x: Tuple[Tensor],
+ batch_img_metas: List[dict],
+ rpn_results_list: InstanceList,
+ rcnn_test_cfg: ConfigType,
+ rescale: bool = False,
+ **kwargs) -> InstanceList:
+ """Perform forward propagation of the bbox head and predict detection
+ results on the features of the upstream network.
+
+ Args:
+ x (tuple[Tensor]): Feature maps of all scale level.
+ batch_img_metas (list[dict]): List of image information.
+ rpn_results_list (list[:obj:`InstanceData`]): List of region
+ proposals.
+ rcnn_test_cfg (obj:`ConfigDict`): `test_cfg` of R-CNN.
+ rescale (bool): If True, return boxes in original image space.
+ Defaults to False.
+
+ Returns:
+ list[:obj:`InstanceData`]: Detection results of each image
+ after the post process.
+ Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ """
+ proposals = [res.bboxes for res in rpn_results_list]
+ num_proposals_per_img = tuple(len(p) for p in proposals)
+ rois = bbox2roi(proposals)
+
+ if rois.shape[0] == 0:
+ return empty_instances(
+ batch_img_metas,
+ rois.device,
+ task_type='bbox',
+ box_type=self.bbox_head[-1].predict_box_type,
+ num_classes=self.bbox_head[-1].num_classes,
+ score_per_cls=rcnn_test_cfg is None)
+
+ rois, cls_scores, bbox_preds = self._refine_roi(
+ x=x,
+ rois=rois,
+ batch_img_metas=batch_img_metas,
+ num_proposals_per_img=num_proposals_per_img,
+ **kwargs)
+
+ results_list = self.bbox_head[-1].predict_by_feat(
+ rois=rois,
+ cls_scores=cls_scores,
+ bbox_preds=bbox_preds,
+ batch_img_metas=batch_img_metas,
+ rescale=rescale,
+ rcnn_test_cfg=rcnn_test_cfg)
+ return results_list
+
+ def predict_mask(self,
+ x: Tuple[Tensor],
+ batch_img_metas: List[dict],
+ results_list: List[InstanceData],
+ rescale: bool = False) -> List[InstanceData]:
+ """Perform forward propagation of the mask head and predict detection
+ results on the features of the upstream network.
+
+ Args:
+ x (tuple[Tensor]): Feature maps of all scale level.
+ batch_img_metas (list[dict]): List of image information.
+ results_list (list[:obj:`InstanceData`]): Detection results of
+ each image.
+ rescale (bool): If True, return boxes in original image space.
+ Defaults to False.
+
+ Returns:
+ list[:obj:`InstanceData`]: Detection results of each image
+ after the post process.
+ Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ - masks (Tensor): Has a shape (num_instances, H, W).
+ """
+ bboxes = [res.bboxes for res in results_list]
+ mask_rois = bbox2roi(bboxes)
+ if mask_rois.shape[0] == 0:
+ results_list = empty_instances(
+ batch_img_metas,
+ mask_rois.device,
+ task_type='mask',
+ instance_results=results_list,
+ mask_thr_binary=self.test_cfg.mask_thr_binary)
+ return results_list
+
+ num_mask_rois_per_img = [len(res) for res in results_list]
+ aug_masks = []
+ for stage in range(self.num_stages):
+ mask_results = self._mask_forward(stage, x, mask_rois)
+ mask_preds = mask_results['mask_preds']
+ # split batch mask prediction back to each image
+ mask_preds = mask_preds.split(num_mask_rois_per_img, 0)
+ aug_masks.append([m.sigmoid().detach() for m in mask_preds])
+
+ merged_masks = []
+ for i in range(len(batch_img_metas)):
+ aug_mask = [mask[i] for mask in aug_masks]
+ merged_mask = merge_aug_masks(aug_mask, batch_img_metas[i])
+ merged_masks.append(merged_mask)
+ results_list = self.mask_head[-1].predict_by_feat(
+ mask_preds=merged_masks,
+ results_list=results_list,
+ batch_img_metas=batch_img_metas,
+ rcnn_test_cfg=self.test_cfg,
+ rescale=rescale,
+ activate_map=True)
+ return results_list
+
+ def _refine_roi(self, x: Tuple[Tensor], rois: Tensor,
+ batch_img_metas: List[dict],
+ num_proposals_per_img: Sequence[int], **kwargs) -> tuple:
+ """Multi-stage refinement of RoI.
+
+ Args:
+ x (tuple[Tensor]): List of multi-level img features.
+ rois (Tensor): shape (n, 5), [batch_ind, x1, y1, x2, y2]
+ batch_img_metas (list[dict]): List of image information.
+ num_proposals_per_img (sequence[int]): number of proposals
+ in each image.
+
+ Returns:
+ tuple:
+
+ - rois (Tensor): Refined RoI.
+ - cls_scores (list[Tensor]): Average predicted
+ cls score per image.
+ - bbox_preds (list[Tensor]): Bbox branch predictions
+ for the last stage of per image.
+ """
+ # "ms" in variable names means multi-stage
+ ms_scores = []
+ for stage in range(self.num_stages):
+ bbox_results = self._bbox_forward(
+ stage=stage, x=x, rois=rois, **kwargs)
+
+ # split batch bbox prediction back to each image
+ cls_scores = bbox_results['cls_score']
+ bbox_preds = bbox_results['bbox_pred']
+
+ rois = rois.split(num_proposals_per_img, 0)
+ cls_scores = cls_scores.split(num_proposals_per_img, 0)
+ ms_scores.append(cls_scores)
+
+ # some detector with_reg is False, bbox_preds will be None
+ if bbox_preds is not None:
+ # TODO move this to a sabl_roi_head
+ # the bbox prediction of some detectors like SABL is not Tensor
+ if isinstance(bbox_preds, torch.Tensor):
+ bbox_preds = bbox_preds.split(num_proposals_per_img, 0)
+ else:
+ bbox_preds = self.bbox_head[stage].bbox_pred_split(
+ bbox_preds, num_proposals_per_img)
+ else:
+ bbox_preds = (None, ) * len(batch_img_metas)
+
+ if stage < self.num_stages - 1:
+ bbox_head = self.bbox_head[stage]
+ if bbox_head.custom_activation:
+ cls_scores = [
+ bbox_head.loss_cls.get_activation(s)
+ for s in cls_scores
+ ]
+ refine_rois_list = []
+ for i in range(len(batch_img_metas)):
+ if rois[i].shape[0] > 0:
+ bbox_label = cls_scores[i][:, :-1].argmax(dim=1)
+ # Refactor `bbox_head.regress_by_class` to only accept
+ # box tensor without img_idx concatenated.
+ refined_bboxes = bbox_head.regress_by_class(
+ rois[i][:, 1:], bbox_label, bbox_preds[i],
+ batch_img_metas[i])
+ refined_bboxes = get_box_tensor(refined_bboxes)
+ refined_rois = torch.cat(
+ [rois[i][:, [0]], refined_bboxes], dim=1)
+ refine_rois_list.append(refined_rois)
+ rois = torch.cat(refine_rois_list)
+
+ # average scores of each image by stages
+ cls_scores = [
+ sum([score[i] for score in ms_scores]) / float(len(ms_scores))
+ for i in range(len(batch_img_metas))
+ ]
+ return rois, cls_scores, bbox_preds
+
+ def forward(self, x: Tuple[Tensor], rpn_results_list: InstanceList,
+ batch_data_samples: SampleList) -> tuple:
+ """Network forward process. Usually includes backbone, neck and head
+ forward without any post-processing.
+
+ Args:
+ x (List[Tensor]): Multi-level features that may have different
+ resolutions.
+ rpn_results_list (list[:obj:`InstanceData`]): List of region
+ proposals.
+ batch_data_samples (list[:obj:`DetDataSample`]): Each item contains
+ the meta information of each image and corresponding
+ annotations.
+
+ Returns
+ tuple: A tuple of features from ``bbox_head`` and ``mask_head``
+ forward.
+ """
+ results = ()
+ batch_img_metas = [
+ data_samples.metainfo for data_samples in batch_data_samples
+ ]
+ proposals = [rpn_results.bboxes for rpn_results in rpn_results_list]
+ num_proposals_per_img = tuple(len(p) for p in proposals)
+ rois = bbox2roi(proposals)
+ # bbox head
+ if self.with_bbox:
+ rois, cls_scores, bbox_preds = self._refine_roi(
+ x, rois, batch_img_metas, num_proposals_per_img)
+ results = results + (cls_scores, bbox_preds)
+ # mask head
+ if self.with_mask:
+ aug_masks = []
+ rois = torch.cat(rois)
+ for stage in range(self.num_stages):
+ mask_results = self._mask_forward(stage, x, rois)
+ mask_preds = mask_results['mask_preds']
+ mask_preds = mask_preds.split(num_proposals_per_img, 0)
+ aug_masks.append([m.sigmoid().detach() for m in mask_preds])
+
+ merged_masks = []
+ for i in range(len(batch_img_metas)):
+ aug_mask = [mask[i] for mask in aug_masks]
+ merged_mask = merge_aug_masks(aug_mask, batch_img_metas[i])
+ merged_masks.append(merged_mask)
+ results = results + (merged_masks, )
+ return results
diff --git a/mmdet/models/roi_heads/double_roi_head.py b/mmdet/models/roi_heads/double_roi_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..f9464ff55bafcca9f3545a3a72dde1eb3939cece
--- /dev/null
+++ b/mmdet/models/roi_heads/double_roi_head.py
@@ -0,0 +1,53 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Tuple
+
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from .standard_roi_head import StandardRoIHead
+
+
+@MODELS.register_module()
+class DoubleHeadRoIHead(StandardRoIHead):
+ """RoI head for `Double Head RCNN `_.
+
+ Args:
+ reg_roi_scale_factor (float): The scale factor to extend the rois
+ used to extract the regression features.
+ """
+
+ def __init__(self, reg_roi_scale_factor: float, **kwargs):
+ super().__init__(**kwargs)
+ self.reg_roi_scale_factor = reg_roi_scale_factor
+
+ def _bbox_forward(self, x: Tuple[Tensor], rois: Tensor) -> dict:
+ """Box head forward function used in both training and testing.
+
+ Args:
+ x (tuple[Tensor]): List of multi-level img features.
+ rois (Tensor): RoIs with the shape (n, 5) where the first
+ column indicates batch id of each RoI.
+
+ Returns:
+ dict[str, Tensor]: Usually returns a dictionary with keys:
+
+ - `cls_score` (Tensor): Classification scores.
+ - `bbox_pred` (Tensor): Box energies / deltas.
+ - `bbox_feats` (Tensor): Extract bbox RoI features.
+ """
+ bbox_cls_feats = self.bbox_roi_extractor(
+ x[:self.bbox_roi_extractor.num_inputs], rois)
+ bbox_reg_feats = self.bbox_roi_extractor(
+ x[:self.bbox_roi_extractor.num_inputs],
+ rois,
+ roi_scale_factor=self.reg_roi_scale_factor)
+ if self.with_shared_head:
+ bbox_cls_feats = self.shared_head(bbox_cls_feats)
+ bbox_reg_feats = self.shared_head(bbox_reg_feats)
+ cls_score, bbox_pred = self.bbox_head(bbox_cls_feats, bbox_reg_feats)
+
+ bbox_results = dict(
+ cls_score=cls_score,
+ bbox_pred=bbox_pred,
+ bbox_feats=bbox_cls_feats)
+ return bbox_results
diff --git a/mmdet/models/roi_heads/dynamic_roi_head.py b/mmdet/models/roi_heads/dynamic_roi_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..3c7f7bd2f68cab0fcdec725501f74b65274eb30e
--- /dev/null
+++ b/mmdet/models/roi_heads/dynamic_roi_head.py
@@ -0,0 +1,163 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Tuple
+
+import numpy as np
+import torch
+from torch import Tensor
+
+from mmdet.models.losses import SmoothL1Loss
+from mmdet.models.task_modules.samplers import SamplingResult
+from mmdet.registry import MODELS
+from mmdet.structures import SampleList
+from mmdet.structures.bbox import bbox2roi
+from mmdet.utils import InstanceList
+from ..utils.misc import unpack_gt_instances
+from .standard_roi_head import StandardRoIHead
+
+EPS = 1e-15
+
+
+@MODELS.register_module()
+class DynamicRoIHead(StandardRoIHead):
+ """RoI head for `Dynamic R-CNN `_."""
+
+ def __init__(self, **kwargs) -> None:
+ super().__init__(**kwargs)
+ assert isinstance(self.bbox_head.loss_bbox, SmoothL1Loss)
+ # the IoU history of the past `update_iter_interval` iterations
+ self.iou_history = []
+ # the beta history of the past `update_iter_interval` iterations
+ self.beta_history = []
+
+ def loss(self, x: Tuple[Tensor], rpn_results_list: InstanceList,
+ batch_data_samples: SampleList) -> dict:
+ """Forward function for training.
+
+ Args:
+ x (tuple[Tensor]): List of multi-level img features.
+ rpn_results_list (list[:obj:`InstanceData`]): List of region
+ proposals.
+ batch_data_samples (list[:obj:`DetDataSample`]): The batch
+ data samples. It usually includes information such
+ as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
+
+ Returns:
+ dict[str, Tensor]: a dictionary of loss components
+ """
+ assert len(rpn_results_list) == len(batch_data_samples)
+ outputs = unpack_gt_instances(batch_data_samples)
+ batch_gt_instances, batch_gt_instances_ignore, _ = outputs
+
+ # assign gts and sample proposals
+ num_imgs = len(batch_data_samples)
+ sampling_results = []
+ cur_iou = []
+ for i in range(num_imgs):
+ # rename rpn_results.bboxes to rpn_results.priors
+ rpn_results = rpn_results_list[i]
+ rpn_results.priors = rpn_results.pop('bboxes')
+
+ assign_result = self.bbox_assigner.assign(
+ rpn_results, batch_gt_instances[i],
+ batch_gt_instances_ignore[i])
+ sampling_result = self.bbox_sampler.sample(
+ assign_result,
+ rpn_results,
+ batch_gt_instances[i],
+ feats=[lvl_feat[i][None] for lvl_feat in x])
+ # record the `iou_topk`-th largest IoU in an image
+ iou_topk = min(self.train_cfg.dynamic_rcnn.iou_topk,
+ len(assign_result.max_overlaps))
+ ious, _ = torch.topk(assign_result.max_overlaps, iou_topk)
+ cur_iou.append(ious[-1].item())
+ sampling_results.append(sampling_result)
+ # average the current IoUs over images
+ cur_iou = np.mean(cur_iou)
+ self.iou_history.append(cur_iou)
+
+ losses = dict()
+ # bbox head forward and loss
+ if self.with_bbox:
+ bbox_results = self.bbox_loss(x, sampling_results)
+ losses.update(bbox_results['loss_bbox'])
+
+ # mask head forward and loss
+ if self.with_mask:
+ mask_results = self.mask_loss(x, sampling_results,
+ bbox_results['bbox_feats'],
+ batch_gt_instances)
+ losses.update(mask_results['loss_mask'])
+
+ # update IoU threshold and SmoothL1 beta
+ update_iter_interval = self.train_cfg.dynamic_rcnn.update_iter_interval
+ if len(self.iou_history) % update_iter_interval == 0:
+ new_iou_thr, new_beta = self.update_hyperparameters()
+
+ return losses
+
+ def bbox_loss(self, x: Tuple[Tensor],
+ sampling_results: List[SamplingResult]) -> dict:
+ """Perform forward propagation and loss calculation of the bbox head on
+ the features of the upstream network.
+
+ Args:
+ x (tuple[Tensor]): List of multi-level img features.
+ sampling_results (list["obj:`SamplingResult`]): Sampling results.
+
+ Returns:
+ dict[str, Tensor]: Usually returns a dictionary with keys:
+
+ - `cls_score` (Tensor): Classification scores.
+ - `bbox_pred` (Tensor): Box energies / deltas.
+ - `bbox_feats` (Tensor): Extract bbox RoI features.
+ - `loss_bbox` (dict): A dictionary of bbox loss components.
+ """
+ rois = bbox2roi([res.priors for res in sampling_results])
+ bbox_results = self._bbox_forward(x, rois)
+
+ bbox_loss_and_target = self.bbox_head.loss_and_target(
+ cls_score=bbox_results['cls_score'],
+ bbox_pred=bbox_results['bbox_pred'],
+ rois=rois,
+ sampling_results=sampling_results,
+ rcnn_train_cfg=self.train_cfg)
+ bbox_results.update(loss_bbox=bbox_loss_and_target['loss_bbox'])
+
+ # record the `beta_topk`-th smallest target
+ # `bbox_targets[2]` and `bbox_targets[3]` stand for bbox_targets
+ # and bbox_weights, respectively
+ bbox_targets = bbox_loss_and_target['bbox_targets']
+ pos_inds = bbox_targets[3][:, 0].nonzero().squeeze(1)
+ num_pos = len(pos_inds)
+ num_imgs = len(sampling_results)
+ if num_pos > 0:
+ cur_target = bbox_targets[2][pos_inds, :2].abs().mean(dim=1)
+ beta_topk = min(self.train_cfg.dynamic_rcnn.beta_topk * num_imgs,
+ num_pos)
+ cur_target = torch.kthvalue(cur_target, beta_topk)[0].item()
+ self.beta_history.append(cur_target)
+
+ return bbox_results
+
+ def update_hyperparameters(self):
+ """Update hyperparameters like IoU thresholds for assigner and beta for
+ SmoothL1 loss based on the training statistics.
+
+ Returns:
+ tuple[float]: the updated ``iou_thr`` and ``beta``.
+ """
+ new_iou_thr = max(self.train_cfg.dynamic_rcnn.initial_iou,
+ np.mean(self.iou_history))
+ self.iou_history = []
+ self.bbox_assigner.pos_iou_thr = new_iou_thr
+ self.bbox_assigner.neg_iou_thr = new_iou_thr
+ self.bbox_assigner.min_pos_iou = new_iou_thr
+ if (not self.beta_history) or (np.median(self.beta_history) < EPS):
+ # avoid 0 or too small value for new_beta
+ new_beta = self.bbox_head.loss_bbox.beta
+ else:
+ new_beta = min(self.train_cfg.dynamic_rcnn.initial_beta,
+ np.median(self.beta_history))
+ self.beta_history = []
+ self.bbox_head.loss_bbox.beta = new_beta
+ return new_iou_thr, new_beta
diff --git a/mmdet/models/roi_heads/grid_roi_head.py b/mmdet/models/roi_heads/grid_roi_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..9eda7f01bcd4e44faca14b61ec4956ee2c372ad6
--- /dev/null
+++ b/mmdet/models/roi_heads/grid_roi_head.py
@@ -0,0 +1,280 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Optional, Tuple
+
+import torch
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.structures import SampleList
+from mmdet.structures.bbox import bbox2roi
+from mmdet.utils import ConfigType, InstanceList
+from ..task_modules.samplers import SamplingResult
+from ..utils.misc import unpack_gt_instances
+from .standard_roi_head import StandardRoIHead
+
+
+@MODELS.register_module()
+class GridRoIHead(StandardRoIHead):
+ """Implementation of `Grid RoI Head `_
+
+ Args:
+ grid_roi_extractor (:obj:`ConfigDict` or dict): Config of
+ roi extractor.
+ grid_head (:obj:`ConfigDict` or dict): Config of grid head
+ """
+
+ def __init__(self, grid_roi_extractor: ConfigType, grid_head: ConfigType,
+ **kwargs) -> None:
+ assert grid_head is not None
+ super().__init__(**kwargs)
+ if grid_roi_extractor is not None:
+ self.grid_roi_extractor = MODELS.build(grid_roi_extractor)
+ self.share_roi_extractor = False
+ else:
+ self.share_roi_extractor = True
+ self.grid_roi_extractor = self.bbox_roi_extractor
+ self.grid_head = MODELS.build(grid_head)
+
+ def _random_jitter(self,
+ sampling_results: List[SamplingResult],
+ batch_img_metas: List[dict],
+ amplitude: float = 0.15) -> List[SamplingResult]:
+ """Ramdom jitter positive proposals for training.
+
+ Args:
+ sampling_results (List[obj:SamplingResult]): Assign results of
+ all images in a batch after sampling.
+ batch_img_metas (list[dict]): List of image information.
+ amplitude (float): Amplitude of random offset. Defaults to 0.15.
+
+ Returns:
+ list[obj:SamplingResult]: SamplingResults after random jittering.
+ """
+ for sampling_result, img_meta in zip(sampling_results,
+ batch_img_metas):
+ bboxes = sampling_result.pos_priors
+ random_offsets = bboxes.new_empty(bboxes.shape[0], 4).uniform_(
+ -amplitude, amplitude)
+ # before jittering
+ cxcy = (bboxes[:, 2:4] + bboxes[:, :2]) / 2
+ wh = (bboxes[:, 2:4] - bboxes[:, :2]).abs()
+ # after jittering
+ new_cxcy = cxcy + wh * random_offsets[:, :2]
+ new_wh = wh * (1 + random_offsets[:, 2:])
+ # xywh to xyxy
+ new_x1y1 = (new_cxcy - new_wh / 2)
+ new_x2y2 = (new_cxcy + new_wh / 2)
+ new_bboxes = torch.cat([new_x1y1, new_x2y2], dim=1)
+ # clip bboxes
+ max_shape = img_meta['img_shape']
+ if max_shape is not None:
+ new_bboxes[:, 0::2].clamp_(min=0, max=max_shape[1] - 1)
+ new_bboxes[:, 1::2].clamp_(min=0, max=max_shape[0] - 1)
+
+ sampling_result.pos_priors = new_bboxes
+ return sampling_results
+
+ # TODO: Forward is incorrect and need to refactor.
+ def forward(self,
+ x: Tuple[Tensor],
+ rpn_results_list: InstanceList,
+ batch_data_samples: SampleList = None) -> tuple:
+ """Network forward process. Usually includes backbone, neck and head
+ forward without any post-processing.
+
+ Args:
+ x (Tuple[Tensor]): Multi-level features that may have different
+ resolutions.
+ rpn_results_list (list[:obj:`InstanceData`]): List of region
+ proposals.
+ batch_data_samples (list[:obj:`DetDataSample`]): Each item contains
+ the meta information of each image and corresponding
+ annotations.
+
+ Returns
+ tuple: A tuple of features from ``bbox_head`` and ``mask_head``
+ forward.
+ """
+ results = ()
+ proposals = [rpn_results.bboxes for rpn_results in rpn_results_list]
+ rois = bbox2roi(proposals)
+ # bbox head
+ if self.with_bbox:
+ bbox_results = self._bbox_forward(x, rois)
+ results = results + (bbox_results['cls_score'], )
+ if self.bbox_head.with_reg:
+ results = results + (bbox_results['bbox_pred'], )
+
+ # grid head
+ grid_rois = rois[:100]
+ grid_feats = self.grid_roi_extractor(
+ x[:len(self.grid_roi_extractor.featmap_strides)], grid_rois)
+ if self.with_shared_head:
+ grid_feats = self.shared_head(grid_feats)
+ self.grid_head.test_mode = True
+ grid_preds = self.grid_head(grid_feats)
+ results = results + (grid_preds, )
+
+ # mask head
+ if self.with_mask:
+ mask_rois = rois[:100]
+ mask_results = self._mask_forward(x, mask_rois)
+ results = results + (mask_results['mask_preds'], )
+ return results
+
+ def loss(self, x: Tuple[Tensor], rpn_results_list: InstanceList,
+ batch_data_samples: SampleList, **kwargs) -> dict:
+ """Perform forward propagation and loss calculation of the detection
+ roi on the features of the upstream network.
+
+ Args:
+ x (tuple[Tensor]): List of multi-level img features.
+ rpn_results_list (list[:obj:`InstanceData`]): List of region
+ proposals.
+ batch_data_samples (list[:obj:`DetDataSample`]): The batch
+ data samples. It usually includes information such
+ as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components
+ """
+ assert len(rpn_results_list) == len(batch_data_samples)
+ outputs = unpack_gt_instances(batch_data_samples)
+ (batch_gt_instances, batch_gt_instances_ignore,
+ batch_img_metas) = outputs
+
+ # assign gts and sample proposals
+ num_imgs = len(batch_data_samples)
+ sampling_results = []
+ for i in range(num_imgs):
+ # rename rpn_results.bboxes to rpn_results.priors
+ rpn_results = rpn_results_list[i]
+ rpn_results.priors = rpn_results.pop('bboxes')
+
+ assign_result = self.bbox_assigner.assign(
+ rpn_results, batch_gt_instances[i],
+ batch_gt_instances_ignore[i])
+ sampling_result = self.bbox_sampler.sample(
+ assign_result,
+ rpn_results,
+ batch_gt_instances[i],
+ feats=[lvl_feat[i][None] for lvl_feat in x])
+ sampling_results.append(sampling_result)
+
+ losses = dict()
+ # bbox head loss
+ if self.with_bbox:
+ bbox_results = self.bbox_loss(x, sampling_results, batch_img_metas)
+ losses.update(bbox_results['loss_bbox'])
+
+ # mask head forward and loss
+ if self.with_mask:
+ mask_results = self.mask_loss(x, sampling_results,
+ bbox_results['bbox_feats'],
+ batch_gt_instances)
+ losses.update(mask_results['loss_mask'])
+
+ return losses
+
+ def bbox_loss(self,
+ x: Tuple[Tensor],
+ sampling_results: List[SamplingResult],
+ batch_img_metas: Optional[List[dict]] = None) -> dict:
+ """Perform forward propagation and loss calculation of the bbox head on
+ the features of the upstream network.
+
+ Args:
+ x (tuple[Tensor]): List of multi-level img features.
+ sampling_results (list[:obj:`SamplingResult`]): Sampling results.
+ batch_img_metas (list[dict], optional): Meta information of each
+ image, e.g., image size, scaling factor, etc.
+
+ Returns:
+ dict[str, Tensor]: Usually returns a dictionary with keys:
+
+ - `cls_score` (Tensor): Classification scores.
+ - `bbox_pred` (Tensor): Box energies / deltas.
+ - `bbox_feats` (Tensor): Extract bbox RoI features.
+ - `loss_bbox` (dict): A dictionary of bbox loss components.
+ """
+ assert batch_img_metas is not None
+ bbox_results = super().bbox_loss(x, sampling_results)
+
+ # Grid head forward and loss
+ sampling_results = self._random_jitter(sampling_results,
+ batch_img_metas)
+ pos_rois = bbox2roi([res.pos_bboxes for res in sampling_results])
+
+ # GN in head does not support zero shape input
+ if pos_rois.shape[0] == 0:
+ return bbox_results
+
+ grid_feats = self.grid_roi_extractor(
+ x[:self.grid_roi_extractor.num_inputs], pos_rois)
+ if self.with_shared_head:
+ grid_feats = self.shared_head(grid_feats)
+ # Accelerate training
+ max_sample_num_grid = self.train_cfg.get('max_num_grid', 192)
+ sample_idx = torch.randperm(
+ grid_feats.shape[0])[:min(grid_feats.shape[0], max_sample_num_grid
+ )]
+ grid_feats = grid_feats[sample_idx]
+ grid_pred = self.grid_head(grid_feats)
+
+ loss_grid = self.grid_head.loss(grid_pred, sample_idx,
+ sampling_results, self.train_cfg)
+
+ bbox_results['loss_bbox'].update(loss_grid)
+ return bbox_results
+
+ def predict_bbox(self,
+ x: Tuple[Tensor],
+ batch_img_metas: List[dict],
+ rpn_results_list: InstanceList,
+ rcnn_test_cfg: ConfigType,
+ rescale: bool = False) -> InstanceList:
+ """Perform forward propagation of the bbox head and predict detection
+ results on the features of the upstream network.
+
+ Args:
+ x (tuple[Tensor]): Feature maps of all scale level.
+ batch_img_metas (list[dict]): List of image information.
+ rpn_results_list (list[:obj:`InstanceData`]): List of region
+ proposals.
+ rcnn_test_cfg (:obj:`ConfigDict`): `test_cfg` of R-CNN.
+ rescale (bool): If True, return boxes in original image space.
+ Defaults to False.
+
+ Returns:
+ list[:obj:`InstanceData`]: Detection results of each image
+ after the post process.
+ Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape \
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4), the last \
+ dimension 4 arrange as (x1, y1, x2, y2).
+ """
+ results_list = super().predict_bbox(
+ x,
+ batch_img_metas=batch_img_metas,
+ rpn_results_list=rpn_results_list,
+ rcnn_test_cfg=rcnn_test_cfg,
+ rescale=False)
+
+ grid_rois = bbox2roi([res.bboxes for res in results_list])
+ if grid_rois.shape[0] != 0:
+ grid_feats = self.grid_roi_extractor(
+ x[:len(self.grid_roi_extractor.featmap_strides)], grid_rois)
+ if self.with_shared_head:
+ grid_feats = self.shared_head(grid_feats)
+ self.grid_head.test_mode = True
+ grid_preds = self.grid_head(grid_feats)
+ results_list = self.grid_head.predict_by_feat(
+ grid_preds=grid_preds,
+ results_list=results_list,
+ batch_img_metas=batch_img_metas,
+ rescale=rescale)
+
+ return results_list
diff --git a/mmdet/models/roi_heads/htc_roi_head.py b/mmdet/models/roi_heads/htc_roi_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..0fdd99ddd5ce4d9d42345d1f1d14ecbcae658124
--- /dev/null
+++ b/mmdet/models/roi_heads/htc_roi_head.py
@@ -0,0 +1,581 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Optional, Tuple
+
+import torch
+import torch.nn.functional as F
+from torch import Tensor
+
+from mmdet.models.test_time_augs import merge_aug_masks
+from mmdet.registry import MODELS
+from mmdet.structures import SampleList
+from mmdet.structures.bbox import bbox2roi
+from mmdet.utils import InstanceList, OptConfigType
+from ..layers import adaptive_avg_pool2d
+from ..task_modules.samplers import SamplingResult
+from ..utils import empty_instances, unpack_gt_instances
+from .cascade_roi_head import CascadeRoIHead
+
+
+@MODELS.register_module()
+class HybridTaskCascadeRoIHead(CascadeRoIHead):
+ """Hybrid task cascade roi head including one bbox head and one mask head.
+
+ https://arxiv.org/abs/1901.07518
+
+ Args:
+ num_stages (int): Number of cascade stages.
+ stage_loss_weights (list[float]): Loss weight for every stage.
+ semantic_roi_extractor (:obj:`ConfigDict` or dict, optional):
+ Config of semantic roi extractor. Defaults to None.
+ Semantic_head (:obj:`ConfigDict` or dict, optional):
+ Config of semantic head. Defaults to None.
+ interleaved (bool): Whether to interleaves the box branch and mask
+ branch. If True, the mask branch can take the refined bounding
+ box predictions. Defaults to True.
+ mask_info_flow (bool): Whether to turn on the mask information flow,
+ which means that feeding the mask features of the preceding stage
+ to the current stage. Defaults to True.
+ """
+
+ def __init__(self,
+ num_stages: int,
+ stage_loss_weights: List[float],
+ semantic_roi_extractor: OptConfigType = None,
+ semantic_head: OptConfigType = None,
+ semantic_fusion: Tuple[str] = ('bbox', 'mask'),
+ interleaved: bool = True,
+ mask_info_flow: bool = True,
+ **kwargs) -> None:
+ super().__init__(
+ num_stages=num_stages,
+ stage_loss_weights=stage_loss_weights,
+ **kwargs)
+ assert self.with_bbox
+ assert not self.with_shared_head # shared head is not supported
+
+ if semantic_head is not None:
+ self.semantic_roi_extractor = MODELS.build(semantic_roi_extractor)
+ self.semantic_head = MODELS.build(semantic_head)
+
+ self.semantic_fusion = semantic_fusion
+ self.interleaved = interleaved
+ self.mask_info_flow = mask_info_flow
+
+ # TODO move to base_roi_head later
+ @property
+ def with_semantic(self) -> bool:
+ """bool: whether the head has semantic head"""
+ return hasattr(self,
+ 'semantic_head') and self.semantic_head is not None
+
+ def _bbox_forward(
+ self,
+ stage: int,
+ x: Tuple[Tensor],
+ rois: Tensor,
+ semantic_feat: Optional[Tensor] = None) -> Dict[str, Tensor]:
+ """Box head forward function used in both training and testing.
+
+ Args:
+ stage (int): The current stage in Cascade RoI Head.
+ x (tuple[Tensor]): List of multi-level img features.
+ rois (Tensor): RoIs with the shape (n, 5) where the first
+ column indicates batch id of each RoI.
+ semantic_feat (Tensor, optional): Semantic feature. Defaults to
+ None.
+
+ Returns:
+ dict[str, Tensor]: Usually returns a dictionary with keys:
+
+ - `cls_score` (Tensor): Classification scores.
+ - `bbox_pred` (Tensor): Box energies / deltas.
+ - `bbox_feats` (Tensor): Extract bbox RoI features.
+ """
+ bbox_roi_extractor = self.bbox_roi_extractor[stage]
+ bbox_head = self.bbox_head[stage]
+ bbox_feats = bbox_roi_extractor(x[:bbox_roi_extractor.num_inputs],
+ rois)
+ if self.with_semantic and 'bbox' in self.semantic_fusion:
+ bbox_semantic_feat = self.semantic_roi_extractor([semantic_feat],
+ rois)
+ if bbox_semantic_feat.shape[-2:] != bbox_feats.shape[-2:]:
+ bbox_semantic_feat = adaptive_avg_pool2d(
+ bbox_semantic_feat, bbox_feats.shape[-2:])
+ bbox_feats += bbox_semantic_feat
+ cls_score, bbox_pred = bbox_head(bbox_feats)
+
+ bbox_results = dict(cls_score=cls_score, bbox_pred=bbox_pred)
+ return bbox_results
+
+ def bbox_loss(self,
+ stage: int,
+ x: Tuple[Tensor],
+ sampling_results: List[SamplingResult],
+ semantic_feat: Optional[Tensor] = None) -> dict:
+ """Run forward function and calculate loss for box head in training.
+
+ Args:
+ stage (int): The current stage in Cascade RoI Head.
+ x (tuple[Tensor]): List of multi-level img features.
+ sampling_results (list["obj:`SamplingResult`]): Sampling results.
+ semantic_feat (Tensor, optional): Semantic feature. Defaults to
+ None.
+
+ Returns:
+ dict: Usually returns a dictionary with keys:
+
+ - `cls_score` (Tensor): Classification scores.
+ - `bbox_pred` (Tensor): Box energies / deltas.
+ - `bbox_feats` (Tensor): Extract bbox RoI features.
+ - `loss_bbox` (dict): A dictionary of bbox loss components.
+ - `rois` (Tensor): RoIs with the shape (n, 5) where the first
+ column indicates batch id of each RoI.
+ - `bbox_targets` (tuple): Ground truth for proposals in a
+ single image. Containing the following list of Tensors:
+ (labels, label_weights, bbox_targets, bbox_weights)
+ """
+ bbox_head = self.bbox_head[stage]
+ rois = bbox2roi([res.priors for res in sampling_results])
+ bbox_results = self._bbox_forward(
+ stage, x, rois, semantic_feat=semantic_feat)
+ bbox_results.update(rois=rois)
+
+ bbox_loss_and_target = bbox_head.loss_and_target(
+ cls_score=bbox_results['cls_score'],
+ bbox_pred=bbox_results['bbox_pred'],
+ rois=rois,
+ sampling_results=sampling_results,
+ rcnn_train_cfg=self.train_cfg[stage])
+ bbox_results.update(bbox_loss_and_target)
+ return bbox_results
+
+ def _mask_forward(self,
+ stage: int,
+ x: Tuple[Tensor],
+ rois: Tensor,
+ semantic_feat: Optional[Tensor] = None,
+ training: bool = True) -> Dict[str, Tensor]:
+ """Mask head forward function used only in training.
+
+ Args:
+ stage (int): The current stage in Cascade RoI Head.
+ x (tuple[Tensor]): Tuple of multi-level img features.
+ rois (Tensor): RoIs with the shape (n, 5) where the first
+ column indicates batch id of each RoI.
+ semantic_feat (Tensor, optional): Semantic feature. Defaults to
+ None.
+ training (bool): Mask Forward is different between training and
+ testing. If True, use the mask forward in training.
+ Defaults to True.
+
+ Returns:
+ dict: Usually returns a dictionary with keys:
+
+ - `mask_preds` (Tensor): Mask prediction.
+ """
+ mask_roi_extractor = self.mask_roi_extractor[stage]
+ mask_head = self.mask_head[stage]
+ mask_feats = mask_roi_extractor(x[:mask_roi_extractor.num_inputs],
+ rois)
+
+ # semantic feature fusion
+ # element-wise sum for original features and pooled semantic features
+ if self.with_semantic and 'mask' in self.semantic_fusion:
+ mask_semantic_feat = self.semantic_roi_extractor([semantic_feat],
+ rois)
+ if mask_semantic_feat.shape[-2:] != mask_feats.shape[-2:]:
+ mask_semantic_feat = F.adaptive_avg_pool2d(
+ mask_semantic_feat, mask_feats.shape[-2:])
+ mask_feats = mask_feats + mask_semantic_feat
+
+ # mask information flow
+ # forward all previous mask heads to obtain last_feat, and fuse it
+ # with the normal mask feature
+ if training:
+ if self.mask_info_flow:
+ last_feat = None
+ for i in range(stage):
+ last_feat = self.mask_head[i](
+ mask_feats, last_feat, return_logits=False)
+ mask_preds = mask_head(
+ mask_feats, last_feat, return_feat=False)
+ else:
+ mask_preds = mask_head(mask_feats, return_feat=False)
+
+ mask_results = dict(mask_preds=mask_preds)
+ else:
+ aug_masks = []
+ last_feat = None
+ for i in range(self.num_stages):
+ mask_head = self.mask_head[i]
+ if self.mask_info_flow:
+ mask_preds, last_feat = mask_head(mask_feats, last_feat)
+ else:
+ mask_preds = mask_head(mask_feats)
+ aug_masks.append(mask_preds)
+
+ mask_results = dict(mask_preds=aug_masks)
+
+ return mask_results
+
+ def mask_loss(self,
+ stage: int,
+ x: Tuple[Tensor],
+ sampling_results: List[SamplingResult],
+ batch_gt_instances: InstanceList,
+ semantic_feat: Optional[Tensor] = None) -> dict:
+ """Run forward function and calculate loss for mask head in training.
+
+ Args:
+ stage (int): The current stage in Cascade RoI Head.
+ x (tuple[Tensor]): Tuple of multi-level img features.
+ sampling_results (list["obj:`SamplingResult`]): Sampling results.
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes``, ``labels``, and
+ ``masks`` attributes.
+ semantic_feat (Tensor, optional): Semantic feature. Defaults to
+ None.
+
+ Returns:
+ dict: Usually returns a dictionary with keys:
+
+ - `mask_preds` (Tensor): Mask prediction.
+ - `loss_mask` (dict): A dictionary of mask loss components.
+ """
+ pos_rois = bbox2roi([res.pos_priors for res in sampling_results])
+ mask_results = self._mask_forward(
+ stage=stage,
+ x=x,
+ rois=pos_rois,
+ semantic_feat=semantic_feat,
+ training=True)
+
+ mask_head = self.mask_head[stage]
+ mask_loss_and_target = mask_head.loss_and_target(
+ mask_preds=mask_results['mask_preds'],
+ sampling_results=sampling_results,
+ batch_gt_instances=batch_gt_instances,
+ rcnn_train_cfg=self.train_cfg[stage])
+ mask_results.update(mask_loss_and_target)
+
+ return mask_results
+
+ def loss(self, x: Tuple[Tensor], rpn_results_list: InstanceList,
+ batch_data_samples: SampleList) -> dict:
+ """Perform forward propagation and loss calculation of the detection
+ roi on the features of the upstream network.
+
+ Args:
+ x (tuple[Tensor]): List of multi-level img features.
+ rpn_results_list (list[:obj:`InstanceData`]): List of region
+ proposals.
+ batch_data_samples (list[:obj:`DetDataSample`]): The batch
+ data samples. It usually includes information such
+ as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components
+ """
+ assert len(rpn_results_list) == len(batch_data_samples)
+ outputs = unpack_gt_instances(batch_data_samples)
+ batch_gt_instances, batch_gt_instances_ignore, batch_img_metas \
+ = outputs
+
+ # semantic segmentation part
+ # 2 outputs: segmentation prediction and embedded features
+ losses = dict()
+ if self.with_semantic:
+ gt_semantic_segs = [
+ data_sample.gt_sem_seg.sem_seg
+ for data_sample in batch_data_samples
+ ]
+ gt_semantic_segs = torch.stack(gt_semantic_segs)
+ semantic_pred, semantic_feat = self.semantic_head(x)
+ loss_seg = self.semantic_head.loss(semantic_pred, gt_semantic_segs)
+ losses['loss_semantic_seg'] = loss_seg
+ else:
+ semantic_feat = None
+
+ results_list = rpn_results_list
+ num_imgs = len(batch_img_metas)
+ for stage in range(self.num_stages):
+ self.current_stage = stage
+
+ stage_loss_weight = self.stage_loss_weights[stage]
+
+ # assign gts and sample proposals
+ sampling_results = []
+ bbox_assigner = self.bbox_assigner[stage]
+ bbox_sampler = self.bbox_sampler[stage]
+ for i in range(num_imgs):
+ results = results_list[i]
+ # rename rpn_results.bboxes to rpn_results.priors
+ if 'bboxes' in results:
+ results.priors = results.pop('bboxes')
+
+ assign_result = bbox_assigner.assign(
+ results, batch_gt_instances[i],
+ batch_gt_instances_ignore[i])
+ sampling_result = bbox_sampler.sample(
+ assign_result,
+ results,
+ batch_gt_instances[i],
+ feats=[lvl_feat[i][None] for lvl_feat in x])
+ sampling_results.append(sampling_result)
+
+ # bbox head forward and loss
+ bbox_results = self.bbox_loss(
+ stage=stage,
+ x=x,
+ sampling_results=sampling_results,
+ semantic_feat=semantic_feat)
+
+ for name, value in bbox_results['loss_bbox'].items():
+ losses[f's{stage}.{name}'] = (
+ value * stage_loss_weight if 'loss' in name else value)
+
+ # mask head forward and loss
+ if self.with_mask:
+ # interleaved execution: use regressed bboxes by the box branch
+ # to train the mask branch
+ if self.interleaved:
+ bbox_head = self.bbox_head[stage]
+ with torch.no_grad():
+ results_list = bbox_head.refine_bboxes(
+ sampling_results, bbox_results, batch_img_metas)
+ # re-assign and sample 512 RoIs from 512 RoIs
+ sampling_results = []
+ for i in range(num_imgs):
+ results = results_list[i]
+ # rename rpn_results.bboxes to rpn_results.priors
+ results.priors = results.pop('bboxes')
+ assign_result = bbox_assigner.assign(
+ results, batch_gt_instances[i],
+ batch_gt_instances_ignore[i])
+ sampling_result = bbox_sampler.sample(
+ assign_result,
+ results,
+ batch_gt_instances[i],
+ feats=[lvl_feat[i][None] for lvl_feat in x])
+ sampling_results.append(sampling_result)
+ mask_results = self.mask_loss(
+ stage=stage,
+ x=x,
+ sampling_results=sampling_results,
+ batch_gt_instances=batch_gt_instances,
+ semantic_feat=semantic_feat)
+ for name, value in mask_results['loss_mask'].items():
+ losses[f's{stage}.{name}'] = (
+ value * stage_loss_weight if 'loss' in name else value)
+
+ # refine bboxes (same as Cascade R-CNN)
+ if stage < self.num_stages - 1 and not self.interleaved:
+ bbox_head = self.bbox_head[stage]
+ with torch.no_grad():
+ results_list = bbox_head.refine_bboxes(
+ sampling_results=sampling_results,
+ bbox_results=bbox_results,
+ batch_img_metas=batch_img_metas)
+
+ return losses
+
+ def predict(self,
+ x: Tuple[Tensor],
+ rpn_results_list: InstanceList,
+ batch_data_samples: SampleList,
+ rescale: bool = False) -> InstanceList:
+ """Perform forward propagation of the roi head and predict detection
+ results on the features of the upstream network.
+
+ Args:
+ x (tuple[Tensor]): Features from upstream network. Each
+ has shape (N, C, H, W).
+ rpn_results_list (list[:obj:`InstanceData`]): list of region
+ proposals.
+ batch_data_samples (List[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ rescale (bool): Whether to rescale the results to
+ the original image. Defaults to False.
+
+ Returns:
+ list[obj:`InstanceData`]: Detection results of each image.
+ Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ - masks (Tensor): Has a shape (num_instances, H, W).
+ """
+ assert self.with_bbox, 'Bbox head must be implemented.'
+ batch_img_metas = [
+ data_samples.metainfo for data_samples in batch_data_samples
+ ]
+
+ if self.with_semantic:
+ _, semantic_feat = self.semantic_head(x)
+ else:
+ semantic_feat = None
+
+ # TODO: nms_op in mmcv need be enhanced, the bbox result may get
+ # difference when not rescale in bbox_head
+
+ # If it has the mask branch, the bbox branch does not need
+ # to be scaled to the original image scale, because the mask
+ # branch will scale both bbox and mask at the same time.
+ bbox_rescale = rescale if not self.with_mask else False
+ results_list = self.predict_bbox(
+ x=x,
+ semantic_feat=semantic_feat,
+ batch_img_metas=batch_img_metas,
+ rpn_results_list=rpn_results_list,
+ rcnn_test_cfg=self.test_cfg,
+ rescale=bbox_rescale)
+
+ if self.with_mask:
+ results_list = self.predict_mask(
+ x=x,
+ semantic_heat=semantic_feat,
+ batch_img_metas=batch_img_metas,
+ results_list=results_list,
+ rescale=rescale)
+
+ return results_list
+
+ def predict_mask(self,
+ x: Tuple[Tensor],
+ semantic_heat: Tensor,
+ batch_img_metas: List[dict],
+ results_list: InstanceList,
+ rescale: bool = False) -> InstanceList:
+ """Perform forward propagation of the mask head and predict detection
+ results on the features of the upstream network.
+
+ Args:
+ x (tuple[Tensor]): Feature maps of all scale level.
+ semantic_feat (Tensor): Semantic feature.
+ batch_img_metas (list[dict]): List of image information.
+ results_list (list[:obj:`InstanceData`]): Detection results of
+ each image.
+ rescale (bool): If True, return boxes in original image space.
+ Defaults to False.
+
+ Returns:
+ list[:obj:`InstanceData`]: Detection results of each image
+ after the post process.
+ Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ - masks (Tensor): Has a shape (num_instances, H, W).
+ """
+ num_imgs = len(batch_img_metas)
+ bboxes = [res.bboxes for res in results_list]
+ mask_rois = bbox2roi(bboxes)
+ if mask_rois.shape[0] == 0:
+ results_list = empty_instances(
+ batch_img_metas=batch_img_metas,
+ device=mask_rois.device,
+ task_type='mask',
+ instance_results=results_list,
+ mask_thr_binary=self.test_cfg.mask_thr_binary)
+ return results_list
+
+ num_mask_rois_per_img = [len(res) for res in results_list]
+ mask_results = self._mask_forward(
+ stage=-1,
+ x=x,
+ rois=mask_rois,
+ semantic_feat=semantic_heat,
+ training=False)
+ # split batch mask prediction back to each image
+ aug_masks = [[
+ mask.sigmoid().detach()
+ for mask in mask_preds.split(num_mask_rois_per_img, 0)
+ ] for mask_preds in mask_results['mask_preds']]
+
+ merged_masks = []
+ for i in range(num_imgs):
+ aug_mask = [mask[i] for mask in aug_masks]
+ merged_mask = merge_aug_masks(aug_mask, batch_img_metas[i])
+ merged_masks.append(merged_mask)
+
+ results_list = self.mask_head[-1].predict_by_feat(
+ mask_preds=merged_masks,
+ results_list=results_list,
+ batch_img_metas=batch_img_metas,
+ rcnn_test_cfg=self.test_cfg,
+ rescale=rescale,
+ activate_map=True)
+
+ return results_list
+
+ def forward(self, x: Tuple[Tensor], rpn_results_list: InstanceList,
+ batch_data_samples: SampleList) -> tuple:
+ """Network forward process. Usually includes backbone, neck and head
+ forward without any post-processing.
+
+ Args:
+ x (List[Tensor]): Multi-level features that may have different
+ resolutions.
+ rpn_results_list (list[:obj:`InstanceData`]): List of region
+ proposals.
+ batch_data_samples (list[:obj:`DetDataSample`]): Each item contains
+ the meta information of each image and corresponding
+ annotations.
+
+ Returns
+ tuple: A tuple of features from ``bbox_head`` and ``mask_head``
+ forward.
+ """
+ results = ()
+ batch_img_metas = [
+ data_samples.metainfo for data_samples in batch_data_samples
+ ]
+ num_imgs = len(batch_img_metas)
+
+ if self.with_semantic:
+ _, semantic_feat = self.semantic_head(x)
+ else:
+ semantic_feat = None
+
+ proposals = [rpn_results.bboxes for rpn_results in rpn_results_list]
+ num_proposals_per_img = tuple(len(p) for p in proposals)
+ rois = bbox2roi(proposals)
+ # bbox head
+ if self.with_bbox:
+ rois, cls_scores, bbox_preds = self._refine_roi(
+ x=x,
+ rois=rois,
+ semantic_feat=semantic_feat,
+ batch_img_metas=batch_img_metas,
+ num_proposals_per_img=num_proposals_per_img)
+ results = results + (cls_scores, bbox_preds)
+ # mask head
+ if self.with_mask:
+ rois = torch.cat(rois)
+ mask_results = self._mask_forward(
+ stage=-1,
+ x=x,
+ rois=rois,
+ semantic_feat=semantic_feat,
+ training=False)
+ aug_masks = [[
+ mask.sigmoid().detach()
+ for mask in mask_preds.split(num_proposals_per_img, 0)
+ ] for mask_preds in mask_results['mask_preds']]
+
+ merged_masks = []
+ for i in range(num_imgs):
+ aug_mask = [mask[i] for mask in aug_masks]
+ merged_mask = merge_aug_masks(aug_mask, batch_img_metas[i])
+ merged_masks.append(merged_mask)
+ results = results + (merged_masks, )
+ return results
diff --git a/mmdet/models/roi_heads/mask_heads/__init__.py b/mmdet/models/roi_heads/mask_heads/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..48a5d4227be41b8985403251e1803f78cf500636
--- /dev/null
+++ b/mmdet/models/roi_heads/mask_heads/__init__.py
@@ -0,0 +1,20 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .coarse_mask_head import CoarseMaskHead
+from .dynamic_mask_head import DynamicMaskHead
+from .fcn_mask_head import FCNMaskHead
+from .feature_relay_head import FeatureRelayHead
+from .fused_semantic_head import FusedSemanticHead
+from .global_context_head import GlobalContextHead
+from .grid_head import GridHead
+from .htc_mask_head import HTCMaskHead
+from .mask_point_head import MaskPointHead
+from .maskiou_head import MaskIoUHead
+from .scnet_mask_head import SCNetMaskHead
+from .scnet_semantic_head import SCNetSemanticHead
+
+__all__ = [
+ 'FCNMaskHead', 'HTCMaskHead', 'FusedSemanticHead', 'GridHead',
+ 'MaskIoUHead', 'CoarseMaskHead', 'MaskPointHead', 'SCNetMaskHead',
+ 'SCNetSemanticHead', 'GlobalContextHead', 'FeatureRelayHead',
+ 'DynamicMaskHead'
+]
diff --git a/mmdet/models/roi_heads/mask_heads/__pycache__/__init__.cpython-37.pyc b/mmdet/models/roi_heads/mask_heads/__pycache__/__init__.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..635ab83a7af9b80a13d22bb0083318ccb47d544c
Binary files /dev/null and b/mmdet/models/roi_heads/mask_heads/__pycache__/__init__.cpython-37.pyc differ
diff --git a/mmdet/models/roi_heads/mask_heads/__pycache__/coarse_mask_head.cpython-37.pyc b/mmdet/models/roi_heads/mask_heads/__pycache__/coarse_mask_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..8a35220019479b98789e2ef8f157599d49d22765
Binary files /dev/null and b/mmdet/models/roi_heads/mask_heads/__pycache__/coarse_mask_head.cpython-37.pyc differ
diff --git a/mmdet/models/roi_heads/mask_heads/__pycache__/dynamic_mask_head.cpython-37.pyc b/mmdet/models/roi_heads/mask_heads/__pycache__/dynamic_mask_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..608a22c91d1a74e2c89a3472593bf2dcad453aec
Binary files /dev/null and b/mmdet/models/roi_heads/mask_heads/__pycache__/dynamic_mask_head.cpython-37.pyc differ
diff --git a/mmdet/models/roi_heads/mask_heads/__pycache__/fcn_mask_head.cpython-37.pyc b/mmdet/models/roi_heads/mask_heads/__pycache__/fcn_mask_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..1c7cc2e8242e41285cb5a12758b3e1e3098fa2ef
Binary files /dev/null and b/mmdet/models/roi_heads/mask_heads/__pycache__/fcn_mask_head.cpython-37.pyc differ
diff --git a/mmdet/models/roi_heads/mask_heads/__pycache__/feature_relay_head.cpython-37.pyc b/mmdet/models/roi_heads/mask_heads/__pycache__/feature_relay_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..c5fe07e22a3a2ecf49a22f2be1e4a67ac23cbdba
Binary files /dev/null and b/mmdet/models/roi_heads/mask_heads/__pycache__/feature_relay_head.cpython-37.pyc differ
diff --git a/mmdet/models/roi_heads/mask_heads/__pycache__/fused_semantic_head.cpython-37.pyc b/mmdet/models/roi_heads/mask_heads/__pycache__/fused_semantic_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..b1ab30b30dcd649db713063194bfd2054ad70a4d
Binary files /dev/null and b/mmdet/models/roi_heads/mask_heads/__pycache__/fused_semantic_head.cpython-37.pyc differ
diff --git a/mmdet/models/roi_heads/mask_heads/__pycache__/global_context_head.cpython-37.pyc b/mmdet/models/roi_heads/mask_heads/__pycache__/global_context_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..7a77d0a26b80d5431761aedfd921c2f665448d2a
Binary files /dev/null and b/mmdet/models/roi_heads/mask_heads/__pycache__/global_context_head.cpython-37.pyc differ
diff --git a/mmdet/models/roi_heads/mask_heads/__pycache__/grid_head.cpython-37.pyc b/mmdet/models/roi_heads/mask_heads/__pycache__/grid_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..ade3e6f8dd6257dc553ccba12ce3697199a97617
Binary files /dev/null and b/mmdet/models/roi_heads/mask_heads/__pycache__/grid_head.cpython-37.pyc differ
diff --git a/mmdet/models/roi_heads/mask_heads/__pycache__/htc_mask_head.cpython-37.pyc b/mmdet/models/roi_heads/mask_heads/__pycache__/htc_mask_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..7946821011621f9a90fad26f2073571568ca5963
Binary files /dev/null and b/mmdet/models/roi_heads/mask_heads/__pycache__/htc_mask_head.cpython-37.pyc differ
diff --git a/mmdet/models/roi_heads/mask_heads/__pycache__/mask_point_head.cpython-37.pyc b/mmdet/models/roi_heads/mask_heads/__pycache__/mask_point_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..e13dbee5b6f810adc5e4dcd0a124b12d2bb3d8b0
Binary files /dev/null and b/mmdet/models/roi_heads/mask_heads/__pycache__/mask_point_head.cpython-37.pyc differ
diff --git a/mmdet/models/roi_heads/mask_heads/__pycache__/maskiou_head.cpython-37.pyc b/mmdet/models/roi_heads/mask_heads/__pycache__/maskiou_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..cb1c430a7a188c903c190a0295c0a39ef145b7b6
Binary files /dev/null and b/mmdet/models/roi_heads/mask_heads/__pycache__/maskiou_head.cpython-37.pyc differ
diff --git a/mmdet/models/roi_heads/mask_heads/__pycache__/scnet_mask_head.cpython-37.pyc b/mmdet/models/roi_heads/mask_heads/__pycache__/scnet_mask_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..b7de348252353e5fb0dd949707d4b716c506dea4
Binary files /dev/null and b/mmdet/models/roi_heads/mask_heads/__pycache__/scnet_mask_head.cpython-37.pyc differ
diff --git a/mmdet/models/roi_heads/mask_heads/__pycache__/scnet_semantic_head.cpython-37.pyc b/mmdet/models/roi_heads/mask_heads/__pycache__/scnet_semantic_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..2831927369f6abb034527de070e6113cb970bcd2
Binary files /dev/null and b/mmdet/models/roi_heads/mask_heads/__pycache__/scnet_semantic_head.cpython-37.pyc differ
diff --git a/mmdet/models/roi_heads/mask_heads/coarse_mask_head.py b/mmdet/models/roi_heads/mask_heads/coarse_mask_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..1caa901228f2439492b82d1890eba468963eb28d
--- /dev/null
+++ b/mmdet/models/roi_heads/mask_heads/coarse_mask_head.py
@@ -0,0 +1,110 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmcv.cnn import ConvModule, Linear
+from mmengine.model import ModuleList
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.utils import MultiConfig
+from .fcn_mask_head import FCNMaskHead
+
+
+@MODELS.register_module()
+class CoarseMaskHead(FCNMaskHead):
+ """Coarse mask head used in PointRend.
+
+ Compared with standard ``FCNMaskHead``, ``CoarseMaskHead`` will downsample
+ the input feature map instead of upsample it.
+
+ Args:
+ num_convs (int): Number of conv layers in the head. Defaults to 0.
+ num_fcs (int): Number of fc layers in the head. Defaults to 2.
+ fc_out_channels (int): Number of output channels of fc layer.
+ Defaults to 1024.
+ downsample_factor (int): The factor that feature map is downsampled by.
+ Defaults to 2.
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ """
+
+ def __init__(self,
+ num_convs: int = 0,
+ num_fcs: int = 2,
+ fc_out_channels: int = 1024,
+ downsample_factor: int = 2,
+ init_cfg: MultiConfig = dict(
+ type='Xavier',
+ override=[
+ dict(name='fcs'),
+ dict(type='Constant', val=0.001, name='fc_logits')
+ ]),
+ *arg,
+ **kwarg) -> None:
+ super().__init__(
+ *arg,
+ num_convs=num_convs,
+ upsample_cfg=dict(type=None),
+ init_cfg=None,
+ **kwarg)
+ self.init_cfg = init_cfg
+ self.num_fcs = num_fcs
+ assert self.num_fcs > 0
+ self.fc_out_channels = fc_out_channels
+ self.downsample_factor = downsample_factor
+ assert self.downsample_factor >= 1
+ # remove conv_logit
+ delattr(self, 'conv_logits')
+
+ if downsample_factor > 1:
+ downsample_in_channels = (
+ self.conv_out_channels
+ if self.num_convs > 0 else self.in_channels)
+ self.downsample_conv = ConvModule(
+ downsample_in_channels,
+ self.conv_out_channels,
+ kernel_size=downsample_factor,
+ stride=downsample_factor,
+ padding=0,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg)
+ else:
+ self.downsample_conv = None
+
+ self.output_size = (self.roi_feat_size[0] // downsample_factor,
+ self.roi_feat_size[1] // downsample_factor)
+ self.output_area = self.output_size[0] * self.output_size[1]
+
+ last_layer_dim = self.conv_out_channels * self.output_area
+
+ self.fcs = ModuleList()
+ for i in range(num_fcs):
+ fc_in_channels = (
+ last_layer_dim if i == 0 else self.fc_out_channels)
+ self.fcs.append(Linear(fc_in_channels, self.fc_out_channels))
+ last_layer_dim = self.fc_out_channels
+ output_channels = self.num_classes * self.output_area
+ self.fc_logits = Linear(last_layer_dim, output_channels)
+
+ def init_weights(self) -> None:
+ """Initialize weights."""
+ super(FCNMaskHead, self).init_weights()
+
+ def forward(self, x: Tensor) -> Tensor:
+ """Forward features from the upstream network.
+
+ Args:
+ x (Tensor): Extract mask RoI features.
+
+ Returns:
+ Tensor: Predicted foreground masks.
+ """
+ for conv in self.convs:
+ x = conv(x)
+
+ if self.downsample_conv is not None:
+ x = self.downsample_conv(x)
+
+ x = x.flatten(1)
+ for fc in self.fcs:
+ x = self.relu(fc(x))
+ mask_preds = self.fc_logits(x).view(
+ x.size(0), self.num_classes, *self.output_size)
+ return mask_preds
diff --git a/mmdet/models/roi_heads/mask_heads/dynamic_mask_head.py b/mmdet/models/roi_heads/mask_heads/dynamic_mask_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..f33612b1b141668d0463435975c14a26fbe5a0cd
--- /dev/null
+++ b/mmdet/models/roi_heads/mask_heads/dynamic_mask_head.py
@@ -0,0 +1,166 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List
+
+import torch
+import torch.nn as nn
+from mmengine.config import ConfigDict
+from torch import Tensor
+
+from mmdet.models.task_modules import SamplingResult
+from mmdet.registry import MODELS
+from mmdet.utils import ConfigType, InstanceList, OptConfigType, reduce_mean
+from .fcn_mask_head import FCNMaskHead
+
+
+@MODELS.register_module()
+class DynamicMaskHead(FCNMaskHead):
+ r"""Dynamic Mask Head for
+ `Instances as Queries `_
+
+ Args:
+ num_convs (int): Number of convolution layer.
+ Defaults to 4.
+ roi_feat_size (int): The output size of RoI extractor,
+ Defaults to 14.
+ in_channels (int): Input feature channels.
+ Defaults to 256.
+ conv_kernel_size (int): Kernel size of convolution layers.
+ Defaults to 3.
+ conv_out_channels (int): Output channels of convolution layers.
+ Defaults to 256.
+ num_classes (int): Number of classes.
+ Defaults to 80
+ class_agnostic (int): Whether generate class agnostic prediction.
+ Defaults to False.
+ dropout (float): Probability of drop the channel.
+ Defaults to 0.0
+ upsample_cfg (:obj:`ConfigDict` or dict): The config for
+ upsample layer.
+ conv_cfg (:obj:`ConfigDict` or dict, optional): The convolution
+ layer config.
+ norm_cfg (:obj:`ConfigDict` or dict, optional): The norm layer config.
+ dynamic_conv_cfg (:obj:`ConfigDict` or dict): The dynamic convolution
+ layer config.
+ loss_mask (:obj:`ConfigDict` or dict): The config for mask loss.
+ """
+
+ def __init__(self,
+ num_convs: int = 4,
+ roi_feat_size: int = 14,
+ in_channels: int = 256,
+ conv_kernel_size: int = 3,
+ conv_out_channels: int = 256,
+ num_classes: int = 80,
+ class_agnostic: bool = False,
+ upsample_cfg: ConfigType = dict(
+ type='deconv', scale_factor=2),
+ conv_cfg: OptConfigType = None,
+ norm_cfg: OptConfigType = None,
+ dynamic_conv_cfg: ConfigType = dict(
+ type='DynamicConv',
+ in_channels=256,
+ feat_channels=64,
+ out_channels=256,
+ input_feat_shape=14,
+ with_proj=False,
+ act_cfg=dict(type='ReLU', inplace=True),
+ norm_cfg=dict(type='LN')),
+ loss_mask: ConfigType = dict(
+ type='DiceLoss', loss_weight=8.0),
+ **kwargs) -> None:
+ super().__init__(
+ num_convs=num_convs,
+ roi_feat_size=roi_feat_size,
+ in_channels=in_channels,
+ conv_kernel_size=conv_kernel_size,
+ conv_out_channels=conv_out_channels,
+ num_classes=num_classes,
+ class_agnostic=class_agnostic,
+ upsample_cfg=upsample_cfg,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ loss_mask=loss_mask,
+ **kwargs)
+ assert class_agnostic is False, \
+ 'DynamicMaskHead only support class_agnostic=False'
+ self.fp16_enabled = False
+
+ self.instance_interactive_conv = MODELS.build(dynamic_conv_cfg)
+
+ def init_weights(self) -> None:
+ """Use xavier initialization for all weight parameter and set
+ classification head bias as a specific value when use focal loss."""
+ for p in self.parameters():
+ if p.dim() > 1:
+ nn.init.xavier_uniform_(p)
+ nn.init.constant_(self.conv_logits.bias, 0.)
+
+ def forward(self, roi_feat: Tensor, proposal_feat: Tensor) -> Tensor:
+ """Forward function of DynamicMaskHead.
+
+ Args:
+ roi_feat (Tensor): Roi-pooling features with shape
+ (batch_size*num_proposals, feature_dimensions,
+ pooling_h , pooling_w).
+ proposal_feat (Tensor): Intermediate feature get from
+ diihead in last stage, has shape
+ (batch_size*num_proposals, feature_dimensions)
+
+ Returns:
+ mask_preds (Tensor): Predicted foreground masks with shape
+ (batch_size*num_proposals, num_classes, pooling_h*2, pooling_w*2).
+ """
+
+ proposal_feat = proposal_feat.reshape(-1, self.in_channels)
+ proposal_feat_iic = self.instance_interactive_conv(
+ proposal_feat, roi_feat)
+
+ x = proposal_feat_iic.permute(0, 2, 1).reshape(roi_feat.size())
+
+ for conv in self.convs:
+ x = conv(x)
+ if self.upsample is not None:
+ x = self.upsample(x)
+ if self.upsample_method == 'deconv':
+ x = self.relu(x)
+ mask_preds = self.conv_logits(x)
+ return mask_preds
+
+ def loss_and_target(self, mask_preds: Tensor,
+ sampling_results: List[SamplingResult],
+ batch_gt_instances: InstanceList,
+ rcnn_train_cfg: ConfigDict) -> dict:
+ """Calculate the loss based on the features extracted by the mask head.
+
+ Args:
+ mask_preds (Tensor): Predicted foreground masks, has shape
+ (num_pos, num_classes, h, w).
+ sampling_results (List[obj:SamplingResult]): Assign results of
+ all images in a batch after sampling.
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes``, ``labels``, and
+ ``masks`` attributes.
+ rcnn_train_cfg (obj:ConfigDict): `train_cfg` of RCNN.
+
+ Returns:
+ dict: A dictionary of loss and targets components.
+ """
+ mask_targets = self.get_targets(
+ sampling_results=sampling_results,
+ batch_gt_instances=batch_gt_instances,
+ rcnn_train_cfg=rcnn_train_cfg)
+ pos_labels = torch.cat([res.pos_gt_labels for res in sampling_results])
+
+ num_pos = pos_labels.new_ones(pos_labels.size()).float().sum()
+ avg_factor = torch.clamp(reduce_mean(num_pos), min=1.).item()
+ loss = dict()
+ if mask_preds.size(0) == 0:
+ loss_mask = mask_preds.sum()
+ else:
+ loss_mask = self.loss_mask(
+ mask_preds[torch.arange(num_pos).long(), pos_labels,
+ ...].sigmoid(),
+ mask_targets,
+ avg_factor=avg_factor)
+ loss['loss_mask'] = loss_mask
+ return dict(loss_mask=loss, mask_targets=mask_targets)
diff --git a/mmdet/models/roi_heads/mask_heads/fcn_mask_head.py b/mmdet/models/roi_heads/mask_heads/fcn_mask_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..3a089dfafcb69784f2fc266f0945e6d56b0466d3
--- /dev/null
+++ b/mmdet/models/roi_heads/mask_heads/fcn_mask_head.py
@@ -0,0 +1,474 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Tuple
+
+import numpy as np
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule, build_conv_layer, build_upsample_layer
+from mmcv.ops.carafe import CARAFEPack
+from mmengine.config import ConfigDict
+from mmengine.model import BaseModule, ModuleList
+from mmengine.structures import InstanceData
+from torch import Tensor
+from torch.nn.modules.utils import _pair
+
+from mmdet.models.task_modules.samplers import SamplingResult
+from mmdet.models.utils import empty_instances
+from mmdet.registry import MODELS
+from mmdet.structures.mask import mask_target
+from mmdet.utils import ConfigType, InstanceList, OptConfigType, OptMultiConfig
+
+BYTES_PER_FLOAT = 4
+# TODO: This memory limit may be too much or too little. It would be better to
+# determine it based on available resources.
+GPU_MEM_LIMIT = 1024**3 # 1 GB memory limit
+
+
+@MODELS.register_module()
+class FCNMaskHead(BaseModule):
+
+ def __init__(self,
+ num_convs: int = 4,
+ roi_feat_size: int = 14,
+ in_channels: int = 256,
+ conv_kernel_size: int = 3,
+ conv_out_channels: int = 256,
+ num_classes: int = 80,
+ class_agnostic: int = False,
+ upsample_cfg: ConfigType = dict(
+ type='deconv', scale_factor=2),
+ conv_cfg: OptConfigType = None,
+ norm_cfg: OptConfigType = None,
+ predictor_cfg: ConfigType = dict(type='Conv'),
+ loss_mask: ConfigType = dict(
+ type='CrossEntropyLoss', use_mask=True, loss_weight=1.0),
+ init_cfg: OptMultiConfig = None) -> None:
+ assert init_cfg is None, 'To prevent abnormal initialization ' \
+ 'behavior, init_cfg is not allowed to be set'
+ super().__init__(init_cfg=init_cfg)
+ self.upsample_cfg = upsample_cfg.copy()
+ if self.upsample_cfg['type'] not in [
+ None, 'deconv', 'nearest', 'bilinear', 'carafe'
+ ]:
+ raise ValueError(
+ f'Invalid upsample method {self.upsample_cfg["type"]}, '
+ 'accepted methods are "deconv", "nearest", "bilinear", '
+ '"carafe"')
+ self.num_convs = num_convs
+ # WARN: roi_feat_size is reserved and not used
+ self.roi_feat_size = _pair(roi_feat_size)
+ self.in_channels = in_channels
+ self.conv_kernel_size = conv_kernel_size
+ self.conv_out_channels = conv_out_channels
+ self.upsample_method = self.upsample_cfg.get('type')
+ self.scale_factor = self.upsample_cfg.pop('scale_factor', None)
+ self.num_classes = num_classes
+ self.class_agnostic = class_agnostic
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.predictor_cfg = predictor_cfg
+ self.loss_mask = MODELS.build(loss_mask)
+
+ self.convs = ModuleList()
+ for i in range(self.num_convs):
+ in_channels = (
+ self.in_channels if i == 0 else self.conv_out_channels)
+ padding = (self.conv_kernel_size - 1) // 2
+ self.convs.append(
+ ConvModule(
+ in_channels,
+ self.conv_out_channels,
+ self.conv_kernel_size,
+ padding=padding,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg))
+ upsample_in_channels = (
+ self.conv_out_channels if self.num_convs > 0 else in_channels)
+ upsample_cfg_ = self.upsample_cfg.copy()
+ if self.upsample_method is None:
+ self.upsample = None
+ elif self.upsample_method == 'deconv':
+ upsample_cfg_.update(
+ in_channels=upsample_in_channels,
+ out_channels=self.conv_out_channels,
+ kernel_size=self.scale_factor,
+ stride=self.scale_factor)
+ self.upsample = build_upsample_layer(upsample_cfg_)
+ elif self.upsample_method == 'carafe':
+ upsample_cfg_.update(
+ channels=upsample_in_channels, scale_factor=self.scale_factor)
+ self.upsample = build_upsample_layer(upsample_cfg_)
+ else:
+ # suppress warnings
+ align_corners = (None
+ if self.upsample_method == 'nearest' else False)
+ upsample_cfg_.update(
+ scale_factor=self.scale_factor,
+ mode=self.upsample_method,
+ align_corners=align_corners)
+ self.upsample = build_upsample_layer(upsample_cfg_)
+
+ out_channels = 1 if self.class_agnostic else self.num_classes
+ logits_in_channel = (
+ self.conv_out_channels
+ if self.upsample_method == 'deconv' else upsample_in_channels)
+ self.conv_logits = build_conv_layer(self.predictor_cfg,
+ logits_in_channel, out_channels, 1)
+ self.relu = nn.ReLU(inplace=True)
+ self.debug_imgs = None
+
+ def init_weights(self) -> None:
+ """Initialize the weights."""
+ super().init_weights()
+ for m in [self.upsample, self.conv_logits]:
+ if m is None:
+ continue
+ elif isinstance(m, CARAFEPack):
+ m.init_weights()
+ elif hasattr(m, 'weight') and hasattr(m, 'bias'):
+ nn.init.kaiming_normal_(
+ m.weight, mode='fan_out', nonlinearity='relu')
+ nn.init.constant_(m.bias, 0)
+
+ def forward(self, x: Tensor) -> Tensor:
+ """Forward features from the upstream network.
+
+ Args:
+ x (Tensor): Extract mask RoI features.
+
+ Returns:
+ Tensor: Predicted foreground masks.
+ """
+ for conv in self.convs:
+ x = conv(x)
+ if self.upsample is not None:
+ x = self.upsample(x)
+ if self.upsample_method == 'deconv':
+ x = self.relu(x)
+ mask_preds = self.conv_logits(x)
+ return mask_preds
+
+ def get_targets(self, sampling_results: List[SamplingResult],
+ batch_gt_instances: InstanceList,
+ rcnn_train_cfg: ConfigDict) -> Tensor:
+ """Calculate the ground truth for all samples in a batch according to
+ the sampling_results.
+
+ Args:
+ sampling_results (List[obj:SamplingResult]): Assign results of
+ all images in a batch after sampling.
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes``, ``labels``, and
+ ``masks`` attributes.
+ rcnn_train_cfg (obj:ConfigDict): `train_cfg` of RCNN.
+
+ Returns:
+ Tensor: Mask target of each positive proposals in the image.
+ """
+ pos_proposals = [res.pos_priors for res in sampling_results]
+ pos_assigned_gt_inds = [
+ res.pos_assigned_gt_inds for res in sampling_results
+ ]
+ gt_masks = [res.masks for res in batch_gt_instances]
+ mask_targets = mask_target(pos_proposals, pos_assigned_gt_inds,
+ gt_masks, rcnn_train_cfg)
+ return mask_targets
+
+ def loss_and_target(self, mask_preds: Tensor,
+ sampling_results: List[SamplingResult],
+ batch_gt_instances: InstanceList,
+ rcnn_train_cfg: ConfigDict) -> dict:
+ """Calculate the loss based on the features extracted by the mask head.
+
+ Args:
+ mask_preds (Tensor): Predicted foreground masks, has shape
+ (num_pos, num_classes, h, w).
+ sampling_results (List[obj:SamplingResult]): Assign results of
+ all images in a batch after sampling.
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes``, ``labels``, and
+ ``masks`` attributes.
+ rcnn_train_cfg (obj:ConfigDict): `train_cfg` of RCNN.
+
+ Returns:
+ dict: A dictionary of loss and targets components.
+ """
+ mask_targets = self.get_targets(
+ sampling_results=sampling_results,
+ batch_gt_instances=batch_gt_instances,
+ rcnn_train_cfg=rcnn_train_cfg)
+
+ pos_labels = torch.cat([res.pos_gt_labels for res in sampling_results])
+
+ loss = dict()
+ if mask_preds.size(0) == 0:
+ loss_mask = mask_preds.sum()
+ else:
+ if self.class_agnostic:
+ loss_mask = self.loss_mask(mask_preds, mask_targets,
+ torch.zeros_like(pos_labels))
+ else:
+ loss_mask = self.loss_mask(mask_preds, mask_targets,
+ pos_labels)
+ loss['loss_mask'] = loss_mask
+ # TODO: which algorithm requires mask_targets?
+ return dict(loss_mask=loss, mask_targets=mask_targets)
+
+ def predict_by_feat(self,
+ mask_preds: Tuple[Tensor],
+ results_list: List[InstanceData],
+ batch_img_metas: List[dict],
+ rcnn_test_cfg: ConfigDict,
+ rescale: bool = False,
+ activate_map: bool = False) -> InstanceList:
+ """Transform a batch of output features extracted from the head into
+ mask results.
+
+ Args:
+ mask_preds (tuple[Tensor]): Tuple of predicted foreground masks,
+ each has shape (n, num_classes, h, w).
+ results_list (list[:obj:`InstanceData`]): Detection results of
+ each image.
+ batch_img_metas (list[dict]): List of image information.
+ rcnn_test_cfg (obj:`ConfigDict`): `test_cfg` of Bbox Head.
+ rescale (bool): If True, return boxes in original image space.
+ Defaults to False.
+ activate_map (book): Whether get results with augmentations test.
+ If True, the `mask_preds` will not process with sigmoid.
+ Defaults to False.
+
+ Returns:
+ list[:obj:`InstanceData`]: Detection results of each image
+ after the post process. Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ - masks (Tensor): Has a shape (num_instances, H, W).
+ """
+ assert len(mask_preds) == len(results_list) == len(batch_img_metas)
+
+ for img_id in range(len(batch_img_metas)):
+ img_meta = batch_img_metas[img_id]
+ results = results_list[img_id]
+ bboxes = results.bboxes
+ if bboxes.shape[0] == 0:
+ results_list[img_id] = empty_instances(
+ [img_meta],
+ bboxes.device,
+ task_type='mask',
+ instance_results=[results],
+ mask_thr_binary=rcnn_test_cfg.mask_thr_binary)[0]
+ else:
+ im_mask = self._predict_by_feat_single(
+ mask_preds=mask_preds[img_id],
+ bboxes=bboxes,
+ labels=results.labels,
+ img_meta=img_meta,
+ rcnn_test_cfg=rcnn_test_cfg,
+ rescale=rescale,
+ activate_map=activate_map)
+ results.masks = im_mask
+ return results_list
+
+ def _predict_by_feat_single(self,
+ mask_preds: Tensor,
+ bboxes: Tensor,
+ labels: Tensor,
+ img_meta: dict,
+ rcnn_test_cfg: ConfigDict,
+ rescale: bool = False,
+ activate_map: bool = False) -> Tensor:
+ """Get segmentation masks from mask_preds and bboxes.
+
+ Args:
+ mask_preds (Tensor): Predicted foreground masks, has shape
+ (n, num_classes, h, w).
+ bboxes (Tensor): Predicted bboxes, has shape (n, 4)
+ labels (Tensor): Labels of bboxes, has shape (n, )
+ img_meta (dict): image information.
+ rcnn_test_cfg (obj:`ConfigDict`): `test_cfg` of Bbox Head.
+ Defaults to None.
+ rescale (bool): If True, return boxes in original image space.
+ Defaults to False.
+ activate_map (book): Whether get results with augmentations test.
+ If True, the `mask_preds` will not process with sigmoid.
+ Defaults to False.
+
+ Returns:
+ Tensor: Encoded masks, has shape (n, img_w, img_h)
+
+ Example:
+ >>> from mmengine.config import Config
+ >>> from mmdet.models.roi_heads.mask_heads.fcn_mask_head import * # NOQA
+ >>> N = 7 # N = number of extracted ROIs
+ >>> C, H, W = 11, 32, 32
+ >>> # Create example instance of FCN Mask Head.
+ >>> self = FCNMaskHead(num_classes=C, num_convs=0)
+ >>> inputs = torch.rand(N, self.in_channels, H, W)
+ >>> mask_preds = self.forward(inputs)
+ >>> # Each input is associated with some bounding box
+ >>> bboxes = torch.Tensor([[1, 1, 42, 42 ]] * N)
+ >>> labels = torch.randint(0, C, size=(N,))
+ >>> rcnn_test_cfg = Config({'mask_thr_binary': 0, })
+ >>> ori_shape = (H * 4, W * 4)
+ >>> scale_factor = (1, 1)
+ >>> rescale = False
+ >>> img_meta = {'scale_factor': scale_factor,
+ ... 'ori_shape': ori_shape}
+ >>> # Encoded masks are a list for each category.
+ >>> encoded_masks = self._get_seg_masks_single(
+ ... mask_preds, bboxes, labels,
+ ... img_meta, rcnn_test_cfg, rescale)
+ >>> assert encoded_masks.size()[0] == N
+ >>> assert encoded_masks.size()[1:] == ori_shape
+ """
+ scale_factor = bboxes.new_tensor(img_meta['scale_factor']).repeat(
+ (1, 2))
+ img_h, img_w = img_meta['ori_shape'][:2]
+ device = bboxes.device
+
+ if not activate_map:
+ mask_preds = mask_preds.sigmoid()
+ else:
+ # In AugTest, has been activated before
+ mask_preds = bboxes.new_tensor(mask_preds)
+
+ if rescale: # in-placed rescale the bboxes
+ bboxes /= scale_factor
+ else:
+ w_scale, h_scale = scale_factor[0, 0], scale_factor[0, 1]
+ img_h = np.round(img_h * h_scale.item()).astype(np.int32)
+ img_w = np.round(img_w * w_scale.item()).astype(np.int32)
+
+ N = len(mask_preds)
+ # The actual implementation split the input into chunks,
+ # and paste them chunk by chunk.
+ if device.type == 'cpu':
+ # CPU is most efficient when they are pasted one by one with
+ # skip_empty=True, so that it performs minimal number of
+ # operations.
+ num_chunks = N
+ else:
+ # GPU benefits from parallelism for larger chunks,
+ # but may have memory issue
+ # the types of img_w and img_h are np.int32,
+ # when the image resolution is large,
+ # the calculation of num_chunks will overflow.
+ # so we need to change the types of img_w and img_h to int.
+ # See https://github.com/open-mmlab/mmdetection/pull/5191
+ num_chunks = int(
+ np.ceil(N * int(img_h) * int(img_w) * BYTES_PER_FLOAT /
+ GPU_MEM_LIMIT))
+ assert (num_chunks <=
+ N), 'Default GPU_MEM_LIMIT is too small; try increasing it'
+ chunks = torch.chunk(torch.arange(N, device=device), num_chunks)
+
+ threshold = rcnn_test_cfg.mask_thr_binary
+ im_mask = torch.zeros(
+ N,
+ img_h,
+ img_w,
+ device=device,
+ dtype=torch.bool if threshold >= 0 else torch.uint8)
+
+ if not self.class_agnostic:
+ mask_preds = mask_preds[range(N), labels][:, None]
+
+ for inds in chunks:
+ masks_chunk, spatial_inds = _do_paste_mask(
+ mask_preds[inds],
+ bboxes[inds],
+ img_h,
+ img_w,
+ skip_empty=device.type == 'cpu')
+
+ if threshold >= 0:
+ masks_chunk = (masks_chunk >= threshold).to(dtype=torch.bool)
+ else:
+ # for visualization and debugging
+ masks_chunk = (masks_chunk * 255).to(dtype=torch.uint8)
+
+ im_mask[(inds, ) + spatial_inds] = masks_chunk
+ return im_mask
+
+
+def _do_paste_mask(masks: Tensor,
+ boxes: Tensor,
+ img_h: int,
+ img_w: int,
+ skip_empty: bool = True) -> tuple:
+ """Paste instance masks according to boxes.
+
+ This implementation is modified from
+ https://github.com/facebookresearch/detectron2/
+
+ Args:
+ masks (Tensor): N, 1, H, W
+ boxes (Tensor): N, 4
+ img_h (int): Height of the image to be pasted.
+ img_w (int): Width of the image to be pasted.
+ skip_empty (bool): Only paste masks within the region that
+ tightly bound all boxes, and returns the results this region only.
+ An important optimization for CPU.
+
+ Returns:
+ tuple: (Tensor, tuple). The first item is mask tensor, the second one
+ is the slice object.
+
+ If skip_empty == False, the whole image will be pasted. It will
+ return a mask of shape (N, img_h, img_w) and an empty tuple.
+
+ If skip_empty == True, only area around the mask will be pasted.
+ A mask of shape (N, h', w') and its start and end coordinates
+ in the original image will be returned.
+ """
+ # On GPU, paste all masks together (up to chunk size)
+ # by using the entire image to sample the masks
+ # Compared to pasting them one by one,
+ # this has more operations but is faster on COCO-scale dataset.
+ device = masks.device
+ if skip_empty:
+ x0_int, y0_int = torch.clamp(
+ boxes.min(dim=0).values.floor()[:2] - 1,
+ min=0).to(dtype=torch.int32)
+ x1_int = torch.clamp(
+ boxes[:, 2].max().ceil() + 1, max=img_w).to(dtype=torch.int32)
+ y1_int = torch.clamp(
+ boxes[:, 3].max().ceil() + 1, max=img_h).to(dtype=torch.int32)
+ else:
+ x0_int, y0_int = 0, 0
+ x1_int, y1_int = img_w, img_h
+ x0, y0, x1, y1 = torch.split(boxes, 1, dim=1) # each is Nx1
+
+ N = masks.shape[0]
+
+ img_y = torch.arange(y0_int, y1_int, device=device).to(torch.float32) + 0.5
+ img_x = torch.arange(x0_int, x1_int, device=device).to(torch.float32) + 0.5
+ img_y = (img_y - y0) / (y1 - y0) * 2 - 1
+ img_x = (img_x - x0) / (x1 - x0) * 2 - 1
+ # img_x, img_y have shapes (N, w), (N, h)
+ # IsInf op is not supported with ONNX<=1.7.0
+ if not torch.onnx.is_in_onnx_export():
+ if torch.isinf(img_x).any():
+ inds = torch.where(torch.isinf(img_x))
+ img_x[inds] = 0
+ if torch.isinf(img_y).any():
+ inds = torch.where(torch.isinf(img_y))
+ img_y[inds] = 0
+
+ gx = img_x[:, None, :].expand(N, img_y.size(1), img_x.size(1))
+ gy = img_y[:, :, None].expand(N, img_y.size(1), img_x.size(1))
+ grid = torch.stack([gx, gy], dim=3)
+
+ img_masks = F.grid_sample(
+ masks.to(dtype=torch.float32), grid, align_corners=False)
+
+ if skip_empty:
+ return img_masks[:, 0], (slice(y0_int, y1_int), slice(x0_int, x1_int))
+ else:
+ return img_masks[:, 0], ()
diff --git a/mmdet/models/roi_heads/mask_heads/feature_relay_head.py b/mmdet/models/roi_heads/mask_heads/feature_relay_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..0c34561fa5fd749329eda164465ce9787278d357
--- /dev/null
+++ b/mmdet/models/roi_heads/mask_heads/feature_relay_head.py
@@ -0,0 +1,68 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional
+
+import torch.nn as nn
+from mmengine.model import BaseModule
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.utils import MultiConfig
+
+
+@MODELS.register_module()
+class FeatureRelayHead(BaseModule):
+ """Feature Relay Head used in `SCNet `_.
+
+ Args:
+ in_channels (int): number of input channels. Defaults to 256.
+ conv_out_channels (int): number of output channels before
+ classification layer. Defaults to 256.
+ roi_feat_size (int): roi feat size at box head. Default: 7.
+ scale_factor (int): scale factor to match roi feat size
+ at mask head. Defaults to 2.
+ init_cfg (:obj:`ConfigDict` or dict or list[dict] or
+ list[:obj:`ConfigDict`]): Initialization config dict. Defaults to
+ dict(type='Kaiming', layer='Linear').
+ """
+
+ def __init__(
+ self,
+ in_channels: int = 1024,
+ out_conv_channels: int = 256,
+ roi_feat_size: int = 7,
+ scale_factor: int = 2,
+ init_cfg: MultiConfig = dict(type='Kaiming', layer='Linear')
+ ) -> None:
+ super().__init__(init_cfg=init_cfg)
+ assert isinstance(roi_feat_size, int)
+
+ self.in_channels = in_channels
+ self.out_conv_channels = out_conv_channels
+ self.roi_feat_size = roi_feat_size
+ self.out_channels = (roi_feat_size**2) * out_conv_channels
+ self.scale_factor = scale_factor
+ self.fp16_enabled = False
+
+ self.fc = nn.Linear(self.in_channels, self.out_channels)
+ self.upsample = nn.Upsample(
+ scale_factor=scale_factor, mode='bilinear', align_corners=True)
+
+ def forward(self, x: Tensor) -> Optional[Tensor]:
+ """Forward function.
+
+ Args:
+ x (Tensor): Input feature.
+
+ Returns:
+ Optional[Tensor]: Output feature. When the first dim of input is
+ 0, None is returned.
+ """
+ N, _ = x.shape
+ if N > 0:
+ out_C = self.out_conv_channels
+ out_HW = self.roi_feat_size
+ x = self.fc(x)
+ x = x.reshape(N, out_C, out_HW, out_HW)
+ x = self.upsample(x)
+ return x
+ return None
diff --git a/mmdet/models/roi_heads/mask_heads/fused_semantic_head.py b/mmdet/models/roi_heads/mask_heads/fused_semantic_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..d20beb2975a563f03e7b6b2afcef287cb41af05a
--- /dev/null
+++ b/mmdet/models/roi_heads/mask_heads/fused_semantic_head.py
@@ -0,0 +1,144 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+from typing import Tuple
+
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule
+from mmengine.config import ConfigDict
+from mmengine.model import BaseModule
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.utils import MultiConfig, OptConfigType
+
+
+@MODELS.register_module()
+class FusedSemanticHead(BaseModule):
+ r"""Multi-level fused semantic segmentation head.
+
+ .. code-block:: none
+
+ in_1 -> 1x1 conv ---
+ |
+ in_2 -> 1x1 conv -- |
+ ||
+ in_3 -> 1x1 conv - ||
+ ||| /-> 1x1 conv (mask prediction)
+ in_4 -> 1x1 conv -----> 3x3 convs (*4)
+ | \-> 1x1 conv (feature)
+ in_5 -> 1x1 conv ---
+ """ # noqa: W605
+
+ def __init__(
+ self,
+ num_ins: int,
+ fusion_level: int,
+ seg_scale_factor=1 / 8,
+ num_convs: int = 4,
+ in_channels: int = 256,
+ conv_out_channels: int = 256,
+ num_classes: int = 183,
+ conv_cfg: OptConfigType = None,
+ norm_cfg: OptConfigType = None,
+ ignore_label: int = None,
+ loss_weight: float = None,
+ loss_seg: ConfigDict = dict(
+ type='CrossEntropyLoss', ignore_index=255, loss_weight=0.2),
+ init_cfg: MultiConfig = dict(
+ type='Kaiming', override=dict(name='conv_logits'))
+ ) -> None:
+ super().__init__(init_cfg=init_cfg)
+ self.num_ins = num_ins
+ self.fusion_level = fusion_level
+ self.seg_scale_factor = seg_scale_factor
+ self.num_convs = num_convs
+ self.in_channels = in_channels
+ self.conv_out_channels = conv_out_channels
+ self.num_classes = num_classes
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.fp16_enabled = False
+
+ self.lateral_convs = nn.ModuleList()
+ for i in range(self.num_ins):
+ self.lateral_convs.append(
+ ConvModule(
+ self.in_channels,
+ self.in_channels,
+ 1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ inplace=False))
+
+ self.convs = nn.ModuleList()
+ for i in range(self.num_convs):
+ in_channels = self.in_channels if i == 0 else conv_out_channels
+ self.convs.append(
+ ConvModule(
+ in_channels,
+ conv_out_channels,
+ 3,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg))
+ self.conv_embedding = ConvModule(
+ conv_out_channels,
+ conv_out_channels,
+ 1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg)
+ self.conv_logits = nn.Conv2d(conv_out_channels, self.num_classes, 1)
+ if ignore_label:
+ loss_seg['ignore_index'] = ignore_label
+ if loss_weight:
+ loss_seg['loss_weight'] = loss_weight
+ if ignore_label or loss_weight:
+ warnings.warn('``ignore_label`` and ``loss_weight`` would be '
+ 'deprecated soon. Please set ``ingore_index`` and '
+ '``loss_weight`` in ``loss_seg`` instead.')
+ self.criterion = MODELS.build(loss_seg)
+
+ def forward(self, feats: Tuple[Tensor]) -> Tuple[Tensor]:
+ """Forward function.
+
+ Args:
+ feats (tuple[Tensor]): Multi scale feature maps.
+
+ Returns:
+ tuple[Tensor]:
+
+ - mask_preds (Tensor): Predicted mask logits.
+ - x (Tensor): Fused feature.
+ """
+ x = self.lateral_convs[self.fusion_level](feats[self.fusion_level])
+ fused_size = tuple(x.shape[-2:])
+ for i, feat in enumerate(feats):
+ if i != self.fusion_level:
+ feat = F.interpolate(
+ feat, size=fused_size, mode='bilinear', align_corners=True)
+ # fix runtime error of "+=" inplace operation in PyTorch 1.10
+ x = x + self.lateral_convs[i](feat)
+
+ for i in range(self.num_convs):
+ x = self.convs[i](x)
+
+ mask_preds = self.conv_logits(x)
+ x = self.conv_embedding(x)
+ return mask_preds, x
+
+ def loss(self, mask_preds: Tensor, labels: Tensor) -> Tensor:
+ """Loss function.
+
+ Args:
+ mask_preds (Tensor): Predicted mask logits.
+ labels (Tensor): Ground truth.
+
+ Returns:
+ Tensor: Semantic segmentation loss.
+ """
+ labels = F.interpolate(
+ labels.float(), scale_factor=self.seg_scale_factor, mode='nearest')
+ labels = labels.squeeze(1).long()
+ loss_semantic_seg = self.criterion(mask_preds, labels)
+ return loss_semantic_seg
diff --git a/mmdet/models/roi_heads/mask_heads/global_context_head.py b/mmdet/models/roi_heads/mask_heads/global_context_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..cb947ea582227d2b74112cbb930e1a3f85b77ff5
--- /dev/null
+++ b/mmdet/models/roi_heads/mask_heads/global_context_head.py
@@ -0,0 +1,127 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Tuple
+
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+from mmengine.model import BaseModule
+from torch import Tensor
+
+from mmdet.models.layers import ResLayer, SimplifiedBasicBlock
+from mmdet.registry import MODELS
+from mmdet.utils import MultiConfig, OptConfigType
+
+
+@MODELS.register_module()
+class GlobalContextHead(BaseModule):
+ """Global context head used in `SCNet `_.
+
+ Args:
+ num_convs (int, optional): number of convolutional layer in GlbCtxHead.
+ Defaults to 4.
+ in_channels (int, optional): number of input channels. Defaults to 256.
+ conv_out_channels (int, optional): number of output channels before
+ classification layer. Defaults to 256.
+ num_classes (int, optional): number of classes. Defaults to 80.
+ loss_weight (float, optional): global context loss weight.
+ Defaults to 1.
+ conv_cfg (dict, optional): config to init conv layer. Defaults to None.
+ norm_cfg (dict, optional): config to init norm layer. Defaults to None.
+ conv_to_res (bool, optional): if True, 2 convs will be grouped into
+ 1 `SimplifiedBasicBlock` using a skip connection.
+ Defaults to False.
+ init_cfg (:obj:`ConfigDict` or dict or list[dict] or
+ list[:obj:`ConfigDict`]): Initialization config dict. Defaults to
+ dict(type='Normal', std=0.01, override=dict(name='fc')).
+ """
+
+ def __init__(
+ self,
+ num_convs: int = 4,
+ in_channels: int = 256,
+ conv_out_channels: int = 256,
+ num_classes: int = 80,
+ loss_weight: float = 1.0,
+ conv_cfg: OptConfigType = None,
+ norm_cfg: OptConfigType = None,
+ conv_to_res: bool = False,
+ init_cfg: MultiConfig = dict(
+ type='Normal', std=0.01, override=dict(name='fc'))
+ ) -> None:
+ super().__init__(init_cfg=init_cfg)
+ self.num_convs = num_convs
+ self.in_channels = in_channels
+ self.conv_out_channels = conv_out_channels
+ self.num_classes = num_classes
+ self.loss_weight = loss_weight
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.conv_to_res = conv_to_res
+ self.fp16_enabled = False
+
+ if self.conv_to_res:
+ num_res_blocks = num_convs // 2
+ self.convs = ResLayer(
+ SimplifiedBasicBlock,
+ in_channels,
+ self.conv_out_channels,
+ num_res_blocks,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg)
+ self.num_convs = num_res_blocks
+ else:
+ self.convs = nn.ModuleList()
+ for i in range(self.num_convs):
+ in_channels = self.in_channels if i == 0 else conv_out_channels
+ self.convs.append(
+ ConvModule(
+ in_channels,
+ conv_out_channels,
+ 3,
+ padding=1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg))
+
+ self.pool = nn.AdaptiveAvgPool2d(1)
+ self.fc = nn.Linear(conv_out_channels, num_classes)
+
+ self.criterion = nn.BCEWithLogitsLoss()
+
+ def forward(self, feats: Tuple[Tensor]) -> Tuple[Tensor]:
+ """Forward function.
+
+ Args:
+ feats (Tuple[Tensor]): Multi-scale feature maps.
+
+ Returns:
+ Tuple[Tensor]:
+
+ - mc_pred (Tensor): Multi-class prediction.
+ - x (Tensor): Global context feature.
+ """
+ x = feats[-1]
+ for i in range(self.num_convs):
+ x = self.convs[i](x)
+ x = self.pool(x)
+
+ # multi-class prediction
+ mc_pred = x.reshape(x.size(0), -1)
+ mc_pred = self.fc(mc_pred)
+
+ return mc_pred, x
+
+ def loss(self, pred: Tensor, labels: List[Tensor]) -> Tensor:
+ """Loss function.
+
+ Args:
+ pred (Tensor): Logits.
+ labels (list[Tensor]): Grouth truths.
+
+ Returns:
+ Tensor: Loss.
+ """
+ labels = [lbl.unique() for lbl in labels]
+ targets = pred.new_zeros(pred.size())
+ for i, label in enumerate(labels):
+ targets[i, label] = 1.0
+ loss = self.loss_weight * self.criterion(pred, targets)
+ return loss
diff --git a/mmdet/models/roi_heads/mask_heads/grid_head.py b/mmdet/models/roi_heads/mask_heads/grid_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..d9514ae7bcfc1b7d5613fa0107e9bd087e13dd46
--- /dev/null
+++ b/mmdet/models/roi_heads/mask_heads/grid_head.py
@@ -0,0 +1,490 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Tuple
+
+import numpy as np
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule
+from mmengine.config import ConfigDict
+from mmengine.model import BaseModule
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmdet.models.task_modules.samplers import SamplingResult
+from mmdet.registry import MODELS
+from mmdet.utils import ConfigType, InstanceList, MultiConfig, OptConfigType
+
+
+@MODELS.register_module()
+class GridHead(BaseModule):
+ """Implementation of `Grid Head `_
+
+ Args:
+ grid_points (int): The number of grid points. Defaults to 9.
+ num_convs (int): The number of convolution layers. Defaults to 8.
+ roi_feat_size (int): RoI feature size. Default to 14.
+ in_channels (int): The channel number of inputs features.
+ Defaults to 256.
+ conv_kernel_size (int): The kernel size of convolution layers.
+ Defaults to 3.
+ point_feat_channels (int): The number of channels of each point
+ features. Defaults to 64.
+ class_agnostic (bool): Whether use class agnostic classification.
+ If so, the output channels of logits will be 1. Defaults to False.
+ loss_grid (:obj:`ConfigDict` or dict): Config of grid loss.
+ conv_cfg (:obj:`ConfigDict` or dict, optional) dictionary to
+ construct and config conv layer.
+ norm_cfg (:obj:`ConfigDict` or dict): dictionary to construct and
+ config norm layer.
+ init_cfg (:obj:`ConfigDict` or dict or list[:obj:`ConfigDict` or \
+ dict]): Initialization config dict.
+ """
+
+ def __init__(
+ self,
+ grid_points: int = 9,
+ num_convs: int = 8,
+ roi_feat_size: int = 14,
+ in_channels: int = 256,
+ conv_kernel_size: int = 3,
+ point_feat_channels: int = 64,
+ deconv_kernel_size: int = 4,
+ class_agnostic: bool = False,
+ loss_grid: ConfigType = dict(
+ type='CrossEntropyLoss', use_sigmoid=True, loss_weight=15),
+ conv_cfg: OptConfigType = None,
+ norm_cfg: ConfigType = dict(type='GN', num_groups=36),
+ init_cfg: MultiConfig = [
+ dict(type='Kaiming', layer=['Conv2d', 'Linear']),
+ dict(
+ type='Normal',
+ layer='ConvTranspose2d',
+ std=0.001,
+ override=dict(
+ type='Normal',
+ name='deconv2',
+ std=0.001,
+ bias=-np.log(0.99 / 0.01)))
+ ]
+ ) -> None:
+ super().__init__(init_cfg=init_cfg)
+ self.grid_points = grid_points
+ self.num_convs = num_convs
+ self.roi_feat_size = roi_feat_size
+ self.in_channels = in_channels
+ self.conv_kernel_size = conv_kernel_size
+ self.point_feat_channels = point_feat_channels
+ self.conv_out_channels = self.point_feat_channels * self.grid_points
+ self.class_agnostic = class_agnostic
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ if isinstance(norm_cfg, dict) and norm_cfg['type'] == 'GN':
+ assert self.conv_out_channels % norm_cfg['num_groups'] == 0
+
+ assert self.grid_points >= 4
+ self.grid_size = int(np.sqrt(self.grid_points))
+ if self.grid_size * self.grid_size != self.grid_points:
+ raise ValueError('grid_points must be a square number')
+
+ # the predicted heatmap is half of whole_map_size
+ if not isinstance(self.roi_feat_size, int):
+ raise ValueError('Only square RoIs are supporeted in Grid R-CNN')
+ self.whole_map_size = self.roi_feat_size * 4
+
+ # compute point-wise sub-regions
+ self.sub_regions = self.calc_sub_regions()
+
+ self.convs = []
+ for i in range(self.num_convs):
+ in_channels = (
+ self.in_channels if i == 0 else self.conv_out_channels)
+ stride = 2 if i == 0 else 1
+ padding = (self.conv_kernel_size - 1) // 2
+ self.convs.append(
+ ConvModule(
+ in_channels,
+ self.conv_out_channels,
+ self.conv_kernel_size,
+ stride=stride,
+ padding=padding,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg,
+ bias=True))
+ self.convs = nn.Sequential(*self.convs)
+
+ self.deconv1 = nn.ConvTranspose2d(
+ self.conv_out_channels,
+ self.conv_out_channels,
+ kernel_size=deconv_kernel_size,
+ stride=2,
+ padding=(deconv_kernel_size - 2) // 2,
+ groups=grid_points)
+ self.norm1 = nn.GroupNorm(grid_points, self.conv_out_channels)
+ self.deconv2 = nn.ConvTranspose2d(
+ self.conv_out_channels,
+ grid_points,
+ kernel_size=deconv_kernel_size,
+ stride=2,
+ padding=(deconv_kernel_size - 2) // 2,
+ groups=grid_points)
+
+ # find the 4-neighbor of each grid point
+ self.neighbor_points = []
+ grid_size = self.grid_size
+ for i in range(grid_size): # i-th column
+ for j in range(grid_size): # j-th row
+ neighbors = []
+ if i > 0: # left: (i - 1, j)
+ neighbors.append((i - 1) * grid_size + j)
+ if j > 0: # up: (i, j - 1)
+ neighbors.append(i * grid_size + j - 1)
+ if j < grid_size - 1: # down: (i, j + 1)
+ neighbors.append(i * grid_size + j + 1)
+ if i < grid_size - 1: # right: (i + 1, j)
+ neighbors.append((i + 1) * grid_size + j)
+ self.neighbor_points.append(tuple(neighbors))
+ # total edges in the grid
+ self.num_edges = sum([len(p) for p in self.neighbor_points])
+
+ self.forder_trans = nn.ModuleList() # first-order feature transition
+ self.sorder_trans = nn.ModuleList() # second-order feature transition
+ for neighbors in self.neighbor_points:
+ fo_trans = nn.ModuleList()
+ so_trans = nn.ModuleList()
+ for _ in range(len(neighbors)):
+ # each transition module consists of a 5x5 depth-wise conv and
+ # 1x1 conv.
+ fo_trans.append(
+ nn.Sequential(
+ nn.Conv2d(
+ self.point_feat_channels,
+ self.point_feat_channels,
+ 5,
+ stride=1,
+ padding=2,
+ groups=self.point_feat_channels),
+ nn.Conv2d(self.point_feat_channels,
+ self.point_feat_channels, 1)))
+ so_trans.append(
+ nn.Sequential(
+ nn.Conv2d(
+ self.point_feat_channels,
+ self.point_feat_channels,
+ 5,
+ 1,
+ 2,
+ groups=self.point_feat_channels),
+ nn.Conv2d(self.point_feat_channels,
+ self.point_feat_channels, 1)))
+ self.forder_trans.append(fo_trans)
+ self.sorder_trans.append(so_trans)
+
+ self.loss_grid = MODELS.build(loss_grid)
+
+ def forward(self, x: Tensor) -> Dict[str, Tensor]:
+ """forward function of ``GridHead``.
+
+ Args:
+ x (Tensor): RoI features, has shape
+ (num_rois, num_channels, roi_feat_size, roi_feat_size).
+
+ Returns:
+ Dict[str, Tensor]: Return a dict including fused and unfused
+ heatmap.
+ """
+ assert x.shape[-1] == x.shape[-2] == self.roi_feat_size
+ # RoI feature transformation, downsample 2x
+ x = self.convs(x)
+
+ c = self.point_feat_channels
+ # first-order fusion
+ x_fo = [None for _ in range(self.grid_points)]
+ for i, points in enumerate(self.neighbor_points):
+ x_fo[i] = x[:, i * c:(i + 1) * c]
+ for j, point_idx in enumerate(points):
+ x_fo[i] = x_fo[i] + self.forder_trans[i][j](
+ x[:, point_idx * c:(point_idx + 1) * c])
+
+ # second-order fusion
+ x_so = [None for _ in range(self.grid_points)]
+ for i, points in enumerate(self.neighbor_points):
+ x_so[i] = x[:, i * c:(i + 1) * c]
+ for j, point_idx in enumerate(points):
+ x_so[i] = x_so[i] + self.sorder_trans[i][j](x_fo[point_idx])
+
+ # predicted heatmap with fused features
+ x2 = torch.cat(x_so, dim=1)
+ x2 = self.deconv1(x2)
+ x2 = F.relu(self.norm1(x2), inplace=True)
+ heatmap = self.deconv2(x2)
+
+ # predicted heatmap with original features (applicable during training)
+ if self.training:
+ x1 = x
+ x1 = self.deconv1(x1)
+ x1 = F.relu(self.norm1(x1), inplace=True)
+ heatmap_unfused = self.deconv2(x1)
+ else:
+ heatmap_unfused = heatmap
+
+ return dict(fused=heatmap, unfused=heatmap_unfused)
+
+ def calc_sub_regions(self) -> List[Tuple[float]]:
+ """Compute point specific representation regions.
+
+ See `Grid R-CNN Plus `_ for details.
+ """
+ # to make it consistent with the original implementation, half_size
+ # is computed as 2 * quarter_size, which is smaller
+ half_size = self.whole_map_size // 4 * 2
+ sub_regions = []
+ for i in range(self.grid_points):
+ x_idx = i // self.grid_size
+ y_idx = i % self.grid_size
+ if x_idx == 0:
+ sub_x1 = 0
+ elif x_idx == self.grid_size - 1:
+ sub_x1 = half_size
+ else:
+ ratio = x_idx / (self.grid_size - 1) - 0.25
+ sub_x1 = max(int(ratio * self.whole_map_size), 0)
+
+ if y_idx == 0:
+ sub_y1 = 0
+ elif y_idx == self.grid_size - 1:
+ sub_y1 = half_size
+ else:
+ ratio = y_idx / (self.grid_size - 1) - 0.25
+ sub_y1 = max(int(ratio * self.whole_map_size), 0)
+ sub_regions.append(
+ (sub_x1, sub_y1, sub_x1 + half_size, sub_y1 + half_size))
+ return sub_regions
+
+ def get_targets(self, sampling_results: List[SamplingResult],
+ rcnn_train_cfg: ConfigDict) -> Tensor:
+ """Calculate the ground truth for all samples in a batch according to
+ the sampling_results.".
+
+ Args:
+ sampling_results (List[:obj:`SamplingResult`]): Assign results of
+ all images in a batch after sampling.
+ rcnn_train_cfg (:obj:`ConfigDict`): `train_cfg` of RCNN.
+
+ Returns:
+ Tensor: Grid heatmap targets.
+ """
+ # mix all samples (across images) together.
+ pos_bboxes = torch.cat([res.pos_bboxes for res in sampling_results],
+ dim=0).cpu()
+ pos_gt_bboxes = torch.cat(
+ [res.pos_gt_bboxes for res in sampling_results], dim=0).cpu()
+ assert pos_bboxes.shape == pos_gt_bboxes.shape
+
+ # expand pos_bboxes to 2x of original size
+ x1 = pos_bboxes[:, 0] - (pos_bboxes[:, 2] - pos_bboxes[:, 0]) / 2
+ y1 = pos_bboxes[:, 1] - (pos_bboxes[:, 3] - pos_bboxes[:, 1]) / 2
+ x2 = pos_bboxes[:, 2] + (pos_bboxes[:, 2] - pos_bboxes[:, 0]) / 2
+ y2 = pos_bboxes[:, 3] + (pos_bboxes[:, 3] - pos_bboxes[:, 1]) / 2
+ pos_bboxes = torch.stack([x1, y1, x2, y2], dim=-1)
+ pos_bbox_ws = (pos_bboxes[:, 2] - pos_bboxes[:, 0]).unsqueeze(-1)
+ pos_bbox_hs = (pos_bboxes[:, 3] - pos_bboxes[:, 1]).unsqueeze(-1)
+
+ num_rois = pos_bboxes.shape[0]
+ map_size = self.whole_map_size
+ # this is not the final target shape
+ targets = torch.zeros((num_rois, self.grid_points, map_size, map_size),
+ dtype=torch.float)
+
+ # pre-compute interpolation factors for all grid points.
+ # the first item is the factor of x-dim, and the second is y-dim.
+ # for a 9-point grid, factors are like (1, 0), (0.5, 0.5), (0, 1)
+ factors = []
+ for j in range(self.grid_points):
+ x_idx = j // self.grid_size
+ y_idx = j % self.grid_size
+ factors.append((1 - x_idx / (self.grid_size - 1),
+ 1 - y_idx / (self.grid_size - 1)))
+
+ radius = rcnn_train_cfg.pos_radius
+ radius2 = radius**2
+ for i in range(num_rois):
+ # ignore small bboxes
+ if (pos_bbox_ws[i] <= self.grid_size
+ or pos_bbox_hs[i] <= self.grid_size):
+ continue
+ # for each grid point, mark a small circle as positive
+ for j in range(self.grid_points):
+ factor_x, factor_y = factors[j]
+ gridpoint_x = factor_x * pos_gt_bboxes[i, 0] + (
+ 1 - factor_x) * pos_gt_bboxes[i, 2]
+ gridpoint_y = factor_y * pos_gt_bboxes[i, 1] + (
+ 1 - factor_y) * pos_gt_bboxes[i, 3]
+
+ cx = int((gridpoint_x - pos_bboxes[i, 0]) / pos_bbox_ws[i] *
+ map_size)
+ cy = int((gridpoint_y - pos_bboxes[i, 1]) / pos_bbox_hs[i] *
+ map_size)
+
+ for x in range(cx - radius, cx + radius + 1):
+ for y in range(cy - radius, cy + radius + 1):
+ if x >= 0 and x < map_size and y >= 0 and y < map_size:
+ if (x - cx)**2 + (y - cy)**2 <= radius2:
+ targets[i, j, y, x] = 1
+ # reduce the target heatmap size by a half
+ # proposed in Grid R-CNN Plus (https://arxiv.org/abs/1906.05688).
+ sub_targets = []
+ for i in range(self.grid_points):
+ sub_x1, sub_y1, sub_x2, sub_y2 = self.sub_regions[i]
+ sub_targets.append(targets[:, [i], sub_y1:sub_y2, sub_x1:sub_x2])
+ sub_targets = torch.cat(sub_targets, dim=1)
+ sub_targets = sub_targets.to(sampling_results[0].pos_bboxes.device)
+ return sub_targets
+
+ def loss(self, grid_pred: Tensor, sample_idx: Tensor,
+ sampling_results: List[SamplingResult],
+ rcnn_train_cfg: ConfigDict) -> dict:
+ """Calculate the loss based on the features extracted by the grid head.
+
+ Args:
+ grid_pred (dict[str, Tensor]): Outputs of grid_head forward.
+ sample_idx (Tensor): The sampling index of ``grid_pred``.
+ sampling_results (List[obj:SamplingResult]): Assign results of
+ all images in a batch after sampling.
+ rcnn_train_cfg (obj:`ConfigDict`): `train_cfg` of RCNN.
+
+ Returns:
+ dict: A dictionary of loss and targets components.
+ """
+ grid_targets = self.get_targets(sampling_results, rcnn_train_cfg)
+ grid_targets = grid_targets[sample_idx]
+
+ loss_fused = self.loss_grid(grid_pred['fused'], grid_targets)
+ loss_unfused = self.loss_grid(grid_pred['unfused'], grid_targets)
+ loss_grid = loss_fused + loss_unfused
+ return dict(loss_grid=loss_grid)
+
+ def predict_by_feat(self,
+ grid_preds: Dict[str, Tensor],
+ results_list: List[InstanceData],
+ batch_img_metas: List[dict],
+ rescale: bool = False) -> InstanceList:
+ """Adjust the predicted bboxes from bbox head.
+
+ Args:
+ grid_preds (dict[str, Tensor]): dictionary outputted by forward
+ function.
+ results_list (list[:obj:`InstanceData`]): Detection results of
+ each image.
+ batch_img_metas (list[dict]): List of image information.
+ rescale (bool): If True, return boxes in original image space.
+ Defaults to False.
+
+ Returns:
+ list[:obj:`InstanceData`]: Detection results of each image
+ after the post process. Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape \
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4), the last \
+ dimension 4 arrange as (x1, y1, x2, y2).
+ """
+ num_roi_per_img = tuple(res.bboxes.size(0) for res in results_list)
+ grid_preds = {
+ k: v.split(num_roi_per_img, 0)
+ for k, v in grid_preds.items()
+ }
+
+ for i, results in enumerate(results_list):
+ if len(results) != 0:
+ bboxes = self._predict_by_feat_single(
+ grid_pred=grid_preds['fused'][i],
+ bboxes=results.bboxes,
+ img_meta=batch_img_metas[i],
+ rescale=rescale)
+ results.bboxes = bboxes
+ return results_list
+
+ def _predict_by_feat_single(self,
+ grid_pred: Tensor,
+ bboxes: Tensor,
+ img_meta: dict,
+ rescale: bool = False) -> Tensor:
+ """Adjust ``bboxes`` according to ``grid_pred``.
+
+ Args:
+ grid_pred (Tensor): Grid fused heatmap.
+ bboxes (Tensor): Predicted bboxes, has shape (n, 4)
+ img_meta (dict): image information.
+ rescale (bool): If True, return boxes in original image space.
+ Defaults to False.
+
+ Returns:
+ Tensor: adjusted bboxes.
+ """
+ assert bboxes.size(0) == grid_pred.size(0)
+ grid_pred = grid_pred.sigmoid()
+
+ R, c, h, w = grid_pred.shape
+ half_size = self.whole_map_size // 4 * 2
+ assert h == w == half_size
+ assert c == self.grid_points
+
+ # find the point with max scores in the half-sized heatmap
+ grid_pred = grid_pred.view(R * c, h * w)
+ pred_scores, pred_position = grid_pred.max(dim=1)
+ xs = pred_position % w
+ ys = pred_position // w
+
+ # get the position in the whole heatmap instead of half-sized heatmap
+ for i in range(self.grid_points):
+ xs[i::self.grid_points] += self.sub_regions[i][0]
+ ys[i::self.grid_points] += self.sub_regions[i][1]
+
+ # reshape to (num_rois, grid_points)
+ pred_scores, xs, ys = tuple(
+ map(lambda x: x.view(R, c), [pred_scores, xs, ys]))
+
+ # get expanded pos_bboxes
+ widths = (bboxes[:, 2] - bboxes[:, 0]).unsqueeze(-1)
+ heights = (bboxes[:, 3] - bboxes[:, 1]).unsqueeze(-1)
+ x1 = (bboxes[:, 0, None] - widths / 2)
+ y1 = (bboxes[:, 1, None] - heights / 2)
+ # map the grid point to the absolute coordinates
+ abs_xs = (xs.float() + 0.5) / w * widths + x1
+ abs_ys = (ys.float() + 0.5) / h * heights + y1
+
+ # get the grid points indices that fall on the bbox boundaries
+ x1_inds = [i for i in range(self.grid_size)]
+ y1_inds = [i * self.grid_size for i in range(self.grid_size)]
+ x2_inds = [
+ self.grid_points - self.grid_size + i
+ for i in range(self.grid_size)
+ ]
+ y2_inds = [(i + 1) * self.grid_size - 1 for i in range(self.grid_size)]
+
+ # voting of all grid points on some boundary
+ bboxes_x1 = (abs_xs[:, x1_inds] * pred_scores[:, x1_inds]).sum(
+ dim=1, keepdim=True) / (
+ pred_scores[:, x1_inds].sum(dim=1, keepdim=True))
+ bboxes_y1 = (abs_ys[:, y1_inds] * pred_scores[:, y1_inds]).sum(
+ dim=1, keepdim=True) / (
+ pred_scores[:, y1_inds].sum(dim=1, keepdim=True))
+ bboxes_x2 = (abs_xs[:, x2_inds] * pred_scores[:, x2_inds]).sum(
+ dim=1, keepdim=True) / (
+ pred_scores[:, x2_inds].sum(dim=1, keepdim=True))
+ bboxes_y2 = (abs_ys[:, y2_inds] * pred_scores[:, y2_inds]).sum(
+ dim=1, keepdim=True) / (
+ pred_scores[:, y2_inds].sum(dim=1, keepdim=True))
+
+ bboxes = torch.cat([bboxes_x1, bboxes_y1, bboxes_x2, bboxes_y2], dim=1)
+ bboxes[:, [0, 2]].clamp_(min=0, max=img_meta['img_shape'][1])
+ bboxes[:, [1, 3]].clamp_(min=0, max=img_meta['img_shape'][0])
+
+ if rescale:
+ assert img_meta.get('scale_factor') is not None
+ bboxes /= bboxes.new_tensor(img_meta['scale_factor']).repeat(
+ (1, 2))
+
+ return bboxes
diff --git a/mmdet/models/roi_heads/mask_heads/htc_mask_head.py b/mmdet/models/roi_heads/mask_heads/htc_mask_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..73ac1e6e5f115927e1a2accdd693aae512cac753
--- /dev/null
+++ b/mmdet/models/roi_heads/mask_heads/htc_mask_head.py
@@ -0,0 +1,65 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Optional, Union
+
+from mmcv.cnn import ConvModule
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from .fcn_mask_head import FCNMaskHead
+
+
+@MODELS.register_module()
+class HTCMaskHead(FCNMaskHead):
+ """Mask head for HTC.
+
+ Args:
+ with_conv_res (bool): Whether add conv layer for ``res_feat``.
+ Defaults to True.
+ """
+
+ def __init__(self, with_conv_res: bool = True, *args, **kwargs) -> None:
+ super().__init__(*args, **kwargs)
+ self.with_conv_res = with_conv_res
+ if self.with_conv_res:
+ self.conv_res = ConvModule(
+ self.conv_out_channels,
+ self.conv_out_channels,
+ 1,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg)
+
+ def forward(self,
+ x: Tensor,
+ res_feat: Optional[Tensor] = None,
+ return_logits: bool = True,
+ return_feat: bool = True) -> Union[Tensor, List[Tensor]]:
+ """
+ Args:
+ x (Tensor): Feature map.
+ res_feat (Tensor, optional): Feature for residual connection.
+ Defaults to None.
+ return_logits (bool): Whether return mask logits. Defaults to True.
+ return_feat (bool): Whether return feature map. Defaults to True.
+
+ Returns:
+ Union[Tensor, List[Tensor]]: The return result is one of three
+ results: res_feat, logits, or [logits, res_feat].
+ """
+ assert not (not return_logits and not return_feat)
+ if res_feat is not None:
+ assert self.with_conv_res
+ res_feat = self.conv_res(res_feat)
+ x = x + res_feat
+ for conv in self.convs:
+ x = conv(x)
+ res_feat = x
+ outs = []
+ if return_logits:
+ x = self.upsample(x)
+ if self.upsample_method == 'deconv':
+ x = self.relu(x)
+ mask_preds = self.conv_logits(x)
+ outs.append(mask_preds)
+ if return_feat:
+ outs.append(res_feat)
+ return outs if len(outs) > 1 else outs[0]
diff --git a/mmdet/models/roi_heads/mask_heads/mask_point_head.py b/mmdet/models/roi_heads/mask_heads/mask_point_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..2084f59f07b48bf2e5b05bb7af61172df8737478
--- /dev/null
+++ b/mmdet/models/roi_heads/mask_heads/mask_point_head.py
@@ -0,0 +1,284 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+# Modified from https://github.com/facebookresearch/detectron2/tree/master/projects/PointRend/point_head/point_head.py # noqa
+
+from typing import List, Tuple
+
+import torch
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+from mmcv.ops import point_sample, rel_roi_point_to_rel_img_point
+from mmengine.model import BaseModule
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmdet.models.task_modules.samplers import SamplingResult
+from mmdet.models.utils import (get_uncertain_point_coords_with_randomness,
+ get_uncertainty)
+from mmdet.registry import MODELS
+from mmdet.structures.bbox import bbox2roi
+from mmdet.utils import ConfigType, InstanceList, MultiConfig, OptConfigType
+
+
+@MODELS.register_module()
+class MaskPointHead(BaseModule):
+ """A mask point head use in PointRend.
+
+ ``MaskPointHead`` use shared multi-layer perceptron (equivalent to
+ nn.Conv1d) to predict the logit of input points. The fine-grained feature
+ and coarse feature will be concatenate together for predication.
+
+ Args:
+ num_fcs (int): Number of fc layers in the head. Defaults to 3.
+ in_channels (int): Number of input channels. Defaults to 256.
+ fc_channels (int): Number of fc channels. Defaults to 256.
+ num_classes (int): Number of classes for logits. Defaults to 80.
+ class_agnostic (bool): Whether use class agnostic classification.
+ If so, the output channels of logits will be 1. Defaults to False.
+ coarse_pred_each_layer (bool): Whether concatenate coarse feature with
+ the output of each fc layer. Defaults to True.
+ conv_cfg (:obj:`ConfigDict` or dict): Dictionary to construct
+ and config conv layer. Defaults to dict(type='Conv1d')).
+ norm_cfg (:obj:`ConfigDict` or dict, optional): Dictionary to construct
+ and config norm layer. Defaults to None.
+ loss_point (:obj:`ConfigDict` or dict): Dictionary to construct and
+ config loss layer of point head. Defaults to
+ dict(type='CrossEntropyLoss', use_mask=True, loss_weight=1.0).
+ init_cfg (:obj:`ConfigDict` or dict or list[:obj:`ConfigDict` or \
+ dict], optional): Initialization config dict.
+ """
+
+ def __init__(
+ self,
+ num_classes: int,
+ num_fcs: int = 3,
+ in_channels: int = 256,
+ fc_channels: int = 256,
+ class_agnostic: bool = False,
+ coarse_pred_each_layer: bool = True,
+ conv_cfg: ConfigType = dict(type='Conv1d'),
+ norm_cfg: OptConfigType = None,
+ act_cfg: ConfigType = dict(type='ReLU'),
+ loss_point: ConfigType = dict(
+ type='CrossEntropyLoss', use_mask=True, loss_weight=1.0),
+ init_cfg: MultiConfig = dict(
+ type='Normal', std=0.001, override=dict(name='fc_logits'))
+ ) -> None:
+ super().__init__(init_cfg=init_cfg)
+ self.num_fcs = num_fcs
+ self.in_channels = in_channels
+ self.fc_channels = fc_channels
+ self.num_classes = num_classes
+ self.class_agnostic = class_agnostic
+ self.coarse_pred_each_layer = coarse_pred_each_layer
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.loss_point = MODELS.build(loss_point)
+
+ fc_in_channels = in_channels + num_classes
+ self.fcs = nn.ModuleList()
+ for _ in range(num_fcs):
+ fc = ConvModule(
+ fc_in_channels,
+ fc_channels,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ self.fcs.append(fc)
+ fc_in_channels = fc_channels
+ fc_in_channels += num_classes if self.coarse_pred_each_layer else 0
+
+ out_channels = 1 if self.class_agnostic else self.num_classes
+ self.fc_logits = nn.Conv1d(
+ fc_in_channels, out_channels, kernel_size=1, stride=1, padding=0)
+
+ def forward(self, fine_grained_feats: Tensor,
+ coarse_feats: Tensor) -> Tensor:
+ """Classify each point base on fine grained and coarse feats.
+
+ Args:
+ fine_grained_feats (Tensor): Fine grained feature sampled from FPN,
+ shape (num_rois, in_channels, num_points).
+ coarse_feats (Tensor): Coarse feature sampled from CoarseMaskHead,
+ shape (num_rois, num_classes, num_points).
+
+ Returns:
+ Tensor: Point classification results,
+ shape (num_rois, num_class, num_points).
+ """
+
+ x = torch.cat([fine_grained_feats, coarse_feats], dim=1)
+ for fc in self.fcs:
+ x = fc(x)
+ if self.coarse_pred_each_layer:
+ x = torch.cat((x, coarse_feats), dim=1)
+ return self.fc_logits(x)
+
+ def get_targets(self, rois: Tensor, rel_roi_points: Tensor,
+ sampling_results: List[SamplingResult],
+ batch_gt_instances: InstanceList,
+ cfg: ConfigType) -> Tensor:
+ """Get training targets of MaskPointHead for all images.
+
+ Args:
+ rois (Tensor): Region of Interest, shape (num_rois, 5).
+ rel_roi_points (Tensor): Points coordinates relative to RoI, shape
+ (num_rois, num_points, 2).
+ sampling_results (:obj:`SamplingResult`): Sampling result after
+ sampling and assignment.
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes``, ``labels``, and
+ ``masks`` attributes.
+ cfg (obj:`ConfigDict` or dict): Training cfg.
+
+ Returns:
+ Tensor: Point target, shape (num_rois, num_points).
+ """
+
+ num_imgs = len(sampling_results)
+ rois_list = []
+ rel_roi_points_list = []
+ for batch_ind in range(num_imgs):
+ inds = (rois[:, 0] == batch_ind)
+ rois_list.append(rois[inds])
+ rel_roi_points_list.append(rel_roi_points[inds])
+ pos_assigned_gt_inds_list = [
+ res.pos_assigned_gt_inds for res in sampling_results
+ ]
+ cfg_list = [cfg for _ in range(num_imgs)]
+
+ point_targets = map(self._get_targets_single, rois_list,
+ rel_roi_points_list, pos_assigned_gt_inds_list,
+ batch_gt_instances, cfg_list)
+ point_targets = list(point_targets)
+
+ if len(point_targets) > 0:
+ point_targets = torch.cat(point_targets)
+
+ return point_targets
+
+ def _get_targets_single(self, rois: Tensor, rel_roi_points: Tensor,
+ pos_assigned_gt_inds: Tensor,
+ gt_instances: InstanceData,
+ cfg: ConfigType) -> Tensor:
+ """Get training target of MaskPointHead for each image."""
+ num_pos = rois.size(0)
+ num_points = cfg.num_points
+ if num_pos > 0:
+ gt_masks_th = (
+ gt_instances.masks.to_tensor(rois.dtype,
+ rois.device).index_select(
+ 0, pos_assigned_gt_inds))
+ gt_masks_th = gt_masks_th.unsqueeze(1)
+ rel_img_points = rel_roi_point_to_rel_img_point(
+ rois, rel_roi_points, gt_masks_th)
+ point_targets = point_sample(gt_masks_th,
+ rel_img_points).squeeze(1)
+ else:
+ point_targets = rois.new_zeros((0, num_points))
+ return point_targets
+
+ def loss_and_target(self, point_pred: Tensor, rel_roi_points: Tensor,
+ sampling_results: List[SamplingResult],
+ batch_gt_instances: InstanceList,
+ cfg: ConfigType) -> dict:
+ """Calculate loss for MaskPointHead.
+
+ Args:
+ point_pred (Tensor): Point predication result, shape
+ (num_rois, num_classes, num_points).
+ rel_roi_points (Tensor): Points coordinates relative to RoI, shape
+ (num_rois, num_points, 2).
+ sampling_results (:obj:`SamplingResult`): Sampling result after
+ sampling and assignment.
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes``, ``labels``, and
+ ``masks`` attributes.
+ cfg (obj:`ConfigDict` or dict): Training cfg.
+
+ Returns:
+ dict: a dictionary of point loss and point target.
+ """
+ rois = bbox2roi([res.pos_bboxes for res in sampling_results])
+ pos_labels = torch.cat([res.pos_gt_labels for res in sampling_results])
+
+ point_target = self.get_targets(rois, rel_roi_points, sampling_results,
+ batch_gt_instances, cfg)
+ if self.class_agnostic:
+ loss_point = self.loss_point(point_pred, point_target,
+ torch.zeros_like(pos_labels))
+ else:
+ loss_point = self.loss_point(point_pred, point_target, pos_labels)
+
+ return dict(loss_point=loss_point, point_target=point_target)
+
+ def get_roi_rel_points_train(self, mask_preds: Tensor, labels: Tensor,
+ cfg: ConfigType) -> Tensor:
+ """Get ``num_points`` most uncertain points with random points during
+ train.
+
+ Sample points in [0, 1] x [0, 1] coordinate space based on their
+ uncertainty. The uncertainties are calculated for each point using
+ '_get_uncertainty()' function that takes point's logit prediction as
+ input.
+
+ Args:
+ mask_preds (Tensor): A tensor of shape (num_rois, num_classes,
+ mask_height, mask_width) for class-specific or class-agnostic
+ prediction.
+ labels (Tensor): The ground truth class for each instance.
+ cfg (:obj:`ConfigDict` or dict): Training config of point head.
+
+ Returns:
+ point_coords (Tensor): A tensor of shape (num_rois, num_points, 2)
+ that contains the coordinates sampled points.
+ """
+ point_coords = get_uncertain_point_coords_with_randomness(
+ mask_preds, labels, cfg.num_points, cfg.oversample_ratio,
+ cfg.importance_sample_ratio)
+ return point_coords
+
+ def get_roi_rel_points_test(self, mask_preds: Tensor, label_preds: Tensor,
+ cfg: ConfigType) -> Tuple[Tensor, Tensor]:
+ """Get ``num_points`` most uncertain points during test.
+
+ Args:
+ mask_preds (Tensor): A tensor of shape (num_rois, num_classes,
+ mask_height, mask_width) for class-specific or class-agnostic
+ prediction.
+ label_preds (Tensor): The predication class for each instance.
+ cfg (:obj:`ConfigDict` or dict): Testing config of point head.
+
+ Returns:
+ tuple:
+
+ - point_indices (Tensor): A tensor of shape (num_rois, num_points)
+ that contains indices from [0, mask_height x mask_width) of the
+ most uncertain points.
+ - point_coords (Tensor): A tensor of shape (num_rois, num_points,
+ 2) that contains [0, 1] x [0, 1] normalized coordinates of the
+ most uncertain points from the [mask_height, mask_width] grid.
+ """
+ num_points = cfg.subdivision_num_points
+ uncertainty_map = get_uncertainty(mask_preds, label_preds)
+ num_rois, _, mask_height, mask_width = uncertainty_map.shape
+
+ # During ONNX exporting, the type of each elements of 'shape' is
+ # `Tensor(float)`, while it is `float` during PyTorch inference.
+ if isinstance(mask_height, torch.Tensor):
+ h_step = 1.0 / mask_height.float()
+ w_step = 1.0 / mask_width.float()
+ else:
+ h_step = 1.0 / mask_height
+ w_step = 1.0 / mask_width
+ # cast to int to avoid dynamic K for TopK op in ONNX
+ mask_size = int(mask_height * mask_width)
+ uncertainty_map = uncertainty_map.view(num_rois, mask_size)
+ num_points = min(mask_size, num_points)
+ point_indices = uncertainty_map.topk(num_points, dim=1)[1]
+ xs = w_step / 2.0 + (point_indices % mask_width).float() * w_step
+ ys = h_step / 2.0 + (point_indices // mask_width).float() * h_step
+ point_coords = torch.stack([xs, ys], dim=2)
+ return point_indices, point_coords
diff --git a/mmdet/models/roi_heads/mask_heads/maskiou_head.py b/mmdet/models/roi_heads/mask_heads/maskiou_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..8901871e754c491f7bc94eb68a27fa1b50e29148
--- /dev/null
+++ b/mmdet/models/roi_heads/mask_heads/maskiou_head.py
@@ -0,0 +1,277 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Tuple
+
+import numpy as np
+import torch
+import torch.nn as nn
+from mmcv.cnn import Conv2d, Linear, MaxPool2d
+from mmengine.config import ConfigDict
+from mmengine.model import BaseModule
+from mmengine.structures import InstanceData
+from torch import Tensor
+from torch.nn.modules.utils import _pair
+
+from mmdet.models.task_modules.samplers import SamplingResult
+from mmdet.registry import MODELS
+from mmdet.utils import ConfigType, InstanceList, OptMultiConfig
+
+
+@MODELS.register_module()
+class MaskIoUHead(BaseModule):
+ """Mask IoU Head.
+
+ This head predicts the IoU of predicted masks and corresponding gt masks.
+
+ Args:
+ num_convs (int): The number of convolution layers. Defaults to 4.
+ num_fcs (int): The number of fully connected layers. Defaults to 2.
+ roi_feat_size (int): RoI feature size. Default to 14.
+ in_channels (int): The channel number of inputs features.
+ Defaults to 256.
+ conv_out_channels (int): The feature channels of convolution layers.
+ Defaults to 256.
+ fc_out_channels (int): The feature channels of fully connected layers.
+ Defaults to 1024.
+ num_classes (int): Number of categories excluding the background
+ category. Defaults to 80.
+ loss_iou (:obj:`ConfigDict` or dict): IoU loss.
+ init_cfg (:obj:`ConfigDict` or dict or list[:obj:`ConfigDict` or \
+ dict], optional): Initialization config dict.
+ """
+
+ def __init__(
+ self,
+ num_convs: int = 4,
+ num_fcs: int = 2,
+ roi_feat_size: int = 14,
+ in_channels: int = 256,
+ conv_out_channels: int = 256,
+ fc_out_channels: int = 1024,
+ num_classes: int = 80,
+ loss_iou: ConfigType = dict(type='MSELoss', loss_weight=0.5),
+ init_cfg: OptMultiConfig = [
+ dict(type='Kaiming', override=dict(name='convs')),
+ dict(type='Caffe2Xavier', override=dict(name='fcs')),
+ dict(type='Normal', std=0.01, override=dict(name='fc_mask_iou'))
+ ]
+ ) -> None:
+ super().__init__(init_cfg=init_cfg)
+ self.in_channels = in_channels
+ self.conv_out_channels = conv_out_channels
+ self.fc_out_channels = fc_out_channels
+ self.num_classes = num_classes
+
+ self.convs = nn.ModuleList()
+ for i in range(num_convs):
+ if i == 0:
+ # concatenation of mask feature and mask prediction
+ in_channels = self.in_channels + 1
+ else:
+ in_channels = self.conv_out_channels
+ stride = 2 if i == num_convs - 1 else 1
+ self.convs.append(
+ Conv2d(
+ in_channels,
+ self.conv_out_channels,
+ 3,
+ stride=stride,
+ padding=1))
+
+ roi_feat_size = _pair(roi_feat_size)
+ pooled_area = (roi_feat_size[0] // 2) * (roi_feat_size[1] // 2)
+ self.fcs = nn.ModuleList()
+ for i in range(num_fcs):
+ in_channels = (
+ self.conv_out_channels *
+ pooled_area if i == 0 else self.fc_out_channels)
+ self.fcs.append(Linear(in_channels, self.fc_out_channels))
+
+ self.fc_mask_iou = Linear(self.fc_out_channels, self.num_classes)
+ self.relu = nn.ReLU()
+ self.max_pool = MaxPool2d(2, 2)
+ self.loss_iou = MODELS.build(loss_iou)
+
+ def forward(self, mask_feat: Tensor, mask_preds: Tensor) -> Tensor:
+ """Forward function.
+
+ Args:
+ mask_feat (Tensor): Mask features from upstream models.
+ mask_preds (Tensor): Mask predictions from mask head.
+
+ Returns:
+ Tensor: Mask IoU predictions.
+ """
+ mask_preds = mask_preds.sigmoid()
+ mask_pred_pooled = self.max_pool(mask_preds.unsqueeze(1))
+
+ x = torch.cat((mask_feat, mask_pred_pooled), 1)
+
+ for conv in self.convs:
+ x = self.relu(conv(x))
+ x = x.flatten(1)
+ for fc in self.fcs:
+ x = self.relu(fc(x))
+ mask_iou = self.fc_mask_iou(x)
+ return mask_iou
+
+ def loss_and_target(self, mask_iou_pred: Tensor, mask_preds: Tensor,
+ mask_targets: Tensor,
+ sampling_results: List[SamplingResult],
+ batch_gt_instances: InstanceList,
+ rcnn_train_cfg: ConfigDict) -> dict:
+ """Calculate the loss and targets of MaskIoUHead.
+
+ Args:
+ mask_iou_pred (Tensor): Mask IoU predictions results, has shape
+ (num_pos, num_classes)
+ mask_preds (Tensor): Mask predictions from mask head, has shape
+ (num_pos, mask_size, mask_size).
+ mask_targets (Tensor): The ground truth masks assigned with
+ predictions, has shape
+ (num_pos, mask_size, mask_size).
+ sampling_results (List[obj:SamplingResult]): Assign results of
+ all images in a batch after sampling.
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It includes ``masks`` inside.
+ rcnn_train_cfg (obj:`ConfigDict`): `train_cfg` of RCNN.
+
+ Returns:
+ dict: A dictionary of loss and targets components.
+ The targets are only used for cascade rcnn.
+ """
+ mask_iou_targets = self.get_targets(
+ sampling_results=sampling_results,
+ batch_gt_instances=batch_gt_instances,
+ mask_preds=mask_preds,
+ mask_targets=mask_targets,
+ rcnn_train_cfg=rcnn_train_cfg)
+
+ pos_inds = mask_iou_targets > 0
+ if pos_inds.sum() > 0:
+ loss_mask_iou = self.loss_iou(mask_iou_pred[pos_inds],
+ mask_iou_targets[pos_inds])
+ else:
+ loss_mask_iou = mask_iou_pred.sum() * 0
+ return dict(loss_mask_iou=loss_mask_iou)
+
+ def get_targets(self, sampling_results: List[SamplingResult],
+ batch_gt_instances: InstanceList, mask_preds: Tensor,
+ mask_targets: Tensor,
+ rcnn_train_cfg: ConfigDict) -> Tensor:
+ """Compute target of mask IoU.
+
+ Mask IoU target is the IoU of the predicted mask (inside a bbox) and
+ the gt mask of corresponding gt mask (the whole instance).
+ The intersection area is computed inside the bbox, and the gt mask area
+ is computed with two steps, firstly we compute the gt area inside the
+ bbox, then divide it by the area ratio of gt area inside the bbox and
+ the gt area of the whole instance.
+
+ Args:
+ sampling_results (list[:obj:`SamplingResult`]): sampling results.
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It includes ``masks`` inside.
+ mask_preds (Tensor): Predicted masks of each positive proposal,
+ shape (num_pos, h, w).
+ mask_targets (Tensor): Gt mask of each positive proposal,
+ binary map of the shape (num_pos, h, w).
+ rcnn_train_cfg (obj:`ConfigDict`): Training config for R-CNN part.
+
+ Returns:
+ Tensor: mask iou target (length == num positive).
+ """
+ pos_proposals = [res.pos_priors for res in sampling_results]
+ pos_assigned_gt_inds = [
+ res.pos_assigned_gt_inds for res in sampling_results
+ ]
+ gt_masks = [res.masks for res in batch_gt_instances]
+
+ # compute the area ratio of gt areas inside the proposals and
+ # the whole instance
+ area_ratios = map(self._get_area_ratio, pos_proposals,
+ pos_assigned_gt_inds, gt_masks)
+ area_ratios = torch.cat(list(area_ratios))
+ assert mask_targets.size(0) == area_ratios.size(0)
+
+ mask_preds = (mask_preds > rcnn_train_cfg.mask_thr_binary).float()
+ mask_pred_areas = mask_preds.sum((-1, -2))
+
+ # mask_preds and mask_targets are binary maps
+ overlap_areas = (mask_preds * mask_targets).sum((-1, -2))
+
+ # compute the mask area of the whole instance
+ gt_full_areas = mask_targets.sum((-1, -2)) / (area_ratios + 1e-7)
+
+ mask_iou_targets = overlap_areas / (
+ mask_pred_areas + gt_full_areas - overlap_areas)
+ return mask_iou_targets
+
+ def _get_area_ratio(self, pos_proposals: Tensor,
+ pos_assigned_gt_inds: Tensor,
+ gt_masks: InstanceData) -> Tensor:
+ """Compute area ratio of the gt mask inside the proposal and the gt
+ mask of the corresponding instance.
+
+ Args:
+ pos_proposals (Tensor): Positive proposals, has shape (num_pos, 4).
+ pos_assigned_gt_inds (Tensor): positive proposals assigned ground
+ truth index.
+ gt_masks (BitmapMask or PolygonMask): Gt masks (the whole instance)
+ of each image, with the same shape of the input image.
+
+ Returns:
+ Tensor: The area ratio of the gt mask inside the proposal and the
+ gt mask of the corresponding instance.
+ """
+ num_pos = pos_proposals.size(0)
+ if num_pos > 0:
+ area_ratios = []
+ proposals_np = pos_proposals.cpu().numpy()
+ pos_assigned_gt_inds = pos_assigned_gt_inds.cpu().numpy()
+ # compute mask areas of gt instances (batch processing for speedup)
+ gt_instance_mask_area = gt_masks.areas
+ for i in range(num_pos):
+ gt_mask = gt_masks[pos_assigned_gt_inds[i]]
+
+ # crop the gt mask inside the proposal
+ bbox = proposals_np[i, :].astype(np.int32)
+ gt_mask_in_proposal = gt_mask.crop(bbox)
+
+ ratio = gt_mask_in_proposal.areas[0] / (
+ gt_instance_mask_area[pos_assigned_gt_inds[i]] + 1e-7)
+ area_ratios.append(ratio)
+ area_ratios = torch.from_numpy(np.stack(area_ratios)).float().to(
+ pos_proposals.device)
+ else:
+ area_ratios = pos_proposals.new_zeros((0, ))
+ return area_ratios
+
+ def predict_by_feat(self, mask_iou_preds: Tuple[Tensor],
+ results_list: InstanceList) -> InstanceList:
+ """Predict the mask iou and calculate it into ``results.scores``.
+
+ Args:
+ mask_iou_preds (Tensor): Mask IoU predictions results, has shape
+ (num_proposals, num_classes)
+ results_list (list[:obj:`InstanceData`]): Detection results of
+ each image.
+
+ Returns:
+ list[:obj:`InstanceData`]: Detection results of each image
+ after the post process. Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ - masks (Tensor): Has a shape (num_instances, H, W).
+ """
+ assert len(mask_iou_preds) == len(results_list)
+ for results, mask_iou_pred in zip(results_list, mask_iou_preds):
+ labels = results.labels
+ scores = results.scores
+ results.scores = scores * mask_iou_pred[range(labels.size(0)),
+ labels]
+ return results_list
diff --git a/mmdet/models/roi_heads/mask_heads/scnet_mask_head.py b/mmdet/models/roi_heads/mask_heads/scnet_mask_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..ffd30c337c37f4e280980e459c126df177fe7efa
--- /dev/null
+++ b/mmdet/models/roi_heads/mask_heads/scnet_mask_head.py
@@ -0,0 +1,28 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmdet.models.layers import ResLayer, SimplifiedBasicBlock
+from mmdet.registry import MODELS
+from .fcn_mask_head import FCNMaskHead
+
+
+@MODELS.register_module()
+class SCNetMaskHead(FCNMaskHead):
+ """Mask head for `SCNet `_.
+
+ Args:
+ conv_to_res (bool, optional): if True, change the conv layers to
+ ``SimplifiedBasicBlock``.
+ """
+
+ def __init__(self, conv_to_res: bool = True, **kwargs) -> None:
+ super().__init__(**kwargs)
+ self.conv_to_res = conv_to_res
+ if conv_to_res:
+ assert self.conv_kernel_size == 3
+ self.num_res_blocks = self.num_convs // 2
+ self.convs = ResLayer(
+ SimplifiedBasicBlock,
+ self.in_channels,
+ self.conv_out_channels,
+ self.num_res_blocks,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg)
diff --git a/mmdet/models/roi_heads/mask_heads/scnet_semantic_head.py b/mmdet/models/roi_heads/mask_heads/scnet_semantic_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..55c5c8e4fae7d4e941a770d985c7253fd70f2226
--- /dev/null
+++ b/mmdet/models/roi_heads/mask_heads/scnet_semantic_head.py
@@ -0,0 +1,28 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmdet.models.layers import ResLayer, SimplifiedBasicBlock
+from mmdet.registry import MODELS
+from .fused_semantic_head import FusedSemanticHead
+
+
+@MODELS.register_module()
+class SCNetSemanticHead(FusedSemanticHead):
+ """Mask head for `SCNet `_.
+
+ Args:
+ conv_to_res (bool, optional): if True, change the conv layers to
+ ``SimplifiedBasicBlock``.
+ """
+
+ def __init__(self, conv_to_res: bool = True, **kwargs) -> None:
+ super().__init__(**kwargs)
+ self.conv_to_res = conv_to_res
+ if self.conv_to_res:
+ num_res_blocks = self.num_convs // 2
+ self.convs = ResLayer(
+ SimplifiedBasicBlock,
+ self.in_channels,
+ self.conv_out_channels,
+ num_res_blocks,
+ conv_cfg=self.conv_cfg,
+ norm_cfg=self.norm_cfg)
+ self.num_convs = num_res_blocks
diff --git a/mmdet/models/roi_heads/mask_scoring_roi_head.py b/mmdet/models/roi_heads/mask_scoring_roi_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..6545c0ed41ee7ad17b5f1b841f8bc8d65a7b6391
--- /dev/null
+++ b/mmdet/models/roi_heads/mask_scoring_roi_head.py
@@ -0,0 +1,208 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Tuple
+
+import torch
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.structures import SampleList
+from mmdet.structures.bbox import bbox2roi
+from mmdet.utils import ConfigType, InstanceList
+from ..task_modules.samplers import SamplingResult
+from ..utils.misc import empty_instances
+from .standard_roi_head import StandardRoIHead
+
+
+@MODELS.register_module()
+class MaskScoringRoIHead(StandardRoIHead):
+ """Mask Scoring RoIHead for `Mask Scoring RCNN.
+
+ `_.
+
+ Args:
+ mask_iou_head (:obj`ConfigDict`, dict): The config of mask_iou_head.
+ """
+
+ def __init__(self, mask_iou_head: ConfigType, **kwargs):
+ assert mask_iou_head is not None
+ super().__init__(**kwargs)
+ self.mask_iou_head = MODELS.build(mask_iou_head)
+
+ def forward(self,
+ x: Tuple[Tensor],
+ rpn_results_list: InstanceList,
+ batch_data_samples: SampleList = None) -> tuple:
+ """Network forward process. Usually includes backbone, neck and head
+ forward without any post-processing.
+
+ Args:
+ x (List[Tensor]): Multi-level features that may have different
+ resolutions.
+ rpn_results_list (list[:obj:`InstanceData`]): List of region
+ proposals.
+ batch_data_samples (list[:obj:`DetDataSample`]): Each item contains
+ the meta information of each image and corresponding
+ annotations.
+
+ Returns
+ tuple: A tuple of features from ``bbox_head`` and ``mask_head``
+ forward.
+ """
+ results = ()
+ proposals = [rpn_results.bboxes for rpn_results in rpn_results_list]
+ rois = bbox2roi(proposals)
+ # bbox head
+ if self.with_bbox:
+ bbox_results = self._bbox_forward(x, rois)
+ results = results + (bbox_results['cls_score'],
+ bbox_results['bbox_pred'])
+ # mask head
+ if self.with_mask:
+ mask_rois = rois[:100]
+ mask_results = self._mask_forward(x, mask_rois)
+ results = results + (mask_results['mask_preds'], )
+
+ # mask iou head
+ cls_score = bbox_results['cls_score'][:100]
+ mask_preds = mask_results['mask_preds']
+ mask_feats = mask_results['mask_feats']
+ _, labels = cls_score[:, :self.bbox_head.num_classes].max(dim=1)
+ mask_iou_preds = self.mask_iou_head(
+ mask_feats, mask_preds[range(labels.size(0)), labels])
+ results = results + (mask_iou_preds, )
+
+ return results
+
+ def mask_loss(self, x: Tuple[Tensor],
+ sampling_results: List[SamplingResult], bbox_feats,
+ batch_gt_instances: InstanceList) -> dict:
+ """Perform forward propagation and loss calculation of the mask head on
+ the features of the upstream network.
+
+ Args:
+ x (tuple[Tensor]): Tuple of multi-level img features.
+ sampling_results (list["obj:`SamplingResult`]): Sampling results.
+ bbox_feats (Tensor): Extract bbox RoI features.
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes``, ``labels``, and
+ ``masks`` attributes.
+
+ Returns:
+ dict: Usually returns a dictionary with keys:
+
+ - `mask_preds` (Tensor): Mask prediction.
+ - `mask_feats` (Tensor): Extract mask RoI features.
+ - `mask_targets` (Tensor): Mask target of each positive\
+ proposals in the image.
+ - `loss_mask` (dict): A dictionary of mask loss components.
+ - `loss_mask_iou` (Tensor): mask iou loss.
+ """
+ if not self.share_roi_extractor:
+ pos_rois = bbox2roi([res.pos_priors for res in sampling_results])
+ mask_results = self._mask_forward(x, pos_rois)
+ else:
+ pos_inds = []
+ device = bbox_feats.device
+ for res in sampling_results:
+ pos_inds.append(
+ torch.ones(
+ res.pos_priors.shape[0],
+ device=device,
+ dtype=torch.uint8))
+ pos_inds.append(
+ torch.zeros(
+ res.neg_priors.shape[0],
+ device=device,
+ dtype=torch.uint8))
+ pos_inds = torch.cat(pos_inds)
+
+ mask_results = self._mask_forward(
+ x, pos_inds=pos_inds, bbox_feats=bbox_feats)
+
+ mask_loss_and_target = self.mask_head.loss_and_target(
+ mask_preds=mask_results['mask_preds'],
+ sampling_results=sampling_results,
+ batch_gt_instances=batch_gt_instances,
+ rcnn_train_cfg=self.train_cfg)
+ mask_targets = mask_loss_and_target['mask_targets']
+ mask_results.update(loss_mask=mask_loss_and_target['loss_mask'])
+ if mask_results['loss_mask'] is None:
+ return mask_results
+
+ # mask iou head forward and loss
+ pos_labels = torch.cat([res.pos_gt_labels for res in sampling_results])
+ pos_mask_pred = mask_results['mask_preds'][
+ range(mask_results['mask_preds'].size(0)), pos_labels]
+ mask_iou_pred = self.mask_iou_head(mask_results['mask_feats'],
+ pos_mask_pred)
+ pos_mask_iou_pred = mask_iou_pred[range(mask_iou_pred.size(0)),
+ pos_labels]
+
+ loss_mask_iou = self.mask_iou_head.loss_and_target(
+ pos_mask_iou_pred, pos_mask_pred, mask_targets, sampling_results,
+ batch_gt_instances, self.train_cfg)
+ mask_results['loss_mask'].update(loss_mask_iou)
+ return mask_results
+
+ def predict_mask(self,
+ x: Tensor,
+ batch_img_metas: List[dict],
+ results_list: InstanceList,
+ rescale: bool = False) -> InstanceList:
+ """Perform forward propagation of the mask head and predict detection
+ results on the features of the upstream network.
+
+ Args:
+ x (tuple[Tensor]): Feature maps of all scale level.
+ batch_img_metas (list[dict]): List of image information.
+ results_list (list[:obj:`InstanceData`]): Detection results of
+ each image.
+ rescale (bool): If True, return boxes in original image space.
+ Defaults to False.
+
+ Returns:
+ list[:obj:`InstanceData`]: Detection results of each image
+ after the post process.
+ Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ - masks (Tensor): Has a shape (num_instances, H, W).
+ """
+ bboxes = [res.bboxes for res in results_list]
+ mask_rois = bbox2roi(bboxes)
+ if mask_rois.shape[0] == 0:
+ results_list = empty_instances(
+ batch_img_metas,
+ mask_rois.device,
+ task_type='mask',
+ instance_results=results_list,
+ mask_thr_binary=self.test_cfg.mask_thr_binary)
+ return results_list
+
+ mask_results = self._mask_forward(x, mask_rois)
+ mask_preds = mask_results['mask_preds']
+ mask_feats = mask_results['mask_feats']
+ # get mask scores with mask iou head
+ labels = torch.cat([res.labels for res in results_list])
+ mask_iou_preds = self.mask_iou_head(
+ mask_feats, mask_preds[range(labels.size(0)), labels])
+ # split batch mask prediction back to each image
+ num_mask_rois_per_img = [len(res) for res in results_list]
+ mask_preds = mask_preds.split(num_mask_rois_per_img, 0)
+ mask_iou_preds = mask_iou_preds.split(num_mask_rois_per_img, 0)
+
+ # TODO: Handle the case where rescale is false
+ results_list = self.mask_head.predict_by_feat(
+ mask_preds=mask_preds,
+ results_list=results_list,
+ batch_img_metas=batch_img_metas,
+ rcnn_test_cfg=self.test_cfg,
+ rescale=rescale)
+ results_list = self.mask_iou_head.predict_by_feat(
+ mask_iou_preds=mask_iou_preds, results_list=results_list)
+ return results_list
diff --git a/mmdet/models/roi_heads/multi_instance_roi_head.py b/mmdet/models/roi_heads/multi_instance_roi_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..fee55b0a5d341c03165649f59737fd34d85c207e
--- /dev/null
+++ b/mmdet/models/roi_heads/multi_instance_roi_head.py
@@ -0,0 +1,226 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Tuple
+
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.structures import DetDataSample
+from mmdet.structures.bbox import bbox2roi
+from mmdet.utils import ConfigType, InstanceList
+from ..task_modules.samplers import SamplingResult
+from ..utils import empty_instances, unpack_gt_instances
+from .standard_roi_head import StandardRoIHead
+
+
+@MODELS.register_module()
+class MultiInstanceRoIHead(StandardRoIHead):
+ """The roi head for Multi-instance prediction."""
+
+ def __init__(self, num_instance: int = 2, *args, **kwargs) -> None:
+ self.num_instance = num_instance
+ super().__init__(*args, **kwargs)
+
+ def init_bbox_head(self, bbox_roi_extractor: ConfigType,
+ bbox_head: ConfigType) -> None:
+ """Initialize box head and box roi extractor.
+
+ Args:
+ bbox_roi_extractor (dict or ConfigDict): Config of box
+ roi extractor.
+ bbox_head (dict or ConfigDict): Config of box in box head.
+ """
+ self.bbox_roi_extractor = MODELS.build(bbox_roi_extractor)
+ self.bbox_head = MODELS.build(bbox_head)
+
+ def _bbox_forward(self, x: Tuple[Tensor], rois: Tensor) -> dict:
+ """Box head forward function used in both training and testing.
+
+ Args:
+ x (tuple[Tensor]): List of multi-level img features.
+ rois (Tensor): RoIs with the shape (n, 5) where the first
+ column indicates batch id of each RoI.
+
+ Returns:
+ dict[str, Tensor]: Usually returns a dictionary with keys:
+
+ - `cls_score` (Tensor): Classification scores.
+ - `bbox_pred` (Tensor): Box energies / deltas.
+ - `cls_score_ref` (Tensor): The cls_score after refine model.
+ - `bbox_pred_ref` (Tensor): The bbox_pred after refine model.
+ - `bbox_feats` (Tensor): Extract bbox RoI features.
+ """
+ # TODO: a more flexible way to decide which feature maps to use
+ bbox_feats = self.bbox_roi_extractor(
+ x[:self.bbox_roi_extractor.num_inputs], rois)
+ bbox_results = self.bbox_head(bbox_feats)
+
+ if self.bbox_head.with_refine:
+ bbox_results = dict(
+ cls_score=bbox_results[0],
+ bbox_pred=bbox_results[1],
+ cls_score_ref=bbox_results[2],
+ bbox_pred_ref=bbox_results[3],
+ bbox_feats=bbox_feats)
+ else:
+ bbox_results = dict(
+ cls_score=bbox_results[0],
+ bbox_pred=bbox_results[1],
+ bbox_feats=bbox_feats)
+
+ return bbox_results
+
+ def bbox_loss(self, x: Tuple[Tensor],
+ sampling_results: List[SamplingResult]) -> dict:
+ """Perform forward propagation and loss calculation of the bbox head on
+ the features of the upstream network.
+
+ Args:
+ x (tuple[Tensor]): List of multi-level img features.
+ sampling_results (list["obj:`SamplingResult`]): Sampling results.
+
+ Returns:
+ dict[str, Tensor]: Usually returns a dictionary with keys:
+
+ - `cls_score` (Tensor): Classification scores.
+ - `bbox_pred` (Tensor): Box energies / deltas.
+ - `bbox_feats` (Tensor): Extract bbox RoI features.
+ - `loss_bbox` (dict): A dictionary of bbox loss components.
+ """
+ rois = bbox2roi([res.priors for res in sampling_results])
+ bbox_results = self._bbox_forward(x, rois)
+
+ # If there is a refining process, add refine loss.
+ if 'cls_score_ref' in bbox_results:
+ bbox_loss_and_target = self.bbox_head.loss_and_target(
+ cls_score=bbox_results['cls_score'],
+ bbox_pred=bbox_results['bbox_pred'],
+ rois=rois,
+ sampling_results=sampling_results,
+ rcnn_train_cfg=self.train_cfg)
+ bbox_results.update(loss_bbox=bbox_loss_and_target['loss_bbox'])
+ bbox_loss_and_target_ref = self.bbox_head.loss_and_target(
+ cls_score=bbox_results['cls_score_ref'],
+ bbox_pred=bbox_results['bbox_pred_ref'],
+ rois=rois,
+ sampling_results=sampling_results,
+ rcnn_train_cfg=self.train_cfg)
+ bbox_results['loss_bbox']['loss_rcnn_emd_ref'] = \
+ bbox_loss_and_target_ref['loss_bbox']['loss_rcnn_emd']
+ else:
+ bbox_loss_and_target = self.bbox_head.loss_and_target(
+ cls_score=bbox_results['cls_score'],
+ bbox_pred=bbox_results['bbox_pred'],
+ rois=rois,
+ sampling_results=sampling_results,
+ rcnn_train_cfg=self.train_cfg)
+ bbox_results.update(loss_bbox=bbox_loss_and_target['loss_bbox'])
+
+ return bbox_results
+
+ def loss(self, x: Tuple[Tensor], rpn_results_list: InstanceList,
+ batch_data_samples: List[DetDataSample]) -> dict:
+ """Perform forward propagation and loss calculation of the detection
+ roi on the features of the upstream network.
+
+ Args:
+ x (tuple[Tensor]): List of multi-level img features.
+ rpn_results_list (list[:obj:`InstanceData`]): List of region
+ proposals.
+ batch_data_samples (list[:obj:`DetDataSample`]): The batch
+ data samples. It usually includes information such
+ as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components
+ """
+ assert len(rpn_results_list) == len(batch_data_samples)
+ outputs = unpack_gt_instances(batch_data_samples)
+ batch_gt_instances, batch_gt_instances_ignore, _ = outputs
+
+ sampling_results = []
+ for i in range(len(batch_data_samples)):
+ # rename rpn_results.bboxes to rpn_results.priors
+ rpn_results = rpn_results_list[i]
+ rpn_results.priors = rpn_results.pop('bboxes')
+
+ assign_result = self.bbox_assigner.assign(
+ rpn_results, batch_gt_instances[i],
+ batch_gt_instances_ignore[i])
+ sampling_result = self.bbox_sampler.sample(
+ assign_result,
+ rpn_results,
+ batch_gt_instances[i],
+ batch_gt_instances_ignore=batch_gt_instances_ignore[i])
+ sampling_results.append(sampling_result)
+
+ losses = dict()
+ # bbox head loss
+ if self.with_bbox:
+ bbox_results = self.bbox_loss(x, sampling_results)
+ losses.update(bbox_results['loss_bbox'])
+
+ return losses
+
+ def predict_bbox(self,
+ x: Tuple[Tensor],
+ batch_img_metas: List[dict],
+ rpn_results_list: InstanceList,
+ rcnn_test_cfg: ConfigType,
+ rescale: bool = False) -> InstanceList:
+ """Perform forward propagation of the bbox head and predict detection
+ results on the features of the upstream network.
+
+ Args:
+ x (tuple[Tensor]): Feature maps of all scale level.
+ batch_img_metas (list[dict]): List of image information.
+ rpn_results_list (list[:obj:`InstanceData`]): List of region
+ proposals.
+ rcnn_test_cfg (obj:`ConfigDict`): `test_cfg` of R-CNN.
+ rescale (bool): If True, return boxes in original image space.
+ Defaults to False.
+
+ Returns:
+ list[:obj:`InstanceData`]: Detection results of each image
+ after the post process.
+ Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ """
+ proposals = [res.bboxes for res in rpn_results_list]
+ rois = bbox2roi(proposals)
+
+ if rois.shape[0] == 0:
+ return empty_instances(
+ batch_img_metas, rois.device, task_type='bbox')
+
+ bbox_results = self._bbox_forward(x, rois)
+
+ # split batch bbox prediction back to each image
+ if 'cls_score_ref' in bbox_results:
+ cls_scores = bbox_results['cls_score_ref']
+ bbox_preds = bbox_results['bbox_pred_ref']
+ else:
+ cls_scores = bbox_results['cls_score']
+ bbox_preds = bbox_results['bbox_pred']
+ num_proposals_per_img = tuple(len(p) for p in proposals)
+ rois = rois.split(num_proposals_per_img, 0)
+ cls_scores = cls_scores.split(num_proposals_per_img, 0)
+
+ if bbox_preds is not None:
+ bbox_preds = bbox_preds.split(num_proposals_per_img, 0)
+ else:
+ bbox_preds = (None, ) * len(proposals)
+
+ result_list = self.bbox_head.predict_by_feat(
+ rois=rois,
+ cls_scores=cls_scores,
+ bbox_preds=bbox_preds,
+ batch_img_metas=batch_img_metas,
+ rcnn_test_cfg=rcnn_test_cfg,
+ rescale=rescale)
+ return result_list
diff --git a/mmdet/models/roi_heads/pisa_roi_head.py b/mmdet/models/roi_heads/pisa_roi_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..45d59879da73b48df790c55d40a4a88f1d099111
--- /dev/null
+++ b/mmdet/models/roi_heads/pisa_roi_head.py
@@ -0,0 +1,148 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Tuple
+
+from torch import Tensor
+
+from mmdet.models.task_modules import SamplingResult
+from mmdet.registry import MODELS
+from mmdet.structures import DetDataSample
+from mmdet.structures.bbox import bbox2roi
+from mmdet.utils import InstanceList
+from ..losses.pisa_loss import carl_loss, isr_p
+from ..utils import unpack_gt_instances
+from .standard_roi_head import StandardRoIHead
+
+
+@MODELS.register_module()
+class PISARoIHead(StandardRoIHead):
+ r"""The RoI head for `Prime Sample Attention in Object Detection
+ `_."""
+
+ def loss(self, x: Tuple[Tensor], rpn_results_list: InstanceList,
+ batch_data_samples: List[DetDataSample]) -> dict:
+ """Perform forward propagation and loss calculation of the detection
+ roi on the features of the upstream network.
+
+ Args:
+ x (tuple[Tensor]): List of multi-level img features.
+ rpn_results_list (list[:obj:`InstanceData`]): List of region
+ proposals.
+ batch_data_samples (list[:obj:`DetDataSample`]): The batch
+ data samples. It usually includes information such
+ as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components
+ """
+ assert len(rpn_results_list) == len(batch_data_samples)
+ outputs = unpack_gt_instances(batch_data_samples)
+ batch_gt_instances, batch_gt_instances_ignore, _ = outputs
+
+ # assign gts and sample proposals
+ num_imgs = len(batch_data_samples)
+ sampling_results = []
+ neg_label_weights = []
+ for i in range(num_imgs):
+ # rename rpn_results.bboxes to rpn_results.priors
+ rpn_results = rpn_results_list[i]
+ rpn_results.priors = rpn_results.pop('bboxes')
+
+ assign_result = self.bbox_assigner.assign(
+ rpn_results, batch_gt_instances[i],
+ batch_gt_instances_ignore[i])
+ sampling_result = self.bbox_sampler.sample(
+ assign_result,
+ rpn_results,
+ batch_gt_instances[i],
+ feats=[lvl_feat[i][None] for lvl_feat in x])
+ if isinstance(sampling_result, tuple):
+ sampling_result, neg_label_weight = sampling_result
+ sampling_results.append(sampling_result)
+ neg_label_weights.append(neg_label_weight)
+
+ losses = dict()
+ # bbox head forward and loss
+ if self.with_bbox:
+ bbox_results = self.bbox_loss(
+ x, sampling_results, neg_label_weights=neg_label_weights)
+ losses.update(bbox_results['loss_bbox'])
+
+ # mask head forward and loss
+ if self.with_mask:
+ mask_results = self.mask_loss(x, sampling_results,
+ bbox_results['bbox_feats'],
+ batch_gt_instances)
+ losses.update(mask_results['loss_mask'])
+
+ return losses
+
+ def bbox_loss(self,
+ x: Tuple[Tensor],
+ sampling_results: List[SamplingResult],
+ neg_label_weights: List[Tensor] = None) -> dict:
+ """Perform forward propagation and loss calculation of the bbox head on
+ the features of the upstream network.
+
+ Args:
+ x (tuple[Tensor]): List of multi-level img features.
+ sampling_results (list["obj:`SamplingResult`]): Sampling results.
+
+ Returns:
+ dict[str, Tensor]: Usually returns a dictionary with keys:
+
+ - `cls_score` (Tensor): Classification scores.
+ - `bbox_pred` (Tensor): Box energies / deltas.
+ - `bbox_feats` (Tensor): Extract bbox RoI features.
+ - `loss_bbox` (dict): A dictionary of bbox loss components.
+ """
+ rois = bbox2roi([res.priors for res in sampling_results])
+ bbox_results = self._bbox_forward(x, rois)
+ bbox_targets = self.bbox_head.get_targets(sampling_results,
+ self.train_cfg)
+
+ # neg_label_weights obtained by sampler is image-wise, mapping back to
+ # the corresponding location in label weights
+ if neg_label_weights[0] is not None:
+ label_weights = bbox_targets[1]
+ cur_num_rois = 0
+ for i in range(len(sampling_results)):
+ num_pos = sampling_results[i].pos_inds.size(0)
+ num_neg = sampling_results[i].neg_inds.size(0)
+ label_weights[cur_num_rois + num_pos:cur_num_rois + num_pos +
+ num_neg] = neg_label_weights[i]
+ cur_num_rois += num_pos + num_neg
+
+ cls_score = bbox_results['cls_score']
+ bbox_pred = bbox_results['bbox_pred']
+
+ # Apply ISR-P
+ isr_cfg = self.train_cfg.get('isr', None)
+ if isr_cfg is not None:
+ bbox_targets = isr_p(
+ cls_score,
+ bbox_pred,
+ bbox_targets,
+ rois,
+ sampling_results,
+ self.bbox_head.loss_cls,
+ self.bbox_head.bbox_coder,
+ **isr_cfg,
+ num_class=self.bbox_head.num_classes)
+ loss_bbox = self.bbox_head.loss(cls_score, bbox_pred, rois,
+ *bbox_targets)
+
+ # Add CARL Loss
+ carl_cfg = self.train_cfg.get('carl', None)
+ if carl_cfg is not None:
+ loss_carl = carl_loss(
+ cls_score,
+ bbox_targets[0],
+ bbox_pred,
+ bbox_targets[2],
+ self.bbox_head.loss_bbox,
+ **carl_cfg,
+ num_class=self.bbox_head.num_classes)
+ loss_bbox.update(loss_carl)
+
+ bbox_results.update(loss_bbox=loss_bbox)
+ return bbox_results
diff --git a/mmdet/models/roi_heads/point_rend_roi_head.py b/mmdet/models/roi_heads/point_rend_roi_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..6a0641549631e243c3db25039b01fed64fb1e0d1
--- /dev/null
+++ b/mmdet/models/roi_heads/point_rend_roi_head.py
@@ -0,0 +1,236 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+# Modified from https://github.com/facebookresearch/detectron2/tree/master/projects/PointRend # noqa
+from typing import List, Tuple
+
+import torch
+import torch.nn.functional as F
+from mmcv.ops import point_sample, rel_roi_point_to_rel_img_point
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.structures.bbox import bbox2roi
+from mmdet.utils import ConfigType, InstanceList
+from ..task_modules.samplers import SamplingResult
+from ..utils import empty_instances
+from .standard_roi_head import StandardRoIHead
+
+
+@MODELS.register_module()
+class PointRendRoIHead(StandardRoIHead):
+ """`PointRend `_."""
+
+ def __init__(self, point_head: ConfigType, *args, **kwargs) -> None:
+ super().__init__(*args, **kwargs)
+ assert self.with_bbox and self.with_mask
+ self.init_point_head(point_head)
+
+ def init_point_head(self, point_head: ConfigType) -> None:
+ """Initialize ``point_head``"""
+ self.point_head = MODELS.build(point_head)
+
+ def mask_loss(self, x: Tuple[Tensor],
+ sampling_results: List[SamplingResult], bbox_feats: Tensor,
+ batch_gt_instances: InstanceList) -> dict:
+ """Run forward function and calculate loss for mask head and point head
+ in training."""
+ mask_results = super().mask_loss(
+ x=x,
+ sampling_results=sampling_results,
+ bbox_feats=bbox_feats,
+ batch_gt_instances=batch_gt_instances)
+
+ mask_point_results = self._mask_point_loss(
+ x=x,
+ sampling_results=sampling_results,
+ mask_preds=mask_results['mask_preds'],
+ batch_gt_instances=batch_gt_instances)
+ mask_results['loss_mask'].update(
+ loss_point=mask_point_results['loss_point'])
+
+ return mask_results
+
+ def _mask_point_loss(self, x: Tuple[Tensor],
+ sampling_results: List[SamplingResult],
+ mask_preds: Tensor,
+ batch_gt_instances: InstanceList) -> dict:
+ """Run forward function and calculate loss for point head in
+ training."""
+ pos_labels = torch.cat([res.pos_gt_labels for res in sampling_results])
+ rel_roi_points = self.point_head.get_roi_rel_points_train(
+ mask_preds, pos_labels, cfg=self.train_cfg)
+ rois = bbox2roi([res.pos_bboxes for res in sampling_results])
+
+ fine_grained_point_feats = self._get_fine_grained_point_feats(
+ x, rois, rel_roi_points)
+ coarse_point_feats = point_sample(mask_preds, rel_roi_points)
+ mask_point_pred = self.point_head(fine_grained_point_feats,
+ coarse_point_feats)
+
+ loss_and_target = self.point_head.loss_and_target(
+ point_pred=mask_point_pred,
+ rel_roi_points=rel_roi_points,
+ sampling_results=sampling_results,
+ batch_gt_instances=batch_gt_instances,
+ cfg=self.train_cfg)
+
+ return loss_and_target
+
+ def _mask_point_forward_test(self, x: Tuple[Tensor], rois: Tensor,
+ label_preds: Tensor,
+ mask_preds: Tensor) -> Tensor:
+ """Mask refining process with point head in testing.
+
+ Args:
+ x (tuple[Tensor]): Feature maps of all scale level.
+ rois (Tensor): shape (num_rois, 5).
+ label_preds (Tensor): The predication class for each rois.
+ mask_preds (Tensor): The predication coarse masks of
+ shape (num_rois, num_classes, small_size, small_size).
+
+ Returns:
+ Tensor: The refined masks of shape (num_rois, num_classes,
+ large_size, large_size).
+ """
+ refined_mask_pred = mask_preds.clone()
+ for subdivision_step in range(self.test_cfg.subdivision_steps):
+ refined_mask_pred = F.interpolate(
+ refined_mask_pred,
+ scale_factor=self.test_cfg.scale_factor,
+ mode='bilinear',
+ align_corners=False)
+ # If `subdivision_num_points` is larger or equal to the
+ # resolution of the next step, then we can skip this step
+ num_rois, channels, mask_height, mask_width = \
+ refined_mask_pred.shape
+ if (self.test_cfg.subdivision_num_points >=
+ self.test_cfg.scale_factor**2 * mask_height * mask_width
+ and
+ subdivision_step < self.test_cfg.subdivision_steps - 1):
+ continue
+ point_indices, rel_roi_points = \
+ self.point_head.get_roi_rel_points_test(
+ refined_mask_pred, label_preds, cfg=self.test_cfg)
+
+ fine_grained_point_feats = self._get_fine_grained_point_feats(
+ x=x, rois=rois, rel_roi_points=rel_roi_points)
+ coarse_point_feats = point_sample(mask_preds, rel_roi_points)
+ mask_point_pred = self.point_head(fine_grained_point_feats,
+ coarse_point_feats)
+
+ point_indices = point_indices.unsqueeze(1).expand(-1, channels, -1)
+ refined_mask_pred = refined_mask_pred.reshape(
+ num_rois, channels, mask_height * mask_width)
+ refined_mask_pred = refined_mask_pred.scatter_(
+ 2, point_indices, mask_point_pred)
+ refined_mask_pred = refined_mask_pred.view(num_rois, channels,
+ mask_height, mask_width)
+
+ return refined_mask_pred
+
+ def _get_fine_grained_point_feats(self, x: Tuple[Tensor], rois: Tensor,
+ rel_roi_points: Tensor) -> Tensor:
+ """Sample fine grained feats from each level feature map and
+ concatenate them together.
+
+ Args:
+ x (tuple[Tensor]): Feature maps of all scale level.
+ rois (Tensor): shape (num_rois, 5).
+ rel_roi_points (Tensor): A tensor of shape (num_rois, num_points,
+ 2) that contains [0, 1] x [0, 1] normalized coordinates of the
+ most uncertain points from the [mask_height, mask_width] grid.
+
+ Returns:
+ Tensor: The fine grained features for each points,
+ has shape (num_rois, feats_channels, num_points).
+ """
+ assert rois.shape[0] > 0, 'RoI is a empty tensor.'
+ num_imgs = x[0].shape[0]
+ fine_grained_feats = []
+ for idx in range(self.mask_roi_extractor.num_inputs):
+ feats = x[idx]
+ spatial_scale = 1. / float(
+ self.mask_roi_extractor.featmap_strides[idx])
+ point_feats = []
+ for batch_ind in range(num_imgs):
+ # unravel batch dim
+ feat = feats[batch_ind].unsqueeze(0)
+ inds = (rois[:, 0].long() == batch_ind)
+ if inds.any():
+ rel_img_points = rel_roi_point_to_rel_img_point(
+ rois=rois[inds],
+ rel_roi_points=rel_roi_points[inds],
+ img=feat.shape[2:],
+ spatial_scale=spatial_scale).unsqueeze(0)
+ point_feat = point_sample(feat, rel_img_points)
+ point_feat = point_feat.squeeze(0).transpose(0, 1)
+ point_feats.append(point_feat)
+ fine_grained_feats.append(torch.cat(point_feats, dim=0))
+ return torch.cat(fine_grained_feats, dim=1)
+
+ def predict_mask(self,
+ x: Tuple[Tensor],
+ batch_img_metas: List[dict],
+ results_list: InstanceList,
+ rescale: bool = False) -> InstanceList:
+ """Perform forward propagation of the mask head and predict detection
+ results on the features of the upstream network.
+
+ Args:
+ x (tuple[Tensor]): Feature maps of all scale level.
+ batch_img_metas (list[dict]): List of image information.
+ results_list (list[:obj:`InstanceData`]): Detection results of
+ each image.
+ rescale (bool): If True, return boxes in original image space.
+ Defaults to False.
+
+ Returns:
+ list[:obj:`InstanceData`]: Detection results of each image
+ after the post process.
+ Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ - masks (Tensor): Has a shape (num_instances, H, W).
+ """
+ # don't need to consider aug_test.
+ bboxes = [res.bboxes for res in results_list]
+ mask_rois = bbox2roi(bboxes)
+ if mask_rois.shape[0] == 0:
+ results_list = empty_instances(
+ batch_img_metas,
+ mask_rois.device,
+ task_type='mask',
+ instance_results=results_list,
+ mask_thr_binary=self.test_cfg.mask_thr_binary)
+ return results_list
+
+ mask_results = self._mask_forward(x, mask_rois)
+ mask_preds = mask_results['mask_preds']
+ # split batch mask prediction back to each image
+ num_mask_rois_per_img = [len(res) for res in results_list]
+ mask_preds = mask_preds.split(num_mask_rois_per_img, 0)
+
+ # refine mask_preds
+ mask_rois = mask_rois.split(num_mask_rois_per_img, 0)
+ mask_preds_refined = []
+ for i in range(len(batch_img_metas)):
+ labels = results_list[i].labels
+ x_i = [xx[[i]] for xx in x]
+ mask_rois_i = mask_rois[i]
+ mask_rois_i[:, 0] = 0
+ mask_pred_i = self._mask_point_forward_test(
+ x_i, mask_rois_i, labels, mask_preds[i])
+ mask_preds_refined.append(mask_pred_i)
+
+ # TODO: Handle the case where rescale is false
+ results_list = self.mask_head.predict_by_feat(
+ mask_preds=mask_preds_refined,
+ results_list=results_list,
+ batch_img_metas=batch_img_metas,
+ rcnn_test_cfg=self.test_cfg,
+ rescale=rescale)
+ return results_list
diff --git a/mmdet/models/roi_heads/roi_extractors/__init__.py b/mmdet/models/roi_heads/roi_extractors/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..0f60214991b0ed14cdbc3964aee15356c6aaf2aa
--- /dev/null
+++ b/mmdet/models/roi_heads/roi_extractors/__init__.py
@@ -0,0 +1,6 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .base_roi_extractor import BaseRoIExtractor
+from .generic_roi_extractor import GenericRoIExtractor
+from .single_level_roi_extractor import SingleRoIExtractor
+
+__all__ = ['BaseRoIExtractor', 'SingleRoIExtractor', 'GenericRoIExtractor']
diff --git a/mmdet/models/roi_heads/roi_extractors/__pycache__/__init__.cpython-37.pyc b/mmdet/models/roi_heads/roi_extractors/__pycache__/__init__.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..09648876cb4dc984c16e9c843d6f67939dd6d882
Binary files /dev/null and b/mmdet/models/roi_heads/roi_extractors/__pycache__/__init__.cpython-37.pyc differ
diff --git a/mmdet/models/roi_heads/roi_extractors/__pycache__/base_roi_extractor.cpython-37.pyc b/mmdet/models/roi_heads/roi_extractors/__pycache__/base_roi_extractor.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..31e0d067ffac363069801afc892ca9bde4847c61
Binary files /dev/null and b/mmdet/models/roi_heads/roi_extractors/__pycache__/base_roi_extractor.cpython-37.pyc differ
diff --git a/mmdet/models/roi_heads/roi_extractors/__pycache__/generic_roi_extractor.cpython-37.pyc b/mmdet/models/roi_heads/roi_extractors/__pycache__/generic_roi_extractor.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..9eb3a31e0c2cea5920053dcdea5d0547c71e7aad
Binary files /dev/null and b/mmdet/models/roi_heads/roi_extractors/__pycache__/generic_roi_extractor.cpython-37.pyc differ
diff --git a/mmdet/models/roi_heads/roi_extractors/__pycache__/single_level_roi_extractor.cpython-37.pyc b/mmdet/models/roi_heads/roi_extractors/__pycache__/single_level_roi_extractor.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..8ad30d1b9f4c5a1d70f0589e2db623dba4c18b36
Binary files /dev/null and b/mmdet/models/roi_heads/roi_extractors/__pycache__/single_level_roi_extractor.cpython-37.pyc differ
diff --git a/mmdet/models/roi_heads/roi_extractors/base_roi_extractor.py b/mmdet/models/roi_heads/roi_extractors/base_roi_extractor.py
new file mode 100644
index 0000000000000000000000000000000000000000..9b2bde31073b56494bd317cee05a2d72ed18ac12
--- /dev/null
+++ b/mmdet/models/roi_heads/roi_extractors/base_roi_extractor.py
@@ -0,0 +1,108 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from abc import ABCMeta, abstractmethod
+from typing import List, Optional, Tuple
+
+import torch
+import torch.nn as nn
+from mmcv import ops
+from mmengine.model import BaseModule
+from torch import Tensor
+
+from mmdet.utils import ConfigType, OptMultiConfig
+
+
+class BaseRoIExtractor(BaseModule, metaclass=ABCMeta):
+ """Base class for RoI extractor.
+
+ Args:
+ roi_layer (:obj:`ConfigDict` or dict): Specify RoI layer type and
+ arguments.
+ out_channels (int): Output channels of RoI layers.
+ featmap_strides (list[int]): Strides of input feature maps.
+ init_cfg (:obj:`ConfigDict` or dict or list[:obj:`ConfigDict` or \
+ dict], optional): Initialization config dict. Defaults to None.
+ """
+
+ def __init__(self,
+ roi_layer: ConfigType,
+ out_channels: int,
+ featmap_strides: List[int],
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(init_cfg=init_cfg)
+ self.roi_layers = self.build_roi_layers(roi_layer, featmap_strides)
+ self.out_channels = out_channels
+ self.featmap_strides = featmap_strides
+
+ @property
+ def num_inputs(self) -> int:
+ """int: Number of input feature maps."""
+ return len(self.featmap_strides)
+
+ def build_roi_layers(self, layer_cfg: ConfigType,
+ featmap_strides: List[int]) -> nn.ModuleList:
+ """Build RoI operator to extract feature from each level feature map.
+
+ Args:
+ layer_cfg (:obj:`ConfigDict` or dict): Dictionary to construct and
+ config RoI layer operation. Options are modules under
+ ``mmcv/ops`` such as ``RoIAlign``.
+ featmap_strides (list[int]): The stride of input feature map w.r.t
+ to the original image size, which would be used to scale RoI
+ coordinate (original image coordinate system) to feature
+ coordinate system.
+
+ Returns:
+ :obj:`nn.ModuleList`: The RoI extractor modules for each level
+ feature map.
+ """
+
+ cfg = layer_cfg.copy()
+ layer_type = cfg.pop('type')
+ assert hasattr(ops, layer_type)
+ layer_cls = getattr(ops, layer_type)
+ roi_layers = nn.ModuleList(
+ [layer_cls(spatial_scale=1 / s, **cfg) for s in featmap_strides])
+ return roi_layers
+
+ def roi_rescale(self, rois: Tensor, scale_factor: float) -> Tensor:
+ """Scale RoI coordinates by scale factor.
+
+ Args:
+ rois (Tensor): RoI (Region of Interest), shape (n, 5)
+ scale_factor (float): Scale factor that RoI will be multiplied by.
+
+ Returns:
+ Tensor: Scaled RoI.
+ """
+
+ cx = (rois[:, 1] + rois[:, 3]) * 0.5
+ cy = (rois[:, 2] + rois[:, 4]) * 0.5
+ w = rois[:, 3] - rois[:, 1]
+ h = rois[:, 4] - rois[:, 2]
+ new_w = w * scale_factor
+ new_h = h * scale_factor
+ x1 = cx - new_w * 0.5
+ x2 = cx + new_w * 0.5
+ y1 = cy - new_h * 0.5
+ y2 = cy + new_h * 0.5
+ new_rois = torch.stack((rois[:, 0], x1, y1, x2, y2), dim=-1)
+ return new_rois
+
+ @abstractmethod
+ def forward(self,
+ feats: Tuple[Tensor],
+ rois: Tensor,
+ roi_scale_factor: Optional[float] = None) -> Tensor:
+ """Extractor ROI feats.
+
+ Args:
+ feats (Tuple[Tensor]): Multi-scale features.
+ rois (Tensor): RoIs with the shape (n, 5) where the first
+ column indicates batch id of each RoI.
+ roi_scale_factor (Optional[float]): RoI scale factor.
+ Defaults to None.
+
+ Returns:
+ Tensor: RoI feature.
+ """
+ pass
diff --git a/mmdet/models/roi_heads/roi_extractors/generic_roi_extractor.py b/mmdet/models/roi_heads/roi_extractors/generic_roi_extractor.py
new file mode 100644
index 0000000000000000000000000000000000000000..39d4c90135d853404d564391f029558841ac9cac
--- /dev/null
+++ b/mmdet/models/roi_heads/roi_extractors/generic_roi_extractor.py
@@ -0,0 +1,102 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Tuple
+
+from mmcv.cnn.bricks import build_plugin_layer
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.utils import OptConfigType
+from .base_roi_extractor import BaseRoIExtractor
+
+
+@MODELS.register_module()
+class GenericRoIExtractor(BaseRoIExtractor):
+ """Extract RoI features from all level feature maps levels.
+
+ This is the implementation of `A novel Region of Interest Extraction Layer
+ for Instance Segmentation `_.
+
+ Args:
+ aggregation (str): The method to aggregate multiple feature maps.
+ Options are 'sum', 'concat'. Defaults to 'sum'.
+ pre_cfg (:obj:`ConfigDict` or dict): Specify pre-processing modules.
+ Defaults to None.
+ post_cfg (:obj:`ConfigDict` or dict): Specify post-processing modules.
+ Defaults to None.
+ kwargs (keyword arguments): Arguments that are the same
+ as :class:`BaseRoIExtractor`.
+ """
+
+ def __init__(self,
+ aggregation: str = 'sum',
+ pre_cfg: OptConfigType = None,
+ post_cfg: OptConfigType = None,
+ **kwargs) -> None:
+ super().__init__(**kwargs)
+
+ assert aggregation in ['sum', 'concat']
+
+ self.aggregation = aggregation
+ self.with_post = post_cfg is not None
+ self.with_pre = pre_cfg is not None
+ # build pre/post processing modules
+ if self.with_post:
+ self.post_module = build_plugin_layer(post_cfg, '_post_module')[1]
+ if self.with_pre:
+ self.pre_module = build_plugin_layer(pre_cfg, '_pre_module')[1]
+
+ def forward(self,
+ feats: Tuple[Tensor],
+ rois: Tensor,
+ roi_scale_factor: Optional[float] = None) -> Tensor:
+ """Extractor ROI feats.
+
+ Args:
+ feats (Tuple[Tensor]): Multi-scale features.
+ rois (Tensor): RoIs with the shape (n, 5) where the first
+ column indicates batch id of each RoI.
+ roi_scale_factor (Optional[float]): RoI scale factor.
+ Defaults to None.
+
+ Returns:
+ Tensor: RoI feature.
+ """
+ out_size = self.roi_layers[0].output_size
+ num_levels = len(feats)
+ roi_feats = feats[0].new_zeros(
+ rois.size(0), self.out_channels, *out_size)
+
+ # some times rois is an empty tensor
+ if roi_feats.shape[0] == 0:
+ return roi_feats
+
+ if num_levels == 1:
+ return self.roi_layers[0](feats[0], rois)
+
+ if roi_scale_factor is not None:
+ rois = self.roi_rescale(rois, roi_scale_factor)
+
+ # mark the starting channels for concat mode
+ start_channels = 0
+ for i in range(num_levels):
+ roi_feats_t = self.roi_layers[i](feats[i], rois)
+ end_channels = start_channels + roi_feats_t.size(1)
+ if self.with_pre:
+ # apply pre-processing to a RoI extracted from each layer
+ roi_feats_t = self.pre_module(roi_feats_t)
+ if self.aggregation == 'sum':
+ # and sum them all
+ roi_feats += roi_feats_t
+ else:
+ # and concat them along channel dimension
+ roi_feats[:, start_channels:end_channels] = roi_feats_t
+ # update channels starting position
+ start_channels = end_channels
+ # check if concat channels match at the end
+ if self.aggregation == 'concat':
+ assert start_channels == self.out_channels
+
+ if self.with_post:
+ # apply post-processing before return the result
+ roi_feats = self.post_module(roi_feats)
+ return roi_feats
diff --git a/mmdet/models/roi_heads/roi_extractors/single_level_roi_extractor.py b/mmdet/models/roi_heads/roi_extractors/single_level_roi_extractor.py
new file mode 100644
index 0000000000000000000000000000000000000000..59229e0b0b0a18dff81abca6f5c20cb50b0d542c
--- /dev/null
+++ b/mmdet/models/roi_heads/roi_extractors/single_level_roi_extractor.py
@@ -0,0 +1,119 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Optional, Tuple
+
+import torch
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.utils import ConfigType, OptMultiConfig
+from .base_roi_extractor import BaseRoIExtractor
+
+
+@MODELS.register_module()
+class SingleRoIExtractor(BaseRoIExtractor):
+ """Extract RoI features from a single level feature map.
+
+ If there are multiple input feature levels, each RoI is mapped to a level
+ according to its scale. The mapping rule is proposed in
+ `FPN `_.
+
+ Args:
+ roi_layer (:obj:`ConfigDict` or dict): Specify RoI layer type and
+ arguments.
+ out_channels (int): Output channels of RoI layers.
+ featmap_strides (List[int]): Strides of input feature maps.
+ finest_scale (int): Scale threshold of mapping to level 0.
+ Defaults to 56.
+ init_cfg (:obj:`ConfigDict` or dict or list[:obj:`ConfigDict` or \
+ dict], optional): Initialization config dict. Defaults to None.
+ """
+
+ def __init__(self,
+ roi_layer: ConfigType,
+ out_channels: int,
+ featmap_strides: List[int],
+ finest_scale: int = 56,
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(
+ roi_layer=roi_layer,
+ out_channels=out_channels,
+ featmap_strides=featmap_strides,
+ init_cfg=init_cfg)
+ self.finest_scale = finest_scale
+
+ def map_roi_levels(self, rois: Tensor, num_levels: int) -> Tensor:
+ """Map rois to corresponding feature levels by scales.
+
+ - scale < finest_scale * 2: level 0
+ - finest_scale * 2 <= scale < finest_scale * 4: level 1
+ - finest_scale * 4 <= scale < finest_scale * 8: level 2
+ - scale >= finest_scale * 8: level 3
+
+ Args:
+ rois (Tensor): Input RoIs, shape (k, 5).
+ num_levels (int): Total level number.
+
+ Returns:
+ Tensor: Level index (0-based) of each RoI, shape (k, )
+ """
+ scale = torch.sqrt(
+ (rois[:, 3] - rois[:, 1]) * (rois[:, 4] - rois[:, 2]))
+ target_lvls = torch.floor(torch.log2(scale / self.finest_scale + 1e-6))
+ target_lvls = target_lvls.clamp(min=0, max=num_levels - 1).long()
+ return target_lvls
+
+ def forward(self,
+ feats: Tuple[Tensor],
+ rois: Tensor,
+ roi_scale_factor: Optional[float] = None):
+ """Extractor ROI feats.
+
+ Args:
+ feats (Tuple[Tensor]): Multi-scale features.
+ rois (Tensor): RoIs with the shape (n, 5) where the first
+ column indicates batch id of each RoI.
+ roi_scale_factor (Optional[float]): RoI scale factor.
+ Defaults to None.
+
+ Returns:
+ Tensor: RoI feature.
+ """
+ # convert fp32 to fp16 when amp is on
+ rois = rois.type_as(feats[0])
+ out_size = self.roi_layers[0].output_size
+ num_levels = len(feats)
+ roi_feats = feats[0].new_zeros(
+ rois.size(0), self.out_channels, *out_size)
+
+ # TODO: remove this when parrots supports
+ if torch.__version__ == 'parrots':
+ roi_feats.requires_grad = True
+
+ if num_levels == 1:
+ if len(rois) == 0:
+ return roi_feats
+ return self.roi_layers[0](feats[0], rois)
+
+ target_lvls = self.map_roi_levels(rois, num_levels)
+
+ if roi_scale_factor is not None:
+ rois = self.roi_rescale(rois, roi_scale_factor)
+
+ for i in range(num_levels):
+ mask = target_lvls == i
+ inds = mask.nonzero(as_tuple=False).squeeze(1)
+ if inds.numel() > 0:
+ rois_ = rois[inds]
+ roi_feats_t = self.roi_layers[i](feats[i], rois_)
+ roi_feats[inds] = roi_feats_t
+ else:
+ # Sometimes some pyramid levels will not be used for RoI
+ # feature extraction and this will cause an incomplete
+ # computation graph in one GPU, which is different from those
+ # in other GPUs and will cause a hanging error.
+ # Therefore, we add it to ensure each feature pyramid is
+ # included in the computation graph to avoid runtime bugs.
+ roi_feats += sum(
+ x.view(-1)[0]
+ for x in self.parameters()) * 0. + feats[i].sum() * 0.
+ return roi_feats
diff --git a/mmdet/models/roi_heads/scnet_roi_head.py b/mmdet/models/roi_heads/scnet_roi_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..e6d2bc1915bae38011cc75a720e48ed53b51ddb5
--- /dev/null
+++ b/mmdet/models/roi_heads/scnet_roi_head.py
@@ -0,0 +1,677 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Optional, Tuple
+
+import torch
+import torch.nn.functional as F
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.structures import SampleList
+from mmdet.structures.bbox import bbox2roi
+from mmdet.utils import ConfigType, InstanceList, OptConfigType
+from ..layers import adaptive_avg_pool2d
+from ..task_modules.samplers import SamplingResult
+from ..utils import empty_instances, unpack_gt_instances
+from .cascade_roi_head import CascadeRoIHead
+
+
+@MODELS.register_module()
+class SCNetRoIHead(CascadeRoIHead):
+ """RoIHead for `SCNet `_.
+
+ Args:
+ num_stages (int): number of cascade stages.
+ stage_loss_weights (list): loss weight of cascade stages.
+ semantic_roi_extractor (dict): config to init semantic roi extractor.
+ semantic_head (dict): config to init semantic head.
+ feat_relay_head (dict): config to init feature_relay_head.
+ glbctx_head (dict): config to init global context head.
+ """
+
+ def __init__(self,
+ num_stages: int,
+ stage_loss_weights: List[float],
+ semantic_roi_extractor: OptConfigType = None,
+ semantic_head: OptConfigType = None,
+ feat_relay_head: OptConfigType = None,
+ glbctx_head: OptConfigType = None,
+ **kwargs) -> None:
+ super().__init__(
+ num_stages=num_stages,
+ stage_loss_weights=stage_loss_weights,
+ **kwargs)
+ assert self.with_bbox and self.with_mask
+ assert not self.with_shared_head # shared head is not supported
+
+ if semantic_head is not None:
+ self.semantic_roi_extractor = MODELS.build(semantic_roi_extractor)
+ self.semantic_head = MODELS.build(semantic_head)
+
+ if feat_relay_head is not None:
+ self.feat_relay_head = MODELS.build(feat_relay_head)
+
+ if glbctx_head is not None:
+ self.glbctx_head = MODELS.build(glbctx_head)
+
+ def init_mask_head(self, mask_roi_extractor: ConfigType,
+ mask_head: ConfigType) -> None:
+ """Initialize ``mask_head``"""
+ if mask_roi_extractor is not None:
+ self.mask_roi_extractor = MODELS.build(mask_roi_extractor)
+ self.mask_head = MODELS.build(mask_head)
+
+ # TODO move to base_roi_head later
+ @property
+ def with_semantic(self) -> bool:
+ """bool: whether the head has semantic head"""
+ return hasattr(self,
+ 'semantic_head') and self.semantic_head is not None
+
+ @property
+ def with_feat_relay(self) -> bool:
+ """bool: whether the head has feature relay head"""
+ return (hasattr(self, 'feat_relay_head')
+ and self.feat_relay_head is not None)
+
+ @property
+ def with_glbctx(self) -> bool:
+ """bool: whether the head has global context head"""
+ return hasattr(self, 'glbctx_head') and self.glbctx_head is not None
+
+ def _fuse_glbctx(self, roi_feats: Tensor, glbctx_feat: Tensor,
+ rois: Tensor) -> Tensor:
+ """Fuse global context feats with roi feats.
+
+ Args:
+ roi_feats (Tensor): RoI features.
+ glbctx_feat (Tensor): Global context feature..
+ rois (Tensor): RoIs with the shape (n, 5) where the first
+ column indicates batch id of each RoI.
+
+ Returns:
+ Tensor: Fused feature.
+ """
+ assert roi_feats.size(0) == rois.size(0)
+ # RuntimeError: isDifferentiableType(variable.scalar_type())
+ # INTERNAL ASSERT FAILED if detach() is not used when calling
+ # roi_head.predict().
+ img_inds = torch.unique(rois[:, 0].detach().cpu(), sorted=True).long()
+ fused_feats = torch.zeros_like(roi_feats)
+ for img_id in img_inds:
+ inds = (rois[:, 0] == img_id.item())
+ fused_feats[inds] = roi_feats[inds] + glbctx_feat[img_id]
+ return fused_feats
+
+ def _slice_pos_feats(self, feats: Tensor,
+ sampling_results: List[SamplingResult]) -> Tensor:
+ """Get features from pos rois.
+
+ Args:
+ feats (Tensor): Input features.
+ sampling_results (list["obj:`SamplingResult`]): Sampling results.
+
+ Returns:
+ Tensor: Sliced features.
+ """
+ num_rois = [res.priors.size(0) for res in sampling_results]
+ num_pos_rois = [res.pos_priors.size(0) for res in sampling_results]
+ inds = torch.zeros(sum(num_rois), dtype=torch.bool)
+ start = 0
+ for i in range(len(num_rois)):
+ start = 0 if i == 0 else start + num_rois[i - 1]
+ stop = start + num_pos_rois[i]
+ inds[start:stop] = 1
+ sliced_feats = feats[inds]
+ return sliced_feats
+
+ def _bbox_forward(self,
+ stage: int,
+ x: Tuple[Tensor],
+ rois: Tensor,
+ semantic_feat: Optional[Tensor] = None,
+ glbctx_feat: Optional[Tensor] = None) -> dict:
+ """Box head forward function used in both training and testing.
+
+ Args:
+ stage (int): The current stage in Cascade RoI Head.
+ x (tuple[Tensor]): List of multi-level img features.
+ rois (Tensor): RoIs with the shape (n, 5) where the first
+ column indicates batch id of each RoI.
+ semantic_feat (Tensor): Semantic feature. Defaults to None.
+ glbctx_feat (Tensor): Global context feature. Defaults to None.
+
+ Returns:
+ dict[str, Tensor]: Usually returns a dictionary with keys:
+
+ - `cls_score` (Tensor): Classification scores.
+ - `bbox_pred` (Tensor): Box energies / deltas.
+ - `bbox_feats` (Tensor): Extract bbox RoI features.
+ """
+ bbox_roi_extractor = self.bbox_roi_extractor[stage]
+ bbox_head = self.bbox_head[stage]
+ bbox_feats = bbox_roi_extractor(x[:bbox_roi_extractor.num_inputs],
+ rois)
+ if self.with_semantic and semantic_feat is not None:
+ bbox_semantic_feat = self.semantic_roi_extractor([semantic_feat],
+ rois)
+ if bbox_semantic_feat.shape[-2:] != bbox_feats.shape[-2:]:
+ bbox_semantic_feat = adaptive_avg_pool2d(
+ bbox_semantic_feat, bbox_feats.shape[-2:])
+ bbox_feats += bbox_semantic_feat
+ if self.with_glbctx and glbctx_feat is not None:
+ bbox_feats = self._fuse_glbctx(bbox_feats, glbctx_feat, rois)
+ cls_score, bbox_pred, relayed_feat = bbox_head(
+ bbox_feats, return_shared_feat=True)
+
+ bbox_results = dict(
+ cls_score=cls_score,
+ bbox_pred=bbox_pred,
+ relayed_feat=relayed_feat)
+ return bbox_results
+
+ def _mask_forward(self,
+ x: Tuple[Tensor],
+ rois: Tensor,
+ semantic_feat: Optional[Tensor] = None,
+ glbctx_feat: Optional[Tensor] = None,
+ relayed_feat: Optional[Tensor] = None) -> dict:
+ """Mask head forward function used in both training and testing.
+
+ Args:
+ stage (int): The current stage in Cascade RoI Head.
+ x (tuple[Tensor]): Tuple of multi-level img features.
+ rois (Tensor): RoIs with the shape (n, 5) where the first
+ column indicates batch id of each RoI.
+ semantic_feat (Tensor): Semantic feature. Defaults to None.
+ glbctx_feat (Tensor): Global context feature. Defaults to None.
+ relayed_feat (Tensor): Relayed feature. Defaults to None.
+
+ Returns:
+ dict: Usually returns a dictionary with keys:
+
+ - `mask_preds` (Tensor): Mask prediction.
+ """
+ mask_feats = self.mask_roi_extractor(
+ x[:self.mask_roi_extractor.num_inputs], rois)
+ if self.with_semantic and semantic_feat is not None:
+ mask_semantic_feat = self.semantic_roi_extractor([semantic_feat],
+ rois)
+ if mask_semantic_feat.shape[-2:] != mask_feats.shape[-2:]:
+ mask_semantic_feat = F.adaptive_avg_pool2d(
+ mask_semantic_feat, mask_feats.shape[-2:])
+ mask_feats += mask_semantic_feat
+ if self.with_glbctx and glbctx_feat is not None:
+ mask_feats = self._fuse_glbctx(mask_feats, glbctx_feat, rois)
+ if self.with_feat_relay and relayed_feat is not None:
+ mask_feats = mask_feats + relayed_feat
+ mask_preds = self.mask_head(mask_feats)
+ mask_results = dict(mask_preds=mask_preds)
+
+ return mask_results
+
+ def bbox_loss(self,
+ stage: int,
+ x: Tuple[Tensor],
+ sampling_results: List[SamplingResult],
+ semantic_feat: Optional[Tensor] = None,
+ glbctx_feat: Optional[Tensor] = None) -> dict:
+ """Run forward function and calculate loss for box head in training.
+
+ Args:
+ stage (int): The current stage in Cascade RoI Head.
+ x (tuple[Tensor]): List of multi-level img features.
+ sampling_results (list["obj:`SamplingResult`]): Sampling results.
+ semantic_feat (Tensor): Semantic feature. Defaults to None.
+ glbctx_feat (Tensor): Global context feature. Defaults to None.
+
+ Returns:
+ dict: Usually returns a dictionary with keys:
+
+ - `cls_score` (Tensor): Classification scores.
+ - `bbox_pred` (Tensor): Box energies / deltas.
+ - `bbox_feats` (Tensor): Extract bbox RoI features.
+ - `loss_bbox` (dict): A dictionary of bbox loss components.
+ - `rois` (Tensor): RoIs with the shape (n, 5) where the first
+ column indicates batch id of each RoI.
+ - `bbox_targets` (tuple): Ground truth for proposals in a
+ single image. Containing the following list of Tensors:
+ (labels, label_weights, bbox_targets, bbox_weights)
+ """
+ bbox_head = self.bbox_head[stage]
+ rois = bbox2roi([res.priors for res in sampling_results])
+ bbox_results = self._bbox_forward(
+ stage,
+ x,
+ rois,
+ semantic_feat=semantic_feat,
+ glbctx_feat=glbctx_feat)
+ bbox_results.update(rois=rois)
+
+ bbox_loss_and_target = bbox_head.loss_and_target(
+ cls_score=bbox_results['cls_score'],
+ bbox_pred=bbox_results['bbox_pred'],
+ rois=rois,
+ sampling_results=sampling_results,
+ rcnn_train_cfg=self.train_cfg[stage])
+
+ bbox_results.update(bbox_loss_and_target)
+ return bbox_results
+
+ def mask_loss(self,
+ x: Tuple[Tensor],
+ sampling_results: List[SamplingResult],
+ batch_gt_instances: InstanceList,
+ semantic_feat: Optional[Tensor] = None,
+ glbctx_feat: Optional[Tensor] = None,
+ relayed_feat: Optional[Tensor] = None) -> dict:
+ """Run forward function and calculate loss for mask head in training.
+
+ Args:
+ x (tuple[Tensor]): Tuple of multi-level img features.
+ sampling_results (list["obj:`SamplingResult`]): Sampling results.
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes``, ``labels``, and
+ ``masks`` attributes.
+ semantic_feat (Tensor): Semantic feature. Defaults to None.
+ glbctx_feat (Tensor): Global context feature. Defaults to None.
+ relayed_feat (Tensor): Relayed feature. Defaults to None.
+
+ Returns:
+ dict: Usually returns a dictionary with keys:
+
+ - `mask_preds` (Tensor): Mask prediction.
+ - `loss_mask` (dict): A dictionary of mask loss components.
+ """
+ pos_rois = bbox2roi([res.pos_priors for res in sampling_results])
+ mask_results = self._mask_forward(
+ x,
+ pos_rois,
+ semantic_feat=semantic_feat,
+ glbctx_feat=glbctx_feat,
+ relayed_feat=relayed_feat)
+
+ mask_loss_and_target = self.mask_head.loss_and_target(
+ mask_preds=mask_results['mask_preds'],
+ sampling_results=sampling_results,
+ batch_gt_instances=batch_gt_instances,
+ rcnn_train_cfg=self.train_cfg[-1])
+ mask_results.update(mask_loss_and_target)
+
+ return mask_results
+
+ def semantic_loss(self, x: Tuple[Tensor],
+ batch_data_samples: SampleList) -> dict:
+ """Semantic segmentation loss.
+
+ Args:
+ x (Tuple[Tensor]): Tuple of multi-level img features.
+ batch_data_samples (list[:obj:`DetDataSample`]): The batch
+ data samples. It usually includes information such
+ as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
+
+ Returns:
+ dict: Usually returns a dictionary with keys:
+
+ - `semantic_feat` (Tensor): Semantic feature.
+ - `loss_seg` (dict): Semantic segmentation loss.
+ """
+ gt_semantic_segs = [
+ data_sample.gt_sem_seg.sem_seg
+ for data_sample in batch_data_samples
+ ]
+ gt_semantic_segs = torch.stack(gt_semantic_segs)
+ semantic_pred, semantic_feat = self.semantic_head(x)
+ loss_seg = self.semantic_head.loss(semantic_pred, gt_semantic_segs)
+
+ semantic_results = dict(loss_seg=loss_seg, semantic_feat=semantic_feat)
+
+ return semantic_results
+
+ def global_context_loss(self, x: Tuple[Tensor],
+ batch_gt_instances: InstanceList) -> dict:
+ """Global context loss.
+
+ Args:
+ x (Tuple[Tensor]): Tuple of multi-level img features.
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes``, ``labels``, and
+ ``masks`` attributes.
+
+ Returns:
+ dict: Usually returns a dictionary with keys:
+
+ - `glbctx_feat` (Tensor): Global context feature.
+ - `loss_glbctx` (dict): Global context loss.
+ """
+ gt_labels = [
+ gt_instances.labels for gt_instances in batch_gt_instances
+ ]
+ mc_pred, glbctx_feat = self.glbctx_head(x)
+ loss_glbctx = self.glbctx_head.loss(mc_pred, gt_labels)
+ global_context_results = dict(
+ loss_glbctx=loss_glbctx, glbctx_feat=glbctx_feat)
+
+ return global_context_results
+
+ def loss(self, x: Tensor, rpn_results_list: InstanceList,
+ batch_data_samples: SampleList) -> dict:
+ """Perform forward propagation and loss calculation of the detection
+ roi on the features of the upstream network.
+
+ Args:
+ x (tuple[Tensor]): List of multi-level img features.
+ rpn_results_list (list[:obj:`InstanceData`]): List of region
+ proposals.
+ batch_data_samples (list[:obj:`DetDataSample`]): The batch
+ data samples. It usually includes information such
+ as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components
+ """
+ assert len(rpn_results_list) == len(batch_data_samples)
+ outputs = unpack_gt_instances(batch_data_samples)
+ batch_gt_instances, batch_gt_instances_ignore, batch_img_metas \
+ = outputs
+
+ losses = dict()
+
+ # semantic segmentation branch
+ if self.with_semantic:
+ semantic_results = self.semantic_loss(
+ x=x, batch_data_samples=batch_data_samples)
+ losses['loss_semantic_seg'] = semantic_results['loss_seg']
+ semantic_feat = semantic_results['semantic_feat']
+ else:
+ semantic_feat = None
+
+ # global context branch
+ if self.with_glbctx:
+ global_context_results = self.global_context_loss(
+ x=x, batch_gt_instances=batch_gt_instances)
+ losses['loss_glbctx'] = global_context_results['loss_glbctx']
+ glbctx_feat = global_context_results['glbctx_feat']
+ else:
+ glbctx_feat = None
+
+ results_list = rpn_results_list
+ num_imgs = len(batch_img_metas)
+ for stage in range(self.num_stages):
+ stage_loss_weight = self.stage_loss_weights[stage]
+
+ # assign gts and sample proposals
+ sampling_results = []
+ bbox_assigner = self.bbox_assigner[stage]
+ bbox_sampler = self.bbox_sampler[stage]
+ for i in range(num_imgs):
+ results = results_list[i]
+ # rename rpn_results.bboxes to rpn_results.priors
+ results.priors = results.pop('bboxes')
+
+ assign_result = bbox_assigner.assign(
+ results, batch_gt_instances[i],
+ batch_gt_instances_ignore[i])
+ sampling_result = bbox_sampler.sample(
+ assign_result,
+ results,
+ batch_gt_instances[i],
+ feats=[lvl_feat[i][None] for lvl_feat in x])
+ sampling_results.append(sampling_result)
+
+ # bbox head forward and loss
+ bbox_results = self.bbox_loss(
+ stage=stage,
+ x=x,
+ sampling_results=sampling_results,
+ semantic_feat=semantic_feat,
+ glbctx_feat=glbctx_feat)
+
+ for name, value in bbox_results['loss_bbox'].items():
+ losses[f's{stage}.{name}'] = (
+ value * stage_loss_weight if 'loss' in name else value)
+
+ # refine bboxes
+ if stage < self.num_stages - 1:
+ bbox_head = self.bbox_head[stage]
+ with torch.no_grad():
+ results_list = bbox_head.refine_bboxes(
+ sampling_results=sampling_results,
+ bbox_results=bbox_results,
+ batch_img_metas=batch_img_metas)
+
+ if self.with_feat_relay:
+ relayed_feat = self._slice_pos_feats(bbox_results['relayed_feat'],
+ sampling_results)
+ relayed_feat = self.feat_relay_head(relayed_feat)
+ else:
+ relayed_feat = None
+
+ # mask head forward and loss
+ mask_results = self.mask_loss(
+ x=x,
+ sampling_results=sampling_results,
+ batch_gt_instances=batch_gt_instances,
+ semantic_feat=semantic_feat,
+ glbctx_feat=glbctx_feat,
+ relayed_feat=relayed_feat)
+ mask_stage_loss_weight = sum(self.stage_loss_weights)
+ losses['loss_mask'] = mask_stage_loss_weight * mask_results[
+ 'loss_mask']['loss_mask']
+
+ return losses
+
+ def predict(self,
+ x: Tuple[Tensor],
+ rpn_results_list: InstanceList,
+ batch_data_samples: SampleList,
+ rescale: bool = False) -> InstanceList:
+ """Perform forward propagation of the roi head and predict detection
+ results on the features of the upstream network.
+
+ Args:
+ x (tuple[Tensor]): Features from upstream network. Each
+ has shape (N, C, H, W).
+ rpn_results_list (list[:obj:`InstanceData`]): list of region
+ proposals.
+ batch_data_samples (List[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ rescale (bool): Whether to rescale the results to
+ the original image. Defaults to False.
+
+ Returns:
+ list[obj:`InstanceData`]: Detection results of each image.
+ Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ - masks (Tensor): Has a shape (num_instances, H, W).
+ """
+ assert self.with_bbox, 'Bbox head must be implemented.'
+ batch_img_metas = [
+ data_samples.metainfo for data_samples in batch_data_samples
+ ]
+
+ if self.with_semantic:
+ _, semantic_feat = self.semantic_head(x)
+ else:
+ semantic_feat = None
+
+ if self.with_glbctx:
+ _, glbctx_feat = self.glbctx_head(x)
+ else:
+ glbctx_feat = None
+
+ # TODO: nms_op in mmcv need be enhanced, the bbox result may get
+ # difference when not rescale in bbox_head
+
+ # If it has the mask branch, the bbox branch does not need
+ # to be scaled to the original image scale, because the mask
+ # branch will scale both bbox and mask at the same time.
+ bbox_rescale = rescale if not self.with_mask else False
+ results_list = self.predict_bbox(
+ x=x,
+ semantic_feat=semantic_feat,
+ glbctx_feat=glbctx_feat,
+ batch_img_metas=batch_img_metas,
+ rpn_results_list=rpn_results_list,
+ rcnn_test_cfg=self.test_cfg,
+ rescale=bbox_rescale)
+
+ if self.with_mask:
+ results_list = self.predict_mask(
+ x=x,
+ semantic_heat=semantic_feat,
+ glbctx_feat=glbctx_feat,
+ batch_img_metas=batch_img_metas,
+ results_list=results_list,
+ rescale=rescale)
+
+ return results_list
+
+ def predict_mask(self,
+ x: Tuple[Tensor],
+ semantic_heat: Tensor,
+ glbctx_feat: Tensor,
+ batch_img_metas: List[dict],
+ results_list: List[InstanceData],
+ rescale: bool = False) -> List[InstanceData]:
+ """Perform forward propagation of the mask head and predict detection
+ results on the features of the upstream network.
+
+ Args:
+ x (tuple[Tensor]): Feature maps of all scale level.
+ semantic_feat (Tensor): Semantic feature.
+ glbctx_feat (Tensor): Global context feature.
+ batch_img_metas (list[dict]): List of image information.
+ results_list (list[:obj:`InstanceData`]): Detection results of
+ each image.
+ rescale (bool): If True, return boxes in original image space.
+ Defaults to False.
+
+ Returns:
+ list[:obj:`InstanceData`]: Detection results of each image
+ after the post process.
+ Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ - masks (Tensor): Has a shape (num_instances, H, W).
+ """
+ bboxes = [res.bboxes for res in results_list]
+ mask_rois = bbox2roi(bboxes)
+ if mask_rois.shape[0] == 0:
+ results_list = empty_instances(
+ batch_img_metas=batch_img_metas,
+ device=mask_rois.device,
+ task_type='mask',
+ instance_results=results_list,
+ mask_thr_binary=self.test_cfg.mask_thr_binary)
+ return results_list
+
+ bboxes_results = self._bbox_forward(
+ stage=-1,
+ x=x,
+ rois=mask_rois,
+ semantic_feat=semantic_heat,
+ glbctx_feat=glbctx_feat)
+ relayed_feat = bboxes_results['relayed_feat']
+ relayed_feat = self.feat_relay_head(relayed_feat)
+
+ mask_results = self._mask_forward(
+ x=x,
+ rois=mask_rois,
+ semantic_feat=semantic_heat,
+ glbctx_feat=glbctx_feat,
+ relayed_feat=relayed_feat)
+ mask_preds = mask_results['mask_preds']
+
+ # split batch mask prediction back to each image
+ num_bbox_per_img = tuple(len(_bbox) for _bbox in bboxes)
+ mask_preds = mask_preds.split(num_bbox_per_img, 0)
+
+ results_list = self.mask_head.predict_by_feat(
+ mask_preds=mask_preds,
+ results_list=results_list,
+ batch_img_metas=batch_img_metas,
+ rcnn_test_cfg=self.test_cfg,
+ rescale=rescale)
+
+ return results_list
+
+ def forward(self, x: Tuple[Tensor], rpn_results_list: InstanceList,
+ batch_data_samples: SampleList) -> tuple:
+ """Network forward process. Usually includes backbone, neck and head
+ forward without any post-processing.
+
+ Args:
+ x (List[Tensor]): Multi-level features that may have different
+ resolutions.
+ rpn_results_list (list[:obj:`InstanceData`]): List of region
+ proposals.
+ batch_data_samples (list[:obj:`DetDataSample`]): Each item contains
+ the meta information of each image and corresponding
+ annotations.
+
+ Returns
+ tuple: A tuple of features from ``bbox_head`` and ``mask_head``
+ forward.
+ """
+ results = ()
+ batch_img_metas = [
+ data_samples.metainfo for data_samples in batch_data_samples
+ ]
+
+ if self.with_semantic:
+ _, semantic_feat = self.semantic_head(x)
+ else:
+ semantic_feat = None
+
+ if self.with_glbctx:
+ _, glbctx_feat = self.glbctx_head(x)
+ else:
+ glbctx_feat = None
+
+ proposals = [rpn_results.bboxes for rpn_results in rpn_results_list]
+ num_proposals_per_img = tuple(len(p) for p in proposals)
+ rois = bbox2roi(proposals)
+ # bbox head
+ if self.with_bbox:
+ rois, cls_scores, bbox_preds = self._refine_roi(
+ x=x,
+ rois=rois,
+ semantic_feat=semantic_feat,
+ glbctx_feat=glbctx_feat,
+ batch_img_metas=batch_img_metas,
+ num_proposals_per_img=num_proposals_per_img)
+ results = results + (cls_scores, bbox_preds)
+ # mask head
+ if self.with_mask:
+ rois = torch.cat(rois)
+ bboxes_results = self._bbox_forward(
+ stage=-1,
+ x=x,
+ rois=rois,
+ semantic_feat=semantic_feat,
+ glbctx_feat=glbctx_feat)
+ relayed_feat = bboxes_results['relayed_feat']
+ relayed_feat = self.feat_relay_head(relayed_feat)
+ mask_results = self._mask_forward(
+ x=x,
+ rois=rois,
+ semantic_feat=semantic_feat,
+ glbctx_feat=glbctx_feat,
+ relayed_feat=relayed_feat)
+ mask_preds = mask_results['mask_preds']
+ mask_preds = mask_preds.split(num_proposals_per_img, 0)
+ results = results + (mask_preds, )
+ return results
diff --git a/mmdet/models/roi_heads/shared_heads/__init__.py b/mmdet/models/roi_heads/shared_heads/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..d56636ab34d1dd2592828238099bcdccf179d6d3
--- /dev/null
+++ b/mmdet/models/roi_heads/shared_heads/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .res_layer import ResLayer
+
+__all__ = ['ResLayer']
diff --git a/mmdet/models/roi_heads/shared_heads/__pycache__/__init__.cpython-37.pyc b/mmdet/models/roi_heads/shared_heads/__pycache__/__init__.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..b0d9ec5e174c40cb0ccee33d67d3cc152cf03ded
Binary files /dev/null and b/mmdet/models/roi_heads/shared_heads/__pycache__/__init__.cpython-37.pyc differ
diff --git a/mmdet/models/roi_heads/shared_heads/__pycache__/res_layer.cpython-37.pyc b/mmdet/models/roi_heads/shared_heads/__pycache__/res_layer.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..49d3f1b0b27ec0d346de6213190802aef32e6d0f
Binary files /dev/null and b/mmdet/models/roi_heads/shared_heads/__pycache__/res_layer.cpython-37.pyc differ
diff --git a/mmdet/models/roi_heads/shared_heads/res_layer.py b/mmdet/models/roi_heads/shared_heads/res_layer.py
new file mode 100644
index 0000000000000000000000000000000000000000..d9210cb928fec92135a195d44d13a8588382b947
--- /dev/null
+++ b/mmdet/models/roi_heads/shared_heads/res_layer.py
@@ -0,0 +1,79 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+
+import torch.nn as nn
+from mmengine.model import BaseModule
+
+from mmdet.models.backbones import ResNet
+from mmdet.models.layers import ResLayer as _ResLayer
+from mmdet.registry import MODELS
+
+
+@MODELS.register_module()
+class ResLayer(BaseModule):
+
+ def __init__(self,
+ depth,
+ stage=3,
+ stride=2,
+ dilation=1,
+ style='pytorch',
+ norm_cfg=dict(type='BN', requires_grad=True),
+ norm_eval=True,
+ with_cp=False,
+ dcn=None,
+ pretrained=None,
+ init_cfg=None):
+ super(ResLayer, self).__init__(init_cfg)
+
+ self.norm_eval = norm_eval
+ self.norm_cfg = norm_cfg
+ self.stage = stage
+ self.fp16_enabled = False
+ block, stage_blocks = ResNet.arch_settings[depth]
+ stage_block = stage_blocks[stage]
+ planes = 64 * 2**stage
+ inplanes = 64 * 2**(stage - 1) * block.expansion
+
+ res_layer = _ResLayer(
+ block,
+ inplanes,
+ planes,
+ stage_block,
+ stride=stride,
+ dilation=dilation,
+ style=style,
+ with_cp=with_cp,
+ norm_cfg=self.norm_cfg,
+ dcn=dcn)
+ self.add_module(f'layer{stage + 1}', res_layer)
+
+ assert not (init_cfg and pretrained), \
+ 'init_cfg and pretrained cannot be specified at the same time'
+ if isinstance(pretrained, str):
+ warnings.warn('DeprecationWarning: pretrained is a deprecated, '
+ 'please use "init_cfg" instead')
+ self.init_cfg = dict(type='Pretrained', checkpoint=pretrained)
+ elif pretrained is None:
+ if init_cfg is None:
+ self.init_cfg = [
+ dict(type='Kaiming', layer='Conv2d'),
+ dict(
+ type='Constant',
+ val=1,
+ layer=['_BatchNorm', 'GroupNorm'])
+ ]
+ else:
+ raise TypeError('pretrained must be a str or None')
+
+ def forward(self, x):
+ res_layer = getattr(self, f'layer{self.stage + 1}')
+ out = res_layer(x)
+ return out
+
+ def train(self, mode=True):
+ super(ResLayer, self).train(mode)
+ if self.norm_eval:
+ for m in self.modules():
+ if isinstance(m, nn.BatchNorm2d):
+ m.eval()
diff --git a/mmdet/models/roi_heads/sparse_roi_head.py b/mmdet/models/roi_heads/sparse_roi_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..19c3e1e335ca4e4a9d5befcbffcf4665b459cb5a
--- /dev/null
+++ b/mmdet/models/roi_heads/sparse_roi_head.py
@@ -0,0 +1,601 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Tuple
+
+import torch
+from mmengine.config import ConfigDict
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmdet.models.task_modules.samplers import PseudoSampler
+from mmdet.registry import MODELS
+from mmdet.structures import SampleList
+from mmdet.structures.bbox import bbox2roi
+from mmdet.utils import ConfigType, InstanceList, OptConfigType
+from ..utils.misc import empty_instances, unpack_gt_instances
+from .cascade_roi_head import CascadeRoIHead
+
+
+@MODELS.register_module()
+class SparseRoIHead(CascadeRoIHead):
+ r"""The RoIHead for `Sparse R-CNN: End-to-End Object Detection with
+ Learnable Proposals `_
+ and `Instances as Queries `_
+
+ Args:
+ num_stages (int): Number of stage whole iterative process.
+ Defaults to 6.
+ stage_loss_weights (Tuple[float]): The loss
+ weight of each stage. By default all stages have
+ the same weight 1.
+ bbox_roi_extractor (:obj:`ConfigDict` or dict): Config of box
+ roi extractor.
+ mask_roi_extractor (:obj:`ConfigDict` or dict): Config of mask
+ roi extractor.
+ bbox_head (:obj:`ConfigDict` or dict): Config of box head.
+ mask_head (:obj:`ConfigDict` or dict): Config of mask head.
+ train_cfg (:obj:`ConfigDict` or dict, Optional): Configuration
+ information in train stage. Defaults to None.
+ test_cfg (:obj:`ConfigDict` or dict, Optional): Configuration
+ information in test stage. Defaults to None.
+ init_cfg (:obj:`ConfigDict` or dict or list[:obj:`ConfigDict` or \
+ dict]): Initialization config dict. Defaults to None.
+ """
+
+ def __init__(self,
+ num_stages: int = 6,
+ stage_loss_weights: Tuple[float] = (1, 1, 1, 1, 1, 1),
+ proposal_feature_channel: int = 256,
+ bbox_roi_extractor: ConfigType = dict(
+ type='SingleRoIExtractor',
+ roi_layer=dict(
+ type='RoIAlign', output_size=7, sampling_ratio=2),
+ out_channels=256,
+ featmap_strides=[4, 8, 16, 32]),
+ mask_roi_extractor: OptConfigType = None,
+ bbox_head: ConfigType = dict(
+ type='DIIHead',
+ num_classes=80,
+ num_fcs=2,
+ num_heads=8,
+ num_cls_fcs=1,
+ num_reg_fcs=3,
+ feedforward_channels=2048,
+ hidden_channels=256,
+ dropout=0.0,
+ roi_feat_size=7,
+ ffn_act_cfg=dict(type='ReLU', inplace=True)),
+ mask_head: OptConfigType = None,
+ train_cfg: OptConfigType = None,
+ test_cfg: OptConfigType = None,
+ init_cfg: OptConfigType = None) -> None:
+ assert bbox_roi_extractor is not None
+ assert bbox_head is not None
+ assert len(stage_loss_weights) == num_stages
+ self.num_stages = num_stages
+ self.stage_loss_weights = stage_loss_weights
+ self.proposal_feature_channel = proposal_feature_channel
+ super().__init__(
+ num_stages=num_stages,
+ stage_loss_weights=stage_loss_weights,
+ bbox_roi_extractor=bbox_roi_extractor,
+ mask_roi_extractor=mask_roi_extractor,
+ bbox_head=bbox_head,
+ mask_head=mask_head,
+ train_cfg=train_cfg,
+ test_cfg=test_cfg,
+ init_cfg=init_cfg)
+ # train_cfg would be None when run the test.py
+ if train_cfg is not None:
+ for stage in range(num_stages):
+ assert isinstance(self.bbox_sampler[stage], PseudoSampler), \
+ 'Sparse R-CNN and QueryInst only support `PseudoSampler`'
+
+ def bbox_loss(self, stage: int, x: Tuple[Tensor],
+ results_list: InstanceList, object_feats: Tensor,
+ batch_img_metas: List[dict],
+ batch_gt_instances: InstanceList) -> dict:
+ """Perform forward propagation and loss calculation of the bbox head on
+ the features of the upstream network.
+
+ Args:
+ stage (int): The current stage in iterative process.
+ x (tuple[Tensor]): List of multi-level img features.
+ results_list (List[:obj:`InstanceData`]) : List of region
+ proposals.
+ object_feats (Tensor): The object feature extracted from
+ the previous stage.
+ batch_img_metas (list[dict]): Meta information of each image.
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes``, ``labels``, and
+ ``masks`` attributes.
+
+ Returns:
+ dict[str, Tensor]: Usually returns a dictionary with keys:
+
+ - `cls_score` (Tensor): Classification scores.
+ - `bbox_pred` (Tensor): Box energies / deltas.
+ - `bbox_feats` (Tensor): Extract bbox RoI features.
+ - `loss_bbox` (dict): A dictionary of bbox loss components.
+ """
+ proposal_list = [res.bboxes for res in results_list]
+ rois = bbox2roi(proposal_list)
+ bbox_results = self._bbox_forward(stage, x, rois, object_feats,
+ batch_img_metas)
+ imgs_whwh = torch.cat(
+ [res.imgs_whwh[None, ...] for res in results_list])
+ cls_pred_list = bbox_results['detached_cls_scores']
+ proposal_list = bbox_results['detached_proposals']
+
+ sampling_results = []
+ bbox_head = self.bbox_head[stage]
+ for i in range(len(batch_img_metas)):
+ pred_instances = InstanceData()
+ # TODO: Enhance the logic
+ pred_instances.bboxes = proposal_list[i] # for assinger
+ pred_instances.scores = cls_pred_list[i]
+ pred_instances.priors = proposal_list[i] # for sampler
+
+ assign_result = self.bbox_assigner[stage].assign(
+ pred_instances=pred_instances,
+ gt_instances=batch_gt_instances[i],
+ gt_instances_ignore=None,
+ img_meta=batch_img_metas[i])
+
+ sampling_result = self.bbox_sampler[stage].sample(
+ assign_result, pred_instances, batch_gt_instances[i])
+ sampling_results.append(sampling_result)
+
+ bbox_results.update(sampling_results=sampling_results)
+
+ cls_score = bbox_results['cls_score']
+ decoded_bboxes = bbox_results['decoded_bboxes']
+ cls_score = cls_score.view(-1, cls_score.size(-1))
+ decoded_bboxes = decoded_bboxes.view(-1, 4)
+ bbox_loss_and_target = bbox_head.loss_and_target(
+ cls_score,
+ decoded_bboxes,
+ sampling_results,
+ self.train_cfg[stage],
+ imgs_whwh=imgs_whwh,
+ concat=True)
+ bbox_results.update(bbox_loss_and_target)
+
+ # propose for the new proposal_list
+ proposal_list = []
+ for idx in range(len(batch_img_metas)):
+ results = InstanceData()
+ results.imgs_whwh = results_list[idx].imgs_whwh
+ results.bboxes = bbox_results['detached_proposals'][idx]
+ proposal_list.append(results)
+ bbox_results.update(results_list=proposal_list)
+ return bbox_results
+
+ def _bbox_forward(self, stage: int, x: Tuple[Tensor], rois: Tensor,
+ object_feats: Tensor,
+ batch_img_metas: List[dict]) -> dict:
+ """Box head forward function used in both training and testing. Returns
+ all regression, classification results and a intermediate feature.
+
+ Args:
+ stage (int): The current stage in iterative process.
+ x (tuple[Tensor]): List of multi-level img features.
+ rois (Tensor): RoIs with the shape (n, 5) where the first
+ column indicates batch id of each RoI.
+ Each dimension means (img_index, x1, y1, x2, y2).
+ object_feats (Tensor): The object feature extracted from
+ the previous stage.
+ batch_img_metas (list[dict]): Meta information of each image.
+
+ Returns:
+ dict[str, Tensor]: a dictionary of bbox head outputs,
+ Containing the following results:
+
+ - cls_score (Tensor): The score of each class, has
+ shape (batch_size, num_proposals, num_classes)
+ when use focal loss or
+ (batch_size, num_proposals, num_classes+1)
+ otherwise.
+ - decoded_bboxes (Tensor): The regression results
+ with shape (batch_size, num_proposal, 4).
+ The last dimension 4 represents
+ [tl_x, tl_y, br_x, br_y].
+ - object_feats (Tensor): The object feature extracted
+ from current stage
+ - detached_cls_scores (list[Tensor]): The detached
+ classification results, length is batch_size, and
+ each tensor has shape (num_proposal, num_classes).
+ - detached_proposals (list[tensor]): The detached
+ regression results, length is batch_size, and each
+ tensor has shape (num_proposal, 4). The last
+ dimension 4 represents [tl_x, tl_y, br_x, br_y].
+ """
+ num_imgs = len(batch_img_metas)
+ bbox_roi_extractor = self.bbox_roi_extractor[stage]
+ bbox_head = self.bbox_head[stage]
+ bbox_feats = bbox_roi_extractor(x[:bbox_roi_extractor.num_inputs],
+ rois)
+ cls_score, bbox_pred, object_feats, attn_feats = bbox_head(
+ bbox_feats, object_feats)
+
+ fake_bbox_results = dict(
+ rois=rois,
+ bbox_targets=(rois.new_zeros(len(rois), dtype=torch.long), None),
+ bbox_pred=bbox_pred.view(-1, bbox_pred.size(-1)),
+ cls_score=cls_score.view(-1, cls_score.size(-1)))
+ fake_sampling_results = [
+ InstanceData(pos_is_gt=rois.new_zeros(object_feats.size(1)))
+ for _ in range(len(batch_img_metas))
+ ]
+
+ results_list = bbox_head.refine_bboxes(
+ sampling_results=fake_sampling_results,
+ bbox_results=fake_bbox_results,
+ batch_img_metas=batch_img_metas)
+ proposal_list = [res.bboxes for res in results_list]
+ bbox_results = dict(
+ cls_score=cls_score,
+ decoded_bboxes=torch.cat(proposal_list),
+ object_feats=object_feats,
+ attn_feats=attn_feats,
+ # detach then use it in label assign
+ detached_cls_scores=[
+ cls_score[i].detach() for i in range(num_imgs)
+ ],
+ detached_proposals=[item.detach() for item in proposal_list])
+
+ return bbox_results
+
+ def _mask_forward(self, stage: int, x: Tuple[Tensor], rois: Tensor,
+ attn_feats) -> dict:
+ """Mask head forward function used in both training and testing.
+
+ Args:
+ stage (int): The current stage in Cascade RoI Head.
+ x (tuple[Tensor]): Tuple of multi-level img features.
+ rois (Tensor): RoIs with the shape (n, 5) where the first
+ column indicates batch id of each RoI.
+ attn_feats (Tensot): Intermediate feature get from the last
+ diihead, has shape
+ (batch_size*num_proposals, feature_dimensions)
+
+ Returns:
+ dict: Usually returns a dictionary with keys:
+
+ - `mask_preds` (Tensor): Mask prediction.
+ """
+ mask_roi_extractor = self.mask_roi_extractor[stage]
+ mask_head = self.mask_head[stage]
+ mask_feats = mask_roi_extractor(x[:mask_roi_extractor.num_inputs],
+ rois)
+ # do not support caffe_c4 model anymore
+ mask_preds = mask_head(mask_feats, attn_feats)
+
+ mask_results = dict(mask_preds=mask_preds)
+ return mask_results
+
+ def mask_loss(self, stage: int, x: Tuple[Tensor], bbox_results: dict,
+ batch_gt_instances: InstanceList,
+ rcnn_train_cfg: ConfigDict) -> dict:
+ """Run forward function and calculate loss for mask head in training.
+
+ Args:
+ stage (int): The current stage in Cascade RoI Head.
+ x (tuple[Tensor]): Tuple of multi-level img features.
+ bbox_results (dict): Results obtained from `bbox_loss`.
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes``, ``labels``, and
+ ``masks`` attributes.
+ rcnn_train_cfg (obj:ConfigDict): `train_cfg` of RCNN.
+
+ Returns:
+ dict: Usually returns a dictionary with keys:
+
+ - `mask_preds` (Tensor): Mask prediction.
+ - `loss_mask` (dict): A dictionary of mask loss components.
+ """
+ attn_feats = bbox_results['attn_feats']
+ sampling_results = bbox_results['sampling_results']
+
+ pos_rois = bbox2roi([res.pos_priors for res in sampling_results])
+
+ attn_feats = torch.cat([
+ feats[res.pos_inds]
+ for (feats, res) in zip(attn_feats, sampling_results)
+ ])
+ mask_results = self._mask_forward(stage, x, pos_rois, attn_feats)
+
+ mask_loss_and_target = self.mask_head[stage].loss_and_target(
+ mask_preds=mask_results['mask_preds'],
+ sampling_results=sampling_results,
+ batch_gt_instances=batch_gt_instances,
+ rcnn_train_cfg=rcnn_train_cfg)
+ mask_results.update(mask_loss_and_target)
+
+ return mask_results
+
+ def loss(self, x: Tuple[Tensor], rpn_results_list: InstanceList,
+ batch_data_samples: SampleList) -> dict:
+ """Perform forward propagation and loss calculation of the detection
+ roi on the features of the upstream network.
+
+ Args:
+ x (tuple[Tensor]): List of multi-level img features.
+ rpn_results_list (List[:obj:`InstanceData`]): List of region
+ proposals.
+ batch_data_samples (list[:obj:`DetDataSample`]): The batch
+ data samples. It usually includes information such
+ as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
+
+ Returns:
+ dict: a dictionary of loss components of all stage.
+ """
+ outputs = unpack_gt_instances(batch_data_samples)
+ batch_gt_instances, batch_gt_instances_ignore, batch_img_metas \
+ = outputs
+
+ object_feats = torch.cat(
+ [res.pop('features')[None, ...] for res in rpn_results_list])
+ results_list = rpn_results_list
+ losses = {}
+ for stage in range(self.num_stages):
+ stage_loss_weight = self.stage_loss_weights[stage]
+
+ # bbox head forward and loss
+ bbox_results = self.bbox_loss(
+ stage=stage,
+ x=x,
+ object_feats=object_feats,
+ results_list=results_list,
+ batch_img_metas=batch_img_metas,
+ batch_gt_instances=batch_gt_instances)
+
+ for name, value in bbox_results['loss_bbox'].items():
+ losses[f's{stage}.{name}'] = (
+ value * stage_loss_weight if 'loss' in name else value)
+
+ if self.with_mask:
+ mask_results = self.mask_loss(
+ stage=stage,
+ x=x,
+ bbox_results=bbox_results,
+ batch_gt_instances=batch_gt_instances,
+ rcnn_train_cfg=self.train_cfg[stage])
+
+ for name, value in mask_results['loss_mask'].items():
+ losses[f's{stage}.{name}'] = (
+ value * stage_loss_weight if 'loss' in name else value)
+
+ object_feats = bbox_results['object_feats']
+ results_list = bbox_results['results_list']
+ return losses
+
+ def predict_bbox(self,
+ x: Tuple[Tensor],
+ batch_img_metas: List[dict],
+ rpn_results_list: InstanceList,
+ rcnn_test_cfg: ConfigType,
+ rescale: bool = False) -> InstanceList:
+ """Perform forward propagation of the bbox head and predict detection
+ results on the features of the upstream network.
+
+ Args:
+ x(tuple[Tensor]): Feature maps of all scale level.
+ batch_img_metas (list[dict]): List of image information.
+ rpn_results_list (list[:obj:`InstanceData`]): List of region
+ proposals.
+ rcnn_test_cfg (obj:`ConfigDict`): `test_cfg` of R-CNN.
+ rescale (bool): If True, return boxes in original image space.
+ Defaults to False.
+
+ Returns:
+ list[:obj:`InstanceData`]: Detection results of each image
+ after the post process.
+ Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ """
+ proposal_list = [res.bboxes for res in rpn_results_list]
+ object_feats = torch.cat(
+ [res.pop('features')[None, ...] for res in rpn_results_list])
+ if all([proposal.shape[0] == 0 for proposal in proposal_list]):
+ # There is no proposal in the whole batch
+ return empty_instances(
+ batch_img_metas, x[0].device, task_type='bbox')
+
+ for stage in range(self.num_stages):
+ rois = bbox2roi(proposal_list)
+ bbox_results = self._bbox_forward(stage, x, rois, object_feats,
+ batch_img_metas)
+ object_feats = bbox_results['object_feats']
+ cls_score = bbox_results['cls_score']
+ proposal_list = bbox_results['detached_proposals']
+
+ num_classes = self.bbox_head[-1].num_classes
+
+ if self.bbox_head[-1].loss_cls.use_sigmoid:
+ cls_score = cls_score.sigmoid()
+ else:
+ cls_score = cls_score.softmax(-1)[..., :-1]
+
+ topk_inds_list = []
+ results_list = []
+ for img_id in range(len(batch_img_metas)):
+ cls_score_per_img = cls_score[img_id]
+ scores_per_img, topk_inds = cls_score_per_img.flatten(0, 1).topk(
+ self.test_cfg.max_per_img, sorted=False)
+ labels_per_img = topk_inds % num_classes
+ bboxes_per_img = proposal_list[img_id][topk_inds // num_classes]
+ topk_inds_list.append(topk_inds)
+ if rescale and bboxes_per_img.size(0) > 0:
+ assert batch_img_metas[img_id].get('scale_factor') is not None
+ scale_factor = bboxes_per_img.new_tensor(
+ batch_img_metas[img_id]['scale_factor']).repeat((1, 2))
+ bboxes_per_img = (
+ bboxes_per_img.view(bboxes_per_img.size(0), -1, 4) /
+ scale_factor).view(bboxes_per_img.size()[0], -1)
+
+ results = InstanceData()
+ results.bboxes = bboxes_per_img
+ results.scores = scores_per_img
+ results.labels = labels_per_img
+ results_list.append(results)
+ if self.with_mask:
+ for img_id in range(len(batch_img_metas)):
+ # add positive information in InstanceData to predict
+ # mask results in `mask_head`.
+ proposals = bbox_results['detached_proposals'][img_id]
+ topk_inds = topk_inds_list[img_id]
+ attn_feats = bbox_results['attn_feats'][img_id]
+
+ results_list[img_id].proposals = proposals
+ results_list[img_id].topk_inds = topk_inds
+ results_list[img_id].attn_feats = attn_feats
+ return results_list
+
+ def predict_mask(self,
+ x: Tuple[Tensor],
+ batch_img_metas: List[dict],
+ results_list: InstanceList,
+ rescale: bool = False) -> InstanceList:
+ """Perform forward propagation of the mask head and predict detection
+ results on the features of the upstream network.
+
+ Args:
+ x (tuple[Tensor]): Feature maps of all scale level.
+ batch_img_metas (list[dict]): List of image information.
+ results_list (list[:obj:`InstanceData`]): Detection results of
+ each image. Each item usually contains following keys:
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ - proposal (Tensor): Bboxes predicted from bbox_head,
+ has a shape (num_instances, 4).
+ - topk_inds (Tensor): Topk indices of each image, has
+ shape (num_instances, )
+ - attn_feats (Tensor): Intermediate feature get from the last
+ diihead, has shape (num_instances, feature_dimensions)
+
+ rescale (bool): If True, return boxes in original image space.
+ Defaults to False.
+
+ Returns:
+ list[:obj:`InstanceData`]: Detection results of each image
+ after the post process.
+ Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ - masks (Tensor): Has a shape (num_instances, H, W).
+ """
+ proposal_list = [res.pop('proposals') for res in results_list]
+ topk_inds_list = [res.pop('topk_inds') for res in results_list]
+ attn_feats = torch.cat(
+ [res.pop('attn_feats')[None, ...] for res in results_list])
+
+ rois = bbox2roi(proposal_list)
+
+ if rois.shape[0] == 0:
+ results_list = empty_instances(
+ batch_img_metas,
+ rois.device,
+ task_type='mask',
+ instance_results=results_list,
+ mask_thr_binary=self.test_cfg.mask_thr_binary)
+ return results_list
+
+ last_stage = self.num_stages - 1
+ mask_results = self._mask_forward(last_stage, x, rois, attn_feats)
+
+ num_imgs = len(batch_img_metas)
+ mask_results['mask_preds'] = mask_results['mask_preds'].reshape(
+ num_imgs, -1, *mask_results['mask_preds'].size()[1:])
+ num_classes = self.bbox_head[-1].num_classes
+
+ mask_preds = []
+ for img_id in range(num_imgs):
+ topk_inds = topk_inds_list[img_id]
+ masks_per_img = mask_results['mask_preds'][img_id].flatten(
+ 0, 1)[topk_inds]
+ masks_per_img = masks_per_img[:, None,
+ ...].repeat(1, num_classes, 1, 1)
+ mask_preds.append(masks_per_img)
+ results_list = self.mask_head[-1].predict_by_feat(
+ mask_preds,
+ results_list,
+ batch_img_metas,
+ rcnn_test_cfg=self.test_cfg,
+ rescale=rescale)
+
+ return results_list
+
+ # TODO: Need to refactor later
+ def forward(self, x: Tuple[Tensor], rpn_results_list: InstanceList,
+ batch_data_samples: SampleList) -> tuple:
+ """Network forward process. Usually includes backbone, neck and head
+ forward without any post-processing.
+
+ Args:
+ x (List[Tensor]): Multi-level features that may have different
+ resolutions.
+ rpn_results_list (List[:obj:`InstanceData`]): List of region
+ proposals.
+ batch_data_samples (list[:obj:`DetDataSample`]): The batch
+ data samples. It usually includes information such
+ as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
+
+ Returns
+ tuple: A tuple of features from ``bbox_head`` and ``mask_head``
+ forward.
+ """
+ outputs = unpack_gt_instances(batch_data_samples)
+ (batch_gt_instances, batch_gt_instances_ignore,
+ batch_img_metas) = outputs
+
+ all_stage_bbox_results = []
+ object_feats = torch.cat(
+ [res.pop('features')[None, ...] for res in rpn_results_list])
+ results_list = rpn_results_list
+ if self.with_bbox:
+ for stage in range(self.num_stages):
+ bbox_results = self.bbox_loss(
+ stage=stage,
+ x=x,
+ results_list=results_list,
+ object_feats=object_feats,
+ batch_img_metas=batch_img_metas,
+ batch_gt_instances=batch_gt_instances)
+ bbox_results.pop('loss_bbox')
+ # torch.jit does not support obj:SamplingResult
+ bbox_results.pop('results_list')
+ bbox_res = bbox_results.copy()
+ bbox_res.pop('sampling_results')
+ all_stage_bbox_results.append((bbox_res, ))
+
+ if self.with_mask:
+ attn_feats = bbox_results['attn_feats']
+ sampling_results = bbox_results['sampling_results']
+
+ pos_rois = bbox2roi(
+ [res.pos_priors for res in sampling_results])
+
+ attn_feats = torch.cat([
+ feats[res.pos_inds]
+ for (feats, res) in zip(attn_feats, sampling_results)
+ ])
+ mask_results = self._mask_forward(stage, x, pos_rois,
+ attn_feats)
+ all_stage_bbox_results[-1] += (mask_results, )
+ return tuple(all_stage_bbox_results)
diff --git a/mmdet/models/roi_heads/standard_roi_head.py b/mmdet/models/roi_heads/standard_roi_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..8d168eba0fb2ccf6aa89bde5c637160f10aea83a
--- /dev/null
+++ b/mmdet/models/roi_heads/standard_roi_head.py
@@ -0,0 +1,419 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Optional, Tuple
+
+import torch
+from torch import Tensor
+
+from mmdet.registry import MODELS, TASK_UTILS
+from mmdet.structures import DetDataSample, SampleList
+from mmdet.structures.bbox import bbox2roi
+from mmdet.utils import ConfigType, InstanceList
+from ..task_modules.samplers import SamplingResult
+from ..utils import empty_instances, unpack_gt_instances
+from .base_roi_head import BaseRoIHead
+
+
+@MODELS.register_module()
+class StandardRoIHead(BaseRoIHead):
+ """Simplest base roi head including one bbox head and one mask head."""
+
+ def init_assigner_sampler(self) -> None:
+ """Initialize assigner and sampler."""
+ self.bbox_assigner = None
+ self.bbox_sampler = None
+ if self.train_cfg:
+ self.bbox_assigner = TASK_UTILS.build(self.train_cfg.assigner)
+ self.bbox_sampler = TASK_UTILS.build(
+ self.train_cfg.sampler, default_args=dict(context=self))
+
+ def init_bbox_head(self, bbox_roi_extractor: ConfigType,
+ bbox_head: ConfigType) -> None:
+ """Initialize box head and box roi extractor.
+
+ Args:
+ bbox_roi_extractor (dict or ConfigDict): Config of box
+ roi extractor.
+ bbox_head (dict or ConfigDict): Config of box in box head.
+ """
+ self.bbox_roi_extractor = MODELS.build(bbox_roi_extractor)
+ self.bbox_head = MODELS.build(bbox_head)
+
+ def init_mask_head(self, mask_roi_extractor: ConfigType,
+ mask_head: ConfigType) -> None:
+ """Initialize mask head and mask roi extractor.
+
+ Args:
+ mask_roi_extractor (dict or ConfigDict): Config of mask roi
+ extractor.
+ mask_head (dict or ConfigDict): Config of mask in mask head.
+ """
+ if mask_roi_extractor is not None:
+ self.mask_roi_extractor = MODELS.build(mask_roi_extractor)
+ self.share_roi_extractor = False
+ else:
+ self.share_roi_extractor = True
+ self.mask_roi_extractor = self.bbox_roi_extractor
+ self.mask_head = MODELS.build(mask_head)
+
+ # TODO: Need to refactor later
+ def forward(self,
+ x: Tuple[Tensor],
+ rpn_results_list: InstanceList,
+ batch_data_samples: SampleList = None) -> tuple:
+ """Network forward process. Usually includes backbone, neck and head
+ forward without any post-processing.
+
+ Args:
+ x (List[Tensor]): Multi-level features that may have different
+ resolutions.
+ rpn_results_list (list[:obj:`InstanceData`]): List of region
+ proposals.
+ batch_data_samples (list[:obj:`DetDataSample`]): Each item contains
+ the meta information of each image and corresponding
+ annotations.
+
+ Returns
+ tuple: A tuple of features from ``bbox_head`` and ``mask_head``
+ forward.
+ """
+ results = ()
+ proposals = [rpn_results.bboxes for rpn_results in rpn_results_list]
+ rois = bbox2roi(proposals)
+ # bbox head
+ if self.with_bbox:
+ bbox_results = self._bbox_forward(x, rois)
+ results = results + (bbox_results['cls_score'],
+ bbox_results['bbox_pred'])
+ # mask head
+ if self.with_mask:
+ mask_rois = rois[:100]
+ mask_results = self._mask_forward(x, mask_rois)
+ results = results + (mask_results['mask_preds'], )
+ return results
+
+ def loss(self, x: Tuple[Tensor], rpn_results_list: InstanceList,
+ batch_data_samples: List[DetDataSample]) -> dict:
+ """Perform forward propagation and loss calculation of the detection
+ roi on the features of the upstream network.
+
+ Args:
+ x (tuple[Tensor]): List of multi-level img features.
+ rpn_results_list (list[:obj:`InstanceData`]): List of region
+ proposals.
+ batch_data_samples (list[:obj:`DetDataSample`]): The batch
+ data samples. It usually includes information such
+ as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
+
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components
+ """
+ assert len(rpn_results_list) == len(batch_data_samples)
+ outputs = unpack_gt_instances(batch_data_samples)
+ batch_gt_instances, batch_gt_instances_ignore, _ = outputs
+
+ # assign gts and sample proposals
+ num_imgs = len(batch_data_samples)
+ sampling_results = []
+ for i in range(num_imgs):
+ # rename rpn_results.bboxes to rpn_results.priors
+ rpn_results = rpn_results_list[i]
+ rpn_results.priors = rpn_results.pop('bboxes')
+
+ assign_result = self.bbox_assigner.assign(
+ rpn_results, batch_gt_instances[i],
+ batch_gt_instances_ignore[i])
+ sampling_result = self.bbox_sampler.sample(
+ assign_result,
+ rpn_results,
+ batch_gt_instances[i],
+ feats=[lvl_feat[i][None] for lvl_feat in x])
+ sampling_results.append(sampling_result)
+
+ losses = dict()
+ # bbox head loss
+ if self.with_bbox:
+ bbox_results = self.bbox_loss(x, sampling_results)
+ losses.update(bbox_results['loss_bbox'])
+
+ # mask head forward and loss
+ if self.with_mask:
+ mask_results = self.mask_loss(x, sampling_results,
+ bbox_results['bbox_feats'],
+ batch_gt_instances)
+ losses.update(mask_results['loss_mask'])
+
+ return losses
+
+ def _bbox_forward(self, x: Tuple[Tensor], rois: Tensor) -> dict:
+ """Box head forward function used in both training and testing.
+
+ Args:
+ x (tuple[Tensor]): List of multi-level img features.
+ rois (Tensor): RoIs with the shape (n, 5) where the first
+ column indicates batch id of each RoI.
+
+ Returns:
+ dict[str, Tensor]: Usually returns a dictionary with keys:
+
+ - `cls_score` (Tensor): Classification scores.
+ - `bbox_pred` (Tensor): Box energies / deltas.
+ - `bbox_feats` (Tensor): Extract bbox RoI features.
+ """
+ # TODO: a more flexible way to decide which feature maps to use
+ bbox_feats = self.bbox_roi_extractor(
+ x[:self.bbox_roi_extractor.num_inputs], rois)
+ if self.with_shared_head:
+ bbox_feats = self.shared_head(bbox_feats)
+ cls_score, bbox_pred = self.bbox_head(bbox_feats)
+
+ bbox_results = dict(
+ cls_score=cls_score, bbox_pred=bbox_pred, bbox_feats=bbox_feats)
+ return bbox_results
+
+ def bbox_loss(self, x: Tuple[Tensor],
+ sampling_results: List[SamplingResult]) -> dict:
+ """Perform forward propagation and loss calculation of the bbox head on
+ the features of the upstream network.
+
+ Args:
+ x (tuple[Tensor]): List of multi-level img features.
+ sampling_results (list["obj:`SamplingResult`]): Sampling results.
+
+ Returns:
+ dict[str, Tensor]: Usually returns a dictionary with keys:
+
+ - `cls_score` (Tensor): Classification scores.
+ - `bbox_pred` (Tensor): Box energies / deltas.
+ - `bbox_feats` (Tensor): Extract bbox RoI features.
+ - `loss_bbox` (dict): A dictionary of bbox loss components.
+ """
+ rois = bbox2roi([res.priors for res in sampling_results])
+ bbox_results = self._bbox_forward(x, rois)
+
+ bbox_loss_and_target = self.bbox_head.loss_and_target(
+ cls_score=bbox_results['cls_score'],
+ bbox_pred=bbox_results['bbox_pred'],
+ rois=rois,
+ sampling_results=sampling_results,
+ rcnn_train_cfg=self.train_cfg)
+
+ bbox_results.update(loss_bbox=bbox_loss_and_target['loss_bbox'])
+ return bbox_results
+
+ def mask_loss(self, x: Tuple[Tensor],
+ sampling_results: List[SamplingResult], bbox_feats: Tensor,
+ batch_gt_instances: InstanceList) -> dict:
+ """Perform forward propagation and loss calculation of the mask head on
+ the features of the upstream network.
+
+ Args:
+ x (tuple[Tensor]): Tuple of multi-level img features.
+ sampling_results (list["obj:`SamplingResult`]): Sampling results.
+ bbox_feats (Tensor): Extract bbox RoI features.
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes``, ``labels``, and
+ ``masks`` attributes.
+
+ Returns:
+ dict: Usually returns a dictionary with keys:
+
+ - `mask_preds` (Tensor): Mask prediction.
+ - `mask_feats` (Tensor): Extract mask RoI features.
+ - `mask_targets` (Tensor): Mask target of each positive\
+ proposals in the image.
+ - `loss_mask` (dict): A dictionary of mask loss components.
+ """
+ if not self.share_roi_extractor:
+ pos_rois = bbox2roi([res.pos_priors for res in sampling_results])
+ mask_results = self._mask_forward(x, pos_rois)
+ else:
+ pos_inds = []
+ device = bbox_feats.device
+ for res in sampling_results:
+ pos_inds.append(
+ torch.ones(
+ res.pos_priors.shape[0],
+ device=device,
+ dtype=torch.uint8))
+ pos_inds.append(
+ torch.zeros(
+ res.neg_priors.shape[0],
+ device=device,
+ dtype=torch.uint8))
+ pos_inds = torch.cat(pos_inds)
+
+ mask_results = self._mask_forward(
+ x, pos_inds=pos_inds, bbox_feats=bbox_feats)
+
+ mask_loss_and_target = self.mask_head.loss_and_target(
+ mask_preds=mask_results['mask_preds'],
+ sampling_results=sampling_results,
+ batch_gt_instances=batch_gt_instances,
+ rcnn_train_cfg=self.train_cfg)
+
+ mask_results.update(loss_mask=mask_loss_and_target['loss_mask'])
+ return mask_results
+
+ def _mask_forward(self,
+ x: Tuple[Tensor],
+ rois: Tensor = None,
+ pos_inds: Optional[Tensor] = None,
+ bbox_feats: Optional[Tensor] = None) -> dict:
+ """Mask head forward function used in both training and testing.
+
+ Args:
+ x (tuple[Tensor]): Tuple of multi-level img features.
+ rois (Tensor): RoIs with the shape (n, 5) where the first
+ column indicates batch id of each RoI.
+ pos_inds (Tensor, optional): Indices of positive samples.
+ Defaults to None.
+ bbox_feats (Tensor): Extract bbox RoI features. Defaults to None.
+
+ Returns:
+ dict[str, Tensor]: Usually returns a dictionary with keys:
+
+ - `mask_preds` (Tensor): Mask prediction.
+ - `mask_feats` (Tensor): Extract mask RoI features.
+ """
+ assert ((rois is not None) ^
+ (pos_inds is not None and bbox_feats is not None))
+ if rois is not None:
+ mask_feats = self.mask_roi_extractor(
+ x[:self.mask_roi_extractor.num_inputs], rois)
+ if self.with_shared_head:
+ mask_feats = self.shared_head(mask_feats)
+ else:
+ assert bbox_feats is not None
+ mask_feats = bbox_feats[pos_inds]
+
+ mask_preds = self.mask_head(mask_feats)
+ mask_results = dict(mask_preds=mask_preds, mask_feats=mask_feats)
+ return mask_results
+
+ def predict_bbox(self,
+ x: Tuple[Tensor],
+ batch_img_metas: List[dict],
+ rpn_results_list: InstanceList,
+ rcnn_test_cfg: ConfigType,
+ rescale: bool = False) -> InstanceList:
+ """Perform forward propagation of the bbox head and predict detection
+ results on the features of the upstream network.
+
+ Args:
+ x (tuple[Tensor]): Feature maps of all scale level.
+ batch_img_metas (list[dict]): List of image information.
+ rpn_results_list (list[:obj:`InstanceData`]): List of region
+ proposals.
+ rcnn_test_cfg (obj:`ConfigDict`): `test_cfg` of R-CNN.
+ rescale (bool): If True, return boxes in original image space.
+ Defaults to False.
+
+ Returns:
+ list[:obj:`InstanceData`]: Detection results of each image
+ after the post process.
+ Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ """
+ proposals = [res.bboxes for res in rpn_results_list]
+ rois = bbox2roi(proposals)
+
+ if rois.shape[0] == 0:
+ return empty_instances(
+ batch_img_metas,
+ rois.device,
+ task_type='bbox',
+ box_type=self.bbox_head.predict_box_type,
+ num_classes=self.bbox_head.num_classes,
+ score_per_cls=rcnn_test_cfg is None)
+
+ bbox_results = self._bbox_forward(x, rois)
+
+ # split batch bbox prediction back to each image
+ cls_scores = bbox_results['cls_score']
+ bbox_preds = bbox_results['bbox_pred']
+ num_proposals_per_img = tuple(len(p) for p in proposals)
+ rois = rois.split(num_proposals_per_img, 0)
+ cls_scores = cls_scores.split(num_proposals_per_img, 0)
+
+ # some detector with_reg is False, bbox_preds will be None
+ if bbox_preds is not None:
+ # TODO move this to a sabl_roi_head
+ # the bbox prediction of some detectors like SABL is not Tensor
+ if isinstance(bbox_preds, torch.Tensor):
+ bbox_preds = bbox_preds.split(num_proposals_per_img, 0)
+ else:
+ bbox_preds = self.bbox_head.bbox_pred_split(
+ bbox_preds, num_proposals_per_img)
+ else:
+ bbox_preds = (None, ) * len(proposals)
+
+ result_list = self.bbox_head.predict_by_feat(
+ rois=rois,
+ cls_scores=cls_scores,
+ bbox_preds=bbox_preds,
+ batch_img_metas=batch_img_metas,
+ rcnn_test_cfg=rcnn_test_cfg,
+ rescale=rescale)
+ return result_list
+
+ def predict_mask(self,
+ x: Tuple[Tensor],
+ batch_img_metas: List[dict],
+ results_list: InstanceList,
+ rescale: bool = False) -> InstanceList:
+ """Perform forward propagation of the mask head and predict detection
+ results on the features of the upstream network.
+
+ Args:
+ x (tuple[Tensor]): Feature maps of all scale level.
+ batch_img_metas (list[dict]): List of image information.
+ results_list (list[:obj:`InstanceData`]): Detection results of
+ each image.
+ rescale (bool): If True, return boxes in original image space.
+ Defaults to False.
+
+ Returns:
+ list[:obj:`InstanceData`]: Detection results of each image
+ after the post process.
+ Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ - masks (Tensor): Has a shape (num_instances, H, W).
+ """
+ # don't need to consider aug_test.
+ bboxes = [res.bboxes for res in results_list]
+ mask_rois = bbox2roi(bboxes)
+ if mask_rois.shape[0] == 0:
+ results_list = empty_instances(
+ batch_img_metas,
+ mask_rois.device,
+ task_type='mask',
+ instance_results=results_list,
+ mask_thr_binary=self.test_cfg.mask_thr_binary)
+ return results_list
+
+ mask_results = self._mask_forward(x, mask_rois)
+ mask_preds = mask_results['mask_preds']
+ # split batch mask prediction back to each image
+ num_mask_rois_per_img = [len(res) for res in results_list]
+ mask_preds = mask_preds.split(num_mask_rois_per_img, 0)
+
+ # TODO: Handle the case where rescale is false
+ results_list = self.mask_head.predict_by_feat(
+ mask_preds=mask_preds,
+ results_list=results_list,
+ batch_img_metas=batch_img_metas,
+ rcnn_test_cfg=self.test_cfg,
+ rescale=rescale)
+ return results_list
diff --git a/mmdet/models/roi_heads/test_mixins.py b/mmdet/models/roi_heads/test_mixins.py
new file mode 100644
index 0000000000000000000000000000000000000000..940490454d9cf1fde4d69c1f890c173b92d522a1
--- /dev/null
+++ b/mmdet/models/roi_heads/test_mixins.py
@@ -0,0 +1,171 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+# TODO: delete this file after refactor
+import sys
+
+import torch
+
+from mmdet.models.layers import multiclass_nms
+from mmdet.models.test_time_augs import merge_aug_bboxes, merge_aug_masks
+from mmdet.structures.bbox import bbox2roi, bbox_mapping
+
+if sys.version_info >= (3, 7):
+ from mmdet.utils.contextmanagers import completed
+
+
+class BBoxTestMixin:
+
+ if sys.version_info >= (3, 7):
+ # TODO: Currently not supported
+ async def async_test_bboxes(self,
+ x,
+ img_metas,
+ proposals,
+ rcnn_test_cfg,
+ rescale=False,
+ **kwargs):
+ """Asynchronized test for box head without augmentation."""
+ rois = bbox2roi(proposals)
+ roi_feats = self.bbox_roi_extractor(
+ x[:len(self.bbox_roi_extractor.featmap_strides)], rois)
+ if self.with_shared_head:
+ roi_feats = self.shared_head(roi_feats)
+ sleep_interval = rcnn_test_cfg.get('async_sleep_interval', 0.017)
+
+ async with completed(
+ __name__, 'bbox_head_forward',
+ sleep_interval=sleep_interval):
+ cls_score, bbox_pred = self.bbox_head(roi_feats)
+
+ img_shape = img_metas[0]['img_shape']
+ scale_factor = img_metas[0]['scale_factor']
+ det_bboxes, det_labels = self.bbox_head.get_bboxes(
+ rois,
+ cls_score,
+ bbox_pred,
+ img_shape,
+ scale_factor,
+ rescale=rescale,
+ cfg=rcnn_test_cfg)
+ return det_bboxes, det_labels
+
+ # TODO: Currently not supported
+ def aug_test_bboxes(self, feats, img_metas, rpn_results_list,
+ rcnn_test_cfg):
+ """Test det bboxes with test time augmentation."""
+ aug_bboxes = []
+ aug_scores = []
+ for x, img_meta in zip(feats, img_metas):
+ # only one image in the batch
+ img_shape = img_meta[0]['img_shape']
+ scale_factor = img_meta[0]['scale_factor']
+ flip = img_meta[0]['flip']
+ flip_direction = img_meta[0]['flip_direction']
+ # TODO more flexible
+ proposals = bbox_mapping(rpn_results_list[0][:, :4], img_shape,
+ scale_factor, flip, flip_direction)
+ rois = bbox2roi([proposals])
+ bbox_results = self.bbox_forward(x, rois)
+ bboxes, scores = self.bbox_head.get_bboxes(
+ rois,
+ bbox_results['cls_score'],
+ bbox_results['bbox_pred'],
+ img_shape,
+ scale_factor,
+ rescale=False,
+ cfg=None)
+ aug_bboxes.append(bboxes)
+ aug_scores.append(scores)
+ # after merging, bboxes will be rescaled to the original image size
+ merged_bboxes, merged_scores = merge_aug_bboxes(
+ aug_bboxes, aug_scores, img_metas, rcnn_test_cfg)
+ if merged_bboxes.shape[0] == 0:
+ # There is no proposal in the single image
+ det_bboxes = merged_bboxes.new_zeros(0, 5)
+ det_labels = merged_bboxes.new_zeros((0, ), dtype=torch.long)
+ else:
+ det_bboxes, det_labels = multiclass_nms(merged_bboxes,
+ merged_scores,
+ rcnn_test_cfg.score_thr,
+ rcnn_test_cfg.nms,
+ rcnn_test_cfg.max_per_img)
+ return det_bboxes, det_labels
+
+
+class MaskTestMixin:
+
+ if sys.version_info >= (3, 7):
+ # TODO: Currently not supported
+ async def async_test_mask(self,
+ x,
+ img_metas,
+ det_bboxes,
+ det_labels,
+ rescale=False,
+ mask_test_cfg=None):
+ """Asynchronized test for mask head without augmentation."""
+ # image shape of the first image in the batch (only one)
+ ori_shape = img_metas[0]['ori_shape']
+ scale_factor = img_metas[0]['scale_factor']
+ if det_bboxes.shape[0] == 0:
+ segm_result = [[] for _ in range(self.mask_head.num_classes)]
+ else:
+ if rescale and not isinstance(scale_factor,
+ (float, torch.Tensor)):
+ scale_factor = det_bboxes.new_tensor(scale_factor)
+ _bboxes = (
+ det_bboxes[:, :4] *
+ scale_factor if rescale else det_bboxes)
+ mask_rois = bbox2roi([_bboxes])
+ mask_feats = self.mask_roi_extractor(
+ x[:len(self.mask_roi_extractor.featmap_strides)],
+ mask_rois)
+
+ if self.with_shared_head:
+ mask_feats = self.shared_head(mask_feats)
+ if mask_test_cfg and \
+ mask_test_cfg.get('async_sleep_interval'):
+ sleep_interval = mask_test_cfg['async_sleep_interval']
+ else:
+ sleep_interval = 0.035
+ async with completed(
+ __name__,
+ 'mask_head_forward',
+ sleep_interval=sleep_interval):
+ mask_pred = self.mask_head(mask_feats)
+ segm_result = self.mask_head.get_results(
+ mask_pred, _bboxes, det_labels, self.test_cfg, ori_shape,
+ scale_factor, rescale)
+ return segm_result
+
+ # TODO: Currently not supported
+ def aug_test_mask(self, feats, img_metas, det_bboxes, det_labels):
+ """Test for mask head with test time augmentation."""
+ if det_bboxes.shape[0] == 0:
+ segm_result = [[] for _ in range(self.mask_head.num_classes)]
+ else:
+ aug_masks = []
+ for x, img_meta in zip(feats, img_metas):
+ img_shape = img_meta[0]['img_shape']
+ scale_factor = img_meta[0]['scale_factor']
+ flip = img_meta[0]['flip']
+ flip_direction = img_meta[0]['flip_direction']
+ _bboxes = bbox_mapping(det_bboxes[:, :4], img_shape,
+ scale_factor, flip, flip_direction)
+ mask_rois = bbox2roi([_bboxes])
+ mask_results = self._mask_forward(x, mask_rois)
+ # convert to numpy array to save memory
+ aug_masks.append(
+ mask_results['mask_pred'].sigmoid().cpu().numpy())
+ merged_masks = merge_aug_masks(aug_masks, img_metas, self.test_cfg)
+
+ ori_shape = img_metas[0][0]['ori_shape']
+ scale_factor = det_bboxes.new_ones(4)
+ segm_result = self.mask_head.get_results(
+ merged_masks,
+ det_bboxes,
+ det_labels,
+ self.test_cfg,
+ ori_shape,
+ scale_factor=scale_factor,
+ rescale=False)
+ return segm_result
diff --git a/mmdet/models/roi_heads/trident_roi_head.py b/mmdet/models/roi_heads/trident_roi_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..5215327296282a8e7ca502f3321aced8a4f840b7
--- /dev/null
+++ b/mmdet/models/roi_heads/trident_roi_head.py
@@ -0,0 +1,112 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Tuple
+
+import torch
+from mmcv.ops import batched_nms
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.structures import SampleList
+from mmdet.utils import InstanceList
+from .standard_roi_head import StandardRoIHead
+
+
+@MODELS.register_module()
+class TridentRoIHead(StandardRoIHead):
+ """Trident roi head.
+
+ Args:
+ num_branch (int): Number of branches in TridentNet.
+ test_branch_idx (int): In inference, all 3 branches will be used
+ if `test_branch_idx==-1`, otherwise only branch with index
+ `test_branch_idx` will be used.
+ """
+
+ def __init__(self, num_branch: int, test_branch_idx: int,
+ **kwargs) -> None:
+ self.num_branch = num_branch
+ self.test_branch_idx = test_branch_idx
+ super().__init__(**kwargs)
+
+ def merge_trident_bboxes(self,
+ trident_results: InstanceList) -> InstanceData:
+ """Merge bbox predictions of each branch.
+
+ Args:
+ trident_results (List[:obj:`InstanceData`]): A list of InstanceData
+ predicted from every branch.
+
+ Returns:
+ :obj:`InstanceData`: merged InstanceData.
+ """
+ bboxes = torch.cat([res.bboxes for res in trident_results])
+ scores = torch.cat([res.scores for res in trident_results])
+ labels = torch.cat([res.labels for res in trident_results])
+
+ nms_cfg = self.test_cfg['nms']
+ results = InstanceData()
+ if bboxes.numel() == 0:
+ results.bboxes = bboxes
+ results.scores = scores
+ results.labels = labels
+ else:
+ det_bboxes, keep = batched_nms(bboxes, scores, labels, nms_cfg)
+ results.bboxes = det_bboxes[:, :-1]
+ results.scores = det_bboxes[:, -1]
+ results.labels = labels[keep]
+
+ if self.test_cfg['max_per_img'] > 0:
+ results = results[:self.test_cfg['max_per_img']]
+ return results
+
+ def predict(self,
+ x: Tuple[Tensor],
+ rpn_results_list: InstanceList,
+ batch_data_samples: SampleList,
+ rescale: bool = False) -> InstanceList:
+ """Perform forward propagation of the roi head and predict detection
+ results on the features of the upstream network.
+
+ - Compute prediction bbox and label per branch.
+ - Merge predictions of each branch according to scores of
+ bboxes, i.e., bboxes with higher score are kept to give
+ top-k prediction.
+
+ Args:
+ x (tuple[Tensor]): Features from upstream network. Each
+ has shape (N, C, H, W).
+ rpn_results_list (list[:obj:`InstanceData`]): list of region
+ proposals.
+ batch_data_samples (List[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ rescale (bool): Whether to rescale the results to
+ the original image. Defaults to True.
+
+ Returns:
+ list[obj:`InstanceData`]: Detection results of each image.
+ Each item usually contains following keys.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ """
+ results_list = super().predict(
+ x=x,
+ rpn_results_list=rpn_results_list,
+ batch_data_samples=batch_data_samples,
+ rescale=rescale)
+
+ num_branch = self.num_branch \
+ if self.training or self.test_branch_idx == -1 else 1
+
+ merged_results_list = []
+ for i in range(len(batch_data_samples) // num_branch):
+ merged_results_list.append(
+ self.merge_trident_bboxes(results_list[i * num_branch:(i + 1) *
+ num_branch]))
+ return merged_results_list
diff --git a/mmdet/models/seg_heads/__init__.py b/mmdet/models/seg_heads/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..b489a905b1e9b6cef2e8b9575600990563128e4e
--- /dev/null
+++ b/mmdet/models/seg_heads/__init__.py
@@ -0,0 +1,3 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .panoptic_fpn_head import PanopticFPNHead # noqa: F401,F403
+from .panoptic_fusion_heads import * # noqa: F401,F403
diff --git a/mmdet/models/seg_heads/__pycache__/__init__.cpython-37.pyc b/mmdet/models/seg_heads/__pycache__/__init__.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..8e3a467323ef18124759c8bf2ec607059911249d
Binary files /dev/null and b/mmdet/models/seg_heads/__pycache__/__init__.cpython-37.pyc differ
diff --git a/mmdet/models/seg_heads/__pycache__/base_semantic_head.cpython-37.pyc b/mmdet/models/seg_heads/__pycache__/base_semantic_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..1a0532b32f0479cf1615b3b255c3a74ef6d00a6e
Binary files /dev/null and b/mmdet/models/seg_heads/__pycache__/base_semantic_head.cpython-37.pyc differ
diff --git a/mmdet/models/seg_heads/__pycache__/panoptic_fpn_head.cpython-37.pyc b/mmdet/models/seg_heads/__pycache__/panoptic_fpn_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..96f45f5073e6028f73a880e8826bfec0b2fd5023
Binary files /dev/null and b/mmdet/models/seg_heads/__pycache__/panoptic_fpn_head.cpython-37.pyc differ
diff --git a/mmdet/models/seg_heads/base_semantic_head.py b/mmdet/models/seg_heads/base_semantic_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..1db71549d89766c45012517c20cef443f4760419
--- /dev/null
+++ b/mmdet/models/seg_heads/base_semantic_head.py
@@ -0,0 +1,113 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from abc import ABCMeta, abstractmethod
+from typing import Dict, List, Tuple, Union
+
+import torch.nn.functional as F
+from mmengine.model import BaseModule
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.structures import SampleList
+from mmdet.utils import ConfigType, OptMultiConfig
+
+
+@MODELS.register_module()
+class BaseSemanticHead(BaseModule, metaclass=ABCMeta):
+ """Base module of Semantic Head.
+
+ Args:
+ num_classes (int): the number of classes.
+ seg_rescale_factor (float): the rescale factor for ``gt_sem_seg``,
+ which equals to ``1 / output_strides``. The output_strides is
+ for ``seg_preds``. Defaults to 1 / 4.
+ init_cfg (Optional[Union[:obj:`ConfigDict`, dict]]): the initialization
+ config.
+ loss_seg (Union[:obj:`ConfigDict`, dict]): the loss of the semantic
+ head.
+ """
+
+ def __init__(self,
+ num_classes: int,
+ seg_rescale_factor: float = 1 / 4.,
+ loss_seg: ConfigType = dict(
+ type='CrossEntropyLoss',
+ ignore_index=255,
+ loss_weight=1.0),
+ init_cfg: OptMultiConfig = None) -> None:
+ super().__init__(init_cfg=init_cfg)
+ self.loss_seg = MODELS.build(loss_seg)
+ self.num_classes = num_classes
+ self.seg_rescale_factor = seg_rescale_factor
+
+ @abstractmethod
+ def forward(self, x: Union[Tensor, Tuple[Tensor]]) -> Dict[str, Tensor]:
+ """Placeholder of forward function.
+
+ Args:
+ x (Tensor): Feature maps.
+
+ Returns:
+ Dict[str, Tensor]: A dictionary, including features
+ and predicted scores. Required keys: 'seg_preds'
+ and 'feats'.
+ """
+ pass
+
+ @abstractmethod
+ def loss(self, x: Union[Tensor, Tuple[Tensor]],
+ batch_data_samples: SampleList) -> Dict[str, Tensor]:
+ """
+ Args:
+ x (Union[Tensor, Tuple[Tensor]]): Feature maps.
+ batch_data_samples (list[:obj:`DetDataSample`]): The batch
+ data samples. It usually includes information such
+ as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
+
+ Args:
+ x (Tensor): Feature maps.
+
+ Returns:
+ Dict[str, Tensor]: The loss of semantic head.
+ """
+ pass
+
+ def predict(self,
+ x: Union[Tensor, Tuple[Tensor]],
+ batch_img_metas: List[dict],
+ rescale: bool = False) -> List[Tensor]:
+ """Test without Augmentation.
+
+ Args:
+ x (Union[Tensor, Tuple[Tensor]]): Feature maps.
+ batch_img_metas (List[dict]): List of image information.
+ rescale (bool): Whether to rescale the results.
+ Defaults to False.
+
+ Returns:
+ list[Tensor]: semantic segmentation logits.
+ """
+ seg_preds = self.forward(x)['seg_preds']
+ seg_preds = F.interpolate(
+ seg_preds,
+ size=batch_img_metas[0]['batch_input_shape'],
+ mode='bilinear',
+ align_corners=False)
+ seg_preds = [seg_preds[i] for i in range(len(batch_img_metas))]
+
+ if rescale:
+ seg_pred_list = []
+ for i in range(len(batch_img_metas)):
+ h, w = batch_img_metas[i]['img_shape']
+ seg_pred = seg_preds[i][:, :h, :w]
+
+ h, w = batch_img_metas[i]['ori_shape']
+ seg_pred = F.interpolate(
+ seg_pred[None],
+ size=(h, w),
+ mode='bilinear',
+ align_corners=False)[0]
+ seg_pred_list.append(seg_pred)
+ else:
+ seg_pred_list = seg_preds
+
+ return seg_pred_list
diff --git a/mmdet/models/seg_heads/panoptic_fpn_head.py b/mmdet/models/seg_heads/panoptic_fpn_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..8d8b901360922f6cdb9f8d15b60dac8d7514ee75
--- /dev/null
+++ b/mmdet/models/seg_heads/panoptic_fpn_head.py
@@ -0,0 +1,174 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, Tuple, Union
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmengine.model import ModuleList
+from torch import Tensor
+
+from mmdet.registry import MODELS
+from mmdet.structures import SampleList
+from mmdet.utils import ConfigType, OptConfigType, OptMultiConfig
+from ..layers import ConvUpsample
+from ..utils import interpolate_as
+from .base_semantic_head import BaseSemanticHead
+
+
+@MODELS.register_module()
+class PanopticFPNHead(BaseSemanticHead):
+ """PanopticFPNHead used in Panoptic FPN.
+
+ In this head, the number of output channels is ``num_stuff_classes
+ + 1``, including all stuff classes and one thing class. The stuff
+ classes will be reset from ``0`` to ``num_stuff_classes - 1``, the
+ thing classes will be merged to ``num_stuff_classes``-th channel.
+
+ Arg:
+ num_things_classes (int): Number of thing classes. Default: 80.
+ num_stuff_classes (int): Number of stuff classes. Default: 53.
+ in_channels (int): Number of channels in the input feature
+ map.
+ inner_channels (int): Number of channels in inner features.
+ start_level (int): The start level of the input features
+ used in PanopticFPN.
+ end_level (int): The end level of the used features, the
+ ``end_level``-th layer will not be used.
+ conv_cfg (Optional[Union[ConfigDict, dict]]): Dictionary to construct
+ and config conv layer.
+ norm_cfg (Union[ConfigDict, dict]): Dictionary to construct and config
+ norm layer. Use ``GN`` by default.
+ init_cfg (Optional[Union[ConfigDict, dict]]): Initialization config
+ dict.
+ loss_seg (Union[ConfigDict, dict]): the loss of the semantic head.
+ """
+
+ def __init__(self,
+ num_things_classes: int = 80,
+ num_stuff_classes: int = 53,
+ in_channels: int = 256,
+ inner_channels: int = 128,
+ start_level: int = 0,
+ end_level: int = 4,
+ conv_cfg: OptConfigType = None,
+ norm_cfg: ConfigType = dict(
+ type='GN', num_groups=32, requires_grad=True),
+ loss_seg: ConfigType = dict(
+ type='CrossEntropyLoss', ignore_index=-1,
+ loss_weight=1.0),
+ init_cfg: OptMultiConfig = None) -> None:
+ seg_rescale_factor = 1 / 2**(start_level + 2)
+ super().__init__(
+ num_classes=num_stuff_classes + 1,
+ seg_rescale_factor=seg_rescale_factor,
+ loss_seg=loss_seg,
+ init_cfg=init_cfg)
+ self.num_things_classes = num_things_classes
+ self.num_stuff_classes = num_stuff_classes
+ # Used feature layers are [start_level, end_level)
+ self.start_level = start_level
+ self.end_level = end_level
+ self.num_stages = end_level - start_level
+ self.inner_channels = inner_channels
+
+ self.conv_upsample_layers = ModuleList()
+ for i in range(start_level, end_level):
+ self.conv_upsample_layers.append(
+ ConvUpsample(
+ in_channels,
+ inner_channels,
+ num_layers=i if i > 0 else 1,
+ num_upsample=i if i > 0 else 0,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ ))
+ self.conv_logits = nn.Conv2d(inner_channels, self.num_classes, 1)
+
+ def _set_things_to_void(self, gt_semantic_seg: Tensor) -> Tensor:
+ """Merge thing classes to one class.
+
+ In PanopticFPN, the background labels will be reset from `0` to
+ `self.num_stuff_classes-1`, the foreground labels will be merged to
+ `self.num_stuff_classes`-th channel.
+ """
+ gt_semantic_seg = gt_semantic_seg.int()
+ fg_mask = gt_semantic_seg < self.num_things_classes
+ bg_mask = (gt_semantic_seg >= self.num_things_classes) * (
+ gt_semantic_seg < self.num_things_classes + self.num_stuff_classes)
+
+ new_gt_seg = torch.clone(gt_semantic_seg)
+ new_gt_seg = torch.where(bg_mask,
+ gt_semantic_seg - self.num_things_classes,
+ new_gt_seg)
+ new_gt_seg = torch.where(fg_mask,
+ fg_mask.int() * self.num_stuff_classes,
+ new_gt_seg)
+ return new_gt_seg
+
+ def loss(self, x: Union[Tensor, Tuple[Tensor]],
+ batch_data_samples: SampleList) -> Dict[str, Tensor]:
+ """
+ Args:
+ x (Union[Tensor, Tuple[Tensor]]): Feature maps.
+ batch_data_samples (list[:obj:`DetDataSample`]): The batch
+ data samples. It usually includes information such
+ as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
+
+ Returns:
+ Dict[str, Tensor]: The loss of semantic head.
+ """
+ seg_preds = self(x)['seg_preds']
+ gt_semantic_segs = [
+ data_sample.gt_sem_seg.sem_seg
+ for data_sample in batch_data_samples
+ ]
+
+ gt_semantic_segs = torch.stack(gt_semantic_segs)
+ if self.seg_rescale_factor != 1.0:
+ gt_semantic_segs = F.interpolate(
+ gt_semantic_segs.float(),
+ scale_factor=self.seg_rescale_factor,
+ mode='nearest').squeeze(1)
+
+ # Things classes will be merged to one class in PanopticFPN.
+ gt_semantic_segs = self._set_things_to_void(gt_semantic_segs)
+
+ if seg_preds.shape[-2:] != gt_semantic_segs.shape[-2:]:
+ seg_preds = interpolate_as(seg_preds, gt_semantic_segs)
+ seg_preds = seg_preds.permute((0, 2, 3, 1))
+
+ loss_seg = self.loss_seg(
+ seg_preds.reshape(-1, self.num_classes), # => [NxHxW, C]
+ gt_semantic_segs.reshape(-1).long())
+
+ return dict(loss_seg=loss_seg)
+
+ def init_weights(self) -> None:
+ """Initialize weights."""
+ super().init_weights()
+ nn.init.normal_(self.conv_logits.weight.data, 0, 0.01)
+ self.conv_logits.bias.data.zero_()
+
+ def forward(self, x: Tuple[Tensor]) -> Dict[str, Tensor]:
+ """Forward.
+
+ Args:
+ x (Tuple[Tensor]): Multi scale Feature maps.
+
+ Returns:
+ dict[str, Tensor]: semantic segmentation predictions and
+ feature maps.
+ """
+ # the number of subnets must be not more than
+ # the length of features.
+ assert self.num_stages <= len(x)
+
+ feats = []
+ for i, layer in enumerate(self.conv_upsample_layers):
+ f = layer(x[self.start_level + i])
+ feats.append(f)
+
+ seg_feats = torch.sum(torch.stack(feats, dim=0), dim=0)
+ seg_preds = self.conv_logits(seg_feats)
+ out = dict(seg_preds=seg_preds, seg_feats=seg_feats)
+ return out
diff --git a/mmdet/models/seg_heads/panoptic_fusion_heads/__init__.py b/mmdet/models/seg_heads/panoptic_fusion_heads/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..41625a61d6d1c38c633062c24b1e3455bd3ae2df
--- /dev/null
+++ b/mmdet/models/seg_heads/panoptic_fusion_heads/__init__.py
@@ -0,0 +1,5 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .base_panoptic_fusion_head import \
+ BasePanopticFusionHead # noqa: F401,F403
+from .heuristic_fusion_head import HeuristicFusionHead # noqa: F401,F403
+from .maskformer_fusion_head import MaskFormerFusionHead # noqa: F401,F403
diff --git a/mmdet/models/seg_heads/panoptic_fusion_heads/__pycache__/__init__.cpython-37.pyc b/mmdet/models/seg_heads/panoptic_fusion_heads/__pycache__/__init__.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..7e602b9c1155662e2ae504b4794753f7f04d803a
Binary files /dev/null and b/mmdet/models/seg_heads/panoptic_fusion_heads/__pycache__/__init__.cpython-37.pyc differ
diff --git a/mmdet/models/seg_heads/panoptic_fusion_heads/__pycache__/base_panoptic_fusion_head.cpython-37.pyc b/mmdet/models/seg_heads/panoptic_fusion_heads/__pycache__/base_panoptic_fusion_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..b33ed6f737651cbc487591ddb6cdfad56015242e
Binary files /dev/null and b/mmdet/models/seg_heads/panoptic_fusion_heads/__pycache__/base_panoptic_fusion_head.cpython-37.pyc differ
diff --git a/mmdet/models/seg_heads/panoptic_fusion_heads/__pycache__/heuristic_fusion_head.cpython-37.pyc b/mmdet/models/seg_heads/panoptic_fusion_heads/__pycache__/heuristic_fusion_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..b1fd372d401775595010111365a6823519209711
Binary files /dev/null and b/mmdet/models/seg_heads/panoptic_fusion_heads/__pycache__/heuristic_fusion_head.cpython-37.pyc differ
diff --git a/mmdet/models/seg_heads/panoptic_fusion_heads/__pycache__/maskformer_fusion_head.cpython-37.pyc b/mmdet/models/seg_heads/panoptic_fusion_heads/__pycache__/maskformer_fusion_head.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..9ce454c418db04d6a18fa09b7901050c2f74c069
Binary files /dev/null and b/mmdet/models/seg_heads/panoptic_fusion_heads/__pycache__/maskformer_fusion_head.cpython-37.pyc differ
diff --git a/mmdet/models/seg_heads/panoptic_fusion_heads/base_panoptic_fusion_head.py b/mmdet/models/seg_heads/panoptic_fusion_heads/base_panoptic_fusion_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..f6b20e1cd144eaebd042b8017f143c0a643adde1
--- /dev/null
+++ b/mmdet/models/seg_heads/panoptic_fusion_heads/base_panoptic_fusion_head.py
@@ -0,0 +1,43 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from abc import ABCMeta, abstractmethod
+
+from mmengine.model import BaseModule
+
+from mmdet.registry import MODELS
+from mmdet.utils import OptConfigType, OptMultiConfig
+
+
+@MODELS.register_module()
+class BasePanopticFusionHead(BaseModule, metaclass=ABCMeta):
+ """Base class for panoptic heads."""
+
+ def __init__(self,
+ num_things_classes: int = 80,
+ num_stuff_classes: int = 53,
+ test_cfg: OptConfigType = None,
+ loss_panoptic: OptConfigType = None,
+ init_cfg: OptMultiConfig = None,
+ **kwargs) -> None:
+ super().__init__(init_cfg=init_cfg)
+ self.num_things_classes = num_things_classes
+ self.num_stuff_classes = num_stuff_classes
+ self.num_classes = num_things_classes + num_stuff_classes
+ self.test_cfg = test_cfg
+
+ if loss_panoptic:
+ self.loss_panoptic = MODELS.build(loss_panoptic)
+ else:
+ self.loss_panoptic = None
+
+ @property
+ def with_loss(self) -> bool:
+ """bool: whether the panoptic head contains loss function."""
+ return self.loss_panoptic is not None
+
+ @abstractmethod
+ def loss(self, **kwargs):
+ """Loss function."""
+
+ @abstractmethod
+ def predict(self, **kwargs):
+ """Predict function."""
diff --git a/mmdet/models/seg_heads/panoptic_fusion_heads/heuristic_fusion_head.py b/mmdet/models/seg_heads/panoptic_fusion_heads/heuristic_fusion_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..7a4a4200edd97f42e9a138e14a1d07328ad9b139
--- /dev/null
+++ b/mmdet/models/seg_heads/panoptic_fusion_heads/heuristic_fusion_head.py
@@ -0,0 +1,159 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List
+
+import torch
+from mmengine.structures import InstanceData, PixelData
+from torch import Tensor
+
+from mmdet.evaluation.functional import INSTANCE_OFFSET
+from mmdet.registry import MODELS
+from mmdet.utils import InstanceList, OptConfigType, OptMultiConfig, PixelList
+from .base_panoptic_fusion_head import BasePanopticFusionHead
+
+
+@MODELS.register_module()
+class HeuristicFusionHead(BasePanopticFusionHead):
+ """Fusion Head with Heuristic method."""
+
+ def __init__(self,
+ num_things_classes: int = 80,
+ num_stuff_classes: int = 53,
+ test_cfg: OptConfigType = None,
+ init_cfg: OptMultiConfig = None,
+ **kwargs) -> None:
+ super().__init__(
+ num_things_classes=num_things_classes,
+ num_stuff_classes=num_stuff_classes,
+ test_cfg=test_cfg,
+ loss_panoptic=None,
+ init_cfg=init_cfg,
+ **kwargs)
+
+ def loss(self, **kwargs) -> dict:
+ """HeuristicFusionHead has no training loss."""
+ return dict()
+
+ def _lay_masks(self,
+ mask_results: InstanceData,
+ overlap_thr: float = 0.5) -> Tensor:
+ """Lay instance masks to a result map.
+
+ Args:
+ mask_results (:obj:`InstanceData`): Instance segmentation results,
+ each contains ``bboxes``, ``labels``, ``scores`` and ``masks``.
+ overlap_thr (float): Threshold to determine whether two masks
+ overlap. default: 0.5.
+
+ Returns:
+ Tensor: The result map, (H, W).
+ """
+ bboxes = mask_results.bboxes
+ scores = mask_results.scores
+ labels = mask_results.labels
+ masks = mask_results.masks
+
+ num_insts = bboxes.shape[0]
+ id_map = torch.zeros(
+ masks.shape[-2:], device=bboxes.device, dtype=torch.long)
+ if num_insts == 0:
+ return id_map, labels
+
+ # Sort by score to use heuristic fusion
+ order = torch.argsort(-scores)
+ bboxes = bboxes[order]
+ labels = labels[order]
+ segm_masks = masks[order]
+
+ instance_id = 1
+ left_labels = []
+ for idx in range(bboxes.shape[0]):
+ _cls = labels[idx]
+ _mask = segm_masks[idx]
+ instance_id_map = torch.ones_like(
+ _mask, dtype=torch.long) * instance_id
+ area = _mask.sum()
+ if area == 0:
+ continue
+
+ pasted = id_map > 0
+ intersect = (_mask * pasted).sum()
+ if (intersect / (area + 1e-5)) > overlap_thr:
+ continue
+
+ _part = _mask * (~pasted)
+ id_map = torch.where(_part, instance_id_map, id_map)
+ left_labels.append(_cls)
+ instance_id += 1
+
+ if len(left_labels) > 0:
+ instance_labels = torch.stack(left_labels)
+ else:
+ instance_labels = bboxes.new_zeros((0, ), dtype=torch.long)
+ assert instance_id == (len(instance_labels) + 1)
+ return id_map, instance_labels
+
+ def _predict_single(self, mask_results: InstanceData, seg_preds: Tensor,
+ **kwargs) -> PixelData:
+ """Fuse the results of instance and semantic segmentations.
+
+ Args:
+ mask_results (:obj:`InstanceData`): Instance segmentation results,
+ each contains ``bboxes``, ``labels``, ``scores`` and ``masks``.
+ seg_preds (Tensor): The semantic segmentation results,
+ (num_stuff + 1, H, W).
+
+ Returns:
+ Tensor: The panoptic segmentation result, (H, W).
+ """
+ id_map, labels = self._lay_masks(mask_results,
+ self.test_cfg.mask_overlap)
+
+ seg_results = seg_preds.argmax(dim=0)
+ seg_results = seg_results + self.num_things_classes
+
+ pan_results = seg_results
+ instance_id = 1
+ for idx in range(len(mask_results)):
+ _mask = id_map == (idx + 1)
+ if _mask.sum() == 0:
+ continue
+ _cls = labels[idx]
+ # simply trust detection
+ segment_id = _cls + instance_id * INSTANCE_OFFSET
+ pan_results[_mask] = segment_id
+ instance_id += 1
+
+ ids, counts = torch.unique(
+ pan_results % INSTANCE_OFFSET, return_counts=True)
+ stuff_ids = ids[ids >= self.num_things_classes]
+ stuff_counts = counts[ids >= self.num_things_classes]
+ ignore_stuff_ids = stuff_ids[
+ stuff_counts < self.test_cfg.stuff_area_limit]
+
+ assert pan_results.ndim == 2
+ pan_results[(pan_results.unsqueeze(2) == ignore_stuff_ids.reshape(
+ 1, 1, -1)).any(dim=2)] = self.num_classes
+
+ pan_results = PixelData(sem_seg=pan_results[None].int())
+ return pan_results
+
+ def predict(self, mask_results_list: InstanceList,
+ seg_preds_list: List[Tensor], **kwargs) -> PixelList:
+ """Predict results by fusing the results of instance and semantic
+ segmentations.
+
+ Args:
+ mask_results_list (list[:obj:`InstanceData`]): Instance
+ segmentation results, each contains ``bboxes``, ``labels``,
+ ``scores`` and ``masks``.
+ seg_preds_list (Tensor): List of semantic segmentation results.
+
+ Returns:
+ List[PixelData]: Panoptic segmentation result.
+ """
+ results_list = [
+ self._predict_single(mask_results_list[i], seg_preds_list[i])
+ for i in range(len(mask_results_list))
+ ]
+
+ return results_list
diff --git a/mmdet/models/seg_heads/panoptic_fusion_heads/maskformer_fusion_head.py b/mmdet/models/seg_heads/panoptic_fusion_heads/maskformer_fusion_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..1b76e6b45bb9be2584f8b3eca2e5e1c0809249fa
--- /dev/null
+++ b/mmdet/models/seg_heads/panoptic_fusion_heads/maskformer_fusion_head.py
@@ -0,0 +1,266 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List
+
+import torch
+import torch.nn.functional as F
+from mmengine.structures import InstanceData, PixelData
+from torch import Tensor
+
+from mmdet.evaluation.functional import INSTANCE_OFFSET
+from mmdet.registry import MODELS
+from mmdet.structures import SampleList
+from mmdet.structures.mask import mask2bbox
+from mmdet.utils import OptConfigType, OptMultiConfig
+from .base_panoptic_fusion_head import BasePanopticFusionHead
+
+
+@MODELS.register_module()
+class MaskFormerFusionHead(BasePanopticFusionHead):
+ """MaskFormer fusion head which postprocesses results for panoptic
+ segmentation, instance segmentation and semantic segmentation."""
+
+ def __init__(self,
+ num_things_classes: int = 80,
+ num_stuff_classes: int = 53,
+ test_cfg: OptConfigType = None,
+ loss_panoptic: OptConfigType = None,
+ init_cfg: OptMultiConfig = None,
+ **kwargs):
+ super().__init__(
+ num_things_classes=num_things_classes,
+ num_stuff_classes=num_stuff_classes,
+ test_cfg=test_cfg,
+ loss_panoptic=loss_panoptic,
+ init_cfg=init_cfg,
+ **kwargs)
+
+ def loss(self, **kwargs):
+ """MaskFormerFusionHead has no training loss."""
+ return dict()
+
+ def panoptic_postprocess(self, mask_cls: Tensor,
+ mask_pred: Tensor) -> PixelData:
+ """Panoptic segmengation inference.
+
+ Args:
+ mask_cls (Tensor): Classfication outputs of shape
+ (num_queries, cls_out_channels) for a image.
+ Note `cls_out_channels` should includes
+ background.
+ mask_pred (Tensor): Mask outputs of shape
+ (num_queries, h, w) for a image.
+
+ Returns:
+ :obj:`PixelData`: Panoptic segment result of shape \
+ (h, w), each element in Tensor means: \
+ ``segment_id = _cls + instance_id * INSTANCE_OFFSET``.
+ """
+ object_mask_thr = self.test_cfg.get('object_mask_thr', 0.8)
+ iou_thr = self.test_cfg.get('iou_thr', 0.8)
+ filter_low_score = self.test_cfg.get('filter_low_score', False)
+
+ scores, labels = F.softmax(mask_cls, dim=-1).max(-1)
+ mask_pred = mask_pred.sigmoid()
+
+ keep = labels.ne(self.num_classes) & (scores > object_mask_thr)
+ cur_scores = scores[keep]
+ cur_classes = labels[keep]
+ cur_masks = mask_pred[keep]
+
+ cur_prob_masks = cur_scores.view(-1, 1, 1) * cur_masks
+
+ h, w = cur_masks.shape[-2:]
+ panoptic_seg = torch.full((h, w),
+ self.num_classes,
+ dtype=torch.int32,
+ device=cur_masks.device)
+ if cur_masks.shape[0] == 0:
+ # We didn't detect any mask :(
+ pass
+ else:
+ cur_mask_ids = cur_prob_masks.argmax(0)
+ instance_id = 1
+ for k in range(cur_classes.shape[0]):
+ pred_class = int(cur_classes[k].item())
+ isthing = pred_class < self.num_things_classes
+ mask = cur_mask_ids == k
+ mask_area = mask.sum().item()
+ original_area = (cur_masks[k] >= 0.5).sum().item()
+
+ if filter_low_score:
+ mask = mask & (cur_masks[k] >= 0.5)
+
+ if mask_area > 0 and original_area > 0:
+ if mask_area / original_area < iou_thr:
+ continue
+
+ if not isthing:
+ # different stuff regions of same class will be
+ # merged here, and stuff share the instance_id 0.
+ panoptic_seg[mask] = pred_class
+ else:
+ panoptic_seg[mask] = (
+ pred_class + instance_id * INSTANCE_OFFSET)
+ instance_id += 1
+
+ return PixelData(sem_seg=panoptic_seg[None])
+
+ def semantic_postprocess(self, mask_cls: Tensor,
+ mask_pred: Tensor) -> PixelData:
+ """Semantic segmengation postprocess.
+
+ Args:
+ mask_cls (Tensor): Classfication outputs of shape
+ (num_queries, cls_out_channels) for a image.
+ Note `cls_out_channels` should includes
+ background.
+ mask_pred (Tensor): Mask outputs of shape
+ (num_queries, h, w) for a image.
+
+ Returns:
+ :obj:`PixelData`: Semantic segment result.
+ """
+ # TODO add semantic segmentation result
+ raise NotImplementedError
+
+ def instance_postprocess(self, mask_cls: Tensor,
+ mask_pred: Tensor) -> InstanceData:
+ """Instance segmengation postprocess.
+
+ Args:
+ mask_cls (Tensor): Classfication outputs of shape
+ (num_queries, cls_out_channels) for a image.
+ Note `cls_out_channels` should includes
+ background.
+ mask_pred (Tensor): Mask outputs of shape
+ (num_queries, h, w) for a image.
+
+ Returns:
+ :obj:`InstanceData`: Instance segmentation results.
+
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ - masks (Tensor): Has a shape (num_instances, H, W).
+ """
+ max_per_image = self.test_cfg.get('max_per_image', 100)
+ num_queries = mask_cls.shape[0]
+ # shape (num_queries, num_class)
+ scores = F.softmax(mask_cls, dim=-1)[:, :-1]
+ # shape (num_queries * num_class, )
+ labels = torch.arange(self.num_classes, device=mask_cls.device).\
+ unsqueeze(0).repeat(num_queries, 1).flatten(0, 1)
+ scores_per_image, top_indices = scores.flatten(0, 1).topk(
+ max_per_image, sorted=False)
+ labels_per_image = labels[top_indices]
+
+ query_indices = top_indices // self.num_classes
+ mask_pred = mask_pred[query_indices]
+
+ # extract things
+ is_thing = labels_per_image < self.num_things_classes
+ scores_per_image = scores_per_image[is_thing]
+ labels_per_image = labels_per_image[is_thing]
+ mask_pred = mask_pred[is_thing]
+
+ mask_pred_binary = (mask_pred > 0).float()
+ mask_scores_per_image = (mask_pred.sigmoid() *
+ mask_pred_binary).flatten(1).sum(1) / (
+ mask_pred_binary.flatten(1).sum(1) + 1e-6)
+ det_scores = scores_per_image * mask_scores_per_image
+ mask_pred_binary = mask_pred_binary.bool()
+ bboxes = mask2bbox(mask_pred_binary)
+
+ results = InstanceData()
+ results.bboxes = bboxes
+ results.labels = labels_per_image
+ results.scores = det_scores
+ results.masks = mask_pred_binary
+ return results
+
+ def predict(self,
+ mask_cls_results: Tensor,
+ mask_pred_results: Tensor,
+ batch_data_samples: SampleList,
+ rescale: bool = False,
+ **kwargs) -> List[dict]:
+ """Test segment without test-time aumengtation.
+
+ Only the output of last decoder layers was used.
+
+ Args:
+ mask_cls_results (Tensor): Mask classification logits,
+ shape (batch_size, num_queries, cls_out_channels).
+ Note `cls_out_channels` should includes background.
+ mask_pred_results (Tensor): Mask logits, shape
+ (batch_size, num_queries, h, w).
+ batch_data_samples (List[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ rescale (bool): If True, return boxes in
+ original image space. Default False.
+
+ Returns:
+ list[dict]: Instance segmentation \
+ results and panoptic segmentation results for each \
+ image.
+
+ .. code-block:: none
+
+ [
+ {
+ 'pan_results': PixelData,
+ 'ins_results': InstanceData,
+ # semantic segmentation results are not supported yet
+ 'sem_results': PixelData
+ },
+ ...
+ ]
+ """
+ batch_img_metas = [
+ data_sample.metainfo for data_sample in batch_data_samples
+ ]
+ panoptic_on = self.test_cfg.get('panoptic_on', True)
+ semantic_on = self.test_cfg.get('semantic_on', False)
+ instance_on = self.test_cfg.get('instance_on', False)
+ assert not semantic_on, 'segmantic segmentation '\
+ 'results are not supported yet.'
+
+ results = []
+ for mask_cls_result, mask_pred_result, meta in zip(
+ mask_cls_results, mask_pred_results, batch_img_metas):
+ # remove padding
+ img_height, img_width = meta['img_shape'][:2]
+ mask_pred_result = mask_pred_result[:, :img_height, :img_width]
+
+ if rescale:
+ # return result in original resolution
+ ori_height, ori_width = meta['ori_shape'][:2]
+ mask_pred_result = F.interpolate(
+ mask_pred_result[:, None],
+ size=(ori_height, ori_width),
+ mode='bilinear',
+ align_corners=False)[:, 0]
+
+ result = dict()
+ if panoptic_on:
+ pan_results = self.panoptic_postprocess(
+ mask_cls_result, mask_pred_result)
+ result['pan_results'] = pan_results
+
+ if instance_on:
+ ins_results = self.instance_postprocess(
+ mask_cls_result, mask_pred_result)
+ result['ins_results'] = ins_results
+
+ if semantic_on:
+ sem_results = self.semantic_postprocess(
+ mask_cls_result, mask_pred_result)
+ result['sem_results'] = sem_results
+
+ results.append(result)
+
+ return results
diff --git a/mmdet/models/task_modules/__init__.py b/mmdet/models/task_modules/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..de8b81ac433812b4ca20d46c8ebec9478da5e3bc
--- /dev/null
+++ b/mmdet/models/task_modules/__init__.py
@@ -0,0 +1,17 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .assigners import * # noqa: F401,F403
+from .builder import (ANCHOR_GENERATORS, BBOX_ASSIGNERS, BBOX_CODERS,
+ BBOX_SAMPLERS, IOU_CALCULATORS, MATCH_COSTS,
+ PRIOR_GENERATORS, build_anchor_generator, build_assigner,
+ build_bbox_coder, build_iou_calculator, build_match_cost,
+ build_prior_generator, build_sampler)
+from .coders import * # noqa: F401,F403
+from .prior_generators import * # noqa: F401,F403
+from .samplers import * # noqa: F401,F403
+
+__all__ = [
+ 'ANCHOR_GENERATORS', 'PRIOR_GENERATORS', 'BBOX_ASSIGNERS', 'BBOX_SAMPLERS',
+ 'MATCH_COSTS', 'BBOX_CODERS', 'IOU_CALCULATORS', 'build_anchor_generator',
+ 'build_prior_generator', 'build_assigner', 'build_sampler',
+ 'build_iou_calculator', 'build_match_cost', 'build_bbox_coder'
+]
diff --git a/mmdet/models/task_modules/__pycache__/__init__.cpython-37.pyc b/mmdet/models/task_modules/__pycache__/__init__.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..11fd8ba745b00c3c13382d6a5c005a30c2fe63b0
Binary files /dev/null and b/mmdet/models/task_modules/__pycache__/__init__.cpython-37.pyc differ
diff --git a/mmdet/models/task_modules/__pycache__/builder.cpython-37.pyc b/mmdet/models/task_modules/__pycache__/builder.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..dba01dec09982edf6ea8d8f6fd43d50cb3ae3960
Binary files /dev/null and b/mmdet/models/task_modules/__pycache__/builder.cpython-37.pyc differ
diff --git a/mmdet/models/task_modules/assigners/__init__.py b/mmdet/models/task_modules/assigners/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..7474f05667299649dad54b6beb47f32274968d81
--- /dev/null
+++ b/mmdet/models/task_modules/assigners/__init__.py
@@ -0,0 +1,34 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .approx_max_iou_assigner import ApproxMaxIoUAssigner
+from .assign_result import AssignResult
+from .atss_assigner import ATSSAssigner
+from .base_assigner import BaseAssigner
+from .center_region_assigner import CenterRegionAssigner
+from .dynamic_soft_label_assigner import DynamicSoftLabelAssigner
+from .grid_assigner import GridAssigner
+from .hungarian_assigner import HungarianAssigner
+from .iou2d_calculator import BboxOverlaps2D
+from .match_cost import (BBoxL1Cost, ClassificationCost, CrossEntropyLossCost,
+ DiceCost, FocalLossCost, IoUCost,IoULossCost)
+from .max_iou_assigner import MaxIoUAssigner
+from .multi_instance_assigner import MultiInstanceAssigner
+from .point_assigner import PointAssigner
+from .region_assigner import RegionAssigner
+from .sim_ota_assigner import SimOTAAssigner
+from .task_aligned_assigner import TaskAlignedAssigner
+from .uniform_assigner import UniformAssigner
+
+# lzx
+
+from .dynamic_hungarian_assigner import DynamicHungarianAssigner
+from .dynamic_iou_hungarian_assigner import DynamicIOUHungarianAssigner
+from .mix_hungarian_iou_assigner import MixHungarianIouAssigner
+__all__ = [
+ 'BaseAssigner', 'MaxIoUAssigner', 'ApproxMaxIoUAssigner', 'AssignResult',
+ 'PointAssigner', 'ATSSAssigner', 'CenterRegionAssigner', 'GridAssigner',
+ 'HungarianAssigner', 'RegionAssigner', 'UniformAssigner', 'SimOTAAssigner',
+ 'TaskAlignedAssigner', 'BBoxL1Cost', 'ClassificationCost',
+ 'CrossEntropyLossCost', 'DiceCost', 'FocalLossCost', 'IoUCost',
+ 'BboxOverlaps2D', 'DynamicSoftLabelAssigner', 'MultiInstanceAssigner',
+ 'DynamicHungarianAssigner', 'DynamicIOUHungarianAssigner','IoULossCost','MixHungarianIouAssigner'
+]
diff --git a/mmdet/models/task_modules/assigners/__pycache__/__init__.cpython-37.pyc b/mmdet/models/task_modules/assigners/__pycache__/__init__.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..d43ba1e1f46307d8279fac649c10ac9ec50cbc2b
Binary files /dev/null and b/mmdet/models/task_modules/assigners/__pycache__/__init__.cpython-37.pyc differ
diff --git a/mmdet/models/task_modules/assigners/__pycache__/approx_max_iou_assigner.cpython-37.pyc b/mmdet/models/task_modules/assigners/__pycache__/approx_max_iou_assigner.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..e282635b5e7efc3d272e87eb1497ff7cdc854b11
Binary files /dev/null and b/mmdet/models/task_modules/assigners/__pycache__/approx_max_iou_assigner.cpython-37.pyc differ
diff --git a/mmdet/models/task_modules/assigners/__pycache__/assign_result.cpython-37.pyc b/mmdet/models/task_modules/assigners/__pycache__/assign_result.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..20f4cfcaaf7ee8ca37102edb9efaf99ffa19178e
Binary files /dev/null and b/mmdet/models/task_modules/assigners/__pycache__/assign_result.cpython-37.pyc differ
diff --git a/mmdet/models/task_modules/assigners/__pycache__/atss_assigner.cpython-37.pyc b/mmdet/models/task_modules/assigners/__pycache__/atss_assigner.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..04970245dd089e764dca3187a0e5664a2aad1d66
Binary files /dev/null and b/mmdet/models/task_modules/assigners/__pycache__/atss_assigner.cpython-37.pyc differ
diff --git a/mmdet/models/task_modules/assigners/__pycache__/base_assigner.cpython-37.pyc b/mmdet/models/task_modules/assigners/__pycache__/base_assigner.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..5d68b2b1c1166e2d70a0b3b7214ef70156450799
Binary files /dev/null and b/mmdet/models/task_modules/assigners/__pycache__/base_assigner.cpython-37.pyc differ
diff --git a/mmdet/models/task_modules/assigners/__pycache__/center_region_assigner.cpython-37.pyc b/mmdet/models/task_modules/assigners/__pycache__/center_region_assigner.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..d6aa7a35539dc646bc7e7e3023beff9c460528dc
Binary files /dev/null and b/mmdet/models/task_modules/assigners/__pycache__/center_region_assigner.cpython-37.pyc differ
diff --git a/mmdet/models/task_modules/assigners/__pycache__/dynamic_hungarian_assigner.cpython-37.pyc b/mmdet/models/task_modules/assigners/__pycache__/dynamic_hungarian_assigner.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..006214a98d4515313d1e00d3dbd962e370aba70d
Binary files /dev/null and b/mmdet/models/task_modules/assigners/__pycache__/dynamic_hungarian_assigner.cpython-37.pyc differ
diff --git a/mmdet/models/task_modules/assigners/__pycache__/dynamic_iou_hungarian_assigner.cpython-37.pyc b/mmdet/models/task_modules/assigners/__pycache__/dynamic_iou_hungarian_assigner.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..8b729ae6b648779fead5aff3ac9ac920945a92d0
Binary files /dev/null and b/mmdet/models/task_modules/assigners/__pycache__/dynamic_iou_hungarian_assigner.cpython-37.pyc differ
diff --git a/mmdet/models/task_modules/assigners/__pycache__/dynamic_soft_label_assigner.cpython-37.pyc b/mmdet/models/task_modules/assigners/__pycache__/dynamic_soft_label_assigner.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..4938de83e54409813ede388884ec674016db50ab
Binary files /dev/null and b/mmdet/models/task_modules/assigners/__pycache__/dynamic_soft_label_assigner.cpython-37.pyc differ
diff --git a/mmdet/models/task_modules/assigners/__pycache__/grid_assigner.cpython-37.pyc b/mmdet/models/task_modules/assigners/__pycache__/grid_assigner.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..4938f525bbfbbe29675110d3622d8d79cd307ee2
Binary files /dev/null and b/mmdet/models/task_modules/assigners/__pycache__/grid_assigner.cpython-37.pyc differ
diff --git a/mmdet/models/task_modules/assigners/__pycache__/hungarian_assigner.cpython-37.pyc b/mmdet/models/task_modules/assigners/__pycache__/hungarian_assigner.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..99a0862cf1581e0b8fd3912f3fc9bbf7b5741dea
Binary files /dev/null and b/mmdet/models/task_modules/assigners/__pycache__/hungarian_assigner.cpython-37.pyc differ
diff --git a/mmdet/models/task_modules/assigners/__pycache__/iou2d_calculator.cpython-37.pyc b/mmdet/models/task_modules/assigners/__pycache__/iou2d_calculator.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..e9f252bde70b0004016e63edad99da3f8c32c952
Binary files /dev/null and b/mmdet/models/task_modules/assigners/__pycache__/iou2d_calculator.cpython-37.pyc differ
diff --git a/mmdet/models/task_modules/assigners/__pycache__/match_cost.cpython-37.pyc b/mmdet/models/task_modules/assigners/__pycache__/match_cost.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..a28e2ae9db27dcb9458a0d6bec808e8220c58b10
Binary files /dev/null and b/mmdet/models/task_modules/assigners/__pycache__/match_cost.cpython-37.pyc differ
diff --git a/mmdet/models/task_modules/assigners/__pycache__/max_iou_assigner.cpython-37.pyc b/mmdet/models/task_modules/assigners/__pycache__/max_iou_assigner.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..9c9c195f6d996200701335a7c553f40a0593dcb7
Binary files /dev/null and b/mmdet/models/task_modules/assigners/__pycache__/max_iou_assigner.cpython-37.pyc differ
diff --git a/mmdet/models/task_modules/assigners/__pycache__/mix_hungarian_iou_assigner.cpython-37.pyc b/mmdet/models/task_modules/assigners/__pycache__/mix_hungarian_iou_assigner.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..9fb526f3c45ca3880faa10ae989fd01f59b503df
Binary files /dev/null and b/mmdet/models/task_modules/assigners/__pycache__/mix_hungarian_iou_assigner.cpython-37.pyc differ
diff --git a/mmdet/models/task_modules/assigners/__pycache__/multi_instance_assigner.cpython-37.pyc b/mmdet/models/task_modules/assigners/__pycache__/multi_instance_assigner.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..16e563df69e6c43da548488de5943a049afcaa34
Binary files /dev/null and b/mmdet/models/task_modules/assigners/__pycache__/multi_instance_assigner.cpython-37.pyc differ
diff --git a/mmdet/models/task_modules/assigners/__pycache__/point_assigner.cpython-37.pyc b/mmdet/models/task_modules/assigners/__pycache__/point_assigner.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..d7a6bd2940bf423a4efe38d6557d0369fc6759d2
Binary files /dev/null and b/mmdet/models/task_modules/assigners/__pycache__/point_assigner.cpython-37.pyc differ
diff --git a/mmdet/models/task_modules/assigners/__pycache__/region_assigner.cpython-37.pyc b/mmdet/models/task_modules/assigners/__pycache__/region_assigner.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..9fad5fbd128c64166507a2539aa9ab4ea81cd061
Binary files /dev/null and b/mmdet/models/task_modules/assigners/__pycache__/region_assigner.cpython-37.pyc differ
diff --git a/mmdet/models/task_modules/assigners/__pycache__/sim_ota_assigner.cpython-37.pyc b/mmdet/models/task_modules/assigners/__pycache__/sim_ota_assigner.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..91ce955aef4cbf655a85da9d5800f68a5ab7c650
Binary files /dev/null and b/mmdet/models/task_modules/assigners/__pycache__/sim_ota_assigner.cpython-37.pyc differ
diff --git a/mmdet/models/task_modules/assigners/__pycache__/task_aligned_assigner.cpython-37.pyc b/mmdet/models/task_modules/assigners/__pycache__/task_aligned_assigner.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..b3c624da9705e92ee96d88e83629a8a645348e01
Binary files /dev/null and b/mmdet/models/task_modules/assigners/__pycache__/task_aligned_assigner.cpython-37.pyc differ
diff --git a/mmdet/models/task_modules/assigners/__pycache__/uniform_assigner.cpython-37.pyc b/mmdet/models/task_modules/assigners/__pycache__/uniform_assigner.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..92c386ec0ffb74d7ab47ce7d1be692b585dc400a
Binary files /dev/null and b/mmdet/models/task_modules/assigners/__pycache__/uniform_assigner.cpython-37.pyc differ
diff --git a/mmdet/models/task_modules/assigners/approx_max_iou_assigner.py b/mmdet/models/task_modules/assigners/approx_max_iou_assigner.py
new file mode 100644
index 0000000000000000000000000000000000000000..471d54e578d640da242355b54cebe05658309ca2
--- /dev/null
+++ b/mmdet/models/task_modules/assigners/approx_max_iou_assigner.py
@@ -0,0 +1,162 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Union
+
+import torch
+from mmengine.config import ConfigDict
+from mmengine.structures import InstanceData
+
+from mmdet.registry import TASK_UTILS
+from .assign_result import AssignResult
+from .max_iou_assigner import MaxIoUAssigner
+
+
+@TASK_UTILS.register_module()
+class ApproxMaxIoUAssigner(MaxIoUAssigner):
+ """Assign a corresponding gt bbox or background to each bbox.
+
+ Each proposals will be assigned with an integer indicating the ground truth
+ index. (semi-positive index: gt label (0-based), -1: background)
+
+ - -1: negative sample, no assigned gt
+ - semi-positive integer: positive sample, index (0-based) of assigned gt
+
+ Args:
+ pos_iou_thr (float): IoU threshold for positive bboxes.
+ neg_iou_thr (float or tuple): IoU threshold for negative bboxes.
+ min_pos_iou (float): Minimum iou for a bbox to be considered as a
+ positive bbox. Positive samples can have smaller IoU than
+ pos_iou_thr due to the 4th step (assign max IoU sample to each gt).
+ gt_max_assign_all (bool): Whether to assign all bboxes with the same
+ highest overlap with some gt to that gt.
+ ignore_iof_thr (float): IoF threshold for ignoring bboxes (if
+ `gt_bboxes_ignore` is specified). Negative values mean not
+ ignoring any bboxes.
+ ignore_wrt_candidates (bool): Whether to compute the iof between
+ `bboxes` and `gt_bboxes_ignore`, or the contrary.
+ match_low_quality (bool): Whether to allow quality matches. This is
+ usually allowed for RPN and single stage detectors, but not allowed
+ in the second stage.
+ gpu_assign_thr (int): The upper bound of the number of GT for GPU
+ assign. When the number of gt is above this threshold, will assign
+ on CPU device. Negative values mean not assign on CPU.
+ iou_calculator (:obj:`ConfigDict` or dict): Config of overlaps
+ Calculator.
+ """
+
+ def __init__(
+ self,
+ pos_iou_thr: float,
+ neg_iou_thr: Union[float, tuple],
+ min_pos_iou: float = .0,
+ gt_max_assign_all: bool = True,
+ ignore_iof_thr: float = -1,
+ ignore_wrt_candidates: bool = True,
+ match_low_quality: bool = True,
+ gpu_assign_thr: int = -1,
+ iou_calculator: Union[ConfigDict, dict] = dict(type='BboxOverlaps2D')
+ ) -> None:
+ self.pos_iou_thr = pos_iou_thr
+ self.neg_iou_thr = neg_iou_thr
+ self.min_pos_iou = min_pos_iou
+ self.gt_max_assign_all = gt_max_assign_all
+ self.ignore_iof_thr = ignore_iof_thr
+ self.ignore_wrt_candidates = ignore_wrt_candidates
+ self.gpu_assign_thr = gpu_assign_thr
+ self.match_low_quality = match_low_quality
+ self.iou_calculator = TASK_UTILS.build(iou_calculator)
+
+ def assign(self,
+ pred_instances: InstanceData,
+ gt_instances: InstanceData,
+ gt_instances_ignore: Optional[InstanceData] = None,
+ **kwargs) -> AssignResult:
+ """Assign gt to approxs.
+
+ This method assign a gt bbox to each group of approxs (bboxes),
+ each group of approxs is represent by a base approx (bbox) and
+ will be assigned with -1, or a semi-positive number.
+ background_label (-1) means negative sample,
+ semi-positive number is the index (0-based) of assigned gt.
+ The assignment is done in following steps, the order matters.
+
+ 1. assign every bbox to background_label (-1)
+ 2. use the max IoU of each group of approxs to assign
+ 2. assign proposals whose iou with all gts < neg_iou_thr to background
+ 3. for each bbox, if the iou with its nearest gt >= pos_iou_thr,
+ assign it to that bbox
+ 4. for each gt bbox, assign its nearest proposals (may be more than
+ one) to itself
+
+ Args:
+ pred_instances (:obj:`InstanceData`): Instances of model
+ predictions. It includes ``priors``, and the priors can
+ be anchors or points, or the bboxes predicted by the
+ previous stage, has shape (n, 4). ``approxs`` means the
+ group of approxs aligned with ``priors``, has shape
+ (n, num_approxs, 4).
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It usually includes ``bboxes``, with shape (k, 4),
+ and ``labels``, with shape (k, ).
+ gt_instances_ignore (:obj:`InstanceData`, optional): Instances
+ to be ignored during training. It includes ``bboxes``
+ attribute data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ :obj:`AssignResult`: The assign result.
+ """
+ squares = pred_instances.priors
+ approxs = pred_instances.approxs
+ gt_bboxes = gt_instances.bboxes
+ gt_labels = gt_instances.labels
+ gt_bboxes_ignore = None if gt_instances_ignore is None else \
+ gt_instances_ignore.get('bboxes', None)
+ approxs_per_octave = approxs.size(1)
+
+ num_squares = squares.size(0)
+ num_gts = gt_bboxes.size(0)
+
+ if num_squares == 0 or num_gts == 0:
+ # No predictions and/or truth, return empty assignment
+ overlaps = approxs.new(num_gts, num_squares)
+ assign_result = self.assign_wrt_overlaps(overlaps, gt_labels)
+ return assign_result
+
+ # re-organize anchors by approxs_per_octave x num_squares
+ approxs = torch.transpose(approxs, 0, 1).contiguous().view(-1, 4)
+ assign_on_cpu = True if (self.gpu_assign_thr > 0) and (
+ num_gts > self.gpu_assign_thr) else False
+ # compute overlap and assign gt on CPU when number of GT is large
+ if assign_on_cpu:
+ device = approxs.device
+ approxs = approxs.cpu()
+ gt_bboxes = gt_bboxes.cpu()
+ if gt_bboxes_ignore is not None:
+ gt_bboxes_ignore = gt_bboxes_ignore.cpu()
+ if gt_labels is not None:
+ gt_labels = gt_labels.cpu()
+ all_overlaps = self.iou_calculator(approxs, gt_bboxes)
+
+ overlaps, _ = all_overlaps.view(approxs_per_octave, num_squares,
+ num_gts).max(dim=0)
+ overlaps = torch.transpose(overlaps, 0, 1)
+
+ if (self.ignore_iof_thr > 0 and gt_bboxes_ignore is not None
+ and gt_bboxes_ignore.numel() > 0 and squares.numel() > 0):
+ if self.ignore_wrt_candidates:
+ ignore_overlaps = self.iou_calculator(
+ squares, gt_bboxes_ignore, mode='iof')
+ ignore_max_overlaps, _ = ignore_overlaps.max(dim=1)
+ else:
+ ignore_overlaps = self.iou_calculator(
+ gt_bboxes_ignore, squares, mode='iof')
+ ignore_max_overlaps, _ = ignore_overlaps.max(dim=0)
+ overlaps[:, ignore_max_overlaps > self.ignore_iof_thr] = -1
+
+ assign_result = self.assign_wrt_overlaps(overlaps, gt_labels)
+ if assign_on_cpu:
+ assign_result.gt_inds = assign_result.gt_inds.to(device)
+ assign_result.max_overlaps = assign_result.max_overlaps.to(device)
+ if assign_result.labels is not None:
+ assign_result.labels = assign_result.labels.to(device)
+ return assign_result
diff --git a/mmdet/models/task_modules/assigners/assign_result.py b/mmdet/models/task_modules/assigners/assign_result.py
new file mode 100644
index 0000000000000000000000000000000000000000..56ca2c3c18fee94cc4a039b769e42521bd14907d
--- /dev/null
+++ b/mmdet/models/task_modules/assigners/assign_result.py
@@ -0,0 +1,198 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+from torch import Tensor
+
+from mmdet.utils import util_mixins
+
+
+class AssignResult(util_mixins.NiceRepr):
+ """Stores assignments between predicted and truth boxes.
+
+ Attributes:
+ num_gts (int): the number of truth boxes considered when computing this
+ assignment
+ gt_inds (Tensor): for each predicted box indicates the 1-based
+ index of the assigned truth box. 0 means unassigned and -1 means
+ ignore.
+ max_overlaps (Tensor): the iou between the predicted box and its
+ assigned truth box.
+ labels (Tensor): If specified, for each predicted box
+ indicates the category label of the assigned truth box.
+
+ Example:
+ >>> # An assign result between 4 predicted boxes and 9 true boxes
+ >>> # where only two boxes were assigned.
+ >>> num_gts = 9
+ >>> max_overlaps = torch.LongTensor([0, .5, .9, 0])
+ >>> gt_inds = torch.LongTensor([-1, 1, 2, 0])
+ >>> labels = torch.LongTensor([0, 3, 4, 0])
+ >>> self = AssignResult(num_gts, gt_inds, max_overlaps, labels)
+ >>> print(str(self)) # xdoctest: +IGNORE_WANT
+
+ >>> # Force addition of gt labels (when adding gt as proposals)
+ >>> new_labels = torch.LongTensor([3, 4, 5])
+ >>> self.add_gt_(new_labels)
+ >>> print(str(self)) # xdoctest: +IGNORE_WANT
+
+ """
+
+ def __init__(self, num_gts: int, gt_inds: Tensor, max_overlaps: Tensor,
+ labels: Tensor) -> None:
+ self.num_gts = num_gts
+ self.gt_inds = gt_inds
+ self.max_overlaps = max_overlaps
+ self.labels = labels
+ # Interface for possible user-defined properties
+ self._extra_properties = {}
+
+ @property
+ def num_preds(self):
+ """int: the number of predictions in this assignment"""
+ return len(self.gt_inds)
+
+ def set_extra_property(self, key, value):
+ """Set user-defined new property."""
+ assert key not in self.info
+ self._extra_properties[key] = value
+
+ def get_extra_property(self, key):
+ """Get user-defined property."""
+ return self._extra_properties.get(key, None)
+
+ @property
+ def info(self):
+ """dict: a dictionary of info about the object"""
+ basic_info = {
+ 'num_gts': self.num_gts,
+ 'num_preds': self.num_preds,
+ 'gt_inds': self.gt_inds,
+ 'max_overlaps': self.max_overlaps,
+ 'labels': self.labels,
+ }
+ basic_info.update(self._extra_properties)
+ return basic_info
+
+ def __nice__(self):
+ """str: a "nice" summary string describing this assign result"""
+ parts = []
+ parts.append(f'num_gts={self.num_gts!r}')
+ if self.gt_inds is None:
+ parts.append(f'gt_inds={self.gt_inds!r}')
+ else:
+ parts.append(f'gt_inds.shape={tuple(self.gt_inds.shape)!r}')
+ if self.max_overlaps is None:
+ parts.append(f'max_overlaps={self.max_overlaps!r}')
+ else:
+ parts.append('max_overlaps.shape='
+ f'{tuple(self.max_overlaps.shape)!r}')
+ if self.labels is None:
+ parts.append(f'labels={self.labels!r}')
+ else:
+ parts.append(f'labels.shape={tuple(self.labels.shape)!r}')
+ return ', '.join(parts)
+
+ @classmethod
+ def random(cls, **kwargs):
+ """Create random AssignResult for tests or debugging.
+
+ Args:
+ num_preds: number of predicted boxes
+ num_gts: number of true boxes
+ p_ignore (float): probability of a predicted box assigned to an
+ ignored truth
+ p_assigned (float): probability of a predicted box not being
+ assigned
+ p_use_label (float | bool): with labels or not
+ rng (None | int | numpy.random.RandomState): seed or state
+
+ Returns:
+ :obj:`AssignResult`: Randomly generated assign results.
+
+ Example:
+ >>> from mmdet.models.task_modules.assigners.assign_result import * # NOQA
+ >>> self = AssignResult.random()
+ >>> print(self.info)
+ """
+ from ..samplers.sampling_result import ensure_rng
+ rng = ensure_rng(kwargs.get('rng', None))
+
+ num_gts = kwargs.get('num_gts', None)
+ num_preds = kwargs.get('num_preds', None)
+ p_ignore = kwargs.get('p_ignore', 0.3)
+ p_assigned = kwargs.get('p_assigned', 0.7)
+ num_classes = kwargs.get('num_classes', 3)
+
+ if num_gts is None:
+ num_gts = rng.randint(0, 8)
+ if num_preds is None:
+ num_preds = rng.randint(0, 16)
+
+ if num_gts == 0:
+ max_overlaps = torch.zeros(num_preds, dtype=torch.float32)
+ gt_inds = torch.zeros(num_preds, dtype=torch.int64)
+ labels = torch.zeros(num_preds, dtype=torch.int64)
+
+ else:
+ import numpy as np
+
+ # Create an overlap for each predicted box
+ max_overlaps = torch.from_numpy(rng.rand(num_preds))
+
+ # Construct gt_inds for each predicted box
+ is_assigned = torch.from_numpy(rng.rand(num_preds) < p_assigned)
+ # maximum number of assignments constraints
+ n_assigned = min(num_preds, min(num_gts, is_assigned.sum()))
+
+ assigned_idxs = np.where(is_assigned)[0]
+ rng.shuffle(assigned_idxs)
+ assigned_idxs = assigned_idxs[0:n_assigned]
+ assigned_idxs.sort()
+
+ is_assigned[:] = 0
+ is_assigned[assigned_idxs] = True
+
+ is_ignore = torch.from_numpy(
+ rng.rand(num_preds) < p_ignore) & is_assigned
+
+ gt_inds = torch.zeros(num_preds, dtype=torch.int64)
+
+ true_idxs = np.arange(num_gts)
+ rng.shuffle(true_idxs)
+ true_idxs = torch.from_numpy(true_idxs)
+ gt_inds[is_assigned] = true_idxs[:n_assigned].long()
+
+ gt_inds = torch.from_numpy(
+ rng.randint(1, num_gts + 1, size=num_preds))
+ gt_inds[is_ignore] = -1
+ gt_inds[~is_assigned] = 0
+ max_overlaps[~is_assigned] = 0
+
+ if num_classes == 0:
+ labels = torch.zeros(num_preds, dtype=torch.int64)
+ else:
+ labels = torch.from_numpy(
+ # remind that we set FG labels to [0, num_class-1]
+ # since mmdet v2.0
+ # BG cat_id: num_class
+ rng.randint(0, num_classes, size=num_preds))
+ labels[~is_assigned] = 0
+
+ self = cls(num_gts, gt_inds, max_overlaps, labels)
+ return self
+
+ def add_gt_(self, gt_labels):
+ """Add ground truth as assigned results.
+
+ Args:
+ gt_labels (torch.Tensor): Labels of gt boxes
+ """
+ self_inds = torch.arange(
+ 1, len(gt_labels) + 1, dtype=torch.long, device=gt_labels.device)
+ self.gt_inds = torch.cat([self_inds, self.gt_inds])
+
+ self.max_overlaps = torch.cat(
+ [self.max_overlaps.new_ones(len(gt_labels)), self.max_overlaps])
+
+ self.labels = torch.cat([gt_labels, self.labels])
diff --git a/mmdet/models/task_modules/assigners/atss_assigner.py b/mmdet/models/task_modules/assigners/atss_assigner.py
new file mode 100644
index 0000000000000000000000000000000000000000..2796b990c5ae4c56bcf314e1342671d950232ae6
--- /dev/null
+++ b/mmdet/models/task_modules/assigners/atss_assigner.py
@@ -0,0 +1,254 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+from typing import List, Optional
+
+import torch
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmdet.registry import TASK_UTILS
+from mmdet.utils import ConfigType
+from .assign_result import AssignResult
+from .base_assigner import BaseAssigner
+
+
+def bbox_center_distance(bboxes: Tensor, priors: Tensor) -> Tensor:
+ """Compute the center distance between bboxes and priors.
+
+ Args:
+ bboxes (Tensor): Shape (n, 4) for , "xyxy" format.
+ priors (Tensor): Shape (n, 4) for priors, "xyxy" format.
+
+ Returns:
+ Tensor: Center distances between bboxes and priors.
+ """
+ bbox_cx = (bboxes[:, 0] + bboxes[:, 2]) / 2.0
+ bbox_cy = (bboxes[:, 1] + bboxes[:, 3]) / 2.0
+ bbox_points = torch.stack((bbox_cx, bbox_cy), dim=1)
+
+ priors_cx = (priors[:, 0] + priors[:, 2]) / 2.0
+ priors_cy = (priors[:, 1] + priors[:, 3]) / 2.0
+ priors_points = torch.stack((priors_cx, priors_cy), dim=1)
+
+ distances = (priors_points[:, None, :] -
+ bbox_points[None, :, :]).pow(2).sum(-1).sqrt()
+
+ return distances
+
+
+@TASK_UTILS.register_module()
+class ATSSAssigner(BaseAssigner):
+ """Assign a corresponding gt bbox or background to each prior.
+
+ Each proposals will be assigned with `0` or a positive integer
+ indicating the ground truth index.
+
+ - 0: negative sample, no assigned gt
+ - positive integer: positive sample, index (1-based) of assigned gt
+
+ If ``alpha`` is not None, it means that the dynamic cost
+ ATSSAssigner is adopted, which is currently only used in the DDOD.
+
+ Args:
+ topk (int): number of priors selected in each level
+ alpha (float, optional): param of cost rate for each proposal only
+ in DDOD. Defaults to None.
+ iou_calculator (:obj:`ConfigDict` or dict): Config dict for iou
+ calculator. Defaults to ``dict(type='BboxOverlaps2D')``
+ ignore_iof_thr (float): IoF threshold for ignoring bboxes (if
+ `gt_bboxes_ignore` is specified). Negative values mean not
+ ignoring any bboxes. Defaults to -1.
+ """
+
+ def __init__(self,
+ topk: int,
+ alpha: Optional[float] = None,
+ iou_calculator: ConfigType = dict(type='BboxOverlaps2D'),
+ ignore_iof_thr: float = -1) -> None:
+ self.topk = topk
+ self.alpha = alpha
+ self.iou_calculator = TASK_UTILS.build(iou_calculator)
+ self.ignore_iof_thr = ignore_iof_thr
+
+ # https://github.com/sfzhang15/ATSS/blob/master/atss_core/modeling/rpn/atss/loss.py
+ def assign(
+ self,
+ pred_instances: InstanceData,
+ num_level_priors: List[int],
+ gt_instances: InstanceData,
+ gt_instances_ignore: Optional[InstanceData] = None
+ ) -> AssignResult:
+ """Assign gt to priors.
+
+ The assignment is done in following steps
+
+ 1. compute iou between all prior (prior of all pyramid levels) and gt
+ 2. compute center distance between all prior and gt
+ 3. on each pyramid level, for each gt, select k prior whose center
+ are closest to the gt center, so we total select k*l prior as
+ candidates for each gt
+ 4. get corresponding iou for the these candidates, and compute the
+ mean and std, set mean + std as the iou threshold
+ 5. select these candidates whose iou are greater than or equal to
+ the threshold as positive
+ 6. limit the positive sample's center in gt
+
+ If ``alpha`` is not None, and ``cls_scores`` and `bbox_preds`
+ are not None, the overlaps calculation in the first step
+ will also include dynamic cost, which is currently only used in
+ the DDOD.
+
+ Args:
+ pred_instances (:obj:`InstaceData`): Instances of model
+ predictions. It includes ``priors``, and the priors can
+ be anchors, points, or bboxes predicted by the model,
+ shape(n, 4).
+ num_level_priors (List): Number of bboxes in each level
+ gt_instances (:obj:`InstaceData`): Ground truth of instance
+ annotations. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ gt_instances_ignore (:obj:`InstaceData`, optional): Instances
+ to be ignored during training. It includes ``bboxes``
+ attribute data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ :obj:`AssignResult`: The assign result.
+ """
+ gt_bboxes = gt_instances.bboxes
+ priors = pred_instances.priors
+ gt_labels = gt_instances.labels
+ if gt_instances_ignore is not None:
+ gt_bboxes_ignore = gt_instances_ignore.bboxes
+ else:
+ gt_bboxes_ignore = None
+
+ INF = 100000000
+ priors = priors[:, :4]
+ num_gt, num_priors = gt_bboxes.size(0), priors.size(0)
+
+ message = 'Invalid alpha parameter because cls_scores or ' \
+ 'bbox_preds are None. If you want to use the ' \
+ 'cost-based ATSSAssigner, please set cls_scores, ' \
+ 'bbox_preds and self.alpha at the same time. '
+
+ # compute iou between all bbox and gt
+ if self.alpha is None:
+ # ATSSAssigner
+ overlaps = self.iou_calculator(priors, gt_bboxes)
+ if ('scores' in pred_instances or 'bboxes' in pred_instances):
+ warnings.warn(message)
+
+ else:
+ # Dynamic cost ATSSAssigner in DDOD
+ assert ('scores' in pred_instances
+ and 'bboxes' in pred_instances), message
+ cls_scores = pred_instances.scores
+ bbox_preds = pred_instances.bboxes
+
+ # compute cls cost for bbox and GT
+ cls_cost = torch.sigmoid(cls_scores[:, gt_labels])
+
+ # compute iou between all bbox and gt
+ overlaps = self.iou_calculator(bbox_preds, gt_bboxes)
+
+ # make sure that we are in element-wise multiplication
+ assert cls_cost.shape == overlaps.shape
+
+ # overlaps is actually a cost matrix
+ overlaps = cls_cost**(1 - self.alpha) * overlaps**self.alpha
+
+ # assign 0 by default
+ assigned_gt_inds = overlaps.new_full((num_priors, ),
+ 0,
+ dtype=torch.long)
+
+ if num_gt == 0 or num_priors == 0:
+ # No ground truth or boxes, return empty assignment
+ max_overlaps = overlaps.new_zeros((num_priors, ))
+ if num_gt == 0:
+ # No truth, assign everything to background
+ assigned_gt_inds[:] = 0
+ assigned_labels = overlaps.new_full((num_priors, ),
+ -1,
+ dtype=torch.long)
+ return AssignResult(
+ num_gt, assigned_gt_inds, max_overlaps, labels=assigned_labels)
+
+ # compute center distance between all bbox and gt
+ distances = bbox_center_distance(gt_bboxes, priors)
+
+ if (self.ignore_iof_thr > 0 and gt_bboxes_ignore is not None
+ and gt_bboxes_ignore.numel() > 0 and priors.numel() > 0):
+ ignore_overlaps = self.iou_calculator(
+ priors, gt_bboxes_ignore, mode='iof')
+ ignore_max_overlaps, _ = ignore_overlaps.max(dim=1)
+ ignore_idxs = ignore_max_overlaps > self.ignore_iof_thr
+ distances[ignore_idxs, :] = INF
+ assigned_gt_inds[ignore_idxs] = -1
+
+ # Selecting candidates based on the center distance
+ candidate_idxs = []
+ start_idx = 0
+ for level, priors_per_level in enumerate(num_level_priors):
+ # on each pyramid level, for each gt,
+ # select k bbox whose center are closest to the gt center
+ end_idx = start_idx + priors_per_level
+ distances_per_level = distances[start_idx:end_idx, :]
+ selectable_k = min(self.topk, priors_per_level)
+ _, topk_idxs_per_level = distances_per_level.topk(
+ selectable_k, dim=0, largest=False)
+ candidate_idxs.append(topk_idxs_per_level + start_idx)
+ start_idx = end_idx
+ candidate_idxs = torch.cat(candidate_idxs, dim=0)
+
+ # get corresponding iou for the these candidates, and compute the
+ # mean and std, set mean + std as the iou threshold
+ candidate_overlaps = overlaps[candidate_idxs, torch.arange(num_gt)]
+ overlaps_mean_per_gt = candidate_overlaps.mean(0)
+ overlaps_std_per_gt = candidate_overlaps.std(0)
+ overlaps_thr_per_gt = overlaps_mean_per_gt + overlaps_std_per_gt
+
+ is_pos = candidate_overlaps >= overlaps_thr_per_gt[None, :]
+
+ # limit the positive sample's center in gt
+ for gt_idx in range(num_gt):
+ candidate_idxs[:, gt_idx] += gt_idx * num_priors
+ priors_cx = (priors[:, 0] + priors[:, 2]) / 2.0
+ priors_cy = (priors[:, 1] + priors[:, 3]) / 2.0
+ ep_priors_cx = priors_cx.view(1, -1).expand(
+ num_gt, num_priors).contiguous().view(-1)
+ ep_priors_cy = priors_cy.view(1, -1).expand(
+ num_gt, num_priors).contiguous().view(-1)
+ candidate_idxs = candidate_idxs.view(-1)
+
+ # calculate the left, top, right, bottom distance between positive
+ # prior center and gt side
+ l_ = ep_priors_cx[candidate_idxs].view(-1, num_gt) - gt_bboxes[:, 0]
+ t_ = ep_priors_cy[candidate_idxs].view(-1, num_gt) - gt_bboxes[:, 1]
+ r_ = gt_bboxes[:, 2] - ep_priors_cx[candidate_idxs].view(-1, num_gt)
+ b_ = gt_bboxes[:, 3] - ep_priors_cy[candidate_idxs].view(-1, num_gt)
+ is_in_gts = torch.stack([l_, t_, r_, b_], dim=1).min(dim=1)[0] > 0.01
+
+ is_pos = is_pos & is_in_gts
+
+ # if an anchor box is assigned to multiple gts,
+ # the one with the highest IoU will be selected.
+ overlaps_inf = torch.full_like(overlaps,
+ -INF).t().contiguous().view(-1)
+ index = candidate_idxs.view(-1)[is_pos.view(-1)]
+ overlaps_inf[index] = overlaps.t().contiguous().view(-1)[index]
+ overlaps_inf = overlaps_inf.view(num_gt, -1).t()
+
+ max_overlaps, argmax_overlaps = overlaps_inf.max(dim=1)
+ assigned_gt_inds[
+ max_overlaps != -INF] = argmax_overlaps[max_overlaps != -INF] + 1
+
+ assigned_labels = assigned_gt_inds.new_full((num_priors, ), -1)
+ pos_inds = torch.nonzero(
+ assigned_gt_inds > 0, as_tuple=False).squeeze()
+ if pos_inds.numel() > 0:
+ assigned_labels[pos_inds] = gt_labels[assigned_gt_inds[pos_inds] -
+ 1]
+ return AssignResult(
+ num_gt, assigned_gt_inds, max_overlaps, labels=assigned_labels)
diff --git a/mmdet/models/task_modules/assigners/base_assigner.py b/mmdet/models/task_modules/assigners/base_assigner.py
new file mode 100644
index 0000000000000000000000000000000000000000..b12280ad746c7557008313dd936a62a99e8c78d5
--- /dev/null
+++ b/mmdet/models/task_modules/assigners/base_assigner.py
@@ -0,0 +1,17 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from abc import ABCMeta, abstractmethod
+from typing import Optional
+
+from mmengine.structures import InstanceData
+
+
+class BaseAssigner(metaclass=ABCMeta):
+ """Base assigner that assigns boxes to ground truth boxes."""
+
+ @abstractmethod
+ def assign(self,
+ pred_instances: InstanceData,
+ gt_instances: InstanceData,
+ gt_instances_ignore: Optional[InstanceData] = None,
+ **kwargs):
+ """Assign boxes to either a ground truth boxes or a negative boxes."""
diff --git a/mmdet/models/task_modules/assigners/center_region_assigner.py b/mmdet/models/task_modules/assigners/center_region_assigner.py
new file mode 100644
index 0000000000000000000000000000000000000000..11c8055c67cdf46c1ae0f877e88192db33795581
--- /dev/null
+++ b/mmdet/models/task_modules/assigners/center_region_assigner.py
@@ -0,0 +1,366 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Tuple
+
+import torch
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmdet.registry import TASK_UTILS
+from mmdet.utils import ConfigType
+from .assign_result import AssignResult
+from .base_assigner import BaseAssigner
+
+
+def scale_boxes(bboxes: Tensor, scale: float) -> Tensor:
+ """Expand an array of boxes by a given scale.
+
+ Args:
+ bboxes (Tensor): Shape (m, 4)
+ scale (float): The scale factor of bboxes
+
+ Returns:
+ Tensor: Shape (m, 4). Scaled bboxes
+ """
+ assert bboxes.size(1) == 4
+ w_half = (bboxes[:, 2] - bboxes[:, 0]) * .5
+ h_half = (bboxes[:, 3] - bboxes[:, 1]) * .5
+ x_c = (bboxes[:, 2] + bboxes[:, 0]) * .5
+ y_c = (bboxes[:, 3] + bboxes[:, 1]) * .5
+
+ w_half *= scale
+ h_half *= scale
+
+ boxes_scaled = torch.zeros_like(bboxes)
+ boxes_scaled[:, 0] = x_c - w_half
+ boxes_scaled[:, 2] = x_c + w_half
+ boxes_scaled[:, 1] = y_c - h_half
+ boxes_scaled[:, 3] = y_c + h_half
+ return boxes_scaled
+
+
+def is_located_in(points: Tensor, bboxes: Tensor) -> Tensor:
+ """Are points located in bboxes.
+
+ Args:
+ points (Tensor): Points, shape: (m, 2).
+ bboxes (Tensor): Bounding boxes, shape: (n, 4).
+
+ Return:
+ Tensor: Flags indicating if points are located in bboxes,
+ shape: (m, n).
+ """
+ assert points.size(1) == 2
+ assert bboxes.size(1) == 4
+ return (points[:, 0].unsqueeze(1) > bboxes[:, 0].unsqueeze(0)) & \
+ (points[:, 0].unsqueeze(1) < bboxes[:, 2].unsqueeze(0)) & \
+ (points[:, 1].unsqueeze(1) > bboxes[:, 1].unsqueeze(0)) & \
+ (points[:, 1].unsqueeze(1) < bboxes[:, 3].unsqueeze(0))
+
+
+def bboxes_area(bboxes: Tensor) -> Tensor:
+ """Compute the area of an array of bboxes.
+
+ Args:
+ bboxes (Tensor): The coordinates ox bboxes. Shape: (m, 4)
+
+ Returns:
+ Tensor: Area of the bboxes. Shape: (m, )
+ """
+ assert bboxes.size(1) == 4
+ w = (bboxes[:, 2] - bboxes[:, 0])
+ h = (bboxes[:, 3] - bboxes[:, 1])
+ areas = w * h
+ return areas
+
+
+@TASK_UTILS.register_module()
+class CenterRegionAssigner(BaseAssigner):
+ """Assign pixels at the center region of a bbox as positive.
+
+ Each proposals will be assigned with `-1`, `0`, or a positive integer
+ indicating the ground truth index.
+ - -1: negative samples
+ - semi-positive numbers: positive sample, index (0-based) of assigned gt
+
+ Args:
+ pos_scale (float): Threshold within which pixels are
+ labelled as positive.
+ neg_scale (float): Threshold above which pixels are
+ labelled as positive.
+ min_pos_iof (float): Minimum iof of a pixel with a gt to be
+ labelled as positive. Default: 1e-2
+ ignore_gt_scale (float): Threshold within which the pixels
+ are ignored when the gt is labelled as shadowed. Default: 0.5
+ foreground_dominate (bool): If True, the bbox will be assigned as
+ positive when a gt's kernel region overlaps with another's shadowed
+ (ignored) region, otherwise it is set as ignored. Default to False.
+ iou_calculator (:obj:`ConfigDict` or dict): Config of overlaps
+ Calculator.
+ """
+
+ def __init__(
+ self,
+ pos_scale: float,
+ neg_scale: float,
+ min_pos_iof: float = 1e-2,
+ ignore_gt_scale: float = 0.5,
+ foreground_dominate: bool = False,
+ iou_calculator: ConfigType = dict(type='BboxOverlaps2D')
+ ) -> None:
+ self.pos_scale = pos_scale
+ self.neg_scale = neg_scale
+ self.min_pos_iof = min_pos_iof
+ self.ignore_gt_scale = ignore_gt_scale
+ self.foreground_dominate = foreground_dominate
+ self.iou_calculator = TASK_UTILS.build(iou_calculator)
+
+ def get_gt_priorities(self, gt_bboxes: Tensor) -> Tensor:
+ """Get gt priorities according to their areas.
+
+ Smaller gt has higher priority.
+
+ Args:
+ gt_bboxes (Tensor): Ground truth boxes, shape (k, 4).
+
+ Returns:
+ Tensor: The priority of gts so that gts with larger priority is
+ more likely to be assigned. Shape (k, )
+ """
+ gt_areas = bboxes_area(gt_bboxes)
+ # Rank all gt bbox areas. Smaller objects has larger priority
+ _, sort_idx = gt_areas.sort(descending=True)
+ sort_idx = sort_idx.argsort()
+ return sort_idx
+
+ def assign(self,
+ pred_instances: InstanceData,
+ gt_instances: InstanceData,
+ gt_instances_ignore: Optional[InstanceData] = None,
+ **kwargs) -> AssignResult:
+ """Assign gt to bboxes.
+
+ This method assigns gts to every prior (proposal/anchor), each prior
+ will be assigned with -1, or a semi-positive number. -1 means
+ negative sample, semi-positive number is the index (0-based) of
+ assigned gt.
+
+ Args:
+ pred_instances (:obj:`InstanceData`): Instances of model
+ predictions. It includes ``priors``, and the priors can
+ be anchors or points, or the bboxes predicted by the
+ previous stage, has shape (n, 4). The bboxes predicted by
+ the current model or stage will be named ``bboxes``,
+ ``labels``, and ``scores``, the same as the ``InstanceData``
+ in other places.
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It usually includes ``bboxes``, with shape (k, 4),
+ and ``labels``, with shape (k, ).
+ gt_instances_ignore (:obj:`InstanceData`, optional): Instances
+ to be ignored during training. It includes ``bboxes``
+ attribute data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ :obj:`AssignResult`: The assigned result. Note that shadowed_labels
+ of shape (N, 2) is also added as an `assign_result` attribute.
+ `shadowed_labels` is a tensor composed of N pairs of anchor_ind,
+ class_label], where N is the number of anchors that lie in the
+ outer region of a gt, anchor_ind is the shadowed anchor index
+ and class_label is the shadowed class label.
+
+ Example:
+ >>> from mmengine.structures import InstanceData
+ >>> self = CenterRegionAssigner(0.2, 0.2)
+ >>> pred_instances.priors = torch.Tensor([[0, 0, 10, 10],
+ ... [10, 10, 20, 20]])
+ >>> gt_instances = InstanceData()
+ >>> gt_instances.bboxes = torch.Tensor([[0, 0, 10, 10]])
+ >>> gt_instances.labels = torch.Tensor([0])
+ >>> assign_result = self.assign(pred_instances, gt_instances)
+ >>> expected_gt_inds = torch.LongTensor([1, 0])
+ >>> assert torch.all(assign_result.gt_inds == expected_gt_inds)
+ """
+ # There are in total 5 steps in the pixel assignment
+ # 1. Find core (the center region, say inner 0.2)
+ # and shadow (the relatively ourter part, say inner 0.2-0.5)
+ # regions of every gt.
+ # 2. Find all prior bboxes that lie in gt_core and gt_shadow regions
+ # 3. Assign prior bboxes in gt_core with a one-hot id of the gt in
+ # the image.
+ # 3.1. For overlapping objects, the prior bboxes in gt_core is
+ # assigned with the object with smallest area
+ # 4. Assign prior bboxes with class label according to its gt id.
+ # 4.1. Assign -1 to prior bboxes lying in shadowed gts
+ # 4.2. Assign positive prior boxes with the corresponding label
+ # 5. Find pixels lying in the shadow of an object and assign them with
+ # background label, but set the loss weight of its corresponding
+ # gt to zero.
+
+ # TODO not extract bboxes in assign.
+ gt_bboxes = gt_instances.bboxes
+ priors = pred_instances.priors
+ gt_labels = gt_instances.labels
+
+ assert priors.size(1) == 4, 'priors must have size of 4'
+ # 1. Find core positive and shadow region of every gt
+ gt_core = scale_boxes(gt_bboxes, self.pos_scale)
+ gt_shadow = scale_boxes(gt_bboxes, self.neg_scale)
+
+ # 2. Find prior bboxes that lie in gt_core and gt_shadow regions
+ prior_centers = (priors[:, 2:4] + priors[:, 0:2]) / 2
+ # The center points lie within the gt boxes
+ is_prior_in_gt = is_located_in(prior_centers, gt_bboxes)
+ # Only calculate prior and gt_core IoF. This enables small prior bboxes
+ # to match large gts
+ prior_and_gt_core_overlaps = self.iou_calculator(
+ priors, gt_core, mode='iof')
+ # The center point of effective priors should be within the gt box
+ is_prior_in_gt_core = is_prior_in_gt & (
+ prior_and_gt_core_overlaps > self.min_pos_iof) # shape (n, k)
+
+ is_prior_in_gt_shadow = (
+ self.iou_calculator(priors, gt_shadow, mode='iof') >
+ self.min_pos_iof)
+ # Rule out center effective positive pixels
+ is_prior_in_gt_shadow &= (~is_prior_in_gt_core)
+
+ num_gts, num_priors = gt_bboxes.size(0), priors.size(0)
+ if num_gts == 0 or num_priors == 0:
+ # If no gts exist, assign all pixels to negative
+ assigned_gt_ids = \
+ is_prior_in_gt_core.new_zeros((num_priors,),
+ dtype=torch.long)
+ pixels_in_gt_shadow = assigned_gt_ids.new_empty((0, 2))
+ else:
+ # Step 3: assign a one-hot gt id to each pixel, and smaller objects
+ # have high priority to assign the pixel.
+ sort_idx = self.get_gt_priorities(gt_bboxes)
+ assigned_gt_ids, pixels_in_gt_shadow = \
+ self.assign_one_hot_gt_indices(is_prior_in_gt_core,
+ is_prior_in_gt_shadow,
+ gt_priority=sort_idx)
+
+ if (gt_instances_ignore is not None
+ and gt_instances_ignore.bboxes.numel() > 0):
+ # No ground truth or boxes, return empty assignment
+ gt_bboxes_ignore = gt_instances_ignore.bboxes
+ gt_bboxes_ignore = scale_boxes(
+ gt_bboxes_ignore, scale=self.ignore_gt_scale)
+ is_prior_in_ignored_gts = is_located_in(prior_centers,
+ gt_bboxes_ignore)
+ is_prior_in_ignored_gts = is_prior_in_ignored_gts.any(dim=1)
+ assigned_gt_ids[is_prior_in_ignored_gts] = -1
+
+ # 4. Assign prior bboxes with class label according to its gt id.
+ # Default assigned label is the background (-1)
+ assigned_labels = assigned_gt_ids.new_full((num_priors, ), -1)
+ pos_inds = torch.nonzero(assigned_gt_ids > 0, as_tuple=False).squeeze()
+ if pos_inds.numel() > 0:
+ assigned_labels[pos_inds] = gt_labels[assigned_gt_ids[pos_inds] -
+ 1]
+ # 5. Find pixels lying in the shadow of an object
+ shadowed_pixel_labels = pixels_in_gt_shadow.clone()
+ if pixels_in_gt_shadow.numel() > 0:
+ pixel_idx, gt_idx =\
+ pixels_in_gt_shadow[:, 0], pixels_in_gt_shadow[:, 1]
+ assert (assigned_gt_ids[pixel_idx] != gt_idx).all(), \
+ 'Some pixels are dually assigned to ignore and gt!'
+ shadowed_pixel_labels[:, 1] = gt_labels[gt_idx - 1]
+ override = (
+ assigned_labels[pixel_idx] == shadowed_pixel_labels[:, 1])
+ if self.foreground_dominate:
+ # When a pixel is both positive and shadowed, set it as pos
+ shadowed_pixel_labels = shadowed_pixel_labels[~override]
+ else:
+ # When a pixel is both pos and shadowed, set it as shadowed
+ assigned_labels[pixel_idx[override]] = -1
+ assigned_gt_ids[pixel_idx[override]] = 0
+
+ assign_result = AssignResult(
+ num_gts, assigned_gt_ids, None, labels=assigned_labels)
+ # Add shadowed_labels as assign_result property. Shape: (num_shadow, 2)
+ assign_result.set_extra_property('shadowed_labels',
+ shadowed_pixel_labels)
+ return assign_result
+
+ def assign_one_hot_gt_indices(
+ self,
+ is_prior_in_gt_core: Tensor,
+ is_prior_in_gt_shadow: Tensor,
+ gt_priority: Optional[Tensor] = None) -> Tuple[Tensor, Tensor]:
+ """Assign only one gt index to each prior box.
+
+ Gts with large gt_priority are more likely to be assigned.
+
+ Args:
+ is_prior_in_gt_core (Tensor): Bool tensor indicating the prior
+ center is in the core area of a gt (e.g. 0-0.2).
+ Shape: (num_prior, num_gt).
+ is_prior_in_gt_shadow (Tensor): Bool tensor indicating the prior
+ center is in the shadowed area of a gt (e.g. 0.2-0.5).
+ Shape: (num_prior, num_gt).
+ gt_priority (Tensor): Priorities of gts. The gt with a higher
+ priority is more likely to be assigned to the bbox when the
+ bbox match with multiple gts. Shape: (num_gt, ).
+
+ Returns:
+ tuple: Returns (assigned_gt_inds, shadowed_gt_inds).
+
+ - assigned_gt_inds: The assigned gt index of each prior bbox \
+ (i.e. index from 1 to num_gts). Shape: (num_prior, ).
+ - shadowed_gt_inds: shadowed gt indices. It is a tensor of \
+ shape (num_ignore, 2) with first column being the shadowed prior \
+ bbox indices and the second column the shadowed gt \
+ indices (1-based).
+ """
+ num_bboxes, num_gts = is_prior_in_gt_core.shape
+
+ if gt_priority is None:
+ gt_priority = torch.arange(
+ num_gts, device=is_prior_in_gt_core.device)
+ assert gt_priority.size(0) == num_gts
+ # The bigger gt_priority, the more preferable to be assigned
+ # The assigned inds are by default 0 (background)
+ assigned_gt_inds = is_prior_in_gt_core.new_zeros((num_bboxes, ),
+ dtype=torch.long)
+ # Shadowed bboxes are assigned to be background. But the corresponding
+ # label is ignored during loss calculation, which is done through
+ # shadowed_gt_inds
+ shadowed_gt_inds = torch.nonzero(is_prior_in_gt_shadow, as_tuple=False)
+ if is_prior_in_gt_core.sum() == 0: # No gt match
+ shadowed_gt_inds[:, 1] += 1 # 1-based. For consistency issue
+ return assigned_gt_inds, shadowed_gt_inds
+
+ # The priority of each prior box and gt pair. If one prior box is
+ # matched bo multiple gts. Only the pair with the highest priority
+ # is saved
+ pair_priority = is_prior_in_gt_core.new_full((num_bboxes, num_gts),
+ -1,
+ dtype=torch.long)
+
+ # Each bbox could match with multiple gts.
+ # The following codes deal with this situation
+ # Matched bboxes (to any gt). Shape: (num_pos_anchor, )
+ inds_of_match = torch.any(is_prior_in_gt_core, dim=1)
+ # The matched gt index of each positive bbox. Length >= num_pos_anchor
+ # , since one bbox could match multiple gts
+ matched_bbox_gt_inds = torch.nonzero(
+ is_prior_in_gt_core, as_tuple=False)[:, 1]
+ # Assign priority to each bbox-gt pair.
+ pair_priority[is_prior_in_gt_core] = gt_priority[matched_bbox_gt_inds]
+ _, argmax_priority = pair_priority[inds_of_match].max(dim=1)
+ assigned_gt_inds[inds_of_match] = argmax_priority + 1 # 1-based
+ # Zero-out the assigned anchor box to filter the shadowed gt indices
+ is_prior_in_gt_core[inds_of_match, argmax_priority] = 0
+ # Concat the shadowed indices due to overlapping with that out side of
+ # effective scale. shape: (total_num_ignore, 2)
+ shadowed_gt_inds = torch.cat(
+ (shadowed_gt_inds,
+ torch.nonzero(is_prior_in_gt_core, as_tuple=False)),
+ dim=0)
+ # Change `is_prior_in_gt_core` back to keep arguments intact.
+ is_prior_in_gt_core[inds_of_match, argmax_priority] = 1
+ # 1-based shadowed gt indices, to be consistent with `assigned_gt_inds`
+ if shadowed_gt_inds.numel() > 0:
+ shadowed_gt_inds[:, 1] += 1
+ return assigned_gt_inds, shadowed_gt_inds
diff --git a/mmdet/models/task_modules/assigners/dynamic_hungarian_assigner.py b/mmdet/models/task_modules/assigners/dynamic_hungarian_assigner.py
new file mode 100644
index 0000000000000000000000000000000000000000..492eefa2dd83998621e763117cd59b44bbd094a2
--- /dev/null
+++ b/mmdet/models/task_modules/assigners/dynamic_hungarian_assigner.py
@@ -0,0 +1,210 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Optional, Union
+
+import torch
+import numpy as np
+from mmengine import ConfigDict
+from mmengine.structures import InstanceData
+from scipy.optimize import linear_sum_assignment
+from torch import Tensor
+
+from mmdet.registry import TASK_UTILS
+from .assign_result import AssignResult
+from .base_assigner import BaseAssigner
+
+
+@TASK_UTILS.register_module()
+class DynamicHungarianAssigner(BaseAssigner):
+ """Computes one-to-one matching between predictions and ground truth.
+
+ This class computes an assignment between the targets and the predictions
+ based on the costs. The costs are weighted sum of some components.
+ For DETR the costs are weighted sum of classification cost, regression L1
+ cost and regression iou cost. The targets don't include the no_object, so
+ generally there are more predictions than targets. After the one-to-one
+ matching, the un-matched are treated as backgrounds. Thus each query
+ prediction will be assigned with `0` or a positive integer indicating the
+ ground truth index:
+
+ - 0: negative sample, no assigned gt
+ - positive integer: positive sample, index (1-based) of assigned gt
+
+ Args:
+ match_costs (:obj:`ConfigDict` or dict or \
+ List[Union[:obj:`ConfigDict`, dict]]): Match cost configs.
+ """
+
+ def __init__(
+ self,
+ match_costs: Union[List[Union[dict, ConfigDict]], dict,
+ ConfigDict],
+ base_match_num: int = 1,
+ match_num: int = 1,
+ base_anomaly_factor: float = -1,
+ anomaly_factor: float = 3,
+ total_num_max: int = 300,
+ dynamic_match: bool = True,
+ normal_outlier: bool = True
+ ) -> None:
+
+ if isinstance(match_costs, dict):
+ match_costs = [match_costs]
+ elif isinstance(match_costs, list):
+ assert len(match_costs) > 0, \
+ 'match_costs must not be a empty list.'
+ self.match_num = match_num
+ self.dynamic_match = dynamic_match
+ self.anomaly_factor= anomaly_factor
+ self.base_match_num = base_match_num
+ self.base_anomaly_factor = base_anomaly_factor
+ self.total_num_max = total_num_max
+ self.match_costs = [
+ TASK_UTILS.build(match_cost) for match_cost in match_costs
+ ]
+ self.normal_outlier = normal_outlier
+ def assign(self,
+ pred_instances: InstanceData,
+ gt_instances: InstanceData,
+ img_meta: Optional[dict] = None,
+ **kwargs) -> AssignResult:
+ """Computes one-to-one matching based on the weighted costs.
+
+ This method assign each query prediction to a ground truth or
+ background. The `assigned_gt_inds` with -1 means don't care,
+ 0 means negative sample, and positive number is the index (1-based)
+ of assigned gt.
+ The assignment is done in the following steps, the order matters.
+
+ 1. assign every prediction to -1
+ 2. compute the weighted costs
+ 3. do Hungarian matching on CPU based on the costs
+ 4. assign all to 0 (background) first, then for each matched pair
+ between predictions and gts, treat this prediction as foreground
+ and assign the corresponding gt index (plus 1) to it.
+
+ Args:
+ pred_instances (:obj:`InstanceData`): Instances of model
+ predictions. It includes ``priors``, and the priors can
+ be anchors or points, or the bboxes predicted by the
+ previous stage, has shape (n, 4). The bboxes predicted by
+ the current model or stage will be named ``bboxes``,
+ ``labels``, and ``scores``, the same as the ``InstanceData``
+ in other places. It may includes ``masks``, with shape
+ (n, h, w) or (n, l).
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It usually includes ``bboxes``, with shape (k, 4),
+ ``labels``, with shape (k, ) and ``masks``, with shape
+ (k, h, w) or (k, l).
+ img_meta (dict): Image information.
+
+ Returns:
+ :obj:`AssignResult`: The assigned result.
+ """
+ assert isinstance(gt_instances.labels, Tensor)
+ num_gts, num_preds = len(gt_instances), len(pred_instances)
+ gt_labels = gt_instances.labels
+ device = gt_labels.device
+
+ # 1. assign -1 by default
+ assigned_gt_inds = torch.full((num_preds, ),
+ -1,
+ dtype=torch.long,
+ device=device)
+ assigned_labels = torch.full((num_preds, ),
+ -1,
+ dtype=torch.long,
+ device=device)
+
+ if num_gts == 0 or num_preds == 0:
+ # No ground truth or boxes, return empty assignment
+ if num_gts == 0:
+ # No ground truth, assign all to background
+ assigned_gt_inds[:] = 0
+ return AssignResult(
+ num_gts=num_gts,
+ gt_inds=assigned_gt_inds,
+ max_overlaps=None,
+ labels=assigned_labels)
+
+ # 2. compute weighted cost
+ cost_list = []
+ for match_cost in self.match_costs:
+ cost = match_cost(
+ pred_instances=pred_instances,
+ gt_instances=gt_instances,
+ img_meta=img_meta)
+ cost_list.append(cost)
+ cost = torch.stack(cost_list).sum(dim=0) # 先求900query与每个gt的cost,不同类型的cost相加
+
+ # 3. do Hungarian matching on CPU using linear_sum_assignment
+ cost = cost.detach().cpu()
+ if linear_sum_assignment is None:
+ raise ImportError('Please run "pip install scipy" '
+ 'to install scipy first.')
+
+ # lzx
+ match_preds_max = self.total_num_max #int(num_preds/3)
+ matched_row_inds_all = np.empty((0,), dtype=np.int64)
+ matched_col_inds_all = np.empty((0,), dtype=np.int64)
+ cost_max = torch.max(cost)
+ matched_row_inds, matched_col_inds = linear_sum_assignment(cost)
+ matched_row_inds_all = np.concatenate((matched_row_inds_all, matched_row_inds))
+ matched_col_inds_all = np.concatenate((matched_col_inds_all, matched_col_inds))
+ th0 = None
+ if self.match_num>1:
+ if self.normal_outlier:
+ th = torch.mean(cost, axis=0) - self.anomaly_factor * torch.std(cost, axis=0)
+ # th = torch.mean(cost) - self.anomaly_factor * torch.std(cost)
+ th = th.detach().cpu().numpy()
+ if self.base_anomaly_factor>=0:
+ # th0 = torch.mean(cost, axis=0) - self.base_anomaly_factor * torch.std(cost, axis=0)
+ th0 = torch.mean(cost) - self.base_anomaly_factor * torch.std(cost)
+ th0 = th0.detach().cpu().numpy()
+ else:
+ q1 = np.percentile(cost, 25, axis=0)
+ q3 = np.percentile(cost, 75, axis=0)
+ iqr = q3 - q1
+ th = q1 - self.anomaly_factor * iqr
+ if self.base_anomaly_factor>0:
+ th0 = q1 - self.base_anomaly_factor * iqr
+ # has_positive = np.any(th > 0)
+ for ii in range(2, self.match_num+1):
+ if len(matched_col_inds_all) < match_preds_max:
+ cost[matched_row_inds,:] = cost_max+1
+ matched_row_inds, matched_col_inds = linear_sum_assignment(cost)
+ if self.dynamic_match:
+ if ii<=self.base_match_num and ii > 1 and th0 is not None :
+ if th0 is not None :
+ matched_costs = cost[matched_row_inds, matched_col_inds]
+ filtered_inds = np.where(matched_costs.detach().cpu().numpy() < th0)
+ matched_row_inds = matched_row_inds[filtered_inds]
+ matched_col_inds = matched_col_inds[filtered_inds]
+ else:
+ matched_costs = cost[matched_row_inds, matched_col_inds]
+ filtered_inds = np.where(matched_costs.detach().cpu().numpy() < th)
+ # if len(filtered_inds[0])>0:
+ # print(ii,"/",self.match_num, "object",len(matched_row_inds),'bbox',len(filtered_inds[0]))
+ # 根据筛选后的索引获取对应的matched_row_inds和matched_col_inds
+ matched_row_inds = matched_row_inds[filtered_inds]
+ matched_col_inds = matched_col_inds[filtered_inds]
+ if len(matched_row_inds) == 0:
+ break
+ if (len(matched_row_inds)+len(matched_col_inds_all))>match_preds_max:
+ need_inds_num = len(matched_row_inds)+len(matched_col_inds_all)-match_preds_max
+ matched_row_inds = matched_row_inds[:need_inds_num]
+ matched_col_inds = matched_col_inds[:need_inds_num]
+ matched_row_inds_all = np.concatenate((matched_row_inds_all, matched_row_inds))
+ matched_col_inds_all = np.concatenate((matched_col_inds_all, matched_col_inds))
+ matched_row_inds = torch.from_numpy(matched_row_inds_all).to(device)
+ matched_col_inds = torch.from_numpy(matched_col_inds_all).to(device)
+ # 4. assign backgrounds and foregrounds
+ # assign all indices to backgrounds first
+ assigned_gt_inds[:] = 0
+ # assign foregrounds based on matching results
+ assigned_gt_inds[matched_row_inds] = matched_col_inds + 1
+ assigned_labels[matched_row_inds] = gt_labels[matched_col_inds]
+ return AssignResult(
+ num_gts=num_gts,
+ gt_inds=assigned_gt_inds,
+ max_overlaps=None,
+ labels=assigned_labels)
diff --git a/mmdet/models/task_modules/assigners/dynamic_hungarian_assignerV1.py b/mmdet/models/task_modules/assigners/dynamic_hungarian_assignerV1.py
new file mode 100644
index 0000000000000000000000000000000000000000..80ac7b579ef4d9c743a324838ab603aa32f49613
--- /dev/null
+++ b/mmdet/models/task_modules/assigners/dynamic_hungarian_assignerV1.py
@@ -0,0 +1,195 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Optional, Union
+
+import torch
+import numpy as np
+from mmengine import ConfigDict
+from mmengine.structures import InstanceData
+from scipy.optimize import linear_sum_assignment
+from torch import Tensor
+
+from mmdet.registry import TASK_UTILS
+from .assign_result import AssignResult
+from .base_assigner import BaseAssigner
+
+
+@TASK_UTILS.register_module()
+class DynamicHungarianAssigner(BaseAssigner):
+ """Computes one-to-one matching between predictions and ground truth.
+
+ This class computes an assignment between the targets and the predictions
+ based on the costs. The costs are weighted sum of some components.
+ For DETR the costs are weighted sum of classification cost, regression L1
+ cost and regression iou cost. The targets don't include the no_object, so
+ generally there are more predictions than targets. After the one-to-one
+ matching, the un-matched are treated as backgrounds. Thus each query
+ prediction will be assigned with `0` or a positive integer indicating the
+ ground truth index:
+
+ - 0: negative sample, no assigned gt
+ - positive integer: positive sample, index (1-based) of assigned gt
+
+ Args:
+ match_costs (:obj:`ConfigDict` or dict or \
+ List[Union[:obj:`ConfigDict`, dict]]): Match cost configs.
+ """
+
+ def __init__(
+ self,
+ match_costs: Union[List[Union[dict, ConfigDict]], dict,
+ ConfigDict],
+ match_nums: int = 1,
+ anomaly_factor: float = 3,
+ dynamic_match: bool = True,
+ base_match_num: int = 1,
+ normal_outlier: bool = True
+ ) -> None:
+
+ if isinstance(match_costs, dict):
+ match_costs = [match_costs]
+ elif isinstance(match_costs, list):
+ assert len(match_costs) > 0, \
+ 'match_costs must not be a empty list.'
+ self.match_nums = match_nums
+ self.dynamic_match = dynamic_match
+ self.anomaly_factor= anomaly_factor
+ self.base_match_num = base_match_num
+ self.match_costs = [
+ TASK_UTILS.build(match_cost) for match_cost in match_costs
+ ]
+ self.normal_outlier = normal_outlier
+ def assign(self,
+ pred_instances: InstanceData,
+ gt_instances: InstanceData,
+ img_meta: Optional[dict] = None,
+ **kwargs) -> AssignResult:
+ """Computes one-to-one matching based on the weighted costs.
+
+ This method assign each query prediction to a ground truth or
+ background. The `assigned_gt_inds` with -1 means don't care,
+ 0 means negative sample, and positive number is the index (1-based)
+ of assigned gt.
+ The assignment is done in the following steps, the order matters.
+
+ 1. assign every prediction to -1
+ 2. compute the weighted costs
+ 3. do Hungarian matching on CPU based on the costs
+ 4. assign all to 0 (background) first, then for each matched pair
+ between predictions and gts, treat this prediction as foreground
+ and assign the corresponding gt index (plus 1) to it.
+
+ Args:
+ pred_instances (:obj:`InstanceData`): Instances of model
+ predictions. It includes ``priors``, and the priors can
+ be anchors or points, or the bboxes predicted by the
+ previous stage, has shape (n, 4). The bboxes predicted by
+ the current model or stage will be named ``bboxes``,
+ ``labels``, and ``scores``, the same as the ``InstanceData``
+ in other places. It may includes ``masks``, with shape
+ (n, h, w) or (n, l).
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It usually includes ``bboxes``, with shape (k, 4),
+ ``labels``, with shape (k, ) and ``masks``, with shape
+ (k, h, w) or (k, l).
+ img_meta (dict): Image information.
+
+ Returns:
+ :obj:`AssignResult`: The assigned result.
+ """
+ assert isinstance(gt_instances.labels, Tensor)
+ num_gts, num_preds = len(gt_instances), len(pred_instances)
+ gt_labels = gt_instances.labels
+ device = gt_labels.device
+
+ # 1. assign -1 by default
+ assigned_gt_inds = torch.full((num_preds, ),
+ -1,
+ dtype=torch.long,
+ device=device)
+ assigned_labels = torch.full((num_preds, ),
+ -1,
+ dtype=torch.long,
+ device=device)
+
+ if num_gts == 0 or num_preds == 0:
+ # No ground truth or boxes, return empty assignment
+ if num_gts == 0:
+ # No ground truth, assign all to background
+ assigned_gt_inds[:] = 0
+ return AssignResult(
+ num_gts=num_gts,
+ gt_inds=assigned_gt_inds,
+ max_overlaps=None,
+ labels=assigned_labels)
+
+ # 2. compute weighted cost
+ cost_list = []
+ for match_cost in self.match_costs:
+ cost = match_cost(
+ pred_instances=pred_instances,
+ gt_instances=gt_instances,
+ img_meta=img_meta)
+ cost_list.append(cost)
+ cost = torch.stack(cost_list).sum(dim=0) # 先求900query与每个gt的cost,不同类型的cost相加
+
+ # 3. do Hungarian matching on CPU using linear_sum_assignment
+ cost = cost.detach().cpu()
+ if linear_sum_assignment is None:
+ raise ImportError('Please run "pip install scipy" '
+ 'to install scipy first.')
+
+ # lzx
+ match_preds_max = 100 # int(num_preds/3)
+ matched_row_inds_all = np.empty((0,), dtype=np.int64)
+ matched_col_inds_all = np.empty((0,), dtype=np.int64)
+ cost_max = torch.max(cost)
+ matched_row_inds, matched_col_inds = linear_sum_assignment(cost)
+ matched_row_inds_all = np.concatenate((matched_row_inds_all, matched_row_inds))
+ matched_col_inds_all = np.concatenate((matched_col_inds_all, matched_col_inds))
+
+ if self.match_nums>1:
+ if self.normal_outlier:
+ # th = torch.mean(cost, axis=0) - self.anomaly_factor * torch.std(cost, axis=0)
+ th = torch.mean(cost) - self.anomaly_factor * torch.std(cost)
+ th = th.detach().cpu().numpy()
+ else:
+ q1 = np.percentile(cost, 25, axis=0)
+ q3 = np.percentile(cost, 75, axis=0)
+ iqr = q3 - q1
+ th = q1 - self.anomaly_factor * iqr
+ # has_positive = np.any(th > 0)
+ for ii in range(2, self.match_nums+1):
+ if len(matched_col_inds_all) < match_preds_max:
+ cost[matched_row_inds,:] = cost_max+1
+ matched_row_inds, matched_col_inds = linear_sum_assignment(cost)
+ if ii>self.base_match_num:
+ if self.dynamic_match:
+ matched_costs = cost[matched_row_inds, matched_col_inds]
+ filtered_inds = np.where(matched_costs.detach().cpu().numpy() < th)
+ if len(filtered_inds[0])>0:
+ print(ii+1,"/",self.match_nums, "object",len(matched_row_inds),'bbox',len(filtered_inds[0]))
+ # 根据筛选后的索引获取对应的matched_row_inds和matched_col_inds
+ matched_row_inds = matched_row_inds[filtered_inds]
+ matched_col_inds = matched_col_inds[filtered_inds]
+ if (len(matched_row_inds)+len(matched_col_inds_all))>match_preds_max:
+ need_inds_num = len(matched_row_inds)+len(matched_col_inds_all)-match_preds_max
+ matched_row_inds = matched_row_inds[:need_inds_num]
+ matched_col_inds = matched_col_inds[:need_inds_num]
+
+ matched_row_inds_all = np.concatenate((matched_row_inds_all, matched_row_inds))
+ matched_col_inds_all = np.concatenate((matched_col_inds_all, matched_col_inds))
+
+ matched_row_inds = torch.from_numpy(matched_row_inds_all).to(device)
+ matched_col_inds = torch.from_numpy(matched_col_inds_all).to(device)
+
+ # 4. assign backgrounds and foregrounds
+ # assign all indices to backgrounds first
+ assigned_gt_inds[:] = 0
+ # assign foregrounds based on matching results
+ assigned_gt_inds[matched_row_inds] = matched_col_inds + 1
+ assigned_labels[matched_row_inds] = gt_labels[matched_col_inds]
+ return AssignResult(
+ num_gts=num_gts,
+ gt_inds=assigned_gt_inds,
+ max_overlaps=None,
+ labels=assigned_labels)
diff --git a/mmdet/models/task_modules/assigners/dynamic_iou_hungarian_assigner.py b/mmdet/models/task_modules/assigners/dynamic_iou_hungarian_assigner.py
new file mode 100644
index 0000000000000000000000000000000000000000..fa1eedca12da6dec9ffb5d81fe38cc80ef6c7483
--- /dev/null
+++ b/mmdet/models/task_modules/assigners/dynamic_iou_hungarian_assigner.py
@@ -0,0 +1,193 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Optional, Union
+
+import torch
+import numpy as np
+from mmengine import ConfigDict
+from mmengine.structures import InstanceData
+from scipy.optimize import linear_sum_assignment
+from torch import Tensor
+
+from mmdet.registry import TASK_UTILS
+from .assign_result import AssignResult
+from .base_assigner import BaseAssigner
+
+
+@TASK_UTILS.register_module()
+class DynamicIOUHungarianAssigner(BaseAssigner):
+ """Computes one-to-one matching between predictions and ground truth.
+
+ This class computes an assignment between the targets and the predictions
+ based on the costs. The costs are weighted sum of some components.
+ For DETR the costs are weighted sum of classification cost, regression L1
+ cost and regression iou cost. The targets don't include the no_object, so
+ generally there are more predictions than targets. After the one-to-one
+ matching, the un-matched are treated as backgrounds. Thus each query
+ prediction will be assigned with `0` or a positive integer indicating the
+ ground truth index:
+
+ - 0: negative sample, no assigned gt
+ - positive integer: positive sample, index (1-based) of assigned gt
+
+ Args:
+ match_costs (:obj:`ConfigDict` or dict or \
+ List[Union[:obj:`ConfigDict`, dict]]): Match cost configs.
+ """
+
+ def __init__(
+ self,
+ match_costs: Union[List[Union[dict, ConfigDict]], dict,
+ ConfigDict],
+ base_match_num: int = 1,
+ match_num: int = 1,
+ iou_loss_th: float =0.05,
+ total_num_max: int = 100,
+ dynamic_match: bool = True,
+ ) -> None:
+
+ if isinstance(match_costs, dict):
+ match_costs = [match_costs]
+ elif isinstance(match_costs, list):
+ assert len(match_costs) > 0, \
+ 'match_costs must not be a empty list.'
+ self.match_num = match_num
+ self.dynamic_match = dynamic_match
+ self.base_match_num = base_match_num
+ self.iou_loss_th =iou_loss_th
+ self.total_num_max = total_num_max
+ self.match_costs = [
+ TASK_UTILS.build(match_cost) for match_cost in match_costs
+ ]
+
+ def assign(self,
+ pred_instances: InstanceData,
+ gt_instances: InstanceData,
+ img_meta: Optional[dict] = None,
+ **kwargs) -> AssignResult:
+ """Computes one-to-one matching based on the weighted costs.
+
+ This method assign each query prediction to a ground truth or
+ background. The `assigned_gt_inds` with -1 means don't care,
+ 0 means negative sample, and positive number is the index (1-based)
+ of assigned gt.
+ The assignment is done in the following steps, the order matters.
+
+ 1. assign every prediction to -1
+ 2. compute the weighted costs
+ 3. do Hungarian matching on CPU based on the costs
+ 4. assign all to 0 (background) first, then for each matched pair
+ between predictions and gts, treat this prediction as foreground
+ and assign the corresponding gt index (plus 1) to it.
+
+ Args:
+ pred_instances (:obj:`InstanceData`): Instances of model
+ predictions. It includes ``priors``, and the priors can
+ be anchors or points, or the bboxes predicted by the
+ previous stage, has shape (n, 4). The bboxes predicted by
+ the current model or stage will be named ``bboxes``,
+ ``labels``, and ``scores``, the same as the ``InstanceData``
+ in other places. It may includes ``masks``, with shape
+ (n, h, w) or (n, l).
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It usually includes ``bboxes``, with shape (k, 4),
+ ``labels``, with shape (k, ) and ``masks``, with shape
+ (k, h, w) or (k, l).
+ img_meta (dict): Image information.
+
+ Returns:
+ :obj:`AssignResult`: The assigned result.
+ """
+ assert isinstance(gt_instances.labels, Tensor)
+ num_gts, num_preds = len(gt_instances), len(pred_instances)
+ gt_labels = gt_instances.labels
+ device = gt_labels.device
+
+ # 1. assign -1 by default
+ assigned_gt_inds = torch.full((num_preds, ),
+ -1,
+ dtype=torch.long,
+ device=device)
+ assigned_labels = torch.full((num_preds, ),
+ -1,
+ dtype=torch.long,
+ device=device)
+
+ if num_gts == 0 or num_preds == 0:
+ # No ground truth or boxes, return empty assignment
+ if num_gts == 0:
+ # No ground truth, assign all to background
+ assigned_gt_inds[:] = 0
+ return AssignResult(
+ num_gts=num_gts,
+ gt_inds=assigned_gt_inds,
+ max_overlaps=None,
+ labels=assigned_labels)
+
+ # 2. compute weighted cost
+ cost_list = []
+ for match_cost in self.match_costs:
+ cost = match_cost(
+ pred_instances=pred_instances,
+ gt_instances=gt_instances,
+ img_meta=img_meta)
+ cost_list.append(cost)
+ cost1 = cost_list[:-1]
+ cost1 = torch.stack(cost1).sum(dim=0)
+ cost2 = cost_list[-1]
+
+ # cost = torch.stack(cost_list).sum(dim=0) # 先求900query与每个gt的cost,不同类型的cost相加
+
+ # 3. do Hungarian matching on CPU using linear_sum_assignment
+ # cost = cost.detach().cpu()
+ cost1 =cost1.detach().cpu()
+ cost2 =cost2.detach().cpu()
+ cost_max1 = torch.max(cost1)
+ cost_max2 = torch.max(cost2)
+ if linear_sum_assignment is None:
+ raise ImportError('Please run "pip install scipy" '
+ 'to install scipy first.')
+
+ # lzx
+ match_preds_max = self.total_num_max #int(num_preds/3)
+ matched_row_inds_all = np.empty((0,), dtype=np.int64)
+ matched_col_inds_all = np.empty((0,), dtype=np.int64)
+
+ matched_row_inds, matched_col_inds = linear_sum_assignment(cost1)
+ matched_row_inds_all = np.concatenate((matched_row_inds_all, matched_row_inds))
+ matched_col_inds_all = np.concatenate((matched_col_inds_all, matched_col_inds))
+ if self.match_num>1:
+ th =self.iou_loss_th
+ # has_positive = np.any(th > 0)
+ for ii in range(2, self.match_num+1):
+ if len(matched_col_inds_all) < match_preds_max:
+ cost1[matched_row_inds,:] = cost_max1
+ cost2[matched_row_inds, :] = cost_max2
+ if self.dynamic_match and ii>self.base_match_num:
+ matched_row_inds, matched_col_inds = linear_sum_assignment(cost2)
+ matched_costs = cost2[matched_row_inds, matched_col_inds]
+ filtered_inds = np.where(matched_costs.detach().cpu().numpy() < th)
+ matched_row_inds = matched_row_inds[filtered_inds]
+ matched_col_inds = matched_col_inds[filtered_inds]
+ if len(matched_row_inds) == 0:
+ break
+ else:
+ matched_row_inds, matched_col_inds = linear_sum_assignment(cost1)
+ if (len(matched_row_inds) + len(matched_col_inds_all)) > match_preds_max:
+ need_inds_num = len(matched_row_inds) + len(matched_col_inds_all) - match_preds_max
+ matched_row_inds = matched_row_inds[:need_inds_num]
+ matched_col_inds = matched_col_inds[:need_inds_num]
+ matched_row_inds_all = np.concatenate((matched_row_inds_all, matched_row_inds))
+ matched_col_inds_all = np.concatenate((matched_col_inds_all, matched_col_inds))
+ matched_row_inds = torch.from_numpy(matched_row_inds_all).to(device)
+ matched_col_inds = torch.from_numpy(matched_col_inds_all).to(device)
+ # 4. assign backgrounds and foregrounds
+ # assign all indices to backgrounds first
+ assigned_gt_inds[:] = 0
+ # assign foregrounds based on matching results
+ assigned_gt_inds[matched_row_inds] = matched_col_inds + 1
+ assigned_labels[matched_row_inds] = gt_labels[matched_col_inds]
+ return AssignResult(
+ num_gts=num_gts,
+ gt_inds=assigned_gt_inds,
+ max_overlaps=None,
+ labels=assigned_labels)
diff --git a/mmdet/models/task_modules/assigners/dynamic_iou_hungarian_assignerV1.py b/mmdet/models/task_modules/assigners/dynamic_iou_hungarian_assignerV1.py
new file mode 100644
index 0000000000000000000000000000000000000000..793350d4cce7a63919e61565b66d07264377c756
--- /dev/null
+++ b/mmdet/models/task_modules/assigners/dynamic_iou_hungarian_assignerV1.py
@@ -0,0 +1,194 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Optional, Union
+
+import torch
+import numpy as np
+from mmengine import ConfigDict
+from mmengine.structures import InstanceData
+from scipy.optimize import linear_sum_assignment
+from torch import Tensor
+
+from mmdet.registry import TASK_UTILS
+from .assign_result import AssignResult
+from .base_assigner import BaseAssigner
+
+
+@TASK_UTILS.register_module()
+class DynamicIOUHungarianAssigner(BaseAssigner):
+ """Computes one-to-one matching between predictions and ground truth.
+
+ This class computes an assignment between the targets and the predictions
+ based on the costs. The costs are weighted sum of some components.
+ For DETR the costs are weighted sum of classification cost, regression L1
+ cost and regression iou cost. The targets don't include the no_object, so
+ generally there are more predictions than targets. After the one-to-one
+ matching, the un-matched are treated as backgrounds. Thus each query
+ prediction will be assigned with `0` or a positive integer indicating the
+ ground truth index:
+
+ - 0: negative sample, no assigned gt
+ - positive integer: positive sample, index (1-based) of assigned gt
+
+ Args:
+ match_costs (:obj:`ConfigDict` or dict or \
+ List[Union[:obj:`ConfigDict`, dict]]): Match cost configs.
+ """
+
+ def __init__(
+ self,
+ match_costs: Union[List[Union[dict, ConfigDict]], dict,
+ ConfigDict],
+ base_match_num: int = 1,
+ match_num: int = 1,
+ iou_loss_th: float =0.05,
+ total_num_max: int = 100,
+ dynamic_match: bool = True,
+ ) -> None:
+
+ if isinstance(match_costs, dict):
+ match_costs = [match_costs]
+ elif isinstance(match_costs, list):
+ assert len(match_costs) > 0, \
+ 'match_costs must not be a empty list.'
+ self.match_num = match_num
+ self.dynamic_match = dynamic_match
+ self.base_match_num = base_match_num
+ self.iou_loss_th =iou_loss_th
+ self.total_num_max = total_num_max
+ self.match_costs = [
+ TASK_UTILS.build(match_cost) for match_cost in match_costs
+ ]
+
+ def assign(self,
+ pred_instances: InstanceData,
+ gt_instances: InstanceData,
+ img_meta: Optional[dict] = None,
+ **kwargs) -> AssignResult:
+ """Computes one-to-one matching based on the weighted costs.
+
+ This method assign each query prediction to a ground truth or
+ background. The `assigned_gt_inds` with -1 means don't care,
+ 0 means negative sample, and positive number is the index (1-based)
+ of assigned gt.
+ The assignment is done in the following steps, the order matters.
+
+ 1. assign every prediction to -1
+ 2. compute the weighted costs
+ 3. do Hungarian matching on CPU based on the costs
+ 4. assign all to 0 (background) first, then for each matched pair
+ between predictions and gts, treat this prediction as foreground
+ and assign the corresponding gt index (plus 1) to it.
+
+ Args:
+ pred_instances (:obj:`InstanceData`): Instances of model
+ predictions. It includes ``priors``, and the priors can
+ be anchors or points, or the bboxes predicted by the
+ previous stage, has shape (n, 4). The bboxes predicted by
+ the current model or stage will be named ``bboxes``,
+ ``labels``, and ``scores``, the same as the ``InstanceData``
+ in other places. It may includes ``masks``, with shape
+ (n, h, w) or (n, l).
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It usually includes ``bboxes``, with shape (k, 4),
+ ``labels``, with shape (k, ) and ``masks``, with shape
+ (k, h, w) or (k, l).
+ img_meta (dict): Image information.
+
+ Returns:
+ :obj:`AssignResult`: The assigned result.
+ """
+ assert isinstance(gt_instances.labels, Tensor)
+ num_gts, num_preds = len(gt_instances), len(pred_instances)
+ gt_labels = gt_instances.labels
+ device = gt_labels.device
+
+ # 1. assign -1 by default
+ assigned_gt_inds = torch.full((num_preds, ),
+ -1,
+ dtype=torch.long,
+ device=device)
+ assigned_labels = torch.full((num_preds, ),
+ -1,
+ dtype=torch.long,
+ device=device)
+
+ if num_gts == 0 or num_preds == 0:
+ # No ground truth or boxes, return empty assignment
+ if num_gts == 0:
+ # No ground truth, assign all to background
+ assigned_gt_inds[:] = 0
+ return AssignResult(
+ num_gts=num_gts,
+ gt_inds=assigned_gt_inds,
+ max_overlaps=None,
+ labels=assigned_labels)
+
+ # 2. compute weighted cost
+ cost_list = []
+ for match_cost in self.match_costs:
+ cost = match_cost(
+ pred_instances=pred_instances,
+ gt_instances=gt_instances,
+ img_meta=img_meta)
+ cost_list.append(cost)
+
+ cost = torch.stack(cost_list).sum(dim=0) # 先求900query与每个gt的cost,不同类型的cost相加
+
+ # 3. do Hungarian matching on CPU using linear_sum_assignment
+ cost = cost.detach().cpu()
+ if linear_sum_assignment is None:
+ raise ImportError('Please run "pip install scipy" '
+ 'to install scipy first.')
+
+ # lzx
+ match_preds_max = self.total_num_max #int(num_preds/3)
+ matched_row_inds_all = np.empty((0,), dtype=np.int64)
+ matched_col_inds_all = np.empty((0,), dtype=np.int64)
+ cost_max = torch.max(cost)
+ matched_row_inds, matched_col_inds = linear_sum_assignment(cost)
+ matched_row_inds_all = np.concatenate((matched_row_inds_all, matched_row_inds))
+ matched_col_inds_all = np.concatenate((matched_col_inds_all, matched_col_inds))
+ th0 = None
+ if self.match_num>1:
+ th =self.iou_loss_th
+ # has_positive = np.any(th > 0)
+ for ii in range(2, self.match_num+1):
+ if len(matched_col_inds_all) < match_preds_max:
+ cost[matched_row_inds,:] = cost_max+1
+ matched_row_inds, matched_col_inds = linear_sum_assignment(cost)
+ if self.dynamic_match:
+ if ii<=self.base_match_num and ii > 1 and th0 is not None :
+ if th0 is not None :
+ matched_costs = cost[matched_row_inds, matched_col_inds]
+ filtered_inds = np.where(matched_costs.detach().cpu().numpy() < th0)
+ matched_row_inds = matched_row_inds[filtered_inds]
+ matched_col_inds = matched_col_inds[filtered_inds]
+ else:
+ matched_costs = cost[matched_row_inds, matched_col_inds]
+ filtered_inds = np.where(matched_costs.detach().cpu().numpy() < th)
+ # if len(filtered_inds[0])>0:
+ # print(ii,"/",self.match_num, "object",len(matched_row_inds),'bbox',len(filtered_inds[0]))
+ # 根据筛选后的索引获取对应的matched_row_inds和matched_col_inds
+ matched_row_inds = matched_row_inds[filtered_inds]
+ matched_col_inds = matched_col_inds[filtered_inds]
+ if len(matched_row_inds) == 0:
+ break
+ if (len(matched_row_inds)+len(matched_col_inds_all))>match_preds_max:
+ need_inds_num = len(matched_row_inds)+len(matched_col_inds_all)-match_preds_max
+ matched_row_inds = matched_row_inds[:need_inds_num]
+ matched_col_inds = matched_col_inds[:need_inds_num]
+ matched_row_inds_all = np.concatenate((matched_row_inds_all, matched_row_inds))
+ matched_col_inds_all = np.concatenate((matched_col_inds_all, matched_col_inds))
+ matched_row_inds = torch.from_numpy(matched_row_inds_all).to(device)
+ matched_col_inds = torch.from_numpy(matched_col_inds_all).to(device)
+ # 4. assign backgrounds and foregrounds
+ # assign all indices to backgrounds first
+ assigned_gt_inds[:] = 0
+ # assign foregrounds based on matching results
+ assigned_gt_inds[matched_row_inds] = matched_col_inds + 1
+ assigned_labels[matched_row_inds] = gt_labels[matched_col_inds]
+ return AssignResult(
+ num_gts=num_gts,
+ gt_inds=assigned_gt_inds,
+ max_overlaps=None,
+ labels=assigned_labels)
diff --git a/mmdet/models/task_modules/assigners/dynamic_iou_hungarian_assignerV2.py b/mmdet/models/task_modules/assigners/dynamic_iou_hungarian_assignerV2.py
new file mode 100644
index 0000000000000000000000000000000000000000..6e481518c60795a041613490c50a262e7034bc36
--- /dev/null
+++ b/mmdet/models/task_modules/assigners/dynamic_iou_hungarian_assignerV2.py
@@ -0,0 +1,192 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Optional, Union
+
+import torch
+import numpy as np
+from mmengine import ConfigDict
+from mmengine.structures import InstanceData
+from scipy.optimize import linear_sum_assignment
+from torch import Tensor
+
+from mmdet.registry import TASK_UTILS
+from .assign_result import AssignResult
+from .base_assigner import BaseAssigner
+
+
+@TASK_UTILS.register_module()
+class DynamicIOUHungarianAssigner(BaseAssigner):
+ """Computes one-to-one matching between predictions and ground truth.
+
+ This class computes an assignment between the targets and the predictions
+ based on the costs. The costs are weighted sum of some components.
+ For DETR the costs are weighted sum of classification cost, regression L1
+ cost and regression iou cost. The targets don't include the no_object, so
+ generally there are more predictions than targets. After the one-to-one
+ matching, the un-matched are treated as backgrounds. Thus each query
+ prediction will be assigned with `0` or a positive integer indicating the
+ ground truth index:
+
+ - 0: negative sample, no assigned gt
+ - positive integer: positive sample, index (1-based) of assigned gt
+
+ Args:
+ match_costs (:obj:`ConfigDict` or dict or \
+ List[Union[:obj:`ConfigDict`, dict]]): Match cost configs.
+ """
+
+ def __init__(
+ self,
+ match_costs: Union[List[Union[dict, ConfigDict]], dict,
+ ConfigDict],
+ base_match_num: int = 1,
+ match_num: int = 1,
+ iou_loss_th: float =0.05,
+ total_num_max: int = 100,
+ dynamic_match: bool = True,
+ ) -> None:
+
+ if isinstance(match_costs, dict):
+ match_costs = [match_costs]
+ elif isinstance(match_costs, list):
+ assert len(match_costs) > 0, \
+ 'match_costs must not be a empty list.'
+ self.match_num = match_num
+ self.dynamic_match = dynamic_match
+ self.base_match_num = base_match_num
+ self.iou_loss_th =iou_loss_th
+ self.total_num_max = total_num_max
+ self.match_costs = [
+ TASK_UTILS.build(match_cost) for match_cost in match_costs
+ ]
+
+ def assign(self,
+ pred_instances: InstanceData,
+ gt_instances: InstanceData,
+ img_meta: Optional[dict] = None,
+ **kwargs) -> AssignResult:
+ """Computes one-to-one matching based on the weighted costs.
+
+ This method assign each query prediction to a ground truth or
+ background. The `assigned_gt_inds` with -1 means don't care,
+ 0 means negative sample, and positive number is the index (1-based)
+ of assigned gt.
+ The assignment is done in the following steps, the order matters.
+
+ 1. assign every prediction to -1
+ 2. compute the weighted costs
+ 3. do Hungarian matching on CPU based on the costs
+ 4. assign all to 0 (background) first, then for each matched pair
+ between predictions and gts, treat this prediction as foreground
+ and assign the corresponding gt index (plus 1) to it.
+
+ Args:
+ pred_instances (:obj:`InstanceData`): Instances of model
+ predictions. It includes ``priors``, and the priors can
+ be anchors or points, or the bboxes predicted by the
+ previous stage, has shape (n, 4). The bboxes predicted by
+ the current model or stage will be named ``bboxes``,
+ ``labels``, and ``scores``, the same as the ``InstanceData``
+ in other places. It may includes ``masks``, with shape
+ (n, h, w) or (n, l).
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It usually includes ``bboxes``, with shape (k, 4),
+ ``labels``, with shape (k, ) and ``masks``, with shape
+ (k, h, w) or (k, l).
+ img_meta (dict): Image information.
+
+ Returns:
+ :obj:`AssignResult`: The assigned result.
+ """
+ assert isinstance(gt_instances.labels, Tensor)
+ num_gts, num_preds = len(gt_instances), len(pred_instances)
+ gt_labels = gt_instances.labels
+ device = gt_labels.device
+
+ # 1. assign -1 by default
+ assigned_gt_inds = torch.full((num_preds, ),
+ -1,
+ dtype=torch.long,
+ device=device)
+ assigned_labels = torch.full((num_preds, ),
+ -1,
+ dtype=torch.long,
+ device=device)
+
+ if num_gts == 0 or num_preds == 0:
+ # No ground truth or boxes, return empty assignment
+ if num_gts == 0:
+ # No ground truth, assign all to background
+ assigned_gt_inds[:] = 0
+ return AssignResult(
+ num_gts=num_gts,
+ gt_inds=assigned_gt_inds,
+ max_overlaps=None,
+ labels=assigned_labels)
+
+ # 2. compute weighted cost
+ cost_list = []
+ for match_cost in self.match_costs:
+ cost = match_cost(
+ pred_instances=pred_instances,
+ gt_instances=gt_instances,
+ img_meta=img_meta)
+ cost_list.append(cost)
+ cost1 = cost_list[0]
+ cost2 = cost_list[1]
+
+ # cost = torch.stack(cost_list).sum(dim=0) # 先求900query与每个gt的cost,不同类型的cost相加
+
+ # 3. do Hungarian matching on CPU using linear_sum_assignment
+ # cost = cost.detach().cpu()
+ cost1 =cost1.detach().cpu()
+ cost2 =cost2.detach().cpu()
+ cost_max1 = torch.max(cost1)
+ cost_max2 = torch.max(cost2)
+ if linear_sum_assignment is None:
+ raise ImportError('Please run "pip install scipy" '
+ 'to install scipy first.')
+
+ # lzx
+ match_preds_max = self.total_num_max #int(num_preds/3)
+ matched_row_inds_all = np.empty((0,), dtype=np.int64)
+ matched_col_inds_all = np.empty((0,), dtype=np.int64)
+
+ matched_row_inds, matched_col_inds = linear_sum_assignment(cost1)
+ matched_row_inds_all = np.concatenate((matched_row_inds_all, matched_row_inds))
+ matched_col_inds_all = np.concatenate((matched_col_inds_all, matched_col_inds))
+ if self.match_num>1:
+ th =self.iou_loss_th
+ # has_positive = np.any(th > 0)
+ for ii in range(2, self.match_num+1):
+ if len(matched_col_inds_all) < match_preds_max:
+ cost1[matched_row_inds,:] = cost_max1
+ cost2[matched_row_inds, :] = cost_max2
+ if self.dynamic_match and ii>self.base_match_num:
+ matched_row_inds, matched_col_inds = linear_sum_assignment(cost2)
+ matched_costs = cost2[matched_row_inds, matched_col_inds]
+ filtered_inds = np.where(matched_costs.detach().cpu().numpy() < th)
+ matched_row_inds = matched_row_inds[filtered_inds]
+ matched_col_inds = matched_col_inds[filtered_inds]
+ if len(matched_row_inds) == 0:
+ break
+ else:
+ matched_row_inds, matched_col_inds = linear_sum_assignment(cost1)
+ if (len(matched_row_inds) + len(matched_col_inds_all)) > match_preds_max:
+ need_inds_num = len(matched_row_inds) + len(matched_col_inds_all) - match_preds_max
+ matched_row_inds = matched_row_inds[:need_inds_num]
+ matched_col_inds = matched_col_inds[:need_inds_num]
+ matched_row_inds_all = np.concatenate((matched_row_inds_all, matched_row_inds))
+ matched_col_inds_all = np.concatenate((matched_col_inds_all, matched_col_inds))
+ matched_row_inds = torch.from_numpy(matched_row_inds_all).to(device)
+ matched_col_inds = torch.from_numpy(matched_col_inds_all).to(device)
+ # 4. assign backgrounds and foregrounds
+ # assign all indices to backgrounds first
+ assigned_gt_inds[:] = 0
+ # assign foregrounds based on matching results
+ assigned_gt_inds[matched_row_inds] = matched_col_inds + 1
+ assigned_labels[matched_row_inds] = gt_labels[matched_col_inds]
+ return AssignResult(
+ num_gts=num_gts,
+ gt_inds=assigned_gt_inds,
+ max_overlaps=None,
+ labels=assigned_labels)
diff --git a/mmdet/models/task_modules/assigners/dynamic_soft_label_assigner.py b/mmdet/models/task_modules/assigners/dynamic_soft_label_assigner.py
new file mode 100644
index 0000000000000000000000000000000000000000..3fc7af39b22cd6dc00248e330547176787c23963
--- /dev/null
+++ b/mmdet/models/task_modules/assigners/dynamic_soft_label_assigner.py
@@ -0,0 +1,227 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Tuple
+
+import torch
+import torch.nn.functional as F
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmdet.registry import TASK_UTILS
+from mmdet.structures.bbox import BaseBoxes
+from mmdet.utils import ConfigType
+from .assign_result import AssignResult
+from .base_assigner import BaseAssigner
+
+INF = 100000000
+EPS = 1.0e-7
+
+
+def center_of_mass(masks: Tensor, eps: float = 1e-7) -> Tensor:
+ """Compute the masks center of mass.
+
+ Args:
+ masks: Mask tensor, has shape (num_masks, H, W).
+ eps: a small number to avoid normalizer to be zero.
+ Defaults to 1e-7.
+ Returns:
+ Tensor: The masks center of mass. Has shape (num_masks, 2).
+ """
+ n, h, w = masks.shape
+ grid_h = torch.arange(h, device=masks.device)[:, None]
+ grid_w = torch.arange(w, device=masks.device)
+ normalizer = masks.sum(dim=(1, 2)).float().clamp(min=eps)
+ center_y = (masks * grid_h).sum(dim=(1, 2)) / normalizer
+ center_x = (masks * grid_w).sum(dim=(1, 2)) / normalizer
+ center = torch.cat([center_x[:, None], center_y[:, None]], dim=1)
+ return center
+
+
+@TASK_UTILS.register_module()
+class DynamicSoftLabelAssigner(BaseAssigner):
+ """Computes matching between predictions and ground truth with dynamic soft
+ label assignment.
+
+ Args:
+ soft_center_radius (float): Radius of the soft center prior.
+ Defaults to 3.0.
+ topk (int): Select top-k predictions to calculate dynamic k
+ best matches for each gt. Defaults to 13.
+ iou_weight (float): The scale factor of iou cost. Defaults to 3.0.
+ iou_calculator (ConfigType): Config of overlaps Calculator.
+ Defaults to dict(type='BboxOverlaps2D').
+ """
+
+ def __init__(
+ self,
+ soft_center_radius: float = 3.0,
+ topk: int = 13,
+ iou_weight: float = 3.0,
+ iou_calculator: ConfigType = dict(type='BboxOverlaps2D')
+ ) -> None:
+ self.soft_center_radius = soft_center_radius
+ self.topk = topk
+ self.iou_weight = iou_weight
+ self.iou_calculator = TASK_UTILS.build(iou_calculator)
+
+ def assign(self,
+ pred_instances: InstanceData,
+ gt_instances: InstanceData,
+ gt_instances_ignore: Optional[InstanceData] = None,
+ **kwargs) -> AssignResult:
+ """Assign gt to priors.
+
+ Args:
+ pred_instances (:obj:`InstanceData`): Instances of model
+ predictions. It includes ``priors``, and the priors can
+ be anchors or points, or the bboxes predicted by the
+ previous stage, has shape (n, 4). The bboxes predicted by
+ the current model or stage will be named ``bboxes``,
+ ``labels``, and ``scores``, the same as the ``InstanceData``
+ in other places.
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It usually includes ``bboxes``, with shape (k, 4),
+ and ``labels``, with shape (k, ).
+ gt_instances_ignore (:obj:`InstanceData`, optional): Instances
+ to be ignored during training. It includes ``bboxes``
+ attribute data that is ignored during training and testing.
+ Defaults to None.
+ Returns:
+ obj:`AssignResult`: The assigned result.
+ """
+ gt_bboxes = gt_instances.bboxes
+ gt_labels = gt_instances.labels
+ num_gt = gt_bboxes.size(0)
+
+ decoded_bboxes = pred_instances.bboxes
+ pred_scores = pred_instances.scores
+ priors = pred_instances.priors
+ num_bboxes = decoded_bboxes.size(0)
+
+ # assign 0 by default
+ assigned_gt_inds = decoded_bboxes.new_full((num_bboxes, ),
+ 0,
+ dtype=torch.long)
+ if num_gt == 0 or num_bboxes == 0:
+ # No ground truth or boxes, return empty assignment
+ max_overlaps = decoded_bboxes.new_zeros((num_bboxes, ))
+ if num_gt == 0:
+ # No truth, assign everything to background
+ assigned_gt_inds[:] = 0
+ assigned_labels = decoded_bboxes.new_full((num_bboxes, ),
+ -1,
+ dtype=torch.long)
+ return AssignResult(
+ num_gt, assigned_gt_inds, max_overlaps, labels=assigned_labels)
+
+ prior_center = priors[:, :2]
+ if isinstance(gt_bboxes, BaseBoxes):
+ is_in_gts = gt_bboxes.find_inside_points(prior_center)
+ else:
+ # Tensor boxes will be treated as horizontal boxes by defaults
+ lt_ = prior_center[:, None] - gt_bboxes[:, :2]
+ rb_ = gt_bboxes[:, 2:] - prior_center[:, None]
+
+ deltas = torch.cat([lt_, rb_], dim=-1)
+ is_in_gts = deltas.min(dim=-1).values > 0
+
+ valid_mask = is_in_gts.sum(dim=1) > 0
+
+ valid_decoded_bbox = decoded_bboxes[valid_mask]
+ valid_pred_scores = pred_scores[valid_mask]
+ num_valid = valid_decoded_bbox.size(0)
+
+ if num_valid == 0:
+ # No ground truth or boxes, return empty assignment
+ max_overlaps = decoded_bboxes.new_zeros((num_bboxes, ))
+ assigned_labels = decoded_bboxes.new_full((num_bboxes, ),
+ -1,
+ dtype=torch.long)
+ return AssignResult(
+ num_gt, assigned_gt_inds, max_overlaps, labels=assigned_labels)
+ if hasattr(gt_instances, 'masks'):
+ gt_center = center_of_mass(gt_instances.masks, eps=EPS)
+ elif isinstance(gt_bboxes, BaseBoxes):
+ gt_center = gt_bboxes.centers
+ else:
+ # Tensor boxes will be treated as horizontal boxes by defaults
+ gt_center = (gt_bboxes[:, :2] + gt_bboxes[:, 2:]) / 2.0
+ valid_prior = priors[valid_mask]
+ strides = valid_prior[:, 2]
+ distance = (valid_prior[:, None, :2] - gt_center[None, :, :]
+ ).pow(2).sum(-1).sqrt() / strides[:, None]
+ soft_center_prior = torch.pow(10, distance - self.soft_center_radius)
+
+ pairwise_ious = self.iou_calculator(valid_decoded_bbox, gt_bboxes)
+ iou_cost = -torch.log(pairwise_ious + EPS) * self.iou_weight
+
+ gt_onehot_label = (
+ F.one_hot(gt_labels.to(torch.int64),
+ pred_scores.shape[-1]).float().unsqueeze(0).repeat(
+ num_valid, 1, 1))
+ valid_pred_scores = valid_pred_scores.unsqueeze(1).repeat(1, num_gt, 1)
+
+ soft_label = gt_onehot_label * pairwise_ious[..., None]
+ scale_factor = soft_label - valid_pred_scores.sigmoid()
+ soft_cls_cost = F.binary_cross_entropy_with_logits(
+ valid_pred_scores, soft_label,
+ reduction='none') * scale_factor.abs().pow(2.0)
+ soft_cls_cost = soft_cls_cost.sum(dim=-1)
+
+ cost_matrix = soft_cls_cost + iou_cost + soft_center_prior
+
+ matched_pred_ious, matched_gt_inds = self.dynamic_k_matching(
+ cost_matrix, pairwise_ious, num_gt, valid_mask)
+
+ # convert to AssignResult format
+ assigned_gt_inds[valid_mask] = matched_gt_inds + 1
+ assigned_labels = assigned_gt_inds.new_full((num_bboxes, ), -1)
+ assigned_labels[valid_mask] = gt_labels[matched_gt_inds].long()
+ max_overlaps = assigned_gt_inds.new_full((num_bboxes, ),
+ -INF,
+ dtype=torch.float32)
+ max_overlaps[valid_mask] = matched_pred_ious
+ return AssignResult(
+ num_gt, assigned_gt_inds, max_overlaps, labels=assigned_labels)
+
+ def dynamic_k_matching(self, cost: Tensor, pairwise_ious: Tensor,
+ num_gt: int,
+ valid_mask: Tensor) -> Tuple[Tensor, Tensor]:
+ """Use IoU and matching cost to calculate the dynamic top-k positive
+ targets. Same as SimOTA.
+
+ Args:
+ cost (Tensor): Cost matrix.
+ pairwise_ious (Tensor): Pairwise iou matrix.
+ num_gt (int): Number of gt.
+ valid_mask (Tensor): Mask for valid bboxes.
+
+ Returns:
+ tuple: matched ious and gt indexes.
+ """
+ matching_matrix = torch.zeros_like(cost, dtype=torch.uint8)
+ # select candidate topk ious for dynamic-k calculation
+ candidate_topk = min(self.topk, pairwise_ious.size(0))
+ topk_ious, _ = torch.topk(pairwise_ious, candidate_topk, dim=0)
+ # calculate dynamic k for each gt
+ dynamic_ks = torch.clamp(topk_ious.sum(0).int(), min=1)
+ for gt_idx in range(num_gt):
+ _, pos_idx = torch.topk(
+ cost[:, gt_idx], k=dynamic_ks[gt_idx], largest=False)
+ matching_matrix[:, gt_idx][pos_idx] = 1
+
+ del topk_ious, dynamic_ks, pos_idx
+
+ prior_match_gt_mask = matching_matrix.sum(1) > 1
+ if prior_match_gt_mask.sum() > 0:
+ cost_min, cost_argmin = torch.min(
+ cost[prior_match_gt_mask, :], dim=1)
+ matching_matrix[prior_match_gt_mask, :] *= 0
+ matching_matrix[prior_match_gt_mask, cost_argmin] = 1
+ # get foreground mask inside box and center prior
+ fg_mask_inboxes = matching_matrix.sum(1) > 0
+ valid_mask[valid_mask.clone()] = fg_mask_inboxes
+
+ matched_gt_inds = matching_matrix[fg_mask_inboxes, :].argmax(1)
+ matched_pred_ious = (matching_matrix *
+ pairwise_ious).sum(1)[fg_mask_inboxes]
+ return matched_pred_ious, matched_gt_inds
diff --git a/mmdet/models/task_modules/assigners/grid_assigner.py b/mmdet/models/task_modules/assigners/grid_assigner.py
new file mode 100644
index 0000000000000000000000000000000000000000..d8935d2df2937f90c71599e5b45ed9a3dff8cd7e
--- /dev/null
+++ b/mmdet/models/task_modules/assigners/grid_assigner.py
@@ -0,0 +1,177 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Tuple, Union
+
+import torch
+from mmengine.structures import InstanceData
+
+from mmdet.registry import TASK_UTILS
+from mmdet.utils import ConfigType
+from .assign_result import AssignResult
+from .base_assigner import BaseAssigner
+
+
+@TASK_UTILS.register_module()
+class GridAssigner(BaseAssigner):
+ """Assign a corresponding gt bbox or background to each bbox.
+
+ Each proposals will be assigned with `-1`, `0`, or a positive integer
+ indicating the ground truth index.
+
+ - -1: don't care
+ - 0: negative sample, no assigned gt
+ - positive integer: positive sample, index (1-based) of assigned gt
+
+ Args:
+ pos_iou_thr (float): IoU threshold for positive bboxes.
+ neg_iou_thr (float or tuple[float, float]): IoU threshold for negative
+ bboxes.
+ min_pos_iou (float): Minimum iou for a bbox to be considered as a
+ positive bbox. Positive samples can have smaller IoU than
+ pos_iou_thr due to the 4th step (assign max IoU sample to each gt).
+ Defaults to 0.
+ gt_max_assign_all (bool): Whether to assign all bboxes with the same
+ highest overlap with some gt to that gt.
+ iou_calculator (:obj:`ConfigDict` or dict): Config of overlaps
+ Calculator.
+ """
+
+ def __init__(
+ self,
+ pos_iou_thr: float,
+ neg_iou_thr: Union[float, Tuple[float, float]],
+ min_pos_iou: float = .0,
+ gt_max_assign_all: bool = True,
+ iou_calculator: ConfigType = dict(type='BboxOverlaps2D')
+ ) -> None:
+ self.pos_iou_thr = pos_iou_thr
+ self.neg_iou_thr = neg_iou_thr
+ self.min_pos_iou = min_pos_iou
+ self.gt_max_assign_all = gt_max_assign_all
+ self.iou_calculator = TASK_UTILS.build(iou_calculator)
+
+ def assign(self,
+ pred_instances: InstanceData,
+ gt_instances: InstanceData,
+ gt_instances_ignore: Optional[InstanceData] = None,
+ **kwargs) -> AssignResult:
+ """Assign gt to bboxes. The process is very much like the max iou
+ assigner, except that positive samples are constrained within the cell
+ that the gt boxes fell in.
+
+ This method assign a gt bbox to every bbox (proposal/anchor), each bbox
+ will be assigned with -1, 0, or a positive number. -1 means don't care,
+ 0 means negative sample, positive number is the index (1-based) of
+ assigned gt.
+ The assignment is done in following steps, the order matters.
+
+ 1. assign every bbox to -1
+ 2. assign proposals whose iou with all gts <= neg_iou_thr to 0
+ 3. for each bbox within a cell, if the iou with its nearest gt >
+ pos_iou_thr and the center of that gt falls inside the cell,
+ assign it to that bbox
+ 4. for each gt bbox, assign its nearest proposals within the cell the
+ gt bbox falls in to itself.
+
+ Args:
+ pred_instances (:obj:`InstanceData`): Instances of model
+ predictions. It includes ``priors``, and the priors can
+ be anchors or points, or the bboxes predicted by the
+ previous stage, has shape (n, 4). The bboxes predicted by
+ the current model or stage will be named ``bboxes``,
+ ``labels``, and ``scores``, the same as the ``InstanceData``
+ in other places.
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It usually includes ``bboxes``, with shape (k, 4),
+ and ``labels``, with shape (k, ).
+ gt_instances_ignore (:obj:`InstanceData`, optional): Instances
+ to be ignored during training. It includes ``bboxes``
+ attribute data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ :obj:`AssignResult`: The assign result.
+ """
+ gt_bboxes = gt_instances.bboxes
+ gt_labels = gt_instances.labels
+
+ priors = pred_instances.priors
+ responsible_flags = pred_instances.responsible_flags
+
+ num_gts, num_priors = gt_bboxes.size(0), priors.size(0)
+
+ # compute iou between all gt and priors
+ overlaps = self.iou_calculator(gt_bboxes, priors)
+
+ # 1. assign -1 by default
+ assigned_gt_inds = overlaps.new_full((num_priors, ),
+ -1,
+ dtype=torch.long)
+
+ if num_gts == 0 or num_priors == 0:
+ # No ground truth or priors, return empty assignment
+ max_overlaps = overlaps.new_zeros((num_priors, ))
+ if num_gts == 0:
+ # No truth, assign everything to background
+ assigned_gt_inds[:] = 0
+ assigned_labels = overlaps.new_full((num_priors, ),
+ -1,
+ dtype=torch.long)
+ return AssignResult(
+ num_gts,
+ assigned_gt_inds,
+ max_overlaps,
+ labels=assigned_labels)
+
+ # 2. assign negative: below
+ # for each anchor, which gt best overlaps with it
+ # for each anchor, the max iou of all gts
+ # shape of max_overlaps == argmax_overlaps == num_priors
+ max_overlaps, argmax_overlaps = overlaps.max(dim=0)
+
+ if isinstance(self.neg_iou_thr, float):
+ assigned_gt_inds[(max_overlaps >= 0)
+ & (max_overlaps <= self.neg_iou_thr)] = 0
+ elif isinstance(self.neg_iou_thr, (tuple, list)):
+ assert len(self.neg_iou_thr) == 2
+ assigned_gt_inds[(max_overlaps > self.neg_iou_thr[0])
+ & (max_overlaps <= self.neg_iou_thr[1])] = 0
+
+ # 3. assign positive: falls into responsible cell and above
+ # positive IOU threshold, the order matters.
+ # the prior condition of comparison is to filter out all
+ # unrelated anchors, i.e. not responsible_flags
+ overlaps[:, ~responsible_flags.type(torch.bool)] = -1.
+
+ # calculate max_overlaps again, but this time we only consider IOUs
+ # for anchors responsible for prediction
+ max_overlaps, argmax_overlaps = overlaps.max(dim=0)
+
+ # for each gt, which anchor best overlaps with it
+ # for each gt, the max iou of all proposals
+ # shape of gt_max_overlaps == gt_argmax_overlaps == num_gts
+ gt_max_overlaps, gt_argmax_overlaps = overlaps.max(dim=1)
+
+ pos_inds = (max_overlaps > self.pos_iou_thr) & responsible_flags.type(
+ torch.bool)
+ assigned_gt_inds[pos_inds] = argmax_overlaps[pos_inds] + 1
+
+ # 4. assign positive to max overlapped anchors within responsible cell
+ for i in range(num_gts):
+ if gt_max_overlaps[i] > self.min_pos_iou:
+ if self.gt_max_assign_all:
+ max_iou_inds = (overlaps[i, :] == gt_max_overlaps[i]) & \
+ responsible_flags.type(torch.bool)
+ assigned_gt_inds[max_iou_inds] = i + 1
+ elif responsible_flags[gt_argmax_overlaps[i]]:
+ assigned_gt_inds[gt_argmax_overlaps[i]] = i + 1
+
+ # assign labels of positive anchors
+ assigned_labels = assigned_gt_inds.new_full((num_priors, ), -1)
+ pos_inds = torch.nonzero(
+ assigned_gt_inds > 0, as_tuple=False).squeeze()
+ if pos_inds.numel() > 0:
+ assigned_labels[pos_inds] = gt_labels[assigned_gt_inds[pos_inds] -
+ 1]
+
+ return AssignResult(
+ num_gts, assigned_gt_inds, max_overlaps, labels=assigned_labels)
diff --git a/mmdet/models/task_modules/assigners/hungarian_assigner.py b/mmdet/models/task_modules/assigners/hungarian_assigner.py
new file mode 100644
index 0000000000000000000000000000000000000000..549d30c5c261eb979e9e87b0d3b4d1c1b16611e2
--- /dev/null
+++ b/mmdet/models/task_modules/assigners/hungarian_assigner.py
@@ -0,0 +1,145 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Optional, Union
+
+import torch
+from mmengine import ConfigDict
+from mmengine.structures import InstanceData
+from scipy.optimize import linear_sum_assignment
+from torch import Tensor
+
+from mmdet.registry import TASK_UTILS
+from .assign_result import AssignResult
+from .base_assigner import BaseAssigner
+
+
+@TASK_UTILS.register_module()
+class HungarianAssigner(BaseAssigner):
+ """Computes one-to-one matching between predictions and ground truth.
+
+ This class computes an assignment between the targets and the predictions
+ based on the costs. The costs are weighted sum of some components.
+ For DETR the costs are weighted sum of classification cost, regression L1
+ cost and regression iou cost. The targets don't include the no_object, so
+ generally there are more predictions than targets. After the one-to-one
+ matching, the un-matched are treated as backgrounds. Thus each query
+ prediction will be assigned with `0` or a positive integer indicating the
+ ground truth index:
+
+ - 0: negative sample, no assigned gt
+ - positive integer: positive sample, index (1-based) of assigned gt
+
+ Args:
+ match_costs (:obj:`ConfigDict` or dict or \
+ List[Union[:obj:`ConfigDict`, dict]]): Match cost configs.
+ """
+
+ def __init__(
+ self, match_costs: Union[List[Union[dict, ConfigDict]], dict,
+ ConfigDict]
+ ) -> None:
+
+ if isinstance(match_costs, dict):
+ match_costs = [match_costs]
+ elif isinstance(match_costs, list):
+ assert len(match_costs) > 0, \
+ 'match_costs must not be a empty list.'
+
+ self.match_costs = [
+ TASK_UTILS.build(match_cost) for match_cost in match_costs
+ ]
+
+ def assign(self,
+ pred_instances: InstanceData,
+ gt_instances: InstanceData,
+ img_meta: Optional[dict] = None,
+ **kwargs) -> AssignResult:
+ """Computes one-to-one matching based on the weighted costs.
+
+ This method assign each query prediction to a ground truth or
+ background. The `assigned_gt_inds` with -1 means don't care,
+ 0 means negative sample, and positive number is the index (1-based)
+ of assigned gt.
+ The assignment is done in the following steps, the order matters.
+
+ 1. assign every prediction to -1
+ 2. compute the weighted costs
+ 3. do Hungarian matching on CPU based on the costs
+ 4. assign all to 0 (background) first, then for each matched pair
+ between predictions and gts, treat this prediction as foreground
+ and assign the corresponding gt index (plus 1) to it.
+
+ Args:
+ pred_instances (:obj:`InstanceData`): Instances of model
+ predictions. It includes ``priors``, and the priors can
+ be anchors or points, or the bboxes predicted by the
+ previous stage, has shape (n, 4). The bboxes predicted by
+ the current model or stage will be named ``bboxes``,
+ ``labels``, and ``scores``, the same as the ``InstanceData``
+ in other places. It may includes ``masks``, with shape
+ (n, h, w) or (n, l).
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It usually includes ``bboxes``, with shape (k, 4),
+ ``labels``, with shape (k, ) and ``masks``, with shape
+ (k, h, w) or (k, l).
+ img_meta (dict): Image information.
+
+ Returns:
+ :obj:`AssignResult`: The assigned result.
+ """
+ assert isinstance(gt_instances.labels, Tensor)
+ num_gts, num_preds = len(gt_instances), len(pred_instances)
+ gt_labels = gt_instances.labels
+ device = gt_labels.device
+
+ # 1. assign -1 by default
+ assigned_gt_inds = torch.full((num_preds, ),
+ -1,
+ dtype=torch.long,
+ device=device)
+ assigned_labels = torch.full((num_preds, ),
+ -1,
+ dtype=torch.long,
+ device=device)
+
+ if num_gts == 0 or num_preds == 0:
+ # No ground truth or boxes, return empty assignment
+ if num_gts == 0:
+ # No ground truth, assign all to background
+ assigned_gt_inds[:] = 0
+ return AssignResult(
+ num_gts=num_gts,
+ gt_inds=assigned_gt_inds,
+ max_overlaps=None,
+ labels=assigned_labels)
+
+ # 2. compute weighted cost
+ cost_list = []
+ for match_cost in self.match_costs:
+ cost = match_cost(
+ pred_instances=pred_instances,
+ gt_instances=gt_instances,
+ img_meta=img_meta)
+ cost_list.append(cost)
+ cost = torch.stack(cost_list).sum(dim=0) # 先求900query与每个gt的cost,不同类型的cost相加
+
+ # 3. do Hungarian matching on CPU using linear_sum_assignment
+ cost = cost.detach().cpu()
+ if linear_sum_assignment is None:
+ raise ImportError('Please run "pip install scipy" '
+ 'to install scipy first.')
+
+ matched_row_inds, matched_col_inds = linear_sum_assignment(cost)
+ matched_row_inds = torch.from_numpy(matched_row_inds).to(device) #
+ matched_col_inds = torch.from_numpy(matched_col_inds).to(device)
+
+ # 4. assign backgrounds and foregrounds
+ # assign all indices to backgrounds first
+ assigned_gt_inds[:] = 0
+ # assign foregrounds based on matching results
+ assigned_gt_inds[matched_row_inds] = matched_col_inds + 1
+ assigned_labels[matched_row_inds] = gt_labels[matched_col_inds]
+ return AssignResult(
+ num_gts=num_gts,
+ gt_inds=assigned_gt_inds,
+ max_overlaps=None,
+ labels=assigned_labels)
diff --git a/mmdet/models/task_modules/assigners/iou2d_calculator.py b/mmdet/models/task_modules/assigners/iou2d_calculator.py
new file mode 100644
index 0000000000000000000000000000000000000000..0e85d1e422c9ec303a455b79ed2cc13a3a1e61b6
--- /dev/null
+++ b/mmdet/models/task_modules/assigners/iou2d_calculator.py
@@ -0,0 +1,68 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+
+from mmdet.registry import TASK_UTILS
+from mmdet.structures.bbox import bbox_overlaps, get_box_tensor
+
+
+def cast_tensor_type(x, scale=1., dtype=None):
+ if dtype == 'fp16':
+ # scale is for preventing overflows
+ x = (x / scale).half()
+ return x
+
+
+@TASK_UTILS.register_module()
+class BboxOverlaps2D:
+ """2D Overlaps (e.g. IoUs, GIoUs) Calculator."""
+
+ def __init__(self, scale=1., dtype=None):
+ self.scale = scale
+ self.dtype = dtype
+
+ def __call__(self, bboxes1, bboxes2, mode='iou', is_aligned=False):
+ """Calculate IoU between 2D bboxes.
+
+ Args:
+ bboxes1 (Tensor or :obj:`BaseBoxes`): bboxes have shape (m, 4)
+ in format, or shape (m, 5) in format.
+ bboxes2 (Tensor or :obj:`BaseBoxes`): bboxes have shape (m, 4)
+ in format, shape (m, 5) in format, or be empty. If ``is_aligned `` is ``True``,
+ then m and n must be equal.
+ mode (str): "iou" (intersection over union), "iof" (intersection
+ over foreground), or "giou" (generalized intersection over
+ union).
+ is_aligned (bool, optional): If True, then m and n must be equal.
+ Default False.
+
+ Returns:
+ Tensor: shape (m, n) if ``is_aligned `` is False else shape (m,)
+ """
+ bboxes1 = get_box_tensor(bboxes1)
+ bboxes2 = get_box_tensor(bboxes2)
+ assert bboxes1.size(-1) in [0, 4, 5]
+ assert bboxes2.size(-1) in [0, 4, 5]
+ if bboxes2.size(-1) == 5:
+ bboxes2 = bboxes2[..., :4]
+ if bboxes1.size(-1) == 5:
+ bboxes1 = bboxes1[..., :4]
+
+ if self.dtype == 'fp16':
+ # change tensor type to save cpu and cuda memory and keep speed
+ bboxes1 = cast_tensor_type(bboxes1, self.scale, self.dtype)
+ bboxes2 = cast_tensor_type(bboxes2, self.scale, self.dtype)
+ overlaps = bbox_overlaps(bboxes1, bboxes2, mode, is_aligned)
+ if not overlaps.is_cuda and overlaps.dtype == torch.float16:
+ # resume cpu float32
+ overlaps = overlaps.float()
+ return overlaps
+
+ return bbox_overlaps(bboxes1, bboxes2, mode, is_aligned)
+
+ def __repr__(self):
+ """str: a string describing the module"""
+ repr_str = self.__class__.__name__ + f'(' \
+ f'scale={self.scale}, dtype={self.dtype})'
+ return repr_str
diff --git a/mmdet/models/task_modules/assigners/match_cost.py b/mmdet/models/task_modules/assigners/match_cost.py
new file mode 100644
index 0000000000000000000000000000000000000000..8188db68d46e83efb28d85e8c5b8b3e95a3a78f0
--- /dev/null
+++ b/mmdet/models/task_modules/assigners/match_cost.py
@@ -0,0 +1,519 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from abc import abstractmethod
+from typing import Optional, Union
+
+import torch
+import torch.nn.functional as F
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmdet.registry import TASK_UTILS
+from mmdet.structures.bbox import bbox_overlaps, bbox_xyxy_to_cxcywh
+
+
+
+class BaseMatchCost:
+ """Base match cost class.
+
+ Args:
+ weight (Union[float, int]): Cost weight. Defaults to 1.
+ """
+
+ def __init__(self, weight: Union[float, int] = 1.) -> None:
+ self.weight = weight
+
+ @abstractmethod
+ def __call__(self,
+ pred_instances: InstanceData,
+ gt_instances: InstanceData,
+ img_meta: Optional[dict] = None,
+ **kwargs) -> Tensor:
+ """Compute match cost.
+
+ Args:
+ pred_instances (:obj:`InstanceData`): Instances of model
+ predictions. It includes ``priors``, and the priors can
+ be anchors or points, or the bboxes predicted by the
+ previous stage, has shape (n, 4). The bboxes predicted by
+ the current model or stage will be named ``bboxes``,
+ ``labels``, and ``scores``, the same as the ``InstanceData``
+ in other places.
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It usually includes ``bboxes``, with shape (k, 4),
+ and ``labels``, with shape (k, ).
+ img_meta (dict, optional): Image information.
+
+ Returns:
+ Tensor: Match Cost matrix of shape (num_preds, num_gts).
+ """
+ pass
+
+
+@TASK_UTILS.register_module()
+class BBoxL1Cost(BaseMatchCost):
+ """BBoxL1Cost.
+
+ Note: ``bboxes`` in ``InstanceData`` passed in is of format 'xyxy'
+ and its coordinates are unnormalized.
+
+ Args:
+ box_format (str, optional): 'xyxy' for DETR, 'xywh' for Sparse_RCNN.
+ Defaults to 'xyxy'.
+ weight (Union[float, int]): Cost weight. Defaults to 1.
+
+ Examples:
+ >>> from mmdet.models.task_modules.assigners.
+ ... match_costs.match_cost import BBoxL1Cost
+ >>> import torch
+ >>> self = BBoxL1Cost()
+ >>> bbox_pred = torch.rand(1, 4)
+ >>> gt_bboxes= torch.FloatTensor([[0, 0, 2, 4], [1, 2, 3, 4]])
+ >>> factor = torch.tensor([10, 8, 10, 8])
+ >>> self(bbox_pred, gt_bboxes, factor)
+ tensor([[1.6172, 1.6422]])
+ """
+
+ def __init__(self,
+ box_format: str = 'xyxy',
+ weight: Union[float, int] = 1.) -> None:
+ super().__init__(weight=weight)
+ assert box_format in ['xyxy', 'xywh']
+ self.box_format = box_format
+
+ def __call__(self,
+ pred_instances: InstanceData,
+ gt_instances: InstanceData,
+ img_meta: Optional[dict] = None,
+ **kwargs) -> Tensor:
+ """Compute match cost.
+
+ Args:
+ pred_instances (:obj:`InstanceData`): ``bboxes`` inside is
+ predicted boxes with unnormalized coordinate
+ (x, y, x, y).
+ gt_instances (:obj:`InstanceData`): ``bboxes`` inside is gt
+ bboxes with unnormalized coordinate (x, y, x, y).
+ img_meta (Optional[dict]): Image information. Defaults to None.
+
+ Returns:
+ Tensor: Match Cost matrix of shape (num_preds, num_gts).
+ """
+ pred_bboxes = pred_instances.bboxes
+ gt_bboxes = gt_instances.bboxes
+
+ # convert box format
+ if self.box_format == 'xywh':
+ gt_bboxes = bbox_xyxy_to_cxcywh(gt_bboxes)
+ pred_bboxes = bbox_xyxy_to_cxcywh(pred_bboxes)
+
+ # normalized
+ img_h, img_w = img_meta['img_shape']
+ factor = gt_bboxes.new_tensor([img_w, img_h, img_w,
+ img_h]).unsqueeze(0)
+ gt_bboxes = gt_bboxes / factor
+ pred_bboxes = pred_bboxes / factor
+
+ bbox_cost = torch.cdist(pred_bboxes, gt_bboxes, p=1)
+ return bbox_cost * self.weight
+
+
+@TASK_UTILS.register_module()
+class IoULossCost(BaseMatchCost):
+ """IoUCost.
+
+ Note: ``bboxes`` in ``InstanceData`` passed in is of format 'xyxy'
+ and its coordinates are unnormalized.
+
+ Args:
+ iou_mode (str): iou mode such as 'iou', 'giou'. Defaults to 'giou'.
+ weight (Union[float, int]): Cost weight. Defaults to 1.
+
+ Examples:
+ >>> from mmdet.models.task_modules.assigners.
+ ... match_costs.match_cost import IoUCost
+ >>> import torch
+ >>> self = IoUCost()
+ >>> bboxes = torch.FloatTensor([[1,1, 2, 2], [2, 2, 3, 4]])
+ >>> gt_bboxes = torch.FloatTensor([[0, 0, 2, 4], [1, 2, 3, 4]])
+ >>> self(bboxes, gt_bboxes)
+ tensor([[-0.1250, 0.1667],
+ [ 0.1667, -0.5000]])
+ """
+ def __init__(self, iou_mode: str = 'giou', weight: Union[float, int] = 1.):
+ super().__init__(weight=weight)
+ self.iou_mode = iou_mode
+ def __call__(self,
+ pred_instances: InstanceData,
+ gt_instances: InstanceData,
+ img_meta: Optional[dict] = None,
+ **kwargs):
+ """Compute match cost.
+
+ Args:
+ pred_instances (:obj:`InstanceData`): ``bboxes`` inside is
+ predicted boxes with unnormalized coordinate
+ (x, y, x, y).
+ gt_instances (:obj:`InstanceData`): ``bboxes`` inside is gt
+ bboxes with unnormalized coordinate (x, y, x, y).
+ img_meta (Optional[dict]): Image information. Defaults to None.
+
+ Returns:
+ Tensor: Match Cost matrix of shape (num_preds, num_gts).
+ """
+ pred_bboxes = pred_instances.bboxes
+ gt_bboxes = gt_instances.bboxes
+ # overlaps = bbox_overlaps(
+ # pred_bboxes, gt_bboxes, mode=self.iou_mode, is_aligned=False
+ # The 1 is a constant that doesn't change the matching, so omitted.
+ # iou_cost = -overlaps
+ # ious = bbox_overlaps(pred, target, is_aligned=True).clamp(min=eps)
+ ious = bbox_overlaps(pred_bboxes, gt_bboxes, mode=self.iou_mode, is_aligned=False)
+ iou_cost = 1 - ious
+ return iou_cost * self.weight
+
+
+@TASK_UTILS.register_module()
+class IoUCost(BaseMatchCost):
+ """IoUCost.
+
+ Note: ``bboxes`` in ``InstanceData`` passed in is of format 'xyxy'
+ and its coordinates are unnormalized.
+
+ Args:
+ iou_mode (str): iou mode such as 'iou', 'giou'. Defaults to 'giou'.
+ weight (Union[float, int]): Cost weight. Defaults to 1.
+
+ Examples:
+ >>> from mmdet.models.task_modules.assigners.
+ ... match_costs.match_cost import IoUCost
+ >>> import torch
+ >>> self = IoUCost()
+ >>> bboxes = torch.FloatTensor([[1,1, 2, 2], [2, 2, 3, 4]])
+ >>> gt_bboxes = torch.FloatTensor([[0, 0, 2, 4], [1, 2, 3, 4]])
+ >>> self(bboxes, gt_bboxes)
+ tensor([[-0.1250, 0.1667],
+ [ 0.1667, -0.5000]])
+ """
+
+ def __init__(self, iou_mode: str = 'giou', weight: Union[float, int] = 1.):
+ super().__init__(weight=weight)
+ self.iou_mode = iou_mode
+
+ def __call__(self,
+ pred_instances: InstanceData,
+ gt_instances: InstanceData,
+ img_meta: Optional[dict] = None,
+ **kwargs):
+ """Compute match cost.
+
+ Args:
+ pred_instances (:obj:`InstanceData`): ``bboxes`` inside is
+ predicted boxes with unnormalized coordinate
+ (x, y, x, y).
+ gt_instances (:obj:`InstanceData`): ``bboxes`` inside is gt
+ bboxes with unnormalized coordinate (x, y, x, y).
+ img_meta (Optional[dict]): Image information. Defaults to None.
+
+ Returns:
+ Tensor: Match Cost matrix of shape (num_preds, num_gts).
+ """
+ pred_bboxes = pred_instances.bboxes
+ gt_bboxes = gt_instances.bboxes
+
+ overlaps = bbox_overlaps(
+ pred_bboxes, gt_bboxes, mode=self.iou_mode, is_aligned=False)
+ # The 1 is a constant that doesn't change the matching, so omitted.
+ iou_cost = -overlaps
+ return iou_cost * self.weight
+
+
+@TASK_UTILS.register_module()
+class ClassificationCost(BaseMatchCost):
+ """ClsSoftmaxCost.
+
+ Args:
+ weight (Union[float, int]): Cost weight. Defaults to 1.
+
+ Examples:
+ >>> from mmdet.models.task_modules.assigners.
+ ... match_costs.match_cost import ClassificationCost
+ >>> import torch
+ >>> self = ClassificationCost()
+ >>> cls_pred = torch.rand(4, 3)
+ >>> gt_labels = torch.tensor([0, 1, 2])
+ >>> factor = torch.tensor([10, 8, 10, 8])
+ >>> self(cls_pred, gt_labels)
+ tensor([[-0.3430, -0.3525, -0.3045],
+ [-0.3077, -0.2931, -0.3992],
+ [-0.3664, -0.3455, -0.2881],
+ [-0.3343, -0.2701, -0.3956]])
+ """
+
+ def __init__(self, weight: Union[float, int] = 1) -> None:
+ super().__init__(weight=weight)
+
+ def __call__(self,
+ pred_instances: InstanceData,
+ gt_instances: InstanceData,
+ img_meta: Optional[dict] = None,
+ **kwargs) -> Tensor:
+ """Compute match cost.
+
+ Args:
+ pred_instances (:obj:`InstanceData`): ``scores`` inside is
+ predicted classification logits, of shape
+ (num_queries, num_class).
+ gt_instances (:obj:`InstanceData`): ``labels`` inside should have
+ shape (num_gt, ).
+ img_meta (Optional[dict]): _description_. Defaults to None.
+
+ Returns:
+ Tensor: Match Cost matrix of shape (num_preds, num_gts).
+ """
+ pred_scores = pred_instances.scores
+ gt_labels = gt_instances.labels
+
+ pred_scores = pred_scores.softmax(-1)
+ cls_cost = -pred_scores[:, gt_labels]
+
+ return cls_cost * self.weight
+
+
+@TASK_UTILS.register_module()
+class FocalLossCost(BaseMatchCost):
+ """FocalLossCost.
+
+ Args:
+ alpha (Union[float, int]): focal_loss alpha. Defaults to 0.25.
+ gamma (Union[float, int]): focal_loss gamma. Defaults to 2.
+ eps (float): Defaults to 1e-12.
+ binary_input (bool): Whether the input is binary. Currently,
+ binary_input = True is for masks input, binary_input = False
+ is for label input. Defaults to False.
+ weight (Union[float, int]): Cost weight. Defaults to 1.
+ """
+
+ def __init__(self,
+ alpha: Union[float, int] = 0.25,
+ gamma: Union[float, int] = 2,
+ eps: float = 1e-12,
+ binary_input: bool = False,
+ weight: Union[float, int] = 1.) -> None:
+ super().__init__(weight=weight)
+ self.alpha = alpha
+ self.gamma = gamma
+ self.eps = eps
+ self.binary_input = binary_input
+
+ def _focal_loss_cost(self, cls_pred: Tensor, gt_labels: Tensor) -> Tensor:
+ """
+ Args:
+ cls_pred (Tensor): Predicted classification logits, shape
+ (num_queries, num_class).
+ gt_labels (Tensor): Label of `gt_bboxes`, shape (num_gt,).
+
+ Returns:
+ torch.Tensor: cls_cost value with weight
+ """
+ cls_pred = cls_pred.sigmoid()
+ neg_cost = -(1 - cls_pred + self.eps).log() * (
+ 1 - self.alpha) * cls_pred.pow(self.gamma)
+ pos_cost = -(cls_pred + self.eps).log() * self.alpha * (
+ 1 - cls_pred).pow(self.gamma)
+
+ cls_cost = pos_cost[:, gt_labels] - neg_cost[:, gt_labels]
+ return cls_cost * self.weight
+
+ def _mask_focal_loss_cost(self, cls_pred, gt_labels) -> Tensor:
+ """
+ Args:
+ cls_pred (Tensor): Predicted classification logits.
+ in shape (num_queries, d1, ..., dn), dtype=torch.float32.
+ gt_labels (Tensor): Ground truth in shape (num_gt, d1, ..., dn),
+ dtype=torch.long. Labels should be binary.
+
+ Returns:
+ Tensor: Focal cost matrix with weight in shape\
+ (num_queries, num_gt).
+ """
+ cls_pred = cls_pred.flatten(1)
+ gt_labels = gt_labels.flatten(1).float()
+ n = cls_pred.shape[1]
+ cls_pred = cls_pred.sigmoid()
+ neg_cost = -(1 - cls_pred + self.eps).log() * (
+ 1 - self.alpha) * cls_pred.pow(self.gamma)
+ pos_cost = -(cls_pred + self.eps).log() * self.alpha * (
+ 1 - cls_pred).pow(self.gamma)
+
+ cls_cost = torch.einsum('nc,mc->nm', pos_cost, gt_labels) + \
+ torch.einsum('nc,mc->nm', neg_cost, (1 - gt_labels))
+ return cls_cost / n * self.weight
+
+ def __call__(self,
+ pred_instances: InstanceData,
+ gt_instances: InstanceData,
+ img_meta: Optional[dict] = None,
+ **kwargs) -> Tensor:
+ """Compute match cost.
+
+ Args:
+ pred_instances (:obj:`InstanceData`): Predicted instances which
+ must contain ``scores`` or ``masks``.
+ gt_instances (:obj:`InstanceData`): Ground truth which must contain
+ ``labels`` or ``mask``.
+ img_meta (Optional[dict]): Image information. Defaults to None.
+
+ Returns:
+ Tensor: Match Cost matrix of shape (num_preds, num_gts).
+ """
+ if self.binary_input:
+ pred_masks = pred_instances.masks
+ gt_masks = gt_instances.masks
+ return self._mask_focal_loss_cost(pred_masks, gt_masks)
+ else:
+ pred_scores = pred_instances.scores
+ gt_labels = gt_instances.labels
+ return self._focal_loss_cost(pred_scores, gt_labels)
+
+
+@TASK_UTILS.register_module()
+class DiceCost(BaseMatchCost):
+ """Cost of mask assignments based on dice losses.
+
+ Args:
+ pred_act (bool): Whether to apply sigmoid to mask_pred.
+ Defaults to False.
+ eps (float): Defaults to 1e-3.
+ naive_dice (bool): If True, use the naive dice loss
+ in which the power of the number in the denominator is
+ the first power. If False, use the second power that
+ is adopted by K-Net and SOLO. Defaults to True.
+ weight (Union[float, int]): Cost weight. Defaults to 1.
+ """
+
+ def __init__(self,
+ pred_act: bool = False,
+ eps: float = 1e-3,
+ naive_dice: bool = True,
+ weight: Union[float, int] = 1.) -> None:
+ super().__init__(weight=weight)
+ self.pred_act = pred_act
+ self.eps = eps
+ self.naive_dice = naive_dice
+
+ def _binary_mask_dice_loss(self, mask_preds: Tensor,
+ gt_masks: Tensor) -> Tensor:
+ """
+ Args:
+ mask_preds (Tensor): Mask prediction in shape (num_queries, *).
+ gt_masks (Tensor): Ground truth in shape (num_gt, *)
+ store 0 or 1, 0 for negative class and 1 for
+ positive class.
+
+ Returns:
+ Tensor: Dice cost matrix in shape (num_queries, num_gt).
+ """
+ mask_preds = mask_preds.flatten(1)
+ gt_masks = gt_masks.flatten(1).float()
+ numerator = 2 * torch.einsum('nc,mc->nm', mask_preds, gt_masks)
+ if self.naive_dice:
+ denominator = mask_preds.sum(-1)[:, None] + \
+ gt_masks.sum(-1)[None, :]
+ else:
+ denominator = mask_preds.pow(2).sum(1)[:, None] + \
+ gt_masks.pow(2).sum(1)[None, :]
+ loss = 1 - (numerator + self.eps) / (denominator + self.eps)
+ return loss
+
+ def __call__(self,
+ pred_instances: InstanceData,
+ gt_instances: InstanceData,
+ img_meta: Optional[dict] = None,
+ **kwargs) -> Tensor:
+ """Compute match cost.
+
+ Args:
+ pred_instances (:obj:`InstanceData`): Predicted instances which
+ must contain ``masks``.
+ gt_instances (:obj:`InstanceData`): Ground truth which must contain
+ ``mask``.
+ img_meta (Optional[dict]): Image information. Defaults to None.
+
+ Returns:
+ Tensor: Match Cost matrix of shape (num_preds, num_gts).
+ """
+ pred_masks = pred_instances.masks
+ gt_masks = gt_instances.masks
+
+ if self.pred_act:
+ pred_masks = pred_masks.sigmoid()
+ dice_cost = self._binary_mask_dice_loss(pred_masks, gt_masks)
+ return dice_cost * self.weight
+
+
+@TASK_UTILS.register_module()
+class CrossEntropyLossCost(BaseMatchCost):
+ """CrossEntropyLossCost.
+
+ Args:
+ use_sigmoid (bool): Whether the prediction uses sigmoid
+ of softmax. Defaults to True.
+ weight (Union[float, int]): Cost weight. Defaults to 1.
+ """
+
+ def __init__(self,
+ use_sigmoid: bool = True,
+ weight: Union[float, int] = 1.) -> None:
+ super().__init__(weight=weight)
+ self.use_sigmoid = use_sigmoid
+
+ def _binary_cross_entropy(self, cls_pred: Tensor,
+ gt_labels: Tensor) -> Tensor:
+ """
+ Args:
+ cls_pred (Tensor): The prediction with shape (num_queries, 1, *) or
+ (num_queries, *).
+ gt_labels (Tensor): The learning label of prediction with
+ shape (num_gt, *).
+
+ Returns:
+ Tensor: Cross entropy cost matrix in shape (num_queries, num_gt).
+ """
+ cls_pred = cls_pred.flatten(1).float()
+ gt_labels = gt_labels.flatten(1).float()
+ n = cls_pred.shape[1]
+ pos = F.binary_cross_entropy_with_logits(
+ cls_pred, torch.ones_like(cls_pred), reduction='none')
+ neg = F.binary_cross_entropy_with_logits(
+ cls_pred, torch.zeros_like(cls_pred), reduction='none')
+ cls_cost = torch.einsum('nc,mc->nm', pos, gt_labels) + \
+ torch.einsum('nc,mc->nm', neg, 1 - gt_labels)
+ cls_cost = cls_cost / n
+
+ return cls_cost
+
+ def __call__(self,
+ pred_instances: InstanceData,
+ gt_instances: InstanceData,
+ img_meta: Optional[dict] = None,
+ **kwargs) -> Tensor:
+ """Compute match cost.
+
+ Args:
+ pred_instances (:obj:`InstanceData`): Predicted instances which
+ must contain ``scores`` or ``masks``.
+ gt_instances (:obj:`InstanceData`): Ground truth which must contain
+ ``labels`` or ``masks``.
+ img_meta (Optional[dict]): Image information. Defaults to None.
+
+ Returns:
+ Tensor: Match Cost matrix of shape (num_preds, num_gts).
+ """
+ pred_masks = pred_instances.masks
+ gt_masks = gt_instances.masks
+ if self.use_sigmoid:
+ cls_cost = self._binary_cross_entropy(pred_masks, gt_masks)
+ else:
+ raise NotImplementedError
+
+ return cls_cost * self.weight
diff --git a/mmdet/models/task_modules/assigners/max_iou_assigner.py b/mmdet/models/task_modules/assigners/max_iou_assigner.py
new file mode 100644
index 0000000000000000000000000000000000000000..b6edabafefd093526c7b12c2007002a20198ff91
--- /dev/null
+++ b/mmdet/models/task_modules/assigners/max_iou_assigner.py
@@ -0,0 +1,245 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Union
+
+import torch
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmdet.registry import TASK_UTILS
+from .assign_result import AssignResult
+from .base_assigner import BaseAssigner
+
+
+@TASK_UTILS.register_module()
+class MaxIoUAssigner(BaseAssigner):
+ """Assign a corresponding gt bbox or background to each bbox.
+
+ Each proposals will be assigned with `-1`, or a semi-positive integer
+ indicating the ground truth index.
+
+ - -1: negative sample, no assigned gt
+ - semi-positive integer: positive sample, index (0-based) of assigned gt
+
+ Args:
+ pos_iou_thr (float): IoU threshold for positive bboxes.
+ neg_iou_thr (float or tuple): IoU threshold for negative bboxes.
+ min_pos_iou (float): Minimum iou for a bbox to be considered as a
+ positive bbox. Positive samples can have smaller IoU than
+ pos_iou_thr due to the 4th step (assign max IoU sample to each gt).
+ `min_pos_iou` is set to avoid assigning bboxes that have extremely
+ small iou with GT as positive samples. It brings about 0.3 mAP
+ improvements in 1x schedule but does not affect the performance of
+ 3x schedule. More comparisons can be found in
+ `PR #7464 `_.
+ gt_max_assign_all (bool): Whether to assign all bboxes with the same
+ highest overlap with some gt to that gt.
+ ignore_iof_thr (float): IoF threshold for ignoring bboxes (if
+ `gt_bboxes_ignore` is specified). Negative values mean not
+ ignoring any bboxes.
+ ignore_wrt_candidates (bool): Whether to compute the iof between
+ `bboxes` and `gt_bboxes_ignore`, or the contrary.
+ match_low_quality (bool): Whether to allow low quality matches. This is
+ usually allowed for RPN and single stage detectors, but not allowed
+ in the second stage. Details are demonstrated in Step 4.
+ gpu_assign_thr (int): The upper bound of the number of GT for GPU
+ assign. When the number of gt is above this threshold, will assign
+ on CPU device. Negative values mean not assign on CPU.
+ iou_calculator (dict): Config of overlaps Calculator.
+ """
+
+ def __init__(self,
+ pos_iou_thr: float,
+ neg_iou_thr: Union[float, tuple],
+ min_pos_iou: float = .0,
+ gt_max_assign_all: bool = True,
+ ignore_iof_thr: float = -1,
+ ignore_wrt_candidates: bool = True,
+ match_low_quality: bool = True,
+ gpu_assign_thr: float = -1,
+ iou_calculator: dict = dict(type='BboxOverlaps2D')):
+ self.pos_iou_thr = pos_iou_thr
+ self.neg_iou_thr = neg_iou_thr
+ self.min_pos_iou = min_pos_iou
+ self.gt_max_assign_all = gt_max_assign_all
+ self.ignore_iof_thr = ignore_iof_thr
+ self.ignore_wrt_candidates = ignore_wrt_candidates
+ self.gpu_assign_thr = gpu_assign_thr
+ self.match_low_quality = match_low_quality
+ self.iou_calculator = TASK_UTILS.build(iou_calculator)
+
+ def assign(self,
+ pred_instances: InstanceData,
+ gt_instances: InstanceData,
+ gt_instances_ignore: Optional[InstanceData] = None,
+ **kwargs) -> AssignResult:
+ """Assign gt to bboxes.
+
+ This method assign a gt bbox to every bbox (proposal/anchor), each bbox
+ will be assigned with -1, or a semi-positive number. -1 means negative
+ sample, semi-positive number is the index (0-based) of assigned gt.
+ The assignment is done in following steps, the order matters.
+
+ 1. assign every bbox to the background
+ 2. assign proposals whose iou with all gts < neg_iou_thr to 0
+ 3. for each bbox, if the iou with its nearest gt >= pos_iou_thr,
+ assign it to that bbox
+ 4. for each gt bbox, assign its nearest proposals (may be more than
+ one) to itself
+
+ Args:
+ pred_instances (:obj:`InstanceData`): Instances of model
+ predictions. It includes ``priors``, and the priors can
+ be anchors or points, or the bboxes predicted by the
+ previous stage, has shape (n, 4). The bboxes predicted by
+ the current model or stage will be named ``bboxes``,
+ ``labels``, and ``scores``, the same as the ``InstanceData``
+ in other places.
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It usually includes ``bboxes``, with shape (k, 4),
+ and ``labels``, with shape (k, ).
+ gt_instances_ignore (:obj:`InstanceData`, optional): Instances
+ to be ignored during training. It includes ``bboxes``
+ attribute data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ :obj:`AssignResult`: The assign result.
+
+ Example:
+ >>> from mmengine.structures import InstanceData
+ >>> self = MaxIoUAssigner(0.5, 0.5)
+ >>> pred_instances = InstanceData()
+ >>> pred_instances.priors = torch.Tensor([[0, 0, 10, 10],
+ ... [10, 10, 20, 20]])
+ >>> gt_instances = InstanceData()
+ >>> gt_instances.bboxes = torch.Tensor([[0, 0, 10, 9]])
+ >>> gt_instances.labels = torch.Tensor([0])
+ >>> assign_result = self.assign(pred_instances, gt_instances)
+ >>> expected_gt_inds = torch.LongTensor([1, 0])
+ >>> assert torch.all(assign_result.gt_inds == expected_gt_inds)
+ """
+ gt_bboxes = gt_instances.bboxes
+ priors = pred_instances.priors
+ gt_labels = gt_instances.labels
+ if gt_instances_ignore is not None:
+ gt_bboxes_ignore = gt_instances_ignore.bboxes
+ else:
+ gt_bboxes_ignore = None
+
+ assign_on_cpu = True if (self.gpu_assign_thr > 0) and (
+ gt_bboxes.shape[0] > self.gpu_assign_thr) else False
+ # compute overlap and assign gt on CPU when number of GT is large
+ if assign_on_cpu:
+ device = priors.device
+ priors = priors.cpu()
+ gt_bboxes = gt_bboxes.cpu()
+ gt_labels = gt_labels.cpu()
+ if gt_bboxes_ignore is not None:
+ gt_bboxes_ignore = gt_bboxes_ignore.cpu()
+
+ overlaps = self.iou_calculator(gt_bboxes, priors)
+
+ if (self.ignore_iof_thr > 0 and gt_bboxes_ignore is not None
+ and gt_bboxes_ignore.numel() > 0 and priors.numel() > 0):
+ if self.ignore_wrt_candidates:
+ ignore_overlaps = self.iou_calculator(
+ priors, gt_bboxes_ignore, mode='iof')
+ ignore_max_overlaps, _ = ignore_overlaps.max(dim=1)
+ else:
+ ignore_overlaps = self.iou_calculator(
+ gt_bboxes_ignore, priors, mode='iof')
+ ignore_max_overlaps, _ = ignore_overlaps.max(dim=0)
+ overlaps[:, ignore_max_overlaps > self.ignore_iof_thr] = -1
+
+ assign_result = self.assign_wrt_overlaps(overlaps, gt_labels)
+ if assign_on_cpu:
+ assign_result.gt_inds = assign_result.gt_inds.to(device)
+ assign_result.max_overlaps = assign_result.max_overlaps.to(device)
+ if assign_result.labels is not None:
+ assign_result.labels = assign_result.labels.to(device)
+ return assign_result
+
+ def assign_wrt_overlaps(self, overlaps: Tensor,
+ gt_labels: Tensor) -> AssignResult:
+ """Assign w.r.t. the overlaps of priors with gts.
+
+ Args:
+ overlaps (Tensor): Overlaps between k gt_bboxes and n bboxes,
+ shape(k, n).
+ gt_labels (Tensor): Labels of k gt_bboxes, shape (k, ).
+
+ Returns:
+ :obj:`AssignResult`: The assign result.
+ """
+ num_gts, num_bboxes = overlaps.size(0), overlaps.size(1)
+
+ # 1. assign -1 by default
+ assigned_gt_inds = overlaps.new_full((num_bboxes, ),
+ -1,
+ dtype=torch.long)
+
+ if num_gts == 0 or num_bboxes == 0:
+ # No ground truth or boxes, return empty assignment
+ max_overlaps = overlaps.new_zeros((num_bboxes, ))
+ assigned_labels = overlaps.new_full((num_bboxes, ),
+ -1,
+ dtype=torch.long)
+ if num_gts == 0:
+ # No truth, assign everything to background
+ assigned_gt_inds[:] = 0
+ return AssignResult(
+ num_gts=num_gts,
+ gt_inds=assigned_gt_inds,
+ max_overlaps=max_overlaps,
+ labels=assigned_labels)
+
+ # for each anchor, which gt best overlaps with it
+ # for each anchor, the max iou of all gts
+ max_overlaps, argmax_overlaps = overlaps.max(dim=0)
+ # for each gt, which anchor best overlaps with it
+ # for each gt, the max iou of all proposals
+ gt_max_overlaps, gt_argmax_overlaps = overlaps.max(dim=1)
+
+ # 2. assign negative: below
+ # the negative inds are set to be 0
+ if isinstance(self.neg_iou_thr, float):
+ assigned_gt_inds[(max_overlaps >= 0)
+ & (max_overlaps < self.neg_iou_thr)] = 0
+ elif isinstance(self.neg_iou_thr, tuple):
+ assert len(self.neg_iou_thr) == 2
+ assigned_gt_inds[(max_overlaps >= self.neg_iou_thr[0])
+ & (max_overlaps < self.neg_iou_thr[1])] = 0
+
+ # 3. assign positive: above positive IoU threshold
+ pos_inds = max_overlaps >= self.pos_iou_thr
+ assigned_gt_inds[pos_inds] = argmax_overlaps[pos_inds] + 1
+
+ if self.match_low_quality:
+ # Low-quality matching will overwrite the assigned_gt_inds assigned
+ # in Step 3. Thus, the assigned gt might not be the best one for
+ # prediction.
+ # For example, if bbox A has 0.9 and 0.8 iou with GT bbox 1 & 2,
+ # bbox 1 will be assigned as the best target for bbox A in step 3.
+ # However, if GT bbox 2's gt_argmax_overlaps = A, bbox A's
+ # assigned_gt_inds will be overwritten to be bbox 2.
+ # This might be the reason that it is not used in ROI Heads.
+ for i in range(num_gts):
+ if gt_max_overlaps[i] >= self.min_pos_iou:
+ if self.gt_max_assign_all:
+ max_iou_inds = overlaps[i, :] == gt_max_overlaps[i]
+ assigned_gt_inds[max_iou_inds] = i + 1
+ else:
+ assigned_gt_inds[gt_argmax_overlaps[i]] = i + 1
+
+ assigned_labels = assigned_gt_inds.new_full((num_bboxes, ), -1)
+ pos_inds = torch.nonzero(
+ assigned_gt_inds > 0, as_tuple=False).squeeze()
+ if pos_inds.numel() > 0:
+ assigned_labels[pos_inds] = gt_labels[assigned_gt_inds[pos_inds] -
+ 1]
+
+ return AssignResult(
+ num_gts=num_gts,
+ gt_inds=assigned_gt_inds,
+ max_overlaps=max_overlaps,
+ labels=assigned_labels)
diff --git a/mmdet/models/task_modules/assigners/mix_hungarian_iou_assigner.py b/mmdet/models/task_modules/assigners/mix_hungarian_iou_assigner.py
new file mode 100644
index 0000000000000000000000000000000000000000..8742c6c84db9b3a029bb7ec64142bc2875a412c0
--- /dev/null
+++ b/mmdet/models/task_modules/assigners/mix_hungarian_iou_assigner.py
@@ -0,0 +1,194 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Optional, Union
+
+import torch
+import numpy as np
+from mmengine import ConfigDict
+from mmengine.structures import InstanceData
+from scipy.optimize import linear_sum_assignment
+from torch import Tensor
+
+from mmdet.registry import TASK_UTILS
+from .assign_result import AssignResult
+from .base_assigner import BaseAssigner
+
+
+@TASK_UTILS.register_module()
+class MixHungarianIouAssigner(BaseAssigner):
+ """Computes one-to-one matching between predictions and ground truth.
+
+ This class computes an assignment between the targets and the predictions
+ based on the costs. The costs are weighted sum of some components.
+ For DETR the costs are weighted sum of classification cost, regression L1
+ cost and regression iou cost. The targets don't include the no_object, so
+ generally there are more predictions than targets. After the one-to-one
+ matching, the un-matched are treated as backgrounds. Thus each query
+ prediction will be assigned with `0` or a positive integer indicating the
+ ground truth index:
+
+ - 0: negative sample, no assigned gt
+ - positive integer: positive sample, index (1-based) of assigned gt
+
+ Args:
+ match_costs (:obj:`ConfigDict` or dict or \
+ List[Union[:obj:`ConfigDict`, dict]]): Match cost configs.
+ """
+
+ def __init__(
+ self,
+ match_costs: Union[List[Union[dict, ConfigDict]], dict,
+ ConfigDict],
+ base_match_num: int = 1,
+ match_num: int = 1,
+ iou_th: float =0.05,
+ total_num_max: int = 100,
+ dynamic_match: bool = True,
+ ) -> None:
+
+ if isinstance(match_costs, dict):
+ match_costs = [match_costs]
+ elif isinstance(match_costs, list):
+ assert len(match_costs) > 0, \
+ 'match_costs must not be a empty list.'
+ self.match_num = match_num
+ self.dynamic_match = dynamic_match
+ self.base_match_num = base_match_num
+ self.iou_th =iou_th
+ self.total_num_max = total_num_max
+ self.match_costs = [
+ TASK_UTILS.build(match_cost) for match_cost in match_costs
+ ]
+
+ def assign(self,
+ pred_instances: InstanceData,
+ gt_instances: InstanceData,
+ img_meta: Optional[dict] = None,
+ **kwargs) -> AssignResult:
+ """Computes one-to-one matching based on the weighted costs.
+
+ This method assign each query prediction to a ground truth or
+ background. The `assigned_gt_inds` with -1 means don't care,
+ 0 means negative sample, and positive number is the index (1-based)
+ of assigned gt.
+ The assignment is done in the following steps, the order matters.
+
+ 1. assign every prediction to -1
+ 2. compute the weighted costs
+ 3. do Hungarian matching on CPU based on the costs
+ 4. assign all to 0 (background) first, then for each matched pair
+ between predictions and gts, treat this prediction as foreground
+ and assign the corresponding gt index (plus 1) to it.
+
+ Args:
+ pred_instances (:obj:`InstanceData`): Instances of model
+ predictions. It includes ``priors``, and the priors can
+ be anchors or points, or the bboxes predicted by the
+ previous stage, has shape (n, 4). The bboxes predicted by
+ the current model or stage will be named ``bboxes``,
+ ``labels``, and ``scores``, the same as the ``InstanceData``
+ in other places. It may includes ``masks``, with shape
+ (n, h, w) or (n, l).
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It usually includes ``bboxes``, with shape (k, 4),
+ ``labels``, with shape (k, ) and ``masks``, with shape
+ (k, h, w) or (k, l).
+ img_meta (dict): Image information.
+
+ Returns:
+ :obj:`AssignResult`: The assigned result.
+ """
+ assert isinstance(gt_instances.labels, Tensor)
+ num_gts, num_preds = len(gt_instances), len(pred_instances)
+ gt_labels = gt_instances.labels
+ device = gt_labels.device
+
+ # 1. assign -1 by default
+ assigned_gt_inds = torch.full((num_preds, ),
+ -1,
+ dtype=torch.long,
+ device=device)
+ assigned_labels = torch.full((num_preds, ),
+ -1,
+ dtype=torch.long,
+ device=device)
+
+ if num_gts == 0 or num_preds == 0:
+ # No ground truth or boxes, return empty assignment
+ if num_gts == 0:
+ # No ground truth, assign all to background
+ assigned_gt_inds[:] = 0
+ return AssignResult(
+ num_gts=num_gts,
+ gt_inds=assigned_gt_inds,
+ max_overlaps=None,
+ labels=assigned_labels)
+
+ # 2. compute weighted cost
+ cost_list = []
+ for match_cost in self.match_costs:
+ cost = match_cost(
+ pred_instances=pred_instances,
+ gt_instances=gt_instances,
+ img_meta=img_meta)
+ cost_list.append(cost)
+ cost1 = cost_list[:-1]
+ cost1 = torch.stack(cost1).sum(dim=0)
+ cost2 = cost_list[-1]
+
+ # cost = torch.stack(cost_list).sum(dim=0) # 先求900query与每个gt的cost,不同类型的cost相加
+
+ # 3. do Hungarian matching on CPU using linear_sum_assignment
+ # cost = cost.detach().cpu()
+ cost1 =cost1.detach().cpu()
+ # cost2 =cost2.detach().cpu()
+ cost_max1 = torch.max(cost1)
+ cost_max2 = torch.max(cost2)
+ if linear_sum_assignment is None:
+ raise ImportError('Please run "pip install scipy" '
+ 'to install scipy first.')
+
+ # lzx
+ match_preds_max = self.total_num_max #int(num_preds/3)
+ matched_row_inds_all = np.empty((0,), dtype=np.int64)
+ matched_col_inds_all = np.empty((0,), dtype=np.int64)
+
+ matched_row_inds, matched_col_inds = linear_sum_assignment(cost1)
+ matched_row_inds_all = np.concatenate((matched_row_inds_all, matched_row_inds)) # 匹配上的查询索引
+ matched_col_inds_all = np.concatenate((matched_col_inds_all, matched_col_inds)) # 匹配上的真值索引
+ for ii in range(2, self.match_num+1):
+ if len(matched_col_inds_all) < match_preds_max:
+ cost1[matched_row_inds,:] = cost_max1
+ matched_row_inds, matched_col_inds = linear_sum_assignment(cost1)
+ if (len(matched_row_inds) + len(matched_col_inds_all)) > match_preds_max:
+ need_inds_num = len(matched_row_inds) + len(matched_col_inds_all) - match_preds_max
+ matched_row_inds = matched_row_inds[:need_inds_num]
+ matched_col_inds = matched_col_inds[:need_inds_num]
+ matched_row_inds_all = np.concatenate((matched_row_inds_all, matched_row_inds))
+ matched_col_inds_all = np.concatenate((matched_col_inds_all, matched_col_inds))
+ matched_row_inds = torch.from_numpy(matched_row_inds_all).to(device)
+ matched_col_inds = torch.from_numpy(matched_col_inds_all).to(device)
+ cost2[matched_row_inds_all, :] = cost_max2
+ overlaps = 1 - cost2.permute(1, 0)
+ # for each anchor, which gt best overlaps with it
+ # for each anchor, the max iou of all gts
+ max_overlaps, argmax_overlaps = overlaps.max(dim=0)
+ # for each gt, which anchor best overlaps with it
+ # for each gt, the max iou of all proposals
+ pos_inds = max_overlaps >= self.iou_th
+ matched_row_inds_new = torch.nonzero(pos_inds)
+ matched_row_inds_new = matched_row_inds_new.flatten()
+ matched_col_inds_new= argmax_overlaps[pos_inds]
+ matched_row_inds = torch.cat((matched_row_inds,matched_row_inds_new),dim=0)
+ matched_col_inds = torch.cat((matched_col_inds, matched_col_inds_new), dim=0)
+ # 4. assign backgrounds and foregrounds
+ # assign all indices to backgrounds first
+ assigned_gt_inds[:] = 0
+ # assign foregrounds based on matching results
+ assigned_gt_inds[matched_row_inds] = matched_col_inds + 1
+ assigned_labels[matched_row_inds] = gt_labels[matched_col_inds]
+
+ return AssignResult(
+ num_gts=num_gts,
+ gt_inds=assigned_gt_inds,
+ max_overlaps=None,
+ labels=assigned_labels)
diff --git a/mmdet/models/task_modules/assigners/multi_instance_assigner.py b/mmdet/models/task_modules/assigners/multi_instance_assigner.py
new file mode 100644
index 0000000000000000000000000000000000000000..1ba32afe856b3c2ad03ed89562d080f15b6ccf30
--- /dev/null
+++ b/mmdet/models/task_modules/assigners/multi_instance_assigner.py
@@ -0,0 +1,140 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional
+
+import torch
+from mmengine.structures import InstanceData
+
+from mmdet.registry import TASK_UTILS
+from .assign_result import AssignResult
+from .max_iou_assigner import MaxIoUAssigner
+
+
+@TASK_UTILS.register_module()
+class MultiInstanceAssigner(MaxIoUAssigner):
+ """Assign a corresponding gt bbox or background to each proposal bbox. If
+ we need to use a proposal box to generate multiple predict boxes,
+ `MultiInstanceAssigner` can assign multiple gt to each proposal box.
+
+ Args:
+ num_instance (int): How many bboxes are predicted by each proposal box.
+ """
+
+ def __init__(self, num_instance: int = 2, **kwargs):
+ super().__init__(**kwargs)
+ self.num_instance = num_instance
+
+ def assign(self,
+ pred_instances: InstanceData,
+ gt_instances: InstanceData,
+ gt_instances_ignore: Optional[InstanceData] = None,
+ **kwargs) -> AssignResult:
+ """Assign gt to bboxes.
+
+ This method assign gt bboxes to every bbox (proposal/anchor), each bbox
+ is assigned a set of gts, and the number of gts in this set is defined
+ by `self.num_instance`.
+
+ Args:
+ pred_instances (:obj:`InstanceData`): Instances of model
+ predictions. It includes ``priors``, and the priors can
+ be anchors or points, or the bboxes predicted by the
+ previous stage, has shape (n, 4). The bboxes predicted by
+ the current model or stage will be named ``bboxes``,
+ ``labels``, and ``scores``, the same as the ``InstanceData``
+ in other places.
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It usually includes ``bboxes``, with shape (k, 4),
+ and ``labels``, with shape (k, ).
+ gt_instances_ignore (:obj:`InstanceData`, optional): Instances
+ to be ignored during training. It includes ``bboxes``
+ attribute data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ :obj:`AssignResult`: The assign result.
+ """
+ gt_bboxes = gt_instances.bboxes
+ priors = pred_instances.priors
+ # Set the FG label to 1 and add ignored annotations
+ gt_labels = gt_instances.labels + 1
+ if gt_instances_ignore is not None:
+ gt_bboxes_ignore = gt_instances_ignore.bboxes
+ if hasattr(gt_instances_ignore, 'labels'):
+ gt_labels_ignore = gt_instances_ignore.labels
+ else:
+ gt_labels_ignore = torch.ones_like(gt_bboxes_ignore)[:, 0] * -1
+ else:
+ gt_bboxes_ignore = None
+ gt_labels_ignore = None
+
+ assign_on_cpu = True if (self.gpu_assign_thr > 0) and (
+ gt_bboxes.shape[0] > self.gpu_assign_thr) else False
+ # compute overlap and assign gt on CPU when number of GT is large
+ if assign_on_cpu:
+ device = priors.device
+ priors = priors.cpu()
+ gt_bboxes = gt_bboxes.cpu()
+ gt_labels = gt_labels.cpu()
+ if gt_bboxes_ignore is not None:
+ gt_bboxes_ignore = gt_bboxes_ignore.cpu()
+ gt_labels_ignore = gt_labels_ignore.cpu()
+
+ if gt_bboxes_ignore is not None:
+ all_bboxes = torch.cat([gt_bboxes, gt_bboxes_ignore], dim=0)
+ all_labels = torch.cat([gt_labels, gt_labels_ignore], dim=0)
+ else:
+ all_bboxes = gt_bboxes
+ all_labels = gt_labels
+ all_priors = torch.cat([priors, all_bboxes], dim=0)
+
+ overlaps_normal = self.iou_calculator(
+ all_priors, all_bboxes, mode='iou')
+ overlaps_ignore = self.iou_calculator(
+ all_priors, all_bboxes, mode='iof')
+ gt_ignore_mask = all_labels.eq(-1).repeat(all_priors.shape[0], 1)
+ overlaps_normal = overlaps_normal * ~gt_ignore_mask
+ overlaps_ignore = overlaps_ignore * gt_ignore_mask
+
+ overlaps_normal, overlaps_normal_indices = overlaps_normal.sort(
+ descending=True, dim=1)
+ overlaps_ignore, overlaps_ignore_indices = overlaps_ignore.sort(
+ descending=True, dim=1)
+
+ # select the roi with the higher score
+ max_overlaps_normal = overlaps_normal[:, :self.num_instance].flatten()
+ gt_assignment_normal = overlaps_normal_indices[:, :self.
+ num_instance].flatten()
+ max_overlaps_ignore = overlaps_ignore[:, :self.num_instance].flatten()
+ gt_assignment_ignore = overlaps_ignore_indices[:, :self.
+ num_instance].flatten()
+
+ # ignore or not
+ ignore_assign_mask = (max_overlaps_normal < self.pos_iou_thr) * (
+ max_overlaps_ignore > max_overlaps_normal)
+ overlaps = (max_overlaps_normal * ~ignore_assign_mask) + (
+ max_overlaps_ignore * ignore_assign_mask)
+ gt_assignment = (gt_assignment_normal * ~ignore_assign_mask) + (
+ gt_assignment_ignore * ignore_assign_mask)
+
+ assigned_labels = all_labels[gt_assignment]
+ fg_mask = (overlaps >= self.pos_iou_thr) * (assigned_labels != -1)
+ bg_mask = (overlaps < self.neg_iou_thr) * (overlaps >= 0)
+ assigned_labels[fg_mask] = 1
+ assigned_labels[bg_mask] = 0
+
+ overlaps = overlaps.reshape(-1, self.num_instance)
+ gt_assignment = gt_assignment.reshape(-1, self.num_instance)
+ assigned_labels = assigned_labels.reshape(-1, self.num_instance)
+
+ assign_result = AssignResult(
+ num_gts=all_bboxes.size(0),
+ gt_inds=gt_assignment,
+ max_overlaps=overlaps,
+ labels=assigned_labels)
+
+ if assign_on_cpu:
+ assign_result.gt_inds = assign_result.gt_inds.to(device)
+ assign_result.max_overlaps = assign_result.max_overlaps.to(device)
+ if assign_result.labels is not None:
+ assign_result.labels = assign_result.labels.to(device)
+ return assign_result
diff --git a/mmdet/models/task_modules/assigners/point_assigner.py b/mmdet/models/task_modules/assigners/point_assigner.py
new file mode 100644
index 0000000000000000000000000000000000000000..4da60a490b0022ac76c46db8a34f814bc9da8e2e
--- /dev/null
+++ b/mmdet/models/task_modules/assigners/point_assigner.py
@@ -0,0 +1,155 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional
+
+import torch
+from mmengine.structures import InstanceData
+
+from mmdet.registry import TASK_UTILS
+from .assign_result import AssignResult
+from .base_assigner import BaseAssigner
+
+
+@TASK_UTILS.register_module()
+class PointAssigner(BaseAssigner):
+ """Assign a corresponding gt bbox or background to each point.
+
+ Each proposals will be assigned with `0`, or a positive integer
+ indicating the ground truth index.
+
+ - 0: negative sample, no assigned gt
+ - positive integer: positive sample, index (1-based) of assigned gt
+ """
+
+ def __init__(self, scale: int = 4, pos_num: int = 3) -> None:
+ self.scale = scale
+ self.pos_num = pos_num
+
+ def assign(self,
+ pred_instances: InstanceData,
+ gt_instances: InstanceData,
+ gt_instances_ignore: Optional[InstanceData] = None,
+ **kwargs) -> AssignResult:
+ """Assign gt to points.
+
+ This method assign a gt bbox to every points set, each points set
+ will be assigned with the background_label (-1), or a label number.
+ -1 is background, and semi-positive number is the index (0-based) of
+ assigned gt.
+ The assignment is done in following steps, the order matters.
+
+ 1. assign every points to the background_label (-1)
+ 2. A point is assigned to some gt bbox if
+ (i) the point is within the k closest points to the gt bbox
+ (ii) the distance between this point and the gt is smaller than
+ other gt bboxes
+
+ Args:
+ pred_instances (:obj:`InstanceData`): Instances of model
+ predictions. It includes ``priors``, and the priors can
+ be anchors or points, or the bboxes predicted by the
+ previous stage, has shape (n, 4). The bboxes predicted by
+ the current model or stage will be named ``bboxes``,
+ ``labels``, and ``scores``, the same as the ``InstanceData``
+ in other places.
+
+
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It usually includes ``bboxes``, with shape (k, 4),
+ and ``labels``, with shape (k, ).
+ gt_instances_ignore (:obj:`InstanceData`, optional): Instances
+ to be ignored during training. It includes ``bboxes``
+ attribute data that is ignored during training and testing.
+ Defaults to None.
+ Returns:
+ :obj:`AssignResult`: The assign result.
+ """
+ gt_bboxes = gt_instances.bboxes
+ gt_labels = gt_instances.labels
+ # points to be assigned, shape(n, 3) while last
+ # dimension stands for (x, y, stride).
+ points = pred_instances.priors
+
+ num_points = points.shape[0]
+ num_gts = gt_bboxes.shape[0]
+
+ if num_gts == 0 or num_points == 0:
+ # If no truth assign everything to the background
+ assigned_gt_inds = points.new_full((num_points, ),
+ 0,
+ dtype=torch.long)
+ assigned_labels = points.new_full((num_points, ),
+ -1,
+ dtype=torch.long)
+ return AssignResult(
+ num_gts=num_gts,
+ gt_inds=assigned_gt_inds,
+ max_overlaps=None,
+ labels=assigned_labels)
+
+ points_xy = points[:, :2]
+ points_stride = points[:, 2]
+ points_lvl = torch.log2(
+ points_stride).int() # [3...,4...,5...,6...,7...]
+ lvl_min, lvl_max = points_lvl.min(), points_lvl.max()
+
+ # assign gt box
+ gt_bboxes_xy = (gt_bboxes[:, :2] + gt_bboxes[:, 2:]) / 2
+ gt_bboxes_wh = (gt_bboxes[:, 2:] - gt_bboxes[:, :2]).clamp(min=1e-6)
+ scale = self.scale
+ gt_bboxes_lvl = ((torch.log2(gt_bboxes_wh[:, 0] / scale) +
+ torch.log2(gt_bboxes_wh[:, 1] / scale)) / 2).int()
+ gt_bboxes_lvl = torch.clamp(gt_bboxes_lvl, min=lvl_min, max=lvl_max)
+
+ # stores the assigned gt index of each point
+ assigned_gt_inds = points.new_zeros((num_points, ), dtype=torch.long)
+ # stores the assigned gt dist (to this point) of each point
+ assigned_gt_dist = points.new_full((num_points, ), float('inf'))
+ points_range = torch.arange(points.shape[0])
+
+ for idx in range(num_gts):
+ gt_lvl = gt_bboxes_lvl[idx]
+ # get the index of points in this level
+ lvl_idx = gt_lvl == points_lvl
+ points_index = points_range[lvl_idx]
+ # get the points in this level
+ lvl_points = points_xy[lvl_idx, :]
+ # get the center point of gt
+ gt_point = gt_bboxes_xy[[idx], :]
+ # get width and height of gt
+ gt_wh = gt_bboxes_wh[[idx], :]
+ # compute the distance between gt center and
+ # all points in this level
+ points_gt_dist = ((lvl_points - gt_point) / gt_wh).norm(dim=1)
+ # find the nearest k points to gt center in this level
+ min_dist, min_dist_index = torch.topk(
+ points_gt_dist, self.pos_num, largest=False)
+ # the index of nearest k points to gt center in this level
+ min_dist_points_index = points_index[min_dist_index]
+ # The less_than_recorded_index stores the index
+ # of min_dist that is less then the assigned_gt_dist. Where
+ # assigned_gt_dist stores the dist from previous assigned gt
+ # (if exist) to each point.
+ less_than_recorded_index = min_dist < assigned_gt_dist[
+ min_dist_points_index]
+ # The min_dist_points_index stores the index of points satisfy:
+ # (1) it is k nearest to current gt center in this level.
+ # (2) it is closer to current gt center than other gt center.
+ min_dist_points_index = min_dist_points_index[
+ less_than_recorded_index]
+ # assign the result
+ assigned_gt_inds[min_dist_points_index] = idx + 1
+ assigned_gt_dist[min_dist_points_index] = min_dist[
+ less_than_recorded_index]
+
+ assigned_labels = assigned_gt_inds.new_full((num_points, ), -1)
+ pos_inds = torch.nonzero(
+ assigned_gt_inds > 0, as_tuple=False).squeeze()
+ if pos_inds.numel() > 0:
+ assigned_labels[pos_inds] = gt_labels[assigned_gt_inds[pos_inds] -
+ 1]
+
+ return AssignResult(
+ num_gts=num_gts,
+ gt_inds=assigned_gt_inds,
+ max_overlaps=None,
+ labels=assigned_labels)
diff --git a/mmdet/models/task_modules/assigners/region_assigner.py b/mmdet/models/task_modules/assigners/region_assigner.py
new file mode 100644
index 0000000000000000000000000000000000000000..df549143086c1195efaf12a2f3e81259da0e6c97
--- /dev/null
+++ b/mmdet/models/task_modules/assigners/region_assigner.py
@@ -0,0 +1,239 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Optional, Tuple
+
+import torch
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmdet.registry import TASK_UTILS
+from ..prior_generators import anchor_inside_flags
+from .assign_result import AssignResult
+from .base_assigner import BaseAssigner
+
+
+def calc_region(
+ bbox: Tensor,
+ ratio: float,
+ stride: int,
+ featmap_size: Optional[Tuple[int, int]] = None) -> Tuple[Tensor]:
+ """Calculate region of the box defined by the ratio, the ratio is from the
+ center of the box to every edge."""
+ # project bbox on the feature
+ f_bbox = bbox / stride
+ x1 = torch.round((1 - ratio) * f_bbox[0] + ratio * f_bbox[2])
+ y1 = torch.round((1 - ratio) * f_bbox[1] + ratio * f_bbox[3])
+ x2 = torch.round(ratio * f_bbox[0] + (1 - ratio) * f_bbox[2])
+ y2 = torch.round(ratio * f_bbox[1] + (1 - ratio) * f_bbox[3])
+ if featmap_size is not None:
+ x1 = x1.clamp(min=0, max=featmap_size[1])
+ y1 = y1.clamp(min=0, max=featmap_size[0])
+ x2 = x2.clamp(min=0, max=featmap_size[1])
+ y2 = y2.clamp(min=0, max=featmap_size[0])
+ return (x1, y1, x2, y2)
+
+
+def anchor_ctr_inside_region_flags(anchors: Tensor, stride: int,
+ region: Tuple[Tensor]) -> Tensor:
+ """Get the flag indicate whether anchor centers are inside regions."""
+ x1, y1, x2, y2 = region
+ f_anchors = anchors / stride
+ x = (f_anchors[:, 0] + f_anchors[:, 2]) * 0.5
+ y = (f_anchors[:, 1] + f_anchors[:, 3]) * 0.5
+ flags = (x >= x1) & (x <= x2) & (y >= y1) & (y <= y2)
+ return flags
+
+
+@TASK_UTILS.register_module()
+class RegionAssigner(BaseAssigner):
+ """Assign a corresponding gt bbox or background to each bbox.
+
+ Each proposals will be assigned with `-1`, `0`, or a positive integer
+ indicating the ground truth index.
+
+ - -1: don't care
+ - 0: negative sample, no assigned gt
+ - positive integer: positive sample, index (1-based) of assigned gt
+
+ Args:
+ center_ratio (float): ratio of the region in the center of the bbox to
+ define positive sample.
+ ignore_ratio (float): ratio of the region to define ignore samples.
+ """
+
+ def __init__(self,
+ center_ratio: float = 0.2,
+ ignore_ratio: float = 0.5) -> None:
+ self.center_ratio = center_ratio
+ self.ignore_ratio = ignore_ratio
+
+ def assign(self,
+ pred_instances: InstanceData,
+ gt_instances: InstanceData,
+ img_meta: dict,
+ featmap_sizes: List[Tuple[int, int]],
+ num_level_anchors: List[int],
+ anchor_scale: int,
+ anchor_strides: List[int],
+ gt_instances_ignore: Optional[InstanceData] = None,
+ allowed_border: int = 0) -> AssignResult:
+ """Assign gt to anchors.
+
+ This method assign a gt bbox to every bbox (proposal/anchor), each bbox
+ will be assigned with -1, 0, or a positive number. -1 means don't care,
+ 0 means negative sample, positive number is the index (1-based) of
+ assigned gt.
+
+ The assignment is done in following steps, and the order matters.
+
+ 1. Assign every anchor to 0 (negative)
+ 2. (For each gt_bboxes) Compute ignore flags based on ignore_region
+ then assign -1 to anchors w.r.t. ignore flags
+ 3. (For each gt_bboxes) Compute pos flags based on center_region then
+ assign gt_bboxes to anchors w.r.t. pos flags
+ 4. (For each gt_bboxes) Compute ignore flags based on adjacent anchor
+ level then assign -1 to anchors w.r.t. ignore flags
+ 5. Assign anchor outside of image to -1
+
+ Args:
+ pred_instances (:obj:`InstanceData`): Instances of model
+ predictions. It includes ``priors``, and the priors can
+ be anchors or points, or the bboxes predicted by the
+ previous stage, has shape (n, 4). The bboxes predicted by
+ the current model or stage will be named ``bboxes``,
+ ``labels``, and ``scores``, the same as the ``InstanceData``
+ in other places.
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It usually includes ``bboxes``, with shape (k, 4),
+ and ``labels``, with shape (k, ).
+ img_meta (dict): Meta info of image.
+ featmap_sizes (list[tuple[int, int]]): Feature map size each level.
+ num_level_anchors (list[int]): The number of anchors in each level.
+ anchor_scale (int): Scale of the anchor.
+ anchor_strides (list[int]): Stride of the anchor.
+ gt_instances_ignore (:obj:`InstanceData`, optional): Instances
+ to be ignored during training. It includes ``bboxes``
+ attribute data that is ignored during training and testing.
+ Defaults to None.
+ allowed_border (int, optional): The border to allow the valid
+ anchor. Defaults to 0.
+
+ Returns:
+ :obj:`AssignResult`: The assign result.
+ """
+ if gt_instances_ignore is not None:
+ raise NotImplementedError
+
+ num_gts = len(gt_instances)
+ num_bboxes = len(pred_instances)
+
+ gt_bboxes = gt_instances.bboxes
+ gt_labels = gt_instances.labels
+ flat_anchors = pred_instances.priors
+ flat_valid_flags = pred_instances.valid_flags
+ mlvl_anchors = torch.split(flat_anchors, num_level_anchors)
+
+ if num_gts == 0 or num_bboxes == 0:
+ # No ground truth or boxes, return empty assignment
+ max_overlaps = gt_bboxes.new_zeros((num_bboxes, ))
+ assigned_gt_inds = gt_bboxes.new_zeros((num_bboxes, ),
+ dtype=torch.long)
+ assigned_labels = gt_bboxes.new_full((num_bboxes, ),
+ -1,
+ dtype=torch.long)
+ return AssignResult(
+ num_gts=num_gts,
+ gt_inds=assigned_gt_inds,
+ max_overlaps=max_overlaps,
+ labels=assigned_labels)
+
+ num_lvls = len(mlvl_anchors)
+ r1 = (1 - self.center_ratio) / 2
+ r2 = (1 - self.ignore_ratio) / 2
+
+ scale = torch.sqrt((gt_bboxes[:, 2] - gt_bboxes[:, 0]) *
+ (gt_bboxes[:, 3] - gt_bboxes[:, 1]))
+ min_anchor_size = scale.new_full(
+ (1, ), float(anchor_scale * anchor_strides[0]))
+ target_lvls = torch.floor(
+ torch.log2(scale) - torch.log2(min_anchor_size) + 0.5)
+ target_lvls = target_lvls.clamp(min=0, max=num_lvls - 1).long()
+
+ # 1. assign 0 (negative) by default
+ mlvl_assigned_gt_inds = []
+ mlvl_ignore_flags = []
+ for lvl in range(num_lvls):
+ assigned_gt_inds = gt_bboxes.new_full((num_level_anchors[lvl], ),
+ 0,
+ dtype=torch.long)
+ ignore_flags = torch.zeros_like(assigned_gt_inds)
+ mlvl_assigned_gt_inds.append(assigned_gt_inds)
+ mlvl_ignore_flags.append(ignore_flags)
+
+ for gt_id in range(num_gts):
+ lvl = target_lvls[gt_id].item()
+ featmap_size = featmap_sizes[lvl]
+ stride = anchor_strides[lvl]
+ anchors = mlvl_anchors[lvl]
+ gt_bbox = gt_bboxes[gt_id, :4]
+
+ # Compute regions
+ ignore_region = calc_region(gt_bbox, r2, stride, featmap_size)
+ ctr_region = calc_region(gt_bbox, r1, stride, featmap_size)
+
+ # 2. Assign -1 to ignore flags
+ ignore_flags = anchor_ctr_inside_region_flags(
+ anchors, stride, ignore_region)
+ mlvl_assigned_gt_inds[lvl][ignore_flags] = -1
+
+ # 3. Assign gt_bboxes to pos flags
+ pos_flags = anchor_ctr_inside_region_flags(anchors, stride,
+ ctr_region)
+ mlvl_assigned_gt_inds[lvl][pos_flags] = gt_id + 1
+
+ # 4. Assign -1 to ignore adjacent lvl
+ if lvl > 0:
+ d_lvl = lvl - 1
+ d_anchors = mlvl_anchors[d_lvl]
+ d_featmap_size = featmap_sizes[d_lvl]
+ d_stride = anchor_strides[d_lvl]
+ d_ignore_region = calc_region(gt_bbox, r2, d_stride,
+ d_featmap_size)
+ ignore_flags = anchor_ctr_inside_region_flags(
+ d_anchors, d_stride, d_ignore_region)
+ mlvl_ignore_flags[d_lvl][ignore_flags] = 1
+ if lvl < num_lvls - 1:
+ u_lvl = lvl + 1
+ u_anchors = mlvl_anchors[u_lvl]
+ u_featmap_size = featmap_sizes[u_lvl]
+ u_stride = anchor_strides[u_lvl]
+ u_ignore_region = calc_region(gt_bbox, r2, u_stride,
+ u_featmap_size)
+ ignore_flags = anchor_ctr_inside_region_flags(
+ u_anchors, u_stride, u_ignore_region)
+ mlvl_ignore_flags[u_lvl][ignore_flags] = 1
+
+ # 4. (cont.) Assign -1 to ignore adjacent lvl
+ for lvl in range(num_lvls):
+ ignore_flags = mlvl_ignore_flags[lvl]
+ mlvl_assigned_gt_inds[lvl][ignore_flags == 1] = -1
+
+ # 5. Assign -1 to anchor outside of image
+ flat_assigned_gt_inds = torch.cat(mlvl_assigned_gt_inds)
+ assert (flat_assigned_gt_inds.shape[0] == flat_anchors.shape[0] ==
+ flat_valid_flags.shape[0])
+ inside_flags = anchor_inside_flags(flat_anchors, flat_valid_flags,
+ img_meta['img_shape'],
+ allowed_border)
+ outside_flags = ~inside_flags
+ flat_assigned_gt_inds[outside_flags] = -1
+
+ assigned_labels = torch.zeros_like(flat_assigned_gt_inds)
+ pos_flags = flat_assigned_gt_inds > 0
+ assigned_labels[pos_flags] = gt_labels[flat_assigned_gt_inds[pos_flags]
+ - 1]
+
+ return AssignResult(
+ num_gts=num_gts,
+ gt_inds=flat_assigned_gt_inds,
+ max_overlaps=None,
+ labels=assigned_labels)
diff --git a/mmdet/models/task_modules/assigners/sim_ota_assigner.py b/mmdet/models/task_modules/assigners/sim_ota_assigner.py
new file mode 100644
index 0000000000000000000000000000000000000000..d54a8b91d132d9bf661267de666bfed7e915a65a
--- /dev/null
+++ b/mmdet/models/task_modules/assigners/sim_ota_assigner.py
@@ -0,0 +1,223 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Tuple
+
+import torch
+import torch.nn.functional as F
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmdet.registry import TASK_UTILS
+from mmdet.utils import ConfigType
+from .assign_result import AssignResult
+from .base_assigner import BaseAssigner
+
+INF = 100000.0
+EPS = 1.0e-7
+
+
+@TASK_UTILS.register_module()
+class SimOTAAssigner(BaseAssigner):
+ """Computes matching between predictions and ground truth.
+
+ Args:
+ center_radius (float): Ground truth center size
+ to judge whether a prior is in center. Defaults to 2.5.
+ candidate_topk (int): The candidate top-k which used to
+ get top-k ious to calculate dynamic-k. Defaults to 10.
+ iou_weight (float): The scale factor for regression
+ iou cost. Defaults to 3.0.
+ cls_weight (float): The scale factor for classification
+ cost. Defaults to 1.0.
+ iou_calculator (ConfigType): Config of overlaps Calculator.
+ Defaults to dict(type='BboxOverlaps2D').
+ """
+
+ def __init__(self,
+ center_radius: float = 2.5,
+ candidate_topk: int = 10,
+ iou_weight: float = 3.0,
+ cls_weight: float = 1.0,
+ iou_calculator: ConfigType = dict(type='BboxOverlaps2D')):
+ self.center_radius = center_radius
+ self.candidate_topk = candidate_topk
+ self.iou_weight = iou_weight
+ self.cls_weight = cls_weight
+ self.iou_calculator = TASK_UTILS.build(iou_calculator)
+
+ def assign(self,
+ pred_instances: InstanceData,
+ gt_instances: InstanceData,
+ gt_instances_ignore: Optional[InstanceData] = None,
+ **kwargs) -> AssignResult:
+ """Assign gt to priors using SimOTA.
+
+ Args:
+ pred_instances (:obj:`InstanceData`): Instances of model
+ predictions. It includes ``priors``, and the priors can
+ be anchors or points, or the bboxes predicted by the
+ previous stage, has shape (n, 4). The bboxes predicted by
+ the current model or stage will be named ``bboxes``,
+ ``labels``, and ``scores``, the same as the ``InstanceData``
+ in other places.
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It usually includes ``bboxes``, with shape (k, 4),
+ and ``labels``, with shape (k, ).
+ gt_instances_ignore (:obj:`InstanceData`, optional): Instances
+ to be ignored during training. It includes ``bboxes``
+ attribute data that is ignored during training and testing.
+ Defaults to None.
+ Returns:
+ obj:`AssignResult`: The assigned result.
+ """
+ gt_bboxes = gt_instances.bboxes
+ gt_labels = gt_instances.labels
+ num_gt = gt_bboxes.size(0)
+
+ decoded_bboxes = pred_instances.bboxes
+ pred_scores = pred_instances.scores
+ priors = pred_instances.priors
+ num_bboxes = decoded_bboxes.size(0)
+
+ # assign 0 by default
+ assigned_gt_inds = decoded_bboxes.new_full((num_bboxes, ),
+ 0,
+ dtype=torch.long)
+ if num_gt == 0 or num_bboxes == 0:
+ # No ground truth or boxes, return empty assignment
+ max_overlaps = decoded_bboxes.new_zeros((num_bboxes, ))
+ assigned_labels = decoded_bboxes.new_full((num_bboxes, ),
+ -1,
+ dtype=torch.long)
+ return AssignResult(
+ num_gt, assigned_gt_inds, max_overlaps, labels=assigned_labels)
+
+ valid_mask, is_in_boxes_and_center = self.get_in_gt_and_in_center_info(
+ priors, gt_bboxes)
+ valid_decoded_bbox = decoded_bboxes[valid_mask]
+ valid_pred_scores = pred_scores[valid_mask]
+ num_valid = valid_decoded_bbox.size(0)
+ if num_valid == 0:
+ # No valid bboxes, return empty assignment
+ max_overlaps = decoded_bboxes.new_zeros((num_bboxes, ))
+ assigned_labels = decoded_bboxes.new_full((num_bboxes, ),
+ -1,
+ dtype=torch.long)
+ return AssignResult(
+ num_gt, assigned_gt_inds, max_overlaps, labels=assigned_labels)
+
+ pairwise_ious = self.iou_calculator(valid_decoded_bbox, gt_bboxes)
+ iou_cost = -torch.log(pairwise_ious + EPS)
+
+ gt_onehot_label = (
+ F.one_hot(gt_labels.to(torch.int64),
+ pred_scores.shape[-1]).float().unsqueeze(0).repeat(
+ num_valid, 1, 1))
+
+ valid_pred_scores = valid_pred_scores.unsqueeze(1).repeat(1, num_gt, 1)
+ # disable AMP autocast and calculate BCE with FP32 to avoid overflow
+ with torch.cuda.amp.autocast(enabled=False):
+ cls_cost = (
+ F.binary_cross_entropy(
+ valid_pred_scores.to(dtype=torch.float32),
+ gt_onehot_label,
+ reduction='none',
+ ).sum(-1).to(dtype=valid_pred_scores.dtype))
+
+ cost_matrix = (
+ cls_cost * self.cls_weight + iou_cost * self.iou_weight +
+ (~is_in_boxes_and_center) * INF)
+
+ matched_pred_ious, matched_gt_inds = \
+ self.dynamic_k_matching(
+ cost_matrix, pairwise_ious, num_gt, valid_mask)
+
+ # convert to AssignResult format
+ assigned_gt_inds[valid_mask] = matched_gt_inds + 1
+ assigned_labels = assigned_gt_inds.new_full((num_bboxes, ), -1)
+ assigned_labels[valid_mask] = gt_labels[matched_gt_inds].long()
+ max_overlaps = assigned_gt_inds.new_full((num_bboxes, ),
+ -INF,
+ dtype=torch.float32)
+ max_overlaps[valid_mask] = matched_pred_ious
+ return AssignResult(
+ num_gt, assigned_gt_inds, max_overlaps, labels=assigned_labels)
+
+ def get_in_gt_and_in_center_info(
+ self, priors: Tensor, gt_bboxes: Tensor) -> Tuple[Tensor, Tensor]:
+ """Get the information of which prior is in gt bboxes and gt center
+ priors."""
+ num_gt = gt_bboxes.size(0)
+
+ repeated_x = priors[:, 0].unsqueeze(1).repeat(1, num_gt)
+ repeated_y = priors[:, 1].unsqueeze(1).repeat(1, num_gt)
+ repeated_stride_x = priors[:, 2].unsqueeze(1).repeat(1, num_gt)
+ repeated_stride_y = priors[:, 3].unsqueeze(1).repeat(1, num_gt)
+
+ # is prior centers in gt bboxes, shape: [n_prior, n_gt]
+ l_ = repeated_x - gt_bboxes[:, 0]
+ t_ = repeated_y - gt_bboxes[:, 1]
+ r_ = gt_bboxes[:, 2] - repeated_x
+ b_ = gt_bboxes[:, 3] - repeated_y
+
+ deltas = torch.stack([l_, t_, r_, b_], dim=1)
+ is_in_gts = deltas.min(dim=1).values > 0
+ is_in_gts_all = is_in_gts.sum(dim=1) > 0
+
+ # is prior centers in gt centers
+ gt_cxs = (gt_bboxes[:, 0] + gt_bboxes[:, 2]) / 2.0
+ gt_cys = (gt_bboxes[:, 1] + gt_bboxes[:, 3]) / 2.0
+ ct_box_l = gt_cxs - self.center_radius * repeated_stride_x
+ ct_box_t = gt_cys - self.center_radius * repeated_stride_y
+ ct_box_r = gt_cxs + self.center_radius * repeated_stride_x
+ ct_box_b = gt_cys + self.center_radius * repeated_stride_y
+
+ cl_ = repeated_x - ct_box_l
+ ct_ = repeated_y - ct_box_t
+ cr_ = ct_box_r - repeated_x
+ cb_ = ct_box_b - repeated_y
+
+ ct_deltas = torch.stack([cl_, ct_, cr_, cb_], dim=1)
+ is_in_cts = ct_deltas.min(dim=1).values > 0
+ is_in_cts_all = is_in_cts.sum(dim=1) > 0
+
+ # in boxes or in centers, shape: [num_priors]
+ is_in_gts_or_centers = is_in_gts_all | is_in_cts_all
+
+ # both in boxes and centers, shape: [num_fg, num_gt]
+ is_in_boxes_and_centers = (
+ is_in_gts[is_in_gts_or_centers, :]
+ & is_in_cts[is_in_gts_or_centers, :])
+ return is_in_gts_or_centers, is_in_boxes_and_centers
+
+ def dynamic_k_matching(self, cost: Tensor, pairwise_ious: Tensor,
+ num_gt: int,
+ valid_mask: Tensor) -> Tuple[Tensor, Tensor]:
+ """Use IoU and matching cost to calculate the dynamic top-k positive
+ targets."""
+ matching_matrix = torch.zeros_like(cost, dtype=torch.uint8)
+ # select candidate topk ious for dynamic-k calculation
+ candidate_topk = min(self.candidate_topk, pairwise_ious.size(0))
+ topk_ious, _ = torch.topk(pairwise_ious, candidate_topk, dim=0)
+ # calculate dynamic k for each gt
+ dynamic_ks = torch.clamp(topk_ious.sum(0).int(), min=1)
+ for gt_idx in range(num_gt):
+ _, pos_idx = torch.topk(
+ cost[:, gt_idx], k=dynamic_ks[gt_idx], largest=False)
+ matching_matrix[:, gt_idx][pos_idx] = 1
+
+ del topk_ious, dynamic_ks, pos_idx
+
+ prior_match_gt_mask = matching_matrix.sum(1) > 1
+ if prior_match_gt_mask.sum() > 0:
+ cost_min, cost_argmin = torch.min(
+ cost[prior_match_gt_mask, :], dim=1)
+ matching_matrix[prior_match_gt_mask, :] *= 0
+ matching_matrix[prior_match_gt_mask, cost_argmin] = 1
+ # get foreground mask inside box and center prior
+ fg_mask_inboxes = matching_matrix.sum(1) > 0
+ valid_mask[valid_mask.clone()] = fg_mask_inboxes
+
+ matched_gt_inds = matching_matrix[fg_mask_inboxes, :].argmax(1)
+ matched_pred_ious = (matching_matrix *
+ pairwise_ious).sum(1)[fg_mask_inboxes]
+ return matched_pred_ious, matched_gt_inds
diff --git a/mmdet/models/task_modules/assigners/task_aligned_assigner.py b/mmdet/models/task_modules/assigners/task_aligned_assigner.py
new file mode 100644
index 0000000000000000000000000000000000000000..220ea8485933ab3243f6c1e205dbf1b973df08d7
--- /dev/null
+++ b/mmdet/models/task_modules/assigners/task_aligned_assigner.py
@@ -0,0 +1,158 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional
+
+import torch
+from mmengine.structures import InstanceData
+
+from mmdet.registry import TASK_UTILS
+from mmdet.utils import ConfigType
+from .assign_result import AssignResult
+from .base_assigner import BaseAssigner
+
+INF = 100000000
+
+
+@TASK_UTILS.register_module()
+class TaskAlignedAssigner(BaseAssigner):
+ """Task aligned assigner used in the paper:
+ `TOOD: Task-aligned One-stage Object Detection.
+ `_.
+
+ Assign a corresponding gt bbox or background to each predicted bbox.
+ Each bbox will be assigned with `0` or a positive integer
+ indicating the ground truth index.
+
+ - 0: negative sample, no assigned gt
+ - positive integer: positive sample, index (1-based) of assigned gt
+
+ Args:
+ topk (int): number of bbox selected in each level
+ iou_calculator (:obj:`ConfigDict` or dict): Config dict for iou
+ calculator. Defaults to ``dict(type='BboxOverlaps2D')``
+ """
+
+ def __init__(self,
+ topk: int,
+ iou_calculator: ConfigType = dict(type='BboxOverlaps2D')):
+ assert topk >= 1
+ self.topk = topk
+ self.iou_calculator = TASK_UTILS.build(iou_calculator)
+
+ def assign(self,
+ pred_instances: InstanceData,
+ gt_instances: InstanceData,
+ gt_instances_ignore: Optional[InstanceData] = None,
+ alpha: int = 1,
+ beta: int = 6) -> AssignResult:
+ """Assign gt to bboxes.
+
+ The assignment is done in following steps
+
+ 1. compute alignment metric between all bbox (bbox of all pyramid
+ levels) and gt
+ 2. select top-k bbox as candidates for each gt
+ 3. limit the positive sample's center in gt (because the anchor-free
+ detector only can predict positive distance)
+
+
+ Args:
+ pred_instances (:obj:`InstaceData`): Instances of model
+ predictions. It includes ``priors``, and the priors can
+ be anchors, points, or bboxes predicted by the model,
+ shape(n, 4).
+ gt_instances (:obj:`InstaceData`): Ground truth of instance
+ annotations. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ gt_instances_ignore (:obj:`InstaceData`, optional): Instances
+ to be ignored during training. It includes ``bboxes``
+ attribute data that is ignored during training and testing.
+ Defaults to None.
+ alpha (int): Hyper-parameters related to alignment_metrics.
+ Defaults to 1.
+ beta (int): Hyper-parameters related to alignment_metrics.
+ Defaults to 6.
+
+ Returns:
+ :obj:`TaskAlignedAssignResult`: The assign result.
+ """
+ priors = pred_instances.priors
+ decode_bboxes = pred_instances.bboxes
+ pred_scores = pred_instances.scores
+ gt_bboxes = gt_instances.bboxes
+ gt_labels = gt_instances.labels
+
+ priors = priors[:, :4]
+ num_gt, num_bboxes = gt_bboxes.size(0), priors.size(0)
+ # compute alignment metric between all bbox and gt
+ overlaps = self.iou_calculator(decode_bboxes, gt_bboxes).detach()
+ bbox_scores = pred_scores[:, gt_labels].detach()
+ # assign 0 by default
+ assigned_gt_inds = priors.new_full((num_bboxes, ), 0, dtype=torch.long)
+ assign_metrics = priors.new_zeros((num_bboxes, ))
+
+ if num_gt == 0 or num_bboxes == 0:
+ # No ground truth or boxes, return empty assignment
+ max_overlaps = priors.new_zeros((num_bboxes, ))
+ if num_gt == 0:
+ # No gt boxes, assign everything to background
+ assigned_gt_inds[:] = 0
+ assigned_labels = priors.new_full((num_bboxes, ),
+ -1,
+ dtype=torch.long)
+ assign_result = AssignResult(
+ num_gt, assigned_gt_inds, max_overlaps, labels=assigned_labels)
+ assign_result.assign_metrics = assign_metrics
+ return assign_result
+
+ # select top-k bboxes as candidates for each gt
+ alignment_metrics = bbox_scores**alpha * overlaps**beta
+ topk = min(self.topk, alignment_metrics.size(0))
+ _, candidate_idxs = alignment_metrics.topk(topk, dim=0, largest=True)
+ candidate_metrics = alignment_metrics[candidate_idxs,
+ torch.arange(num_gt)]
+ is_pos = candidate_metrics > 0
+
+ # limit the positive sample's center in gt
+ priors_cx = (priors[:, 0] + priors[:, 2]) / 2.0
+ priors_cy = (priors[:, 1] + priors[:, 3]) / 2.0
+ for gt_idx in range(num_gt):
+ candidate_idxs[:, gt_idx] += gt_idx * num_bboxes
+ ep_priors_cx = priors_cx.view(1, -1).expand(
+ num_gt, num_bboxes).contiguous().view(-1)
+ ep_priors_cy = priors_cy.view(1, -1).expand(
+ num_gt, num_bboxes).contiguous().view(-1)
+ candidate_idxs = candidate_idxs.view(-1)
+
+ # calculate the left, top, right, bottom distance between positive
+ # bbox center and gt side
+ l_ = ep_priors_cx[candidate_idxs].view(-1, num_gt) - gt_bboxes[:, 0]
+ t_ = ep_priors_cy[candidate_idxs].view(-1, num_gt) - gt_bboxes[:, 1]
+ r_ = gt_bboxes[:, 2] - ep_priors_cx[candidate_idxs].view(-1, num_gt)
+ b_ = gt_bboxes[:, 3] - ep_priors_cy[candidate_idxs].view(-1, num_gt)
+ is_in_gts = torch.stack([l_, t_, r_, b_], dim=1).min(dim=1)[0] > 0.01
+ is_pos = is_pos & is_in_gts
+
+ # if an anchor box is assigned to multiple gts,
+ # the one with the highest iou will be selected.
+ overlaps_inf = torch.full_like(overlaps,
+ -INF).t().contiguous().view(-1)
+ index = candidate_idxs.view(-1)[is_pos.view(-1)]
+ overlaps_inf[index] = overlaps.t().contiguous().view(-1)[index]
+ overlaps_inf = overlaps_inf.view(num_gt, -1).t()
+
+ max_overlaps, argmax_overlaps = overlaps_inf.max(dim=1)
+ assigned_gt_inds[
+ max_overlaps != -INF] = argmax_overlaps[max_overlaps != -INF] + 1
+ assign_metrics[max_overlaps != -INF] = alignment_metrics[
+ max_overlaps != -INF, argmax_overlaps[max_overlaps != -INF]]
+
+ assigned_labels = assigned_gt_inds.new_full((num_bboxes, ), -1)
+ pos_inds = torch.nonzero(
+ assigned_gt_inds > 0, as_tuple=False).squeeze()
+ if pos_inds.numel() > 0:
+ assigned_labels[pos_inds] = gt_labels[assigned_gt_inds[pos_inds] -
+ 1]
+ assign_result = AssignResult(
+ num_gt, assigned_gt_inds, max_overlaps, labels=assigned_labels)
+ assign_result.assign_metrics = assign_metrics
+ return assign_result
diff --git a/mmdet/models/task_modules/assigners/uniform_assigner.py b/mmdet/models/task_modules/assigners/uniform_assigner.py
new file mode 100644
index 0000000000000000000000000000000000000000..9a83bfd0b46a3690dce9cf0adf2c1e676f304d06
--- /dev/null
+++ b/mmdet/models/task_modules/assigners/uniform_assigner.py
@@ -0,0 +1,173 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional
+
+import torch
+from mmengine.structures import InstanceData
+
+from mmdet.registry import TASK_UTILS
+from mmdet.structures.bbox import bbox_xyxy_to_cxcywh
+from mmdet.utils import ConfigType
+from .assign_result import AssignResult
+from .base_assigner import BaseAssigner
+
+
+@TASK_UTILS.register_module()
+class UniformAssigner(BaseAssigner):
+ """Uniform Matching between the priors and gt boxes, which can achieve
+ balance in positive priors, and gt_bboxes_ignore was not considered for
+ now.
+
+ Args:
+ pos_ignore_thr (float): the threshold to ignore positive priors
+ neg_ignore_thr (float): the threshold to ignore negative priors
+ match_times(int): Number of positive priors for each gt box.
+ Defaults to 4.
+ iou_calculator (:obj:`ConfigDict` or dict): Config dict for iou
+ calculator. Defaults to ``dict(type='BboxOverlaps2D')``
+ """
+
+ def __init__(self,
+ pos_ignore_thr: float,
+ neg_ignore_thr: float,
+ match_times: int = 4,
+ iou_calculator: ConfigType = dict(type='BboxOverlaps2D')):
+ self.match_times = match_times
+ self.pos_ignore_thr = pos_ignore_thr
+ self.neg_ignore_thr = neg_ignore_thr
+ self.iou_calculator = TASK_UTILS.build(iou_calculator)
+
+ def assign(
+ self,
+ pred_instances: InstanceData,
+ gt_instances: InstanceData,
+ gt_instances_ignore: Optional[InstanceData] = None
+ ) -> AssignResult:
+ """Assign gt to priors.
+
+ The assignment is done in following steps
+
+ 1. assign -1 by default
+ 2. compute the L1 cost between boxes. Note that we use priors and
+ predict boxes both
+ 3. compute the ignore indexes use gt_bboxes and predict boxes
+ 4. compute the ignore indexes of positive sample use priors and
+ predict boxes
+
+
+ Args:
+ pred_instances (:obj:`InstaceData`): Instances of model
+ predictions. It includes ``priors``, and the priors can
+ be priors, points, or bboxes predicted by the model,
+ shape(n, 4).
+ gt_instances (:obj:`InstaceData`): Ground truth of instance
+ annotations. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ gt_instances_ignore (:obj:`InstaceData`, optional): Instances
+ to be ignored during training. It includes ``bboxes``
+ attribute data that is ignored during training and testing.
+ Defaults to None.
+
+ Returns:
+ :obj:`AssignResult`: The assign result.
+ """
+
+ gt_bboxes = gt_instances.bboxes
+ gt_labels = gt_instances.labels
+ priors = pred_instances.priors
+ bbox_pred = pred_instances.decoder_priors
+
+ num_gts, num_bboxes = gt_bboxes.size(0), bbox_pred.size(0)
+
+ # 1. assign -1 by default
+ assigned_gt_inds = bbox_pred.new_full((num_bboxes, ),
+ 0,
+ dtype=torch.long)
+ assigned_labels = bbox_pred.new_full((num_bboxes, ),
+ -1,
+ dtype=torch.long)
+ if num_gts == 0 or num_bboxes == 0:
+ # No ground truth or boxes, return empty assignment
+ if num_gts == 0:
+ # No ground truth, assign all to background
+ assigned_gt_inds[:] = 0
+ assign_result = AssignResult(
+ num_gts, assigned_gt_inds, None, labels=assigned_labels)
+ assign_result.set_extra_property(
+ 'pos_idx', bbox_pred.new_empty(0, dtype=torch.bool))
+ assign_result.set_extra_property('pos_predicted_boxes',
+ bbox_pred.new_empty((0, 4)))
+ assign_result.set_extra_property('target_boxes',
+ bbox_pred.new_empty((0, 4)))
+ return assign_result
+
+ # 2. Compute the L1 cost between boxes
+ # Note that we use priors and predict boxes both
+ cost_bbox = torch.cdist(
+ bbox_xyxy_to_cxcywh(bbox_pred),
+ bbox_xyxy_to_cxcywh(gt_bboxes),
+ p=1)
+ cost_bbox_priors = torch.cdist(
+ bbox_xyxy_to_cxcywh(priors), bbox_xyxy_to_cxcywh(gt_bboxes), p=1)
+
+ # We found that topk function has different results in cpu and
+ # cuda mode. In order to ensure consistency with the source code,
+ # we also use cpu mode.
+ # TODO: Check whether the performance of cpu and cuda are the same.
+ C = cost_bbox.cpu()
+ C1 = cost_bbox_priors.cpu()
+
+ # self.match_times x n
+ index = torch.topk(
+ C, # c=b,n,x c[i]=n,x
+ k=self.match_times,
+ dim=0,
+ largest=False)[1]
+
+ # self.match_times x n
+ index1 = torch.topk(C1, k=self.match_times, dim=0, largest=False)[1]
+ # (self.match_times*2) x n
+ indexes = torch.cat((index, index1),
+ dim=1).reshape(-1).to(bbox_pred.device)
+
+ pred_overlaps = self.iou_calculator(bbox_pred, gt_bboxes)
+ anchor_overlaps = self.iou_calculator(priors, gt_bboxes)
+ pred_max_overlaps, _ = pred_overlaps.max(dim=1)
+ anchor_max_overlaps, _ = anchor_overlaps.max(dim=0)
+
+ # 3. Compute the ignore indexes use gt_bboxes and predict boxes
+ ignore_idx = pred_max_overlaps > self.neg_ignore_thr
+ assigned_gt_inds[ignore_idx] = -1
+
+ # 4. Compute the ignore indexes of positive sample use priors
+ # and predict boxes
+ pos_gt_index = torch.arange(
+ 0, C1.size(1),
+ device=bbox_pred.device).repeat(self.match_times * 2)
+ pos_ious = anchor_overlaps[indexes, pos_gt_index]
+ pos_ignore_idx = pos_ious < self.pos_ignore_thr
+
+ pos_gt_index_with_ignore = pos_gt_index + 1
+ pos_gt_index_with_ignore[pos_ignore_idx] = -1
+ assigned_gt_inds[indexes] = pos_gt_index_with_ignore
+
+ if gt_labels is not None:
+ assigned_labels = assigned_gt_inds.new_full((num_bboxes, ), -1)
+ pos_inds = torch.nonzero(
+ assigned_gt_inds > 0, as_tuple=False).squeeze()
+ if pos_inds.numel() > 0:
+ assigned_labels[pos_inds] = gt_labels[
+ assigned_gt_inds[pos_inds] - 1]
+ else:
+ assigned_labels = None
+
+ assign_result = AssignResult(
+ num_gts,
+ assigned_gt_inds,
+ anchor_max_overlaps,
+ labels=assigned_labels)
+ assign_result.set_extra_property('pos_idx', ~pos_ignore_idx)
+ assign_result.set_extra_property('pos_predicted_boxes',
+ bbox_pred[indexes])
+ assign_result.set_extra_property('target_boxes',
+ gt_bboxes[pos_gt_index])
+ return assign_result
diff --git a/mmdet/models/task_modules/builder.py b/mmdet/models/task_modules/builder.py
new file mode 100644
index 0000000000000000000000000000000000000000..6736049fef688e0d663d6195c79ec9688dc4c5d7
--- /dev/null
+++ b/mmdet/models/task_modules/builder.py
@@ -0,0 +1,62 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+
+from mmdet.registry import TASK_UTILS
+
+PRIOR_GENERATORS = TASK_UTILS
+ANCHOR_GENERATORS = TASK_UTILS
+BBOX_ASSIGNERS = TASK_UTILS
+BBOX_SAMPLERS = TASK_UTILS
+BBOX_CODERS = TASK_UTILS
+MATCH_COSTS = TASK_UTILS
+IOU_CALCULATORS = TASK_UTILS
+
+
+def build_bbox_coder(cfg, **default_args):
+ """Builder of box coder."""
+ warnings.warn('``build_sampler`` would be deprecated soon, please use '
+ '``mmdet.registry.TASK_UTILS.build()`` ')
+ return TASK_UTILS.build(cfg, default_args=default_args)
+
+
+def build_iou_calculator(cfg, default_args=None):
+ """Builder of IoU calculator."""
+ warnings.warn(
+ '``build_iou_calculator`` would be deprecated soon, please use '
+ '``mmdet.registry.TASK_UTILS.build()`` ')
+ return TASK_UTILS.build(cfg, default_args=default_args)
+
+
+def build_match_cost(cfg, default_args=None):
+ """Builder of IoU calculator."""
+ warnings.warn('``build_match_cost`` would be deprecated soon, please use '
+ '``mmdet.registry.TASK_UTILS.build()`` ')
+ return TASK_UTILS.build(cfg, default_args=default_args)
+
+
+def build_assigner(cfg, **default_args):
+ """Builder of box assigner."""
+ warnings.warn('``build_assigner`` would be deprecated soon, please use '
+ '``mmdet.registry.TASK_UTILS.build()`` ')
+ return TASK_UTILS.build(cfg, default_args=default_args)
+
+
+def build_sampler(cfg, **default_args):
+ """Builder of box sampler."""
+ warnings.warn('``build_sampler`` would be deprecated soon, please use '
+ '``mmdet.registry.TASK_UTILS.build()`` ')
+ return TASK_UTILS.build(cfg, default_args=default_args)
+
+
+def build_prior_generator(cfg, default_args=None):
+ warnings.warn(
+ '``build_prior_generator`` would be deprecated soon, please use '
+ '``mmdet.registry.TASK_UTILS.build()`` ')
+ return TASK_UTILS.build(cfg, default_args=default_args)
+
+
+def build_anchor_generator(cfg, default_args=None):
+ warnings.warn(
+ '``build_anchor_generator`` would be deprecated soon, please use '
+ '``mmdet.registry.TASK_UTILS.build()`` ')
+ return TASK_UTILS.build(cfg, default_args=default_args)
diff --git a/mmdet/models/task_modules/coders/__init__.py b/mmdet/models/task_modules/coders/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e12fd64e12b5e76a014da9bd724f1b6f50b488c4
--- /dev/null
+++ b/mmdet/models/task_modules/coders/__init__.py
@@ -0,0 +1,15 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .base_bbox_coder import BaseBBoxCoder
+from .bucketing_bbox_coder import BucketingBBoxCoder
+from .delta_xywh_bbox_coder import DeltaXYWHBBoxCoder
+from .distance_point_bbox_coder import DistancePointBBoxCoder
+from .legacy_delta_xywh_bbox_coder import LegacyDeltaXYWHBBoxCoder
+from .pseudo_bbox_coder import PseudoBBoxCoder
+from .tblr_bbox_coder import TBLRBBoxCoder
+from .yolo_bbox_coder import YOLOBBoxCoder
+
+__all__ = [
+ 'BaseBBoxCoder', 'PseudoBBoxCoder', 'DeltaXYWHBBoxCoder',
+ 'LegacyDeltaXYWHBBoxCoder', 'TBLRBBoxCoder', 'YOLOBBoxCoder',
+ 'BucketingBBoxCoder', 'DistancePointBBoxCoder'
+]
diff --git a/mmdet/models/task_modules/coders/__pycache__/__init__.cpython-37.pyc b/mmdet/models/task_modules/coders/__pycache__/__init__.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..7b304d41ef3c1eddf44ee9a34fe1a64c398c843d
Binary files /dev/null and b/mmdet/models/task_modules/coders/__pycache__/__init__.cpython-37.pyc differ
diff --git a/mmdet/models/task_modules/coders/__pycache__/base_bbox_coder.cpython-37.pyc b/mmdet/models/task_modules/coders/__pycache__/base_bbox_coder.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..d596ab99db850a0a6eb6197e1a82738634608d25
Binary files /dev/null and b/mmdet/models/task_modules/coders/__pycache__/base_bbox_coder.cpython-37.pyc differ
diff --git a/mmdet/models/task_modules/coders/__pycache__/bucketing_bbox_coder.cpython-37.pyc b/mmdet/models/task_modules/coders/__pycache__/bucketing_bbox_coder.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..a360dade6b4f222646e8942b724a34ef5dd0687a
Binary files /dev/null and b/mmdet/models/task_modules/coders/__pycache__/bucketing_bbox_coder.cpython-37.pyc differ
diff --git a/mmdet/models/task_modules/coders/__pycache__/delta_xywh_bbox_coder.cpython-37.pyc b/mmdet/models/task_modules/coders/__pycache__/delta_xywh_bbox_coder.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..66c1e1f75f59be477e303bfd4ad75863ac6844dc
Binary files /dev/null and b/mmdet/models/task_modules/coders/__pycache__/delta_xywh_bbox_coder.cpython-37.pyc differ
diff --git a/mmdet/models/task_modules/coders/__pycache__/distance_point_bbox_coder.cpython-37.pyc b/mmdet/models/task_modules/coders/__pycache__/distance_point_bbox_coder.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..6109ea4e5abba82988bf95daf99c0acda8a7216e
Binary files /dev/null and b/mmdet/models/task_modules/coders/__pycache__/distance_point_bbox_coder.cpython-37.pyc differ
diff --git a/mmdet/models/task_modules/coders/__pycache__/legacy_delta_xywh_bbox_coder.cpython-37.pyc b/mmdet/models/task_modules/coders/__pycache__/legacy_delta_xywh_bbox_coder.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..f6f7aaa1b4d8262b655d441a4c0b60380a2e5945
Binary files /dev/null and b/mmdet/models/task_modules/coders/__pycache__/legacy_delta_xywh_bbox_coder.cpython-37.pyc differ
diff --git a/mmdet/models/task_modules/coders/__pycache__/pseudo_bbox_coder.cpython-37.pyc b/mmdet/models/task_modules/coders/__pycache__/pseudo_bbox_coder.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..ab69b140436adc028b5c24f30fcfd331f35429ac
Binary files /dev/null and b/mmdet/models/task_modules/coders/__pycache__/pseudo_bbox_coder.cpython-37.pyc differ
diff --git a/mmdet/models/task_modules/coders/__pycache__/tblr_bbox_coder.cpython-37.pyc b/mmdet/models/task_modules/coders/__pycache__/tblr_bbox_coder.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..7448c88d821830cf49b91330e3a63ebb9ebf56b5
Binary files /dev/null and b/mmdet/models/task_modules/coders/__pycache__/tblr_bbox_coder.cpython-37.pyc differ
diff --git a/mmdet/models/task_modules/coders/__pycache__/yolo_bbox_coder.cpython-37.pyc b/mmdet/models/task_modules/coders/__pycache__/yolo_bbox_coder.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..06b441d4c0c23d54675d4fec2e4ddd6ede61e9eb
Binary files /dev/null and b/mmdet/models/task_modules/coders/__pycache__/yolo_bbox_coder.cpython-37.pyc differ
diff --git a/mmdet/models/task_modules/coders/base_bbox_coder.py b/mmdet/models/task_modules/coders/base_bbox_coder.py
new file mode 100644
index 0000000000000000000000000000000000000000..806d2651869e02173578c9eb331758743a068dd9
--- /dev/null
+++ b/mmdet/models/task_modules/coders/base_bbox_coder.py
@@ -0,0 +1,26 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from abc import ABCMeta, abstractmethod
+
+
+class BaseBBoxCoder(metaclass=ABCMeta):
+ """Base bounding box coder.
+
+ Args:
+ use_box_type (bool): Whether to warp decoded boxes with the
+ box type data structure. Defaults to False.
+ """
+
+ # The size of the last of dimension of the encoded tensor.
+ encode_size = 4
+
+ def __init__(self, use_box_type: bool = False, **kwargs):
+ self.use_box_type = use_box_type
+
+ @abstractmethod
+ def encode(self, bboxes, gt_bboxes):
+ """Encode deltas between bboxes and ground truth boxes."""
+
+ @abstractmethod
+ def decode(self, bboxes, bboxes_pred):
+ """Decode the predicted bboxes according to prediction and base
+ boxes."""
diff --git a/mmdet/models/task_modules/coders/bucketing_bbox_coder.py b/mmdet/models/task_modules/coders/bucketing_bbox_coder.py
new file mode 100644
index 0000000000000000000000000000000000000000..4044e1cd91d619521606f3c03032a40a9fc27130
--- /dev/null
+++ b/mmdet/models/task_modules/coders/bucketing_bbox_coder.py
@@ -0,0 +1,366 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Sequence, Tuple, Union
+
+import numpy as np
+import torch
+import torch.nn.functional as F
+from torch import Tensor
+
+from mmdet.registry import TASK_UTILS
+from mmdet.structures.bbox import (BaseBoxes, HorizontalBoxes, bbox_rescale,
+ get_box_tensor)
+from .base_bbox_coder import BaseBBoxCoder
+
+
+@TASK_UTILS.register_module()
+class BucketingBBoxCoder(BaseBBoxCoder):
+ """Bucketing BBox Coder for Side-Aware Boundary Localization (SABL).
+
+ Boundary Localization with Bucketing and Bucketing Guided Rescoring
+ are implemented here.
+
+ Please refer to https://arxiv.org/abs/1912.04260 for more details.
+
+ Args:
+ num_buckets (int): Number of buckets.
+ scale_factor (int): Scale factor of proposals to generate buckets.
+ offset_topk (int): Topk buckets are used to generate
+ bucket fine regression targets. Defaults to 2.
+ offset_upperbound (float): Offset upperbound to generate
+ bucket fine regression targets.
+ To avoid too large offset displacements. Defaults to 1.0.
+ cls_ignore_neighbor (bool): Ignore second nearest bucket or Not.
+ Defaults to True.
+ clip_border (bool, optional): Whether clip the objects outside the
+ border of the image. Defaults to True.
+ """
+
+ def __init__(self,
+ num_buckets: int,
+ scale_factor: int,
+ offset_topk: int = 2,
+ offset_upperbound: float = 1.0,
+ cls_ignore_neighbor: bool = True,
+ clip_border: bool = True,
+ **kwargs) -> None:
+ super().__init__(**kwargs)
+ self.num_buckets = num_buckets
+ self.scale_factor = scale_factor
+ self.offset_topk = offset_topk
+ self.offset_upperbound = offset_upperbound
+ self.cls_ignore_neighbor = cls_ignore_neighbor
+ self.clip_border = clip_border
+
+ def encode(self, bboxes: Union[Tensor, BaseBoxes],
+ gt_bboxes: Union[Tensor, BaseBoxes]) -> Tuple[Tensor]:
+ """Get bucketing estimation and fine regression targets during
+ training.
+
+ Args:
+ bboxes (torch.Tensor or :obj:`BaseBoxes`): source boxes,
+ e.g., object proposals.
+ gt_bboxes (torch.Tensor or :obj:`BaseBoxes`): target of the
+ transformation, e.g., ground truth boxes.
+
+ Returns:
+ encoded_bboxes(tuple[Tensor]): bucketing estimation
+ and fine regression targets and weights
+ """
+ bboxes = get_box_tensor(bboxes)
+ gt_bboxes = get_box_tensor(gt_bboxes)
+ assert bboxes.size(0) == gt_bboxes.size(0)
+ assert bboxes.size(-1) == gt_bboxes.size(-1) == 4
+ encoded_bboxes = bbox2bucket(bboxes, gt_bboxes, self.num_buckets,
+ self.scale_factor, self.offset_topk,
+ self.offset_upperbound,
+ self.cls_ignore_neighbor)
+ return encoded_bboxes
+
+ def decode(
+ self,
+ bboxes: Union[Tensor, BaseBoxes],
+ pred_bboxes: Tensor,
+ max_shape: Optional[Tuple[int]] = None
+ ) -> Tuple[Union[Tensor, BaseBoxes], Tensor]:
+ """Apply transformation `pred_bboxes` to `boxes`.
+ Args:
+ boxes (torch.Tensor or :obj:`BaseBoxes`): Basic boxes.
+ pred_bboxes (torch.Tensor): Predictions for bucketing estimation
+ and fine regression
+ max_shape (tuple[int], optional): Maximum shape of boxes.
+ Defaults to None.
+
+ Returns:
+ Union[torch.Tensor, :obj:`BaseBoxes`]: Decoded boxes.
+ """
+ bboxes = get_box_tensor(bboxes)
+ assert len(pred_bboxes) == 2
+ cls_preds, offset_preds = pred_bboxes
+ assert cls_preds.size(0) == bboxes.size(0) and offset_preds.size(
+ 0) == bboxes.size(0)
+ bboxes, loc_confidence = bucket2bbox(bboxes, cls_preds, offset_preds,
+ self.num_buckets,
+ self.scale_factor, max_shape,
+ self.clip_border)
+ if self.use_box_type:
+ bboxes = HorizontalBoxes(bboxes, clone=False)
+ return bboxes, loc_confidence
+
+
+def generat_buckets(proposals: Tensor,
+ num_buckets: int,
+ scale_factor: float = 1.0) -> Tuple[Tensor]:
+ """Generate buckets w.r.t bucket number and scale factor of proposals.
+
+ Args:
+ proposals (Tensor): Shape (n, 4)
+ num_buckets (int): Number of buckets.
+ scale_factor (float): Scale factor to rescale proposals.
+
+ Returns:
+ tuple[Tensor]: (bucket_w, bucket_h, l_buckets, r_buckets,
+ t_buckets, d_buckets)
+
+ - bucket_w: Width of buckets on x-axis. Shape (n, ).
+ - bucket_h: Height of buckets on y-axis. Shape (n, ).
+ - l_buckets: Left buckets. Shape (n, ceil(side_num/2)).
+ - r_buckets: Right buckets. Shape (n, ceil(side_num/2)).
+ - t_buckets: Top buckets. Shape (n, ceil(side_num/2)).
+ - d_buckets: Down buckets. Shape (n, ceil(side_num/2)).
+ """
+ proposals = bbox_rescale(proposals, scale_factor)
+
+ # number of buckets in each side
+ side_num = int(np.ceil(num_buckets / 2.0))
+ pw = proposals[..., 2] - proposals[..., 0]
+ ph = proposals[..., 3] - proposals[..., 1]
+ px1 = proposals[..., 0]
+ py1 = proposals[..., 1]
+ px2 = proposals[..., 2]
+ py2 = proposals[..., 3]
+
+ bucket_w = pw / num_buckets
+ bucket_h = ph / num_buckets
+
+ # left buckets
+ l_buckets = px1[:, None] + (0.5 + torch.arange(
+ 0, side_num).to(proposals).float())[None, :] * bucket_w[:, None]
+ # right buckets
+ r_buckets = px2[:, None] - (0.5 + torch.arange(
+ 0, side_num).to(proposals).float())[None, :] * bucket_w[:, None]
+ # top buckets
+ t_buckets = py1[:, None] + (0.5 + torch.arange(
+ 0, side_num).to(proposals).float())[None, :] * bucket_h[:, None]
+ # down buckets
+ d_buckets = py2[:, None] - (0.5 + torch.arange(
+ 0, side_num).to(proposals).float())[None, :] * bucket_h[:, None]
+ return bucket_w, bucket_h, l_buckets, r_buckets, t_buckets, d_buckets
+
+
+def bbox2bucket(proposals: Tensor,
+ gt: Tensor,
+ num_buckets: int,
+ scale_factor: float,
+ offset_topk: int = 2,
+ offset_upperbound: float = 1.0,
+ cls_ignore_neighbor: bool = True) -> Tuple[Tensor]:
+ """Generate buckets estimation and fine regression targets.
+
+ Args:
+ proposals (Tensor): Shape (n, 4)
+ gt (Tensor): Shape (n, 4)
+ num_buckets (int): Number of buckets.
+ scale_factor (float): Scale factor to rescale proposals.
+ offset_topk (int): Topk buckets are used to generate
+ bucket fine regression targets. Defaults to 2.
+ offset_upperbound (float): Offset allowance to generate
+ bucket fine regression targets.
+ To avoid too large offset displacements. Defaults to 1.0.
+ cls_ignore_neighbor (bool): Ignore second nearest bucket or Not.
+ Defaults to True.
+
+ Returns:
+ tuple[Tensor]: (offsets, offsets_weights, bucket_labels, cls_weights).
+
+ - offsets: Fine regression targets. \
+ Shape (n, num_buckets*2).
+ - offsets_weights: Fine regression weights. \
+ Shape (n, num_buckets*2).
+ - bucket_labels: Bucketing estimation labels. \
+ Shape (n, num_buckets*2).
+ - cls_weights: Bucketing estimation weights. \
+ Shape (n, num_buckets*2).
+ """
+ assert proposals.size() == gt.size()
+
+ # generate buckets
+ proposals = proposals.float()
+ gt = gt.float()
+ (bucket_w, bucket_h, l_buckets, r_buckets, t_buckets,
+ d_buckets) = generat_buckets(proposals, num_buckets, scale_factor)
+
+ gx1 = gt[..., 0]
+ gy1 = gt[..., 1]
+ gx2 = gt[..., 2]
+ gy2 = gt[..., 3]
+
+ # generate offset targets and weights
+ # offsets from buckets to gts
+ l_offsets = (l_buckets - gx1[:, None]) / bucket_w[:, None]
+ r_offsets = (r_buckets - gx2[:, None]) / bucket_w[:, None]
+ t_offsets = (t_buckets - gy1[:, None]) / bucket_h[:, None]
+ d_offsets = (d_buckets - gy2[:, None]) / bucket_h[:, None]
+
+ # select top-k nearest buckets
+ l_topk, l_label = l_offsets.abs().topk(
+ offset_topk, dim=1, largest=False, sorted=True)
+ r_topk, r_label = r_offsets.abs().topk(
+ offset_topk, dim=1, largest=False, sorted=True)
+ t_topk, t_label = t_offsets.abs().topk(
+ offset_topk, dim=1, largest=False, sorted=True)
+ d_topk, d_label = d_offsets.abs().topk(
+ offset_topk, dim=1, largest=False, sorted=True)
+
+ offset_l_weights = l_offsets.new_zeros(l_offsets.size())
+ offset_r_weights = r_offsets.new_zeros(r_offsets.size())
+ offset_t_weights = t_offsets.new_zeros(t_offsets.size())
+ offset_d_weights = d_offsets.new_zeros(d_offsets.size())
+ inds = torch.arange(0, proposals.size(0)).to(proposals).long()
+
+ # generate offset weights of top-k nearest buckets
+ for k in range(offset_topk):
+ if k >= 1:
+ offset_l_weights[inds, l_label[:,
+ k]] = (l_topk[:, k] <
+ offset_upperbound).float()
+ offset_r_weights[inds, r_label[:,
+ k]] = (r_topk[:, k] <
+ offset_upperbound).float()
+ offset_t_weights[inds, t_label[:,
+ k]] = (t_topk[:, k] <
+ offset_upperbound).float()
+ offset_d_weights[inds, d_label[:,
+ k]] = (d_topk[:, k] <
+ offset_upperbound).float()
+ else:
+ offset_l_weights[inds, l_label[:, k]] = 1.0
+ offset_r_weights[inds, r_label[:, k]] = 1.0
+ offset_t_weights[inds, t_label[:, k]] = 1.0
+ offset_d_weights[inds, d_label[:, k]] = 1.0
+
+ offsets = torch.cat([l_offsets, r_offsets, t_offsets, d_offsets], dim=-1)
+ offsets_weights = torch.cat([
+ offset_l_weights, offset_r_weights, offset_t_weights, offset_d_weights
+ ],
+ dim=-1)
+
+ # generate bucket labels and weight
+ side_num = int(np.ceil(num_buckets / 2.0))
+ labels = torch.stack(
+ [l_label[:, 0], r_label[:, 0], t_label[:, 0], d_label[:, 0]], dim=-1)
+
+ batch_size = labels.size(0)
+ bucket_labels = F.one_hot(labels.view(-1), side_num).view(batch_size,
+ -1).float()
+ bucket_cls_l_weights = (l_offsets.abs() < 1).float()
+ bucket_cls_r_weights = (r_offsets.abs() < 1).float()
+ bucket_cls_t_weights = (t_offsets.abs() < 1).float()
+ bucket_cls_d_weights = (d_offsets.abs() < 1).float()
+ bucket_cls_weights = torch.cat([
+ bucket_cls_l_weights, bucket_cls_r_weights, bucket_cls_t_weights,
+ bucket_cls_d_weights
+ ],
+ dim=-1)
+ # ignore second nearest buckets for cls if necessary
+ if cls_ignore_neighbor:
+ bucket_cls_weights = (~((bucket_cls_weights == 1) &
+ (bucket_labels == 0))).float()
+ else:
+ bucket_cls_weights[:] = 1.0
+ return offsets, offsets_weights, bucket_labels, bucket_cls_weights
+
+
+def bucket2bbox(proposals: Tensor,
+ cls_preds: Tensor,
+ offset_preds: Tensor,
+ num_buckets: int,
+ scale_factor: float = 1.0,
+ max_shape: Optional[Union[Sequence[int], Tensor,
+ Sequence[Sequence[int]]]] = None,
+ clip_border: bool = True) -> Tuple[Tensor]:
+ """Apply bucketing estimation (cls preds) and fine regression (offset
+ preds) to generate det bboxes.
+
+ Args:
+ proposals (Tensor): Boxes to be transformed. Shape (n, 4)
+ cls_preds (Tensor): bucketing estimation. Shape (n, num_buckets*2).
+ offset_preds (Tensor): fine regression. Shape (n, num_buckets*2).
+ num_buckets (int): Number of buckets.
+ scale_factor (float): Scale factor to rescale proposals.
+ max_shape (tuple[int, int]): Maximum bounds for boxes. specifies (H, W)
+ clip_border (bool, optional): Whether clip the objects outside the
+ border of the image. Defaults to True.
+
+ Returns:
+ tuple[Tensor]: (bboxes, loc_confidence).
+
+ - bboxes: predicted bboxes. Shape (n, 4)
+ - loc_confidence: localization confidence of predicted bboxes.
+ Shape (n,).
+ """
+
+ side_num = int(np.ceil(num_buckets / 2.0))
+ cls_preds = cls_preds.view(-1, side_num)
+ offset_preds = offset_preds.view(-1, side_num)
+
+ scores = F.softmax(cls_preds, dim=1)
+ score_topk, score_label = scores.topk(2, dim=1, largest=True, sorted=True)
+
+ rescaled_proposals = bbox_rescale(proposals, scale_factor)
+
+ pw = rescaled_proposals[..., 2] - rescaled_proposals[..., 0]
+ ph = rescaled_proposals[..., 3] - rescaled_proposals[..., 1]
+ px1 = rescaled_proposals[..., 0]
+ py1 = rescaled_proposals[..., 1]
+ px2 = rescaled_proposals[..., 2]
+ py2 = rescaled_proposals[..., 3]
+
+ bucket_w = pw / num_buckets
+ bucket_h = ph / num_buckets
+
+ score_inds_l = score_label[0::4, 0]
+ score_inds_r = score_label[1::4, 0]
+ score_inds_t = score_label[2::4, 0]
+ score_inds_d = score_label[3::4, 0]
+ l_buckets = px1 + (0.5 + score_inds_l.float()) * bucket_w
+ r_buckets = px2 - (0.5 + score_inds_r.float()) * bucket_w
+ t_buckets = py1 + (0.5 + score_inds_t.float()) * bucket_h
+ d_buckets = py2 - (0.5 + score_inds_d.float()) * bucket_h
+
+ offsets = offset_preds.view(-1, 4, side_num)
+ inds = torch.arange(proposals.size(0)).to(proposals).long()
+ l_offsets = offsets[:, 0, :][inds, score_inds_l]
+ r_offsets = offsets[:, 1, :][inds, score_inds_r]
+ t_offsets = offsets[:, 2, :][inds, score_inds_t]
+ d_offsets = offsets[:, 3, :][inds, score_inds_d]
+
+ x1 = l_buckets - l_offsets * bucket_w
+ x2 = r_buckets - r_offsets * bucket_w
+ y1 = t_buckets - t_offsets * bucket_h
+ y2 = d_buckets - d_offsets * bucket_h
+
+ if clip_border and max_shape is not None:
+ x1 = x1.clamp(min=0, max=max_shape[1] - 1)
+ y1 = y1.clamp(min=0, max=max_shape[0] - 1)
+ x2 = x2.clamp(min=0, max=max_shape[1] - 1)
+ y2 = y2.clamp(min=0, max=max_shape[0] - 1)
+ bboxes = torch.cat([x1[:, None], y1[:, None], x2[:, None], y2[:, None]],
+ dim=-1)
+
+ # bucketing guided rescoring
+ loc_confidence = score_topk[:, 0]
+ top2_neighbor_inds = (score_label[:, 0] - score_label[:, 1]).abs() == 1
+ loc_confidence += score_topk[:, 1] * top2_neighbor_inds.float()
+ loc_confidence = loc_confidence.view(-1, 4).mean(dim=1)
+
+ return bboxes, loc_confidence
diff --git a/mmdet/models/task_modules/coders/delta_xywh_bbox_coder.py b/mmdet/models/task_modules/coders/delta_xywh_bbox_coder.py
new file mode 100644
index 0000000000000000000000000000000000000000..f65748ac3471ac89ddbee2b8d78344ce739a4444
--- /dev/null
+++ b/mmdet/models/task_modules/coders/delta_xywh_bbox_coder.py
@@ -0,0 +1,412 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+from typing import Optional, Sequence, Union
+
+import numpy as np
+import torch
+from torch import Tensor
+
+from mmdet.registry import TASK_UTILS
+from mmdet.structures.bbox import BaseBoxes, HorizontalBoxes, get_box_tensor
+from .base_bbox_coder import BaseBBoxCoder
+
+
+@TASK_UTILS.register_module()
+class DeltaXYWHBBoxCoder(BaseBBoxCoder):
+ """Delta XYWH BBox coder.
+
+ Following the practice in `R-CNN `_,
+ this coder encodes bbox (x1, y1, x2, y2) into delta (dx, dy, dw, dh) and
+ decodes delta (dx, dy, dw, dh) back to original bbox (x1, y1, x2, y2).
+
+ Args:
+ target_means (Sequence[float]): Denormalizing means of target for
+ delta coordinates
+ target_stds (Sequence[float]): Denormalizing standard deviation of
+ target for delta coordinates
+ clip_border (bool, optional): Whether clip the objects outside the
+ border of the image. Defaults to True.
+ add_ctr_clamp (bool): Whether to add center clamp, when added, the
+ predicted box is clamped is its center is too far away from
+ the original anchor's center. Only used by YOLOF. Default False.
+ ctr_clamp (int): the maximum pixel shift to clamp. Only used by YOLOF.
+ Default 32.
+ """
+
+ def __init__(self,
+ target_means: Sequence[float] = (0., 0., 0., 0.),
+ target_stds: Sequence[float] = (1., 1., 1., 1.),
+ clip_border: bool = True,
+ add_ctr_clamp: bool = False,
+ ctr_clamp: int = 32,
+ **kwargs) -> None:
+ super().__init__(**kwargs)
+ self.means = target_means
+ self.stds = target_stds
+ self.clip_border = clip_border
+ self.add_ctr_clamp = add_ctr_clamp
+ self.ctr_clamp = ctr_clamp
+
+ def encode(self, bboxes: Union[Tensor, BaseBoxes],
+ gt_bboxes: Union[Tensor, BaseBoxes]) -> Tensor:
+ """Get box regression transformation deltas that can be used to
+ transform the ``bboxes`` into the ``gt_bboxes``.
+
+ Args:
+ bboxes (torch.Tensor or :obj:`BaseBoxes`): Source boxes,
+ e.g., object proposals.
+ gt_bboxes (torch.Tensor or :obj:`BaseBoxes`): Target of the
+ transformation, e.g., ground-truth boxes.
+
+ Returns:
+ torch.Tensor: Box transformation deltas
+ """
+ bboxes = get_box_tensor(bboxes)
+ gt_bboxes = get_box_tensor(gt_bboxes)
+ assert bboxes.size(0) == gt_bboxes.size(0)
+ assert bboxes.size(-1) == gt_bboxes.size(-1) == 4
+ encoded_bboxes = bbox2delta(bboxes, gt_bboxes, self.means, self.stds)
+ return encoded_bboxes
+
+ def decode(
+ self,
+ bboxes: Union[Tensor, BaseBoxes],
+ pred_bboxes: Tensor,
+ max_shape: Optional[Union[Sequence[int], Tensor,
+ Sequence[Sequence[int]]]] = None,
+ wh_ratio_clip: Optional[float] = 16 / 1000
+ ) -> Union[Tensor, BaseBoxes]:
+ """Apply transformation `pred_bboxes` to `boxes`.
+
+ Args:
+ bboxes (torch.Tensor or :obj:`BaseBoxes`): Basic boxes. Shape
+ (B, N, 4) or (N, 4)
+ pred_bboxes (Tensor): Encoded offsets with respect to each roi.
+ Has shape (B, N, num_classes * 4) or (B, N, 4) or
+ (N, num_classes * 4) or (N, 4). Note N = num_anchors * W * H
+ when rois is a grid of anchors.Offset encoding follows [1]_.
+ max_shape (Sequence[int] or torch.Tensor or Sequence[
+ Sequence[int]],optional): Maximum bounds for boxes, specifies
+ (H, W, C) or (H, W). If bboxes shape is (B, N, 4), then
+ the max_shape should be a Sequence[Sequence[int]]
+ and the length of max_shape should also be B.
+ wh_ratio_clip (float, optional): The allowed ratio between
+ width and height.
+
+ Returns:
+ Union[torch.Tensor, :obj:`BaseBoxes`]: Decoded boxes.
+ """
+ bboxes = get_box_tensor(bboxes)
+ assert pred_bboxes.size(0) == bboxes.size(0)
+ if pred_bboxes.ndim == 3:
+ assert pred_bboxes.size(1) == bboxes.size(1)
+
+ if pred_bboxes.ndim == 2 and not torch.onnx.is_in_onnx_export():
+ # single image decode
+ decoded_bboxes = delta2bbox(bboxes, pred_bboxes, self.means,
+ self.stds, max_shape, wh_ratio_clip,
+ self.clip_border, self.add_ctr_clamp,
+ self.ctr_clamp)
+ else:
+ if pred_bboxes.ndim == 3 and not torch.onnx.is_in_onnx_export():
+ warnings.warn(
+ 'DeprecationWarning: onnx_delta2bbox is deprecated '
+ 'in the case of batch decoding and non-ONNX, '
+ 'please use “delta2bbox” instead. In order to improve '
+ 'the decoding speed, the batch function will no '
+ 'longer be supported. ')
+ decoded_bboxes = onnx_delta2bbox(bboxes, pred_bboxes, self.means,
+ self.stds, max_shape,
+ wh_ratio_clip, self.clip_border,
+ self.add_ctr_clamp,
+ self.ctr_clamp)
+
+ if self.use_box_type:
+ assert decoded_bboxes.size(-1) == 4, \
+ ('Cannot warp decoded boxes with box type when decoded boxes'
+ 'have shape of (N, num_classes * 4)')
+ decoded_bboxes = HorizontalBoxes(decoded_bboxes)
+ return decoded_bboxes
+
+
+def bbox2delta(
+ proposals: Tensor,
+ gt: Tensor,
+ means: Sequence[float] = (0., 0., 0., 0.),
+ stds: Sequence[float] = (1., 1., 1., 1.)
+) -> Tensor:
+ """Compute deltas of proposals w.r.t. gt.
+
+ We usually compute the deltas of x, y, w, h of proposals w.r.t ground
+ truth bboxes to get regression target.
+ This is the inverse function of :func:`delta2bbox`.
+
+ Args:
+ proposals (Tensor): Boxes to be transformed, shape (N, ..., 4)
+ gt (Tensor): Gt bboxes to be used as base, shape (N, ..., 4)
+ means (Sequence[float]): Denormalizing means for delta coordinates
+ stds (Sequence[float]): Denormalizing standard deviation for delta
+ coordinates
+
+ Returns:
+ Tensor: deltas with shape (N, 4), where columns represent dx, dy,
+ dw, dh.
+ """
+ assert proposals.size() == gt.size()
+
+ proposals = proposals.float()
+ gt = gt.float()
+ px = (proposals[..., 0] + proposals[..., 2]) * 0.5
+ py = (proposals[..., 1] + proposals[..., 3]) * 0.5
+ pw = proposals[..., 2] - proposals[..., 0]
+ ph = proposals[..., 3] - proposals[..., 1]
+
+ gx = (gt[..., 0] + gt[..., 2]) * 0.5
+ gy = (gt[..., 1] + gt[..., 3]) * 0.5
+ gw = gt[..., 2] - gt[..., 0]
+ gh = gt[..., 3] - gt[..., 1]
+
+ dx = (gx - px) / pw
+ dy = (gy - py) / ph
+ dw = torch.log(gw / pw)
+ dh = torch.log(gh / ph)
+ deltas = torch.stack([dx, dy, dw, dh], dim=-1)
+
+ means = deltas.new_tensor(means).unsqueeze(0)
+ stds = deltas.new_tensor(stds).unsqueeze(0)
+ deltas = deltas.sub_(means).div_(stds)
+
+ return deltas
+
+
+def delta2bbox(rois: Tensor,
+ deltas: Tensor,
+ means: Sequence[float] = (0., 0., 0., 0.),
+ stds: Sequence[float] = (1., 1., 1., 1.),
+ max_shape: Optional[Union[Sequence[int], Tensor,
+ Sequence[Sequence[int]]]] = None,
+ wh_ratio_clip: float = 16 / 1000,
+ clip_border: bool = True,
+ add_ctr_clamp: bool = False,
+ ctr_clamp: int = 32) -> Tensor:
+ """Apply deltas to shift/scale base boxes.
+
+ Typically the rois are anchor or proposed bounding boxes and the deltas are
+ network outputs used to shift/scale those boxes.
+ This is the inverse function of :func:`bbox2delta`.
+
+ Args:
+ rois (Tensor): Boxes to be transformed. Has shape (N, 4).
+ deltas (Tensor): Encoded offsets relative to each roi.
+ Has shape (N, num_classes * 4) or (N, 4). Note
+ N = num_base_anchors * W * H, when rois is a grid of
+ anchors. Offset encoding follows [1]_.
+ means (Sequence[float]): Denormalizing means for delta coordinates.
+ Default (0., 0., 0., 0.).
+ stds (Sequence[float]): Denormalizing standard deviation for delta
+ coordinates. Default (1., 1., 1., 1.).
+ max_shape (tuple[int, int]): Maximum bounds for boxes, specifies
+ (H, W). Default None.
+ wh_ratio_clip (float): Maximum aspect ratio for boxes. Default
+ 16 / 1000.
+ clip_border (bool, optional): Whether clip the objects outside the
+ border of the image. Default True.
+ add_ctr_clamp (bool): Whether to add center clamp. When set to True,
+ the center of the prediction bounding box will be clamped to
+ avoid being too far away from the center of the anchor.
+ Only used by YOLOF. Default False.
+ ctr_clamp (int): the maximum pixel shift to clamp. Only used by YOLOF.
+ Default 32.
+
+ Returns:
+ Tensor: Boxes with shape (N, num_classes * 4) or (N, 4), where 4
+ represent tl_x, tl_y, br_x, br_y.
+
+ References:
+ .. [1] https://arxiv.org/abs/1311.2524
+
+ Example:
+ >>> rois = torch.Tensor([[ 0., 0., 1., 1.],
+ >>> [ 0., 0., 1., 1.],
+ >>> [ 0., 0., 1., 1.],
+ >>> [ 5., 5., 5., 5.]])
+ >>> deltas = torch.Tensor([[ 0., 0., 0., 0.],
+ >>> [ 1., 1., 1., 1.],
+ >>> [ 0., 0., 2., -1.],
+ >>> [ 0.7, -1.9, -0.5, 0.3]])
+ >>> delta2bbox(rois, deltas, max_shape=(32, 32, 3))
+ tensor([[0.0000, 0.0000, 1.0000, 1.0000],
+ [0.1409, 0.1409, 2.8591, 2.8591],
+ [0.0000, 0.3161, 4.1945, 0.6839],
+ [5.0000, 5.0000, 5.0000, 5.0000]])
+ """
+ num_bboxes, num_classes = deltas.size(0), deltas.size(1) // 4
+ if num_bboxes == 0:
+ return deltas
+
+ deltas = deltas.reshape(-1, 4)
+
+ means = deltas.new_tensor(means).view(1, -1)
+ stds = deltas.new_tensor(stds).view(1, -1)
+ denorm_deltas = deltas * stds + means
+
+ dxy = denorm_deltas[:, :2]
+ dwh = denorm_deltas[:, 2:]
+
+ # Compute width/height of each roi
+ rois_ = rois.repeat(1, num_classes).reshape(-1, 4)
+ pxy = ((rois_[:, :2] + rois_[:, 2:]) * 0.5)
+ pwh = (rois_[:, 2:] - rois_[:, :2])
+
+ dxy_wh = pwh * dxy
+
+ max_ratio = np.abs(np.log(wh_ratio_clip))
+ if add_ctr_clamp:
+ dxy_wh = torch.clamp(dxy_wh, max=ctr_clamp, min=-ctr_clamp)
+ dwh = torch.clamp(dwh, max=max_ratio)
+ else:
+ dwh = dwh.clamp(min=-max_ratio, max=max_ratio)
+
+ gxy = pxy + dxy_wh
+ gwh = pwh * dwh.exp()
+ x1y1 = gxy - (gwh * 0.5)
+ x2y2 = gxy + (gwh * 0.5)
+ bboxes = torch.cat([x1y1, x2y2], dim=-1)
+ if clip_border and max_shape is not None:
+ bboxes[..., 0::2].clamp_(min=0, max=max_shape[1])
+ bboxes[..., 1::2].clamp_(min=0, max=max_shape[0])
+ bboxes = bboxes.reshape(num_bboxes, -1)
+ return bboxes
+
+
+def onnx_delta2bbox(rois: Tensor,
+ deltas: Tensor,
+ means: Sequence[float] = (0., 0., 0., 0.),
+ stds: Sequence[float] = (1., 1., 1., 1.),
+ max_shape: Optional[Union[Sequence[int], Tensor,
+ Sequence[Sequence[int]]]] = None,
+ wh_ratio_clip: float = 16 / 1000,
+ clip_border: Optional[bool] = True,
+ add_ctr_clamp: bool = False,
+ ctr_clamp: int = 32) -> Tensor:
+ """Apply deltas to shift/scale base boxes.
+
+ Typically the rois are anchor or proposed bounding boxes and the deltas are
+ network outputs used to shift/scale those boxes.
+ This is the inverse function of :func:`bbox2delta`.
+
+ Args:
+ rois (Tensor): Boxes to be transformed. Has shape (N, 4) or (B, N, 4)
+ deltas (Tensor): Encoded offsets with respect to each roi.
+ Has shape (B, N, num_classes * 4) or (B, N, 4) or
+ (N, num_classes * 4) or (N, 4). Note N = num_anchors * W * H
+ when rois is a grid of anchors.Offset encoding follows [1]_.
+ means (Sequence[float]): Denormalizing means for delta coordinates.
+ Default (0., 0., 0., 0.).
+ stds (Sequence[float]): Denormalizing standard deviation for delta
+ coordinates. Default (1., 1., 1., 1.).
+ max_shape (Sequence[int] or torch.Tensor or Sequence[
+ Sequence[int]],optional): Maximum bounds for boxes, specifies
+ (H, W, C) or (H, W). If rois shape is (B, N, 4), then
+ the max_shape should be a Sequence[Sequence[int]]
+ and the length of max_shape should also be B. Default None.
+ wh_ratio_clip (float): Maximum aspect ratio for boxes.
+ Default 16 / 1000.
+ clip_border (bool, optional): Whether clip the objects outside the
+ border of the image. Default True.
+ add_ctr_clamp (bool): Whether to add center clamp, when added, the
+ predicted box is clamped is its center is too far away from
+ the original anchor's center. Only used by YOLOF. Default False.
+ ctr_clamp (int): the maximum pixel shift to clamp. Only used by YOLOF.
+ Default 32.
+
+ Returns:
+ Tensor: Boxes with shape (B, N, num_classes * 4) or (B, N, 4) or
+ (N, num_classes * 4) or (N, 4), where 4 represent
+ tl_x, tl_y, br_x, br_y.
+
+ References:
+ .. [1] https://arxiv.org/abs/1311.2524
+
+ Example:
+ >>> rois = torch.Tensor([[ 0., 0., 1., 1.],
+ >>> [ 0., 0., 1., 1.],
+ >>> [ 0., 0., 1., 1.],
+ >>> [ 5., 5., 5., 5.]])
+ >>> deltas = torch.Tensor([[ 0., 0., 0., 0.],
+ >>> [ 1., 1., 1., 1.],
+ >>> [ 0., 0., 2., -1.],
+ >>> [ 0.7, -1.9, -0.5, 0.3]])
+ >>> delta2bbox(rois, deltas, max_shape=(32, 32, 3))
+ tensor([[0.0000, 0.0000, 1.0000, 1.0000],
+ [0.1409, 0.1409, 2.8591, 2.8591],
+ [0.0000, 0.3161, 4.1945, 0.6839],
+ [5.0000, 5.0000, 5.0000, 5.0000]])
+ """
+ means = deltas.new_tensor(means).view(1,
+ -1).repeat(1,
+ deltas.size(-1) // 4)
+ stds = deltas.new_tensor(stds).view(1, -1).repeat(1, deltas.size(-1) // 4)
+ denorm_deltas = deltas * stds + means
+ dx = denorm_deltas[..., 0::4]
+ dy = denorm_deltas[..., 1::4]
+ dw = denorm_deltas[..., 2::4]
+ dh = denorm_deltas[..., 3::4]
+
+ x1, y1 = rois[..., 0], rois[..., 1]
+ x2, y2 = rois[..., 2], rois[..., 3]
+ # Compute center of each roi
+ px = ((x1 + x2) * 0.5).unsqueeze(-1).expand_as(dx)
+ py = ((y1 + y2) * 0.5).unsqueeze(-1).expand_as(dy)
+ # Compute width/height of each roi
+ pw = (x2 - x1).unsqueeze(-1).expand_as(dw)
+ ph = (y2 - y1).unsqueeze(-1).expand_as(dh)
+
+ dx_width = pw * dx
+ dy_height = ph * dy
+
+ max_ratio = np.abs(np.log(wh_ratio_clip))
+ if add_ctr_clamp:
+ dx_width = torch.clamp(dx_width, max=ctr_clamp, min=-ctr_clamp)
+ dy_height = torch.clamp(dy_height, max=ctr_clamp, min=-ctr_clamp)
+ dw = torch.clamp(dw, max=max_ratio)
+ dh = torch.clamp(dh, max=max_ratio)
+ else:
+ dw = dw.clamp(min=-max_ratio, max=max_ratio)
+ dh = dh.clamp(min=-max_ratio, max=max_ratio)
+ # Use exp(network energy) to enlarge/shrink each roi
+ gw = pw * dw.exp()
+ gh = ph * dh.exp()
+ # Use network energy to shift the center of each roi
+ gx = px + dx_width
+ gy = py + dy_height
+ # Convert center-xy/width/height to top-left, bottom-right
+ x1 = gx - gw * 0.5
+ y1 = gy - gh * 0.5
+ x2 = gx + gw * 0.5
+ y2 = gy + gh * 0.5
+
+ bboxes = torch.stack([x1, y1, x2, y2], dim=-1).view(deltas.size())
+
+ if clip_border and max_shape is not None:
+ # clip bboxes with dynamic `min` and `max` for onnx
+ if torch.onnx.is_in_onnx_export():
+ from mmdet.core.export import dynamic_clip_for_onnx
+ x1, y1, x2, y2 = dynamic_clip_for_onnx(x1, y1, x2, y2, max_shape)
+ bboxes = torch.stack([x1, y1, x2, y2], dim=-1).view(deltas.size())
+ return bboxes
+ if not isinstance(max_shape, torch.Tensor):
+ max_shape = x1.new_tensor(max_shape)
+ max_shape = max_shape[..., :2].type_as(x1)
+ if max_shape.ndim == 2:
+ assert bboxes.ndim == 3
+ assert max_shape.size(0) == bboxes.size(0)
+
+ min_xy = x1.new_tensor(0)
+ max_xy = torch.cat(
+ [max_shape] * (deltas.size(-1) // 2),
+ dim=-1).flip(-1).unsqueeze(-2)
+ bboxes = torch.where(bboxes < min_xy, min_xy, bboxes)
+ bboxes = torch.where(bboxes > max_xy, max_xy, bboxes)
+
+ return bboxes
diff --git a/mmdet/models/task_modules/coders/distance_point_bbox_coder.py b/mmdet/models/task_modules/coders/distance_point_bbox_coder.py
new file mode 100644
index 0000000000000000000000000000000000000000..ab26bf4b96c48df689da3722c23aa65e646348db
--- /dev/null
+++ b/mmdet/models/task_modules/coders/distance_point_bbox_coder.py
@@ -0,0 +1,85 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Sequence, Union
+
+from torch import Tensor
+
+from mmdet.registry import TASK_UTILS
+from mmdet.structures.bbox import (BaseBoxes, HorizontalBoxes, bbox2distance,
+ distance2bbox, get_box_tensor)
+from .base_bbox_coder import BaseBBoxCoder
+
+
+@TASK_UTILS.register_module()
+class DistancePointBBoxCoder(BaseBBoxCoder):
+ """Distance Point BBox coder.
+
+ This coder encodes gt bboxes (x1, y1, x2, y2) into (top, bottom, left,
+ right) and decode it back to the original.
+
+ Args:
+ clip_border (bool, optional): Whether clip the objects outside the
+ border of the image. Defaults to True.
+ """
+
+ def __init__(self, clip_border: Optional[bool] = True, **kwargs) -> None:
+ super().__init__(**kwargs)
+ self.clip_border = clip_border
+
+ def encode(self,
+ points: Tensor,
+ gt_bboxes: Union[Tensor, BaseBoxes],
+ max_dis: Optional[float] = None,
+ eps: float = 0.1) -> Tensor:
+ """Encode bounding box to distances.
+
+ Args:
+ points (Tensor): Shape (N, 2), The format is [x, y].
+ gt_bboxes (Tensor or :obj:`BaseBoxes`): Shape (N, 4), The format
+ is "xyxy"
+ max_dis (float): Upper bound of the distance. Default None.
+ eps (float): a small value to ensure target < max_dis, instead <=.
+ Default 0.1.
+
+ Returns:
+ Tensor: Box transformation deltas. The shape is (N, 4).
+ """
+ gt_bboxes = get_box_tensor(gt_bboxes)
+ assert points.size(0) == gt_bboxes.size(0)
+ assert points.size(-1) == 2
+ assert gt_bboxes.size(-1) == 4
+ return bbox2distance(points, gt_bboxes, max_dis, eps)
+
+ def decode(
+ self,
+ points: Tensor,
+ pred_bboxes: Tensor,
+ max_shape: Optional[Union[Sequence[int], Tensor,
+ Sequence[Sequence[int]]]] = None
+ ) -> Union[Tensor, BaseBoxes]:
+ """Decode distance prediction to bounding box.
+
+ Args:
+ points (Tensor): Shape (B, N, 2) or (N, 2).
+ pred_bboxes (Tensor): Distance from the given point to 4
+ boundaries (left, top, right, bottom). Shape (B, N, 4)
+ or (N, 4)
+ max_shape (Sequence[int] or torch.Tensor or Sequence[
+ Sequence[int]],optional): Maximum bounds for boxes, specifies
+ (H, W, C) or (H, W). If priors shape is (B, N, 4), then
+ the max_shape should be a Sequence[Sequence[int]],
+ and the length of max_shape should also be B.
+ Default None.
+ Returns:
+ Union[Tensor, :obj:`BaseBoxes`]: Boxes with shape (N, 4) or
+ (B, N, 4)
+ """
+ assert points.size(0) == pred_bboxes.size(0)
+ assert points.size(-1) == 2
+ assert pred_bboxes.size(-1) == 4
+ if self.clip_border is False:
+ max_shape = None
+ bboxes = distance2bbox(points, pred_bboxes, max_shape)
+
+ if self.use_box_type:
+ bboxes = HorizontalBoxes(bboxes)
+ return bboxes
diff --git a/mmdet/models/task_modules/coders/legacy_delta_xywh_bbox_coder.py b/mmdet/models/task_modules/coders/legacy_delta_xywh_bbox_coder.py
new file mode 100644
index 0000000000000000000000000000000000000000..9eb1bedb3fbe19433c8bdb37f80891efa2cb72fc
--- /dev/null
+++ b/mmdet/models/task_modules/coders/legacy_delta_xywh_bbox_coder.py
@@ -0,0 +1,235 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Sequence, Union
+
+import numpy as np
+import torch
+from torch import Tensor
+
+from mmdet.registry import TASK_UTILS
+from mmdet.structures.bbox import BaseBoxes, HorizontalBoxes, get_box_tensor
+from .base_bbox_coder import BaseBBoxCoder
+
+
+@TASK_UTILS.register_module()
+class LegacyDeltaXYWHBBoxCoder(BaseBBoxCoder):
+ """Legacy Delta XYWH BBox coder used in MMDet V1.x.
+
+ Following the practice in R-CNN [1]_, this coder encodes bbox (x1, y1, x2,
+ y2) into delta (dx, dy, dw, dh) and decodes delta (dx, dy, dw, dh)
+ back to original bbox (x1, y1, x2, y2).
+
+ Note:
+ The main difference between :class`LegacyDeltaXYWHBBoxCoder` and
+ :class:`DeltaXYWHBBoxCoder` is whether ``+ 1`` is used during width and
+ height calculation. We suggest to only use this coder when testing with
+ MMDet V1.x models.
+
+ References:
+ .. [1] https://arxiv.org/abs/1311.2524
+
+ Args:
+ target_means (Sequence[float]): denormalizing means of target for
+ delta coordinates
+ target_stds (Sequence[float]): denormalizing standard deviation of
+ target for delta coordinates
+ """
+
+ def __init__(self,
+ target_means: Sequence[float] = (0., 0., 0., 0.),
+ target_stds: Sequence[float] = (1., 1., 1., 1.),
+ **kwargs) -> None:
+ super().__init__(**kwargs)
+ self.means = target_means
+ self.stds = target_stds
+
+ def encode(self, bboxes: Union[Tensor, BaseBoxes],
+ gt_bboxes: Union[Tensor, BaseBoxes]) -> Tensor:
+ """Get box regression transformation deltas that can be used to
+ transform the ``bboxes`` into the ``gt_bboxes``.
+
+ Args:
+ bboxes (torch.Tensor or :obj:`BaseBoxes`): source boxes,
+ e.g., object proposals.
+ gt_bboxes (torch.Tensor or :obj:`BaseBoxes`): target of the
+ transformation, e.g., ground-truth boxes.
+
+ Returns:
+ torch.Tensor: Box transformation deltas
+ """
+ bboxes = get_box_tensor(bboxes)
+ gt_bboxes = get_box_tensor(gt_bboxes)
+ assert bboxes.size(0) == gt_bboxes.size(0)
+ assert bboxes.size(-1) == gt_bboxes.size(-1) == 4
+ encoded_bboxes = legacy_bbox2delta(bboxes, gt_bboxes, self.means,
+ self.stds)
+ return encoded_bboxes
+
+ def decode(
+ self,
+ bboxes: Union[Tensor, BaseBoxes],
+ pred_bboxes: Tensor,
+ max_shape: Optional[Union[Sequence[int], Tensor,
+ Sequence[Sequence[int]]]] = None,
+ wh_ratio_clip: Optional[float] = 16 / 1000
+ ) -> Union[Tensor, BaseBoxes]:
+ """Apply transformation `pred_bboxes` to `boxes`.
+
+ Args:
+ boxes (torch.Tensor or :obj:`BaseBoxes`): Basic boxes.
+ pred_bboxes (torch.Tensor): Encoded boxes with shape
+ max_shape (tuple[int], optional): Maximum shape of boxes.
+ Defaults to None.
+ wh_ratio_clip (float, optional): The allowed ratio between
+ width and height.
+
+ Returns:
+ Union[torch.Tensor, :obj:`BaseBoxes`]: Decoded boxes.
+ """
+ bboxes = get_box_tensor(bboxes)
+ assert pred_bboxes.size(0) == bboxes.size(0)
+ decoded_bboxes = legacy_delta2bbox(bboxes, pred_bboxes, self.means,
+ self.stds, max_shape, wh_ratio_clip)
+
+ if self.use_box_type:
+ assert decoded_bboxes.size(-1) == 4, \
+ ('Cannot warp decoded boxes with box type when decoded boxes'
+ 'have shape of (N, num_classes * 4)')
+ decoded_bboxes = HorizontalBoxes(decoded_bboxes)
+ return decoded_bboxes
+
+
+def legacy_bbox2delta(
+ proposals: Tensor,
+ gt: Tensor,
+ means: Sequence[float] = (0., 0., 0., 0.),
+ stds: Sequence[float] = (1., 1., 1., 1.)
+) -> Tensor:
+ """Compute deltas of proposals w.r.t. gt in the MMDet V1.x manner.
+
+ We usually compute the deltas of x, y, w, h of proposals w.r.t ground
+ truth bboxes to get regression target.
+ This is the inverse function of `delta2bbox()`
+
+ Args:
+ proposals (Tensor): Boxes to be transformed, shape (N, ..., 4)
+ gt (Tensor): Gt bboxes to be used as base, shape (N, ..., 4)
+ means (Sequence[float]): Denormalizing means for delta coordinates
+ stds (Sequence[float]): Denormalizing standard deviation for delta
+ coordinates
+
+ Returns:
+ Tensor: deltas with shape (N, 4), where columns represent dx, dy,
+ dw, dh.
+ """
+ assert proposals.size() == gt.size()
+
+ proposals = proposals.float()
+ gt = gt.float()
+ px = (proposals[..., 0] + proposals[..., 2]) * 0.5
+ py = (proposals[..., 1] + proposals[..., 3]) * 0.5
+ pw = proposals[..., 2] - proposals[..., 0] + 1.0
+ ph = proposals[..., 3] - proposals[..., 1] + 1.0
+
+ gx = (gt[..., 0] + gt[..., 2]) * 0.5
+ gy = (gt[..., 1] + gt[..., 3]) * 0.5
+ gw = gt[..., 2] - gt[..., 0] + 1.0
+ gh = gt[..., 3] - gt[..., 1] + 1.0
+
+ dx = (gx - px) / pw
+ dy = (gy - py) / ph
+ dw = torch.log(gw / pw)
+ dh = torch.log(gh / ph)
+ deltas = torch.stack([dx, dy, dw, dh], dim=-1)
+
+ means = deltas.new_tensor(means).unsqueeze(0)
+ stds = deltas.new_tensor(stds).unsqueeze(0)
+ deltas = deltas.sub_(means).div_(stds)
+
+ return deltas
+
+
+def legacy_delta2bbox(rois: Tensor,
+ deltas: Tensor,
+ means: Sequence[float] = (0., 0., 0., 0.),
+ stds: Sequence[float] = (1., 1., 1., 1.),
+ max_shape: Optional[
+ Union[Sequence[int], Tensor,
+ Sequence[Sequence[int]]]] = None,
+ wh_ratio_clip: float = 16 / 1000) -> Tensor:
+ """Apply deltas to shift/scale base boxes in the MMDet V1.x manner.
+
+ Typically the rois are anchor or proposed bounding boxes and the deltas are
+ network outputs used to shift/scale those boxes.
+ This is the inverse function of `bbox2delta()`
+
+ Args:
+ rois (Tensor): Boxes to be transformed. Has shape (N, 4)
+ deltas (Tensor): Encoded offsets with respect to each roi.
+ Has shape (N, 4 * num_classes). Note N = num_anchors * W * H when
+ rois is a grid of anchors. Offset encoding follows [1]_.
+ means (Sequence[float]): Denormalizing means for delta coordinates
+ stds (Sequence[float]): Denormalizing standard deviation for delta
+ coordinates
+ max_shape (tuple[int, int]): Maximum bounds for boxes. specifies (H, W)
+ wh_ratio_clip (float): Maximum aspect ratio for boxes.
+
+ Returns:
+ Tensor: Boxes with shape (N, 4), where columns represent
+ tl_x, tl_y, br_x, br_y.
+
+ References:
+ .. [1] https://arxiv.org/abs/1311.2524
+
+ Example:
+ >>> rois = torch.Tensor([[ 0., 0., 1., 1.],
+ >>> [ 0., 0., 1., 1.],
+ >>> [ 0., 0., 1., 1.],
+ >>> [ 5., 5., 5., 5.]])
+ >>> deltas = torch.Tensor([[ 0., 0., 0., 0.],
+ >>> [ 1., 1., 1., 1.],
+ >>> [ 0., 0., 2., -1.],
+ >>> [ 0.7, -1.9, -0.5, 0.3]])
+ >>> legacy_delta2bbox(rois, deltas, max_shape=(32, 32))
+ tensor([[0.0000, 0.0000, 1.5000, 1.5000],
+ [0.0000, 0.0000, 5.2183, 5.2183],
+ [0.0000, 0.1321, 7.8891, 0.8679],
+ [5.3967, 2.4251, 6.0033, 3.7749]])
+ """
+ means = deltas.new_tensor(means).repeat(1, deltas.size(1) // 4)
+ stds = deltas.new_tensor(stds).repeat(1, deltas.size(1) // 4)
+ denorm_deltas = deltas * stds + means
+ dx = denorm_deltas[:, 0::4]
+ dy = denorm_deltas[:, 1::4]
+ dw = denorm_deltas[:, 2::4]
+ dh = denorm_deltas[:, 3::4]
+ max_ratio = np.abs(np.log(wh_ratio_clip))
+ dw = dw.clamp(min=-max_ratio, max=max_ratio)
+ dh = dh.clamp(min=-max_ratio, max=max_ratio)
+ # Compute center of each roi
+ px = ((rois[:, 0] + rois[:, 2]) * 0.5).unsqueeze(1).expand_as(dx)
+ py = ((rois[:, 1] + rois[:, 3]) * 0.5).unsqueeze(1).expand_as(dy)
+ # Compute width/height of each roi
+ pw = (rois[:, 2] - rois[:, 0] + 1.0).unsqueeze(1).expand_as(dw)
+ ph = (rois[:, 3] - rois[:, 1] + 1.0).unsqueeze(1).expand_as(dh)
+ # Use exp(network energy) to enlarge/shrink each roi
+ gw = pw * dw.exp()
+ gh = ph * dh.exp()
+ # Use network energy to shift the center of each roi
+ gx = px + pw * dx
+ gy = py + ph * dy
+ # Convert center-xy/width/height to top-left, bottom-right
+
+ # The true legacy box coder should +- 0.5 here.
+ # However, current implementation improves the performance when testing
+ # the models trained in MMDetection 1.X (~0.5 bbox AP, 0.2 mask AP)
+ x1 = gx - gw * 0.5
+ y1 = gy - gh * 0.5
+ x2 = gx + gw * 0.5
+ y2 = gy + gh * 0.5
+ if max_shape is not None:
+ x1 = x1.clamp(min=0, max=max_shape[1] - 1)
+ y1 = y1.clamp(min=0, max=max_shape[0] - 1)
+ x2 = x2.clamp(min=0, max=max_shape[1] - 1)
+ y2 = y2.clamp(min=0, max=max_shape[0] - 1)
+ bboxes = torch.stack([x1, y1, x2, y2], dim=-1).view_as(deltas)
+ return bboxes
diff --git a/mmdet/models/task_modules/coders/pseudo_bbox_coder.py b/mmdet/models/task_modules/coders/pseudo_bbox_coder.py
new file mode 100644
index 0000000000000000000000000000000000000000..9ee74311f6d12bde49d0c678edb60540a8c95c8b
--- /dev/null
+++ b/mmdet/models/task_modules/coders/pseudo_bbox_coder.py
@@ -0,0 +1,29 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Union
+
+from torch import Tensor
+
+from mmdet.registry import TASK_UTILS
+from mmdet.structures.bbox import BaseBoxes, HorizontalBoxes, get_box_tensor
+from .base_bbox_coder import BaseBBoxCoder
+
+
+@TASK_UTILS.register_module()
+class PseudoBBoxCoder(BaseBBoxCoder):
+ """Pseudo bounding box coder."""
+
+ def __init__(self, **kwargs):
+ super().__init__(**kwargs)
+
+ def encode(self, bboxes: Tensor, gt_bboxes: Union[Tensor,
+ BaseBoxes]) -> Tensor:
+ """torch.Tensor: return the given ``bboxes``"""
+ gt_bboxes = get_box_tensor(gt_bboxes)
+ return gt_bboxes
+
+ def decode(self, bboxes: Tensor, pred_bboxes: Union[Tensor,
+ BaseBoxes]) -> Tensor:
+ """torch.Tensor: return the given ``pred_bboxes``"""
+ if self.use_box_type:
+ pred_bboxes = HorizontalBoxes(pred_bboxes)
+ return pred_bboxes
diff --git a/mmdet/models/task_modules/coders/tblr_bbox_coder.py b/mmdet/models/task_modules/coders/tblr_bbox_coder.py
new file mode 100644
index 0000000000000000000000000000000000000000..74b388f7bad6ebc1911cee5b0b7d73bbd04de17a
--- /dev/null
+++ b/mmdet/models/task_modules/coders/tblr_bbox_coder.py
@@ -0,0 +1,228 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Sequence, Union
+
+import torch
+from torch import Tensor
+
+from mmdet.registry import TASK_UTILS
+from mmdet.structures.bbox import BaseBoxes, HorizontalBoxes, get_box_tensor
+from .base_bbox_coder import BaseBBoxCoder
+
+
+@TASK_UTILS.register_module()
+class TBLRBBoxCoder(BaseBBoxCoder):
+ """TBLR BBox coder.
+
+ Following the practice in `FSAF `_,
+ this coder encodes gt bboxes (x1, y1, x2, y2) into (top, bottom, left,
+ right) and decode it back to the original.
+
+ Args:
+ normalizer (list | float): Normalization factor to be
+ divided with when coding the coordinates. If it is a list, it should
+ have length of 4 indicating normalization factor in tblr dims.
+ Otherwise it is a unified float factor for all dims. Default: 4.0
+ clip_border (bool, optional): Whether clip the objects outside the
+ border of the image. Defaults to True.
+ """
+
+ def __init__(self,
+ normalizer: Union[Sequence[float], float] = 4.0,
+ clip_border: bool = True,
+ **kwargs) -> None:
+ super().__init__(**kwargs)
+ self.normalizer = normalizer
+ self.clip_border = clip_border
+
+ def encode(self, bboxes: Union[Tensor, BaseBoxes],
+ gt_bboxes: Union[Tensor, BaseBoxes]) -> Tensor:
+ """Get box regression transformation deltas that can be used to
+ transform the ``bboxes`` into the ``gt_bboxes`` in the (top, left,
+ bottom, right) order.
+
+ Args:
+ bboxes (torch.Tensor or :obj:`BaseBoxes`): source boxes,
+ e.g., object proposals.
+ gt_bboxes (torch.Tensor or :obj:`BaseBoxes`): target of the
+ transformation, e.g., ground truth boxes.
+
+ Returns:
+ torch.Tensor: Box transformation deltas
+ """
+ bboxes = get_box_tensor(bboxes)
+ gt_bboxes = get_box_tensor(gt_bboxes)
+ assert bboxes.size(0) == gt_bboxes.size(0)
+ assert bboxes.size(-1) == gt_bboxes.size(-1) == 4
+ encoded_bboxes = bboxes2tblr(
+ bboxes, gt_bboxes, normalizer=self.normalizer)
+ return encoded_bboxes
+
+ def decode(
+ self,
+ bboxes: Union[Tensor, BaseBoxes],
+ pred_bboxes: Tensor,
+ max_shape: Optional[Union[Sequence[int], Tensor,
+ Sequence[Sequence[int]]]] = None
+ ) -> Union[Tensor, BaseBoxes]:
+ """Apply transformation `pred_bboxes` to `boxes`.
+
+ Args:
+ bboxes (torch.Tensor or :obj:`BaseBoxes`): Basic boxes.Shape
+ (B, N, 4) or (N, 4)
+ pred_bboxes (torch.Tensor): Encoded boxes with shape
+ (B, N, 4) or (N, 4)
+ max_shape (Sequence[int] or torch.Tensor or Sequence[
+ Sequence[int]],optional): Maximum bounds for boxes, specifies
+ (H, W, C) or (H, W). If bboxes shape is (B, N, 4), then
+ the max_shape should be a Sequence[Sequence[int]]
+ and the length of max_shape should also be B.
+
+ Returns:
+ Union[torch.Tensor, :obj:`BaseBoxes`]: Decoded boxes.
+ """
+ bboxes = get_box_tensor(bboxes)
+ decoded_bboxes = tblr2bboxes(
+ bboxes,
+ pred_bboxes,
+ normalizer=self.normalizer,
+ max_shape=max_shape,
+ clip_border=self.clip_border)
+
+ if self.use_box_type:
+ decoded_bboxes = HorizontalBoxes(decoded_bboxes)
+ return decoded_bboxes
+
+
+def bboxes2tblr(priors: Tensor,
+ gts: Tensor,
+ normalizer: Union[Sequence[float], float] = 4.0,
+ normalize_by_wh: bool = True) -> Tensor:
+ """Encode ground truth boxes to tblr coordinate.
+
+ It first convert the gt coordinate to tblr format,
+ (top, bottom, left, right), relative to prior box centers.
+ The tblr coordinate may be normalized by the side length of prior bboxes
+ if `normalize_by_wh` is specified as True, and it is then normalized by
+ the `normalizer` factor.
+
+ Args:
+ priors (Tensor): Prior boxes in point form
+ Shape: (num_proposals,4).
+ gts (Tensor): Coords of ground truth for each prior in point-form
+ Shape: (num_proposals, 4).
+ normalizer (Sequence[float] | float): normalization parameter of
+ encoded boxes. If it is a list, it has to have length = 4.
+ Default: 4.0
+ normalize_by_wh (bool): Whether to normalize tblr coordinate by the
+ side length (wh) of prior bboxes.
+
+ Return:
+ encoded boxes (Tensor), Shape: (num_proposals, 4)
+ """
+
+ # dist b/t match center and prior's center
+ if not isinstance(normalizer, float):
+ normalizer = torch.tensor(normalizer, device=priors.device)
+ assert len(normalizer) == 4, 'Normalizer must have length = 4'
+ assert priors.size(0) == gts.size(0)
+ prior_centers = (priors[:, 0:2] + priors[:, 2:4]) / 2
+ xmin, ymin, xmax, ymax = gts.split(1, dim=1)
+ top = prior_centers[:, 1].unsqueeze(1) - ymin
+ bottom = ymax - prior_centers[:, 1].unsqueeze(1)
+ left = prior_centers[:, 0].unsqueeze(1) - xmin
+ right = xmax - prior_centers[:, 0].unsqueeze(1)
+ loc = torch.cat((top, bottom, left, right), dim=1)
+ if normalize_by_wh:
+ # Normalize tblr by anchor width and height
+ wh = priors[:, 2:4] - priors[:, 0:2]
+ w, h = torch.split(wh, 1, dim=1)
+ loc[:, :2] /= h # tb is normalized by h
+ loc[:, 2:] /= w # lr is normalized by w
+ # Normalize tblr by the given normalization factor
+ return loc / normalizer
+
+
+def tblr2bboxes(priors: Tensor,
+ tblr: Tensor,
+ normalizer: Union[Sequence[float], float] = 4.0,
+ normalize_by_wh: bool = True,
+ max_shape: Optional[Union[Sequence[int], Tensor,
+ Sequence[Sequence[int]]]] = None,
+ clip_border: bool = True) -> Tensor:
+ """Decode tblr outputs to prediction boxes.
+
+ The process includes 3 steps: 1) De-normalize tblr coordinates by
+ multiplying it with `normalizer`; 2) De-normalize tblr coordinates by the
+ prior bbox width and height if `normalize_by_wh` is `True`; 3) Convert
+ tblr (top, bottom, left, right) pair relative to the center of priors back
+ to (xmin, ymin, xmax, ymax) coordinate.
+
+ Args:
+ priors (Tensor): Prior boxes in point form (x0, y0, x1, y1)
+ Shape: (N,4) or (B, N, 4).
+ tblr (Tensor): Coords of network output in tblr form
+ Shape: (N, 4) or (B, N, 4).
+ normalizer (Sequence[float] | float): Normalization parameter of
+ encoded boxes. By list, it represents the normalization factors at
+ tblr dims. By float, it is the unified normalization factor at all
+ dims. Default: 4.0
+ normalize_by_wh (bool): Whether the tblr coordinates have been
+ normalized by the side length (wh) of prior bboxes.
+ max_shape (Sequence[int] or torch.Tensor or Sequence[
+ Sequence[int]],optional): Maximum bounds for boxes, specifies
+ (H, W, C) or (H, W). If priors shape is (B, N, 4), then
+ the max_shape should be a Sequence[Sequence[int]]
+ and the length of max_shape should also be B.
+ clip_border (bool, optional): Whether clip the objects outside the
+ border of the image. Defaults to True.
+
+ Return:
+ encoded boxes (Tensor): Boxes with shape (N, 4) or (B, N, 4)
+ """
+ if not isinstance(normalizer, float):
+ normalizer = torch.tensor(normalizer, device=priors.device)
+ assert len(normalizer) == 4, 'Normalizer must have length = 4'
+ assert priors.size(0) == tblr.size(0)
+ if priors.ndim == 3:
+ assert priors.size(1) == tblr.size(1)
+
+ loc_decode = tblr * normalizer
+ prior_centers = (priors[..., 0:2] + priors[..., 2:4]) / 2
+ if normalize_by_wh:
+ wh = priors[..., 2:4] - priors[..., 0:2]
+ w, h = torch.split(wh, 1, dim=-1)
+ # Inplace operation with slice would failed for exporting to ONNX
+ th = h * loc_decode[..., :2] # tb
+ tw = w * loc_decode[..., 2:] # lr
+ loc_decode = torch.cat([th, tw], dim=-1)
+ # Cannot be exported using onnx when loc_decode.split(1, dim=-1)
+ top, bottom, left, right = loc_decode.split((1, 1, 1, 1), dim=-1)
+ xmin = prior_centers[..., 0].unsqueeze(-1) - left
+ xmax = prior_centers[..., 0].unsqueeze(-1) + right
+ ymin = prior_centers[..., 1].unsqueeze(-1) - top
+ ymax = prior_centers[..., 1].unsqueeze(-1) + bottom
+
+ bboxes = torch.cat((xmin, ymin, xmax, ymax), dim=-1)
+
+ if clip_border and max_shape is not None:
+ # clip bboxes with dynamic `min` and `max` for onnx
+ if torch.onnx.is_in_onnx_export():
+ from mmdet.core.export import dynamic_clip_for_onnx
+ xmin, ymin, xmax, ymax = dynamic_clip_for_onnx(
+ xmin, ymin, xmax, ymax, max_shape)
+ bboxes = torch.cat([xmin, ymin, xmax, ymax], dim=-1)
+ return bboxes
+ if not isinstance(max_shape, torch.Tensor):
+ max_shape = priors.new_tensor(max_shape)
+ max_shape = max_shape[..., :2].type_as(priors)
+ if max_shape.ndim == 2:
+ assert bboxes.ndim == 3
+ assert max_shape.size(0) == bboxes.size(0)
+
+ min_xy = priors.new_tensor(0)
+ max_xy = torch.cat([max_shape, max_shape],
+ dim=-1).flip(-1).unsqueeze(-2)
+ bboxes = torch.where(bboxes < min_xy, min_xy, bboxes)
+ bboxes = torch.where(bboxes > max_xy, max_xy, bboxes)
+
+ return bboxes
diff --git a/mmdet/models/task_modules/coders/yolo_bbox_coder.py b/mmdet/models/task_modules/coders/yolo_bbox_coder.py
new file mode 100644
index 0000000000000000000000000000000000000000..2e1c766789bec844ff359e225435bc3b2f5dd736
--- /dev/null
+++ b/mmdet/models/task_modules/coders/yolo_bbox_coder.py
@@ -0,0 +1,94 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Union
+
+import torch
+from torch import Tensor
+
+from mmdet.registry import TASK_UTILS
+from mmdet.structures.bbox import BaseBoxes, HorizontalBoxes, get_box_tensor
+from .base_bbox_coder import BaseBBoxCoder
+
+
+@TASK_UTILS.register_module()
+class YOLOBBoxCoder(BaseBBoxCoder):
+ """YOLO BBox coder.
+
+ Following `YOLO `_, this coder divide
+ image into grids, and encode bbox (x1, y1, x2, y2) into (cx, cy, dw, dh).
+ cx, cy in [0., 1.], denotes relative center position w.r.t the center of
+ bboxes. dw, dh are the same as :obj:`DeltaXYWHBBoxCoder`.
+
+ Args:
+ eps (float): Min value of cx, cy when encoding.
+ """
+
+ def __init__(self, eps: float = 1e-6, **kwargs):
+ super().__init__(**kwargs)
+ self.eps = eps
+
+ def encode(self, bboxes: Union[Tensor, BaseBoxes],
+ gt_bboxes: Union[Tensor, BaseBoxes],
+ stride: Union[Tensor, int]) -> Tensor:
+ """Get box regression transformation deltas that can be used to
+ transform the ``bboxes`` into the ``gt_bboxes``.
+
+ Args:
+ bboxes (torch.Tensor or :obj:`BaseBoxes`): Source boxes,
+ e.g., anchors.
+ gt_bboxes (torch.Tensor or :obj:`BaseBoxes`): Target of the
+ transformation, e.g., ground-truth boxes.
+ stride (torch.Tensor | int): Stride of bboxes.
+
+ Returns:
+ torch.Tensor: Box transformation deltas
+ """
+ bboxes = get_box_tensor(bboxes)
+ gt_bboxes = get_box_tensor(gt_bboxes)
+ assert bboxes.size(0) == gt_bboxes.size(0)
+ assert bboxes.size(-1) == gt_bboxes.size(-1) == 4
+ x_center_gt = (gt_bboxes[..., 0] + gt_bboxes[..., 2]) * 0.5
+ y_center_gt = (gt_bboxes[..., 1] + gt_bboxes[..., 3]) * 0.5
+ w_gt = gt_bboxes[..., 2] - gt_bboxes[..., 0]
+ h_gt = gt_bboxes[..., 3] - gt_bboxes[..., 1]
+ x_center = (bboxes[..., 0] + bboxes[..., 2]) * 0.5
+ y_center = (bboxes[..., 1] + bboxes[..., 3]) * 0.5
+ w = bboxes[..., 2] - bboxes[..., 0]
+ h = bboxes[..., 3] - bboxes[..., 1]
+ w_target = torch.log((w_gt / w).clamp(min=self.eps))
+ h_target = torch.log((h_gt / h).clamp(min=self.eps))
+ x_center_target = ((x_center_gt - x_center) / stride + 0.5).clamp(
+ self.eps, 1 - self.eps)
+ y_center_target = ((y_center_gt - y_center) / stride + 0.5).clamp(
+ self.eps, 1 - self.eps)
+ encoded_bboxes = torch.stack(
+ [x_center_target, y_center_target, w_target, h_target], dim=-1)
+ return encoded_bboxes
+
+ def decode(self, bboxes: Union[Tensor, BaseBoxes], pred_bboxes: Tensor,
+ stride: Union[Tensor, int]) -> Union[Tensor, BaseBoxes]:
+ """Apply transformation `pred_bboxes` to `boxes`.
+
+ Args:
+ boxes (torch.Tensor or :obj:`BaseBoxes`): Basic boxes,
+ e.g. anchors.
+ pred_bboxes (torch.Tensor): Encoded boxes with shape
+ stride (torch.Tensor | int): Strides of bboxes.
+
+ Returns:
+ Union[torch.Tensor, :obj:`BaseBoxes`]: Decoded boxes.
+ """
+ bboxes = get_box_tensor(bboxes)
+ assert pred_bboxes.size(-1) == bboxes.size(-1) == 4
+ xy_centers = (bboxes[..., :2] + bboxes[..., 2:]) * 0.5 + (
+ pred_bboxes[..., :2] - 0.5) * stride
+ whs = (bboxes[..., 2:] -
+ bboxes[..., :2]) * 0.5 * pred_bboxes[..., 2:].exp()
+ decoded_bboxes = torch.stack(
+ (xy_centers[..., 0] - whs[..., 0], xy_centers[..., 1] -
+ whs[..., 1], xy_centers[..., 0] + whs[..., 0],
+ xy_centers[..., 1] + whs[..., 1]),
+ dim=-1)
+
+ if self.use_box_type:
+ decoded_bboxes = HorizontalBoxes(decoded_bboxes)
+ return decoded_bboxes
diff --git a/mmdet/models/task_modules/prior_generators/__init__.py b/mmdet/models/task_modules/prior_generators/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..7795e98ca77bb5ffc77ff1da848130717d8f85a6
--- /dev/null
+++ b/mmdet/models/task_modules/prior_generators/__init__.py
@@ -0,0 +1,11 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .anchor_generator import (AnchorGenerator, LegacyAnchorGenerator,
+ SSDAnchorGenerator, YOLOAnchorGenerator)
+from .point_generator import MlvlPointGenerator, PointGenerator
+from .utils import anchor_inside_flags, calc_region
+
+__all__ = [
+ 'AnchorGenerator', 'LegacyAnchorGenerator', 'anchor_inside_flags',
+ 'PointGenerator', 'calc_region', 'YOLOAnchorGenerator',
+ 'MlvlPointGenerator', 'SSDAnchorGenerator'
+]
diff --git a/mmdet/models/task_modules/prior_generators/__pycache__/__init__.cpython-37.pyc b/mmdet/models/task_modules/prior_generators/__pycache__/__init__.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..a9a4071d3529965a0fc58cf7c7a4466ca118b5b7
Binary files /dev/null and b/mmdet/models/task_modules/prior_generators/__pycache__/__init__.cpython-37.pyc differ
diff --git a/mmdet/models/task_modules/prior_generators/__pycache__/anchor_generator.cpython-37.pyc b/mmdet/models/task_modules/prior_generators/__pycache__/anchor_generator.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..d59064a0a72809b50aa666a28f4ae0d6b0296725
Binary files /dev/null and b/mmdet/models/task_modules/prior_generators/__pycache__/anchor_generator.cpython-37.pyc differ
diff --git a/mmdet/models/task_modules/prior_generators/__pycache__/point_generator.cpython-37.pyc b/mmdet/models/task_modules/prior_generators/__pycache__/point_generator.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..084b3df846b81eb544c8e307557a737116c04d4e
Binary files /dev/null and b/mmdet/models/task_modules/prior_generators/__pycache__/point_generator.cpython-37.pyc differ
diff --git a/mmdet/models/task_modules/prior_generators/__pycache__/utils.cpython-37.pyc b/mmdet/models/task_modules/prior_generators/__pycache__/utils.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..cb62a269d28cb4fc62c9cc37bc7b712b24c9313f
Binary files /dev/null and b/mmdet/models/task_modules/prior_generators/__pycache__/utils.cpython-37.pyc differ
diff --git a/mmdet/models/task_modules/prior_generators/anchor_generator.py b/mmdet/models/task_modules/prior_generators/anchor_generator.py
new file mode 100644
index 0000000000000000000000000000000000000000..2757697ce2283ec8b46ba89325e63fad0be4a7e8
--- /dev/null
+++ b/mmdet/models/task_modules/prior_generators/anchor_generator.py
@@ -0,0 +1,848 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+from typing import List, Optional, Tuple, Union
+
+import numpy as np
+import torch
+from mmengine.utils import is_tuple_of
+from torch import Tensor
+from torch.nn.modules.utils import _pair
+
+from mmdet.registry import TASK_UTILS
+from mmdet.structures.bbox import HorizontalBoxes
+
+DeviceType = Union[str, torch.device]
+
+
+@TASK_UTILS.register_module()
+class AnchorGenerator:
+ """Standard anchor generator for 2D anchor-based detectors.
+
+ Args:
+ strides (list[int] | list[tuple[int, int]]): Strides of anchors
+ in multiple feature levels in order (w, h).
+ ratios (list[float]): The list of ratios between the height and width
+ of anchors in a single level.
+ scales (list[int], Optional): Anchor scales for anchors
+ in a single level. It cannot be set at the same time
+ if `octave_base_scale` and `scales_per_octave` are set.
+ base_sizes (list[int], Optional): The basic sizes
+ of anchors in multiple levels.
+ If None is given, strides will be used as base_sizes.
+ (If strides are non square, the shortest stride is taken.)
+ scale_major (bool): Whether to multiply scales first when generating
+ base anchors. If true, the anchors in the same row will have the
+ same scales. By default it is True in V2.0
+ octave_base_scale (int, Optional): The base scale of octave.
+ scales_per_octave (int, Optional): Number of scales for each octave.
+ `octave_base_scale` and `scales_per_octave` are usually used in
+ retinanet and the `scales` should be None when they are set.
+ centers (list[tuple[float]], Optional): The centers of the anchor
+ relative to the feature grid center in multiple feature levels.
+ By default it is set to be None and not used. If a list of tuple of
+ float is given, they will be used to shift the centers of anchors.
+ center_offset (float): The offset of center in proportion to anchors'
+ width and height. By default it is 0 in V2.0.
+ use_box_type (bool): Whether to warp anchors with the box type data
+ structure. Defaults to False.
+
+ Examples:
+ >>> from mmdet.models.task_modules.
+ ... prior_generators import AnchorGenerator
+ >>> self = AnchorGenerator([16], [1.], [1.], [9])
+ >>> all_anchors = self.grid_priors([(2, 2)], device='cpu')
+ >>> print(all_anchors)
+ [tensor([[-4.5000, -4.5000, 4.5000, 4.5000],
+ [11.5000, -4.5000, 20.5000, 4.5000],
+ [-4.5000, 11.5000, 4.5000, 20.5000],
+ [11.5000, 11.5000, 20.5000, 20.5000]])]
+ >>> self = AnchorGenerator([16, 32], [1.], [1.], [9, 18])
+ >>> all_anchors = self.grid_priors([(2, 2), (1, 1)], device='cpu')
+ >>> print(all_anchors)
+ [tensor([[-4.5000, -4.5000, 4.5000, 4.5000],
+ [11.5000, -4.5000, 20.5000, 4.5000],
+ [-4.5000, 11.5000, 4.5000, 20.5000],
+ [11.5000, 11.5000, 20.5000, 20.5000]]), \
+ tensor([[-9., -9., 9., 9.]])]
+ """
+
+ def __init__(self,
+ strides: Union[List[int], List[Tuple[int, int]]],
+ ratios: List[float],
+ scales: Optional[List[int]] = None,
+ base_sizes: Optional[List[int]] = None,
+ scale_major: bool = True,
+ octave_base_scale: Optional[int] = None,
+ scales_per_octave: Optional[int] = None,
+ centers: Optional[List[Tuple[float, float]]] = None,
+ center_offset: float = 0.,
+ use_box_type: bool = False) -> None:
+ # check center and center_offset
+ if center_offset != 0:
+ assert centers is None, 'center cannot be set when center_offset' \
+ f'!=0, {centers} is given.'
+ if not (0 <= center_offset <= 1):
+ raise ValueError('center_offset should be in range [0, 1], '
+ f'{center_offset} is given.')
+ if centers is not None:
+ assert len(centers) == len(strides), \
+ 'The number of strides should be the same as centers, got ' \
+ f'{strides} and {centers}'
+
+ # calculate base sizes of anchors
+ self.strides = [_pair(stride) for stride in strides]
+ self.base_sizes = [min(stride) for stride in self.strides
+ ] if base_sizes is None else base_sizes
+ assert len(self.base_sizes) == len(self.strides), \
+ 'The number of strides should be the same as base sizes, got ' \
+ f'{self.strides} and {self.base_sizes}'
+
+ # calculate scales of anchors
+ assert ((octave_base_scale is not None
+ and scales_per_octave is not None) ^ (scales is not None)), \
+ 'scales and octave_base_scale with scales_per_octave cannot' \
+ ' be set at the same time'
+ if scales is not None:
+ self.scales = torch.Tensor(scales)
+ elif octave_base_scale is not None and scales_per_octave is not None:
+ octave_scales = np.array(
+ [2**(i / scales_per_octave) for i in range(scales_per_octave)])
+ scales = octave_scales * octave_base_scale
+ self.scales = torch.Tensor(scales)
+ else:
+ raise ValueError('Either scales or octave_base_scale with '
+ 'scales_per_octave should be set')
+
+ self.octave_base_scale = octave_base_scale
+ self.scales_per_octave = scales_per_octave
+ self.ratios = torch.Tensor(ratios)
+ self.scale_major = scale_major
+ self.centers = centers
+ self.center_offset = center_offset
+ self.base_anchors = self.gen_base_anchors()
+ self.use_box_type = use_box_type
+
+ @property
+ def num_base_anchors(self) -> List[int]:
+ """list[int]: total number of base anchors in a feature grid"""
+ return self.num_base_priors
+
+ @property
+ def num_base_priors(self) -> List[int]:
+ """list[int]: The number of priors (anchors) at a point
+ on the feature grid"""
+ return [base_anchors.size(0) for base_anchors in self.base_anchors]
+
+ @property
+ def num_levels(self) -> int:
+ """int: number of feature levels that the generator will be applied"""
+ return len(self.strides)
+
+ def gen_base_anchors(self) -> List[Tensor]:
+ """Generate base anchors.
+
+ Returns:
+ list(torch.Tensor): Base anchors of a feature grid in multiple \
+ feature levels.
+ """
+ multi_level_base_anchors = []
+ for i, base_size in enumerate(self.base_sizes):
+ center = None
+ if self.centers is not None:
+ center = self.centers[i]
+ multi_level_base_anchors.append(
+ self.gen_single_level_base_anchors(
+ base_size,
+ scales=self.scales,
+ ratios=self.ratios,
+ center=center))
+ return multi_level_base_anchors
+
+ def gen_single_level_base_anchors(self,
+ base_size: Union[int, float],
+ scales: Tensor,
+ ratios: Tensor,
+ center: Optional[Tuple[float]] = None) \
+ -> Tensor:
+ """Generate base anchors of a single level.
+
+ Args:
+ base_size (int | float): Basic size of an anchor.
+ scales (torch.Tensor): Scales of the anchor.
+ ratios (torch.Tensor): The ratio between the height
+ and width of anchors in a single level.
+ center (tuple[float], optional): The center of the base anchor
+ related to a single feature grid. Defaults to None.
+
+ Returns:
+ torch.Tensor: Anchors in a single-level feature maps.
+ """
+ w = base_size
+ h = base_size
+ if center is None:
+ x_center = self.center_offset * w
+ y_center = self.center_offset * h
+ else:
+ x_center, y_center = center
+
+ h_ratios = torch.sqrt(ratios)
+ w_ratios = 1 / h_ratios
+ if self.scale_major:
+ ws = (w * w_ratios[:, None] * scales[None, :]).view(-1)
+ hs = (h * h_ratios[:, None] * scales[None, :]).view(-1)
+ else:
+ ws = (w * scales[:, None] * w_ratios[None, :]).view(-1)
+ hs = (h * scales[:, None] * h_ratios[None, :]).view(-1)
+
+ # use float anchor and the anchor's center is aligned with the
+ # pixel center
+ base_anchors = [
+ x_center - 0.5 * ws, y_center - 0.5 * hs, x_center + 0.5 * ws,
+ y_center + 0.5 * hs
+ ]
+ base_anchors = torch.stack(base_anchors, dim=-1)
+
+ return base_anchors
+
+ def _meshgrid(self,
+ x: Tensor,
+ y: Tensor,
+ row_major: bool = True) -> Tuple[Tensor]:
+ """Generate mesh grid of x and y.
+
+ Args:
+ x (torch.Tensor): Grids of x dimension.
+ y (torch.Tensor): Grids of y dimension.
+ row_major (bool): Whether to return y grids first.
+ Defaults to True.
+
+ Returns:
+ tuple[torch.Tensor]: The mesh grids of x and y.
+ """
+ # use shape instead of len to keep tracing while exporting to onnx
+ xx = x.repeat(y.shape[0])
+ yy = y.view(-1, 1).repeat(1, x.shape[0]).view(-1)
+ if row_major:
+ return xx, yy
+ else:
+ return yy, xx
+
+ def grid_priors(self,
+ featmap_sizes: List[Tuple],
+ dtype: torch.dtype = torch.float32,
+ device: DeviceType = 'cuda') -> List[Tensor]:
+ """Generate grid anchors in multiple feature levels.
+
+ Args:
+ featmap_sizes (list[tuple]): List of feature map sizes in
+ multiple feature levels.
+ dtype (:obj:`torch.dtype`): Dtype of priors.
+ Defaults to torch.float32.
+ device (str | torch.device): The device where the anchors
+ will be put on.
+
+ Return:
+ list[torch.Tensor]: Anchors in multiple feature levels. \
+ The sizes of each tensor should be [N, 4], where \
+ N = width * height * num_base_anchors, width and height \
+ are the sizes of the corresponding feature level, \
+ num_base_anchors is the number of anchors for that level.
+ """
+ assert self.num_levels == len(featmap_sizes)
+ multi_level_anchors = []
+ for i in range(self.num_levels):
+ anchors = self.single_level_grid_priors(
+ featmap_sizes[i], level_idx=i, dtype=dtype, device=device)
+ multi_level_anchors.append(anchors)
+ return multi_level_anchors
+
+ def single_level_grid_priors(self,
+ featmap_size: Tuple[int, int],
+ level_idx: int,
+ dtype: torch.dtype = torch.float32,
+ device: DeviceType = 'cuda') -> Tensor:
+ """Generate grid anchors of a single level.
+
+ Note:
+ This function is usually called by method ``self.grid_priors``.
+
+ Args:
+ featmap_size (tuple[int, int]): Size of the feature maps.
+ level_idx (int): The index of corresponding feature map level.
+ dtype (obj:`torch.dtype`): Date type of points.Defaults to
+ ``torch.float32``.
+ device (str | torch.device): The device the tensor will be put on.
+ Defaults to 'cuda'.
+
+ Returns:
+ torch.Tensor: Anchors in the overall feature maps.
+ """
+
+ base_anchors = self.base_anchors[level_idx].to(device).to(dtype)
+ feat_h, feat_w = featmap_size
+ stride_w, stride_h = self.strides[level_idx]
+ # First create Range with the default dtype, than convert to
+ # target `dtype` for onnx exporting.
+ shift_x = torch.arange(0, feat_w, device=device).to(dtype) * stride_w
+ shift_y = torch.arange(0, feat_h, device=device).to(dtype) * stride_h
+
+ shift_xx, shift_yy = self._meshgrid(shift_x, shift_y)
+ shifts = torch.stack([shift_xx, shift_yy, shift_xx, shift_yy], dim=-1)
+ # first feat_w elements correspond to the first row of shifts
+ # add A anchors (1, A, 4) to K shifts (K, 1, 4) to get
+ # shifted anchors (K, A, 4), reshape to (K*A, 4)
+
+ all_anchors = base_anchors[None, :, :] + shifts[:, None, :]
+ all_anchors = all_anchors.view(-1, 4)
+ # first A rows correspond to A anchors of (0, 0) in feature map,
+ # then (0, 1), (0, 2), ...
+ if self.use_box_type:
+ all_anchors = HorizontalBoxes(all_anchors)
+ return all_anchors
+
+ def sparse_priors(self,
+ prior_idxs: Tensor,
+ featmap_size: Tuple[int, int],
+ level_idx: int,
+ dtype: torch.dtype = torch.float32,
+ device: DeviceType = 'cuda') -> Tensor:
+ """Generate sparse anchors according to the ``prior_idxs``.
+
+ Args:
+ prior_idxs (Tensor): The index of corresponding anchors
+ in the feature map.
+ featmap_size (tuple[int, int]): feature map size arrange as (h, w).
+ level_idx (int): The level index of corresponding feature
+ map.
+ dtype (obj:`torch.dtype`): Date type of points.Defaults to
+ ``torch.float32``.
+ device (str | torch.device): The device where the points is
+ located.
+ Returns:
+ Tensor: Anchor with shape (N, 4), N should be equal to
+ the length of ``prior_idxs``.
+ """
+
+ height, width = featmap_size
+ num_base_anchors = self.num_base_anchors[level_idx]
+ base_anchor_id = prior_idxs % num_base_anchors
+ x = (prior_idxs //
+ num_base_anchors) % width * self.strides[level_idx][0]
+ y = (prior_idxs // width //
+ num_base_anchors) % height * self.strides[level_idx][1]
+ priors = torch.stack([x, y, x, y], 1).to(dtype).to(device) + \
+ self.base_anchors[level_idx][base_anchor_id, :].to(device)
+
+ return priors
+
+ def grid_anchors(self,
+ featmap_sizes: List[Tuple],
+ device: DeviceType = 'cuda') -> List[Tensor]:
+ """Generate grid anchors in multiple feature levels.
+
+ Args:
+ featmap_sizes (list[tuple]): List of feature map sizes in
+ multiple feature levels.
+ device (str | torch.device): Device where the anchors will be
+ put on.
+
+ Return:
+ list[torch.Tensor]: Anchors in multiple feature levels. \
+ The sizes of each tensor should be [N, 4], where \
+ N = width * height * num_base_anchors, width and height \
+ are the sizes of the corresponding feature level, \
+ num_base_anchors is the number of anchors for that level.
+ """
+ warnings.warn('``grid_anchors`` would be deprecated soon. '
+ 'Please use ``grid_priors`` ')
+
+ assert self.num_levels == len(featmap_sizes)
+ multi_level_anchors = []
+ for i in range(self.num_levels):
+ anchors = self.single_level_grid_anchors(
+ self.base_anchors[i].to(device),
+ featmap_sizes[i],
+ self.strides[i],
+ device=device)
+ multi_level_anchors.append(anchors)
+ return multi_level_anchors
+
+ def single_level_grid_anchors(self,
+ base_anchors: Tensor,
+ featmap_size: Tuple[int, int],
+ stride: Tuple[int, int] = (16, 16),
+ device: DeviceType = 'cuda') -> Tensor:
+ """Generate grid anchors of a single level.
+
+ Note:
+ This function is usually called by method ``self.grid_anchors``.
+
+ Args:
+ base_anchors (torch.Tensor): The base anchors of a feature grid.
+ featmap_size (tuple[int]): Size of the feature maps.
+ stride (tuple[int, int]): Stride of the feature map in order
+ (w, h). Defaults to (16, 16).
+ device (str | torch.device): Device the tensor will be put on.
+ Defaults to 'cuda'.
+
+ Returns:
+ torch.Tensor: Anchors in the overall feature maps.
+ """
+
+ warnings.warn(
+ '``single_level_grid_anchors`` would be deprecated soon. '
+ 'Please use ``single_level_grid_priors`` ')
+
+ # keep featmap_size as Tensor instead of int, so that we
+ # can convert to ONNX correctly
+ feat_h, feat_w = featmap_size
+ shift_x = torch.arange(0, feat_w, device=device) * stride[0]
+ shift_y = torch.arange(0, feat_h, device=device) * stride[1]
+
+ shift_xx, shift_yy = self._meshgrid(shift_x, shift_y)
+ shifts = torch.stack([shift_xx, shift_yy, shift_xx, shift_yy], dim=-1)
+ shifts = shifts.type_as(base_anchors)
+ # first feat_w elements correspond to the first row of shifts
+ # add A anchors (1, A, 4) to K shifts (K, 1, 4) to get
+ # shifted anchors (K, A, 4), reshape to (K*A, 4)
+
+ all_anchors = base_anchors[None, :, :] + shifts[:, None, :]
+ all_anchors = all_anchors.view(-1, 4)
+ # first A rows correspond to A anchors of (0, 0) in feature map,
+ # then (0, 1), (0, 2), ...
+ return all_anchors
+
+ def valid_flags(self,
+ featmap_sizes: List[Tuple[int, int]],
+ pad_shape: Tuple,
+ device: DeviceType = 'cuda') -> List[Tensor]:
+ """Generate valid flags of anchors in multiple feature levels.
+
+ Args:
+ featmap_sizes (list(tuple[int, int])): List of feature map sizes in
+ multiple feature levels.
+ pad_shape (tuple): The padded shape of the image.
+ device (str | torch.device): Device where the anchors will be
+ put on.
+
+ Return:
+ list(torch.Tensor): Valid flags of anchors in multiple levels.
+ """
+ assert self.num_levels == len(featmap_sizes)
+ multi_level_flags = []
+ for i in range(self.num_levels):
+ anchor_stride = self.strides[i]
+ feat_h, feat_w = featmap_sizes[i]
+ h, w = pad_shape[:2]
+ valid_feat_h = min(int(np.ceil(h / anchor_stride[1])), feat_h)
+ valid_feat_w = min(int(np.ceil(w / anchor_stride[0])), feat_w)
+ flags = self.single_level_valid_flags((feat_h, feat_w),
+ (valid_feat_h, valid_feat_w),
+ self.num_base_anchors[i],
+ device=device)
+ multi_level_flags.append(flags)
+ return multi_level_flags
+
+ def single_level_valid_flags(self,
+ featmap_size: Tuple[int, int],
+ valid_size: Tuple[int, int],
+ num_base_anchors: int,
+ device: DeviceType = 'cuda') -> Tensor:
+ """Generate the valid flags of anchor in a single feature map.
+
+ Args:
+ featmap_size (tuple[int]): The size of feature maps, arrange
+ as (h, w).
+ valid_size (tuple[int]): The valid size of the feature maps.
+ num_base_anchors (int): The number of base anchors.
+ device (str | torch.device): Device where the flags will be put on.
+ Defaults to 'cuda'.
+
+ Returns:
+ torch.Tensor: The valid flags of each anchor in a single level \
+ feature map.
+ """
+ feat_h, feat_w = featmap_size
+ valid_h, valid_w = valid_size
+ assert valid_h <= feat_h and valid_w <= feat_w
+ valid_x = torch.zeros(feat_w, dtype=torch.bool, device=device)
+ valid_y = torch.zeros(feat_h, dtype=torch.bool, device=device)
+ valid_x[:valid_w] = 1
+ valid_y[:valid_h] = 1
+ valid_xx, valid_yy = self._meshgrid(valid_x, valid_y)
+ valid = valid_xx & valid_yy
+ valid = valid[:, None].expand(valid.size(0),
+ num_base_anchors).contiguous().view(-1)
+ return valid
+
+ def __repr__(self) -> str:
+ """str: a string that describes the module"""
+ indent_str = ' '
+ repr_str = self.__class__.__name__ + '(\n'
+ repr_str += f'{indent_str}strides={self.strides},\n'
+ repr_str += f'{indent_str}ratios={self.ratios},\n'
+ repr_str += f'{indent_str}scales={self.scales},\n'
+ repr_str += f'{indent_str}base_sizes={self.base_sizes},\n'
+ repr_str += f'{indent_str}scale_major={self.scale_major},\n'
+ repr_str += f'{indent_str}octave_base_scale='
+ repr_str += f'{self.octave_base_scale},\n'
+ repr_str += f'{indent_str}scales_per_octave='
+ repr_str += f'{self.scales_per_octave},\n'
+ repr_str += f'{indent_str}num_levels={self.num_levels}\n'
+ repr_str += f'{indent_str}centers={self.centers},\n'
+ repr_str += f'{indent_str}center_offset={self.center_offset})'
+ return repr_str
+
+
+@TASK_UTILS.register_module()
+class SSDAnchorGenerator(AnchorGenerator):
+ """Anchor generator for SSD.
+
+ Args:
+ strides (list[int] | list[tuple[int, int]]): Strides of anchors
+ in multiple feature levels.
+ ratios (list[float]): The list of ratios between the height and width
+ of anchors in a single level.
+ min_sizes (list[float]): The list of minimum anchor sizes on each
+ level.
+ max_sizes (list[float]): The list of maximum anchor sizes on each
+ level.
+ basesize_ratio_range (tuple(float)): Ratio range of anchors. Being
+ used when not setting min_sizes and max_sizes.
+ input_size (int): Size of feature map, 300 for SSD300, 512 for
+ SSD512. Being used when not setting min_sizes and max_sizes.
+ scale_major (bool): Whether to multiply scales first when generating
+ base anchors. If true, the anchors in the same row will have the
+ same scales. It is always set to be False in SSD.
+ use_box_type (bool): Whether to warp anchors with the box type data
+ structure. Defaults to False.
+ """
+
+ def __init__(self,
+ strides: Union[List[int], List[Tuple[int, int]]],
+ ratios: List[float],
+ min_sizes: Optional[List[float]] = None,
+ max_sizes: Optional[List[float]] = None,
+ basesize_ratio_range: Tuple[float] = (0.15, 0.9),
+ input_size: int = 300,
+ scale_major: bool = True,
+ use_box_type: bool = False) -> None:
+ assert len(strides) == len(ratios)
+ assert not (min_sizes is None) ^ (max_sizes is None)
+ self.strides = [_pair(stride) for stride in strides]
+ self.centers = [(stride[0] / 2., stride[1] / 2.)
+ for stride in self.strides]
+
+ if min_sizes is None and max_sizes is None:
+ # use hard code to generate SSD anchors
+ self.input_size = input_size
+ assert is_tuple_of(basesize_ratio_range, float)
+ self.basesize_ratio_range = basesize_ratio_range
+ # calculate anchor ratios and sizes
+ min_ratio, max_ratio = basesize_ratio_range
+ min_ratio = int(min_ratio * 100)
+ max_ratio = int(max_ratio * 100)
+ step = int(np.floor(max_ratio - min_ratio) / (self.num_levels - 2))
+ min_sizes = []
+ max_sizes = []
+ for ratio in range(int(min_ratio), int(max_ratio) + 1, step):
+ min_sizes.append(int(self.input_size * ratio / 100))
+ max_sizes.append(int(self.input_size * (ratio + step) / 100))
+ if self.input_size == 300:
+ if basesize_ratio_range[0] == 0.15: # SSD300 COCO
+ min_sizes.insert(0, int(self.input_size * 7 / 100))
+ max_sizes.insert(0, int(self.input_size * 15 / 100))
+ elif basesize_ratio_range[0] == 0.2: # SSD300 VOC
+ min_sizes.insert(0, int(self.input_size * 10 / 100))
+ max_sizes.insert(0, int(self.input_size * 20 / 100))
+ else:
+ raise ValueError(
+ 'basesize_ratio_range[0] should be either 0.15'
+ 'or 0.2 when input_size is 300, got '
+ f'{basesize_ratio_range[0]}.')
+ elif self.input_size == 512:
+ if basesize_ratio_range[0] == 0.1: # SSD512 COCO
+ min_sizes.insert(0, int(self.input_size * 4 / 100))
+ max_sizes.insert(0, int(self.input_size * 10 / 100))
+ elif basesize_ratio_range[0] == 0.15: # SSD512 VOC
+ min_sizes.insert(0, int(self.input_size * 7 / 100))
+ max_sizes.insert(0, int(self.input_size * 15 / 100))
+ else:
+ raise ValueError(
+ 'When not setting min_sizes and max_sizes,'
+ 'basesize_ratio_range[0] should be either 0.1'
+ 'or 0.15 when input_size is 512, got'
+ f' {basesize_ratio_range[0]}.')
+ else:
+ raise ValueError(
+ 'Only support 300 or 512 in SSDAnchorGenerator when '
+ 'not setting min_sizes and max_sizes, '
+ f'got {self.input_size}.')
+
+ assert len(min_sizes) == len(max_sizes) == len(strides)
+
+ anchor_ratios = []
+ anchor_scales = []
+ for k in range(len(self.strides)):
+ scales = [1., np.sqrt(max_sizes[k] / min_sizes[k])]
+ anchor_ratio = [1.]
+ for r in ratios[k]:
+ anchor_ratio += [1 / r, r] # 4 or 6 ratio
+ anchor_ratios.append(torch.Tensor(anchor_ratio))
+ anchor_scales.append(torch.Tensor(scales))
+
+ self.base_sizes = min_sizes
+ self.scales = anchor_scales
+ self.ratios = anchor_ratios
+ self.scale_major = scale_major
+ self.center_offset = 0
+ self.base_anchors = self.gen_base_anchors()
+ self.use_box_type = use_box_type
+
+ def gen_base_anchors(self) -> List[Tensor]:
+ """Generate base anchors.
+
+ Returns:
+ list(torch.Tensor): Base anchors of a feature grid in multiple \
+ feature levels.
+ """
+ multi_level_base_anchors = []
+ for i, base_size in enumerate(self.base_sizes):
+ base_anchors = self.gen_single_level_base_anchors(
+ base_size,
+ scales=self.scales[i],
+ ratios=self.ratios[i],
+ center=self.centers[i])
+ indices = list(range(len(self.ratios[i])))
+ indices.insert(1, len(indices))
+ base_anchors = torch.index_select(base_anchors, 0,
+ torch.LongTensor(indices))
+ multi_level_base_anchors.append(base_anchors)
+ return multi_level_base_anchors
+
+ def __repr__(self) -> str:
+ """str: a string that describes the module"""
+ indent_str = ' '
+ repr_str = self.__class__.__name__ + '(\n'
+ repr_str += f'{indent_str}strides={self.strides},\n'
+ repr_str += f'{indent_str}scales={self.scales},\n'
+ repr_str += f'{indent_str}scale_major={self.scale_major},\n'
+ repr_str += f'{indent_str}input_size={self.input_size},\n'
+ repr_str += f'{indent_str}scales={self.scales},\n'
+ repr_str += f'{indent_str}ratios={self.ratios},\n'
+ repr_str += f'{indent_str}num_levels={self.num_levels},\n'
+ repr_str += f'{indent_str}base_sizes={self.base_sizes},\n'
+ repr_str += f'{indent_str}basesize_ratio_range='
+ repr_str += f'{self.basesize_ratio_range})'
+ return repr_str
+
+
+@TASK_UTILS.register_module()
+class LegacyAnchorGenerator(AnchorGenerator):
+ """Legacy anchor generator used in MMDetection V1.x.
+
+ Note:
+ Difference to the V2.0 anchor generator:
+
+ 1. The center offset of V1.x anchors are set to be 0.5 rather than 0.
+ 2. The width/height are minused by 1 when calculating the anchors' \
+ centers and corners to meet the V1.x coordinate system.
+ 3. The anchors' corners are quantized.
+
+ Args:
+ strides (list[int] | list[tuple[int]]): Strides of anchors
+ in multiple feature levels.
+ ratios (list[float]): The list of ratios between the height and width
+ of anchors in a single level.
+ scales (list[int] | None): Anchor scales for anchors in a single level.
+ It cannot be set at the same time if `octave_base_scale` and
+ `scales_per_octave` are set.
+ base_sizes (list[int]): The basic sizes of anchors in multiple levels.
+ If None is given, strides will be used to generate base_sizes.
+ scale_major (bool): Whether to multiply scales first when generating
+ base anchors. If true, the anchors in the same row will have the
+ same scales. By default it is True in V2.0
+ octave_base_scale (int): The base scale of octave.
+ scales_per_octave (int): Number of scales for each octave.
+ `octave_base_scale` and `scales_per_octave` are usually used in
+ retinanet and the `scales` should be None when they are set.
+ centers (list[tuple[float, float]] | None): The centers of the anchor
+ relative to the feature grid center in multiple feature levels.
+ By default it is set to be None and not used. It a list of float
+ is given, this list will be used to shift the centers of anchors.
+ center_offset (float): The offset of center in proportion to anchors'
+ width and height. By default it is 0.5 in V2.0 but it should be 0.5
+ in v1.x models.
+ use_box_type (bool): Whether to warp anchors with the box type data
+ structure. Defaults to False.
+
+ Examples:
+ >>> from mmdet.models.task_modules.
+ ... prior_generators import LegacyAnchorGenerator
+ >>> self = LegacyAnchorGenerator(
+ >>> [16], [1.], [1.], [9], center_offset=0.5)
+ >>> all_anchors = self.grid_anchors(((2, 2),), device='cpu')
+ >>> print(all_anchors)
+ [tensor([[ 0., 0., 8., 8.],
+ [16., 0., 24., 8.],
+ [ 0., 16., 8., 24.],
+ [16., 16., 24., 24.]])]
+ """
+
+ def gen_single_level_base_anchors(self,
+ base_size: Union[int, float],
+ scales: Tensor,
+ ratios: Tensor,
+ center: Optional[Tuple[float]] = None) \
+ -> Tensor:
+ """Generate base anchors of a single level.
+
+ Note:
+ The width/height of anchors are minused by 1 when calculating \
+ the centers and corners to meet the V1.x coordinate system.
+
+ Args:
+ base_size (int | float): Basic size of an anchor.
+ scales (torch.Tensor): Scales of the anchor.
+ ratios (torch.Tensor): The ratio between the height.
+ and width of anchors in a single level.
+ center (tuple[float], optional): The center of the base anchor
+ related to a single feature grid. Defaults to None.
+
+ Returns:
+ torch.Tensor: Anchors in a single-level feature map.
+ """
+ w = base_size
+ h = base_size
+ if center is None:
+ x_center = self.center_offset * (w - 1)
+ y_center = self.center_offset * (h - 1)
+ else:
+ x_center, y_center = center
+
+ h_ratios = torch.sqrt(ratios)
+ w_ratios = 1 / h_ratios
+ if self.scale_major:
+ ws = (w * w_ratios[:, None] * scales[None, :]).view(-1)
+ hs = (h * h_ratios[:, None] * scales[None, :]).view(-1)
+ else:
+ ws = (w * scales[:, None] * w_ratios[None, :]).view(-1)
+ hs = (h * scales[:, None] * h_ratios[None, :]).view(-1)
+
+ # use float anchor and the anchor's center is aligned with the
+ # pixel center
+ base_anchors = [
+ x_center - 0.5 * (ws - 1), y_center - 0.5 * (hs - 1),
+ x_center + 0.5 * (ws - 1), y_center + 0.5 * (hs - 1)
+ ]
+ base_anchors = torch.stack(base_anchors, dim=-1).round()
+
+ return base_anchors
+
+
+@TASK_UTILS.register_module()
+class LegacySSDAnchorGenerator(SSDAnchorGenerator, LegacyAnchorGenerator):
+ """Legacy anchor generator used in MMDetection V1.x.
+
+ The difference between `LegacySSDAnchorGenerator` and `SSDAnchorGenerator`
+ can be found in `LegacyAnchorGenerator`.
+ """
+
+ def __init__(self,
+ strides: Union[List[int], List[Tuple[int, int]]],
+ ratios: List[float],
+ basesize_ratio_range: Tuple[float],
+ input_size: int = 300,
+ scale_major: bool = True,
+ use_box_type: bool = False) -> None:
+ super(LegacySSDAnchorGenerator, self).__init__(
+ strides=strides,
+ ratios=ratios,
+ basesize_ratio_range=basesize_ratio_range,
+ input_size=input_size,
+ scale_major=scale_major,
+ use_box_type=use_box_type)
+ self.centers = [((stride - 1) / 2., (stride - 1) / 2.)
+ for stride in strides]
+ self.base_anchors = self.gen_base_anchors()
+
+
+@TASK_UTILS.register_module()
+class YOLOAnchorGenerator(AnchorGenerator):
+ """Anchor generator for YOLO.
+
+ Args:
+ strides (list[int] | list[tuple[int, int]]): Strides of anchors
+ in multiple feature levels.
+ base_sizes (list[list[tuple[int, int]]]): The basic sizes
+ of anchors in multiple levels.
+ """
+
+ def __init__(self,
+ strides: Union[List[int], List[Tuple[int, int]]],
+ base_sizes: List[List[Tuple[int, int]]],
+ use_box_type: bool = False) -> None:
+ self.strides = [_pair(stride) for stride in strides]
+ self.centers = [(stride[0] / 2., stride[1] / 2.)
+ for stride in self.strides]
+ self.base_sizes = []
+ num_anchor_per_level = len(base_sizes[0])
+ for base_sizes_per_level in base_sizes:
+ assert num_anchor_per_level == len(base_sizes_per_level)
+ self.base_sizes.append(
+ [_pair(base_size) for base_size in base_sizes_per_level])
+ self.base_anchors = self.gen_base_anchors()
+ self.use_box_type = use_box_type
+
+ @property
+ def num_levels(self) -> int:
+ """int: number of feature levels that the generator will be applied"""
+ return len(self.base_sizes)
+
+ def gen_base_anchors(self) -> List[Tensor]:
+ """Generate base anchors.
+
+ Returns:
+ list(torch.Tensor): Base anchors of a feature grid in multiple \
+ feature levels.
+ """
+ multi_level_base_anchors = []
+ for i, base_sizes_per_level in enumerate(self.base_sizes):
+ center = None
+ if self.centers is not None:
+ center = self.centers[i]
+ multi_level_base_anchors.append(
+ self.gen_single_level_base_anchors(base_sizes_per_level,
+ center))
+ return multi_level_base_anchors
+
+ def gen_single_level_base_anchors(self,
+ base_sizes_per_level: List[Tuple[int]],
+ center: Optional[Tuple[float]] = None) \
+ -> Tensor:
+ """Generate base anchors of a single level.
+
+ Args:
+ base_sizes_per_level (list[tuple[int]]): Basic sizes of
+ anchors.
+ center (tuple[float], optional): The center of the base anchor
+ related to a single feature grid. Defaults to None.
+
+ Returns:
+ torch.Tensor: Anchors in a single-level feature maps.
+ """
+ x_center, y_center = center
+ base_anchors = []
+ for base_size in base_sizes_per_level:
+ w, h = base_size
+
+ # use float anchor and the anchor's center is aligned with the
+ # pixel center
+ base_anchor = torch.Tensor([
+ x_center - 0.5 * w, y_center - 0.5 * h, x_center + 0.5 * w,
+ y_center + 0.5 * h
+ ])
+ base_anchors.append(base_anchor)
+ base_anchors = torch.stack(base_anchors, dim=0)
+
+ return base_anchors
diff --git a/mmdet/models/task_modules/prior_generators/point_generator.py b/mmdet/models/task_modules/prior_generators/point_generator.py
new file mode 100644
index 0000000000000000000000000000000000000000..c87ad656c61cb251bfdfcbd23b1cc5263c68bf5f
--- /dev/null
+++ b/mmdet/models/task_modules/prior_generators/point_generator.py
@@ -0,0 +1,321 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Tuple, Union
+
+import numpy as np
+import torch
+from torch import Tensor
+from torch.nn.modules.utils import _pair
+
+from mmdet.registry import TASK_UTILS
+
+DeviceType = Union[str, torch.device]
+
+
+@TASK_UTILS.register_module()
+class PointGenerator:
+
+ def _meshgrid(self,
+ x: Tensor,
+ y: Tensor,
+ row_major: bool = True) -> Tuple[Tensor, Tensor]:
+ """Generate mesh grid of x and y.
+
+ Args:
+ x (torch.Tensor): Grids of x dimension.
+ y (torch.Tensor): Grids of y dimension.
+ row_major (bool): Whether to return y grids first.
+ Defaults to True.
+
+ Returns:
+ tuple[torch.Tensor]: The mesh grids of x and y.
+ """
+ xx = x.repeat(len(y))
+ yy = y.view(-1, 1).repeat(1, len(x)).view(-1)
+ if row_major:
+ return xx, yy
+ else:
+ return yy, xx
+
+ def grid_points(self,
+ featmap_size: Tuple[int, int],
+ stride=16,
+ device: DeviceType = 'cuda') -> Tensor:
+ """Generate grid points of a single level.
+
+ Args:
+ featmap_size (tuple[int, int]): Size of the feature maps.
+ stride (int): The stride of corresponding feature map.
+ device (str | torch.device): The device the tensor will be put on.
+ Defaults to 'cuda'.
+
+ Returns:
+ torch.Tensor: grid point in a feature map.
+ """
+ feat_h, feat_w = featmap_size
+ shift_x = torch.arange(0., feat_w, device=device) * stride
+ shift_y = torch.arange(0., feat_h, device=device) * stride
+ shift_xx, shift_yy = self._meshgrid(shift_x, shift_y)
+ stride = shift_x.new_full((shift_xx.shape[0], ), stride)
+ shifts = torch.stack([shift_xx, shift_yy, stride], dim=-1)
+ all_points = shifts.to(device)
+ return all_points
+
+ def valid_flags(self,
+ featmap_size: Tuple[int, int],
+ valid_size: Tuple[int, int],
+ device: DeviceType = 'cuda') -> Tensor:
+ """Generate valid flags of anchors in a feature map.
+
+ Args:
+ featmap_sizes (list(tuple[int, int])): List of feature map sizes in
+ multiple feature levels.
+ valid_shape (tuple[int, int]): The valid shape of the image.
+ device (str | torch.device): Device where the anchors will be
+ put on.
+
+ Return:
+ torch.Tensor: Valid flags of anchors in a level.
+ """
+ feat_h, feat_w = featmap_size
+ valid_h, valid_w = valid_size
+ assert valid_h <= feat_h and valid_w <= feat_w
+ valid_x = torch.zeros(feat_w, dtype=torch.bool, device=device)
+ valid_y = torch.zeros(feat_h, dtype=torch.bool, device=device)
+ valid_x[:valid_w] = 1
+ valid_y[:valid_h] = 1
+ valid_xx, valid_yy = self._meshgrid(valid_x, valid_y)
+ valid = valid_xx & valid_yy
+ return valid
+
+
+@TASK_UTILS.register_module()
+class MlvlPointGenerator:
+ """Standard points generator for multi-level (Mlvl) feature maps in 2D
+ points-based detectors.
+
+ Args:
+ strides (list[int] | list[tuple[int, int]]): Strides of anchors
+ in multiple feature levels in order (w, h).
+ offset (float): The offset of points, the value is normalized with
+ corresponding stride. Defaults to 0.5.
+ """
+
+ def __init__(self,
+ strides: Union[List[int], List[Tuple[int, int]]],
+ offset: float = 0.5) -> None:
+ self.strides = [_pair(stride) for stride in strides]
+ self.offset = offset
+
+ @property
+ def num_levels(self) -> int:
+ """int: number of feature levels that the generator will be applied"""
+ return len(self.strides)
+
+ @property
+ def num_base_priors(self) -> List[int]:
+ """list[int]: The number of priors (points) at a point
+ on the feature grid"""
+ return [1 for _ in range(len(self.strides))]
+
+ def _meshgrid(self,
+ x: Tensor,
+ y: Tensor,
+ row_major: bool = True) -> Tuple[Tensor, Tensor]:
+ yy, xx = torch.meshgrid(y, x)
+ if row_major:
+ # warning .flatten() would cause error in ONNX exporting
+ # have to use reshape here
+ return xx.reshape(-1), yy.reshape(-1)
+
+ else:
+ return yy.reshape(-1), xx.reshape(-1)
+
+ def grid_priors(self,
+ featmap_sizes: List[Tuple],
+ dtype: torch.dtype = torch.float32,
+ device: DeviceType = 'cuda',
+ with_stride: bool = False) -> List[Tensor]:
+ """Generate grid points of multiple feature levels.
+
+ Args:
+ featmap_sizes (list[tuple]): List of feature map sizes in
+ multiple feature levels, each size arrange as
+ as (h, w).
+ dtype (:obj:`dtype`): Dtype of priors. Defaults to torch.float32.
+ device (str | torch.device): The device where the anchors will be
+ put on.
+ with_stride (bool): Whether to concatenate the stride to
+ the last dimension of points.
+
+ Return:
+ list[torch.Tensor]: Points of multiple feature levels.
+ The sizes of each tensor should be (N, 2) when with stride is
+ ``False``, where N = width * height, width and height
+ are the sizes of the corresponding feature level,
+ and the last dimension 2 represent (coord_x, coord_y),
+ otherwise the shape should be (N, 4),
+ and the last dimension 4 represent
+ (coord_x, coord_y, stride_w, stride_h).
+ """
+
+ assert self.num_levels == len(featmap_sizes)
+ multi_level_priors = []
+ for i in range(self.num_levels):
+ priors = self.single_level_grid_priors(
+ featmap_sizes[i],
+ level_idx=i,
+ dtype=dtype,
+ device=device,
+ with_stride=with_stride)
+ multi_level_priors.append(priors)
+ return multi_level_priors
+
+ def single_level_grid_priors(self,
+ featmap_size: Tuple[int],
+ level_idx: int,
+ dtype: torch.dtype = torch.float32,
+ device: DeviceType = 'cuda',
+ with_stride: bool = False) -> Tensor:
+ """Generate grid Points of a single level.
+
+ Note:
+ This function is usually called by method ``self.grid_priors``.
+
+ Args:
+ featmap_size (tuple[int]): Size of the feature maps, arrange as
+ (h, w).
+ level_idx (int): The index of corresponding feature map level.
+ dtype (:obj:`dtype`): Dtype of priors. Defaults to torch.float32.
+ device (str | torch.device): The device the tensor will be put on.
+ Defaults to 'cuda'.
+ with_stride (bool): Concatenate the stride to the last dimension
+ of points.
+
+ Return:
+ Tensor: Points of single feature levels.
+ The shape of tensor should be (N, 2) when with stride is
+ ``False``, where N = width * height, width and height
+ are the sizes of the corresponding feature level,
+ and the last dimension 2 represent (coord_x, coord_y),
+ otherwise the shape should be (N, 4),
+ and the last dimension 4 represent
+ (coord_x, coord_y, stride_w, stride_h).
+ """
+ feat_h, feat_w = featmap_size
+ stride_w, stride_h = self.strides[level_idx]
+ shift_x = (torch.arange(0, feat_w, device=device) +
+ self.offset) * stride_w
+ # keep featmap_size as Tensor instead of int, so that we
+ # can convert to ONNX correctly
+ shift_x = shift_x.to(dtype)
+
+ shift_y = (torch.arange(0, feat_h, device=device) +
+ self.offset) * stride_h
+ # keep featmap_size as Tensor instead of int, so that we
+ # can convert to ONNX correctly
+ shift_y = shift_y.to(dtype)
+ shift_xx, shift_yy = self._meshgrid(shift_x, shift_y)
+ if not with_stride:
+ shifts = torch.stack([shift_xx, shift_yy], dim=-1)
+ else:
+ # use `shape[0]` instead of `len(shift_xx)` for ONNX export
+ stride_w = shift_xx.new_full((shift_xx.shape[0], ),
+ stride_w).to(dtype)
+ stride_h = shift_xx.new_full((shift_yy.shape[0], ),
+ stride_h).to(dtype)
+ shifts = torch.stack([shift_xx, shift_yy, stride_w, stride_h],
+ dim=-1)
+ all_points = shifts.to(device)
+ return all_points
+
+ def valid_flags(self,
+ featmap_sizes: List[Tuple[int, int]],
+ pad_shape: Tuple[int],
+ device: DeviceType = 'cuda') -> List[Tensor]:
+ """Generate valid flags of points of multiple feature levels.
+
+ Args:
+ featmap_sizes (list(tuple)): List of feature map sizes in
+ multiple feature levels, each size arrange as
+ as (h, w).
+ pad_shape (tuple(int)): The padded shape of the image,
+ arrange as (h, w).
+ device (str | torch.device): The device where the anchors will be
+ put on.
+
+ Return:
+ list(torch.Tensor): Valid flags of points of multiple levels.
+ """
+ assert self.num_levels == len(featmap_sizes)
+ multi_level_flags = []
+ for i in range(self.num_levels):
+ point_stride = self.strides[i]
+ feat_h, feat_w = featmap_sizes[i]
+ h, w = pad_shape[:2]
+ valid_feat_h = min(int(np.ceil(h / point_stride[1])), feat_h)
+ valid_feat_w = min(int(np.ceil(w / point_stride[0])), feat_w)
+ flags = self.single_level_valid_flags((feat_h, feat_w),
+ (valid_feat_h, valid_feat_w),
+ device=device)
+ multi_level_flags.append(flags)
+ return multi_level_flags
+
+ def single_level_valid_flags(self,
+ featmap_size: Tuple[int, int],
+ valid_size: Tuple[int, int],
+ device: DeviceType = 'cuda') -> Tensor:
+ """Generate the valid flags of points of a single feature map.
+
+ Args:
+ featmap_size (tuple[int]): The size of feature maps, arrange as
+ as (h, w).
+ valid_size (tuple[int]): The valid size of the feature maps.
+ The size arrange as as (h, w).
+ device (str | torch.device): The device where the flags will be
+ put on. Defaults to 'cuda'.
+
+ Returns:
+ torch.Tensor: The valid flags of each points in a single level \
+ feature map.
+ """
+ feat_h, feat_w = featmap_size
+ valid_h, valid_w = valid_size
+ assert valid_h <= feat_h and valid_w <= feat_w
+ valid_x = torch.zeros(feat_w, dtype=torch.bool, device=device)
+ valid_y = torch.zeros(feat_h, dtype=torch.bool, device=device)
+ valid_x[:valid_w] = 1
+ valid_y[:valid_h] = 1
+ valid_xx, valid_yy = self._meshgrid(valid_x, valid_y)
+ valid = valid_xx & valid_yy
+ return valid
+
+ def sparse_priors(self,
+ prior_idxs: Tensor,
+ featmap_size: Tuple[int],
+ level_idx: int,
+ dtype: torch.dtype = torch.float32,
+ device: DeviceType = 'cuda') -> Tensor:
+ """Generate sparse points according to the ``prior_idxs``.
+
+ Args:
+ prior_idxs (Tensor): The index of corresponding anchors
+ in the feature map.
+ featmap_size (tuple[int]): feature map size arrange as (w, h).
+ level_idx (int): The level index of corresponding feature
+ map.
+ dtype (obj:`torch.dtype`): Date type of points. Defaults to
+ ``torch.float32``.
+ device (str | torch.device): The device where the points is
+ located.
+ Returns:
+ Tensor: Anchor with shape (N, 2), N should be equal to
+ the length of ``prior_idxs``. And last dimension
+ 2 represent (coord_x, coord_y).
+ """
+ height, width = featmap_size
+ x = (prior_idxs % width + self.offset) * self.strides[level_idx][0]
+ y = ((prior_idxs // width) % height +
+ self.offset) * self.strides[level_idx][1]
+ prioris = torch.stack([x, y], 1).to(dtype)
+ prioris = prioris.to(device)
+ return prioris
diff --git a/mmdet/models/task_modules/prior_generators/utils.py b/mmdet/models/task_modules/prior_generators/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..3aa2dfd49669ba931d20ad9482cb841698cceb8a
--- /dev/null
+++ b/mmdet/models/task_modules/prior_generators/utils.py
@@ -0,0 +1,70 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Tuple
+
+import torch
+from torch import Tensor
+
+from mmdet.structures.bbox import BaseBoxes
+
+
+def anchor_inside_flags(flat_anchors: Tensor,
+ valid_flags: Tensor,
+ img_shape: Tuple[int],
+ allowed_border: int = 0) -> Tensor:
+ """Check whether the anchors are inside the border.
+
+ Args:
+ flat_anchors (torch.Tensor): Flatten anchors, shape (n, 4).
+ valid_flags (torch.Tensor): An existing valid flags of anchors.
+ img_shape (tuple(int)): Shape of current image.
+ allowed_border (int): The border to allow the valid anchor.
+ Defaults to 0.
+
+ Returns:
+ torch.Tensor: Flags indicating whether the anchors are inside a \
+ valid range.
+ """
+ img_h, img_w = img_shape[:2]
+ if allowed_border >= 0:
+ if isinstance(flat_anchors, BaseBoxes):
+ inside_flags = valid_flags & \
+ flat_anchors.is_inside([img_h, img_w],
+ all_inside=True,
+ allowed_border=allowed_border)
+ else:
+ inside_flags = valid_flags & \
+ (flat_anchors[:, 0] >= -allowed_border) & \
+ (flat_anchors[:, 1] >= -allowed_border) & \
+ (flat_anchors[:, 2] < img_w + allowed_border) & \
+ (flat_anchors[:, 3] < img_h + allowed_border)
+ else:
+ inside_flags = valid_flags
+ return inside_flags
+
+
+def calc_region(bbox: Tensor,
+ ratio: float,
+ featmap_size: Optional[Tuple] = None) -> Tuple[int]:
+ """Calculate a proportional bbox region.
+
+ The bbox center are fixed and the new h' and w' is h * ratio and w * ratio.
+
+ Args:
+ bbox (Tensor): Bboxes to calculate regions, shape (n, 4).
+ ratio (float): Ratio of the output region.
+ featmap_size (tuple, Optional): Feature map size in (height, width)
+ order used for clipping the boundary. Defaults to None.
+
+ Returns:
+ tuple: x1, y1, x2, y2
+ """
+ x1 = torch.round((1 - ratio) * bbox[0] + ratio * bbox[2]).long()
+ y1 = torch.round((1 - ratio) * bbox[1] + ratio * bbox[3]).long()
+ x2 = torch.round(ratio * bbox[0] + (1 - ratio) * bbox[2]).long()
+ y2 = torch.round(ratio * bbox[1] + (1 - ratio) * bbox[3]).long()
+ if featmap_size is not None:
+ x1 = x1.clamp(min=0, max=featmap_size[1])
+ y1 = y1.clamp(min=0, max=featmap_size[0])
+ x2 = x2.clamp(min=0, max=featmap_size[1])
+ y2 = y2.clamp(min=0, max=featmap_size[0])
+ return (x1, y1, x2, y2)
diff --git a/mmdet/models/task_modules/samplers/__init__.py b/mmdet/models/task_modules/samplers/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..3782eb898cf8acace63b4f16204cae6c07eb6e30
--- /dev/null
+++ b/mmdet/models/task_modules/samplers/__init__.py
@@ -0,0 +1,22 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .base_sampler import BaseSampler
+from .combined_sampler import CombinedSampler
+from .instance_balanced_pos_sampler import InstanceBalancedPosSampler
+from .iou_balanced_neg_sampler import IoUBalancedNegSampler
+from .mask_pseudo_sampler import MaskPseudoSampler
+from .mask_sampling_result import MaskSamplingResult
+from .multi_instance_random_sampler import MultiInsRandomSampler
+from .multi_instance_sampling_result import MultiInstanceSamplingResult
+from .ohem_sampler import OHEMSampler
+from .pseudo_sampler import PseudoSampler
+from .random_sampler import RandomSampler
+from .sampling_result import SamplingResult
+from .score_hlr_sampler import ScoreHLRSampler
+
+__all__ = [
+ 'BaseSampler', 'PseudoSampler', 'RandomSampler',
+ 'InstanceBalancedPosSampler', 'IoUBalancedNegSampler', 'CombinedSampler',
+ 'OHEMSampler', 'SamplingResult', 'ScoreHLRSampler', 'MaskPseudoSampler',
+ 'MaskSamplingResult', 'MultiInstanceSamplingResult',
+ 'MultiInsRandomSampler'
+]
diff --git a/mmdet/models/task_modules/samplers/__pycache__/__init__.cpython-37.pyc b/mmdet/models/task_modules/samplers/__pycache__/__init__.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..83edaf7270ca93c574c8e6f50f5c7c51baed74f1
Binary files /dev/null and b/mmdet/models/task_modules/samplers/__pycache__/__init__.cpython-37.pyc differ
diff --git a/mmdet/models/task_modules/samplers/__pycache__/base_sampler.cpython-37.pyc b/mmdet/models/task_modules/samplers/__pycache__/base_sampler.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..bcdfdcb85bb048dcef5569bf189753f3c42cb28c
Binary files /dev/null and b/mmdet/models/task_modules/samplers/__pycache__/base_sampler.cpython-37.pyc differ
diff --git a/mmdet/models/task_modules/samplers/__pycache__/combined_sampler.cpython-37.pyc b/mmdet/models/task_modules/samplers/__pycache__/combined_sampler.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..b049243e7fba8d89ec3cf100e86c20977caccf1c
Binary files /dev/null and b/mmdet/models/task_modules/samplers/__pycache__/combined_sampler.cpython-37.pyc differ
diff --git a/mmdet/models/task_modules/samplers/__pycache__/instance_balanced_pos_sampler.cpython-37.pyc b/mmdet/models/task_modules/samplers/__pycache__/instance_balanced_pos_sampler.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..c6e4aa40161d0415533124b7747cebd4ed5ee1cc
Binary files /dev/null and b/mmdet/models/task_modules/samplers/__pycache__/instance_balanced_pos_sampler.cpython-37.pyc differ
diff --git a/mmdet/models/task_modules/samplers/__pycache__/iou_balanced_neg_sampler.cpython-37.pyc b/mmdet/models/task_modules/samplers/__pycache__/iou_balanced_neg_sampler.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..1aa41c83b0cc2bd0c582e63d37cab7907f3eff77
Binary files /dev/null and b/mmdet/models/task_modules/samplers/__pycache__/iou_balanced_neg_sampler.cpython-37.pyc differ
diff --git a/mmdet/models/task_modules/samplers/__pycache__/mask_pseudo_sampler.cpython-37.pyc b/mmdet/models/task_modules/samplers/__pycache__/mask_pseudo_sampler.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..10602b97f062520f802534bb5265234ecbfc162a
Binary files /dev/null and b/mmdet/models/task_modules/samplers/__pycache__/mask_pseudo_sampler.cpython-37.pyc differ
diff --git a/mmdet/models/task_modules/samplers/__pycache__/mask_sampling_result.cpython-37.pyc b/mmdet/models/task_modules/samplers/__pycache__/mask_sampling_result.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..b262f836fe092adb8b179b9e48d4a4a5a2d972c2
Binary files /dev/null and b/mmdet/models/task_modules/samplers/__pycache__/mask_sampling_result.cpython-37.pyc differ
diff --git a/mmdet/models/task_modules/samplers/__pycache__/multi_instance_random_sampler.cpython-37.pyc b/mmdet/models/task_modules/samplers/__pycache__/multi_instance_random_sampler.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..8781e87eaa905a193c0eba7ceb5a90c7b4d58358
Binary files /dev/null and b/mmdet/models/task_modules/samplers/__pycache__/multi_instance_random_sampler.cpython-37.pyc differ
diff --git a/mmdet/models/task_modules/samplers/__pycache__/multi_instance_sampling_result.cpython-37.pyc b/mmdet/models/task_modules/samplers/__pycache__/multi_instance_sampling_result.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..ffef048467697699ea151a4b0d49a6e9f6e22982
Binary files /dev/null and b/mmdet/models/task_modules/samplers/__pycache__/multi_instance_sampling_result.cpython-37.pyc differ
diff --git a/mmdet/models/task_modules/samplers/__pycache__/ohem_sampler.cpython-37.pyc b/mmdet/models/task_modules/samplers/__pycache__/ohem_sampler.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..35ac365cb4046ca327bec14232e801956b370676
Binary files /dev/null and b/mmdet/models/task_modules/samplers/__pycache__/ohem_sampler.cpython-37.pyc differ
diff --git a/mmdet/models/task_modules/samplers/__pycache__/pseudo_sampler.cpython-37.pyc b/mmdet/models/task_modules/samplers/__pycache__/pseudo_sampler.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..2b53616fc1eff21171d4a61f365911789f5d1b67
Binary files /dev/null and b/mmdet/models/task_modules/samplers/__pycache__/pseudo_sampler.cpython-37.pyc differ
diff --git a/mmdet/models/task_modules/samplers/__pycache__/random_sampler.cpython-37.pyc b/mmdet/models/task_modules/samplers/__pycache__/random_sampler.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..6cdad81efa44c2337e9f0a5afd40128c155dd8e4
Binary files /dev/null and b/mmdet/models/task_modules/samplers/__pycache__/random_sampler.cpython-37.pyc differ
diff --git a/mmdet/models/task_modules/samplers/__pycache__/sampling_result.cpython-37.pyc b/mmdet/models/task_modules/samplers/__pycache__/sampling_result.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..0818898339e8acd25db1cbb4e61996b8060f3a74
Binary files /dev/null and b/mmdet/models/task_modules/samplers/__pycache__/sampling_result.cpython-37.pyc differ
diff --git a/mmdet/models/task_modules/samplers/__pycache__/score_hlr_sampler.cpython-37.pyc b/mmdet/models/task_modules/samplers/__pycache__/score_hlr_sampler.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..864060653f76f451f76e5c9e3ec69b78b8a6220c
Binary files /dev/null and b/mmdet/models/task_modules/samplers/__pycache__/score_hlr_sampler.cpython-37.pyc differ
diff --git a/mmdet/models/task_modules/samplers/base_sampler.py b/mmdet/models/task_modules/samplers/base_sampler.py
new file mode 100644
index 0000000000000000000000000000000000000000..be8a9a5ee3ec4e70b19aeea21b7998cf2b131d59
--- /dev/null
+++ b/mmdet/models/task_modules/samplers/base_sampler.py
@@ -0,0 +1,136 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from abc import ABCMeta, abstractmethod
+
+import torch
+from mmengine.structures import InstanceData
+
+from mmdet.structures.bbox import BaseBoxes, cat_boxes
+from ..assigners import AssignResult
+from .sampling_result import SamplingResult
+
+
+class BaseSampler(metaclass=ABCMeta):
+ """Base class of samplers.
+
+ Args:
+ num (int): Number of samples
+ pos_fraction (float): Fraction of positive samples
+ neg_pos_up (int): Upper bound number of negative and
+ positive samples. Defaults to -1.
+ add_gt_as_proposals (bool): Whether to add ground truth
+ boxes as proposals. Defaults to True.
+ """
+
+ def __init__(self,
+ num: int,
+ pos_fraction: float,
+ neg_pos_ub: int = -1,
+ add_gt_as_proposals: bool = True,
+ **kwargs) -> None:
+ self.num = num
+ self.pos_fraction = pos_fraction
+ self.neg_pos_ub = neg_pos_ub
+ self.add_gt_as_proposals = add_gt_as_proposals
+ self.pos_sampler = self
+ self.neg_sampler = self
+
+ @abstractmethod
+ def _sample_pos(self, assign_result: AssignResult, num_expected: int,
+ **kwargs):
+ """Sample positive samples."""
+ pass
+
+ @abstractmethod
+ def _sample_neg(self, assign_result: AssignResult, num_expected: int,
+ **kwargs):
+ """Sample negative samples."""
+ pass
+
+ def sample(self, assign_result: AssignResult, pred_instances: InstanceData,
+ gt_instances: InstanceData, **kwargs) -> SamplingResult:
+ """Sample positive and negative bboxes.
+
+ This is a simple implementation of bbox sampling given candidates,
+ assigning results and ground truth bboxes.
+
+ Args:
+ assign_result (:obj:`AssignResult`): Assigning results.
+ pred_instances (:obj:`InstanceData`): Instances of model
+ predictions. It includes ``priors``, and the priors can
+ be anchors or points, or the bboxes predicted by the
+ previous stage, has shape (n, 4). The bboxes predicted by
+ the current model or stage will be named ``bboxes``,
+ ``labels``, and ``scores``, the same as the ``InstanceData``
+ in other places.
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It usually includes ``bboxes``, with shape (k, 4),
+ and ``labels``, with shape (k, ).
+
+ Returns:
+ :obj:`SamplingResult`: Sampling result.
+
+ Example:
+ >>> from mmengine.structures import InstanceData
+ >>> from mmdet.models.task_modules.samplers import RandomSampler,
+ >>> from mmdet.models.task_modules.assigners import AssignResult
+ >>> from mmdet.models.task_modules.samplers.
+ ... sampling_result import ensure_rng, random_boxes
+ >>> rng = ensure_rng(None)
+ >>> assign_result = AssignResult.random(rng=rng)
+ >>> pred_instances = InstanceData()
+ >>> pred_instances.priors = random_boxes(assign_result.num_preds,
+ ... rng=rng)
+ >>> gt_instances = InstanceData()
+ >>> gt_instances.bboxes = random_boxes(assign_result.num_gts,
+ ... rng=rng)
+ >>> gt_instances.labels = torch.randint(
+ ... 0, 5, (assign_result.num_gts,), dtype=torch.long)
+ >>> self = RandomSampler(num=32, pos_fraction=0.5, neg_pos_ub=-1,
+ >>> add_gt_as_proposals=False)
+ >>> self = self.sample(assign_result, pred_instances, gt_instances)
+ """
+ gt_bboxes = gt_instances.bboxes
+ priors = pred_instances.priors
+ gt_labels = gt_instances.labels
+ if len(priors.shape) < 2:
+ priors = priors[None, :]
+
+ gt_flags = priors.new_zeros((priors.shape[0], ), dtype=torch.uint8)
+ if self.add_gt_as_proposals and len(gt_bboxes) > 0:
+ # When `gt_bboxes` and `priors` are all box type, convert
+ # `gt_bboxes` type to `priors` type.
+ if (isinstance(gt_bboxes, BaseBoxes)
+ and isinstance(priors, BaseBoxes)):
+ gt_bboxes_ = gt_bboxes.convert_to(type(priors))
+ else:
+ gt_bboxes_ = gt_bboxes
+ priors = cat_boxes([gt_bboxes_, priors], dim=0)
+ assign_result.add_gt_(gt_labels)
+ gt_ones = priors.new_ones(gt_bboxes_.shape[0], dtype=torch.uint8)
+ gt_flags = torch.cat([gt_ones, gt_flags])
+
+ num_expected_pos = int(self.num * self.pos_fraction)
+ pos_inds = self.pos_sampler._sample_pos(
+ assign_result, num_expected_pos, bboxes=priors, **kwargs)
+ # We found that sampled indices have duplicated items occasionally.
+ # (may be a bug of PyTorch)
+ pos_inds = pos_inds.unique()
+ num_sampled_pos = pos_inds.numel()
+ num_expected_neg = self.num - num_sampled_pos
+ if self.neg_pos_ub >= 0:
+ _pos = max(1, num_sampled_pos)
+ neg_upper_bound = int(self.neg_pos_ub * _pos)
+ if num_expected_neg > neg_upper_bound:
+ num_expected_neg = neg_upper_bound
+ neg_inds = self.neg_sampler._sample_neg(
+ assign_result, num_expected_neg, bboxes=priors, **kwargs)
+ neg_inds = neg_inds.unique()
+
+ sampling_result = SamplingResult(
+ pos_inds=pos_inds,
+ neg_inds=neg_inds,
+ priors=priors,
+ gt_bboxes=gt_bboxes,
+ assign_result=assign_result,
+ gt_flags=gt_flags)
+ return sampling_result
diff --git a/mmdet/models/task_modules/samplers/combined_sampler.py b/mmdet/models/task_modules/samplers/combined_sampler.py
new file mode 100644
index 0000000000000000000000000000000000000000..8e0560e372efffe865fa32028d823280a8bd5d87
--- /dev/null
+++ b/mmdet/models/task_modules/samplers/combined_sampler.py
@@ -0,0 +1,21 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmdet.registry import TASK_UTILS
+from .base_sampler import BaseSampler
+
+
+@TASK_UTILS.register_module()
+class CombinedSampler(BaseSampler):
+ """A sampler that combines positive sampler and negative sampler."""
+
+ def __init__(self, pos_sampler, neg_sampler, **kwargs):
+ super(CombinedSampler, self).__init__(**kwargs)
+ self.pos_sampler = TASK_UTILS.build(pos_sampler, default_args=kwargs)
+ self.neg_sampler = TASK_UTILS.build(neg_sampler, default_args=kwargs)
+
+ def _sample_pos(self, **kwargs):
+ """Sample positive samples."""
+ raise NotImplementedError
+
+ def _sample_neg(self, **kwargs):
+ """Sample negative samples."""
+ raise NotImplementedError
diff --git a/mmdet/models/task_modules/samplers/instance_balanced_pos_sampler.py b/mmdet/models/task_modules/samplers/instance_balanced_pos_sampler.py
new file mode 100644
index 0000000000000000000000000000000000000000..e48d8e9158e8dabf0bb4072b8e421de9b6410d00
--- /dev/null
+++ b/mmdet/models/task_modules/samplers/instance_balanced_pos_sampler.py
@@ -0,0 +1,56 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import numpy as np
+import torch
+
+from mmdet.registry import TASK_UTILS
+from .random_sampler import RandomSampler
+
+
+@TASK_UTILS.register_module()
+class InstanceBalancedPosSampler(RandomSampler):
+ """Instance balanced sampler that samples equal number of positive samples
+ for each instance."""
+
+ def _sample_pos(self, assign_result, num_expected, **kwargs):
+ """Sample positive boxes.
+
+ Args:
+ assign_result (:obj:`AssignResult`): The assigned results of boxes.
+ num_expected (int): The number of expected positive samples
+
+ Returns:
+ Tensor or ndarray: sampled indices.
+ """
+ pos_inds = torch.nonzero(assign_result.gt_inds > 0, as_tuple=False)
+ if pos_inds.numel() != 0:
+ pos_inds = pos_inds.squeeze(1)
+ if pos_inds.numel() <= num_expected:
+ return pos_inds
+ else:
+ unique_gt_inds = assign_result.gt_inds[pos_inds].unique()
+ num_gts = len(unique_gt_inds)
+ num_per_gt = int(round(num_expected / float(num_gts)) + 1)
+ sampled_inds = []
+ for i in unique_gt_inds:
+ inds = torch.nonzero(
+ assign_result.gt_inds == i.item(), as_tuple=False)
+ if inds.numel() != 0:
+ inds = inds.squeeze(1)
+ else:
+ continue
+ if len(inds) > num_per_gt:
+ inds = self.random_choice(inds, num_per_gt)
+ sampled_inds.append(inds)
+ sampled_inds = torch.cat(sampled_inds)
+ if len(sampled_inds) < num_expected:
+ num_extra = num_expected - len(sampled_inds)
+ extra_inds = np.array(
+ list(set(pos_inds.cpu()) - set(sampled_inds.cpu())))
+ if len(extra_inds) > num_extra:
+ extra_inds = self.random_choice(extra_inds, num_extra)
+ extra_inds = torch.from_numpy(extra_inds).to(
+ assign_result.gt_inds.device).long()
+ sampled_inds = torch.cat([sampled_inds, extra_inds])
+ elif len(sampled_inds) > num_expected:
+ sampled_inds = self.random_choice(sampled_inds, num_expected)
+ return sampled_inds
diff --git a/mmdet/models/task_modules/samplers/iou_balanced_neg_sampler.py b/mmdet/models/task_modules/samplers/iou_balanced_neg_sampler.py
new file mode 100644
index 0000000000000000000000000000000000000000..dc1f46413c99d115f31ef190b4fb198b588a156e
--- /dev/null
+++ b/mmdet/models/task_modules/samplers/iou_balanced_neg_sampler.py
@@ -0,0 +1,158 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import numpy as np
+import torch
+
+from mmdet.registry import TASK_UTILS
+from .random_sampler import RandomSampler
+
+
+@TASK_UTILS.register_module()
+class IoUBalancedNegSampler(RandomSampler):
+ """IoU Balanced Sampling.
+
+ arXiv: https://arxiv.org/pdf/1904.02701.pdf (CVPR 2019)
+
+ Sampling proposals according to their IoU. `floor_fraction` of needed RoIs
+ are sampled from proposals whose IoU are lower than `floor_thr` randomly.
+ The others are sampled from proposals whose IoU are higher than
+ `floor_thr`. These proposals are sampled from some bins evenly, which are
+ split by `num_bins` via IoU evenly.
+
+ Args:
+ num (int): number of proposals.
+ pos_fraction (float): fraction of positive proposals.
+ floor_thr (float): threshold (minimum) IoU for IoU balanced sampling,
+ set to -1 if all using IoU balanced sampling.
+ floor_fraction (float): sampling fraction of proposals under floor_thr.
+ num_bins (int): number of bins in IoU balanced sampling.
+ """
+
+ def __init__(self,
+ num,
+ pos_fraction,
+ floor_thr=-1,
+ floor_fraction=0,
+ num_bins=3,
+ **kwargs):
+ super(IoUBalancedNegSampler, self).__init__(num, pos_fraction,
+ **kwargs)
+ assert floor_thr >= 0 or floor_thr == -1
+ assert 0 <= floor_fraction <= 1
+ assert num_bins >= 1
+
+ self.floor_thr = floor_thr
+ self.floor_fraction = floor_fraction
+ self.num_bins = num_bins
+
+ def sample_via_interval(self, max_overlaps, full_set, num_expected):
+ """Sample according to the iou interval.
+
+ Args:
+ max_overlaps (torch.Tensor): IoU between bounding boxes and ground
+ truth boxes.
+ full_set (set(int)): A full set of indices of boxes。
+ num_expected (int): Number of expected samples。
+
+ Returns:
+ np.ndarray: Indices of samples
+ """
+ max_iou = max_overlaps.max()
+ iou_interval = (max_iou - self.floor_thr) / self.num_bins
+ per_num_expected = int(num_expected / self.num_bins)
+
+ sampled_inds = []
+ for i in range(self.num_bins):
+ start_iou = self.floor_thr + i * iou_interval
+ end_iou = self.floor_thr + (i + 1) * iou_interval
+ tmp_set = set(
+ np.where(
+ np.logical_and(max_overlaps >= start_iou,
+ max_overlaps < end_iou))[0])
+ tmp_inds = list(tmp_set & full_set)
+ if len(tmp_inds) > per_num_expected:
+ tmp_sampled_set = self.random_choice(tmp_inds,
+ per_num_expected)
+ else:
+ tmp_sampled_set = np.array(tmp_inds, dtype=np.int64)
+ sampled_inds.append(tmp_sampled_set)
+
+ sampled_inds = np.concatenate(sampled_inds)
+ if len(sampled_inds) < num_expected:
+ num_extra = num_expected - len(sampled_inds)
+ extra_inds = np.array(list(full_set - set(sampled_inds)))
+ if len(extra_inds) > num_extra:
+ extra_inds = self.random_choice(extra_inds, num_extra)
+ sampled_inds = np.concatenate([sampled_inds, extra_inds])
+
+ return sampled_inds
+
+ def _sample_neg(self, assign_result, num_expected, **kwargs):
+ """Sample negative boxes.
+
+ Args:
+ assign_result (:obj:`AssignResult`): The assigned results of boxes.
+ num_expected (int): The number of expected negative samples
+
+ Returns:
+ Tensor or ndarray: sampled indices.
+ """
+ neg_inds = torch.nonzero(assign_result.gt_inds == 0, as_tuple=False)
+ if neg_inds.numel() != 0:
+ neg_inds = neg_inds.squeeze(1)
+ if len(neg_inds) <= num_expected:
+ return neg_inds
+ else:
+ max_overlaps = assign_result.max_overlaps.cpu().numpy()
+ # balance sampling for negative samples
+ neg_set = set(neg_inds.cpu().numpy())
+
+ if self.floor_thr > 0:
+ floor_set = set(
+ np.where(
+ np.logical_and(max_overlaps >= 0,
+ max_overlaps < self.floor_thr))[0])
+ iou_sampling_set = set(
+ np.where(max_overlaps >= self.floor_thr)[0])
+ elif self.floor_thr == 0:
+ floor_set = set(np.where(max_overlaps == 0)[0])
+ iou_sampling_set = set(
+ np.where(max_overlaps > self.floor_thr)[0])
+ else:
+ floor_set = set()
+ iou_sampling_set = set(
+ np.where(max_overlaps > self.floor_thr)[0])
+ # for sampling interval calculation
+ self.floor_thr = 0
+
+ floor_neg_inds = list(floor_set & neg_set)
+ iou_sampling_neg_inds = list(iou_sampling_set & neg_set)
+ num_expected_iou_sampling = int(num_expected *
+ (1 - self.floor_fraction))
+ if len(iou_sampling_neg_inds) > num_expected_iou_sampling:
+ if self.num_bins >= 2:
+ iou_sampled_inds = self.sample_via_interval(
+ max_overlaps, set(iou_sampling_neg_inds),
+ num_expected_iou_sampling)
+ else:
+ iou_sampled_inds = self.random_choice(
+ iou_sampling_neg_inds, num_expected_iou_sampling)
+ else:
+ iou_sampled_inds = np.array(
+ iou_sampling_neg_inds, dtype=np.int64)
+ num_expected_floor = num_expected - len(iou_sampled_inds)
+ if len(floor_neg_inds) > num_expected_floor:
+ sampled_floor_inds = self.random_choice(
+ floor_neg_inds, num_expected_floor)
+ else:
+ sampled_floor_inds = np.array(floor_neg_inds, dtype=np.int64)
+ sampled_inds = np.concatenate(
+ (sampled_floor_inds, iou_sampled_inds))
+ if len(sampled_inds) < num_expected:
+ num_extra = num_expected - len(sampled_inds)
+ extra_inds = np.array(list(neg_set - set(sampled_inds)))
+ if len(extra_inds) > num_extra:
+ extra_inds = self.random_choice(extra_inds, num_extra)
+ sampled_inds = np.concatenate((sampled_inds, extra_inds))
+ sampled_inds = torch.from_numpy(sampled_inds).long().to(
+ assign_result.gt_inds.device)
+ return sampled_inds
diff --git a/mmdet/models/task_modules/samplers/mask_pseudo_sampler.py b/mmdet/models/task_modules/samplers/mask_pseudo_sampler.py
new file mode 100644
index 0000000000000000000000000000000000000000..307dd5d15c962b97dc60b899e60170d0bfed90a7
--- /dev/null
+++ b/mmdet/models/task_modules/samplers/mask_pseudo_sampler.py
@@ -0,0 +1,60 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+"""copy from
+https://github.com/ZwwWayne/K-Net/blob/main/knet/det/mask_pseudo_sampler.py."""
+
+import torch
+from mmengine.structures import InstanceData
+
+from mmdet.registry import TASK_UTILS
+from ..assigners import AssignResult
+from .base_sampler import BaseSampler
+from .mask_sampling_result import MaskSamplingResult
+
+
+@TASK_UTILS.register_module()
+class MaskPseudoSampler(BaseSampler):
+ """A pseudo sampler that does not do sampling actually."""
+
+ def __init__(self, **kwargs):
+ pass
+
+ def _sample_pos(self, **kwargs):
+ """Sample positive samples."""
+ raise NotImplementedError
+
+ def _sample_neg(self, **kwargs):
+ """Sample negative samples."""
+ raise NotImplementedError
+
+ def sample(self, assign_result: AssignResult, pred_instances: InstanceData,
+ gt_instances: InstanceData, *args, **kwargs):
+ """Directly returns the positive and negative indices of samples.
+
+ Args:
+ assign_result (:obj:`AssignResult`): Mask assigning results.
+ pred_instances (:obj:`InstanceData`): Instances of model
+ predictions. It includes ``scores`` and ``masks`` predicted
+ by the model.
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It usually includes ``labels`` and ``masks``
+ attributes.
+
+ Returns:
+ :obj:`SamplingResult`: sampler results
+ """
+ pred_masks = pred_instances.masks
+ gt_masks = gt_instances.masks
+ pos_inds = torch.nonzero(
+ assign_result.gt_inds > 0, as_tuple=False).squeeze(-1).unique()
+ neg_inds = torch.nonzero(
+ assign_result.gt_inds == 0, as_tuple=False).squeeze(-1).unique()
+ gt_flags = pred_masks.new_zeros(pred_masks.shape[0], dtype=torch.uint8)
+ sampling_result = MaskSamplingResult(
+ pos_inds=pos_inds,
+ neg_inds=neg_inds,
+ masks=pred_masks,
+ gt_masks=gt_masks,
+ assign_result=assign_result,
+ gt_flags=gt_flags,
+ avg_factor_with_neg=False)
+ return sampling_result
diff --git a/mmdet/models/task_modules/samplers/mask_sampling_result.py b/mmdet/models/task_modules/samplers/mask_sampling_result.py
new file mode 100644
index 0000000000000000000000000000000000000000..adaa62e8a0af28bb004a34b961f672ec03988d2c
--- /dev/null
+++ b/mmdet/models/task_modules/samplers/mask_sampling_result.py
@@ -0,0 +1,68 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+"""copy from
+https://github.com/ZwwWayne/K-Net/blob/main/knet/det/mask_pseudo_sampler.py."""
+
+import torch
+from torch import Tensor
+
+from ..assigners import AssignResult
+from .sampling_result import SamplingResult
+
+
+class MaskSamplingResult(SamplingResult):
+ """Mask sampling result."""
+
+ def __init__(self,
+ pos_inds: Tensor,
+ neg_inds: Tensor,
+ masks: Tensor,
+ gt_masks: Tensor,
+ assign_result: AssignResult,
+ gt_flags: Tensor,
+ avg_factor_with_neg: bool = True) -> None:
+ self.pos_inds = pos_inds
+ self.neg_inds = neg_inds
+ self.num_pos = max(pos_inds.numel(), 1)
+ self.num_neg = max(neg_inds.numel(), 1)
+ self.avg_factor = self.num_pos + self.num_neg \
+ if avg_factor_with_neg else self.num_pos
+
+ self.pos_masks = masks[pos_inds]
+ self.neg_masks = masks[neg_inds]
+ self.pos_is_gt = gt_flags[pos_inds]
+
+ self.num_gts = gt_masks.shape[0]
+ self.pos_assigned_gt_inds = assign_result.gt_inds[pos_inds] - 1
+
+ if gt_masks.numel() == 0:
+ # hack for index error case
+ assert self.pos_assigned_gt_inds.numel() == 0
+ self.pos_gt_masks = torch.empty_like(gt_masks)
+ else:
+ self.pos_gt_masks = gt_masks[self.pos_assigned_gt_inds, :]
+
+ @property
+ def masks(self) -> Tensor:
+ """torch.Tensor: concatenated positive and negative masks."""
+ return torch.cat([self.pos_masks, self.neg_masks])
+
+ def __nice__(self) -> str:
+ data = self.info.copy()
+ data['pos_masks'] = data.pop('pos_masks').shape
+ data['neg_masks'] = data.pop('neg_masks').shape
+ parts = [f"'{k}': {v!r}" for k, v in sorted(data.items())]
+ body = ' ' + ',\n '.join(parts)
+ return '{\n' + body + '\n}'
+
+ @property
+ def info(self) -> dict:
+ """Returns a dictionary of info about the object."""
+ return {
+ 'pos_inds': self.pos_inds,
+ 'neg_inds': self.neg_inds,
+ 'pos_masks': self.pos_masks,
+ 'neg_masks': self.neg_masks,
+ 'pos_is_gt': self.pos_is_gt,
+ 'num_gts': self.num_gts,
+ 'pos_assigned_gt_inds': self.pos_assigned_gt_inds,
+ }
diff --git a/mmdet/models/task_modules/samplers/multi_instance_random_sampler.py b/mmdet/models/task_modules/samplers/multi_instance_random_sampler.py
new file mode 100644
index 0000000000000000000000000000000000000000..8b74054e3a11ed6025e98e90bd0addb131a1dc02
--- /dev/null
+++ b/mmdet/models/task_modules/samplers/multi_instance_random_sampler.py
@@ -0,0 +1,130 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Union
+
+import torch
+from mmengine.structures import InstanceData
+from numpy import ndarray
+from torch import Tensor
+
+from mmdet.registry import TASK_UTILS
+from ..assigners import AssignResult
+from .multi_instance_sampling_result import MultiInstanceSamplingResult
+from .random_sampler import RandomSampler
+
+
+@TASK_UTILS.register_module()
+class MultiInsRandomSampler(RandomSampler):
+ """Random sampler for multi instance.
+
+ Note:
+ Multi-instance means to predict multiple detection boxes with
+ one proposal box. `AssignResult` may assign multiple gt boxes
+ to each proposal box, in this case `RandomSampler` should be
+ replaced by `MultiInsRandomSampler`
+ """
+
+ def _sample_pos(self, assign_result: AssignResult, num_expected: int,
+ **kwargs) -> Union[Tensor, ndarray]:
+ """Randomly sample some positive samples.
+
+ Args:
+ assign_result (:obj:`AssignResult`): Bbox assigning results.
+ num_expected (int): The number of expected positive samples
+
+ Returns:
+ Tensor or ndarray: sampled indices.
+ """
+ pos_inds = torch.nonzero(
+ assign_result.labels[:, 0] > 0, as_tuple=False)
+ if pos_inds.numel() != 0:
+ pos_inds = pos_inds.squeeze(1)
+ if pos_inds.numel() <= num_expected:
+ return pos_inds
+ else:
+ return self.random_choice(pos_inds, num_expected)
+
+ def _sample_neg(self, assign_result: AssignResult, num_expected: int,
+ **kwargs) -> Union[Tensor, ndarray]:
+ """Randomly sample some negative samples.
+
+ Args:
+ assign_result (:obj:`AssignResult`): Bbox assigning results.
+ num_expected (int): The number of expected positive samples
+
+ Returns:
+ Tensor or ndarray: sampled indices.
+ """
+ neg_inds = torch.nonzero(
+ assign_result.labels[:, 0] == 0, as_tuple=False)
+ if neg_inds.numel() != 0:
+ neg_inds = neg_inds.squeeze(1)
+ if len(neg_inds) <= num_expected:
+ return neg_inds
+ else:
+ return self.random_choice(neg_inds, num_expected)
+
+ def sample(self, assign_result: AssignResult, pred_instances: InstanceData,
+ gt_instances: InstanceData,
+ **kwargs) -> MultiInstanceSamplingResult:
+ """Sample positive and negative bboxes.
+
+ Args:
+ assign_result (:obj:`AssignResult`): Assigning results from
+ MultiInstanceAssigner.
+ pred_instances (:obj:`InstanceData`): Instances of model
+ predictions. It includes ``priors``, and the priors can
+ be anchors or points, or the bboxes predicted by the
+ previous stage, has shape (n, 4). The bboxes predicted by
+ the current model or stage will be named ``bboxes``,
+ ``labels``, and ``scores``, the same as the ``InstanceData``
+ in other places.
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It usually includes ``bboxes``, with shape (k, 4),
+ and ``labels``, with shape (k, ).
+
+ Returns:
+ :obj:`MultiInstanceSamplingResult`: Sampling result.
+ """
+
+ assert 'batch_gt_instances_ignore' in kwargs, \
+ 'batch_gt_instances_ignore is necessary for MultiInsRandomSampler'
+
+ gt_bboxes = gt_instances.bboxes
+ ignore_bboxes = kwargs['batch_gt_instances_ignore'].bboxes
+ gt_and_ignore_bboxes = torch.cat([gt_bboxes, ignore_bboxes], dim=0)
+ priors = pred_instances.priors
+ if len(priors.shape) < 2:
+ priors = priors[None, :]
+ priors = priors[:, :4]
+
+ gt_flags = priors.new_zeros((priors.shape[0], ), dtype=torch.uint8)
+ priors = torch.cat([priors, gt_and_ignore_bboxes], dim=0)
+ gt_ones = priors.new_ones(
+ gt_and_ignore_bboxes.shape[0], dtype=torch.uint8)
+ gt_flags = torch.cat([gt_flags, gt_ones])
+
+ num_expected_pos = int(self.num * self.pos_fraction)
+ pos_inds = self.pos_sampler._sample_pos(assign_result,
+ num_expected_pos)
+ # We found that sampled indices have duplicated items occasionally.
+ # (may be a bug of PyTorch)
+ pos_inds = pos_inds.unique()
+ num_sampled_pos = pos_inds.numel()
+ num_expected_neg = self.num - num_sampled_pos
+ if self.neg_pos_ub >= 0:
+ _pos = max(1, num_sampled_pos)
+ neg_upper_bound = int(self.neg_pos_ub * _pos)
+ if num_expected_neg > neg_upper_bound:
+ num_expected_neg = neg_upper_bound
+ neg_inds = self.neg_sampler._sample_neg(assign_result,
+ num_expected_neg)
+ neg_inds = neg_inds.unique()
+
+ sampling_result = MultiInstanceSamplingResult(
+ pos_inds=pos_inds,
+ neg_inds=neg_inds,
+ priors=priors,
+ gt_and_ignore_bboxes=gt_and_ignore_bboxes,
+ assign_result=assign_result,
+ gt_flags=gt_flags)
+ return sampling_result
diff --git a/mmdet/models/task_modules/samplers/multi_instance_sampling_result.py b/mmdet/models/task_modules/samplers/multi_instance_sampling_result.py
new file mode 100644
index 0000000000000000000000000000000000000000..438a0aa91c0cc8904f6d8bba7139408dd99b98cf
--- /dev/null
+++ b/mmdet/models/task_modules/samplers/multi_instance_sampling_result.py
@@ -0,0 +1,56 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+from torch import Tensor
+
+from ..assigners import AssignResult
+from .sampling_result import SamplingResult
+
+
+class MultiInstanceSamplingResult(SamplingResult):
+ """Bbox sampling result. Further encapsulation of SamplingResult. Three
+ attributes neg_assigned_gt_inds, neg_gt_labels, and neg_gt_bboxes have been
+ added for SamplingResult.
+
+ Args:
+ pos_inds (Tensor): Indices of positive samples.
+ neg_inds (Tensor): Indices of negative samples.
+ priors (Tensor): The priors can be anchors or points,
+ or the bboxes predicted by the previous stage.
+ gt_and_ignore_bboxes (Tensor): Ground truth and ignore bboxes.
+ assign_result (:obj:`AssignResult`): Assigning results.
+ gt_flags (Tensor): The Ground truth flags.
+ avg_factor_with_neg (bool): If True, ``avg_factor`` equal to
+ the number of total priors; Otherwise, it is the number of
+ positive priors. Defaults to True.
+ """
+
+ def __init__(self,
+ pos_inds: Tensor,
+ neg_inds: Tensor,
+ priors: Tensor,
+ gt_and_ignore_bboxes: Tensor,
+ assign_result: AssignResult,
+ gt_flags: Tensor,
+ avg_factor_with_neg: bool = True) -> None:
+ self.neg_assigned_gt_inds = assign_result.gt_inds[neg_inds]
+ self.neg_gt_labels = assign_result.labels[neg_inds]
+
+ if gt_and_ignore_bboxes.numel() == 0:
+ self.neg_gt_bboxes = torch.empty_like(gt_and_ignore_bboxes).view(
+ -1, 4)
+ else:
+ if len(gt_and_ignore_bboxes.shape) < 2:
+ gt_and_ignore_bboxes = gt_and_ignore_bboxes.view(-1, 4)
+ self.neg_gt_bboxes = gt_and_ignore_bboxes[
+ self.neg_assigned_gt_inds.long(), :]
+
+ # To resist the minus 1 operation in `SamplingResult.init()`.
+ assign_result.gt_inds += 1
+ super().__init__(
+ pos_inds=pos_inds,
+ neg_inds=neg_inds,
+ priors=priors,
+ gt_bboxes=gt_and_ignore_bboxes,
+ assign_result=assign_result,
+ gt_flags=gt_flags,
+ avg_factor_with_neg=avg_factor_with_neg)
diff --git a/mmdet/models/task_modules/samplers/ohem_sampler.py b/mmdet/models/task_modules/samplers/ohem_sampler.py
new file mode 100644
index 0000000000000000000000000000000000000000..f478a448cde00d64caeba1d0ba613d2497a7fb12
--- /dev/null
+++ b/mmdet/models/task_modules/samplers/ohem_sampler.py
@@ -0,0 +1,111 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+
+from mmdet.registry import TASK_UTILS
+from mmdet.structures.bbox import bbox2roi
+from .base_sampler import BaseSampler
+
+
+@TASK_UTILS.register_module()
+class OHEMSampler(BaseSampler):
+ r"""Online Hard Example Mining Sampler described in `Training Region-based
+ Object Detectors with Online Hard Example Mining
+ `_.
+ """
+
+ def __init__(self,
+ num,
+ pos_fraction,
+ context,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=True,
+ loss_key='loss_cls',
+ **kwargs):
+ super(OHEMSampler, self).__init__(num, pos_fraction, neg_pos_ub,
+ add_gt_as_proposals)
+ self.context = context
+ if not hasattr(self.context, 'num_stages'):
+ self.bbox_head = self.context.bbox_head
+ else:
+ self.bbox_head = self.context.bbox_head[self.context.current_stage]
+
+ self.loss_key = loss_key
+
+ def hard_mining(self, inds, num_expected, bboxes, labels, feats):
+ with torch.no_grad():
+ rois = bbox2roi([bboxes])
+ if not hasattr(self.context, 'num_stages'):
+ bbox_results = self.context._bbox_forward(feats, rois)
+ else:
+ bbox_results = self.context._bbox_forward(
+ self.context.current_stage, feats, rois)
+ cls_score = bbox_results['cls_score']
+ loss = self.bbox_head.loss(
+ cls_score=cls_score,
+ bbox_pred=None,
+ rois=rois,
+ labels=labels,
+ label_weights=cls_score.new_ones(cls_score.size(0)),
+ bbox_targets=None,
+ bbox_weights=None,
+ reduction_override='none')[self.loss_key]
+ _, topk_loss_inds = loss.topk(num_expected)
+ return inds[topk_loss_inds]
+
+ def _sample_pos(self,
+ assign_result,
+ num_expected,
+ bboxes=None,
+ feats=None,
+ **kwargs):
+ """Sample positive boxes.
+
+ Args:
+ assign_result (:obj:`AssignResult`): Assigned results
+ num_expected (int): Number of expected positive samples
+ bboxes (torch.Tensor, optional): Boxes. Defaults to None.
+ feats (list[torch.Tensor], optional): Multi-level features.
+ Defaults to None.
+
+ Returns:
+ torch.Tensor: Indices of positive samples
+ """
+ # Sample some hard positive samples
+ pos_inds = torch.nonzero(assign_result.gt_inds > 0, as_tuple=False)
+ if pos_inds.numel() != 0:
+ pos_inds = pos_inds.squeeze(1)
+ if pos_inds.numel() <= num_expected:
+ return pos_inds
+ else:
+ return self.hard_mining(pos_inds, num_expected, bboxes[pos_inds],
+ assign_result.labels[pos_inds], feats)
+
+ def _sample_neg(self,
+ assign_result,
+ num_expected,
+ bboxes=None,
+ feats=None,
+ **kwargs):
+ """Sample negative boxes.
+
+ Args:
+ assign_result (:obj:`AssignResult`): Assigned results
+ num_expected (int): Number of expected negative samples
+ bboxes (torch.Tensor, optional): Boxes. Defaults to None.
+ feats (list[torch.Tensor], optional): Multi-level features.
+ Defaults to None.
+
+ Returns:
+ torch.Tensor: Indices of negative samples
+ """
+ # Sample some hard negative samples
+ neg_inds = torch.nonzero(assign_result.gt_inds == 0, as_tuple=False)
+ if neg_inds.numel() != 0:
+ neg_inds = neg_inds.squeeze(1)
+ if len(neg_inds) <= num_expected:
+ return neg_inds
+ else:
+ neg_labels = assign_result.labels.new_empty(
+ neg_inds.size(0)).fill_(self.bbox_head.num_classes)
+ return self.hard_mining(neg_inds, num_expected, bboxes[neg_inds],
+ neg_labels, feats)
diff --git a/mmdet/models/task_modules/samplers/pseudo_sampler.py b/mmdet/models/task_modules/samplers/pseudo_sampler.py
new file mode 100644
index 0000000000000000000000000000000000000000..a8186cc3364516f34abe1c293017db6e2042d92a
--- /dev/null
+++ b/mmdet/models/task_modules/samplers/pseudo_sampler.py
@@ -0,0 +1,60 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+from mmengine.structures import InstanceData
+
+from mmdet.registry import TASK_UTILS
+from ..assigners import AssignResult
+from .base_sampler import BaseSampler
+from .sampling_result import SamplingResult
+
+
+@TASK_UTILS.register_module()
+class PseudoSampler(BaseSampler):
+ """A pseudo sampler that does not do sampling actually."""
+
+ def __init__(self, **kwargs):
+ pass
+
+ def _sample_pos(self, **kwargs):
+ """Sample positive samples."""
+ raise NotImplementedError
+
+ def _sample_neg(self, **kwargs):
+ """Sample negative samples."""
+ raise NotImplementedError
+
+ def sample(self, assign_result: AssignResult, pred_instances: InstanceData,
+ gt_instances: InstanceData, *args, **kwargs):
+ """Directly returns the positive and negative indices of samples.
+
+ Args:
+ assign_result (:obj:`AssignResult`): Bbox assigning results.
+ pred_instances (:obj:`InstanceData`): Instances of model
+ predictions. It includes ``priors``, and the priors can
+ be anchors, points, or bboxes predicted by the model,
+ shape(n, 4).
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It usually includes ``bboxes`` and ``labels``
+ attributes.
+
+ Returns:
+ :obj:`SamplingResult`: sampler results
+ """
+ gt_bboxes = gt_instances.bboxes
+ priors = pred_instances.priors
+
+ pos_inds = torch.nonzero(
+ assign_result.gt_inds > 0, as_tuple=False).squeeze(-1).unique()
+ neg_inds = torch.nonzero(
+ assign_result.gt_inds == 0, as_tuple=False).squeeze(-1).unique()
+
+ gt_flags = priors.new_zeros(priors.shape[0], dtype=torch.uint8)
+ sampling_result = SamplingResult(
+ pos_inds=pos_inds,
+ neg_inds=neg_inds,
+ priors=priors,
+ gt_bboxes=gt_bboxes,
+ assign_result=assign_result,
+ gt_flags=gt_flags,
+ avg_factor_with_neg=False)
+ return sampling_result
diff --git a/mmdet/models/task_modules/samplers/random_sampler.py b/mmdet/models/task_modules/samplers/random_sampler.py
new file mode 100644
index 0000000000000000000000000000000000000000..fa03665fc36cc6a0084431324b16727b2dc8993e
--- /dev/null
+++ b/mmdet/models/task_modules/samplers/random_sampler.py
@@ -0,0 +1,109 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Union
+
+import torch
+from numpy import ndarray
+from torch import Tensor
+
+from mmdet.registry import TASK_UTILS
+from ..assigners import AssignResult
+from .base_sampler import BaseSampler
+
+
+@TASK_UTILS.register_module()
+class RandomSampler(BaseSampler):
+ """Random sampler.
+
+ Args:
+ num (int): Number of samples
+ pos_fraction (float): Fraction of positive samples
+ neg_pos_up (int): Upper bound number of negative and
+ positive samples. Defaults to -1.
+ add_gt_as_proposals (bool): Whether to add ground truth
+ boxes as proposals. Defaults to True.
+ """
+
+ def __init__(self,
+ num: int,
+ pos_fraction: float,
+ neg_pos_ub: int = -1,
+ add_gt_as_proposals: bool = True,
+ **kwargs):
+ from .sampling_result import ensure_rng
+ super().__init__(
+ num=num,
+ pos_fraction=pos_fraction,
+ neg_pos_ub=neg_pos_ub,
+ add_gt_as_proposals=add_gt_as_proposals)
+ self.rng = ensure_rng(kwargs.get('rng', None))
+
+ def random_choice(self, gallery: Union[Tensor, ndarray, list],
+ num: int) -> Union[Tensor, ndarray]:
+ """Random select some elements from the gallery.
+
+ If `gallery` is a Tensor, the returned indices will be a Tensor;
+ If `gallery` is a ndarray or list, the returned indices will be a
+ ndarray.
+
+ Args:
+ gallery (Tensor | ndarray | list): indices pool.
+ num (int): expected sample num.
+
+ Returns:
+ Tensor or ndarray: sampled indices.
+ """
+ assert len(gallery) >= num
+
+ is_tensor = isinstance(gallery, torch.Tensor)
+ if not is_tensor:
+ if torch.cuda.is_available():
+ device = torch.cuda.current_device()
+ else:
+ device = 'cpu'
+ gallery = torch.tensor(gallery, dtype=torch.long, device=device)
+ # This is a temporary fix. We can revert the following code
+ # when PyTorch fixes the abnormal return of torch.randperm.
+ # See: https://github.com/open-mmlab/mmdetection/pull/5014
+ perm = torch.randperm(gallery.numel())[:num].to(device=gallery.device)
+ rand_inds = gallery[perm]
+ if not is_tensor:
+ rand_inds = rand_inds.cpu().numpy()
+ return rand_inds
+
+ def _sample_pos(self, assign_result: AssignResult, num_expected: int,
+ **kwargs) -> Union[Tensor, ndarray]:
+ """Randomly sample some positive samples.
+
+ Args:
+ assign_result (:obj:`AssignResult`): Bbox assigning results.
+ num_expected (int): The number of expected positive samples
+
+ Returns:
+ Tensor or ndarray: sampled indices.
+ """
+ pos_inds = torch.nonzero(assign_result.gt_inds > 0, as_tuple=False)
+ if pos_inds.numel() != 0:
+ pos_inds = pos_inds.squeeze(1)
+ if pos_inds.numel() <= num_expected:
+ return pos_inds
+ else:
+ return self.random_choice(pos_inds, num_expected)
+
+ def _sample_neg(self, assign_result: AssignResult, num_expected: int,
+ **kwargs) -> Union[Tensor, ndarray]:
+ """Randomly sample some negative samples.
+
+ Args:
+ assign_result (:obj:`AssignResult`): Bbox assigning results.
+ num_expected (int): The number of expected positive samples
+
+ Returns:
+ Tensor or ndarray: sampled indices.
+ """
+ neg_inds = torch.nonzero(assign_result.gt_inds == 0, as_tuple=False)
+ if neg_inds.numel() != 0:
+ neg_inds = neg_inds.squeeze(1)
+ if len(neg_inds) <= num_expected:
+ return neg_inds
+ else:
+ return self.random_choice(neg_inds, num_expected)
diff --git a/mmdet/models/task_modules/samplers/sampling_result.py b/mmdet/models/task_modules/samplers/sampling_result.py
new file mode 100644
index 0000000000000000000000000000000000000000..cb510ee68f24b8c444b6ed447016bfc785b825c2
--- /dev/null
+++ b/mmdet/models/task_modules/samplers/sampling_result.py
@@ -0,0 +1,240 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+
+import numpy as np
+import torch
+from torch import Tensor
+
+from mmdet.structures.bbox import BaseBoxes, cat_boxes
+from mmdet.utils import util_mixins
+from mmdet.utils.util_random import ensure_rng
+from ..assigners import AssignResult
+
+
+def random_boxes(num=1, scale=1, rng=None):
+ """Simple version of ``kwimage.Boxes.random``
+
+ Returns:
+ Tensor: shape (n, 4) in x1, y1, x2, y2 format.
+
+ References:
+ https://gitlab.kitware.com/computer-vision/kwimage/blob/master/kwimage/structs/boxes.py#L1390
+
+ Example:
+ >>> num = 3
+ >>> scale = 512
+ >>> rng = 0
+ >>> boxes = random_boxes(num, scale, rng)
+ >>> print(boxes)
+ tensor([[280.9925, 278.9802, 308.6148, 366.1769],
+ [216.9113, 330.6978, 224.0446, 456.5878],
+ [405.3632, 196.3221, 493.3953, 270.7942]])
+ """
+ rng = ensure_rng(rng)
+
+ tlbr = rng.rand(num, 4).astype(np.float32)
+
+ tl_x = np.minimum(tlbr[:, 0], tlbr[:, 2])
+ tl_y = np.minimum(tlbr[:, 1], tlbr[:, 3])
+ br_x = np.maximum(tlbr[:, 0], tlbr[:, 2])
+ br_y = np.maximum(tlbr[:, 1], tlbr[:, 3])
+
+ tlbr[:, 0] = tl_x * scale
+ tlbr[:, 1] = tl_y * scale
+ tlbr[:, 2] = br_x * scale
+ tlbr[:, 3] = br_y * scale
+
+ boxes = torch.from_numpy(tlbr)
+ return boxes
+
+
+class SamplingResult(util_mixins.NiceRepr):
+ """Bbox sampling result.
+
+ Args:
+ pos_inds (Tensor): Indices of positive samples.
+ neg_inds (Tensor): Indices of negative samples.
+ priors (Tensor): The priors can be anchors or points,
+ or the bboxes predicted by the previous stage.
+ gt_bboxes (Tensor): Ground truth of bboxes.
+ assign_result (:obj:`AssignResult`): Assigning results.
+ gt_flags (Tensor): The Ground truth flags.
+ avg_factor_with_neg (bool): If True, ``avg_factor`` equal to
+ the number of total priors; Otherwise, it is the number of
+ positive priors. Defaults to True.
+
+ Example:
+ >>> # xdoctest: +IGNORE_WANT
+ >>> from mmdet.models.task_modules.samplers.sampling_result import * # NOQA
+ >>> self = SamplingResult.random(rng=10)
+ >>> print(f'self = {self}')
+ self =
+ """
+
+ def __init__(self,
+ pos_inds: Tensor,
+ neg_inds: Tensor,
+ priors: Tensor,
+ gt_bboxes: Tensor,
+ assign_result: AssignResult,
+ gt_flags: Tensor,
+ avg_factor_with_neg: bool = True) -> None:
+ self.pos_inds = pos_inds
+ self.neg_inds = neg_inds
+ self.num_pos = max(pos_inds.numel(), 1)
+ self.num_neg = max(neg_inds.numel(), 1)
+ self.avg_factor_with_neg = avg_factor_with_neg
+ self.avg_factor = self.num_pos + self.num_neg \
+ if avg_factor_with_neg else self.num_pos
+ self.pos_priors = priors[pos_inds]
+ self.neg_priors = priors[neg_inds]
+ self.pos_is_gt = gt_flags[pos_inds]
+
+ self.num_gts = gt_bboxes.shape[0]
+ self.pos_assigned_gt_inds = assign_result.gt_inds[pos_inds] - 1
+ self.pos_gt_labels = assign_result.labels[pos_inds]
+ box_dim = gt_bboxes.box_dim if isinstance(gt_bboxes, BaseBoxes) else 4
+ if gt_bboxes.numel() == 0:
+ # hack for index error case
+ assert self.pos_assigned_gt_inds.numel() == 0
+ self.pos_gt_bboxes = gt_bboxes.view(-1, box_dim)
+ else:
+ if len(gt_bboxes.shape) < 2:
+ gt_bboxes = gt_bboxes.view(-1, box_dim)
+ self.pos_gt_bboxes = gt_bboxes[self.pos_assigned_gt_inds.long()]
+
+ @property
+ def priors(self):
+ """torch.Tensor: concatenated positive and negative priors"""
+ return cat_boxes([self.pos_priors, self.neg_priors])
+
+ @property
+ def bboxes(self):
+ """torch.Tensor: concatenated positive and negative boxes"""
+ warnings.warn('DeprecationWarning: bboxes is deprecated, '
+ 'please use "priors" instead')
+ return self.priors
+
+ @property
+ def pos_bboxes(self):
+ warnings.warn('DeprecationWarning: pos_bboxes is deprecated, '
+ 'please use "pos_priors" instead')
+ return self.pos_priors
+
+ @property
+ def neg_bboxes(self):
+ warnings.warn('DeprecationWarning: neg_bboxes is deprecated, '
+ 'please use "neg_priors" instead')
+ return self.neg_priors
+
+ def to(self, device):
+ """Change the device of the data inplace.
+
+ Example:
+ >>> self = SamplingResult.random()
+ >>> print(f'self = {self.to(None)}')
+ >>> # xdoctest: +REQUIRES(--gpu)
+ >>> print(f'self = {self.to(0)}')
+ """
+ _dict = self.__dict__
+ for key, value in _dict.items():
+ if isinstance(value, (torch.Tensor, BaseBoxes)):
+ _dict[key] = value.to(device)
+ return self
+
+ def __nice__(self):
+ data = self.info.copy()
+ data['pos_priors'] = data.pop('pos_priors').shape
+ data['neg_priors'] = data.pop('neg_priors').shape
+ parts = [f"'{k}': {v!r}" for k, v in sorted(data.items())]
+ body = ' ' + ',\n '.join(parts)
+ return '{\n' + body + '\n}'
+
+ @property
+ def info(self):
+ """Returns a dictionary of info about the object."""
+ return {
+ 'pos_inds': self.pos_inds,
+ 'neg_inds': self.neg_inds,
+ 'pos_priors': self.pos_priors,
+ 'neg_priors': self.neg_priors,
+ 'pos_is_gt': self.pos_is_gt,
+ 'num_gts': self.num_gts,
+ 'pos_assigned_gt_inds': self.pos_assigned_gt_inds,
+ 'num_pos': self.num_pos,
+ 'num_neg': self.num_neg,
+ 'avg_factor': self.avg_factor
+ }
+
+ @classmethod
+ def random(cls, rng=None, **kwargs):
+ """
+ Args:
+ rng (None | int | numpy.random.RandomState): seed or state.
+ kwargs (keyword arguments):
+ - num_preds: Number of predicted boxes.
+ - num_gts: Number of true boxes.
+ - p_ignore (float): Probability of a predicted box assigned to
+ an ignored truth.
+ - p_assigned (float): probability of a predicted box not being
+ assigned.
+
+ Returns:
+ :obj:`SamplingResult`: Randomly generated sampling result.
+
+ Example:
+ >>> from mmdet.models.task_modules.samplers.sampling_result import * # NOQA
+ >>> self = SamplingResult.random()
+ >>> print(self.__dict__)
+ """
+ from mmengine.structures import InstanceData
+
+ from mmdet.models.task_modules.assigners import AssignResult
+ from mmdet.models.task_modules.samplers import RandomSampler
+ rng = ensure_rng(rng)
+
+ # make probabilistic?
+ num = 32
+ pos_fraction = 0.5
+ neg_pos_ub = -1
+
+ assign_result = AssignResult.random(rng=rng, **kwargs)
+
+ # Note we could just compute an assignment
+ priors = random_boxes(assign_result.num_preds, rng=rng)
+ gt_bboxes = random_boxes(assign_result.num_gts, rng=rng)
+ gt_labels = torch.randint(
+ 0, 5, (assign_result.num_gts, ), dtype=torch.long)
+
+ pred_instances = InstanceData()
+ pred_instances.priors = priors
+
+ gt_instances = InstanceData()
+ gt_instances.bboxes = gt_bboxes
+ gt_instances.labels = gt_labels
+
+ add_gt_as_proposals = True
+
+ sampler = RandomSampler(
+ num,
+ pos_fraction,
+ neg_pos_ub=neg_pos_ub,
+ add_gt_as_proposals=add_gt_as_proposals,
+ rng=rng)
+ self = sampler.sample(
+ assign_result=assign_result,
+ pred_instances=pred_instances,
+ gt_instances=gt_instances)
+ return self
diff --git a/mmdet/models/task_modules/samplers/score_hlr_sampler.py b/mmdet/models/task_modules/samplers/score_hlr_sampler.py
new file mode 100644
index 0000000000000000000000000000000000000000..0227585b92329625d053f1e9f8c161fd02af8aef
--- /dev/null
+++ b/mmdet/models/task_modules/samplers/score_hlr_sampler.py
@@ -0,0 +1,290 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Union
+
+import torch
+from mmcv.ops import nms_match
+from mmengine.structures import InstanceData
+from numpy import ndarray
+from torch import Tensor
+
+from mmdet.registry import TASK_UTILS
+from mmdet.structures.bbox import bbox2roi
+from ..assigners import AssignResult
+from .base_sampler import BaseSampler
+from .sampling_result import SamplingResult
+
+
+@TASK_UTILS.register_module()
+class ScoreHLRSampler(BaseSampler):
+ r"""Importance-based Sample Reweighting (ISR_N), described in `Prime Sample
+ Attention in Object Detection `_.
+
+ Score hierarchical local rank (HLR) differentiates with RandomSampler in
+ negative part. It firstly computes Score-HLR in a two-step way,
+ then linearly maps score hlr to the loss weights.
+
+ Args:
+ num (int): Total number of sampled RoIs.
+ pos_fraction (float): Fraction of positive samples.
+ context (:obj:`BaseRoIHead`): RoI head that the sampler belongs to.
+ neg_pos_ub (int): Upper bound of the ratio of num negative to num
+ positive, -1 means no upper bound. Defaults to -1.
+ add_gt_as_proposals (bool): Whether to add ground truth as proposals.
+ Defaults to True.
+ k (float): Power of the non-linear mapping. Defaults to 0.5
+ bias (float): Shift of the non-linear mapping. Defaults to 0.
+ score_thr (float): Minimum score that a negative sample is to be
+ considered as valid bbox. Defaults to 0.05.
+ iou_thr (float): IoU threshold for NMS match. Defaults to 0.5.
+ """
+
+ def __init__(self,
+ num: int,
+ pos_fraction: float,
+ context,
+ neg_pos_ub: int = -1,
+ add_gt_as_proposals: bool = True,
+ k: float = 0.5,
+ bias: float = 0,
+ score_thr: float = 0.05,
+ iou_thr: float = 0.5,
+ **kwargs) -> None:
+ super().__init__(
+ num=num,
+ pos_fraction=pos_fraction,
+ neg_pos_ub=neg_pos_ub,
+ add_gt_as_proposals=add_gt_as_proposals)
+ self.k = k
+ self.bias = bias
+ self.score_thr = score_thr
+ self.iou_thr = iou_thr
+ self.context = context
+ # context of cascade detectors is a list, so distinguish them here.
+ if not hasattr(context, 'num_stages'):
+ self.bbox_roi_extractor = context.bbox_roi_extractor
+ self.bbox_head = context.bbox_head
+ self.with_shared_head = context.with_shared_head
+ if self.with_shared_head:
+ self.shared_head = context.shared_head
+ else:
+ self.bbox_roi_extractor = context.bbox_roi_extractor[
+ context.current_stage]
+ self.bbox_head = context.bbox_head[context.current_stage]
+
+ @staticmethod
+ def random_choice(gallery: Union[Tensor, ndarray, list],
+ num: int) -> Union[Tensor, ndarray]:
+ """Randomly select some elements from the gallery.
+
+ If `gallery` is a Tensor, the returned indices will be a Tensor;
+ If `gallery` is a ndarray or list, the returned indices will be a
+ ndarray.
+
+ Args:
+ gallery (Tensor or ndarray or list): indices pool.
+ num (int): expected sample num.
+
+ Returns:
+ Tensor or ndarray: sampled indices.
+ """
+ assert len(gallery) >= num
+
+ is_tensor = isinstance(gallery, torch.Tensor)
+ if not is_tensor:
+ if torch.cuda.is_available():
+ device = torch.cuda.current_device()
+ else:
+ device = 'cpu'
+ gallery = torch.tensor(gallery, dtype=torch.long, device=device)
+ perm = torch.randperm(gallery.numel(), device=gallery.device)[:num]
+ rand_inds = gallery[perm]
+ if not is_tensor:
+ rand_inds = rand_inds.cpu().numpy()
+ return rand_inds
+
+ def _sample_pos(self, assign_result: AssignResult, num_expected: int,
+ **kwargs) -> Union[Tensor, ndarray]:
+ """Randomly sample some positive samples.
+
+ Args:
+ assign_result (:obj:`AssignResult`): Bbox assigning results.
+ num_expected (int): The number of expected positive samples
+
+ Returns:
+ Tensor or ndarray: sampled indices.
+ """
+ pos_inds = torch.nonzero(assign_result.gt_inds > 0).flatten()
+ if pos_inds.numel() <= num_expected:
+ return pos_inds
+ else:
+ return self.random_choice(pos_inds, num_expected)
+
+ def _sample_neg(self, assign_result: AssignResult, num_expected: int,
+ bboxes: Tensor, feats: Tensor,
+ **kwargs) -> Union[Tensor, ndarray]:
+ """Sample negative samples.
+
+ Score-HLR sampler is done in the following steps:
+ 1. Take the maximum positive score prediction of each negative samples
+ as s_i.
+ 2. Filter out negative samples whose s_i <= score_thr, the left samples
+ are called valid samples.
+ 3. Use NMS-Match to divide valid samples into different groups,
+ samples in the same group will greatly overlap with each other
+ 4. Rank the matched samples in two-steps to get Score-HLR.
+ (1) In the same group, rank samples with their scores.
+ (2) In the same score rank across different groups,
+ rank samples with their scores again.
+ 5. Linearly map Score-HLR to the final label weights.
+
+ Args:
+ assign_result (:obj:`AssignResult`): result of assigner.
+ num_expected (int): Expected number of samples.
+ bboxes (Tensor): bbox to be sampled.
+ feats (Tensor): Features come from FPN.
+
+ Returns:
+ Tensor or ndarray: sampled indices.
+ """
+ neg_inds = torch.nonzero(assign_result.gt_inds == 0).flatten()
+ num_neg = neg_inds.size(0)
+ if num_neg == 0:
+ return neg_inds, None
+ with torch.no_grad():
+ neg_bboxes = bboxes[neg_inds]
+ neg_rois = bbox2roi([neg_bboxes])
+ bbox_result = self.context._bbox_forward(feats, neg_rois)
+ cls_score, bbox_pred = bbox_result['cls_score'], bbox_result[
+ 'bbox_pred']
+
+ ori_loss = self.bbox_head.loss(
+ cls_score=cls_score,
+ bbox_pred=None,
+ rois=None,
+ labels=neg_inds.new_full((num_neg, ),
+ self.bbox_head.num_classes),
+ label_weights=cls_score.new_ones(num_neg),
+ bbox_targets=None,
+ bbox_weights=None,
+ reduction_override='none')['loss_cls']
+
+ # filter out samples with the max score lower than score_thr
+ max_score, argmax_score = cls_score.softmax(-1)[:, :-1].max(-1)
+ valid_inds = (max_score > self.score_thr).nonzero().view(-1)
+ invalid_inds = (max_score <= self.score_thr).nonzero().view(-1)
+ num_valid = valid_inds.size(0)
+ num_invalid = invalid_inds.size(0)
+
+ num_expected = min(num_neg, num_expected)
+ num_hlr = min(num_valid, num_expected)
+ num_rand = num_expected - num_hlr
+ if num_valid > 0:
+ valid_rois = neg_rois[valid_inds]
+ valid_max_score = max_score[valid_inds]
+ valid_argmax_score = argmax_score[valid_inds]
+ valid_bbox_pred = bbox_pred[valid_inds]
+
+ # valid_bbox_pred shape: [num_valid, #num_classes, 4]
+ valid_bbox_pred = valid_bbox_pred.view(
+ valid_bbox_pred.size(0), -1, 4)
+ selected_bbox_pred = valid_bbox_pred[range(num_valid),
+ valid_argmax_score]
+ pred_bboxes = self.bbox_head.bbox_coder.decode(
+ valid_rois[:, 1:], selected_bbox_pred)
+ pred_bboxes_with_score = torch.cat(
+ [pred_bboxes, valid_max_score[:, None]], -1)
+ group = nms_match(pred_bboxes_with_score, self.iou_thr)
+
+ # imp: importance
+ imp = cls_score.new_zeros(num_valid)
+ for g in group:
+ g_score = valid_max_score[g]
+ # g_score has already sorted
+ rank = g_score.new_tensor(range(g_score.size(0)))
+ imp[g] = num_valid - rank + g_score
+ _, imp_rank_inds = imp.sort(descending=True)
+ _, imp_rank = imp_rank_inds.sort()
+ hlr_inds = imp_rank_inds[:num_expected]
+
+ if num_rand > 0:
+ rand_inds = torch.randperm(num_invalid)[:num_rand]
+ select_inds = torch.cat(
+ [valid_inds[hlr_inds], invalid_inds[rand_inds]])
+ else:
+ select_inds = valid_inds[hlr_inds]
+
+ neg_label_weights = cls_score.new_ones(num_expected)
+
+ up_bound = max(num_expected, num_valid)
+ imp_weights = (up_bound -
+ imp_rank[hlr_inds].float()) / up_bound
+ neg_label_weights[:num_hlr] = imp_weights
+ neg_label_weights[num_hlr:] = imp_weights.min()
+ neg_label_weights = (self.bias +
+ (1 - self.bias) * neg_label_weights).pow(
+ self.k)
+ ori_selected_loss = ori_loss[select_inds]
+ new_loss = ori_selected_loss * neg_label_weights
+ norm_ratio = ori_selected_loss.sum() / new_loss.sum()
+ neg_label_weights *= norm_ratio
+ else:
+ neg_label_weights = cls_score.new_ones(num_expected)
+ select_inds = torch.randperm(num_neg)[:num_expected]
+
+ return neg_inds[select_inds], neg_label_weights
+
+ def sample(self, assign_result: AssignResult, pred_instances: InstanceData,
+ gt_instances: InstanceData, **kwargs) -> SamplingResult:
+ """Sample positive and negative bboxes.
+
+ This is a simple implementation of bbox sampling given candidates,
+ assigning results and ground truth bboxes.
+
+ Args:
+ assign_result (:obj:`AssignResult`): Assigning results.
+ pred_instances (:obj:`InstanceData`): Instances of model
+ predictions. It includes ``priors``, and the priors can
+ be anchors or points, or the bboxes predicted by the
+ previous stage, has shape (n, 4). The bboxes predicted by
+ the current model or stage will be named ``bboxes``,
+ ``labels``, and ``scores``, the same as the ``InstanceData``
+ in other places.
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It usually includes ``bboxes``, with shape (k, 4),
+ and ``labels``, with shape (k, ).
+
+ Returns:
+ :obj:`SamplingResult`: Sampling result.
+ """
+ gt_bboxes = gt_instances.bboxes
+ priors = pred_instances.priors
+ gt_labels = gt_instances.labels
+
+ gt_flags = priors.new_zeros((priors.shape[0], ), dtype=torch.uint8)
+ if self.add_gt_as_proposals and len(gt_bboxes) > 0:
+ priors = torch.cat([gt_bboxes, priors], dim=0)
+ assign_result.add_gt_(gt_labels)
+ gt_ones = priors.new_ones(gt_bboxes.shape[0], dtype=torch.uint8)
+ gt_flags = torch.cat([gt_ones, gt_flags])
+
+ num_expected_pos = int(self.num * self.pos_fraction)
+ pos_inds = self.pos_sampler._sample_pos(
+ assign_result, num_expected_pos, bboxes=priors, **kwargs)
+ num_sampled_pos = pos_inds.numel()
+ num_expected_neg = self.num - num_sampled_pos
+ if self.neg_pos_ub >= 0:
+ _pos = max(1, num_sampled_pos)
+ neg_upper_bound = int(self.neg_pos_ub * _pos)
+ if num_expected_neg > neg_upper_bound:
+ num_expected_neg = neg_upper_bound
+ neg_inds, neg_label_weights = self.neg_sampler._sample_neg(
+ assign_result, num_expected_neg, bboxes=priors, **kwargs)
+
+ sampling_result = SamplingResult(
+ pos_inds=pos_inds,
+ neg_inds=neg_inds,
+ priors=priors,
+ gt_bboxes=gt_bboxes,
+ assign_result=assign_result,
+ gt_flags=gt_flags)
+ return sampling_result, neg_label_weights
diff --git a/mmdet/models/test_time_augs/__init__.py b/mmdet/models/test_time_augs/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..f5e4926efb011b45b3ab7d3d303fb2d105aaa192
--- /dev/null
+++ b/mmdet/models/test_time_augs/__init__.py
@@ -0,0 +1,10 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .det_tta import DetTTAModel
+from .merge_augs import (merge_aug_bboxes, merge_aug_masks,
+ merge_aug_proposals, merge_aug_results,
+ merge_aug_scores)
+
+__all__ = [
+ 'merge_aug_bboxes', 'merge_aug_masks', 'merge_aug_proposals',
+ 'merge_aug_scores', 'merge_aug_results', 'DetTTAModel'
+]
diff --git a/mmdet/models/test_time_augs/__pycache__/__init__.cpython-37.pyc b/mmdet/models/test_time_augs/__pycache__/__init__.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..4c27c27fe00b3f6c05d0f464549bb24da30a9ac9
Binary files /dev/null and b/mmdet/models/test_time_augs/__pycache__/__init__.cpython-37.pyc differ
diff --git a/mmdet/models/test_time_augs/__pycache__/det_tta.cpython-37.pyc b/mmdet/models/test_time_augs/__pycache__/det_tta.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..5b811962f892b7046160bf2124f4561d1b3d23cb
Binary files /dev/null and b/mmdet/models/test_time_augs/__pycache__/det_tta.cpython-37.pyc differ
diff --git a/mmdet/models/test_time_augs/__pycache__/merge_augs.cpython-37.pyc b/mmdet/models/test_time_augs/__pycache__/merge_augs.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..1ad6b6dbecd1af310ef09695c06a2ea0b83cca2b
Binary files /dev/null and b/mmdet/models/test_time_augs/__pycache__/merge_augs.cpython-37.pyc differ
diff --git a/mmdet/models/test_time_augs/det_tta.py b/mmdet/models/test_time_augs/det_tta.py
new file mode 100644
index 0000000000000000000000000000000000000000..95f91db9e1250358db0e1a572cf4c37cc7fe6e6f
--- /dev/null
+++ b/mmdet/models/test_time_augs/det_tta.py
@@ -0,0 +1,144 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Tuple
+
+import torch
+from mmcv.ops import batched_nms
+from mmengine.model import BaseTTAModel
+from mmengine.registry import MODELS
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmdet.structures import DetDataSample
+from mmdet.structures.bbox import bbox_flip
+
+
+@MODELS.register_module()
+class DetTTAModel(BaseTTAModel):
+ """Merge augmented detection results, only bboxes corresponding score under
+ flipping and multi-scale resizing can be processed now.
+
+ Examples:
+ >>> tta_model = dict(
+ >>> type='DetTTAModel',
+ >>> tta_cfg=dict(nms=dict(
+ >>> type='nms',
+ >>> iou_threshold=0.5),
+ >>> max_per_img=100))
+ >>>
+ >>> tta_pipeline = [
+ >>> dict(type='LoadImageFromFile',
+ >>> backend_args=None),
+ >>> dict(
+ >>> type='TestTimeAug',
+ >>> transforms=[[
+ >>> dict(type='Resize',
+ >>> scale=(1333, 800),
+ >>> keep_ratio=True),
+ >>> ], [
+ >>> dict(type='RandomFlip', prob=1.),
+ >>> dict(type='RandomFlip', prob=0.)
+ >>> ], [
+ >>> dict(
+ >>> type='PackDetInputs',
+ >>> meta_keys=('img_id', 'img_path', 'ori_shape',
+ >>> 'img_shape', 'scale_factor', 'flip',
+ >>> 'flip_direction'))
+ >>> ]])]
+ """
+
+ def __init__(self, tta_cfg=None, **kwargs):
+ super().__init__(**kwargs)
+ self.tta_cfg = tta_cfg
+
+ def merge_aug_bboxes(self, aug_bboxes: List[Tensor],
+ aug_scores: List[Tensor],
+ img_metas: List[str]) -> Tuple[Tensor, Tensor]:
+ """Merge augmented detection bboxes and scores.
+
+ Args:
+ aug_bboxes (list[Tensor]): shape (n, 4*#class)
+ aug_scores (list[Tensor] or None): shape (n, #class)
+ Returns:
+ tuple[Tensor]: ``bboxes`` with shape (n,4), where
+ 4 represent (tl_x, tl_y, br_x, br_y)
+ and ``scores`` with shape (n,).
+ """
+ recovered_bboxes = []
+ for bboxes, img_info in zip(aug_bboxes, img_metas):
+ ori_shape = img_info['ori_shape']
+ flip = img_info['flip']
+ flip_direction = img_info['flip_direction']
+ if flip:
+ bboxes = bbox_flip(
+ bboxes=bboxes,
+ img_shape=ori_shape,
+ direction=flip_direction)
+ recovered_bboxes.append(bboxes)
+ bboxes = torch.cat(recovered_bboxes, dim=0)
+ if aug_scores is None:
+ return bboxes
+ else:
+ scores = torch.cat(aug_scores, dim=0)
+ return bboxes, scores
+
+ def merge_preds(self, data_samples_list: List[List[DetDataSample]]):
+ """Merge batch predictions of enhanced data.
+
+ Args:
+ data_samples_list (List[List[DetDataSample]]): List of predictions
+ of all enhanced data. The outer list indicates images, and the
+ inner list corresponds to the different views of one image.
+ Each element of the inner list is a ``DetDataSample``.
+ Returns:
+ List[DetDataSample]: Merged batch prediction.
+ """
+ merged_data_samples = []
+ for data_samples in data_samples_list:
+ merged_data_samples.append(self._merge_single_sample(data_samples))
+ return merged_data_samples
+
+ def _merge_single_sample(
+ self, data_samples: List[DetDataSample]) -> DetDataSample:
+ """Merge predictions which come form the different views of one image
+ to one prediction.
+
+ Args:
+ data_samples (List[DetDataSample]): List of predictions
+ of enhanced data which come form one image.
+ Returns:
+ List[DetDataSample]: Merged prediction.
+ """
+ aug_bboxes = []
+ aug_scores = []
+ aug_labels = []
+ img_metas = []
+ # TODO: support instance segmentation TTA
+ assert data_samples[0].pred_instances.get('masks', None) is None, \
+ 'TTA of instance segmentation does not support now.'
+ for data_sample in data_samples:
+ aug_bboxes.append(data_sample.pred_instances.bboxes)
+ aug_scores.append(data_sample.pred_instances.scores)
+ aug_labels.append(data_sample.pred_instances.labels)
+ img_metas.append(data_sample.metainfo)
+
+ merged_bboxes, merged_scores = self.merge_aug_bboxes(
+ aug_bboxes, aug_scores, img_metas)
+ merged_labels = torch.cat(aug_labels, dim=0)
+
+ if merged_bboxes.numel() == 0:
+ return data_samples[0]
+
+ det_bboxes, keep_idxs = batched_nms(merged_bboxes, merged_scores,
+ merged_labels, self.tta_cfg.nms)
+
+ det_bboxes = det_bboxes[:self.tta_cfg.max_per_img]
+ det_labels = merged_labels[keep_idxs][:self.tta_cfg.max_per_img]
+
+ results = InstanceData()
+ _det_bboxes = det_bboxes.clone()
+ results.bboxes = _det_bboxes[:, :-1]
+ results.scores = _det_bboxes[:, -1]
+ results.labels = det_labels
+ det_results = data_samples[0]
+ det_results.pred_instances = results
+ return det_results
diff --git a/mmdet/models/test_time_augs/merge_augs.py b/mmdet/models/test_time_augs/merge_augs.py
new file mode 100644
index 0000000000000000000000000000000000000000..a2f3562ffcfc9c806380243d41bc3dbfcdbe1a52
--- /dev/null
+++ b/mmdet/models/test_time_augs/merge_augs.py
@@ -0,0 +1,219 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+import warnings
+from typing import List, Optional, Union
+
+import numpy as np
+import torch
+from mmcv.ops import nms
+from mmengine.config import ConfigDict
+from torch import Tensor
+
+from mmdet.structures.bbox import bbox_mapping_back
+
+
+# TODO remove this, never be used in mmdet
+def merge_aug_proposals(aug_proposals, img_metas, cfg):
+ """Merge augmented proposals (multiscale, flip, etc.)
+
+ Args:
+ aug_proposals (list[Tensor]): proposals from different testing
+ schemes, shape (n, 5). Note that they are not rescaled to the
+ original image size.
+
+ img_metas (list[dict]): list of image info dict where each dict has:
+ 'img_shape', 'scale_factor', 'flip', and may also contain
+ 'filename', 'ori_shape', 'pad_shape', and 'img_norm_cfg'.
+ For details on the values of these keys see
+ `mmdet/datasets/pipelines/formatting.py:Collect`.
+
+ cfg (dict): rpn test config.
+
+ Returns:
+ Tensor: shape (n, 4), proposals corresponding to original image scale.
+ """
+
+ cfg = copy.deepcopy(cfg)
+
+ # deprecate arguments warning
+ if 'nms' not in cfg or 'max_num' in cfg or 'nms_thr' in cfg:
+ warnings.warn(
+ 'In rpn_proposal or test_cfg, '
+ 'nms_thr has been moved to a dict named nms as '
+ 'iou_threshold, max_num has been renamed as max_per_img, '
+ 'name of original arguments and the way to specify '
+ 'iou_threshold of NMS will be deprecated.')
+ if 'nms' not in cfg:
+ cfg.nms = ConfigDict(dict(type='nms', iou_threshold=cfg.nms_thr))
+ if 'max_num' in cfg:
+ if 'max_per_img' in cfg:
+ assert cfg.max_num == cfg.max_per_img, f'You set max_num and ' \
+ f'max_per_img at the same time, but get {cfg.max_num} ' \
+ f'and {cfg.max_per_img} respectively' \
+ f'Please delete max_num which will be deprecated.'
+ else:
+ cfg.max_per_img = cfg.max_num
+ if 'nms_thr' in cfg:
+ assert cfg.nms.iou_threshold == cfg.nms_thr, f'You set ' \
+ f'iou_threshold in nms and ' \
+ f'nms_thr at the same time, but get ' \
+ f'{cfg.nms.iou_threshold} and {cfg.nms_thr}' \
+ f' respectively. Please delete the nms_thr ' \
+ f'which will be deprecated.'
+
+ recovered_proposals = []
+ for proposals, img_info in zip(aug_proposals, img_metas):
+ img_shape = img_info['img_shape']
+ scale_factor = img_info['scale_factor']
+ flip = img_info['flip']
+ flip_direction = img_info['flip_direction']
+ _proposals = proposals.clone()
+ _proposals[:, :4] = bbox_mapping_back(_proposals[:, :4], img_shape,
+ scale_factor, flip,
+ flip_direction)
+ recovered_proposals.append(_proposals)
+ aug_proposals = torch.cat(recovered_proposals, dim=0)
+ merged_proposals, _ = nms(aug_proposals[:, :4].contiguous(),
+ aug_proposals[:, -1].contiguous(),
+ cfg.nms.iou_threshold)
+ scores = merged_proposals[:, 4]
+ _, order = scores.sort(0, descending=True)
+ num = min(cfg.max_per_img, merged_proposals.shape[0])
+ order = order[:num]
+ merged_proposals = merged_proposals[order, :]
+ return merged_proposals
+
+
+# TODO remove this, never be used in mmdet
+def merge_aug_bboxes(aug_bboxes, aug_scores, img_metas, rcnn_test_cfg):
+ """Merge augmented detection bboxes and scores.
+
+ Args:
+ aug_bboxes (list[Tensor]): shape (n, 4*#class)
+ aug_scores (list[Tensor] or None): shape (n, #class)
+ img_shapes (list[Tensor]): shape (3, ).
+ rcnn_test_cfg (dict): rcnn test config.
+
+ Returns:
+ tuple: (bboxes, scores)
+ """
+ recovered_bboxes = []
+ for bboxes, img_info in zip(aug_bboxes, img_metas):
+ img_shape = img_info[0]['img_shape']
+ scale_factor = img_info[0]['scale_factor']
+ flip = img_info[0]['flip']
+ flip_direction = img_info[0]['flip_direction']
+ bboxes = bbox_mapping_back(bboxes, img_shape, scale_factor, flip,
+ flip_direction)
+ recovered_bboxes.append(bboxes)
+ bboxes = torch.stack(recovered_bboxes).mean(dim=0)
+ if aug_scores is None:
+ return bboxes
+ else:
+ scores = torch.stack(aug_scores).mean(dim=0)
+ return bboxes, scores
+
+
+def merge_aug_results(aug_batch_results, aug_batch_img_metas):
+ """Merge augmented detection results, only bboxes corresponding score under
+ flipping and multi-scale resizing can be processed now.
+
+ Args:
+ aug_batch_results (list[list[[obj:`InstanceData`]]):
+ Detection results of multiple images with
+ different augmentations.
+ The outer list indicate the augmentation . The inter
+ list indicate the batch dimension.
+ Each item usually contains the following keys.
+
+ - scores (Tensor): Classification scores, in shape
+ (num_instance,)
+ - labels (Tensor): Labels of bboxes, in shape
+ (num_instances,).
+ - bboxes (Tensor): In shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ aug_batch_img_metas (list[list[dict]]): The outer list
+ indicates test-time augs (multiscale, flip, etc.)
+ and the inner list indicates
+ images in a batch. Each dict in the list contains
+ information of an image in the batch.
+
+ Returns:
+ batch_results (list[obj:`InstanceData`]): Same with
+ the input `aug_results` except that all bboxes have
+ been mapped to the original scale.
+ """
+ num_augs = len(aug_batch_results)
+ num_imgs = len(aug_batch_results[0])
+
+ batch_results = []
+ aug_batch_results = copy.deepcopy(aug_batch_results)
+ for img_id in range(num_imgs):
+ aug_results = []
+ for aug_id in range(num_augs):
+ img_metas = aug_batch_img_metas[aug_id][img_id]
+ results = aug_batch_results[aug_id][img_id]
+
+ img_shape = img_metas['img_shape']
+ scale_factor = img_metas['scale_factor']
+ flip = img_metas['flip']
+ flip_direction = img_metas['flip_direction']
+ bboxes = bbox_mapping_back(results.bboxes, img_shape, scale_factor,
+ flip, flip_direction)
+ results.bboxes = bboxes
+ aug_results.append(results)
+ merged_aug_results = results.cat(aug_results)
+ batch_results.append(merged_aug_results)
+
+ return batch_results
+
+
+def merge_aug_scores(aug_scores):
+ """Merge augmented bbox scores."""
+ if isinstance(aug_scores[0], torch.Tensor):
+ return torch.mean(torch.stack(aug_scores), dim=0)
+ else:
+ return np.mean(aug_scores, axis=0)
+
+
+def merge_aug_masks(aug_masks: List[Tensor],
+ img_metas: dict,
+ weights: Optional[Union[list, Tensor]] = None) -> Tensor:
+ """Merge augmented mask prediction.
+
+ Args:
+ aug_masks (list[Tensor]): each has shape
+ (n, c, h, w).
+ img_metas (dict): Image information.
+ weights (list or Tensor): Weight of each aug_masks,
+ the length should be n.
+
+ Returns:
+ Tensor: has shape (n, c, h, w)
+ """
+ recovered_masks = []
+ for i, mask in enumerate(aug_masks):
+ if weights is not None:
+ assert len(weights) == len(aug_masks)
+ weight = weights[i]
+ else:
+ weight = 1
+ flip = img_metas.get('filp', False)
+ if flip:
+ flip_direction = img_metas['flip_direction']
+ if flip_direction == 'horizontal':
+ mask = mask[:, :, :, ::-1]
+ elif flip_direction == 'vertical':
+ mask = mask[:, :, ::-1, :]
+ elif flip_direction == 'diagonal':
+ mask = mask[:, :, :, ::-1]
+ mask = mask[:, :, ::-1, :]
+ else:
+ raise ValueError(
+ f"Invalid flipping direction '{flip_direction}'")
+ recovered_masks.append(mask[None, :] * weight)
+
+ merged_masks = torch.cat(recovered_masks, 0).mean(dim=0)
+ if weights is not None:
+ merged_masks = merged_masks * len(weights) / sum(weights)
+ return merged_masks
diff --git a/mmdet/models/utils/__init__.py b/mmdet/models/utils/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..af3b2448dbeae8eed8e0b579b7bbc159a623fa3c
--- /dev/null
+++ b/mmdet/models/utils/__init__.py
@@ -0,0 +1,30 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .gaussian_target import (gather_feat, gaussian_radius,
+ gen_gaussian_target, get_local_maximum,
+ get_topk_from_heatmap, transpose_and_gather_feat)
+from .make_divisible import make_divisible
+from .misc import (aligned_bilinear, center_of_mass, empty_instances,
+ filter_gt_instances, filter_scores_and_topk, flip_tensor,
+ generate_coordinate, images_to_levels, interpolate_as,
+ levels_to_images, mask2ndarray, multi_apply,
+ relative_coordinate_maps, rename_loss_dict,
+ reweight_loss_dict, samplelist_boxtype2tensor,
+ select_single_mlvl, sigmoid_geometric_mean,
+ unfold_wo_center, unmap, unpack_gt_instances)
+from .panoptic_gt_processing import preprocess_panoptic_gt
+from .point_sample import (get_uncertain_point_coords_with_randomness,
+ get_uncertainty)
+
+__all__ = [
+ 'gaussian_radius', 'gen_gaussian_target', 'make_divisible',
+ 'get_local_maximum', 'get_topk_from_heatmap', 'transpose_and_gather_feat',
+ 'interpolate_as', 'sigmoid_geometric_mean', 'gather_feat',
+ 'preprocess_panoptic_gt', 'get_uncertain_point_coords_with_randomness',
+ 'get_uncertainty', 'unpack_gt_instances', 'empty_instances',
+ 'center_of_mass', 'filter_scores_and_topk', 'flip_tensor',
+ 'generate_coordinate', 'levels_to_images', 'mask2ndarray', 'multi_apply',
+ 'select_single_mlvl', 'unmap', 'images_to_levels',
+ 'samplelist_boxtype2tensor', 'filter_gt_instances', 'rename_loss_dict',
+ 'reweight_loss_dict', 'relative_coordinate_maps', 'aligned_bilinear',
+ 'unfold_wo_center'
+]
diff --git a/mmdet/models/utils/__pycache__/__init__.cpython-37.pyc b/mmdet/models/utils/__pycache__/__init__.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..c9de2787630222314c303939be830b2ef753cca7
Binary files /dev/null and b/mmdet/models/utils/__pycache__/__init__.cpython-37.pyc differ
diff --git a/mmdet/models/utils/__pycache__/gaussian_target.cpython-37.pyc b/mmdet/models/utils/__pycache__/gaussian_target.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..148ad00309c6fdd105fd54ebcb1646252d89216e
Binary files /dev/null and b/mmdet/models/utils/__pycache__/gaussian_target.cpython-37.pyc differ
diff --git a/mmdet/models/utils/__pycache__/make_divisible.cpython-37.pyc b/mmdet/models/utils/__pycache__/make_divisible.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..e95b9231a9e6d1623ce84e8e43f06b3549ffd1c1
Binary files /dev/null and b/mmdet/models/utils/__pycache__/make_divisible.cpython-37.pyc differ
diff --git a/mmdet/models/utils/__pycache__/misc.cpython-37.pyc b/mmdet/models/utils/__pycache__/misc.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..f489fee893a5cca46dfd44342982af43fe487b09
Binary files /dev/null and b/mmdet/models/utils/__pycache__/misc.cpython-37.pyc differ
diff --git a/mmdet/models/utils/__pycache__/panoptic_gt_processing.cpython-37.pyc b/mmdet/models/utils/__pycache__/panoptic_gt_processing.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..ed1eee26e85e21af4aeed79f479acad2697f1fb8
Binary files /dev/null and b/mmdet/models/utils/__pycache__/panoptic_gt_processing.cpython-37.pyc differ
diff --git a/mmdet/models/utils/__pycache__/point_sample.cpython-37.pyc b/mmdet/models/utils/__pycache__/point_sample.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..19965a7edf1bea27946550f36386bb217ea840b9
Binary files /dev/null and b/mmdet/models/utils/__pycache__/point_sample.cpython-37.pyc differ
diff --git a/mmdet/models/utils/gaussian_target.py b/mmdet/models/utils/gaussian_target.py
new file mode 100644
index 0000000000000000000000000000000000000000..5bf4d558ce05c4f953e1c3fcf75016e5874afce1
--- /dev/null
+++ b/mmdet/models/utils/gaussian_target.py
@@ -0,0 +1,268 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from math import sqrt
+
+import torch
+import torch.nn.functional as F
+
+
+def gaussian2D(radius, sigma=1, dtype=torch.float32, device='cpu'):
+ """Generate 2D gaussian kernel.
+
+ Args:
+ radius (int): Radius of gaussian kernel.
+ sigma (int): Sigma of gaussian function. Default: 1.
+ dtype (torch.dtype): Dtype of gaussian tensor. Default: torch.float32.
+ device (str): Device of gaussian tensor. Default: 'cpu'.
+
+ Returns:
+ h (Tensor): Gaussian kernel with a
+ ``(2 * radius + 1) * (2 * radius + 1)`` shape.
+ """
+ x = torch.arange(
+ -radius, radius + 1, dtype=dtype, device=device).view(1, -1)
+ y = torch.arange(
+ -radius, radius + 1, dtype=dtype, device=device).view(-1, 1)
+
+ h = (-(x * x + y * y) / (2 * sigma * sigma)).exp()
+
+ h[h < torch.finfo(h.dtype).eps * h.max()] = 0
+ return h
+
+
+def gen_gaussian_target(heatmap, center, radius, k=1):
+ """Generate 2D gaussian heatmap.
+
+ Args:
+ heatmap (Tensor): Input heatmap, the gaussian kernel will cover on
+ it and maintain the max value.
+ center (list[int]): Coord of gaussian kernel's center.
+ radius (int): Radius of gaussian kernel.
+ k (int): Coefficient of gaussian kernel. Default: 1.
+
+ Returns:
+ out_heatmap (Tensor): Updated heatmap covered by gaussian kernel.
+ """
+ diameter = 2 * radius + 1
+ gaussian_kernel = gaussian2D(
+ radius, sigma=diameter / 6, dtype=heatmap.dtype, device=heatmap.device)
+
+ x, y = center
+
+ height, width = heatmap.shape[:2]
+
+ left, right = min(x, radius), min(width - x, radius + 1)
+ top, bottom = min(y, radius), min(height - y, radius + 1)
+
+ masked_heatmap = heatmap[y - top:y + bottom, x - left:x + right]
+ masked_gaussian = gaussian_kernel[radius - top:radius + bottom,
+ radius - left:radius + right]
+ out_heatmap = heatmap
+ torch.max(
+ masked_heatmap,
+ masked_gaussian * k,
+ out=out_heatmap[y - top:y + bottom, x - left:x + right])
+
+ return out_heatmap
+
+
+def gaussian_radius(det_size, min_overlap):
+ r"""Generate 2D gaussian radius.
+
+ This function is modified from the `official github repo
+ `_.
+
+ Given ``min_overlap``, radius could computed by a quadratic equation
+ according to Vieta's formulas.
+
+ There are 3 cases for computing gaussian radius, details are following:
+
+ - Explanation of figure: ``lt`` and ``br`` indicates the left-top and
+ bottom-right corner of ground truth box. ``x`` indicates the
+ generated corner at the limited position when ``radius=r``.
+
+ - Case1: one corner is inside the gt box and the other is outside.
+
+ .. code:: text
+
+ |< width >|
+
+ lt-+----------+ -
+ | | | ^
+ +--x----------+--+
+ | | | |
+ | | | | height
+ | | overlap | |
+ | | | |
+ | | | | v
+ +--+---------br--+ -
+ | | |
+ +----------+--x
+
+ To ensure IoU of generated box and gt box is larger than ``min_overlap``:
+
+ .. math::
+ \cfrac{(w-r)*(h-r)}{w*h+(w+h)r-r^2} \ge {iou} \quad\Rightarrow\quad
+ {r^2-(w+h)r+\cfrac{1-iou}{1+iou}*w*h} \ge 0 \\
+ {a} = 1,\quad{b} = {-(w+h)},\quad{c} = {\cfrac{1-iou}{1+iou}*w*h}
+ {r} \le \cfrac{-b-\sqrt{b^2-4*a*c}}{2*a}
+
+ - Case2: both two corners are inside the gt box.
+
+ .. code:: text
+
+ |< width >|
+
+ lt-+----------+ -
+ | | | ^
+ +--x-------+ |
+ | | | |
+ | |overlap| | height
+ | | | |
+ | +-------x--+
+ | | | v
+ +----------+-br -
+
+ To ensure IoU of generated box and gt box is larger than ``min_overlap``:
+
+ .. math::
+ \cfrac{(w-2*r)*(h-2*r)}{w*h} \ge {iou} \quad\Rightarrow\quad
+ {4r^2-2(w+h)r+(1-iou)*w*h} \ge 0 \\
+ {a} = 4,\quad {b} = {-2(w+h)},\quad {c} = {(1-iou)*w*h}
+ {r} \le \cfrac{-b-\sqrt{b^2-4*a*c}}{2*a}
+
+ - Case3: both two corners are outside the gt box.
+
+ .. code:: text
+
+ |< width >|
+
+ x--+----------------+
+ | | |
+ +-lt-------------+ | -
+ | | | | ^
+ | | | |
+ | | overlap | | height
+ | | | |
+ | | | | v
+ | +------------br--+ -
+ | | |
+ +----------------+--x
+
+ To ensure IoU of generated box and gt box is larger than ``min_overlap``:
+
+ .. math::
+ \cfrac{w*h}{(w+2*r)*(h+2*r)} \ge {iou} \quad\Rightarrow\quad
+ {4*iou*r^2+2*iou*(w+h)r+(iou-1)*w*h} \le 0 \\
+ {a} = {4*iou},\quad {b} = {2*iou*(w+h)},\quad {c} = {(iou-1)*w*h} \\
+ {r} \le \cfrac{-b+\sqrt{b^2-4*a*c}}{2*a}
+
+ Args:
+ det_size (list[int]): Shape of object.
+ min_overlap (float): Min IoU with ground truth for boxes generated by
+ keypoints inside the gaussian kernel.
+
+ Returns:
+ radius (int): Radius of gaussian kernel.
+ """
+ height, width = det_size
+
+ a1 = 1
+ b1 = (height + width)
+ c1 = width * height * (1 - min_overlap) / (1 + min_overlap)
+ sq1 = sqrt(b1**2 - 4 * a1 * c1)
+ r1 = (b1 - sq1) / (2 * a1)
+
+ a2 = 4
+ b2 = 2 * (height + width)
+ c2 = (1 - min_overlap) * width * height
+ sq2 = sqrt(b2**2 - 4 * a2 * c2)
+ r2 = (b2 - sq2) / (2 * a2)
+
+ a3 = 4 * min_overlap
+ b3 = -2 * min_overlap * (height + width)
+ c3 = (min_overlap - 1) * width * height
+ sq3 = sqrt(b3**2 - 4 * a3 * c3)
+ r3 = (b3 + sq3) / (2 * a3)
+ return min(r1, r2, r3)
+
+
+def get_local_maximum(heat, kernel=3):
+ """Extract local maximum pixel with given kernel.
+
+ Args:
+ heat (Tensor): Target heatmap.
+ kernel (int): Kernel size of max pooling. Default: 3.
+
+ Returns:
+ heat (Tensor): A heatmap where local maximum pixels maintain its
+ own value and other positions are 0.
+ """
+ pad = (kernel - 1) // 2
+ hmax = F.max_pool2d(heat, kernel, stride=1, padding=pad)
+ keep = (hmax == heat).float()
+ return heat * keep
+
+
+def get_topk_from_heatmap(scores, k=20):
+ """Get top k positions from heatmap.
+
+ Args:
+ scores (Tensor): Target heatmap with shape
+ [batch, num_classes, height, width].
+ k (int): Target number. Default: 20.
+
+ Returns:
+ tuple[torch.Tensor]: Scores, indexes, categories and coords of
+ topk keypoint. Containing following Tensors:
+
+ - topk_scores (Tensor): Max scores of each topk keypoint.
+ - topk_inds (Tensor): Indexes of each topk keypoint.
+ - topk_clses (Tensor): Categories of each topk keypoint.
+ - topk_ys (Tensor): Y-coord of each topk keypoint.
+ - topk_xs (Tensor): X-coord of each topk keypoint.
+ """
+ batch, _, height, width = scores.size()
+ topk_scores, topk_inds = torch.topk(scores.view(batch, -1), k)
+ topk_clses = topk_inds // (height * width)
+ topk_inds = topk_inds % (height * width)
+ topk_ys = topk_inds // width
+ topk_xs = (topk_inds % width).int().float()
+ return topk_scores, topk_inds, topk_clses, topk_ys, topk_xs
+
+
+def gather_feat(feat, ind, mask=None):
+ """Gather feature according to index.
+
+ Args:
+ feat (Tensor): Target feature map.
+ ind (Tensor): Target coord index.
+ mask (Tensor | None): Mask of feature map. Default: None.
+
+ Returns:
+ feat (Tensor): Gathered feature.
+ """
+ dim = feat.size(2)
+ ind = ind.unsqueeze(2).repeat(1, 1, dim)
+ feat = feat.gather(1, ind)
+ if mask is not None:
+ mask = mask.unsqueeze(2).expand_as(feat)
+ feat = feat[mask]
+ feat = feat.view(-1, dim)
+ return feat
+
+
+def transpose_and_gather_feat(feat, ind):
+ """Transpose and gather feature according to index.
+
+ Args:
+ feat (Tensor): Target feature map.
+ ind (Tensor): Target coord index.
+
+ Returns:
+ feat (Tensor): Transposed and gathered feature.
+ """
+ feat = feat.permute(0, 2, 3, 1).contiguous()
+ feat = feat.view(feat.size(0), -1, feat.size(3))
+ feat = gather_feat(feat, ind)
+ return feat
diff --git a/mmdet/models/utils/make_divisible.py b/mmdet/models/utils/make_divisible.py
new file mode 100644
index 0000000000000000000000000000000000000000..ed42c2eeea2a6aed03a0be5516b8d1ef1139e486
--- /dev/null
+++ b/mmdet/models/utils/make_divisible.py
@@ -0,0 +1,28 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+def make_divisible(value, divisor, min_value=None, min_ratio=0.9):
+ """Make divisible function.
+
+ This function rounds the channel number to the nearest value that can be
+ divisible by the divisor. It is taken from the original tf repo. It ensures
+ that all layers have a channel number that is divisible by divisor. It can
+ be seen here: https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py # noqa
+
+ Args:
+ value (int): The original channel number.
+ divisor (int): The divisor to fully divide the channel number.
+ min_value (int): The minimum value of the output channel.
+ Default: None, means that the minimum value equal to the divisor.
+ min_ratio (float): The minimum ratio of the rounded channel number to
+ the original channel number. Default: 0.9.
+
+ Returns:
+ int: The modified output channel number.
+ """
+
+ if min_value is None:
+ min_value = divisor
+ new_value = max(min_value, int(value + divisor / 2) // divisor * divisor)
+ # Make sure that round down does not go down by more than (1-min_ratio).
+ if new_value < min_ratio * value:
+ new_value += divisor
+ return new_value
diff --git a/mmdet/models/utils/misc.py b/mmdet/models/utils/misc.py
new file mode 100644
index 0000000000000000000000000000000000000000..823d73c0ac3470f90f7e8780c827f37e8e0ce889
--- /dev/null
+++ b/mmdet/models/utils/misc.py
@@ -0,0 +1,652 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from functools import partial
+from typing import List, Sequence, Tuple, Union
+
+import numpy as np
+import torch
+from mmengine.structures import InstanceData
+from mmengine.utils import digit_version
+from six.moves import map, zip
+from torch import Tensor
+from torch.autograd import Function
+from torch.nn import functional as F
+
+from mmdet.structures import SampleList
+from mmdet.structures.bbox import BaseBoxes, get_box_type, stack_boxes
+from mmdet.structures.mask import BitmapMasks, PolygonMasks
+from mmdet.utils import OptInstanceList
+
+
+class SigmoidGeometricMean(Function):
+ """Forward and backward function of geometric mean of two sigmoid
+ functions.
+
+ This implementation with analytical gradient function substitutes
+ the autograd function of (x.sigmoid() * y.sigmoid()).sqrt(). The
+ original implementation incurs none during gradient backprapagation
+ if both x and y are very small values.
+ """
+
+ @staticmethod
+ def forward(ctx, x, y):
+ x_sigmoid = x.sigmoid()
+ y_sigmoid = y.sigmoid()
+ z = (x_sigmoid * y_sigmoid).sqrt()
+ ctx.save_for_backward(x_sigmoid, y_sigmoid, z)
+ return z
+
+ @staticmethod
+ def backward(ctx, grad_output):
+ x_sigmoid, y_sigmoid, z = ctx.saved_tensors
+ grad_x = grad_output * z * (1 - x_sigmoid) / 2
+ grad_y = grad_output * z * (1 - y_sigmoid) / 2
+ return grad_x, grad_y
+
+
+sigmoid_geometric_mean = SigmoidGeometricMean.apply
+
+
+def interpolate_as(source, target, mode='bilinear', align_corners=False):
+ """Interpolate the `source` to the shape of the `target`.
+
+ The `source` must be a Tensor, but the `target` can be a Tensor or a
+ np.ndarray with the shape (..., target_h, target_w).
+
+ Args:
+ source (Tensor): A 3D/4D Tensor with the shape (N, H, W) or
+ (N, C, H, W).
+ target (Tensor | np.ndarray): The interpolation target with the shape
+ (..., target_h, target_w).
+ mode (str): Algorithm used for interpolation. The options are the
+ same as those in F.interpolate(). Default: ``'bilinear'``.
+ align_corners (bool): The same as the argument in F.interpolate().
+
+ Returns:
+ Tensor: The interpolated source Tensor.
+ """
+ assert len(target.shape) >= 2
+
+ def _interpolate_as(source, target, mode='bilinear', align_corners=False):
+ """Interpolate the `source` (4D) to the shape of the `target`."""
+ target_h, target_w = target.shape[-2:]
+ source_h, source_w = source.shape[-2:]
+ if target_h != source_h or target_w != source_w:
+ source = F.interpolate(
+ source,
+ size=(target_h, target_w),
+ mode=mode,
+ align_corners=align_corners)
+ return source
+
+ if len(source.shape) == 3:
+ source = source[:, None, :, :]
+ source = _interpolate_as(source, target, mode, align_corners)
+ return source[:, 0, :, :]
+ else:
+ return _interpolate_as(source, target, mode, align_corners)
+
+
+def unpack_gt_instances(batch_data_samples: SampleList) -> tuple:
+ """Unpack ``gt_instances``, ``gt_instances_ignore`` and ``img_metas`` based
+ on ``batch_data_samples``
+
+ Args:
+ batch_data_samples (List[:obj:`DetDataSample`]): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+
+ Returns:
+ tuple:
+
+ - batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ - batch_gt_instances_ignore (list[:obj:`InstanceData`]):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+ - batch_img_metas (list[dict]): Meta information of each image,
+ e.g., image size, scaling factor, etc.
+ """
+ batch_gt_instances = []
+ batch_gt_instances_ignore = []
+ batch_img_metas = []
+ for data_sample in batch_data_samples:
+ batch_img_metas.append(data_sample.metainfo)
+ batch_gt_instances.append(data_sample.gt_instances)
+ if 'ignored_instances' in data_sample:
+ batch_gt_instances_ignore.append(data_sample.ignored_instances)
+ else:
+ batch_gt_instances_ignore.append(None)
+
+ return batch_gt_instances, batch_gt_instances_ignore, batch_img_metas
+
+
+def empty_instances(batch_img_metas: List[dict],
+ device: torch.device,
+ task_type: str,
+ instance_results: OptInstanceList = None,
+ mask_thr_binary: Union[int, float] = 0,
+ box_type: Union[str, type] = 'hbox',
+ use_box_type: bool = False,
+ num_classes: int = 80,
+ score_per_cls: bool = False) -> List[InstanceData]:
+ """Handle predicted instances when RoI is empty.
+
+ Note: If ``instance_results`` is not None, it will be modified
+ in place internally, and then return ``instance_results``
+
+ Args:
+ batch_img_metas (list[dict]): List of image information.
+ device (torch.device): Device of tensor.
+ task_type (str): Expected returned task type. it currently
+ supports bbox and mask.
+ instance_results (list[:obj:`InstanceData`]): List of instance
+ results.
+ mask_thr_binary (int, float): mask binarization threshold.
+ Defaults to 0.
+ box_type (str or type): The empty box type. Defaults to `hbox`.
+ use_box_type (bool): Whether to warp boxes with the box type.
+ Defaults to False.
+ num_classes (int): num_classes of bbox_head. Defaults to 80.
+ score_per_cls (bool): Whether to generate classwise score for
+ the empty instance. ``score_per_cls`` will be True when the model
+ needs to produce raw results without nms. Defaults to False.
+
+ Returns:
+ list[:obj:`InstanceData`]: Detection results of each image
+ """
+ assert task_type in ('bbox', 'mask'), 'Only support bbox and mask,' \
+ f' but got {task_type}'
+
+ if instance_results is not None:
+ assert len(instance_results) == len(batch_img_metas)
+
+ results_list = []
+ for img_id in range(len(batch_img_metas)):
+ if instance_results is not None:
+ results = instance_results[img_id]
+ assert isinstance(results, InstanceData)
+ else:
+ results = InstanceData()
+
+ if task_type == 'bbox':
+ _, box_type = get_box_type(box_type)
+ bboxes = torch.zeros(0, box_type.box_dim, device=device)
+ if use_box_type:
+ bboxes = box_type(bboxes, clone=False)
+ results.bboxes = bboxes
+ score_shape = (0, num_classes + 1) if score_per_cls else (0, )
+ results.scores = torch.zeros(score_shape, device=device)
+ results.labels = torch.zeros((0, ),
+ device=device,
+ dtype=torch.long)
+ else:
+ # TODO: Handle the case where rescale is false
+ img_h, img_w = batch_img_metas[img_id]['ori_shape'][:2]
+ # the type of `im_mask` will be torch.bool or torch.uint8,
+ # where uint8 if for visualization and debugging.
+ im_mask = torch.zeros(
+ 0,
+ img_h,
+ img_w,
+ device=device,
+ dtype=torch.bool if mask_thr_binary >= 0 else torch.uint8)
+ results.masks = im_mask
+ results_list.append(results)
+ return results_list
+
+
+def multi_apply(func, *args, **kwargs):
+ """Apply function to a list of arguments.
+
+ Note:
+ This function applies the ``func`` to multiple inputs and
+ map the multiple outputs of the ``func`` into different
+ list. Each list contains the same type of outputs corresponding
+ to different inputs.
+
+ Args:
+ func (Function): A function that will be applied to a list of
+ arguments
+
+ Returns:
+ tuple(list): A tuple containing multiple list, each list contains \
+ a kind of returned results by the function
+ """
+ pfunc = partial(func, **kwargs) if kwargs else func
+ map_results = map(pfunc, *args)
+ return tuple(map(list, zip(*map_results)))
+
+
+def unmap(data, count, inds, fill=0):
+ """Unmap a subset of item (data) back to the original set of items (of size
+ count)"""
+ if data.dim() == 1:
+ ret = data.new_full((count, ), fill)
+ ret[inds.type(torch.bool)] = data
+ else:
+ new_size = (count, ) + data.size()[1:]
+ ret = data.new_full(new_size, fill)
+ ret[inds.type(torch.bool), :] = data
+ return ret
+
+
+def mask2ndarray(mask):
+ """Convert Mask to ndarray..
+
+ Args:
+ mask (:obj:`BitmapMasks` or :obj:`PolygonMasks` or
+ torch.Tensor or np.ndarray): The mask to be converted.
+
+ Returns:
+ np.ndarray: Ndarray mask of shape (n, h, w) that has been converted
+ """
+ if isinstance(mask, (BitmapMasks, PolygonMasks)):
+ mask = mask.to_ndarray()
+ elif isinstance(mask, torch.Tensor):
+ mask = mask.detach().cpu().numpy()
+ elif not isinstance(mask, np.ndarray):
+ raise TypeError(f'Unsupported {type(mask)} data type')
+ return mask
+
+
+def flip_tensor(src_tensor, flip_direction):
+ """flip tensor base on flip_direction.
+
+ Args:
+ src_tensor (Tensor): input feature map, shape (B, C, H, W).
+ flip_direction (str): The flipping direction. Options are
+ 'horizontal', 'vertical', 'diagonal'.
+
+ Returns:
+ out_tensor (Tensor): Flipped tensor.
+ """
+ assert src_tensor.ndim == 4
+ valid_directions = ['horizontal', 'vertical', 'diagonal']
+ assert flip_direction in valid_directions
+ if flip_direction == 'horizontal':
+ out_tensor = torch.flip(src_tensor, [3])
+ elif flip_direction == 'vertical':
+ out_tensor = torch.flip(src_tensor, [2])
+ else:
+ out_tensor = torch.flip(src_tensor, [2, 3])
+ return out_tensor
+
+
+def select_single_mlvl(mlvl_tensors, batch_id, detach=True):
+ """Extract a multi-scale single image tensor from a multi-scale batch
+ tensor based on batch index.
+
+ Note: The default value of detach is True, because the proposal gradient
+ needs to be detached during the training of the two-stage model. E.g
+ Cascade Mask R-CNN.
+
+ Args:
+ mlvl_tensors (list[Tensor]): Batch tensor for all scale levels,
+ each is a 4D-tensor.
+ batch_id (int): Batch index.
+ detach (bool): Whether detach gradient. Default True.
+
+ Returns:
+ list[Tensor]: Multi-scale single image tensor.
+ """
+ assert isinstance(mlvl_tensors, (list, tuple))
+ num_levels = len(mlvl_tensors)
+
+ if detach:
+ mlvl_tensor_list = [
+ mlvl_tensors[i][batch_id].detach() for i in range(num_levels)
+ ]
+ else:
+ mlvl_tensor_list = [
+ mlvl_tensors[i][batch_id] for i in range(num_levels)
+ ]
+ return mlvl_tensor_list
+
+
+def filter_scores_and_topk(scores, score_thr, topk, results=None):
+ """Filter results using score threshold and topk candidates.
+
+ Args:
+ scores (Tensor): The scores, shape (num_bboxes, K).
+ score_thr (float): The score filter threshold.
+ topk (int): The number of topk candidates.
+ results (dict or list or Tensor, Optional): The results to
+ which the filtering rule is to be applied. The shape
+ of each item is (num_bboxes, N).
+
+ Returns:
+ tuple: Filtered results
+
+ - scores (Tensor): The scores after being filtered, \
+ shape (num_bboxes_filtered, ).
+ - labels (Tensor): The class labels, shape \
+ (num_bboxes_filtered, ).
+ - anchor_idxs (Tensor): The anchor indexes, shape \
+ (num_bboxes_filtered, ).
+ - filtered_results (dict or list or Tensor, Optional): \
+ The filtered results. The shape of each item is \
+ (num_bboxes_filtered, N).
+ """
+ valid_mask = scores > score_thr
+ scores = scores[valid_mask]
+ valid_idxs = torch.nonzero(valid_mask)
+
+ num_topk = min(topk, valid_idxs.size(0))
+ # torch.sort is actually faster than .topk (at least on GPUs)
+ scores, idxs = scores.sort(descending=True)
+ scores = scores[:num_topk]
+ topk_idxs = valid_idxs[idxs[:num_topk]]
+ keep_idxs, labels = topk_idxs.unbind(dim=1)
+
+ filtered_results = None
+ if results is not None:
+ if isinstance(results, dict):
+ filtered_results = {k: v[keep_idxs] for k, v in results.items()}
+ elif isinstance(results, list):
+ filtered_results = [result[keep_idxs] for result in results]
+ elif isinstance(results, torch.Tensor):
+ filtered_results = results[keep_idxs]
+ else:
+ raise NotImplementedError(f'Only supports dict or list or Tensor, '
+ f'but get {type(results)}.')
+ return scores, labels, keep_idxs, filtered_results
+
+
+def center_of_mass(mask, esp=1e-6):
+ """Calculate the centroid coordinates of the mask.
+
+ Args:
+ mask (Tensor): The mask to be calculated, shape (h, w).
+ esp (float): Avoid dividing by zero. Default: 1e-6.
+
+ Returns:
+ tuple[Tensor]: the coordinates of the center point of the mask.
+
+ - center_h (Tensor): the center point of the height.
+ - center_w (Tensor): the center point of the width.
+ """
+ h, w = mask.shape
+ grid_h = torch.arange(h, device=mask.device)[:, None]
+ grid_w = torch.arange(w, device=mask.device)
+ normalizer = mask.sum().float().clamp(min=esp)
+ center_h = (mask * grid_h).sum() / normalizer
+ center_w = (mask * grid_w).sum() / normalizer
+ return center_h, center_w
+
+
+def generate_coordinate(featmap_sizes, device='cuda'):
+ """Generate the coordinate.
+
+ Args:
+ featmap_sizes (tuple): The feature to be calculated,
+ of shape (N, C, W, H).
+ device (str): The device where the feature will be put on.
+ Returns:
+ coord_feat (Tensor): The coordinate feature, of shape (N, 2, W, H).
+ """
+
+ x_range = torch.linspace(-1, 1, featmap_sizes[-1], device=device)
+ y_range = torch.linspace(-1, 1, featmap_sizes[-2], device=device)
+ y, x = torch.meshgrid(y_range, x_range)
+ y = y.expand([featmap_sizes[0], 1, -1, -1])
+ x = x.expand([featmap_sizes[0], 1, -1, -1])
+ coord_feat = torch.cat([x, y], 1)
+
+ return coord_feat
+
+
+def levels_to_images(mlvl_tensor: List[torch.Tensor]) -> List[torch.Tensor]:
+ """Concat multi-level feature maps by image.
+
+ [feature_level0, feature_level1...] -> [feature_image0, feature_image1...]
+ Convert the shape of each element in mlvl_tensor from (N, C, H, W) to
+ (N, H*W , C), then split the element to N elements with shape (H*W, C), and
+ concat elements in same image of all level along first dimension.
+
+ Args:
+ mlvl_tensor (list[Tensor]): list of Tensor which collect from
+ corresponding level. Each element is of shape (N, C, H, W)
+
+ Returns:
+ list[Tensor]: A list that contains N tensors and each tensor is
+ of shape (num_elements, C)
+ """
+ batch_size = mlvl_tensor[0].size(0)
+ batch_list = [[] for _ in range(batch_size)]
+ channels = mlvl_tensor[0].size(1)
+ for t in mlvl_tensor:
+ t = t.permute(0, 2, 3, 1)
+ t = t.view(batch_size, -1, channels).contiguous()
+ for img in range(batch_size):
+ batch_list[img].append(t[img])
+ return [torch.cat(item, 0) for item in batch_list]
+
+
+def images_to_levels(target, num_levels):
+ """Convert targets by image to targets by feature level.
+
+ [target_img0, target_img1] -> [target_level0, target_level1, ...]
+ """
+ target = stack_boxes(target, 0)
+ level_targets = []
+ start = 0
+ for n in num_levels:
+ end = start + n
+ # level_targets.append(target[:, start:end].squeeze(0))
+ level_targets.append(target[:, start:end])
+ start = end
+ return level_targets
+
+
+def samplelist_boxtype2tensor(batch_data_samples: SampleList) -> SampleList:
+ for data_samples in batch_data_samples:
+ if 'gt_instances' in data_samples:
+ bboxes = data_samples.gt_instances.get('bboxes', None)
+ if isinstance(bboxes, BaseBoxes):
+ data_samples.gt_instances.bboxes = bboxes.tensor
+ if 'pred_instances' in data_samples:
+ bboxes = data_samples.pred_instances.get('bboxes', None)
+ if isinstance(bboxes, BaseBoxes):
+ data_samples.pred_instances.bboxes = bboxes.tensor
+ if 'ignored_instances' in data_samples:
+ bboxes = data_samples.ignored_instances.get('bboxes', None)
+ if isinstance(bboxes, BaseBoxes):
+ data_samples.ignored_instances.bboxes = bboxes.tensor
+
+
+_torch_version_div_indexing = (
+ 'parrots' not in torch.__version__
+ and digit_version(torch.__version__) >= digit_version('1.8'))
+
+
+def floordiv(dividend, divisor, rounding_mode='trunc'):
+ if _torch_version_div_indexing:
+ return torch.div(dividend, divisor, rounding_mode=rounding_mode)
+ else:
+ return dividend // divisor
+
+
+def _filter_gt_instances_by_score(batch_data_samples: SampleList,
+ score_thr: float) -> SampleList:
+ """Filter ground truth (GT) instances by score.
+
+ Args:
+ batch_data_samples (SampleList): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ score_thr (float): The score filter threshold.
+
+ Returns:
+ SampleList: The Data Samples filtered by score.
+ """
+ for data_samples in batch_data_samples:
+ assert 'scores' in data_samples.gt_instances, \
+ 'there does not exit scores in instances'
+ if data_samples.gt_instances.bboxes.shape[0] > 0:
+ data_samples.gt_instances = data_samples.gt_instances[
+ data_samples.gt_instances.scores > score_thr]
+ return batch_data_samples
+
+
+def _filter_gt_instances_by_size(batch_data_samples: SampleList,
+ wh_thr: tuple) -> SampleList:
+ """Filter ground truth (GT) instances by size.
+
+ Args:
+ batch_data_samples (SampleList): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ wh_thr (tuple): Minimum width and height of bbox.
+
+ Returns:
+ SampleList: The Data Samples filtered by score.
+ """
+ for data_samples in batch_data_samples:
+ bboxes = data_samples.gt_instances.bboxes
+ if bboxes.shape[0] > 0:
+ w = bboxes[:, 2] - bboxes[:, 0]
+ h = bboxes[:, 3] - bboxes[:, 1]
+ data_samples.gt_instances = data_samples.gt_instances[
+ (w > wh_thr[0]) & (h > wh_thr[1])]
+ return batch_data_samples
+
+
+def filter_gt_instances(batch_data_samples: SampleList,
+ score_thr: float = None,
+ wh_thr: tuple = None):
+ """Filter ground truth (GT) instances by score and/or size.
+
+ Args:
+ batch_data_samples (SampleList): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ score_thr (float): The score filter threshold.
+ wh_thr (tuple): Minimum width and height of bbox.
+
+ Returns:
+ SampleList: The Data Samples filtered by score and/or size.
+ """
+
+ if score_thr is not None:
+ batch_data_samples = _filter_gt_instances_by_score(
+ batch_data_samples, score_thr)
+ if wh_thr is not None:
+ batch_data_samples = _filter_gt_instances_by_size(
+ batch_data_samples, wh_thr)
+ return batch_data_samples
+
+
+def rename_loss_dict(prefix: str, losses: dict) -> dict:
+ """Rename the key names in loss dict by adding a prefix.
+
+ Args:
+ prefix (str): The prefix for loss components.
+ losses (dict): A dictionary of loss components.
+
+ Returns:
+ dict: A dictionary of loss components with prefix.
+ """
+ return {prefix + k: v for k, v in losses.items()}
+
+
+def reweight_loss_dict(losses: dict, weight: float) -> dict:
+ """Reweight losses in the dict by weight.
+
+ Args:
+ losses (dict): A dictionary of loss components.
+ weight (float): Weight for loss components.
+
+ Returns:
+ dict: A dictionary of weighted loss components.
+ """
+ for name, loss in losses.items():
+ if 'loss' in name:
+ if isinstance(loss, Sequence):
+ losses[name] = [item * weight for item in loss]
+ else:
+ losses[name] = loss * weight
+ return losses
+
+
+def relative_coordinate_maps(
+ locations: Tensor,
+ centers: Tensor,
+ strides: Tensor,
+ size_of_interest: int,
+ feat_sizes: Tuple[int],
+) -> Tensor:
+ """Generate the relative coordinate maps with feat_stride.
+
+ Args:
+ locations (Tensor): The prior location of mask feature map.
+ It has shape (num_priors, 2).
+ centers (Tensor): The prior points of a object in
+ all feature pyramid. It has shape (num_pos, 2)
+ strides (Tensor): The prior strides of a object in
+ all feature pyramid. It has shape (num_pos, 1)
+ size_of_interest (int): The size of the region used in rel coord.
+ feat_sizes (Tuple[int]): The feature size H and W, which has 2 dims.
+ Returns:
+ rel_coord_feat (Tensor): The coordinate feature
+ of shape (num_pos, 2, H, W).
+ """
+
+ H, W = feat_sizes
+ rel_coordinates = centers.reshape(-1, 1, 2) - locations.reshape(1, -1, 2)
+ rel_coordinates = rel_coordinates.permute(0, 2, 1).float()
+ rel_coordinates = rel_coordinates / (
+ strides[:, None, None] * size_of_interest)
+ return rel_coordinates.reshape(-1, 2, H, W)
+
+
+def aligned_bilinear(tensor: Tensor, factor: int) -> Tensor:
+ """aligned bilinear, used in original implement in CondInst:
+
+ https://github.com/aim-uofa/AdelaiDet/blob/\
+ c0b2092ce72442b0f40972f7c6dda8bb52c46d16/adet/utils/comm.py#L23
+ """
+
+ assert tensor.dim() == 4
+ assert factor >= 1
+ assert int(factor) == factor
+
+ if factor == 1:
+ return tensor
+
+ h, w = tensor.size()[2:]
+ tensor = F.pad(tensor, pad=(0, 1, 0, 1), mode='replicate')
+ oh = factor * h + 1
+ ow = factor * w + 1
+ tensor = F.interpolate(
+ tensor, size=(oh, ow), mode='bilinear', align_corners=True)
+ tensor = F.pad(
+ tensor, pad=(factor // 2, 0, factor // 2, 0), mode='replicate')
+
+ return tensor[:, :, :oh - 1, :ow - 1]
+
+
+def unfold_wo_center(x, kernel_size: int, dilation: int) -> Tensor:
+ """unfold_wo_center, used in original implement in BoxInst:
+
+ https://github.com/aim-uofa/AdelaiDet/blob/\
+ 4a3a1f7372c35b48ebf5f6adc59f135a0fa28d60/\
+ adet/modeling/condinst/condinst.py#L53
+ """
+ assert x.dim() == 4
+ assert kernel_size % 2 == 1
+
+ # using SAME padding
+ padding = (kernel_size + (dilation - 1) * (kernel_size - 1)) // 2
+ unfolded_x = F.unfold(
+ x, kernel_size=kernel_size, padding=padding, dilation=dilation)
+ unfolded_x = unfolded_x.reshape(
+ x.size(0), x.size(1), -1, x.size(2), x.size(3))
+ # remove the center pixels
+ size = kernel_size**2
+ unfolded_x = torch.cat(
+ (unfolded_x[:, :, :size // 2], unfolded_x[:, :, size // 2 + 1:]),
+ dim=2)
+
+ return unfolded_x
diff --git a/mmdet/models/utils/panoptic_gt_processing.py b/mmdet/models/utils/panoptic_gt_processing.py
new file mode 100644
index 0000000000000000000000000000000000000000..7a3bc95fc04040b4a2a13fa63f2d02f092f725e6
--- /dev/null
+++ b/mmdet/models/utils/panoptic_gt_processing.py
@@ -0,0 +1,70 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Tuple
+
+import torch
+from torch import Tensor
+
+
+def preprocess_panoptic_gt(gt_labels: Tensor, gt_masks: Tensor,
+ gt_semantic_seg: Tensor, num_things: int,
+ num_stuff: int) -> Tuple[Tensor, Tensor]:
+ """Preprocess the ground truth for a image.
+
+ Args:
+ gt_labels (Tensor): Ground truth labels of each bbox,
+ with shape (num_gts, ).
+ gt_masks (BitmapMasks): Ground truth masks of each instances
+ of a image, shape (num_gts, h, w).
+ gt_semantic_seg (Tensor | None): Ground truth of semantic
+ segmentation with the shape (1, h, w).
+ [0, num_thing_class - 1] means things,
+ [num_thing_class, num_class-1] means stuff,
+ 255 means VOID. It's None when training instance segmentation.
+
+ Returns:
+ tuple[Tensor, Tensor]: a tuple containing the following targets.
+
+ - labels (Tensor): Ground truth class indices for a
+ image, with shape (n, ), n is the sum of number
+ of stuff type and number of instance in a image.
+ - masks (Tensor): Ground truth mask for a image, with
+ shape (n, h, w). Contains stuff and things when training
+ panoptic segmentation, and things only when training
+ instance segmentation.
+ """
+ num_classes = num_things + num_stuff
+ things_masks = gt_masks.to_tensor(
+ dtype=torch.bool, device=gt_labels.device)
+
+ if gt_semantic_seg is None:
+ masks = things_masks.long()
+ return gt_labels, masks
+
+ things_labels = gt_labels
+ gt_semantic_seg = gt_semantic_seg.squeeze(0)
+
+ semantic_labels = torch.unique(
+ gt_semantic_seg,
+ sorted=False,
+ return_inverse=False,
+ return_counts=False)
+ stuff_masks_list = []
+ stuff_labels_list = []
+ for label in semantic_labels:
+ if label < num_things or label >= num_classes:
+ continue
+ stuff_mask = gt_semantic_seg == label
+ stuff_masks_list.append(stuff_mask)
+ stuff_labels_list.append(label)
+
+ if len(stuff_masks_list) > 0:
+ stuff_masks = torch.stack(stuff_masks_list, dim=0)
+ stuff_labels = torch.stack(stuff_labels_list, dim=0)
+ labels = torch.cat([things_labels, stuff_labels], dim=0)
+ masks = torch.cat([things_masks, stuff_masks], dim=0)
+ else:
+ labels = things_labels
+ masks = things_masks
+
+ masks = masks.long()
+ return labels, masks
diff --git a/mmdet/models/utils/point_sample.py b/mmdet/models/utils/point_sample.py
new file mode 100644
index 0000000000000000000000000000000000000000..1afc957f3da7d1dc030c21d40311c768c6952ea4
--- /dev/null
+++ b/mmdet/models/utils/point_sample.py
@@ -0,0 +1,88 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+from mmcv.ops import point_sample
+from torch import Tensor
+
+
+def get_uncertainty(mask_preds: Tensor, labels: Tensor) -> Tensor:
+ """Estimate uncertainty based on pred logits.
+
+ We estimate uncertainty as L1 distance between 0.0 and the logits
+ prediction in 'mask_preds' for the foreground class in `classes`.
+
+ Args:
+ mask_preds (Tensor): mask predication logits, shape (num_rois,
+ num_classes, mask_height, mask_width).
+
+ labels (Tensor): Either predicted or ground truth label for
+ each predicted mask, of length num_rois.
+
+ Returns:
+ scores (Tensor): Uncertainty scores with the most uncertain
+ locations having the highest uncertainty score,
+ shape (num_rois, 1, mask_height, mask_width)
+ """
+ if mask_preds.shape[1] == 1:
+ gt_class_logits = mask_preds.clone()
+ else:
+ inds = torch.arange(mask_preds.shape[0], device=mask_preds.device)
+ gt_class_logits = mask_preds[inds, labels].unsqueeze(1)
+ return -torch.abs(gt_class_logits)
+
+
+def get_uncertain_point_coords_with_randomness(
+ mask_preds: Tensor, labels: Tensor, num_points: int,
+ oversample_ratio: float, importance_sample_ratio: float) -> Tensor:
+ """Get ``num_points`` most uncertain points with random points during
+ train.
+
+ Sample points in [0, 1] x [0, 1] coordinate space based on their
+ uncertainty. The uncertainties are calculated for each point using
+ 'get_uncertainty()' function that takes point's logit prediction as
+ input.
+
+ Args:
+ mask_preds (Tensor): A tensor of shape (num_rois, num_classes,
+ mask_height, mask_width) for class-specific or class-agnostic
+ prediction.
+ labels (Tensor): The ground truth class for each instance.
+ num_points (int): The number of points to sample.
+ oversample_ratio (float): Oversampling parameter.
+ importance_sample_ratio (float): Ratio of points that are sampled
+ via importnace sampling.
+
+ Returns:
+ point_coords (Tensor): A tensor of shape (num_rois, num_points, 2)
+ that contains the coordinates sampled points.
+ """
+ assert oversample_ratio >= 1
+ assert 0 <= importance_sample_ratio <= 1
+ batch_size = mask_preds.shape[0]
+ num_sampled = int(num_points * oversample_ratio)
+ point_coords = torch.rand(
+ batch_size, num_sampled, 2, device=mask_preds.device)
+ point_logits = point_sample(mask_preds, point_coords)
+ # It is crucial to calculate uncertainty based on the sampled
+ # prediction value for the points. Calculating uncertainties of the
+ # coarse predictions first and sampling them for points leads to
+ # incorrect results. To illustrate this: assume uncertainty func(
+ # logits)=-abs(logits), a sampled point between two coarse
+ # predictions with -1 and 1 logits has 0 logits, and therefore 0
+ # uncertainty value. However, if we calculate uncertainties for the
+ # coarse predictions first, both will have -1 uncertainty,
+ # and sampled point will get -1 uncertainty.
+ point_uncertainties = get_uncertainty(point_logits, labels)
+ num_uncertain_points = int(importance_sample_ratio * num_points)
+ num_random_points = num_points - num_uncertain_points
+ idx = torch.topk(
+ point_uncertainties[:, 0, :], k=num_uncertain_points, dim=1)[1]
+ shift = num_sampled * torch.arange(
+ batch_size, dtype=torch.long, device=mask_preds.device)
+ idx += shift[:, None]
+ point_coords = point_coords.view(-1, 2)[idx.view(-1), :].view(
+ batch_size, num_uncertain_points, 2)
+ if num_random_points > 0:
+ rand_roi_coords = torch.rand(
+ batch_size, num_random_points, 2, device=mask_preds.device)
+ point_coords = torch.cat((point_coords, rand_roi_coords), dim=1)
+ return point_coords
diff --git a/mmdet/registry.py b/mmdet/registry.py
new file mode 100644
index 0000000000000000000000000000000000000000..3a5b2b28a4f80a488994b48a99043a20c604e55e
--- /dev/null
+++ b/mmdet/registry.py
@@ -0,0 +1,121 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+"""MMDetection provides 17 registry nodes to support using modules across
+projects. Each node is a child of the root registry in MMEngine.
+
+More details can be found at
+https://mmengine.readthedocs.io/en/latest/tutorials/registry.html.
+"""
+
+from mmengine.registry import DATA_SAMPLERS as MMENGINE_DATA_SAMPLERS
+from mmengine.registry import DATASETS as MMENGINE_DATASETS
+from mmengine.registry import EVALUATOR as MMENGINE_EVALUATOR
+from mmengine.registry import HOOKS as MMENGINE_HOOKS
+from mmengine.registry import LOG_PROCESSORS as MMENGINE_LOG_PROCESSORS
+from mmengine.registry import LOOPS as MMENGINE_LOOPS
+from mmengine.registry import METRICS as MMENGINE_METRICS
+from mmengine.registry import MODEL_WRAPPERS as MMENGINE_MODEL_WRAPPERS
+from mmengine.registry import MODELS as MMENGINE_MODELS
+from mmengine.registry import \
+ OPTIM_WRAPPER_CONSTRUCTORS as MMENGINE_OPTIM_WRAPPER_CONSTRUCTORS
+from mmengine.registry import OPTIM_WRAPPERS as MMENGINE_OPTIM_WRAPPERS
+from mmengine.registry import OPTIMIZERS as MMENGINE_OPTIMIZERS
+from mmengine.registry import PARAM_SCHEDULERS as MMENGINE_PARAM_SCHEDULERS
+from mmengine.registry import \
+ RUNNER_CONSTRUCTORS as MMENGINE_RUNNER_CONSTRUCTORS
+from mmengine.registry import RUNNERS as MMENGINE_RUNNERS
+from mmengine.registry import TASK_UTILS as MMENGINE_TASK_UTILS
+from mmengine.registry import TRANSFORMS as MMENGINE_TRANSFORMS
+from mmengine.registry import VISBACKENDS as MMENGINE_VISBACKENDS
+from mmengine.registry import VISUALIZERS as MMENGINE_VISUALIZERS
+from mmengine.registry import \
+ WEIGHT_INITIALIZERS as MMENGINE_WEIGHT_INITIALIZERS
+from mmengine.registry import Registry
+
+# manage all kinds of runners like `EpochBasedRunner` and `IterBasedRunner`
+RUNNERS = Registry(
+ 'runner', parent=MMENGINE_RUNNERS, locations=['mmdet.engine.runner'])
+# manage runner constructors that define how to initialize runners
+RUNNER_CONSTRUCTORS = Registry(
+ 'runner constructor',
+ parent=MMENGINE_RUNNER_CONSTRUCTORS,
+ locations=['mmdet.engine.runner'])
+# manage all kinds of loops like `EpochBasedTrainLoop`
+LOOPS = Registry(
+ 'loop', parent=MMENGINE_LOOPS, locations=['mmdet.engine.runner'])
+# manage all kinds of hooks like `CheckpointHook`
+HOOKS = Registry(
+ 'hook', parent=MMENGINE_HOOKS, locations=['mmdet.engine.hooks'])
+
+# manage data-related modules
+DATASETS = Registry(
+ 'dataset', parent=MMENGINE_DATASETS, locations=['mmdet.datasets'])
+DATA_SAMPLERS = Registry(
+ 'data sampler',
+ parent=MMENGINE_DATA_SAMPLERS,
+ locations=['mmdet.datasets.samplers'])
+TRANSFORMS = Registry(
+ 'transform',
+ parent=MMENGINE_TRANSFORMS,
+ locations=['mmdet.datasets.transforms'])
+
+# manage all kinds of modules inheriting `nn.Module`
+MODELS = Registry('model', parent=MMENGINE_MODELS, locations=['mmdet.models'])
+# manage all kinds of model wrappers like 'MMDistributedDataParallel'
+MODEL_WRAPPERS = Registry(
+ 'model_wrapper',
+ parent=MMENGINE_MODEL_WRAPPERS,
+ locations=['mmdet.models'])
+# manage all kinds of weight initialization modules like `Uniform`
+WEIGHT_INITIALIZERS = Registry(
+ 'weight initializer',
+ parent=MMENGINE_WEIGHT_INITIALIZERS,
+ locations=['mmdet.models'])
+
+# manage all kinds of optimizers like `SGD` and `Adam`
+OPTIMIZERS = Registry(
+ 'optimizer',
+ parent=MMENGINE_OPTIMIZERS,
+ locations=['mmdet.engine.optimizers'])
+# manage optimizer wrapper
+OPTIM_WRAPPERS = Registry(
+ 'optim_wrapper',
+ parent=MMENGINE_OPTIM_WRAPPERS,
+ locations=['mmdet.engine.optimizers'])
+# manage constructors that customize the optimization hyperparameters.
+OPTIM_WRAPPER_CONSTRUCTORS = Registry(
+ 'optimizer constructor',
+ parent=MMENGINE_OPTIM_WRAPPER_CONSTRUCTORS,
+ locations=['mmdet.engine.optimizers'])
+# manage all kinds of parameter schedulers like `MultiStepLR`
+PARAM_SCHEDULERS = Registry(
+ 'parameter scheduler',
+ parent=MMENGINE_PARAM_SCHEDULERS,
+ locations=['mmdet.engine.schedulers'])
+# manage all kinds of metrics
+METRICS = Registry(
+ 'metric', parent=MMENGINE_METRICS, locations=['mmdet.evaluation'])
+# manage evaluator
+EVALUATOR = Registry(
+ 'evaluator', parent=MMENGINE_EVALUATOR, locations=['mmdet.evaluation'])
+
+# manage task-specific modules like anchor generators and box coders
+TASK_UTILS = Registry(
+ 'task util', parent=MMENGINE_TASK_UTILS, locations=['mmdet.models'])
+
+# manage visualizer
+VISUALIZERS = Registry(
+ 'visualizer',
+ parent=MMENGINE_VISUALIZERS,
+ locations=['mmdet.visualization'])
+# manage visualizer backend
+VISBACKENDS = Registry(
+ 'vis_backend',
+ parent=MMENGINE_VISBACKENDS,
+ locations=['mmdet.visualization'])
+
+# manage logprocessor
+LOG_PROCESSORS = Registry(
+ 'log_processor',
+ parent=MMENGINE_LOG_PROCESSORS,
+ # TODO: update the location when mmdet has its own log processor
+ locations=['mmdet.engine'])
diff --git a/mmdet/structures/__init__.py b/mmdet/structures/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..b72a5b8f6586200b0b87c77d834ac9b7733f0f3f
--- /dev/null
+++ b/mmdet/structures/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .det_data_sample import DetDataSample, OptSampleList, SampleList
+
+__all__ = ['DetDataSample', 'SampleList', 'OptSampleList']
diff --git a/mmdet/structures/__pycache__/__init__.cpython-37.pyc b/mmdet/structures/__pycache__/__init__.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..829e71c7f4ca65a1544b404334867fe92d7502fe
Binary files /dev/null and b/mmdet/structures/__pycache__/__init__.cpython-37.pyc differ
diff --git a/mmdet/structures/__pycache__/det_data_sample.cpython-37.pyc b/mmdet/structures/__pycache__/det_data_sample.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..881f3e0bccd54f4b886301e2d9a9f8567fb869a2
Binary files /dev/null and b/mmdet/structures/__pycache__/det_data_sample.cpython-37.pyc differ
diff --git a/mmdet/structures/bbox/__init__.py b/mmdet/structures/bbox/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..c4c60df85de7510de83286c50ccc73bbd5c376d5
--- /dev/null
+++ b/mmdet/structures/bbox/__init__.py
@@ -0,0 +1,24 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .base_boxes import BaseBoxes
+from .bbox_overlaps import bbox_overlaps
+from .box_type import (autocast_box_type, convert_box_type, get_box_type,
+ register_box, register_box_converter)
+from .horizontal_boxes import HorizontalBoxes
+from .transforms import (bbox2corner, bbox2distance, bbox2result, bbox2roi,
+ bbox_cxcywh_to_xyxy, bbox_flip, bbox_mapping,
+ bbox_mapping_back, bbox_project, bbox_rescale,
+ bbox_xyxy_to_cxcywh, cat_boxes, corner2bbox,
+ distance2bbox, empty_box_as, find_inside_bboxes,
+ get_box_tensor, get_box_wh, roi2bbox, scale_boxes,
+ stack_boxes)
+
+__all__ = [
+ 'bbox_overlaps', 'bbox_flip', 'bbox_mapping', 'bbox_mapping_back',
+ 'bbox2roi', 'roi2bbox', 'bbox2result', 'distance2bbox', 'bbox2distance',
+ 'bbox_rescale', 'bbox_cxcywh_to_xyxy', 'bbox_xyxy_to_cxcywh',
+ 'find_inside_bboxes', 'bbox2corner', 'corner2bbox', 'bbox_project',
+ 'BaseBoxes', 'convert_box_type', 'get_box_type', 'register_box',
+ 'register_box_converter', 'HorizontalBoxes', 'autocast_box_type',
+ 'cat_boxes', 'stack_boxes', 'scale_boxes', 'get_box_wh', 'get_box_tensor',
+ 'empty_box_as'
+]
diff --git a/mmdet/structures/bbox/__pycache__/__init__.cpython-37.pyc b/mmdet/structures/bbox/__pycache__/__init__.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..58c704172f32718028154245ca52f326f2c7b73b
Binary files /dev/null and b/mmdet/structures/bbox/__pycache__/__init__.cpython-37.pyc differ
diff --git a/mmdet/structures/bbox/__pycache__/base_boxes.cpython-37.pyc b/mmdet/structures/bbox/__pycache__/base_boxes.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..f9bd2a875d3aff3cb950eb2b5a0752f3af145629
Binary files /dev/null and b/mmdet/structures/bbox/__pycache__/base_boxes.cpython-37.pyc differ
diff --git a/mmdet/structures/bbox/__pycache__/bbox_overlaps.cpython-37.pyc b/mmdet/structures/bbox/__pycache__/bbox_overlaps.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..859d8b8dd74b46e5a37326714df3e92e47ed387c
Binary files /dev/null and b/mmdet/structures/bbox/__pycache__/bbox_overlaps.cpython-37.pyc differ
diff --git a/mmdet/structures/bbox/__pycache__/box_type.cpython-37.pyc b/mmdet/structures/bbox/__pycache__/box_type.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..00dc27159872bfd8d081f4de50c42b7ae21ae992
Binary files /dev/null and b/mmdet/structures/bbox/__pycache__/box_type.cpython-37.pyc differ
diff --git a/mmdet/structures/bbox/__pycache__/horizontal_boxes.cpython-37.pyc b/mmdet/structures/bbox/__pycache__/horizontal_boxes.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..81f35357036545ee39b21bce249efc1d2afc2b11
Binary files /dev/null and b/mmdet/structures/bbox/__pycache__/horizontal_boxes.cpython-37.pyc differ
diff --git a/mmdet/structures/bbox/__pycache__/transforms.cpython-37.pyc b/mmdet/structures/bbox/__pycache__/transforms.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..126908d7d0ba52b6aec541eca70e66bf07f39a56
Binary files /dev/null and b/mmdet/structures/bbox/__pycache__/transforms.cpython-37.pyc differ
diff --git a/mmdet/structures/bbox/base_boxes.py b/mmdet/structures/bbox/base_boxes.py
new file mode 100644
index 0000000000000000000000000000000000000000..0ed667664a8a57a1b9b7e422af03d41274882747
--- /dev/null
+++ b/mmdet/structures/bbox/base_boxes.py
@@ -0,0 +1,549 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from abc import ABCMeta, abstractmethod, abstractproperty, abstractstaticmethod
+from typing import List, Optional, Sequence, Tuple, Type, TypeVar, Union
+
+import numpy as np
+import torch
+from torch import BoolTensor, Tensor
+
+from mmdet.structures.mask.structures import BitmapMasks, PolygonMasks
+
+T = TypeVar('T')
+DeviceType = Union[str, torch.device]
+IndexType = Union[slice, int, list, torch.LongTensor, torch.cuda.LongTensor,
+ torch.BoolTensor, torch.cuda.BoolTensor, np.ndarray]
+MaskType = Union[BitmapMasks, PolygonMasks]
+
+
+class BaseBoxes(metaclass=ABCMeta):
+ """The base class for 2D box types.
+
+ The functions of ``BaseBoxes`` lie in three fields:
+
+ - Verify the boxes shape.
+ - Support tensor-like operations.
+ - Define abstract functions for 2D boxes.
+
+ In ``__init__`` , ``BaseBoxes`` verifies the validity of the data shape
+ w.r.t ``box_dim``. The tensor with the dimension >= 2 and the length
+ of the last dimension being ``box_dim`` will be regarded as valid.
+ ``BaseBoxes`` will restore them at the field ``tensor``. It's necessary
+ to override ``box_dim`` in subclass to guarantee the data shape is
+ correct.
+
+ There are many basic tensor-like functions implemented in ``BaseBoxes``.
+ In most cases, users can operate ``BaseBoxes`` instance like a normal
+ tensor. To protect the validity of data shape, All tensor-like functions
+ cannot modify the last dimension of ``self.tensor``.
+
+ When creating a new box type, users need to inherit from ``BaseBoxes``
+ and override abstract methods and specify the ``box_dim``. Then, register
+ the new box type by using the decorator ``register_box_type``.
+
+ Args:
+ data (Tensor or np.ndarray or Sequence): The box data with shape
+ (..., box_dim).
+ dtype (torch.dtype, Optional): data type of boxes. Defaults to None.
+ device (str or torch.device, Optional): device of boxes.
+ Default to None.
+ clone (bool): Whether clone ``boxes`` or not. Defaults to True.
+ """
+
+ # Used to verify the last dimension length
+ # Should override it in subclass.
+ box_dim: int = 0
+
+ def __init__(self,
+ data: Union[Tensor, np.ndarray, Sequence],
+ dtype: Optional[torch.dtype] = None,
+ device: Optional[DeviceType] = None,
+ clone: bool = True) -> None:
+ if isinstance(data, (np.ndarray, Tensor, Sequence)):
+ data = torch.as_tensor(data)
+ else:
+ raise TypeError('boxes should be Tensor, ndarray, or Sequence, ',
+ f'but got {type(data)}')
+
+ if device is not None or dtype is not None:
+ data = data.to(dtype=dtype, device=device)
+ # Clone the data to avoid potential bugs
+ if clone:
+ data = data.clone()
+ # handle the empty input like []
+ if data.numel() == 0:
+ data = data.reshape((-1, self.box_dim))
+
+ assert data.dim() >= 2 and data.size(-1) == self.box_dim, \
+ ('The boxes dimension must >= 2 and the length of the last '
+ f'dimension must be {self.box_dim}, but got boxes with '
+ f'shape {data.shape}.')
+ self.tensor = data
+
+ def convert_to(self, dst_type: Union[str, type]) -> 'BaseBoxes':
+ """Convert self to another box type.
+
+ Args:
+ dst_type (str or type): destination box type.
+
+ Returns:
+ :obj:`BaseBoxes`: destination box type object .
+ """
+ from .box_type import convert_box_type
+ return convert_box_type(self, dst_type=dst_type)
+
+ def empty_boxes(self: T,
+ dtype: Optional[torch.dtype] = None,
+ device: Optional[DeviceType] = None) -> T:
+ """Create empty box.
+
+ Args:
+ dtype (torch.dtype, Optional): data type of boxes.
+ device (str or torch.device, Optional): device of boxes.
+
+ Returns:
+ T: empty boxes with shape of (0, box_dim).
+ """
+ empty_box = self.tensor.new_zeros(
+ 0, self.box_dim, dtype=dtype, device=device)
+ return type(self)(empty_box, clone=False)
+
+ def fake_boxes(self: T,
+ sizes: Tuple[int],
+ fill: float = 0,
+ dtype: Optional[torch.dtype] = None,
+ device: Optional[DeviceType] = None) -> T:
+ """Create fake boxes with specific sizes and fill values.
+
+ Args:
+ sizes (Tuple[int]): The size of fake boxes. The last value must
+ be equal with ``self.box_dim``.
+ fill (float): filling value. Defaults to 0.
+ dtype (torch.dtype, Optional): data type of boxes.
+ device (str or torch.device, Optional): device of boxes.
+
+ Returns:
+ T: Fake boxes with shape of ``sizes``.
+ """
+ fake_boxes = self.tensor.new_full(
+ sizes, fill, dtype=dtype, device=device)
+ return type(self)(fake_boxes, clone=False)
+
+ def __getitem__(self: T, index: IndexType) -> T:
+ """Rewrite getitem to protect the last dimension shape."""
+ boxes = self.tensor
+ if isinstance(index, np.ndarray):
+ index = torch.as_tensor(index, device=self.device)
+ if isinstance(index, Tensor) and index.dtype == torch.bool:
+ assert index.dim() < boxes.dim()
+ elif isinstance(index, tuple):
+ assert len(index) < boxes.dim()
+ # `Ellipsis`(...) is commonly used in index like [None, ...].
+ # When `Ellipsis` is in index, it must be the last item.
+ if Ellipsis in index:
+ assert index[-1] is Ellipsis
+
+ boxes = boxes[index]
+ if boxes.dim() == 1:
+ boxes = boxes.reshape(1, -1)
+ return type(self)(boxes, clone=False)
+
+ def __setitem__(self: T, index: IndexType, values: Union[Tensor, T]) -> T:
+ """Rewrite setitem to protect the last dimension shape."""
+ assert type(values) is type(self), \
+ 'The value to be set must be the same box type as self'
+ values = values.tensor
+
+ if isinstance(index, np.ndarray):
+ index = torch.as_tensor(index, device=self.device)
+ if isinstance(index, Tensor) and index.dtype == torch.bool:
+ assert index.dim() < self.tensor.dim()
+ elif isinstance(index, tuple):
+ assert len(index) < self.tensor.dim()
+ # `Ellipsis`(...) is commonly used in index like [None, ...].
+ # When `Ellipsis` is in index, it must be the last item.
+ if Ellipsis in index:
+ assert index[-1] is Ellipsis
+
+ self.tensor[index] = values
+
+ def __len__(self) -> int:
+ """Return the length of self.tensor first dimension."""
+ return self.tensor.size(0)
+
+ def __deepcopy__(self, memo):
+ """Only clone the ``self.tensor`` when applying deepcopy."""
+ cls = self.__class__
+ other = cls.__new__(cls)
+ memo[id(self)] = other
+ other.tensor = self.tensor.clone()
+ return other
+
+ def __repr__(self) -> str:
+ """Return a strings that describes the object."""
+ return self.__class__.__name__ + '(\n' + str(self.tensor) + ')'
+
+ def new_tensor(self, *args, **kwargs) -> Tensor:
+ """Reload ``new_tensor`` from self.tensor."""
+ return self.tensor.new_tensor(*args, **kwargs)
+
+ def new_full(self, *args, **kwargs) -> Tensor:
+ """Reload ``new_full`` from self.tensor."""
+ return self.tensor.new_full(*args, **kwargs)
+
+ def new_empty(self, *args, **kwargs) -> Tensor:
+ """Reload ``new_empty`` from self.tensor."""
+ return self.tensor.new_empty(*args, **kwargs)
+
+ def new_ones(self, *args, **kwargs) -> Tensor:
+ """Reload ``new_ones`` from self.tensor."""
+ return self.tensor.new_ones(*args, **kwargs)
+
+ def new_zeros(self, *args, **kwargs) -> Tensor:
+ """Reload ``new_zeros`` from self.tensor."""
+ return self.tensor.new_zeros(*args, **kwargs)
+
+ def size(self, dim: Optional[int] = None) -> Union[int, torch.Size]:
+ """Reload new_zeros from self.tensor."""
+ # self.tensor.size(dim) cannot work when dim=None.
+ return self.tensor.size() if dim is None else self.tensor.size(dim)
+
+ def dim(self) -> int:
+ """Reload ``dim`` from self.tensor."""
+ return self.tensor.dim()
+
+ @property
+ def device(self) -> torch.device:
+ """Reload ``device`` from self.tensor."""
+ return self.tensor.device
+
+ @property
+ def dtype(self) -> torch.dtype:
+ """Reload ``dtype`` from self.tensor."""
+ return self.tensor.dtype
+
+ @property
+ def shape(self) -> torch.Size:
+ return self.tensor.shape
+
+ def numel(self) -> int:
+ """Reload ``numel`` from self.tensor."""
+ return self.tensor.numel()
+
+ def numpy(self) -> np.ndarray:
+ """Reload ``numpy`` from self.tensor."""
+ return self.tensor.numpy()
+
+ def to(self: T, *args, **kwargs) -> T:
+ """Reload ``to`` from self.tensor."""
+ return type(self)(self.tensor.to(*args, **kwargs), clone=False)
+
+ def cpu(self: T) -> T:
+ """Reload ``cpu`` from self.tensor."""
+ return type(self)(self.tensor.cpu(), clone=False)
+
+ def cuda(self: T, *args, **kwargs) -> T:
+ """Reload ``cuda`` from self.tensor."""
+ return type(self)(self.tensor.cuda(*args, **kwargs), clone=False)
+
+ def clone(self: T) -> T:
+ """Reload ``clone`` from self.tensor."""
+ return type(self)(self.tensor)
+
+ def detach(self: T) -> T:
+ """Reload ``detach`` from self.tensor."""
+ return type(self)(self.tensor.detach(), clone=False)
+
+ def view(self: T, *shape: Tuple[int]) -> T:
+ """Reload ``view`` from self.tensor."""
+ return type(self)(self.tensor.view(shape), clone=False)
+
+ def reshape(self: T, *shape: Tuple[int]) -> T:
+ """Reload ``reshape`` from self.tensor."""
+ return type(self)(self.tensor.reshape(shape), clone=False)
+
+ def expand(self: T, *sizes: Tuple[int]) -> T:
+ """Reload ``expand`` from self.tensor."""
+ return type(self)(self.tensor.expand(sizes), clone=False)
+
+ def repeat(self: T, *sizes: Tuple[int]) -> T:
+ """Reload ``repeat`` from self.tensor."""
+ return type(self)(self.tensor.repeat(sizes), clone=False)
+
+ def transpose(self: T, dim0: int, dim1: int) -> T:
+ """Reload ``transpose`` from self.tensor."""
+ ndim = self.tensor.dim()
+ assert dim0 != -1 and dim0 != ndim - 1
+ assert dim1 != -1 and dim1 != ndim - 1
+ return type(self)(self.tensor.transpose(dim0, dim1), clone=False)
+
+ def permute(self: T, *dims: Tuple[int]) -> T:
+ """Reload ``permute`` from self.tensor."""
+ assert dims[-1] == -1 or dims[-1] == self.tensor.dim() - 1
+ return type(self)(self.tensor.permute(dims), clone=False)
+
+ def split(self: T,
+ split_size_or_sections: Union[int, Sequence[int]],
+ dim: int = 0) -> List[T]:
+ """Reload ``split`` from self.tensor."""
+ assert dim != -1 and dim != self.tensor.dim() - 1
+ boxes_list = self.tensor.split(split_size_or_sections, dim=dim)
+ return [type(self)(boxes, clone=False) for boxes in boxes_list]
+
+ def chunk(self: T, chunks: int, dim: int = 0) -> List[T]:
+ """Reload ``chunk`` from self.tensor."""
+ assert dim != -1 and dim != self.tensor.dim() - 1
+ boxes_list = self.tensor.chunk(chunks, dim=dim)
+ return [type(self)(boxes, clone=False) for boxes in boxes_list]
+
+ def unbind(self: T, dim: int = 0) -> T:
+ """Reload ``unbind`` from self.tensor."""
+ assert dim != -1 and dim != self.tensor.dim() - 1
+ boxes_list = self.tensor.unbind(dim=dim)
+ return [type(self)(boxes, clone=False) for boxes in boxes_list]
+
+ def flatten(self: T, start_dim: int = 0, end_dim: int = -2) -> T:
+ """Reload ``flatten`` from self.tensor."""
+ assert end_dim != -1 and end_dim != self.tensor.dim() - 1
+ return type(self)(self.tensor.flatten(start_dim, end_dim), clone=False)
+
+ def squeeze(self: T, dim: Optional[int] = None) -> T:
+ """Reload ``squeeze`` from self.tensor."""
+ boxes = self.tensor.squeeze() if dim is None else \
+ self.tensor.squeeze(dim)
+ return type(self)(boxes, clone=False)
+
+ def unsqueeze(self: T, dim: int) -> T:
+ """Reload ``unsqueeze`` from self.tensor."""
+ assert dim != -1 and dim != self.tensor.dim()
+ return type(self)(self.tensor.unsqueeze(dim), clone=False)
+
+ @classmethod
+ def cat(cls: Type[T], box_list: Sequence[T], dim: int = 0) -> T:
+ """Cancatenates a box instance list into one single box instance.
+ Similar to ``torch.cat``.
+
+ Args:
+ box_list (Sequence[T]): A sequence of box instances.
+ dim (int): The dimension over which the box are concatenated.
+ Defaults to 0.
+
+ Returns:
+ T: Concatenated box instance.
+ """
+ assert isinstance(box_list, Sequence)
+ if len(box_list) == 0:
+ raise ValueError('box_list should not be a empty list.')
+
+ assert dim != -1 and dim != box_list[0].dim() - 1
+ assert all(isinstance(boxes, cls) for boxes in box_list)
+
+ th_box_list = [boxes.tensor for boxes in box_list]
+ return cls(torch.cat(th_box_list, dim=dim), clone=False)
+
+ @classmethod
+ def stack(cls: Type[T], box_list: Sequence[T], dim: int = 0) -> T:
+ """Concatenates a sequence of tensors along a new dimension. Similar to
+ ``torch.stack``.
+
+ Args:
+ box_list (Sequence[T]): A sequence of box instances.
+ dim (int): Dimension to insert. Defaults to 0.
+
+ Returns:
+ T: Concatenated box instance.
+ """
+ assert isinstance(box_list, Sequence)
+ if len(box_list) == 0:
+ raise ValueError('box_list should not be a empty list.')
+
+ assert dim != -1 and dim != box_list[0].dim()
+ assert all(isinstance(boxes, cls) for boxes in box_list)
+
+ th_box_list = [boxes.tensor for boxes in box_list]
+ return cls(torch.stack(th_box_list, dim=dim), clone=False)
+
+ @abstractproperty
+ def centers(self) -> Tensor:
+ """Return a tensor representing the centers of boxes."""
+ pass
+
+ @abstractproperty
+ def areas(self) -> Tensor:
+ """Return a tensor representing the areas of boxes."""
+ pass
+
+ @abstractproperty
+ def widths(self) -> Tensor:
+ """Return a tensor representing the widths of boxes."""
+ pass
+
+ @abstractproperty
+ def heights(self) -> Tensor:
+ """Return a tensor representing the heights of boxes."""
+ pass
+
+ @abstractmethod
+ def flip_(self,
+ img_shape: Tuple[int, int],
+ direction: str = 'horizontal') -> None:
+ """Flip boxes horizontally or vertically in-place.
+
+ Args:
+ img_shape (Tuple[int, int]): A tuple of image height and width.
+ direction (str): Flip direction, options are "horizontal",
+ "vertical" and "diagonal". Defaults to "horizontal"
+ """
+ pass
+
+ @abstractmethod
+ def translate_(self, distances: Tuple[float, float]) -> None:
+ """Translate boxes in-place.
+
+ Args:
+ distances (Tuple[float, float]): translate distances. The first
+ is horizontal distance and the second is vertical distance.
+ """
+ pass
+
+ @abstractmethod
+ def clip_(self, img_shape: Tuple[int, int]) -> None:
+ """Clip boxes according to the image shape in-place.
+
+ Args:
+ img_shape (Tuple[int, int]): A tuple of image height and width.
+ """
+ pass
+
+ @abstractmethod
+ def rotate_(self, center: Tuple[float, float], angle: float) -> None:
+ """Rotate all boxes in-place.
+
+ Args:
+ center (Tuple[float, float]): Rotation origin.
+ angle (float): Rotation angle represented in degrees. Positive
+ values mean clockwise rotation.
+ """
+ pass
+
+ @abstractmethod
+ def project_(self, homography_matrix: Union[Tensor, np.ndarray]) -> None:
+ """Geometric transformat boxes in-place.
+
+ Args:
+ homography_matrix (Tensor or np.ndarray]):
+ Shape (3, 3) for geometric transformation.
+ """
+ pass
+
+ @abstractmethod
+ def rescale_(self, scale_factor: Tuple[float, float]) -> None:
+ """Rescale boxes w.r.t. rescale_factor in-place.
+
+ Note:
+ Both ``rescale_`` and ``resize_`` will enlarge or shrink boxes
+ w.r.t ``scale_facotr``. The difference is that ``resize_`` only
+ changes the width and the height of boxes, but ``rescale_`` also
+ rescales the box centers simultaneously.
+
+ Args:
+ scale_factor (Tuple[float, float]): factors for scaling boxes.
+ The length should be 2.
+ """
+ pass
+
+ @abstractmethod
+ def resize_(self, scale_factor: Tuple[float, float]) -> None:
+ """Resize the box width and height w.r.t scale_factor in-place.
+
+ Note:
+ Both ``rescale_`` and ``resize_`` will enlarge or shrink boxes
+ w.r.t ``scale_facotr``. The difference is that ``resize_`` only
+ changes the width and the height of boxes, but ``rescale_`` also
+ rescales the box centers simultaneously.
+
+ Args:
+ scale_factor (Tuple[float, float]): factors for scaling box
+ shapes. The length should be 2.
+ """
+ pass
+
+ @abstractmethod
+ def is_inside(self,
+ img_shape: Tuple[int, int],
+ all_inside: bool = False,
+ allowed_border: int = 0) -> BoolTensor:
+ """Find boxes inside the image.
+
+ Args:
+ img_shape (Tuple[int, int]): A tuple of image height and width.
+ all_inside (bool): Whether the boxes are all inside the image or
+ part inside the image. Defaults to False.
+ allowed_border (int): Boxes that extend beyond the image shape
+ boundary by more than ``allowed_border`` are considered
+ "outside" Defaults to 0.
+ Returns:
+ BoolTensor: A BoolTensor indicating whether the box is inside
+ the image. Assuming the original boxes have shape (m, n, box_dim),
+ the output has shape (m, n).
+ """
+ pass
+
+ @abstractmethod
+ def find_inside_points(self,
+ points: Tensor,
+ is_aligned: bool = False) -> BoolTensor:
+ """Find inside box points. Boxes dimension must be 2.
+
+ Args:
+ points (Tensor): Points coordinates. Has shape of (m, 2).
+ is_aligned (bool): Whether ``points`` has been aligned with boxes
+ or not. If True, the length of boxes and ``points`` should be
+ the same. Defaults to False.
+
+ Returns:
+ BoolTensor: A BoolTensor indicating whether a point is inside
+ boxes. Assuming the boxes has shape of (n, box_dim), if
+ ``is_aligned`` is False. The index has shape of (m, n). If
+ ``is_aligned`` is True, m should be equal to n and the index has
+ shape of (m, ).
+ """
+ pass
+
+ @abstractstaticmethod
+ def overlaps(boxes1: 'BaseBoxes',
+ boxes2: 'BaseBoxes',
+ mode: str = 'iou',
+ is_aligned: bool = False,
+ eps: float = 1e-6) -> Tensor:
+ """Calculate overlap between two set of boxes with their types
+ converted to the present box type.
+
+ Args:
+ boxes1 (:obj:`BaseBoxes`): BaseBoxes with shape of (m, box_dim)
+ or empty.
+ boxes2 (:obj:`BaseBoxes`): BaseBoxes with shape of (n, box_dim)
+ or empty.
+ mode (str): "iou" (intersection over union), "iof" (intersection
+ over foreground). Defaults to "iou".
+ is_aligned (bool): If True, then m and n must be equal. Defaults
+ to False.
+ eps (float): A value added to the denominator for numerical
+ stability. Defaults to 1e-6.
+
+ Returns:
+ Tensor: shape (m, n) if ``is_aligned`` is False else shape (m,)
+ """
+ pass
+
+ @abstractstaticmethod
+ def from_instance_masks(masks: MaskType) -> 'BaseBoxes':
+ """Create boxes from instance masks.
+
+ Args:
+ masks (:obj:`BitmapMasks` or :obj:`PolygonMasks`): BitmapMasks or
+ PolygonMasks instance with length of n.
+
+ Returns:
+ :obj:`BaseBoxes`: Converted boxes with shape of (n, box_dim).
+ """
+ pass
diff --git a/mmdet/structures/bbox/bbox_overlaps.py b/mmdet/structures/bbox/bbox_overlaps.py
new file mode 100644
index 0000000000000000000000000000000000000000..8e3435d28b38a5479a6c791f52a76d8ba293a6eb
--- /dev/null
+++ b/mmdet/structures/bbox/bbox_overlaps.py
@@ -0,0 +1,199 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+
+
+def fp16_clamp(x, min=None, max=None):
+ if not x.is_cuda and x.dtype == torch.float16:
+ # clamp for cpu float16, tensor fp16 has no clamp implementation
+ return x.float().clamp(min, max).half()
+
+ return x.clamp(min, max)
+
+
+def bbox_overlaps(bboxes1, bboxes2, mode='iou', is_aligned=False, eps=1e-6):
+ """Calculate overlap between two set of bboxes.
+
+ FP16 Contributed by https://github.com/open-mmlab/mmdetection/pull/4889
+ Note:
+ Assume bboxes1 is M x 4, bboxes2 is N x 4, when mode is 'iou',
+ there are some new generated variable when calculating IOU
+ using bbox_overlaps function:
+
+ 1) is_aligned is False
+ area1: M x 1
+ area2: N x 1
+ lt: M x N x 2
+ rb: M x N x 2
+ wh: M x N x 2
+ overlap: M x N x 1
+ union: M x N x 1
+ ious: M x N x 1
+
+ Total memory:
+ S = (9 x N x M + N + M) * 4 Byte,
+
+ When using FP16, we can reduce:
+ R = (9 x N x M + N + M) * 4 / 2 Byte
+ R large than (N + M) * 4 * 2 is always true when N and M >= 1.
+ Obviously, N + M <= N * M < 3 * N * M, when N >=2 and M >=2,
+ N + 1 < 3 * N, when N or M is 1.
+
+ Given M = 40 (ground truth), N = 400000 (three anchor boxes
+ in per grid, FPN, R-CNNs),
+ R = 275 MB (one times)
+
+ A special case (dense detection), M = 512 (ground truth),
+ R = 3516 MB = 3.43 GB
+
+ When the batch size is B, reduce:
+ B x R
+
+ Therefore, CUDA memory runs out frequently.
+
+ Experiments on GeForce RTX 2080Ti (11019 MiB):
+
+ | dtype | M | N | Use | Real | Ideal |
+ |:----:|:----:|:----:|:----:|:----:|:----:|
+ | FP32 | 512 | 400000 | 8020 MiB | -- | -- |
+ | FP16 | 512 | 400000 | 4504 MiB | 3516 MiB | 3516 MiB |
+ | FP32 | 40 | 400000 | 1540 MiB | -- | -- |
+ | FP16 | 40 | 400000 | 1264 MiB | 276MiB | 275 MiB |
+
+ 2) is_aligned is True
+ area1: N x 1
+ area2: N x 1
+ lt: N x 2
+ rb: N x 2
+ wh: N x 2
+ overlap: N x 1
+ union: N x 1
+ ious: N x 1
+
+ Total memory:
+ S = 11 x N * 4 Byte
+
+ When using FP16, we can reduce:
+ R = 11 x N * 4 / 2 Byte
+
+ So do the 'giou' (large than 'iou').
+
+ Time-wise, FP16 is generally faster than FP32.
+
+ When gpu_assign_thr is not -1, it takes more time on cpu
+ but not reduce memory.
+ There, we can reduce half the memory and keep the speed.
+
+ If ``is_aligned`` is ``False``, then calculate the overlaps between each
+ bbox of bboxes1 and bboxes2, otherwise the overlaps between each aligned
+ pair of bboxes1 and bboxes2.
+
+ Args:
+ bboxes1 (Tensor): shape (B, m, 4) in format or empty.
+ bboxes2 (Tensor): shape (B, n, 4) in format or empty.
+ B indicates the batch dim, in shape (B1, B2, ..., Bn).
+ If ``is_aligned`` is ``True``, then m and n must be equal.
+ mode (str): "iou" (intersection over union), "iof" (intersection over
+ foreground) or "giou" (generalized intersection over union).
+ Default "iou".
+ is_aligned (bool, optional): If True, then m and n must be equal.
+ Default False.
+ eps (float, optional): A value added to the denominator for numerical
+ stability. Default 1e-6.
+
+ Returns:
+ Tensor: shape (m, n) if ``is_aligned`` is False else shape (m,)
+
+ Example:
+ >>> bboxes1 = torch.FloatTensor([
+ >>> [0, 0, 10, 10],
+ >>> [10, 10, 20, 20],
+ >>> [32, 32, 38, 42],
+ >>> ])
+ >>> bboxes2 = torch.FloatTensor([
+ >>> [0, 0, 10, 20],
+ >>> [0, 10, 10, 19],
+ >>> [10, 10, 20, 20],
+ >>> ])
+ >>> overlaps = bbox_overlaps(bboxes1, bboxes2)
+ >>> assert overlaps.shape == (3, 3)
+ >>> overlaps = bbox_overlaps(bboxes1, bboxes2, is_aligned=True)
+ >>> assert overlaps.shape == (3, )
+
+ Example:
+ >>> empty = torch.empty(0, 4)
+ >>> nonempty = torch.FloatTensor([[0, 0, 10, 9]])
+ >>> assert tuple(bbox_overlaps(empty, nonempty).shape) == (0, 1)
+ >>> assert tuple(bbox_overlaps(nonempty, empty).shape) == (1, 0)
+ >>> assert tuple(bbox_overlaps(empty, empty).shape) == (0, 0)
+ """
+
+ assert mode in ['iou', 'iof', 'giou'], f'Unsupported mode {mode}'
+ # Either the boxes are empty or the length of boxes' last dimension is 4
+ assert (bboxes1.size(-1) == 4 or bboxes1.size(0) == 0)
+ assert (bboxes2.size(-1) == 4 or bboxes2.size(0) == 0)
+
+ # Batch dim must be the same
+ # Batch dim: (B1, B2, ... Bn)
+ assert bboxes1.shape[:-2] == bboxes2.shape[:-2]
+ batch_shape = bboxes1.shape[:-2]
+
+ rows = bboxes1.size(-2)
+ cols = bboxes2.size(-2)
+ if is_aligned:
+ assert rows == cols
+
+ if rows * cols == 0:
+ if is_aligned:
+ return bboxes1.new(batch_shape + (rows, ))
+ else:
+ return bboxes1.new(batch_shape + (rows, cols))
+
+ area1 = (bboxes1[..., 2] - bboxes1[..., 0]) * (
+ bboxes1[..., 3] - bboxes1[..., 1])
+ area2 = (bboxes2[..., 2] - bboxes2[..., 0]) * (
+ bboxes2[..., 3] - bboxes2[..., 1])
+
+ if is_aligned:
+ lt = torch.max(bboxes1[..., :2], bboxes2[..., :2]) # [B, rows, 2]
+ rb = torch.min(bboxes1[..., 2:], bboxes2[..., 2:]) # [B, rows, 2]
+
+ wh = fp16_clamp(rb - lt, min=0)
+ overlap = wh[..., 0] * wh[..., 1]
+
+ if mode in ['iou', 'giou']:
+ union = area1 + area2 - overlap
+ else:
+ union = area1
+ if mode == 'giou':
+ enclosed_lt = torch.min(bboxes1[..., :2], bboxes2[..., :2])
+ enclosed_rb = torch.max(bboxes1[..., 2:], bboxes2[..., 2:])
+ else:
+ lt = torch.max(bboxes1[..., :, None, :2],
+ bboxes2[..., None, :, :2]) # [B, rows, cols, 2]
+ rb = torch.min(bboxes1[..., :, None, 2:],
+ bboxes2[..., None, :, 2:]) # [B, rows, cols, 2]
+
+ wh = fp16_clamp(rb - lt, min=0)
+ overlap = wh[..., 0] * wh[..., 1]
+
+ if mode in ['iou', 'giou']:
+ union = area1[..., None] + area2[..., None, :] - overlap
+ else:
+ union = area1[..., None]
+ if mode == 'giou':
+ enclosed_lt = torch.min(bboxes1[..., :, None, :2],
+ bboxes2[..., None, :, :2])
+ enclosed_rb = torch.max(bboxes1[..., :, None, 2:],
+ bboxes2[..., None, :, 2:])
+
+ eps = union.new_tensor([eps])
+ union = torch.max(union, eps)
+ ious = overlap / union
+ if mode in ['iou', 'iof']:
+ return ious
+ # calculate gious
+ enclose_wh = fp16_clamp(enclosed_rb - enclosed_lt, min=0)
+ enclose_area = enclose_wh[..., 0] * enclose_wh[..., 1]
+ enclose_area = torch.max(enclose_area, eps)
+ gious = ious - (enclose_area - union) / enclose_area
+ return gious
diff --git a/mmdet/structures/bbox/box_type.py b/mmdet/structures/bbox/box_type.py
new file mode 100644
index 0000000000000000000000000000000000000000..c7eb5494c36c8efcbb414897f7c2532a6d3a1ddb
--- /dev/null
+++ b/mmdet/structures/bbox/box_type.py
@@ -0,0 +1,296 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Callable, Optional, Tuple, Type, Union
+
+import numpy as np
+import torch
+from torch import Tensor
+
+from .base_boxes import BaseBoxes
+
+BoxType = Union[np.ndarray, Tensor, BaseBoxes]
+
+box_types: dict = {}
+_box_type_to_name: dict = {}
+box_converters: dict = {}
+
+
+def _register_box(name: str, box_type: Type, force: bool = False) -> None:
+ """Register a box type.
+
+ Args:
+ name (str): The name of box type.
+ box_type (type): Box mode class to be registered.
+ force (bool): Whether to override an existing class with the same
+ name. Defaults to False.
+ """
+ assert issubclass(box_type, BaseBoxes)
+ name = name.lower()
+
+ if not force and (name in box_types or box_type in _box_type_to_name):
+ raise KeyError(f'box type {name} has been registered')
+ elif name in box_types:
+ _box_type = box_types.pop(name)
+ _box_type_to_name.pop(_box_type)
+ elif box_type in _box_type_to_name:
+ _name = _box_type_to_name.pop(box_type)
+ box_types.pop(_name)
+
+ box_types[name] = box_type
+ _box_type_to_name[box_type] = name
+
+
+def register_box(name: str,
+ box_type: Type = None,
+ force: bool = False) -> Union[Type, Callable]:
+ """Register a box type.
+
+ A record will be added to ``bbox_types``, whose key is the box type name
+ and value is the box type itself. Simultaneously, a reverse dictionary
+ ``_box_type_to_name`` will be updated. It can be used as a decorator or
+ a normal function.
+
+ Args:
+ name (str): The name of box type.
+ bbox_type (type, Optional): Box type class to be registered.
+ Defaults to None.
+ force (bool): Whether to override the existing box type with the same
+ name. Defaults to False.
+
+ Examples:
+ >>> from mmdet.structures.bbox import register_box
+ >>> from mmdet.structures.bbox import BaseBoxes
+
+ >>> # as a decorator
+ >>> @register_box('hbox')
+ >>> class HorizontalBoxes(BaseBoxes):
+ >>> pass
+
+ >>> # as a normal function
+ >>> class RotatedBoxes(BaseBoxes):
+ >>> pass
+ >>> register_box('rbox', RotatedBoxes)
+ """
+ if not isinstance(force, bool):
+ raise TypeError(f'force must be a boolean, but got {type(force)}')
+
+ # use it as a normal method: register_box(name, box_type=BoxCls)
+ if box_type is not None:
+ _register_box(name=name, box_type=box_type, force=force)
+ return box_type
+
+ # use it as a decorator: @register_box(name)
+ def _register(cls):
+ _register_box(name=name, box_type=cls, force=force)
+ return cls
+
+ return _register
+
+
+def _register_box_converter(src_type: Union[str, type],
+ dst_type: Union[str, type],
+ converter: Callable,
+ force: bool = False) -> None:
+ """Register a box converter.
+
+ Args:
+ src_type (str or type): source box type name or class.
+ dst_type (str or type): destination box type name or class.
+ converter (Callable): Convert function.
+ force (bool): Whether to override the existing box type with the same
+ name. Defaults to False.
+ """
+ assert callable(converter)
+ src_type_name, _ = get_box_type(src_type)
+ dst_type_name, _ = get_box_type(dst_type)
+
+ converter_name = src_type_name + '2' + dst_type_name
+ if not force and converter_name in box_converters:
+ raise KeyError(f'The box converter from {src_type_name} to '
+ f'{dst_type_name} has been registered.')
+
+ box_converters[converter_name] = converter
+
+
+def register_box_converter(src_type: Union[str, type],
+ dst_type: Union[str, type],
+ converter: Optional[Callable] = None,
+ force: bool = False) -> Callable:
+ """Register a box converter.
+
+ A record will be added to ``box_converter``, whose key is
+ '{src_type_name}2{dst_type_name}' and value is the convert function.
+ It can be used as a decorator or a normal function.
+
+ Args:
+ src_type (str or type): source box type name or class.
+ dst_type (str or type): destination box type name or class.
+ converter (Callable): Convert function. Defaults to None.
+ force (bool): Whether to override the existing box type with the same
+ name. Defaults to False.
+
+ Examples:
+ >>> from mmdet.structures.bbox import register_box_converter
+ >>> # as a decorator
+ >>> @register_box_converter('hbox', 'rbox')
+ >>> def converter_A(boxes):
+ >>> pass
+
+ >>> # as a normal function
+ >>> def converter_B(boxes):
+ >>> pass
+ >>> register_box_converter('rbox', 'hbox', converter_B)
+ """
+ if not isinstance(force, bool):
+ raise TypeError(f'force must be a boolean, but got {type(force)}')
+
+ # use it as a normal method:
+ # register_box_converter(src_type, dst_type, converter=Func)
+ if converter is not None:
+ _register_box_converter(
+ src_type=src_type,
+ dst_type=dst_type,
+ converter=converter,
+ force=force)
+ return converter
+
+ # use it as a decorator: @register_box_converter(name)
+ def _register(func):
+ _register_box_converter(
+ src_type=src_type, dst_type=dst_type, converter=func, force=force)
+ return func
+
+ return _register
+
+
+def get_box_type(box_type: Union[str, type]) -> Tuple[str, type]:
+ """get both box type name and class.
+
+ Args:
+ box_type (str or type): Single box type name or class.
+
+ Returns:
+ Tuple[str, type]: A tuple of box type name and class.
+ """
+ if isinstance(box_type, str):
+ type_name = box_type.lower()
+ assert type_name in box_types, \
+ f"Box type {type_name} hasn't been registered in box_types."
+ type_cls = box_types[type_name]
+ elif issubclass(box_type, BaseBoxes):
+ assert box_type in _box_type_to_name, \
+ f"Box type {box_type} hasn't been registered in box_types."
+ type_name = _box_type_to_name[box_type]
+ type_cls = box_type
+ else:
+ raise KeyError('box_type must be a str or class inheriting from '
+ f'BaseBoxes, but got {type(box_type)}.')
+ return type_name, type_cls
+
+
+def convert_box_type(boxes: BoxType,
+ *,
+ src_type: Union[str, type] = None,
+ dst_type: Union[str, type] = None) -> BoxType:
+ """Convert boxes from source type to destination type.
+
+ If ``boxes`` is a instance of BaseBoxes, the ``src_type`` will be set
+ as the type of ``boxes``.
+
+ Args:
+ boxes (np.ndarray or Tensor or :obj:`BaseBoxes`): boxes need to
+ convert.
+ src_type (str or type, Optional): source box type. Defaults to None.
+ dst_type (str or type, Optional): destination box type. Defaults to
+ None.
+
+ Returns:
+ Union[np.ndarray, Tensor, :obj:`BaseBoxes`]: Converted boxes. It's type
+ is consistent with the input's type.
+ """
+ assert dst_type is not None
+ dst_type_name, dst_type_cls = get_box_type(dst_type)
+
+ is_box_cls = False
+ is_numpy = False
+ if isinstance(boxes, BaseBoxes):
+ src_type_name, _ = get_box_type(type(boxes))
+ is_box_cls = True
+ elif isinstance(boxes, (Tensor, np.ndarray)):
+ assert src_type is not None
+ src_type_name, _ = get_box_type(src_type)
+ if isinstance(boxes, np.ndarray):
+ is_numpy = True
+ else:
+ raise TypeError('boxes must be a instance of BaseBoxes, Tensor or '
+ f'ndarray, but get {type(boxes)}.')
+
+ if src_type_name == dst_type_name:
+ return boxes
+
+ converter_name = src_type_name + '2' + dst_type_name
+ assert converter_name in box_converters, \
+ "Convert function hasn't been registered in box_converters."
+ converter = box_converters[converter_name]
+
+ if is_box_cls:
+ boxes = converter(boxes.tensor)
+ return dst_type_cls(boxes)
+ elif is_numpy:
+ boxes = converter(torch.from_numpy(boxes))
+ return boxes.numpy()
+ else:
+ return converter(boxes)
+
+
+def autocast_box_type(dst_box_type='hbox') -> Callable:
+ """A decorator which automatically casts results['gt_bboxes'] to the
+ destination box type.
+
+ It commenly used in mmdet.datasets.transforms to make the transforms up-
+ compatible with the np.ndarray type of results['gt_bboxes'].
+
+ The speed of processing of np.ndarray and BaseBoxes data are the same:
+
+ - np.ndarray: 0.0509 img/s
+ - BaseBoxes: 0.0551 img/s
+
+ Args:
+ dst_box_type (str): Destination box type.
+ """
+ _, box_type_cls = get_box_type(dst_box_type)
+
+ def decorator(func: Callable) -> Callable:
+
+ def wrapper(self, results: dict, *args, **kwargs) -> dict:
+ if ('gt_bboxes' not in results
+ or isinstance(results['gt_bboxes'], BaseBoxes)):
+ return func(self, results)
+ elif isinstance(results['gt_bboxes'], np.ndarray):
+ results['gt_bboxes'] = box_type_cls(
+ results['gt_bboxes'], clone=False)
+ if 'mix_results' in results:
+ for res in results['mix_results']:
+ if isinstance(res['gt_bboxes'], np.ndarray):
+ res['gt_bboxes'] = box_type_cls(
+ res['gt_bboxes'], clone=False)
+
+ _results = func(self, results, *args, **kwargs)
+
+ # In some cases, the function will process gt_bboxes in-place
+ # Simultaneously convert inputting and outputting gt_bboxes
+ # back to np.ndarray
+ if isinstance(_results, dict) and 'gt_bboxes' in _results:
+ if isinstance(_results['gt_bboxes'], BaseBoxes):
+ _results['gt_bboxes'] = _results['gt_bboxes'].numpy()
+ if isinstance(results['gt_bboxes'], BaseBoxes):
+ results['gt_bboxes'] = results['gt_bboxes'].numpy()
+ return _results
+ else:
+ raise TypeError(
+ "auto_box_type requires results['gt_bboxes'] to "
+ 'be BaseBoxes or np.ndarray, but got '
+ f"{type(results['gt_bboxes'])}")
+
+ return wrapper
+
+ return decorator
diff --git a/mmdet/structures/bbox/horizontal_boxes.py b/mmdet/structures/bbox/horizontal_boxes.py
new file mode 100644
index 0000000000000000000000000000000000000000..360c8a24e0b267fe982420b4aebbef7a0b66ddce
--- /dev/null
+++ b/mmdet/structures/bbox/horizontal_boxes.py
@@ -0,0 +1,412 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Tuple, TypeVar, Union
+
+import cv2
+import numpy as np
+import torch
+from torch import BoolTensor, Tensor
+
+from mmdet.structures.mask.structures import BitmapMasks, PolygonMasks
+from .base_boxes import BaseBoxes
+from .bbox_overlaps import bbox_overlaps
+from .box_type import register_box
+
+T = TypeVar('T')
+DeviceType = Union[str, torch.device]
+MaskType = Union[BitmapMasks, PolygonMasks]
+
+
+@register_box(name='hbox')
+class HorizontalBoxes(BaseBoxes):
+ """The horizontal box class used in MMDetection by default.
+
+ The ``box_dim`` of ``HorizontalBoxes`` is 4, which means the length of
+ the last dimension of the data should be 4. Two modes of box data are
+ supported in ``HorizontalBoxes``:
+
+ - 'xyxy': Each row of data indicates (x1, y1, x2, y2), which are the
+ coordinates of the left-top and right-bottom points.
+ - 'cxcywh': Each row of data indicates (x, y, w, h), where (x, y) are the
+ coordinates of the box centers and (w, h) are the width and height.
+
+ ``HorizontalBoxes`` only restores 'xyxy' mode of data. If the the data is
+ in 'cxcywh' mode, users need to input ``in_mode='cxcywh'`` and The code
+ will convert the 'cxcywh' data to 'xyxy' automatically.
+
+ Args:
+ data (Tensor or np.ndarray or Sequence): The box data with shape of
+ (..., 4).
+ dtype (torch.dtype, Optional): data type of boxes. Defaults to None.
+ device (str or torch.device, Optional): device of boxes.
+ Default to None.
+ clone (bool): Whether clone ``boxes`` or not. Defaults to True.
+ mode (str, Optional): the mode of boxes. If it is 'cxcywh', the
+ `data` will be converted to 'xyxy' mode. Defaults to None.
+ """
+
+ box_dim: int = 4
+
+ def __init__(self,
+ data: Union[Tensor, np.ndarray],
+ dtype: torch.dtype = None,
+ device: DeviceType = None,
+ clone: bool = True,
+ in_mode: Optional[str] = None) -> None:
+ super().__init__(data=data, dtype=dtype, device=device, clone=clone)
+ if isinstance(in_mode, str):
+ if in_mode not in ('xyxy', 'cxcywh'):
+ raise ValueError(f'Get invalid mode {in_mode}.')
+ if in_mode == 'cxcywh':
+ self.tensor = self.cxcywh_to_xyxy(self.tensor)
+
+ @staticmethod
+ def cxcywh_to_xyxy(boxes: Tensor) -> Tensor:
+ """Convert box coordinates from (cx, cy, w, h) to (x1, y1, x2, y2).
+
+ Args:
+ boxes (Tensor): cxcywh boxes tensor with shape of (..., 4).
+
+ Returns:
+ Tensor: xyxy boxes tensor with shape of (..., 4).
+ """
+ ctr, wh = boxes.split((2, 2), dim=-1)
+ return torch.cat([(ctr - wh / 2), (ctr + wh / 2)], dim=-1)
+
+ @staticmethod
+ def xyxy_to_cxcywh(boxes: Tensor) -> Tensor:
+ """Convert box coordinates from (x1, y1, x2, y2) to (cx, cy, w, h).
+
+ Args:
+ boxes (Tensor): xyxy boxes tensor with shape of (..., 4).
+
+ Returns:
+ Tensor: cxcywh boxes tensor with shape of (..., 4).
+ """
+ xy1, xy2 = boxes.split((2, 2), dim=-1)
+ return torch.cat([(xy2 + xy1) / 2, (xy2 - xy1)], dim=-1)
+
+ @property
+ def cxcywh(self) -> Tensor:
+ """Return a tensor representing the cxcywh boxes."""
+ return self.xyxy_to_cxcywh(self.tensor)
+
+ @property
+ def centers(self) -> Tensor:
+ """Return a tensor representing the centers of boxes."""
+ boxes = self.tensor
+ return (boxes[..., :2] + boxes[..., 2:]) / 2
+
+ @property
+ def areas(self) -> Tensor:
+ """Return a tensor representing the areas of boxes."""
+ boxes = self.tensor
+ return (boxes[..., 2] - boxes[..., 0]) * (
+ boxes[..., 3] - boxes[..., 1])
+
+ @property
+ def widths(self) -> Tensor:
+ """Return a tensor representing the widths of boxes."""
+ boxes = self.tensor
+ return boxes[..., 2] - boxes[..., 0]
+
+ @property
+ def heights(self) -> Tensor:
+ """Return a tensor representing the heights of boxes."""
+ boxes = self.tensor
+ return boxes[..., 3] - boxes[..., 1]
+
+ def flip_(self,
+ img_shape: Tuple[int, int],
+ direction: str = 'horizontal') -> None:
+ """Flip boxes horizontally or vertically in-place.
+
+ Args:
+ img_shape (Tuple[int, int]): A tuple of image height and width.
+ direction (str): Flip direction, options are "horizontal",
+ "vertical" and "diagonal". Defaults to "horizontal"
+ """
+ assert direction in ['horizontal', 'vertical', 'diagonal']
+ flipped = self.tensor
+ boxes = flipped.clone()
+ if direction == 'horizontal':
+ flipped[..., 0] = img_shape[1] - boxes[..., 2]
+ flipped[..., 2] = img_shape[1] - boxes[..., 0]
+ elif direction == 'vertical':
+ flipped[..., 1] = img_shape[0] - boxes[..., 3]
+ flipped[..., 3] = img_shape[0] - boxes[..., 1]
+ else:
+ flipped[..., 0] = img_shape[1] - boxes[..., 2]
+ flipped[..., 1] = img_shape[0] - boxes[..., 3]
+ flipped[..., 2] = img_shape[1] - boxes[..., 0]
+ flipped[..., 3] = img_shape[0] - boxes[..., 1]
+
+ def translate_(self, distances: Tuple[float, float]) -> None:
+ """Translate boxes in-place.
+
+ Args:
+ distances (Tuple[float, float]): translate distances. The first
+ is horizontal distance and the second is vertical distance.
+ """
+ boxes = self.tensor
+ assert len(distances) == 2
+ self.tensor = boxes + boxes.new_tensor(distances).repeat(2)
+
+ def clip_(self, img_shape: Tuple[int, int]) -> None:
+ """Clip boxes according to the image shape in-place.
+
+ Args:
+ img_shape (Tuple[int, int]): A tuple of image height and width.
+ """
+ boxes = self.tensor
+ boxes[..., 0::2] = boxes[..., 0::2].clamp(0, img_shape[1])
+ boxes[..., 1::2] = boxes[..., 1::2].clamp(0, img_shape[0])
+
+ def rotate_(self, center: Tuple[float, float], angle: float) -> None:
+ """Rotate all boxes in-place.
+
+ Args:
+ center (Tuple[float, float]): Rotation origin.
+ angle (float): Rotation angle represented in degrees. Positive
+ values mean clockwise rotation.
+ """
+ boxes = self.tensor
+ rotation_matrix = boxes.new_tensor(
+ cv2.getRotationMatrix2D(center, -angle, 1))
+
+ corners = self.hbox2corner(boxes)
+ corners = torch.cat(
+ [corners, corners.new_ones(*corners.shape[:-1], 1)], dim=-1)
+ corners_T = torch.transpose(corners, -1, -2)
+ corners_T = torch.matmul(rotation_matrix, corners_T)
+ corners = torch.transpose(corners_T, -1, -2)
+ self.tensor = self.corner2hbox(corners)
+
+ def project_(self, homography_matrix: Union[Tensor, np.ndarray]) -> None:
+ """Geometric transformat boxes in-place.
+
+ Args:
+ homography_matrix (Tensor or np.ndarray]):
+ Shape (3, 3) for geometric transformation.
+ """
+ boxes = self.tensor
+ if isinstance(homography_matrix, np.ndarray):
+ homography_matrix = boxes.new_tensor(homography_matrix)
+ corners = self.hbox2corner(boxes)
+ corners = torch.cat(
+ [corners, corners.new_ones(*corners.shape[:-1], 1)], dim=-1)
+ corners_T = torch.transpose(corners, -1, -2)
+ corners_T = torch.matmul(homography_matrix, corners_T)
+ corners = torch.transpose(corners_T, -1, -2)
+ # Convert to homogeneous coordinates by normalization
+ corners = corners[..., :2] / corners[..., 2:3]
+ self.tensor = self.corner2hbox(corners)
+
+ @staticmethod
+ def hbox2corner(boxes: Tensor) -> Tensor:
+ """Convert box coordinates from (x1, y1, x2, y2) to corners ((x1, y1),
+ (x2, y1), (x1, y2), (x2, y2)).
+
+ Args:
+ boxes (Tensor): Horizontal box tensor with shape of (..., 4).
+
+ Returns:
+ Tensor: Corner tensor with shape of (..., 4, 2).
+ """
+ x1, y1, x2, y2 = torch.split(boxes, 1, dim=-1)
+ corners = torch.cat([x1, y1, x2, y1, x1, y2, x2, y2], dim=-1)
+ return corners.reshape(*corners.shape[:-1], 4, 2)
+
+ @staticmethod
+ def corner2hbox(corners: Tensor) -> Tensor:
+ """Convert box coordinates from corners ((x1, y1), (x2, y1), (x1, y2),
+ (x2, y2)) to (x1, y1, x2, y2).
+
+ Args:
+ corners (Tensor): Corner tensor with shape of (..., 4, 2).
+
+ Returns:
+ Tensor: Horizontal box tensor with shape of (..., 4).
+ """
+ if corners.numel() == 0:
+ return corners.new_zeros((0, 4))
+ min_xy = corners.min(dim=-2)[0]
+ max_xy = corners.max(dim=-2)[0]
+ return torch.cat([min_xy, max_xy], dim=-1)
+
+ def rescale_(self, scale_factor: Tuple[float, float]) -> None:
+ """Rescale boxes w.r.t. rescale_factor in-place.
+
+ Note:
+ Both ``rescale_`` and ``resize_`` will enlarge or shrink boxes
+ w.r.t ``scale_facotr``. The difference is that ``resize_`` only
+ changes the width and the height of boxes, but ``rescale_`` also
+ rescales the box centers simultaneously.
+
+ Args:
+ scale_factor (Tuple[float, float]): factors for scaling boxes.
+ The length should be 2.
+ """
+ boxes = self.tensor
+ assert len(scale_factor) == 2
+ scale_factor = boxes.new_tensor(scale_factor).repeat(2)
+ self.tensor = boxes * scale_factor
+
+ def resize_(self, scale_factor: Tuple[float, float]) -> None:
+ """Resize the box width and height w.r.t scale_factor in-place.
+
+ Note:
+ Both ``rescale_`` and ``resize_`` will enlarge or shrink boxes
+ w.r.t ``scale_facotr``. The difference is that ``resize_`` only
+ changes the width and the height of boxes, but ``rescale_`` also
+ rescales the box centers simultaneously.
+
+ Args:
+ scale_factor (Tuple[float, float]): factors for scaling box
+ shapes. The length should be 2.
+ """
+ boxes = self.tensor
+ assert len(scale_factor) == 2
+ ctrs = (boxes[..., 2:] + boxes[..., :2]) / 2
+ wh = boxes[..., 2:] - boxes[..., :2]
+ scale_factor = boxes.new_tensor(scale_factor)
+ wh = wh * scale_factor
+ xy1 = ctrs - 0.5 * wh
+ xy2 = ctrs + 0.5 * wh
+ self.tensor = torch.cat([xy1, xy2], dim=-1)
+
+ def is_inside(self,
+ img_shape: Tuple[int, int],
+ all_inside: bool = False,
+ allowed_border: int = 0) -> BoolTensor:
+ """Find boxes inside the image.
+
+ Args:
+ img_shape (Tuple[int, int]): A tuple of image height and width.
+ all_inside (bool): Whether the boxes are all inside the image or
+ part inside the image. Defaults to False.
+ allowed_border (int): Boxes that extend beyond the image shape
+ boundary by more than ``allowed_border`` are considered
+ "outside" Defaults to 0.
+ Returns:
+ BoolTensor: A BoolTensor indicating whether the box is inside
+ the image. Assuming the original boxes have shape (m, n, 4),
+ the output has shape (m, n).
+ """
+ img_h, img_w = img_shape
+ boxes = self.tensor
+ if all_inside:
+ return (boxes[:, 0] >= -allowed_border) & \
+ (boxes[:, 1] >= -allowed_border) & \
+ (boxes[:, 2] < img_w + allowed_border) & \
+ (boxes[:, 3] < img_h + allowed_border)
+ else:
+ return (boxes[..., 0] < img_w + allowed_border) & \
+ (boxes[..., 1] < img_h + allowed_border) & \
+ (boxes[..., 2] > -allowed_border) & \
+ (boxes[..., 3] > -allowed_border)
+
+ def find_inside_points(self,
+ points: Tensor,
+ is_aligned: bool = False) -> BoolTensor:
+ """Find inside box points. Boxes dimension must be 2.
+
+ Args:
+ points (Tensor): Points coordinates. Has shape of (m, 2).
+ is_aligned (bool): Whether ``points`` has been aligned with boxes
+ or not. If True, the length of boxes and ``points`` should be
+ the same. Defaults to False.
+
+ Returns:
+ BoolTensor: A BoolTensor indicating whether a point is inside
+ boxes. Assuming the boxes has shape of (n, 4), if ``is_aligned``
+ is False. The index has shape of (m, n). If ``is_aligned`` is
+ True, m should be equal to n and the index has shape of (m, ).
+ """
+ boxes = self.tensor
+ assert boxes.dim() == 2, 'boxes dimension must be 2.'
+
+ if not is_aligned:
+ boxes = boxes[None, :, :]
+ points = points[:, None, :]
+ else:
+ assert boxes.size(0) == points.size(0)
+
+ x_min, y_min, x_max, y_max = boxes.unbind(dim=-1)
+ return (points[..., 0] >= x_min) & (points[..., 0] <= x_max) & \
+ (points[..., 1] >= y_min) & (points[..., 1] <= y_max)
+
+ @staticmethod
+ def overlaps(boxes1: BaseBoxes,
+ boxes2: BaseBoxes,
+ mode: str = 'iou',
+ is_aligned: bool = False,
+ eps: float = 1e-6) -> Tensor:
+ """Calculate overlap between two set of boxes with their types
+ converted to ``HorizontalBoxes``.
+
+ Args:
+ boxes1 (:obj:`BaseBoxes`): BaseBoxes with shape of (m, box_dim)
+ or empty.
+ boxes2 (:obj:`BaseBoxes`): BaseBoxes with shape of (n, box_dim)
+ or empty.
+ mode (str): "iou" (intersection over union), "iof" (intersection
+ over foreground). Defaults to "iou".
+ is_aligned (bool): If True, then m and n must be equal. Defaults
+ to False.
+ eps (float): A value added to the denominator for numerical
+ stability. Defaults to 1e-6.
+
+ Returns:
+ Tensor: shape (m, n) if ``is_aligned`` is False else shape (m,)
+ """
+ boxes1 = boxes1.convert_to('hbox')
+ boxes2 = boxes2.convert_to('hbox')
+ return bbox_overlaps(
+ boxes1.tensor,
+ boxes2.tensor,
+ mode=mode,
+ is_aligned=is_aligned,
+ eps=eps)
+
+ @staticmethod
+ def from_instance_masks(masks: MaskType) -> 'HorizontalBoxes':
+ """Create horizontal boxes from instance masks.
+
+ Args:
+ masks (:obj:`BitmapMasks` or :obj:`PolygonMasks`): BitmapMasks or
+ PolygonMasks instance with length of n.
+
+ Returns:
+ :obj:`HorizontalBoxes`: Converted boxes with shape of (n, 4).
+ """
+ num_masks = len(masks)
+ boxes = np.zeros((num_masks, 4), dtype=np.float32)
+ if isinstance(masks, BitmapMasks):
+ x_any = masks.masks.any(axis=1)
+ y_any = masks.masks.any(axis=2)
+ for idx in range(num_masks):
+ x = np.where(x_any[idx, :])[0]
+ y = np.where(y_any[idx, :])[0]
+ if len(x) > 0 and len(y) > 0:
+ # use +1 for x_max and y_max so that the right and bottom
+ # boundary of instance masks are fully included by the box
+ boxes[idx, :] = np.array(
+ [x[0], y[0], x[-1] + 1, y[-1] + 1], dtype=np.float32)
+ elif isinstance(masks, PolygonMasks):
+ for idx, poly_per_obj in enumerate(masks.masks):
+ # simply use a number that is big enough for comparison with
+ # coordinates
+ xy_min = np.array([masks.width * 2, masks.height * 2],
+ dtype=np.float32)
+ xy_max = np.zeros(2, dtype=np.float32)
+ for p in poly_per_obj:
+ xy = np.array(p).reshape(-1, 2).astype(np.float32)
+ xy_min = np.minimum(xy_min, np.min(xy, axis=0))
+ xy_max = np.maximum(xy_max, np.max(xy, axis=0))
+ boxes[idx, :2] = xy_min
+ boxes[idx, 2:] = xy_max
+ else:
+ raise TypeError(
+ '`masks` must be `BitmapMasks` or `PolygonMasks`, '
+ f'but got {type(masks)}.')
+ return HorizontalBoxes(boxes)
diff --git a/mmdet/structures/bbox/transforms.py b/mmdet/structures/bbox/transforms.py
new file mode 100644
index 0000000000000000000000000000000000000000..310538e9e734d37062196c58e1347334bb0d6052
--- /dev/null
+++ b/mmdet/structures/bbox/transforms.py
@@ -0,0 +1,467 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Optional, Sequence, Tuple, Union
+
+import numpy as np
+import torch
+from torch import Tensor
+
+from mmdet.structures.bbox import BaseBoxes
+
+
+def find_inside_bboxes(bboxes: Tensor, img_h: int, img_w: int) -> Tensor:
+ """Find bboxes as long as a part of bboxes is inside the image.
+
+ Args:
+ bboxes (Tensor): Shape (N, 4).
+ img_h (int): Image height.
+ img_w (int): Image width.
+
+ Returns:
+ Tensor: Index of the remaining bboxes.
+ """
+ inside_inds = (bboxes[:, 0] < img_w) & (bboxes[:, 2] > 0) \
+ & (bboxes[:, 1] < img_h) & (bboxes[:, 3] > 0)
+ return inside_inds
+
+
+def bbox_flip(bboxes: Tensor,
+ img_shape: Tuple[int],
+ direction: str = 'horizontal') -> Tensor:
+ """Flip bboxes horizontally or vertically.
+
+ Args:
+ bboxes (Tensor): Shape (..., 4*k)
+ img_shape (Tuple[int]): Image shape.
+ direction (str): Flip direction, options are "horizontal", "vertical",
+ "diagonal". Default: "horizontal"
+
+ Returns:
+ Tensor: Flipped bboxes.
+ """
+ assert bboxes.shape[-1] % 4 == 0
+ assert direction in ['horizontal', 'vertical', 'diagonal']
+ flipped = bboxes.clone()
+ if direction == 'horizontal':
+ flipped[..., 0::4] = img_shape[1] - bboxes[..., 2::4]
+ flipped[..., 2::4] = img_shape[1] - bboxes[..., 0::4]
+ elif direction == 'vertical':
+ flipped[..., 1::4] = img_shape[0] - bboxes[..., 3::4]
+ flipped[..., 3::4] = img_shape[0] - bboxes[..., 1::4]
+ else:
+ flipped[..., 0::4] = img_shape[1] - bboxes[..., 2::4]
+ flipped[..., 1::4] = img_shape[0] - bboxes[..., 3::4]
+ flipped[..., 2::4] = img_shape[1] - bboxes[..., 0::4]
+ flipped[..., 3::4] = img_shape[0] - bboxes[..., 1::4]
+ return flipped
+
+
+def bbox_mapping(bboxes: Tensor,
+ img_shape: Tuple[int],
+ scale_factor: Union[float, Tuple[float]],
+ flip: bool,
+ flip_direction: str = 'horizontal') -> Tensor:
+ """Map bboxes from the original image scale to testing scale."""
+ new_bboxes = bboxes * bboxes.new_tensor(scale_factor)
+ if flip:
+ new_bboxes = bbox_flip(new_bboxes, img_shape, flip_direction)
+ return new_bboxes
+
+
+def bbox_mapping_back(bboxes: Tensor,
+ img_shape: Tuple[int],
+ scale_factor: Union[float, Tuple[float]],
+ flip: bool,
+ flip_direction: str = 'horizontal') -> Tensor:
+ """Map bboxes from testing scale to original image scale."""
+ new_bboxes = bbox_flip(bboxes, img_shape,
+ flip_direction) if flip else bboxes
+ new_bboxes = new_bboxes.view(-1, 4) / new_bboxes.new_tensor(scale_factor)
+ return new_bboxes.view(bboxes.shape)
+
+
+def bbox2roi(bbox_list: List[Union[Tensor, BaseBoxes]]) -> Tensor:
+ """Convert a list of bboxes to roi format.
+
+ Args:
+ bbox_list (List[Union[Tensor, :obj:`BaseBoxes`]): a list of bboxes
+ corresponding to a batch of images.
+
+ Returns:
+ Tensor: shape (n, box_dim + 1), where ``box_dim`` depends on the
+ different box types. For example, If the box type in ``bbox_list``
+ is HorizontalBoxes, the output shape is (n, 5). Each row of data
+ indicates [batch_ind, x1, y1, x2, y2].
+ """
+ rois_list = []
+ for img_id, bboxes in enumerate(bbox_list):
+ bboxes = get_box_tensor(bboxes)
+ img_inds = bboxes.new_full((bboxes.size(0), 1), img_id)
+ rois = torch.cat([img_inds, bboxes], dim=-1)
+ rois_list.append(rois)
+ rois = torch.cat(rois_list, 0)
+ return rois
+
+
+def roi2bbox(rois: Tensor) -> List[Tensor]:
+ """Convert rois to bounding box format.
+
+ Args:
+ rois (Tensor): RoIs with the shape (n, 5) where the first
+ column indicates batch id of each RoI.
+
+ Returns:
+ List[Tensor]: Converted boxes of corresponding rois.
+ """
+ bbox_list = []
+ img_ids = torch.unique(rois[:, 0].cpu(), sorted=True)
+ for img_id in img_ids:
+ inds = (rois[:, 0] == img_id.item())
+ bbox = rois[inds, 1:]
+ bbox_list.append(bbox)
+ return bbox_list
+
+
+# TODO remove later
+def bbox2result(bboxes: Union[Tensor, np.ndarray], labels: Union[Tensor,
+ np.ndarray],
+ num_classes: int) -> List[np.ndarray]:
+ """Convert detection results to a list of numpy arrays.
+
+ Args:
+ bboxes (Tensor | np.ndarray): shape (n, 5)
+ labels (Tensor | np.ndarray): shape (n, )
+ num_classes (int): class number, including background class
+
+ Returns:
+ List(np.ndarray]): bbox results of each class
+ """
+ if bboxes.shape[0] == 0:
+ return [np.zeros((0, 5), dtype=np.float32) for i in range(num_classes)]
+ else:
+ if isinstance(bboxes, torch.Tensor):
+ bboxes = bboxes.detach().cpu().numpy()
+ labels = labels.detach().cpu().numpy()
+ return [bboxes[labels == i, :] for i in range(num_classes)]
+
+
+def distance2bbox(
+ points: Tensor,
+ distance: Tensor,
+ max_shape: Optional[Union[Sequence[int], Tensor,
+ Sequence[Sequence[int]]]] = None
+) -> Tensor:
+ """Decode distance prediction to bounding box.
+
+ Args:
+ points (Tensor): Shape (B, N, 2) or (N, 2).
+ distance (Tensor): Distance from the given point to 4
+ boundaries (left, top, right, bottom). Shape (B, N, 4) or (N, 4)
+ max_shape (Union[Sequence[int], Tensor, Sequence[Sequence[int]]],
+ optional): Maximum bounds for boxes, specifies
+ (H, W, C) or (H, W). If priors shape is (B, N, 4), then
+ the max_shape should be a Sequence[Sequence[int]]
+ and the length of max_shape should also be B.
+
+ Returns:
+ Tensor: Boxes with shape (N, 4) or (B, N, 4)
+ """
+
+ x1 = points[..., 0] - distance[..., 0]
+ y1 = points[..., 1] - distance[..., 1]
+ x2 = points[..., 0] + distance[..., 2]
+ y2 = points[..., 1] + distance[..., 3]
+
+ bboxes = torch.stack([x1, y1, x2, y2], -1)
+
+ if max_shape is not None:
+ if bboxes.dim() == 2 and not torch.onnx.is_in_onnx_export():
+ # speed up
+ bboxes[:, 0::2].clamp_(min=0, max=max_shape[1])
+ bboxes[:, 1::2].clamp_(min=0, max=max_shape[0])
+ return bboxes
+
+ # clip bboxes with dynamic `min` and `max` for onnx
+ if torch.onnx.is_in_onnx_export():
+ # TODO: delete
+ from mmdet.core.export import dynamic_clip_for_onnx
+ x1, y1, x2, y2 = dynamic_clip_for_onnx(x1, y1, x2, y2, max_shape)
+ bboxes = torch.stack([x1, y1, x2, y2], dim=-1)
+ return bboxes
+ if not isinstance(max_shape, torch.Tensor):
+ max_shape = x1.new_tensor(max_shape)
+ max_shape = max_shape[..., :2].type_as(x1)
+ if max_shape.ndim == 2:
+ assert bboxes.ndim == 3
+ assert max_shape.size(0) == bboxes.size(0)
+
+ min_xy = x1.new_tensor(0)
+ max_xy = torch.cat([max_shape, max_shape],
+ dim=-1).flip(-1).unsqueeze(-2)
+ bboxes = torch.where(bboxes < min_xy, min_xy, bboxes)
+ bboxes = torch.where(bboxes > max_xy, max_xy, bboxes)
+
+ return bboxes
+
+
+def bbox2distance(points: Tensor,
+ bbox: Tensor,
+ max_dis: Optional[float] = None,
+ eps: float = 0.1) -> Tensor:
+ """Decode bounding box based on distances.
+
+ Args:
+ points (Tensor): Shape (n, 2) or (b, n, 2), [x, y].
+ bbox (Tensor): Shape (n, 4) or (b, n, 4), "xyxy" format
+ max_dis (float, optional): Upper bound of the distance.
+ eps (float): a small value to ensure target < max_dis, instead <=
+
+ Returns:
+ Tensor: Decoded distances.
+ """
+ left = points[..., 0] - bbox[..., 0]
+ top = points[..., 1] - bbox[..., 1]
+ right = bbox[..., 2] - points[..., 0]
+ bottom = bbox[..., 3] - points[..., 1]
+ if max_dis is not None:
+ left = left.clamp(min=0, max=max_dis - eps)
+ top = top.clamp(min=0, max=max_dis - eps)
+ right = right.clamp(min=0, max=max_dis - eps)
+ bottom = bottom.clamp(min=0, max=max_dis - eps)
+ return torch.stack([left, top, right, bottom], -1)
+
+
+def bbox_rescale(bboxes: Tensor, scale_factor: float = 1.0) -> Tensor:
+ """Rescale bounding box w.r.t. scale_factor.
+
+ Args:
+ bboxes (Tensor): Shape (n, 4) for bboxes or (n, 5) for rois
+ scale_factor (float): rescale factor
+
+ Returns:
+ Tensor: Rescaled bboxes.
+ """
+ if bboxes.size(1) == 5:
+ bboxes_ = bboxes[:, 1:]
+ inds_ = bboxes[:, 0]
+ else:
+ bboxes_ = bboxes
+ cx = (bboxes_[:, 0] + bboxes_[:, 2]) * 0.5
+ cy = (bboxes_[:, 1] + bboxes_[:, 3]) * 0.5
+ w = bboxes_[:, 2] - bboxes_[:, 0]
+ h = bboxes_[:, 3] - bboxes_[:, 1]
+ w = w * scale_factor
+ h = h * scale_factor
+ x1 = cx - 0.5 * w
+ x2 = cx + 0.5 * w
+ y1 = cy - 0.5 * h
+ y2 = cy + 0.5 * h
+ if bboxes.size(1) == 5:
+ rescaled_bboxes = torch.stack([inds_, x1, y1, x2, y2], dim=-1)
+ else:
+ rescaled_bboxes = torch.stack([x1, y1, x2, y2], dim=-1)
+ return rescaled_bboxes
+
+
+def bbox_cxcywh_to_xyxy(bbox: Tensor) -> Tensor:
+ """Convert bbox coordinates from (cx, cy, w, h) to (x1, y1, x2, y2).
+
+ Args:
+ bbox (Tensor): Shape (n, 4) for bboxes.
+
+ Returns:
+ Tensor: Converted bboxes.
+ """
+ cx, cy, w, h = bbox.split((1, 1, 1, 1), dim=-1)
+ bbox_new = [(cx - 0.5 * w), (cy - 0.5 * h), (cx + 0.5 * w), (cy + 0.5 * h)]
+ return torch.cat(bbox_new, dim=-1)
+
+
+def bbox_xyxy_to_cxcywh(bbox: Tensor) -> Tensor:
+ """Convert bbox coordinates from (x1, y1, x2, y2) to (cx, cy, w, h).
+
+ Args:
+ bbox (Tensor): Shape (n, 4) for bboxes.
+
+ Returns:
+ Tensor: Converted bboxes.
+ """
+ x1, y1, x2, y2 = bbox.split((1, 1, 1, 1), dim=-1)
+ bbox_new = [(x1 + x2) / 2, (y1 + y2) / 2, (x2 - x1), (y2 - y1)]
+ return torch.cat(bbox_new, dim=-1)
+
+
+def bbox2corner(bboxes: torch.Tensor) -> torch.Tensor:
+ """Convert bbox coordinates from (x1, y1, x2, y2) to corners ((x1, y1),
+ (x2, y1), (x1, y2), (x2, y2)).
+
+ Args:
+ bboxes (Tensor): Shape (n, 4) for bboxes.
+ Returns:
+ Tensor: Shape (n*4, 2) for corners.
+ """
+ x1, y1, x2, y2 = torch.split(bboxes, 1, dim=1)
+ return torch.cat([x1, y1, x2, y1, x1, y2, x2, y2], dim=1).reshape(-1, 2)
+
+
+def corner2bbox(corners: torch.Tensor) -> torch.Tensor:
+ """Convert bbox coordinates from corners ((x1, y1), (x2, y1), (x1, y2),
+ (x2, y2)) to (x1, y1, x2, y2).
+
+ Args:
+ corners (Tensor): Shape (n*4, 2) for corners.
+ Returns:
+ Tensor: Shape (n, 4) for bboxes.
+ """
+ corners = corners.reshape(-1, 4, 2)
+ min_xy = corners.min(dim=1)[0]
+ max_xy = corners.max(dim=1)[0]
+ return torch.cat([min_xy, max_xy], dim=1)
+
+
+def bbox_project(
+ bboxes: Union[torch.Tensor, np.ndarray],
+ homography_matrix: Union[torch.Tensor, np.ndarray],
+ img_shape: Optional[Tuple[int, int]] = None
+) -> Union[torch.Tensor, np.ndarray]:
+ """Geometric transformation for bbox.
+
+ Args:
+ bboxes (Union[torch.Tensor, np.ndarray]): Shape (n, 4) for bboxes.
+ homography_matrix (Union[torch.Tensor, np.ndarray]):
+ Shape (3, 3) for geometric transformation.
+ img_shape (Tuple[int, int], optional): Image shape. Defaults to None.
+ Returns:
+ Union[torch.Tensor, np.ndarray]: Converted bboxes.
+ """
+ bboxes_type = type(bboxes)
+ if bboxes_type is np.ndarray:
+ bboxes = torch.from_numpy(bboxes)
+ if isinstance(homography_matrix, np.ndarray):
+ homography_matrix = torch.from_numpy(homography_matrix)
+ corners = bbox2corner(bboxes)
+ corners = torch.cat(
+ [corners, corners.new_ones(corners.shape[0], 1)], dim=1)
+ corners = torch.matmul(homography_matrix, corners.t()).t()
+ # Convert to homogeneous coordinates by normalization
+ corners = corners[:, :2] / corners[:, 2:3]
+ bboxes = corner2bbox(corners)
+ if img_shape is not None:
+ bboxes[:, 0::2] = bboxes[:, 0::2].clamp(0, img_shape[1])
+ bboxes[:, 1::2] = bboxes[:, 1::2].clamp(0, img_shape[0])
+ if bboxes_type is np.ndarray:
+ bboxes = bboxes.numpy()
+ return bboxes
+
+
+def cat_boxes(data_list: List[Union[Tensor, BaseBoxes]],
+ dim: int = 0) -> Union[Tensor, BaseBoxes]:
+ """Concatenate boxes with type of tensor or box type.
+
+ Args:
+ data_list (List[Union[Tensor, :obj:`BaseBoxes`]]): A list of tensors
+ or box types need to be concatenated.
+ dim (int): The dimension over which the box are concatenated.
+ Defaults to 0.
+
+ Returns:
+ Union[Tensor, :obj`BaseBoxes`]: Concatenated results.
+ """
+ if data_list and isinstance(data_list[0], BaseBoxes):
+ return data_list[0].cat(data_list, dim=dim)
+ else:
+ return torch.cat(data_list, dim=dim)
+
+
+def stack_boxes(data_list: List[Union[Tensor, BaseBoxes]],
+ dim: int = 0) -> Union[Tensor, BaseBoxes]:
+ """Stack boxes with type of tensor or box type.
+
+ Args:
+ data_list (List[Union[Tensor, :obj:`BaseBoxes`]]): A list of tensors
+ or box types need to be stacked.
+ dim (int): The dimension over which the box are stacked.
+ Defaults to 0.
+
+ Returns:
+ Union[Tensor, :obj`BaseBoxes`]: Stacked results.
+ """
+ if data_list and isinstance(data_list[0], BaseBoxes):
+ return data_list[0].stack(data_list, dim=dim)
+ else:
+ return torch.stack(data_list, dim=dim)
+
+
+def scale_boxes(boxes: Union[Tensor, BaseBoxes],
+ scale_factor: Tuple[float, float]) -> Union[Tensor, BaseBoxes]:
+ """Scale boxes with type of tensor or box type.
+
+ Args:
+ boxes (Tensor or :obj:`BaseBoxes`): boxes need to be scaled. Its type
+ can be a tensor or a box type.
+ scale_factor (Tuple[float, float]): factors for scaling boxes.
+ The length should be 2.
+
+ Returns:
+ Union[Tensor, :obj:`BaseBoxes`]: Scaled boxes.
+ """
+ if isinstance(boxes, BaseBoxes):
+ boxes.rescale_(scale_factor)
+ return boxes
+ else:
+ # Tensor boxes will be treated as horizontal boxes
+ repeat_num = int(boxes.size(-1) / 2)
+ scale_factor = boxes.new_tensor(scale_factor).repeat((1, repeat_num))
+ return boxes * scale_factor
+
+
+def get_box_wh(boxes: Union[Tensor, BaseBoxes]) -> Tuple[Tensor, Tensor]:
+ """Get the width and height of boxes with type of tensor or box type.
+
+ Args:
+ boxes (Tensor or :obj:`BaseBoxes`): boxes with type of tensor
+ or box type.
+
+ Returns:
+ Tuple[Tensor, Tensor]: the width and height of boxes.
+ """
+ if isinstance(boxes, BaseBoxes):
+ w = boxes.widths
+ h = boxes.heights
+ else:
+ # Tensor boxes will be treated as horizontal boxes by defaults
+ w = boxes[:, 2] - boxes[:, 0]
+ h = boxes[:, 3] - boxes[:, 1]
+ return w, h
+
+
+def get_box_tensor(boxes: Union[Tensor, BaseBoxes]) -> Tensor:
+ """Get tensor data from box type boxes.
+
+ Args:
+ boxes (Tensor or BaseBoxes): boxes with type of tensor or box type.
+ If its type is a tensor, the boxes will be directly returned.
+ If its type is a box type, the `boxes.tensor` will be returned.
+
+ Returns:
+ Tensor: boxes tensor.
+ """
+ if isinstance(boxes, BaseBoxes):
+ boxes = boxes.tensor
+ return boxes
+
+
+def empty_box_as(boxes: Union[Tensor, BaseBoxes]) -> Union[Tensor, BaseBoxes]:
+ """Generate empty box according to input ``boxes` type and device.
+
+ Args:
+ boxes (Tensor or :obj:`BaseBoxes`): boxes with type of tensor
+ or box type.
+
+ Returns:
+ Union[Tensor, BaseBoxes]: Generated empty box.
+ """
+ if isinstance(boxes, BaseBoxes):
+ return boxes.empty_boxes()
+ else:
+ # Tensor boxes will be treated as horizontal boxes by defaults
+ return boxes.new_zeros(0, 4)
diff --git a/mmdet/structures/det_data_sample.py b/mmdet/structures/det_data_sample.py
new file mode 100644
index 0000000000000000000000000000000000000000..d7b7f354a8584eecf29f2e89e0367e0753740f2a
--- /dev/null
+++ b/mmdet/structures/det_data_sample.py
@@ -0,0 +1,213 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Optional
+
+from mmengine.structures import BaseDataElement, InstanceData, PixelData
+
+
+class DetDataSample(BaseDataElement):
+ """A data structure interface of MMDetection. They are used as interfaces
+ between different components.
+
+ The attributes in ``DetDataSample`` are divided into several parts:
+
+ - ``proposals``(InstanceData): Region proposals used in two-stage
+ detectors.
+ - ``gt_instances``(InstanceData): Ground truth of instance annotations.
+ - ``pred_instances``(InstanceData): Instances of model predictions.
+ - ``ignored_instances``(InstanceData): Instances to be ignored during
+ training/testing.
+ - ``gt_panoptic_seg``(PixelData): Ground truth of panoptic
+ segmentation.
+ - ``pred_panoptic_seg``(PixelData): Prediction of panoptic
+ segmentation.
+ - ``gt_sem_seg``(PixelData): Ground truth of semantic segmentation.
+ - ``pred_sem_seg``(PixelData): Prediction of semantic segmentation.
+
+ Examples:
+ >>> import torch
+ >>> import numpy as np
+ >>> from mmengine.structures import InstanceData
+ >>> from mmdet.structures import DetDataSample
+
+ >>> data_sample = DetDataSample()
+ >>> img_meta = dict(img_shape=(800, 1196),
+ ... pad_shape=(800, 1216))
+ >>> gt_instances = InstanceData(metainfo=img_meta)
+ >>> gt_instances.bboxes = torch.rand((5, 4))
+ >>> gt_instances.labels = torch.rand((5,))
+ >>> data_sample.gt_instances = gt_instances
+ >>> assert 'img_shape' in data_sample.gt_instances.metainfo_keys()
+ >>> len(data_sample.gt_instances)
+ 5
+ >>> print(data_sample)
+
+ ) at 0x7f21fb1b9880>
+ >>> pred_instances = InstanceData(metainfo=img_meta)
+ >>> pred_instances.bboxes = torch.rand((5, 4))
+ >>> pred_instances.scores = torch.rand((5,))
+ >>> data_sample = DetDataSample(pred_instances=pred_instances)
+ >>> assert 'pred_instances' in data_sample
+
+ >>> data_sample = DetDataSample()
+ >>> gt_instances_data = dict(
+ ... bboxes=torch.rand(2, 4),
+ ... labels=torch.rand(2),
+ ... masks=np.random.rand(2, 2, 2))
+ >>> gt_instances = InstanceData(**gt_instances_data)
+ >>> data_sample.gt_instances = gt_instances
+ >>> assert 'gt_instances' in data_sample
+ >>> assert 'masks' in data_sample.gt_instances
+
+ >>> data_sample = DetDataSample()
+ >>> gt_panoptic_seg_data = dict(panoptic_seg=torch.rand(2, 4))
+ >>> gt_panoptic_seg = PixelData(**gt_panoptic_seg_data)
+ >>> data_sample.gt_panoptic_seg = gt_panoptic_seg
+ >>> print(data_sample)
+
+ gt_panoptic_seg:
+ ) at 0x7f66c2bb7280>
+ >>> data_sample = DetDataSample()
+ >>> gt_segm_seg_data = dict(segm_seg=torch.rand(2, 2, 2))
+ >>> gt_segm_seg = PixelData(**gt_segm_seg_data)
+ >>> data_sample.gt_segm_seg = gt_segm_seg
+ >>> assert 'gt_segm_seg' in data_sample
+ >>> assert 'segm_seg' in data_sample.gt_segm_seg
+ """
+
+ @property
+ def proposals(self) -> InstanceData:
+ return self._proposals
+
+ @proposals.setter
+ def proposals(self, value: InstanceData):
+ self.set_field(value, '_proposals', dtype=InstanceData)
+
+ @proposals.deleter
+ def proposals(self):
+ del self._proposals
+
+ @property
+ def gt_instances(self) -> InstanceData:
+ return self._gt_instances
+
+ @gt_instances.setter
+ def gt_instances(self, value: InstanceData):
+ self.set_field(value, '_gt_instances', dtype=InstanceData)
+
+ @gt_instances.deleter
+ def gt_instances(self):
+ del self._gt_instances
+
+ @property
+ def pred_instances(self) -> InstanceData:
+ return self._pred_instances
+
+ @pred_instances.setter
+ def pred_instances(self, value: InstanceData):
+ self.set_field(value, '_pred_instances', dtype=InstanceData)
+
+ @pred_instances.deleter
+ def pred_instances(self):
+ del self._pred_instances
+
+ @property
+ def ignored_instances(self) -> InstanceData:
+ return self._ignored_instances
+
+ @ignored_instances.setter
+ def ignored_instances(self, value: InstanceData):
+ self.set_field(value, '_ignored_instances', dtype=InstanceData)
+
+ @ignored_instances.deleter
+ def ignored_instances(self):
+ del self._ignored_instances
+
+ @property
+ def gt_panoptic_seg(self) -> PixelData:
+ return self._gt_panoptic_seg
+
+ @gt_panoptic_seg.setter
+ def gt_panoptic_seg(self, value: PixelData):
+ self.set_field(value, '_gt_panoptic_seg', dtype=PixelData)
+
+ @gt_panoptic_seg.deleter
+ def gt_panoptic_seg(self):
+ del self._gt_panoptic_seg
+
+ @property
+ def pred_panoptic_seg(self) -> PixelData:
+ return self._pred_panoptic_seg
+
+ @pred_panoptic_seg.setter
+ def pred_panoptic_seg(self, value: PixelData):
+ self.set_field(value, '_pred_panoptic_seg', dtype=PixelData)
+
+ @pred_panoptic_seg.deleter
+ def pred_panoptic_seg(self):
+ del self._pred_panoptic_seg
+
+ @property
+ def gt_sem_seg(self) -> PixelData:
+ return self._gt_sem_seg
+
+ @gt_sem_seg.setter
+ def gt_sem_seg(self, value: PixelData):
+ self.set_field(value, '_gt_sem_seg', dtype=PixelData)
+
+ @gt_sem_seg.deleter
+ def gt_sem_seg(self):
+ del self._gt_sem_seg
+
+ @property
+ def pred_sem_seg(self) -> PixelData:
+ return self._pred_sem_seg
+
+ @pred_sem_seg.setter
+ def pred_sem_seg(self, value: PixelData):
+ self.set_field(value, '_pred_sem_seg', dtype=PixelData)
+
+ @pred_sem_seg.deleter
+ def pred_sem_seg(self):
+ del self._pred_sem_seg
+
+
+SampleList = List[DetDataSample]
+OptSampleList = Optional[SampleList]
diff --git a/mmdet/structures/mask/__init__.py b/mmdet/structures/mask/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..f78394701df1b493259c4c23a79aea5c5cb8be95
--- /dev/null
+++ b/mmdet/structures/mask/__init__.py
@@ -0,0 +1,11 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .mask_target import mask_target
+from .structures import (BaseInstanceMasks, BitmapMasks, PolygonMasks,
+ bitmap_to_polygon, polygon_to_bitmap)
+from .utils import encode_mask_results, mask2bbox, split_combined_polys
+
+__all__ = [
+ 'split_combined_polys', 'mask_target', 'BaseInstanceMasks', 'BitmapMasks',
+ 'PolygonMasks', 'encode_mask_results', 'mask2bbox', 'polygon_to_bitmap',
+ 'bitmap_to_polygon'
+]
diff --git a/mmdet/structures/mask/__pycache__/__init__.cpython-37.pyc b/mmdet/structures/mask/__pycache__/__init__.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..11e78468b22a392afae8d589aec8e0af05021948
Binary files /dev/null and b/mmdet/structures/mask/__pycache__/__init__.cpython-37.pyc differ
diff --git a/mmdet/structures/mask/__pycache__/mask_target.cpython-37.pyc b/mmdet/structures/mask/__pycache__/mask_target.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..52cc42618ed2799cd1c1de999e2c2a8496cc5c70
Binary files /dev/null and b/mmdet/structures/mask/__pycache__/mask_target.cpython-37.pyc differ
diff --git a/mmdet/structures/mask/__pycache__/structures.cpython-37.pyc b/mmdet/structures/mask/__pycache__/structures.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..8758cca77ffbade99022950fe59820df8423dd55
Binary files /dev/null and b/mmdet/structures/mask/__pycache__/structures.cpython-37.pyc differ
diff --git a/mmdet/structures/mask/__pycache__/utils.cpython-37.pyc b/mmdet/structures/mask/__pycache__/utils.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..2eac32d755678559bca48fa1bca30a13dc8c8126
Binary files /dev/null and b/mmdet/structures/mask/__pycache__/utils.cpython-37.pyc differ
diff --git a/mmdet/structures/mask/mask_target.py b/mmdet/structures/mask/mask_target.py
new file mode 100644
index 0000000000000000000000000000000000000000..b2fc5f1878300446b114c9f57c6a885fea8c927c
--- /dev/null
+++ b/mmdet/structures/mask/mask_target.py
@@ -0,0 +1,127 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import numpy as np
+import torch
+from torch.nn.modules.utils import _pair
+
+
+def mask_target(pos_proposals_list, pos_assigned_gt_inds_list, gt_masks_list,
+ cfg):
+ """Compute mask target for positive proposals in multiple images.
+
+ Args:
+ pos_proposals_list (list[Tensor]): Positive proposals in multiple
+ images, each has shape (num_pos, 4).
+ pos_assigned_gt_inds_list (list[Tensor]): Assigned GT indices for each
+ positive proposals, each has shape (num_pos,).
+ gt_masks_list (list[:obj:`BaseInstanceMasks`]): Ground truth masks of
+ each image.
+ cfg (dict): Config dict that specifies the mask size.
+
+ Returns:
+ Tensor: Mask target of each image, has shape (num_pos, w, h).
+
+ Example:
+ >>> from mmengine.config import Config
+ >>> import mmdet
+ >>> from mmdet.data_elements.mask import BitmapMasks
+ >>> from mmdet.data_elements.mask.mask_target import *
+ >>> H, W = 17, 18
+ >>> cfg = Config({'mask_size': (13, 14)})
+ >>> rng = np.random.RandomState(0)
+ >>> # Positive proposals (tl_x, tl_y, br_x, br_y) for each image
+ >>> pos_proposals_list = [
+ >>> torch.Tensor([
+ >>> [ 7.2425, 5.5929, 13.9414, 14.9541],
+ >>> [ 7.3241, 3.6170, 16.3850, 15.3102],
+ >>> ]),
+ >>> torch.Tensor([
+ >>> [ 4.8448, 6.4010, 7.0314, 9.7681],
+ >>> [ 5.9790, 2.6989, 7.4416, 4.8580],
+ >>> [ 0.0000, 0.0000, 0.1398, 9.8232],
+ >>> ]),
+ >>> ]
+ >>> # Corresponding class index for each proposal for each image
+ >>> pos_assigned_gt_inds_list = [
+ >>> torch.LongTensor([7, 0]),
+ >>> torch.LongTensor([5, 4, 1]),
+ >>> ]
+ >>> # Ground truth mask for each true object for each image
+ >>> gt_masks_list = [
+ >>> BitmapMasks(rng.rand(8, H, W), height=H, width=W),
+ >>> BitmapMasks(rng.rand(6, H, W), height=H, width=W),
+ >>> ]
+ >>> mask_targets = mask_target(
+ >>> pos_proposals_list, pos_assigned_gt_inds_list,
+ >>> gt_masks_list, cfg)
+ >>> assert mask_targets.shape == (5,) + cfg['mask_size']
+ """
+ cfg_list = [cfg for _ in range(len(pos_proposals_list))]
+ mask_targets = map(mask_target_single, pos_proposals_list,
+ pos_assigned_gt_inds_list, gt_masks_list, cfg_list)
+ mask_targets = list(mask_targets)
+ if len(mask_targets) > 0:
+ mask_targets = torch.cat(mask_targets)
+ return mask_targets
+
+
+def mask_target_single(pos_proposals, pos_assigned_gt_inds, gt_masks, cfg):
+ """Compute mask target for each positive proposal in the image.
+
+ Args:
+ pos_proposals (Tensor): Positive proposals.
+ pos_assigned_gt_inds (Tensor): Assigned GT inds of positive proposals.
+ gt_masks (:obj:`BaseInstanceMasks`): GT masks in the format of Bitmap
+ or Polygon.
+ cfg (dict): Config dict that indicate the mask size.
+
+ Returns:
+ Tensor: Mask target of each positive proposals in the image.
+
+ Example:
+ >>> from mmengine.config import Config
+ >>> import mmdet
+ >>> from mmdet.data_elements.mask import BitmapMasks
+ >>> from mmdet.data_elements.mask.mask_target import * # NOQA
+ >>> H, W = 32, 32
+ >>> cfg = Config({'mask_size': (7, 11)})
+ >>> rng = np.random.RandomState(0)
+ >>> # Masks for each ground truth box (relative to the image)
+ >>> gt_masks_data = rng.rand(3, H, W)
+ >>> gt_masks = BitmapMasks(gt_masks_data, height=H, width=W)
+ >>> # Predicted positive boxes in one image
+ >>> pos_proposals = torch.FloatTensor([
+ >>> [ 16.2, 5.5, 19.9, 20.9],
+ >>> [ 17.3, 13.6, 19.3, 19.3],
+ >>> [ 14.8, 16.4, 17.0, 23.7],
+ >>> [ 0.0, 0.0, 16.0, 16.0],
+ >>> [ 4.0, 0.0, 20.0, 16.0],
+ >>> ])
+ >>> # For each predicted proposal, its assignment to a gt mask
+ >>> pos_assigned_gt_inds = torch.LongTensor([0, 1, 2, 1, 1])
+ >>> mask_targets = mask_target_single(
+ >>> pos_proposals, pos_assigned_gt_inds, gt_masks, cfg)
+ >>> assert mask_targets.shape == (5,) + cfg['mask_size']
+ """
+ device = pos_proposals.device
+ mask_size = _pair(cfg.mask_size)
+ binarize = not cfg.get('soft_mask_target', False)
+ num_pos = pos_proposals.size(0)
+ if num_pos > 0:
+ proposals_np = pos_proposals.cpu().numpy()
+ maxh, maxw = gt_masks.height, gt_masks.width
+ proposals_np[:, [0, 2]] = np.clip(proposals_np[:, [0, 2]], 0, maxw)
+ proposals_np[:, [1, 3]] = np.clip(proposals_np[:, [1, 3]], 0, maxh)
+ pos_assigned_gt_inds = pos_assigned_gt_inds.cpu().numpy()
+
+ mask_targets = gt_masks.crop_and_resize(
+ proposals_np,
+ mask_size,
+ device=device,
+ inds=pos_assigned_gt_inds,
+ binarize=binarize).to_ndarray()
+
+ mask_targets = torch.from_numpy(mask_targets).float().to(device)
+ else:
+ mask_targets = pos_proposals.new_zeros((0, ) + mask_size)
+
+ return mask_targets
diff --git a/mmdet/structures/mask/structures.py b/mmdet/structures/mask/structures.py
new file mode 100644
index 0000000000000000000000000000000000000000..b4fdd27570b0d11d92eba4e8f854e153750135a4
--- /dev/null
+++ b/mmdet/structures/mask/structures.py
@@ -0,0 +1,1193 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import itertools
+from abc import ABCMeta, abstractmethod
+from typing import Sequence, Type, TypeVar
+
+import cv2
+import mmcv
+import numpy as np
+import pycocotools.mask as maskUtils
+import shapely.geometry as geometry
+import torch
+from mmcv.ops.roi_align import roi_align
+
+T = TypeVar('T')
+
+
+class BaseInstanceMasks(metaclass=ABCMeta):
+ """Base class for instance masks."""
+
+ @abstractmethod
+ def rescale(self, scale, interpolation='nearest'):
+ """Rescale masks as large as possible while keeping the aspect ratio.
+ For details can refer to `mmcv.imrescale`.
+
+ Args:
+ scale (tuple[int]): The maximum size (h, w) of rescaled mask.
+ interpolation (str): Same as :func:`mmcv.imrescale`.
+
+ Returns:
+ BaseInstanceMasks: The rescaled masks.
+ """
+
+ @abstractmethod
+ def resize(self, out_shape, interpolation='nearest'):
+ """Resize masks to the given out_shape.
+
+ Args:
+ out_shape: Target (h, w) of resized mask.
+ interpolation (str): See :func:`mmcv.imresize`.
+
+ Returns:
+ BaseInstanceMasks: The resized masks.
+ """
+
+ @abstractmethod
+ def flip(self, flip_direction='horizontal'):
+ """Flip masks alone the given direction.
+
+ Args:
+ flip_direction (str): Either 'horizontal' or 'vertical'.
+
+ Returns:
+ BaseInstanceMasks: The flipped masks.
+ """
+
+ @abstractmethod
+ def pad(self, out_shape, pad_val):
+ """Pad masks to the given size of (h, w).
+
+ Args:
+ out_shape (tuple[int]): Target (h, w) of padded mask.
+ pad_val (int): The padded value.
+
+ Returns:
+ BaseInstanceMasks: The padded masks.
+ """
+
+ @abstractmethod
+ def crop(self, bbox):
+ """Crop each mask by the given bbox.
+
+ Args:
+ bbox (ndarray): Bbox in format [x1, y1, x2, y2], shape (4, ).
+
+ Return:
+ BaseInstanceMasks: The cropped masks.
+ """
+
+ @abstractmethod
+ def crop_and_resize(self,
+ bboxes,
+ out_shape,
+ inds,
+ device,
+ interpolation='bilinear',
+ binarize=True):
+ """Crop and resize masks by the given bboxes.
+
+ This function is mainly used in mask targets computation.
+ It firstly align mask to bboxes by assigned_inds, then crop mask by the
+ assigned bbox and resize to the size of (mask_h, mask_w)
+
+ Args:
+ bboxes (Tensor): Bboxes in format [x1, y1, x2, y2], shape (N, 4)
+ out_shape (tuple[int]): Target (h, w) of resized mask
+ inds (ndarray): Indexes to assign masks to each bbox,
+ shape (N,) and values should be between [0, num_masks - 1].
+ device (str): Device of bboxes
+ interpolation (str): See `mmcv.imresize`
+ binarize (bool): if True fractional values are rounded to 0 or 1
+ after the resize operation. if False and unsupported an error
+ will be raised. Defaults to True.
+
+ Return:
+ BaseInstanceMasks: the cropped and resized masks.
+ """
+
+ @abstractmethod
+ def expand(self, expanded_h, expanded_w, top, left):
+ """see :class:`Expand`."""
+
+ @property
+ @abstractmethod
+ def areas(self):
+ """ndarray: areas of each instance."""
+
+ @abstractmethod
+ def to_ndarray(self):
+ """Convert masks to the format of ndarray.
+
+ Return:
+ ndarray: Converted masks in the format of ndarray.
+ """
+
+ @abstractmethod
+ def to_tensor(self, dtype, device):
+ """Convert masks to the format of Tensor.
+
+ Args:
+ dtype (str): Dtype of converted mask.
+ device (torch.device): Device of converted masks.
+
+ Returns:
+ Tensor: Converted masks in the format of Tensor.
+ """
+
+ @abstractmethod
+ def translate(self,
+ out_shape,
+ offset,
+ direction='horizontal',
+ border_value=0,
+ interpolation='bilinear'):
+ """Translate the masks.
+
+ Args:
+ out_shape (tuple[int]): Shape for output mask, format (h, w).
+ offset (int | float): The offset for translate.
+ direction (str): The translate direction, either "horizontal"
+ or "vertical".
+ border_value (int | float): Border value. Default 0.
+ interpolation (str): Same as :func:`mmcv.imtranslate`.
+
+ Returns:
+ Translated masks.
+ """
+
+ def shear(self,
+ out_shape,
+ magnitude,
+ direction='horizontal',
+ border_value=0,
+ interpolation='bilinear'):
+ """Shear the masks.
+
+ Args:
+ out_shape (tuple[int]): Shape for output mask, format (h, w).
+ magnitude (int | float): The magnitude used for shear.
+ direction (str): The shear direction, either "horizontal"
+ or "vertical".
+ border_value (int | tuple[int]): Value used in case of a
+ constant border. Default 0.
+ interpolation (str): Same as in :func:`mmcv.imshear`.
+
+ Returns:
+ ndarray: Sheared masks.
+ """
+
+ @abstractmethod
+ def rotate(self, out_shape, angle, center=None, scale=1.0, border_value=0):
+ """Rotate the masks.
+
+ Args:
+ out_shape (tuple[int]): Shape for output mask, format (h, w).
+ angle (int | float): Rotation angle in degrees. Positive values
+ mean counter-clockwise rotation.
+ center (tuple[float], optional): Center point (w, h) of the
+ rotation in source image. If not specified, the center of
+ the image will be used.
+ scale (int | float): Isotropic scale factor.
+ border_value (int | float): Border value. Default 0 for masks.
+
+ Returns:
+ Rotated masks.
+ """
+
+ def get_bboxes(self, dst_type='hbb'):
+ """Get the certain type boxes from masks.
+
+ Please refer to ``mmdet.structures.bbox.box_type`` for more details of
+ the box type.
+
+ Args:
+ dst_type: Destination box type.
+
+ Returns:
+ :obj:`BaseBoxes`: Certain type boxes.
+ """
+ from ..bbox import get_box_type
+ _, box_type_cls = get_box_type(dst_type)
+ return box_type_cls.from_instance_masks(self)
+
+ @classmethod
+ @abstractmethod
+ def cat(cls: Type[T], masks: Sequence[T]) -> T:
+ """Concatenate a sequence of masks into one single mask instance.
+
+ Args:
+ masks (Sequence[T]): A sequence of mask instances.
+
+ Returns:
+ T: Concatenated mask instance.
+ """
+
+
+class BitmapMasks(BaseInstanceMasks):
+ """This class represents masks in the form of bitmaps.
+
+ Args:
+ masks (ndarray): ndarray of masks in shape (N, H, W), where N is
+ the number of objects.
+ height (int): height of masks
+ width (int): width of masks
+
+ Example:
+ >>> from mmdet.data_elements.mask.structures import * # NOQA
+ >>> num_masks, H, W = 3, 32, 32
+ >>> rng = np.random.RandomState(0)
+ >>> masks = (rng.rand(num_masks, H, W) > 0.1).astype(np.int64)
+ >>> self = BitmapMasks(masks, height=H, width=W)
+
+ >>> # demo crop_and_resize
+ >>> num_boxes = 5
+ >>> bboxes = np.array([[0, 0, 30, 10.0]] * num_boxes)
+ >>> out_shape = (14, 14)
+ >>> inds = torch.randint(0, len(self), size=(num_boxes,))
+ >>> device = 'cpu'
+ >>> interpolation = 'bilinear'
+ >>> new = self.crop_and_resize(
+ ... bboxes, out_shape, inds, device, interpolation)
+ >>> assert len(new) == num_boxes
+ >>> assert new.height, new.width == out_shape
+ """
+
+ def __init__(self, masks, height, width):
+ self.height = height
+ self.width = width
+ if len(masks) == 0:
+ self.masks = np.empty((0, self.height, self.width), dtype=np.uint8)
+ else:
+ assert isinstance(masks, (list, np.ndarray))
+ if isinstance(masks, list):
+ assert isinstance(masks[0], np.ndarray)
+ assert masks[0].ndim == 2 # (H, W)
+ else:
+ assert masks.ndim == 3 # (N, H, W)
+
+ self.masks = np.stack(masks).reshape(-1, height, width)
+ assert self.masks.shape[1] == self.height
+ assert self.masks.shape[2] == self.width
+
+ def __getitem__(self, index):
+ """Index the BitmapMask.
+
+ Args:
+ index (int | ndarray): Indices in the format of integer or ndarray.
+
+ Returns:
+ :obj:`BitmapMasks`: Indexed bitmap masks.
+ """
+ masks = self.masks[index].reshape(-1, self.height, self.width)
+ return BitmapMasks(masks, self.height, self.width)
+
+ def __iter__(self):
+ return iter(self.masks)
+
+ def __repr__(self):
+ s = self.__class__.__name__ + '('
+ s += f'num_masks={len(self.masks)}, '
+ s += f'height={self.height}, '
+ s += f'width={self.width})'
+ return s
+
+ def __len__(self):
+ """Number of masks."""
+ return len(self.masks)
+
+ def rescale(self, scale, interpolation='nearest'):
+ """See :func:`BaseInstanceMasks.rescale`."""
+ if len(self.masks) == 0:
+ new_w, new_h = mmcv.rescale_size((self.width, self.height), scale)
+ rescaled_masks = np.empty((0, new_h, new_w), dtype=np.uint8)
+ else:
+ rescaled_masks = np.stack([
+ mmcv.imrescale(mask, scale, interpolation=interpolation)
+ for mask in self.masks
+ ])
+ height, width = rescaled_masks.shape[1:]
+ return BitmapMasks(rescaled_masks, height, width)
+
+ def resize(self, out_shape, interpolation='nearest'):
+ """See :func:`BaseInstanceMasks.resize`."""
+ if len(self.masks) == 0:
+ resized_masks = np.empty((0, *out_shape), dtype=np.uint8)
+ else:
+ resized_masks = np.stack([
+ mmcv.imresize(
+ mask, out_shape[::-1], interpolation=interpolation)
+ for mask in self.masks
+ ])
+ return BitmapMasks(resized_masks, *out_shape)
+
+ def flip(self, flip_direction='horizontal'):
+ """See :func:`BaseInstanceMasks.flip`."""
+ assert flip_direction in ('horizontal', 'vertical', 'diagonal')
+
+ if len(self.masks) == 0:
+ flipped_masks = self.masks
+ else:
+ flipped_masks = np.stack([
+ mmcv.imflip(mask, direction=flip_direction)
+ for mask in self.masks
+ ])
+ return BitmapMasks(flipped_masks, self.height, self.width)
+
+ def pad(self, out_shape, pad_val=0):
+ """See :func:`BaseInstanceMasks.pad`."""
+ if len(self.masks) == 0:
+ padded_masks = np.empty((0, *out_shape), dtype=np.uint8)
+ else:
+ padded_masks = np.stack([
+ mmcv.impad(mask, shape=out_shape, pad_val=pad_val)
+ for mask in self.masks
+ ])
+ return BitmapMasks(padded_masks, *out_shape)
+
+ def crop(self, bbox):
+ """See :func:`BaseInstanceMasks.crop`."""
+ assert isinstance(bbox, np.ndarray)
+ assert bbox.ndim == 1
+
+ # clip the boundary
+ bbox = bbox.copy()
+ bbox[0::2] = np.clip(bbox[0::2], 0, self.width)
+ bbox[1::2] = np.clip(bbox[1::2], 0, self.height)
+ x1, y1, x2, y2 = bbox
+ w = np.maximum(x2 - x1, 1)
+ h = np.maximum(y2 - y1, 1)
+
+ if len(self.masks) == 0:
+ cropped_masks = np.empty((0, h, w), dtype=np.uint8)
+ else:
+ cropped_masks = self.masks[:, y1:y1 + h, x1:x1 + w]
+ return BitmapMasks(cropped_masks, h, w)
+
+ def crop_and_resize(self,
+ bboxes,
+ out_shape,
+ inds,
+ device='cpu',
+ interpolation='bilinear',
+ binarize=True):
+ """See :func:`BaseInstanceMasks.crop_and_resize`."""
+ if len(self.masks) == 0:
+ empty_masks = np.empty((0, *out_shape), dtype=np.uint8)
+ return BitmapMasks(empty_masks, *out_shape)
+
+ # convert bboxes to tensor
+ if isinstance(bboxes, np.ndarray):
+ bboxes = torch.from_numpy(bboxes).to(device=device)
+ if isinstance(inds, np.ndarray):
+ inds = torch.from_numpy(inds).to(device=device)
+
+ num_bbox = bboxes.shape[0]
+ fake_inds = torch.arange(
+ num_bbox, device=device).to(dtype=bboxes.dtype)[:, None]
+ rois = torch.cat([fake_inds, bboxes], dim=1) # Nx5
+ rois = rois.to(device=device)
+ if num_bbox > 0:
+ gt_masks_th = torch.from_numpy(self.masks).to(device).index_select(
+ 0, inds).to(dtype=rois.dtype)
+ targets = roi_align(gt_masks_th[:, None, :, :], rois, out_shape,
+ 1.0, 0, 'avg', True).squeeze(1)
+ if binarize:
+ resized_masks = (targets >= 0.5).cpu().numpy()
+ else:
+ resized_masks = targets.cpu().numpy()
+ else:
+ resized_masks = []
+ return BitmapMasks(resized_masks, *out_shape)
+
+ def expand(self, expanded_h, expanded_w, top, left):
+ """See :func:`BaseInstanceMasks.expand`."""
+ if len(self.masks) == 0:
+ expanded_mask = np.empty((0, expanded_h, expanded_w),
+ dtype=np.uint8)
+ else:
+ expanded_mask = np.zeros((len(self), expanded_h, expanded_w),
+ dtype=np.uint8)
+ expanded_mask[:, top:top + self.height,
+ left:left + self.width] = self.masks
+ return BitmapMasks(expanded_mask, expanded_h, expanded_w)
+
+ def translate(self,
+ out_shape,
+ offset,
+ direction='horizontal',
+ border_value=0,
+ interpolation='bilinear'):
+ """Translate the BitmapMasks.
+
+ Args:
+ out_shape (tuple[int]): Shape for output mask, format (h, w).
+ offset (int | float): The offset for translate.
+ direction (str): The translate direction, either "horizontal"
+ or "vertical".
+ border_value (int | float): Border value. Default 0 for masks.
+ interpolation (str): Same as :func:`mmcv.imtranslate`.
+
+ Returns:
+ BitmapMasks: Translated BitmapMasks.
+
+ Example:
+ >>> from mmdet.data_elements.mask.structures import BitmapMasks
+ >>> self = BitmapMasks.random(dtype=np.uint8)
+ >>> out_shape = (32, 32)
+ >>> offset = 4
+ >>> direction = 'horizontal'
+ >>> border_value = 0
+ >>> interpolation = 'bilinear'
+ >>> # Note, There seem to be issues when:
+ >>> # * the mask dtype is not supported by cv2.AffineWarp
+ >>> new = self.translate(out_shape, offset, direction,
+ >>> border_value, interpolation)
+ >>> assert len(new) == len(self)
+ >>> assert new.height, new.width == out_shape
+ """
+ if len(self.masks) == 0:
+ translated_masks = np.empty((0, *out_shape), dtype=np.uint8)
+ else:
+ masks = self.masks
+ if masks.shape[-2:] != out_shape:
+ empty_masks = np.zeros((masks.shape[0], *out_shape),
+ dtype=masks.dtype)
+ min_h = min(out_shape[0], masks.shape[1])
+ min_w = min(out_shape[1], masks.shape[2])
+ empty_masks[:, :min_h, :min_w] = masks[:, :min_h, :min_w]
+ masks = empty_masks
+ translated_masks = mmcv.imtranslate(
+ masks.transpose((1, 2, 0)),
+ offset,
+ direction,
+ border_value=border_value,
+ interpolation=interpolation)
+ if translated_masks.ndim == 2:
+ translated_masks = translated_masks[:, :, None]
+ translated_masks = translated_masks.transpose(
+ (2, 0, 1)).astype(self.masks.dtype)
+ return BitmapMasks(translated_masks, *out_shape)
+
+ def shear(self,
+ out_shape,
+ magnitude,
+ direction='horizontal',
+ border_value=0,
+ interpolation='bilinear'):
+ """Shear the BitmapMasks.
+
+ Args:
+ out_shape (tuple[int]): Shape for output mask, format (h, w).
+ magnitude (int | float): The magnitude used for shear.
+ direction (str): The shear direction, either "horizontal"
+ or "vertical".
+ border_value (int | tuple[int]): Value used in case of a
+ constant border.
+ interpolation (str): Same as in :func:`mmcv.imshear`.
+
+ Returns:
+ BitmapMasks: The sheared masks.
+ """
+ if len(self.masks) == 0:
+ sheared_masks = np.empty((0, *out_shape), dtype=np.uint8)
+ else:
+ sheared_masks = mmcv.imshear(
+ self.masks.transpose((1, 2, 0)),
+ magnitude,
+ direction,
+ border_value=border_value,
+ interpolation=interpolation)
+ if sheared_masks.ndim == 2:
+ sheared_masks = sheared_masks[:, :, None]
+ sheared_masks = sheared_masks.transpose(
+ (2, 0, 1)).astype(self.masks.dtype)
+ return BitmapMasks(sheared_masks, *out_shape)
+
+ def rotate(self,
+ out_shape,
+ angle,
+ center=None,
+ scale=1.0,
+ border_value=0,
+ interpolation='bilinear'):
+ """Rotate the BitmapMasks.
+
+ Args:
+ out_shape (tuple[int]): Shape for output mask, format (h, w).
+ angle (int | float): Rotation angle in degrees. Positive values
+ mean counter-clockwise rotation.
+ center (tuple[float], optional): Center point (w, h) of the
+ rotation in source image. If not specified, the center of
+ the image will be used.
+ scale (int | float): Isotropic scale factor.
+ border_value (int | float): Border value. Default 0 for masks.
+ interpolation (str): Same as in :func:`mmcv.imrotate`.
+
+ Returns:
+ BitmapMasks: Rotated BitmapMasks.
+ """
+ if len(self.masks) == 0:
+ rotated_masks = np.empty((0, *out_shape), dtype=self.masks.dtype)
+ else:
+ rotated_masks = mmcv.imrotate(
+ self.masks.transpose((1, 2, 0)),
+ angle,
+ center=center,
+ scale=scale,
+ border_value=border_value,
+ interpolation=interpolation)
+ if rotated_masks.ndim == 2:
+ # case when only one mask, (h, w)
+ rotated_masks = rotated_masks[:, :, None] # (h, w, 1)
+ rotated_masks = rotated_masks.transpose(
+ (2, 0, 1)).astype(self.masks.dtype)
+ return BitmapMasks(rotated_masks, *out_shape)
+
+ @property
+ def areas(self):
+ """See :py:attr:`BaseInstanceMasks.areas`."""
+ return self.masks.sum((1, 2))
+
+ def to_ndarray(self):
+ """See :func:`BaseInstanceMasks.to_ndarray`."""
+ return self.masks
+
+ def to_tensor(self, dtype, device):
+ """See :func:`BaseInstanceMasks.to_tensor`."""
+ return torch.tensor(self.masks, dtype=dtype, device=device)
+
+ @classmethod
+ def random(cls,
+ num_masks=3,
+ height=32,
+ width=32,
+ dtype=np.uint8,
+ rng=None):
+ """Generate random bitmap masks for demo / testing purposes.
+
+ Example:
+ >>> from mmdet.data_elements.mask.structures import BitmapMasks
+ >>> self = BitmapMasks.random()
+ >>> print('self = {}'.format(self))
+ self = BitmapMasks(num_masks=3, height=32, width=32)
+ """
+ from mmdet.utils.util_random import ensure_rng
+ rng = ensure_rng(rng)
+ masks = (rng.rand(num_masks, height, width) > 0.1).astype(dtype)
+ self = cls(masks, height=height, width=width)
+ return self
+
+ @classmethod
+ def cat(cls: Type[T], masks: Sequence[T]) -> T:
+ """Concatenate a sequence of masks into one single mask instance.
+
+ Args:
+ masks (Sequence[BitmapMasks]): A sequence of mask instances.
+
+ Returns:
+ BitmapMasks: Concatenated mask instance.
+ """
+ assert isinstance(masks, Sequence)
+ if len(masks) == 0:
+ raise ValueError('masks should not be an empty list.')
+ assert all(isinstance(m, cls) for m in masks)
+
+ mask_array = np.concatenate([m.masks for m in masks], axis=0)
+ return cls(mask_array, *mask_array.shape[1:])
+
+
+class PolygonMasks(BaseInstanceMasks):
+ """This class represents masks in the form of polygons.
+
+ Polygons is a list of three levels. The first level of the list
+ corresponds to objects, the second level to the polys that compose the
+ object, the third level to the poly coordinates
+
+ Args:
+ masks (list[list[ndarray]]): The first level of the list
+ corresponds to objects, the second level to the polys that
+ compose the object, the third level to the poly coordinates
+ height (int): height of masks
+ width (int): width of masks
+
+ Example:
+ >>> from mmdet.data_elements.mask.structures import * # NOQA
+ >>> masks = [
+ >>> [ np.array([0, 0, 10, 0, 10, 10., 0, 10, 0, 0]) ]
+ >>> ]
+ >>> height, width = 16, 16
+ >>> self = PolygonMasks(masks, height, width)
+
+ >>> # demo translate
+ >>> new = self.translate((16, 16), 4., direction='horizontal')
+ >>> assert np.all(new.masks[0][0][1::2] == masks[0][0][1::2])
+ >>> assert np.all(new.masks[0][0][0::2] == masks[0][0][0::2] + 4)
+
+ >>> # demo crop_and_resize
+ >>> num_boxes = 3
+ >>> bboxes = np.array([[0, 0, 30, 10.0]] * num_boxes)
+ >>> out_shape = (16, 16)
+ >>> inds = torch.randint(0, len(self), size=(num_boxes,))
+ >>> device = 'cpu'
+ >>> interpolation = 'bilinear'
+ >>> new = self.crop_and_resize(
+ ... bboxes, out_shape, inds, device, interpolation)
+ >>> assert len(new) == num_boxes
+ >>> assert new.height, new.width == out_shape
+ """
+
+ def __init__(self, masks, height, width):
+ assert isinstance(masks, list)
+ if len(masks) > 0:
+ assert isinstance(masks[0], list)
+ assert isinstance(masks[0][0], np.ndarray)
+
+ self.height = height
+ self.width = width
+ self.masks = masks
+
+ def __getitem__(self, index):
+ """Index the polygon masks.
+
+ Args:
+ index (ndarray | List): The indices.
+
+ Returns:
+ :obj:`PolygonMasks`: The indexed polygon masks.
+ """
+ if isinstance(index, np.ndarray):
+ if index.dtype == bool:
+ index = np.where(index)[0].tolist()
+ else:
+ index = index.tolist()
+ if isinstance(index, list):
+ masks = [self.masks[i] for i in index]
+ else:
+ try:
+ masks = self.masks[index]
+ except Exception:
+ raise ValueError(
+ f'Unsupported input of type {type(index)} for indexing!')
+ if len(masks) and isinstance(masks[0], np.ndarray):
+ masks = [masks] # ensure a list of three levels
+ return PolygonMasks(masks, self.height, self.width)
+
+ def __iter__(self):
+ return iter(self.masks)
+
+ def __repr__(self):
+ s = self.__class__.__name__ + '('
+ s += f'num_masks={len(self.masks)}, '
+ s += f'height={self.height}, '
+ s += f'width={self.width})'
+ return s
+
+ def __len__(self):
+ """Number of masks."""
+ return len(self.masks)
+
+ def rescale(self, scale, interpolation=None):
+ """see :func:`BaseInstanceMasks.rescale`"""
+ new_w, new_h = mmcv.rescale_size((self.width, self.height), scale)
+ if len(self.masks) == 0:
+ rescaled_masks = PolygonMasks([], new_h, new_w)
+ else:
+ rescaled_masks = self.resize((new_h, new_w))
+ return rescaled_masks
+
+ def resize(self, out_shape, interpolation=None):
+ """see :func:`BaseInstanceMasks.resize`"""
+ if len(self.masks) == 0:
+ resized_masks = PolygonMasks([], *out_shape)
+ else:
+ h_scale = out_shape[0] / self.height
+ w_scale = out_shape[1] / self.width
+ resized_masks = []
+ for poly_per_obj in self.masks:
+ resized_poly = []
+ for p in poly_per_obj:
+ p = p.copy()
+ p[0::2] = p[0::2] * w_scale
+ p[1::2] = p[1::2] * h_scale
+ resized_poly.append(p)
+ resized_masks.append(resized_poly)
+ resized_masks = PolygonMasks(resized_masks, *out_shape)
+ return resized_masks
+
+ def flip(self, flip_direction='horizontal'):
+ """see :func:`BaseInstanceMasks.flip`"""
+ assert flip_direction in ('horizontal', 'vertical', 'diagonal')
+ if len(self.masks) == 0:
+ flipped_masks = PolygonMasks([], self.height, self.width)
+ else:
+ flipped_masks = []
+ for poly_per_obj in self.masks:
+ flipped_poly_per_obj = []
+ for p in poly_per_obj:
+ p = p.copy()
+ if flip_direction == 'horizontal':
+ p[0::2] = self.width - p[0::2]
+ elif flip_direction == 'vertical':
+ p[1::2] = self.height - p[1::2]
+ else:
+ p[0::2] = self.width - p[0::2]
+ p[1::2] = self.height - p[1::2]
+ flipped_poly_per_obj.append(p)
+ flipped_masks.append(flipped_poly_per_obj)
+ flipped_masks = PolygonMasks(flipped_masks, self.height,
+ self.width)
+ return flipped_masks
+
+ def crop(self, bbox):
+ """see :func:`BaseInstanceMasks.crop`"""
+ assert isinstance(bbox, np.ndarray)
+ assert bbox.ndim == 1
+
+ # clip the boundary
+ bbox = bbox.copy()
+ bbox[0::2] = np.clip(bbox[0::2], 0, self.width)
+ bbox[1::2] = np.clip(bbox[1::2], 0, self.height)
+ x1, y1, x2, y2 = bbox
+ w = np.maximum(x2 - x1, 1)
+ h = np.maximum(y2 - y1, 1)
+
+ if len(self.masks) == 0:
+ cropped_masks = PolygonMasks([], h, w)
+ else:
+ # reference: https://github.com/facebookresearch/fvcore/blob/main/fvcore/transforms/transform.py # noqa
+ crop_box = geometry.box(x1, y1, x2, y2).buffer(0.0)
+ cropped_masks = []
+ # suppress shapely warnings util it incorporates GEOS>=3.11.2
+ # reference: https://github.com/shapely/shapely/issues/1345
+ initial_settings = np.seterr()
+ np.seterr(invalid='ignore')
+ for poly_per_obj in self.masks:
+ cropped_poly_per_obj = []
+ for p in poly_per_obj:
+ p = p.copy()
+ p = geometry.Polygon(p.reshape(-1, 2)).buffer(0.0)
+ # polygon must be valid to perform intersection.
+ if not p.is_valid:
+ continue
+ cropped = p.intersection(crop_box)
+ if cropped.is_empty:
+ continue
+ if isinstance(cropped,
+ geometry.collection.BaseMultipartGeometry):
+ cropped = cropped.geoms
+ else:
+ cropped = [cropped]
+ # one polygon may be cropped to multiple ones
+ for poly in cropped:
+ # ignore lines or points
+ if not isinstance(
+ poly, geometry.Polygon) or not poly.is_valid:
+ continue
+ coords = np.asarray(poly.exterior.coords)
+ # remove an extra identical vertex at the end
+ coords = coords[:-1]
+ coords[:, 0] -= x1
+ coords[:, 1] -= y1
+ cropped_poly_per_obj.append(coords.reshape(-1))
+ # a dummy polygon to avoid misalignment between masks and boxes
+ if len(cropped_poly_per_obj) == 0:
+ cropped_poly_per_obj = [np.array([0, 0, 0, 0, 0, 0])]
+ cropped_masks.append(cropped_poly_per_obj)
+ np.seterr(**initial_settings)
+ cropped_masks = PolygonMasks(cropped_masks, h, w)
+ return cropped_masks
+
+ def pad(self, out_shape, pad_val=0):
+ """padding has no effect on polygons`"""
+ return PolygonMasks(self.masks, *out_shape)
+
+ def expand(self, *args, **kwargs):
+ """TODO: Add expand for polygon"""
+ raise NotImplementedError
+
+ def crop_and_resize(self,
+ bboxes,
+ out_shape,
+ inds,
+ device='cpu',
+ interpolation='bilinear',
+ binarize=True):
+ """see :func:`BaseInstanceMasks.crop_and_resize`"""
+ out_h, out_w = out_shape
+ if len(self.masks) == 0:
+ return PolygonMasks([], out_h, out_w)
+
+ if not binarize:
+ raise ValueError('Polygons are always binary, '
+ 'setting binarize=False is unsupported')
+
+ resized_masks = []
+ for i in range(len(bboxes)):
+ mask = self.masks[inds[i]]
+ bbox = bboxes[i, :]
+ x1, y1, x2, y2 = bbox
+ w = np.maximum(x2 - x1, 1)
+ h = np.maximum(y2 - y1, 1)
+ h_scale = out_h / max(h, 0.1) # avoid too large scale
+ w_scale = out_w / max(w, 0.1)
+
+ resized_mask = []
+ for p in mask:
+ p = p.copy()
+ # crop
+ # pycocotools will clip the boundary
+ p[0::2] = p[0::2] - bbox[0]
+ p[1::2] = p[1::2] - bbox[1]
+
+ # resize
+ p[0::2] = p[0::2] * w_scale
+ p[1::2] = p[1::2] * h_scale
+ resized_mask.append(p)
+ resized_masks.append(resized_mask)
+ return PolygonMasks(resized_masks, *out_shape)
+
+ def translate(self,
+ out_shape,
+ offset,
+ direction='horizontal',
+ border_value=None,
+ interpolation=None):
+ """Translate the PolygonMasks.
+
+ Example:
+ >>> self = PolygonMasks.random(dtype=np.int64)
+ >>> out_shape = (self.height, self.width)
+ >>> new = self.translate(out_shape, 4., direction='horizontal')
+ >>> assert np.all(new.masks[0][0][1::2] == self.masks[0][0][1::2])
+ >>> assert np.all(new.masks[0][0][0::2] == self.masks[0][0][0::2] + 4) # noqa: E501
+ """
+ assert border_value is None or border_value == 0, \
+ 'Here border_value is not '\
+ f'used, and defaultly should be None or 0. got {border_value}.'
+ if len(self.masks) == 0:
+ translated_masks = PolygonMasks([], *out_shape)
+ else:
+ translated_masks = []
+ for poly_per_obj in self.masks:
+ translated_poly_per_obj = []
+ for p in poly_per_obj:
+ p = p.copy()
+ if direction == 'horizontal':
+ p[0::2] = np.clip(p[0::2] + offset, 0, out_shape[1])
+ elif direction == 'vertical':
+ p[1::2] = np.clip(p[1::2] + offset, 0, out_shape[0])
+ translated_poly_per_obj.append(p)
+ translated_masks.append(translated_poly_per_obj)
+ translated_masks = PolygonMasks(translated_masks, *out_shape)
+ return translated_masks
+
+ def shear(self,
+ out_shape,
+ magnitude,
+ direction='horizontal',
+ border_value=0,
+ interpolation='bilinear'):
+ """See :func:`BaseInstanceMasks.shear`."""
+ if len(self.masks) == 0:
+ sheared_masks = PolygonMasks([], *out_shape)
+ else:
+ sheared_masks = []
+ if direction == 'horizontal':
+ shear_matrix = np.stack([[1, magnitude],
+ [0, 1]]).astype(np.float32)
+ elif direction == 'vertical':
+ shear_matrix = np.stack([[1, 0], [magnitude,
+ 1]]).astype(np.float32)
+ for poly_per_obj in self.masks:
+ sheared_poly = []
+ for p in poly_per_obj:
+ p = np.stack([p[0::2], p[1::2]], axis=0) # [2, n]
+ new_coords = np.matmul(shear_matrix, p) # [2, n]
+ new_coords[0, :] = np.clip(new_coords[0, :], 0,
+ out_shape[1])
+ new_coords[1, :] = np.clip(new_coords[1, :], 0,
+ out_shape[0])
+ sheared_poly.append(
+ new_coords.transpose((1, 0)).reshape(-1))
+ sheared_masks.append(sheared_poly)
+ sheared_masks = PolygonMasks(sheared_masks, *out_shape)
+ return sheared_masks
+
+ def rotate(self,
+ out_shape,
+ angle,
+ center=None,
+ scale=1.0,
+ border_value=0,
+ interpolation='bilinear'):
+ """See :func:`BaseInstanceMasks.rotate`."""
+ if len(self.masks) == 0:
+ rotated_masks = PolygonMasks([], *out_shape)
+ else:
+ rotated_masks = []
+ rotate_matrix = cv2.getRotationMatrix2D(center, -angle, scale)
+ for poly_per_obj in self.masks:
+ rotated_poly = []
+ for p in poly_per_obj:
+ p = p.copy()
+ coords = np.stack([p[0::2], p[1::2]], axis=1) # [n, 2]
+ # pad 1 to convert from format [x, y] to homogeneous
+ # coordinates format [x, y, 1]
+ coords = np.concatenate(
+ (coords, np.ones((coords.shape[0], 1), coords.dtype)),
+ axis=1) # [n, 3]
+ rotated_coords = np.matmul(
+ rotate_matrix[None, :, :],
+ coords[:, :, None])[..., 0] # [n, 2, 1] -> [n, 2]
+ rotated_coords[:, 0] = np.clip(rotated_coords[:, 0], 0,
+ out_shape[1])
+ rotated_coords[:, 1] = np.clip(rotated_coords[:, 1], 0,
+ out_shape[0])
+ rotated_poly.append(rotated_coords.reshape(-1))
+ rotated_masks.append(rotated_poly)
+ rotated_masks = PolygonMasks(rotated_masks, *out_shape)
+ return rotated_masks
+
+ def to_bitmap(self):
+ """convert polygon masks to bitmap masks."""
+ bitmap_masks = self.to_ndarray()
+ return BitmapMasks(bitmap_masks, self.height, self.width)
+
+ @property
+ def areas(self):
+ """Compute areas of masks.
+
+ This func is modified from `detectron2
+ `_.
+ The function only works with Polygons using the shoelace formula.
+
+ Return:
+ ndarray: areas of each instance
+ """ # noqa: W501
+ area = []
+ for polygons_per_obj in self.masks:
+ area_per_obj = 0
+ for p in polygons_per_obj:
+ area_per_obj += self._polygon_area(p[0::2], p[1::2])
+ area.append(area_per_obj)
+ return np.asarray(area)
+
+ def _polygon_area(self, x, y):
+ """Compute the area of a component of a polygon.
+
+ Using the shoelace formula:
+ https://stackoverflow.com/questions/24467972/calculate-area-of-polygon-given-x-y-coordinates
+
+ Args:
+ x (ndarray): x coordinates of the component
+ y (ndarray): y coordinates of the component
+
+ Return:
+ float: the are of the component
+ """ # noqa: 501
+ return 0.5 * np.abs(
+ np.dot(x, np.roll(y, 1)) - np.dot(y, np.roll(x, 1)))
+
+ def to_ndarray(self):
+ """Convert masks to the format of ndarray."""
+ if len(self.masks) == 0:
+ return np.empty((0, self.height, self.width), dtype=np.uint8)
+ bitmap_masks = []
+ for poly_per_obj in self.masks:
+ bitmap_masks.append(
+ polygon_to_bitmap(poly_per_obj, self.height, self.width))
+ return np.stack(bitmap_masks)
+
+ def to_tensor(self, dtype, device):
+ """See :func:`BaseInstanceMasks.to_tensor`."""
+ if len(self.masks) == 0:
+ return torch.empty((0, self.height, self.width),
+ dtype=dtype,
+ device=device)
+ ndarray_masks = self.to_ndarray()
+ return torch.tensor(ndarray_masks, dtype=dtype, device=device)
+
+ @classmethod
+ def random(cls,
+ num_masks=3,
+ height=32,
+ width=32,
+ n_verts=5,
+ dtype=np.float32,
+ rng=None):
+ """Generate random polygon masks for demo / testing purposes.
+
+ Adapted from [1]_
+
+ References:
+ .. [1] https://gitlab.kitware.com/computer-vision/kwimage/-/blob/928cae35ca8/kwimage/structs/polygon.py#L379 # noqa: E501
+
+ Example:
+ >>> from mmdet.data_elements.mask.structures import PolygonMasks
+ >>> self = PolygonMasks.random()
+ >>> print('self = {}'.format(self))
+ """
+ from mmdet.utils.util_random import ensure_rng
+ rng = ensure_rng(rng)
+
+ def _gen_polygon(n, irregularity, spikeyness):
+ """Creates the polygon by sampling points on a circle around the
+ centre. Random noise is added by varying the angular spacing
+ between sequential points, and by varying the radial distance of
+ each point from the centre.
+
+ Based on original code by Mike Ounsworth
+
+ Args:
+ n (int): number of vertices
+ irregularity (float): [0,1] indicating how much variance there
+ is in the angular spacing of vertices. [0,1] will map to
+ [0, 2pi/numberOfVerts]
+ spikeyness (float): [0,1] indicating how much variance there is
+ in each vertex from the circle of radius aveRadius. [0,1]
+ will map to [0, aveRadius]
+
+ Returns:
+ a list of vertices, in CCW order.
+ """
+ from scipy.stats import truncnorm
+
+ # Generate around the unit circle
+ cx, cy = (0.0, 0.0)
+ radius = 1
+
+ tau = np.pi * 2
+
+ irregularity = np.clip(irregularity, 0, 1) * 2 * np.pi / n
+ spikeyness = np.clip(spikeyness, 1e-9, 1)
+
+ # generate n angle steps
+ lower = (tau / n) - irregularity
+ upper = (tau / n) + irregularity
+ angle_steps = rng.uniform(lower, upper, n)
+
+ # normalize the steps so that point 0 and point n+1 are the same
+ k = angle_steps.sum() / (2 * np.pi)
+ angles = (angle_steps / k).cumsum() + rng.uniform(0, tau)
+
+ # Convert high and low values to be wrt the standard normal range
+ # https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.truncnorm.html
+ low = 0
+ high = 2 * radius
+ mean = radius
+ std = spikeyness
+ a = (low - mean) / std
+ b = (high - mean) / std
+ tnorm = truncnorm(a=a, b=b, loc=mean, scale=std)
+
+ # now generate the points
+ radii = tnorm.rvs(n, random_state=rng)
+ x_pts = cx + radii * np.cos(angles)
+ y_pts = cy + radii * np.sin(angles)
+
+ points = np.hstack([x_pts[:, None], y_pts[:, None]])
+
+ # Scale to 0-1 space
+ points = points - points.min(axis=0)
+ points = points / points.max(axis=0)
+
+ # Randomly place within 0-1 space
+ points = points * (rng.rand() * .8 + .2)
+ min_pt = points.min(axis=0)
+ max_pt = points.max(axis=0)
+
+ high = (1 - max_pt)
+ low = (0 - min_pt)
+ offset = (rng.rand(2) * (high - low)) + low
+ points = points + offset
+ return points
+
+ def _order_vertices(verts):
+ """
+ References:
+ https://stackoverflow.com/questions/1709283/how-can-i-sort-a-coordinate-list-for-a-rectangle-counterclockwise
+ """
+ mlat = verts.T[0].sum() / len(verts)
+ mlng = verts.T[1].sum() / len(verts)
+
+ tau = np.pi * 2
+ angle = (np.arctan2(mlat - verts.T[0], verts.T[1] - mlng) +
+ tau) % tau
+ sortx = angle.argsort()
+ verts = verts.take(sortx, axis=0)
+ return verts
+
+ # Generate a random exterior for each requested mask
+ masks = []
+ for _ in range(num_masks):
+ exterior = _order_vertices(_gen_polygon(n_verts, 0.9, 0.9))
+ exterior = (exterior * [(width, height)]).astype(dtype)
+ masks.append([exterior.ravel()])
+
+ self = cls(masks, height, width)
+ return self
+
+ @classmethod
+ def cat(cls: Type[T], masks: Sequence[T]) -> T:
+ """Concatenate a sequence of masks into one single mask instance.
+
+ Args:
+ masks (Sequence[PolygonMasks]): A sequence of mask instances.
+
+ Returns:
+ PolygonMasks: Concatenated mask instance.
+ """
+ assert isinstance(masks, Sequence)
+ if len(masks) == 0:
+ raise ValueError('masks should not be an empty list.')
+ assert all(isinstance(m, cls) for m in masks)
+
+ mask_list = list(itertools.chain(*[m.masks for m in masks]))
+ return cls(mask_list, masks[0].height, masks[0].width)
+
+
+def polygon_to_bitmap(polygons, height, width):
+ """Convert masks from the form of polygons to bitmaps.
+
+ Args:
+ polygons (list[ndarray]): masks in polygon representation
+ height (int): mask height
+ width (int): mask width
+
+ Return:
+ ndarray: the converted masks in bitmap representation
+ """
+ rles = maskUtils.frPyObjects(polygons, height, width)
+ rle = maskUtils.merge(rles)
+ bitmap_mask = maskUtils.decode(rle).astype(bool)
+ return bitmap_mask
+
+
+def bitmap_to_polygon(bitmap):
+ """Convert masks from the form of bitmaps to polygons.
+
+ Args:
+ bitmap (ndarray): masks in bitmap representation.
+
+ Return:
+ list[ndarray]: the converted mask in polygon representation.
+ bool: whether the mask has holes.
+ """
+ bitmap = np.ascontiguousarray(bitmap).astype(np.uint8)
+ # cv2.RETR_CCOMP: retrieves all of the contours and organizes them
+ # into a two-level hierarchy. At the top level, there are external
+ # boundaries of the components. At the second level, there are
+ # boundaries of the holes. If there is another contour inside a hole
+ # of a connected component, it is still put at the top level.
+ # cv2.CHAIN_APPROX_NONE: stores absolutely all the contour points.
+ outs = cv2.findContours(bitmap, cv2.RETR_CCOMP, cv2.CHAIN_APPROX_NONE)
+ contours = outs[-2]
+ hierarchy = outs[-1]
+ if hierarchy is None:
+ return [], False
+ # hierarchy[i]: 4 elements, for the indexes of next, previous,
+ # parent, or nested contours. If there is no corresponding contour,
+ # it will be -1.
+ with_hole = (hierarchy.reshape(-1, 4)[:, 3] >= 0).any()
+ contours = [c.reshape(-1, 2) for c in contours]
+ return contours, with_hole
diff --git a/mmdet/structures/mask/utils.py b/mmdet/structures/mask/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..6bd445e4fce1a312949f222d54d230a1a622d726
--- /dev/null
+++ b/mmdet/structures/mask/utils.py
@@ -0,0 +1,77 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import numpy as np
+import pycocotools.mask as mask_util
+import torch
+from mmengine.utils import slice_list
+
+
+def split_combined_polys(polys, poly_lens, polys_per_mask):
+ """Split the combined 1-D polys into masks.
+
+ A mask is represented as a list of polys, and a poly is represented as
+ a 1-D array. In dataset, all masks are concatenated into a single 1-D
+ tensor. Here we need to split the tensor into original representations.
+
+ Args:
+ polys (list): a list (length = image num) of 1-D tensors
+ poly_lens (list): a list (length = image num) of poly length
+ polys_per_mask (list): a list (length = image num) of poly number
+ of each mask
+
+ Returns:
+ list: a list (length = image num) of list (length = mask num) of \
+ list (length = poly num) of numpy array.
+ """
+ mask_polys_list = []
+ for img_id in range(len(polys)):
+ polys_single = polys[img_id]
+ polys_lens_single = poly_lens[img_id].tolist()
+ polys_per_mask_single = polys_per_mask[img_id].tolist()
+
+ split_polys = slice_list(polys_single, polys_lens_single)
+ mask_polys = slice_list(split_polys, polys_per_mask_single)
+ mask_polys_list.append(mask_polys)
+ return mask_polys_list
+
+
+# TODO: move this function to more proper place
+def encode_mask_results(mask_results):
+ """Encode bitmap mask to RLE code.
+
+ Args:
+ mask_results (list): bitmap mask results.
+
+ Returns:
+ list | tuple: RLE encoded mask.
+ """
+ encoded_mask_results = []
+ for mask in mask_results:
+ encoded_mask_results.append(
+ mask_util.encode(
+ np.array(mask[:, :, np.newaxis], order='F',
+ dtype='uint8'))[0]) # encoded with RLE
+ return encoded_mask_results
+
+
+def mask2bbox(masks):
+ """Obtain tight bounding boxes of binary masks.
+
+ Args:
+ masks (Tensor): Binary mask of shape (n, h, w).
+
+ Returns:
+ Tensor: Bboxe with shape (n, 4) of \
+ positive region in binary mask.
+ """
+ N = masks.shape[0]
+ bboxes = masks.new_zeros((N, 4), dtype=torch.float32)
+ x_any = torch.any(masks, dim=1)
+ y_any = torch.any(masks, dim=2)
+ for i in range(N):
+ x = torch.where(x_any[i, :])[0]
+ y = torch.where(y_any[i, :])[0]
+ if len(x) > 0 and len(y) > 0:
+ bboxes[i, :] = bboxes.new_tensor(
+ [x[0], y[0], x[-1] + 1, y[-1] + 1])
+
+ return bboxes
diff --git a/mmdet/testing/__init__.py b/mmdet/testing/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..967817496f8bb5723b0dcd0e92f1689550c4c10c
--- /dev/null
+++ b/mmdet/testing/__init__.py
@@ -0,0 +1,10 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from ._fast_stop_training_hook import FastStopTrainingHook # noqa: F401,F403
+from ._utils import (demo_mm_inputs, demo_mm_proposals,
+ demo_mm_sampling_results, get_detector_cfg,
+ get_roi_head_cfg, replace_to_ceph)
+
+__all__ = [
+ 'demo_mm_inputs', 'get_detector_cfg', 'get_roi_head_cfg',
+ 'demo_mm_proposals', 'demo_mm_sampling_results', 'replace_to_ceph'
+]
diff --git a/mmdet/testing/_fast_stop_training_hook.py b/mmdet/testing/_fast_stop_training_hook.py
new file mode 100644
index 0000000000000000000000000000000000000000..f8e3d11439f875d2c9a6ce6b8a0b33acc832c2c5
--- /dev/null
+++ b/mmdet/testing/_fast_stop_training_hook.py
@@ -0,0 +1,27 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmengine.hooks import Hook
+
+from mmdet.registry import HOOKS
+
+
+@HOOKS.register_module()
+class FastStopTrainingHook(Hook):
+ """Set runner's epoch information to the model."""
+
+ def __init__(self, by_epoch, save_ckpt=False, stop_iter_or_epoch=5):
+ self.by_epoch = by_epoch
+ self.save_ckpt = save_ckpt
+ self.stop_iter_or_epoch = stop_iter_or_epoch
+
+ def after_train_iter(self, runner, batch_idx: int, data_batch: None,
+ outputs: None) -> None:
+ if self.save_ckpt and self.by_epoch:
+ # If it is epoch-based and want to save weights,
+ # we must run at least 1 epoch.
+ return
+ if runner.iter >= self.stop_iter_or_epoch:
+ raise RuntimeError('quick exit')
+
+ def after_train_epoch(self, runner) -> None:
+ if runner.epoch >= self.stop_iter_or_epoch - 1:
+ raise RuntimeError('quick exit')
diff --git a/mmdet/testing/_utils.py b/mmdet/testing/_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..ce74376250ee3bddc8d4740aed57699771e5af75
--- /dev/null
+++ b/mmdet/testing/_utils.py
@@ -0,0 +1,317 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+from os.path import dirname, exists, join
+
+import numpy as np
+import torch
+from mmengine.config import Config
+from mmengine.dataset import pseudo_collate
+from mmengine.structures import InstanceData, PixelData
+
+from ..registry import TASK_UTILS
+from ..structures import DetDataSample
+from ..structures.bbox import HorizontalBoxes
+
+
+def _get_config_directory():
+ """Find the predefined detector config directory."""
+ try:
+ # Assume we are running in the source mmdetection repo
+ repo_dpath = dirname(dirname(dirname(__file__)))
+ except NameError:
+ # For IPython development when this __file__ is not defined
+ import mmdet
+ repo_dpath = dirname(dirname(mmdet.__file__))
+ config_dpath = join(repo_dpath, 'configs')
+ if not exists(config_dpath):
+ raise Exception('Cannot find config path')
+ return config_dpath
+
+
+def _get_config_module(fname):
+ """Load a configuration as a python module."""
+ config_dpath = _get_config_directory()
+ config_fpath = join(config_dpath, fname)
+ config_mod = Config.fromfile(config_fpath)
+ return config_mod
+
+
+def get_detector_cfg(fname):
+ """Grab configs necessary to create a detector.
+
+ These are deep copied to allow for safe modification of parameters without
+ influencing other tests.
+ """
+ config = _get_config_module(fname)
+ model = copy.deepcopy(config.model)
+ return model
+
+
+def get_roi_head_cfg(fname):
+ """Grab configs necessary to create a roi_head.
+
+ These are deep copied to allow for safe modification of parameters without
+ influencing other tests.
+ """
+ config = _get_config_module(fname)
+ model = copy.deepcopy(config.model)
+
+ roi_head = model.roi_head
+ train_cfg = None if model.train_cfg is None else model.train_cfg.rcnn
+ test_cfg = None if model.test_cfg is None else model.test_cfg.rcnn
+ roi_head.update(dict(train_cfg=train_cfg, test_cfg=test_cfg))
+ return roi_head
+
+
+def _rand_bboxes(rng, num_boxes, w, h):
+ cx, cy, bw, bh = rng.rand(num_boxes, 4).T
+
+ tl_x = ((cx * w) - (w * bw / 2)).clip(0, w)
+ tl_y = ((cy * h) - (h * bh / 2)).clip(0, h)
+ br_x = ((cx * w) + (w * bw / 2)).clip(0, w)
+ br_y = ((cy * h) + (h * bh / 2)).clip(0, h)
+
+ bboxes = np.vstack([tl_x, tl_y, br_x, br_y]).T
+ return bboxes
+
+
+def _rand_masks(rng, num_boxes, bboxes, img_w, img_h):
+ from mmdet.structures.mask import BitmapMasks
+ masks = np.zeros((num_boxes, img_h, img_w))
+ for i, bbox in enumerate(bboxes):
+ bbox = bbox.astype(np.int32)
+ mask = (rng.rand(1, bbox[3] - bbox[1], bbox[2] - bbox[0]) >
+ 0.3).astype(np.int64)
+ masks[i:i + 1, bbox[1]:bbox[3], bbox[0]:bbox[2]] = mask
+ return BitmapMasks(masks, height=img_h, width=img_w)
+
+
+def demo_mm_inputs(batch_size=2,
+ image_shapes=(3, 128, 128),
+ num_items=None,
+ num_classes=10,
+ sem_seg_output_strides=1,
+ with_mask=False,
+ with_semantic=False,
+ use_box_type=False,
+ device='cpu'):
+ """Create a superset of inputs needed to run test or train batches.
+
+ Args:
+ batch_size (int): batch size. Defaults to 2.
+ image_shapes (List[tuple], Optional): image shape.
+ Defaults to (3, 128, 128)
+ num_items (None | List[int]): specifies the number
+ of boxes in each batch item. Default to None.
+ num_classes (int): number of different labels a
+ box might have. Defaults to 10.
+ with_mask (bool): Whether to return mask annotation.
+ Defaults to False.
+ with_semantic (bool): whether to return semantic.
+ Defaults to False.
+ device (str): Destination device type. Defaults to cpu.
+ """
+ rng = np.random.RandomState(0)
+
+ if isinstance(image_shapes, list):
+ assert len(image_shapes) == batch_size
+ else:
+ image_shapes = [image_shapes] * batch_size
+
+ if isinstance(num_items, list):
+ assert len(num_items) == batch_size
+
+ packed_inputs = []
+ for idx in range(batch_size):
+ image_shape = image_shapes[idx]
+ c, h, w = image_shape
+
+ image = rng.randint(0, 255, size=image_shape, dtype=np.uint8)
+
+ mm_inputs = dict()
+ mm_inputs['inputs'] = torch.from_numpy(image).to(device)
+
+ img_meta = {
+ 'img_id': idx,
+ 'img_shape': image_shape[1:],
+ 'ori_shape': image_shape[1:],
+ 'filename': '.png',
+ 'scale_factor': np.array([1.1, 1.2]),
+ 'flip': False,
+ 'flip_direction': None,
+ 'border': [1, 1, 1, 1] # Only used by CenterNet
+ }
+
+ data_sample = DetDataSample()
+ data_sample.set_metainfo(img_meta)
+
+ # gt_instances
+ gt_instances = InstanceData()
+ if num_items is None:
+ num_boxes = rng.randint(1, 10)
+ else:
+ num_boxes = num_items[idx]
+
+ bboxes = _rand_bboxes(rng, num_boxes, w, h)
+ labels = rng.randint(1, num_classes, size=num_boxes)
+ # TODO: remove this part when all model adapted with BaseBoxes
+ if use_box_type:
+ gt_instances.bboxes = HorizontalBoxes(bboxes, dtype=torch.float32)
+ else:
+ gt_instances.bboxes = torch.FloatTensor(bboxes)
+ gt_instances.labels = torch.LongTensor(labels)
+
+ if with_mask:
+ masks = _rand_masks(rng, num_boxes, bboxes, w, h)
+ gt_instances.masks = masks
+
+ # TODO: waiting for ci to be fixed
+ # masks = np.random.randint(0, 2, (len(bboxes), h, w), dtype=np.uint8)
+ # gt_instances.mask = BitmapMasks(masks, h, w)
+
+ data_sample.gt_instances = gt_instances
+
+ # ignore_instances
+ ignore_instances = InstanceData()
+ bboxes = _rand_bboxes(rng, num_boxes, w, h)
+ if use_box_type:
+ ignore_instances.bboxes = HorizontalBoxes(
+ bboxes, dtype=torch.float32)
+ else:
+ ignore_instances.bboxes = torch.FloatTensor(bboxes)
+ data_sample.ignored_instances = ignore_instances
+
+ # gt_sem_seg
+ if with_semantic:
+ # assume gt_semantic_seg using scale 1/8 of the img
+ gt_semantic_seg = torch.from_numpy(
+ np.random.randint(
+ 0,
+ num_classes, (1, h // sem_seg_output_strides,
+ w // sem_seg_output_strides),
+ dtype=np.uint8))
+ gt_sem_seg_data = dict(sem_seg=gt_semantic_seg)
+ data_sample.gt_sem_seg = PixelData(**gt_sem_seg_data)
+
+ mm_inputs['data_samples'] = data_sample.to(device)
+
+ # TODO: gt_ignore
+
+ packed_inputs.append(mm_inputs)
+ data = pseudo_collate(packed_inputs)
+ return data
+
+
+def demo_mm_proposals(image_shapes, num_proposals, device='cpu'):
+ """Create a list of fake porposals.
+
+ Args:
+ image_shapes (list[tuple[int]]): Batch image shapes.
+ num_proposals (int): The number of fake proposals.
+ """
+ rng = np.random.RandomState(0)
+
+ results = []
+ for img_shape in image_shapes:
+ result = InstanceData()
+ w, h = img_shape[1:]
+ proposals = _rand_bboxes(rng, num_proposals, w, h)
+ result.bboxes = torch.from_numpy(proposals).float()
+ result.scores = torch.from_numpy(rng.rand(num_proposals)).float()
+ result.labels = torch.zeros(num_proposals).long()
+ results.append(result.to(device))
+ return results
+
+
+def demo_mm_sampling_results(proposals_list,
+ batch_gt_instances,
+ batch_gt_instances_ignore=None,
+ assigner_cfg=None,
+ sampler_cfg=None,
+ feats=None):
+ """Create sample results that can be passed to BBoxHead.get_targets."""
+ assert len(proposals_list) == len(batch_gt_instances)
+ if batch_gt_instances_ignore is None:
+ batch_gt_instances_ignore = [None for _ in batch_gt_instances]
+ else:
+ assert len(batch_gt_instances_ignore) == len(batch_gt_instances)
+
+ default_assigner_cfg = dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.5,
+ neg_iou_thr=0.5,
+ min_pos_iou=0.5,
+ ignore_iof_thr=-1)
+ assigner_cfg = assigner_cfg if assigner_cfg is not None \
+ else default_assigner_cfg
+ default_sampler_cfg = dict(
+ type='RandomSampler',
+ num=512,
+ pos_fraction=0.25,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=True)
+ sampler_cfg = sampler_cfg if sampler_cfg is not None \
+ else default_sampler_cfg
+ bbox_assigner = TASK_UTILS.build(assigner_cfg)
+ bbox_sampler = TASK_UTILS.build(sampler_cfg)
+
+ sampling_results = []
+ for i in range(len(batch_gt_instances)):
+ if feats is not None:
+ feats = [lvl_feat[i][None] for lvl_feat in feats]
+ # rename proposals.bboxes to proposals.priors
+ proposals = proposals_list[i]
+ proposals.priors = proposals.pop('bboxes')
+
+ assign_result = bbox_assigner.assign(proposals, batch_gt_instances[i],
+ batch_gt_instances_ignore[i])
+ sampling_result = bbox_sampler.sample(
+ assign_result, proposals, batch_gt_instances[i], feats=feats)
+ sampling_results.append(sampling_result)
+
+ return sampling_results
+
+
+# TODO: Support full ceph
+def replace_to_ceph(cfg):
+ backend_args = dict(
+ backend='petrel',
+ path_mapping=dict({
+ './data/': 's3://openmmlab/datasets/detection/',
+ 'data/': 's3://openmmlab/datasets/detection/'
+ }))
+
+ # TODO: name is a reserved interface, which will be used later.
+ def _process_pipeline(dataset, name):
+
+ def replace_img(pipeline):
+ if pipeline['type'] == 'LoadImageFromFile':
+ pipeline['backend_args'] = backend_args
+
+ def replace_ann(pipeline):
+ if pipeline['type'] == 'LoadAnnotations' or pipeline[
+ 'type'] == 'LoadPanopticAnnotations':
+ pipeline['backend_args'] = backend_args
+
+ if 'pipeline' in dataset:
+ replace_img(dataset.pipeline[0])
+ replace_ann(dataset.pipeline[1])
+ if 'dataset' in dataset:
+ # dataset wrapper
+ replace_img(dataset.dataset.pipeline[0])
+ replace_ann(dataset.dataset.pipeline[1])
+ else:
+ # dataset wrapper
+ replace_img(dataset.dataset.pipeline[0])
+ replace_ann(dataset.dataset.pipeline[1])
+
+ def _process_evaluator(evaluator, name):
+ if evaluator['type'] == 'CocoPanopticMetric':
+ evaluator['backend_args'] = backend_args
+
+ # half ceph
+ _process_pipeline(cfg.train_dataloader.dataset, cfg.filename)
+ _process_pipeline(cfg.val_dataloader.dataset, cfg.filename)
+ _process_pipeline(cfg.test_dataloader.dataset, cfg.filename)
+ _process_evaluator(cfg.val_evaluator, cfg.filename)
+ _process_evaluator(cfg.test_evaluator, cfg.filename)
diff --git a/mmdet/utils/__init__.py b/mmdet/utils/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..1a8643425631e9e090afa8e0f8dcca3a63e29476
--- /dev/null
+++ b/mmdet/utils/__init__.py
@@ -0,0 +1,27 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .collect_env import collect_env
+from .compat_config import compat_cfg
+from .dist_utils import (all_reduce_dict, allreduce_grads, reduce_mean,
+ sync_random_seed)
+from .logger import get_caller_name, log_img_scale
+from .memory import AvoidCUDAOOM, AvoidOOM
+from .misc import (find_latest_checkpoint, get_test_pipeline_cfg,
+ update_data_root)
+from .replace_cfg_vals import replace_cfg_vals
+from .setup_env import (register_all_modules, setup_cache_size_limit_of_dynamo,
+ setup_multi_processes)
+from .split_batch import split_batch
+from .typing_utils import (ConfigType, InstanceList, MultiConfig,
+ OptConfigType, OptInstanceList, OptMultiConfig,
+ OptPixelList, PixelList, RangeType)
+
+__all__ = [
+ 'collect_env', 'find_latest_checkpoint', 'update_data_root',
+ 'setup_multi_processes', 'get_caller_name', 'log_img_scale', 'compat_cfg',
+ 'split_batch', 'register_all_modules', 'replace_cfg_vals', 'AvoidOOM',
+ 'AvoidCUDAOOM', 'all_reduce_dict', 'allreduce_grads', 'reduce_mean',
+ 'sync_random_seed', 'ConfigType', 'InstanceList', 'MultiConfig',
+ 'OptConfigType', 'OptInstanceList', 'OptMultiConfig', 'OptPixelList',
+ 'PixelList', 'RangeType', 'get_test_pipeline_cfg',
+ 'setup_cache_size_limit_of_dynamo'
+]
diff --git a/mmdet/utils/__pycache__/__init__.cpython-37.pyc b/mmdet/utils/__pycache__/__init__.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..b99e51bc7cca6a3edbeac4b281bc77cc504dbe50
Binary files /dev/null and b/mmdet/utils/__pycache__/__init__.cpython-37.pyc differ
diff --git a/mmdet/utils/__pycache__/benchmark.cpython-37.pyc b/mmdet/utils/__pycache__/benchmark.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..372585a871c87f27e08db355fd9ddb673736b578
Binary files /dev/null and b/mmdet/utils/__pycache__/benchmark.cpython-37.pyc differ
diff --git a/mmdet/utils/__pycache__/collect_env.cpython-37.pyc b/mmdet/utils/__pycache__/collect_env.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..0b696500ae08aa328ce263572769b9b873ad4b92
Binary files /dev/null and b/mmdet/utils/__pycache__/collect_env.cpython-37.pyc differ
diff --git a/mmdet/utils/__pycache__/compat_config.cpython-37.pyc b/mmdet/utils/__pycache__/compat_config.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..0e8269adcb2aa8c8807676d830a3c31515c00af8
Binary files /dev/null and b/mmdet/utils/__pycache__/compat_config.cpython-37.pyc differ
diff --git a/mmdet/utils/__pycache__/dist_utils.cpython-37.pyc b/mmdet/utils/__pycache__/dist_utils.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..fb2543b732a99b59d247f94592d2bd8770dea23f
Binary files /dev/null and b/mmdet/utils/__pycache__/dist_utils.cpython-37.pyc differ
diff --git a/mmdet/utils/__pycache__/logger.cpython-37.pyc b/mmdet/utils/__pycache__/logger.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..6bada5e09208b46a26362a394480786ec77f0cda
Binary files /dev/null and b/mmdet/utils/__pycache__/logger.cpython-37.pyc differ
diff --git a/mmdet/utils/__pycache__/memory.cpython-37.pyc b/mmdet/utils/__pycache__/memory.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..5e62f374cd6617c2e17934d0ebf31a8fe5626b9d
Binary files /dev/null and b/mmdet/utils/__pycache__/memory.cpython-37.pyc differ
diff --git a/mmdet/utils/__pycache__/misc.cpython-37.pyc b/mmdet/utils/__pycache__/misc.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..752c7f8b83d2b8e776c5b1c39c00488ebe9d1a37
Binary files /dev/null and b/mmdet/utils/__pycache__/misc.cpython-37.pyc differ
diff --git a/mmdet/utils/__pycache__/replace_cfg_vals.cpython-37.pyc b/mmdet/utils/__pycache__/replace_cfg_vals.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..b27396cd773a20a24bec2b429d37992cd3c6d440
Binary files /dev/null and b/mmdet/utils/__pycache__/replace_cfg_vals.cpython-37.pyc differ
diff --git a/mmdet/utils/__pycache__/setup_env.cpython-37.pyc b/mmdet/utils/__pycache__/setup_env.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..1bcc36fbe164e8a8c7b0764af3ad66cc6b9604b6
Binary files /dev/null and b/mmdet/utils/__pycache__/setup_env.cpython-37.pyc differ
diff --git a/mmdet/utils/__pycache__/split_batch.cpython-37.pyc b/mmdet/utils/__pycache__/split_batch.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..587f4f4d1afa9ef255ff4eb8ad6b0f20e44febda
Binary files /dev/null and b/mmdet/utils/__pycache__/split_batch.cpython-37.pyc differ
diff --git a/mmdet/utils/__pycache__/typing_utils.cpython-37.pyc b/mmdet/utils/__pycache__/typing_utils.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..d243869c365dc663a249fa23e1008d49f7a49878
Binary files /dev/null and b/mmdet/utils/__pycache__/typing_utils.cpython-37.pyc differ
diff --git a/mmdet/utils/__pycache__/util_mixins.cpython-37.pyc b/mmdet/utils/__pycache__/util_mixins.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..c85b61c3296f3f5872b02018b27cce6e2b1a3210
Binary files /dev/null and b/mmdet/utils/__pycache__/util_mixins.cpython-37.pyc differ
diff --git a/mmdet/utils/__pycache__/util_random.cpython-37.pyc b/mmdet/utils/__pycache__/util_random.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..de9ad36b9ca565758081eea0c45e5047863f321f
Binary files /dev/null and b/mmdet/utils/__pycache__/util_random.cpython-37.pyc differ
diff --git a/mmdet/utils/benchmark.py b/mmdet/utils/benchmark.py
new file mode 100644
index 0000000000000000000000000000000000000000..1714b46474074b51f8241d2c9afccd2f54240b10
--- /dev/null
+++ b/mmdet/utils/benchmark.py
@@ -0,0 +1,522 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+import time
+from functools import partial
+from typing import List, Optional, Union
+
+import numpy as np
+import torch
+import torch.nn as nn
+from mmcv.cnn import fuse_conv_bn
+# TODO need update
+# from mmcv.runner import wrap_fp16_model
+from mmengine import MMLogger
+from mmengine.config import Config
+from mmengine.device import get_max_cuda_memory
+from mmengine.dist import get_world_size
+from mmengine.runner import Runner, load_checkpoint
+from mmengine.utils.dl_utils import set_multi_processing
+from torch.nn.parallel import DistributedDataParallel
+
+from mmdet.registry import DATASETS, MODELS
+
+try:
+ import psutil
+except ImportError:
+ psutil = None
+
+
+def custom_round(value: Union[int, float],
+ factor: Union[int, float],
+ precision: int = 2) -> float:
+ """Custom round function."""
+ return round(value / factor, precision)
+
+
+gb_round = partial(custom_round, factor=1024**3)
+
+
+def print_log(msg: str, logger: Optional[MMLogger] = None) -> None:
+ """Print a log message."""
+ if logger is None:
+ print(msg, flush=True)
+ else:
+ logger.info(msg)
+
+
+def print_process_memory(p: psutil.Process,
+ logger: Optional[MMLogger] = None) -> None:
+ """print process memory info."""
+ mem_used = gb_round(psutil.virtual_memory().used)
+ memory_full_info = p.memory_full_info()
+ uss_mem = gb_round(memory_full_info.uss)
+ pss_mem = gb_round(memory_full_info.pss)
+ for children in p.children():
+ child_mem_info = children.memory_full_info()
+ uss_mem += gb_round(child_mem_info.uss)
+ pss_mem += gb_round(child_mem_info.pss)
+ process_count = 1 + len(p.children())
+ print_log(
+ f'(GB) mem_used: {mem_used:.2f} | uss: {uss_mem:.2f} | '
+ f'pss: {pss_mem:.2f} | total_proc: {process_count}', logger)
+
+
+class BaseBenchmark:
+ """The benchmark base class.
+
+ The ``run`` method is an external calling interface, and it will
+ call the ``run_once`` method ``repeat_num`` times for benchmarking.
+ Finally, call the ``average_multiple_runs`` method to further process
+ the results of multiple runs.
+
+ Args:
+ max_iter (int): maximum iterations of benchmark.
+ log_interval (int): interval of logging.
+ num_warmup (int): Number of Warmup.
+ logger (MMLogger, optional): Formatted logger used to record messages.
+ """
+
+ def __init__(self,
+ max_iter: int,
+ log_interval: int,
+ num_warmup: int,
+ logger: Optional[MMLogger] = None):
+ self.max_iter = max_iter
+ self.log_interval = log_interval
+ self.num_warmup = num_warmup
+ self.logger = logger
+
+ def run(self, repeat_num: int = 1) -> dict:
+ """benchmark entry method.
+
+ Args:
+ repeat_num (int): Number of repeat benchmark.
+ Defaults to 1.
+ """
+ assert repeat_num >= 1
+
+ results = []
+ for _ in range(repeat_num):
+ results.append(self.run_once())
+
+ results = self.average_multiple_runs(results)
+ return results
+
+ def run_once(self) -> dict:
+ """Executes the benchmark once."""
+ raise NotImplementedError()
+
+ def average_multiple_runs(self, results: List[dict]) -> dict:
+ """Average the results of multiple runs."""
+ raise NotImplementedError()
+
+
+class InferenceBenchmark(BaseBenchmark):
+ """The inference benchmark class. It will be statistical inference FPS,
+ CUDA memory and CPU memory information.
+
+ Args:
+ cfg (mmengine.Config): config.
+ checkpoint (str): Accept local filepath, URL, ``torchvision://xxx``,
+ ``open-mmlab://xxx``.
+ distributed (bool): distributed testing flag.
+ is_fuse_conv_bn (bool): Whether to fuse conv and bn, this will
+ slightly increase the inference speed.
+ max_iter (int): maximum iterations of benchmark. Defaults to 2000.
+ log_interval (int): interval of logging. Defaults to 50.
+ num_warmup (int): Number of Warmup. Defaults to 5.
+ logger (MMLogger, optional): Formatted logger used to record messages.
+ """
+
+ def __init__(self,
+ cfg: Config,
+ checkpoint: str,
+ distributed: bool,
+ is_fuse_conv_bn: bool,
+ max_iter: int = 2000,
+ log_interval: int = 50,
+ num_warmup: int = 5,
+ logger: Optional[MMLogger] = None):
+ super().__init__(max_iter, log_interval, num_warmup, logger)
+
+ assert get_world_size(
+ ) == 1, 'Inference benchmark does not allow distributed multi-GPU'
+
+ self.cfg = copy.deepcopy(cfg)
+ self.distributed = distributed
+
+ if psutil is None:
+ raise ImportError('psutil is not installed, please install it by: '
+ 'pip install psutil')
+
+ self._process = psutil.Process()
+ env_cfg = self.cfg.get('env_cfg')
+ if env_cfg.get('cudnn_benchmark'):
+ torch.backends.cudnn.benchmark = True
+
+ mp_cfg: dict = env_cfg.get('mp_cfg', {})
+ set_multi_processing(**mp_cfg, distributed=self.distributed)
+
+ print_log('before build: ', self.logger)
+ print_process_memory(self._process, self.logger)
+
+ self.model = self._init_model(checkpoint, is_fuse_conv_bn)
+
+ # Because multiple processes will occupy additional CPU resources,
+ # FPS statistics will be more unstable when num_workers is not 0.
+ # It is reasonable to set num_workers to 0.
+ dataloader_cfg = cfg.test_dataloader
+ dataloader_cfg['num_workers'] = 0
+ dataloader_cfg['batch_size'] = 1
+ dataloader_cfg['persistent_workers'] = False
+ self.data_loader = Runner.build_dataloader(dataloader_cfg)
+
+ print_log('after build: ', self.logger)
+ print_process_memory(self._process, self.logger)
+
+ def _init_model(self, checkpoint: str, is_fuse_conv_bn: bool) -> nn.Module:
+ """Initialize the model."""
+ model = MODELS.build(self.cfg.model)
+ # TODO need update
+ # fp16_cfg = self.cfg.get('fp16', None)
+ # if fp16_cfg is not None:
+ # wrap_fp16_model(model)
+
+ load_checkpoint(model, checkpoint, map_location='cpu')
+ if is_fuse_conv_bn:
+ model = fuse_conv_bn(model)
+
+ model = model.cuda()
+
+ if self.distributed:
+ model = DistributedDataParallel(
+ model,
+ device_ids=[torch.cuda.current_device()],
+ broadcast_buffers=False,
+ find_unused_parameters=False)
+
+ model.eval()
+ return model
+
+ def run_once(self) -> dict:
+ """Executes the benchmark once."""
+ pure_inf_time = 0
+ fps = 0
+
+ for i, data in enumerate(self.data_loader):
+
+ if (i + 1) % self.log_interval == 0:
+ print_log('==================================', self.logger)
+
+ torch.cuda.synchronize()
+ start_time = time.perf_counter()
+
+ with torch.no_grad():
+ self.model.test_step(data)
+
+ torch.cuda.synchronize()
+ elapsed = time.perf_counter() - start_time
+
+ if i >= self.num_warmup:
+ pure_inf_time += elapsed
+ if (i + 1) % self.log_interval == 0:
+ fps = (i + 1 - self.num_warmup) / pure_inf_time
+ cuda_memory = get_max_cuda_memory()
+
+ print_log(
+ f'Done image [{i + 1:<3}/{self.max_iter}], '
+ f'fps: {fps:.1f} img/s, '
+ f'times per image: {1000 / fps:.1f} ms/img, '
+ f'cuda memory: {cuda_memory} MB', self.logger)
+ print_process_memory(self._process, self.logger)
+
+ if (i + 1) == self.max_iter:
+ fps = (i + 1 - self.num_warmup) / pure_inf_time
+ break
+
+ return {'fps': fps}
+
+ def average_multiple_runs(self, results: List[dict]) -> dict:
+ """Average the results of multiple runs."""
+ print_log('============== Done ==================', self.logger)
+
+ fps_list_ = [round(result['fps'], 1) for result in results]
+ avg_fps_ = sum(fps_list_) / len(fps_list_)
+ outputs = {'avg_fps': avg_fps_, 'fps_list': fps_list_}
+
+ if len(fps_list_) > 1:
+ times_pre_image_list_ = [
+ round(1000 / result['fps'], 1) for result in results
+ ]
+ avg_times_pre_image_ = sum(times_pre_image_list_) / len(
+ times_pre_image_list_)
+
+ print_log(
+ f'Overall fps: {fps_list_}[{avg_fps_:.1f}] img/s, '
+ 'times per image: '
+ f'{times_pre_image_list_}[{avg_times_pre_image_:.1f}] '
+ 'ms/img', self.logger)
+ else:
+ print_log(
+ f'Overall fps: {fps_list_[0]:.1f} img/s, '
+ f'times per image: {1000 / fps_list_[0]:.1f} ms/img',
+ self.logger)
+
+ print_log(f'cuda memory: {get_max_cuda_memory()} MB', self.logger)
+ print_process_memory(self._process, self.logger)
+
+ return outputs
+
+
+class DataLoaderBenchmark(BaseBenchmark):
+ """The dataloader benchmark class. It will be statistical inference FPS and
+ CPU memory information.
+
+ Args:
+ cfg (mmengine.Config): config.
+ distributed (bool): distributed testing flag.
+ dataset_type (str): benchmark data type, only supports ``train``,
+ ``val`` and ``test``.
+ max_iter (int): maximum iterations of benchmark. Defaults to 2000.
+ log_interval (int): interval of logging. Defaults to 50.
+ num_warmup (int): Number of Warmup. Defaults to 5.
+ logger (MMLogger, optional): Formatted logger used to record messages.
+ """
+
+ def __init__(self,
+ cfg: Config,
+ distributed: bool,
+ dataset_type: str,
+ max_iter: int = 2000,
+ log_interval: int = 50,
+ num_warmup: int = 5,
+ logger: Optional[MMLogger] = None):
+ super().__init__(max_iter, log_interval, num_warmup, logger)
+
+ assert dataset_type in ['train', 'val', 'test'], \
+ 'dataset_type only supports train,' \
+ f' val and test, but got {dataset_type}'
+ assert get_world_size(
+ ) == 1, 'Dataloader benchmark does not allow distributed multi-GPU'
+
+ self.cfg = copy.deepcopy(cfg)
+ self.distributed = distributed
+
+ if psutil is None:
+ raise ImportError('psutil is not installed, please install it by: '
+ 'pip install psutil')
+ self._process = psutil.Process()
+
+ mp_cfg = self.cfg.get('env_cfg', {}).get('mp_cfg')
+ if mp_cfg is not None:
+ set_multi_processing(distributed=self.distributed, **mp_cfg)
+ else:
+ set_multi_processing(distributed=self.distributed)
+
+ print_log('before build: ', self.logger)
+ print_process_memory(self._process, self.logger)
+
+ if dataset_type == 'train':
+ self.data_loader = Runner.build_dataloader(cfg.train_dataloader)
+ elif dataset_type == 'test':
+ self.data_loader = Runner.build_dataloader(cfg.test_dataloader)
+ else:
+ self.data_loader = Runner.build_dataloader(cfg.val_dataloader)
+
+ self.batch_size = self.data_loader.batch_size
+ self.num_workers = self.data_loader.num_workers
+
+ print_log('after build: ', self.logger)
+ print_process_memory(self._process, self.logger)
+
+ def run_once(self) -> dict:
+ """Executes the benchmark once."""
+ pure_inf_time = 0
+ fps = 0
+
+ # benchmark with 2000 image and take the average
+ start_time = time.perf_counter()
+ for i, data in enumerate(self.data_loader):
+ elapsed = time.perf_counter() - start_time
+
+ if (i + 1) % self.log_interval == 0:
+ print_log('==================================', self.logger)
+
+ if i >= self.num_warmup:
+ pure_inf_time += elapsed
+ if (i + 1) % self.log_interval == 0:
+ fps = (i + 1 - self.num_warmup) / pure_inf_time
+
+ print_log(
+ f'Done batch [{i + 1:<3}/{self.max_iter}], '
+ f'fps: {fps:.1f} batch/s, '
+ f'times per batch: {1000 / fps:.1f} ms/batch, '
+ f'batch size: {self.batch_size}, num_workers: '
+ f'{self.num_workers}', self.logger)
+ print_process_memory(self._process, self.logger)
+
+ if (i + 1) == self.max_iter:
+ fps = (i + 1 - self.num_warmup) / pure_inf_time
+ break
+
+ start_time = time.perf_counter()
+
+ return {'fps': fps}
+
+ def average_multiple_runs(self, results: List[dict]) -> dict:
+ """Average the results of multiple runs."""
+ print_log('============== Done ==================', self.logger)
+
+ fps_list_ = [round(result['fps'], 1) for result in results]
+ avg_fps_ = sum(fps_list_) / len(fps_list_)
+ outputs = {'avg_fps': avg_fps_, 'fps_list': fps_list_}
+
+ if len(fps_list_) > 1:
+ times_pre_image_list_ = [
+ round(1000 / result['fps'], 1) for result in results
+ ]
+ avg_times_pre_image_ = sum(times_pre_image_list_) / len(
+ times_pre_image_list_)
+
+ print_log(
+ f'Overall fps: {fps_list_}[{avg_fps_:.1f}] img/s, '
+ 'times per batch: '
+ f'{times_pre_image_list_}[{avg_times_pre_image_:.1f}] '
+ f'ms/batch, batch size: {self.batch_size}, num_workers: '
+ f'{self.num_workers}', self.logger)
+ else:
+ print_log(
+ f'Overall fps: {fps_list_[0]:.1f} batch/s, '
+ f'times per batch: {1000 / fps_list_[0]:.1f} ms/batch, '
+ f'batch size: {self.batch_size}, num_workers: '
+ f'{self.num_workers}', self.logger)
+
+ print_process_memory(self._process, self.logger)
+
+ return outputs
+
+
+class DatasetBenchmark(BaseBenchmark):
+ """The dataset benchmark class. It will be statistical inference FPS, FPS
+ pre transform and CPU memory information.
+
+ Args:
+ cfg (mmengine.Config): config.
+ dataset_type (str): benchmark data type, only supports ``train``,
+ ``val`` and ``test``.
+ max_iter (int): maximum iterations of benchmark. Defaults to 2000.
+ log_interval (int): interval of logging. Defaults to 50.
+ num_warmup (int): Number of Warmup. Defaults to 5.
+ logger (MMLogger, optional): Formatted logger used to record messages.
+ """
+
+ def __init__(self,
+ cfg: Config,
+ dataset_type: str,
+ max_iter: int = 2000,
+ log_interval: int = 50,
+ num_warmup: int = 5,
+ logger: Optional[MMLogger] = None):
+ super().__init__(max_iter, log_interval, num_warmup, logger)
+ assert dataset_type in ['train', 'val', 'test'], \
+ 'dataset_type only supports train,' \
+ f' val and test, but got {dataset_type}'
+ assert get_world_size(
+ ) == 1, 'Dataset benchmark does not allow distributed multi-GPU'
+ self.cfg = copy.deepcopy(cfg)
+
+ if dataset_type == 'train':
+ dataloader_cfg = copy.deepcopy(cfg.train_dataloader)
+ elif dataset_type == 'test':
+ dataloader_cfg = copy.deepcopy(cfg.test_dataloader)
+ else:
+ dataloader_cfg = copy.deepcopy(cfg.val_dataloader)
+
+ dataset_cfg = dataloader_cfg.pop('dataset')
+ dataset = DATASETS.build(dataset_cfg)
+ if hasattr(dataset, 'full_init'):
+ dataset.full_init()
+ self.dataset = dataset
+
+ def run_once(self) -> dict:
+ """Executes the benchmark once."""
+ pure_inf_time = 0
+ fps = 0
+
+ total_index = list(range(len(self.dataset)))
+ np.random.shuffle(total_index)
+
+ start_time = time.perf_counter()
+ for i, idx in enumerate(total_index):
+ if (i + 1) % self.log_interval == 0:
+ print_log('==================================', self.logger)
+
+ get_data_info_start_time = time.perf_counter()
+ data_info = self.dataset.get_data_info(idx)
+ get_data_info_elapsed = time.perf_counter(
+ ) - get_data_info_start_time
+
+ if (i + 1) % self.log_interval == 0:
+ print_log(f'get_data_info - {get_data_info_elapsed * 1000} ms',
+ self.logger)
+
+ for t in self.dataset.pipeline.transforms:
+ transform_start_time = time.perf_counter()
+ data_info = t(data_info)
+ transform_elapsed = time.perf_counter() - transform_start_time
+
+ if (i + 1) % self.log_interval == 0:
+ print_log(
+ f'{t.__class__.__name__} - '
+ f'{transform_elapsed * 1000} ms', self.logger)
+
+ if data_info is None:
+ break
+
+ elapsed = time.perf_counter() - start_time
+
+ if i >= self.num_warmup:
+ pure_inf_time += elapsed
+ if (i + 1) % self.log_interval == 0:
+ fps = (i + 1 - self.num_warmup) / pure_inf_time
+
+ print_log(
+ f'Done img [{i + 1:<3}/{self.max_iter}], '
+ f'fps: {fps:.1f} img/s, '
+ f'times per img: {1000 / fps:.1f} ms/img', self.logger)
+
+ if (i + 1) == self.max_iter:
+ fps = (i + 1 - self.num_warmup) / pure_inf_time
+ break
+
+ start_time = time.perf_counter()
+
+ return {'fps': fps}
+
+ def average_multiple_runs(self, results: List[dict]) -> dict:
+ """Average the results of multiple runs."""
+ print_log('============== Done ==================', self.logger)
+
+ fps_list_ = [round(result['fps'], 1) for result in results]
+ avg_fps_ = sum(fps_list_) / len(fps_list_)
+ outputs = {'avg_fps': avg_fps_, 'fps_list': fps_list_}
+
+ if len(fps_list_) > 1:
+ times_pre_image_list_ = [
+ round(1000 / result['fps'], 1) for result in results
+ ]
+ avg_times_pre_image_ = sum(times_pre_image_list_) / len(
+ times_pre_image_list_)
+
+ print_log(
+ f'Overall fps: {fps_list_}[{avg_fps_:.1f}] img/s, '
+ 'times per img: '
+ f'{times_pre_image_list_}[{avg_times_pre_image_:.1f}] '
+ 'ms/img', self.logger)
+ else:
+ print_log(
+ f'Overall fps: {fps_list_[0]:.1f} img/s, '
+ f'times per img: {1000 / fps_list_[0]:.1f} ms/img',
+ self.logger)
+
+ return outputs
diff --git a/mmdet/utils/collect_env.py b/mmdet/utils/collect_env.py
new file mode 100644
index 0000000000000000000000000000000000000000..b0eed80fe2e4630b78ea3b13fde6046914e47e8b
--- /dev/null
+++ b/mmdet/utils/collect_env.py
@@ -0,0 +1,17 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmengine.utils import get_git_hash
+from mmengine.utils.dl_utils import collect_env as collect_base_env
+
+import mmdet
+
+
+def collect_env():
+ """Collect the information of the running environments."""
+ env_info = collect_base_env()
+ env_info['MMDetection'] = mmdet.__version__ + '+' + get_git_hash()[:7]
+ return env_info
+
+
+if __name__ == '__main__':
+ for name, val in collect_env().items():
+ print(f'{name}: {val}')
diff --git a/mmdet/utils/compat_config.py b/mmdet/utils/compat_config.py
new file mode 100644
index 0000000000000000000000000000000000000000..133adb65c2276401eca947e223e5b7c1760de418
--- /dev/null
+++ b/mmdet/utils/compat_config.py
@@ -0,0 +1,139 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+import warnings
+
+from mmengine.config import ConfigDict
+
+
+def compat_cfg(cfg):
+ """This function would modify some filed to keep the compatibility of
+ config.
+
+ For example, it will move some args which will be deprecated to the correct
+ fields.
+ """
+ cfg = copy.deepcopy(cfg)
+ cfg = compat_imgs_per_gpu(cfg)
+ cfg = compat_loader_args(cfg)
+ cfg = compat_runner_args(cfg)
+ return cfg
+
+
+def compat_runner_args(cfg):
+ if 'runner' not in cfg:
+ cfg.runner = ConfigDict({
+ 'type': 'EpochBasedRunner',
+ 'max_epochs': cfg.total_epochs
+ })
+ warnings.warn(
+ 'config is now expected to have a `runner` section, '
+ 'please set `runner` in your config.', UserWarning)
+ else:
+ if 'total_epochs' in cfg:
+ assert cfg.total_epochs == cfg.runner.max_epochs
+ return cfg
+
+
+def compat_imgs_per_gpu(cfg):
+ cfg = copy.deepcopy(cfg)
+ if 'imgs_per_gpu' in cfg.data:
+ warnings.warn('"imgs_per_gpu" is deprecated in MMDet V2.0. '
+ 'Please use "samples_per_gpu" instead')
+ if 'samples_per_gpu' in cfg.data:
+ warnings.warn(
+ f'Got "imgs_per_gpu"={cfg.data.imgs_per_gpu} and '
+ f'"samples_per_gpu"={cfg.data.samples_per_gpu}, "imgs_per_gpu"'
+ f'={cfg.data.imgs_per_gpu} is used in this experiments')
+ else:
+ warnings.warn('Automatically set "samples_per_gpu"="imgs_per_gpu"='
+ f'{cfg.data.imgs_per_gpu} in this experiments')
+ cfg.data.samples_per_gpu = cfg.data.imgs_per_gpu
+ return cfg
+
+
+def compat_loader_args(cfg):
+ """Deprecated sample_per_gpu in cfg.data."""
+
+ cfg = copy.deepcopy(cfg)
+ if 'train_dataloader' not in cfg.data:
+ cfg.data['train_dataloader'] = ConfigDict()
+ if 'val_dataloader' not in cfg.data:
+ cfg.data['val_dataloader'] = ConfigDict()
+ if 'test_dataloader' not in cfg.data:
+ cfg.data['test_dataloader'] = ConfigDict()
+
+ # special process for train_dataloader
+ if 'samples_per_gpu' in cfg.data:
+
+ samples_per_gpu = cfg.data.pop('samples_per_gpu')
+ assert 'samples_per_gpu' not in \
+ cfg.data.train_dataloader, ('`samples_per_gpu` are set '
+ 'in `data` field and ` '
+ 'data.train_dataloader` '
+ 'at the same time. '
+ 'Please only set it in '
+ '`data.train_dataloader`. ')
+ cfg.data.train_dataloader['samples_per_gpu'] = samples_per_gpu
+
+ if 'persistent_workers' in cfg.data:
+
+ persistent_workers = cfg.data.pop('persistent_workers')
+ assert 'persistent_workers' not in \
+ cfg.data.train_dataloader, ('`persistent_workers` are set '
+ 'in `data` field and ` '
+ 'data.train_dataloader` '
+ 'at the same time. '
+ 'Please only set it in '
+ '`data.train_dataloader`. ')
+ cfg.data.train_dataloader['persistent_workers'] = persistent_workers
+
+ if 'workers_per_gpu' in cfg.data:
+
+ workers_per_gpu = cfg.data.pop('workers_per_gpu')
+ cfg.data.train_dataloader['workers_per_gpu'] = workers_per_gpu
+ cfg.data.val_dataloader['workers_per_gpu'] = workers_per_gpu
+ cfg.data.test_dataloader['workers_per_gpu'] = workers_per_gpu
+
+ # special process for val_dataloader
+ if 'samples_per_gpu' in cfg.data.val:
+ # keep default value of `sample_per_gpu` is 1
+ assert 'samples_per_gpu' not in \
+ cfg.data.val_dataloader, ('`samples_per_gpu` are set '
+ 'in `data.val` field and ` '
+ 'data.val_dataloader` at '
+ 'the same time. '
+ 'Please only set it in '
+ '`data.val_dataloader`. ')
+ cfg.data.val_dataloader['samples_per_gpu'] = \
+ cfg.data.val.pop('samples_per_gpu')
+ # special process for val_dataloader
+
+ # in case the test dataset is concatenated
+ if isinstance(cfg.data.test, dict):
+ if 'samples_per_gpu' in cfg.data.test:
+ assert 'samples_per_gpu' not in \
+ cfg.data.test_dataloader, ('`samples_per_gpu` are set '
+ 'in `data.test` field and ` '
+ 'data.test_dataloader` '
+ 'at the same time. '
+ 'Please only set it in '
+ '`data.test_dataloader`. ')
+
+ cfg.data.test_dataloader['samples_per_gpu'] = \
+ cfg.data.test.pop('samples_per_gpu')
+
+ elif isinstance(cfg.data.test, list):
+ for ds_cfg in cfg.data.test:
+ if 'samples_per_gpu' in ds_cfg:
+ assert 'samples_per_gpu' not in \
+ cfg.data.test_dataloader, ('`samples_per_gpu` are set '
+ 'in `data.test` field and ` '
+ 'data.test_dataloader` at'
+ ' the same time. '
+ 'Please only set it in '
+ '`data.test_dataloader`. ')
+ samples_per_gpu = max(
+ [ds_cfg.pop('samples_per_gpu', 1) for ds_cfg in cfg.data.test])
+ cfg.data.test_dataloader['samples_per_gpu'] = samples_per_gpu
+
+ return cfg
diff --git a/mmdet/utils/contextmanagers.py b/mmdet/utils/contextmanagers.py
new file mode 100644
index 0000000000000000000000000000000000000000..fa12bfcaff1e781b0a8cc7d7c8b839c2f2955a05
--- /dev/null
+++ b/mmdet/utils/contextmanagers.py
@@ -0,0 +1,122 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import asyncio
+import contextlib
+import logging
+import os
+import time
+from typing import List
+
+import torch
+
+logger = logging.getLogger(__name__)
+
+DEBUG_COMPLETED_TIME = bool(os.environ.get('DEBUG_COMPLETED_TIME', False))
+
+
+@contextlib.asynccontextmanager
+async def completed(trace_name='',
+ name='',
+ sleep_interval=0.05,
+ streams: List[torch.cuda.Stream] = None):
+ """Async context manager that waits for work to complete on given CUDA
+ streams."""
+ if not torch.cuda.is_available():
+ yield
+ return
+
+ stream_before_context_switch = torch.cuda.current_stream()
+ if not streams:
+ streams = [stream_before_context_switch]
+ else:
+ streams = [s if s else stream_before_context_switch for s in streams]
+
+ end_events = [
+ torch.cuda.Event(enable_timing=DEBUG_COMPLETED_TIME) for _ in streams
+ ]
+
+ if DEBUG_COMPLETED_TIME:
+ start = torch.cuda.Event(enable_timing=True)
+ stream_before_context_switch.record_event(start)
+
+ cpu_start = time.monotonic()
+ logger.debug('%s %s starting, streams: %s', trace_name, name, streams)
+ grad_enabled_before = torch.is_grad_enabled()
+ try:
+ yield
+ finally:
+ current_stream = torch.cuda.current_stream()
+ assert current_stream == stream_before_context_switch
+
+ if DEBUG_COMPLETED_TIME:
+ cpu_end = time.monotonic()
+ for i, stream in enumerate(streams):
+ event = end_events[i]
+ stream.record_event(event)
+
+ grad_enabled_after = torch.is_grad_enabled()
+
+ # observed change of torch.is_grad_enabled() during concurrent run of
+ # async_test_bboxes code
+ assert (grad_enabled_before == grad_enabled_after
+ ), 'Unexpected is_grad_enabled() value change'
+
+ are_done = [e.query() for e in end_events]
+ logger.debug('%s %s completed: %s streams: %s', trace_name, name,
+ are_done, streams)
+ with torch.cuda.stream(stream_before_context_switch):
+ while not all(are_done):
+ await asyncio.sleep(sleep_interval)
+ are_done = [e.query() for e in end_events]
+ logger.debug(
+ '%s %s completed: %s streams: %s',
+ trace_name,
+ name,
+ are_done,
+ streams,
+ )
+
+ current_stream = torch.cuda.current_stream()
+ assert current_stream == stream_before_context_switch
+
+ if DEBUG_COMPLETED_TIME:
+ cpu_time = (cpu_end - cpu_start) * 1000
+ stream_times_ms = ''
+ for i, stream in enumerate(streams):
+ elapsed_time = start.elapsed_time(end_events[i])
+ stream_times_ms += f' {stream} {elapsed_time:.2f} ms'
+ logger.info('%s %s %.2f ms %s', trace_name, name, cpu_time,
+ stream_times_ms)
+
+
+@contextlib.asynccontextmanager
+async def concurrent(streamqueue: asyncio.Queue,
+ trace_name='concurrent',
+ name='stream'):
+ """Run code concurrently in different streams.
+
+ :param streamqueue: asyncio.Queue instance.
+
+ Queue tasks define the pool of streams used for concurrent execution.
+ """
+ if not torch.cuda.is_available():
+ yield
+ return
+
+ initial_stream = torch.cuda.current_stream()
+
+ with torch.cuda.stream(initial_stream):
+ stream = await streamqueue.get()
+ assert isinstance(stream, torch.cuda.Stream)
+
+ try:
+ with torch.cuda.stream(stream):
+ logger.debug('%s %s is starting, stream: %s', trace_name, name,
+ stream)
+ yield
+ current = torch.cuda.current_stream()
+ assert current == stream
+ logger.debug('%s %s has finished, stream: %s', trace_name,
+ name, stream)
+ finally:
+ streamqueue.task_done()
+ streamqueue.put_nowait(stream)
diff --git a/mmdet/utils/dist_utils.py b/mmdet/utils/dist_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..2f2c8614a181ec0594ba157002a2760737e2c6e3
--- /dev/null
+++ b/mmdet/utils/dist_utils.py
@@ -0,0 +1,184 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import functools
+import pickle
+import warnings
+from collections import OrderedDict
+
+import numpy as np
+import torch
+import torch.distributed as dist
+from mmengine.dist import get_dist_info
+from torch._utils import (_flatten_dense_tensors, _take_tensors,
+ _unflatten_dense_tensors)
+
+
+def _allreduce_coalesced(tensors, world_size, bucket_size_mb=-1):
+ if bucket_size_mb > 0:
+ bucket_size_bytes = bucket_size_mb * 1024 * 1024
+ buckets = _take_tensors(tensors, bucket_size_bytes)
+ else:
+ buckets = OrderedDict()
+ for tensor in tensors:
+ tp = tensor.type()
+ if tp not in buckets:
+ buckets[tp] = []
+ buckets[tp].append(tensor)
+ buckets = buckets.values()
+
+ for bucket in buckets:
+ flat_tensors = _flatten_dense_tensors(bucket)
+ dist.all_reduce(flat_tensors)
+ flat_tensors.div_(world_size)
+ for tensor, synced in zip(
+ bucket, _unflatten_dense_tensors(flat_tensors, bucket)):
+ tensor.copy_(synced)
+
+
+def allreduce_grads(params, coalesce=True, bucket_size_mb=-1):
+ """Allreduce gradients.
+
+ Args:
+ params (list[torch.Parameters]): List of parameters of a model
+ coalesce (bool, optional): Whether allreduce parameters as a whole.
+ Defaults to True.
+ bucket_size_mb (int, optional): Size of bucket, the unit is MB.
+ Defaults to -1.
+ """
+ grads = [
+ param.grad.data for param in params
+ if param.requires_grad and param.grad is not None
+ ]
+ world_size = dist.get_world_size()
+ if coalesce:
+ _allreduce_coalesced(grads, world_size, bucket_size_mb)
+ else:
+ for tensor in grads:
+ dist.all_reduce(tensor.div_(world_size))
+
+
+def reduce_mean(tensor):
+ """"Obtain the mean of tensor on different GPUs."""
+ if not (dist.is_available() and dist.is_initialized()):
+ return tensor
+ tensor = tensor.clone()
+ dist.all_reduce(tensor.div_(dist.get_world_size()), op=dist.ReduceOp.SUM)
+ return tensor
+
+
+def obj2tensor(pyobj, device='cuda'):
+ """Serialize picklable python object to tensor."""
+ storage = torch.ByteStorage.from_buffer(pickle.dumps(pyobj))
+ return torch.ByteTensor(storage).to(device=device)
+
+
+def tensor2obj(tensor):
+ """Deserialize tensor to picklable python object."""
+ return pickle.loads(tensor.cpu().numpy().tobytes())
+
+
+@functools.lru_cache()
+def _get_global_gloo_group():
+ """Return a process group based on gloo backend, containing all the ranks
+ The result is cached."""
+ if dist.get_backend() == 'nccl':
+ return dist.new_group(backend='gloo')
+ else:
+ return dist.group.WORLD
+
+
+def all_reduce_dict(py_dict, op='sum', group=None, to_float=True):
+ """Apply all reduce function for python dict object.
+
+ The code is modified from https://github.com/Megvii-
+ BaseDetection/YOLOX/blob/main/yolox/utils/allreduce_norm.py.
+
+ NOTE: make sure that py_dict in different ranks has the same keys and
+ the values should be in the same shape. Currently only supports
+ nccl backend.
+
+ Args:
+ py_dict (dict): Dict to be applied all reduce op.
+ op (str): Operator, could be 'sum' or 'mean'. Default: 'sum'
+ group (:obj:`torch.distributed.group`, optional): Distributed group,
+ Default: None.
+ to_float (bool): Whether to convert all values of dict to float.
+ Default: True.
+
+ Returns:
+ OrderedDict: reduced python dict object.
+ """
+ warnings.warn(
+ 'group` is deprecated. Currently only supports NCCL backend.')
+ _, world_size = get_dist_info()
+ if world_size == 1:
+ return py_dict
+
+ # all reduce logic across different devices.
+ py_key = list(py_dict.keys())
+ if not isinstance(py_dict, OrderedDict):
+ py_key_tensor = obj2tensor(py_key)
+ dist.broadcast(py_key_tensor, src=0)
+ py_key = tensor2obj(py_key_tensor)
+
+ tensor_shapes = [py_dict[k].shape for k in py_key]
+ tensor_numels = [py_dict[k].numel() for k in py_key]
+
+ if to_float:
+ warnings.warn('Note: the "to_float" is True, you need to '
+ 'ensure that the behavior is reasonable.')
+ flatten_tensor = torch.cat(
+ [py_dict[k].flatten().float() for k in py_key])
+ else:
+ flatten_tensor = torch.cat([py_dict[k].flatten() for k in py_key])
+
+ dist.all_reduce(flatten_tensor, op=dist.ReduceOp.SUM)
+ if op == 'mean':
+ flatten_tensor /= world_size
+
+ split_tensors = [
+ x.reshape(shape) for x, shape in zip(
+ torch.split(flatten_tensor, tensor_numels), tensor_shapes)
+ ]
+ out_dict = {k: v for k, v in zip(py_key, split_tensors)}
+ if isinstance(py_dict, OrderedDict):
+ out_dict = OrderedDict(out_dict)
+ return out_dict
+
+
+def sync_random_seed(seed=None, device='cuda'):
+ """Make sure different ranks share the same seed.
+
+ All workers must call this function, otherwise it will deadlock.
+ This method is generally used in `DistributedSampler`,
+ because the seed should be identical across all processes
+ in the distributed group.
+
+ In distributed sampling, different ranks should sample non-overlapped
+ data in the dataset. Therefore, this function is used to make sure that
+ each rank shuffles the data indices in the same order based
+ on the same seed. Then different ranks could use different indices
+ to select non-overlapped data from the same data list.
+
+ Args:
+ seed (int, Optional): The seed. Default to None.
+ device (str): The device where the seed will be put on.
+ Default to 'cuda'.
+
+ Returns:
+ int: Seed to be used.
+ """
+ if seed is None:
+ seed = np.random.randint(2**31)
+ assert isinstance(seed, int)
+
+ rank, world_size = get_dist_info()
+
+ if world_size == 1:
+ return seed
+
+ if rank == 0:
+ random_num = torch.tensor(seed, dtype=torch.int32, device=device)
+ else:
+ random_num = torch.tensor(0, dtype=torch.int32, device=device)
+ dist.broadcast(random_num, src=0)
+ return random_num.item()
diff --git a/mmdet/utils/logger.py b/mmdet/utils/logger.py
new file mode 100644
index 0000000000000000000000000000000000000000..9fec08bbad5517c9169eedb15b4768e7d88d39c7
--- /dev/null
+++ b/mmdet/utils/logger.py
@@ -0,0 +1,49 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import inspect
+
+from mmengine.logging import print_log
+
+
+def get_caller_name():
+ """Get name of caller method."""
+ # this_func_frame = inspect.stack()[0][0] # i.e., get_caller_name
+ # callee_frame = inspect.stack()[1][0] # e.g., log_img_scale
+ caller_frame = inspect.stack()[2][0] # e.g., caller of log_img_scale
+ caller_method = caller_frame.f_code.co_name
+ try:
+ caller_class = caller_frame.f_locals['self'].__class__.__name__
+ return f'{caller_class}.{caller_method}'
+ except KeyError: # caller is a function
+ return caller_method
+
+
+def log_img_scale(img_scale, shape_order='hw', skip_square=False):
+ """Log image size.
+
+ Args:
+ img_scale (tuple): Image size to be logged.
+ shape_order (str, optional): The order of image shape.
+ 'hw' for (height, width) and 'wh' for (width, height).
+ Defaults to 'hw'.
+ skip_square (bool, optional): Whether to skip logging for square
+ img_scale. Defaults to False.
+
+ Returns:
+ bool: Whether to have done logging.
+ """
+ if shape_order == 'hw':
+ height, width = img_scale
+ elif shape_order == 'wh':
+ width, height = img_scale
+ else:
+ raise ValueError(f'Invalid shape_order {shape_order}.')
+
+ if skip_square and (height == width):
+ return False
+
+ caller = get_caller_name()
+ print_log(
+ f'image shape: height={height}, width={width} in {caller}',
+ logger='current')
+
+ return True
diff --git a/mmdet/utils/memory.py b/mmdet/utils/memory.py
new file mode 100644
index 0000000000000000000000000000000000000000..b6f9cbc7f9e5f54e2cc429e5e655b2a27d38d61f
--- /dev/null
+++ b/mmdet/utils/memory.py
@@ -0,0 +1,212 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+from collections import abc
+from contextlib import contextmanager
+from functools import wraps
+
+import torch
+from mmengine.logging import MMLogger
+
+
+def cast_tensor_type(inputs, src_type=None, dst_type=None):
+ """Recursively convert Tensor in inputs from ``src_type`` to ``dst_type``.
+
+ Args:
+ inputs: Inputs that to be casted.
+ src_type (torch.dtype | torch.device): Source type.
+ src_type (torch.dtype | torch.device): Destination type.
+
+ Returns:
+ The same type with inputs, but all contained Tensors have been cast.
+ """
+ assert dst_type is not None
+ if isinstance(inputs, torch.Tensor):
+ if isinstance(dst_type, torch.device):
+ # convert Tensor to dst_device
+ if hasattr(inputs, 'to') and \
+ hasattr(inputs, 'device') and \
+ (inputs.device == src_type or src_type is None):
+ return inputs.to(dst_type)
+ else:
+ return inputs
+ else:
+ # convert Tensor to dst_dtype
+ if hasattr(inputs, 'to') and \
+ hasattr(inputs, 'dtype') and \
+ (inputs.dtype == src_type or src_type is None):
+ return inputs.to(dst_type)
+ else:
+ return inputs
+ # we need to ensure that the type of inputs to be casted are the same
+ # as the argument `src_type`.
+ elif isinstance(inputs, abc.Mapping):
+ return type(inputs)({
+ k: cast_tensor_type(v, src_type=src_type, dst_type=dst_type)
+ for k, v in inputs.items()
+ })
+ elif isinstance(inputs, abc.Iterable):
+ return type(inputs)(
+ cast_tensor_type(item, src_type=src_type, dst_type=dst_type)
+ for item in inputs)
+ # TODO: Currently not supported
+ # elif isinstance(inputs, InstanceData):
+ # for key, value in inputs.items():
+ # inputs[key] = cast_tensor_type(
+ # value, src_type=src_type, dst_type=dst_type)
+ # return inputs
+ else:
+ return inputs
+
+
+@contextmanager
+def _ignore_torch_cuda_oom():
+ """A context which ignores CUDA OOM exception from pytorch.
+
+ Code is modified from
+ # noqa: E501
+ """
+ try:
+ yield
+ except RuntimeError as e:
+ # NOTE: the string may change?
+ if 'CUDA out of memory. ' in str(e):
+ pass
+ else:
+ raise
+
+
+class AvoidOOM:
+ """Try to convert inputs to FP16 and CPU if got a PyTorch's CUDA Out of
+ Memory error. It will do the following steps:
+
+ 1. First retry after calling `torch.cuda.empty_cache()`.
+ 2. If that still fails, it will then retry by converting inputs
+ to FP16.
+ 3. If that still fails trying to convert inputs to CPUs.
+ In this case, it expects the function to dispatch to
+ CPU implementation.
+
+ Args:
+ to_cpu (bool): Whether to convert outputs to CPU if get an OOM
+ error. This will slow down the code significantly.
+ Defaults to True.
+ test (bool): Skip `_ignore_torch_cuda_oom` operate that can use
+ lightweight data in unit test, only used in
+ test unit. Defaults to False.
+
+ Examples:
+ >>> from mmdet.utils.memory import AvoidOOM
+ >>> AvoidCUDAOOM = AvoidOOM()
+ >>> output = AvoidOOM.retry_if_cuda_oom(
+ >>> some_torch_function)(input1, input2)
+ >>> # To use as a decorator
+ >>> # from mmdet.utils import AvoidCUDAOOM
+ >>> @AvoidCUDAOOM.retry_if_cuda_oom
+ >>> def function(*args, **kwargs):
+ >>> return None
+ ```
+
+ Note:
+ 1. The output may be on CPU even if inputs are on GPU. Processing
+ on CPU will slow down the code significantly.
+ 2. When converting inputs to CPU, it will only look at each argument
+ and check if it has `.device` and `.to` for conversion. Nested
+ structures of tensors are not supported.
+ 3. Since the function might be called more than once, it has to be
+ stateless.
+ """
+
+ def __init__(self, to_cpu=True, test=False):
+ self.to_cpu = to_cpu
+ self.test = test
+
+ def retry_if_cuda_oom(self, func):
+ """Makes a function retry itself after encountering pytorch's CUDA OOM
+ error.
+
+ The implementation logic is referred to
+ https://github.com/facebookresearch/detectron2/blob/main/detectron2/utils/memory.py
+
+ Args:
+ func: a stateless callable that takes tensor-like objects
+ as arguments.
+ Returns:
+ func: a callable which retries `func` if OOM is encountered.
+ """ # noqa: W605
+
+ @wraps(func)
+ def wrapped(*args, **kwargs):
+
+ # raw function
+ if not self.test:
+ with _ignore_torch_cuda_oom():
+ return func(*args, **kwargs)
+
+ # Clear cache and retry
+ torch.cuda.empty_cache()
+ with _ignore_torch_cuda_oom():
+ return func(*args, **kwargs)
+
+ # get the type and device of first tensor
+ dtype, device = None, None
+ values = args + tuple(kwargs.values())
+ for value in values:
+ if isinstance(value, torch.Tensor):
+ dtype = value.dtype
+ device = value.device
+ break
+ if dtype is None or device is None:
+ raise ValueError('There is no tensor in the inputs, '
+ 'cannot get dtype and device.')
+
+ # Convert to FP16
+ fp16_args = cast_tensor_type(args, dst_type=torch.half)
+ fp16_kwargs = cast_tensor_type(kwargs, dst_type=torch.half)
+ logger = MMLogger.get_current_instance()
+ logger.warning(f'Attempting to copy inputs of {str(func)} '
+ 'to FP16 due to CUDA OOM')
+
+ # get input tensor type, the output type will same as
+ # the first parameter type.
+ with _ignore_torch_cuda_oom():
+ output = func(*fp16_args, **fp16_kwargs)
+ output = cast_tensor_type(
+ output, src_type=torch.half, dst_type=dtype)
+ if not self.test:
+ return output
+ logger.warning('Using FP16 still meet CUDA OOM')
+
+ # Try on CPU. This will slow down the code significantly,
+ # therefore print a notice.
+ if self.to_cpu:
+ logger.warning(f'Attempting to copy inputs of {str(func)} '
+ 'to CPU due to CUDA OOM')
+ cpu_device = torch.empty(0).device
+ cpu_args = cast_tensor_type(args, dst_type=cpu_device)
+ cpu_kwargs = cast_tensor_type(kwargs, dst_type=cpu_device)
+
+ # convert outputs to GPU
+ with _ignore_torch_cuda_oom():
+ logger.warning(f'Convert outputs to GPU (device={device})')
+ output = func(*cpu_args, **cpu_kwargs)
+ output = cast_tensor_type(
+ output, src_type=cpu_device, dst_type=device)
+ return output
+
+ warnings.warn('Cannot convert output to GPU due to CUDA OOM, '
+ 'the output is now on CPU, which might cause '
+ 'errors if the output need to interact with GPU '
+ 'data in subsequent operations')
+ logger.warning('Cannot convert output to GPU due to '
+ 'CUDA OOM, the output is on CPU now.')
+
+ return func(*cpu_args, **cpu_kwargs)
+ else:
+ # may still get CUDA OOM error
+ return func(*args, **kwargs)
+
+ return wrapped
+
+
+# To use AvoidOOM as a decorator
+AvoidCUDAOOM = AvoidOOM()
diff --git a/mmdet/utils/misc.py b/mmdet/utils/misc.py
new file mode 100644
index 0000000000000000000000000000000000000000..51cb2af8dbfc25e569d4f2d0f16fab12f632dbd5
--- /dev/null
+++ b/mmdet/utils/misc.py
@@ -0,0 +1,105 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import glob
+import os
+import os.path as osp
+import warnings
+from typing import Union
+
+from mmengine.config import Config, ConfigDict
+from mmengine.logging import print_log
+
+
+def find_latest_checkpoint(path, suffix='pth'):
+ """Find the latest checkpoint from the working directory.
+
+ Args:
+ path(str): The path to find checkpoints.
+ suffix(str): File extension.
+ Defaults to pth.
+
+ Returns:
+ latest_path(str | None): File path of the latest checkpoint.
+ References:
+ .. [1] https://github.com/microsoft/SoftTeacher
+ /blob/main/ssod/utils/patch.py
+ """
+ if not osp.exists(path):
+ warnings.warn('The path of checkpoints does not exist.')
+ return None
+ if osp.exists(osp.join(path, f'latest.{suffix}')):
+ return osp.join(path, f'latest.{suffix}')
+
+ checkpoints = glob.glob(osp.join(path, f'*.{suffix}'))
+ if len(checkpoints) == 0:
+ warnings.warn('There are no checkpoints in the path.')
+ return None
+ latest = -1
+ latest_path = None
+ for checkpoint in checkpoints:
+ count = int(osp.basename(checkpoint).split('_')[-1].split('.')[0])
+ if count > latest:
+ latest = count
+ latest_path = checkpoint
+ return latest_path
+
+
+def update_data_root(cfg, logger=None):
+ """Update data root according to env MMDET_DATASETS.
+
+ If set env MMDET_DATASETS, update cfg.data_root according to
+ MMDET_DATASETS. Otherwise, using cfg.data_root as default.
+
+ Args:
+ cfg (:obj:`Config`): The model config need to modify
+ logger (logging.Logger | str | None): the way to print msg
+ """
+ assert isinstance(cfg, Config), \
+ f'cfg got wrong type: {type(cfg)}, expected mmengine.Config'
+
+ if 'MMDET_DATASETS' in os.environ:
+ dst_root = os.environ['MMDET_DATASETS']
+ print_log(f'MMDET_DATASETS has been set to be {dst_root}.'
+ f'Using {dst_root} as data root.')
+ else:
+ return
+
+ assert isinstance(cfg, Config), \
+ f'cfg got wrong type: {type(cfg)}, expected mmengine.Config'
+
+ def update(cfg, src_str, dst_str):
+ for k, v in cfg.items():
+ if isinstance(v, ConfigDict):
+ update(cfg[k], src_str, dst_str)
+ if isinstance(v, str) and src_str in v:
+ cfg[k] = v.replace(src_str, dst_str)
+
+ update(cfg.data, cfg.data_root, dst_root)
+ cfg.data_root = dst_root
+
+
+def get_test_pipeline_cfg(cfg: Union[str, ConfigDict]) -> ConfigDict:
+ """Get the test dataset pipeline from entire config.
+
+ Args:
+ cfg (str or :obj:`ConfigDict`): the entire config. Can be a config
+ file or a ``ConfigDict``.
+
+ Returns:
+ :obj:`ConfigDict`: the config of test dataset.
+ """
+ if isinstance(cfg, str):
+ cfg = Config.fromfile(cfg)
+
+ def _get_test_pipeline_cfg(dataset_cfg):
+ if 'pipeline' in dataset_cfg:
+ return dataset_cfg.pipeline
+ # handle dataset wrapper
+ elif 'dataset' in dataset_cfg:
+ return _get_test_pipeline_cfg(dataset_cfg.dataset)
+ # handle dataset wrappers like ConcatDataset
+ elif 'datasets' in dataset_cfg:
+ return _get_test_pipeline_cfg(dataset_cfg.datasets[0])
+
+ raise RuntimeError('Cannot find `pipeline` in `test_dataloader`')
+
+ return _get_test_pipeline_cfg(cfg.test_dataloader.dataset)
diff --git a/mmdet/utils/profiling.py b/mmdet/utils/profiling.py
new file mode 100644
index 0000000000000000000000000000000000000000..2f53f456c72db57bfa69a8d022c92d153580209e
--- /dev/null
+++ b/mmdet/utils/profiling.py
@@ -0,0 +1,40 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import contextlib
+import sys
+import time
+
+import torch
+
+if sys.version_info >= (3, 7):
+
+ @contextlib.contextmanager
+ def profile_time(trace_name,
+ name,
+ enabled=True,
+ stream=None,
+ end_stream=None):
+ """Print time spent by CPU and GPU.
+
+ Useful as a temporary context manager to find sweet spots of code
+ suitable for async implementation.
+ """
+ if (not enabled) or not torch.cuda.is_available():
+ yield
+ return
+ stream = stream if stream else torch.cuda.current_stream()
+ end_stream = end_stream if end_stream else stream
+ start = torch.cuda.Event(enable_timing=True)
+ end = torch.cuda.Event(enable_timing=True)
+ stream.record_event(start)
+ try:
+ cpu_start = time.monotonic()
+ yield
+ finally:
+ cpu_end = time.monotonic()
+ end_stream.record_event(end)
+ end.synchronize()
+ cpu_time = (cpu_end - cpu_start) * 1000
+ gpu_time = start.elapsed_time(end)
+ msg = f'{trace_name} {name} cpu_time {cpu_time:.2f} ms '
+ msg += f'gpu_time {gpu_time:.2f} ms stream {stream}'
+ print(msg, end_stream)
diff --git a/mmdet/utils/replace_cfg_vals.py b/mmdet/utils/replace_cfg_vals.py
new file mode 100644
index 0000000000000000000000000000000000000000..a3331a36ce5a22fcc4d4a955d757f5e8b6bfc6bb
--- /dev/null
+++ b/mmdet/utils/replace_cfg_vals.py
@@ -0,0 +1,70 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import re
+
+from mmengine.config import Config
+
+
+def replace_cfg_vals(ori_cfg):
+ """Replace the string "${key}" with the corresponding value.
+
+ Replace the "${key}" with the value of ori_cfg.key in the config. And
+ support replacing the chained ${key}. Such as, replace "${key0.key1}"
+ with the value of cfg.key0.key1. Code is modified from `vars.py
+ < https://github.com/microsoft/SoftTeacher/blob/main/ssod/utils/vars.py>`_ # noqa: E501
+
+ Args:
+ ori_cfg (mmengine.config.Config):
+ The origin config with "${key}" generated from a file.
+
+ Returns:
+ updated_cfg [mmengine.config.Config]:
+ The config with "${key}" replaced by the corresponding value.
+ """
+
+ def get_value(cfg, key):
+ for k in key.split('.'):
+ cfg = cfg[k]
+ return cfg
+
+ def replace_value(cfg):
+ if isinstance(cfg, dict):
+ return {key: replace_value(value) for key, value in cfg.items()}
+ elif isinstance(cfg, list):
+ return [replace_value(item) for item in cfg]
+ elif isinstance(cfg, tuple):
+ return tuple([replace_value(item) for item in cfg])
+ elif isinstance(cfg, str):
+ # the format of string cfg may be:
+ # 1) "${key}", which will be replaced with cfg.key directly
+ # 2) "xxx${key}xxx" or "xxx${key1}xxx${key2}xxx",
+ # which will be replaced with the string of the cfg.key
+ keys = pattern_key.findall(cfg)
+ values = [get_value(ori_cfg, key[2:-1]) for key in keys]
+ if len(keys) == 1 and keys[0] == cfg:
+ # the format of string cfg is "${key}"
+ cfg = values[0]
+ else:
+ for key, value in zip(keys, values):
+ # the format of string cfg is
+ # "xxx${key}xxx" or "xxx${key1}xxx${key2}xxx"
+ assert not isinstance(value, (dict, list, tuple)), \
+ f'for the format of string cfg is ' \
+ f"'xxxxx${key}xxxxx' or 'xxx${key}xxx${key}xxx', " \
+ f"the type of the value of '${key}' " \
+ f'can not be dict, list, or tuple' \
+ f'but you input {type(value)} in {cfg}'
+ cfg = cfg.replace(key, str(value))
+ return cfg
+ else:
+ return cfg
+
+ # the pattern of string "${key}"
+ pattern_key = re.compile(r'\$\{[a-zA-Z\d_.]*\}')
+ # the type of ori_cfg._cfg_dict is mmengine.config.ConfigDict
+ updated_cfg = Config(
+ replace_value(ori_cfg._cfg_dict), filename=ori_cfg.filename)
+ # replace the model with model_wrapper
+ if updated_cfg.get('model_wrapper', None) is not None:
+ updated_cfg.model = updated_cfg.model_wrapper
+ updated_cfg.pop('model_wrapper')
+ return updated_cfg
diff --git a/mmdet/utils/setup_env.py b/mmdet/utils/setup_env.py
new file mode 100644
index 0000000000000000000000000000000000000000..a7b37845a883752a1659fabf62c7404cff971191
--- /dev/null
+++ b/mmdet/utils/setup_env.py
@@ -0,0 +1,118 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import datetime
+import logging
+import os
+import platform
+import warnings
+
+import cv2
+import torch.multiprocessing as mp
+from mmengine import DefaultScope
+from mmengine.logging import print_log
+from mmengine.utils import digit_version
+
+
+def setup_cache_size_limit_of_dynamo():
+ """Setup cache size limit of dynamo.
+
+ Note: Due to the dynamic shape of the loss calculation and
+ post-processing parts in the object detection algorithm, these
+ functions must be compiled every time they are run.
+ Setting a large value for torch._dynamo.config.cache_size_limit
+ may result in repeated compilation, which can slow down training
+ and testing speed. Therefore, we need to set the default value of
+ cache_size_limit smaller. An empirical value is 4.
+ """
+
+ import torch
+ if digit_version(torch.__version__) >= digit_version('2.0.0'):
+ if 'DYNAMO_CACHE_SIZE_LIMIT' in os.environ:
+ import torch._dynamo
+ cache_size_limit = int(os.environ['DYNAMO_CACHE_SIZE_LIMIT'])
+ torch._dynamo.config.cache_size_limit = cache_size_limit
+ print_log(
+ f'torch._dynamo.config.cache_size_limit is force '
+ f'set to {cache_size_limit}.',
+ logger='current',
+ level=logging.WARNING)
+
+
+def setup_multi_processes(cfg):
+ """Setup multi-processing environment variables."""
+ # set multi-process start method as `fork` to speed up the training
+ if platform.system() != 'Windows':
+ mp_start_method = cfg.get('mp_start_method', 'fork')
+ current_method = mp.get_start_method(allow_none=True)
+ if current_method is not None and current_method != mp_start_method:
+ warnings.warn(
+ f'Multi-processing start method `{mp_start_method}` is '
+ f'different from the previous setting `{current_method}`.'
+ f'It will be force set to `{mp_start_method}`. You can change '
+ f'this behavior by changing `mp_start_method` in your config.')
+ mp.set_start_method(mp_start_method, force=True)
+
+ # disable opencv multithreading to avoid system being overloaded
+ opencv_num_threads = cfg.get('opencv_num_threads', 0)
+ cv2.setNumThreads(opencv_num_threads)
+
+ # setup OMP threads
+ # This code is referred from https://github.com/pytorch/pytorch/blob/master/torch/distributed/run.py # noqa
+ workers_per_gpu = cfg.data.get('workers_per_gpu', 1)
+ if 'train_dataloader' in cfg.data:
+ workers_per_gpu = \
+ max(cfg.data.train_dataloader.get('workers_per_gpu', 1),
+ workers_per_gpu)
+
+ if 'OMP_NUM_THREADS' not in os.environ and workers_per_gpu > 1:
+ omp_num_threads = 1
+ warnings.warn(
+ f'Setting OMP_NUM_THREADS environment variable for each process '
+ f'to be {omp_num_threads} in default, to avoid your system being '
+ f'overloaded, please further tune the variable for optimal '
+ f'performance in your application as needed.')
+ os.environ['OMP_NUM_THREADS'] = str(omp_num_threads)
+
+ # setup MKL threads
+ if 'MKL_NUM_THREADS' not in os.environ and workers_per_gpu > 1:
+ mkl_num_threads = 1
+ warnings.warn(
+ f'Setting MKL_NUM_THREADS environment variable for each process '
+ f'to be {mkl_num_threads} in default, to avoid your system being '
+ f'overloaded, please further tune the variable for optimal '
+ f'performance in your application as needed.')
+ os.environ['MKL_NUM_THREADS'] = str(mkl_num_threads)
+
+
+def register_all_modules(init_default_scope: bool = True) -> None:
+ """Register all modules in mmdet into the registries.
+
+ Args:
+ init_default_scope (bool): Whether initialize the mmdet default scope.
+ When `init_default_scope=True`, the global default scope will be
+ set to `mmdet`, and all registries will build modules from mmdet's
+ registry node. To understand more about the registry, please refer
+ to https://github.com/open-mmlab/mmengine/blob/main/docs/en/tutorials/registry.md
+ Defaults to True.
+ """ # noqa
+ import mmdet.datasets # noqa: F401,F403
+ import mmdet.engine # noqa: F401,F403
+ import mmdet.evaluation # noqa: F401,F403
+ import mmdet.models # noqa: F401,F403
+ import mmdet.visualization # noqa: F401,F403
+
+ if init_default_scope:
+ never_created = DefaultScope.get_current_instance() is None \
+ or not DefaultScope.check_instance_created('mmdet')
+ if never_created:
+ DefaultScope.get_instance('mmdet', scope_name='mmdet')
+ return
+ current_scope = DefaultScope.get_current_instance()
+ if current_scope.scope_name != 'mmdet':
+ warnings.warn('The current default scope '
+ f'"{current_scope.scope_name}" is not "mmdet", '
+ '`register_all_modules` will force the current'
+ 'default scope to be "mmdet". If this is not '
+ 'expected, please set `init_default_scope=False`.')
+ # avoid name conflict
+ new_instance_name = f'mmdet-{datetime.datetime.now()}'
+ DefaultScope.get_instance(new_instance_name, scope_name='mmdet')
diff --git a/mmdet/utils/split_batch.py b/mmdet/utils/split_batch.py
new file mode 100644
index 0000000000000000000000000000000000000000..0276fb331f23c1a7f7451faf2a8f768e616d45fd
--- /dev/null
+++ b/mmdet/utils/split_batch.py
@@ -0,0 +1,45 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+
+
+def split_batch(img, img_metas, kwargs):
+ """Split data_batch by tags.
+
+ Code is modified from
+ # noqa: E501
+
+ Args:
+ img (Tensor): of shape (N, C, H, W) encoding input images.
+ Typically these should be mean centered and std scaled.
+ img_metas (list[dict]): List of image info dict where each dict
+ has: 'img_shape', 'scale_factor', 'flip', and may also contain
+ 'filename', 'ori_shape', 'pad_shape', and 'img_norm_cfg'.
+ For details on the values of these keys, see
+ :class:`mmdet.datasets.pipelines.Collect`.
+ kwargs (dict): Specific to concrete implementation.
+
+ Returns:
+ data_groups (dict): a dict that data_batch splited by tags,
+ such as 'sup', 'unsup_teacher', and 'unsup_student'.
+ """
+
+ # only stack img in the batch
+ def fuse_list(obj_list, obj):
+ return torch.stack(obj_list) if isinstance(obj,
+ torch.Tensor) else obj_list
+
+ # select data with tag from data_batch
+ def select_group(data_batch, current_tag):
+ group_flag = [tag == current_tag for tag in data_batch['tag']]
+ return {
+ k: fuse_list([vv for vv, gf in zip(v, group_flag) if gf], v)
+ for k, v in data_batch.items()
+ }
+
+ kwargs.update({'img': img, 'img_metas': img_metas})
+ kwargs.update({'tag': [meta['tag'] for meta in img_metas]})
+ tags = list(set(kwargs['tag']))
+ data_groups = {tag: select_group(kwargs, tag) for tag in tags}
+ for tag, group in data_groups.items():
+ group.pop('tag')
+ return data_groups
diff --git a/mmdet/utils/typing_utils.py b/mmdet/utils/typing_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..6caf6de53274594e139dbe7c1973c747229bf010
--- /dev/null
+++ b/mmdet/utils/typing_utils.py
@@ -0,0 +1,22 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+"""Collecting some commonly used type hint in mmdetection."""
+from typing import List, Optional, Sequence, Tuple, Union
+
+from mmengine.config import ConfigDict
+from mmengine.structures import InstanceData, PixelData
+
+# TODO: Need to avoid circular import with assigner and sampler
+# Type hint of config data
+ConfigType = Union[ConfigDict, dict]
+OptConfigType = Optional[ConfigType]
+# Type hint of one or more config data
+MultiConfig = Union[ConfigType, List[ConfigType]]
+OptMultiConfig = Optional[MultiConfig]
+
+InstanceList = List[InstanceData]
+OptInstanceList = Optional[InstanceList]
+
+PixelList = List[PixelData]
+OptPixelList = Optional[PixelList]
+
+RangeType = Sequence[Tuple[int, int]]
diff --git a/mmdet/utils/util_mixins.py b/mmdet/utils/util_mixins.py
new file mode 100644
index 0000000000000000000000000000000000000000..b83b6617f5e4a202067e1659bf448962a2a2bc72
--- /dev/null
+++ b/mmdet/utils/util_mixins.py
@@ -0,0 +1,105 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+"""This module defines the :class:`NiceRepr` mixin class, which defines a
+``__repr__`` and ``__str__`` method that only depend on a custom ``__nice__``
+method, which you must define. This means you only have to overload one
+function instead of two. Furthermore, if the object defines a ``__len__``
+method, then the ``__nice__`` method defaults to something sensible, otherwise
+it is treated as abstract and raises ``NotImplementedError``.
+
+To use simply have your object inherit from :class:`NiceRepr`
+(multi-inheritance should be ok).
+
+This code was copied from the ubelt library: https://github.com/Erotemic/ubelt
+
+Example:
+ >>> # Objects that define __nice__ have a default __str__ and __repr__
+ >>> class Student(NiceRepr):
+ ... def __init__(self, name):
+ ... self.name = name
+ ... def __nice__(self):
+ ... return self.name
+ >>> s1 = Student('Alice')
+ >>> s2 = Student('Bob')
+ >>> print(f's1 = {s1}')
+ >>> print(f's2 = {s2}')
+ s1 =
+ s2 =
+
+Example:
+ >>> # Objects that define __len__ have a default __nice__
+ >>> class Group(NiceRepr):
+ ... def __init__(self, data):
+ ... self.data = data
+ ... def __len__(self):
+ ... return len(self.data)
+ >>> g = Group([1, 2, 3])
+ >>> print(f'g = {g}')
+ g =
+"""
+import warnings
+
+
+class NiceRepr:
+ """Inherit from this class and define ``__nice__`` to "nicely" print your
+ objects.
+
+ Defines ``__str__`` and ``__repr__`` in terms of ``__nice__`` function
+ Classes that inherit from :class:`NiceRepr` should redefine ``__nice__``.
+ If the inheriting class has a ``__len__``, method then the default
+ ``__nice__`` method will return its length.
+
+ Example:
+ >>> class Foo(NiceRepr):
+ ... def __nice__(self):
+ ... return 'info'
+ >>> foo = Foo()
+ >>> assert str(foo) == ''
+ >>> assert repr(foo).startswith('>> class Bar(NiceRepr):
+ ... pass
+ >>> bar = Bar()
+ >>> import pytest
+ >>> with pytest.warns(None) as record:
+ >>> assert 'object at' in str(bar)
+ >>> assert 'object at' in repr(bar)
+
+ Example:
+ >>> class Baz(NiceRepr):
+ ... def __len__(self):
+ ... return 5
+ >>> baz = Baz()
+ >>> assert str(baz) == ''
+ """
+
+ def __nice__(self):
+ """str: a "nice" summary string describing this module"""
+ if hasattr(self, '__len__'):
+ # It is a common pattern for objects to use __len__ in __nice__
+ # As a convenience we define a default __nice__ for these objects
+ return str(len(self))
+ else:
+ # In all other cases force the subclass to overload __nice__
+ raise NotImplementedError(
+ f'Define the __nice__ method for {self.__class__!r}')
+
+ def __repr__(self):
+ """str: the string of the module"""
+ try:
+ nice = self.__nice__()
+ classname = self.__class__.__name__
+ return f'<{classname}({nice}) at {hex(id(self))}>'
+ except NotImplementedError as ex:
+ warnings.warn(str(ex), category=RuntimeWarning)
+ return object.__repr__(self)
+
+ def __str__(self):
+ """str: the string of the module"""
+ try:
+ classname = self.__class__.__name__
+ nice = self.__nice__()
+ return f'<{classname}({nice})>'
+ except NotImplementedError as ex:
+ warnings.warn(str(ex), category=RuntimeWarning)
+ return object.__repr__(self)
diff --git a/mmdet/utils/util_random.py b/mmdet/utils/util_random.py
new file mode 100644
index 0000000000000000000000000000000000000000..dc1ecb6c03b026156c9947cb6d356a822448be0f
--- /dev/null
+++ b/mmdet/utils/util_random.py
@@ -0,0 +1,34 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+"""Helpers for random number generators."""
+import numpy as np
+
+
+def ensure_rng(rng=None):
+ """Coerces input into a random number generator.
+
+ If the input is None, then a global random state is returned.
+
+ If the input is a numeric value, then that is used as a seed to construct a
+ random state. Otherwise the input is returned as-is.
+
+ Adapted from [1]_.
+
+ Args:
+ rng (int | numpy.random.RandomState | None):
+ if None, then defaults to the global rng. Otherwise this can be an
+ integer or a RandomState class
+ Returns:
+ (numpy.random.RandomState) : rng -
+ a numpy random number generator
+
+ References:
+ .. [1] https://gitlab.kitware.com/computer-vision/kwarray/blob/master/kwarray/util_random.py#L270 # noqa: E501
+ """
+
+ if rng is None:
+ rng = np.random.mtrand._rand
+ elif isinstance(rng, int):
+ rng = np.random.RandomState(rng)
+ else:
+ rng = rng
+ return rng
diff --git a/mmdet/version.py b/mmdet/version.py
new file mode 100644
index 0000000000000000000000000000000000000000..24951882f40e606446e5e8defec72f763f228053
--- /dev/null
+++ b/mmdet/version.py
@@ -0,0 +1,27 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+
+__version__ = '3.0.0'
+short_version = __version__
+
+
+def parse_version_info(version_str):
+ """Parse a version string into a tuple.
+
+ Args:
+ version_str (str): The version string.
+ Returns:
+ tuple[int | str]: The version info, e.g., "1.3.0" is parsed into
+ (1, 3, 0), and "2.0.0rc1" is parsed into (2, 0, 0, 'rc1').
+ """
+ version_info = []
+ for x in version_str.split('.'):
+ if x.isdigit():
+ version_info.append(int(x))
+ elif x.find('rc') != -1:
+ patch_version = x.split('rc')
+ version_info.append(int(patch_version[0]))
+ version_info.append(f'rc{patch_version[1]}')
+ return tuple(version_info)
+
+
+version_info = parse_version_info(__version__)
diff --git a/mmdet/visualization/__init__.py b/mmdet/visualization/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..71881ac1ee3b77061bc9f7d9290ad536d5909690
--- /dev/null
+++ b/mmdet/visualization/__init__.py
@@ -0,0 +1,5 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .local_visualizer import DetLocalVisualizer
+from .palette import get_palette, jitter_color, palette_val
+
+__all__ = ['palette_val', 'get_palette', 'DetLocalVisualizer', 'jitter_color']
diff --git a/mmdet/visualization/__pycache__/__init__.cpython-37.pyc b/mmdet/visualization/__pycache__/__init__.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..4f87f572be73c9ecaa83e97adcd1454c8c09e620
Binary files /dev/null and b/mmdet/visualization/__pycache__/__init__.cpython-37.pyc differ
diff --git a/mmdet/visualization/__pycache__/local_visualizer.cpython-37.pyc b/mmdet/visualization/__pycache__/local_visualizer.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..0457765af40b0568cbcd9f6a194b93bf94bbff43
Binary files /dev/null and b/mmdet/visualization/__pycache__/local_visualizer.cpython-37.pyc differ
diff --git a/mmdet/visualization/__pycache__/palette.cpython-37.pyc b/mmdet/visualization/__pycache__/palette.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..fef0b80c46590b4b962ce29f7e389f57c5a1bc8b
Binary files /dev/null and b/mmdet/visualization/__pycache__/palette.cpython-37.pyc differ
diff --git a/mmdet/visualization/local_visualizer.py b/mmdet/visualization/local_visualizer.py
new file mode 100644
index 0000000000000000000000000000000000000000..46f77b0e863c595504d81f184504ced5a373f3d4
--- /dev/null
+++ b/mmdet/visualization/local_visualizer.py
@@ -0,0 +1,401 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Optional, Tuple, Union
+
+import cv2
+import mmcv
+import numpy as np
+import torch
+from mmengine.dist import master_only
+from mmengine.structures import InstanceData, PixelData
+from mmengine.visualization import Visualizer
+
+from ..evaluation import INSTANCE_OFFSET
+from ..registry import VISUALIZERS
+from ..structures import DetDataSample
+from ..structures.mask import BitmapMasks, PolygonMasks, bitmap_to_polygon
+from .palette import _get_adaptive_scales, get_palette, jitter_color
+
+
+@VISUALIZERS.register_module()
+class DetLocalVisualizer(Visualizer):
+ """MMDetection Local Visualizer.
+
+ Args:
+ name (str): Name of the instance. Defaults to 'visualizer'.
+ image (np.ndarray, optional): the origin image to draw. The format
+ should be RGB. Defaults to None.
+ vis_backends (list, optional): Visual backend config list.
+ Defaults to None.
+ save_dir (str, optional): Save file dir for all storage backends.
+ If it is None, the backend storage will not save any data.
+ bbox_color (str, tuple(int), optional): Color of bbox lines.
+ The tuple of color should be in BGR order. Defaults to None.
+ text_color (str, tuple(int), optional): Color of texts.
+ The tuple of color should be in BGR order.
+ Defaults to (200, 200, 200).
+ mask_color (str, tuple(int), optional): Color of masks.
+ The tuple of color should be in BGR order.
+ Defaults to None.
+ line_width (int, float): The linewidth of lines.
+ Defaults to 3.
+ alpha (int, float): The transparency of bboxes or mask.
+ Defaults to 0.8.
+
+ Examples:
+ >>> import numpy as np
+ >>> import torch
+ >>> from mmengine.structures import InstanceData
+ >>> from mmdet.structures import DetDataSample
+ >>> from mmdet.visualization import DetLocalVisualizer
+
+ >>> det_local_visualizer = DetLocalVisualizer()
+ >>> image = np.random.randint(0, 256,
+ ... size=(10, 12, 3)).astype('uint8')
+ >>> gt_instances = InstanceData()
+ >>> gt_instances.bboxes = torch.Tensor([[1, 2, 2, 5]])
+ >>> gt_instances.labels = torch.randint(0, 2, (1,))
+ >>> gt_det_data_sample = DetDataSample()
+ >>> gt_det_data_sample.gt_instances = gt_instances
+ >>> det_local_visualizer.add_datasample('image', image,
+ ... gt_det_data_sample)
+ >>> det_local_visualizer.add_datasample(
+ ... 'image', image, gt_det_data_sample,
+ ... out_file='out_file.jpg')
+ >>> det_local_visualizer.add_datasample(
+ ... 'image', image, gt_det_data_sample,
+ ... show=True)
+ >>> pred_instances = InstanceData()
+ >>> pred_instances.bboxes = torch.Tensor([[2, 4, 4, 8]])
+ >>> pred_instances.labels = torch.randint(0, 2, (1,))
+ >>> pred_det_data_sample = DetDataSample()
+ >>> pred_det_data_sample.pred_instances = pred_instances
+ >>> det_local_visualizer.add_datasample('image', image,
+ ... gt_det_data_sample,
+ ... pred_det_data_sample)
+ """
+
+ def __init__(self,
+ name: str = 'visualizer',
+ image: Optional[np.ndarray] = None,
+ vis_backends: Optional[Dict] = None,
+ save_dir: Optional[str] = None,
+ bbox_color: Optional[Union[str, Tuple[int]]] = None,
+ text_color: Optional[Union[str,
+ Tuple[int]]] = (200, 200, 200),
+ mask_color: Optional[Union[str, Tuple[int]]] = None,
+ line_width: Union[int, float] = 3,
+ alpha: float = 0.8) -> None:
+ super().__init__(
+ name=name,
+ image=image,
+ vis_backends=vis_backends,
+ save_dir=save_dir)
+ self.bbox_color = bbox_color
+ self.text_color = text_color
+ self.mask_color = mask_color
+ self.line_width = line_width
+ self.alpha = alpha
+ # Set default value. When calling
+ # `DetLocalVisualizer().dataset_meta=xxx`,
+ # it will override the default value.
+ self.dataset_meta = {}
+
+ def _draw_instances(self, image: np.ndarray, instances: ['InstanceData'],
+ classes: Optional[List[str]],
+ palette: Optional[List[tuple]]) -> np.ndarray:
+ """Draw instances of GT or prediction.
+
+ Args:
+ image (np.ndarray): The image to draw.
+ instances (:obj:`InstanceData`): Data structure for
+ instance-level annotations or predictions.
+ classes (List[str], optional): Category information.
+ palette (List[tuple], optional): Palette information
+ corresponding to the category.
+
+ Returns:
+ np.ndarray: the drawn image which channel is RGB.
+ """
+ self.set_image(image)
+
+ if 'bboxes' in instances:
+ bboxes = instances.bboxes
+ labels = instances.labels
+
+ max_label = int(max(labels) if len(labels) > 0 else 0)
+ text_palette = get_palette(self.text_color, max_label + 1)
+ text_colors = [text_palette[label] for label in labels]
+
+ bbox_color = palette if self.bbox_color is None \
+ else self.bbox_color
+ bbox_palette = get_palette(bbox_color, max_label + 1)
+ colors = [bbox_palette[label] for label in labels]
+ self.draw_bboxes(
+ bboxes,
+ edge_colors=colors,
+ alpha=self.alpha,
+ line_widths=self.line_width)
+
+ positions = bboxes[:, :2] + self.line_width
+ areas = (bboxes[:, 3] - bboxes[:, 1]) * (
+ bboxes[:, 2] - bboxes[:, 0])
+ scales = _get_adaptive_scales(areas)
+
+ for i, (pos, label) in enumerate(zip(positions, labels)):
+ label_text = classes[
+ label] if classes is not None else f'class {label}'
+ if 'scores' in instances:
+ score = round(float(instances.scores[i]) * 100, 1)
+ label_text += f': {score}'
+
+ self.draw_texts(
+ label_text,
+ pos,
+ colors=text_colors[i],
+ font_sizes=int(13 * scales[i]),
+ bboxes=[{
+ 'facecolor': 'black',
+ 'alpha': 0.8,
+ 'pad': 0.7,
+ 'edgecolor': 'none'
+ }])
+
+ if 'masks' in instances:
+ labels = instances.labels
+ masks = instances.masks
+ if isinstance(masks, torch.Tensor):
+ masks = masks.numpy()
+ elif isinstance(masks, (PolygonMasks, BitmapMasks)):
+ masks = masks.to_ndarray()
+
+ masks = masks.astype(bool)
+
+ max_label = int(max(labels) if len(labels) > 0 else 0)
+ mask_color = palette if self.mask_color is None \
+ else self.mask_color
+ mask_palette = get_palette(mask_color, max_label + 1)
+ colors = [jitter_color(mask_palette[label]) for label in labels]
+ text_palette = get_palette(self.text_color, max_label + 1)
+ text_colors = [text_palette[label] for label in labels]
+
+ polygons = []
+ for i, mask in enumerate(masks):
+ contours, _ = bitmap_to_polygon(mask)
+ polygons.extend(contours)
+ self.draw_polygons(polygons, edge_colors='w', alpha=self.alpha)
+ self.draw_binary_masks(masks, colors=colors, alphas=self.alpha)
+
+ if len(labels) > 0 and \
+ ('bboxes' not in instances or
+ instances.bboxes.sum() == 0):
+ # instances.bboxes.sum()==0 represent dummy bboxes.
+ # A typical example of SOLO does not exist bbox branch.
+ areas = []
+ positions = []
+ for mask in masks:
+ _, _, stats, centroids = cv2.connectedComponentsWithStats(
+ mask.astype(np.uint8), connectivity=8)
+ if stats.shape[0] > 1:
+ largest_id = np.argmax(stats[1:, -1]) + 1
+ positions.append(centroids[largest_id])
+ areas.append(stats[largest_id, -1])
+ areas = np.stack(areas, axis=0)
+ scales = _get_adaptive_scales(areas)
+
+ for i, (pos, label) in enumerate(zip(positions, labels)):
+ label_text = classes[
+ label] if classes is not None else f'class {label}'
+ if 'scores' in instances:
+ score = round(float(instances.scores[i]) * 100, 1)
+ label_text += f': {score}'
+
+ self.draw_texts(
+ label_text,
+ pos,
+ colors=text_colors[i],
+ font_sizes=int(13 * scales[i]),
+ horizontal_alignments='center',
+ bboxes=[{
+ 'facecolor': 'black',
+ 'alpha': 0.8,
+ 'pad': 0.7,
+ 'edgecolor': 'none'
+ }])
+ return self.get_image()
+
+ def _draw_panoptic_seg(self, image: np.ndarray,
+ panoptic_seg: ['PixelData'],
+ classes: Optional[List[str]]) -> np.ndarray:
+ """Draw panoptic seg of GT or prediction.
+
+ Args:
+ image (np.ndarray): The image to draw.
+ panoptic_seg (:obj:`PixelData`): Data structure for
+ pixel-level annotations or predictions.
+ classes (List[str], optional): Category information.
+
+ Returns:
+ np.ndarray: the drawn image which channel is RGB.
+ """
+ # TODO: Is there a way to bypass?
+ num_classes = len(classes)
+
+ panoptic_seg = panoptic_seg.sem_seg[0]
+ ids = np.unique(panoptic_seg)[::-1]
+ legal_indices = ids != num_classes # for VOID label
+ ids = ids[legal_indices]
+
+ labels = np.array([id % INSTANCE_OFFSET for id in ids], dtype=np.int64)
+ segms = (panoptic_seg[None] == ids[:, None, None])
+
+ max_label = int(max(labels) if len(labels) > 0 else 0)
+ mask_palette = get_palette(self.mask_color, max_label + 1)
+ colors = [mask_palette[label] for label in labels]
+
+ self.set_image(image)
+
+ # draw segm
+ polygons = []
+ for i, mask in enumerate(segms):
+ contours, _ = bitmap_to_polygon(mask)
+ polygons.extend(contours)
+ self.draw_polygons(polygons, edge_colors='w', alpha=self.alpha)
+ self.draw_binary_masks(segms, colors=colors, alphas=self.alpha)
+
+ # draw label
+ areas = []
+ positions = []
+ for mask in segms:
+ _, _, stats, centroids = cv2.connectedComponentsWithStats(
+ mask.astype(np.uint8), connectivity=8)
+ max_id = np.argmax(stats[1:, -1]) + 1
+ positions.append(centroids[max_id])
+ areas.append(stats[max_id, -1])
+ areas = np.stack(areas, axis=0)
+ scales = _get_adaptive_scales(areas)
+
+ text_palette = get_palette(self.text_color, max_label + 1)
+ text_colors = [text_palette[label] for label in labels]
+
+ for i, (pos, label) in enumerate(zip(positions, labels)):
+ label_text = classes[label]
+
+ self.draw_texts(
+ label_text,
+ pos,
+ colors=text_colors[i],
+ font_sizes=int(13 * scales[i]),
+ bboxes=[{
+ 'facecolor': 'black',
+ 'alpha': 0.8,
+ 'pad': 0.7,
+ 'edgecolor': 'none'
+ }],
+ horizontal_alignments='center')
+ return self.get_image()
+
+ @master_only
+ def add_datasample(
+ self,
+ name: str,
+ image: np.ndarray,
+ data_sample: Optional['DetDataSample'] = None,
+ draw_gt: bool = True,
+ draw_pred: bool = True,
+ show: bool = False,
+ wait_time: float = 0,
+ # TODO: Supported in mmengine's Viusalizer.
+ out_file: Optional[str] = None,
+ pred_score_thr: float = 0.3,
+ step: int = 0) -> None:
+ """Draw datasample and save to all backends.
+
+ - If GT and prediction are plotted at the same time, they are
+ displayed in a stitched image where the left image is the
+ ground truth and the right image is the prediction.
+ - If ``show`` is True, all storage backends are ignored, and
+ the images will be displayed in a local window.
+ - If ``out_file`` is specified, the drawn image will be
+ saved to ``out_file``. t is usually used when the display
+ is not available.
+
+ Args:
+ name (str): The image identifier.
+ image (np.ndarray): The image to draw.
+ data_sample (:obj:`DetDataSample`, optional): A data
+ sample that contain annotations and predictions.
+ Defaults to None.
+ draw_gt (bool): Whether to draw GT DetDataSample. Default to True.
+ draw_pred (bool): Whether to draw Prediction DetDataSample.
+ Defaults to True.
+ show (bool): Whether to display the drawn image. Default to False.
+ wait_time (float): The interval of show (s). Defaults to 0.
+ out_file (str): Path to output file. Defaults to None.
+ pred_score_thr (float): The threshold to visualize the bboxes
+ and masks. Defaults to 0.3.
+ step (int): Global step value to record. Defaults to 0.
+ """
+ image = image.clip(0, 255).astype(np.uint8)
+ classes = self.dataset_meta.get('classes', None)
+ palette = self.dataset_meta.get('palette', None)
+
+ gt_img_data = None
+ pred_img_data = None
+
+ if data_sample is not None:
+ data_sample = data_sample.cpu()
+
+ if draw_gt and data_sample is not None:
+ gt_img_data = image
+ if 'gt_instances' in data_sample:
+ gt_img_data = self._draw_instances(image,
+ data_sample.gt_instances,
+ classes, palette)
+
+ if 'gt_panoptic_seg' in data_sample:
+ assert classes is not None, 'class information is ' \
+ 'not provided when ' \
+ 'visualizing panoptic ' \
+ 'segmentation results.'
+ gt_img_data = self._draw_panoptic_seg(
+ gt_img_data, data_sample.gt_panoptic_seg, classes)
+
+ if draw_pred and data_sample is not None:
+ pred_img_data = image
+ if 'pred_instances' in data_sample:
+ pred_instances = data_sample.pred_instances
+ pred_instances = pred_instances[
+ pred_instances.scores > pred_score_thr]
+ pred_img_data = self._draw_instances(image, pred_instances,
+ classes, palette)
+ if 'pred_panoptic_seg' in data_sample:
+ assert classes is not None, 'class information is ' \
+ 'not provided when ' \
+ 'visualizing panoptic ' \
+ 'segmentation results.'
+ pred_img_data = self._draw_panoptic_seg(
+ pred_img_data, data_sample.pred_panoptic_seg.numpy(),
+ classes)
+
+ if gt_img_data is not None and pred_img_data is not None:
+ drawn_img = np.concatenate((gt_img_data, pred_img_data), axis=1)
+ elif gt_img_data is not None:
+ drawn_img = gt_img_data
+ elif pred_img_data is not None:
+ drawn_img = pred_img_data
+ else:
+ # Display the original image directly if nothing is drawn.
+ drawn_img = image
+
+ # It is convenient for users to obtain the drawn image.
+ # For example, the user wants to obtain the drawn image and
+ # save it as a video during video inference.
+ self.set_image(drawn_img)
+
+ if show:
+ self.show(drawn_img, win_name=name, wait_time=wait_time)
+
+ if out_file is not None:
+ mmcv.imwrite(drawn_img[..., ::-1], out_file)
+ else:
+ self.add_image(name, drawn_img, step)
diff --git a/mmdet/visualization/palette.py b/mmdet/visualization/palette.py
new file mode 100644
index 0000000000000000000000000000000000000000..af24df0fbf659628867808f0bf053a0ec34854db
--- /dev/null
+++ b/mmdet/visualization/palette.py
@@ -0,0 +1,108 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Tuple, Union
+
+import mmcv
+import numpy as np
+from mmengine.utils import is_str
+
+
+def palette_val(palette: List[tuple]) -> List[tuple]:
+ """Convert palette to matplotlib palette.
+
+ Args:
+ palette (List[tuple]): A list of color tuples.
+
+ Returns:
+ List[tuple[float]]: A list of RGB matplotlib color tuples.
+ """
+ new_palette = []
+ for color in palette:
+ color = [c / 255 for c in color]
+ new_palette.append(tuple(color))
+ return new_palette
+
+
+def get_palette(palette: Union[List[tuple], str, tuple],
+ num_classes: int) -> List[Tuple[int]]:
+ """Get palette from various inputs.
+
+ Args:
+ palette (list[tuple] | str | tuple): palette inputs.
+ num_classes (int): the number of classes.
+
+ Returns:
+ list[tuple[int]]: A list of color tuples.
+ """
+ assert isinstance(num_classes, int)
+
+ if isinstance(palette, list):
+ dataset_palette = palette
+ elif isinstance(palette, tuple):
+ dataset_palette = [palette] * num_classes
+ elif palette == 'random' or palette is None:
+ state = np.random.get_state()
+ # random color
+ np.random.seed(42)
+ palette = np.random.randint(0, 256, size=(num_classes, 3))
+ np.random.set_state(state)
+ dataset_palette = [tuple(c) for c in palette]
+ elif palette == 'coco':
+ from mmdet.datasets import CocoDataset, CocoPanopticDataset
+ dataset_palette = CocoDataset.METAINFO['palette']
+ if len(dataset_palette) < num_classes:
+ dataset_palette = CocoPanopticDataset.METAINFO['palette']
+ elif palette == 'citys':
+ from mmdet.datasets import CityscapesDataset
+ dataset_palette = CityscapesDataset.METAINFO['palette']
+ elif palette == 'voc':
+ from mmdet.datasets import VOCDataset
+ dataset_palette = VOCDataset.METAINFO['palette']
+ elif is_str(palette):
+ dataset_palette = [mmcv.color_val(palette)[::-1]] * num_classes
+ else:
+ raise TypeError(f'Invalid type for palette: {type(palette)}')
+
+ assert len(dataset_palette) >= num_classes, \
+ 'The length of palette should not be less than `num_classes`.'
+ return dataset_palette
+
+
+def _get_adaptive_scales(areas: np.ndarray,
+ min_area: int = 800,
+ max_area: int = 30000) -> np.ndarray:
+ """Get adaptive scales according to areas.
+
+ The scale range is [0.5, 1.0]. When the area is less than
+ ``min_area``, the scale is 0.5 while the area is larger than
+ ``max_area``, the scale is 1.0.
+
+ Args:
+ areas (ndarray): The areas of bboxes or masks with the
+ shape of (n, ).
+ min_area (int): Lower bound areas for adaptive scales.
+ Defaults to 800.
+ max_area (int): Upper bound areas for adaptive scales.
+ Defaults to 30000.
+
+ Returns:
+ ndarray: The adaotive scales with the shape of (n, ).
+ """
+ scales = 0.5 + (areas - min_area) / (max_area - min_area)
+ scales = np.clip(scales, 0.5, 1.0)
+ return scales
+
+
+def jitter_color(color: tuple) -> tuple:
+ """Randomly jitter the given color in order to better distinguish instances
+ with the same class.
+
+ Args:
+ color (tuple): The RGB color tuple. Each value is between [0, 255].
+
+ Returns:
+ tuple: The jittered color tuple.
+ """
+ jitter = np.random.rand(3)
+ jitter = (jitter / np.linalg.norm(jitter) - 0.5) * 0.5 * 255
+ color = np.clip(jitter + color, 0, 255).astype(np.uint8)
+ return tuple(color)
diff --git a/pytest.ini b/pytest.ini
new file mode 100644
index 0000000000000000000000000000000000000000..9796e871e70c7c67345b1d6bcf708c0c82377a98
--- /dev/null
+++ b/pytest.ini
@@ -0,0 +1,7 @@
+[pytest]
+addopts = --xdoctest --xdoctest-style=auto
+norecursedirs = .git ignore build __pycache__ data docker docs .eggs
+
+filterwarnings= default
+ ignore:.*No cfgstr given in Cacher constructor or call.*:Warning
+ ignore:.*Define the __nice__ method for.*:Warning
diff --git a/requirements/albu.txt b/requirements/albu.txt
new file mode 100644
index 0000000000000000000000000000000000000000..f421fbbdc472527e6010cb62a7d0236cf034f24f
--- /dev/null
+++ b/requirements/albu.txt
@@ -0,0 +1 @@
+albumentations>=0.3.2 --no-binary qudida,albumentations
diff --git a/requirements/build.txt b/requirements/build.txt
new file mode 100644
index 0000000000000000000000000000000000000000..81558298594a9619f3187d220f1accede1865de7
--- /dev/null
+++ b/requirements/build.txt
@@ -0,0 +1,3 @@
+# These must be installed before building mmdetection
+cython
+numpy
diff --git a/requirements/docs.txt b/requirements/docs.txt
new file mode 100644
index 0000000000000000000000000000000000000000..d251554cb4e65ccbef06cd21fb6eeac9b9d94a33
--- /dev/null
+++ b/requirements/docs.txt
@@ -0,0 +1,7 @@
+docutils==0.16.0
+myst-parser
+-e git+https://github.com/open-mmlab/pytorch_sphinx_theme.git#egg=pytorch_sphinx_theme
+sphinx==4.0.2
+sphinx-copybutton
+sphinx_markdown_tables
+sphinx_rtd_theme==0.5.2
diff --git a/requirements/mminstall.txt b/requirements/mminstall.txt
new file mode 100644
index 0000000000000000000000000000000000000000..4213aa6bbd90fda67235d81313e34f54ba02a50d
--- /dev/null
+++ b/requirements/mminstall.txt
@@ -0,0 +1,2 @@
+mmcv>=2.0.0rc4,<2.1.0
+mmengine>=0.7.1,<1.0.0
diff --git a/requirements/optional.txt b/requirements/optional.txt
new file mode 100644
index 0000000000000000000000000000000000000000..4f0065a9b4d86ff0909ce8db000ebe54e51743c8
--- /dev/null
+++ b/requirements/optional.txt
@@ -0,0 +1,3 @@
+cityscapesscripts
+imagecorruptions
+scikit-learn
diff --git a/requirements/readthedocs.txt b/requirements/readthedocs.txt
new file mode 100644
index 0000000000000000000000000000000000000000..bf5ee9a4696e1bf9061a4258957365fd534a2704
--- /dev/null
+++ b/requirements/readthedocs.txt
@@ -0,0 +1,5 @@
+mmcv>=2.0.0rc4,<2.1.0
+mmengine>=0.7.1,<1.0.0
+scipy
+torch
+torchvision
diff --git a/requirements/runtime.txt b/requirements/runtime.txt
new file mode 100644
index 0000000000000000000000000000000000000000..f5d310519274b594efbabddd694dc6a48da877b2
--- /dev/null
+++ b/requirements/runtime.txt
@@ -0,0 +1,7 @@
+matplotlib
+numpy
+pycocotools
+scipy
+shapely
+six
+terminaltables
diff --git a/requirements/tests.txt b/requirements/tests.txt
new file mode 100644
index 0000000000000000000000000000000000000000..08104b7b8c360caf0f86d0840dee367c4fdc9de6
--- /dev/null
+++ b/requirements/tests.txt
@@ -0,0 +1,21 @@
+asynctest
+cityscapesscripts
+codecov
+flake8
+imagecorruptions
+instaboostfast
+interrogate
+isort==4.3.21
+# Note: used for kwarray.group_items, this may be ported to mmcv in the future.
+kwarray
+memory_profiler
+-e git+https://github.com/open-mmlab/mmtracking@dev-1.x#egg=mmtrack
+onnx==1.7.0
+onnxruntime>=1.8.0
+parameterized
+protobuf<=3.20.1
+psutil
+pytest
+ubelt
+xdoctest>=0.10.0
+yapf
diff --git a/setup.cfg b/setup.cfg
new file mode 100644
index 0000000000000000000000000000000000000000..70dd621c8f50b78c4a105fdfa69edd917893a314
--- /dev/null
+++ b/setup.cfg
@@ -0,0 +1,21 @@
+[isort]
+line_length = 79
+multi_line_output = 0
+extra_standard_library = setuptools
+known_first_party = mmdet
+known_third_party = PIL,asynctest,cityscapesscripts,cv2,gather_models,matplotlib,mmcv,mmengine,numpy,onnx,onnxruntime,pycocotools,parameterized,pytest,pytorch_sphinx_theme,requests,scipy,seaborn,six,terminaltables,torch,ts,yaml
+no_lines_before = STDLIB,LOCALFOLDER
+default_section = THIRDPARTY
+
+[yapf]
+BASED_ON_STYLE = pep8
+BLANK_LINE_BEFORE_NESTED_CLASS_OR_DEF = true
+SPLIT_BEFORE_EXPRESSION_AFTER_OPENING_PAREN = true
+
+# ignore-words-list needs to be lowercase format. For example, if we want to
+# ignore word "BA", then we need to append "ba" to ignore-words-list rather
+# than "BA"
+[codespell]
+skip = *.ipynb
+quiet-level = 3
+ignore-words-list = patten,nd,ty,mot,hist,formating,winn,gool,datas,wan,confids,TOOD,tood,ba,warmup,nam,DOTA,dota
diff --git a/setup.py b/setup.py
new file mode 100644
index 0000000000000000000000000000000000000000..535d90eff44ba6f68a8388e08dea8cb6487650ed
--- /dev/null
+++ b/setup.py
@@ -0,0 +1,220 @@
+#!/usr/bin/env python
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+import os.path as osp
+import platform
+import shutil
+import sys
+import warnings
+from setuptools import find_packages, setup
+
+import torch
+from torch.utils.cpp_extension import (BuildExtension, CppExtension,
+ CUDAExtension)
+
+
+def readme():
+ with open('README.md', encoding='utf-8') as f:
+ content = f.read()
+ return content
+
+
+version_file = 'mmdet/version.py'
+
+
+def get_version():
+ with open(version_file, 'r') as f:
+ exec(compile(f.read(), version_file, 'exec'))
+ return locals()['__version__']
+
+
+def make_cuda_ext(name, module, sources, sources_cuda=[]):
+
+ define_macros = []
+ extra_compile_args = {'cxx': []}
+
+ if torch.cuda.is_available() or os.getenv('FORCE_CUDA', '0') == '1':
+ define_macros += [('WITH_CUDA', None)]
+ extension = CUDAExtension
+ extra_compile_args['nvcc'] = [
+ '-D__CUDA_NO_HALF_OPERATORS__',
+ '-D__CUDA_NO_HALF_CONVERSIONS__',
+ '-D__CUDA_NO_HALF2_OPERATORS__',
+ ]
+ sources += sources_cuda
+ else:
+ print(f'Compiling {name} without CUDA')
+ extension = CppExtension
+
+ return extension(
+ name=f'{module}.{name}',
+ sources=[os.path.join(*module.split('.'), p) for p in sources],
+ define_macros=define_macros,
+ extra_compile_args=extra_compile_args)
+
+
+def parse_requirements(fname='requirements.txt', with_version=True):
+ """Parse the package dependencies listed in a requirements file but strips
+ specific versioning information.
+
+ Args:
+ fname (str): path to requirements file
+ with_version (bool, default=False): if True include version specs
+
+ Returns:
+ List[str]: list of requirements items
+
+ CommandLine:
+ python -c "import setup; print(setup.parse_requirements())"
+ """
+ import re
+ import sys
+ from os.path import exists
+ require_fpath = fname
+
+ def parse_line(line):
+ """Parse information from a line in a requirements text file."""
+ if line.startswith('-r '):
+ # Allow specifying requirements in other files
+ target = line.split(' ')[1]
+ for info in parse_require_file(target):
+ yield info
+ else:
+ info = {'line': line}
+ if line.startswith('-e '):
+ info['package'] = line.split('#egg=')[1]
+ elif '@git+' in line:
+ info['package'] = line
+ else:
+ # Remove versioning from the package
+ pat = '(' + '|'.join(['>=', '==', '>']) + ')'
+ parts = re.split(pat, line, maxsplit=1)
+ parts = [p.strip() for p in parts]
+
+ info['package'] = parts[0]
+ if len(parts) > 1:
+ op, rest = parts[1:]
+ if ';' in rest:
+ # Handle platform specific dependencies
+ # http://setuptools.readthedocs.io/en/latest/setuptools.html#declaring-platform-specific-dependencies
+ version, platform_deps = map(str.strip,
+ rest.split(';'))
+ info['platform_deps'] = platform_deps
+ else:
+ version = rest # NOQA
+ info['version'] = (op, version)
+ yield info
+
+ def parse_require_file(fpath):
+ with open(fpath, 'r') as f:
+ for line in f.readlines():
+ line = line.strip()
+ if line and not line.startswith('#'):
+ for info in parse_line(line):
+ yield info
+
+ def gen_packages_items():
+ if exists(require_fpath):
+ for info in parse_require_file(require_fpath):
+ parts = [info['package']]
+ if with_version and 'version' in info:
+ parts.extend(info['version'])
+ if not sys.version.startswith('3.4'):
+ # apparently package_deps are broken in 3.4
+ platform_deps = info.get('platform_deps')
+ if platform_deps is not None:
+ parts.append(';' + platform_deps)
+ item = ''.join(parts)
+ yield item
+
+ packages = list(gen_packages_items())
+ return packages
+
+
+def add_mim_extension():
+ """Add extra files that are required to support MIM into the package.
+
+ These files will be added by creating a symlink to the originals if the
+ package is installed in `editable` mode (e.g. pip install -e .), or by
+ copying from the originals otherwise.
+ """
+
+ # parse installment mode
+ if 'develop' in sys.argv:
+ # installed by `pip install -e .`
+ if platform.system() == 'Windows':
+ # set `copy` mode here since symlink fails on Windows.
+ mode = 'copy'
+ else:
+ mode = 'symlink'
+ elif 'sdist' in sys.argv or 'bdist_wheel' in sys.argv:
+ # installed by `pip install .`
+ # or create source distribution by `python setup.py sdist`
+ mode = 'copy'
+ else:
+ return
+
+ filenames = ['tools', 'configs', 'demo', 'model-index.yml']
+ repo_path = osp.dirname(__file__)
+ mim_path = osp.join(repo_path, 'mmdet', '.mim')
+ os.makedirs(mim_path, exist_ok=True)
+
+ for filename in filenames:
+ if osp.exists(filename):
+ src_path = osp.join(repo_path, filename)
+ tar_path = osp.join(mim_path, filename)
+
+ if osp.isfile(tar_path) or osp.islink(tar_path):
+ os.remove(tar_path)
+ elif osp.isdir(tar_path):
+ shutil.rmtree(tar_path)
+
+ if mode == 'symlink':
+ src_relpath = osp.relpath(src_path, osp.dirname(tar_path))
+ os.symlink(src_relpath, tar_path)
+ elif mode == 'copy':
+ if osp.isfile(src_path):
+ shutil.copyfile(src_path, tar_path)
+ elif osp.isdir(src_path):
+ shutil.copytree(src_path, tar_path)
+ else:
+ warnings.warn(f'Cannot copy file {src_path}.')
+ else:
+ raise ValueError(f'Invalid mode {mode}')
+
+
+if __name__ == '__main__':
+ add_mim_extension()
+ setup(
+ name='mmdet',
+ version=get_version(),
+ description='OpenMMLab Detection Toolbox and Benchmark',
+ long_description=readme(),
+ long_description_content_type='text/markdown',
+ author='MMDetection Contributors',
+ author_email='openmmlab@gmail.com',
+ keywords='computer vision, object detection',
+ url='https://github.com/open-mmlab/mmdetection',
+ packages=find_packages(exclude=('configs', 'tools', 'demo')),
+ include_package_data=True,
+ classifiers=[
+ 'Development Status :: 5 - Production/Stable',
+ 'License :: OSI Approved :: Apache Software License',
+ 'Operating System :: OS Independent',
+ 'Programming Language :: Python :: 3',
+ 'Programming Language :: Python :: 3.7',
+ 'Programming Language :: Python :: 3.8',
+ 'Programming Language :: Python :: 3.9',
+ ],
+ license='Apache License 2.0',
+ install_requires=parse_requirements('requirements/runtime.txt'),
+ extras_require={
+ 'all': parse_requirements('requirements.txt'),
+ 'tests': parse_requirements('requirements/tests.txt'),
+ 'build': parse_requirements('requirements/build.txt'),
+ 'optional': parse_requirements('requirements/optional.txt'),
+ 'mim': parse_requirements('requirements/mminstall.txt'),
+ },
+ ext_modules=[],
+ cmdclass={'build_ext': BuildExtension},
+ zip_safe=False)
diff --git a/test.py b/test.py
new file mode 100644
index 0000000000000000000000000000000000000000..6ca5e42bff0b91896b75e5d5ff636e4a080e0ed3
--- /dev/null
+++ b/test.py
@@ -0,0 +1,153 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os
+os.environ["CUDA_VISIBLE_DEVICES"] = "0"
+import os.path as osp
+import warnings
+from copy import deepcopy
+
+from mmengine import ConfigDict
+from mmengine.config import Config, DictAction
+from mmengine.runner import Runner
+
+from mmdet.engine.hooks.utils import trigger_visualization_hook
+from mmdet.evaluation import DumpDetResults
+from mmdet.registry import RUNNERS
+from mmdet.utils import setup_cache_size_limit_of_dynamo
+
+
+# TODO: support fuse_conv_bn and format_only
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='MMDet test (and eval) a model')
+ parser.add_argument('--config', default='./configs/specdetr_sb-2s-100e_hsi.py',
+ help='test config file path')
+ parser.add_argument('--checkpoint',
+ default='./work_dirs/SpecDETR/SpecDETR_100e.pth',
+ help='checkpoint file')
+ parser.add_argument(
+ '--work-dir',default='./work_dirs/SpecDETR/',
+ help='the directory to save the file containing evaluation metrics')
+ parser.add_argument(
+ '--out',
+ type=str,default='./work_dirs/SpecDETR/result.pkl',
+ help='dump predictions to a pickle file for offline evaluation')
+ parser.add_argument(
+ '--show', action='store_true', help='show prediction results')
+ parser.add_argument(
+ '--show-dir',
+ help='directory where painted images will be saved. '
+ 'If specified, it will be automatically saved '
+ 'to the work_dir/timestamp/show_dir')
+ parser.add_argument(
+ '--wait-time', type=float, default=2, help='the interval of show (s)')
+ parser.add_argument(
+ '--cfg-options',
+ nargs='+',
+ action=DictAction,
+ help='override some settings in the used config, the key-value pair '
+ 'in xxx=yyy format will be merged into config file. If the value to '
+ 'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
+ 'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
+ 'Note that the quotation marks are necessary and that no white space '
+ 'is allowed.')
+ parser.add_argument(
+ '--launcher',
+ choices=['none', 'pytorch', 'slurm', 'mpi'],
+ default='none',
+ help='job launcher')
+ parser.add_argument('--tta', action='store_true')
+ # When using PyTorch version >= 2.0.0, the `torch.distributed.launch`
+ # will pass the `--local-rank` parameter to `tools/train.py` instead
+ # of `--local_rank`.
+ parser.add_argument('--local_rank', '--local-rank', type=int, default=0)
+ args = parser.parse_args()
+ if 'LOCAL_RANK' not in os.environ:
+ os.environ['LOCAL_RANK'] = str(args.local_rank)
+ return args
+
+
+def main():
+ args = parse_args()
+
+ # Reduce the number of repeated compilations and improve
+ # testing speed.
+ setup_cache_size_limit_of_dynamo()
+
+ # load config
+ cfg = Config.fromfile(args.config)
+ cfg.launcher = args.launcher
+ if args.cfg_options is not None:
+ cfg.merge_from_dict(args.cfg_options)
+
+ # work_dir is determined in this priority: CLI > segment in file > filename
+ if args.work_dir is not None:
+ # update configs according to CLI args if args.work_dir is not None
+ cfg.work_dir = args.work_dir
+ elif cfg.get('work_dir', None) is None:
+ # use config filename as default work_dir if cfg.work_dir is None
+ cfg.work_dir = osp.join('./work_dirs',
+ osp.splitext(osp.basename(args.config))[0])
+
+ cfg.load_from = args.checkpoint
+
+ if args.show or args.show_dir:
+ cfg = trigger_visualization_hook(cfg, args)
+
+ if args.tta:
+
+ if 'tta_model' not in cfg:
+ warnings.warn('Cannot find ``tta_model`` in config, '
+ 'we will set it as default.')
+ cfg.tta_model = dict(
+ type='DetTTAModel',
+ tta_cfg=dict(
+ nms=dict(type='nms', iou_threshold=0.5), max_per_img=100))
+ if 'tta_pipeline' not in cfg:
+ warnings.warn('Cannot find ``tta_pipeline`` in config, '
+ 'we will set it as default.')
+ test_data_cfg = cfg.test_dataloader.dataset
+ while 'dataset' in test_data_cfg:
+ test_data_cfg = test_data_cfg['dataset']
+ cfg.tta_pipeline = deepcopy(test_data_cfg.pipeline)
+ flip_tta = dict(
+ type='TestTimeAug',
+ transforms=[
+ [
+ dict(type='RandomFlip', prob=1.),
+ dict(type='RandomFlip', prob=0.)
+ ],
+ [
+ dict(
+ type='PackDetInputs',
+ meta_keys=('img_id', 'img_path', 'ori_shape',
+ 'img_shape', 'scale_factor', 'flip',
+ 'flip_direction'))
+ ],
+ ])
+ cfg.tta_pipeline[-1] = flip_tta
+ cfg.model = ConfigDict(**cfg.tta_model, module=cfg.model)
+ cfg.test_dataloader.dataset.pipeline = cfg.tta_pipeline
+
+ # build the runner from config
+ if 'runner_type' not in cfg:
+ # build the default runner
+ runner = Runner.from_cfg(cfg)
+ else:
+ # build customized runner from the registry
+ # if 'runner_type' is set in the cfg
+ runner = RUNNERS.build(cfg)
+
+ # add `DumpResults` dummy metric
+ if args.out is not None:
+ assert args.out.endswith(('.pkl', '.pickle')), \
+ 'The dump file must be a pkl file.'
+ runner.test_evaluator.metrics.append(
+ DumpDetResults(out_file_path=args.out))
+
+ # start testing
+ runner.test()
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/analysis_tools/analyze_logs.py b/tools/analysis_tools/analyze_logs.py
new file mode 100644
index 0000000000000000000000000000000000000000..926412e27bad8817c0efb4c729f7dfedd9d10de1
--- /dev/null
+++ b/tools/analysis_tools/analyze_logs.py
@@ -0,0 +1,211 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import json
+from collections import defaultdict
+
+import matplotlib.pyplot as plt
+import numpy as np
+import seaborn as sns
+
+
+def cal_train_time(log_dicts, args):
+ for i, log_dict in enumerate(log_dicts):
+ print(f'{"-" * 5}Analyze train time of {args.json_logs[i]}{"-" * 5}')
+ all_times = []
+ for epoch in log_dict.keys():
+ if args.include_outliers:
+ all_times.append(log_dict[epoch]['time'])
+ else:
+ all_times.append(log_dict[epoch]['time'][1:])
+ if not all_times:
+ raise KeyError(
+ 'Please reduce the log interval in the config so that'
+ 'interval is less than iterations of one epoch.')
+ epoch_ave_time = np.array(list(map(lambda x: np.mean(x), all_times)))
+ slowest_epoch = epoch_ave_time.argmax()
+ fastest_epoch = epoch_ave_time.argmin()
+ std_over_epoch = epoch_ave_time.std()
+ print(f'slowest epoch {slowest_epoch + 1}, '
+ f'average time is {epoch_ave_time[slowest_epoch]:.4f} s/iter')
+ print(f'fastest epoch {fastest_epoch + 1}, '
+ f'average time is {epoch_ave_time[fastest_epoch]:.4f} s/iter')
+ print(f'time std over epochs is {std_over_epoch:.4f}')
+ print(f'average iter time: {np.mean(epoch_ave_time):.4f} s/iter\n')
+
+
+def plot_curve(log_dicts, args):
+ if args.backend is not None:
+ plt.switch_backend(args.backend)
+ sns.set_style(args.style)
+ # if legend is None, use {filename}_{key} as legend
+ legend = args.legend
+ if legend is None:
+ legend = []
+ for json_log in args.json_logs:
+ for metric in args.keys:
+ legend.append(f'{json_log}_{metric}')
+ assert len(legend) == (len(args.json_logs) * len(args.keys))
+ metrics = args.keys
+
+ # TODO: support dynamic eval interval(e.g. RTMDet) when plotting mAP.
+ num_metrics = len(metrics)
+ for i, log_dict in enumerate(log_dicts):
+ epochs = list(log_dict.keys())
+ for j, metric in enumerate(metrics):
+ print(f'plot curve of {args.json_logs[i]}, metric is {metric}')
+ if metric not in log_dict[epochs[int(args.eval_interval) - 1]]:
+ if 'mAP' in metric:
+ raise KeyError(
+ f'{args.json_logs[i]} does not contain metric '
+ f'{metric}. Please check if "--no-validate" is '
+ 'specified when you trained the model. Or check '
+ f'if the eval_interval {args.eval_interval} in args '
+ 'is equal to the eval_interval during training.')
+ raise KeyError(
+ f'{args.json_logs[i]} does not contain metric {metric}. '
+ 'Please reduce the log interval in the config so that '
+ 'interval is less than iterations of one epoch.')
+
+ if 'mAP' in metric:
+ xs = []
+ ys = []
+ for epoch in epochs:
+ ys += log_dict[epoch][metric]
+ if log_dict[epoch][metric]:
+ xs += [epoch]
+ plt.xlabel('epoch')
+ plt.plot(xs, ys, label=legend[i * num_metrics + j], marker='o')
+ else:
+ xs = []
+ ys = []
+ for epoch in epochs:
+ iters = log_dict[epoch]['step']
+ xs.append(np.array(iters))
+ ys.append(np.array(log_dict[epoch][metric][:len(iters)]))
+ xs = np.concatenate(xs)
+ ys = np.concatenate(ys)
+ plt.xlabel('iter')
+ plt.plot(
+ xs, ys, label=legend[i * num_metrics + j], linewidth=0.5)
+ plt.legend()
+ if args.title is not None:
+ plt.title(args.title)
+ if args.out is None:
+ plt.show()
+ else:
+ print(f'save curve to: {args.out}')
+ plt.savefig(args.out)
+ plt.cla()
+
+
+def add_plot_parser(subparsers):
+ parser_plt = subparsers.add_parser(
+ 'plot_curve', help='parser for plotting curves')
+ parser_plt.add_argument(
+ 'json_logs',
+ type=str,
+ nargs='+',
+ help='path of train log in json format')
+ parser_plt.add_argument(
+ '--keys',
+ type=str,
+ nargs='+',
+ default=['bbox_mAP'],
+ help='the metric that you want to plot')
+ parser_plt.add_argument(
+ '--start-epoch',
+ type=str,
+ default='1',
+ help='the epoch that you want to start')
+ parser_plt.add_argument(
+ '--eval-interval',
+ type=str,
+ default='1',
+ help='the eval interval when training')
+ parser_plt.add_argument('--title', type=str, help='title of figure')
+ parser_plt.add_argument(
+ '--legend',
+ type=str,
+ nargs='+',
+ default=None,
+ help='legend of each plot')
+ parser_plt.add_argument(
+ '--backend', type=str, default=None, help='backend of plt')
+ parser_plt.add_argument(
+ '--style', type=str, default='dark', help='style of plt')
+ parser_plt.add_argument('--out', type=str, default=None)
+
+
+def add_time_parser(subparsers):
+ parser_time = subparsers.add_parser(
+ 'cal_train_time',
+ help='parser for computing the average time per training iteration')
+ parser_time.add_argument(
+ 'json_logs',
+ type=str,
+ nargs='+',
+ help='path of train log in json format')
+ parser_time.add_argument(
+ '--include-outliers',
+ action='store_true',
+ help='include the first value of every epoch when computing '
+ 'the average time')
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='Analyze Json Log')
+ # currently only support plot curve and calculate average train time
+ subparsers = parser.add_subparsers(dest='task', help='task parser')
+ add_plot_parser(subparsers)
+ add_time_parser(subparsers)
+ args = parser.parse_args()
+ return args
+
+
+def load_json_logs(json_logs):
+ # load and convert json_logs to log_dict, key is epoch, value is a sub dict
+ # keys of sub dict is different metrics, e.g. memory, bbox_mAP
+ # value of sub dict is a list of corresponding values of all iterations
+ log_dicts = [dict() for _ in json_logs]
+ for json_log, log_dict in zip(json_logs, log_dicts):
+ with open(json_log, 'r') as log_file:
+ epoch = 1
+ for i, line in enumerate(log_file):
+ log = json.loads(line.strip())
+ val_flag = False
+ # skip lines only contains one key
+ if not len(log) > 1:
+ continue
+
+ if epoch not in log_dict:
+ log_dict[epoch] = defaultdict(list)
+
+ for k, v in log.items():
+ if '/' in k:
+ log_dict[epoch][k.split('/')[-1]].append(v)
+ val_flag = True
+ elif val_flag:
+ continue
+ else:
+ log_dict[epoch][k].append(v)
+
+ if 'epoch' in log.keys():
+ epoch = log['epoch']
+
+ return log_dicts
+
+
+def main():
+ args = parse_args()
+
+ json_logs = args.json_logs
+ for json_log in json_logs:
+ assert json_log.endswith('.json')
+
+ log_dicts = load_json_logs(json_logs)
+
+ eval(args.task)(log_dicts, args)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/analysis_tools/analyze_results.py b/tools/analysis_tools/analyze_results.py
new file mode 100644
index 0000000000000000000000000000000000000000..a7baba009e7631b0b9672554432eaee823432b3e
--- /dev/null
+++ b/tools/analysis_tools/analyze_results.py
@@ -0,0 +1,398 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os.path as osp
+from multiprocessing import Pool
+
+import mmcv
+import numpy as np
+from mmengine.config import Config, DictAction
+from mmengine.fileio import load
+from mmengine.registry import init_default_scope
+from mmengine.runner import Runner
+from mmengine.structures import InstanceData, PixelData
+from mmengine.utils import ProgressBar, check_file_exist, mkdir_or_exist
+
+from mmdet.datasets import get_loading_pipeline
+from mmdet.evaluation import eval_map
+from mmdet.registry import DATASETS, RUNNERS
+from mmdet.structures import DetDataSample
+from mmdet.utils import replace_cfg_vals, update_data_root
+from mmdet.visualization import DetLocalVisualizer
+
+
+def bbox_map_eval(det_result, annotation, nproc=4):
+ """Evaluate mAP of single image det result.
+
+ Args:
+ det_result (list[list]): [[cls1_det, cls2_det, ...], ...].
+ The outer list indicates images, and the inner list indicates
+ per-class detected bboxes.
+ annotation (dict): Ground truth annotations where keys of
+ annotations are:
+
+ - bboxes: numpy array of shape (n, 4)
+ - labels: numpy array of shape (n, )
+ - bboxes_ignore (optional): numpy array of shape (k, 4)
+ - labels_ignore (optional): numpy array of shape (k, )
+
+ nproc (int): Processes used for computing mAP.
+ Default: 4.
+
+ Returns:
+ float: mAP
+ """
+
+ # use only bbox det result
+ if isinstance(det_result, tuple):
+ bbox_det_result = [det_result[0]]
+ else:
+ bbox_det_result = [det_result]
+ # mAP
+ iou_thrs = np.linspace(
+ .5, 0.95, int(np.round((0.95 - .5) / .05)) + 1, endpoint=True)
+
+ processes = []
+ workers = Pool(processes=nproc)
+ for thr in iou_thrs:
+ p = workers.apply_async(eval_map, (bbox_det_result, [annotation]), {
+ 'iou_thr': thr,
+ 'logger': 'silent',
+ 'nproc': 1
+ })
+ processes.append(p)
+
+ workers.close()
+ workers.join()
+
+ mean_aps = []
+ for p in processes:
+ mean_aps.append(p.get()[0])
+
+ return sum(mean_aps) / len(mean_aps)
+
+
+class ResultVisualizer:
+ """Display and save evaluation results.
+
+ Args:
+ show (bool): Whether to show the image. Default: True.
+ wait_time (float): Value of waitKey param. Default: 0.
+ score_thr (float): Minimum score of bboxes to be shown.
+ Default: 0.
+ runner (:obj:`Runner`): The runner of the visualization process.
+ """
+
+ def __init__(self, show=False, wait_time=0, score_thr=0, runner=None):
+ self.show = show
+ self.wait_time = wait_time
+ self.score_thr = score_thr
+ self.visualizer = DetLocalVisualizer()
+ self.runner = runner
+ self.evaluator = runner.test_evaluator
+
+ def _save_image_gts_results(self,
+ dataset,
+ results,
+ performances,
+ out_dir=None,
+ task='det'):
+ """Display or save image with groung truths and predictions from a
+ model.
+
+ Args:
+ dataset (Dataset): A PyTorch dataset.
+ results (list): Object detection or panoptic segmentation
+ results from test results pkl file.
+ performances (dict): A dict contains samples's indices
+ in dataset and model's performance on them.
+ out_dir (str, optional): The filename to write the image.
+ Defaults: None.
+ task (str): The task to be performed. Defaults: 'det'
+ """
+ mkdir_or_exist(out_dir)
+
+ for performance_info in performances:
+ index, performance = performance_info
+ data_info = dataset[index]
+ data_info['gt_instances'] = data_info['instances']
+
+ # calc save file path
+ filename = data_info['img_path']
+ fname, name = osp.splitext(osp.basename(filename))
+ save_filename = fname + '_' + str(round(performance, 3)) + name
+ out_file = osp.join(out_dir, save_filename)
+
+ if task == 'det':
+ gt_instances = InstanceData()
+ gt_instances.bboxes = results[index]['gt_instances']['bboxes']
+ gt_instances.labels = results[index]['gt_instances']['labels']
+
+ pred_instances = InstanceData()
+ pred_instances.bboxes = results[index]['pred_instances'][
+ 'bboxes']
+ pred_instances.labels = results[index]['pred_instances'][
+ 'labels']
+ pred_instances.scores = results[index]['pred_instances'][
+ 'scores']
+
+ data_samples = DetDataSample()
+ data_samples.pred_instances = pred_instances
+ data_samples.gt_instances = gt_instances
+
+ elif task == 'seg':
+ gt_panoptic_seg = PixelData()
+ gt_panoptic_seg.sem_seg = results[index]['gt_seg_map']
+
+ pred_panoptic_seg = PixelData()
+ pred_panoptic_seg.sem_seg = results[index][
+ 'pred_panoptic_seg']['sem_seg']
+
+ data_samples = DetDataSample()
+ data_samples.pred_panoptic_seg = pred_panoptic_seg
+ data_samples.gt_panoptic_seg = gt_panoptic_seg
+
+ img = mmcv.imread(filename, channel_order='rgb')
+ self.visualizer.add_datasample(
+ 'image',
+ img,
+ data_samples,
+ show=self.show,
+ draw_gt=False,
+ pred_score_thr=self.score_thr,
+ out_file=out_file)
+
+ def evaluate_and_show(self,
+ dataset,
+ results,
+ topk=20,
+ show_dir='work_dir'):
+ """Evaluate and show results.
+
+ Args:
+ dataset (Dataset): A PyTorch dataset.
+ results (list): Object detection or panoptic segmentation
+ results from test results pkl file.
+ topk (int): Number of the highest topk and
+ lowest topk after evaluation index sorting. Default: 20.
+ show_dir (str, optional): The filename to write the image.
+ Default: 'work_dir'
+ """
+
+ self.visualizer.dataset_meta = dataset.metainfo
+
+ assert topk > 0
+ if (topk * 2) > len(dataset):
+ topk = len(dataset) // 2
+
+ good_dir = osp.abspath(osp.join(show_dir, 'good'))
+ bad_dir = osp.abspath(osp.join(show_dir, 'bad'))
+
+ if 'pred_panoptic_seg' in results[0].keys():
+ good_samples, bad_samples = self.panoptic_evaluate(
+ dataset, results, topk=topk)
+ self._save_image_gts_results(
+ dataset, results, good_samples, good_dir, task='seg')
+ self._save_image_gts_results(
+ dataset, results, bad_samples, bad_dir, task='seg')
+ elif 'pred_instances' in results[0].keys():
+ good_samples, bad_samples = self.detection_evaluate(
+ dataset, results, topk=topk)
+ self._save_image_gts_results(
+ dataset, results, good_samples, good_dir, task='det')
+ self._save_image_gts_results(
+ dataset, results, bad_samples, bad_dir, task='det')
+ else:
+ raise 'expect \'pred_panoptic_seg\' or \'pred_instances\' \
+ in dict result'
+
+ def detection_evaluate(self, dataset, results, topk=20, eval_fn=None):
+ """Evaluation for object detection.
+
+ Args:
+ dataset (Dataset): A PyTorch dataset.
+ results (list): Object detection results from test
+ results pkl file.
+ topk (int): Number of the highest topk and
+ lowest topk after evaluation index sorting. Default: 20.
+ eval_fn (callable, optional): Eval function, Default: None.
+
+ Returns:
+ tuple: A tuple contains good samples and bad samples.
+ good_mAPs (dict[int, float]): A dict contains good
+ samples's indices in dataset and model's
+ performance on them.
+ bad_mAPs (dict[int, float]): A dict contains bad
+ samples's indices in dataset and model's
+ performance on them.
+ """
+
+ if eval_fn is None:
+ eval_fn = bbox_map_eval
+ else:
+ assert callable(eval_fn)
+
+ prog_bar = ProgressBar(len(results))
+ _mAPs = {}
+ data_info = {}
+ for i, (result, ) in enumerate(zip(results)):
+
+ # self.dataset[i] should not call directly
+ # because there is a risk of mismatch
+ data_info = dataset.prepare_data(i)
+ data_info['bboxes'] = data_info['gt_bboxes'].tensor
+ data_info['labels'] = data_info['gt_bboxes_labels']
+
+ pred = result['pred_instances']
+ pred_bboxes = pred['bboxes'].cpu().numpy()
+ pred_scores = pred['scores'].cpu().numpy()
+ pred_labels = pred['labels'].cpu().numpy()
+
+ dets = []
+ for label in range(len(dataset.metainfo['classes'])):
+ index = np.where(pred_labels == label)[0]
+ pred_bbox_scores = np.hstack(
+ [pred_bboxes[index], pred_scores[index].reshape((-1, 1))])
+ dets.append(pred_bbox_scores)
+ mAP = eval_fn(dets, data_info)
+
+ _mAPs[i] = mAP
+ prog_bar.update()
+ # descending select topk image
+ _mAPs = list(sorted(_mAPs.items(), key=lambda kv: kv[1]))
+ good_mAPs = _mAPs[-topk:]
+ bad_mAPs = _mAPs[:topk]
+
+ return good_mAPs, bad_mAPs
+
+ def panoptic_evaluate(self, dataset, results, topk=20):
+ """Evaluation for panoptic segmentation.
+
+ Args:
+ dataset (Dataset): A PyTorch dataset.
+ results (list): Panoptic segmentation results from test
+ results pkl file.
+ topk (int): Number of the highest topk and
+ lowest topk after evaluation index sorting. Default: 20.
+
+ Returns:
+ tuple: A tuple contains good samples and bad samples.
+ good_pqs (dict[int, float]): A dict contains good
+ samples's indices in dataset and model's
+ performance on them.
+ bad_pqs (dict[int, float]): A dict contains bad
+ samples's indices in dataset and model's
+ performance on them.
+ """
+ pqs = {}
+ prog_bar = ProgressBar(len(results))
+
+ for i in range(len(results)):
+ data_sample = {}
+ for k in dataset[i].keys():
+ data_sample[k] = dataset[i][k]
+
+ for k in results[i].keys():
+ data_sample[k] = results[i][k]
+
+ self.evaluator.process([data_sample])
+ metrics = self.evaluator.evaluate(1)
+
+ pqs[i] = metrics['coco_panoptic/PQ']
+ prog_bar.update()
+
+ # descending select topk image
+ pqs = list(sorted(pqs.items(), key=lambda kv: kv[1]))
+ good_pqs = pqs[-topk:]
+ bad_pqs = pqs[:topk]
+
+ return good_pqs, bad_pqs
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='MMDet eval image prediction result for each')
+ parser.add_argument('config', help='test config file path')
+ parser.add_argument(
+ 'prediction_path', help='prediction path where test pkl result')
+ parser.add_argument(
+ 'show_dir', help='directory where painted images will be saved')
+ parser.add_argument('--show', action='store_true', help='show results')
+ parser.add_argument(
+ '--wait-time',
+ type=float,
+ default=0,
+ help='the interval of show (s), 0 is block')
+ parser.add_argument(
+ '--topk',
+ default=20,
+ type=int,
+ help='saved Number of the highest topk '
+ 'and lowest topk after index sorting')
+ parser.add_argument(
+ '--show-score-thr',
+ type=float,
+ default=0,
+ help='score threshold (default: 0.)')
+ parser.add_argument(
+ '--cfg-options',
+ nargs='+',
+ action=DictAction,
+ help='override some settings in the used config, the key-value pair '
+ 'in xxx=yyy format will be merged into config file. If the value to '
+ 'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
+ 'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
+ 'Note that the quotation marks are necessary and that no white space '
+ 'is allowed.')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+
+ check_file_exist(args.prediction_path)
+
+ cfg = Config.fromfile(args.config)
+
+ # replace the ${key} with the value of cfg.key
+ cfg = replace_cfg_vals(cfg)
+
+ # update data root according to MMDET_DATASETS
+ update_data_root(cfg)
+
+ if args.cfg_options is not None:
+ cfg.merge_from_dict(args.cfg_options)
+ init_default_scope(cfg.get('default_scope', 'mmdet'))
+
+ cfg.test_dataloader.dataset.test_mode = True
+
+ cfg.test_dataloader.pop('batch_size', 0)
+ if cfg.train_dataloader.dataset.type in ('MultiImageMixDataset',
+ 'ClassBalancedDataset',
+ 'RepeatDataset', 'ConcatDataset'):
+ cfg.test_dataloader.dataset.pipeline = get_loading_pipeline(
+ cfg.train_dataloader.dataset.dataset.pipeline)
+ else:
+ cfg.test_dataloader.dataset.pipeline = get_loading_pipeline(
+ cfg.train_dataloader.dataset.pipeline)
+ dataset = DATASETS.build(cfg.test_dataloader.dataset)
+ outputs = load(args.prediction_path)
+
+ cfg.work_dir = args.show_dir
+ # build the runner from config
+ if 'runner_type' not in cfg:
+ # build the default runner
+ runner = Runner.from_cfg(cfg)
+ else:
+ # build customized runner from the registry
+ # if 'runner_type' is set in the cfg
+ runner = RUNNERS.build(cfg)
+
+ result_visualizer = ResultVisualizer(args.show, args.wait_time,
+ args.show_score_thr, runner)
+ result_visualizer.evaluate_and_show(
+ dataset, outputs, topk=args.topk, show_dir=args.show_dir)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/analysis_tools/benchmark.py b/tools/analysis_tools/benchmark.py
new file mode 100644
index 0000000000000000000000000000000000000000..dfc06e2a3ade9d254c637ded42a7760213473c09
--- /dev/null
+++ b/tools/analysis_tools/benchmark.py
@@ -0,0 +1,133 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os
+
+from mmengine import MMLogger
+from mmengine.config import Config, DictAction
+from mmengine.dist import init_dist
+from mmengine.registry import init_default_scope
+from mmengine.utils import mkdir_or_exist
+
+from mmdet.utils.benchmark import (DataLoaderBenchmark, DatasetBenchmark,
+ InferenceBenchmark)
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='MMDet benchmark')
+ parser.add_argument('config', help='test config file path')
+ parser.add_argument('--checkpoint', help='checkpoint file')
+ parser.add_argument(
+ '--task',
+ choices=['inference', 'dataloader', 'dataset'],
+ default='dataloader',
+ help='Which task do you want to go to benchmark')
+ parser.add_argument(
+ '--repeat-num',
+ type=int,
+ default=1,
+ help='number of repeat times of measurement for averaging the results')
+ parser.add_argument(
+ '--max-iter', type=int, default=2000, help='num of max iter')
+ parser.add_argument(
+ '--log-interval', type=int, default=50, help='interval of logging')
+ parser.add_argument(
+ '--num-warmup', type=int, default=5, help='Number of warmup')
+ parser.add_argument(
+ '--fuse-conv-bn',
+ action='store_true',
+ help='Whether to fuse conv and bn, this will slightly increase'
+ 'the inference speed')
+ parser.add_argument(
+ '--dataset-type',
+ choices=['train', 'val', 'test'],
+ default='test',
+ help='Benchmark dataset type. only supports train, val and test')
+ parser.add_argument(
+ '--work-dir',
+ help='the directory to save the file containing '
+ 'benchmark metrics')
+ parser.add_argument(
+ '--cfg-options',
+ nargs='+',
+ action=DictAction,
+ help='override some settings in the used config, the key-value pair '
+ 'in xxx=yyy format will be merged into config file. If the value to '
+ 'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
+ 'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
+ 'Note that the quotation marks are necessary and that no white space '
+ 'is allowed.')
+ parser.add_argument(
+ '--launcher',
+ choices=['none', 'pytorch', 'slurm', 'mpi'],
+ default='none',
+ help='job launcher')
+ parser.add_argument('--local_rank', type=int, default=0)
+ args = parser.parse_args()
+ if 'LOCAL_RANK' not in os.environ:
+ os.environ['LOCAL_RANK'] = str(args.local_rank)
+ return args
+
+
+def inference_benchmark(args, cfg, distributed, logger):
+ benchmark = InferenceBenchmark(
+ cfg,
+ args.checkpoint,
+ distributed,
+ args.fuse_conv_bn,
+ args.max_iter,
+ args.log_interval,
+ args.num_warmup,
+ logger=logger)
+ return benchmark
+
+
+def dataloader_benchmark(args, cfg, distributed, logger):
+ benchmark = DataLoaderBenchmark(
+ cfg,
+ distributed,
+ args.dataset_type,
+ args.max_iter,
+ args.log_interval,
+ args.num_warmup,
+ logger=logger)
+ return benchmark
+
+
+def dataset_benchmark(args, cfg, distributed, logger):
+ benchmark = DatasetBenchmark(
+ cfg,
+ args.dataset_type,
+ args.max_iter,
+ args.log_interval,
+ args.num_warmup,
+ logger=logger)
+ return benchmark
+
+
+def main():
+ args = parse_args()
+ cfg = Config.fromfile(args.config)
+ if args.cfg_options is not None:
+ cfg.merge_from_dict(args.cfg_options)
+
+ init_default_scope(cfg.get('default_scope', 'mmdet'))
+
+ distributed = False
+ if args.launcher != 'none':
+ init_dist(args.launcher, **cfg.get('env_cfg', {}).get('dist_cfg', {}))
+ distributed = True
+
+ log_file = None
+ if args.work_dir:
+ log_file = os.path.join(args.work_dir, 'benchmark.log')
+ mkdir_or_exist(args.work_dir)
+
+ logger = MMLogger.get_instance(
+ 'mmdet', log_file=log_file, log_level='INFO')
+
+ benchmark = eval(f'{args.task}_benchmark')(args, cfg, distributed, logger)
+ benchmark.run(args.repeat_num)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/analysis_tools/browse_dataset.py b/tools/analysis_tools/browse_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..05208fd729ff3cbf836854a9d88f0a49c46a9eed
--- /dev/null
+++ b/tools/analysis_tools/browse_dataset.py
@@ -0,0 +1,90 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os.path as osp
+
+from mmengine.config import Config, DictAction
+from mmengine.registry import init_default_scope
+from mmengine.utils import ProgressBar
+
+from mmdet.models.utils import mask2ndarray
+from mmdet.registry import DATASETS, VISUALIZERS
+from mmdet.structures.bbox import BaseBoxes
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='Browse a dataset')
+ parser.add_argument('--config',default='/media/ubuntu/lzx/HSI_OD/mmdetection/configs/1_htd/faster-rcnn_r50_fpn_1x_hsic.py', help='train config file path')
+ parser.add_argument(
+ '--output-dir',
+ default='../show',
+ type=str,
+ help='If there is no display interface, you can save it')
+ parser.add_argument('--not-show', default=False, action='store_true')
+ parser.add_argument(
+ '--show-interval',
+ type=float,
+ default=2,
+ help='the interval of show (s)')
+ parser.add_argument(
+ '--cfg-options',
+ nargs='+',
+ action=DictAction,
+ help='override some settings in the used config, the key-value pair '
+ 'in xxx=yyy format will be merged into config file. If the value to '
+ 'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
+ 'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
+ 'Note that the quotation marks are necessary and that no white space '
+ 'is allowed.')
+ args = parser.parse_args()
+ return args
+
+
+
+def main():
+ args = parse_args()
+ cfg = Config.fromfile(args.config)
+ if args.cfg_options is not None:
+ cfg.merge_from_dict(args.cfg_options)
+
+ # register all modules in mmdet into the registries
+ init_default_scope(cfg.get('default_scope', 'mmdet'))
+
+ dataset = DATASETS.build(cfg.train_dataloader.dataset)
+ visualizer = VISUALIZERS.build(cfg.visualizer)
+ visualizer.dataset_meta = dataset.metainfo
+
+ progress_bar = ProgressBar(len(dataset))
+ for item in dataset:
+ img = item['inputs'].permute(1, 2, 0).numpy()
+ data_sample = item['data_samples'].numpy()
+ gt_instances = data_sample.gt_instances
+ img_path = osp.basename(item['data_samples'].img_path)
+
+ out_file = osp.join(
+ args.output_dir,
+ osp.basename(img_path)) if args.output_dir is not None else None
+
+ img = img[..., [2, 1, 0]] # bgr to rgb
+ gt_bboxes = gt_instances.get('bboxes', None)
+ if gt_bboxes is not None and isinstance(gt_bboxes, BaseBoxes):
+ gt_instances.bboxes = gt_bboxes.tensor
+ gt_masks = gt_instances.get('masks', None)
+ if gt_masks is not None:
+ masks = mask2ndarray(gt_masks)
+ gt_instances.masks = masks.astype(bool)
+ data_sample.gt_instances = gt_instances
+
+ visualizer.add_datasample(
+ osp.basename(img_path),
+ img,
+ data_sample,
+ draw_pred=False,
+ show=not args.not_show,
+ wait_time=args.show_interval,
+ out_file=out_file)
+
+ progress_bar.update()
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/analysis_tools/coco_error_analysis.py b/tools/analysis_tools/coco_error_analysis.py
new file mode 100644
index 0000000000000000000000000000000000000000..102ea4ebb294114199ad2574cde2a374ec4374c9
--- /dev/null
+++ b/tools/analysis_tools/coco_error_analysis.py
@@ -0,0 +1,339 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+import os
+from argparse import ArgumentParser
+from multiprocessing import Pool
+
+import matplotlib.pyplot as plt
+import numpy as np
+from pycocotools.coco import COCO
+from pycocotools.cocoeval import COCOeval
+
+
+def makeplot(rs, ps, outDir, class_name, iou_type):
+ cs = np.vstack([
+ np.ones((2, 3)),
+ np.array([0.31, 0.51, 0.74]),
+ np.array([0.75, 0.31, 0.30]),
+ np.array([0.36, 0.90, 0.38]),
+ np.array([0.50, 0.39, 0.64]),
+ np.array([1, 0.6, 0]),
+ ])
+ areaNames = ['allarea', 'small', 'medium', 'large']
+ types = ['C75', 'C50', 'Loc', 'Sim', 'Oth', 'BG', 'FN']
+ for i in range(len(areaNames)):
+ area_ps = ps[..., i, 0]
+ figure_title = iou_type + '-' + class_name + '-' + areaNames[i]
+ aps = [ps_.mean() for ps_ in area_ps]
+ ps_curve = [
+ ps_.mean(axis=1) if ps_.ndim > 1 else ps_ for ps_ in area_ps
+ ]
+ ps_curve.insert(0, np.zeros(ps_curve[0].shape))
+ fig = plt.figure()
+ ax = plt.subplot(111)
+ for k in range(len(types)):
+ ax.plot(rs, ps_curve[k + 1], color=[0, 0, 0], linewidth=0.5)
+ ax.fill_between(
+ rs,
+ ps_curve[k],
+ ps_curve[k + 1],
+ color=cs[k],
+ label=str(f'[{aps[k]:.3f}]' + types[k]),
+ )
+ plt.xlabel('recall')
+ plt.ylabel('precision')
+ plt.xlim(0, 1.0)
+ plt.ylim(0, 1.0)
+ plt.title(figure_title)
+ plt.legend()
+ # plt.show()
+ fig.savefig(outDir + f'/{figure_title}.png')
+ plt.close(fig)
+
+
+def autolabel(ax, rects):
+ """Attach a text label above each bar in *rects*, displaying its height."""
+ for rect in rects:
+ height = rect.get_height()
+ if height > 0 and height <= 1: # for percent values
+ text_label = '{:2.0f}'.format(height * 100)
+ else:
+ text_label = '{:2.0f}'.format(height)
+ ax.annotate(
+ text_label,
+ xy=(rect.get_x() + rect.get_width() / 2, height),
+ xytext=(0, 3), # 3 points vertical offset
+ textcoords='offset points',
+ ha='center',
+ va='bottom',
+ fontsize='x-small',
+ )
+
+
+def makebarplot(rs, ps, outDir, class_name, iou_type):
+ areaNames = ['allarea', 'small', 'medium', 'large']
+ types = ['C75', 'C50', 'Loc', 'Sim', 'Oth', 'BG', 'FN']
+ fig, ax = plt.subplots()
+ x = np.arange(len(areaNames)) # the areaNames locations
+ width = 0.60 # the width of the bars
+ rects_list = []
+ figure_title = iou_type + '-' + class_name + '-' + 'ap bar plot'
+ for i in range(len(types) - 1):
+ type_ps = ps[i, ..., 0]
+ aps = [ps_.mean() for ps_ in type_ps.T]
+ rects_list.append(
+ ax.bar(
+ x - width / 2 + (i + 1) * width / len(types),
+ aps,
+ width / len(types),
+ label=types[i],
+ ))
+
+ # Add some text for labels, title and custom x-axis tick labels, etc.
+ ax.set_ylabel('Mean Average Precision (mAP)')
+ ax.set_title(figure_title)
+ ax.set_xticks(x)
+ ax.set_xticklabels(areaNames)
+ ax.legend()
+
+ # Add score texts over bars
+ for rects in rects_list:
+ autolabel(ax, rects)
+
+ # Save plot
+ fig.savefig(outDir + f'/{figure_title}.png')
+ plt.close(fig)
+
+
+def get_gt_area_group_numbers(cocoEval):
+ areaRng = cocoEval.params.areaRng
+ areaRngStr = [str(aRng) for aRng in areaRng]
+ areaRngLbl = cocoEval.params.areaRngLbl
+ areaRngStr2areaRngLbl = dict(zip(areaRngStr, areaRngLbl))
+ areaRngLbl2Number = dict.fromkeys(areaRngLbl, 0)
+ for evalImg in cocoEval.evalImgs:
+ if evalImg:
+ for gtIgnore in evalImg['gtIgnore']:
+ if not gtIgnore:
+ aRngLbl = areaRngStr2areaRngLbl[str(evalImg['aRng'])]
+ areaRngLbl2Number[aRngLbl] += 1
+ return areaRngLbl2Number
+
+
+def make_gt_area_group_numbers_plot(cocoEval, outDir, verbose=True):
+ areaRngLbl2Number = get_gt_area_group_numbers(cocoEval)
+ areaRngLbl = areaRngLbl2Number.keys()
+ if verbose:
+ print('number of annotations per area group:', areaRngLbl2Number)
+
+ # Init figure
+ fig, ax = plt.subplots()
+ x = np.arange(len(areaRngLbl)) # the areaNames locations
+ width = 0.60 # the width of the bars
+ figure_title = 'number of annotations per area group'
+
+ rects = ax.bar(x, areaRngLbl2Number.values(), width)
+
+ # Add some text for labels, title and custom x-axis tick labels, etc.
+ ax.set_ylabel('Number of annotations')
+ ax.set_title(figure_title)
+ ax.set_xticks(x)
+ ax.set_xticklabels(areaRngLbl)
+
+ # Add score texts over bars
+ autolabel(ax, rects)
+
+ # Save plot
+ fig.tight_layout()
+ fig.savefig(outDir + f'/{figure_title}.png')
+ plt.close(fig)
+
+
+def make_gt_area_histogram_plot(cocoEval, outDir):
+ n_bins = 100
+ areas = [ann['area'] for ann in cocoEval.cocoGt.anns.values()]
+
+ # init figure
+ figure_title = 'gt annotation areas histogram plot'
+ fig, ax = plt.subplots()
+
+ # Set the number of bins
+ ax.hist(np.sqrt(areas), bins=n_bins)
+
+ # Add some text for labels, title and custom x-axis tick labels, etc.
+ ax.set_xlabel('Squareroot Area')
+ ax.set_ylabel('Number of annotations')
+ ax.set_title(figure_title)
+
+ # Save plot
+ fig.tight_layout()
+ fig.savefig(outDir + f'/{figure_title}.png')
+ plt.close(fig)
+
+
+def analyze_individual_category(k,
+ cocoDt,
+ cocoGt,
+ catId,
+ iou_type,
+ areas=None):
+ nm = cocoGt.loadCats(catId)[0]
+ print(f'--------------analyzing {k + 1}-{nm["name"]}---------------')
+ ps_ = {}
+ dt = copy.deepcopy(cocoDt)
+ nm = cocoGt.loadCats(catId)[0]
+ imgIds = cocoGt.getImgIds()
+ dt_anns = dt.dataset['annotations']
+ select_dt_anns = []
+ for ann in dt_anns:
+ if ann['category_id'] == catId:
+ select_dt_anns.append(ann)
+ dt.dataset['annotations'] = select_dt_anns
+ dt.createIndex()
+ # compute precision but ignore superclass confusion
+ gt = copy.deepcopy(cocoGt)
+ child_catIds = gt.getCatIds(supNms=[nm['supercategory']])
+ for idx, ann in enumerate(gt.dataset['annotations']):
+ if ann['category_id'] in child_catIds and ann['category_id'] != catId:
+ gt.dataset['annotations'][idx]['ignore'] = 1
+ gt.dataset['annotations'][idx]['iscrowd'] = 1
+ gt.dataset['annotations'][idx]['category_id'] = catId
+ cocoEval = COCOeval(gt, copy.deepcopy(dt), iou_type)
+ cocoEval.params.imgIds = imgIds
+ cocoEval.params.maxDets = [100]
+ cocoEval.params.iouThrs = [0.1]
+ cocoEval.params.useCats = 1
+ if areas:
+ cocoEval.params.areaRng = [[0**2, areas[2]], [0**2, areas[0]],
+ [areas[0], areas[1]], [areas[1], areas[2]]]
+ cocoEval.evaluate()
+ cocoEval.accumulate()
+ ps_supercategory = cocoEval.eval['precision'][0, :, k, :, :]
+ ps_['ps_supercategory'] = ps_supercategory
+ # compute precision but ignore any class confusion
+ gt = copy.deepcopy(cocoGt)
+ for idx, ann in enumerate(gt.dataset['annotations']):
+ if ann['category_id'] != catId:
+ gt.dataset['annotations'][idx]['ignore'] = 1
+ gt.dataset['annotations'][idx]['iscrowd'] = 1
+ gt.dataset['annotations'][idx]['category_id'] = catId
+ cocoEval = COCOeval(gt, copy.deepcopy(dt), iou_type)
+ cocoEval.params.imgIds = imgIds
+ cocoEval.params.maxDets = [100]
+ cocoEval.params.iouThrs = [0.1]
+ cocoEval.params.useCats = 1
+ if areas:
+ cocoEval.params.areaRng = [[0**2, areas[2]], [0**2, areas[0]],
+ [areas[0], areas[1]], [areas[1], areas[2]]]
+ cocoEval.evaluate()
+ cocoEval.accumulate()
+ ps_allcategory = cocoEval.eval['precision'][0, :, k, :, :]
+ ps_['ps_allcategory'] = ps_allcategory
+ return k, ps_
+
+
+def analyze_results(res_file,
+ ann_file,
+ res_types,
+ out_dir,
+ extraplots=None,
+ areas=None):
+ for res_type in res_types:
+ assert res_type in ['bbox', 'segm']
+ if areas:
+ assert len(areas) == 3, '3 integers should be specified as areas, \
+ representing 3 area regions'
+
+ directory = os.path.dirname(out_dir + '/')
+ if not os.path.exists(directory):
+ print(f'-------------create {out_dir}-----------------')
+ os.makedirs(directory)
+
+ cocoGt = COCO(ann_file)
+ cocoDt = cocoGt.loadRes(res_file)
+ imgIds = cocoGt.getImgIds()
+ for res_type in res_types:
+ res_out_dir = out_dir + '/' + res_type + '/'
+ res_directory = os.path.dirname(res_out_dir)
+ if not os.path.exists(res_directory):
+ print(f'-------------create {res_out_dir}-----------------')
+ os.makedirs(res_directory)
+ iou_type = res_type
+ cocoEval = COCOeval(
+ copy.deepcopy(cocoGt), copy.deepcopy(cocoDt), iou_type)
+ cocoEval.params.imgIds = imgIds
+ cocoEval.params.iouThrs = [0.75, 0.5, 0.1]
+ cocoEval.params.maxDets = [100]
+ if areas:
+ cocoEval.params.areaRng = [[0**2, areas[2]], [0**2, areas[0]],
+ [areas[0], areas[1]],
+ [areas[1], areas[2]]]
+ cocoEval.evaluate()
+ cocoEval.accumulate()
+ ps = cocoEval.eval['precision']
+ ps = np.vstack([ps, np.zeros((4, *ps.shape[1:]))])
+ catIds = cocoGt.getCatIds()
+ recThrs = cocoEval.params.recThrs
+ with Pool(processes=48) as pool:
+ args = [(k, cocoDt, cocoGt, catId, iou_type, areas)
+ for k, catId in enumerate(catIds)]
+ analyze_results = pool.starmap(analyze_individual_category, args)
+ for k, catId in enumerate(catIds):
+ nm = cocoGt.loadCats(catId)[0]
+ print(f'--------------saving {k + 1}-{nm["name"]}---------------')
+ analyze_result = analyze_results[k]
+ assert k == analyze_result[0]
+ ps_supercategory = analyze_result[1]['ps_supercategory']
+ ps_allcategory = analyze_result[1]['ps_allcategory']
+ # compute precision but ignore superclass confusion
+ ps[3, :, k, :, :] = ps_supercategory
+ # compute precision but ignore any class confusion
+ ps[4, :, k, :, :] = ps_allcategory
+ # fill in background and false negative errors and plot
+ ps[ps == -1] = 0
+ ps[5, :, k, :, :] = ps[4, :, k, :, :] > 0
+ ps[6, :, k, :, :] = 1.0
+ makeplot(recThrs, ps[:, :, k], res_out_dir, nm['name'], iou_type)
+ if extraplots:
+ makebarplot(recThrs, ps[:, :, k], res_out_dir, nm['name'],
+ iou_type)
+ makeplot(recThrs, ps, res_out_dir, 'allclass', iou_type)
+ if extraplots:
+ makebarplot(recThrs, ps, res_out_dir, 'allclass', iou_type)
+ make_gt_area_group_numbers_plot(
+ cocoEval=cocoEval, outDir=res_out_dir, verbose=True)
+ make_gt_area_histogram_plot(cocoEval=cocoEval, outDir=res_out_dir)
+
+
+def main():
+ parser = ArgumentParser(description='COCO Error Analysis Tool')
+ parser.add_argument('result', help='result file (json format) path')
+ parser.add_argument('out_dir', help='dir to save analyze result images')
+ parser.add_argument(
+ '--ann',
+ default='data/coco/annotations/instances_val2017.json',
+ help='annotation file path')
+ parser.add_argument(
+ '--types', type=str, nargs='+', default=['bbox'], help='result types')
+ parser.add_argument(
+ '--extraplots',
+ action='store_true',
+ help='export extra bar/stat plots')
+ parser.add_argument(
+ '--areas',
+ type=int,
+ nargs='+',
+ default=[1024, 9216, 10000000000],
+ help='area regions')
+ args = parser.parse_args()
+ analyze_results(
+ args.result,
+ args.ann,
+ args.types,
+ out_dir=args.out_dir,
+ extraplots=args.extraplots,
+ areas=args.areas)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/analysis_tools/coco_occluded_separated_recall.py b/tools/analysis_tools/coco_occluded_separated_recall.py
new file mode 100644
index 0000000000000000000000000000000000000000..e61f2ccd94517c47674747a0732380db6e2a18c9
--- /dev/null
+++ b/tools/analysis_tools/coco_occluded_separated_recall.py
@@ -0,0 +1,48 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from argparse import ArgumentParser
+
+import mmengine
+from mmengine.logging import print_log
+
+from mmdet.datasets import CocoDataset
+from mmdet.evaluation import CocoOccludedSeparatedMetric
+
+
+def main():
+ parser = ArgumentParser(
+ description='Compute recall of COCO occluded and separated masks '
+ 'presented in paper https://arxiv.org/abs/2210.10046.')
+ parser.add_argument('result', help='result file (pkl format) path')
+ parser.add_argument('--out', help='file path to save evaluation results')
+ parser.add_argument(
+ '--score-thr',
+ type=float,
+ default=0.3,
+ help='Score threshold for the recall calculation. Defaults to 0.3')
+ parser.add_argument(
+ '--iou-thr',
+ type=float,
+ default=0.75,
+ help='IoU threshold for the recall calculation. Defaults to 0.75.')
+ parser.add_argument(
+ '--ann',
+ default='data/coco/annotations/instances_val2017.json',
+ help='coco annotation file path')
+ args = parser.parse_args()
+
+ results = mmengine.load(args.result)
+ assert 'masks' in results[0]['pred_instances'], \
+ 'The results must be predicted by instance segmentation model.'
+ metric = CocoOccludedSeparatedMetric(
+ ann_file=args.ann, iou_thr=args.iou_thr, score_thr=args.score_thr)
+ metric.dataset_meta = CocoDataset.METAINFO
+ for datasample in results:
+ metric.process(data_batch=None, data_samples=[datasample])
+ metric_res = metric.compute_metrics(metric.results)
+ if args.out is not None:
+ mmengine.dump(metric_res, args.out)
+ print_log(f'Evaluation results have been saved to {args.out}.')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/analysis_tools/confusion_matrix.py b/tools/analysis_tools/confusion_matrix.py
new file mode 100644
index 0000000000000000000000000000000000000000..a1c4c8ec86f70d28dfe7dc3d0173df4f4b46b8c3
--- /dev/null
+++ b/tools/analysis_tools/confusion_matrix.py
@@ -0,0 +1,273 @@
+import argparse
+import os
+
+import matplotlib.pyplot as plt
+import numpy as np
+from matplotlib.ticker import MultipleLocator
+from mmcv.ops import nms
+from mmengine import Config, DictAction
+from mmengine.fileio import load
+from mmengine.registry import init_default_scope
+from mmengine.utils import ProgressBar
+
+from mmdet.evaluation import bbox_overlaps
+from mmdet.registry import DATASETS
+from mmdet.utils import replace_cfg_vals, update_data_root
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Generate confusion matrix from detection results')
+ parser.add_argument('config', help='test config file path')
+ parser.add_argument(
+ 'prediction_path', help='prediction path where test .pkl result')
+ parser.add_argument(
+ 'save_dir', help='directory where confusion matrix will be saved')
+ parser.add_argument(
+ '--show', action='store_true', help='show confusion matrix')
+ parser.add_argument(
+ '--color-theme',
+ default='plasma',
+ help='theme of the matrix color map')
+ parser.add_argument(
+ '--score-thr',
+ type=float,
+ default=0.3,
+ help='score threshold to filter detection bboxes')
+ parser.add_argument(
+ '--tp-iou-thr',
+ type=float,
+ default=0.5,
+ help='IoU threshold to be considered as matched')
+ parser.add_argument(
+ '--nms-iou-thr',
+ type=float,
+ default=None,
+ help='nms IoU threshold, only applied when users want to change the'
+ 'nms IoU threshold.')
+ parser.add_argument(
+ '--cfg-options',
+ nargs='+',
+ action=DictAction,
+ help='override some settings in the used config, the key-value pair '
+ 'in xxx=yyy format will be merged into config file. If the value to '
+ 'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
+ 'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
+ 'Note that the quotation marks are necessary and that no white space '
+ 'is allowed.')
+ args = parser.parse_args()
+ return args
+
+
+def calculate_confusion_matrix(dataset,
+ results,
+ score_thr=0,
+ nms_iou_thr=None,
+ tp_iou_thr=0.5):
+ """Calculate the confusion matrix.
+
+ Args:
+ dataset (Dataset): Test or val dataset.
+ results (list[ndarray]): A list of detection results in each image.
+ score_thr (float|optional): Score threshold to filter bboxes.
+ Default: 0.
+ nms_iou_thr (float|optional): nms IoU threshold, the detection results
+ have done nms in the detector, only applied when users want to
+ change the nms IoU threshold. Default: None.
+ tp_iou_thr (float|optional): IoU threshold to be considered as matched.
+ Default: 0.5.
+ """
+ num_classes = len(dataset.metainfo['classes'])
+ confusion_matrix = np.zeros(shape=[num_classes + 1, num_classes + 1])
+ assert len(dataset) == len(results)
+ prog_bar = ProgressBar(len(results))
+ for idx, per_img_res in enumerate(results):
+ res_bboxes = per_img_res['pred_instances']
+ gts = dataset.get_data_info(idx)['instances']
+ analyze_per_img_dets(confusion_matrix, gts, res_bboxes, score_thr,
+ tp_iou_thr, nms_iou_thr)
+ prog_bar.update()
+ return confusion_matrix
+
+
+def analyze_per_img_dets(confusion_matrix,
+ gts,
+ result,
+ score_thr=0,
+ tp_iou_thr=0.5,
+ nms_iou_thr=None):
+ """Analyze detection results on each image.
+
+ Args:
+ confusion_matrix (ndarray): The confusion matrix,
+ has shape (num_classes + 1, num_classes + 1).
+ gt_bboxes (ndarray): Ground truth bboxes, has shape (num_gt, 4).
+ gt_labels (ndarray): Ground truth labels, has shape (num_gt).
+ result (ndarray): Detection results, has shape
+ (num_classes, num_bboxes, 5).
+ score_thr (float): Score threshold to filter bboxes.
+ Default: 0.
+ tp_iou_thr (float): IoU threshold to be considered as matched.
+ Default: 0.5.
+ nms_iou_thr (float|optional): nms IoU threshold, the detection results
+ have done nms in the detector, only applied when users want to
+ change the nms IoU threshold. Default: None.
+ """
+ true_positives = np.zeros(len(gts))
+ gt_bboxes = []
+ gt_labels = []
+ for gt in gts:
+ gt_bboxes.append(gt['bbox'])
+ gt_labels.append(gt['bbox_label'])
+
+ gt_bboxes = np.array(gt_bboxes)
+ gt_labels = np.array(gt_labels)
+
+ unique_label = np.unique(result['labels'].numpy())
+
+ for det_label in unique_label:
+ mask = (result['labels'] == det_label)
+ det_bboxes = result['bboxes'][mask].numpy()
+ det_scores = result['scores'][mask].numpy()
+
+ if nms_iou_thr:
+ det_bboxes, _ = nms(
+ det_bboxes, det_scores, nms_iou_thr, score_threshold=score_thr)
+ ious = bbox_overlaps(det_bboxes[:, :4], gt_bboxes)
+ for i, score in enumerate(det_scores):
+ det_match = 0
+ if score >= score_thr:
+ for j, gt_label in enumerate(gt_labels):
+ if ious[i, j] >= tp_iou_thr:
+ det_match += 1
+ if gt_label == det_label:
+ true_positives[j] += 1 # TP
+ confusion_matrix[gt_label, det_label] += 1
+ if det_match == 0: # BG FP
+ confusion_matrix[-1, det_label] += 1
+ for num_tp, gt_label in zip(true_positives, gt_labels):
+ if num_tp == 0: # FN
+ confusion_matrix[gt_label, -1] += 1
+
+
+def plot_confusion_matrix(confusion_matrix,
+ labels,
+ save_dir=None,
+ show=True,
+ title='Normalized Confusion Matrix',
+ color_theme='plasma'):
+ """Draw confusion matrix with matplotlib.
+
+ Args:
+ confusion_matrix (ndarray): The confusion matrix.
+ labels (list[str]): List of class names.
+ save_dir (str|optional): If set, save the confusion matrix plot to the
+ given path. Default: None.
+ show (bool): Whether to show the plot. Default: True.
+ title (str): Title of the plot. Default: `Normalized Confusion Matrix`.
+ color_theme (str): Theme of the matrix color map. Default: `plasma`.
+ """
+ # normalize the confusion matrix
+ per_label_sums = confusion_matrix.sum(axis=1)[:, np.newaxis]
+ confusion_matrix = \
+ confusion_matrix.astype(np.float32) / per_label_sums * 100
+
+ num_classes = len(labels)
+ fig, ax = plt.subplots(
+ figsize=(0.5 * num_classes, 0.5 * num_classes * 0.8), dpi=180)
+ cmap = plt.get_cmap(color_theme)
+ im = ax.imshow(confusion_matrix, cmap=cmap)
+ plt.colorbar(mappable=im, ax=ax)
+
+ title_font = {'weight': 'bold', 'size': 12}
+ ax.set_title(title, fontdict=title_font)
+ label_font = {'size': 10}
+ plt.ylabel('Ground Truth Label', fontdict=label_font)
+ plt.xlabel('Prediction Label', fontdict=label_font)
+
+ # draw locator
+ xmajor_locator = MultipleLocator(1)
+ xminor_locator = MultipleLocator(0.5)
+ ax.xaxis.set_major_locator(xmajor_locator)
+ ax.xaxis.set_minor_locator(xminor_locator)
+ ymajor_locator = MultipleLocator(1)
+ yminor_locator = MultipleLocator(0.5)
+ ax.yaxis.set_major_locator(ymajor_locator)
+ ax.yaxis.set_minor_locator(yminor_locator)
+
+ # draw grid
+ ax.grid(True, which='minor', linestyle='-')
+
+ # draw label
+ ax.set_xticks(np.arange(num_classes))
+ ax.set_yticks(np.arange(num_classes))
+ ax.set_xticklabels(labels)
+ ax.set_yticklabels(labels)
+
+ ax.tick_params(
+ axis='x', bottom=False, top=True, labelbottom=False, labeltop=True)
+ plt.setp(
+ ax.get_xticklabels(), rotation=45, ha='left', rotation_mode='anchor')
+
+ # draw confution matrix value
+ for i in range(num_classes):
+ for j in range(num_classes):
+ ax.text(
+ j,
+ i,
+ '{}%'.format(
+ int(confusion_matrix[
+ i,
+ j]) if not np.isnan(confusion_matrix[i, j]) else -1),
+ ha='center',
+ va='center',
+ color='w',
+ size=7)
+
+ ax.set_ylim(len(confusion_matrix) - 0.5, -0.5) # matplotlib>3.1.1
+
+ fig.tight_layout()
+ if save_dir is not None:
+ plt.savefig(
+ os.path.join(save_dir, 'confusion_matrix.png'), format='png')
+ if show:
+ plt.show()
+
+
+def main():
+ args = parse_args()
+
+ cfg = Config.fromfile(args.config)
+
+ # replace the ${key} with the value of cfg.key
+ cfg = replace_cfg_vals(cfg)
+
+ # update data root according to MMDET_DATASETS
+ update_data_root(cfg)
+
+ if args.cfg_options is not None:
+ cfg.merge_from_dict(args.cfg_options)
+
+ init_default_scope(cfg.get('default_scope', 'mmdet'))
+
+ results = load(args.prediction_path)
+
+ if not os.path.exists(args.save_dir):
+ os.makedirs(args.save_dir)
+
+ dataset = DATASETS.build(cfg.test_dataloader.dataset)
+
+ confusion_matrix = calculate_confusion_matrix(dataset, results,
+ args.score_thr,
+ args.nms_iou_thr,
+ args.tp_iou_thr)
+ plot_confusion_matrix(
+ confusion_matrix,
+ dataset.metainfo['classes'] + ('background', ),
+ save_dir=args.save_dir,
+ show=args.show,
+ color_theme=args.color_theme)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/analysis_tools/eval_metric.py b/tools/analysis_tools/eval_metric.py
new file mode 100644
index 0000000000000000000000000000000000000000..450828735cacd79f59c4ab796301737b30adff1c
--- /dev/null
+++ b/tools/analysis_tools/eval_metric.py
@@ -0,0 +1,50 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+
+import mmengine
+from mmengine import Config, DictAction
+from mmengine.evaluator import Evaluator
+from mmengine.registry import init_default_scope
+
+from mmdet.registry import DATASETS
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='Evaluate metric of the '
+ 'results saved in pkl format')
+ parser.add_argument('config', help='Config of the model')
+ parser.add_argument('pkl_results', help='Results in pickle format')
+ parser.add_argument(
+ '--cfg-options',
+ nargs='+',
+ action=DictAction,
+ help='override some settings in the used config, the key-value pair '
+ 'in xxx=yyy format will be merged into config file. If the value to '
+ 'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
+ 'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
+ 'Note that the quotation marks are necessary and that no white space '
+ 'is allowed.')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+
+ cfg = Config.fromfile(args.config)
+ init_default_scope(cfg.get('default_scope', 'mmdet'))
+
+ if args.cfg_options is not None:
+ cfg.merge_from_dict(args.cfg_options)
+
+ dataset = DATASETS.build(cfg.test_dataloader.dataset)
+ predictions = mmengine.load(args.pkl_results)
+
+ evaluator = Evaluator(cfg.val_evaluator)
+ evaluator.dataset_meta = dataset.metainfo
+ eval_results = evaluator.offline_evaluate(predictions)
+ print(eval_results)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/analysis_tools/get_flops.py b/tools/analysis_tools/get_flops.py
new file mode 100644
index 0000000000000000000000000000000000000000..90c3c5bebf0d720eb0820c4d0b150f7e7bfc0e13
--- /dev/null
+++ b/tools/analysis_tools/get_flops.py
@@ -0,0 +1,139 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import tempfile
+from functools import partial
+from pathlib import Path
+
+import numpy as np
+import torch
+from mmengine.config import Config, DictAction
+from mmengine.logging import MMLogger
+from mmengine.model import revert_sync_batchnorm
+from mmengine.registry import init_default_scope
+from mmengine.runner import Runner
+
+from mmdet.registry import MODELS
+
+try:
+ from mmengine.analysis import get_model_complexity_info
+ from mmengine.analysis.print_helper import _format_size
+except ImportError:
+ raise ImportError('Please upgrade mmengine >= 0.6.0')
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='Get a detector flops')
+ parser.add_argument('--config',default='.../configs/1_paper_specdetr/dino_sb-2s-100e_hsi.py', help='train config file path')
+ parser.add_argument(
+ '--num-images',
+ type=int,
+ default=100,
+ help='num images of calculate model flops')
+ parser.add_argument(
+ '--cfg-options',
+ nargs='+',
+ action=DictAction,
+ help='override some settings in the used config, the key-value pair '
+ 'in xxx=yyy format will be merged into config file. If the value to '
+ 'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
+ 'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
+ 'Note that the quotation marks are necessary and that no white space '
+ 'is allowed.')
+ args = parser.parse_args()
+ return args
+
+
+def inference(args, logger):
+ if str(torch.__version__) < '1.12':
+ logger.warning(
+ 'Some config files, such as configs/yolact and configs/detectors,'
+ 'may have compatibility issues with torch.jit when torch<1.12. '
+ 'If you want to calculate flops for these models, '
+ 'please make sure your pytorch version is >=1.12.')
+
+ config_name = Path(args.config)
+ if not config_name.exists():
+ logger.error(f'{config_name} not found.')
+
+ cfg = Config.fromfile(args.config)
+ cfg.val_dataloader.batch_size = 1
+ cfg.work_dir = tempfile.TemporaryDirectory().name
+
+ if args.cfg_options is not None:
+ cfg.merge_from_dict(args.cfg_options)
+
+ init_default_scope(cfg.get('default_scope', 'mmdet'))
+
+ # TODO: The following usage is temporary and not safe
+ # use hard code to convert mmSyncBN to SyncBN. This is a known
+ # bug in mmengine, mmSyncBN requires a distributed environment,
+ # this question involves models like configs/strong_baselines
+ if hasattr(cfg, 'head_norm_cfg'):
+ cfg['head_norm_cfg'] = dict(type='SyncBN', requires_grad=True)
+ cfg['model']['roi_head']['bbox_head']['norm_cfg'] = dict(
+ type='SyncBN', requires_grad=True)
+ cfg['model']['roi_head']['mask_head']['norm_cfg'] = dict(
+ type='SyncBN', requires_grad=True)
+
+ result = {}
+ avg_flops = []
+ data_loader = Runner.build_dataloader(cfg.val_dataloader)
+ model = MODELS.build(cfg.model)
+ if torch.cuda.is_available():
+ model = model.cuda()
+ model = revert_sync_batchnorm(model)
+ model.eval()
+ _forward = model.forward
+
+ for idx, data_batch in enumerate(data_loader):
+ if idx == args.num_images:
+ break
+ data = model.data_preprocessor(data_batch)
+ result['ori_shape'] = data['data_samples'][0].ori_shape
+ result['pad_shape'] = data['data_samples'][0].pad_shape
+ if hasattr(data['data_samples'][0], 'batch_input_shape'):
+ result['pad_shape'] = data['data_samples'][0].batch_input_shape
+ model.forward = partial(_forward, data_samples=data['data_samples'])
+ outputs = get_model_complexity_info(
+ model,
+ None,
+ inputs=data['inputs'],
+ show_table=False,
+ show_arch=False)
+ avg_flops.append(outputs['flops'])
+ params = outputs['params']
+ result['compute_type'] = 'dataloader: load a picture from the dataset'
+ del data_loader
+
+ mean_flops = _format_size(int(np.average(avg_flops)))
+ params = _format_size(params)
+ result['flops'] = mean_flops
+ result['params'] = params
+
+ return result
+
+
+def main():
+ args = parse_args()
+ logger = MMLogger.get_instance(name='MMLogger')
+ result = inference(args, logger)
+ split_line = '=' * 30
+ ori_shape = result['ori_shape']
+ pad_shape = result['pad_shape']
+ flops = result['flops']
+ params = result['params']
+ compute_type = result['compute_type']
+
+ if pad_shape != ori_shape:
+ print(f'{split_line}\nUse size divisor set input shape '
+ f'from {ori_shape} to {pad_shape}')
+ print(f'{split_line}\nCompute type: {compute_type}\n'
+ f'Input shape: {pad_shape}\nFlops: {flops}\n'
+ f'Params: {params}\n{split_line}')
+ print('!!!Please be cautious if you use the results in papers. '
+ 'You may need to check if all ops are supported and verify '
+ 'that the flops computation is correct.')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/analysis_tools/optimize_anchors.py b/tools/analysis_tools/optimize_anchors.py
new file mode 100644
index 0000000000000000000000000000000000000000..9b6a02b86443c4cbdbd0787ca3277534f3580806
--- /dev/null
+++ b/tools/analysis_tools/optimize_anchors.py
@@ -0,0 +1,382 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+"""Optimize anchor settings on a specific dataset.
+
+This script provides two method to optimize YOLO anchors including k-means
+anchor cluster and differential evolution. You can use ``--algorithm k-means``
+and ``--algorithm differential_evolution`` to switch two method.
+
+Example:
+ Use k-means anchor cluster::
+
+ python tools/analysis_tools/optimize_anchors.py ${CONFIG} \
+ --algorithm k-means --input-shape ${INPUT_SHAPE [WIDTH HEIGHT]} \
+ --output-dir ${OUTPUT_DIR}
+ Use differential evolution to optimize anchors::
+
+ python tools/analysis_tools/optimize_anchors.py ${CONFIG} \
+ --algorithm differential_evolution \
+ --input-shape ${INPUT_SHAPE [WIDTH HEIGHT]} \
+ --output-dir ${OUTPUT_DIR}
+"""
+import argparse
+import os.path as osp
+
+import numpy as np
+import torch
+from mmengine.config import Config
+from mmengine.fileio import dump
+from mmengine.logging import MMLogger
+from mmengine.registry import init_default_scope
+from mmengine.utils import ProgressBar
+from scipy.optimize import differential_evolution
+
+from mmdet.registry import DATASETS
+from mmdet.structures.bbox import (bbox_cxcywh_to_xyxy, bbox_overlaps,
+ bbox_xyxy_to_cxcywh)
+from mmdet.utils import replace_cfg_vals, update_data_root
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='Optimize anchor parameters.')
+ parser.add_argument('config', help='Train config file path.')
+ parser.add_argument(
+ '--device', default='cuda:0', help='Device used for calculating.')
+ parser.add_argument(
+ '--input-shape',
+ type=int,
+ nargs='+',
+ default=[608, 608],
+ help='input image size')
+ parser.add_argument(
+ '--algorithm',
+ default='differential_evolution',
+ help='Algorithm used for anchor optimizing.'
+ 'Support k-means and differential_evolution for YOLO.')
+ parser.add_argument(
+ '--iters',
+ default=1000,
+ type=int,
+ help='Maximum iterations for optimizer.')
+ parser.add_argument(
+ '--output-dir',
+ default=None,
+ type=str,
+ help='Path to save anchor optimize result.')
+
+ args = parser.parse_args()
+ return args
+
+
+class BaseAnchorOptimizer:
+ """Base class for anchor optimizer.
+
+ Args:
+ dataset (obj:`Dataset`): Dataset object.
+ input_shape (list[int]): Input image shape of the model.
+ Format in [width, height].
+ logger (obj:`logging.Logger`): The logger for logging.
+ device (str, optional): Device used for calculating.
+ Default: 'cuda:0'
+ out_dir (str, optional): Path to save anchor optimize result.
+ Default: None
+ """
+
+ def __init__(self,
+ dataset,
+ input_shape,
+ logger,
+ device='cuda:0',
+ out_dir=None):
+ self.dataset = dataset
+ self.input_shape = input_shape
+ self.logger = logger
+ self.device = device
+ self.out_dir = out_dir
+ bbox_whs, img_shapes = self.get_whs_and_shapes()
+ ratios = img_shapes.max(1, keepdims=True) / np.array([input_shape])
+
+ # resize to input shape
+ self.bbox_whs = bbox_whs / ratios
+
+ def get_whs_and_shapes(self):
+ """Get widths and heights of bboxes and shapes of images.
+
+ Returns:
+ tuple[np.ndarray]: Array of bbox shapes and array of image
+ shapes with shape (num_bboxes, 2) in [width, height] format.
+ """
+ self.logger.info('Collecting bboxes from annotation...')
+ bbox_whs = []
+ img_shapes = []
+ prog_bar = ProgressBar(len(self.dataset))
+ for idx in range(len(self.dataset)):
+ data_info = self.dataset.get_data_info(idx)
+ img_shape = np.array([data_info['width'], data_info['height']])
+ gt_instances = data_info['instances']
+ for instance in gt_instances:
+ bbox = np.array(instance['bbox'])
+ wh = bbox[2:4] - bbox[0:2]
+ img_shapes.append(img_shape)
+ bbox_whs.append(wh)
+
+ prog_bar.update()
+ print('\n')
+ bbox_whs = np.array(bbox_whs)
+ img_shapes = np.array(img_shapes)
+ self.logger.info(f'Collected {bbox_whs.shape[0]} bboxes.')
+ return bbox_whs, img_shapes
+
+ def get_zero_center_bbox_tensor(self):
+ """Get a tensor of bboxes centered at (0, 0).
+
+ Returns:
+ Tensor: Tensor of bboxes with shape (num_bboxes, 4)
+ in [xmin, ymin, xmax, ymax] format.
+ """
+ whs = torch.from_numpy(self.bbox_whs).to(
+ self.device, dtype=torch.float32)
+ bboxes = bbox_cxcywh_to_xyxy(
+ torch.cat([torch.zeros_like(whs), whs], dim=1))
+ return bboxes
+
+ def optimize(self):
+ raise NotImplementedError
+
+ def save_result(self, anchors, path=None):
+ anchor_results = []
+ for w, h in anchors:
+ anchor_results.append([round(w), round(h)])
+ self.logger.info(f'Anchor optimize result:{anchor_results}')
+ if path:
+ json_path = osp.join(path, 'anchor_optimize_result.json')
+ dump(anchor_results, json_path)
+ self.logger.info(f'Result saved in {json_path}')
+
+
+class YOLOKMeansAnchorOptimizer(BaseAnchorOptimizer):
+ r"""YOLO anchor optimizer using k-means. Code refer to `AlexeyAB/darknet.
+ `_.
+
+ Args:
+ num_anchors (int) : Number of anchors.
+ iters (int): Maximum iterations for k-means.
+ """
+
+ def __init__(self, num_anchors, iters, **kwargs):
+
+ super(YOLOKMeansAnchorOptimizer, self).__init__(**kwargs)
+ self.num_anchors = num_anchors
+ self.iters = iters
+
+ def optimize(self):
+ anchors = self.kmeans_anchors()
+ self.save_result(anchors, self.out_dir)
+
+ def kmeans_anchors(self):
+ self.logger.info(
+ f'Start cluster {self.num_anchors} YOLO anchors with K-means...')
+ bboxes = self.get_zero_center_bbox_tensor()
+ cluster_center_idx = torch.randint(
+ 0, bboxes.shape[0], (self.num_anchors, )).to(self.device)
+
+ assignments = torch.zeros((bboxes.shape[0], )).to(self.device)
+ cluster_centers = bboxes[cluster_center_idx]
+ if self.num_anchors == 1:
+ cluster_centers = self.kmeans_maximization(bboxes, assignments,
+ cluster_centers)
+ anchors = bbox_xyxy_to_cxcywh(cluster_centers)[:, 2:].cpu().numpy()
+ anchors = sorted(anchors, key=lambda x: x[0] * x[1])
+ return anchors
+
+ prog_bar = ProgressBar(self.iters)
+ for i in range(self.iters):
+ converged, assignments = self.kmeans_expectation(
+ bboxes, assignments, cluster_centers)
+ if converged:
+ self.logger.info(f'K-means process has converged at iter {i}.')
+ break
+ cluster_centers = self.kmeans_maximization(bboxes, assignments,
+ cluster_centers)
+ prog_bar.update()
+ print('\n')
+ avg_iou = bbox_overlaps(bboxes,
+ cluster_centers).max(1)[0].mean().item()
+
+ anchors = bbox_xyxy_to_cxcywh(cluster_centers)[:, 2:].cpu().numpy()
+ anchors = sorted(anchors, key=lambda x: x[0] * x[1])
+ self.logger.info(f'Anchor cluster finish. Average IOU: {avg_iou}')
+
+ return anchors
+
+ def kmeans_maximization(self, bboxes, assignments, centers):
+ """Maximization part of EM algorithm(Expectation-Maximization)"""
+ new_centers = torch.zeros_like(centers)
+ for i in range(centers.shape[0]):
+ mask = (assignments == i)
+ if mask.sum():
+ new_centers[i, :] = bboxes[mask].mean(0)
+ return new_centers
+
+ def kmeans_expectation(self, bboxes, assignments, centers):
+ """Expectation part of EM algorithm(Expectation-Maximization)"""
+ ious = bbox_overlaps(bboxes, centers)
+ closest = ious.argmax(1)
+ converged = (closest == assignments).all()
+ return converged, closest
+
+
+class YOLODEAnchorOptimizer(BaseAnchorOptimizer):
+ """YOLO anchor optimizer using differential evolution algorithm.
+
+ Args:
+ num_anchors (int) : Number of anchors.
+ iters (int): Maximum iterations for k-means.
+ strategy (str): The differential evolution strategy to use.
+ Should be one of:
+
+ - 'best1bin'
+ - 'best1exp'
+ - 'rand1exp'
+ - 'randtobest1exp'
+ - 'currenttobest1exp'
+ - 'best2exp'
+ - 'rand2exp'
+ - 'randtobest1bin'
+ - 'currenttobest1bin'
+ - 'best2bin'
+ - 'rand2bin'
+ - 'rand1bin'
+
+ Default: 'best1bin'.
+ population_size (int): Total population size of evolution algorithm.
+ Default: 15.
+ convergence_thr (float): Tolerance for convergence, the
+ optimizing stops when ``np.std(pop) <= abs(convergence_thr)
+ + convergence_thr * np.abs(np.mean(population_energies))``,
+ respectively. Default: 0.0001.
+ mutation (tuple[float]): Range of dithering randomly changes the
+ mutation constant. Default: (0.5, 1).
+ recombination (float): Recombination constant of crossover probability.
+ Default: 0.7.
+ """
+
+ def __init__(self,
+ num_anchors,
+ iters,
+ strategy='best1bin',
+ population_size=15,
+ convergence_thr=0.0001,
+ mutation=(0.5, 1),
+ recombination=0.7,
+ **kwargs):
+
+ super(YOLODEAnchorOptimizer, self).__init__(**kwargs)
+
+ self.num_anchors = num_anchors
+ self.iters = iters
+ self.strategy = strategy
+ self.population_size = population_size
+ self.convergence_thr = convergence_thr
+ self.mutation = mutation
+ self.recombination = recombination
+
+ def optimize(self):
+ anchors = self.differential_evolution()
+ self.save_result(anchors, self.out_dir)
+
+ def differential_evolution(self):
+ bboxes = self.get_zero_center_bbox_tensor()
+
+ bounds = []
+ for i in range(self.num_anchors):
+ bounds.extend([(0, self.input_shape[0]), (0, self.input_shape[1])])
+
+ result = differential_evolution(
+ func=self.avg_iou_cost,
+ bounds=bounds,
+ args=(bboxes, ),
+ strategy=self.strategy,
+ maxiter=self.iters,
+ popsize=self.population_size,
+ tol=self.convergence_thr,
+ mutation=self.mutation,
+ recombination=self.recombination,
+ updating='immediate',
+ disp=True)
+ self.logger.info(
+ f'Anchor evolution finish. Average IOU: {1 - result.fun}')
+ anchors = [(w, h) for w, h in zip(result.x[::2], result.x[1::2])]
+ anchors = sorted(anchors, key=lambda x: x[0] * x[1])
+ return anchors
+
+ @staticmethod
+ def avg_iou_cost(anchor_params, bboxes):
+ assert len(anchor_params) % 2 == 0
+ anchor_whs = torch.tensor(
+ [[w, h]
+ for w, h in zip(anchor_params[::2], anchor_params[1::2])]).to(
+ bboxes.device, dtype=bboxes.dtype)
+ anchor_boxes = bbox_cxcywh_to_xyxy(
+ torch.cat([torch.zeros_like(anchor_whs), anchor_whs], dim=1))
+ ious = bbox_overlaps(bboxes, anchor_boxes)
+ max_ious, _ = ious.max(1)
+ cost = 1 - max_ious.mean().item()
+ return cost
+
+
+def main():
+ logger = MMLogger.get_current_instance()
+ args = parse_args()
+ cfg = args.config
+ cfg = Config.fromfile(cfg)
+ init_default_scope(cfg.get('default_scope', 'mmdet'))
+
+ # replace the ${key} with the value of cfg.key
+ cfg = replace_cfg_vals(cfg)
+
+ # update data root according to MMDET_DATASETS
+ update_data_root(cfg)
+
+ input_shape = args.input_shape
+ assert len(input_shape) == 2
+
+ anchor_type = cfg.model.bbox_head.anchor_generator.type
+ assert anchor_type == 'YOLOAnchorGenerator', \
+ f'Only support optimize YOLOAnchor, but get {anchor_type}.'
+
+ base_sizes = cfg.model.bbox_head.anchor_generator.base_sizes
+ num_anchors = sum([len(sizes) for sizes in base_sizes])
+
+ train_data_cfg = cfg.train_dataloader
+ while 'dataset' in train_data_cfg:
+ train_data_cfg = train_data_cfg['dataset']
+ dataset = DATASETS.build(train_data_cfg)
+
+ if args.algorithm == 'k-means':
+ optimizer = YOLOKMeansAnchorOptimizer(
+ dataset=dataset,
+ input_shape=input_shape,
+ device=args.device,
+ num_anchors=num_anchors,
+ iters=args.iters,
+ logger=logger,
+ out_dir=args.output_dir)
+ elif args.algorithm == 'differential_evolution':
+ optimizer = YOLODEAnchorOptimizer(
+ dataset=dataset,
+ input_shape=input_shape,
+ device=args.device,
+ num_anchors=num_anchors,
+ iters=args.iters,
+ logger=logger,
+ out_dir=args.output_dir)
+ else:
+ raise NotImplementedError(
+ f'Only support k-means and differential_evolution, '
+ f'but get {args.algorithm}')
+
+ optimizer.optimize()
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/analysis_tools/robustness_eval.py b/tools/analysis_tools/robustness_eval.py
new file mode 100644
index 0000000000000000000000000000000000000000..56e534176006f4b710d936cbe872755dccc0a2c7
--- /dev/null
+++ b/tools/analysis_tools/robustness_eval.py
@@ -0,0 +1,263 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+from argparse import ArgumentParser
+
+import numpy as np
+from mmengine.fileio import load
+
+
+def print_coco_results(results):
+
+ def _print(result, ap=1, iouThr=None, areaRng='all', maxDets=100):
+ titleStr = 'Average Precision' if ap == 1 else 'Average Recall'
+ typeStr = '(AP)' if ap == 1 else '(AR)'
+ iouStr = '0.50:0.95' \
+ if iouThr is None else f'{iouThr:0.2f}'
+ iStr = f' {titleStr:<18} {typeStr} @[ IoU={iouStr:<9} | '
+ iStr += f'area={areaRng:>6s} | maxDets={maxDets:>3d} ] = {result:0.3f}'
+ print(iStr)
+
+ stats = np.zeros((12, ))
+ stats[0] = _print(results[0], 1)
+ stats[1] = _print(results[1], 1, iouThr=.5)
+ stats[2] = _print(results[2], 1, iouThr=.75)
+ stats[3] = _print(results[3], 1, areaRng='small')
+ stats[4] = _print(results[4], 1, areaRng='medium')
+ stats[5] = _print(results[5], 1, areaRng='large')
+ # TODO support recall metric
+ '''
+ stats[6] = _print(results[6], 0, maxDets=1)
+ stats[7] = _print(results[7], 0, maxDets=10)
+ stats[8] = _print(results[8], 0)
+ stats[9] = _print(results[9], 0, areaRng='small')
+ stats[10] = _print(results[10], 0, areaRng='medium')
+ stats[11] = _print(results[11], 0, areaRng='large')
+ '''
+
+
+def get_coco_style_results(filename,
+ task='bbox',
+ metric=None,
+ prints='mPC',
+ aggregate='benchmark'):
+
+ assert aggregate in ['benchmark', 'all']
+
+ if prints == 'all':
+ prints = ['P', 'mPC', 'rPC']
+ elif isinstance(prints, str):
+ prints = [prints]
+ for p in prints:
+ assert p in ['P', 'mPC', 'rPC']
+
+ if metric is None:
+ metrics = [
+ 'mAP',
+ 'mAP_50',
+ 'mAP_75',
+ 'mAP_s',
+ 'mAP_m',
+ 'mAP_l',
+ ]
+ elif isinstance(metric, list):
+ metrics = metric
+ else:
+ metrics = [metric]
+
+ for metric_name in metrics:
+ assert metric_name in [
+ 'mAP', 'mAP_50', 'mAP_75', 'mAP_s', 'mAP_m', 'mAP_l'
+ ]
+
+ eval_output = load(filename)
+
+ num_distortions = len(list(eval_output.keys()))
+ results = np.zeros((num_distortions, 6, len(metrics)), dtype='float32')
+
+ for corr_i, distortion in enumerate(eval_output):
+ for severity in eval_output[distortion]:
+ for metric_j, metric_name in enumerate(metrics):
+ metric_dict = eval_output[distortion][severity]
+
+ new_metric_dict = {}
+ for k, v in metric_dict.items():
+ if '/' in k:
+ new_metric_dict[k.split('/')[-1]] = v
+ mAP = new_metric_dict['_'.join((task, metric_name))]
+ results[corr_i, severity, metric_j] = mAP
+
+ P = results[0, 0, :]
+ if aggregate == 'benchmark':
+ mPC = np.mean(results[:15, 1:, :], axis=(0, 1))
+ else:
+ mPC = np.mean(results[:, 1:, :], axis=(0, 1))
+ rPC = mPC / P
+
+ print(f'\nmodel: {osp.basename(filename)}')
+ if metric is None:
+ if 'P' in prints:
+ print(f'Performance on Clean Data [P] ({task})')
+ print_coco_results(P)
+ if 'mPC' in prints:
+ print(f'Mean Performance under Corruption [mPC] ({task})')
+ print_coco_results(mPC)
+ if 'rPC' in prints:
+ print(f'Relative Performance under Corruption [rPC] ({task})')
+ print_coco_results(rPC)
+ else:
+ if 'P' in prints:
+ print(f'Performance on Clean Data [P] ({task})')
+ for metric_i, metric_name in enumerate(metrics):
+ print(f'{metric_name:5} = {P[metric_i]:0.3f}')
+ if 'mPC' in prints:
+ print(f'Mean Performance under Corruption [mPC] ({task})')
+ for metric_i, metric_name in enumerate(metrics):
+ print(f'{metric_name:5} = {mPC[metric_i]:0.3f}')
+ if 'rPC' in prints:
+ print(f'Relative Performance under Corruption [rPC] ({task})')
+ for metric_i, metric_name in enumerate(metrics):
+ print(f'{metric_name:5} => {rPC[metric_i] * 100:0.1f} %')
+
+ return results
+
+
+def get_voc_style_results(filename, prints='mPC', aggregate='benchmark'):
+
+ assert aggregate in ['benchmark', 'all']
+
+ if prints == 'all':
+ prints = ['P', 'mPC', 'rPC']
+ elif isinstance(prints, str):
+ prints = [prints]
+ for p in prints:
+ assert p in ['P', 'mPC', 'rPC']
+
+ eval_output = load(filename)
+
+ num_distortions = len(list(eval_output.keys()))
+ results = np.zeros((num_distortions, 6, 20), dtype='float32')
+
+ for i, distortion in enumerate(eval_output):
+ for severity in eval_output[distortion]:
+ mAP = [
+ eval_output[distortion][severity][j]['ap']
+ for j in range(len(eval_output[distortion][severity]))
+ ]
+ results[i, severity, :] = mAP
+
+ P = results[0, 0, :]
+ if aggregate == 'benchmark':
+ mPC = np.mean(results[:15, 1:, :], axis=(0, 1))
+ else:
+ mPC = np.mean(results[:, 1:, :], axis=(0, 1))
+ rPC = mPC / P
+
+ print(f'\nmodel: {osp.basename(filename)}')
+ if 'P' in prints:
+ print(f'Performance on Clean Data [P] in AP50 = {np.mean(P):0.3f}')
+ if 'mPC' in prints:
+ print('Mean Performance under Corruption [mPC] in AP50 = '
+ f'{np.mean(mPC):0.3f}')
+ if 'rPC' in prints:
+ print('Relative Performance under Corruption [rPC] in % = '
+ f'{np.mean(rPC) * 100:0.1f}')
+
+ return np.mean(results, axis=2, keepdims=True)
+
+
+def get_results(filename,
+ dataset='coco',
+ task='bbox',
+ metric=None,
+ prints='mPC',
+ aggregate='benchmark'):
+ assert dataset in ['coco', 'voc', 'cityscapes']
+
+ if dataset in ['coco', 'cityscapes']:
+ results = get_coco_style_results(
+ filename,
+ task=task,
+ metric=metric,
+ prints=prints,
+ aggregate=aggregate)
+ elif dataset == 'voc':
+ if task != 'bbox':
+ print('Only bbox analysis is supported for Pascal VOC')
+ print('Will report bbox results\n')
+ if metric not in [None, ['AP'], ['AP50']]:
+ print('Only the AP50 metric is supported for Pascal VOC')
+ print('Will report AP50 metric\n')
+ results = get_voc_style_results(
+ filename, prints=prints, aggregate=aggregate)
+
+ return results
+
+
+def get_distortions_from_file(filename):
+
+ eval_output = load(filename)
+
+ return get_distortions_from_results(eval_output)
+
+
+def get_distortions_from_results(eval_output):
+ distortions = []
+ for i, distortion in enumerate(eval_output):
+ distortions.append(distortion.replace('_', ' '))
+ return distortions
+
+
+def main():
+ parser = ArgumentParser(description='Corruption Result Analysis')
+ parser.add_argument('filename', help='result file path')
+ parser.add_argument(
+ '--dataset',
+ type=str,
+ choices=['coco', 'voc', 'cityscapes'],
+ default='coco',
+ help='dataset type')
+ parser.add_argument(
+ '--task',
+ type=str,
+ nargs='+',
+ choices=['bbox', 'segm'],
+ default=['bbox'],
+ help='task to report')
+ parser.add_argument(
+ '--metric',
+ nargs='+',
+ choices=[
+ None, 'AP', 'AP50', 'AP75', 'APs', 'APm', 'APl', 'AR1', 'AR10',
+ 'AR100', 'ARs', 'ARm', 'ARl'
+ ],
+ default=None,
+ help='metric to report')
+ parser.add_argument(
+ '--prints',
+ type=str,
+ nargs='+',
+ choices=['P', 'mPC', 'rPC'],
+ default='mPC',
+ help='corruption benchmark metric to print')
+ parser.add_argument(
+ '--aggregate',
+ type=str,
+ choices=['all', 'benchmark'],
+ default='benchmark',
+ help='aggregate all results or only those \
+ for benchmark corruptions')
+
+ args = parser.parse_args()
+
+ for task in args.task:
+ get_results(
+ args.filename,
+ dataset=args.dataset,
+ task=task,
+ metric=args.metric,
+ prints=args.prints,
+ aggregate=args.aggregate)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/analysis_tools/test_robustness.py b/tools/analysis_tools/test_robustness.py
new file mode 100644
index 0000000000000000000000000000000000000000..a701d23fe5157b771ad3e5be13d7dde65e886012
--- /dev/null
+++ b/tools/analysis_tools/test_robustness.py
@@ -0,0 +1,239 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import copy
+import os
+import os.path as osp
+
+from mmengine.config import Config, DictAction
+from mmengine.dist import get_dist_info
+from mmengine.evaluator import DumpResults
+from mmengine.fileio import dump
+from mmengine.runner import Runner
+
+from mmdet.engine.hooks.utils import trigger_visualization_hook
+from mmdet.registry import RUNNERS
+from tools.analysis_tools.robustness_eval import get_results
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='MMDet test detector')
+ parser.add_argument('config', help='test config file path')
+ parser.add_argument('checkpoint', help='checkpoint file')
+ parser.add_argument(
+ '--out',
+ type=str,
+ help='dump predictions to a pickle file for offline evaluation')
+ parser.add_argument(
+ '--corruptions',
+ type=str,
+ nargs='+',
+ default='benchmark',
+ choices=[
+ 'all', 'benchmark', 'noise', 'blur', 'weather', 'digital',
+ 'holdout', 'None', 'gaussian_noise', 'shot_noise', 'impulse_noise',
+ 'defocus_blur', 'glass_blur', 'motion_blur', 'zoom_blur', 'snow',
+ 'frost', 'fog', 'brightness', 'contrast', 'elastic_transform',
+ 'pixelate', 'jpeg_compression', 'speckle_noise', 'gaussian_blur',
+ 'spatter', 'saturate'
+ ],
+ help='corruptions')
+ parser.add_argument(
+ '--work-dir',
+ help='the directory to save the file containing evaluation metrics')
+ parser.add_argument(
+ '--severities',
+ type=int,
+ nargs='+',
+ default=[0, 1, 2, 3, 4, 5],
+ help='corruption severity levels')
+ parser.add_argument(
+ '--summaries',
+ type=bool,
+ default=False,
+ help='Print summaries for every corruption and severity')
+ parser.add_argument('--show', action='store_true', help='show results')
+ parser.add_argument(
+ '--show-dir', help='directory where painted images will be saved')
+ parser.add_argument(
+ '--wait-time', type=float, default=2, help='the interval of show (s)')
+ parser.add_argument('--seed', type=int, default=None, help='random seed')
+ parser.add_argument(
+ '--launcher',
+ choices=['none', 'pytorch', 'slurm', 'mpi'],
+ default='none',
+ help='job launcher')
+ parser.add_argument('--local_rank', type=int, default=0)
+ parser.add_argument(
+ '--final-prints',
+ type=str,
+ nargs='+',
+ choices=['P', 'mPC', 'rPC'],
+ default='mPC',
+ help='corruption benchmark metric to print at the end')
+ parser.add_argument(
+ '--final-prints-aggregate',
+ type=str,
+ choices=['all', 'benchmark'],
+ default='benchmark',
+ help='aggregate all results or only those for benchmark corruptions')
+ parser.add_argument(
+ '--cfg-options',
+ nargs='+',
+ action=DictAction,
+ help='override some settings in the used config, the key-value pair '
+ 'in xxx=yyy format will be merged into config file. If the value to '
+ 'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
+ 'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
+ 'Note that the quotation marks are necessary and that no white space '
+ 'is allowed.')
+ args = parser.parse_args()
+ if 'LOCAL_RANK' not in os.environ:
+ os.environ['LOCAL_RANK'] = str(args.local_rank)
+ return args
+
+
+def main():
+ args = parse_args()
+
+ assert args.out or args.show or args.show_dir, \
+ ('Please specify at least one operation (save or show the results) '
+ 'with the argument "--out", "--show" or "show-dir"')
+
+ # load config
+ cfg = Config.fromfile(args.config)
+ cfg.launcher = args.launcher
+ if args.cfg_options is not None:
+ cfg.merge_from_dict(args.cfg_options)
+
+ # work_dir is determined in this priority: CLI > segment in file > filename
+ if args.work_dir is not None:
+ # update configs according to CLI args if args.work_dir is not None
+ cfg.work_dir = args.work_dir
+ elif cfg.get('work_dir', None) is None:
+ # use config filename as default work_dir if cfg.work_dir is None
+ cfg.work_dir = osp.join('./work_dirs',
+ osp.splitext(osp.basename(args.config))[0])
+
+ cfg.model.backbone.init_cfg.type = None
+ cfg.test_dataloader.dataset.test_mode = True
+
+ cfg.load_from = args.checkpoint
+ if args.show or args.show_dir:
+ cfg = trigger_visualization_hook(cfg, args)
+
+ # build the runner from config
+ if 'runner_type' not in cfg:
+ # build the default runner
+ runner = Runner.from_cfg(cfg)
+ else:
+ # build customized runner from the registry
+ # if 'runner_type' is set in the cfg
+ runner = RUNNERS.build(cfg)
+
+ # add `DumpResults` dummy metric
+ if args.out is not None:
+ assert args.out.endswith(('.pkl', '.pickle')), \
+ 'The dump file must be a pkl file.'
+ runner.test_evaluator.metrics.append(
+ DumpResults(out_file_path=args.out))
+
+ if 'all' in args.corruptions:
+ corruptions = [
+ 'gaussian_noise', 'shot_noise', 'impulse_noise', 'defocus_blur',
+ 'glass_blur', 'motion_blur', 'zoom_blur', 'snow', 'frost', 'fog',
+ 'brightness', 'contrast', 'elastic_transform', 'pixelate',
+ 'jpeg_compression', 'speckle_noise', 'gaussian_blur', 'spatter',
+ 'saturate'
+ ]
+ elif 'benchmark' in args.corruptions:
+ corruptions = [
+ 'gaussian_noise', 'shot_noise', 'impulse_noise', 'defocus_blur',
+ 'glass_blur', 'motion_blur', 'zoom_blur', 'snow', 'frost', 'fog',
+ 'brightness', 'contrast', 'elastic_transform', 'pixelate',
+ 'jpeg_compression'
+ ]
+ elif 'noise' in args.corruptions:
+ corruptions = ['gaussian_noise', 'shot_noise', 'impulse_noise']
+ elif 'blur' in args.corruptions:
+ corruptions = [
+ 'defocus_blur', 'glass_blur', 'motion_blur', 'zoom_blur'
+ ]
+ elif 'weather' in args.corruptions:
+ corruptions = ['snow', 'frost', 'fog', 'brightness']
+ elif 'digital' in args.corruptions:
+ corruptions = [
+ 'contrast', 'elastic_transform', 'pixelate', 'jpeg_compression'
+ ]
+ elif 'holdout' in args.corruptions:
+ corruptions = ['speckle_noise', 'gaussian_blur', 'spatter', 'saturate']
+ elif 'None' in args.corruptions:
+ corruptions = ['None']
+ args.severities = [0]
+ else:
+ corruptions = args.corruptions
+
+ aggregated_results = {}
+ for corr_i, corruption in enumerate(corruptions):
+ aggregated_results[corruption] = {}
+ for sev_i, corruption_severity in enumerate(args.severities):
+ # evaluate severity 0 (= no corruption) only once
+ if corr_i > 0 and corruption_severity == 0:
+ aggregated_results[corruption][0] = \
+ aggregated_results[corruptions[0]][0]
+ continue
+
+ test_loader_cfg = copy.deepcopy(cfg.test_dataloader)
+ # assign corruption and severity
+ if corruption_severity > 0:
+ corruption_trans = dict(
+ type='Corrupt',
+ corruption=corruption,
+ severity=corruption_severity)
+ # TODO: hard coded "1", we assume that the first step is
+ # loading images, which needs to be fixed in the future
+ test_loader_cfg.dataset.pipeline.insert(1, corruption_trans)
+
+ test_loader = runner.build_dataloader(test_loader_cfg)
+
+ runner.test_loop.dataloader = test_loader
+ # set random seeds
+ if args.seed is not None:
+ runner.set_randomness(args.seed)
+
+ # print info
+ print(f'\nTesting {corruption} at severity {corruption_severity}')
+
+ eval_results = runner.test()
+ if args.out:
+ eval_results_filename = (
+ osp.splitext(args.out)[0] + '_results' +
+ osp.splitext(args.out)[1])
+ aggregated_results[corruption][
+ corruption_severity] = eval_results
+ dump(aggregated_results, eval_results_filename)
+
+ rank, _ = get_dist_info()
+ if rank == 0:
+ eval_results_filename = (
+ osp.splitext(args.out)[0] + '_results' + osp.splitext(args.out)[1])
+ # print final results
+ print('\nAggregated results:')
+ prints = args.final_prints
+ aggregate = args.final_prints_aggregate
+
+ if cfg.dataset_type == 'VOCDataset':
+ get_results(
+ eval_results_filename,
+ dataset='voc',
+ prints=prints,
+ aggregate=aggregate)
+ else:
+ get_results(
+ eval_results_filename,
+ dataset='coco',
+ prints=prints,
+ aggregate=aggregate)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/dataset_converters/cityscapes.py b/tools/dataset_converters/cityscapes.py
new file mode 100644
index 0000000000000000000000000000000000000000..23ad431ce0b570b122ae5cf1afd50e9c2bdb1788
--- /dev/null
+++ b/tools/dataset_converters/cityscapes.py
@@ -0,0 +1,153 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import glob
+import os.path as osp
+
+import cityscapesscripts.helpers.labels as CSLabels
+import mmcv
+import numpy as np
+import pycocotools.mask as maskUtils
+from mmengine.fileio import dump
+from mmengine.utils import (Timer, mkdir_or_exist, track_parallel_progress,
+ track_progress)
+
+
+def collect_files(img_dir, gt_dir):
+ suffix = 'leftImg8bit.png'
+ files = []
+ for img_file in glob.glob(osp.join(img_dir, '**/*.png')):
+ assert img_file.endswith(suffix), img_file
+ inst_file = gt_dir + img_file[
+ len(img_dir):-len(suffix)] + 'gtFine_instanceIds.png'
+ # Note that labelIds are not converted to trainId for seg map
+ segm_file = gt_dir + img_file[
+ len(img_dir):-len(suffix)] + 'gtFine_labelIds.png'
+ files.append((img_file, inst_file, segm_file))
+ assert len(files), f'No images found in {img_dir}'
+ print(f'Loaded {len(files)} images from {img_dir}')
+
+ return files
+
+
+def collect_annotations(files, nproc=1):
+ print('Loading annotation images')
+ if nproc > 1:
+ images = track_parallel_progress(load_img_info, files, nproc=nproc)
+ else:
+ images = track_progress(load_img_info, files)
+
+ return images
+
+
+def load_img_info(files):
+ img_file, inst_file, segm_file = files
+ inst_img = mmcv.imread(inst_file, 'unchanged')
+ # ids < 24 are stuff labels (filtering them first is about 5% faster)
+ unique_inst_ids = np.unique(inst_img[inst_img >= 24])
+ anno_info = []
+ for inst_id in unique_inst_ids:
+ # For non-crowd annotations, inst_id // 1000 is the label_id
+ # Crowd annotations have <1000 instance ids
+ label_id = inst_id // 1000 if inst_id >= 1000 else inst_id
+ label = CSLabels.id2label[label_id]
+ if not label.hasInstances or label.ignoreInEval:
+ continue
+
+ category_id = label.id
+ iscrowd = int(inst_id < 1000)
+ mask = np.asarray(inst_img == inst_id, dtype=np.uint8, order='F')
+ mask_rle = maskUtils.encode(mask[:, :, None])[0]
+
+ area = maskUtils.area(mask_rle)
+ # convert to COCO style XYWH format
+ bbox = maskUtils.toBbox(mask_rle)
+
+ # for json encoding
+ mask_rle['counts'] = mask_rle['counts'].decode()
+
+ anno = dict(
+ iscrowd=iscrowd,
+ category_id=category_id,
+ bbox=bbox.tolist(),
+ area=area.tolist(),
+ segmentation=mask_rle)
+ anno_info.append(anno)
+ video_name = osp.basename(osp.dirname(img_file))
+ img_info = dict(
+ # remove img_prefix for filename
+ file_name=osp.join(video_name, osp.basename(img_file)),
+ height=inst_img.shape[0],
+ width=inst_img.shape[1],
+ anno_info=anno_info,
+ segm_file=osp.join(video_name, osp.basename(segm_file)))
+
+ return img_info
+
+
+def cvt_annotations(image_infos, out_json_name):
+ out_json = dict()
+ img_id = 0
+ ann_id = 0
+ out_json['images'] = []
+ out_json['categories'] = []
+ out_json['annotations'] = []
+ for image_info in image_infos:
+ image_info['id'] = img_id
+ anno_infos = image_info.pop('anno_info')
+ out_json['images'].append(image_info)
+ for anno_info in anno_infos:
+ anno_info['image_id'] = img_id
+ anno_info['id'] = ann_id
+ out_json['annotations'].append(anno_info)
+ ann_id += 1
+ img_id += 1
+ for label in CSLabels.labels:
+ if label.hasInstances and not label.ignoreInEval:
+ cat = dict(id=label.id, name=label.name)
+ out_json['categories'].append(cat)
+
+ if len(out_json['annotations']) == 0:
+ out_json.pop('annotations')
+
+ dump(out_json, out_json_name)
+ return out_json
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Convert Cityscapes annotations to COCO format')
+ parser.add_argument('cityscapes_path', help='cityscapes data path')
+ parser.add_argument('--img-dir', default='leftImg8bit', type=str)
+ parser.add_argument('--gt-dir', default='gtFine', type=str)
+ parser.add_argument('-o', '--out-dir', help='output path')
+ parser.add_argument(
+ '--nproc', default=1, type=int, help='number of process')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ cityscapes_path = args.cityscapes_path
+ out_dir = args.out_dir if args.out_dir else cityscapes_path
+ mkdir_or_exist(out_dir)
+
+ img_dir = osp.join(cityscapes_path, args.img_dir)
+ gt_dir = osp.join(cityscapes_path, args.gt_dir)
+
+ set_name = dict(
+ train='instancesonly_filtered_gtFine_train.json',
+ val='instancesonly_filtered_gtFine_val.json',
+ test='instancesonly_filtered_gtFine_test.json')
+
+ for split, json_name in set_name.items():
+ print(f'Converting {split} into {json_name}')
+ with Timer(print_tmpl='It took {}s to convert Cityscapes annotation'):
+ files = collect_files(
+ osp.join(img_dir, split), osp.join(gt_dir, split))
+ image_infos = collect_annotations(files, nproc=args.nproc)
+ cvt_annotations(image_infos, osp.join(out_dir, json_name))
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/dataset_converters/images2coco.py b/tools/dataset_converters/images2coco.py
new file mode 100644
index 0000000000000000000000000000000000000000..a893de8421ce8dffab5cd788c884400750d79f06
--- /dev/null
+++ b/tools/dataset_converters/images2coco.py
@@ -0,0 +1,102 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os
+
+from mmengine.fileio import dump, list_from_file
+from mmengine.utils import mkdir_or_exist, scandir, track_iter_progress
+from PIL import Image
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Convert images to coco format without annotations')
+ parser.add_argument('img_path', help='The root path of images')
+ parser.add_argument(
+ 'classes', type=str, help='The text file name of storage class list')
+ parser.add_argument(
+ 'out',
+ type=str,
+ help='The output annotation json file name, The save dir is in the '
+ 'same directory as img_path')
+ parser.add_argument(
+ '-e',
+ '--exclude-extensions',
+ type=str,
+ nargs='+',
+ help='The suffix of images to be excluded, such as "png" and "bmp"')
+ args = parser.parse_args()
+ return args
+
+
+def collect_image_infos(path, exclude_extensions=None):
+ img_infos = []
+
+ images_generator = scandir(path, recursive=True)
+ for image_path in track_iter_progress(list(images_generator)):
+ if exclude_extensions is None or (
+ exclude_extensions is not None
+ and not image_path.lower().endswith(exclude_extensions)):
+ image_path = os.path.join(path, image_path)
+ img_pillow = Image.open(image_path)
+ img_info = {
+ 'filename': image_path,
+ 'width': img_pillow.width,
+ 'height': img_pillow.height,
+ }
+ img_infos.append(img_info)
+ return img_infos
+
+
+def cvt_to_coco_json(img_infos, classes):
+ image_id = 0
+ coco = dict()
+ coco['images'] = []
+ coco['type'] = 'instance'
+ coco['categories'] = []
+ coco['annotations'] = []
+ image_set = set()
+
+ for category_id, name in enumerate(classes):
+ category_item = dict()
+ category_item['supercategory'] = str('none')
+ category_item['id'] = int(category_id)
+ category_item['name'] = str(name)
+ coco['categories'].append(category_item)
+
+ for img_dict in img_infos:
+ file_name = img_dict['filename']
+ assert file_name not in image_set
+ image_item = dict()
+ image_item['id'] = int(image_id)
+ image_item['file_name'] = str(file_name)
+ image_item['height'] = int(img_dict['height'])
+ image_item['width'] = int(img_dict['width'])
+ coco['images'].append(image_item)
+ image_set.add(file_name)
+
+ image_id += 1
+ return coco
+
+
+def main():
+ args = parse_args()
+ assert args.out.endswith(
+ 'json'), 'The output file name must be json suffix'
+
+ # 1 load image list info
+ img_infos = collect_image_infos(args.img_path, args.exclude_extensions)
+
+ # 2 convert to coco format data
+ classes = list_from_file(args.classes)
+ coco_info = cvt_to_coco_json(img_infos, classes)
+
+ # 3 dump
+ save_dir = os.path.join(args.img_path, '..', 'annotations')
+ mkdir_or_exist(save_dir)
+ save_path = os.path.join(save_dir, args.out)
+ dump(coco_info, save_path)
+ print(f'save json file: {save_path}')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/dataset_converters/pascal_voc.py b/tools/dataset_converters/pascal_voc.py
new file mode 100644
index 0000000000000000000000000000000000000000..fd238bfcf2826c4c57c5dc2f60969171421e9062
--- /dev/null
+++ b/tools/dataset_converters/pascal_voc.py
@@ -0,0 +1,238 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os.path as osp
+import xml.etree.ElementTree as ET
+
+import numpy as np
+from mmengine.fileio import dump, list_from_file
+from mmengine.utils import mkdir_or_exist, track_progress
+
+from mmdet.evaluation import voc_classes
+
+label_ids = {name: i for i, name in enumerate(voc_classes())}
+
+
+def parse_xml(args):
+ xml_path, img_path = args
+ tree = ET.parse(xml_path)
+ root = tree.getroot()
+ size = root.find('size')
+ w = int(size.find('width').text)
+ h = int(size.find('height').text)
+ bboxes = []
+ labels = []
+ bboxes_ignore = []
+ labels_ignore = []
+ for obj in root.findall('object'):
+ name = obj.find('name').text
+ label = label_ids[name]
+ difficult = int(obj.find('difficult').text)
+ bnd_box = obj.find('bndbox')
+ bbox = [
+ int(bnd_box.find('xmin').text),
+ int(bnd_box.find('ymin').text),
+ int(bnd_box.find('xmax').text),
+ int(bnd_box.find('ymax').text)
+ ]
+ if difficult:
+ bboxes_ignore.append(bbox)
+ labels_ignore.append(label)
+ else:
+ bboxes.append(bbox)
+ labels.append(label)
+ if not bboxes:
+ bboxes = np.zeros((0, 4))
+ labels = np.zeros((0, ))
+ else:
+ bboxes = np.array(bboxes, ndmin=2) - 1
+ labels = np.array(labels)
+ if not bboxes_ignore:
+ bboxes_ignore = np.zeros((0, 4))
+ labels_ignore = np.zeros((0, ))
+ else:
+ bboxes_ignore = np.array(bboxes_ignore, ndmin=2) - 1
+ labels_ignore = np.array(labels_ignore)
+ annotation = {
+ 'filename': img_path,
+ 'width': w,
+ 'height': h,
+ 'ann': {
+ 'bboxes': bboxes.astype(np.float32),
+ 'labels': labels.astype(np.int64),
+ 'bboxes_ignore': bboxes_ignore.astype(np.float32),
+ 'labels_ignore': labels_ignore.astype(np.int64)
+ }
+ }
+ return annotation
+
+
+def cvt_annotations(devkit_path, years, split, out_file):
+ if not isinstance(years, list):
+ years = [years]
+ annotations = []
+ for year in years:
+ filelist = osp.join(devkit_path,
+ f'VOC{year}/ImageSets/Main/{split}.txt')
+ if not osp.isfile(filelist):
+ print(f'filelist does not exist: {filelist}, '
+ f'skip voc{year} {split}')
+ return
+ img_names = list_from_file(filelist)
+ xml_paths = [
+ osp.join(devkit_path, f'VOC{year}/Annotations/{img_name}.xml')
+ for img_name in img_names
+ ]
+ img_paths = [
+ f'VOC{year}/JPEGImages/{img_name}.jpg' for img_name in img_names
+ ]
+ part_annotations = track_progress(parse_xml,
+ list(zip(xml_paths, img_paths)))
+ annotations.extend(part_annotations)
+ if out_file.endswith('json'):
+ annotations = cvt_to_coco_json(annotations)
+ dump(annotations, out_file)
+ return annotations
+
+
+def cvt_to_coco_json(annotations):
+ image_id = 0
+ annotation_id = 0
+ coco = dict()
+ coco['images'] = []
+ coco['type'] = 'instance'
+ coco['categories'] = []
+ coco['annotations'] = []
+ image_set = set()
+
+ def addAnnItem(annotation_id, image_id, category_id, bbox, difficult_flag):
+ annotation_item = dict()
+ annotation_item['segmentation'] = []
+
+ seg = []
+ # bbox[] is x1,y1,x2,y2
+ # left_top
+ seg.append(int(bbox[0]))
+ seg.append(int(bbox[1]))
+ # left_bottom
+ seg.append(int(bbox[0]))
+ seg.append(int(bbox[3]))
+ # right_bottom
+ seg.append(int(bbox[2]))
+ seg.append(int(bbox[3]))
+ # right_top
+ seg.append(int(bbox[2]))
+ seg.append(int(bbox[1]))
+
+ annotation_item['segmentation'].append(seg)
+
+ xywh = np.array(
+ [bbox[0], bbox[1], bbox[2] - bbox[0], bbox[3] - bbox[1]])
+ annotation_item['area'] = int(xywh[2] * xywh[3])
+ if difficult_flag == 1:
+ annotation_item['ignore'] = 0
+ annotation_item['iscrowd'] = 1
+ else:
+ annotation_item['ignore'] = 0
+ annotation_item['iscrowd'] = 0
+ annotation_item['image_id'] = int(image_id)
+ annotation_item['bbox'] = xywh.astype(int).tolist()
+ annotation_item['category_id'] = int(category_id)
+ annotation_item['id'] = int(annotation_id)
+ coco['annotations'].append(annotation_item)
+ return annotation_id + 1
+
+ for category_id, name in enumerate(voc_classes()):
+ category_item = dict()
+ category_item['supercategory'] = str('none')
+ category_item['id'] = int(category_id)
+ category_item['name'] = str(name)
+ coco['categories'].append(category_item)
+
+ for ann_dict in annotations:
+ file_name = ann_dict['filename']
+ ann = ann_dict['ann']
+ assert file_name not in image_set
+ image_item = dict()
+ image_item['id'] = int(image_id)
+ image_item['file_name'] = str(file_name)
+ image_item['height'] = int(ann_dict['height'])
+ image_item['width'] = int(ann_dict['width'])
+ coco['images'].append(image_item)
+ image_set.add(file_name)
+
+ bboxes = ann['bboxes'][:, :4]
+ labels = ann['labels']
+ for bbox_id in range(len(bboxes)):
+ bbox = bboxes[bbox_id]
+ label = labels[bbox_id]
+ annotation_id = addAnnItem(
+ annotation_id, image_id, label, bbox, difficult_flag=0)
+
+ bboxes_ignore = ann['bboxes_ignore'][:, :4]
+ labels_ignore = ann['labels_ignore']
+ for bbox_id in range(len(bboxes_ignore)):
+ bbox = bboxes_ignore[bbox_id]
+ label = labels_ignore[bbox_id]
+ annotation_id = addAnnItem(
+ annotation_id, image_id, label, bbox, difficult_flag=1)
+
+ image_id += 1
+
+ return coco
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Convert PASCAL VOC annotations to mmdetection format')
+ parser.add_argument('devkit_path', help='pascal voc devkit path')
+ parser.add_argument('-o', '--out-dir', help='output path')
+ parser.add_argument(
+ '--out-format',
+ default='pkl',
+ choices=('pkl', 'coco'),
+ help='output format, "coco" indicates coco annotation format')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ devkit_path = args.devkit_path
+ out_dir = args.out_dir if args.out_dir else devkit_path
+ mkdir_or_exist(out_dir)
+
+ years = []
+ if osp.isdir(osp.join(devkit_path, 'VOC2007')):
+ years.append('2007')
+ if osp.isdir(osp.join(devkit_path, 'VOC2012')):
+ years.append('2012')
+ if '2007' in years and '2012' in years:
+ years.append(['2007', '2012'])
+ if not years:
+ raise IOError(f'The devkit path {devkit_path} contains neither '
+ '"VOC2007" nor "VOC2012" subfolder')
+ out_fmt = f'.{args.out_format}'
+ if args.out_format == 'coco':
+ out_fmt = '.json'
+ for year in years:
+ if year == '2007':
+ prefix = 'voc07'
+ elif year == '2012':
+ prefix = 'voc12'
+ elif year == ['2007', '2012']:
+ prefix = 'voc0712'
+ for split in ['train', 'val', 'trainval']:
+ dataset_name = prefix + '_' + split
+ print(f'processing {dataset_name} ...')
+ cvt_annotations(devkit_path, year, split,
+ osp.join(out_dir, dataset_name + out_fmt))
+ if not isinstance(year, list):
+ dataset_name = prefix + '_test'
+ print(f'processing {dataset_name} ...')
+ cvt_annotations(devkit_path, year, 'test',
+ osp.join(out_dir, dataset_name + out_fmt))
+ print('Done!')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/deployment/mmdet2torchserve.py b/tools/deployment/mmdet2torchserve.py
new file mode 100644
index 0000000000000000000000000000000000000000..91d13287f22cf5e8db36ba663531ca697eeaf2a8
--- /dev/null
+++ b/tools/deployment/mmdet2torchserve.py
@@ -0,0 +1,111 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from argparse import ArgumentParser, Namespace
+from pathlib import Path
+from tempfile import TemporaryDirectory
+
+from mmengine.config import Config
+from mmengine.utils import mkdir_or_exist
+
+try:
+ from model_archiver.model_packaging import package_model
+ from model_archiver.model_packaging_utils import ModelExportUtils
+except ImportError:
+ package_model = None
+
+
+def mmdet2torchserve(
+ config_file: str,
+ checkpoint_file: str,
+ output_folder: str,
+ model_name: str,
+ model_version: str = '1.0',
+ force: bool = False,
+):
+ """Converts MMDetection model (config + checkpoint) to TorchServe `.mar`.
+
+ Args:
+ config_file:
+ In MMDetection config format.
+ The contents vary for each task repository.
+ checkpoint_file:
+ In MMDetection checkpoint format.
+ The contents vary for each task repository.
+ output_folder:
+ Folder where `{model_name}.mar` will be created.
+ The file created will be in TorchServe archive format.
+ model_name:
+ If not None, used for naming the `{model_name}.mar` file
+ that will be created under `output_folder`.
+ If None, `{Path(checkpoint_file).stem}` will be used.
+ model_version:
+ Model's version.
+ force:
+ If True, if there is an existing `{model_name}.mar`
+ file under `output_folder` it will be overwritten.
+ """
+ mkdir_or_exist(output_folder)
+
+ config = Config.fromfile(config_file)
+
+ with TemporaryDirectory() as tmpdir:
+ config.dump(f'{tmpdir}/config.py')
+
+ args = Namespace(
+ **{
+ 'model_file': f'{tmpdir}/config.py',
+ 'serialized_file': checkpoint_file,
+ 'handler': f'{Path(__file__).parent}/mmdet_handler.py',
+ 'model_name': model_name or Path(checkpoint_file).stem,
+ 'version': model_version,
+ 'export_path': output_folder,
+ 'force': force,
+ 'requirements_file': None,
+ 'extra_files': None,
+ 'runtime': 'python',
+ 'archive_format': 'default'
+ })
+ manifest = ModelExportUtils.generate_manifest_json(args)
+ package_model(args, manifest)
+
+
+def parse_args():
+ parser = ArgumentParser(
+ description='Convert MMDetection models to TorchServe `.mar` format.')
+ parser.add_argument('config', type=str, help='config file path')
+ parser.add_argument('checkpoint', type=str, help='checkpoint file path')
+ parser.add_argument(
+ '--output-folder',
+ type=str,
+ required=True,
+ help='Folder where `{model_name}.mar` will be created.')
+ parser.add_argument(
+ '--model-name',
+ type=str,
+ default=None,
+ help='If not None, used for naming the `{model_name}.mar`'
+ 'file that will be created under `output_folder`.'
+ 'If None, `{Path(checkpoint_file).stem}` will be used.')
+ parser.add_argument(
+ '--model-version',
+ type=str,
+ default='1.0',
+ help='Number used for versioning.')
+ parser.add_argument(
+ '-f',
+ '--force',
+ action='store_true',
+ help='overwrite the existing `{model_name}.mar`')
+ args = parser.parse_args()
+
+ return args
+
+
+if __name__ == '__main__':
+ args = parse_args()
+
+ if package_model is None:
+ raise ImportError('`torch-model-archiver` is required.'
+ 'Try: pip install torch-model-archiver')
+
+ mmdet2torchserve(args.config, args.checkpoint, args.output_folder,
+ args.model_name, args.model_version, args.force)
diff --git a/tools/deployment/mmdet_handler.py b/tools/deployment/mmdet_handler.py
new file mode 100644
index 0000000000000000000000000000000000000000..28c93c99f6e3bb0898f8ac2237e890f4e261cc7f
--- /dev/null
+++ b/tools/deployment/mmdet_handler.py
@@ -0,0 +1,72 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import base64
+import os
+
+import mmcv
+import numpy as np
+import torch
+from ts.torch_handler.base_handler import BaseHandler
+
+from mmdet.apis import inference_detector, init_detector
+
+
+class MMdetHandler(BaseHandler):
+ threshold = 0.5
+
+ def initialize(self, context):
+ properties = context.system_properties
+ self.map_location = 'cuda' if torch.cuda.is_available() else 'cpu'
+ self.device = torch.device(self.map_location + ':' +
+ str(properties.get('gpu_id')) if torch.cuda.
+ is_available() else self.map_location)
+ self.manifest = context.manifest
+
+ model_dir = properties.get('model_dir')
+ serialized_file = self.manifest['model']['serializedFile']
+ checkpoint = os.path.join(model_dir, serialized_file)
+ self.config_file = os.path.join(model_dir, 'config.py')
+
+ self.model = init_detector(self.config_file, checkpoint, self.device)
+ self.initialized = True
+
+ def preprocess(self, data):
+ images = []
+
+ for row in data:
+ image = row.get('data') or row.get('body')
+ if isinstance(image, str):
+ image = base64.b64decode(image)
+ image = mmcv.imfrombytes(image)
+ images.append(image)
+
+ return images
+
+ def inference(self, data, *args, **kwargs):
+ results = inference_detector(self.model, data)
+ return results
+
+ def postprocess(self, data):
+ # Format output following the example ObjectDetectionHandler format
+ output = []
+ for data_sample in data:
+ pred_instances = data_sample.pred_instances
+ bboxes = pred_instances.bboxes.cpu().numpy().astype(
+ np.float32).tolist()
+ labels = pred_instances.labels.cpu().numpy().astype(
+ np.int32).tolist()
+ scores = pred_instances.scores.cpu().numpy().astype(
+ np.float32).tolist()
+ preds = []
+ for idx in range(len(labels)):
+ cls_score, bbox, cls_label = scores[idx], bboxes[idx], labels[
+ idx]
+ if cls_score >= self.threshold:
+ class_name = self.model.dataset_meta['classes'][cls_label]
+ result = dict(
+ class_label=cls_label,
+ class_name=class_name,
+ bbox=bbox,
+ score=cls_score)
+ preds.append(result)
+ output.append(preds)
+ return output
diff --git a/tools/deployment/test_torchserver.py b/tools/deployment/test_torchserver.py
new file mode 100644
index 0000000000000000000000000000000000000000..5160a2fbdefb67550967047eef04b6104e4abd5f
--- /dev/null
+++ b/tools/deployment/test_torchserver.py
@@ -0,0 +1,113 @@
+import os
+from argparse import ArgumentParser
+
+import mmcv
+import requests
+import torch
+from mmengine.structures import InstanceData
+
+from mmdet.apis import inference_detector, init_detector
+from mmdet.registry import VISUALIZERS
+from mmdet.structures import DetDataSample
+
+
+def parse_args():
+ parser = ArgumentParser()
+ parser.add_argument('img', help='Image file')
+ parser.add_argument('config', help='Config file')
+ parser.add_argument('checkpoint', help='Checkpoint file')
+ parser.add_argument('model_name', help='The model name in the server')
+ parser.add_argument(
+ '--inference-addr',
+ default='127.0.0.1:8080',
+ help='Address and port of the inference server')
+ parser.add_argument(
+ '--device', default='cuda:0', help='Device used for inference')
+ parser.add_argument(
+ '--score-thr', type=float, default=0.5, help='bbox score threshold')
+ parser.add_argument(
+ '--work-dir',
+ type=str,
+ default=None,
+ help='output directory to save drawn results.')
+ args = parser.parse_args()
+ return args
+
+
+def align_ts_output(inputs, metainfo, device):
+ bboxes = []
+ labels = []
+ scores = []
+ for i, pred in enumerate(inputs):
+ bboxes.append(pred['bbox'])
+ labels.append(pred['class_label'])
+ scores.append(pred['score'])
+ pred_instances = InstanceData(metainfo=metainfo)
+ pred_instances.bboxes = torch.tensor(
+ bboxes, dtype=torch.float32, device=device)
+ pred_instances.labels = torch.tensor(
+ labels, dtype=torch.int64, device=device)
+ pred_instances.scores = torch.tensor(
+ scores, dtype=torch.float32, device=device)
+ ts_data_sample = DetDataSample(pred_instances=pred_instances)
+ return ts_data_sample
+
+
+def main(args):
+ # build the model from a config file and a checkpoint file
+ model = init_detector(args.config, args.checkpoint, device=args.device)
+ # test a single image
+ pytorch_results = inference_detector(model, args.img)
+ keep = pytorch_results.pred_instances.scores >= args.score_thr
+ pytorch_results.pred_instances = pytorch_results.pred_instances[keep]
+
+ # init visualizer
+ visualizer = VISUALIZERS.build(model.cfg.visualizer)
+ # the dataset_meta is loaded from the checkpoint and
+ # then pass to the model in init_detector
+ visualizer.dataset_meta = model.dataset_meta
+
+ # show the results
+ img = mmcv.imread(args.img)
+ img = mmcv.imconvert(img, 'bgr', 'rgb')
+ pt_out_file = None
+ ts_out_file = None
+ if args.work_dir is not None:
+ os.makedirs(args.work_dir, exist_ok=True)
+ pt_out_file = os.path.join(args.work_dir, 'pytorch_result.png')
+ ts_out_file = os.path.join(args.work_dir, 'torchserve_result.png')
+ visualizer.add_datasample(
+ 'pytorch_result',
+ img.copy(),
+ data_sample=pytorch_results,
+ draw_gt=False,
+ out_file=pt_out_file,
+ show=True,
+ wait_time=0)
+
+ url = 'http://' + args.inference_addr + '/predictions/' + args.model_name
+ with open(args.img, 'rb') as image:
+ response = requests.post(url, image)
+ metainfo = pytorch_results.pred_instances.metainfo
+ ts_results = align_ts_output(response.json(), metainfo, args.device)
+
+ visualizer.add_datasample(
+ 'torchserve_result',
+ img,
+ data_sample=ts_results,
+ draw_gt=False,
+ out_file=ts_out_file,
+ show=True,
+ wait_time=0)
+
+ assert torch.allclose(pytorch_results.pred_instances.bboxes,
+ ts_results.pred_instances.bboxes)
+ assert torch.allclose(pytorch_results.pred_instances.labels,
+ ts_results.pred_instances.labels)
+ assert torch.allclose(pytorch_results.pred_instances.scores,
+ ts_results.pred_instances.scores)
+
+
+if __name__ == '__main__':
+ args = parse_args()
+ main(args)
diff --git a/tools/dist_test.sh b/tools/dist_test.sh
new file mode 100644
index 0000000000000000000000000000000000000000..dea131b43ea8f1222661d20603d40c18ea7f28a1
--- /dev/null
+++ b/tools/dist_test.sh
@@ -0,0 +1,22 @@
+#!/usr/bin/env bash
+
+CONFIG=$1
+CHECKPOINT=$2
+GPUS=$3
+NNODES=${NNODES:-1}
+NODE_RANK=${NODE_RANK:-0}
+PORT=${PORT:-29500}
+MASTER_ADDR=${MASTER_ADDR:-"127.0.0.1"}
+
+PYTHONPATH="$(dirname $0)/..":$PYTHONPATH \
+python -m torch.distributed.launch \
+ --nnodes=$NNODES \
+ --node_rank=$NODE_RANK \
+ --master_addr=$MASTER_ADDR \
+ --nproc_per_node=$GPUS \
+ --master_port=$PORT \
+ $(dirname "$0")/test.py \
+ $CONFIG \
+ $CHECKPOINT \
+ --launcher pytorch \
+ ${@:4}
diff --git a/tools/dist_train.sh b/tools/dist_train.sh
new file mode 100644
index 0000000000000000000000000000000000000000..3fca7641dec4090930c85991a079c28409529d4e
--- /dev/null
+++ b/tools/dist_train.sh
@@ -0,0 +1,19 @@
+#!/usr/bin/env bash
+
+CONFIG=$1
+GPUS=$2
+NNODES=${NNODES:-1}
+NODE_RANK=${NODE_RANK:-0}
+PORT=${PORT:-29500}
+MASTER_ADDR=${MASTER_ADDR:-"127.0.0.1"}
+
+PYTHONPATH="$(dirname $0)/..":$PYTHONPATH \
+python -m torch.distributed.launch \
+ --nnodes=$NNODES \
+ --node_rank=$NODE_RANK \
+ --master_addr=$MASTER_ADDR \
+ --nproc_per_node=$GPUS \
+ --master_port=$PORT \
+ $(dirname "$0")/train.py \
+ $CONFIG \
+ --launcher pytorch ${@:3}
diff --git a/tools/dist_trainrt.sh b/tools/dist_trainrt.sh
new file mode 100644
index 0000000000000000000000000000000000000000..e4aed9ce9e2302ae13aa4432894713e9eea04dcd
--- /dev/null
+++ b/tools/dist_trainrt.sh
@@ -0,0 +1,20 @@
+#!/usr/bin/env bash
+
+CONFIG=$1
+GPUS=$2
+NNODES=${NNODES:-1}
+NODE_RANK=${NODE_RANK:-0}
+PORT=${PORT:-29500}
+MASTER_ADDR=${MASTER_ADDR:-"127.0.0.1"}
+
+CUDA_VISIBLE_DEVICES="0,1" \
+PYTHONPATH="$(dirname $0)/..":$PYTHONPATH \
+python -m torch.distributed.launch \
+ --nnodes=$NNODES \
+ --node_rank=$NODE_RANK \
+ --master_addr=$MASTER_ADDR \
+ --nproc_per_node=$GPUS \
+ --master_port=$PORT \
+ $(dirname "$0")/train_rooftop.py\
+ $CONFIG \
+ --launcher pytorch ${@:3}
diff --git a/tools/misc/download_dataset.py b/tools/misc/download_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..a67771f86ea384a721d47945136a3dbae5a5d4b1
--- /dev/null
+++ b/tools/misc/download_dataset.py
@@ -0,0 +1,194 @@
+import argparse
+import tarfile
+from itertools import repeat
+from multiprocessing.pool import ThreadPool
+from pathlib import Path
+from tarfile import TarFile
+from zipfile import ZipFile
+
+import torch
+from mmengine.utils.path import mkdir_or_exist
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Download datasets for training')
+ parser.add_argument(
+ '--dataset-name', type=str, help='dataset name', default='coco2017')
+ parser.add_argument(
+ '--save-dir',
+ type=str,
+ help='the dir to save dataset',
+ default='data/coco')
+ parser.add_argument(
+ '--unzip',
+ action='store_true',
+ help='whether unzip dataset or not, zipped files will be saved')
+ parser.add_argument(
+ '--delete',
+ action='store_true',
+ help='delete the download zipped files')
+ parser.add_argument(
+ '--threads', type=int, help='number of threading', default=4)
+ args = parser.parse_args()
+ return args
+
+
+def download(url, dir, unzip=True, delete=False, threads=1):
+
+ def download_one(url, dir):
+ f = dir / Path(url).name
+ if Path(url).is_file():
+ Path(url).rename(f)
+ elif not f.exists():
+ print(f'Downloading {url} to {f}')
+ torch.hub.download_url_to_file(url, f, progress=True)
+ if unzip and f.suffix in ('.zip', '.tar'):
+ print(f'Unzipping {f.name}')
+ if f.suffix == '.zip':
+ ZipFile(f).extractall(path=dir)
+ elif f.suffix == '.tar':
+ TarFile(f).extractall(path=dir)
+ if delete:
+ f.unlink()
+ print(f'Delete {f}')
+
+ dir = Path(dir)
+ if threads > 1:
+ pool = ThreadPool(threads)
+ pool.imap(lambda x: download_one(*x), zip(url, repeat(dir)))
+ pool.close()
+ pool.join()
+ else:
+ for u in [url] if isinstance(url, (str, Path)) else url:
+ download_one(u, dir)
+
+
+def download_objects365v2(url, dir, unzip=True, delete=False, threads=1):
+
+ def download_single(url, dir):
+
+ if 'train' in url:
+ saving_dir = dir / Path('train_zip')
+ mkdir_or_exist(saving_dir)
+ f = saving_dir / Path(url).name
+
+ unzip_dir = dir / Path('train')
+ mkdir_or_exist(unzip_dir)
+ elif 'val' in url:
+ saving_dir = dir / Path('val')
+ mkdir_or_exist(saving_dir)
+ f = saving_dir / Path(url).name
+
+ unzip_dir = dir / Path('val')
+ mkdir_or_exist(unzip_dir)
+ else:
+ raise NotImplementedError
+
+ if Path(url).is_file():
+ Path(url).rename(f)
+ elif not f.exists():
+ print(f'Downloading {url} to {f}')
+ torch.hub.download_url_to_file(url, f, progress=True)
+
+ if unzip and str(f).endswith('.tar.gz'):
+ print(f'Unzipping {f.name}')
+ tar = tarfile.open(f)
+ tar.extractall(path=unzip_dir)
+ if delete:
+ f.unlink()
+ print(f'Delete {f}')
+
+ # process annotations
+ full_url = []
+ for _url in url:
+ if 'zhiyuan_objv2_train.tar.gz' in _url or \
+ 'zhiyuan_objv2_val.json' in _url:
+ full_url.append(_url)
+ elif 'train' in _url:
+ for i in range(51):
+ full_url.append(f'{_url}patch{i}.tar.gz')
+ elif 'val/images/v1' in _url:
+ for i in range(16):
+ full_url.append(f'{_url}patch{i}.tar.gz')
+ elif 'val/images/v2' in _url:
+ for i in range(16, 44):
+ full_url.append(f'{_url}patch{i}.tar.gz')
+ else:
+ raise NotImplementedError
+
+ dir = Path(dir)
+ if threads > 1:
+ pool = ThreadPool(threads)
+ pool.imap(lambda x: download_single(*x), zip(full_url, repeat(dir)))
+ pool.close()
+ pool.join()
+ else:
+ for u in full_url:
+ download_single(u, dir)
+
+
+def main():
+ args = parse_args()
+ path = Path(args.save_dir)
+ if not path.exists():
+ path.mkdir(parents=True, exist_ok=True)
+ data2url = dict(
+ # TODO: Support for downloading Panoptic Segmentation of COCO
+ coco2017=[
+ 'http://images.cocodataset.org/zips/train2017.zip',
+ 'http://images.cocodataset.org/zips/val2017.zip',
+ 'http://images.cocodataset.org/zips/test2017.zip',
+ 'http://images.cocodataset.org/zips/unlabeled2017.zip',
+ 'http://images.cocodataset.org/annotations/annotations_trainval2017.zip', # noqa
+ 'http://images.cocodataset.org/annotations/stuff_annotations_trainval2017.zip', # noqa
+ 'http://images.cocodataset.org/annotations/panoptic_annotations_trainval2017.zip', # noqa
+ 'http://images.cocodataset.org/annotations/image_info_test2017.zip', # noqa
+ 'http://images.cocodataset.org/annotations/image_info_unlabeled2017.zip', # noqa
+ ],
+ lvis=[
+ 'https://s3-us-west-2.amazonaws.com/dl.fbaipublicfiles.com/LVIS/lvis_v1_train.json.zip', # noqa
+ 'https://s3-us-west-2.amazonaws.com/dl.fbaipublicfiles.com/LVIS/lvis_v1_train.json.zip', # noqa
+ ],
+ voc2007=[
+ 'http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar', # noqa
+ 'http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar', # noqa
+ 'http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCdevkit_08-Jun-2007.tar', # noqa
+ ],
+ # Note: There is no download link for Objects365-V1 right now. If you
+ # would like to download Objects365-V1, please visit
+ # http://www.objects365.org/ to concat the author.
+ objects365v2=[
+ # training annotations
+ 'https://dorc.ks3-cn-beijing.ksyun.com/data-set/2020Objects365%E6%95%B0%E6%8D%AE%E9%9B%86/train/zhiyuan_objv2_train.tar.gz', # noqa
+ # validation annotations
+ 'https://dorc.ks3-cn-beijing.ksyun.com/data-set/2020Objects365%E6%95%B0%E6%8D%AE%E9%9B%86/val/zhiyuan_objv2_val.json', # noqa
+ # training url root
+ 'https://dorc.ks3-cn-beijing.ksyun.com/data-set/2020Objects365%E6%95%B0%E6%8D%AE%E9%9B%86/train/', # noqa
+ # validation url root_1
+ 'https://dorc.ks3-cn-beijing.ksyun.com/data-set/2020Objects365%E6%95%B0%E6%8D%AE%E9%9B%86/val/images/v1/', # noqa
+ # validation url root_2
+ 'https://dorc.ks3-cn-beijing.ksyun.com/data-set/2020Objects365%E6%95%B0%E6%8D%AE%E9%9B%86/val/images/v2/' # noqa
+ ])
+ url = data2url.get(args.dataset_name, None)
+ if url is None:
+ print('Only support COCO, VOC, LVIS, and Objects365v2 now!')
+ return
+ if args.dataset_name == 'objects365v2':
+ download_objects365v2(
+ url,
+ dir=path,
+ unzip=args.unzip,
+ delete=args.delete,
+ threads=args.threads)
+ else:
+ download(
+ url,
+ dir=path,
+ unzip=args.unzip,
+ delete=args.delete,
+ threads=args.threads)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/misc/gen_coco_panoptic_test_info.py b/tools/misc/gen_coco_panoptic_test_info.py
new file mode 100644
index 0000000000000000000000000000000000000000..dc928e66f0a6e8b02488c8959f0a12fbf331bb5b
--- /dev/null
+++ b/tools/misc/gen_coco_panoptic_test_info.py
@@ -0,0 +1,33 @@
+import argparse
+import os.path as osp
+
+from mmengine.fileio import dump, load
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Generate COCO test image information '
+ 'for COCO panoptic segmentation.')
+ parser.add_argument('data_root', help='Path to COCO annotation directory.')
+ args = parser.parse_args()
+
+ return args
+
+
+def main():
+ args = parse_args()
+ data_root = args.data_root
+ val_info = load(osp.join(data_root, 'panoptic_val2017.json'))
+ test_old_info = load(osp.join(data_root, 'image_info_test-dev2017.json'))
+
+ # replace categories from image_info_test-dev2017.json
+ # with categories from panoptic_val2017.json which
+ # has attribute `isthing`.
+ test_info = test_old_info
+ test_info.update({'categories': val_info['categories']})
+ dump(test_info, osp.join(data_root,
+ 'panoptic_image_info_test-dev2017.json'))
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/misc/get_crowdhuman_id_hw.py b/tools/misc/get_crowdhuman_id_hw.py
new file mode 100644
index 0000000000000000000000000000000000000000..8ed9142a42383768cd57246676fc8e7011a38056
--- /dev/null
+++ b/tools/misc/get_crowdhuman_id_hw.py
@@ -0,0 +1,87 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+"""Get image shape on CrowdHuman dataset.
+
+Here is an example to run this script.
+
+Example:
+ python tools/misc/get_crowdhuman_id_hw.py ${CONFIG} \
+ --dataset ${DATASET_TYPE}
+"""
+import argparse
+import json
+import logging
+import os.path as osp
+from multiprocessing import Pool
+
+import mmcv
+from mmengine.config import Config
+from mmengine.fileio import dump, get, get_text
+from mmengine.logging import print_log
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='Collect image metas')
+ parser.add_argument('config', help='Config file path')
+ parser.add_argument(
+ '--dataset',
+ choices=['train', 'val'],
+ help='Collect image metas from which dataset')
+ parser.add_argument(
+ '--nproc',
+ default=10,
+ type=int,
+ help='Processes used for get image metas')
+ args = parser.parse_args()
+ return args
+
+
+def get_image_metas(anno_str, img_prefix):
+ id_hw = {}
+ anno_dict = json.loads(anno_str)
+ img_path = osp.join(img_prefix, f"{anno_dict['ID']}.jpg")
+ img_id = anno_dict['ID']
+ img_bytes = get(img_path)
+ img = mmcv.imfrombytes(img_bytes, backend='cv2')
+ id_hw[img_id] = img.shape[:2]
+ return id_hw
+
+
+def main():
+ args = parse_args()
+
+ # get ann_file and img_prefix from config files
+ cfg = Config.fromfile(args.config)
+ dataset = args.dataset
+ dataloader_cfg = cfg.get(f'{dataset}_dataloader')
+ ann_file = osp.join(dataloader_cfg.dataset.data_root,
+ dataloader_cfg.dataset.ann_file)
+ img_prefix = osp.join(dataloader_cfg.dataset.data_root,
+ dataloader_cfg.dataset.data_prefix['img'])
+
+ # load image metas
+ print_log(
+ f'loading CrowdHuman {dataset} annotation...', level=logging.INFO)
+ anno_strs = get_text(ann_file).strip().split('\n')
+ pool = Pool(args.nproc)
+ # get image metas with multiple processes
+ id_hw_temp = pool.starmap(
+ get_image_metas,
+ zip(anno_strs, [img_prefix for _ in range(len(anno_strs))]),
+ )
+ pool.close()
+
+ # save image metas
+ id_hw = {}
+ for sub_dict in id_hw_temp:
+ id_hw.update(sub_dict)
+
+ data_root = osp.dirname(ann_file)
+ save_path = osp.join(data_root, f'id_hw_{dataset}.json')
+ print_log(
+ f'\nsaving "id_hw_{dataset}.json" in "{data_root}"',
+ level=logging.INFO)
+ dump(id_hw, save_path, file_format='json')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/misc/get_image_metas.py b/tools/misc/get_image_metas.py
new file mode 100644
index 0000000000000000000000000000000000000000..5644fa8c1ab7c65583374d65a4e68b3faed86d42
--- /dev/null
+++ b/tools/misc/get_image_metas.py
@@ -0,0 +1,125 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+"""Get image metas on a specific dataset.
+
+Here is an example to run this script.
+
+Example:
+ python tools/misc/get_image_metas.py ${CONFIG} \
+ --out ${OUTPUT FILE NAME}
+"""
+import argparse
+import csv
+import os.path as osp
+from multiprocessing import Pool
+
+import mmcv
+from mmengine.config import Config
+from mmengine.fileio import dump, get
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='Collect image metas')
+ parser.add_argument('config', help='Config file path')
+ parser.add_argument(
+ '--dataset',
+ default='val',
+ choices=['train', 'val', 'test'],
+ help='Collect image metas from which dataset')
+ parser.add_argument(
+ '--out',
+ default='validation-image-metas.pkl',
+ help='The output image metas file name. The save dir is in the '
+ 'same directory as `dataset.ann_file` path')
+ parser.add_argument(
+ '--nproc',
+ default=4,
+ type=int,
+ help='Processes used for get image metas')
+ args = parser.parse_args()
+ return args
+
+
+def get_metas_from_csv_style_ann_file(ann_file):
+ data_infos = []
+ cp_filename = None
+ with open(ann_file, 'r') as f:
+ reader = csv.reader(f)
+ for i, line in enumerate(reader):
+ if i == 0:
+ continue
+ img_id = line[0]
+ filename = f'{img_id}.jpg'
+ if filename != cp_filename:
+ data_infos.append(dict(filename=filename))
+ cp_filename = filename
+ return data_infos
+
+
+def get_metas_from_txt_style_ann_file(ann_file):
+ with open(ann_file) as f:
+ lines = f.readlines()
+ i = 0
+ data_infos = []
+ while i < len(lines):
+ filename = lines[i].rstrip()
+ data_infos.append(dict(filename=filename))
+ skip_lines = int(lines[i + 2]) + 3
+ i += skip_lines
+ return data_infos
+
+
+def get_image_metas(data_info, img_prefix):
+ filename = data_info.get('filename', None)
+ if filename is not None:
+ if img_prefix is not None:
+ filename = osp.join(img_prefix, filename)
+ img_bytes = get(filename)
+ img = mmcv.imfrombytes(img_bytes, flag='color')
+ shape = img.shape
+ meta = dict(filename=filename, ori_shape=shape)
+ else:
+ raise NotImplementedError('Missing `filename` in data_info')
+ return meta
+
+
+def main():
+ args = parse_args()
+ assert args.out.endswith('pkl'), 'The output file name must be pkl suffix'
+
+ # load config files
+ cfg = Config.fromfile(args.config)
+ dataloader_cfg = cfg.get(f'{args.dataset}_dataloader')
+ ann_file = osp.join(dataloader_cfg.dataset.data_root,
+ dataloader_cfg.dataset.ann_file)
+ img_prefix = osp.join(dataloader_cfg.dataset.data_root,
+ dataloader_cfg.dataset.data_prefix['img'])
+
+ print(f'{"-" * 5} Start Processing {"-" * 5}')
+ if ann_file.endswith('csv'):
+ data_infos = get_metas_from_csv_style_ann_file(ann_file)
+ elif ann_file.endswith('txt'):
+ data_infos = get_metas_from_txt_style_ann_file(ann_file)
+ else:
+ shuffix = ann_file.split('.')[-1]
+ raise NotImplementedError('File name must be csv or txt suffix but '
+ f'get {shuffix}')
+
+ print(f'Successfully load annotation file from {ann_file}')
+ print(f'Processing {len(data_infos)} images...')
+ pool = Pool(args.nproc)
+ # get image metas with multiple processes
+ image_metas = pool.starmap(
+ get_image_metas,
+ zip(data_infos, [img_prefix for _ in range(len(data_infos))]),
+ )
+ pool.close()
+
+ # save image metas
+ root_path = dataloader_cfg.dataset.ann_file.rsplit('/', 1)[0]
+ save_path = osp.join(root_path, args.out)
+ dump(image_metas, save_path, protocol=4)
+ print(f'Image meta file save to: {save_path}')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/misc/print_config.py b/tools/misc/print_config.py
new file mode 100644
index 0000000000000000000000000000000000000000..291943bc2ba093080b6e4f5d498b1f0d615c8458
--- /dev/null
+++ b/tools/misc/print_config.py
@@ -0,0 +1,60 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os
+
+from mmengine import Config, DictAction
+
+from mmdet.utils import replace_cfg_vals, update_data_root
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='Print the whole config')
+ parser.add_argument('config', help='config file path')
+ parser.add_argument(
+ '--save-path',
+ default=None,
+ help='save path of whole config, suffixed with .py, .json or .yml')
+ parser.add_argument(
+ '--cfg-options',
+ nargs='+',
+ action=DictAction,
+ help='override some settings in the used config, the key-value pair '
+ 'in xxx=yyy format will be merged into config file. If the value to '
+ 'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
+ 'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
+ 'Note that the quotation marks are necessary and that no white space '
+ 'is allowed.')
+ args = parser.parse_args()
+
+ return args
+
+
+def main():
+ args = parse_args()
+
+ cfg = Config.fromfile(args.config)
+
+ # replace the ${key} with the value of cfg.key
+ cfg = replace_cfg_vals(cfg)
+
+ # update data root according to MMDET_DATASETS
+ update_data_root(cfg)
+
+ if args.cfg_options is not None:
+ cfg.merge_from_dict(args.cfg_options)
+ print(f'Config:\n{cfg.pretty_text}')
+
+ if args.save_path is not None:
+ save_path = args.save_path
+
+ suffix = os.path.splitext(save_path)[-1]
+ assert suffix in ['.py', '.json', '.yml']
+
+ if not os.path.exists(os.path.split(save_path)[0]):
+ os.makedirs(os.path.split(save_path)[0])
+ cfg.dump(save_path)
+ print(f'Config saving at {save_path}')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/misc/split_coco.py b/tools/misc/split_coco.py
new file mode 100644
index 0000000000000000000000000000000000000000..075623f3d7237eef3f4dfe343bbce8d53829f129
--- /dev/null
+++ b/tools/misc/split_coco.py
@@ -0,0 +1,110 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os.path as osp
+
+import numpy as np
+from mmengine.fileio import dump, load
+from mmengine.utils import mkdir_or_exist, track_parallel_progress
+
+prog_description = '''K-Fold coco split.
+
+To split coco data for semi-supervised object detection:
+ python tools/misc/split_coco.py
+'''
+
+
+def parse_args():
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ '--data-root',
+ type=str,
+ help='The data root of coco dataset.',
+ default='./data/coco/')
+ parser.add_argument(
+ '--out-dir',
+ type=str,
+ help='The output directory of coco semi-supervised annotations.',
+ default='./data/coco/semi_anns/')
+ parser.add_argument(
+ '--labeled-percent',
+ type=float,
+ nargs='+',
+ help='The percentage of labeled data in the training set.',
+ default=[1, 2, 5, 10])
+ parser.add_argument(
+ '--fold',
+ type=int,
+ help='K-fold cross validation for semi-supervised object detection.',
+ default=5)
+ args = parser.parse_args()
+ return args
+
+
+def split_coco(data_root, out_dir, percent, fold):
+ """Split COCO data for Semi-supervised object detection.
+
+ Args:
+ data_root (str): The data root of coco dataset.
+ out_dir (str): The output directory of coco semi-supervised
+ annotations.
+ percent (float): The percentage of labeled data in the training set.
+ fold (int): The fold of dataset and set as random seed for data split.
+ """
+
+ def save_anns(name, images, annotations):
+ sub_anns = dict()
+ sub_anns['images'] = images
+ sub_anns['annotations'] = annotations
+ sub_anns['licenses'] = anns['licenses']
+ sub_anns['categories'] = anns['categories']
+ sub_anns['info'] = anns['info']
+
+ mkdir_or_exist(out_dir)
+ dump(sub_anns, f'{out_dir}/{name}.json')
+
+ # set random seed with the fold
+ np.random.seed(fold)
+ ann_file = osp.join(data_root, 'annotations/instances_train2017.json')
+ anns = load(ann_file)
+
+ image_list = anns['images']
+ labeled_total = int(percent / 100. * len(image_list))
+ labeled_inds = set(
+ np.random.choice(range(len(image_list)), size=labeled_total))
+ labeled_ids, labeled_images, unlabeled_images = [], [], []
+
+ for i in range(len(image_list)):
+ if i in labeled_inds:
+ labeled_images.append(image_list[i])
+ labeled_ids.append(image_list[i]['id'])
+ else:
+ unlabeled_images.append(image_list[i])
+
+ # get all annotations of labeled images
+ labeled_ids = set(labeled_ids)
+ labeled_annotations, unlabeled_annotations = [], []
+
+ for ann in anns['annotations']:
+ if ann['image_id'] in labeled_ids:
+ labeled_annotations.append(ann)
+ else:
+ unlabeled_annotations.append(ann)
+
+ # save labeled and unlabeled
+ labeled_name = f'instances_train2017.{fold}@{percent}'
+ unlabeled_name = f'instances_train2017.{fold}@{percent}-unlabeled'
+
+ save_anns(labeled_name, labeled_images, labeled_annotations)
+ save_anns(unlabeled_name, unlabeled_images, unlabeled_annotations)
+
+
+def multi_wrapper(args):
+ return split_coco(*args)
+
+
+if __name__ == '__main__':
+ args = parse_args()
+ arguments_list = [(args.data_root, args.out_dir, p, f)
+ for f in range(1, args.fold + 1)
+ for p in args.labeled_percent]
+ track_parallel_progress(multi_wrapper, arguments_list, args.fold)
diff --git a/tools/model_converters/detectron2_to_mmdet.py b/tools/model_converters/detectron2_to_mmdet.py
new file mode 100644
index 0000000000000000000000000000000000000000..7e55d1fad20a8a223cacf50300c819f446115a2d
--- /dev/null
+++ b/tools/model_converters/detectron2_to_mmdet.py
@@ -0,0 +1,48 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+from collections import OrderedDict
+
+import torch
+from mmengine.fileio import load
+from mmengine.runner import save_checkpoint
+
+
+def convert(src: str, dst: str, prefix: str = 'd2_model') -> None:
+ """Convert Detectron2 checkpoint to MMDetection style.
+
+ Args:
+ src (str): The Detectron2 checkpoint path, should endswith `pkl`.
+ dst (str): The MMDetection checkpoint path.
+ prefix (str): The prefix of MMDetection model, defaults to 'd2_model'.
+ """
+ # load arch_settings
+ assert src.endswith('pkl'), \
+ 'the source Detectron2 checkpoint should endswith `pkl`.'
+ d2_model = load(src, encoding='latin1').get('model')
+ assert d2_model is not None
+
+ # convert to mmdet style
+ dst_state_dict = OrderedDict()
+ for name, value in d2_model.items():
+ if not isinstance(value, torch.Tensor):
+ value = torch.from_numpy(value)
+ dst_state_dict[f'{prefix}.{name}'] = value
+
+ mmdet_model = dict(state_dict=dst_state_dict, meta=dict())
+ save_checkpoint(mmdet_model, dst)
+ print(f'Convert Detectron2 model {src} to MMDetection model {dst}')
+
+
+def main():
+ parser = argparse.ArgumentParser(
+ description='Convert Detectron2 checkpoint to MMDetection style')
+ parser.add_argument('src', help='Detectron2 model path')
+ parser.add_argument('dst', help='MMDetectron model save path')
+ parser.add_argument(
+ '--prefix', default='d2_model', type=str, help='prefix of the model')
+ args = parser.parse_args()
+ convert(args.src, args.dst, args.prefix)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/model_converters/detectron2pytorch.py b/tools/model_converters/detectron2pytorch.py
new file mode 100644
index 0000000000000000000000000000000000000000..fe0920ada194d4387029cdf45899f9fd31a7dd18
--- /dev/null
+++ b/tools/model_converters/detectron2pytorch.py
@@ -0,0 +1,83 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+from collections import OrderedDict
+
+import torch
+from mmengine.fileio import load
+
+arch_settings = {50: (3, 4, 6, 3), 101: (3, 4, 23, 3)}
+
+
+def convert_bn(blobs, state_dict, caffe_name, torch_name, converted_names):
+ # detectron replace bn with affine channel layer
+ state_dict[torch_name + '.bias'] = torch.from_numpy(blobs[caffe_name +
+ '_b'])
+ state_dict[torch_name + '.weight'] = torch.from_numpy(blobs[caffe_name +
+ '_s'])
+ bn_size = state_dict[torch_name + '.weight'].size()
+ state_dict[torch_name + '.running_mean'] = torch.zeros(bn_size)
+ state_dict[torch_name + '.running_var'] = torch.ones(bn_size)
+ converted_names.add(caffe_name + '_b')
+ converted_names.add(caffe_name + '_s')
+
+
+def convert_conv_fc(blobs, state_dict, caffe_name, torch_name,
+ converted_names):
+ state_dict[torch_name + '.weight'] = torch.from_numpy(blobs[caffe_name +
+ '_w'])
+ converted_names.add(caffe_name + '_w')
+ if caffe_name + '_b' in blobs:
+ state_dict[torch_name + '.bias'] = torch.from_numpy(blobs[caffe_name +
+ '_b'])
+ converted_names.add(caffe_name + '_b')
+
+
+def convert(src, dst, depth):
+ """Convert keys in detectron pretrained ResNet models to pytorch style."""
+ # load arch_settings
+ if depth not in arch_settings:
+ raise ValueError('Only support ResNet-50 and ResNet-101 currently')
+ block_nums = arch_settings[depth]
+ # load caffe model
+ caffe_model = load(src, encoding='latin1')
+ blobs = caffe_model['blobs'] if 'blobs' in caffe_model else caffe_model
+ # convert to pytorch style
+ state_dict = OrderedDict()
+ converted_names = set()
+ convert_conv_fc(blobs, state_dict, 'conv1', 'conv1', converted_names)
+ convert_bn(blobs, state_dict, 'res_conv1_bn', 'bn1', converted_names)
+ for i in range(1, len(block_nums) + 1):
+ for j in range(block_nums[i - 1]):
+ if j == 0:
+ convert_conv_fc(blobs, state_dict, f'res{i + 1}_{j}_branch1',
+ f'layer{i}.{j}.downsample.0', converted_names)
+ convert_bn(blobs, state_dict, f'res{i + 1}_{j}_branch1_bn',
+ f'layer{i}.{j}.downsample.1', converted_names)
+ for k, letter in enumerate(['a', 'b', 'c']):
+ convert_conv_fc(blobs, state_dict,
+ f'res{i + 1}_{j}_branch2{letter}',
+ f'layer{i}.{j}.conv{k+1}', converted_names)
+ convert_bn(blobs, state_dict,
+ f'res{i + 1}_{j}_branch2{letter}_bn',
+ f'layer{i}.{j}.bn{k + 1}', converted_names)
+ # check if all layers are converted
+ for key in blobs:
+ if key not in converted_names:
+ print(f'Not Convert: {key}')
+ # save checkpoint
+ checkpoint = dict()
+ checkpoint['state_dict'] = state_dict
+ torch.save(checkpoint, dst)
+
+
+def main():
+ parser = argparse.ArgumentParser(description='Convert model keys')
+ parser.add_argument('src', help='src detectron model path')
+ parser.add_argument('dst', help='save path')
+ parser.add_argument('depth', type=int, help='ResNet model depth')
+ args = parser.parse_args()
+ convert(args.src, args.dst, args.depth)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/model_converters/publish_model.py b/tools/model_converters/publish_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..6c64b00e30a4a75db9a51785fd79b02530dbb102
--- /dev/null
+++ b/tools/model_converters/publish_model.py
@@ -0,0 +1,61 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import subprocess
+
+import torch
+from mmengine.logging import print_log
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Process a checkpoint to be published')
+ parser.add_argument('in_file', help='input checkpoint filename')
+ parser.add_argument('out_file', help='output checkpoint filename')
+ parser.add_argument(
+ '--save-keys',
+ nargs='+',
+ type=str,
+ default=['meta', 'state_dict'],
+ help='keys to save in the published checkpoint')
+ args = parser.parse_args()
+ return args
+
+
+def process_checkpoint(in_file, out_file, save_keys=['meta', 'state_dict']):
+ checkpoint = torch.load(in_file, map_location='cpu')
+
+ # only keep `meta` and `state_dict` for smaller file size
+ ckpt_keys = list(checkpoint.keys())
+ for k in ckpt_keys:
+ if k not in save_keys:
+ print_log(
+ f'Key `{k}` will be removed because it is not in '
+ f'save_keys. If you want to keep it, '
+ f'please set --save-keys.',
+ logger='current')
+ checkpoint.pop(k, None)
+
+ # if it is necessary to remove some sensitive data in checkpoint['meta'],
+ # add the code here.
+ if torch.__version__ >= '1.6':
+ torch.save(checkpoint, out_file, _use_new_zipfile_serialization=False)
+ else:
+ torch.save(checkpoint, out_file)
+ sha = subprocess.check_output(['sha256sum', out_file]).decode()
+ if out_file.endswith('.pth'):
+ out_file_name = out_file[:-4]
+ else:
+ out_file_name = out_file
+ final_file = out_file_name + f'-{sha[:8]}.pth'
+ subprocess.Popen(['mv', out_file, final_file])
+ print_log(
+ f'The published model is saved at {final_file}.', logger='current')
+
+
+def main():
+ args = parse_args()
+ process_checkpoint(args.in_file, args.out_file, args.save_keys)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/model_converters/regnet2mmdet.py b/tools/model_converters/regnet2mmdet.py
new file mode 100644
index 0000000000000000000000000000000000000000..fbf8c8f33a90839fef055aea0a775e76ff84afd3
--- /dev/null
+++ b/tools/model_converters/regnet2mmdet.py
@@ -0,0 +1,90 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+from collections import OrderedDict
+
+import torch
+
+
+def convert_stem(model_key, model_weight, state_dict, converted_names):
+ new_key = model_key.replace('stem.conv', 'conv1')
+ new_key = new_key.replace('stem.bn', 'bn1')
+ state_dict[new_key] = model_weight
+ converted_names.add(model_key)
+ print(f'Convert {model_key} to {new_key}')
+
+
+def convert_head(model_key, model_weight, state_dict, converted_names):
+ new_key = model_key.replace('head.fc', 'fc')
+ state_dict[new_key] = model_weight
+ converted_names.add(model_key)
+ print(f'Convert {model_key} to {new_key}')
+
+
+def convert_reslayer(model_key, model_weight, state_dict, converted_names):
+ split_keys = model_key.split('.')
+ layer, block, module = split_keys[:3]
+ block_id = int(block[1:])
+ layer_name = f'layer{int(layer[1:])}'
+ block_name = f'{block_id - 1}'
+
+ if block_id == 1 and module == 'bn':
+ new_key = f'{layer_name}.{block_name}.downsample.1.{split_keys[-1]}'
+ elif block_id == 1 and module == 'proj':
+ new_key = f'{layer_name}.{block_name}.downsample.0.{split_keys[-1]}'
+ elif module == 'f':
+ if split_keys[3] == 'a_bn':
+ module_name = 'bn1'
+ elif split_keys[3] == 'b_bn':
+ module_name = 'bn2'
+ elif split_keys[3] == 'c_bn':
+ module_name = 'bn3'
+ elif split_keys[3] == 'a':
+ module_name = 'conv1'
+ elif split_keys[3] == 'b':
+ module_name = 'conv2'
+ elif split_keys[3] == 'c':
+ module_name = 'conv3'
+ new_key = f'{layer_name}.{block_name}.{module_name}.{split_keys[-1]}'
+ else:
+ raise ValueError(f'Unsupported conversion of key {model_key}')
+ print(f'Convert {model_key} to {new_key}')
+ state_dict[new_key] = model_weight
+ converted_names.add(model_key)
+
+
+def convert(src, dst):
+ """Convert keys in pycls pretrained RegNet models to mmdet style."""
+ # load caffe model
+ regnet_model = torch.load(src)
+ blobs = regnet_model['model_state']
+ # convert to pytorch style
+ state_dict = OrderedDict()
+ converted_names = set()
+ for key, weight in blobs.items():
+ if 'stem' in key:
+ convert_stem(key, weight, state_dict, converted_names)
+ elif 'head' in key:
+ convert_head(key, weight, state_dict, converted_names)
+ elif key.startswith('s'):
+ convert_reslayer(key, weight, state_dict, converted_names)
+
+ # check if all layers are converted
+ for key in blobs:
+ if key not in converted_names:
+ print(f'not converted: {key}')
+ # save checkpoint
+ checkpoint = dict()
+ checkpoint['state_dict'] = state_dict
+ torch.save(checkpoint, dst)
+
+
+def main():
+ parser = argparse.ArgumentParser(description='Convert model keys')
+ parser.add_argument('src', help='src detectron model path')
+ parser.add_argument('dst', help='save path')
+ args = parser.parse_args()
+ convert(args.src, args.dst)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/model_converters/selfsup2mmdet.py b/tools/model_converters/selfsup2mmdet.py
new file mode 100644
index 0000000000000000000000000000000000000000..bc8cce1bd1cde22d09bd200b813bf67b4d066892
--- /dev/null
+++ b/tools/model_converters/selfsup2mmdet.py
@@ -0,0 +1,42 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+from collections import OrderedDict
+
+import torch
+
+
+def moco_convert(src, dst):
+ """Convert keys in pycls pretrained moco models to mmdet style."""
+ # load caffe model
+ moco_model = torch.load(src)
+ blobs = moco_model['state_dict']
+ # convert to pytorch style
+ state_dict = OrderedDict()
+ for k, v in blobs.items():
+ if not k.startswith('module.encoder_q.'):
+ continue
+ old_k = k
+ k = k.replace('module.encoder_q.', '')
+ state_dict[k] = v
+ print(old_k, '->', k)
+ # save checkpoint
+ checkpoint = dict()
+ checkpoint['state_dict'] = state_dict
+ torch.save(checkpoint, dst)
+
+
+def main():
+ parser = argparse.ArgumentParser(description='Convert model keys')
+ parser.add_argument('src', help='src detectron model path')
+ parser.add_argument('dst', help='save path')
+ parser.add_argument(
+ '--selfsup', type=str, choices=['moco', 'swav'], help='save path')
+ args = parser.parse_args()
+ if args.selfsup == 'moco':
+ moco_convert(args.src, args.dst)
+ elif args.selfsup == 'swav':
+ print('SWAV does not need to convert the keys')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/model_converters/upgrade_model_version.py b/tools/model_converters/upgrade_model_version.py
new file mode 100644
index 0000000000000000000000000000000000000000..f06e836a579062f25eca5e64c446d79dc390dce2
--- /dev/null
+++ b/tools/model_converters/upgrade_model_version.py
@@ -0,0 +1,210 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import re
+import tempfile
+from collections import OrderedDict
+
+import torch
+from mmengine import Config
+
+
+def is_head(key):
+ valid_head_list = [
+ 'bbox_head', 'mask_head', 'semantic_head', 'grid_head', 'mask_iou_head'
+ ]
+
+ return any(key.startswith(h) for h in valid_head_list)
+
+
+def parse_config(config_strings):
+ temp_file = tempfile.NamedTemporaryFile()
+ config_path = f'{temp_file.name}.py'
+ with open(config_path, 'w') as f:
+ f.write(config_strings)
+
+ config = Config.fromfile(config_path)
+ is_two_stage = True
+ is_ssd = False
+ is_retina = False
+ reg_cls_agnostic = False
+ if 'rpn_head' not in config.model:
+ is_two_stage = False
+ # check whether it is SSD
+ if config.model.bbox_head.type == 'SSDHead':
+ is_ssd = True
+ elif config.model.bbox_head.type == 'RetinaHead':
+ is_retina = True
+ elif isinstance(config.model['bbox_head'], list):
+ reg_cls_agnostic = True
+ elif 'reg_class_agnostic' in config.model.bbox_head:
+ reg_cls_agnostic = config.model.bbox_head \
+ .reg_class_agnostic
+ temp_file.close()
+ return is_two_stage, is_ssd, is_retina, reg_cls_agnostic
+
+
+def reorder_cls_channel(val, num_classes=81):
+ # bias
+ if val.dim() == 1:
+ new_val = torch.cat((val[1:], val[:1]), dim=0)
+ # weight
+ else:
+ out_channels, in_channels = val.shape[:2]
+ # conv_cls for softmax output
+ if out_channels != num_classes and out_channels % num_classes == 0:
+ new_val = val.reshape(-1, num_classes, in_channels, *val.shape[2:])
+ new_val = torch.cat((new_val[:, 1:], new_val[:, :1]), dim=1)
+ new_val = new_val.reshape(val.size())
+ # fc_cls
+ elif out_channels == num_classes:
+ new_val = torch.cat((val[1:], val[:1]), dim=0)
+ # agnostic | retina_cls | rpn_cls
+ else:
+ new_val = val
+
+ return new_val
+
+
+def truncate_cls_channel(val, num_classes=81):
+
+ # bias
+ if val.dim() == 1:
+ if val.size(0) % num_classes == 0:
+ new_val = val[:num_classes - 1]
+ else:
+ new_val = val
+ # weight
+ else:
+ out_channels, in_channels = val.shape[:2]
+ # conv_logits
+ if out_channels % num_classes == 0:
+ new_val = val.reshape(num_classes, in_channels, *val.shape[2:])[1:]
+ new_val = new_val.reshape(-1, *val.shape[1:])
+ # agnostic
+ else:
+ new_val = val
+
+ return new_val
+
+
+def truncate_reg_channel(val, num_classes=81):
+ # bias
+ if val.dim() == 1:
+ # fc_reg | rpn_reg
+ if val.size(0) % num_classes == 0:
+ new_val = val.reshape(num_classes, -1)[:num_classes - 1]
+ new_val = new_val.reshape(-1)
+ # agnostic
+ else:
+ new_val = val
+ # weight
+ else:
+ out_channels, in_channels = val.shape[:2]
+ # fc_reg | rpn_reg
+ if out_channels % num_classes == 0:
+ new_val = val.reshape(num_classes, -1, in_channels,
+ *val.shape[2:])[1:]
+ new_val = new_val.reshape(-1, *val.shape[1:])
+ # agnostic
+ else:
+ new_val = val
+
+ return new_val
+
+
+def convert(in_file, out_file, num_classes):
+ """Convert keys in checkpoints.
+
+ There can be some breaking changes during the development of mmdetection,
+ and this tool is used for upgrading checkpoints trained with old versions
+ to the latest one.
+ """
+ checkpoint = torch.load(in_file)
+ in_state_dict = checkpoint.pop('state_dict')
+ out_state_dict = OrderedDict()
+ meta_info = checkpoint['meta']
+ is_two_stage, is_ssd, is_retina, reg_cls_agnostic = parse_config(
+ '#' + meta_info['config'])
+ if meta_info['mmdet_version'] <= '0.5.3' and is_retina:
+ upgrade_retina = True
+ else:
+ upgrade_retina = False
+
+ # MMDetection v2.5.0 unifies the class order in RPN
+ # if the model is trained in version=2.5.0
+ if meta_info['mmdet_version'] < '2.5.0':
+ upgrade_rpn = True
+ else:
+ upgrade_rpn = False
+
+ for key, val in in_state_dict.items():
+ new_key = key
+ new_val = val
+ if is_two_stage and is_head(key):
+ new_key = 'roi_head.{}'.format(key)
+
+ # classification
+ if upgrade_rpn:
+ m = re.search(
+ r'(conv_cls|retina_cls|rpn_cls|fc_cls|fcos_cls|'
+ r'fovea_cls).(weight|bias)', new_key)
+ else:
+ m = re.search(
+ r'(conv_cls|retina_cls|fc_cls|fcos_cls|'
+ r'fovea_cls).(weight|bias)', new_key)
+ if m is not None:
+ print(f'reorder cls channels of {new_key}')
+ new_val = reorder_cls_channel(val, num_classes)
+
+ # regression
+ if upgrade_rpn:
+ m = re.search(r'(fc_reg).(weight|bias)', new_key)
+ else:
+ m = re.search(r'(fc_reg|rpn_reg).(weight|bias)', new_key)
+ if m is not None and not reg_cls_agnostic:
+ print(f'truncate regression channels of {new_key}')
+ new_val = truncate_reg_channel(val, num_classes)
+
+ # mask head
+ m = re.search(r'(conv_logits).(weight|bias)', new_key)
+ if m is not None:
+ print(f'truncate mask prediction channels of {new_key}')
+ new_val = truncate_cls_channel(val, num_classes)
+
+ m = re.search(r'(cls_convs|reg_convs).\d.(weight|bias)', key)
+ # Legacy issues in RetinaNet since V1.x
+ # Use ConvModule instead of nn.Conv2d in RetinaNet
+ # cls_convs.0.weight -> cls_convs.0.conv.weight
+ if m is not None and upgrade_retina:
+ param = m.groups()[1]
+ new_key = key.replace(param, f'conv.{param}')
+ out_state_dict[new_key] = val
+ print(f'rename the name of {key} to {new_key}')
+ continue
+
+ m = re.search(r'(cls_convs).\d.(weight|bias)', key)
+ if m is not None and is_ssd:
+ print(f'reorder cls channels of {new_key}')
+ new_val = reorder_cls_channel(val, num_classes)
+
+ out_state_dict[new_key] = new_val
+ checkpoint['state_dict'] = out_state_dict
+ torch.save(checkpoint, out_file)
+
+
+def main():
+ parser = argparse.ArgumentParser(description='Upgrade model version')
+ parser.add_argument('in_file', help='input checkpoint file')
+ parser.add_argument('out_file', help='output checkpoint file')
+ parser.add_argument(
+ '--num-classes',
+ type=int,
+ default=81,
+ help='number of classes of the original model')
+ args = parser.parse_args()
+ convert(args.in_file, args.out_file, args.num_classes)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/model_converters/upgrade_ssd_version.py b/tools/model_converters/upgrade_ssd_version.py
new file mode 100644
index 0000000000000000000000000000000000000000..48302d84000298858069d05d93e27c6b22a5b1ab
--- /dev/null
+++ b/tools/model_converters/upgrade_ssd_version.py
@@ -0,0 +1,58 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import tempfile
+from collections import OrderedDict
+
+import torch
+from mmengine import Config
+
+
+def parse_config(config_strings):
+ temp_file = tempfile.NamedTemporaryFile()
+ config_path = f'{temp_file.name}.py'
+ with open(config_path, 'w') as f:
+ f.write(config_strings)
+
+ config = Config.fromfile(config_path)
+ # check whether it is SSD
+ if config.model.bbox_head.type != 'SSDHead':
+ raise AssertionError('This is not a SSD model.')
+
+
+def convert(in_file, out_file):
+ checkpoint = torch.load(in_file)
+ in_state_dict = checkpoint.pop('state_dict')
+ out_state_dict = OrderedDict()
+ meta_info = checkpoint['meta']
+ parse_config('#' + meta_info['config'])
+ for key, value in in_state_dict.items():
+ if 'extra' in key:
+ layer_idx = int(key.split('.')[2])
+ new_key = 'neck.extra_layers.{}.{}.conv.'.format(
+ layer_idx // 2, layer_idx % 2) + key.split('.')[-1]
+ elif 'l2_norm' in key:
+ new_key = 'neck.l2_norm.weight'
+ elif 'bbox_head' in key:
+ new_key = key[:21] + '.0' + key[21:]
+ else:
+ new_key = key
+ out_state_dict[new_key] = value
+ checkpoint['state_dict'] = out_state_dict
+
+ if torch.__version__ >= '1.6':
+ torch.save(checkpoint, out_file, _use_new_zipfile_serialization=False)
+ else:
+ torch.save(checkpoint, out_file)
+
+
+def main():
+ parser = argparse.ArgumentParser(description='Upgrade SSD version')
+ parser.add_argument('in_file', help='input checkpoint file')
+ parser.add_argument('out_file', help='output checkpoint file')
+
+ args = parser.parse_args()
+ convert(args.in_file, args.out_file)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/slurm_test.sh b/tools/slurm_test.sh
new file mode 100644
index 0000000000000000000000000000000000000000..6dd67e57442b741fc30f26102eb5afe16139edb1
--- /dev/null
+++ b/tools/slurm_test.sh
@@ -0,0 +1,24 @@
+#!/usr/bin/env bash
+
+set -x
+
+PARTITION=$1
+JOB_NAME=$2
+CONFIG=$3
+CHECKPOINT=$4
+GPUS=${GPUS:-8}
+GPUS_PER_NODE=${GPUS_PER_NODE:-8}
+CPUS_PER_TASK=${CPUS_PER_TASK:-5}
+PY_ARGS=${@:5}
+SRUN_ARGS=${SRUN_ARGS:-""}
+
+PYTHONPATH="$(dirname $0)/..":$PYTHONPATH \
+srun -p ${PARTITION} \
+ --job-name=${JOB_NAME} \
+ --gres=gpu:${GPUS_PER_NODE} \
+ --ntasks=${GPUS} \
+ --ntasks-per-node=${GPUS_PER_NODE} \
+ --cpus-per-task=${CPUS_PER_TASK} \
+ --kill-on-bad-exit=1 \
+ ${SRUN_ARGS} \
+ python -u tools/test.py ${CONFIG} ${CHECKPOINT} --launcher="slurm" ${PY_ARGS}
diff --git a/tools/slurm_train.sh b/tools/slurm_train.sh
new file mode 100644
index 0000000000000000000000000000000000000000..b3feb3d9c7a6c33d82739cdf5ee10365673aaded
--- /dev/null
+++ b/tools/slurm_train.sh
@@ -0,0 +1,24 @@
+#!/usr/bin/env bash
+
+set -x
+
+PARTITION=$1
+JOB_NAME=$2
+CONFIG=$3
+WORK_DIR=$4
+GPUS=${GPUS:-8}
+GPUS_PER_NODE=${GPUS_PER_NODE:-8}
+CPUS_PER_TASK=${CPUS_PER_TASK:-5}
+SRUN_ARGS=${SRUN_ARGS:-""}
+PY_ARGS=${@:5}
+
+PYTHONPATH="$(dirname $0)/..":$PYTHONPATH \
+srun -p ${PARTITION} \
+ --job-name=${JOB_NAME} \
+ --gres=gpu:${GPUS_PER_NODE} \
+ --ntasks=${GPUS} \
+ --ntasks-per-node=${GPUS_PER_NODE} \
+ --cpus-per-task=${CPUS_PER_TASK} \
+ --kill-on-bad-exit=1 \
+ ${SRUN_ARGS} \
+ python -u tools/train.py ${CONFIG} --work-dir=${WORK_DIR} --launcher="slurm" ${PY_ARGS}
diff --git a/train.py b/train.py
new file mode 100644
index 0000000000000000000000000000000000000000..26e6600a949df807771a1a4362be632741659b38
--- /dev/null
+++ b/train.py
@@ -0,0 +1,152 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import logging
+import os
+import os.path as osp
+os.environ["CUDA_VISIBLE_DEVICES"] = "0"
+from mmengine.config import Config, DictAction
+from mmengine.logging import print_log
+from mmengine.registry import RUNNERS
+from mmengine.runner import Runner
+from mmdet.utils import setup_cache_size_limit_of_dynamo
+import torch
+import random
+import numpy as np
+
+
+def set_random_seed(seed=42, deterministic=False):
+ os.environ["PYTHONHASHSEED"] = str(seed)
+ random.seed(seed)
+ np.random.seed(seed)
+ torch.manual_seed(seed)
+ torch.cuda.manual_seed(seed)
+ torch.cuda.manual_seed_all(seed)
+ if deterministic:
+ torch.backends.cudnn.deterministic = True
+ torch.backends.cudnn.benchmark = False
+
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='Train a detec tor')
+ parser.add_argument('--config',default='./configs/specdetr_sb-2s-100e_hsi.py', help='train config file path')
+ # parser.add_argument('config', help='train config file path')
+ parser.add_argument('--work-dir',default='./work_dirs/SpecDETR', help='the dir to save logs and models')
+ parser.add_argument(
+ '--amp',
+ action='store_true',
+ default=False,
+ help='enable automatic-mixed-precision training')
+ parser.add_argument(
+ '--auto-scale-lr',
+ action='store_true',
+ help='enable automatically scaling LR.')
+ parser.add_argument(
+ '--resume',
+ nargs='?',
+ # default='./work_dirs/atss_swin-l-p4-w12_fpn_dyhead_ms-2x_hsicbig/epoch_3.pth',
+ type=str,
+ const='auto',
+ help='If specify checkpoint path, resume from it, while if not '
+ 'specify, try to auto resume from the latest checkpoint '
+ 'in the work directory.')
+ parser.add_argument(
+ '--cfg-options',
+ nargs='+',
+ action=DictAction,
+ help='override some settings in the used config, the key-value pair '
+ 'in xxx=yyy format will be merged into config file. If the value to '
+ 'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
+ 'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
+ 'Note that the quotation marks are necessary and that no white space '
+ 'is allowed.')
+ parser.add_argument(
+ '--launcher',
+ choices=['none', 'pytorch', 'slurm', 'mpi'],
+ default='none',
+ help='job launcher')
+ # When using PyTorch version >= 2.0.0, the `torch.distributed.launch`
+ # will pass the `--local-rank` parameter to `tools/train.py` instead
+ # of `--local_rank`.
+ parser.add_argument('--local_rank', '--local-rank', type=int, default=0)
+ args = parser.parse_args()
+ if 'LOCAL_RANK' not in os.environ:
+ os.environ['LOCAL_RANK'] = str(args.local_rank)
+
+ return args
+
+
+def main():
+ seed = 42
+ set_random_seed(seed=seed)
+ args = parse_args()
+ # Reduce the number of repeated compilations and improve
+ # training speed.
+ setup_cache_size_limit_of_dynamo()
+
+ # load config
+ cfg = Config.fromfile(args.config)
+ cfg.launcher = args.launcher
+ if args.cfg_options is not None:
+ cfg.merge_from_dict(args.cfg_options)
+
+ # work_dir is determined in this priority: CLI > segment in file > filename
+ if args.work_dir is not None:
+ # update configs according to CLI args if args.work_dir is not None
+ cfg.work_dir = args.work_dir
+ elif cfg.get('work_dir', None) is None:
+ # use config filename as default work_dir if cfg.work_dir is None
+ cfg.work_dir = osp.join('./work_dirs',
+ osp.splitext(osp.basename(args.config))[0])
+
+ # enable automatic-mixed-precision training
+ if args.amp is True:
+ optim_wrapper = cfg.optim_wrapper.type
+ if optim_wrapper == 'AmpOptimWrapper':
+ print_log(
+ 'AMP training is already enabled in your config.',
+ logger='current',
+ level=logging.WARNING)
+ else:
+ assert optim_wrapper == 'OptimWrapper', (
+ '`--amp` is only supported when the optimizer wrapper type is '
+ f'`OptimWrapper` but got {optim_wrapper}.')
+ cfg.optim_wrapper.type = 'AmpOptimWrapper'
+ cfg.optim_wrapper.loss_scale = 'dynamic'
+
+ # enable automatically scaling LR
+ if args.auto_scale_lr:
+ if 'auto_scale_lr' in cfg and \
+ 'enable' in cfg.auto_scale_lr and \
+ 'base_batch_size' in cfg.auto_scale_lr:
+ cfg.auto_scale_lr.enable = True
+ else:
+ raise RuntimeError('Can not find "auto_scale_lr" or '
+ '"auto_scale_lr.enable" or '
+ '"auto_scale_lr.base_batch_size" in your'
+ ' configuration file.')
+
+ # resume is determined in this priority: resume from > auto_resume
+ if args.resume == 'auto':
+ cfg.resume = True
+ cfg.load_from = None
+ elif args.resume is not None:
+ cfg.resume = True
+ cfg.load_from = args.resume
+ cfg.randomness = dict(seed=seed)
+ # build the runner from config
+ if 'runner_type' not in cfg:
+ # build the default runner
+ runner = Runner.from_cfg(cfg)
+ else:
+ # build customized runner from the registry
+ # if 'runner_type' is set in the cfg
+ runner = RUNNERS.build(cfg)
+
+ # start training
+ runner.train()
+
+
+if __name__ == '__main__':
+ set_random_seed()
+ main()
 +
+ +
+ +
+ +
+ +
+ +
+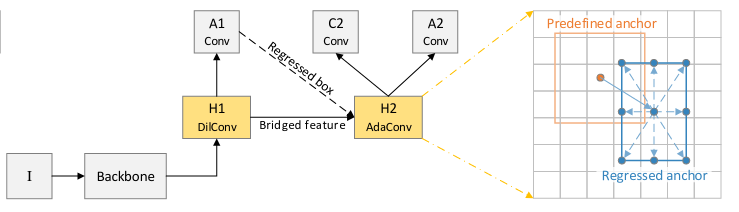 +
+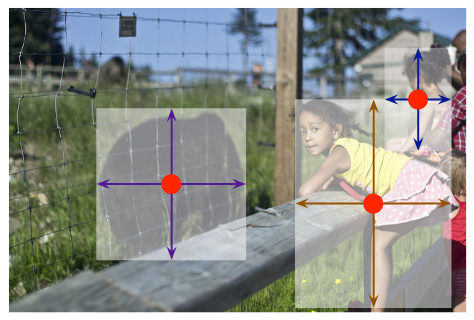 +
+ +
+ +
+ +
+ +
+ +
+ +
+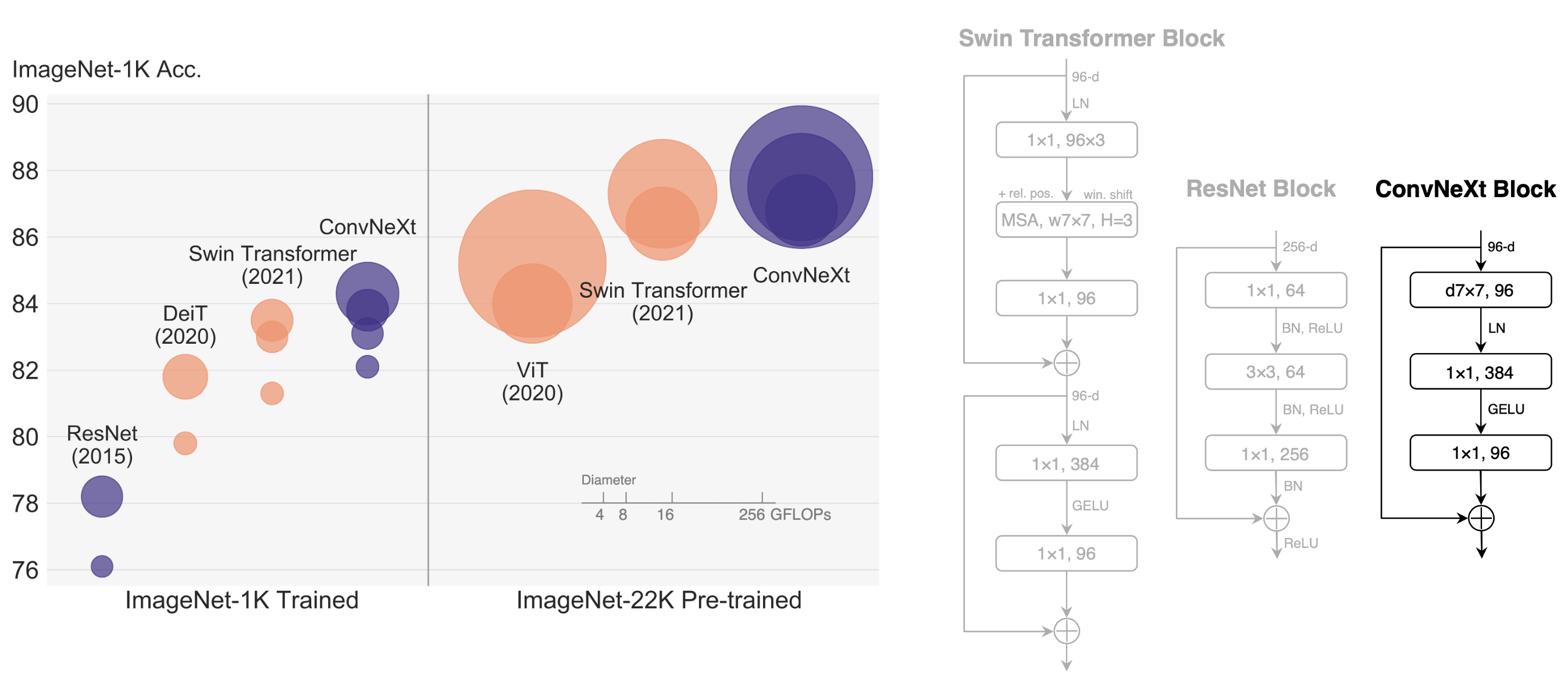 +
+ +
+ +
+ +
+ +
+ +
+ +
+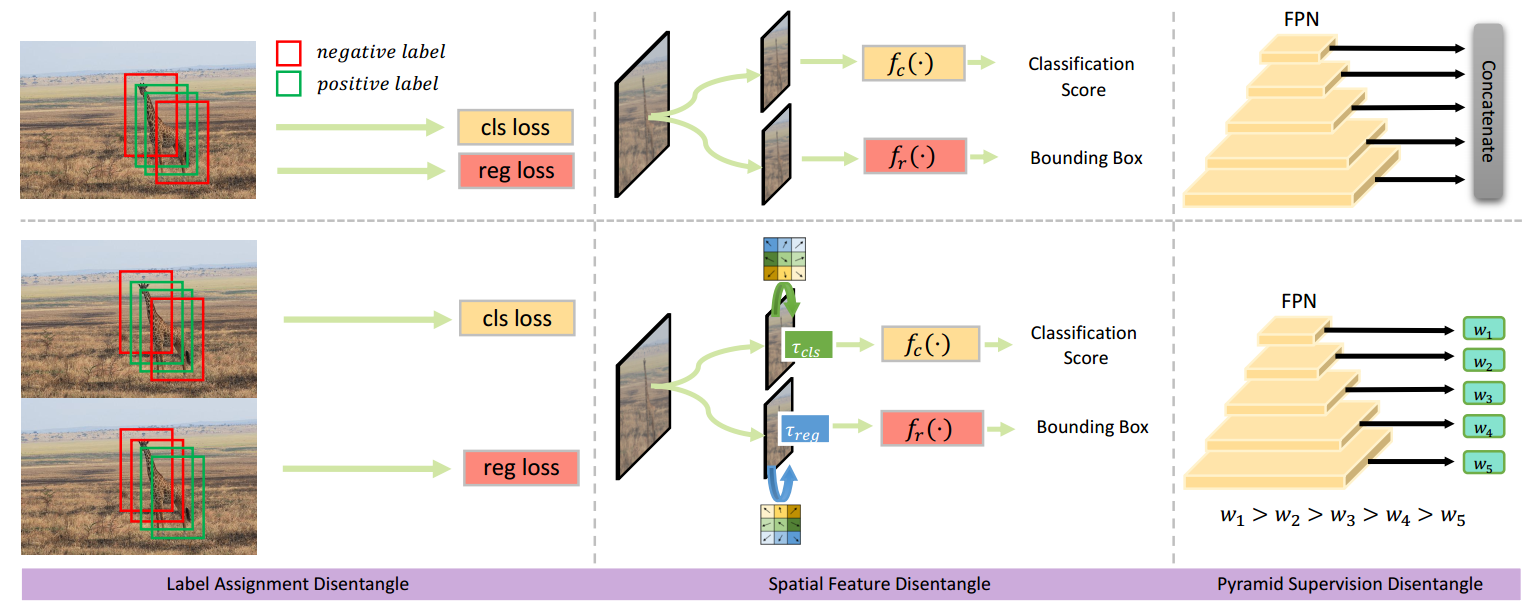 +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+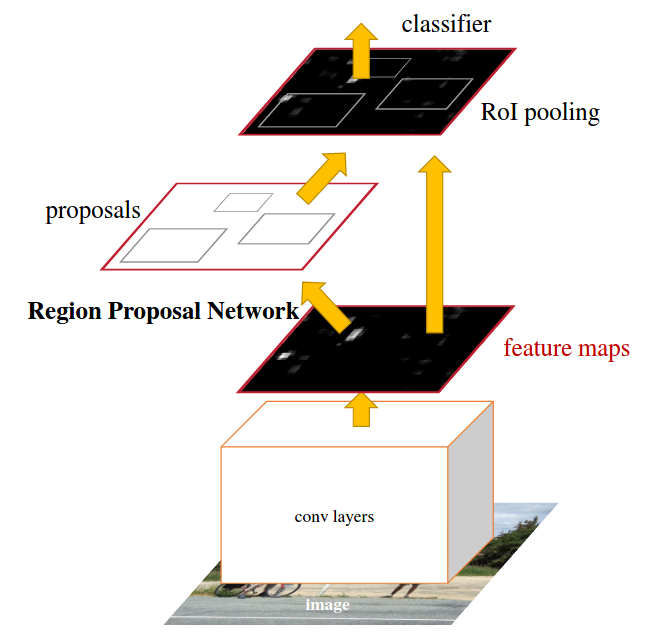 +
+ +
+ +
+ +
+ +
+ +
+ +
+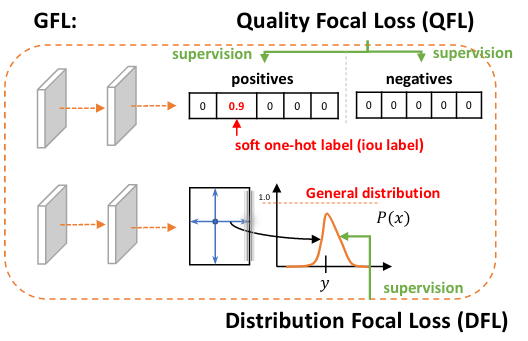 +
+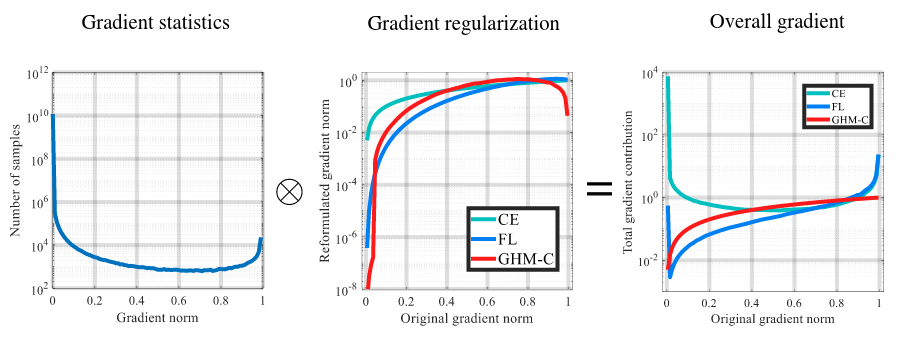 +
+ +
+ +
+ +
+ +
+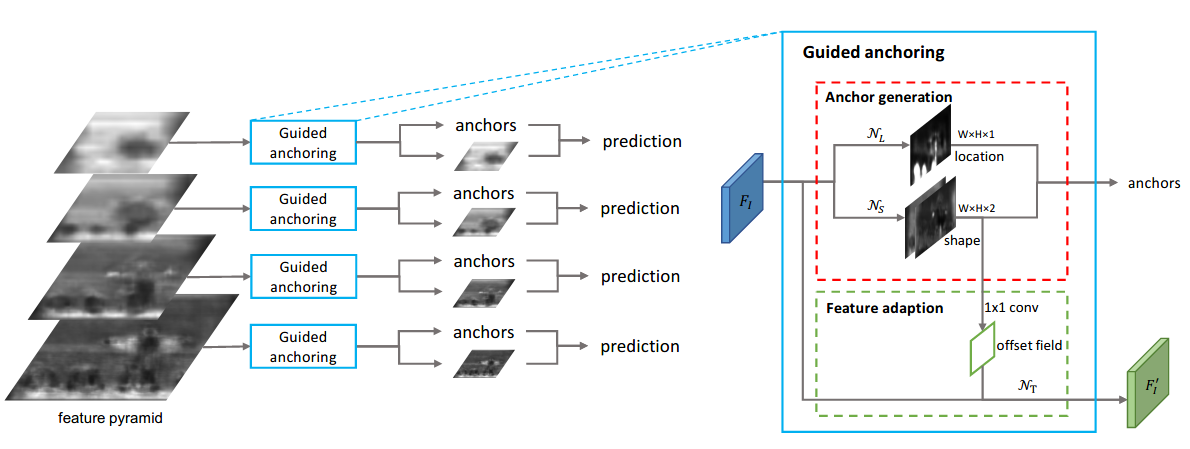 +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+